#FSRS Megathread
1 messages · Page 10 of 1
Now if only we could finally make D that depends on R, I would consider FSRS to be complete
- short term memory model
...oh, right
You bet your sweet potato I won't forget about this
FSRS-6 with optimizable decay reduces 16% RMSE(bins) relatively.
The absolute difference is 0.0085, which is equal to the difference between FSRS v4 and FSRS-5 recency
😎 So it's good enough for a major version.
😅 The only problem is I have to refactor fsrs-rs to support it...
Nooo not my simple retreivbility calculations! XD
We have to pass the decay value to forgetting curve function.
So, there are two ways: 1) store the decay in parameters, or 2) store it in the card
Oh, yeah, decay will probably have to be stored in card info
It will be stored in parameters anyway, no?
Yeah I'd say the best option is both like we do for desired retention?
When is Dae releasing the next Anki version
yep, I mean, the source when the code need to read it from
He will release it soon because of a security issue.
I’m afraid that FSRS-6 cannot catch up this release.
Remember when Dae said "Let's make FSRS the default in the next update after 24.11?" 🤣

Now I have wet dream about D shenanigans (clustered parameters etc …) but let’s celebrate first 😂
Just let me run 50 more tests with neural D, surely I will find something good
🍃

we gotta throw a party!
hmm... so do we gotta update the manual too? optimise if u change DR.
@unique salmon please confirm before I open an issue.
Not really
oh ok then it's a nice change
D has a lot of properties (“higher D lower Interval”) that might fit really well how it’s already computed no ?
We aren't sure. And the fact that D doesn't depend on R is theoretically crappy
Sure
Imagine two scenarios: the user presses “Easy” when R=99% and the user presses “Easy” when R=1%. Clearly, in the latter case this is a very surprising outcome, whereas in the former case it’s not surprising at all. Meaning that D should be updated by a different amount in those cases.
Yeah as I see it the optimizer find already the best way to set how D move to fit user history, and the fact it optimizes itself into very distinct clusters might be a sign that instead of trying to bind the equation with those D parameters, we could just optimize every other parameters based on D clusters
Wait, so you might need to optimise after you've changed your DR?
Because you'll have more reviews in a different R region?
someone other than expertium confirm it for me.
I think I'm confused. I'll leave it upto others. Signing off.
No, it's a sign that D is updated in fixed amounts that depend on the grade
Like
Again = +2
Hard = +1
Good = +0
Easy = -1
No, I've already said that
If you change DR your data won't change
At least not until you actually do reviews
But the optimizer still decided that those amount should be almost null for good and easy
It could have decided differently if that would have been the optimal way
Nope. The linear relationship is hard-coded
My low D has a more healthy D management for example
The D update formula is basically just new_d = old_d - (parameter * (grade - 3))
Where Again=1, Hard=2, Good=3, Easy=4
So for Good new_d = old_d - (parameter * (3 - 3)), which is just old_d
For Again new_d = old_d - (parameter * (1 - 3)), which is old_d + 2* parameter
We've tried making the values associated with each grade optimizable, it didn't do shit
So overall
Again -> new_d = old_d + 2*parameter
Hard -> new_d = old_d + parameter
Good -> new_d = old_d
Easy -> new_d = old_d - parameter
Hence why you get clusters
Then there is extra stuff to make it a little smoother
Hmmm for Good this is not the implementation, it's controlled by w[7] for example

My "Low-Normal D deck" : 0.3888, 1.4114, 3.4578, 32.9702, 7.4108, 0.4662, 1.5312, 0.0677, 1.3478, 0.3241, 0.8557, 1.9796, 0.0889, 0.2942, 2.2884, 0.1258, 3.3983, 0.3663, 0.7039

And the distribution is quite nice too

w[7] + "linear damping" at high D smooth it, yes
But overall most of the change is done like this
u take things too literally and end up arguing with yourself
that's what I meant ofc
Because you'll have more reviews in a different R region
Oh, ok, my bad. Still, I'm not sure if I would recommend optimizing parameters more than before FSRS-6
hmm, fair enough.
I would like to ask if there is an exam at the end of next month, is one month of "fsrs" review enough?

I'm evaluating some collections with extremely low decay.
Their retention is > 93%.
And their decay is < 0.03.
which user?
i guess decay would be low whenever you have data where R looks like it is increasing over time, which can happen by chance if the collection size is small
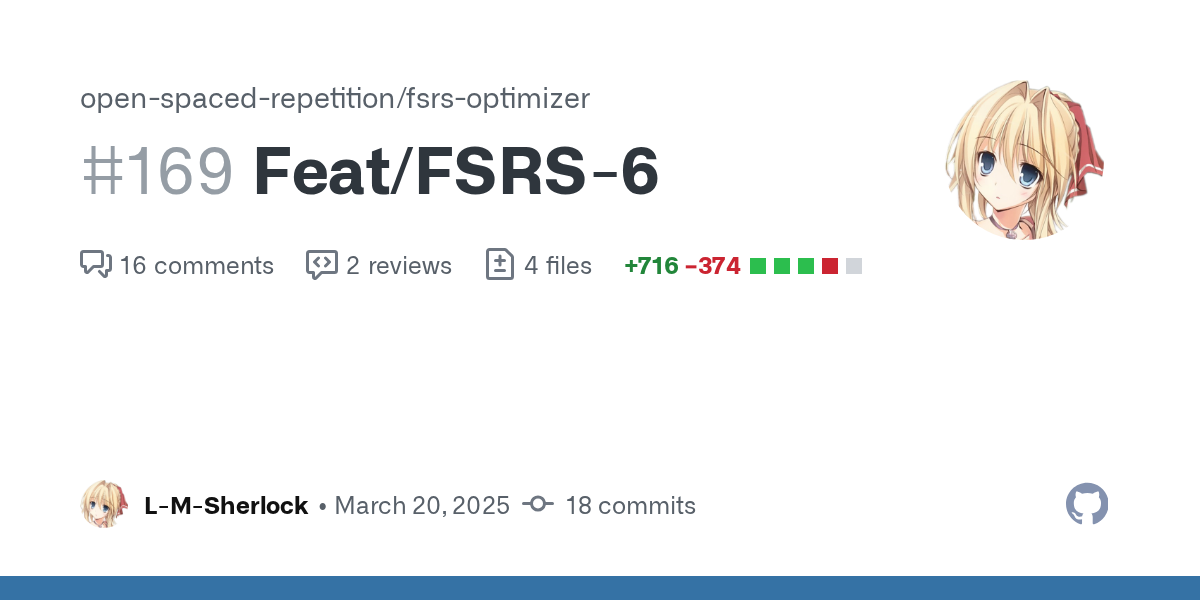
GitHub
candidate for FSRS-6
Log Loss: 0.3273 -> 0.3257 (-0.0016)
RMSE(bins): 0.0518 -> 0.0510 (-1.5%)
Model: FSRS-5-dev
Total number of users: 9999
Total number of reviews: 349923850
Weighte...
It will depends on the amount of material, the type of material, and the score desired :). But if you have all the material already learnt, learnt in Anki, and you have a good Desired Retention (Above 80%), yes ! If no, you should learnt all the cards ASAP in Anki + outside Anki
We can try the new optimizable decay with our collection somewhere ? For ex here ? https://colab.research.google.com/github/open-spaced-repetition/fsrs4anki/blob/v5.3.3/fsrs4anki_optimizer.ipynb#scrollTo=wG7bBfGJFbMr

https://github.com/open-spaced-repetition/fsrs-optimizer/pull/176 is this what you want?
You can install fsrs-optimizer via pip+git
I have a question about the parameters I use for FSRS:
When I switched to FSRS I followed some explanations suggesting to use something along preset:"Bases" -is:suspended as parameter for the optimization field. But now that I think about it, as I suspend the leeches it means FSRS never use the data on them to optimize. So maybe the -is:suspended part creates some kind of survivor bias 🤔
Should I remove that part?


@quasi shadow here are the results of trying optimizable decay
It's very slightly better than decay=-0.2, according to my tests. Regularization doesn't help much, and increasing learning speed makes results worse
Regarding clamping, I already said it on Github - even if for some users decay >-0.1 provides a better fit, we shouldn't use it for scheduling reasons. We don't want people to have intervals measured in thousands of years

Slightly better?
In my test, it’s ~5% better.
Here it's like 2-4% better
In these tests the decay parameter is clamped between (-0.1, -0.7) btw
Again, as I said on Github, we can extend the lower limit to -1, but the upper limit must be -0.1. Anything closer to 0 than that will not be usable for scheduling
For example, with S=1 and decay=-0.025, the first interval at DR=80% would be something like 120 days, and the first interval at DR=70% would be something like 25000 days
If you have suspended cards, they are probably very different from the rest of your cards. So having FSRS learn from them is not going to make it better on your normal cards
S=1
Decay=-0.025, the first interval at DR=80% is around 120 days, the first interval at DR=70% is around 25000 days
Decay=-0.1, the first interval at DR=80% is around 4.5 days, the first interval at DR=70% is around 18 days
Decay=-0.15, the first interval at DR=80% is around 3.4 days, the first interval at DR=70% is around 9.5 days
On second thought, even -0.1 is a little crazy for scheduling. Let's make the limit -0.15. Again, I understand that for some users it won't provide the best fit, but we have to worry about the intervals being reasonable.
@bold terrace @polar maple @hasty fractal your input is welcome
I feel like we have a spectrum, where Alex is on the far end of "Screw scheduling as long as metrics look good", Jarrett somewhat closer to the center, and me at the other end (but not super far) of "Screw metrics a long as scheduling looks good"
Personally I think if an user has a profile that lead the optimizer to get a decay very close to 0, I think it's fine as long as he realize that he will have to push the DR very high, or set some max interval limit. I don't think it's very healthy to put restrictions on decay itself if the problem is the interval.
After all, if S=1, if DR=90% then in all cases the first interval would be 1d, by definition, right ? So it's not per say a big big issue as long as the user is aware that since he don't drop to 70-80% easily, either he chose a higher DR, either he chose to "never see those cards".
But I'm not 100% against putting some limit, I'm just worried about the kind of compouding effect it could have : If the decay is limited let's say to 0.15, but the user truly would need a 0.10, then other parameters will be optimized to try to make the reviews anyhow longer. Sure, it won't really have the same drastic effect than a decay lower, but if the user keep outperforming the prediction, the other parameter will try to compensate for that decay we didn't allow to go to 0.10, for ex
So personally I'd put myself in : Let's keep the scheduling as pure as possible so it gets the best metrics it can, and let's build ways for the user to be able to navigate what those parameters might means for him (He needs a high DR, or to accept he won't see much cards if he initially rate them good, etc)

I'm a centrist.
actually I'm a left-leaning moderate liberal.
We now have SRS-left and SRS-right 🤣
I'd be vertically aligned lol : The model itself should be metric-focused, but the UX could be controlled by external factor than the model itself 😄
SRS political compass
(rightly so)
To me anything political has bad connotations tbh
expertium hides his political opinions behind an apolitical mask
we've seen it all
I also think that people might consider things as "not looking good" when they don't necessarly realize that it's their history that led their current interval to be what is is, and even if the scheduler overshoot, it will self-correct once those overshoot will be indeed evaluated as being overshot. And even if the card getting scheduled 2y later won't be re-reviewd for the next 2 year, a lot other card will be, and the optimizer will take those in account, and with some regular reschedule, those will be adjusted
So 2 cases scenario : Either you're in fact studying for something in 1 month, and you're not in a mood to see as little as possible but you want to maximise your score : Then crank up the DR, do mass-review, set your max interval to 1d, whatever.
But if in contrary your goal is long term learning of something, forgetting a few things for a few months is in the grand scheme of things, a really trivial thing
Personally I think if an user has a profile that lead the optimizer to get a decay very close to 0, I think it's fine as long as he realize that he will have to push the DR very high, or set some max interval limit. I don't think it's very healthy to put restrictions on decay itself if the problem is the interval.
Sadly, I'm pretty sure the result of this approach will be 100 posts with "Why is my first interval 100 years?"
Those guys can be recommended to put a max interval in the settings
Max Interval means : Whatever the DR, I always want to be recalled something every X interval
And then every single interval will max out
Nah, we gotta set a reasonable limit to decay
And if with time they realize they have a 99.99% retention in that hardcoded interval, they will gradually get more confidence increasing it 🙂
I'm not against a reasonable one, but maybe we should based it on observation, something like 95th percentile of the lowest decay observed in real user
The thing about decay is that the difference between -0.1 and -0.01 is not 10x longer intervals, more like x50000 longer intervals (at DR=80%, specifically)
Because in fine, I think most of those people are people not confident enough to trust an algorithm, so maybe the max interval route for them is not the worst. Let's not forget that at a max interval of 90d, you could have 1000 card and still it will give you an average daily workload of ˜11 reviews per day .... The price to pay "to be sure to never go north to 90d" is not that big to pay right ?
And I'm pretty sure those guys have less than 500 cards in a review state
Personally at 3k and having done Anki for the past ~15 months, I'm in a state that if you tell me ~20% of my cards will ahve a 1y interval instead of 30d, I'll tell you thank you lol
@quasi shadow what are the 5th and 95th percentiles here?
(if the 5th percentile is >-0.1 [aka <0.1 in absolute values], let's just pretend it's -0.1 😉)

What if I have knowledge that was seared into my mind by the old ones the first time I saw it but I want Anki to make me revise it in 100 years just in case? ;p
Lol
Set the max intervalto 100 years 😄
I mean, I think algorithm should be as "pure" of any external alteration, while setting external limits are OK 🙂 By doing so, you can more easily troubleshoot if you have a clear information that : "Right now, the system thinks you'll need X months to remember it, but the interval will be 30d because you wanted it like that"
Just by eyeballing it, it seems around 20% of users have decay <=0.1 (absolute values)
The thing is, even people for whom it provides a better fit wouldn't be happy, because nobody wants 100 years intervals
I really don't think that making R 0.1% more accurate is worth making users 100x more concerned about interval lengths
Yeah but the restriction you'll put on the decay will impact the others parameters somewhat
And maybe those users have a big DR
*cough* *points vigorously at book covered in sigils and giving off a menacing aura*
Oh, speaking of which
Can you guess what interval length with S=100 and DR=95% people will have at -0.01 decay? 🤣
After all, the decay was optimized that way, because predicting the next interval to be 100 years later, was indeed the better prediction
Ok but 0.01 might be excessive xD
I'd say, let's see already what the top 95th percentile has as a decay
Just guess
S=100 days, DR=95%, decay=-0.01
maybe we're arguing for 0.10 instead of 0.09 or 0.11
0.45 days
At DR=99% and decay=-0.01 and S=100 days, the interval would be something like 0.0045 days
Strange that between [100,90] and [90, 0] you have a compressing/expanding effect on interval no ?
I mean, mathematically it make sense
but then it means people with low decay might just be people with DR<90%
and people with higher decay people with DR>90% ?
https://www.desmos.com/calculator/6fwtu0dzbf
Here, have fun

Desmos
As long as the prediction are accurate 🤷
This is decay=-0.5 (purple) vs decay=-0.01 (green) at S=100 days

But once again, might be a sign that the prediction are good because it was training at that specific DR
Not because the forgetting curve is truly good
The optimized decay might just be a way to accomdate slightly the prediction around DR
but going from 90% DR to 60% or from 60% to 90% is asking for very bad prediction
Nope, not according to this

It's only bad for people with REALLY low retention, like, 20-35%
This graph is kinda weird because people with really low retentions were combined into one bin and I'm not sure what their average retention within that bin is, I assume around 20%

Then again, this is optimizable decay, not fixed
(I think)
(Jarrett, is it fixed here?)
I think there are still a lot of stuff we don't understand behind short memory and long term memory relation 😅
Man, this is getting tiresome
@quasi shadow, my guy, can we just agree to make the limits of decay (-0.1, -0.8) and be done with it? 😅
Maybe it's something like "You have a certain level of recall probability in long term memory, and short term recall might both make you more able to recall it right now, as well as bumping SLIGHTLY your long term recall chance"
Which could explain that kindof "baseline" recall that people seems to never get below (~20-40% let's say) but they drop like crazy initially
and maybe thus multiple decay rate would be necessary 
Can we have me on "screw most things as long as the standard user has a reasonable experience"
One to represent the short term loss, one to represent the long term baseline
Let's calculate TWO stabilities for TWO forgetting curves and then take their average

Actually, let's take it even further, like Alex
Let's calculate THREE stabilities for THREE curves with THREE different decays and then take their WEIGHTED average
Ngl, I actually kinda want to try that. It sounds horrible, but I want to see the metrics
Yeah the weigheted average would make more sense I think
At a certain point you just end up putting it all into the Memotron 9000 Neural Network
Short Term probability after 5d might be 0%
Mid term might be ~60%
Long Term might be 40%
A pure avg would account the 0% of short term as being as important as the other
Still, the good thing with FSRS is how we can interpret after the parameters
Memotron is all fun until he decide to kill everyone
Alex is working on something like that 🤣
His unreleased neural net can achieve RMSE of around 1.4% and logloss of around 0.27, beating the hell out of everything you see here

Let me guess, we dont use it because it gives some weird intervals❓
Holy shit I just realized the number of params
The downside of going full NN is that it becomes much more difficult to fine tune and fine tuning can break it entirely if done wrong.
Also, all of this is real fun but to be honest we tend to forget how much FSRS is already god tier

I mean since switching to DR=90% and spliting in Low/High D my deck
I have not a single day with a difference of more than 1.5% from my DR
Sure 1.3% would be better than 1.5%
But it's already completely god tier
Or how clean my average stability doesn't deviate from the trend

Where do you get these graphs
sum(R*f(S)) same

It's kind of amazing that any of this works at all considering how little information we give the scheduling algorithms.
There is so much information FSRS is missing out on (Time of Day, Sleeping Time, Answer Time, Contextual Content of the cards, Interference and Similarity of cards with other cards etc.. etc.)
Might be a sign that all those things doesn't really much haha
Well, that one in particular would be almost impossible to use for scheduling. He has another one with RMSE of around 2.5% and log-loss of around 0.3, which is more promising for scheduling, but I wouldn't bet that any of it will ever be used in Anki
Btw, his neural net uses answer time, deck ID, preset ID, sibling information and whatnot
why not
Next graph I'd like to do is this one but with percentile on x-axis instead of actual repetitions count

Would be great to see that the 90-100th percentile represent ~20% of your workload
Really  So what is stopping it from being implemented
So what is stopping it from being implemented
FSRS is bound to reach its full potential. Any other improvement above what it could give would require a change in framework
I think Alex's net has like 1 mil parameters
Full blow Neural Network Mode
Holy-
And instead of optimizing it for each user and testing on the same user, it's just pre-trained on 5k users and tested on the other 5k
So it could be even better than expected
So the optimization procedure is very different
?
I'm not sure what you mean
Should it not be trained and optimized on the same users
I'm saying that unlike FSRS, where you optimize parameters for each user, this one is trained on a massive dataset and then parameters are kept fixed
So there would be no "Optimize" if it was used in Anki
I think FSRS-6 will be good enough that there won't be much of a reason to use a neural net
When is it coming out presumably. I cannot wait
Idk
Oh, and Alex's net uses fractional interval lengths too
If it can inherently learn enough that it doesn't need fine-tuning it would be amazing. A lot fewer support requests if there are fewer dials to twiddle 😅
Why are you trying to seduce me😭
So it kind of has a short-term memory model somewhere within it's matrices with tons of floating point numbers
Now I am REALLY intrigued
I dont understand these graphs. Could you help me understand them



Load is 1/interval grouped by cards with that number of lapses
Distribution is just the amount of cards with that number of lapses
Total is the amount of lapses total on cards with that number of lapses
Replace the word "lapses" with "repetitions" and you get the explanation for the repetitions one
Speaking of which, I made some progress on the percentile x-axis 🙂

It's really nice because now each bar represent 5% of your card
and you see the total load ratio it represents
in my case, my last 5% represent 10% of my load
But the 5% between 60 and 65%, represent only 4%
Is this your addon
no it's the same but it's still in a feature branch
new name dropped for him
2.7 mil
@polar maple explain why it won't be implemented in Anki
(aside from Dae saying "FSRS is good enough", which is quite likely)
the model size isn't a big issue, i could make a smaller version
the problem is probably syncing issues which i don't understand fully
100%
What about scheduling? I assume it's completely impossible with RWKV-P, but possible with RKWV that uses an average of three forgetting curves
Does your NN save some kind of state in the cards? I thought it just looked at the entire revlog each time it did scheduling.
iirc this is fixed decay=0.5 vs fixed decay=0.2
yeah RWKV does use forgetting curves so scheduling is possible, now it is an average of 128 exponential forgetting curves
128 exponential forgetting curves
why
Surely there are no benefits beyond 2-4 curves
it's a recurrent nn that keeps a hidden state for each card, note, preset, deck, and a global state, on each line of the revlog the corresponding states get updated
for theoretical interest
because now we can maybe later on interpret it as a probability distribution over stabilities
Oh, that's interesting
Isn't that state just regenerated from scratch at runtime as you pass it the revlog? (i.e. not persisted in the Anki DB anywhere) I'm confused how it could create sync problems.
it would need to be stored to improve cpu performance
also for cpu performance i expect maybe around 200 rows of the revlog / second, which is enough in the amortized sense imo but there could be other problems that i'm not aware of
Oh, I didn't realise it would be slow enough to be significant. I guess the issue is any cached state would become invalid when you merge non-linear revlogs.
Hmmm. That's a tricky one. My first thought is you could save "snapshots" at each sync so you only have to reset to the oldest common point, but that doesn't solve it completely. You could always have a rogue device that hasn't been synced for a while that forces you to go really far back in time.
Is it even possible for Anki to even have a neural network. Does it work like FSRS, easy to run on basic consumer grade laptops
An example of a user with decay=-0.028 that Jarrett shared
That negative slope 🤣
FSRS's predictions are anti-correlated with his retention - the lower the value of R that FSRS predicts, the higher the user's retention

According to Alex, yes
It depends on the complexity. The bigger problem is it will also have to run on quite old phones.
Distillation time! Just train a 10x smaller net on the big "teacher" net's predictions
You can make it a compatiblity issue, no upgrade to newer versions unless you have better hardware
But that is alien to the concept of Anki
And you would exclude a lot of people
People who live in poorer countries
You would be surprised what you can get running on phones though. You can even run LLMs that give vaguely sensible output on phones now.
someone's going to provide anki as a service in that case (i guess that's already ankiweb xD)
Yes, phones now have almost reached the limit of innovation.
Is it because of the millions of params that this NN is tough on a device
already happens a lot though, being held back by addons or ankidroid's minimum supported android version being raised
even qt5 being dropped
Alright so that precedence is already there
i could try to train a version of the nn later on that is more robust in the order of the revlog, like maybe i randomly drop out certain chunks of the revlog, feed them out of order, etc, so in theory some of this problem could be mitigated. When there is a sync conflict, just drop one of the states and keep the more updated one, but idk how much this would affect performance yet
@polar maple would you want to personally use a NN on your own Anki cards
if it implemented rn? yeah
I have heard neural nets do some weird crap thanks to @unique salmon
If it is safe enough, I am all for it
not wrong but we'll have to try it to see
Anyway, can we all just collectively convince Jarrett to clamp decay to (-0.15, -0.7) or (-0.15, -0.8)?
what gives
keep the internal memory model at (-0.01, ) maybe since it does seem to improve the metrics, but when scheduling clamp it
He said he would add optimizable decay didnt he
It's just that with something like FSRS it's easy to ensure certain behavior, like the Hard interval never being greater than Good interval, Again always decreasing the interval and never increasing, etc.
it's much harder to do that with neural nets

Do you want your first interval to be 10,000,000,000 days?
At 70% DR
f no
sure if it's the truth
But only the weak would choose DR at 70%

if i input the 100 most common english words to anki and i want a 99% DR then i also expect an infinite interval 🤣
there's no short-term memory model, and there's no long-term dementia-or-death model either apparently
anki now predicts your death
If it does some neural shit then yeah
a good scheduler easily falls out of a good memory model
so we should get a good memory model first
CIVIL WAR
that's what separates FSRS and SM-2 in the first place

Sure, but at some point making R more accurate by a fraction of a percent at the cost of user experience is just a terrible trade-off
It turns out the only way to get a perfect scheduler is to first invent an oracle algorithm that perfectly simulates the future. All the "this is the day you die" stuff is just a bonus. ;p
And decay between 0 and -0.1 is exactly such case
Still drafty, but if people are interested in checking their avg load by 5% quantile

sum load sry
so we have the scheduler be a layer on top of the memory model that makes the user experience nicer
How? Please no "We predict R using one value of decay but use a different value for scheduling"
Capping max. interval? Then all intervals will just be equal to the max. interval
Capping the relative increase between two consecutive intervals? Same issue, though probably better in practice because it's harder for the user to spot
Maybe some combination of capping both interval lengths AND the relative increase. But then that could lead to TR not being equal to DR
Decay close to 0 just introduces intervals that are way too insane
why not?

GitHub
candidate for FSRS-6
Log Loss: 0.3273 -> 0.3257 (-0.0016)
RMSE(bins): 0.0518 -> 0.0510 (-1.5%)
Model: FSRS-5-dev
Total number of users: 9999
Total number of reviews: 349923850
Weighte...
S=1 day
Decay=-0.01, the first interval at DR=80% is around 130 000 days, the first interval at DR=70% is around 10^11 days
Decay=-0.025, the first interval at DR=80% is around 120 days, the first interval at DR=70% is around 25 000 days
Decay=-0.1, the first interval at DR=80% is around 4.5 days, the first interval at DR=70% is around 18 days
Decay=-0.15, the first interval at DR=80% is around 3.4 days, the first interval at DR=70% is around 9.5 days
remember that predicted R does affect S updates so it is in our best interest to have it be as accurate as possible
💀 tbh
truth doesn't matter if people don't use anki and it's not like there's a global state that'll help us
it'll be fine, just have sane defaults in the scheduler layer
i just want the memory model and the scheduler to have separate responsibilities
don't lie in the memory model to get good scheduling, keep them separate
Are you actually going to go ahead with the Neural Net thing. It seems to have some sort of short term memory model inside it
S=1 day
Decay=-0.01, the first interval at DR=80% is around 130 000 days, the first interval at DR=70% is around 10^11 days
Decay=-0.025, the first interval at DR=80% is around 120 days, the first interval at DR=70% is around 25 000 days
Decay=-0.1, the first interval at DR=80% is around 4.5 days, the first interval at DR=70% is around 18 days
Decay=-0.15, the first interval at DR=80% is around 3.4 days, the first interval at DR=70% is around 9.5 days
Let's just vote based on this
@bold terrace @hasty fractal @polar maple @lapis hearth @cursive badge @cosmic hedge
I want to choose the limit of of the "decay" parameter in the upcoming FSRS-6. The closer it is to 0, the longer the intervals at DR<90%. I want you guys to vote on what the limit should be based on these examples
oh yea, then it probably doesn't matter? develop a value-alignment scheduler that cares about user experience to filter out anything crazy.
TBF this would not be such a big problem. A 10k card at 1y interval is like 27/day
no it's too much work for now, i'd have to find the motivation and this would be for a fork since there is a low chance this would get into the main anki
exactly
you cannot just ignore the idea of keeping the scheduler as a separate layer
how about 0.01 internally and 0.1 externally?
I vote on Alex's idea.
I've said before - I HIGHLY doubt that other parameters are "decay-agnostic" aka that they converge to the same values regardless of the choice of decay, so for any decay all other parameters will remain the same
If you use a different value of decay, the other parameters will be sub-optimal
You messed up the description of Decay =-0.0025 (and it's -0.025 btw), but oh well
I dont think we should have an influence on it ourselves, then you would allow an arbitrary factor into it. It should come from within the model that no such absurd intervals appear
yeah but 0.1 wouldn't be used as a true decay in this case, it would just be a way to make intervals shorter. Any way that makes intervals shorter would work here
Btw, with decay of -0.01 for a card with S=100 days, at 95% DR the first interval would be half a day
You would love it 🤣
Nothing like reviewing every card every day, lel
there is a conflict when a memory model tries to model R exactly but we schedule according to DR. If I want to study common english words, my R will never reach 0.9 so the intervals will be really long. But I want to keep the memory model pure rather than having it make wrong predictions on purpose, rather, i'd let a scheduler layer do the dirty work
I abstain because I've not been following the conversation close enough to make an informed choice.
Also isn't it suspected that at a certain stability memories enter another domain where they are effectively permanent. Hence that other algorithm that begins with S that Jarrett worked on.
it could be accurate, if a user adds 9 known cards for every 1 card that they actually need to learn, this would be the sort of forgetting curve that you would expect
Some things might just be so easy to remember that they one-shot into permanent status and the tiny decays are just silly ways to try to model that.
This is the thing. You dont know where this decay value or not however absurd it is. Only the algorithm knows. The question asked is not a valid question
@unique salmon btw how did you implement the regularization for decay?

GitHub
A benchmark for spaced repetition schedulers/algorithms - open-spaced-repetition/srs-benchmark
I have an extremely dumb and janky idea:
- Optimize parameters
- If decay >-0.1 (aka <0.1 in absolute terms), optimize them again with decay=-0.1
- Keep both sets of parameters
- Use the first set with very small decay to schedule intervals
- Use the second set as a "sanity check": the intervals given by the first set of parameters AT ANY DR should not be shorter than with the second set at DR=99% AND they also should not be longer than with the second set at 70%
So when Anki calculates the interval length for a card, it checks this:
interval(params_2, S, 99%) <= interval(params_1, S, users_DR) <= interval(params_2, S, 70%)
if the resulting forgetting curve accurately models R, i don't see the problem?
just add a scheduling layer to play nice to human values and output a smaller interval
not sure what you mean
What I mean is an interval could look very absurd to you when it is actually the truth. But then you want to end up choosing some decay value which makes intervals look better to the eye.
I am saying it should not come to this
well that's what expertium wants, 0.01 decay could be closer to the truth but we have a prior that says 0.1 looks better to us
@unique salmon can you try with a much higher std?
Now I know where you belong on this scale

increase std to a very high value until you can see the decays are stuck at 0.2, then decrease it a bit to let it learn near the neighbourhood of [-0.1, etc]
You mean lower? Higher = less regularization
I mean at a certain point is it even worth trying to model R any more because it has entered another domain where external interference matters more than time since you saw it last. You can just stop scheduling it and retire the card as "memorized". It is up the the user to then decide if/when they want to cram the retired cards.
yeah lower
im onn both sides at once
in order to know the latter, you need to model R accurately. Only after we have modelled R can we make these decisions that you want
Man you are all for whipping people who complain about having FSRS schedule them long intervals 😭
https://github.com/open-spaced-repetition/fsrs-optimizer/pull/169#issuecomment-2796547056
https://github.com/open-spaced-repetition/fsrs-optimizer/pull/169#issuecomment-2798453145
what are metrics for if not deciding the answers to things like this?

GitHub
candidate for FSRS-6
Log Loss: 0.3273 -> 0.3257 (-0.0016)
RMSE(bins): 0.0518 -> 0.0510 (-1.5%)
Model: FSRS-5-dev
Total number of users: 9999
Total number of reviews: 349923850
Weighte...
But you get into this weird place where if your optimisation finds decay to be tiny for a preset do you even bother ever modelling R. You can just retire a cards as soon as they graduate their learning steps.
I wonder what's the ratio of "time spent arguing about the limits of decay" versus "time spent coding FSRS-6"
At that point it R kind of a lie anyway because we are operating outside of the bounds where it is valid 🤷♂️
R is never a lie unless the user is lying about their answer buttons
woulden't that just be arguing 1-0 coding for everyone but Jarret XD
Don't make us get Jake back in here to bully you into learning rust ;p
Hm, yeah
given that ratio, I'm inclined to trust Jarrett's judgement on things like clamping decay.
Well, it wouldn't be zero for Jarrett, since me and him have been arguing
yeah this is a win, i don't want to study cards that don't need to be studied. but my point was that to know this in the first place, you need to accurately model memory and if a very low decay is what is required then we should be using that
Do you like it when your first interval is 273 million years?
I'm not even joking, first interval for S=1 at decay=-0.01 is like 10^11 days at DR=70%
if id remember that card in 273 million years then yes

I don't think Jarrett has uploaded a file with metrics for all 10k users with optimizable decay, has he?
Actually, no, I think we need something a little different - find all users with decay >-0.1 and re-run the optimization for them with decay clamped to -0.1, and see how much worse the metrics become
I agree it is a win. I'm not saying any of this is necessarily bad. I'm just saying a certain point maybe we accept that the decay value is so off the scale it is silly and the modelled R is not really something we should pay attention to any more. External factors are going to be much more important than our interval in determining if we remember something.
yep. So we still accurately model R with a low decay as this is what would tell us that we have this problem in the first place, and then let a scheduler deal with making the user experience right
i count 20 parameters so there is prob decay
Guess we wait for Jarrett to do this
How many people have a decay of 0.01 ?
Also, for DR between 90% and 100%, decay of 0.01 will make it learn learn almost every day
So, all those risk of millions of year of interval, can be easily controlled by DR
If the guy has 10 million year of interval for DR=70% but only a few days for DR=90%, I don't think it's a big issue
It's just that yes, workload compared to DR won't be that easy to map anymore, but that's normal
Based on the scientific method of "bro look at the image", I'd say 20% of users have decay between 0 and (-)0.1, and 0.5-1.0% have decay of around (-)0.01

Reviewing every day is also a "risk"
It defeats the purpose of Anki
Maybe but that's why the fact it's controlled by DR is fine
To be honest, it depends a lot of the approach of the guy, but I think with a dynamic Decay, now everyone can be represented, so it's a big win
The people who want to never review anymore a card if they have at least 70% chance of recalling forever ? That's a win
THe people who want to review endlessly their card with a DR at 99% and a agressive decay ? That's a win
People who want sensible interval and control their workload with DR ? That's a win
Alright, on Github I told Jarrett that if he wants to, he can re-run FSRS-6 with opt. decay clamped to (-0.1, -0.8) or (-0.15, -0.8) and check how much worse metrics become
Anyone knows how to get the revlog in csv format for the optimizer ? https://github.com/open-spaced-repetition/fsrs-optimizer

GitHub
FSRS Optimizer Package. Contribute to open-spaced-repetition/fsrs-optimizer development by creating an account on GitHub.
SELECT cid as card_id, id as review_time, ease as review_rating, type as review_state, time as review_duration FROM revlog ?
Anki nerds arguing whether some parameter in the Poopen-Farten algorithm should be 0.1234 or 0.1235

40min later the optimizer runs
0.2924
I guess that would be my new decay
For my normal D deck the result would be
"w": [0.1687, 1.1435, 3.1934, 20.4036, 7.2316, 0.5491, 2.0316, 0.0686, 1.3334, 0.1155, 0.8393, 1.8538, 0.1024, 0.3336, 2.3554, 0.1919, 3.0933, 0.7447, 0.3726, 0.079, 0.1328],
My current log loss being 0.3530 and RMSE 3.23, the optimizer tell me now :
Loss before training: 0.3686
Loss after training: 0.3654
Last rating = all
R-squared: 0.8470
MAE: 0.0077
ICI: 0.0064
E50: 0.0043
E90: 0.0154
EMax: 0.1520
RMSE(bins): 0.0257
AUC: 0.6197
RMSE from 3.23 to 0.0257 seems like a violent upgrade
Seems my decay for that deck is a .13 instead of the previous 0.20
Let's see on the hard now
"w": [0.0104, 0.0222, 0.0743, 0.0617, 7.766, 0.2282, 2.4887, 0.0302, 0.9422, 0.2648, 0.4128, 1.8164, 0.1254, 0.2906, 2.2589, 0.2292, 2.9629, 0.6093, 0.1445, 0.1923, 0.3794],
current logloss : 0.4395, RMSE:4.42%
Loss before training: 0.7136
Loss after training: 0.6013
Last rating = all
R-squared: 0.9718
MAE: 0.0177
ICI: 0.0129
E50: 0.0103
E90: 0.0233
EMax: 0.0565
RMSE(bins): 0.0470
AUC: 0.6616
Not much gain on that one, seem it's even worst 🤔
It's weird that there is such a big discrepancy in log-loss. Something's off
The 0.13 decay and 3.79 might make sense though since the first deck, I would highly doubt my retention would drop lower than 50-60% even if I was not reviewing them for multiple month
It's from 3.23% to 2.57%
current logloss : 0.4395, RMSE:4.42%
Loss before training: 0.7136
Loss after training: 0.6013
yeah idk man, something's really off. I cannot think of any explanation why log-loss is so different that doesn't involve at least one of the following 2:
- Anki/google Colab include/exclude different cards
- One of the optimizers is bugged


is this with the optimizable decay?
lol
I got ~.12 decay for my normal D deck, and ~.37 for my hard one
Thing is, I only review things at my DR
For your hard one there's almost no correlation between predicted retention and actual retention
Soooo I guess the "actual R" for everything outside 90% is dogshit 😄
for the hard deck was it from taking lower D cards from the normal deck?
High D
its like

every day the topic of discussion is changed so much
my Retention for the hard above
The one for the normal

I don't have to complain to be honest
But yeah those graphs are funky
ok so i guess since D is closely related to the lapse ratio, it is already going to be flattened to be a certain R
Yep
That's why I also think some clustering could be interesting
there's really different profiles of card/review story inside the same deck
Oh, right, you haven't participated in The Civil War of Decay
Here: #1282005522513530952 message
yk what i vote for .001 decay
Last test, I'll run on both
Paste this into your scheduling code
{
// Generated, Optimized anki deck settings
"deckName": "revlog.yomitan.both",// PLEASE CHANGE THIS TO THE DECKS PROPER NAME
"w": [0.0564, 0.3174, 2.3289, 17.0138, 6.991, 0.8772, 2.3117, 0.001, 1.1084, 0.1602, 0.6028, 1.7299, 0.122, 0.2495, 2.1961, 0.1854, 3.1603, 0.7786, 0.3116, 0.1502, 0.3762],
"requestRetention": 0.7,
"maximumInterval": 36500,
},
Loss before training: 0.5829
Loss after training: 0.5331
Last rating = all
R-squared: 0.9567
MAE: 0.0181
ICI: 0.0109
E50: 0.0087
E90: 0.0280
EMax: 0.0573
RMSE(bins): 0.0332
AUC: 0.6626
From logloss .4225 and RMSE .0344
Dogshit version 2

😄
Congrats, now there is negative correlation between FSRS predictions and real retention
on fsrs-optimizer does it use a train/test split?
i don't see how the calibration can be so bad if it is trained and evaluated on the same data
To be fair I have almost no card with Predicted R under 80%
https://github.com/open-spaced-repetition/fsrs-optimizer/blob/5bc00d74dc6d09af8b657171ba9ba5b66bd8175f/src/fsrs_optimizer/fsrs_optimizer.py#L1232
It can, but it's set to False by default
GitHub
FSRS Optimizer Package. Contribute to open-spaced-repetition/fsrs-optimizer development by creating an account on GitHub.
Maybe you excluded suspended cards in Anki, but not in the optimizer?
In Anki suspended cards are excluded by default, but in the google colab optimizer it's the opposite
That could explain the difference in log-loss
Btw, this is the hardest deck I have and it has reasonable calibration

Not great, but at least somewhat reasonable
The distribution of your predicted R also look better
But for example I can't really having review with predicted 0.2-0.6
My DR was at 80-90 and I never skip any day so having a 40% is quite unlikely
Sure, but on your image you can see bins where predicted R is not 90%
Sure Sure
With my Filtered Deck I also think I'm able to really squeeze the predcited R close to the DR
which can also explain that distribution
I really want you to try not using filtered decks in whatever version will Anki will have FSRS-6 + fine-tuned LB
Fine-tuned LB is guaranteed to make it into the next release, idk about FSRS-6
Well my workflow is quite simple, I have one Filtered Deck for R<DR, and I keep checking the ratio it represents
Interestingly, moving from 85% to 90% DR made the number of items scheduled by the Filtered Deck lower than before

I also have higher and higher stability those past weeks so I think it also plays a role
The future avg predicited R is also closer to DR, thus limiting the need of those Filtered Reviews

Still, this is without LB

So I get it's the Fuzz that still push the due date a bit further than what they should
I increased the weight of interval lengths in the fuzz formula, making it more likely to schedule cards earlier
So in the next Anki release LB will be better
GitHub
Copying my Discord comment:
Alright, I've set up the optimization loop (using a Bayesian optimizer) to optimize these powers that are used in the load balancer's weight formula:
(1 ...
Does it also affect the fuzz or only the LB ?
...unless the simulations are very inaccurate
I'm not sure what you mean, considering that fuzz = LB
Just different names
LB is more appropriate
LB is just "fuzz that chooses the random interval in a less random way"
Nice !
From what I remember from @ashen light , even if I disabled the LB by doing mw.col._set_enable_load_balancer(False) the due date is still shitfed by the fuzz
The Fuzz apparently is there in Anki for years now
Yes
LB is new, fancier fuzz
I didn't know you can disable LB but still have the old fuzz
You might be the only person on the planet using it 🤣
Probably 😛
Load by Lapse 20-quantile 🙂 Definitely a bit more gradual than Load by Reps 20-quantile


I can think of one other person 🍃
I said so many times flagging a leech based on lapse was dumb
But now I realize it was my statement that was dumb
I check other deck for another language, same tendency

GitHub
A benchmark for spaced repetition schedulers/algorithms - open-spaced-repetition/srs-benchmark
I'm benchmarking it
The preliminary result:
Model: FSRS-6-dev
Total number of users: 844
Total number of reviews: 27826685
Weighted average by reviews:
FSRS-6-dev LogLoss (mean±std): 0.3346±0.1594
FSRS-6-dev RMSE(bins) (mean±std): 0.0491±0.0330
FSRS-6-dev AUC (mean±std): 0.7109±0.0790
Weighted average by log(reviews):
FSRS-6-dev LogLoss (mean±std): 0.3557±0.1665
FSRS-6-dev RMSE(bins) (mean±std): 0.0652±0.0432
FSRS-6-dev AUC (mean±std): 0.7056±0.0874
Weighted average by users:
FSRS-6-dev LogLoss (mean±std): 0.3583±0.1680
FSRS-6-dev RMSE(bins) (mean±std): 0.0675±0.0444
FSRS-6-dev AUC (mean±std): 0.7048±0.0895
parameters: [0.20255, 1.1585, 2.8436, 15.9828, 6.96915, 0.562, 2.2429, 0.00835, 1.51745, 0.11915, 1.0329, 1.7994, 0.11795, 0.2945, 2.28385, 0.21265, 3.00505, 0.7968, 0.29115, 0.14205, 0.204]
Model: FSRS-6
Total number of users: 844
Total number of reviews: 27826685
Weighted average by reviews:
FSRS-6 LogLoss (mean±std): 0.3342±0.1593
FSRS-6 RMSE(bins) (mean±std): 0.0486±0.0327
FSRS-6 AUC (mean±std): 0.7103±0.0806
Weighted average by log(reviews):
FSRS-6 LogLoss (mean±std): 0.3552±0.1667
FSRS-6 RMSE(bins) (mean±std): 0.0646±0.0430
FSRS-6 AUC (mean±std): 0.7050±0.0885
Weighted average by users:
FSRS-6 LogLoss (mean±std): 0.3578±0.1682
FSRS-6 RMSE(bins) (mean±std): 0.0669±0.0441
FSRS-6 AUC (mean±std): 0.7042±0.0906
parameters: [0.19025, 1.1416, 2.84035, 16.0223, 6.96865, 0.56225, 2.24175, 0.00775, 1.52485, 0.11935, 1.0378, 1.79665, 0.11955, 0.2907, 2.27985, 0.2125, 3.00505, 0.81515, 0.28365, 0.13125, 0.2077]
The clipper I apply to FSRS-6-dev is w[20] = w[20].clamp(0.15, 0.8).
IMO I find it too arbitrary to clamp just based on what we feel should be right or not
It's ~1% worse than (0.01, 1.0)
If we really want to clamp, we could always use the 2th/98th percentile of the training set
1% relative only ?
Feels random but quite good actually 😅
2% percentile of decay values: 0.0347
98% percentile of decay values: 0.7270
At least we can assume that 96% of people will fit in that clamp 🙂
And the 4% we can just ask them to reflect on how they use the algorithm haha
If the I use (0.1, 0.8) as the clipper:
Model: FSRS-6-dev
Total number of users: 876
Total number of reviews: 28673715
Weighted average by reviews:
FSRS-6-dev LogLoss (mean±std): 0.3339±0.1604
FSRS-6-dev RMSE(bins) (mean±std): 0.0486±0.0325
FSRS-6-dev AUC (mean±std): 0.7101±0.0785
Weighted average by log(reviews):
FSRS-6-dev LogLoss (mean±std): 0.3557±0.1667
FSRS-6-dev RMSE(bins) (mean±std): 0.0646±0.0426
FSRS-6-dev AUC (mean±std): 0.7053±0.0869
Weighted average by users:
FSRS-6-dev LogLoss (mean±std): 0.3582±0.1681
FSRS-6-dev RMSE(bins) (mean±std): 0.0669±0.0437
FSRS-6-dev AUC (mean±std): 0.7046±0.0891
parameters: [0.19415, 1.13795, 2.8374, 15.98545, 6.9694, 0.56155, 2.2378, 0.00775, 1.51735, 0.11995, 1.0336, 1.799, 0.1187, 0.29145, 2.28435, 0.2106, 3.0051, 0.81215, 0.28495, 0.1352, 0.2056]
Model: FSRS-6
Total number of users: 876
Total number of reviews: 28673715
Weighted average by reviews:
FSRS-6 LogLoss (mean±std): 0.3338±0.1605
FSRS-6 RMSE(bins) (mean±std): 0.0485±0.0325
FSRS-6 AUC (mean±std): 0.7091±0.0804
Weighted average by log(reviews):
FSRS-6 LogLoss (mean±std): 0.3556±0.1670
FSRS-6 RMSE(bins) (mean±std): 0.0645±0.0427
FSRS-6 AUC (mean±std): 0.7046±0.0881
Weighted average by users:
FSRS-6 LogLoss (mean±std): 0.3581±0.1684
FSRS-6 RMSE(bins) (mean±std): 0.0668±0.0438
FSRS-6 AUC (mean±std): 0.7039±0.0902
parameters: [0.1933, 1.1416, 2.84035, 16.0035, 6.9689, 0.5619, 2.2396, 0.0077, 1.5194, 0.1196, 1.03675, 1.79805, 0.1194, 0.2913, 2.28145, 0.2105, 3.0053, 0.8154, 0.2847, 0.1302, 0.2079]
It's only 0.2% worse.
OK, let's use it.
@polar maple @unique salmon The Civil War of Decay has its ending!
😂 In this week, I have run a dozen of benchmarks.
Computer goes brrr
Btw I played a bit with fsrs-optimizer yesterday, I tried to run it on my "normal D" deck (~ low lapse), "high D" (higher lapse count), and on both aggregate. I got as decays 0.1328, 0.3794 and on both 0.3762
I get more and more the feeling those past weeks that behind a user or even a deck, there might be multiple population of cards/review.
Thing that right now is somewhat handle with D, but since we can see even the decay could be very different based on which population we're in, wouldn't make a sense to try to see how to cluster the reviews and having different sets of parameters for different populations ?
Due to the limitation, FSRS could only distinguish different cards/review based on the history of rating and elapsed days.
So, the heterogeneity is still very high.
Sure but look at D and how for many people it is a proxy for "Lapse" (which can be infered from the reviews alone)
Also, isn't it possible to run a first optimization, and based on Difficulty to then cluster it and run 2nd-layer optimization on each ?
(But I agree that then, implementing that in Anki would be difficult, having parameters not really based on deck but attached to cards, based on a population-id..)

No, you misunderstood
96% of people fit between 0.0347 and 0.7270, but it doesn't mean that 96% of people fit between 0.1 and 0.8
@quasi shadow how many users (%) have decay between 0.1 and 0.8?
I assume something like 80%?
Number of users with decay between 0.1 and 0.8: 8074
Percentage of users with decay between 0.1 and 0.8: 80.75%
Yeah indeed but I sent this message when we were talking about [0.0347, 0.7270]
But if [.1, .8] is only 0.2% worse ... I mean ... being in that 20% (1-80.75%) is probably fine
We could argue that for those 20%, the prediction will be worst than what they could, but I guess they'll already be way better than before
http://www.incompleteideas.net/IncIdeas/BitterLesson.html
TLDR: forget about carefully crafted rule-based models that utilize human knowledge, just use general-purpose models AND LOTS OF COMPUTE and get better results
Chess? Just use a lot of compute and a general-purpose model
Go? Just use a lot of compute and a general-purpose model
Image recognition and speech recognition? Just use a lot of compute and a general-purpose model
I like this article because right now we have a crystal clear example of it: a neural net outperforming the carefully crafted FSRS with its simple formulas based on our understanding of human memory. If all we want is maximum predictive accuracy, making a giant neural net and just taking advantage of more compute would be a better approach
😄 if you want to run the general-purpose model in your device, please buy a dozen of RTX 5090.
Lol
Well, according to Alex, I only need one CPU to run his model
so why not implement it in Anki?
Ask Alex
@polar maple is there any problem to implement it in Anki?
I don't know that it is the only problem, but from the discussion I had with them yesterday speed / sync is one problem.
It doesn't run fast enough to just give it the entire revlog each time you start Anki (~200 reviews/s) so you need to cache the NN internal state.
Caching the internal state causes sync problems when you want to merge non-linear revlogs.
 So FSRS will survive.
So FSRS will survive.
Wasnt there a time you or someone else wanted to see what maximal accuracy that could potentially be ever achieved by FSRS in numbers❓ Isnt this what neural nets are showing, that there is still a considerable amount of stuff to improve upon, through whichever way you would like
Yes, hopefully me and Alex will get to the whole "estimate the limits of accuracy on the 10k dataset" thing, but he seems to not be super interested in that
Anyway, the point is that FSRS will (almost certainly) never outperform big neural nets
So in which direction is Anki heading right now
FSRS or neural nets
FSRS
the NN nets currently used are super small (thousands), if you talk about big neural nets they go into bilions of parameters
The largest neural net in the srs-benchmark repo has 9k params, but Alex has another with 2.7 million params that he hasn't released yet. It blows all other algorithms out of the water, according to his preliminary tests
llama 4 behemoth apparently has 2 trillion parameters 😮
a 2.7m network should be able to run on cpu at ok speed depending on architecture, but anki can currently run on pretty much anything
Don't know, sure any kind of algorithm that is able to "learn by itself" is impressive, but I also noticed how, difficult they might be to actually make better without become hugely inefficient in terms of energy, and how the black-box aspect of it make it difficult as a dev to make a good feedback loop with them (Train them, test them, improve their weakness...)
But it's still a very useful tool in the toolkit
And they still end up being better. For example, is there anything even remotely close to ChatGPT (or any other modern LLM) that doesn't rely on deep learning and instead has rules entirely specified by the developers? Nope.
Same goes for image generation
And image recognition too
what NN are good at is noticing patterns that can be non linear which is hard to achieve if you want to model things like FSRS
Question is, what kind of app GPT is able to completely replaces though ?
That's a strange question. I was talking about generating realistic, human-like text
You are asking a completely different question
Oh, btw, this Veritasium video is also about the "bitter lesson", even if he doesn't say it that way
https://youtu.be/P_fHJIYENdI
Neural nets outperformed algorithms made by expert biologists
The biggest problems in the world might be solved by tiny molecules unlocked using AI. Take your big idea online today with https://ve42.co/hostinger - code VE at checkout.
A huge thank you to John Jumper and Kathryn Tunyasuvunakool at Google Deepmind; and to David Baker and the Institute for Protein Design at the University of Washington for t...
I mean I work in software development for the past 10 years, went the computer science route, did a few projects on AI, a project on computer vision, and while of course AI is a super super super great tool, I still felt regularly the 2 limitations I explained above
You said they still end up being better, implying better than anything else
Which is not necessarly true
For problems fundamentally related to probability, with different layers of fact-checking the results, it can be immensely useful
ELIZA ;p
But for problem requiring a very specific solution, it fall a bit short.
I even find it very funny how the most common example of job that could be replaced by AI would be software development, when in fact I think it's probably all the others jobs of this industry (project management, analyst, manager...) that could more easily be
Better than anything else for a specific task, yes. Text generation, image recognition, image generation, speech recognition, speech generation, protein folding, chess, go, spaced repetition even
We don't have an AI that can do all of that and more and replace all humans...yet 🙂
so why not use it for anki then
@polar maple you should write a "Why My Neural Net Won't Be Used In Anki" blog post 🤣
Yes
That sounds boring. Make an LLM do it ;p
Not necessarily Alex's
But hey, I spent already 3-4y in that industry with everyone explaining how blockchain would change absolutely everyting in the society
I guess the next 2-3y will be AI hype
Blockchain was just entirely dumb from the start though.
LLMs at least do something useful.
Well, it's still a tool in the toolkit, but the problem it could solve were indeed a bit too much specific to really be a broad revolution
Oh come on. I get that people love saying "X is a bubble" and "X is just a trend, it's gotta end", but this is AI we're talking about. The only way it won't be a revolutionary technology is if achieving general intelligence is - for whatever reason - so incredibly difficult that it will take 1000+ years and in the meantime we will just have ChatGPT-7-Pro or something
Blockchain has such vanishingly narrow use cases. Even its big initial example of "decentralised money" never really worked, it was far too unstable to be used as cash. It was so weird seeing so many people trying to shoehorn it into completely irrelevant things.
And for the record, I don't think that making AGI is going to take a 1000 years
Or even 100 for that matter
100 starting from today, I mean
Why people associate LLM and AGI though
We're talking AI-hype, LLM replacing humans
you talk about AGI
I mean, doing prolog was considered AI at some point
When I did AI, I did Alpha-Beta/Min-Max
The current AI stuff was called Datamining in my classes back then
AGI has never had anything to do with all those things
If you think modern LLMs will never be generally intelligent (fair enough, btw, I won't argue with that), do you envision the future like this?
- LLMs plateau around 2028-2030 when the current "just throw in more compute" paradigm runs out of gas as it's physically impossible to build bigger datacenters and produce more chips to train larger models + the entire Internet is used for training, so there is no more unused training data
- Instead of the paradigm shifting to something else, all of the progress just dies out and then there are no interesting news about AI for decades
Because I ABSOLUTELY do not think that number 2 will happen
I'm definitely more on option 1. AI/LLM will continue to exist, will continue to solve very very interesting problem with a way nothing else can solve right now, but unfortunately most startup based on it will die out, big companies will find something else to promote to make investors excited
It might not be no interesting news, but there could be a gap before anything new that gets people widely excited comes out.
Porn Industry might be an exception though
I mean Zuck' spent I don't know how much million in VR
I was really excited about AlphaGo. I don't think normal people were 😂
2 comes after 1, it's not "either or", it's "first, then second"
I thought you will say "1 and 2"
Like, I thought you will say "Yes, this is what I imagine"
Then why are we arguing again? 🤔
I thought you will say "Yes, I imagine that the progress will halt for decades"
This is the internet you know. It's what people do.
Maybe we used both AI-hype to refer to different things, I'm more criticizing how the IT industry is right now completely crazy about anything relating to AI
recently it's the whole "vibe coding" that everyone talks about
My biggest personal gripe is AI hype made all the GPUs cost silly money 😦
You know what ? Sometimes I wonder if all that hype is not really just to make people buy GPUs, especially devs haha
When I see that nvidia box at 3000$, even as a skeptical about AI and coding, I almost pull the trigger
My Github Copilot right now goes "Enable/Disable" every 10min, it's kinda maniac
So when my CEO say "AI will replaces Devs" I'm like "I WISH IT WOULD"
I mean, making me saving time
But I guess he has better insights than poor me haha
Can the next fad please involve something does not require GPUs. I want to upgrade my 1080ti at some point before I die.
lol ! I bought a 4070 Ti S one year ago
I'm happy now when I see the 5070 is basically a worst model
I also saw on reddit a lot of people are very very disappointed with the latest Llama scout
maybe you'll be able to buy a new GPU soon ;D
We can already make AI that talks in a human-like way and, by some metrics, even outperforms humans. For example, frontier LLMs definitely know more simple facts like "When was Shakespeare born?" than the average person, and are better at solving math problems than the average person. So can we get to general intelligence via more compute, more training data, and some incremental improvements to the Transformer architecture? Or do we need some special sauce?
In the straight-line-goes-brrrr world we just need to work on how we train AI, scale it up even more, and tweak the Transformer architecture. And then we get AGI.
In the secret-sauce world, ChatGPT-7.5.5-Pro-Ulta will be better at answering PhD-level questions than any human alive, yet will be unemployable as a software engineer, let alone as a movie director or a CEO. And things will remain that way for who knows how long.
So the crux is: how straightforward is the path from the current AI (which, again, is in some sense already superhuman, compared to an average Joe) to AGI that is actually undeniably superhuman at everything?

Just to follow-up on that question I asked yesterday: since I have a specific tag for the card I suspend because they became leeches and I'm pretty sure they're just difficult cards and not badly design cards, I had the option to add those specific cards for the FSRS optimization field. I did that, and rescheduled all cards, and that added ~1000 cards to my backlog.
Today I followed my usual procedure to reduce that backlog, reviewing by decreasing retrievability. It's a little to soon to draw conclusion, but I was surprise by the feeling that many of those cards were on the "edge of being forgotten". Also the scheduler is less optimistic with new cards introduced today, which seems good since it's difficult to judge the difficulty of a card with only one review.
So, I'm even more convinced that the usual advice "suspend the leeches" and "don't use the suspended card for the optimizer" are good advice in isolation but don't go well together.
interesting
i have never thought about this
what if i just make it so fsrs doesnt use leeches for the optimizer
Yeah very interesting, I also wondered about that
well i already kinda split the leeches out in all my decks
probs shouldve left a control deck
To optimize WITH suspended, you change that to preset:"..." then ?

Just preset:"Vocabulary"
OKok
Something I also wonder a bit, is when a card was suspended, but now you want to give it a new try, ideally you'd like to reset it, but by reseting it I'm not entirely sure the past revlog will be used or not
the counter on the browse view say 0 reps, 0 lapse
but in the history you still see the reviews
so not sure how they get taken into account or not



the suspended I guess no ?
😅

True that the default might be "Let's consider the suspended with those"
Sure you don't review them anymore, but they're still part of your well or not you review things

@quasi shadow once again: how does FSRS works with "Reset"? Does it only use the info after the card has been reset?
I promise I will make a card so that I don't ask again 🤣

Gimme a sec to think the shortest way to explain it
Basically, most of the time :
- D : Lapse in disguise
- D : goes up, D never goes down.
- Splitting that deck into 2, one with "High D" and one with "Normal D" could benefit your parameters
For example, my "normal D" has very good logloss/rmse with even default FSRS parameters
based on that screenshot how should i divide it
💀
i got like 3 sky highers and 4 wide ones
this is language learning
yk i probably neeed to divide them depending on the back to front
my brains gonna kaboom
What I did, is I did "prop:d" > 0.80 and played with it to see where I had relatively a good chunk in both (like half half), and that it was clear that NO cards with prop:d>0.80 had lapse under X (5, 6...)
At the end I did prop:d>0.9 in my case
but looking at you I think the 0.80 -> 1 might make more sense
Now in my "normal D" I have a lapse threshold of 6-7, and in my "high D" at 12-14. If I reach the first, I tag them and weekly I move them to the High D
in High D, at 12-14, it's auto-suspend
I'm not sure I understand what you're doing with you decks @robust hill and @bold terrace, are you making subdecks depending on the difficulty of the cards?
BTW it's still draft but you can use my new graphs to check how bad the workload of your high lapses/reps are

Yeah basically I split my main deck into 2
The previous one become my "normal difficulty", and the new one gets all the difficult one
The RMSE and workload of the normal one was hugely improved
but what happens for new cards then?
New Card still in the normal D
after 5-6 lapse they go in the difficult one
(as they would in the previous deck)
so FSRS will be too optimistic for new cards, I don't see this as an improvement
It only uses the reviews after the reset.
yeah
Thanks for confirmation !
maybe it wont work for some decks
but i have a finished deck
i have a deck with 1156 cards, no longer new
In fact there is no many other options than :
- Be too optimistic about new card
- Be too pessimistic about new card
- Be a bit of both
I need some more specific info
Imagine a card with a history like this:
L R R | L R R
where L - "Learn", R - "Review" and | means "This is where the reset happened"
- Does FSRS only use the second half for optimization?
- Does FSRS only use the second half for scheduling?
I'm also using Anki for language learning, and I prefer the scheduler to be a bit pessimistic for the first reviews, then of course I expect it to adjust depending on how well the reviews went
Sure but in a split-deck scenario then you need a discriminant to know when to move it to the easy deck then
The Low->High D is quite clear
They are the same. The only difference is how to deal with cards with incomplete review history.
So yes and yes to both?
Yes
I'm not conviced by this kind of split-deck at all 🙂 I split decks depending of how I want to review the cards, or how "essential" the card is (so I can change the parameters), but splitting the deck by difficulty feels like doing the scheduler job manually to me 🙂
which language are you learning
Korean
i see
not sure if my advice would work
but at the moment i am splitting my decks into 2 ways
That's fine ! And indeed it is doing a bit the job of what the scheduler shoudl be able to do 🙂
I am learning Greek, so
1 deck with options that encompass anything that the question is English, and I have to say it in Greek
another deck with options that encompass the reverse, so question is Greek and i have to say it in English
The main initial motivation in my case was the fact I realized the "average stability by repetition" was a purely decreasing function
The more I reviewed card, the less their interval seems to be
So having more and more workload, didn't resulted really in better stability
also I'm probably on the ADHD spectrum, so I need the scheduler to be a little bit pessimistic 😄
Just the same stability with higher workload
On the opposite, the card with long interval, had all at most 1-2 lapse
me too
and a very few number of reps, something like 10-20
So while mass-repetition feels like "you don't allow it to be forgotten", I was in fact hiding the fact that I wasn't really helping them building higher stability
4 deck options i am making
Question being : Why didn't they ? A lot of different factors, but it's not reping them every day that will help
English -> Greek
English -> Greek - leeches
Greek -> English
Greek -> English - Leeches
🔥
I have:
- Vocabulary: simple words, audio+written word in Korean-> French definition / audio+hint if needed->writting + French definition
- Sentences or collocations: various note types including close, dictation, French->Korean for basic greattings, ..
This second deck as 3 levels of priority: Essential, Normal, Optional
Leeches stay in their decks, suspended until I see them again in the wild and/or decide to try to learn them again
French is your mothertongue ? It's mine
amusant 🙂
Front back for me 🙂 The reading is not shown in the preview, but I have to type it in the front card and it's highlighting mistake in the back


maybe we could switch to the #language-learning channel?
I removed every single thing from the front because otherwise my brain would memorize words by silly things like the sentence shown, the color of the hint, etc etc
I'm curious how much more performant it would be if you distilled it into a smaller model + used int8 for inference instead of fp16/fp32. You could probably make it 10x faster, or even more
poll_question_text
Vote you neeks
victor_answer_votes
2
total_votes
3
victor_answer_id
1
victor_answer_text
Decay -0.01 --> 130000 days at DR =80%
Whatever, Jarrett already agreed to make it -0.1
So now nobody will ever get a first interval of a million years, yay!
rwkv could be problematic for syncing issues but i can't rule out a small nn like LSTM or an even smaller version that works similarly to how FSRS works rn, occasionally the user presses optimize to update the nn weights, if there is a syncing issue just reoptimize from scratch
but idk how cpu friendly the training would be for a small nn, would need to investigate
idk how to distill and don't wanna learn rn
RWKV would be cooler though - more accurate and no need to optimize if you pretrain it on a large dataset
At 200 reviews/s RWKV would take ~6.5 mins to process my collection if it had to discard its cache. That's kind of a blocker if sync invalidating the cache cannot be worked around.
there are possible workarounds such as training RWKV on only the last 2k reviews for a reasonable optimization time, perhaps it would still have a decent performance
or as i mentioned before, training a robust version of the nn by mangling the revlogs that it is trained on
yea but for now a LSTM-like model would be way easier to implement, everything is mostly in place in anki already
👍
I meant in response to Expertium that a small loss in accuracy may be worth it for a large gain in convenience.
The more I think about it, the more I think it's actually very desirable
- We can make R more accurate
- We won't have to show parameters, which means one less thing for users to worry about
- We can support proper same-day scheduling instead of the current mess
- We can throw in new input features, like time of the day, workload, etc. Not just interval lengths and grades
- We can remove "Optimize", which means even less stuff for users to worry about
They mean if FSRS is superseded by a NN that does not need optimisation.
oh
I would still like the optimize button to be there, if only as a placebo
Yeaaaaah I mean
People are worrying because they feel losing control with FSRS
It's not the existence of parameters that stress, it's the fact you don't understand them
so giving them 9000 params ?
See how people freak out about hard misuse
let's now make them stress about NN thinking on saturday every retention is -10% because they were drunk 2 saturdays in a row
So while I would be super super excited to try that NN
I don't think they will be less stressed lol
Hard misuse would still be a problem btw
It can't be solved "inside" the algorithm
Though, I imagine that for people who misuse Hard a NN would still do better than FSRS
it could theoritically infer that for some user, Hard might result in a reduced stability ?
just like an Again
You could almost create new buttons and have your own rules about them ;D
"Don't remember" "Misspelled" "Confused"
It's about the training and how the loss is calculated. Again = 0, Hard/Good/Easy = 1. That is not something that the algorithm can change, it's something the algorithm learns from
ah yeah
If Hard=1 but the user uses it as if it was 1, welp...
Actually, now I'm really curious if a NN would be better than FSRS in that case
Then again, how do you determine what is "better" if you can't tell corrupted labels apart from good ones?
I mean
sometimes I watch for a few seconds too long a video of Sabrina Carpenter
And then Facebook decide I'm her biggest fan
and I should have every single ads about her
I will continue to advocate for an "almost" button that is just the again button (maybe +5minutes on the relearn step so people feel like its different)
But then it realize I'm infact a bit more inclined to watch videos about videogames, so it adapts again
Personally I use hard/good/easy based on speed of good answer
quick quick good answer, 1-2s -> easy
3-4 -> good
7 hard
who cares about 5-6
Ok, after thinking about it some more, I have no idea whether we would even be able to tell whether FSRS or a NN is better for people who misuse Hard, if we can't un-corrupt the labels aka if we can't confidently say "Here Hard=1 and here Hard=0"
Well at least it's the goal

In practice it's Good-Good-Good-Oshit
IMO who cares about misuse
it will fix itself with time
Huh?
man on youtube any vid that I want to watch but also don't want destroying my recs I watch in a private window
I think I might have misused hard for maybe ˜500 reviews when I started Anki
I stopped worrying after the 50k one
Got a problem against Sabrina Carpenter ?
I have no idea who that is
Lucky guy
I didn't too, and now even fortnite ads are about her
she's like the female equivalent of bieber
It would help if the evaluation criteria (for success of the NN) were not also the input (with a time offset) (Later edit: nah, the issue is that the data changes with user error, ie non-stationarity)
If you mean that people will hear about it from other people and be like "Oh, wow, I didn't know this was a problem, thanks my dude, you saved my Anki life!", I'm afraid that this will be the minority, and most people people who misuse Hard will keep misusing it
Not everyone browses r/Anki or watched youtube videos about Anki or whatever
people don't want to fail so they need an almost-fail button
?
Let's make a poll about that
The most biased poll of all your history
"I failed but it's not my fault"
Let's ask people on r/Anki whether they browse r/Anki

placebo buttons are important I think
The "Show Less" on Sabrina Carpenter videos
TBH
most normal people use Anki for 2 days and then never use it anymore
yeah see everyone has those buttons
I know 3 colleagues that tried Anki. NEver more than for 2 days
yeah this is the most real take
Main reason has nothing to do with scheduling, it's the clunky UI
They were amazed I had images, sound, I could type answer ...
like I have a friend who married some chinese girl and got anki (of his own motivation) to learn chinese and spent maybe like a week on it before giving up

Except for that one reddit guy who quit Anki because of interval lengths
I see that screenshot
FIrst thing I wonder is if I need a compatibility mode for windows 95 to run it
or some kind of DOS emulator
Lol
The article with that image is from 2015
reddit self-selects for a specific type, 99% of people who quit anki aren't going to go make a reddit post about it
Yeah reddit is a very very very tiny echo chamber
honestly, any anki reddit complaint should be treated as an outlier
Did Anki really look like this in 2015? Or is the article using an even older screenshot?
yeah I think it looked like that back then

The most good linking search tool ever existed
People on that page are sure to not download any of those deck, in fear to get russian malware
Look how user friendly it is to tweak your own cards


Even as a dev it took me 2-3 months before daring trying to do something myself
I mean even creating cards ...
"Manage Note Type" > "Create Field"
So when we're talking "the average user", we should not imagine an "average normal human being"
Dae is interested in making a sharable template system so it might be easier one day. He wants to do it after Svelte migration so who knows when it will actually be started on though.
Oh, yeah, and apparently we're not actually getting a two-button mode any time soon
I guess what I'm thinking is something like:
Wouldn't it be nice if:
- Users had a slider to decide their own interval length when grading
- A dataset of many such gradings for specific cards existed
- The model only needed to exist for those specific cards
Users had a slider to decide their own interval length when grading
That defeats the point of having a scheduling algorithm
That would be for the training input, the later implementation would be just a 'okay I saw the card' 'next'
I still don't see how this would be beneficial
And it sounds impractical as heck
Ideally, we want to make it so that users don't have to think about intervals at all
Yes (the end user would have only one button, next)
People are probably terrible at guessing intervals.
True
Training a model to predict what intervals the user wants is an interesting idea, but most people probably want constant intervals and/or very short intervals
I imagine if you took a bunch of people and asked them to do this for a year, most of them would end up with intervals that are either constant or grow very slowly
I did previously think it might be interesting to let people grade cards on more than one axis to give the scheduler more info, but it would be terribly impractical and bad UX.
Though, it would be interesting just for research purposes, to see what intervals people like
Maybe it could help to pick better default FSRS parameters and a better default value of desired retention
Might how long a card takes between front and final grading be a useful datapoint? It exists without any UX overhead. (Or total time spent on a card per that session, same idea.)
It could be used, yeah
Anki currently records the time from first showing the card to you giving it a grade. I think ideally we would also have time to first input (for typed answers) and time to answer/card flip.
Hey guys
Dont know if this is the appropriate time to mention this
When is it time that the R=100 for learning cards be changed
Should this not be also changed with FSRS 6
Yes, R as in Retention column
R is 100% every time for learning cards no matter what
which is simply not accurate
I know that Anki did it in the earlier days as a simplifiying method
There was no need for Anki to register it because there was no FSRS back then
But with the new decay thing, would it not be worth the short to try and see if it is advantageos
Nope
The decay thing is still a long-term thing.

The short-term memory model is still inaccurate.
Oh well....here is to waiting for however long...
When are you releasing FSRS 6 (totally not excited as a golden retriever)
Maybe this week.
I have caught a dozen of bugs since the last weekend.
Oh, and Jarrett decided to reduce minimum S by 10 times after all
Then again, without a short-term memory model, it's not an improvement
It is a bandage-over-crack makeshift solution
I am aware
But how long would it take to find a short-term memory model
Weeks, Fortnights, Months, Quartals, Tertials, Years..
Idk
Once I'm done with experimenting with D, I'll see if I can use a neural net for this
Actually, nvm. The idea with neural D didn't work. I was getting really shitty results and tried a bunch of things, but nothing worked. And on top of getting shit results, now I'm also getting errors sometimes
Idk why I said this, I guess I was hoping that I would fix the errors, but nope
Does this mean you will start experimenting with NN on short term memory
What was the procedure ? You give the NN a shitton of revlog, you ask him to give you related D for each card, but what about D increase/decrease based on hard/good/easy ? What was the approach
I tried two architectures:
- I give it the grade, last D (squished between 0 and 1) and R as input, and it predicts new D (also squished between 0 and 1)
- I give it the grade, last D (unlimited, from -inf to inf) and R as input, and it predicts the difference between new D (unlimited) and last D (unlimited), I add the difference to last D to obtain new D and then I squish it for it to be used in the S formulas
The first one was shit, the second one was shit AND was throwing errors sometimes for some reason
I see ! Thanks for the explanation
have you done any overfitting tests?
freeze fsrs params, make only the D nn learn, overfit on a small amount of data
alternatively you should check that with the nn, you achieve a lower training loss than what FSRS-5 achieves
Nope
I made a comment here: https://github.com/open-spaced-repetition/srs-benchmark/pull/199#issuecomment-2801388093
Feel free to try it out, or try other approaches

GitHub
close #198
Edit: I tried several hyper-parameters and structures of the network, none of which performed better than FSRS-5.
at least print out the training loss in the Trainer class and make sure that the nn is training for long enough so that the training loss from the nn is lower than for FSRS-5
@quasi shadow https://github.com/open-spaced-repetition/srs-benchmark/blob/main/plots/w[11].png
I'm worried about w11, it seems like it barely changes. According to this graph, all values are close to the default value, which is close to 2. You could say "Well, maybe that's just a really good default value and this distribution is just very narrow", but I'm not so sure.
For example, I'm testing a new D function, and I changed the default value of w11 to 10, and I get this (based on 132 users so far):
5th percentile of w[11]=9.790
95th percentile of w[11]=10.020
This means that this parameter barely changes
![https://github.com/open-spaced-repetition/srs-benchmark/blob/main/plots/w[11].png](https://github.com/open-spaced-repetition/srs-benchmark/blob/main/plots/w%5B11%5D.png){kind=link}
Maybe it's just that my implementation is flawed, but I suggest you do some tests:
- Try different default values of w11, like 3-5 values, with any version of FSRS you want
- See how it affects the final distribution of w11 across all users
If the distribution of values of w11 ALWAYS ends up being very narrow and centered around the default value, even if you change the default value by at least a factor of 2, then we have a problem
GitHub
A benchmark for spaced repetition schedulers/algorithms - open-spaced-repetition/srs-benchmark

It is the diff between without and with L2 regularization.
Please try different default values, for example, 1, 2 and 4, and plot the resulting distributions
I'm running the benchmark.
Well, we already have approximately 2, so try 1, 3 and 4, or 1, 3 and 5
So my device is not available now.
Could you test it?
You can modify the init_w in other.py.
I'm running my own stuff 😅
I'll add it to ideas here: https://github.com/orgs/open-spaced-repetition/discussions/36
GitHub
The purpose of this discussion is for me to link to issues/PRs that are related to FSRS and where I have something to say and don't want Jarrett to forget about it/miss my comment. VERY IMPORTA...
That's how I got this
For example, I'm testing a new D function, and I changed the default value of w11 to 10, and I get this (based on 132 users so far):
5th percentile of w[11]=9.790
95th percentile of w[11]=10.020
OK, maybe two or three days later

The distribution of w[14] is also very narrow, isn't it?
So I calculated the coefficient of variation, defined as std(x)/mean(x)
https://en.wikipedia.org/wiki/Coefficient_of_variation
I took the absolute value of the mean just because. I did it for FSRS-5 with an extra parameter for decay
Coef. of variation of w[0]=4.752
Coef. of variation of w[1]=2.254
Coef. of variation of w[2]=1.997
Coef. of variation of w[3]=1.066
Coef. of variation of w[4]=0.051
Coef. of variation of w[5]=0.441
Coef. of variation of w[6]=0.291
Coef. of variation of w[7]=1.333
Coef. of variation of w[8]=0.228
Coef. of variation of w[9]=0.952
Coef. of variation of w[10]=0.306
Coef. of variation of w[11]=0.100
Coef. of variation of w[12]=0.349
Coef. of variation of w[13]=0.420
Coef. of variation of w[14]=0.172
Coef. of variation of w[15]=0.805
Coef. of variation of w[16]=0.230
Coef. of variation of w[17]=0.445
Coef. of variation of w[18]=0.620
Coef. of variation of w[19]=0.387
w[4], w[11] and w[14] have the lowest coefficient of variation
In probability theory and statistics, the coefficient of variation (CV), also known as normalized root-mean-square deviation (NRMSD), percent RMS, and relative standard deviation (RSD), is a standardized measure of dispersion of a probability distribution or frequency distribution. It is defined as the ratio of the standard deviation
...
This isn't inherently bad, but again, if their distributions end up being centered around the default value even when you change it by 2-4 times, that suggests that something is wrong with optimization

@unique salmon I cannot find the source where you ask for it
Now the hist only shows values between 2%-ile and 98%-ile.
...that's a unique way of saying "98th percentile" 🤣
😂 OK, I correct it.
I learnt it from https://danluu.com/p95-skill/
Btw, it's an interesting post about improving performance.
I was wondering where you manage to find articles like that? Do people send them to you or do you hunt them down?
I found it here: https://gwern.net/note/competence
Incompetence is the norm; most people who engage in a task (even when incentivized for performance or engaging in it for countless hours) may still be making basic errors which could be remedied with coaching or deliberate practice.
Do you know Gwern?
Nope who is he?

Efficient memorization using the spacing effect: literature review of widespread applicability, tips on use & what it’s good for.
He is the author of the best literature review of spaced repetition.
(16 years ago)

Spaced Repetition is a technique for long-term retention of learned material where instead of attempting to memorize by ‘cramming’, memorization can be done far more efficiently by instead spacing out each review, with increasing durations as one learns the item, with the scheduling done by software.
See Also: Scholarship & Learning
The c...
If you search spaced repetition in LessWrong, you will find his artical, lol.
I don't know what LessWrong is either 😂 😭
😂 Fine. It's a long story about how I knew it.
Autism cult for nerds
Mostly dedicated to obscure philosophical problems and "AI WILL KILL AS ALL, DOOM IS NIGH!"
On the flip side, you can find interesting papers about AI, like this one: https://www.lesswrong.com/posts/deesrjitvXM4xYGZd/metr-measuring-ai-ability-to-complete-long-tasks

Summary: We propose measuring AI performance in terms of the length of tasks AI agents can complete. We show that this metric has been consistently e…
Sounds like my kinda place 😂

OK, it works🤣
But I don't know whether the decay is optimal.

...It is stuck...

The py version gets a better result.

If I provide the optimal parameters found by the py version, it will output it.
So... the py version is correct.
...I even cannot set boundaries for the parameters.
I need L-BFGS-B method which is the default method if the params have bounds in the python version.
@unique salmon man, the infrastructure of numerical optimization is not good enough in Rust.

GitHub
First of all I want to say thanks to all the contributors of this crate, you've done an amazing job. I'm getting started with argmin running some basic examples. I wanted to run a simple co...
Time to implement L-BFGS-B yourself

Maybe I can ask Claude to translate SciPy to Rust 😂
Idk, try particle swarm, apparently it's pretty easy to implement
After reading the source code of L-BFGS-B of the SciPy
I give up
😅 I need to learn some math at first.
Give me some data and I'll try to implement particle swarm
Good news: I figure it out how to add bounds to the NelderMead method.
impl CostFunction for OptimizationProblem {
type Param = Vec<f64>;
type Output = f64;
fn cost(&self, param: &Self::Param) -> Result<Self::Output, Error> {
let s = param[0];
let decay = param[1];
let y_pred = power_forgetting_curve(&self.delta_t, s, -decay);
let logloss = (-(self.recall.clone() * y_pred.clone().mapv_into(|v| v.ln())
+ (1.0 - self.recall.clone()) * (1.0 - y_pred).mapv_into(|v| v.ln()))
* self.count.clone())
.sum();
let l1 = ((s - self.default_s0).abs() + (decay - self.default_decay).abs()) / 16.0;
let mut total = logloss + l1;
if decay < 0.1 || decay > 0.8 || s < S_MIN.into() || s > INIT_S_MAX.into() {
total *= 1000.0;
}
Ok(total)
}
}
It's not elegant but it works.
Oh, wait.
we have four decays because there are four ratings.
Yep, just take a weighted average, weighted by the number of reviews for each first rating
Anyway, gimme some data, like what you used here
let delta_t = Array1::from(vec![1.0, 2.0, 3.0, 4.0, 5.0]);
let recall = Array1::from(vec![
0.86684181, 0.90758192, 0.73348482, 0.76776996, 0.68769064,
]);
let count = Array1::from(vec![435.0, 97.0, 63.0, 38.0, 28.0]);
here you are
wait
The four initial stabilities are optimal when the decay is optimal.
But if we use the weighted average, the stabilities are not optimal.
😅
For example:
[src/pre_training.rs:31:5] &stability_map = {
3: 4.8061557,
4: 13.298449,
1: 0.6919513,
}
[src/pre_training.rs:32:5] &decay_map = {
4: 0.1,
1: 0.12588397,
3: 0.1,
}
Yeah, but the hope is that it will provide a better starting point anyway
@quasi shadow Here
What's the result?
SciPy

PSO

It's slow as ass though
170 ms vs 5 ms
welp
It's kind of like an evolutionary algorithm, so no wonder
---- pre_training::tests::test_search_parameters stdout ----
search_parameters took 253.875µs
😎 The speed of Rust.
I've got something better than PSO for you
👍

It's extremely simple:
- Try reducing a parameter by
step_sizewhile holding all other parameters constant - Try increasing a parameter by
step_sizewhile holding all other parameters constant - If neither helps, reduce step size
@quasi shadow
Actually, now that I think about it, it's a bit inefficient - it doesn't compare the results of both increasing and decreasing a parameter, it just does one of them first, but it's possible that the second change would be better
That is easy to fix
Oh well, it doesn't make it converge faster
Oh wait, no, hold up
Welp, it still doesn't converge faster
Whatever, it's very fast anyway
It's super simple man + it's fast
Oh my. I just had a peek at L-BFGS-B to see what you were talking about.
Every time I look beneath the surface of ML stuff a part of me just immediately starts internally screaming.
I don't think it's robust to local minima aka I don't think it can crawl up from a local minimum, but we don't have to worry about that with our data...right? 😅
You need.
I have run into some weird cases.
It's time to have a rest.
No more coding!
God damn it
Still, I recommend coordinate descent (see my file above). It's so much faster than particle swarm that you can just run it from 10 different starting points (to worry less about local minima) and still beat particle swarm optimization in terms of speed
Actually, on second thought, if we do have to worry about local minima, particle swarm is probably better
Meanwhile, here are some graphs comparing metrics of different FSRS versions (the values for FSRS-6 may change)

(yes, FSRS v2 is better than v3 here)


While I don't have a really good estimate of the limits of accuracy on this dataset, I'd say:
- 0.27-0.26 is the limit of log-loss (aka no algorithm ever will achieve less than that on this dataset)
- 0.5%-1.0% is the limit of RMSE
- 0.83-0.84 is the limit of AUC
And if some algorithm will get close to these limits, it won't be FSRS 🤣
It will be a giant neural net
@quasi shadow NOW it's time for you to contact Duolingo and tell them "Your algorithm sucks, look at mine"
(well, maybe not now, but once FSRS-6 is done)
I got an idea for a very high effort and obscure meme
You know the scene with business cards from American Psycho? That, but with algorithm metrics 🤣