#FSRS Megathread
1 messages · Page 6 of 1
It's tricky, I think.
Sounds fun 😂 😭
def stability_short_term(self, state: Tensor, rating: Tensor) -> Tensor:
new_s = (
state[:, 0]
* torch.exp(self.w[17] * (rating - 3 + self.w[18]))
* torch.pow(state[:, 0], -self.w[19])
)
It depends on Stability.
GitHub
FSRS for Rust, including Optimizer and Scheduler. Contribute to open-spaced-repetition/fsrs-rs development by creating an account on GitHub.
So, this function needs refactor.
But, the previous simplification doesn't work for the new formula.
Why doesn't it?
For example, with the old formula, the S0(G=1) = w[0], right?
Then, you grade good in the same day, S0' = S0 * e^(w[17]*w[18]).
You grade good twice, S0'' = S0' * e^(w[17]*w[18]).
So, S0'' = w[0] * e^(w[17]*w[18]) * e^(w[17]*w[18]) = w[0] * e^(2*w[17]*w[18]).
The two reviews have the same multiple on previous stability.
Even if you give other grades, they can be composed easily.
So, we can simplify the simulation of short-term reviews.
Oh I think I see, so we would need a loop in the short term function?
The simplification doesn't need the possibilities of each grade of the short-term reviews.
It's not harder than my above problem.

It's easy to get these stats from the revlog.
So we'd need first_review_prob and intra_day_review_prob?
wait no
To simplify the new problem, we need introduce a Markov chain.
The Markov chain is used to describe the distribution of the next grade based on the last grade.
Like in your paper?
Nope. The state in my paper is (S, D).
But we don't have a short-term memory model.
So... We can use the last grade as the state.
OK, it has... 16 parameters!
Last Grades: 1, 2, 3, 4
Next Grades: 1, 2, 3, 4
4 * 4 = 16 possbilities.
😂 And we need to implement (re)learning steps in the simulator.
So does only the last grade affect it? This is too much maths for me 😂
* torch.pow(state[:, 0], -self.w[19])
wouldent state be an aggregate of all the last grades
I've always wanted re-learning steps 👀
Of course not, but it's simple.
Right!
Hey Jarrett. I know this may not be on your radar at this moment, but when would you consider making FSRS scheduling intervals <13m. I believe the reason why you said why it is doing so in the first place was the desired retention.
Ideally it should be getting ever so small the more I press again and again and then I would start to work my way up.
Yeah, that's also why I don't want to mess around with it
The current short-term formula has a very convenient property: if you want to know how multiple same-day reviews will affect S, you can just plug the average number of same-day reviews into it an the average grade of those reviews. You don't need to account for every review individually.
Making that formula more complex could easily break that property. Then simulations will become a huge pain.
It requires to reduce the minimum stability.
The current minimum stability is 0.01 day =14 mins 24 secs.
But it actually has some severe problems.
Yes, so when would FSRS be able to schedule intervals lower than that. Or is it undoable under the current state?
I can make a PR tomorrow.
But I need to benchmark it.
Yes please!
Nothing interesting to report. I have not spent any time on it this week.
I have a quick play with leeches every now and again between other projects. I wasn't planning to work on it continuously for now.
I just shared my work this time to make it easier for others who were interested in playing with the Poisson Binomial idea too.
Would be cool if Jarrett implemented it in the Helper add-on, for convenience
It's interesting for helping pick out potential leeches but it still doesn't feel like something I would trust to automatically suspend cards without me checking.
Btw, a reminder: #1282005522513530952 message
I did that one didn't I?
I don't think the current version of the leechkit reports the average number of crossovers, does it?
Maybe I didn't push it? I'll check.
IIRC you only tested it on your own

I think the only bit we discussed that I didn't push was the separate "set" vs "unset" thresholds because I was just hard-coding it to experiment instead of implementing it nicely.
Ah, ok
Hm. I'll see what I can do about it later

Maybe I'll use two thresholds, that's a good idea
Actually, can you share your code with two thresholds? 😅
This was what I was last playing with (N.B. reset_t):
def _classify_incrementally(
trials_data: TrialsData,
initial_threshold: float,
threshold_fn: ThresholdFn,
) -> (bool, dict):
leech_data = _calculate_incremental_leech_probabilities(
trials_data=trials_data,
initial_threshold=initial_threshold,
threshold_fn=threshold_fn,
)
triggered_at_least_once = False
last_triggered = False
curr_triggered = False
crossover_count = 0
crossover_idxs = []
# Mark as leech as soon as we see it drop below the threshold
for i in range(leech_data.n_trials):
p = leech_data.probabilities[i]
t = leech_data.thresholds[i]
reset_t = 0.2
if p < t:
triggered_at_least_once = True
curr_triggered = True
elif p > reset_t:
curr_triggered = False
if curr_triggered != last_triggered:
crossover_count += 1
crossover_idxs.append(i)
last_triggered = curr_triggered
metadata = {
"crossover_count": crossover_count,
"crossover_idxs": crossover_idxs,
}
return triggered_at_least_once, metadata
I want to print the average n crossovers at the end, can you help with that?
Here
diff --git a/src/leechkit/__main__.py b/src/leechkit/__main__.py
index ea0d1bf..b31e047 100644
--- a/src/leechkit/__main__.py
+++ b/src/leechkit/__main__.py
@@ -46,6 +46,7 @@ def main(
selected_card_ids: Sequence[CardId] = col.find_cards(query=query)
leech_count = 0
+ total_crossover_count = 0
print("")
print("[bold]Searching for leeches[/bold]")
@@ -86,6 +87,9 @@ def main(
highlight=False,
)
+ if incremental_check:
+ total_crossover_count += metadata["crossover_count"]
+
leech_count += 1
progress.update(task, advance=1)
@@ -94,5 +98,8 @@ def main(
print(f"Processed {len(selected_card_ids)} cards")
print(f"Found {leech_count} leeches")
+ if incremental_check:
+ print(f"Mean crossover count {total_crossover_count/leech_count:.2f}")
+
typer.run(main)
The most likely reason is different parameters (have you reoptimized?) since those cards were last scheduled.
How long ago is considered "recently reviewed?"
I expect that is the same as the whatever you have configured at the top level (perhaps just using abbreviated text for that per-deck menu?). The default is 7 days.

Yeah I reoptimized all presets before I did the rescheduling
Yeah I guess it did get abbreviated, 7 days works for me for now but is there a way to change that parameter?

Tools -> Add-ons -> FSRS Helper -> Config -> "days_to_reschedule", change the number
@quasi shadow are we able to look at historical R of cards now? I think there was a PR from u.
I wanted to have something like this before: https://forums.ankiweb.net/t/record-and-show-r-values-in-hourly-breakdown/51576?u=sorata
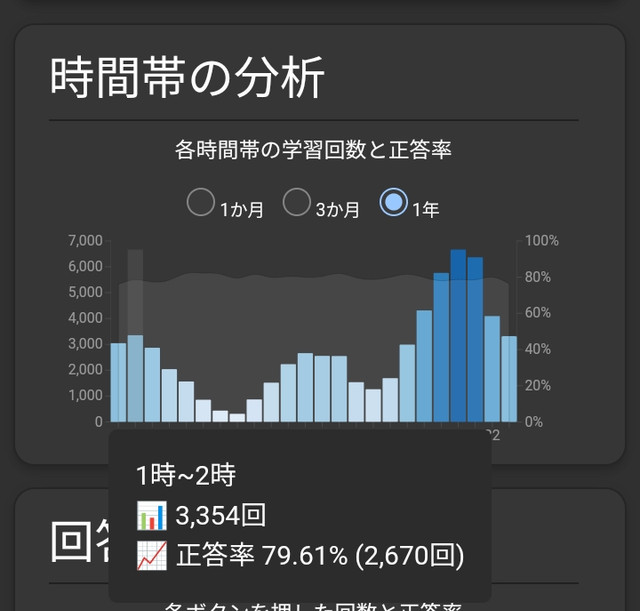
Anki Forums
In the Hourly Breakdown graph, can we also show the Average Retreivability of the cards? Knowing only the recall rate doesn’t help much.
can we do this now maybe?
@polar maple @quasi shadow if Mean cross-over count is exactly 1.00, that means that once a card is a leech, it never recovers. If our detector was perfect AND difficult cards never became easy, that would be good, but it's not perfect, so we need to allow cards to go back to not being leeches.
I set the threshold to 3.5% and the second threshold to 40%. I think 1.20 is a reasonable amount of cross-overs, maybe we could even allow more.
On the second image the first threshold is also 3.5%, but the second threshold is 25%. This means that a card needs to fall below 3.5% to be considered a leech, and rise above 25% to stop being considered a leech. This results in the average of 1.39, which is good IMO. But again, it depends on how often difficult cards become easy. If it almost never happens, then this amount of cross-overs is too high.

i think it needs to be implemented for the 10k dataset so we can get a better idea
especially for the calibration part
Hopefully Jarrett will do it 😅
I added a --max-reviews for the leech detector, because it really doesn't make that much sense for me to have past leech detection being reported.
I tried a lot of different setup, and something that I was Ok with was something like
uv run -m leechkit '/Users/jschoreels/Library/Application Support/Anki2/User 1/collection.anki2' --query "Yomitan" --flag --write --leech-threshold 0.01 --max-reviews 5 --incremental-check --tag leech-max-5-threshold-0.01
I got only 2 results over thousands of cards but to me, the goal is not really to detect much, just the one the most problematic right now that I might need to take extra care.


GitHub
Example :
uv run -m leechkit '/Users/[...]/Library/Application Support/Anki2/User 1/collection.anki2' --query "Yomitan" --flag --write --leech-threshold 0.01 --max...
Would you make an issue in the benchmark repo, please?
https://forums.ankiweb.net/t/desired-retention-ui-overhaul/57678
Meanwhile I wrote this. I really hope everyone in this channel will read it

Anki Forums
(partially backed up by @David. We don’t agree on the details, but we agree that something like this is necessary) Right now a lot of users don’t realize that desired retention is related to interval lengths and workload. I could write a list of 100+ posts where someone has DR at 90% and asks “Why are my intervals so long? What do I do?”. My i...
Alright, I made one
https://github.com/open-spaced-repetition/srs-benchmark/issues/188

GitHub
https://github.com/rbrownwsws/leechkit We want to find out a few things: If we set the threshold to X and go over every review of every card, how many cards (X') will actually be tagged as leec...
The laziest issue I've ever made 🤣
You might want to precompute a dataset based on Anki 10k where you annotate all reviews with retrievability rather than trying to shoehorn leech detecting into the benchmark code.
Last time I tried playing with the 10k dataset it took my computer a few seconds per preset just to optimise FSRS params.
It would probably be painfully slow to try out lots of different leech detection settings / algorithms.
I highly recommend you to comment that in the issue, since that way Jarrett is more likely to see it
This is probably the best we can do without a short-term memory model 👍
This would be a really good change, since then we could try more complex formulas for short-term SInc
So to sum it up for other people who might be lost:
Right now we just take the average number of same-day reviews and the average grade of those reviews to do simulations.
Jarrett proposed a more complex approach: while we don't have a short-term memory model for predicting the probability of recall, we can instead use these 16 probabilities, all for same-day reviews:
- Probability of Again if the previous grade was also Again
- Probability of Again if the previous grade was Hard
- Probability of Again if the previous grade was Good
... - Probability of Easy if the previous grade was Good
- Probability of Easy if the previous grade was also Easy
32 if you do it separately for learning and re-learning steps 😅
Idk if that would be beneficial though
Also, I guess we don't actually need the probability of G given that last G=Easy, because if last G=Easy, the next review cannot be a same-day review in Anki. If you press Easy, the next interval is never <1d
So it's actually 12 probabilities. Well, 24 if you want to do learning and re-learning separately
To be clear, this is still an oversimplified model and not a proper way to predict the probability of recall for same-day reviews. It assumes that p(Grade_1 | Grade_2) is a constant that doesn't depend on interval lengths or anything else.
But it's way better than the current approach
Actually, 3 * 3 = 9 possibilities.
Because the sum of possibilities of four grades is always 100%.
GitHub
Contribute to open-spaced-repetition/Anki-button-usage development by creating an account on GitHub.
I will add two new fields into button_usage.jsonl.
{"user": 9, "size": 4729, "first_rating_prob": [0.2364, 0.0993, 0.6349, 0.0294], "review_rating_prob": [0.0234, 0.973, 0.0036], "learn_costs": [52.86, 56.85, 12.46, 8.06], "review_costs": [39.19, 16.6, 6.44, 49.01], "first_rating_offset": [-1.62, -0.3, -0.13, 0.0], "first_session_len": [2.73, 1.64, 0.83, 0.0], "forget_rating_offset": -0.74, "forget_session_len": 1.22, "short_term_recall": [0.7424, 0.9816, 0.953, 0.7244], "learning_step_transition": [[661, 7, 1068, 83], [12, 81, 337, 3], [292, 53, 2677, 34]], "relearning_step_transition": [[64, 0, 148, 0], [0, 0, 0, 0], [0, 0, 0, 0]]}
learning_step_transition and relearning_step_transition.
[[661, 7, 1068, 83], [12, 81, 337, 3], [292, 53, 2677, 34]] means, there are 661 again and 1068 good in the next same-day review when the last grade is again during learning.
There are 2677 good in the next same-day review when the last grade is good.
Then we can calculate the Transition probability matrix from it.
It's convenient to apply any kind of smoothing method to the raw data.
You can look at historical R of cards at the card info's forgetting curve, right?
The only problem is it requires Numpy but I cannot use it in anki addon.
If I set desired retention to for example 88% which stat should I look at to see if im reaching that goal or not? Currently im looking at this graph on mature cards:
Is that correct?

Please check the True Retention Stats.



In the manual for FSRS they recommend setting the relearning steps blank because seeing the same card several times a day is not that efficient. Which setting is that?
Is it this one?
Because earlier the manual said to put it to 1m 10m

Do the cards it tags all appear to be actual leeches?
There's another one below it labelled "relearning" steps, and also I don't think they should be left blank

😂 I find a bug, so I need to fix it before check it(
You can play with it.
The bug won't occur if you don't build Anki from the latest source code.
According to the manual, if it is left blank, FSRS will decide on that number

Reddit
Explore this post and more from the Anki community
Thats... interesting 😂
Because the bug is caused by my PR😅
😐


well this gives me confidence that my implementation wasn't wrong when I tried it at least.
OK, I submitted the PR to fix the bug.
Btw, the detector will cause lag in Anki 25.02.
It will be alleviated by https://github.com/ankitects/anki/pull/3872

GitHub
This PR fixes an issue where viewing card statistics for some cards would cause an index out of bounds panic in the Rust backend.
This bug is introduced in:
Improve performance of stats revlog ent...

OK, now we have the transition matrix calculated from 10k collections.
GitHub
Contribute to open-spaced-repetition/Anki-button-usage development by creating an account on GitHub.
😎 @cosmic hedge would you like to work on the refactor of the simulator?
ok! XD
bear in mind you may have to swoop in and save me when I can't manage it 😂
Some traps appear in my mind:
- ensure the short-term simulation could end in finite epochs.
- the cost of short-term reviews should be refactored, too.
refactored in what way?
🤔 I'm thinking about it.
Now we uses the sum of duration of (re)learning reviews as the cost.
cost_dict = (
df.groupby(by=["first_state", "first_rating"])["sum_duration"]
.median()
.to_dict()
)
For example, the forget_cost is the sum of duration of the first review entry with rating again and the remaining relearning entries.
In the refactor frame, each relearning entry has its own duration.
This duration may depend on the rating.
yeah I think that would work
does it mean you have to re-run the anki buttons script again though? 😂
so just to confirm we will have relearning-costs-median?

😅 State: Learning, Review, Relearning
3 * 4 = 12 costs!
wow the state affects the duration more than I thought 😳
It's common that learning takes more time than review.
Oh I'm blind I thought state was the previous review 😅
Update to Anki 25.02
ah yes I forgot
Very good link, thank you!!
relearn_costs = np.array([1, 2, 3, 4])
relearn_chances = np.array(
[
[0.3, 0.05, 0.5, 0.15],
[0.3, 0.05, 0.5, 0.15],
[0.3, 0.05, 0.5, 0.15],
[0.3, 0.05, 0.5, 0.15],
]
)
MAX_RELEARN_STEPS = 5
# learn_state: 1: Learning, 2: Review, 3: Relearning
def stability_short_term(s: np.array, init_rating=None):
def step(s, next_weights):
rating = np.random.choice(relearn_costs, p=next_weights)
new_s = s *
(math.e ** (w[17] * (rating - 3 + w[18]))) *
(s ** -w[19])
return (new_s, rating)
def loop(s, init_rating):
i = 0
consecutive = 0
rating = init_rating or 1
while i < MAX_RELEARN_STEPS and consecutive < 2 and rating < 4:
(s, rating) = step(s, relearn_chances[rating - 1])
i += 1
if rating > 2:
consecutive += 1
else:
consecutive = 0
return s
if len(s) != 0:
new_s = np.vectorize(loop)(s, init_rating)
else:
new_s = np.array([])
return new_s
``` I may be completely wrong. Is this at least close to what you had in mind?
not sure how we'd get the costs implemented with this though@quasi shadow after beating Claude with a stick multiple times I just barely managed to make it write a fully "torched" version of my Poisson binomial approximation
It still has issues though: unused variables and one last "if" instead of "torch.where". No matter how many times I try, it always either has unused variables or one "if", I just can't get it to finish this properly.
I really hope you can implement this directly in FSRS itself. In other words, if Claude did 80% of the work, I hope that you can do the remaining 20%
Why torch?
I have implemented it in the helper add-on with standard lib.
Because I want to use it in FSRS itself, as a new variable
Yes
I'm making a github issue right now

GitHub
After beating Claude with a stick multiple times I just barely managed to make it write a fully "torched" version of my Poisson binomial approximation It still has issues though: unused v...
Btw, I have not checked whether this code even produces the correct results 🤣
I mean, wherther the results match the non-torch implementation
I guess I should give you the numpy implementation, for comparison
I added the numpy code in the github issue
They work quite differently (calculating the PMF vs CDF, returning p vs log(p), but hopefully it's still useful
Right now I just want the function to be implemented. Then I'll think how exactly to incorporate the output (log probability) into the FSRS formulas
Ok, yeah, I checked it - it works fine. The outputs match the numpy version
So now we just need to implement it inside FSRS 😅
fyi hypothesis can be nice for checking things like this: https://hypothesis.works/
I used it to double check that the PMF implementation you gave me matched what I had be getting from SciPy:
https://github.com/rbrownwsws/leechkit/blob/master/tests/test_fast_pbd.py
Most testing is ineffective Test faster, fix more
GitHub
Contribute to rbrownwsws/leechkit development by creating an account on GitHub.
Damn kids and their fancy frameworks! I just manually type in the inputs and then eyeball the outputs!
I suggest using
if rating > 2: consecutive += 1
Pressing Hard will never graduate the card
Actually, that's not correct either, since Easy always graduates the card, so you need to stop counting "consecutive" after Easy
Oh man, this will be a pain. Thankfully, not for me 🤣
Btw @quasi shadow will the real number of re-learning steps be used?
Yep
Fine. I will implement it in the next week.
the idea is that if this leech detector signal (I'll call it historical likelihood) actually provides more predictive power than what is provided by raw DSR from FSRS then there should be some formulas that incorporate historical retention to improve FSRS predictions, otherwise what is the point of using historical likelihood for leech detection if it has no predictive power? ie why not just use D and S directly instead?
"Answer Buttons" and "True Retention"
--> https://forms.gle/iUxNg25A9Qb55WzC6 <--
I made a short (4 questions) survey regarding some charts and tables in Stats. Everyone is welcome to participate!

out of curiosity, what prompted this poll
death

Anki Forums
Since we have the True Retentino table now, I don’t see a reason to keep the Answer Buttons chart.
oh just another "expertium hates features" poll
why not just leave the answer graph but remove the %s from the labels
people who want to use it as a count of presses still get it and the ability to confuse it for any sort of % metric goes away
(no ones gonna be crunching those numbers themselves when theres readily available %s next to it)
perhaps I should post that in the thread instead of here no one reads this channel
GitHub
This adds additional info as clarification, which was taken from the anki manual.
Also see:
https://forums.ankiweb.net/t/let-s-remove-the-answer-buttons-chart-from-stats/56170/24?u=anon_0000
🤣
wow confidentiality breach
gg
that's a gigachad option
How does FSRS handle difficulty in cards, I might have one deck with difficult words and another with easy words, will the algorithm adjust to that?
Yep. You can also assign different presets to dfferent decks, so that each preset has its own parameters.
How do I do that?
Does it require that I've had a similarly difficult deck before?
Anki's user manual. Anki is a flashcard program that makes learning easier.
some user pressing hard because they're getting very long intervals (another "not knowing difference between again/hard" situation): https://forums.ankiweb.net/t/crazy-long-fsrs-intervals/57465/8?u=sorata
@ashen light remind me, how exactly load balancer deals with siblings?
- Do you need to enable "Bury review siblings"?
- Do you need to enable "Bury interday learning siblings"?
- Does it just always tries to avoid siblings regarding of these settings?
I'm looking at the code and can't figure it out
https://github.com/ankitects/anki/blob/d52889f45c3f7999a45fd2dde367f79f3bc3bad4/rslib/src/scheduler/states/load_balancer.rs

GitHub
Anki's shared backend and web components, and the Qt frontend - ankitects/anki
It just says "if a note_id is provided, it attempts to avoid placing a card on a day that already has that note_id (aka avoid siblings)", but it's not clear how that is related to these settings

Perhaps I should PR just to add a comment about which of these three toggles affects load balancer. Except I need Jake to tell me that 😭
bury review siblings turns on the lb's sibling splitter
GitHub
Anki's shared backend and web components, and the Qt frontend - ankitects/anki

GitHub
modified from https://github.com/rbrownwsws/leechkit
patch: fsrs4anki-helper.ankiaddon.zip
Does anyone want to develop a standalone add-on for leech detector?
The helper add-on is too complex now.
😂 And the leech detector code is not written by me.
I make this PR just for verify the feasibility.
If there is going to be an automatic leex detector, I would really REALLY hope for an In-card-reviewer indicator which shows whether the cards memory state is moving for the worse or the better inside the card as I keep on reviewing - like an up green arrow, a red down arrow or a grey dash. (whether average stability over time is generally decreasing or increasing or smth like that) This would make my decision making much more easier in regarding what I should do with some of these godforsaken cards that eat up 80% of my time.
Even better if the indicator surrounds the entire Anki card display with a colour hue to make finding the state of the card easier and quicker
Just my thought
To get the best fit for the data I guess it would be best to have a separate preset for each deck?
No worries and sorry for the confusion 🙂
Through my test with leechkit, I start to see @polar maple point though. It's maybe a nice reflective tool to mark old that had "highly improbable failure rate at some point", but I'm not sure it's really that that useful if it doesn't bring much prediction.
When I started playing with --max-reviews and very very low threshold (.01), I started to get something I was a bit more expecting and that could be translated as : "Cards that just got very improbable failure streak". This might have a bit more prediction value (even than D/S) since it might also be an indicator that "You're now outside predicted model in a negative way", which could also predict unexpected failure afterwards.
If it will be integrated into Anki, it will just tag cards, like the current one. The difference being that it will also be able to un-tag cards if they stopped being leeches
And to anticipate @polar maple about using only D/S : Very high D, low S, can be perfectly non-leech in a sense that they still fit perfectly FSRS prediction (Let say R=50% every day, you fail them every other day, it's within the realm of FSRS prediction). But if you fail it at 200d stability with 90% R, 30d with 90% R, 10d with 90%, then something is fishy
(And counter measure like : Reseting stability to 1d after manual confirmation, could be taken)
Nah
If we're talking about how to actually implement it in Anki, it should be just one toggle that enables automatic leech detection, that's it
Yes I mean "The user could then decide what to do with it, for example reset it if he doesn't want to fail for the next ~30d before the card get a more manageable stability"
But nothing to be implemented like this
He could also just let it fail and so FSRS would be trained with those inputs
I'm just explaining why a leech detection can be useful
Because that's also a good point : Why do we even want to flag them ? What would be the possible action on those ? If it's just for the sake of stats, it shouldn't be really in the main public release of Anki
But that's a different topic, the one I'm more focused on is : Why the algo in leechkit, might not be really that useful
Nooo maaan 😭
Why can't power users understand that the other 99% of users want a streamlined experience...
With as little tweaking as possible
Unironically, this is a huge problem with Anki's development
So don't introduce them with some probability-based leech detection maybe ?
I don't see why it won't confuse them even more
They don't need to understand the inner workings of the detector. They just click one toggle
Yeah but if that detector send them "This card is a leech" but they see the last 10 reviews were answred "Good", they'll be confused
If you want to do a poll, maybe one interesting would be
"When you hear leech, what do you think of ?"
"If you could know what are your leech (based on that definition), do you have anything you want to do with them (in anki) ?"
"If you have something you would like to do with them, what would it be ? Reset, Cram, Time outside Anki, ..."
But then personally, to those questions, I would answer :
- Cards I fail too much and can't grow stability just by reviewing them
- Yes
- I'd put more time and reviews inside and outside Anki.
But based on those, then I might indeed seek something more related to D/S/# Repetition then historical statistics on reviews compared to R 🤔
Tagging doesnt work with cloze cards. It tags the entire note which is dumb
leechkitlets you flag individual cards as well as tagging notes (and shows you thecidin the terminal)- Jarrett's addon proof-of-concept gives you a per-card "Is Leech" column
If we did overhaul how leeches work in Anki it would be nice to give it its own searchable property on cards instead of just tagging the note. e.g. prop:leech=true, prop:leech-p>0.95
I'm not planning to. I deliberately didn't make an addon so it was easier to use external libs like scipy, scikit-learn, etc. while trying things out.
The Poisson Binomial stuff is interesting, but I still don't think it is a complete solution.
I wouldn't personally want to make an addon until I'm sure it is something more useful for a wider audience.
I have cards that are very similar, made in the same day (therefore they come up for review at pretty similar dates) but aren't siblings. how can i disperse them? afaik fsrs helper only disperses siblings
You can't


Anki doesn't allow making arbitrary connections between cards. So...yeah, I mean it

You could use a filtered deck to study some of them early and force them to be more offset, but there is nothing that would automatically keep them dispersed in Anki natively.
ohhhh that's a good idea, thanks!
GitHub
Contribute to open-spaced-repetition/Anki-button-usage development by creating an account on GitHub.

@cosmic hedge I updated the analysis.
Not necessarily. Depends on the whether the decks are substantially different in subjective difficulty, or how you study and grade them. Giving FSRS more data to consider is a virtue of its own.


?
Do we really need to hold him out for ridicule for asking for help with his (supposed) mental health issues?
u never remove them
That was me. It's redundant with a screenshot.
so expertium didn't lol
ye we're all like like him anyway
I sometimes think what if I pressed a button wrong and so I have to check card info again and again

u obsess over stuff too! this thread is the proof.
and the rants in forums where u ping dae five thousand times 🤣
Trust me man, I have things much more worrying than Anki 🤣
Advanced words in a language vs beginner words in a different language
It's still up to you. If one is significantly harder/easier for you than the other, you might have a reason to split them -- but have you noticed an issue that you're trying to solve? Otherwise, it's probably not worth the bother.
IMO, if you have not a bunch of reviews in any of those, having the same preset can help
But once you have a good amount of reviews in both ? Could help
But again, depends what's the RMSE/logloss and the delta between your DR and what you have
If your DR is 80% and your R is around 75-80%, the trouble won't be super worth it
If your DR is 80%, one deck is 90% and the other is 70%, yeah
@quasi shadow remind me, did someone create a solution to prevent scheduling on different devices from breaking every time there is a new FSRS version with a different number of parameters? Or are we destined to keep telling people "please wait until the newest FSRS version is supported in Anki on all devices" forever?
I mean like how FSRS-5 has 2 more parameters than FSRS-4.5, and if someone has FSRS-4.5 in desktop Anki and FSRS-5 in AnkiDroid, they are not compatible
IIRC it's "fixed" in the sense that both devices switch to the older version
Well, first the device that doesn't support the new version switches to the old one, then you sync, then the other device switches to the old one as well
Instead of just throwing an error and dying 🤣
I think the solution was that FSRS-4.5 params and FSRS-5 params are stored in different locations.
Each app will schedule based on the newest version it understands.
I think the solution was that FSRS-4.5 params and FSRS-5 params are stored in different locations.
Yeah, but I thought that instead of "Each app will schedule based on the newest version it understands." it's "Both switch to the older version of FSRS"
I could be wrong, but I don't think so. How would the newer app know that you were ever going to use an old version of FSRS again? You would be stuck on FSRS-4.5 forever.
I mean like this:
- You activate FSRS-5 on desktop
- You sync to AnkiDroid
- AnkiDroid switches to FSRS-4.5
- You sync again
- Desktop switches to FSRS-4.5
- You stop using AnkiDroid (never sync with new app that supports FSRS-5)
Stuck on FSRS-4.5 forever?
I haven't actually checked the logic, but I can only see the two sets of params in the preset config. I cannot see an "active FSRS version".
https://github.com/ankitects/anki/blob/d52889f45c3f7999a45fd2dde367f79f3bc3bad4/proto/anki/deck_config.proto#L111-L112
That's why I assumed each app would just schedule using the latest version it supported.
Yeah, my understanding is that there is nothing akin to an "active FSRS version"
an old App would just schedule using old algo and the preserved old parameters, or old default parameters if there are none
Why not let step() return the cost?
Or you can get the cost based on the rating returned by step().
I'm just glad that all the non cost parts are ok 😂
learn_step_costs = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
MAX_RELEARN_STEPS = 5
# learn_state: 1: Learning, 2: Review, 3: Relearning
def stability_short_term(s: np.ndarray, init_rating: np.ndarray=None):
if init_rating is not None:
costs = learn_step_costs[0]
else:
costs = learn_step_costs[1]
cost = 0
def step(s, next_weights):
rating = np.random.choice([1, 2, 3, 4], p=next_weights) # Somethings wrong here
new_s = s * (math.e ** (w[17] * (rating - 3 + w[18]))) * (s ** -w[19])
return (new_s, rating)
def loop(s, init_rating):
nonlocal cost
i = 0
consecutive = 0
rating = init_rating or 1
while i < MAX_RELEARN_STEPS and consecutive < 2 and rating < 4:
(s, rating) = step(s, relearn_chances[rating - 1])
cost_per_day[today] += costs[rating - 1]
i += 1
if rating > 2:
consecutive += 1
else:
consecutive = 0
return s
I should probably just make a pull request 😂. Idk what to call it though.

For Memorized Graph, I tried to plot R*f(S) with S defined as the red function. The idea is to have a Memorized curve with something more intuitive than R*sqrt(S) that have similar shape, but that gives number without much meaning. Here, the meaning would still be "The amount of word you know", with "know" based on a word you know perfectly at R=1 and S>360d.


Compared to R*sqrt(S)

Any opinion @unique salmon ? Could be injected in CMRR
(For comparison, my SUM(R))

local build if anyone want to check
Why is there 8 in the formula? Also, this isn't based on a formula of the forgetting curve that is used in FSRS. I don't understand where this formula comes from
Speaking of plotting memorized cards...
@cosmic hedge https://forums.ankiweb.net/t/estimated-total-knowledge-graph-over-time/57390/5?u=expertium
Thoughts?
Anki Forums
As vaibhav said, we can make it so that the user has to click a button, in other words, the chart doesn’t render (and the underlying data isn’t calculated) unless the user explicitly requested it. And we can make it so that it’s always “all history”, with no “last week” or “last month” options.
sounds good to me
I based myself on the hypothesis that stability of 1y means forever good
It’s not really a forgettive curve though
So basically something with 0 stability shouldn’t even be considered as known (thus 0) and s=365d is considered as known (thus 1)
(And never more)
The thing is, I can't think of a way to test which one would be better for CMRR: S or sqrt(S) or ln(S) or your formula or something
I think we can’t 😅
It’s super subjective I think
At least R vs R*f(S)
But in the end for f I think the result would be similar 🤔
The curve is really similar for both
The benefit of the exp is to have some human friendly number
And capping at 1
we can make something that sort of looks like the red curve but with more meaning. two separate but similar ideas:
- for a hyperparameter t, the score is the average retention for the next t days, so
(f(0) + f(1) + ... + f(t)) / (t + 1)where f maps time to retention - for a discount factor r < 1, the score is
f(0) + rf(1) + r^2f(2) + ....
both of these can be converted into an integral if you want exact area over the forgetting curve
I'd rather not make a change to CMRR if I can't test whether it's beneficial or not
Who here follow the computed minimum recommended retention? Mine says 0.72 while my selected is 0.88 and my total true retention is 86.2%
mine are all exactly the same at 85%
As God Jarrett intended

88% desired retention and 86% true retention is pretty good
When it comes to this stuff, it's hard to say how much deviation is ok and how much is a sign of a problem
Since your minimum recommended retention is lower, you can lower your desired retention so that you can have a better amount of stuff memorized/time spent ratio
Good if you don’t care how long you’ll remember that knowledge bad otherwise
In general it will push you to add more cards
10 cards at 50% count as 5
6 at 80% with high stability will count as 4.8
Even if the 10 have very low stability
I care a lot about how long I will remember the knowledge
To compensate for the lack of "last year", "last month", etc., would it be possible to make it so that the user can zoom in on a specific part of the graph?
I'm talking about like what matplotlib allows (I just quickly made some random crap just to illustrate zooming):
Keep your DR where it’s at 😄
Failing is also super frustrating
You have to recheck things etc
I really don't see your point
DR is not directly related to how quickly probability of recall decreases. "Keeping your cards at high DR" and "Making sure the probability of recall decreases slowly" are different things
Yeah and the optimizer doesn’t care about it
So don’t use it
It’s bad
So don’t drop DR because of it
To me low DR is only a good strategy if you’re too late with too much stuff to learn and you want to maximinse your chance of getting the grades
So you can increase the number of new items per day
But when I did my median stability went from 15d to 4-5
I knew a lot of words for a very short amount of time and at a low retrieval
Making me stutter at every words I wanted to recall
yeah I kinda wanted that even for SSE
Well, then both problems are solved. The memorization data is calculated and the graph is rendered only when the user presses a button, that + Rust solves performance issues. Zooming in solves not having "Last year", "Last month" and all that
If anything, zooming is even better
we can hope.
for some reason I'm getting a feeling that I knew something while actively working on it that I've since forgotten but I hope I'm wrong 😂 .
yeah im pretty sure it was just the partial history thing
Oh, btw, don't forget to do the same smoothing thing that we use for other parameters for the simulator. I'm talking about using a weighted average of the default value and user-specific value
Also, this will be the first graph in Anki that is zoomable 

@cosmic hedge regarding this: https://github.com/ankitects/anki/pull/3829
Can you add a hint that says that "Smooth" only affects the visual representation and not scheduling? I'm afraid some users might start asking "What is this Smooth setting that I don't see anywhere else? How do I enable it?"
GitHub
Key Changes
Updated FSRS dependency to use a version that supports post-scheduling hooks
Added post_scheduling_fn to simulator that applies load balance and easy days
Added easy days percentages t...
it is already called "Smooth graph"
i feel like the "graph" would be a hint but you never know 😂
where would the hint fit?

Can you make it appear when the user hovers over "Smooth Graph" with the cursor?
Like a little text box under the cursor
Actually, I have a better idea - move "Smooth graph" under Reviews - Time - Memorized and make it a check box

Advanced settings is perfect place for the Smooth graph toggle and it is already enabled by default. If you afraid that anybody can misunderstand it then just add the hint on hover/click.
Or, even better, dedicated help modal for the whole simulator as in https://github.com/ankitects/anki/pull/3874
I guess let's leave it up to Bloke to decide

Best solution - don't change anything. Graph in the Smooth graph already implies that this setting affects only the graph below.
yeah adding a hover would probably be more effort than its worth
i guess i could reuse the tooltip from the graph though 🤔
maybe under the graph?
That sounds awkward
I feel like it's better either at the top or on the right
Please, don't move it anywhere. Even just renaming it to Smooth the simulated graph is better.
But then the simulation number thingy is on the right as well. So I guess on the right is not good either

Hm. I guess let's do that
That seems like the easiest way
Again, I don't think it is worth it. Smooth graph is already obvious. Changing it can cause problems on narrow screens (string length)
It's just that right now it's placed together with other settings that aren't purely cosmetical, which can make people think that this one is also not purely cosmetical

All of these except for Smooth Graph are real Anki settings that affect scheduling, so placing a purely cosmetical setting among them is kinda eeeehhhh
https://github.com/ankitects/anki/blob/45bb56808a555e5b3e92e9620a57a3809d5388db/ts/routes/deck-options/SimulatorModal.svelte#L299 if you want to do that you can edit this string and make the pr urself

GitHub
Anki's shared backend and web components, and the Qt frontend - ankitects/anki
i mean i could do it and then test it but idk if i wanna get stuck justifying this 😂
yeah i dont like it that either tbf
Maybe move Smooth Graph under Simulate?
Inbetween Simulate and the graph itself
I'll try it gimme a sec
Like this


Is it not possible to place it under Simulate?

Yep, let's go with this
id probably move the flicky bit over to the left if i could honestly
Oh, yeah, the text and the toggle are on the opposite sides of the screen 🤣
Whatever, it's fine
ok finally XD

oh wait i think dae said there were problems with mac not being able to scroll
i think this might cut off the bottom axis for mac users
idk im just gonna make the pr @ you in it and call it a day 😂
https://github.com/ankitects/anki/pull/3881 there you go
GitHub
@Expertium wanted to make it clearer to the user that the smooth button had no effect on the simulation.
I am personally ambivalent to this change, especially if it runs into issues with scrolling ...
Did you mean "move smooth button below simulate graph"?
Bloke, the Simulate, Clear last simulation, Save to Preset options (and with this PR Smooth graph) area is overloaded with buttons in one place - it is easy to misclick.
below the simulate button, above the simulate graph
Ah, ok
copy this into the pr comments so people have something to "👍"
the algorithm is not my forte
I had an idea though and i was just wondering if it held any water
I figured if the user uses hard as again, hard_penalty (w[15]) would be 1 right
so at risk of wasting your time, what if we let hard_penalty go below 0 and in that circumstance apply it as a bonus to stability_on_fail
python evaluate.py --fast
Model: FSRS-5-dev
Total number of users: 577
Total number of reviews: 17758320
Weighted average by reviews:
FSRS-5-dev LogLoss (mean±std): 0.3394±0.1659
FSRS-5-dev RMSE(bins) (mean±std): 0.0568±0.0379
FSRS-5-dev AUC (mean±std): 0.7064±0.0823
Weighted average by log(reviews):
FSRS-5-dev LogLoss (mean±std): 0.3700±0.1728
FSRS-5-dev RMSE(bins) (mean±std): 0.0747±0.0487
FSRS-5-dev AUC (mean±std): 0.7002±0.0878
Weighted average by users:
FSRS-5-dev LogLoss (mean±std): 0.3722±0.1743
FSRS-5-dev RMSE(bins) (mean±std): 0.0769±0.0499
FSRS-5-dev AUC (mean±std): 0.6995±0.0900
Model: FSRS-5
Total number of users: 577
Total number of reviews: 17758320
Weighted average by reviews:
FSRS-5 LogLoss (mean±std): 0.3396±0.1660
FSRS-5 RMSE(bins) (mean±std): 0.0570±0.0380
FSRS-5 AUC (mean±std): 0.7052±0.0798
Weighted average by log(reviews):
FSRS-5 LogLoss (mean±std): 0.3702±0.1730
FSRS-5 RMSE(bins) (mean±std): 0.0749±0.0489
FSRS-5 AUC (mean±std): 0.6997±0.0873
Weighted average by users:
FSRS-5 LogLoss (mean±std): 0.3724±0.1745
FSRS-5 RMSE(bins) (mean±std): 0.0771±0.0500
FSRS-5 AUC (mean±std): 0.6991±0.0896
I think this means it works? idk 😂

So S decreasing after the user pressed Hard? That would mean that intervals can shrink after Hard, idk about that
wait no
I'm trying to understand what you're doing
So success depends not only on the grade, but also on another parameter
I figured if the user uses hard as again, hard_penalty (w[15]) would be 1 right
It would be 0
If we allow it to be negative and just use it in the same way, it would mean that SInc<1 when grade=Hard, so intervals could shrink after Hard
But you are doing something more involved
yeah its aimed to combat hard abuse
The thing is, if we allow intervals to shrink after Hard and the user uses Hard a lot, the intervals would just keep shrinking
That seems bad
not if the users using hard as again
wait no it would be 1 wouldent it?

w[15] ranges between 0 and 1. 1=Hard as Good. 0=Hard as Again
If w[15]=1, then pressing Hard and Good increases S by the same amount
if w[15]=0, then pressing Hard doesn't increase S at all
https://github.com/open-spaced-repetition/srs-benchmark/blob/main/result/FSRS-5-recency.jsonl
It's probably better to look at this since we use recency weighting for reviews now

GitHub
A benchmark for spaced repetition schedulers/algorithms - open-spaced-repetition/srs-benchmark
And in Anki too
-dev:
{"metrics": {"RMSE": 0.400651, "LogLoss": 0.49325, "RMSE(bins)": 0.112599, "ICI": 0.033374, "AUC": 0.784574}, "user": 1, "size": 10620, "parameters": {"0": [0.3387, 0.6238, 0.7773, 3.9799, 7.4677, 0.3263, 1.7317, 0.0256, 1.2388, 0.2723, 0.684, 2.1162, 0.062, 0.5889, 2.4239, 0.5144, 2.3553, 0.3103, 0.7159]}}
{"metrics": {"RMSE": 0.265203, "LogLoss": 0.269664, "RMSE(bins)": 0.039755, "ICI": 0.016234, "AUC": 0.647728}, "user": 3, "size": 4255, "parameters": {"0": [4.0653, 10.1024, 10.2528, 10.0513, 7.2597, 0.692, 1.7276, 0.001, 1.5279, 0.1049, 1.0048, 1.9723, 0.1203, 0.4359, 2.3265, 0.1556, 2.9898, 0.6101, 0.643]}}
FSRS-5:
{"metrics": {"RMSE": 0.401261, "LogLoss": 0.494693, "RMSE(bins)": 0.114298, "ICI": 0.032853, "AUC": 0.782499}, "user": 1, "size": 10620, "parameters": {"0": [0.3527, 0.6238, 0.7818, 3.9533, 7.4838, 0.3735, 1.7316, 0.0229, 1.2548, 0.2462, 0.6704, 2.1209, 0.0661, 0.585, 2.3421, 0.5017, 2.2118, 0.31, 0.7001]}}
{"metrics": {"RMSE": 0.395004, "LogLoss": 0.494957, "RMSE(bins)": 0.13308, "ICI": 0.091856, "AUC": 0.675933}, "user": 2, "size": 35900, "parameters": {"0": [0.2922, 1.8544, 12.6882, 28.0778, 7.212, 0.2171, 1.9473, 0.001, 1.3647, 0.5441, 0.9483, 1.787, 0.1504, 0.3284, 2.5254, 0.2847, 2.8317, 0.4484, 0.9641]}}
if i run script with --dev then the values are different
is that because its -recency now?
i'm on the simulator branch if that counts 😂

hold on
Fine. Forget it.
"metrics": {"RMSE": 0.400651, "LogLoss": 0.49325, "RMSE(bins)": 0.112599, "ICI": 0.033374, "AUC": 0.784574}, "user": 1, "size": 10620, "parameters": {"0": [0.3387, 0.6238, 0.7773, 3.9799, 7.4677, 0.3263, 1.7317, 0.0256, 1.2388, 0.2723, 0.684, 2.1162, 0.062, 0.5889, 2.4239, 0.5144, 2.3553, 0.3103, 0.7159]}}
{"metrics": {"RMSE": 0.265203, "LogLoss": 0.269664, "RMSE(bins)": 0.039755, "ICI": 0.016234, "AUC": 0.647728}, "user": 3, "size": 4255, "parameters": {"0": [4.0653, 10.1024, 10.2528, 10.0513, 7.2597, 0.692, 1.7276, 0.001, 1.5279, 0.1049, 1.0048, 1.9723, 0.1203, 0.4359, 2.3265, 0.1556, 2.9898, 0.6101, 0.643]}}
yeah nothing changed

{"metrics": {"RMSE": 0.265203, "LogLoss": 0.269664, "RMSE(bins)": 0.039755, "ICI": 0.016234, "AUC": 0.647729}, "user": 3, "size": 4255, "parameters": {"0": [4.0653, 10.1024, 10.2528, 10.0513, 7.2597, 0.692, 1.7276, 0.001, 1.5279, 0.1049, 1.0048, 1.9723, 0.1203, 0.4359, 2.3265, 0.1556, 2.9898, 0.6101, 0.643]}}```
same resultDo you have CUDA?
Could you disable it and optimize the parameters via CPU?
Oh, wait
I guess script.py doesn't support CUDA.
Maybe it's the difference between Windows and Mac?
I will re-run the benchmark tomorrow.
DEVICE = torch.device("cpu")
"metrics": {"RMSE": 0.400651,
yep
sorry 😭
--dev
{"metrics": {"RMSE": 0.401261, "LogLoss": 0.494693, "RMSE(bins)": 0.114298, "ICI": 0.032853, "AUC": 0.782499}, "user": 1, "size": 10620, "parameters": {"0": [0.3527, 0.6238, 0.7818, 3.9533, 7.4838, 0.3735, 1.7316, 0.0229, 1.2548, 0.2462, 0.6704, 2.1209, 0.0661, 0.585, 2.3421, 0.5017, 2.2118, 0.31, 0.7001]}}
FSRS-5:
{"metrics": {"RMSE": 0.401261, "LogLoss": 0.494693, "RMSE(bins)": 0.114298, "ICI": 0.032853, "AUC": 0.782499}, "user": 1, "size": 10620, "parameters": {"0": [0.3527, 0.6238, 0.7818, 3.9533, 7.4838, 0.3735, 1.7316, 0.0229, 1.2548, 0.2462, 0.6704, 2.1209, 0.0661, 0.585, 2.3421, 0.5017, 2.2118, 0.31, 0.7001]}}
I guess it's related to the difference of float32 computing between MacOS and Windows.
@unique salmon would you mind testing it?
Maybe you will get the same result as @cosmic hedge .
Jarrett will you implement reducing stability to <0.01 or whatever so that we get smaller intervals
GitHub
Make the results slightly worse.
$ python evaluate.py --fast
Model: FSRS-5-dev
Total number of users: 9999
Total number of reviews: 349923850
Weighted average by reviews:
FSRS-5-dev LogLoss (mean±s...
The result becomes worse.
That's not surprising considering that we don't have a good model of how S behaves at values <<1
I'm running other stuff now, so later
I ran it on linux so it still could be it i guess
pip freeze | grep torch
torch==2.6.0
torchcache==0.5.2
[project]
name = "FSRS-Optimizer"
dependencies = [
"torch>=1.13.1",
]
``` I think it might be that my torch is 1 major version above what it should be
Edit: I can't test it easily.
pip install torch==1.13.1
ERROR: Could not find a version that satisfies the requirement torch==1.13.1 (from versions: 2.5.0, 2.5.1, 2.6.0)
Me expecting that plotting Stability Mean/Median over number of repetition would show a correlation like "The more you have reviewed, the more your stability will be bigger"

More like "the more you review, the less stability it might translate too"
Which is logical
but also depressing
wait wut
Is it because of leeches?
No I think it’s just that card that you learn quickly you’ll get them high stability quickly and those who you struggle more Anki itself won’t really compensate enough to make them high stability
I have a local build if you want to see with you
It's the graph after "Card Stability over Time"
it's still a draft so no legend no title etc etc
but wanted to see how it would look
But still ... It kind mean just reviewing again and again and again a card is not really what will make it stick better
It's true that all my High S cards are all with reviews<10

While my low Stability, have in general at least 30-40 reps

https://www.reddit.com/r/Anki/comments/1jkam65/how_to_recreate_this_behavior_from_vocabeo_in_anki/
People really like simple and interpretable algorithms, huh
Reddit
Explore this post and more from the Anki community
Well, FSRS is also interpretable, just not for most people, it seems
The average person seems to want something where it's just "Multiply the last interval length by a fixed modifier like 0.2 or 1.5"
The custom scheduling script may fit the OP's need.
Yeah, but the kind of person who wants a "Multiply the last interval by 0.5 or by 2" is not the kind of person to mess around with code
Honestly, custom scheduling in Anki is a solution looking for a problem
Someone who wants an advanced algorithm can just use FSRS without having to reinvent their own algo
Someone who wants a simple algorithm won't touch custom scheduling at all
So the only people who use custom scheduling at this point are super advanced users who know how to code yet don't want to just use FSRS for some reason
Which is like 0.00000000000000000000000001% of all users
😎 I was the super advanced user two years ago.
Lol, yeah
Btw, how is your FSRS-H going on?
Slow. It makes benchmarking 1.7-2x times slower. And the results don't look all that impressive. I'll report back in that github issue once I have tried all my ideas
But even if it's mildly better, it won't justify the increase of optimization time. To justify that, the improvement would have to be MASSIVE
Maybe we would have FSRS-5.5 with an extra parameter in 2025H1.
The ~2% improvement is my best finding since last two months.
quick question
current fsrs version how much does it lower review load compared to sm2
I know I can run the optimizer in the notebook
just asking if somebody already knows
It's hard to say. Some time ago I estimated about 20% based on simulations, but idk
@quasi shadow maybe you have a better answer
The only real way to know is to try, I would first check your SM2 observed retention, switch to FSRS, use that observed retention as the desired one, do a reschedule, and try to do an educate guess based on future review + mentally spreading the potential backlog
Also a lot of people try to have with SM2 a very high retention for mature card, which is not really the case with FSRS, in FSRS, young or mature, doesn't change the fact it want to achieve your DR
So if right now you have half young with 70% Retention and half mature with 90% Retention, maybe it would be more or less equivalent to a FSRS workload of 80% retention (not an exact computation but to give you a sense of what could influence the workload)
We could estimate "worst case" improvement like this:
- For each user from the 10k dataset, record their FSRS parameters and the optimal Anki parameters using the modificaiton of SM-2 that predicts probabilities
- For each user, run simulations using both FSRS and SM-2 (predictive) at the same DR, with SM-2 probabilities considered "faulty" and FSRS probabilities considered "true", meaning that whether the review ends up being a lapse or not is based on FSRS probabilities
- Calculate two values of workload: using SM-2 and using FSRS, compare how much FSRS is better/worse in terms of reviews/day
@quasi shadow wanna try it?
Though running 10k simulations will take forever
This would tell us how much FSRS outperforms fine-tuned SM-2
Or, alternatively, we could do that but with default SM-2 parameters, not fine-tuned for each user
To get a "best case" improvement - what if FSRS is competing against unoptimized SM-2?
Or we could do both
There's also always a slight chance FSRS will increase the review load. Though unlikely, if it concludes that your memory sucks, it might show you stuff quite often :D
True, with SM2 I think when I did something wrong it would divide by 2 or something similar the interval, while in FSRS in my case it divide it by 6-7
With SM2 by default if you hit Again, a card would be fully reset as if it just graduated
Oh
But it's a multiplier you can configure, it just defaults to 0
That's actually quite aggressive lol
At the same time .... I think for learning it might make sense
Yeah, I had that multiplier set to 0.5
It definitely is the best to ensure retention
Yeaaah
but if it's a hard deck, it also creates an intense review load
With FSRS it always feel knowledge is kept "at warm temperature"
never too mature, never too young
Eh, if I let it do as the optimizer wants, it goes too hard imo
Like, 9-12d after graduating, and then multiple months
For example this is my graph of "Stability / Repetitions done" ...

The more I review them with FSRS, the lower the stability lol
Not if you set DR to 99%

Sure
In the same amount of time (not in terms of review), more reviews seems to lead to faster increase of S
Unrelated, but maybe we should just add a "I use Hard as fail" toggle in Anki and adapt FSRS formulas so that they work well with both
Otherwise we will never fully solve the problem
Over the past 4 months, I did increase my DR from 80% (but more effectively 75% average R), to a "true" 86, and each time I do a step up, I see my stability plateau going a bit faster up

I guess making a 2-button mode the default and adding a warning when enabling the 4-button mode would help, but...
Optimize params with Hard=Fail, Hard=Good, and even with ignoring them, and then take the minimum ? 😄
At this rate a neural network will be easier to implement lol
I have considered running two optimizations and selecting whichever results in better parameters, but that could lead to extremely unintuitive behavior - both parameters and intervals changing drastically after the user adds a few more reviews. If both result in more or less the same RMSE/logloss, so that which one is better is a coin toss, this would happen a lot
It would be better to just ask the user himself
Then again, maybe after 2 buttons become the default + enabling 4 buttons gives a warning about Hard misuse, this won't be a problem, at least for new users
If RMSE/logless is more or less the same, is it even a problem 🙂 ?
I think initially I did sometimes "Hard" as a fake "Again", but I never really stress about it too much
I was < 500 reviews back then, I'm at 60K right now
I just feel like it would create a lot more problems than simply asking the user
Gotcha
I just think some user will be "That night, at 3AM, I DID USE IT !! Should I stop using FSRS until then ?"
If at least the RMSE/logless is similar
it's pretty much guaranteed that it doesn't really change anything
I wanted to reduce my workload recently, but didn't want to risk forgetting too many mature cards.
I set DR 90%->80% and use a filtered deck with prop:s>21 prop:r<0.9 to keep it at 90% for mature card.
It reduced my workload by more than 50% and seems to be working so far:

That's quite smart !
I think ideally we all would like to see that "with time and reviews, we know better our stuff"
and the retention is something in which we search those answers
more recently I shifted a bit my mindset to be able to see it also in my stability
Even if I still do 80%, I feel confident seeing my stability rising
But linking those things like you did is smart because it's a way to say "For those young card, I'm fine having a bit more errors, if it means reducing my workload" (and god knows how young card is often the majority of our workload), but "when you go in mature more, I want to lock you in"
Said differently, it's also a way to express "As long as I'm not really able to encode it long enough, I don't want to have too much expectation on that card, but once the signs of having it well encoded start to show up (stability > 21), then I'll have higher expectation of not failing it (prop:r <0.9)
How to determine the DR?
I think my method might at least find the hard abusers #1282005522513530952 message
(all the values here are log loss except w15= )

Just use 90%
I actually plan to test something similar
ah cool!
@quasi shadow do you have a "X reviews take Y seconds to optimize" kind of test for fsrs-rs?
I'm asking because David is interested
Like, a standardized test for how long the optimization takes
Actually, I'm surprised that we don't have a speed benchmark. We could benchmark tweaks to the optimizer code to see how we can make it faster. This could improve user experience and would be one more reason to have automatic optimization when/if the optimizer is fast enough
It should be fairly easy to do, just add some extra code that measures time to the benchmark: https://github.com/open-spaced-repetition/srs-benchmark
And then for each user record the time, and then calculate average time per X reviews
GitHub
A benchmark for spaced repetition schedulers/algorithms - open-spaced-repetition/srs-benchmark
how would you account for hardware differences?
Just run it on Jarrett's hardware 🤣
Ok, idk, honestly
There are already some benchmarks in fsrs-rs. (Not one for optimising though):
https://github.com/open-spaced-repetition/fsrs-rs/tree/main/benches
GitHub
FSRS for Rust, including Optimizer and Scheduler. Contribute to open-spaced-repetition/fsrs-rs development by creating an account on GitHub.
I think the idea of that kind of benchmark is you just do a before and after on the same machine to ensure there is not a regression when you make changes rather than having an "objective" measure.
GitHub
A benchmark for spaced repetition schedulers/algorithms - open-spaced-repetition/srs-benchmark
Yeah. I vaguely remembered that you added something like that, but wasn't sure
Does this use FSRS (Python) or FSRS-rs? Ideally, we want to benchmark FSRS-rs, as that's what is used in Anki
Also, to get the most accurate comparison to Anki's FSRS, what command should I use?B=1 N=100 MEM=1 python performance.py --dev?
And one more thing - I want time per X reviews (say, 100 000) rather than total time or time per user
B=1 is if you want 2 changes on the same graph which you get by modifying these functions (runs it twice for each user)
def process_wrapper_a(uid: int):
torch.set_num_threads(2)
return process_wrapper(uid)
def process_wrapper_b(uid: int):
torch.set_num_threads(3) # Num threads example
return process_wrapper(uid)
MEM=1 shows memory but really throws the speed benchmark outa whack
i think you can add --rust as an argument and that should be pretty close but i never tested it
So B=0 N=100 MEM=0 python performance.py --dev --rust?
yeah that would probably work
also it is plotted by the number of user reviews as the x axis if thats what you wanted.

I don't really care about plotting tbh, I just want time per review
I'm looking at performance.py, but can't figure out how to get the total number of reviews across all users that were used
Maybe sum of row_counts?
It's the number of reviews...I think...maybe
look at the bottom axis 👍
plt.xlabel(f"Revlogs (total={sum(row_counts)})")
yeah you were bang on
Seems like you can't break the "benchmarking code never works on the first try" curse

I'll try it 😭
That's not how environment variables work in cmd.exe
oh yeah i'm blind
You either need to use set VAR="value" before calling python in cmd.exe or use $env:VAR="value" in powershell
It just does nothing

you need to run them as separate commands before the python one
> set var="val"
> python ...

pip install fsrs_rs_python?


Rick astley never gonna give you up parody
#RickAstley
The original video this clip came from. https://youtu.be/6Mc-Thl1kTQ
Newest Rick Video
https://youtu.be/DBYMPrUKAXw
where do you have anki 10k downloaded?
Oh, right, it's because right now I'm only using a subset of the dataset
Screw it then, it's faster for you or Jarrett to test it
Than for me to do the copy-pasting 🤣
I'll do it once I benchmark my ideas to improve FSRS, but that's DEFINITELY slower than having you guys test it
do you not have the full anki-10k downloaded???
you can use script-path or whatever that arguments called if you have it downloaded somewhere
I do
i'll try run it anyway
But I'm benchmarking stuff on a 1k subset
# Don't change
USER_COUNT = 10000
``` you can try change this conspicuous variable to 1000 if you want 🤣should say "dont change unless you only have 1000 users for some reason"
Yay, it works!

So on my Ryzen 5 3600 (using only one thread) FSRS-rs takes around 57.6 seconds per 100,000 reviews. What's strange is that in Anki itself I have a preset with around 170k reviews, yet the optimization is WAY faster. And based on CPU utilization, it doesn't seem like Anki is using more than one thread 🤔
I haven't actually looked at any code but there could be a large overhead in Python <--> Rust bridge
There could be a load of small presets biasing the result with that overhead.
performance.py calls script.processwhich has to read and process the dataset and this step is very slow
So the only accurate way to estimate time is...to add the timer inside Anki 😅
https://github.com/Luc-Mcgrady/srs-benchmark/tree/rust-performance I tried to remove the overhead from the timer

GitHub
A benchmark for spaced repetition schedulers/algorithms - GitHub - Luc-Mcgrady/srs-benchmark at rust-performance
idk if it worked very well but it might be better
wait i'll run the original one to compare
yeah it helps

Is it not a million dollar idea? All the brightest minds are here, I wanna know your opinion.
Low DR (80%) for young cards:
- intervals grow super fast (at 80% DR it's 2.4x faster than at 90% DR)
- low workload (e.g. 2/3 of my everyday cards are young) + consider that @rossgb claims his workload dropped by more than 50% (!)
High DR for mature cards:
- You have confidence that you actually remember stuff
- Intervals don't grow as fast but it matters less since stability is high (= intervals still grow really fast)
What am I missing? Custom DR for young cards and mature cards seems like best of both worlds (low workload + good long-term memory).
Jarrett did something like that, it ended up barely being 5% more time-efficient than a good fixed value of DR over like 10 years, according to out simulations
https://github.com/open-spaced-repetition/SSP-MMC-FSRS

GitHub
Stochastic-Shortest-Path-Minimize-Memorization-Cost for FSRS - open-spaced-repetition/SSP-MMC-FSRS
There might be a phychological benefit in that it gives you a sense of progress towards mastery, but no real benefit in terms of time spent on reviews, or a minor benefit at best
I'm not claiming it's significantly "better". It just makes me feel sad and like I've wasted lots of time if I forget mature cards.
I see. You guys thought of everything.
5% would be huge but it's just not there. I think maybe the FSRS memory model is too simple to yield interesting scheduling strategies
Currently it is 0.35% better than 88% fixed dr
Caveat : Knowledge is based on SUM(R) and doesn't take in account S.
Knowing 1000 words for 1 day vs knowing 900 for 100 days.
Sure, since lower stability would translate into higher workload, it is "somewhat" taking it in account for the "per minute" part.
Caveat 2 : Forget Cost is estimated at ... 2x the recall_cost https://github.com/maimemo/SSP-MMC/blob/216b349b500c843c7c76503b36a2a22838341aba/simulator.py#L26-L28
Cost should include :
- Time spent on average answering the card (2x)
- Time spent to "process what would have been the right answer" + Finding ways to recall it better next time, to understand why the card might be mixed with another one ( ~30-90s/card)
All those simulations and stats might sound convincing but they are just as biased as the hypothesis on which they are build.
It's just based on the data, man
It's based on how long people answer cards
It's not like we pulled the numbers out of our asses
Which is only a sub part of the total time of the time lost
It only account the front part
Ok, idk where those values are from. Maybe from Jarrett's ass 🤣
Data can be wrongly interpreted, it's not a bulletproof argument
Caveat 3 : Considering that even if a card was difficult to encode, failing it might means having to repeat a lot of small cycles to rebuild a good encoding, which disrupt short and long term acquisition

Very far from the pretty theoretical assumptions of what will happen if you just space you repetition a bit larger each time.

Note that one key point between SM2/FSRS might be the fact that SM2 treat the fact that you forget as a "start a new cycle"
Where for FSRS, a forgotten card is not the end of the world
SSP-MMC-FSRS seems to use costs from actual data
https://github.com/open-spaced-repetition/SSP-MMC-FSRS/blob/bd9558f015ca25e72908d1c126527c20bf18222e/simulator.py#L29
Yes, which is why I was confused by what Sound linked
I was like "huh, I could've sworn it was based on real data"
Whatever the weight, I guess it was gathered from what Anki recorded : The Front timer
Yes
cost spent finding a better encoding is impossible to model given the current dataset but we need this data
How much time the user spent on the back, trying to understand the card, is not accounted
No, timer doesn't stop after you click "Show Answer"
Yes, and a goal function that take in account R and S
But how do you get that info? In the revlog, the timer is just the front oen
Also, it's caped
@quasi shadow pretty sure in the revlogs it's the full time (front+back)
Caveat 3 seems more of a criticism of FSRS than it is of SSP-MMC, the claim is that FSRS fails to model those cards correctly
I answered this one in 1 sec. Right now, I'm still in the back view.

Now, let me go the the card info view
Wait 12s is strange I spent more than that

Hmmm seems to take the back in account, now the question is for how much time, I'll wait a bit here
Seems to be capped at 12s somehow

Which is my Addon limit though

Default is 60
sum(R) vs sum(R*f(S)), for a deck of 102 kana. From the very first days, the SUM(R) was already at 99-101 when it was only a few days I knew them. With S taken in account, you get a better goal function IMO



To re-implement the SM-2 in simulator is terrible.
I can write one for the test collection in fsrs-rs' CI.
Oops, it's harder than I thought.
Anyway, the benchmark of 10k collections costs me ~7 hours. So the average optimization time is 10000/7/60/60 = 0.4s
I feel like S should definitely be taken into account. R&S graph makes much more sense imo. But isn't it weird that only 80% of those cards are considered "memorised" after a year period (assuming you do your reviews daily)? Shouldn't it be closer to 95%+? I just think that if a card is Mature and has R > DR, then it should be considered memorized in 100% of the cases.
PS. And pure R graph (if you do your reviews daily) kinda shows "Introduced cards over time" rather than "Memorised over time".
(0.4 collections per second right? (7*60*60)/10000 = 2.52s average)
Is that per user? Can you calculate it per review or per 100,000 reviews?
It would be more useful
If performance.py is to be believed
sum(a[1] for a in sizes)=727666579 (revlogs total)
so assuming it takes 7 hours
100,000*(7*60*60)/727666579=3.46s per 100,000 revlogs
right
And the benchmark is slower than Anki because the time series split strategy.
I can’t because The computing complexity is O(kn^2).
k is the number of cards
n is the number of reviews per card
Gonna be honest, in my case at least, words I only practice through anki can stay with an extremely low stability even after 100 reviews, I plotted avg and median Stability over Repetitions and the result is a bit sad.
But I think it's a good thing to realize that anki-alone, bruteforcing words just by doing SRS, might not be a viable strategy. Most words that I have with high Stability are the ones with less than ~ 10 reviews.
Right now I'm playing with the idea of increasing DR higher. I think with DR too "warm" (60-80%), you fail too much, and my only guess is that failing can just "destroy" your learning cycle. I think if DR is higher, and workload is higher, there's a change that if I recalled a word a lot for a long period (instead of trying to do the bare minimum) then I might be able to encode them more effectively this time.
It's also why with only sum(R), all the CMRR and smart-computation of some "optimal DR" is pointless. I remember when @unique salmon tried R*sqrt(S), he got higher recommended DR from that optimizer for example.

FYI I've been using Anki and FSRS ~15 month ago, I have around ~80-90k review with it
Doesn't mean I'm necessarly "right" but at least I start to have a grasp of how it translates to actual learning in my daily usage of japanese. I'd say for now 1h of active immersion (lookup, analyzing sentences, going over and over some sentences, finding nuances) really really really push my further than 1h of Anki for now
I think that outside the algo-side of things, the problem with anki is how you can do it a bit in "bruteforce mode", not taking enough time, trying to go through all your reviews as fast as possible, with less chance to build a "network" of knowledge than when you analyze real life sentences
@quasi shadow I want to resurrect an old idea: use a neural net to calculate D as a function of (last D, grade, R). Then plot that output and try to come up with a simple(-ish) formula that approximates it. Basically, let a neural net figure out how to update D based on its last value, grade and and R, and then try to achieve the same output using simpler functions.
I wanted Alex to do it, but he said "beg Jarrett" 🤣
So you would have a neural net that takes D (a value between 1 and 10), grade and R as input and outputs D (again, between 1 and 10), and then you use that D in FSRS formulas as usual
Actually, maybe Claude 3.7 will help me
..nevermind
I just get errors in other, completely unrelated parts of the benchmark code
Rick astley never gonna give you up parody
#RickAstley
The original video this clip came from. https://youtu.be/6Mc-Thl1kTQ
Newest Rick Video
https://youtu.be/DBYMPrUKAXw
Actually no, it works, I just have to solve the least intuitive problem ever in the least intuitive way ever
Alright. We'll see how well it works
How many parameters does that nn have?
I haven't checked, but you can use the code here to replicate it: https://github.com/open-spaced-repetition/srs-benchmark/pull/192#issuecomment-2762238040
self.difficulty_nn = nn.Sequential( nn.Linear(3, 16), # Input: retrievability, difficulty, rating Mish(), nn.Linear(16, 16), Mish(), nn.Linear(16, 1) # Output: new difficulty )
class Mish(nn.Module): def forward(self, x): # Numerically stable version delta = torch.log1p(torch.exp(x)) # For large x values, use an approximation mask = x > 20 # Threshold where exp(x) would cause an overflow delta = torch.where(mask, x, delta) return x * torch.tanh(delta)
I tried this transformation on the forgetting curve and it looks pretty good so far. The values in the transformation were not fine tuned or anything, I only just eyeballed reasonable values and verified that they help on the first 10 users. I don't have enough cpu resources to test all 10k users
Total number of users: 557
Total number of reviews: 18550740
Weighted average by reviews:
FSRS-5-dev LogLoss (mean±std): 0.3376±0.1709
FSRS-5-dev RMSE(bins) (mean±std): 0.0516±0.0336
FSRS-5-dev AUC (mean±std): 0.7061±0.0840
Model: FSRS-5-recency
Total number of users: 557
Total number of reviews: 18550740
Weighted average by reviews:
FSRS-5-recency LogLoss (mean±std): 0.3406±0.1735
FSRS-5-recency RMSE(bins) (mean±std): 0.0542±0.0354
FSRS-5-recency AUC (mean±std): 0.7112±0.0780```
I'm not sure what is going on here, can you explain?
i take the original R predicted from the current forgetting curve and then input it into the blue function to shift it a little bit
def forgetting_curve(self, t, s):
base = (1 + FACTOR * t / s) ** DECAY
l = 0.1
r = 0.995
p = 1.07
return l + (r - l) * base ** p```Ah. That's interesting, but it has issues. Your version cannot predict anything less than 0.1 and more than 0.995
I'd like some sort of transformation such that R is still between 0 and 1
not necessarily a big issue since it helps the average case a ton and we can fix it like how RWKV would fix it
add a term that decays immediately, and another term that decays very slowly
this would make it so that t(0) = 1 and t(infinity) = 0 still
but you get the same effect
Also, remember that different values of decay are optimal at different retention rates
I think that's what we should be working on
Using the same curve for everyone isn't optimal - flatter curves are better at higher retentions and steeper curves are better at lower retentions
maybe you're right but this is already a huge improvement
and the values weren't finetuned yet
https://www.desmos.com/calculator/lzzgd5gz0s
I tried this before. My goal was to make a curve that falls off very quickly initially, but after that is more or less the same as the original
It helped a little bit, but not that much. And I don't want to make the curve flatter - it's better for higher retentions, so it will get better metrics on average, but screw up people at lower retentions


The next "big thing" for FSRS should be better D or a curve with an adaptive shape. Ideally, the former would lead to the latter
is this with your custom dataset? can you try my shift function on it as well
No, this is just the first 1000 users
If you want the custom "uniform retentions" dataset: https://drive.google.com/file/d/1iHq26LpDOlCWBSHeymjy6koSWnaodBrR/view?usp=drive_link
Google Docs
how much worse is lower decay for the lower retention people?
I haven't tested that, and neither did Jarrett, I believe. He only provided this graph that shows which decay fits which retention the best: https://github.com/open-spaced-repetition/srs-benchmark/issues/166#issuecomment-2652751232
You can try to determine how much worse yourself, the dataset only has 100 users, so it shouldn't take long


GitHub
Some time ago I plotted this for FSRS-4.5: https://i.imgur.com/DSjaW5e.png https://i.imgur.com/1JsW2Jy.png (can't upload images directly for some reason) While the exact numbers will vary depen...
in that picture it looks like 0.5 decay doesn't even target the average case
Yeah
well couldn't it be said that it's way worse for the 0.8-1.0 retention judging by that graph
so just taking the average would balance it out a bit?
"Optimal" decay is around 0.15-0.2 or something like that
Not on the uniform dataset
I mean, decay that results in the best metrics on the whole dataset
then we need to investigate how much worse is 0.2 decay actually for the lower retention users
sure 0.6 might be optimal for them but maybe the logloss difference is negligible
Again, this is just 100 users
i dont have cpu resources rn
The more users I add, the harder it is to keep retentions uniform
So I had to only use 100
Since retentions aren't uniformly distributed in the big dataset, so I have to "cherry pick" users
i still have doubts about the validity of the uniform dataset
people with retention < 0.3 are probably not using anki like the rest of us
It's just to have something where we don't have to worry about the results being screwed by data imbalances
I'll test how much worse different values of decay are for users with different retentions once I'm done with NN D. But that will probably take a while, especially since I will have to give you the code so that you can actually do something like:
for R in r_range: for D in d_range: for grade in [1, 2, 3, 4]: new_d = neural_stuff(R, D, G)
And analyze it
Realistically, you will have to run this on the entire dataset and somehow find the median parameters...or something
idk
u mean the parameters of the nn?
Yes
i don't think you can average the params of an nn like that
you should pool the data from 100 users into one set and do a joint optimization over all of that data
And you should probably pretrain it, which I don't know how to do. I'm just praying that it will work well enough without pretraining
I mean, if you plan to run it on individual users
i think it'll be bad without pretraining
Well, then we're back to me asking you or Jarrett to do it
Which historically had a 50/50 chance of being realized 🤣
i don't think the nn should be optimized per-user since that would be akin to changing the formulas themselves on the spot
instead train it on 100+ users, freeze the params, then analyze and extract formulas from them
There you go
The floor is yours
Look at class FSRS5(FSRS) and this:
self.optimizer = torch.optim.Adam([{'params': self.model.w}, {'params': self.model.difficulty_nn.parameters(), 'weight_decay': 0.0003}], lr=lr)
Alternatively, you could tell me how the hell to combine revlogs of multiple users into one
Idk if my RAM can handle that though 🤣
keep the revlogs separate, then on each iteration randomly sample a user's revlog and do a training step on that revlog
Rick astley never gonna give you up parody
#RickAstley
The original video this clip came from. https://youtu.be/6Mc-Thl1kTQ
Newest Rick Video
https://youtu.be/DBYMPrUKAXw
Logloss for users where the transform does better than the identity function:
transform: 0.3620
id: 0.3658
where the transform does worse:
transform: 0.1984
id: 0.1968
The transform does better on 88.3% of users
Is this on the uniform dataset?
Then it has the same problem - most users have high retentions
why do we not care about the average case?
We do, we just want to make sure that the worst case isn't getting even worse
almost everything you do will result in some user getting worse
with this metric we would reject most FSRS changes
And based on how often people complain about interval lengths and low true retention, making the curve flatter does not sound good
Making the curve flatter is particularly bad
Most changes improve FSRS's flexibility, this one doesn't
So this one definitely throws some users under the bus
you're throwing most users under the bus by not doing this though..?
i've shown in the stats that you improve the average case way more than the worse case gets worse
👆
arguably, every complaint about workload being high is an argument for a flatter curve
but you would never hear it framed in this way
If we flatten the curve, it will increase the number of complaints about long intervals and would likely make things even worse for people who go from, say, 90% DR to 70% DR
Let's just work on D for now
Except I need you or Jarrett for that
also i maintain that FSRS memory should try to be as pure of a predictor as possible, but the scheduler should be allowed to fudge values in order to improve user experience
Claude isn't going to help here since I would have to feed it the entire repo and not just a code snippet, for it to figure out how to do pretrain
the uniform dataset does not measure people who go from 90% dr to 70%, we need to find vacations in the revlog or something
we just don't have much data on this type of user rn
And we won't, since Anki doesn't keep track of DR
So we won't get data annotated with DR values
well, i'm guessing that most data is from SM-2 anyways
Anyway, I'd really like to focus on NN D, which means running this code on one mega-revlog, which means you and Jarrett are the bottleneck

i have other things to do
@quasi shadow would you please run this on a combined dataset of 100 users and save the resulting parameters of the neural net?
(look at the FSRS5 class and at self.optimizer = torch.optim.Adam(...), that's where the changes are)
ok simple. make FSRS have a lower decay for the memory model, but when scheduling a card use a curve with a different decay for better user experience
it is already inaccurate since you are using an inccorect decay
How does this make any sense? How will R be calculated?
Just, no
That's a terrible idea
You'll get a model optimized for one curve working with a different curve
There is no way it will be good
a decay of -0.2 models memory better
but it causes longer intervals
so when scheduling, use a decay of -0.5 to get shorter intervals
but when you do DS updates, go back to -0.2 decay
since that more accurately models memory
in some sense it is pretty much doing the following: take a user's DR, add some value 0.05 to it or something, and pretend its that instead
I first proposed NN D, like, at the end of 2023 or something
but this is actually what anki currently does with the wrong decay of -0.5! i'm asserting that this is stupid, we should just use -0.2 decay since it more truly models memory
you are lying with a wrong decay just to get shorter intervals
and with my 0.2 -> 0.5 convert for scheduling idea, i'm trying to get back this weird anki behaviour
since you want it so much
but we can have a proper underlying memory model that remains as true as possible
@polar maple alright, since I don't know how to combine revlogs, I'll just use the revlogs of The Big Dude - the user with the most reviews out of the entire 10k dataset, which is this one: https://drive.google.com/file/d/12CyIVPjtctpj2p6H6PFruccLY9NBbGyQ/view?usp=sharing. He has 4 million reviews. Sheesh. Bro, I have 600k reviews and I thought I'm a power user. Whoever this guy is, he is the king of power users. Either he has been using Anki since 2006 or he is doing some kind of crazy number of reviews per day.
Anyway, I'll run FSRS-5 on him and then I'll experiment with NN D with regularization and see if I can make it perform better on just this one guy. Then I'll just draw conclusions about D'=f(R, D, grade) from that
Google Docs
Though I still have no idea how to extract parameters for the neural net after training
I've changed the way I rate cards (previously 4-button, now 2-button) and created a new preset for the cards I've been learning with the 2-button method and will continue to optimize the FSRS for that preset every few weeks. This preset currently at around 700 reviews and has about 7-10 cards/day added to it. (RMSE is like 10% if that matters, but I think it's higher bc it's a younger deck so I'm too worried)
Should I back-port those values to the older decks/presets? An older deck and preset started back in FSRS4 (and maybe before) has something like 73k reviews and an RSME of like 3.47%, with values separated (and different) from the younger deck, but with no new cards beieng introduced. Or should I just optimize the values within that preset?
I don't want to combine the two decks into the same preset as I wouldn't want the older easy/hard values to get accounted for within the newer preset's algos, but would instead just hand-copy them if this is idea isn't a crazy one.
what user id is that guy?
I doubt that creating a new preset after changing from 4 buttons to 2 buttons is worth it, honestly. Just keep all that in the same preset
It won't mess up FSRS
Do you think it'd be worth if I switched the order I introduce the cards? Like I always found card1 harder, but card2 would show up more often and remind me of card1 even though card one was the thing i needed to work on irl production vs recognition in a foregin language).
now that i'm typing this out i'm not sure it'd make a difference because fsrs isn't tied to which side of the card you're looking at, but the difficulty at which they're assigned and how you rate them at that assigned difficulty, kinda
thanks!
If you mean siblings (https://docs.ankiweb.net/studying.html?siblings-and-burying#siblings-and-burying), FSRS treats them as independent cards, each with it's own review history
Ok, yeah, I tried saving parameters but I just keep getting errors.
@polar maple so what this means is that I will try different levels of regularization, find something that works, and then have to give the code to you, and then you will have to run it on your own again (on user 6810 from the 10k dataset), and THEN you can do
for R in r_range: for D in d_range: for grade in [1, 2, 3, 4]: new_d = neural_stuff(R, D, G)
And THEN we can finally analyze it
I did some play around with the vizualiser again and I came to some observations/interpretations/conclusion :
- For people "difficulty hell" (w[7] < 0.01), you'll basically get "difficult class" based on how much you failed a card. Cards with each lapse will go to a worst class, but won't realistically come up.
- To get a better idea of how your interval will grow, it's better in the vizualiser to start with enough fail to represent the number of lapse you can have in your normal card life (~10)
Now it gets interesting :
- Assuming you do the "perfect sequence" of 3 and 1 based on our DR (For ex, DR=90%, 9 '3' for 1 '1'), based on your DR, you might or might not get an increasing Stability/Interval after each lapse.
- In my case, with perfect sequences of 80% DR, after those all initial fail, I won't get an increasing Stability. I only get it when I start to be north of ~84% DR.
- If I do perfect sequence of 90% DR, the Stability at the end of each lapse increase ... until it doesn't. When you look on it, you realize those cycles got a final stability higher when because Difficulty got a bit lower but when Difficulty get lower, a mistake is now more impactful.
Based on that, my current interpretation is :
- While increasing DR will theoretically increase stability, if you keep repeating those lapses, it will just plateau higher, at a higher workload.
- While your stability increase through repetitions, if you're not able to overperform FSRS prediction on your way up again, you won't really get better result (stability increasing past the plateau)
- To get that never-ending increasing stability, you'd have to naturally, compared to FSRS prediction, outperform it a bit more each time. It sound obvious, but in my own experience with Anki, it feels doing Anki alone is not really achieving just by doing reviews. There's a lot of potential discussions/theories to have on this, but it's a bit out of scope for now. But still, it might show why Anki is not a bullet-proof solution for long term learning. It might be a just a "short/mid-term optimizer of memorization", without necessarly being strong on the long run


Yeah, I've said before that currently D is just a fancier lapse counter
You probably have tested already, but what about having D have also exponents more than multipliers ? What I mean by that, is that even if a card is now becoming "one that would never got lapsed again", it won't potentially since the step are very very small, but with an exponent, it could (if necessary) reward long sequences of good answers to make it "move back to lower D"
Well, hopefully soon we'll figure out a good way to change D by imitating the outputs of a neural net
Assuming "neural D" can outperform normal D. And assuming I can somehow convince Alex/Jarret to help me
this #1282005522513530952 message ?
A sad but also possible option is that even with a new formula or a NN, we might not see gain because well, most user in the datatest are people that rarely really transformed a "High-D" into a low one.
Having no limits on D could mean having lower and lower interval for each lapse, which should in theory increase your R and thus reduce their difficulty, moving them from "higher D class" to "lower D class" step by step
Thing is, how often does it happen
If it doesn't happen that often, it's the kind of thing that RMSE/logloss won't measure that much
idk 😂
it feels like D is pegged at 100% the moment I fail a card once
It's also purely a highly subjective observation, but I feel like cards that never lapsed get too long intervals, while cards that lapsed even once get too short ones.
For example :
All my -is:new cards : 3277 cards
-is:new prop:lapses>8 prop:s>21 : 5 cards
-is:new prop:lapses>7 prop:s>21 : 10 cards
-is:new prop:lapses>6 prop:s>21 : 13 cards
-is:new prop:lapses>5 prop:s>21 : 17 cards
-is:new prop:lapses>4 prop:s>21 : 27 cards
If I take those 27 cards, I see they have then probably too large D since the lower D one is 95% and I failed it once for the past year, and succeded it ~20 times.
So that card, could benefit from it.
But even if all the 27 were benefiting, it's <1% than the total amount of card. logloss/RMSE wouldn't flinch on that


why the s>21?
I only take the mature (in a fsrs way)
How much mature cards do I have, that had at least 5 lapses
I have 1474 mature cards, 1447 of them never lapsed more than 4 times
Only 27, lapsed and were able to become mature
1.8%
but I'd venture to guess that an exponential difficulty would probably benefit the young cards more? because more leeches are probably young cards?
996 mature cards never ever lapsed once
I mean you're right anyway because we know it doesn't work 😂 #1282005522513530952 message
Well
It's true that I checked
with 99% difficulty, and starting from 0.1 stability, I need 25 good reviews to go to 21 stability
but still
You'd expect after >100 reviews you'd find a way to be able to recall it ~98% of the time
But yeah
I'm not sure how large and impactful on a collectiion-level it would be
Probably because most people dont' have enough actual case of those
We talk about it because we wish we had a lighter backlog because of that
Truth is, we just lapse and FSRS just got it right without us thinking we surely have improved when in fact we have not 😂
I'll just try to blame the cards instead of my memory 😔
What worries me a bit is how the simulator basically goes into an equilibrium of ~200 reviews every day forever.
seeing that is what made me turn suspend leeches on (at 14 lapses)
Just not learning it seems rather counterproductive
Thing is, if you stick to your DR, you're stability will plateau
And the simulator is simulating you sticking to your DR
Normally, you should outperform your prediction at some point
if you're improvin
nothing to say i cant come back and make the card better
I haven't hit the set DR in ages
What's the difference ? And RMSE?
Also, LB/Fuzz will lead you to a lower Daily Retention than your actual DR
DR is 90%, on good days I have 88% at best. Realistically more between 80% and 85%
Yeah 90 for 80-85% seems normal if you don't hijack the LB in my own experience
I'd expect the actual DR to be higher than 90% though, if all was well
given each note spawns two cards with huge cross-bleed between them
Another thing is that FSRS adapt to make you fail more if you outperform it
So normally you'd be sticking to 90% with increasing Stability if you optimize often
If you never optimize, then you'd outperform the DR
I think FSRS got poisoned by the early stages of the deck
Cause those are a) easy and b) appear every day everywhere in content I consome
And the first ~year or so of the deck was mostly that
How many reviews total do you have ?
like, just accross all cards you mean?
Yep
Where do I even see that?


with 217K reviews I think your early phase is not an issue 😛
also FSRS use some recency weights now
If I'd let FSRS do as it pleases, I think it'd ruin my retention
I'm still using the Parameters thar Jarred hand-tuned for me, and specifially disabled short term stuff, since it was highly detrimental
With the anki Search Stats Extended plugin, a nice one is this one
You can see the average R of your next day like that

For example, even if my DR is 86, my avg(R) is 82.39

so with RMSE 3, having a 79% would be perfectly normal for my DR=86%
Fuzz/LB is one part culprit, but the low stability cards are something we can't do much about
Two weeks ago, I had a span of 5 days where I averaged at 75% actual retention
and now it's back to ~85%. No idea has happened there.
unless there is a change in how you are learning you should not be expected to outperform your prediction, so i wouldn't call this normal
unless of course that FSRS is wrong about the prediction
but if there is a perfect memory model you wouldn't 'outperform' it in the same way you cannot outperform a coin flip
what's the error when you try saving the parameters?

GitHub
Contribute to open-spaced-repetition/fsrs-trained-on-simulated-data development by creating an account on GitHub.
According my previous simulation, the optimizer tends to flatten the forgetting curve even when the real decay is -1.
If we could find a mechanism to explain it, I would consider use -0.2 as the decay.
Otherwise, the flat forgetting curve may be just a cheat.

This is the decay used to generate the simulated data.

However, the optimized decay from the simulated data deviate the real value.
how was the dr selected? I only see an 0.8 in there and some of the graphs are quite centered around 0.8
if only values near 0.8 was possible then i can see decay not really being represented
The DR is fixed in 0.8 and I add fuzz to the interval.
@quasi shadow I wonder if there is some sort of bug somewhere. I think you can investigate by trying something like: freeze all parameters except for one and optimize, see if the new value is similar to the old value
i think the improvement in log loss is unreasonable given the sample size
OK, I will try.
Is the simulate function this one? It doesn't seem to use w[19] which contains the decay value
https://github.com/open-spaced-repetition/fsrs-optimizer/blob/main/src/fsrs_optimizer/fsrs_simulator.py#L91
You need to switch to the branch Expt/trainable-forgetting-decay
also you can try to uniformly sample a DR whenever a card gets scheduled to get full coverage

🤣 Now it converges to 1.0.
I think the decay parameter tends to compensate other parameters' error.
in a cheating way...
OK but maybe the new set of params will miraculously predict new data better than the old parameters?
this would be another bug test i guess
so maybe you can try to generate another set of data with the old parameters, and try the new parameters on them
so this way we can see if it is just overfitting very well or if it is actually generalizing
But if it is generalizing then i expect there to be an underlying bug, it just wouldn't make sense at all
What do you mean?
Evaluate the new parameters on the simulated data?

Oops, some weird things happen

old params generates two sets of simulated data, s1, s2
new params are trained on s1
new params are then tested on s2

OK, I will try.
i think this sort of thing wouldn't appear frequently in the 10k set given how much of a logloss improvement 0.2 decay seems to give
if it is hard to distinguish like in that plot, it wouldn't give such a log loss improvement
so maybe this is just a problem with this specific simulation, idk


cool, then there is probably no bug and it really is just the case that decay doesn't seem to matter in this optimizatoin
but why do you say that decay is cheating here?
For this case, I wouldn't to say that.
But it's still a problem.
The optimized decay should be 1.0 insteal of 0.35.
I will combine simulated data with DR = 0.9, 0.8 and 0.7 to optimize the parameters.
I disabled it.
ok, what if you only freeze decay to 1.0? how much worse does it overfit than if you allow it to freely learn?
it could just be that in this specific simulation there isn't enough spread for decay to truly matter




OK, let me try.


what about the values on s1, the data it was trained on?
not surprising that it generalized better; in practice for the 10k set we don't need a trainable decay either, we would just lower the decay from the constant 0.5 to 0.2
which would be kind of similar to what you are doing here actually, imagine if you instead froze decay to 0.5 in this simulation, you would expect it to generalize worse than if you froze it to 1.0
we can still use trainable decay if it does better on the metrics though since we don't cheat with the 5-way split 🙂
My concern here is, as @bold terrace mentioned before, when the DR is decreased from 90% to 80%, the true retention is decreased from 85%+ to 60%+. (I forget the specific figures, sorry)
If we lower the decay, this problem would be worse.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
@polar maple another problem: if the model is perfect , the retention range will converge to a point: desired retention.
we only have his one anecdote. we don't have any other data on this. But we know that changing decay results in better predictions for ~90% of users, that it already proven. So why are we so reluctant? If the criteria for any change in FSRS is to improve on 90%+ of users then most changes would no longer be accepted
this is an issue with trainable decay, but with fixed decay it should be fine or you use some form of heavy regularization
Because I have a strong prior: https://supermemo.guru/wiki/Exponential_nature_of_forgetting
The current power decay is a compromise.
actually one of my first experiments was a weighed sum of exponential curves but it did very poorly
so I think this assumption is just wrong
luckily we have tons of data now to prove it
Fine, I will do another experiment later to verify my assumption.
but either way isn't this off topic? changing decay from 0.5 to 0.2 is still going from a power curve to a power curve
I wonder the reason why the decay tends to become lower and lower in previous simulation.
Even when I extend the retention range.
what happens if you freeze it at 1.5?
perhaps in the range [0.1, 1.0] the decay value is easily compensated by the other parameters, so the gradient descent just makes it end up near the middle
you could also make it train for more than 5 epochs to see if more interesting stuff happens
I will try it tomorrow.
@polar maple

GitHub
Contribute to open-spaced-repetition/fitting-forgetting-curve development by creating an account on GitHub.
The sample data is generated by exponential forgetting curve.
However, the power forgetting curve fits it better.
isn't this the same hetergogeneity problem? if there is always this problem, an exponential forgetting curve may as well not exist