
#🎥┃video-shoutout
1 messages · Page 2 of 1

Last Epoch Crit Runemaster Frost Claw Starter Build for beginners echo farmer and immortal tank
Last Epoch 1.0 Starter ready build as a Runemaster crit based Frost Claw
This build stacks around 10k ward, hence it is pretty immortal and tanky
This video is a quick showcase of the builds gameplay
Last Epoch Tools : https://www.lastepochtools.com/...

Join the Discord! https://discord.gg/ebRaKANeJB
Disco Mage (Newbie friendly version of this build): https://www.youtube.com/watch?v=T0gouCApzJg&t=424s
In this video, I present to you one of the BEST BUILD in Last Epoch. It's a Runemaster who uses Runebolt and Frost Wall to cast Plasma Orb to devastating effect B)
Build planner: It's at the e...

Last Epoch 1 Button Projectile Abomination Necromancer Build Guide Showcase No Uniques Required
Last Epoch Planner :
https://www.lastepochtools.com/planner/EAL32kjo
How To Level This Build :
Play this build first, https://youtu.be/bFz3zKwnsIQ till you can afford to
swap into Abomination when you unlock it! Don't be afraid to wait a little,...

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?si=Edg5tvAUn9tsSvjJ
-Necromancer Ultimate Fire: https://youtu.be/YngSp2WDbpA
-Necromancer Necro TANK: https://...

Bone Shattering Golem Retaliation!
🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝
𝐓𝐢𝐦𝐞 𝐒𝐭𝐚𝐦𝐩𝐬:
0:00 Intro / Shout out to new members / About the Build
2:27 Skills
2:48 Transplant
3:59 Bone Curse
4:34 Dread Shade
5:45 Rip Blood
7:30 Summon Bone Golem
9:17 Passives
10:40 Character Sheet
11:38 Gear / Idols / Blessings
14:05 How to play this build
16:01 Gameplay
🐝🐝🐝🐝🐝🐝🐝🐝...

Leaguestarter Guide for Necromancer Flame Wraith !! Everything that you need for a smooth leaguestart experience! Hope you enjoy it :)
Planners
Level 45 : https://www.lastepochtools.com/planner/YQWreq9A
Level 80 : https://www.lastepochtools.com/planner/0AKzvXLo
Endgame : https://www.lastepochtools.com/planner/YQWrL74A
Loot Filter : https://www...

New to Last Epoch and unsure where to start? Fear not, my friend! This video is your ultimate guide to getting started and making your OWN BUILD. I'll walk you through the process of choosing a mastery, understanding your build, and unleashing your true potential. Whether you're a seasoned ARPG gamer or a beginner, this video has something for y...

---DMGCREW---
Click show more below
If you like everything in one place - https://allmylinks.com/idodmg1227
Otherwise its all laid out for you below, thanks for reading this 💗👇
PC Specs
- GPU - ...

If you are looking for a robust, season start friendly loot filter that can support all of your builds, then this should be perfect for you:
https://drive.google.com/file/d/1vErWxjK7XG3gQnTk047uy3364dwiY2EX/view?usp=sharing
It's great for newer players but also valuable for veterans as well. It can serve as a template for you to augment into you...

Stack up over 1000 bleeds with an army of Squirrels and Bees!
🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝
𝐓𝐢𝐦𝐞 𝐒𝐭𝐚𝐦𝐩𝐬:
0:00 Intro / Shout out to new members / About the Build
2:21 Skills
2:31 Eterras Blessing
3:19 Summon Frenzy Totem
3:49 Warcry
5:25 Fury Leap
6:15 Summon Wolf
7:18 Passives
8:47 Character Sheet
9:53 Gear / Idols / Blessings
12:30 How to play this bu...

My Favorite LeagueStarter for everyone out there!! Very new player friendly and easy to setup !! Hope you enjoy it :)
Planners
Early Progression : https://www.lastepochtools.com/planner/mQkEybao
Endgame : https://www.lastepochtools.com/planner/MA1mnPVA
LootFilter : https://www.lastepochtools.com/loot-filters/view/MA1G6VBw
Campaign Run : https:...

Join the Discord! https://discord.gg/ebRaKANeJB
The King build guide: https://www.youtube.com/watch?v=6GGrns903aM
In this video, I present to you a showcase of the STRONGEST MAN in Last Epoch. It's a Runemaster who uses Runebolt and Frost Wall to cast Plasma Orb to devastating effect.
Hope you enjoy the music video B)
hi smk :3
Track: Netr...

Last Epoch Swipe Primalist Skill New Player Guide
In this video I go over Swipe, its functionality and its skill tree. This is meant for someone who wants to learn how a skill functions without having to watch a bunch of build guides.
Now I promised there would be some recommended builds using Swipe :
How Lightning Crit Swipe is used :
htt...

E ai, como você tá?
Nesse vídeo trago para vocês os melhores e também piores Farms para o lançamento do jogo!
Se liga que vai ter drop na twitch também!
Compre o Last Epoch na Steam: https://store.steampowered.com/app/89...
Discord: https://discord.gg/2skBNbAcad
Live: https://twitch.tv/ddartx
#circleoffortune #merchantsguild #arpg #last...

unlimited rage, massives heals, and incredible damage reduction. This is one tanky spriggan!
Be sure to check out tons of the top guides made for Last Epoch here at Maxroll:
https://maxroll.gg/last-epoch/
🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝
𝐓𝐢𝐦𝐞 𝐒𝐭𝐚𝐦𝐩𝐬:
0:00 Intro / Shout out to new members / About the Build
3:52 Skills
4:01 Spriggan Form
6:02 Earthquake
7:...
https://www.youtube.com/watch?v=N6v5T7DoGRE if anybody needs any boosting for xp loot or any help just ask I got you 😎

Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #MAGE #RATLEYINKLLC #diablo4 #walkthrough #guide

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?si=Edg5tvAUn9tsSvjJ
-Necromancer Ultimate Fire: https://youtu.be/YngSp2WDbpA
-Necromancer Necro TANK: https://...

Zizaran reviews Last Epoch, a new ARPG set to fully release on February 21.
Last Epoch features a multitude of deep systems, while remaining an easy to approach Action RPG.
Buy Last Epoch through Ziz at https://www.nexus.gg/ziz
Join this channel to get access to perks:
https://www.youtube.com/channel/UCAG3CiKOUkQysyKCXSFEBPA/join
Check out St...

Warlock Mastery Finally Revealed For Last Epoch Part 1/2
Hopefully we can all learn from this and I can also get all the info put into one video at the end of the week, eh?
All of the income from this video is doing towards the Animal Rescue Corps. If you want to know more about their valiant efforts, read here :
https://animalrescuecorps.o...
new skills look interesting and visually good!
https://www.youtube.com/watch?v=XJIAl5TXcHw

MAXROLL: https://maxroll.gg/last-epoch/team?team=last-epoch
Warlock Footage From - https://www.youtube.com/watch?v=joJCOsF7wU0
𝐒𝐮𝐩𝐩𝐨𝐫𝐭 𝐌𝐞 𝐎𝐧 𝐏𝐚𝐭𝐫𝐞𝐨𝐧 𝐇𝐞𝐫𝐞:
https://www.patreon.com/boardman21
𝐉𝐨𝐢𝐧 𝐌𝐲 𝐃𝐢𝐬𝐜𝐨𝐫𝐝 𝐇𝐞𝐫𝐞:
https://discord.gg/Eb42DpR9nZ
𝐁𝐮𝐲 𝐋𝐄 𝐨𝐧 𝐍𝐞𝐱𝐮𝐬 𝐇𝐞𝐫𝐞:
https://www.nexus.gg/boardman21
𝐁𝐞𝐜𝐨𝐦𝐞 𝐚 𝐘𝐨𝐮𝐭𝐮𝐛𝐞 𝐌𝐞𝐦𝐛𝐞𝐫 𝐇𝐞𝐫𝐞:
https://www.you...
Enjoy 🙂 https://youtu.be/QcGky4Jy0b0

---DMGCREW---
Click show more below
Thank you to @action for sharing the information! https://youtu.be/joJCOsF7wU0?si=r3l0Zt1V-_dLEKVa
@last@LastEpochGame
If you like everything in one place - https://allmylinks.com/idodmg1227
Otherwise its all laid out for you below, thanks for reading this 💗👇
-----------------------------------------------...

The Build:
https://www.lastepochtools.com/planner/WQJJ0rYQ
My Twitch:
https://www.twitch.tv/ter3k
LE speedrun discord:
https://discord.gg/7mRwqM5hgY
0:00 Chapter 1
14:08 Chapter 2
30:55 Chapter 3
52:15 Chapter 4
1:07:13 Chapter 5
1:19:26 Chapter 6
1:33:25 Chapter 7
1:47:37 Chapter 8
2:12:39 Chapter 9

Warlock Week Video Links:
Skills / Curses: https://youtu.be/joJCOsF7wU0?si=GovZsgA1NheJ2t8x
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?si=Edg5tvAUn9tsSvj...
For reading purposes all nodes timestamped
https://www.youtube.com/watch?v=sWZTu1N9Eto

MAXROLL: https://maxroll.gg/last-epoch/team?team=last-epoch
Timestamps:
0:00 Intro
0:07 Choas Flames
0:12 Soul Stealer
0:17 Occultist's Mind
0:22 Unholy Torment
0:27 Spirit Leech
0:32 Spiteful Decay
0:37 Cauldron of Blood
0:42 Crimson Favors
0:47 Harrowing Armor
0:52 Dark Protections
0:57 Ward of Malevolence
1:02 Imperishable
1:07 Doom Herald
1...
https://www.youtube.com/watch?v=x1sL9dKQJww if anyone needs a carry or loot I got you 😎

Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #runemaster #RATLEYINKLLC #diablo4 #walkthrough #guide

How To Build Rive | Last Epoch New Player Guide
In this video I go over Rive, its functionality and its skill tree node by node in extreme detail. This is meant for someone who wants to learn how a skill functions without having to watch a bunch of build guides.
Physical Crit Ignite Consumption Rive usage :
https://youtu.be/ivnGA5D2ZRg
Utili...

Warlock Week Video Links:
Skills / Curses: https://youtu.be/joJCOsF7wU0?si=GovZsgA1NheJ2t8x
Passive Tree: https://youtu.be/NjQbtue4z-Q?si=yhcZyeI4JR_8Ybe7
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necroman...
Lets theorycraft that tree!
https://www.youtube.com/watch?v=nKya8zMTURA

MAXROLL: https://maxroll.gg/last-epoch/team?team=last-epoch
Footage Link: https://www.youtube.com/watch?v=sGI63zOWJYs
𝐒𝐮𝐩𝐩𝐨𝐫𝐭 𝐌𝐞 𝐎𝐧 𝐏𝐚𝐭𝐫𝐞𝐨𝐧 𝐇𝐞𝐫𝐞:
https://www.patreon.com/boardman21
𝐉𝐨𝐢𝐧 𝐌𝐲 𝐃𝐢𝐬𝐜𝐨𝐫𝐝 𝐇𝐞𝐫𝐞:
https://discord.gg/Eb42DpR9nZ
𝐁𝐮𝐲 𝐋𝐄 𝐨𝐧 𝐍𝐞𝐱𝐮𝐬 𝐇𝐞𝐫𝐞:
https://www.nexus.gg/boardman21
𝐁𝐞𝐜𝐨𝐦𝐞 𝐚 𝐘𝐨𝐮𝐭𝐮𝐛𝐞 𝐌𝐞𝐦𝐛𝐞𝐫 𝐇𝐞𝐫𝐞:
https://www.youtube.com/...

Warlock Week Video Links:
Skills / Curses: https://youtu.be/joJCOsF7wU0?si=GovZsgA1NheJ2t8x
Passive Tree: https://youtu.be/NjQbtue4z-Q?si=yhcZyeI4JR_8Ybe7
Skill Ghostflame: https://youtu.be/sGI63zOWJYs?si=bOwjvAWlukD45WlP
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-L...

Last Epoch Ghostmaker Infernal Shade Necromancer 2.0 Build Guide Showcase
In this video, we talk about Ghostmaker Infernal Shade Necromancer, a fun build that I always keep tabs on whenever I play Last Epoch, as its become a pet build of mine!
Planner :
https://www.lastepochtools.com/planner/LB7zxlGQ
Email : dr3adfulr3aper@gmail.com
Twitch :...

Warlock Week Video Links:
Skills / Curses: https://youtu.be/joJCOsF7wU0?si=GovZsgA1NheJ2t8x
Passive Tree: https://youtu.be/NjQbtue4z-Q?si=yhcZyeI4JR_8Ybe7
Skill Ghostflame: https://youtu.be/sGI63zOWJYs?si=bOwjvAWlukD45WlP
Skill Soul Feast: https://youtu.be/n6dyttCWZUs?si=5lwSedEKWCARU69d
Official Action RPG Patreon Link: https://www.patreon.com/...

Warlock Week Video Links:
Skills / Curses: https://youtu.be/joJCOsF7wU0?si=GovZsgA1NheJ2t8x
Passive Tree: https://youtu.be/NjQbtue4z-Q?si=yhcZyeI4JR_8Ybe7
Skill Ghostflame: https://youtu.be/sGI63zOWJYs?si=bOwjvAWlukD45WlP
Skill Soul Feast: https://youtu.be/n6dyttCWZUs?si=5lwSedEKWCARU69d
Skill Profane Veil: https://youtu.be/y4dcvhmnMKs?si=RX8IK4...
Salut à tous, voici une vidéo sur le loot filter pour apprendre à le faire solo. https://youtu.be/iM1AYkeAzx0?si=KKniZbT0gvlbR-iD
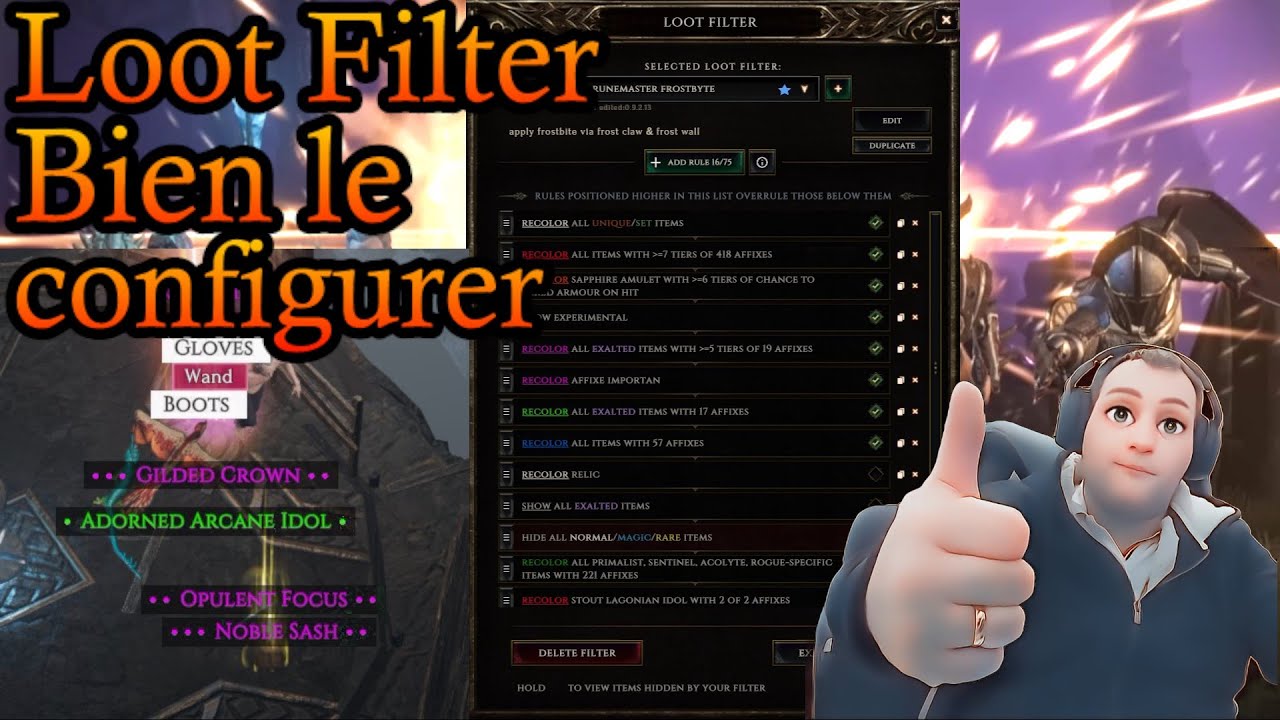
Salut à tous voici une vidéo sur le Loot Filter. Bon visionnage à vous.
Si vous avez des questions n’hésiter à les mettre dans les commentaire ou même à passer sur twitch
TWITCH https://www.twitch.tv/saony06
DISCORD https://discord.gg/6GezYFRjAC
Youtube : https://youtube.com/@saony0626
Pour me soutenir Regarde par ici https://www.nexus.gg/sao...

MAXROLL: https://maxroll.gg/last-epoch/team?team=last-epoch
Footage Link: https://www.youtube.com/watch?v=HOX0rPWOX1Q
𝐒𝐮𝐩𝐩𝐨𝐫𝐭 𝐌𝐞 𝐎𝐧 𝐏𝐚𝐭𝐫𝐞𝐨𝐧 𝐇𝐞𝐫𝐞:
https://www.patreon.com/boardman21
𝐉𝐨𝐢𝐧 𝐌𝐲 𝐃𝐢𝐬𝐜𝐨𝐫𝐝 𝐇𝐞𝐫𝐞:
https://discord.gg/Eb42DpR9nZ
𝐁𝐮𝐲 𝐋𝐄 𝐨𝐧 𝐍𝐞𝐱𝐮𝐬 𝐇𝐞𝐫𝐞:
https://www.nexus.gg/boardman21
𝐁𝐞𝐜𝐨𝐦𝐞 𝐚 𝐘𝐨𝐮𝐭𝐮𝐛𝐞 𝐌𝐞𝐦𝐛𝐞𝐫 𝐇𝐞𝐫𝐞:
https://www.youtube.com/...
Fire minions are always fun!
https://www.youtube.com/watch?v=P7afSkdisio

LizardIRL Maxroll Guide : https://maxroll.gg/last-epoch/build-guides/wraith-necromancer-guide
Be sure to check out tons of the top guides made for Last Epoch here at Maxroll:
https://maxroll.gg/last-epoch/
🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝
𝐓𝐢𝐦𝐞 𝐒𝐭𝐚𝐦𝐩𝐬:
0:00 Intro / Shout out to new members / About the Build
1:30 Skills
1:46 Dread Shade
3:15 Drain Life
5:0...

Warlock Week Video Links:
Skills / Curses: https://youtu.be/joJCOsF7wU0?si=GovZsgA1NheJ2t8x
Passive Tree: https://youtu.be/NjQbtue4z-Q?si=yhcZyeI4JR_8Ybe7
Skill Ghostflame: https://youtu.be/sGI63zOWJYs?si=bOwjvAWlukD45WlP
Skill Soul Feast: https://youtu.be/n6dyttCWZUs?si=5lwSedEKWCARU69d
Skill Profane Veil: https://youtu.be/y4dcvhmnMKs?si=RX8IK4...

Hey Guys and welcome to a new Video!
Livestream:
https://www.twitch.tv/mbXtreme
It was a TON of work and I would greatly appreciate if you would LIKE the Video, tell me what you think about the Video and the Content itself in a Comment and Subscribe to my YouTube Channel to become a Part of the great Community!
YouTube: https://www.youtube.co...

MAXROLL: https://maxroll.gg/last-epoch/team?team=last-epoch
Top 5 Arena Pushers:
1 - LizardIRL - Swipe Werebear Druid:
https://maxroll.gg/last-epoch/build-guides/swipe-werebear-druid-guide
2 - Bina - Runemaster Frost Claw:
https://maxroll.gg/last-epoch/build-guides/frostbite-frost-claw-runemaster-guide
3 - Volca Hammerdin Nova:
https://maxro...

Join Binashole on Twitch! | https://www.twitch.tv/binashole
Find All My Written Guides on https://maxroll.gg/last-epoch
Discord | https://discord.gg/zSm65G5
Build Planner - https://maxroll.gg/last-epoch/planner/mj1qy011
Current Gear Planner - https://maxroll.gg/l...

One of my favourite endgame builds, strong, reliable and fun! My first official guide, with many more to follow! Hope you enjoy it as much as I do.
TIMESTAMPS
00:00 Intro
00:32 Gear
03:33 Skills
08:57 Passives
14:20 Echo Run 1
16:40 Totally Scripted Death
17:08 Echo Run 2
19:21 Conclusion
Links to guide/twitch coming after verification
Music ...

Last Epoch Top 3 Builds I Recommend From LE Tools 0.9.2
In this video I showcase some very brilliant members of the community and the builds they come up with, as I simply cannot cover every single build under the sun, so I want to give them some coverage and show what the community has been up too!
Cookbooks Guide :
https://www.lastepochtoo...

Join Binashole on Twitch! | https://www.twitch.tv/binashole
Find All My Written Guides on https://maxroll.gg/last-epoch
Discord | https://discord.gg/zSm65G5
Build Planner - https://maxroll.gg/last-epoch/planner/llee0yhe
0:00 - Intro
1:50 - Skills
6:23 - Gear
11:4...

MAXROLL: https://maxroll.gg/last-epoch/team?team=last-epoch
Top 5 Speed Farmers:
1 - McFluffin - Shadow Daggers Bladedancer:
https://maxroll.gg/last-epoch/build-guides/shadow-daggers-bladedancer-guide
2 - LizardIRL - Hydrahedron Runemaster:
https://maxroll.gg/last-epoch/build-guides/hydrahedron-runemaster-guide
3 - McFluffin - Echo Warpath Voi...

Warlock Week Video Links:
Skills / Curses: https://youtu.be/joJCOsF7wU0?si=GovZsgA1NheJ2t8x
Passive Tree: https://youtu.be/NjQbtue4z-Q?si=yhcZyeI4JR_8Ybe7
Skill Ghostflame: https://youtu.be/sGI63zOWJYs?si=bOwjvAWlukD45WlP
Skill Soul Feast: https://youtu.be/n6dyttCWZUs?si=5lwSedEKWCARU69d
Skill Profane Veil: https://youtu.be/y4dcvhmnMKs?si=RX8IK4...
Maxroll Link:
https://maxroll.gg/last-epoch/news/warlock-wrap-up-falconer-teaser
𝐒𝐮𝐩𝐩𝐨𝐫𝐭 𝐌𝐞 𝐎𝐧 𝐏𝐚𝐭𝐫𝐞𝐨𝐧 𝐇𝐞𝐫𝐞:
https://www.patreon.com/boardman21
𝐉𝐨𝐢𝐧 𝐌𝐲 𝐃𝐢𝐬𝐜𝐨𝐫𝐝 𝐇𝐞𝐫𝐞:
https://discord.gg/Eb42DpR9nZ
𝐁𝐮𝐲 𝐋𝐄 𝐨𝐧 𝐍𝐞𝐱𝐮𝐬 𝐇𝐞𝐫𝐞:
https://www.nexus.gg/boardman21
𝐁𝐞𝐜𝐨𝐦𝐞 𝐚 𝐘𝐨𝐮𝐭𝐮𝐛𝐞 𝐌𝐞𝐦𝐛𝐞𝐫 𝐇𝐞𝐫𝐞:
https://www.youtube.com/channel/UCcKCZPldPq-8YRTLxUF0t4A/join
...

Due to popular demand, I have started working on a Build Making Guide for Last Epoch! This is part 1 - Damage Optimization. It fits perfectly into my LE 1.0 Prep so I hope you check it out and utilize ideas from this video when Last Epoch launches on February 21st. I guarantee that it will be valuable for beginners and even veterans might find s...
https://www.youtube.com/watch?v=WulbDYWUi2k if anybody needs boosting or gear I help people everyday on stream 😎

Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #runemaster #RATLEYINKLLC #diablo4 #walkthrough #guide
A Loot Filter guide for Italians who have struggle with english content
(Una guida sul filtro dei loot per italiani che non conoscono bene l'inglese)

canale twitch: https://www.twitch.tv/zarketti
server Discord: https://discord.com/invite/hN2wZfzSaB
Nexus: https://www.nexus.gg/matilde
00:00 - basi del filtro
09:22 - creazione filtro avanzato
Bello (good)
Legendary Potential guide for Italians who have struggle with english content
(Una guida sul potenziale leggendario per italiani che non conoscono bene l'inglese)

canale twitch: https://www.twitch.tv/zarketti
server Discord: https://discord.com/invite/hN2wZfzSaB
Nexus: https://www.nexus.gg/matilde
^^

---DMGCREW---
Click show more below
Pre-order the game here - https://lastepoch.com/press-kit
If you like everything in one place - https://allmylinks.com/idodmg1227
Otherwise its all laid out for you below, thanks for reading this 💗👇
--------------------------------------------------------------------------------------------------------------...

Warlock Wrap-up & Falconer Teaser:
https://maxroll.gg/last-epoch/news/warlock-wrap-up-falconer-teaser
Find me on Twitch ► https://www.twitch.tv/volca_
Discord ► https://discord.gg/ahBHyVqAuc
Maxroll ► https://maxroll.gg/last-epoch
Nexus store ► https://www.nexus.gg/volca
00:00 Intro
02:00 Passives
10:00 Chthonic Fissure (Torment)
16:18 Chaos B...

Warlock Week Video Links:
Skills / Curses: https://youtu.be/joJCOsF7wU0?si=GovZsgA1NheJ2t8x
Passive Tree: https://youtu.be/NjQbtue4z-Q?si=yhcZyeI4JR_8Ybe7
Skill Ghostflame: https://youtu.be/sGI63zOWJYs?si=bOwjvAWlukD45WlP
Skill Soul Feast: https://youtu.be/n6dyttCWZUs?si=5lwSedEKWCARU69d
Skill Profane Veil: https://youtu.be/y4dcvhmnMKs?si=RX8IK4...
I agree with this post 1000% percent. https://www.youtube.com/watch?v=P5BGMSjDV2w

This POE player is super excited for Last Epoch's release. Here are my thoughts as we near LE's official 1.0 launch in under a month. Succinctly, people should play Last Epoch without build guides on release. I'm confident you'll have a wildly fun time playing the game that way. Enjoy, fellow travelers and exiles.
Support: https://www.patreon.c...

Maxroll Link:
https://maxroll.gg/last-epoch/news/warlock-wrap-up-falconer-teaser
Follow VisionGL here:
https://www.twitch.tv/VisionGL
𝐒𝐮𝐩𝐩𝐨𝐫𝐭 𝐌𝐞 𝐎𝐧 𝐏𝐚𝐭𝐫𝐞𝐨𝐧 𝐇𝐞𝐫𝐞:
https://www.patreon.com/boardman21
𝐉𝐨𝐢𝐧 𝐌𝐲 𝐃𝐢𝐬𝐜𝐨𝐫𝐝 𝐇𝐞𝐫𝐞:
https://discord.gg/Eb42DpR9nZ
𝐁𝐮𝐲 𝐋𝐄 𝐨𝐧 𝐍𝐞𝐱𝐮𝐬 𝐇𝐞𝐫𝐞:
https://www.nexus.gg/boardman21
𝐁𝐞𝐜𝐨𝐦𝐞 𝐚 𝐘𝐨𝐮𝐭𝐮𝐛𝐞 𝐌𝐞𝐦𝐛𝐞𝐫 𝐇𝐞𝐫𝐞:
https://...
If you havent played hydra yet, I recommend it! Super fun!
https://www.youtube.com/watch?v=DTdkjYyDwWE

𝐓𝐢𝐦𝐞 𝐒𝐭𝐚𝐦𝐩𝐬:
0:00 Intro / About the leveling guide
1:56 Level 6
5:59 Level 8
9:18 Level 15
12:09 Level 21
15:44 Level 29
20:06 Level 35
24:22 Level 43
29:11 Level 50
34:38 Level 60
40:07 Level 76
🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝
𝐀𝐥𝐥 𝐓𝐢𝐦𝐞 𝐋𝐞𝐚𝐝𝐞𝐫𝐬: 𝐁𝐢𝐠𝐠𝐞𝐬𝐭 𝐏𝐚𝐭𝐫𝐞𝐨𝐧!
💜💘💗👉👉👉👉 VEYO 👈👈👈👈💘💗💜
𝐏𝐚𝐭𝐫𝐞𝐨𝐧 𝐒𝐮𝐩𝐩𝐨𝐫𝐭𝐞𝐫𝐬! 𝐓𝐡𝐚𝐧𝐤 𝐘𝐨𝐮!
💜💘💗 JUSTIN ----------- 💘💗💜
💜💘💗 DAN ...
My top 5 list for starting fresh, new cycle, or a new player!
https://www.youtube.com/watch?v=O3lGon5QAQ8

MAXROLL: https://maxroll.gg/last-epoch/team?team=last-epoch
Top 5 Cycle Starters
1 - Terek - Autobomber -
https://maxroll.gg/last-epoch/build-guides/void-knight-leveling-guide
2 - Terek - Hydrahedron Runemaster -
https://maxroll.gg/last-epoch/build-guides/runemaster-leveling-guide
3 - Terek - Shadow Daggers Bladedancer -
https://maxroll.gg/la...

My favorite Last Epoch build tailored for leaguestarter! Hope you enjoy the guide and the build.
Planners :
Level 100 Planner : https://www.lastepochtools.com/planner/DQ9v6RnB
Level 80 Planner (midgame): https://www.lastepochtools.com/planner/5BxlgJOB
Level 45 Planner : https://www.lastepochtools.com/planner/MA1kZ0ZB
Loot Filter : https://www...

Join Binashole on Twitch! | https://www.twitch.tv/binaqc
Find All My Written Guides on https://maxroll.gg/last-epoch
Discord | https://discord.gg/zSm65G5
Support Binashole by purchasing Last Epoch on his Nexus Store!
https://www.nexus.gg/Binashole
---------------...

Really excited for this fix. At times the loading works great. But others, it can be really rough.
#lastepoch #lastepochbuilds #news
👍 Like and Subscribe for more content!

Zizaran Original Interview: https://www.twitch.tv/videos/2047350018
Warlock Week Video Links:
Skills / Curses: https://youtu.be/joJCOsF7wU0?si=GovZsgA1NheJ2t8x
Passive Tree: https://youtu.be/NjQbtue4z-Q?si=yhcZyeI4JR_8Ybe7
Skill Ghostflame: https://youtu.be/sGI63zOWJYs?si=bOwjvAWlukD45WlP
Skill Soul Feast: https://youtu.be/n6dyttCWZUs?si=5lwSed...

Last Epoch Warlock Finished Reveal Ft. Zizaran
Zizaran's Channel :
https://www.youtube.com/@UCAG3CiKOUkQysyKCXSFEBPA
Timestamps :
00:00 - Intro
02:42 - Cthonic Fissure
11:07 - Chaos Bolts
20:17 - Profane Veil
26:56 - Soul Feast
31:02 - Ghostflame
34:09 - Warlock Passive Tree
Imgur Links :
Warlock Passives : https://imgur.com/a/9B2QgoJ
Gh...

E ai, como você tá?
Nesse vídeo trago para vocês a revelação completa da nova especialização WARLOCK
O que vocês acharam?
O conteúdo desse vídeo foi revelado com exclusividade por: https://www.icy-veins.com/ e https://www.youtube.com/@UCHsSnExLE-YAhIz0-i3aWDw
Compre o Last Epoch na Steam (Há versões com skins exclusivas):
https://lastepoc...

MAXROLL: https://maxroll.gg/last-epoch/team?team=last-epoch
All Masteries Ranked Worst to Best
0:06 Number 13 - Forge Guard
1:17 Number 12 - Shaman
1:56 Number 11 - Spellblade
2:37 Number 10 - Lich
3:22 Number 9 - Druid
4:10 Number 8 - Sorcerer
5:07 Number 7 - Necromancer
6:05 Number 6 - Paladin
7:13 Number 5 - Void Knight
8:12 Number 4 - Beastm...
My thoughts on the full reveal of warlock and my favorite nodes in the skills/passives
https://www.youtube.com/watch?v=yaX9mCYmOtA

Maxroll Link:
https://maxroll.gg/last-epoch/news/warlock-wrap-up-falconer-teaser
Timestamps:
0:00 Intro
1:57 Overloads
9:20 Curses
12:17 Skills/Favorite Interaction
15:40 Warlock Leveling
18:50 Warlock Endgame
𝐒𝐮𝐩𝐩𝐨𝐫𝐭 𝐌𝐞 𝐎𝐧 𝐏𝐚𝐭𝐫𝐞𝐨𝐧 𝐇𝐞𝐫𝐞:
https://www.patreon.com/boardman21
𝐉𝐨𝐢𝐧 𝐌𝐲 𝐃𝐢𝐬𝐜𝐨𝐫𝐝 𝐇𝐞𝐫𝐞:
https://discord.gg/Eb42DpR9nZ
𝐁𝐮𝐲 𝐋𝐄 𝐨𝐧 𝐍𝐞𝐱𝐮𝐬 𝐇...
ask and you shall receive
https://www.youtube.com/watch?v=RQ30jehMJhM

Join Us On Maxroll:
https://maxroll.gg/last-epoch/build-guides
𝐒𝐮𝐩𝐩𝐨𝐫𝐭 𝐌𝐞 𝐎𝐧 𝐏𝐚𝐭𝐫𝐞𝐨𝐧 𝐇𝐞𝐫𝐞:
https://www.patreon.com/boardman21
𝐉𝐨𝐢𝐧 𝐌𝐲 𝐃𝐢𝐬𝐜𝐨𝐫𝐝 𝐇𝐞𝐫𝐞:
https://discord.gg/Eb42DpR9nZ
𝐁𝐮𝐲 𝐋𝐄 𝐨𝐧 𝐍𝐞𝐱𝐮𝐬 𝐇𝐞𝐫𝐞:
https://www.nexus.gg/boardman21
𝐁𝐞𝐜𝐨𝐦𝐞 𝐚 𝐘𝐨𝐮𝐭𝐮𝐛𝐞 𝐌𝐞𝐦𝐛𝐞𝐫 𝐇𝐞𝐫𝐞:
https://www.youtube.com/channel/UCcKCZPldPq-8YRTLxUF0t4A/join
𝐖𝐚𝐭𝐜𝐡 𝐌𝐞 𝐋𝐢𝐯𝐞 𝐎𝐧 ...

Last Epoch Warlock Mastery Reveal! Reacting To New Skills, Passive Tree, and Curses!
If you enjoyed the content and would like to preorder the game go here: https://lastepoch.com/pre-order
If you enjoyed my content please subscribe and make sure to catch me on Twitch @ KahnerTV
warlo-0290d2b

Everything you need to know about Legendary items and Legendary Potential !! Hope you find the video usefull :)

Last Epoch | Warlock Character Reveal & Gameplay
Discover the secrets of the Warlock, the final mastery of the Acolyte base class, and find out how to use its five curses to create devastating effects on enemies.
Let's kick off Warlock Week!
Today is the first day of our week-long video series on Icy Veins and YouTube. For the next week, we w...

Last Epoch Top 3 Warlock Theorycrafted Builds I Came Up With
Remember, this is just for theorycrafting, I haven't played with any of these ingame so I don't know if any of these ideas will end up being good, so you will have to wait until I get to play with them when 1.0 comes around, which will be February 21st!
My Warlock In One Place Vide...

Join Binashole on Twitch! | https://www.twitch.tv/BinaQc
Find All My Written Guides on https://maxroll.gg/last-epoch
Discord | https://discord.gg/zSm65G5
Support Binashole by purchasing Last Epoch on his Nexus Store!
https://www.nexus.gg/Binashole
---------------...


MAXROLL: https://maxroll.gg/last-epoch/team?team=last-epoch
Top 5 Bossing Builds
0:06 - Number 1 - McFluffin - Shatter Strike Spellblade -
https://maxroll.gg/last-epoch/build-guides/shatter-strike-spellblade-guide
1:30 - Number 2 - LizardIRL - Squirel Beastmaster -
https://maxroll.gg/last-epoch/build-guides/squirrel-beastmaster-guide
2:34 - Nu...

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?si=Edg5tvAUn9tsSvjJ
-Necromancer Ultimate Fire: https://youtu.be/YngSp2WDbpA
-Necromancer Necro TANK: https://...

Join Us On Maxroll:
https://maxroll.gg/last-epoch/build-guides
𝐒𝐮𝐩𝐩𝐨𝐫𝐭 𝐌𝐞 𝐎𝐧 𝐏𝐚𝐭𝐫𝐞𝐨𝐧 𝐇𝐞𝐫𝐞:
https://www.patreon.com/boardman21
𝐉𝐨𝐢𝐧 𝐌𝐲 𝐃𝐢𝐬𝐜𝐨𝐫𝐝 𝐇𝐞𝐫𝐞:
https://discord.gg/Eb42DpR9nZ
𝐁𝐮𝐲 𝐋𝐄 𝐨𝐧 𝐍𝐞𝐱𝐮𝐬 𝐇𝐞𝐫𝐞:
https://www.nexus.gg/boardman21
𝐁𝐞𝐜𝐨𝐦𝐞 𝐚 𝐘𝐨𝐮𝐭𝐮𝐛𝐞 𝐌𝐞𝐦𝐛𝐞𝐫 𝐇𝐞𝐫𝐞:
https://www.youtube.com/channel/UCcKCZPldPq-8YRTLxUF0t4A/join
𝐖𝐚𝐭𝐜𝐡 𝐌𝐞 𝐋𝐢𝐯𝐞 𝐎𝐧 ...

Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #warpath #RATLEYINKLLC #diablo4 #walkthrough #guide

DMGCREW
Click show more below
In this @LastEpochGame I breakdown everything you need to know about the Rogue skill shurikens. My goal with this video is to help you learn how to fit shurikens into your Rogue build. Lots on information in this video and all of it is time stamped! I hope you enjoy this skill breakdown video.
Time Stamps
00:00 in...

Due to popular demand, I have started working on a Build Making Guide for Last Epoch! This is part 2 - Defensive Layers. It fits perfectly into my LE 1.0 Prep so I hope you check it out and utilize ideas from this video when Last Epoch launches on February 21st. I guarantee that it will be valuable for beginners and even veterans might find some...
https://www.youtube.com/watch?v=2bwIgAZSgcM Watch what happens to the exiled mage lol, if anybody needs help or boosting/gear I got you on stream everyday 😎

Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #MAGE #RATLEYINKLLC #diablo4 #walkthrough #guide

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?si=Edg5tvAUn9tsSvjJ
-Necromancer Ultimate Fire: https://youtu.be/YngSp2WDbpA
-Necromancer Necro TANK: https://...


Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?si=Edg5tvAUn9tsSvjJ
-Necromancer Ultimate Fire: https://youtu.be/YngSp2WDbpA
-Necromancer Necro TANK: https://...

Join Us On Maxroll:
https://maxroll.gg/last-epoch/build-guides
𝐒𝐮𝐩𝐩𝐨𝐫𝐭 𝐌𝐞 𝐎𝐧 𝐏𝐚𝐭𝐫𝐞𝐨𝐧 𝐇𝐞𝐫𝐞:
https://www.patreon.com/boardman21
𝐉𝐨𝐢𝐧 𝐌𝐲 𝐃𝐢𝐬𝐜𝐨𝐫𝐝 𝐇𝐞𝐫𝐞:
https://discord.gg/Eb42DpR9nZ
𝐁𝐮𝐲 𝐋𝐄 𝐨𝐧 𝐍𝐞𝐱𝐮𝐬 𝐇𝐞𝐫𝐞:
https://www.nexus.gg/boardman21
𝐁𝐞𝐜𝐨𝐦𝐞 𝐚 𝐘𝐨𝐮𝐭𝐮𝐛𝐞 𝐌𝐞𝐦𝐛𝐞𝐫 𝐇𝐞𝐫𝐞:
https://www.youtube.com/channel/UCcKCZPldPq-8YRTLxUF0t4A/join
𝐖𝐚𝐭𝐜𝐡 𝐌𝐞 𝐋𝐢𝐯𝐞 𝐎𝐧 ...

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Twitch Drop Link: https://twitch.lastepoch.com/
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?si=Edg5tvAUn9tsSvjJ
-Necromancer Ultimate Fire: https://youtu....

Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #warpath #RATLEYINKLLC #diablo4 #walkthrough #guide

McFluffin: https://maxroll.gg/last-epoch/build-guides/shadow-daggers-bladedancer-guide
Be sure to check out tons of the top guides made for Last Epoch here at Maxroll:
https://maxroll.gg/last-epoch/
🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝
𝐓𝐢𝐦𝐞 𝐒𝐭𝐚𝐦𝐩𝐬:
0:00 Intro / Shout out to new members / About the Build
2:35 Skills
2:44 Umbral Blades
4:17 Shift
5:26 Shadow C...

Join Us On Maxroll:
https://maxroll.gg/last-epoch/build-guides
𝐒𝐮𝐩𝐩𝐨𝐫𝐭 𝐌𝐞 𝐎𝐧 𝐏𝐚𝐭𝐫𝐞𝐨𝐧 𝐇𝐞𝐫𝐞:
https://www.patreon.com/boardman21
𝐉𝐨𝐢𝐧 𝐌𝐲 𝐃𝐢𝐬𝐜𝐨𝐫𝐝 𝐇𝐞𝐫𝐞:
https://discord.gg/Eb42DpR9nZ
𝐁𝐮𝐲 𝐋𝐄 𝐨𝐧 𝐍𝐞𝐱𝐮𝐬 𝐇𝐞𝐫𝐞:
https://www.nexus.gg/boardman21
𝐁𝐞𝐜𝐨𝐦𝐞 𝐚 𝐘𝐨𝐮𝐭𝐮𝐛𝐞 𝐌𝐞𝐦𝐛𝐞𝐫 𝐇𝐞𝐫𝐞:
https://www.youtube.com/channel/UCcKCZPldPq-8YRTLxUF0t4A/join
𝐖𝐚𝐭𝐜𝐡 𝐌𝐞 𝐋𝐢𝐯𝐞 𝐎𝐧 ...
Agree or disagree?
https://www.youtube.com/watch?v=N-eq63IpJD8

Join Us On Maxroll:
https://maxroll.gg/last-epoch/build-guides
𝐒𝐮𝐩𝐩𝐨𝐫𝐭 𝐌𝐞 𝐎𝐧 𝐏𝐚𝐭𝐫𝐞𝐨𝐧 𝐇𝐞𝐫𝐞:
https://www.patreon.com/boardman21
𝐉𝐨𝐢𝐧 𝐌𝐲 𝐃𝐢𝐬𝐜𝐨𝐫𝐝 𝐇𝐞𝐫𝐞:
https://discord.gg/Eb42DpR9nZ
𝐁𝐮𝐲 𝐋𝐄 𝐨𝐧 𝐍𝐞𝐱𝐮𝐬 𝐇𝐞𝐫𝐞:
https://www.nexus.gg/boardman21
𝐁𝐞𝐜𝐨𝐦𝐞 𝐚 𝐘𝐨𝐮𝐭𝐮𝐛𝐞 𝐌𝐞𝐦𝐛𝐞𝐫 𝐇𝐞𝐫𝐞:
https://www.youtube.com/channel/UCcKCZPldPq-8YRTLxUF0t4A/join
𝐖𝐚𝐭𝐜𝐡 𝐌𝐞 𝐋𝐢𝐯𝐞 𝐎𝐧 ...

This Item Is Immensely Powerful And Needs Changes | Last Epoch 0.9
Builds In Video :
https://youtu.be/hv3B34qc0Kk
https://youtu.be/z1rLNKFk5Ho
Email : dr3adfulr3aper@gmail.com
Twitch : https://www.twitch.tv/dr3adful__
Discord : https://discord.gg/tGqngsB
#lastepoch

Join Binashole on Twitch! | https://www.twitch.tv/BinaQc
Find All My Written Guides on https://maxroll.gg/last-epoch
Discord | https://discord.gg/zSm65G5
0:00 - Intro
0:42 - Thorn Totem Shaman
1:47 - Swarmblade Druid
https://youtu.be/vF47Ld37IaA
https://youtu.be/...

Guide for crafting and forging in Italian.
(Guida per crafting e forgia in lingua italiana)

Se siete interessati all'acquisto del gioco potete farlo anche dal mio NEXUS e risparmiare qualcosa
Nexus: https://www.nexus.gg/matilde
canale twitch: https://www.twitch.tv/zarketti
server Discord: https://discord.com/invite/hN2wZfzSaB
Nexus: https://www.nexus.gg/matilde
00:00 - Intro
00:43 - Introduzione al crafting
05:54 - Glifi
09:19 - E...

Should you play Last Epoch??
Last Epoch Review
From entrance to boss mechanic to creating a legendary in just 5 mins!
https://www.youtube.com/watch?v=ZtRBFL8OmEQ

Join Us On Maxroll:
https://maxroll.gg/last-epoch/build-guides
𝐒𝐮𝐩𝐩𝐨𝐫𝐭 𝐌𝐞 𝐎𝐧 𝐏𝐚𝐭𝐫𝐞𝐨𝐧 𝐇𝐞𝐫𝐞:
https://www.patreon.com/boardman21
𝐉𝐨𝐢𝐧 𝐌𝐲 𝐃𝐢𝐬𝐜𝐨𝐫𝐝 𝐇𝐞𝐫𝐞:
https://discord.gg/Eb42DpR9nZ
𝐁𝐮𝐲 𝐋𝐄 𝐨𝐧 𝐍𝐞𝐱𝐮𝐬 𝐇𝐞𝐫𝐞:
https://www.nexus.gg/boardman21
𝐁𝐞𝐜𝐨𝐦𝐞 𝐚 𝐘𝐨𝐮𝐭𝐮𝐛𝐞 𝐌𝐞𝐦𝐛𝐞𝐫 𝐇𝐞𝐫𝐞:
https://www.youtube.com/channel/UCcKCZPldPq-8YRTLxUF0t4A/join
𝐖𝐚𝐭𝐜𝐡 𝐌𝐞 𝐋𝐢𝐯𝐞 𝐎𝐧 ...
the ultimate gold sink in Last epoch
https://www.youtube.com/watch?v=RueddjYAIWg

Join Us On Maxroll:
https://maxroll.gg/last-epoch/build-guides
𝐒𝐮𝐩𝐩𝐨𝐫𝐭 𝐌𝐞 𝐎𝐧 𝐏𝐚𝐭𝐫𝐞𝐨𝐧 𝐇𝐞𝐫𝐞:
https://www.patreon.com/boardman21
𝐉𝐨𝐢𝐧 𝐌𝐲 𝐃𝐢𝐬𝐜𝐨𝐫𝐝 𝐇𝐞𝐫𝐞:
https://discord.gg/Eb42DpR9nZ
𝐁𝐮𝐲 𝐋𝐄 𝐨𝐧 𝐍𝐞𝐱𝐮𝐬 𝐇𝐞𝐫𝐞:
https://www.nexus.gg/boardman21
𝐁𝐞𝐜𝐨𝐦𝐞 𝐚 𝐘𝐨𝐮𝐭𝐮𝐛𝐞 𝐌𝐞𝐦𝐛𝐞𝐫 𝐇𝐞𝐫𝐞:
https://www.youtube.com/channel/UCcKCZPldPq-8YRTLxUF0t4A/join
𝐖𝐚𝐭𝐜𝐡 𝐌𝐞 𝐋𝐢𝐯𝐞 𝐎𝐧 ...

LEVELING VOID KNIGHT AFK AUTOBOMBER guide Build for beginners Last Epoch tanky echo farmer
☞ twitch.tv/mmografia
☞ discord.gg/VcfNgcHF5t
Last Epoch Tools : https://www.lastepochtools.com/planner/ko3Mv4nQ
Link to mail build : https://www.youtube.com/watch?v=Vy32BzLnTyk
Time stamps :
0:00 Intro
0:36 First words
2:16 Passives
5:20 Skil...
by request
https://www.youtube.com/watch?v=UCZikAo3OEg

Be sure to check out tons of the top guides made for Last Epoch here at Maxroll:
https://maxroll.gg/last-epoch/
🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝
𝐓𝐢𝐦𝐞 𝐒𝐭𝐚𝐦𝐩𝐬:
0:00 Intro / Shout out to new members / About the Build
1:43 Summon Skeleton
3:06 Transplant
4:10 Sacrifice
5:19 Aura of Decay
6:03 Reaper Form
6:51 Passives
8:08 Character Sheet
9:00 Gear / Idols /...

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Time Stamps:
00:00 - Dev Chat 123
00:13 - Intro
00:40 - New Stuff
01:42 - Legacy vs Cycle
03:47 - Patch Notes
04:57 - Con Air The Rock
05:40 - UI
06:36 - Genders
06:55 - Teaser 1
08:55 - Cursors
09:20 - Revive
10:04 - Sets
11:01 - Teaser 2
Current Build Guide...
Gamble your soul away!

Join Us On Maxroll:
https://maxroll.gg/last-epoch/build-guides
𝐒𝐮𝐩𝐩𝐨𝐫𝐭 𝐌𝐞 𝐎𝐧 𝐏𝐚𝐭𝐫𝐞𝐨𝐧 𝐇𝐞𝐫𝐞:
https://www.patreon.com/boardman21
𝐉𝐨𝐢𝐧 𝐌𝐲 𝐃𝐢𝐬𝐜𝐨𝐫𝐝 𝐇𝐞𝐫𝐞:
https://discord.gg/Eb42DpR9nZ
𝐁𝐮𝐲 𝐋𝐄 𝐨𝐧 𝐍𝐞𝐱𝐮𝐬 𝐇𝐞𝐫𝐞:
https://www.nexus.gg/boardman21
𝐁𝐞𝐜𝐨𝐦𝐞 𝐚 𝐘𝐨𝐮𝐭𝐮𝐛𝐞 𝐌𝐞𝐦𝐛𝐞𝐫 𝐇𝐞𝐫𝐞:
https://www.youtube.com/channel/UCcKCZPldPq-8YRTLxUF0t4A/join
𝐖𝐚𝐭𝐜𝐡 𝐌𝐞 𝐋𝐢𝐯𝐞 𝐎𝐧 ...
Hey, hey! My first video about Last Epoch here~ it's in Spanish tho haha https://youtu.be/3Jl4QMFxcdU

Last Epoch combina viajes en el tiempo, emocionante exploración de mazmorras, fascinante personalización de personajes y rejugabilidad infinita para crear un RPG de acción para veteranos y recién llegados por igual. Si estás interesado en este juego, subscríbete y no te pierdas novedades sobre el.
Directos todos los días: https://www.twitch.tv/...

Join Us On Maxroll:
https://maxroll.gg/last-epoch/build-guides
𝐒𝐮𝐩𝐩𝐨𝐫𝐭 𝐌𝐞 𝐎𝐧 𝐏𝐚𝐭𝐫𝐞𝐨𝐧 𝐇𝐞𝐫𝐞:
https://www.patreon.com/boardman21
𝐉𝐨𝐢𝐧 𝐌𝐲 𝐃𝐢𝐬𝐜𝐨𝐫𝐝 𝐇𝐞𝐫𝐞:
https://discord.gg/Eb42DpR9nZ
𝐁𝐮𝐲 𝐋𝐄 𝐨𝐧 𝐍𝐞𝐱𝐮𝐬 𝐇𝐞𝐫𝐞:
https://www.nexus.gg/boardman21
𝐁𝐞𝐜𝐨𝐦𝐞 𝐚 𝐘𝐨𝐮𝐭𝐮𝐛𝐞 𝐌𝐞𝐦𝐛𝐞𝐫 𝐇𝐞𝐫𝐞:
https://www.youtube.com/channel/UCcKCZPldPq-8YRTLxUF0t4A/join
𝐖𝐚𝐭𝐜𝐡 𝐌𝐞 𝐋𝐢𝐯𝐞 𝐎𝐧 ...

Collaboration LeagueStarter with Cookbook from LE community !!! Many many thanks to him for this awesome build :)
Build Planners :
Endgame = https://www.lastepochtools.com/planner/ZA8Zz6kB
Midgame (lvl 80) = https://www.lastepochtools.com/planner/zQq5VKRQ
Early Campaign = https://www.lastepochtools.com/planner/VBM4jEwQ
Loot Filter = https://w...

Gamescom Interview - https://youtu.be/tp2Twpd8cZ8?si=rfZbOTqp022N7D6w
Unofficial Roadmap - https://forum.lastepoch.com/t/unofficial-roadmap-to-1-0-and-beyond/60203
Twitch: https://www.twitch.tv/lonestar_mcfluffin
Discord: https://discord.gg/245dfV3
Patreon: https://www.patreon.com/Lonestar_McFluffin

Join Binashole on Twitch! | https://www.twitch.tv/BinaQc
Find All My Written Guides on https://maxroll.gg/last-epoch
Discord | https://discord.gg/zSm65G5
Bina's Last Epoch Master Spreadsheet - https://docs.google.com/spreadsheets/d/1S6OZ36Gmosu5UBjpwd3Ve106YZ0RMhYL2ipo_KYrFYY/edit?usp=sharing
-----------------------------------------------------...

Soxy Rabbit reacts to footage released on Icy Veins' website regarding the new Warlock Mastery Class coming to the Last Epoch in the Launch 1.0 on the 21st of February 2024.
Last Epoch is a top down, rpg, skill-based game similar to that of Path of Exile, Diablo 4 etc. You start off with a class and then branch down into a mastery ie Acolyte h...

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?si=Edg5tvAUn9tsSvjJ
-Necromancer Ultimate Fire: https://youtu.be/YngSp2WDbpA
-Necromancer Necro TANK: https://...

Maxroll:
https://maxroll.gg/last-epoch/
🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝
𝐓𝐢𝐦𝐞 𝐒𝐭𝐚𝐦𝐩𝐬:
0:25 Number 1 - Mad Autobomber Void Knight:
https://www.youtube.com/watch?v=cWdLwQOd_eM
1:27 Number 2 - Bow mage Marksman:
https://www.youtube.com/watch?v=pauUfTmu9iY
2:34 Number 3 - Squirrels Beastmaster:
https://www.youtube.com/watch?v=kFymKAPknP4
3:20 Number 4 - Avalan...

Maxroll: https://maxroll.gg/last-epoch/
0.9.2 Builds By Class:
Sentinel: Updated 2/3/24
https://www.youtube.com/watch?v=cWdLwQOd_eM
Mage: Updated 2/3/24
https://www.youtube.com/watch?v=7HdzcukfGsE
Rogue: Updated 2/3/24
https://youtu.be/U5hbiY8Ld9Y
Acolyte: Updated 2/3/24
https://www.youtube.com/watch?v=P7afSkdisio
https://www.youtube.com/wat...

Due to popular demand, I have started working on a Build Making Guide for Last Epoch! This is part 3 - BIS Affixes and Blessings. It fits perfectly into my LE 1.0 Prep so I hope you check it out and utilize ideas from this video when Last Epoch launches on February 21st. I guarantee that it will be valuable for beginners and even veterans might ...

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?si=Edg5tvAUn9tsSvjJ
-Necromancer Ultimate Fire: https://youtu.be/YngSp2WDbpA
-Necromancer Necro TANK: https://...

Maxroll: https://maxroll.gg/last-epoch/
𝐓𝐢𝐦𝐞 𝐒𝐭𝐚𝐦𝐩𝐬:
0:06 Intro about the build
1:06 Level 4
3:47 Level 8
6:36 Level 14
10:56 Level 20
15:20 Level 28
18:30 Level 35
21:57 Level 42
26:44 Level 52
32:04 Level 63
37:26 Level 76
🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝
0.9.2 Builds By Class:
Sentinel: Updated 2/3/24
https://www.youtube.com/watch?v=cWdLwQOd_eM
Mage: Up...

Very fast and very powerful build that is a lot of fun to play and has a lot of potential to go even further. Written guide goes into more detail about everything. I hope you all enjoy it as much as I do!
TIMESTAMPS
00:00 Intro
00:50 Gear
02:05 Skills
07:44 Passives
13:25 Echo Run
15:15 Boss Kill
15:50 Conclusion
Detailed Written Guide: https:...
https://www.youtube.com/watch?v=T-6cKepKd7k If you need any help or boosting/any gear im live everyday on twitch . Just ask 😎

Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #runemaster #RATLEYINKLLC #diablo4 #walkthrough #guide

Join Binashole on Twitch! | https://www.twitch.tv/BinaQc
Find All My Written Guides on https://maxroll.gg/last-epoch
Discord | https://discord.gg/zSm65G5
Bina's Last Epoch Master Spreadsheet - https://docs.google.com/spreadsheets/d/1S6OZ36Gmosu5UBjpwd3Ve106YZ0RMhYL2ipo_KYrFYY/edit?usp=sharing
-----------------------------------------------------...


DMGCREW
Click show more below
Last Epoch Launches Feb. 21st 2024
Pick up the game here and support the channel - https://www.nexus.gg/idodmg
@LastEpochGame
If you like everything in one place - https://allmylinks.com/idodmg1227
Otherwise its all laid out for you below, thanks for reading this 💗👇
---------------------------------------------...

Last Epoch Biggest Possible Nerfs For Runemaster For 1.0
Builds in Video :
https://youtu.be/VroXiizRkgU
https://youtu.be/rKzmMdAefSU
https://youtu.be/ea-Mit5W334
https://youtu.be/XK93eTHFQKg
Email : dr3adfulr3aper@gmail.com
Twitch : https://www.twitch.tv/dr3adful__
Discord : https://discord.gg/tGqngsB
#lastepoch

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Time Stamps:
00:00 - 10 Things
00:04 - Intro
00:32 - 10 Shattering
01:08 - 9 Gambling
01:42 - 8 Ascendance
02:27 - 7 Scaling
03:22 - 6 Lagon
04:01 - 5 Lootfilter
06:10 - 4 Side Quest
07:35 - 3 Dungeons
08:17 - 2 Travel
08:57 - 1 Crafting
09:57 - Wrap Up
Cur...

Best Builds For Each Mastery
0:06 Druid - Lightning Swipe Werebear - https://www.youtube.com/watch?v=NlVUJiAshZg
1:15 Runemaster - Hydrahedron - https://www.youtube.com/watch?v=DTdkjYyDwWE
1:58 Bladedancer - Shadow Dagger - https://www.youtube.com/watch?v=U5hbiY8Ld9Y
2:36 Sorcerer - Elemental Nova - https://www.youtube.com/watch?v=243cbBrVNLI
3...

Maxroll: https://maxroll.gg/last-epoch/
0.9.2 Builds By Class:
Sentinel: Updated 2/3/24
https://www.youtube.com/watch?v=cWdLwQOd_eM
Mage: Updated 2/3/24
https://www.youtube.com/watch?v=7HdzcukfGsE
Rogue: Updated 2/3/24
https://youtu.be/U5hbiY8Ld9Y
Acolyte: Updated 2/3/24
https://www.youtube.com/watch?v=P7afSkdisio
https://www.youtube.com/wat...

How to pick the best mastery for you with this in-depth Mastery breakdown for Last Epoch
0:00 Intro
0:44 Acolyte
1:18 Necromancer
2:57 Lich
4:54 Mage
5:52 Sorcerer
7:57 Runemaster
10:51 Spellblade
12:49 Primalist
13:33 Beastmaster
17:28 Druid
20:24 Shaman
22:33 Rogue
23:06 Bladedancer
25:24 Marksman
27:13 Sentinel
28:20 Paladin
30:18 Forge Guar...

Maxroll: https://maxroll.gg/last-epoch/
0.9.2 Builds By Class:
Sentinel: Updated 2/3/24
https://www.youtube.com/watch?v=cWdLwQOd_eM
Mage: Updated 2/3/24
https://www.youtube.com/watch?v=7HdzcukfGsE
Rogue: Updated 2/3/24
https://youtu.be/U5hbiY8Ld9Y
Acolyte: Updated 2/3/24
https://www.youtube.com/watch?v=P7afSkdisio
https://www.youtube.com/wat...

Top 5 Favorite Minion Builds
0:00 Number 1 - Retaliation Bear - https://www.youtube.com/watch?v=dTaB3LNTzRQ
1:42 Number 2 - Multiple Golems Necromancer - https://www.youtube.com/watch?v=CQtqX6TcA8E
2:46 Number 3 - Squirrel Beastmaster - https://www.youtube.com/watch?v=kFymKAPknP4
3:34 Number 4 - retaliation Bone Golem - https://www.youtube.com/...

Last Epoch Best Warpath Leveling Experience I've Had | Flameburst Paladin Road to 1.0
Level 1-25 Planner (Hammer Throw) :
https://www.lastepochtools.com/planner/DQ98ypXA
Level 25 Transition (Holy Trail) :
https://www.lastepochtools.com/planner/kB4J8l1A
Level 25-60 (Holy Trail) :
https://www.lastepochtools.com/planner/YQWpq40B
Level 60 Trans...
my magnum opus
https://www.youtube.com/watch?v=WiiKWOLFaXg If you need any help, gear or boosting . Just ask , I help people on stream everyday on twitch 😎

Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #runemaster #RATLEYINKLLC #diablo4 #walkthrough #guide

Finally Time To Talk Warlock | Epic Epoch Episode 38 #lastepoch
PerryThePig's YouTube Channel :
https://www.youtube.com/c/PerrythePig
Dr3ad's YouTube Channel :
https://www.youtube.com/channel/UCRI3Xo9aUbdXh2RlD9pC2rg
#lastepoch


Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Time Stamps:
00:00 - Why Last Epoch
00:08 - Intro
01:25 - Systems
03:58 - Customization
07:02 - $$$
09:42 - Endgame
12:04 - Future
13:53 - Underdog
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer ...

Maxroll: https://maxroll.gg/last-epoch/
𝐓𝐢𝐦𝐞 𝐒𝐭𝐚𝐦𝐩𝐬:
0:00 Intro about the build
1:01 Level 4
2:56 Level 8
5:21 Level 14
9:19 Level 20
12:56 Level 22
15:26 Level 28
18:05 Level 35
22:02 Level 41
25:56 Level 50
31:55 Level 60
34:50 Level 76
🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝
0.9.2 Builds By Class:
Sentinel: Updated 2/3/24
https://www.youtube.com/watch?v=cWdLwQO...

Be sure to check out tons of the top guides made for Last Epoch here at Maxroll:
https://maxroll.gg/last-epoch/
🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝
𝐓𝐢𝐦𝐞 𝐒𝐭𝐚𝐦𝐩𝐬:
0:00 Intro / Shout out to new members / About the Build
2:17 Skills
2:26 Werebear Form
4:08 Swipe
4:50 Summon Storm Crow
5:36 Warcry
6:42 Maelstrom
7:25 Passives
9:00 Character Sheet
10:04 Gear / Id...

Maxroll: https://maxroll.gg/last-epoch/
🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝
𝐓𝐢𝐦𝐞 𝐒𝐭𝐚𝐦𝐩𝐬:
0:00 Intro / Shout out to new members / About the Build
0:07 Arboreal Circuit
1:06 Advert of the Erased
1:56 Bleeding Hear
2:45 The Claw
3:18 Doublet of Onus Tull
3:54 Tome of Elements
4:24 Reach of the Grave
4:52 The Falcon
5:28 Keepers Gloves
5:59 Tongue of the Abarrant ...

Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #warpath #RATLEYINKLLC #diablo4 #walkthrough #guide

Do you agree with this list? What is your current feedback on rogue? Would love to hear your opinions about it.
Twitch:
https://www.twitch.tv/trikster08
Timestamps
0:00 - Intro
1:00 - Flurry
3:31 - Shurikens
4:55 - Shift
6:10 - Acid Flask
7:31 - Puncture
9:24 - Cinder Strike
11:06 - Umbral Blades
12:37 - Smoke Bomb
14:37 - Decoy
16:03 - Ballis...
Para Player Iniciantes, Language in video [PT-BR] Automatic Trans to EN ES
https://youtu.be/B3jfuT4Y5ng

Neste video trago a vocês de modo geral e sem aprofundamento de cada Master Classe existente no LE!
Canais Oficiais do Jogo:
Site: https://lastepoch.com/
Discord: https://discord.gg/lastepoch
Meus Canais:
Roxinha: https://www.twitch.tv/13lives1
Parceiro:
Marlon Kampff
Soundcloud: https://soundcloud.com/djmarlonkampff
Para Player Iniciantes, Language in video [PT-BR] Automatic Trans to EN ES
https://youtu.be/F3KKlPK7b9g

Neste video trago a vocês de modo geral e sem aprofundamento como funciona as passivas e skill ao pegar uma classe, tambem falo um pouco sobre as abas Monetaria do jogo!
Canais Oficiais do Jogo:
Site: https://lastepoch.com/
Discord: https://discord.gg/lastepoch
Meus Canais:
Roxinha: https://www.twitch.tv/13lives1
Parceiro:
Marlon Kampff
So...

I've put together a list of the best unique items to use when leveling an alt, as well as some tips for alt magic/rare gear. Let me know what you think!
I'll put a full list of the items here soon:tm:.
Music: Cullah - "Rocket Into The Future"
Under CC BY license: http://cullah.com

Last Epoch Erasing Strike Slam Zoomer VoidKnight Build Guide Showcase
Last Epoch Planner :
https://www.lastepochtools.com/planner/kA2ymVDo
Leveling Build :
https://youtu.be/8pKLtxXMT9Y
Email : dr3adfulr3aper@gmail.com
Twitch : https://www.twitch.tv/dr3adful__
Discord : https://discord.gg/tGqngsB
#lastepoch

Crafting basics in Ukrainian / Крафт Українською https://youtu.be/qyL5cys28bU

Всім привіт, з вами Дайкер :)
Вибачайте, я дуже невдале місце для камери обрав - і помітив це тільки в процесі запису, коли вже половину всього що хотів розказав - сподіваюсь, це не сильно буде вас дратувати при перегляді :)
Лінк на те як виглядає крафт легендарки: https://www.twitch.tv/videos/2055987338
Для донатів: https://donatello.to/Dai...

Maxroll: https://maxroll.gg/last-epoch/
0.9.2 Builds By Class:
Sentinel: Updated 2/3/24
https://www.youtube.com/watch?v=cWdLwQOd_eM
Mage: Updated 2/3/24
https://www.youtube.com/watch?v=7HdzcukfGsE
Rogue: Updated 2/3/24
https://youtu.be/U5hbiY8Ld9Y
Acolyte: Updated 2/3/24
https://www.youtube.com/watch?v=P7afSkdisio
https://www.youtube.com/wat...

Maxroll: https://maxroll.gg/last-epoch/
0.9.2 Builds By Class:
Sentinel: Updated 2/3/24
https://www.youtube.com/watch?v=cWdLwQOd_eM
Mage: Updated 2/3/24
https://www.youtube.com/watch?v=7HdzcukfGsE
Rogue: Updated 2/3/24
https://youtu.be/U5hbiY8Ld9Y
Acolyte: Updated 2/3/24
https://www.youtube.com/watch?v=P7afSkdisio
https://www.youtube.com/wat...

Join Binashole on Twitch! | https://www.twitch.tv/BinaQc
Find All My Written Guides on https://maxroll.gg/last-epoch
Discord | https://discord.gg/zSm65G5
Bina's Last Epoch Master Spreadsheet - https://docs.google.com/spreadsheets/d/1S6OZ36Gmosu5UBjpwd3Ve106YZ0RMhYL2ipo_KYrFYY/edit?usp=sharing
-----------------------------------------------------...

Last Epoch Top 5 Uniques I've Used So Far
In Last Epoch, there is a large amount of unique diversity thanks to the legendary potential system, which means most items, even some bad ones, can eventually see use thanks to being able to make your own stats on it. This video is meant to highlight 5 I've used in the past that are fond to me, and I'v...


Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Time Stamps:
00:00 - Top 3 Acolyte Builds
00:11 - Intro
01:07 - Fire
02:27 - Lazy
03:50 - Crit
05:21 - Witchfire
06:46 - Wrap Up
Acolyte:
-Lich Crit Harvest Written Guide: https://www.icy-veins.com/last-epoch/lich-crit-harvest-endgame-build
-Lich Crit Harve...

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Time Stamps:
00:00 - Falconer Reveal
00:11 - Intro
00:58 - Skill 1
02:35 - Skill 2
03:58 - Skill 3
05:22 - Skill 4
07:14 - Skill 5
09:03 - Wrap Up
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer A...
https://www.youtube.com/watch?v=5wRJDyOYUwA Im live everyday on twitch if you need any help for anything

Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #crafting #RATLEYINKLLC #diablo4 #walkthrough #guide
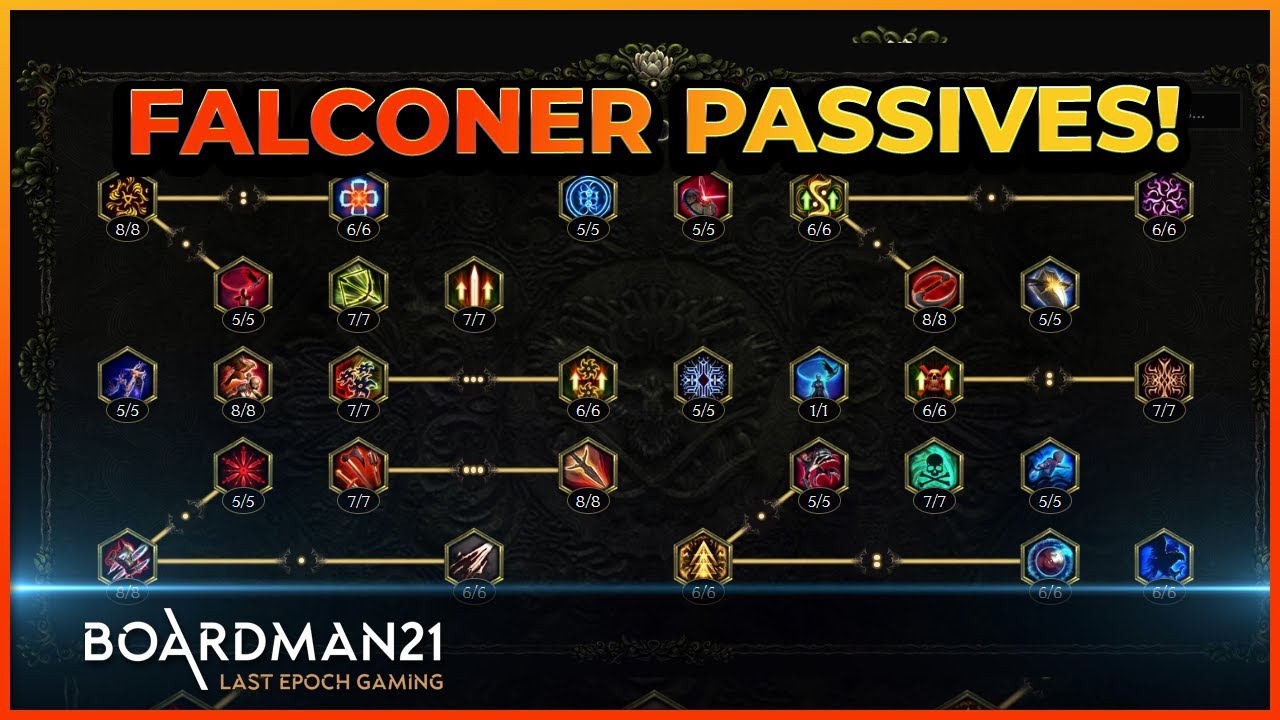
Check out all those new falconer skills!
https://www.youtube.com/watch?v=oZYRWpwUSTI

Maxroll Falconer: https://maxroll.gg/last-epoch/news/falconer-reveal
Ziz: https://www.youtube.com/watch?v=ZlxyfrJuVVI
0.9.2 Builds By Class:
Sentinel: Updated 2/3/24
https://www.youtube.com/watch?v=cWdLwQOd_eM
Mage: Updated 2/3/24
https://www.youtube.com/watch?v=7HdzcukfGsE
Rogue: Updated 2/3/24
https://youtu.be/U5hbiY8Ld9Y
Acolyte: Updated...

Sick new bow build incoming with Explosive Trap!
Zizaran video: https://www.youtube.com/watch?v=ZlxyfrJuVVI
Falconer reveal post: https://maxroll.gg/last-epoch/news/falconer-reveal
Planners: https://maxroll.gg/last-epoch/planner/ttml043n#1million
Find me on Twitch ► https://www.twitch.tv/volca_
Discord ► https://discord.gg/ahBHyVqAuc
Maxroll ...

Last Epoch Most Exciting New Skill Isn't Falconry?
In this video I go over a very small portion of the Falconer reveal and talk about my favorite things from it, which happens to not include Falconry at all.
Maxroll Official Post :
https://maxroll.gg/last-epoch/news/falconer-reveal
Zizaran Video :
https://www.youtube.com/watch?v=ZlxyfrJuV...

Join Binashole on Twitch! | https://www.twitch.tv/BinaQc
Find All My Written Guides on https://maxroll.gg/last-epoch
Discord | https://discord.gg/zSm65G5
Bina's Last Epoch Master Spreadsheet - https://docs.google.com/spreadsheets/d/1S6OZ36Gmosu5UBjpwd3Ve106YZ0RMhYL2ipo_KYrFYY/edit?usp=sharing
-----------------------------------------------------...

Maxroll Falconer: https://maxroll.gg/last-epoch/news/falconer-reveal
0.9.2 Builds By Class:
Sentinel: Updated 2/3/24
https://www.youtube.com/watch?v=cWdLwQOd_eM
Mage: Updated 2/3/24
https://www.youtube.com/watch?v=7HdzcukfGsE
Rogue: Updated 2/3/24
https://youtu.be/U5hbiY8Ld9Y
Acolyte: Updated 2/3/24
https://www.youtube.com/watch?v=P7afSkdis...

Maxroll Falconer: https://maxroll.gg/last-epoch/news/falconer-reveal
0.9.2 Builds By Class:
Sentinel: Updated 2/3/24
https://www.youtube.com/watch?v=cWdLwQOd_eM
Mage: Updated 2/3/24
https://www.youtube.com/watch?v=7HdzcukfGsE
Rogue: Updated 2/3/24
https://youtu.be/U5hbiY8Ld9Y
Acolyte: Updated 2/3/24
https://www.youtube.com/watch?v=P7afSkdis...

Maxroll Falconer: https://maxroll.gg/last-epoch/news/falconer-reveal
0.9.2 Builds By Class:
Sentinel: Updated 2/3/24
https://www.youtube.com/watch?v=cWdLwQOd_eM
Mage: Updated 2/3/24
https://www.youtube.com/watch?v=7HdzcukfGsE
Rogue: Updated 2/3/24
https://youtu.be/U5hbiY8Ld9Y
Acolyte: Updated 2/3/24
https://www.youtube.com/watch?v=P7afSkdis...

Maxroll Falconer: https://maxroll.gg/last-epoch/news/falconer-reveal
0.9.2 Builds By Class:
Sentinel: Updated 2/3/24
https://www.youtube.com/watch?v=cWdLwQOd_eM
Mage: Updated 2/3/24
https://www.youtube.com/watch?v=7HdzcukfGsE
Rogue: Updated 2/3/24
https://youtu.be/U5hbiY8Ld9Y
Acolyte: Updated 2/3/24
https://www.youtube.com/watch?v=P7afSkdis...

Maxroll Falconer: https://maxroll.gg/last-epoch/news/falconer-reveal
0.9.2 Builds By Class:
Sentinel: Updated 2/3/24
https://www.youtube.com/watch?v=cWdLwQOd_eM
Mage: Updated 2/3/24
https://www.youtube.com/watch?v=7HdzcukfGsE
Rogue: Updated 2/3/24
https://youtu.be/U5hbiY8Ld9Y
Acolyte: Updated 2/3/24
https://www.youtube.com/watch?v=P7afSkdis...

Last Epoch 1k HP Regen Tank Shattered Lance Werebear Druid Build Guide Showcase
Last Epoch Build Planner :
https://www.lastepochtools.com/planner/kB49vVlo
Email : dr3adfulr3aper@gmail.com
Twitch : https://www.twitch.tv/dr3adful__
Discord : https://discord.gg/tGqngsB
#lastepoch


Nel weekend scorso ho giocato a last epoch, uscirà dal suo accesso anticipato il 21 Febbraio.
Chiavi di gioco a prezzi scontati fino al 70%: https://www.instant-gaming.com/?igr=Cyberluk
GIVEAWAY MENSILE esclusivo Vinci un gioco a tua scelta: https://www.instant-gaming.com/it/giveaway/CYBERLUK
Iscrivetevi e Condividete per supportare il canale !...
Falconer Reveal in Ukrainian / Огляд Фальконера Українською https://youtu.be/zBnRLMDSwGk

Всім привіт, з вами Дайкер :)
У відео повинно вилізти повідомлення, але додатково проговорю, що це відео спонсороване розробниками, а саме тема відео - думки вже мої персональні :)
У відео використані наступні матеріали:
Maxroll: https://maxroll.gg/last-epoch/news/falconer-reveal
Zizaran : https://www.youtube.com/watch?v=ZlxyfrJuVVI
На дани...

DMGCREW
Click show more below
I hope you enjoy the video and thank you for being here!
Support me by
Picking up Last Epoch https://www.nexus.gg/idodmg
Become a channel member https://www.youtube.com/@idodmg/join
Leave a super thanks to support the channel
Thanks for watching!
Time stamps
00:00 intro
00:40 Classes and Masteries
2:33 Starting...

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Time Stamps:
00:00 - Top 3 Primalist Builds
00:08 - Intro
00:46 - Squirrels
02:04 - Bug
02:59 - Bear
04:20 - Avalanche
05:36 - Tempest
06:34 - Wrap Up
Primalist:
-Squirrels Written Guide: https://www.icy-veins.com/last-epoch/beastmaster-squirrels-endgame-b...
EHG revealing the Falconer Mastery for the Rogue class, brings Last Epoch's 1.0 release on February 21st closer and closer! In this video we'll take a look at the exclusive reveal on maxroll.gg and discuss the class' pet master nature, its skills and its passive tree.
https://youtu.be/GfKbAJbSRPU #sponsored

EHG revealing the Falconer mastery for the Rogue class, brings Last Epoch's 1.0 release on February 21st closer and closer! In this video we'll take a look at the exclusive reveal on maxroll.gg and discuss the class' pet master nature, its skills and its passive tree.
DISCLAIMER: I'm obliged to disclose that this is a sponsored video (not a 'su...

Bonjour à tous,
Voici une vidéo de starter build pour chacune des matrises de la classe sentinelle sur Last Epoch 1.0, Paladin, Forge Guard et Void Knight
Chaque build est jouable durant la campagne ainsi qu'en endgame sans nécessité d'item unique spécifique.
Ci dessous les différents planer pour chaque mastery :
Paladin Holy trail :
Lvl 4...

Last Epoch FALCONER Gameplay Review. New builds for Rogue
Last Epoch Preorder buy : https://lastepoch.com/pre-order
Our totally subjective and honest opinion about just revealed new mastery Falconer in Last Epoch.
Falconer footage used in video comes from :
youtube.com/@Zizaran
maxroll.gg
Made by: Zetu
Edit: Zetu
▶️Music Promoted by
Epic M...

Join Binashole on Twitch! | https://www.twitch.tv/BinaQc
Find All My Written Guides on https://maxroll.gg/last-epoch
Discord | https://discord.gg/zSm65G5
Bina's Last Epoch Master Spreadsheet - https://docs.google.com/spreadsheets/d/1S6OZ36Gmosu5UBjpwd3Ve106YZ0RMhYL2ipo_KYrFYY/edit?usp=sharing
-----------------------------------------------------...

Last Epoch Just Revealed A New Class
zizaran here: https://youtu.be/ZlxyfrJuVVI?si=WDbBk3dZBWp0jyRJ
maxroll falconer reveal: https://maxroll.gg/last-epoch/news/falconer-reveal
live now: https://www.twitch.tv/darthmicrotransaction
#lastepoch

What do you think about the Falconer class? Any build ideas you wanna try out for 1.0?
Looking forward to play with the bird!
Twitch:
https://www.twitch.tv/trikster08
Timestamps
0:00 - Intro
1:00 - Passive Tree
8:35 - Explosive Trap
11:47 - Net
13:50 - Falconry
16:10 - Aerial Assault
17:51 - Dive Bomb
19:14 - Summary
21:00 - Important Info

E ai, como você tá?
Nesse vídeo trago para vocês a revelação completa da nova especialização FALCONER
O que vocês acharam?
O conteúdo desse vídeo foi revelado com exclusividade por: https://maxroll.gg/last-epoch/news/falconer-reveal
https://www.youtube.com/watch?v=ZlxyfrJuVVI&ab_channel=Zizaran
Compre o Last Epoch na Steam (Há versões com ...


#lastepoch #arpg
Vemos la nueva clase, el Falconer y analizamos sus habilidades de cara
a su salida el próximo día 21 de febrero.
👉 link compra Last Epoch: https://www.nexus.gg/masther10
💜 Sígueme en Twitch: https://www.twitch.tv/masther10
💙 Twitter: https://twitter.com/ TwitchMasther10
🎮 Comunidad de discord: https://discord.gg/e7sjtKp...

⏬⏬⏬⏬ Möchte Ausgeklappt werden ⏬⏬⏬⏬
Kommentiertes LETS PLAY by EDGamingTV
► SteamLink:
► Last Epoch Standard Edition: https://bit.ly/3uqN5j1
► Last Epoch Deluxe Edition: https://bit.ly/3HRc6XL
► Last Epoch Ultimate Edition: https://bit.ly/3I0fAa8
❤Mein Keyseller des Vertrauens: MMOGA
---------------------------------------------------------...

Falconer Reveal: https://maxroll.gg/last-epoch/news/falconer-reveal
My Nexus Store: https://www.nexus.gg/lonestar-mcfluffin
Twitch: https://www.twitch.tv/lonestar_mcfluffin
Discord: https://discord.gg/245dfV3
Patreon: https://www.patreon.com/Lonestar_McFluffin

This is the Warlock build that I'm planning on running for Last Epoch 1.0 Season Start! I am not a Community Tester so I have no certainty whether every single element in the build will actually work but we will pivot until we get something awesome. Let me know what you think of the build and I hope to see you after 1.0 launches!
Build Planner ...

Watch Daily At ► https://www.twitch.tv/BinaQc
My Discord Server ► https://discord.gg/zSm65G5
My Website ► https://www.Binashole.com/
Written Guides ► https://maxroll.gg/last-epoch
Master Spreadsheet ► https://docs.google.com/spreadsheets/d/1S6OZ36Gmosu5UBjpwd3Ve106YZ0RMhYL2ipo_KYrFYY/edit?usp=sharing
Support me by purchasing Last Epoch on my ...
BREAKING NEWS FROM INTERNET EXPLORER - Falconer Reveal!
https://youtu.be/44J4TIZ2d2I

Last Epoch's Falconer Mastery releases on Feburary 21st, alongside the game's full release! Check out my thoughts on the new skills, and a couple of builds I put together. Thanks for watching, this one was a lot of work!
Check me out on Twitch @ExoTheTerrible for Last Epoch's release; I'm streaming for FIVE days in a row!
Umbral Falconer: http...

Really super serious reasons.
*Some statements in this video are for entertainment purposes only and should not be taken as facts.
Credit to many of the clips in this video go to the Last Epoch Youtube page.
Last Epoch Youtube: https://www.youtube.com/@UCzo4PHA91qM-jWp_bWVOzqQ
gotta watch this now^

I'm live everyday- https://www.twitch.tv/novarics
All skills & passives - https://maxroll.gg/last-epoch/news/falconer-reveal
Buy Last Epoch Here - https://www.nexus.gg/novarics


Last Epoch Meta Fragment Spark Charge Mana Strike Spellblade Build Guide Showcase
In this video I go over the most vanilla spark charge build humanly possible!
Last Epoch Planner :
https://www.lastepochtools.com/planner/eoyDd72B
My Last Spark Charge Build :
https://youtu.be/VroXiizRkgU
PerryThePig's Version :
https://youtu.be/rE06J1gAgno
...

Bonjour à tous,
Voici une vidéo de starter build pour chacune des maitrises de la classe Mage sur Last Epoch 1.0, Sorcerer, Spellblade et Runemaster
Chaque build est jouable durant la campagne ainsi qu'en endgame sans nécessité d'item unique spécifique.
Ci dessous les différents planer pour chaque mastery :
Sorcerer fireball :
Lvl 40 : htt...
Salut à tous, voici une vidéo faite non pas pour le best starter mais pour orienter les nouveaux joueurs vers un gameplay qui leur plaît. Bon visionnage à tous.
https://youtu.be/gXyR60GBjdk?si=Q2KL7IfnBTtVYIQa

Salut à tous, voici une vidéos pour choisir votre starter, oui par ce que le meilleure starter c'est dit en fin vidéos. bon visionnage
TWITCH https://www.twitch.tv/saony06
DISCORD https://discord.gg/6GezYFRjAC
Youtube : https://youtube.com/@saony0626
Pour me soutenir Regarde par ici https://www.nexus.gg/saony
00:00 intro
01:19 Sentinel
06:5...

E ai, como você tá?
Nesse vídeo trago para vocês o primeiro episódio da série educacional de Last Epoch.
O que vocês acharam?
Compre o Last Epoch na Steam (Há versões com skins exclusivas):
https://lastepoch.com/pre-order
https://store.steampowered.com/app/89...
Criadores de conteúdo que eu indico e que são apoiadores do nosso trabalho!
@...

Guia en español para last epoch, crea filtros para tus personajes de manera sencilla.
🔹 Discord - https://discord.gg/ZVcdK7WKv7
🔹 TWITCH - https://www.twitch.tv/chupi_sama
Last Epoch es un juego de rol de acción hack and slash de acceso temprano desarrollado por Eleventh Hour Games. Descubre el Pasado, Forja el Futuro. Asciende a una de las 15 ...

Join the Discord! https://discord.gg/ebRaKANeJB
In this video, I share with you lovely people my Last Epoch loot filter. With this filter, you will have an organized way to control what items you do and do not see. This video is part 1 of a two part series. Part 3 may come out in the future if the release of this game warrants a part 3.
Link...
Crappy video made https://youtu.be/CHJ2_CeI2-Q?si=ASKFEY8v-4f1lgoz

Here we have Falconer - The third mastery for the rogue. #lastepoch #falconer #class #falcon #falconry #mastery #build #release #soon #arpg #action #gaming #gameplay #adventure #petbuilds #pets #hackandslash #loot #hardcore #fun #multiplayer #fantasy #preorder #EleventhHourGames #rpg #rogue #likevideo
Please press the like button!
You can Pre ...

Build Guide:
https://www.lastepochtools.com/build-guides/shadow-hoa-marksman
Build Planner:
https://www.lastepochtools.com/planner/3Ap1OGKQ
Shadow HoA Leveling Guide:
https://youtu.be/llBdoyRrFMI
Old Build Guide:
https://youtu.be/xoe5ohPHb6c
Twitch:
https://www.twitch.tv/trikster08
Timestamps
0:00 - Intro
2:08 - Gameplay Showcase
5:05 - Boss...

this one is even better haha: https://www.youtube.com/watch?v=T6wirFNPItw

by @Frostylaroo https://www.youtube.com/watch?v=5IFY3gblZ28
► Asmongold's Twitch: https://www.twitch.tv/zackrawrr
► Asmongold's Twitter: https://twitter.com/asmongold
► Asmongold's 2nd YT Channel: https://www.youtube.com/user/ZackRawrr
► Asmongold's Sub-Reddit: https://www.reddit.com/r/Asmongold/
Channel Editors: CatDany & Daily Dose of Asmongo...

E ai, como você tá?
Nesse vídeo trago para vocês o segundo episódio da série educacional de Last Epoch.
O que vocês acharam?
Compre o Last Epoch na Steam (Há versões com skins exclusivas):
https://lastepoch.com/pre-order
https://store.steampowered.com/app/89...
Criadores de conteúdo que eu indico e que são apoiadores do nosso trabalho!
@v...

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Time Stamps:
00:00 - Top 5 Sentinel Builds
00:09 - Intro
00:59 - Smiter
02:40 - Unstoppable
04:29 - Erasing
05:33 - Warpath
06:38 - Forged Minions
07:54 - Wrap Up
Sentinel:
-Holy Smiter Written Guide: https://www.icy-veins.com/last-epoch/paladin-holy-smite...

Last Epoch Trading Better Than PoE Trading? Ft Sirgog
In this video I bring on Sirgog so we can talk about the future of trade in Last Epoch, and the only other game that comes even close to what LE's Merchant Guild will look like is Path of Exile, so we are using that to give a lot of people an idea what MG will be like!
Builds in this video...

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Giveaway Link: https://gleam.io/2FzOQ/last-epoch-314999-rtx-4070ti-super-gaming-pc
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?si=Edg5tvAUn9tsSvjJ
-Necro...

Salve amici, oggi voglio parlarvi di Last Epoch, un ARPG che se siete appassionati del genere non potete perdere.
In questa recensione non farò sviolinate su aspetti superficiali ma scenderò nel dettaglio degli aspetti che più interessano ai giocatori di ARPG.
Fatemi sapere nei commenti cosa ne pensate, se avete domande che non sono state ris...

420 gamer
- PC Specs -
RTX 3080
i7-12700KF 3.61GHz
16GB RAM

Original video: https://www.youtube.com/watch?v=5IFY3gblZ28&pp=ygUTbGFzdCBlcG9jaCBkaWFibG8gNA%3D%3D
Join the community:
Twitch ► https://twitch.tv/quin69
Twitter ► https://twitter.com/quinrex
Discord ► https://discord.com/invite/rats
Credits:
Thumbnail ► https://twitter.com/garyukov
Editing ► https://twitter.com/atomboy7
Lmao

Be sure to check out tons of the top guides made for Last Epoch here at Maxroll:
https://maxroll.gg/last-epoch/
🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝
𝐓𝐢𝐦𝐞 𝐒𝐭𝐚𝐦𝐩𝐬:
0:00 Intro / Shout out to new members / About the Build
1:25 Skills
1:36 Smite
2:53 Rebuke
4:02 Devouring Orb
5:27 Anomaly
6:30 Shield Rush
7:26 Passives
8:35 Character Sheet
9:10 Gear / Idols / Ble...

DMGCREW
Click show more below
#ad
Pick up Last Epoch and support the channel - https://www.nexus.gg/idodmg/last-epoch
Time Stamps
00:00 Intro
00:55 Mastery Overview
1:15 Passive Skill Tree
12:40 Falconry and Falcon Strikes
22:05 Explosive Trap
34:31 Net
44:27 Dive Bomb
53:53 Aerial Assault
1:00:20 Build Ideas
1:01:54 Closing Thoughts
If you...

Become A Supporter: https://www.youtube.com/Games4Kickz/join
Uncover the Past, Reforge the Future. Ascend into one of 15 mastery classes and explore dangerous dungeons, hunt epic loot, craft legendary weapons, and wield the power of over a hundred transformative skill trees. Last Epoch is being developed by a team of passionate Action RPG enthu...

One of my potential starters come 1.0 incase the meta gets flipped upside down as the Druid will be tanky enough to survive the patchnotes!
- Gameplay: 00:00
- Gear, Idols, Blessings: 02:14
- The Skills: 08:29
- Passive Tree: 13:46
Build Planner (Yes, I got a red item, listen to the video)
---...
Hey all,
Not sure if any of you are interested but I’m a content creator who gets free keys.
🔑
I was given free premium keys to skull and bones but since I’m doing content for last epoch I got no time so I’m giving them away FREE. This is for pc only. All you have to do is go to my latest last epoch video and like and leave a comment. I appreciate it if you give me a chance I work hard to make LE content
Last Epoch How to Craft 101
https://youtu.be/lCsuHx4-noY

This is the BEST 101 Last Epoch "How to" Crafting Guide made for complete beginners to the game. You need absolutely zero in-game knowledge and this can be done from level 1 of the campaign. Let's learn How to Craft in Last Epoch 1.0 Together!
Haven't bought the game yet?
Get a copy here and support me and the devs!
https://www.nexus.gg/thatanxi...

https://forum.lastepoch.com/t/last-epoch-starforge-collaboration-giveaways-master-thread/62276
0.9.2 Builds By Class:
Sentinel: Updated 2/3/24
https://www.youtube.com/watch?v=cWdLwQOd_eM
Mage: Updated 2/3/24
https://www.youtube.com/watch?v=7HdzcukfGsE
Rogue: Updated 2/3/24
https://youtu.be/U5hbiY8Ld9Y
Acolyte: Updated 2/3/24
https://www.you...
Ё!йф Ё/*-++-,3+*62,5104
Ъ=-Х0З9Щ8Ш7Г6Н5Е4ПК3УА2ЦВ1ЙЫЁФЯфйыцвукаспемрни7готшлщ9д80-зжхэ-ъ
https://www.youtube.com/watch?v=wfQPBcVXZF0 if anybody needs any help on any boss or level, just ask. I am live everyday on twitch 😎

Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #warpath #RATLEYINKLLC #diablo4 #walkthrough #guide

Last Epoch Cold DoT Werebear Druid Build Guide Showcase
This is an update to an old friend, Cold DoT Werebear. May he forever stay relevant. This is like my child, and now I've watched it go through grade school, highschool, and at this point he is past college and getting his first job, that is to be an insanely good build for 1.0 hopefully, ...

Thank you for your support as a disabled content creator it means alot for all the subs like and view.
Welcome to our gaming channel! We bring you immersive gameplay, thrilling adventures, and the latest updates in the gaming world. Join us as we explore new worlds, conquer challenges, and share our gaming expertise. Whether you're a casual pla...


0:00 intro
0:52 Glacier Sorcerer: https://maxroll.gg/last-epoch/build-guides/glacier-sorcerer-guide
2:04 Frost Claw Runemaster: https://maxroll.gg/last-epoch/build-guides/frost-claw-runemaster-guide
3:02 Shatterstrike Spellblade: https://maxroll.gg/last-epoch/build-guides/shatter-strike-spellblade-guide
4:14 Lightning blast and static orb Sorcer...
Hey, hey~ new video here about Falconer in Spanish! https://youtu.be/33cO8nOULAg

Last Epoch combina viajes en el tiempo, emocionante exploración de mazmorras, fascinante personalización de personajes y rejugabilidad infinita para crear un RPG de acción para veteranos y recién llegados por igual. Si estás interesado en este juego, subscríbete y no te pierdas novedades sobre el.
Directos todos los días: https://www.twitch.tv/...

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Giveaway Link: https://gleam.io/2FzOQ/last-epoch-314999-rtx-4070ti-super-gaming-pc
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?si=Edg5tvAUn9tsSvjJ
-Necro...
Made a video showing all runemaster invocations, https://youtu.be/kJKn3uc-0MM?si=GXXn0fYYfPW6gY_w

I am a PoE player new to last epoch and just wanted to see what all the spells did visually / mechanically since I will probably start with a Mage on launch. This was tested in 0.9.2Q beta on a level 15 Runemaster immediately after I unlocked the mastery. Many of these spells will also probably be buffed or nerfed in 1.0, but maybe the mechanics...
https://www.youtube.com/watch?v=KCL2PGKdCi8 A bit of trolling and some tech shown 😎

Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #warpath #RATLEYINKLLC #diablo4 #walkthrough #guide

https://maxroll.gg/last-epoch/team?team=last-epoch
Timestamps:
0:00 Intro
1:22 Level 4
3:41 Level 8
5:54 Level 14
8:11 Level 20
11:28 Level 28
14:32 Level 35
18:45 Level 42
22:23 Level 51
26:48 Level 60
33:52 Level 76
0.9.2 Builds By Class:
Sentinel: Updated 2/3/24
https://www.youtube.com/watch?v=cWdLwQOd_eM
Mage: Updated 2/3/24
https://www....
First attempt at a youtube video 🙂 Feel free to give me any constructive criticism or advice

To reiterate any speculation on the build theory here is subject to change based on number tuning that will be coming with patch notes!
Want to purchase last epoch while supporting me? Follow the link here https://www.nexus.gg/mercwhere
Twitch: https://www.twitch.tv/mercwhere

Be sure to check out tons of the top guides made for Last Epoch here at Maxroll:
https://maxroll.gg/last-epoch/
🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝
𝐓𝐢𝐦𝐞 𝐒𝐭𝐚𝐦𝐩𝐬:
0:00 Intro / Shout out to new members / About the Build
1:31 Skills
1:43 Eterra's Blessing
2:29 Spriggan Form
3:37 Summon Thorn Totem
4:40 Summon Spriggan
5:17 Maelstrom
5:58 Passives
7:20 Character...
Here is my Falconer Reveal video ~ With a special guest performance by my Falcon-- err I mean Cat -- Frisco!
https://www.youtube.com/watch?v=lz8oxwuwJSw&ab_channel=KahnerTV

#lastepoch #falconer #arpg #newgame #sponsored
A deep dive into the new mastery for Last Epoch, the Falconer!
If you enjoyed the video please make sure to Like and Subscribe!
Just a reminder, Last Epoch 1.0 release is February 21st, 2024
Interested in Preordering Last Epoch? Click Here: https://www.nexus.gg/kahnertv/last-epoch
Video Conten...
So i kinda made a video, it's my first "editing" project, it's not great but i will work on improving 💪
https://www.youtube.com/watch?v=-3GAEvcWB9s&t=332s

A quick TLDR about the game. Last Epoch is an interesting arpg with alot of cool features. It officialy releases on February 21.
I stream most days live on twitch.tv/melloquence
Sorry for the poor quality, most clips are from my live stream and on one of them my bitrate was fluctuating alot. Also i'm not very good at video editing, but I will ...

In this video I answer the boiling question everyone has had, does Dr3ad hate Last Epoch? Spoilers, no lmao.
But it seems like a lot of people think I do, so we can talk about that real quick.
Email : dr3adfulr3aper@gmail.com
Twitch : https://www.twitch.tv/dr3adful__
Discord : https://discord.gg/tGqngsB
#lastepoch

Watch Daily At ► https://www.twitch.tv/BinaQc
My Discord Server ► https://discord.gg/zSm65G5
My Website ► https://www.Binashole.com/
Written Guides ► https://maxroll.gg/last-epoch
Master Spreadsheet ► https://docs.google.com/spreadsheets/d/1S6OZ36Gmosu5UBjpwd3Ve106YZ0RMhYL2ipo_KYrFYY/edit?usp=sharing
Ressource ► https://lastepoch.tunklab.com/
...

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Time Stamps:
00:00 - Top 5 Rogue Builds
00:07 - Intro
00:51 - Shadow Master
01:46 - Shadow Daggers
02:39 - Shotgun
03:47 - Cinder Strike
04:44 - Falconer
05:06 - Wrap Up
Sentinel:
-Shadow Master Written Guide: https://www.icy-veins.com/last-epoch/bladedanc...


https://maxroll.gg/last-epoch/
𝐓𝐢𝐦𝐞 𝐒𝐭𝐚𝐦𝐩𝐬:
0:00 Intro
0:35 Holy trail paladin: https://www.youtube.com/watch?v=BfC5GwIrJQU
2:08 Nova Hammerdin: https://maxroll.gg/last-epoch/build-guides/nova-hammerdin-guide
3:27 Echo Warpath: https://maxroll.gg/last-epoch/build-guides/echo-warpath-void-knight-guide
4:41 Manifest Armor Leveling: https://maxroll...

Patch notes pending....
This is the build I plan on starting the cycle with for Last Epoch 1.0. This will probably end up being one of the best ways of playing Net Trap Puncture Traps, and I plan on refining this build and then eventually moving on after about a week? Also btw all of this is reliant on patch notes as well!
Last Epoch Planner (...
Hey there, fellow adventurers! Stepping into the world of Last Epoch for the first time? Feeling a bit overwhelmed with choosing your starting class? No worries! Join me in this video and let's take a closer look at why the Acolyte class might just be the perfect fit for beginners like you and me.
We'll explore the Acolyte's knack for summoning minions, its powerful golem builds, and how simple it is to manage resources with its life-draining spells. Plus, hear firsthand how I, as a beginner myself, conquered the campaign and reached endgame content in just 10 hours with the Acolyte.
So, if you're eager to command your own army of minions and dive into Last Epoch with confidence, this guide is for you! Hit play now and let's embark on this epic journey together.

BEST CLASS FOR BEGINNERS IN LAST EPOCH
Hey there, fellow adventurers! Stepping into the world of Last Epoch for the first time? Feeling a bit overwhelmed with choosing your starting class? No worries! Join me in this video and let's take a closer look at why the Acolyte class might just be the perfect fit for beginners like you and me.
We'll ...

Bonjour à tous,
Voici une vidéo de starter build pour chacune des maitrises de la classe Primaliste sur Last Epoch 1.0, Shaman, Druide et Beastmaster / Maitre des bêtes.
Chaque build est jouable durant la campagne ainsi qu'en endgame sans nécessité d'item unique spécifique.
Ci dessous les différents planer pour chaque mastery :
!EN COURS!
...

https://maxroll.gg/last-epoch/
https://forum.lastepoch.com/t/gathering-storm-and-tempest-strike-rework-coming-to-last-epoch-feb-21st/62368
🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝
0.9.2 Builds By Class:
Sentinel: Updated 2/13/24
https://www.youtube.com/watch?v=osMCaoeloFY
https://www.youtube.com/watch?v=cWdLwQOd_eM
Mage: Updated 2/13/24
https://www.youtube.com/wa...

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Giveaway Link: https://gleam.io/2FzOQ/last-epoch-314999-rtx-4070ti-super-gaming-pc
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?si=Edg5tvAUn9tsSvjJ
-Necro...


This is the leveling setup for the Warlock build that I'm planning on running for Last Epoch 1.0 Season Start! I am not a Community Tester so I have no certainty whether every single element in the build will actually work but we will pivot until we get something awesome. Let me know what you think of the build and I hope to see you after 1.0 la...

Thank you for your support as a disabled content creator it means alot for all the subs like and view.
Welcome to our gaming channel! We bring you immersive gameplay, thrilling adventures, and the latest updates in the gaming world. Join us as we explore new worlds, conquer challenges, and share our gaming expertise. Whether you're a casual pla...

E ai, como você tá?
Nesse vídeo trago para vocês o terceiro episódio da série educacional de Last Epoch.
O que vocês acharam?
Compre o Last Epoch na Steam (Há versões com skins exclusivas):
https://lastepoch.com/pre-order
https://store.steampowered.com/app/89...
Criadores de conteúdo que eu indico e que são apoiadores do nosso trabalho!
@...

This is the leveling build I recommend if you want to cycle start Lightning Wolves Beastmaster or Squirrel Beastmaster. Now its not as fast as totems, but it lets you enjoy the wolf playstyle early without needing massive respecs in the endgame later.
Build This Transitions Into :
https://youtu.be/n_hnKS24E3o
Level 1-21 Planner (Thorn Totem)...

DMGCREW
Click show more below
Pick up @LastEpochGame on our nexus store to support the game and the channel - https://www.nexus.gg/idodmg
Shaman Dev Blog - https://forum.lastepoch.com/t/gathering-storm-and-tempest-strike-rework-coming-to-last-epoch-feb-21st/62368
If you like everything in one place - https://allmylinks.com/idodmg1227
Otherwis...


Tips día 1 en Last epoch, comienza fuerte con esta guía e consejos básicos cuando empieces a jugar este Arpg destinado a cubrir el vacío de diablo 4.
GUIAS LAST EPOCH
🔹https://youtu.be/-ySuWzhMvg8
🔹https://youtu.be/Q8a3DQYqyr4
🔹 Discord - https://discord.gg/ZVcdK7WKv7
🔹 TWITCH - https://www.twitch.tv/chupi_sama
#lastepoch #arpg
Last Epoch es...

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Time Stamps:
00:00 - Top 5 Mage Builds
00:07 - Intro
00:56 - Hydra
02:05 - Iron Man
03:02 - Raiden
04:01 - Glacier
05:01 - Spark Charge
06:04 - Wrap Up
Sentinel:
-Hydra Runemaster Written Guide: https://www.icy-veins.com/last-epoch/runemaster-flame-hydra-e...

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Giveaway Link: https://gleam.io/2FzOQ/last-epoch-314999-rtx-4070ti-super-gaming-pc
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?si=Edg5tvAUn9tsSvjJ
-Necro...

https://maxroll.gg/last-epoch/
https://forum.lastepoch.com/t/new-enemies-models-coming-to-last-epoch-february-21st/62384
🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝
0.9.2 Builds By Class:
Sentinel: Updated 2/13/24
https://www.youtube.com/watch?v=osMCaoeloFY
https://www.youtube.com/watch?v=cWdLwQOd_eM
Mage: Updated 2/13/24
https://www.youtube.com/watch?v=7HdzcukfGsE
...

https://maxroll.gg/last-epoch/
𝐓𝐢𝐦𝐞 𝐒𝐭𝐚𝐦𝐩𝐬:
0:00 Intro
0:28 Number 1 - Boardman21: Thorn Totem Shaman - https://www.youtube.com/watch?v=HO2PqJA_3Vs
1:27 Number 2 - Boardman21: Squirrel Beastmaster - https://www.youtube.com/watch?v=kFymKAPknP4
2:28 Number 3 - Boardman21: Lightning Rampage Werebear - https://www.youtube.com/watch?v=maAE46svV44
4:1...

Last Epoch Lazy Rebuke Bleed Manifest Armor Paladin Build Guide Showcase
In this video I wanted to showcase a lazy version of the popular Manifest Armor Bleed Build, which utilizes Apostate Sanctuary and Cleaver Solution to be able to sit there, AFK while your big burly boi does all the work for you!
Last Epoch Planner :
https://www.lastepo...
EHG loves clearspeed meta right?

In today's video we cover some basic tips for farming the Monolith, and how to best make use of our time spent in Echoes.
Hopefully this teaches some new players how to be more efficient when Last Epoch releases next week. Let me know what you think in the comments!
01:07 - Last Epoch Tools - https://www.lastepochtools.com/
Music by Cullah
W...
Hi All)
https://youtu.be/Aqr_VZRGfRI

В данном видео, без воды и деталей я расскажу и покажу основные механики игры Las Epoch, которая вот-вот выйдет из бета теста в релиз.
And my starter builds
https://youtu.be/-kOynjQao30

В этом видео Вы найдете три хороших и надежных стартовых билда, для первого сезона в Last Epoch.
Ссылки на билды:
Хаммердин -смайтер - https://www.lastepochtools.com/profile/byfbir/character/Palamet
Шаман - https://www.lastepochtools.com/profile/PAADA/character/PAADP
Некромант повелитель бабок - https://www.lastepochtools.com/profile/byfb...
https://www.youtube.com/watch?v=gV5FF2MFnA8&t=5s full guide and breakdown with extra tech 😎

Follow my twitch channel on : https://www.twitch.tv/captainp67
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #warpath #RATLEYINKLLC #diablo4 #walkthrough #guide


DMGCREW
Click show more below
In this @LastEpochGame Video we covering everything you need to know about crafting. We break down Forge Power, affix shards, glyphs, runes, and more! Time stamped below, for your convenience. Enjoy
Shop our Last Epoch store https://www.nexus.gg/idodmg
Become a channel member https://www.youtube.com/@idodmg/join...

This is a leveling showcase for Acolyte. We spec lich in order to proxy Warlock as much as possible. In the run we complete Chapter 9, all passives, all idols, and get level 60. We also do it online. We tried a duo multiplayer run as well but the load times were too brutal. This is roughly the pace I expect as warlock when 1.0 comes out.
Links ...

Watch Me Live at ► https://www.twitch.tv/palsteron
#LastEpoch #LastEpochReview
00:00 Intro
01:03 Last Epoch Overview
04:28 What I Like! 1) Items
10:27 2) Character Customisation
12:50 3) Trading System
14:57 Honorable Mentions
17:48 What I Dislike!
20:16 Story & Campaign
21:47 Performance Is Rough
23:39 Dishonorable Mentions
25:19 Opinion on ...

Last Epoch 1.5 Mill Tick 150% MS Poison Wandering Spirits Wrongwarp Lich Build Guide Showcase
In this video I have the longest intro I've ever done. Much to talk about now that 1.0 is around the corner, and its time to start pulling out the big guns.
Last Epoch Planner :
https://www.lastepochtools.com/planner/3Apw0Nko
Email : dr3adfulr3aper@...

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Time Stamps:
00:00 - Warlock
00:09 - Intro
00:35 - Skills
07:47 - Passives
11:11 - Gear
14:04 - Wrap Up
Fissue Warlock Build Planner: https://www.lastepochtools.com/planner/5Q0az0zB
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://y...

https://maxroll.gg/last-epoch/
https://forum.lastepoch.com/t/healing-hands-skill-tree-coming-to-last-epoch-february-21st/62387
🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝
0.9.2 Builds By Class:
Sentinel: Updated 2/13/24
https://www.youtube.com/watch?v=osMCaoeloFY
https://www.youtube.com/watch?v=cWdLwQOd_eM
Mage: Updated 2/13/24
https://www.youtube.com/watch?v=7Hdzcu...

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Giveaway Link: https://gleam.io/2FzOQ/last-epoch-314999-rtx-4070ti-super-gaming-pc
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?si=Edg5tvAUn9tsSvjJ
-Necrom...

E ai, como você tá?
Vale a pena comprar?
O que vocês acharam?
Compre o Last Epoch na Steam (Há versões com skins exclusivas):
https://lastepoch.com/pre-order
https://store.steampowered.com/app/89...
Criadores de conteúdo que eu indico e que são apoiadores do nosso trabalho!
@vigiabr
@Camarguets
@exotheterrible
Discord: https://di...

#lastepoch #beginnersguide #leveling #endgame #maxroll
Sign Up to Win the Last Epoch PC ► https://thecrimsonmarket.com/club
Subscribe/Follow me here, Thank you for the support!
Youtube ► https://www.youtube.com/channel/UCs20qCPrd1AXRviSTdVCoAg/join
Twitch ► https://www.tw...

The fight for Eterra begins on February 21st, 2024.
Pre-Order your copy to get the exclusive "Golden Guppy" cosmetic pet, and if you already have a copy of Last Epoch you can upgrade to one of the fantastic editions!
Last Epoch - Deluxe Edition: https://store.steampowered.com/sub/990874/
Last Epoch - Ultimate Edition: https://store.steampowe...

Crafting - Last Epoch - Kompletny Poradnik po Polsku
Wszystko co musicie wiedzieć na temat Craftingu w Last Epoch jest prawdopodobnie w tym filmie.
W przypadku gdybym o czymś zapomniał dajcie znać w komentarzu, żeby inni na tym zyskali!
Subskrybować, żeby mi miło było i żebym miał motywację tłumaczyć wam więcej :D
Twitch: https://www.twitch.t...
Voltamos a ativa para as redes com video e lives..!! segue se inscreve e maanda ekele beijo pra mim kkkkkk
https://youtu.be/1CtPhe--vQA?si=7LCPbExhK6O77xQd

► Siga o Canal no Instagram ◄
~~ https://www.instagram.com/malonegamesbr/ ~~
~~ https://www.twitch.tv/malonegamesbr ~~
📝Ajude o Canal
~~ https://livepix.gg/malonegamesbr ~~
===== Características do Jogo =====
MODOS DE DESAFIO
Escolha como deseja jogar - Hardcore para a emoção da morte permanente, Solo Self-Found para o individualista ro...

https://maxroll.gg/last-epoch/
𝐓𝐢𝐦𝐞 𝐒𝐭𝐚𝐦𝐩𝐬:
0:00 Intro
0:45 Number 1 - Abomination non decay: https://www.youtube.com/watch?v=RmSeM0V-peo
1:43 Number 2 - Bone golem Retaliation: https://www.youtube.com/watch?v=i0i1eSFPZLY
2:56 Number 3 - Minion Army: https://www.youtube.com/watch?v=9Fl8TlMyyH4
4:07 Number 4 - Hungering Souls Spirit plague: https...

Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?si=Edg5tvAUn9tsSvjJ
-Necromancer Ultimate Fire: https://youtu.be/YngSp2WDbpA
-Necromancer Necro TANK: https://...
Reaction to the new trailer in Ukrainian / Реакція на останній трейлер перед релізом Українською 🇺🇦 https://youtu.be/k7TsiVTL2nY

Всім привіт, з вами Дайкер :)
Для донатів: https://donatello.to/DaikerUA
STREAMBEATS Copyright Free Music for Streamers (and YouTubers!)
https://open.spotify.com/artist/6GTRLqqiBPUqaOgyxOraHp?si=Fmeo7L5EQDK64gSLqigUqQ
Walkthrough https://youtu.be/UdaPzp6N8M4
https://www.youtube.com/watch?v=PyXGTyaCa9A Thanks for Listening Diablo 4 Fans Not Last Epoch
Here's how I utilize the loot filter in last epoch. Enjoy https://youtu.be/g2DBzD6XVe0
Last Epoch vs. Diablo4
https://www.youtube.com/shorts/_eaDkwN7Qpw
https://www.youtube.com/watch?v=JjVDwChiJdc
Documentary on the history of Last Epoch 0.5 Alpha-1.0
MASTER The META: Last Epoch 1.0 Tier Lists LIVE on Maxroll
https://www.youtube.com/watch?v=pOjdPoxc0IA
Rogue Time
https://www.youtube.com/watch?v=vnN1KKvoDgM
https://youtu.be/m9p8_M4qElY filtro de loot?
https://youtu.be/PyXGTyaCa9A Frostylaroo is back with another Last Epoch Diablo 4 video
SteamLink + Mobil and lets go Last Epoch on the road...
https://youtube.com/shorts/acLsLWNwTe8?si=WIoXaHd-iHDxrS7r
Tips and tricks, enjoy https://youtu.be/73u0RVCnYAE
I just started but I found this item to be super clever: https://www.youtube.com/watch?v=YA5MrR9IKIQ
bring YT embeds back please
https://youtu.be/r1p1dvvtYns - 5 Cycle Start Tips for Last Epoch 1.0
https://www.youtube.com/watch?v=XxRPGCsW-pw&t=191s my 95 level Lich vs 140 corruption
https://youtu.be/Tmka5DVAvMs ZiggyD starter build video
https://www.youtube.com/watch?v=JjVDwChiJdc&t=1113s has anyone seen this yet? its realy well done i even subbed to him after watching
For the sweaty tryhard levelers out there - https://youtu.be/9tSAIDZ0U68

Discord Race Sign Up Link: https://discord.gg/YHa2UGhFQ5
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?si=Edg5tvAUn9tsSvjJ
-Necromancer Ultimate Fire: https...

In the video all the channels are named without the intention of profiting only to grow the game and its community.
Walk through ... https://youtu.be/FZ8OAP5clw8

Thank you for your support as a disabled content creator it means alot for all the subs like and view.
Welcome to our gaming channel! We bring you immersive gameplay, thrilling adventures, and the latest updates in the gaming world. Join us as we explore new worlds, conquer challenges, and share our gaming expertise. Whether you're a casual pla...

Last Epoch Ignite Celestial Conflux Sorcerer, Finally A Good Sorc Build | Build Guide Showcase
In this video, Dr3ad abuses his large amount of wealth on the 0.9.2 patch to play some builds to provide a screen filling experience.
Last Epoch Planner :
https://www.lastepochtools.com/planner/MA1yxEeA
Email : dr3adfulr3aper@gmail.com
Twitch : ht...

Zdravím vás Válečníci,
jsem Qwadrax, a v tomto videu vám představím 10 Tipů do začátku ve hře Last Epoch,.
Stream: https://www.twitch.tv/qwadrax
FB k LE: https://www.facebook.com/groups/613959910114217
Discord: https://discord.gg/CtCSXPfyJm
00:00 Úvod + jak a kde získám mastery
00:35 Skill Tagy a Lootfilter
06:22 Rune of Shattering
10:03 Org...


FLAME WRAITHS NECROMANCER BEST STARTER Build Guide for beginners Last Epoch tanky monolith farmer
Last Epoch Tools : https://www.lastepochtools.com/planner/3Ap47geA
Loot filter : https://pastebin.com/fZbQym97
Time stamps :
0:00 Intro
0:54 Build Overview
2:20 How it works?
3:39 Passives
4:54 Skills overview
6:00...

Monolity Poradnik - Co po kampanii Last Epoch? Jak wygląda Endgame
Szybki tutorial na temat monolithów i ECH w Last Epoch. Czyli co dokładnie powinienem zrobić po przejściu kampanii.
Monolithy i blessingi: https://www.lastepochtools.com/endgame/monolith
Twitch: https://www.twitch.tv/thewyplosz
Twitter: https://twitter.com/TheWyplosz
Instagr: ...

Check Out All My Guides On My Icy Veins HUB: https://www.icy-veins.com/last-epoch/aaronactionrpg-last-epoch-guide-hub
Discord Race Sign Up Link: https://discord.gg/YHa2UGhFQ5
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/J...

In partnership with Maxroll and Eleventh Hour Games, I have the opportunity to showcase these three new builds, coming with 1.0!
- Written guides *
Blast Rain Marksman:
Torment Warlock:
Tempest EQ Beastmaster:
Find me on Twitch ► https://www.twitch.tv/volca_
Discord ► https://discord.gg/ahBHyVqAuc
Maxroll ► https://maxroll.gg/last-epoch
Nexus ...

Last Epoch Patch 1.0 Overview
Join Game Director Judd Cobler for a very special Patch Notes Overview, as we celebrate the launch of Last Epoch and the 1.0 Patch.
Link to the full Patch Notes on the forums: https://forum.lastepoch.com/t/last-epoch-1-0-patch-notes/62536
The fight for Eterra begins on February 21st, 2024.
Pre-Order your copy ...

#lastepoch #arpg #crafting #poradnik #leveling #lastepoch #beginnersguide
Pre-ordery: https://lastepoch.com/pre-order
Last Epoch to gra akcji typu hack and slash z wczesnym dostępem, opracowana przez Eleventh Hour Games. W kwietniu 2018 r. w ramach akcji Last Epoch na Kickstarterze ukazało się bezpłatne demo, w które można grać. W kwietniu 2...
@everyone https://www.twitch.tv/bibulandia En directo!!! ❤️ Pasate a saludar. 🇪🇸 🔴PARTNER OFICIAL🔴DROPS DIA 21🔴PASATE Y SALUDA


Maxroll leveling builds:
https://maxroll.gg/last-epoch/build-guides?filter[misc][taxonomy]=taxonomies.misc&filter[misc][value]=leveling
My twitch:
https://www.twitch.tv/ter3k
LE speedrun discord:
https://discord.gg/7mRwqM5hgY

Last Epoch 1.0 Patch Notes:
https://forum.lastepoch.com/t/last-epoch-1-0-patch-notes/62536
If I forgot something, I will add it in the comments section.
Twitch:
https://www.twitch.tv/trikster08
Timestamps
0:00 - Intro

Last Epoch 1.0 Patch Notes, Quick Dirty And No Bullsh*t
In this video I speed run the patch notes to give you guys a massive TL:DR of everything! Your one stop shop for learning whats changing for 1.0!
Patch note notepad doc :
http://notepad.link/share/s2pvLcK1v8k1OAoBaWHF
Full Patch Notes Here :
https://forum.lastepoch.com/t/last-epoch-1-0-...
1.0 Faction Deep Dive, 2x Warlock Builds and 2x Falconer Builds: https://www.youtube.com/watch?v=c34T_pehWhk

Ghazzy is collaborating with Icyveins for an EXCLUSIVE Gameplay look on the Falconeer and Warlock classes and their possible skills and builds you can around with, PLUS the video also covers a deep insight into the new faction system - ALL of this is being released THIS Wednesday, the 21st of February!
If you're interested in buying the game - ...

***Note: Currently the node Corrupted Consciousness that is suppose to give us increased dmg based on % missing health, is doing nothing, so due to this, we are missing roughly 10% overall damage output. ***
I thought it would be a good time to go over Death seal for lich since 1.0 is around the corner and with the influx of new players that mi...

UNCHANGED IN 1.0 Last Epoch Lazy Warslash Warpath VoidKnight Build Guide Showcase
Last Epoch Planner :
https://www.lastepochtools.com/planner/0AKm6gLB
Email : dr3adfulr3aper@gmail.com
Twitch : https://www.twitch.tv/dr3adful__
Discord : https://discord.gg/tGqngsB
#lastepoch

Last Epoch - A brand new ARPG Diablo-esq game which is finally hitting full release on Wednesday 21st Feb 2024! I cover what you need to know about the game and what it offers plus how YOU can get involved in getting the game and coming along for Twitch Drops to earn yourself some nice juicy rewards!
Pre Order Last Epoch - https://www.nexus.gg/...

https://maxroll.gg/last-epoch/
0:00 Intro/Gameplay
2:58 My Thoughts
6:32 New Trailer
0.9.2 Builds By Class:
Sentinel: Updated 2/13/24
https://www.youtube.com/watch?v=osMCaoeloFY
https://www.youtube.com/watch?v=cWdLwQOd_eM
Mage: Updated 2/13/24
https://www.youtube.com/watch?v=7HdzcukfGsE
Rogue: Updated 2/13/24
https://www.youtube.com/watch?v...

Support the stream: https://streamlabs.com/boardman21

https://maxroll.gg/last-epoch/
0:00 Intro
0:28 Wheel of Torment
1:20 Unvar’s Rise
2:06 Unvar’s Exile
2:27 Unvar’s Hegemony
2:42 Communion of the Erased
3:01 Stygian Coal
4:07 Sigeon’s Reprisal
4:34 Spine of Malatros
5:14 Vial of Volatile Ice
5:37 Blood Roost
6:08 Falcon Fists
7:21 Talons of Valor
8:09 Wraithlord’s Harbour
0.9.2 Builds By Class...

The best builds for Last Epoch 1.0 for all classes.
Maxroll Last Epoch tier list: https://maxroll.gg/last-epoch/tierlists
Lizard: https://www.twitch.tv/lizard_irl
McFluffin: https://www.twitch.tv/lonestar_mcfluffin
Volca: https://www.twitch.tv/volca_
Bina: https://www.twitch.tv/binaqc
Hydrahedron Runemaster: https://maxroll.gg/last-epoch/bui...

Hey everyone just making a quick-ish video on changes related to Necromancer. Let me know what you think about today's patch notes in the comments below! Soooo PUMPED!
Discord: Zeckar
Old Skele Rogue Guide: https://www.lastepochtools.com/build-guides/lichs-scorn-skeleton-rogues-by-qwark28
Skills & Passive Changes 0:00
Unique Changes 9:23
Gener...

Hello this is my favorite necro starter that I thought I would share you with you guys! I've played this build for many years and have iterated on it each patch. Hope you try it out and enjoy it let me know if you have any questions or concerns :)
Discord: Zeckar
Boardman's Necro Leveling Guides:
Fire Wratih - https://www.youtube.com/watch?v=B...

Quick TLDR from the Patch Notes for 1.0 Release for Last Epoch !! Enjoy :)
Every Topic with links below :
Patch notes = https://forum.lastepoch.com/t/last-epoch-1-0-patch-notes/62536
Endgame Rebalance = https://forum.lastepoch.com/t/last-epoch-1-0-patch-notes/62536/3#endgame-rebalance-2
Corruption Scaling = https://forum.lastepoch.com/t/last-e...

How to make loot filters for any build in Last Epoch - hiding clutter, showing good gear and highlighting the best gear for your build. Most importantly - done as simply as possible. It really doesn't have to be as confusing as it looks.
The Template for You to Edit:
https://www.lastepochtools.com/loot-filters/view/0AK8avQb
Export to clipboard ...


🔴 WATCH LIVE: https://www.twitch.tv/ChronikzTR
🔵 JOIN: https://discord.gg/2je9aWrqdt
🎮 BUY: https://www.nexus.gg/chronikz/last-epoch
🚀 MORE POWER: https://bit.ly/Chronikz
Hi everyone! In this video I'm showing you guys the 1.0 version of Last Epoch releasing on the 21.02. at 6pm CET.
Due to my relationship with Maxroll.gg I was given press acce...

Last Epoch Holy Flame Caster Paladin Looks Insane | Build Guide Starter Theorycraft 1.0
This build utilizes self cast healing hands
Theorycrafted Planner :
https://www.lastepochtools.com/planner/mQkKJ0DQ
Email : dr3adfulr3aper@gmail.com
Twitch : https://www.twitch.tv/dr3adful__
Discord : https://discord.gg/tGqngsB
#lastepoch
Want to play for 24 hours while servers go up for 1.0?
https://youtu.be/nKGDGX7Q7UA

Want to play Last Epoch while servers are down for patch 1.0? Create an offline character and log into it before 9:00AM PST on Feb 20th.
Join this channel to get access to perks:
https://www.youtube.com/channel/UCTpUh0XCJOv_pmtNsJAkC2A/join
You can support me and the channel by following and subscribing.
https://www.youtube.com/watch?v=Fxfafc0ipqQ something from the german content community 🙂

zu Holy: https://de.weareholy.com/discount/MOO5?ref=moo
Last Epoch ist das neue Action-RPG am Horizont und bringt vor allem Diablo 4 und Path of Exile ins Schwanken. Ich zeige euch heute einmal alles rund um das Spiel und gebe euch meinen ersten Eindruck. Wir schauen uns das Leveln, ein paar der Systeme zu Skills & Passiven und auch das Endgame...

Reaccionamos al video de @Frostylaroo por qué los jugadores de DIABLO IV odian LAST EPOCH
Vídeo original: https://www.youtube.com/watch?v=5IFY3gblZ28&t=0s&ab_channel=Frostylaroo
🔴🔥Si estás pensando en comprar Last Epoch, te agradezco que lo hagas a través de mi referido apoyando el canal :D https://www.nexus.gg/morttimer
Directos en mi ca...
this is my first video about last epoch on youtube, "Last epoch starter pack for dummies" in italian: https://www.youtube.com/watch?v=F1m6WZBabRI

Benvenuti alla mia prima guida definitiva su Last Epoch, l'epico hack'n'slash! In questa esaustiva guida, esploreremo tutti i segreti, trucchi e strategie necessari per dominare questo gioco al massimo livello. Dalla creazione di oggetti di endgame alla navigazione attraverso il mondo di Last Epoch, questa guida è un must per tutti i giocatori a...
Really super serious reasons.
*Some statements in this video are for entertainment purposes only and should not be taken as facts.
Credit to many of the clips in this video go to the Last Epoch Youtube page.
Last Epoch Youtube: https://www.youtube.com/@LastEpochGame

Follow my twitch channel on : https://www.twitch.tv/captainp67
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #MAGE #RATLEYINKLLC #diablo4 #walkthrough #guide
https://youtu.be/pNTDF_qSTOU guia de monolito

E ai, como você tá?
Nesse vídeo trago para vocês o quinto episódio da série educacional de Last Epoch Escola.
Material de apoio monolitos: https://www.lastepochtools.com/endgame/monolith
O que vocês acharam?
Compre o Last Epoch na Steam (Há versões com skins exclusivas):
https://lastepoch.com/pre-order
https://store.steampowered.com/app/89....

Zizaran is yet again joined by @Terek_LE to bring you numerous tips to make Last Epoch a little bit smoother for beginner, when it launches on February 21st.
Join this channel to get access to perks:
https://www.youtube.com/channel/UCAG3CiKOUkQysyKCXSFEBPA/join
Check out Starforge Systems! The best PCs in the universe: https://starforgepc.com/...

https://www.lastepochtools.com/planner/wBEmjGeB
What I reckon is the perfect balance of offence and defence in the falconer board. 83 in falconer, 5 in bladedancer and 25 in rogue. Been theorycrafting it for a week and this is the best I could come up with.
The bird gains acid flask charges (5 max?) when you throw a flask at 125% chance meani...

Shadow Hail of Arrows Marksman:
https://youtu.be/gIWIl1tE64g
Lightning Chakram Bladedancer:
https://youtu.be/ApVUpUHS3nk
Shadow Cascade Bladedancer:
https://youtu.be/eYvGs3_fqSY
Shadow Daggers Bladedancer:
https://youtu.be/mIVx7sMeqYc
Shadow Daggers Marksman:
https://youtu.be/jmhQZFVaCMA
Twitch:
https://www.twitch.tv/trikster08
Timestamps
0:00...

This video goes over some good starter tips for Last Epoch.
*Some statements in this video are for entertainment purposes only and should not be taken as facts.
Action RPG crafting guide: https://youtu.be/IyT7uuV-_28?si=SDdBFwupiE8ueFRR
Credit to many of the clips in this video go to the Last Epoch Youtube page.
Last Epoch Youtube: https://ww...
https://youtu.be/qqokNf65id8 stallmage video Im in apparently

Steelmage prepares for the full release of Last Epoch with some build prep help from @Dr3adful before finalizing his plans
Last Epoch 1.0 Patch Notes - https://forum.lastepoch.com/t/last-epoch-1-0-patch-notes/62536
Stream: Feb 19th, 2024
Support the Stream - https://www.twitch.tv/steelmage
Twitter - https://twitter.com/Steelmage2
Discord - htt...
Lets look at all the Sentinel changes coming in Patch 1.0 - https://youtu.be/VeiHRH3P0tQ

Lets look at all the changes coming to the Sentinel in Patch 1.0!
- #lastepoch #patchnotes #lastepochbuilds
👍 Like and Subscribe for more content!
📱 Twitter : https://twitter.com/teszro
Patch notes 1.0 : https://forum.lastepoch.com/t/last-epoch-1-0-patch-notes/62536
Healing Hand : https://forum.lastepoch.com/t/healing-hands-skill-tree-com...
I made an accessibility review/first impressions stream. I'm going to do a second one tomorrow to see what (if anything) has been changed. https://www.youtube.com/watch?v=4_hOx4hA9as

I ken to it a lot more than Grim Gawn and a LOT more than POE. Actually, I ken to it maybe a little more (definitely faster) than I did with Diablo 3. My only concerns are the UI, some auto-target fookery (both of which can be fixed and might already be fixed by 1.0) and whether anyone else I know will play it alongside me. Not even for MP or lo...

twitch: https://www.twitch.tv/smerlowtv
#lastepoch #diablo4 #gaming

Last Epoch Top 5 Intermediate Builds I Suggest For 1.0
This video does not include Warlock or Falconer, as I have not played them yet, which means I cannot recommend them. They are stupidly strong, but I can't give any examples so you will have to wing it!
Ziggy's Top 3 Cheap Build Video I Collaborated With :
https://youtu.be/Tmka5DVAvMs
Ma...
https://www.youtube.com/watch?v=bLfrot6VyaA
good one 🤣
twitch: https://www.twitch.tv/smerlowtv
#lastepoch #diablo4 #gaming

#라스트에폭 #디아4 #POE
라스트에폭 입문자 가이드 및 디아4, POE 비교 리뷰
▶ 매주 월, 화, 수 오후 9시 유튜브와 치지직에서 방송합니다!
[치지직 방송국 링크]
https://chzzk.naver.com/5cdf08ca5d6366d6a5a87b976fb6947b
시청해 주셔서 감사합니다 ㅋ_ㅋ
타임라인
00:00 영상 소개
01:32 플레이 리뷰
03:47 다양한 클래스 (직업 선택 가이드)
05:50 스킬 시스템
09:27 미쳐버린 편의성
12:56 장비 제작 시스템 (아이템 크래프팅)
15:44 마무리 인사

#라스트에폭 #디아4 #POE
디아4 난민, POE 시즌 오프 유저 다 모여라!!!
▶ 매주 월, 화, 수 오후 9시 유튜브와 치지직에서 방송합니다!
[치지직 방송국 링크]
https://chzzk.naver.com/5cdf08ca5d6366d6a5a87b976fb6947b
시청해 주셔서 감사합니다 ㅋ_ㅋ
타임라인
00:00 영상 소개
00:30 운명의 모노리스
04:56 열쇠 던전
05:42 시간의 성소
06:44 영혼불 요새
07:26 어두운 정자
08:22 아레나
08:59 해외 빌드 사이트 보는 법

LAST EPOCH - NAJLEPSZY ARPG na RYNKU? Patch 1.0! [OKIEM CASUALA]
WAŻNE LINKI
💻 Moja Strona: xbambus.pl
📸 IG: xbambusxidolx
#lastepoch #arpg #diablo4 #le
Tagi:
Last Epoch, LE, LastEpochPL, Diablo4, ARGP, Pidzam, Ravv, Piotr Maciejczyk, Kiszak, Narzekamy i Gramy, Siba MMO, DDras, Czy Warto

Check Out All My Guides On My Icy Veins HUB: https://www.icy-veins.com/last-epoch/aaronactionrpg-last-epoch-guide-hub
Discord Race Sign Up Link: https://discord.gg/YHa2UGhFQ5
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/J...
my first in depth guide for Last Epoch! How to create and import loot filters. https://youtu.be/YKixa5fCtpQ

Last Epoch 1.0 launches on Feb 21st and one of the systems you'll want to learn right away is LOOT FILTERS. Filters will help you remove all the garbage gear and only focus on amazing loot for your build! Last Epoch has a LOOT FILTER built right into their game. I'm going to show you how to import a loot filter and how to create your own loot fi...

#lastepoch #arpg #beginnersguide #arpg #crafting #poradnik #leveling #lastepoch #epoch #leveling
Pre-ordery: https://lastepoch.com/pre-order
Last Epoch to gra akcji typu hack and slash z wczesnym dostępem, opracowana przez Eleventh Hour Games. W kwietniu 2018 r. w ramach akcji Last Epoch na Kickstarterze ukazało się bezpłatne demo, w które mo...
Last Epoch - A brand new ARPG Diablo-esq game which is finally hitting full release on Wednesday 21st Feb 2024! I cover what you need to know about the game and what it offers plus how YOU can get involved in getting the game and coming along for Twitch Drops to earn yourself some nice juicy rewards!
Pre Order Last Epoch - https://www.nexus.gg/...



HI, this is luminoushank
If you have any questions about the build you can always ask me on https://www.twitch.tv/luminoushank
Join my discord server https://discord.gg/KmcX97VQGZ
0:00 Intro
00:34 Build info
01:46 Passives
05:31 Gearing,stats and idols
14:28 outro

Wake up babe, new Starter Build Video just dropped.
https://youtu.be/QGl2imB4GU8

Post Patch Notes, served up hot and fresh.
Want even more starter builds? Check my Previous Video:
https://youtu.be/ezFg-2vkVvA
Note
I expect some links are broken. LETools.com is facing a lot of issues today, including Cloudflare web hosting. You may experience issues loading the page. If you experience a non-DNS Issue, let me know.
L...

I'm not planning on playing Falconer for a while but I can't help myself but theorycraft! My build challenge to you is - can you take this build concept of falcon strikes crit as main source of DPS with explosive traps as dmg boost and clear T4 Julra under 20s as well as Monoliths Corruption 300? If you pass those benchmarks, come share your acc...

In todays video we take a look at all of the class icons and rank them on personal preference
Remember the game launches on the 21st of February 2024!
📌Steam Link ► https://store.steampowered.com/app/899770/Last_Epoch/
📌Pre Order Link ►https://lastepoch.com/pre-order
--------------------------------------- LINKS ------------------------------...
https://www.youtube.com/watch?v=8-AxiGRucLw non shadow dagger crit explo falconer/bladedancer

Build Planner: https://www.lastepochtools.com/planner/ZA8az7yQ
My Lootfilter: https://pastebin.com/PuNhRyqn
Speedfarming and Bossing like your favorite League of Legends character Zed, This is a template how you can start your journey as a Bladedancer Falconer and dont rely on broken mechanics like shadow daggers(no sd build) ( boring or on th...

Discord Race Sign Up Link: https://raid-helper.dev/event/1208976184961015838
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?si=Edg5tvAUn9tsSvjJ
-Necromancer ...

Last Epoch Best Mastery Tierlist For 1.0
In this video I go over my own tierlist, since at this point its a tradition. Thanks for all the support and kind words guys!
Email : dr3adfulr3aper@gmail.com
Twitch : https://www.twitch.tv/dr3adful__
Discord : https://discord.gg/tGqngsB
#lastepoch

Всем привет! В этом ролике я вкратце расскажу о новой Action RPG под названием Last Epoch, которая выходит уже 21 февраля в 20:00. Расскажу о внутриигровом билдере, системе крафта и подбора вещей, высокоуровневом контенте, да и в целом о том достоин ли внимания проект. Приятного просмотра!
Игра в Steam - https://store.steampowered.com/app/8997...

Written guide: https://maxroll.gg/last-epoch/build-guides/blast-rain-marksman-guide
Gameplay video: https://www.youtube.com/watch?v=z8Z3oIPctbQ
Find me on Twitch ► https://www.twitch.tv/volca_
Discord ► https://discord.gg/ahBHyVqAuc
Maxroll ► https://maxroll.gg/last-epoch
Nexus store ► https://www.nexus.gg/volca
00:00 Intro/Leveling
01:02 Exp...

Written guide: https://maxroll.gg/last-epoch/build-guides/torment-warlock-guide
Gameplay video: https://www.youtube.com/watch?v=z8Z3oIPctbQ
Find me on Twitch ► https://www.twitch.tv/volca_
Discord ► https://discord.gg/ahBHyVqAuc
Maxroll ► https://maxroll.gg/last-epoch
Nexus store ► https://www.nexus.gg/volca
00:00 Intro
00:36 Chthonic Fissure...

Dive Bomb Guide: https://maxroll.gg/last-epoch/build-guides/dive-bomb-falconer
Planner Early: https://maxroll.gg/last-epoch/planner/43et0shj
Planner Later: https://maxroll.gg/last-epoch/planner/lffl0k6j
0:00 Intro
1:20 Starting Rogue Passives
3:12 Flurry
4:27 Smoke Bomb
5:10 Falconry
7:23 More Passives
8:50 More Flurry
9:10 Removing Smoke Bomb...

Written guide: https://maxroll.gg/last-epoch/build-guides/tempest-earthquake-beastmaster-guide
Gameplay video: https://www.youtube.com/watch?v=z8Z3oIPctbQ
Find me on Twitch ► https://www.twitch.tv/volca_
Discord ► https://discord.gg/ahBHyVqAuc
Maxroll ► https://maxroll.gg/last-epoch
Nexus store ► https://www.nexus.gg/volca
00:00 Intro
00:32 T...

Here are 3 existing builds that are top tier and 2 builds for the brand new classes that I hope will be top tier. :) Check them out and see if any one of them look interesting! You can find YouTube videos and build planners / guides below.
Beastmaster:
YouTube Video - https://www.youtube.com/watch?v=uH4rem-xc_k
Build Planner (Aspirational) UPDA...

Struggling to decide which faction, I break it down in playstyle from casual to veteran to help you figure our which faction maybe worth it for you.

O Last Epoch é um RPG de ação online que combina viagens no tempo, classes personalizáveis, criação de itens e uma história envolvente. O jogo está em acesso antecipado e recebe atualizações constantes, incluindo o modo multiplayer, que foi lançado recentemente. Se você gosta de jogos como Diablo, Path of Exile e Grim Dawn, você vai adorar o Las...

Last Epoch Frostbite Tornado Shaman Might Kill Your Instance | Last Epoch Build Starter Theorycraft
Theorycrafted Build Planner :
https://www.lastepochtools.com/planner/VBMmw9EB
Email : dr3adfulr3aper@gmail.com
Twitch : https://www.twitch.tv/dr3adful__
Discord : https://discord.gg/tGqngsB
#lastepoch

Last Epoch 1.0 Mad Lightning Runemaster Build Guide
This is a Runemaster build guide focusing on the Lightning Blast skill to apply Spark Charges. This build is extremely tanky with great damage both on single target and aoe clear.
Watch me live at:
https://www.twitch.tv/pinchingloaf
Runemaster Leveling Guide by Dr3adful:
https://www.youtub...

Last Epoch is an early access hack and slash action role-playing game developed by Eleventh Hour Games (EHG). In April 2018, a free playable demo was released as part of Last Epoch's Kickstarter drive. In April 2019, the game's beta was made available via Steam Early Access. TODAY it has an official release! And i will stream it on Twitch as wel...

#lastepoch #arpg #beginnersguide #necromancer
#lastepoch #arpg #beginnersguide #arpg #crafting #poradnik #leveling
Pre-ordery: https://lastepoch.com/pre-order
/////////////////////////////
Kup Last Epoch TANIEJ niż na steam ► https://www.nexus.gg/asorintv
///////////////////////////
Last Epoch to gra akcji typu hack and slash z wczesnym dostę...

Discord Race Sign Up Link: https://raid-helper.dev/event/1208976184961015838
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?si=Edg5tvAUn9tsSvjJ
-Necromancer ...
Have 20-25 minutes for a lore dump?
Let me know how I did and how I can improve! Everyone have a blast in 1.0 ❤️

Greetings Travelers!
Welcome to my lore and class fantasy analysis of every class and mastery within Last Epoch. I hope to provide accurate, informative and entertaining lore content to the community as I both learn and interpret it for myself. I've always loved writing and this is now my outlet :)
Forewarning! All of my videos will contain so...
Devs answer community questions, lets take a closer look! - https://youtu.be/H90yMeTs8b0

The Devs held a AMA on reddit, here are some of the answers they gave back to the community!
- #lastepoch #patchnotes #lastepochbuilds
👍 Like and Subscribe for more content!
📱 Twitter : https://twitter.com/teszro
AMA Reddit Link : https://www.reddit.com/r/Games/comments/1avmmnx/ama_we_are_eleventh_hour_games_makers_of_last/

Hi, this is luminoushank
catch me on twitch https://www.twitch.tv/luminoushank
my discord server for guides https://discord.gg/RcmCUMxu
watch my Falcon bomber build for 1.0 guide
https://youtu.be/Jx2R2a9lUU4?si=xAZ03SgMk9uEEFDf
wtf is that
yes
hmm

Last Epoch is already getting slammed with negative reviews from the current launch issues. Some people are going as far as leaving nasty reviews that the game did not launch perfectly.
- #lastepoch #patchnotes #lastepochbuilds
👍 Like and Subscribe for more content!
📱 Twitter : https://twitter.com/teszro
HI @abstract oxide WE SEE YOU! Great Stream BRUH! ❤️
Today's character creation video covers Last Epoch. This includes all the classes, their updated visuals for launch, their mastery choices, and much more!

I decided to take a quick look at character 'creation' in Last Epoch for its full 1.0 launch. This includes all the classes, their updated visuals for launch, their mastery choices, and much more!
● Twitch Channel - https://www.twitch.tv/talesoflumin/
● Ko-Fi Page - https://ko-fi.com/talesoflumin
● Last Epoch Official Site - https://lastepoch.c...

Bienvenidos a un nuevo video de Last Epoch, juegazo ARPG disponible en Steam!! 🥳🔥
https://youtu.be/7gMx_PirxMA?si=ske_46yn3QW8vUSD

#lastepoch #arpg #steam #rpg
📣CORREO
✔ juanjorc0590@hotmail.com
📣MIEMBRO DEL CANAL AQUÍ!
✓https://www.youtube.com/channel/UCADAlsNvEJ4A6HX8JhqDvHw/join
📣GRUP...
My initial 1.0 experience. Acolyte being on point with the voiceline haha https://www.youtube.com/shorts/LJhx0ib0J5Y

Last Epoch 1.0 launch experience #lastepoch #arpg #shorts #launch #diablo #diablo4 #server #networking

Last Epoch 1.0 Steam Deck Gameplay Performance | SteamOS 3.5 | Launch Day | Steam | All Graphics Settings
00:00 - Very Low
01:15 - Settings
01:49 - Low
04:22 - Medium
07:11 - High
09:25 - Very High
12:17 - Ultra
14:07 - 30FPS Ultra
15:29 - 30FPS Medium
16:47 - 30FPS Low
Steam - https://store.steampowered.com/app/899770/Last_Epoch/
📖 Last Epoc...
https://www.youtube.com/watch?v=_fewn-Fg8u8 t4 julra kill with bees. this is on legacy and with the bugged interaction with hive mind and tainted ammunition. will attempt this again on a falconer without tainted ammunition and hopefully damage would be similar

yup. hive mind + tainted ammunition is still bugged.
https://www.youtube.com/watch?v=biUq69AiS-g showcase is on 0.9.2 but still the same for 1.0
my referral code: skrambol
Add my referral code : ThePhat I want the bee

Build is online. Just a quick update if you're looking to play it. Once you unlock cluster bombs it will deplete a lot more mana, look to rush 4/6 Stamina of the Rover and 1/1 Hunters Spoils for sustain. Got neither on in the vid so expect a lot more sustain. Got lucky with a dope Cradle of the Erased shield so running that over dual wield and b...
https://youtu.be/V_EyRqwjV68
i think this may be a little busted lol
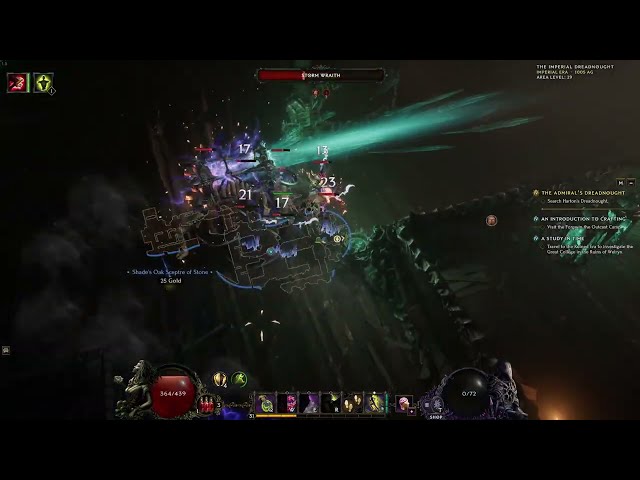
https://www.lastepochtools.com/planner/0oNmDd7B
Now running x2 -3 throw attack mana cost rings and both Hunters Spoils in Falconry and Stamina of the Rover in Falconer passives and the sustain is a LOT better with cluster bomb (4/5 Alchemical Proficiency mind you) but not there yet vs bosses.
Highest crit so far was around 2.5k at lvl 30 with ...
First HC Death for me 😦 https://clips.twitch.tv/GlamorousOriginalDragonflyKappa-ef_d87shSPN9zdqP


Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Fissure Warlock Build Planner: https://www.lastepochtools.com/planner/
Fissure Warlock Loot Filter: https://docs.google.com/document/d/1BKMoBELjznl9V8dJPfyPwdvD6brtpSHt7L11xzKSbdg/edit?usp=sharing
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjap...
https://www.lastepochtools.com/planner/0oNmDd7B
Build is popping off. No points in Splash Zone yet. Highest crit so far was 7k by the bird at around lvl 42. Avian Hurl 5 point bonus in Falconer passives is a huge dps boost.
Shurikens is for an armor buff when you use Shift. Eventually, don't need this on bar and can swap to Decoy. Nice synergy...
Made a video outlining briefly what happened today and my thoughts on it all
https://youtu.be/mnulABPoYkk

Last Epoch 1.0 launched today, with some issues. I go over why it's not a bad thing. Also we are getting a free gift the Autumnnal Wrap
Join this channel to get access to perks:
https://www.youtube.com/channel/UCTpUh0XCJOv_pmtNsJAkC2A/join
You can support me and the channel by following and subscribing.

Just don't get hit by his moon beam which does cold/lightning and you're good. Shit slaps hard.
Fight has 3 phases.
In phase 1 and 3 go for his tentacles not him as he is immune.
In phase 2 in the bottom half of the map, kill the tentacles which spawn all over.
ATB
✅Survive Lagon's Trial For Last Epoch 1.0
---------------------------------...
First HCSSF rip of the 1.0 For me https://youtu.be/AOTJfGf2lqk 😄


What's up, gamers? Neeknog here, and guess what? I was glued to my computer, eagerly awaiting the moment the Last Epoch 1.0 patch dropped. Was it a good idea? Well, let's just say it's been an adventure.
In this video, I'm sharing my first impressions of the highly anticipated 1.0 patch of Last Epoch. Despite a few hiccups and chaotic moments e...

Last Epoch Electrify Smite Healing Hands Paladin Already In Empowered Monos
In this video we right the wrong that I accidentally caused by not reading nodes properly by providing a REAL smite + healing hands build.
Day 1 Last Epoch Planner :
https://www.lastepochtools.com/planner/9Qnkb9EB
Email : dr3adfulr3aper@gmail.com
Twitch : https://ww...

https://www.lastepochtools.com/planner/0oNmDd7B
Had no issues with the final campaign boss, killed her first try. Haven't specced into all 3 glancing blow nodes yet nor Stymphalian Feathers. Saving defences for last. Looking to max Tailwind, Needle Like Precision then Pursuit in Bladedancer next. Movement speed scales the Agility node in Rogue....
https://youtube.com/live/fUAxEb82myg?feature=share
working on poison plague lich

Last Epoch 1.0 - Poison PLAGUE Build - ACOLYTE LICH - Going without any guide! #lastepoch #build #poison #plague #acolyte #lich #guide

Idk if anyone is really interested, but I'll be posting my journey through the story first time playing Last Epoch 🙂

Never played Last Epoch before. Playing through the story for the first time on the official launch day and recording the whole experience. I will take my time with the game first time playing through it, listening to NPCs, reading on skills, items, learn the game and just enjoy it. I am eager to try the endgame but not in a hurry. I will probab...

Мой твич с ежедневными стримами - https://www.twitch.tv/irutasan
Telegram - https://t.me/rutasanium
Discord - https://discord.gg/wkQAzANx
Boosty - https://boosty.to/irutasan
Поддержать монетой - https://www.donationalerts.com/r/irutasan
https://www.lastepochtools.com/planner/0oNmDd7B
Missing 4 glancing blow nodes (Fencing Weave bonus converts from block to glancing blow off of Deflect And Weave bonus, 6% endurance threshold off of Outlander's Tenacity and armor off of 4/6 Stymphalian Feathers bonus so could get a lot tankier with the full build. Always have the option of a dag...
how to get in game stuck in loading screen?
Dumb video I reocrded yesterday. I was having a very "SouthPark killing boars" moment because I was stuck in a quest instance and could keep resetting it and farming level 5 mobs over and over... but could not zone back into town.
https://www.youtube.com/watch?v=CNRlZFJS-bY

So Last Epoch 1.0 Launched today and there are some server issues. Most folks are stuck in the first town, but somehow I managed to get on the other side into an instance. However I can't zone back out of the instance... but this allows me to essentially keep resetting a quest zone over and over and still level. Purely degenerate gameplay bu...

LAST EPOCH is a classic action RPG. You create a character, explore the world of Eterra and fight all kinds of monsters. In the process, you collect equipment, learn new skills and become stronger and stronger.
Should you play Last Epoch in 2024. This game is not as complex as path of exile and not so shallow like a diablo 4. If you getting bor...
test

0:00 - Intro
0:15 - Low Settings
5:00 - High Settings
Get CapCut Pro 7 Day Trial:
https://www.capcut.com/t/ZmFqe56dX/
Get discounted games here:
https://www.instant-gaming.com/?igr=gamer-7940472
Steam Deck OLED:
- 6nm APU AMD
- 16GB LPDDR5-6400 RAM
- 7.4-inch OLED display with HDR
- 90hz refresh rate
- 1TB storage
If you liked the video, h...
Can"t post in bug report so : https://medal.tv/fr/games/last-epoch/clips/1WOErnQLr-U0uS/d1337hbIc9dq?invite=cr-MSxvSTksMjA5NzY5OTYwLA

Watch Untitled and millions of other Last Epoch videos on Medal, the largest Game Clip Platform.
Hey @everyone check out this INSANE bug! https://youtube.com/shorts/-wfjJcXrc34?feature=share

Playing Last Epoch today I encountered a bug where I was unkillable!
Please Like & Subscribe for my content!
#lastepoch #bug #unkillable #arpg #fail #funny

O Last Epoch é um RPG de ação online que combina viagens no tempo, classes personalizáveis, criação de itens e uma história envolvente. O jogo está em acesso antecipado e recebe atualizações constantes, incluindo o modo multiplayer, que foi lançado recentemente. Se você gosta de jogos como Diablo, Path of Exile e Grim Dawn, você vai adorar o Las...
TENCENT IS EVIL

1ª y ultima muerte en hardcore !!!
shoutout to my brother loading screen without him I would have never beaten the endgame boss

Last Epoch 1.0 Twitch Highlights 2024 Day1-Rip, Crafting, Legendaries
FEATURED IN THIS EPISODE:
https://www.twitch.tv/aaronactionrpg
https://www.twitch.tv/arcadebulls
https://www.twitch.tv/carn_
https://www.twitch.tv/ceee
https://www.twitch.tv/chronikztr
https://www.twitch.tv/cohhcarnage
https://www.twitch.tv/ds_lily
https://www.twitch.tv/havoc...

Обращение к Разработчикам Last Epoch в связи с ситуацией на релизе игры.
Спасибо за просмотр!
https://www.lastepochtools.com/ - Официальный сайт игры, там же вы найдёте гайды, билд пл...


My thoughts on Last Epoch 1.0 Launch and Release. Stop by to watch on Twitch at PwnW0lf!

Of course I get lucky with the yellow item for the sake of the video! 😂
#lastepoch #crafting #tips
"LE-61" - (noun) A notorious bug within the Last Epoch game, known for its unpredictable and game-breaking effects. When triggered, LE-61 causes the player character to become stuck in a perpetual loop, rendering them unable to progress or interact with the game environment. This glitch is often accompanied by graphical distortions and erratic behavior of in-game elements. Players encountering LE-61 are frequently forced to restart their game session, leading to frustration and lost progress. Despite numerous attempts by developers to patch the bug, LE-61 remains a persistent and elusive anomaly within the Last Epoch universe.

Last Epoch Loot Filter Template For Everyone
So in this video I showcase a loot filter template I have made for everyone, based on my own preferences.
WATCH VIDEO FIRST OR THIS IS USELESS :
https://pastebin.com/BxZR5Dhh
Email : dr3adfulr3aper@gmail.com
Twitch : https://www.twitch.tv/dr3adful__
Discord : https://discord.gg/tGqngsB
#lastepoch
**bees, need more bees **
also:
Please for the Love and understanding of all us. I have 400 hours in game till now. If it API service issues. I would personally migrate to different server option or service. Fire the team you have running servers at this current. Good read.
Infrastructure failure
When resource usage exceeds capacity, servers in an API backend may run slowly or become unresponsive. Individual nodes in a cluster can stop working due to local hardware failure, operating system crashes, application crashes, or loss of network connectivity to the rest of the cluster. When a node fails, clusters without failover capabilities can take the API endpoint offline.
Container orchestration is the layer that streamlines container deployment, management, scaling, and networking. Microservice APIs running on containers without proper orchestration may fail when the containers crash.
A widely adopted container orchestration technology is Kubernetes. APIs can experience outages when pods in a Kubernetes cluster crash and don't come up in another node. Kubernetes pods can crash for many reasons, including the following:
incorrect configuration
out-of-memory events
readiness probe failing
liveness probe check failing
application crashing
Network failure
Networks without redundant paths, connections, subnets, or devices can experience outages. The network architecture for APIs, therefore, should include failover zones, routing mechanisms, and load balancers.
High availability at a network level means the loss of a subnet in one part of the network does not disrupt the API. Client requests are seamlessly routed to a standby subnet with the same service running in it.
Without proper routing configuration, API gateways may not be able to send client requests to the appropriate API instance. An API gateway must employ either client-side or server-side discovery patterns to route requests to available service instances.
Thats alot of stuff nobody is gonna read
also he saves you time by putting "fire the team you have now", if you decide to start reading you know to stop here

Trying different ways to fix LE-61 and Unable To Play Online Errors
Its Not A Guaranteed Fix, Still Took Me 10+ LE 61 Errors Using Another Door From Other Side!
Unable To Play Online & LE-61 Matchmaking Fail Error Potential By Pass Instructions
- Go Offline Then Swap To Online At Character Selection
- Attempt To Character Select, Could Tak...

Review will be out sometime next week.
SONGS
Sigala - Sweet Lovin' ft. Bryn Christopher (Official Video)
https://youtu.be/qj5zT4t7S6c?si=6oihu_zMbS8554DR
Love Me Like That · Bleeding Fingers Chilled Pop:
https://youtu.be/CIDGzIFwY-g?si=PTHiMlWXy-_7BG3d
For now Monolith echo maps seems to be less laggy, not advised to attemp leveling new character with constant DC & LE 61

👉 Abonne toi et clique sur la 🔔 pour ne rater aucune vidéo (+👍)
🔱 Rejoins le Discord ➜ https://discord.com/invite/BBMqdKfHNK
🐤 Follow mon twitter ➜ https://twitter.com/OxemTV
🧲 Tous mes réseaux ➜ https://linktr.ee/oxem
💳 Soutiens la chaine sur ➜ https://fr.tipeee.com/oxem
🧪 Soutiens mes RPG en développement https://ko-fi.com/regalia_project
...

My thoughts on Last Epoch 1.0 Launch and Release. Stop by to watch on Twitch at PwnW0lf!
Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #spineofmalatrose #RATLEYINKLLC #diablo4 #walkthrough #guide

Is Last Epoch the future of the ARPG genre? With the failure of Diablo 4 there is definitely space in the market and the recent 1.0 update has made Last Epoch a strong contender to face up against the upcoming Path of Exile 2.
Sources used in this video (in order of appearance) are:
Game V | “Diablo 4 Epic 15 Minutes Exclusive Gameplay (4K 60F...

Devs hated that the referal event was ruining the experience and promised...... come find out in the video. GREAT NEWS
#2024 #gamingnews @WeAreViledNation
Hey everyone please check out my short! I got this insane bug! https://youtube.com/shorts/-wfjJcXrc34?feature=share
Playing Last Epoch today I encountered a bug where I was unkillable!
Please Like & Subscribe for my content!
#lastepoch #bug #unkillable #arpg #fail #funny

Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #VIALOFVOLATILEICE #RATLEYINKLLC #diablo4 #walkthrough #guide
let go
https://www.twitch.tv/fuobr

Twitch
SR ON! !sr !meta @fuobr - !kaspersky !amazon - subathon #noping #pokemon Catapult #PALWORLD #PAL #lineage #ravendawn #iox #daredrop #ad

Thank you for your support as a disabled content creator it means alot for all the subs like and view.
Welcome to our gaming channel! We bring you immersive gameplay, thrilling adventures, and the latest updates in the gaming world. Join us as we explore new worlds, conquer challenges, and share our gaming expertise. Whether you're a casual pla...
Of course I get lucky with the yellow item for the sake of the video! 😂
#lastepoch #crafting #tips

Where is support, online not available

One of my potential starters come 1.0 incase the meta gets flipped upside down as the Druid will be tanky enough to survive the patchnotes!
- Gameplay: 00:00
- Passive Tree: 03:54
- The Skills: 06:45
Build Planner (Experimental food for thought)
https://www.lastepochtools.com/planner/VBMDLkPQ
- So not sure about the gear...
-----------------...

Continuing to build perfect POISON build on lich
https://youtube.com/live/59X4k3159nU?feature=share

Last Epoch 1.0 Poison PLAGUE Build - LICH - Part 2 - Going without guides and improvized build. #lastepoch #build #poison #plague
My thoughts on Last Epoch 1.0 Launch and Release. Stop by to watch on Twitch at PwnW0lf!

Live TWITCH Stream: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Deathly Harbour Loot Filter: Coming Soon
Build Planner: Coming Soon Site Down
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?s...

Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #WHEELOFTORMENT #RATLEYINKLLC #diablo4 #walkthrough #guide

https://www.lastepochtools.com/planner/0oNmDd7B
Highest crit so far was around 29k @ lvl 69. Build scales hard with crit chance/multiplier and flat throwing damage, try get these everywhere possible.
Audio issues should be fixed now.
ATB
If you enjoyed the video don't forget to like, subscrib...

Hi again! Hopefully everyone has been able to play at least a little bit. I am just sharing my experience on the first cycle and how my start went. Also, showing off the build I am using currently. Let me know if you want a guide or are interested in any of the other builds I mentioned! :)
Discord: Zeckar

W tym filmie dowiesz się wszystkiego o systemie crafcenia przedmiotów w grze Last Epoch. Czym są shardy, runy, glyphy, prefiksy oraz sufiksy.
00:00 - 00:08 Intro
00:09 - 00:38 Crafting
00:39 - 01:58 Affix shardy
01:59 - 02:36 Potencjał wykucia
02:37 - 05:31 Skille
05:32 - 06:35 Runy
06:36 - 06:47 Outro
➡️ Kup Last Epoch taniej o 20 zł!: htt...
Of course I get lucky with the yellow item for the sake of the video! 😂
#lastepoch #crafting #tips
https://youtube.com/shorts/CuvSm0aC2rw?feature=share
Super short video on necromancer in a nutshell for a giggle or two


Last Epoch Boss Lagon - Faça tranquilo
Um pequeno vídeo matando um bom que é realmente chato e que tem golpes Hit Kill.


Last Epoch Electrify Smite Healing Hands Paladin In 300 Corruption, MG Looks "Fine"?
Last Epoch Planner :
https://www.lastepochtools.com/planner/0AKKNOZA
Email : dr3adfulr3aper@gmail.com
Twitch : https://www.twitch.tv/dr3adful__
Discord : https://discord.gg/tGqngsB
#lastepoch
Hows the game since launch? https://youtu.be/AdK7azacpew

Its been 2 days since the launch of Last Epoch. How is the game doing since then. Well, there is a few things to talk about.
- #lastepoch #patchnotes #lastepochbuilds
👍 Like and Subscribe for more content!
📱 Twitter : https://twitter.com/teszro
TWITCH DROP LINK : https://twitch.lastepoch.com/

Thank you "Diablo 4 Super Fans" all so much for your support and great comments in my "Why Diablo 4 Players Hate Last Epoch Video".
I was shocked by how popular my video was, and seeing all my favorite youtuber / streamers comment and watch the video really meant so much to me.
*Some statements in this video are for entertainment purposes onl...

https://maxroll.gg/last-epoch/build-guides/nova-hammerdin-guide
If you have any questions ask in the comments.
Ever wanted a 3d printed last epoch sign ? https://youtube.com/shorts/IplDJ8-HLoQ?si=9tmamgkW5kBfgofs

i designed a Last Epoch sign live on stream and felt in love...
Like & Subsribe! :)
twitch.tv/lokthran
wrong i read it cause i know what he speaking about maybe you dont understand it 🙂
Your sister and I couldn't be more proud of you 🫂
The Storm Crow + Tempest Strike giga scaling Guide (in its early version)

Build Planner: https://www.lastepochtools.com/planner/jAvxavYB
Tips in the pinned comment as well!
More of Me:
TWITCH: https://www.twitch.tv/neeko2lo
TWITTER: https://twitter.com/Neeko2loTV
DISCORD: https://discord.gg/m2yHbmV
E-MAIL: neeko2lo@t-online.de
Chapters:
00:00-00:31 Intro and Showcase
00:32-10:54 Build explanation
10:55-14:0...
RIP Lvl 95 Bladedancer, #7 in HCSSF when died https://clips.twitch.tv/GoldenCuriousPresidentWholeWheat-CHLE8TOfm-BkuTAZ

My thoughts on Last Epoch 1.0 Launch and Release. Stop by to watch on Twitch at PwnW0lf!

O Last Epoch é um RPG de ação online que combina viagens no tempo, classes personalizáveis, criação de itens e uma história envolvente. O jogo está em acesso antecipado e recebe atualizações constantes, incluindo o modo multiplayer, que foi lançado recentemente. Se você gosta de jogos como Diablo, Path of Exile e Grim Dawn, você vai adorar o Las...
Of course I get lucky with the yellow item for the sake of the video! 😂
#lastepoch #crafting #tips

https://www.lastepochtools.com/planner/rBryGzOQ
Subject to changes. Ultimately going for a core of Elecoe's Abandon chest + Jungle Queen's belt to machine gun cunts down. Once Shurikens is 20, gonna start leveling Decoy which will be nice vs bosses. Don't need Shurikens on bar as it autocasts every shift providing 30% x 5 Shurikens = 150% armor...

Hej,
Szybkie spojrzenie na to jak działa Last Epoch w wersji 1.0 na Steam Decku.
Chcesz mnie wesprzeć?
https://streamlabs.com/admiral_avalon...


Feels like we've been down this road before doesn't it? Sad it even needs to be said
#gaming #lastepoch #diablo4
Good stuff.

I finished leveling my Warlock to 100 yesterday, most likely at rank 5 in the world. During the leveling process, I learned a lot about how to get to lvl 100 as fast as possible. I wanted to share my findings in this video so we can all get to 100 faster and then move on to non-leveling related activities in Last Epoch :D Let me know if you find...

made a lore video cause its super cool so far!
https://www.youtube.com/watch?v=5S-aKSt7AyI&ab_channel=Priskyy

This video will review the lore of chapters 1-6 of Last Epoch. Much of this information was gathered straight from the gameplay or through talking with others on the forums.
SOCIALS:
https://www.twitch.tv/priskyylol
https://twitter.com/Priskyylol
https://www.instagram.com/priskyylol/
#lastepoch #twitch #lore #arpg #diablo4 #asmongold #gameplay

#lastepoch Hi guys! Last Epoch is out and with it comes a very powerful crafting system! The is a simple guide and explanation to crafting in Last Epoch!
►Twitch Stream: https://www.twitch.tv/lattimere
►Be sure to check out my other videos here: https://www.youtube.com/@lattimere/videos
If you want to support me and is very much appreciated:
►...

Last Epoch Has A Secret You Can Unlock
live now for drops: https://www.twitch.tv/darthmicrotransaction

Twitch : https://www.twitch.tv/aayrron
Planner end-game V1 : https://www.lastepochtools.com/planner/mQkXJWDB
Planner leveling : https://www.lastepochtools.com/planner/0QdwDJpA
Volcanus sert principalement à booster les dégâts de vos divines bolt et flame burst via son flat spell damage présent sur l'épée. Magma shards cast par volcanus scale a...
where is chat "memes"?
Hi - I'm the voice actor who played the mage, and voiced the Last Epoch trailer 😃
Please follow my YouTube link below for lots more of my work 🧙♂️
https://www.youtube.com/@WarmVoice

YouTube
Award-Nominated Voice Actor
Please send me an email, or DM me on Twitter if you'd like to collaborate on a project.
Just a handful of the video games I've worked on :
➡️ Last Epoch (Trailer Narrator and Mage Character)
➡️ Dagon (Lead Character & Narrator)
➡️ Dinner With An Owl (Lead Character - Mr Brown the Owl)
➡️ Albion Online (Trailer...
The fight for Eterra begins on February 21st, 2024.
Pre-Order your copy to get the exclusive "Golden Guppy" cosmetic pet, and if you already have a copy of Last Epoch you can upgrade to one of the fantastic editions!
Last Epoch - Deluxe Edition: https://store.steampowered.com/sub/990874/
Last Epoch - Ultimate Edition: https://store.steampowe...
Im recording my first playthrough of Last Epoc and uploading it to youtube as a Let's Play series 🙂
No Commentary, blind playthrough. Didn't know much about the game before launchday.
Hope anyone find some joy from it, either as a background-video while sleeping or maybe just to watch some gameplay from a noob 🤷♂️
Playing through the game on softcore online. Mage / Runemaster.
Im a Invoker enjoyer from Dota 2. Played Diablo 2 on and off since it was released. Some D3, D4 and PoE aswell.
Happy Launch-weekend everyone 🙏
7 Epsiodes so far.
New Episodes will come faster now that the loading screen issues and server problems seems to be alot better! Also alot less editing and cutting the lonng loadscreens 👌😂
https://www.youtube.com/watch?v=xceGmVRmcR0&list=PLoTZkWZowmOgXM0Y-p5Vd8GoEYtuvlYLc
Never played Last Epoch before. Playing through the story for the first time on the official launch day and recording the whole experience. I will take my time with the game first time playing through it, listening to NPCs, reading on skills, items, learn the game and just enjoy it. I am eager to try the endgame but not in a hurry. Will probably...
O Last Epoch é um RPG de ação online que combina viagens no tempo, classes personalizáveis, criação de itens e uma história envolvente. O jogo está em acesso antecipado e recebe atualizações constantes, incluindo o modo multiplayer, que foi lançado recentemente. Se você gosta de jogos como Diablo, Path of Exile e Grim Dawn, você vai adorar o Las...

Link to the planner for the build : https://maxroll.gg/last-epoch/planner/671oj0w5
Explanation : 00:00
Monolith Run : 02:24
#LastEpoch #Warlock #Ignite #Build

Be sure to check out tons of the top guides made for Last Epoch here at Maxroll: https://maxroll.gg/last-epoch/build-guides/dive-bomb-falconer
🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝
𝐓𝐢𝐦𝐞 𝐒𝐭𝐚𝐦𝐩𝐬:
0:00 Intro / Shout out to new members / About the Build
1:55 Skills
2:00 Falconry
5:39 Aerial Assault
6:09 Dive Bomb
6:48 Explosive Trap
7:50 Smoke Bomb
8:30 Passives
10...
Hey @everyone check out this CRAZY bug I got lol! https://youtube.com/shorts/-wfjJcXrc34?feature=share
Playing Last Epoch today I encountered a bug where I was unkillable!
Please Like & Subscribe for my content!
#lastepoch #bug #unkillable #arpg #fail #funny
My thoughts on Last Epoch 1.0 Launch and Release. Stop by to watch on Twitch at PwnW0lf!

Thank you for your support as a disabled content creator it means alot for all the subs like and view.
Welcome to our gaming channel! We bring you immersive gameplay, thrilling adventures, and the latest updates in the gaming world. Join us as we explore new worlds, conquer challenges, and share our gaming expertise. Whether you're a casual pla...
Check out this CRAZY bug in Last Epoch! https://youtube.com/shorts/-wfjJcXrc34?feature=share
Playing Last Epoch today I encountered a bug where I was unkillable!
Please Like & Subscribe for my content!
#lastepoch #bug #unkillable #arpg #fail #funny
My thoughts on Last Epoch 1.0 Launch and Release. Stop by to watch on Twitch at PwnW0lf!

Last Epoch Falconer Starter Guide 🦅 Dive Bomb Ballista Trapper
Starter Guide for the Mastery Falconer for the Videogame Last Epoch.
Short Build Guide for up to Level 60
Endgame build will follow sub for updates.
cheers
Join the Wasted666 Fam!
- Discord https://discord.gg/Zm43XzSAhB
- Our Youtube: https://www.youtube.com/channel/UC0B55-pVjdY...

Live TWITCH Stream: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Golemancer Loot Filter: Coming Soon!
Golemancer Build Planner: https://www.lastepochtools.com/planner/1oR9LR4B
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoManc...

https://www.youtube.com/watch?v=hIqA-UeVnSM Good campaign tipperino , for easier life! 🙂

Hey gamers , here's a quick tip you can do to get some early loots and shards!
Dropped 6/8 Leog's Strategem for 5/5 Expediency + 1/5 Coordinated Fade. Gives haste for 5s every pot use (when you throw a flask, bird can consume pot charges too) and 3 silver shroud stacks for 10s, dodging the next 3 hits and gaining ward per stack. Throwing attack damage % doesn't scale as hard as flat throwing attack damage plus we've got it...
https://www.youtube.com/watch?v=dT08J78jIFk (Minion Stats are used on Summon - Double Equip for Nekros ^^)

Minion Stats are taken and saved as long as they are alive or you switch the zone. In theory, you can use that to summon your minions and then switch into a defense loadout or something with spell damage in case you deal damage on your own.
Website: http://urzasarchives.com/
Facebook: https://www.facebook.com/urzasarchives/
Youtube Channel: h...

O Last Epoch é um RPG de ação online que combina viagens no tempo, classes personalizáveis, criação de itens e uma história envolvente. O jogo está em acesso antecipado e recebe atualizações constantes, incluindo o modo multiplayer, que foi lançado recentemente. Se você gosta de jogos como Diablo, Path of Exile e Grim Dawn, você vai adorar o Las...

Build Planner Link (build in this vid)
https://www.lastepochtools.com/planner/5BxYK46o
Build Planner Link (Endgame Goal)
https://www.youtube.com/watch?v=dZkooGbD24U
https://www.lastepochtools.com/planner/9QnyY19A
Filter
https://www.lastepochtools.com/loot-filters/view/OBjG5WoD
Links
Buy me a coffee :) htt...

Here is a quick update on what boss fights would look like using the unique chest armour Elecoe's Abandon. Would obviously do more burst the higher + pots you've got on belt. Bakuli's isn't worth it though unless your pot sustain is fkn amazing; you can generate shitloads of pots off of hitting the boss. Belts can get 120% increased chance to fi...

Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #SIGEONSREPRISAL #RATLEYINKLLC #diablo4 #walkthrough #guide


Last Epoch 1.0 Twitch Highlights 2024 Day2-Rip, Crafting, Legendaries
FEATURED IN THIS EPISODE:
https://www.twitch.tv/aaronactionrpg
https://www.twitch.tv/darthmicrotransaction
https://www.twitch.tv/zizaran
https://www.twitch.tv/anniefuchsia
https://www.twitch.tv/chtitou
https://www.twitch.tv/cutedog_
https://www.twitch.tv/ds_lily
https://www.t...

Last Epoch Item Filter Advanced Hacking Item Filter for Builds. Settings and configuration guide.
This video will show you how to setup Item Filter in Last epoch in a way that is normally impossible to do.
Normally you cannot put for example 2 affix modes in the filter but with this trick this becomes a possibility.
Enjoy your Item Filter with t...

Support mazur_32 by downloading Warpath on PC.
Last Epoch 1.0 gameplay is fun and addicting plus with factions being introduced there is a new best way to get items fast and all you have to do is join the Circle Of Fortune! In this guide I am going to be going over everything you need to know on the Circle Of Fortune. - https://youtu.be/9ryhTDQ-XNw?si=opfihTq-n3xurje7

#lastepoch #prophecy #circleoffortune
Last Epoch 1.0 gameplay is fun and addicting plus with factions being introduced there is a new best way to get items fast and all you have to do is join the Circle Of Fortune! In this guide I am going to be going over everything you need to know on the Circle Of Fortune.
Join My Discord! | https://discor...
<@&1161418687471956101> Sorry to ping you all, please delete this toxic post.
thats what the ping is for. ty

Last Epoch Merchants Guild And How I Got To Rank 8 Quickly
In this video I go over how I got to rank 8 in Merchants guild quickly, and how to progress through the faction to get to the best parts which are located at rank 7 and 8.
Email : dr3adfulr3aper@gmail.com
Twitch : https://www.twitch.tv/dr3adful__
Discord : https://discord.gg/tGqngsB
#...
❤️ keep up the good work brothers xoxo
My thoughts on Last Epoch 1.0 Launch and Release. Stop by to watch on Twitch at PwnW0lf!

I'm really glad I waited till launch to play this game. Going in blind has been quite the experience.
To give you an idea of how it's going, here's a highlight of yesterday's stream. Attempting to ''survive'' lagon's trial
https://www.youtube.com/watch?v=tf7r9y-klnA&t=2s

▬ Follow me on Twitch to join me when I play: https://www.twitch.tv/mikey_zerog
Went in there trying to kill a boss, turns out you need to survive.
Hah, yeah! Good luck with that.
Last Epoch in a nutshell
https://clips.twitch.tv/ManlyCheerfulCurryCmonBruh-3y3Ja2-vW-XBZaYv


Build Planner: https://maxroll.gg/last-epoch/planner/wn2er0ww
End Game Guide: https://maxroll.gg/last-epoch/build-guides/dive-bomb-falconer
Timestamps:
0:00 Intro
1:28 Level 4
2:46 Level 8
5:26 Level 15
8:44 Level 20
12:03 Level 23
15:32 Level 27
19:30 Level 35
12:59 Level 48
27:14 Level 53
22:46 Level 60
38:12 Level 76
0.9.2 Builds By Class:
...
Last Epoch is an ARPG developed by Eleventh Hour Games.
It's been released since 3 days(21.02.2024) and the devs were sneaky enough to hide the "hidden masochist" mode that we had in early access inside the game!
I AM LIVE RIGHT NOW ON TWITCH !! Come and see me progressing in Hardcore as Druid!
Buy the game at https://nexus.gg/blinnx
See me li...

Killed Lagon on my shadow dagger Falconer in patch 1.0
My son has wanted me to try making youtube channel sooo i'm doing my best bahaha still so much to learn and its only very short clips but hey, everyone starts somewhere - if anyone is willing to click "subscribe" or comment on any videos id be eternally grateful and my son would think i am super dad 😛 - if you tag me with your channel I will absolutley subscribe on youtube back
https://www.youtube.com/@GravityDAD/videos
YouTube
Gravity Gaming GG
Diablo 4, Last Epoch, Warcraft 3, World of Warcraft - - I like to have fun gaming! - GG

YouTube
Diablo 4, Last Epoch, Warcraft 3, World of Warcraft - - I like to have fun gaming! - GG
Hey, I'm just a casual gaming dad playing LE for the first time - playing Druid on my learning journey. Here's a bunch of my stream highlights for you to check out! I really appreciate it. https://youtu.be/E77r41tP_I8

Check out the highlights from my Feb 23 Stream! Thanks all for joining in and hanging out for a bit. It's been a great leveling experience so far - the druid is finally coming online (no pun intended) and this game definitely has my attention now.


I stream ARPGs @ https://twitch.tv/schmidtwerd
Join my ARPG Discord here- https://discord.gg/tUKPqdHMkH
Thanks for watching!


My friends and I are all struggling to defeat this boss!!!

Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #BLOODROOST #RATLEYINKLLC #diablo4 #walkthrough #guide

Live TWITCH Stream: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Totem Master Loot Filter: Coming Soon!
Totem Master Build Planner: https://www.lastepochtools.com/planner/wBEbn7Ro
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer Auto...

Thank you for your support as a disabled content creator it means alot for all the subs like and view.
Welcome to our gaming channel! We bring you immersive gameplay, thrilling adventures, and the latest updates in the gaming world. Join us as we explore new worlds, conquer challenges, and share our gaming expertise. Whether you're a casual pla...
My thoughts on Last Epoch 1.0 Launch and Release. Stop by to watch on Twitch at PwnW0lf!


Twitch
Всем привет, провожу стримы в свободное время, иногда бывает не так его много, но зато будет качественно и весело, так что подписывайтесь на канал и смотрите стримы с удовольствием :)

Here is the Wraithlord guide :D This build is so awesome. I've been loving it ever since I swapped on day 1. It's a great corruption pusher, great bosser, and just decimates content! I think it would be nice to squeeze a bit more defensively, but I'm a damage enjoyer ;) Anyway hope y'all enjoy it!
You can look up my character using LETools or M...
Level 27 vs Level 43 boss fight
https://youtu.be/WFBJ3ZBWtSU

Fun and challenging fight between a level 27 and level 43 boss
#lastepoch


Если вдруг кто не знал, на войне вообще в целом люди вот эээ...как сделать максимально опасного воина? Который нихуя не умеет? Берем простого крестьянина, который вообще ничё не умеет и мы его обучаем работать с копьем, там 2 недели. Всё, отправляем на войну. Крестьянин с копьем затыкает кого угодно блять, любого элитного бойца рыцаря, который т...

Learn how to use the forge in Last Epoch so you can craft the best weapons and armor for your build. It's so easy once you start playing around with the runes and glyphs. I'll show you many different examples and strategies for crafting the best items.
💌 Subscribe for more: https://www.youtube.com/channel/UCnH8WSFM63gtEWSqufh4kQg?sub_confirmati...


Which Last Epoch Faction is the BEST? This video will discuss the differences between the Circle of Fortune and Merchants Guild and explain which one is right for YOU.
Confused man in thumbnail from pngtree | https://pngtree.com/freepng/anxious-person-thinking-confused-flat-illustration_6728196.html
进不去了吗
Stay away from the corpses when they die (soul bomb rapes) and you're good.
https://www.lastepochtools.com/planner/PAVD8JdB
LOOT FILTER (download, open, copy code and "past clipboard contents" to import ingame): https://drive.google.com/file/d/1vnD-V0t8ZMkQaLqhExeHnPFYzLx8cgxG/view?usp=drive_link
It looks for the following damage affixes:
On...

Hi everyone! Today I'm taking a break from my Let's Play series to try out Last Epoch. I don't usually play these kinds of games, but Last Epoch has me hooked now!
Interested in more of my content? Check out the links below!!
♡ Twitch: https://www.twitch.tv/lydialunavt
♡ Twitter: https://twitter.com/LydiaLunaVT
♡ TikTok: https://www.tiktok.com/...
trush game fXXk
this ones for the people in gen chat
https://youtu.be/G5H1TzxecwE

This is despicable and outrageous!!!!! so incompetent!
It will forever and always shock me the amount of people that think typing
"how is it not fixed yet" or "if it isn't fixed soon, I'm never coming back!" is going
to fix anything or just magically bring everything up.
but anyway, yeah, I just wanted to rant because it's hilarious the amoun...

Easy fight. Mana sustain will be better once you get T6-7 rings. -4 to -5 mana cost per flask throw.
https://www.lastepochtools.com/planner/PAVD8JdB
LOOT FILTER (download, open, copy code and "past clipboard contents" to import ingame): https://drive.google.com/file/d/1vnD-V0t8ZMkQaLqhExeHnPFYzLx8cgxG/view?usp=drive_link
It looks for the foll...

It's Judgment day for Last Epoch, and who better to Judge then a Diablo 4 Super Fan like myself....
Also there are clips of my first night playing Last Epoch.
Twitch: FrostylarooTV (Will start to stream one day soon)
*Some statements in this video are for entertainment purposes only and should not be taken as facts.
A small video on my thoughts, how LE will hold up against PoE and D4 enjoy - https://youtu.be/TUTeX42au-k

Discussed in this interview is Zizaran's interview with CEO of Eleventh Hour Games Judd Cobler which can be found here - https://www.youtube.com/watch?v=xyg2m2tozJ8&t=1s
My previous video on Larian Studios https://youtu.be/q0apgu3uZ4Q
Thanks for checking out this video on Last Epoch, a small video discussion on the merit it brings to the ARPG...

Level 87 gameplay, missing 12 glancing blow nodes, got 5 reses capped or almost capped. May drop Omnis from the build. Question is, can it survive high corruption (300+). Aim is at least 2.5k hp endgame with innate glancing blow + armor tankiness and less dodge reliance. Dunno if it'll work for corruption pushing at this point and may need to sp...
DoT based warlock with infinite ward (not even close to min-maxed)
https://www.youtube.com/watch?v=dUR9cNYcZvk


Last Epoch Holy Winds Electrify Smite HH Paladin Full Build Guide Showcase
Last Epoch Planner :
https://www.lastepochtools.com/planner/KoPZVvgQ
Day 1 Update :
https://www.youtube.com/watch?v=lkOJFD0vYr0
Day 3 Update :
https://youtu.be/OdB8NrxsXXo
My Loot Filter :
https://youtu.be/qAwN7xdAEVs
Email : dr3adfulr3aper@gmail.com
Twitch : https:/...

Last Epoch 1.0 Twitch Highlights 2024 Day3 - Compilation
FEATURED IN THIS EPISODE:
https://www.twitch.tv/lizard_irl
https://www.twitch.tv/ceee
https://www.twitch.tv/anniefuchsia
https://www.twitch.tv/steelmage
https://www.twitch.tv/wudijo
https://www.twitch.tv/pohx
https://www.twitch.tv/cohhcarnage
https://www.twitch.tv/datmodz
https://www.twi...
@woeful bison
@real trench is this allowed?
https://www.youtube.com/watch?v=uTD2uD58Oxs Killed Heorot


Build Guide : https://youtu.be/trsAGe95UQ0
Build Planner : https://www.lastepochtools.com/planner/mQkXJWDB
Heya everyone today i jump at First place in arena sentinel ladder in online new season and im 8 at general ranking with my build !
For arena pushing i swap abyssal echoes for vengeance to put one vengeance hit each 2second for defensive ...

Last Epoch Falconer lvl88 6Ballista vs Empowered Rahyeh Black sun
ANOTHER 4 YEAR DEVELOPMENT GAME THAT DOESNT WORK ON LAUNCH, SERVERS DOWN AGAIN. 9 HOTFIXES A DAY TO PATCH THE MULTIPLAYER, BUT STILL DONT WORK. WHEN WILL YOU STOP DEFENDING THESE PPLE. IF SOMEONE SOLD YOU A CAR AND IT DIDNT WORK YOU WOULD RETURN IT.
No one expected that the game would have 250k + active players at the same time BUT ged gud
why are you comparing a car with a game 😄 lel please use your brain next time
am stuck at end of times loading screen any solutions ?
do you go yelling to car repair shop where you car is ready to be repaired and they cant give you eta when its finished because they are in hurry? grow up
not every one have time like you fat kid

Here is a compilation of Hardcore deaths in Last Epoch. All creators in this video have their link down below in order!
- #lastepoch #patchnotes #lastepochhardcore
👍 Like and Subscribe for more content!
📱 Twitter : https://twitter.com/teszro
🎮 LINKS IN ORDER AS SHOWN
Twitch links in Order :
ANNIEFUCHSIA : https://www.twitch.tv/anniefuchsia...
Beat Majasa for the first time! This is me killing her, took me about 30 or 40 tries 😂
Showing my gear and build at the end of the video. Please feel free to roast my build 💀 🤣
Now that I've beaten her I can finaly go check youtube how fast people usually kill her ^^

Firs time playing Last Epoch, started playing a the launch of V1.0 that came out a few days ago. Only seen about 5 minute of footage of the game a few years ago. Decided to do my first playthrough blind and record and upload it to YouTube.
This boss proved to be a challenge for me, I think it took me 30 tries, at least! In the end it felt like ...
Melee Gathering Storm (Work in progress, but my current planner is added)
https://youtu.be/vPF7-nMHZdM

This is my official update to my previous Shaman video. May it inspire you as it has inspired me!
- Gameplay: 00:00
- The Gear, Idols, Blessings: 02:10
- Passive Tree: 09:30
- The Skills: 12:00
Build Planner (Work in progress)
https://www.lastepochtools.com/planner/KBaNDNyo
----------------------------------------------------------------------...


Follow my twitch channel on : https://www.twitch.tv/captainp67
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #WARLOCK #RATLEYINKLLC #diablo4 #walkthrough #guide
Hey made my second guide on last epoch on not just how to craft in last epoch, but also how to approach crafting in general which i find alot of guides miss out https://youtu.be/Ld3eukMWac8 its my second ever video so go easy on me 😉

#lastepoch #arpg
In this guide i give you a few simple strategies on how to approach crafting in Last Epoch
Twitch: https://www.twitch.tv/goodfoxxy
Streaming this Thursday at 6pm BST
Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #crafting #RATLEYINKLLC #diablo4 #walkthrough #guide

https://clips.twitch.tv/EnergeticBrightBasenjiDAESuppy-XKzoRctUrUG2lTXm 🤣
all life, games...

Servers on the Fritz? POLKA TIME. https://clips.twitch.tv/RespectfulHonorableLettuceFailFish-TzDBHS2mZalrnBup


In this video I am sharing an easy farm you can do anywere were is a solid chest on ground or bosses you want to far. it takes between 10-15 seconds for chests and boss depends on your damage.
Watch the entire video for full information.
#lastepoch #guide #gaming
My thoughts on Last Epoch 1.0 Launch and Release. Stop by to watch on Twitch at PwnW0lf!
Rank 1 Runemater Arena : https://www.youtube.com/watch?v=so_rMQm3tGw

Credits to Pinchedloaf for the build.
Chapters :
00:00 Intro
00:50 Arena Gameplay
21:34 Passives & Skills


Of course I get lucky with the yellow item for the sake of the video! 😂
#lastepoch #crafting #tips

Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #STYGIANCOAL #RATLEYINKLLC #diablo4 #walkthrough #guide

my planner: https://maxroll.gg/last-epoch/planner/3c38h0mj
leveling guide: https://maxroll.gg/last-epoch/build-guides/warlock-leveling-guide
maxroll lizardirl planner with more words but some differences for passives / skills: https://maxroll.gg/last-epoch/build-guides/bleed-warlock-guide
timestamps:
0:00 intro ...

Thank you for your support as a disabled content creator it means alot for all the subs like and view.
Welcome to our gaming channel! We bring you immersive gameplay, thrilling adventures, and the latest updates in the gaming world. Join us as we explore new worlds, conquer challenges, and share our gaming expertise. Whether you're a casual pla...

Bonjour à tous,
Voici une vidéo de starter build pour les masteries Bladedancer et Marksman du Rogue pour la version 1.0 de LAST EPOCH.
Ci dessous les différents planer pour chaque mastery :
Bladedancer Shadow daggers
Lvl 40 : https://www.lastepochtools.com/planner/jQe0rmKA
Lvl 80 : https://www.lastepochtools.com/planner/kB4baVaA
Lvl 100 opt...
CHeck out my lastest short on YouTube! https://youtube.com/shorts/SoRF9SDw8Ys?feature=share

I'v been trying to play Last Epoch since launch and barely got to play!
Leave a comment if you still can't connect!
This shit had me straight kekin yo 🤣
Last Epoch Twitch Highlights:
https://www.youtube.com/channel/UCMbuANWfjVFR4m5MC5FyTmA

YouTube
just a dude - making videos after work
Last Epoch centred gaming channel.
EVERYONE FEATURED IN THESE VIDEOS HAVE GRANTED EXPLICIT WRITTEN PERMISSION TO USE THEIR MATERIAL.
HOW TO SUBMIT CLIPS:
If you want to submit a clip for one of my compilations / highlights just send me a Twitch whisper (RiqDE) even if your clip is on Youtube.
@woeful hearth thanks so much man!! Means so much!!
https://youtu.be/xpi0ZPEVgFY my new concept let me know if you are interested in building more class and builds on this filter

Here is our new guide & plan on Last Epoch 1.0 Loot Filter
Join Our Discord & Then Send Me A Direct Message If You Would Like To Help Our Last Epoch Community On This Loot Filter Project! And Share Your Great Knowledge In Various Builds!
https://discord.gg/a4xANA2V7t
Instruction To Use Multi Class Filter (WARNING Its Endgame Targets With T7 A...
Funny Ghostflame bug  https://youtube.com/shorts/TiJXmEkMwVU?feature=share
https://youtube.com/shorts/TiJXmEkMwVU?feature=share

I am not sure if this is even playable as a build, but I thought it was funny. I'll have to do more testing, but haha thought it was funny to see this bug on Ghostflame using Spirit Kindling node. One day I will get to messing with it more :P

Hi guys! Today I go over how to craft the Fractured Crown Unique Mage helm in 1.0!
Links
Buy me a coffee :) https://ko-fi.com/bigdaddy
or support me at patreon: https://patreon.com/user?u=45835184
Twitch: https://www.twitch.tv/ooohbigdaddy
Discord: https://discord.gg/cvSUVBvFX2
------------------------------...

Build Planner Link (build in this vid)
https://www.lastepochtools.com/planner/KQbJ81NQ
https://www.lastepochtools.com/profile/rammsteinn/character/pepe
Build Planner Link (Endgame Goal)
https://www.youtube.com/watch?v=dZkooGbD24U
https://www.lastepochtools.com/planner/9QnyY19A
Filter
https://www.lastepochtools.com/loot-filters/view/boY7LVQJ
-...

Live TWITCH Stream: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Paladin Loot Filter: Coming Soon!
Paladin Build Planner: https://www.lastepochtools.com/planner/0Qd9dzYB
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: htt...

Join us in our adventures for the Last Epoch as we level a necromancer!
Defeating one of the hardest boss in Last Epoch
T4 Julra vs Storm Bolt Werebear Druid

Beating my very first T4 Julra with my Storm Bolt Werebear Druid build!
I stream Last Epoch!
https://www.twitch.tv/gitgudmak
My thoughts on Last Epoch 1.0 Launch and Release. Stop by to watch on Twitch at PwnW0lf!

Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #COMMUNIONOFTHEERASED #RATLEYINKLLC #diablo4 #walkthrough #guide

Follow my twitch channel on : https://www.twitch.tv/captainp67
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #WARLOCK #RATLEYINKLLC #diablo4 #walkthrough #guide

O Last Epoch é um RPG de ação online que combina viagens no tempo, classes personalizáveis, criação de itens e uma história envolvente. O jogo está em acesso antecipado e recebe atualizações constantes, incluindo o modo multiplayer, que foi lançado recentemente. Se você gosta de jogos como Diablo, Path of Exile e Grim Dawn, você vai adorar o Las...

In this Episode beats plays Last Epoch Hydrahedron Runemaster and gets to around level 20. The game has been running poorly on load times since launch but we overcome the adversity and push through. Make sure to like follow and subscribe! -- Watch live at https://www.twitch.tv/beats4president

BUILD GUIDE COMING SOON
Build Planner (Glancing Blow): WiP
https://www.lastepochtools.com/planner/9QnPnwVo
Build Planner (Cradle of the Erased):
https://www.lastepochtools.com/planner/boYVw10A
Lightning Chakram Bladedancer:
https://youtu.be/ApVUpUHS3nk
Twitch:
https://www.twitch.tv/trikster08
Timestamps
0:00 - Intro
0:40 - Monolith Gameplay...

Last Epoch Merchants Guild Or CoF? Which is Better? Level 100 Gear Comparison
CoF (AlmostPI) :
https://www.lastepochtools.com/planner/eoy6PrwA
MG (Dr3adful) :
https://www.lastepochtools.com/planner/kB58aX8Q
Email : dr3adfulr3aper@gmail.com
Twitch : https://www.twitch.tv/dr3adful__
Discord : https://discord.gg/tGqngsB
#lastepoch

I hope this solves the problem.

New tankier setup: https://www.lastepochtools.com/planner/zowejGMQ
Dropped some haste, AoE and damage nodes. Dropped Splash Zone for 4/4 Firebomb Cocktail and 5/5 flask mana efficiency (goes to show how much flat throwing damage scales flask). Honestly the AoE isn't that bad with just 30% on the chest. Dex is important as it scales armor throug...

Upgrade each path in the monolith - Find the reset in the outer web.
#fun #singleplayer #RPG #Online #offline #Multiplayer #Indie #release #gaming #Adventure #Action #fun #loot #gameplay #gaming #lastepoch #arpggaming #arpg
Get in! https://discord.gg/9BHf9tdSSd |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| @everyone

Last Epoch 1.0 - Fireball Killing machine Part 2 - Going without guides and improvized build. #lastepoch #build #poison #plague

Join us in our adventures for the Last Epoch as we level a necromancer!
Universal loot filter for tier 26 S A build for auction https://www.youtube.com/watch?v=8sbhVFMzBmg&ab_channel=АртёмСамохин

В фильтре выделены отдельным цветом все топ базы+топ ноды из 26 билдов Максрола. Также отдельно выделены все базы с 2-3 хорошими нодами и отдельно все т7 и дабл т6.
https://pastebin.com/QcwjPUFt
Кто забрал поставьте лайк, интересно скольким пригодится.

When the devs of Last Epoch asked me to test their firebombs for them, I don't think they realized exactly what they had just signed up for.
Time to see how well everything melts, bleeds, slows and burns. All at the same time.
|| MUSIC ||
Background B - Bomb Corp (Jackbox)
Plimbo - Cult of the Lamb
Fastfall - Dustforce
Praise the Lamb - Cult o...
https://www.youtube.com/watch?v=DgL2u6viPTo ha ha ha u hear on 2:47 that he use Wemod to cheat and you see it on his mana bar 😄

I got a chance to sit down and actually grind away a bit on the beta of lost epoch and I'm definitely enjoying myself, have made it to 58 on my paladin and wanted to share this insane glass cannon HC self found build I have put together so far!
Hello! I've been making a Last Epoch minecraft project for a while now: here is a video of it near completion.
https://www.youtube.com/watch?v=dEGTnsVGfkI

Invocations mod on Curseforge and Modrinth
Of course I get lucky with the yellow item for the sake of the video! 😂
#lastepoch #crafting #tips

#arpg #lastepoch #voidknight #autobomber #lastepochfarm

Something seems wrong here...
Wanted to make something a little different, and more my style :)
If you enjoyed it, Please give this video a like and subscribe as that helps me ball.
Thanks for watching! :)
SOCIALS:
https://twitch.tv/priskyylol
https://twitter.com/priskyylol
DISCORD:
https://discord.gg/EkufUyppkA
#twitch #gaming #funny
I WISH TO BE ABLE TO SPEAK IN LAST EPOCH, I AM ALL ALONE I SEE PEOPLE IN CHAT TALKING AND I AM NOT ALLOWED TO RESPOND BECAUSE EVRYTHING I SAY IS BLOCKED BY CODE OF CONDUCT APPARENTLY EVEN WHEN I JUST SAY HI TO MY FRIEND WHY IS THIS? I WANT TO SPEAK TOO I WANT TO TALK TO OTHER PLAYERS BUT I CANNOT SINCE 1.0 LAUNCH

#Last Epoch #AAAARPG #rpg #ARPG #игрs #games #game #игра #ps4 #like #ps #playstation4 #gaming #console #gamer#игрушки #playstation #plays #winter #геймер #дети #мем #memes #подарок #mem
MEMORY LEAK PLEASE FIX DEVS https://www.youtube.com/watch?v=267nFgSIFlk


Smango gives his 1st impressions over the last Action RPG game released this year Last Epoch.
It's been a bumpy launch....
🌟 Support the Channel by Shopping on Amazon!
🖱️ Mouse – Logitech G502 Hero (Wired): https://amzn.to/3ZajC6b
💻 Computer Case – Lian Li Lancool 216 (Mid Tower ATX): https://amzn.to/3TGlCCc
🎮 GPU – ASUS TUf RTX 4080: https...

Be sure to check out tons of the top guides made for Last Epoch here at Maxroll: https://maxroll.gg/last-epoch/build-guides/
🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝
𝐓𝐢𝐦𝐞 𝐒𝐭𝐚𝐦𝐩𝐬:
0:00 Intro / Shout out to new members / About the Build
1:40 Skills
1:50 Swipe
3:00 Summon Storm Crow
5:20 Warcry
6:57 Tempest Strike
8:45 Summon Wolf
9:00 Passives
11:12 Character Sheet ...

Background: I respec'd a bunch of skills when I logged in today and was re-leveling them so my powerlevel had gone down quite a bit but was going to long-term improve the build. Unfortunately, I experienced this poison Monolith boss and got CLAPPED. Really bummed to lose the build-enabling Smite proc Idols.
I stream ARPGs @ https://twitch.tv/sc...
Hey @everyone CHeck out my new Last Epoch Short! https://youtube.com/shorts/SRQYmMCX-iA?si=tMSOdGI1sMc6OXk4

@ramblle
I got this crazy mana bug in last epoch I was dying laughing!
If this video made you laugh please leave a like and don't forget it Subscribe for more content!
#arpg #lastepoch #fail #funny #tyler1 #bug

Hoy os traigo una GUIA de como funciona la facción del Circulo de la fortuna para los usuarios que todavía tenéis dudas al respecto. El juego es LAST EPOCH, y ha salido hace poco a la venta. Es un arpg, al estilo diablo.
#lastepoch #diablo4 #arpg #games
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
🤩 Directos: https://www.twitch.tv/imcabolo
😇Aquí os dejo mi twitt...
https://www.youtube.com/watch?v=LPXfsjDv0wA chilled 708 corruption with the falconer leaguestarter 😛

pushing for 1k corruption
https://www.lastepochtools.com/planner/5Q0p6XzQ
smooth mapper, questionable bosser with the movement skill being the dps
every abillity can be used on autocast if needed i like to manualy dash most of the time tho
#lastepoch #falconer #lowlife #leaguestarter #rogue
Nuevo video de Last Epoch! Muchas gracias por el apoyo y espero que les guste 👍🔥😉
https://youtu.be/DcK35Sg_QrU?si=Bf5okF7eiT_NoOFO

#lastepoch #arquitectaliath #lagon #arpg #consejoslastepoch
📣CORREO
✔ juanjorc0590@hotmail.com
📣MIEMBRO DEL CANAL AQUÍ!
✓https://www.youtube.com/channel/UCADAlsNvEJ4A6HX8JhqDvHw/join
--------------------------------------...
Get your loot while its hot! Not my video btw...

#lastepoch Hi guys! Last Epoch is out I have come across one of the best and easy farms I can think of for early game and new characters. With this farm you can easily set up your character for mid to late game with ease as well as stock up for other alts. Loads of unique items, set items and shards!
►Twitch Stream: https://www.twitch.tv/lattim...

Live TWITCH Stream: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Werebear Loot Filter: https://docs.google.com/document/d/1NmVNrg-g9kTmcwvMwDMj54863SCfkTh8wnfRRkboJr0/edit?usp=sharing
Werebear Build Planner: https://www.lastepochtools.com/planner/EALezwzQ
Acolyte:
-L...
It's Judgment day for Last Epoch, and who better to Judge then a Diablo 4 Super Fan like myself....
Also there are clips of my first night playing Last Epoch. Server problems and fun times.
Twitch: FrostylarooTV (Will start to stream one day soon)
*Some statements in this video are for entertainment purposes only and should not be taken as f...

After finishing Top5-Top10 in the race to level 100 for Last Epoch 1.0, I went back to the drawing board to elevate my Torment setup into an end-game crushing variant. This build guide is the result of that 2-3 day process! Also, please give some love to Bor of Sol for highlighting the ward interaction that we minmaxed the defensive layers of ou...
https://www.youtube.com/watch?v=il4-eSCMIWw PT-BR Showcase da minha variação do Fire wraith necromancer, confiram! PT-BR

Showcase/Demonstração da build fazendo Monólito 100
Build Completa: https://maxroll.gg/last-epoch/build-g...
Lives na roxinha: mestrezennn
Transcrição
https://streamable.com/9kab6k
unkillable godlock infinite ward glass cannon dps

Hi everyone! Today I'm taking a break from my Let's Play series to try out Last Epoch. I don't usually play these kinds of games, but Last Epoch has me hooked now! Bandle Tale will return either sometime tomorrow or Monday! Oki byee ♡
Interested in more of my content? Check out the links below!!
♡ Twitch: https://www.twitch.tv/lydialunavt
♡ Twi...

DMGCREW
Click show more below
Shop Last Epoch https://www.nexus.gg/idodmg/last-epoch
Time Stamps
00:00 Lightless Arbor
6:27 Corrupted Lake
11:25 Felled Wood
12:30 Soulfire Bastion
18:15 Kolheim Pass
19:47 Shining Cove
20:43 Ruined Coast
21:52 Temporal Sanctum
30:57 The Radiant Dunes
32:52 Majelka and factions unlocked!
If you like everything ...

Live TWITCH Stream: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Fire Necro Loot Filter: https://docs.google.com/document/d/1fZBd4XkJMHfqqm2T7frS-YK_8uYJcuT_juKSFl3tIJU/edit?usp=sharing
Fire Necro Build Planner: https://www.lastepochtools.com/planner/boYZZEmA
Acolyte:...

Thank you for your support as a disabled content creator it means alot for all the subs like and view.
Welcome to our gaming channel! We bring you immersive gameplay, thrilling adventures, and the latest updates in the gaming world. Join us as we explore new worlds, conquer challenges, and share our gaming expertise. Whether you're a casual pla...

В фильтре выделены отдельным цветом все топ базы+топ ноды из 26 билдов Максрола. Также отдельно выделены все базы с 2-3 хорошими нодами и отдельно все т7 и дабл т6.
Upd доделал идолы https://pastebin.com/VXpu9Sud
Кто забрал поставьте лайк, интересно скольким пригодится.
a very quick video showing a powerful necro build i did last couple of days that deletes everything in its path ^

Powerful and easy to play Build that i created which basically revolves around the damage output of Skeleton warriors, mages and the bone golem. it has HIGH minion dps, HP, and armor regen, with Rip blood used for survivability and to buff minions with splatter and blood infusion. Transplant is used for mobility and survivability as well. This ...

Alternatywny tytuł: POLSKA GUROM
Z okazji 1 miliona wyświetleń ustanawiam dzień 16.10 światowym dniem Pudziana.

O Last Epoch é um RPG de ação online que combina viagens no tempo, classes personalizáveis, criação de itens e uma história envolvente. O jogo está em acesso antecipado e recebe atualizações constantes, incluindo o modo multiplayer, que foi lançado recentemente. Se você gosta de jogos como Diablo, Path of Exile e Grim Dawn, você vai adorar o Las...
¡Let's do a Honest (Spanish) Review of Last Epoch! https://youtu.be/0-GO-okIwts

LAST EPOCH 🐈⬛ Entre PoE y Diablo IV ¡REVIEW!
▬▬▬▬▬▬▬▬▬▬▬▬ 🪓 RESUMEN 🪓▬▬▬▬▬▬▬▬▬▬▬▬
Web OFICIAL ✂️ https://ashesofcreation.com/
WIKI ✨ https://ashesofcreation.wiki/Alpha
▬▬▬▬▬▬▬▬▬▬▬ 🐦 REDES SOCIALES 🐦▬▬▬▬▬▬▬▬▬▬
Puedes encontrarnos en:
Twitch 🎮 https://www.twitch.tv/Raghnar0k
Twitter 🐦 https://twitter.com/raghnar0k
Discord 📱 https:/...
Dont do this mistake! https://youtu.be/lif8h_EX3T0

I just wanted the loot but i lost it all!
#lastepoch

Last Epoch Fire Cold Crit Tornado Low Life Shaman Redeemed The Mastery
Last Epoch Planner (Still WIP) :
https://www.lastepochtools.com/planner/1oRV4Kzo
Email : dr3adfulr3aper@gmail.com
Twitch : https://www.twitch.tv/dr3adful__
Discord : https://discord.gg/tGqngsB
#lastepoch

E ai, como você tá?
Nesse vídeo trago para vocês uma build de falconer muito divertida rápida e forte pra um cacete!
Planner/Build: https://www.lastepochtools.com/profile/ddartx/character/Ddartx
Material de apoio monolitos: https://www.lastepochtools.com/endgame/monolith
O que vocês acharam?
Compre o Last Epoch na Steam (Há versões com skin...

Last Epoch 1.0 - Fireball EQ REWORKING - Maybe LIGHTNING METEOR? Part 3 - Going without guides and improvized build. #lastepoch #build #poison #plague

0:00 My "Review" of Last Epoch After 30 Hours
28:15 Asmongold plays Last Epoch – Ep.5
► Asmongold's Twitch: https://www.twitch.tv/zackrawrr
► Asmongold's Twitter: https://twitter.com/asmongold
► Asmongold's 2nd YT Channel: https://www.youtube.com/user/ZackRawrr
► Asmongold's Sub-Reddit: https://www.reddit.com/r/Asmongold/
Channel Editors: CatDa...
Latest lore video is live covering: The Chronowyrm.
As much info as I could dig up on these magnificent creatures and speculation on the Ancient one seen floating around End of Time.
Thanks to all who take the time to watch ❤️

Greetings Travelers!
Welcome to my latest Last Epoch lore video on: The Chronowyrm. Going over all the known types and as much about the beast as I could dig up, I hope it's informative!
Forewarning! All of my videos will contain some level of spoilers in order to talk comprehensively on the narrative.
If you find anything super cool to shar...

Join us in our adventures for the Last Epoch as we level a necromancer!

tierlist
#tierlist
#gamingcommunity
satire and ironic
this was ingame community
If anyone wants some help with crafting https://youtu.be/Ld3eukMWac8
#lastepoch #arpg
In this guide i give you a few simple strategies on how to approach crafting in Last Epoch
Twitch: https://www.twitch.tv/goodfoxxy
Streaming this Thursday at 6pm BST
Of course I get lucky with the yellow item for the sake of the video! 😂
#lastepoch #crafting #tips

Be sure to check out tons of the top guides made for Last Epoch here at Maxroll: https://maxroll.gg/last-epoch/build-guides/
🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝🐝
𝐓𝐢𝐦𝐞 𝐒𝐭𝐚𝐦𝐩𝐬:
0:00 Intro / Shout out to new members / About the Build
2:24 Skills
2:38 Chaos Bolt
4:59 Summon Bone Golem
5:41 Dread Shade
6:19 Summon Skeleton
6:58 Summon Skeleton Mage
7:31 Passives
8...
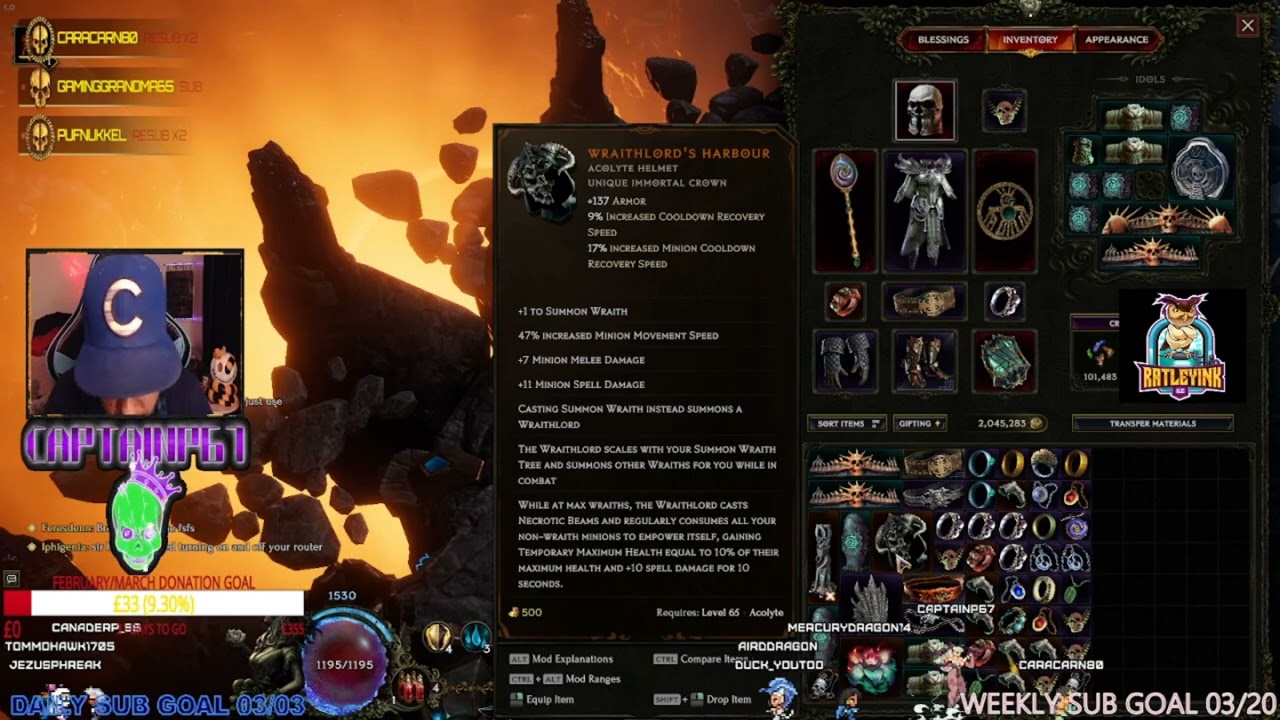
Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #WRAITHLORDSHARBOUR #RATLEYINKLLC #diablo4 #walkthrough #guide

Last Epoch 1.0 Twitch Highlights 2024 Day4+5 - Rip, Crafting, Legendaries
FEATURED IN THIS EPISODE:
https://www.twitch.tv/anniefuchsia
https://www.twitch.tv/binaqc
https://www.twitch.tv/goratha
https://www.twitch.tv/gratnill
https://www.twitch.tv/iamjustacrazy
https://www.twitch.tv/kingkongor
https://www.twitch.tv/kondyss
https://www.twitch.tv...
made a guide for safely offline modding https://www.youtube.com/watch?v=oIeKtidGPcY

https://www.nexusmods.com/lastepoch/mods/4?tab=files
My second save file location and command for steam:
"F:\Last epoch modded\Last Epoch\Last Epoch.exe" %command%
Delete the command and reenable online play to play normally again, DO NOT go online with the mod.

Follow my twitch channel on : https://www.twitch.tv/captainp67
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #WARLOCK #RATLEYINKLLC #diablo4 #walkthrough #guide
This is powerful and user-friendly build centered on maximizing the damage output of Skeleton warriors, mages, and the Bone Golem. Passives, equipment, and talents should focus exclusively on enhancing minion DPS, critical minion strikes, minion HP, minion armor, and minion HP regeneration. Rip Blood serves to bolster survivability and further e...
Really super serious reasons.
Twitch: FrostylarooTV (Will start to stream one day soon)
*Some statements in this video are for entertainment purposes only and should not be taken as facts.
Credit to many of the clips in this video go to the Last Epoch Youtube page.
Last Epoch Youtube: https://www.youtube.com/@LastEpochGame

Build Planner: https://maxroll.gg/last-epoch/planner/jk8g0sdt
End Game Guide: https://maxroll.gg/last-epoch/build-guides/torment-warlock-guide
Timestamps:
0:00 Intro
1:19 Level 4
2:51 Level 9
5:27 Level 13
7:28 Level 20
10:25 Level 28
13:20 Level 35
16:40 Level 42
19:57 Level 50
24:06 Level 60
28:59 Level 76
0.9.2 Builds By Class:
Sentinel: ...
https://youtube.com/shorts/d4SASeUSLX4?feature=share pick your darn exp nodes after reaching lvl 100
https://youtu.be/3S854D24oeQ?si=YxZ6AG5wQnYEbosF
Been loving the game! My main concern was that it's just way too easy, but this morning I stepped into empowered monoliths, and... well then!

I've just started doing Empowered Monoliths in Last Epoch. Loving the game but felt that everything has been way too easy up until this point! Looking forward to grinding out and crafting better gear. @LastEpochGame #lastepoch
theres your answer for "too easy" i guess
For anyone not sure which faction to pick
https://youtu.be/Fw82aSvOh4c

Which faction should you pick in Last epoch:
Last Epoch is an ARPG where you have to choose between two factions, the Circle of Fortune or the Merchant's Guide. The faction you choose impacts how items work, how trading works and how you farm gear at endgame. So lets go over both of the factions and talk about which is the best.
No matter wha...

Live TWITCH Stream: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Fire Necro Loot Filter: https://docs.google.com/document/d/1fZBd4XkJMHfqqm2T7frS-YK_8uYJcuT_juKSFl3tIJU/edit?usp=sharing
Fire Necro Build Planner: https://www.lastepochtools.com/planner/DQ97Dnko
Acolyte:...
https://www.youtube.com/watch?v=HRzRXvAhBlE game crashing by falconer dealing hundrets of millions of dps ^^ 40k ward on falconer memes

#shorts #lastepoch
over 9000 for sure, take this with a grain of salt this is not in map damage (most of the time)
OK, now this was an epic boss fight! I LOVED IT!!!! https://youtu.be/VMcn-JSVcI8?si=4vVi9p2DUaalzp_l

No... You're just a... human, a worm! I was supposed to be unstoppable... Got my Wings of Argentus Unique chest armour on my 2nd attempt. Love this boss fight!
#lastepoch @LastEpochGame

Last Epoch: What's Wrong With The Merchant's Guild?
VIDEO DESCRIPTION:
In this video- I go into detail about what the Merchant's Guild is in Last Epoch, and explain ...

The Truth Is Out There
Link to Exiled Mage Ladle drop rates google sheet:
https://docs.google.com/spreadsheets/d/1qvF5OQLkuaMI34SmNI_QoIIDSRE0pggWCwuvRvNHq3E/edit?usp=sharing
Links to my:
Discord - https://discord.gg/Dxje9s2mmV
Twitch - https://www.twitch.tv/thecursebg
Patreon - https://patreon.com/TheCurseGaming
Support my channel by purch...
https://www.youtube.com/watch?v=RebPyVH_Q2E german review :D

Bleibt ein Weilchen und hört zu: https://www.twitch.tv/mauriceweber
Endlose Truhenplätze: https://discord.gg/sFMb9Ekzjk
Last Epoch ist Diablo mit allem was dort fehlt und Path of Exile ohne alles was dort nervt. Mich hat seit Diablo 2 kein Spiel dieser Art mehr so uneingeschränkt begeistert. Wenn sie jetzt noch ihre Server-Probleme in den Griff...
Experimental Melee Shaman
https://www.youtube.com/watch?v=s5ECrZho9gs

A melee shaman build in last epoch in 2024, can you imagine?
Now it is with more Damage and a tiny bit more tank.
- Gameplay: 00:00
- The Gear, Idols, Blessings: 01:52
- The Skills: 07:02
- Passive Tree: 11:03
Last Epoch Planner (Experimental)
https://www.lastepochtools.com/planner/kB4lVY1B
Lightning Version (Pure Gathering Storm)
https://you...

This is a crazy Ghostflame bug I found to give yourself INFINITE Ignite & INFINITE Ward :D I think I messed that up a few times in the video. Anyway, I'll keep it short, let me know what y'all think and if anyone does anything with it! THIS WILL BE PATCHED!
Planner for Char in vid: https://www.lastepochtools.com/planner/0oND567Q
Intro 0:00
Ski...
Monolith of Fate bug ?? https://www.youtube.com/watch?v=RbaLmKd_zEY

We found a bug by accident during our multiplayer session in last epoch

Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #FALCONFISTS #RATLEYINKLLC #diablo4 #walkthrough #guide

O Last Epoch é um RPG de ação online que combina viagens no tempo, classes personalizáveis, criação de itens e uma história envolvente. O jogo está em acesso antecipado e recebe atualizações constantes, incluindo o modo multiplayer, que foi lançado recentemente. Se você gosta de jogos como Diablo, Path of Exile e Grim Dawn, você vai adorar o Las...
Follow my twitch channel on : https://www.twitch.tv/captainp67
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #WARLOCK #RATLEYINKLLC #diablo4 #walkthrough #guide

Знакомство с Last Epoch, новой игрой жанра Action RPG, 2024 года.
Рассказываю о новом конкуренте Diablo 4. Новая игра привносит свежий игровой опыт в жанр.
Таймкоды:
00:00 Пролог
00:21 История создания
01:02 Похожие игры
01:47 Создание персонажа и прокачка
02:45 Создание Билда
04:20 Боевая система
04:35 Сюжет и доп. квесты
05:24 Проблемы игры...

Starting Last Epoch at the release! I will make a sorcerer build without any guide! Let's play and see how far can i go!
Uncover the Past, Reforge the Future. Ascend into one of 15 mastery classes and explore dangerous dungeons, hunt epic loot, craft legendary weapons, and wield the power of over a hundred transformative skill trees. Last Epoch ...

Last Epoch H2O's Acid Flask Explosive Trap Trapuchet Falconer Build Guide Showcase
In this episode of Hall of Fame, we talk about H2O's explosive trap acid flask falconer, a build that finally can make Acid Flask great again!
Planner :
https://www.lastepochtools.com/planner/0QdOrE3A
So funnily enough, ZiggyD also uploaded his Acid Flask buil...
Hardcore https://youtu.be/9ySsf1oZsKo

Thank you for your support as a disabled content creator it means alot for all the subs like and view.
Welcome to our gaming channel! We bring you immersive gameplay, thrilling adventures, and the latest updates in the gaming world. Join us as we explore new worlds, conquer challenges, and share our gaming expertise. Whether you're a casual pla...


Last Epoch 1.0 - Falconer - Halfway to story - Part 2Going without guides and improvized build. #lastepoch #build #poison #plague
Last Epoch is a Bloody Brilliant Game. Find out why in 5 mins within my 3rd ever edited video!
https://www.youtube.com/watch?v=VQxc8R8KkBc&t=13s

#LastEpoch #ARPG #Gaming #review
Last Epoch is a game I haven't been able to put down since its 1.0 release. It scratches all of my APRG itches & any fan of the genre definitely needs to try.
Thank you for watching this video. Super new to my YouTube & video editing journey so hope you like it.
Chapters:
00:00 - Intro
00:18 - Game Overview,...
How to kill Lagon? Subtitels in english and german.
https://youtu.be/DtnzniPpAmc

#lastepoch #arpg #gaming #lagon
🌀 Discord: https://discord.gg/yfhzHd2n
📱 Tiktok: https://www.tiktok.com/@diablovortex
🎥 Twitch: https://www.twitch.tv/diablovortexxx
🌐 Battlenet: DiabloVortex#3788
Lagon jest jednym z bossów w grze Last Epoch, który stanowi znaczące wyzwanie dla graczy. Jest to potężna istota, która pojawia się w późniejszej ...

Hepinize merhabalar sizlere last epoch runemastır clasının yetenek kombolarından bahsettim gerçekten ben yaptıgımda şok olmuştum hepinize iyi swyirler.
Ayrıcalıklardan yararlanmak için bu kanala katılın:
https://www.youtube.com/channel/UCQaglbzF5nHvrlWmNBRaGqw/join

O Last Epoch é um RPG de ação online que combina viagens no tempo, classes personalizáveis, criação de itens e uma história envolvente. O jogo está em acesso antecipado e recebe atualizações constantes, incluindo o modo multiplayer, que foi lançado recentemente. Se você gosta de jogos como Diablo, Path of Exile e Grim Dawn, você vai adorar o Las...
First Impressions of Last Epoch
https://youtu.be/_yaFHwBYhYc
Smango gives his 1st impressions over the last Action RPG game released this year Last Epoch.
It's been a bumpy launch....
🌟 Support the Channel by Shopping on Amazon!
🖱️ Mouse – Logitech G502 Hero (Wired): https://amzn.to/3ZajC6b
💻 Computer Case – Lian Li Lancool 216 (Mid Tower ATX): https://amzn.to/3TGlCCc
🎮 GPU – ASUS TUf RTX 4080: https...

Live TWITCH Stream: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Holy Smiter Loot Filter: https://docs.google.com/document/d/1nGF4kzQed5kGxk8eEiezYTJvMC3hEc3DT7jOZvsVoko/edit?usp=sharing
Holy Smiter Build Planner: https://www.lastepochtools.com/planner/OBjMlqxQ
Acolyt...

Best Shatter Strike build for Endgame last Epoch
--
Best Spellblade Flame Reave Build - https://youtu.be/TL7w2itjwU8
50 hours Last Epoch Review - https://youtu.be/FPFlTGm8GBU
Last Epoch Tools (LINK TO BUILDS) -
Beginning Endgame Shatter Strike Build
https://www.lastepochtools.com/planner/9ozqegxB
Ultimate Shatter Strike Build
https://w...

Hi guys! Here's my endgame build guide for my Mana Stacking Spark Charge Sorc! Enjoy.
LIKES/COMMENTS help the videos reach more people!
SUBSCRIBE lets you to see more content from me!
CLICK THE BELL to enable notifications to see when new content goes live!
Current Gear
https://www.lastepochtools.com/planner/aBZNeRPB
Ideal Gearing
https://www...

Buy Last Epoch Here: https://www.nexus.gg/luckyluciano/last-epoch
TWITCH ►► https://www.twitch.tv/luckyluciano
DISCORD ►► https://discord.gg/LuckyLuciano
TWITTER ►► https://twitter.com/LuckyLuciano610
You can use this with Bladedancer, Falconer or Marksmen
Planner: https://maxroll.gg/last-epoch/planner/c61k30sn
BinaQc's Explosive Tr...

Surf's up
Come join me on Twitch: https://www.twitch.tv/amarathy
↓↓↓ Build Planners ↓↓↓
Endgame : https://www.lastepochtools.com/planner/lom8N9YB
Mana can be an issue - drop Of Gloom and Flames in Fissure
No loot filters.
Support the channel:
https://www.nexus.gg/amarathy/games

Been playing last epoch (when the servers allow me to), and despite having a bit of a rough launch, the game is a blast. Someone on reddit said to have a go at the end of time track, so I figured why not and I'm glad I did. Recorded the gameplay with my ignite runemaster build, almost unlocked empowered monos with it so pretty happy about that. ...
<@&1161418687471956101>

Join us in our adventures for the Last Epoch as we level a necromancer!


Hey guys! It's been awhile! Here's a sneak peek on my first build in LE 1.0! :D
I've been wanting to try out a mage class in last epoch, so here it is! Introducing our【300% Cast Speed Lightning Blast Runemaster】!
*This build is still in mid progress, and i will be min-maxing it for high corruption & leaderboard pushing~ I will be sharing the bu...

Thank you for your support as a disabled content creator it means alot for all the subs like and view.
Welcome to our gaming channel! We bring you immersive gameplay, thrilling adventures, and the latest updates in the gaming world. Join us as we explore new worlds, conquer challenges, and share our gaming expertise. Whether you're a casual pla...

Level 95 gameplay of a 123 corruption echo. As you can see it starves for mana and I wouldn't recommend playing it with trap until you can get 0 mana cost on flask or you'd be flushing your attack speed buff and gear rolls down the dunny.
https://www.lastepochtools.com/planner/wBEz6k7o
Notes:
- To understand how the build works, Frostbite = A ...

I heard your feedback and decided to make a more in-depth Runemaster guide.
This utilizes the same build as my previous video but this time I explain what makes it work, which Uniques to go for, what items make the best bases, blessings, and more.
I hope you enjoy!
Chapters :
00:00 Intro
00:49 Overview
01:18 FAQ
02:30 How to play the build
0...

sick build dude looks really fun
https://www.reddit.com/r/LastEpoch/comments/1b2wi0v/dread_shade_wraithlord_killing_350_corruption/ Dread Shade Wraithlord killing 350 corruption bosses in under 10 seconds
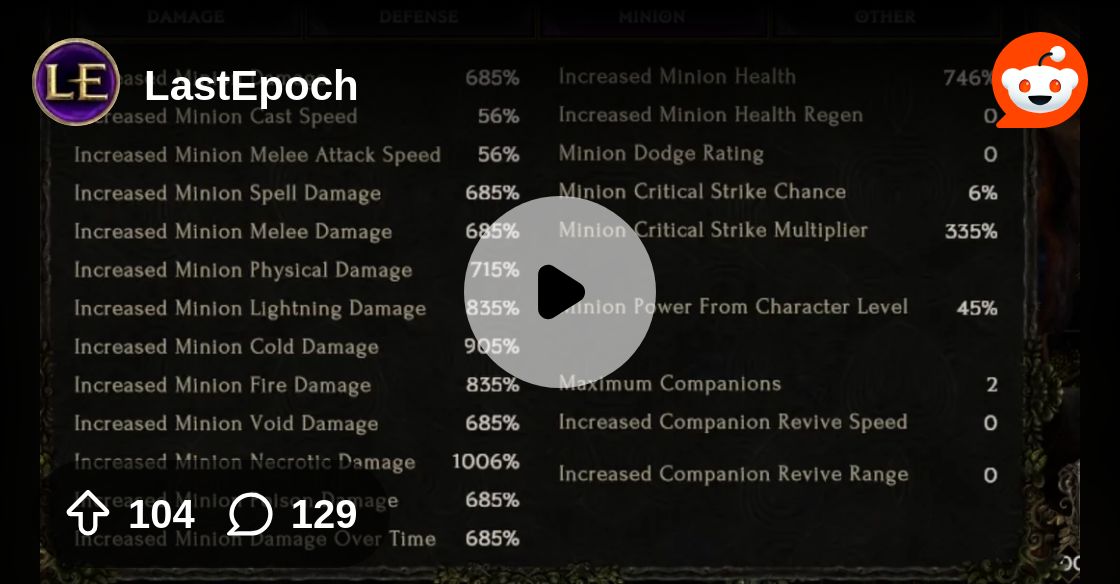
Reddit
Explore this post and more from the LastEpoch community
Last Epoch Twitch Highlights - RIP, crafting, legendaries

YouTube
just a dude - making videos after work
Last Epoch centred gaming channel.
EVERYONE FEATURED IN THESE VIDEOS HAVE GRANTED EXPLICIT WRITTEN PERMISSION TO USE THEIR MATERIAL.
HOW TO SUBMIT CLIPS:
If you want to submit a clip for one of my compilations / highlights just send me a Twitch whisper (RiqDE) even if your clip is on Youtube.
Of course I get lucky with the yellow item for the sake of the video! 😂
#lastepoch #crafting #tips

In this video i share you a following up video of my last treasure room. This area has 3 minor chests in it. More followup will be soon once i killed lagon!
#gameplay #guide #lastepoch #tipsandtricks
Few bugs I've found and some memes what I've created while played.
Hoping to answer the question of: "Who is Shtrak?"

Greetings Travelers!
This video isn't about me, or Eterra. It's about a fallen Traveler named Shtrak. I hope that this was any kind of tribute to their memory and that it fully answers the question surrounding this tomb and the question: "Who is Shtrak?"
More lore and gameplay soon to come, I'm working to summarize the entire campaign as we sp...

This is a very early tier list i will do part 2 soon explaining even further
Meeting a stranger and discussing what video game you play and what rank!
#tierlist
#gamingcommunity
#gaming
#lastepoch
#gw2
#wow
#seasonofdiscovery
#gta
#tierracaliente
#water
#gamingchannel
Turn off Bazaar

This video was a bit too long for my liking. Sorry about that.
https://www.youtube.com/watch?v=1CXOsPL5kNM i hope zizaran wont be mad for using him as intro 😄

1000 Corruption feeling like its day1 on 100s
feel free to ask questions
Day5: https://www.lastepochtools.com/planner/5Q0p6XzQ
https://www.youtube.com/watch?v=LPXfsjDv0wA day5 version
Day7: https://www.lastepochtools.com/planner/zQql6YPA
! every abillity can be used on autocast
this starts as your regular life version falconer with 0 ge...

Thank you and i am sorry please forgive me,
#review
#water
#hydrohomie
#hyundai
#toyota
#gamingcommunity
#gaming
#lastepoch
#diabetes
#diablo4
#update
#apology
#iamsorry
#coolgadgets
#4you

Last Epoch 1.0 Twitch Highlights 2024 Day4+5 - Rip, Crafting, Legendaries - COMPILATION
FEATURED IN THIS EPISODE:
https://www.twitch.tv/binaqc
https://www.twitch.tv/cohhcarnage
https://www.twitch.tv/crouching_tuna
https://www.twitch.tv/dr3adful__
https://www.twitch.tv/empyriangaming
https://www.twitch.tv/lizard_irl
https://www.twitch.tv/mathil1...
https://youtu.be/AkJJnOLLQoc work in progress 😄

https://www.youtube.com/watch?v=uA1p91I1-Pg Hi friends. Very new to video recording and editing so bare with me, but here's a video I made about the monolith guide. Feedback would be much appreciated!

Hey there everyone, here I have a simple monolith endgame guide that gives you a little insight on what the monolith is and how to progress through it. I hope you enjoyed the video and stick with me as I learn how to properly edit and create content. Enjoy!
Follow my twitch channel on : https://www.twitch.tv/captainp67
SPONSORED BY RATLEY INK LLC : https://www.ratleyink.com/
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #UNVARSRISE #RATLEYINKLLC #diablo4 #walkthrough #guide
https://youtu.be/1giJRqSLfGk?si=SCw0UyMJO-wIYinX
First of all, deep, meaningful video from @lament walrus And his lore videos deserve more attention, too
Greetings Travelers!
This video isn't about me, or Eterra. It's about a fallen Traveler named Shtrak. I hope that this was any kind of tribute to their memory and that it fully answers the question surrounding this tomb and the question: "Who is Shtrak?"
More lore and gameplay soon to come, I'm working to summarize the entire campaign as we sp...

Follow my twitch channel on : https://www.twitch.tv/captainp67
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #WARLOCK #RATLEYINKLLC #diablo4 #walkthrough #guide

Sub-A-Thon Event Link: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
1.0.1 Patch Notes: https://forum.lastepoch.com/t/last-epoch-1-0-1-patch-notes/65666
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMan...
https://youtu.be/lz0eTxxD-qA Video by indie game reviewer and enjoyer splattercat who has almost million subscribers.

Last Epoch gameplay with Splattercat! Let's Play Last Epoch and check out a game fashioned in the vein of classic ARPG's. Make a character and crusade your way across time while building up a gearstack that would make odin blush.
Download Last Epoch : https://store.steampowered.com/app/899770/Last_Epoch/
Nerd Castle on Twitch: https://www.twitc...

In this Episode beats plays Last Epoch Hydrahedron Runemaster and gets to around level 40. We reworked the build since the leveling guide felt very mid to play. Make sure to like follow and subscribe! -- Watch live at https://www.twitch.tv/beats4president -- Watch live at https://www.twitch.tv/beats4president


Thank you for your support as a disabled content creator it means alot for all the subs like and view.
Welcome to our gaming channel! We bring you immersive gameplay, thrilling adventures, and the latest updates in the gaming world. Join us as we explore new worlds, conquer challenges, and share our gaming expertise. Whether you're a casual pla...
🇫🇷 Guide francophone pour débuter
https://youtu.be/fICiEDYmswk

▶️ Soutenir mon activité en rejoignant mon Patreon : https://www.patreon.com/exserv
Le jeu du jour : Last Epoch
Et salut à tous ! J'ai le plaisir d'inaugurer une nouvelle série de vidéos guide pour Last Epoch. Dans cette première vidéo, l'idée c'est de rester très généraliste pour que tout le monde soit sur la même longueur d'onde et par la sui...

Last Epoch Factions | Circle of Fortune
Circle of Fortune is a mystical Faction that had banded together to seek fortune through arcane research and astrology. Aligning with the Circle of Fortune will grant you powerful benefits towards finding more and better items. You will also have the ability to purchase Prophecies with Favor which will be...

O Last Epoch é um RPG de ação online que combina viagens no tempo, classes personalizáveis, criação de itens e uma história envolvente. O jogo está em acesso antecipado e recebe atualizações constantes, incluindo o modo multiplayer, que foi lançado recentemente. Se você gosta de jogos como Diablo, Path of Exile e Grim Dawn, você vai adorar o Las...

Swipe Werebear Druid vs. Monoliths
Hey, I’m Axxicus! In this video, I've clipped my latest stream highlights of my werebear druid making his way through level 75 & 80 monoliths.
Build Guide: https://maxroll.gg/last-epoch/build-guides/swipe-werebear-druid-guide
Timestamps:
0:00 - Introduction/Welcome
0:32 - World's Longest Rampage Warm-up
0:55...
https://youtu.be/6Xv6gx_OPPU
как обещал Гайд на Мой билд в Last epoch

Подобрал для вас один из лучших билдов для варлока и в общем в игре. Показал геймплей, применение и попытался уместить в максимально короткие сроки.
Ссылка на телеграмм: https://t.me/stlklive
Ссылка на твич: https://www.twitch.tv/stlk
Компания Eleventh Hour Games выпустила экшн-RPG Last Epoch в зоне раннего доступа. Уже сейчас игроки могут оцен...

Consider subscribing if you like the video.
Contents...
00:00 Intro
00:35 Classes
02:23 Lore
03:01 Skills
04:49 Builds
06:21 Passive skill tree
07:38 Lagon
08:10 Itemization & crafting
10:51 endgame
14:08 Verdict

O Last Epoch é um RPG de ação online que combina viagens no tempo, classes personalizáveis, criação de itens e uma história envolvente. O jogo está em acesso antecipado e recebe atualizações constantes, incluindo o modo multiplayer, que foi lançado recentemente. Se você gosta de jogos como Diablo, Path of Exile e Grim Dawn, você vai adorar o Las...
Last Epoch is a new ARPG from Eleventh Hour Games, which was released at the very end of February. The development path of this project was quite long, difficult and unusual, because in the process, the team not only successfully went to Kickstarter and raised the funds necessary for development, but also managed to accept help from Tencent, which acted as the main beneficiary of the project. In today's material, we will talk about the advantages and disadvantages that are most often highlighted by users who have already played it.
Check my first video about that game on my channel

Last Epoch is a new ARPG from Eleventh Hour Games, which was released at the very end of February. The development path of this project was quite long, difficult and unusual, because in the process, the team not only successfully went to Kickstarter and raised the funds necessary for development, but also managed to accept help from Tencent, whi...

Has the Alchemist's Gift node been slept on? Gear is doggo and getting 60k ticks, would be x2 damage as the bird throws at the same speed. Doesn't wanna attack the dummy unfortunately and can't get the 15% attack speed buff off Wake of Wings. Haven't tested with fire/cluster bombs but it works nice with DoT or frostbite at least and if you get -...
I Played 100 Hours Of Last Epoch So You Don't Have To (But maybe you should)

This is my full Last Epoch Review after a grand total of over 250 Hours played, and over 100 of those after 1.0 release.
More of Me:
TWITCH: https://www.twitch.tv/neeko2lo
TWITTER: https://twitter.com/Neeko2loTV
DISCORD: https://discord.gg/m2yHbmV
E-MAIL: neeko2lo@t-online.de
Chapters:
00:00-00:35 Intro
00:36-02:41 Characters
02:42-1...
Chilling in T4 Julra slams and dots
Reddit
Explore this post and more from the LastEpoch community
Swipe Werebear Druid vs. Monoliths
Hey, I’m Axxicus! In this video, I've clipped my latest stream highlights of my werebear druid making his way through level 75 & 80 monoliths.
Build Guide: https://maxroll.gg/last-epoch/build-guides/swipe-werebear-druid-guide
Timestamps:
0:00 - Introduction/Welcome
0:32 - World's Longest Rampage Warm-up
0:55...

Follow my twitch channel on : https://www.twitch.tv/captainp67
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #WARLOCK #RATLEYINKLLC #diablo4 #walkthrough #guide

Live TWITCH Stream: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Swarmbolt Loot Filter: https://docs.google.com/document/d/1tpf-oZQy3rwjv5zKP7fBQD4yapOLlP1aSRyZYoYvYoA/edit?usp=sharing
Swarmbolt Build Planner: https://www.lastepochtools.com/planner/GBOnP7EQ
Acolyte:
...
Newba Death Seal Lich doing the first actual challenging content early game (first playthrough)
https://youtu.be/Xh0tZiF7RUQ

lv 53 Acolyte early game Chapter 8 Lagon boss
death seal build insane dps
Streams at
https://www.twitch.tv/sirmorgan

The Build:
https://maxroll.gg/last-epoch/planner/o53ro0sl
Lucky Luciano vid:
https://www.youtube.com/watch?v=mI3PDTekPHU
My Twitch:
https://www.twitch.tv/ter3k
LE speedrun discord:
https://discord.gg/7mRwqM5hgY
0:00 Intro
1:47 E...
Using a new build that is not finished. Far from it... and well emperor of corpses had a bad day.
Auto Ballista Explosion Bow Falconer Build .-Mapping
It is registered in the build guide on the Last Epoch Tools site! https://youtu.be/_nuTFUnNZjA?si=6aGnBQvPzpvitsue

자동 발리스타 폭발 활 매사냥꾼 빌드 맵핑영상 입니다.
라스트에폭툴스 사이트의 빌드 가이드에 등록 되어 있습니다!
더 높은 오염도는 차후 업데이트 됩니다. 보스전은 1:30초 부터.
Auto Ballista Explosion Bow Falconer Build.
It is registered in the build guide on the Last Epoch Tools site!
Higher contamination levels will be updated later. The boss fight starts at 1:30.
빌드 가이드 - www.lastepochtools.com/build-guides/aut...


Tornado rampage lightning werebear build.
This strategy works very well against this boss as he doesnt spawn in until you get near the center.

Last Epoch is finally running with significantly less issues, so we're bringing you some pro Last Epoch tips that will help beginners or veterans alike. We're going over Last Epoch crafting tips, itemization info, legendaries, the loot filter, and tons more. If you've got your own Last Epoch tips, don't forget to leave them in the comments to he...
<@&1161418687471956101> there's spam here
How to craft Unique items? Subtitels in English and German. https://youtu.be/-i1pZr6SL_w

#lastepoch #arpg #gaming
🌀 Discord: https://discord.gg/yfhzHd2n
📱 Tiktok: https://www.tiktok.com/@diablovortex
🎥 Twitch: https://www.twitch.tv/diablovortexxx
🌐 Battlenet: DiabloVortex#3788
W tym kompleksowym przewodniku video, zagłebiam się w tajniki wytwarzania unikatowych przedmiotów w grze Last Epoch, jednym z najbardziej intrygujących...
<@&1161418687471956101>

hey i just made my first ever youtube video. and i wanted you all to watch it see what you think. it took me a bit. but i got it done. here's the link. go easy on me, lol the youtube link is right here, https://www.youtube.com/watch?v=SE7BO4nJ6sk

https://youtu.be/_6bpyhbZBEY?si=41RQWM8geiebbmQ2 Last epoch is such amazing game cant wait to see what this build will do next

Twitch: https://www.twitch.tv/chadly99
Discord: https://discord.gg/5hMGWEA
GFuel Code "CHADLY" at checkout: http://gfuel.ly/3tDqQ4U
Build Planner: https://www.lastepochtools.com/planner/kB4axX6o
Final true form of our endgame Falconer build. This is hands down the craziest thing I have ever used in Last Epoch. I have yet to encounter a boss th...

O Last Epoch é um RPG de ação online que combina viagens no tempo, classes personalizáveis, criação de itens e uma história envolvente. O jogo está em acesso antecipado e recebe atualizações constantes, incluindo o modo multiplayer, que foi lançado recentemente. Se você gosta de jogos como Diablo, Path of Exile e Grim Dawn, você vai adorar o Las...
Sentinel all passives and idol slots speedrun in 2h
https://www.youtube.com/watch?v=3PtWb_w7ysQ

Broadcasted live on Twitch -- Watch live at https://www.twitch.tv/megami_infini

In this Episode beats plays Last Epoch Hydrahedron Runemaster and gets from level 73 to 76. We got a new Staff and Neck piece and we are able to run content 10 levels higher than our level. Make sure to like follow and subscribe! -- Watch live at https://www.twitch.tv/beats4president

Follow my twitch channel on : https://www.twitch.tv/captainp67
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #WARLOCK #RATLEYINKLLC #diablo4 #walkthrough #guide

This may be holding your pc back! ✅✅✅
ATB
If you enjoyed the video don't forget to like, subscribe, & share with a friend to help the channel grow!
Twitch: https://www.twitch.tv/jusedofus
Lilith's Lords Diablo 4 Community: https://discord.gg/PX6bj8YM42
Ascendance Lost Ark Community: https://di...
Hi, I've started creating content related to "LE." If you're interested, feel free to check out the materials. Thanks! https://www.youtube.com/watch?v=ukm6QXwNBFA

Doing some empowered monoliths, random gameplay of Dive Bomb Falconer
https://www.youtube.com/watch?v=wE9U2skE-zs


Build Guide:
Coming Soon (Waiting for Approval)
Build Planner:
https://www.lastepochtools.com/planner/QWXEzEZB
Twitch:
https://www.twitch.tv/trikster08
Timestamps
0:00 - Intro
2:00 - Gameplay Showcase
4:05 - Boss Showcase
5:10 - Build Mechanics
6:55 - Shurikens
9:12 - Synchronized Strike
10:10 - Umbral Blades
11:15 - Aerial Assault
12:40 - Fal...

Hi, this is luminoushank
catch me on twitch https://www.twitch.tv/luminoushank
my discord server for guides https://discord.gg/RcmCUMxu
The build guide on Last epoch tools website will be out soon
Build planner : https://www.lastepochtools.com/planner/oR66Ex2o
If you have any questions about the build you can find me on twitch, i stream everyd...

Tempted to use the gambler? Wonder why so many streamers say it is so bad? Well I decided to test it out by spending 1 million gold and this is what I got:

Gamba in Last Epoch is not worth it -- Watch live at https://www.twitch.tv/bigdonnycal
Death Seal Lich doing the first actual challenging content early game (first playthrough)
https://www.youtube.com/watch?v=Xh0tZiF7RUQ&t=149s
lv 53 Acolyte early game Chapter 8 Lagon boss
death seal build insane dps
Streams at
https://www.twitch.tv/sirmorgan

https://www.lastepochtools.com/planner/oXzz6NzQ
Level 97 gameplay in corruption 170.
Still using -3 throw cost rings. Thought i'd share this before I upgrade for cunts who want to play the build but don't have the funds to get -4/-5 rings yet. It's playable with the experimental mana affix on a belt (try get 20+). You'll auto consume a pot wit...

Last Epoch's launch was a massive one.. Because of the amount of players that played, sure, but also because of the server issues! It seems to be a hot topic in the community so I decided I would give my opinion on everything that happenened.
Twitch stream : www.twitch.tv/musmio
Join the community on Discord! : https://discord.gg/sVBDea3jdY
I ...

Detonating Arrow Marksman Build
https://www.lastepochtools.com/planner/Q9JJNKDB

Link da live no comentário fixado.
#lastepoch #twitch #gameplay #farming

Last Epoch 250+ Corruption Guide for Soloing on Spellblade on shatter strike build
--
Best Spellblade Flame Reave Build - https://youtu.be/TL7w2itjwU8
50 hours Last Epoch Review - https://youtu.be/FPFlTGm8GBU
Shatter Strike for 250@SteveMoua+ Corruption Monoliths
Last Epoch Tools (LINK TO BUILDS) -
Beginning Endgame Shatter Strike Build ...
DJ Lizard_IRL - BALISTA DISCO BUILD
Last Epoch 1.0 Twitch Highlights 2024 Day 8+9 - Rip, Crafting, Legendaries

Last Epoch 1.0 Twitch Highlights 2024 Day 8+9 - Rip, Crafting, Legendaries - COMPILATION
FEATURED IN THIS EPISODE:
https://www.twitch.tv/allliee_
https://www.twitch.tv/chefnunu
https://www.twitch.tv/chronikztr
https://www.twitch.tv/cohhcarnage
https://www.twitch.tv/crouching_tuna
https://www.twitch.tv/ds_lily
https://www.twitch.tv/elgamervieju...
For anyone looking for a simple the crafting system guide 🙂
https://youtu.be/bpaUdCt13Hw

Last Epoch Beginner Crafting Guide:
Crafting in Last Epoch is intimidating for new players, so here is a full beginner crafting guide. Going over everything from upgrading, re-rolling and adding affixes to gear.
I hope this helps get over the initial confusion of forging and crafting in Last Epoch and if you have any tips for new players plea...
WIP preview of a thorns build I’m currently working on https://youtu.be/WAzC-QccIAQ?si=4VlGZd3i6_hA7aPC

this is a WIP! leave a comment below if you want to see more of the progress as i complete the build!

This video teaches players about the Crafting system in Last Epoch and goes over use cases for all of the Glyphs and Runes available.
Anvil from thumbnail created by Freepik | https://www.flaticon.com/free-icons/anvil
Chapters
0:00 - Intro
0:25 - Items
1:24 - Affixes
1:49 - Glyphs
3:28 - Runes
6:15 - Exalted and Legendary Items
7:04 - Outro
Ever wonder what a full echo web looks like?
https://www.reddit.com/r/LastEpoch/comments/1b57rgb/ever_wondered_what_a_completed_monolith_web_looks/
Reddit
Explore this post and more from the LastEpoch community

After having a few extra days with Profane Veil, I wanted to share my findings on the ward gain bug as well as some recommendations for those looking to mitigate it's impact (either on your future enjoyment or on your current enjoyment of the game). The vampiric pool node is amazing and I would prefer to fit it in most of my Warlock builds becau...
Ding Level 100 HCSAF Marksman
#shorts #LastEpoch #arpg #hcssf #hardcore #worldfirst #marksman #rogue #blastrain #level100 #hc

Live TWITCH Stream: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Falcon Fist Loot Filter: https://docs.google.com/document/d/1HWPiv2QK3wUyqbAnPk1U2NI1CsfwxL6sKlSaHeVxwEI/edit?usp=sharing
Falcon Fist Build Planner: https://www.lastepochtools.com/planner/AVaN5Evo
Acolyt...

Level 98 gameplay in corruption 192. Lowkey playable now but the sustain isn't there yet vs bosses. Hopefully T7 rings with a big enough mana pool will be enough - gone mana implicit on wand. No T7 rings up for sale today. Hit rank 7, upgraded rare gear to full exalted, not got BiS rolls on gear eg. missing cold res on the belt and would want a ...
<@&1082357055484071997>
Thanks!

A Diablo 4 Super Fans Perspective on if Last Epoch is too Easy.
*Some statements in this video are for entertainment purposes only and should not be taken as facts.
Twitch: FrostylarooTV (Will start to stream one day soon)
Rax's (Raxxanterax): Last Epoch Beginner's Guide
https://youtu.be/xOh9eEHA8Ng?si=llhhl1IdCJlBEY0g
Maxroll guide used in ...

Follow my twitch channel on : https://www.twitch.tv/captainp67
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #WARLOCK #RATLEYINKLLC #diablo4 #walkthrough #guide
Last Epoch - Riq Channel Trailer - Rip, Crafting, Builds, Legendaries
Twitch Highlights

Last Epoch - Riq Channel Trailer - Rip, Crafting, Builds, Legendaries
Channel Link: https://www.youtube.com/c/RiqDE
FEATURES IN THIS CHANNEL:
https://www.twitch.tv/zizaran
https://www.twitch.tv/steelmage
https://www.twitch.tv/anniefuchsia
https://www.twitch.tv/quietforme
https://www.twitch.tv/nugiyen
https://www.twitch.tv/quin69
https://www.t...
Little update to my last video of the thorns build https://youtu.be/smeq4zAL2Jc?si=k6WEFI9Sf8JJqDfs

This is a WiP Auto Healer Thorns build! Don't forget to like and subscribe as I post WIP and the completed build
follow me on twitch as well to watch this build live as I handcraft it into something amazing https://www.twitch.tv/sharkbytesgaming
If you like this game or are thinking about buying the game why not check out at https://www.nexus.gg...
Hardcore https://youtu.be/PZ65ODCNPPQ

Thank you for your support as a disabled content creator it means alot for all the subs like and view.
Welcome to our gaming channel! We bring you immersive gameplay, thrilling adventures, and the latest updates in the gaming world. Join us as we explore new worlds, conquer challenges, and share our gaming expertise. Whether you're a casual pla...



#lastepoch #arpg
In this guide i give you my view on what is the best faction in Last Epoch Cycle 1 - highlighting the good the bad and the ugly for each faction
Twitch: https://www.twitch.tv/goodfoxxy
Streaming this Thursday at 6pm BST
Shadow Cascade quick showcase 350 corruption https://www.youtube.com/watch?v=ycgDlz6U02A

Last epoch shadow cascade rogue build showcase - fast 350 corruption map clear
/planner/Qqwgj53o - build planner
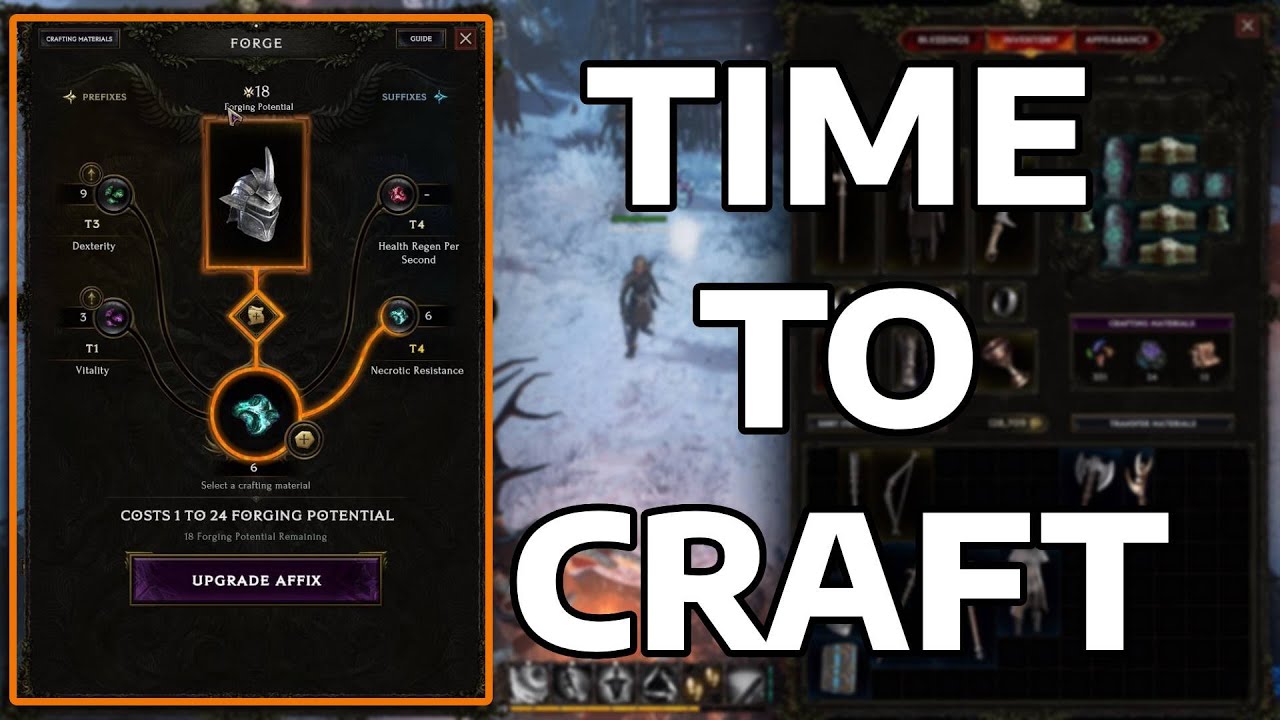
Welcome to my new channel just for Last Epoch!
In this video I discuss my thoughts on Crafting and why its important! There is so much junk loot that its almost always best to CRAFT your own its important and you should learn more about it!
#lastepoch #actionrpg #pcgaming
Website - https://techholler.com
TWitter/X - https://x.com/thes...
Famous Last Words....https://www.instagram.com/p/C4EAydON50k/


Endgame Void Knight Eraser Strike Guide for Last Epoch
Void Knight Leveling Livestream - https://youtube.com/live/bAXs9ZcDfuU
Best Spellblade Flame Reave Build - https://youtu.be/TL7w2itjwU8
50 hours Last Epoch Review - https://youtu.be/FPFlTGm8GBU
Last Epoch Tools (LINK TO BUILDS) -
Critical Eraser Strike Build -
https://www.lastepoch...
How Do i get a refund? game is piece of ♥♥♥♥ it is not playable in the endgame.
echo mapping loading until next day. this game is still in ALPHA or BETA.
I'm getting bored. Not the single player type, miss LFG tools and random runs.
You can farm but there is no reason to do so, no goal to chase or meaningfull gear progression.

With this video, we set out to spice up the Warlock meta by making a Crit build viable! And I'm very happy with the results we got from Crit Bone Curse. The damage is very similar to Torment. The defensive layers, itemization requirements and overall smoothness of the build are worse. So if you are just looking for pure performance, my Torment b...
Is it too late in the evening for some Last Epoch lore?
Chapter 1 - The Keepers is up on my channel 🙂

Greetings Travelers,
Welcome to another Last Epoch lore video! Today's video is my retelling of Chapter 1 - The Keepers. Join me as we travel zone by zone making sense of the story and finding secrets and other hidden lore throughout.
This is 1 of 9 in this series, some chapters will be longer than others but each will be this detailed and thi...
900+ Corruption Sorc Update! 140k EHP (mana stacking spark charge)
title is a bit messed up lol
https://youtu.be/NiU586vYJGY
Yea it regular monlith but still funny watching a boss that you dreaded fighting a while back get spanked later on.
My first video for last epoch, chill run for fun, #No.1 Leaderboard on maxroll softcore https://youtu.be/mYy8h8VCXoU?feature=shared

Necrotic Resistance, Damage Over Time, Necrotic Damage
EDIT: Realised after uploading that you don't need 5/5 Alchemical Proficiency anymore. Not a single point in it. 2 options: 5/5 Hydrochloric Acid or 2/4 Hindering Mixture + 4/4 Splash Zone for +120% area. Update soon. Also opens up the possibility of Alchemist Gift x Barrage Traps.
https://www.lastepochtools.com/planner/QDxk1PJQ
Aspirational (...

Hi guys! In this video I go over how I am making gold and my Trade filter that is linked below! The goal is to have a filter that shows valuable items for all classes that anyone can use to make lots of gold :).
Filter (version 1, latest version will always be in my discord! send comments and requests in my discord!)
https://www.lastepochtools...

DO NOT PLAY THIS UNTIL ITS BUGGED FIXED LMAO
Last Epoch Tool Planner :
https://www.lastepochtools.com/planner/oYEmXL3o
Email : dr3adfulr3aper@gmail.com
Twitch : https://www.twitch.tv/dr3adful__
Discord : https://discord.gg/tGqngsB
#lastepoch
#lastepoch #arpg
In this guide i give you my view on what is the best faction in Last Epoch Cycle 1 - highlighting the good the bad and the ugly for each faction
Twitch: https://www.twitch.tv/goodfoxxy
Streaming this Thursday at 6pm BST

Profiles:
https://www.lastepochtools.com/profile/snapbackkilla/character/snap_snapfreeze
https://www.lastepochtools.com/profile/randalfire/character/Randal_Snap
https://www.lastepochtools.com/profile/naliaa/character/nawiwa
https://www.lastepochtools.com/profile/chillychilly/character/chilly_snap
0:00 -- Intro
1:05 -- Runemaster Carry
9:58 --...
Check out my latest video! https://youtu.be/CIB_JSmOHPw
Crafting a Legendary Siphon of Anguish
Hey, I’m Axxicus! In this video, we're running Temporal Sanctum on my Werebear Druid in hopes of crafting a Legendary Siphon of Anguish. Want to roll Strength on it!
Timestamps:
0:00 - Introduction
0:24 - Start of Dungeon
1:49 - Second Floor
3:02 - Chronomancer Julra
5:22 - Legendary Crafting
See if you...
My new build seems a bit broken:


Ссылка на таблицу в комментах. Актуально на 04.03.2024
Не является руководством, что надо делать именно так))
Salut à tous voici une vidéo sur la faction Circle of Fortune, bon visionnage. https://youtu.be/398-9zpqDo4?si=sgqP4i_--_MnwYVF

Salut à tous, aujourd'hui on parle de Circle of fortune. On aborde les lens, les prophecie. Bon visionnage à vous
TWITCH https://www.twitch.tv/saony06
DISCORD https://discord.gg/6GezYFRjAC
Youtube : https://youtube.com/@saony0626
Pour me soutenir Regarde par ici https://www.nexus.gg/saony
00:01 Intro
00:17 Observatory
01:33 Région
03:27 les ...
Destroyed the empowered emperor of corpses for first time. Felt good
My first build on a runemaster (wip)
https://youtu.be/wumUqAjFAYE

Hopefully I don't have to invest in sunglasses...
- Gameplay: 00:00
- The Gear, Idols, Blessings: 01:57
- Passive Tree: 10:04
- The Skills: 13:31
Last Epoch Planner: (04-03-2024) Experimental
https://www.lastepochtools.com/planner/oy4JZYaB
Uncover the Past, Reforge the Future. Ascend into one of 15 mastery classes and explore dangerous dungeo...
 Warlock 1 Million + Damage ! Record !
Warlock 1 Million + Damage ! Record !
https://youtu.be/DnTj13ZgGVQ

Torment Warlock 1 Million + Damage ! Record !
https://www.youtube.com/watch?v=RmaIx164SwM my hydra runemaster

Build: https://maxroll.gg/last-epoch/build-guides/hydrahedron-runemaster-guide#gear--header
Build made by: @lizardirl
My gear is kinda trash so I didnt bother showing it.
https://www.youtube.com/watch?v=nWgDueSUC3U A lil showcase of my Build

This is my build not urs XD
By - Crazy

So I heard about an interaction that sounded really fun from Apocrypha Scribe in chat so we decided to minmax the DPS and forego all survivability to see what we get. The interaction is fun so I thought I'd share it! Let me know what you think - is there a viable build hidden somewhere in there?!
Links to my:
Discord - https://discord.gg/Dxje9...
https://www.youtube.com/watch?v=e0i40QAYeiA explode ballista 4 second julra no prestacking


All content in the game is cleared !! Temporarily Rank 1 Primalist Arena aswell :) Time to push another build , no idea what that would be right now.
Character Profile : https://www.lastepochtools.com/profile/Cursedboy/character/ScorpionProwess
Full Arena Run : https://www.twitch.tv/videos/2080747441
Livestreams : https://www.twitch.tv/cursed...
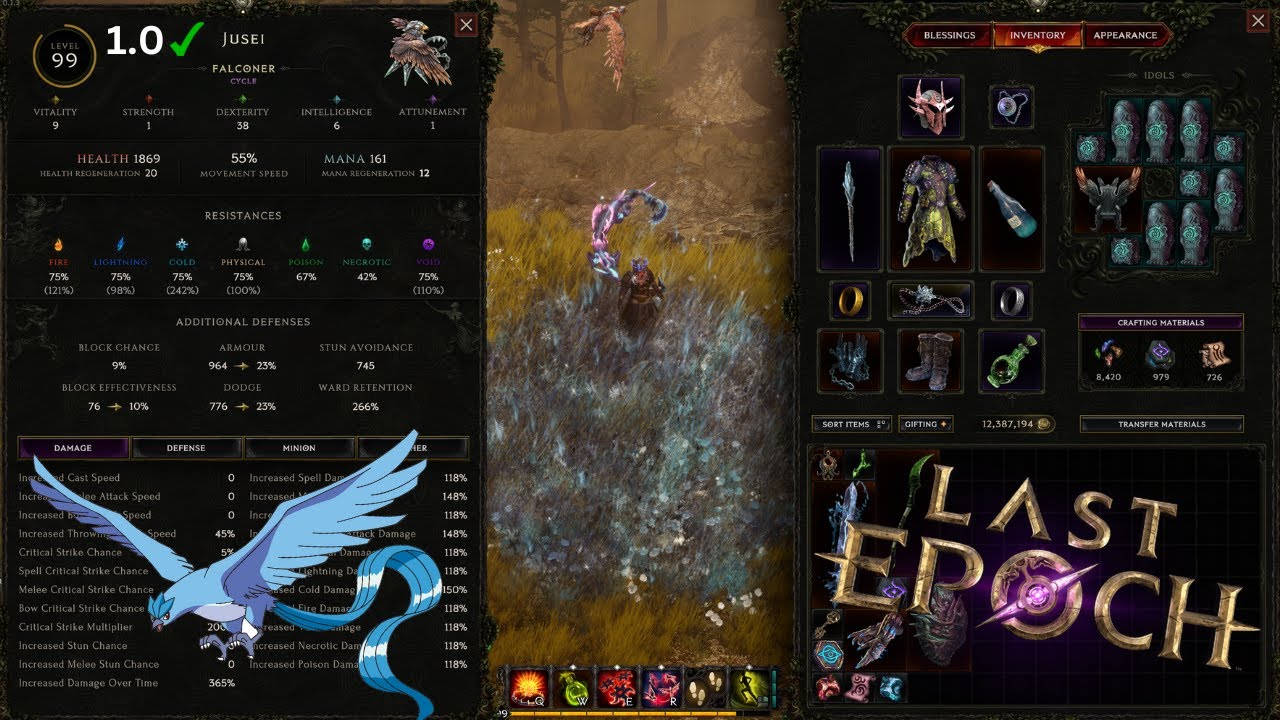
Level 99 in Corruption 305 @ 1829 frostbite damage.
https://www.lastepochtools.com/planner/AKgO0anA
Starting off you'd have +20% all resistance blessing, swap to crit strike avoidance in high corruption.
Aspirational (will never get this): https://www.lastepochtools.com/planner/QWX7wk0B
I hit rank 8 MG today but wanna show you the build befor...

Character: https://www.lastepochtools.com/planner/Qdz77VYo
I hope you don't mind the music in the background. Right now I'm farming at 500 corruption and I think this build probably still be able to push to 600-700 as I can still oneshot all the rare and twoshot exiled mage. The build is pure life relying on armor, dodge, and glancing blow as m...
pretty sure this is for last epoch related only videos
Doesn’t matter he is not spamming it, it’s fine
- No advertising or self promotion
However, if you've made any videos about Last Epoch, feel free to share them in 🎥┃video-shoutout
I know just didn’t wanna be harsh about his 1 hr long vid. I guess ppl won’t spam it or post multiple different vids. Hope u get me

O Last Epoch é um RPG de ação online que combina viagens no tempo, classes personalizáveis, criação de itens e uma história envolvente. O jogo está em acesso antecipado e recebe atualizações constantes, incluindo o modo multiplayer, que foi lançado recentemente. Se você gosta de jogos como Diablo, Path of Exile e Grim Dawn, você vai adorar o Las...

Last Epoch Leviathan Carver Harvest Chaos Bolt Warlock Is Almost There | Build Guide Showcase
Build Planner (I do not suggest this build as of the moment, maybe they buff harvest in the future) :
https://www.lastepochtools.com/planner/AVa7nPXo
Email : dr3adfulr3aper@gmail.com
Twitch : https://www.twitch.tv/dr3adful__
Discord : https://discord...

Level 100 in corruption 344 @ 3095 frostbite damage.
4 LP Vials are extremely cheap as expected. Scored mine for 1m with solid rolls but they start at 50k. 4 LP. For 50k....... You want a high (80/85 is solid but rare) chance to apply frostbite on hit roll above all. Roll priority order is frostbite chance, area for cold skills (since we aren't...


Build Planner: https://www.lastepochtools.com/planner/BEdxerMQ
Basic filter: https://pastebin.com/LWje4RhA
Endgame filter: https://pastebin.com/betTzWvA
Discord https://discord.gg/XkVWhzBN5v
All PasteBin https://pastebin.com/u/MrJimo
All Pastebin.in https://pobb.in/u/MrJimo
#Mrjimgaming
Timestamp
0:00 General inf...


Follow my twitch channel on : https://www.twitch.tv/captainp67
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #WARLOCK #RATLEYINKLLC #diablo4 #walkthrough #guide

TWITCH https://www.twitch.tv/saony06
DISCORD https://discord.gg/6GezYFRjAC
Youtube : https://youtube.com/@saony0626
Pour me soutenir Regarde par ici https://www.nexus.gg/saony

Follow my twitch channel on : https://www.twitch.tv/captainp67
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #WARLOCK #RATLEYINKLLC #diablo4 #walkthrough #guide
This dude is actually spamming with videos from other games

Hey everyone, Rabbit here. Today I wanted to show you guys what leveling uniques I use whenever I make my alts to speed through the early campaign and into monoliths as fast as possible.
As usual, here are the timestamps listing all the items as well as a short demo on firestarters torch!
Your offhand doesn't matter too much, just take somethi...
This is my 1st ever video so try to act like its not 🙂 !
Some thoughts and ideeas on the game. UNGA !
https://www.youtube.com/watch?v=vLVWheZbEFo&t=25s&ab_channel=UngaBunga

This is my 1st video so act like it's not sh*t. Tyvm.
Going to be following up with another video soon, hopefully better audio quality.
I have no ideea what I'm doing.
Follow me on twitch, i just started : twitch.tv/unga___bunga
Last Epoch is on the right path. BUNGA!

Last Epoch is the best ARPG out there, but let's make it even better! 😇
0:11 - Re-color also showing in the inventory
3:48 - Remove the "Forging Potential" RNG
5:26 - Selective Rune of Removal
7:46 - Auto pick-up items option
10:19 - Add 'transfer all' button
#lastepoch #top5 #ideas

Live TWITCH Stream: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Echo Rive Loot Filter: https://docs.google.com/document/d/12sigXv45S2juzEPzXFZr-OWvBmOskyg1KdSE_GE8-sc/edit?usp=sharing
Echo Rive Build Planner: https://www.lastepochtools.com/planner/B4XVZ69B
Acolyte:
...

In This Video I played a game called Schizo who I saw Caseoh Playing. It was a fun and scary experience which had me shivering when I was playing.
NEXT VID COMING OUT NEXT WEEK!


LIKES/COMMENTS help the videos reach more people!
SUBSCRIBE lets you to see more content from me!
CLICK THE BELL to enable notifications to see when new content goes live!
Build Guides
https://www.youtube.com/watch?v=NiU586vYJGY
https://www.youtube.com/watch?v=8pgw4ir9ILc
Damage Calculation (https://lastepoch.tunklab.com/ehp)
https://lastepoc...
Link da live no comentário fixado.
#lastepoch #twitch #gameplay #farming

✅Телеграм - https://t.me/umbras_team
✅ВК - https://vk.com/umbras
#lastepoch #arpggaming #arpg #mmorpg #umbras #игры

Last Epoch | How to Respec Mastery And Skill points
In this Last Epoch guide we will talk about how to respect the mastery passive points and how to respect the Skill points
#lastepoch #Lastepochguide #Lastepochfactions
SUBSCRIBE GAMEHAUNTINGS ► http://bit.ly/Gh_sub
Welcome to Our Haunted Channel...
Καλως ήρθατε στο στοιχειωμένο μας κανάλι .....
Squirrrels and storm bolts shaman build guide:
https://www.youtube.com/watch?v=8UTY4Oxy4kA&t=1334s

Last Epoch build guide for Squirrels and physical storm bolts.
Last epoch tools: https://www.lastepochtools.com/planner/AVaV1ZPo
My twitch: https://www.twitch.tv/fortyz_
Timestamps:
0:00 Intro
0:35 Primalist passives
1:25 Beastmaster/Druid passives
2:21 Shaman passives
3:38 Maelstrom Skill Tree
5:02 Gathering Storm Skill Tree
7:30 Tempest St...
first ever build guide video was a little nervous but heres a quick overview of thorns spriggan and the full guide will be published this weekend hopefully friday https://youtu.be/KV64isJysxs

Welcome to the ultimate Last Epoch Thorns Spriggan build guide! Dive into the depths of nature's fury with this powerful build designed to maximize thorns damage and survivability. Learn how to harness the full potential of the Spriggan's abilities, master the skill tree, optimize equipment choices, and dominate the battlefield with strategic ga...

Last Epoch 1.0 Twitch Highlights 2024 Day 10+11+12 - Rip, Crafting, Legendaries
FEATURED IN THIS EPISODE:
https://www.twitch.tv/darthmicrotransaction
https://www.twitch.tv/lizard_irl
https://www.twitch.tv/dalkora
https://www.twitch.tv/rektbyprotoss
https://www.twitch.tv/expaer
https://www.twitch.tv/jaymodest
https://www.twitch.tv/kingkongor
htt...

Follow my twitch channel on : https://www.twitch.tv/captainp67
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #WARLOCK #RATLEYINKLLC #diablo4 #walkthrough #guide

Hey everyone! I hope you enjoyed the video and found it helpful. If you have any feedback, please do not hesitate to leave it in the comments. If you enjoyed the video make sure you give it a like! Thanks!

Sub-A-Thon Event Link: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?si=Edg5tvAUn9tsSvjJ
-Necromancer Ultimate Fire: ht...


Want your patch notes and updates read by a hillbilly?
Why sure you do!
Patch Notes here - https://forum.lastepoch.com/t/last-epoch-patch-1-0-2-notes/66953
#lastepoch #actionrpg #pcgaming
Website - https://techholler.com
TWitter/X - https://x.com/thesmango

Thank you for your support as a disabled content creator it means alot for all the subs like and view.
Welcome to our gaming channel! We bring you immersive gameplay, thrilling adventures, and the latest updates in the gaming world. Join us as we explore new worlds, conquer challenges, and share our gaming expertise. Whether you're a casual pla...

Всем привет! В этом ролике я расскажу вам о самых сильных билдах в Last Epoch 1.0
Таймкоды и ссылки на видеогайды по билдам из ролика:
00:00 - Вступление
00:30 - Пернатые девочки
00:54 - Instakill Falconer
https://www.youtube.com/watch?v=_6bpyhbZBEY
01:32 - Acid Flast Explosive Trap
ДМГ версия - https://www.youtube.com/watch?v=MkBx3JH9H1w
Пожир...

Timecodes
0:00 - Corpse Dragon (Dragon Timeline) 1000 corruption
1:15 - Oroboros 1000 corruption
3:25 - T4 Julra Dungeon Boss/Crafting
4:40 - Build and Gear overview
I have completed destroying Last Epoch after 150+ hours, reaching corruption levels over 1000, in solo mode (hard mode). Unlike trade merchant faction, you have no access in COF t...

Was fighting Empowered Lagon (for the 3rd time that evening for the right Blessing) and didn't respect the Moon Beam enough to really focus on dodging it. Was really only looking out for the laser (as that was the only attack that even tickled me in the fight, previously). Lesson learned, kek.
I stream ARPGs @ https://twitch.tv/schmidtwerd
Joi...

How the build does damage: spam Trap detonations to fling multiple flasks that stack frostbite DoTs.
How to sustain mana: T7 throwing cost red rings x2, using a pot with 'mana gained on potion use' experimental affix on belt, Sapping Strikes x direct Flask cast (x2 value with Elecoe), 6/6 Rover Stamina mana regen/mana on dodge, Hunters Spoils....
<@&1161418687471956101> these two community members are being off topic on top of not giving a damn about rule.6
#🎥┃video-shoutout message
#🎥┃video-shoutout message
Thanks, remember this channel is for LE related stuff

1700+ Health Regen 8k Ward Vessel Ignite Warlock | Last Epoch Build Guide Showcase
Last Epoch Planner :
https://www.lastepochtools.com/planner/o3ZRrDkB
Email : dr3adfulr3aper@gmail.com
Twitch : https://www.twitch.tv/dr3adful__
Discord : https://discord.gg/tGqngsB
#lastepoch

This game just hits different for some reason
#lastepoch #final #bossfight
Last Epoch - Comparing value of ADDED vs INCREASED vs MORE --> No fancy stuff, just me with some formulas 🙂
https://youtu.be/TJGhJUZBxuA?si=xBofKmBMZPseGC1T

Three part video to go through how to derive a formula to compare each individual contribution of a new ADDED, INCREASED or MORE modifier.
Part 1: TLDR + Calcs for contribution of an ADDED modifier
Part 2: Calcs for contribution of an INCREASED modifier + EQUAL RATIO for ADDED vs INCREASED, INCREASED vs MORE and ADDED vs INCREASED.
Part 3: Fi...

Live TWITCH Stream: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Golemstorm Loot Filter: https://docs.google.com/document/d/1Ahk8EQ3NCuKgT_1SpZZ8_PFTFBlcXMVxi4Db8Td2Rcw/edit?usp=sharing
Golemstorm Build Planner: https://www.lastepochtools.com/planner/BjqkzE5Q
Acolyte:...
my favorite boss fight so far
https://www.youtube.com/watch?v=ZHQztTLCFYw

Runemaster is lovely, my melee shaman is crying though
https://youtu.be/xMz4j1EnGqU

A more fully formed build (version 2) of my Spark Charge Elemental Nova Runemaster.
Great damage, Great speed, Great tank!
- Gameplay: 00:00
- The Gear, Idols, Blessings: 02:50
- Passive Tree: 11:29
- The Skills: 15:06
Last Epoch Planner:
https://www.lastepochtools.com/planner/A6PRr2pB
Lootfilter (My personal loot filter, and I'm weird)
- h...

Thank you for your support as a disabled content creator it means alot for all the subs like and view.
Welcome to our gaming channel! We bring you immersive gameplay, thrilling adventures, and the latest updates in the gaming world. Join us as we explore new worlds, conquer challenges, and share our gaming expertise. Whether you're a casual pla...


Here is a Devouring Orb build updated for 1.0 that works decently well in the end game.
I usually answer every comment so if you have any question just hit me up.
I hope you enjoy and stay tuned for future content!
Chapters :
00:00 Intro
01:42 Passives
02:18 Skills
05:28 How to play the build
06:28 Leveling
07:46 Itemization
10:10 Blessings
1...
[Lore] Chapter 2/9 in my story retelling on my channel now 🙂

Greetings Travelers,
Welcome to another Last Epoch lore video! Today's video is my retelling of Chapter 2 - The Ruined Future. Join me as we travel zone by zone making sense of the story and finding secrets and other hidden lore throughout.
This is 2 of 9 in this series, some chapters will be longer than others but each will be this detailed ...
Feel like cheating

Showcasing my Void Knight performance on all TierIV dungeon..right now still effortlessly pushing 400+ corruption..
Timecodes
0:00 - Soulfire Bastion
0:20 - Lightless Arbor Key
1:53 - Temporal Sanctum

3 LP Elecoe's was 2m. The +4 flask exalted chest was 200k. Actually gives your Flask some meaningful DoT @ 50k tooltip but won't compare to frostbite shred. If Hydrochloric Acid or Contamination converted to cold i'd 100% be using those.
Saving Heirloom slams for last as +5 throwing cost red rings are expensive. Got a 3 LP Heirloom for around 4...
New players experience cold spellblade leveling build
https://youtu.be/PtJa_jsMWvg?si=DU1Pa_9L85FoqftH
Just a quick look at the build I am currently using to level on my Spellblade. I have been having a lot of fun and success on this lately and wanted to share it with you! Will post an update video at higher level/difficulty.

Follow my twitch channel on : https://www.twitch.tv/captainp67
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #WARLOCK #RATLEYINKLLC #diablo4 #walkthrough #guide

We went over Patch 1.02 notes on stream and discussed them at length. We also had a poll on whether To Fix or Not To Fix the Veil bug. Then I shared my thoughts on the topic. Now we chill and let EHG do their thing!
Links to my:
Discord - https://discord.gg/Dxje9s2mmV
Twitch - https://www.twitch.tv/thecursebg
Patreon - https://patreon.com/TheC...

Top 3 Builds From The Last Epoch Community For 1.0
Build #1 @amityqt :
https://youtu.be/4S_VHXoBEnI
Build #2 @Milkybk_ :
https://youtu.be/ngVxJ-Wn13o
Build #3 @pinchingloaf :
https://www.youtube.com/watch?v=AkwJg5IdDYA&t=143s
Email : dr3adfulr3aper@gmail.com
Twitch : https://www.twitch.tv/dr3adful__
Discord : https://discord.gg/tGqngsB
#las...
Here is a Devouring Orb build updated for 1.0 that works decently well in the end game.
I usually answer every comment so if you have any question just hit me up.
I hope you enjoy and stay tuned for future content!
Chapters :
00:00 Intro
01:42 Passives
02:18 Skills
05:28 How to play the build
06:28 Leveling
07:46 Itemization
10:10 Blessings
1...

Endgame Void Knight Build using Healing Hands, Void Cleave, Rive, and Erasure Strike as main dps skills.
Anamoly and Lunge are utility.
Immortal Void Knight Build Planner
https://www.lastepochtools.com/planner/B4Xeg69B
--
Damage Erasure Strike Build - https://youtu.be/jcfvMubfOdU
Void Knight Leveling Livestream - https://youtube.com/live/b...

Empowered Monolith & Thoughts on D4
In this video, we're taking the Werebear Druid for a spin through empowered monoliths and opining on various aspects of Last Epoch and D4.
Timestamps:
0:00 - Introduction
1:02 - Shoutout @lizardirl
1:49 - Werebear Druid Gameplay
4:15 - Positives of Last Epoch
6:25 - Thoughts on D4
If you enjoyed the vid...
Feels no different to corruption 300 lol. Shit melts like butter. Let's see how high we can push before they can one tap us. Only halfway there, aim is at least 1k corruption with the life build before sussing out the low life version.
Will be swapping 20% all res blessing to 65% poison on hit (crit strike avoidance was planned but i've been ru...

Last Epoch GameplayWebsite: https://lastepoch.com/Available on: PC via SteamDiscord: https://discord.gg/lastepochAll credits of this video and links are to ...
MY RING JUST VANISHED FROM INVENTORY! AT THE START
https://youtube.com/live/1N-AhXUHTfE?feature=share

Last Epoch 1.0 TESTING New LIGHT SPELLBLADE part 1Going without guides and improvized build. #lastepoch #build #poison #plague

Survey Link: https://forum.lastepoch.com/t/mid-cycle-build-balance-survey/67482
Sub-A-Thon Event Link: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer:...

E ai, como você tá?
Nesse vídeo trago para vocês uma build de Void Knight muito tank e com um ótimo dano especializada em derreter boss.
Planner/Build: https://www.lastepochtools.com/planner/QdzRbROo
Material de apoio monolitos: https://www.lastepochtools.com/endgame/monolith
O que vocês acharam?
Compre o Last Epoch na Steam (Há versões com...

Last Epoch 1.0 Twitch Highlights 2024 Day 13+14+15 - Rip, Crafting, Legendaries
FEATURED IN THIS EPISODE:
https://www.twitch.tv/1mlucky
https://www.twitch.tv/aaronactionrpg
https://www.twitch.tv/barbarousking
https://www.twitch.tv/braskin
https://www.twitch.tv/carn_
https://www.twitch.tv/chefnunu
https://www.twitch.tv/darthmicrotransaction
http...

Live TWITCH Stream: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Hail Hydra Loot Filter: https://docs.google.com/document/d/1QUm7lxfo_4nVuQJ2oKFSprDxBFB3wzJJ5n0UjQqIH10/edit?usp=sharing
Hail Hydra Build Planner: https://www.lastepochtools.com/planner/QDx80GGQ
Acolyte:...
Last Epoch Guide for beginners| How to make YOUR OWN Builds
https://youtu.be/1AZCvDGnHcM

Hey travellers, this is a beginner's guide for Last Epoch - a new ARPG by Eleventh Hour Games.
This guide takes you through How to build your character, looking at your skills, passives, build your defences, identify farmable gear, idols and blessing
Last Epoch 1.0 release beginner guide new player
Last Epoch endgame
Last Epoch patch 1.0 cha...
https://youtu.be/32yiD0E9ucc
Гайд на НЕ МЕТОВОГО ЛИЧА КОТОРЫЙ УНИЧТОЖАЕТ JULRA За 2 СЕКУНДЫ

Не Метовый но более сильный билд на Лича чем большинство метовых билдов. Возможность фармить 1000+ Корапты
Ссылка на телеграмм: https://t.me/stlklive
Ссылка на твич: https://www.twitch.tv/stlk
0:00 Примеры убийства боссов
0:24 Описание Билда
1:21 Прокачка
1:51 Необходимые предметы
3:45 Рекомендую Афиксы и Префиксы
8:45 Пассивные очки
12:03 На...

最近有Bug技能過強
引來玩家質疑為甚麼沒有改弱
官方亦因此想更清楚了解玩家真正的想法
Nexus購買: https://www.nexus.gg/hfok/games
======================
其他平台搵我吹水/交流
POE: /global 852 korean
Telegram: https://t.me/joinchat/ssbMhhWs-ZdmMGM1
Discord: https://discord.gg/faEcd7cJte
======================
呢條片相關資訊

Character: https://www.lastepochtools.com/planner/QWXwmd2B
The build is pure life relying on armor, dodge, and glancing blow as main defensive mechanic. This build is most suitable for clearing Monolith but it also have very high single target damage (1.7M damage record on dummy), however it is very susceptible to being oneshoted by boss mechan...
Exiled Mages Target Farm

Find a "Lakeside Trail" Echo and Spamfarm it for Exile Mages.
If you get lucky and have the dmg you can get 5+ Mages / min

Hi guys! Just finished my Frostbite Shatter Strike build for Spellblade!
Overall was very happy with the result and the character is VERY fun to play!
LIKES/COMMENTS help the videos reach more people!
SUBSCRIBE lets you to see more content from me!
CLICK THE BELL to enable notifications to see when new content goes live!
Ideal Gearing
https:/...
Last Epoch Guide | How to make YOUR OWN Builds
https://youtu.be/1AZCvDGnHcM
Hey travellers, this is a beginner's guide for Last Epoch - a new ARPG by Eleventh Hour Games.
This guide takes you through How to build your character, looking at your skills, passives, build your defences, identify farmable gear, idols and blessing
Last Epoch 1.0 release beginner guide new player
Last Epoch endgame
Last Epoch patch 1.0 cha...
Runemaster Spark charge caster/300% cast speed FR
https://youtu.be/hjDF7W6QqWs

Twitch : https://www.twitch.tv/aayrron
V1 Build Planner : https://www.lastepochtools.com/planner/A6PNNJ8B
V2 Build Planner : https://www.lastepochtools.com/planner/AL0jbJWA
V3 Build Planner : https://www.lastepochtools.com/planner/AKg4bEZA v3
Actuellement un des builds les plus satisfaisant que j'ai monté, un clean speed de fou, et des dégâts e...

Гайд на Паладина, который в состоянии лицом танковать боссов, прекрасно чуствует себя на высокой порче и нехило так вносит дамаг.
Last Epoch is the best ARPG out there, but let's make it even better! 😇
0:11 - Re-color also showing in the inventory
3:48 - Remove the "Forging Potential" RNG
5:26 - Selective Rune of Removal
7:46 - Auto pick-up items option
10:19 - Add 'transfer all' button
#lastepoch

4 LP Vipertail was 18m, there's another decent one up for 15 and 3 LP's go for 5. Sold off a 2 LP Twisted Heart today for 29; merchant guild OP. 70% poison chance on hit is converted to frostbite = BIG. 70% slow for faster Strike Their Flank stack and 60% dodge multiplier for faster Smoke Traps stack are nice freebies but the rest is useless. Pr...

Kripparrian Video Link: https://youtu.be/fwNByaabq2k?si=QS0tTTmgISKctx1q
Sub-A-Thon Event Link: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https:...

DMGCREW
Click show more below
Shop Last Epoch https://www.nexus.gg/idodmg/last-epoch
Time Stamps
00:00 Intro
1:09 Level 1-25
1:41 Level 25
3:00 Level 26-35
4:20 Level 36-45
6:20 Level 45
7:28 Level 46-60
7:55 Level 60
If you like everything in one place - https://allmylinks.com/idodmg1227
Otherwise its all laid out for you below, thanks for ...

Follow my twitch channel on : https://www.twitch.tv/captainp67
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #WARLOCK #RATLEYINKLLC #diablo4 #walkthrough #guide
Don't make the mistake that I made. I did it so you don't have to. https://youtu.be/LnTRLDXEgcE?si=kjnckClkICKh2V61

Link to Gear and Build:
https://www.lastepochtools.com/planner/Q0V3YWzo
I did it so you don't have to. It is a great concept how everything works together. I don't enjoy a button mash playstyle but the reality of it is that it is just bad.
At last! i made it to the 1000 corruption club! Waaaaaa build is in the description of the link XD the crazy thing is this build is real easy to complete, if you're in merchant guild, you can easily get all the gears with 0 gold XD just search in the bazaar for 0-1 LP :)))))))))))))))))))
https://www.youtube.com/watch?v=p_jCcCkxdFU

My build:
https://www.lastepochtools.com/planner/QeYl7vPQ
How to ezpz play:
Use Frostwall - Flame Rush - Frostwall then use Runic Invocation to activate "Frostguard" (Cold - fire - Cold)
Then Just spam Frost Claw alternating with Lightning Blast for crit rate and damage buff.
https://www.twitch.tv/videos/2086584686 there goes another hc character 🥹 👍

Twitch
trashcanfiend went live on Twitch. Catch up on their Last Epoch VOD now.

Note that this guide is meant to be a quick-build guide, essentially a lootfilter you can build in under 15 minutes to level up your character. The second part of the guide will be coming out soon and will get deeper into the weeds; we will cover creating precise filters to get exactly what we want whilst also being able to modify our filter qui...

TODAY we're hunting down THE PERFECT RELIC in Last Epoch + taking a look at the build - HEALING HANDS RIVE - The LEECHING BERSERKER! A little overview of my current gear and skill trees to EFFORTLESSLY clear 100 Corruption echoes!
THE BUILD IS WORK IN PROGRESS - IT WILL BE UPGRADED & UPDATED MORE AND FOR HARDER CORRUPTION LEVELS AS WE GO! :)
T...
Last Epoch - IMMORTAL Runemaster Frostbite Frost Claw Build - INFINITE MANA Guide! https://www.youtube.com/watch?v=THrT_j3-o3o&t=26s

BUILD: https://www.lastepochtools.com/planner/AKgNMMvA
LOOT FILTER: https://pastebin.com/dgFDf5eP
🔊 IRONWOLF Discord - https://discord.gg/7H9FVaKq
🟢 Watch me live every day! https://www.twitch.tv/cagedbeastttv
@TUGACLAN Member
Join this channel to have access to benefits:
/ @cagedbeastyt
🔴 Sign up! ▶ https://www.youtube.com/channel/UCQ...
https://twitch.com/yS0salty Drop me a follow!


Hit this shortly after recording this GG https://imgur.com/a/uhk9p76
12m 3LP Frozen Ire, 100k double T6 exalted. Didn't want the cold damage. No 4 LPs up.
How the build does damage: spam Explosive Trap detonations to fling multiple Acid Flasks that stack frostbite DoTs.
How to sustain mana: T7 throwing cost red rings x2, using a pot with 'man...

Présentation de mon rogue avec la spécialisation Marksman.
Le stuff est pas du tout fini, il me manque deux uniques (anneau et ceinture) et mes uniques ne sont pas très optimisé en stats.
Le potentiel est incroyable.
Curse DoT Warlock! Fast, fun, easy, and great clear. Corruption 400+ and decent bossing!
Uses all 8 curses for Warlock, to make some punishing 200k+ bleed stacks on bosses!

"More"lock Warlock -- Last Epoch Damage Over Time Build - Low-life Bleed Build
Build Link (Low-life End-game): https://www.lastepochtools.com/planner/ozwJy98A
Build Link (Life / Leveling): https://www.lastepochtools.com/planner/ozwJwleA
Capable of doing Corruption 400+ with easy. Easy to transition from life and leveling gear to low-life! Only...

Overpowered build with too much damage, fast clear speed and fun playstyle!
Planners: https://maxroll.gg/last-epoch/planner/zd33n017
Find me on Twitch ► https://www.twitch.tv/volca_
Discord ► https://discord.gg/ahBHyVqAuc
Maxroll ► https://maxroll.gg/last-epoch
Nexus store ► https://www.nexus.gg/volca
00:00 Gameplay
04:15 Build explanation
06...

Starting Last Epoch at the release! I will make a sorcerer build without any guide! Let's play and see how far can i go!
Uncover the Past, Reforge the Future. Ascend into one of 15 mastery classes and explore dangerous dungeons, hunt epic loot, craft legendary weapons, and wield the power of over a hundred transformative skill trees. Last Epoch ...

#gaming #lastepoch #lastepochbuilds
Just a quick T4 Julra kill with Lightning Marksman build. If you're tired of seeing Warlock and Falconers, give this build a try , it's really fun. Build is from @mattjesticmultigaming2758 and his friend, original video here: https://www.youtube.com/watch?v=hkqekWxhQgQ&t=29s
Build link here: https://www....
My best build of the cycle yet (Runemaster)
https://youtu.be/JBF5XHRP7zY

The final version of my Runemaster, a build that can honestly do it all with great haste and ease. My best Last Epoch build for cycle 1. This is not a cycle starter.
- Gameplay: 00:00
- T4 Julra: 02:12
- Live Gear: 02:53
- Build planner Gear: 06:23
- Build planner Passives: 12:19
- Build planner Skills: 15:05
Last Epoch Planner:
https://www...

Last Epoch 1.0 Twitch Clip Highlights 2024 Day 16+17 - Rip, Crafting, Legendaries
FEATURED IN THIS EPISODE:
https://www.twitch.tv/AlterMMO_pl
https://www.twitch.tv/Bajheera
https://www.twitch.tv/dalkora
https://www.twitch.tv/dr3adful__
https://www.twitch.tv/expaer
https://www.twitch.tv/fame89
https://www.twitch.tv/ghazzytv
https://www.twitch.tv...
New shaman build and the start of my seriers "shaman build of the week" episode 1.

Shaman Build of the week episode 1
Last Epoch build guide: upheaval Shatter shaman
Last epoch tools (easier gear): https://www.lastepochtools.com/planner/Q9J3Z3XB
Last epoch tools (aspirational gear): https://www.lastepochtools.com/planner/BEdRrPpQ
My twitch: https://www.twitch.tv/fortyz_
Other Guides:
Squirrels and Storm bolts shaman: https:...
Lowlife Fire Acid Flask/Explosive Trap Bladedancer, currently breezing through 400+ corruption
https://www.youtube.com/watch?v=rGL_PPqlxXo&ab_channel=ThatsRealNeato

Build Planner:
https://www.lastepochtools.com/planner/QnalXWLA
0:00 Intro
0:32 400+ Corruption Monolith
2:17 Acid Flask + Explosive Trap Skill Trees
8:50 Int Stacking
9:30 Gear
13:40 Utility Skill Trees
18:19 Passives
22:12 Idols
22:41 Crit Multi vs. Increased Damage
24:25 Orobis Fight
Join the Noteworthy Interactions Discord:
https://discord....
Here is a Devouring Orb build updated for 1.0 that works decently well in the end game.
I usually answer every comment so if you have any question just hit me up.
I hope you enjoy and stay tuned for future content!
Chapters :
00:00 Intro
01:42 Passives
02:18 Skills
05:28 How to play the build
06:28 Leveling
07:46 Itemization
10:10 Blessings
1...
Enjoying my adventure into Last Epoch. Still a lot to learn, but here's what I'm currently up to.
https://www.youtube.com/watch?v=40rJDySTq9k

Easy to play and build. Sentinel/Paladin Healing Hands Build.
Currently at 98 and running up corruption past 200, with plenty of headroom and build min/max and adjustments to come.
I hope it inspires you with your build.
#lastepoch
#sentinel
#paladin
#healinghands

Here is our new Last Epoch Build Guide on Marksman! Amazing For Endgame Monolith Farming, Boss Slayer, Arena Ladder Leader Board Pushing & Leveling To 100!
6th Setup (New 2000 Dodge Adjustments) https://www.lastepochtools.com/planner/QqwJeRko
5th Setup (Using Few Exalted) https://www.lastepochtools.com/planner/BGzNnnmQ
4th Setup (Warding Focus...
Wraithlord not following orders. Think he need some spanking.

My dear wraithlord is very grumpy and refuses to follow me except when I am using transplant teleport skill.
Easy 1k+ Corruption! Melts the Monolith with this【INT Stacking Lightning Master】build! // Cycle 1.0

Hey guys! Here's the 2nd progress update on my gigachad Lightning Runemaster build! I made some minor changes on this build and now im pushing 1k corruption fairly EASY lol, i believe it could even push up to 2k+ (If i dont get bored of this build)~
Anyway, i've been having a BLAST with this build and i hope you will too!
0:00 - 1:58 1K+ C Mo...

Thank you for your support as a disabled content creator it means alot for all the subs like and view.
Welcome to our gaming channel! We bring you immersive gameplay, thrilling adventures, and the latest updates in the gaming world. Join us as we explore new worlds, conquer challenges, and share our gaming expertise. Whether you're a casual pla...

Here is our new Last Epoch Build Guide on The Necromancer Wraith Build! For Leveling, Beginner Friendly & Early Game Monolith Farming, Boss Slayer & Endgame Setup!!
Our NEW Endgame 1000+ Corruption Setup https://www.lastepochtools.com/planner/BgRar85Q
See Our Wraith Necro Detail Guide https://youtu.be/u5TUk3704wo
1-80 Necro Speed Leveling Gui...

0:00 T4 Julra
0:17 DPS dummy
0:27 1290+ Corruption runs
3:23 1200+ Shade fight
4:12 1200+ Lagon Boss fight
1200+ CORRUPTION (SOLO)RUNS, T4 JULRA, 1200 SHADE, 1200 BOSSFIGHT, TARGET DUMMY DPS. CURSE WARLOCH .
more content on https://www.twitch.tv/kehjjn
Music:
Hey travellers, this is a beginner's guide for Last Epoch - a new ARPG by Eleventh Hour Games.
This guide takes you through How to build your character, looking at your skills, passives, build your defences, identify farmable gear, idols and blessing
Last Epoch 1.0 release beginner guide new player
Last Epoch endgame
Last Epoch patch 1.0 cha...

407% poison chance (including 100% off Caustic Concoction) + 250% frostbite chance test.
Looks like total frostbite stacks are capped at 999... ok EHG "it can stack an unlimited number of times" as per game guide. Unless it actually does but the icon is capped at 999 or it's capped vs bosses. Fuck knows. I've hit 999 previously without poison o...

✅Телеграм - https://t.me/umbras_team
✅ВК - https://vk.com/umbras
✅По вопросам СОТРУДНИЧЕСТВА - umbras.gaming.community@gmail.com
#lastepoch #arpggaming #arpg #mmorpg #umbras #игры
let continue.. https://youtube.com/live/3u_Sb3C4o_A
Last Epoch GameplayWebsite: https://lastepoch.com/Available on: PC via SteamDiscord: https://discord.gg/lastepochAll credits of this video and links are to ...

I believe this to be the best method for target farming Mad Alchemist's Ladles and exalted experimental bases. It could also be good favor/hr, density is usually good and there's lots of shrines. -- Watch live at https://www.twitch.tv/skurgexd
Planned Build (my gear is nowhere near this good) - https://maxroll.gg/last-epoch/planner/cga0s01g

O Last Epoch é um RPG de ação online que combina viagens no tempo, classes personalizáveis, criação de itens e uma história envolvente. O jogo está em acesso antecipado e recebe atualizações constantes, incluindo o modo multiplayer, que foi lançado recentemente. Se você gosta de jogos como Diablo, Path of Exile e Grim Dawn, você vai adorar o Las...
https://twitch.com/yS0salty Rolling endgame gear farming!
Twitch
Grinding endgame gear pushing corruption! Chilling will try to answer any question about game!
You hit, you win
https://youtu.be/zVsJudcRM3Q

Showcasing my void knight rive dual wielder build, defense/offense number and a little bit of tips how to play it..still smooth playing at corruption 600..Gear used in this video is not cheap ( 2-3 LP gear )
Planner : https://www.lastepochtools.com/planner/QWXKm7PB
(This is an upgrade version from before have which more damage)
Timecodes
0:00 ...

Survey Link: https://forum.lastepoch.com/t/mid-cycle-build-balance-survey/67482
Sub-A-Thon Event Link: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer:...

Become an unstoppable force of death with this Last Epoch Lich build focused on the Reaper Form and Soul Feast. This high-damage, fast-paced build utilizes the power of the Lich class to clear hordes of enemies with ease. We'll delve into skill selection, passive choices, gear optimization, and how to maximize your Reaper of Souls potential.
Ti...

Last Epoch 1.0 Twitch Clip Highlights 2024 Day 18 - Rip, Crafting, Legendaries - COMPILATION
"I STILL GET LOOT?!?!?!?"
FEATURED IN THIS EPISODE:
https://www.twitch.tv/carn_
https://www.twitch.tv/dr3amt
https://www.twitch.tv/ds_lily
https://www.twitch.tv/kingkongor
https://www.twitch.tv/travic
https://www.twitch.tv/nugiyen
https://www.twitch.tv/...
How to make YOUR OWN Builds | Last Epoch Guide
https://youtu.be/1AZCvDGnHcM
Hey travellers, this is a beginner's guide for Last Epoch - a new ARPG by Eleventh Hour Games.
This guide takes you through How to build your character, looking at your skills, passives, build your defences, identify farmable gear, idols and blessing
Last Epoch 1.0 release beginner guide new player
Last Epoch endgame
Last Epoch patch 1.0 cha...

Sub-A-Thon Event Link: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Current Build Guide Links:
Acolyte:
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew?si=Edg5tvAUn9tsSvjJ
-Necromancer Ultimate Fire: ht...
Last Epoch 1.0 with and without EGPU on Surface Pro 9 i7 - https://youtu.be/6RzBO2b9Yq0

Surface Pro 9 i7 16gb Intel iris XE Gaming - Last Epoch 1.0 w/ EGPU (Amd rx6800)
Resolution: 1440x900
settings: high
fps: 100 (dips to 70 during combat)
*** without egpu *** 1440x900 - very low settings - 40-50 fps
plugged in with 120hz on and set to best performance battery options
and using @cbutters usb fan on back of surface plugged into...
https://www.youtube.com/watch?v=tpNXVAYCkGw
Well done EHG. You got Bellular's attention.

Play War Thunder now for free with my link, and get a massive bonus pack including vehicles, boosters and more: https://playwt.link/bellularnews Sponsored by War Thunder.
Diablo 4 has made excellent progress, but, it's a game that exists under Blizzard. A company with large, well paid teams who're under a corporate flavour of financial pressure....
<@&1161418687471956101> #🎥┃video-shoutout message begging followers instead of posting LE content
#🎥┃video-shoutout message baiting nsfw discord

The tests are in and the results aren't looking promising. Let me know if you suss out different results!!!
Additionally, with only Vial of Volatile Ice on, removing 3/3 Knowledge of Immunity doesn't affect the base damage of frosbite but reduces the base damage of Acid Flask (a cold skill) which in turn reduces the damage of ailments: Frostbit...
https://youtu.be/wv70fOpjlj8
2 МИЛЛИАРДА УРОНА 1 УДАРОМ!

Баганый Абузный Билд на Варлока, который убивает все на своему пути!
фарм любых кораптов
Ссылка на телеграмм: https://t.me/stlklive
Ссылка на твич: https://www.twitch.tv/stlk
Гайд на варлока: https://youtu.be/6Xv6gx_OPPU
Гайд на Лича: https://youtu.be/32yiD0E9ucc
Гайд на Торговую Лигу: https://youtu.be/ESz8fRtSaJs
BUILD: https://www.lastepochtools.com/planner/AKgNMMvA
LOOT FILTER: https://pastebin.com/dgFDf5eP
🔊 IRONWOLF Discord - https://discord.gg/7H9FVaKq
🟢 Watch me live every day! https://www.twitch.tv/cagedbeastttv
@TUGACLAN Member
Join this channel to have access to benefits:
/ @cagedbeastyt
🔴 Sign up! ▶ https://www.youtube.com/channel/UCQ...

Gameplay résumé et premières impressions sur Last Epoch, LE hack n slash KIller de Diablo 4 le juste milieu entre entre Diablo 4 un jeu sans profondeur et Path of exile un jeu avec trop de profondeur !
Ca sent très bon ! Le jeu a l'air bien plus abouti et pensé que le D4.
#Last epoch
#Hackn slash
#gameplay #test

Watch Daily At ► https://www.twitch.tv/BinaQc
My Discord Server ► https://discord.gg/zSm65G5
My Website ► https://BinaQc.com/
Written Guides ► https://maxroll.gg/last-epoch
Master Spreadsheet ► https://docs.google.com/spreadsheets/d/1S6OZ36Gmosu5UBjpwd3Ve106YZ0RMhYL2ipo_KYrFYY/edit?usp=sharing
Master Loot Filter ► https://raw.githubusercontent....
BUILD: https://www.lastepochtools.com/planner/AKgNMMvA
LOOT FILTER: https://pastebin.com/dgFDf5eP
🔊 IRONWOLF Discord - https://discord.gg/7H9FVaKq
🟢 Watch me live every day! https://www.twitch.tv/cagedbeastttv
@TUGACLAN Member
Join this channel to have access to benefits:
/ @cagedbeastyt
🔴 Sign up! ▶ https://www.youtube.com/channel/UCQ...
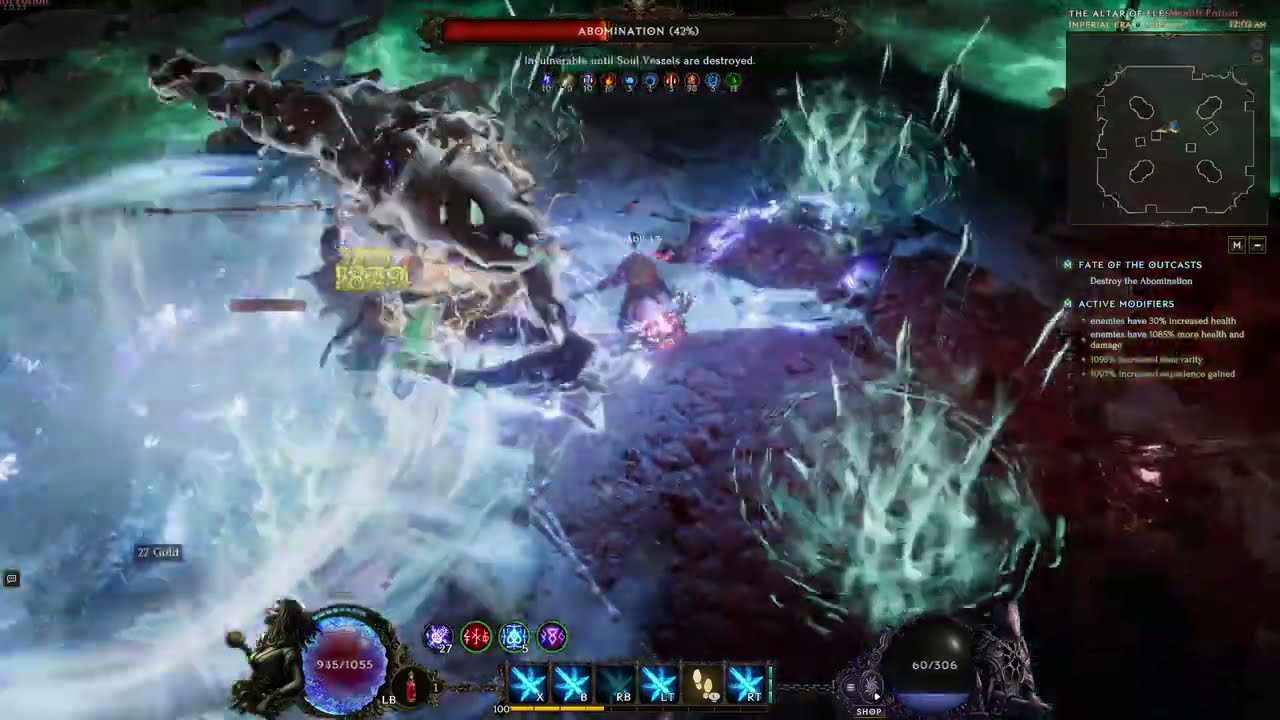
1 button skill build:
https://www.lastepochtools.com/planner/QDx25v7Q
How to play:
3 words - Just press frostclaw.

Celestial Conflux Ignite Sorcerer Almost Tripled In Damage? Last Epoch Build Guide Showcase
Original Video :
https://www.youtube.com/watch?v=5Eg2JXI4LTc&t=1s
In this episode of Hall of Fame, we are going over Pokerkids update to the Celestial Conflux Ignite Sorcerer, which got a gigantic facelift with the buffs coming in 1.0.
Last Epoch Plan...

Here is our new Last Epoch Build Guide on Marksman! Amazing For Endgame Monolith Farming, Boss Slayer, Arena Ladder Leader Board Pushing & Leveling To 100!
High DMG Legendary HP Setup: https://www.lastepochtools.com/planner/BGz3VlYQ
Tankier Less Legendary HP Setup: https://www.lastepochtools.com/planner/Q0V1mpvo
1 Red Ring Setup https://www.la...
Last Epoch Fast Transplant Wraithlord Necromancer 2500+
https://www.youtube.com/watch?v=T7fn8p5Q-xc

장비의 경우 현재 시세가 매우 급등하였으므로 가능한 저렴하게 사용 중입니다. 냉기 관통의 경우 저렴하지만 유일한 옵션인 세트 보조촉매제를 이용합니다. 패시브 효과와 미니언 데미지 상승 옵션의 더블효과로 어느정도 딜 상승에 도움이 됩니다. 최후에는 맥스치의 강탈자의 통치 혹은 맥스치의 뼈 낫을 이용해 딜상승을 노리면 될 것같네요.
빠른 이식과 보스전 폭딜이 장점인데, 다소 와드가 부족할 수 있지만 보스전(오로비스 및 에코보스) 장비 스왑을 최소화하고 편하게 하기 위해서 어느정도 컨트롤로 극복하는 편이며, 원할 때 이식을 쓸 수 있다는 점은 생존에 매우 도움이 됩니다.
오로비스 잡을 때는 미리 패턴을 보는 걸...
[Lore] Chapter 3 Story Deep Dive | 1-3 completed and onto Chapter 4!
https://youtu.be/-cyHfq2eOCc

Greetings Travelers,
Welcome to another Last Epoch lore video! Today's video is my retelling of Chapter 3 - Seeking the Last Shard. Join me as we travel zone by zone making sense of the story and finding secrets and other hidden lore throughout.
This is 3 of 9 in this series, some chapters will be longer than others but each will be about thi...
Become an unstoppable force of death with this Last Epoch Lich build focused on the Reaper Form and Soul Feast. This high-damage, fast-paced build utilizes the power of the Lich class to clear hordes of enemies with ease. We'll delve into skill selection, passive choices, gear optimization, and how to maximize your Reaper of Souls potential.
Ti...

Endgame Ward Tank Spellblade Build - Last Epoch
EpochTools Build -
https://www.lastepochtools.com/planner/Q0Vg7mKo
Loot Filter -
https://www.lastepochtools.com/loot-filters/view/zQqbkNBN
Best Spellblade Flame Reave Build - https://youtu.be/TL7w2itjwU8
50 hours Last Epoch Review - https://youtu.be/FPFlTGm8GBU
Last Epoch Tools (LINK T...

Live TWITCH Stream: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Iron Man Loot Filter: https://docs.google.com/document/d/1O4NKbtd9K9NFokNftbMng1QjK2cCt4kqK-2DTO9vWAc/edit?usp=sharing
Iron Man Build Planner: https://www.lastepochtools.com/planner/BrXLaRyA
Acolyte:
-W...

This was the most fun leveling experience I've had in LE! Special thanks to Zryn, AllmightyJustice, and RomanTrojan for joining in and making the 4x Necro Party work! Share any other meme leveling ideas you have and who knows they might make an appearance in another season. :)
Links to my:
Discord - https://discord.gg/Dxje9s2mmV
Twitch - https...

This video is a bleed falconer build that can quickly clear monoliths and tear bosses to shreds.
Build Planner Link: https://www.lastepochtools.com/planner/Bjqzel1Q
All Simpsons and Futarama imagery is not owned by me, is used under fair use laws and I do not claim rights to it.
Chapters
0:00 - Intro
0:26 - Pros and Cons
1:06 - Skills
2:51 - ...
mana stacking Sorcerer has some damage! https://clips.twitch.tv/ShyCrackyDuckTheRinger-bpy9CJTVlGKxwJVP

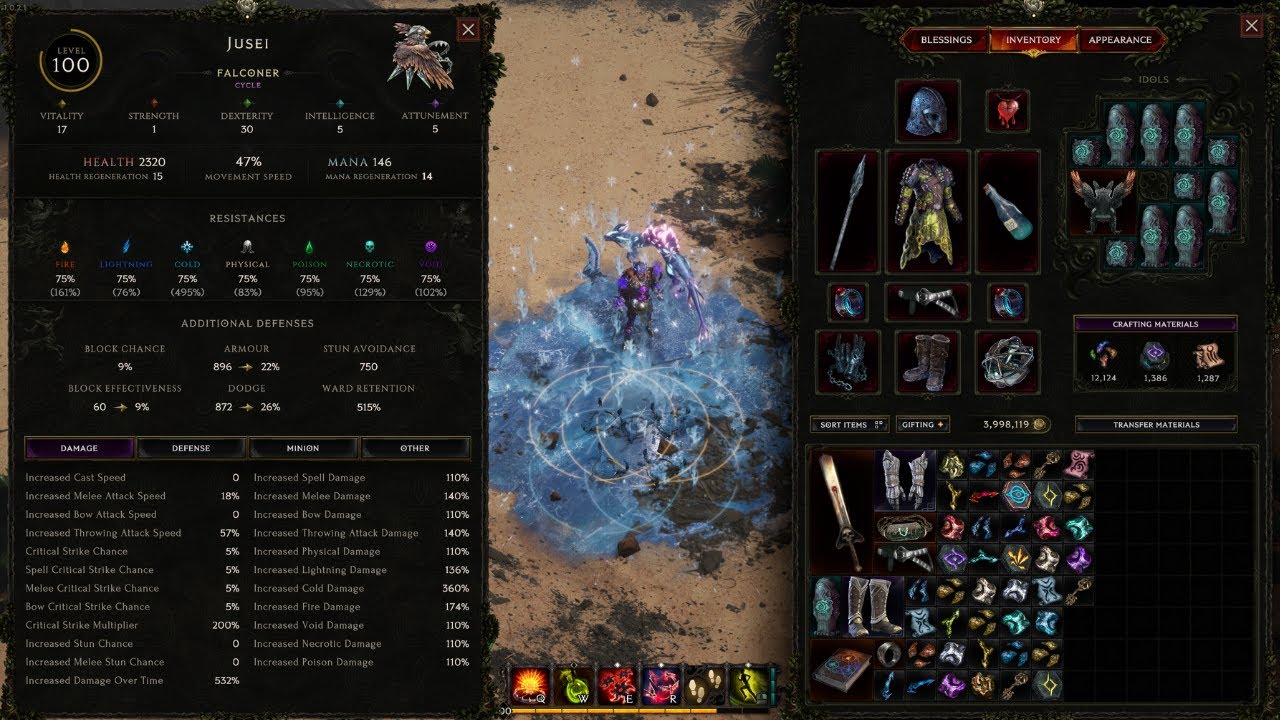
Didn't think it'd get this far but here we are almost at 1k with a lot of room for improvement with gear. Bosses still melt at this corruption and multiple gaze orobyss fights are easy to secure with kite spamming traps anywhere, dodging most nasties.
Gonna suss out whether the low life is possible if we manage to hit 1k with the life build. Th...

Hey les potes ! Dans cette vidéo, je vous montre comment j'ai mis KO Julra en seulement 3 secondes avec mon build Marksman Lightning sur Last Epoch ! Et vous n'allez pas en croire vos yeux, restez jusqu'à la fin pour un crafting d'item qui va vous épater ! Allez, c'est parti !
<@&1161418687471956101> they are at it again

Follow my twitch channel on : https://www.twitch.tv/captainp67
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #falconer #RATLEYINKLLC #diablo4 #walkthrough #guide
【The Samurai Reen】Project | Strongest Spin2Win build ! Last Epoch Cycle 1.0 (W.I.P)

Hey guys! Here's my next LE project -【The Samurai Reen】! This will be a min-maxed Spin2Win Paladin build that i dreamt of! :D I'm still progressing with this build (Currently hitting 300+C Monolith, and damage is insane AF!) Final build will be a beast! Stay tuned :D
*This spin2win build is the wet dream of many players, since i will be balanci...
Sorry it took so long but the full guide is now up https://youtu.be/EAhcaMrTKjM

Intro- 00:00-00:18
Overview- 00:19-06:31
Gear- 06:32-16:50
Passives- 16:51-25:13
Skills- 25:14-37:10
Rotation and Leveling- 37:11-43:52
🌿 Ready to turn the tables on your foes and harness the power of nature's vengeance? Dive into the ultimate Spriggan Damage Reflect Build guide! In this comprehensive breakdown, we unveil the secrets behind mas...

Live TWITCH Stream: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Acolyte:
-Warlock Torment Fissure: https://youtu.be/iEgvEErgDOk
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necromancer AutoMancer: https://youtu.be/6nGCJlXlcew
-Necromancer Ultimate Fir...

Last Epoch 1.0 Twitch Clip Highlights 2024 Day 19-20 - Rip, Crafting, Legendaries - COMPILATION
"That's the only thing i wanted"
FEATURED IN THIS EPISODE:
https://www.twitch.tv/allliee
https://www.twitch.tv/cctech_
https://www.twitch.tv/datmodz
https://www.twitch.tv/ds_lily
https://www.twitch.tv/groundzero_games
https://www.twitch.tv/kondyss
ht...
https://www.youtube.com/watch?v=_TS52a4cyoA i guess after the fix it is fine to play warlock now 😄 ?

Rank 1 Baby
https://www.lastepochtools.com/planner/Qna7Z5aA
yes this still works after the nerfs, yes this tanky warlock is even more relevant now, yes the pure dps builds on your favorite website still works but this one was made to survive
#lastepoch #arena #leaguestarter #warlock #leaderboard
Spreading the last epoch love with a quick review ! https://youtu.be/CD8g_9KdbP8?si=iOzB-OP-mCu78xBz

I quickly run through my review of Last Epoch! I discuss my opinion on the game after 100 hours of gameplay, and if I think it has the staying power of some of the big boys.
For more of my content, please follow me on twitch: https://twitch.tv/shimmystix85
#lastepoch #arpg #twitch #gaming #videogamereview #gamereview #actionrpg #Diablo #Patho...
Become an unstoppable force of death with this Last Epoch Lich build focused on the Reaper Form and Soul Feast. This high-damage, fast-paced build utilizes the power of the Lich class to clear hordes of enemies with ease. We'll delve into skill selection, passive choices, gear optimization, and how to maximize your Reaper of Souls potential.
Ti...
<@&1161418687471956101>

Live TWITCH Stream: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Infernal Whip Loot Filter: https://docs.google.com/document/d/1fpWfXetCsiEvq4YqdNoxwHHqLRb1_mcIXTg8UK-JTvc/edit?usp=sharing
Infernal Whip Build Planner: https://www.lastepochtools.com/planner/oXznVxwQ
Ac...

Hi guys! Update to my Shatter Strike Spellblade! Now at 500 Corruption!
Check the Build GUIDE on how to build this!
https://www.youtube.com/watch?v=nS9wEn0jEUc
LIKES/COMMENTS help the videos reach more people!
SUBSCRIBE lets you to see more content from me!
CLICK THE BELL to enable notifications to see when new content goes live!
Endgame - D...

O Last Epoch é um RPG de ação online que combina viagens no tempo, classes personalizáveis, criação de itens e uma história envolvente. O jogo está em acesso antecipado e recebe atualizações constantes, incluindo o modo multiplayer, que foi lançado recentemente. Se você gosta de jogos como Diablo, Path of Exile e Grim Dawn, você vai adorar o Las...

Собираю 10к на новый комп, если кто может помочь, буду очень признателен.
+DONATE+
https://www.donationalerts.com/r/madjasti
+DISCORD+
https://discord.gg/Zz3vf7EnPW
+СОЦ СЕТИ+
Телега: https://t.me/MadjastiYT
Трово: : https://trovo.live/Madjasti
Паблик VK: https://vk.com/madjasti
+РЕКЛАМА+
https://vk.cc/cfZM9t
magilay@ro.ru
+МОЙ ПК+
Процессо...

Website to find items with value :
https://arreatsummit.gg/last-epoch/database/prices/relic
Loot filter for gold making :
https://www.lastepochtools.com/loot-filters/view/WQJJNmQe
Chapters :
00:00 Intro
00:25 General Strategy
00:48 Timelines to farm
01:12 Blessings
02:36 What mods to look for
03:15 Market Analysis
04:44 Conclusion
Thank you ...

Update on my Healing hands build after hitting level 100.
Ideal build for non competitive casual gsamers who want to experience Last Epoch in the end game.
Viable for all level 4 dungeons.
#healinghands
#lastepoch
#build
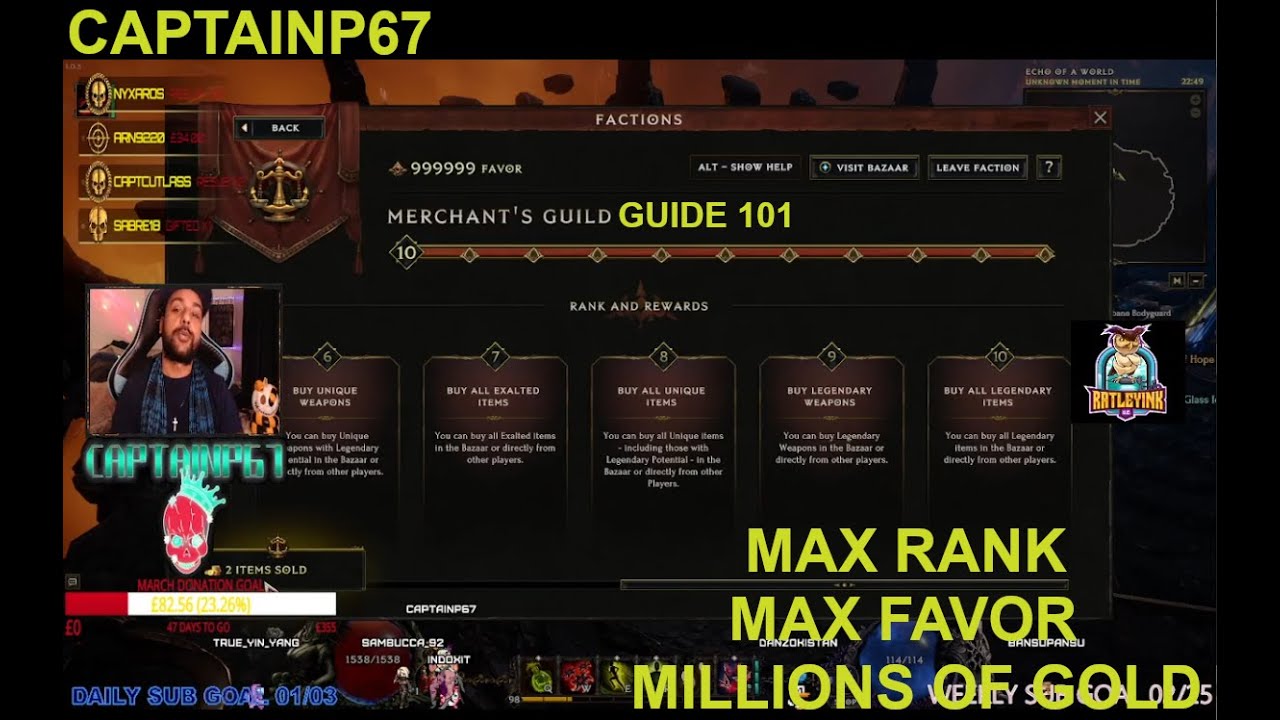
Follow my twitch channel on : https://www.twitch.tv/captainp67
Sub and Donation Links are on my twitch profile
Sub for a Shoutout and get invited to the discord
I stream on twitch everyday
#CAPTAINP67 #lastepoch #MERCHANTSGUILD #RATLEYINKLLC #diablo4 #walkthrough #guide

Hey everybody, I've been having fun on Last Epoch, and I wanted to share my current Lightning Build that I've been playing with. It is going to be changed quite a bit but I've been having fun with it. Any tips or feedback is certainly welcome.
Uncover the Past, Reforge the Future. Ascend into one of 15 mastery classes and explore dangerous dunge...

Patch 1.03 reduced the ward gain of Vampiric Pool from 40% to 4%. But Torment Warlock is still S-Tier! In this video I go over my recommended pivots given the recent patch. The patch also bugfixed/buffed some skills and items like Wandering Spirits and the two new warlock uniques. I'll test out the new uniques next and hopefully they are endgame...

ติดตามรับชมเพิ่มเติมได้ทาง Twitch https://www.twitch.tv/rottweilerrrrr/

Twitch
winnervswinner went live on Twitch. Catch up on their Last Epoch VOD now.

Channeling Healing Hands Melee Crit Paladin Is Insane...But Also Bugged. | Last Epoch Build Showcase
In this episode of the Hall of Fame, we bring a long time viewer and supporter of the channel, and our resident sentinel lover, Misha, to talk about their insanely strong Channeled Healing Hands setup. The build is so fantastic that I am looking...

Je continue a prendre un plaisir immense sur Last Epoch , let's play justqu'au niveau 16, builds, boss :)
#Last epoch
#Hack n slash
#gameplay
#Mage GLACIER GEL
#test


Thank you for your support as a disabled content creator it means alot for all the subs like and view.
Welcome to our gaming channel! We bring you immersive gameplay, thrilling adventures, and the latest updates in the gaming world. Join us as we explore new worlds, conquer challenges, and share our gaming expertise. Whether you're a casual pla...

{kind=link}
{kind=link}

FILTRE DEBUTIN L'OPTION INDISPENSABLE DU JEU POUR LOOTER UNIQUEMENT DES OBJETS PERTINENTS ! JE vous explique tout en 3 min chrono !
#Loot filtre
#filtre de butin
#LAST EPOCH
Site loot filter: https://www.lastepochtools.com/loot-filters/

Live TWITCH Stream: https://www.twitch.tv/aaronactionrpg
Official Action RPG Patreon Link: https://www.patreon.com/actionrpg?fan_landing=true
Acolyte:
-Warlock Flame Whip: https://youtu.be/-dXhyWtW_oA?si=PsxoG9NjDh314mpx
-Warlock Torment Fissure: https://youtu.be/iEgvEErgDOk
-Lich Crit Harvest Undertaker: https://youtu.be/JRjaptAZK_g
-Necroman...

Я на трово: https://trovo.live/_VULA_
Или на твиче: https://www.twitch.tv/ded_vula
💳 Задонь чуть-чуть, порадуй стримера:
💳 http://www.donationalerts.ru/r/vula
💳5536 9141 0196 7697 - Tinkoff
📞 Дискорд:
📞 https://discord.gg/Guz3p9Tkhm
🎮 Мой Steam:
🎮 http://steamcommunity.com/profiles/76561198140798037/
🖥 Железо:
🖥 - Материнка: MSI B450-A PRO
...

Optimisation from here:
- Try slam a 2nd Heirloom with at least t7 throwing attack cost reduction and t5 throwing attack speed/cold res (missing 23% AS on mine)
- Slam t7 hybrid health/t5 % health or flat health on as many pieces possible. 4 LP Frostbite Shackles/Snowdrifts are basically impossible to get in cycle though. Aspirational build has ...
I made a dumb build about summoning a bunch of bees (100+)
~1m poison dps.
Mostly a gimmick build.
https://youtu.be/t7YP1PEBpF4?si=j8DXkgthGMpgjKzN

I made a Last epoch build about summoning a lot of bees.
It is fun 🙂
Basic interactions are:
-Summon bunch of bees via acid flask idol affix (28% chance to summon bee on acid flask)
-Use explosive trap to shit out a lot of acid flasks
-Using the Hive Mind helmet, we give stupid amounts of poison chance to the bees via acid flasks.