#FSRS Megathread
1 messages · Page 13 of 1
where do i find this
Honestly, having note-wise and deck-wise memory states (or something analogous to memory states as the term is used in FSRS) would be epic, but I have no clue what that would look like with FSRS
For cards the whole Difficulty Stability Retrievability thing is more or less figured out
I dont have a leech card on me right now.
But tomorrow when i get back to reviewing i will let you know
But shit man, that hit me like a rock
If you have one that you think is troublesome, that would be interesting. I'm trying to figure out some common characteristics to see what could help finding those sooner than after 200+ reviews 😄
So you have been meaning to say that the 95% DR was not exactly a like but does not show the entire truth
I indeed know 95% of my shit
Just that I have not made progress on my leech cards
You can have cards that consume a lot of workload but still progress steadily lapse through lapse, cards that just yoyo between very high and very low "max interval in a lapse", etc
Cards that are actually in need of my attention
I think you are conflating "95% probability of recall" and "stability of cards keeps increasing" aka "progress"
This has made me completely lose my shit
Yeah also 95% you see with the TR is like an average. Some cards might not have that 95%, maybe because you review them when they are lower (low stab), or maybe they just can't be predicated as good as others
Enlighten me. What is happening to my leech cards when FSRS says I got 95% TR when my DR is 95%. Keep in mind I am adding new cards everyday
You could do 95% TR but still having a 1d interval if your parameters evolves like that
In theory FSRS could show you the same 95 cards every day that you know by heart, and 5 random other ones you likely long forgot. 95% right there, easy.
Stability of easy cards will grow quickly, stability of difficult cards will grow slowly. Both are capable of achieving x% of being recalled. Well, unless difficult cards also have some sort of fundamental "error rate" such that p(recall) cannot approach 100%
Am I doing progress on my leech cards or difficult cards
That is all I need to know
hell if I know man
if you keep hitting Good on them, you're making progress
How would you describe progress ?
Better R ? Better S ? Less Variability ?
That state of the card after is better than before.
Thats how I would define it
I dont know how you would put it
How would you define a better state of the card ?
what state? after what? before what?
Genuine question, we might all have very different answers to that
Compared to when I first saw it
For me, better state is an increasing stability with time
Idk how you would put it into FSRS terms
I'm just saying, you might have cards where S grows at a snail's pace and they still hit 95% p(recall)
When you first saw it you knew nothing about it?
Yes, like generally is becoming more and more likely to be recalled at ease
Yes I know. That happens with me a lot
Exactly why I implemented the Stability over Time. Everyday, I havea consistant trend of 0.20day of average stabilty for my all deck. You can't see that with a 80% TR that you do everyday
That's not really a metric that Anki/FSRS tracks
I have a lot of cards with 100% Difficulty where R is 95%
Over the past of the last year, I earnt 1d of stability in avg every 15 days

It's very slow
But at least now I see it
FSRS for me seems to have concluded that 1 Again = D:100%, and it virtually never goes back down ever
like, after 5 Good, it's at 99% still
Splitting deck into 2 might help, I did it
Before I had 2 spikes : 60% of 98% D, now I have 2 nice distribution


Yes, somehow I don't doubt that.
But all I need to know is whether I am doing progress on my leech cards, REGARDLESS of how slow it can be. Otherwise I am just wasting my time in a cycle of doom with forgetfulness
Check the 4 values I asked you before 🙂
this is an absolute mess really :D

- I am aware that cards can have D=100% and still have high R
- I am aware that cards can have D=100% and still have their S increase (but rather extremely slowly)
Yeah basically FSRS concluded it achieved better precision by treating D as a way to group cards by lapse count
What happens when D is updated in discrete chunks 😄
If you split it in 2, FSRS might be able to get better precision without discreting splitting those things in spikes
The 0% Difficulty cards seem bugged?
Nah, I've explained it before, the way D is calculated is fundamentally discrete
Well, there is some smoothing, but it doesn't make a big difference
It's still mostly discrete
no, like, when I click on them, they're not 0%
Maybe, but with my new parameters now, in 4 easy I can revert 4 again

Before 1 again = 30.000 easy
Mine is just really skewed:

FSRS gave me SM2 ease factor, finally ! lol

With my normal deck, it's more like 2 again = 3 easy = 8 good

Hm, that 0% category seems to be basically exclusively the cards I initially hit Good on
There are some legit easy cards in there, like this one

Ok so you didn't lapsed it much, the first time you achieved 18d max duration without failing, second time 5d. Now you're current max is 1d, but doesn't mean it won't grow
Soooo... Why do you consider it as a leech ? SHow my the full revlog

I mean, going from 18d to 5d isn't great but on 2 lapse it might be a first over optimistic lapse and then a second very bad

I feel like I'll need to do a special review session of some kind, and go through all the cards that are in that 0% category
But it's bloody 2100
Doesn't look super leechy though
It just never escapes the learning period 😂
You just had a heart attack on Again button
I just opened a random card with high D
find one with big lapse count
I am aware not every card with high d is a leech
the highest lapse count you have let's say
man, this is though. I'm skimping over all the cards in there that are past 2027. And a lot of them are legit easy
but others I already forgot

You know what ? @lapis hearth , I thikn same-day review for people like you might kill yours gains haha
The D got crushed with all those failed at a few secs of interval
Nice ! You see, that one feel leechy because you were suddenly able to succeed it with 15d, but then only 2d, then 6d, then 3d ...
Which is warranted since I cannot get it into my head anymore
Would you say answering those cards are a bit of a coin-flip ?
yes
Maybe it's the problem of "Stability" being part "Time Stability" and "Knowledge (for lack of better term) Stability"
Oh, btw, in the end Jarrett did reduce minimum stability from 0.01 to 0.001
So enjoy your 1.4 minute intervals 🤣
I mean, Time Stability really work if the Knowledge is stable enough. If the knowledge is "What is the result of the coin flip", answering "Good" will make FSRS believe you remembered it, but in fact you got "lucky"
If you feel like you need 1.4 minute intervals, are you sure you aren't forgetting to actually... re-learn a lapse? :D
Like, if you get the card wrong, and just blindly mash Again... how would you possibly learn what was wrong?
I've said this before, we can't model something like that because then it would mean that for some cards scheduling them at high DR is literally impossible
There are some leech cards I could answer when I have a really good day in the office
I'd say a large percentage of my leech cards are 50/50s
Others come out of Satans asscrack of doom
Yeaah. Those past 3 days I spent much more time on my cards, wether they are Again OR even if they are "Good" but I felt some "luck factor" going on.
Needless to say, my R went from 90% to 96% for 3 days in a row
It's not a luck factor, but just the brain passively recalling it
I'm not asking to model it, I'm asking the users to understand it, so they can try to solve the K Stability problem on their end 😛
it's why I make a point out of always typing in an answer, even though it's slow
Huh, weirdly my lowest difficulty (tied at 46%) are: 林, 毎月, 五, 山, 月
@cursive badge
whoops
I have A LOT of cards with a flat out 0% difficulty, which seems wrong
How on earth are they easier than 一? 😂
Cognitive engagement ! Rushing through reviews won't make anything stick long term
I mean, it's also 0%, but has a much shorter interval
A Review is more like a "Intelligent Grader/Tester" than a "Teacher"
Honestly, at this point I wonder if making D depend on R and making it update continuously rather than in "quants" is worth it even if the metrics don't budge even by 0.01%, just to make users feel better
I think once my review load has gone down a little, I'll make a custom study with all the 0% cards, and work through them
So @unique salmon I am a bit disillusioned by all this. @quasi shadow I am pinging you just in case
- Does having TR=95% where DR=95% and new cards are added everyday mean that I am making progress on my leech cards (by progress I mean that my general encoding of the cards and likelihood to recall them and remain stable inside my head has increase than previous states when I reviewed them befee)
- I am aware that D=100% can also mean R=95%
-I am aware that D=100% also does not prevent from S increasing and therefore progress
I will pin this mesage for me just in case I need to get back to
Because this is an important revelation to me
I'm not Jarrett of Expertium, but my take is : Having TR=95% when DR=95% only shows FSRS is able to predict your TR. Doesn't say anything about how well you know your stuff (let alone your leeches)
So what good does TR do me
Important Revelation #2 : Don't treat your again button like shit
as long as you have enough easy cards, you can have some leeches that you NEVER remember, and it'll still be 95%
It show you FSRS gives you cards when it reaches the DR you want
No I am not spamming again buttons like shit. I am just employing a no bull-shit pollicy. No half-assed recalls
There's no contract between FSRS and you, like FSRS will take your hand in the wedding aisle
It's just a prediction tool
what you do with it, doesn't concern it
With full-assed time spent actually trying to learn
Yeah and what does a DR of 95% mean in the real world for me.
I am learning indeed
That if you get tested on the knowledge you have in your deck, you should be able to get 95% good answers
It means you should be able to recall at least 95% of your cards if you were quizzed on them randomly (actually more than 95% because average R will be higher than desired)
Yes but I am now speaking of the probabilty regarding my leech cards
That, you don't really know
If you take my leech cards right now, would you say I would have a 95% good answers as well
no clue
That is the question
Aha
In other words I am f0000ked
Because leech cards are keeping on increasing for me
I think the harsh truth is that no scheduling algorithm can save you for certain things. You have to find something outside of Anki to make those really leechy things stick.
I mean, FSRS parameters get optimized to get the minimum error rate, but it has to sacrifice stuff, right ? If leeches are by definition extreme cases, they will probably diverge the most from the group, but there's not guarantee it is the case
I am aware of the increase of leech cards in my deck and I started to wonder if I am actually doing progress on those
Yep, pretending and finding excuse doesn't change much. If you have ADHD, trying to focus more than 2 second will help you more than trying to have reviews every 0.25 seconds
I really struggle to understand how you'd define progress
Mate
Like, hitting again less often?
You have focus issues, practice learning books, not liking tiktoks

All those 2 seconds
Dude, in 1-2 min you did 5 reviews

You should stop being delusional first
Trying to not see the issue won't solve the issue
What on earth is that revlog oO
Not mine, that's for sure
that is completely pointless
First of all, my cards come in different shapes and sizes
That cards answer is a small one, a two worded answer
no matter the size, that is too many reviews in too little time

I have 18000 cards that are basically one word answers, and I don't machinegun them
Definitely not machine gunning

There's multiple reviews within the same minute in there
Look mine dude

What can I say, I am able to review fast. You wouldnt show the same energy for my good cards
as far as Anki and SRS learning is concerned, that is insanity and does not gain you anything
There is no problem with reviewing fast
0.71s for the goods

there is a problem with doing it AGAIN just seconds later
So fast you're complaining about having a short-short-short-term memory model
I mean what else do you want me to do. I see the card, I read the question, I try to formulate the card answer in time, I say it out loud, I compare the answer, I rate and then I move
That is literally my reviewing method
It's crazy how fast you switch from "I struggle with anki" to "I know my stuff"
Like, seeing a chain of "Again", all within the same minute, screams to me like "actually LEARN the thing, don't just hit again"
I struggle with Anki when it comes to these leech cards
All in 0.7s
I just went to look at the timings on one of my bad cards. Spot when the interfering card was introduced 😂

I actually sometimes hit Undo after hitting Again
just cause I realized I did nothing except hit Again, so I'd still not know it next time around
You're delusional. You keep trying to push away the fact you do wrong by finding things that are wrong with the tool
You feel trapped in your workflow, you know you need to change something but you don't know what, so you hope someone will change it for you
But you're alone in this
No I am not delusional. Sometimes, the question remains in my working memory from before, so all I have to do the instant I see the card is to repeat the answer
The first thing I'd say to fix this would be fixed re-learning steps, that are double digits
The difference what people may do and I admit, is that people may repeat the answer more than one time the moment they see the answer
I just repeat one time
Yep that's why I did the "max interval by lapse" thing 🙂 I also had those kind of things, so seeing if I'm currently recovering or not help ! In this case for example, I'm clearly not recovering at all lol


If you just got the answer wrong, what point is there to trying to answer it again immediately?
And for every repetition I say that I fail, I press again
You already KNOW what is wrong, so a "retry" is entirely pointless
So that is why my again count is high for cards that are so difficult to memorize
How much time do you study OUTSIDE anki @lapis hearth ?
Absolute zilch
What are you even studying?
One again per every single repitition
repetition*
I am literally learnining inside of anki
Repetitions make no sense though. They gain you nothing
And I mean it
And to you, is it a healthy pattern to build a connected set of knowledge ?
No
I mean, even Kanji I have to take some time outside Anki and try to connect them in some ways
You can't bruteforce massive amount of interconnected knowledge by SRS alone
The thing with Kanji is, you kinda eventually forget them, but can still read them :D
I have complained before that I am suffering from disconnection in my knowledge
So I know that that is the reason
Just Hardcore-Anki is what causes completely disconnected knowledge though
Taking more time "Outside" anki (or at least, on the back of the card, editing it, rereading it, adding examples...) would MASSIVELY help
Whatever that knowledge is, you need to bring it to life
but my cards are already made to perfection
I have perfected the art of making cards I say
@polar maple remember when I said that we could use a neural net as a teacher for FSRS, so that FSRS learns to predict the predictions of the neural net? While we can't use that in Anki, we can do that to figure out the best default parameters if you release RWKV
- Use RWKV to predict R for every review for 500 users
- Optimize FSRS on a combined revlog of 500 users, but add a second term to the loss function to penalize FSRS not only for poorly predicting ground truth labels, but also for poorly predicting RWKV's predictions. That way it will learn to predict what RWKV predicts, potentially making it more accurate
One more reason for you to finally release the thing

I've been over-Ankiing as well the last couple weeks, cause I wanted to finish the bloody deck :D

Do you know what causes my stability to dip down that heavily in the center ? I stopped doing any kind of immersion to do 3h of anki perday

And I can very much tell that fatigue plays a role in the poor performance recently
There again the "Confident" guy
Like, 80-90% of my Agains are in the last 50~100 cards of the ~400 I review per day.
Yes, cards, but again, does not necessarily mean I am able to learn.
Why are you so passive aggressive
Like relax
IMO, once you start to do your reviews "to get done with it", it's when you should stop lol
Get done with the Deck, not the daily reviews
Now I really take time, if I even hesitated a bit, I go check some sentence with some words in it, I check words composed of that kanji, etc
around 300 reviews a day seems to be where the tipping point is for me
and according to the simulator, I'll be well below that soon
Here is what my cards look like

I'd say I'm openly aggressive haha. But no worries, I'm not your ennemies, I'm actually trying to help xD
When I won't be willing to help I'll be actively silent xD
Yeah ˜200 seems to be my threshold too
What surprised me is that taking out new cards makes me perform worse, retention percentage wise
So yes, the inflated again count is because that is literally the amount of times I repeated that same thing inside my head
Not sure what's up with that
it's saves almost 30-45 minutes not to have new cards anymore
I noticed that too !!!
so what gives

I think new cards play different roles ...
Motivational, new connections that bridge older things ...
Sure there are interferneces, but sometimes they help too
Like, did I need the new cards as "breaks" from just review?
Or did I accidentally cheat, since the new cards inevitably contain Kanji that some of the young cards also have?
Hey that's me !
IMO this is not cheating, otherwise even reading outside Anki would be cheating
The only nice thing is that poor performance at this level is largely irrelevant
So you guys are brushing me aside. Okay...😓
But yeah, sometimes we tend to so much rely on Anki, having our TR=DR, doing as much as possible new/day ... That Anki becomes the goal and not the material itself
I'm not sure what you want us to say at this point 😕
Yeah, any discussion about that just goes in the same circle.
No nothing its okay
Personnally, I use Anki to learn Japanese. Not the opposite
Your delusional.
(feels better ?)
My favourite Japanese-Learning-Decks abuse the hell out of Anki, and are FSRS's worst enemy :D
They really are just learning Japanese in Anki, bending Anki quite massively to work
With SM2 it happens to work out, but FSRS goes absolutely crazy if you ever hit Optimize on those decks
Yeah that's always an option but to be honest at some point it's less effort to just use any kind of media as SRS
IN FACT, for every words I see in a book I try to read it : if I can't, I do a lookup. It's exactly the same protocol than with Anki 
No FSRS for sure, but at least I have higher frequency of things more used, and less of things no used
I just explained myself. I would rather say I am trapped, but yeah probably delusional is some way to put it. I dont really have a problem with my experience with Anki outside my leech cards (believe it or not with my learning method). They take the lions share of my time. I mean I cannot suspend them
Using a skill is in fact, its own SRS xD
This surprisingly does look okay enough lol

You mean it's insanely good right ?
I've been using that deck with default parameters only
You did only answers "Good" and you train the model with DR=99% ?
Log loss: 0.3549, RMSE(bins): 3.05%. Smaller numbers indicate a better fit to your review history.
since when using optimized ones, it pretty much shows a card only once, and then in half a decade
This also illustrates part of the problem :D

This is simply not a learning deck
A "I have too much time on my hand deck"
so FSRS adapt by creating immense interval
so you adapt by setting immense DR
(Btw you can do DR=0.99999) with filtered decks
Not even, I spent like 10~15 minutes on this deck per day
If you want to push the limit
It's just not single memorable items, but entire sentences with audio, to then translate, and see how well you did
And after a certain point, you just never get the old ones wrong ever
Yeah I doubt it has a lot of value to do that TBH for language acquisition
It does though
You just get drilled to recognized the sentence to the very first sounds
This deck is what thought my Japanese
Like when you know a music so well you recognize it in 0.5s
almost exclusively that deck got me to a level where I could start watching and understanding native content
It's just simply not really SRS compatible. But the author made it as an Anki deck anyway
While in reality being a fully integrated iterative Grammar course
I wonder what would happen if you tried to train a model where you removed random reviews / added phantom reviews in training as noise.
Could you get a model that is more resilient to learning outside of Anki or would everything just break?
That deck is exposure
It has a sentence and its audio from native content on the front
Yeaaah but dynamic one is very engaging you
and then on the back has the translation and explains the new grammar point
But again, if it works it works !
And the cards are ordered in such a way that they always introduce a new grammar point, then the next couple new cards use it in combination with pre-existing ones
and then the next grammar point is introduced, and so on
Which I also stopped believing in the n+1, because by the time you're at N=1000, you forgot 20% of the previous N, so 1001 might have 10-20 things you completely forgotten
N+1 assume N and all lesser are known
Well, all the old N's keep getting re-used all the time
Yeah, vocab does not work like that
but Grammar does
There isn't really "rare grammar"
I'm sure there is, but it's rare enough that I don't care then :D
Still, even with exposure you learn them quite fast I think
I mean, I did bunpro before
It's how I did this
I did all the content to end of N2
I used that deck to learn about the grammar points
most of the points I never saw them in any media xD
and then just consumed native content, and saw the grammar in action, and connected all the dots
And the ones I saw in anime/books/vlogs, are super frequent so yeah, 2-3 times and it's all good
The deck does not go into super detail about the grammar. It's intentionally fuzzy.
Just enough to be able to comprehend it well enough, and then it tells you to just consume content, and experience it in action
And I have to say, for me that works exceptionally well
there's a lot of Grammar in Japanese I'd struggle to explain, but I understand it perfectly
If it's perfectly then, all the better 🙂 ! Have to get some sleep though 😆
The follow-up intermediat learner deck by the same author bastardized Anki even more I think
it still does the grammar point introduction, but after introducing the grammar, it has cards full of hand-picked YT videos
3~5 of them usually, all picked so that you should be able to fully comprehend them with the grammar you learned so far
But how the hell do you rate a card that just has 5 YT links on it?
[1.7049980163574219, 4.760904788970947, 9.27336311340332, 35.39059066772461, 7.6221489906311035, 0.2847740054130554, 3.810476064682007, 0.13781799376010895, 1.5367180109024048, 0.19009700417518616, 1.2515840530395508, 0.8537999987602234, 0.11784599721431732, 0.4837470054626465, 2.191098928451538, 0.2806600034236908, 2.033750057220459, 0.8850420117378235, 0.23119600117206573, 0.1744070053100586, 0.22846099734306335]
these params are potentially slightly better

Because FSRSv1 has three state variable: stability, difficulty and lapse
@cosmic hedge

Reddit
Explore this post and more from the Anki community
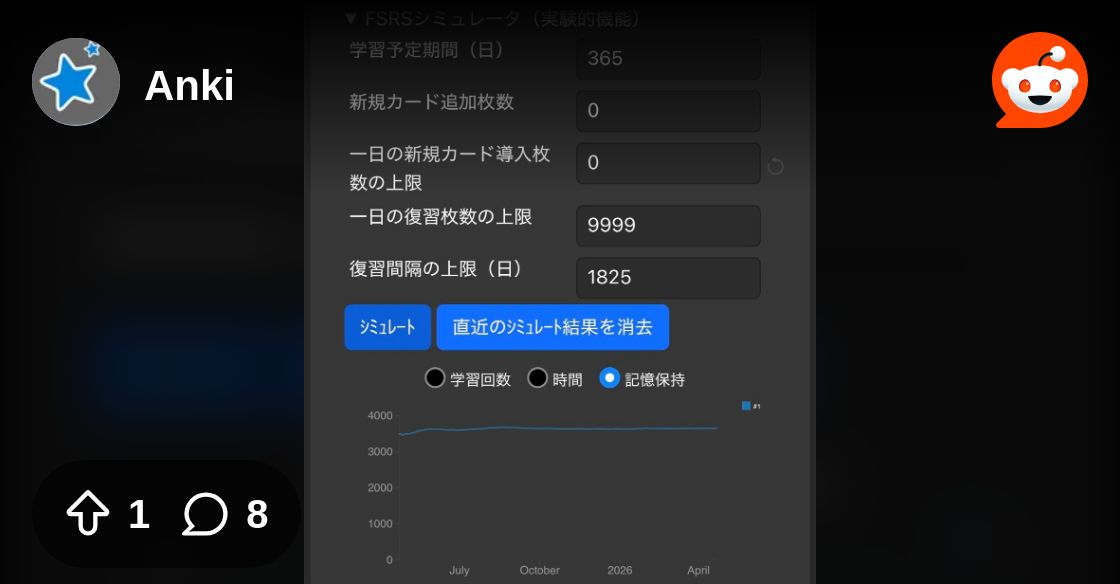
The cards without memory state are treated as new cards in the simulator.
And moving cards to a new deck/preset removes the memory state.
Yep I wasnt sure what to do about it
#1282005522513530952 message
🤔 recompute the memory state for these cards?

ah ok. I'd assumed that we wanted to keep the simulator from affecting anything but it shouldent affect anything really?
https://www.reddit.com/r/Anki/comments/1k507tz/fsrs_simulator_still_shows_new_cards_after_i/mofihsv/ this guys problem was caused by ignore_reviews_before which i'm also not sure how to solve 😭
Reddit
Explore this conversation and more from the Anki community

I guess these cards still could have a valid memory state?
yeah that's what I'd think but I haven't looked into it
hmm op's right?


whats weirder is that that should ignore pretty much all my cards because I haven't learned 4000 cards in 3 months 😂
do you have clue?
Not yet 😂 I'll have a look in a little while.
@quasi shadow shouldn't the memory states also be recalculated when ignore before is changed? I have to change the parameters to reproduce the bug.
🤔 do you mean the memory states should be recalculated when the user saves the preset after they changed the ignore before?
But the parameters haven't been optimized with this changed ignore before.
The parameters still fit the reviews with the old config of ignore before.
ahh yes of course
😅 The current UX is terrible and confusing.
We should make sure the users optimize their parameters after they changes the ignore before.
could it still lead to problems if their parameters are already optimal when its optimised though?
because it does affect the memory state right?
even without the parameters changing iirc?
If their parameters are already optimal for cards whose first review happened after the ignore date, it's reasonable to use previous the parameters.
We should make sure the consistency between training and inference.
@quasi shadow I want you to try this:
- Run LSTM on a combined revlog of 500 users
- Save LSTM's predicted R for every review
- Run FSRS on that big revlog and add a second term to the loss function.
loss_final = a * loss(fsrs_predictions, labels) + (1-a) * loss(fsrs_predictions, lstm_predictions).ais a tunable hyperparameter
The idea is to use LSTM as a teacher for FSRS since we know that LSTM is more accurate than FSRS. Then you can vary the hyperparameter to control how much FSRS is penalized for not predicting the value of R that LSTM predicted
Hopefully we can get good default parameters that way. I'm busy running all versions of FSRS and Alex is also busy, so I hope you will do this
How exactly? Forced optimization after "Ignore cards reviewed before" is changed sounds annoying.
If someone changes the date multiple times, the optimizer will run multiple times
how about that: pop up a warning when they save the preset.
ok
https://github.com/orgs/open-spaced-repetition/discussions/36
I've added my idea here

GitHub
The purpose of this discussion is for me to link to issues/PRs that are related to FSRS and where I have something to say and don't want Jarrett to forget about it/miss my comment. VERY IMPORTA...
https://github.com/ankitects/anki/pull/3940 there you go

GitHub
Cards without memory states (likely due to being moved) are currently treated as new cards. This recalculates them.
Before:
After:
This does slow the simulation down with "ignore reviews...
still doesn't fix it for ignore before though
How it started: don't use Hard as "fail" with FSRS
How it continued: don't use Hard with FSRS
How it ended:


I thought that the fact that the "don't use Hard as "fail" with FSRS" advice mutated into "don't use Hard with FSRS" was bad, but this is a new low
I'm genuinely curious what buttons that user is using if he thinks that using Again and Good messes up FSRS
@quasi shadow ok, I'm giving you a bit too much work, but still
Remember my idea of doing a two-pass optimization? First, we do pretrain with a fixed -0.2 decay, optimize parameters, then we grab that decay, do another pretrain with optimized decay, and then optimize parameters again with that fixed decay
I want you to try it
EDIT: to clarify, I mean FSRS-6 in general, not specifically pretrain.py
I added it to the list of ideas as well
Also, turns out I can't plot the calibration graph based on more than ~2k users because I run out of RAM 😅
but why though
also we need to figure out what to do with w[16] first, you would still expect to see w[16] = 1 if you do the LSTM thing
To see if it's better, duh
I'm hoping maybe it will magically fix the issue 😅
you're not likely to do any better than a joint optimization with all parameters including decay
just a waste of time imo
i think we should just fix w[16] = 1.5 and then optimize around that or something
Not if gradient descent does a bad job at adjusting S0 after pretrain
for pretrain we can just leave it optimizing for longer
part of the problem is that pretrain can run for longer than it currently does
S0 would then likely be adjusted properly
Is it?
Well, even if it is, that's not the problem. The problem is that S0 that is optimal at decay=-0.2 is not good at another value of decay
you could be right about that, but it doesn't make it wrong that a joint optimization is still expected to do better
I'm surprised you're saying that pretrain could do better, though
Maybe I'm misunderstanding
res = minimize(
loss,
x0=init_s0,
bounds=((S_MIN, 100),),
options={"maxiter": int(sum(count))},
)
GitHub
FSRS Optimizer Package. Contribute to open-spaced-repetition/fsrs-optimizer development by creating an account on GitHub.
Maxiter is equal to the number of reviews, so it's plenty
i'm mixing up two things, the way that FSRS optimizes params for each user uses 5 epochs but that is not necessarily enough to fix S0 if S0 was not initialized well, and that's assuming that the value of S0 matters a lot and can't be compensated elsewhere
i vaguely recall that prior to fixing S0 initialization in reptile i still got similar test metrics, so maybe it doesn't matter that S0 is theoretically correct
but in pretrain.py we don't need to use 5 epochs as well, we could increase that number to whatever we want
it was higher than 5 epochs but you suggested changing it to 5
See my comment above

lol
for this decay idea are you talking about within FSRS? i thought you were talking about pretrain.py
I mean for FSRS-6
ok
Like, in general, not for pretrain.py
@quasi shadow why don't we just include extra unused parameters in Anki so that new parameters do not require a major update?
maybe i'm missing something
Wouldent that make it harder to tell what version of the optimiser the parameters were trained with? E.g 19 parameters = fsrs5
maybe include the version name as part of the parameters
I feel like it would just be a major update in a trenchcoat anyway. I think it would be possible to add an extra param and call it fsrs5.5 like he was going to do.I think it is just convention to bump the major version?
yeah i get this feeling as well
Oh wow, working with the Anki 10k dataset is slow. Just querying which cards exist in a single preset takes ~7s on my computer.
I don't think I'm doing anything stupid, but that seems silly.
what does the 10k dataset look like exactly, I assume its not 10k .anki2 files?
An Arrow Hive of Parquet files.
I don't even know what that is
Neither did I until I had a look at the dataset 😅
oh hey its an apache.org project, isn't that where code goes to die?

l-m-sherlock on Notion
(It’s still a draft. The last updated date: 2025-04-24.)
😎 It would be the last work before I quit.
GitHub
Fixes regressions in the 25.02.1 security update:
Use an alternative approach for securing the editor, which should be less disruptive.
Improve add-on compatibility (thanks in part to @glutanimate...
So we are at 25.02.4 right now
This is confusing me a lot
Dae is popping out releases like there is no tomorrow
And still no FSRS 6 to be seen

Why. Do you have other interests or projects (or probably just a life to get to)
Security issue is more important than FSRS-6.
At least FSRS is still not the default algorithm.
So it won’t affect too many people.
I'm sorry for asking but on a scale of unplug the Ethernet cable to last time you quit how much are you quitting? 😂
I have spent less time in FSRS recently.
It's a progressive process.
As I mentioned before, I have a formal work and I need to refactor the old algorithm of long-term memory.
Oh yes
Ahh so you're just gradually winding down? Got you.
why does anki not show the card
my desired retention is at 90%
yet

the card is not being shown today, its being shown tomorrow, when retreivability decreases even more
now the retrievability is 78%, am i interpreting something incorrectly?
should i reschedule
Do you usually have a backlog
That you struggle to finish everyday
Sometimes
That's me 🤣

Wait, was FSRS v2 used by other people? I thought the first version that people other than you used was FSRS v3.
Btw, I suggest using a space between FSRS and v1/v2/v3
I think so.
But FSRS v3 was released in the next week after the release of FSRS v2.
So I guess only a few users used it.
@quasi shadow ok, I am stumped by this bug


I'm running this on 2000 users. As you can see, there are no files for FSRS v3 and FSRS v2, I deleted them. Yet look

Honestly, at this point you doing this and then sending me the .jsonl files would be easier 😅
Wait, so this creates files both in raw and in result folders?
oh my god why
Alright, well, that answers my question
Also, take a look at this: https://www.reddit.com/r/Anki/comments/1k653go/fsrs_discrepancy_in_retrievability_stats_in/

I can't reproduce this user's problem
https://forums.ankiweb.net/t/bug-retrievability-in-browser-doesnt-match-retrievability-in-stats-histogram/56547/6 might be this? He might be using an older Anki.

Anki Forums
I will take a look! Edit: OK, it will be fixed in

I cant read XD
ahh thats the histogram anyway
oh its going to be the cleared memory states again

Dae finally responded after his respite
The ancient one awakens from his slumber
Is there a way for me to make edits/suggestions?


please send DM to me
In the Anki 10k dataset what is going on with user 92? They have no cards but have revlogs. Is my copy messed up or is that expected?
Deleting cards doesn't delete the revlogs.
Oh. Weird.
Otherwise the stats will mess up.
@quasi shadow on the main branch if you open the card info screen for a card which is completely ignored by ignored before except 1 review Anki panics
thread '<unnamed>' panicked at rslib/src/stats/card.rs:158:40:
attempt to subtract with overflow
Some(memory_states[memory_states.len() - 1].into())
this is because memory_states is empty.
[rslib/src/stats/card.rs:152:13] &memory_states = []
should starting_state be included in memory_states (it doesn't crash then). If it should be done, should it be done in Anki or fsrs.historical_memory_states?
let mut memory_states =
fsrs.historical_memory_states(item.item, item.starting_state)?;
if let Some(starting_state) = item.starting_state {
memory_states.insert(0, starting_state);
}
Any ideas?
Edit: Ok i'm worrying too much I'll just make the PR for fsrs-rs and you can close it if its crap 😆
Well maybe because of the backlog that this card gets pushed back in the queue so you are not seeing it in time.
More often than not is that I see cards with R values way below the desired retention scheduled way past due time
i trained a model that learns the functions f, d, fine-tuned per user with backpropagation (~2k parameters):
decay := d(S_current, S_previous)```
and S_next and decay are fed into a single power forgetting curve to get R.
The purpose is to investigate the limit of what a DSR model can achieve. Although the model doesn't model D, D can be estimated from S_current and S_previous. Also it could be interesting to fix `S_current, S_previous, rating` and see how `S_next` changes as a function of `elapsed_time`
I would recommend giving it R rather than elapsed_time
S_next := f(S_current, S_previous, R_current, rating)
And estimating decay from S seems like a strange choice
RWKV curves were less flat for higher S so maybe S matters
also i tried adding a separate decay for initial rating 1-2, another decay for initial rating 3-4, and it seems to improve FSRS-6 log loss by 0.0005
How exactly is it implemented?
literally another parameter
but i transformed the decay parameters to be in log-space instead
so it was initialized at -1.6 and bounded at -2.3 so that it starts at 0.2 and is bounded at 0.1
You mean that different decay is used in pretrain?
(the "calculate 4 values of S0" kind of pretrain)
nah not in pretrain
Then how
is there a way to see learning steps & retention
would 3 same day learning steps be more effective than 2
Helper add-on has a table with retention for learning steps, but it's hard to read

it seems to always recommend 2 learning steps tho
or maybe its because i have 2 learning steps
Ok, but then the same value of decay is used for all reviews after that?
yep
well yea i dont have data for 3 learning steps
:/
cause ive never done 3 learning steps so ofc it wont have data nvm my b
I think that's intended
i will try 3 learning steps for my new greek words
and i will come back in a few weeks
Having per-card decay would be epic, but then we would need decay = f(D, S)
that's exactly why i tried the formulation decay := d(S_current, S_previous)
Then I'd rather you experiment in a different way: use FSRS-6 and add a neural net for decay = f(D, S), without changing anything else about how D or S are calculated
Then we can (try to) extract a simple f(D, S) formula with 1-3 parameters from the neural net
Like, try to find a function that provides a good fit to the outputs of the net
And just plug that into FSRS
the problem is that if f(D, S) is a fixed function that never adapts then it just won't possibly work well, so it would still need some form of optimization either in the form of adapting the neural network during finetuning or using f(D, S, theta) where f is kept constant and theta is a small set of user-specific parameters, maybe 1-2 numbers
for the former it is basically just using LSTM but worse, so that's no fun
for the latter i'm still thinking if it's even possible to extract formulas out of it
That's what I had in mind - f(D, S) would have 1-3 parameters
Just plot the outputs of the neural net and try different functions and see what approximates the outputs well
ill think about it some more
Welcome to LB / Fuzz world my friend
Solution to all your problems :
Create Filter Deck => prop:r<[your_dr]
"deck:Japan::1. Vocabulary" prop:r<0.9 -is:due for ex
Having said that, I remark that the higher the DR, the higher your average stability, the less of an issue

But when you have a lot of low-S card, unfortunately that's to be expected
a 1-day shift will cost you ~10-20% depending on parameters for card with stability <1
Typically for my high D deck, more than half my review are done through Filtered Deck

But for normal D, it's not that much an issue (first screenshot) because my S is way higher, my forgetting curve less aggressive etc
@unique salmon this one is more usable, the idea is that perhaps decay contains sufficient information regarding difficulty
S_next, decay_next := f(S, decay, elapsed_time, rating)
it is slightly worse than the previous one with S_current, S_previous. I'll work on some plots to see if there is anything interesting going on here, also might want to try the baseline:
decay := d(S)```
GitHub
wait for open-spaced-repetition/fsrs-rs#313
I will release FSRS-rs v3.0.0 after the above PR is merged.
FSRS 6.0 Integration
Changes
Updated FSRS dependency to version 6.0
Added support for FSRS 6...
FSRS-6 is merged.
@cosmic hedge I plan to release FSRS-rs v3.0.0
Do you have any unfinished major changes?

GitHub
What's Changed
Notable Changes
FSRS-6 brings further algorithm improvements by @L-M-Sherlock in #3929
Add "grade now" action by @L-M-Sherlock in #3840
Support load balance and easy d...
FSRS 6 is released!  🎉
🎉
Am I going crazy
0.6486, 1.8043, 3.6737, 6.7319, 7.1765, 0.4157, 2.2263, 0.0010, 1.3604, 0.2420, 0.8515, 1.8349, 0.0867, 0.2744, 2.3250, 0.2191, 3.0073, 0.3597, 0.1444, 0.0837, 0.1000
These are my params
Do we have 21 params now
I thought FSRS 6 has 20 params
version got bumped to 25.05, new beta next week maybe
i stand corrected, one dropped 15 mins ago
I literally posted the link above 😅
I guess you haven't submitted the patch to Anki?
+1 for same-day reviews
+1 for decay (the shape of the forgetting curve)
Btw, should we use log loss instead of rmse the determine which parameters to use?
I haven't update the code.
as @polar maple mentioned before, the rmse(bins) is cheatable.
Luc tried CMRR with the simulator config, but it still outputs 70% too often (though he hasn't tried my integral thingy)
So the question is: do we keep working on CMRR hooked up to the simulator or no? I really feel like losing CMRR is bad, because "What desired retention should I choose?" is a question that is guaranteed to be asked by users.
Yeah, but FSRS isn't cheating, so it's fine IMO
I am noticing that FSRS 6 is not scheduling same day reviews when I am inside reviewing with some custom learning steps on like the case was with FSRS 5
@quasi shadow How do I reenable this. Didnt you have a console code made to reenable this
Could you provide a case to elaborate?

These are my learning and relearning steps
Usually in FSRS 5, once I get past the 25s, if FSRS thinks I need a further <1d interval
It will give me that
Could you check the card info's forgetting curve?
But doesnt go below 13min
please check the stability
Btw, what were your previous parameters?
I don't know. I already optimized
dont u have backups
before optimization


is it new that a 100 day interval wil become 3 days less
like is it new that, that box changes
dont remember seeing it before
changing the last parameter, you will see the box also changes.
before and after rescheduling
same amount of reviews for today which is alright


for me
i see, very cool
thank you
how do i get the new parameters because it says its already optimal
for some decks

clear the old parameters and optimize it again.
sounds good
It's 2025 and I still have to manually kill mpv.exe
sigh

Yep, that box now depends on your last parameter
Either one of the patches would solve it, either patching anki or fsrs-rs so long as the initial memory state is there
😂 Oops. I guess my PR missed the latest commit of FSRS-rs.

weird

the rev disappears?
that is weird? XD
wait no wrong reply XD
That is weird? XD
no i dont have any changes i hope

it didnt disappear, that commit got squashed into 3e2f0b423fed194d238cdcb55c1baccd0eca63f0 right
a few XD
lul

👆
we can do that as fsrs-rs currently is
I'm not sure whats going on with CMRR XD
we cant do it with pre-existing cards though
no way
when the forgetting curve is a forgetting line
horizontal line
And remember, this is after me starting a civil war against ultra-low decay. Without that, it could be something like "A 100 day interval will become 21456790 days"
If we made fsrs just never show you cards again, could we achieve 100% true retention?
a fellow subscriber to the "vacuous truth is truth" way
I have had this problem on my other device. What is the cause behind this and what is to be done to prevent this
the installer overwrites anki.exe, mpv.exe and lame.exe, among other files
and there are issues with mpv remaining behind even after anki is closed
the fix is as simple as duplicating this snippet https://github.com/ankitects/anki/blob/365d50012c61463d49e77194cddbd1ad59559c8e/qt/bundle/win/anki.template.nsi#L59

GitHub
Anki's shared backend and web components, and the Qt frontend - ankitects/anki
Alright since I am starting my reviews with Descending Retrievabilityies, the stabilities for the learn cards in question are in the 14 hours. So maybe if I reach the cards that are tougher, then I will be better able to judge
Wjere exactly do we put this fix for the uninitiated
in that file? it's the template for generating the windows installer
til nsis is open source too 
I am too braindead to understand this
I plan to remove it after FSRS-6 is merged.
But dae released the Beta faster than I thought.
#1282005522513530952 message I'm not sure to the degree which using the simulate config works but it might be worth looking into? https://github.com/Luc-Mcgrady/anki/tree/cmmr-uses-simulate-config
GitHub
Anki for desktop computers. Contribute to Luc-Mcgrady/anki development by creating an account on GitHub.
should I pr it or is CMRR gone?
which solution?
We could still try the integral (average R over the next N years) as I proposed, but it will probably just move the output from 70% to 73% or 75%, so idk
Time per answer depends on R
But in an extremely un-rigorous and ad hoc way
This one
The best we can do is using the simulator config + sum(average R over the next 3-5 years) instead of just sum(current R) for calculating the knowledge/workload ratio
But again, it will probably just shift the output from 70% to 73-75%

I can try it really quick but it would require updating fsrs-rs again which would be super annoying 😅
and i have my doubts
It's OK. I won't update the major version. We can use with style: _with_hook(..., fn)
I wonder
we have user's average retention and users average time spent per card right?
could we use that to get what the "time factor" should be without having to compute all the retreivabilities? 🤔
Idk probably a stupid idea 😂
Not without computing all retrievabilities
Btw, I do like the idea of simulated answer time being a function of both R and grade, but I guess Jarrett thought it would be too slow to calculate and too complicated to implement?
@lapis hearth has 2M reviews.
How much time do you take to optimize the parameters?
was this problem solved?
I cannot find a place to keep track of it.
Maybe we need let dae know it.
Nope, cards completely ignored by ignored before get treated as if their new in the simulator because they don't have a memory state
we'd need to put something other than "None" here. I guess the state converted from sm2 possibly?

it didn't get clamped

@cosmic hedge #1282005522513530952 message
Here's the code for integration (remove the special handling of decay=-1)
i did
let total_memorized = memorized_cnt_per_day.iter().sum::<f32>();
let total_cost = cost_per_day.iter().sum::<f32>();
Ok(total_cost / total_memorized)
``` is that ok?That's the same as before, no?
let total_memorized = memorized_cnt_per_day.iter().sum::<f32>();
My idea with the integral is to use the average R over the next few years
Instead of the sum of R at the end of the simulation
increasing the days to simulate made it go down

yeah it does, this is the sum of all the memorised values
maybe infer the stability and difficulty from the interval and ease
imo the Simulator should warn about/refuse non-new cards with no memory state
and not just treat them as new
Hm, wonder if it's worth updating to the Beta for FSRS6
https://github.com/ankitects/anki/pull/3940 The problem you were having with the simulator from moving your cards should fixed now just in case you didn't know 😄
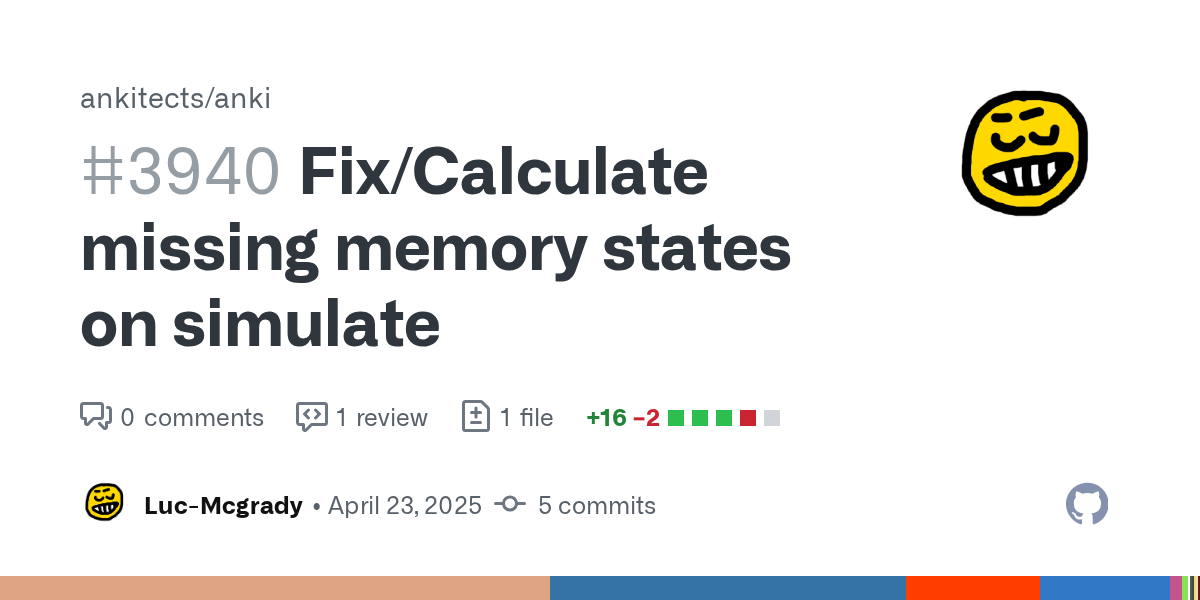
GitHub
Cards without memory states (likely due to being moved) are currently treated as new cards. This pr recalculates their memory state when the simulator is run.
Before:
After:
This does slow the si...
Just installed the beta to play around with it
not too much a fan of the new Simulator UI
https://github.com/ankitects/anki/pull/3829#issuecomment-2664959558 it got too crowded so it had to be moved
GitHub
Key Changes
Updated FSRS dependency to use a version that supports post-scheduling hooks
Added post_scheduling_fn to simulator that applies load balance and easy days
Added easy days percentages t...
It's just hella confusing that scrolling now visibly scrolls stuff behind the simulator, but not the simulator itself
and it also makes it very annoying to change a parameter and see what it changed in the simulation
you shouldn't be doing that 😅
But that's the whole point of the simulator?
by parameter you mean like the fsrs-weight numbers?
Anything. The parameters themselves, historical retention, max interval, ignore cards before, ...
you can change them here

New Cards ignore review limit having a globe there looks odd?
I'd assume all settings within that Simulator Window have no impact on anything except the simulation
And yes, I indeed have to change my parameters themselves
Cause I have nearly 2000 cards from when I started with the deck where I used "Good" when I shouldn't have
so I have to crank down the initial stability for Good, or those cards will be broken
under fsrs 6, my log loss fell by 0.004 but rmse(bins) rose by 0.4% 
hopefully ankidroid adopts it soon
It'll get it quickly once Anki proper is released with it
maybe you could try tagging those cards and adding -tag:wrong here?
though this seems like this is what ignore before is built for?
Ignore Before would ignore almost half my deck though
it ignores the entire card, not just those initial reviews
And there practically are no cards where I legitimately pressed "Good" on the first reviews
The few there are are few enough to not matter seeing them more often than neccesary
so just lowering the initial stability of Good seems a fine enough fix to me
Finding those affected cards would be stupidly annoying as well, cause it's so many
if all of you're cards are affected by the same problem then isnt that consistant in a way?
But it's not all of them by far
Just a large amount of the earlier ones
What happened was that I read and learned both Meaning and Reading on the first time a Kanji/Vocab came around
and then when the sibling card came around later that same day, I hit "Good", cause I obviously knew it well...
Since I learned it minutes prior
With SM2, that worked out fine enough
With FSRS, that heavily messes with the model
Since it now thinks those siblings are much easier than they actually are, so it pushed them much too far away, even after many iterations and even failures
I said the same thing on the forum
imo scrolling should just be locked while the Simulator is open
where is the thing explaining each fsrs parameter
yea same
seems normal
What concerns me a bit is that now, optimized with FSRS-6 and Simulating, my reviews spike up to nearly 400 a day
Though tbf, that is probably correct if it wants to get me back to 90% retention.
https://expertium.github.io/Algorithm.html
I haven't yet updated it to include FSRS-6 though
ty and can u explain to me fsrs-6 new ones
i want to relay to my friend
I'm gonna see how reviews develop in reality, and if it gets too out of hand, just lower DR
+1 parameter for better handling same-day reviews
+1 parameter for controlling the shape of the forgetting curve (previously, the shape was the same for all people)
Wasn't the same-day one in FSRS5 already?
Yeah, we just added another parameter to the formula
It's for any review of a given card that isn't the first review of that day
If you review a card once per day, same-day formulas are unused
If you review a card more than once per day, they are used
<1min
It is surprisingly fast
Probably even faster than before
But that is probably recency bias
Unless there is a change that I dont know of
so even new cards
with multiple learning steps
sorry i am stupid
Yep
what are the 19 parameters
am struggling to understand which is which
im reading this

https://expertium.github.io/Algorithm.html
Read this. I think my article does a better job explaining the algorithm
yep
I don't remember off the top of my head. The first 4 are the only ones that are easy to interpret
i see
Yeah, the next 4 are related to difficulty
now this forgetting curve/decay thing, what is this based off of
is there somewhere to read
im curious
.
i wanna read about it
It's just a number that controls how flat the curve is
alright
https://www.desmos.com/calculator/9nmzffvssz
Here, you can play around with it

Desmos
@quasi shadow

I have made a new card from scratch
Got the stability down to 7 min
how do you have 17 reviews already

SHow your params
the stability number thats here
can i import it from my anki to see the graph
or nah

its just an arbitrary number
Just look at card info of any of your cards
not sigma....

I have a custom learning step
Ah, I see
you dont memorize with 1s intervals bro

thats just recency effect
Well, FSRS thinks it's fine to give you a 1d interval, what else can I say
That does not make any sense
With FSRS 5 there was no problem with getting <1d intervals
So what is going on here
Like am I able to even get <1d intervals with custom learning steps on
Remove your current steps and find out

nope

huh
Stability literally says 7 min dammit
@quasi shadow
Wtf
I suspected this behaviour from the start
Returned the custom steps back and got the stability as low as 4 min

Still not budging
This is not how it was working in FSRS 5
with the console code, i was referring to this
Does someone has it lying around
mw.col._set_enable_fsrs_short_term_with_steps(True)
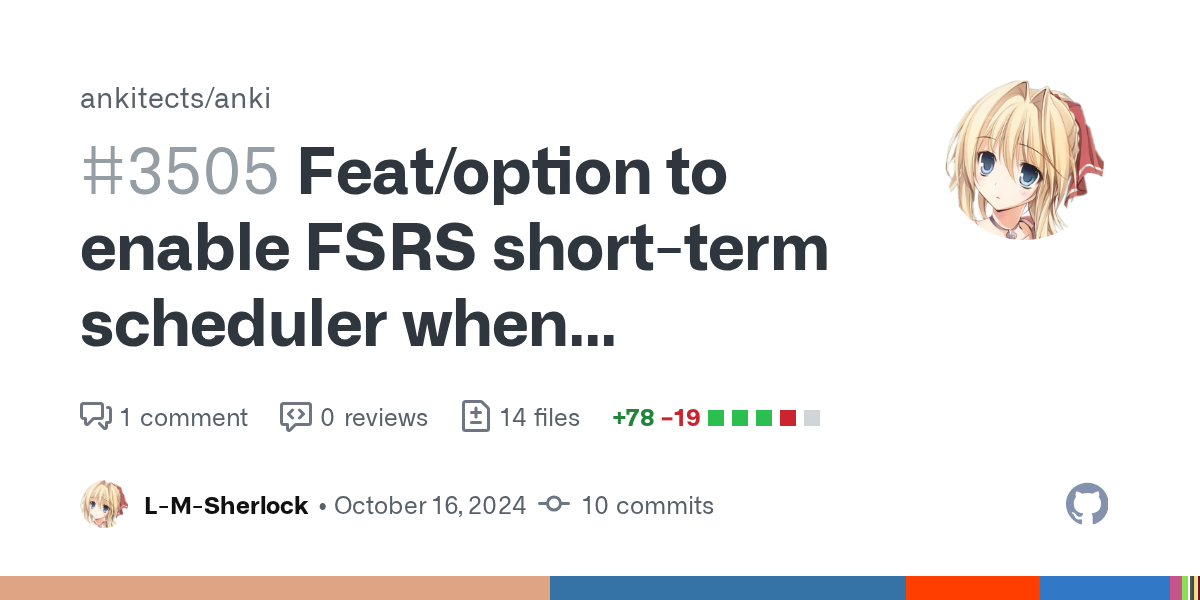
GitHub
close #3497
To enable it, please execute mw.col._set_enable_fsrs_short_term_with_steps(True) in Debug Console.
Finally found it
Guess you did
But this just enables your steps + FSRS steps
If FSRS doesn't show you <1d intervals, idk
Works on my end

No, wait, it doesn't
Huh❓

I cannot get it below <1d
Wtf
No matter how hard I try
No matter what I do
Console on
Console off
Custom Steps On and Off
@quasi shadow even with S0 set to minimum possible values and 99% DR, I can't get an interval <50 minutes

This is what is happening to me

This might take time to make a new fix
So I think I have to regress to the previous build
But won't that f my collection if i have 21 params now
Just reset them and re-optimize
Alright how do I downgrade
You mean reset before I donwgrade or after I downgrade
Just uninstall Anki and reinstall it
After
So it just yoinked the last 2 params from me

Now back to 19 params
the stone ages
But here is a sight I am used to seeing

So FSRS 6 is definitely bugged
I will try to reproduce this bug.

Anki Forums
Bug: even with S0 set to minimum possible values and DR=99%, the shortest interval that I get is 50 minutes On another preset I can’t get <1d intervals at all Just a speculation, but I think these are two separate bugs: some kind of parent deck->subdeck interaction went wrong and the calculation of intervals also went wrong

Now it's Anki-Man's turn.
since FSRS does directly use RMSE (bins) when optimizing, it can be slightly cheating
yeah
btw, how's going on about the debate of removing evaluate button?
Same as any debate on UI: nobody ever agrees on anything, so we are stuck in a situation where at least one proposed solution is an improvement over the current situation, but because no solution has enough supporters, nothing gets done
I think many people fail to notice this particular pitfall: it's entirely possible that one or two or three solutions would be better than the current implementation, but endlessly arguing will lead to none of those being implemented, making everyone worse off than if they just agreed on any solution at all
Fine. What if I use log loss instead of rmse to determine the parameters? Would it cause complaints when users click evaluate button and find that their RMSE(bins) increases?
this is fine, we should start telling others that log loss is the better metric
OK
or we can consider changing the formula of RMSE (bins) a bit to make it uncheatable
but how?
I read a lot of papers. But every metric related to calibration is cheatable.
i think if you remove the mean(R_predicted) part then it would work, instead we have another inner summation with R_predicted - mean(R_measured)
Have you tried any of these fancy metrics? How do you know they're cheatable?
(the math in the paper goes over my head)
Can you explain the full math?
So we calculate measured R via binning and then calculate the average of (predicted_R - avg_measured_R)^2?
And then take the square root
yeah
🤔
- no more weighting by w anymore since the extra summation would take care of that
I suppose we could try it. I'm curious what the results will be like
@unique salmon
this graph is from user 601, where i set S = 3 and elapsed_time = 3 (such that R=0.9)
maybe we can try a trainable decay for rating=1 and separate one for rating=2,3,4?

You mean based on the first rating? I don't like the idea of assigning that much importance to the first rating
nah, on the latest rating
for S = 0.1

next, i'll plot next_stability vs R
So four optimizable parameters instead of 1? Interesting
Though f(D, S) should be better
S=20

maybe it would be just 1 extra parameter, we can change the current interpretation of the current parameter
1 parameter for rating=1, 1 parameter for rating=2,3,4
for this one, stability decreases most of the time for rating=2
That sounds like crap compared to f(D, S)
what does f(D, S) have to do with it?
i'm just suggesting a possible thing to try right now
actionable immediately
You need to find somewhere that lets you do ranked choice voting 😅
We're trying to improve decay, right?
Having a nice continuous function of difficulty and stability sounds way better than two parameters, one for last_rating=1, one for all other cases
okay but consider the fact that the latter we can try right away within a few minutes of coding
also i just don't think it will be possible to get a nice function even if we do the idea where we train a few user-specific values to feed into a fixed nn
I'm not sure if there is way to do that with Google Forms. I don't think there is
and even if we do go down this route, i don't think decay = f(D, S) is where we should be working on, it would instead be the S_next, D_next functions aka just full nn guided FSRS improvement
I think discourse allows you to do multiple answers, but that's not quite as good as real ranked choice.
But the whole point of FSRS is that it's a transparent algorithm with few parameters rather than an inscrutable neural net with thousands of parameters
that's your point, i don't think the users care
most of them at least
i didn't know what every FSRS params did until recently
now i know what some of them do
like 6 of them
Lol
Alright, but still, it's the philosophy of FSRS
If you want a neural net, release RWKV already
@unique salmon my concern is that even if we only have something like two user parameters, it would be f(D, S, x1, x2) where f is any function for anything, but this is still a function on a 4-dimensional input which is almost surely impossible to get a nice smooth approximation of
sure you can fix x1 and x2 to get a graph that looks something like this (from jarrett's paper)

but then you imagine x1 and x2 changing and the whole graph shifts...
pretty much impossible to get a nice smooth function out of this, other than saying "the entire nn IS the function"
I had in mind using a neural net that takes D and S as inputs, outputs decay, we train it on a combined revlog of 100+ users, then freeze the weights, then plot f(D, S), which is 2D, so it can be visualized
this might not well because users already have their own range of decays that work well for them
Jarrett does
He won't be enthusiastic about turning some (or most) of FSRS into a nn
If nn decay works better than the current version, then surely we can find an approximation of it that also works better than the current version. That's what I think
Do the new parameters not sync yet?
I just got home, wanted to do my reviews, and they're not there from earlier on another PC
Only on PC right now
yes, this was from PC to PC
Then...welp
Report it on the forum: https://forums.ankiweb.net/t/anki-25-05-beta-1/59710/9
So I read the paper a bit more and it seems like we have an advantage - we can use other data, not just y_pred and y_true, whereas the paper is concerned only with cases where that's all you have
We'll see how well Alex's idea goes
#1282005522513530952 message
Oh, btw. Alex will benchmark using this
A new parameter that acts as a lower limit of R. If it works, you'll have to re-release FSRS-6 🤣

"jk guys, that wasn't FSRS-6, now this is FSRS-6"
Nope, not with how f is calculated
f2 on the image
It takes a into account

Desmos
fsrs 8 🔥

Oooh it's new FSRS day!
Let me note all my previous RMSE/logloss and then upgrade hehe
# Vocabulary :
## FSRS-5-recency
0.3363, 1.3148, 3.3909, 33.0426, 7.3786, 0.4214, 1.5160, 0.0507, 1.3376, 0.2761, 0.8667, 1.9764, 0.0853, 0.2928, 2.3306, 0.0488, 3.4780, 0.4079, 0.5950
Log loss: 0.3526, RMSE(bins): 3.02%. Smaller numbers indicate a better fit to your review history.
## FSRS-6
0.1217, 0.8517, 3.2918, 31.4605, 7.2158, 0.4052, 2.0269, 0.1194, 1.3239, 0.2824, 0.8562, 1.8707, 0.1099, 0.3280, 2.2948, 0.0869, 3.2930, 0.7316, 0.2369, 0.0610, 0.1000
Log loss: 0.3515, RMSE(bins): 2.92%. Smaller numbers indicate a better fit to your review history.
# Vocabulary Hard :
## FSRS-5-recency
0.1220, 0.1620, 0.1973, 0.2333, 8.0867, 0.1933, 1.9428, 0.1287, 0.8387, 0.3855, 0.2303, 2.1288, 0.0038, 0.5387, 1.9831, 0.1850, 3.0211, 0.1765, 0.7725
Log loss: 0.4182, RMSE(bins): 4.33%. Smaller numbers indicate a better fit to your review history.
## FSRS-6
0.0155, 0.0457, 0.0973, 0.1849, 7.9506, 0.1462, 2.6543, 0.1023, 0.8218, 0.1856, 0.2998, 2.0352, 0.0410, 0.5785, 2.3866, 0.1682, 3.0502, 0.4503, 0.5200, 0.1905, 0.3141
Log loss: 0.4159, RMSE(bins): 3.72%. Smaller numbers indicate a better fit to your review history.
# Sentences :
## FSRS-5-recency
0.2052, 1.1936, 4.0570, 11.5037, 7.0698, 0.5526, 1.6654, 0.0264, 1.6670, 0.0000, 1.1399, 1.9599, 0.1157, 0.3064, 2.3464, 0.2009, 3.2929, 0.4068, 0.5817
Log loss: 0.3573, RMSE(bins): 4.03%. Smaller numbers indicate a better fit to your review history.
## FSRS-6
0.0642, 0.7611, 4.2415, 18.3252, 6.8678, 0.6328, 2.1626, 0.0327, 1.6939, 0.0890, 1.1799, 1.8456, 0.1377, 0.3111, 2.3136, 0.1975, 3.2133, 0.7683, 0.2973, 0.0864, 0.1053
Log loss: 0.3546, RMSE(bins): 3.69%. Smaller numbers indicate a better fit to your review history.
# Sentence (Hard) :
## FSRS-5-recency
0.1160, 0.3412, 0.9144, 4.5219, 7.5361, 0.4300, 1.7579, 0.0182, 1.2160, 0.2674, 0.6890, 1.9222, 0.1085, 0.2310, 2.2059, 0.2525, 2.9150, 0.4491, 0.6621
Log loss: 0.5586, RMSE(bins): 10.08%. Smaller numbers indicate a better fit to your review history.
## FSRS-6
0.0010, 0.0054, 0.0150, 0.0744, 7.2731, 0.4980, 2.3959, 0.0071, 1.2739, 0.2540, 0.7703, 1.8689, 0.0939, 0.2899, 2.3056, 0.2363, 2.9442, 0.6523, 0.3023, 0.1649, 0.2344
Log loss: 0.5482, RMSE(bins): 7.93%. Smaller numbers indicate a better fit to your review history.
Some big winners here. Sentence (Hard) got a 20% reduction of RMSE, Sentence ~10%, Word 3.3%, Words Hard 14% !
The adaptive decay is looking very promising for those hard deck ! It's funny to see that for my normal deck, my decay was bounded by the 0.10 for Words, and got close to be bounded by .0053 margin for Sentences
In terms of workload, somewhat similar,
Vocabulary went from 173 (as-is) (184 after reschedule FSRS5) -> 176 FSRS6
Sentences : 21 (23 after reschedule) FSRS5 -> 27 FSRS-6
BTW looking at the Simulartor @cosmic hedge , what do you think about a "Compute my recommended New Cards/Day, with a set Daily Workload ?
I think it could be easy to comptue with some dichotomy

I think it's quite nice because if I look at my hard preset, I see 1 new/day is basically asking already for ~90 reviews/day

While 5 news/day for my normal is more like 80-90 reviews/day
And in all the non immutable things of the universe, CMRR still return 0.70 😆

FYI FSRS-6 also uses recency weighting
That's an interesting idea, but I think "What should my desired retention be?" is a more pressing question for users
Quite obviously though, since in my case the workload 5news/d DR=90% ~= 10news/d DR=80% = 15news/d DR=70%
While of course, since Memorized = Active Card * DR, you get way more "Memorized" score for ~similar review workload


Not that obvious though, the Time is indeed different

I'd say, let's change the return 0.70 to return 0.90
(I think the current implementation is "return 0.70", right ? 😆 )
It might as well be with FSRS-6 😅
The depressing part is that even if we put the avg integral, I think it might change to .80, but it might be ALWAYS returning .80 for everyone 😆
More like 73-75%, but yeah
So at this point, it's a bit like we're trying to find the formula to return something closer to .85 than what we have hehe
So maybe "return .85" would work as well 😆
Just joking
I'm super eager to see how well my new prediction will be now with FSRS 6
Your LB improvement has been merged right @unique salmon ?
Yeah yeah I have, I'll keep the Filtered Deck but I'll see if the proportion Filtered/Normal review change in the upcoming days
Well, idk about days. It will probably take at least a month to notice a difference, if it's even noticeable
It should help with low intervals too no ?
You think it will be visible only for longer intervals ?
Yes
It's just that most of your cards have already been scheduled with old LB
I just have a backlog fof 50 cards if I reschedule now on my vocabulary
I'll do them now
For every FSRS release, there's a backlog reschedule to do in tribute of everyone's effort
lol
sound i will check mine with the new fsrs 6 update
unless i cooked myself
and did it without measuring
Looking at this, I wonder: imagine if FSRS-15 will have an absolutely incomprehensible monstrosity of a curve with tons of parameters 🤣
i did it without measuring
but like
its pointless no?
?
like
its an exponential curve now of like effective gains
the gains from sm2 to fsrs4 was a lot
then fsrs 4 to 5 idk, good?
and 5 to 6 still good but small
only so far you can go
Once I finish running tons of calculations, I will show fancy graphs comparing different FSRS versions
Preview here: https://imgur.com/a/KfJ32EV

{kind=link}
{kind=link}
It takes like 8-10 hours to compute data to do this
For one graph
And I need 7 graphs
have fun
Does Initial Stability have ANY merit when there are no more new cards? Is it ever used retroactively?
Yes. In order to calculate DSR values accurately, FSRS goes from the first review to the last review. If you change parameters, DSR values will have to be recalculated, which means FSRS will go over all your cards, from their beginning to their end, which means it will need S0