#numerical-analysis
1 messages · Page 10 of 1
I mean, should I pay close attention to the different topologies that happen in rudin's functional analysis? Or should I focus on normed spaces or Banach spaces, to assume almost all theorems hold, without having to remember so many topologies.
Each of his theorems have different hypotheses that make it much difficult to track. Maybe I just have to study harder and it will be worth it? I heard there is even functional analysis on graphs that would be cool
Sobolev spaces
Evil Bean


yo
The one on the left probably won't converge.
Whereas the one on the right does.
$ln(1)=0$ so $\frac{1}{\ln(x)}$ is going to have a vertical asymptote in this domain.
Why is this important?
At an asymptote the derivative is going to be massive and is going to get bigger.
(I'd suggest actually differentiating and observing the derivative of the function on the right in this domain).
Whereas the expression on the right has a nice derivative and is a smooth function on the domain.
I'd suggest looking up the 1D Fixed point theorem, one of the conditions is that near the root you need: the function to have an absolute derivative less than 1.
Max

Hello, I have a question about the rayleigh quotient itération. Whats the theorical convergence of the method if x0 (the initial vector we choose) and v (the eigenvector to wich we converge) if |x0-v| > 1 ?
Have you looked at the convergence proof in Demmel
Nah but I can ask him he’s my professor rn 😭
Yeah lmao how you know
I too took 221 with jim
LMAO
Anyways you should read the proof in the book before asking him
i had this qn i had to answr
Let ℝd be equipped with the Euclidean norm, let D⊂ℝd be a closed set, let g: D→D be a contraction with Lipschitz constant L=1/3, let x0∈D and assume that D⊂B2(x0). By the contraction mapping principle, there exists a fixed point x*∈D of g, and the sequence (xk)k generated by the iteration
x_{k+1}=g(x_k)\quad\text{for}\ k\in\mathbb{N}
converges to x*.
What is the smallest number N∈ℕ such that for any dimension d≥1, and for any D, g and x0 as characterised above, we have
x_k\in B_{10^{-8}}(x^*)\quad\forall,k\ge N?
Hint: Consider the concrete example D=[0,2], g(x)=x/3 and x_0=2 and find the index N_1 in that particular case; this shows that, in general, the smallest possible N working for all cases is larger N_1.
To then find an N that works for all cases of D,g as in the statement of the question, you have to write down a short mathematical argument. You manage to make N=N_1, you have identified N.
the answer is N=18
ok nice the latex didnt convert

this is the written explanation for why n=18 but tbh i dont really understand lol...like the whole shabang. if anyone could help me out id be forever grateful 🙏

What does "$O(1)$ numbers" mean?
My understanding is that if $f=O(g)$, then there exists $C>0$ s.t. $\qty| \frac{f(x)}{g(x)} | \leq C$
So if you say a constant $A$ is $O(1)$, you're saying that $|A/1|=|A|\leq C$, which doesn't seem to be particularly meaningful, as it is true of every number


Douglas

Meaning what exactly?
okie dokie
Which part don’t you understand?
related question... given that A=O(1) means A is close to 1, I presume it means that A=[integral up to some point in the interval]/[integral over entire interval], rather than just the numerator?

cos if the total integral is 4π eg and A is just the integral across some fraction of the interval, then A might be 11 or something, in which case A is certainly closer to 10 than 1
this is in the context of the trapezium rule btw
Scaling an integrand by a constant doesn't change any of the theory
what's the significance of specifying O(1) then, as opposed to O(10), or any other?
f=O(1) means f<=C*1 for some c>0
O(•) implicitly means some constant times the general order of convergence
so we pull out all constant terms into that C
Machine epsilon is the distance between 1 and the next floating point number
right but what does eps have to do with O(1)?
eps changes when you get further away from 1
does anyone know how we can compute an error bound for Romberg integration?
Start with the error bound for the trapezoidal rule, then see how the error behaves under Richardson extrapolation
Thank you. I will try that
How are we getting 5.27?


What is S_i defined as
It's defined as in 5.21



When doing quadrature by decomposing domain into piecewise polynomial approximations(lagrange), is there anything we can say about the error depending where you are at in the interval?
To restate:
For lagrange polynomial interpolation the error increases at the bounds. What can we say when we do a piecewise polynomial interpolation? What about in case of quadrature?
Do you mean that the error is large at the endpoints of the interval?
Yea not bounds
This is dependent a lot on grid spacing
Well assuming equidistant
For the interpolation points used for the polynomial approximation
Ok well equidistant points are bad
Yes but it doesnt matter for quadrature
For quadrature, you can do better with non equidistant points
At any rate, this is the error for polynomial interpolation

For interpolation points x_i
The product on the right hand side will vary in your interval, and for equidistant points, is minimized at x=x_i and x at the center of the interval
Yea I get this but I guess my question was more about quadrature because it was covered in class recently
We discussed newton cotes formulas
And we also discussed a possible way to minimize errors was by breaking the integration interval into subintervals and applying polynomial interpolations there
Yea we talked about that a little. I don’t know the extended story though.
I guess my question was more like can we say anything about where error is highest or lowest when doing this subinterval polynomial interpolation
As it relates to quadrature tho
Well, precisely because equidistant point based polynomial interpolation is useless at high degree
You don't want your interpolation weights to come from a polynomial interpolation
You want to do a least squares method to get the weights instead
How can one show: A matrix ( A \in M_n(\mathbb{R}) ) is invertible if and only if there exists a permutation matrix ( P \in \prod_n ) such that all principal minors ( (P \cdot A)_m ) of ( P \cdot A ) are invertible for ( m = 1, \dots, n ).
Sentinel

Hmmm #linear-algebra
its actaully from a numerical analysis lecture
thats why i posted it here
but it may not fit here u are righjt
would you like to help 🙂
I regret to inform you that I do not want to think about permutation matrices at the moment
Thanks though i ve posted it in linear algebra with my intended solution
which doesnt work fully
I dont know either but my guess is something like invertible principle minors things relates to gaussian elimination way of finding determinants
And you want to show thats non zero
Id try that atleast
Yeah isn’t that cus of evenly spaced points?
Just staying I read none of the messages above or below that message I just saw it and instantly replied

I have a question about subspace iteration. If we run this algorithm on symmetrical matrices to calculate the 10 largest eigenvalues. We simulate matrices with size ranging from 10 to n. I simulated my algorithm and for each bigger matrix n, I saved the amount of iterations until convergence.
The relation between amount of runs & size of matrix was linear. But I fail to understand why...
By subspace iteration, do you mean arnoldi iteration?
I'm not sure what arnoldi iteration is. I use this algorithm:

Iteration matrix Q, QR decomposition in second step
I really appreciate your reply
Hey
im trying to read more about butcher tablaues, implicit RK and diagonally implicit RK methods, where do i look at?
my ultimate goal is implementing a parallel DIRK solve
Yes
im pretty much vanilla in numerical analysis
just learned about runge-kutta a couple of days back
This should be good
I'm not entirely sure what you mean by a parallel DIRK solve
Like do you have a pde that you want to use DIRK to time step for
Or are you trying to do a parallel in time thing
yk normal parallel RK?
parallel in time yes
you can set it up for implicit and diagonally implicit RK as well
If I have a sparse matrix and I assign it as sparse(B) in matlab. Then when doing gram schmidt on vectors, do I have to do this step? vector1 = sparse(vector1 ./ norm(vector1));
Mister angetenar, does this statement ring any bells?
Hmmm, operations in gram schmidt might make elements nearly zero instead of zero, which would make a vector not sparse anymore
hmmmmmmmmm
Gram Schmidt is generally not preferred for a numerical algorithm
Are you doing a QR factorization?
Yessir, and Gram Schmidt is obligatory
What do you mean obligatory
EUh if I don't do it I won't pass
Ok
Is it correct that that algorithm can cause 0 elements to become non zero?
Gram schmidt will not preserve sparsity
Check the modified gram-schmidt presented here
So my matrix becomes non sparse, but would zero elements become non zero?
ok I will check it out, thanks angetenar!
Why are the nodes indexed by n,i rather than i only?

So when he refers to "two groups of parameters", they are the nodes and the approximation weights, not n and i?
The author may be trying to emphasize that the x_n,i will vary with different numbers of quadrature points
Paramters isn't the best term, I would say degrees of freedom
But yes, you can vary the qudrature nodes and the quadrature weights at each node
right ok
I would say it is more common to use x_{i,n} but it just means x_{n,i}=h*i+a=(b-a)i/n+a, i=0...n
(or some other grid)
for a specific grid type, the node points are usually defined by n and the point indices i, not more complicated
and if you use multiple grid types you need one or more extra indices to define which
I am not seeing the thing that is supposed to be easy to see (5.48)



Have you done the integration by parts k+1 times
This is as far as I got before thinking I had gone wrong somewhere

there should be alternating signs in the margin of the D/I table
You can ignore the n!/(2n)!, that won't affect the integral
yeah i included the n! (and not the (2n)!) so as to avoid a 1/facotrial thing
Hmmmm
it just makes the table look a little bit tidier i think
Yeah sure
Ok let's see how I would do this
First, recognize that if n is even, then phi_n only contains even degree terms
Similarly if n is odd, then phi_n contains only odd degree terms
So if n is even and k is odd or vice versa, the integral will be 0 right
Integral of an odd function on a symmetric interval
Now, we consider when both n and k are even
Hmmmmm
Ok really what you should do is show that the integral of phi_n(x) from -1 to 1 is 0
There are much better presentations of Legendre polynomials that actually discuss their properties
(Namely being an orthogonal basis)
(In which case 5.48 follows immediately)
how exactly does this argument work in this context?
we have an inner product $(f,g)=\int_{-1} ^1 f(x) g(x) \dd{x}$
then what?
Douglas

(phi_i, phi_j)=0, i≠j, is what we're saying?
Yes
and how does that get you (x^k, phi_n)=0
If k<n, then you can write x^k as a sum of phi_i for i<=k and split the integral up
And each piece of the integral will be 0
hmmmm yes
you are right this is a much nicer argument than doing the integral by tabulation
ty for the help
<@&268886789983436800>
gone
Anyone here knows about b-spline?
What about it?
I just want to understand it, for example what are the knots and control points in a spline?

Also how do I define a B-spline?
Sorry, I'm a bit preoccupied rn, but I can try to answer later if no one does
np, tysm
so basically you first choose some arbitrary knots, which are points on the x-axis
this choice defines a set of functions constructed with a recursive relation, where each function (B-spline) is nonzero only on some limited interval
and then you choose control points, which are something like coefficients in linear combination of vectors
but in multiple dimensions
so you take some average of these B-splines (basis splines) weighted by control points
or if you're familiar with the notion of partition of unity, it's a very similar idea with basis splines as functions
What is this term? I looked it up and it says blending functions that are used to blend the control points

yea, maybe it's better to view it as a weighted average of control points
B-splines look something like this

if you enforce them to sum up to 1, you get something like a "smoothly changing weight" for the weighted average of control points
yea exactly
Another question, how do I calculate the points on the b-spline curve?
I read that there's an Algorithm called DeBoor-Cox
But how to apply that Algorithm?
I found the Cox-de boor formula
tysm, for explaining b-spline
sorry i had a call
yeah you apply the Cox-de boor formula which is just computing the values recursively from the splines of lower degree
I forgot to mention that I'm making a presentation about b-spline
I have an amazing video for you to watch then
why are splines? well my god I have good news for you, here's why splines!
if you like my work, please consider supporting me 💖
https://www.patreon.com/acegikmo
This project grew much larger in scope than I had originally intended, and burnout made it impossible for me to do more with it. It was already getting incredibly unwieldy, so I apolog...
you caaan skip straight to the B-Splines chapter (also what I did originally) but you will likely end up watching the whole video. especially if youre presenting on b-splines, like I had to
shes really good at telling the story and the visuals just keep you entranced
Care to copy over what is going on
I'm using a modified Newton's method for solving a 2x2 non-linear system. I've substituted the Jacobian's elements with the following expressions:
[
\begin{cases}
\frac{\partial f_1}{\partial K_1}\approx\frac{f_1(K_1+s,,K_2)-f_1(K_1,,K_2)}{s}\
\frac{\partial f_1}{\partial K_2}\approx\frac{f_1(K_1,,K_2+s)-f_1(K_1,,K_2)}{s}\
\frac{\partial f_2}{\partial K_1}\approx\frac{f_2(K_1+s,,K_2)-f_2(K_1,,K_2)}{s}\
\frac{\partial f_2}{\partial K_2}\approx\frac{f_2(K_1,,K_2+s)-f_2(K_1,,K_2)}{s}
\end{cases}
]
What system are you solving
Eruc

Also what are you plotting
The truncation error (Y) plotted against different values for the small supplement s in the expressions (X).
The truncation error is the total of the entire problem (it's a combination of different methods feeding into each other) but the only thing being varied here is the value of s
After 6 iterations, sufficiently converged for the problem
But so it seems there's a certain value of s that minimises the truncation error, and then it grows, and then starts approaching the same minimum asymptotically. What's going on with that? Where can I look more into this?
Hmmmm
It's hard to say what is going on without knowing more about what f is, but this kind of reminds me of what happens when you vary the parameter in successive over relaxation
To be more specific, the system being solved is to optimise two constants of a second order non-linear ODE so that the solution to the ODE fullfils two separate criteria
So the entire problem involves errors from ODE-solving (RK4), polynomial interpolation, Newton-Rhapson, and then this error dependent on s
Are the two lines two different error measures
They're the errors of the two different constants being optimised
What does f look like
I don't really have a expression for them, but f1 gives the distance between two points on the ODE curve that have two specific properties. The constants are being optimised so that f1 = 0 (i.e. the same point is supposed to have both properties)
And f2 is something similar but less complicated
Do you have any method of directly computing the error in the derivative calculation of f
Hey guys, what's the link between the fourier transform and the fourier series? If there is one at all. I kinda what they each are on their own, not sure how they relate though. Thanks 🙂
Fourier series are the Fourier transform on a periodic interval
Ask further questions in #advanced-analysis
im using gauss seidel iteration (+ overrelaxation) to remove the divergence from a velocity field when simulation the incompressible uniform euler fluid equations, but its slow for high resolutions because i need a bunch of iterations. when iteratively reducing the divergence im subtracting it from the velocity field at every step.
i want to use a multigrid method but im confused on whether im supposed to be projecting and restricting the actual velocities of each cell (thus seemingly destroying local information when interpolating back onto the fine grid) or if im supposed to keep a separate error array, and after solving for it at each level interpolate it onto the fine grid by subtracting it from the actual velocity array (thus keeping local velocity differences but subtracting an interpolated divergence term)
like what
Compatible finite elements or a Lagrangian approach a la Chorin's vortex method
Projection methods avoid having to deal with divergence too
wouldn't it make more sense to use the notation $P_N (n)$?
N is a parameter that we control, whereas n is entirely random



Douglas

maybe
but it feels weird
like you wouldnt diffeentiate wrt an index
i mean you could
but it would be a little weird
Ratking behavior is not channel appropriate
oh
Rafiking
At any rate, there is far worse notation that you will come across I imagine
Why is $\sigma$ not equal to $p_1 p_2/N$?
This is what you get if you compare coefficients of 5.67 and 5.68


Douglas

ye sorry these are from my numerical methods lecture notes
so just defaulted to this channel
but u r correct
prob makes more sense here
Does anyone know why for sparse matrices randomized truncated SVD (like Halko et al.) performs empirically poorly something like Arnoldi iteration (for example ARPACK)? Specifically for PCA
In my numerical analysis course. We get some theory questions too. Like what are the draw backs of newton ralphson theory. The topics we have are.
- Error calculation
- taylor theorem
- Newton raphson method
- secant method
- bisection method
- interpolation (linear quadratic)
- newton dividend diff interpolation
- lagrangian
- trapeziod
- Simpsons 1/3 rule
How do i study the theories. I never studied theory for maths before and our teacher does not tell us
Can ppl here tell me?
Anyone has good recommendations for introductory books on numerical optimisation?
I would say just read books, there are many good books on numerical methods/analysis. I recommend James F. Epperson's book, it is very good at the introductory level. You can always search on the web for other recommendations or ask in the books channel.
okay thank you very much ❤️
A good classic is "An Introduction to Numerical Analysis" by Atkinson.
Nocedal should be the one of the most commonly used.
can i send link here?
we are following a book at uni and that book is uploaded in internet by the ppl i think
Numerical Methods with Applications by Authors: Autar K Kaw | Co-Author: Egwu E Kalu, Duc Nguyen
You can also check out convex optimization books, usually they include a significant amount of numerical algorithms inside.
https://nm.mathforcollege.com/textbook-numerical-methods-with-applications/
chapter 9 is optimization
Sounds like a very applied book.
ikr but we get question in exam like:
- in which of the following function does root jumping occure while useing the newton raphson methods? analyse graphically.
a. y = x^2
b. y = sinx
c. y = cosx
this is maybe explanation of the draw back of newton.
idk
Um... this is an applied question.
The maths i know is proof based maths
What is wrong with that question
Nothing wrong, but its something where you can just draw and guess.
No proof needed.
But not a theoretical question (in my opinion).
It seems fine as introductory if you aren’t really coming from a math background. Seems like the book is geared towards engineering majors
hello, does anyone have any references for error analysis/estimation for various spline interpolation methods? (cubic spline, spline with tension, thin plate spline), or does anyone know any methods and can explain?
Taylor series
Most approximation theory textbooks should cover rigorous error estimates for splines.
The techniques used depend on the function spaces. For instance, taylor series would work for C^k functions but probably not so helpful for H^k functions.
Hello everyone i need a reference for the research im doing on weddle’s method so if anyone could help me i would appreciate it alot
Seems to be an obscure Newton-Cotes method, never heard of it 🙂
so I assume compare it with with the standard ones?
I want to choose $n+1$ pairwise distinct points $x_0, \dots, x_n \in [0,1]$ to extremize the value of the integral
$$L = \int_0^1 |w(x)| , dx, \qquad w(x) = \prod_{k=0}^n (x - x_k).$$
I know that $L$ is minimized when we take the $x_k$ to be the zeros of the Chebyshev polynomial of the second kind $U_{n+1}(x)$. But what choice of the $x_k$ maximizes $L$?
Eduardo León

Lol
LR = A where L and R are up and down triangle matrizes, prove that $\frac{|| \left|L\right|\left|R\right| ||\infty}{||A||\infty} \leq \kappa_\infty(L)$
Jemaseda

can someone help me with this? i have no idea what im doing
What have you tried
Well not much pure algebra playing and the < things to approximate or smtn
Well you can prove it for diagonal matrices at least right
any suggestions on how to handle (d)? I tried the hint but I keep getting cross terms that I dont know to handle

the derived scheme with $f=0$ is
$$\frac{1}{2}(W_2^{m+1}+W_2^{m},\chi)=\frac{1}{\tau}(W_1^{m+1}-W_1^{m},\chi)$$
$$a(\frac{1}{2}(W_{1}^{m+1}+W_{1}^{m}),\chi)=\frac{1}{\tau}(W_2^{m+1}-W_2^{m},\chi).$$
ansh

W^(m+1/2)=(W^(m+1)+W^(m))/2 btw
Well what do you get after multiplying the system
so if i test eq1 with $W_1^{m+1/2}$ and eq2 with $\triangle_h W_2^{m+1/2}$ the new system is
$$(W_1^{m+1/2},W_2^{m+1/2})=\frac{1}{2\tau}(|W_1^{m+1}|^2-|W_1^{m}|^2)$$
$$(\triangle W_1^{m+1/2}, \triangle W_2^{m+1/2})=-\frac{1}{2\tau}(|\nabla W_2^{m+1}|^2-|\nabla W_2^{m}|^2)$$
ansh

(with some rearranging and integrating by parts)
but how do you show stability from here?
oh theres a typo it should be grad(W2) instead of grad(W1) in the second equation RHS
is there some standard method of computing step in multivariate newton method up to quadratic term in taylor expansion
$$ 0 = f(x) + Df(x) h + \frac 1 2 D^2 f(x) (h, h) $$
how to get h is my question
Bwoonoid, a crank

Newton's method for root finding?
I've literally never seen anyone include the quadratic term before lol
the exercise probably aims to show that including it is not needed
theoretically it could make sense however, but idk how to calculate the step
Where is A+B=1 coming from? Is that imposed just to make A and B "nice" numbers?

If you are integrating a constant function, you need A+B=1 for the quadrature to be correct
This is a common thing that you'll see in numerical quadrature
what's quadrature?
Numerical integration
You are integrating an arbitrary function f yes
so how does
If you are integrating a constant function, you need A+B=1 for the quadrature to be correct
help us with integrating arbitrary f?
It's a basic check on accuracy for the easiest functions to integrate
If you cannot numerically integrate a constant, then you have no hope of doing anything more sophisticated
Hi guys, can I get some help? Suppose $$A = \begin{bmatrix} A_{11} & A_{21}^T \ A_{21} & A_{22}\end{bmatrix}$$ is symmetric PD. I want to prove that $|A_{21}A_{11}^{-1}|2 \leq \kappa{2}(A)^{1/2}$, where $\kappa_2$ is the condition number under the operator 2-norm. The hint is considering $A$'s Cholesky factorization, but I can't seem to figure it out...
{Wilhelm}

Well, what is the cholesky factorization of A
We don't assume anything about its factorization, only since it is PSD it can be done. The hint suggests using the block Cholesky factorization $$A = \begin{bmatrix}R_{11}^T & 0 \ R_{12}^T & R_{22}^T \end{bmatrix} \begin{bmatrix}R_{11} & R_{12} \ 0 & R_{22}\end{bmatrix}$$
{Wilhelm}

Where $A_{11} = R_{11}^TR_{11}$ is its Cholesky factorization itself
{Wilhelm}

I managed to bound it by $\kappa_2(A)$, but not its square root
{Wilhelm}

I really appreciate any insights :)
2 norm
This is part (c) of an exercise, and this is what I have proved so far, first this factorization: $$\begin{bmatrix} I & 0 \ -A_{21} A_{11}^{-1} & I \end{bmatrix} \begin{bmatrix}
A_{11} & A_{21}^\tp \ A_{21} & A_{22} \end{bmatrix} \begin{bmatrix} I & -
A_{11}^{-1}A_{21}^\tp \ 0 & I \end{bmatrix} = \begin{bmatrix} A_{11} & 0 \ 0 & S
\end{bmatrix}.$$
{Wilhelm}
Compile Error! Click the  reaction for more information.
reaction for more information.
(You may edit your message to recompile.)

$\lVert A_{ij} \rVert_2 \le \lVert A \rVert_2, \quad i,j \in {1,2}$
{Wilhelm}

and $\kappa_2(S) \le \kappa_2(A)$
{Wilhelm}

Interestingly, the Schur complement $S$ simplifies to $R_{22}^TR_{22}$, and of course it should be enough to show that $|A_{21}A_{11}^{-1}|_2^2 \leq \kappa_2(S)$, which might be where the exercise is leading to
{Wilhelm}

Oh, I think the root part comes in by the fact that $\kappa_2(A) = \kappa_2(R^TR) = \kappa_2^2(R)$
{Wilhelm}

OHHHHH SOLVED IT :)))))
you use cholesky to show $A_{21}A_{11}^{-1} = R_{12}^TR_{11}^{-T}$, then the whole norm is less than $|R_{12}|2|R{11}^{-1}|_2$, and then you use the bound on block matrix norms above
{Wilhelm}

Ok, if anyone can give me a hint on this following problem that would be great:
Suppose that you have a solution to the following least squares problem,
$$
\min \left| \begin{bmatrix} A \ \textbf{c}^T \end{bmatrix} \textbf{x} - \begin{bmatrix} \textbf{b} \ d \end{bmatrix} \right|_2
$$
You can make no assumptions on the method that was used to solve it. How can you leverage the solution above to efficiently solve $\min |A\textbf{x} - \textbf{b}|_2$? The method should probably include the use of the Sherman-Morrison formula https://en.wikipedia.org/wiki/Sherman–Morrison_formula. Thanks!
{Wilhelm}

yo i think i desparately need some help
on numerical analysis
https://ustspace.s3-ap-southeast-1.amazonaws.com/upload/lbTzVGpf53mxcwyg286fCz60MufPq36f/FinalExam2019.pdf
I need some help with Q2, Q4 and Q5b
we wait 120mins and answer 😄
yes
correct
this is a pastpaper from 2019

My progress so far with Q2
wait no the linear system is solved wrong
well to be honest now i am not too sure if my previous step is even correct
i somehow got a = (h-1)/(h+1) c
pls help
well that works too but this is a pastpaper lol
the year is written

My current progress with Q4

But somehow the error term become zero
Idk what’s wrong for now, pls help
i will be back in around 3 hours, i need a quick nap
I've recently started a project and I am trying to implement numerical methods using python.
https://github.com/TheKidKy/numerical_analysis

GitHub
numerical analysis methods using python. Contribute to TheKidKy/numerical_analysis development by creating an account on GitHub.
Nice, although I would suggest making sure you maximise the use of libraries if possible as they will use code, most likely written in C which is WAY faster than Python.
Python is generally considered slow, if you like the syntax but want more speed without losing the Syntax I'd recommend learning Julia
should I switch to C?
Personally I would switch to Julia, but that has its own problems (slow compile times) but after that it is as fast as C but has a python feel
C is probably the fastest all around, ie. in compile time and run time
But python is the most convenient to code and there are lots of libraries
For instance, say you decide to use Python that would be fine just make sure to do as much code as possible in libraries such as Pandas, Numpy ext. which are written in C
Also Python has some really nice numerical analysis libraries such as Mpmath which I'm not sure the others have
hello guys i am back again

anyone have any idea on how to do Q5b?
FYI THIS IS NOT AN ONGOING EXAM, THIS IS A PASTPAPER FOR PRACTICE
to confirm this is not an ongoing exam, i am trying to do it since yesterday so....
What have you tried
well fun fact, i just found the proof in a textbook
Lol nice
taylor series expansion y around a and compute the difference
hi
Hello
suggest any playlist for this topic man ..i have exams coming in 3months
Look at your notes and watch videos by topic rather than one set course...
this is the stage of maths where you need to be learning how to learn from notes and text as opposed to videos... as rarely does specialized content have video tutorials


This is how i decided to solve this.
As i'm supposed to pick 3 random ODE methods and either secant/bisection method for task b i have 6 possible solutions.
import numpy as np
from solvers import solver
# RHS of ODE
def rhs(t, y, m, k, g):
v = y[1]
dydt = v
dvdt = -k/m * v**2 - g/m
return np.array([dydt, dvdt])
def nonlinear_function(H, m, k, g, T, target_position, method):
initial_conditions = np.array([0.0, H])
# Wrapper
def rhs_with_params(t, y):
return rhs(t, y, m, k, g)
t0 = 0.0
dt = 0.01
t, y = solver(rhs_with_params, initial_conditions, t0, dt, T, method)
# Final position at t = T
final_position = y[-1][0]
# Return the difference from the target position
return final_position - target_position
# Parameters
m = 1.3
g = 9.81
k = 0.05
T = 1.5
target_position = 10.0
# Differential methods
methods = ["Heun", "Ralston", "Runge-Kutta"]
# Results storage
results = []
for method in methods:
print(f"\nUsing Differential Solver: {method}")
def F(H):
return nonlinear_function(H, m, k, g, T, target_position, method)
# Bisection
root_bisection = bisection(F, 0, 20)
print(f"Bisection root: {root_bisection}")
results.append((method, "Bisection", root_bisection))
# Secant
root_secant = secant(F, 0, 20)
print(f"Secant root: {root_secant}")
results.append((method, "Secant", root_secant))
print("\nSummary of Results:")
for method, solver, root in results:
print(f"{method} with {solver}: Root = {root}")```bisection() and secant() come from a worksheet we used in a lab and they're known to work
Fairs but it's numerical analysis
If you think there is a simple mistake it could be worth asking an AI chat bot, they good at picking up on simple mistakes
Well they also didn’t ask a question
If you are just asking if it's right then look at the accuracy of your answer, are they accurate? If not how can you make it more accurate
At least not that I can see
True 😭😂
/ what could you change to make your answer more accurate, if it doesn't make it more accurate then it's likely you've made a mistake
If you can't spot the mistake after a bit of investigation then just redo the whole thing again lmao honestly has helped me spot so many mistakes in the past
!da2a
No need to ask “Can I ask…?” or “Does anyone know about…?”—it’s faster for everyone if you just ask your question! See https://dontasktoask.com/
Such a mathematician thing to say lmao
Dear all, I having trouble with the discontinuous Garlerkin method (DG). My question is the following , by applying the DG method could I deduce a upwind/downwind discretization scheme for my PDE (a PDE to the convection diffusion type) ?
Is it true that accuracy in floating point numbers cannot be accurately calculated for precise precision and accuracy: https://en.wikipedia.org/wiki/Floating-point_arithmetic

In computing, floating-point arithmetic (FP) is arithmetic on subsets of real numbers formed by a signed sequence of a fixed number of digits in some base, called a significand, scaled by an integer exponent of that base.
Numbers of this form are called floating-point numbers.: 3 : 10
For example, the number 2469/200 is a floating-point number ...
Yes, you can't rely on floating point numbers to be exactly accurate, try doing $0.1+0.2$ in python or something. Even if you write doing 0.3 on a computer, its really being stored as a slightly different number close to 0.3
jamiecjx

Floating point numbers generally only satisfy the standard arithmetic operations up to a known error, so for example, given floating point numbers $x,y \in \bb{F}$, we have $x \oplus y = (x+y)(1+\delta)$ where $|\delta| < \frac{\eps_M}{2}$ and a $\eps_M$ is a constant
jamiecjx
Compile Error! Click the reaction for more information.
(You may edit your message to recompile.)

said constant is usually about 2 * 10^{-15} in double precision, so whilst you can't calculate precisely with floating point, you can rigorously bound computations (with things like interval arithmetic)
also a related topic https://en.wikipedia.org/wiki/Machine_epsilon
Can someone please suggest me a good book/resource to study Runge Kutta methods, very funadmentally and in great detail? Would be great if it also mentions any suggestions on programming the different models of RK, like RK 7, 8 or higher in Python.
But, primarily I want to understand the method, the derivation of the formula, and it's application in real life problems.
Apparently the golden ratio pops out of nowhere when doing natural cubic spline interpolation! Basically knots (nodes) at phi^2k makes the interpolation neither converge nor diverge. Is this well-known?

I'm also open to using another library for this task.
I solved my first numerical eigenvalue problems yesterday lol.
Can someone please suggest me a good
I was helped :)
please would someone explain the highlighted bit?

Also...
- "The case mu=1 is called "1-sublinear convergence". Don't you identify the nature of the convergence by the order q (q-convergence), so wouldn't it make more sense to say "the case q=1"?
- Why does he talk about mu=0 when the inequality mu satisfies prohibits that case? And what does it mean to lie between q=1 and q>1?

if the approximation is correct to two decimal places then the errror (x_k - x*) is on the order of 10^(-3) meaning -log(x_k - x*) is somewhere between 2 and 3. similarly if they agree at 5 decimal places the expression would be 5--6
ok
what about this
if you say q = 1 then people would assume you are referring to the linear case unless otherwise specified. both special cases start with "1-" to refer to the order q
Maybe you should look into why that is
That’s the beauty of math after all
so is it the case that if q=1 then 0≤mu≤1 (i.e. closed interval, not open)?
possibly one for probability, but what does it mean to choose the nodes?
the nodes are the data points, i.e. a random sample from a population, so how is there any choice in their spacing?

There are a few variants of the interpolation problem
One is scattered data interpolation where you have no choice over where the data is located
But in other cases, you might have a function that is very expensive to compute so you fit a polynomial approximation to evaluate it more efficiently
In which case you do have a choice over the interpolation nodes
Maybe someone here can help me with a question about numerical integration.
Specifically, the remainder theorem for the "midpoint method". I highlighted it in red.
I can't find a proof of this theorem anywhere that does not assume the second derivative of the function is continuous. The theorem's formulation seems to state only that the second derivative must exist, i.e., continuity is not guaranteed.
I have found only these proofs so far:
https://math.stackexchange.com/a/4327333/861268
https://www.macmillanlearning.com/studentresources/highschool/mathematics/rogawskiapet2e/additional_proofs/error_bounds_proof_for_numerical_integration.pdf
But they both assume continuity of second derivative.
I'm exhausted from searching. It feels like this is some completely unimportant detail.
P.S.: Maybe I should've posted it in calculus chat because I've found this theorem in calculus book? Here: https://openstax.org/books/calculus-volume-2/pages/3-6-numerical-integration

Essentially you are approximating the curve using a straight line
Or in other words the first order Taylor series of the function.
Then integrating the straight line.
The error for a first order Taylor series is dependent on the second derivative.
I'll let you put it together more formally but that's the gist.
It says "If M is the maximum value of |f''(x)| over [a, b], ..."
That's an additional condition that replaces the requirement of continuity of the second derivative
The maximum value might not exist in general if f'' is not continuous on [a, b]
That's what's done in this proof https://math.stackexchange.com/a/4327333/861268 At first, he integrates the Taylor's approximation of the function for one interval and then summing it for n intervals. But I've no idea how this can be done without assuming that f''(xi) (which is used in remainder for Taylor's approximation) is continuous on interval.
So, am I right in understanding, based on what has been said, that the theorem states that whether the second derivative is continuous or discontinuous, we should have an M value for this formula to make sense?
Yeah, the requirement that the second derivative is continuous is usually only required in the theorems to ensure that the second derivative is bounded
And how, then, can it be proven? I mean, I’ve kept the proofs above in my main post, so is it correct to assume in the proof that it's continuous? The reason why I'm so curious about that is: what if in some practical case/problem I'll come across a case where f'' is discontinuous?
Well, check in which parts of the proof do you need continuity of the second derivative
The intermediate value property still holds for derivatives even though they are not continuous, for example
In mathematics, Darboux's theorem is a theorem in real analysis, named after Jean Gaston Darboux. It states that every function that results from the differentiation of another function has the intermediate value property: the image of an interval is also an interval.
When ƒ is continuously differentiable (ƒ in C1([a,b])), this is a consequence ...
So this part of the proof (1st one, where he uses mean value theorem for integrals) can be performed by using Darboux's theorem without assuming the continuity, right?

Instead of using the mean value theorem (which is possible, but might require monotonicity of f''), you can just bound f'' by M
He refers to 4.8 as the absolute error. How are we justifying the absorption of O(e^2) into the other error terms?
Do we know that e/h is bigger than e^2, so we can ignore O(e^2) altogether?


epsilon and h are both small quantities (much less than 1), so ε² is guaranteed to be much smaller than ε and ε/h will be much larger than ε (even if h were larger than 1 it would not be much smaller, certainly not as small as ε²)
but how do you know that e is not approx equal to h, in which case e/h≈1?
ε and h are both much less than 1 so that would be a much larger error
right ok i was thinking about things the complete wrong way around
yes you only care about the largest term, and (small)^2 is smaller than (small)/(small)
where are the highlighted terms coming from?

like i understand that there will be some error
but how do you know that those terms give the correct error
taylor expand f centered at x
But this will do it for one interval as I understand it. Will not the fact that the value of M might be different for different intervals to be obstacle to sum this error n times (for n different intervals I mean)?
M is the maximum value of |f''(x)| over [a, b]
It should say "order" where it says "rate".
Is smoothness actually a necessary condition? If you had non-vanishing first derivative and f was only twice differentiable, wouldn't you still have quadratic convergence?

Continuous differentiability and a Lipschitz condition will be sufficient
How do we get (9)?
I was using a slightly different formula for Simpson's, i.e. with $n-1/2$ and $n-1$ in the exponents, so I got the following.
$$\frac{h}{6} \frac{6-3h+h^2 -\cdots}{h+h^2/2 + \cdots} = \frac{1-h/2+h^2/6 +\cdots}{1+h/2+\cdots}$$
Using $(1+y)^{-1} \approx 1-y$, we find that the above expression is equal to $$ (1-h/2+\cdots) (1-h/2+h^2/6+\cdots)$$
But this gives $I_S = (e-1) (1+O(h))$ I think, and that isn't right.
Where have I gone wrong?

Douglas

Should just be a taylor series?
Which bit are you referring to? I've used Taylor series to get 1+O(h)
Same but with $$1+4e^{-h/2}+e^{-h}$$
Douglas

Just a sign change
Are you sure nothing else changes
You should have different bounds on the sum as well


@wide spear ^
actually i think i can see the mistake now
i've evaluated those sums incorrectly bc of the bounds being different
i will fix when i return to my desk
Nice
Not entirely "all good" as it turns out...
I've got a Taylor series with a quadratic term
The coefficient on the cubic term seems to be incorrect in my working, but I cba to find the arithmetical mistake


You need to include a few more terms in both the numerator and denominator I think


yeah but if i didnt have the worked solution available then i wouldnt know to go to h^5

hmmmm
ok so what wolfram says agrees with the answer once you multiply by h/6
i think this is the main problem im having
i assume from the worked solution that the fact that the dots start after quadratic means thats how many terms he's going up to
Could someone please give a (very ELIUndergrad) reason for why we care about (and how to account for) numerical stability in algorithms? I'm trying to write a basic matrix library for fun and every source I look at warns about naive algorithms leading to instability and I'm unsure of how to interpret any of this.
For context, we finished a first course in linear algebra at uni a few weeks ago and today I got the idea to write a basic toy library to handle basic matrix maths,but got bit scared by mentions of stability and such
Do you know what numerical stability means
not really
AFAIK it has to do with small deviations in input data leading to large/undesirable changes in the output
But that's about all I know
Are you familiar with floating point arithmetic
Yes
Ok so
Let's take an algorithm that isn't numerically stable
The computation of the jordan decomposition
Consider the matrix $\begin{bmatrix}1&1\x&1\end{bmatrix}$
Angetenar

okay
If $x=0$, then the jordan form is the matrix, or $\begin{bmatrix}1&1\0&1\end{bmatrix}$
Angetenar

If $x\neq0$, then the jordan form is $\begin{bmatrix}1+\sqrt{x}&0\0&1-\sqrt{x}\end{bmatrix}$
Angetenar

So any perturbation to x can dramatically change the output
ahhhh yeah I see
This interacts poorly with floating point arithmetic
Okay so if we get any floating point inaccuracies then our resulting matrix could be completely wrong
yeah
And then you can get things that are very wrong
If you are using things that are not numerically stable
that makes sense, so if JNF is unstable like this due to the way it works overall, is it just avoided in general? or are there tricks to still compute it
JNF is numerically unsalvageable
The Schur decomposition is the preferred numerical alternative
can u do this with another representation that is not floating point, something like fixed point?
does the problem persist in that representation?
I mean the jordan form is not stable
Regardless of what arithmetic you use
Doing something like fixed point eliminates one source of perturbations
But doing something like 9*(1/9) in fixed point still wouldn't equal 1 would it
it would not
So that doesn't really help
In the fourth picture, shouldn't it say "quadratic convergence order", as $q=2$ whereas $\mu=f''(x^)/2f'(x^)$




Douglas

mu is the rate and depends on f'' and f'
but q is always 2 in the non-degenerate case
oh actually
hmmm
"q-convergence rate"
that seems like a weird way of phrasing things if q is the order
Newton’s method is a method for root finding. Modify Newton’s method in one
dimension as a method for finding minimum/minimizer of a function. Write down
such an algorithm and using the convergence theorem proved in class, state the
differentiability requirements on the function whose minimum/minimizer is being
sought.
someone please explain me this question.
What don't you understand
Where do minimums/maximums occur @dull coral
Hence what equation are you solving?
Input this into NR
What are the requirements for NR to converge?
Hence what are the requirements for this function that we are minimizing / maximizing
How do you explain the nature of unary and binary from a numerical analysis standpoint
It all boils down to how those numbers are stored and operated on within a computer. Lots of work already done on binary because that is how computers stored floats anyways
If I'm answering a problem and the problem boils down to "find m where m is the largest value s.t. m! < 0.9999*10^15" is stating "17! < max, 18! > max" sufficient?
I realized that i interpreted the question wrong
it's actually "find m where m is the largest value s.t. for 0 < k < m, k!(m-k)! < 0.9999*10^15"
nvm m! > k!(m-k!) for all k < m?
someone kill me
For 0 < k < m yes (binomial coefficients), though that doesn't seem too relevant to what you previously said
Nah I figured it out
Nice
hello, i would like to have some help
Result:
2

Assuming delta t = epsilon, and using milstein formula, the mark scheme is wrong

i just dont get it
why is there epsilon next to the 2nd term
Do you mean delta
sorry, delta yes
well, i got 1/4 ..... and then (....) - delta
how can delta go above the fraction
can it?
yes
What is your solution

<@&268886789983436800>
thanks
So recently I was looking into ways to approximate different numerical series. Like series that apply to natural numbers. And I derived this formula for approximating the factorial function (basically the gamma function):
where
b = floor(x)
d = x - b
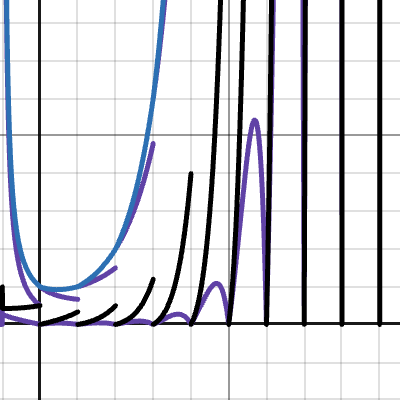
and this function does converge to x! for all real numbers as k grows to infinity. What i dont understand though is that if i replace b = floor(x) with c = ceiling(x) the function still converges to x! except much much quicker. And this is strange to me because I designed this formula with b = floor(x) without even thinking about ceiling(x) until much later. This also doesnt make sense to me because d is almost always negative. Anyways heres the graph of both and if anybody could help me that would be great.
Also heres the Desmos graph:



Mittag-Leffler functions are more than just obscure math—they’re a key tool in understanding fractional calculus and complex systems. In this video, we break down what they are, why they matter, and how they’re used in fields like physics and engineering. Explore the beauty and power of this fascinating mathematical function with us!
00:34 One-...
Ummmmmm
What is the role of k?
Isn't d just the fractional part? But when we change to c we are finding d=the negative fractional part
so perhaps the speed of convergence is due to the convexity, does have you tested a mix of values and their range of convergence?
(ie. when using c we are approaching the limit from below but when we are using b we are approaching the limit from above, which we would expect to have different rates of convergence)
As k approaches infinity the equation converges to x! for all real numbers
Yeah i have tried testing a lot of things https://www.desmos.com/calculator/setly6ocqm
Desmos
And i think i understand why they look different but i dont understand why ceil is much more exact
i may be able to get floor to look like that tho if i tweak it enough
Also this method does converge extremely quickly whith k values of 12 having an error of 0.001
is this the correct channel for a question about a problem from Finite Elements Method?
or more exactly the theory behind the problem
Yes
How are you calculating this error? As x get's larger we would also expect the error between $\Gamma(x)$ and your approximation to get bigger?
Max

Whenever studying something it's great to find your own way, but perhaps do some research on what other methods people have done and compare. It may be that actually this is quite slow. (Like newton raphson method converges quadratically so in 12 iterations we get a root that is roughly 4096 times as accurate as the first root...)
Also for error, doing some sort of integral might be better? Ie. $$\int_a^b\lvert \Gamma(x)-ApproxOfGamma(x)\rvert dx$$, where $a,b$ is the interval of interest.
Max

ok so, when we were solving the Poisson equation generally using 2D FEM with linear polynomials, we derived an element-wise computation formula for the local stiffness matrix components that doesnt really depend on the shape function since it uses the transformation to the standart triangle
Similarly when we were on the theory of L2-projection for 2D FEM using linear polynomials a formula was given to us for the local mass matrix components something of the sort $$\frac{|\tau|}{12}*
\begin{matrix}
2 & 1 & 1 \
1 & 2 & 1 \
1 & 1 & 2
\end{matrix}$$
Both of which are firmulas for triangulation mesh
(Im not familiar how the discord bot for TeXiT works so idk if that will render and im a newbie at using LaTeX as a whole)
My question is, why would those formulas not work for solving the wave equation (where its requried to compute both the mass and stiffness matrix) when both of them are independent on the shape functions but only on the type of the mesh (to be triangulation) and on the triangle you are in currently?
HelODeh

Ok wait this is really smart thanks for the help
however
one very strange thing i have noticed
Sorry it took a little bit to test this
but ive noticed that for large values being apporximated
like say the approximation of 216.513!
taking the approximation of like 1.513!
and then scaling it up ith 2.513 * 3.513 * 4.513... and so on until 216.513
there is actually less error in doing it that way then just straight up taking the approximation of 216.513!
which is really starange to me because i dont understand how that could happen unless the error for larger numbers was not proportional to theyre size

yes wait a min
n = a.shape[0]
for k in range(0, n - 1):
if a[k, k] == 0: # stop if pivot is zero
raise LinAlgError("Singular matrix")
for j in range(k + 1, n):
for i in range(k + 1, n):
m_ik = a[i, k] / a[k, k] # compute multipliers for current column
# a[i, k] = m_ik
a[i, j] = a[i, j] - m_ik * a[k, j] # apply transformation to remaining submatrix```so this is my implementation of lu decomp without pivoting. somehow it's not correct. i based my on above algo

this is step by step
my result is
[ 4 -4 -6]
[ 4 -2 -1]]```
which is the supposed U. but I can't do L at the same timeso this algo according to bhte book, you are not suppose to store L, or U, instead change U in place in A as upper triangluar including diagonal, L as lower traangluar portion of A, but not including diagonal as it's unit diagonal. so my result is correct in U, but that A[3, 2] should be 0.5 according the hand-calculation.
[ 4 -4 -6]
[ 4 0.5 -1]]
this is intended.
how to correct it?
oh I got it. np.array has dtype. if you do
a[i, k] = m_ik```
on a integer matrix, with m_ik = 0.5, numpy will make it 0. Just declare dtype=floathere is the iterations for newton raphson method. They are computing relative error in each iterations and i was wondering why is it that eps = (x(k+1)-x(k))/x(k)

my problem with this formula is that i think that the denominator should be the closest value to the real value which is x(k+1)

im like wondering how to compute both because my teacher isnt very clear
Here is an outline
coding it for me inst the issue i think its more connceputally
Well, do you understand gaussian elimination?
yes kind of essientially isnt the point of it getting it to row echelon form without any swaps or zeros
Do you understand how gaussian elimination helps us solve systems of linear equations
@wide spear you familiar with taylor series and how they help integrate differential equations?
i have a problem that states the following:
derive and explain the method of Taylor series for integrating a differential equation
y' = f(x,y) , y(x0) = y0
Then asks what is the main issue of using this method to integrate such equations
This is more appropriate for #odes-and-pdes
it involves ODE but its a numerical method that approximates the integral thats why i thought to ask here first but thanks ill try there as well
i mean not entirely
all ik is u get a answer but im really bad at thinking of things abetrially with math 18
linear algerbra *
is there any good textbooks or videos i can watch to learn this stuff
Any intro linear algebra textbook should cover this
Friedberg Insel Spence is what I used
I don't remember
Hi, how would you solve problems like this?

Numerically?
Yes
is there any good youtube videos on this stuff
im debating if its even possible to get a 60 % in this class
I didn't take good notes in the first couple lectures and I am worried because I can't find resources on our problems 😭
plot and visually pick an interval
my professor did not use a graphing calculator in class while solving this but i don't remember his approach
do you know a numerical approach?
test a few values and see where there sign of the functions changes. you can use newton's method to find the roots
my guess is that it intends you to evaluate at a bunch of points and note where the sign changes, then go "by IVT there is a solution here"
like on the first one, you have different signs for x=0 and x=1
which should tell you something
that's true, so [0, 1] would be a solution?
since f(0) < 0 < f(1)
yes, like cloud said above, ivt: https://en.wikipedia.org/wiki/Intermediate_value_theorem
on b you have 3 roots = 3 sign changes = 3 intervals
Why is discrete 1-d laplacian poorly conditioned
Like its supposed to be O(N^2) but i dont see it immediately, do I have to go thru what row reduction or is there a quciker way
Where N is 1/h
What is supposed to be O(N^2)?
it has a zero of order 2, since the spectral symbol is 4sin^2(t/2)
the smallest eigenvalue (dirichlet) is 4sin^2(pi/(2(n+1))) and the largest is 4sin^2(npi/(2(n+1)))
Matrix condition number
Are u supposed to get this with the greens function thing?
Im not exactly sure what a spectral symbol is sorry
spectral symbol describes the eigenvalue distribution. it will also describe haw fast the smallest eigenvalue goes to zero
Ok that sounds important
I would appreciate this thanks!
it is describe for example in here https://link.springer.com/book/10.1007/978-3-319-53679-8
Wow this is cool
);
I lost internet but I have mobile data
Does this book introduce spectral symbols too?
In class we are going to go over spectral methods in more depth
But that doesnt show up until page 300 of the textbook
yes and for the laplacian you have it for example in remark 10.2
it is a rather obscure concept for most people. but very powerful
Yeah it sounds obscure but it seems like it that would be a lot of information
Its just linear algebra though?
yes
Like spectral symbol is probably only relevant for those high dimensional operators
Yeah my book doesnt have anything about spectral symbol
it comes from operator theory, i use it for highly efficient and accurate eigenvalue computations
Imma see if trefethens book has it
probably not
Ok cool
if you look at any book about pseudospectra or structured matrices you will find it
Yeah I dont know if I am ready to formally learn operator theory as I havent taken a class on functional analysis yet
anyone doing FEM has experience with NGSolve? If I want to create a 3by3 squares (like tic tac toe) geometries in 2D do I have to create nice Rectangles? I feel like there is a easier way to do this?
I'm having a brainfart or something & can't figure out how/why Clenshaw summation works.
No, the efficient method for evaluating finite sums of functions satisfying 3-term recurrences.
It’s described in this paper if you can grasp it & somehow explain it to me: https://www.ams.org/journals/mcom/1955-09-051/S0025-5718-1955-0071856-0/S0025-5718-1955-0071856-0.pdf
Is there a specific part that you don't understand
The proof of why the method is correct. I guess I don't follow the penultimate line «Then application of the recurrence relation (6) shows that…» and the final equation.
Ok I would first try to understand why this works for just chebyshev polynomials as shown in equations 1-3
In particular, pick some A_n and compute the sum directly and using the reversed recurrence relation by hand
the way I do it is set the endpoints and draw lines between them
and then set an index inside and out to denote the boundary
there might be an easier way tho
I just tried that & must have miscalculated or something because the results didn't line up.
Well, let's see the calculation
$2\cdot T_0(x)+3\cdot T_1(x)+5\cdot T_2(x)+7\cdot T_3(x)$ was what I just tried.
Nadia

I actually did it on Microsoft whiteboard on my iPad Mini, so in principle, there should be some way to capture it.
Here:

I'll give it another shot.
I got it wrong again.
Angetenar

The reverse recurrence gives $B_4=B_3=0$, $B_2=A_2$, $B_1=A_1+(4x-2)B_2=A_1+(4x-2)A_2$, and $B_0=A_0-B_2+(4x-2)B_1=A_0-A_2+(4x-2)A_1+(4x-2)^2A_2$ right?
Angetenar

So in theory, $f(x)=B_0-(2x-1)B_1=A_0-A_2+(4x-2)A_1+(4x-2)^2A_2-(2x-1)A_1-(2x-1)(4x-2)A_2$
Angetenar

And using $2x-1=\cos\theta$ and grouping like terms, this becomes $A_0+A_1\cos\theta+A_2(2\cos^2\theta-1)$
Angetenar

Which is correct
I'm getting wrong answers repeating this in Maxima.
Do you understand the computation I did at least
Yes, something is going seriously awry in my hand calculations.
Hopefully you figure that out
Now as to the intuition as to why this works
As we perform the reverse recursion down to n=0, we use the recurrence relation that defines the T_n right
So like if we look at the A2 part
We start with A2, then (4x-2)A2, then (4x-2)^2A2-A2
Which recursively builds up T2
Still unsure why it's not working.

There is the maxima file.
I don't know maxima
What's done there is trivial enough that it shouldn't be an issue.
I think the only issue might be the expansions of FA vs FB
I'm not sure what you mean.
The Chebyshev polynomials are shifted i.e. $T^*_n(x)=T_n(2x-1)$.
Nadia

The updated maxima file:
Is it correct?
The two match now. The problem was that the example in Clenshaw's paper used the recurrence coefficients for $T^*_n(x)=T_n(2x-1)$ and I was using the recurrence coefficients for $T_n(x)$. When I used a consistent set of recurrence coefficients for a consistent orthogonal polynomial basis it all worked.
Nadia

Ok nice
Did the example I worked by hand help to provide some intuition about why clenshaw works?
I should probably do a similar exercise instead of using a concrete orthogonal polynomial basis.
Sure
But doing some calculations by hand should provide some insight into why it works
I think there should be an orthogonal polynomial product formula like $\phi_{m}(x) \phi_{n}(x)=\sum_{k=0}^{mn}\alpha_{k}\phi_k(x)$ out there somewhere but am not finding generalisations of what I see for e.g. Chebyshev polynomials.
Nadia

If you want to come up with one for Chebyshev polynomials then use: $T_n(\cos \theta)=\cos(n\theta)$
Max

I think the result you are looking for follows pretty quickly when you use product of sum, ie.

I have the one for Chebyshev polynomials and am hoping for a more general version for orthogonal polynomials.
I doubt it exists
I'm willing to take restrictions on the class of orthogonal polynomials.
Things in general are really tricky, Chebyshev polynomials have some super nice identities and follow nice rules, generalizing them to even really nice and well known orthogonal polynomials such as Laguerre polynomials is usually unfruitful
Yeah I'm not aware of any such product formulas even for the Legendre polynomials
I think Legendre have them.
Maybe it's Sturm-Liouville eigenfunctions, maybe it's some kind of umbral calculus. It's tougher to use the things as a basis without being able to take products.
I'm not sure I agree
I very rarely need to multiply elements of a basis
Unless I'm taking an inner product of two functions in which case I don't want to explicitly multiply them either
For my purposes I do need multiplication.
What are you trying to do?
These guys are representing probability densities with splines that are in plain monomial form, so the alternative strategy I'm thinking about is being able to represent the splines' polynomial pieces in a basis that facilitates taking expectations using the modelled density.
One of the tasks they do is computing a centile histogram.
By splines you mean a bunch of polynomials of degree n on intervals with some continuity/differentiability condition at the endpoints right
If you're working with splines, sort of the natural basis to work with are the Bernstein polynomials
I can't actually tell how they're computing the spline to represent the probability density. I might be missing how their code is getting invoked because it's mostly the centile histogram root-finding.
Not M-splines?
Well now it depends on what types of splines are being used
(Basically B-splines renormalised to integrate to 1.)
Spline is very overloaded
Anyways are chebyshev polynomials not satisfactory for some reason
Maybe ignoring the orthogonal polynomials for a moment, they're trying to do Descartes' rule of signs or Vincent's and need to do $(cx+d)^{\deg p}p\left(\frac{ax+b}{cx+d}\right)$ efficiently somehow. Or at minimum a translation $p(x+a)$.
Nadia

Quantile histograms for distributions with densities given by splines, basically.
Is direct evaluation too slow?
I'm not sure if it's a performance hot path or anything, but they (and I) seem to be adrift from much grounding in literature/theory/etc.
Still looking around for more quantile algorithms for distributions whose densities are represented by splines.
I'm pretty sure that their spline density functions are empirically determined but I have no idea how, so there's some weirdness about dynamically updating the quantile histograms as new samples are acquired.
Schumaker (2007) has Chebyshev splines and gives Budan-Fourier theorems for polynomials in the Chebyshev basis.
Hi is there anyone familiar with nonlinear parabolic pde?
This can't be right. Somehow 1D Newton with bracketing interval & fallback to bisection has nowhere obvious to look it up.
What do you mean look it up
When I look up Newton's method I don't see more stuff about how it's plugged into frameworks to stay within bracketing intervals, detect multiple root issues etc.
I mean you can find an implementation of newton's method and see how they do it
But there's really not that much to it
aren’t multiple roots just handled by sampling lots of initial conditions
I believe that Newton deals with n-fold roots by an integer factor in the denominator of the update.
(I´m not sure if this questions goes here or in the cs channel!)
Hey! I have a doubt about some methods we have been using for proving some elementary bounds in a introductory numerical analysis class.
For example, we made bounds for the relative error of calculating a^3b with a, b numbers of the machine that were like 3\eps + O(\eps^2); in the proof we use constantly that x* = x(1 + \delta) (being x* the rounding of x as a number of the machine), and we use it operation by operation, i.e:
a^3b => ( ((a^2)* a)* b )* = ( ((a^2)(1 + \delta_1) a)* b )* = ( ((a^3(1 + \delta_1)(1 + \delta_2) b )* = a^3b(1 + \delta_1)(1 + \delta_2)(1 + \delta_3)
And for this we get the bound, knowing that |\delta_i| \leq \eps.
It was said in the class that one could "replace the operation in the machine with the real operation times a factor (1 + \delta)" with every normal operation except with substracting, and that this was related to the known catastrophic cancellation that happens when you substract similar numbers.
I get that with catastrophic cancellation in mind you have the fact that there is no good bound for substracting numbers in a machine, but I do not get how to precisely formalize the idea that if you want to multiply, sum or divide machine numbers you have a good bound (and you can operate like before) but with the substracting you can´t.
Any advice or resource would be helpful.
Have you seen the proof of the sterbenz lemma
No, thx for mentioning it. It seems useful for the doubts I have.
guys, anyone knows if there exists an efficient way to compute the full QR decomposition?
more specifically, if there exists clever way to obtain an orthogonal basis of Nu(A^T)
the reason for my question is because you can always obtain an orthogonal basis for the orthogonal complement of a single vector using house holder transformations
There exist efficient QR algorithms, yes
$Rx= e_1 \Rightarrow R^2x = Re_1 \Rightarrow x = Re_1$
jeca tatu

where R is the householder reflection matrix
One method is indeed based on householder reflections
and because R is orthogonal and R_1 = x, then all the other columns form a basis for the orthogonal complement of x
ok, but the full QR requires obtaining a basis for Nu(A^T) right?
I dont know if theres a clever way to do that without much effort
How efficient of an algorithm do you want
something like to obtain an orthogonal basis for span{v1,...,vk} and get the complement for almost free
I dont know if thats possible
Practically speaking, all QR decomposition algorithms will be O(n^3) unless your matrix is structured in some way
hmm
I just find curious how you can obtain the orth. complement of a single vector in a easy way
and I suspect that this trick could work for a collection of more vectors
What does easy mean to you
I dont know, really
I just wanna know if it is at least something that can be visualized by some operations after performing householder to the set
Ill try to investigate it a little bit more
in the case of 1 vector the result is trivially by construction of the reflection of the first vector always to a multiple of e1
but for the subsequent operations you kinda look to the submatrices and things gets more complicated

pls help <@&286206848099549185>
what is the best introductory book on numerical analysis (preferably at the graduate level) that is a good mix of theory and application?
Are you looking for numerical linear algebra or numerical differential equations or numerical optimization or something else
honestly a bit of everything, nla, diff eq, integration differentiation, rootfinding, polynomial interpolation
if you have multiple book reccs I wouldn't mind
There is an introductory textbook to numerical analysis, Burden and Faires, but I would say that it is at the undergraduate level
For grad level books, they are generally specialized into one of the specific areas that I mentioned
E.g. Demmel for numerical linear algebra and Iserles for numerical differential equations
okay thanks, I'll check them out
Does anyone know a good introductory text on the Diffuse element method / Diffuse Approximation ?
this seems to be the first hit and mostly cited https://link.springer.com/article/10.1007/BF00364252 any reason to use this? (probably pretty obscure method?)
sounds a bit like RBF:s?
RBFs + moving least squares it seems to me
I am trying to find a robust way of computing the principal curvatures and principal directions of a smooth manifold defined as an SDF
So I am trying to find robust numerical ways of getting the partial derivatives
This is the original paper. But papers are usually much harder to understand, I was hopping for a textbook chapter or course notes. Those tend to be much more digestible.
Alternatively the paper i am currently reading suggests using lagange differentiation
no idea, never heard of this before
fair enough, thank you for the help still
What techniques have you tried and deemed unsuitable?
regular finite differences (centered)
it's too unstable
too sensitive to the h parameter (the spacing)
Hmmm did you try regular finite element
Or a voronoi method
Or a triangularization/spline based method
iga
I read your messages, are you trying to find real roots of a polynomial? I have an implementation on my GitHub which uses continued fractions if you need, it’s in TypeScript
It doesn’t have arbitrary precision or exact arithmetic though but you can just makes some changes if you need numerical stability
I went down a super deep rabbit hole on this too
I don't have a mesh so direct FEM won;t work. I am actually tring to triangluate the isosurface with a new method, so any method that relies on a mesh is redundant.
What is a voronoi mehtod? That is new to me? Can you offer an exmaple/resource?
Generate a voronoi triangulation of your surface, then use that triangulation to do things
How do you generate a voronoi triangulation of an implicit?
In what form is the SDF given to you?
Is it a function that you can evaluate wherever you want?
Yes, it;s a funciton pointer
so just some f(x,y,z)
that returns a scalar
arXiv.org
Volumetric shape representations have become ubiquitous in multi-view reconstruction tasks. They often build on regular voxel grids as discrete representations of 3D shape functions, such as SDF or radiance fields, either as the full shape model or as sampled instantiations of continuous representations, as with neural networks. Despite their pr...
Bit of a long shot, but does anyone know how compute peak indexing for a sample that exhibits multiple bravais lattice structures in GSAS-II (or any other refinement software)
Let $-\pi \leq \theta \leq \pi$. The sequence $S_n = { sin(\theta)}$. This is an example of a bounded sequence but not a Cauchy Sequence?
Ashp116

The sequence $S_n = { 1/xsin(x)}$ is a Cauchy Sequence? If so, it is not monotonic right?
Ashp116

Question In this document, section 2.2 talks about a technique called lagrange differentiation. I have not heard about this concept before (although it seems to come from a generalization of lagrange polynomials to higher dimensions).
I was hoping someone here would have so pointers to other resources. The mentioned paragraph doesn;t seem to have a reference to anything.
lagrange interpolation and then take derivatives of those
I don't think it is quite that. If you look at the coefficients. There is no parameter. It entirely yields constants.
So at minimum it has to be evaluating the parameters somehow.
It's also multiplying multiple basis together.
What about the paragraph is unclear
This is not directly a lagrange polynomial. It is similar, but note how the numerator does not have a difference, it's just a constant. (Similar to the others)
And then look at the application of the polynomials. There is no paramater, the direct derivative of a lagrange polynomial would have a parameter. So at most this is taking the derivative of a LP and then evaluating its derivative at a fixed parameter


that's the only way I can think of where you would get a constant
Not sure, I am tempted to say it is x=0 because then it would explain why the numberator is only the constants
however nrmally LPs start at 0 on the first knot
which is not what's happening here
that's why I am confused
Are you confusing Lagrange polynomials with splines
no
Lagrange interpolation does not have any parameters
?
https://en.wikipedia.org/wiki/Lagrange_polynomial
Any interpolation will have a parameter, because your input set you are interpolating over is just a point set

In numerical analysis, the Lagrange interpolating polynomial is the unique polynomial of lowest degree that interpolates a given set of data.
Given a data set of coordinate pairs
(
x
j
,
y
j
...
to get in betweens you need to blend them
for that you need a parameter

No, you weight the basis according to the values at the interpolation points and add them
Which one of those is a parameter
The xi are the interpolation points
Ok that’s not how we use the term parameter
That's how it was used in the classes I took
parametric curves are called parametric curves because they take a parameter
Ok whatever
the parameter being the free variable that allows you to interpolate
So the reason why I am confused with the text is precisely because that free variable/parameter is missing
so it should have been evaluated somehwere
If I understand the text correctly, that is over a stencil with a fixed grid spacing delta x
but the text doesn;t say to what
It gives the derivative values the grid points
Yes, but if you were to evaluate any of the lagrange basis polynomials at a given grid point, you would have a difference in the numerator

so that $b_{ik}$ should instead be something like $b_{ik} - b_{im}$
Makogan

like if oyu just grab the definition of a lagrange basis polynomial and evaluate it to a given point in space you get differences in the numerator
Yes, the b_ik are differences
After 10c, for example, it says that b_i1=-delta x, bi2=0, and bi3=delta x
Yes, but that's only for the specific example given. I assume that you can express them as relative offsets from the pint at which you are taking hte derivative
does anyone know that if i have
minimize $_\beta \vert \vert A \beta - y \vert \vert^2$
Jonathan

and A is a compex matrix
if the solution is:
$\beta = (A^A)^{-1}A^ y$
where A^* is the conjugate transpose matrix of A ?
Jonathan

Yes
$\frac{dP(r)}{dr} = -\frac{G}{r^2}\left[\rho(r) + \frac{P(r)}{c^2}\right] \left[M(r) + 4\pi r^3 \frac{P(r)}{c^2}\right] \left[1 - \frac{2GM(r)}{r c^2}\right]^{-1},$
Farm

Hello, I'm trying to solve the Tolman–Oppenheimer–Volkoff equation for modeling a neutron star using a polytropic equation of state of the form
What numerical method is recommended for integrating these equations? I've heard that Runge-Kutta methods are commonly used, but I'm not sure how to deal with the stiffness that might arise in the equations, especially near the center.
Sorry if this isn't the correct channel, but it is one of the most active.
-using a polytropic equation of state of the form
$P = K \rho^{\gamma},$
Farm

Have you tried anything yet
If you haven't, start with RK4
If you have stiffness issues, then come back and we can discuss more
I started with addressing the singularity at $r = 0$, then I tried to derive a Taylor series expansion for $M (r) and P (r) near R = 0$ and used the approximations for a small, non-zero radius. But really that's all.
I eventually added a standard fourth-order Runge-Kutta method to integrate the TOV equations. However, I've encountered some problems in the results that suggest there might be errors introduced when I used the method.
Farm

Hmmmm
What happens if instead of integrating from 0 to r_1 you integrate from eps to r_1
Prescribing an initial condition for P(eps)
What problems are there in the results?
I'm trying to figure out how to get the orientation of a face-transitive polyhedron given a rotation matrix. Specifically, I'm thinking dice (beyond just 6-sided). If I label each face in some starting orientation and calculate normals for each face, I could rotate the normals once the polyhedron itself is rotated and find one which is pointing roughly "up", but that gets to be a lot of work as the number of faces increases. Is there some other method I'm missing?