#linear-algebra
2 messages · Page 250 of 1


first part is trivial
second part i'm thinking:
M^3 = -|a|^2 M iff:
M^3 (b) = (-|a|^2 M) (b) for all b
is the hat a cross prod?
i can't see it either
For question (b), is it a not equals to 0 and b not equals to minus 1

bruh
no, b must not be 0
why can't a be -1
just add u1 once
and you just have bu2
i don't see why a can't be -1
$M^3 = -|a|^2M$ \
iff $M^3b = -|a|^2Mb$ $ \forall b$\
iff $M^2(a\cross b) = -(a\cdot a)(a\cross b)$ $\forall b$
Kaisheng21

Okay I understand now
k
wait
holy shit, does cross product distribute over matrix multiplication?
or the reverse idek
don't think so
ok well i'm completely out of ideas
trayan_b
Compile Error! Click the  reaction for more information.
reaction for more information.
(You may edit your message to recompile.)

but to get a vector normal to both a and b you just have to do a x b
so why is |a||b|sin(theta) there
the cross product yields a vector perpendicular to the two original vectors and with length equal to the area of a parallelogram defined by the vectors a and b
those terms are there because they define the area of a parallelogram
that makes a lot of sense
just 1 more question
the distance of a plane from the origin can be found by using d = k/|n| where r.n = k
but how do i derive d = k/|n|
i dont see where it comes from
you can derive this from the equation of a plane
given a normal vector n and a point p0 on the plane, a vector p - p0 is also on the plane if it is perpendicular to the normal
this means $n \cdot (p - p_0) = 0$
Edd

distributed the dot product to get $n \cdot p = n \cdot p_0$
Edd

we can divide both sides by the length of n, so that the right hand side yields $$\frac{n \cdot p_0}{\norm{n}}$$
Edd

after that if a plane does not pass through the origin, p0 cannot be 0, and this quantity is nonzero
and geometrically, what it does is yield the amount of p0 in the direction of n, i.e. the scalar projecto of p0 on n
which is precisely a distance from the origin to the plane
it's also the shortest distance because n is normal to the plane
wait
oh yeah, you had it right, i misread, sorry
aight
how do i prove that R is a subspace of C?
use the definition of a subspace
consider the set of complex numbers ${z \vert z = a + 0i, a \in \mathbb{R}}$
Edd

and show they satisfy the def of a subspace
yes that's actually exactly how i did it, i just didn't know if it would've been enough
if you have already shown C is a vector space, then it suffices to show this set is closed under addition and scalar mult
though you have to be careful with the scalar mult
the scalars can only come from R
yes i was going to ask if my field is R or C in this case
oh ok
why?
if the field for the scalar is C then R is not a subspace, if the field is R then it is a subspace
right

I think this is true right
So we say V is a subspace when vectors u, v in V and scalars k
u+v is an element of V
and ku is also an element of v for all scalars k
and the condition for a transformation to be linear is
for a transformation T: Rn -> Rm
let u,v be vectors in Rn and let a be a scalar
T is a linear transformation if
T(u+v) = T(u) = T(v)
T(au) = aT(u)
Or is this not enough information?
I was trying to say that T(V) always being a subspace implies that T must be closed under addition and multiplication but I dont think that implies it distributes over addition and multiplication
<@&286206848099549185> Can anyone give me some insight on this?
@native ore In $\mathbb{R}$ we have $T(x) = x^3$ as a counterexample.
IlIIllIIIlllIIIIllll

Oh true.
Ok, that makes a lot of sense actually.
Thank you @torn stag
You cant place powers on vectors though right?
A but you said in R
So I would define it T: R -> R
T(x) = x^3 is valid for a linear transformation?
I gave a counterexample for $T \colon \mathbb{R} \to \mathbb{R}$.
IlIIllIIIlllIIIIllll

I'm not sure about $\mathbb{R}^2 \to \mathbb{R}^2$ though.
IlIIllIIIlllIIIIllll

Id imagine R2 -> R2
we could say T: R2->R2 defined by [x^3,y^3]
also achieves the same goal does it not?
from rank nullity theorem
if its linear then T(ax+by) = aT(x) + bT(y) holds.
Im pretty sure yours isnt a linear transform
no, x^3 is not linear. but it is a counter example from R to R. it maps all of R to all of R and it maps to trivial vector space to itself. on R^2 its a bit more difficult to come up with a c.e., if there is one
is it since its just 5x there is no x^2 and a constant you just put 0 ?
yup
they just wrote 5x as a quadratic to make the matching up of the coefficients more explicit
thanks
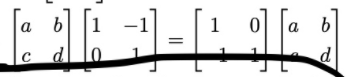
https://i.gyazo.com/0fd1e03e1ef7b57213ede51f801d1675.png do the products

wdym ?
each side is a matrix product
on the left side if i multiply i get [ a -b 0 d ]
that's not how matrix products are defined
im confused :/
how is a negative and c negative ?
c is 0
you must know how matrix products are defined. see https://www.mathsisfun.com/algebra/matrix-multiplying.html
got it thank you sm!
I will give you a hint, if $A = [I]^{\gamma}{\beta}$ for some ordered basis $\gamma, \beta$ of $\mathbb{F}^{n}$, then there exists $P,Q \in \text{GL}{n}(\mathbb{F})$ invertible matrices such that:
$$
A = P^{-1} I Q
$$
Now, suppose that $A$ is invertible, try applying elementary row and elementary collumn operations to $A$ to get a basis under which $A = [I]^{\gamma}_{\beta}$.
MISTERSYSTEM
Compile Error! Click the reaction for more information.
(You may edit your message to recompile.)

You literally just apply gaussian elimination
I don't want to type it down because it would be a pain

You want to prove a version of this.
let's make that visible

Thanks
Your first proof is not correct
We are saying that the map T is invertible
Not that AXB is invertible for some nxm matrix X
it doesn't even make sense because n is not necessarily qual to m
so that it doesn't make sense to ask AXB to be invertible.
It is.
Hey I have a quick question so when I say modulo 11 how does it work in negative numbers does it go to -11 or 0?
since T is invertible
what can we say
Does -12 and -1 have the same value ij modulo 11
We can take block matrices:
$$
L_{1}
\begin{bmatrix}
I_{n} & 0 \
0 & 0
\end{bmatrix}
$$
and
$$
L_{2}
\begin{bmatrix}
I_{m} & 0 \
0 & 0
\end{bmatrix}
$$
Which are both $n \times m$ and we can find $X_{1},X_{2} \in \mathcal{M}{n,m}(\mathbb{F})$ such that:
$$
L{1} = AX_{1}B
$$
and
$$
L_{2} = AX_{2} B
$$
Can anyone answer ;-;
@winter harbor I’m sorry to bother you but can you answer my question 😅
Its a fast one
damn
D:
Alright
MISTERSYSTEM

Maybe playing around with this can lead you to something @granite kraken but I didn't think this through.
Can you answer me now 😅
I need to eat lmao
Oh :(
Alright
Well enjoy
Yeah yeah
ok so
Does negative numbers work the same when we say mod 11
Alright perfect so -12 mod 11 is -1 correct ?
and you have to apply euclidean division in the same way
It is
Alright amazing
also
thank you!
Alright thank you!
Is this enf to show T is a linear transformation...
T(e1 + e2) = T(e1) + T(e2)
T(c*e1) = cT(e1)

Yes

is anyone willing to help me understand what a change of basis matrix is
how to find it

hey guys, so I get this problem generally
S and T are both just transformations which take some polynomial P
and output a new polynomial
S(P) = P`
T(P) = yP`
Where P is a polynomial in terms of y
for example P = y^2 + y + 1
I'm just a little confused on how I'm meant to write out a standard matrix for a polynomial linear transformation like this?
it says "with respect to the basis {1 to y^3}"
so I can understand the standard matrix for the linear transformation S
will by 4 by 4
but how do I write out these values?
is it that I just plug in?
S(1), S(y), S(y^2) and S(y^3)?
You need to find the coordinates of (S+T)(1),(S+T)(y), (S+T)(y^2) and (S+T)(y^3) with respect to {1,y,y^2,y^3}. For example, we have that:
(S+T)(1) = S(1)+T(1) = 0 + 0*y = 0, so
(S+T)(1) = 0*1 + 0*y + 0*y^2 + 0 * y^3
And the coordinates of (S+T)(1) wrt to the standard basis is (0,0,0,0). So that will be the first collumn of the matrix [S+T] wrt the standard basis.
For the second column, we have that
(S+T)(y) = S(y) + P(y) = 1 + y* 1 = 1*1 + 1 * y + 0 *y^2 + 0*y^3. Therefore, the coordinates of (S+T)(y) wrt the standard basis is (1,1,0,0) and that will be your second collumn.
Yup
and write it out as the columns
of our matrix
could the question
potentially be rewritten to something like
"with respect to the basis {1, cos(y)}"
or do the y functions have to be
polynomials?
is cos(y) a polynomial?
no
then it cant be a basis vector for a polynomial space
thanks for that
(Whatever) spaces has a basis consisting of (Whatever)
had me dying for a second if cos(y) could be in there
ah wait, so could the question, be written as trigonometric functions spaces
How can I determine value of alpha

@torpid socket You want to write the equations in matrix form
?

I would write it out like this first
matrix on the left is all of the coefficients of the equations
the one on the right is the solutions

and then you can multiply both sides
by the inverse of the matrix on the left
Oh I don’t think we learned that yet :D
this is what I would do tbh, it just seems like the easiest way
cause then it means
you need to find out if that matrix can have an inverse, and calculate it
and then multiply the inverse, by the matrix on the right
and it pretty much just directly gives the answer
you can also do stuff like
calculate the determinant
of that matrix
which should tell you if the equation has any solutions
I see
or what "a" has to be for it to have solutions
that's just factorizing out x1, x2, x3
in a matrix way

if you take just this part
Oh
and you multiply the 2 matrices on the left together
you'll see that it comes out with the same equation
4 X1 + 5X2 + aX3
It would probably be allowed cause augmented matrix form is just another way
of doing the same thing
tho tbh
I suck at row-reducing lol
even tho I shouldn't
I did this question like this

Oh

I will see what get
that's alg
sorry I'm not sure if I understand this fully, but what's a+b=0 from?
I'm not too sure how to approach this, but I believe that your final answer is correct
in that if v1, v2, and v3 are all linearly independent
then they must be be able to form a basis for the vector space V
I'm just not sure where you got a+b=0 from
ah nvm you just multiplied
av1 + bv2 + cv3 = 0
tbh the working seems fine, but I would've written a little more
before you started writing a + b = 0
I would've started with av1 + bv2 + cv3 = 0, with no coefficients being non-zero
ah sorry. thats from setting scalars for each row and equating them to 0
arigatoo!
the working seems good, just needs to be a tiny bit more clear
but otherwise good job dude
thanks1

does anyone know how to generally find the basis of the orthogonal component to S?
I can get that the orthogonal component of S, will just be a vector space
damn so I just apply this algorithm
and it gives me the 2 vectors I need for the basis
Yeah
why is it v2 = u2-v1 tho?
is that just how general formula is done
cause like, what happens
if they gave me 3 different vectors for the original span
S = span{u1, u2, u3}

Yeah lol
Was having trouble typing it lmao.
that's algs bro
thanks for the help on it
I'll pray I get something easy like least square and polynomial standard matrices
in a couple of months

does anyone know how to show the coordinate map?
like if p = x
does that mean that [p] = (0, 1)?
and then to calculate the matrix A, I'm assuming
I just need to plug in a = 1, b = x
and then also b = 1, a = x
calculate (a, b) using the integral formula
and then calculate that separate equation at the bottom
and just match them up
to find matrix A?
basically you are given be basis {1, x}. Find the matrix of the inner product A
Show the coordinate map? It's just:
[3x + 5]= (5,3)
where your $A_{ij} = \int_{-1}^1 e_ie_j \dd x$
Ryuzaki

ah ok, just confirming a lot rn, I'm starting to learn that the final numbers
are all just about the coefficients really
and cause it's respect to basis {1, x}
p and q, just have to be some polynomials where
$p = a_1 + a_2x$
ehff

there has to be that constant a1
but if the question was different
and just asked for basis {x}
then we would only be looking in the perspective
of polynomials that are just
$p = a_1x$
ehff

Let $A$ be a positive semi-definite matrix (not be necessarily symmetric).
I would ask that $|(A+A^\top)x|_2^2=0$ implies $x=0$?
keith_1

Hi there all I have a question
If B is a basis of H consisting of three basis matrices, then if K is a subspace of H, would K share the same basis matrices as H?

looks ok
hint : what is the basis of a trivial vector space?
the empty set
I have a question.
If A is diagonalizable then what does this imply about the dimensions of the eigenspaces of A?
I find eigenvalues as somewhat related to the nullspace but the connections are still unclear.
the book hints to use inner products to solve this but I don't see it immediately. Anyone see ITV

cauchy schwarz
recognize that the left hand side is of the same form as a dot product
oh, you havent seen cauchy schwarz before?
Maybe I have maybe we just haven't named it
Is it that famous inequality?
I still am not sure how to use it
you might have seen it as a property of the dot product
have you seen dot products yet?
and how to use them to check if vectors are parallel, orthogonal, or if they make some other angle
to show that a set is a vector subspace of a vector space, do we just need to show that it's closed under addition and closed under scalar multiplication? or do we also need to show that the zero vector is in the set too
the zero vector part is related to being closed under addition, since v - v needs to be in the set
thank you

what's assignment 5 question 7
Let $A$ be a positive semi-definite matrix (not be necessarily symmetric).
I would ask that $|(A+A^\top)x|_2^2=0$ implies $x=0$?
keith_1

I am assuming you have done the previous exercises. Given $\lambda$ is a eigen value of $A$, then for a polynomial $p(x) \ \in \mbb{C}[x]$ we know $p(A)$ eigen value $p(\lambda)$. So, as $A$ is diagonalizable, assume the eigen values are $\lambda_1, \lambda_2, \cdots, \lambda_{10}$. Given $A^2+A = J+2I$, LHS and RHS must have same eigen values. So, $\lambda_i^2+\lambda_i \quad(i=1, 2,\cdots 10)$ is a eigen value of $A^2+A$. But the eigen values are given 12 with mult 1 and 2 with mul 9. So $\lambda_1^2+\lambda_1 = 12$. This gives us $3$. now for other eigen values $\lambda^2+\lambda = 2$ means $\lambda = 1, -2$ now assume $1$ has multiplicity $k$, then $-2$ will have mult $10-k-1$. gien $\tr(A)=0$ we can solve for $k$.
Ryuzaki

@empty ibex
no, since they're only semi-definite
No, ex 0 matrix
a simple counter example is to take an identity matrix and replace the last row with all zeros. or a 0 matrix, and ryu says
@small vigil
for the 7'th one you can use contradiction. Assume they are disjoint, then their direct sum has dim 10 but it is also subspace, so dim <= 9 is a contradiction.
Is this related to linear independence again?

what do you think?
The dim(A) is equal to the number of bases, now I know that the eigenspaces is similar to the null space so can I say that the basis of the kernel of the matrix is the basis for the eigenspace and hence are equal in dim(A)?
I'm not that familiar with diagonalization.
Diagonalization requires linear independence right?
diagonalizable means you have enough eigen vectors to construct a basis.
Ok first can you show that eigen vectors corresponding to distinct eigen value are LI?
Not sure what you are implying with this sorry
These eigenvectors must be LI then.
NO not necessarily
I see, I see. So they are LI when the EV are distinct and nonzero.
what I meant was is if all the eigen values are different, then what can you say about the eigen space ( specifically the dimension of the E space)
There can be cases where A diagonalizable matrix has repeated eigen values, we count them by their multiplicity. example $\mqty[\imat{2}]$ has eigen values $1, 1$ so we say that 1 has multiplicity 2.
Ryuzaki

algebraic multiplicity*
yeah didn't wanna confuse if further so I omitted it
I guess I'll have to read on this first.
@zinc timber
I've got this idea now thanks.
If there exists a diagonalizable matrix $A_{n*n}$ then the sum of the dimensions of the eigenspaces of A must be equal to $n$?
Elfenkaiser

but I think they asked a more specific answer
What I meant to say is that for diagonalizable matrix, the dim of the eigen space equals to the (algebraic) multiplicity of the eigen value
This is not generally try if A is not diagonalizable. Example $\mqty[1 & 1 \ 0 & 1 ]$
Ryuzaki

Hiya! I was wondering if anyone knows, if I have two vector solutions to a linear system of equations $\mqty[1 \ 0 \ -1 \ 1 ]$ and $\mqty[2 \ 3 \ 1 \ 0 ]$ how would I start to try to determine a formula to all the solutions in general?
you can't find them all just from that
foldie

but you can guarantee that the difference of the two solutions is in the null space, so adding a scalar multiple of the difference is always a solution
you need the transformation itself to figure out of the null space has dimension 1 or more, though
hmmm, ok. thanks very much for the help!
can someone explain to me the intuition behind why every hyperspace(dim n-1) of a finite vector space V is the null space of some non-zero linear functional on V
[like i get that f maps to a field of scalars and by rank nullity the null space has dim n-1 but i dont see how to prove each hyperspace is the null space of some f]
Let $U \subset V$ be a codimension $1$ subspace of $V$, a finite dimensional vector space of dimension $m$. Let $e_{1}, \cdots, e_{m-1}$ be a basis for $U$ and extend it to a basis $e_{1}, \cdots, e_{m}$ of $V$.
\
\
Let $f : V \rightarrow \mathbb{K}$ be such that $f(e_{i}) = 0, \forall i \in {1, \cdots, m-1}$ and $f(e_{m}) = 1$. Then, by linearity, $f$ extends to a unique rank $1$ linear functional on $V$ such that $\text{ker}(f) = U$.
MISTERSYSTEM

You need to need the linear functional to have full rank btw.
So that there's a one to one correspondence between full rank linear functionals on V and codimension 1 subspaces of V.
i dont see how this applies to multiple linear functionals it seems like it proved each hyperspace is the null-space of a unique linear functional but cant we have multiple functionals such that ker(f)=U
maybe im missing something
in the theorem its stated as such
if f is a non-zero linear functional on the space V then the null-space f is a hyperspace in V. conversely ,every hyperspace in V is the null space of a (not unique)non-zero linear functional on V
It does not prove that each hyperspace is the null space of a UNIQUE linear functional tho.
I constructed a particular one
What is unique
Is the extension of f
So that f is well defined as a linear functional on the whole of V
ye i mean i get that
but i want to generalize that idea
For instance
K could be a field of characteristic 0
So that N embeds in V
And if you put f(e_m) = n
For some natural number n
And f(U) = 0
This gives you a new linear functional
That vanishes on U
For each natural number n
So it is definitely not unique
You don't need to, you need to prove that there exists at least one.
ohhh i see the issue fair enough
Yeah
What I am basically using
Is the fact that a linear functional is uniquely specified
By how it acts on a basis of V
And since e_1,...,e_m is a basis of V
If I choose what f(e_i) equals to for i in {1,...,m}
By linearity, this induces a unique linear functional on V
But I could specify how f acts on this basis
In a bunch of different ways
And this is where the (generally) non uniqueness of f comes from.
I want f(e_i) = 0 always for e_i in U
But f(e_m) could be anything
As long as it is non zero
aight i think i get the catch here ile write it down to fully grasp it
ty ty
i’m giving you a counter example. just let K be the zero subspace
Well maybe I should be more specific
I suppose what im asking implies different things
Than the answer i am looking for
this is a counter example to your question. let H be the space of 2 by 2 real matrices spanned by B = {e1, e2, e3}. The trivial subspace K = {0} is a subspace of H which shares no basis vectors with H because it’s basis is the empty set
hey can anyone help me out with part (b) of this question

so this is the formula for shortest distance between two lines

given that P is some point on line 1 and Q is the perpendicular point on line 2
this is how far i got but im struggling a little because of the cosθ

i just don't see that going to the answer which is( √ 66 )/33
<@&286206848099549185>
Hey guys, does anyone know how to apporach this question?

notice that only basic row operations are taking place
and these affect the determinant in very specific ways
I'm given 2 vectors { [cos(theta), sin(theta)] , [-sin(theta), cos(theta)] }. I'm trying to prove these vectors form an orthonormal basis for all values of theta but I don't even know how to find the length.
I know I have to do (cos(theta) * cos(theta)) + (sin(theta) * sin(theta)) = 1 but not sure how to show it for all values of theta.
What I do know are the requirements to show its orthonormal but I'm not sure how to proceed with this specific question.
oh wait im dumb
cos^2(theta) + sin^2(theta) = 1
👍
if you have [cos t, sin t] and [-sin t, cos t], the dot prod is -cos t sin t + cos t sin t
i dont think i follow
what's the problem?
i don't recognize what ur trying to explain
do you know how to take the dot product of 2 vectors?
and do you know what it means when the dot prod of 2 vectors is 0?
yes it means it is orthogonal
this adds up to 0
so the 2 vectors are orthogonal
i think this is from me not being familiar with how the trig identities cause it to add up to 0
there is no need to use any trig identities
just look at it
it's of the form -x + x
ahh i just noticed when u said look at it
but then -sin^2(theta) + cos^2(theta) = 1?
and im not familiar with how its equal to 1
no, that's not equal to 1
i guess you mean when taking the norm of [- sin t, cos t]
the proper way is $\sqrt{(-\sin(\theta))^2 + (\cos(\theta))^2}$
Edd

the negative goes away
this would be different from the 2nd given vector no?
how can u just square root it?
i thought i have to show that (-sin(theta) * -sin(theta)) + (cos(theta) * cos(theta)) = 1
well sure, and the square root of 1 is 1
because you had a negative sign that was wrong

1 please

so i just define what it means and how it was applied?
Can anyone see why the last part implies that null T^{tilde} = 0 ?

Just state what it means for each vector to be orthogonal to each other and normalized.

I've just looked at the book's online errata, and it's supposed to say $null \tilde{T} = {0}$, which makes more sense, but I don't see why $v + null T = 0 + null T$ should imply $v=0$.
Kaishin

Well, they have proved that if $v \in \text{null}(\tilde{T}) \implies v \in \text{null}(T)$. This means that $v$ is equivalent to $0$ mod $\text{null} , T$, but the equivalence class of $0$ mod $\text{null} , T$ is precisely the additive identity (i.e, the zero vector) for the quotient vector space $V / (\text{null} , T)$.
MISTERSYSTEM

It does not imply v = 0
for instance
T could be the zero map 0 : V -> W which sends every vector v to 0.
so that the kernel of T is precisely V
thus
for any non zero v
how are you defining modular arithmetic wrt a subspace...?
we have v + ker(T) = 0 + ker(T)
Haven't you seen the quotient of a vector space by a subspace before?
Nope
If you take any vector space $V$ over a field $\mathbb{K}$ and a subspace $W \subset V$, then we can define a vector space $V/W$ over $\mathbb{K}$ as follows. As a set, $V/W$ consists of equivalence classes of vectors in $v$ under the equivalence relation:
$$
v \sim u \iff v - u \in W
$$
We denote the equivalence class of a vector $v$ under this equivalence relation as $v+W$ so that for any $v + W$ and $u + W$ in $V/W$ we may define their sum as:
$$
(v+W)+(u+W) = (v+u) + W
$$
and for any $\alpha \in \mathbb{K}$ we define the scalar multiplication as:
$$
\alpha \cdot (v+W) = (\alpha v) + W
$$
We can verify that these operations are well defined and endow $V/W$ with the structure of a vector space over $\mathbb{K}$.
k, gonna google the quicker explanation

this is pretty quick...
there is also the issue of well defined-ness of addition and representatives and blah blah blah, but it works because of group theory stuff
MISTERSYSTEM

Yeah, it's not hard to verify tho.
See, just saying group theory would have been enough, cause I haven't taken group theory yet.
It can be done as an exercise
Instead of assuming I know (X Y Z)
I mean, you don't need any group theory to understand quotient vector spaces
ofc there are related notions
for instance, in group theory we can quotient a group G by a normal subgroup H
and since V under addition is abelian
then any subspace W under addition is a normal subgroup of V
so that V/W under addition has the same group structure as V/W (viewed as a group quotient)
but do you need any of this?
No
The intuitive explanation
is that the quotient V/W
collapses W to to the 0 vector
so V/W is the 0 map
Not really, it's just that we are dealing with V modulo W, in the sense that we are treating two vectors of V as equal unless they differ by an element of W.
Right, so don't say not really, then yeah
we have a canonical projection map
$\pi : V \rightarrow V/W$ which sends every vector in $v$ in $V$ to its equivalence class $v+W$. this is actually a linear map, and turns out that its kernel is precisely the subspace $W$.
MISTERSYSTEM

No clue what an equivalence class is.
The idea is that we are ''forgetting'' W and treating it as 0 under V/W
again, you assume I know things when you explain it
Oh 😦
Might take a look at a bit of set theory then
I know set theory
bruh how is he supposed to know what you dont know
ask
Ah, yes, thank you MISTERSYSTEM, I just realized that I hadn't noticed that the definition of the quotient space makes to the affine subset of v and w equal if they give the same affine subset. Just stupid me considering them separate.
Like if you have a quintesential aspect in an explanation, you would know "ok, you need to have a rough idea of X Y Z in order to understand this explanation of W"
I am sorry
I didn't know tho
I hope at least I gave you a brief description of what it is
and what are the prerequisites to understand it
sorry they tried to help you but didnt do it in the specific manner you were hoping for?
like...?
If I explain intervals of increasing/decreasing to someone on here, I need to know if they know calculus or not, so I ask "are you in a calc class"
as an example of knowing your audience
It's just that I really have no idea how would I talk about quotient vector spaces without mentioning equivalence relations
They are defined in terms of an equivalence relation
Np 
Yeah I know im being a bit irrational, and I apologize however I dont want you to waste your time explaining stuff just for it to be above someone's head
y'know?
Aight 
In any case, I mentioned set theory because intro to set theory courses usually deal with equivalence classes.

You may take a look at Paul Halmos Naive Set Theory book for an explanation of that, or the first chapter of Munkres Topology (it talks about logic and set theory).
me when i thought there was a shorter proof of change of variables and didnt pay attention in class
this was a very nice explanation mistersystem

 ❤️
❤️

All m x n matrix has determinant. true or false?
whats the determinant of [0 1]
only square matrices do
zero, obviously. it takes the unit hypercube in R^2 to something with zero two-dimensional volume, so the scaling factor is zero
unit cube?
?

bruh i stopped reading after hypercube lol
im so tired
i just want to figure out how hash tables work
if $T$ is a linear operator on $\bR^n$ then $T([0, 1]^n)$ has lebesgue measure $|\det T|$
TTerra

im just starting to learn basics of lebesgue measure theory. i wonder how you show this tho
change of variables theorem
aight imma head out
TTerra

We need a vector v that is orthogonal to every element in W. I am inexperienced but you have the basis for W. Thus let find a vector that is orthogonal to each w_i. So you have 3 equation <w_1, v> = 0, <w_2, v> = 0, and <w_3, v> = 0. Just solve this system. Maybe this helps a bit.
do this with the riemann integral instead and start worrying about orientation and you'll probably get a perfectly good definition of determinant
this also falls out of $$T^*(e^1\wedge\cdots\wedge e^n) = (\det T)e^1\wedge\cdots\wedge e^n,$$ which says the same thing geometrically, and has the benefit of making sense for more general vector spaces
TTerra

though you need some multilinear algebra for that to make sense
I wish there didn’t say non-zero vector
Damn, I remember asking you something related to this almost a year ago.

This
REE
lmao back when i had the gay legosi pfp
yeah
all of what i just wrote makes perfect sense with the riemann integral btw
i just didnt wanna think about orientation so i wrote lebesgue here
francais
Now I got to actually learn some exterior algebra memery / differential forms memery and can understand your answer to that old question of mine 

Wait this isn't his job lol
He's not obligated to help you
Hes just trying his best to help you, and you're retorting...
Not sure why you're responding to something from 2h ago but ok
can you not be so abrasive


i don't think im understanding what Q is exactly. if someone could explain that would be great
i calculated the distance though
need help 
Didn't you draw the Q there already?
To find Q, you can use that vector i-2j+3k is normal to plane T.
yeah lol i drew it but didn't know what to do with it.
sorry you said do what with the normal?
(position vector of P_0)+(some scalar)*(vector normal to T) = position vector of Q
You can solve for (some scalar) and hence, find Q
okthanks so much:)
I have three distinct eigenvalues so each of them has AM of 1?
yes
I have found that when the eigenvectors' AM = GM= n , then a matrix $A_{n \times n}$ is diagonalizable.
Elfenkaiser

Is this correct?
for all eigen values, then yes
I have another question.
I have a characteristic polynomial $\lambda^3+3\lambda^2+4\lambda-12$. What does this have to do with the inverse?
Elfenkaiser

the determinant is the product of the eigenvalues, so if you find this poly has a root that is 0, the inverse does not exist
with the information Edd already mentioned, can you determine if 0 is root of you polynomial just by looking at it? hint || constant term ||
this seems like a better fit for #prealg-and-algebra
i'm gonna put that in a help room

First, find the matrix (with respect to the standard basis) corresponding to the linear transfomration which projects a vector the the y-axis.
Then, find the matrix corresponding to the reflection with respect to the line -2x.
Since we are dealing with matrices wrt to the standard basis of R^2
We basically just need to know how both of these transformations act on the vectors (1,0) and (0,1)
Then, you take the corresponding product of the the projection matrix with the reflection matrix.
how can i get spanning vector for $U=[(x, y, z) \in \mathbb{R}^3 | 2x-y=0]?$
leonardomoura

do you recognize the geometric shape?
We have that $y = 2x$, thus, if $(x,y,z) \in U$, then:
$$
(x,y,z) = (x,2x,z) = (1,2,0) \cdot x + (0,0,1) \cdot z
$$
MISTERSYSTEM

Can you continue from here?
Yup, it is.
what about y?
y is completely determined by x. So in some sense it restricts the degree of freedom for U.
y = 2x
Well, the minimal number of vector vectors that span U is 2.
but we could have more
if this makes it look more familiar to you, what you are given is equivalent to $\begin{bmatrix} 2 && -1 && 0 \\ 0 && 0 && 0 \\ 0 && 0 && 0 \end{bmatrix} \begin{bmatrix} x \\ y \\ z \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \\ 0 \end{bmatrix}$
Edd

you can just find the null space of this as usual
rref and look for free parameters
For instance, U itself is a spanning set for U.
So yeah, we could have an infinite amount of vectors that span U.
But
ohh
It is useful
i get it
Quick question: what's the third condition for a something to be defined as a vector subspace. I know two of them are closed under addition and closded under muliplication
scalar multiplication*
that's enough if you know it's a subset of a vector space
These were the lecture notes I got, does the highlighted portion mean that the 0 vector is in subspace?

that's a consequence of me being dumb
but you do find it as a separate condition in some cases, sure
It is not 👀
hmm i suppose not
It's a consequence of being closed under scalar multiplication assuming nonempty
So you usually either have W is nonempty or 0 in W
And yes, the highlighted part means the zero vector is in W
ah, that's the right explanation
👍 Thanks
how can I find the first matrix
See what that matrix does to (0,1) and (1,0)
Then have it be an arbitrary matrix
a b
c d
And solve for a,b,c,d
Or, recognize this as a matrix multiplication of other matricies
show that not (definition of nilpotent) holds
An arbitrary vector space does not have a standard basis, there can be many different bases for the same vector space. And sometimes you know what the basis looks like, and sometimes you just know there is one but don't know what it looks like. That's context dependent.
If {e1, e2} is a basis then span{e1, e2} = V. That is correct.
there must be simpler ways. do you have a specific example in mind?
one way is to show that it has a non zero eigenvalue
that might be the easiest
cause if A^n = 0 and Av = cv, then A^nv = c^nv = 0, and since v isn't zero, c^n = 0 giving c = 0
or if you like element-free proofs, some monomial x^n annihilates A, so the minimal polynomial divides x^n, hence has only the root 0
I'm totally unable to read what you wrote
It looks like computer code more than math
Why is your function's name a whole phrase  just call it f or T
just call it f or T
it's fine if you write like this for yourself but this isn't how people communicate math lol
feynman was a crank and a misogynist
So what I think you have is that V is a 2 dimensional real vector space with some fixed basis {b1, b2}. That means every v in V can be written as a1b1 + a2b2 for real numbers a1, a2, and the column vector [a1, a2] is called the coordinate vector. Now you are considering the functions which maps v to [a1, a2]?
Note that you need to fix a basis for V before considering this function, because the coordinate vector depends on the basis
That is the same as the function I described
What's your question though?
There is no standard basis in V
There are many different bases
And each different basis defines a different phi
Phi depends on the basis
Yes
Only K^n has a standard basis
Yes
K^n also has many bases, but the standard basis refers to a specific one
i would argue that polynomial rings have a standard/canonical basis as well (but thats kinda besides the point)
Yes
I don't know what you mean by "to see the vectors"
Well, now you don't, because V is an arbitrary vector space. But for a specific vector space, you can know what its elements look like
Sure
You can have a vector space of all polynomials of degree 5 or less
Then the elements of the vector space looks like ax^5 + bx^4 + cx^3 + dx^2 + ex + f
So I know what the elements look like
That's one basis
Yes
If you use the basis you defined up there
Then phi(ax^5 + bx^4 + cx^3 + dx^2 + ex + f) = (a,b,c,d,e,f)
Or (f,e,d,c,b,a) since you reversed the order
The polynomials are the vectors
A vector is an element of the vector space. If your vector space consists of polynomials, then the polynomials are the vectors.
I don't know what you mean, sorry
Vectors are things you can add/subtract. So, at the very least, you have to be able to do that. How exactly you do this depends on the vectors.
You can't really have a vector space where the vectors are completely intangible because of this, haha
But you could have one where "assigning them to a coordinate" is difficult
Yes all finite dim vector spaces have a map to F^n
Where n is the dimension
I should say an isomorphic map, as you can also map back from F^n
There's a layer of abstraction here for sure. When you say v, w in the context of "any vector space", you don't need to declare which vector space u and v belong to.
Obvious pro: You can prove things about all vector spaces this way
Con: It can be hard to think about u and v since they aren't "real things" until you come up with a vector space to attach them to
I can say "They're 3rd degree polynomials" and suddenly you know what the elements look like, and how they add
But the process of "adding vectors" always exists. You're guaranteed of that, at least
Just, you don't always know how I guess, haha
Yes, an isomorphic map is invertible and respects addition (Or, I like to say the function splits over addition). I should have said linear transformation though, which is more common in linear algebra
Haha so high school uses a different idea for vectors. They can move and be placed anywhere, and be line segments.
This is useful for solving physics problems, but not useful for talking about algebraic structures
Linear algebra has vectors always start at the origin, and prefers an algebraic interpretation
what does it mean to "start at the origin"?
Yes. f can be written as a matrix, but that depends on the coordinate basis of V and W
Mind you, any two matricies for f will be similar matricies
equivalent not similar
That is, if A and B are matrices for f, then
A = PBP^(-1) for some invertible matrix P
no
they said f is from V to W
V not necessarily same as W
A=PBQ^(-1) for invertible P and Q
Not really. You see, a matrix associated to a linear map between vector spaces is not an ''intrinsic notion'', in the sense that in general there's no notion of canonical/natural basis for both V and W such that we can write f wrt to these bases.
The choice of a basis for a vector space is pretty much arbitrary in nature.
Are you asking if these diagrams commute ?
Well
I kind of see what you are going for, I guess your question is about if a map f : V - > W between finite dimensional vector spaces and a choice of isomorphisms phi_1 : V - > F^n and phi_2 : V -> F^m induces a map f' : F^n - > F^m which is pretty much ''the representative of f wrt to phi_1 and phi_2''.
Is that so?
You can do phi_2 ° f ° phi_1^(-1) : F^n -> F^m
This is basically what the map f ''looks like''
wrt to the basis induced by the isomorphisms phi_1 : V -> F^n and phi_2 : W -> F^m
Yeah, but any choice of isomorphism, say phi : V -> F^n gives us a basis for V if we take the i-th basis vector b_i of V to be b_i = phi^(-1)(e_i). Where, e_i is the vector consisting of zeroes everywhere except for the i-th entry.
and this is what we are gonna do now
wdym
No
n is fixed
and I am not choosing any map
but an isomorphism
so dim(V) = n
Remember that to construct a matrix for a linear map f :V -> W between finite dimensional vector spaces V and W is basically to make a choice of basis for V and to W and see how f acts wrt to both of these basis.
and choosing a basis for a finite dimensional vector space E (over a field F) is basically to make a choice of isomorphism phi : E -> F^n
and this is what we are using now
Yeah, phi is an isomorphism
and to get a matrix represenation for f : V -> W wrt to these isomorphisms
Exactly
The idea is that a coordinate representation (wrt to given bais) for a map f : V -> W is basically an induced map f' : F^n -> F^m where dim(V) = n and dim(W) = m.
There's a less abstract way to define the matrix of a linear map
And I will give you a description of that
but now
I want to try to make sense of your intuition
mistersystem literally carrying this channel recently
Now we have an induced map phi_2 ° f ° phi_1^(-1) : F^n -> F^m. And we define the i-th column of matrix f wrt to phi_1, phi_2 to be the image of e_i = (0,...,1,...,0) under phi_2 ° f ° phi_1^(-1). Where e_i is the vector where all entries are equal to 0 and the i-th entry is equal to 1.
This is kind of abstract lol
So I will give an example
if $A=[v_1, v_2]$ is a spanning set of $v_1=(1, -2, -1)$ and $v_2=(2, 1, 1)$ what does the det of the matrix being zero implies? $\begin{pmatrix}
1&2&x\
-2&1&y \
-1&1&z
\end{pmatrix}$
leonardomoura

hmmm
Let $V = \mathcal{P}{1}(\mathbb{R}) = {f \in \mathbb{R}[x] , \vert , \text{deg}(f) \leq 1 }$, i.e $V$ is the real vector space consisting of all real polynomials of degree less than or equal to 1. We have that $\text{dim}(V) = 2$, since $\mathcal{B} = {1,x}$ and $\mathcal{B}' = {1-2x,2+3x}$ are both basis for $V$. As such they induce isomorphisms $\varphi{1}, \varphi_{2} : V \rightarrow \mathbb{R}^{2}$ given by:
\begin{align*}
\varphi_{1}& : V \rightarrow \mathbb{R}^{2} \
1 \mapsto& (1,0) \
x \mapsto & (0,1)
\end{align*}
and
\begin{align*}
\varphi_{2}& : V \rightarrow \mathbb{R}^{2} \
1-2x \mapsto & (1,0) \
2+3x \mapsto & (0,1)
\end{align*}
MISTERSYSTEM

Is this good so far?
To make myself clearer
phi_1 is the map associated to the basis B
And I am only defining how it acts on B
because we can extend it by linearity
so phi_1 is well defined
similarly, phi_2 is the isomorphism associated to B'
Now
Vector space of real polynomials with degree less than or equal to 1.
R[x] is the set of all real polynomials of one variable
that's a notation
deg(f) is a notation for the degree of f
yup
now
let's take the map f : V -> V
which takes a polynomial p(x) and sends it to its derivative p'(x)
Alright
So now let's calculate phi_2 ° f ° phi_1^(-1)(1,0)
this will be the first coordinate of the matrix of f
wrt to the basis B and B'
so we have
$$
\varphi_{2} \circ f \circ \varphi_{1}^{-1}(1,0) = \varphi_{2}(f(1))
$$
But f(1) is the derivative of 1, which is 0, so:
$$
\varphi_{2}(f(1)) = \varphi_{2}(0) = (0,0)
$$
MISTERSYSTEM

so the first column of the matrix f wrt to B and B'
will be (0,0)
now let's calculate the second column
1 is a polynomial too
and f is the derivative of this polynomial
the derivative of 1 is 0
$$
\varphi_{2} \circ f \circ \varphi{1}^{-1}(0,1) = \varphi_{2}(f(x))
$$
Now, $f(x)$ is the derivative of $x$, which is $1$, so:
$$
\varphi_{2}(f(x)) = \varphi_{2}(1)
$$
Now, we have to try to find the coordinates of $1$ wrt to the basis $\mathcal{B}'$, we then see that we in fact have:
$$
1 = \dfrac{3}{7} \cdot (1-2x) + \dfrac{2}{7} \cdot (2+3x)
$$
and then:
$$
\varphi_{2}(1) = \varphi_{2}\left(\dfrac{3}{7} \cdot (1-2x) + \dfrac{2}{7} \cdot (2+3x) \right)
$$
Since $\varphi_{2}$ is linear, this is in fact equal to:
$$
\dfrac{3}{7} \varphi_{2}(1-2x) + \dfrac{2}{7} \varphi_{2}(2+3x)
$$
since $\varphi_{2}(1-2x) = (1,0)$ and $\varphi_{2}(2+3x) = (0,1)$, then this simplies down to
$$
\dfrac{3}{7} (1,0) + \dfrac{2}{7} \varphi_{2} (0,1) = (3/7, 2/7)
$$
MISTERSYSTEM

So the second collumn of $f$ is given by
\begin{bmatrix}
3/7 \
2/7
\end{bmatrix}
MISTERSYSTEM
Compile Error! Click the reaction for more information.
(You may edit your message to recompile.)

and the matrix of f wrt to $\mathcal{B}$ and $\mathcal{B}'$ is given by
\
\
\begin{bmatrix}
0 & 3/7 \
0 & 2/7
\end{bmatrix}
MISTERSYSTEM
Compile Error! Click the reaction for more information.
(You may edit your message to recompile.)

That was some work 
Is this so far so good?
Np
I'd recommend you coming up with more examples
And doing this all by yourself
like
take a map f : V -> W between finite dimensional vector spaces
take a basis for V and a basis for W
construct the induced isomorphism phi_1 : V -> F^n and phi_2 : V -> F^m
and then calculate the values for phi_2 ° f ° phi_{1} : F^n -> F^m on the canonical basis of F^n
I will tell you
This is a big ammount of work
And you don't necessarily need to do this
to find a matrix for V
But I will give you some time to play around with this idea
And later I will show you how to find a matrix for f (wrt to given choice of basis)
without doing this
I have a question that asks me to solve least squares straight line to fit some data points and then the minimum square error. What is the minimum square error? Is it the same as the least squares error?
Let $f : V \rightarrow W$ be a linear transformation between finite dimensional vector spaces over a field $\mathbb{F}$ and $\mathcal{B} = {e_{1}, \cdots, e_{n}} \subset V$ be an ordered basis for $V$ and $\mathcal{B}' = {b_{1}, \cdots, b_{m} } \subset W$ be an ordered basis for $W$.
\
\
Thus $\forall j \in {1, \cdots, n}$ we have that $f(e_{j}) \in W$ is a vector in $W$, thus, since $\mathcal{B}'$ is a basis for $W$, there exists unique constants $\alpha_{1,j}, \cdots, \alpha_{m,j} \in \mathbb{F}$ for which $T(e_{j})$ is given by the linear combination:
$$
f(e_{j}) = \sum\limits_{i=1}^{m} \alpha_{i,j} b_{i}
$$
We define the matrix of $f$ wrt to the ordered basis basis $\mathcal{B}$ and $\mathcal{B}'$ to be the matrix $[f]^{\mathcal{B}}{\mathcal{B}'}$ whose $(i,j)$-th entry is $\alpha{i,j}$. Thus, the $j$-th column of $[f]^{\mathcal{B}}{\mathcal{B}'}$ is precisely given by the coordinates of $f(e{j})$ wrt to the ordered basis $\mathcal{B}$ and $\mathcal{B}'$, i.e the $j$-th column of $[f]^{\mathcal{B}}{\mathcal{B}'}$ is
$$
(\alpha{1,j}, \cdots, \alpha_{m,j})
$$
@wintry steppe here's another way to find the matrix of a linear transformation between finite dimensional vector spaces
wrt to ordered basis
MISTERSYSTEM

phi_2 maps to the 0 vector because phi_2 is a linear transformation.
phi_1 and phi_2 are both defined on a basis
and by linearity we can extend it to the whole of V
to a linear function
which is unique and well defined
and that satisfies phi_2(1-2x) = (1,0) and phi_2(2+3x) = (0,1)
idk if you have seen this before
This is usually how we define the matrix of a linear transformation btw.
yup
1 = ...
because basically
since 1-2x and 2+3x are a basis for V
I want to find constants a and b
such that 1 = a(1-2x) + b(2+3x)
this is good
because varphi_2 is linear
and we know how it acts on 1-2x and 2+3x
and to find a and b we basically have to solve a system of linear equations (can you see how?) with unknowns a and b.
Nice
Try to make sure you understand why both these descriptions of a matrix of a linear map are equivalent.

Did you come up with the phi_1, phi_2 stuff on your own tho?
That's actually really good
This comes up later
In some sense
good luck
Nah, I'm good
I should be studying something else now tho
Can you apply linear transformation to functions? Could the rotation matrix be used to rotate $\ln(x)$ by any angle for example? $$ \begin{bmatrix}
\cos(\theta) -\sin(\theta) \\sin(\theta) \cos(\theta))
\end{bmatrix}
\begin{bmatrix}
x
\
\ln(x)
\end{bmatrix}$$
azeem321

You can do that

Without Matrices!
Try it out yourself:
https://www.desmos.com/calculator
Basically what they do in this video
thanks just what i was looking for
❤️
On the left side, you have < f + g, f + g > = < f, f + g > + <g, f + g >
= < f, f > + < f, g > + < g, f > + < g, g >
= < f, f > + < f, g > + conj(< f, g >) + < g, g >
= < f, f > + 2 * Re(< f, g >) + < g, g >
Note that < g, f > is the conjugate of < f, g > and they are just complex numbers
no, the field you’re working in is C so < f, g > is an element in C — call it x + iy. Then Re < f, g > = x while Im < f, g > = y
But < g, f > is the conjugate of < f, g > so if < f, g > = x + iy, then < g, f > = conjugate of x + iy = x - iy
So adding the two inner products together gives you 2x = 2 * Re < f, g >
could someone help me out with a matrix question

does anyone know how i could approach this

apply gaussian elimination with an augmented identity matrix
how would i do that
do you know how to do gaussian elimination?
yes
well, then you know how to do this problem
when your doing gaussian elimination here, tack on a four by four identity matrix to the right of the original matrix
proceed with gaussian elimination normally with the identity matrix tacked on
the rightmost four by four matrix you get afterwards will be the inverse of the matrix
post it again
perform gaussian elimination on this matrix
\begin{pmatrix}
1 && 0 && 0 && 0 && 1 && 0 && 0 && 0\
0 && 1 && 0 && 0 && 0 && 1 && 0 && 0\
0 && m_1 && 1 && 0 && 0 && 0 && 1 && 0\
0 && m_2 && 0 && 1 && 0 && 0 && 0 && 1
\end{pmatrix}
c squared
Compile Error! Click the reaction for more information.
(You may edit your message to recompile.)

wot
something like this

god why does the bot hate me
$$
\begin{pmatrix}
1 & 0 & 0 & 0 & && 1 & 0 & 0 & 0 \
0 & 1 & 0 & 0 & && 0 & 1 & 0 & 0\
0 & m_1 & 1 & 0 & && 0 & 0 & 1 & 0\
0 & m_2 & 0 & 1 & && 0 & 0 & 0 & 1
\end{pmatrix}
$$
TTerra

thank you guys
yeah idk bot was being funky
ill lyk if i get it
$$
\begin{pmatrix}
1 & 0 & 0 & 0 & & 1 & 0 & 0 & 0 \\
0 & 1 & 0 & 0 & & 0 & 1 & 0 & 0\\
0 & m_1 & 1 & 0 & & 0 & 0 & 1 & 0\\
0 & m_2 & 0 & 1 & & 0 & 0 & 0 & 1
\end{pmatrix}
$$
i think it just doesnt like double dollar signs in the matrix?
double and sign
not dollar
latex is stupid
yea only one ampersand ig

{kind=link}
They should have arrow heads to indicate direction
But yes, it would be right
A+B starts at the beginning of A and ends at the end of B

That's a really nice work,
Tho there's some mistakes
specifically on page 5/6

This can't be a basis for P_3
because it is not linearly independent
no subset of a vector space that contains the zero vector is linearly independent
thus, can't be a basis.
In this particular case
this isn't even a spanning set for P_3
there's no way we could write x^3 as a linear combination of {0,1,2x,3x^2}
You didn't particularly have to write down this map also

You could have worked through all your calculations using this map you defined in the first page
if you wanted to find the basis of the differentiation map wrt to the basis {1,x,x^2,x^3}.
But you pretty much got the whole idea correctly
what you needed to do was to calculate phi ° f ° phi^(-1) : R^4 -> R^4 applied on the canonical basis vectors e_1,e_2,e_3 and e_4.
Where phi is the map defined on the first page.