#linear-algebra
2 messages · Page 171 of 1
so n would be a vector of length one, pointing in the direction of the cross product
who cares about n
that's not the takeaway from this formula
it's just a different way of writing it
The two formulae
I see, so we gotta agree on |a||b|sin(theta), but when it comes to the n its just each to their own?
$||v|| = 2$ and $v = 2 \hat v$ mean exactly the same thing
Saccharine
where hat v is a unit vector in the direction of v
this not an issue of "to each his own"; this is just that you're ascribing more meaning to the n than you should
so do you just define a unit vector as a vector of length one in this case?
i see i see
the exact same analogy carries over to the cross product formula you've seen
that formula is about the magnitude of the cross product
but in the formula |a||b|sin(theta)n, n is a unit vector pointing in the direction of the cross product
and |a||b|sin(theta) defines the length of that vector
so the formula only tells you the length of the cross product
unless you know n
but you don't
which you proabbly wont
the geometric formula will never tell you the direction of the cross product
that's what I mean by
the formula only tells you the length of the cross product
it is assuming you know the direction of the cross product?
you have to know the direction from somewhere else; that is knowing n
that makes so much sense
you know the direction from right hand rule, but neither the formula nor right hand rule tells you what the unit vector would be explicitly
yeah, there's the whole issue of handedness too
if you're left handed sucks to suck
is there a nother way
but what you have to understand is that there is always at least one vector orthogonal to a pair of vectors
or does it take way to much meth
ok, that makes sense, thank you
no, not the cross product
an alternative to the right hand rule
no, the cross product is defined by the right-hand rule; otherwise there are two choices for cross product
is there a way to mathematically prove the right hand rule besides the idea that space is being flipped?
no there's no way to prove it, because it's just a convention
we just define the cross product to be in that particular choice of direction
you could easily assume the left-hand rule
I think I have a better idea of this formula now
Right hand rule is the best part of cross product
the handedness is just a way of picking a choice of orientation; what's important is that you're consistent
but other than that, it's pretty arbitrary
wouldn't be surprised if a civilization of lefties picked the left-hand rule
Pretty sure left hand rule just gives the negative cross product vector
well, yeah, it's in the opposite direction
but my point is that you can define the cross product that way and be okay
hello there i'm trying to solve this problem here
i've done
x + x = 2v
x + (x + (-x)) = 2v + (-x)
x + 0 = 2v + (-x)
x = 2v + (-x)
not too sure where to go from here
if you assume there is another solution, plugging it into the equation and dividing both sides by 2 shows that the two solutions are actually equal
x = v, x = w, then 2x = 2v = 2w, and x = v = w
so i don't need to use any axioms?
well being able to divide out factors uses scalar multiplication on vectors
How do you know you're allowed to safely multiply both sides by 1/2?
Is this a leading question?
it's a pedantic question to check boxes off in my head?
Because 2 is a member of a field
And is not equal to 0, assuming this is not F_2
Over F_2 that is not true
I see -_-a
In everything other than F_2,2 has a multiplicative inverse
I see, so it depends on division ring
I mean,with vector spaces it's always a field
You just don't ever use divison rings which are not fields
So with a rough estimation how much time does each of this question take to solve? If I were to fully understand spectral theory then it shouldnt be hard to apply it? Or is there more knowledge required for these problems that isnt just spectral theory?
https://gyazo.com/2994e805c065450c0efd509849aab721 wouldnt this be horizontal shrink by 4 but that isnt an option

horizontal compress is probably the right answer but a horizontal compress of 1/4 would actually be a stretch by 4
like the second and last answer choice are the same thing
this isnt a linear algebra question
i didnt know where else to ask
ok
or one of the help channels...?
sorry
if a set spans a vector space, is it guaranteed for the set to be linearly independent?
no
if a set spans and is linearly independent, we call it a "basis"
not all spanning sets are bases
thanks
i'm assuming you're asking why the integers aren't a field?
a single integer can't be a field since it's not an algebraic structure, its... a number
the integers are an algebraic structure, but they don't have multiplicative inverses
e.g. there is no integer x such that 2 * x = 1
1/2 is not an integer.
it is a rational number, yes, but not an integer
Im pretty sure that's what Nami just said
are you saying g would be 1/2 in this example?
i don't understand what the confusion is
the rationals form a field, the integers do not
oh you mean how it defines the rationals?
"the ordinary integers subject to ... arithmetic" just means integers but we can also divide
giving us the rational numbers
there are various ways to formally justify this; a handwavy way is to observe that if we take the rational numbers then 2 * x = 1 implies x = 1/2
but 1/2 is not an integer
yet arithmetic in the rationals behaves the same as arithmetic in the integers, so we should expect x to be the same. since the only rational solution is x = 1/2, this means there can be no integer solutions.
this way technically is a bit circular since we havent really defined how arithmetic of rationals should even work
but i'd wager that's beyond the scope of your linear algebra course
(if not, it's an easy application of the peano axioms)
(1 is only the successor of 0, and 0 is not the successor of anything, hence it's impossible to get from 2 to 1 just by applying the successor function; but multiplication only uses the successor function)
(so 2x = 1 has no nonnegative integer solutions, and the nonexistence of negative integer solutions follows from the fact that positive * negative = negative)
(again though this stuff is probably beyond the scope of your course - it probably cares about the linear algebra, not the underlying formal logic)
of course I could just do ye ol subspace proof technique, but for the space of symmetric matrices, if I show that all symmetric matrices can be written as A+At, and that S: A -> symmetric matrices is a linear transformation, defined by S(A)=A+At, will that also prove symmetric matrices are a vector subspace?
yes, the image of a linear operator is a vector space.
Does a matrix in row echelon form, always go to the right?
So like here
On the bottom row see how theres a 8 and 9 next to the 2 on the bottom
Usually theres only 1 number next to the pivot position in the last row
But this would count as chelon form right?
I believe Row Echelon always goes to the right
So then the one in the pic is in reduced row right?
Oh yea sorry meant just row echelon
How about this
Would this count as row reduced even though the 1 at the top isnt at the far left?
iirc you want 0 columns/rows to the bottom/rightmost
Wait why cant you always move 0 cols to the right?
how would you
Same way you can move a 0 row to the bottom?
...elaborate?
Oh so it wouldn't be then?
For this one, why would the answer be always consistent ? I get that it could be consistent but wouldn't the matrix I provided be an example of an inconsistent example?
Is it because the last 1 doesn't count as a pivot because it's at the very end?
what definition of consistency are you using
The book just said a system is consistent if it has 1 or infinitely many solutions
Basically if it has atleast 1 solution its consistent
what do you call a solution here? i ask because the board says it is only a coefficient matrix
but you usually test for consistency by augmenting the matrix
The question is question 3 here
what am i looking at
Where the problem came from, I have no idea what a solution would entail here
That's all they gave in the question
i might be wrong here, but i don't think that's enough to answer the question? let's see if someone else can help
does that thing have the solution to number 3? maybe i can read it and try to interpret it
Yea at the top
i guess that's fair enough
let me start by your question of "wouldn't it be inconsistent?"
what makes you say that?
Because the bottom row is pretty much saying 0=1 right?
can you hold up for a bit, racer?
In the matrix I made
aha
let me take a pic really quick
your matrix ONLY has coefficients
there is no equality to be interpreted there as 0=1
the last row only tells you some variable z has a coefficient of 1
the empty rectangle i added to the right of the matrix is where stuff at the other side of the equal sign would go
but this is NOT an augmented matrix
Are covectors just row vectors?
or any linear function that maps from a vector space to its underlying field
but row vectors are example
I mean you need to specify the dual vector space
All vectors are covectors wrt some vector space (atleast in fin dim)
I see. My confusion comes from quantum mechanics where a covector is just the conjugate transpose of a column vector so I was confused by the difference or lack there of
So it would be safe to say a row vector is a specific type of a linear functional?
Btw, Covector is just a synonym for linear functional
So if I transpose a column vector and turn it into a row vector, is that row vector then in the dual space?
Kind of
I see. I guess a better question to ask would be when can I not write a covector as a row vector
If you Identity the 1x1 matrix with an element of the field
If you mutliply a 1xn matrix A with a nx1 matrix B, you get a unique 1x1 matrix AB
Define f_A to be the function such that f_A(B)=unique element in AB
Set of such f_A is your dual vector space
And this f_A can be identified with A
I understand
I think you can always do that
Not sure about infinite dimensional case
I wasn't introduced to the concept of the dual space and covectors until after I took my linear algebra so I wasn't aware that I was doing it all this time
So then when you do dot products, wouldn't one of those vectors have to be a covector
You can say that
I see I see
anyone done linear algebra with numpy?
so the question is this.. i have done 80% of the code, but i'm stuck at the verification part..if anyone is interesting let me know i'll upload the code
What is the importance of row equivalency & elementary matrices?
Very useful for solving linear systems of equations
Probably the "most useful" part of linear algebra
Are you familiar with gauss jordan elimination?
Yes
Performing a row operation is the same as multiplying the matrix with a elementary matrix
Yes, what's so special or important about that?
Gauss jordan is much faster than other methods,afaik
Why does the elementary matrix bit matter though? Why do we bother with it instead of just performing G-J elimination on its own?
It's a nice way of seeing the connections between matrix multiplication and G-J elimination
(Also,They generate the group of all invertible matrices GL_n(F))
a whole bunch of stuff.
originally they were invented to be used as an "intermediary" step in finding real roots of cubics, but eventually mathematicians started caring about the complex roots too
that said, their more common equation-solving role nowadays is in differential equations
solving polynomial ODEs often involves factoring a characteristic polynomial into its complex factorization
even if the resulting solutions are real-valued functions, it's a handy tool to have
no, values of $x$ such that $ax^3 + bx^2 + cx + d = 0$ for fixed $a, b, c, d$
Namington
ie solutions to cubic polynomials
anyway, since then their uses have branched out - they're used extensively in EE and signal processing for example since they often come up in various transforms [they're also used everywhere in physics, naturally]
what do you mean by a "use"?
one of the first ones you see is the solution of the forced response of differential equations
like in electrical circuits
Are complex numbers useful in physics, engineering etc., because C is a closed field? Or is there another reason?
yeah, complex numbers behave the same way as 2D vectors
i mean C being a closed field specifically is kinda irrelevant
what matters is it being closed under radicals
which come up frequently [also it simply being a way to create a nice multiplicative structure on R^2, which is probably its most common engineering use]
it feels like you're asking this question before you even understand what they are
that makes it fairly hard to answer
Multiplication of complex numbers ends up being an easy way to add angles. So, lots of things that deal with circles, or sinusoidal motion can apply them
one solution to x^2 + 1 = 0.
if you mean in kaynex's angle example
multiplication by i would represent a counterclockwise rotation of 90 degrees
typically at least
sure, but the point is that we can now do algebra on it
which is very convenient
I can't rotate a vector by multiplying it by 90, no
The point is that "rotation" gets baked into the algebra. Scaling and rotating vectors can be noisy, complex numbers are able to able to simplify
v × i × i
no, multiplication by 2i would not be rotation by 180 degrees
it'd be rotation by 90 degrees and then scaling by 2
(or vice versa)
since the 2 scales by 2, and the i rotates by 90
multiplication by i^2 = -1 represents rotation by 180 degrees
and this makes sense, as multiplying a number by -1 "reverses" where it is on the number line
no, the angle isnt what gets scaled
the magnitude is what gets scaled
this is why its useful to have a mathematical notation for this stuff; it avoids these confusions
as an example, 3 * 2i = 6i
so we went from 3
which has magnitude ("distnace") 3 and goes "rightward" on a R-I plane
to 6i
which has magnitude 6 and goes "upward"
hence rotation by 90 degrees, scaling of magnitude by 2
You're on a good idea, and you're correct - by rotating 90 twice, you rotate 180. But multiplying by i and then multiplying by 2 isn't the same as rotating 90 twice
if instead we multiplied 3 by i^2 = -1
we of course get -3
which is the same thing as rotating 3 by 180 degrees
and of course i^3 is rotation by 270 degrees, i^4 is rotation by 360 degrees (which is the same thing as not rotating at all)
and this should make sense as i^3 = -i, i^4 = 1
the pattern continues
i^5 rotates by 90, i^6 by 180, i^7 by 270, i^8 by 0, i^9 by 90...
you get the idea
if your vector is from C, sure.
otherwise not really
3+2i and -1+4i would be vectors
in that image
you might be more familiar with writing vectors like $\begin{pmatrix}3\2\end{pmatrix}$ and $\begin{pmatrix}-1\4\end{pmatrix}$
Namington
but writing them in this complex-number way basically accomplishes the same thing
except now we also get multiplication
We can make this concrete:
3 + 2i is a vector
If we multiply it by i:
3i - 2
Is rotating it by 90 degrees
Note how crazy easy that is, haha
yeah, the isomorphism maps $a + ib$ to $\begin{pmatrix}a\b\end{pmatrix}$
Namington
and vice versa
i * (3+2i) = 3i + 2i^2
but i^2 = -1
so 2i^2 = -2
hence i * (3+2i) = 3i + 2i^2 = 3i - 2
you can write this as -2 + 3i if you prefer a+bi format.
in general, you can treat complex number multiplication like polynomial multiplication
except i^2 becomes -1
(which means i^3 becomes -i, i^4 becomes 1, i^5 becomes i, i^6 becomes -1, i^7 becomes -i, and so on)
right, which should make sense as i represents rotation by 90 degrees
and of course rotations by 90 degrees cycle through 4 "effective" rotations as well
well, we need to find a complex number with an angle of 30 degrees
the way we do this is through the formula s(cos(theta) + i*sin(theta))
s can be any real number
in this case, i'll let s = 1, and then theta = 30 degrees
in which case we get cos(30) + i*sin(30) which evaluates to sqrt(3)/2 + i/2
since scaling doesn't affect the angle, we could multiply by 2 to get sqrt(3) + i
adn this would also have an angle of 30 degrees
but now it'll also scale (by 2)
a lot of this theoretical content for complex numbers is based on trig
in fact, a lot of the geometric stuff in linear algebra is based off trig in general
see, for example, the relationship between the dot product and the law of cosines
you shouldn't need like, a deep knowledge of all the trig identities or whatever
but i'd recommend trying to learn what the trig functions mean geometrically and how the unit circle works
3+2i is a vector in the vector space C; i is also a vector in C
but it's also a scalar in C over the field C
though the distinction doesnt really matter here
so yeah, you can regard it as a vector.
use parentheses pl0x
Let's just talk any basic equation.
If you have a² = -1
Then you multiply by a
What do you get?
and on thr other side?
Yeah. You'd get
a³ = -a
It's all the same here. If you have the equation:
i² = -1
And you multiply by i, you get:
i³ = -i
This one?
What are you asking?
3i, when rotated by 90 degrees, gives -3
You're correct. 3i*i = -3
What?
If you multiply 2 by i, you'll have 2i. Correct
Look above, Namington fully worked it out
The multiplication of two complex numbers might be visualized as the sum of their angles and the product of their lengths
It allows you to separately manipulate these two quantities
Okay, so I have some confusion with this one right now
If v1,...,vm is linearly independent, then wouldn't a1v1+...+amvm=0 imply a1=...=am=0?
I guess Im just confused on where we’re using the fact that v1,...,vm is linearly independent
<@&286206848099549185>
A list is lin. dep. if the only solution to a1v1+...+amvm=0 is if all the scalars are 0
correct
But we dont seem to have to use that in the proof
So where should I be using that assumption?
well, they ask you to test that v1 + w, v2 + w, ... are dependent
that means that a1(v1 + w) + a2(v2 + w) +... = 0 has a solution where the a_i are not all zero, yes?
Exactly
ok
now, we split the sum up
and we have (a1v1 + a2v2 + ... ) + (a1 + a2 +a3 + ... = C)*w = 0
and we know 2 things
(a1v1 + a2v2 + ...) is nonzero, because the coeffs are not all 0
and also (a1 + a2 + ... = C) is a nonzero constant, for the same reason
yeah?
Right
w is a linear combination of the vectors v1,v2,etc
we're done
when we split the sum into 2 components, we used the definition of linear independence to assert that the coefficients are not all 0
yep yep
in rank-nullity theorem, for f:V->W how do you figure W if you know the transformation matrix A?
should have spesified, the base for W
what is b?
typo, sorry
so span W is (rank f)?
what are you trying to say
W is a space
it is spanned, it does not span something
wait a second
since A looks like this
and W is spanned by colums of A can i just ignore the 0 colums after dim im f colums?
they are just finite dimensional vector spaces with bases (v1...vn) and (w1...wm)
since colums of A span the W, and A has dim im f amount of "full" colums then shouldnt base of W be span(dim im f)
i just wanted to find out if you were doing something like w = Av or v = Aw
cuz that changes if the space is spanned by the rows or the columns
aha, so w = Av
yeah, W is spanned by the columns of A, but A only has rank dim im f
it's the same space though
the 0 vectors are linearly dependent to the other columns, so leaving them in does not change the span
so basically my V is spanned by (v1...vn) and W is spanned by dim im f
if your transformation is of the form $w = Av, w \in W$, yeah
yeah i think it is
Edd
im 99% sure
i didnt get any more info on the task than the one on fphoto
idk what nomenclature you are using, to me dim im f is just a scalar
the "rank" of the matrix
dimension of image f
no
W is spanned by (e1, e2, --- , ek)
W is a K-dimensional space spanned by (e1,e2,..., ek)
yeh
it's the "cookie cat" from steven universe
i think i understand it now
aight
just need to find math lemma for that for f:V->W, and A is transformation matrix then W is spanned by colums of A
it's called
fundamental theorem of linear algebra
In mathematics, the fundamental theorem of linear algebra is a collection of statements regarding vector spaces and linear algebra, popularized by Gilbert Strang. The naming of these results is not universally accepted.
More precisely, let f be a linear map between two finite-dimensional vector spaces, represented by a m×n matrix M of rank r, th...
tbh this problem looked more scary then it actually was
and this is the first time i got wrong asnwer by not realizing + was not commutative
this course i mean
Linear algebra does get less scary ... once you start becoming fluent in transforming space in your mind.
Linear Algebra is the most petite theory I've seen so far in terms of fitting in your brain
HS calculus in comparison feels like 4x stuff to remember and much more disorganized
I didn’t have calc in hs but I feel like calc 1 had less theory but that the excercises were less straight forward than in linalg. I just started reading the chapter on linear transformations so maybe I’ll change my mind. So far it has been pretty intuitive the foundation started with geometric intuition and it has built on that while in calc 1 you sometimes got lost. It is like ok I got this limit with some trigonometric expressions, I know these standard limits I just need to push some symbols until I get the argument to approach what I want and then I can refer to a standard limit and then you see the list of all trig identities so you kinda just trial and error picking some of them to transform them and then you think to yourself that life would be easier with l’hopital which you aren’t allowed to use since the “limit is trivial anyway! Lhopital should be last exit always!”. I haven’t felt that in LA yet, if I see a problem and have experience with it the solution is just mechanical
yeah, it's just that linalg usually appears at a point when students haven't been un touch with abstract definitions
boys, what conical shape is this?
hyperbola?
Options are:
Ellipse/Circle
Parable
Hyperbola
Degenerate Conic
it's one of the bottom 2 obv
Is this a test?
It's not an hyperbola
That's an hyperbola
yes
but this -15 isn't
so is it just that it is an hyperbola that under a specific angle it doesn't look so?
it's the same equation but -15 removed
cause in theory any numbers being added/subtracted just move the graph up/down
they can't actually change its shape right?
try rewriting your equation in the form (x-a)^2 + (y-b)^2 by closing the square
how does that help?
then u'll see that it cant be a hyperbola
make sense
which implies
that this is wrong
right?
when we have something of the form y = f(x) and we add/subtract constants to make it y = f(x) + k, then it only goes up and down. if we have y=f(x) and we shift it horizontally, we get y=f(x+h). but here we have something like f(x,y) and so adding/subtract constants has effects on the y values as well as the x values, so I can't say anything but it does seem from this example that the shape indeed changes
Hii, dumb question. Is the inverse of matrix A is equal to 1/A?
how do you plan on defining 1/A
wait actually my question doesnt help me at all
I was looking to define matrix B from AB-BC=D
that sounds kinda tough
everything I needed, was on the book all along 
If I say the "dimensions" of a linear map
Is it clear that I'm talking about the rank and nullity?
no
I'm sinking into shame when I realized it was in the Matrix Properties all along 
- What does it mean when inner products are noted like <-, -> or <*, *>?
- https://i.imgur.com/3lgEBk9.png
https://i.imgur.com/wyDF1Jj.png
I need to find the formula of the projection p in the direction v2 to v1
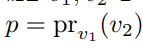
what does this mean exactly?
the notation isn't important
you just need to know it means inner product, and how that is defined
well this question doesn't actually define one
so I just assume it's something general
that just holds the inner product characteristics?
what is V
inner product space
if that is literally all you know, then you can only define the projection in terms of the inner product in general
if V is just a generic vector space equipped with inner product $< \cdot , \cdot>$, just use the definition of a projection
Edd
also, is pr there scalar projection or just projection?
right, so what does it mean to have a projection from v2 to the direction of v1?
uhm, I'm not sure
the question is writing the formula for the projection
what kind of projection though
you project v2 onto the line spanned by v1
"Let v1, v2 be in inner product space V over R or C
write the formula for projection p = pr_v1(v2) of v2 in the in the direction v1"
that is the translation
ok
what does that mean?
that has all the info
Like, what does it actually mean to project a vector into another one?
Do you know what projection means at all
I understand projection to be something you can perform multiple times on itself without changing the result
Like Pw * Pw = Pw
and Pw = w
in that case, the inner product $<\boldsymbol{v_1},\boldsymbol{v_2}> = \boldsymbol{v_1}^{\text{H}} \boldsymbol{v_2}$
and then the vector projection is easy
find out how much of v2 goes in the direction of v1, and multiply that amount by the unit vector parallel to v1
Edd
What is 'H' and how do you know this?
$p = \text{pr}_{v_1}(v_2) = <v_2, \hat{v}_1> \hat{v}_1$, with $\hat{(\cdot)}$ denoting a unit vector
Edd
So if they are going literally in the same direction that would be 0?
H is hermitian transpose or conjugate transpose
completely the opposite
same direction means it is as large as possible
ah okay I see
sorry yeah
that makes sense
I'm just failing to see how the projection operator is relevant here
we're trying to find out how much v2 goes in the direction of v1
the inner product for vector spaces over $\mathbb{C}$ and $\mathbb{R}$ is the "scalar product"
Edd
that is literally what projection means, isn't it?
can't it be defined otherwise?
Like <x,y> := xy
you can define it in any way that satisfies those conditions
i get the feeling you need to go back a little bit
yeah that is what I was saying
You said the inner product for vector spaces is the scalar product which is the sum of v_i * w_i
in v and w respectively
you'll notice, anyway, that the one you wrote is exactly the same one i gave
just with 1D vectors
OK, so just to clarify
over the real or complex numbers
can there or can there not be a different inner product than the scalar product?
there can be, sure
aight
since you found p by this equation
but is it going to work for any legitimate inner product?
like say I had some other inner product that's not the scalar product
my p would be different
the projection definition i gave below that was defined using only the inner product
you could use any inner product there
should be ok
mm I thought p was singular
how do you mean?
because when you define an inner product space, you give the field AND the definition of the inner product
so that works in general, and in the case of euclidean space, the inner product is the example i put up there with a hermitian transpose
the hermitian transpose is just a normal transpose only you also change the sign for the i element?
I'm not sure what the English name for it is
yeah, complex conjugate and transpose
Like
(a + bi, c + di)^H =
(a - bi
c - di)
yeah
righttt
Okay
I'm slowly starting to get it
but something isn't quite clicking, you said it is basically the definition of the projection
I don't really understand how
here
looking at the euclidean space example should make it clearer
the vector projection is a vector that tells you how much of v2 goes in the direction of v1
recall that, in euclidean space, $<v_2,v_1> = \Vert v_2 \Vert \Vert v_1 \Vert \cos \theta$
Isn't it like a number in the field?
Edd
okay
ok, that is why i was asking you
did you want the scalar or the vector projection
the two exist and are related
we'll get to it right now, anyway
I don't know, the question doesn't specify beyond what I've told you
now, if we take a unit vector in the direction of v_1, we get this
$<v_2,\hat{v}_1> = \Vert v_2 \Vert \cos \theta$
Edd
the left hand side is the "scalar projection"
the right hand side has its definition in euclidean space
it's the length of v2 that goes in the direction of v1, and it is a scalar
you can turn this into a vector that goes in the direction of v1 by simply multiplying again by a unit vector in the direction of v1
mm
$<v_2,\hat{v}_1>\hat{v}_1 = (\Vert v_2 \Vert \cos \theta) \hat{v}_1 = c \hat{v}_1$
Edd
right.
so
if I'm looking for a formula for p
isn't it like... also like pythagoras?
in euclidean space only
yes
I mean it feels like the distance
you can express v2 as a linear combination of v1 and a vector orthogonal to v1
and yeah, the distance between them is whatever part of v2 was orthogonal to v1
as you say
So is the question there just writing like p(w) = <w, v1>v1?
v1 has to have unit norm, but yeah
if v1 is not unit norm, the inner product is multiplied by the norm of v1
and then it is not how much of v2 goes in the direction of v1
look again at the euclidean example
right
if they have difference lengths
so really I need both of them normalized at least relative to each other
no
or ehm
you just need v1 to have unit norm
why not just v2?
but the projection is how much of v2 goes in the direction of v1
so you just need the direction of v1, i.e. its unit vector
$<v_2,\hat{v}_1>\hat{v}_1 = (\Vert v_2 \Vert \cos \theta) \hat{v}_1 = c \hat{v}_1$ in euclidean space
Edd
the hats there denote unit norm
I'm a little confused now. Who says v1 is the unit vector? I'd need to normalize v1
that's what i said
So p(v2) = <v2, v1>v1 is incorrect, I need v1' that is normalized mm
if
I'm getting you
i put a hat over v1 because you need to find a vector that has unit norm and goes in the same direction as v1
see, all the v1's in what i wrote have a hat. that means you have to take v1 and normalize it yourself
basically v1' = ||v1 ||
and I can take any valid inner product
for example the scalar one
but since v1 is undefined I can just leave it that
$\hat{v}_1 = \frac{v_1}{\Vert v_1 \Vert}$
Edd
i mean, you can just expand the whole thing
p(v2) = <v2, (v1 / ||v1||)> * (v1 / ||v1||)
$\left<v_2,\frac{v_1}{\Vert v_1 \Vert} \right>\frac{v_1}{\Vert v_1 \Vert} = (\Vert v_2 \Vert \cos \theta) \frac{v_1}{\Vert v_1 \Vert} = c \frac{v_1}{\Vert v_1 \Vert}$ in euclidean space
Edd
aight
hey guys
im unsure of whether Q is a subspace of V (i think Q contains the zero vector, i.e. the zero function, and is closed under scalar multiplication--but im unsure about whether it is closed under addition)
Let $V$ be the set of all continuously differentiable functions on the real numbers and [ Q={f\in V \mid \int_{-\infty}^\infty f(x)dx=0}. ]
VyacheslavMenzhinsky
well if you take the integral of the sum of functions, you get the sum of the integrals
so $\int_{\mathbb{R}} f + g , dx = \int_{\mathbb{R}} f , dx + \int_{\mathbb{R}} g , dx = 0 + 0 = 0$
bacono
so it should be closed under addition and thus a subspace
can i turn this into one matrix?
You don't need to use a matrix to solve this question
You have 3 vectors and are asking whether it spans a 4-dimensional space
so it doesn't span since there isn't a pivot in every row
since the only values you will get are x_1 and x_2
linear algebra or regular algebra?
linear algebra
i should probably ask this sooner but maybe theres still hope for me
what do you struggle with is the question
actually its hard to even say
i would say the first thing i really didnt get were the isomorphism theorems
then its also like i just dont grasp those things
like i do in real analysis
in analysis i can think about everything but i just cant make any sense of linear algebra
whenever a new concept is introduced im totally confused for some time and even later i feel i dont really know it well
most recently we began by defining multilinearity and then defined the determinand but i didnt understand almost anything ther
oof
im not even that high in linear algebra that's a whole different class for me
i'm just starting off with matrices and vectors
oh interesting we started by some general algebra basics sush as groups and rings and permutations ... but really only the basics
have you made the effort to go through the text book (if one is recommended in the class) or even watched videos on it?
then we started with vector spaces and linear maps
it was long before we began with matrices
seems like we have it completely reversed
that's weird lmao
LinAl in some schools are taught in first year.. so my guess is your course isnt a first year math course
it is a first year course
it is called algebra 1
but its basically linear algebra
it's just that it is taught with linear maps first
and we define matrices later
which makes sense to me
Well of course it makes sense to you... that's how you were taught
since you need to undestand linear maps to find matrices useful to even define
linear systems
yes youre right lol
what do you mean
Matrices can be defined from Linear Systems, so you dont "need to understand maps" to find them useful to define
^ tru that's how i learned it
we went over system of equations in the first lecture and then he turned it into a matrix
My LinAl course started with Euclidean vectors -> Linear systems -> Matrix Algebra -> Det
i learned about matrices from perspective of linear maps
that I learned about systems of equeations
after both matrices and maps
euclidean vectors? sounds like the other linear algebra class that is for seniors
oh yes i forgot we did vectors in R^3 before everything else too
i see that we are gonna do eigenvectors in like 2 months
Euclidean = Geometric tldr
well we just defined determinants for now lets see where we're going
i think the professor said most od our second semester will be about similar matrices
i have one question for you guys
how did you first define rank
rank(A) = dim(Col(A))
Idk we were just taught the operation
oh okay im just comparing the two ways of structuring the course
I think one way to approach linear alg
is you define all the operations on matrix as it is, without deep reason
It turns out its associative and satisfies certain properties e.g. distributivity, linearity, etc.
and then it also turns out that each linear transformations from V->W, where dimV = n and dimW = m are "equivalent" to a mxn matrices. Of course given a particular ordered basis B of V, B' of W.
so basically you can express any linear transformation as matrices, and most commonly you deal with matrices corresponding to a transformation T:V->V where the basis is unchanged
one motivation for the definition of matrix multiplication is that
its the only real choice if youw ant to represent systems of linear equations as multiplication of a matrix by a solution vector
so that gives you your rule for Matrix x Column Vector
and then extending that to Matrix x Matrix is natural from there
just repeat column vector multiplication a bunch

{kind=link}
{kind=link}
if you try and extend arithmetic to such a system, you immediately run into issues
in particular,
i^2 = i^3 implies -1 = -1 * i
which means 1 = i
so we've constructed a system where 1^2 = -1
it follows that -1 = 1
and voila, your system has collapsed into the positive real numbers
except with "i" as alternate notation for 1
the point is that just randomly defining things might not end up with you having well-behaved things
if you let your solutions to x^2 = -1 and x^3 = -1 coincide, your arithmetic immediately starts behaving pretty badly
unless you restrict your system so that you cant do arithmetic on i, that is
but then what's the point?
the "miracle" of complex numbers is that they actually are well-behaved
in many respects, more well-behaved than the real numbers
same way you multiply polynomials
replace i with x
what's x(3+2x)?
urm
that might make linear algebra pretty hard
okay well
to multiply polynomials, you "distribute in the x"
giving you this
and hence 3x + 2x^2
right, the ^2 only applies to the x.
otherwise we'd write (2x)^2
anyway, we're working with i instead of x here
so we should actually have 3i + 2i^2
but i^2 = -1
so we have 3i + 2 * -1
which is 3i - 2.
it doesn't matter which order you multiply things
(2 * 5) * 3 = 2 * (5 * 3) for example
well, this particular property is associativity
but yeah, multiplication commutes as well
$\sqrt{-1} = i$
moshill1
I know you already know this but just want to clarify for the rest to be alert that this can lead to confusion.
Always just define i as the following:
$i^2 = -1$
ds.b16rts
This avoids ppl having to remember specific rules, it avoids them using fallacies that lead them to prove 1 equals -1
In mathematics, certain kinds of mistaken proof are often exhibited, and sometimes collected, as illustrations of a concept called mathematical fallacy. There is a distinction between a simple mistake and a mathematical fallacy in a proof, in that a mistake in a proof leads to an invalid proof while in the best-known examples of mathematical fal...
I write things the way I learned them 
It means your teachers has great trust in you being careful. I guess mine saw us as retards 
I mean I self-taught myself complex numbers and then later on saw why that fallacy came up
fyi
defining i by i^2 = -1 doesnt quite work either
since there are actually two solutions to x^2 = -1
i and -i
so you need to arbitrarily tie i to one of these solutions
this doesnt really matter since theres literally no difference between i and -i
but its worth mentioning.
would the set of all real valued functions whose limit as x->inf is zero be a subspace of the set of continuous functions?
What do you think?
@wintry steppe see if your intuition's right, check the criteria
I'm gonna make a stupid question
Given a plane equation ax+by+cz=d
What is the geometric meaning of d?
@floral thistle
Suppose you have vector (a,b,c) which you know to be normal to your plane
fix then point (x_0,y_0,z_0) on the plane
and let (x,y,z) be some point on plane
then (x-x_0, y-y_0, z-z_0) is vector in plane
since (a,b,c) is normal to the plane it is orthogonal to (x-x_0, y-y_0, z-z_0) as well
thus their dot product is zero
in other words
a(x-x_0)+b(y-y_0)+c(z-z_0)=0
now if you expand a bit and move something to the right you will get ax+by+cz=d
nice explanation. From it one can also derive that the distance from the plane to the origin is $\frac{d}{\sqrt{a^2+b^2+c^2}}$ - or just $d$, if the normal vector is a unit one.
ConfusedReptile
$T: \mathbb{R}[t]_{\leq 2} \to \mathbb{R}^3$ defined by $T[p(t)] = [p(-1),p'(-1),p''(-1)]^T$
moshill1
The image is all of R^3 right?
should be
Ok cause we never covered actually computing images/kernels so wasn't 100% sure
I meant geometric
Although I ended up reaching the conclusion that d is a translation of all the points of the plane in the direction of the normal vector
but you can set e.g x = y = 0 and see what happens with z
the "d' just reperesents some number and it geometrically means that your plane doesn't contain the origin
assuming d isn't 0
Yeah, but according to you x+y+z=3 and x+y+z=9 are the same
And that's not true

I don't follow this.
Nvm, give me some mins to chew his point
What does the distance from the plane to the origin mean? The distance of the origin to its projection on the plane?
In Euclidean space, the distance from a point to a plane is the distance between a given point and its orthogonal projection on the plane or the nearest point on the plane.
He's right
This is true
i have the transformation matrix, how do i proceed?
Edd
that matrix has v and w as columns
you can take vectors in the canonical basis and multiply by B from the right to obtain linear combinations of v and w
the inverse of this matrix will do the opposite: it will take vectors in the basis v,w and give out vectors in the canonical basis
you want Av = v + 2w, which is equal to B [1,2]^T
B^-1 v should be [1, 0]
similarly, Aw = -w, which is equal to B [0, -1]^T
B^-1 w is [0, 1], yeah?
so you can express A as some BCB^-1 for some matrix C that takes the canonical basis and turns it into the required weights
Av = BCB^-1v = BC[1,0]^T = v + 2w
which essentially tells you the first column of C must be [1,2]
similarly for w, you'd get that the second column of C must be [0,-1]
and so the matrix A is $A =
\begin{bmatrix}
5 & 2 \
4 & 2
\end{bmatrix}
\begin{bmatrix}
1 & 0 \
2 & -1
\end{bmatrix}
\begin{bmatrix}
5 & 2 \
4 & 2
\end{bmatrix}
^{-1}$
Edd
might not be the cleanest way of doing it, but it's pretty straightforward
quick sanity check
@jade cosmos
thank you very much
If I talk about the dimensionality of the domain of a linear map
Is it clear I'm talking about rank and nullity?
wym
Commander Vimes
Yeah, that's what I meant
except I don't necessarily mean to talk about the range
otherwise that's just the rank nullity theorem
I just want to talk about the "input space"
or perhaps "Dimensionality of the input space for linear maps" is better?
wym
ah
just say dimension of domain
you could also speak of the range of the adjoint
i dont really understand my probbblem: i have ∆: F(V ) → F(V ) and i need to find f ∈ F(V )
for those c1,c5,c6
when i have that net that is defined on upper part of that pic
could i just make trivial f, such that if f(p1), fp5) or f(p6) then c_i else f(pj)=0
In this proof that similar matrices A and B (B = (X^-1)(A)(X)) have the same eigenvalues, how do they go from
det(S^-1AS -tI) = det(S^-1(A-tI)S )?
work backwards and I think you'll see
distribute it from det(S^-1(A-tI)S ) and see what you get
How does the algebra inside a determinant work?
just as usual
S^-1(A-tI)S
there are no special rules for distributing the matrices here because it happens to be inside a determinant
don't think too much, just do it
okay so
$$\begin{align*} S^-1AS - t I &= 0 \\ S^-1AS &= tI \\ A &= tIX^-1X \\ X^-1A &= tIX^-1 \end{align*}$$
Doukutem
Compile Error! Click the  reaction for more information.
reaction for more information.
(You may edit your message to recompile.)
well yeah this is sort of the idea
I can't get it to be such that there is X^-1 on one side and X on another in this equation
this is not right
there's no equation, it was only an expression
$S^{-1}(A-tI)S$
Merosity
now distribute $S^{-1}$ to get $(S^{-1}A - S^{-1} tI)S$
Merosity
now distribute S to get $S^{-1}AS - S^{-1} t I S$
Merosity
t is a scalar so it commutes with $S^{-1}$ and then you have the identity matrix which does nothing so you have, $S^{-1}AS - t S^{-1} S$
Merosity
having trouble with this, im just not sure how to make sure that a3 is not in span {a1, a2} (btw i have to construct a matrix. the black box represents any value besides zero and an asterisk represents any value including zero)
okay sure, you have a start then; so now can you come up with a vector that isnt in the span of a_1 and a_2?
does that mean c1a1+c2a2 /=/ a3?
sure, for any c_1, c_2
[you might notice that this is a very similar property to a_3 being linearly independent with a_1 and a_2; this might be discussed in more detail when your course covers bases and dimension]
im assuming this is correct then because there is no c1a1 or c2a2 that could possibly add up to be a3
right, that works
would i be able to put an asterisk in the last row of a3?
im not sure what your course's standard is for that
i mean certainly that can be a nonzero entry and the third column still wont be in span(a_1, a_2)
it just wont be fully row reduced
im not sure if that's what they're looking for or what
how are you defining determinant of a polynomial?
right, that's why i'm asking what they mean
it's not linear for many reasons
the +21 is not the only one
sure but it doesnt necessarily make sense to take the det of vectors either
there are senses where you can define this but
i dont think theres a canonical one
hence my question
if x is supposed to be a square matrix then you can view this as a matrix poly and compute the det of that
though it wont be a very nice determinant
rip I meant discriminant
can someone help with a proof
“if A is a square matrix such that A^2 is invertible, then A is invertible”
what have you tried?
this one theorem in my linear alg textbook that they say to use in a hint
“let a and b be two square matrices such that ba= the identity matrix. then a and b are both invertible, they are inverses of each other, and ab= identity”
so since A^2 is invertible, there exists an (A^2)^-1
such that $A^2 \cdot (A^2)^{-1} = I$
i wrote that down earlier
Namington
yes
now what do you know about $(XY)^{-1}$?
Namington
if anything
it is equal to $(Y)^{-1} X^{-1}$
Botpo2
Namington
@devout yoke
yes
so $A(A(A^{2})^{-1}) = I$
Namington
we have found an inverse for A
i thought about that but i was hesitant to declare it outright
is matrix multiplication associative?
alright thanks a ton
if you're familiar with determinants, you could use that too
though that's pretty overengineered
when this is a simple manipulation
determinant
the "laplace expansion of the determinant"
wait
no
thats the leibniz expansion
sorry
GX Racer
Compile Error! Click the reaction for more information.
(You may edit your message to recompile.)
$a_{\alpha_{1}1}$
Namington
no
\alpha is a permutation here
so the row is whatever \alpha maps 1 to
it's the same thing
That is a matrix
(2x3)*(3x2) = (2x2)
Okay, and A^T =
1 0
2 1
-3 2

wait
oops not AA^T, A^T*A
Anyways still 2x2 but
That's gonna be 1*1+0*0 in entry 11
Yeah when I started matrix multiplication I always wrote out the dimensions off to the side
Ohhh now I see why I was confused
I also wrote the dimensions off to the side
but in my head I was imagining (2x3)(3x2)
But that's AA^T not A^TA