
#Railbound Solver [Python Script] COMPLETE! Working on Interface...
1 messages · Page 4 of 1
so kinda like a switch statement
but for objects
i get that it assigns and isnt an if statement but its just a comparison
how would an enum value be better
It's mostly that it has a useful name associated with it and you use that name everywhere. You can just use classes as namespaces for integers, but then you lose type safety and it's harder to work backwards when logging
that makes sense but how would the code be reformatted then cause looking at the article you cant just do this
would you need to have like all of the information i put in reference.py put in that class
i feel like that isnt organized
also how would i organize all of these 25 tile objects? cause if i put them in an array to have their positions as well thats the same as what im doing right now basically
unless you think i should add the positions to the tiles but then its still not organized, because how do i fetch a tile from a specific position?
So that would be where the Grid object comes in. You can make it store a 5x5 tuple or you could use a dict where the key is a tuple of the coordinates and the value is a Tile, then you'd only have entries for the coordinates that have anything in them
You don't need to keep 25 tile objects somewhere, because if you implement __hash__ then any tile object created with the same data will be equal. If you wanted though, you could have a class method which turns the correct one for a given set of parameters, creating it if it doesn't exist
I can think of positives and negatives for each approach, so I'm tempted to Keep It Simple
@fervent tusk are you drawing these ? Can I use it in my blog?
Ok so here is my draft: https://thinhcorner.com/blog/railbound-solver

Nice! I'm looking at the TODO sections and wondering whether they'll end up being way longer than the rest of the post, maybe it would be better to make it a multipart series (i.e say that they'll be addressed in future posts, add forward links when you write them)?
For sure, the todo section could be longer than what I wrote
I think it's gonna take more than 2 posts to explain this. There are a lot of special interactions to consider, especially from level 2 onwards. I'm not sure if I should include the actual code (which is super complex) or just put in some pseudocode for brevity. In the todo part, there will be a lot of charts to visualize the results of the algorithm
And in the final post, I really hope I can make the playground so users can place tiles on it and solve for the solution in real time, on the browser.
oh man i just read some of it and it reminds me so much of when my program was in the beginning
theres so many improvements i could drop on you 
now that i know what dfs and bfs stand for im gonna look through what they are
after looking through them and also learning more about yield more of what you guys said makes sense now
i dont know how or if dfs or bfs would really work here because there are a lot of rules at play
for generation at least
i think i finally understand what most of this means but what i dont really understand the purpose of the state class
i still need a better understanding of the classes before i can convert to oop
I'll probably write to that class this weekend.
I'd be tempted to write pseudocode but link to the actual implementation in the repo?
The purpose is that it encapsulates all the data you need to get the next versions of the State all in one immutable object that you can
a) hash
b) pass off to another process if you parallelise it
That way you only have one function that relies on global state (which could then be made local to that function), which can manage everything else.
The State object should also be the thing you visualise - it contains everything you need to draw the level
so its basically the thing that sends the given state off to the generation function to be branched off of
Well
The function that sends the State to be branched does that, but it's the only argument needed by the branching function
so the state just holds all the generation params?
Basically
why couldnt i just use an array? with an object wouldnt i need 12 different properties
ohh naming for debugging
right thats why oop is good
So nothing the branching function uses comes from anywhere else, which makes following what's going on a lot more simple. So the data is encapsulated together
also, how exactly does the yield and tail call thing in my program work that you added?
yield passes data back to the caller
which is the tail call gen?
So instead of the function that yields calling itself recursively, it gives the caller the information it needs to iteratively keep calling the function with different arguments
thats really smart
so the generation line is the same concerning what branch it picks to do first, but it just doesnt make the branching function call it
Like, I know the set of all known states is going to be big, but you were creating such a deep stack frame that you were storing more data about stack frames than I expect that set to take
Lets cross that bridge when we come to it - it'll actually be pretty simple once Grid can be hashed
so grid is an object thats structured the same as board, but the tile objects are in the positions they represent?
why would the grid need to be hashed
even if 2 tiles have the same data the position is going to always be different and the position is needed for testing adjacent tiles from it for things like semaphores and out of bounds
The Grid what holds what tiles have been placed where. The State holds the current Grid along with the cart position and direction, and how many of what remains to still be placed
The Grid doesn't necessarily need to be hashable, but if it is then you can use the hash of the Grid in calculating the hash of the State
Because how you generate that hash it's doing to be dependent on how you implement Grid
Therefore making Grid response for generating its own metadata leads to a cleaner separation of concerns, which in turn makes it easier to follow the code
i still dont understand what grid is supposed to look like
the way you say it makes it sound like i only need to store tiles with tracks on them
i know its supposed to be a dict or an array but im not fully understanding
A track or a modifier, yes
That's one implementation anyway
You can consider it a sparse 2d array if you like
id rather just have grid be a near replica of board i feel it makes the most sense
in the sense itd be an array with every pos a tile
It can have a __repr__ function that outputs that
?
It's the method that defines what's output if you try to __repr__esent it as a string
i think i understand
But having the underlying data be a dict would be significantly more efficient
how so
oh it can have cars on it too right
so instead of having a list for every pos in the array its a dict where the 2 values are at each keyed slot
that makes sense
Because accessing board[x][y] takes x+y operations, while accessing grid[x, y] takes only 1
actually i dont think cars would be associated with the grid at all
No, they could be on State
Because then when the only change from one State to the next is car position, it can reference the existing Grid object rather than making a new one
yeah smart
doesnt numpy do this?
numpy is probably how you're getting away with a less efficient algorithm 😂
But it's one of those optimisations I prefer to leave until the end, because it can make it more awkward to make larger optimisations
if it works it works and it worked 
It's a bit like... searching for an analogy if you're making something out of wood, you can remove all the materials you want to with sandpaper, and it'll work, but it'll take you a whole load of effort, and once you start, you're not going to want to switch tool because it means undoing all the work you've done so far, so instead you start with a saw to get things approximately the right dimensions, then you might use a router or a chisel to make things the right shape, and then once things are close, you break out the sandpaper to make the finish as good as it can be
This analogy not at all based on what I've been doing today whistles



It still needs sandpaper, but everything is the right shape, and it works
is all i need to do right now make the classes and transform the data?
I guess the analogy follows that your current algorithm is going a load of extra work that it didn't need to be doing, but it's doing that extra work as efficiently as possible
Yup
at least i optimized the program as much as i possibly could (for now) thanks to it being slower
Sure, and you did a pretty great job of the algorithm you came up with. I'm honestly very impressed, especially given your age and amount of experience. This is all just about how you can make further progress, because I think the current algorithm is at a dead end unless we can add these tweaks to prevent it doing unnecessary work
Like, honestly back when I was doing this stuff professionally I knew junior developers who couldn't do it as well as you have
nice phone stand btw
ive never done anything with wood but im taking a woodworking class for one of my electives next year it seems pretty fun
Heh, now that it's mechanically sound, I might add some curves and more organic shapes
is it possible to use 2 enums in a single class?
all the documentation ive found only shows 1 and im not sure how i would assign to different enums in the class
cause you wanted track and mod in tiles right
the only other thing i can think of is making a dict inside the class where tiles and mods can be keyed into it for the name (value), would be close to Enum
mm but youd need 2 dicts depending on if its a mod or track defeating some of the purpose of Enum being easy to debug
this works but i feel like the dicts are too long to put in there



i could put the dicts in a different file
seeing this now i feel enums would be impractical as well if i needed that many lines to do it
i feel like how long the dicts are kind of overtakes the practicality of the debugging
ill just wait for a second opinion and continue
unless the classes altogether should be in a different file in which case im undecided
In my case i use class and create 3 base class tile then just rotate and add to a list:
tiles.append(empty_tile)
tiles.append(curve_tile)
tiles.append(curve_tile.rotate(1))
tiles.append(curve_tile.rotate(2))
tiles.append(curve_tile.rotate(3))
tiles.append(straight_tile)
tiles.append(straight_tile.rotate(1))
tiles.append(t_turn_tile)
tiles.append(t_turn_tile.rotate(1))
tiles.append(t_turn_tile.rotate(2))
tiles.append(t_turn_tile.rotate(3))
tiles.append(t_turn_tile.flip())
tiles.append(t_turn_tile.flip().rotate(1))
tiles.append(t_turn_tile.flip().rotate(2))
tiles.append(t_turn_tile.flip().rotate(3)) ```id prefer not to rotate because it makes it harder to discern what the tile is
i will also move the dicts out of the __iter__ function so it doesnt get created every time (i think thats how it works? variables should probably also just be in the class and not function)
Yeah, you can just save the number for light weight
To debug, you make a print function like repr and use that dict to get the name
i think im just gonna put the classes into a different file so main.py doesnt get bloated
Yea, every class should in a file since it gonna be so long xD
When you make the grid class, i recommended 2 function in it, get_possibles_grid(pos_to_place:list(tuple[int,int]) return all possible grid based on the postions to replace. simulate(carts) run simulate and modify cart position, return is the simulate break: cart crash or finish:all cart finish or a list of empty that should be place a new track
if we make an editor i might have to make some modifications to... the modifications board
because the purpose for it is to list a mechanic and then the type it is (the number)
so if we were to make an editor itd be ideal to have at least 9 of every mechanic but seeing what it is with 4 right now i feel that manual solution wouldnt work
so i might have a 3rd overlay saying what type the mechanic is and then the user can have as many types as they want
the 3rd thing wouldnt be a list itd just be a number saying what type the mechanic on that tile is
So when create tiles it should be like
Tile(name.VERTICAL_TRACK,mod.SWITCH_1,....)
Instead of number, track and mod should be a enum
look at this
that whole section
Oh i missed that
The tile class is not enum but it use 2 other enum class as input
yes, so itd be something like class Tile(Enum, Enum) but how do i differentiate between them
ohhhh wait is enum just defining the type?
the variable type
and __iter__ defines the parameter name
thatd work then if i can do that
Yeah
Since the tile have more variables so it hard to be enum it self
do you think it would be a better convention to rename reference.py to classes.py or just delete reference.py and make a new file called classes.py?
i dont know coding etiquette that well yet
yes but to make the new classes.py file should i rename reference.py or delete it and make a new file
I prefer make new file
how do i assign variables for different enums?
all the documentation ive found only uses 1 enum and just does something like 1 = name, 2 = name so how would i specify what variables i want to be for mods and what for tracks
i feel like dicts work fine and enums overcomplicate things, all we'd really need for clarity is the track/mod name
from enum import Enum
class TrackType(Enum):
EMPTY = 0
HORIZONTAL_TRACK = 1
VERTICAL_TRACK = 2
ENDING_TRACK = 3
FENCE_ROCK_STATION = 4
BOTTOM_RIGHT_TURN = 5
BOTTOM_LEFT_TURN = 6
TOP_RIGHT_TURN = 7
TOP_LEFT_TURN = 8
BOTTOM_RIGHT_LEFT_3WAY = 9
BOTTOM_RIGHT_TOP_3WAY = 10
BOTTOM_LEFT_RIGHT_3WAY = 11
BOTTOM_LEFT_TOP_3WAY = 12
TOP_RIGHT_LEFT_3WAY = 13
TOP_RIGHT_BOTTOM_3WAY = 14
TOP_LEFT_RIGHT_3WAY = 15
TOP_LEFT_BOTTOM_3WAY = 16
LEFT_FACING_TUNNEL = 17
RIGHT_FACING_TUNNEL = 18
DOWN_FACING_TUNNEL = 19
UP_FACING_TUNNEL = 20
NUMERAL_CAR_ENDING_TRACK_RIGHT = 21
NUMERAL_CAR_ENDING_TRACK_LEFT = 22
class ModificationType(Enum):
EMPTY = 0
SWITCH_1 = 1
SWITCH_2 = 2
SWITCH_3 = 3
SWITCH_4 = 4
TUNNEL_1 = 5
TUNNEL_2 = 6
TUNNEL_3 = 7
CLOSED_GATE_1 = 8
OPEN_GATE_1 = 9
CLOSED_GATE_2 = 10
OPEN_GATE_2 = 11
CLOSED_GATE_3 = 12
OPEN_GATE_3 = 13
CLOSED_GATE_4 = 14
OPEN_GATE_4 = 15
SWAPPING_TRACK_1 = 16
SWAPPING_TRACK_2 = 17
SWAPPING_TRACK_3 = 18
SWAPPING_TRACK_4 = 19
STATION_1 = 20
STATION_2 = 21
STATION_3 = 22
STATION_4 = 23
SWITCH_RAIL = 24
SEMAPHORE = 25
DEACTIVATED_SEMAPHORE_STATION_POST_OFFICE = 26
STARTING_CAR_TILE = 27
POST_OFFICE_1 = 28
POST_OFFICE_2 = 29
POST_OFFICE_3 = 30
POST_OFFICE_4 = 31
class Tile:
def __init__(self, track: TrackType, mod: ModificationType):
self.track = track
self.mod = mod
def __repr__(self):
return f'Tile(track={self.track.name}, mod={self.mod.name})'
# Example usage
ti = Tile(TrackType.HORIZONTAL_TRACK, ModificationType.POST_OFFICE_1)
print(ti)
later when you want to check track type you can do
if ti.track==TrackType.TOP_RIGHT_TURN instead of if ti.track==7
it easy to understand than looking at a number
i suppose
there are still going to be scenarios where the numbers need to be used, and that happens in most of them
i dont normally check for specific track ids i check if theyre in a range like if im searching for tunnel id's for crashing which would be if 17 <= tile_ahead <= 20:
it a number itself but have a name, you can access the number by TrackType.HORIZONTAL_TRACK.value
 i feel like thats really long to be typing a number instead
i feel like thats really long to be typing a number instead
even if its for clarity
or better you can make a function to check in the enum:
from enum import Enum
class TrackType(Enum):
EMPTY = 0
HORIZONTAL_TRACK = 1
VERTICAL_TRACK = 2
....
@classmethod
def is_something(cls, track_type):
return 17 <= track_type.value <= 20
print(TrackType.is_something(TrackType.HORIZONTAL_TRACK))
no thats ridiculous id have to make functions for every time i wanted to check something like that
😂 that whaat OOP is hehe
even if i made one thatd be customizable to get whatever range you wanted its less discernable than even numbers
make every as long as possible
couldnt i just put a comment explaining the numbers?
you can
the trade-off of OOP is that readability is good but you have to write a lot of long functions.
all the functions youd want me to write serve the same purpose but barely different
i think theres a difference between writing a lot of qol functions for a class and writing a bunch of functions that accomplish around the same task
yeah
with OOP you have more control
with function program it hard to have control when you need
It's a classic debate subject in the programming world: Functional Programming vs OOP
but when making game, OOP still better
i think the numbers should just stay numbers and not use anything else to substitute it
theres too many specific instances where they get used and trying to explain each one would just make the code line longer and messier
if they really need to they can check the track name for the value
yeah, just 2 class grid and tile is enough
hows this
gonna remove gridx and gridy for now because all we're using the board class for is converting levels_car data into the new format
once we need it to create custom boards i can reformat stuff
Look clean, good work
actually i probably shouldnt need it regardless because we can just make the editor give it a numpy array to convert into the new format
car class

will probably modify how move() works once i actually implement it for the code but thats later
ill implement the state class tomorrow, seems more complicated than the ones ive just done

So Tile there is mutable, which means you can't reasonably hash it. I would change the change method to construct a new Tile object and return it
(well, you can hash it, but you can't rely on the hash meaningfully because either the hash isn't based on the meaningful properties on the object, or the hash will change when the object changes, which means that checking whether it exists in a set doesn't work, because it is stored based on what the hash was, and looked up based on what the hash has changed to)
I would do similar for the Car class
Also it's a convention that classes are named in PascalCase
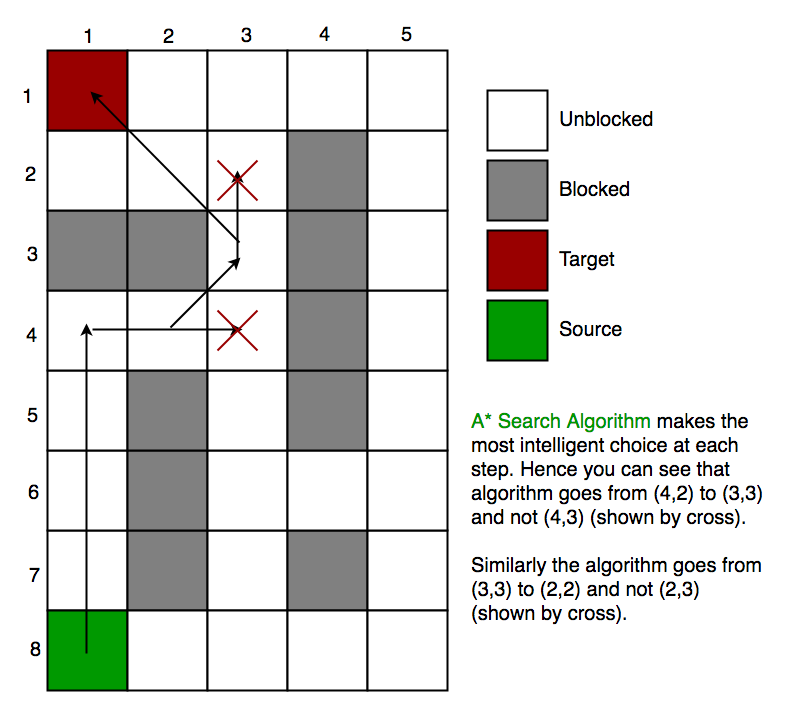
I think it's also worth questioning whether we're looking for the shortest solution, or all solutions. For the shortest solution there's a decent chance we want A* search. For all solutions then you meet as well just do the simplest visible BFS
how you will do A*?
As in what's A*, or as in what's the heuristic?
Here's a decent rundown of the algorithm: https://www.geeksforgeeks.org/a-search-algorithm/
The tricky part is representing the problem space as a graph
GeeksforGeeks
A* Search algorithm is one of the best and popular technique used in path-finding and graph traversals.


Yeah but how do you know what grid state is better then other, how to compare them
So the heuristic. I would say the sum of distance to goal per cart, minus the number of pieces left to place
the cart can go far away before go to the goal destination
Sure, but with, say, a maze search that's also true
find the node with the least f on
So this gonna be a priority queue
Hmm, I may try this A* after complete the mechanic for all the levels
It might not be the quickest to find the fastest solution for a given level, but it should be the fastest on average
But obviously if you want all solutions you're going to need to search the entire possibility space
This blog post has a cool animation of the algorithm running: https://levelup.gitconnected.com/a-star-a-search-for-solving-a-maze-using-python-with-visualization-b0cae1c3ba92

im not sure
the main problem with using any generation method is rules need to be applied
Actually, I think there might be better heuristics, just trying to think it through
I was thinking about minimax
But yeah, even if we don't go for something as sophisticated as A*, a BFS that culls duplicate state should find the shortest solution before all others, so if you're only interested in the shortest solution, you can stop there
were only looking for the shortest solution but how do we define thst for bfs
theres a lot of rules to be applied
Minimum pieces laid, I would think
It like a mix between minimax and Monte Carlo Simulation
Our algorithm is simply exploring a tree, move from top to bottom, at each node it count have many node below it have crash. The node with the bigger value may less possibility for us to choose to generate new possibility
if we use bfs it would have to be integrated into the gen function so all the rules can be applied
but i suppose it could work
i feel this assumes the "best path" the program sees during generation is the best path which i dont think would always be the case
If when you generate new State objects you put them in a queue bucketed by the number of tracks laid, and only ever expand from the queue in the bucket for the shortest length, you'll never get to the longer solutions
Were you culling previously seen states?
Because otherwise it's easy to end up in infinite loops
im not sure if this would change anything because you cant really determine how long a solution is until it reaches the train and tracks are finalized
it would also prioritize paths where cars are constantly riding over tracks they already placed (and a LOT of loops)
Depends whether you're counting the longest by runtime or by pieces laid
Because you always know how many pieces have been laid
runtime would just be how many states were generated on that branch
Indeed
my point is due to how the cars move and railbounds fundamentals you cant really assume whats the best path early on
Now you could have a generation number on each state, which is ignored in the hash function and increases every time you branch
Then you could include the generation in your heuristic
runtime shouldnt be hashed
Indeed
if the board, cars, mechanics, and tracks are the same its going to follow the same result regardless
though i suppose different runtime could mean a duplicate
Basically you treat entering a state you've already seen as a crash
but then theyre different hashes so you cant confirm
correct
a long time ago i tried implementing a distance map from the train thatd kill cars early if they were generating too far from the train but that got cut short very early because factoring mechanics make it not worth it
So distance from car to exit is not something I'd worry about unless we're doing A*
bfs seems most viable but i need to be able to restrict it
It's part of the heuristic cost, but not the actual cost
Which is why the hashing is vital
Some of the optimisations are good and should be kept, others may be obsolete if the algorithm is improved
So things like the loop detection
If we're tracking known states, that's entirely taken care of
loop detection is done by the heatmaps
When you place 11 tracks in a row it gonna be 6^11 ~ 10^8
and there are cases (like with switching tracks) where cars can loop
maybe
For the loop detection i think it easier when you hash all the cart position, then check for the hash
I'm pretty sure most of those will be culled though because they're either duplicates, or they crash
i cant think of any scenarios where thatd be false off the top of my head
It's by definition, because if the cars have looped and the grid is the same, then you're no closer to a solution
But you still store it in the queue and check it later
i suppose heatmaps could become obsolete but we'll see
Unless you check for the crash before push it in the queue
how would bfs even be implemented
That would be my temptation
would i generate a path that connects all cars to the train and then test if every track along the way is placable?
also how would bfs handle loops
BFS would be incredibly similar to your current algorithm
thats what im thinking
It's just about how you prioritise which node to search from next
Breadth first meaning that you always prioritise the minimum 'distance' travelled
How you define distance is the trick
im thinking
to speed up the program, what if i pregenerated paths until one connected to the train and then tested every track?
its technically running the same amount of combinations as it normally would but theres no rules along the way
that might be slower then
I would be tempted to make it a tuple of (pieces_placed, state_generation), where the second tuple item is only relevant when the first is equal
distance is just tracks placed though isnt it whatd the state_generation be for
that would minimise runtime between solutions with the same number of pieces placed
But if we agree that's unimportant, then pieces placed it's indeed distance
state_generation is how many times you've branched from the initial state to reach the current state
unimportant
there was a veeeeery long solution i posted a long time ago with the min tracks
there were many other solutions that saved tracks that did it faster but that had the lowest
Yeah, I was just thinking if there were other equal solutions for a level
But if it's unimportant that's great
checking for shortest runtime just means more generation
One fewer thing to check
the goal is to just find the most tracks saved
I mean to be fair it should also fall out of using a FIFO queue
a what
First In First Out
Well the items with the lowest generation for a number of tracks placed would go in that bucket's queue
Before any further generations
runtime doesnt really correlate to tracks
No it doesn't
But it does correlate to where ends up processed first
Thinking out loud here, but the current algorithm is BFS where the distance is generation
If we changed from a queue to a stack (FILO, First In Last Out) then it would be DFS where distance is generation
runtime doesnt correlate to tracks so it wouldnt get us any faster to the best solution
But the reason we want to bucket by tracks placed it's to change what's considered to be distance
oh by tracks
Yeah I'm not saying what we should do, I'm thinking about how the algorithm works currently, what its characteristics are
i suppose it could work
But yeah, BFS by tracks placed should guarantee we find the shortest solution first, but unless we do anything hinky, if there are two shortest solutions we should arrive at the one with the lowest generation first without doing anything special
whats my goal for today then
Have you made those classes immutable?
i still need to add the state class and modify tiles to be immutable
should cars be immutable?
Everything that's referenced by anything referenced by State
yeah
Because it's the only way State is going to have a meaningful hash
after i make them immutable should i work on a hash
Yeah
and then after that i can probably start implementing it into the actual program
how does one produce a hash
I feel like tile is simple because you have two integers with a known range
before that we need the variables to hash though
...which is probably all 12 passed through the generation function
So you multiply one number by (the largest possible value of the other number) and add the other number
i can think of a few variables that can be removed but theres so many variables to account for in a state
Or you could just bitshift one by 7 (which multiplies by 32 in a single efficient operation, your numbers end up bigger, but it's computationally simpler)
But either way, a hash for a class that holds two numbers is very simple
i think i see how to make it
the hash count for boards alone would be MASSIVE though
For the grid I would call hash on a tuple((k, v) for (k, v) in your_dict)
but wouldnt you be accounting for all the elements together to get the board hash?
dont know what you mean by calling hash on each tuple
there are 23 possible tracks so on a 5x5 grid wouldnt that be 23^25?
Hmm, I'm starting to wonder if we need to worry about hash collisions
Which might mean having to also implement __eq__
Basically a hash will only get so big, and in case of a hash collision in a set, the set will create a list of values matching that hash, and check all of them when checking if an item with a matching hash is in the set
Which means it's still much faster than checking through one big list, but it's slower than when you have few enough items that you don't get collisions
We could bucket the seen states by pieces placed, which would help a bit
is hash collision when the hash is bigger than the var type allows for
A hash collision is where two different objects have the same hash
You generally want to avoid it where possible
But we might not be able to avoid it here
the only way i can think of to get all the possible hashes would be to run the program to find every possible generation but then itd have to be run twice and the first time wouldnt even be using hashes and thus much slower
Yeah, I wouldn't worry about that
we cant allow every hash thats "technically" possible though
would be too many bytes regardless
I think it would actually be something more like 25! - 2^25 but it has been decades since I've done that sort of maths by hand
Because for each tile allocated, you can't place anything else there for each set of pieces
That's still a huge number though, so we're banking on only exploring a small part of the possibility space
Like, it's 9 orders of magnitude smaller, but still way too big
Now obviously most of those possibilities will either contain track that's unreachable, or will crash the cars
Which probably makes the actual total possibility space irrelevant when considering the possibility space of tracks we might generate and store
I guess I'm taking a gamble on 1.5e25 actually coming down to somewhere in the region of a few billion
Otherwise the set might need to turn into a sqlite database indexed by hash
the entire purpose of the program is to search for every possible path thats usable so if there was some way to hash specifically based on how the program generates then the number could be brought down
The problem is that it can still generate the same grid in multiple ways, and can still generate loops
is there anything else we can use to hash than a number?
or would a number be the best option
A hash is always an integer
can you give me an example of how id make the tile class immutable yet changeable
changeable as in modified copy of course
So I think when I looked at what you were doing, you had a method that changed both the tile and the modification at the same time, do those ever get changed at the same time?
i dont think it can happen in the vanilla game
I think it was something like
class Tile:
piece
modifier
def change(self, p, m):
...
the only way a track and mod would be changed at the same time is if a mechanic typically placed on tracks had no track under it on a custom level
I would do something like
class Tile:
piece
modifier
def with_piece(self, p):
return self.__class__(p, self.modifier)
def with_modifier(self, m):
return self.__class__(self.piece, m)
Sorry it's terse, I'm on mobile
is it possible to change both at the same time or is it better to just call both functions
I mean sure, but if you're changing both, surely you may as well just create a new Tile?
true
Because you're not using anything about the existing one
Sorry for this you could probably just call Tile rather than self.__class__, the latter is important if you have inheritance happening, but nothing in this project is inheriting from anything
👍
I'm just used to doing the latter as a good habit
on the subject of the hashing stuff do you think theres some way i could do hash(board.tiles) or is that not ideal
tiles is a dict
Try it, it won't work
yeah i did its mutable
dict isn't hashable because, yeah
My temptation would be to make the __hash__ functions idempotent, i.e you calculate the value the first time, but you store it in a protected attribute to reuse later
Like
def__hash__(self):
if not hasattr(self, '_hash'):
self._hash = …
return self._hash
Alternatively you could just compute _hash in __init__
Anyway, I'm on BST so I'm heading to bed, talk more tomorrow
state class

for now at least because we need to figure out hashing
didnt include mods because its going to be included with the board object
i pushed the new stuff and it renamed/deleted images and theres Images now again for some reason
i never named it Images in pycharm i have no idea why its there
@delicate nymph please excuse the folder rename i have no idea why it did that
Maybe it some windows stuff
I'm curious whether crashed_decoys belongs in cars
Also you might, instead of rolling your own dictionary hashing for Grid, consider using frozendict, a package you can get through pip that provides an immutable dict with a built-in hash
I don't know why that didn't occur to me earlier
We already have library for everything xD
When I first began learning programming, I had to write all of my code from scratch using C++ 💻🤓
looking at some of the gen params i think we can get rid of solved
cause you can just check if the car thats trying to solve is the lowest of its type
crashed_decoys could possibly put in cars but itd have to be done at the very end of branch creation and then removed at the start of the next generation
station_stalled and stalled could possibly be combined but since they still serve 2 different things the variable would be messier and harder to look at
i think thats all
i mightve been doing something wrong with frozendict cause whenever i tried to make it hash itd always give a different result when i ran it
im sure i was using it on the frozendict and not the class
That may well be because the items you're storing have different hashes each time?
does that mean the tiles are mutable?
how do i change that they shouldnt be modifiable any more
You need to implement __hash__
So you have ```py
class Tile:
def init(self, track: TrackName, mod: ModName):
self.track = track
self.mod = mod
def newtrack(self, track):
return Tile(track, self.mod)
def newmod(self, mod):
return Tile(self.track, mod)
def __repr__(self):
return f'Track:{self.track.value} ({self.track.name}), Mod:{self.mod.value} ({self.mod.name})'
I would make that ```py
class Tile:
def init(self, track: TrackName, mod: ModName):
self.track = track
self.mod = mod
self._hash = (track.value << 5) + mod.value
def __hash__(self):
return self._hash
def newtrack(self, track):
return Tile(track, self.mod)
def newmod(self, mod):
return Tile(self.track, mod)
def __repr__(self):
return f'Track:{self.track.value} ({self.track.name}), Mod:{self.mod.value} ({self.mod.name})'
Bitshifting 5 to the left is the same as multiplying by 32, which means you won't have any collisions for that class
itd be better to do track.value * 23 though so numbers can be packed tighter right
nvm theres 32 mod values i forgot
that number should go down once i implement mod types though
...mod types also might be a problem for hashing but thats a later problem
on a sidenote, one of the other things i thought would be cool if the project ever got this far would be if the code could generate puzzles for you to solve at different complexity values (how hard it is)
it could probably be done with ai but thatd be a headache and youd have to solve a LOT of puzzles to feed it and tell it what complexity you think it is
probably simpler to figure out a formula for level elements and turn that into complexity somehow
also why bitshift instead of multiply?
Because for the CPU it's a single operation
And given that 32² is only 1024, the largest possible hash is still plenty small
I think you'll only actually have about 768 possible hashes
Also given that hashes for that type are unique, you can also implement __eq__ as ((type(self) = type(other)) and (self._hash == hash(other)))? True: NotImplementedError
i saw eq while looking at hash stuff and i know its used for object == object stuff but why is it used specifically for hashing
Equality isn't used for hashing, but IIRC it is used for what something is in a set, after using the hash to find it
It might be worth experimenting to make sure
I published the first post so I gonna try to solve level 2 now
768^25 is still a very big number

it is also less bytes than id prefer to use

for a single id
i dont even know what math is the correct math at this point
seems like the max id hash can return is 8 bytes
so not sure how thats supposed to work if we can have more than 8 bytes of information
itll probably work
how do i turn this hash back into a dict anyways
if i dont know the formula
A hash is generally one-way
If you can work backwards for a given item then that's an implementation detail
By default hashes are lossy, which is why hash collisions are possible
It's just that for Tile we're working with so little entropy it fits, so we may as well make the hashes unique
why shouldnt i make my own formula so i can debug dupes
Huh?
What do you mean, precisely?
The hash is generated so that objects can be stored and retrieved efficiently from a hash-based collection like a set or a dict
So you store the whole object
The hash is used to figure out where to place it in memory
(or more precisely, where to store the reference)
So a hash can be up to 8 bytes, but the number of bytes used by the collection implementation depends on the size of the collection
how would i figure out what a board is based on the hash then though
You don't, you figure out what the hash is for a board
Then you store the board in a hash-based collection
hash-based collection?
Doing so uses the hash to figure out where in memory to put the reference
Then when you look on the collection to see if the board is already in there, then it used the hash to look for where it would be stored, and if there's anything there, it looks at the items in that location to see if there's a match
Think of it like books in a library
The hash is the dewey-decimal number, but with way more precision
Ideally most of the time you put in the hash and it takes you to a shelf that has zero or one books on it
But sometimes you'll find that one subject has a shelf with 200 books you need to look through
i still dont understand
For the most part you don't need to, you just need to know that being able to generate a hash for an object means you can store it in one of these collections with really efficient lookups
The inner working of it is stuff I struggled to fully grok in my first year of university, so I'm just trying to give you a bit of a feel for what's going on
Sets and dictionaries (aka hashsets and hashmaps)
What do you mean by debug dupes?
I could help you write unit tests, but that's a whole 'nother rabbithole
if i solve a board and i put an if statement in there that tells me a hash was used twice that gets triggered, id want to debug that and fix it because duplicate boards shouldnt happen
technically i could just get the id and then throw another if statement in the program that stops it when the hash is found so i can see the board but its less ideal
A hash being used twice, given the amount of data we're looking at, doesn't mean a board was used twice
Because there's more entropy than we can fit in an 8 byte number
i know but theres a chance it is because and i want to make sure it cant
If we're using the set correctly, there's no chance
ill just use this method then
im fairly confident the level with 1b iterations i replied to earlier for the 300m example had some duplicates, as i have a feel for the results my program should show depending whats in a level
and that level shouldnt have that much i think
Try out ```py
a = -1
print(f'{a} -> {hash(a)}')
b = -2
print(f'{b} -> {hash(b)}')
s = set()
s.add(a)
print(b in s)
It's a well known trivial hash collision
i could stop it early like that so i have the 2nd duplicate hashes items for debugging but i wouldnt have the first
its fine
If you're getting duplicates then either you're making the hashes incorrectly, equality isn't working, or you're not coming the set
or my program generated 2 states with the same data
im just saying i want to confirm my generation is working correctly by using the hashes
if i debug it and no 2 hashes have the same data for any level, thats good. if they have the same, then i debug it and fix it
Have you pushed your latest code?
yes
as of yesterday at least i havent done much today
im going to make the State class able to return a hash of the state so i can try and see if there are any duplicates during generation
Can you push that? I want to take a look
i can push what i have right now but im still working on the state hashing
Ah, gotcha
So that will mean the hash for a State object isn't related to its content
pushed what i have right now
IIRC it'll be related to its address in memory, which isn't useful for objects with the same content that have been created independently
the push note is just Fixed because i couldnt figure out how to change the description after i commited it lol
right forgot about that
Neither are implemented for Board
And on State you're returning the hash function itself
im still working on state
for board i didnt add a hash because i never reference the class, i just hash the tiles because the tiles are only ever whats referenced and used
i can add the __hash__ and just make it return hash(self.tiles) though
I can help you simplify Board.__init__ with a dictionary comprehension: ```py
class Board:
def init(self, tracks, mods):
self.tiles = frozendict({
Tile(TrackName(track), ModName(mods[pos]))
for pos, track in np.ndenumerate(tracks)
})
thatd work
anyways thats just what i have at the current moment because you asked
what would purpose would __eq__ serve in hashing again
i know its something about comparing set values but i dont really understand why that matters
Yeah, just gives me more of an idea why it wouldn't be working yet
In the library analogy, the hash is the dewey-decimal reference number, __eq__ is how you compare the book you've got to the books on the shelf you've found
By default __eq__(self, other) checks if they're the same object, but you should define it to check whether the contents are the same
So currently ```py
a = Tile(1, 1)
b = Tile(1, 1)
hash(a) == hash(b)
True
a == b
False
And because a != b, if you add a to the set, it won't say that b is in there
Because when you find the shelf with a on, you find that it isn't b
Whereas if you define a as being equal to b, then it'll see b as already being in the set
i will add that
i think the only 2 variables needed for getting the hash of a state is the cars and the board
the only case where checking for duplicate hashes would be avoided is if all the cars are stalled at a station
there might be some others but i think thats it
I'm currently wondering whether it would be simpler to make these dataclasses
Because it defines equality for you, and if you set frozen=True it'll give you a hash function too
But then if this is a learning exercise, doing things by hand is good practice
You'll probably want to add a method on Board that's add_tile(self, x, y, tile) which returns a new board with the Tile added
(which will also replace the tile in a position, if there's one there already)
theres a tile in every position
i dont feel like dataclasses are needed the code works as is
concerning this though when hashing the board i should probably only look at nonzero elements so theres less hashes and less chance for hash collision
id need to store a second variable though because i need the empty ones for generation (i could maybe change it though)
Why a Tile in positions that don't have anything placed?
so the program can check if that position is empty and therefore can be placed on
...which i could modify so the program just checks if that position is keyed in tiles
But you can tell it's empty if there's nothing at that dictionary key
Ah you got there without me
How so?
in the game mechanics like gates, stations, switches, are always placed on tracks
but if we make an editor they can be placed on nothing
which could allow for very cool solutions imo
So then you have a Tile object where tile.track is 0
so if we allow these mechanics to be on empty tiles then i cant have any tile objects missing
yeah
then whats the point of having empty positions with no tile obj
Because you're not creating extra objects to represent nothing
the program would have to check both situations though: if the track.value is 0 or the position doesnt exist
You create a Tile object if there's either a track or a mod in that position
I would be tempted to add methods to Board that are track_at(self, x, y) and mod_at(self, x, y)
They look for a tile at that position, if there's nothing there it returns the Enum(0), but if there is, it returns the tile's attribute
See that way the Board class is entirely responsible for its implementation, nothing needs to know it's a frozendict, they can treat it the same even if you change the underlying implementation later
It's a key principle of OOP
You can prefix attributes with a single underscore to denote them as implementation details, like _hash, and your IDE will complain if you try to interact with it from elsewhere. It's known as a protected attribute
It depends on whether it should be interacted with from other objects
Like, for Tile it makes sense to leave the attributes public
i see
Like, if you're doing strict OOP by the book everything would be either private or protected, and stuff you need to access would be exposed through properties and methods
But generally there's little benefit to that
im trying to make Car hashable and it wont do it because CarType is an enum
i think im just going to do:
class CarType(Enum):
NORMAL = 0
NUMERAL = 1
DECOY = 2
def __hash__(self):
return hash(self.value)
class Car:
def __init__(self, x, y, xvelo, yvelo, num, type: CarType):
self.x = x
self.y = y
self.xvelo = xvelo
self.yvelo = yvelo
self.num = num
self.type = type
def move(self, x, y, xvelo, yvelo):
return Car(x, y, xvelo, yvelo, self.num, self.type)
def __hash__(self):
return hash((self.x, self.y, self.xvelo, self.yvelo, self.num, self.type))
def __repr__(self):
return f'(pos:{self.x, self.y}, velo:{self.xvelo, self.yvelo}, n:{self.num}, typ:{self.type.value} ({self.type.name}))'
actually return self.value is better
already an int
For CarType I would just return the value as the hash, target than then hashing it
Damn, ninja'd
hehe im learning
I feel like Car.move should probably, instead of taking coordinates and velocity, take a Board? Then it can use its position and move based on the tile it contacts
i thought about that already but its not really usable because when i make a new car im making it with each new branches pos and velo
branch 1 could go into a tunnel while branch 2 goes straight
oh use a board i see
im not sure it would be wise because the part of the code that creates new cars also handles track confirmation
so the class would also have to handle track confirmation
Because the car knows its velocity and position, so it knows what tile it'll enter, and therefore how that changes its position and velocity going forward
Can the two not be decoupled?
?
The car object should ideally be responsible for its movement, but not branching
I should get to bed, but I'm likely to be busy tomorrow, so want to try to finish this up
every time a new car should be created it needs to be confirmed during track confirmation if that car should even be made

to feed it a board would mean i need all of these if statements inside of the class too
instead of just doing rb.Car(x, y, xvelo, yvelo, n, typ)
honestly if i were to feed it a board id need to feed it each new branched board with the new tile which means creating 3 different boards
Ah, so if the move isn't legal, return None, the caller can try amending the track to make it a 3way, and try the move again
the purpose of track confirmation is to check whether or not all 3 of those boards should be created
so itd just make the code slower
creating all 3 boards is also more convoluted than just giving it 6 new variables
Or you could have the car tell you the position that's important, then you call move with a Tile
the image i sent is just 3 instances of new cars being created as an example
there are other situations that i couldnt capture in one image
The issue is that this code is incredibly baroque, it's hard to reason about because all the various concerns of different parts of the algorithm are mashed together and it's not obvious what's going on, making it difficult to improve without breaking things
If you can separate those concerns into the responsible object, you can spot opportunities to make further improvements
the generation function is using the for loop to iterate all 3 tracks for each new car velocity, i think its best left to the generation function to give the variables regardless because its managing all 3 new cases
the board doesnt manage any of it
So what about instead of the board, passing the track?
the track needs to be confirmed
ergo why the generation function should handle the variables and different if statement-scenarios
The generation function should be responsible for creating the tracks, and confirming they're good, but everything else should be handed off to other responsible objects
once the code gets reorganized for classes that can be talked about again
Otherwise it'll always be spaghetti
alright then
no hashing vs hashing


hashed_state = hash(rb.State(tuple((rb.Car(*c[:5], rb.CarType(c[5])) for c in cars_to_use)), rb.Board(board_to_use, mods_to_use)))
if hashed_state in hashes:
raise Exception
hashes.add(hashed_state)
is all i added
might be because of object conversion for now but i hope it doesnt end up slowing down the program that much
why are we using hashes again 
just type this long function xD

was this so loop prevention would be easier?
Yes
i can try converting the cars and board to objects so its not getting converted during hashing but the speed at which its running is significantly slower than id like to see
hashing vs no hashing on world 4 (where looping would be applicable)


dont see improvements
Are you making sure you're only processing nodes with the least number of pieces placed? If so you can stop when you've generated the first solution, at which point you've gone from 235s to 45s
The real point, however, being that there are levels where you currently get a few solutions and then pycharm crashes before you can finish executing, but if the new version finds a solution it can stop before it finishes searching the rest of the possibility space because what it has found is guaranteed to be the shortest solution
There's also the question of scaling - the old solution takes about 87x as long on the more complex level, while the new solution takes 69x as long. It would be interesting to see how that trend continues as you continue to add complexity
Obviously the real question is how long it takes to achieve our goal of finding the shortest solution, rather than all solutions we have currently
If the first solution is the shortest then not only is it faster overall, but going to a more complex level has only resulted in it taking 11x as long to find the shortest solution
Once we have an algorithm that's processing as few iterations as possible before finding the shortest solution, then we can look at making that algorithm execute faster
You can already see in that more complex level that you're running under half as many iterations having thrown out duplicates
i forgot about this
its an incredibly good idea in retrospect i cant believe i didnt think of it when i was still working on the generation
how do i choose what branch to generate first though? yield doesnt make a queue
the only variable id need to save for each state is available_tracks but i still need the parameters so i can actually generate it
and the hash wouldnt give parameters
thinh talked about deques earlier which is what is probably ideal here but i still dont think i should be saving the parameters based on everything al has taught me because it sounds too slow
the parameters would be saved as a state object of course
im gonna work on making the generation function use objects and then test for speed again (because there wouldnt be any object conversion)
after that ill make a deque and test that ones speed
as for how the deque works im just going to store every new branch generated, and then if a new one is found with a lower track count than the lowest in the deque, the program immediately starts generating that one, stores every new branch generated, repeat...
im also gonna keep the heatmap because its used for crashing and preventing cars from altering other cars paths during generation
heatmap_limits isnt necessary any more though
nvm the program takes significantly longer when i remove it
65k -> 253k iterations on one level
will look into that later
after been though a lot of frustration. I manage to create a precompute dict to check if 2 tracks can place to each other. Can be use like:
# IS_CONNECTED_DICT[source_track][to_check_track][direction to the source_track]
if IS_CONNECTED_DICT[Tile.CURVE_BR][Tile.STRAIGHT_H][Direction.RIGHT]:
print(f"Track {Tile.STRAIGHT_H} is connected to {Tile.CURVE_BR} on the right")

The change would be in tail_call_gen. Instead of argslist being a list, you make a dict, where the key is the number of available tracks and the value is a deque containing all the State objects with that number of available tracks.
Then instead of popping from the list, you do something like
while args_queue := state_dict[key := max(state_dict.keys()]:
while args_queue:
for new_state in func(args_queue.popleft()):
if (k := new_state.available) not in state_dict:
state_dict[k] = deque()
state_dict[k].appendright(new_state)
state_dict.remove(key)
(Typing on a phone, I'm sure it could be prettier and I'm sure I've made mistakes with the deque API)
couldnt i just shove the state object (state1) into the deque and look at the lowest state's track count (state2) and then if state1 has the same or lower count its appended to the lower side otherwise the higher
that wouldnt be ordered well by tracks though
I guess you could do that, and then when the number of tracks on the left increases, sort the deque
But buckets are probably better. Try both?
~~I'm kinda tempted to suggest you write a class for the queue data structure so you can just create one, iterate over it, extend it with new state objects, and the class itself can be what controls how things are stored and retrieved. ~~
My latest thought is that you should only be generating state objects with either the same number of remaining tracks, or one fewer, so:
next_queue = deque([initial_state])
while next_queue:
args_queue, next_queue = next_queue, deque()
remaining = args_queue[0].remaining
while args_queue:
for new_state in func(args_queue.popleft()):
(args_queue if new_state.remaining == remaining else next_queue).appendright(new_state)
ive come across the first issue with the board being unmodifiable which is with gates

The first paragraph of that was before I had the new idea
the 2nd and 3rd lines both are meant to do the same thing
so it changes the gate to closed before it starts with generation, but all the variables were already copied so id have to create a new board again here for the new gates which is not ideal
Why is that not ideal?
the ""easy"" solve (not really) would be to move the switch code and everything before it to after branch creation so that way it gets tampered before copying but i dont think thats a good idea
the board needs to be copied again which means its going to be slower whenever it needs to close/open a gate
I'm just sure how big a deal it is in practice? Maybe add a Todo comment to remind you to look again if you're having issues?
i might just be stuck in an optimization mindset from when i was still making the generation so i dont really want anything that could possibly slow the program down to exist
Don't worry about microoptimisations until we've got the structure right
It's a lot easier to make the big changes in a way that is flexible, and then make the smaller optimisations later
mmmmm ok
Add a Todo so you don't forget
pycharm is so cool

Indeed
green text is so convenient
You won't forget, and you don't have to do it now
Like, the absolute worst case scenario would be that it slows things down by a factor of two (I don't see it being possible to design a level that does that), and the optimisations we're looking for currently should save waaay more than that
Once we've got it sorted we can profile the code and see whether it's actually an issue
3-8B
anyways
Oh, I forgot, for each new_state you should check if it's solved, and return if so

Even then not every tile is changing a gate
Or you could raise an exception after printing the solution
is there a way i can make a class function change the variable that called it kinda like list.sort
so i could do
board_to_use.closegate(gate_pos[1], gate_pos[0])
instead of
board_to_use = board_to_use.closegate(gate_pos[1], gate_pos[0])
You mean mutate an argument?
ye
What are you trying to mutate?
uhh
i want the board to be able to run the method and then the method makes the board a new one with the tile changed
Ah, no
Well
Yes, but it would require mutating board, and then the hash is invalid and you're going to have a bad time

Basically everything we're hashing is only immutable by convention
But if you break that convention it's a one way trip to bugtown , population you
I still dont know how to handle the T_turn correctly if I only place 3 tile: straight, turn left, turn right on each step. For now I just place all tile and that so annoying :(. Any advice ? @fervent tusk
3-ways are a curious thing to add, and i needed heatmaps for mine so im not sure if your generation can do it without
3-ways can be created when a corner gets intersected like this or this


it can be created if a car is intersecting a horizontal or vertical rail, but it must not interfere with any car's path


so in the first image no 3-way should be placed, as it would mess with car 1's path
and it can be created if a car changes already placed tracks, but it must not interfere with any car's path


so the first image wouldn't work because it'd mess up car 2's path
the reason that it cant interfere with any cars path is why i needed heatmaps to check if a car had been there or not
im just saying this based off of my generation so yours might be different
3-ways are a part of the fundamental flaw with the generation which is that tracks are progressively created, unlike the game where the tracks are all made and then the board is run
luckily 3-ways can be solved fairly easily like i detailed above but semaphores are the second part of this issue which i havent yet solved and thus semaphores still slow my program down way too much
See I could see another way to go about it, but I don't think it's necessarily better than the heatmaps
Basically the idea would be that once placed a track can't change, but any type of track can be placed. When you place a 3-way or a corner you put a placeholder on the tiles that would need a track piece to make the corner or 3-way valid, and you take those from the number available. Then when you'd enter that track you replace the placeholder with the next possible tiles
Obviously then to do BFS you need to bucket your tracks because from a state with N available tracks those generated can have range(N-3,N+1) available
thats partially what i do with semaphores and the heatmaps are probably the best and simplest solution for 3-ways
that method just makes it more convoluted in my eyes
Again, heatmaps are probably more optimal - that's just a way to get away without them
semaphores are so annoying if i can talk about them for a little bit
Sure
like how thinh is doing with his 3-ways currently i haven't found a workaround for semaphores yet, so when i generate levels that use them i just have to generate 6 paths (ex. straight, turn, turn, semaphore on a straight, semaphore on a turn, etc.)
which is because semaphores have to be placed next to a 3-way to be useful
but that already becomes a problem on 9-2 (sorry searching for an image...)
Maybe when you generate a 3-way you try to create 4 branches: a plain 3w and a version with a semaphore on each entrance/exit?

a semaphore needs to be generated next to a 3-way, but a 3-way cant be placed unless the 2nd car passes through the gate
...which cant happen because theres a semaphore there
and the 3-way cant be generated for the semaphore to be placed next to because car 2 will never intersect to make it
See as long as you're doing a queue rather than a stack you should just end up with a bunch of branches where one or more cars can't move
But you cull any loops because of the set of seen state, and you should get a solution before it gets that far anyway
In fact that works without the queue, you just exhaust the branch before moving on to the next
And I feel like you'd probably reach the solution faster doing BFS, using the queue
you always use so many fancy words
are you saying that its not that bad of a problem because the program will be able to solve the board quickly regardless
Uh, which words are jargon, I'm in too deep
cull, set of seen
Ah, right
i think i know what bfs is now but vaguely
the set of seen states is literally the set data structure we're putting states in as we get them so we don't double-handle anything
Branch-culling is where you discard a load of the branches on your state tree because you know they're not going to lead to a solution
So basically if a car is waiting at a semaphore it won't be able to move, so you mark it as having already moved, so all the other cars keep moving. Eventually they'll all loop, solve, or crash without triggering the semaphore, and so you stop processing that branch.
But I would expect that most of the time you've already found a solution before it gets that far
i actually need to look at my code for semaphores i kinda forgot how i did it because theyre so annoyingly complex with the generation system
but this is about along the lines of it, a car will get stalled if it chooses to place a semaphore and the program kills a branch if all cars are stalled
Yeah. I feel like there's a bunch of ways to go about it, but they're all pretty complex and the only difference is where you put that complexity
My tendency is to try and keep the logic for each system self-contained and allow them to interact as necessary, rather than mixing things together, because it makes them easier to understand, test and debug, as well as it being easier to layer on new systems as needed
Not that we're writing tests for this code, just that it's a major concern for anything you write professionally
unfortunately i dont have coding experience
for placing semaphores the code just checks if its placing a tile that can hold one (any basic tile like horizontal, any turn) and then if the heat of the adjacent tiles is 0 (meaning no cars could've triggered the semaphore before it was placed making it useless) it allows it to also place a semaphore'd option of the tile
and then if any cars pass it the semaphore gets opened
and since the car behind the semaphore will always make a 3-way theres no need to check if theres 3-ways adjacent to placed semaphores
because if the semaphore is opened a 3-way will be placed and it becomes legitimate, but if it isnt then no 3-way is made and it therefore isnt valid and the branch gets killed
its a headache but it works
for reference this is the code which is kinda spaghetti now that i look back at it i cant believe i understood it

maybe reformatting everything and using oop is a good idea
it solves it but levels like this take much longer than they should

Let's try making sure it finds the shortest solution first and then killing it
Because that finds both solutions within a ⅕ second but then spends another 26 searching the rest of the possibility space
generating the whole board takes longer than it should, i know its going to be faster once the solve is changed
my point is semaphores are slowing it down regardless
Sure, I guess thinking about what they do, they might just always slow things down, it might not be possible to prevent
But once things are refactored to be easier to change, we can try different strategies, see what works best
alright
i guess what im really getting at is that the fundamental problem with generation needs to be dealt with if this were to be made faster
Making large structural changes its always going to get slower before you have the chance to speed things up
The aim is to eventually end up somewhere better, rather than for each change to improve the result
Returning to this analogy, I'd still be sanding

nice varnish
It's a Danish Oil with some stain in it
I just need to leave it a few days to become fully hard before I give it a final polish with wet & dry paper, otherwise it can be a bit gooey and you end up with a messy streaky finish that's an absolute PITA to do anything about
my dad gets diamond willow sticks and then turns them into walking sticks occasionally but its cool when he does it
just some carving and sanding and varnishing
Nice
can change tiles now woop


instead of trying to convert between frozendict to dict and back to frozendict for changing tiles i just added a property thats just the unfrozen version of tiles so it can be modified
better pic

so when a board is created for the first time using the numpy data itd use tracks and mods, and then if a different method (like changetile) wants to change a tile it gives the class shape and tiles so it can be copied and frozen with the new stuff
shape is just used so the board can be printed as a numpy array because its the best way to view it in console imo
not sure if opengate and closedgate are even necessary given they just check if the tile is a gate and send it to changetile but i think its easier to understand
You don't need to convert and mutate, you can use frozendict.set to get a new frozendict with one key/value pair changed
well isnt that nice
You can also use | with a dict to get a frozendict which is the union of both dicts, so
change = self._tiles[key]
if track is not None:
change = change.change_track(track)
if mod is not None:
change = change.change_mod(mod)
return Board(
shape=self._shape,
tiles=self._tiles | {key: change}
)
change would be self._tiles[key] in change = ..., no?
Although also I'd be tempted instead of passing in a track and a mod, to pass in the tile and let the caller be the one to call the copy constructor
Isn't that what I typed?
As a side note: The | is a union operation here, borrowing syntax from set operations
Looking at the two paths through the init method, I would be tempted to add a class method for the numpy stuff which constructs the arguments for init, and therefore init can be simpler
i thought about that but then wouldnt the properties need to be declared outside of the method
Can you paste me the code so I can show you what I mean without retyping it (on my phone again)
class Board:
def __init__(self, tracks=None, mods=None, shape=None, tiles=None):
if tiles is None:
self.shape = np.shape(tracks)
self._tiles = frozendict({pos[::-1]: Tile(TrackName(track), ModName(mods[pos]))
for pos, track in np.ndenumerate(tracks)})
else:
self.shape = shape
self._tiles = tiles
class Board:
def __init__(self, shape=None, tiles=None):
self.shape = shape
self._tiles = tiles
@classmethod
def from_numpy(cls, tracks=None, mods=None):
shape = np.shape(tracks)
tiles = frozendict(
(pos[::-1], Tile(TrackName(track), ModName(mods[pos])))
for pos, track in np.ndenumerate(tracks))
return cls(shape, tiles)
cls?
You can call a dict or frozendict constructor with a generator expression to avoid constructing a whole dictionary. You could also add a filter to the constructor to ignore empty tiles
So a class method is a method on the class rather than an object of said class
So the first argument is the class, rather than an object of said class, and it's convention to use cls just like it's convention to use self for an object
And yeah, one of the main uses for a class method is for providing an alternative constructor
since the board and mods params used to be numpy arrays there are some instances where i did masks on them
is there any easy solution to that now that the params are an object or
What were you doing with the masks again?
used to get all the permanent tiles on a board
used to get positions of all swapping tracks
used to get positions of tunnels
So you could keep a collection with the keys for that data, it can be an optional argument for init, constructed if not set, and you can pass it through to copies, and update it in change_tile if necessary
completely unrelated but i started using leetcode today and its amazing


congrats
I use your tip but have some modify:
1.After place straight or turn tracks, I check if any surround tracks is connected to it but the track is not connected to that surround track. Then try to turn the track to T_turn so it connect to it.
2. If step 1 can't be done, I'm check the position of the next track that the current track head to then try to change that track to T_turn
Here is some benchmark I have run:

would you guys like me to implement some A* algorithm or continue to solve other levels?
BTW I think the main problem that make my code slow is I deepcopy everywhere. But i'm happy with the result for now and maybe fix this in the future.

It would be interesting to see what a difference it makes if instead of deepcopying mutable data, you simply used immutable data. I suspect there would be a saving but I have no idea how large
the speed is okay for now but when on next levels when it slow down I'm going to try something else
I quickfix the deepcopy by implementing the deepcopy method in all classes. I don't know why it happened like that, lol. The speed was improved by 40%.
i used to use copy methods for my program but i benchmarked it and saw how slow it was so i did np.array()and list() instead
Part of the problem with deepcopy is that it doesn't necessarily know what data needs to be copied rather than just referenced, whereas if you know your data is immutable you know you only need to copy-on-change
Most of the underlying data can be references to existing objects rather than newly allocated objects
Obviously implementing the special methods lets you tell it what needs to be copied, but you also don't necessarily know what will be mutated on the copy, so you still need to allocate more new objects than strictly necessary to prevent bugs
leetcode is so much fun i have to peel myself off of it to work on railbound again
ive started converting the generation function to using objects but it still might be a few days before i can make it work like it did before
after that should i work on making generation go in order of tracks?
Try codingame tooo
You code a bot and let it fight with others bot
I was addicted to it for some months before.
it looks super fun

Play the Spring Challenge now for free on CodinGame: https://www.codingame.com/contests/spring-challenge-2022
Join the CodinGame community today: https://codingame.com/start
Discover our solution to test developer skills during your recruitment process: https://www.codingame.com/work
This challenge makes me lose sleep.
for this class constructor how do you know which method is being called when you write the function
because they both have 2 parameters
do you just have to define them?
oh nvm i see youd do Board.from_numpy()
its an actual method not an alternative init 🤦♂️
nooo al please dont smite me with your wisdom
Oh I was serious, it shows how much new stuff you're starting to understand on your own, it's great to see

Eh, I wouldn't go that far, I just have a few decades of experience on you
i apologize for disregarding this idea thinh
its actually clearer and more concise plus classes are supposed to have many functions to make it more readable
you are quite smart.
though the problem still remains of long variable names... is there any better way to make this readable?

i feel itd be reasonable to use numbers there at least
but this is also a single line in the code which could definitely be shorter:
if (tracks_to_check[0] == rb.TrackName.ENDING_TRACK and car.type != rb.CarType.NORMAL) or (rb.TrackName.is_ncar_end(tracks_to_check[0]) and car.type != rb.CarType.NUMERAL):
everything concerning comparing track types used to be 1 character in length (a number) but now i have to type the whole name out and i feel it ends up just looking worse
You could always alias T = rb.TrackName in that file and then it's just T.{enum_key} which saves 10 characters each time, while keeping the names human-readable
should i import everything from rb (classes) so its shorter as well or would that look worse
I tend to prefer from {module} import {class or function} next it keeps things short
But you could even from rb import TrackName as T
hm
im considering just importing the 2 classes then because adding T. doesnt really make it any more readable
like the classes are interconnected with the program enough i dont think it should be specified what library (or in this case file) it comes from
hehe
Nice
Yeah i scroll to select xD
Oh I had a thought about the whole "how to get the solver into the browser" thing - have you looked at Anvil?
What is it ?
It's a framework for web development in python that includes frontend python
You'd still probably want to rewrite in native JavaScript, but it would allow you to do so piecemeal
I and @fervent tusk have discussed this before; we want to create a 'backend' that sends the processing status to the 'frontend'.
Yeah, it includes machinery for doing that
in machine learning and data science we have streamlit or gradio
I've not used Anvil personally, but I have friends who swear by it for contract work
However, these tools can be too complicated and not suitable for our situation
Can I have the link? I search google and just found the image of the anvil 😂

Anvil
Yes, really, nothing but Python! Anvil has a drag-and-drop editor, Python in the browser and on the server, and one-click deployment.
It looks really lovely right now xD. I sincerely hope we can make it to the point where we can choose between running Foxtrot's approach and my own by using the solve button and method select button.

i just gotta do the improvements alistair is suggesting (which are great) and then i can continue trying to make mine work with yours
it's easy, you could send me the state each step and i visual it
The more modular things get, the easier it should be to add interoperability
ehhhh not each step LOL
but yeah like every 10k or something
yeah something like that
ill make mod images soon
we will have a configuration for that
I mean if you put the io in a queue for an async thread to send, it might not need to be quite that sparse a sampling
good point
the program wouldnt need to be delayed then when sending states to be visualized
My temptation would be to send every state to the queue, but flush the queue every time you pop something off, so sample rate is limited by io
the visualization would be delayed though if too much data is sent at once
unless the image making process is faster than generation
the visualization is seperate from the python code so it handle it self
This way it would only ever be a frame behind the current state of what's being processed
otherwise i suppose you could discard states that are behind so the visualizer can keep up
That's exactly what I was suggesting
btw when run visualize on browser it may faster to render an image in python since it not actually make the image with pillow in python, it just place a png on the screen
TFW I've lived with the jargon too long to be able to tell what's jargon
thinh if possible, could you also make an output box so if the program fails the error can be recorded
because i am 100% sure there are very specific scenarios where my solver would fail
Sure
I feel like it would be cool to generate a graph of states, but I'm not sure how you'd represent it, or store it, to make it browsable. My first thought is to stick it in an object database but I worry that the file size for a single solution would be quite large, let alone a database of all the levels
Like, I know how I'd do it with a production-class database but I don't really want to run a terabyte-scale postgresql server on my local machine
Assume we store only the 2d array of the grid. I tried 252109 state and when pickle to a file, it's about ~40mb
That seems like a small number of states for any of the later levels
Would be interesting to see the filesize for shoving that same data in a sqlite db
when come to browser there many way to do it, we can even use pglite to run Postgres in browser
I hadn't come across pglite, interesting
Does it have to be run entirely in memory?
it's work 100% like postgres
really cool stuff
it's save the data in IndexedDB
something like cookies
Yeah, basically the replacement for localStorage
I have no idea how IndexedDB performs but I'm guessing it's broadly fine
how do you make method overloads
cause i want something like this

so i could do like car.getdir() or rb.Car.getdir(xvelo, yvelo)
or would it be better to just make 2 different functions or wrap it into one
what i did before was
def getdir(self, xvelo=None, yvelo=None):
if xvelo is None:
xvelo, yvelo = self.xvelo, self.yvelo
return ((4, 2, 3), (1, 4, 4), (0, 4, 4))[xvelo][yvelo]
but to get specific dirs for non-cars you have to use it on a car obj which is confusing, and if you make it a class method then the parameters will always have to be included because the xvelo and the yvelo cant be grabbed from the car
what ive looked up either uses imported method decorators or just says to use default params like what i did here
Python cant do that
The only solution is to make 2 function
_getdir1
_getdir2
Then you check if else in the function getdir
:v
lame but i guess 2 functions works
finally moved generation to using objects, it is INSANELY slower though
(obj generation vs no obj generation)


5s -> 101s is nuts
the new obj generation works up to world 4 right now


There's a way you can effectively do this:
def get_dir(self):
if isinstance(self, Car):
x, y = self.xvelo, self.yvelo
else:
x, y = self
...
When you call it as an unbound method on the class like Car.get_dir((xvelo, yvelo)) then the tuple is passed as self rather than an instance of car, so you get roughly the behaviour you were after
I'd probably add a docstring that says how it's supposed to be called though, because that's extremely non-obvious behaviour
one thing i could do to speed this up is to make it so changetile can change multiple at once
because for every iteration right now it makes a new board for every tile changed which is probably insanely slow
i think 2 functions would be the best bet and also i feel this is even stranger than the method i was using before
Yeah if you're calling it a lot of times from one place then a bulk change method makes sense. That said, I would still probably leave making optimisations until you've got the main changes you're trying to make sorted, i.e getting it so you only find the shortest solution and making sure nothing's done twice. Then it's likely that running with the profiler you'll find a whole load of things to optimise, and often what's important isn't what you'd expect
the change is simple and significant enough id think its worth it
im gonna try to debug stuff so the obj gen can work up to world 6 and then work on the bucket sort thing
Sure - I guess a fairly consistent 20x performance degradation doesn't feel as urgent as trying to reduce the computational complexity of the algorithm
is that sarcasm or your opinion
a faster output will be more convenient when trying to debug
If simple stuff takes longer, but more complex stuff doesn't take as much longer, it means you can solve stuff you simply couldn't before
i know the bucket sort will be a substantial improvement but the change is good enough to be done first imo
If you look at how much of the time is spent after finding a solution, that seems to more than offset the degradation, but until the BFS has been implemented, it's hard to tell how real that is
Because BFS may take longer to find its first solution
To me it makes sense to prioritise finding that out
the extra time likely comes from this

the program changes all the tiles on the best to permanent in case they were changed during generate so the appearance is more accurate
if you can see that much of an offset by just this think of the impact itll have if i change it for every iteration
But surely that's only happening on a subset of found solutions?
ohhhh you mean after it finds the minimum
oops completely different
nevermind forget all of that
its a simple change dw about it
Yeah I was referring to it spending 90+% of the time searching the possibility space after finding the best solution
I'm probably also being overly opinionated, just trying to nudge you towards the work most likely to produce results, because otherwise it's easy to become demotivated by the inevitable performance degradations from all the work required to change the algorithm
ive worked on this project for 7 months and i still am optimizations will not stop me
That's fair
Was just sharing where I was coming from, as I got the impression it might be coming across differently
main issue with making this change queue is i need to decide whether to make an entirely new frozendict or change every key
only up to like 6 might be changed at once (6 cars)
I'd be tempted to make a dict of changes and union it with the existing frozendict to get the new version
Uh, use the | operator to merge them
did not know you could do that i know of the | operator though
wouldnt that just merge it and not actually overlay changes?
or does the union override already placed keys (which would be an overlay and would work)
Like new_fdict = old_fdict | change_dict
The latter
If you're not sure it's always easy to try it out in an interpreter
But yeah, it's an incredibly convenient operator for frozendict, it's basically like dict.update
i love it
did a timeit test and i think one is better than the other
>>> print(timeit(lambda: self._tiles.set((1, 2), Tile(TrackName(2), ModName(0))), number=10000))
2.411757600028068
>>> print(timeit(lambda: self._tiles | frozendict({(1, 2): Tile(TrackName(2), ModName(0))}), number=10000))
0.06885069992858917
not sure if im doing it incorrectly but set seems kinda useless
LMAO

speed change? what speed change?

went from 101s back down to 9 just by making it copy less and use unions
speed decrease is only about x2 now which is definitely manageable
so excited to work on bucket sort soon and see the massive improvement that gives
yeah i used it when i was still making the gen function to do improvements
im not gonna use it yet because like al said if i get caught up in improvements we wont get to see the real progress
def __deepcopy__(self, memo):
return Train(
copy.deepcopy(self.position, memo),
self.direction,
self.order,
copy.deepcopy(self.previous_position, memo),
)
This is my copy function
I got addicted to Black Myth Wukong, so the progress of my code may slow down. 🙈🙉🙊
is the tail call optimization still needed if were going to use a queue
I was thinking the queue logic is in the tco decorator
So it's still tco but it's being a bit smarter about it
But also it wouldn't be the end of the world to change it more
The yield/decorator was just the least effort way to implement tco
im not fully sure how it works honestly
I think I explained back when we implemented it
how i think itll go is making a state object with parameters, appending to dict, and once something loops through all of the states in a dict entry (or the starting board) it goes through the queue
ill look back then but i mean moreso every line
You might find stepping through with a debugger and breakpoints helps make things obvious
I'm a strong advocate for stepping through code as a way of understanding what happens when it's run - it helps you build an accurate mental model so that you can figure things out yourself and don't end up stuck when there's bad documentation and nobody to help out
i think i understand it partially now
im not sure why it uses .pop() here though, so i dont know how to fix this error

im tyring to yield a state obj now instead of the params