#linear-algebra
2 messages · Page 98 of 1
iff finite dimensional
yea
Take $(e_1,\hdots, e_n)$ to be a basis of $V$, and define for each $e_i$ a linear functional $\epsilon_i:V\to F$ by $\epsilon_i(e_j)=\delta_{ij}$.
mart:
whats delta
claim: that gives a basis for V^* and consequently dimV=dimV^*
kronecker delta search it up
okay so its like a function that outputs 1 if matrix
sqaure
and 0 if not
square*
?
identity/
the identity of dimension i*j?
yea
i got it
okay
okay i got the proof , for each element in the basis define a linear functional that sends to the corrosponding entry of the identity
thats a basis for the dual
right?

what i read was thtat the delta_(ij) is the ith,jth entry of the identity matrix of dim ij
thats what i meant if i phrased it wrongly
δ_ij is just a shorthand for 1(i=j)
hey,
could someone help me find this permutation`s inverse?
is it just 1, 2, 3, 4, 5, 6
no?
what is it then?
can give $\sigma$
deekaan:
once you have sigma it's pretty easy
just write it backwards
i dont understand.. wym by having sigma
deekaan:
yes
then do like mo2men said and turn that around and you're done
so when i get the inverse does it go like (1), (5,2) and so on?
yes
how would you write in the form i sent here at the beginning
1 leads to 1, 5 leads to 2 and 2 leads to 5
how do you write that?
just flip it bro
up becomes down and down becomes up
no you have to flip it
yea but still
but 5 is mapped to 2 and 2 is mapped to 5 in the inverse.. cant i just write it in ascending order
$\sigma (\sigma^{-1}(5))$
deekaan:
actually it does work
sorry
ya you can just keep it like it is
because 2 and 5 are the only elements that change
and they map to each other
so it equals to its inverse yeah?
yes
@torn silo I had my exam yesterday bro
I got 75%
A Parametric Matrix destroyed me lol
Thanks a lot !
is this a thank you thank you or a fuck you asshole thank you?
I could have gotten a 100% if it wasnt for that parameter
Could have gotten is well written ?

ya it's fine
Oh
and really well done
Maybe if you want I can send you a pic of the parametr I got
I dont know why it was SO hard
I spent 1/2 the test doing it
sure
I do not know how to do Latex matrix lol
$\begin{pmatrix}
1 & 3 & \alpha & -2\
\alpha &11 &8 &-3 \
1 & 18 &14 & 1
\end{pmatrix}$
AfterJack:
Its so simple....
I can not still find the way to solve it
You need to find a value for a that made the system with infinite solutions
Now that I m looking it better I could have switched columns
hmm that isn't so simple
I mean the matrix is pretty tricky
one trick for the future
if you add the third row twice to the first and three times to the second
then you have the first condition for infinite solutions
now all you have to do is find alpha so that the two upper rows become linearly dependent
it's a bit cheesy but using those kinds of tricks you can avoid doing a lot of arithmetic
@gritty frigate
Do I need to understand prealg-alg to understand linear-algebra?
Alright just want to make sure I am doing it right
Yeap, that's fine. Focus on getting comfortable with basic algebra. The elements of linear algebra are easy to understand with a basic understanding of set theory but it's better to have a strong background since linear algebra is pretty abstract.
I agree with  Foundations are important. Make sure you are good with basic arithmetic, linear equations, and functions before you hop in to linear algebra. Having a background in calculus can help, but only in that things like the derivative are secretly linear transformations.
Foundations are important. Make sure you are good with basic arithmetic, linear equations, and functions before you hop in to linear algebra. Having a background in calculus can help, but only in that things like the derivative are secretly linear transformations.
Yeah I am starting off with basic Arithmetic in KhanAcademy although I have learnt it before its just pretty foggy with so much time going by without using advanced math.
Not to worry. The more you do it, the easier it gets.
On the other hand, there are a few books out there that focus on teaching linear algebra in 2 & 3 dimensions alongside geometry. If you really do want to get a taste of linear algebra without the full force of the abstraction, you can certainly use those books.
A line segment has one end point A at (-3, 5) and a slope of -2/3. State Two locations (x, y) of the other endpoint B.
Yeah I got the gist of linear algebra as I study them using vectors and matrices
@slender marsh "Two locations (x,y) of the other endpoint B" ?
I assume that this question is asking you to find two possible points that could be endpoints of the line segment. In that case, what have you tried?
idk what to do
Well, okay, take this to #geometry-and-trigonometry first, it probably belongs to that channel.
given a vector space V with vectors w,v, u; is there a more abstract/general name for vector-addition
f: V \rightarrow V
f(u,w) = v \in V
??
(there are vector-additions that don't look like regular old addition, yeah?)
If you want, you can refer to vector addition in a vector space as $+_V$, where $V$ is the set underlying the vector space.
Abhijeet Vats:
That will probably be helpful in distinguishing between vector addition & the addition on real numbers.
Also, no. The map you wrote above is an incorrect representation of vector addition. It is actually:
$+_V: V \times V \to V$
$(u,w) \to v$
Abhijeet Vats:
they don't care because most vector additions act like regular addition?
or
they dont care because it doesn't matter that much?
(i'm reading a pdf where the vector addition and scalar multiplication are defined using symbols that i rarely encounter)
In many ways, vector addition is very much like regular addition. There are ways in which it is not.
The formalism does matter but it's very rare for it to come up in many problems. Like, when you're doing addition on R, you rarely think of yourself as using a map to associate a real number with a pair of real numbers. You usually just do the addition straight away
So, it's the same story over here
Can you show me the pdf?
Axler doesn't make a big deal about it, and just uses the standard notation that I always encounter.
this author wanted to make a point: http://faculty.etsu.edu/joynerm/documents/VectorSpaces.pdf
He makes a very valid point at that. This isn't just regular addition.
goes through the pain of using abstract symbols, but stays in the real field 😆
linear algebra over the real numbers and complex numbers look pretty different from other fields
Even though these axioms stay the same, some of the theorems can differ
linear algebra over the real numbers and complex numbers look pretty different from other fields
@sonic osprey i'm sure that's true, but axler said dont worry about it.
When you begin learning some abstract algebra, authors tend to use $\circ$ to denote binary operations on sets. Once it's clear that we must disassociate the symbols from their typical meanings, some authors start using + or whatever.
Abhijeet Vats:
I mean, so its still important to look at abstract vector spaces like this, but the trouble of working over general fields is a lot more difficult
I think I need to calculate the vector that spans the null space of a given matrix. How do I do this? This is the line in my notes but I'm very confused, they also seem to have transposed a vector?
aight, thanks for the discourse folks. I don't know how deep to dive into abstraction, so this sanity check has been helpful.
(im a math noob, i'm more used to concrete things like physics 🤪 )
It'll stick to you over time. Just work with it and you'll be okay.
tyty
@autumn basin Can you post the entire question?
(battery's about to run out so i might not be around to help)
You can make very odd vector spaces.
But Axler never will.
well so this is the entire relevant portion of the lecture notes, I'll also post the matrix I need to consider
and my matrix is
8 0 2
0 8 2sqrt15
2 2sqrt15 8
(Not sure how to format that with latex, sorry 😦 )
For context, this is probability but I'm required to use linear algebra concepts here
Let $T_{\Sigma}$ be the associated linear map of the given matrix $\Sigma$. A very quick calculation shows that:
$T(x,y,z) = (x+2z,y+3z,2x+3y+13z)$
If we set the above to 0, then we get $x = - 2z$ and $y = -3z$. So, we are essentially looking at a space of vectors of the form $(-2z,-3z,z) = -z(2,3,-1)$. In other words, the space is made up of scalar multiples of $(2,3,-1)$.
Abhijeet Vats:
@autumn basin
Ah so is your use of T there analogous to the lecturer's use of T that I thought meant transpose?
In that case your explanation makes sense
No. Your professor is using T to denote the transpose of the given vector. I'm using T to denote the linear map associated with your matrix.
yeahh true
In that case, the vector he wrote is a 1 x 3 matrix & he needed a 3 x 1 matrix because that's the only circumstance where the multiplication would make sense
ah right I understand now, the need for the transposition is because of "Theorem 46" which basically just wants you to take that null space vector, and do T* sigma* T transpose
er I used T but I mean (2,3,-1)
Well, technically, it's $\Sigma \cdot (2,3,-1)^T$ but yea
Abhijeet Vats:
$\Sigma$ is the matrix. $T_{\Sigma}$ is the linear map associated with the matrix. They are intimately connected but they're not the same thing.
Abhijeet Vats:
seems like taking a linear algebra module this year would've helped quite a lot with this, huh
thanks for your help mate, think I understand what I need to know 😄
Indeed, a linear algebra class would've been useful for a module which requires linear algebra
who would've thunk
You're welcome.
They're saying the two equations above are both equal to the underlined one, and derive the eigenvector from that assumption. How does one come up with this y = (1-i)x? What is the process to finding this? I'm able to calculate whether they're indeed equal to it, but I want to be able to find it myself
$(1-i)x-y = 0 \implies y = (1-i)x$
Abhijeet Vats:
the first one, just add y to both sides
$2x+(-1-i)y = 0 \implies y = \frac{2}{1+i}x = \frac{2}{1+i} \cdot \frac{1-i}{1-i}x = (1-i)x$
Abhijeet Vats:
@sour jetty
alternatievely, 2x- y - iy = 0 implies 2x - y = iy, so divide by i and simplify
Oh, I see. Thanks a lot!
Does anyone know how to get from second last line to last line?
Specifically how to calculate Re(B-a|r)
it seems like Im(b-a|r) = 0, but I don't know why
Are there any assumptions about alpha and/or beta?
i.e. What's the statement that's being proven?
This is the statement @eager burrow
Oh, I think I might understand
Is your scalar product in such a way that you complex conjugate a factor from the right argument? i.e. (x, a y) = comp.conj(a) (x,y)
yes
because you swap it and then pull the constant out
(conj(ay), conj(x)) then conj(a)(x,y)
Because then, what's happening is
$\text{Re} (\beta - \alpha | (\beta - \alpha |\alpha - \gamma) (\alpha - \gamma))
\text{Re} \overline{(\beta - \alpha | \alpha - \gamma)} (\beta - \alpha | \alpha - \gamma)$
Lartomato:
pray to god this compiles
Okay, neat! And then, inside the real part, you just have the product of a complex number with its complex conjugate
Hence a real numbah
This is a bit messy, but maybe you get what I mean
(i didn't include the 1/|...|^2 factor)
Wait I'll try to derive this but I don't see how the imaginary part is 0?
I'm not sure what you're trying to derive; do you understand what I'm doing in the equation above?
Awright; so, I'm inserting this $\tau$ (which you called r) into the inequality
Lartomato:
I'm focusing on the first summand, so this part
Oh, so does it make sense to you now?
yea
neat
thanks
np
kunze pisses me off
my poor brain cannot understand his "Of course cj = f(aj)" in the last part
and why f(a) =c1x1+...+cnxn
same lmao
<@&286206848099549185>
quickie
is Hom(V,W) the same as L(V,W)
im looking for psets and i keep seeing this Hom
(L(V,W) is the set of all linear transformations between V and W vec spaces)
whats your definition of Hom, all ring homomorphism?
I believe they are the same but I could be wrong
you should ask experts, but a ring homomorphism satisfies
- f(a+b) = f(a)+f(b) 2)f(ab) = f(a)f(b)
so essentially I think L(V,W) is a subset
of Hom(V,W)
linear maps are the homomorphisms of vector spaces
If an mxn homogeneous system has non trivial solutions then m < n. Is this True or False?
I'm thinking that it is True, since rank = min(m, n) = m since m < n. Then m = r < n which means infinitely many solutions which means it has non trivial solutions. I don't see anything wrong with this statement...
wait nvm, its False, there are counter examples
@elfin ingot L(V,W) and Hom(V,W) are two notations for the same set. Both represent the set of linear maps between V & W
can someone explain to me question 5c?
I do not understand why T(b_1) = T(1) = (t+5)(1)
Since if you take T(b_1) = T(1) = 0 (the derivative of it)
How is it still possible that (t+5) is in the answer?
? Why take the derivative of it?
because the example in the book does it
also a person on yt did the same
I just dont know what I have to do ... so I follow the steps from example and a vid I found on yt but the things dont add up
Maybe you should do a bit of reading up from an actual book? It will be easier to approach such problems if you have a good understanding of the theory
the book is good
I just dont get this point
there is not much more to read lmao
do you know what I am doing wrong?
Okay let me try and show you how you might think about this in an easier way.
Let $p(t) = at^2+bt+c$. Then we know that:
$(t+5)p(t) = at^3+(b+5a)t^2 + (c+5b)t+ 5c$
So, a good way of thinking about what $T$ does is to think of it as transforming the coefficients of the polynomial. In other words:
$T(a,b,c) = (a, b+5a,c+5b, 5c)$
Now, finding the matrix relative to the given bases shouldn’t be too difficult
Abhijeet Vats:
now I know how xD
What they’ve done in their working is to consider the image of the polynomial p= 1. That’s the same thing as setting a=0 and b=0 and c =1. In other words, the image is going to be the vector:
(0, 0,1,5) —-> t+5
but what does the image of the polynomial p = 1 mean?
It refers to the polynomial that p =1 is mapped to under the transformation. A linear map is just a function of a particular kind. It’s no different from, say, f(x) = x^3, for example. So when we say that f(1) = 1^3 = 1, then we can say that 1 is the image of 1 under the map f.
(Of course, they are very different in many ways. The basic principle still applies in both cases.)
I understand the gist of what you are telling me
and there are more ways to the same answer
this is what my book does
It’s exactly the same thing. The rule for how T transforms a general 2nd degree polynomial gives you the images of the basis vectors too
In a survey of 200 students of a school, it was found that 120 study Mathematics, 90 study
Physics and 70 study Chemistry, 40 study Mathematics and Physics, 30 study Physics and
Chemistry, 50 study Chemistry and Mathematics and 20 study none of these subjects. Find
the number of students who study all three subjects.
Does this question fall under linear algebra?
Okay thanks
i will try to understand
For the example in the book, think of it as a map:
$T(a_0,a_1,a_2) = (a_1,2a_2,0)$
Abhijeet Vats:
So mapping coefficients of one polynomial to the coefficients of another polynomial
You're welcome.
Shouldn't the determinent of this be 0
E_2 - 4E_3
Then you have the same equation at the top an middle
sorry if this is the wrong channel, but is there a variant of https://en.wikipedia.org/wiki/Bresenham's_line_algorithm, that is specifically for "discrete" grids that only use the 8 basic directions (NESW, NE SE SW NW)?
Basically my goal is to find which grid cells are between two other cells, in a simpler grid cell. Such as
X1 = 5, Y1 = 5
X2 = 10, Y2 = 5
I want to get a result of 6, 5, 7, 5, 8, 5, 9, 5
or is there a simpler way to determine that I am stupidly overlooking?
maybe check out redblob games
Guide to math, algorithms, and code for hexagonal grids in games
that could give you a starting point
ty will give a read
do you want a formal definition or an intuitive one?
an eigenvector is a vector $v$ such that $Av = \lambda v$, where $\lambda$ is an eigenvalue
Namington:
to entangle this more "intuitively"
this means that, when we multiply some vector v by the matrix A
this is the same thing as just scaling the vector
by a scalar factor we call the "eigenvalue"
yes, eigenvalues are defined by the eigenvectors we scale
so if you think of the matrix A as a linear transformation
it's basically saying "there's some vector v for which A is just multiplying v by a constant lambda"
"then, v is an eigenvector and lambda, the constant, is its eigenvalue"
an example of this might be if we have a linear reflection which "reflects" the coordinate plane about the line y = x
in that case, a vector on the line y = x would be untouched
so Av = v
therefore this would be an eigenvector with eigenvalue 1
meanwhile, a vector along the line y = -x would be reflected "strictly"
but the reflection would correspond to multiplication by -1
Those eigenvalues should be obtained by doing det(A - λI) = 0
like if the white line is the line of reflection, the red line is the original vector v, then the reflected vector is the blue line
(if everything is centred at the origin)
then you can see thsi corresponds to just multiplying by -1
so this red vector is also an eigenvector
but it has eigenvalue -1
Ax = -x
the blue vector is the red vector times -1
mhm, I start to see it's purpose
Can I think it as a way to simplify a matrix for determined vectors?
the matrix job*
sure, although it's perhaps better thought of as "special behaviour" at a certain vector
I think of the eigenvectors as being the nicest basis you could wish for
Sorry for the quesiton I will do but
Can I change columns ?
For example x = y
Specially for parametric equations
I am breaking my head over this proof question
Any help would be greatly appreciated
If V⊆W, then dim(V)≤dim(W)
Where: V and W are subspaces of Rn
suppose B is a subset of V that forms a basis of V. clearly, then B is also a subset of W. what must B be in the context of W?
suppose for contradiction that dim(V) > dim(W). what does the above tell you, then?
you should be able to derive a contradiction
@limber sierra Question
I did it this way
I said that if V is a subset of W, this implies that the basis of V is: (v1,...,vn) and the basis of W is: (w1,.....wk) where both sets of vectors are linearly independent. This implies that n ≤ k and so dim(V) ≤ dim(W).
Is this the wrong approach?
Since V is a subset
It has to have at most k vectors
But could have less than that
Right?
why?
Since it's a subset right
you dont sound very confident of this fact you're asserting without justification
sure, it's a subset; what does that mean?
That every element in V is also in W
so...
So at most V would be equal to W
so...
So this means that the basis of V would be at most equal to basis of W
i think i get what you mean
but youre not really explaining the full chain of reasoning
Yeah I'm not sure how else to explain it, trying to think
let $B_V$ be the basis of $V$ and $B_W$ the basis of $W$. Suppose for contradiction that $\abs{B_V} > \abs{B_W}$. But, since $B_V$ is a linearly independent subset of $V$, this means it must also be linearly independent in $W$. So, $B_V$ is a linearly independent subset of $W$; but it is a theorem that a subset of a vector space is a basis iff it is a maximal linearly independent subset, so $B_W$ can't be a basis, since it is smaller than some linearly independent subset (i.e. $B_V$) and thus is not maximal.
Namington:
contradiction, QED
i was really explicit, you dont have to be that wordy
but that's the chain of reasoning
why is this wrong?
So for contradiction, are we saying P->Q is the same as P and not Q?
I am always confused by contradiction
Namington:
if it's not true that (not P)
then P is true
so we're assuming not P
ie we're assuming dim(V) > dim(W)
Got it
p(t) = -4 - 2t
what is p(-2)? what is p(0)? what is p(1)?
here p is a function
you're not multiplying it by anything, you're evaluating a function at certain values.
oh
i see
wow
So I wanted to clarify what I said earlier - since V is a subset of you don't we know the entire basis of V is in W?
right
So then the basis of W should have at least the number of vectors in V
since V subset W we know B_V is a subset of W
Yes so that's why I was saying n<=k
you skipped all the intermediate reasoning, though
the logic is "B_V must be linearly independent, but then W would have a linearly independent subset bigger than its basis, contradiction"
this proof doesnt have to be phrased by contradiction, fwiw
it could be rephrased another way:
"B_V is linearly independent since it is a basis, and is contained in W since V is a subset of W. the dimension of W is the size of a maximal linearly independent subset of W. so, |B_W| is an upper bound on the size of a linearly independent subset of W. Since B_V is a linearly independent subset of W, this means that |B_V| <= |B_W|"
So you are saying I should explain all of that instead of just stating n<=k?
Just want to make sure
you probably don't need to be quite as explicit as I was.
the point is just that you can't randomly say "therefore n <= k", you have to give some sort of justification
of why these two facts connect
Got it
Much appreciated
What do you mean by maximal linearly independent?
I know what linearly independent is
Not maximal
Okay I just found the definition online
sorry, i just mean "the largest possible linearly independent subset"
maximal means "largest"
No problem, thank you!
you might not have proved that "the dimension of W is the size of a maximal linearly independent subset of W"
but the proof isnt too hard
at least in the finite dimensional case
I have another question I'm working on so if I'm facing an issue I'll post it here
I don't think we have
well here's a quick proof for you:
let B = {b_1, ... b_k} be a basis for W
so dim(W) = k
B must be linearly independent, since it's a basis
Yes
Yeah
since B was a basis, we can write any element of W as a lin. comb. of b_1, b_2, ... b_k
including b_k+1
but this means B' is not linearly independent
since b_{k+1} can be written as a linear combination of the rest of B'
hence B' is not a basis
so, any subset larger than B can't be a basis
therefore, if B is a basis, then it is a maximal linearly independent set
hence dim(W) = |B| = size of a maximal linearly independent subset of W
QED
one notes that this only works "nicely" in the finite dimensional case
but fortunately, subspaces of R^n are necessarily finite dimensional
so you dont have to worry about that
So you are saying because b_k+1 is in span of B that B' is linearly dependent?
Got it, makes sense!
If you don't mind - could I post one more question and have you check my solution?
If V⊆W and dim(V) = dim(W), thenV=W. Suppose that dim(V) = dim(W) and V ⊆ W means that the basis of V: (v1,....,vn) of linearly independent vectors spans V, and also, because V is a subset of W, this means that basis of V lives within W and spans W
So span(V) = span(W)
V = W
"that basis of V lives within W and spans W"
you should probably say "and spans W because it is a linearly independent set of the same size as a basis of W" or something similar
also uh, dont say span(V) or span(W), say
span(basis of V)
but yeah since
V = span(basis of V) = W
V = W
"and spans W because it is a linearly independent set" so what exactly does it being a linearly independent have an affect on this?
I get the same size part of your explanation
well, something like $\left{\begin{pmatrix}1\1\end{pmatrix}, \begin{pmatrix}2\2\end{pmatrix}\right}$ does not span $\bR^2$
Namington:
despite the fact that $\dim(\bR^2) = 2$ and this set has two vectors
Namington:
because it's not linearly independent
for example, you cant write $\begin{pmatrix}1\0\end{pmatrix}$ using these vectors
Namington:
But since it was a basis in V it was linearly independent right
right, in the case of your problem
we know its lin. ind. because it was a basis of V
Should I still restate it?
so this issue doesnt arise
i mean, I would
personally
just to make it clear that that's the reasoning
Got it
Also, could $\begin{pmatrix}1\0\end{pmatrix}$ and $\begin{pmatrix}0\1\end{pmatrix}$
Supreme:
Compile Error! Click the  reaction for details. (You may edit your message)
reaction for details. (You may edit your message)
Idk Latex - um could the vectors (1,0) and (0,1) be a basis of R2?
I don't think it spans right?
Google says: "In fact, any collection containing exactly two linearly independent vectors from R 2 is a basis for R 2"
I'm an idiot - it spans
My bad
those span yeah
ninnymonger:
Or maybe constant functions is a better word here?
yep
Quick, indeed. TYVM
you're welcome
so $\mathcal{P}_0 (\mathbb{F}) = \mathbb{F}$ ?
soαρ:
ignoring some set theoretic stuff, yes
Does anyone know why Pa is that given value?
nvm thats just the definition of orthogonal projection onto compl(W) since compl(W) has degree 1 right
From the equation $f(\alpha) = (\alpha|\gamma) \cdot \frac{f(\gamma)}{|\gamma|^2}$, you can see that you can express $f(\alpha)$ as a scalar product $(\alpha | \beta)$ if you define $\beta$ the way that they do
Lartomato:
You're just pulling the factor $\frac{f(\gamma)}{|\gamma|^2}$ into the right side of the scalar product, which means that have you have to complex-conjugate it on the way
Lartomato:
@wintry steppe does that make sense
What about what he said is confusing to you?
You can express f(a) as a scalar product (a|B) if you define B the way they do
yeah
Go look at the properties of the dot product
especially the one about scalars
f(y)/||y||^2 is just a scalar
Yea I know all the properties its just that I don't know where everything comes together
Okay, well use the property
what do you get when you use that property on the scalar
f(y)/||y||^2 like I just said
You have $ (\alpha|\gamma) \cdot \frac{f(\gamma)}{|\gamma|^2}$
Zopherus:
use the property of the dot product
isn't • just the ordinary multiplication
ordinary multiplication of scalars yes
You said you knew your properties of dot product? There's a property that looks a lot like this
(a, y compl(f(y)/|y|^2))
B is equal to that value right?
And you should think about what B even represents in the theorem
How is B equal to the RHS value?
Look back at your theorem, what property do you want B to satisfy?
Actually I'm not even sure of the meaning of a linear functional
A linear functional is a mapping from a vector space to its underlying field
Beta is being defined as that thing
Typically its a map from a vector back to R or C
a linear functional is a linear function from V to the field that V is defined voer
Linear functional != linear function
I.e., R^n to R
ok, I see, so its saying for every linear functional there is a b such that the linear functional is represented by f(a) = (a|b)?
For a linear function you are correct
Yes, exactly
(its important that V is finite dimensional here too)
And if they define beta the way that they do, then it fulfils that property
so here B is defined as the vector such that <a,b> = f(a), and if b = y*compl(f(y))/|f(y)|^2 this holds?
kind of
The whole point of the proof it to show such a vector b exists with that property
We don't know if it exists, we're trying to prove that it does
And taking the value of b = that makes b have that property, so we know such a value of b exists
oh god
im so stupid
I realized
thanks
do you plug B into the RHS in y to show this?
Ah, they actually do show that b is unique, but not really clearly
I'm not sure what you mean by that
like f(a) = (a|y)f(y)/|y|^2
and do they just let B = y
since they defined f(a) already
Sorry this wasn't clear, I think what I'm trying to say that they are trying to show that f(a) = (a|b) by defining b to be compl(f(y))y/|y|^2 and then replacing y with b
I don't know if this is wrong
Oh right
yea
makes sense
thanks, and they did prove uniqueness using first proof it seems
This is confusing me. Why do they define f to be both the thing that is integrated as defined by the inner product <f,g> AND also the linear functional?
L(f) = f(z) is a notation I don't understand also
and finally I am clueless to why (hf)(z) = 0
if h = x-z
the other parts are ok
L is a function from V to C, where V is the vector space of polynomials with complex coefficients, and C is the complex numbers
so L takes in polynomials, and outputs complex numbers
so if f is a polynomial, then L is defined to be the function such that L(f) = f(z)
Ok, I understand that, now I don't know why (hf)(z) = 0?
do you understand what hf means
not quite, is h h(x) = x-z or h(z) = x-z
Ok, so L(f) = f(z) because a linear operator on a polynomial is still a polynomial?
then why?
So they defined L(f) as f(z)? its not something required?
That is how they defined L yes
I see, and this definition makes L linear
Still I don't know why h(f(z)) = that integral - z = 0?
ok, but it becomes x•(integral)-z•(integral), which I don't see is 0
or I don't know how to multiply them together
it says for suppose we have f(z) = from 0 to 1 of f(t)compl(g(t))
Okay sure
even if it is polynomial, I cannot see why its 0..
No like, I mean
I was confused why z was not a variable
but then realized its fixed
So I was misinterpreting the proof by thinking that L is all linear functionals, instead they just chose 1 of them and showed with that particular L they can reach a contradiction
L is not an arbitrary linear functional correct
thanks again
How do you show the basis used here is orthonormal? and what is the special case of the corollary?
the standard basis for C^{nx1} is orthonormal. The special case of the corollary is the line where they show that the conjugate transpose of A is the adjoint operator. @wintry steppe
oh ok, just a further question to clarify: given any ordered orthonormal basis, and some matrix A corresponding to transformation T, is conjugate transpose of A always the adjoint?
I think thats true right? directly follows from the corollary
isn't that exactly what it says?
npnp
the words here confused me a bit because it says its a special case of the corollary
so I thought maybe there was cases within the corollary to explore
ah yea, ig by special case, they just meant the case when V = C^nx1
Also do you know how they can rearrange like this?
like from 1st line to second line, and subsequently to 3rd line.
is trace of product commutative or what?
yep it is, as long as the multiplication is defined ofc.
so trace of standard matrix multiplication?
is commutative?, but not necessarily self-defined matrix multiplication?
nvm i got it I think, I think I skipped over early sections of the book
idk what u mean by "self-defined" but basically y'know if u have two non-square matrices where the multiplication works one way, it doesn't necessarily make sense the other way.
yea, my question was not well thought
Does anyone know why U1 = (U1)* and U2= (U2)*. Is it because of the property T** = T?
Not really
then why
You should note that this isn't true for all U1 and U2
such that T = U1 + iU2
It's saying that there exists U1 and U2 such that T = U1 + iU2 and U1 = (U1)* and U2 = (U2)*
One thing I'm confused is it talks about self-adjoint T=T*, then suddenly it talks about representing any T linear on complex inner product space as T = U1+iU2
like I cannot see the connection of that to self-adjoint
Given any complex number z, you can represent it as a + bi right
Yea, though a,b real is the whole purpose of doing that
And that's basically what they're saying
self adjoint operators are like the real numbers
T here is a complex operator, its an operator on a complex vector space
So you can write it like T = U1 + iU2
just like you can write z = a + bi
and the property of real numbers is that conjugate of a real number is itself
just like for operators
yea, thanks
Im lost on how this shows B is in W
oh nevermind I get it
its proving that B is also an eigenvector
What are quantifiers in the context of systems of equations?
How does this relate to the concept of free and bound variables
What is the difference between a quantified variable and a bound variable
Hey all
Just checking that x^2+y^2+z^2<=3 describes all points contained in a sphere ?
yes
Seconded
Let's say I have 3 independent linear equations with 8 variables in total. Not 8 variables in each mind you, but 8 unique variables total.
What can be expressed in terms of what else? There are rules clearly. For example, if each variable only appears in one equation, the variables in each equation cannot be related to those in the others at all.
Anyone interested in working through a linear algebra course as a group?
Or know where I can find a group if not
Hi
Prove that dim(U+V) = dim(U) + dim(V) if and only if U∩V={0}
I am trying to prove: if U∩V={0} then dim(U+V) = dim(U) + dim(V)
I am sort of just not sure where to even start
U+V = { u + v | u in u v in V }
find the general case first
let b be a basis of u and b' be a basis of v
how can u write any element in U+V
dimension wise
@wintry steppe
Okay, so just a rough outline of what I am thinking - if we let b be a basis of U and b' be a basis of V, then b + b' - (b∩b') = U + V
Right?
And since (b∩b') = 0
Something like that? @elfin ingot
an element in u would have to be written as n linear combinations and in v as n' linear combinations
n and n' dimension of U and V
and the chance of an element beingf in both
but yea ig ur right
One second, let me think about this
Okay I'll write it out and let you know if I have any questions
sure
@elfin ingot I started off by saying: let (u1,....un) be a basis for U and (v1,....vn) be a basis for V
Not sure what to do next - would I then pick an element u in U and v in V and write them as a linear combination of (u1,....un) and (v1,.....vn)?
this assumes both spaces have the same dimension
yea
Sorry, I mean v1.....vk
do you see why the dimension of U+V can be at most the sum of the dimensions?
Yes, I do
then it suffices to find a set of n+k linearily independent elements in U+V
(this will then be a basis)
Okay, one sec... So now I did u+v = m1u1+...mnun+n1v1+...nkvk -- so this should be linearly independent in U+V?
what is u and v?
I let u be an element of U and v be an element of V -- u1...un is a basis for U and v1...vk is a basis for V
ok, what do you mean by "this" when talk about linear independence?
u+v should be linearly independent?
that statement makes no sense
linear independence is defined for sets of vectors
and a singleton is always linearily independent in that sense
like ${u_1, u_2, \dots, u_n}$ is a linearily independent set for example
Lochverstärker:
(because it is a basis)
you now need to find such a set of size n+k in U+V
||there is an obvious choice||
I see
Okay one sec, I'm kind of losing sight of this problem - so we are given U intersect V is 0 and we want to show that equality
So what exactly am I supposed to do to show this again?
the dimension of a vector space is defined as the size of a basis
Yes
so ultimately you need to find a basis of U+V
That has the same size as U + size of V
a basis is a set of vectors that is both linearily independent and spans the space
yeah
Yes
you are given a basis of U and a basis of V
so it is natural to construct a basis of U+V from that
So just basis of u + basis of v
if + is set union, then yes
well, you still have to prove that this actually is a basis
so that it a) spans the space and b) that it is linearily independent in U+V
huh?
I meant, after I prove the fact that it is a basis
How would I use the fact that U intersect V = {0} satisfies the equation
dim(U+V) = dim(U) + dim(V)
oh, so the other direction?
Wait, I'm proving right now: if U intersect V = {0} then dim(U+V) = dim(U) + dim(V)
yes
Yes
if you find a basis of U+V of size dim(U) + dim(V), you are done
Okay got it, I'll do that
And I need to prove that basis spans and is linearly independent
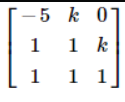
otherwise it wouldnt be a basis
how do i do this?
the determinant is 0 whenever you have linearly dependent rows/columns
Calculate the determinant of M in terms of k, then set that expression to 0, then solve for k
by imagining expanding along the first row or last column (cause there's a 0 there it's convenient) you can tell it's a quadratic. That means it has at most 2 distinct roots for k. Doing what kxrider says by looking at the first two columns and last two rows makes it obvious what they are.
Yes.
does sum mean add?
yes

ok so i add them, then put them back into the original, which SHOULD equal 0?
no way
they just want you to add them, has nothing to do with plugging them back in
it's only 0 when you plug in 1 or -5
no if it's 0 it's linearly dependent
k
plug in k and tell me what the linearly dependent vectors are
x1=-x2
x2=x2
x3=0
no no
if you plug in k=-5 then the first two columns are the same vector
if you plug in k=1 the last two rows are the same vector
that's what's making the determinant spit out 0 by being linearly dependent
ahhh
How about htis one?
Think about how each type of row reduction will effect the determinant of a matrix
And think about how you can row reduce M into A, since the determinant of A is given
Hey everyone
What's this called in english
In french it's Composante
the formula is
(dotP(a, b))/norm(a)
@wintry steppe A scalar projection of b onto a, I think.
thanks
any help for mine? @eternal finch
I've done this before but it's been a while
so all I need is something to jot my memory
oh sorry
Most people here are in uni classes I'd imagine right
on the left you can see this channel is in the "early uni" category
That's the level of math I thought, not necessarily related to the people here
Could someone explain back substitution to me over voice? Specifically this problem
its where you put the system in row echelon form, and then you start from the bottom, z = [something] and plug it into the equation above, solve for y, and then plug in y and z into the top equation and solve for x
@wintry steppe When you have a matrix in row echolon form/reduced row echolon form, you will know which variable's value you can find first.
Then others will follow.
so the spectral theorem says that in the complex case, all normal matrices can be unitarily diagonalized, but are there any matrices that can be diagonalized, just not unitarily so?
because complex numbers are algebraically closed there'll definitely be "enough" eigenvalues
but is it possible that the eigenspaces will have high enough dimension, but there is no orthogonal set of eigen vectors that span the whole space?
Consider an operator defined by the rule
L1(P(t)) = P(t).
How can I find its eigenvectors and eigenvalues and prove that it is not diagonalizable?
umm is it just me or does that look like the identity @placid oracle
Hmm which one
L(p) = p
Prove that dim(U+V) = dim(U) + dim(V) if and only if U∩V={0} - I have hit yet another snag with this question
After picking a basis for U and V and adding them together
I am not sure how to show that it is linearly independent
Well, you still haven't used the fact that U intersect V is {0} yet, so try to use that
How would I use it? if U intersect V is 0 then I know the basis of U and basis of V - their linear combinations - none would be the same
Right?
So let's say basis U is u1.....un and basis V is v1....vn. Then, c1u1+....+cnun+a1v1+...akvk = 0...
I know c1u1 != c2u2 != .... akvk, right?
You can't assume c1u1 != c2u2 here. A counter example would be when c1 = c2 = 0.
I think you are on the right track with the bases
I am just slightly confused how to show c1......ak = 0
To show linearly independent
I've been stuck on this for a while, it's frustrating me :/
but you do know how to show linear independency of vectors, right?
Yes
what's the solution to this?
Show that the relation c1v1+...+ckvk = 0 can only be done when c1...ck = 0
@radiant jasper I am pretty sure that's how to show linear independence
So the issue is I don't know how to show those constants are 0 lol
I don't understand how if U intersect V = {0} should help with this
Since I am proving if U intersect V = {0} then.....
If you don't have that condition then how could you assume u1..un and v1..vl are linear independent
@foggy lodge This is the definition
Oh yes, you're right
Well then if they are linearly independent then we know using that fact the constants are 0
So that's it?
Given that we know U intersect V is {0} we know that basis of U and basis of V are linearly independent
But you have to prove it first right?
||yeah, the basis of the sum will become the basis elements of U and V, because then any element of a basis will not be expressable as a linear combination of the other terms.||
Hmm, yeah but I still don't get how I show the constants are 0
I don't see what information they provided can help me arrive at that conclusion
By they I mean the question
U and V are subspaces of some vector space W, right?
Then that means that U + V is all possible linear combination of all the vectors in U and V. However, we can use a basis of U and a basis of V to find all possible sums, which creates a new subspace
You create a new basis, and at most it can have all the elements in both of the original bases, however, if we can express one or more of the vectors in the bases as a linear combination of the other, i.e. U intersect V being nonempty, then the dimension will be smaller
This is my understanding so far
https://cdn.discordapp.com/attachments/540211747613704221/715423432711471104/unknown.png anyone know how to solve this?
{kind=link}

ill give it a look @sick dragon
U intersect V is empty though so this means that dimension will be the exact same
not quite, this just means that there isnt an element in both of those subspaces
so the basis elements are unique across both of the bases
I see
so if they are unique, all of the elements in both of those bases form a new basis for this new subspace
which means that dim(U+V) = dim(U)+dim(V)
where dim(U) = |some Basis of U|
Ok @sick dragon, what have you tried so far
yeah this isnt in my class slides
I see
so im just trying to remember stuff from calc
Are you familiar with applying matrices to other matrices? I can give a quick rundown
sure
When we have Ax, that represents a linear transformation A being applied on a vector x.
Yeah
Now, if we have BAx, we first apply A to x, giving us x', then we apply B to x'
However, we can represent BA as one composite transformation
When we multiply the matrix B with A, B acts on the ROWS of A. Similarly, A acts on the COLUMNS of B
Therefore, in your problem, we can introduce a new matrix B that does row operations in order to get the modified matrix
The first two rows are the same, so in this newly introduced matrix, we will take 1 of row 1, 0 of row 2, and 0 of row 3
So our first row is 1 0 0
Our second row is unchanged, so we want 0 of row 1, 1 of row 2, and 0 of row 3, so the second row is 0 1 0
Try the third row yourself
0 of row1, 0 of row 2, 1 of row 3. 0 0 1
Not quite
That would just give us the original row
We want 3g+a, 3h+b, 3i+c
How would we get that
Try again
We want x quantity of row 1, y quantity of y, and z quantity of row 3
When we do that, we get x y z
We would scale row 1 by x, row 2 by y, and row 3 by z
Then add them all up
Ok great
So you see, 3g+a, 3h+b, 3i+c is a sum of 3 times row 3 + 1 times row 1
So our bottom row is going to be 1 0 3
We then have
1 0 0
0 1 0
1 0 3
We apply this matrix to matrix A
Since det(AB) = det(A)det(B), we get det(this new matrix)*10
The determinant of this new matrix is 3, so the answer is 30
@sick dragon
Lmfao
This is wrong
Somehow it gives the right answer though lol
My method is the intended one
😄
Honestly if I was the professor I wouldn't even be mad
But just to clarify, you can only pull out scalars from a matrix if you divide ALL of the elements by that scalar
i see
Also that middle step is illegal lol
can i just plot these and take the area
It's a good idea to plot it yeah
since this is linear algebra and you know it's a parallelogram
you should probably use a determinant to compute it
well, triple product gets you volume
Yeah
you want cross product effectively
knowing it's a parallelogram, just subtract one vector from the other three to put it at the origin
one vector should be obviously the sum of the other two
i think im supposed to move it to the origin (dunno why)
so you just take the cross product of those two to get the area
then use determinant 🤷
yep that's what I just said
cool
subtracting one vector from the other 3 is translating it
I think of it as finding the side vectors of a parallelogram because visually that's what subtraction gives you
Though, what's the intuition for taking the cross product
Huh ok
I think it's certainly an interesting thought you have
Because the determinant is a measure of how much you're scaling the volume/area
I never thought about that
However, I think it's incredibly difficult to do that problem that way, and I think the point is to use the multiplicative nature of the determinant function to find the answer
dimension of a matrix M_mn, is the result of m times n. right?