#linear-algebra
2 messages · Page 230 of 1

Yes, you can do row operations
well what im saying is
we so far have only been taught Ra-Rb->Rb
Not Ra-Rb->Ra
and to then go off of that, if I followed the way of Row 3 - Row 2 -> Row 2 it would be -1-1 which would give me -2
And that is not the correct answer, it has to be +2
It still should have been a legal move
You're subtracting from the a row, so the result replaces the a row
and in this case the a row is row 3?
no, you're subtracting row 3 from row 2
so Ra(0,1,1,0,1) is row 2 and Rb(0,0,1,0,-1) is row 3 and that gives a new Ra
so Ra-Rb-> Ra
The number being replaced is is Row 2
why would it matter?
I get that
This problem is the first way seeing this
but why cant you do the other way
it gives -2 instead of positive 2
This problem has a unique solution
So my understanding is -2 is an incorrect answer
Could someone explain this explanation of hte solution better thanks!

The identity only has the eigenvalue 1
?
In a diagonal matrix, the eigenvalues are the values on the diagonal
Generally if you have a polynomial p(x), and a matrix A, if c is an eigenvalue of A, then p(c) is an eigenvalue of p(A)
So the eigenvalues of A^4 are lambda^4
Where lambda are the eigenvalues of A
Were A^4 the identity its only eigenvalue would be 1
But it isn't, so it can't be the identity
right
that's kind of a roundabout way of disproving the claim tbh
oh ok well i just used the complex diagonalizaiton and raised it to the 4th power xD
That's the same thing pretty much
This is a stronger claim though, since it works even when A isn't diagonalisable
k
Btw guys I need some help in finding a mistake in my working. I need to calculate XL given in the formula at the start of this page, and I'm given matrix A. The end result on the solutions is -(1/3)(e^(-3t)-1) on the top right corner of the final matrix, rest is correct. Where have I gone wrong?

Sorry i cant... exactly read your hand writing
Is it bad? I can try better
Basically I'm diagonalizing A because of the property of exponents of matrices
It makes things easier
also what is x(a)? or...?
But for some reason my answer is slightly different compared to solution
X(0) is just a multiplication value, I do nothing with jt
You can just ignore it
Seems like T^-1 is off by a minus sign?
It should be negative, ny handwriting was just confusing there
If you see under theres negative signs
Ic
If you are wondering about that property basically it works like this

Where T are the matrices that diagonalize A and Ad is the diagonalised matrix
So basically this saves me the pain of using Taylor expansion with matrices
Any ideas?
Can't seem to find a mistake
perhaps it might be because you did P^-1 D P but idk
Huh
Nah the formula is just the reverse
Maybe solution is wrong idk
Actually wait I do think it should be TDT^-1 in this case
@lone quail what did you do on the last step
Just multiplied by -1/3
Oh i see nvm i thought the squeezed in equals sign was an F xD
@lone quail it seems you did your matrix multiplication wrong
I just checked on matrixcalc and it seems doing Te^DT^-1 gives the solution in the answers

Could be
Where?
The other way doesn't make sense
wait
Since T is the COB matrix from the diagonalising basis to the standard basis
If you're sandwiching the diagonal matrix
PDP^-1 != P^- D P
It should be to the left

Where did I do my mistake?
This
It should be Te^Ad T^-1
You did the wrong factoriazation
Not the other way around
^
Nah im 100% sure thats the correct formula
Uhh
It's not
no
Multiply them

See if you get back A
From textbook
It says TAT^-1
It depends if you take T to be the COB from the diagonalising basis to the standard one or the other way around
...
Fedelisk
Take the diagonal matrix Ad
Multiply T^-1 Ad T
And see if you get back A
^
But im not multiplying by Ad here
Thats the issue
Thats the difference
I know the theory
It's not reversed when you do matrix exponents
It is here is the proof

They're originally taking TAT^-1 = Ad
In your case it's T^-1 A T = Ad
Noooo
I'm talking about the very top line
You have the order reversed in the very top line already
So it carries over
Guys to diagonalose a matrix is TAT-1
It's saying that given
A= T^-1 Ad T
Then the below formula holds.
But in your notation you have
A= T Ad T^-1
No because at the top Ad is the result
@lone quail
????
This part

In your notation
Yes that part not given that A = TAT^-1
Where is this?
This textbook/lecture nots are trash
The way you did the diagonalisation
Nope
Yes
That's not what I did
Ok the multiply T^-1 Ad T and see if you get A. The way you did the diagonalisation you get T Ad T^-1 = A
So the signs are reversed compared to the lecture notes
And that's where the confusion is coming from
Fedelisk you did the diagonalization for PDP^-1
and used P^-1DP
So you didn't do the factorizaiton correctly
If you don't believe me look up any lecture notes concerning matrix exponentiation
Yes but thats another formula, the diagonalised matrix in the middle
You are not listening
THOSE T ARE NOT THE DIAGONALISATION MATRIX OF THE MIDDLE MATRIX I USED
they are the T of a different matrix
Look at this
They are starting the process with the assumption I circled
Yes
In your case, your factorisation is yhe other way around
@lone quail if you are asking for help stop being such a bullheaded frog
So the proof will have the signs reversed
That is, the thing you call T, they would call T^-1
Guys just look at start and end of proof
That is the only difference
I've explained like 5 times by now. It's just the way you did the factorisation
Im not getting what you mean still
essentially you factorized A = PDP^-1 then tried to asume that PDP^-1 was equal to P^-1 D P which it is not
Where have I assumed that?
That's what im not getting
?
Roughly why?
It just makes it slightly easier to explain
@lone quail try computing the factorization you got.... like multiply it out
and see what you get
Which factorization?
ok so, when you take a matrix and set its vectors to the vectors of some basis B, then that matrix is the change of basis matrix from the basis B into the standard basis E right
so in your case, T is the change of basis matrix from the diagonalising basis B to E
Yes but what im doing here is T-1 x e^D x T
and T^-1 is the change of basis from E to B

except for hte middle matrix remove the e^blah
I understand where the confusion is coming from
and I'm trying to resolve that
Let me make it clear i'm talking about your specific example
not the textbook
So the matrix A_d is the same as the matrix A represented in the diagonalising basis B
So to get from A_d to A you'd have
A = T * A_d * T^-1
Since you need to go from E to B, then from B to E
No should be T-1 at start
Because Ad is already diagonalised
Ad is the matrix A in the basis B
So you need to undo
T^-1 takes us from the standard basis E into the basis B
then T takes us back to E
Yes but those Ts are not diagonalisation matrices anynire
Just change of base matrices
Nope
's the same thing
diagonalising matrices are change of basis matrices into a diagonalising basis
no you are
Ad is diagonalised
T takes you FROM B to E
A is non diagonalised
so T^-1 takes you from E (your starting point) To B
and then T takes you back
so you end up going from E to E
which is how A is represented
You agree that Ad = TAT-1?
Absolutely not
it's the wrong way around
if you still don't believe me
try multiplying it out
So what i'm getting at is that in your exercise A = T A_d T^-1, whereas in the textbook we have (Using different notation for clarity) B = P^-1 B_d P. So in the end they do get that e^B = P^-1 e^B_d P, but in your example it'll be e^A = T e^A_d T^-1 because of the same proof
great
glad we broke through in the end
np
consider the simplest invertible matrices
I think so but wouldn't know how to prove it. If you think about it tho, the determinant can sort of be imagined as an area in space, of a and b are different then the determinant of a^2-b^2 will not be 0
(it is not true)
So they can be not invertible?
There are some cases where it turns out not intervitble
Ah wait your right because because they can have the same determinant
oh haha!
fair enough, my counterexample was just taking A and B to be the identity
that was my instinctive thought too aha
a=b
or yea A=B
I mean if A and B got the same determinant
The result of the operation is prob 0
Maybe
for 1x1 yes
not necessarily in general e.g. diagonal matrices with det 1 but different entries to one another
spoiler it's still not true
just take A = -B
What if A^2 \neq B^2 tho 👀
probably still not true just slightly more annoying to come up with a counterexample to
det(a^2 - b^2) = det(a+b) det(a-b)
so we need a+b or a-b to have det 0 and so that should provide us with examples ig? i'll think
just take a= b+c with c being non invertible
yeah, try something like
gives infinite examples
yeah
But this is true as well

Can you give me an example?
just take say diag(2,0.5) and diag(0.5,2)
does that actually work, shiN
sorry but what's the link to this problem?
Just two random matrices I squared up
oh fair, sorry yeah that does work as a counter example
I was giving a counterexample to what fedelisk asked. It doesn't work for the original question
Btw those squared keep determinant 1
yes they do
Yeah
yea determinant is multiplicative
i see
if a matrix has determinant 1 then so does its square
Yeah
i was just worried as i thought you thought det(a^2 - b^2) = det(a^2) - det(b^2)
What I was saying in fact if the determinant is different from the start then a squared minus b squared is invertible
that's not true, as our counterexamples showed
It didn't?
e.g. a= diag(2,1) and b = diag(1,1) have different determinants
but a^2 - b^2 has determinant 0
Ok so if I square a matrix I square the determinant but I can't subtract?
yeah, det(a + b) is not det(a) + det(b) in general
I see
but det(ab) = det(a)det(b) as shin said which is cool
Yeah
If you think of determinants as areas it does make sense
Theres a nice visualization of 3blue1brown
hi guys, anyone can solve 8b ?

over what field?
don't know what formula to use. I can't solve it
matrix
whatever. The point is that when the matrix is multiplied by 3 times it will produce an identity matrix 3x3
i'd assume R then
perhaps a better question is - have matrices always been real so far in the class? do you know what a field is? etc
hmm, maybe just real number
sure
so, how to solve it ?
[-1 -1 0]
[ 1 0 0]
[-4 24 1]
seems to work (power 3 is indeed the identity matrix)
I don't see how to generate general solutions so I just searched random matrices until I found one with B^3 = I
I can see they have to satisfy B^2 + B + I = 0 for example (multiply by B - I to see that) but I wouldn't know anything useful
Maybe try to restrict B like a 2x2 matrix with B =
[1 0 0]
[0 a b]
[0 c d]
and search for 2x2 Matrices B' = [a b // c d] with B'^3 = I because they should get you B automatically with the condition
[ 0 -1]
[ 1 -1]
should do the trick as B' (again random matrices)
wow I've tried multiplying this one. and the result is true that B^3= I
sage: M = MatrixSpace(ZZ, 3)
sage: M
Full MatrixSpace of 3 by 3 dense matrices over Integer Ring
sage: M.identity_matrix()
[1 0 0]
[0 1 0]
[0 0 1]
sage: I = M.identity_matrix()
sage: while True:
....: i = M.random_element()
....: if i != I and i^3 == I:
....: print(i)
....: break
....:
[-1 -1 0]
[ 1 0 0]
[-4 24 1]
sage: a = Matrix([[-1, -1, 0], [1, 0, 0], [-4, 24, 1]])
sage: a^3
[1 0 0]
[0 1 0]
[0 0 1]
sage: M = MatrixSpace(ZZ, 2)
sage: I = M.identity_matrix()
sage: while True:
....: i = M.random_element()
....: if i != I and i^3 == I:
....: print(i)
....: break
....:
[ 0 -1]
[ 1 -1]
sage: a = Matrix([[1,0,0], [0,0,-1], [0,1,-1]])
sage: a^3
[1 0 0]
[0 1 0]
[0 0 1]
say thank you to SageMath I didn't do shit
right.. thank you so much SageMath and T0lgi
SageMath is a Program not a person
They do have a website where I downloaded it on my Computer (it's about 5GB in total, though) and actually an App on iOS (and probably other) making use of server computation (so you need WiFi)
Try to minimize usage from external programs because trying to find solutions by hand is also exercise by itself
sorry I just need confirmation for an extremely quick question but
https://i.imgur.com/SJPvdE9.png this is incorrect, right?
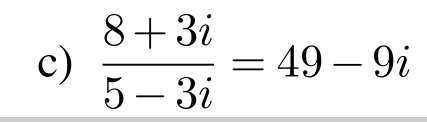
(it wants me to get the Cartesian form a + bi)
im getting the answer 31/34 - (39/34)*i
Yeah it seems p wrong
(for future reference, wrong channel sorry, a question channel might be better :p)
no worriesss
Technically it's fine to ask about C in here, at least my first formal learning of C was in a LinAl course when we "rigourously" defined scalars
Companion matrix of x^3 - 1?
$ \begin{pmatrix} 0 & 0 & 1 \ 1 & 0 & 0 \ 0 & 1 & 0 \end{pmatrix}$
Mike Desgrottes

yep thats the natural linear algebra way to view this
alternatively you can look at it "algebraically" by looking for the matrix representation of a permutation in S_3 of order 3
which would give the same result
and i think is probably the best way to approach this
(if youre not familiar with the group terms, i just mean we're looking for a permutation ["swapping"] operation that "cycles back to the start" when applied 3 times)
(and then representing that with a matrix)
@opal mortar pinging in case this adds to your understanding, though your current answer is fine as well.

So the gradient of f transposed is a row vector right?
When I do it for a system of equations then, the n'th row of J should be the gradient of f_n?
But J is the Jacobian
And the Jacobian has the n'th column as the gradient of f_n
Should that be J transposed in C.11?
definitions of these quantities are not standard and depend on the book
transpose stuff as needed
if f(x) is scalar-valued, then grad(f(x)) as written there is a column vector, and you transpose it to get a dot product
so that the first order taylor approx is also a scalar quantity
it seems like the f_i(x) are the entries of a vector, let's call it F(x) (seems that's what they did, too)
so now if you have a vector F(x) and you take its derivative w.r.t. x, the derivatives are along the rows
so J is a matrix where each row contains the derivative of the corresponding f_i(x) w.r.t. x
seems your book follows the convention of "all vectors are column vectors" and "differentiation w.r.t. vector quantities go in the next available 'way' "
Oh rly fair lol, interesting
can someone help me how to simplify this

how much do you know about determinants?
When the prof wants to make sure you know the properties 
@sinful knoll ???
I do know there are properities but none by heart :(\
oh yeah
and also det(A^T) = det(A)
i used wolfram alpha to calculate the SVD of this matrix

but, i dont understand how the last column of the U matrix is calculated?
wdym by "how"
do you wanna know about the algorithm for computing SVDs? otherwise just get a 4th vector orthogonal to the previous 3
yeah i dont really understand this svd stuff right now but, basically, you can compute an extra singular vector beyond whats in V and just use that?
what
U and V are, in general, not related at all to each other
matrices have left and right singular vectors
those depend on the original matrix's column space and left null space (left sing. vecs.) and row and null space (right sing. vecs.)
ok well
i am clearly way out of my depth here and fundamentally misunderstand all this
but just what i was reading said, to calculate each column in U, we multiply each singular vector in V with the original matrix A
which does indeed work looking at the wolfram output, except for the fact that the final column in U doesnt seem to have a corresponding singular vector to calculate it from, which is why i was confused
but yeah clearly i am totally misunderstanding this on some base level so i will try to read into it
well, since V is orthonormal, and a matrix M is decomposed into M = USV^H, when you multiply by the singular vectors in V (i.e. the right singular vectors), you get USV^HV = US
so the result is a matrix U times a rectangular matrix S with entries only along its main diag.
i think the best you can get this way is the set of vectors U_c that span the column space of the matrix
not the ones for the left null space
you can extend the vectors U_c into an orthonormal basis for R^m or C^m using gram schmidt tho
just generate random vectors of the correct size, check they're all linearly independent when put in a set with the vectors in U_c, and put the vectors U_c first when you do gram schmidt so that you modify the randomly generated vectors instead of the ones you already know are correct
ok thank you, i will look into it
what you were doing is related to the so-called "economy-sized SVD"
will $S ={x(a_1, a_2) + y(a_3, a_4) \mid x,y,a_i \in \bR}$ always be a subspace of $\bR^2$ if $(a_1,a_2)$ and $(a_3, a_4)$ are non parallel vectors?
CoolShot

your notation needs fixing right now
you do not want to quantify over all possible values of a_i in your set
as-is, what you have is an overly elaborate description of R^2
if you meant $S = { x(a_1, a_2) + y(a_3, a_4) \mid x, y \in \bR }$, with $a_i$ arbitrary but fixed, this will \textbf{always} be a subspace of $\bR^2$ even if $(a_1, a_2)$ and $(a_3, a_4)$ happen to be parallel.
Ann

nvm youre right i confused myself
even if they were parallel it'd be closed under vector addition and scalar multiplication and have a zero vector
so itd be a subspace
yup
ty
You can view this as essentially taking (a1,a2) and (a3,a4) and forcing S to be a subspace
'oh, if u and v in the set then so must xu + yv for all x,y in R? well let's just chuck them all in'
Numer d is not a vector space right?

because if u add x^3 with -x^3 = get somethign thats not in teh set?
the only sensible candidate fields are Z/pZ, but those end up failing distributivity
so no
(this isnt the most formal argument; for a more formal one, see https://math.stackexchange.com/questions/151850/prove-mathbbz-is-not-a-vector-space-over-a-field)

Mathematics Stack Exchange
This is an exercise from Chapter 3 of Golan's linear algebra book.
Problem: Show $\mathbb{Z}$ is not a vector space over a field.
Solution attempt:
Suppose there is a such a field and proceed by
another simple argument: observe that Z would necessarily be a 1-dimensional vector space since Z is generated additively by (1)
but a 1-dimensional vector space would necessarily have "itself" as a base field (upon fixing a basis)
except Z isnt a field
$A = \begin{pmatrix} 1 & 1 &\ 0 & 1 \end{pmatrix}$ is not, for example
potato

only eigenvalue is 1 and if Ax = x then we must have x being a multiple of (1,0) i.e. the eigenspace is 1 dimensional so not diagonalisable
There are nice types of matrices you can prove you can diagonalise (stuff like normal/unitary/real symmetric matrices) though
it is a crime that no one has mentioned jordan canonical form yet
this is also called a defective matrix and something worth knowing about symmetric matrcies is that they have orthognoal eigenvectors
canonical tteppa
Yea think so
So like if b=0 just show for any f,g in space then cf+g also integrate to 0, and if b not 0 u can find counterexample by taking day 2*f
Say*
is P the price vector?

in the exercise they asked me to determine the price vector with a system
but I wonder, that vector p that I have there is the vector of prices?

if you have no pivot columns that means all ur vars are free
so wouldnt that make it so that all b values would have solutions
What is meant by saying "a set of functions"?
What it sounds like
a set, containing functions
different functions
wiki "In mathematics, a function space is a set of functions between two fixed sets"
i'd be careful using the term "space" here since that usually refers to a set of functions with some extra structure (such as that of a vector space)

yeah... it's what it sounds like
the set of functions b/w 2 sets
so I'm reading about vector spaces "If S is a set, then F^S denotes the set of functions from S to F" but I just have a question in my mind, what function?
Any
all of them
Like, let's say we have 2 vector spaces V and W, then we can say the set of functions $W^V$ would be all functions who map vectors from V to vectors in W
Is this correct so far? At this point, can I do an epsilon delta proof? I'm not sure if it is the same for functions with complex domain.

Mosh

pick any norm, it's finite dimensional so they all give the same topology
yea I know, it
s just weird they didn't specify
wait actually you don't need a topology on V here nvm
I misread the problem
you can do smth like an epsilon delta proof but just using open balls in C instead of open intervals I think
just handwave and say "function jumps at an eigenvalue so it's discontinuous there"
if it's a linear algebra class i doubt you have to give the rigorous analytical details
maybe add that there are finitely many eigenvalues so there is a nbhd of lambda_0 in which it is the only eigenvalue
so clearly there is a discontinuity at that point
what is nbhd?
neighborhood
Ah, thanks. So I can find the delta neighborhood in my discontinuity proof.
Just self-teaching rn
yea, so it's constant at all points in that nbhd except lambda
where it jumps
actually if you're disproving continuity you don't actually need that
you want to show that there exists some $\varepsilon>0$, such that for all $\delta>0$, there is a point $x$ in the delta-nbhd of $\lambda$ such that $\abs{x-\lambda}<\delta$ but $\abs{f(x)-f(\lambda)}\geq \varepsilon$
ah true.
ShiN

where the first absolute value is complex
Does this check out at the end?

seems good
thanks for the help
np
just started my intro to linear algebra class... what does this question mean?

do i leave in REF or RREF?
Continue row reducing until you can read off the solution set
So i know this is an inconsistent solution set
for example, 7 you dont have to do anything else cause you can read off that there is no solution
Nope, however for 8 there is still work to be done
Oh ok
cause you can easily tell the system will row reduce to $[I|b]$
Mosh

so it will have a unique solution
If i put this into desmos I get that there is a common point of intersection

But my reduction work says that there are infinitely many solutions
what am i doing wrong?
sorry didnt see the ping: You further row reduce like I said

it doesnt
well you didnt link a video
copy pasting from mac doesnt show up 

❖ A linear system Ax=b has one of three possible solutions:
- The system has only one solution.
- The system has no solution.
- The system has infinitely many solutions.
So, we have explained how to determine if a system of equations has the three types of solution which are a unique solution, no solution, or infinitely many solutions. Als...
there we go
i mean even from the thumbnail
yeah, that's different
oh ok
cause one of the columns in that example is free
how can I prove u+v belongs to W for u,v belongs to W.

ask yourself: is the sum of two singular matrices necessarily singular?
the answer should become obvious if you consider something like the identity matrix and how it can be written as a sum.
thanks
sup
Say I have 2 matrices, A and B, is there a way to find every possible result of matrix multiplication of A and B (ie. ABB, ABBAB, AAABBA, etc.) assuming that there's a finite set of results?
Gonna say no, cause there are an uncountable number of binary strings
There's a countable amount of finite binary strings though. The only case I can think of a finite number of possible products happening tho is when the eigenvalues are 0 and 1.
or -1
So, I want to calculate the determinant of the matrix
$$\begin{pmatrix}\vert & \ldots & 1 \ e_1 + e_n & \ldots & 1 \ \vert & \ldots & n-2\end{pmatrix}$$
For arbitrary $n$ ($e_i$ are the standard basis vectors). I suspect it always comes out to -1 but i'm not immediately seeing an inductive argument for it
ShiN

also eigenvalues seem to be a pain
any ideas?
the n-1 first vectors are $e_i+e_n$ and the last vector is all 1s except the last coordinate which is n-2
ShiN

Here's n=8 if that helps visualise it

I think maybe splitting it into the diagonal part and the part with only the row and column of 1s might make it easier? then you could use induction on that part
does it help to rewrite the last column as the sum of all the previous ones minus e_n?
me neither, i was just throwing the idea around
Ah ok
maybe rules of how the determinant of a matrix changes when you do column operations, for example
idk
😌
ok so actually using multilinearity it reduces to the last row just being -e_n
and now the matrix is lower triangular
aha
nice
thanks
the eigenvalues are always 1 with multiplicity $n-2$ and the last 2 eigenvalues are $((n-1)\pm \sqrt{(n-1)^2+4})/2$
Sven-Erik

matrixcalc gave me a different eigendecomposition for n=6
not really important tho
julia> A
6×6 Matrix{Float64}:
1.0 0.0 0.0 0.0 0.0 1.0
0.0 1.0 0.0 0.0 0.0 1.0
0.0 0.0 1.0 0.0 0.0 1.0
0.0 0.0 0.0 1.0 0.0 1.0
0.0 0.0 0.0 0.0 1.0 1.0
1.0 1.0 1.0 1.0 1.0 4.0
julia> eigvals(A)
6-element Vector{Float64}:
-0.19258240356725248
1.0
1.0
1.0
1.0
5.192582403567252
julia> [((n-1)+sqrt((n-1)^2+4))/2, ((n-1)-sqrt((n-1)^2+4))/2]
2-element Vector{Float64}:
5.192582403567252
-0.19258240356725187
oh wait the matrix I entered in matrixcalc was slightly different
by a column operation
not sure if that would affect the EVs
All EV can also be expressed explicitly
anyone know a visual learning instructor for intro to linear and differential equations. its a struggle, keep running into instructors that have a vibe of "dont ask questions, do it yourself". i think my only option is taking online and self teach.
you could check out the "Essence of linear Algebra" Playlist on youtube
has a lot of good visuals
Here to verify a question, it looks right to me but im not 100% sure ```
Given any nonzero vectors u and v, determine the scalar c so that the vector u + cv is perpendicular to v.
v * (u + cv) = 0
(v1,v2) * (u1 + c * v1, u2 + c * v2) = 0
v1(u1 + c * v1) + v2(u2 + c * v2) = 0
c(v1^2 + v2^2) + v1 * u1 + v2 * u2 = 0
c = -v1u1 - v2u2 / (v1^2 + v2^2)
If v and u were in 3 dimensions (question does not specify)
would
c = -v1u1 - v2u2 - v3*u3 / (v1^2 + v2^2 + v3^2)
be correct?
thx for taking the time to read this
$c=\frac{-(v\cdot u)}{\norm{v}^2}$
That looks right
Mosh

yes
yes
you can simplify it however
you don't need to write them as (v1,v2)
$v\cdot (u+cv)=0 \implies v\cdot u + v\cdot cv=0 \implies v\cdot u = -||v||^2c \implies \frac{-(v\cdot u)}{||v||^2}$
v.(cv) in the 2nd line
jswatj

Ann
$||v||$ vs $\|v\|$

oh, i had no idea
you can also do \Vert (capitalization matters)
\vec{}
nice
vector arrows 
any recommendations for instructors at a community college?
alright thx, i just read this, ill write it in the simpler form
need help on a particular problem ... let me type out how far ive gone so far

so for 5a i would just do like
x1 + x3 = b1
-x1 + 2*x2 = b2
2*x1 + 3*x3 = b3
right?
for 5b am i bit confused. by solve it do they just mean put x1 x2 and x3 in terms of b? if they meant that then why doesnt it say so? would x3 = -b3 + 2*b1 be correct if this is the case
and for 5c i was gonna guess
3 0 -1
3/2 1/2 -1/2
2 0 -1
based off my answers from b.
is that right?
thanks
can a matrix with infinitely many solutions be consistent?
how does that work
i am confused


find the temperatures at 1,2,3 and 4
then solve the system
for example, $4T_1=10+20+T_2+T_4$
Mosh

which comes from examining node 1
okay
do that for all 4 nodes, and you'll have 4 equations in 4 variables
each temperature does not need to have a coefficient though right
or does it not matter
There is, it just doesnt affect T_1
It will help when writing the augmented matrix, but for 43 it doesnt matter
$4T_1-T_2+0T_3-T_4=30$ makes it clear the 1st row of $[A|b]$ will be $[4,-1,0,-1|30]$
Mosh

oh ok
@nocturne jewel correct me if im wrong but
T_2 would be (20 + 40 + T_1 + T_3) / 4 correct?
yeah sorry
forgot the average
i was just having difficulty understanding how to read the diagram
thank you though for your explanation
this isn't too hard
for 5b you can just put it in an augmented matrix and row reduce it accordingly
actually for 5c just write it out like they want u dont need to invert it
then pull out b and get the coeffecients for A^-1
i think what you have is right
if you row reduced properly
Can anyone explain how points P and Q end up as a vector?

one can use vectors to indicate positions, so-called position vectors
these vectors have tail at the prigin and head at the point
you see they took the coprdinates of p and q and directly put them into vectors. this is the same as doing e.g. p - (0,0)
coordinates and pos. vectors behave similarly to each other and the distinction is slight.
ok, i'd initially plotted them as follows. i've read that they don't have to start from 0 on a cartesian plane

tje what doesnt start at 0?
vectors dont have a location
you can assign a location to them if it helps you, but this is extra info
in this sense, you need to express the vector in terms of both the head and the tail
once you subtravt the 2, you habe a single vector with no location. you could place it anywhere on your plane if youd like
though it is customary to again set ita tail at the origin
how would one draw them graphically?
I got this... but doesn't seem to make sense cos the - signs are no longer there

This seems to conform to the answers

Q - P = Q + (- P) = - (Q - P)
youd need to look up how that plotter's vector() function works
cuz you see changing the order of P,Q changes the direction the vector points in

is this an exam? it seems to have points assigned to it
bout to ace his exam 🙏
with discord help 
its a question from a sample question paper
what about the geometric discription
rotate x by an angle theta
range will be the sum of the vector and the rotated vector, ryt?
mhm. and well, that's a linear operation. now say the result is called y = Rx. what does x_0 + y do to y?
what does that mean geometrically
let's see it this way. Rx is some random vector. let's say we fix its length to 1. we still don't know its angle though, so for practical purposes, we can depict Rx as a circle with center at the origin.
what happens if we now add x_0 to Rx?
what happens if you add x_0 to every single point on a circle?
radius of circle changes?
try it yourself on a piece of paper. say the circle passes thru (0,1), (1,0), (-1,0), (0,-1), which a circle with radius one and center at the origin does
all of those points can be represented with position vectors
those are possible results of Rx
now add a vector x_0 = [2,2] to all of them
and draw the circle that passes through those points
what do you get
displaces the origin?
bingo
so you can describe this as first rotating the vector x and then displacing it
got it
now you can test the linearity yourself, but as a direct consequence of the displacement, 0 is no longer mapped to 0
this should already tell you if it's linear or not
alternatively, see whether T(v + w) = T(v) + T(w), which is a property that must hold if T is linear
thanks for the help
that's the take-home message
Can I ask a question here or is that not allowed?

It's about vectors and the problem is:

I know what to do if vectors c + d is a single vector and it goes from the initial point of vector A to the terminal point of vector B, but I'm unsure how to approach this problem because that isn't the case
Yes, that'll make the same vector but just pointing the opposite direction
yeah so now you can draw the vector -c + d onto that graph
Shouldn't -d be better than -c?
looking at the directions of the arrows
cant you straight up say c -2a = b + d
and simplify that
it's the same as ehat vee says, but without modifying any of the given vectors in the plot
Ahh. I was looking at the question wrong, I don't know why I kept thinking it was a=c-d-b
I understand now, since a has a scalar value of 2, and the question is looking for a by itself, we need to divide by 2.
How can you draw that conclusion that you can straight up say c-2a=b+d, can you elaborate a little bit? You're right but I just want to understand how you were able to make that deduction right away
you draw a line from where 2a and b meet to where c and d meet
or you imagine that line
follow -2a + c is the same as follow b+d
i feel like we imagine these differently though, so this just how i see it
alternatively, you could have also done: a + a + b + d = c by the process of vector addition (resultant vector is formed by connecting tail of first vector to the head of the last vector)
either way, u arrive at the same answer
many ways to imagine these
I see
either way, u arrive at the same answer
Well, thank you all for the generous help
as they said
vector addition sets vectors one after the other. the head of one is the tail of the other
subtraction instead joins the heads of two vectors, and the head of the resulting vector follows the classic vector = head - tail principle
how do i get rid of the bracket inverses in this (matrix btw)
just take the inverse of both sides
how?
by inversing both sides?
both sides of the equation?
im not sure how A^{-1} or C^{-1} showed up
B^{-1}D on the right side is correct
when you take the inverse on the left it just cancels out the inverse already there
you'd get N^{-1}A + C
you can also multiply both sides by the inverse of the LHS and see if that helps in any way
multiply both sides by tteppa


guys, im confusing with definition of dependent variables. can someone help me if its right or not?
if there is y that dependent on linear 3 variables (in this case with noted as x0, x1, x2) and some constant, is it posible i write this as below?
y = x0 + x1 + x2 + C
what was the definition given to you?
well, i was thinking on implementation (the question is just made by myself) on some data. there are 3 variables that plotted with 1 output varible, and all of them is shown graphicly linear
and statement above is my conclusion.
so you want to do a linear regression?
yes
you're close, but forgot possible scalars for the x_i
$y = \beta_0 x_0 + \beta_1 x_1 + \beta_2 x_2 + c$ i guess
Ann


oh nvm its just schur complement
you can usually take all the vector equations and just stack all the vectors on top of each other
you could build it that way
dual problems are usually formulated that way
you get a new problem with different constraints, and then make a huge inefficient matrix that you would never actually code
but looks nice on paper
R is presumably a correlation matrix, yeah?
hermitian positive (semi) definite
you can factor it
yada yada
B^H B
yea
what does the P_m (F) = span(1,z,..,z^m) notation mean here

and what is this saying:

you know what the span of a set of vectors is?
yep
the vectors are 1, z, z^2, ..., z^m
for example, you can construct any order 1 polynomial by considering linear combinations of 1 and z
i am confused because i dont know what it means for 1, z, z^2, .., z^m to be vectors, their variables in a polynomial expression with degree m
vectors in a vector space can be anything that satisfies the definition 😛
look at this example
can i see an example , yah
you know what a linear combination is, yeah?
yea
so let's say we have the vectors 1 and z
ok
order here means degree, yeah?
ah, i see
(where a and b are from F)
yep
you could also build an isomorphism to R^{m+1} if it helps you
some sort of correspondence between these monomials and canonical basis vectors
e.g.
for quadratic polys
so it's saying the set of polynomial functions with degree up to m that map F -> F can be expressed as span(1,z,..,z^m) ?
yes, cause polynomials are just linear combinations of monomials
yep
just open up your mind to what "vector" means
ok that helps
review the definition of vector spaces and subspaces and notice it's just a set of basic rules
vectors are just things that can have a notion of "adding" and "scaling"
literally anything that satisfies those rules is a "vector" in a very abstract sense
i am used to think of vectors strictly as F^n as oppose to any thing that satisfies the vector space axioms
that tends to be the first example one sees, indeed
but that makes a lot more sense
can you help break down what this is saying as well
is it saying polynomial functions are uniquely determined by their coefficients? i dont understand
what it is saying
yes
ok i see
Basically if I have $p(t)=\sum_{i=0}^{n-1}a_it^i$ then I can make an isomorphic map which maps $p(t)$ to $$[a_0,a_1,...,a_{n-1}]^T$$
Mosh

so if you have: a1 + a2 z^2 + ... + an z^m and b1 + b2 z^2 + ... + bn z^m, then in order for the two polynimials to be equal then a_i = b_is have the be equal?
yes
awesome, thank you
if p(z)=q(z), then constants must match, linear terms must match, etc
ok, that makes a lot more sense now thank you
that answers all my questions for now, thanks for all of the help
ok, so i think this is saying y, R are fixed, and saying that if t is varying, then min t = y^HR^-1 y must hold for the block to be PSD
maybe im not used to it but was hard to parse what the statment is saying...
i would need to read all of the context to know. idk what the goal is. estimate y? estimate R? get t?
yea, i think the context agrees

theorem is this

they basically break Y, which is fixed matrix into columns y_t
now, in here, why can't we have y^H R^-1 y < min|x|^2


you say that, but what you get is the minimum 2-norm solution for x
depending on how A looks, there might be no or infinitely many such x
true, this is only supposing there is some x?
they used tikhonov so i guess they want a smooth one
hm thnaks ill look it up
that R + \sigma I stuff
I think its ok to assume A full column rank here and theres a solution, so all is good
since the context is T(u) is toeplitz with decomposition A^HD^1/2 D^1/2 A
and applying there, y is in the span of A
Heya all, super sorry if I’m in the wrong channel here; it wasn’t a specific homework problem or anything and I think it has to do with la so I decided to put it here but does anyone know what this is?

I searched up Vandermonde Determinant and just saw a bunch of matrices?
Not sure how it would be calculated in this context,,,
do you know the general form of a vandermonde matrix? And do you know what a determinant is?
The general form of it is
$$ M =
\begin{pmatrix}
1 & a_1 & a_1^2 & \dots & a_1^n \
1 & a_2 & a_2^2 & \dots & a_2^n \
\vdots & \vdots & \vdots & \vdots & \vdots \
1 & a_n & a_n^2 & \dots & a_n^n \
\end{pmatrix}
$$
The usual time complexity of calculating a Determinant of a Matrix is usually $O(n^3)$, basically a polynomial of degree 3 with respect to the number of rows/columns of the Matrix.
The Vandermonde Matrix is a special form of Matrix that comes up in other areas in math and Vandermonde found a trick to calculate the Determinant of this certain form of a Matrix (which is $O(n^2)$). It's not that complicated as we got this as a homework problem but I'll spoil the result here
$$
\det M = \prod_{1 \leq i < j \leq n} (a_j-a_i)
$$
So for example, the Matrix
$$ M =
\begin{pmatrix}
1 & 1 & 1 \
1 & 2 & 4 \
1 & 4 & 16 \
\end{pmatrix}
$$
(why is this in the vandermonde form?) has the Determinant
$$\det M = \prod_{1 \leq i < j \leq 3} (a_j-a_i) = (4-2)(4-1)(2-1) = 6$$
The sequence looks at increasing matrices. The matrices get solely defined by the second column (hope that's clear). The sequence asks $a_1, a_2, a_3, \dots$ to be $1, 2, 4, \dots$ so $a_i = 2^{i-1}$. Since we know the Determinant of these matrices, we can rewrite the series as
$$
\det M = \prod_{1 \leq i < j \leq n} (2^{j-1}-2^{i-1})
$$
So the sequence would be
$$1, (2-1), (4-2)(4-1)(2-1), (8-4)(8-2)(8-1)(4-2)(4-1)(2-1), \dots = 1, 1, 6, 1008$$
Hopefully you can see by looking at what factors gets added (or here multiplied) at each step that each term divides its successor. The second note that $2\cdot v(n+1)/v(n)$ divides $v(n+2)/v(n+1)$ is a bit tricker. If you want to know more, you can play around with these terms in the factorised form and try to get an intuition for why this should be true.
@lucid pasture
T0lgi01

Hi and sorry I just saw this ahaha, thank you so much for the thorough and helpful explanation!! that makes a lot more sense 😅 🥰

i dont know how to set up the initial system
is it like kx+y=0 for the first equation?
i dont think thats right bc then the last equation would be 2y-3z=0 but if y and z are 1 then that equation is never true
Can't you just... do the multiplication then get a polynomial in k = 0?
oh like just multiply the matrixs left to right
Yeah
idk what i was thinking
you'll get a 1x1 whose entry is a function of k
i think i was trying to take it as a coefficient matrix or something
so f(k)=0
There might be some neat trick cause ik $x^TAx$ is a common form of things, but I've never learned it
Mosh


thats over my head as of now
im sure theres alot of neat tricks and stuff you can do with matrix and transpose and trace
Yeah, here A is symmetric and diagonalising A makes this much simpler
But that's almost certainly over the top here
Hello - i am trying to utilize the rref command in my MATLAB script but it is not working
Does anyone know why?
It is just printing out the exact same matrix
B = [1 -2 0 0 -9 -8 ; 3 -5 -4 1 -29 -27 ; -1 2 0 1 11 11 ; -4 6 82 -6 32 26];
B([1,4],:) = B([4,1],:);
B(4,:) = B(3,:) + B(4,:);
B(3,:) = -1 * B(4,:) + B(3,:);
B(2,:) = 3 * B(3,:) + B(2,:);
B(1,:) = -6 * B(2,:) + B(1,:);
B(1,:) = 1/2 * B(1,:);
B([3,4],:) = B([4,3],:);
B(1,:) = -2 * B(4,:) + B(1,:);
B([4,1],:) = B([1,4],:);
B([3,4],:) = B([4,3],:);
B([2,3],:) = B([3,2],:);
B(2,:) = 4 * B(3,:) + B(2,:);
B([2,3],:) = B([3,2],:); %REF
B(3,:) = 2 * B(4,:) + B(3,:);
B(2,:) = -1 * B(4,:) + B(2,:);
B(3,:) = 1/37 * B(3,:);
B(2,:) = 4 * B(3,:) + B(2,:);
B(1,:) = -2 * B(2,:) + B(1,:);
B(1,:) = -1 * B(1,:); %RREF
B = [1 -2 0 0 -9 -8 ; 3 -5 -4 1 -29 -27 ; -1 2 0 1 11 11 ; -4 6 82 -6 32 26];
rref(B);
i reset the matrix to the original one stated in the problem to test the command but i have no idea as to why it the rref is not working

what's meant by consistent
check if it has >= 1 solution
any ideas so far
Row reduce until you get something lower triangular, then check for consistency
@nocturne jewel i tried to reduce but all i get is extra baggage whenever i try to do something
im so lost
u know about spans?
but u can write it in matrix form
yes
and I guessing u don't know much about determinants
wdym extra baggage
you should be able to just row reduce it and see if theres more than one solution

which half do you need help with? what have you tried?
I've tried the first half
might be prudent to try a contrapositive argument
but I'm not able to prove the first part
we know that |a+b| ≤ |a| + |b|, so suppose a, b are linearly independent and prove |a+b| < |a| + |b|
actually nah that works but its probably not the easiest approach
how about this
wtf
we want to show $\phi \alpha + \psi \beta = 0$ has nonzero solution scalars $\phi, \psi$; we can divide through to get $\alpha + (\psi/\phi)\beta = 0$ (or if $\phi = 0$ divide by $\psi$ analogously). take the norm of both sides and work from there
???
i just copy-pasted
whatever
Namington

I got norm of alpha + (norm of beta)psi/phi = 0
You can just use the fact that 2 vectors are linearly independent iff one is a scalar multiple of the other. It's the same as what nami said but stated a but more succinctly
I have v1=(a,b,c,d) and v2=(a',b',c',d'), 2 linearly independant vectors from R^4. How do i write Vect{v1,v2}?
what is vect(v1,v2) suppose to denote?
The vector space defined by those 2 vectors
Just span{v1,v2} I suppose
$\text{span}{v_1,v_2}={v\in\mathbb{R}^4| v=xv_1+yv_2; x,y\in\mathbb{R}}$
Mosh

Yes i know that, but it isn't what they're asking actually. Im also kinda confused with their answer, i'll send a pic (its in french tho)
well you asked for the vector space of those vectors so...

{kind=link}
Thats what they're asking as well, but i think we need to be more precise i guess
The value of k for which the linear system 2x+ky+z=4
-kx+2y+2z=2
x+y=0
Does NOT have a single solution.

I found 6. Is this correct?
you can check yourself, you can rref the resulting matrix
what is rref?
reduced row echelon form
RREF the matrix is synonymous w/ using row operations to get it into RREF
Isn't that a long procedure?
"Row operations" oh well I guess my question is answered already
I mean... it scales in complexity as the size gets bigger
but generally a pretty quick algorithm
hey guys, could someone help me prove why non symmetric real matrix can't be diagonalized by any orthogonal or unitary transformation? I just can't get a grip on how to begin at all. (I'm really sorry if this is too trivial and is basically dumb to ask)
prove the contrapositive
so prove that only symmetric matrices can be diagonalised by the aforemrntioned transformations?
Can anyone tell me what "det" means?

'det' means determinant
Ahhh thank you so much.
If I have a symmetric $(k \cross k )$ matrix A, I know it will have a set of orthogonal eigenvector with real eigenvalues. The eigenvectors may be normalized. Now if I construct a matrix $P$ where each colomn contains one of the eigenvectors, how can I prove that it's orthogonal? i.e $P^{T}P = \mathbb{I}$
shadowplayer67

I tried proving $PP^{T}$ by examining what I get from multiplying the i-th row in P by the j-th colomn in $P^T$ but it was nonsensical because I ended up with $\sum_{n= 1}^{k} e_n^{(i)}e_n^{(j)}$ so adding the sum of the products between i-th coordinate and j-th coordinate of the n-th eigenvector. When I instead looked at $P^TP$ ,I got the following sum $\sum_{n= 1}^{k} e_i^{(n)}e_j^{(n)}$ which is just the dot product of the i-th and j-th eigenvector
shadowplayer67

sorry I know it's a lot. I just wanted to show my working/results. I know from $PP^T=(P^TP)^T=I^T=I$ but that feels like cheating because I'm bypassing a proof I can't show. It feels so simple that I don't know what's going wrong 
shadowplayer67

If P is an orthogonal matrix then P^t = P^-1 I believe
And P * P^-1 is the identity
sure, but that's the thing.,I KNOW that P^t should P^-1 but I'm wondering why the equality doesn't hold when I decide to expand it in terms of row-coloumn multiplication
The best way to go about this honestly is to work it out with a 2 by 2 example
Think in terms of the inner product, and apply P^TP to the basis vectors
For example, Pe1 is just the first vector in the orthonormal basis
And thus P^TPe1 is just e1, as multiplying any row other than 1 with Pe1 gives you 0 (due to the fact that the columns of P are an orthonormal basis)