#linear-algebra
2 messages · Page 204 of 1
what
i mean
there is no real difference for points and vectors at least for finite dimensional case
like each vector for finite dimensional case is just n-tuple (x_1, \ldots, x_n)
which can be viewed as point in F^n
Could you explain a bit more please. I’m still not following.
what is not clear in that we define span() = {0}?
Are you referring to the coordinate space, $$R^{n}$$?
dldh06

I get that span() ≡ {0}. I understand that it is defined to be this way.
The span of the empty list is defined to be the singleton set containing the zero-vector, i.e., the most trivial of vector spaces.
What is span({0})?
=={a0 : a \in F }
so {0}
yes
thus span of empty set and span of set containing only zero vector match
so you are correct here
What exactly is the difference between field and R?
in your claim of span emtpy set = span {0}
So the span of the two objects we’ve been discussing are in fact equal:
span() = {0} = span ({0}).
field is type of algebraic structure and R is one of these algebraic structures
yes
Well that was easy. THANK YOU.
simply saying F is any set with two operations such and "zero" and "identity" such that it behaves like R with its addition, multiplication and 0 wand 1
for example Q is also field
and C is field
Some hopefully helpful intuition building. https://thinkzone.wlonk.com/Numbers/NumberSets.htm
Real and complex number sets
So I looked up field space and R space. Is field space technically within R space or am I understanding that wrong?
A field is any set, and any two operations on that set, that obeys a selection of 11 axioms: https://docs.google.com/spreadsheets/d/11rri7XubkLaX6ZXxDDhuE0y79u_Of34fSLOXxNebev4/edit

Google Docs
public
Field Axioms
+
- : 𝔽 x 𝔽 → 𝔽,*
- : 𝔽 x 𝔽 → 𝔽
1.,closure,6.,closure
2.,associative,7.,associative
abelian group axioms,Group Axioms
3.,identity,8.,identity
4.,inverse,9.,inverse
a ≠ 0
5.,commutative,10.,commutative
11.,distributive
Vector Space Axioms
( a vector space V over a f...
The canonical examples of fields are:
- The real numbers
- The complex numbers
- The rational numbers
- The set of all rational polynomials.
I've only dealt with vector space so field space is a new concept to me
well, the scalars in a vector space have to come from a field, by definition.
so inadvertently you’ve dealt with fields
They’re easy-ish to get started with. Try and prove zero times any number is zero using the field axioms only. Should take about thirteen lines at most.
how do you define a multiplication on F^n?
and also get a field.....?
for F^2 you have something C-like
n>= 3 ??

Isn't this basically true all the time because of basic multiplication rules, 0 times anything is always zero?
Commander Vimes

Yes, of course it’s true. Now prove it using the field axioms.
Commander Vimes

There’s an analogous proof for vectors:
-1 v =?= -v
yes
The basic rules of multiplications are really basic lemmas of multiplication, and lemmas need proof.
Anyway. Thanks for you kind attention #linear-algebra . I will meditate on this result.
I don't understand any of this terminology. The most I've dealt with was the basic linear algebra, where we do SVD, eigenvalue decomposition, Gram-Schmidt, orthogonal projection, etc. That basic stuff
linear algebra usually does not treats fields much
it just admits them as having nice property
fields are treated in abstract algebra and analysis
So all those topics, I stated, I understand real world applications where they could be used. SVD for image compression, Gram-Schmidt to create orthogonal vectors. But the one topic I learned was LU decomposition. I asked my professor how is was useful, but they couldn't think of one on the spot. What kind of applications would LU decomposition be used in? Besides forward and backwards substitution?
@dire thunder Perhaps you could enlighten me on how LU decomposition is useful?
Is that the only thing that LU decomposition is useful for?
when it can be used, it is faster than many other methods of solving linear equations
for computational efficiency, you'd use it whenever you can
many decompositions are useful for this reason. when a matrix has a special structure, a particular decomposition makes it easier to handle. it might seem trivial off the top of one's head, but matrix-vector products happen by the truckload when dealing with data, graphics, physics simulations, etc., and one usually has to invert them in some sense
guys what's numerical analysis?
the study of numerical techniques for obtaining solutions of continuous problems?
Hello. Is there any example of a matrix in an infinite dimensional vector space such that it is not similar to its transpose?
operators on infinite-dimensional vector spaces tend not to be described with matrices
why does the sequence A_k converge? if we assume Q_k converges to plus or minus I

likewhhy does $\lim_{k\to \infty}A^{(k)}$ exist
Anticipation

would something like showing $|A^{(k)}|$ is cauchy work?
Anticipation

have no idea tbh
Ok. Please replace "matrix" with "operator".
Hello. Is there any example of an operator in an infinite dimensional vector space such that it is not similar to its transpose?
No, transpose
you want an operator $A$ that is not similar to $A^$, where $A^$ is the unique operator satisfying $\ang{Ax, y} = \ang{x, A^*y}$
Ann

(this A* is called the adjoint even in real infdim spaces)
i'm tempted to say that the forward shift operator on $\ell^2$ may fit your description, though i'm not 100% sure...
Ann

The space need not to be a product space; I meant "transpose", not "adjoint"
how are you even defining the transpose without an inner product then
If $T: X \to Y$ is a linear map; its transpose $T^t: Y' \to X'$, prime denotes dual space, such that $T^t(f)=f \circ T$.
MathPhysics

okay then how are you defining similarity
what does it mean for T to be similar to T^t
they're operations with different domains and codomains
You can take the domain and codomain the same
an infdim space need not be isomorphic to its own dual
so again, what would it mean for T and T^t to be similar or not
Assume that they are the same.
what do you mean
i'm still trying to figure out what you want, because i'm getting a little lost and tongue-tied
The meaning of similarity is not clear?
it sounds to me like whether or not two operators are similar an operator is similar to its own transpose may depend on which isomorphism you choose between X and X'
I am confused.
like, ok, we have two operators, $A: X \to X$ and $B : X' \to X'$ and we wish to define what it means for $A$ and $B$ to be similar
Ann

as-is, similarity only makes sense (to me) if we take two operators with the same domain and codomain
and ask whether there exists an automorphism phi of the space such that conjugating one operator by phi gives the other
but we cannot ask this same question for our A and B, because they're operators on different spaces
even if we assume X is isomorphic to X', this still requires fixing an isomorphism p between X and X', and asking whether or not A and p^-1Bp are similar
and at the moment i am not convinced that this is independent of our choice of p
Assume that the vector space and its dual are isomorphic.
i am already assuming that
... fixing an isomorphism p between X and X' ...
there isn't just one of these, you know
You say the definition of "transpose" depends on the isomorphism map?
no
i'm saying that the definition of similarity between an operator on the primal space and an operator on the dual space depends on the isomorphism we choose
Sorry, I meant similarity.
????
I meant "similarity".
then see this again
need i repeat myself?
Why does that depend?
so let's say we have two arbitrary isomorphisms $p, q: X \to X'$, and the same operators $A: X \to X$ and $B: X' \to X'$ as before.
and let's say $A$ is $p$-similar [resp. $q$-similar] to $B$ if $A$ is similar (in the ordinary sense) to $p^{-1}Bp$ [resp. $q^{-1}Bq$].
my question is: is $p$-similarity equivalent to $q$-similarity?
Ann

even if it is, that's something i would like to see a proof of.
Why not? Do you have any counterexample?
do not confuse my casting doubt on a statement for an assertion of its falsehood.
though after writing it out it looks like the answer is yes, since $$p^{-1}Bp = r^{-1}(q^{-1}Bq)r,$$ where $r = q^{-1}p$...
Ann

okay
fine, we can speak of similarity between T and T'
the forward shift operator on $\ell^2$ may still fit your description
Ann

for clarity, i'm considering $\ell^2$ as the space of all real sequences $(x_1, x_2, \dots)$ such that $$\sum_{k=1}^{\infty} x_k^2 < +\infty,$$ and i define the forward shift operator as $T(x_1, x_2, \dots) = (0, x_1, x_2, \dots)$
Ann

hey I'm calculating the eigenvectors associated to an eigenvalue, after reducing the corresponding matrix i get that rank(A) = nº variables, I computed then the cartesian equations associated to that matrix, is the solution vector associated to this system the eigenvector?
or do I need to compute the parametric equations too?
<@&286206848099549185>
it's not exactly clear what you're talking about
its about computing the eigenvectors associated to an eigenvalue, for that you compute (A-zId)x=0, and the solution of that system is supposed to be the eigenvector right
(z being the eigenvalue)
so you have a matrix A and an eigenvalue z... yes, the eigenvectors are by defn the solutions of (A-zI)x = 0
that's it

this is my problem, I end with a (0,0,0) vector, with can't be an eigenvector right?
are you sure you have the right eigenvalue?
what is your matrix and what eigenvalue are you considering for it?
the eigenvalues I got are : 3,2 and 6

in the example I showed the eigenvalue that I'm using is 3
,w eigenvalues {{3,-1,1}, {-1,5,-1},{1,-1,3}}

okay
well sorry if i sniped
so you have $A - 3I = \bmqty{ 0 & -1 & 1 \ -1 & 2 & -1 \ 1 & -1 & 0}$
Ann

how exactly did you get that third row in your reduced matrix?
i think you messed up the arithmetic while doing row reduction somewhere
okay I'm seing now the error
I used -1 -1 0 in the 3rd row
instaed of 1 -1 0
nvm
And why is this operator not similar to its transpose?
its transpose is backward shift which isn't injective
Why is its transpose the backward shift?
you can do the calculations
How?
for each natural number $k$ let $e_k$ be the sequence in $\ell^2$ consisting of a 1 at position $k$ and 0 elsewhere, and let $\hat{e}_k$ be the element in $\ell^2$ which maps each sequence in $\ell^2$ to its $k$'th term
Ann

and consider the isomorphism p between these which sends each e_k to its corresponding ê_k
and consider what $\hat{e}_kT$ might be
Ann

(where T is the forward shift, of course)
you should get that $\hat{e}k T = \hat{e}{k-1}$
Ann

and $\hat{e}_1T = 0$
Ann

And, an operator similar to an injective operator must be injective?
yes
why are you thanking me when i haven't had the chance to answer your latest question
I got it.
ok
...wait, so do you need an explanation of why injectivity is preserved across similarity or not
Yes, but it is obvious, isn't it?
it is
take two similar operators $A$ and $B = \varphi^{-1} A \varphi$ and suppose $A$ is injective (which is equivalent to saying $Ax \neq 0$ when $x \neq 0$)
Ann

then $Bx = \varphi^{-1}A\varphi x$
Ann

since phi is an automorphism we have phi x ≠ 0
since A is injective we have A(phi x) ≠ 0
and since phi^-1 is an automorphism we have phi^-1(A phi x) ≠ 0
We cannot say the composition of injective maps is injective?
or you could say that too if you want
Hey guys, what do I have to do here?

I only know that the rotation counterclockwise is (0 -1 ) (1 0)
U are looking for the function (in this case a linear illustration (not sure about the phrasing here as we call it "lineare Abbildung" in germany)) that will take an input vector v (2 dimensional) and rotate it counter clockwise by 90 degrees. A matrix can be seen as a tool to perform a linear illustration , as when u rightwise multiply the matrix with a vector this will perform a certain manipulation on the vector. Thus in your case you are looking for a 2x2 matrix that, when rightwise multiplied by a 2 dim. vector, will rotate that vector counterclockwise by 90 degrees.
As u stated correctly this matrix is
(0 -1)
(1 0)
which is the solution to the question.
Do you understand why it is exactly that matrix that gets the job done or do you need an explanation?
I understood it fully, but I dont unterstand the last sentence in my question
@wintry steppe to give you the general formula for rotating any 2dimensional vector by any angle, this would be the matrix needed:
(cos(alpha) -sin(alpha) )
(sin(alpha) cos(alpha))
whith alpha being the angle by which the vector is supposed to be rotated by. With alpha=90 degrees (thus cos(90)=0 and sin(90)=1) this evaluates to the matrix above
(Im also german but translated it myself 😄 )
Meaning of last sentence: Find the 2x2 matrix that performs the linear illustration f (which as described in the first sentence depicts from R^2 into R^2) on a given 2 dimensional vector v
OK:D I dont think german is allowed here so lets keep it in english:D
Sure! Now I understand the question fully, thank you but I think the question is to hard for me to solve and maybe I will skip this one
Well you have already solved it ^^ No problem and good luck
Yes but I dont know what to put in f(u) = Au. But nevermind thanks for your help 🙂
Let F be a field, A an nxn matrix over F and p(x) a polynomial in F[x], show that there exists a polynomial q(x) with degree less than n such that p(A)=q(A)
so if degree of p is n then i can just use the division algorithm along with cayley hamilton to get the result
but not sure how to go about this if the degree is less than equal to n
does anyone here know the intuition behind the magnitude of the cross product, why is it equal to the area of a parallelogram? and also, i noticed that it's a necessary defining condition for the cross product to be distributive, what i mean is that if you start with the assumption that the cross product is distributive (along with a couple other properties about the cross products of the unit vectors i, j and k) you end up implying that its magnitude is the area of the parallelogram spanned by the two vectors, and i wonder why thats true exactly
@empty copper Hi, so can you help me with the inequality?
i'm looking for a tutor for Linear Algebra. I'll be paying $30~60 an hour. If you DM me, please turn on the setting to accept messages from nonfriends, or else I cannot reply. Or, send me friend request to accept.
@digital solstice if it still is on ur mind here's a link to a Youtube vid I found helpful

This covers the main geometric intuition behind the 2d and 3d cross products.
Help fund future projects: https://www.patreon.com/3blue1brown
An equally valuable form of support is to simply share some of the videos.
Home page: https://www.3blue1brown.com/
*Note, in all the computations here, I list the coordinates of the vectors as columns of a...
you'd probably need to watch this vid before that though
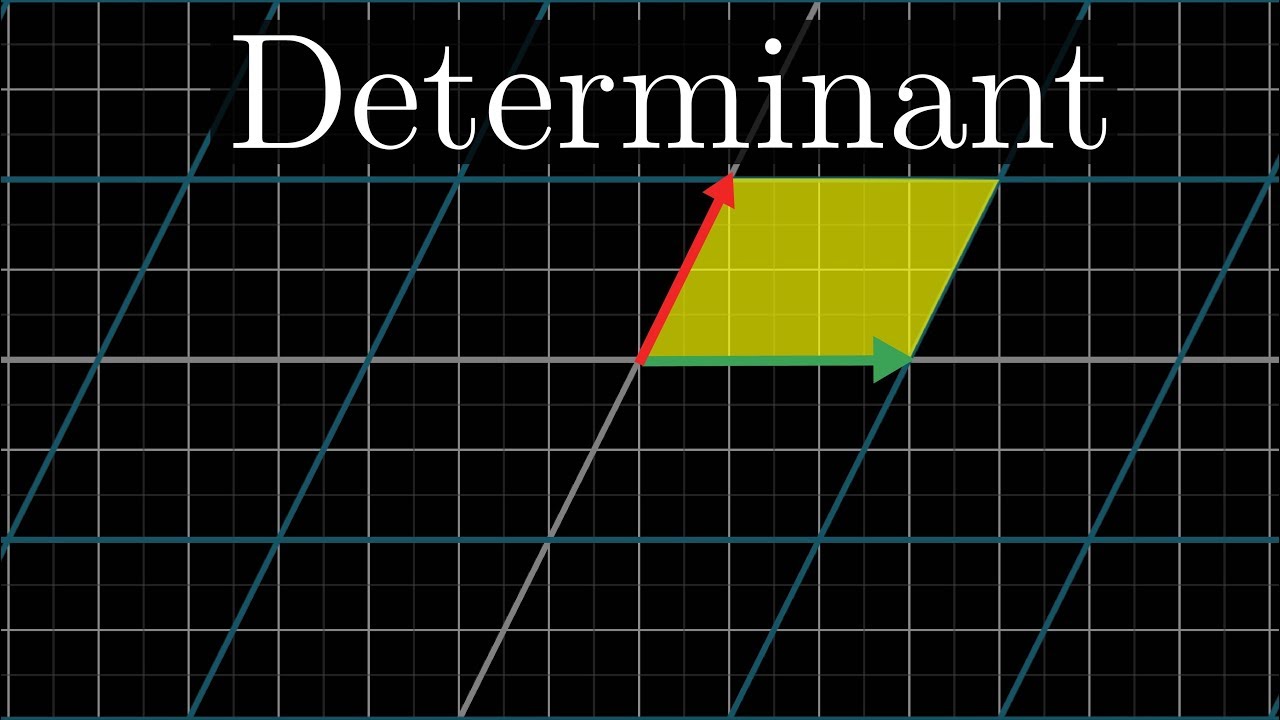
The determinant measures how much volumes change during a transformation.
Help fund future projects: https://www.patreon.com/3blue1brown
An equally valuable form of support is to simply share some of the videos.
Home page: https://www.3blue1brown.com/
Full series: http://3b1b.co/eola
Future series like this are funded by the community, throug...
i guess it would be nice if you would also indicate what level of LA you are interested in
right, thanks
basic to around medium level. fairly simple stuff revolving around eigens, but i need dumbed-down intuitive explanations


Will this proof work for the => direction? Sorry for long paste.
delete the source messages
watching 3b1bs "the essence of linear algebra" might save you a lot of money.you should definitely try it out
i did. loved it
it's hard to explain
for the current assignment im doing, the topic seems to be overly easy. so much that it makes me anxious
@wintry steppe done, sorry
the only challenge is needing to explain it at a super-elementary level, where i'm also anxious that i might miss something
idk but maybe youre just understanding the concepts so good that the task isnt har for you.i found most of my hw in LA1 quite simple too
Or just post questions you're stuck on and save yourself some money 
Can anyone look at my proof and tell me if it works?
Go on
guys i am not understanding something
When calculating the
Legendre momentos of a MxN array (image in this case)
many sites say it is this way
https://gyazo.com/04423e0600a12dd9513df531eb162b30
So
for the pixel[0][0], the legendre moment is L_00?
i mean, does each pixel have its own Legendre moment?
@azure trout I posted it asbove
lmao
The assumption is null T_1 is a subset of null T_2. There's no necessity that T_2x=0 implies implies T_1 x=0
in fact, it's the other way around, by definition of subset
more precisely, x in null T_1 implies that x is in null T_2
writing that any map S will work might sound contradictory to what you need to prove
when writing another image of a vector under a map, use another variable, like w_j
it's fine to use a different index (e.g. j) for the second summation
... Why?
because w_i is the same thing all throughout your proof
you don't need it confused with the other w_i
you'd be implying that T2vi = wi = T1vi
when doing by-cases proof u have to state it explicitly
Case 1.
.
.
Case 2.
.
.
and remember to state explicitly what you're proving at the end of each case, or at the end of the whole proof if it's one consequent
.
.
Hence T2 = ST1
I don't understand this notation at all.

Whose entries Aj,k are defined by Tvk = A1,k w1 + ... + Am,k wm
How do I find A1,k and so on?
It seems circular that the Aj,k entry is defined as that
Since I need to use the Aj,k entry to find the Aj,k entry.
You find the transformed vector under the basis of the output space, then the column of the matrix is just those scalars
so take your v_k and apply T to it and you'll get a vector in W
that means you can write it as a linear combination of W basis vectors
the scalars of the linear combination become the column of the matrix
with the fact that the kth v vector will be placed in the kth column
@nocturne jewel But this doesn't tell us how to find the matrix.
Are we reading the same thing?
Whose entries Aj,k are defined by Tvk = A1,k w1 + ... + Am,k wm
Yeah, this definition makes 0 sense.
uh
Tv_k is an element of W, so it's a linear combination of w_1, ..., w_m with unique coefficients (since w_1, ..., w_m is a basis). we define the kth column of A to be those coefficients.
what's wrong with that?
I mean what I said is equivalent / uses co-ordinate vectors
The definition is perfectly fine
slightly edited for clarity
we define the kth column of A to be those coefficients.
I seem to be missing this sentence from the definition.

?

Yes, so?
that's what terra said
do you agree that for each k there exist scalars A_{1, k}, ..., A_{m, k} such that this is true
yes or no
furthermore do you agree that these are unique
Of course, but that's not what the definition says to write the column k of the matrix M as
The word column is literally never used
$T[v_1]=A_{1,1}w_1+...+A_{m,1}w_m$ means the 1st column of the matrix would be $[A_{1,1},...,A_{m,1}]^T$ since $k=1$ in this instance

moshill1

A_{j, k} means the entry in the jth row, kth column.
I know that
But then it's written as if the entry of Aj,k is Tvk
????????????????????????????????????????????????????????????????
it's not
How's it not?
Cause it never says that

yeah, then the scalars are of the form A_{j,k}
the entries of the matrix ARE NOT the Tv_k themselves. they are the SCALARS in the linear combination in terms of w_1, ..., w_m that Tv_k equals
whose entries Ajk are defined as the scalars of the linear combination
It's not
(maybe not how I would personally write it, but that's cause I learned it with co-ordinate vectors)
$A_{j, k} = w^j(Tv_k)$ qed
狼人

where w^1, ..., w^m is the dual basis to w_1, ..., w_m
there you go
this is as concise as it could possibly be
 in not knowing dual basis
in not knowing dual basis
the solution to n/c's confusion is for them to switch to a better book
This is so confusing
If I want to make the differentiation map of polynomials with real coefs from deg 2 to deg 1 into a matrix
A basis for the P2(R) is (1,x,x^2) and a basis of P1(R) is (1,x)
yes
I know?
$D(1)=0=0\cdot 1+0\cdot x$
moshill1

moshill1

so the 2nd column is [1,0]
But you need to input a basis vector into the map
Yeah, and I did that
So what did I do?
We defined a polynomial to be a list
i think their D(...) notation was more like a divergence sorta thing
D(0,0,x^2) = [0,0,2x]^T, for example
giving the benefit of the doubt
weird notation, but ok
Okay wait
We could do it like this instead
D(1,0,0), where (1,0,0) represents 1 * 1 + 0 * x + 0 * x^2
right
D(0,1,0) where 0 * 1 + 1 * x + 0 * x^2
yes you can write the functions as their co-ordinate vectors
And D(0,0,1) where 0 * 1 + 0 * x + 1 * x^2
But now, how do we get a list of length 2 back? If we define a polynomial to be a list
cause it outputs to a 2 dimensional space
@lavish jewel ?
you will get a 2 dimensional subspace regardless
Yeah but how do we know which place to truncate in the list
it doesn't matter
For example, D(1,0,0) = D(0,0) but how would you know?
the dimensionality or rank or whatever you wanna call it won't change
cause $\mathbb{R}[x]_{\leq 1}$ has a basis ${1,x}$
moshill1

so your output vectors will be written as a linear combination of basis vectors, in which there are 2
yeah, that was already correct, if each of those is a column
Yes
just make it clear your D(...) is a vector-valued function that puts the input vector as coefficients of a 2nd order poly and then takes its derivative in some special way
$D[f]=\dv{x}f \to D[(f)_B]=A(f)_B$ where $B={1,x,x^2}$ and A is the desired matrix
moshill1

But I don't see how the basis of the codomain impacts it
you want the output to be made up of coordinate vectors in the codomain's basis
you'll have to do an extra transformation into the correct basis
Look, if T(x,y) = (x + 3y, 2x + 5y, 7x + 9y)
So T in L(F^2, F^3)
What is the difference if we use the standard basis for F^3 or some other basis?
the same way any change of basis works
Haven't learned about that
e.g. you have a vector [1,0,0] in the canonical basis
but for whatever reason you are told to use the basis [5,0,0], [0,10,0], [0,0,-1]
the coordinates of that vector whose coords were [1,0,0] in the canonical basis are now different w.r.t. the new basis
But what about the matrix?
you need to transform it
either directly when you write it, or by multiplying it from the left by a transformation of some sort
How do you do it directly?
you look at it and go "oh, i have to transform it"
i don't have a good example because it's the sort of stuff one should see immediately
if you don't, you'll have to take an extra step
post your question if you want help
Alright
So this is the way basis are transformed according to my notes
Where
And the same for the ones with the hat
But in the case of vectors

So I have two questions
@lavish jewel How would the differentiation map from P2(R) to P1(R) look like if P1(R) had basis 2,2x or something instead of 1,x
you'd have to divide by 2.2
for example
in more complicated cases, you have to multiply by an inverse mat
1: In the first case, each basis vector is written by itself, without components. But how would you write that up in the case of a real basis? Do you just make every column a basis vector, like you would with vector components?
2: Why is the inverse being used in the case of transforming vectors?
hello
I have a question
if u have a matrix A and find it’s eigenvalues, and then u plug in one of the eigenvalues (call it lambda) into A-lambda*I
that matrix should be non-invertible right?
since det(A-lambda*I)=0
yes
am I making a stupid mistake then

also, the kernel of A-lambda*I is just the eigenspace corresponding to lambda
wouldn’t the matrix at the bottom be invertible since it has 3 pivot positions
If the eigenspace is nontrivial then the map cannot be surjective
Because you calculated the eigenvalues wrong I believe
I don't think you wrote down the correct characteristic polynomial
oh right
I forgot to subtract 1
ok so stupid mistake was true ok got it thanks needed another pair of eyes
I believe it's (2-a)((3+a)²-1)
👍 
does anyone know if it's true that, if a matrix has conjugate complex eigenvalues, the matrix is a rotational matrix?
This is false
thank you
none of these are rotation matrices $$\begin{pmatrix}0 & -2\2 & 0\end{pmatrix},;;;\begin{pmatrix}
e^{-i\theta} & 0\0 & e^{i\theta}\end{pmatrix},;;;\begin{pmatrix}0 & -1 & 0 & 0\1 & 0& 0 & 0\0 & 0& 2 & 0\0 & 0& 0 & 2\\end{pmatrix}$$
Timon

i already saw that video but i dont think it answers my question in particular
My questions might be better answered on here
I was trying to find a connection between this theorem and 3b1b's vid on change of basis:

https://www.youtube.com/watch?v=P2LTAUO1TdA&list=PLZHQObOWTQDPD3MizzM2xVFitgF8hE_ab&index=15
at 11:03, he discusses "How to translate a matrix"
ofc, u have to watch the vid to know what im gonna talk about
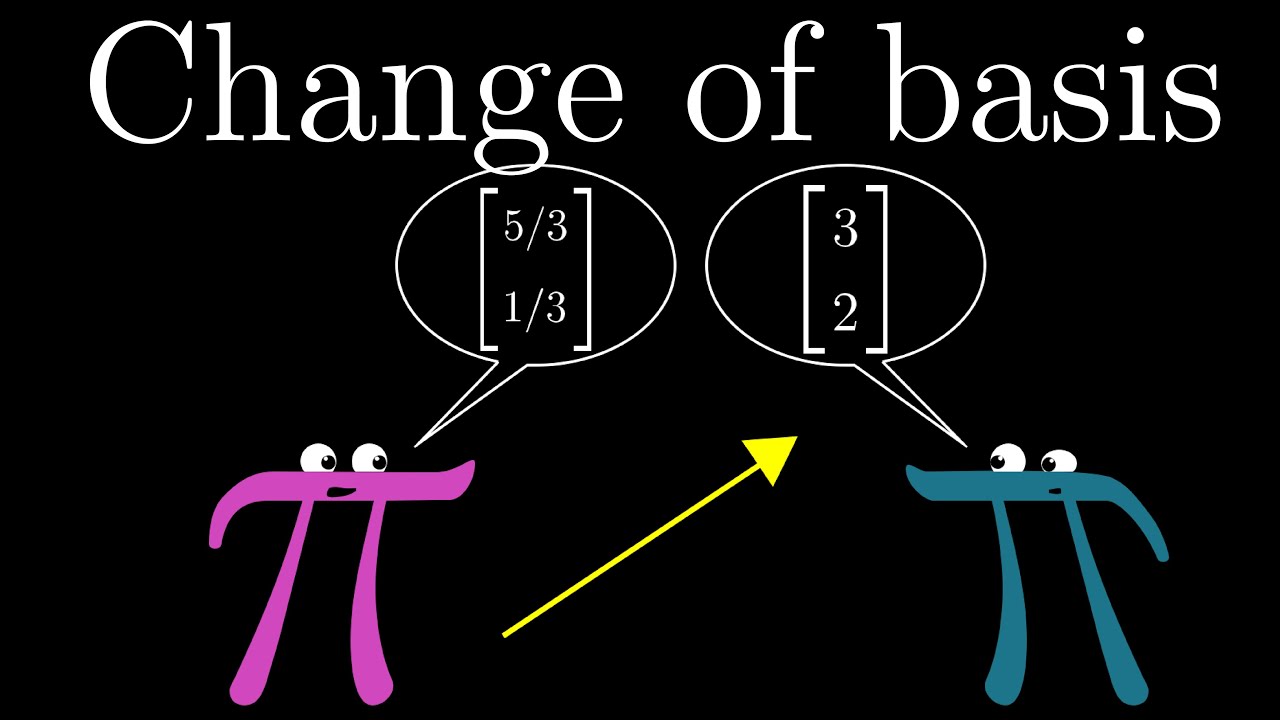
How do you translate back and forth between coordinate systems that use different basis vectors?
Help fund future projects: https://www.patreon.com/3blue1brown
An equally valuable form of support is to simply share some of the videos.
Home page: https://www.3blue1brown.com/
Future series like this are funded by the community, through Patreon, w...



- did i make all the connections between the vid and Theorem 10 correctly?
- does any change of basis matrix (B1, B2 are bases of R^2) correspond to some linear operator on R^2?


Thanks a lot👍
<@&286206848099549185>
Hi #linear-algebra 😄


I have an Axler QQ: why does the lemma about spanning lists being reduced to form a basis say nothing about finite dimensionality?
He implicitly assumes VS is finite dimensional
The partner of that particular lemma, the one about linearly independent lists makes a point to call out the fact that the vector space is finite dimensional.
For example ,R is spanned by the set of irrational numbers along with 1 as a Q vector space
Ok, it's more like he assumes choice
It's not obvious that R as a Q vector space has a basis if you don't assume choice
Wait, what‽
There a A LOT of irrationals...
Yes
So that list is like VERY LONG?
That list is infinitely long
good lord
It's not obvious there's a basis for that list
There are people who think there is
So if you assume choice, any infinite dimensional vector space can have a SPANNING list reduced to a basis ??
Yes

But that basis is still infinitely long?
I don’t know enough functional analysis to keep up with this....
Yes
bumpu
Maybe a dumb question but, is there a generic matrix I can multiply another Matrix by to make all the lower diagonal elements 0
?
0
Can a spanning list really be reduced to a basis in infinite dimensional case? The proof i know for existence of a basis does not involve reducing a spanning list
No. Suppose there is such M = [x y] [z w], then in particular works for A= [1 0][1 1] but then can show M = [1 0][-1 1]. But that M doesnt work for every matrix (this is the case for right multiplication)
actually even easier: you would have IM = I So M = I
and i should have taken less time to solve it
for part v wasn't this already shown in part ii because the null is kernel and the col is the image?

well, almost. you just have to take the isomorphism back to R_3[x] and R_2[x]
wdym
one of the two things deals with coordinate vectors. the other deals with polynomials

do you know where i can find this on the book linear algebra done right?
well read more about it
you already applied this when you solved (i)
you apply such an isomorphism every time you write vectors in basis coordinates
now you do the opposite and convert from basis coordinates back
what does "the rank of AB is at most the rank of A and B" mean in inequality form?
rank(AB) <= min(rank(A), rank(B))
in case you're asking "how do i write this as an inequality"

oh ty
is it because the basis spans R^4 at this point because we can literally make anything out of the basis ?
B has rank 4 meaning it's column space is a 4-dimensional subspace of R^4, i.e., all of R^4
the rref tells you this
ah yeah
and how was he able to deduce the nullity(b) = 0
well i can kinda just eye it and see any possbile x will just be equal to zero
and hence the null(B) = {0}
sounds good
How to solve this please?

a nice way to check linear independence in this case is to put the vectors together into a 3x3 matrix and take the determinant
so for the 1st part i got r can be anything but 0 in the real numbers
for part 2 and 3 i am a bit confused
Jordan normal form
3 to n get killed
(0 1)
(0 0)
^2
= 0
(0 1)
(0 0)

n=5 example (we're using VC as well if this makes no sense)
Using Cayley Hamilton theorem
It's because the matrix is full rank and based on the Rank-nullity theorem rank(B) + nullity(B) = n, where n is the number of columns in a m x n matrix


$0=a_1v_1+a_2v_2+...+a_nv_n$ when $a_1=...=a_n=0$
moshill1

$f(0)=f(a_1v_1+...+a_nv_n)$
moshill1

yes agreed
wait no, that's wrong
i'm wrong or your wrong?
My answer is wrong cause it doesnt show that only the scalars all 0 make 0
what i meant to show there is the transition from the first set to the second
and since we know the first sets a_i are equal to zero
only when writing the 0 vector
isn't the defintion of linear independent just
$0=a_1v_1+a_2v_2+...+a_nv_n$ when $a_1=...=a_n=0$
redd

yes, you never wrote that
you wrote for a general element in V, which is span not independence
Assume {f(v1),...,f(vn)} is a dependent set, show that's a contradiction
but in the question we assume the first set is linearly independent don't we
so i can automatically assume a_i = 0
yes, and that will show that all scalars 0 will make the 0 vector
but that doesnt meant they're indep
${v,2v}$ is clearly dependent, but $0=0(v)+0(2v)$
moshill1

hmm
the way i normally show independence is showing it's under addition and multiplication
what?
nvm, do you know a way to do this question?
.
when showing that would it be similar to how i attempted the question
it'd show that only the set of scalars {0,0,...0} would work
which is what is desired
What is the reasoning behind defining a conjugate transpose as (where $A^\dagger$ is the conjugate transpose):
$<u|A^\dagger(v)>=<A(u)|v>$
rcatalang

Assuming it's a linear application and not a matrix
I would like to understand this idea for the matrix of a vector x in V in basis B, where x = x1 v1 + ... + xn vn. xi in F,=
And we can view any vector x in V as defining a linear map x : F -> V, where 1 gets mapped to x, and lambda gets mapped to lambda * x
Where 1 is the standard basis element of F
What to do after taking the determinant?
well, the determinant will tell you whether or not it's linearly independent
det A = 0 if and only if the columns of A are linearly dependent
guys, acording to this

what is L_mn??
like, mn loop through the pixels of the image?
Or it is the degree?
no, the image is f(x,y). m n are indices which identify a particular moment
@wintry steppe
so every pixels needs its moment?
Completely new to linear algebra. How do I convert this problem into linear algebra equations: (1/2)at^2 + v0 + c0 is distance of object from observer at time t, where a is acceleration, v0 is initial velocity and c0 is initial distance from observer.
At 1 second, object is 20 metres from observer, 2 seconds it is 55 metres away, 3 seconds it is 110 metres away
Is it simply:
0.5a v0 c0 20
2a v0 c0 55
4.5a v0 c0 110
v0t or v0? @viral isle
v0
I think I'm wrong because v0 and c0 all being 1 means I can't get it into Reduced Row Echelon Form since they'd all end up being 0s or 1s
@dawn fractal
!superficialsicko

oops, I actually had 4.5a
Edited
Thanks
I'm still not sure it's correct because when I try to get it into reduced row echelon form my v0's and c0's are always identical
use Gauss-Jordan elimination method
I currently have:
1 2 2 40
0 3 3 25
0 8 8 70
then what
I'm unsure how to proceed tbh
do the same thing u did from the first step
ok
where u reduced the other entries in the first column to 0
do that for the 2nd column
My first step was to take the first row from the second and third to get the 0s
but if I do that now won't it just but numbers back in the first column's 2nd and third rows?
that's basically what we're doing
now u need to make sure column 2 has a leading 1 in row 2
but we're working with a smaller matrix now
ignore the first column and row for now
then consider the matrix obtained from that
oh
essentially make row 2 equal to 0 1 ... ...
and row 3 equal to 0 0 ... ...
and after that, make row 3 equal to 0 0 1 ... (or 0 0 0 ..., otherwise )
do this by dividing row 2 by its 2nd entry
1 2 2 40
0 1 1 8.33
0 8 8 70
Then eight times row two from three, I guess?
1 2 2 40
0 1 1 25/3
0 8 8 70
yes, subtract row 3 from that
1 2 2 40
0 1 1 25/3
0 0 0 (200/3)-70
yep
So dumb question, but how can 0 0 0 = anything other than 0?
we're actually searching only the first 3 columns for leading 1s
yes
this is why i asked if u were sure about v0
im familiar with the formula (1/2)at^2 + v0t + c0 = distance
not (1/2)at^2 + v0 + c0
yep, it's definitely the latter
it means the system has no solution, so there's something wrong with your setup
probably a typo
and forgot to type t after v0
try it
replace v0 by v0t
and the system will be consistent
Hmm, that might be it
we have only been shown the elimination steps, not how to put formula into linear algebra equations form. I thought it was a simple as what I was doing but assumed I was wrong because I kept getting an answer on the right in the third column with all 0s, as we have done here
Guess it's good to know I was on the right track
Feel like I just wasted your time though
Thanks for your help, I'll check with the teacher on Monday
Hi I feel like this is a really easy question but I'm getting it all wrong. Could I get some assistance thank you

Hi #linear-algebra.
If I have a vector space V, with subspace U. And I have a linearly independent list of vectors is U, how do I know the linear independence is preserved in V.
This feels intuitively true, but I don’t actually know how to prove it.
Like obviously if ONLY the trivial combination is the only way to get the ZERO vector in U....I need it to be the case that the trivial combination is also the ONLY way to get the ZERO vector in V.
And the two, V and U are over the same field.....
i mean
the defn of linear independence doesn't quantify over vectors of the space you're in
but rather over tuples of coefficients
like, any linear combination of your list (of vectors in U) will still be in U
and it's not like U and V have different zero vectors anyway
So a list of linearly independent vectors forms a span. The span is a subspace of the ambient vector space....
Yeah....i don’t think that does it....
why is span coming up?
any list has a span
you dont care about span, you care about linear independence
I’m shooting in the dark
ie the equation $a_1v_1 + a_2v_2 + \dots + a_nv_n = 0$
Namington

if $v_1, v_2, \dots, v_n$ are linearly independent, then this implies $a_1 = a_2 = \dots = a_n = 0$
Namington

Im still following
this is preserved regardless of whether you talk about a subspace or the whole space
Do I need to prove this?
since a subspace is over the same field by definition
its immediate
your possible coefficients (ie possible values of a_1, a_2, ... a_n) are the same
since subspaces have the same base field as the vector space
Yes. Since same field
so the equation carries over without any changes
and has the same solutions
namely, just a_1 = a_2 = ... = a_n = 0
hence we still have linear independence
I believe every thing you are saying. It’s just crazy that I’ve not seen Axler prove it.
I don’t know. Maybe Im just being paranoid
its kind of an obvious fact
considering a different subspace does nothing to the linear independence equation a_1v_1 + ... + a_nv_n = 0
(assuming v_1, ..., v_n are still in your subspace)
so itll have the same solutions
hence linear independence is preserved.
you can think of the space as giving some properties to the vectors. if changing the subspace does not change the vectors, linear independence is shown via exactly the same equation, no changes at all.
what if you operate on an absolute "no such thing as obvious" maxim
If I tried to show that a set B is linearly independent in U and linearly Dependent in the ambient V....i should get a contradiction, right?
you would struggle to show that
Lol. Okay
if you managed to show it, that would be a contradiction, yes
if im understanding you correctly
just as you would struggle to show 2+2=5 
i'm pretty sure such a scenario would imply that U isn't a subspace of V
i mean...i could try and contradict that 2 plus 2 equals 5
this is the face of someone unenlightened to the glories of characteristic 1
Any way. Thanks for your kind attention. I will write down “it is obvious”
truly tragic that they dont know what theyre missing
F_1 moment
alas
such is the harshness of life
man now i wanna make an arxiv april fools paper
"Applications of Commutative Algebra to the Ring of One Element"
which just proves a bunch of comm alg theorems in the special case of the trivial ring
(each proof, of course, is "Trivial.  ")
")
all modules over the zero ring are isomorphic
did I understand correctly what does the Gram matrix mean?

the gram matrix, for a given matrix M, is M^T M (over the reals)
@snow jetty yes
yep that looks ok
Oh yes, indeed, it works if the scalar product as the abstract "bilinear application" and the M lines as the basis. thanks. didn't think about that
bilinear form with extra properties (symmetry and posdef)
Yes, in fact the dimension of bilinear applications for R^3 must be "9", but how can they be constructed?
I mean: according to the theory, the set of bilinear applications over a vector space V (Bil(V) aka "f:V->V, bilinear") is also a vector space. And its dimension is dim(Bil(V)) = (dim(V))²
...yes? what does that have to do with your previous question?
Like suppose I have R³, so how can I define the basis?
basis of what
of Bil(R³)
well
you could define nine bilinear forms $p_{ij}$ ($i,j \in {1,2,3}$) by requiring that for all $i,j,k,l \in {1,2,3}$ you have $$p_{ij}(e_k, e_l) = \delta_{ik}\delta_{jl},$$ where $\delta$ is the kronecker delta
in essence, each form sends one of the 9 possible pairs of basis vectors to 1, and all the other pairs to 0
does this make sense?
Ann

alternatively, you could also write this definition as $p_{ij}(x,y) = x_iy_j$
Ann

yes probably, there will be like the "dual basis" of {e1, e2, e3}, and then I make the product of the "covectors", for every possible combination, and it will be like the basis of (Bil(V))
if you wish...
ngl, idk why we ended up here when we started at Gramian
😅 because for every bilinear we have its own Gramian...
The scalar product is just a particular case like M^T * M
Yes, indeed, I didn't even consider the distinction before 😮
The ones that are VxV -> K

they said that should be the basis. trying to understand the ⦻ sign...

looks like outer product/kronecker product
but this Bil(v) seems to be a map, not a form
is it now V x V -> V?
(i might be wrong)
They still mean a form VxV. But I think I understand, omg it's so easy in fact 🤯
The basis will be just {x1y1, x1,y2, x1y3, x2y1, x2y2, x2y3, x3y1, x3y2, x3y3}
Yes but... I thought like it should be a composition of matrices or something like this... but in fact it is impossible to define a matrix for a bilinear form
Because it takes** two damn vectors** and it is a linear map only if one of them is fixed if I understand correctly
this stuff is way too abstract
Can someone give me a good resource on determining when an operator is normal vs self adjoint vs unitary
So it's normal if TT* = T*T
If we have an orthonormal basis of V consisting of eigenvectors of T then T = T* (self adjoint)
And then if it's normal and the eigenvalues for all those eigenvectors are have absolute value 1 then it's unitary?
pretty sure
if theres an ON basis of V with eigenvectors of T, then T can still be normal
Is the only self adjoint unitary operator the identity matrix?
Cause we'd need such an operator to be TT* = T*T = I
But also T = T*
So then T^2 = T*^2 = I
Oh so then either the identity or negative identity matrix are the only unitary self adjoint operators
I think?
no i dont think so
take for example householder transforms
visually u see its a reflection so its its gonna be diagonalizable, and unitary since it doesnt stretch anything
and its easy to verify
Householder Transform?
Basically a reflection on any hyperplane
I see
proofing positive definit of the L2 scalar

I'm not sure if I see it right, but the p(x)^2 is always positive, so the integral is only 0 if p(x)^2 is 0.
But now I have a slightly different scalar product definition


Can't I argue with the same way, and just say p(x)^2 is positive and has to be 0 therefore ?
Because the proof in the script is a little bit weird and unnecessarily complicated, not sure where my problem is.
well, you'll get p(x_i) = 0 for each i. what are the assumptions on p and on the x_i's?
hi, can somebody tell me, do u know some kind of book, that has exercises for jordans canonical form with results? i would appreciate it thank u ❤️
friedberg insel spence
it seems good, thank u
can someone explain row echelon form to me? apparently this is in REF but i read that there has to be a row of all zeros below entries

you read wrong
Its about Lagrange Polynoms, interpolation. p is element of Polynom Space of degree n

This was the proof in the script, which even looks wrong to me at line 3.10
the coefficient aj is missing before the lj and the result would be two sums, one over i and one over j at the end of the aj^2.
The proof is based on the idea that the lagrange polynoms lj are a basis, so linear independant.

is the row space of a matrix a span of all its row vectors?
Is strang or axler better in your opinions?
question really boils down to why isnt axler listed in resources when it seems to be a popular choice in schools
ah okay ty
if you're looking more in the applied/computational direction Strang may be better, and may be better overall, put if you're looking for pure math maybe look at Axler
yeah
Axler has a bent against determinants which isn't great so you'll have to learn about those elsewhere
didnt axler come up with his method of determinants?
idk, his book is famous for not using determinants
but otherwise is has a nice clean presentation that's good from a pure math perspective
yeah i appreciate the rigorous foundations of spans, directsums and such as presented in his texts - it builds off from these concepts
this is the function defined

i don't get the 1st sentence

in particular, the 2nd equality
in this definition, you have f(x,y)
here, f(y,x), so the x is conjugated instead of the y
after that, just use your regular complex conjugate properties
it distributes over products and sums
and a_i is real, so it is not affected
yes
what
hmmm
i think you mixed up the subindex i with the imaginary unit
there
still
wdym
$\sum_n a_n x_n y^*_n$
Edd

the star there is complex conjugate
i literally meant $xi$
!superficialsicko

and $yi$
!superficialsicko

like multiplied by i?
yes
well, are x and y real or complex?
i think in this scenario they are in general complex
so $\text{conj}(i\cdot x) = -i \cdot \overline{x}$
x_i is of the form x + i b
i literally meant 0+xi and 0+yi
ok, sure, but that's not what you have in the text above. just so you know.
Edd

this is always valid btw, even if x is real
sure
sure, if n = 1 you have $a_1 x_1 \overline{y_1}$
Edd

so is f(0+xi,0+yi)=a_1(0+xi)(0-yi)?
sure
ok
just to reiterate though, that is not the form of the x and y up there
i was asking about the specific case
ok
so real conjugate of a+bi is -a+bi?
real conjugate
?
i have never heard of that
maybe it's defined in some scenario, but i have never seen that
as in "complex" conjugate
maybe to denote that it only makes sense for complex numbers
hm
is this by definition?
you can prove it
it isn't a definition
it's a consequence of the definition and properties of the complex conjugate
let's say all x_i's and y_i's are respectively of forms a+bi and c+di
then f((x_1,...,x_n),(y_1,...,y_n)) = a_1x_1(c'-d'i) + ... + a_nx_n(c^(n)-d^(n)i)
i don't understand your notation there
wait
basically the first sentence follows from f being an inner product?
since f(x,y) = conjugate of f(y,x)
isn't it backwards?
wdym
you're trying to show that this is an inner product
ah
i still don't follow from this
i'm not much acquainted with complex numbers
now factor out a -i
-i (a-bi)
and if x = a + bi, what is a - bi?
conj x
there you go
but i don't see any i in the summation
me neither. this is for the expression you made up
the imaginary number i mean
this is the general form of the example you made up, for whatever reason
so how do i show the first equality
i didn't know if you meant to use $x, y \in \mathbb{C}^n$ as in the original problem, or if $x, y \in \mathbb{R}^n$
Edd

you show the first equality the same way we just did
first, show that the complex conjugate distributes over sums
then, show it distributes over products
and that's it
so to do that i need to add the terms of the summation first?
to get a complex number
use an ersatz sum that is simpler
let w_n = a_n x_n y^*_n be a generic complex number a_n + i b_n
work with the sum of w_n's first to show what happens if you complex conj the whole sum
and then show what happens if you conjugate one individual w_n
the way they present this just in passing kinda implies these are things one should've learned before. i guess now is as good a moment as any for you to do so 😛
that's just my prof assuming xD
i haven't learned complex numbers in-depth before college, only a bit
sum of w_n's vs only one w_n?
yeah
if you show the conjugate goes into each summand individually, you don't need to bother with the sum anymore
so show it goes into the sum, and then apply it to one element to see what happens when you conjugate a product
past this point i would suggest you go to #real-complex-analysis
i see
what type of "modulus" are we talking
you could use an inequality
if you absolutely must split it, all you can do is provide a bound
since the result depends on how x is represented as a linear comb. of the matrix's row space/domain and its orthogonal complement
smth like |Ax | <= |A|_(induced 2 norm) |x|
otherwise, decompose x in the basis of the row space and factorize A somehow
but if you have A and x, the easiest is to multiply first, take norm after
Let T : R^3 -> R^4 be a linear map such that T(1,0,0) = (1,0,1,0), T(0,1,0) = (0,1,0,1), and T(0,0,1) = (1,1,1,1). Find a basis for null T and range T
I think it's clear that a basis for the range of T is (1,0,1,0),(0,1,0,1)
And a basis for null T would be (1,1,-1)
(I think)
How would I make sure these answers are correct, if they are?
Use rank nullity
I don't know what that is
rank(T)+null(T)=3 here
Yeah, so that's one sanity check
well the range of T is spanned by the values of T at (1,0,0), (0,1,0) and (0,0,1)
Which is good
for the nullspace you can just write out the explicit formula for T and find the nullspace as the solution set of T(x)=0 [treating this as a linear system]
That's what I did I think
So to write the matrix for Tv, where v in R^3, I had this
$\begin{bmatrix} 1 & 0 & 1 \ 0 & 1 & 1 \ 1 & 0 & 1 \ 0 & 1 & 1 \end{bmatrix} \begin{bmatrix} a \ b \ c \end{bmatrix} = \begin{bmatrix} a + c \ b + c \ a + c \ b + c \end{bmatrix}$
n/c

Because 1,0,0, 0,1,0 and 0,0,1 form a basis for R^3
I just looked where they are sent by Tv and put them as the columns of the matrix
And a,b,c is an arbitrary vector in R^3
So then for the null space, we want a + c = b + c = 0, which gave me (1,1,-1)
For the basis of the null space
Yes
But how do I make sure it's correct?
So you need a+c=0 and b+c=0
doublecheck your work? idk
Implies a has to be -c and b has to be -c
triple check
That's it
How do I double check it"
you doublecheck a piece of your own work by going through it again and reading every step out loud making sure you know exactly why each step was taken and why it is all correct
this should be done only a certain time after writing it, so as not to lull yourself into a false sense of security like "oh i know this is ok"
if you got the spaces right, you should be able to check they satisfy all the definitions.you can also pseudo invert stuff in the image back onto the row space
So basically
I need to check that ${ a_1(1,0,1,0) + a_2(0,1,0,1) : a_i \in \mathbb{R} } \subseteq \mathrm{range~}T$ and $\mathrm{range~}T \subseteq { a_1(1,0,1,0) + a_2(0,1,0,1) : a_i \in \mathbb{R} }$
n/c

And similarly for null space?
And then also that they're linearly independent, but that's obvious
?
i mean yeah you could do this
neither check is really all that hard
it's more bookkeeping than anything
every vector of the form (a1, a2, a1, a2) is the value of T at some point
I need to let x = (a + c, b + c, a + c, b + c) right?
?
you are showing that every vector of the form a1(1,0,1,0) + a2(0,1,0,1) is the value of T at some point
more concretely in this case it happens to be equal to T(a1, a2, 0)
thats all you need
What?