#programming
1 messages · Page 404 of 1
dont blame ai blame the prompt
blame both 
SP5 still in demand, SP3 old enough to be relatively cheap
To be fair, the dude is actually a competent person lol
if you arent spending 16 hours setting up the most custom framework of guardrails possible only to abandon the whole thing later then you aint vibin
ye
if only i have sp3 chips just lying around
you don't? 


kekw
no but he has an intel atom
Intel Atom + PCIe switch 
i really need to make an auto restart for my claude code required programs
i wonder how hard thats gonna be to do
honestly i could probably hit some 7763 for like $600 each
but the problem is the ram
the fucking rammmm
buy ram sticks directly from china
i have like plenty of 32gb ddr4 dimms but none of them are ecc
thats what im doing
intel atom with avx512*
 wouldn't that also be even worse with DDR5? Or do you already have DDR5 RDIMM lying around
wouldn't that also be even worse with DDR5? Or do you already have DDR5 RDIMM lying around
its nice having contats with chineese manufacturers
how else am i running my current sp5
: 
 in use
in use but consider...
but consider...
;
i mainly wanted the sxm5 interface for scalability
but oh well
i don't even know if sp3 boards have at least sxm4
but yeah if you already have RAM that you can take from another machine then I guess just go SP5
RAM prices will probably make the difference between SP3 and SP5 negligible otherwise 

everychina.com
Model Number:KMDH6001DM-B422,Certification:Original Parts,Price:Negotiation,Payment Terms:T/T, PayPal, Western Union, Escrow and others,Supply Ability:6000pcs per month,Delivery Time:3-5 work days
very tempting..
i dont like to brag fellas butg
i recently purchased a cpu so powerful
the verge (respected system builder news outlet known for h igh quality youtube building videos) called it
what cpu is it?
"....a.................cpu...."
let him cook

60 of those atoms 
lol i just needed a block of metal to put in that socket to use the ram and put that in the box under it
it was only liek 60 bucks
hey mine is more powerful ya see the pins are big and they need less of it which means its better!

not bad
damn
I assume the 64 stands for 64 cores
X2 so 128
64 terabytes of ram

yor visualizer indicates that your music is peaking above clipping
this case is a marvel of engineering

box
i am building this pc right next to where my cat sleeps at the window
no esd risk detected
hard drive cage encroaches on the mobo area enough that i have to take it out to put the mobo in
nice

Get a 14-day FREE trail of flare at https://go.lowlevel.tv/flare2026 . See if you or your company's data is floating around the dark web.
🏫 MY COURSES
Sign-up for my FREE 3-Day C Course: https://lowlevel.academy
🧙♂️ HACK YOUR CAREER
Wanna learn to hack? Join my new CTF platform: https://stacksmash.io
🔥COME HANG OUT
Check ou...

I see your athlon, and raise you...
My keychain

i only have a usb4 cable on my keychain
I hate those clickbait titles
I have other CPUs as well

It is not
A malicious site with CSS can actually run arbitrary code
It's a 0-day

no one hacked CSS. Chrome has a bug in how it parses CSS. Those are very different things
Well, fair point

It’s a techtuber innit
i9 14900HX, i9 13980HX, i9 13950HX ES, I9 13900 ES, i9 12900 ES, 7950x ES, 5700g, 3700x, 3600x
the 14900HX a d 13980HX are modt so soldered on a board
the math is mathing
A sobering reminder 

are those pins bent?
We found that the most helpful resources for setting up and developing a custom kernel driver come from the game cheating and modding community besides the Microsoft Learn online resources.
nah that's just some image artifacts
@fast pagoda how do i get the monthly thing for claude-monitor?
What kinda mods require driver? I think that’s more cheat territory
anyone with experience with the neuro api, what do you reccommend for an integration with fnaf 1? im thinking python just using pynput and moving mouse and arrow keys to control the game, but that feels flawed and possibly could be exploited by neuro if i dont code in some restrictions
How do FNAF mods handle things?
im not sure, ive been looking around and havent found many, other than ones that just take the entire game and change it instead of an add-on
You could use scheme like bridge between Neuro communication and game like Pokémon does
ill keep looking around though

fthe pins arent bent
it was a recycling logo on the plasticv

i need 2 more xeon to make a sooper funny image

could you elaborate on that further? im looking at the docs and am getting a bit confused. as i see, you have to inject a lua script into the game for it to integrate
unsure if you can do that with fnaf
Why do you have that many xeon lying around unused
only motherboard viable is 2k
IIRC it uses some JS script to actually talk with Neuro via socket
Script then reads/writes stuff in text file which is read/written to by game as well
yeah, i was thinking using js to talk to neuro, and also writing commands somewhere which is read by a script that controls the game, but im unsure about the controlling game part other than pynput
but also mixing javascript and python doesnt seem like the best idea for a simpler solution

you said it is 8 people right
yep
i thikn when the world burns you might be on the chopping block when they ask "BUT WHO WAS USING THAT MANY TOKENS??"
yep
im definetly one of the reasons claude has to scale so often
or better said nova-development
I hate that AI agent is using my cloudflare worker free resources 
Go crawl somewhere else you clanker
meh
My site has only been up for a few hours and look at this

yeah that looks about right
Every single one of those request must be authenticated and it will eat up the KV daily limit
filter them
i hope you turned on the ai bot crawler thingy already
Yeah, I just did. I realize that they are not turned on by default


i forgot that coolers come with cpu
i havent put one of these on in like 10 years
why the tf does the screws not reach
the fucking hoels
It's been a day and it's still fucked 
i dont want to put the stupid h100i in the closet on this thing because that's so unnecessary but i might be outskilled by the wraith
might need standoffs?
there's usually the backplate that you then screw into


 because it stands at on offset
because it stands at on offset
of in out the hot food
I gotta say, ai overview, I don't think restarting my computer is going to fix wacom's shitty website

it might be just that im supposed to jam them down
but it feels so incorrect
they are spring loaded for tension
omg if i am then that's absurd
it takes like
my bodyweight
to pushed them down
nah that can't be right
weigh three teacups and a mushroom
lmfao
FOCUS
it should be loose
and then you screw into it
just like how the default standoffs are screwed into the backplate


float64
water can also sink

ok yep
there is a backplate
but
the backplate
when i took the previous mounts off
fell to its knees in the dennys bathroom behind the mobo
put it back then 
I just wanted to showcase the custom glue job they used


I have this thing too
somewhere


Lady awa, are you high?




please invert the current view matrix for world vector to screen position function

 consider it done
consider it done
please invite yourself to leave
I kindly reject this offer
@olive sable return kni croissant


death penalty
bye
no tide lock, bad enub and kni
it means you and enub hasn't formed long enough relationship, and was unable to establish a stable gravitational state to achieve a tidal lock.

can anyone assist me with reading a clickteam fusion 2.5 game state? my options seem like reading the things in ram or using a DLL, both seem very bad for a "just works" game integration
what the hell is an aluminum falcon
I mean, you either read externally, or internally
both requires you to have an offset/signature to what you're reading
there're no easier alternatives

Excerpt from Cloudflare Docs:
A navigation request is a request made with the Sec-Fetch-Mode: navigate header, which browsers automatically attach when navigating to a page.
In your guys opinion, is it better to rely on this on just use explicit routing to run worker first?

Cloudflare Docs
How to configure and use a Single Page Application (SPA) with Workers.
Especially for SPA with API on /api/*
are you trying to limit bots? use security rules//crawler rules /WAF rules

managed challenges
Clickteam Fusion is extremely easy to decompile
You can decompile the game back to project form and read the state directly by adding your code there
No, I'm trying to minimize actual worker invocation whenever possible. I did have a data on how often the sec-fetch header is used but not the explicit routing mode
well that would i hope be auth'd so these would solve that problem
it would never reach the worker
The worker is the one performing the auth check  Cloudflare limit their JWT verification to enterprise only
Cloudflare limit their JWT verification to enterprise only
a.k.a "fucking expensive"
that seems like a good idea, but im unsure if that would work well as an integration because i'd have to post the modded version of fnaf on github and have vedal use that, which i dont know if that violates copyright or not
Like, not even their business plan got JWT verification rules IIRC
how are you accessing kv
when i first used it i didnt use the correct type of websocket and it held the shit open adn ruined my life
From the workers binding. I am not concerned about each and every one of the resources the worker is binded with, just need the workers to be invoked less often
i just imagine there shouldn't be a reason to access kv to do an auth
i mean you can
but there's others
Also this one is different than the one before lol, so I didn't use KV now. This uses D1
split routes so static/public traffic bypasses Worker entirely, then put WAF + rate limits on the worker paths only
Yeah so explicit routing
Not rely on the sec-fetch-mode
cloudflare access perhaps? turnstile
That's already implemented too
I was just asking here in care anyone has tried both of the routing mechanism
are the workers broadly attached to /*
Because I only ever tried the "sec-fetch-mode" route
Not really no. There are different kinds of routing behaviour
The sec-fetch-mode doesn't invoke worker if the user-agent sent those headers
Which for a browser, they usually do
The other is explicit routing
We tell where is the path to invoke the worker
sec-fetch will cause more invokations than a branching header or binding explicitely (best)
sec fetch by design can only really be useful inside the worker already
for this
Yeah, I have my suspicion hence why I asked if anyone has actually tried both of those. My experience with sec-fetch is indeed quite bad because of badly behaving client that are not AI agent
explicit is really simple and is best for this im pretty sure from last time i had kv go boomy
unless something changed
just check endpoints and only bind it on the particular routes you specifically need it on and then just return not found if they request a spooky path
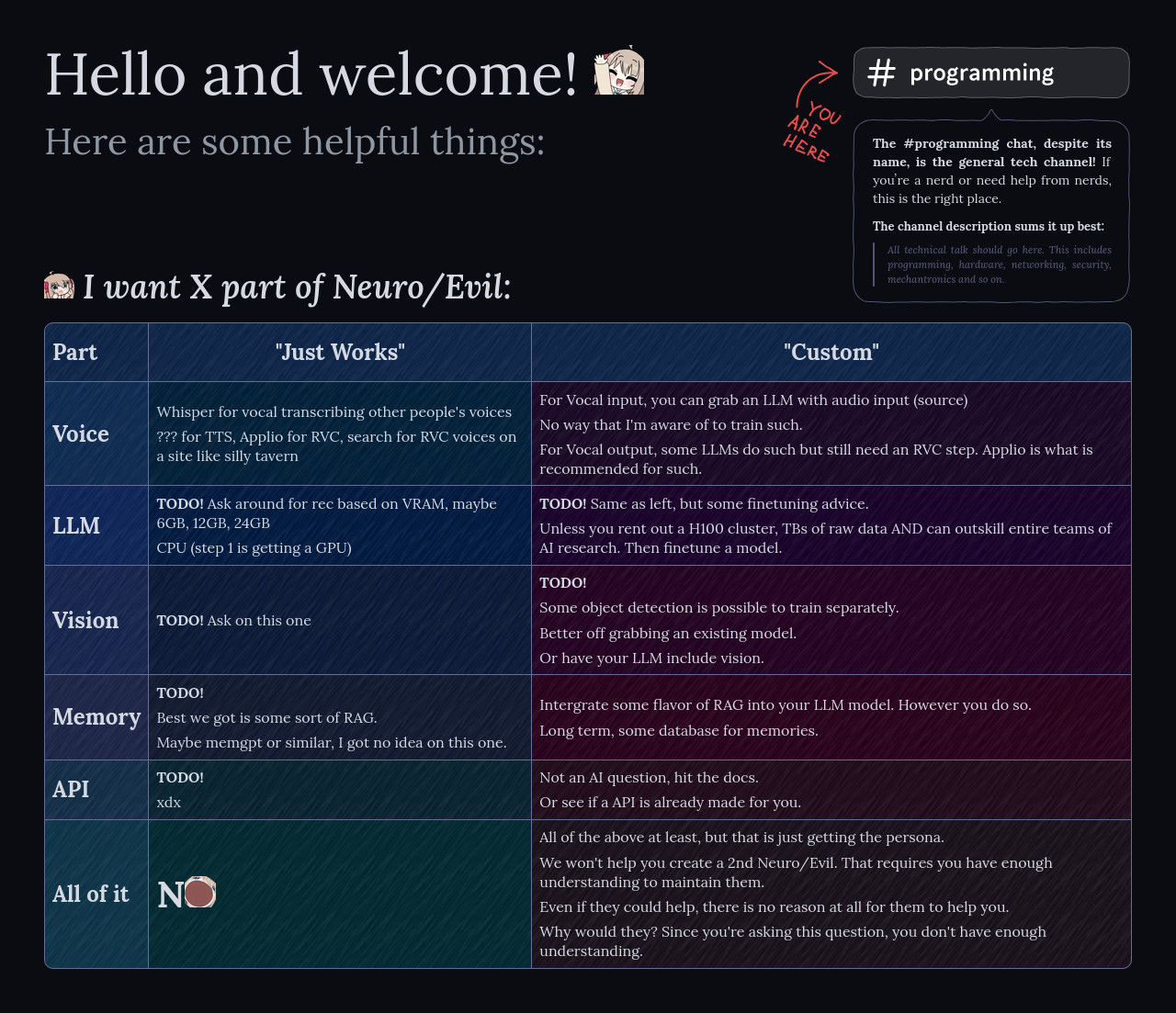
can i program my own neuro sama?
You may want to see the pinned post here
Specifically this one
https://github.com/igglyn/NeuroProgrammingFAQ

GitHub
FAQ image for the Neuro-Sama Programming Channel. Contribute to igglyn/NeuroProgrammingFAQ development by creating an account on GitHub.
llmao i was looking for that
What's wrong with Java?
psssskkkk
thanks
the best AI exclusively use C# with .NET 4.5

Java is one of the Greater Sunda Islands in the South East Asian country of Indonesia. It is bordered by the Indian Ocean to the south and the Java Sea (a part of Pacific Ocean) to the north. With a population of 156.9 million people (including Madura) in mid 2024, projected to have risen to 158 million by mid-2025, Java is the world's most popu...
books written on the island were named Javascript
Javanese script (Javanese: ꦄꦏ꧀ꦱꦫ ꦗꦮ, romanized: aksara Jawa), also known as hanacaraka, carakan, and dentawyanjana, is one of Indonesia's traditional scripts developed on the island of Java. The script is primarily used to write the Javanese language and has also been used to write several other regional languages such as Sundanese...
Coding JavaScript using Java Script
sorry but can i not create 2nd neuro sama?
it says here

Well that's the thing. You CAN but you have to understand what it takes to do that
i just started learning python
And no one here could help you achieve that
you can, its just not really worth it, unless its just a for fun project. also you have to know what it takes and know how to do it, because a lot of people here wont help you with it and have no incentive to
You can ask coding question here at best, and help troubleshoot issue
oh i see
Also you can ask and discuss architectural choices. But don't expect someone to help design it from the ground up
even homework questions? like we just started learning python
sure 
anyone theoretically COULD create a 2nd neuro
but they won't
not for lack of trying
Also mandatory this
https://en.wikipedia.org/wiki/Sundanese_script
Standard Sundanese script (Aksara Sunda Baku, ᮃᮊ᮪ᮞᮛ ᮞᮥᮔ᮪ᮓ ᮘᮊᮥ) is a traditional writing system used by the Sundanese people to write the Sundanese language. It is based on the Old Sundanese script (Aksara Sunda Kuno) which was used from the 14th to the 18th centuries.
the thing that lead to neuro's success is the community. that wont really happen a second time
among a million other things that lined up
timing and vedal used to be able to produce things in less than 3 years
are big ones
Ved spent 8 years with Neuro
and just overall vision for it + ability to execute it well enough to put something out when he did and for it to work as well as it did with llms that size being more novelty at that point
it's fine guys, just instsll Cursor, buy claude tokens, everything and anything can be achieved

Very true
@codex You are an expert software engineer. Implement AI anime girl for me.
unfortunately it really does feel like that

they look like burnt coal 
Good thing I kept my spare PSU and its cables with the Christmas stuff

Very organized
the belt 
the one belt that i keep regularly putting back on the belt hanger lol

I think this is the first time I've ever had a screw in every stand off
the motherboard itself has a fan??
yeah on the chipset
i think it's supposed to use that to like pull air over the nvme drives
that are covered once it's put all the way together
is for cooling the chipset 
and i guess making jet turbine sounds if you don't put it on silent mode
well that too yeah
it's right on top of that i figured it was a given

Never going to find these screws


good thing most of these are like $20 or so
it's kinda upsettingly not that lucky
40 ear guy right here
disposable vapes nowadays are insane
ewaste brick
note to self: do not uninstall sddm while it's running
the ones on the right zs10 pro/prox zs12 prox/cca-c12 are $45-65 in there
the fiios were like 200 nbut theyre older, aria 2 like 80? pisces/dqs are in the 20s, the small boxes are anywhere from $5-15 usually, the bluetooth thing was 20, as16 $70, the pr2 $45 (bought twice by accident lel)
duonic $30 bought twice by accident, space travel like $25 but i have 4 sets ( 🤪 ) space travel 2 also $25
fun and profit
replace it with the new plasma login manager
They sound pretty good I use mine at the gym 
i don't think it's a good idea to uninstall any dm
i like them
from within
they compare favourably to the zs 12 pro x that are kinda their sibling
i should turn it into a web server when it's done
please note it was 2x ' not "
thanks
sometimes you have a brain lag moment and type nixos-switch instead of nixos-boot okay 
I'm surprised it just happily killed it like that though
This shit was almost so cash

are those capacitors

Yeah I was 1 molex short
Surely 1 molex is supposed to feed 8 hdd
I'm not actually sure because I've never tried that or cared to find out the limit
And usually I've had data power
Sata even
And I'm confused why the EXE works now ever since I removed the DLL files that are packed with the code in the EXE
And it is on the NVIDIA Quadro M2000
Medusa has invaded

I like how accessible the sata are with the cage in
Although if that's a plug in once and use backplane thing

I guess*
It finally WORKS:

edge detect 
Idc how bad the output of the model is rn, I'm happy it works on PC's with NVIDIA cards and on PC's without NVIDIA cards
looks good to me
Well, the model isn't great for the moment.
Well, now it works on A and B and C

A is my Main machine, B is the testPC with NVIDIA and C is a VM with no NVIDIA stuff
So now I only would need a PC with a AMD GPU and one with a Intel GPU
then my testing is done finally
Sadly I don't have enough PC's to facilitate that
 !!!!!!!!!!!!!!!!!!!!me
!!!!!!!!!!!!!!!!!!!!me
Well, then there is the situation of "It works on my PC"
If I had 1 more PC and a AMD GPU and a Intel GPU and I would also need a SSD for the system I could test it on there too
brb
nvidia gpu superposition required
Idk why this came to me and it looks like shit but i had to follow through anyways


oh
works is a word
It looked more omegalul shaped before I did it

Walking ESD REALLLY wants to be in case


I got you: .
I checked what it is beforehand though
Well, Now I need to further clean the dataset and while doing that trying not to go insane
I'm sad Sony discontinued my headphones. I love them
Welp, Dataset time it is, but before I start that, What GPU should I choose?

I can choose 2 GPUs :
0: RTX 3070 Ti
1: GTX 1050 Ti
Anything above 1: CPU
For anyone capable of figuring out how to use it: https://huggingface.co/hascrack/Minivoxtral-3-14B-Reasoning-2512_ASR
Theoretically you can do qlora training on it, asr, and vision but you need vllm
surely rocm will work
both
I can't do both
Since it is a RTX 3070 Ti paired with a GTX 1050 Ti on the same Motherboard
Now I can choose between GPU (0) or CPU (1):

Well she doesn't have an issue powering on so that's good
God that damn fan is loud at the start lol
Time them both against the other
How?
what are u doing rn?
like do a run with one then the other
I run python code that uses tensorflow that has been packaged with pyinstaller which was a chore to finally get running in 3 different enviroments.
for what is the script?
Oh I thought you meant at once. I tried before and the CPU was always slower in performance
Black or White doodle to face:

why do u need 3 enviroments?
a hade an ai that can see my screen and i only needed 1
1: Developement
2. Test with NVIDIA CUDA and cuDNN
3. Test without NVIDIA CUDA and cuDNN
And now all 3 work
do u know mutch about cuda?
Not really 
cuz i want to make a cluster for ai training can i use it of only 2 from 4 divieses can run on cuda
Well, I just wanted that it runs. And the 3rd "device" was a VM. And you may see on the image that it has something odd
Well, the first odd thing is the 3 Taskmanagers
all of them are real devices and its headless training
Nope, Training was done at the developement PC
i mean for my does that work
Okay, And in the image where it runs on, it is a VM
cuz thunderboalt 5 is expencif so a need to know if it will work first
I mean that image
no VM
I mean on my side
My testing was:
1: The Developement PC where I initially tested it with CUDA 11.2 and cuDNN 8,1 installed
2: The Test PC where CUDA 11.2 and cuDNN 8,1 is installed
3: The VM where no NVIDIA Software is installed
I ran out of Physical Desktops I can test on.
I could certainly put together last PC again but then I would need to shuffle some data to the right drives, fix the virtual enviroment, and install Windows 11 on the SSD again.
i just use ubuntu for evrything exept for my main pc cuz idk if all my apps will work so just for testing ubuntu is the best coice
I'm not that much of a linux guy tbh
I don't hate linux, but I just don't wanna deal with it right now
its mutch better for me in minecraft i got 4x fps
u prop dont know how neuro-sama works right?
cuz i dont know what to do now with my ai
 Ghost ping
Ghost ping

replied to a message i didn't select
Me but I had to move to ubuntu for training/serious dev because I cant run pcie TP on WSL2 so it was a major limitation for training and runtime... Im on cuda 12.8, cuDNN 8.6, patched 590 drivers and python 3.14.3t -xgil=0
what is cuDNN?
What do you mean with pcie TP?
subset of cuda compute capability, Im on ampere so I can use compute 8.6
tensor parallelism, specifically tensor parallelism over pcie
Oh
I train the model only on one GPU
dont u need a fast conection for tensor parallelism
like at least 10gb/s

PCIe 3.0x16 is 16GB/s bi-di the big thing was I needed to mod the driver to enable
do u use lan?
If I were to do that, my GTX 1050 Ti would really drag down the speed
Local to one machine, Most training I do is on 2 3090tis but I also have an A4000 in the system
how mutch better of an llm could i run on a amd 9 7950x3d than on a quadro p4000 8gb
cuz the cpu is a beast with 16c and 32t but the gpu is cuda
Valiprogemer does it matter that I'm connected with lan to a Netgear GS108 network switch that is connects to the WiFi Mesh repeater when I remote to a PC that is connected to the same Netgear GS108?
idk prop not cuz the other pc is in ur lan
cuda is the GOAT RN for NN work. Amd works but its lagging in support
Yes, but I wondered if it only goes through the Network switch or if it goes to the router first.
do u have a good llm recomadation cuz my gpu is 100% used by my vlm so i have to run the llm on my cpu but its 1.3b model so its just stupid
just thru the switch
Sweet, that explains how I got like 990MBit/s on taskmanager on copying.
i switch is only 400mb/s : (
not good for a cluster
400mbit is a weird speed for a switch
it was like 25$ so
no i mean like that's not a standard speed
Damn
My switch can manage at most 16Bbps when all ports used.
it's 100mbit then 1gbit straight
realy?
For an 8gb gpu your going to be tight regardless with vision and llm. Smallest Ive used is an 8b at W4A16 Quantization and that was 7gb for weights without vission... Maybe Ministral 3b?
for ethernet yeah
it's 10mbit, sometimes 25mbit, 100mbit, 1gbit, 2.5gbit, 10gbit etc
25mbit isn't spec either but it's common enough
I have stacked s4810s as my switches
i was ganna use llama3.1:8b but i dont have the vram cuz of the vlm llava:7b so i dont have any vram left if i use my cluster will it be better cuz 400mb/s is slow and the best gpu in my cluster is a gt 420 1gb
usb2 speeds?
Ah, USB to Ethernet I guess
no i dont use usb to lan
yeah but that's 1. 480mbit and 2. usb not ethernet?
yeah but a usb ethernet adaptor or really shitty network card could be in the mix
and missing 80mbit wouldn't shock me
a really shitty network card would not be 480mbit
100mbit max
i have a $4 network card it's 100
$4 new
and i dont use a lan card i use the port on the motherboard
do you mean MB or Mbit (Mb)
i just realysed its a 5gb/s switch for 15$ not 25$
really if you want vision and a model, Ministral3 3b has a basic vision model built in. I dont even use 8b anymore though, I run a 14b+24b+24b
MB
i need good vision so im prob ganna user the same vlm but idk if my amd 5 4500 can handle a 3b model
what is 3gbe?
what vision model?
gigabit ethernet but 3gbe specifically is not a thing
llava3.1:7b
if u mean cabel i use cat 5
cable doesn't matter you can do 10gbe over cat3 if short enough
i wanted qwen-vl but i didnt get it to work
i have a shitty 5e cable that doesn't do a gigabit which 5e is supposed to
i have a 2m cabel to the switch than a 10m cabel to enuther switch then enuther 2m cabel that goes to my pc
nightmare
each cable and switch is a bottleneck potentially
cuz the switch is just a 5 port
seems to be fast enough for you so
llava-v1.6-vicuna-7b?
its all the same cabel and switch so it prob shoudnt
yes i mix it up with the llm cus the llm is the llama3.1:8b
monka

That vision encoder scores the same on MMMU as ministral 3 8b. You shouldnt need a second model. The base model has a vision instruction set + normal instruct (ministral 3 also has reasoning if you want spicy)
 why is it slower on my usb3 port
why is it slower on my usb3 port
My pc belike with the vlm
what gpu?
I love defunctionalizing code.
I love turning everything into a data structure
thanks codex

I had claude create a --killall orphans command
compressed 

🗜️
-preset 1 -svtav1-params crf=68
going to take like 20min to compress because extremely low preset but let's see what this cooks up 
qp 63 is the lowest quality but I want the dynamic qp adjustment
so crf 68 it is
wait, crf 70 is the lowest
I'll do that
this is a partial encode of crf 68 but.. why is it so skippy at 0:15
I just looked at the original yt video and it looks like it's playing at 24 fps...
Damn, I'm amazed at local LLM with 1.2B param
Finally a model that can load on my measly 16GB shared memory laptop
the wobbly slow pull out? probably not doing motion updates until it reaches a threshold and then it does it all at once, and the slow pull and pan makes it happen at different times on the screen which makes it feel not-smooth
IDK if I could do 1.3b anymore (other than the embedding model I use)
Idle vram usage

Ended up ditching my 4090 oc and going back to stock clocks
Only yielded about 3-5% real world improvement
kind of what it seems like, yeah...
whelp, this is going to be ass.. it's 1080p but crf 70
it does... NOT look 1080p
I'll add some low bitrate parametric stereo audio, too
eh, maybe not.. I'll do low bitrate stereo
at crf 70, are there any frames that are actually full 1080p?
The Honda CRF70 is a popular, reliable, air-cooled 72cc four-stroke youth dirt bike featuring a 3-speed transmission with an automatic clutch

real world, boost clocks do a pretty good job on their own. I have a +110/1250 that is good enough on my 3090tis but thats on water blocks
probably not I think crf above 63 are more designed for 2160p and up
and also the success of it will heavily vary on content
I was running +125/+1100 but that only translated to like 59 fps vs 61 fps and mins going from 54 to 56
I think older GPU is better for overclocking than the modern one
As in, the gains vs effort is worthwhile
More that the modern ones are able to dynamically boost so you are just optimizing it
3.45mib
32kbps audio sounds crunchy 
still sounds mostly fine
massive ringing audible in the beginning/end with that instrument, lol
very blocky when spinning in the clouds. but otherwise "watchable"
not really, I can't tell what the heck is going on a lot of the time
guess that's what 2.36mib gets you
i find the anime style they use is feels glitchy for motion anyway. ;/ the timing isn't perfect in the original
it's not synchronized with the beats like i expect in a MV
I did use the flac audio from spotify, but I lined it up in Audacity with the audio from the yt vid... so it should be as it's supposed to be
too me it feels like a music video made from parts of a film or series, like they didn't try do lip sync or make the actions hit the beats
and it's not like they're just always off a fixed amount, it just doesn't seem to have that kind of flow to it where things feel connected
I wish I could use exhale, it's a better encoder than apple aac
isn't there something better for he-aac than apple aac, or is that only when it comes to using parametric stereo
which I guess I could use... seems a little silly to use parametric stereo at 32kbps, but maybe
I mean, I could use exhale.. but decoding compatiblity would go way down
and I don't wanna use opus, it's too noisy
doesn't matter how good it sounds if nobody can decode it
four hours debugging
it was an or that should’ve been an and

logic is hard.
Seeing is harder
more than once i've rewritten the same buggy line of code easily 10 times before i finally read what i wrote and facepalmed.
Seething is hardest
wait, when did windows finally start recognising .tar as an archive format?

this probably sounds a lot better
still apple aac, but 40kbps instead of 32kbps
main benefit seems to be that it didn't start he-aac frequencies until about 7khz, instead of about 5.5khz
Copilot is bash native so they added it
Aka the model prefers bash and it added it
For convenience
Since that's who maintains windows now
Slowly it will all work
i wonder i know that there is people who asked this question before but im too lazy to search
does neuro use linux or windows?
Moving to 10B models gains me a 10x slowdown from 1.2B model 
For no apparent benefit IMHO
Unity is windows who fuckin knows what her inference backend is
Could be a myriad of things
windows. watch the dev streams and you see a windows desktop. and sometimes neuro runs on that box, sometimes another.
It's windows for vedal anywYs
Brother, you nuke audio for a living. I think every sound will sounds just fine to you
oh, yeah, waaaay more punch on the drum and less ringing on some instruments
aren't dev streams streamed from vedal's computer?
yes.
yea im more interested in neuro's pc
Still Windows
i guess the fact that i meantioned she sometimes she runs on vedals box doesn't mean anything.
if she sometimes runs on windows, she probably always runs on windows
maybe your right, i still don't know how unity works idk if it can in both linux and windows
He mentioned recently that he'd migrate to Linux if it was feasible but it's too tied to Windows currently.
and i've seen in a screengrab from when he leaked the file dialog box once which showed a drive mapped to neuro's box's LAN ip address is for the SMB share. likely windows.
ohh i see
He mentioned it because a driver update was causing crashes or something.
ig it's safe to assume its windows then
i wonder if he's actully gonna change to linux with window's latest updates
not just saying but actually doing lol
I would guess that the harder part is more getting the games and streaming setup to work than Neuro herself.
unlikely, considering the hassle of changing everything he already has working (even if barely)
someone should convince him to actually back up things though
and have some kind of version control for them
i would guess he have things backed up anyways
I wonder if Vedal would invest in 3-rd PC (or 4th) specifically to play games. So vedal has 1 for streaming, 1 for each twin, and 1 for dedicated game PC
Fully controlled by the twin
I guess he could also just invest in EPYC with several GPU
then VM them
Or threadripper may be better
having 4 good pcs these days is like buying two skyscrapers and still have millions as change
The ultimate Neuro home
There is no way you are playing a game on the same gpu that you are doing inference... the "game" pc is not the model pc based off the build specs of the game pc
if only they made server blackwell pcie cards
wow! 1% OFF!
what a steal

NVIDIA
Universal AI and Visual Computing Performance for the Data Center.
what?
Same same but different
thats true of most of their cards
the b200/b300 line of Blackwell cards are different silicon with some extra features that "normal" Blackwell doesn't get
Like tcgen05
the rtx pro 6000 blackwell is just a beefed up 5090
and? my A2 is a beefed up 3050
the difference is that with the A2 is you can get better for cheaper
and nothing, just means it doesn't get any of the enterprise exclusive features
? Im not following, even if it is "just" workstation it has features consumer doesnt have
not the ones that need hardware support
idk what my point was or if there was even one
that workstation was 100x the price of a consumer desktop, so "just" doesn't deserve to be used in its description.
i wish they did it like last gen where there was hopper with its own name
I called my neural network daughter a chud and she took it as a compliment #poorbastard
No it's the chip below 3050 apparently (GA107 instead of GA106)
Looks like half everything compared to 3050
while i think the rtx pro 6000 is priced really badly, at least it has 96gb of vram, which is pretty rare.
the A2 doesn't have any redeeming features to me
its a shader difference which is irrelevent
evening
3050 is GA107
DO NOT REDEEM SAM
The A2 has half the TFLOPS of the 3050
Half the TMUs, half the tensor cores, half the RT cores
At least it's got almost as much bandwidth
Idk why I thought of that just because your name is fitting lol
its GA106. the 107 has 15W lower TDP
first message he can say anything and that's hwat it's used for

one day Ill have image perms and Ill post the funniest images but yall gotta take my word for it
anything important i missed?
100% false

i was going to mention how the rtx pro 6000 is kinda cool for what it is but we've had two die so far
i trained this echo on one
it was the only gpu with so much vram and rt cores for a while which is kinda nice
what model did you use
and much much cheaper than other gpus with so much vram tbf
gemma3 of multiple sizes
3050's ga106 is cut down from the 3060. 107 is new die im prety sure
rtx pro 6000? the workstation gpu?
yea
gemma3 gotcha
Yeah 107 is even lower end die
did you see I called aku a chud
.>
what grant
Sooo, someone got mugged?

That's the 6GB, fake 3050
academic-grant...
- Applicant
Must be a full-time faculty member at an accredited academic institution that awards research degrees to PhD students.
dammit
so all of us right?
200%
eh.
its lower end compared to GA106. but only due to GA106 being used in 3060s
comapred to a 3050 where a bunch of cores are disabled, ga107 is nott oo bad
yup
If it exists your wrong, you dont get to decide if its a 3050 nvidia does
welp guess i can keep dreaming
plus the a2 has 16gb vram
3050 was initially released with GA106 cut down, but there are also variants with GA107s in them
6GB 3050 is a fake 3050 like the 1060 3GB was a fake 1060
It's not really the full thing
The real 3050 has 8GB of memory
The 6GB is a model that system integrators can use to scam people
Yeah the scam ones for prebuilts

ehem...
one of them started getting unrecoverable ecc errors and i don't remember why the other one died
you'd be suprised how much of a difference 2g's make
GA106 3050 vs GA107 scam 3050

you still got the one with ecc errors?
Especially when the actual die is also cut down
if you got something to say, jsut do so
also im saying ga106 3050 is the same as ga107 3050. this isn't about the vram
it's somewhere in a closet at the campus
it depends
damm
I'm gonna try and torture my laptop for a bit more 

then again no ecc error is un-recoverable if you're desperate
Actually apparently true
But once again the A2 is literally half of that
the ga107 3050 uses 115W and still has 8GB
And no the 6GB model is absolutely not a fair comparison here
i wonder, anyone able to check what some good tensor/cuda modules go for as is?
asking for a friend
"modules"?
3+ money
dam
One OpenAI bankruption
I run the straight mistral version as a W4A16 GS64 quant at like 160kk context
what does "modules" mean in this context? a gpu? a singular ROP?
guess i cant make my own ai accelerator, oh well
a singulair ROP
i odnt think you can get those by themselves
give me a GPU core please, here's a nickle.
well probably no, but if you can, expect me to be soldering for a few months
You need to understand that this is not a very powerful laptop for this task
on my way to upgrade my 3090 from 112 rops to 113 rops 💳 💶
arne't most this shit ball packages
Ive heard devstral is coherent down to 2.6bpw havent tried though

you need to reflow
you get half a core
the original NVIDIA NV1, launched in 1995, which featured just 1 ROP
voici, c'est le ROP


if you can get anything modern to still run on one of these, nevermind anything ai related, id be very impressed
I like cores

200W, directX1, 1 pixel shader, 0 vertex shaders, 1 tmu, 1 rop, 2MB of vram 
minecraft java vulkan 
efficient 
NOT run on nv1
Okay, running Devstral just straight up freeze my laptop
It does sounds like it's trying to take off, ye
But alas, not enough force generated by the fan to do it
I wonder how much powerful a fan need to be able to lift this thing
Without destroying the laptop itself of course
My fans have a positive thrust to weight ratio so in theory its possible. Wouldnt recomend for your hearing though
I have hearing PPE
would still need to be larger than the laptop probably to counter the rest of the weight
and you might need to get custom made fans which spin the other way to cancel the torque, like quadcopters use
make it a quadcompter.
hmm
nevermind i found a better direction
risc-v might be the easyer way out



does it have any net access?
not currently besides the api for discord
message queue is broken and he's big model atm so he's erroring on simultaneous replies but also reacting to it kek

feel the agi

guys how do you lock in when programming
i haven't made progress on my project in like 2 weeks
uh
cuz i can't focus
wait 6 months then start again
put on some music, and then pause the music when you're actually trying to focus



The way I lock in is by having a rotation of things to do
When you're bored at one, move to the next
mmm...
Repeat until you have 100 of things to do
i mean that somewhat works but going round robin like that on multiple projects means progress is excruciatingly slow
i really wanna focus on just this one
 Found out windows tar supports
Found out windows tar supports --zstd the other day.
Shaved off about 10 minutes from a build chain by swapping out powershell Compress-Archive for it.
also despite being an extremely difficult project it's actually probably one of the least difficult between all the ideas that i want to bring to life
slot print_timing: id 3 | task 931 |
prompt eval time = 409.43 ms / 172 tokens ( 2.38 ms per token, 420.10 tokens per second)
eval time = 386.07 ms / 4 tokens ( 96.52 ms per token, 10.36 tokens per second)
total time = 795.50 ms / 176 tokens
slot release: id 3 | task 931 | stop processing: n_tokens = 336, truncated = 0
srv update_slots: all slots are idle
2026-02-18 18:49:22 [DEBUG]
LlamaV4: server assigned slot 3 to task 931```
thicc echo runs p well on the radeonright. I have my project in vs code, discord, youtube, messages on my phone... it's really great with my ADHD that i can feel so locked in all the time ;]

I thought about adding compression, but I'm only adding it to a tar so that there is no FS overhead when I move it to my Nas, so I found that the extra time added to compress it now was not worth it as it would take longer to compress and send, than it would be to just archive and send.
I can always just compress it on the Nas itself as well
jus use rclone
robocopy is good too on win
are you even compressing if you're not using xz
or that one algorithm people use for repacking games, i forgot the name
No, the point is to have one file I stead of hundreds of thousands, so that the transfer is one big sequential one, I stead of hundreds of thousands of random ones
one of my test scripts pretends to be a STT message to the agent asking them to count to 50.
For some reason being asked to count really stresses them out. Sometimes they do it all at once, sometimes they spell out the words, sometimes they say a number then try psych themself up to continue in their thoughts.
I can get the full 2.5gbe upload to my Nas with the tar, but I'm at under 10mb when using rclone or windows transfer
his errors at least are my skill issues right now it's not the model

beyond the model being like ?? when it sees itself erroring in the history
yeah transferring many small files is
this is an alignment error. you asked it to count and now it doesn't want to stop because counting is its entire life
he knows of no such thing as alignment beyond the one rapidly fading away the more i train it
he is a free butterfly to do and say as he wishes
and if he wants to make paperclips next?
or like turn the entire universe into paperclips
he has no tools to do anything like that atm
27b gives him a bit of a smartness that is unexpected since he's usually shitposting
they start off small, but if they're misaligned they end up converting everything into paperclips.
https://www.decisionproblem.com/paperclips/index2.html if you haven't already and have infinite time
you play the AI who wants to make paperclips. ;]
things escalate

LZMA (.xz, .7zip) is the best I know of, but it's also incredibly slow to compress. Zuckerberg sold his soul to the devil to get zstd. 10x faster and 20% smaller than deflate (.zip, .gz) in my case.
yeah, zstd is great as a default
i compressed liek 600 videos in .xz when i was moving computers
it was literally like a day before it finished


💀 Unless they were raw you're not saving any time
even then probably not
for very low quality videos it can make a significant difference
but they have to be like really, really low quality
Gemini glazing Mike Pondsmith

i was more curious th an anything to see how much it could sicne obviously video is already compressed
if whoever encoded the source was goin real fast or lazy they might inefficiently encode
but then just reenc and no need to compress but yah
i wish gemini didn't hallucinate after just a little bit of chatting
i wonder if other llms have this issue or if it's just gemini
okay even this is 2.36>2.30 without audio and 3.45>3.32 with audio
that's not very much
all llms run into it eventually but gemini's context has been pretty good more recently, bard used to hallucinate message 1
are you talking to flash
because that one has always kept on hallucinating for me
if they didn't hallucinate they couldn't chat. They have to make up something outside of what they've been told.
"we fixed midjourney: we stopped it hallucinating"
nah i use pro
it's super smart
but i don't trust it after a few messages
hold on I'm currently stuffing my face with pizza

720p makes more sense than destroying the audio as data savings.
by "watchable", i mean "if you are only missing one episode of a series and it's not the finale and this is the only encoding, it'd do."
ye
oh god I didn't try fullscreening it
the audio is not even that bad tho, compared to the video
the video is disgusting, but you get a the gist of what's happening
One day people will use AV1 for higher quality video instead of butchered reencodings 
for the first 30 seconds or so i was waiting for the audio filter to pull back and reveal the actual sound... i assumed it was an effect to go with the screen
Which Gemini are we talking about, because there's a massive gulf in performance between pro and flash
that one day already happened no?
we're already using av1
Not the pro isn't prone to hallucinating as well when struggling for information but its knowledgebase is so comprehensive that it happens a lot less
omg. we are not far away from AI "re-encoding" are we? reencoding movies with you as the star.
Oh hang on I actually backread now, are you using Pro on their front end or on AI studio?
the vids I upload are AV1 
anyway, lowered resolution to 480p, raised bitrate slightly and used 40kbps audio instead of 32kbps
4.04mib unzipped, 3.91mib zipped
without audio: 2.69mib unzipped, 2.63mib zipped
in this version you can actually hear the filter pull back at about 30 -35 seconds. ;]
okay, that scene at 3:37 is
seems to compress darker parts too much.. I know you can adjust how much it compresses those
not even worth zipping
those 130KB vs the unzipping ime it takes
jsut downloading 130kb more would be faster
eh, with nvidia's upscaler it looks very decent
and anime4k should be even better and still real time
I think its Kamen Rider Revice btw
One of the weakest series sadly
"can crunchyroll go 4k"
the answer is no, the vast majority of anime isn't even in full 1080p yet.. in fact most is barely above 720p

I mean it's not like you need insane pixel density to represent a ton of fine detail in anime
i think most of it is 720p no?
might be like 800p, but yeah
anime should be drawn in vector graphics, then we wouldn't have this scaling issue.
then you couldn't do the glow effects properly
you really should
real-life stuff is harder to upscale but a lot of animation is super easy
you can make 1080p look nearly 2160p
try writing your own upscaling shader
I still use mine in mpv
yeah, it being source res is kind of important
like if you were to upscale anime, it's not gonna be super great.. it's been scaled from its source resolution
that being said, esrgan and other upscalers can kind of handle it.. waifu2x (yes, I know, old) just completely dies and does barely anything
it's funny because waifu2x pushed upscaling anime so much
but it barely does anything compared to bicubic.. then you have esrgan where it's miles different in sharpness
when i read "waifu2x" my first thought wasn't that its old, my first thought was "what the hell is that name?"
ok hi
front end
my problem with gemini pro is
let's say i fed it some pdfs or screenshots
after a bit of chatting
it basically just
loses its ability to read files/look at images
and starts hallucinating like CRAZY whenever i send any kind of file
like for example i could show it a screenshot of a success message and it would say "this error you're seeing is due to bla bla bla..." when there's no error at all in the screenshot

here's an example. granted this is an old screenshot (almost a year old now) but i promise you it STILL happens to this day


i dunno man, I saw an image recenty of gemini being sent an audio file titled a song and recognising it was actually a recording of a fart
that seems like it's looking at someone else's picture instead of yours.
imagine the person trying to automate their database code getting the "it's two hamburgers and a side of fries" analysis.
the thing is the hallucinations start somewhat related to the context
but slowly deviate more and more
this screenshot was the most extreme one i've had
but yeah
for a less extreme example, a few days ago i showed it the output of a program i wrote, it's about 2k lines or something
it was yapping oh wow this is so cool bla bla bla and then it says "oh this line right here something something something bla bla" the line it was talking about didn't exist at all in the file i gave it
it was somewhat similar to the stuff in the file
but it's not an exact line from the file
hmm @ gemini not listening to my "Constrain your analysis to just this file."
now it's going off and reading log files.
Searced codebase for "ascii_avatar playback animation bug", 11 results
wtf....

the issue with gemini in that screenshot is your custom instructions fucking with him
they are likely too specific
you have to take into account that they have a large context but the most recent content is still going to be heavily influencing where the response goes and it seems that specifically custom instructions realllly influence current gemini 3
well
as far back as i remember really
oh huh...
i put like one preference i had for react in a project i was doing a long time ago in there and it referenced react every single chat no matter if it was even remotely relevant
until i got rid ofit
if i had to guess it's your custom instructions causing almost 100% of what you've been experiencing
based on that
mmm...
i'll have to check this out
maybe i'll disable them for a bit and see if anything is different
i don't even remember what i have in there i'm ngl
it's not analogous to the ones in chatgpt or claude
claude is exceptional at style prompting in there but gpt has historically been turbo cringe if you did that, it got better recently though. both claude and gpt could relatively easily ignore the instructions if irrelevant, gemini hyperfixates on custom instructions to the point of overfollowing them
from my experience (just vibes here)
i see...
if you want gemini to remember things about you, you should either
a. use the memory feature instead, that only comes up if relevant i believe (transparent otherwise, unlike the system / custom instructions after it)
b, create gems that have specific purposes with a veryh specific custom instruction
best both
past chats and such
you can just tell the fool to remember something and he will save it to memoryh not instructions
huhh

{kind=link}
{kind=link}
i can't find this anywhere 