#linear-algebra
2 messages · Page 50 of 1
Find (A^n)v, wasn't it?
yeah
Not (D^n)v
here's what i got for that
A=SDS-¹
(SJS-¹)^n=SJ^nS-¹, you can prove this inductively
It's a sequence with a closed form
That you will.find if you calculate
(SJ^nS-¹)v and leave it in terms of x1,x2,n
And x3
i've figured it out via wolfram, but im not sure how to backtrack to the 'mathematically proven' version
Hear me out
Do the mtx multiplication in terms of n
You should get a linear combination of (number)^n
That's the closed form
Wait no
Said a stupid thing, nm
Life is [[a, -b], [b, a]]
@vast torrent sorry im very bad with proofs and that sort of thing
thanks btw all functions, dont wanna @ you just in case you're busy
So I'm asked to find the length of the radius of a circle on a graph with the extremities of the diameter being 2,3 and 6,1
The answer is 2,2 although I'm not entirely sure why
wrong channel dude
U sure
yes
this is not linear algebra
It's precal but I thought that algebra was variable functions
That's what I was told
That isn't really accurate
I know cuz it's on a graph not a grid
Let V be a inner product space over R,and let T be an endomorphism of V. How can we relate the minimal polynomial of T, T^* to the minimal polynomial of the operator S(v_1,v_2) = (T(v_1),T^{*}(v_2)) ?
where S acts on V x V
Can I get some help with vectors and axioms? I'm supposed to explain if A subspace of R3: the set of all dimension -3 vectors [x; y; z] such that x+y+z = 0 where x, y, and z are real-valued numbers. holds or doesn't hold using axiom 4: There is a zero vector 0 in V such that u+0=u.
The zero vector in R3 is (0, 0, 0). Indeed, for any other (x,y,z), we have (x,y,z) + (0,0,0) = (x,y,z). So, does (0,0,0) satisfy the conditions to be in the subspace you defined in R3? @obsidian rapids
See that's how I thought about it too. Just wanted to make sure I wasn't overly simplifying it.
ah ok.
when diagnolizing a matrix, you can write the answer in many ways depending on the order of matrix P where P is the matrix of eigen vectors right?
@ me when reply
@north sierra the JNF is unique up to permutation of blocks
There's no "best" way to order the blocks, though if all eigenvalues are real we often order them
does imf(A) = imf(B) implies A=B?
or
implies A = kB?
or
exists x, y
Ax = By?
I mean my prob is
AB=BA
imf(BA) = imf(B)
A^2017 = 0
how to prove
imf(A^2017.B) = imf(B)?
wha's imf
no, im(A) = im(B) doesn't even NEARLY imply A=B
$ \int 3x^2\sin(x^{-1})-x\cos(x^{-1}) dx $
how do
oh shit so sorry
i thought i was typing in calculus
<@&286206848099549185>
@wintry steppe whats V? A Hilbert space and V** it's double dual?
Isn't this trivial from definition of min poly
i.e smallest degree poly such that f(A) = 0
yes it is
hey, why is -2pi = 0 ?
Is there a way i can google this problem to educate myself?
uh
i only know, that sin(-2pi) is 0
Ask in one of the questions chat ill help you
@young urchin you can type equation in wolframalpha
$e^{-2\pi i}=1$ though
⚡Amphy⚡:
look into Euler's identity if you are unsure about this
Hi guys
I don't havean immediate question in regards to linear-algebra. I actually just signed up for this class and I'm quite familiar with some of the applications of the class.
However, I wanted to get a head start on the proofs, what books (if any) would you guys suggest for how to approach proofing for an undergrad?
(or a beginner)
Velleman's How to Prove It
Revisiting this question I had yesterday. Prove or disprove: Every square matrix is similar to an upper triangular matrix. By similar it means similar over reals. I was given an answer but figure out the answer was wrong since matrixes aren’t similar to their rref.
?
@wintry steppe similar over C implies similar over R
I believe schur decomposition implies this
this depends on the entries in your matrix
it is false if your vs is over R
So how would I know if a matrix isn’t similar to any upper triangular matrices? Do I just prove that there is no such S matrix?
Ah nvm I got it
@wintry steppe yeah sorry i confused similarity A=SPS-¹ to equivalence A= SPJ-¹
Howd you solve the problem?
@vast torrent V is just a finite dimensional v.s and V** it's double dual
so you have some inner product
can't you just use Riesz twice?
or is that circular
okay so you just need the uniqueness of the adjoint
I dont know how to prove uniqueness of adjoint though 😅
if V is f.d., V is iso to V*
and V* is to V**
oh, how are you defining V* then
linear functionals?
yeah I'm used to dealing with Hilbert spaces so you can write lin.funs. as inner products
I think the strategy is to compose isomorphisms to V* and then to V**
V is iso to V* by the evaluation map
hmm
Number 1
bruh
 ok
ok
different channel ty
oh
O ok
@wintry steppe are you not satisfied with just taking the composition of the evaluation maps eval1[v](ell1) = ell(v) and eval2eval1[v] = ell2(eval1(v)(ell1))
$\varphi: V \to V^{**}: v \mapsto \varphi(v)$ with $\varphi(v): V^* \to K: w \mapsto w(v)$ should do the trick
mop:
ty @vast torrent
Why are they smashing two theorems into one theorem
You should not
other then that?
no
i think i remember seeing it hoffman kunze or something
but i can't really remember it
this seems like an attempt to convey the idea that span(U) is the intersection of all the subspaces containing U but the notation and wording is just wonky af and kinda falls flat on its face
oh cool ty n.n
writing it in symbols will only serve to obscure it imo
Let V be ann-dimensional vector space, and letT:V→V be a linear map. The map T is called diagonalizable if there exists a basis (b1, . . . ,bn) of V such that b1, . . . ,bn are all eigenvectors of T. Prove that if T is diagonalizable, then the composition T◦T:V→V is diagonalizable.
Pls help 0.0
matrix representation of the linear map is my intuition 🤔
T is diagonalizable iff there exists a basis in which the matrix of T is diagonal
the matrix of T^2 will be diagonal in the exact same basis
w
why am I not getting the right thing
don't I just multiply that matrix
by 24
19
then mod 26
the first 2 letters of the answer are pa
S E N D N U D E S
@rose grotto
Oh I see the problem. That matrix is used to encrypt, not decrypt.
1 34/7
2 33/7
I get that
as my answer in that case
but it stil ldoesn't give me
the right stuff
@half ice
idk
this is the inverse
Hmmstv. That's far from an integer matrix
can someone help me with this plz
I tried using that matrix * [24,19] and mod(26) the numbers
but didn't get the right thing
I also tried using the inverse matrix * [24,19] and mod(26) and still not right
im using 24,19 cuz its the first two letter
in the answer the first 2 letters
are p and a
this is false
V = [ 2 -1 ; 1 2 ] satisfies the condition they state, but V^TV is 5I, not I.
But from what I've looked up online, orthogonal columns imply ATA = I
@dusky epoch
@dusky epoch Your matrix satisfies the condition
V.T V = [5 0; 0 5]
=[1 0; 0 1]
Ann:
I promise you this theory holds
It's well known
I just don't know how to prove it lol

Mathematics Stack Exchange
When $A^TA = I$, I am told it is orthogonal. What does that mean?
$A = \begin{bmatrix}cos\theta & & -sin\theta \ \ sin\theta & & cos\theta\end{bmatrix}, A^T = \begin{bmatrix}cos...
"A is orthogonal" isn't the same as "the cols of A are mutually orthogonal"
it's "the cols of A are orthogonal to one another and the norm of each col is 1"
i don't think you understand what it means for two matrices to be EQUAL.
Perhaps I should have clarified
they gave this to us
the norm of each col is 1
o
o
p
s
[ 5 0 ; 0 5 ] is NOT EQUAL to [ 1 0 ; 0 1 ] because their (1,1) entries are 5 and 1 respectively, which are NOT equal
$\left< v, w \right> = v^Tw$
Ann:
the $(i,j)$'th entry of $V^TV$ is equal to $v_i^Tv_j$
Ann:
Sure
ohhh
so would that mean
<V_i, V_i> = 1
How would I explain that rigorously though
that was the missing bit
the norm of each col of V should be 1
and you should know the connection between inner product and norm
no
i mean first off what even are theta and phi
but second no that is not what i meant
the inner product of a vector with itself is the square of its norm

...................
Is it just c1v1 + c2v2 + ... = 0?
no
😦
a set S spans V iff every vector in V can be written as a linear combination of vectors in S
Isnt that what I just said
"V = c1v1 + c2v2 + ..." is just
so nonsensical
you can't equate a vector space to a single vector
ah gotcha
How do we know if every vector in V can be written as a linear combination of vectors in S
If V is R^n
In particular, I'm trying to solve this:
the cols of V are guaranteed LI
Yes I agree
and so the dimension of their span is N
the only subspace of R^N that has dimension N is R^N itself
"and so the dimension of their span is N"
How do you know this?
there's N of them!
tf is up with that lemma 1.15
you basically just said "all linear transformations are surjective" lmfao
why does lemma 1.15 say "the image of beta under phi spans W"
seems good?
sorry for the beep but idk what that meant @dusky epoch
no np ty for pointing that mistake out 
How do i write 6x^2 − 2xy + 6y^2 + 19(√2)x − 9 (√2)y = 37 on standard form?
define standard form
on a form of a hyperbola/parabola/ellipse
is there like a formula to find the distance between a vector and a matrix
There's no usual way to define a "distance" between these two things
What did you have in mind?
@mint sentinel it's possible to do by making a symmetric matrix out of the first 3 terms, diagonalizing the matrix to get a change of basis which corresponds to a rotation
after that, just complete the squares
@merry shuttle you need to define "distance" first in this context. The regular distance definition is based on the pythagorean theorem. here you don't have that natural geometry definition
your notation is a little off, you're writing vector components u and v with vector arrows over them @mint sentinel
looks like you normalized it, well the upshoot is the P matrices are orthogonal so their inverse is their transpose, I'll rewrite what you had shortly
$\vec z^T A \vec z + \vec b^T \vec z -37=0$
Merosity:
hopefully it's clear what everything is here, z = (x y)^T this is the vector of x,y, A the symmetric matrix
$A=P^TDP$
Merosity:
this is effectively what you just found so now just plug it in, although I it might be the reverse of how you put your P, I didn't check your work
$z^TP^TDPz + b^T P^TPz - 37 =0$
Merosity:
make sure that all makes sense, I'm not really doing anything except plugging in A = P^TDP and I = P^TP
this gives us the change of coordinates
$Pz =u$
Merosity:
Merosity:
c=Pb of course
now it's diagonal and your cross terms are gone
geometrically all this has done is given you a rotation of the graph that removes the "cross" terms
at this point you can complete the squares
keep asking questions, I left out some details but I knew it was going to get long so I tried to get to the point as fast as possible
complete the square?
it's a trick they teach kids around the time they learn the quadratic formula
i mean
i was looking at this example
i just dont see how the numbers in "9x^2+4x^2...." are derived at
explain back to me what I explained a minute ago so I understand what you're thinking
in my mind, I already explained that
don't do this to me... >.<
yes
quick way to verify with small matrices
try a 2x2
then do a 3x3 using cofactor expansion
just think about what happens when you do a cofactor expansion along the bottom row of an upper triangular matrix or along the top row of a lower triangular matrix
I don't understand how this matrix is in reduced row echelon form?
The third column contains a -1
I thought the first entry of a 1 in a non zero column, should have zeros everywhere else in the column for a reduced row echelon
<@&286206848099549185>
Sorry what was that?
Read #❓how-to-get-help please
<@&286206848099549185> Sorry to ping, can someone please help explain why the matrix I posted above is in row echelon form?
@native ore They're all true and right
You posted that question in the wrong channel though. Go to #precalculus next time. 👍 @native ore
Sure I can try
<@&286206848099549185>
in 1.21 $\delta_{ij}$ should be $\delta_{ji}$
mop:
plz halp
If I have a row reduced augmented matrix of the form Ax=b, what do I do with the b when finding the basis of row(A)?
the only place b comes in is when you are finding the particular solution
wow free present
Ty, so it's just the row vectors correct?
Then if I was finding the solutions and I had a 0 column vector, how would that affect my solution?
you can have this then lol
It doesn't tell you how to find the particular solution, but it does say how to find all the bases
Ty
tell me if anything is unclear or if you don't get it, always looking to improve how to present the material there
Sounds good
Question: Is it possible to get multiple answers with eigenvectors?
You mean multiple eigenvectors from the same eiganvalue?
I did the following problem and got:
[4 2 ]
[3 -1 ]
Lambda1 = 5, lambda2 = -2
...
5 [2]
[1]
...
-2 [ 1 ]
[-3]
I checked my eigenvalues on symbolab and I think they're correct.
Symbolab says I should be getting [-1] for the second eigenvector.
[3]
It's exactly the opposite of what I have.
@toxic pendant I mean different eigenvectors for the same eigenvalue.
Yes that's possible
You can have multiple eigenvectors from the same eiganvalue
Anyways I just did the question and I got two eigenvectors
Okay cool. Thanks. 🙂 I was just wondering if I screwed up.
The last part is kind of arbitrary. We assign a value to x1 or x2 and then solve for the other.
So I guess it depends on which one you choose to solve for first.
you can multiply an eigen vector by any scalar value and it's still a valid eigenvector, it's just somewhere else along its span now
in your case, you are only different by a factor of -1
Thanks. That's kind of what I thought might be happening. 🙂
<@&286206848099549185> plz help
Hey guys can I have help in a lag question
post it
How many injective linear maps f :V to W are there for two vector spaces over a finite field Z/pZ, p prime, with V d dimensional and W e dimensional
I know the total amount of linear maps is p^(de)
So it's definitely less than that
it's equal to the number of linearly independent ordered sequences (w_1, ..., w_d) of vectors in W
What do you mean by linearly independent ordered sequence
Oh NVM I get you
Oh so that means that if d > e there are no injective maps? Or am I confusing myself
indeed.
there are no injective maps from a higher dimension to a lower dimension space
Now that I think about it that can be proved using rank nullity
Can you give me a hint as to how to count them?
And finally is in not the case that for any linearly independent sequence (w_1,...,w_d) we have d! Injective maps using those vectors
no, because we're counting them as ordered
makes it easier
because each ORDERED sequence uniquely determines a linear map
bc you can pick a basis (v_1, ..., v_d) for V
and then send v_i to w_i
and extend by linearity
anyway i believe the total count of linearly independent sequences of $d$ vectors in $W$ would be $(p^e - 1)(p^e - p)(p^e - p^2)\cdots(p^e - p^{d-1})$
Ann:
Ah ok thank you so much
How do I show that F1 is not a linear transformation, by using addition?
$F_1 = (e_1 x_1 + e_2 x_2) = x_2^2e_1 + x_2e_2$
Ann:
what on earth is that line supposed to mean
the line under the e?
that entire line
what is it supposed to mean
is that supposed to mean the input to the function is $\left(e_{1}x_{1}+e_{2}x_{2}\right)$ and the output is $e_{1}x_{2}^{2}+e_{2}x_{2}$
PorosInMyAshe:
oh, accidentally put an equal-sign there
F1 is not a linear transformation, and i wanna show that by using addition, i already know how to do that by using a scalar.
i mean
if you want to show it ISN'T linear
just give a concrete counterexample
why not... idk let's go with u_1 = 3e_1 + 4e_2 and u_2 = 2e_1 + 7e_2
check that F_1(u_1 + u_2) ≠ F_1(u_1) + F_2(u_2)
I in no way know linear algebra, but is there anyway you can get this from two normal vectors in 3d space?
I can also turn them around
I'm trying to find the diagonal line
what am i looking at
what are they perpendicular to
I assume that the thing at the end of the lines is the perpendicular angle thing
but to what
uhhh
"they"?
no like
what am i looking at. what are these arrows supposed to be. why are there right angle-like marks at their tails.
they as in the two solid arrows
if i wanna find the unit vector, why is that i am allowed to scale vector c (to remove the fractions ) and use that
@north sierra scaling it by a positive constant doesn’t change the direction
That’s why you can do that
thx
No problem

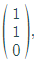
$\begin{bmatrix} (\text{case 1 $\to$ case 1}) &(\text{case 1 $\to$ case 2}) \ (\text{case 2 $\to$ case 1}) & (\text{case 2 $\to$ case 2} )\end{bmatrix}$
gfauxpas:
@rose grotto
shouldn't it be
$\begin{bmatrix} (\text{case 1 $\to$ case 1}) &(\text{case 2 $\to$ case 1}) \ (\text{case 1 $\to$ case 2}) & (\text{case 2 $\to$ case 2} )\end{bmatrix}$
assuming your case vector is
$\begin{bmatrix} \text{case 1} \ \text{case 2} \end{bmatrix}$
PorosInMyAshe:
let me think about that for a few minutes, I could be wrong
yes
your version is correct
oops, soryr
@vast torrent @steady fiber what numbers would I put : O
cuz
won't I need
4 diff numbers
then [1,0]
yes, you need four different numbers
you're given 2 probabilities
the probability of something happening must be 100%
so you can easily find the other 2 probabilities
1 other probability for each case
wat numbers would I use so I can understand better v-v @steady fiber
in a probability matrix
the columns sum to 1
actually wait
rows or columns, I remember there were differng conventions
A common convention in English language mathematics literature is to use row vectors of probabilities and right stochastic matrices rather than column vectors of probabilities and left stochastic matrices; this article follows that convention.[2]:1-8
-WP
right okay but why would you use row vectors
weird convention
if you're using column vectors, the columns sum to 1
yeah I remember they mentioned this when I took probability, that some books use row vectors for stochastic matrices
I dont remember why
I'm prolly missing something dumb but a little confused by this?
I understand mod26
encoding
decoding
but
how is that the answer to this
it doesn't make sense
I tried inversing it then mod(26) the determinant and multypling it by that
encoded how?
@north sierra I don't know what im trying to find
considering
I can't figure out
how to get the answer
but the decryption matrix
its not just
the inverse
you can tell just by looking at it
true yeah
dont know what that is unfortunately
what level Linear Algebra is this?
@rose grotto you got 25 for the determinant right?
yes
then wat
usual 2x2 inverse process
25 * [11, -2][-4, 3]
25 * 11 (mod 26) = 15 right?
25 * -2 (mod 26) = 2
and so on
should mention
25^-1 = 25 (mod 26)
since 25 * 25 = 1 (mod 26)
how do i do this?
unit vector means the norm is 1
so it made me think of the formula
u dot v = ||u|| ||v|| cos theta
it's the square root of the components squared
"Both unit vectors" is the trick here
What's ||v||?
hmmm
whats u.u
so u.u = 1
yeah so just use that ivey-kun
thanks !
New notation proposal: <u,u>=uwu
Oh thats why
why do we need the absolute value for vectors often?
context?
what does it mean for 2 matrices to be similar?
do you know the definition
we say A is similar to B iff there exists a matrix P s.t. PAP^-1 = B
well
basically if two matrices are similar you can pick two (potentially) bases on R^n such that the matrices' actions on their respective bases are the same
uhh do you have a quick numerical example to show it?
a diagonalizable matrix
no unfortunately i don't
outside of diagonalizablematrix plz
i know it in the context of eigenvectors/eigenvalues
what about outside of that context
ok uhh
idk
let V be a vector space of dimension 3
wait no
this is gonna be too abstract nvm
rip
Honestly no need for intuition.
A ~ B if there's a P such that A = PBP'
This just ends up being a natural way to group matricies together, and similar matricies have a lot of the same properties
i'm not sure if this is the right way to think of it, but i just think of it as language translating
P is your translator
Oh yeah change of basis is a great example of this
But this is larger than change of basis
how is it larger than change of basis?
I used P' as P^(-1) was too lazy to write it
In a change of basis, you'd have to think of a basis, a new basis to express it in, and a transformation
yes
Too much machinery for this, where we can say that two matricies are similar, and therefore share properties
oh wait that's a great way to put it that i never thought about
basis A<-> some transformation <-> basis B
makes A ~ B
Also change of basis ignores the grouping part, which is important to think about. Similarity is a great way to group matricies together
this is such a mindfuck
Yes, if you can express a matrix A as a matrix B using a change of basis, A~B
You'd expect something like this, since both transformations are the same and should have the same determinant/eigens
yup
that makes each and every diagonalizable matrix unique, if they are even different by one entry in the diagonal
is that true?
That's true! Diagonalizations are unique
and i'm assuming
each diaognalizable matrix has its own defining eigenvectors
or can two identical diagonal matrix have different corresponding eigenvectors
or does a diagonal matrix always have a set and only one set of corresponding eigenvectors
oh wait nvm i thik i figured it out
eigenvectors = P
you chose the right P to have a diagonal only entries matrix
if you chose any other P, they wouldnt be eigenvectors anymore, and ur matrix aint gonna be diagonal
so does that mean
diagonal iff eigenvectors/eigenvalues?
i hope my question made sense lol
A matrix of size n×n can be diagonalized if you have n eigenvalues with multiplicity
does it go the other way
Or, that the characteristic equation splits over the field
if you have n eigenvalues with multiplicity, a matrix of size n*n can be diagonalized
Yes
ah so its an iff relationship between a diagonal matrix and eigenvectors/eigenvalues
Wait that's what I said lol
eigenvectors/eigenvalues ALWAYS yield a diagonal matrix and
a diagonal matrix always implies eigenvectors/eigenvalues
wait hold on
sorry
how about
if a matrix of size n*n can be diagonalized, u have n eigenvalues
i'm trying to understand the relationship between diagonal/eigen
ah so diagonal matrix is strictly unique for eigenvectors/eigenvalues and the other way around too
eigenvectors/eigenvalues is strictly unique for one diagonal matrix
and only one
Yeah no matrix has two characteristic equations
oh SHIT
characteristic equation is the way u group matrices together
HOLY CRAP
IT"S ALL CONNECTING TOGETHER
!!!!!!!!!!!!!!!!!!!
bRO
this is big brain
damn this was basiclaly my whole semester in 30 mins
i feel like a god
Oh yeah true. If A~B then they both have the same characteristic
I think? That one I'm not sure about
you mean charpoly?
Yaya
yeah that's not an iff. goes only one way.
two matrices can have the same charpoly yet not be similar
[ 1 0 ; 0 1 ] and [ 1 1 ; 0 1 ] both have (x-1)^2 as charpoly
yet one's diagonalizable and the other isn't
^^ The bae example
yes
😦
The identity matrix is similar to nothing else, since
P'IP = P'P = I
it has one eigenvalue, 1, with multiplicity 2
but only one eigenvector for that eigenvalue
[ 1 ; 0 ]
But two similar matricies will have the same charpoly
so outside of identity matrices, i.e exlcluding identity, does the statenet still hold true? same characteristic implies A~B
oh damn that wouldve been perfect if it went both ways lol
$A = \begin{bmatrix} 2 \ & 2 \ & & 3 & 1 \ & & & 3 & 1 \ & & & & 3 \end{bmatrix} \ B = \begin{bmatrix} 2 & 1 \ & 2 \ & & 3 \ & & & 3 \ & & & & 3 \end{bmatrix}$
Ann:
$\chi_A = \chi_B = (x-2)^2(x-3)^3$
Ann:
yes
but the dimension of their eigenspaces are different
and that's something that gets preserved with similarity
dimension of eigenspace = geometric multiplicity
anyway
but their multiplicity gets a little sketch
for λ=2, the dimension of A's eigenspace is 2 while that of B's is 1
and for λ=3, the dimension of A's eigenspace is 1 while that of B's is 3
so would this be true then
A~B iff char poly, and eigenspaces are identical for each corresponding eigenvalue
Nop. That's not true either
what the
Well, wait, eigens are identical?
you might want to look into something called jordan normal form
uh i mean
If the eigens are identical they're the same matrix
each corresopnding eigenvalue, has same geom mult
ok
This idea extends pretty well. In abstract algebra, two elements a,b in a group are conjugate if for some g, g'ag = b. Two conjugate elements have similar properties.
so what'll make it go both ways? what condition for A~B
same JNF
lemme look that up
(jordan normal form)
If I want to find a vector orthogonal to two lines, do I just construct a vector on each line and take the cross product of them?
Yeah my bad missed to include that
the proprieties of subspace i learned was
- subspace must not be empty
- given x y in subspace, x+y also in subspace
- given k in Real, kx also in subspace
i don't see how i can prove that abc is/isnot a subspace...
if abc=0 what do you know about a,b,c?
well, I'm just asking about the 3 numbers not talking about vectors yet
then one of them is 0
ok good
so write some examples of what your vectors would be like
with the idea of trying to see if you can find an easy contradiction to the properties of a subspace that you just listed
that would be one possibility yup
I was thinking more concretely like (1,1,0) would be one
since 1*1*0=0
similarly (1,0,1) would also be one cause 1*0*1=0
k(a,b,0) = (ka,kb,0) -> ka(1,0,0) + kb(0,1,0)
and n(a,b,0) + m(a,b,0) = na(1,0,0) + nb(0,1,0) +ma(1,0,0) + mb(0,1,0)
what about (a, 0, c)
i will just change it to ka(1,0,0) + kc(0,0,1)
hey, was just wondering if the converse of If hermitian, then unitarily diagonalizable. is true?
you have to have both of them
simultaneously
(1,1,0) and (1,0,1) are both in the set
you can't pick and choose
ah so the set is actually empty?
yeah it's not a subspace because it's an empty set?
you know the 3 conditions of a subspace
so attempt to show
- non empty
- closed under addition
- closed under scalar mult
so is it that if i add 110 to 101 it becomes 212 which doesn't satisfy abc=0
so it's not closed under addition
bingo
yup
ay thanks
hi I don't understand how it goes from this
to this
its not just the inverse
they do something else to it
but im not sure what
when im decrypting something
you get the determinant
and do mod 26
it's probably mod 26 or some shit like that
and times it by the inverse
I tried that
maybe the answers wrong
even if you did do mod 26
it makes no sense how they are all positive
and how the 2 and 4 stay the same
they took the coeffs mod 26 i suppose also
what u mean
well what have you got?
if matrix A is unitarily diagonalizable, does it mean its hermitian?
unitarily diagonalizable means A* A = AA *
A* = A
idk i recall the dude sayign something in class about a certain converse
being not true
idk if its this one though loool
prolly not ?
I wouldn't have defined unitarily diagonalizable as what you wrote down
but it's clear to see (A*A)*=A*A so it's certainly hermitian according to your definition
U*AU = D -- oh i could compare it with A * and find out that its the same thing
in fact it's independent of A*A=AA*
hm lemme play with it
if the entries of D have imaginary numbers, then it's not hermitian
since hermitian matrices have all real eigenvalues
so if you can write 'unitarily diagonalizable matrix' as U*AU all the diagonal entries should be real
ok ill try and construct a proof of 'if A is unitarily diagonalizable, then it only has real eigenvalues'
@rose grotto rip
?
when I do it regularly
I forget
but its not that answer
its
det 25*the inverse
mod 26 of 25 is 25
so its 25*(3,-4,-2,11)
it should be $$25\begin{bmatrix} 11 & -4 \ -2 & 3\end{bmatrix}$$
emeric75:
but yeah
(i'll just use the fact that 25 is -1 mod 26 to simplify a bit)
so it becomes
$$\begin{bmatrix} -11 & 4 \ 2 & -3\end{bmatrix}$$
emeric75:
and then reduce it mod 26 (get the coefficients in the matrix between 0 and 25)
$$\begin{bmatrix} 15 & 4 \ 2 & 23\end{bmatrix}$$
emeric75:
which gives the answer they have @rose grotto
ty

the 2 values that z are equal to
are both positive
so how do you maximize it
usually you take the lowest negative number
and then do the pivot and all that
but what do you do
if its already all positive
I'd start by introducing a slack variable and turning the inequalities into equalities
but I'm not very experienced in linear programming 😦
asked yesterday but still a bit confused on this one
i mean yeah their thing clearly misses a row
what's the first thing you learn when multiplying two matrices, when are you allowed?
oh so the solution is wrong?
1000%
if im trying to show that a set of vectors is an orthogonal basis, what's the point of showing that each vector is a unit vector?
that would be if you wanted an orthonormal basis
oh snap i kept reading orthonormal as orthogonal
Can the spectral radius of a matrix be negative
Like if -5 is my largest eigenvalue in magnitude is the spectral radius 5 or -5
no the spectral radius cannot be negative
if -5 is my largest eigenvalue in magnitude is the spectral radius 5 or -5
it's +5
Hello everybody...
Could I get some help on how to begin this problem?
I’m specifically confused about the latter half (computing basis of hull space)
Prob 4
null*
well
what is the null space of d^2/dt^2
i.e. what polynomials in P4 become 0 upon differentiating twice
@dusky epoch I see 1 and t become zero, so that is the basis?
And the range as well
its the basis for the null space
Also is the range then just 1 t and t2 since that is the column space
is p_4 polynomials of degree 4?
Yus
Basis of the range*
yea then thats right
is p_4 polynomials of degree 4?
at most 4*
the polynomials of degree exactly 4 don't form a vector space.
so this is a True/False question
I was wondering what normalized means?
it's not clear in my book
normalized means they are unit vectors
ohh okay
so magnitude of 1
thx that makes answering the question much easier now
orthonormal basis means your basis consists of orthogonal unit vectors
yup!
u dont have to delete all of your messages when you figure something out lol
Lol I’m still tryna figure it out 😅 just need time if I wanna ask something again, don’t wanna flood
Repost:
Given a basis B w/ 3 vectors and T:R^3–>R^3 so that I have T(v1) T(v2) and T(v3). Once I calculate [T]B how do I find the standard matrix of T?
So you know what T does to beta. And you already have that T outputs in standard coordinates. So basically, T is a map that takes vectors in beta to the standard basis.
To find what T does to the standard basis, you should find a matrix that sends vectors in the standard basis to vectors in beta. In other words, something like this: $$ [T]{\mathcal E\beta} [I]{\beta \mathcal E} $$
kxrider:
So question is: what does [I]_betaE look like.
The tricky part about change of basis, is that anytime you are given a basis (like beta), by writing down coordinates you are assuming the standard basis convention (unless told otherwise). So v_1 = (2, 1, 1) is actually v_1 in the standard basis (while v_1 in the basis of beta is just (1, 0, 0)).
Hm @slow scroll
I thought I would call those vectors Matrix A and A^-1*[T]B*A to get the standard matrix of T
$A^{-1}[T]_{B}A$
⚡Amphy⚡:
@native lodge you think that is the case here? In the problem, it says that T outputs to the standard basis already.
I was just writing it in Latex so it looked better
since the _ messed up the formatting
Hm, @violet field lets say you were told what T does to the basis beta, in terms of the basis beta. So T takes inputs in beta and outputs in beta. THEN your change of basis matrix would look like that. However, the problem is saying that T already outputs to the standard basis, so the left multiplication at the end is unnecessary.

{kind=link}
{kind=link}
{kind=link}
Yeah it is
take note that T(v2) = 2v1 So you should expect that in the basis of beta, you have T((0,1,0)) = (2, 0, 0) as an example. Does that make sense?
Yeah, I’m still figuring this out. I think I did It incorrectly. I should have created a linear combination of the basis and set them equal to each T(vi) and the solutions to the augmented matrix would be the columns of the matrix TB
part b is sort of the opposite of part c. The input part is done for you i.e. we know what T does to inputs in beta, but we need the outputs in beta as well.
So you need a change of basis matrix that sends vectors in the standard basis to vectors in beta. i.e. (-4, 2, 2) would map to (2, 0, 0)
[0 1 0]^t [2 0 0]^t [-1 1/2 1]^t should be the columns of [T]B
nope. What do I get when I plug v1 into T?
I should have created a linear combination of the basis and set them equal to each T(vi) and the solutions to the augmented matrix would be the columns of the matrix TB
?
Its given in the problem that T(v1) = v3. So that means in the basis of beta that T((1,0,0)) = (0, 0, 1), or in other words, the first column of T_B is [0,0,1]^T by the definition of matrix multiplication with a vector. We did something similar with v2 earlier, so check the second column.
Then the third column is not so obvious, but luckly, you did the work in part a already