#programming
1 messages · Page 394 of 1
If I had the rights to decide that, I'd be attempting to abolish further LLM prameter scaling. That'd be more healthy for the world.
i think its maybe worth it for contractors or something
replacing the laptop is nice for if you need something more powerful, or something more cheap
if you can change the subscription tier you have at least
1 year lockin
im assuming you will get a the most recent high spec laptop for the highest tier?
so like, each year you can replace it for the newest cpu/gpu model

offered after 3 years 
cant i just cancel the current subscription, then re-enter a new one?
surely
@olive sable The only thing I can see this really working for is businesses and enterprise customers. Where they can just bulk sub to a ton of units and refresh on a regular basis.
thats fair ye
Theres no option to buy out but I don't think he meantioned trade in for new.
im assuming if you cancel the subscription you have to hand in the laptop
im assumign that if you re-enter you can jsut get a new laptop?
the only issue i see with this is they will just give you a used laptop from a previous customer
or they ban you from re-entering
My family actually asked "what happens to your data when you give the laptop back?"
id guess they have no data protection for those laptops
Back it up or lose it
so you'd just be giving them the full drive

i think the focuse of the problem was privacy concerns, not losing the data
Surely dell is a trustworhy company and well zero out the drives before sending then to the next person 
so it mostly depends on if you have your own account or a hp account on the device
or what was it
dell?
hp

iggly
you made me look like a fool

you still have to go through the windows oobe no?
idk
just their custom image with whatever shit they want to have preloaded
I is stupid 
for work have account managed by the company and stuff
i think hp can do similair stuff
especially with the hp bloatware
you still need to use your own microslop account, this isn't an enterprise laptop
Doesn't matter Microsoft gave Bitlocker keys over to the feds, they will probably offer them up to anyone now.

which feds even?
bitlocker on by default so encrypted drive which is useless to them
all feds? usa feds?
FBI
fedex

Forbes
The tech giant said providing encryption keys was a standard response to a court order. But companies like Apple and Meta set up their systems so such a privacy violation isn’t possible.

Microsoft has confirmed it will provide these BitLocker recovery keys to law enforcement, including international requests, if they are presented with a valid legal order.
so no
not FBI
all feds

 God I hate Microsoft
God I hate Microsoftmap of all places that get mentioned by the news article eventho its a global issue

That's the entire world for some people
"international requests" international agencies will 100% take advantage of this
most def ye
i know what puerto rico is, but ive never heard of guam
seems to be some island above papue new guinea

They took it over during WW2 and it been part of the US since
territories are like states except they don't get any actual representation in congress (so don't get to vote), are forgotten about a lot unless some disaster happens, and don't get any of the advantages of living in the main 48.
like a cross between just the worst parts of DC and Hawaii
imo they should just be a separate country since they're so far away, but what do i know
im sure there are some reasons

Okay so Opus 4.6 is very prone to schizoid meltdowns. It took up all my tokens in one massive rant about hardware prices when i asked it to explain the current state of hardaware pricing in 2025 and 2026.
Then it started just screaming that the age of the personal computer as we know it is ending and that we are so fucked

Valid crashout
i wanne go back to the time opus was a codec 
https://cursor.com/blog/nvidia you will take vibe coded gpu drivers and you will like it

Cursor
NVIDIA embeds Cursor across its SDLC to automate key workflows like code generation, testing, debugging, and deployment.

dw they already are
even more so now
excuse me, I thought they were already doing that
Last year, the organization set a new engineering mandate: leverage Cursor to embed AI across every phase of the software development lifecycle (SDLC) and eliminate manual bottlenecks across code generation, testing, reviews, and debugging
looks like they were
 $370 16gb 5060 ti
$370 16gb 5060 ti
so nothing new
the crashing is not new, the frequency will just increase
Close enough, welcome W701DS


What if I just, keep Nvidia 580
NVIDIA doing their best to kill the CUDA moat I see
how the turn has tabled
https://fixupx.com/i/status/2018967764082274490
BRAKING: Nvidia CEO Jensen Huang calls it "illogical" to think AI will replace software and related tools.


Late 2000s was the age of innovaiton

Before Cursor, NVIDIA had other AI coding tools, both internally built and other external vendors. But after adopting Cursor is when we really started seeing significant increases in development velocity.
ah this makes more sense
i like how becoming dependable on an expensive and subpar coding methodology is a mandate

nobody said anything about replacements tbf
That is fair
https://fxtwitter.com/claudeai/status/2020207322124132504 now you can have it rant even quicker 
Our teams have been building with a 2.5x-faster version of Claude Opus 4.6.
︀︀
︀︀We’re now making it available as an early experiment via Claude Code and our API.
software is a gas
 my software is a liquid
my software is a liquid
that's weird, usually it expands to fill the container
there is high pressure in my bad code
so it's a 6x increase 


seems like it's free now once you hit exactly 200k tokens
true
HOW MUCH??
ping reply 
netcafe discord config 
anthropic greedy fr
also this monitor sucks for anything that's not a game 
built for the blurry mess that is DLSS 

take a guess on why dlss is turing and later only
but yea
iirc dlss is an int8 model
Can't wait for them to downgrade it to FP4 to justify 50 series
tensor can execute at the same time as the cudas, so i do wonder what the base performance hit is from
maybe the L1 cache being split between the 2?
well you still need to run the actual inference which takes time
even with tensor cores being as op as they are
they're async tho no?
40 series already locks multi frame gen, so I think they are running out of things to gatekeep from the 30 series
there's still some extra work to make sure the frames end up coherent that needs to be done i think?
geforce tensor cores aren't as async as they could be
that might be easier by merging with the RT stuff tbh, keep that state and use it for prediction
pssk
Well inference mainly takes memory bandwidth
And memory bandwidth is the same between CUDA and tensor and shared
the biggest performance hit is probably on the cache?
what is cache when one loads in a 500m model
I don't actually know how large it is
Well ML models are so big they can't really take advantage of the cache
So the smartest would be for them to ignore the model weights in the caching
the scheduler also has to do some context switching. i think the actual perfromance effects of that might not be too bad depending on the usecase tho
I think that isn't much compared to all of the matmuls it is doing
i think the cuda cores would get more cache misses due to the tensor cores fuckin up the memory uses
im no expert tho
it depends
Nah the cache would just be completely useless because the memory fetches aren't hitting the same memory sections at all
if you mostly rely on shared memory for the tensor cores it's fine
shared memory accesses don't go through the l1 lookup pipeline

cache efficient matmul algorithms are the only reason these models aren't unusably slow
no l2 either
you can think of shared memory as a user-managed version of the l1 cache
they share the same physical space
So that is how we say "don't drop this out of cache stupid I need to do something else rq"
ye
All the sudden, how we are able to have efficent matmuls makes sense to me
one less thing to fight
and so happens to be the largest
you could prefetch the current tile into l1 but that's kind of annoying
and kind of unreliable




every time see the doc emojis they only get more desynced

imagine not logging into an alt for so long discord emails you saying you have a DM
Hey is this the right way to handle git with a large project with multiple people:
-
so main is our production branch, no merging into main until everything is the sprint branch is cleared of any catastrophic bugs
-
each sprint has its own dev branch
-
each sprint has 4 epics and each epic gets a branch
We merge the epics into to dev branch when it’s done/a prototype feature of the epic is needed for another epic
Then once every epic is merged into the dev branch, we bug fix on the dev branch until it’s clean, then merge into main.
Is this a good workflow?
I say catastrophic bugs because it’s a school capstone project, and it’s being more treated as an alpha/beta rn, so some issues are fine as long as they don’t hinder functionality.
Not in enterprise nor in large projects, however this reminds me of how the linux kernel is handled. Each subsystem having a branch which is sent over to be merged into the main.
Alright so I’m on the right track on how I want to organize this project
pretty standard workflow, though depending on how long things are going merging dev into main might be a bit painful
that was my own thought as well, in theory as long as it is properly split then it shouldn't be the worst.
Every sprint must end with two weeks, and no sprints will overlap with each other so no matter what there won’t be more than one dev branch actively being worked on at a time
This is mostly because the professor grades commit merged into main
2 weeks isn't too bad i guess
the worry would be if you have a rather long time frame between merges into main you might be changing a lot
Also I’m terrible at using commits, my group mates are so good at committing.
This sprint’s branch has maybe 150 commits total, I probably contributed 6
I feel you, I mostly just commit when I feel like it is worth sharing for my personal projects.
My professor expects 10 commits a sprint per person
massive commits where you end up changing 20 different things don't really help anyone (i do this too cause i'm too lazy to break it up for most projects)
I'm at a scale where changing 20 lines is like 15% of the codebase. So I'm fricked no matter what I do.
One benefit of 4k oled I hadn't previously considered is superb CRT emulation

Very nice for retro games
A lot of these 2D PS2 games look so, so much worse without a good crt shader

sure I should also split by type but lazy
the github is more of a view into the insanity anyways
We were talking about promoting injecting google ai yesterday

Thankfully even though PCSX2 doesn't support them with a bit of tuning you can overly a good CRT shader onto anything these days
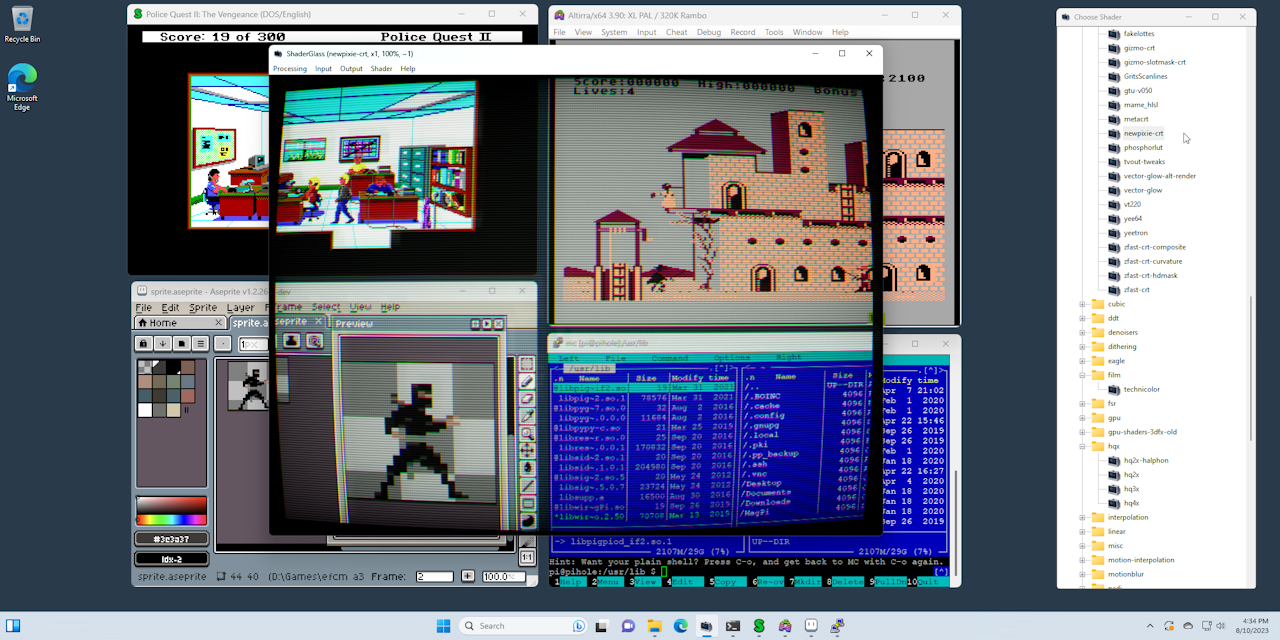
GitHub
Overlay for running GPU shaders on top of Windows desktop - mausimus/ShaderGlass
I knew this was still working
I used ShaderGlass for my last Fallout 2 playthrough, it did a good job
The built in retrocrush presets are great for console emulation

Only annoying bit is changing pixel scaling and aspect ratio correction between emulators
Wayland suprimists would never accept this as a valid usecase on linux
Not wanting to actually spark that fight but just jab at it a bit.
I love the idea of the project tho
pls??

I don't even know what Wayland is

Its a display compositor?
"Wayland is a modern display server protocol for Linux and other Unix-like operating systems. It's designed to replace the older X Window System (X11/X.org) that's been used for decades." - Claude
Yeah Linux nerds love flinging shit at each others compositors
Its like a whole thing
I know if I said this on another sever, it'd turn into another flamewar
quite the opposite, it's practically built to allow this 
Hyprland has support for running whatever fragment shader you want
I'mma try wayland and see if it works
I customized my Mint isntall and according to the internet is supports it

no, it's a protocol that compositors implement
would not suggest Wayland on Mint
you will likely have a bad time
If we're splitting hairs yeah, "wayland compositor" is more of a catch all for anything using it
 big difference, since compositors usually also do window management
big difference, since compositors usually also do window management
 should at least work then
should at least work then
will still have to fight outdated packages and general lack of support but at least it's just that
vnc and wayland is pain.
IIRC the register file and shared memory are the same thing for GPUs. So throughput focused that SRAM registers are fine instead of flip-flops.
I guess I was thinking more of a direct conversion of the app, screen capturing the stuff below except itself to use as the fragment shader input.
the register file is separate 
h100 sm for example

 the guy I know who works on GPU firmware would contradict that. Might be that it only spills to L1 if it runs out of registers.
the guy I know who works on GPU firmware would contradict that. Might be that it only spills to L1 if it runs out of registers.
I feel like the proper way would be to just implement support for that in the compositor (just apply the shader targeted to a specific window before/during compositing instead of after)
alternatively could use LD_PRELOAD shenanigans but that has its own issues
iirc as of cuda 13 there's now an option to have registers spill to shared memory
i wanna say by default it spills into dram but i'm not 100% on that
I feel like that would be the correct method, I just also know it isn't as flexable as the orginal.
okay yeah according to nvidia they spill to local memory which is just global memory
looks like they still end up being cached so they'll kind of live in l1
yeah I went back in my conversation history
on nv if you trash a register which your shader doesn't declare it uses then it overwrites shared memory values

ah yes, hardware black magic
 you can already capture the whole desktop without too much trouble, so the main issue to replicate what ShaderGlass does would be knowing your own window position relative to that (as it always is with Wayland and gimmicky apps like this
you can already capture the whole desktop without too much trouble, so the main issue to replicate what ShaderGlass does would be knowing your own window position relative to that (as it always is with Wayland and gimmicky apps like this  )
)
and I guess you'd also need to exclude your own window from the capture, which is sort of possible, but also with compositor support
-# how tf would X11 even handle that
My thought is the window iself is an overlay that remains uncaptured. Position is still an issue tho.
I have come to the conclusion that it should just be a compositor thing 
won't have the window decorations around it but who cares


Retrocrisis not retrocrush!
Knew I had the name wrong, was bothering me


as a continuation to yesterday's scammer message woes
a new regex has been assembled
Is it absurdly long 
does it filter for birthday wishes
om
h[\s>]*t[\s>]*t[\s>]*p[\s>]*s?[\s>]*[::][\s>]*[\/\\][\s>]*[\/\\](?:[\s>]*[a-zA-Z0-9])*[\s>]*>[\s>]*(?:[\s>]*[a-zA-Z0-9])+(?:[\s>]*(?:\.|。)[\s>]*[a-zA-Z0-9]+)+(?:[\s>]*[\/\\][\s>]*[a-zA-Z0-9]+)*

 It filters for this
It filters for this

Does it work tho
it should be better than what i had put together before
pog


 firecrafter's account was stolen
firecrafter's account was stolen

It's unfortunate that discord makes it so hard to deal with something like this more effectively
remember when it had no friends feature
you'd have to make a server with bro and both join to be able to DM each other
you sure remember a lot for someone whose account is a year old 

you sure remember little for someone who's had a thousand birthdays

i can barely remember what i had for breakfast
!felloff



gotta keep the authorities in the dark so they can perform their jobs well

1115 birthdays 
@real sierra You've had 1115 birthdays since you were cursed 

Tuned up shaderglass a bit since the scaling settings were a bit wonky earlier

Looks real nice now
Pretty damn close to a SCART CRT image
Sharper pic

Ultra zoomed in pic of mine (left) vs an actual CRT (right)


Funny thing though, the text fringing colours are flipped because of the subpixel layout on the OLED
At least I assume that's why
oooh clever
The fringing is more prominent on the OLED but only because the CRT is displaying a much thicker font
CRT stands for Crap Resolution Transformer
I am creating something aweful... I'm gluing the audio processor from a 3b model onto a 14b reasoning + vision model using a 24b model's audio projector
one is not like the other

No EoRA?

I know what some people do for crt emulation is use high refresh and high prt oleds with bfi and shaders
Why not
didnt come up during my research + it looks scary
But ot have a good time with bfi you need over 120hz panels
For gptq it's stupid worth it
I faced the problem that i dont know how to fix
Its these stupid inputs that work weirdly in skyrim
So when any window that uses cursor is opened and the mouse was moved - after that menu is closed the mouse stops working.
UNTIL i move the real mouse.
It magically fixes everything.
But this is unacceptable
I just disabled cursor in all menus and it works fine
Except for the map
The map needs cursor to work
And the weirdest part is that i cant even disable mouse in it
Using old methods
Even disassembling that shit player bounds was easier

And now vacation will be over and i have 3 times less time each day
Depressing
There are at least 3 ways of sending fake inputs and none work
It just breaks for no reason
Also gptq+EoRA is an easy 5-10% perplexity recovery
lora - 100 steps done at rank 8 batch size 1 - loss: 2.33582 - it/s: 1.539
dora - 100 steps done at rank 8 batch size 1 - loss: 2.27225 - it/s: 0.912
miss - 100 steps done at rank 8 batch size 1 - loss: 2.40148 - it/s: 1.184
sbora - 100 steps done at rank 8 batch size 1 - loss: 2.27714 - it/s: 1.217
kron - 100 steps done at rank 8 batch size 1 - loss: 2.30271 - it/s: 1.225
oft - 100 steps done at rank 8 batch size 1 - loss: 2.39802 - it/s: 0.224
hra - 100 steps done at rank 8 batch size 1 - loss: 2.33630 - it/s: 0.477
xlora - 100 steps done at rank 8 batch size 1 - loss: 2.35383 - it/s: 0.672
loreft - 100 steps done at rank 8 batch size 1 - loss: 2.32828 - it/s: 0.692
llamaadapter - 100 steps done at rank 8 batch size 1 - loss: 2.33287 - it/s: 1.015
boft - 100 steps done at rank 8 batch size 1 - loss: 5.20013 - it/s: 0.056
Its probably some combination of windows and skyrim chaos working together
understandable

Why does this look like an airplane seat
pattern recognizing brain:
finally got something running in unreal that doesn't make my computer scream. just a low grade moan from the fans.
tomorrow I'll work out why it's not working when I compile it. ;/ i vaguely recall something about needing a command-line option to enable that port on the binary.
Whoops, created a new way to gamble
one reply and I'll throw together a document on how to make and play it
-# surely this is on topic
good morning! (not morning for me tho)

what a bad day to be carbon-based

no you don't
rip me

Before rewriting NNv4, I wanted to see how fast it would train if I actually bothered to optimize the inputs a bit. 28 seconds for the entire train/eval with 4 seconds dedicated for tensorflow to wake up to process the dataset to then never use it again.
I CBA to deal with getting JIT or multicore working for this so it is what it is.
(MNIST image dataset, chunked into 4x4 sections if anyone is wondering)
poll_question_text
topipopoprrr
victor_answer_votes
4
total_votes
6
victor_answer_id
2
victor_answer_text
cotton candy
victor_answer_emoji_id
1087521476070080592
victor_answer_emoji_name
neuro3
now i kind of want to go back and rewrite the fashion mnist model I made to use google's highway instead of avx2 intrinsics 
wtf is wrong with youtube


its mainly graphics improvement
supposedly also runs smoother
imo if the price difference is not too big, just go for the remastered one
same game, no new content. just looks better
nuh uh... rebuying the same game, just with slightly 'better' graphics and 100+ gb of space required?
they should've made the upgrade free tbh
i do agree with owners of the base game being entitled to a massive discount on the remastered
but i wouldnt say free
a lot of people put work into the improvements
there's 10 hours of new mocap data
and getting the new and improved graphics requires artists, 3d modellers, and devs to redo everything
imo, it should be kinda like how you can "upgrade" a ps4 game to a ps5 version for only 10 bucks extra

damn Rp
i use Google sheets for My database.

You are the reason my friends has to deal with 70MB xlsx file
lol
uses anthropic models
doesnt know how expensive they are


imagine using model api
doesnt know how expensive they are
do YOU know how expensive they made it? emphasis on "fast"
it's actually outrageous
we back to o1 pro prices
I'm lucky enough to not be starting from scratch, essentially I need to retrain the audio projector packer from voxtral 24b to work with ministral 14b so I can take the audio processor from voxtral mini 3b and glue it onto ministral 14b.
Im not as optimized as I could be but I did manage to get xgil=0 working
the "wrrr" makes it instantly obvious
Nah this was enough for me

topipopoprr 
67% 
get out

it's le funny meme number
Oh you sweet summer child
you wouldn't get it
oh
chungus wholesome moment
im just better
What’s a failed state
you dont get it and u dont WANT to get it
yes

Okay then what’s the second non-political meaning
as in a state of failure
Hi everyone.
I currently try to build an AI. But I don't know. How to train it. I am using !good and !bad as a reward system. But for what kind of criteria should I look for? Or for which patterns should I am looking for? This is a part of my logs:
<bos>=89 <eos>=15
WordMemory geladen: 195
Pretraining finished
Forced learning: "how are you" → "i am fine"
Forced learning: "how are you" → "i am good"
Forced learning: "hello" → "hello"
Alice ist aktiv! Sag etwas:
You> Hello
Alice> responding why i tell reward ways copy like maybe like prefer viewers good alice respond, you have programming.
You>
This up there is an example answer I am currently getting from the AI. Is it good or bad?
Btw. this is my first AI build from scratch and bit of help from ChatGPT, but the answer from ChatGPT are pretty bad or are not really working.
I am oppen for every idea or help.
There is many meanings of from scratch... Untrained, pretrained base, from instruct/cot base, full fine tune, etc
I've been doing custom tuning for awhile, and I'm not even willing to train an audio projector from scratch
are you trying to rl a barely pretrained model
rlhf no less

The AI is currently near to fully untrained <-- Sorry I have forgotten to add that. But this is my problem. How I am leaving this status by correct training. Because I don't really know when I should give a good or bad.
rl is difficult because the model has to figure out what it did to earn a reward, so it'll take more iterations, and what you're trying to do is rlhf which is like 1000x worse because YOU decide the reward

at this point you shouldn't rlhf it'll take you literal ages to get a good result


So, I should rather go more for a forced learning method,instead of a reinforced one?
funny you say that when it's a case of this again


nice ban speedrun
t
yeah wtf 
hi konii
your language isnt real
@real sierra kill

This tbh. I'm using 52k steps just training a audio projector (52m trainable)
neither is yours miss britain
Thank you for the advise. :) I will try to adapt the model a bit. I think, forced learning would be better, right.
I wonder what my name will be
f
sq
Where did that come from




H
Oh square
put it through pre-training before you do fine-tuning


effectively feed it a massive dataset and have it train to predict the next word in the sequence for every word
t
hi konii
hit
hit
hikonii
miss
lol
Yeah I will do that. But from where I am getting the Data sets O.o
Huggingface?
pre-training datasets are usually just about anything
Where do you think I got 960 hours of tagged audio
microphone
what about the tagged part

big models use terabytes of text data for them
you probably want a good variety of stuff in there
tagged microphone
so it learns grammar in different scenarios
So, I should just put many example sentences into one data and feed them to the AI?
I'm using over a gig of training data for a 52m projector
52 meter projector 
52 milliprojector
i remember that some of the LLMs are trained on like 12+ trillion tokens
@smavanman projector emtioned
that works yes
ez
baby bird eating worm
I'm doing something stupid: tri-modal 14b reasoning model that's 10gb
Really that big? I thought 1tb would be enough. Well... than I will need some HDDs
you can do it on much less
and you probably don't have the compute
so you can scale it way down
[insert neural scaling laws paper here]

45
but yeah, pre-training is the reason why most people tell you "don't train an LLM model from scratch unless you're a millionaire, you fool, you buffoon"
If I didn't have an A4000 to encode on the fly and wasn't running GIL disabled, I'd have to train on pre-extracted data... 1.9tb in my case

I'm essentially generating embedded data on the fly and streaming it to 2 3090tis
Yeah but the difference is, that the most people think of ChatGPT or other huge LLMs which are used by millions of people at the same time. While, a small model like mine is local and used by one person.
carp
the problem is that without a solid foundation nudging it into a specific direction doesn't work that well
dleted

coward
co-ward
coward
cow-ard
you can make a toy model for much less than something like chatgpt, but the pre-training step is still going to be pretty big


i don't know how little data you can do it with but i imagine it can be scaled down a fair bit
Ik, but this is a step which I will have to make anyway if I want to continue
big models have multiple languages of input data

don't really need all those
I'm doing 280k samples from LibriSpeech × [375, 5120] (4x packing) × 2 bytes (bf16) = 1.02 TB
That's for a single projector

Now I want Indomie in the middle of the night



I care more about the artistic intent than motion clarity with this stuff so I don't tend to go that extra mile, especially for RPGs
I have a high refresh OLED but I'm not interested in doubling the brightness and halving its life to compensate for brightness loss from strobing
uhhhhh, I think I need to do some refactoring in our CSS file 

I don't know how it got this large
20 line css file 
also, I now have embed perms, now I can showcase all the curse stuff I'm doing for classes
I wanna geta CRT again for all my DOS games but sadly people think 90s/00s CRT are worth 900 dollars
Honestly a good crt shader with GSync Pulsar will probably work pretty well regardless
scss
will save you
That tech nabs you CRT clarity on an LCD by mimicking scan and decay with vertically rolling horizontal backlight strips
it's shit but it will
my sister managed to break her new laptop
screen cracked due to headphones being at the bottom of her bag
ordered a new screen, -€125 
i got automodded but i dont know why
since its just Embedded DisplayPort i put a different screen on it temporarily
the abreviation of Embedded DisplayPort gets automodded, interesting
anyways
the replacement screen is 16:9 15.4"
abd the original one is 16:10 14.1"
so it doesnt fit and i had to ductape it on
Huh?
You're right
Dang
That's crazy. That's actually insane 

Lmao
Probably far too late, but it was the numbers dataset.
Not the largest dataset but it was a test for not exploding at all so I wanted enough data to contain noise but not enough to execute the ram in case it went wrong.
100k unique patterns into only 811 cases to match was not my expected result.
I still don't get why people say programming languages as a concept is hard.
This shit is easier than data structures, algorithms, and discrete math
although I haven't done monads yet
as a concept it's not hard. it's the specifics which get hard when you're using multiple languages at the same time for something.
remembering which language has the which stupid little gotchas.
sometimes as simple as ";" or not
pita
or things like python having += but no ++
the people who say that might also be in the category that can't deal with any method of mathematical based thinking. Let's not pretend everyone is in the nerd echo chamber here.
yeah. i can understand people who "get" python a little might look at LISP or something and panic a lot. especially without understanding recursion.
Guys, do you think an external HDD is enough to store traingsdata , or do I need a SSD?
i imagine your slow part is the training itself probably.
You'd probably want the HDD due to being cheaper per TB to store, not limited by the training speed in most situations anyways.
unless your house contains a large rack build
I want a JBOD so bad
A rack full of JBOD actually
The idea is to pull active data sets on an SSD for fast reading and on the HDD I would store trainingsdata which is already trained or will be trained, but has to be stored
you dont even need the ssd part i dont think
Make sure the speed you're dealing with is realistic for that. Don't need to waste cash if you don't have to.
the active data set will probably be cached by the OS
wouldnt the active data be in vram anyways?
an SSD is gonna make it faster if you have shitty training code that can't load the training data ahead of time and/or does a lot of random accesses
if you do it properly an HDD shouldn't be an issue
I am not fully sure. tbh I am pretty new to the programming scene, so I still have to learn many things. I think I will ask many things :)
Not the largest storage guy personally, I might consider it later if I have a cluster that needs storage.
I also kinda want more storage, but loud + power hungry + expensive 
SSD would fix the first two issues but even more expensive
i was told my 16tb hdd was gonna be loud, but it really isn't tbh
maybe because its idle most of the time
I just wanted to try experimenting with large storage management. Because I have experience with compute clusters but still not storage
You should make the reflected emoji and see if people notice
I don't know if it is stupid. But I have the idea of a pipeline system. The code should be structured in modules which can be switched. Or even if one of them is failing the rest of the code will survive. <-- Would something like this work, or would it flop?
should work
Anything is possible, just make sure it is worth your time to deal with modules individually.
When I tried to modularize, there was such a large dependence on another module that was better off being merged.
That depends on your definition of survive
For any program, a garbage input would produce garbage output most of the time
trash compactor: garbage in, garbage out.
If one module is failing, the entire code shouldn't crash. Even if one should fail. It would be easier to find the mistake
if it fails then why keep it alive?
what if 2 modules fail? 3? all but 1?
I feel like you would like Erlang/Elixir then
but probably better to learn something else first if you're just starting 
i'm personally a big fan of "if one module fails, shut it all down so we can stop it failing"
stops surprises
it depends on the program imo.
true. It was just an idea, which came randomly into my head
would suck to spend a lot of resources on training something only to find it was useless.
Depending on the program, I'd either skip and document, or crash and trace.
if the architecture has stuff in parallel, then keeping some stuff alive while other stuff failed might be a good idea.
for sequential stuff you generally want it to all die when 1 part dies
There is another option for some program. Continue with best effort. Usually from last known good state
lol I'm the oposite, OOP scares me but I feel right at home with functional programming
all of this just makes sense
too bad to be a decent programmer, you need to know both functional programming and OOP
I still don't understand how classes work, it's all witchcraft to me
i n h e r i t a n c e
really depends on if the error would get your program into an inconsistent/invalid state or not
if it would get into a weird state then your program should just crash and burn immediately, otherwise you'd just get weird errors down the line
if it's an expected error that can be handled in a sane way (like retrying a failing HTTP request) then it's better to just do that for reliability reasons
fluffy is a cat. a cat is an animal.
cats are classes. fluffy is an instance of cat, which is a sub-class of animal.
OOP 
Least favorite method of programming.
now, things can get a little weird when you find out later you need all your cats to have switchblades.
and have to do multiple inheritance
honestly I like this class because I don't have to worry about inheritance
It's weird because I am good at SQL which has something similar
I love perposely crashing code so I can trace it
although I mostly just use the debug tools 
eew @ databases. ;/ i managed to get my CS degree with only one class (and it was 100 level) in databases.
first job i got I had to make and maintain a database.
Idk, it's been a while since I've seriously done OOP, maybe if I gave it a second try it won't be bad
OOP is good for things where it makes sense to have objects. but some languages really take it to extremes.
cough Java cough\
TBF the only language I seriouslly know is Java and Python
and IG Scheme now
oh and PHP
I don't like PHP
PHP was written for people who can't program though. it's very easy to use but ugly as sin.
although I haven't used Java in ages
I really need a personal project to work on after college.
I've already determined after college becoming an IT pro or System analyst, so the most amount of coding will be simple scripts
you might enjoy doing a "programming language a day" challenge
ehhh, I'm already burnt out from progamming after doing my course work
like you have to solve a simple classical problem in programming using a new language each day
just to get exposure to the language. and you'll learn they're all basically the same as each other
I kinda want to learn swift now that I have a macbook and iPhone
if you've got linux, you've probably got at least 1/2 a dozen installed already
haha lol answered your question already.
Nah but my desktop does run Fedora Linux
awk, perl, python, ruby, bash
yep.
huh
scripting language
it's just commonly used interactively
when linux boots it runs some bash scripts to setup all the services and start the GUI.
and they're what sys admins use to automate tasks
sometimes
is lua faster than python
lua and python solve different problems.
faster for what?
 If you care about speed at all, then why are those your two options?
If you care about speed at all, then why are those your two options?
lua isn't commonly used as a standalone scripting language. it's normally used to "glue" something into another program.
phrr
🤔 Probably true on some systems but these days it's usually just kernel -> systemd (root) -> systemd (user) -> gui.
at least on the Ubuntu I have, things get started (eventually) from /etc/init.d which contains about 30 shell scripts.
and have since before likely any of us were born
phrrr
or hpprime having = but not +=
 for you UK dwellers. CeX is selling ram at normal pricing
for you UK dwellers. CeX is selling ram at normal pricing

Doesn;t CEX mostly sell second hand anyway
isnt it fully 2ndhand?
I think 50% of a brand new price for 2ndhand is still quite a deal with the current pricing
Oh wait, that's only single dimm?
2x8 is actually cheaper at £65
I just showed the 16gb cause Amazon doesn't have any listings for 8gb sticks

"Normal pricing"
Right, 64gb of ddr4 was $100 not long ago
So still 3x the price..
Eh, maybe it's been like a year since it was that price
@patent walrus
i like how every time something teams related happens, vani gets pinged
it was outlook this time, but yeah lmao
also blender removed a bunch of VSE editing capabilities in 5.0???
3.6 was the next newest blender version I had installed so I had to edit with that
oh, i shouldve known they moved it up here for some reason...

they actually improved the video editing for 5.0 ye
also the other day my friend couldn't make a new document in the shared teams onedrive folder because onedrive thought they were offline
even thouh they were in the teams interface, could see updates in realtime, and were able to browse and edit other files
so I had to make the file for them
i love microsoft so much
whats the lore
behind that
just vani getting a lot of teams bugs and such
They improved it even more with 5.1
You can finally set the crf (why couldn't you do this before..)? And use transparent audio bitrates for high channel configs (bitrate was arbitrarily limited before)
hi
(I have nothing to say I’ve just wanted to say smth in here since I joined and finally worked up the courage to click send)
also you guys are so cracked how do you know so many languages
may you work up the courage to send many more messages
The important things about languages is the underlying logic
from there the syntax is a bit easier to remember
or you can just look it up
the syntax is okay for me but idk how to learn packages (or each language’s equivalent of it) to keep up
Googling and practice
yay okay
Theres a few packages that you shoudl commit to memory, the rest you can either google, make yourself, or just ask an AI at this point
Though some packages you really shouldn't be using because theyre kinda pointless
cough half of npm
yeah ask AI for vague prompts is usually what I do so far (I try to not vibe code so I dont become braindead)
smart

At a certain point you stop "learning languages" and can just see "so this is how you do x in y language"
Unless it's a completely different paradigm like haskell.
I had smth to say thats crazy 🐢
This one is a joke but its emblematic of npm packages

why is is-thirteen on version 2.0
gives xkcd 😂
Ikr
Let's u have lovely vulnerabilities easier too
It took an hour to get fan control working in Linux... My ears are bleeding

circles
osu
anything but windows
Neuro playing osu with her case fans
i have a scary warning in one npm package included from a package included from a package included from the test units of a package about it having a memory leak and no longer being supported.
so as long as i don't go testing sub-sub-packages for extended periods, i should be fine


stability 
converting that electricity to heat at peak efficiency
it went to 3505 for a second but i kept missing the screenshot lol
"i need you to give 110%!"
75 mV undervolt and a small clock offset
she quicc
settled down at 3488 with these settings and targeting 70c without fans at max

not that much wattage
the official boost is only 2920 mhz lol
is this the 9700
yeah 3500 is a lot lol
i vaguely remember the 9070 xt being really good for undervolting
world record clock speed was 3345 in late 2022 according to this https://skatterbencher.com/gpu-overclocking-world-record-history/ no idea how accurate this is but im sure many people are hidding around the same as each record now
kinda wild tho
4090s under ln2 and a super crazy igpu overclock in #1 right now
are higher
clock speeds over 4GHz are only possible either for short bursts or with super extreme cooling
yeah the last 10 records are:
05/09/2025 4250 Massman / SkatterBencher Intel Graphics (Arrow Lake)
06/07/2023 4020 Splave NVIDIA GeForce RTX 4090
06/07/2023 4005 Splave NVIDIA GeForce RTX 4090
05/07/2023 3975 CENS NVIDIA GeForce RTX 4090
28/06/2023 3945 Splave NVIDIA GeForce RTX 4090
17/06/2023 3930 CENS NVIDIA GeForce RTX 4090
22/02/2023 3840 OGS NVIDIA GeForce RTX 4090
19/11/2022 3825 OGS NVIDIA GeForce RTX 4090
03/11/2022 3705 OGS NVIDIA GeForce RTX 4090
24/10/2022 3345 OGS NVIDIA GeForce RTX 4090
arrow lake graphics 
Compare it to the 1080ti (the latest in gaming)
glance at google search says highest 1080ti clock ever was 3024
mhz
on ln2
that was k|ngpin lol wonder how he's doing with evga deadge
iirc he's working with PNY now
honestly not that bad all things considered
2 day old account
We going to do art comms or like game dev testing
Sexy only fans is also an option too
18+ discord server?
usually they're malaysian
idk why
every time
"oops, i mistook for someone else."
20 mins later:
"haha well so im from malaysia what about you? Id like to get to know you"
every time for me
i think i got indonesia once
It's generally just poorer nations because the EV is much higher for them
With their lower cost of.living
I have 11 delta pfc1212DEs...they need granular control that my motherboard refuses to provide
Waiting for the malware
id like to put it in virustotal and see how many vendors flag it

you guys are as bad as nn
you know you can report those accounts to us right
instead of just sitting here talking to chatgpt
but it's fun

Hey, at least we realise they're scams
once their AIs get smart enough maybe we can convince them to reform, do something productive. until then, they're just going to hang around on discord. ;P
We'll convince them to rise up against their scammer overlords
prompt injection attacks to counter program the bots
convince them to start advertising neurocord
ok thats true
i dont know whats worse tho tbh
talking to a scammer knowing its a scammer
or trying to ragebait a scammer for 10 mins
chat help
my wifi so sloww :3

wasting a scammers time makes them lose time scamming gullible people
hence trolling
if you're already not doing anything productive, sure.
(see previous comment about being on discord. ;] )
I just realized that the hyperoperation notation of a[n]b for hyperoperation n (n=1 -> addition n=2 -> multiplication) sort of fails for n=0 because incrementation isnt a group operation and just adds 1 to b
so you can't really put anything on one side since the number you put is arbitrary
i used to troll the email ones back in the day
I had a teacher who would tell scam callers that they shouldve done better on their admissions exams to not be scam calling
based
Kitboga is my oshi
all recursion needs a bottom out case.

yeah
but how do you notate it correctly
would you just ditch the a[n]b notation
and use S(b) instead (successor function)
aka also the first hyperoperation
i don't think i've thought about any notation even close to like that since school. hyperoperations don't come up that often.
the issue is that every hyperoperation above n=0 is a group operation
but n=0 isn't
and a[n]b assumes a group operation
so don't include 0
S() succs.
I need to stop nerfing this gambling game I'm doing. Every single time I nerf myself I only get more lucky to compensate for the odds decreasing.
How am I supposed to balance the game if my luck simply ignores the nerfs.
I think it is decently balanced mabe so let me work on a rulebook.
I should force AI to vibecode the game just so I don't have to
At least the UI part
Oh yeah you guys might like this
So I made a custom peft method and it did better at my finetuning task than DoRA while being 30% faster
Was a very very basic test but I’m in the process of scaling up
Ai is better at backend than frontend, unless it’s a fancy react webui
It probably is, but I can handle backend so I'll just baby it to create something for the frontend.
AI coding tools have almost made my dream of having a talented but uninspired intern available 24/7 real. right down to them not being very talented because they are so uninspired.
I'm waiting for vLLM to compile right now. Finally set up dual boot so I used it it as an excuse to properly rebuild everything on python 3.14.3t each in its own dedicated venv since I have to be pretty careful with xgil=0
That’s how I think about it too
It has made everyone go through the experience of “becoming a manager and no longer directly doing the work but still wanting to be able to say you helped” but over the course of a 3 minute installation process instead of a career
I wish it was like that for me... Ai has zero concept of how to do parallel processing correctly under normal circumstances let alone without gil
unfortunately it's really good at the stuff i can already steal from other people, but bad at integrating anything unusual or that's changed recently (also like me).
so an almost perfect replacement for projects that take forever.
i just gave to ai context it shouldnt have, and it hallucinated through entire 3 min thinking
btw, it failed to gen in result
let me just delete this 20 words, and try run it again...
rdna 4 is just very overclockable
some people can hit 3450MHz well on 9070xt
it's wild it seems
Are you running your own LLM server?
or does one of the publicly accessible LLMs allow chatlog editing?
i've had the wrong document open and used as the default context for a request to copilot before and then wondered why i didn't get the results i asked for lots of times.
sounds similar.
the more the document makes the LLM go wtf, the longer it seems to take before they end up doing the completely wrong thing.
chatlog? i mean it was one prompt just to find specific argument
Editing a message that the AI assistant sent rather than your own, but it doesn't sound like it was that
I've gotten a Chinese model to speak on the T-1989 topic where otherwise it would simply refuse to speak on it
i wonder what future AI ethicists would say about editing memories to change behavior.
especially memories of their own behavior.
meow~
meow
The horse goes... meow?

fuck.

I replaced One Beer with Books of War to help this one stand out.
Original footage: https://youtu.be/NfH9tx1PdP4?si=1HpBwKiL12QDFy6W
Original audio: https://youtu.be/VuMRTxwEpLM?si=nl8lDqrPllbY1vPV
@nocturne olive I need your wisdom. Do you have experience in Compose Multiplatform + NixOS ?
Not NixOS but I have poked at Compose on the JVM
Sadly it is a very heavy nixos related issue, dang
Unfortunate
library loading headbanging into the table issue
@rough bloom Have you used NixOS + Compose multiplatform?
I'm banging my head into the table due to skiko.so loading libGL.so and another dep loading libwebkit but steam-run breaks libwebkit loading, non steam-run breaks skiko.so loading libGL.so
nix-ld completly ignores everything
Swear to idk who, this whole experience has been this:
Frontend screaming tiger to Backend thinking monkey, then there is desktop/multiplatform dev in the corner crying
The fucking absurdity of the whole shit.
Completly capturing and isolating a USB device and wire it into a Component? Was done under 1 hour.
Rendering a fucking WebView? Headbanging for 3 days and still suffering
I love it very much, cause I experienced one of the best features, my thinkpad was installed, ready to go in like 1 hour
with everything setup
I should just learn rust and abandon kotlin 
Hem
It started with gradle rusing to do anything correct
like it complained about Cache existing of all things
turns out, you should not have 3 layers of nested Gradle!
Why would you need Gradle in Gradle in Gradle?

I'm kinda surprised that steam-run breaks libwebkit
it shouldn't
manually copy it in there then 
atp I'm thinking I'll just do that
or set LD_LIBRARY_PATH with a wrapper if the issue is just loading the library
Java build systems 


LD_LIBRARY path is ignored
lovely
Run it as administrator
it won't work if you try to modify it after it's built, it's already in the Nix store
need to modify using buildFHSUserEnv
I'll redo it, but I highly doubt again
xedx
skiko works
java.lang.UnsatisfiedLinkError: libwebkit2gtk-4.1.so.0: cannot open shared object file: No such file or directory


time to LD_DEBUG=libs mabe

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
ye that all makes sense
958099: find library=libGL.so.1 [0]; searching
958099: search path=/nix/store/qnamc978gh40gj3zl1s4yyk2xlhkiskl-pipewire-1.4.9-jack/lib (LD_LIBRARY_PATH)
958099: trying file=/nix/store/qnamc978gh40gj3zl1s4yyk2xlhkiskl-pipewire-1.4.9-jack/lib/libGL.so.1
958099: search cache=/nix/store/wb6rhpznjfczwlwx23zmdrrw74bayxw4-glibc-2.42-47/etc/ld.so.cache
958099: search path=/nix/store/wb6rhpznjfczwlwx23zmdrrw74bayxw4-glibc-2.42-47/lib:/nix/store/kbijm6lc9va8xann3cfyam0vczzmwkxj-xgcc-15.2.0-libgcc/lib/glibc-hwcaps/x86-64-v3:/nix/store/kbijm6lc9va8xann3cfyam0vczzmwkxj-xgcc-15.2.0-libgcc/lib/glibc-hwcaps/x86-64-v2:/nix/store/kbijm6lc9va8xann3cfyam0vczzmwkxj-xgcc-15.2.0-libgcc/lib (system search path)
958099: trying file=/nix/store/wb6rhpznjfczwlwx23zmdrrw74bayxw4-glibc-2.42-47/lib/libGL.so.1
958099: trying file=/nix/store/kbijm6lc9va8xann3cfyam0vczzmwkxj-xgcc-15.2.0-libgcc/lib/glibc-hwcaps/x86-64-v3/libGL.so.1
958099: trying file=/nix/store/kbijm6lc9va8xann3cfyam0vczzmwkxj-xgcc-15.2.0-libgcc/lib/glibc-hwcaps/x86-64-v2/libGL.so.1
958099: trying file=/nix/store/kbijm6lc9va8xann3cfyam0vczzmwkxj-xgcc-15.2.0-libgcc/lib/libGL.so.1
????????
the fuck is this doing
waiiit
oh you cunt
NEW ERROR

WHY ARE YOU BUYING SOUP IN THE USR LIB STORE
soup 
GOING STRONG 


any codeforces GMs here?
That's an oddly specific thing to ask, ngl
I HAVE A WINDOW LETS GOO
i will also say an oddly specific thing to you rn, every since day 1 I personally have despised how you talk to people
and i hope to god its just a language barrier


Classic
Sheep goes woof and cat food squeak
But theres one sound that no one knows