#numerical-analysis
1 messages · Page 17 of 1
@scarlet sphinx What does the @ symbol and the (L) do?
the @(L) defines V as a function of L
@topaz harness
so it knows to take in L as a variable
Oh ok
try using this https://en.wikipedia.org/wiki/Karush-Kuhn-Tucker_conditions
im taking a nonlinear optimization class right now and almost all of the problems boil down to using kkt
that's all i can think of
alternatively you can realize that this problem is equivalent (as in you will have the same minimizer) to minimizing the distance to the origin and then use some geometric intuition
that's probably the nicest way to do this
the first way will result in managing a few cases and it might get tricky, so the second one is probably the nicer way to do it
moreover, the solution you were given in #help-1 is wrong, since (0,0) fails to satisfy the first inequality constraint
@gaunt compass let me know if you can find the solution using the geometric hint i gave you
Would applied linear algebra be for this channel?
Probably if you're talking about numerical linear algebra
or application to another area in applied math
No. The builtins are very fast @warm otter
If you want more digits, I suppose you could use a very large Taylor expansion, but be sure your language can display all these haha
Error of what?
Is this the numerical analysis section?
so what kinda numerical schemes are ye guys interested in?
🤷♀️
Anyone here familiar with normal equation?
$\theta=\left(X^{T}X\right)^{-1}\cdot\left(X^Ty\right)$
Kellermann:
where $x^{(i)}=\begin{bmatrix}x^{(i)}_0\x^{(i)}_1\x^{(i)}_2\\vdots\x^{(i)}_n\end{bmatrix}\$, and $X=\begin{bmatrix}(x^{(1)})^T\(x^{(2)})^T\\vdots\(x^{(m)})^T\end{bmatrix}$
Kellermann:
It's in the ML course I'm doing, but I cant wrap my head around it
If you need more context, dm me
Nevermind, I found this :)
https://eli.thegreenplace.net/2014/derivation-of-the-normal-equation-for-linear-regression
If you want you can take a look at the different norms, it might help peak your curiosity of why we square the values for least squares regression. Look up p-norms or l2 norm both should pop up results
It make sense when we take at a look at what normal means. Because in geometry what it means to be normal is that we are perpendicular to the object. But when we induce the l2 norm on to a line (which we do in the normal equation) we get a point that is perpendicular to the line.
Hopefully this link explains better than me https://stats.stackexchange.com/questions/305720/why-do-we-call-the-equations-of-least-square-estimation-in-linear-regression-the/305748#305748

Cross Validated
When we want to estimate parameters of linear regression, we make normal equations as many as the linear model contain number of unknowns. Why are these equation called normal equations?
I am doing explicit MPC, I was wondering if there was a known algorithm to solve creating an exact Relu Net from a pwa function
super cool. i just realized that the k-th base b digit of a positive integer n can be computed as Floor(n/b^k) mod b
is this a well known fact? i've never seen it before
so if $n \in [0,b^w)$ we have $n = \sum \limits_{k=0}^{w-1} (\lfloor n/b^k \rfloor \mod b) b^k$
Auvera:
actually, this seems to work for negative k also. so using an infinite sum i think you can represent every real number this way
yeah it's used for looking at indices of a 2D array that's been packed into a 1D array
you can imagine it being a b x w array
@jovial flame
oh that makes sense
@finite ingot in the website you gave, why is the cost function not an mse?
Are "dual linear programming problems" related in any way to the dual vector space?
Like, can I interpret the dual problem as performing optimalization on the dual space?
The usual statement involves an inner product, but I can replace that with a linear form being applied to the vector I am optimalizing over
Can anyone help with my numerical methods question in #help-7|zen1thxyz ?
It'x on fixed point iteration specifically
Oh nice, thanks!
Is cryptography on-topic in this channel? If so, is it possible to have perfectly secure public-key cryptography, if both people had infinitely long private keys?
anyone here good with computational stuff? i'm getting some uh. weird shit going on
in an assignment that our class just got sent
so we have a generalized $n \times n$ vandermonde matrix $A$ with $A_{ij} = (a_i)^{b_j}$ and in my problem $a_k = b_k = 1/(n+1-k)^3$
Ann:
and we need to find the square root of A using newton's method
but for n=5 matlab goes completely haywire at it
@rare schooner If you're still having issues with this, I would first look at the condition number of the matrix that solve inside newton's method (cond(matrix) in matlab). If its getting close to 10^15 matlab's normal solver can start to have problems. Alternatively, you might just have a typo in your code.
yeah the condition number was bad
thats always the problem 
same with calculating higher order derivatives or using explicit methods to solve PDEs
also a numerical analysis question but hopefully introductory: is there any nicer way to rewrite sin(x) - tan(x) to reduce loss of accuracy? taylor series are a last resort; im wondering if im missing a trig identity or trick
@sonic wharf You are trying to compute sin-tan for very small x, and thus subtracting two numbers that are very close to each other, thus losing lots of precision, right? You can rewrite sin-tan as -sin^2*tan/(cos+1). There are probably a million other ways, some of them a lot better than this. This is just the first I thought of that doesn't involve subtraction.
Can anyone recommend a book for low level computing with respect to mathematics?
@brave crypt You mean teaching things like assembly language, vectorization, caching, etc?
Not exactly but how the parts in my computer actually work and most of all how my displays what it is displaying and also the mice knowing in which direction it is being moved.
Anyone here good at explaining Calculus of Variations?
@brave crypt You probably want to look at computer architecture and graphics books, maybe computer engineering. A computer science group would probably be better to ask. The only book in the general area I know is Hennessy and Patterson's architecture book, but it's more focused on the topics phao mentioned.
i'm looking for resources on iterative (non combinatorial) optimization problems in a group context, ie, maximizing some function F(g(x)), (where g is a member of group G acting on elements of set X and F: X -> R) by moving varying which element of G is acting on x. I'm mostly interested in problems where X is R^n and G is some lie subgroup of GL(n, R). are there any optimization methods which naturally restrict the search -- which when unrestricted is through all nxn matrices -- to those in the subgroup of interest, or is it just a matter of encoding the group structure as constraints?
@green solstice Not sure how effective it is, but you can compute the usual gradient and project it to the tangent space at your current point. Infinitesimally that'll at least keep you on the subgroup, but numerically I could see you falling off. Some subgroups might allow you to project back on, e.g. if you can find the closest element of your subgroup to a given matrix. So you could do a kind of projected gradient descent I guess. Anyway googling these terms I found this https://dl.acm.org/doi/10.1023/A%3A1016586831090 which will at least point you towards some literature.
oh , yeah I guess the better thing to do with gradient descent would be to apply the exponential map once you have a gradient vector in the lie algebra
thats what they do in the last paper I linked, see page 7
awesome, basically exactly what i'm looking for.
@brave crypt So you'd like to know the math which appears in the engineering of the physical components, for example?
Display technology is its own thing. I doubt people in CS will be able to tell much tbh. You seem to be asking about how math appears in some of the sub-areas of applied physics and electrical/mechanical enegineering really.
"low level" in "computer land" can mean tons of different things. A good idea here is to be specific. Like maybe search for a book on electronics which is math-focused.
From what I understood, you want to learn about display technology, sensors and electronics. There are certainly math-focused books on those subjects, but each of them can be a "black-hole" that will consume years of study of yours.
Specially if you insist in learning the math in there.
You mentioned "low level computing" in your question. That term is usually associated to programming taking into consideration how your processor work on a more detailed level. This can include actually writing assembly language code, but it can be a kind of guided programming, in which you'll still program in C++ (for example) or even something like C# and you'll write your code having in mind how your CPU is going to execute it in more detail so that you use that knowledge in order to produce better code (in the sense of your CPU being able to execute it more efficiently).
And this usually involve learning about caching, vectorization, branch prediction, assembly language and related stuff.
There can be (I guess) math in there, but from what I've looked, it (i.e. math) is not really something that comes up in there (there = "low level computing").
I didn't look much though 🙂
@green solstice What group specifically are you working with? If it's SO(n), another reasonable thing you can do is extend your functional to GL_n via the Gram-Schmidt orthogonalization map and minimize in that easier space.
i'm just a curious lay-person scratching an itch
the actual problem i'm trying to work out for my own edification is sorting numbers with gradient descent /numerical optimization. i understand this is almost sure to run in O(n^2) even if it's possible, but i think it's an interesting problem which could apply to other more difficult combinatorial problems. for sorting a vector v of n numbers, the objective is to maximize the dot product with Wv * [0,1, ..., n]. to make the search space continuous you can imagine moving through the space of doubly stochastic matrices to and eventually taking the argmax of each column of the final weights matrix to be the indices which sort the vector
@green solstice Interesting idea. I guess you know probably that (for other combinatorial problems), that actually is a technique with some wide use. For instance, randomized rounding / primal-dual algorithms for set cover. https://en.wikipedia.org/wiki/Randomized_rounding
Within computer science and operations research,
many combinatorial optimization problems are computationally intractable to solve exactly (to optimality).
Many such problems do admit fast (polynomial time) approximation algorithms—that is, algorithms that are guaranteed to re...
i'm not familiar with it
😮 well you are in for a treat then. it's basically what you describe. maybe check out Vazirani's book on approximation algorithms.
another great one is the SDP relaxation for max-cut (Goemans-Williams)
This is a more modern book which will cover some similar topics I think : https://convex-optimization.github.io/
but yeah basically this idea of relaxing combinatorial problems to convex optimization problems and then doing stuff to get a combinatorial solution in the end is a big deal in approximation algorithms
another question i was thinking about was if the "derivative of indexing" a list could be made rigorous by associating the indices to their corresponding permutation matrix, and thinking of them as above as members of the doubly stochastic matrices so that the matrix derivative with respect to the objective can be framed in terms of "index derivatives" so that the algorithm i was describing could maybe work without the need for constructing the nxn matrix
max-flow / min-cut can also be viewed this way
I'm not sure, maybe you can do that. Maybe take a look at the max matching problems, which do LP over the Birkoff polytope (doubly stochstic matrix polytope).
i will take a look. thanks for your help
enjoy. it's really neat stuff. 🙂
if you're still here i had another question which i asked in the math help yesterday, but was maybe too left field and got no response. it's not exactly computational math, but maybe numerical methods could be used to determine the answer? if you give a mouse a cookie...
given a 2-airy function F which takes as arguments a finite indexed set w/ elements taken from some metric space along with a metric in the space and maps to a permutation of the index set of the first argument. I'm interested in finding/characterizing/categorizing functions G such that if S := (s1, s2, ..., sn), and M, N are metrics F(S, M) = F(G(S), N) where S is a set with elements taken from an arbitrary metric space and M, N are metrics which are well defined on the elements of S and G(S) respectively.
In the simplest case N = M and we are looking for functions which preserve the image of S under F(*, M). As a concrete example, let S = (5, 3, 7, 2), with indices (0, 1, 2, 3) and N = M = |s_i - s_j|, and let F be the function which returns the indices of S sorted by distance from the origin under the provided metric, which in this case returns (3, 1, 0, 2). Clearly, the class of functions G such that F(S, M) = F(G(S), M) includes scaling by any non-negative real number, permutations of S, constant additions, all monotonically increasing functions w/ appropriate domain, etc. Slightly more interesting is the case when N is different than M. Given the same F, which orders by distance from origin, what functions preserve distance from origin under the new metric.
Another example which I'm interested is in R2, where F returns the permutation of the index set of its first argument which corresponds to the optimal traveling salesman path using the provided metric. As we smoothly vary the Lp distance for example, what can we say about the viable classes of function G which preserve the image of the input set under F?
i guess to rephrase in simpler, more relevant language: when can a combinatorial optimization problem be changed into a different metric/norm such that the solution is the same?
hmmmm idk sounds like a very very general question. i don't have anything useful to say, sry. 😦
I guess for the last question -- there are lots of comparisons between L^p norms, but depending on the context things can be known for L^1 that are much harder for L^2 (I think compressed sensing is like this? maybe check here: https://cdn.fs.pathlms.com/RQQidBgMT2mWA3OvsYqf )
But I'm not sure.
If your solutions are 0/1 vectors then its all the same though lol.
I guess a good thing to add is that people like using L^1 regularization or L^2 regularizations in different contexts. L^1 makes things sparse, L^2 makes things smoothed out? Starting to crawl away from things I actually know about here though.
it's related to my first question in a way. doubly stochastic matrices preserve l1 norm, but methods to optimize in l2 -- such as the paper on Lie methods you posted may be computationally easier in some instances
although, sorting is probably the worst example
its true that every double stochastic matrix has the same L^1 norm, but that might not necessarily mean anything for the objective function you are optimizing over it?
e.g. whether you are using L^2 or L^1 losses
makes sense.
to illustrate what i mean. imagine traveling salesman with the points (0,0), (1,1), (0,2). starting at (0,0), this is the solution under l2, but under l1 (0,0), (0,2), (1,1) is also a solution. i'm wondering about when we are justified in changing the norm, and if there's ever an easily checked condition that lets us know that for example solving the problem in l1 gives the same solution as l2
but you're likely right that the question is too general and there probably isn't anything interesting to say
there are general bounds between L^p norms that you should know if you don't
so planar Euclidean Travelling salesman has a fptas under l^2 I think
there's work on generalizing it to other metrics ( just found via google, but the keyword is 'doubling metric' ) : https://arxiv.org/pdf/1112.0699.pdf
I'm not sure what is known about planar L^1 travelling salesman -- I'm sure its been studied.
Cool, thanks for indulging my half-baked questions
its cool, not many other people here seem to be interested in that kind of stuff 😦
@hard escarp I see, thank you
Does anyone here have MAGMA Computational Computational Algebra System downloaded on their computer? As I have a script I wrote to solve a problem, however I do not have access to MAGMA on my PC as it costs around 2k as it is proprietary software. I have used it in the past. But I do not have access anymore.
And the online MAGMA algebraic software for my problem/script is limited to compute for 120 seconds which is too short for my script.
If anyone has the downloaded version, can you please contact me privately in PM or chat. And I will provide the script I wrote to run.
So this currently looks like the best place for a question like this. I have a homework problem that I need help with if anyone has the time or interest.
Prove that if $f:\mathbb{R}^{n}\mapsto\mathbb{R}$ can be written in quadratic form and is coercive, A is Positive Definite.
HisMajestytheSquid:
The quadratic form they're referring to is a multivariable function that can be written in the form $f(x) = \langle Ax, x\rangle +\langle b,x\rangle +\alpha$ where $\alpha$ is a constant.
HisMajestytheSquid:
I'm not sure that I've started it right but what I have so far is: Let $f:\mathbb{R}^{n}\mapsto\mathbb{R}$ defined by $f(x) = \langle Ax, x\rangle +\langle b,x\rangle +\alpha$. Suppose also that $f$ is coercive. This means that for all $x_{1},x_{2},\ldots,x_{n}\in\mathbb{R}$, $\lim_{x\to\infty} f(x) = \infty$.
i thought quadratic forms can be written as <Ax, x> without the other terms?
HisMajestytheSquid:
They can but I feel like the other terms can't be left out since there are functions out there that have them
I actually wrote that down wrong as well because there should be a leading 1/2
I'm not really sure where to go from there. I know that PD matrices correspond to a multivariable function having a minimum but I'm not a) sure that's relevant here or b) sure how I can use that fact to prove that A must be positive definite.
btw, coercive means $f(x)\to\infty$ as $|x|\to\infty$ rigtht? maybe like this, let $\lambda>0$ be arbitrary and $x$ fixed nonzero, then $f(\lambda x) = <A (\lambda x), \lambda x> + <b, \lambda x> + \alpha = \lambda^2 <Ax, x> + \lambda <b, x> + \alpha$, this goes to infinity as $\lambda$ goes to infinity by $f$ coercive. so the leading coefficient must be positive, ie $<Ax, x> > 0$. therefore A is PD
88ddda:
since <Ax, x> and <b, x> and alpha are constants, the thing above is a quadratic in lambda
(based on the common trick in these convex optimization problems to reduce to one variable)
Forgive my confusion but what exactly is lambda here an arbitrary strictly positive constant?
yah (or even negative works too)
well more like it doesn't really matter positive or negative, just some variable
the idea is to reduce f to a quadratic in a single variable (lambda), and use f coercive to show that this quadratic has to be upward facing, then conclude that the leading coefficient is positive
for sure
So I'm here for a bit more help
Determine whether the function $f(x_{1},x_{2}) = x_{1}^{2}+x_{2}^{2}$ has a global minimum or maximum of the set $C = {(x_{1},x_{2})^{T}|x_{1}+x_{2}\leq -1}$
HisMajestytheSquid:
The follow-up to that is: If the answer is positive, then find those points.
The working definition I currently have for finding global minimums is: Assume that $f:\mathbb{R}^{n}\to\mathbb{R}$ is continuous, coercive, and that $C$ is a non-empty and closed set in $\mathbb{R}$. Then $f$ has a global minimum over $C$.
HisMajestytheSquid:
So I know for a fact that my f(x1,x2) is coercive and continuous. And C doesn't appear to be empty. So those bases are covered.
I guess I'm just a little unsure of how to go about this problem. I don't have the notes for the lecture this would have been covered under and I can't find anything all that helpful online to push me in the right direction.
hm not sure about resources, but im familiar that these topics are covered in "Theory 1: Fundamentals" section (and hw1) of http://www.stat.cmu.edu/~ryantibs/convexopt/
it is true that f has a global minimum over C
How might i go about fitting a fourier series to a set of zeros, with the condition that they are the only zeros on a provided interval? For example, I want to fit a fourier series where (0, 1, 3, 4, 6, 7) are the only zeros on the interval [0, 8]. In general, I'm looking to find closed form expressions for periodic functions which have zeros at integer values, of the form n zeros followed by m non-zeros.
sorry just a quick question, can householder transformation works from bottom to top for n-vectors?
Eg. transform x=[1;2;3] -> y=[0;0;sqrt(14)]
or is it only able to transform from top to down [1;2;3] -> [sqrt(14);0;0]
I think so
Is there a canonical approach to solving this sort of problem? I have time-series CO2 values at various points along the perimeter of the room generated by a CO2 cfd simulation for a room with known steady-state CO2 value of 400ppm (this is the concentration the room starts at and is the CO2 concentration of incoming air), fixed fan speed, and varying numbers of occupants with known breathing rates. Ultimately, I would like to calculate a running estimate of the fan speed given the CO2 readings, but for now I am settling on the percentage of outside air coming in, call this quantity p*100.
I've formulated the problem in this manner: Call the CO2 concentration at time $t = i$, $c_i$, then $c_i = p(400 )+ (1 - p)(c_{i - 1} + d*o_i)$, where $o_i$ is the amount of CO2 breathed out by all occupants in the space at time $t = i$, and $d$ is a factor which attempts to capture the dissipation of exhaled CO2 as it is read at the perimeter. I know the fan rate is fixed in the simulation, so p should be constant, but I'm hoping to apply the final method to spaces where the fan rate changes in a discrete manner, infrequently. Currently what I'm doing is minimizing the difference between the calculated $c_i$ equation and the observed CO2 with respect to $p$ and $d$ at every time-step with constraints given by:
$\max(0.001, p_{i-1} - .0001) < p_{i-1} < \ min(p_{i-1} + .0001, .006)$ and similarly for d. Essentially I am bounding $p$ and $d$ both by their absolute ranges of appropriate values, as well as some small epsilon from their previous value in order to capture the fact that these values -- especially the fan rate, should be changing infrequently.
Any better approach I should be trying?
Anyone here good with cryptography/cryptanalysis? Specifically to do with padding Oracle attacks, it's a python program you have to analyze. PM if you are interested, willing to pay for it
You arent going to learn anything from getting someone to write a program for you
go write it yourself
and fail
and learn
and eventually youll get it
it's quite ridiculous to pay to exploit padding oracle, it's such a well known exploit
spend some time on google and github
Does kalman filtering seem like an appropriate method for my problem?
hi guys, i have an exercise where i have to prove that for all $p \in \mathbb{N}$ there exists a linear explicit p-Linear multistep method with consistency p
Cone:
ive no idea where and how to start, does anyone have an idea?
I have this problem, I can see that to prove that c`d = 0 => x is optimal solution I can just apply the theorem that states that if the vector of reduced costs for each direction is >= 0, then x is optimal, but I don't see how I can get it to work in the opposite direction
ie how do I prove that if x is an optimal solution, c`d is equal to zero
for reference this is the theorem I am using
total guess, maybe you can fix $x'$ with $Ax'=b$ and transform $Ax=b$ to $A(x-x')=0$?
88ddda:
or, minimize c'd subject to Ad=0, d_i geq 0 is equivalent to minimize c'd-c'x subject to Ad=b, d_i geq 0 (call this problem P). but P is less constrained than minimize c'x given Ax=b, x geq 0, so solution to P can be no better than c'x-c'x=0
er fuck that made no sense lol, it could make sense only if P is more constrained
Most constructions of universal one-way functions I’ve come across start off by constructing a weak one-way function and then make it into a strong one-way function through hardness amplification. But this one constructs a strong one way function directly: http://www.cs.cornell.edu/courses/cs6830/2009fa/scribes/lecture5.pdf Can anyone tell me how to prove this is a universal one-way function or where I can find a proof of that?
It's not correct; for instance if $M_1$ is just the identity function then $f_{univ}$ is not one way. To fix this you have to evaluate $f_{univ}$ on a decomposition of blocks of $x$ -- so the $i$th Turing machine uses the $i$th block. Once you've made that change, then inverting $f$ can be reduced to inverting (the block evaluated version of ) $f_{univ}$ -- just pick the all zero strings for the other blocks, for instance. @brave crypt
Crustle:
@hidden copper That’s the only way to fix it, right? In the construction as it stands, if the identity function occurs later than M_K, that is still a problem, right?
yeah if the identity function occurs anywhere it is a problem, unless you break things into blocks. The issue is that without blocking in order to make the reduction work you'd have to invert $f(x)$ in order to calculate $f_univ(x)$.
not sure if literally only way to fix it, but you need to do something
and the identity function will occur somewhere, since we've enumerated all Turing machines running in quadratic time. 🙂
@hidden copper By the way, in the modification you’re proposing, do the Turing machines still run in time |x|^2 or in the square of the blocklength?
I think either would do, but you'd need to allow at least the square of the blocklength in order to use the previous lemma about quadratic time one-way functions
( I think you could probably get rid of that by just truncating after a growing polynomial amount of time, not sure if there's a reason to reduce things to quadratic time case first. But haven't thought through this very carefully.)
@hidden copper I emailed Rafael Pass, the one whose course the lecture notes were based on. He just replied back:
@hidden copper But his reply only makes me more confused. Because “outputting a random one of those outputs” is not in fact what he does in his actual lecture notes. Instead he parses the input into a Turing machine description and an input for the Turing machine, and uses that to make a weak one-way function, and then uses hardness amplification to construct a strong one-way function from it. See page 63 here (77 of the PDF): https://www.cs.cornell.edu/courses/cs4830/2010fa/lecnotes.pdf
@hidden copper But outputting a random one of those outputs seems like a simpler thing, so I’d like to explore it further. First of all aren’t one-way functions deterministic?
yeah , usually one-way functions are deterministic
(although the inversion is phrased probabilistically)
@hidden copper So what he’s describing in the email differs both from the definition of one-way functions and from what he actually does in his lecture notes. So I’m confused. But I’ll follow-up with him and let you know what I find out.
yeah I'm not seeing why that's a universal one-way function either - maybe the Turing machine is encoded in unary, so for any given input size there's only a linear number of Turing machines that can be relevant? (but even so, the inversion of f_univ could just use the easiest Turing machine on that list.) Also the notation makes it seem like the encoding is binary. anyway I'm not seeing it right now, but could easily be missing something easy.
ohhh
wait
yeah you are only allowed log(|y|) bits to encode the Turing machine.
which means that you can run through all the possible Turing machines there in polynomial time. not immediately clear how that fixes it but that's probably used.
I still don't see why an inverse for $f_{univ}$ won't just spit out < nice Turing machine, x> as the inverse, and "nice Turing machine" gives you no information about the one-way function you are after.
@hidden copper Wait, maybe what you do is you run this probabilistic thing enough times till it outputs M_k of the value you’re interested in.
@hidden copper Oh that won’t work, because if it did you could also run it enough times so it outputs the identity function if it’s in there.
I don't think there's any requirement for the inverse to the function to give you a uniformly random preimage
it could just give one preimage
@hidden copper Yeah, that’s not an issue.
and even if uniformly random it could still be exponentially weighted to 'nice Turing machine' inputs
@hidden copper But how exactly are you supposed to reduce this probabilistic f_univ to a given f = M_K? How can you exploit an algorithm that inverts f_univ to invert f?
one thing: the definition of one-way function here uses probabilistic polynomial time to compute: "Easy to compute. There is a p.p.t. C that computes f(x) on all inputs x ∈ {0, 1}..."
@hidden copper But how exactly are you supposed to reduce this probabilistic f_univ to a given f = M_K? How can you exploit an algorithm that inverts f_univ to invert f?
@brave crypt Yeah I am not seeing this.
one thing: the definition of one-way function here uses probabilistic polynomial time to compute: "Easy to compute. There is a p.p.t. C that computes f(x) on all inputs x ∈ {0, 1}..."
@hidden copper Yeah, on Googling I see there are probabilistic one-way functions.
Also not sure that the random version works either thinking about it again
seems a lot more confusing than breaking it into blocks
Also not sure that the random version works either thinking about it again
@hidden copper Yeah, because on any given run you don’t even know which of the Turing machines it output, so the output gives you no useful info of any kind.
Although maybe that’s a good thing.
yeah. And the inverse could just choose an easy Turing machine to invert, again
ah well his "hard to invert" seems to be with probability 1 (!?)
Yeah I’m very confused about all of this.
oh I see he changes that definition later to allow negligeability
hmmm
yet idk
maybe look in Goldreichs books on crypto, they are very detailed
@hidden copper Yeah, both Goldreich’s book, and Pass’s actual lecture notes, use the same construction, which is to break x into blocks. But I’m still trying to figure out this random construction.
@hidden copper One thing that occurs to me is, that if an algorithm A has a very high probability of inverting this probabilistic f_univ, then it had better be good at inverting each individual M_i. Except that’s not quite true, it could be extremely good at inverting almost all the M_i’s, but then never invert M_k. And it would still have a high probability of inverting f_univ.
yeah I agree with you
@hidden copper By the way, in the construction you were proposing where you break x up, how many pieces should you break x up into? Should you just choose a fixed block-length?
you need to let the block length scale also. one way to do it is to have $\sqrt{x}$ blocks of size $\sqrt{x}$, but I don't think the specific choicematters that much beyond the scaling (so that you eventually account for every possible input).
Crustle:
<@&286206848099549185>
@brave crypt Try using recursion. What is p(0), and what is p(n+1) given p(n)?
So p(n+1)=p(n)+1 and p(1)=0
Is that literally it because the way they laid out proofs for it in notes is v weird
@brave crypt Yeah, that’s it. How do they lay it out in notes?
im not sure how to put notes on here but i guess it confused me with slightly more complicated examples
like this one @brave crypt
so i think i did this one by
letting f(m,n+1)=mf(m,n)=g(m,n,f(m,n)) where g(x,y,z)=xz (and f(m,0)=1)
@brave crypt Yeah, that’s fine, as long as you’ve already defined multiplication by recursion on addition, which is defined by recursion on the successor function.
yeh but what I don't really understand about these examples is
what is the point of the function g
and in the case of the polynomial one
what do i actually increase by 1? x?
what is the point of the function g
@brave crypt In general when you’re doing recursion, f(n+1) will be a function of both n and f(n). That’s the point of g. Given the values m, n, and f(m,n), g tells you the value of f(m,n+1).
what do i actually increase by 1? x?
@brave crypt Well, I wouldn’t suggest you do (b) by recursion. I would just use composition of additions and multiplications in the appropriate order. Though addition and multiplication are defined by recursion.
Is this how you would write it
Like clearly it's trivial by composition of addition/multiplication
@brave crypt Yeah, that looks good.
same:
So to show that the primes are recursive I need to show that $$g(x)=
\left\{
\begin{array}{ll}
1 & \mbox{if } x \in P \\
-x & \mbox{if } x \notin P
\end{array}
\right$$
where $P$ is the set of primes is computable. Can I just do that by Church's Thesis by saying that given and $x$ can check whether $2,...,x-1$ divide $x$. If at least one does can return $g(x)=0$ else return $g(x)=1$. As division is prim rec this should work right
```Compile error! Output:
! Missing delimiter (. inserted).
<to be read again>
$
l.60 \right$
$
I was expecting to see something like (' or {' or
\}' here. If you typed, e.g., {' instead of \{', you should probably delete the {' by typing 1' now, so that braces don't get unbalanced. Otherwise just proceed. Acceptable delimiters are characters whose \delcode is nonnegative, or you can use \delimiter <delimiter code>'.
Hi! I'm implementing the inverse power method to get the most negative eigenvalue of a matrix. What is the appropriate shift?
Do you know the most positive eigenvalue?
well I can find that using the power method
Are the gerschgorin circles disjoint?
Ohh I haven't checked yet
If I remember correctly, inverse power iteration converges to the eigenvalue with smallest absolute value
If the gerschgorin circles are disjoint, then you can shift by a value that is in the circle that is the most negative
Then the most negative eigenvalue will become the eigenvalue with the smallest magnitude
I think
So I get the gershgorin circles, take the most negative value in it and use it as the shift, correct?
okay thank you but the matrix has to be diagonally dominant yes?
or is this for any matrix?
*square matrix
The gershgorin circle theorem holds for any matrix
For diagonally dominant matrices, the eigenvalues tend to be very close to the center of the gershgorin discs
Ohhh that makes sense why my classmate does not want me to use the gershgorin matrix
I am trying to apply Hardy-Littlewood conjecture to Cramer model for twin primes. But I am not sure how to modify my mathematica code for that
CramerPrimesGen[n_] := Module[
{},
CramerPrimes = Range[3, n];
IndexList =
RandomVariate[BernoulliDistribution[1/Log[#]]] & /@ CramerPrimes;
CramerPrimes = Pick[CramerPrimes, IndexList, 1];
Return[CramerPrimes]
]

Mathematics Stack Exchange
I was reading on counting the number of twin primes and I found this heuristic explanation on the Hardy-Littlewood conjecture, which states that $$\pi_2(x)\sim 2\Pi_2 \frac{x}{\log^2(x)},$$ where $...
How does the orthogonality condition in the conjugate gradient method make it converge faster than the gradient method? Thanks!
Orthogonality in which part?
orthogonality of the search direction to the previous ones
because the basic gradient method does not require that
yes. it's looking for an approximation using space of polynomials right?
"Polynomials" meaning A^nx_0
yes.
So the orthogonality condition just means that when you go in a certain direction, you go enough that there is no need to go more
With gradient descent, you just find the locally best update
You aren't taking into account previous information
It's just calculate the gradient, go in the steepest direction
ohhhh so the gradient method is just dependent on the previous one?
With conjugate gradient, you're taking into account previous moves
To find a better update
If we have this image
Green is GD, red is CG
You see how they have the same first update, but GD for the second just goes in a locally orthogonal direction
Whereas CG takes into account the previous update
Ohh yeah and also the conjugate gradient method will theoretically converge in n steps where n is the dimension of the vector space
This makes so much sense. Thank you so much
Glad to help
My professor did not discuss this but does Krylov method (GMRES) converge faster that CG? I see a lot of papers use it.
Or is it because GMRES is a less restrictive method?
GMRES is less restrictive
CG requires positive-definite symmetric A
Also
GMRES is technically for linear least squares
That's what it's called generalized min residual method
And it doesn't require symmetric A
Yeah. and it does not even require A to be a square matrix
Cool. Thanks for the help! 🦾

If you want a reference book I would recommend Demmel's Linear Algebra book
Johnathan Shewchuk also has a 50 page writeup of CG
Ohh great! Thank you. I will look into this too. I'm using Quarteroni's
If you have institutional access you should be able to get Demmel for free but if you can't let me know and I'll send you the pdf
Ohhh I don't have one either. Is it also available via AMS?
I will look on AMS server if they have it for free. If not, I will reach out to you. Thanks
Does anyone know of a public-key encryption scheme based on the hardness of the Discrete Log problem?
literally any reasonable cryptosystems
but most cryptosys like
get a shared number abG
hashes it and uses the hash as the key to like aes
the shared number step is problematic in context of qc
so we have qkd and post quantum crypto (mainly for key dist)
@wide spear Diffie-Hellman key-exchange and the resultant El Gamal encryption scheme is based on the hardness of the Decisional Diffie-Hellman (DDH) problem, which is a stronger hardness assumption than the hardness of the Discrete Log (DLog) problem.
I want a public-key encryption scheme whose security is based on the hardness of DLog alone.
ahhhhh
@dawn viper So do you know of any?
cant rlly think of any off the top of my head im not sure if i have actually seen one only based of hardness of dlog
@dawn viper Do you know if DLog hardness even implies the existence of secure public-key encryption?
iirc theres some theorem that is like if a np(hard) problem exists then a secure public key encryption exists or smt like that
need to hunt for it tho
iirc theres some theorem that is like if a np(hard) problem exists then a secure public key encryption exists or smt like that
@dawn viper Pretty sure that’s false, because first of all NP-hard is about worst-case complexity whereas what’s relevant to cryptographic security is average-case complexity. Second of all in general mathematical hardness assumptions only imply the existence of one-way functions. And it’s been proven that one-way functions do not suffice to build public-key encryption, only private-key encryption. For public-key encryption you need trapdoor functions or at least trapdoor predicates.
Impagliazzo’s paper is great in regard to all this: https://www.karlin.mff.cuni.cz/~krajicek/ri5svetu.pdf
what is the reason we choose q for 1??
The explanation at the bottom of you picture actually explains it pretty well. I can try to clarify it a bit, if it becomes more clear to you:
-
Assume that x* = 5.8, it clearly converges to that number (or something very close to it). If you look at the values of the iterates in the table, you'll see that the absolute error for each iteration is decreasing by a constant factor 100. Thus, |x_(n+1) - x*|/|x_(n) -x*| = 1/100 or more cleraly |new error|/|old error| = 1/100, and here q = 1 for it to hold.
-
Alternatively, you can consider the number of zeros in the absolute error of the iterates. It is clearly increasing by a constant number of two between each iteration. Since it increases constantly, it must be linear convergence. If the number of zeros had for example been doubled between each iteration, then it would have been quadratic convergence (q = 2).
Is this the appropriate channel to ask about linear programming/optimization? I'm curious if someone can help me understand what is meant by "normal basic feasible solutions" and "basic feasible directions". Thanks much and feel free to ping me.
A basic feasible solution minimizes the number of nonzero entries
Essentially it is in the corner of the feasible region
Not quite sure where normal comes in
yeah, the "normal" part is what i'm unfamiliar with. I've seen them mentioned in problems of the form Ax = b, where there are some bounds on b; as well as when the problem is adjusted to the form Ax \leq b, but I don't quite follow
Oh is it just talking about the normal form of the problem?
I've heard of a standard form and a canonical form for linear programs but never a normal form
Sorry for posting sporadically - been a weird day
anyways, the first two screenshots are when the concept is first introduced, and a normal BFS looks to be pretty clear
What I get a little confused about is when they translate notion over to systems of the form Ax \leq b... i.e. in the following image.
Also, is this a more generalized version of LPs than the x (vector) \geq 0 (vector) problems? At first I thought it was just a different formulation of the same problems, but now I'm wondering if it's its own animal
Given a 31bit-number if i mod it by 6, the low bit of the remainder is also the low bit of the 31bit-number? Why?
In short because 2 divides 6
The low bit is whether the number is even or not. And a number is even if and only if the last digit after reducing mod 6 is 0
@brave crypt thank you, may i ask what type/ branch of maths is involved here
Modular arithmetic
@brave crypt thank you
Does anyone understand how the guy arrived at the following conclusions:
Referring from this question:

Cryptography Stack Exchange
Given a set of numbers within the range of 1-6:
[3,4,3,4,5,6,2,3,1,5,2,3,6,2,2,3,3,6,6,4,5,2,5,3,5,2,4,4,2,6,3,6,1,5,1,3,6,1,1,2,2,4,5,3,1,2,3,4,4,6]
generated using Java's nextInt(6)+1, is it poss...
this is essentially known as modulo bias
tldr
we need to discard some output to avoid modulo bias
Does anybody know any applications of numerical integration?
For context, I implemented algorithms for Simpson's rule and Gauss quadrature and my professor asked us to use them to solve a problem related to numerical integration. I guess I could do something like calculate the volume of solids of revolution but I was looking for something a bit more... complicated.
I thought of working with nonelementary integrals, but I could not come up with something that uses them
Solving ODEs
See the SIR model and how numerical quadrature relates to numerical methods for ODEs
There are also stuff like computing probabilities $\int_a^b f(x) dx$ and expectations $\int_a^b xf(x)dx$, assuming there is no closed form/other algorithms
88ddda:
The Stefan-Boltzmann law has some messed up integral in it, which is solved numerically and replaced with a constant σ
@craggy mauve
Oops, I lied it does have an exact solution. It's an interesting one either way.
Question relates to function approximation in 1D via LaGrange-Interpolation. I want to half the error of approximation, how many more degrees (n) should the interpolating polynomial have? (algebraic vs. exponential convergence). I've came up with two Big-O bounds and was wondering if they were correct.
hi guys. How do computers solve equations? any type?
And why could the miss some solutions?
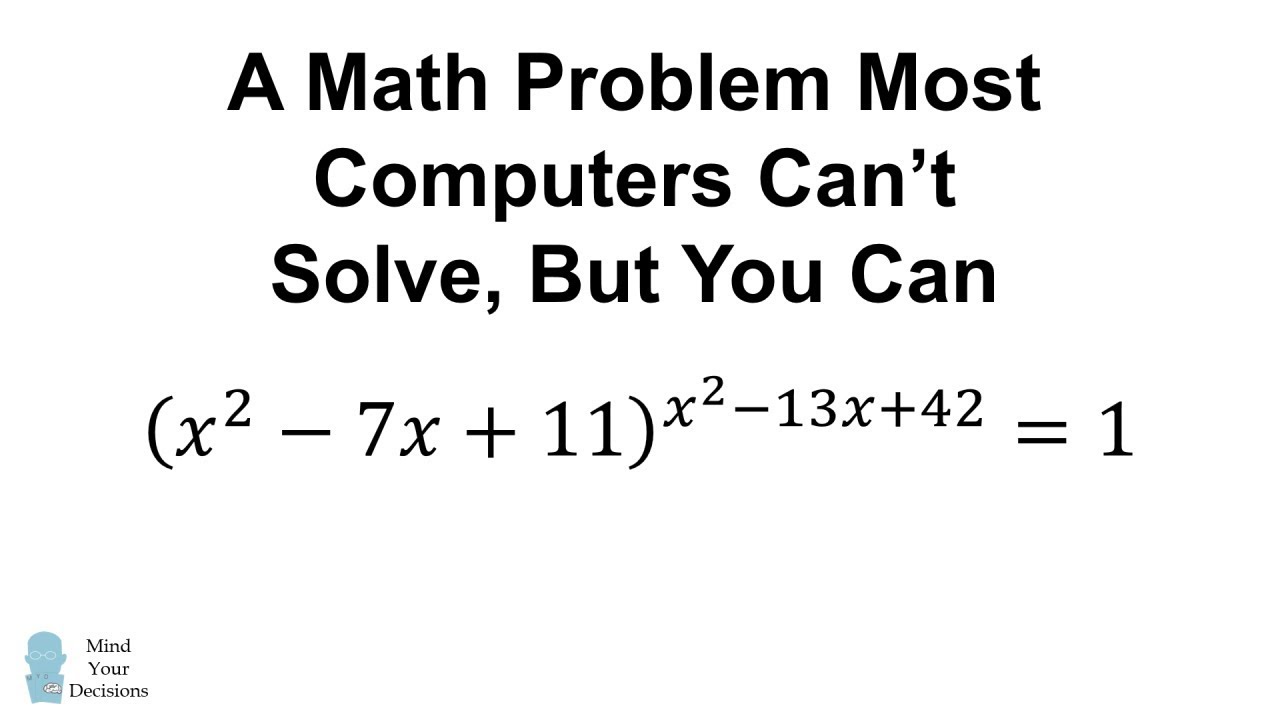
Photomath can't solve this, and neither can Mathway, Symbolab, or Desmos. Can you? I explain how you can. A similar problem was given to high school students in Massachusetts, and you really have to know what you're doing to figure it out.
Thanks to all patrons! Special thanks this month to:
Shrihari Puranik
Richard Ohnemus
Michael Anvari
Kyle
...
In mathematics and computing, a root-finding algorithm is an algorithm for finding zeroes, also called "roots", of continuous functions. A zero of a function f, from the real numbers to real numbers or from the complex numbers to the complex numbers, is a number x such that f(x) = 0. As, generally, the zeroes of a function cannot be computed exa...
i wouldnt really consider photomath to be a decent CAS to solve equations...
numerically you have root finding algorithms, but programs like mathematica are able to manipulate equations based on handwritten rules as an attempt to solve them
that would be known as a bug
from my experience with mathematica it tends to try to find too many solutions or be too general
oh ye and branch cuts
Solve::ifun: Inverse functions are being used by Solve, so some solutions may not be found; use Reduce for complete solution information.
which mathematica suggests although it does find all solutions xd
What is (1)?
Given 15 mod 6 = 3
Why is it the lowest bit of 15 is also == to the lowest bit of 3
Is anyone good at population dynamics, finding time till extinction?
Is this for numerical methods?
Sure
I have a solution but I don't believe it is the way to go
My solution was looking at every option for the piecewise function
Which gives me this
And since x_{i+1}^{n+1} can be recursively given since x_{M}^{n+1} is explicitly given we can always find it for case 2 so solutions exist for the implicit case, and obviously for the explicit cases. And since all of the intervals are on their own, no overlap, so unique
But I hate this solution with all my heart
I think I'm supposed to look at Lipschitz something somehow
Can you recreate the proof of the Picard-Lindelof theorem but discretely?
I don't think so, can you nudge me in the correct direction?
I don't think I need to prove the theorem, but maybe I can cite the theorem and prove the theorem applies?
Picard-Lindelof just says that if a differential equation is Lipschitz, then it has a unique solution
I guess you can cite the theorem and prove that backwards Euler converges to the solution everywhere
Yeah but how do I prove that the nonlinear equation has a solution and its unique, the iteration step. I can't find anything online :(
anyone have an idea on where to start with this?
I have only used it for linear systems
I'll be honest, I missed a lecture and he hasn't uploaded it yet. I can't find a good example of a similar problem being done online either.
In numerical analysis, Newton's method, also known as the Newton–Raphson method, named after Isaac Newton and Joseph Raphson, is a root-finding algorithm which produces successively better approximations to the roots (or zeroes) of a real-valued function. The most basic version starts with a single-variable function f defined for a real variable...
Given n+1 points x0, x1, ..., xn how can I show that this equality holds?
I tried expanding L_j(0), but can't seem to make it equal to the RHS
What is L_j(0)?
oops, my bad, it's the Lagrange polynomial
Can you induct on n, the number of points?
I don't think I know how to do that
Angetenar
$L_j(0) = \frac{(- x_0) \cdot (-x_1) \cdot \dots \cdot (-x_n)}{(x_i - x_0)(x_i - x_1) \dots (x_i - x_n)}$
LGN
I believe that's it
I can see the signals alternating as we let j = 0, 1, 2... n
if we have an even number of x_n terms on the numerator it's positive and it's negative if odd
so I guess that's a hint of where (-1)^n comes from
I also believe the denominator cancels out once we start summing L_j
Yep
Is there applied math topics used in computer architecture that people are familiar with? Also, is the right channel to ask this ques?
Maybe finite state machine type stuff with cache coherence (MOESI, etc) if that counts? Tbh not much comes to mind, although admittedly I am not that good at computer architecture
Ummmmm
It depends on what sorts of applied math topics you are using in computer architecture
I guess this channel seems appropriate
If no one answers here, I would recommend asking in the Computer Science server
You can find a link in #old-network
@red brook do you have supplemental notes to help answer it?
Nope
Is NP the complexity class and are L_1 and L_2 problems? What is the intersection of L_1 and L_2?
@red brook did you figure out the solution?
There is a pset with similar questions online https://people.eecs.berkeley.edu/~luca/cs172-07/solutions/sol7.pdf
Oh whoops it has the solutions lol
Anyone know if there is a discord server for algorithms? And would this be the place to ask algorithms questions lol?
Depending on the algorithm, the computer science discord potentially?
im planning to implement that as the last part of my first semester comp sci project.
What i think ill end up doing is taking the unary minus of the RHS and shifting it to the LHS, then using my shunting yard algorithm i can evaluate the expression. then u can find the roots of this using numerical method (since RHS = 0) and that should give u a very good approximation of the solution to any equation.
since I assume u cannot compute the derivative of any arbitrary expression (tho u could code that too using derivative rules or automatic derivation (https://en.m.wikipedia.org/wiki/Automatic_differentiation )) best choice would be to use secant method or regula falsi method

In mathematics and computer algebra, automatic differentiation (AD), also called algorithmic differentiation, computational differentiation, auto-differentiation, or simply autodiff, is a set of techniques to numerically evaluate the derivative of a function specified by a computer program. AD exploits the fact that every computer program, no ma...
but the issue with both of those methods of root finding is that u can run into newton fractals if ur initial guessing point is on a local minima/maxima/inflexion point, etc, (x^3 and initial guess of 0 for example) and its also not very good to find the solutions to equations with multiple solutions
so what i am planning to use is an altered version of the method described here:
https://www.youtube.com/watch?v=FD3BPTMGJds

Newton Bisection Hybrid Method for root finding. Example code available at https://www.github.com/osveliz/numerical-veliz
Chapters
0:00 Intro
0:26 Viewer Request
0:49 Numerical Recipes
1:12 Numerical Methods That Work
1:54 Motivation Examples
3:04 Problems with Newton Recap
3:17 Newt-Safe Basic Algorithm
4:00 Newt-Safe Basic Examples
4:53 Addit...
but since i cant compute the derivative of any arbitrary function, i can use secant bisection hybrid which is a slight alteration to this method and a bit slower than the newton method, but hey, at least it works
there is also a wikipedia article u can refer to to find several techniques of solving equations, though all of these seem worse than root finding numerical methos if u want it to fit for any arbitrary equation
https://en.wikipedia.org/wiki/Equation_solving
In mathematics, to solve an equation is to find its solutions, which are the values (numbers, functions, sets, etc.) that fulfill the condition stated by the equation, consisting generally of two expressions related by an equals sign. When seeking a solution, one or more variables are designated as unknowns. A solution is an assignment of values...
all of the methods i described find a very good approximation of the actual answer, up to 8 to 10, perhaps more decimal points, these are known as numrical methods, but if u want to have an exact answer, u will need to look into symbolic computing
pretty sure it missed a solution cuz it was trying to use numerical root finding methods, but since there is a disconnect on the graph where the last two solutions are found(3,4), it may be that 3,4 are infinitesimal points with the correct solutions, and u cannot apply numerical root finding methods on infinitesimals like that, it may not have even graphed those two points, potentially
wolfram alpha by contrast uses a lot of symbolical math and has a HUGGEEE sourcecode accounting for almost any weird edge cases u could throw at it to break it
thanks, i will read it latter. gtg now
what u said seems pretty interesting. But what i mean is
On the video we had x^y = 1
We know 1^y = 1, so lets make x = 1
also x^0 = 1, x != 0
so lets do y = 0 and check x
but also (-1)^2n = 1. So lets make x = -1 and check y
this is because we can think
but a computer wont do that. So i was asking why wolfram alpha could find these 2 last solutions
mathematica solving capabilities isnt purely numerical
it tries to get exact solutions
through who knows what means
presumably it has somewhere in the code
if we have the case of f^g=1
then f=1 or g=0
wolfram alpha by contrast uses a lot of computational algebra and has a HUGGEEE sourcecode accounting for almost any weird edge cases u could throw at it to break it
it uses actual rules of algebra, and only uses numerical methods when it cant solve it algebraically
Is there a list of all numeric problems like
- Initial value problem
- Boundary value problem
- Characteristic (Eigen) value problem
- Stochastic initial value problem?
- Terminal value problem?
- ...
Is there a resource (book, web, anything) that catches them all?
Each of the topics you listed easily fill entire books
Yea I know, which is why I wonder if anyone built a taxonomy
yeah
I'd say yes because all functions bounded by x^2 are bounded by 2^x in this way
and I'd say O(2^x) is not O(x^2)
in particular if f(x)=O(x^2) then it is definitely true that f(x)=O(2^x)
but if f(x)=O(2^x) then it's possible f(x)=O(x^2) or f(x) != O(x^2)
I only add those last two lines because that's concretely true, I've not really seen people say stuff like O(x^2)=O(2^x) like you're asking, but if you wrote it probably the other person would assume you meant it like I'm assuming you mean it.
it's an abuse of notation, technically, the O(...) are sets of functions and when you do a long computation, all the = signs have to be understood as inclusion signs ; but we keep the = signs because it's how the normal computations are written
so you can say (x+h)³-x³ = 3x²h+3xh²+h³ = 3x²h+O(h²) + O(h³) = 3x²h+O(h²)
but the last "equality" is basically saying that for all functions a(h) and b(h) such that a is a O(h²) and b is a O(h³), a+b is going to be a O(h²)
so it says that O(h²)+O(h³) is a subset of O(h²) after you define + appropriately on sets of functions and interpret O(h²) and O(h³) as sets of functions
Ok so this book gave this cryptosystem as an example of something that can be broken easily with lattices
They gave a description of how Eve could break it, but the part with the vectors makes no sense to me
Can you elaborate on what you find confusing?
Well I see that they just modified the equation from earlier into Fh – Rq = G
But why do they make h, q, and G into vectors and why do they choose those x-values
Do you understand why the circled part is equivalent to the previous problem?
$F$ and $R$ are scalars so $F(1,h)=(F,Fh)$ and $R(0,q)=(0,Rq)$ so $F(1,h)-R(0,q)=(F,Fh)-(0,Rq)=(F,Fh-Rq)=(F,G)$
Angetenar
That makes a lot more sense, I think the parentheses notation are throwing me off
Thank you

Oh — one more thing
The linear combination part
Shoot what am I saying
Uhh they want w = O(sqrt q) for f and g to satisfy the requirements in the “key creation” section right
Right
What’s the connection between a linear combination and f and g satisfying the requirements
I'm not entirely sure
But I think that because we want $w=O(\sqrt{q})$ this means that we want $w$ to be small because I guess $\sqrt{q}$ is asymptotically small? This matches up with $w=(F,G)$ and how we want $F$ and $G$ to be small
Angetenar
abs_0
I think if $|w| = \sqrt{F^2 + G^2} = O(\sqrt q)$ then like... $f$ and $g$ satisfy the ``key creation’’ requirements?
abs_0
Oh wait that’s basically what you said
Are the red symbols XOR
Angetenar
@wide spear do you know bayesian stats?
No, but if you give me the question I can pass it on to someone who does
You can also try #probability-statistics
oh, it's sort of a basic clarification
i was wondering if, when you have a hierarchical model, say for the sake of concreteness $X_i \mid \mu_i \sim N(\mu_i, 1)$ and $\mu_i \sim N(\mu, 2)$, then do i always assume $X_i$ is independent of $\mu_j$ given $\mu_i$, ie $p(X_i \mid \mu_i, \mu_j) = p(X_i \mid \mu_i)$, where $i\neq j$ (or even, is $X_i$ independent of $\mu_j$ regardless of given $\mu_i$ or not?)
8da
i think it must be true, but i've never seen it explicitly clarified
@wide spear what are the green symbols then
"I thinking
I would think yes
Xi is conditionally independent of muj given mui
But no not given mui they are not independent" @brave crypt
Do you want a proof?
Oh wait, if you are not given mui, then muj tells you something about mu, which tells you something about mui?
A proof that they are independent given mui? But I think this would have to be assumed
Thanks dog
@brave crypt "Yes
That’s the intuition"
Ah ok thanks
About this
when we are talking about real non-necessarily-symmetric matrices, does the "spectral radius" mean $\max_i(|\lambda_i|)$ where $\lambda_i$ are real eigenvalues, or $\lambda_i$ are complex eigenvalues?
8da
Thanks. I guess this makes sense, stuff like gelfands spectral radius formula wouldn't work if it was only real eigenvalues (the casual definition "the largest of the absolute values of the eigenvalues" sounds really ambiguous)
hey, im writing a script in python to calculate the most efficient bets. there's a roulette and it can land on a number between 1,3,5,10,20. thse are the chances (look at image below). we can simulate the first problem. lets say you have $100 and spread it between 5 people. you're dealing with $1 bills. how many ways can you split the money. next problem i have to take those values and put them into an array. how do i go around doing this?
Oh what is this channel?
Is this where you shitpost in HoTT discuss computational theories


👀
i'm not sure i follow your last message, but they explain that the data follows ydata = f(xdata, *params) + eps, so if eps (and thus ydata) is a random variable, then hat(params) is a random variable that is a function of xdata (fixed) and eps ydata (random), hat(params) = \min_\theta \sum_i (y_i - f(x_i, \theta))^2
i'm not particularly familiar in the case of non linear least squares but eg in the context of linear regression there is page 9 of this pdf that briefly discusses the distribution of the fitted parameter https://www.stat.purdue.edu/~boli/stat512/lectures/topic3.pdf
Im trying to figure out the complexity of an algorithm I have and in doing so, I've come across this formula. The part I'm confused on is when it says C_q(ψ/A), what does /A mean? Additionally, in the second part , C_p(ψ/A; Q) what does ;Q mean in this context?
Based on how while works, I guess that X/Y stands for the state of the program after the Y steps have already been performed on the input X.
So the first term gives the cost of performing Q after entering the while loop.
The next term gives the cost of what has to be done after an iteration of the while loop is completed, i.e. after checking A and doing Q.
Going off of this, I see several methods
One is to construct the two vector spaces, then check if they are both subsets of each other
Do numerical analysis question go here?
Yes
In the case of short (10 bit mantissa) just wanted to check
machine epsilon is 2^-10 right?
Also for largest representable float, why is it 1 11110 1111111111 rather than 1 11111 1111111111?
is it because the latter is reserved for representation of +inf?
oh, i thought largest representable float would be 0 11110 1111111111 (but sort of as you say i do believe all 1s in the mantissa is used for infinity representation sry 😞 i have gotten mantissa and exponent mixed up (and another mistake), all exponent 1 is infinity or nan, and only when mantissa is all 0 is it infinity, rest are nan)
generally besides subnormals and infinity/nan, nothing is weird, i just remember this
i never understood the root word of "mantissa"/what this word is "about"
oh yea i made a typo with the sign bit
Anticipation
So I'm trying to use cubic interpolation to create an airfoil with n number of points based on a data file containing some other number of points. I'm running into an issue that I believe is caused by the way I’m creating each ‘spline’.
What I’ve done is split the airfoil into an upper surface and lower surface and I start interpolation from the trailing edge (i.e. x=1) to the leading edge (i.e. x=0). However, since I need to retain the curvature of the leading edge when interpolating points near the leading edge, I’ve included the first 3 points of the opposing surface in the data I’m interpolating (e.g. the upper surface data goes from x=1 -> x=0 then the first three points of the lower surface from the leading edge x=0). I then join the interpolated upper and lower surfaces to create the full airfoil surface
This seems to be causing errors when interpolating points near the leading edge. Is there another method I could use or a way to correct the errors I’m getting?
Here’s an image of an airfoil.
Consider spline interpolation
Alternatively, it may depend on how the cubic interpolation works
The points may need to be in some order
I briefly looked at spline interpolation. I need to dig into it more. It seems that the underlying issue is that polynomial interpolation equations are derived with the assumption the the data doesn't have repeating y values for any given x (That's my hunch at least). So if spline interpolation doesn't have the same issue then perhaps?? However, someone in another discord suggested using polar coordinates instead and I think that will fully solve the problem. @wide spear
If you still want to use cubic interpolation you could also slightly perturb the x/y values so you don't have repeats
Why do aitken acceleration guarantee the next value in the sequence is a value in the original fp iteration sequence? I don't get it
oh, where does it say that?
I saw it in like a video by

Discussion of Steffensen's Method and Aitken's Delta-Squared Method with their relation to Fixed Point Iteration including examples, convergence acceleration, order, and code.
GitHub: https://github.com/osveliz/numerical-veliz
Chapters
0:00 Intro
0:08 Aitken's Δ² Method History
0:23 Derivation with Example
1:01 Aitken's Δ² Method
1:21 Solve for...
not sure if it's true in general
i guess it must be a coincidence, of this equation and of x_1=2
maybe a fun problem to find a sequence such that its normal fp sequence and its accelerated sequence are disjoint 🙂
not quite disjoint, but you can eg show that for the fp sequence $x_{n+1}=\sqrt{x_n}$, the first aitken accelerated iteration does not equal to any element in the original sequence for various starting values $x_1$ by some simple field theoretic considerations
z_8da
Anticipation
I meant contraction, not only lipschitz continuous
Anyone understand steffensen method here can explain something?
What about it?
The definition of steffensen method using delta(x) = f(x) and 2 fixed point iteration followed by an aitken iteration is equivalent right
So what i mean for the first definition is
Yes I think so
Have you checked the derivation on Wikipedia?
yea I did it's not the problem I have though I wanted to show these 2 are equivalent
but I think I just made some stupid error
should be just straightforward rearranging stuff
Like I'm assuming the wiki page derivation is to show how the heuristics of aitken can be derived into steffensen
How in the world do you make sense of this?
I'm gonna take a guess this comes from,
$$\frac{1}{1+O(x)} = 1-O(x)+O(x)^2-\cdots = 1+O(x)$$
Merosity
I feel like this is safe to say cause if O(x) wasn't smaller than 1 it would just consume it and make 1+O(x)=O(x)
Anyone knows what is the most convenient way of parallelizing a stencil using OpenMP?
Some useful links/tutorials would be appreciated
i need to prove that this statement is not true. I tried doing the limit of $\frac{e^x-1}{x^2}$ but that DNE. the taylor series of $e^x = 1+x+O(x^2)$ but not sure what to do from there
bakes
We know that $e^x=1+x+O(x^2)$ so $e^x-1=x+O(x^2)=O(x)$ as $x\to0$ and not $O(x^2)$
Angetenar
Intuitively, we ignore the constant part, and for small x, x^2 is much smaller than x is, so e^x-1 is approximately linear near x=0
Also your first attempt is fine
$\lim_{x\to0}\frac{e^x-1}{x^2}$ does not exist, which means that $e^x-1$ is not $O(x^2)$
Angetenar
If it was, the limit would exist
In the k-means clustering algorithm, the maximization process readjusts the the centroid of the cluster by taking the average of assigned data points. But how do you take the average of coordinates (i.e [2,3], [5,3]) to get a new centroid? Is it average of X's and average of Y's? Because average euclidean distances won't give me a coordinate for my centroid
Yes, it is the pointwise averages
Hi, i have this challenge to solve but i don't know what cipher was used to encode this text. I tried Caesar, vinegere, and a lot other alphabetic ciphers but none of them mathced.
Here is the text for the challenge: cebh gs sqka, dtpw adkgak qtwrjfdgo thz yakbidn yl fntttsmhr eicwlzotb bi ngbckwhbn bhy zkybeqmeao. mh bxmv tcrwpp qzhkaagj hmu atdvey, uzkh aewfdcr yxugwblw cff efsvadc is gpnpsgdkp.
Does someone have an idea on what cipher was used here ?
What does constraint: aucune mean?
aucune == None
Oh ok
How would I obtain the strong formulation of $-\frac{\dd^2u}{\dd x} + u = x$ for finite element method
The_Visor_Guy
Angetenar
Oh yes it’s a second derivative, my bad
Oh it’s already strong?
Must have had an error in my work deriving weak formulation then
Yes, the strong formulation refers to when you have derivatives
The weak formulation is when you multiply by a test function and integrate by parts
Part b is where I started to derive the weak formulation, could you maybe point to where I started to go wrong?
It’s between lines 2-3 I believe, but not sure what I did
I don't know why you substitute in the u you get from part a
You start with $-u''+u=x$ with $u(0)=u(1)=0$ right
Angetenar
Then you multiply by a test function $v$ that is smooth and satisfies $v(0)=v(1)=0$ so we have $-u''v+uv=vx$
Angetenar
We then integrate from $0$ to $1$ so we have $\int_0^1-u''v+uvdx=\int_0^1dx$
Angetenar
We integrate by parts the $-u''v$ term so $\int_0^1-u''vdx=\int_0^1u'v'dx$ with no boundary terms because $v(0)=v(1)=0$
Angetenar
We thus end up with $\int_0^1u'v'+uvdx=\int_0^1vxdx$
Angetenar
This is the weak formulation
||Lax-Milgram go brrr||
Ohh I see, thank you so much!
Can I ask Graph Theory questions here?
Graph Theory goes in #discrete-math I think
Or maybe #combinatorial-structures ? It is not entirely clear to me
typing this made me sad
doing vc dimension of ellipses in standard form
oh i have C_16 twice lol
depending on how much your grader cares, i guess you could reduce it to 4 and write "symmetry" as the explanation (er, and assuming you pick a different set of points)
If this was in LaTeX you probably could have defined a macro to do it faster
i was able to just copy the formulas from desmos
so that sped it up
was still annoying though
Could one suggest fast converging numerical methods for stationery Poisson equation with mixed derivatives?
$P_{xx}+P_{xy}+P_{yy}=-f(x,y)$
DvaNapasa
What have you tried that doesn’t converge fast enough?
The standard fast solver for a Poisson equation is the multigrid method, I don't think you can go any faster
You can get rid of the mixed derivative with a change of variables
See https://en.wikipedia.org/wiki/Elliptic_partial_differential_equation#Derivation_of_canonical_form to see how to do so
Second-order linear partial differential equations (PDEs) are classified as either elliptic, hyperbolic, or parabolic. Any second-order linear PDE in two variables can be written in the form
A
u
x
x
+
2
B
u...
In spectral clustering, we find the values of eigenvector by determining what values multiplied by a laplacian matrix gives us a eigenvalue of 0. On a high level, intuitively a laplacian matrix tells us how the nodes are connected, and the eigenvector tells us which nodes belong in which group. What is the significance of setting an eigenvalue to 0 to solve this, like, what does it mean intuitively/on a high level?
Is a running time of $O(\sqrt n)$ exponential? Or polynomial? I don’t really know what this is classified as
abs_0
exponential => x^n
ie the number of inputs are in the exponent
I would call O(sqrt(n)) polynomial
even though that feels very wrong in a math context
@pearl ingot probably should have pinged you
I’m probably being slow
But isn’t polynomial a good thing? Then why would O(sqrt n) be slow?
@slate zinc
that's a good question! I can't tell if they are referring to "in some special cases there are fast (subexponential), ..., and indeed have running time O(sqrt(p))"
OR if they mean it's 2^sqrt(p)
Well the ECDLP is considered computationally intractable to solve
So obviously O(sqrt p) must be slow, but like
Apparently Shor’s algorithm, which breaks it in polynomial time, is really fast
Which makes like no sense
yeah I mean you can think about it that if say, shor's algorithm runs in p^2, sqrt(p) < p^2
so it doesn't make sense to call O(sqrt(p)) slow
I'm unfortunately a little out of my depth on the ecdlp stuff
Ah
but to my understanding, there are two algorithms with indeed runtime O(sqrt(n))
unless it's just due to the scale that the runtime sucks?
as you said it's intractable
As an apology for my “April Fool’s” blog post, I thought I would present a summary of what is known about algorithms for ECDLP that run in asymptotic time less than the square-roo…
so this link seems to imply that q = p^n, and therefore even if the runtime is O(sqrt(q)) it's still exponential, because it's technically O(p^(n/2))
which then would be classified as exponential
sqrt(p) is terrible
what you really want is some polynomial in log(p)
but sadly it probably isnt possible usually
it is polynomial
or in the case n=1 sublinear or smt
but in crypto we call it exponential
cuz really what you care is number of bits of q
shor's algorithm breaks in polynomial time in the sense that like
polynom in number of bits of the order of the group
seems like the wordpress talks about precomputation
iirc there are some systems where like
one can just spend years doing some precomputation
then break anything quickly after all those computation
i cant recall which one isit rn tho
Ah
Also I just wanna say @dawn viper you’re literally cracked
I’m just looking at your website, you literally play Liszt and do graduate level math and physics and cryptography... seemingly in your free time
That’s absolutely nuts
I think u linked ur website on the cryptohack server or something idk
i tried solving that stupid problem
You’re in high school?
#advanced-number-theory message
i remembered i decided idk how to proceed lol
haha yea

Can’t comprehend how you have time to do all of that
Do you do other stuff? I mean it sounds like u take APs
my school makes us take ap lessons
but i am refusing to take ap
and i will refuse to take them
it's just a money sink lol
it's so sad
instead of like
learning proper math and chemistry
Oh you mean you take the classes but don’t take the exams
Yeah honestly hs math sucks
like how does one even explain "describe a randomization process for the study"
Bruh I wish I got into this stuff earlier, I’m in HS too but i have much less work ethic
just run python random.randint() 
Lol
Have you written a research paper or anything?
You absolutely have the prerequisites I think
i mean i do hope i can publish on arxiv but im too self conscious to do so lmao
even tho there are some super garbage published crypto papers
Arxiv? Bruh I mean like an actual journal or conference
i may try for JMM
ill prob like
submit the curious curve one haha
ive been working on it in my free time
or i may submit some other hyperbolic memes im poking at idk haha
Like there’s tons of conferences coming up and u could absolutely do something
istg some crypto publications has such low standards
but then there are people like boneh
Yeah
who are so 
i havent actly touched too much post quant crypto lolz
They’ve got YT videos from 2020, u should check out some of the lectures
only memed a bit with quantum crypto
Considering you read those books in ur free time tho, you could totally learn the prerequisites (you already know most of it)
Yeah
Was gonna say, u should look at that
Lots of opportunities for new research there
Haha
Yeah
Dog I swear if u don’t try doing some research in HS like
You’ve already done so much
i mean
Idk
if i really wanted to
Only if u want to tho
i could just like
try to get something done
but i have no mentor or anything lol
i tried asking my school teachers on the curious curve i think they think im insane
I know for a fact literally 99% of high schoolers don’t know this type of math as well as you do

Yes understandably, my calc teacher didn’t know what an isomorphism was
lolz
And she’s like the most knowledgeable about math at our school
Well if you need help just email professors, they’d prob be happy
lol
hihihihhi i iahve fun thingsiosegsvdj
They’d think ur joking, a high schooler who knows algebraic number theory
mildly ironic that im mentioning it here
oh lolz
But then again, I don’t think an undergraduate would need those books to self study cause they have classes
at this point i have no idea how it feels like to be in a class lolz
Have u done like math Olympiad or any other stuff
Wait what
Thought u were in the US
Jeez
then in this team they would select 6
so in theory if i tryhard
Oh yeah they have that here too
yea but idt i would haha
Ur literally cracked
I can’t dawg like
Yeah IMO would be sick but it would take a lot of time away from studying other stuff
yea
i decided like
2 years ago?
that olympiads wasnt worth it
ok i got like super annoyed cuz i had everything prepared for ipho
then singapore is like
oh sorry you are too young
like

then i started memeing with qft and realized i preferred math
yea so like
in singapore to go ipho, you need to be 18 (or equivalent in your institution)
basically the las year of your high school life
then you can go ipho
or icho
imo is the exception
it's quite dumb tbh
yea IMO is the exception
i was aiming for ipho initially lol
i still have like
my folder of phys olym notes/papers
haha
but it's just collecting dust
Wow
Dog I can’t believe you
Like, in the US unless I’m living under a rock, people like you don’t exist
Except maybe like IMO but like
top math papers at science fairs are literally not even close to the level ur reading
i mean there are people who are more chad in math in hs lolz
also
south korea
their ctf players
omg
literal
insane
they are more insane than me
Is high school CTF a big thing?
I didn’t know what a CTF was until like 20 minutes ago lol

I’m still lowly reading silverman’s intro to mathematical crypto lol
haha nice
Trying to do more stuff but yeah
that makes perfect sense! I was wondering what the hell was going on. me and regular cs knowledge lmao
it's kinda the thing if you know you know if you dont it seems like everyone has gone insane or smt
Posted a proof for program in Q6 -would appreciate any help
the program doesn't do at all what it should be doing
The 🍵 is hot


Which specific method are you discussing? Discretizing the integral first and then looking at the functional variation?
yes
why discretize the integral instead of the differential equation?
and is 7.56 right? looks more like they chose rectangular strips instead of trapeziums
Yes it does look like a midpoint rule
For step 3, does it mean if k = 5, we compute the eigenvector and eigenvalue from columns 1 to 5? And then run kmeans on that eigenvector we compute?
What is L?
Laplacian Matrix
Ok
So each eigenvector has a corresponding eigenvalue right?
You can order them and find the smallest ones
In this case, it would be the 5 smallest eigenvalues
You compute the corresponding 5 eigenvectors
Then you do k-means on those 5 eigenvectors
can someone explain horner's method
im so lost for the c's
my brain cannot function, I don't know why the recursion for the ci's work
I know bi's are obtained from nesting the polynomial
The Horner's method that I am familiar with is about evaluating polynomials with nested operations
What is this Horner's method?
Are you computing roots or something?
yea
like why c0 is the derivative f'(x_0) if you let cn-1 = bn-2, etc. etc.
You understand where c_0 comes from right? The recursion is just using a variant of horner's method to calculate c_0

{kind=link}
So the first slide explains why c_0 is the derivative f'(x_n) (not f'(x_0))
And computing c_0 is the same as computing q(x_n)
Oh ok x_n=x_0 or whatever
you know what doesnt make sense to me
regularization
like, if you have a system $Ax = b$ with a poorly conditioned $A$ and instead of solving it as-is you solve $(A^*A + \alpha I)x = A^*b$ which somehow \textit{works}???
Ann
where alpha is a small positive number like 1e-5
i've seen it in action but intuitively it makes no sense to me whatsoever
does anyone by any chance have an intuitive explanation for why this works
Imo it's like least squares plus a small perturbation ensuring an non singular matrix
and the assumption is that the perturbation won't fuck up the solution too badly?