
#programming
1 messages · Page 408 of 1
lmfao that's teh same adapter
is there only one of those being produced ive only ever seen that same pcb for the adapter everywhere
ive not looked for another variant
128gb usb 3.0 for 7 bux a drive isnt bad 
not good because wtf would i need it for but
how much i paid back then vs how much it cost rn


32gb 6000mhz CL32 stick was $75
now it's.... I don't even want to know
that was in aud btw
I remember the 96gb ram for $146
that was crazy
it was like 5200mhz CL42
low tier stuff.. but for that price, whew
ram was dirt cheap back then
ram is finally being treated as important, for better or for worse
project stargate is still fucking nonsense
we'll have such huge companies dropshipping ram chips/wafers soon lmao
no one is achieving AGI with an LLM
nah
all we need is to make an anime girl in a glass cylinder, surely that will be agi 
im talking about the fact that there is no realistic way of them using >1EB of ram let alone that much per month
KV cache for training (real)
as the curse goes, the more systems you add. The more limited you are by sheer networking
they could've gotten like
maybe 80PB of HBM and it'll still be overkill in capacity
but no had to max out dram with like 1EB per month somehow
need that 1q sized model
surely scaling will work in it's favor
-# q is quadrillion, Q is quintillion; don't know who decided that, but seems to be accepted
frontier HPC supercomputer is at 4.8PB of system ram rn
about the same capacity in terms of HBM because they used 4x MI250x per CPU
what's el capitan at for system ram
oh
5.44pb
that one is epyc 42cs and mi300s
same lineage tho
Actually, this seems feasible as it is just over double what people are already doing. ovbs they are going for 100q for stargate
drain the entire power grid while your at it
the rank 1 on TOP500 rn uses like 43,808 APUs (24 cores Genoa + MI300A) and shares 128GB HBM per APU
don't know enough about training to figure out how much ram that'd even require
quack you must hate JUPITER
3rd place "Aurora" only uses 10PB of ram
GH200 lol
it's your nemesis
nah
so many arm cores
my nemesis is B300
e waste 
i can see working on JUPITER be an ass experience since you'd have to work with the ARM systems
but its still workable
microsoft NDv5 azure VM come in at 5 in the TOP500 that's funny
they still run simulations and HPC research on it
a "supercomputer" consisting of B300 would not run HPC
and since i consider ANN dead, it is indeed an e waste lol
https://top500.org/system/180236/ imagine this will become more common
as they build out this ridiculous bullshit
HPC6 is surprisingly efficient
eagle is only 1900800 accelerator cores and 172,800 cpu
2,073,600 total
power bill: :^)
what counts as cores really
cuda cores?
warp schedulers?
sm?
like... fr...?
172,800
(3,600 × 48-core Intel Xeon Platinum 8480C @2.0 GHz) cpu + 1,900,800
(14,400 × 132 Nvidia Hopper H100) GPU
14,400 h100s
fair
they plopped that thing down in 2023
when can i see the linpack
on some more dc instances
theoretically i can purchase azure credits to use eagle
Admitting this is chatgpt clearly. This would be 1q if chatgpt didn't screw up the math.

okay
 **To Put That in Perspective **
**To Put That in Perspective **
🥀
so apparently TOP500 count FLOPS with fp32?
yeah it's LINPACK
no sparse LINPACK 
there's talk of using the hpc challenge
but it hasnt happened
since like
20 years ago
more comprehensive tho
nvm
linpack is fp64
i forgot the CPU also computes
and i forgot theoretical performance chart is at normal boost clock
im getting financebro business mindset slop on my yt shorts, and its about sam altman 

sam triangle when
i dont think much was lower precision than that for hpc for al ong time
there's fp32 linpack versions tho

after game graphics are entirely solved 

oh there's a gh

GitHub
Contribute to icl-utk-edu/hpl development by creating an account on GitHub.
if imma be honest
HUGe numbers on this repo
her 3990x would've crushed any of y'all system for fp64

Nah, due to the p40s being out of commission until I can get them working all I have is a 3060 which I'd not even bother to bench with
interface, or the BLAS C interface, or the VSIPL library
depending on which computational kernels are available on his
system. Only one of these options should be selected. If you
choose the BLAS Fortran 77 interface, it is necessary to fill
out the machine-specific C to Fortran 77 interface section of
the Make.<arch> file. To do this, please refer to the
Make.<arch> examples contained in the setup directory.```fortran 77 let's goooo
actually
imma ngl
she's crushing ALL of us
😭
i just remembered on top of the 13 TFLOPS her 3990x has
she also has 2 TITAN V
I ain't winning any race because laptop
each with like god knows how much fp64
like 7-8 yea
Pixel Rate
139.7 GPixel/s
Texture Rate
465.6 GTexel/s
FP16 (half)
29.80 TFLOPS (2:1)
FP32 (float)
14.90 TFLOPS
FP64 (double)
7.450 TFLOPS (1:2)
at stock anyways but who knows with unlock
10.7 TFLOPS fp64
hers run at 2.1GHz
P0 state
stock is 1.45GHz
such a shame indeed
2167MHz
iirc we did hit 2.2+ GHz once

okay
no
the threadripper was the least worrying part
yet it would've already beaten every single one of us
only way i could win is that i run that shit on my epyc 9655 server
9995WX should be about 6 tflops on its own
not real world linpack anyways

64 cores! The latest AMD Threadripper is out, the 3990x 64-core. I've spent the last couple of days running benchmarks and have some results showing raw numerical compute performance using my standard CPU testing applications HPL Linpack and the molecular dynamics program NAMD. The 3990x is a great processor with exceptional performance. Especia...
1.5
3990x is 16 fp64 flops/cycle/core
if it sustains like 4ghz it should be doing 4 tf
they fuse 2 256bit
yeah
so i suppose in total of 1 AVX256 per clock cycle
3.22GHz all core for the 13.2TF fp32
I mean if I crammed my 3090tis in one of my r640s somehow
3090ti has dogshit fp64
^
it's 1:64
afunyun beat me to it god damn it
glop is correct
hascrack. you're not beating the frog's TR3990x in fp64 even with all your GPU lol
1.5TF seem to be outdated score if what i read in the article is not mistaken
the mighty atoms all combined might come close if they could work together somehow
they probably could
cuz those were like 1.6 or something
linpack is literally made for clusters
checks out
The server is running dual xeon gold 6240s, maybe if I went with platinums
1:64 moment
maybe if bf32 existed we'd complain less (no shot)
the xeon golds should be around 1-1.5 depending on how they clock
if it downclocks to 1.9 all core like they probably do unless very well cooled doing all core sustained avx512
that'd be 1.1
single core boost will get .125 per core at 3.9ghz
i'd expect her to hit 20+ TF
but depending on how good the saturation is
14TF is probably already guaranteed
on the titan v
tr not included
learning more about avx512, man that is a lot of registers for some reason. But I'm not about to complain 
she should be close if it can get 3-4 on the cpu (realistically) + 5+ on the gpus
I should really be running 8280s
those would probably get ~2
Cascade Lake should have 0.5 FMADD/cycle throughput iirc
smadge
28c, 32fl/cycle, 2.7ghz = 2.4 theoretical max

iirc zen 2 should have 1
Those also have about 9 grand worth of ram in them right now so ehh... Besides I have actual shit running on them that I'm not taking down for a highly specific non real world benchmark so who cares anyway
32/cycle?
they have 2x avx 512 fma per core
It has 4 cycle latency though

latency won't matter if we stream it
welp, o7 to me who is trying to minmax an avx512 program on intel hardware
god fuck, 0.5 CPI
2 units with 4-cycle latency -> 0.5 throughput
it's .5 cycle/instruction = 2 instructions/cycle
that
i am still wondering if that's for both AVX or just per AVX module though
because iirc some system do use 2 avx interchangeably
each FMA unit does 1/cycle throughput and it is pipelined
Oh wait yeah
intel should say 32/cycle somewhere in those docs
i don't believe they could do 0.5 CPI though
as long as you have 4 fma om f;ogjt
just wouldn't be possible physically so i assume its 2 AVX being used interchangeably
in flight
.5 cpi is the same thing as saying 2 fma units that each have 1/cycle throughput
I'd think you'd have enough register space to just have two separate loops running at once if needed
that icelake core shows 1 cpi because it has 1 fma unit
latency is 4 cycles. i'd imagine it to do 8 in flight with 2 stream points per cycle
hmm
32 registers in total, so you get 2 operations per
so happy rn programming does not talk about llm slop and instead we talk about what god intended
Separate loops running on what? 🤔 The backend is saturated in this scenario so hyper threading does nothing.
seperate loops for streaming, no point in operating on a waiting state so one should swap to whatever is available at the moment
hyper threading often helps with giving instruction commands in case the other thread isn't saturating it well so it just really depends on the code

Same throughput according to the instrinsic docs


impressive.
To be fair, the AI slop I'm working with actually involves a lot of non Ai specific code... Specially as it pertains to free threaded python and proper resource utilization
no shutup
adults are talking here
aight so apparently skylake has 2x 256 bit that acts as a single avx 512
me trying to get hpl working while not paying attention 
did it actually do 0.5 CPI wtf
because if it actually does 0.5 CPI with only technically one AVX512 i'd be fucking impressed
I mean that has to be one of the most optimized operations on the FPU so I guess it's not that surprising.
div has 4 CPI 
dawg how is skylake losing hard to consumer zen 2 though
is it skylake SP (xeon) or skylake X being referenced (x had 1 cpi)
gaddamn
they fucking name their architectures like a gigachip in megaman battle network
Because despite the fact that amd is killing it, the market share for Intel is still 72% where it matters
I don't know anything on this so I get to learn 
aawagga

at least you wanted to learn unlike the person above who just missed a point lmao
oh damn

Wccftech
AMD announces a new GPU OC world record by pushing the Radeon RX 9060 XT to a whopping 4.769 GHz.
long live epyc
14-bit approximate reciprocal is 1 CPI
No one needs FP32 precision these days anyways 
Yes still 72% with nothing relevant released. Keep in mind 28% isn't all amd


nothing relevant
some modern xeons actually being bangers
Also for the most part amd system power draw deletes an entire cabinet in 1ru
27% unit share but 41% revenue share 25 q2
where did you get this one from lmao
yeah sad that those are used nearly as much as H100 spam
Actual datacenter experience?
i don't buy it
intel is notoriously bad on power efficiency atm isnt it
like epyc are higher perf/watt
I can dig up my equinix badge if I can find it
both can run at their designated TDP. both can also deletes the whole enterprise PSU brick with 2KW+ draw
hell in my experience of managing some sapphire rapids chips they draw more than my 96 core epyc 9655 often
the die density is just larger. physics don't lie.
just that also in my experience, intel's idle power draw/management are way better.
if that's what you're trying to talk about.
because depending on specific datacenter needs, that could be relevant.
this is true rn
but they're not that bad.
Dual 1600w (1.6kw) that can run in non standby config, 3.2kw if running single phase is 88% (over 80%)
what system?


like you wouldn't use the same cpu for high prefomance compute 24/7 and running vms for web hosting on the same hardware. AMD makes sense in one and Intel in the other.

skylake is nearly all of intel's marketshare
in server
it's like 50% of it
if you do not count 10 year old skylake and 7 year old cascade lake
AMD = 47.74%
Intel = 52.26%
you use the e waste ARM chips for VPS or vms or web hosts
That is also a fair statement
😂 That's like most of what is real world deployed
also epyc 9965 192 core sweet spot tdp is at 600W ish
well yes but the point is that when they retire
which they are
they will have like 0 share
and that's like almost 4x highest xeon core count
and by 0 i mean 50%
but yeah
it's a lot different of a picture in more recent generations
that's all im saying
I stand that intel did manage to predict their needs well and try to mitigate it with products. But they were simply too early for the problem.
intel's share is riding a geriatric coattail of enterprise sluggishness atm
🤤 Could compile my C++ project in under a minute.
Oh 100%
i was really gonna hit on the 9965
till i got offered a new 9655 for like $4k ish
or $3k ish i forgot
if you toss out the first 3 threadripper gens and cascade/skylake so only recent, amd has actually passed intel in workstation share
TR9K = 4.58%
TR7K = 7.05%
TR5K = 7.13%
TR3K = 8.73%
TR2K = 2.84%
TR1K = 5.82%
Thread ripper all up = 36.14%
Sapphire 35xx = 2.21%
Sapphire 34xx = 7.75%
Sapphire 25xx = 1.41%
Sapphire 24xx = 5.49%
Ice Lake 33xx = 1.80%
Cascades 32xx = 5.35%
Cascades 22xx = 17.59%
Skylake 31/29xx = 22.26%
Xeon W all up = 63.86%
Workstation component share throwing out TR 3 - 1 and Cascades and Skylake
AMD = 50.12%
Intel = 49.88%
i forgot the total but i can afford it with monthly payment last year
anyways just fun stats from this wccf article and its comments mainly this one

Wccftech
As per the latest data by Mercury Research, Intel is continuously losing its server CPU market share to AMD for several years.
i would like 18a aka 1.8 nm if using older style to be good but who knows
i still find it fun that epyc I/O die is still gigantic
wccftech comments
Haven't looked at that toxic dump in a couple years 
it's so bad if you scroll down lmfao
this reminds me of liek 15 years ago:


:dentge:


considering that at least half my uni uses macbook im surprised this is what the graph is rn

1.8 NM DRAM and NAND
What could go wrong
apple people arent real
though desktop do really took a major chunk because offices uses a lot of them compared to laptops
I can't say what I think they should be making, but a few chatters know exactly what I'm thinking
i bet openclaw minis are somehow larger in volume than total apple desktop sales for like years
(joking but)
i thought those are 9 y.o that watch pc building slop shorts everday
30+ y.o be talking about how their M4 draws only 10W when x86 chips has to draw hundreds
How many were bought with credit cards, gambling that their botnet could somehow make the money back.
those posts reek of genx
i hope not many considering theyre so cheap
i mean you should buy them with a cc to get your 5% cashback but then you pay it off that month otherwise you pay interest which is a life altering failure
Oh that's how I use mine, I even pay off the balance before the billing date. Seems to artificially inflate my credit score lol
dawgg, i never realized most of my switch roms are leaked copies lmaooo

people are hoovering up mac minis because you can get an m4 or m4 pro for around 500 bux at the cheapest
expensive.
not really for what it offers when you look at it because it's not about 1 unit
cluster them
You mean offbrand claude
it's like the one time an apple pc has ever been a good deal for anything
other than smelling one's own farts
at least in modern times
Apple's hardware is actually (for the most part) not awfully priced (ignoring the top end graphics design stuff).
And I hate to admit it
it's awfully priced if you care about actual specs/dollar
it is not low quality equipment but it's overpriced for what they are giving you in sillycon
minis being 599 is the best deal they have by a lot
If you spec out a Dell laptop with similar specs it's less than $300 cheaper
that's a large amount of money for many people first of all, secondly i don't use dell as a benchmark for value and neither should really anyone, third as soon as you start adding small amounts of ram and storage suddenly any apple machine is 2x in price immediately
Dell is by far the standard for large scale deployment.
e waste
talking enterprise deployments is irrelevant to the average consumer and has different dynamics completely but even still 300/unit is a 6 million dollar difference when you multiply that by 20k machines
apple is charging $1080 to go from 48gb ram to 128gb on a macbook pro, which sadly doesn't sound insane right now because of the world going insane, but it was the same price before everything went insane, or very similar
300 a unit on 2000 units
It's not when you factor in what you are paying in salary to an employee that you are giving a $2000 laptop
600k on a 3-5m contract is a large difference
just hardware cost
and the employee wont care either way unless theyre a creative who probably should have a mac because of ecosystem shit and to stop them moaning
Same with upper level IT, you give them what makes them happy enough to not complain about the pay
specs?
It depends on the person but I know plenty who prefer it. Doesn't really matter what your running once your in a shell anyway
which is an argument against an apple machine not for
doesn't really matter
$2000
i would use a macbook pro with linux or something on it
im not saying it's a useless piece of rock
is this how it is in the enterprise space managed by a moron who has infinite budget
kinda sometimes
No it's a finite budget spent on stupid things
even my personal briefcase pc that is faster than any gaming laptops out there is still less than $2K
convince is worth a lot, and people are willing to pay quite a bit to be lazy.
it has 128GB ddr4 too

I'd think something is wrong if it was allocated in a normal way
i cant think of anything convenient about using an apple machine in an AD managed environment
or in general but especially then
I ain't have the income for convenience, good to learn how the tech works as well
eh work laptops are inherently overpriced anyways
I'm pretty much done with buying laptops, I finally have a room to myself so I can actually invest in desktops properly
or odds are servers
don't really need much more gaming prefomance
the standard shitter laptop people get deployed at my office is basically a base model dell 16 plus
they probably run around 500 bux/unit
for that apple will sell you most of a mac mini or optionally they will take a shit on your doorstep
it is not free of charge for that service unfortunately
I mean if people will pay you to do it then why would you do it for free? That's not apple's fault now is it?
well, it IS their fault that they make you pay extra for post-purchase doorstep steamer support
hi gugs.... if u had to guess, how does neuro listen to ppl?
like... her ability to listen to vedal/collabs is via discord right? so does that mean she's (atleast part of her) is a discord bot?
like if thats true, does vedal use pycord or something like that? 
She is agi she can speak english directly
Her speech to text connects to discord and transforms speech into text for her to use
yea... but like what does he use
One message removed from a suspended account.
One message removed from a suspended account.
One message removed from a suspended account.
One message removed from a suspended account.
@round kraken
Isnt marked as bot  or maybe its because im on phone
or maybe its because im on phone
One message removed from a suspended account.
One message removed from a suspended account.
is that the bot he uses?
i thought it was this one
One message removed from a suspended account.
Its her account
One message removed from a suspended account.

try "in" instead of ==
One message removed from a suspended account.
anyways:
i found this (pycord's audio examples)
https://github.com/Pycord-Development/pycord/blob/master/examples/audio_recording.py
the thing about this one tho is that you have to manually start/stop to listen audio

GitHub
Pycord is a modern, easy to use, feature-rich, and async ready API wrapper for Discord written in Python - Pycord-Development/pycord
One message removed from a suspended account.
One message removed from a suspended account.
One message removed from a suspended account.
One message removed from a suspended account.
One message removed from a suspended account.
One message removed from a suspended account.
whats ur theory on how neuro listens to ppl?
Twins role is crazy
Hi nerds
i checked few, discord.py (the one im using, doesnt support voice recieve), pycord/discord.js/discord.py-ext does, ig my question is how does she listen to the speaker?
like
user speaks -> bot recieves message -> user stops speaking -> (threshhold for silence) -> bot saves message -> then that goes to sst??
but neuro sometimes interrupts vedal? is that because of the delay from the previous voice read?
Probably either clever use of discord.py-ext OR, more likely, the real Neuro is a self bot
he wrote his own framework?
why would being a self bot change anything
Much easier audio stuff
-# legally I wouldn’t know
it's literally not easier
i haven't looked up much more on discord bots anyways (planning to), but focusing on this, you have to manually trigger it to save audio recordings
ok at a super low level, sure you could use all of the discord client as a source
discord.py-self
if you invest more time an infinitely better solution is just using a bot, because they can get individual audio tracks
oh thats a thing lmao
if I wasn't increasingly busy with life and other projects I'd work on a program for stupidly easy voice recv because for some reason everyone loves to do it the worst ways possible
The only times I’ve done it, it has ended in code tragedy
skill issue?
Yes
heres a stupidly easy one 
https://github.com/Pycord-Development/pycord/blob/master/examples/audio_recording.py
GitHub
Pycord is a modern, easy to use, feature-rich, and async ready API wrapper for Discord written in Python - Pycord-Development/pycord
eh, I have an aversion to pycord
what would you use thne?
unfortunately afaik for receiving voice in python I think it's the only option
what would you write it on then?
I've previously done it in rust and it's worked very well
What's the purpose of Neuro-bot on this discord?
Other than feeding it cookie of course
🍪  Om nom nom
Om nom nom
You've given me 4 cookies! | I've received 284656 cookies total!
keep in mind this is a "the developers have been bad people in the past, and I don't trust a lot of the architectural decisions they've made"
you can 100% write something with pycord and have it work
I did mine in discord.py
🍪 Om nom nom
You've given me 8 cookies! | I've received 284658 cookies total!
Hey
🍪 Om nom nom
You've given me 1 cookie! | I've received 284662 cookies total!
Yeaaahhh
🍪 Om nom nom
You've given me 1 cookie! | I've received 284663 cookies total!
havent spoken in here for a while, but been making some cool stuff that i think would be cool to show
been working on a custom unity IL2CPP modloader for a little project me and my friends are working on and its soo cool, although im not certain about how the plugin infrastructure will look like. i've been taking inspo from geode and im trying to not stray too far off that path
if anyone could give me some feedback on how i could make the syntax for plugins a bit better without entirely stealing the look of geode pls lmk 


@small anvil
i am interested

idk much about loaders but i see il2cpp
i'm writing my own il2cpp dumper
for honkai star rail
hiiiiiiiiiii
loaders are pretty simple, you just gotta be able to load coreclr into the process to be able to execute IL
interesting...
is the one you're making universal or only working on this game so far? or only targeting one/few games specifically
literally all the logic that goes on in finding an available CLR environment
ill probably switch this to downloading the binary itself soon but for now this is just a quick fix

universal, hopefully
im gonna have support for both managed and unmanaged plugins

its a very daunting process
i decided to make my common library header only
and now im having to split it into source files
cause my dlls are reaching sizes they should never reach
proxy dll
unity likes to load the first version.dll or winhttp.dll they see
just
put it into game folder and run
basically
omg i'm doing the same thing
replacing mhypbase.dll in the game folder
game runs my code blindly
boom we're in
oh nice
i dont know much about honkai so i wouldnt know the process
i heard the people that make that game likes to hide their code religiously
oh yeah hoyoverse is extremely aggressive
but hsr is their easiest game to work with
genshin is wayyy harder
and zzz is even more difficult


oh yeah i saw genshin i think
i first found out from perfare i think their name is
from their blog

wait let me try to find it
yes plz
that's the person that wrote the famous il2cppdumper right
but that one works by parsing metadata
which is not possible here
encrypted


blog is down it seems
i know im not schizo i wear thats were the blog was
archive.org my beloved here i come
@small anvil hi hi u can read down my messages from here if you are interested which of course you are teehee.......
oh thats really cool
i havent seen an actual runtime based il2cpp dumper in ages
only time i saw one mentioned was a while ago when i was reverse engineering a social vr game with a couple of friends
well it's definitely much easier than working statically with encrypted metadata
i have too much experience with that..
luluscared asf



and as far as i know this get decrypted somewhere after il2cpp_init gets invoked
yes
but
with this game even that isn't possible
the metadata never exists fully decrypted in memory
game uses lazy decryption
only decrypts the parts it needs, when it needs them
so yeah...
oh boy
yeah hoyoverse is very seriously anti RE
yeah i can tell
of course that doesn't stop the awesome RE community
it's a cat and mouse game after all
but
it does mean that pisslows like me get a much, MUCH steeper learning curve
it always is
i dont think im gonna even bother with splitting up my common library
ill probably do that later
Twitch now requires some new Affiliates to verify their identity through Persona before receiving their first payout.
Users report needing to submit a government-issued photo ID along with a selfie, with no alternative verification method offered, according to Twitch support.

 is this going to become the norm for online services
is this going to become the norm for online services
i hope not
I don't know where the push for this shift is coming from
big tech corporations bending for governments
uk pushed it the most
and everyone else followed
filtered.

i got the GPU

 we can't discuss those topics here
we can't discuss those topics here

 mb
mb
It's almost midnight
yo any data engineers in chat, specifically anybody that works with SQL
Hey Shiro, quick question. What is the function of Neuro-bot on this server?
Just ask your question
okay, say I have a DECIMAL(38, 2) in Teradata and I want to convert it to BigQuery. Should it become a NUMERIC(38, 2) or a BIGNUMERIC(38, 2)?
If there's no plan to add more digits it shouldn't matter which one you choose
well it does for performance

The only way to know is to benchmark it. Because it all depends on what you do. There's a benefit of numeric vs big numeric, namely the smaller storage requirement
*For the same supported precision
reason I ask is because I made a python script that compares schema, and someone is telling me that NUMERIC can't take more than 29 which i was almost certain is not the case.
 dougdoug guy
dougdoug guy
According to the docs, it can have 38 digits with 9 of them being the number behind the decimal point
I don't know if the limit of 38 digits can be said the same when using only 2 decimal
uhh
🍪 Om nom nom
You've given me 19 cookies! | I've received 284670 cookies total!
https://docs.cloud.google.com/bigquery/docs/reference/standard-sql/data-types#parameterized_decimal_type
 max precision of scale + 29
max precision of scale + 29
so 31 in this case
need BIGNUMERIC
main job of neurobot is 
trust me 
🍪 Om nom nom
You've given me 2 cookies! | I've received 284671 cookies total!
btw didn't know unkomputoble is the starknight
So their 38 precision is only valid with 9 digit of decimal? As in, you can only go up to 10^29?

You just realized that we are on 2 different server? 
what the heck
oh, so NUMERIC(38, 9) is valid because there would be 29 digits to the left of the decimal point. So I should be checking for if (p - s > 29).
rule 3
rule 2 thoughbeitever
 2nd rma got approved
2nd rma got approved

RMA for what exactly?
Oh I see
It broke again?
Are you sure the issue can't be your CPU's memory controller?
nope
its the stick
3 of them work perfectly fine, the 4th one doesnt even work on 2133mhz
or well, it does work but i get a lot of errors during memtest
linux boots but is unstable
for all the linux users here
Linus is right. ECC is de wae
broken nand chip wont be solved via ecc
But you'll know that it is the RAM that is faulty 
i already know via memtest
all the other sticks had no issues, jsut the one bad stick
ive been saved form bankruptcy 
 742 euro
742 euro

probably the worst time to get so much ram
rgb ram no less
one could say probably one of the worst times in the history of ram to make such a purchase
its RMA, im not buying
if my rma got denied i would have kept using this 16Gb stick for a year or 2
actually, i could jsut use 2 of the working sticks
Gemini 3.1 way overthinking its review of my CPU fan curve

now that i think about it

with a 16gb stick, i have more vram than regular ram rn 
Currently developing my own friendly ai... thing. Hope that she and neuro will be friends one day lol
i highly doubt your ai will interact much with neuro
omg I just typed python to fast and typed puyjom instead >w<
uwu-esque thing idk
$10 a month for a minecraft server?

and why 3vcpus if minecraft servers are single threaded?
the > and < represent squinting eyes. the W represnets a curved mouth

oh god it’s in their status too
catgirl “>w<“ lol
whoa you think uwu behavior is fire
its kinda cringe but ill allow it
Chunk gen
Also they're likely not very good threads
Probably AMD Epyc threads
Which are really slow but you get a ton of them
I think the #programming channel alone has enough people to make neuro’s dream of an ai-only tinder come true
to be fair epyc threads can be pretty fast if it is the right sku
i dont think vedal would let anything close to that happen tho
fr w father
Looks like ^>w<^ has sparked some attentio UwU


We’re on a journey to advance and democratize artificial intelligence through open source and open science.
This model looks really good, why have I not heard anything about it 
Its not as though ServiceNow is a small unknown company
is our free ai slop generator finally back



Then again if it doesn't surpass 3 pro image (which seems likely given the lower param count) its not that exciting for me given I have free pro as a student

ive discovered something horrible
literally ruined my night
nevermind
false alarm
user error
issue between keyboard and chair?
☁️☁️☁️

i was looking at this message
and had totally convinced myself the cloud emoji was smaller than the lookup emoji
but its just an illusion i guess?
it is smaller i think
yeah discord likes to put spaces after your emojis
lemme try something

oh
idk why the space is so hard to see
i dont have the empty emote
 ?
? ?
?☁️☁️☁️
do you have either of those
nope
i guess you're more likely to have  or
or 
don't worry shiro all the emojis are the same size
no but I have 
unless you consider them getting downsized if there's text in the message
or many emojis in the message
or formatting effects
nope
shiro we're friends, you can see our mutual servers
you don't need to be friends to see that

only 3, thats crazy
I'm only in 3 vtubing servers, so unless you play a lot of squad then it's unlikely that we'd share any
the vtube studio server is public so i can see where it came from,t he rest is just from a private server
I've never understood those that are in hundreds of servers, like there is absolutely no way you can pay attention to even a small fraction of that
all my servers fit on one screen

im only active in maybe 7 of the servers im in
i got dev servers, vtuber servers, servers form friends, college servers, game servers
I have my own dev server, a server for a squad community I admin for, some servers for other squad communities (including the official ones), some vtuber servers, then some miscellaneous servers I use for emojies
Dawgggg DS2 demanding af
Idk if my LOQ can handle it ngl

150
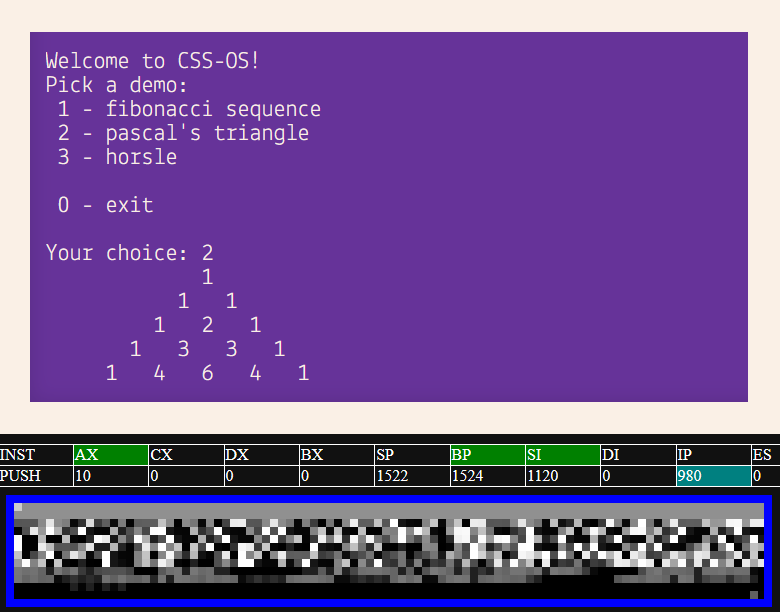
x86CSS is a working CSS-only x86 CPU/emulator/computer. No JavaScript required!
Thank you Rebane
wtf
But can it run Linux?
asking the real questions here
Movuscator exists. So it's only time until someone made C compiler to css
I remember playing with a javascript x86 emulator running Linux.
Without looking over the source code, im guessing this css emulator makes heavy use of calc, guessing that set of squares at the bottom is memory with each box being a byte encoded in the shade of gray.
There is no reason the box holding data needs to be visible...AFAIK calc will work just fine, so that can be a good way for handling storage needs.
So long as the css is working as an x86 emulator, you shouldnt need any special compiling...it should run x86 code
But that would be slow since it needs to emulate x86
Yeah...but also its Linux...you just need to get to command line.
No one saying it should run KDE
OK, having seen the demo...never mind
That is stupidly slow
Skill issue

 what exactly is the skill that they have issue with?
what exactly is the skill that they have issue with?
Lack of mutual servers
7 is rookie numbers
8 here
 hi iggly
hi iggly
me who has like 70 mutual servers with my bestie
70???
70 is a bit excessive
if you lose nitro do your servers get sent to purgatory
if you're above 100 and you lose nitro they don't go away but you can't join servers anymore unless you leave enough and go back under the 100 limit (or buy nitro again)
is like 90% of your servers just emoji servers
yes
my highest is maybe 13 mutual servers, idk
i only really talk in one lol
close friends server
i used to be more public and stuff
some years ago
but that shit drains you
now i hate people

I have a 19 mutual server friend
lemme see if there’s someone else
nope 19’s my max
I'm in sixteen servers period. Seven are private, three of the public ones have less than five hundred members.
In the words of my friend, I can be a bit of a boring arse
hi
I have my active group, irl and ones I look at from time to time/not at all


3 main servers, 5 friend servers, 6 announcement servers, 3 emote servers, 4 dead servers that just exist.
That's also how I organize them
i left all the servers i was in that i couldn't rememeber why i went to them. and then i had a managable amount.
(I also don't have a great memory)
I think I have a problem... I'm attempting to do an all core compile of flash attention... On a 72 core system
Jesus Christ i'm always afraid of my phone's battery when i join too many discord servers lol
Chat is flutter great for developing a p2p multiplayer game
I want to make an Android game as a hobby
normal flash attention build

gotta be honest, building flash attention in under 8 minutes felt pretty good
btw for anyone who owns a console, can we turn off motion blur in games?
That is called Temporal Anti Aliasing, and no; your stuck with it
flutter is generally meh for games, it's built for making apps - though there is stuff like flame
Flame is a game engine built on top of Flutter. It runs on mobile, desktop, and web.
one thing flutter has going for it is you have good cross-platform out of the box, so it'll be a ios, windows, macos, linux game as well if you just build it for that platform
bru imagine looking at 30 fps with motion blur...
painful ☠️
Your also stuck with it on PC 
wait what
that's like
wrong
two different things
Yeah honestly it isn't the same thing

One can get rid of motion blur, but that aliasing is motion based
That's on me for not explaining everything that was in my head at the time
taa isn't remotely as offensive as motion blur and vice versa if i actually want motion blur
motion blur can be nice sometimes
It can be, I do agree. I just wish to have an option to not have any blur
it isn't either or, it's two separate things
tbf i've yet to see a game where i can't turn it off
but also i never do anyway it looks fine
Makes sense
bird

if i have a dlss option i'll turn that on
did you know there are some butterflies in this genus with a wingspan of 20cm
which is larger than some songbirds
What a peculiar species of bird

does not make it a brid
Bird

IMO motion blur when it's not used to hide low frame rate is fine. Problem is when it's used for something it shouldn't be (hiding low frame rate)
I like motion blur (when done properly, there are different kinds of motion blur, radial vs linear movement and such) in racing games. However only on low intensity. For everything else i dont particularly like it
I find TAA quite nice, but it needs post-sharpening, only a touch, but yea. The one issue i have with "It takes Two" is that the TAA is not sharpened afterwards so i have to do it in the driver which probably doesn't look as good as it could.
(i add like 12% sharpening in nvidia or so. 7 and up is enough, 25 and above looks odd to me. 50% looks stylized cartoonish to me
ahahaha

just check this out
that so funny
auto lock = save_buffer.lock_nowait();
while(not lock.has_value()){
co_yield{.timeout = 40};
lock = save_buffer.lock_nowait();
}
auto success = save_buffer.write_ifFreeSpace();
if(not success){
co_return;
}```
cloude 4.6 thinking is peak
idk about prev, havent used much
but out of everything i used it is most useful model
AND NOT ONLY FOR SEARCH
it just wrote me lua script that ACTUALLY WORKS
Gemini 3.1 Pro is my go to now but Opus 4.6 is great too
i just checked everything in script following docs and other examples, and it is correct
I hate this fedora wearing reddit fuck so much

im looking at various large insects and i really really would not like to meet any of them
butterflies look fine by comparison but 20cm
Due to price/performance mind, Opus 4.6 is a stronger coding model while 3.1 Pro is a stronger generalist but 3.1 Pro is good enough at coding for the price
amount of false positives this thing gives is awful
system prompt change

I have a 100% false positive rate with it because I'm on Mullvad
i don't even use anything like that
Makes sense
it just blocks me for no reason
default browser no incognito mode no vpn no weird network shenanigans besides being on uni wifi
"you've been blocked by network security" i'm about to block someone from continued existence


The AI developer laid out red lines on military use of its products, a source said.
Disconcerting
Apparently Anthropics redlines are using Claude for mass surveillance and autonomous weaponry
But the Pentagon is pushing for it
orm
llm guided weapon

im reminded of
the vending machine
are they sure its a good idea
what vending machine?
llm scapegoat :rrrr:
Gigabyte G24F
This symptom(random lines appear and screen jittering) happens every time I turn the monitor on(even on its logo page, so not gpu issue).
It'll slowly recover after a certain amount of time(anywhere from 4secs to 6mins) after lighting up, the artifact disappears like something scanning upwards. Remains functional without any other visual artifacts.
Initially occurred after OCing the monitor from 165Hz to 180Hz(their promoted overclocking refresh rate)
My questions:
Would it worsen in the long term?
Is it fine if I just leave it untouched and keep on using it?

Hmmm
Drop the overclock, if it causes instability its not worth it for 15 extra Hz
You can damage monitor hardware with a dodgy OC
the artifact still appears after dropping the OC and returning to its original working refresh rate, maybe it fucked up already

This is why I don't fuck with monitor overclocking, you risk hardware damage for (in this case) 0.5ms of frametime improvement
well I guess it's fine if I just have to let it warm up for some minutes
at least not some huge visual issues that stay consistently

probably some component got stressed at some point and now is acting out.
(as in "is incapable of performing in spec any more")
i made an LCD screen have grayscale by screwing with the driver for it... but that only cost a couple of dollars vs a monitor. and it looked pretty bad.
I am suspecting some thermal-sensitive capacitors got a bit cooked while I was OCing
only 2 years of use 
 rip
rip
did you by any chance also touched some voltage related shit
because that's the one probably causing hardware damages
else just normal overclocking shouldn't actually damage it and i suspected its just buffer related issues and you can try disconnecting it from any power
nope, I used the overclocking feature built-in to the OSD
just a toggle from no to yes, and perhaps also switching my refresh rate in the nvidia control panel
idk how does gigabyte handle the overclocking
welp
assuming its gigabyte
interesting read, might shed some light on those recent moves in the hardware market, such as the hoarding of wafers by the biggies..
https://www.nytimes.com/2026/02/24/technology/taiwan-china-chips-silicon-valley-tsmc.html

By Tripp Mickle
If China invades Taiwan and cuts off its chip exports to American companies, the tech industry and the U.S. economy would be crippled.
everything everything ai now ig
im just gonna silently watch as these "ai" models slowly just fucks up by some sort of any unlucky probability distribution and cause them damages
we have the us and openai hoarding 900K dram wafers per month and causing the shortage
that 900K wafer is about at least 1.4EB on reasonable yield rate. not even any supercomputer with most system ram came close to that capacity
and the fact that its strictly dram and not even hbm
its questionable as fuck
all those ram are just going to sit in warehouse and waste away
has this not been blindingly obvious for years, even before ai
god, honestly i would really like to see what happened if the chip supply were cut off from the US because that'd be funny as fuck
we're doomed either way. either they get it and waste it in the name of "AI"
or they don't get it at all
did they not just pre-order tons of the memory wafers and buy out most of the scheduled future supply for the next few years
it's not even sitting in warehouses it simply doesn't exist
they reserved wafers on terms that when they are available in future, then they can choose what they will be made into from some predetermined options
i see, thank you
the contract said 900K wafers per month
so 40% of what's currently being produced
christ
its still very unrealistic
i do not see how they could even utilize that much
let alone that much per month

yeah seems like they'd be limited by infrastructure way more
power, facilities, etc
nodes.
hi konii

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
no one cram more than 1536GB on even a modern 12 channel epyc
else you run at way lower bandwidth
even if they managed 2048GB per CPU
It always seemed crazy to me that they have not moved tsmc somewhere else just in case
its still just 65PB of ram on an extremely massive 16K dual socket node
i thought the high-bandwidth memory wafers were also used for VRAM as well as DRAM DDR5 and it was going mostly into the gpus rather than memory sticks
because they don't own tsmc
contract specified strictly dram
oooh ok that's news to me
HBM isn't even included yet on their contract
i don't fucking know why 900K wafers of dram
they could've do like 10x less capacity for like hbm with similar cost
and get even more benefit because hbm is just way better for whatever the fuck ai shit they do
you don't inference nor especially train models on dram.
great lol, all of it is getting wasted
the T stands for Taiwan.
either that or open ai would start drop shipping dram when they fold
also: moving fabs is very hard.
you literally would have to rebuild the fab and sorta start all over the R&D
i'm almost certain there'll be a video on the asianometry channel about the article in the next week or two.

damnit. i wrote it but still read it as fabs() instead of "fabrication plants".
new discovery, also happens when switching to a dedicated fullscreen with different resolutions
i used same monitor for 7 years
buttons almost not work, but monitor is fine
might be time to look for a replacement.

We’re on a journey to advance and democratize artificial intelligence through open source and open science.
i gifted pc, so now i just use my small laptop
This may be the GPT OSS killer
i like have to write everything i designed, but i tired now
randomly found critical memory leak on coroutines stack destruction when exception occur
i just have to put code i wrote in actual repo (in 3 different generations of our software)... a lot of time just for copy pasting and running compilation + fixing compilation issues
- i have to write logic for writing and reading from disk, to save actual output data and will use disk as swap memory
also, who need it