#SDNext WebUI on Intel ARC
1 messages · Page 4 of 1

yea idk what motherboard you have and im not really familiar with any other ones...
MAG B760 TOMAHAWK WIFI (MS-7D96)
I have mine enabled cuz I usually look at it to see if deep link is actually working on Handbrake
i'll poke around in the bios. also, I have no idea what deep link or hnadbrake is
deep link is nice since you have an intel igpu and dgpu. Im just not sure if its working if I have igpu multimonitor off and I havent done any test. According to the website about deep link, it is automatically on but im just making sure
omw to bios thank you so much
just to be on the safe side, make sure that you have no monitor(s) connected to ur motherboard.

Yeah
yea so from my experience, once you disable it, your task manager will only show ur dgpu
If this fixes it ur my hero
also, if u check device manager, under display adapters, youll only have the A770 after disabling it that is.
Haha

looks good so far, hopefully it works on u ^^
otherwise, Im sorry but it was worth a shot :>>. you can enable ur igpu again using the same process
IM IN
I don't know why I'm still using my phone for screen shots. You are the man. And disty and everyone else thx

there are some settings you might have to change. Im not really familiar with them
disty has some screenshots but u gotta scroll up for them. Have fun playing around with it ^^

it works bros
i even upscaled it by accident
OpenVINO doesn't hires fix yet..
I love them but I feel like there's more capability here
nice nice! but if you want to us sdxl, refiner, etc. youll have to modify ur settings.
yeah, I'm gonna stick to 1.5 for a while till I get used to the differences in the ui
I'm a slow learner but I learn
also interested in learning this out of curiosity
SDNext WebUI on Intel ARC
I searched through the repo and seems like the ControlNet pipelines are from an external plugin
Speaking of controlnet https://github.com/Mikubill/sd-webui-controlnet/pull/1952
GitHub
Under Construction
Estimated finish date is 2023 Aug 27 2023 Aug 31.
This thread only contains models from SAI/HuggingFace/diffuser/community.
This workload does not include any models from Stanfor...

🤔


I didn't know you could install wsl 2 on another drive, and how did you link another drive in wsl2??
i heard its recommended to have it on the drive where your OS is installed so i just figured i would link stuff around like this
installing wsl2 on another drive is quite convoluted.. and you can even install it on usb drive if you prefer. theres absolutely no down side about it (except it will load slow)
cd
ln -s (the location you have the files, but through mnt) (where the system is already going to look for the folders, use /home/ unless you want to type /mnt/c/users/ again )
oh my bad you werent asking me
im stoned that should explain it
the only folder i cant get link to work right is outputs, so i just did it for a few things like sd models, vae folder, loras and embeddings for now

you can make another instance of Ubuntu or other distro by exporting it and importing it with a different name.
So you run this at startup ot webui? Then in webui link the folders? Or does this just add it to wsl forever? If so I can link it to the same folder like I do in native linux and just delete my models out of wsl2 and regain that space. I will look this up although I think i did before and just read it wasn't possible lol
I’m only guessing but I believe @onyx moth ran the installation first via webui and said no to downloading SD 1.5 then closed the server and performed the command ln -s which created a FILE that links directories. After that, my best bet would be that skeleton ran webui again.
I think you can delete the FILE created by ln -s so they are linked until you delete it.
interesting, if there is a way to link to other drivers in wsl2 you can add that link inside the options in both sd.next and a1111 I believe. I'm going to look this up so I can free up more space on my main drive and just use the same models for wsl2 and native windows.
yes I already had the models in a folder on my d: drive, but the engine is in c: drive in wsl. so using the link puts a file in the folder inside wsl that points it to the folder on d: drive
space-efficient 👍
and to delete the file you navigate to the folder its in inside wsl and go rm nameoffile
this way I have OpenVINO and SD.NEXT both essentially using the same folder yeah definitely saves space
does anybody know how to enable the extension browser? aka load available extensions through the webui? thanks
It should be in the extensions tab almost the same as a1111, might have an option to show all or something but I am not in the webui atm to be 100%.

Manage extensions, refresh
I haven't checked back in a hot minute, is the windows install less complex now/intel uploaded the complete whls this time?
or do we still gotta self compile/share with a neighbour on those and the other hacky parts?
I haven't seen any claim that they uploaded new wheels
but you can install it really easily and do JIT
compiling wheels with AOT took me 5.5 hours
I'm just going to pretend I did not ask that
They have wheels just not any compiled with aot so the initial generation is extremely slow, but it is still hacky with setting up environment with conda afaik.
I think its usuable if you use it for a long time and don't mind a 15minute startup. However you can use openvino now, which only requires one file edit for native windows
openvino is limited though right?
Openvino backend really likes alot of system ram @.@, using xl models while it compiles into the openvino format i see it use 100% of ram and start using the pagefile, i have 32gb btw, could be why xl models take 5-6 mins on the first generation while it compiles because it has to use my pagefile
I think in sd.next Disty said it takes 48gb for sdxl
not sure about the a1111 webui
yeah im using sd.next it just works better imo then the a1111, is more streamlined
Is there a known issue in sd.next regarding ipex and sdxl refiner?
openvino is working for sdxl models yes, disty has shown it though i have encountered something odd, i get this error C:\Users\KingOfMemes\automatic\modules\processing.py:584: RuntimeWarning: invalid value encountered in cast
sample = sample.astype(np.uint8) when trying to run at a res thats not 1024x1024 in my case 1024x1536, not running out of resources or anything but i get that error and a black image but 1024x1024 works fine
not that im aware of, what issue are you having?
wait ipex works with sdxl right
Yes
With or without refiner tho from most of what ive seen the refiner is pretty unnecessary
I followed the instructions here on github
VRAM Optimization: Chose option 1- did
Fixed FP16 VAE
BUT for Using SD-XL
everything works but (optional) Finally select the sd_xl_refiner_1.0.safetensors file from the Refiner dropdown.
I get the error in the picture with --ipex and then it kills the server. Without ipex, it doesnt send me the error but kills the server either way
Main Issue: Fails to load the refiner


How much RAM do you have?
32 but 16 on wsl
it works now! Thanks
So with openvino you need to have double the space for your cache folder it seems? Since it makes a new model each time. Any way to have it only complied once and remember the cached model when chosing models?
It will use the cached model
Also different resolutions compiles to different models
Each model can do only one resolution
Interesting, well I think I will stick to Ipex as I don't have enough space or memory atm.
out technically don't need the default model or onnx intermediate after you done the openVINO IR conversion
I got another newbie question if anybody got a sec - since ipex is run in wsl, does the output save location have to also be in wsl? or can I get it to save outputs on a different drive
aka a folder on my d: drive desktop
Well if you can create a link like you did before you should be able to set the output folder location inside the webui settings
I think there is an easier way. If you go
settings > Image Paths, you should be able to set the directory for the images. Im just not sure if you have to include mnt relative to wsl or just the drive letter D: for example.
o crap
i changed the diffusers backend from original
didnt like it because couldnt use controlnet from the webui built in
so changed it back
not some settings are missing
aka in settings I dont see a few things including the options for SDXL
should i reinstall the whole dam thing?
yeah i think theres a bug where once you changed to diffuser you cannot enable back some extensions
you dont have to reinstall the whole thing though
just delete config.json and ui-config.json
thank you thank you
SDXL will only run in diffusers, and Controlnet should work for diffusers just not sdxl?
@pastel geode Hey bro you were right, just add /mnt/d/ in the output destinations to output to the drive I want
in image paths

is this something I have to revert if I want to go back to 1.5 sometime? edit: I meant VAE Upcasting
Disable VAE Upcast on Diffusers SD 1.5 too
SD 1.5 doesn't need a special VAE when VAE Upcast is set to false
Only base SDXL VAE is broken with it and needs a fixed VAE
Also Diffusers works with SD 1.5 too
And Diffusers is faster and uses less VRAM
would controlnet work in 1.5 w diffusers
Not yet


This is 1024x1024 curse on ARC
Use 1080x1080
oh ok I had no idea

any tips on where to go from here? haha
had some pretty good qualities coming out of 1.5 - haven't really got a feel for the xl samplers yet

ask them to implement it
DPM 2M is DPM++ 2M SDE Karras by default
DPM 2M is the base and rest are an option in the settings
But Euler a is the best sampler for SDXL
@proper cradle If you made a YouTube channel with various tutorials related to the arc a770 I'd subscribe day one
what's the process for changing back the checkpoint to a 1.5 sd? Last night something broke trying it
Just chose a SD 1.5 model
If you want to use ControlNet, set backend to original from Diffusers Settings.
If you don't use ControlNet, use diffusers. Diffusers is better than original backend.
and the refiner I just leave selected on sdxl refiner right? After I changed that to none all kinds of errors came up and I couldn't do anything any more
I forgot what order I did things that broke everything. Think I switched the refiner off then the checkpoint then the VAE
yeah I've never been able to get 1.5 to work after I've used sdxl setup, it just breaks for some reason I haven't figured out yet
I go with Refiner = None (I never use Refiner tbh) then VAE, then model
Also set Diffusers Pipeline to Autodetect from Diffusers Settings
If you switch to original backend, do a full restart
Also enable the disabled extensions if you go back to the original backend
From what I am reading controlnet 1.1 should support diffusers?
uncheck autoload model on startup
i had sdxl refiner as the checkpoint and it would load up and break everything, system wouldnt let me change anything related to models and nothing worked
wait
'StableDiffusionXLPipeline' object has no attribute 'parameterization'
still broken
Are you in diffusers? sd1.5 will run in both original and diffusers, SDXL will only run in diffusers. might have to shutdown and restart to swap iirc.

need that obscenely fat gerbil
ok its fixed after a restart
here's a hamster from 1.5 lol

and i meant to inpaint this but got sidetracked with xl

HIS HAAAAAANDS
anybody have methods of getting multiple subjects? I keep getting hybrids.
here is an example

you cant afaik
you have to inpaint it
like selecting the raptor behind and prompt raptor
In sd1.5? I think its called latent couple, its hit or miss for me when I tried.
1.5, xl both
finally got around to setting up the conda on windows and oneapi and all the fun stuff. used default whl, but during the long windup to first render, I just crash to Native API -997 

oh, i managed to get a couple of images out, but they looked awful, and then I changed backend and it crashed again 
try and run this in python "import torch
import intel_extension_for_pytorch
torch.xpu.is_available()"
Also using the default whl should take about 15 minutes to start up the first time.
yeah it takes a really long time to start up. it just usually crashes halfway, and if it does work, it spits out mostly garbage

curiously though, when I went to import intel pytorch, i got

not sure if that can cause issues
Yeah, its looking for cuda in an nvidia folder? You have multi-gpus in the system?
Make sure to run it in the oneapi env, call all 3 vars each run
nope, I uninstalled and DDU'd my nvidia half a year ago
though I did have the cuda toolkit for back when I did use the card
a li'l ol' 1050 ti
right now i'm just following this page for the setup:
https://github.com/vladmandic/automatic/discussions/2023
this is necessary if I want to upscale 2x right? since I have to use XL at 1080 instead of 1024

Did it work after uninstalling that toolkit? Is that the folder it's trying to reference in the error? If not, what exactly is in that folder? If you did uninstall try reinstalling ipex again afterward
@proper cradle since I'm generating at 1080 x 1080 should I go 1920 x 1080 for landscapes or something else? thanks!
I think it's actually trained on 1024x1024, but I guess it glitches on arc. I found this a long time ago when it first came out https://www.reddit.com/r/StableDiffusion/comments/15c3rf6/sdxl_resolution_cheat_sheet/
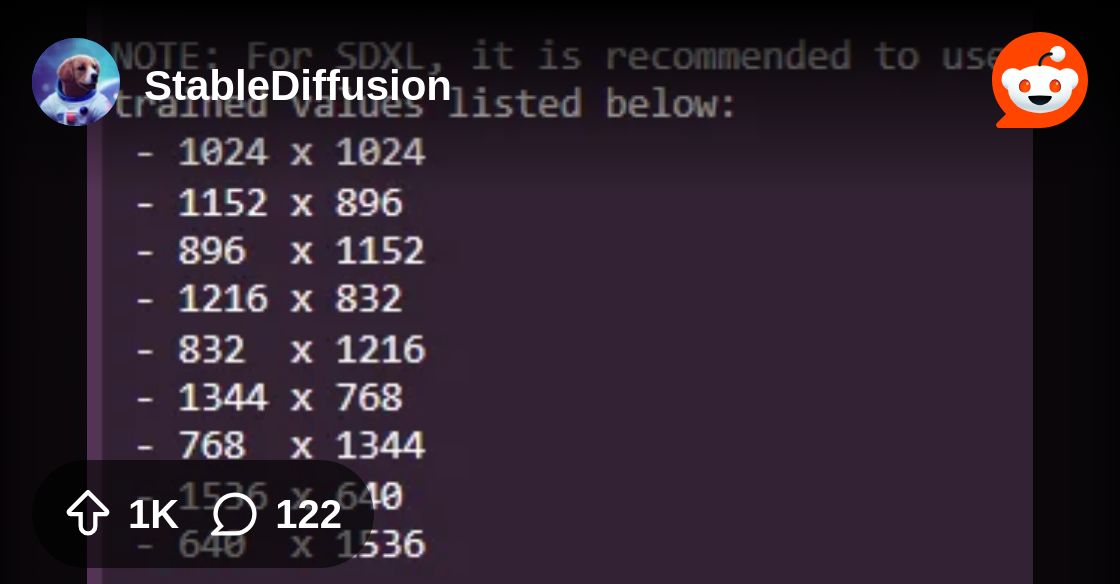
Reddit
Explore this post and more from the StableDiffusion community
oh, after uninstalling, the sdnext doesn't want to run at all now 
although, if it was actually using cuDNN somehow, I'm not sure how it managed to actually generate a pair of images on the gpu
confusing, but I'll try to get it back to running state
oh wait, i'm a moron, i was trying to run the wrong sd install
not before mind you, just this time
btw, i've never really been clear on this for the months i've been playing with this: what is ipex?
removed all nvidia toolkit stuff, we still getting -997
native pytorch can use device "cuda" just fine but not for xpu
this is where ipex comes in
now that intel dev made its way into pytorch maintainers (i think this is how its called) we can expect to use xpu without ipex in a not so distant future... hopefully
intel pytorch extension
It is a bit confusing since they call it intel extension for pytorch, yet short hand it IPEX for intel Pytoch extension. 🤷♂️
OH
I'm an idiot for not noticing I P EX this whole time
yeah I'll try removing and readding it, though the package does seem correct on the git version number
RuntimeError: Native API failed. Native API returns: -5 (PI_ERROR_OUT_OF_RESOURCES) -5 (PI_ERROR_OUT_OF_RESOURCES)
um help thanks lol
im seeing this
the normal (correct pipeline) was selected
happening when it tries to load up the refiner i guess
Out of System RAM
You can go directly for 1920x1080
Needs more luck tho
And you can 2x from 1920x1080 with Attention Slicing enabled
A770 16 GB can go up to 4096x4096
I was just confused since I had loaded up the refiner before and done several images over a few days
thats amazing
Also Refiner is pretty much useless if you are using a finetuned model
yeah I went back to base to try it just couldnt get it to work again
Refiner generally makes images worse with finetuned models
...can refiner be finetuned for a finetuned model??
Can be but no one did
It probably should be lol, but I guess there has to be a good reason nobody has yet. Maybe just to save time and resources, fine tuned models already "refine" the image anyway, just in very model specific ways I guess.
is the 1024 x 1024 curse for the arc fixable? genning from 1920 x 1080 needs a lot of luck proportions get messed up all the time etc
I mean is it something in the works/being looked at etc
also can someone please give me any tip you can about inpainting

thats what I got out of this

CrystalClearXL btw
Try 1024x1536 or 1536x1024. Only 1024x1024 is cursed.
Or try these:
resolutions = [
# SDXL Base resolution
{"width": 1024, "height": 1024},
# SDXL Resolutions, widescreen
{"width": 2048, "height": 512},
{"width": 1984, "height": 512},
{"width": 1920, "height": 512},
{"width": 1856, "height": 512},
{"width": 1792, "height": 576},
{"width": 1728, "height": 576},
{"width": 1664, "height": 576},
{"width": 1600, "height": 640},
{"width": 1536, "height": 640},
{"width": 1472, "height": 704},
{"width": 1408, "height": 704},
{"width": 1344, "height": 704},
{"width": 1344, "height": 768},
{"width": 1280, "height": 768},
{"width": 1216, "height": 832},
{"width": 1152, "height": 832},
{"width": 1152, "height": 896},
{"width": 1088, "height": 896},
{"width": 1088, "height": 960},
{"width": 1024, "height": 960},
# SDXL Resolutions, portrait
{"width": 960, "height": 1024},
{"width": 960, "height": 1088},
{"width": 896, "height": 1088},
{"width": 896, "height": 1152},
{"width": 832, "height": 1152},
{"width": 832, "height": 1216},
{"width": 768, "height": 1280},
{"width": 768, "height": 1344},
{"width": 704, "height": 1408},
{"width": 704, "height": 1472},
{"width": 640, "height": 1536},
{"width": 640, "height": 1600},
{"width": 576, "height": 1664},
{"width": 576, "height": 1728},
{"width": 576, "height": 1792},
{"width": 512, "height": 1856},
{"width": 512, "height": 1920},
{"width": 512, "height": 1984},
{"width": 512, "height": 2048},
]

thanks Disty
There's a setting in inpainting that determines whether the rest of the canvas is taken into account, or if it basically "zooms in" on the masked out area and does a full scale render and just shrinks it into place
I forget what exactly it is right now though, since I haven't gotten sdnext working again yet...



hamster man. . . .
If I were to try my hand at getting some basic form of training working, what would be the most straightforward approach?
Reimplementing gradscaler?
Training works on the dev branch
Patching CPU GradScaler did the trick
hmm
training starts and proceeds for a dozen or so steps, before throwing a TypeError, log attached. This is with BF16, going to try FP16.
this actually happened when I tried the gradscaler patch from 1.5
on 1.5
nope, needs bf16...dman
it appears to be an issue with preview image generator
commenting out these lines lets it proceed until instructed to generate a preview image

that patch, plus cranking up interim images to some hilariously large number, fixes the crashes. let me check the output of the training
okay, training is working correctly outside image generation during training
wowie, training was a primary reason I wanted an arc a770 for originally, exciting if it can work now (in a dumb enough manner for me to understand)
Training is for the original backend
Did you remove that patch?
It will use that if it's available
Yeah this is all reasonably fresh
by the way, can I use sdxl through original backend? is diffusers just a way to conserve ram or vram or somethin?
afaik, sdxl is only in diffusers.
how are people having access to new samplers? I thought it was a diffusers difference
https://github.com/vladmandic/automatic/issues/1885#issuecomment-1657212135 this is what I could find

GitHub
Feature description The original backend is tried and true and generally very stable, especially compared to diffusers support. It also tends to use less VRAM. They've also released all the fil...
Applied 4GB patch to SDP as well:
https://github.com/vladmandic/automatic/commit/9cadf4fc10e4e3918f283b2581cae95fc0d3478d
SDP is the default optimizer now.
And this 32 batch size, 20 steps, 512x512 generation took 40 seconds:

And speed on original backend with SDP is 7.5 it/s
intel drivers just dropped
did something change with styles? Seems my csv file isn't being read right anymore
on windows SDP uses about 2gb more vram than Sub-quadratic about 6gb with sub and 8.5 with SDP at 960x544. Not great for the a750. This is using Ipex in original backend.
Also was garbage collection disabled? seems to hold more vram now and I don't see the option anymore.
You can set it manually, default on Nvidia is like this too.
whats garbage collection
its a term referring to how memory is managed in computing. useless data doesn't need to stick around in ram/vram, but its a pain in the neck to manage removal manually when developing software. For this reason, there's a lot of libraries made that are really good at handling it automatically, and a lot of higher level languages just handle it for you by defualt. If garbage collection doesn't work correctly though or if its turned off, memory will just fill and fill and fill until the program is terminated.
Vlad removed to force option. I won't clear it unless it hits %95.
garbage collection is an action to empty memory for objects that are no longer referenced. iirc in python it is automatically done when certain threshold is met but you can call it manually. examining if objects are referenced in general lower your perf so only do it when necessary
DPM 2M 50 step cfg 7 sdxl

Also training on Kohya SS GUI is working now:
#1142086112014237857 message
Forgot to put artifacts and jpeg artifacts in the negatives
is there a good way to benchmark hardware? I got PVC access but only 10GB of storage but want to try stable Diffusion inference
man, this is weird. it hits embeddings and then declares it can't find the device

the device listed up here

also listed here when running sycl-ls, so oneapi access is exposed

also still getting error -997 if I try to infer anything. This is on latest version, just deleted config and ui-config to ensure i'm starting mostly fresh, although this was already basically fresh the first time I got the error a week or two ago
native api failed mostly means oom afaik
it has its own error call for oom, i think -5?
I've got plenty of overhead though. loading orange mix on a770 16gb with 64gb system ram
you can probably monitor vram usage while you use it
16gb is nothing for sdxl if you dont utilize all memory saving tricks you have
yep i think he is.
I'm trying to run windows yep. vram doesn't go over 20%
it's literally failing before even hitting render on anything
some of the others have no problem, so I'm just wondering if I screwed the setup somewhere
oh yeah, I'm also only trying to run 1.5 models and backend for now, I've had enough troubles even without trying to run SDXL/diffusers
Try diffusers backend
start with --backend diffusers if you can't get into settings.
well, I was having issues with diffusers backend too, but I'll give it a try now since I'm having a slightly different issue than I was before
Also OpenVINO will be better on Windows
Create a new install and use --use-openvino
switching to diffusers crashed my card and i had to reboot 🫠
what are the disadvantages of open-vino? I heard there were still some issues/features that don't work
I want to do upscaling and training at some point
resloutions more tthan 768x768 on SD 1.5 and 1024x1536 on SDXL
Compiling models takes time and RAM
If I'm using a conda venv, should I not use the same venv as ipex install?
thanks
Also SDNext has full Python 3.11 support now

well, I certainly get an image which is much better than I was getting on ipex

Do LORAs work with openvino at all?
the system log seems to suggest it is, but I see no effect from it
also, vram use keeps climbing, and the quality of outputs gets lower over time...

Yes but Lora's runs on the CPU
weird, my loras didn't affect the output at all

Yep, this is right
testing same seed with and without lora, i get very minor change
Without lora

with lora

having the lora set to maximum weight
its a pretty influential lora, and this isn't the effect it should have
how to enable DPM++ 3M SDE Exponential??
for non training (i can't speak on that) the downsides are compiling the model every resolution, more vram usage, and need for more disk space (for compiled models). Advantage is it is much faster after initial run. 10it/s on a750 in native windows vs 6it/s in diffusers with ipex.
They fixed some of the duplicated VRAM usage in openVINO (if you export via optimum/onnx)
There is a large patch coming 2023.1. Sometime next week most likely
it's meant to improve GPU inference performance for language models. But might bring more improvements with it
also might be crucial to some MTL products that Intel wants to show at InnovatiON. So that's the proper deadline
does sdxl controlnet work in sdnext? I just read they updated the webui version.
holy crap

I tried using 3 loras
wait that's.... ok, i misread the digits. that's only 5 gb
ahh, i finally managed to get the lora working, ish
the result is still awful 'cause I think my vae's are actually not getting used, and its 1.4 s/it and almost all of my vram
i didn't mess anything up did i?

You are back on master branch if that was what you were trying to do, you can easily return to the commit you were on if needed.
i dont know how to go back
you can do git checkout <branch>

my bad i forgot to mention i dont know much about any of this
if it wasnt obvious lol
 ..
..
you need to replace <branch> with branch name
so suppose you were on dev, you can run git checkout dev

heres a list of branch available for this repo
whats the branch of this thread
you can also checkout to a specific commit (which is a snapshot of a repo)
like this

whats the uh. the branch for sd.next
you can choose from master, dev, and fix_init_latent_diffusers
the other 2 is stale and i doubt theres any use case
so if i just leave it on master is the best then
for normies yeah
im somewhat of a normie myself

thank you btw
Yeah, you don't usually need to change the branch unless something breaks or there is a preview for a new feature or something
I see you're the one writing the doc. I take it you're on python 3.11 with arch so you need to use --experimental. it looks like --use-ipex doesn't work on Arch as well. I would like to know exactly how you got it running cause last time I tried i had to do the whole intel_extension_for_pytorch rigmarole and it would never succeed, between pip being an actual a**hole about non-package manager packages, to compiled binary deps not being happy it never worked.
🙃
I see a lot of XL images on civitai using DPM++ 2M SDE Karras and DPM++ 3M SDE Karras but not seeing them available here. Is that an IPEX limitation? Are these people using Comfy or something?
I know that @proper cradle said DPM 2M is the base and rest are an option in the settings but the images being produced are using normal scheduling.
I tried using comfy extension on ipex and it just hard crashes my server launch 
i'll try to just install comfy on its own and see if I can run it, 'cause if I can't run comfy on its own either then i probably have something messed up in my oneapi install or something
Python 3.11 works, don't use --experimental
Did you install OneAPI, intel-compute-runtime and rest of the necessary packages?
It's not an IPEX limitation
You can also ask SD.Next issues on SD.Next discord server
oh, there's an sdnext server?
Yep, link is on the readme
sweet, I'll hop on tomorrow
@proper cradle have you seen this red/green pixel dot artifact on sdxl? it seems to be it's related to invisible-watermark

https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9/discussions/31 could be solved by overriding the diffusers XL pipe.watermark

I was working on the A1111 fork and ran into this issue for some reason. but after overriding pipe.watermark then issue seems to be fixed
not sure why
add_watermark=False?
It's disabled in SDNext for 2 months already
If you still have this issue then don't use the original base VAE
thanks for the info 😄

oh uh hey. is 1 to 2 it/s normal with the arc a770 on sdxl?
1.85 it/s at 1024x1024
That's about what I'm getting. Nice.
hey disty, out of curiousity im just wondering if the 1024 curse is something that might be fixed in the future
It was way worse with IPEX 1.13
It reduced to 1024x1024 only after a few updates to IPEX itself and the compute runtime stack
I see, I'm glad to know there is/has been progress with that
such a weird bug
Sdxl doesn't want to work at all in native windows anymore with ipex. Error diffuser model not loaded. Maybe some setting I have is wrong its been a while
Also getting massive memory usage and slow down of system like back with wsl2
Seems like a memory leak? Python isn't even using it. Oh I seez it reset itself to fp32 again lol, why does it do this again?
Still won't load any sdxl model with xl backend for some reason. Actually nothing will load in diffusers.
okay figured it out, Ipex optimize causes the problem. but now native API failed error. 😦 Might have to pull an older commit. okay, shutdown fixed that lol
Fixed that one
Put the return model on wrong place
I keep getting an api error when loading a Vae or the refiner etc that requires a complete Ui shutdown to work again. I used to be able to swap out no problem, only had to restart when chaning the medvram/lowvram setting etc
Disabling IPEX Optimize and Compile is the same?
I have them both disabled
It seems to be hanging on loading the Vae or something. I tried to swap vaes and it it just says it's loading in the cmd window, but nothing in the webui, and if I load a model it will load that and then say it's loading the vae still.
Only change with the latest update on IPEX was IPEX Optimize and Compile
All i did was moving them to a function so i can call compile with OpenVINO
I don't know, I haven't used it in a while it could be something from a while ago. Also could be just windows ipex stuff
same, still happening
when trying to change checkpoint. also, it used to say in the command prompt the details of the checkpoint being loaded, now it only mentions the VAE. And when prompting it always says loading vae approx instead of the checkpoint (baked vae or not)
like it doesn't say loading weights about it
am attempting to setup via docker on fedora as icba to setup intel stuff there. Also docker desktop wont connect to the gpu as it is setup without sudo lol (atleast docker-ce works when using sudo)
hasnt crashed yet so it may work hmhm
idk i think sd xl works uhh

is this a good speed with an a770?

tbh i need more ram lol
works well enough i am satisfied

LMAO
Attention Slicing is turned on by default on IPEX now
New speed you should expect at 1024x1024 is 1.70 it/s
Slicing Scaled Dot Product to workaround 4GB limit made it slower than Sliced Attention
yeah i think i get that
has there been a solution to the 4GB thing?
Slicing the attention layer did the trick
And Scaled Dot Product is the default sampler instead of Sub-Quad on Original backend now
And it's still faster than sub-quad
Any changes with the new Openvino update? Any optimizations etc, or compatibility issues?
lots of improvements in that release. but I suppose wait a few days for all other libraries to incorporate those
Updating OpenVINO to latest one caused a slight performance loss on my end
Reading the notes, it looks like openvino no longer needs to convert the models? That could be pretty big
oh? that was a big issue for me. because changing even the resolution had to let it convert and the cache would get huge fast
it still needs to convert models from torch to openvino ir. However, you no longer need to export torch to onnx and then onnx to openvino ir. additionally they implemented the reusing of weights properly, that should reduce the memory footprint with language models for example (where the input embeddings are reused for the lm head)
Still a huge improvement should lower the time to compile the models and such
yes, the torch.compile backend is interesting to compare to ipex now. But it will take a few days for optimum updates to properly change their backends etc
The 4GB VRAM limit on Arc GPUs seems to be related to the memory usage of the attention layers in Stable Diffusion models.
Some key points:
-
The attention mechanism is very memory intensive, since it calculates relationships between all tokens in the input.
-
For higher resolutions like 1024x1024, the attention layers start exceeding 4GB of VRAM usage on Arc GPUs.
-
This was causing crashes or failures to load models at 1024x1024 and above.
-
A technique called attention slicing was implemented to work around this issue. It splits the attention calculation into smaller chunks to reduce peak memory usage.
-
After adding attention slicing, Arc GPUs can now run 1024x1024 resolutions at decent speeds of around 1.7 iterations/sec.
-
But the 4GB limit still remains as an architectural restriction of current Arc GPUs. So higher resolutions like 1536x1536 remain out of reach for now.
-
The attention slicing approach helps make 1024x1024 feasible, but doesn't fundamentally lift the 4GB barrier. Further memory optimization work is still needed for higher resolutions.
So in summary, attention slicing was an optimization to make 1024x1024 possible by reducing memory usage, but the fundamental 4GB VRAM limit on Arc still poses challenges for resolutions above 1024x1024.
is it true? Then where did I see people saying Arc can generate upto 4096x
@proper cradle Based on my research, it seems there are a few key points:
-
Intel Arc GPUs currently have a 4GB limit on memory allocations per buffer in OpenCL and Level Zero APIs. This is due to the "stateful addressing model" used and 32-bit integer overflow in index calculations.
-
It is possible to workaround this limitation by:
-
Using the CL_MEM_ALLOW_UNRESTRICTED_SIZE_INTEL flag in OpenCL API calls to disable the error and allow larger allocations. However, this can lead to incorrect results if the kernel is not compiled properly.
-
Passing the ze_relaxed_allocation_limits_exp_desc_t struct in Level Zero API calls to disable the size restriction.
-
Compiling kernels with -cl-intel-greater-than-4GB-buffer-required (OpenCL) or -ze-opt-greater-than-4GB-buffer-required (Level Zero) build flags. This puts the kernel into "stateless addressing model" to support larger buffers.
-
Even with workarounds, there seem to be issues with performance degradation and incorrect results when using buffers over 4GB. This points to deeper architectural limitations in supporting large allocations efficiently.
-
The 4GB per buffer limit severely restricts the usable VRAM capacity, especially on high memory cards like the A770 16GB. Many applications require larger allocations.
-
Other GPU vendors like Nvidia and AMD support full VRAM utilization with large single buffer allocations.
Overall, the 4GB allocation limit needs to be revisited in Intel GPU drivers and hardware. Larger memory sizes should be supported natively through 64-bit indexing and removing arbitrary limits. This will allow more software to take advantage of the available VRAM capacity. Workarounds help but have drawbacks. Long term, Intel GPUs should match the memory flexibility provided by competitors.
You can generate 4096x4096 with attention slicing on IPEX
OpenVINO still hits that 4GB limit because you can't use Attention Slicing with OpenVINO
I will still keep dynamic attention slicing with IPEX because not everyone is using a custom compute runtime
And performance drop is not too bad
1.85 to 1.75 it/s at 1024x1024
Also 4GB limit isn't an issue wil LLMs since they are not a single block of a model.
Models with layers (almost every model) are fine unless a single layer goes above 4GB (and you probably won't be able to fit that model into 16 GB VRAM even if you could allocate more than 4GB).
4096x4096 with SD 1.5 12.5 s/it

4096x4096 with SDXL 10.8 s/it

These are direct generations without any upscaling
Those are the changes that enabled OpenVINO to be compatible with Stable Diffusion WebUI
And we were already using pre-release OpenVINO 2023.1.0
So no big changes for Stable Diffusion WebUI
There are a few changes in the WebUI tho
Loras are working now (but needs to recompile with Lora)
And caching isn't broken anymore
I appreciate you sharing the detailed info and performance metrics. 👍
How about Ipex vs openvino performance
7.5-8.5 it/s on IPEX
9-11 it/s on OpenVINO
SD 1.5 at 512x512
SDXL needs 48GB RAM to compile with OpenVINO
OpenVINO supports iGPUs too
and CPU performance is double if you use CPU Backend with OpenVINO
On my R7 5800 X3D at 512x512
6 s/it normal
3 s/it OpenVINO
double !!
SDXL at 1024x1024
1.75 - 1.85 it/s on IPEX
1.9 - 2.0 it/s on OpenVINO
But i would recommend 1080x1080 because Intel ARC is cursed at 1024x1024
ipex is simpler overall .. i have 32gb ram
SD 1.5 needs 12 GB
still.. i would love if openvino compile on low ram
how about disk space?
oh, i could actually manage that reasonably
11 GB per SDXL model
Do loras balloon ram or vram requirements massively? I tried using 3 of them and hit memory out every attempt
64gb ram, a770 LE
do i need to compile each time any distribution friendly way ... maybe open a hf repo for openvino compiled models..
It will recompile a new model with Lora
It will compile once then will use the cached models
Only single Lora is supported with Diffusers method rn
OpenVINO will work with Diffusers method
i dont think I was using diffusers method?
just openvino
though i can't recall the settings of that

Also --use-openvino will lock you in Diffusers backend
oh so it automatically uses diffusers
shame only 1 lora i guess, i usually use 2 for style and 1 for negative
but hey, having the openvino method at all is fantastic
Also VAE decoding step is almost instant on OpenVINO
This is a big improvement over IPEX
merging loras with model can maybe bypass that limitation
openvino needs more optimizations and compatability for lower end devices for daily use
I wonder if I could like, garbage cleanup the openvino model cache folder at a certain size so it doesn't eat my whole drive
no openvino support for comfy?
I never used ComfyUI
bummer.. ever since sdxl .. i got addictive to comfy..
comfy is pretty cool for folk who come from node based workflows
though sadly I never had a really good success rate in running comfy myself
webui is easier to learn for beginners but you are limited to the workflow provided by webui. Maybe use extentions to get same limited workflow set. but comfy gives you freedom ;V
Generation times are slower because of OBS recording
I will just use bare code and drop the UI at that point tbh
node based systems limitations :V nodes are just snippets of codes after all
its a cool concept, but i have much less reason to use nodes for ai than for say, blender
Diffusers library is already easy enough to use as bare code without any UI.
ComfyUI is just a UI above that.
still I can skip many steps for repeated tasks or even automate some stuff with comfy.. then maybe make some comfybox compatible workflows.. a1111 replicated.. no coding
node based system could be more useful for LLM based system
could help out with visualizing complex multistep prompts
There are supposedly new compile optimization in the new openvino, not sure if other things need to be updated as well to support it lole vipitis said for it to help stable diffusion yet.
ComfyUI is slower than sd.next with ipex, it doesn't seem to have any optimizations
That's already what SD WebUI is using
We were using the pre-release OpenVINO, not the old one
Oh, interesting. Didn't know that. So basically already as optimized as it can be.
the full release is ahead of the prerelease for all the LLM stuff. They used openVINO for torch compile as dynamo backend with their own stable Diffusion fork
non stable diffusion related, Disty do you think it would be possible to run your Koboldai United Ipex in native windows? Or are some dependencies not available? (if this is the wrong place to talk about it let me know)
Added Windows packages im my last PR
Only thing left is adding play-ipex.bat file for Windows
oh wow, amazing! Appreciate the work man, forreal.
Is it just me or is SD.next using a lot more vram than it did before(maybe a month ago). Using -lowvram and it's taking about 4.8gb of vram now and just keeping it. I think it used to take about 2 or something. Can't generate much with -medvram anymore either, but I am not sure how big a file I was able to do before. I might just be misremembering. Anybody on a750 what is the larget you can gemerate on medvram?
windows?
Yeah, or Linux/wsl2. I tried to update native Linux version and everything broke on me lol, wsl2 works for me.
1024*1536 is about where I cap at with medvram now, 1080p ooms
Using FP16 fixed VAE?
Using the fp16 vae (workaround) that was suggested a month ago or so. Where you created a folder etc
Try disabling attention slicing
It's on by default now
Even if I disable the vae completely, if i turn off attention slicing it runs out of memory at 1536*1024 which runs with it enabled.
Just reworked the tutorial for IPEX native windows. We can install all oneAPI dependencies in the conda env instead. https://github.com/vladmandic/automatic/discussions/2023
GitHub
Background Issue of current official IPEX wheel Intel released IPEX wheels for native windows in Aug'23. However, the official IPEX wheel was built without AOT (Ahead Of Time) compilation suppo...
getting this error

did you install libuv in the conda env?
libuv seems to be a dependency, even if you don't run Ipex in a conda env
Are the aot compiled wheels still about 20% slower with generation speed? I compiled myself but they may have fixed that in latest commits (if it can be fixed)
Diffusers is about even, so my current workflow is sdxl in native windows and sd1.5 original backend in wsl2.
anyone here experiment with v-prediction or "vpred" models on diffusers backend? seems like it needs a different scheduler
Sampler settings

aye, I did try that; got an error about it being v-prediction and not v_prediction so I manually set it in config.json, but model still gave bad results
i gotta get some work done today so I'll have to try again later
So much stuff, I don't even know what that is. About to look it up
Have you guys noticed that there seems to be much less variation with the same prompt in sdxl? Like even with different seeds it will be a very similar painting or almost the same exact same person. Seems the same with the few finetuned models i have tried as well.
Most of them are overtrained with too small dataset
Only model worth trying for anime stuff are AstreaPixie's models imo
Rest are merges of merges based on CounterfeitXL which is overtrained with too small dataset
This is with the base model too though
My guess is its a side effect of better understanding of prompt
Less happy accidents but better fine tune control maybe
the larger the model the more training is needed. i'd say its undertrained instead
by that i mean the model does not generalize well. a more diverse training sample is needed
Pushed some optimizations to SDP attention on dev branch.
Speed is back to normal now. (8.2 it/s on SD 1.5 and 1.8 it/s on SDXL)
I want to get into the generative AI business. It looks like fun and seems very interesting.
in my experience, IPEX native windows is ~6.5it/s for 512x512 Euler (comparing with ~8it/s in WSL)
AOT wheel built from https://github.com/intel/intel-extension-for-pytorch/commit/0f2597b9cb94dd9534f00cfcafaff177d61b5b74

GitHub

for batch size = 16, native windows is as good as WSL/linux
512x512 at batch size 1 is CPU bottlenecked both on OpenVINO and IPEX

And it's not isolated to SDNext
Barebone Diffusers scripts are the same
Also IPEX performance catched up to OpenVINO with the new Diffusers
Both of them takes 2.75 seconds to generate a 512x512 image
If i want 4k images will it work with 16 ram and ARc a750 ,ryzen 3600 ? or will crash ?
Direct 4096x4096 generation?
yup or should i scale up ?
4096x4096 will mosty likely crash with 8GB VRAM
--lowvram can help but it's too slow
A770 16GB can generate direct 4096x4096
u can try generating?
SDNext with IPEX, SDXL 3840x2160:
Default settings used 12GB.
--medvram used 10GB
--lowvram used 4GB (half the speed and needs more RAM to offload)
thanks 😭
This is about what I get in diffusers, with original aot wheel is about 4.8it/s. It seems something to do with aot, with the official wheel after the initial 15min load the speed is on par with linux (7it/s in original on a750)
@paper horizon added your wheels for Windows to installer.py in dev branch:
https://github.com/vladmandic/automatic/commit/2f17cef6f6e44dab52b0a3d56e9cdbe100e0796f
Used Github releases as file hosting
Hi, can you clarify this for me? I'd like to use DPM++ SDE Karras

so for the checkboxes would this be it?

The default? Or do I pick dpmsolver++
with this

dpmsolver does nothing with DPM SDE
Karras is checked so you are using the sampler in this photo
Also removed that OneAPI not detected warning
Can someone with an iGPU or multi GPUs try setting this environment value and try OpenVINO?
OPENVINO_TORCH_BACKEND_DEVICE="MULTI:GPU.1,GPU.0"
I am curious if it will use both GPUs.
curious theory, I can try when i get home. where do i set this value?
i have openvino sdnext set up in a conda venv, if i can just tweak something in there
while I figure out what part of the init file is safe to edit if any, I gave a Lora a go, nice to see its working nicely now, although only one at a time

set VALUE
or
VALUE webui.bat
set "OPENVINO_TORCH_BACKEND_DEVICE=MULTI:GPU.1,GPU.0"
tried with lora

tried without lora

this is on a770 LE + i5-13600k
oh yeah, i noticed that while using openvino mode, i can't switch models anymore. it errors out about a config and then goes back to what i was already using

removing the current model entirely let it pick a new default, but i couldn't just unload the checkpoint and pick a new one from the dropdown
oh nvm, it died on loading
Run this
set "OPENVINO_TORCH_BACKEND_DEVICE=GPU"
Also OpenVINO device logging is in dev branch:

is this just to revert the multi gpu variable? I just ended up closing the prompt out and restarting it to bring it back the inability to switch models is another problem
Yes, it's to revert
I can't reproduce the model switching issue
Try removing the cache folder
hmm, removing cache still has the issue
I tried all of the models I have on hand, and only the one i started on (AOM) works
Anythingv5, CounterfeitXL, and SDXL don't load
Did you change the default settings?
There was a use dict from curret model setting that can cause this but i can't find it
Yep it is

oh wtf, it actually was using that
Set this to none

Probably mixed that up with model selection
I was having a vae loading issue of some sort iirc, so I just set everything i could to point to the model I was using

Multiple Loras are working with the new diffusers
It's currently in dev branch
Kurokawa Akane + Hoshino Ai

oh? will that work for openvino as well?
This is OpenVINO
ooooh
IPEX was already working with sequential apply method
VRAM size is reporting correctly too:

Device name works with CPUs too

IPEX:
is that 512x512 1.5?
has it got faster
i need help for installation... any one ??
New Diffusers + More IPEX optimizations i added
https://www.technopat.net/sosyal/konu/installing-stable-diffusion-webui-with-intel-arc-gpus.2593077/
Technopat Sosyal
In this guide, we will install Stable Diffusion WebUI SD.Next with Intel ARC GPU's.
Intel PyTorch Library doesn't have native support for Windows so we have to use Native Linux or Linux via WSL.
Setup WSL on Windows:
Follow these instructions to setup Linux environment in Windows, then...
stop using a1111
first
u using ubuntu?
ill be honest the easiest way to do it is on linux with ubuntu
follow this right?

E: Unable to locate package intel-oneapi-compiler-dpcpp-cpp
E: Unable to locate package intel-oneapi-mkl
Paste these one line at a time


N: Ignoring file 'oneAPI.listsudo' in directory '/etc/apt/sources.list.d/' as it has an invalid filename extension
E: Unable to locate package intel-oneapi-compiler-dpcpp-cpp
E: Unable to locate package intel-oneapi-mkl
aipriom@DESKTOP-IVNLUFL:~$
sudo apt-get install -y gpg-agent wget
wget -qO - https://repositories.intel.com/graphics/intel-graphics.key |
sudo gpg --dearmor --output /usr/share/keyrings/intel-graphics.gpg
echo 'deb [arch=amd64,i386 signed-by=/usr/share/keyrings/intel-graphics.gpg] https://repositories.intel.com/graphics/ubuntu jammy arc' |
sudo tee /etc/apt/sources.list.d/intel.gpu.jammy.list
wget -O- https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-PRODUCTS.PUB \ |gpg --dearmor |
sudo tee /usr/share/keyrings/oneapi-archive-keyring.gpg > /dev/null
echo "deb [signed-by=/usr/share/keyrings/oneapi-archive-keyring.gpg] https://apt.repos.intel.com/oneapi all main" | sudo tee /etc/apt/sources.list.d/oneAPI.list
sudo apt update && sudo apt upgrade -y
if it still doesnt work i can help u do the docker way as it just requires properly setting up docker-ce to work
https://www.digitalocean.com/community/tutorials/how-to-install-and-use-docker-on-ubuntu-22-04 follow this step and install docker


Docker is an application that simplifies the process of managing application processes in containers. In this tutorial, you’ll install and use Docker Commun…
then u can easily setup the web ui with 1 cmd, hopefully...
atleast it was that simple for me
i installed it
u got docker?
Run this cmd in SUDO, if u havent setup the group thing that obfuscates that. https://blog.nuullll.com/ipex-sd-docker-for-arc-gpu/#/getting-started

Description
sudo usermod -aG docker username ???
dont bother with the group thing for now
just make sure when running docker in sudo it works
run that cmc and it should setup everything
--device /dev/dri \
-v ~/docker-mount/sd-webui:/sd-webui \
-v deps:/deps \
-v huggingface:/root/.cache/huggingface \
-p 7860:7860 \
--name sd-server \
nuullll/ipex-arc-sd:latest```that cmd right in the link

ok brother thanks for your support
actually bro my nvidia was good.. arc fucks my head. 😦
setting it up is mostly fine, but if ur using wsl it may be problematic. Native windows support seems to be coming soon with pre-compiled aot wheels but it will perform a bit worse i think?
look i m not a devoloper. even i dont have 2% knowlage on this... but nvidia was user frirndly....
well yeah arc never touted a complete support for sd
i bought this arc last months..
but it works with a little work
nvidia is always what u get if u care about cuda stuff
though intel is working on ipex and their various things like openvino its still all new stuff
nd i faced unbeatable issues .. which i dont even imagine...
for games?
my first issue was (game shut down)
then i faced issue on Adobe premiere pro
u cnt blv my pc got stuck while color grading.... fully hang..
😦
naw this...
actually i m sweating after thinking that i have to use this gpu next 2years.
?? whats the issue lol
stable diffusion works fine it just requires a bit more setuo
the same is true for amd
i dont know about amd.
amd does not work on windows native aswell
if u wanted stable diffusion performance with ease of use you go with nvidia, but intel is also about a 3060 ti in performance and totally fine running on a linux distro, and with native aot wheels coming it should do fine (i hope) on windows with degrabed performance. If you just want 1.5 there is also open vino
the setup ur doing rn is similar to nvidia its just that you need to install it on linux for it to work, and add the packages required for ipex and whatnot to run
you cant ask for much more except making it do this for you i guess
the docker ur using does this environment setup for you, thus the single command
intel arc will always be a rather precarious card because of it being first gen, and naturally with drivers that have a host of things needing work doing. Choosing intel as a long term choice can be fine if you understand that some things may not work, and if they dont it can take a while for it to get fixed
Using the docker image is actually easier than Nvidia
yeah its true..
I mean it is a single command once u have docker installed so it cant get more complicated than that
why u gues dont tell me about docker before...
idk native is a bit easier to use once its done i guess
u have to start the docker up when u want to use it, but you can rename the container to a nickname to make this easier
it does bind to a diorectory so u can easily add ur models and whatnot to the container so it isnt much different
if u need help doing that its quite easy to do
i just named the container sdnext and so whenever i want it i just start up sdnext with docker run or something

ignore
Do you have an iGPU?
oh is it an actual error
tbh i think hes doing it in wsl so idk if that does anything weird
yes i have igpu
Let it do it's thing and eventually crash
After that disable your iGPU from device manager
then??
In windows docker has a memory leak from my experience, never tried it in native linux. It also just hogs all my drive space and never gives it back
These are typical for a VM
VM disks generally need manual pruning
Yeah, it doesn't free it even uninstalled had to manually find the vm files and delete them, its a pita in windows
Wsl2 by itself is fine though, can run a cmd line and prune it
i tried docker in native linux, and i just got a lot of errors somehow
never did manage to get it working
yeah i got the same error and it fixed itself when switching to docker-ce and using sudo
I tried that too, and using sudo just gave me a different error
weird lol
I'm new to docker so its entirely possible i screwed something up, but I do find it amusing that I can still screw up something so turn-key as docker
I can also say, i never got any stable diffusion docker to work either, it just ate my sdd space lol
I feel like docker for windows wouldn't perform well in this case simply because docker (to my knowledge) still relies on the current system kernel, and since its on windows its not any better than running it as a VM due to how there are specific kernel needs for the card with the current oneapi environment. I could easily be wrong, but that's my interpretation of the issues for VMs and containers with arc
They have some custom kernels for wsl2 (not sure if they could be usable with docker though). I am on one of the 6.* Kernels
I installed this, it works fine, but I cannot generate with sdxl models. It gives "Error loading model weights" error. Does this setup not support sdxl or am I having another problem? @proper cradle
Use the Diffusers backend
I have A770 16GB. I changed Execution backend from original to diffusers and diffusers pipeline to Stable Diffusion XL. It didn't work at first, but after restarting the server few times, it started working. But I'm getting problematic results. I hope I can figure it out.
1024x1024 is cursed on ARC
Try aything other than 1024x1024 like 1080x1080 or 1024x1536
I wonder if there are any other cursed resolutions
it works, thank you so much! I wonder one more thing. When I switched to sdxl, some sampling methods were lost. Like "DPM++ 2M Karras" which I use the most. But I see these sampling methods on civitai with sdxl models. How can I use them on sdxl?
Use DMP 2M and enable karras in settings (it's enabled by default)
Also DMP 2M isn't good with SDXL
Best one is Euler a with higher CFG
DPM SDE is good but slow
I wrote down this, thank you again.
I'm about to start my SD journey.
Anything I should do or avoid?
Things you wish that you had known before starting on your journey?
9900k
32GB RAM
A770 LE 16GB
Lots of NVMe
Its so weird that I have never noticed any problem with 1024 res at all. I wonder if it's because i am onlu on an a750? Or that I use med-vram usually?
Disable your iGPU
1024x1344 works nicely for me
dpm sde very nice, the convergence is powerful enough that I can usually use less than a third or even a quarter as many samples as I would euler to get a coherent result
I feel like I do use more vram with it though?
euler is a pretty dated solver
heres a comparison table made by creators of DPM++, the value in table is FID score (lower is better), NFE is number of steps

if I'm reading this right, isn't DDIM doing really well here? not that I'd complain, DDIM my beloved
yeah it is. but DPM SDE is stochastic and that gives your picture more variability
I find all the dpm settings give me bad outputs in sd.next diffusers, tried all the settings and sde just gave a blank image iirc.
I havent really had good performance from SDXL models in the first place, so I just went back to 1.5
need good anime models before i have any use of it
It def has a ways to go, but it has some advantages with high res off the bat. I can do higher resolution in it than with 1.5 without ooms. I have to tile upacale just to get the base res that xl gives.
So i tried to use a lora with ipex, and it imediately shutdown webui. Then I tried to move to dev branch and it shutdown just trying to load a sdxl model, now I switched back and it shuts down as soon as I load an xl model in diffusers. No errors just shuts down, tried debug too. Edit I see now, it deleted my custom folder location in the settings.
Nope, still just shuts down. lol, wtf?
can't load any models or vae's, it just crashes. Went back to an older commit and the same. No clue what broke, guess I have to reinstall again. okay got original backend to load up finally.
nope

doesn't even tell me what file just line 198
try removing --use-ipex if you are on Linux
ipexrun can cause random errors
Welp you are on Windows
I will see, I downloaded a whole new folder to try and see. There were some new extensions from the dev branch that may have broken it i dunno
well I am completely at a loss now, redownloaded everything from scratch and it's still just quiting when trying to generate an image. Maybe I will try a system restart?
okay, just tried comfy ui and it seemed to crash as well, might be an issue with the latest drivers.
iGPU is disabled? Don't really know else.
Don't have one, I thik it's the driver. I actually hadn't generated anything on it since I updated yesterday
I also may try the whl you guys compiled to see if mine is just too old
So yeah, it was the latest drivers. They somehow break something in Ipex
Is this a new extension?
So multi gpu with igpu does weird things and i do not recommend, it appears to load the model into the vram on the dgpu but then inferences on just the igpu? The igpu usage ping pongs between 100 and 0 with no dgpu usage besides vram being shown. Its obviously much slower than just using the dgpu at like 2.5s/it vs the almost 11it/s i get on just the a770
I think it's prioritizing the igpu
Built in with dev branch
Yes
Can you try exporting this on terminal before running webui;
OPENVINO_TORCH_BACKEND_DEVICE=MULTI:GPU.1,GPU.0
Muti GPU option on SDNext uses MULTI:GPU.0,GPU.1 and so on
If you check Remove iGPU option, it will remove GPU.0 from the list
But it will probably end up ignoring the iGPU with MULTI:GPU.1,GPU.0 since iGPU is too slow to be useful.
even just using the dgpu alone i barely see any usage
yeah setting 1 then 0 just uses the arc i see no igpu usage
Okay just looked it up, this looks promising https://www.reddit.com/r/StableDiffusion/comments/16y0u0o/hypertile_tiledoptimizations_for_stablediffusion/
Reddit
Explore this post and more from the StableDiffusion community
actually using multi with igpu second is still worse than just igpu
it uses more system ram like that
Nice gonna try it out now that I know it was the windows drivers that messed my install up.
im getting errors with hypertile but im using openvino
so iot might not be compatible
OpenVINO doesn't work with any slicing/tiling
ahh that explains it
RuntimeError: Check 'backward_compatible_check || in_out_elements_equal' failed at src\core\src\op\reshape.cpp:433:
While validating node 'opset1::Reshape Reshape_57436 (input1[0]:f32[2,77,768], Constant_57435[0]:i32[2]) -> (f32[?,?])'
with friendly_name 'Reshape_57436':
Requested output shape [8192,320] is incompatible with input shape [2,77,768]
this is what i get
Apparently Dynamic Slicing i added for IPEX actually makes generating faster at higher resolutions.
(Both of them are with HyperTile.)
Dynamic Slicing: Time: 1m 15.78s
No Dynamic Slicing: Time: 1m 32.74s
thats pretty good
20 Steps SDXL 2048x3072
Definitely the new driver in windows breaks ipex somehow
Openvino is fine
Just reverted from 4885 to 4826 and ipex works
Hypertile is faster goes from 8.2 it/s to 9.5 it/s, neat
I made a support thread on here , might make one on the github too. Might be something they have to update in ipex, sucks since latest driver has a lot of game updates
yeah and has the starfield update but yeah, i might still update and just use the openvino tho its more limited, been testing diff things today
openvino on win is still a bit faster too
more resource intensive tho
Does wsl still work? I didn't actually try it before downgrading
Oh idk i dont have wsl setup anymore
Hopefully they see my thread and fix it soon.
I mean it uses the same driver but idk, i wonder what causes the issue, seems random
I have both, wsl for sd1.5 and native for sdxl, better workflow than trying to reactivate plugins constantly
Yeah, no error message so no clue what is wrong
Yeah it just loads everything fine you click generate and after a few secs it just doesn't do anything says press any key to continue and that's that
Followed the install instructions for Sd next (ipex)
During the first run/instal I run into an error.

I need help getting ipex working in the python venv.
running it will just produce an error like ModuleNotFoundError: No module named 'intel_extension_for_pytorch'
I’m doing this on Linux
then ipex is not install in that env
Try running this in automatic folder:
source venv/bin/activate
Then:
pip install torch==2.0.1a0 torchvision==0.15.2a0 intel_extension_for_pytorch==2.0.110+xpu --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
20 steps 512x768 + 20 steps 1024x1536 with hires took 13 seconds with HyperTile

20 steps 512x512 takes 2.2 seconds
How is vram usage? About the same or more efficient?
that did it thanks. but I do have a question. The read me at https://github.com/intel/intel-extension-for-pytorch had something similar python -m pip install torch==2.0.1a0 torchvision==0.15.2a0 intel_extension_for_pytorch==2.0.110+xpu -f https://developer.intel.com/ipex-whl-stable-xpu I tried that and failed. Yours worked. the only think that jumps out at for being different is the source url.
Why did https://pytorch-extension.intel.com/release-whl/stable/xpu/us/ work? while https://developer.intel.com/ipex-whl-stable-xpu did not
Alright, good to know, thanks
could the callback to show inference step be done more often? So you really get like a 20fps experience?
Wsl got an experimental prelease update a while back that added aome automatic memory and disk size settings, just trying it out now https://github.com/microsoft/WSL/releases

GitHub
Issues found on WSL. Contribute to microsoft/WSL development by creating an account on GitHub.
Update by command " wsl --update --pre-release "
Did a sampler XYZ


Native windows Ipex still broken on latest drivers 😦
Don't think it's just native

tried to do vlad under wsl
Is that previews or final images?
Cause sometimes previews randomly break on original backend.
That shouldn't happen, rip Windows drivers.
Try diffusers with attention slicing enabled
have you somehow seen the exit status 3221225477 ?
seemed to work for me? At least with original backend and sd1.5
Good news, both the driver team and ipex team are looking into it though.
I only got the error about something in line 198 with with no file reference
hm, I got issues trying language model inference via accelerate that I clearly hadn't before. And now worry it's the driver. What was the last known good driver? 4672?
hmm, i'll redownload the repo 🤔
4676 worked fine for me
Also I have a thread on here and on the github, so if you get a specific error it may help them isolate the issue.
i am using 4878 beta, and while vlad is downloading i wonder if the whql is any different
so many drivers
updating the repo fixed it... interesting
oh well
wonder if i broke something trying to get sdxl to work
well, sdxl still has things just die under wsl
welp, i guess i'll stick to ubuntu, i have a feeling i don't want to have headaches tryint to train either
Killed
descriptive

That's most likely not enough RAM
damn, why
https://learn.microsoft.com/en-us/windows/wsl/wsl-config#example-wslconfig-file
Increase it by editing .wslconfig file in Windows

A guide to the wsl.conf and .wslconfig files used for configuring settings when running multiple Linux distributions on Windows Subsystem for Linux.
ooh, thanks!
Yup, I had sdxl in native windows and sd1.5 in wsl, sdxl works better native and it is easier to have two instances rather than having all my extensions disable when swapping etc. And wsl is 20% faster than windows as well, just less resource efficient
I had some other issues getting native windows to work at all, but I'll have to check again I guess
Check sd.next they have their own compiled aot whls and a guide to install
Does training also work natively or no idea
Well, training a lora
I'm in the convenient situation of actually having lightweight games i can play while training
Mindustry is a pretty enjoyable factoriolike
It should but I have never tried myself, if it works in ipex it should work.
Just expect about 20% decrease in speed with aot whls, the regular whls will give faster generation technically but a 10-15min startup time lol
guess i'm glad i've been too lazy to update my arc driver since before starfield updates, a lot of things seem to have been breaking
Sadly, its the driver that fixes starfield that breaks ipex lol
Welcome to the arc experience 🙃
Dual booting has never worked for me with an arc card ive tried several distros and once whatever linux os i try installs and tries to reboot i never get a display and constantly see the light on my monitor flicker on and off over and over. Tried Ubuntu, EndeavorOS, Manjaro sane thing every time and tried with secure boot enabled and disabled and with igpu enabled and disabled to see if any of that was creating conflicts and no luck.
good thing I don't intend to play any bethesda games any time soon i guess
I installed on an external HDD and it worked fine, although second screen didn't output until I installed the arc drivers (pre 6.2 kernel) in ubuntu
I tried both on the same ssd as windows and also on a seperate one and same exact thing makes me think possibly something with grub idk and all distros had 6.2 kernel or newer
I was using Arch Linux before i bought my A770 and it worked fine without doing anything when i bought my A770.
I haven't tried just linux bc i unfortunately need windows for certain games and such but dual booting i havent ever had success with
u must use new kernels with arc
fedora works for me on a partition with the same drive
linux is always plug and play as the drivers are in the kernel
well might be igpu weirdness but it shouldnt be that much of an issue
I was using new kernels as i stated along with turning off my igpu
There is a way to install it on a usb without having it dual boot its basically installed on the external drive. I don't have the link offhand but shouldn't be hard to find
The easiest way is just unhook your windows drives while you install, then you can also use that usb on any computer
Yeah i def aint goin through all that lol my windows drive is an nvme on my board i honestly dont have a real need for native linux just something i experimented with to no success
😐
when i make it generate an image on windows, it just flat out crashes
no message, no nothing
ok, even with everything fresh i still get this weird crash
Yeah, I did it another way https://www.makeuseof.com/install-ubuntu-on-usb-drive/ this should show it under the windows boot file section. But honestly if you can boot into a Ubuntu install usb it should work as a dual boot as well.

MUO
If you want a portable Linux installation that you can use on the go, consider installing Ubuntu on a USB drive.
Latest drivers are broken for ipex, 4676 is the last working driver
Oh, so that is what's broken
I wasn't expecting such a.. straight up, nothing said crash
Yeah, sometimes it will reference a file line but no file lol.
So far wsl2 still works
Anybody gotten the Ipadapter in controlnet to work on arc? I keep getting a dtype error?

Wow fast, awesome work man.
updated dev branch but now TypeError: 'Logger' object is not callable
Logs?
Went backa bunch of commits and tehy all were broken, don't remember which i was on before I updated but back on master and it works. Let me update again and get the log.
Oh and also I get a different error with "--use-ipex" which is what I always use. also, I am now getting a different error without too. It's now an error in ui extensions.
Someone with the same error opened a bug report on SDNext
"b55bb8c still works when I switch to it.
74fb8fb breaks it."
I just got this one, the other error was different. about typeerror: logger, nto getting it now though. I will try that commit and see
New error after switching to b55bb8c
something with the Ui again, not sure maybe it's my settings
try removing config.json
Also 1024x1024 workaround is in dev branch with IPEX and OpenVINO:
https://github.com/vladmandic/automatic/commit/343e0dcd1713423c124cfb63bb5d664e150a5df9

It will use 1080x1080 if you select 1024x1024
okay, deleting the UI-config fixed it. Gonna try and edit that file so i can use try the Ipadapter
Dev branch finally merged
Now Windows should be supported with:
webui.bat --use-ipex

{kind=link}
Looks great
Disty and Nuullll, THANK YOU for all you do. Been having a blast with SD on Linux and I love seeing it work on intel GPUs
I'm trying to run this but running into the following issue with TensorFlow:
2023-10-19 20:06:49.362030: F tensorflow/c/experimental/stream_executor/stream_executor.cc:808] Non-OK-status: stream_executor::MultiPlatformManager::RegisterPlatform( std::move(cplatform)) status: INTERNAL: platform is already registered with name: "XPU"
Any ideas?
I'm thinking it might be the fact that I have two Intel GPU devices, but I cannot say for certain.
Must have igpu disabled
How do you do that.
In bios
I cannot do that, the host system is a laptop.
What exactly is using TensorFlow?
This is really cursed.
Device Manager
You can ignore that error if everything else runs fine.
Seems like OpenVINO works with AMD GPUs on Windows too.
Speeds are comparable to Shark.
openVINO has an experimental Nvidia GPU plugin as well
plus it can do ONNX runtime which should work across everything
OpenVINO can run on anything then
and openVINO as a torch.compile backend should avoid requiring the whole openVINO IR conversion and saving that model somewhere
Many options and I haven't tried them all, as I currently struggle with implementation. Once I get into running a lot of evals, I will take a closer look there.
Linux
What GPU do you have?
I don't know if there is a laptop with Intel ARC dGPU.
Use OpenVINO if you want to use non ARC GPUs.
I have an XPS 15 9560 with an Arc A770 LE attached over Thunderbolt 3.
Try xpu_VISIBLE_DEVICES=1 ./webui.sh --use-ipex
You can't really disable iGPU with that config
Ah I was looking for an environment variable like that, I'll try and report back.
Thanks.
No dice.
TensorFlow still registers two XPU platforms.
If SD is workig fine, ignore it
Well it crashes so…
if not try;
ONEAPI_DEVICE_SELECTOR="ext_oneapi_level_zero_gpu:1"
Or;
ONEAPI_DEVICE_SELECTOR="ext_oneapi_level_zero_gpu:0"
try these with sycl-ls
Now it is only seeing a single device, but still registering two XPU platforms.
Does it crash?
Yes.
Same error.
Neither.
SDNext is stopping with that error?
run sycl-ls and write the results here
source /opt/intel/oneapi/setvars.sh
Run this if it says sycl-ls not found
Nah I use modulefiles. 😛
sycl-ls
``````ansi
[opencl:cpu:0] Intel(R) OpenCL, Intel(R) Core(TM) i7-7700HQ CPU @ 2.80GHz 3.0 [2023.16.7.0.21_160000]
[opencl:gpu:1] Intel(R) OpenCL Graphics, Intel(R) Arc(TM) A770 Graphics 3.0 [23.35.27191.9]
[opencl:gpu:2] Intel(R) OpenCL Graphics, Intel(R) HD Graphics 630 3.0 [23.35.27191.9]
[opencl:acc:3] Intel(R) FPGA Emulation Platform for OpenCL(TM), Intel(R) FPGA Emulation Device 1.2 [2023.16.7.0.21_160000]
[ext_oneapi_level_zero:gpu:0] Intel(R) Level-Zero, Intel(R) Arc(TM) A770 Graphics 1.3 [1.3.27191]
[ext_oneapi_level_zero:gpu:1] Intel(R) Level-Zero, Intel(R) HD Graphics 630 1.3 [1.3.27191]
ONEAPI_DEVICE_SELECTOR=level_zero:0 ./webui.sh
2023-10-20 13:01:03.512410: I itex/core/wrapper/itex_gpu_wrapper.cc:35] Intel Extension for Tensorflow* GPU backend is loaded.
2023-10-20 13:01:03.587475: W itex/core/ops/op_init.cc:58] Op: _QuantizedMaxPool3D is already registered in Tensorflow
2023-10-20 13:01:03.597085: I itex/core/devices/gpu/itex_gpu_runtime.cc:129] Selected platform: Intel(R) Level-Zero
2023-10-20 13:01:03.597432: I itex/core/devices/gpu/itex_gpu_runtime.cc:154] number of sub-devices is zero, expose root device.
2023-10-20 13:01:03.683572: F tensorflow/c/experimental/stream_executor/stream_executor.cc:808] Non-OK-status: stream_executor::MultiPlatformManager::RegisterPlatform( std::move(cplatform)) status: INTERNAL: platform is already registered with name: "XPU"
Aborted (core dumped)