#linear-algebra
2 messages · Page 275 of 1
ooh ok i kind of get that logic but the first one and second one already has x term and a constant if you get me?
@thorn yacht why did you delete it?
Nvm my question: figured it out.
we haven't learnt orthogonal vectors yet? whats that?
lol I was in the middle of reading
u^T v =0 -> u and v orthogonal
Ah, sorry, I was just confused about some notation for the double dual vector space
You probably have something about an orthogonal complement of a subspace in your textbook
i just checked the notes n didnt see it in chapter 10 we only on 6

havent done any of that yet
You can think of it as 2 vectors spanning a plane through the origin, and the orthogonal complement being a vector perpendicular to the plane
basically when you have Ax = 0
Then if the rows of A are linearly independent, they can be thought as basis vectors
And the solutions x lie in the orthogonal complement to those
That is if a row is a R^n vectors
okk slow down lol sorry so here is that what i did initially with the matrix stuff?
And you have m linearly independent rows
Then you need to find n-m linearly independent vectors orthogonal to the m
And they will dpan you the orthogonal complement
let m<n
look at the polynomial x, its outside of the span of p1 and p2 because you cannot reach it using a linear combination.
so you need to include p3 = x in your basis for P3
same goes for the polynomial p4 = 1
when you include it you will have their span as well and can construct any polynomial in P3
Then your system is underdetermined and you can write the general solution in terms of n-m unknowns
Plug in something for those unknowns, that's how you get the first vector
Then add it as a row to A, ribse and repeat
Until you find all n-m basis vectors of the orthogonal complement
The plug in something part means you have freedom of choice btw
Is there any method to do this one except taking specific vectors?

lol uno i dont think ive learnt half the stuff uve mentioned here
You've learned how to solve linear systems?
The above is just an interpretation of where the solutions of Ax = 0 lie
Pick a simple example
in 3d
(1,2,3), (1,1,0)
These two vectors span a plane, and any point of the plane can be written as
p(s,t) = s * (1,2,3) + t * (1,1,0)
Now say you want to find an orthogonal vector to this plane
Then you need a vector v which is orthogonal to both basis vectors
That is (1,2,3) dot v = 0, (1,1,0) dot v = 0
waitt why are u doing this? the multiplying and coordinates?
it's just a parametric definition of a plane
To give you some intuition
You can think of 1d spaces as lines through the origin
2d spaces as planes through the origin
oh havent done that yet
well the idea is, if you have Ax = 0, and the rows of A are linearly independent, then they form a basis
Any solution of the above lies in the orthogonal complement of the spaces spanned by that basis
So if A is made of 2 3d vectors
Then this basis spans a plane through the origin
And the solution space being the orthogonal complement means that the basis vector for it is perpendicular to this plane
In you problem they essentially ask you to complete the basis, you can do so by finding a basis gor the orthogonal complement
So having a set of vectors a1,...,am
You can find a set of vectors b1,...,b_{n-m}
wait look this is the only stuff ive learnt so far it dont talk about any of that

Such that ai^T bj = 0, and bk^T bl = 0
The last guarantees that the b are linearly independent
The former guarantees that they are also linearly independent wrt the as
Then it's the right time to learn it
Because your problem is essentially asking for that
although it is possible to solve it purely algorithmically, it's probably not a good idea to skip over the understanding
But the purely algorithmic version is what I mentioned: Ax =0 -> find 1 solution, add the solution vector as a new row in the matrix, rinse and repeat
What this process does is it finds a new orthogonal vector to the previous ones at each step
So at the first step it finds an orthogonal vector b1 to all rows of A, and thus it cannot be linearly dependent
dot here means times right
Then add b1 as a last row to A to get A1, now A1 x = 0 -> find solution b2 -> it is orthogonal to all rows of A -> cannot be linearly dependent,add it as a last row to A1 to get A2
$(1,2,3)\cdot v = 1v_1 + 2v_2 + 3v_3$
Matrix-vector multiplication can be written as the dot products of the rows with the vector
criver

And the meaning of dot(u,v) =0 is that u and v are orthogonal, so u and v cannot be linearly dependent if both of those are non-zero
In geometric terms u and v are perpendicular
I am guessing the problem is meant to prepare you for whst's to come,as in make you think about the above
Or it could be just a problem that's there just for the sake of there being problems in the book 💩
Anyways you know the algorithm now, and I hope you got at least an idea of what thd meaning behind ssid algorithm is
yeah it kind of makes a little bit of sense now- Thank you so much for everything!!

MIT RES.18-009 Learn Differential Equations: Up Close with Gilbert Strang and Cleve Moler, Fall 2015
View the complete course: http://ocw.mit.edu/RES-18-009F15
Instructor: Gilbert Strang
Vectors are a basis for a subspace if their combinations span the whole subspace and are independent: no basis vector is a combination of the others. Dimension...
Thank you- ill have a look at it 🙂
Only 13 minutes
and ok yes i watched it and that makes sense so thanks again!
Ah yeah I see
anyone?
not really, because they are asking you which properties are true. you can spot the false ones by coming up with specific counter examples and plugging them in, but to show which ones are true, you need to show it holds for all vectors and all n
I can give you one hint to work on, calculate T^2
also you can write V as $Rv \oplus v^{\perp}$ if that helps

I highly recommend this too: https://www.engineering.iastate.edu/~julied/classes/CE570/Notes/strangpaper.pdf
it's a fairly short read, but it should give you some motivation regarding what the course you're studying is about
okk yeah thanks- ill read it in a bit
okay
Any good advice on doing proofs :)
I understand the questions that involve computing something
But i can't for the love of me understand proofs
Or like come up with them
try going through some exercises in: Linear Algebra Problem Book by Halmos
he has detailed answers at the end
it takes practice I guess
there are books that are focused on proofs too so maybe that would help
my other advice is to pick several books up on linear algebra and see the different proofs
Hello guys, I am a newbie in linear algebra. Can you please give me some advice on what I should focus on or how I should think of linear algebra?
Any ideas?

First assume that beta is nonzero.
Huh?
The second row has to be beta times the first.
Is this because we are assume we have only one linearly independent vector
so the other is a linear combination of the first
Yes, it is an explicit assumption that the rank of the matrix is 1, unless I'm misreading the image.
Yo, what should I use to solve this?

My first guess is gaussian elimination but I'm not 100% sure
that will work fine
you seem to have more variables than equations though, so keep in mind how this might affect your solution
yeah, i don't remember exact question, i didn't copy it to my paper and now i try to figure it out for a retake xd
it was probably something like "for what w something something"

det(A) = dot(r1, cross(r2,r3))
where ri is the ith row of A and it is a 3x3 matrix
It's the part r11 * (r22 * r33 - r23 * r32)
alr thx g
if the determinant of a matrix is non-zero, why is it that the matrix is linearly independent?
i've been taught that it's just a fact and i am not too sure why that is
one does not speak of a matrix being linearly independent
a set of vectors may be linearly independent or not
a set of vectors yes
one must not confuse a set of vectors and a matrix assembled from said set of vectors
but anyway, this all has to do with the myriad different ways to say "this matrix is invertible" in linear algebra which are all equivalent to one another
you might consider reading up on the formula for the inverse of a matrix that involves determinants
and in particular the formula contains 1/det(A)
which hints at matrices only being invertible when their determinants are invertible
would this be a seperate property from the "a set of vectors is considered linearly independent if only the trivial solution exists"?
hmmm
nvm i will go read those
there are multiple things wrong with this
oh no
first is painting linear independence as a matter of consideration
and then the whole "trivial solution" thing needs a lot of added details to make it make sense
Ax = 0 only if x = 0 there you go
then you have to say that A is a matrix with your vectors as columns
Equivalent to the orthogonal complement of the space spanned by the row vectors being {0}

yea idk my teacher does not use Ax = b form
The above is Ax=b form expanded
Whether you use
Matrix notation or the above is the same
so is this solvable with REF? we have not gone over determinant properties
idk what ref is
reduced elechon form
You'll just get sone denominator there too, so yes
But the easiest is to just compute the determinant
what we usually do in class is get the bottom row to all equal 0 and then if its unique solution then the equation does not equal 0 like you said
but i cannot seem to get reduced elechon form without crazy fractions
The point in the above is to make the last row non-zero
just use det!= 0
It's easier
Any hints

Take u from R^n, decompose in u = u_parallel + u_perp
Then negate u_parallel
u_parallel = k * v, k = dot(u,v), u_perp = u - u_parallel
u' = u_perp - u_parallel = u - 2 * dot(u,v) * v
What does it mean to say v1, v2, and v3 are linearly independent
It means that c1 * v1 + c2 * v2 + c3 * v3 = 0 only for (c1,c2,c3) = 0
assume this were not the case, and without loss of generality let c1!= 0
Then c2 * v2 + c3 * v3 = -c1 * v1
And thus v1 = -c2/c1 * v2 - c3/c1 * v3
But this means that v1 is linearly dependent with v2, v3
More precisely it lies in the plane spanned by v2,v3
At coordinates -c2/c1, -c3/c1
Wow. Thank you!
MIT RES.18-009 Learn Differential Equations: Up Close with Gilbert Strang and Cleve Moler, Fall 2015
View the complete course: http://ocw.mit.edu/RES-18-009F15
Instructor: Gilbert Strang
Vectors are a basis for a subspace if their combinations span the whole subspace and are independent: no basis vector is a combination of the others. Dimension...
I fixed a minus sign that I missed
To understand the practical importance of this maybe I should mention a corollary. If you have a vector u in the span of v1, v2, v3 and they are linearly independent, then there's a unique set of coordinates (c1,c2,c3) such that u = c1 * v1 + c2 * v2 + c3 * v3. If they were linearly dependent then there could be infinitely many coefficients representing the same vector. This may be undesirable in practice, e.g. when you want a unique representation. It could also be desirable to have many different representation of the same vector, e.g. if some data has noise, then instead of a basis you get an overcomplete basis/frame.
I was just speaking to someone and they kept using the term eigenvector to mean basis vector
This person has been working in the field for a really long time so they must understand something I don’t
Is there a relationship between eigenvectors and basis vectors I don’t see?
A basis consisting of eigenvectors (an eigenbasis) is very useful to have if it exists; that's a basis that diagonalizes the matrix (or map) you're looking at.
for homogeneous linear systems
the system can only have one solution (the zero vector) or infinitely many solutions
is there any other case?
if your base field is R or C, then no.

The answer to this is to consider vector spaces over non-algebraically closed fields, right?
yes, you are in the right direction
well then that's it
so what's the example you came up with
I can't think of a nice example tbh, other than constructing artifical examples
i.e. examples where the characteristic polynomial factors, say in the real numbers, as x^mQ(x) where Q(x) is a product of irreducible quadratics
I'm thinking maybe in R^3 define a plane A. If x not in A send it to 0. If x is in A, rotate it in A (with a non trivial angle)
I think that's nicer
well you would define that on the basis. Two vectors on the basis define that plane, the third is sent to zero
Guys can anyone tell me where people discuss about 8th maths
uhm idk tbh
(responding to ryu sama)
there is a two dimensional space such that T^2=-I, so T^2 acts as some kind of reflection
idk
probably #prealg-and-algebra
Oh thx lemme check
what about rotations?
no
say rotation of π/2 radians


that's a rotation
so not nilpotent
so far you both said rotate + project
haha lol I thought it was something more misterious. Because I did say about rotations on a subspace and sending to zero on another subspace
ryu's char poly is the result of a block diagonal matrix of rotations and projections
I'm not good at coming up with specific examples anyway
admittedly only for R^3, but it generalizes

so you want some power of x and a product of irreducible quadratics
sounds about right
haha no the thought process was fun
yes that should be a general construction
btw
ok I'm giving away my example
i think you need the rotated coordinates not to be projected
so maybe the rotations and projections need to be able to commute
at least pairwise?
when solving polynomial equations we talk about field extensions and so on. What is the analog concept to vector spaces?

what's dmat 0
$\m{0 && \ && -1 \ & 1 & }$

yeah
right
diagonal matrix with first entry 0
this is the same as $\Pi \circ R = R \circ \Pi$
19eddy4

yes
To determine this kind of maps we need just worry about 2 dimensional spaces when they are over R
yes
but I think its not just rotations

xd what
wym not just rotation?
oh
I mean that the action of the linear operator on these 2 dimensional subspaces is not always a rotation
I'm thinking, but idk
because the characteristic polynomial of rotations is x^2-2cost x+1=0, and there are many other forms for irreducible polynomials
true
(cost -x)^2+sin^2 t=0 ?
yeah ok
derp moment
you can try and see if you can rewrite other polys in this form
is it just dilations with rotations?
We would need a+b and ab to be able to take arbitrary independent values. And the condition that the polynomial is irreducible is given by cos^2(t)(a+b)^2<4ab, which can always be satisfied taking arbitrary values for t
I think that's the case, yeah
well not exactly, because a or b could be negative, but we disallow that possibility. I think that's the argument
Is addition of two non zero vectors consididered linear cobination
yes
What would a Proof of thatlook like
this isnt an assignment
This is just for my own knowing
Let c1,c2...,ck be a scalar
Let v1,v2,.. vk be a vector
the vector in r^n
??
what are you asking again?
"let v, w be two nonzero vectors. is v + w a linear combination of v and w?"
Oh im stupid
and the answer is yes, obviously it is. it's 1v + 1w
Why is the addition of vectors called a linear combination?
a linear combination of v and w looks like this: av + bw
(where a and b are scalars)
would that be a linear combination
sure, the sum is a linear combination of your two matrices
the concept of 'linear combination' makes sense in any vector space
Thats exactly how 3Blue1Brown defined it
because that's the definition

no
Can someone help me see where my fault in understanding is so I can work on it more?
your fault seems to be "a+b is a linear combination of a and b therefore any time i see 'linear combination of <blah>' im supposed to just add them"
probably u didn't understand the question
you are supposed to write $\bmqty{-9\4}$ as a linear combination of $\bmqty{1\-3}, \bmqty{3\1}$ and $\bmqty{-1\2}$
Ann

no!
.
accordingly, a linear combination of more than one vector, or matrix, or whatever, looks like that same sum, except that each term has a scalar coefficient attached to it
does that mean just multiple
no
im having trouble seeing the conection
it's not "JUST ADD" or "JUST MULTIPLY" stop trying to reduce it to JUST something if you keep trying to do that youll NEVER stop being confused
idk how else to tell you this
just some random vectors?
in Rn
nothing to do with your problem?
yes
and where did i claim "V+B is not a linear combination of V and B"?
are you sure you're not putting words in my mouth rn
You did not
I am just asking to understanding
so you are putting words in my mouth rn?
"How is V + B not a linear combination"
as if someone said it was not
I was under the impression that it needs a scalar to multiply to be a vector addition
Where do I learn about Lp spaces?
I don't think Axler, for example, will go over them
usually functional analysis
Im sorry if i offended you
Hey just quick test, If matrix A is symmetric then eigen vector of A is orthogonal?
Only if eigenvalues are distinct?
if the eigen values are distinct then eigen vectors are orthogonal
not the other way around
Okay
Unitary diagonalizable is true for normal matrix right and symmetry matrix are normal but here we are getting eigen vectors which are not orthogonal then how can we unitary diagonalize?
how are you getting eigen vectors that are not orthogonal?
That’s the question, and you just told that it is not true for all symmetric matrix?
I didn't say if the eigen values are same then the eigen vectors can't be orthogonal
for example take M = I_2 then (0,1) and (1,0) are EV with ev 1 and they are orthogonal
(1,0) and (1,2) are also EV with ev =1 but they are not orthogonal
they're asking about symmetric matrices, ryu
I2 is symmetric

If suppose A is symmetric and all the eigen vectors are not orthogonal then how we proceed for unitary diagonalizable?
Is there exist such matrix?
if A is symmetric, you will always find a orthogonal basis
they are orthogonal if corresponding eigen values are different
if ev is the same then you look at the null(A-aI) and find a orthogonal basis of this
The answer to the first part of this question is "Yes. Since Col A is a five-dimensional subspace of R5, it coincides with R5.". But we only have four pivot columns, meaning four linearly independent vectors in R5. Hence they aren't a basis in R5 and can't span R5 fully?

Then unitary daigonalization is true for any diagonalizable matrix? Due to gram schmith
noo, diagonalizable does not mean it's unitarily diagonalizable,, you are mixing up things
if A is symmetric then A is unitarily diagonalizable,
Normal matrix are
yes normal matrices are
for example take the projection onto x axis along (1,1) then it's diagonalizable but not unitarily diagonalizable
Look, we are make U just picking the ev of matirx A if ev are not orthogonal then how we proceed that’s the dout
For A=UDU*
Gram Schmith gives you an orthogonal/orthonormal basis of a vector space, that's different from finding an orthogonal basis consisting of eigenvectors which you need to diagonalize a matrix
So if they are not orthogonal then?
because in general case D = P^{-1}AP, if how ever A is happened to be normal, your P is orthonormal (can be made into one)
in that case P^{-1}AP=P*AP
You said that, if they are not orthogonal then how we change that vectors in orthogonal and why we can’t do that this process apply for any matrix?
i think you may hv mis interpreted my words
as you see eigen vectors are not unique
for example if v is an eigen vector then so is cv (c≠0)
And $P=[ev_1 ev_2 … ev_n] $ if p is unitary then $ev_i$ are orthogonal
BLツ

then v and cv is clearly not orthogonal as <v, cv> = c |v|²
Yes it is true
all I said was if you don't mention the eigen values are distinct then you can't say eigen vectors are orthogonal, it doesn't however mean that you can't find eigen vector corresponding to same eigen values which are orthogonal for example the I_2 matrix
Alright got it
If GM>1 then we can always find orthogonal vectors for normal matrix right
now ask again what your doubt it
yes
My doubt is if AM>1 since it is normal so AM =GM, so if we are not able to find all eigen vectors that’s are orthogonal so we need to construct others?
your matrix is normal then why won't you be able to find orthonormal eigen basis?
if the matrix is normal then you will always be able to find orthonormal basis wrt which the matrix is diagonal, that's the complex spectral theorem
just bumping my noob question :^)
Maybe a simple question, but if we want to prove something for inner products of $\langle x, x\rangle > 0$ and $\langle y, y \rangle < 0$, why can we assume that $\langle x, x\rangle = 1$ and $\langle y, y\rangle = -1$ "due to scaling"?
n/c

because the inner product is a bilinear form
Can you elaborate?
hence you can always find some scalar a to make it 1 for a* <x,x> and and pull it into the the product
to get new vectors
that make it 1 or -1
i think at least
there is a mistake in what n/c wrote though
inner products are positive definite
<y,y> = -1 cannot be an inner product
Not if we replace the axiom of positivity with <x,x> = 0 iff x = 0
hmm?
wait i forgot about it being positive definite lol
you often deal with dot products that are not positive definite
But anyway that's not the point of my question
not sure if you use different terminology in english 
(also note that positive definite doesnt make sense in general fields)
the one i often see is positive semidefiniteness, at least
this still excludes getting negative values
uuh
but either way if its bilinear
and we wanna prove something about the product itself
and not about the vector in the product
we can scale it
So basically, we can define $\langle x,x \rangle = 1$ because $\langle x,x \rangle = \frac{\langle a, a\rangle}{|\langle a,a \rangle|}$..? Or something?
pretty much, you could multiply the inner product result by some scalar so that the result is normalized
n/c

and this results in another inner product
i mean you're not really defining it but you can assume it without loss of generality in your proof
Sorry that's what I meant yes
are you working with indefinite inner product spaces?
What are indefinite product spaces?
The exercise was just about changing one of the axioms to what I listed above
inner product spaces where indefinite and semi definite inner products are used, kinda generalizations of inner product spaces
because in usual inner product spaces you do need positive definiteness
I don't know what that means sorry
The axioms I'm working with for an inner product is (x,y) = (y,x), (x, y + z) = (x,y) + (x,z), (cx,y) = c(x,y), (x,x) > 0 for nonzero x, and (x,y) = (y,x)* (hermitian symmetry)
I know
But there was a particular exercise in this chapter which told us to change (x,x) > 0 to (x,x) = 0 iff x = 0
that's the same as positive definiteness
What is this word, definiteness?
exactly what you're writing
<x,x> = 0 if and only if x = 0
that's the definition
and <x,x> >= 0, and equality is only achieved if x = 0
the result is always positive, unless x = 0
hello, i hope i'm posting this in the correct topic.
What exactly am i doing here?

ok that's a long question
hmm maybe not
for the first case, A is diagonalizable means the char eq has 2 distinct root or it's the constant multiple of the identity.
the char eq is given by x^2-(a+d)x+(ad-bc) so it'll have distinct root if (a+d)^2-4(ad-bc) > 0 ( not < 0 as that will give complex roots which we don't want)
and if B^2-4AC = 0 then it means both roots are equal, so it has to be constant multiple of the identity, which means b=c=0 and a=d
follow similar method for ii
@quaint escarp
might take a while for me to understand lol
Thank you for your input 🙂

me=
[-10 0 \ 0 10] = 

Looking for help on my logic here
https://i.imgur.com/H3PBbXv.png
I have this transformation and this A and I want to prove that if A != zero matrix then Dim(Im(T_A)) = 2
my idea here is that no matter what matrix A is, you can find an X s.t AX=XA that is also non-zero, which means X is in Ker T_A, so Ker T_a has a dimension of 1 meaning Im(T_A) has a dimension of 2(since the overall dimension is 3 and DimKer + DimIm = DimV)
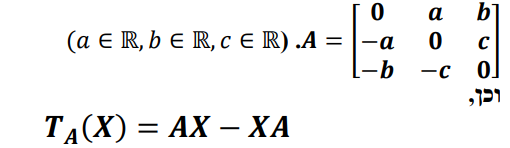
am I wrong here? X would be the antisymmetrical matrix with a,b,c=1
I can give you a different approach to this
try to find the kernel of the transformation and use first isomorphism theorem
see that kernel of T_A is the vs of all matrices that commute with A
be back in a sec
I know there are different approaches, but I'm wondering if mine is correct because I wrote this down in the test.
FFS, hope no one saw
🙂

😉

Hey for |U1-v|² what should i do there ?
I think they asked me to calculate thr firt two to use it there
solve (u1-v, u1-v) using inner product axioms
can you tell me what you think of my solution?
your idea is similar to what I just said
problem is "there is an X s.t. AX=XA" doesn't mean that kerT has dim 1
has at least 1?
and also your V is M_3x3(R) here not R^3 so dimV = 9 not 3
is that the issue?
dim is atleast 1 yes but not =1

would I need to prove that? 🤔
that's a known fact, but if you are not sure then you can try to prove it
ok so X is skew symm matrix and A is given
I wrote X explicitly
you need the find the dim of the matrices that commutes with A
you wrote A=[] not X=[]
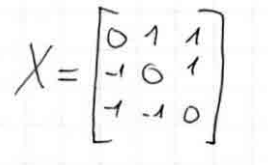
that's just one X
like
you need to find for all X
well the kernel is all AX-XA=0
ok tell me this, is A = [] what have you written with a,b,c is correct?
so AX=XA
you surely confused me, so
yes and what is A?
A is antisymmetrical
any?
ok so you don't even know what A is then how are you supposed to calc the dim?
like A could be zero giving you rank = 0
you need to fix A
no no the A is non-zero
that is part of the question details
A is non-zero, prove dim(T_A)=2

now it is known that dimV=3 as we're shown
and so we need to find AX=XA
so X= what I wrote will always give me that
huh
^
the transformation is defined : T_A(X) = AX - XA
so T_A(X)= 0 => AX=XA
that's the kernel
so we only know A is non zero anti symmetric matrix
the better approach for this will be to see where A sends the basis then
since all vector fields have 0 it doesn't change the dimension
wait, please ryu sama, I'm trying to understand if my solution was correct because I want to appeal...
I got 0 points
(for the question)
no, you can't just say the dimension is atleast one so dim is 1
you have to show dim is actually 1
well it's exactly 1 because that's the only solution...
but I wrote it in general..
then you are literally skipping 5-10 steps of showing that's the only solution
and also you can't assert that there is one X s.t. AX=XA
AX=XA, A is non-zero anti-symmetrical, X is non-zero anti-symmetrical
clearly this X is the only linearly independent solution here right?
it's like proof by assumption, assume it's true the it's true
yeah, I guess.
no it's not clear in any way, you have to show it
there's no loose ends in mathematics
I should've written that the only solution is X or X^T as I wrote it, but they're linearly dependent by definition(multiple of -1 of each other)
fk.
I guess it does deserve 0 points?
heck if you know there's even a non zero X s.t. AX=XA
yes
like it's not even trivial to me and you are taking an exam
like if you really want a solution, I can guide u to one, but yeah your argument is not valid
which problem are you talking about

@earnest dock here's an short argument, AX-XA has trace 0 always, so it cuts down one degree of freedom giving you 2
so where are you stuck exactly? the instructions are crystal clear
No like should i do u1-v and then the ||² or is there a fromule i should follow
thanks.
like yeah
Given a polynomial, how does one find the companion matrix?. My proffesor just gave the campanion matrix without explanantion
that's how

thanks
So there is no way to go from the polynomial to the matrix form without?
Without already knowing the polynomial form.
?
So assume that you dont know the matrix A, how do you determine A given a polynomial?
Well, what is give there is that you already know the form of A and then you prove by induction that A is the companion matrix op de polynomial P. (I understand that totally).
But let's assume that you don't know how A looked like, how would you then come up to that?


well, I think you don't understand what I really mean. So let me explain once more. Say $p_A = t^n + a_{n-1}t^{n-1} +.....+a-O$. How would you find the companion matrix A?
Croq

if u never knew that A is this
if it's still not clear to you by now, you just reverse the construction
given this
this is the companion matrix
Yes, I know that the reverse-order construction works (but just considering uniqueness)
I guess I am good, thanks though!
what uniqueness? companion matrix is unique
I have been saying "assume". So act like you don't know A, how should A look like if $det(A-t*I) = p_A$
Croq

But I am good, thxx!
if you want a "general A" then will be PSP^{-1} where S is matrix I showed before
but that is no longer called the "companion matrix" because companion matrix have a specific form, which looks like this and this only
yess I agree, but how could you know it only looks like that if you didn't know how it looks like?

Just a quick question:
Is the matrix of a linear map f in the basis B the same as the matrix of the linear map f in the pair of basis (B, B)?
Yes but only if the linear map is an operator
operator, as in codomain = domain?
yes exactly
If you talk generally about a linear map f, then the basis in the domain and codomain are different
I meant codomain=domain from the beginning, sorry for poorly formulating the question
thanks
no worries, you are welcome
So, I figured I have to calulate $| xx^T-yy^T |_2$, but I'm not sure how

Sydd

Something like $\sup_{v \in S^1} | x^T v x - y^T v y |$ felt like the way but I just got stuck
Sydd

what's the def of dist(S1, S2)?
Is this formula of computational interest or nah?

I know there is another formula, but it involves a lot of determinants
nah
distance between orthogonal projections onto subspace
no that's what I'm asking how are they defining the dist because to me it feels like it should be zero
because 0 is a common element
every subspace S has an unique orthogonal projection, so the way you define dist between subspace is by setting it to be dist between the projections
for a one dimensional subspace like span{x} the projection is xx^T
hey quick question, does this mean that a can be equal to any value when the rank of the matrix is = 3?

It's definitely not the case that the rank is 3 when a = 0, at least.
are you sure that this is what you are supposed to do?
ant hint?


Rank is increasing
so...
If somehow we can get its jc form then we can find gm of 0
rank(A^2)<rank(A^3) is literally impossible no matter what A is, lol
if it was > you can try to find a possible jcf
Yes
Lets consider this
look at the principal component of x
if B is the submatrix then B⁴=0 but B³=B⁴= 0 means that max size of jordan 0 block is 3
since B² ≠0 gives min size =3
can you construct the jordan form of B now?
Ok,I will try
don't worry about other eigen values
I have no idea about this ( component. From)
dont worry about it
just think as if you are working with a matrix with char poly x^4
rest you can ignore
(it comes from the principle decomposition theorem)
This is only possible if matrix is a nilpotent matrix
All disgonal entries zero
But how you get here , i have doubt
Here our matrix is of order 9
Wait
And B is of order 4
since x^3 = 0 and x^2 neq 0 this means that B has a jordan block of size 3 with ev 0
So number of block in jc is gm of that eigenvalue ,so 0 has gm =3
since 4-3=1 then there's only 1 other jordan block of size 1
no 0 has gm 2
why do you think gm=3?
First thing is ,how you get this?
primary decomposition
(A-kI)^n cannot be singular unless k is an eigen value
you can write $V$ as $V = \mbb{R}[x]/(x^4)\oplus \mbb{R}[x] / ( (x-1)^2) \oplus \mbb{R} / ((x-2)^3)$

in other words V has a generalized eigen basis
only the generalized eigen vectors corresponding to eigen value 0 can contribute in reducing the rank of A^k
So here i have to focus on x^4 because we want to find gm of 0?
This is something new for me
Nop

ok so don't know if there's an easy way to say this
but say you have any jcf of that matrix
than any jordan block where the eigen value is not zero cannot have rank A^2 < rank A
so the jordan blocks with ev 1 or 2 will never loose rank as you raise the power
only block that will loose rank is the jordan blocks with ev 0
this is very easy to check as say $A = J_2(a) = \m{a & 1 \ 0 & a}$ then $A^2 = \m{a^2 & 2a \ 0 & a^2}$ and $A^3 = \m{a^3 & 3a^2 \ 0 & a^3}$

This something interesting, is this applicable to any matrix?
well yes, if all eigen values of A are non zero then A^n always has full rank
A^n can loose rank if 0 is an eigen value (with am > 2)
i can make this statement more precise but nah
Thanyou @zinc timber , i think i should leave this question.
for an easy proof, say A^k has rank < rank A means A^k has 0 as an eigen value but all eigen values of A^k are of the form a^k where a is ev of a. so a^k=0 means a=0 so 0 is an eigen value of A
your main question is still unanswered, were you able to solve it?
Its ok @zinc timber , i will try it myself with my little knowledge
First i think i should read primary decomposition
that's nothing ground breaking really
it's kinda similar to ax+by=1 if (a,b) = 1 from number theory
I must show $| xx^T-yy^T |_2=\sqrt{1-(x^Ty)^2}$ somehow
Sydd

you can try just expanding the terms first
you could also separate consider the case where x and y are lin dep and lin indep
expand in what sense? like $x=(x_1,x_2), y=(y_1,y_2)$?
Sydd

i meant expanding the two norm you have there
you can rewrite that as a sum of scaled rank 1 matrices
and then do a change of basis onto an orthonormal one
the expression you have there is a diagonalized matrix of rank at most 2, and this is related to the definition of the 2 norm of a matrix
I was thinking of a different approach but the calculation seems long so I'm dropping it
the 2norm of that operator is the largest eigen values as it's symmetric, say we know the angle between x and y then we can project any unit vector in the plane of x, y onto the vectors then they'll have magnitude cos(theta) and cos(theta+phi)
i think the term in the square root is pretty much gonna be the result of doing gram schmidt
then we have to maximize the sum of their mag using basic calx
cuz then you get a matrix diagonalized on an orthogonal basis, and the largest singular value is just the 2 norm of one of the basis vectors
this might actually work
just a hunch to be fair, but since it's only rank 2, it should be fairly straightforward to do it this way
and you can still consider the rank 1 and rank 2 cases separately, doing the rank 1 one as a sanity check
(at a glance, yes, the rank 1 case checks out)
or you can do it ryu's way
i just immediately go "dat SVD" whenever i see a sum of rank 1 matrices
no mine is complicated
I have tried
unless someone points out a better way to calculate eigen values of xx'-yy'
yeah that feels like a good gut feeling to have
gonna try these approaches in a bit
but thanks already, it's so nice to have these ideas thrown around here, it helps a lot!
In and Out

@wind anvil please check #prealg-and-algebra
Let $P$ be the vector space of all real polynomials. Why is $(f,g) = f(1)g(1)$ not an inner product of $P$?
n/c

Because $f(1)g(1) = g(1)f(1) = (g,f)$, $(f,g+h) = f(1)[g(1) + h(1) = f(1)g(1) + f(1)h(1) = (f+g,f+h), (cf,g) = (cf)(1)g(1) = cf(1)g(1) = c(f,g)$
n/c

n/c

this
are you sure?
Hahahah I'm so dumb.
thaaaaanks
can i get a hint on part 2, it seems really simple and im missing something basic

Hi, this is a statement that got me confused. "Let vectors u and v be in R^n, vector b be in R^m, and A be an m x n matrix. If there exist scalars c and d such that c(A times vector u) + d(A time vector v) = vector b, then vector b is in the span of the columns of A, but is not necessarily in Span(u, v)." I have to answer either true or false, but I just don't know how to approach it. I first thought that any vector that is in Span(u,v) must be in R^n. If n and m are not equal, b is not in R^n, and therefore, not in the span of {u,v}. Would the above statement be true then? Thanks
triangle inequality
|u| = |u -v + v|
cool, thanks
hey all is this a prediction or inference problem? determining which variables are relevant for predicting an output variable
i got it wrong and id be curious to hear ur thoughts
Anyone have a good resource on duals? Only thing I’ve had on it was in axlers LA

he guys, does anyone know how to approach this problem?
for b)
this is the answer

@tired fossil You just need three polynomials which are linearly independent and of degree 0, 1 and 2
So you're given a list of polynomials, you should check if there are any redundancies
Or, if you can show that some combination of them are linearly independent, and span P_2, then that shows it is a basis too
so, if they span P_2 and are independent, it is okay?
@tired fossil That's the definition of a finite basis
First row is x + kz = 0 and last row is -kx + 2y + 3kz = 0. Then {kx + k^2z = 0} + {-kx + 2y + 3kz = 0} gives us 0 + 2y + (k^2 + 3k)z = 0
Then -2 * (y - z) = -2y + 2z = 0, and that with the new last row gives us 0x + 0y + (k^2 + 3k + 2)z = 0
are there any good video lectures about linear algebra on youtube? do you guys have any recommendations?
MIT lecture series by gilbert strang
Thanks
how would i describe this in geometrical terms?

like what do 'geometrical terms' even mean?
like a geometric figure
i recommend you do a couple of low dimensional examples and see if you can find the pattern
try R, R^2, R^3
for these cases, you can easily substitute the 2-norm of a difference of vectors for a simple algebraic expression
i guess im a bit lost about what the general form even looks like, do u have any resources on this?
we didnt learn this
@wintry steppe If I gave you the set {x in R : | |x - x_0 | | ≤ 1}
What is this set, given some random x_0?
a hyperplane right?
What is a hyperplane?
you already took geometry
its a subspace where the dimension is one less than n
do you recognize the shape x^2 + y^2 = r^2?
yea circle
ok
now expand the expression you have for a generic pair of vectors x and x0 in R^2
do you know what the || || stands for?
Euclidean length right
/ norm
we're in R^2
well i guess hypersphere is fine if you mean a 1-sphere here
BUT
they don't say = 1
it's <= 1
so it's a disk or a 2-ball
ah ok so ur saying since its not = 1 we cant say its a hypersphere
right
ball
the sphere is only the boundary
hmm?
closed ball? it this not what op is asking?
ok awesome tysm
what shape are matrices typically used to represent?
linear subspaces
that's a nice shape
this was the last one i was confused on and its bc ive never seen a matrix in a 'geometrical context' so i didnt know how to describe it

its this one^^
just this Describe the following sets in geometrical terms.
intersection of flats is a new term to me 
and then lists the four sub problems to solve which two were confusing
the first one i posted
and this one
i didn't know that, nice
Is axlers treatment of duals good enough for a first class in diff geo
Asking cause that’s all I know
Isn't $P^2=P$ and $| P | > 1$ a contradiction? Cuz if $v$ is an eigenvector of $P$ with $\lambda$ as eigenvalue then $P^2v=Pv \implies \lambda^2 v=\lambda v \implies \lambda \pm 1$, so we'd have $| P |=1$. Where am I wrong here??

Sydd

Let $V$ be a vector space over finite-dimensional $\mathbb{K}$ and $U \subset V$ be a subspace of $V$.
For $g \in (V/U)^{}$ define $Ig \in V^$ such that $(Ig)(v) := g(v+U)$ for all $v \in V$. The linear transformation $I: (V/U)^* \to V^$ is referred to as inflation. Show that $\operatorname{im}(I) = U^\perp$, where $U^\perp \subset V:= {f \in V^ \mid f(u) =0) \text{ for all } u \in U$
lewis

(Note that V* is the dual space and V/U a vector space V by a subspace U (quotient space))



<@&286206848099549185> I'd be glad if anyone could help me
Can someone explain how unitary dilation works? Like how I could embed an operator $V(t) = e^{-iAt} \in C^{n \times n}$ (where A is antihermitian) into another unitary operator $U(t) \in C^{2n \times 2n}$
AdamF

Sorry if I phrased it wrong, but I've never heard of this
maybe also ask in #advanced-analysis . Looks like unitary dilation is an operator theory concept
how does part b really work?

i believe our professor just used b = <0 0 0>, however that makes nearly no sense to me
right but we don't have specified values for b
You can express the solution in terms of b.
If b = 0 then the problem is not very interesting. A is invertible so x would be zero.
i dont think we're supposed to use gaussian elimination on the problem though
it was discussed today
guess i just dont understand what the problem wants
Maybe solve it in a more ad-hoc manner? The first row tells you that x3 = x2 - b1, and the third row tells you that x1 = (x2 - b3)/2. Substituting these into the second row allows you to solve for x2.

It would be helpful if I can get help on this problem. "Let vectors u and v be in R^n, vector b be in R^m, and A be an m x n matrix. If there exist scalars c and d such that c(A times vector u) + d(A time vector v) = vector b, then vector b is in the span of the columns of A, but is not necessarily in Span(u, v)." I have to answer either true or false, but I just don't know how to approach it. I first thought that any vector that is in Span(u,v) must be in R^n. If n and m are not equal, b is not in R^n, and therefore, not in the span of {u,v}. Would the above statement be true then? Thanks
So I know how to solve echelon form and all that, but I have a homework problem asking me to determine if a vector represented by a matrix is in the span of S. Im not sure how I should interpret this problem, I put the components of each vector in S on a corresponding row and solved, but I dont know how this implies if it is or isnt in Sp(S)

From the looks of it you just need to determine if this system is consistent $\x_1+ 2x_2 -2x_3 = -9 \2x_1 -x_2 + x_3 = 12 \ 2x_1 + x_2 + x_3 = 8 \ x_1 + 3x_2 + x_3 = 1$.
Plegasus

ah, that makes sense
not sure if this would go in linear algebra, but can someone explain to me why
$(\vec{b}-\vec{a})^2 = |\vec{a}|^2 - 2|\vec{a}||\vec{b}| + |\vec{b}|^2$
Leon

when we square something is that the same as taking the dot product of itself
I'm very confused on how all this dot produce cross product thing works
I find the $- 2|\vec{a}||\vec{b}|$ especially confusing
Leon

Do you mean |b-a|^2?
whoops
I think
I asked the wrong question
okay
what I meant to be asking is
how does the cosine law work with vectors?
I don't believe what you wrote is true
yeah my bad
the law of cosines with vectors? could be stated as (a dot b) = |a| |b| cos theta
I'm confused to how you arrive at that
a bit of rearrangement yields |b-a|^2 = |a|^2 + |b|^2 - 2 |a||b| cos theta
I think I just took bad notes
okay yeah I see now
I think it's because I wrote (a-b)^2 = |a|^2 + |b|^2 - 2ab cos theta
the a-b should be |a-b| and the ab should be |a||b|

{kind=link}
{kind=link}
{kind=link}
wrong channel but
it has to do with inverses if im not mistaken
it is because -1/4 (the slope) is negative reciprocal to 4. Thus, 4 is the slope of the perpendicular line
not 100% sure but the reasoning is that when you graph the functions, its something to do with how slope works
and then eventually they'll intercept on a point which the lines are perpendicular to each other
Define $T \in \mathcal{L}\left(\mathbf{F}^{n}\right)$ by
$$
T\left(x_{1}, x_{2}, x_{3}, \ldots, x_{n}\right)=\left(x_{1}, 2 x_{2}, 3 x_{3}, \ldots, n x_{n}\right)
$$
(b) Find all invariant subspaces of $T$.
for this question I've found a proof online but there are some parts that I don't understand
jinichi


someone pls help me walkthrough to this proof
this is from sheldon axler, linear algebra done right book
check what happens to the basis e_i
OK So I have started linear alegbra and so far it doesnt seem too bad.
But proffessor is making us come on campus to take exam and we only have an hour to do it.
She also of course wont be grading to solve the aug matrix's using ref rref etc.
My issue is what do you guys do in this situation where you need to calculator the matrix fast to get your variables?
Is there a faster process then just multiple/reducing rows to add or subtract to other rows?
not by hand, no
okayyyy
it's an algorithm that you'll implement later, so it's good to know how it works but no, you won't be calculating solutions by hand with it in the higher level
<@&286206848099549185> any insights??
yes, all projectors have norm at most 1
Prove that the column space of AB is contained in the column space of A. What
happens with B=transpose(A)?
I know that AB has column space contained in column space of A. Since it can be written as the linear combination of columns of A. But how to prove that column space of AA' = column space of A?
same way
column space of AB = ABx, x\in V. take Bx=y
associate the products from the right
I can't find an elegant argument for the second one but you can try to show C(AA') \subseteq C(A) and dim(N(AA')) = dim(N(A) and conclude they are same
maybe edd has something better
the what
like a better argument to why C(AA') = C(A)
can't you just rewrite the product as linear combinations of the columns of A and gather the coefficients?
can you elaborate, it's not obvious to me
We have a matrix A given and do the lu-decomposition with column pivoting. We try to get the PA = LU structure, where P is a permutationmatrix.
I only show the last part of the solution.

P3 = I btw.
Is the form (P2 L1 P2) always a triangular matrix?
I guess this is always the trick to insert Permutationmatrixes here, since two same permutationsmatrices multiplicated equal unit matrix.
Question. I have an exercise in which I have a 3x3 symmetrical matrix A and it asked me to make A=LDU'=LDL^T and then based on that result to find an R matrix in order to make A=R^TR. How do I use the answer the matrixes L and D to find the R? I hope I make sense
you can get a square root of a diagonal matrix by square rooting the diagonal and so $$A = L\sqrt{D} \sqrt{D} L^T = L\sqrt{D} \sqrt{D}^T L^T= L\sqrt{D} (L\sqrt{D})^T = R^TR$$ here I've defined $R=(L\sqrt{D})^T$
Merosity

idk I might be making a mistake, I don't know if the eigenvalues are all positive, just that they're real uhh is it positive definite I'm a bit rusty I'm realizing
well I will try that out. The A matrix is positive definite
oh ok then you're fine then
positive definite => positive eigenvalues so sqrt(D) as I've defined it works fine
thanks!
yeah, you're welcome 👍
why is beta_hat = arg min_beta RSS(Beta)
ya, I was thinking if we show that both have the same null space then by rank nullity theorem we can say they also have the same column space
but then again, how to prove they have the same null space?
hint: $\norm{Av}^2 = \ip{Av, Av} = \ip{AA^*v, v} = 0$

@zealous flame

im a bit confused on this thing
{kind=link}

so my work for part one is correct i think
{kind=link}

but i dont understand how to explain the second part
what is RSS again?
residual sum of squares
im not even quite sure what the arg min is :/
there seem to be weird issues with what you posted
since the first equation isn't a function of beta hat
at least to me, the notation makes no sense
i thought so too but then when i expanded it, it seemed to work out
all right after drinking some water i finally realized that beta_hat is the true solution, not the estimate
kinda weird
your arithmetic for the first part is correct
there's still some mistake in the notation they used, they mixed up beta and beta_hat somewhere
beta_hat being the result of the minimization depends on the rank of X
this overall looks poorly formulated
anyway, to answer your question, argmin_beta means that you look for the argument or parameter beta for which some function of beta is minimized
hmm
i guess my question is
im not quite sure how to get that :/
/ how to find it
that's a convex problem, you can minimize it by simply finding a point where the gradient is 0
well in it, it justs asks why beta hat is the arg min, so it gives us the solution and just asks to explain