

1 messages · Page 1 of 1 (latest)
sina alasa e sona nimi lon ilo Muni la o pana e nasin e sitelen lon tomo ni!
wan
tan seme
san

I actually have cool graphs I'm just not at home rn 😔
yes, that's true
there's less toki pona going on that far back
the data actually goes to 2010, but barely so, so i ignored it lol
this is why there are multiple scales offered tho
nanpa wan is roughly twice as common as nanpa tu

https://gregdan3.github.io/ilo-muni/?query=nanpa+open%2C+nanpa+pini&minSentLen=1&scale=rel&start=1533081600&end=1722470400&smoothing=1
it's interesting how nanpa open and nanpa pini only started to be used around 2020, with nanpa pini being way more common than nanpa open (probably cause nanpa wan expresses a similar idea)

indirect evidence for unpopularity of sona-preverb


if 20 people says something and there's 1,000 texts in the month, then that's 2%
but if 20 people say something and there's 100,000 texts in the months, then that's 0.02%
indirect evidence for the popularity(?) of preverb open and preverb pini

mi anpa lon e kokosila :3 https://gregdan3.github.io/ilo-muni/?query=penpo%2C+penpo+-+ilo+penpo+o+lukin+ala%2C+kokosila&minSentLen=1&scale=rel&start=1659312000&end=1722470400&smoothing=2

there's a related phenomenon where the frequency of the most used words is going down relative to less used words since anywhere from march 2020 to may 2021, continuing to today
(you can see it in that graph of pona above)
i... don't know what this means tho :P
psst, check the absolute mode
there's like 30 occurrences there :P
damn, its not often that you can attribute a word to one month and then essentially never again

oh gosh it's The Dip™️ mk. 2 /musi
i will present my data in the most biased way as to make my opinion seem more correct
-# /musi
but yea fair lol

in general, take anything that has fewer than ~400 occurrences all-time (you can check with cumulative) with a grain of salt
that data can be relevant, but it can be much more easily swayed by errors, or affected by an individual speaker
if you wanna know how powerful exactly one speaker is, look up ilo o ken e toki ni
do you think it might be cause the community in general are speaking about more diverse topics? pona, toki and other common words are also more common among beginners/ the start of conversations, so them decreasing in usage might imply that people are having more in-depth cconversations/that "beginner conversations" are getting more uncommon
idk im thinking out loud
essentially yes! i said a similar thing yesterday, altho i described it as more complex topics rather than more diverse topics, but same principle
gotcha
that might just be cause the toki pona community is bigger and has gotten less,,, meta for lack of a better term
ehehhe, yep
using tp as the medium of conversation instead of as the topic
i am surprised i haven't seen anyone look up ki yet
to be clear, ki's results are nonsense and unavoidably so lmao
there are at least 7 things i'm aware of which ki appears in that are not uses of the toki pona word ki
indirect evidence of the unpopularity of preverb open/pini 😔

eeeheheh
nimi ki seme pi toki pona :p · ona tu li lon
@quaint wagon feature suggestion: create a list of commentary matching particular search requests
use it to comment on searches that could be misleading
e.g. if someone looks up san remind them the search is partially "spoiled" by your presence
the counterargument to adding this is we cant possibly account for every misleading search so it might be better done in conversation than in gui
the countercounterargument is that we can account for the most potentially frequent of those
a lot of people, i have noticed, seem to think my name is a toki pona question word /musi
i guess most of the speakers (at least the beginner ones) don't even know about this preverb🦦
it's almost like this word died along with the meme
what was itomi

ah
https://gregdan3.github.io/ilo-muni/?query=linluwi%2C+majuna%2C+jami&minSentLen=6&scale=abs&start=1470009600&end=1722470400&smoothing=2 compared the 3 finalists of utala pi nimi sin

https://gregdan3.github.io/ilo-muni/?query=ojuta%2C+mijun&minSentLen=1&scale=abs&start=1596240000&end=1722470400&smoothing=2 ojuta vs mijun
alasa is growing in relative terms, both as a "standalone" predicate and as a preverb

how does that compare to lukin preverb?
isn't there a special syntax for marking only preverbs or only verbs or only smth?

^ tenpo kama la mi weka e tomo ni tan sona pi ilo Muni

woah how's it transparent
SINA LI IJO E NI
yep thats a thing
a
MI PANA E NANPA E NASIN TASO E SITELEN ALA
peli pani
gonna be real, this will probably never not be a feature (necessity) of ilo muni
there's just Way too many ways to write words if i don't collapse duplicate letters
which makes the database too massive to deliver as i'm currently doing it
yeah thats fair
there's a similar but less massive problem with capitals
mhm
fwiw, in processing it's more like
you could solve that by first reading an english dictionary, then refusing to deduplicate letters if they match an english word
but thats frankly silly and unhelpful
these are really all the same problem
this also assumes the english words are, themselves, rendered appropriately
okay. replace "solve" with "improve"
i'm not honestly sure it would even do that
not without a pretty sizeable manual processing step, anyway
apparently there was a little stella bump in june 2021

my hypothesis is that 1 is essentially not affected, and 2 3 are fewer than the number of english words that are correctly preserved by this
but like yeah
its so far removed from the point of the tool that its just not worth your time


"mi li" and "sina li" can still be found in sentences like "soweli mi li pona"
unfortunately this can't be used to draw conclusions about the frequency of ungrammatical li because what ilo tani said yeah
sona mi la mun li wile ken e ni: ^ mi li la ni li alasa e toki lon open toki taso
@quaint wagon check this out

two bits of insight from this
nope the scale is wrong
fuc
right, its the same scale problem
check again in relative; you'll have exactly one line anyway
anyway insight two is not affected by that issue
20% of toki pona is those words, btw
roughly
minor gui nuisance: you might not want to allow users to do this

the math will be done against the total number of words, not sents of len 3+, but more words = more opportunities to score correctly
nah they're a default of chart js that I did not investigate
i could do a ton more presentation wise
noted
@quaint wagon whats the correct way to compare the frequency of a vs a a vs a a a
i tried a - a a, a a - a a a, a a a - a a a a but from the vibe of the chart i feel like ive not considered something
misali has been declining in mentions

oh, the
apeja li mi peaks during every sptp because we're a crowd and we shout it

pretty expected. had to use log scale to see toki Inli taso



the unpa season
I am going to listen and see what you are trying to say
Oh I've listened to þis before
I listened to þe whole song really trying to interpret þe lyrics in a sexual way and it feels so much like a stretch þat I don't þink þis is what your talking about or maybe I am just really misunderstandign what she is saying
Oh þere are lyrics
I'll come back
in case youre in doubt, read what acronym the album name "utala ni (li) pona a" spells out :p
the best you can do is limit the sentence length and deal with that limited perspective
subtracting the number of a two up is actually more accurate, but more limited
otherwise, i still errantly double count in this context
this is a mistake google makes too, if their docs are to be trusted
sona pona
Þis is really ugh
I really misunderstood her
Like misheard her words a lot
I loved þis song because it sounded like
two lovers who are apart woefully missing each oþer
But now þat I'm reading þe lyrics
It's just like
not þat
ugh
Anyways I want to find out what Majeka was being referred to here

Oh I found it
No?
Þere are instances of majeka as a magic nimisin in 2021
Like 3 times which ig aren't here
or maybe I'm dumb because I don't know how þis þing works
do these spikes really exists?

mi ni e mama sina li is powe 
nimi "AAA" li lon toki [🇨🇦] :p
a tomo ni li lon
nanpa li lili mute a · o lukin lon nasin [Absolute]
mi kalama e sitelen akesi
(there are slight rounding errors due to how i made the wave in audacity: 1, normalizing to be within +/-1; 2, rounding to 1 decimal point; 3, each month was 1 sample point of a wave, so i slowed it down in audacity to auto smooth it)


It seems þat (ik pi li is an old grammatical þing) people's grammar's getting better

but this nanpa tu includes nanpa tu wan and nanpa tu tu
i'm also curious about
data volume too low to be reliable
but for li pi we can at least say it was probably more used pre pandemic

and pre pandemic you legitimately had a lot of people learn from jan Pije so
then again jan Pije's site already purged weird usages after pu came out
pandemic probably meant that lots of people were learning for the first time with good resources
not necessarily
jan lentan's came out in like what 2021? i forget
someone should check tbh
good = avoiding li pi
what about pi * e? like "soweli pi moku e kala"
(i can't run Muni because it doesn't work in my browser at this time, i've filed a GitHub issue)
the thing is that ilo Muni doesn't do a straightup regex-like search over the text, it finds appropriate trigrams
and there are few trigrams that fit pi * e
most are too infrequent to be included
so the result is unrepresentative
and you cant sum them up, it shows as different lines
ahhh
so for example
if there were 2 results for pi walo e
in all texts
ilo Muni doesn't store that trigram because not enough data
and won't display it here at all
it also only displays the top 10 ish(?) when doing a wildcard search
@quaint wagon smoothing suggestion: try a kernel with soft edges
google ngrams doesn't do that but it feels like itd be better at literal smoothing of the graph
so instead of peaks becoming plateaus, they would become more spread out peaks
-# ofc this comes with the disclaimer that this feature request is for whenever you feel like working on muni again
I replied btw, with a few sites you can test to investigate what component is the broken one
https://gregdan3.github.io/ilo-muni/?query=mu%2C+kalama&minSentLen=1&scale=rel&start=1470009600&end=1722470400&smoothing=2
mu li kama suli tawa kalama
I wonder if I could deliver the given graph as the open graph image for the site, if the URL params are filled in
That's... Probably irresponsible with my database? I actually don't know what it looks like networking wise when you fetch the metadata of a link
Is discord doing that for you and then sending you the result? Or is it each individual who sees the link?
it does it for everyone individually
theres this one website whose embed is a simple math problem, except its randomly generated every time, so when you post it, everyone sees something different
its still an interesting graph tho

pi * e = pie 🥧 👍
ooooh
Ooo that's super neat
And actually brings up a different question:
I probably need to have an actual server to do this trick, huh?
All my JS is client side lmao, so that idea is not happening
Although it does occur to me that an alternate way for me to deliver the app would be to have the entire thing be hosted on like, Vercel? And keep the entire DB in memory, using just sql.js on the server side
Something to investigate for later
LMAO
7
nah its 19 trust
actually, this is a search i could allow
the reason I limit it to standing in for a single word is because if you search for the top 10 matches of a given form like this, you'll only get back 10 phrases of the minimum matchable length for the search; shorter phrases are also more numerous.
granted there are some places around funky grammatical features that could be exceptions, but there won't be many of them
ooh
what i could do is performance testing on allowing multiple wildcards; there are few enough terms available that it could work
it's interesting how, despite interjection lon becoming more unpopular, interjection ni has stayed at a steady level

also cool to see how "mi mute" for "we" is on a steady decline
back when i learnt tp originally way back when, it was almost universal to use it (as i remember it anyways)

lon-yes was quiiite commonplace
its been backlashed
@icy turret i think it was you who posted it but i can't find it; you posted the comparison between nimisin and a few of the other "standard low use but around" type words like linluwi and majuna? and i have thoughts about that as well, actually
well, one thought really:
a user of the word nimisin is much more likely to talk about lower use words; conversely, those who don't use the word nimisin talk about newer words less, resulting in the phrase nimi sin being about as used as the word nimisin.
in fact, this is something i could probably demonstrate in my primary db? by counting the number of distinct authors who have sentences containing nimisin, versus the number of distinct authors who have sentences containing the phrase nimi sin
i am generally curious about like
if Muni describes a word as popular
is it because many people are using the word, or because spiders Georg is using the word a lot
i know for a fact this is happening to lipamanka and nano, because their names are primarily said by themselves
but determining that currently requires checking manually
you can be extremely confident that words over rank 150 are actually in use by a variety of speakers, but the range of confidence drops significantly after that since you go from several thousand uses at rank 150 to several hundred uses at rank 200; that's an amount which you could swing by in a single day of being silly
idk the privacy implications of this but
if Muni could say whether a word is being used by under 10, 100, 1000, 10000 people
and then lines could have different thickness or opacity depending on the category
that would maybe make it easy to visualize if a spike is a silly spike
this wouldn't catch mu mu mu
ooooo wait that actually is interesting and i don't think it would be hard to check
uagh it would be a lot of queries tho lmao
well, not on ilo muni's side
db generation side
i'm unsure how to represent it on the graph tho; line thickness gets difficult to judge if there are more than 3 distinct thicknesses
3 might be enough? for 10, 100, 1000
also, for reference, distinct author count is imprecise bc of pluralkit and more generally bc i can't combine authors across platforms
idk how often a word will be used by more than 1000 people
jan mute ala li kepeken nimi Nimisin. ni li tan ike nanpa tan ni: nimisin Georg li kepeken nimi ni mute la nanpa li ante ike la ona o lon ala nanpa
in one month
oh i see, you want that info on a monthly basis
that could be harder
that makes sense tho
not necessarily! this is just the first idea that came to me
and wouldn't change the UI too much anu seme
we found a spiders moment yesterday
@quaint wagon you could create some kind of measure for how concentrated word use to one person vs many people

this sounds vaguely similar to the gini coefficient
o tonsi tawa ale 
idk at least it's clear it's a spike of silliness
o tonsi tawa ale
sina alasa e pipi Georg
this would show up as an under-10-people line in my proposal, which may help
right
makes sense
you know, i can ruin your data by posting procedurally generated text at least once a month in large quantities
i would omit you, personally, from the data in that case
actually i think i neglected to mention this entirely but i do omit #jaki from the data
yeye
reasonable
which i think is completely understandable ye
uagh i've been fiddling with postgres all morning at work and now i'm looking at the sqlite db
explodes due to slightly different keywords
starting a public server and calling the general chat #jaki /utala
other stuff i did yesterday was making these sorts of graphs to compare the relative popularity of two words, pretty fun to look at

you can do that! ma pona's jaki is the only bot channel i omit bc it's the largest channel on the server and it isn't even close
worse you can create a thread and invite ten people to spam it with plausibly real text
that channel, in text, is 4gb of the 56gb of the entire raw discord dataset
holy shit lmao

i'll grant that text is a lot of spare discord fluff i.e. authors and their roles and metadata on a per message basis
but.
i also learned that nobody said mije in november 2016

why do you have a-a on the graph?
on the previous ones it was to highlight the 0 line
i just didnt bother removing it for this one
no one on reddit did cause reddit was small and discord communities didnt exists yet
makes sense
yeah, until i think march 2017? the data is all telegram and reddit
a time when men didn't exist
mije is reliably less used than meli which is very amusing to me
tenpo pi mije ala
this graph shows meli vs mije and yeah, meli is almost always more popular except for the weird spikiness at the beginning
im guessing this is cause demographics
which is probably just because of the small volume of data
there was a time in early 2023 tho where mije was more popular
i just saw someone say minisin and this is making gears turn in my head
misinin
gears grinding violently, making a terrible screeching noise, but just barely turning
what would a minisin look like
ok i think i can do author counts on a per ngram basis
look into the gini coeff genuimely
it might be better
would i not need author count in order to get that info
the sqlite db side of it would be easier than i thought initially, since i can just add another row to the frequency table "num_authors"; the number of authors of a given word or phrase is always containable in the same dimensions as a frequency entry i.e. some phrase, some min sent len, and some date (representing a range)
in order to count authorship, i need a way to know what distinct authors have said a given term, for which i can use their edgedb generated uuid (note: authors are joined by their combo of platform and platform id+name, and only may be entered when i enter a new message) and probably stuff that in a per-entry set for the lifetime of the ngram counter, which is the time it takes me to count a month of data
when i query sentences, i just tack on the additional info of sentence.message.author.id and use that to update the authorship sets corresponding to the phrase i'm updating
and at the end of a month, write back the length of each set side by side with the frequency data
i think it might just be num authors of all ngrams per month? if you count authors for every ngram individually you lose the 0 case
not sure tho, maybe thats stupid
i am intent on getting num authors of all ngrams per month and num authors for each ngram
the frequency table and ranks table are nearly identical for a reason
that reason is, while you can count the ranks info from the frequency table, it takes over 20x the reads
i'm essentially packing a more specific type of query into that table
question:
if i implement a selector for smoothing method, would that be overwhelming
there's already. a lot of options lmao
@icy turret @fresh sentinel @whole epoch @tall rune
i haven't actually used the tool yet ehehe
ah fair
did you see my suggested search btw
it really shouldn't take more than 3s to resolve a simple text search even with the default settings
and since those other tools all work, it must be something I'm doing that's breaking on your browser
idk what tho, and you can't pull up dev tools on mobile, aaaaaaa
i was the one to propose it so i have to say no
I would call the options soft kernel (smooth) and hard kernel (google ngrams style) which should indicate to people why theyd ever want to use the hard kernel (they don't), but maybe you have better naming conventions in mind
uh, my naming method would have been to use the name of the smoothing method as i discover it on Wikipedia pages about stats w.r.t . timeseries data
wouldnt mind it so go for it if you wanna do that
it like, wouldnt get in the way of anything except a tiny bit of screen realestate on the top
and if it's too much you can just not use it (assuming the default is good)
@wanton shoal (hi) suggested exponential smoothing and it's pretty good bc it mostly preserves changes in direction while moving the peaks and troughs nearer to one another; it also passes the tonsi and misikeke tests, correctly showing 0 for any point prior to the initial non-zero point of those graphs
i have also found gaussian and median, which are respectively extra curvy and extra blocky; gaussian fails the tonsi/misikeke tests but is good for trend analysis; median does decently at those tests, passing them up to 30 smoothing
actually median technically fails the tonsi test bc of the 3 occurrences in July 2019, 0 in Aug/sep, and 21 in Oct; it omits the July data for a while
might be good to add a dropdown where u can choose from multiple methods? and maybe do a little explainer on what they do and don’t do, for the uninitiated?
ye, a drop-down was what i was suggesting here
that's basically what's done for the different charting modes and i assume it'd be the same for smoothing
in the help page there are explanations
oh am on phone and didn’t scroll up that far soz xd
np!
granted I think omitting tiny early data is a better failure mode than extending early data to earlier than the word existed
i played around yesterday with only including data up to time T, but not beyond it, so data wouldn’t get extended into the past
however it didn’t seem to work all that well tbh
nimis in pi toki [Mini] anu seme
normal sliding avg
the thing is, it works to some extent, but imo the data only barely resembles the input haha
here's the input:

and 5 smoothing applied

i can see the resemblance, but in the original the peaks aren't nearly the same height (i suppose the second peak is flattened a lot)
(also, "the tonsi test" is a very funny phrase to me for some reason)
median smoothing also sucks
destroys the data, yet suffers from the same issues as simple avg
mi sona ala. pilin mi li ni: ken tu li lon.
... 3. some data analyst helps out :D
lots of research into things that deal well with cyclic data, passing only certain bands for signal processing, whatever
but i feel like just stat vis isn't really a focus of any research. very thin info online
taso mi toki taso. jan Kekan San o toki e pali :D
mi wile pana e nasin ken mute li wile pana e ilo Exponential lon open tan ni: linja sin li sama linja open
lon
ken suli la nasin ona li pona nanpa wan tawa lukin pi tenpo pini
taso, mi awen alasa e sona li wile toki tawa jan pi sona nanpa, a a
lon. mi pilin e ni: ilo wan li pona lon ijo p# wan. ilo tu li pona ala lon ona li pona lon ijo p# tu.
aaaaa ken
a a a, lon
.... belarusians?
Þe only oþer example of pokasi I've seen is it being used for Belarus
… pokasi?
anyway this increases the necessity of unique author tracking ehehhehe
Yes
How much have I contributed to þe Pokasi population
Probably most because I made it up
Þe greatest þing I ever did was make a nimisin in my first SP sentence
I didn't even know what a nimisin was
power move
wawa
This PR is more or less to propose an implementation. I've implemented a simple exponential smoother, as I've talked about. The current smoother remains the default.
i am halfway through writing this as we speak LMAO
also re: issue #13 regex having look-behind and look-ahead is cursed anyways, makes it a CFG
lmao
fair enough tho, this is easy to slot into my work!
i was faster >:)
ehehe
would have been a good 20 mins faster still if i didn't accidentally work on the unforked branch lmao
👏
preach
even when working alone, i've noticed that as soon as a project grows in size and i wanna do some quick fixes, PRs are still a godsent
cuz manually selecting what to include in the diff is annoying, when you've refactored half a file :D
true, ehe
lazygit makes it smooth when necessary tho
i very rarely have to dip into my git plugin's diff view to fix things
i guess it's also a result of me refusing to use the command line for git anymore, since i only work in IDEs nowadays, and it's just so much easier for me xd
so i'm kinda accustomed to select all, commit, push
but that does hide the fact i forgor to checkout another branch haha
ehehe, np
i've merged your branch to a separate branch merge-smoother which i wish i just called smoother; gonna add a smoother url param and some logic to disable the button as necessary!
aside: oh god i have no idea if my js is any good, i am not good at computer
ah jk i just missed that you did so in reading the github diff!
u made a thing, which is more than a lot of people can say ab themselves! :D
...but yes, some refactoring might be good haha
yeahhhhh
ehehhehe
see the thing is
sona toki is the best code i've ever written
aaaand this whole project was downhill from there :D
i do know at a minimum that the sqlite file is a mess bc i've mixed the responsibilities of querying and mutating the data there
and that the input file sucks bc i'm doing a bunch of crappy splitting instead of like, actually parsing user input
btw, are you analyzing each message or sentences within a message?
if i put a full stop or semicolon would that turn the message into two sentences
sentences within a message
my sentence tokenizer isn't perfect
quotes count for it too
altho i am considering removing them honestly
sona
i wanna sit down and do some analysis to that end
on one hand,
also, i wanna do intra-word punctuation in the word tokenizer for isn't don't
not because i need that to tokenize toki pona, but because doing so would slightly increase my accuracy of detecting toki pona
@wanton shoal turns out that exponential is misleading for peak-y data! Fook

I don't get what þe smooþing does so I'll assume it's doing good here
the data is really noisy to begin with, so smoothing attempts to reduce that noise while still representing the data faithfully
but the problem is, under some circumstances the smoothing is inaccurate
ok having the realization that i can't really produce an appropriate smoothing algorithm without knowing what it means for there to be a "signal"
really, the smoothing necessary just depends on the input
and different terms will have different signals
median works extremely well on continuous data, but demolishes seasonal data instantly
extremely funny

no smoothing for comparison

exponential is reliably the least silly of all the smooting methods
relative minmax is nice for comparison multiple test cases at once

lmao
im skeptical of smoothing and just turn it off when i use the tool usually

tenpo Mopiju li lon


as you can observe, in times of tenpo pi kama sona la troughs form

here's the usage trend of various video games that were played on ma pona, i ought to add gartic phone but i don't know what the common tokiponization of it is

each instance of a larger string of letters adds to the count of the smaller strings here
snazzy
oo that little jump in lu near the end is because of april fools day when everybody spoke tuki tiki
muti muta
(sona mi la “muta” li nimi majuna pi toki sike)
i mean i guess
but i think just a afterwords sounds more natural
anyways, here's jan Wano's graph that looks at each string individually without accumulation

take away the first line and we can see the trend of how many as are used for laughter


A AA A A A A
LMAO YOU DID ALL OF THEM?
send link? @merry walrus
sina wan a li suli e "ijo sama"

MI WAWA
It's only þrough L, I just wanted to see how long until þe particles got outpaced (ignoring a because it would give any side an unfair advantage)
i know this for a fact: the pure particles are only about 20% of toki pona
I did it from memorie so I might be missing a couple words in L
you haven't included "toki" or "pona" or "sona", or any of the pronouns for that matter which will ofc be a huge portion of all toki pona
i get that was the point to be clear :P
Oh I missed kule and laso damn
those won't make much of a difference ehehe
Critical words
i mean number wise
i found the source of the wan/tu/mute/luka/ale spike in oct 2021
there is a channel in one server where people genuinely counted to the high thousands in the pu numbering system
well, i say people, but it seems to have been almost entirely one person

based
aaa musi
things brings on an entirely new question
like, do i exclude that
how much is that reflective of "using the language"
Anoþer reason for a unique auþor feature
@quaint wagon how did you get the data for Muni? Ik it was through online to communities, but how did you download the data itself?
Illegal meþods /idk
i talk about that on the about page! In short, Reddit has an archival project, Telegram lets you export chats, and Discord you'll have to read on the site


ah mi sona :D
what are the little numbers that people add?
like "a a a_6
that's the minimum length needed
ah okay
so like
toki_4 only shows toki from phrases with 4 or more words
it's very useful!
i found another interesting spike

lmao??
hows this?

too little to say anything tbh, only a handful of uses
for some reason the tool isnt letting me search "unpa li ken *"
i wanna find out what the next word isssss
just unpa li ken has no results found so that's probably why
thats incorrect
maybe youre in a too specific timeframe
"unpa li ken" is the big spike in march 2016
musi la:

what is it?
its not pakala
ah
i cant search for it because its not from this server
since it's 2016 i assume it must've been like, a meme or running gag on telegram?
or maybe reddit
i guess
that's a "spike" up to 5 occurrences tbf :P
granted it's odd it happened all at once, but probably makes sense to whatever discussion happened there
yeah, there was just a lot less conversation going on at the time

big spaghetti time:
here's my relative minmax graph attempting to convey the trends in focus over time of various meme phrases throughout ma pona's history. by "meme" phrases, i mean any word or phrase that is often repeated among speakers or has some sort of server addon like an emoji or a sticker. obviously incomplete. o lukin pona a!
https://gregdan3.github.io/ilo-muni/?query=a+-+a_2%2C+omekapo%2C+omekalike%2C+ale+li+pona%2C+mu%2C+kijetesantakalu%2C+ikea%2C+ilo+nanpa%2C+kekan+san%2C+jan+telakoman+li%2C+misali%2C+lonsi%2C+mi+tawa+tomo%2C+mi+tawa+e+tomo%2C+lon+-+lon+a+-+lon+ala%2C+lon+ala%2C+mi+sona+ala+a%2C+pingo%2C+kasi+ike+mute%2C+usawi%2C+nimi+sin%2C+nimisin%2C+tonsi%2C+su%2C+owe%2C+kamalawala%2C+wawa%2C+waken%2C+akesi+kule%2C+lon+a&minSentLen=1&scale=normrel&start=1470009600&end=1722470400&smoothing=0&smoother=cwin
something interesting that can be found by max smoothing it out is how, depending on what shape is portrayed, "wawa" is in a steady trend upward and either has passed over or is on the verge of passing over "ale li pona"
for standalone sentences it's been surpassed

fun

i feel like wawa interjection is maybe the closest pu equivalent to epiku interjection
that's how i use it anyway
also pona a
pona a - pona a_3
uh
wawa_2 ?
wawa_2 is all messages that contain wawa with length 2 or more

so if i do wawa - wawa_2, it's the number of sentences containing wawa minus the number of sentences containing wawa of length 2 or more; aka how many times wawa was a standalone sentence/message
i added a few more memes and changed the wawa parameters to have it be standalone, it drastically drops in terms of relativity (naturally because it is a word that people say outside of commending someone)
https://gregdan3.github.io/ilo-muni/?query=a+-+a_2%2C+omekapo%2C+omekalike%2C+jipi%2C+slape%2C+jans%2C+ale+li+pona%2C+mu%2C+kijetesantakalu%2C+ikea%2C+ku%2C+nja%2C+yutu%2C+osu%2C+ilo+nanpa%2C+epiku%2C+tuki%2C+kekan+san%2C+jan+telakoman+li%2C+misali%2C+lonsi%2C+mi+tawa+tomo%2C+mi+tawa+e+tomo%2C+lon+-+lon_2%2C+lon+ala+-+lon+ala_3%2C+mi+sona+ala+a%2C+pingo%2C+kasi+ike+mute%2C+usawi%2C+nimi+sin%2C+ojuta%2C+a+pilin+ike%2C+o+uta+e+sike+mi%2C+toki+a+-+toki+a_3%2C+moku+wapa%2C+apeja+li+mi%2C+mi+unpa+e+mama+sina%2C+o+luka+e+kasi%2C+ma+masina%2C+mijun%2C+nimisin%2C+o+moku+e+kala+pona%2C+sutopatikuna%2C+o+moku+e+kala+ike%2C+o+wawa%2C+tonsi%2C+su%2C+owe%2C+kamalawala%2C+wawa+-+wawa_2%2C+waken%2C+akesi+kule%2C+lon+a&minSentLen=1&scale=normrel&start=1470009600&end=1722470400&smoothing=0&smoother=cwin
jsyk a link in þe help article is missing a slash

this is because of sptp!
thanks! fixed it
well, fix is publishing in like 1 minute
https://gregdan3.github.io/ilo-muni/?query=kepeken+pi%2C+kepeken+e%2C+kepeken+lon%2C+lon+kepeken&minSentLen=1&scale=rel&start=1470009600&end=1722470400&smoothing=2&smoother=cwin
nasin pi te kepeken e to li kama lili anu seme

ona li lili mute, taso alasa sina li pana ala e sona ni
nasin pi te kepeken pi to en
nasin pi te kepeken lon to en
nasin pi te lon kepeken to li awen nasa

^ tan fucking seme la ilo pi toki pona taso li pipi e mi?!
o alasa e ni: kepeken *, kepeken ala *
ni la sina ken lukin e ni: nasin ni li lon; ona li suli tawa nasin wan mute pi nasin ante. taso ona li ijo wan lon poka pi nasin ante mute li lili wawa tawa ona ale.
lon! ona li suli nanpa tu, taso ona li open e poki. ona li suli nanpa tu lon poka pi nimi ale ni: open poki en ijo poki li lon.
sina wile alasa e ni:
nimi kepeken la ni li ale ala. taso, nasin "kepeken e" la ni li ale.
https://gregdan3.github.io/ilo-muni/?query=kepeken+e+%2B+kepeken+ala+e%2C+kepeken+toki+%2B+kepeken+ilo+%2B+kepeken+nimi+%2B+kepeken+nasin+%2B+kepeken+tenpo+%2B+kepeken+sitelen+%2B+kepeken+ona+%2B+kepeken+ni+%2B+kepeken+ala+nimi+%2B+kepeken+ala+ilo+%2B+kepeken+ala+ona+%2B+kepeken+ala+nasin+%2B+kepeken+ala+toki+%2B+kepeken+ala+sitelen&minSentLen=1&scale=rel&start=1470009600&end=1722470400&smoothing=2&smoother=cwin
ni la sina ken sona e ni:
wawa
https://gregdan3.github.io/ilo-muni/?query=mi+e%2C+sina+e%2C+ona+e&minSentLen=1&scale=rel&start=1470009600&end=1722470400&smoothing=2&smoother=cwin
mi e, sina e, ona e
transitive pronouns li lon

https://gregdan3.github.io/ilo-muni/?query=li+mi+e%2C+li+sina+e%2C+li+ona+e&minSentLen=1&scale=rel&start=1470009600&end=1722470400&smoothing=2&smoother=cwin though nobody has ever said li sina e
ilo penpo li pipi tu e sina
seme a?
(cw: flashing lights) mmh rendering soup
what did that one person say about forbidden spaghetti
i should Probably prevent people from doing this for exactly the reason you're seeing
but I also don't think it matters enough lmao
maybe it does to avoid bandwidth problems
so why did mun Kekan San choose to say walo loje rather than loje walo?

ona li kule ante

nimi suli li suli
nimi sewi li sewi lili
taso, nimi suwi li suwi e sewi ona
nimi seli li awen lili sama seli moli
pakala ni li seme a

ni kin li nasa


theres a lot of these
both in #sitelen-pona and in the now archived #spt-jaki
@quaint wagon would it be worth excluding that channel?
i remember we talked about how identifying webhooks (which is what these are) didnt work out for you
but excluding spt-jaki from the data seems like a good idea

cumulativeeeee
hmm!
this is a case where i think the following two improvements would be better:
i would like to avoid poking more channels out of the list, preferring a code based solution that more correctly separates good and bad sentences, so that i can keep the intended fairness of the system
in this case, a document level score would ideally mark that first sentence low because it's among a bunch of non-tp words
also, there are other weird spikes that would be fixed by document level scoring! like pipi Kewapi saying "ilo o ken e toki ni a" genuinely some thousand times which i think is absolutely hilarious
if you can do that, great!
i just thought cutting out that channel would be an easy solution
it feels like a channel where not much would be lost anyway
that's probably true, yes
but i need an excuse to do the webhook check and the document scorer anyway :P
fair

sitelen pi ilo Muni /musi /literal

musi a
seme a la ona li ilo tawa
@quaint wagon sona pona wants the ilo muni logo cc-licensed btw
talk to em for details idk shit
couldnt they just ask for permision to use the picuture?
sorry for asking
i dont know alot of things
mi kama lukin e sitelen ilo… la

pakala...
among ku!!!
ken a · taso jan [Juwan] li wile cc e ale tan,, ijo pi sona mi ala
ona li wile pana e sitelen ale tawa poki Wikimilija
i believe in waso supremacy (not accounting for soweli which is giant in comparison)

aa seme la kijetesantakalu li suli sama akesi sama pipi
psst, the relative log is a bit misleading rn because it shows the actual logarithm of the value rather than changing the y axis to be logarithmic
(it's like this because i was running out of time)
you should post the actual relative graph of this
the shape of the relative log graph is ultimately correct, but the numbers don't mean much
(wink wink)

pretty linjas
tan tomo https://discord.com/channels/301377942062366741/1187212477155528804 la, ni:

over the past year, anu seme has been, on average, 65% of all instances of anu

sonja put ilo muni on tokipona.org! which is super exciting.
nasin ni kin la sina ken lukin e ni!

sona a
a okie :3
32/4+15 = 19 23
(i can haz more?)
oh i'm silly
that's what they mean when they say 99% fail
hey look it's txnor the home of the unpa hack
woa what's with that random jump in anu toki
sama nimi wawa la, nimi sona kin li kama mute:
seme a
ilo li toki e ni:
"tenpo wan la... toki ni li lon."
what is "XXX_n" ("a_3", "sona_2", etc.)?
what are + and -?
@quaint wagon
the number after the underscore means to only count the times that word occurred in sentences with that many words or more! e.g. toki_2 counts only times where toki was in a sentence with at least 2 words.
and the plus and minus are literal- add or subtract two or more things. the math being done is, for every period of time that is represented, add together all the words. or, add/subtract, from left to right, to be exact.
Kokosila isn't ÞAT far ahead

Huh
Stupid þought
but I wonder how much affect I had on þat huge isipin spike in Oct and Dec
Oh it's a bot reposting some nimisin
And maybe Giggity Mantis yapping about using isipin
bots aren't counted in ilo Muni
lmaoo

is there any info on how the data is handled here, by the way? I couldn't see any info about how or if it was anonymised
ni li tan seme a?!

kalama lon sptp???? toki jaki ala la, mi sona ala e tan ken ante
didnt notice this until now but you should probably add somewhere that wildcard ignores e and li


nnnnn...
nasa mute a

erm seme a
pakala nasa a
ona li pana e nimi pi mute nanpa 11-19??????? tan seme a??????? 😵💫

Uhhhhhh
It should not
What the fuck
That's a lil cursed and given the query I'm doing is incredibly simple and the processing I'm doing after that is also simple, I think I can only blame the library I'm using to query the DB?
And it's a funny one so fair
know why it would skip the top 10?
Uh, not really, no
The query as written should fetch the top 10 items, because it searches the ranks table and orders that by occurrences
The only way that could return something other than the actual top 10 would be if the query were convinced of having the top 10 items early/incorrectly
ni li ken musi Mapo
musi Mapo la ilo li toki e ni
ILO
I KNOW WHY THIS HAPPENED
there's a funny but unavoidable oversight in how i detect bots vs webhooks
i don't actually have specific info about whether a given author is a webhook
all i know is whether they're a bot, and what roles they have
webhooks never have roles, while bots do if they're in the server
this is all i have to distinguish them as far as i'm aware?
so if i encounter a bot user with no roles, i mark them as a webhook
anyway mappo is not in the server!
if i just do the pluralkit message check thing i can fix this but i have not yet
a, sona!
note that when a bot is in the server, they're obligated to have at least one role- their own, which they create on joining, and which cannot be assigned to any user beside that bot
pog
mi alasa e linja sama kepeken ilo Nanpa
mute la nasin [UCSUR] en nanpa suli li lon · taso ni kin · seme a

suno wan la toki tu wan ni li lon · ma ni ala · ma pi kama sona ala · la ma seme
ni li musi wile mi

wile mi la mi ni ala https://xkcd.com/1138/
mi kepeken nanpa pi mute kepeken la linja ale li sama mute tan ante tenpo pi suli kulupu · taso mi alasa e linja pi sama mute mute · la ni ala anu seme
ma wan li lon tawa ni: sina sitelen lon lipu sina
ona la ilo li kama lon tenpo suno ale li toki e ni
mi lukin e ni lon tenpo ni: mi kama sin lon tomo!
ilo ni li lon nasin Webhook
ilo Pulaki kin li ni la mi ken ala sona e ante
nasin tu wan li ken:
mi sin e sona lon tenpo kama la nasin nanpa tu wan o lon anu seme...
sona mi la, ilo Pulaki li weka e sona mama pi toki majuna
mi sona ala e suli tenpo
taso mi alasa e sona pi toki majuna la ilo Pulaki li toki ala
ona li ni ala
tenpo ale la sina ken pana e sitelen ❓ tawa toki pi ilo Pulaki
ni la ona li toki e sijelo open tawa sina
n, pakala mi li ken tan ijo ante
mi ante e ilo li weka e nasin [UCSUR] e nimi lili e toki pi nanpa taso
mi kama lukin e ijo pi tuki tiki e ijo musi mute ala · ni li musi lili

ken la ilo o moku e toki anpa tan sitelen pi ma [YouTube] · pali li lili tan ilo sewi [yt-dlp] · taso mi sona ala e ni → mute li pona ala pona
sona kiwen

ni, kin, li sona kiwen
ni li ken wile, taso pali li suli ike
sona mi la mi wile ni la mi o kama jo e toki tan sitelen ale
ni la mi o jo e sitelen ale...
sina ken jo ala a e sitelen
sina o sona e sitelen wile · taso poki pi kalama musi li lon
mi ni
yt-dlp https://www.youtube.com/playlist?list=PL3meDZ0v1E3e5hwSyfz9Os9ZUsMw4ecwz --get-comments --exec pre_process:"del %(id)s.comments.json" --print-to-file "%(comments)j" "%(id)s.comments.json" --exec "type %(id)s.comments.json" --skip-download
la ale li pona
a taso kalama pi mute ala li lon poki · la n
"ytsearchall:toki pona" li ken
mi toki ala e sitelen suli li toki e sitelen wile
mi o jo e ona ale
alasa mute a
sina jo e ale pi ma mute anu seme · la o alasa e nimi linjuwi pi ma [YouTube] lon ona
i still don't know the sona kiwen joke
-a mi toki ike · mi wile toki e toki anpa pi jan ante e toki pilin · e ni ala → jan li sitelen nimi e toki pi sitelen ona
ni nanpa tu li pona kin · taso lili a
ni kin li olin Juli

there is not even a joke anymore, it's basically a way to irritate lipamanka
at two separate times, I defended the idea that somebody could use the phrase sona kiwen to refer to something which is difficult to understand
once in toki pona, where the response was middling
the second time in English, the true place where nasin discussion lives, and my defense bugged lipamanka so it argued against my point for a few Hours
mind you after like 20 minutes i was barely involved anymore, but as these things go the discussion remained for a while
eventually most the participants were so annoyed that bringing up sona kiwen genuinely irritated them
naturally pipi Kewapi and I think this is hilarious
sina lukin e toki pi kili Juli!
mi sona! mi kin li wile e toki anpa kulupu
aaaa
#toki-ale message kepeken ni pi nimi Juwi li lon ala tan seme
nimi li wile lon ilo la ona o mute mute
(mute li nanpa)
mi weka e nimi ale pi mute ni ala tan ni:
ona li mute wawa li anpa e ken ilo
a
wild
what is that "SITEŚ"?
site's
x/sites/
/siteɕ/
ilo pre_process li wile seme lon ni?
mi,, sona wawa ala
mi kama jo tan lipu pana mi
ken la --write-comments --skip-download taso li pona sama
sona, lukin la ni
sitelen ale la ona li kama jo e toki
wawa
lukin la pali ale ante li wile poki e toki taso
wawa
musi la, toki ~luka luka tu tu mute ale li lon lipu ni taso:
#pana message
taso, mi kepeken ilo alasa la toki pi mute wawa li lon...
mi o kepeken nasin nanpa ni anu seme:
toki wan li lon kulupu lili la toki luka tu li lon kulupu suli.
mi open e alasa lon tenpo luka pini.
poka pi ma [sanpansiko] la ilo tawa li lon • nimi ona li ilo [muni] a
[Reply to:](#1272180068721889290 message) musi a
seme a la ona li ilo tawa
"mute ale" · seme a · toki,, tu ale mute mute mute mute ale anu seme · ni anu ni ala la wawa
a! musi
(luka luka) (tu tu mute) (ale)
sina ken sona e poki tan kama lili nimi
mi awen sona ala :p
pakala
ni li ike nanpa
tu tu mute li mute mute mute mute
luka luka li lili tawa ni la o suli e ona kepeken mute mute mute mute
ni o suli lon tenpo ale. ale li nanpa.
(5+5) * ((2+2)*20) * (100)
taso seme li pana e sona ni → tu en luka ala li lon poki mute
nanpa lili li lon poka pini pi nanpa suli
luka tu wan mute li seme
a. mi kama sona e pakala.
ni li nasa seme?
mi pilin ni: toki "kxk" li lon mute
aaa sona
taso toki "ken ala ken" li mute ala kin lon lipu nanpa la mi ken sona
toki mute pi nimi tu wan li mute lili taso
lon, taso mi pana e ona tawa poki la ona li lukin lon nimi ale toki, lon ala lon?
taso.. ona li suli ala
lukin a
kin la toki lili "kxk" li lon lipu nimi pi ilo alasa
lipu seme?
a, ilo alasa li ilo Sona Toki. ona li kama jo e toki li alasa e sona ni: ni li toki ala toki pona?
lipu ni li toki pona nanpa wan tawa ilo
nimi pi nasin kalama pona li nanpa tu
nimi ijo li suli lon sitelen open li nanpa tu wan
nimi pi sitelen ale ken li nanpa tu tu
nimi mute li lon ala ni ale la, toki li pona ala
Damn a completely fucking blows it out of þe water (I wonder how much oþer languages have affected it)

Obviously not none, but given the absolute graph for a follows a similar trend to every other word in the top 20 most frequent, I feel extremely confident its frequency is accurate to its actual occurrence in Toki Pona!
pog pog
i prefer ala la o e soweli
ala la o e soweli: No results found for this query.
sadness
-# ilo pi penpo kama
pakala nimi wawa
kon san li kama lon lape mi · kon pi penpo weka · kon pi penpo lon · kon pi penpo kama
khdhkdsgg
ona li kon kekan san

....apparently russia(n(s)) died in 2019

also oof @ that peak around early 2022
apeja consistently peaks every august and i love that
why is that

sona musi
which one is red and which one is blue? for both of these
lon is blue, ala is red
people singing the lyrics of apeja li mi in chat on suno pi toki pona
a
and this one?
this one wasnt actually a comparison, rather the same trend for both words
but anyway the first entry is blue, the second is red
ahh
the ✨ hierarchy ✨

it would really help if you include the labels on these, most of us don't have the color order memorized
ordered from top to bottom
pona
noka and nena probably experience the monsi effect
they do, as far as the charts show, yes
seme li tu e linja meso
sina toki e ni anu seme

ni
jan li kepeken ala ->
log(0) = undefined ->
sitelen li ala
tan li nanpa.
Why is þat profound /gen
Oh it is explained later down
sorry
she's a gamer
What's the monsi effect?
direction words and body part words are used less frequently in text and VC, and more frequently IRL and in VR
so they show up less frequently in ilo Muni
which only looks at text
first i thought "what, that's crazy" and then i thought "oh yeah that makes sense"

mijun

me
jan Mijun li kama lon

ni li tan seme?


a sona

lmao
o tonsi tawa ali (:<
Be all moving nonbinary-ers
uhhhhhhhhh, perhaps that copy/paste blurb where lon is nearly every word in the sentence?
will check db and report back when able
-remindme 7h30m o alasa e lon lon
Set a reminder in 7 hours and 30 minutes from now (<t:1725130846:f>)
View reminders with the reminders command
ooh, mysterious
try looking up lon lon lon lon etc in ma pona
im guesing its someokne playing around with "bubble wrap spoiler shields"
lipu ni li pu?
#jaki message
jan li musi sitelen ilo!
aa mi sona
aaaaaa
taso, ni li lon tomo jaki ala anu seme?
ilo Muni li lukin ala e tomo ni
pakalaaaa
i cant find the link a
thanks
ni anu seme?

niiiiii
nasa
Reminder for @quaint wagon
o alasa e lon lon
alasa li pini (anu seme)
a, pini
taso kulupu ni pi nimi "lon" li tan seme a‽
lukin la ona li musi sitelen kepeken ilo

a sona nasa
a
lmao

toki. mi Sam. mi li pana wile en sona ijo toki pona.
sina sona ala sona?
a lot of words and phrases exhibit a significant change in usage starting in 2020, and while it's pretty easy to see the correlation with the pandemic, there's no telling what exactly that implies about the language
i would say something like, a sudden increase is skillful conversation? tenpo ni is a pretty simple and even first day of learning sort of construction used for basic conversation
try contrasting with "tenpo ni la sina pali"?
it goes too low usage
but yeah
this is a similar dropoff but slower imo
oh fuck nvm, wrong smoothing

similar yeah

a a mi kala
hmm i wonder whats missing
poki wesi - reddit containment center
ma siko pi toki siko
so it’s lipu Wesi, but ilo Siko
oh shit, new sources? youtube i assume?
YouTube, and the old forum + its archive of the yahoo group
the data is very sparse there, but it will be available soon!
awesome
once again asking for any archived irc conversations lmao
they certainly don't exist beyond the few well known examples, sadly
you know how tokipona.net had a corpus
was it just jan Kipo's corpus or
i don't know tbh
i think it was though
I saw a 2017 fb post where kipo referred to that corpus with a lot more detailed information than anyone but its author would have
whats responsible for higher traffic in 2007 and 2010 btw
no clue!
this is another instance where i spent a long time running tests and manual queries to be sure i wasn't making some error
for 2010, perhaps the newness of the forum itself?
it came out in Oct 2009

a
seme la ona li jan ala
tenpo weka la ona li soko
aaaaa sona
kapesi..

nasa a
kapilu

nimi kapesi en nimi kapilu li suli lon tenpo sama
nimi kap- li wawa lon sike 2021
n, nimi kapa ala

definitely been done before, but i find it very interesting that people are saying "o kama pona" more now vs. just "kama pona"
jan mute pi tenpo pini li toki e "kama pona" tan seme? mi la "o kama pona" makes more sense. maybe it's a difference between announcing somebody has "come well" vs. telling somebody to "well come" but msa

my uneducated guess is that people are trying to steer clear of calques, and kama pona looks like an english calque for "well come"
perhaps "o kama pona" is more tokiponalike. though i don't see a problem with "kama pona" being an exclamation- though nanpa tu la it could be considered a lexicalization
i don't know
hmmmmm, interesting

to complete the set

interesting
something happened mid 2020
the global pandemic, along with other factors, caused toki pona to have a surge in popularity around then
but this is relative data, right?
lon
taso toki pona li ante mute lon tenpo ni
ken
with the influx of people, nasins ante'd mute
i arrived some time after that, so i don't know how different the community was before then
and specifically phrases like "kama pona" were popular because new people were coming lots
hmm but i'm not sure why that would have caused people to prefer one or the other
mi kin li sona ala
overall "monthly volume of toki pona" seen by ilo Muni:

there are high plateaus in 2007 and 2010 and we don't know what they correspond to, as of now
so 2017 represents the first time toki pona escapes this average level of activity, by virtue of reddit + discord
unless, ofc, the communities not yet in muni (like obvs all the irc chat logs which may or may not exist) reshape this graph starkly
@quaint wagon any reason it goes back to march 2002 instead of august 2001 btw?
in the sparse data pre-2017, mi + sina vs li show some amount of inverse relation, which to me sounds alternating between mostly chatting (hence 1st 2nd person) and prose (hence 3rd person)

whereas by now the community is large enough that the movement cancels out
🔵 mi + sina 🔴 li

..right fair
do we have any known posts from even earlier?
regardless of ilomuniability
https://web.archive.org/web/20220808015056/https://wyub.github.io/tokiponaarchive/2001-08-08.html
this, archive of an archive,?
facebook could
idk its exact active years but it may make a difference in the 2014-2019 range
facebook groups is a pain
the API didn't work back when facebook had it normal for groups, and now they restricted it further
i look forward to mKS singlehandedly creating a working facebook scraper
it would be the second
unfortunately, the first is proprietary
altho granted my work wasn't singlehanded on that first one but it was A Lot
interesting
btw honrstly
like
is the reason for not using the proprietary one legal or academic (repeatability)
cause the contemporary fb group probably generates a negligible ampunt of traffic and having just a dunp that never gets updated is sufficient for muni
Both of these
I can't use it for private purposes, and nobody else would have access to it
alright fair
it's repeatable because someone else can just write another facebook scraper /musi
anu-predicate

nimi o li lon poka la seme?
ken la o lukin e "anu ala e" kin?
ive done that on a separate occasion but it wouldn't count towards "anu e" so
i'll just post screenshots
first off, the absolute scale! you can see how toki pona has grown over time

(i am interested to know what occurred the first half of 2023 where there is a notable trough)
watch the sptp2024 ilo muni presentation!
it's more visible in the absolute entropy scale

first recorded usage of the entropy scale
the entropy scale is very fun
kulupu lawa pi ma ni (en mi) li pini e tomo ale ni:
#toki-moku #toki-nanpa #kalama-tpt #nasin-tpt #tpt-ale-kin
mi pini e ona tan ni: mi lukin e toki mute pi nasin ni:
1: "toki!"
2: "toki, sina pona ala pona?"
1: "mi pona. sina seme"
ni la toki li kama pini. jan li toki wawa ala li toki lon weka tenpo la ona li kama ala toki suli.
mi pini e tomo la mi pilin e ni: tenpo toki li kama lili, tan ni: jan li kama lukin e toki pi jan ante lon tenpo pona!
taso! mi kama sona e ni: lon la jan li wile e ijo toki. ni li kama e toki wawa mute. mi weka e tomo pi ijo toki la jan o toki lon seme? ala a. ni la ona li kama toki ala.
(sina ken ala lukin e tomo la ona ale li pini. o kama jo e poki pi lukin pini.)
a. mi pana ike e ona tu. taso, tomo pi nasin sama li lon tenpo pi weka tomo li pini.
sona!
sina wile pali e tomo toki e kulupu la, o pana e ijo toki!
ijo toki li pona
sitelen sama, taso linja li supa ala
(nena suli loje li nimi "nena", nena suli walo li nimi "luka", nena suli laso li nimi "unpa")

nimi nanpa li kama suli nasa tan ni: tenpo suno tu tu la jan wan li nasin e nanpa mute lon tomo wan lon ma wan.
wan. tu. tu wan. tu tu. luka. luka wan. luka tu.
ona li ni li pini lon poka pi mute ale. (ni li nanpa).
nanpa mute
sitelen ni la, sina ken lukin e suli pi kama suli nimi lon tenpo. linja walo sewi li nimi "pu." jan li toki mute ala e nimi ni la ona li sewi tawa nanpa wan.

mi supa ale e sitelen nasa la sina ken lukin e kama suli pi toki pona lon tenpo

nasin a

nasa, toki pini pi wile sona li kama suli a lon tenpo
tenpo wan la mi lukin e toki pi tenpo weka li kama sona e ni: sike pini la toki "anu seme" li nasa lili tawa ijo Osuka. ni li nasa tawa mi! toki ni li suli a tawa nasin mi toki
toki ona la ona li kepeken toki "anu seme" lon tenpo pi mute lili taso li pilin e ni: toki "X ala X" li pona nanpa wan
oh my god 😭

is this when kijetesantakalu was coined?
thats the record for the usage of "suwi" from august of 2001 to aug. 2024
the hovered spike I mean
feb 2009, too early
what happened 😭
[Reply to:](#1272180068721889290 message) oh my god 😭 📎
I don't think there's much data for that time period, so maybe someone used suwi a bunch and it became a significant percentage of all toki pona recorded that month
oh
its gonna be someone who uses kawaii on a minutely basis watch


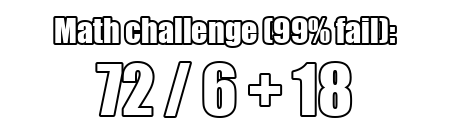
















 mi pilin nasa tan ni
mi pilin nasa tan ni















