
#linear-algebra
2 messages · Page 216 of 1
all symmetric matrices over the reals are diagonalizable but just because a matrix is not symmetric doesn’t mean it’s not diagonalizable.
i agree it seems to be the first that is false
the last three options are true, so the first must be false.
ninja'd
lol
that just doesn’t seem satisfying tho
i think it’s because C!=E that the first one is wrong. you would need a change of basis matrix to find out what [T(v_1)]_E is
right, you get coords in the C basis
you'd need to transform them once more still to get to E, e.g. with a matrix whose columns are the u_i
How to solve these equations for x y z w

is theta known?
No actually i am proving that inverse of rotation matrix exist by finding unknowns in the inverse matrix
By comparing it to R(theta)R(theta) inverse=I
an easy way by inspection would be to try stuff like letting y and w be cos theta and sin theta, for example
that'll give you cos^2 theta + sin^2theta = 1 for the last eq
idk if that works for the others tbh
it works for the second equation
Is there any other way to prove inverse of rotation matrix exist
rotate it back in the opposite direction? finding the determinant (reasonable in 2D)
take x=cos(t) and z=-sin(t) for the other equations
Okay
i was about to suggest case work 🤮 thank god you said something before i did.

Actually problem is . We know the inverse of rotation matrix is the transpose of itself thats why i k we can take x=cos(theta) z=-sin(theta) and this will easily solve the problem . But can we prove it without this eqn stuff n equating it with I
why not do the usual inverse of a 2x2 matrix?
i believe this is a special case of a more general property of orthonormal matrices
an orthonormal matrix is one whose rows and columns are orthonormal vectors. if you have an inner product space and an orthonormal matrix A, then AA^t = Id = A^tA.
Actually i haven't come across the concept of orthonormal matrices 😅. Just started the 2 chap of s lang intro to linear algebra
well, i mean, you secretly have if you’re working with rotation matrices
if you can show that the dot product of any column with itself is one and the dot product of any column with a different column is 0, then you’re done.
The inverse of a rotation matrix is just rotating the opposite way
also it's the 2x2 matrix, so the formula for the inverse is known explicitly
$\begin{bmatrix}a&b\c&d\end{bmatrix}^{-1}=\frac{1}{ad-bc}\begin{bmatrix}d&-b\-c&a\end{bmatrix}$
Mosh

Hey guys, I have a question about the rank of a matrix. Is the rank of a row space simply equal to the number of independent rows? Also, are the column rank and row rank always the same? Is the rank of the matrix just equal to the rank of the row or column space?
the inverse of a rotation matrix is its transpose
Yeah ik
and you prove this by noting that the columns are orthonormal
@quiet heron
-
the dimension of the row space is the number of linearly independent rows.
-
yes. one way to see this is because of gauss jordan elimination and row equivalence.
-
the rank of a matrix is the number of linearly independent columns, so yes it would be the dimension of the column space.
the rank of a matrix is the number of linearly independent columns of a matrix, or equivalently, the dimension of the image. you don’t talk about the rank of a subspace, you talk about the dimension of a subspace.
dimension is the size of a basis
rank is dimension of the column/row space
Gotcha

What's the difference between part a & b? For a, I determined that B is in the span.
Then, for the next part, can't I just set B=[3,2,1] and call it a day?
B could also not be [3,2,1]
i think they might want you to check if no matter what the values of a,b,c are, it will still be in the span
another way to phrase it is "does there always exist a solution to the system regardless of the value of B?"
How did you figure that out so quickly? I just rrefed the matrix
That [a,b,c] is in the span of those vectors.
Before starting part b, I assumed there would have to be restrictions for a,b,c. Turns out after rrefing the matrix, It works for all values
if there is no stated restrictions on [a,b,c] u assume that a,b,c are any from you field
and it happens so that indeed any vector of the form (a,b,c) is in the span
Where did you get LI from?
Bc you said basis and I only wanted to show that B is in span
you have list of three vectors spanning R^3
it is forced to be linearly independent
since R^3 has dim 3
dimension is basically the length of smallest spanning list
ahhh rank-nullity I see
the matrix has 3 pivots
Help me plis 😦

Find how to represent $\begin{bmatrix}4&3\2&1\end{bmatrix}$ as a coordinate vector of B
Mosh

how would i prove or disprove that A and B are similar ?
they have the same Eigenvalues, Eigenvectors, Dimension , Rank and Determinant.
so i am thinking they are similar but not sure how to prove it.

two matrices are similar if there exists a P such that A = PBP^-1
if they have the same eigenvalues and eigenvectors, you already have that AP = BP = PD, with a diagonal matrix D that has the eigenvalues along its diagonal
maybe you can use that in some way
i knew this part had no idea a about the digonal matrix thing, but i am not sure how to find P, for 2x2 matrix it is usually easy to figure it out but for a 4x4 matrix it seems really hard.
is there a method or an algorithm i can use ?
you can do it in software
also, are you sure they have both the same eigenvalues and eigenvectors?
that just kinda sounds like they're the same matrix
yes i calculated it by hand and then used an online calculator
the issue is this question has only 2 points on it, and it just seems too hard for 2 points so it feels like i am missing something obvious

cant you find their span?
A and B are defined for rational numbers does it make sense for P to be non rational ?
ya it is in the picture 😅
i was negligent
wait ignore i am dumb af
row reductions would change the eigenvalues
seems kinda weird to me, if BP = AP and P is a full rank matrix, then you can multiply by P^-1 from the right and get that A = B
but i never with with Q, so i defer to someone who knows what they're doing
ok ,thanks for trying
could u use jordan decomposition? I dont know much about it though
I just googled it and if my prof. expects me to do this for 2 points on an exercise sheet then he is an asshole 😂
The number of eigenvectors aren’t the same right?
so they have the same eigen values. are they both diagonalizable?
That is true i just double checked their geometric multiplicity is not equal
neither is diagonalizable but i think i have an answer now they are not similar because B has a geometric multiplicity = 1 and A = 2
I am not able to proceed any further can someone help ?

Chapter - Vectors
Topic - Triple Product
@wintry steppe
From step a) to b), the “plus” changed to a “cross”.
Can you use doodle or any marking so I can know which step are you talking about ?@lost dragon
What's the reasoning behind the cross product existing only in the R^3 and R^7?
I think the best explanation I've seen is that when we add say some 4th perpendicular axis, say w, we need (?) 3 more dimensions as w forms cross products with the other axes.
But why this is necessary isn't clear to me.
Like why can't the following be true instead:
$$\hat{x} \cross \hat{w} = \hat{y}$$
$$\hat{y} \cross \hat{w} = \hat{z}$$
$$\hat{z} \cross \hat{w} = \hat{x}$$
Thomas

Or something similar
How do you show that a linear map with a trivial kernel is surjective (assuming domain and codomain are of equal dimension)?
i wanna say division algebras right? somebody more qualified can correct me if i’m wrong tho
like, the cross product is based off of some properties of quaternions and octernions or something and it only plays nicely in some dimensions.
dimension formula
So that gives you that the dimension of the codomain and the dimension of the range of the linear map are equal.
How does that prove surjectiveness?
because the image is a subspace of the vector space with the same dimension as the vector space
$dim(V)=dim(W)=dim(Im(T))$ if $T:V\to W$ is injective
Mosh

so W and Im(T) are isomorphic
So I'm trying to do it from definition, if I take an arbitrary vector in the codomain how do I know something maps onto it given the assumptions
oh duh, if $dim(V)=dim(W)$, then V is isomorphic to W, which implies there is an invertible map between them. So the map is injective and surjective
Mosh

basically it's proving that characterization of invertible operators holds so long as domain and codomain are isomorphisms
I'm trying to prove that first line. You're assuming it.
well kind of
I'm trying to prove that if I have a fixed linear map and the kernel is trivial, then it's an isomorphism.
Without the theorem that there exists an isomorphism if the domain and codomain are of equal dimension
$\text{im}(T)\subseteq W$ and $\dim\text{im}(T)=\dim W$ so $\text{im}(T)=W$
coycoy

OK, I think that's what I'm looking for.
or you could go overkill and apply the first isomorphism theorem
Is there no way to prove it from the definition of surjectiveness?
i mean, that is the definition…the image is the whole space W
well I guess that gives it to you
surjective maps are characterized by im(T)=codomain
Yea I just realized that Axler defines surjectiveness like that
I thought it was like the set-theoretic definition.
Which is corollary now
I guess
ker(T)={0} means injective
im(T)=W means surjective
both means bijective
only when dealing with linear transformations from two isomorphic vector spaces
I was trying to construct, I guess explicitly, the vector that maps onto the arbitrary vector I chose, but I got stuck because I don't know what maps onto the basis vectors in the codomain for an arbitrary linear map.
So I guess, how do I prove that ^ ?
Now that it's shown that the map is surjective as defined with imt(T)=W
choose a basis for v, call this v’=(v1,…,vn)
since T is, in particular, injective, then w’=(T(v1),…,T(vn)) is a basis of W
Wait, how do you know that it maps onto a linearly independent set?
injective maps always map linearly independent families to linearly independent families
OK, I'll review that theorem after. I'll take it for granted for now.
it’s not too hard to show.
anyway, take your w in W. write it in terms of the basis vectors of w’
then use linearity of T and apply T inverse to w and the expansion of w in terms of w’
yessir
can i swap columns in a matrix?
no its illegal
you can but you will most likely change the kernel of the matrix
whats the kernel?
the set of vectors x such that Ax=0
yeah i have no clue what that means looool
the reason you can swap rows in for instance, row reduction, is because row operations don’t change that set.
they just started LinAl coy btw

ok, so just stay away from column swapping for now, got it
Does column swapping preserve anything?
What about row swapping?
row swapping is fine i think
i believe it preserves the image
it preserves the absolute value of the determinant 
row swapping changes the sign, right?
column swapping preserves the image, yes
swapping anything changes the sign of the det
wait im confused, does row swapping change anything? like if i row swap do i have to do anything
what's the det?
It changes certain properties about the matrix that you will learn about later.
oh no
I guess no need to worry about it now.
no no no. row swap definitely for row reduction
If you're just doing row-reduction, it's fine.
But like if you were going to calculate the determinant (whatever it is) you want to be careful with that
Row swapping would just be writing the linear equations in a different order
the determinant is a function of square matrices that tells you various things such as invertibility and, at least in R^n, how the linear mapping changes the volume of the unit cube
okkkkkkkkkk that makes sense why when i column swapped the answer made no fucking sense
let’s just dump all of linear algebra on him rn
And swapping columns would be something like x y z to x z y
the rank-nullity theorem in essence is....
the spectral theorem in C states...
a special case of the first isomorphism theorem
stfu
the determinant is very geometric and you should not let anyone convince you otherwise
@teal grotto that's basically what that last 9 hours of my life has been...my book threw this shit expecting that I already knew how to do it. IDK if we were supposed to learn this in alg 1 or not because we didnt, and im sure i didnt miss an intro lesson to this unit, last lesson i was working with complex numbers and imaginary units which the book throroughly explained but i literally have been stuck on matrices and gausshittian elimination for the last day and a half
why are you sullying me coycoy
or im prob just stupid
*linear algebra
agreed
idk. what even is a volume
This is a chat
some differential form, right?
damn higher math strikes again
(so more correctly, the integral of the volume form dx^1 \wedge \cdots \wedge dx^n)
this is basically second year calculus
precalc has no integrals
real shit though, wtf is a form?
idk. i just haven’t seen volume other than area under a curve made precise yet
it's a thing to be integrated
woops wrong message
meant to reply to the previous
a differential k-form, morally, assigns to each point a tool that measures the volume of infinitesimal k-dimensional parallelepipeds at that point. when you sum up all of these infinitesimal volumes (integration) you get the area of a surface
(take "area" and "volume" to be synonymous in this explanation)
in a few minutes i just got out of the shower

i might need to handwave a little on the "infinitesimal" part since that's formalized using the tangent space
meh tangent space to R^n is easy to get
i’ve heard it described as something like equivalence classes of functions or something but i didn’t get too familiar with them
ok so
i can probably get away with not even mentioning tangent space, but for the sake of generalization i will
SSussy

so it's just like a copy of R^n at p
SSussy

(star means dual space)
ok gotcha
example time
so you know how some people say "dx is a one-form," right?
time to unwrap that
OK so we have vector spaces parametrized by vectors with linear maps for each one
this is going to be a good day
i'll do things in R^2 to keep the notation simple
the expression $dx$ stands for the one-form on $\bR^2$ defined by $$(dx)_p(p, (v, w)) = v$$
SSussy

that might take a second to decipher
remember first that dx takes in a point p, and then it takes in an element of the tangent space to R^2 to at p
the idea is that, once eating a point p, we want to measure things in the tangent space to p
dx, for example, measures the "horizontal component" of a vector in the tangent space at p
oh shit
wanna guess what dy does?
= w?
yes
wet
lol
we have notions of continuity and smoothness for differential forms
I'm not sure if I got an intuition about dx, but I mostly follow. lol
Like imagining a tangent space to a point in R^2 is a bit tricky
just imagine a copy of R^2 centered at p
Yea OK, in some orientation
SSussy

for higher degree forms (not yet defined) it just gets complicated in notation
yea that’s what i meant to say. a lot of notation going on
yea wtf can I do with this shit?
integrate
And who was high enough to think about this?
I'm going to take every element of a group and assign a group to it. I'll call it the 'tangent group'.
just wait until you hear of algebraic topology
Next, I'll assign isomorphisms to each group....
totally high
I hate algebraic topology. It's just algebra.
elie cartan was apparently
It makes sense though
AT, makes sense, not forms
You want to count holes on a smooth space? Rigidify it with something like a simplicial complex and you can define a hole.
forms are fake tho
facts lol
Hi guys, I have a question that I can't solve it, can I ask for some help here?
go for it, we've left the solar system already
The question is to find the cartesian coordinates of this parameterization

My brain is checked out, can i post a problem here and come back tomorrow to see if anyone solves it?
I hope i wrote it right
hold on my carbon monoxide detector is going bonkers i can't keep explaining the forms stuff

low battery
FINALLY
I KNOW HOW TO DO IT
I CAN USE GAUSS-JORDAN ELIMINATION
IT HAS TAKEN EXACTLY 11 HOURS AND 58 MINUTES
BUT I GOT IT

these are the moments to grind for
matrix algebra time
Those?
like the concepts i learn
i'm learning from youtube and other resources for now
just i want to solve some problems and do stuff around
Get a textbook. Maybe some engineering book that includes linear algebra?
It will have problems to do
Payable?
like is it a paid service or free one?

can you link me any of those ?
I just Google. This is how I find textbooks.
https://www.google.com/search?q=engineering+linear+algebra+textbook+pdf&client=ms-android-samsung-ss&sxsrf=ALeKk01nw1EwMBzB3OVSur6eBRCPuE_ZBw%3A1624593204685&ei=NFPVYLypKYa-tAajoZrwDw&oq=engineering+linear+algebra+textbook+pdf&gs_lcp=ChNtb2JpbGUtZ3dzLXdpei1zZXJwEAMyBggAEAgQHjIGCAAQCBAeOgQIABBHOggIABAIEAcQHjoECCEQClD4_gFY4YECYP2DAmgAcAF4AYABwQGIAfcDkgEDMi4ymAEAoAEByAEIwAEB&sclient=mobile-gws-wiz-serp
Sorry for the awful url

nah lol i don't mind it
thanks for that i found a book idk how it's enough for me
i'll learn it anyway
can someone help me in finding basic applications of matrix methods except circuit diagrams,crypto,traffic flow,balance equations... someone pls?
solving any system of linear equations, multivariable curve fitting can be done w/ matrices
Computer Graphics
I have a problem, I am given this matrix with K=Z_2

And I have to find a matrix B

with

And I have no clue how the image of A looks here
nvm, I found the image of A
But now I'm stuck again, how do I construct a function whose kernel is that?
@late canyon You mean something like this?
https://en.wikipedia.org/wiki/Kernel_(linear_algebra)#Computation_by_Gaussian_elimination
In mathematics, the kernel of a linear map, also known as the null space or nullspace, is the linear subspace of the domain of the map which is mapped to the zero vector. That is, given a linear map L : V → W between two vector spaces V and W, the kernel of L is the vector space of all elements v of V such that L(v) = 0, where 0 denotes the zero...
well, if it helps, Ker(A^T) = Im(A) perp (i.e. the orthogonal complement of Im(A)) for all matrices A
or wait did I mess that up
idk
nope

Support the channel on Steady: https://steadyhq.com/en/brightsideofmaths
Then you can see when I'm doing a live stream.
Here I present some short calculation for the kernel of a matrix. I apologise for my pronunciation. The focus is on the mathematics and not my English skills :)
(This exercise fits to lectures for students in their first yea...
I have the inverse problem, but I think I've solved it
i believe this implies that BA=0
but since ker(B)=Im(A), dim(ker(B))=4 so you do need rank(B)=3 by rank-nullity
Can pivots in REF be ANY number? Including negatives?
Example:
[ 1 2 0 ]
l 0 -1 1 l
[ 0 0 -1 ]
SO i'd have to make r2 column 2 & r3 column 3 into 1s?
You sure you aren't talking about RREF?
I know RREF all pivots must be 1s and on top and below the 1s has to be 0s
So then basically if they do have to be 1s. Then for both r2 c2 and r3 c3 all I have to do is do is -1R2 -> R2 & -1R3 -> R3
yes pivot columns are when there's 1 1 in it and the rest is 0
pivots can't be 0 but other than that yes they can be anything
ty all
the subspace theorem?
that's
the definition
is it not?
you don't prove a definition

This matrix in the 3rd row doesn't have a pivot in column 3. So would this mean I won't be able to solve my system?
[ 1 -1 2 4 ]
l 0 5 -5 -7 l
[ 0 0 0 -7 ]
is this the augmented matrix of your system?
Original was:
[ 1 -1 2 4 ]
l 2 3 -1 1 l
[ 7 3 4 7 ]
is this the augmented matrix of your system?
okay
then the system is inconsistent.
you will only be "unable to solve it" if a mysterious force prevents you from writing down the word "inconsistent"
lol i see
So look at this..
I got to this point in my matrix right:
[ 1 -1 2 4 ]
l 0 5 -5 -7 l
[ 0 10 -10 -21 ]
Would it had been correct to go about and saying.. 10R1 + R3 -> R3 ... or not? I first went with -2R2 + R3 -> R3
Doing it as 10R1 + R3 -> R3 would had gotten me a Z = answer?
What's that about?
Just an immensely annoying subject someone decided to squeeze into my linalg 2 curriculum
Sorry didn’t mean to take these sideways. I am not sure how to get those values in part E. Or just not sure how to read it. Everything else makes sense. Can someone break down the values found for E? This is a study guide btw



How would you start this? New to linalg and proofs in general

$(v_1, \dots, v_n)$ spans $V$, which means any vector $u \in V$ can be written as [u = a_1v_1 + a_2v_2 + \dots + a_nv_n] for some scalars $a_1, a_2, \dots, a_n$. what you want to show is that there exist scalars $b_1, b_2, \dots, b_n$ such that:[
u = b_1(v_1 - v_2) + b_2(v_2 - v_3) + \dots + b_{n-1}(v_{n-1} - v_n) + b_nv_n]
Namington

this is just unpacking the definitions
in other words, we want to show we can choose $b_1, b_2, \dots, b_n$ so that[a_1v_1 + a_2v_2 + \dots + a_nv_n = b_1(v_1 - v_2) + b_2(v_2 - v_3) + \dots + b_{n-1}(v_{n-1} - v_n) + b_nv_n]
Namington

(since the LHS is equal to u)
oh that second image got cut off a bit
hopefully you get the idea
\begin{align*}
&a_1v_1 + a_2v_2 + \dots + a_nv_n \=& b_1(v_1 - v_2) + b_2(v_2 - v_3) + \dots + b_{n-1}(v_{n-1} - v_n) + b_nv_n\end{align*}
Namington

to start with this, its probably best to try rewriting the RHS in a simpler form; say, by distributing each b_k into the brackets. then figure out what each b_k must be to "match" a_k based on that.
does that all make sense?
and do you see why, once you do this, it proves that the list spans V?
I'm about to go to sleep but yeah it makes sense, thanks
Since you can write an arbitrary vector u (that's in V) with a linear combination of the new list, the list spans V
,iam studying
You already have the selfroles studying!, do you want to remove them? (y(es)/n(o))
(Tip: use ,iamnot to remove roles without this prompt.)
Session timed out waiting for user response.

T(e_i) is a sum wrt to the basis vectors of the codomain space, so there’s like \plus signs tucked inbetween the entries…..
and a matrix has no \plus signs hidden in it
I’ve seen so many sites do this and lecturers also…..
AS A POINT OF CONTRAST,
this is how Axler writes it, which is more circumspect (and less clear), but also more accurate

T(e_i) is indeed a sum over the codomain basis vectors, which would mean it represents a column vector. The collection of these column vectors is what makes T as a whole. That is, the columns of T are where each basis vector in the domain gets mapped to
$$\begin{bmatrix} a_{1,1} w_1 \ + \ a_{2,1} w_2 \ + \ \vdots\ + \ a_{m,1} w_m \end{bmatrix}$$
a rainbow powered ninny

But no one writes a column matrix that way
$$\begin{bmatrix} a_{1,1} w_1 \\ a_{2,1} w_2 \\ \vdots\\ a_{m,1} w_m \end{bmatrix}$$
$$\begin{bmatrix} a_{1,1} w_1 \ a_{2,1} w_2 \ \vdots\ a_{m,1} w_m \end{bmatrix}$$
a rainbow powered ninny

My thinking is that the notation in the green box is convenient, but ultimately incorrect……is my thinking wrong? is my question.
Remember each of the $w_i$ represent a column vector with a single 1 in the $i$th row (I’m tacitly assuming an orthonormal basis). So if
$T(e_i) = a_{1,i}w_1 + \dots + a_{n,i}w_n$, then we can write this as
$T(e_i) = \begin{pmatrix}
a_{1,i} \ \vdots \ a_{n,i}
\end{pmatrix}$
MemeMachine420


whered the + come from
T(e_1) = a_1,1 w_1 + ,,\cdots, , + a_m,1 w_m
no?
Its a linear combo of the basis vectors of w_i
each column is the image of a single basis vector
Lmao. seriously. The plus signs just vanish and you say this is a column vector?
Okay. Ive not seen that convention before
Yes, lol.
compute [\begin{pmatrix}a&b\c&d\end{pmatrix}\begin{pmatrix}1\0\end{pmatrix}] and [\begin{pmatrix}a&b\c&d\end{pmatrix}\begin{pmatrix}0\1\end{pmatrix}] for me
Namington

what do you get?
It’s not that the plus signs vanish, it’s that each $w_i$ is already a column vector. For example,
$aw_1 + bw_2 = a\begin{pmatrix} 1\ 0 \end{pmatrix} + b\begin{pmatrix} 0\ 1 \end{pmatrix} = \begin{pmatrix} a\ b \end{pmatrix} $
Axler, page 70.

missing a \
before third begin
MemeMachine420

Was fixing it
thats the exact same definition
except it takes an arbitrary basis rather than fixing the standard basis
Okay. Yeah. This is making sense.
i see it
Yeah. Imma LaTex some examples to be perfectly sure, but I think that’s what I was missing
Ye, so the original notation will all the $T(e_i)$ is just saying that each of those is a column vector and together they make up the entire transformation $T$
MemeMachine420

\begin{bmatrix} a \ c \end{bmatrix} and \begin{bmatrix} b \ d \end{bmatrix}
a rainbow powered ninny
Compile Error! Click the  reaction for more information.
reaction for more information.
(You may edit your message to recompile.)

lol. I didn’t even put the dollar signs
$\begin{bmatrix}a&-b\b&a\end{bmatrix}$ and $\begin{bmatrix}a&b\-b&a\end{bmatrix}$ can both be used to represent the complex number $a+bi$. Is one clearly better or more standard than the other?
nix (@ me for the love of euler)

basically which isomorphism is better i guess
first one feels more natural

$e^{i\theta}=\cos\theta+i\sin\theta$ under the second correspondence is the matrix $$\begin{pmatrix}\cos \theta & \sin \theta \ -\sin \theta & \cos \theta \end{pmatrix},$$ which represents a rotation \textit{clockwise} by $\theta$ degrees. but we always work with counterclockwise rotations.
TTerra

The current time for TTerra is 03:40 AM (EDT) on Sat, 26/06/2021.
^this is my excuse if i just said something dumb
that seems like a weird argument 😛
i woulda just said the second looks more like a - ib
i have no time related excuse other than i am dumb 24/7
proof by confusion
idk
there really is not much of a difference between the two identifications
just transpose one of them xd
i guess you could say the first one is more natural because a complex number a + ib is also an element of R^2, so a column vector (a, b), and the first column of the matrix rep should be that?
who knows
so that would be part of my argument tho
i can say for certain that the first one is more standard
transpose is "but now it's in dat dual space tho" moment
guys what's the difference between row echelon form and reduced row echelon form?


gaussian elimination and gauss jordan elimination
i learned both is like the same i think
i guess i'll head to Crout's method
From Wiki, you only need that pivots exist, and zero rows are at the bottom
REF isn't a very strong condition haha. It's just enough to read off some matrix properties
like an identity matrix right?
It becomes "reduced" when
- Pivots are 1
- Any column with a pivot has only 0s otherwise

So for example:
4 1 2 3
0 3 3 3
0 0 0 2
Is REF
This matrix will RREF as
1 0 0 0
0 1 0 0
0 0 0 1
Your textbook may disagree slightly on these definitions, I'm going off wikipedia here
yeah i see wait a minute
it's similiar to that right?
That picture is an RREF.

this ?
REF?
both RREF and REF does the same thing i can't classify what's the difference between them
See my examples. The REF is definitely not an RREF.
4 1 2 3
0 3 3 3
0 0 0 2
Is REF
This matrix will RREF as
1 0 0 0
0 1 0 0
0 0 0 1
I see a distinct difference between those two
so REF has the lower diagonal variables as 0s but RREF is an identity matrix right?
1 0 0 0
0 1 0 0
0 0 0 1
Is an RREF matrix, but is not an identity matrix
uhh
in the last row
there must be an one in the 3rd column
but it's in zero

here's an simple explanation
Uwat
umm
this is only for square matrices

i'll learn those things again and come back
now i get row echelon from
i were confused with the namings btw
thanks for your help 😄
Haha np. Feel free to ask if you have anything else!

I saw this in a lecture and I just wanted to know if I typed it correctly.

I think the w_k are all out of place….. none of them should be there.
Yea,They shouldn't exist
I actually write out a gory example in section 4. https://www.overleaf.com/read/wkktvyvtcntr
An online LaTeX editor that's easy to use. No installation, real-time collaboration, version control, hundreds of LaTeX templates, and more.
Any guesses why he would write them in: start at 6:55
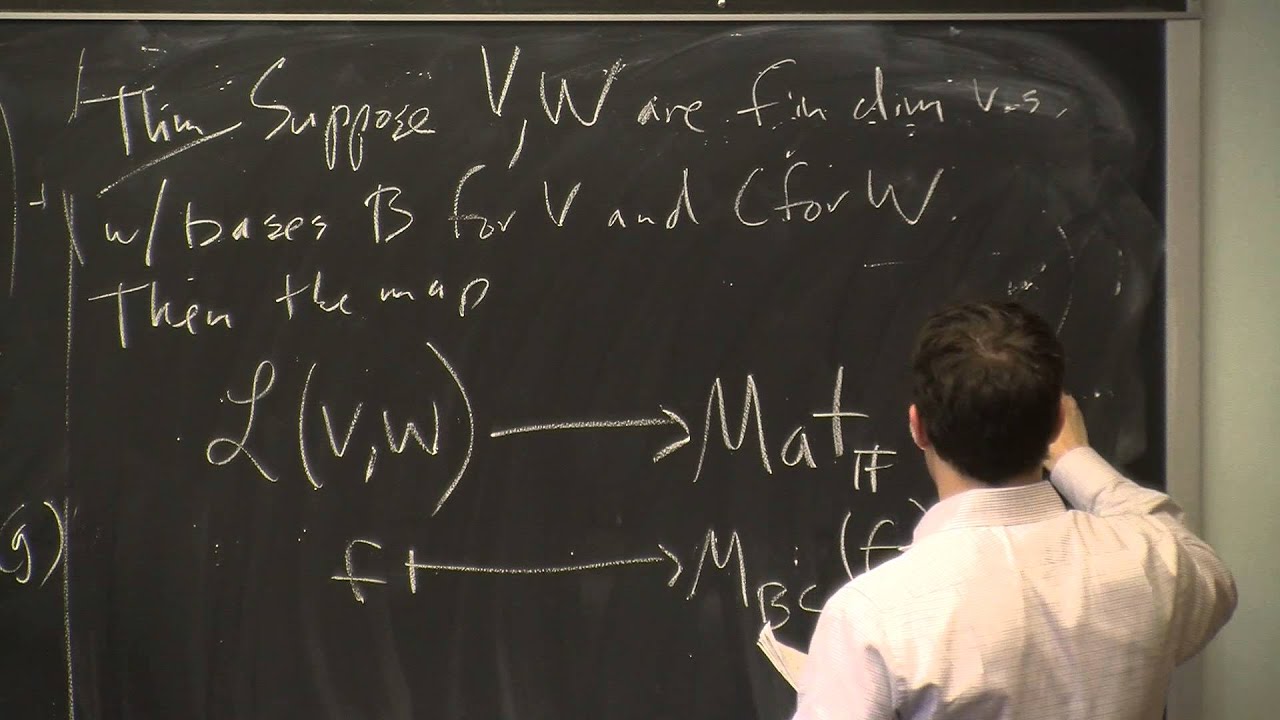
Actually…..I think I figured it out. He was doing this.

But he was writing the sums vertically….
Im going to rewrite the matrix but ill throw pluses in between the entries vertically
If f: E->F, h:F->G are linear and h is injective. How do i prove that rg(f)=rg(hof)?
i started by saying let v_i=f(w_i) be a base of ImF, then h(v_i)=hof(w_i) => Imh(v_i)=Im(hof), but i fail to prove that Imh(v_i)=Im f
what is rg? rank?
prolly range?


an easier way to do this is to use the rank nullity formula on f and on h o f, and this works under the assumption that E is finite dimensional
rank
sorry i come from a french system so half the terms im just guessing how theyre written in english lol
usually rank or rk
sometimes dim im if you're feeling groovy
so is this a good start
(maybe base=basis in english)
im(h o f) need not equal im(f), btw
only the dimension of the image is equal
h: F -> G injective means dim(G) >= dim(F)
both terms are common
okay yea, i feel like i should use somewhere that Ker h=0
if you want to do it by choosing a basis you could use the fact that h will take linearly independent sets of vectors to linearly independent sets of vectors
in particular
since your v_i's are linearly independent, your h(v_i)'s are, and that tells you something about the dimensions
i saw that but how does it help me
so dim h(vi)>=dimE?
wait no
no i think its that actually
you don't know anything about the relationship between E and h
v_1, ..., v_d is a basis of im f, and h(v_1), ..., h(v_d) are linearly independent vectors in im(h o f), so what does that tell you about the dimension of im(h o f)?
wouldnt i know something since vi's are the basis of E, and dimh(vi)<=dimG
what are the assumptions in the first place on the dimensions of the spaces?
h cannot be applied to the vi's unless E is related to F somehow
its <=rkhof
they said the v_i's were in im f
so NOT of E
aight, then yea
i confused them
i dont follow lmao, yea refered to what lol
yea thats how i defined them
that's not true either tho
why
cuz we dunno if f is injective
oh yea, damn
the argument you were going for doesn't need the w_i's to form a basis anyways
at least how i see it
unless im high
yea i dont think it needs to
at least i didnt envision it that way but idk
what i was going for with this is that rank(f) = d <= rank(h o f)
okay yea i follow
to finish it off you wanna show the other inequality, that rank(f) >= rank(h o f)
that's one way to continue the argument you started
less obscure than what i was thinking
the point of the exercise is that injective maps preserve the dimensions of finite-dimensional subspaces

thats since ker h if h injective is equal to 0 right?
i guess it could follow from that
if you used rank nullity
yea
i dont see thus
this
same thing, choose a basis of im(h o f) and do some stuff
it's the exact same thing i did earlier
okay ill try, thanks
on a side note, do you see how i could show that rk h(vi)=rk f?
to finish my inital proof
im not really sure what rk h(vi) means
vi=f(wi) => h(vi)=hof(wi)
i don't either but it should somehow turn out to be the other thing lol
if v_i are a basis of F, you can express the f(w_i) as linear combinations of v_i
then h is injective, so h(v_i) yields a set of linearly independent vectors, as many as "went in"
wave your jazzy hands
buncha sums and linearity
nice
actually what i did isnt good, i didnt manage to properly make an application for a base of Im(hof) so that at the end i get rk(hof)<=rkf
could (h^-1 o f)(a_1) be a base of Im(hof)
.

Why is this false?
rref of 3 unknowns is a diagonal matrix since each row is nonzero
which means x,y,z, the unknowns each are assigned a value
for a counterexample, consider the following system
x = 1
y = 1
z = 1
z = 0
why are there two z's
anyway this is a false statement
nothing in the original question said that the system had to have 3 equaitons
although in fact, if the system does have 3 equations, R will be 3x4
so it cant be a diagonal matrix
(since its an augmented matrix, so theres 3 rows - 3 equations - but 4 columns since theres 3 unknowns + a solution column)
as an example, consider the system x = 1, y = 1, z = 1.
the augmented matrix of this - which is already in RREF - is [\begin{pmatrix}1&0&0&1\0&1&0&1\0&0&1&1\end{pmatrix}]
Namington

that isnt meant to be a counterexample to that image
just the specific message i replied to
I mean
It can't have 2 solutions
It's either 1 or infinite
so it can't be at least 1
"at least 1" means either 1 or infinite, yes
(assuming your underlying field is infinite)
Is it false because you can have two identical rows?
they can't be identical because the matrix has to be rref
oh, right right
they can be identical in the system, just not in R.
anyway, heres a useful theorem

(rouche-capelli)

is a scalar is 1/2, then this fails.
I just want to make sure. Scalars can be rational right?
yes
to be more explicit, if youre considering this as a subspace of ℝ³, then that means your "base field" or "scalar field" is ℝ
so your scalars can be ANY real number
including rationals like 1/2
i have not taken abstract yet
so that fails closure under scalar multiplication
what is the character
naruto from naruto is my favorite character i really relate to him hes really well written and hes so strong and cool
of all the things to praise naruto for, its prose is pretty low on the list
symbol for the set of real numbers
a ton of mathematical symbols have a unicode character btw
ℝ is fairly mundane, theres some pretty damn specific shit
theres a triple contour integral character
∰
also stuff ive never seen like "Dot Plus" ∔
thats its official name, its classified as a mathematiocal operator
so its not some weird language that has an i with a line through it
⊌
apparently this \cup with a ← denotes a "multiset"
there is no \cup with a →, from what i can tell
unicode is weird.
⋇
"Division Times"
its like \pm but for * and the division sign
also ⋻ and ⋼
two separate "contains with vertical bar at end of horizontal stroke"s
anyway thats enough ranting about unicode
but it has weird stuff
haha ik that, was asking for the unicode char. thanks tho
ah
U+211D "Double-Struck Capital R"
but i use wincompose to type it, i dont memorize the code
thanks, will check that out
unicode is exhaustive
set of all chars is less than set possible to be represented by unicode
that’s why ascii sucks
if I want to get length 1 of my vector
v1 = (1,1, 0,0) I've to do this right ?
v1 / | v1 |
where |v1|= sqrt ( < v1, v1> )
what I'm I doing wrong here ?

what
it is meaningless then
since as it is written \tilde v_1 is scalar
and notation is bad also
you did not done anything wrong
v/|v| produces vector of length 1
assuming |v| != 0
you should have v/|v| as (1/sqrt(2), 1/sqrt(2), 0,0 )

Can someone explain this statement
Ping me if ur willing to help
Nvm I think I got it
Actually I don’t get the second sentence (“Therefore....”)
what are you confused on exactly?
yep
How would I have the same determinant
matrix representations of a transformation have to preserve eigen, so they have to have the same det is my guess
so phi with respect to basis B and basis C, have to give matrices with the same determinant, regardless of the fact B and C are different, since they're both phi (loose terminology)
Haven’t gotten to Eigen vectors yet
the idea can be followed through with change of basis matrices
edd faster than I can google

A is similar to B iff $B=P^{-1}AP$
What would the mapping in the second line be with respect to this image
Mosh

if A and B are the matrix representations, P is the change of basis matrix b/w them
A, B, and P are all V -> V
Ok
So in this image B and B’ are in the same vector space
If I’m talking about this scenario that we are discussing
idk what the image is trying to show tbh
Like change of Basis
They are just representing linear transformations with arrow marks
if you start at the upper left
going down is A
going right, down, left is P B P^-1
they don't necessarily have to be, to be fair
Ok
But in the end the mapping is still V to V tho?
yes
I see
in R^n, for example, B and B' would be the same
Yeh
but it doesn't necessarily have to be, as you pointed out
just gotta be nicely, invertibly mapable
So A and Lamda with respect to this image are in the same vector space
When correlating our discussion with this diagram
well
A isn't in a vector space, yeah?
it's a linear transformation
A and Lambda are endomorphisms or something
that's the idea
If we consider them all to be in same vector space

I think I got it
Det(S inverse) would cancel with det(S)
Yeh I’m actually trying to find a geometric meaning to all this
U know changing space and stuff
I was trying to compare the areas
Or volume in that matter
Dealing with R^2
So a mapping V to V
Using Lambda and A
Would still result in the same determinant
Or the areas would remain unchanged
Correct?
mhm
Ok thanks

hint: the coefficients of X and Y give you the two equations. the answer is the spoiler'd message
||x_1 + 2x_3 = 0 and x_1 - x_2 + 2x_4 = 0||
I'm trying to understand why that's the case.
Can we bump this down a few dimensions? Maybe 2D vectors?
I don't know if the analogue should still use a system of two equations.
two 2D vectors, 2 equations, 2 unknowns?
OK, so X and Y span the solution space.
So I'm trying to understand how you can just take the solution space and form a system that has it as a solution space
I'm trying a trivial example: x-y=0
The solution space is spanned by [1,1]
But I can't just say that x+y=0 is a system of equations with [1,1] spanning the solution
what breaks down in this trivial examples?
Also, I tried this and didn't get X and Y back, but my linear is rough and I might be stupid (not sure).
wait, I got that for the solution of the system coycoy gave.
something fishy is going on here
OK so how did you derive that system of equations?
my guess is they want some null space action
so rrefing wouldve worked
mhm
you could do it in a different basis, maybe
anyway
2 eqs with 4 variables is a 2 x 4 mat, call it A. we wanna have something like Ax = b, and they're asking for x
so x is indeed spanned by 4x1 vectors
as someone said above, this is done by just taking those vectors straight up
you can use the null space to give infinitely many sols tho
they didn't say it's homogeneous
oof mb
you can take Ax = b, and just let b be any linear comb. of the columns of A
then b is for sure in the span of the cols of A
and x is the corresponding linear comb, of which there are infinitely many. BUT, they WANT it to be in the span of the rows
so set the null space components to 0
since x = x_row + x_null, yeah?
for x to be in the span of X and Y, x_null has to be 0
i'm just waking up, so do correct me if i messed up
Aren't they asking for A? The system of equations?
A alone does not describe a system of equations
the system of equations requires A and b
without b, you don't have equations
and notice they ask for "a" system
meaning there's more than one
Hmm... I think I understand. And the solution given takes b = 0?
to keep it simple
no
if you put b and you follow the instructions
the only solution is the 0 vector
i doubt they want that... thought it is technically correct
this one here
and y'all are arguing about whether or not the system has to be homogeneous?
it MUST be
i mean, homogeneous works, but then the solution has to be x = 0
you could make up any system
the solution set of our system is known, and it is {c1X + c2Y | c1, c2 in R}
as long as x is in the row space, with no component in the null space
the solution set of a non-homogeneous system doesnt contain the zero vector and so isnt a subspace of its domain and so cannot be the span of anything
...........
what's your point
the wording tho, they don't say the solution has to be the span of the 2 vectors, but be in the span
same thing
i see
i'm pretty sure they want the opposite of that
going by ann's insight, you either let b = 0 or let b be some generic vector in the column space of A
and then the sol is 0 in the first case, cuz there has to be no component in the null space, or some linear combination (which includes 0) of X and Y

do correct me :x
our system must be Ax = 0 because x=0 must be one of its solutions
because the solution set is {aX + bY | a, b in R}
which contains 0
i fail to see how that could be in any way hard to grasp
who said it wasn't correct
ann, in what i wrote above, i let x be any aX + bY to consider the whole solution space. could you point out for me what was wrong? i fail to see it myself 3:
yes, sorry
that was a typo
or well, to be precise, i put b in the column space, but they require the solution to be in the row space
in this case, A is invertible, so kinda the same thing, no?

yes, but if x is spanned by X and Y, it's in a dim 2 subspace
and so is the output
the pseudo inverse is the inverse if x_null = 0
x is, for example, in R^4, but we only care about the dim 2 subspace of R^4 spanned by X and Y
the null space is its orthogonal complement
the pseudo inverse can map im(A) to the row space, which is aX + cY

what's the difference between regula falsi method and bisection method?
is that calculus?
after finally waking up and thinking about it for a while longer, yeah
big oof from my side
you want b = 0 and the null space to be spanned by X and Y
I want that Kermit gif back.

{kind=link}

two similar real matrices are congruent? how can it follow from the spectral theorem that just states that all eigenvalues are real, that eigenspaces are orthogonal, and that there is an orthogonal basis?

How does one find a vector that is in the span{cosx,sinx} and what makes a vector not in that span?

somethings in a span if it can be written as a linear combination of the spanning set vectors
and vice versa for not in span
those are examples of vectors not in the span..
yeah..
and I was waiting for the person to respond
sorry i was away
Ok
so would it be k1cos(x) + k2(sinx) ?
something like that?
k_1 k_2, but yes, assuming the k's are from your scalar field
how would you determine what k1 and k2 are if you dont know what x is?
so would any scalars work?
any from the scalar field, yes
so would (1,0) and (0,1) work?
yes, since the spanning vectors are in the span themselves
cause (1,0) = 1cos(0)+0sin(0)?
why did you change x to 0?
$\cos(x)+\sin(x)\in span{\cos(x),\sin(x)}$ for example
Mosh

im not sure myself
the concept of spanning set kinda confuses me
it's just the set that contains all linear combinations of the vectors in the set
so a vector b is in the span{cos(x),sin(x)} if and only if k1cos(x) + k2sin(x) = b
no
k1 and k2 being scalars
yes, assuming the 1 and 2 are subscripts
does it matter what x is? or just any x?
it's just x
the result should be a function
so "x" does not matter, it is just a variable.
if two functions are equal they are equal for any "x" in their domain of definition
oh okay
so 2cos(x) + sin(x) would be in that spanning
then x^2 or x^3 would not be in the spanning
thank you
f(x) = 0, cos(x) and sin(x) also work
then there are scalar fields where 2 does not really exist (for example F2 = {0,1} s.t. 1+1=0)
$\mathbb{Z}_2$
Mosh

ye


This would not be a vector space because u + (v+w) != (u+v)+w
where u,v,w are vectors of V
is that correct or did i do something wrong?
Commander Vimes

V is a vector space if $0_{\mathbb{R}^2}\in V$ firstly
Herels

thank you
\begin{equation*}
\begin{bmatrix} 1 & 0 \end{bmatrix} \equiv \begin{bmatrix} 1 & 1 \end{bmatrix}
\begin{bmatrix}
1 & 1 \
7 & 1
\end{bmatrix}^ n \mod x
\end{equation*}
LordPoseidon

find n for a given x
a sublinear algorithm should do
[it is given that gcd(x,6) = 1, therefore such an n exists for any x]
looks like n+1 will be the smallest divisor of phi(x) just thinking about what happens when you diagonalize it
it looks like it's asking what's the smallest power that makes $1+\sqrt{7}$ and $1-\sqrt{7}$ both equal 1 mod x. Basically a discrete logarithm type of problem
Merosity

since that's exponential time, you're probably not going to find a sublinear algo lol
when i searched this type of problem up, the technique shown was to determine the rank of the matrix with these vectors as its rows. however, in this text row reduction hasn't shown up yet, so that's not the way to go for this i think. the relevant stuff i have access to is a) if dimV=n, then each basis of V consists of exactly n vectors, and b) if v_1, v_2, ..., v_n in the n-dimensional vector space V are linearly independent then they constitute a (unique) basis for V.
i've determined the vectors of V have the form [a,b,a,b] but i don't know how to proceed? does this mean it's of dimension 2?

yes
since span(v1,v2,v3)=span(v1,v2) cause the 3rd vector is 1st + 2nd
i feel kind of stupid, how do we know that span(v1,v2) has dimension 2?
cause the basis of a spanning set is just the set of vectors
it's the fact that the vectors themselves are in R^4 that's putting me off
which has 2 cause we removed the 3rd vector to make the set independent
$V=\text{span}([0,1,0,1],[1,0,1,0]) \ \text{dim}(V)=2$
Mosh

(I presume that the conversation between sm and Mosh is at least on hold since it's been 20+ minutes since the last message. Forgive me if I'm interrupting here.)

I'm struggling a bit with this problem, but I have a proposed solution that I'd like to run by you all.
I'm going to draft it into latex to make it easier to read actually ill brb
@woven haven it would be pretty immediate using the dual basis for V from beta’
@teal grotto I dont believe we've ever mentioned dual bases in class so I'm hesitant to use that idea.
mmm. that makes it really easy. i could also see it being done by induction
but anyways, curious to see you approach


A bit wordy, I know, but here's my idea:
If the change-of-coordinate matrix is the identity matrix, then the bases are the same. To show this, I merely use the fundamental property of the change-of-coordinate matrix (i.e. changing bases) to show that the resulting phi representations are always the same. If that's the case, then the bases of the phi transformations must be the same.