#FSRS Megathread
1 messages · Page 5 of 1
I remember that there was weird unintuitive stuff with compounding, but it should only affect intervals >=2.5, no?
And here #1282005522513530952 message
ah !
Yes sorry
If interval >= 2.5
soooo stability 1 with DR=79% it will mach
Or stability 1.1 with DR=80%
@bold terrace heres some motivation to get anki to build on your system, change that 2.5 to like 7 and see waht happens
and then you can do the leech thing everyone wants but I still don't even understand
You know
Recently I realized in 30min I can do ~300 reviews
So with this discussion I could have done 300 reviews extra today lol
Soooo unfortunately I had to remember to myself that Anki is a mean to learn the stuff I want and not the endgoal lol
You calculate how likely it is that a card has been successfully reviewed <=k times out of n reviews, given FSRS probabilities. If it's <1% or whatever threshold, it's a leech - it has been failed much more than would be expected
or you coulda been tricked into discussing here
But yeah sure I'll check to build it and try a few things
For now my focus is still to have the average median per day a bit better than what I did
so its just an alternate (or replacement?) way to tag something a leech?
Expertium, how you look on this change: delete 2.5 to 7.0 fuzz range here:
https://github.com/ankitects/anki/blob/9b5da546be49f37c8d6c286e09c86074b2f0c278/rslib/src/scheduler/states/fuzz.rs#L17-L21
Change the interval < 2.5 to interval < 7 here https://github.com/ankitects/anki/blob/9b5da546be49f37c8d6c286e09c86074b2f0c278/rslib/src/scheduler/states/fuzz.rs#L110
is this really that large a feature that you're trying to trick me into doing work?
Yes, and it should be able to un-tag cards as well, if they have recovered
oh untagging is interesting
Again, there are two (2) (duo) (два) (二) people on this planet who can do it, you and Jarrett
The problem with the current "leech" feature is that it's not bringing much to the discussion ... Saying that something is a leech because you failed it 8 time, is stupid when the whole point of FSRS is to "fail at an expected rate"
So people with lower stability, WILL have huge amount of leeches with that simplistic rule
yall should really learn how to do these thigns on your own
if I'm a bottleneck in any capacity things are just doomed
Yeah to be honest @unique salmon if you can do Python I don't see why you couldn't code other things too lol
Also, you're pretty much the full day in discord, so just cut 1h and learn rust 😄
We'll even call you Jarrett_2
I don't mind
Jarrett in a few months will go full proprietary route
We need our Jarrett2
Expertium the savior 😄
oh hes goin full sellout?
idk, this is the first time I'm hearing about it
Just joking lol but he said his company was building some FSRS app or something
But I'm joking
I'm sure he'll keep contributing ❤️
Ah, yeah, he said his company is making an Anki-like app
well expertium aka jarret2 it looks like you gotta step up
imagine the endless possibilities for Anki if Expertium learns Rust
I know right? golden age of anki
Lol
expertium learns rust
yea I can't imagine that
It's out of date. Please see the easy day simulator.

GitHub
Contribute to open-spaced-repetition/easy-days-simulator development by creating an account on GitHub.
Rust is not very difficult. But you need to learn git, IDE, terminal before it...
In short, become a programmer/developer!
😭 The number of notification on GitHub exceeds 30 again.

rust requires a lot of practice. Once you write a bunch of code. You get used to the borrow checker.
At the start I found it so difficult to get my head around. Now I don't think about it. I think it's like wa and ga in japanese.
Yeah. And the checker helped me overcome many bad habits about coding which formed when I wrote Python.
Reddit
Explore this conversation and more from the Anki community

In this video, I discuss Anki’s latest updates (25.02, 24.11, 24.06, 24.04, and 23.12), including a complete overview of the best settings to use with the new FSRS-5. I also cover new features, such as the option to select Easy Days to reduce your study load, the CMRR, the new statistics, and the benefits of the FSRS Helper add-on.
⍟ OUTLINE 📋:...
It's coming soon!
when tag deck options coming
i have a question with fsrs helper add on optimization again
paremeters were optimal and i rescheuled with fsrs helper addon
and finished all cards, then i tried to reschedule again and no cards were added
this was yesterday
and today, i have reviews to doo and i click reschedule and this time it changes the # of reviews and gave me some more
why did it give me some more with the optimization of today
Could you share the screenshot of the Future Due graph before the rescheduling and after the rescheduling?
I wonder you have more reviews due tomorrow and the helper tried to apply load balance for this case.
For example, if you finished 100 reps today and have 110 cards due tomorrow, the helper may reschedule 5 cards to today from tomorrow.


The number of card due tomorrow decreases (141 - > 130).
How many cards did you review today?
0
🤔 some weird things happened.
Could you send your collection file to me?
I want to reproduce this problem.
is it possible to send the deck only with all the boxes checked or no
my collection is huge and my internnet is very very slow
You can exclude the media file.
okay i sent it 👍
Thank you. The issue is that the previous one allowed me to simulate pure fuzz (no LB), which is good for establishing a baseline. I don't know how to do it with this code.
Oh, wait, I'm dumb. I can just set all weights to 1
Alright, now we wait for 12-13 hours for a crapton of simulations to run
@cosmic hedge I improved the graph to have the median / avg based on the true values and not the bins (So instead of having a bunch of 16d stability and then a jump to 17d, you have a more incremental progress)

GitHub
Hello !
In action :
CleanShot.2025-03-03.at.21.12.10.mp4
I don't think I'm completely finished with this one, I'd like to do some extra ...
I'm just glad that ```js
const sorted = day.map((count, index) => Array(count).fill(index)).flat()
The most inintuitive piece of code lol
I think Copilot gave me that one 😂
Problem with the new one is that basically I build the full list for each day of each stability
I check my process manager but the RAM doesn't seem to explode
so I think it's fine
If your really concerned about memory usage you might be able to return the values from the memorised function rather than store them all to calculate on the fly from the array
if that makes sence?
but "so long as it works" 😂
For the average it would be possible yes but for the median it's not that easy I think
I saw there are some algo to compute the median with N/2 space for each array
And I don't know when the revlog is built, if we have "all things for one day" before going to the next one
(to be able to discard the previous day each time)
I just meant still build the array in the function you just don't return it so it gets garbage collected when its done calculating
and instead return the median and mean for each day
yeah honestly i'd probably prefer just returning the array
Opening stats make the memory go from 250MB to 450MB but then it doesn't grow much more when I trigger Memorised graph
Yep can also be useful for other graph
before -> after
this change basically doubles memory usage of the entire addon but its only 50mb so does it really matter?


^

You open anki in chrome or something ?
My SxR heatmap would never have been finished without being able to use the Inspector. The number of times the cells all went to something like x=-3000 because I did my maths wrong 😂
It's definitely helped me get out of a pinch or two 😂
I mean, it is a statistical test. It's like scipy.stats.binomtest with alternative='less', but using a generalized distribution so that we can do math when the probabilities aren't all equal. In fact, you can check that when all probabilities are the same, binomtest gives the same result
(I have no clue why it's so slow though 🤣)



the problem is that in this sort of process you are taking the unluckiest moment in time of a card and that can bias the results. What I want is some sort of correction factor to ensure that some specific value like only the bottom 1% of cards is eventually flagged
a basic correction is that where n is the number of reviews, only flag if it is under the threshold 1% / 2^n
That's why it should be able to remove the leech tag as well if the p-value was <threshold at some point, but went up after more reviews
Bro, freaking nothing is going to get tagged with that threshold
that's sort of the point, if you don't have a correction you might have many many cards that are wrongly tagged as leeches
and i don't want many false positives
i want leeches to be informative
is the current leech system informative?
not really
We can set the threshold to 0.1% or 0.05%. But not 1% / 2^n, that's crazy
And I'm pretty sure that's not how you correct the p-value threshold anyway
okay let's hear it
if we knew in advance that the number of reviews that a card will have will be n, then we can use 1% / n or something
but we don't know it, so at the very least we can bound the total threshold by a finite number: 1% / 1 + 1% / 2 + 1% / 4 + .... = 2%
that's where teh 2^n comes from
this argument is fine and all but apparently I'm the one actually doing the work so that means I get to decide all the numbers right?
🍃
not wrong
on a more serious note, @unique salmon given your previous examples how would these proposed numbers look in that situation
I can barely count to 5 so I need it explained
I'm not sure if there even is a correction in the sense that you are thinking about
There is this: https://en.wikipedia.org/wiki/Bonferroni_correction and other corrections, but that's not exactly what you're thinking of, it?
In statistics, the Bonferroni correction is a method to counteract the multiple comparisons problem.
I don't understand the question
don't worry my mind is a jumbled mess right now
that's where / n comes from if you know that a card will have n reviews
I don't think I do either
maybe: you're complaining about his numbers being too whatever, how would that actually affect this
makes stuff never be flaged, but how many WOULD it take to flag something?
I feel like I am spouting nonsense I don't know whats up with my brain right now
If you want an example, here
5 reviews, each was done at 90% probability of recall (predicted by FSRS). 2 successes, 3 fails. p-value would be 0.856%, meaning that there is a 0.856% chance that this card would have this many or fewer successes (aka not Again), given these probabilities.
The first review and same-day reviews are unused, btw

Why 1% / (2^n) instead of 1% / n then?
we don't know n, the number of reviews that a card will have in its lifetime, in advance
but sure, can try / n
since 2^n is about as arbitrary
We just use the current number of reviews
yeah it will still overestimate though
but you still have to give proper reasons why we cannot use D
remember that from FSRS's perspective, even with a card with a low history likelihood, its probability from then on at that point should still approximately hit the DR if FSRS is modelling well
that is, the history likelihood should have no bearing as to the future R
You have got to be kidding me...
Do you really not agree that using the number of Agains AND probabilities is better than ONLY the number of Agains?
well of course it is better, but it shouldn't be used in that way, rather you should instead let D be updated using the probability instead of just Again
unless you are suggesting that probabilities helps with memory modelling, in which case, introduce it to FSRS already, prove that it helps!
D already predicts well, we know that from FSRS's performance
Tried it many times, didn't improve the metrics
then find another way
unless you admit that historical likelihood doesn't predict anything at all
in which case, this leech idea is pointless
Probability of recall is used in the S formula
And post-lapse S
btw, it is also technically in D as well in terms of the transition probability
Anyway, here's a good correction: https://en.wikipedia.org/wiki/Šidák_correction
I can look into modern papers to see if I can find something better
In statistics, the Šidák correction, or Dunn–Šidák correction, is a method used to counteract the problem of multiple comparisons. It is a simple method to control the family-wise error rate. When all null hypotheses are true, the method provides familywise error control that is exact for tests that are stochastically independent, conservative ...
then find a formula that users D + S or something for leeches
remember a core hypothesis of FSRS: the entire memory state can be summarized as 3 variables: D, S, R
to say that historical likelihood is used for leech detection is to say that this is not true
It's not true for leeches
then, add historical likelihood to DSR and improve FSRS
make it true
I tried it and it gives almost the same values as Bonferroni, lol
- I have no idea how to code it using pytorch tensors
- Even if I did, FSRS currently doesn't store all past values of R, so this would require major changes to both FSRS and Anki
Btw, I bet Jarrett wouldn't be happy about 2
wouldn't 2) be an argument against your entire leech idea in the first place?
No? It won't be a part of FSRS itself, just an extra thing
Like the forgetting curve
Which requires recalculating all R values
for 2) then consider it as a infrastructure investment, idk
if you truly believe that historical likelihood is such a strong predictor, just use it in FSRS already
Oh, ok, I get what you mean now
We can use α for the first review (uh, second, but whatever), α/2 for the second, α/3 for the third, etc. But then the sum of all these terms diverges as n->inf. Yeah, that's a bit of an issue 😅
the intuition behind the 1 + 1/2 + 1/4 + ... version is that we might actually be able to interpret it as each card has ~2% chance of being tagged as a leech in its lifetime
but idk for sure
Ok, I have an idea
c=pi^2/6
threshold=alpha/(c*(n^2))
Basically, we use the fact that the sum of 1/n^2 converges to pi^2/6.
This way we ensure that the sum of all thresholds across the card's entire life approaches alpha as n increases.
Call it Expertium's correction 🤣
This still leaves the question: what's a good choice of alpha? 1%? 2%? 5%?
I guess we need some empirical data on how many leeches people have, and I mean subjective leeches
Now we just need to find people who are willing to go over all their cards and tell us how many of them they consider to be leeches
Actually, it should be threshold=alpha/(c*((n-2)^2)), if we plan to start using the detector only after there are at least 3 reviews to avoid early false positives, excluding same-day reviews and the first review. So we turn the detector on when n=3.
we can use a smaller exponent like 1.1 for 1/1.1^n as long as we divide out the sum as well
yeah pi^2/6 is cool
1/n^2 seems to have a lot of weight at the start, less in the middle, and more at high reviews (n > 80) compared to 1/1.1^2
high weight at the start can be beneficial to detect leeches early
#general message
Here comes the first data point

I'd say about 20% of my kanji cards are leeches, but that's because there are very similar kanji that are hard to tell apart, so I might be an outlier
#general message
So far the numbers are 1.5%, 5% and 20%
We really need a survey. The problem is that not a lot of people will bother counting
@polar maple there is a recursive way to calculate the PMF
`def update_poisson_binomial_pmf(current_pmf, p):
"""
Update the PMF of Poisson binomial distribution when a new Bernoulli trial with
probability p is observed.
Args:
current_pmf: List containing current PMF values
p: Success probability of the new trial
Returns:
List containing updated PMF
"""
n = len(current_pmf)
new_pmf = [0] * (n + 1)
# Update PMF using dynamic programming (working backwards to avoid overwriting)
for k in range(n - 1, -1, -1):
# No success case
new_pmf[k] += (1 - p) * current_pmf[k]
# Success case
new_pmf[k + 1] += p * current_pmf[k]
return new_pmf
def calculate_poisson_binomial_pmf(probabilities):
"""
Calculate the PMF of Poisson binomial distribution for a list of success probabilities.
Args:
probabilities: List of success probabilities for each Bernoulli trial
Returns:
List containing the PMF
"""
# Start with PMF for 0 trials: 100% probability of 0 successes
pmf = [1.0]
# Process each trial one at a time
for p in probabilities:
pmf = update_poisson_binomial_pmf(pmf, p)
return pmf`
But it requires storing the entire PMF, so it's still not ideal if we want to try to integrate it directly into FSRS
We either have to store all values of R or the PMF
Claude also made a normal approximation formula (with some correction for skewness) with O(1) time and space complexity, but it's...just look


It's ass
we can compute and cache the value so it shouldnt be a big issue
I don't think you understand what the problem is. Right now FSRS only stores one last value of D and one last value of S. It doesn't store any n-2 or n-3 or whatever values
So unless we want to rewrite a whoooole loooot of code (and in Anki itself too), we'd better only store one last value
it shouldn't be too hard right? we already have a full history of the cards including the S and D at each point in time, we just add another value to it
then we do the little O(n^2) compute to get the exact pmf after every review, so we avoid having to store the entire pmf as well
Man, screw it. Let's just implement the leech detector outside of FSRS
ah yeah i was talking about if implementing it for anki, oops
i think for the current data setup in other.py, FSRS will get the full review history explicitly at each review
so it should be simple to compute the pmf on the spot
can't you see it in the card info sectoin?
at the very least it shows D, but it shouldn't be difficult to add other information as well
Yes, but you can't get the scheduler to see it. Because...because
Idk, I guess "historical reasons"
Maybe Dae wasn't planning that far ahead, for the future where this is needed
I mean if you need some data structure in a specific part of the code, just pass it through the 20 functions till it gets where it needs to be
I'd say the only "historical reason" is that the code hasn't needed it there thus far?
In my view, we should build a dataset to train the leech detector...

Anki Forums
Assuming there are dozens of cards with revlogs, you can label them with leech or non-leech. Then we can train a classifier based on machine learning from your labeled cards’ revlogs.
The argument is not very helpful here.
Without data, we cannot validate the idea.

#general message
Another data point
So far we have 0.7%, 1.5%, 5% and 20%
That is strictly more difficult than using my idea
Since you would need many thousands of manually labeled cards, good luck collecting that
Yeah, it's difficult. But it's more difficult to me to implement an untested idea and get a rejection from dae.
Maybe you can ask someone else... good luck.

Then I guess it's over. Jarrett and Jake don't want to implement my idea with a leech detector based on FSRS probabilities, and training a machine learning based detector requires data that we don't have and won't be able to obtain unless we get like 100 insanely dedicated volunteers or something

advancedleech detection is qutie a high effort low impact though compared to other things
I had a go at doing it on my collection with a python script. It said ~24% of my cards were leeches 😂 .
I did not spent much time on it, and not filtering out same-day and [re]learn reviews probably didn't help.
If you used same-day reviews, then the results are pretty much worthless. Plus, you need to select the threshold properly: #1282005522513530952 message
If you care about researching in this direction, I suggest removing the first review and same-day reviews, and using alpha of 1% or 2% with my correction
I did it based on the original discussion before you considered a dynamic threshold. I just ignored the first 5 reviews and then had a static threshold of 1%.
I might have another look later, but cannot make any promises.


Anki Forums
@dae I want to bring your attention to this Right now we have two ideas for a new leech detector: this (with a little bit of extra math and rules not mentioned in this topic) and a machine learning based detector. The latter would require thousands, if not hundreds of thousands of manually labeled (leech/not a leech) cards, so that is not going...
maybe this will be the motivation you need to just do it yourself 🍃
In this video, I discuss Anki’s latest updates (25.02, 24.11, 24.06, 24.04, and 23.12), including a complete overview of the best settings to use with the new FSRS-5. I also cover new features, such as the option to select Easy Days to reduce your study load, the CMRR, the new statistics, and the benefits of the FSRS Helper add-on.
⍟ OUTLINE 📋:...
"CMRR" ... "Optimal"...
This is what drives me crazy with how much bad faith there is
When you point out how CMRR issues people say "It's why it's the minimum recommended, it's not an optimal"
But then when no one points out the issues
"It's the optimal DR"
Incoming waves of people trusting the CMRR and putting their DR at 70% with a true retention at 50-60% because FSRS was trained on their 80-90%
This you?

This me
Isn't it beautiful how card stability improves slowly but surely with time ?

The declining phase was when I was doing 40 new cards per day

This one is without adding any new cards per day
It shows how stability improve better at first then improves more slowly based on repetitions
And with a balanced number of new/day, of ~8-10/day

I'm wondering if Higher DR means faster Stability Gains
With default parameters and DR=90%, 3 goods will make you have a 34 stability after 49 (cumulativeInterval)

With DR=96%, 6 goods will give you Stability 61 after 49d (cumulativeInterval)

So in that simple setup, you do twice the amount of review in the same lapse of time, but you get +44% stability
It depends
For low S lower DR is better for two reasons: S grows fast and the cost of re-learning is low
For high S higher DR is better because S grows slowly and the cost of re-learning is enormous
That's pretty much how SSP-MMC behaves
I see
When you say S is growing faster for lower DR
YOu mean faster "by review" ? Or "faster for the same interval of time"
S depends on R at the time of the review. Lower R = higher increase in S
So "per review"
Sure but also longer to wait before having that increase
But probably workload-wise more optimal
I guess I'll create a new Filtered Deck 😂 prop:s > 14d prop:r < .95 or something
1240 cards match it, ouch
(Over 3600)
That's pretty much what SSP-MMC does
It may be more time-efficient by a tiny margin, compared to a good fixed value of desired retention
Basically dynamic desired retention
i see
well at this point
arent we so far along that any gains in accuracy are like really low
like it could be more effective to get proper sleep & nutrition etc
According to simulations it's like 5% more time efficient over the course of 10 years, compared to a fixed value of desired retention
oh
gg
Right now I'm running simulations to see if we can improve load balance (spoiler: only a tiny bit), but that's like TWEAKING tweaking
Like, tweaking the tweaks of tweaks
Like, twenty layers deep into tweaking
Love me some 0.000001% improvements
we need sleep tracking in Anki
that's the next paradigm shift
repeating whatever SM does
actually it's not so clear anymore with my latest commit, if you give fixed DR the knowledge of the arbitrary rule of "a stability of 3 years is treated as infinite stability" then the gap is mostly closed
but theres still hope, as jarrett said before SSP-MMC does not actually aim to minimize knowledge per minute
so there could still be some improvement somewhere
?
a very basic strategy is to never/rarely review difficult cards and only study cards with an initial rating of 'easy'
if you do this you can get a knowledge/minute of 1300 or so
but this is obviously not a good learning strategy
You mean "maximize knowledge per minute"?
Anyway, it does minimize time spent on reviews, right?
anki gambling
Unless I am somehow wrong even about that
i've heard before that SM will purposefully schedule difficult cards longer so you don't get bogged down in reviews by them
this strategy i just outlined where you only study cards with initial rating 'easy' is like that idea but put on its max
basically there whould be a spectrum of this idea where perhaps with proper leech detection, we purposefully drop the bottom 2% in order to increase knowledge/minute by a lot
That sounds terrible for maintaining retention at DR
ssp-mmc doesn't aim to achieve a target DR so its not relevant
Fair enough, I guess
Maximizing KPIs in jobs be like
IMO to know if something is better we should also wonder if the measure of better is good enough
The more I put importance on Stability and the more sad I feel about Knowledge not taking it into account
I was wondering if D should not also be taken into account though
To similar S and R you’d like a lower D no ?
Hello. (Still learning English)
Approximately two weeks ago I started using FSRS with default settings. After 1100 reviews I clicked the "optimize" button and then something weird happened. New intervals are HUGE. For example after I clicked the "good" button on the NEW card the first interval is 1,5 month. And huge intervals are also happening to the old cards, I learned before. I don't really know what to do. Now I'm learning with default FSRS parameters.
Desire retention is 0.90
Wait... I don't really know how the hell I done this but it seems good. I just deleted all parameters, leaving blanks space. Then some parameters appeared so I clicked "optimize" and now It works good. XD nevermind.
Yes sometimes 1000 can be quite few if for example you rate rarely as good first and when you do you never fail then afterwards for example
But if you have the same pattern again check what is the history of those cards if they are all good that might be it
Sometimes the best is to let them have those huge interval and review them again later, if you still succeed them then you’re just underestimating yourself
If you fail them a lot FSRS will adjust
1.5m is quite peanuts compared to the language learning process
And if really you want the shortest possible interval just crank your DR to 95-99

I'm not sure if you're joking or not. Thank you if not! BTW I just checked this "impeccable" word so my English is not impeccable🙂
😮
I tried this before and then the first interval was great (5 days instead of 1,5 month) but intervals for old flashcards were way too short. Shorter than Super Memo 2.0 intervals
Yeah but to be honest don't expect FSRS to match SM2 too much. The idea is quite different, SM2 is simply "old interval * ease_factor", while FSRS has 18 parameters to describe the initial "interval" (stability to be precise but if you're new with it, and have 90% DR, stabiltiy=interval), multipliers, exponents ...

So let say FSRS observed that when you rate directly "Good" a new card, in general, you never fail them 2 months later ... he will probably recommend you to wait 2 months before reviewing them again
In the opposite side, if you fail them almost all after 2 months, he will probably recommend you less, like 2w, 4w
sounds logical
But the problem is with 1000 review, you might have only 5% of your total reviews "in that case", so FSRS sometimes take a long time to learn those edge cases
Also, if you never had such long interval with SM2, FSRS optimizer is a bit "blind" in that area so it's trying to do educated guess, but it might be off
This is probably what happened to me
I'm learning for two weeks
Yeah personally I'd advice to keep FSRS enabled, and it will learn by itself along those next weeks/months 🙂 Hit "Optimize" as much as you want, and check the "Evaluate" button output (What does it say right now ? What's the "logloss" and "RMSE" when you press "Evaluate" ?)
I'll check it out
You see, the lower, the better. log loss can be lower by nature by having a higher Desired Retention, and RMSE can be lower by nature by having more reviews

RMSE can be more or less interpreted as "how much in terms of % FSRS will be wrong based on your history"
So in my case, ~90DR might very well lead to ~87-93% actual retention depending on the case
Before I did it the "evaluate" button showed something like this what you sent but now this appears:

Thank you for everything I think I should go with these parameters and optimize from time to time
No worries, feel free to ask if you have other doubts/questions ! Glad to help
@polar maple @ashen light @hasty fractal @bold terrace @sonic forge @quasi shadow just pinging everyone who may care, lol. It's Load Balancing time!
Alright, I've set up the optimization loop (using a Bayesian optimizer) to optimize these powers that are used in the load balancer's weight formula:
(1 / np.power(r, due_power)) * (1 / np.power(delta_t, interval_power))
due_power and interval_power are parameters to be fine-tuned. The range for both is from 0.5 (square root) to 3 (cube).
We have two optimization objectives here: average absolute difference between true retention and desired retention, which I called avg_abs_ret_diff; and volatility, which is a measure of how much workload varies day-by-day. Example: if you had 120 due cards today and 100 due cards yesterday, volatility=20%.
We want to minimize both. However, when minimizing two different objectives, you often run into a situation where you cannot make one better without making the other one worse. It's called a Pareto frontier.
So instead of getting one set of parameters as a result, we will get a bunch of Pareto-optimal (can't-improve-A-without-making-B-worse) sets of parameters.
Simulation parameters
maximumInterval = 36500
new_cards_limits = 10
review_limits = 9999
max_time_limits = 10000 (IIRC this is in seconds)
learn_days = 100
deck_size = 1000
sample_size = 5
retentions = [0.7, 0.8, 0.85, 0.9, 0.95, 0.97, 0.99]
For each value of desired retention, the simulation runs sample_size times, for a total of 7*5=35 simulations per each set of parameters. Then this is done 100 times for different parameters. The same seeds are used across all retentions, for the sake of consistency.
Here are baseline averages and their 95% confidence intervals:
Fuzz (no LB)
avg_abs_ret_diff=1.06%±0.18%, volatility=0.170±0.026
Current double-weighted LB: due_power = 2 and interval_power = 1
avg_abs_ret_diff=1.16%±0.16%, volatility=0.115±0.014
Current double-weighted LB (predicted by the Bayesian model)
avg_abs_ret_diff=1.06%, volatility=0.117
The first one is a "raw" experimental result, the second one is given by the Bayesian model after it has processed 100 experimental results. And by "experimental" I mean "simulated".
Notice how much volatility is reduced compared to random fuzz!
I wanted to add a table with Pareto-optimal values, but decided that it's better as a graph.
Also, I tested removing
{ "start": 2.5, "end": 7.0, "factor": 0.15, },
from FUZZ_RANGES entirely, so that intervals <7 aren't fuzzed.
I have attached a visualization of the Pareto frontier. Well, two frontiers.
As you can see, the frontier with the current fuzz ranges and one with that first range removed are nearly identical. I wonder if it's because the simulation duration is 100 days, and if the effects would be noticeable if it was, say, 15 days.
The "utopia point" is a hypothetical point where both objectives are minimized. It's not actually obtainable. What we can obtain instead instead is a "knee point" - a point closest to the utopia point.
So what's the best course of action given all of this? I suppose we can modify the powers. We can use due_power=2.150 and interval_power=3.000 (knee point), which would give us 0.88% abs. diff. in retenton and 0.115 volatility, which is better than the current implementation. I doubt anyone would notice a difference, but even more so I doubt that it would make anything worse, so I guess why not.

Not related to the message above me but I think one thing people are missing is that leech should not depend on what has already happened but what is going to happen to a card.
For example, if a metric starts at low and goes at a high after some time that's not a good metric. So volatility of the metric itself is something that matters. I know I've repeated this a few times before but that was a long long time ago.
If it doesn't depend on the card's history, then there is literally NO way to detect leeches algorithmically
"volatility" is key
more like, by looking at "history", if u can't say the future (which is the case if the metric is really volatile) then it's not working
we can look at history, but I'm saying the goal is in the future so that matters
We'll see how my leech detector behaves if Jarrett manages to implement it in the Helper add-on. Worst case, we can just add a rule that a card cannot change it's status as leech/not a leech after every review, only once per 2 reviews or per 3. Though I don't think we will actually need that, especially with the correction I described here: #1282005522513530952 message
If it's reactive enough to tell you something bad is happening right now, I don't see the issue though
You get a review wrong, but you didn't necessarly noticed it's the third time in a row with a DR of 95% ... Well, at least that detection would be useful
I may have completely messed something up, but the dynamic threshold didn't really work for me.
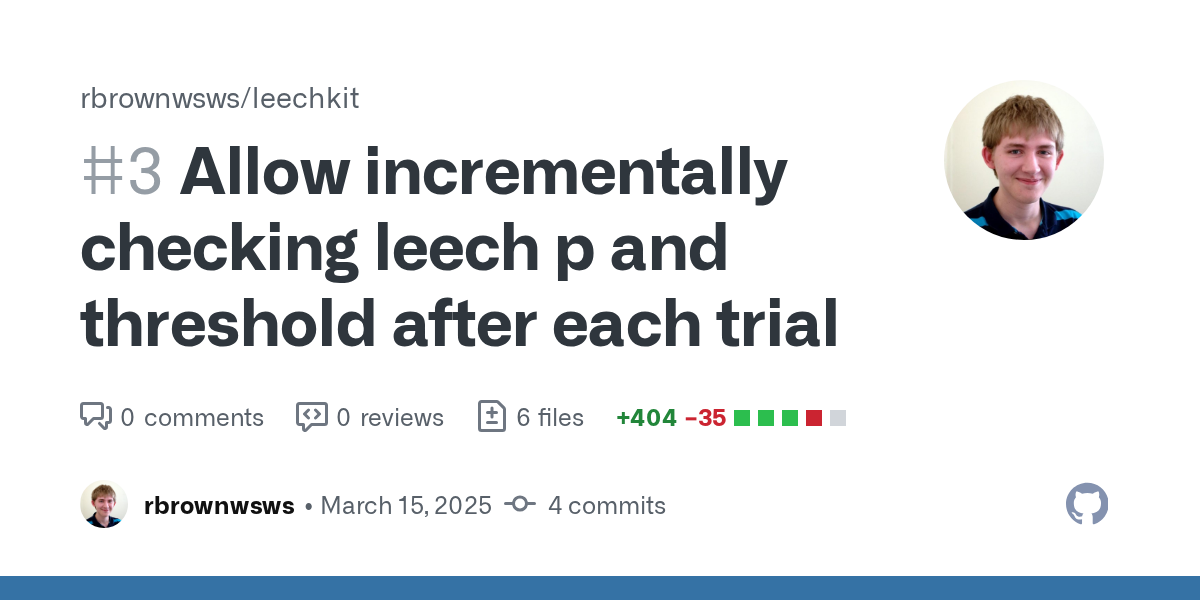
https://github.com/rbrownwsws/leechkit
GitHub
Contribute to rbrownwsws/leechkit development by creating an account on GitHub.
my loads have been balanced wow
yeah shove those numbers in go make a pr
you can do it
Oh, interesting. I guess the scipy guys added poisson_binom very recently. I had to update scipy, otherwise it didn't have that function.
Anyway, this isn't correct, I actually made the same mistake initially. You are getting p(successes=k), not p(successes<=k)
It should be like this:
for k in range(trial_success_count+1):
p += poisson_binom.pmf(k, trial_probabilities)```Alternative:
"""
Calculate the exact PMF of the Poisson Binomial distribution using
dynamic programming and vectorized NumPy operations.
Parameters:
-----------
p : array-like
Array of success probabilities for each Bernoulli trial
Returns:
--------
numpy array of PMF values for k=0,1,...,len(p)
"""
p = np.asarray(p, dtype=np.float64)
n = len(p)
# Validate input
if not np.all((0 <= p) & (p <= 1)):
raise ValueError("All probabilities must be between 0 and 1")
# Handle trivial cases
if n == 0:
return np.array([1.0])
# Initialize the PMF - we'll use a dynamic programming approach
# pmf[j] will represent P(X = j) after considering the first i trials
pmf = np.zeros(n + 1, dtype=np.float64)
pmf[0] = 1.0 # Base case: probability of 0 successes with 0 trials is 1
# Process each probability one at a time
for prob in p:
# For each new Bernoulli trial, we update the entire PMF
# We do this in reverse order to avoid overwriting values we still need
# The key insight: P(X=k after adding new trial) =
# P(X=k with no success in new trial) + P(X=k-1 with success in new trial)
# Calculate the effect of this probability on the entire PMF at once
# This is where the vectorization happens
pmf_shifted = np.zeros_like(pmf)
pmf_shifted[1:] = pmf[:-1] * prob # Probability of success for this trial
# Update PMF by combining the two possibilities
pmf = pmf * (1 - prob) + pmf_shifted # No success + success for this trial
return pmf```
And then just
```pmf = fast_poisson_binomial_pmf(trial_probabilities)
p = sum(pmf[0:trial_success_count + 1])```protip: use ``` instead of `

Ok, nvm, just commited again and it worked, lol
GitHub
Copying my Discord comment:
Alright, I've set up the optimization loop (using a Bayesian optimizer) to optimize these powers that are used in the load balancer's weight formula:
(1 ...


@unique salmon your post text references the 7day test stuff, which kinda distracts from the issue
It's relevant if we want to know whether removing that range is worth it or no
It's related to tuning the load balancer though
basically: this pr has a bunch of information that has nothing to do with the pr
whats gonna happen is dae is gonna ask about it
and this merge will be delayed for weeks over disucssing things that have zero relevance to what we want merged right now
So business as usual?
like for sure do the 7day stuff, just in a separate issue/thread
yeah but this is just chumming the fucking waters
my point is if you want focused discussion, leave out as much unnecessary info as possible
Alright
(and when you've fixed that go make an issue detailing the 7day stuff and paste all the stuff removed from this pr into that)
Meh
It doesn't seem like it's worth it
The only thing it would achieve is making Yuki and Sound happier 🤣
yeah who cares about them
Lol
let them toil in the leech mines
I mean, no offense to them, but that doesn't seem like a strong argument to tweak fuzz, especially if simulations show that it makes like a 0.001% difference
as they continue to fail short-term cards forever instead of just maybe studying that card harder or something I dunno
Maybe after the new tweak they will magically notice that fuzz now works better
I wouldn't bet on that, though
@unique salmon another thing: I notice that FSRS performs slightly worse in very low R range (for some of my deck I mean). Maybe we should consider that too. So, the threshold should depend not only on how many time you failed it but also on how many times you failed other cards in that R range if that makes sense. Wdyt?
That's a known issue, yes. However, I can't think of a way to incorporate that into the detector
one step ahead of me haha
btw, have u thought about calculating the optimal threshold for suspension using the simulator maybe?
because I think it shouldn't just be smth arbitrary
That's why I'm asking people how many leeches they have
#general message
Another data point
So far we have 0.7%, 1.5%, 5% and 20%
But we need an actual survey. The problem is that there aren't that many people who will go over hundreds or thousands of cards to report to us
I don't know why you want that honestly
that data in itself sounds arbitrary
I have 5% leech but I could've had more if I decided a different leech threshold
I just had a go with the successes <= k version and the threshold correction still seems to be wonky. I set the threshold to 0.9 and it still only found 3 leeches 😂 . Either I've messed it up or it doesn't work.
I mean whos to say someone didn't make the leech threshold something completely silly like 300
and so they have zero leeches
I may or may not be referring to myself here
sus
There is no other way
If people themselves can't decide on how many leeches they have, then this idea is doomed
Give me some data so that I can verify that it works correctly: a list of probabilities and the number of successes
I'd love to try it out myself so that I can just put print() everywhere, but I have no clue how to run it
u can't decide on the threshold by using CMRR sorta thing? (maximising knowledge:workload)

The second part just means "put the path to your Anki db here" if that's what you mean
Oh, yeah, I didn't know about uv
I mean "what is uv and where do I even input this"
Ah. The uv bit just sets up the venv, gets dependencies, then runs the python module.
You just run it in the terminal from the repo directory.
So if I want to put print() everywhere to see what's going on, how do I do that?
open your text editor and put prints in there
src/leechkit/detector.py is the main bit you would be interested in.
I get that
I don't get the rest
Btw, I made a PR, in case you didn't see it
Doing a bunch of math is the easy part, the hard part is running it on Anki data
Oops, I didn't see and did a similar thing separately.
What is the bit you need help with? If you make changes it should still work with the same uv run commands.
can there be a feature that instead of tagging, it just prints out the cards it flagged
So I downloaded the code from my github branch, what next?
If you don't give it --write it just prints the CIDs
oh perfect I just saw "This will directly modify your Anki collection. If things go wrong you may experience data loss." and walked away
like this:
Found leech - cid:1722559395989 - p:2.7166874125840693e-06 - thresh:8.993004465296252e-05
Found leech - cid:1722559396215 - p:6.650463663121781e-08 - thresh:6.907390375819012e-05
Found leech - cid:1722559396279 - p:2.4991422915605144e-06 - thresh:9.991497291245872e-05
I just don't want to accidentally break someone's collection if I mess up.
- Install
uvhttps://docs.astral.sh/uv/getting-started/installation/ - Find the location of your Anki DB (something like this on windows:
C:\Users\USERNAME\AppData\Roaming\Anki2\PROFILE\collection.anki2) - Close Anki
- Open a terminal and
cdto the local copy of the repo - Run one of the example commands e.g.
uv run -m leechkit PATH_TO_ANKI_DB
By default it will try to find leeches in the last deck you had open. See the README.md for options to twiddle with this.
You could also export a .colpkg, unzip it, and use the collection.anki2 inside there if you want to be extra safe. You cannot use --write and the deck browser to inspect cards if you do that though.
Found 35 leeches``` @unique salmon add this to your leech samples@cursive badge your thing shouldn't count new cards in the process count, those don't exactly have the opportunity to be leeches yet
(I manually removed the new cards from my numbers above)
It prints a bunch of stuff, not the stuff I want, and I get an error

Oh. I have no idea why stability would be 0 😕
For the record, this card is suspended and has never been reviewed using FSRS
It also has this for some reason

As a quick and dirty fix you can just do a search that excludes it. e.g. --query "deck:current -is:suspended"
Oh jesus, now it just goes brrrrrr
Can I limit it to, say, 10 cards?
I haven't put anything in to limit it because it didn't take too long with my collection. You could just manually tag the notes you want to play with and put that in the query.
How?
In the Anki browser add a tag e.g. test then give my script --query "tag:test". It should let you do anything you can search in the Anki browser I think.
Hello, watched the latest video about Anking 2025 settings, and got asked about using empty learning steps
are they recommended over single 10-30min learning steps as mentioned in FAQ?
Will empty learning steps be the default when FSRS are auto toggled in future releases?
well with the default settings, I went through the cids that it deemed as leeches and those cards definitely are leechy
Ok, the correction is insanely conservative. Let's just turn it off and use a flat 2% threshold. Correction makes it basically impossible for anything to be identified as a leech
The math on probabilities checks out, btw
With this code, btw: https://github.com/rbrownwsws/leechkit/pull/1
GitHub
Also, this is faster than
p = 0
for k in range(trial_success_count+1):
p += poisson_binom.pmf(k, trial_probabilities)
@cursive badge how do I configure the threshold in the query?
e.g. --leech-threshold 0.02
Oops. I did underscores in the README instead of hyphens
Man it's slow 😔
Btw, the "Checking cards" percentage seems to be bugged
Either it's bugged, or it will take longer than the age of the Universe to complete
But yeah, I'm going over cards that are identified as leeches at a 2% threshold, and they definitely feel like ones
I don't see any false positives so far
A lot of the slowness seems to be from jank, not inherently in the algorithm.
Anki was printing out lots of annoying messages about blocking the main thread. When I suppressed them the script became a lot slower for some reason.
Even if you don't @ me I see you
Even cards that ae just barely below the threshold, like 1.9%, feel like leeches
Interesting
I wonder if 5% would be ok
Then again, I have a ton of leeches
At least it is not like my first buggy implementation that claimed 24% leaches 😂
"After careful examination, we noticed your whole life is a leech"
Let's hope Skynet don't use your algo at some point
At least it's more gentle than Thanos
(24% vs 50%)
Processed 34472 cards
Found 120 leeches
That's 0.35%. I definitely have more leeches than that
Man, we need a survey so bad
I had a huge swing from the buggy version (you have >1000 leeches) to the fixed "dynamic" version (you have 3 leeches).
The current static threshold version seems to give vaguely sensible results.
Oh, sorry I didn't make it clear. I didn't see your PR at the time. By the time you pinged me in discord I had already done basically the same thing and pushed it to master
I left the PR open because I didn't know if you were going to rebase and add something else.
I can't find fast_poisson_binomial_pmf in your repo, even though it must exist
wat
how
Like, it's clearly used
But it doesn't exist
But it's used...
But it's nowhere to be found...
What kind of african american sorcery is this...
✨ magic ✨ (src/leechkit/pbd.py)

Processed 6262 cards
Found 44 leeches
Oh, ok
Idk why Github can't find it
(Seems for hiearchical deck it's not matching all of those)
What's your query?
(If I select "Japan" which contains a lot of deck, he found 0 on 500 cards)
uv run -m leechkit '/Users/<user>/Library/Application Support/Anki2/User 1/collection.anki2' --query "Yomitan" --flag --write
Are you looking at the right repo/branch? If you are looking at your fork and did not pull it will not be there.
┏━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┓
┃ Option ┃ Value ┃
┡━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━┩
│ query │ Yomitan │
│ skip_reviews │ 3 │
│ leech_threshold │ 0.05 │
│ dynamic_threshold │ False │
│ tag │ maybe-leech │
│ flag │ True │
│ write │ True │
└───────────────────┴─────────────┘
the default values 🙂
I'm on master
On yours technically
Try --leech_threshold 0.02
Btw @cursive badge --dynamic-threshold False doesn't work, idk why
commit c8379e0b52f3c61014c4f8d864f8cd954bcb3674 (HEAD -> master, origin/master, origin/HEAD)
Author: Ross Brown [email protected]
Date: Fri Mar 14 20 24 2025 +0000
24 2025 +0000
Processed 6262 cards
Found 21 leeches
with threshold .02
I think the cli library I use only accepts --dynamic-threshold or --no-dynamic-threshold
It worked !
│ No such option: --leech_threshold (Possible options: --dynamic-threshold, --leech-threshold, --no-dynamic-threshold) │
it was --leech-threshold
but apart from that underscore->dash, it worked fine
let me review them 🙂
ah wait anki was open
seems I need to close it first
It needs to get a lock on the DB.
Alright, so 2% works well, at least for me. Now we need to see how much the p-value changes after every review. Give me a moment
Actually, no, I won't be able to do that
Since I need the number of successes after every review, not just the most recent value
Also note if you are using --write it does not remove the tags/flags it added last time. You have to manually remove them first.
Ross, can you plot how the p-value changes after every review?
For any card you want
We need to see the dynamic
Well, preferably for a card that is currently at around 2%
So first observation, it seems indeed to be quite related with Difficulty, my 21 result, are on the "most difficult card"

Well, it uses the number of successes, after all
So of course there is some correlation with D
The one flagged that was in the "middle pack" of FSRS D, is one that indeed, seems fishy

it's the 2350 most "difficult" card over 3186
@polar maple come join us
#1282005522513530952 message
https://github.com/rbrownwsws/leechkit
GitHub
Contribute to rbrownwsws/leechkit development by creating an account on GitHub.
but indeed, from the look of the recent shape, for those, it brings some value
N.B. if you want to be able to play with plots you can do uv add matplotlib and it will add it to the venv for you.
It would be a lot faster than relaying things through me.
I don't know how to plot it, since the detector function is called once per review, and I need to store the p-values and successes
It will be a huge pain to figure out how to do this
If anything, manually writing down a list of successes sounds easier 🤣
By default it take the full history in account right ? Also, the doc for
--skip_reviews - The number of days with reviews to ignore to let the FSRS state stabilise
Is not super super clear to me 🤔
Like [1, 2, 3, 3, 3, 4, 5, 5, 5, 6]
It's basically "do you want to avoid early false positives?"
In reality we probably want to start once we have at least 3 reviews
Another observation, it feels indeed like an evolution of the "Lapses" threshold, since most leech are indeed with high lapse, but certain high lapse are just "normal"

I wasn't sure how to put it. It groups reviews by day, then skips the first n of those groups.
Kind of.
Ok ! But it's good, for example the top most lapses, I have a lot of 2-3 fail in a row, but often "the same day"

If there are same-day reviews it counts as one, but it calculates the elapsed time between reviews by looking at the first/last review of the day depending on which side you come from.
Anyway, I want to plot the p-value as a function of the number of reviews for some card. I guess I'll just write values down manually later, probably tomorrow
It's unclear how to treat successes and lapses, though. I mean, what would be on the X axis?
Reviews? Successes only? Lapses only?
One graph for each lol
Reviews makes the most sense, but then how do I differentiate between successes and lapses?
Maybe I'm oversimplifying, but isn't it Reviews-Lapse=Success ?
I check a few example here it seems to be that for smaller history cards
Hmm "Learn" steps messed it up
It's 16 reviews, 1 lapse, but the 4 learn are included in the 16 reviews but not in the lapse

How do you tell whether the p-value changed after a success or after a lapse?

I'll stop here for today, but for now at least, I think it looks consistent enough so it doesn't mark something should not be a leech as a leech (I tried with .02 and .01), so that's already better than the current leech = lapse > threshold of anki
Where I'm a bit wondering if we shouldn't show the p-value for the cards to the user, and also maybe only look at X last reviews
It's not always super super clear why one is a leech and not the other with big histories
I definitely don't intend to show it to the user. I don't see the point in only using the last X reviews, though
For example this is not a leech :

But this is :

And this is not :

You see it has some consistency, but it's a bit difficult to understand why certain were not detected
Lol
Maybe anything with >15 lapses should just forever be labeled as a leech 🤣
I really don't think so
I don't think that using only the last X reviews will make it more consistent, though
And it can lead to the card's status changing all the time
It's just that right now, I don't know if something were detected as a leech because of a bad streak of last year
does the code right now only detect a leech after looking at the full history or does it indicate if any prefix of the history would put the card in the leech threshold?
Also, after ~14months of learning japanese, this is my median stability over time
As you can see, for the past half year, my stability median was lower than 8d, for a 80% DR, it means having higher lapse count is not that "rare"

And that's why I think the current leech detection in Anki is just bad : It's perfectly normal to have high lapse count when your stability is still low in average/median-wise
So I don't criticize really that algo by itself, I think it might be more nuanced than simply the lapse>threshold
The full history
It's just a bit difficult to interpret ("Was it a specific event that caused me that leech ? Was it something from the past ? Something recent ?)
Right now, I see some High D/High Lapse card are leech and other are not
then isn't that maybe why you were finding so little leeches with the dynamic threshold? it is only considering one timestep rather than the sum of them
But I'm not sure which one need some "extra care"
All of their p-values were like 2-5 orders of magnitude above the dynamic threshold
Well, not all, probably, since Ross got a few leeches
The thresholds just get too conservative too fast as the number of reviews increases
I got 0 leech with dynamic threshold
But once again most of my leech are >70 reviews
And thank you @cursive badge for that implementation 🙂 Very instructive
can try a 1.1^n threshold, it is less conservative for medium-sized reviews
like 5-70
I don't think it's necessary. For example, with a "nominal" threshold of 2% it actually tagged only 0.35% of my cards
So we probably have the opposite issue
Then again, we still haven't seen how it behaves if we calculate the p-value after every review
but this 0.35% is also just for one point in time after the full history, when you use it in anki it would tag more than 0.35%
so we don't know if it is necessary or not yet
@cursive badge I'd like you to add an extra command to iterate over all reviews and calculate the p-value after every review, and if it dropped below the threshold at any point, tag the card as a leech. So if the p-value has dipped below the threshold once in N reviews, it's a leech
So we calculate the p-value for each card AND each review
I want to see how many cards will be tagged
Also, I feel like we're better off just using the Bonferroni correction and assuming some average number of reviews per card's life
We can estimate that average from the 10k dataset
why not exponential decay?
?
1 / 1.1^n or something
I don't like the infinite series dumbassery
Let's just analyze 10k and find the average number of reviews per card
Btw, I ran the code with a 5% threshold and 0.74% of my cards got tagged
what does the FSRS calibration graph look like on your collection?
Wait, if we only use the last N reviews, then we can just use N in the Bonferroni correction. Problem solved
no the math doesn't check out
if a card has n reviews but you only use a sliding window of the last m reviews, you are still calculating the p value n times but the bonferroni correction is using m
Oh, yeah
Right
Then let's just analyze the 10k dataset and find the real average
for now just make a random guess like 15 and see if it gets what you want
this could indicate that FSRS might be underestimating retention after lapses or something
a perfect memory model should always achieve around 5% tags
Maybe it is because this metric defines a leech as something that FSRS does not predict well. You have a big clump of reviews that had a really low R at the start. If FSRS predicts that you would fail a lot and you do, that is not considered a leech.

then it makes more sense why you would get less than 5%
I don't understand. If FSRS is inaccurate and we are measuring how likely it is that the card's history doesn't align with FSRS probabilities, wouldn't more cards be tagged as leeches, not less? In fact, the less accurate FSRS is, the more cards would be tagged as leeches, no?
Also true that even if my DR is around 80%, in general for low stability one, the real R is more around 50-60%
Or even sometimes way lower if I fail it multiple time in learning phase
I remember I had a few cards with 30-50% R when I really struggled them to recall them just for one day
Which also means the algorithm here is a bit more lenient with very very very low stability cards
Well, it does what it's asked to do, it mark things that FSRS didn't predict well
But if a card has every day a very very low R, because of such a low stability, it won't necessarly see it as a leech, because FSRS indeed, also agreed it was a very low R
Which is funny, because then it means there's even a third way of defining a "leech" !
- Card being failed way more than what FSRS would expect
- Card very difficult (High D)
- Card with very low stability (thus low R at time of review).
More Philosophy I guess, @unique salmon
It just reinforces my opinion that "leech" is a very ambiguous and not that helpful term haha
And that algo is then quite a very valuable one, since a "fail", more than just compared to the "expected DR", is actually compared to the "R" which might have been way lower than the DR. Nice !
I disagree about 3, since it only applies to cards with S<1d
If a card's S isn't <1, then, assuming the user reviews it when it's due, R should be close to DR
It's just that Anki is jank when it comes to short-term reviews
(close to DR you mean ?)
Yeah, my bad
Sure
Anyway, I wouldn't call cards with S<1d leeches
But my point is not really I believe in those 3 points but more like I can understand that for some people, having a card taht stay at low stability, could be a "leech" by their definition
Not "I sorta kinda disagree", but "I can't imagine any argument that could convince me otherwise"
Personally I don't know
Leeches are thing that suck blood, not sure how well it applies to memorization
It leeches if it decrease your performance ?
😄
Joke aside, the "leech" definition I see the most is "it leeches your workload"
Like, you do more workload because of it, for just one card
Buuuuuuuuut then people might be tempted to only add card they already know quite well
Isn't it a bit strange to do a lot of Anki cards for things you might really need SRS in the first place ?
If I'm able to remember "Self-Loathing" (a word I learnt a few months ago) many weeks from the first occurence, and then for multiple months at the second occurence ... Should I put it in Anki ?
Or should I, add those worst I keep forgeting again and again (Dweller, Delver, ...)
If you listen to "anti-leech" people, they'll say they would be leeches so not worth my time
Ok big boys, but when do I actually memorize those though
Next step : "Let's add only cards for things you'll never lapses more than N time !"
The goal is not to Anki-fy your life, it's the material that you want to learn
this metric doesn't necessarily measure where FSRS is inaccurate. You can do the same calculation with a fair coin, yet, how would you interpret the bottom 1%? It really just comes down to luck and no other underlying explanation for this case. Or alternatively, think of how you would interpret this metric if you had a perfect memory model. The hope is that with this metric, the detected leeches do actually correlate with incorrect FSRS predictions, but its hard to tell how well the metric does this.
for your question, imagine if FSRS only ever predicts R = 50% but the truth is 100%. Cards would never lapse and nothing would fall below the 1% threshold. If the truth is 90% and the predicted is 50%, you get less detections, etc etc. This might be what is happening judging by the calibration graph, predicted 50% by FSRS corresponds to actual 70% for your collection
For a perfect memory model I expect that the number of cards that are tagged as leeches is very close to the nominal threshold. For an imperfect model I would expect it to be higher, but not lower
imagine if FSRS only ever predicts R = 50% but the truth is 100%. Cards would never lapse and nothing would fall below the 1% threshold.
Nvm, I get your example now
Yeah, since we're only measuring p "from the left", if some cards are never failed, we will not detect those anti-leeches
I mean, we could try to detect those as well, it's just that in the context of Anki and spaced repetition I don't see a good reason to find anti-leeches
to adjust for calibration we can instead define leeches to be in the bottom 1% of historical likelihood, aka use percentiles instead of comparing it to a fixed threshold
Nah, let's just use a fixed threshold
I'll try some plotting tomorrow, unless Ross will be ahead of me
I want to see how the p-value changes after every review
Bump
- Right now the steps from the Helper add-on are recommended
- Probably no, I doubt they will be the default
I'm analyzing 10k. Either I screwed up or a card gets reviewed on average...5.7 times in its lifetime. Without same-day reviews and the first review, that is
Cards=77559205
Average n reviews=5.7
Median n reviews=4.0
99th percentile=37.0
I did a first pass at this, but will not have time to check I did not break things until later:
https://github.com/rbrownwsws/leechkit/pull/3
New flag: --incremental-check
I think _calculate_incremental_leech_probabilities should give you the data you want for plotting if you want to give it a go. (maybe draw a line then plot red/green points on top to show success/failure?)
you might wanna post a link to your repo on the forum post https://forums.ankiweb.net/t/automated-leech-detection/56887

Anki Forums
Given the card’s history, we can either store or re-calculate the probability of recall predicted by FSRS, and then use the Poisson binomial distribution to calculate the probability of a given number of successes. I am not even going to try to understand the math with complex numbers, but the usage is actually fairly simple. You just give...
I did in a comment
Oh... I think I discovered why FSRS gives me such huge intervals. My desire retention is 0.90 but when I was studying with default settings my true retention was 98%
if I understood correctly

In this case I don't know what to do. I'm currently studying with default FSRS parameters
Why not optimize them?
When I do it FSRS gives me HUGE intervals
For example 1,5 month for a new learned card

I think I didn't use the "hard" button, but I'll try this "Remedy Hard misuse" and see how it goes
If you don't use Hard, then there is no reason to use "Remedy Hard misuse"
When it comes to adjusting desire retention another problem appears. New cards have optimal intervals but mature cards have too small intervals
I have an idea. Is there an opportunity to optimize the algorithm with the review history from only one deck instead of my whole review history? I have two decks with the same cards but reversed, and the second deck with reversed cards is harder for me. So intervals should be smaller when optimizing with this deck review history.
Anki's user manual. Anki is a flashcard program that makes learning easier.
So I think I finally managed to make FSRS useful for me. I made two different settings for two different decks, and based on my "true retention" I set desire retention at 98%. I started session and it looks great.
thank you all for your help
@unique salmon cg on the pr merge 🍃
nows the time to keep that momentum and do the leech thing 🍃
SSP-MMC's metric of "expected cost to reach target stability" could be of interest, it uses both S and D
Are you suggesting finding the optimal desired retention based on minimizing the cost (minutes of studying) to reach 1 year/3 years/whatever N years S?
not this specifically, but rather just as a generic metric of the memory strength of a card that uses all of S, D, and R
so like how you wanted S*R instead of just sum of R
also such a definition could function as a leech detector, if this expected cost is too high then you count it as a leech
@cursive badge I ran your code with --leech-threshold 0.05 --no-dynamic-threshold --incremental-check. It tagged 2405 cards as leeches out of 35024 cards, or 6.87%. That's actually not so bad, only a little above the nominal 5% value.
I re-ran it with a threshold of 3.6% and it tagged 1889 cards as leeches out of 35024 cards, or 5.39%. So it seems that at least on my collection we just need to divide the nominal value by a constant (1.3-1.5) to get good coverage. Good = close to nominal.
@polar maple @bold terrace try it out, guys.
but don't you get 0.3% with only one detection at the end of the history? So it's like a 15x increase or something?
?
this
your collection was way already lower than the 5% to begin with
Ah, yeah, x9 increase
Try it and report the results, I'm curious. Sound, you too
For science:
--query "deck:JapAnki is:review" --leech-threshold 0.05
Processed 5774 cards
Found 77 leeches
(~1.3%)
--query "deck:JapAnki is:review" --leech-threshold 0.05 --incremental-check
Processed 5774 cards
Found 435 leeches
(~7.5%)
So with the incremental check, in your case it also overshoots by about 7.5/5=1.5 times
I really hope that we can just divide the threshold by 1.3-1.5 and everything will work just fine 😅
I can see why some of these cards will trip the leech detector at some point with --incremental-check, but not really be what I would consider a leech right now.
e.g. I obviously went through a rough patch with this card (interference?) but recovered:

Ok, I want you to implement one more thing: report the average number of "cross-overs" per card: when a card dips below the threshold or above the threshold.
Something like:
if p[this_review] < threshold and p[last_review] >= threshold: crossover = True elif p[this_review] >= threshold and p[last_review] < threshold: crossover = True else: crossover = False
If this number is high, that means that this method will cause a lot of "This card is a leech...oh, sorry, it's not...oh, nvm it is...oh, nvm, it isn't..."
the better the memory model, the more this would happen
Why?
because it becomes equivalent to flipping a coin
Hmmm
Well, I guess we can always just implement a "don't change the card's leech status more often than once per 2/3/n reviews" rule
even easy cards will, given a long enough time, become a leech with high probability
Wait, I re-ran it without the incremental check and got 1.56% leeches, even though it was <1% last time 🤔
@cursive badge I wasn't really following the PRs, but wasn't there a bug with using the wrong S value?
That should be fixed now.
Yeah, that's what I thought
Ok, so the incremental check increases the chances of a card being tagged as a leech by x4.5 times, not x9
also need to see how many times the test happens
maybe its a more straightforward formula
Also see this: #1282005522513530952 message
Some are very flip-floppy. This apparently went back and forth 12 times @0.05:

I guess you would want a higher "reset" threshold (hysteresis?) to prevent the flip-flopping.
Yeah, as I said, in practice we can just make it so that the leech tag can be added/removed only once per N reviews
Still, this isn't good news
But if they hover around the threshold that could still be flip-floppy. A higher "reset" threshold might prevent that.
i.e. there is a low threshold you have to go under to become a leech, then once you are a leech there is a higher threshold you need to go over to become non-leech again.
Alright, implement that then
I haven't done it properly, but I've had a play by just hard-coding things. It's interesting but might be annoying tuning two thresholds.
I just tried 0.05 -- 0.20 and one card took 12 reviews to climb out of leechdom only to fail the next review and immediately become a leech again 😂
I don't have "--incremental-check", is it on a specific other branch?
ah wait I might not be on that branch
Ok now it's running
Hmmm
"--incremental-check - Check if card is a leech after every review. Mark as leech if card ever drops below threshold."
How is it different from before 😄 ?
Aah gotcha
Get flagged if at half the reviews it would have been marked as leech, even if it wouldn't with the full history
My only complaint is that having decks from 1.3y with a lot of review 80-12, it's never super super clear if the leech was detected because of something recent (that I should fix) or something old (that might be fixed since then)
So basically when you play with the threshold to get a certain %-age like 5%, the problem is that it might be too conservative because otherwise you would flag your entire collection, BUT, maybe it's OK that a lot of card went through the "leech' status at some point
For example that one was detected as a leech

While it's on a good track right now

So I could make the threshold lower ...
But this one is not flagged already, so it wouldnt really make sense

So I don't know ? Some kind of "limit", or some "decay" that older reviews are less important than newer one ?
It's easier to just limit it to the last N reviews
@polar maple I finally made a good O(1) time and memory approximation
You use it like this:
approximator = HighProbabilityBinomialApproximatorCDF()
for p in p_succ:
approximator.add_trial(p)
p_value_binom_approx = approximator.cdf(n_succ)```
Later I will try to integrate it into FSRS. For now I'm trying the decay=f(D) stuff
It's fine-tuned for high probabilities, so it's not that great when there are low probabilities, but still WAY batter than the normal distribution approximation

oO now how on earth did this happen. This was on default parameters.

Just wondered why that one graph looked so weird, having that one lonely card out there, in 2035
I hit reschedule on it via the FSRS helper, and now it's due on April first :D
(of this year)
What was your desired retention?
Huh. Yeah, that definitely shouldn't be >11 years
1.8y matches what the FSRS addon rescheduled it to I think

well, no. It did almost exactly 1y
rescheduling it didn't fix the graph though. The marked column is the last one with a card in it

Most probably your parameters changed since then ? Early parameters with lack of input might have thought that 4-5 good in a row = you'll never forget those.
I also see Ease=250%, so I guess it was already ease-maxed-out with SM2 ? YOu never pressed Easy but the ease factor was already 250%, strange
I'd were you I'd reschedule all cards with interval >6-12 month
That's how SM2 works though?
I think the initial ease factor is something like 150-170% no ?
But it's configurable
wasn't it 250%?
I never touched any of that
neither SM2 params nor FSRS params, like I said
Maybe then !
And it's only that one card which ended up so far away
I didn't use it very long SM2, maybe a few days lol
so I'm really not sure how it happened
Like, did I accidentally optimize for one day, and then undid it? But then why only that one card?
🤷
BTW that would be great that the rescheduler had an easy option for people like "Recommended : Only reschedule >6m cards" or something
Rescheduling <1-3 months cards is not providing much benefits and creates huge backlogs
So often what I do is I just select all cards with intervals/due due bigger/further than 3-6months and I reschedule only those
the ones shorter than that, it'll be rescheduled when I review them 
Not that I need it (since I can do without it)
but I think most people are afraid of rescheduling because of that
do you have "ignore reviews before" set?
nah, this deck is as vanilla as it gets
it's not really a memorization-based deck, so has to stay on default parameters
Could you share the screenshot of the forgetting curve below?

interesting
whatever happened to that card in the past, clearly current Anki/FSRS realizes it's nonsense

It means you need to review it right now...
I guess the built-in rescheduling doesn't work, due to some unknown problems.
Did you install the helper add-on?

You can reschedule this card in the browser.
@quasi shadow https://www.reddit.com/r/languagelearning/comments/1jcv6lm/just_launched_my_flashcard_app_for_lazy_language/
FSRS is getting popular, random people are starting to use it in their random apps 🤣

Reddit
Explore this post and more from the languagelearning community
I used the addon to re-schedule it, and it scheduled it for 01.04.25, not right now.
hey everyone would someone be able to help me turn on CMRR or is there a how-to guide pinned somewhere? I tried looking but couldn't find one
https://docs.ankiweb.net/deck-options.html#compute-minimum-recommended-retention
You just click "Compute"
Anki's user manual. Anki is a flashcard program that makes learning easier.
Oh. It's been so long since I've checked the options that I didn't think to see that it had updated and added the CMRR option since I guess a while back
For the "days to simulate" part, if we want it to take into account our entire study review history, do we just set the value to 99999? or am I misunderstanding what "Days to Simulate" means?
It's how many simulated days it will, well, simulate. You can think of it as "How far into the future it will look", if that makes more sense to you
Also, CMRR was in deck options ever since the first version of Anki that supported FSRS, Anki 23.10, which came out more than a year ago
That was one of my interpretations but the "duration of the simulated study history" made me confused and thought it was looking back and taking x days of review history as a sample to calculate
So to confirm if I wanted to simulate a CMRR for basically forever I'd set the days to 999999?
Oh I must've missed it then; when I was first looking into it I was reading posts about downloading this whole extra program to calculate it but ig that was way off into the weeds
The max is 3650 days
You mean custom scheduling code and the Google Colab optimizer? That was before Anki 23.10, which was released in October 2023. So you must've been in a coma for a while 🤣
Ohh yeah it was the Google Collab optimizer lol, and tbh the last time I looked into CMRR could've been around then or I could've just neglected to scroll down this entire time
Once I set it, I'm guessing it's something that I can tweak/update as I accumulate more review history similar to the log loss/RMSE parameters?
Something like that, yeah. It uses things like average time per review to do simulations, so more reviews = better
Oh interesting. Why does it use review time as a factor? Wouldn't that vary depending on the length of the card? I have typical atomic cards as well as long one-by-one medicine cards that can take 10x the review time
How else would it calculate how much time you spend reviewing?
Btw, it doesn't use just one number, it uses 8: for Again, for Hard, for Good and for Easy during the first review (which gets a bit of a special tratment, I guess), and the same but for all other reviews
Time per button is estimated from your review history
Hmm I guess I just have a misunderstanding of what CMRR fundamentally is/does
I was thinking of it as setting a "lower bound" to a "desired retention range", with the regular DR being the ceiling, and that it would use the exact same parameters only (I see that it does use some FSRS parameters, but I wasn't expecting the review avg review time variable to be factored in as well) and calculate the DR "floor" from there
It runs a bunch of simulations with different DRs, calculates amount of cards memorized divided by time spent, then looks for DR that provides the best ratio
How does FSRS actually determine what the learning phase is?
i.e. what makes it switch from Learning to Review in the card info
It's not up to FSRS. In Anki, a card is in the "learning" phase is you didn't go through all your learning steps yet
That's what I thought, but my learning steps are just within one day, and cards are called "learning" for multiple days.
Show Card Info of those cards, and your deck options

I guess "Learn" displays the status before you pressed the answer button, not after. So this one here is "it was in the learning stage before you pressed Good", not "it is in the learning stage after you pressed Good"
yeah, looks about right.
I implemented the R*sqrt(S) to see how it would look

knowing I never stopped reviewing but I stopped adding cards for 3-4 months
With just R it was more like this

Knowing that the "rebound" aronud 2025 align with how my stability started growing again when I stopped adding too much words again

I think R*sqrt(S) gives a good idea of progress being made even if the sum of R doesn't seem to be that big
a local build if someone want to try it

Anki 25.02 (038d85b1) (ao)
Python 3.9.18 Qt 6.6.2 PyQt 6.6.1
Platform: macOS-15.3-arm64-arm-64bit
Traceback (most recent call last):
File "aqt.webview", line 53, in cmd
File "aqt.webview", line 169, in _onCmd
File "aqt.webview", line 728, in _onBridgeCmd
File "aqt.toolbar", line 429, in _linkHandler
File "aqt.toolbar", line 450, in _statsLinkHandler
File "aqt.main", line 1301, in onStats
File "aqt", line 149, in open
File "aqt.stats", line 77, in init
File "decorator", line 232, in fun
File "anki.hooks", line 92, in decorator_wrapper
File "anki.hooks", line 84, in repl
File "/Users/davidtrayanov/Library/Application Support/Anki2/addons21/1613056169/init.py", line 22, in new_refresh
innerJs = f.read()
File "encodings.ascii", line 26, in decode
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe2 in position 1034709: ordinal not in range(128)
===Add-ons (active)===
(add-on provided name [Add-on folder, installed at, version, is config changed])
Advanced Browser ['874215009', 2024-10-27T16:20, 'None', '']
AnKing Note Types Easy Customization ['952691989', 2025-03-14T14:40, 'None', mod]
Anki Leaderboard - Compete with friends to boost motivation Custom by Shige ['175794613', 2025-03-17T17:59, 'None', mod]
AnkiHub ['1322529746', 2025-03-17T18:25, 'None', mod]
AwesomeTTS - Add speech to your flashcards ['1436550454', 2025-02-15T10:23, 'None', '']
Bible Memorizer ['2012700632', 2023-12-23T13:52, 'None', '']
Colorful Tags Hierarchical Tags ['594329229', 2022-09-15T18:06, 'None', '']
Countdown To Events and Exams ['1143540799', 2022-06-27T14:50, 'None', '']
Deck duplication ['1779572689', 2022-06-11T17:24, 'None', '']
FSRS Helper Postpone Advance Load Balance Easy Days Disperse Siblings ['759844606', 2025-03-09T07:31, 'None', mod]
Fill the blanks - Multiple typecloze support ['1933645497', 2025-03-08T14:00, 'None', '']
FrequencyMan - Sort your new cards i1 ['909420026', 2025-02-02T05:22, 'None', mod]
History Visualizer ['1545338943', 2025-01-18T14:29, 'None', '']
More Overview Stats 21 ['738807903', 2025-02-17T23:14, 'None', '']
Multi-Decker ['1110722673', 2023-06-11T09:20, 'None', '']
Multiple Choice for Anki ['1566095810', 2023-11-17T22:59, 'None', '']
Progress Graphs and Stats for Learned and Matured Cards ['266436365', 2020-03-29T09:26, 'None', '']
Review Heatmap ['1771074083', 2022-06-30T04:43, 'None', '']
Search Stats Extended ['1613056169', 2025-03-02T01:16, 'None', '']
Study Time Stats ['1247171202', 2024-02-24T18:59, 'None', '']
show overview deck browser options name ['684236185', 2023-09-09T02:01, 'None', '']
===IDs of active AnkiWeb add-ons===
1110722673 1143540799 1247171202 1322529746 1436550454 1545338943 1566095810 1613056169 175794613 1771074083 1779572689 1933645497 2012700632 266436365 594329229 684236185 738807903 759844606 874215009 909420026 952691989
===Add-ons (inactive)===
(add-on provided name [Add-on folder, installed at, version, is config changed])
Anki Simulator ['817108664', 2023-11-06T19:26, 'None', '']
Ankimon by Unlucky-life ['1908235722', 2024-05-16T18:07, 'None', mod]
Custom Background Image and Gear Icon ['1210908941', 2025-01-29T10:31, 'None', mod]
Dynamic Text Window ['Dynamic Text Window', 0, 'None', '']
Remaining time for Anki 21 ['1508357010', 2024-04-16T05:15, '24.4.16i24', '']
hmmm I think I had something like that
I just restarted Anki though
and it was OK again
someones got some unicode in their ascii
try opening the file as binary
innerJs = f.read().decode('utf8')
with open(addon_dir / "stats.min.css", "b") as f:
innerCss = f.read().decode('utf8')
I see those lines were changed yesterday

I can rebuild with your snippet
Hmmm no luck
File "/Users/.../Library/Application Support/Anki2/addons21/1613056169/__init__.py", line 22, in new_refresh
innerJs = f.read().decode('utf8')
File "encodings.ascii", line 26, in decode
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe2 in position 1034709: ordinal not in range(128)
chatgpt tell me to try rb instead of b
that won't do anything probably but go ahead
also I'm a boomer file isnt a thing anymore
this feels like a platform difference? on linux it just works without needing "b"
<_io.TextIOWrapper name='stats.min.js' mode='r' encoding='UTF-8'>``` it seems to correctly identify it as utf8try encoding="utf-8" in the open call
>>> open('stats.min.js')
<_io.TextIOWrapper name='stats.min.js' mode='r' encoding='UTF-8'>
too it seems
based on his traceback hes also on mac so not a platform issue...?
Yeah strange suddenly I get it too
Tried with
with open(addon_dir / "stats.min.js", "rb", encoding="utf-8") as f: # Putting this inside the function allows you to rebuild the page without restarting anki
innerJs = f.read().decode('utf8')
with open(addon_dir / "stats.min.css", "rb", encoding="utf-8") as f:
innerCss = f.read().decode('utf8')
btw
this is some nerd speak
the encoding was to replace the rb/decode stuff
ah ok
smth like
with open(addon_dir / "stats.min.js", encoding="utf-8") as f: # Putting this inside the function allows you to rebuild the page without restarting anki
innerJs = f.read()
with open(addon_dir / "stats.min.css", encoding="utf-8") as f:
innerCss = f.read()
yeah
ValueError: binary mode doesn't take an encoding argument
at least it's a different error now lol

Stack Overflow
Code:
import nltk
eng_lish= open("C:/Users/Nouros/Desktop/Thesis/english.csv","rb", encoding='utf8').read()
bang_lish= open("C:/Users/Nouros/Desktop/Thesis/banglish.csv","rb", encoding='utf8').rea...
let's revert to stackoverflow
gpt has its limit
binary mode implies the b is still there?
Don't seem so
with open(addon_dir / "stats.min.js", "r", "encoding="utf-8") as f: # Putting this inside the function allows you to rebuild the page without restarting anki
ValueError: binary mode doesn't take an encoding argument
it raise on the "open" so nothing before it
stats.min.js: ASCII text, with very long lines (807)
``` its not even utf8 its ascii why is it choking on thiseeeerrr
with open(addon_dir / "stats.min.js", "r") as f: # Putting this inside the function allows you to rebuild the page without restarting anki
ValueError: binary mode doesn't take an encoding argument
there's some kind of caching somewhere
Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'ascii' codec can't decode byte 0xe2 in position 1034709: ordinal not in range(128)
>>> k = open('stats.min.js', 'rb').read().decode('utf8')
>>> ``` ¯\_(ツ)_/¯>>> k = open('stats.min.js', 'rb').read().decode('ascii')
Traceback (most recent call last):
File "<python-input-0>", line 1, in <module>
k = open('stats.min.js', 'rb').read().decode('ascii')
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe2 in position 1034709: ordinal not in range(128)
``` yep sameare you editing the right file 🍃
>>> k = open('stats.min.js', 'rb').read().decode('utf8')
>>>
then all good
I think there is some caching
because now I did :
def new_refresh(self: NewDeckStats):
with open(addon_dir / "stats.min.js", "r", encoding="utf-8") as f: # Putting this inside the function allows you to rebuild the page without restarting anki
innerJs = f.read()
with open(addon_dir / "stats.min.css", "r", encoding="utf-8") as f:
innerCss = f.read()
I rebuild, I update the plugin : Fail
I stop anki, restart anki : All good
This is the last build
@robust hill , can you try to install it in Anki, if you get the error, just restart anki and reclick on "Stats" ?
maybe the first version I was not able to reproduce because I had still the "good code" in my anki or something
I pulled changes from upstream afterwards but I'm not sure I restarted Anki at first
so it's maybe why I didn't notice it
looks good now
Thanks for the check, I'll update the PR and ping @cosmic hedge (oops just did it)
@bold terrace you gotta up your git skillz and add me as a coauthor on those commits
I tried to @mention you

GitHub
The idea is to be able to switch from a Memorized view based on R to one based on R*Sqrt(S), to "reward" times when you might have reduced the amount of new cards/day but have ach...
but once again
Ah no
This time Jake did not refuse to help
But he refuse to take credits
😄
Thanks
thank you for the sigma tag
i just got emailed in the middle of my anki reviews which caused me to panic which caused me to fail my card. i will be contacting my lawyer soon. ||/j||
man I wish I was cool enough to have jake as my github account name
so I was like, ok @ashen light doesn't exist but who cares
But when I saw @robust hill message I was like "But who did I tag then ?"

No wonder the guy has so many contribution
When in doubt, tag @ashen light
dude has a real job where he codes

I obsensibly do but I really can't confirm that anymore (yes we use github at my job)

I was memeing about how I no longer program at my job, but mostly produce suffering
I've been spending my last ~5-7 days trying to build a project we need to "follow" since it upgrade to java 21
And all the stupidiest shits are happening at the same time
- Can't do any "apk update" in a docker image because the corporate proxy decided that we were not worthy of having access to internet again
- Can't curl sonatype for security scan because the same fucking proxy
- The CI/CD has a UID different than the UID of the process in the docker container, leading either to not being able to create new folder in the container, or not being able to clean them in the host
Came to plot nice graphs, stayed to solve encoding issues
:/
So now I'll spent the last 30min of my day spending the money I got in some waifu-gachas, see ya
BTW @robust hill I see @cosmic hedge added a zoom for the difficulty graph :
I know you were interested so check it out 🙂

(my last build should include it)
welll glad i didnt release without that XD
not the first time i screwed that up
@bold terrace could you not branch off your other prs in future and just use the main branch please XD
I tried
I added your remote as an upstream git remote add upstream ...., then get pull upstream main, get checkout -b ... and then chery-picked normally, but it seems there are many things coming with it 🥲
I'll check more calmly tomorrow where I might have screwed
do
git checkout upstream/main
git checkout -b new-branch
see if that works
Oooh
"git pull upstream main" instead of upstream/main and not reading well enough

GitHub
Added a new graph for Memorised with R*sqrt(S). The goal is to try to show how well the knowledge, is stable on top of being retrievable. Useful to see progress when no new card/day are added but s...
So clean 🥲
Deep inside me I was curious if there was a limit on the number of commits and PR depending on each other 😦
😄
not so deep apparently 😂
Could smn tell me what this is
why should we do it via the add-on instead? and how do we do it? will clicking the highlighted option bring me to another window where I can choose the new DR or is it gonna reschedule based on something I need to change beforehand?

why should we do it via the add-on instead?
Because it doesn't add an extra entry to every card's review history.
will clicking the highlighted option bring me to another window where I can choose the new DR or is it gonna reschedule based on something I need to change beforehand?
There's no second window. It will use the current parameters and DR for every options group/deck/card. You should have all of that set how you want before you run the reschedule-all.
right click the deck, there should be an FSRS helper submenu, with a reschedule option
or you can reschedule individual or groups of cards via the browser with it
@wind palm
Hmm, I set my DR lower (90→88) and it gave me a higher card burden adding 500 cards... any reason why this is?
If the deck contains a lot of cards that are overdue would that be why? I tried the option to reschedule "recently reviewed cards" and it decreased burden. How long ago is considered "recently reviewed?"
probably cause they would already been added with 90%
lowering the desired retention should otherwise always lower the load
hmm it's interesting b/c all my overdue cards are in an overdue filtered deck yet the deck is pulling other cards from elsewhere in the deck; maybe siblings of the overdue filtered cards?
but otherwise what you said makes sense
well, they weren't overdue until you hit reschedule
How does rescheduling via the add on work with decks and subdecks, esp if they have different DRs?
both were at 90 but I'm trying to change the main deck to 88 and the subdeck "UWorld" to 89 for starters
do I need to reschedule one before the other? does rescheduling the main deck from the home screen apply to the subdeck as well?

a card is only in exactly one deck
no idea if hitting the button on a deck also reschedules all subdecks
there's one easy way to find out though
yeah I went ahead and tried different combinations of rescheduling to find the lowest card burden but did confirm that hitting reschedule on the main deck did affect/lower the number of reviews in the subdeck as well
for anyone else in a similar situation and curious
You still seem to be confused about what is actually happening.
There is no load for a specific deck or its subdecks
It's just cards being rescheduled, which can push them away further when you lowered DR, but if you optimized since the last reschedule, it might as well just pull a ton of them to the front

GitHub
some manuscripts and notebooks about spaced repetition research - open-spaced-repetition/heterogeneous-memory-research
🤔 I made a simulation based on a naive atomic-memory model without Difficulty.
How's the leech detector going on?
Good News: I find out an extra parameter that can improve 2% RMSE(bins) and 0.0018 log loss in the preliminary benchmark.

$ python evaluate.py --fast
Model: FSRS-5-dev
Total number of users: 634
Total number of reviews: 19967510
Weighted average by reviews:
FSRS-5-dev LogLoss (mean±std): 0.3344±0.1687
FSRS-5-dev RMSE(bins) (mean±std): 0.0549±0.0372
FSRS-5-dev AUC (mean±std): 0.7077±0.0817
Weighted average by log(reviews):
FSRS-5-dev LogLoss (mean±std): 0.3682±0.1717
FSRS-5-dev RMSE(bins) (mean±std): 0.0734±0.0481
FSRS-5-dev AUC (mean±std): 0.7028±0.0879
Weighted average by users:
FSRS-5-dev LogLoss (mean±std): 0.3709±0.1729
FSRS-5-dev RMSE(bins) (mean±std): 0.0758±0.0493
FSRS-5-dev AUC (mean±std): 0.7022±0.0900
parameters: [0.29835, 1.36215, 2.9813, 15.3283, 7.15575, 0.5576, 1.75015, 0.0036, 1.52275, 0.1081, 1.0048, 1.9078, 0.1162, 0.30265, 2.2646, 0.2315, 2.99725, 0.6267, 0.5094, 0.14805]
Model: FSRS-5
Total number of users: 634
Total number of reviews: 19967510
Weighted average by reviews:
FSRS-5 LogLoss (mean±std): 0.3362±0.1698
FSRS-5 RMSE(bins) (mean±std): 0.0561±0.0368
FSRS-5 AUC (mean±std): 0.7048±0.0788
Weighted average by log(reviews):
FSRS-5 LogLoss (mean±std): 0.3708±0.1735
FSRS-5 RMSE(bins) (mean±std): 0.0744±0.0478
FSRS-5 AUC (mean±std): 0.7001±0.0865
Weighted average by users:
FSRS-5 LogLoss (mean±std): 0.3736±0.1748
FSRS-5 RMSE(bins) (mean±std): 0.0767±0.0490
FSRS-5 AUC (mean±std): 0.6996±0.0887
parameters: [0.4014, 1.2663, 2.6931, 15.3206, 7.1801, 0.53625, 1.75455, 0.0065, 1.50165, 0.1313, 0.9943, 1.925, 0.11, 0.28685, 2.27865, 0.23165, 2.99595, 0.454, 0.60975]
😎 Maybe we will have FSRS-5.5 this year.
do we have plans to fix this abomination

(deleted/reposted to not destroy jarrett's message)
What's your expected solution?
is that with smooth on? 😭
oh wait no that features not out yet
well looks like Jarret pre-emptively fixed it for u then 👍