#linear-algebra
2 messages · Page 147 of 1
im confused about v and v-perp dimensions, dont want spoilers though but like where should I start to figure out their relation to eachother?
think about the 3-dimensional case
like if v is the plane then v-perp is a line perpendicular to the plane, I feel like if v is a subset of R^n with dimension k then dim(v-perp)=n-k but dont know how to prove that.
i'd first prove a more general result given subspaces M & N, dim(M+N)=dim(M)+dim(N)-dim(M cap N), which reads as dim(sum)=sum of dims-dim(overlap)
alright
I feel like I can do that directly with the definition of span
then the rest would come easy because I can easily show that there is no overlap between v and vperp
thanks!
I feel like theres an easier way just talking about sets tbh
I think it will work out as well
|a|+|b|=|a U b| + |aintersectionb| right
then rearrange
and its the same thing as the general result he talked about
With a lot of linear, there's freedom to prove things by speaking of elements, or alternatively talking about sets as the spans of elements.
Or dimensions
can I talk about dimension like I would cardinality?
A lot of the same stuff works because of what @gray dust said.
I can easily show that there is no overlap between v and vperp
not really, v cap vperp={0} by definition
oof
but that's okay
dim=card(basis)
omg
Here's more than you would want to know about it, by H. Whitney: https://graal.ens-lyon.fr/~abenoit/algo09/matroids.pdf
Any intuition for why a complex linear transformation might not be diagonalizable if it has a duplicate eigenvalue? I don't really see how it differs from the case where eigenvalues are distinct
so eigenvectors with distinct eigenvalues are linearly independent
if all the eigenvalues are distinct, that gives you a basis you can diagonalize by
namely the eigenvectors corresponding to those eigenvalues
but when the eigenvalues duplicate, this argument no longer works
if an eigenvalue had degree k, you need k linearly independent eigenvectors corresponding to that eigenvalue
this doesn’t always happen, but it obviously has to happen if k = 1 always
and here’s a simple matrix that isn’t diagonalizable
$A = \begin{pmatrix} 1 & 1 \ 0 & 1 \end{pmatrix}$
by the characteristic polynomial, the only eigenvalue is 1
doubledual:
but you can quickly check the only eigenvectors with eigenvalue 1 are in the span of (1,0)
so it’s not diagonalizable
diagonalizable is equivalent to saying there’s a basis of eigenvectors, and that’s usually how I think of it
@west spade hope that helps!
So two eigenvalues of 1 does not mean a 2-dimensional subspace of eigenvalue 1
yes exactly!
degree of eigenvalue in characteristic polynomial =/= degree of eigenspace
the degree in the characteristic polynomial is an upper bound though
if you have k linearly independent eigenvectors with eigenvalue lambda, use them to make a basis. then compute the characteristic polynomial. you get a factor of (x-lambda)^k, in the characteristic polynomial
so the degree of lambda is >= k
I know the matrix you mention is invertible, but is there any way in which "both" eigenspaces of eigenvalue one are dependent? It feels like there's some way in which there is kinda an eigenbasis it's just deficient
there’s only one eigenspace, and it has dimension 1
that space in the above example is span(1,0)
Yeah, I got that. Was just spitballing
have you learned about jordan normal form yet?
I ask because I'm wondering whether transformations of finite order must be diagonalizable so that's kinda the flavor I was getting at
I don’t think I could explain that well, but it’s the moral answer to this question
I'll look into it
basically it says any transformation has a matrix in this form
where the lambda_i are the eigenvalues, and the amount of times they show up is their degree in the char-polynomial
those square submatricies on the diagonal are called “jordan blocks”
There doesn't need to be ones in those slots, right? Could be zeros?
yeah right, it depends on the dimension of the eigenspace for the eigenvalue
and other stuff too
if your characteristic polynomial is (x-1)(x-2)^2, there’s a few possible jordan normal form matrices corresponding to that
one is the diagonal matrix
the other is the one where you have a 1, then a 2x2 jordan block with eigenvalue 2
you get a jordan block for every linearly independent eigenvector basically
That actually is enough to prove what I want, so I'll just get to this first
Because the blocks will never have finite orders with 1s above the diagonal
cool, glad it helped 🙂
if i remember right, there’s always are jordan normal form for complex matrices, and for real ones you need some other conditions
so you should be good for your particular problem
Yeah, trying to classify representations for finite commutative groups and this does it
ok i just checked: there’s a JNF if the characteristic polynomial splits over the field you’re working in
so obviously good in C, and not necessarily good in other fields
only if too, right? take your completion to be the base field and take the roots you just added in the diagonal
yeah that’s right
there’s actually a nice proof of JNF using fairly simple ring theory stuff, lemme see if I can find a reference...
that proof is better than the ones found in linear algebra books
yeah, I've definitely put the cart before the horse in terms of my LA education so that would be perfect
@red prawn Thanks for sending me that paper!
dummit and foote covers it in chapter 12
you need to also know how modules work, which you should be able to handle if you haven’t run into them yet
Ill probably look at it and see if I should review it byself or if I should take it into office hours some day
@knotty raven Woah he was in to graph theory up until this point. According to Wiki, at this time he got interested in smooth functions, and the following year he did the Whitney Embedding Theorem
It's so surprising to me, that he could go from primarily interested in dots and lines and counting, to investigating extremes of just how bent and twisted shapes can get
I really want to learn spectral graph theory
it feels like it will be a cool way to use all the linear algebra im learning
plus matrix theory seems cool I like playing with different types of matrices
There's some crazy hard math related to that...
if a matrix is diagonalizable and its eigenvalues are all the same value, does the matrix have to be diagonal?
I want to say it does but I'm not 100% sure if it's true, because I've tried a few matrices and any that satisfy the multiple eigenvalue condition are never diagonalizable because they don't have enough independent eigenvectors
does anyone have any intuition in what direction I should follow to create a proper proof?
if a matrix is diagonalizable it can be written $P\Lambda P^{-1}$ where $\Lambda$ is diagonal right? And the eigenvalues are on the diagonal of $\Lambda$ right? And if the eigenvalues are all the same then $\Lambda = \lambda I$, right? So then what is $P\Lambda P^{-1}$ ?
@uncut fjord
Timon:
oh wow that gets you lambda I right? because $P\lambda I P^{-1} = $P\lambda P^{-1} = \lambda PP^{-1} = \lambda I$
yes
yw
Hi I’m currently taking 3rd years university course which is Linear algebra course(even tho I’m doing duo, high school and Uni(UCLA) so technically I’m 1st years Uni and G12 student) but that’s not the problem, so in the next chapter after the Gaussian Elimination, we will learn to through a new chapter, and that chapter include Rienman Sum theory which i don’t remembered much , so can someone here explaining or give me a briefly explanation about the Rienman sum for me thanks
P/s I did remembered Intergral
#calculus
@native rampart yes but I also mean to ask the related of the Rienman sum and Linear Algebra because I’m going to study about that soon, so I want a briefly understanding before studied
Finding the general solution for this:
$$y_1' = -y_1 + 3y_2$$
$$y_2' = 2y_1 - 2y_2$$
I find eigenvalues for matrix:
$$\begin{pmatrix}-1&3\ 2&-2\end{pmatrix}$$
Which are 1 and -4.
So general solution is:
$$y = c_1e^t\begin{pmatrix}3\ 2\end{pmatrix}+c_2e^{-4t}\begin{pmatrix}-1\ 1\end{pmatrix}$$
ryаn:
@native rampart I know the derivation of the eigen values and eigen vectors.
The final part is from some weird equation iirc.
For finding y(0) = (5, 0), is it just plugging c1 and c2 with 5 and 0?
Or does it just get worse?
Just plug
Oh ok, thats good.
@uncut fjord supposing that $\lambda$ has multiplicity greater than 1, just calculate the eigenvectors corresponding to that eigenvalue. If the dimension of its eigenspace is equal to the multiplicity, then it’s definitely diagonalizable.
Majez_tic:
Hey I need help with this question... I am trying to solve it for a while but I am unable to. I tried to learn it through videos but all is going in vain
This is the question 👇🏻
Investigate for consistency of the following equations and if possible then find the solutions:
2x-3y+7z=5
3x+y-3z=13
2x+19y-47z=3
Can anyone help me? Also if you will explain it a little I would be very grateful to you because I have similar questions in my plate that I need to solve. xx
its consistent if there exists a solution
have you tried putting into an augmented matrix and row reducing
Can someone teach me how to do vectors?
It's been a while since I've linear algebra and I was wondering about this particular part in my book:
I understand the whole concept and like addition and stuff but I just dont understand it past that
I need it for my computer science at uni
yeah ik
im asking just for someone to help me with them
I don't get the need for transposing the vector w. Wouldn't it give the same result if you just take the dot product of the given column vectors w and x_n as they appear above? Why is w transposed times x_n equal to the equation above whilst the dot product of w (not transposed) and x_n isn't?
I was just asking if someone could go through my material with me
and just explain the stuff I dont understand
In comment 1.7 as the book suggests I read, it says the following, but I could use someone to ELI5 what the author means:
Yes but my question is why does the author transpose the column vector w?
why is that? as long as the amount of columns and rows is the same surely the matrix multiplication is defined, no?
damn this guys annoying
So since there are two rows in the column vectors
but only one column
the matrix multiplication is undefined unless one of them is transposed?
have I understood this correctly?
that's what it says above, right?
in the transposed w there are two columns and 1 row.
and in x_n there is 1 column and 2 rows
Ok cool, it makes sense now. It's coming back to me. It's been a while since I've had the linear algebra course, but we're going to be using matrix notation and rules in this course, so it might be a good idea to read my notes from my LinAlg course. Anyway, thanks for the help! :)

read pinned post
How do you go from a matrix to the basis of row,col,null ?
@nocturne jewel do gaussian elimination
Yeah i know it's something todo with the rref, but i cant remember exactly
row is take pivot rows of the original matrix?
yeah when you get the rref form you can easily see the linearly independent rows and columns
null(A) is augment rref w/ 0, then take the vectors which make the "plane"
not sure what to call it past 3D lol
if you want the dim of null space then you can use rank nullity theorem.
no i need bases of row, col, null space
as I said the linearly independent rows form a basis of row space, lin indep col for the col space
The dual space is essentially just the set of all linear forms, right?
the dual space of say V , call it V* is the vector space of all linear functionals on V. that is the set of all linear maps from V to F
where F is the field
Hey, so I'm trying to understand what has been done here:
Resident Tracksuit Advisor:
Could somebody explain this to me?
Apparently the answer is ƛ=0 but I don't really understand why
a matrix with linearly dependent rows always has a 0 eigenvalue
there are a variety of proofs/justifications of this fact, its not particularly difficult to see
if a matrix has a linearly dependent row, then its determinant is 0
you're familiar with that fact, right?
(1,0,0) - (0,1,0) is a vector that is sent to zero
i.e., an eigenvector with eigenvalue 0
if a matrix has a linearly dependent row, then its determinant is 0
@limber sierra what's the reasoning behind this?
sorry if i'm a bit slow on this lol
are you familiar with the determinant?
recall that "determinant 0" means "not invertible"
they're the same thing
and certainly if a matrix has a linearly dependent row
if you reduce to rref you'll end up with a zero along the diagonal
it can be row reduced into something with a 0 row
so det = 0
right
yep
which cant be invertible, hence has determinant 0
So any time you see linear dependence among rows or columns, you don't have to calculate the full determinant formula, you already know the det is 0
an isometry is an isomorphism between two vector spaces such that B(v1,v2)=B(L(v1),L(v2)) for all v1,v2 in V
@simple hornet Sorry for a supre old reply I am on chapter 8.B
Given a set of vectors, how can I determine the subspace they form?
Do you mean their span?
well the problem asks for the subspace. but the span is a subspace, so i guess
Well, the smallest subspace that contains those vectors will be the span.
Idk what else you could mean
let me translate it, wait a sec
Find the linear subspace of $R^4$ generated by the following vectors: $((1, 2, 0, 0), (0, 3, −1, 0), (0, 0, 5, 4).$
Solution: $E = {(x^1, x^2, x^3, x^4) ∈ R^4 / 8x^1 - 4x^2 - 12x^3 + 15x^4 = 0}$
rcatalang:
Yes, they mean the span
So $E = { a(1,2,0,0) + b(0,3,-1,0) + c(0,0,5,4) | a, b, c \in \bR } $
Lunasong:
can someone check my work for a math problem
alright, yeah, according to $\sum_{i=1}^{i=n}a^i\cdotv_i$ right?
where that equals the span ofc
Yes
how do you get from that to the set conditions, though?
i cant find the correct subject ... :/
seems like abstract algebra to me
read pinned message
Let (a, 2a+3b,-b+5c, 4c) = (x1, x2, x3, x4). Then a = x1, c = x4 / 4. So x2 = 2a + 3b = 2x1 + 3b, so b = x2 / 3 - 2x1 /3. Then x3 = -b + 5c = 2x1 / 3 - x2 / 3 + 5x4 / 4.
Then multiply through by 12
Np
Hey can I get help with this, not sure how to do a) i
Since there two different size of parameters
Is it just multiplying the two matrices?
sorry if this is obvious but why is this true/false?
theoretically couldn't have an eigenvalue that corresponded to more than one eigenvector?
or am i misunderstanding lol
Can i get some help understanding 3.b from the question I posted above?
@wintry steppe what does it mean for W to be a subspace of R4?
I'm not entirely sure, I imagine it could be turned into a matrix
nonono dont overcomplicate it
what is the def of a subspace
no matrices are necessary for this at all
Its like zero vector, additoin and scalar
Like i gotta like prove it for each
prove what
That zero vector exists in that subspace
Addition works in that subspace
And scalar multiplication works in that subspace.
But idk, how that links with a?
Oh, that it maintains consistency kinda
go back to your textbook if you need to
Yeah I'll look into it again.
y is the value that c attains at the corresponding values of x
that is c(-2) =5, c(-1) =2 , c(1)=1.... Anyone correct me if I am wrong
hello my lovely people! can anyone explain me why E is a subspace?
Because when I write the matrice as span, the condition c+d is not always satisfied no?
you have to say it is a subspace, not just a vector space, the basis of vector space may not be the basis of its subspace
sorry i meant subspace yeah mb not vector space
for that look if it is contained in the vector space, then see if all the operations are inherited as well from the vector space
sorry can you explain what you meant?
look over the definition of subspace again
yeah i know what the definition is. do you mind explaining to me why what I did was wrong then?
You created a basis for M2×2(R)
I don't see how it relates in any way to E.
Worth knowing is the subspace test, which is very general. You only need to use a few facts to prove something is a subspace
it wasn't my intention to write E as a basis. Since any spans is a subspace, that's why I tried to write E as spans and I did that because that's also how one of a similar question from my textbook was answered:
Yeah, that would work. However, what you have above is not a span of E
hmmmm
Here's a hint. Use d = -c
kk
oh ok
yeah i get it now
still though, could you explain to me why what I wrote previously is not a span of E?
Because I can set a,b,c,d such that the result is not a member of E
I'll use E to represent the set of matricies I guess, lol
For example
a = b = c = d = 1
yes
Gives the matrix
[1 1]
[1 1]
Which is not a member of E because c + d ≠ 0
kk, i get it now, thanks for your help @half ice !
Np! Feel free to ask if you need anything else!
is there some trick to expressing a vector in a span as a linear combination of all the other vectors in the span?
You wouldn't want to use... all of the elements in the span. That would be a rather large linear combination
@pearl elm
Yes. It is equivalent to solving a matrix equation and so can be done with row reduction
Like expressing (2,3) using (1,2) and (5,6) is solving the augmented system:
[1 5 | 2]
[2 6 | 3]
Which probably has some ugly solutions but that's what I get when I come up with the numbers randomly
write some vector in the span S as a linear combination of the others
is S the set of these three vectors?
yes
so just write a linear combination of them, what is the field? Is it R
the vector you would get will be in span S
- (1,0,3) + 2 .(2,-1,1) -1. ( 5,-4,-5) = (0,2, 10)
is $\lambda v + (1- \lambda)w$ a theorem for an affine set?
bakes:
going through a textbook solution and v and w were plugged into that equation and resulted in 1 and then it says by the theorem its an affine subset
what does it mean to call a vector a theorem 
@crude oasis wat
sorry if i explained it horribly but the question was to show A is an affline subset and near the bottom where it says to plug into the theorem idk what theorem its talking about

is there context for this question? is this from a textbook or other source you can link us to?
like i don't see any "theorems" being used
what are the other steps? what comes before what you showed us?
sorry for late response but this was the question, maybe that solution is just incorrect i was just confused why it said at the bottom plug into that theorem
haha looks like it might be , becuase i have no clue what it was doing
me neither
the fact that you are given sum of \lambda _i =1 is a hint, a big giveaway. Don't go on solution.
the poor formatting of the solution leads me to believe it's one of those crappy solution manuals online that someone wrote on a $ per solution basis
gotcha, thank you i didnt know if i was missing something from the chapter
hi guys
i have an exercise that i have no idea how to solve
maybe some one of you guys knows hoy
how*
It's problem 2
Okay, I just grab my paper and pen.
Use coordinates vertor? What does that mean to you?
@fading plaza can I call you and I tell you details?
Nah, like you can show your work here and we can go on together
Like you can use the vectors and compare them if they are linear independent to each other
The thins es that the aren't vectors
They are the components x y z of the vectors in subspace P
X=p1 and so on
From that you are supposed to find a basis
It would be easy if there were two independent parameters instead o t and t^2
I'm kinda working on it with this
p1= (1 0 1)(1 t t²)^T
p2= (0 1 -3)(1 t t²)^T
p3= (1 1 -3)(1 t t²)^T
So that you can compare it with the basis
e1=1
e2=t
e3=t²
Of IP_2
Don't understand
I am currently practicing some electrostatics problems and got stuck because of math.
Mostly vectors.
I found this site for multiplication https://nrich.maths.org/2393
An account of multiplication of vectors, both scalar products and
vector products.
but I am not sure if a.b is the same as a * b
<@&286206848099549185>
and is there anything else must-know about vectors and trig?
scalar product is just the dot product
the two main operations youll probably see are dot and cross products
In mathematics, the dot product or scalar product is an algebraic operation that takes two equal-length sequences of numbers (usually coordinate vectors), and returns a single number. In Euclidean geometry, the dot product of the Cartesian coordinates of two vectors is widely...

In mathematics, the cross product or vector product (occasionally directed area product, to emphasize its geometric significance) is a binary operation on two vectors in three-dimensional space
R
...
a dot product makes a scalar from two vectors and the cos of the angle formed by the vectors
a cross product makes a vector from two vectors and the sin of the angle formed by the vectors
@rugged scarab Would love to have a pancake in this cold. There's load of material on wikipedia check out the links. You will understand it better there than asking here
thanks, I think I have a clearer picture on what to do next
@rugged scarab Would love to have a pancake in this cold.
@round coral same. Started studying almost 5h ago and still haven't eaten anything today. Math definitely isn't helping my apetite, though
I need assistance understanding what the heck my book is talking about. It uses a notation that, to quote the book, “isn’t what most linear algebra books do”.
The problem lies on this page, and the notation it sets up (poorly imo) is very confusing
It’s a big block of text that claims to give “rules of covariant indices” when in reality it summarizes their concept without giving any rules.
Later, it makes references to something that it doesn’t appear to go over
“L83” and the footnote are where my problems lie
Check the last paragraph in the first pic. "...covariant notation is an important aid in discriminating between objects that are fundamentally vectors and others that are not." Upper index things are for vectors, which you will think of as tangent vector fields to your given manifold. Lower index things are for covectors - things that you input a point, vector or vectors, and it gives you a number, vectors, etc. The vector product behaves less like a tangent vector; it gives you a vector perpendicular to the inputs, and he's pointing out that you can observe this distinction in terms of violation of notational rules (what things are allowed to live upstairs vs downstairs)
If you're wondering where L.83 comes from: L.82 is a Definition. Applying the dot*e_k to both sides yields L.83.
I have a problem in understanding this definition. By ""There exists j", we can choose an arbitrary j?
j in {2,3...m} just means that one of the vectors except v_1 is dependent on the others
@nocturne jewel "one"?
for example in the list {(1,2), {2,4}} that is linearly dependent, we can verify that (1,2) is in span(2,4) and (2,4) is in span (1,2) though @nocturne jewel
yeah
yeah, so that set has 1 linearly independent vector
at least 1
cause the 2nd one is already accounted for in the span of the 1st
@wintry steppe If, for example, they had instead wanted to assert the existence of more than one object, the statement would be more like "there exists a set of v such that the following conditions hold and this set has more than one element" or some other such quantification.
@stray granite
It's interesting and all, but have you got any thoughts on the question, or anything you've tried? What's your sense of what a subspace is?
@opaque plover yes but line 4 equates 3x2 matrices, should give a system in 6 eqns
ye if I solve the first column i get the first 3 x and the second column for the next 3 x
What can you conclude from the Fundamental Theorem of Algebra about factorization of real polynomials
that if the degree of a polynomial is d, then there are at most d real roots
Ok so I’m derping real hard on how to do row reduction in this case
Err number 47
Do I just solve for r since there seems to be no clear way to do row manipulation all the way?
I also skipped 42 for now for the same reason
yea im still stuck. Trying to solve for r doesn't seem to do anything
You could try taking the determinant of the matrixes and finding the values of r for which the determinant is 0
have not covered that section yet
is there another way?
so im forced to calculate a determinant here?
No, probably just Row Reduce. Sorry 😔
find a linear combination of (1,2) and (2,1) giving (-1,7). Then use those coefficients to compute the value of r that makes it linearly dependent
so we are ignoring the last row?
why that specifically?
anyway this problem doesn't row reduce to an obvious form where we know what r is. I have tried it like 3 times already.
maybe just take determinant without doing row reductions? would that work?
doing what kxrider says and ignoring the last row just ensures the first 2 components work out
then whatever the bottom entries are will just go along for the ride to give you the value of r
so does this always work?
I don't think you understand what's happening here, cause your question doesn't make sense
ok so for number 47
I'm not psychic, try to describe what you're thinking this does
so basically, lets say I am trying to solve 42, would i exclude the row that includes r and do row reduction and solve?
like let's say 3 of the first and 2 of the second gave you that vector
what would r be?
yeah @pearl elm that would work for 42
so what do i do after the row reduction with the 2x3
it doesn't seem like it helps
basically like... all i got was "here is a linearly dependent matrix and here are your solutions to it"
you should have c_1, c_2 such that c_1(1,2) + c_2(2,1) = (-1,7), right?
oh yea
well
not quite
oh wait
you meant an augmented matrix
i fucked up then
lol
give me a sec
c_1, c_2 are the solutions to
c_1 + 2c_2 = -1
2c_1 + c_2 = 7
ok so how does that help me find r
add the third components back in and compute c_1 (1,2,-1) + c_2 (2,1,-3) = (-1, 7, r). There is only one thing that r can be here
Hold on
Does this look right
Hold on I made a fix
uh i feel like i should of done the augmented row reduction just with the 3x3
what was the point of this
ok
i just used the original matrix and did augmented row reduce
got the answers i was looking for doing that
Another option is just to put all 3 in a matrix and row reduce to identity. At some point you'll be forced to divide something with r in it, just remember that you can't divide by 0
As such, row reduction to identity is impossible for some r
@pearl elm
It looks like ur working too hard here. You have
5(1,2,-1) - 3(2,1,-3) = (-1,7,4) = (-1,7,r)
so what does r have to be?
helo
maybe they did more row reduction and got diff answer for r
you can have multiple answers for r
aye
you can maybe verify your solution if that makes you feel better
ye
how would i verify that answer
also
not sure if my intuition is right for this answer
number 49
use the definition of linear dependence
and solve them system of equations
are you solving the matrix by substitution method?
erm >.<
i just go right to solving it if i don't see an intuitive row reduction
isnt it boring 😆
im not sure if that intuition for 49 is correct tho
okay yeh, its not possible
by not possible, i mean the solution of (1) and (2) is not a solution of (3)
yea
cuz solving for r
so it is neither lin dep or ind
no its lin ind
how so
im gonna say the first vector is v1, second v2, and third v3 okay?
you solved x1v1 + x2v2= v3
and you saw that there are no possible x1s and x2s such that this holds true
im gonna multiply the entire equation by x3
wdym by x3, there is x1 and x2
multiply it, what do u get
im still a little confused by what you mean
sorry my keyboard is kinda broken i cant type x
let x3 be an arbitrary real number, okay?
now i multiply it on both sides, that still preserves the equality
can you type the new equation?
earlier you were solving the third column vector as a linear combinatiion of the first two
now, we are considering the third column vector as a vector in its own right
yea it is an indepedent vector
and lin ind is a set of all independent vectors
uhh- can we join on vc? i cant type well
i think i get it
the third vector is its own independent vector, which is why we can't get a solution in the augmented matrix, rendering the set S as linearly independent
YES!
there's one tiny part remaining- that you show that the first two vectors are independent as well
Does this look right?
So far anyway
The answer in book says solution is all reals
But I don’t see how it’s getting that
because (0,0,0,0) ruins any chance for linear independence on its own
but can't you just throw in a zero vector into any matrix
if I remove it from this I still get a 4x3
if I had a 3x4 then it is lin dep for sure
you can't just remove vectors from your list, even if its 0
ahhh ok
Also does this look correct
It’s a diff solution than book but I am using x3 and x4 as free variables
if you have any collection of vectors v1, v2, ..., 0,..., vn containing the zero vector, then there are always nontrivial linear combinations of these vectors giving the zero vector:
c_1 v_1 + ... + c0 + ... + c_n v_n = 0
where you take all of the c_i = 0, and c != 0. If you were to remove 0 from the list, then v1, v2, ..., vn very well could be linearly independent.
that's what i meant by (0,0,0,0) "ruining any chance for linear independence"
thanks for clarification
so for that problem i chose different free variables
than book did
i think its correct. I just end up with fractions cause I just kinda brute forced it
lol
,w rref [[1,-2,-1,-4],[2,-4,3,7],[-2,4,1,5]]

x2 and x4 are free here
hiii i'm not sure if this is allowed
but i have a final in 2 weeks
and i was just wondering if someone has time to tutor me tmmrw
paid of course!
please dm! thanks!
Umm
I’m not sure
I could
But
I would rather not earn
I would do it voluntarily since I don’t wanna break tos @wintry steppe
So yeah
i don't think rules are broken unless you do their homework for them
honestly you could probably just join vc when there are people in it and start asking away
lmao row reduction makes these problems much easier. I'll finish the last 6 problems in this section later. Thanks
linear algebra is so nice with my prof this semester
I'm trying to prove the Cayley Hamilton theorem a certain way
by showing that if p is a polynomial, and c(x) = det(xI-A), and if p is divided by c to get a quotient q(x) and remainder r(x) then p(A) = r(A)
I'm stuck though
this implies Cayley Hamilton cause if p(x)=c(x) then r is 0 so c(A)=0
how is this different from the usual false proof of just plugging in A?
The cardinality of the set Map(X, X) of maps from X to itself is n! if X is a finite set with cardinality n, right?
the false proof is just saying det(AI-A) = det(0) = 0. This proof is showing that for any polynomial p which divided by c(x) (the characteristic equation) gives a remainder r, p(A) = r(A). It isn't cheating to let p(x)=c(x) as a special case of this, once it has already been proved
<@&286206848099549185>
But don't they have to be bijective? nani
do you think non-bijective maps don't deserve to be called maps?
But it's the set of maps from X to itself
How can a map from a set to itself not be bijective
very easily
take X = {1, 2, 3, 4, 5, 6} for the sake of example
you can have a map f: X -> X which sends everything to 1
uhhhh
i think that might be a bit context-dependent, it's not an actual rigorous term unless you get into category theory or something
I can give context if you want
sure
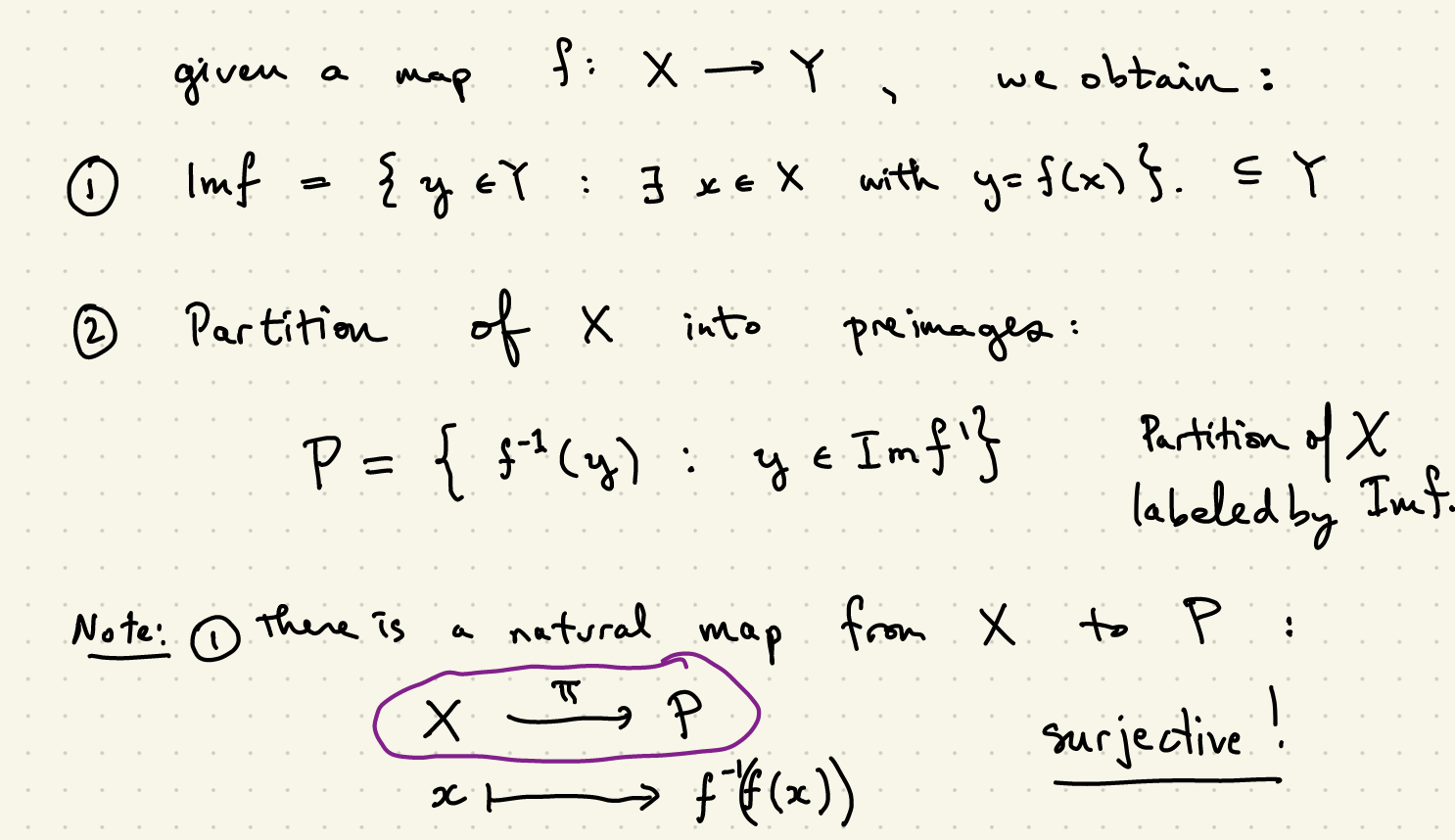
yeah "natural" is kinda... informal here ig?
it's a bit hard to pin down exactly what it means since its meaning is a bit subjective
Do you have a best guess maybe
hey
no it was someone who's b& just now
anyway yeah like
idk
dont take the word "natural" too seriously i guess?
its more of a "doesnt require much additional legwork to construct" thing
@wintry steppe
"Natural" is informal to mean "It is an easy thing to recieve from our construction". There's no special property of this map.
I don't know what factorization of maps is in general, but I'm guessing in linear algebra it can be thought of as writing a matrix as a product of two matricies instead. Have a picture of that one too? Lol
Yeah just to get some context haha. Sorry to make you work so hard
yes i totally agree with you.
Hey I can't complain here thanks for helping
Ah okay. Much like one can factorize
6 = 3×2
We can take any function f and break it into two parts, such that their composition is that function again:
f = i∘π
Special thing to note, if π is surjective and i is injective we can still always do this, via that picture's construction
These functions don't have to be linear, but if they are we can represent this whole thing with matrix multiplication instead.
Trivially, yes haha.
x² = x² ∘ x
It's boring but it works
The injective/surjective thing makes it a little more interesting
@thorn lichen
I've actually never understood that notation. Does that mean:
"expressed in the basis B, [1,2] is the same as, expressed in the standard basis, [1,2,1]"?
If that were the case, then there's two "vectors" such that:
2a + 3b = i + 2j + k
Blu3_bear:
There's no two unique such vectors haha. Just any will do
Why not set a few and see if you have to decide the last entry?
but like
ok nvm
i see
is the basis jsut two vectors
or do i combine them?
i used [ 1 1] and [ 3 1 0]
How do you add those? Haha
You care about:
2a + 3b = i + 2j + k
The right side has vectors in R³ so naturally the left must as well
Yes a and b will be vectors in R³
thanks !
if i know two matrices A and B are similar, is there a way to find the "change of basis matrix" P such that PAP^-1=B?
Maybe calculating SVD of both matrices can help. Then make a matrix that takes the first list of right singular vectors to the second list of right singular vectors as the change of basis matrix.
I am not actually sure, but this is an idea
Ups: actually, nevermind
also @gritty kelp sigma is the same dimension as A so not always square. you also must have made a mistake because the eigenvalues of A^TA and AA^T are always nonnegative
hm well if theyre both square then SVD may be a bit heavy handed. maybe investigating the jordan forms
$$TAT^{-1}=B$$
$$T(PJP^{-1})T^{-1}=P'JP'^{-1}$$
$$(P'^{-1}TP)J(P^{-1}T^{-1}P')=J$$
$$(P'^{-1}TP)J(P'^{-1}TP)^{-1}=J$$
nix:
i decided to use T instead. does it follow that P'^{-1}TP must be the identity matrix?
do you want to prove that to change the basis of a square matrix/ operator , you need to multiply with the identity matrix both right and left
the identity matrix which maps the old basis vectors to the new basis and its inverse which maps the new basis vectors to the old basis vectors
that's right
@hollow finch I would suggest looking at this through linear maps/transformations. It will be easier to understand this fact
That matrix could just be in the centraliser of J
what is centraliser?
basically matrices I,such that IJ=JI
The transformation could have the exact same matrix in another basis
Yeah! That's quite obvious. We prove that the first we study transformations
hm wait so could i do this
$$(P'^{-1}TP)J(P'^{-1}TP)^{-1}=J$$
$$TP=P'$$
$$T=P'P^{-1}$$
nix:
i guess that would make sense lmao
i dont know what youre trying to do
what is the yellow area supposed to represent? why is this in #linear-algebra ?
I don't know, linear algebra class
The yellow area is supposed to represent R x R as in the top right
But I don't think it's correct, it should be all 4 quadrants highlighted?
read the pinned message
Where should it go?
RxR is the entire plane
idk, probably not here
Yeah where though?
pinned message
I disagree with the first
the first one is obviously linear algebra
solving a system of linear equations
i would not consider "solving a system of linear equations" to be linear algebra ceteris paribus
certainly if youre using linear algebraic techniques
like row reduction or w/e
perhaps, but I can write the first question as "find the x that minimizes ||[4 - (3x + 1)]||^2
alright, tell that to the typical 14 year old who comes into #linear-algebra thinking it'll help them with their algebra 1 homework
I am struggling with this question
I am suppose to be able to find dim(L(V))
in terms of dim(V)
Then I assume k>dim(L(V)) so k can generate the Z function
I want to show that A and A*A have the same null space
it's obvious that NS(A) is a subset of NS(A*A)
and if AAx = 0 taking the conjugate transpose on both sides gives xA*A=0
oops discord is weird
backslash the *s
that was supposed to be A*A=0
ok
so if A*Ax = 0 taking conjugate transpose gives x*A*A=0
which means also (Ax)*A=0
so x COULD be in the null space of A as well
but x*A could also be zero
which is A*x is zero
hint: ||look at <x, A*Ax>||
k I'm gonna try that thabks
but based on my manipulation, doesn't that mean that A* and A also have the same null space?
cause that doesn't make sense
ah thanks for the hint I think I have it
can you check
sure
so if x is in the nullspace of A*A then <x,A*Ax> is just <x,0> which is 0, but it is also |Ax|² therefore Ax=0 and x is also in the nullspace of A
correct
yay thanks
k this led to a curiosity of mine
if A is square do A* and A have the same nullspace?
here is my reason why I think this should be the case:
we already see that A*A has the same nullspace as A, and if x is in NS(A*) then A*Ax = ((A*Ax)*)*
which is
(x*A*A)*
which is
((Ax)*A)*
@rain echo in general, the kernel of A* is the orthogonal complement of the image of A (try proving this if it's new to you), which should help you find a simple counterexample
nice I think I will try to prove that
does that imply that their null spaces are disjoint?
actually no it doesn't
all vector spaces have zero 😉
well I meant besides 0
lol
and even so it's wrong
i guess you meant direct sum?
ah sorry i see what you mean
yeah
I still find it extremely satisfying that the euclidian inner product just accidentally also is similar to matrix multiplication which gives stuff like NS and RS are orthogonal complements and like unless the vectors were lists of numbers idk if that would be the case
well let me think
I guess rowspace has no meaning unless each vector is a list of elemenrs from a field
just take A to be the zero matrix lol
took me longer than it should have
i think in some specific situations (e.g. A unitary, maybe even normal or self-adjoint too - play around with it) you can say something nice though
well I know
that
nvm
k I have an inner products question
I have this idea that I used as intuition when learning quotient soaces
spaces
I want to see if you think it's truw
if L is a subspace of K
hold on its hard to word this
so like
if you have an inner product defined
then the orthogonal complement of L has a basis which is linearly independent over L
I'm wondering
wdym linearly independent over L?
oh that's the terminology my book ussz
it means that no linear combination of the set of vectors is in L unless all coefficients are zero
i see
my book uses that to define what the quotient space iz
is
well not to define it but to understand it better
so a set S is linearly independent over L if its image in K / L is linearly independent
yes exactly
ok i get it
in fact the way I understand it is that you have a basis for K which contains a basis for L, and the basis for K/L is the classes of vectors which contain each basis vector for K that wasn't one of the vectors in L
so I was wondering
the orthogonal complement is a very nice example of this
so like if x and y have the same image in K/L then their projection to the orthogonal complement of L is the same
so I was wondering, if L and M are subspaces of K whose direct sum is K
and a basis for M is linearly dependent over L
does there always exist an inner product on K such that M and L are orthogonal complements?
alright
if x and y have the same image in K/L then their projection to the orthogonal complement of L is the same
i'm not so sure about this
why not?
if B is a basis for the orthogonal complement, then x and y having the same image in K/L is the same thing as their B coordinates being identical and their L coordinates can differ by whatever
similarly, the projection of x and y onto the orthogonal space is determined by their B-coordinates
I'm using the expression "B-coordinates" loosely here, I just mean, in a basis for K which contains the basis B, the coefficients of the vectors in B for the representation of x will be the same as for y
oh i was having a brain fart oops
forgot how quotient spaces work for a sec 
yeah i see it
now lemme think about the inner product question
ok
it's a good question
:)
just throwing an idea out there
let $\ell = \dim L$ and $m = \dim M$, and choose an isomorphism $\Phi : L \oplus M \to \bR^\ell \oplus \bR^m = \bR^{\ell + m}$ with $\Phi(L) = \bR^\ell \times {0}$ and $\Phi(M) = {0} \times \bR^m$. this defines an inner product on $L \oplus M$, and maybe you get $L^\perp = M$ with it
TTerra:
after this I have an interesting fact about linear algebra that I already proved but it's a very sexy theorem
ok let me read for a sec
i'm leaving a few details out that i don't wanna type in lol
the little L didn't show up on line 1 I assume it's supposed to be there
where
it looks fine for me
lol
i feel like this will work
ofc you should write out what such an isomorphism is and what not
yes I get the point you are making
let me think on it for a sec
it seems a little too magic
a lot of linear algebra does 😌
hagag
ok
so
I like how you put us in a very easy vector space
now I feel like
let's just let l+m=n to make things easy
all of finite-dimensional linear algebra is just reduction to euclidean space
which is why you study infinite-dimensional spaces where fucking everything goes wrong
well fourier is very sexy though
alright so the isomorphism construction i just did kinda ignored the condition "a basis for M is linearly dependent over L"
ye i'm just pointing it out
also
I'm pretty sure just by geometry this should hold on Rⁿ
right?
would that prove it?
I just assume yes
you mean whether or not there's an inner product on R^n that makes L and M orthogonal complements?
let me write down some more detail for the isomorphism thing i proposed
just to make sure nothing goes wrong
it looked straight forward
especially considering L and M have bases which are linearly dependent over each other
which must be the case in order for you to say that phi(L) is R^l x {0}
I think so at least
alright here is a sexy theorem
and if you row reduce with the euclidian division algorithm it becomes really easy to see why
if you have n, n digit numbers represented in base b
and you put their digits as entries in an nxn matrix
if all n of those integers were divisible by k
then the determinant of the matrix will be divisible by k
Let ${v_1, \dots, v_\ell}$ be a basis of $L$ and let ${w_1, \dots, w_m}$ be a basis of $M$, and consider $L \oplus M = K$. Define an isomorphism $\Phi : L \oplus M \to \bR^\ell \times \bR^m$ by $$ \Phi\left( \sum_{i=1}^\ell a^i v_i, \sum_{j=1}^m b^jw_j \right) = (a^1, \dots, a^\ell, b^1, \dots, b^m). $$ Consider the unique inner product structure on $L \oplus M$ turning $\Phi$ into an isometric isomorphism, namely $$ \langle v, w \rangle = \langle \Phi(v), \Phi(w) \rangle. $$ Then, since $\Phi(L) = \bR^\ell \times {0}$ and $\Phi(M) = {0} \times \bR^m$, the subspaces $\Phi(L)$ and $\Phi(M)$ of $\bR^\ell \oplus \bR^m$ are orthogonal complements. Since $\Phi$ is an isometry of inner product spaces, $L$ and $M$ must be orthogonal complements. (Note that we didn't need to impose any conditions about bases of one space being linearly independent over another.)
sorry im just gonna drop that
outta nowhere lol
bot slow?
👻
TTerra:
good god that is long
note that im considering the internal direct sum (L, M are subspaces of K, adding to K with trivial intersection) - this doesn't really matter but i just wanna point it out
omfg
so the answer to your question is yes
hello
and it's so simple
my intuition was basically to pretend that everything is subspaces of euclidean space
it seems obvious now
now how can this go wrong in infinite dimensions 
alright here is a sexy theorem
and if you row reduce with the euclidian division algorithm it becomes really easy to see why
if you have n, n digit numbers represented in base b
and you put their digits as entries in an nxn matrix
if all n of those integers were divisible by k
then the determinant of the matrix will be divisible by k
this sounds neat, although i have no clue how to approach it lmao
might be useful to try some special cases
like R^infinity
and maybe functions from R to R roo
then try to abstract
do you want me to take you through the proof with you?
\ell^2 would be good to start with, i think
of the determinant thing
it's okay, thanks though
what's \ell^2
set of sequences converging in the 2-norm
more explicitly
well i guess it's basically R^\infty
but slap a hilbert space structure on it so it becomes just a teeny bit nicer
$$ \ell^2 = \left{ (a_1,a_2,a_3,\dots) \in \bR^\bN : \sum_{n=1}^\infty a_n^2 < \infty \right} $$
TTerra:
i'd look at something like that if i want to think about infinite dimensional examples to finite dimensional things
ell^2 isn't very... unwieldy
unlike certain spaces
if you take functional analysis you will probably see this every single day
such a wildly defined vector space
hahaha
not taking that for a while
am I wrong or is functional analysis all about infinite dimensional space?
that's not that far off
finite dimensional inner product space stuff is generally well-understood
so one prefers to study infinite-dimensional inner product spaces
that's where the topology and analysis comes in
thus placing functional analysis somewhere in the intersection of linear algebra, topology, and analysis
that sounds scaryyyy
but also fun
cause finite dimensional inner product spaces are like really happy and nice things
they are a comfort zone
interesting things happen when you get out of your comfort zone 
I mean that's what math is all about
func anal is more analysis-y than linear algebra-y in my experience
a lot of its examples come from and are motivated by analysis
all of finite dimensional linear algebra is just fucking with bases, so when you get rid of a finite basis....
hahaha I guess so
but if you are concerning yourself with inner products I bet most of the structure comes from linear algebra
so by definition wouldn't it always be linear algebra-y
inner product gives you a norm, which gives you a metric, letting you do topology/analysis
if you've ever heard of a banach space or a hilbert space
it's when the metric induced by the norm is complete (banach), and in this case, if the norm comes from an inner product, you call it a hilbert space
can I post my question now?
if ethan has no mroe questions, go ahead
we were basically just chatting about math lol
Does that mean that the vector wasn't turned into probability vector? which means it doesn't have to be equal to 1
it normalizes eigenvectors by default
prob. whats happening
result of scaling an eigenvector is still an eigenvector
for reasons that should be fairly obvious
so it scales them so that the norm is 1
so it means it's the scaler value which makes the difference otherwise both are the same
yes, they both correspond to the same subspace and have the same eigenvalue
the scale factor is arbitrary basically
@wintry steppe I guess I never saw the connection between linear algebra and metric spaces
but it was there all along
very interesting
why is v1, v2, ..., v(k-1) LI?
i think it might be due to linear dependence lemma, but i'm kinda unsure
cause of how k is defined
worded differently
vk is the first vector that is in the span of the previous ones
that means before that point
no vector was in the span of the previous ones
to say it loosely it "added to the span"
and k is the smallest integer where the vector added is "useless"
i don't get it either way
so let's build up the set of all vectors v
starting with v1 and add v2 then add v3 and so on
if the entire set (up to m) is linearly dependent
then there is some point
when as you are building up the set, the vector you add is in the span of the vectors you have already added
so maybe v1 and v2 are LI, so v2 is not in the span of v1
and then you add v3, and v3 isn't in the span of v1, v2, v3 so everything is STILL LI
but then maybe v4 is v1+v2+v3
and if that is the first vector that you add that has this property
then you know the vectors that came before have to be independent
cause if they were dependent, then one of them would be a combination of the others
but that contradicts the fact that k is the SMALLEST integer for which they are independent
make sense?

{kind=link}
{kind=link}
{kind=link}
nice
there's another proof that the eigenvectors are independent too if you want that
I find it a bit more straightforward
I saw it by using induction, but I was trying to get it in this way
induction gives you an argument that's veryyy similar to this one
could you disclosure?
I'm a bit lost on what I'm supposed to do with the A^5 part, I know what to do if it's just A, but what do I do with the 5
yes!!
Ooooh ok, thank you, let me go give that a try
np
alright here it goes. base case n=1 is pretty obvious, any set of 1 vector that isn't zero is linearly independent. Even for 2 you can see that if v1 and v2 are linearly dependent, then v2 is a scalar multiple of v2, but that implies that it corresponds to the same eigenvalue as v1 which is not the case. Inducvitve hypothesis is that this holds up to n distinct eigenvalues where n>=2. Then suppose you have a combination a1v1+a2v2+...+anvn+a(n+1)v(n+1)=0. Make 2 mental copies of this equation and manipulate them both in different ways. if you multiply this equation by A you get each term multiplied by a different eigenvalue. If you multiply the original equation by the n+1th eigenvalue and subtract this equation from the first one, you get that the term with v(n+1) cancels since you subtract lambda(n+1) of it from lambda(n+1) of it. For all of the other terms you get ai(lambda(n+1) - lambda(i))vi. but now you have a combination of the first n vectors which gives zero. since the inductive hypothesis is that these are independent, that gives you that each coefficient must be zero. since the difference of distinct eigenvalues is not ever zero (I mean they are distinct real numbers) that leaves that each a_i must be zero. therefore the original equation gives you simply a(n+1)v(n+1)=0 which gives you a(n+1)=0 and that proves the linear independence
sorry the notation is so weird
idk how to use the bot
also sorry, just a picky note, I said one time in the proof that the eigenvalues are real numbers
that obviously doesn't have to be the case
they are elements of whatever field you are working with
put single dollar signs around things you want inline, double dollar signs around things you want presented in the middle
like
here is inline: $G = \bZ / p\bZ$, and here is display mode (i think it's called that): $$ \frac{1}{2}E''(0) = \int_0^a \left\langle V, \frac{D}{dt}\frac{dc}{dt} \right\rangle , dt $$
TTerra:
after that it just boils down to how much latex you know
messed up a sign on the displayed formula but whatever
0
I guess I should learn that
it's worth it to be able to visualize the formulas in a discussion
#linear-algebra message
here's an example of using it
learn by osmosis 
@wintry steppe where are u from
why
your name reminds me a portuguese name
im canadian
canada > US (does that break the offensive rules of the server?)
it's the truth though