#Fixing UB in random crates
1 messages · Page 2 of 1
I would fix this by not using Box
I'm trying to campaign for fixing this by removing the LLVM attributes from Box, but it's hard to know if I'm making my voice heard or being annoying
At least Ralf expects me to say the line now
What would be a good replacement for box here? Rc, using alloc?
Rolling your own Box so that it doesn't have the attributes
API documentation for the Rust AliasableBox struct in crate aliasable.
But that crate also has a few silly issues someone should fix
They are minor
Would a PR that pulled in this crate as a dependency be reasonable, or would it be better to just reuse the relevant parts of it?
That's a question for the maintainer.
I often find it hard to predict what tolerance people have for these patches and also for more dependencies
I have said already that this lint is good 
Luckily there's a ton of activity on the ucg issue 

Swapping in that crate gives me a weird error
match self.map.remove(k) {
None => None,
// old_node was a Box<..> and is now AliasableBox<..>
Some(mut old_node) => {
unsafe {
ptr::drop_in_place(old_node.key.as_mut_ptr());
}
let node_ptr: *mut LruEntry<K, V> = &mut *old_node;
self.detach(node_ptr);
unsafe { Some(old_node.val.assume_init()) }
}
}
}
error[E0507]: cannot move out of dereference of `AliasableBox<LruEntry<K, V>>`
--> src/lib.rs:704:31
|
704 | unsafe { Some(old_node.val.assume_init()) }
| ^^^^^^^^^^^^ ------------- value moved due to this method call
| |
| move occurs because value has type `MaybeUninit<V>`, which does not implement the `Copy` trait
I'm not quite seeing why this works with box and not aliasablebox?
I guess I can turn it back into a regular box here 
Perhaps
But I think this is DerefMove
Not that this helps you make the code compile, it just explains why you have the error without stdlib Box
time to write it all by hand using raw pointers and making the code 5x worse
i love box
I fixed that bit and then got another SB error with the invalidation not being local so I will simply give up for now
Saethlin would be proud of me. I optimised some code today to work well in debug
It did require a lot of effort though. I also had to avoid the desire to reach for unsafe

I had to do a str utf8 validation 😦
good
I wonder if it optimises away in release
I don't think utf8 validation will ever optimize away will it
?godbolt
pub fn foo() -> &'static str {
static B: &[u8] = b"hello";
std::str::from_utf8(B).unwrap()
}
core::ptr::drop_in_place<core::str::error::Utf8Error>:
ret
example::foo:
sub rsp, 56
lea rsi, [rip + .L__unnamed_1]
lea rdi, [rsp + 8]
mov edx, 5
call qword ptr [rip + core::str::converts::from_utf8@GOTPCREL]
cmp qword ptr [rsp + 8], 0
jne .LBB1_1
mov rax, qword ptr [rsp + 16]
mov rdx, qword ptr [rsp + 24]
add rsp, 56
ret
.LBB1_1:
movups xmm0, xmmword ptr [rsp + 16]
movaps xmmword ptr [rsp + 32], xmm0
lea rdi, [rip + .L__unnamed_2]
lea rcx, [rip + .L__unnamed_3]
lea r8, [rip + .L__unnamed_4]
lea rdx, [rsp + 32]
mov esi, 43
call qword ptr [rip + core::result::unwrap_failed@GOTPCREL]
ud2
.L__unnamed_2:
.ascii "called `Result::unwrap()` on an `Err` value"
.L__unnamed_3:
.quad core::ptr::drop_in_place<core::str::error::Utf8Error>
.asciz "\020\000\000\000\000\000\000\000\b\000\000\000\000\000\000"
.quad <core::str::error::Utf8Error as core::fmt::Debug>::fmt
.L__unnamed_5:
.ascii "/app/example.rs"
.L__unnamed_4:
.quad .L__unnamed_5
.asciz "\017\000\000\000\000\000\000\000\003\000\000\000\034\000\000"
.L__unnamed_1:
.ascii "hello"
Rip 😦
you can do that if const is OK
?godbolt ```rust
pub fn foo() -> &'static str {
const B: &[u8] = b"hello";
const A: &str = match std::str::from_utf8(B) {
Ok(s) => s,
Err(_) => panic!(),
};
A
}
example::foo:
lea rax, [rip + .L__unnamed_1]
mov edx, 5
ret
.L__unnamed_1:
.ascii "hello"
Nah non const 😦
why'd you not use const for this
My use case is more more complex
It was a minimum example
You might as well ask why I didn't use a string instead of raw bytes
Do you need all of UTF8
If it's an ASCII literal you may be able to wrap in an ASCII fast path and get the optimization
I need a string output. I'm working on ascii bytes already
But I'm not reaching for unsafe because its work

Actually I wonder what happens if you crank the inline threshold
Yeah I was thinking of writing a macro crate that does it inline
To force inline across crates
You can get the innards to inline, but LLVM doesn't erase the code. Bummer.
I wonder if a from_ascii method could do better
?godbolt
pub fn foo() -> &'static str {
static B: &[u8] = b"hello";
from_ascii(B).unwrap()
}
fn from_ascii(bytes: &[u8]) -> Result<&str, ()> {
if bytes.iter().copied().all(|b| b.is_ascii()) {
unsafe { Ok(std::str::from_utf8_unchecked(bytes)) }
} else {
Err(())
}
}
example::foo:
lea rax, [rip + .L__unnamed_1]
mov edx, 5
ret
.L__unnamed_1:
.ascii "hello"
oh shit it does

As predicted
pyo3 wat r u doin https://asan.saethlin.dev/ub?crate=pyo3&version=0.17.2
Oh it's a classico
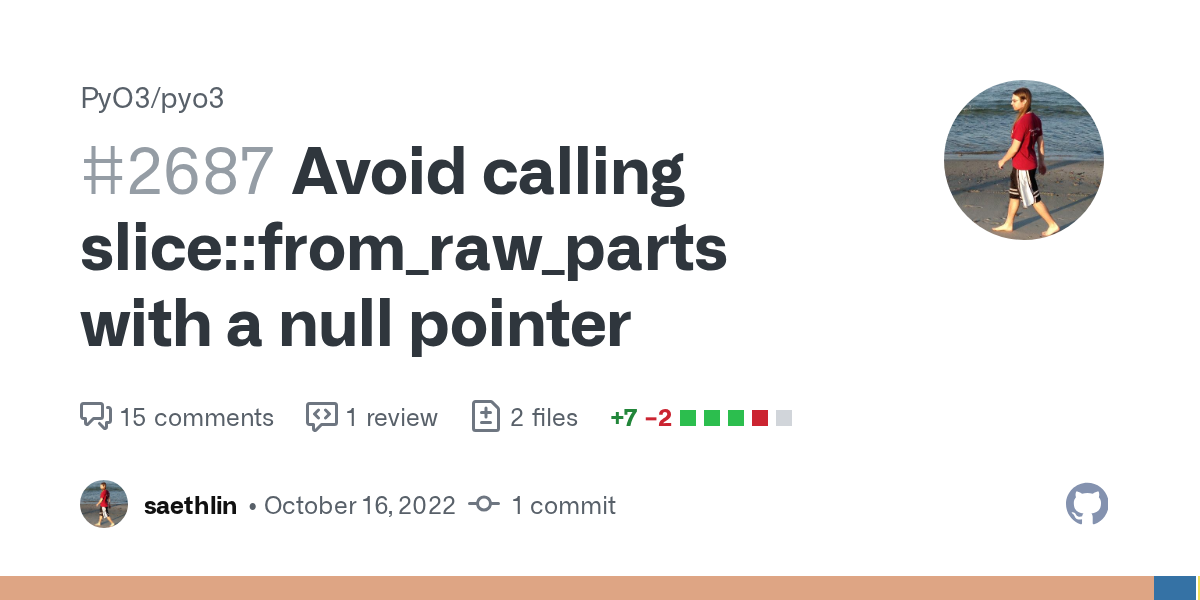
GitHub
slice::from_raw_parts requires that the pointer not be null, even if the length is zero. This is because the pointer is converted into a reference, and references must not be null. This is detected...

I just learned that cargo-careful has been eating my attempt to run on ASan

Not sure if this is a false positive https://asan.saethlin.dev/logs/criterion/0.4.0.html

This is the read_volatile implementation of black_box
pub fn black_box<T>(dummy: T) -> T {
unsafe {
let ret = std::ptr::read_volatile(&dummy);
std::mem::forget(dummy);
ret
}
}
yeah tbh i don't see how that can segfault, if this is the code being ran
but say T = Box<_>, now you do have sb issues
this should be using ManuallyDrop
or the real black box once we finally manage to stabilize that 
#[stable(feature = "bench_black_box", since = "CURRENT_RUSTC_VERSION")]
oh nice
we did
lol
There is no segfault
ASan just thinks this is like a wild pointer access
I should minimize this
I can't even reproduce this. Fuck.
I'm sure it's some kind of ASan bug
Another crate with the same issue: https://asan.saethlin.dev/logs/benchmarking/0.4.11.html
FWIW I'm with you on this
know this is some spicy low-level code but a stack buffer overflow seems a bit much https://asan.saethlin.dev/logs/trapframe/0.9.0.html
https://github.com/vorner/arc-swap/pull/80#issuecomment-1287312728
bumping the MSRV will only cause them staying at the previous version of the code which has the same problem. So bumping it solves nothing.
but still unsound on 1.31
unsound with a stacked borrows violation?
or unsound how?
if you know that you're only compiling against old versions, soundness suddenly matters a lot less
Writing through a pointer derived from &*ref with no interior mutability
hmm
i mean
it will probably be fine
maybe a few noalias/readonly shenanigans but no one found a "miscompilation" so far so it's gonna be fine
I know that the read is just a bitwise copy and into_raw currently calls the forget. In the current version, these are enough. Nevertheless, this is with the knowledge of internal implementation
given thatinto_rawis documented as 'Consumes the Rc, returning the wrapped pointer.', can my implementation here be relied on?
fn as_ptr(me: &Rc<T>) -> *mut T {
let ptr = Rc::into_raw(unsafe { std::ptr::read(me) } );
ptr as *mut T
}
``` for contextI'm trying to persuade them to bump so I can use the definitely-documented-as-working-this-way method, and this seems like a weird argument for not doing that?
Since either way people on 1.31 are going to be using technically unsafe code which can't be made safe
just keep on unsound on the old version
Well I think the options are to
- bump MSRV, allowing use of the documented and safe way of doing it but blocking 1.31
- use this method, which is definitely safe now, possibly safe in future, and definitely UB on 1.31
Not sure which to argue for
the one with less arguing
I can't really tell what the author wants here
This is why Zurr suggested doing version detection
If someone really wants to stay on an old an possibly-broken compiler, fine. But you can add version detection to ship a fix to users of a newer toolchain
yeah that's the best way probably (and i say this as someone who hates version detection)
Alright, I'll go with that 
But also, there's no sense in annoying a maintainer
They've been fairly positive in other discussions, just difficult to communicate over Github i guess
Kinda wish we had native version detection instead of the somewhat ad-how stuff we’ve got
Someone should RustSec this: https://asan.saethlin.dev/logs/grin_secp256k1zkp/0.7.11.html
(stack use after scope and heap buffer overflow)
The stack use after scope is typical cryptography code UB
The heap buffer overflow I do not recognize
typical cryptography ub
@strange egret do you want to rustsec it
I'm happy to review and merge it if someone makes the PR. But the first step is always to notify the maintainer.
It also has a ton of the typical: let mut ret: [$ty; $len] = mem::MaybeUninit::uninit().assume_init() ($ty is u8).
Sometimes the deprecation of mem::uninitialized seems not to have provided sufficient nudging to doing the right thing
wtf, this crate is an outdated fork of something from rust-bitcoin wtf
and the bitcoin one passes asan
rare coiner W
(well, this fork is also made by blockchain people for a cryptography which seems to be mainly focused on privacy?)
wait is this crate literally just a fork that didn't change anything
This branch is 376 commits behind rust-bitcoin:master.
I have no idea wtf they're doing

common coiner L
lmao
^

warning: the following packages contain code that will be rejected by a future version of Rust: traitobject v0.1.0
note: to see what the problems were, use the option `--future-incompat-report`, or run `cargo report future-incompatibilities --id 3`
Running `target/debug/playground`
1
traitobject is a dependency of unsafe-any which is a dependency of typemap. All lovely UB crates, but still have high download numbers
waiit which fcw is tha
It transmutes fat pointers
lmao it'a an FCP now because the way the lint is implemented will break 
There is some really spicy stuff far down on the list on https://asan.saethlin.dev/ub
Such as an ODR violation: https://asan.saethlin.dev/ub?crate=whosly&version=0.1.5
I feel like that one is on me but I don't know how
Not sure if this is a UB in the Rust library or the C library: https://asan.saethlin.dev/ub?crate=clickhouse-driver-lz4&version=0.1.0
average memcpy use
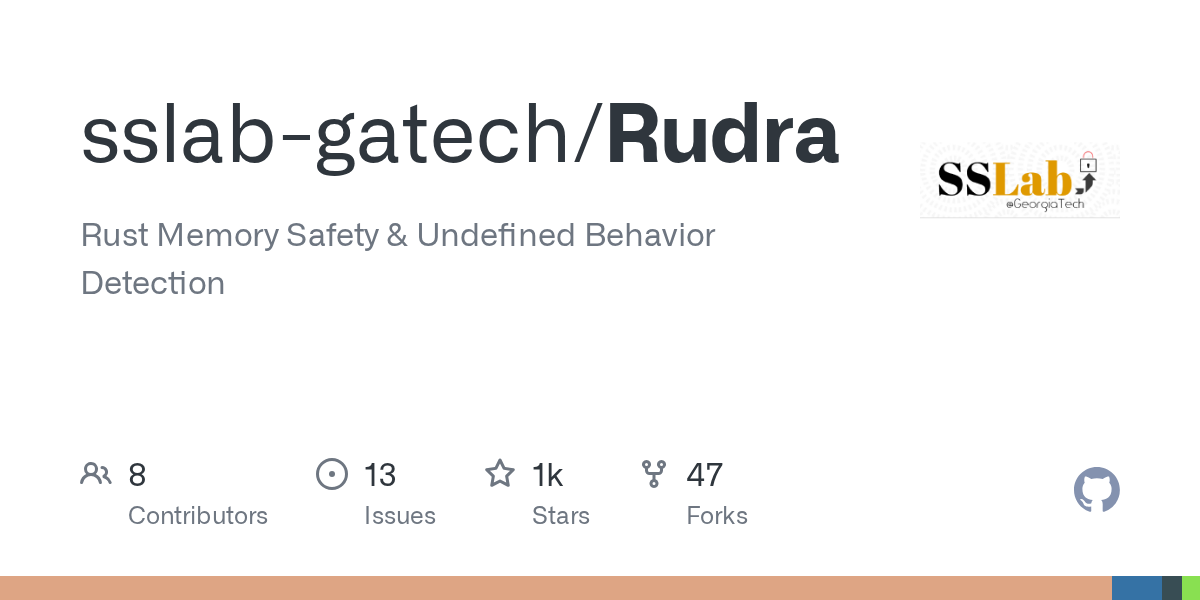
GitHub
Rust Memory Safety & Undefined Behavior Detection. Contribute to sslab-gatech/Rudra development by creating an account on GitHub.
I know you’ve probably seen it but it’d be interesting to see if parts of it can be integrated into miri

It’s a dataflow analysis thingy
Ah ah yeah
So it’s not really going for "all the ub", specifically some incorrect unsafe code
I'm not sure why it would be integrated into Miri
Well probably not integrated per say, more like miri could implement that algo
Or something along those lines
What is happening here?? https://asan.saethlin.dev/ub?crate=gltfgen&version=0.6.1
Custom test framework maybe?
owo i forgor about this
uwu
if someone is using unsafe { mem::unitialized() } for a [u64; N] i can just replace that with [0; N] right?
Might want to profile it
And if it's noticeably slower, you can try to use MaybeUninit
ty
wait nvm i wasn't understanding the code, i'll just use a maybeuninit array
That is correct yes, we 'fixed' uninitialized because it was guaranteed UB, and the fix was always producing an init value (notably, not always a valid value).
However, yeah, use MaybeUninit instead
sometimes a zeroed array will be just as fast
or something like array::from_fn could be used
That's an implementation detail 
Yeah but performance wise they would be correct
Performance is never a documented behaviour
mem::uninitialized will be exactly as fast as [0; N] nowadays
because it is
well, 1-filled
but still
it does init the array :)
but yeah, [0; N] is fine
Add sleep(100000) to all deprecated methods as a non breaking change to really get people to stop using it

This is no longer a relevant concern, because mem::uninitialized is not actually uninitialized.
More fool me for not scrolling
Well, presumably you'd have to profile it on an older version of Rust
or perhaps profile it against MaybeUninit::uninit().assume_init()
yeah but you'd probably want to restore the original performance if it exists
but yes you need to profile against MU
Eh
My point is just that a PR which removes the unsafe entirely is not a perf regression
So it would be illogical for a maintainer to object saying that the PR regresses perf
Well, it would be the Rust version update that regressed perf
So the comparison would really have to be against the prior status quo
This is unironically the real solution to this problem
Just increase the delay exponentially each Rust version
The main problem is, that would completely break our backcompat promises if we did it for every deprecated function
e.g., I worked with an old crate a while back that ran just fine but spat out a million warnings for r#try!()
mem::uninit (and to a lesser extent mem::zeroed) are special because they're UB in the way basically everyone uses them
so treating them specially here makes sense
You can't control the Rust version that your users are using
Sure, but I think it's somewhat deceptive to say "you did this unsafe operation that had good perf and you thought was correct, now it has bad perf and the safe operation is equivalently slow, therefore the safe operation is just as good"
That is, when they wrote mem::uninitialized(), they intended to get an uninitialized array in O(1) time
I submit to you that if they haven't changed the code away from mem::uninitialized in the meantime, they probably don't care enough about performance to merit the unsafe
So just because we changed it on our end because it didn't fit with our model, doesn't mean that now the safe O(n) operation is as good as the original O(1) operation
I agree that there is some violation of programmer intent, but there is more to the situation
People write codebases without keeping them regularly up to date with the latest warnings, that's just the way of the world
Oh lmao
0x1-filling is a 1.64 feature
Ignore me
My messages will apply in a few months
Once it is stable-4 everyone who cares deeply about perf should have noticed
in the threads too????
except nowadays old crates using it are pretty fine and it doesn't matter that much
with the filling? yeah
without? i'd be worried about noundef once we emit that
yes but we have filling do the latter question doesn't matter 
^ this would make the profiling much more annoying if it goes through
And crate authors that don't care about UB will probably just replace MaybeUninit::uninit().assume_init() with {let x=MaybeUninit::uninit();x.assume_init()}
profiling?
it won't change correct code, only insert panics into UB functions
hm?
how would this impact profiling????
the extra function call will be yeeted away by the optimizer
If you want to quickly evaluate how long zero-filling takes without loads of assume_init() churn
so you want to quickly write some UB to find out whether using MU properly would make it faster?
like my earlier suggestion
exactly
It's lying to LLVM, but as long as you don't leave it in prod (and don't try to read the memory before initializing it) it's not gonna be the end of the world
eh, it's not the strongest argument against it
"it won't change correct code, only insert panics into UB functions" is the obvious rebuttal
Who cares about people that just pull out another footgun when you take theirs away lol
At some point people are beyond help
Sure, and I think MaybeUninit::uninit().assume_init() is an obvious-enough footgun by itself that we shouldn't go beyond linting it
counterpoint: it's the correct way to make a [MaybeUninit<String>; 4]
Yes, and in that case you know what you're doing
In every other case you're knowingly (afaik) using a footgun
maybe an extra bonk will get them to use it properly
but also I'm not sure whether it will
Imo, we should change the deprecation status of mem::uninitialized() if this rewrite is the only consequence users take after the deprecation.
Panicking here feels very much like playing whack-a-mole with bad code, the proper fix would be ensuring that the correct use is easier to write than the incorrect use.
The correct way of that was mem::uninitialized(). That remains correct, only deprecated without technical need for it.
Not necessarily undeprecated the method, MaybeUninit is potentially more useful, but there clearly is use for more actionable advice on how to change common code pattern that use it into correct use of MaybeUninit. Potentially something that involves some form of (miri-based) checks if new use is an actual improvement.
the correct code is very easy to write don't worry
no it does not remain correct, it's not the correct way to do that anymore at all
in fact it won't even leave it uninit as mem::uninitialized just fills all bytes with 1 nowadays
mem::uninit is a good way of making a [MaybeUninit<String>; 4]
edited
or, would be
honestly i think some form of safe transmute would be useful here
filling with 1's is still correct.
It's just more obviously wrong for types that are not uninit.
but you want uninit memory for a reason
if you don't want uninit memory just initialize it lol
using mem::uninitialized is ALWAYS wrong
no?
It's not always incorrect though.
well, pre-mitigation
I am talking about post mitigation
All the lints and all the deprecation make it appear like it is always unsound, and that MaybeUninit::assume_init is less unsound.
Neither of these is the case.
It never does what you want which I would classify as incorrect
yes because we changed it
We have a lint for obviously invalid MaybeUninit::assume_init usage
What I want is not to have to choose any specific value.
Which is exactly what it still does, the specified effects of both ways are exactly the same.
I don't quite follow this discussion actually
Never use mem::uninitialized, always use MaybeUninit in the correct way which is not hard
Quite apparently it is hard. There's lots of MaybeUninit::uninit().assume_init()
No it's not
Those people are just too lazy to migrate
We literally cannot make it easier
(apart from making the creation of uninit arrays nicer which is being worked on)
That's my hypothesis, it didn't make the tasks that people want to achieve signficantly easier nor harder.
So they aren't switching because they see no point, or are switching to the exactly still unsound pattern which motivated 100423
Somewhere in documentation, lint, and information available the guide to a reasonable use of MaybeUninit is lost on developers.
mem::uninitialized is a little easier to use than MU
But we cannot make MU quite as easy that's the whole point
It's not bad
On a separate note, I contend that saying 'mem::uninitialized is always incorrect' doesn't make it any easier.
Because it fails to explain the concept of MU, the correct explanation is inconsistent with the messaging.
The correct semantics of MU are recognizing that that the defined semantics of both methods are the same.
Initializing with 0x1 is just the compiler's freedom to choose / do anything undefined semantics.
And it's not complete enough because a fairly relevant point is that different reads may ''return'' different values.
The choice of filling with 0x1 could easily be confused with the statement that uninitialized is freeze.
Which it isn't.
Evidence: https://dtolnay.github.io/noisy-clippy/uninit_assumed_init.html#local
There's a grep for ignoring uninit_assumed_init. You're welcome to take a look and judge if they are sound.
There's gems such as these (dup-crypto):
let mut tmp: [u8; 4] = MaybeUninit::uninit().assume_init();
ptr::copy_nonoverlapping(input.get_unchecked(0), tmp.as_mut_ptr(), 4);
u32::from_le_bytes(tmp)
That seems to have an obvious underlying usability issue.
all of them are unsound
if they were sound the lint wouldn't fire
to fix these you'd do:
Change the type from an array of things to an array of MU<thing>
Slightly change the code accessing it
we literally cannot make it easier apart from the initialization of uninit arrays which isn't too bad what do you want
I want for people to write sound code. The full context is this:
fn read_u32_le(input: &[u8]) -> u32 {
assert_eq!(input.len(), 4);
unsafe {
let mut tmp: [u8; 4] = MaybeUninit::uninit().assume_init();
ptr::copy_nonoverlapping(input.get_unchecked(0), tmp.as_mut_ptr(), 4);
u32::from_le_bytes(tmp)
}
}
You wouldn't even have to cast anything, but for some reason the try_into().unwrap() was less preferred to the author than a literal unsafe block.
I'm not a behavioral scientist but some line of reasoning caused this and I'd really like to know what.
There's some underlying misinformation; and maybe the lint could be more specific in resolving this misinformation and demonstrating alternatives; and maybe that would increase adoption of appropriate uses; especially when the author is in the process of transitioning away from mem::uninitialized().
The .try_into().unwrap() conversion isn't immediately obvious
You'd have to think to look all the way down in the TryFrom impls to find it
That's one of my main annoyances with rustdoc, sometimes critical functionality can get hidden among the endless boilerplate impls
but btw, to make this sound using MU (you should of course be using try_into) ```diff
-
let mut tmp: [u8; 4] = MaybeUninit::uninit().assume_init();
-
let mut tmp: [MaybeUninit<u8>; 4] = [MaybeUninit::uninit(); 4];
-
u32::from_le_bytes(tmp)
-
u32::from_le_bytes(tmp.assume_init())
it's really easy, isn't it?(also that get_unchecked hurts lol)
yeah, it's wrong too due to provenance..
nah it's not ub just extremely unnecessary
That does seem appropriate. Is there some analysis that would allow adding this as a lint, can it be generalizable somewhat readily?
wait no it is found when references shrink provenance
i guess we could? but also it's often a little more than that (for example you'd need to change a field type as well)
Maybe if the only use of the uninitialized assignment is a move, it would be possible to recognize when the assume_init() could be delayed until the move?
Scratch 'only use', that's nonsense. Let's say, the last or something
The fact that the author of this is using get_unchecked(0) instead of as_ptr() makes me think it is not worth reading into the thought behind this code because it clearly wasn't reviewed carefully anyway
I see all of your objections to this work and idk. They don't bother me? We are ahead of the curve. We are trying to get people to patch their code before the release where a new compiler turns a previously-working program into a pile of vulnerabilities or a crashing mess. Of course people are going to be upset or skeptical. There are still a lot of people who are butthurt about the UB in their C which is actively exploited by existing compilers.
This specific case will probably be fine actually, I think.
It isn't fine for SB but it should be fine in the next model I think
yeah that's what I was trying to say with words that don't make sense
Molly White is in here
Ergo, not that kind of space
You should join for the schadenfreude
Ok you are forgiven. Web3 is going great
Hot damn the cope in here is unreal
I do love a bit of copium
this reads like a song title
hi pen ping
at your service
to the tune of jingle bells
Crypto bros
Crypto bros
Mining all the way
Oh what fun it is to ride
This line up all day, hey!
Crypto bros
Crypto bros
Exchange went bust today
Oh what fun it is to see
No more tokens today, hey!
I have UB and idk why
https://github.com/conradludgate/futures-buffered/actions/runs/3462352787/jobs/5781129414
Essentially I have ArcSlice which has a pointer to ArcSliceInner. This contains ArcSliceInnerMeta and [ArcSlotInner].
ArcSlot is supposed to have the same ownership over the entire arc as ArcSlice, but points to a single ArcSlotInner only.
I can track back the ArcSlotInner pointer to a ArcSliceInnerMeta pointer fine with no UB according to miri, but I can't turn it into a full on ArcSliceInner without triggering the stacked borrow error
- let ptr = Self::meta_raw(ptr);
+ let ptr = Self::meta_raw_ptr(ptr);
Oh 👀
Having raw for a non-fully-raw function might have been the footgun that lead to this 😄
meta_raw
meta_rawer
meta_rawest_of_them_raw_things
Also, there could be a lint for things such as let len = *core::ptr::addr_of!(ptr.len); when ptr is a & reference
I originally had it as (*ptr).len and then the lint complained so I thought "sure I guess"
ty yandros
Now I just have to find the source of the regression
oh wait shit - it's a benchmark issue 😛
the usual
I swapped the order of the benchmarks and they flipped their speed
I have an interesting deadlock now though 😦
lol
It's very sus too
It only happens on concurrency > 128
See how the last one is 128... 
#[tokio::test]
async fn join_all_large() {
let mut start = Instant::now();
for i in 1..256 {
crate::join_all((0..i).map(|i| async move {
tokio::time::sleep(Duration::from_micros(1)).await;
i
}))
.await;
println!("join {i} in {:?}", start.elapsed());
start = Instant::now();
}
}

Do you think it could be a tokio-specific issue?
potentially. But it doesn't happen with the futures version of join_all/FuturesUnordered
if waker.is_the_one_from_futures() && concurrency <= 128 {
work_properly()
}
Ok - this time it got further than 128 but I found the symptom that seems to cause the busy looping. It's happily polling along (the bounded.rs:183 is the poll call) and then it got unlucky and got stuck in a poll-wake cycle - now I'm not sure why it doesn't progress in this case

I think it is actually
I really hate the use of the term "toot"
Makes me think this is somehow a fart joke
I'm a frequent tooter
do toot 

sorry for the maybe super silly question, but I am struggling to find the link to the website that reports on the different bugs that miri is detecting in recent crate compiles.. is it somewhere higher up in the chat history?
that'd be saethlin's thing right
ah yess, exactly, that is it! thank youu ! 😄
it's also in the pinned messages in this thread! but discord doesn't make it easy to remember pinned messages exist…
There are pinned messages? Where?
pin

very good hiding place! i'll try to remember ! 😄
hey guys,i had quick question! i made a pull request to fix some UB for the lru-rs crate, yet I ended up going maybe a bit overboard in the process haha! i am still quite new to this, so i was wondering of anyone had time to review and give me advice for improvement/point out where i went wrong with things! https://github.com/jeromefroe/lru-rs/pull/161
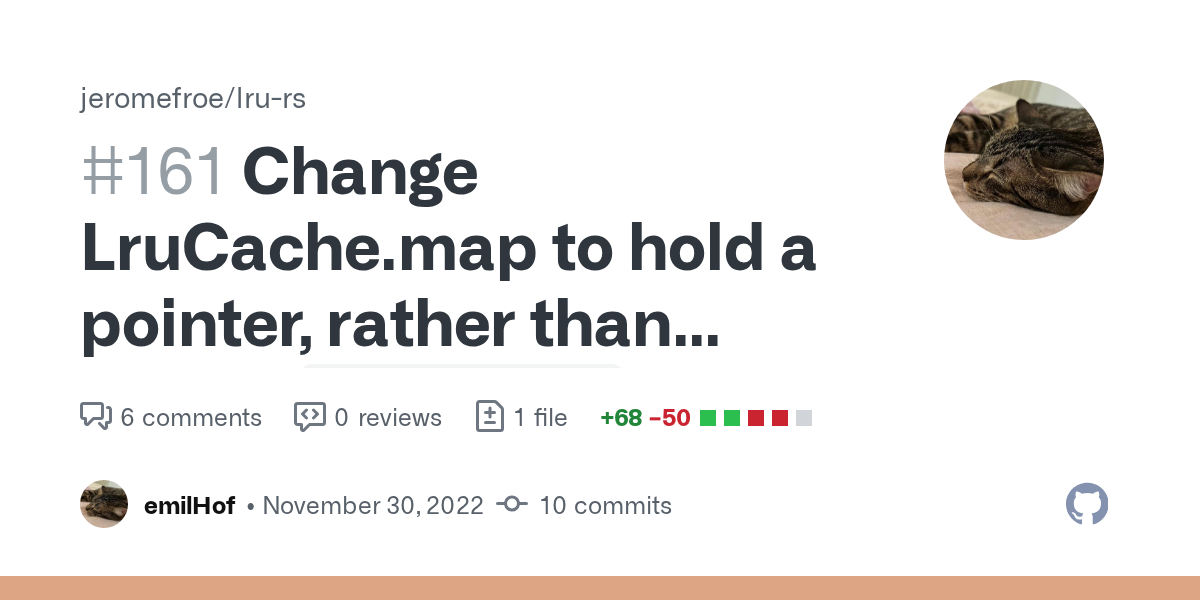
GitHub
This is meant as more of rough proposal, and I do not expect this to be merged in its current form. The aim of this pull request is to showcase a potential fix to an miri error that is inherent to ...
the issue was the invalidation of a tag through a Unique retag, if that helps?
This doesn't look like a hue drastic change to me
This is just a classic replacement of box with a pointer
btw you should use NonNull instead of *mut
oh, i see! i was not to sure! does the reasoning for it make sense?
also, what is the usual premise for using NonNull rather than *mut in these cases?
Box can't be null, it has a niche. So Option<Box> is the same size as Box, but Option<*mut T> is the size of two pointers, because *mut T can be null.
ahh, that makes a lot of sense! in my mind i was confusing ‘NonNull’ with ‘MaybeUninit’ which made it even more more confusing haha! does the niche optimization also apply for ‘MaybeUninit’ or is this also allowed to be ‘null’ and this not have a niche?
MaybeUninit has no niches
even if the inner type does
because that would be a validity invariant on a type that explicitly has no validity invariants
i.e. what would Option<MaybeUninit<NonNull<T>>> do if you have Some(MaybeUninit::zeroed())
that is fair! is that part of MaybeUninit’s contract, that is has absolutely no validity invariants?
it has to be, since the point is that it can contain entirely uninitialized memory …
huh https://doc.rust-lang.org/stable/std/mem/union.MaybeUninit.html doesn't really explain that.
Argh, I hate protectors

GitHub
I've been testing this crate some more in Miri, and I've found an intermittent issue where it reports UB. /* Patch the desync repo: --- a/src/scheduler/desync_scheduler.rs +++ b/s...
You aren't allowed to tell another thread to invalidate one of your &mut function arguments, even if you never use that reference again
Is it really theoretical UB
Is this code pattern giving LLVM license to do an oopsie because of dereferenceable
Technically, but there's no real reason for LLVM to dereference it again, since the reference is lexically never accessed again
This code takes a value out of the reference, then the other thread observes that the value is taken
In fact, LLVM would have to be extremely smart to know that accessing the value again wouldn't cause a data race with the other thread
That's not how optimizers work
They specifically do not have to reason about "will this cause a data race"
They do if they want the assembly to make any sense, data races come from the processor after all
No, they don't
Optimizations don't reason about other threads
This is the fundamental reason that data races are UB
Any function can be optimized to hell and back without wondering about "what if another thread observes this"
And optimizations at the level of LLVM IR don't reason about assembly or processors
They have to assume that possibly-aliased memory may be modified on a synchronization operation
(but I'll grant that it's a bigger problem for noalias &mut)
No, they don't
You're confusing the rules about reordering with reasoning about multiple threads
Are they not inextricably interlinked?
Reasoning about multiple threads is needed to justify the reordering rules, is it not?
I'm talking about this effect:
?godbolt
use std::cell::Cell;
use std::sync::atomic::{self, Ordering};
pub fn example1(cell: &Cell<i32>) -> i32 {
cell.set(42);
cell.get()
}
pub fn example2(cell: &Cell<i32>) -> i32 {
cell.set(42);
atomic::fence(Ordering::AcqRel);
cell.get()
}
example::example1:
mov dword ptr [rdi], 42
mov eax, 42
ret
example::example2:
mov dword ptr [rdi], 42
mov eax, dword ptr [rdi]
ret
In example2(), the optimizer is forced to dereference dword ptr [rdi] again, because the value could have changed
I don't really care about the exact rule
but the fact that a synchronization operation gives other threads free reign to do unsynchronized accesses
Unless the current thread does its own unsynchronized accesses following the operation, like in this example
but in something like
pub fn example3(cell: &Cell<i32>) {
cell.set(42);
atomic::fence(Ordering::AcqRel);
}
The value behind cell can be modified arbitrarily between the fence and the function returning
So the optimizer can't insert a read from cell during that time and expect to get a meaningful value
And to return to the &mut case, consider
pub fn example4(r: &mut i32) {
GLOBAL_CHANNEL.send(r as *mut i32).unwrap();
atomic::fence(Ordering::AcqRel);
}
Since r has escaped, its value can be modified between the fence and the function returning
So once again, the optimizer can't expect to get a meaningful value from reading it after the fence
The only thing it knows is that it's dereferenceable, since that's what we promise for &mut parameters
Call it reordering rules or whatever you want, it doesn't change the fact that there's not much that LLVM can usefully perform with an access after the fence

lmao, allocators
alloc::alloc() is an automatic footgun for the average person
The average person doesn't actually read preconditions, they just imagine what the preconditions probably say
You didn't report any of those?
Haven't gotten around to it yet
Now that the new Layout restriction is stabilized, they can't deflect with "But my libc always refuses such allocations!"
(Although I still maintain that your libc is dumb if it doesn't refuse malloc()s larger than PTRDIFF_MAX)
Oh, and I should really post a PR fixing GlobalAlloc's preconditions, unless we want to invoke stdlib privilege to let it create overlarge Layouts
Many of those are libraries
So it doesn't matter what libc the author uses, they need to work with any global allocator the user installs
Yeah, I know, it's just that I was trying to judge just how much of an immovable rock we'd have to move to require GlobalAlloc::alloc() to always fail past isize::MAX
As it turns out, the name of the immovable rock is likely "the BSDs"
from cxx code-source: https://docs.rs/crate/cxx/1.0.85/source/src/rust_string.rs
// ABI compatible with C++ rust::String (not necessarily alloc::string::String).
#[repr(C)]
pub struct RustString {
repr: [MaybeUninit<usize>; mem::size_of::<String>() / mem::size_of::<usize>()],
}
impl RustString {
pub fn from(s: String) -> Self {
unsafe { mem::transmute::<String, RustString>(s) }
}
…}
(Mobile sorry can’t find the backsticks.)
I’m confused, doesn’t the code and comment contradict themselves?
If you're using iOS, you can long-press single-quote to use backticks
Oh nice
Uhh
ABI compatible
this means for example the way it's passed as function arguments
for example there's no guarantee that String isn't just passed in 3 registers on days where rustc feels like it
and passed in 2 + a usize on the stack on other days
but this struct will always be passed the same (at least on extern "C" fn)
I hope they verify somewhere that size_of::<string::String>() is a multiple of size_of::<usize>()
But how does transmute work in both days then? I thought it was only reading memory with different type, which for me is the same as ABI
I think it's guaranteed that String is 2 usize + ptr
At least, vec is?
this cannot be an ABI/layout guarantee
Not a layout guarantee
gtg but will read your explanations later
But any such padding will align it so that all the usizes will be usize aligned
True, but if it's guaranteed to store the length and capacity as a usize, then the alignment will do the rest of the work
So it must be a multiple if usize len?
transmute is basically equal to writing the struct to memory and then reading the other struct from memory
here, only layout matters
which will be equal
That's assuming that align_of::<usize>() == size_of::<usize>(), which isn't entirely guaranteed
Alignment 1 usize when
It's not really an issue since it would be caught during compilation if it failed? Meaning the String and Rustring types didn't have the same size
Right, duh
crisis averted
Forgot that transmute protects against that
Yay, I found unwind safety bug #320498530495783489057: https://gitlab.com/tspiteri/rug/-/issues/47

GitLab
After executing the user-provided closure, Rational::mutate_numer_denom() calls xmpq::canonicalize(self) to canonicalize the resulting value. However, if the closure unwinds, then self is never canonicalized, and its non-canonical value can...
We really do need an "unsafe Rust tips and tricks" document
So that people don't about unwinding existing, or forget to check for isize::MAX before making an allocation
(The latter is now handled by Layout, but a whole lot of crates call Layout::from_size_align_unchecked())

Why do you say that?
i think it has had soundness issues before hasnt it
Hoyl
It's just... Sloppy and has poor tests

GitHub
Going through as_ptr does not give write provenance
since it creates an intermediary shared reference.

Anyway, it should pass Miri finally so obviously that makes it good
i knew there was something
some, you could say.
still better than using *const char
with that you at least know what you're getting
https://crates.io/crates/crop new rope crate with unsafe code just dropped
i have run miri on some of the tests and it looks fine
but it would be cool if someone added all the necessary cfgs to make all tests work and then PRed miri ci
it uses str_indices which has a SIMD feature that doesn't disable all SIMD so you need to use an obscure target like aarch64 where it doesnt support SIMD
or make a PR to str_indices that properly gates all SIMD behind the feature
I feel like that makes things easier?
i don't know how easy it'd be to build a UTF-8 enforcing rope over a Rope<u8>
but a Rope<T> is a type that should exist
agreed
stack: Vec<Vec<Arc<Node<FANOUT, L>>>>
Crikey
we've found the antiperf
oh dear
captnproto has some UB in it :(
ptr::copy_nonoverlapping precondition
at the very least
ah
they fail miri
O u c h
is there any non-self describing binary file format that's not cursed
flatbuffers has the rust code say "yeah you need FFI into the C++ code in order to call the buffer verifier"
captnproto has this (but granted it's probably not exploitable or anything, just funky)
rkyv was also weird
fuck it, using bincode
simply fix it
i'll fix the test failures that assume that vecs are aligned
the underlying allocation
overaligned i mean
(they have a Vec<u8> which no reasonable allocator would misalign. however.)
Well, IMO a binary format that isn't self-describing is already cursed
Self describing formats should really be more cursed imo, but they don’t usually have expectations of high perf so there’s more checks in practice
But there’s always things like .net object deserialisation which is a CVE hellscape
🥒:D
No I mean the lack of a description itself is cursed
Because they inevitably end up on disk without the description and then it's like what are we doing here
Oh yeah… if you’re putting it on disk then that’s much more cursed
True also
Most things eventually escape to disk
"it's just a wire format"
So what do I do with this core dump from the deserializer
The deserializer cannot be trusted as a description in this case; if it were trustworthy it wouldn't have dumped core
In addition, if the format doesn't describe itself exactly, you run into compatibility problems that have led to the erosion of protobuf
have each message be prefixed with a plaintext URL on where to find the schema
(and internally publish and archive all schemas used, even temporary ones for dev work)
Yay, I found an unsoundness in hashbrown now: https://github.com/rust-lang/hashbrown/issues/412

GitHub
If the &Bucket<T> comes from a different RawTable<T, A> than the RawIter<T> comes from, then these methods sometimes call offset_from() between the...
(That's what happens when you wrap your function in a huge unsafe {} block without thinking about it)
I love contrived trait impls

GitHub
The safety comment in the function says "pos is set only to values smaller than block size", but if the block size of the StreamCipherCore is equal to 0 (in a contrived scenario),...
And it looks like they duplicated their code: https://github.com/RustCrypto/utils/issues/843

GitHub
This is effectively another instance of RustCrypto/traits#1275. // RUSTFLAGS=-Cdebug-assertions=off cargo +nightly miri run // block-buffer = "=0.10.3" use block_buffer::{generic_...
generic_array
Hush, it's fine now
It has arithmetic, that's more than you can say for the silly "const generics"
"nooo, you'd need a full SAT solver, it would be inconsistent", so many excuses
Forked a repo and clippy straight away found UB
This project does some cool stuff but the code is
GitHub
Desktop GUI Framework. Contribute to fschutt/azul development by creating an account on GitHub.
and what the clippy output?
a lot of stuff
The blatant UB it found was
let mut stack_mem = mem::MaybeUninit::<U>::uninit();
ptr::copy_nonoverlapping((ptr as *mut c_void) as *const U, stack_mem.as_mut_ptr(), size_of::<U>());
// copy is not in bytes ^^^^^^^^^^^^^^
I'm not trying to fix it all because it's too much for me to go through. I don't need all the functionality it offers and I certainly don't need c interop so I'm getting rid of all that shit
Meanwhile
warning: the following packages contain code that will be rejected by a future version of Rust: allsorts-rental v0.5.6, allsorts_no_std v0.5.2
note: to see what the problems were, use the option `--future-incompat-report`, or run `cargo report future-incompatibilities --id 1`
DUDE WHAT
5.4k starts
thankfully/sadly it doesn't appear to be maintained anymore
yeah that's why I'm just stealing the parts I need
hahaha
amazing
that's actually a good lint, i did that the other day
What the fuck
Did he think ptr::copy_nonoverlapping was just a shim around memcpy?!
Tbh I have made that mistake myself a few times
can you explain it i dont understand
copy_nonoverlapping has a length for how many values to copy. In libc, memcpy counts how many bytes to copy
ok
It's pretty easy to automatically fall back to size_of(T) * n
that just means the source and destination byte ranges can't overlap
This is a very reasonable mistake. A lot of code is written based on vibes and "look the tests pass"
We have a clippy lint for this because it's such a common mistake.
memcpy also assumes src and dst don’t overlap
rust just has a better name for it
although tbh ptr::copy should be called ptr::copy_overlapping
yea
eh, seems similar to [T]::sort vs [T]::sort_unstable
in that the shorter name goes to the one with stronger guarantees (preserves order of equal items/works even if overlapping) but that's less optimized if those aren't needed
yeah, using copy when you mean copy_nonoverlapping is always correct
same for sort instead of sort_unstable
I also think that sort should’ve been called sort_stable (and keep sort_unstable also)
Optimization missed opportunities should be made clear in code
Or if it requires it, the invariant should be made explicit
we do have a lint for "you're using sort on something that doesn't need it"
but maybe it should also use specialisation
pub trait IndistinguishableEq
I’d prefer ```rs
trait PartialEq {
fn is_indistinguishable(&self) -> bool { false }
}
or maybe we could have fn sort have a bound for IndistinguishableEq
no because you might not care
where things end up that compare equal
even if you can distinguish
wait isn't it?
in what case isn't it a memcpy / memcpy analog?
It's semantically equivalent, but count is the amount of instances you want to copy, not the byte size of the type
This guy was passing size_of::<U>()
oh right yeah
I missed that detail
not to mention the whole mem::MaybeUninit::<U>::uninit() thing
This is safe
He's using a ptr to the MaybeUninit as the write-out destination
wouldn't that be UB for the same reason that std::mem::uninit is UB?
oh rip, I thought it was assume_init not ::uninit
mem::uninitialized returns an uninitialized T. MaybeUninit is a union between T and ()
I obviously haven't gotten enough sleep
Then sort_unstable makes that explicit in code
The ideä is just that .sort() with no qualification should only occur when it literally cannot matter
Yay, I love unsafe code that takes &mut self and panics partway through modifying it
GitLab
xmpq::canonicalize() panics when the denominator is zero, but catching this panic will leave the previous non-canonical value in place.
me too
❤️
malachite or num-bigint my beloved
I think once I rewrote my application in rug and it was faster
I like how this is an or, so you actually only love one of them, but you’re not telling us which one
Well malachite is GPL, so that tends to stop most people 👀
GPL :(
gnu poland
I want a Rust-specific license like MPL but per-crate
for our polish gnu lovers
so non-viral but still copyleft enough for libraries
LGPL, not GPL. still an obstacle for some people but less so than GPL
ah right
iirc it's LGPL because many of the algorithms are sufficiently close translations of GMP algorithms that it could reasonably be considered at least partially a derivative work, and GMP is itself LGPL-licensed
interesting
I have one GPL project for that reason
🙃
Turns out I ported the GPL algorithm wrong though so I might just try to reinvent it from scratch and switch to MIT/Apache-2.0
based
Y tho
lmao
I guess they did want to prove utf-8 resilience somewhere else in the code, but that format! is
This wouldn't be an issue if we had format!(b"...")
bzzzt - this fails the "I can decode the file with no network access" test
it would be informational only
you should know the schema of what you're decoding
somehow Google manages to use non-self describing formats in prod just fine
So we're inventing XML schemas all over again?
Make it an URN instead of an URL while we're at it
oh yeah that's okay then

GitHub
In src/features.rs, kernel_version() is defined as: fn kernel_version() -> Result<usize> { static mut KERNEL_VERS: usize = 0; unsafe { if KERNEL_VERS == 0 { KERNEL_VERS = parse_kernel_vers...
naughty nix, using a static mut
O u c h
Before I started using nextest I was using multiple test threads specifically to detect this, but the timeouts from nextest are just too good
the fuck
annoyingly, I can't demonstrate it in Miri, since Miri doesn't support uname
You can fix that
You have the power
And/or open an issue and one of the Miri helper people will swoop by
There are a few community members who will contribute easy shims if you hold their hand a bit. It's very cool.
I think this is one of the cases where you don't need any demonstration 
static mut bad is an absolute zero take, after all
GitHub
Resolves #2028
Note that this is (AFAICT) the first use of Atomic* types in nix (other than tests). However, this shouldn't be a portability issue, since nix is not #![no_std], and (IIUC) std r...
dont you love it when you make a pr and ci fails horribly for reasons you didnt cause
yes
(i still don't like the name :( )
1.70
I think I found the issue: rustix 0.37.16 started using linux_raw_sys::ioctl without enabling linux-raw-sys's ioctl feature on some targets.
https://github.com/bytecodealliance/rustix/pull/645
nix dev dep -> tempfile -> rustix so nix's tests don't compile on those targets.
GitHub
... when using libc backend.
May fix issue described in #637 (comment) and CI errors for nix under some Linux and Android targets, when using rustix >=0.37.16. (Tested locally)
(Fixed in rustix 0.37.18)
cargo features
https://asan.saethlin.dev/ub updated btw. Might be more UB than before. Unclear.
hashbrown is fine
oh yeah that's just allocation fail
libunwind-sys could do with a look
I'm tweaking the settings to get allocation failures off the page
Also there are some crates that are trying to mem::uninitialized types with a niche 
Maybe they just really want 0x01-initialization and don't want to risk calling ptr::write_bytes() incorrectly
broke: using mem::uninitialized because you haven't heard of MaybeUninit
woke: relying on mem::uninitialized for simple RNG, which isn't so random anymore
bespoke: using mem::uninitialized to fill an array with 0x01
Wait for speed? Is there a speed difference?
nah they just couldn't be arsed to switch to MaybeUninit
fn random_seed(_: &Path, _: &str) -> [u64; 2] {
use std::mem::uninitialized as rand;
unsafe { [rand::<u64>() ^ 0x12345678, rand::<u64>() ^ 0x87654321] }
}
Ah yes, very sound and normal
Lgtm
god that alias is so evil
use std::mem::uninitialized as rand;
deeply deeply cursed line
fn random() -> u8 {
0x01 // determined by fair dice-roll
}
const RAND_VALUE: u8 = 1; // determined by fair dice-roll
Not making mem::uninit produce 0x04 was a missed opportunity
lmao
cons: breaks bool
pros: funny

?miri
#![cfg_attr(all(), feature(generic_const_exprs), allow(incomplete_features))]
// Safety: bruh.
unsafe trait Randomizable {}
trait Get : Randomizable {
const RANDOM: Self;
}
macro_rules! Sized {( $T:ty $(,)? ) => ( [(); ::core::mem::size_of::<T>()] )}
impl<T : Randomizable> Get for T
where
Sized!(T) :,
{
const RANDOM: Self = unsafe {
#[repr(u8)]
#[derive(Clone, Copy)]
enum TheRandomValue {
/// Determined by fair dice roll
Is = 0x01,
}
#[repr(C)] // <- EDIT: whoops
union Bruh<T>
where
Sized!(T) :,
{
src: [TheRandomValue; ::core::mem::size_of::<T>()],
dst: ::core::mem::ManuallyDrop<T>,
}
::core::mem::ManuallyDrop::into_inner(Bruh {
src: [TheRandomValue::Is; ::core::mem::size_of::<T>()],
}.dst)
};
}
unsafe impl Randomizable for u16 {}
const RAND_VALUE: u16 = u16::RANDOM;
dbg!(RAND_VALUE);
[src/main.rs:42] RAND_VALUE = 257```AHHHHHHH
I petition for forbidding Yandros to write code, for the sake of everyone's sanity
I petition for Yandros to write all the code for everyone
You have my vote
Reimplement coq out of rust macros
-days-since missing repr(C) on union (#981649653764333598 message)
Days since last missing repr(C) on union in #981649653764333598: 0
hahaha
I really want to just require that all union fields are at the same offset in repr(Rust). When everything overlaps anyway, I don't see any reason that there'd be a need to ever do anything else, and everyone assumes it's true anyway.
If it overlaps yes, that's quite plausible (no reason to artificially make the whole union bigger), but I could imagine
#[repr(Rust)]
union U {
a: InOrder<u8, bool>,
b: bool,
}
being laid out with .b starting at offset 1
It's just not at all obvious to me that that's better in any way than having all the fields at the same offset. Given that nobody could rely on it, what would it make better for anyone?
To make Option<U> smaller etc. I guess 🤷
FWIW, I'm not saying this is better, and imho I do think this shouldn't really be the default repr (#[repr(niched)] pls ); but it's at least something plausible.
Right, but that requires that unions have niches, which today they don't, which Ralf at least seems pretty sure about.
Ah, I wasn't caught up with that aspect, my bad
Even more reason to at least not have it as default repr
I'm not personally convinced that not having niches is right -- it penalizes the "I just wanted to store two things" cases -- but it is what it is right now.
So yeah, in that case I fail to see any other plausible reason to use non-0 offsets for union variants under the default repr
And MaybeUninit::<MyUnion>::uninit()::assume_init() is thus not insta-UB for unions right now, and thus changing that might be difficult because it would make currently-sound code into insta-UB-but-still-compiles code, which is the worst kind of breaking change.
I really wish that "all unions can have niches" was the default, though, since adding a unit field to a union is such an obvious way to opt-in to the "nope, fully uninit is legal too" behaviour if people want that.
would be interesting to run Miri against the ecosystem with that change and see what things actually break with it
That was my naïve intuition as well
But who knows, maybe we'll get repr(strict) on unions one day, or something
repr(active variant rule)
for when you're not going to be doing transmutations using the union

?eval unsafe { std::mem:: uninitialized::<[u8; 128]>() }
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]```we don't return uninit data anymore :)
The problem with relying on UB is that it may not do what you expect :P
Decided by fair dice roll
I knew Nils made it "all ones" but I thought that meant !0
Wouldn't be a valid bool
is bool always 0 / 1 byte?
Yes
Wait you want it to be a valid bool?
IIUC the whole point of 1-filling std::mem::uninitialized() was to make it stop being insta-UB to use for primitive types like ints; if the mitigation didn't make it not insta-UB for bool when it could have, that would be less than ideal.
(Obviously ideally no-one would have been using it in a UB manner to begin with )
(and not 0-fill because then its insta-UB for NonNull things)
Ideally using uninitialized would actively try to break your assumptions
(In debug mode)
The point of 1-filling is that it doesn't turn into surprise compilation
Fair ig
that was Ralf
My b I thought you (or someone else here) implemented that
It makes all the primitives, as well as &str and NonZeroUsize, not trivially instant-UB with mem::uninitialized, which is the point. It doesn't solve everything, but it was an easy way to deal with the known-bad cases.
I don't have test cases pushed (I can do that tonight). But it looks like xz2 has some unaligned memory access when run on non x86 systems.
This only happens when I have the arm filter enabled. Can't run miri and I'm not that experienced in fixing these. Any help?

GitHub
Bindings to liblzma in Rust (xz streams in Rust). Contribute to alexcrichton/xz2-rs development by creating an account on GitHub.
do you know where the unaligned access happens? through a debugger or something like that
The code I linked to caused one of them. I can fix that with some as * const u64 (I think)
The other one that I put a print before and after to find is this one
GitHub
Bindings to liblzma in Rust (xz streams in Rust). Contribute to alexcrichton/xz2-rs development by creating an account on GitHub.
do you have any way to reproduce it
I can tonight
Any chance the new debug-mode alignment assertions trigger on it? If not, that could be a good bug too.
What do you mean by "unaligned when not run on x86 systems"?
Unaligned accesses are unaligned only depending on the value of the pointer and the alignment of the pointee, the arch doesn't matter
For sure, I misspoke on that
yah the whole read/write for everything is weird imo
If that's what you're referencing
I'm not at home rn, but something like this.
I'm not actually sure this is UB, looks like just the wrong bindings (which is UB?). I can provide a gdb(gef) output later. Notice running it on x86_64-unknown-linux-gnu works fine.
use xz2::stream::{Filters, LzmaOptions, MtStreamBuilder};
fn main() {
let dict_size = 0x40000;
let mut opts = LzmaOptions::new_preset(6).unwrap();
opts.dict_size(dict_size);
let mut filters = Filters::new();
filters.ia64();
filters.arm();
filters.arm_thumb();
filters.lzma2(&opts);
let stream = MtStreamBuilder::new()
//.block_size(0x1000)
.filters(filters)
.check(xz2::stream::Check::Crc32)
.encoder()
.unwrap();
}
cross r --release --target arm-unknown-linux-musleabi
Ah, just using -musl makes this crash?
> gdb ./target/x86_64-unknown-linux-musl/debug/xz-issue
GNU gdb (GDB) 13.1
Copyright (C) 2023 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-pc-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<https://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from ./target/x86_64-unknown-linux-musl/debug/xz-issue...
warning: Missing auto-load script at offset 0 in section .debug_gdb_scripts
of file /home/wcampbell/projects/wcampbell/xz-issue/target/x86_64-unknown-linux-musl/debug/xz-issue.
Use `info auto-load python-scripts [REGEXP]' to list them.
(gdb) r
Starting program: /home/wcampbell/projects/wcampbell/xz-issue/target/x86_64-unknown-linux-musl/debug/xz-issue
Program received signal SIGSEGV, Segmentation fault.
0x00007ffff7f8a2f3 in lzma_mt_block_size (filters=0x7ffff7f638e0) at xz-5.2/src/liblzma/common/filter_encoder.c:237
237 if (fe->block_size != NULL) {
-gnu is fine 
I went ahead and pushed an issue: https://github.com/alexcrichton/xz2-rs/issues/114

GitHub
The following code: use xz2::stream::{Filters, LzmaOptions, MtStreamBuilder}; fn main() { let dict_size = 0x40000; let mut opts = LzmaOptions::new_preset(6).unwrap(); opts.dict_size(dict_size); let...
how does the website work?
https://github.com/saethlin/crater-at-home
cargo r -- run --tool=miri --bucket=your-bucket-here
Then I have an Cloudfront Distribution in front of the bucket so that you get caching, TLS, and a nice URL.

GitHub
We have Crater At Home. Contribute to saethlin/crater-at-home development by creating an account on GitHub.
Oh
im surprised theres so much ub
It's a bit abstracted, but yes it runs the test suites of crates: https://github.com/saethlin/crater-at-home/blob/985667303836eca2aecf5735f3f78cbc94b843bc/docker/run.sh#L56-L63
also, did you make your own ansi2html crate?
I started with the published one but yes I eventually rewrote every line in it I think
thats cool
This looks like a useful Solana exploit if someone wants it 😂 https://asan.saethlin.dev/logs/spl-token-2022/0.9.0
Lmao
owo
cryptoshit aside, damn since when did asan have good diagnostics
that looks rly nice
mainly the showing locals
It's been like this for a while
Though back when I did C++ I don't remember seeing them
/// # Safety
///
/// This method makes assumptions about the layout and location of memory
/// referenced by `AccountInfo` fields. It should only be called for
/// instances of `AccountInfo` that were created by the runtime and received
/// in the `process_instruction` entrypoint of a program.
pub fn realloc(&self, new_len: usize, zero_init: bool) -> Result<(), ProgramError> {
This signature appears to be a keyword short, but I can't quite put my finger on it...
Also,
pub struct Pubkey(pub(crate) [u8; 32]);
impl<'a> AccountInfo<'a> {
#[rustversion::attr(since(1.72), allow(invalid_reference_casting))]
pub fn assign(&self, new_owner: &Pubkey) {
// Set the non-mut owner field
unsafe {
std::ptr::write_volatile(
self.owner as *const Pubkey as *mut [u8; 32],
new_owner.to_bytes(),
);
}
}
}
AHHHHH
Lmao
wonder how many safe functions have safety comments
Cursed
Anyway, I just looked at all the callers of AccountInfo::realloc(), only those tests in spl-token-2022 actually violate the precondition by constructing an AccountInfo<'_> on the stack
The rate at which people misuse their unsafe APIs in tests is extraordinary
At some point I'll submit patches to fix some of them
Most of the global buffer overflows I have looked at are people forgetting to null terminate a string they're passing to a C binding.
solana_program::account_info::AccountInfo::realloc(); solana_program::program::invoke_unchecked() and invoke_signed_unchecked(); solana_program::program_memory::sol_memcmp(), sol_memcpy(), and sol_memset(); and solana_geyser_plugin_manager::geyser_plugin_manager::load_plugin_from_config() and GeyserPluginManager::load_plugin().
Jesus
Most of them say
This function is incorrectly missing an
unsafedeclaration.
lmfao
wait holy shit this is from the actual Solana repo wtf
crypto is such a meme
Yes
It shouldn't surprise anyone that people who just assume they know better about finance take the same attitude towards writing the code that runs their financial systems
And yet it still surprises me on occasion
I suppose it's the particular combination of "move fast and break things" and "adopt an immutable ledger as a source of truth", both of which can be work on their own but cause problems when taken together
I don't think that's it
Thanks for this. I had dinner tonight with a friend who was excited about Rust being used to build safe, secure systems and it gave me a really good laugh to mention financial infrastructure in rust having stack buffer exploits
Please let me unsee this. There should be snarky lints for trying to use &T as if it was merely const T*.
#[rustversion::attr(since(1.72), allow(invalid_reference_casting))]
error: assigning to `&T` is undefined behavior, consider using an `UnsafeCell`
--> src/main.rs:6:13
|
6 | / std::ptr::write_volatile(
7 | | self.owner as *const Pubkey as *mut [u8; 32],
8 | | new_owner.to_bytes(),
9 | | );
| |_____________^
|
= note: for more information, visit <https://doc.rust-lang.org/book/ch15-05-interior-mutability.html>
= note: `#[deny(invalid_reference_casting)]` on by default
Yup, it is also very common in the "holy shit that's just UB" code that people have disabled lints put there to detect the problem
@haughty mica https://miri.saethlin.dev/no-sb/ub seems to be 403ed
Correct, it is gonezo
The pinned message should point to https://asan.saethlin.dev/ub that's where the really spicy UB is
smh my 403 page is even broken
make them forbid() 
at least... most of these are crates i've not heard of
that's how you fix the issue, right?
I love how it's volatile, probably because the non volatile write wasn't getting compiled correctly
need eyebleach
hint: pc points to the zero page.
perhaps there should be a clippy lint for this
OTOH I think std also has safety comments on some safe APIs that are like "this is a safe function but take heed: it interacts in the following manner with these other unsafe APIs"
A collection of lints to catch common mistakes and improve your Rust code.
I think # Safety as a header is special and you probably shouldn't use # Safety to denote poor interactions with other functions
name it something else
hmm
indeed checking std docs now I can't find any such place
I looked at a few "sussy but not itself unsafe" things in ManuallyDrop, AssertUnwindSafe and Pin
they go into why it might be scary but none of them use # Safety
my only rust checkout is THOROUGHLY fucked atm sorry
no I do not have time to chat about our lord and savior git worktrees
Same
I have two worktrees and keep getting annoyed that I can't check out master on both of them
wait is that a thing? that sounds terrible
that's just cloning the repo twice but worse
if you want to save space you can use a reference repo I guess
the point of worktrees is that it shares .git
yes but isn't that also the point with reference repos?
yeeees 
you can use a .git from another place on your filesystem
but I think it only shares one way
Might be an interesting rustc lint, actually -- if you have a # Safety section in the doc-comment, it needs to be unsafe fn
It's already a Clippy lint
(and imho Clippy is where it belongs, doc comments being a social convention rather than anything lang-related; you could have your own private crate ecosystem where # Safety means whatever you want)
there are a select few lints in rustc itself around social conventions, like identifier casing. but yes I agree this should stay in clippy
git fetch && git checkout origin/master
I never check out master/main or w/e as its own branch, only detached heads of it
doesn't rustc have style lints
oh already mentioned
To me this is the kind of convention that is fine for rustc, because it's so easily avoided if you didn't want it. You just have to call it # IO Safety or # Float Safety or ...
Having "# Safety" consistently mean "real unsafe-related safety" would be a good thing, IMHO.
It's the "this is unsafe; you should have a # Safety section" lint that's less applicable for rustc, to me, since it's a "you ought to do this" lint rather than a "don't do that" lint.
yeah, that lint will be awkward for FFI bindings too
the compiler says its ub but it seems to work fine so it's fine
(average C enjoyer)
5 months later: omg a rust upgrade broke our stuff, rust is a terrible language
It's true, but not for that reason
binary search moment
Wow, the hostility in this thread is stunning.
unless there's deleted comments i can't see, i dont see how this is hostile
i'm guessing that message is a prediction of what the comments will look like
One great way to help the ecosystem is to check out https://miri.saethlin.dev/ub (it's sorted by recent downloads), find some interesting crates with UB, and open PRs fixing the UB.
For more spicy UB, checkout https://asan.saethlin.dev/ub.
It's often a pretty simple fix, and running miri with the env var MIRIFLAGS='-Zmiri-strict-provenance -Zmiri-check-number-validity' will help you a lot.
I would also recommend adding miri with the above mentioned miriflags to the CI of the crate in your PR.
For more infos, @haughty mica can probably tell some more things about this.
GitHub
Calling .as_mut_ptr on a String actually goes through &mut str, which shrinks the provenance of the pointer to only contain the initialized bytes. This caused issues when a reconstructed String...
-Zmiri-check-number-validity is no longer required
ah, was it -Zmiri-symbolic-alignment-check that still is? or is this defaulted or implied in strict provenance now as well?
Symbolic alignment check has false positives, so I don't recommend it
The number validity check isn't part of strict provenance, it's just the default behavior of Miri now
@pastel lily write this down for your #dark-arts edit
there's also RUSTFLAGS="-Zstrict-init-checks" which makes the mem::uninitialized/mem::zeroed checks stricter
otherwise known as the "panic on http" flag, because that's all you find
can you also expand on how to approach a crater owner about this? e.g., how do you convince them there is a problem? some crate owners have been very defensive about this
Don't bother them if they're defensive
Note that the site uses RUSTFLAGS=-Zrandomize-layout. This is only rarely important.
In general, if you are looking for something to do in this list I would prioritize fixes both according to position in the list and the kind of UB. In descending order of badness (most dangerous at the top)
Definitely UB with or without any aliasing model:
miasligned pointer
unaligned reference
invalid pointer offset
Probably UB without any aliasing model:
uninitialized memory
Probably UB in any model that supports normal provenance optimizations:
ptr-int transmute
Probably UB in any aliasing model that supports noalias which rustc currently emits:
&->&mut
write-via-&
SB-use-outside-provenance
Debatably UB, depending on the exact details of the aliasing model:
SB-invalidation
Technically not UB but it would be awesome if people did this less because diagnostics go to crap when you do them:
int-to-ptr cast
if I were trying to optimize reception I'd make sure to phrase the PR in as neutral-to-positive language as I could (e.g. if you can eliminate the unsafe code entirely, that can be pitched as a benefit without needing to get into definition-of-UB at all) and maybe include benchmarks showing that the replacement is not slower (since unsafe is often motivated by performance)
FWIW I don't think a single one of my patches has reduced the amount of unsafe code in a crate
Though it would be very cool if people took that approach
"a tiny diff that slightly changes code so that it's now better? interesting, weird, but lgtm"
is a pretty common reaction i guess
i think many people would be surprised that if you write things in a safe way it can often be as fast or faster than an unsafe solution
i've had that thing where i wanted to speed something up and introduced unsafe, only to make it slower
yeah when i was removing unsafe code from httpdate i removed the unsafe code and then replaced it with more complex (but entirely safe) code, which i felt confident doing because it was entirely safe, and therefore could only panic
and it was faster overall
One great low hanging fruit is to search for &->&mut
and replace the x.as_ptr() as *mut T with x.as_mut_ptr()


Also contributing Miri in CI is cool, but without -Zmiri-tag-raw-pointers or -Zmiri-strict-aliasing you're opted into a very permissive model.
It would be very cool if someone has a pluggable way to drop Miri into CI
maybe you could make one of those action things
i will make an exception to my hate of rocket emojis and give you a rocket emoji: 🚀
🔥 🚀 blazingly ub 🚀
Yeah if someone made one of those action things that might be nice
Maybe
The Miri readme has this: https://github.com/rust-lang/miri#running-miri-on-ci
Dunno if that's easy enough already
doesn't use miriflags
also.i'd like to see non-miri sanitizers be actually good
you don't need miri to notice a move of an invalid type
Does randomize work on box now?
No?
The standard library still doesn't build with the flag if that's what you mean?
Yeah the error seems impenetrable to me
Hm, miri doesn't really pinpoint the location too well. For image-canvas:
Undefined Behavior: trying to reborrow <255625> for Unique permission at alloc103546[0x0], but that tag only grants SharedReadOnly permission for this location
|
= help: this indicates a potential bug in the program: it performed an invalid operation, but the rules it violated are still experimental
= help: see https://github.com/rust-lang/unsafe-code-guidelines/blob/master/wip/stacked-borrows.md for further information
help: <255625> was created by a retag at offsets [0x0..0x1]
--> src/shader.rs:1713:24
|
1713 | let ne_bytes = texel.to_mut_bytes(core::slice::from_mut(val));
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
The fault is actual inside image_texel::to_mut_bytes. But good to know, will be fixed asap.

GitHub
Home for the Unsafe Code Guidelines working group. - unsafe-code-guidelines/stacked-borrows.md at master · rust-lang/unsafe-code-guidelines
It's one of those as_ptr() -> &mut _ instances 😅
@haughty mica looks like this error is missing a span
I wonder if clippy could lint on that
Or does it already
Definitely doesn't
Yea was pretty sure it was a miri bug that this diagnostic didn’t have the code that went wrong
I reran the top 1000 to update them then introduced this problem then never uploaded the re-rerun logs
Now my internet is dying???
I really need a good rerun mechanism. image-canvas is surprisingly far down the list (currently all I have is "run the top N")
So I deleted image-canvas's log and now I'm waiting for the other 200 crates ahead of it that have had new versions to run
@haughty mica it would be cool if there was a flag to show nice stack traces for the location where the tag was created/invalidated
help: <210780> was created by a retag at offsets [0x0..0xffc]
--> /home/nilsh/.rustup/toolchains/nightly-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/core/src/slice/mod.rs:507:9
|
507 | self as *mut [T] as *mut T
| ^^^^
help: <210780> was later invalidated at offsets [0x0..0xffc]
--> /home/nilsh/.rustup/toolchains/nightly-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/core/src/mem/maybe_uninit.rs:1019:5
|
1019 | / pub const fn slice_as_mut_ptr(this: &mut [MaybeUninit<T>]) -> *mut T {
1020 | | this.as_mut_ptr() as *mut T
1021 | | }
| |_____^
that's not very helpful
This is not really possible
You're asking for a stack trace to be collected on every invalidation which is an incredible amount of data
can miri have an option to run twice and then collect that way?
The data you want can be collected with tag tracking, but you need to run a second time
that does require determinism
But pointer tags are not necessarily stable with isolation off
Yeah
This particular problem though is a FnEntry retag which I'm aware are problematic
You should report this tbh so that Ralf cares more about it
If we reported the span of that function call instead, I bet that would be helpful
I discussed this problem in the PR that adds these diagnostics
lmao, just ran into a case where #[may_dangle] made it compile, lmao
Read from here on down https://github.com/rust-lang/miri/pull/2030#issuecomment-1072928828
Oof uh your issue is wrong
When a pointer tag is created/invalidated somewhere in std or a dependency, the diagnostics point at that code. That's not very helpful for finding the actual problem.
Look around at other diagnostics
The created/invalidated spans are always your code
You should post the exact situation you're looking at
are they?

Aaaaaaa
That's the backtrace
This is a lot of me fighting with Ralf
Ralf wants to be technically exactly correct and I want to be helpful
What's actually going on is you have a backtrace from the actual case where the program becomes UB. The top frame is formatted a bit differently, and between the topmost frame and the next one there are a bunch of helps inserted
The help spans are always in a local crate
When a tag is created or invalidated, we walk up the stack from the actual place the interpreter is at until we hit a frame which is part of a crate in the local workspace, according to Cargo
according to Cargo
aaaaaaaaa, that explains the issue
I'm in the same workspace as core
Mmmmmm
i guess I'll close that issue then
i think leaving it as is is ok tbh
Keep the issue open just explain more about what your situation is
I'm in rustc_arena
The diagnostics could be better for you, so explain why
and there was ub
You should explain that in the issue instead of attempting to generalize it 🙂
(with storing box, as I easily found out because the function where the tag is invalidated is only used once)
i guess the issue is "rustc is in the same workspace as core so i get bad diagnostics"?
No
but actually the backtrace point still stands
The issue is that I made a bug over here but the diagnostics are pointing over there and I want them to point here instead
because this could happen in other workspaces as well
I think the question is whether we want to expose any control over the crate selection
cargo-miri tells miri about what crates are local, and if you're running miri directly I think you can give it any list of crates you feel like
You can search for local_crates in the code to find the logic
Finally fixed this: https://miri.saethlin.dev/ub?crate=image-canvas&version=0.3.1
Being able to point it at a file that has an array of crate names (and maybe versions?) would be useful maybe?
Sounds useful, post it on the issue
I think Callie is thinking of a feature for my tool not Miri
Most of the whole thing is in this one file https://github.com/saethlin/miri-tools/blob/main/src/main.rs
The site now lists more than half of all published crates (crates, not versions)

https://github.com/Nercury/android_logger-rs/commit/f1500f8c456fd97f82ee9b56b9cfae1a0d9e016d
why did they create an issue instead of just - you know - fixing it
I have investigated this, and it would be useful for maybe_uninit_uninit_array to be stabilized before trying to implement this.
maybe_uninit_uninit_arrayit would save a singleunsafeblock, wow, definitely worth it
also,
mem::uninitialized() was used to put outgoing messages on stack and avoid hitting allocator for each and every message.
they store this on the stack
zero-initing it would not hit the allocator
lmao
out of all the clues that exist in the wide world, android_logger might not contain all of them

lmaooooo
are you called blue because you're gonna give them a clue?

not even ```rs
struct MaybeUninitConsts<T>(T);
impl<T> MaybeUninitConsts<T> {
const UNINIT: MaybeUninit<T> = MaybeUninit::uninit();
}
let array = [<MaybeUninitConsts<T>>::UNINIT; N];
It works in a const context so I imagine it would be const-folded