#linear-algebra
2 messages · Page 252 of 1

we actually extend the concept of basis to the 0dim space
so in some way it is correct,
is this an appropriate restatement of cayley hamilton: the characteristic polynomial of a matrix A annihilates said matrix
Gotcha, thanks for the help!
ig
i mean wikipedia has every square matrix over a commutative ring (such as the real or complex field) satisfies its own characteristic equation.
now idk what a commutative ring is (yet) but it sounds at least close to interchangeable
im just tryna find my own wording so it's easier to grasp

shriller44


Mathematics Stack Exchange
In my math lectures, we talked about the Gram-Determinant where a matrix times its transpose are multiplied together.
Is $A A^\mathrm T$ something special for any matrix $A$?
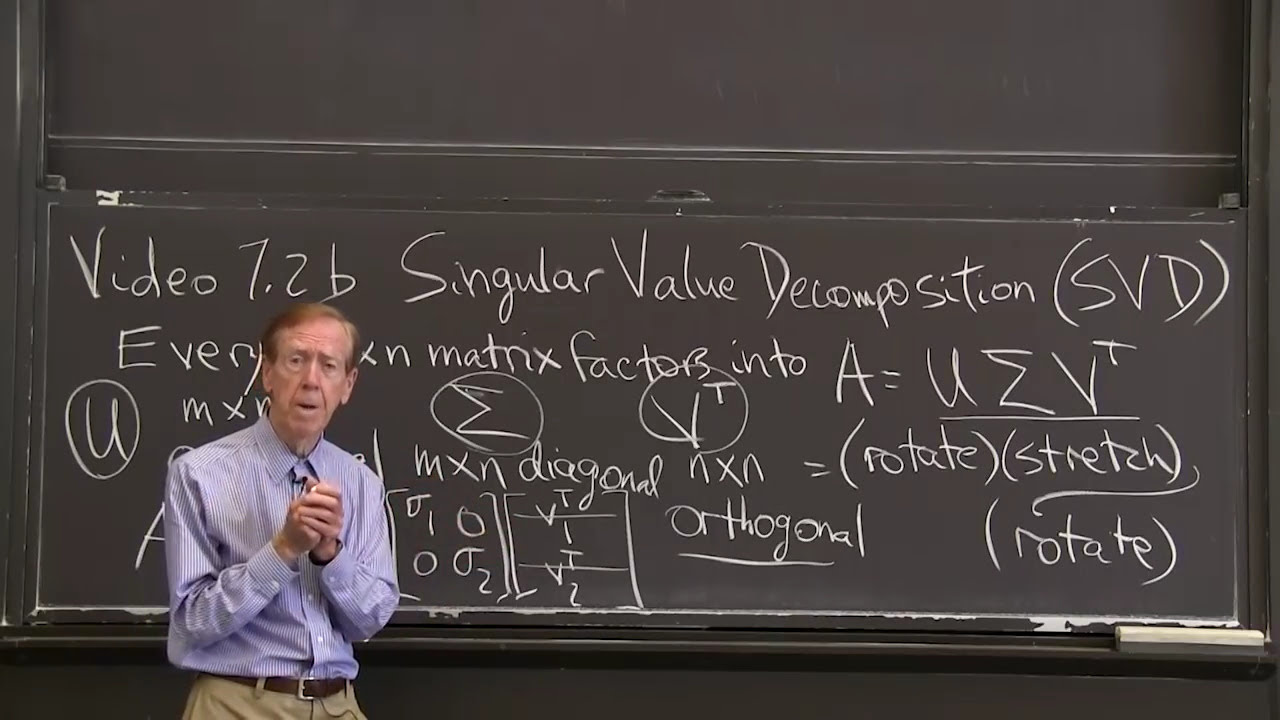
MIT RES.18-009 Learn Differential Equations: Up Close with Gilbert Strang and Cleve Moler, Fall 2015
View the complete course: http://ocw.mit.edu/RES-18-009F15
Instructor: Gilbert Strang
The SVD factors each matrix into an orthogonal matrix times a diagonal matrix (the singular value) times another orthogonal matrix: rotation times stretch tim...
AA^T and A^TA are symmetric, and therefore diagonalizable
so yeah the idea is just getting the same orthogonal matrices
as in same sense as eigenvalue decomp before this was mentioned
just that that eigenvalues and vectors are taken as squared to get singular values
wait nah S^2 and U/U^T is the eigenvalues n vectors of AA^T
but we are interested in singular values of course
presumably theres more than this just method to do SVD but yeah its calm
B is a 5 × 5 matrix with minimal polynomial (x - 1)(x − 2)^2
is it possible to determine the characteristic polynomial of B from this info
it's over complexes btw
No
there are a limited number of possibilities though right
it could be anything of the following
\begin{align*}
(x-1)(x-2)^4 \
(x-1)^2(x-2)^3 \
(x-1)^3(x-2)^2
\end{align*}
Ryuzaki

alright cool that's what i thought, just double checking :)
now if a 5x5 matrix has minimal polynomial x^3, then that must mean that the characteristic is x^5 right...?
bc the only eigen value would be 0

well if it's min polynomial is x^3 can't it have two possible JCFs
either two blocks of single 0's or a block w two 0's and a 1
ok then there's something wrong in my understanding can you elaborate pls
an eigen value of algebraic multiplicity m and geometric multiplicity k means there are k-1 blocks of 1x1 and one large jordan block of size m-k+1
let's take a simple example
say min = x² and chr = x³ then
$A=\mqty[ 0&0&0\0&0&1\0&0&0]$
Ryuzaki

do you agree?
yes
recognize the 1x1 and 2x2 blocks
yeah there is a 3x3 jordan block as you might have deduced
but remember that in the 3x3 block there are only 2 ones
number of ones = size of block - 1
so you get 3-1=2 ones, giving you rank 2
i'm gonna have to learn this stuff at some point
but what are you calling rank here
rank of the entire matrix given min poly = x³ and char poly = x⁵
context was different here
aight
hmmm
i did not deduce this, why is there a 3x3
does the min polynomial kinda tell us what the largest block can be
^^that could be very wrong
what do you think the blocks should be
2x2 and 1x1
no together with the chr poly it tells the exact size
ig you can find the max block size but not the exact size
@still lodge no no I was talking about the x⁵ and x³ case
ohhhhhh ok yeah i was gonna say
u did deduce right?
yeah
ok then number of 1's = ?
but if you have the 3x3 block in the 5x5 matrix, couldnt the remaining slot(s) be a 2x2 or 2 1x1s?
and if you have a 2x2 block you have another 1
yeah but min poly discards the 2x2 block
why
ok this was still helpful ty <3
there will be 2x2 block giving rank 3
you were right
whole time I was thinking it's x²
Can someone help me w this one
Question: Determine the pairs (a, b) ∈ R × R such that the system
respectively
(a) has no solution
(b) has a unique solution,
(c) has several solutions.
Show how you arrive at these conditions.


I found this but I don't know what to do now
can you tell me what is the condition for unique solution
(a,b) element R x R that?
no not that
the one involving the ranks of the augmented matrix
ok if you don't remember it then say our unknowns were x,y,z then the last row gives us
the question above that's the only thing we got
1 and -1?
0?
0=-2
so you see how you are supposed to derive the conditions?
but where did you get the (1-b²)z=-(a+2) from
the last column of your matrix
(b) has a unique solution then a can't be -2 and 2 / b can't be -1 and 1 right
for (c) has several solutions: b=1/-1 and a=-2
(a) has no solution if a is not -2
is this correct
for unique solution, it doesn't matter what a is, all you need to care about is 1-b² is not 0
Then a can be everything
yeah
How can I say that symbolic is that a element R
Oké thanks a lot
your other conclusions are also wrong tho
Yeah?
(1-b^2)a=-(a+b) or b is 1 and -1
see
infinite solution means that the last equation is degenerate. like 0=0. which values of a and b give you 0=0?
that should be the condition for infinitely many solutions
it just means you get no additional information from the 3rd equation
b = 1 or -1 you get 0 and a = -2 or am I dumb
yeah
Yeah bcs I’m dumb or yeah that is correct
correct, lol
Then why is it wrong you said
bcz that's not what u hv written here
Ah oké Ty and is this correct
no solution if u get some kind of contradiction like 0= 1
b=±1 but a≠2 gives 0 = some non zero number
which is impossible
Then a can be everything but can’t be -2
ya
a ∈R / {-2} ?
maybe i have a quetion later but i'm ok for now thank you for your time
hi i have a few questions
The matrix A and (B^-1)(A)(B) then they have the same set of eigenvalues for every invertible matrix B <- This is true correct?
If 2 is an eigenvalue of A, then A-2I is not invertible. (I believe this is true as well)
If two matrices have the same set of eigenvalues, then they are similar (True? Not sure)
I found out that this is true if you let the vector space to be $\brc{f\in C^\infty([-\pi,\pi]):f(-\pi)=f(\pi)}$
Whoever

what's the difference between elementary divisors and invariant factors
ive found the the characteristic polynomial of a 2x2 matrix A is x^2 - tr(A)x+det(A), and that for a 3x3 matric A, we have x^3 -tr(A)x^2 -det(A)
Is there a similar way to find the coefficient of the linear term of the characteristic equation of the cubic or is it not possible
Yup, you can!
You write it in terms of the exterior powers of your matrix.
More specifically.
Let $A$ be an $n \times n$ matrix over a field $\mathbb{K}$ and denote $p_{A}(x) \in \mathbb{K}[x]$ its characteristic polynomial, then:
$$
p_{A}(x) = \sum\limits_{k=0}^{n} x^{n-k} (-1)^{k} \text{tr} \left(\bigwedge^{k} A \right)
$$
MISTERSYSTEM

This is a consequence of something called the newton identities, which relates elementary symmetric polynomials and power sum symmetric polynomials.
This can also be derived by embeding your matrix into the splitting field of the characteristic polynomial and using something called vieta's formula.
You can do this because the minimal and characteristic polynomials are invariant wrt field extensions.
Mathematics Stack Exchange
Let $T$ be an endomorphism of a finite-dimensional vector space $V$. Let $$f(x)=x^n+c_1x^{n-1}+ \dots + c_n$$ be the characteristic polynomial of $T$. It is well known that $c_m=(-1)^m\text{tr}(\bi...
Mathematics Stack Exchange
Looking at wiki, I want to
$p_A (t) = \sum_{k=0}^n t^{n-k} (-1)^k \operatorname{tr}(\Lambda^k A) $
where ${\displaystyle \operatorname {tr} (\Lambda ^{k}A)={\frac {1}{k!}}{\begin{vmatrix}\operatorn...
I found these two stack exchange threads which might give a more in depth explanation.
so I just need to learn how to compute the exterior powers of a 3x3 matrix and then I will be able to write the characteristic polynomial just by looking at it nearly?
Yeah
You actually just need the trace of the exterior powers tho
If the characteristic of your field is 0
there's an explicit formula
which relies on computing a certain determinant
but idk if it is worth it
I think it would be nice to just go straight to the characteristic polynomial without the typical steps of det(A - lambda*I) personally
There's an ''intrinsic way'' to define the characteristic polynomial of a given linear operator on a finite dimensional vector space without going into determinant stuff.
Axler presents this in a short ''paper'' entitled ''down with determinants''
which motivated him to write his book ''linear algebra done right''
but like
Computing characteristic polynomials like that is just...
why would you do that
The determinant is a tool made for computation
so like, if you really need to calculate something explicitly, go for it.
i found it
hi does det(-A) == det(A)
i like his opening two paragraphs already
No
for instance
take the 2x2 identity matrix
the determinant of - I_2 is 1
ahh ic
what is true tho
is that det(A) = c^n det(A) where n is the size of the matrix, i.e A is an n x n matrix.
so that det(-A) = (-1)^n det(A)
If 𝑞(𝐴)=0, then 𝑞 is divisible by the minimal polynomial of 𝐴
why isnt this named lmao
this feels really important
@/MISTERSYSTEM ive done some problems since we last discussed this stuff and i think ive gotten better :)
it's not named because it's basically the definition of the minimal polynomial
Yeah, TTerra is right lol
Remember how I said F[x] is a PID for F a field and we define the minimal polynomial of a matrix A as the monic polynomial that generates the ideal
Ann(A) = {f \in F[x] : f(A) = 0 } ?
That's the idea nitez

Nice
monic!!!!!!!!!!!!!!!!!!!!!!!!!!
yeahhh i havent taken abstract alg yet so i only have a loose idea of what a field even is
but our original discussion prompted me to at least make note of it to look into over winter break
i feel better about not knowing what a field is bc 8 year old terance tau didn’t either 🥲
terrence 2pi
sorry to nag but
nada?
for #1, im having trouble to find two matrices that dont satisfy closed under addition / multiplication


what is that tool you are using?
the scalar mult part is also easy. take an identity matrix of size 2n+1 x 2n+1 and multiply it by -1
it's octave 😛
interesting, is it some sort of computational tool for math?
oh cool
for the purpose of this problem, one counter example for a property would suffice right?
for the purpose of any problem in which they ask if something is true, one counter example is enough to say it isn't
gotcha
and for the 2nd problem, we should show each set is a subset of the other right?
So something like let s in Span(S). then s is a linear combination of each of the elements in S
should be enough to show that the elements in S are linearly independent
then mention the dimension of P3(R)
each of the elements in S have x^3 in it
hm i guess i should expand it out firsrt
to show the elements in S are linearly independent, i would need to show theres a non-trivial linear combination that equals the 0 vector
oh whoops i got the definitions mixed up
thats for dependant
Is anyone using the latest calculator from Texas Instruments which is the Texas Instruments C version? The one with the python programming that was released in the fall? If so, does it support Linear Algebra?

My teacher meant "noncolinear" instead of "nonparallel" right?
Oh wait no he didn't if they were parallel it would become some sort of line equation
Wait,,, don't they mean the same thing with 2 vectors?
Ugh
What does noncolinear mean for 2 vectors? If you seem them as points, then any 2 points lies on the same line. If you see them as directions and you just mean colinear as they point in the same direction, then that is the same as parallel. So I think the right word here is nonparallel.
yeah you can say that they are non- parallel
$\vec{v}_1 = c \vec{v}_2$ is also another way of saying they are co linear, so, if there is no contant c satisfying this, they are non co-linear
Ryuzaki

Anyone know good websites to practise linear alg problems
can i get a hint for this? i have an expression for the inverse of A-I by factoring A^k - I, but how can i use that to find the inverse of A+I?

(-A)^0 + (-A)^1 + ... = (I - (-A))^{-1}
Hi everyone currently studying linear algebra
can someone further explain to me these example on why they are not invertible?

what does it mean 1 is not in the range?
It means that there is no x such that f(x)=1
In general a function is invertible if and only if it is bijective.
but then x^2 is not surjective so it's not invertible?
Namington

but as the image notes, $1$ is not in the range of the multiply-by-$x^2$ map
Namington

so $f^{-1}(1)$ makes no sense
Namington

hence an inverse cant exist
okay i kinda understood it already for example 2, what does backward shift means?
take all of the elements in the list and shift them one of the left
does it mean like $R^3$ going to $R^2$ for example?
jinichi

if you start with (0,1,1,...) the transformation yields (1,1,0,...)
so they note that if you have a nonzero element in the first position, the transformation gives you 0, so it has a nontrivial kernel
oh so basically the linear map backward shift rotates the input to the left and make the first input goes last?
I'll probably gonna ask more questions later.
Guys, I'm dealing with a rotation matrix rotating vectors by an angle 30 degrees about the z axis. I've found one of the eigenvectors which is (0, 0, 1).
but is it the same as (0, 0, 1)^T ?
Transpose of that vector?
I'd just say that eigenvector and the transpose of it are the same thing.
(0, 0, 1)^T = (0, 0, 1)
they're not the same thing, but they are both eigenvectors of the matrix
call your matrix R and this vector v, with eigenvalue lambda
then v^T R = v^T lambda, and R v = lambda v
I mean yeah one of them is column vector and the second is a row vector.
this is in general not true btw
but a rotation matrix is block diagonal, with a block that has just a 1, so it holds in this case, for this eigenvector
How can I show that they are both eigenvectors of the same eigenvalue?
apply the definition of eigenvector twice
once from each side 😛
you can also stop for a while to consider what it means for one matrix to be the inverse of another, and then assume your rotation matrix is diagonalizable
if AB = BA = I, and you consider the matrix product and a bunch of dot products, it might become clearer

orthogonal matrix doesn't necessarily mean rotation

what does he mean exactyl
the inverse is the same as the complex conjugate transpose
is that $AVV^{-1}=\hat{U}\hat{\Sigma}V^{-1}$?
Ryuzaki

yes
its just another video i was watching on svd its really good just missing this one fact
looks like some kind of svd decomposition
yeah it is

Perhaps the most important concept in this course, an introduction to the SVD is given and its mathematical foundations.
you need to tell the context before I can answer
this is the timestamp exactly
but hes just constructing the SVD
its just the * thing im not sure about
its often transpose
probably that U and V are unitary matrices
so their inverse is their complex conjugate transpose

Oh he already derived $AV = \hat{U}\hat{\Sigma}$ and then multiplying both sides by $V^{-1}$
Ryuzaki

right, and V is unitary, so V^-1 = V^H
yeah basically
in some places this is written as V^*
unitary matrices i have never heard of ill have to check that
basically orthogonal but in the context of complex sapce
it's the complex flavor of orthogonal matrices
wdym
complex number version you mentioned
they all mention that U and V are unitary. in the real case, they mention they are orthogonal
uh some didnt i dont remember but
yeah ill just see
is there any use case for the complex numbers in svd though?
more than use case, you can't avoid it
when all the entries in the matrix are real though, the SVD will be as well
or at least it CAN be, since the svd is not unique
not unique as is in its general to any matrix you mean
means given a matrix, the u, v, s matrix will always be the same(upto permutation)

yeah wikipedia said there is like 4 notations to use

that dagger looks cool tbf might use that
the dagger and + I use for pseudo inverse, never knew physicians use that for conj-transpose
lol
so in my guys video then
he has used a unitary matrix to include all real/complex basically
to make it general ig
cause my book only cares about real so it just say orthogonal
yeah
ight
you can get away with saying orthogonal if the space is real
when would you use an svd in complex space though
whenever it's handy to use complex numbers
so usually engineering and physics applications
yeah thats fair in computer science i dont see many uses tbf
also, the svd unique up to rotations
as far as i know at least
unless you have repeated singular values, permutations won't show up
you might use it in CS as well, since stuff like rotations are easily done with complex numbers
at least in the more applied stuff like computer graphics
yeah this is for CG this content
the only complex numbers i cant think of are in the fast fourier transform
are you referring to quaternions
in cg
thats true tbf i havent done much on them but they seem like complex numbers
more of an extension of them to more dimensions
i was talking more like rotations on a 2d plane, but sure
you don't need quaternions either, strictly speaking
nah you dont
but using them makes the computations easier
yeah its also gimbal lock or sumn
but i dont knwo much bout that
i just remember doing a non quat one you cant liek go all around without ebing cut off
like you get locked you cant freely rotate
yeah depending on the rotational system you use, it can happen

hello, I was lloking at the solution for this problem but i do not understand how they can map some of the basis vectors to 0 because wouldn't that make the set of vectors that get mapped to w linearly dependent?

wouldn't that make the set of vectors that get mapped to w linearly dependent?
why would it do that
wait ok no i think i see
you are looking at the finite version of the Hahn-Banach theorem
but is my intuiton corect?
i don't think it's quite correct
why
so why should it
make them linearly dependent
you can't map all the vectors that aren't in U to 0
but you can map the basis vectors that aren't in U's basis to 0
and then the remaining basis vectors, the basis vectors of U, determine the actual position of things
i don't get this
my idea is that by doing the mapping shown in the picture
u map over all the basis vectors of U + the 0 vector
yr intuition is correct
so why does that not make it linearly dependent
why would it make it linearly dependent
also why is the 0 vector important
you can get the 0 vector out of the basis vectors
because any vector can be written as a linear combination of another
why
oh is it by the theorem which says that if u have a set of vectors that span a vector space
u can reduce it to a basis ?
if it has 0 it cannot be a basis
sorry back
dw
this list is linearly dependent because you can get a linear combination of those elements where not all the coefficients are 0, but they sum to 0
yes i agree
ok
so...
you can just remove 0
and then it's independent
it's like
why bother talking about 0
and you can remove the 0
0 always goes to 0

??
like u confirmed
ok if you got something from that that's good
ye
i don't know what's happening here lol
i was confused but now i get it
dw haha
i wanted to understand if removing the 0 was possible

i don't understand
the heck q vegitable doing in liner algebra
@winged prairie also search Hahn-Banach theorem
for more info
any hint on how to do this, i don't wannt look at the solution right away

You can explicitly construct linearly independent vectors in L(v, w)
I mean that's just a way to construct maps V to W so yes i guess

,w det {{1,-2,3,1},{0,2,4,-1},{2,0,1,2},{1,0,5,0}}



,w det {{1,-2,1},{0,2,-1},{2,0,2}}

🤦♂️

u got a generous teacher ngl


I tried to use the Gramm Schmidt process to solve this problem, was that the correct approach?
can't read. what's the question?
what would be the vector of function f(x)=cos(2x) when [-pi,pi]?
Gimme a sec I'll just post a screen shot
????????????

and u hv to use GS orthogonalization fr tht?
hint: ||extend the basis to a basis of R⁴ then apply GSO||
Thats the section it's in, so that's my assumption
ok I know I'm showing my L.A. iq here, but what do you mean extend the basis to a basis of R^4?
extend (v1,v2) witch is a basis of W to a basis of R⁴
take u and v and come up with 2 more vectors such that all 4 are lin indep, and therefore span R^4
there are easier methods however
like $ \mqty[u^T \ u^T]\mqty[a \b \c \d] = 0$
...
tf?
you left a space after the first $
so I know if took u cross v, that would give me one more of the vectors I need to get to R^4, how would I get the 4th? could it just be arbitrary?
apparently I wrote 2 u's


sadly the x prod is only defined in R^3
when I copied it only one \ was copied
ahh, I didn't even think of that.
like wtf
Is it true for operators that (ST)^n = S^n T^n?
an alternative is to build a matrix with u and v as rows, and find its null space
ah
that's what ryu was getting at
in general, no
only if they commute
what i currently have is $(T - \lambda I)^{n}$ and $(\lambda T)^{-n}$. Is it true that $(\lambda T)^{-n} (T - \lambda I)^{n} = ((\lambda T)^{-1} (T - \lambda I))^{n}$
Sup?

You guys may answer Heathus first, I'm sorry to interrupt.
in this specific example it's true
Thanks!
I'm going to find the null space given V and U are transposed, please feel free to help others while I work on this.
Then we can see what happens next! 
that will be much more easier than extending the basis, then orthogonalizing
ok good for my skill level that's the best choice 😉 Thank you
Hello I'm struggling a bit with homework problems involving eigenvalues and eigenvectors. I understand how to do the full problem conceptually like ik the steps but the part where u do det(A) = 0 and have to solve for 0 im really not getting anywhere.
the help channels appear to be only for pre-uni hw so this was my safest bet
post the question statement and your work

i skipped the first step of writing the question but the matrix is all 1's accept the diagonal is all 2's
so u r struggling finding the characteristic equation?
ye
my prof said to not multiply anything out but for everything after the 1st det its all single values
it's just routine calculation
ik but for some reason im struggling with this. like which route is best for solving it
is the very bottom correct?
,w char poly {{2,1,1},{1,2,1},{1,1,2}}

looks like you've messed something
ok the first part of line 2 is correct somewhere below it i missed something
Looks like finding the null space of U^T and V^T was indeed the answer! Thank y'all so much.
My question is, how did we know that finding the null space of their transposes would be the orthogonal compliment of the those two vectors? Is that just always the case?
the null space is by definition orthogonal to the row space of a matrix
this is because you can write matrix-vector multiplication as the result of taking dot products between a matrix's rows and another vector
say you have a matrix [u v]^T, where u and v are column vectors. this gives you a matrix that is size 2 x n
now multiply that by some vector x of size n x 1
the resulting vector is of size 2 x 1, and the elements of the vector are u^T x and v^T x
u^T x = u dot x
so if all the entries of the resulting vector are zero, the vectors that satisfy this are orthogonal to both u and v
furthermore, if these vectors are linearly independent from u and v (and they are, because they're orthogonal to them) you can use them to extend u and v into a basis of R^4
and now consider the subspace spanned by u and v, and the one spanned by the vectors you just found
any pair of vectors where one vector is taken from one subspace and the other, from the other subspace, are mutually orthogonal
Thank you so much for breaking that down. That makes so much sense!

ok i figured out where i went wrong
but now i dont remember how to solve for x^3
ik the quadratic formula for x^2 and x^4
but this is where im gonna struggle
so for cubics you just want to stare at it until you find a solution
they won't give you a cubic with awful roots
in a question
so for example -1 should work here
i need a formula / system or ill be staring til im handed an F
-1
basically
you try 0, 1, -1, 2, -2, 3, -3
and if none of those work then you cry
isn't it 1?
well idk if you meant the factor or the root tbf
but lambda = 1 should make the poly 0
you can go from there. maybe divide the poly and then use the quadratic formula if needed

this video looks good
ye my math brain died in high school so now im just praying that i pass any required math for my major
but thx for the help!
ok so i played with it and the video did not help at all.
but ye 1 works
but how do i get the rest
there arent any like terms and all i can really do is factor out a lambda
ok so the only thing i noticed from just finding the answer online is that since the answer contains a (x-4).... one of the factors is actually 4 so maybe thats a hint
Practicing some exercise in the book. Is my proof correct? Is there a better proof?

can you elaborate further on your 1st proof im not sure i follow what you did,
as to how i would do it ||probably prove injectivity by assuming ST(u1)=ST(u2) and reach u1=u2 since injectivity is equivalent to invertiblility in finite dimensional spaces for some transformation(if dimemsions are equal for U and W )||
this is new to me.That injectivity is equivalent to invertibility. For my first proof i just assume that since S is invertible and S(Tu) so the linear map here must also be invertible.
Idk if it's the right track.
doesnt invertibility require bijection
injectivity is equivalent to invertiblility in finite dimensional spaces for some transformation(if dimemsions are equal for U and W )
the spaces could be infinite-dimensional in this exercise, so this might not apply. you'd need to go the extra step and show surjectivity as well
how does this prove that ST is also invertible? you haven't explained why ST has an inverse, you just wrote down the definition of ST and said "and it follows that this is invertible"
you need to elaborate
this proves both parts anyways, btw

how would i go about creating a subspace in a?

visualize it :^)
we want to show every vector in R^4 can be written as a sum of an element in W and some subspace
how can you visualize R^4 
it might help to consider a hyperplane in R^3 first, where you can argue geometrically. then, see if you can transfer your reasoning over to a hyperplane in R^4
weed
3blue1brown
😹


Visualizing high-dimensional spheres to understand a surprising puzzle.
Help fund future projects: https://www.patreon.com/3blue1brown
This video was sponsored by Brilliant: https://brilliant.org/3b1b
An equally valuable form of support is to simply share some of the videos.
Special thanks to these supporters: http://3b1b.co/high-d-thanks
Home p...
you know if i had a shape like on a graph right

with the original F already there
so i know the coordinates of start and end
how would i calculate transformation matrix to get there
get the basis vectors?
which vertices are that
basically you can construct basis vectors by drawing them on top of the F
[9.812, 10.1963302752294, 14.1855010660981, 13.4, 10.8298217179903, 10.6398305084746, 12.0611940298507, 11.7371879106439, 10.4931163954944, 10.2813455657492, 9.812],
[5.649, 8.39266055045871, 7.79957356076759, 6.91607142857143, 7.39059967585089, 6.74435028248588, 6.44328358208955, 5.95532194480946, 6.24530663329161, 5.5249745158002, 5.649]
you see the issue xd
right so get the bottom left vertex, get the bottom right
can i like plug these into a linear equation though
these are just x, y pairing first array is x second is y
subtract bottom right from bottom left, theres your horizontal basis
sorry been busy. So, i can use this for the first proof?
in my book it says you can just line up the coordinates in an equation though will that not work
yes and presumably the F starts out completely straight?

thats weird, whats with the big matrix
I guess I'm not familiar with whatever this is :)

oh wait, it's a transformation that includes translations?
I see
so in that recent slide they have the column with some single vertex
on LHS with the trasnformed point
and they are solving teh matrix to get to it i think
where the matrix is the unknowns
in my example i think i would just have a fat column vector
I guess the thing with the basis vectors wont work then
with [x1,y1, x2, y2...., xn, yn]
ill see if there is an online tool to solve this exact issue
hmm, I feel like 3 points should be enough to characterize any affine transformation
are there any named theorems besides cayley hamilton that i should know as an undergrad
I hear Pythagoras Theorem is all the rage
2 is enough for linear transform
but like, you need to distinguish between a translation and a series of linear transforms
hence the third point
yeah I get that
uh just need to find out how to compute these things
by that then are you saying from my F
I need to get any 3 points of x and y
probably!
You mean, in linear algebra?
Stuff you need to know (In my opinion)
Cayley-Hamilton Theorem
Steinitz Exchange Lemma and the Dimension Theorem (Existence of a basis and Uniqueness of dimension)
Spectral Theorem for Normal Operators (and its corollaries such as Spectral Theorem for Hermitian (Self-Adjoint) and real symmetric operators).
Rank-Nullity Theorem (First Isomorphism Theorem)
Lémme de Noyaux (a.k.a primary decomposition theorem)
Jordan Canonical Form Decomposition
Jordan-Chevalley Decomposition
Schur's Theorem (Schur's Decomposition)
SVD decomposition theorem
Rational Canonical Form and Smith Normal Form (maybe?)
Cholesky decomposition theorem
Cayley-Hamilton's Theorem
Stuff you maybe need to know (I guess).
Gershgorin Circle Theorem
Sylvester's Law of Inertia
Spectral Mapping Theorem
Witt's Extension Theorem and Witt's Decomposition Theorem
Hadamard's Inequality
Cartan-Dieudonné theorem
Idk, these are prolly all the linear algebra theorems I know that have a name I guess.
The "stuff you need to know" is prolly shit people go through in most intro to linear algebra classes I guess.
I'm sorry if I'm constantly asking if my proof is correct. I don't have anyone to ask to. And i don't have a solution manual to check. So yeah Is my proof on this exercise correct?

I'm an undergrad and really new to college maths

So for this problem, I know I can just set up "Ax=b" and multiply the right vector by the inverse to solve for "x", which would be the coordinates being requested. But is that the ideal way to solve it? Should i be using QR factorization for this problem?
Choose a basis $e_{1}, \cdots, e_{n} \in V$ of $V$ and let $T,U \in \mathcal{L}(V)$ be such that:
\begin{align*}
T(e_{1}) = 1
\
\
T(e_{i}) = 0 ; \forall i > 1
\end{align*}
and
\begin{align*}
U(e_{1}) = 0
\
\
U(e_{i}) = 1 ; \forall i > 1
\end{align*}
Then, notice that
$$
(T+U)(e_{i}) = 1 ; \forall i \geq 1
$$
And thus, $T+U = \text{Id}_{V}$ is the Identity on $V$, which is invertible.
\
\
Therefore, we have that the set of non invertible operators is not closed under addition and as such is not a subspace of $\mathcal{L}(V)$.
Notice that we are explicitly using the fact that dim(V) > 1 here in order to construct T and V.
Moreover
You can fill in the details yourself if you want
But T and U are well defined
Because we especified how the act on a basis of V
And we can use this to extend T and U to to whole of V by linearity like this.
And uniquely as such
I should be more precise on why your argument does not apply.
It is NOT true that every linear operator T : V -> V between finite dimensional vector spaces is invertible.
You could take, for example, the 0 linear operator.
But that are more interesting examples
Such as the ones I have constructed.
Nilpotent operators are another important class of operators which are not invertible.
MISTERSYSTEM

What is true tho
ohhhh so what does this mean?

That's what I was about to say
As a consequence of the rank-nullity theorem
If an operator T : V -> V is injective, then it is invertible.
Or if it is surjective, then it is invertible.
But not every linear operator between finite dimensional vector spaces satisfy these criteria.
For example, 0 : V -> V which takes a vector v in V and does 0(v) = 0 is not injective nor surjective.
ohhhhhh
thank you very much
im taking notes
one of the things which define a normed space is that $| x | = 0 \iff x = 0$ where $x \in X$ where $X$ is a vector space
but i dont understand why that's needed
is there an example of something which satisfies the other two norm axioms but doesn't satisfy this one?
Joy!

Yup, there are.
isn't it obvious from the definition of the modulus that this will be the case though?
take the constant 0 map
random unrelated interjection - i asked about the studying role before but what is/how do i get permastudying (i saw it on system)
ask for it. want it now?
smh
ok yeah the constant 0 map does indeed satisfy the other two while violating positive definiteness
im still not fully comfortable with the idea of a norm tbh, does it get more natural once you learn topology?
Let $(X, \mathcal{B}, \mu)$ be a measure space, where $X$ is a set, $\mathcal{B}$ is a sigma algebra on $X$ and $\mu : \mathcal{B} \rightarrow \mathbb{R}{\geq 0} \cup {+ \infty}$ is a measure on $X$.
\
\
Let $1 \leq p < + \infty$. We define the real vector space:
$$
L^{p}(\mu) = \left{f : X \rightarrow \mathbb{R} : \int\limits{X} |f|^{p} , d \mu < + \infty \right}
$$
We can prove that for any $f \in L^{p}(\mu)$ we have that the function defined as:
$$
|f |{L^{p}} := \left(\int\limits{X} |f|^{p} , d \mu \right)^{\dfrac{1}{p}}
$$
Satisfies all the other product of a norm. I.e, the triangle inequality (here known as Minkowski inequality). It is positive homogeneous and we have that $| f |{L^{p}} \geq 0$ for every $L^{p}$ function.
\
\
But, we have function with $|f |{L^{p}} = 0$, but $f \neq 0$. Basically, if $f$ is 0 almost everywhere (i.e 0 everywhere up to a set of null measure), then $|f|_{L^{p}} = 0$ even if $f \neq 0$.
Oof
damn yeah buddy I'm still a few months away from learning about measure spaces
This example comes from functional analysis.
Yeah
I couldn't think of a good example on finite dimensional vector spaces
The 0 one is prolly the easiest
MISTERSYSTEM

whats interesting is that what inspired my question is the proofwiki proof of the p norm on the p sequence space being a vector space norm
ahahahaha
bruh just when i thought the rabbit hole doesnt get any deeper
I can't think of any non zero pseudo norm which is not a norm.
Btw
The thing with L^p spaces is that we usually identity functions that agree almost everywhere.
yeah i looked at the definition of the pseudo norm and immediately II . II_0 popped in my mind
proofwiki is kinda weird
So that we in fact have a norm.
And not a pseudonorm
This is usually a technical detail
is this a vector subspace ?

what are the requirements for something to be a subspace
1 include zero vector
2 closure under vector addition
3 closure under scalar multiplicatioon
These 3 conditions are equivalent to
1 it is a non empty subset
2 closure under vector addition
3 closure under scalar multiplication
i mean youre right but no need to be condescending, it can be helpful to check if 0 vector is included as a way to eliminate the other 2 sometimes
?
We need the subset to be NON EMPTY in order for it to be a subspace.
no i was saying i was about to ask a stupid question
i wasn't saying your q was stupid
oh
right
then yeah
but are these of two vector subspaces ? I'm struggling with a notation of proof
i mean you seem to have two sets there
so it depends on the particular instructions...?
I need to prove for every set if it is a subspace
iirc a subspace is closed under linear transformation
i dont think the method is working tbf

this one i solved the values
but somethign is off
im not even sure if this is even possible
subspace is closed under addition and scaling
to which similar properties are linearity
is there any other way to find the parameters of an affine trasnformation
given the start and end shape

like we have this F right and i computed the transformation for a using that method
but the matrix didnt move it correctly not sure why
what is the standard method of getting the affine matrix uesd in a transformation
I have no idea how to work on this question

seems like it should be orthogonal to the other two basis vectors

It dosen't work. For example, <-6/5,-2/5,1,0> is the vector orthogonal to the other but it's not the answer. okay I've figured out the method.
-> Prove that every m × n matrix over the field F is row-equivalent to a row-reduced matrix.
-> Let e be an elementary row operation and I be the m × m identity matrix. Prove that for every m × n matrix A, e(I)A = e(A).
Hey someone help me prove these two theorems??? pls
can someone help me understand why a matrix (let's say B = {1 1}{0 1}) acts as a change of basis from B to E where E is the standard basis pls
ive been trying to get this into my head since fucking freshman year and it still doesnt click
just a discussion would be v nice
@glad acorn has it been resolved?
obviously
yeah i was gonna say, isnt that like... the definition of those things...?
i mean my teacher asked for a neat proof
given a matrix, u apply row operations blah blah and u get a row reduced matrix
so original matrix~the row reduced matrix we have just calculated
ig you could do some visual stuff?
do I need to?
also pls 👉 👈
I would have but I'm on my phone now, hard to type, I'll try once I get back to my pc
<3
any chance on an ETA? i'll be here for a while but will probably close discord for a while
ok i'll whatever I can for now
say in 2D you have 2 LI vectors (1, 1) and (1,0). say I want to use them as my new coordinate vector. so any (x,y) vector in 2D can be written as a•v1+b•v2
i.e. the vectors (1,0) and (0,1) which was our old basis can be represented in terms of the new basis v1, v2
so let the the new coordinates of e1, e2 be
$a v_1 + b v_2 = e_1 \
c v_1 + d v_2 =e_2$
Ryuzaki

Now this can be written in the compact form
$\mqty(v_1 & v_2 ) \mqty(a & b \ c & d) =\mqty( \imat{2})$
Ryuzaki

now you can solve for a,b,c,d with it
similarly given we know the coordinate wrt one basis we can transform them into another just by multiplying the inverse of the basis transformation matrix
so ig it's bc of how that matrix of the new basis vectors (or rather each basis vector) acts upon our basis E...?
Hi again, practicing another exercise in the textbook. Is my proof correct? Can it be proved better?

no
you are supposed to show a invertible lt exists given S is injective
but here u assumed the existence
all rightt
hint: || extend to a basis ||
if S is injective, then take a basis {u1,…,uk} of U. then extend this to a basis {u1,…,uk,v1,…,vr} of V (where of course k = dim U and k + r = dim V). try to define a new function T determined solely by the new basis of V
Thank you. I kinda get it already. I also saw the proof online

I have constructed the matrix with importance scores, but dont know how to solve to get the page rankings
Can anyone guide me?
Wanted to doubel check something: Given an arbitrary inner product, does that change how matrix mulitplication works? I.e, say that my inner product is <u, v>, then is matrix multiplication now applying <u, v>, or is it still applying the "standard" dot product?
didn't understand what your question is exactly
So say that you define an inner product over R3, $<x, y> = x_1y_1 + 2x_2y_2 + 4x_3y_3$
Liria ^(;,;)^

Ryuzaki

Then normally, when you do matrix multiplication of $AB$, you're applying the standard dot product between the rows of $A$ and the columns of $B$
Liria ^(;,;)^

for that you must have a positive definite matrix Q
Then in this IPS over $R^3$, when we multiply $A$ and $B$, do we apply the standard dot product, or do we apply this inner product?
Liria ^(;,;)^

Yes, I believe that is my question
As this is the definition of inner product in my textbook

actually no, matrix multiplication is universal
IP acts on the vectors, so idk why you're worried about its effect on matrices
when matrices arent the vectors
probably cuz they noted the result of matrix mult is an array of dot products
Yea
but when you need to interpret it as such, it'll be apparent
And so matrix multiplication, even though it looks like a series of dot products, isn't really so?
it won't just be the composition of 2 linear transformations, but explicitly written as a matrix whose elements are inner products
it's a composition of LT's (in their matrix form). The basis is already taken into account in the matrix representation so you don't need to apply it again while multiplying
ok
for a nice symmetric pos semi def matrix M, if you want to compose something whose elements are inner products w.r.t. that matrix, you'd get a matrix whose elements are of the form u^T M v, and then you could factor it as U^T M V or something
but then that no longer has the interpretation of composition of linear transformations
so, not a "matrix" in the usual sense
yeah but when you try to multiply with the adjoint, then it'll be different. but I'll not go into the rabbit hole for now
Hey Liria if you don't mind me asking what book is that?
Some prof at my school wrote a textbook specifically for our linear algebra courses
I see thanks.

For a symmetric bilinear form (which is a symmetric matrix) we must have $a_{ij} = a_{ji}$ given $i\neq j$
Ryuzaki

means you are only free to choose arbitrary value for matrix where j>= i
ahhh yeah
that answers your question?
is it accurate to say that the alg multiplicity of an eigenvalue is the degree of the part of the polynomial in which said lambda sits (ik this is worded weird) and the geometric multiplicity is how many vectors make up it's nullspace..?
yeah
symmetric bilinear form correspond to symmetric matrix
though your terminology is not accurate, I get what you are trying to say. Yes it is the case
i can do problems with it i just wanna make sure the wording in my head is right so merci
*or at least the idea behind it
and a matrix is defective is the alg multiplicity of any of its eigenvalues is greater than the corresponding geometric multiplicity
If
\begin{align}
p(\lambda) = (\lambda-\alpha_1)^{k_1}(\lambda-\alpha_2)^{k_2}\cdots(\lambda-\alpha_n)^{k_n}
\end{align}
then $k_i$ is the algebraic multiplicity of the eigen value $\alpha_k$ and the geometric multiplicity is $\dim \text{ null } (T-\lambda_iI)$
Ryuzaki

yep that is what i meant, epic
is there a faster way to do this than rational root thm

that's easy enough to apply but tedious ofc


yeah i was thinking 3 from the start
yeah i'll just pull out WA on my exam no biggie
just stare at it until you see something that looks good
,w formula for cubic equation

because it is shit
no like even shittier than usual
anyway here's how you actually solve cubics
basically
try 0, 1, -1, 2, -2, 3, -3
and if none of them work then you're doomed
yall got any way to intuit how many roots it might have
it will always have at least one root of the form 0, 1, -1, 2, -2, 3, -3, by Kai's Conjecture
then just do the long division trivially
and you can tell pretty easily if it'll have more
bleh fine
What does this fancy R means?

range of T2
all right thank you
ive asked this before but... what's the dif between invariant factors and elementary divisors
ik the latter depends on our choice of minimal polynomial
are invariant factors just each distinct elementary divisor of every possible minimal polynomial (in cases where you dont know the minimal polynomial ofc)
I solved this question using adjunct matrices but my professor said to solve it without using adjunct matrices. Does anyone see a possible solutions start or tips to this problem?

if A is diagonalizable, the matrix exponentiation is pretty simple, one need only exponentiate the diagonal matrix of eigenvalues
then you can factor out the matrices of eigenvectors to the left and right, leaving you with a sum of diagonal matrices of the form of the polynomial
Hi I have a question
If you have two bases B and C
would the change of coordinates matrix from B to C be the inverse of C to B and vise versa?
B to C is the inverse of C to B
C to B is the inverse of B to C
yes
in general, you put the basis vectors as columns of a matrix M
the inverse of B to C is is C to B
but I did not know if the converse would be true
thank you nonetheless
then if x are the coordinates in that basis, we have that v = Mx, so that v has coordinates x in the basis M
if you do it backwards, then you get that M^-1 v = x, and now v is the coordinate vector for x in the basis of the columns of M^-1
Is there an easy way to LU Factorize a nxm matrix? The method I know and use is to RREF to get U, but in the process, get values for L.
by hand, that's about the easiest
Hi i need help
If A,B are squared matrix, and AxB is unsymmetrical so A and B are transposed
To disprove it, you just need to give a counterexample
do you have any example? i have tried
i didn't find any
is it a proof or disproof
@swift minnow Sure
Consider any symmetric matrix
Then take one of the entries not on the diagonal
And +1 to it
And then take the same entry and -1 to it
The two matrices you get won't be symmetric
But their sum will be
is this conclusion right?

like, h(x)=-h(x) breaks the definition of function right
nope
let h(x) = 0
it would be the x-axis right?
and the only function that obeys h(x)=-h(x)
yes bc 0=-0
oh i got it
thank u
can you give me an example?
I told you how to construct an example just now
so is it a disprove?
i asked you the wrong question at start and i guess you answered it , my apologoy.
i edited the question
i typed the wrong question
Is the new question: If A and B are square matrices such that AB is not symmetric, then A = B^T?
Or what do you mean by A and B are transposed?
I don't get it
it means that a x b = b x a
that's what i mean by transposed
a x b = anti symmetric
I don't think you are using terminology correctly
Can you send a screenshot of your actual question?
Ye thing is that’s in a different language 😅
Hello I have a possible LA question in #computing-software 😄 any help is appreciated
Anyone got any clue how to start this problem,

let p=algebraic multiplicity of the eigen value
Where have I done wrong? The correct answer is sqrt(186)/2.

Wouldnt it be (2, -1, 5) then? On P1P2.
Can anyone help?
ryuzaki gave you a hint
If I have an $n\times n$-matrix with integers on the diagonal and 1s on the "immediate parallels" of the diagonal, can I say something about its signature?
To be more precise, I mean matrices like
[ \begin{pmatrix} a_1 & 1 & 0 \ 1 & a_2 & 1 \ 0 & 1 & a_3 \end{pmatrix} ]
and by signature, I mean $#$ positive eigenvalues $- #$ negative eigenvalues
expectTheUnexpected

i.e. this

can immediately think of Gresgorion thm, other than that, I'll have to think
You mean Gershgorin Circle Theorem?
yeah but that won't be of much help I think
there's also one convoluted method usigng strum sequence
Ok, I guess I'll just not write a general formula then would have been nice, but I suspect that it's hard


oh no, recursion

was to be expeceted
then you can put v=0 and check for sign changes
I'wd like to know anything better myself