#discrete-math
1 messages · Page 26 of 1
Think about what such numbers look like in binary. Try describing what they look like in language, then afterwards try and think about what a DFA that accepts them looks like.
You can work on trimming down the number of states after you've got something that works.
So if i have 5 states, q0 - q4
Would it make sense to do q0 to q1 if 1, q1 to q2 if 0, q2 to q3 if 0, q3 to q4 if 0 and q4 is the final?
1000 would be accepted then, yes?
That should be 8, which I believe is divisible by 4
you have to think critically, not just sequentially place the 5 states
What numbers are accepted
Maybe you’ll see a pattern

The strings you're considering here don't even consist of a and b!
Why do you think this will work, instead?
obviously thats just a pic from my text book
i feel like a, b can be substituted in for 0,1
The first step here is to get a more text-oriented understanding which strings should be accepted in the first place. Until you have that, it's too early to start drawing states.
just bc i dont feel like writing it out in latex
well its just strings divisible by 2 and not 4
Is 101000110 accepted, yes or no
THat is not a text-oriented (i.e. syntactical) understanding.
How do you see on 101000110 that it should be accepted?
If you can’t tell just by looking at the binary, that’s an issue
If you can tell, why can you tell
What exactly tips you off
#1s != #0s
So is 1010 accepted?
nope
Wrong, it is
that is 10
1010 in base 2 is 10, which is divisible by 2 but not 4.
10 is divisible by 2..
Yes
Maybe you should reread the question
Ok, so is 10000 accepted?
Is 0110 accepted
Ya know what I can’t type clearly so I’m just leaving it
But what’s 4 in binary
So its always the last 2 digits
(I don't think it is completely clear from the problem description whether 0110 should be accepted).
I think it’s pretty clearly divisible by 2 but not 4?
What about the last two digits? Explain in words what needs to be true.
If the last digit is 0 and the last two are not both 00, it is divisble by 2
but not 4
The issue with 0110 is not the divisibility, but whether we consider 0110 to belong to "binary representations of natural numbers" in the first place.
I.e. are leading zeroes allowed.
He listed 0 and 00
The last digit of 0 is 0, and the last two digits are not both 00. So this seems to say that 0 is accepted.
As things that should be rejected.
If the last two digits are 00, it is divisible by 4, so it must fail.
If the last two are not 00 but the last is 0, then it passes
0 is listed as rejected in your example
You're getting there.
that is what i said
Let's give it a moment – it's easy to adjust an automaton to accept only this 'proper' version, so let's get the main requirement done
Yeah, it was a bit premature of Sharp to bring 0110 up.
If it's only 0, then the finite state machine will loop
on q0
until it goes to a 1
You shouldn't be thinking about states yet.
DFA**
Id honestly just say it should be accepted all the same tbh
You're still on "understanding which strings to accept" -- you're almost there, but it can be tighter.
If the last digit is 0 and the last two digits are not 00, then what are the last two digits actually?
I’ll ask a very suggestive question: this is saying what it isn’t. What does it have to be
Dang it sniped
the preceding digits must be 0s
What?
??!
all digits prior to the last two must be 0
So 10000000000010 doesn't get accepted?
Are you saying that 110 should be rejected?
You don't know if 110 is accepted or rejected, is this what you're saying?
You seem to have ignored this question.
No ik it shopuld be excepted
they must not be the same??
So if the last digit is zero, and they're not both the same...
then it is divisible by 2, but not 4.
What ARE the only combination of two digits where the second digit is 0 and the two digits are not the same?
01
The last digit of 01 isn't 0.
So 101 should be accepted?
Yes to "it should be 10".
if it is 4 then it isnt allowed
If you see a 4 anywhere, that should be rejected immeiately, because 4 is not the binary representation of anything.
Why isn't 4 allowed? Are you saying 10 is rejected?
because 4 IS DIVISIBLE BY 4!
10 is not the binary representation of 4, perhaps that's what's confusing the discussion right now.
Yes I misread 4 as 2, and mistyped.
Then I'm confused why you're bringing up the symbol 4 at all.
its because the problem states it must not be divisible by 4
Especially what you meant by "aka 4".
yes
yeah hold on, apparently I didn't misread
the aka 4 is in response to the previous message above mine
10 is 2 my guy
Okay, lets cut to (a slightly later stage in) the chase.
Have you now convinced yourself that
binary representations of natural numbers divisable by 2 by not 4
is the same language as
strings of0and1that end with10
?
Indeed

the problem is this
How can i know what the numbers before the last two must be
Ya feel
You can't. A string that ends with 10 must be acceped no matter what comes before that (as long as it's made of zeroes and ones).
Well, you agreed that it’s numbers that end in 10
Ok but why am i in my DFA for STEP 1 only accepting if its a 0, if a 1 is allowed too?
We haven't started construcing a DFA yet.
Okay
We're now ready to start constructing the DFA, but none of that has actually happened.
I think it’s wrong to do it that way
Right, so now we must consider the initial case.
We do not want any leading 0s
So, we can wait until there is a 1.
Not wanting any leading 0s is a reasonable decision, but "wait until there's a 1" is not the way to do that.
My thought is to do this: a loop for 0s on state initial, else succeed to state 1 if there's a 1 indicating an allowance [thus far]
What you you want a loop for?
If 0, stay on initial state.
Why? If you see a 0 as the first symbol, that is a leading zero, and you've just decided that you want to reject those strings!
No?
If you stay on the initial state, that would lead to a risk of accepting.
Ignoring a string is the same as rejecting it, isn't it?
Well the question ig is if you want leading zeroes or not
With a DFA, you can't ignore an input. It will either be rejected or accepted, not in-betweens.
Bananza said here he doesn't want strings with leading zeroes.
Right.
i was just thinking to do the same as this dfa where we check for the odd number of 1s

So you need to make a decision one way or the other (and then explain in your solution how you've understood the ambiguous description).
That machine allows leading zeroes. That's also a defensible decision.
Are you suggesting that because (I assume your textbook's example of) a machine to recognize odd numbers allows leading zeroes in the numbers, then your machine for recognizing divisible-by-2-but-not-4 numbers shouldn't allow leading zeroes?
Well the machine stays on q0 if the digit is 0, until it sees a 1, then it goes to q1. If there is a 0, it stays on q1, and if there's a 1, it goes to q0
...
Same
I believe both machiens must accept leading 0s
I'm trying to get you to make a decision about whether you want your machine to accept string with leading zeroes, and then stick to that decision.
Okay then.
i literally just said
read*
in the problem description
010 is accepted
So leading 0s should be accepted
so i am invalid
I wish you had said that in the problem description. As it is your original message did not explicitly say that 010 was valid.
But for what it's worth, this makes things easier
I apologize I left out 010 because I thought it wasnt important at the time
||I think you can do it with 3 states even?||
Well now you just need to find out how to read the last 2 digits are 10
Since starting 0s don’t matter
So 0,1 either one will allow a transition from inital to q1?
You haven't decide yet what the intuitive meaning of "q1" is going to be.
q1 is gonna be where we have discovered up to n-2 digits?
But since 00 should be rejected and 10 should be accepted, I don't think it's a good idea to move to the same state no matter whether the first symbol is 0 or 1.
Try to explain what the intuitive meaning of each of your 4 states are. Not the transitions between them, just what you know in each case.
My interpretaiton of the states is the digit present at that step
idk how else to think of it
Please humor me and write a description of each of them down.
Four bulleted points (or however many states you need), each with a description of one state.
- Q0: initial state, no input yet
- Q1: accepting state, has seen a 10
- q2: rejecting, doesnt end in 10
If everything that doesn't end in 10 leads you to the same state, then you will be in the same state after reading 00 as after reading 11.
That's a problem because then the state after reading 000 or 110 would still be the same. But only one of them should accept.
so then q1 is the second to last digit is 1, but if its a 0 it will remain in this state. if its 1 it goes to q2 wich mean success.
This is good progress by the way. But I don't understand whether your last post is a counterargument to your objection, or you're modifying your description of q2.
I think that’s a bit off, that sounds like reading a 11
Just so we can follow along, perhaps you should post your new state descriptions, then.
- Q0: The initial state waiting for input
- Q1: Second to last digit is a 1, so if it sees any addtl 0 it stays in q1, and if it sees a 1 it goes to q2
- Q2: accepting state
If we've read 1010010 so far, should we be in state q1 or q2? Both state descriptions seem to be satisfied.
q2
But the second-to-last digit of 1010010 is 1 like the description of q1 says.
so at q1, we need to check if its a 0, or 1
You're still skipping ahead to transitions.
I'm trying to make you think about what does the machine know when it's entering each state.
You're still talking about transitions.
Q0: initial state, no input yet
Q1: Second to last digit is a 1
q2: Last digit is a 0, success
Would that be correct
Okay, do it your way. Good luck.
I dont think im understanding what ur saying bro
i dont see it any other way
im not being stubborn this is the only way im processing ur question
I'm saying that after reading 1010010 you are both in the situation you have described as q1 and in the situation you have described as q2.
You can't have a DFA where you're both in state q1 and in state q2 after reading 1010010.
so i guess q1 is the possibility of divisible by 2, but for sure not divisible by 4... but q2 is that the possiblity of the string being divisible by 4?
Why are you now talking about divisibility again?
It's more than half an hour since we decided the problem is simply to find our whether the input ends in 10.
😨
😱 🤯
Yes, our issue is in terms of state 1 and 2 being ambiguous
in what order are you reading the number
I'm assuming from largest to smallest digit right
I'm pretty sure it's really hard to program a state machine to figure out what the last two digits are
Hmm, to get some progress, here's what I would do:
- We need a state that says "the last symbols I saw were 10"
- We need a state that says "the last symbol I saw was 1" (since we need to be in such a state in order to move to the above one".
- We need a state to be in when none of those things are true.
tbh I would just do a 4 states: 0,1,2,3 mod 4
That could also work (but would be a completely different approach).
I feel like it's a bit less complicated like that
but do it your way
I didn't mean to intrude on this lesson lol
There's something to be said for doing it that way from the beginning, certainly.
tbh I feel like "ends in 10" would be better used if you were reading the number in reverse, lol
i just dont know what state we'd be in for rejections
In a DFA there can be multiple accepting states, and any state that is not accepting is a rejecting state.
yeah, again, it's not a bad plan -- I'm just wary of further confusing Bananza by scrapping everything when we're so close to the finish.
so using this can we worry about transitions now
Yes.
or is it too early
to be fair scrapping everything and restarting happens in math a good amt🥲 , but yeah I see
We need a state that says "the last symbols I saw were 10" if 0 go here if 1 go to state q1
We need a state that says "the last symbol I saw was 1" (since we need to be in such a state in order to move to the above one". if 1 go here
We need a state to be in when none of those things are true if 0 loop
is that correct
Uhm, are you saying that if "the last symbols I saw were 10" and we then see a 0, then we're still in "the last symbols we saw were 10"?
we go back a state
So "go here" is your way of saying "go back a state", whatever that means?
q0 ------------ (1) q1 ------------- (0) q2 (1) ---- q1
(And I'm not completely sure which of my three state descriptions you're calling q1 either).
the 2nd one
You may have the right idea, but you haven't succeeded in writing it down fully.
Since you have 3 states, you need to describe 6 transitions, namely two out of each state.
At q0, the state which the last symbol wasn't a 1 / the last symbols i've seen were not 10 (initial), we will stay on this state if there's a 0 seen. Otherwise, if we have a 1, we've obviously seen a 1, so we can transition to state q1. At q1, if we have seen a 0, we can obviously transition to state q2, since we've now seen a 10 symbol. At q1 if we see a 1 though, we just stay on q1, since so far the last symbol we've seen is just a 1. Once we're at q2, the success state, if the next symbol is a 1, it should go back to state q1, since we've just last seen a 1. And lastly at q2 if we've seen another 0, then we can go back to state q0 since we have yet to have seen a 1 previously or 10 [we saw a 00 instead]
Right, that sounds correct.
Thank you all for your help. One more question though.
Now that bananza has completed the task, I will comment on this.
The remainder modulo 4 is entirely determined by the last two digits, so this approach is totally the same as simply having states corresponding to the last two digits.
As it happens we can produce a smaller automaton if we consider the digits, since we may consider only three states rather than four, since we may merge the 01 and 11 states.
In the example [unrelated, but I brought into the convo] regarding this:
^
I'm confused on why this DFA is counting the odd number of 1s.
I tried to walk through an example with my own binary string but didn't get it
to me it looks like it accepts a word iff the word has an even amount of 1's
The initial state has not been specified
Start is q0
oh thats something
I believe it says
but I guess the arrow going into q0 is just cutoff in this picture
So in fact it does accept if there's an even – not odd – quantity of 1s occuring in the string.
do you understand why that is true, bananza ?
Not really
how would you compute the word 1010 ?
Is it because we've seen at least 2 1s
So like state 0 is we've seen an even amount, state 1 is an odd amount
yes
as soon as you read a 1 you have to transition from q0 to q1 or q1 to q0 respectively
so starting at q0 you will need an even amount of 1's to land at q0, the final state, again
its going back and forth
So the language that the dfa is deciding is even number of 1s?
That's why I was confused
yeah, the set of words that contain an even number of 1's, corrct
you could try to formulate that as a set
or regex
On the other hand, the modulus approach generalizes to divisors with prime factors that are not in the base, so it is more general.
Yeah
The intention with my examples was to show that the theorem is false without some restriction on s.
oh
I'm not sure whether s = |S| will actually make it work, but I haven't found a counterexample to that yet.
If I had 2 problems and the inputs were (code, x) for problem 1 and just the code for problem 2, and the output of problem 1 is true/false depending on if it'll halt with the input x, and for problem 2 its if the code takes at least 1400 steps before eventually returning true on the inputs
can I prove that 1 is reducable to 2 simply by showing that the first is a true instance of itself if and only if the code inputted is a true instance of problem 2?
wait I think I can see a HC
One that includes all of the red edges?
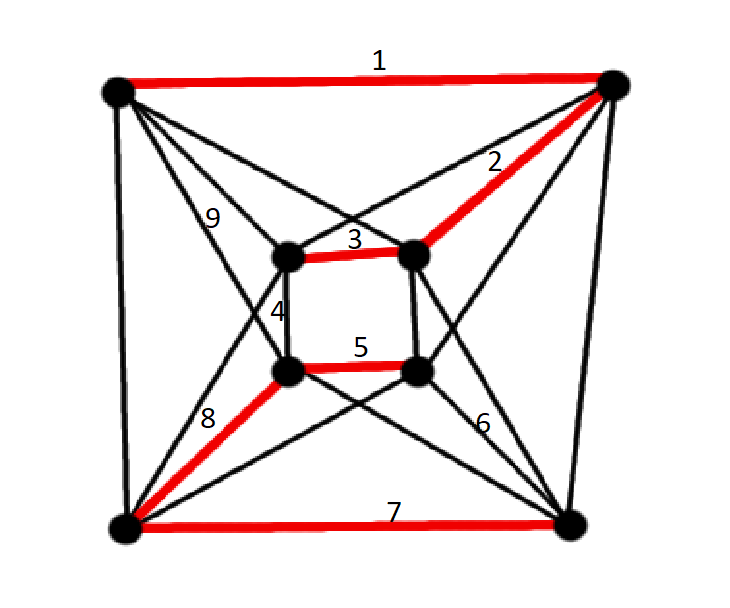
The bottom left vertex of the inner square is visited twice there.
Sure, I don't see why not.
isn't this graph 5-regular tho
yeah? my example was wrong though
wouldn't it have a hc by dirac's tho
not on that particular path
(including all red lines)
oh yeah it can't always give you an hc for a specific path
the theorem(not dirac) states that every component of G[S] - where S is a subgroup of the edges, and satisfying d(G) >= ( n + |S| )/ 2 has a Hamiltonian cyle containing S
So you can see the group S highlighted in red here
however d(g) isn't >= (8 + 6)/2 = 7 , so it's a counter example
Ah I see
If I had 2 problems and the inputs were (code, x) for problem 1 and just the code for problem 2, and the output of problem 1 is true/false depending on if it'll halt with the input x, and for problem 2 its if the code takes at least 1400 steps before eventually returning true on the inputs
can I prove that 1 is reducable to 2 simply by showing that the first is a true instance of itself if and only if the code inputted is a true instance of problem 2?
What if it takes fewer than 1400 steps
Or more, I’m not sure which direction this is in
You know what I mean
If it would give a true output on 1 but the steps are too big/small for 2
Problem 1
Input (code, x) where code is the source code and x in the input to pass to prgoram
Output is true/false depending whether the program in code will NOT halt on x
Problem 2
(code) is input without x
output -> true/false depending on whether the program in code takes at least 1400 steps before eventually returning true on every input. a step is execution of line of code
Well, iirc problem 1 is kinda infamous
wanna show that 1 can reduce to 2
You know, the halting problem
Being able to decide that does indeed imply you can decide the other since
Ya know
Undecidable
wdym
False implies everything right?
I don’t think that’s what I’m saying
Reduction is not just "2 decidable implies 1 decidable".
Maybe I’m mixing up the direction of reducibility
It requires that theres a computable map from instances of 1 to instances of 2 such that every 1-instance maps to a 2-instance with the same answer.
(This is "many-one reducibility"; there are other related concepts also called "reducibility").
Ok since I’m an idiot and mixed things up, take an input to problem 1. Can you turn it into problem 2 with the same input
It sounds a little difficult to me
So we'll need to take a program and its input, and somehow produce another program, such that:
If program 1 diverges on input 1, then program 2 takes >1400 steps and halts with true on every input.
If program 1 halts on input 1, then there's an input to program 2 that either makes stop before >1400 steps, or diverge, or halt with false.
This doesn't immediately look particularly likely.
Also I think I just noticed the original question, uhhh no that’s not the way to do it, since you just need an algorithm to turn an input to problem 1 to one of problem 2 with the same result
It doesn’t have to be the literal same code inputs
In fact, it looks like if we had such a reduction, we could use that reduction to decide the halting problem: Given a program and its input, derive a program 2 with the supposed reduction, and then run the original program and program 2 in parallel until one of them terminates.
right but im just trying to PROVE it reduces
I've just argued that it doesn't.
I wouldn’t be surprised if it reduces
Can you show the exact text of that question? Perhaps I need to revise my assumption that we're talking about many-one reductions.
Since problem two is true iff the input code takes over 1400 steps and returns true on all inputs
which is a lot probably
Look, before you took it upon yourself to hide the example that showed leading zeroes were allowed.
I think we can say here that we need to actually see a picture of the same problem text you're looking at to be sure.
It’s always a good idea to give the explicit problem
Unless there’s a good reason not to, it’s good to prevent ambiguity or typos
Well, consider we had an input (c, x) to problem 1, that would be true iff c does not halt right?
Hmm, that's poorly phrased indeed. Do you have a definition of "reduces to"?
Alternatively it might be a typo in the problem statement, and one of the problems was actually supposed to return the negation of what is described here.
I was definitely getting my reducibility the wrong way around sorry 
I hate some phrasing
I meant the problem in Bananza's image is poorly phrased.
I am aware
Ah, okay then.
I am venting complaints on a related but dissimilar issue
Huh, why did the post with the problem text disappear?
What 
Bananza posted a screenshot of his reduction problem, but that's deleted now.
I’m just confused as to why it would be deleted
Oh. 🙂
it’s very concerning to me but

It means the first.
There is no set that contains all sets, so the 2nd thing you wrote is just “False <-> False”.
i don't really understand how this relates with no set containing all sets
“Forall x, x \in S n T” means that S n T contains all sets.
Working through this right now https://www.statlect.com/mathematical-tools/k-permutations for deriving the Number of k-permutations without repetition to get ordered samplying without replacement why is it in general that it's n * (n-1) * ... * (n-k +1) (i.e) why does the author add + 1 ?
Definition and intuitive explanation of k-permutations. The number of all possible k-permutations. Examples.
Is adding +1 to avoid undercounting ?
Wait figured it out to get the last position in the list one needs to regonize before you get to the kth end of the list everything is (k-1) before you reach the end of the list
I'm studying and I'm interested in graphs, which I believe is a part of discrete mathematics. Is there a website where I can find information about graph diameter and related concepts
this graph is huge

and it takes time to determine the diameter
@weary tiger , so in truth, this one is not that hard. The graph just looks all mangled up at the moment making it seem more complicated then it is.
Give me 5 minutes to show you what I mean
No not exactly. You're looking at the longest possible distance between any two points
without repetition
Distance of points x and y is defined as the shortest path between the two
You're looking for the longest possible distance you can find for every set of two points
okey for example A:7 is that good
You're misunderstanding what distance means. Give me a second
The diameter of this graph is 3 btw
howwww
(...wait what's the path from D to H?)
If I did it right, we have this isomorphism

Also, bee, you are right
The right graph is much simpler to digest
i also got that so yeah i think that's right
That makes the diameter 4 rather than 3, doesn't it?
Yes, bee caught that just a second ago
i did it myself, in ms paint so my version of the graph looks like this

It looks beautiful
so i already knew the diameter was 4 and then you said 3 and i was confused
Nah, I just blundered, that's all
but don't I need two graphs for isomorphism?
Do you notice graph #2 on the right? 😅
yeah we're saying that this graph is isomorphic to the graphs we drew
Point is, the way the graph looked originally just sucked, so we used an isomorphism to create a simpler graph
it then makes the task much easier
Yes, but you also weren't addressing distance correctly
To be fair, I made the same exact mistake with diameter myself at first
but I somehow count all 7 again
what are you counting 7 of?
We should first establish what distance is
i write ecc
Depending on the formalism you're using, we may be looking at not just isomorphic graphs, but the same graph drawn in two different ways,
The distance for vertices x,y is the total number of edges along the shortest possible path between x and y.
For instance, the shortest possible path between G and B is just G->B, which has exactly one edge. So d(G,B)=1
but isn't ecc max distance? between two points
$diam(X)=\max_{x,y\in X} d(x,y)$.
dackid

We'll denote d as the distance function
Diameter is the maximum distance between any two points. But each of those distances you take the maximum of is still defined by looking at shortest paths.
So we are looking at the largest distance we can have between any two vertices
Distance, not path, is the key here
what's "ecc"?
probably eccentricity
eccentricity or sm
Didn't realize this was a conic section
Ah, so it's the same thing here
waitt
the shortest path between two points? but then I have to write for each point separately
A b , a c a d
Each set of points separately. However, with the right graph it is pretty clear what the diameter is
Yes for each pair of points find the shortest path between them -- and then pick the longest among those shortest paths.
It's admittedly not an easy question
not sure
This graph wasn't half bad, but generally speaking, finding the diameter can be tricky
let's go through the picture together
But, for example C-F-B-G-E-A doesn't enter into the diameter calculation because it is not shortest between C and A.
oh oki I make pairs and write the short number in the table
That's the systematic by-the-book way of doing it, yes.
You can if you want, but in the graph, notice that D,H have the largest distance.
radius...?
what if I need to determine the radius on that graph
Care to elaborate on what the radius is?
radius is min ecc
I did this 30 minutes ago and I somehow managed to solve it, but now I have no idea what's wrong with me
I guess you can call that isomorphic; it's the same graph, just drawn differently
That's a graph isomorphism for ya
wait, if I'm looking for the distance between how it is here for A =2, shouldn't it be 3? a-->d

I also need to fill in the table ecc
for each point I write with a short way, I guess I understood well now
Distance between two points is the shortest path length
A, b, c, d, e, phi.
how is here h = 6? , h->g have 5

What do you mean by h=6
No, the distance is a function for two points. The distance of a point does not make any sense
this is nonsense, first I do well and then I don't do well later
I think that might mean you don’t know it well?
producing the right answer sometimes probably means you don't know how to reliably arrive at the correct answer and you're just sometimes getting lucky
this is an example from the notebook and it says that for h =6
...what exactly does it say is 6 about h?
its ecc for point H
Eccentricity looks like the longest distance from H right?

,rccw

what's the distance between b and h?
that's what i think too
i say its 5
but here we have 6
Are you sure you drew it right?

does c->d exist?
yes
It’s drawn in pencil
It looks like h->a and c->d were added after the fact
Should I count from the beginning of the point
now then it makes sense
but e is 5 now
and d is 4
break
I’m pretty sure the two pencil lines aren’t supposed to be there?
now makes sense
Making sure you are looking at the right problem is important sometimes
it's 5 am and I have an exam at 1, I didn't get a good night's sleep
also stress
If you didn’t get it before tonight it’s probably not much help to cram
Sleep is better chief
how does it "follow immediately" that $\pi_i\phi = \phi_i$ for all $i \in I$? If I'm not wrong, for any $c \in C$ we have $\pi_i\phi(c) = \pi_if_c$ and then for any $i \in I$, $\pi_if_c(i) = \pi_i\phi_i(c)$ but $\phi_i(c)$ is in $A_i$, so it doesn't map to the domain of $\pi_i$

oops used the wrong phi
okeyokay

oh is it because they're considering $f_c$ a tuple uniquely determined by c so it's in the domain of $\pi_i$
okeyokay

Well f_c is in D so it’s definitely in the domain of pi_i
And it’s uniquely determined because functions equal at all points are equal as functions
@novel ore is this what you mean?
pi_i f_c = f_c(i)
Since the pi projection maps in the canonical product is just function application

Any other doubts?
nop i'm still reading through the rest of the proof
It really do be like
yeah the product has this property
and because it does, it’s unique up to bijection
cool
@weary tiger this is what the clusters look like if you're wondering:
it's an implementation of a definition for what i call "the collapsables of a node"
which is basically what you can see in the vid, if you "collapse a node", certain other nodes disappear
i don't undertsand why the tri-connected node at the top is collapsible but the uniconnected node immediately below it is not
you mean node F?
or how it decides which nodes out of a connected group to collapse
i can't read the labels, my eyes are too old
especially for thjat one node that has four neighbors, three of which are leaves and the fourth is the rest of the graph
so it's actually a directed graph, i know it's hard to see, but the arrow heads are the red dots
what if you collapse the one at the bottom left
Looks like collapsing all successors of a node
that should be the entire graph if i'm right, but i'm not sure
sort of yea, except that it can collapse only one node in a cycle
yea it is
i can't see the arrows either, which is a hindrance
actually lemme give the definition, maybe that might make things more clear
yea
ok, that helps
transitive successorship yes
so really it comes down to how you resolve cycles
so, a node N is a collapsable of a node A, if:
- There exists a path from A to N
- Every reverse path from node N can be extended to contain A, or it already contains A
- All imports of N are collapsable
when i click "collapse" on a node, it finds all its collapsables, and makes them disappear from the editor basically
now, with the definition of collapsables, here goes the definition of clusters:
so, every cluster is basically the set of collapsables of a node, which are only the collapsables of that node, they may not be a collapsable of another node as well
so in this graph:

there are two clusters:
{A, B, C} and {C, E, D, F}
does that sorta make sense?
or am i forgetting something in my def? is it poorly defined? are there contradictions in it? any feedback is much appreciated
(feel free to ping me if you reply so i don't miss it)
Hey guys does anyone know how to prove this or like how to approach it? Prove that when working modulo 4, it is not possible for a perfect square to be congruent to 2 or 3.
Hence (and not otherwise) prove that there do not exist three consecutive integer values of n for which 11n +5 is a perfect square.
The straightforward way would be to compute n² mod 4 for each of the four possible values of n mod 4.
does A=S n T considers as a statement (or proposition) in this case? I know that the whole biconditional does seem to be count as a statement


is this best possible?
well I know its not in some cases
assume that every vertex has degree delta
then in some cases you can have the bound n/(delta+1)
but idk if you can always have
mmh this is only on some special family of graphs tho
Is that Alon's probabilistic method
hi
I need some help
How many bit strings of length 8
- exactly three 0s?
- more 0s than 1s
- at least five 1s?

I'm not sure about my answer
Looks okay.
You could also shortcut and say the number of string with "more 0s than 1s" must be exactly half of those that don't have equally many, and then you only have to calculate one binomial coefficient for it.
What about this answer

I got this one from my friend
How does he justify including C(8,4) in (2)?
And in (3) it looks like he's counting strings with at most five ones.
okay
btw, can you show me the shortcut?
Half of (2^8 minus C(8,4))?
I got the same answer, 93, but I don't understand why 2^8 minus C(8,4)?
There are 2^8 possible strings in total. C(8,4) of them have equally many 0s and 1s. Of the remaining 186 strings there are equally many with more 0s than 1s as there are strings with more 1s than 0s, so half of them is what you're looking for.
I get it now
thank you so much


Indeed, they are not equivalent. For example plug in p=false, q=true, r=true.
So, the above solution is correct?
Well, yes, inasmuch at it can be a "solution" to a task that wants you to prove something false. :-)
Thanks again for your help
I'm having trouble with factoring coefficients in a sum of sum. I have this polynomial in $(z - z_0)$ coming from a series expansion of a second order differential equation that is identically zero, and looks like
\begin{align*}
&\sum_{n=0}^\infty c_n (z-z_0)^n \left[ (n + \alpha)(n + \alpha-1) + (n + \alpha) \sum_{k=0}^\infty a_k (z-z_0)^k + \right. \
&+ \left. \sum_{k=0}^\infty b_k (z-z_0)^k \right] = 0
\end{align*}
I need a way to nicely factor out common powers of $(z-z_0)$ so that I can set all the coefficients order by order to 0. In the end I should get a recursive equation for the $j$-th coefficient. I'm having trouble doing this
.siupa

Is this not just saying A=R or are they somehow different

Lol, yeah that's just R
that’s my favorite definition of R
Trying to think of an elegant proof of the following obvious fact: in an n x n x n cube composed of n^3 1 x 1 x 1 cubes, the furthest apart cubes are the opposite corners (where a path between two cubes A and B consists of list of consecutive (face) touching cubes starting with A and ending with B
and then the distance between A and B is one minus the length of the smallest path between them
for instance the distance between two opposite corners would be 3(n-1)
I guess am trying to prove that manhattan distance is the true distance in manhattan, or something
what happens when you find a path between A and B of length smaller then their manhattan distance… something must go wrong
oh ok I got it nvm that should’ve been obvious
$$n(n-1)c_n + \sum_{k=0}^n (ka_{n-k} + b_{n-k})c_k = 0$$
I should plug in $a_0 = c, b_0 = 0$ and $a_k = c-a-b-1, b_k = -ab$ for $k \geq 1$ to get
$$n(n-1+c)c_n - (n-1+a)(n-1+b)c_{n-1} = 0$$
How? Where did all the $c_k$ with $k< n-1$ go?
.siupa

I read about Matching Edge Set (or Independent Edge Set) recently and I was doing some problems. I'm supposed to find the value of matching number for a Bipartite Graph of the form Kₘ,ₙ . I am unable to think of the way to deduce a formula for it, can anybody help in this?
What is the matching edge set?
a set of pairwise non-adjacent edges in a graph
Does it help if you assume m <= n?
So are you trying to figure out how many edges an edge in K_mn is not adjacent to?
Matching number is the maximum number of elements we can keep in the Matching Edge set so yes but +1 to count for the egde itself as an element of the set
i'm not sure
I think I understand, can you try answering my question first
Maybe that will help
Suppose you have a K_(mn) graph, which has mn edges. Choose an edge, we'll call it e, how many edges are not adjacent to e?
an undirected graph is a set of edges without common vertices
Alternatively, try working it out by brute force for m,n both small (say, up to 3 or 4). A pattern ought to show pretty clearly.
I personally found this useful because once you solve this, you'll learn that ||removing all the adjacent edges gives you a K_(m-1)(n-1) graph||. And with this ||reductive process||, it's not too difficult to get to your answer.

are you gonna show us the original question or should we guess at what it was
@vapid drift
uh am I dumb or
if we know that for a function f with domain X and x, y as elements in the domain:
x < y implies f(x) < f(y)
then the reverse implication is automatically satisfied too
like if we had f(x) < f(y) and x >= y then it would contradict the premise
It certainly would
no it wouldn’t I’m stupid nvm
No it would
I edited
x >= y means y = x or x > y
If y = x then f(x) = f(y), so that can't be true
and if x > y then f(x) > f(y), which is a contradiction
So yes, you're right.
how is this one a contradiction
oh I’m stupid
lol
f(x) > f(y), but we assumed f(x) < f(y).
I'm assuming here that you're working with a totally ordered set. You didn't specify, so I'm guessing you're working with real numbers.
wait so is there anything special about this particular implication that let us get the reverse implication for free
like usually I’m suspect when that sort of thing happens
For an arbitrary poset this won't be true. If you don't know what a poset is, don't worry.
It is to do with the fact that for any two real numbers, exactly one of x < y, x = y, or x > y holds.
is it sorta like this
we were given a statement P implies Q, but also it happens to be that “not P” is tractable in that there are two relevant cases (trichotomy)
Sure
Ok I was just going crazy that I proved the converse of a statement by using the original statement
My textbook gave this pseudocode example of determining if a relationship R is transitive by giving a result value of T or F depending on whether or not the relation in transitive but then says that the algorithm doesn't report whether or not R is transitive
The logic seems sound, so I'm not sure what it means by that statement

Seems an odd statement but perhaps they're referring to the fact that they don't, at any point, say that "now the algorithm outputs the result"
Also I'm sure you can see that the algorithm will typically do a lot of unnecessary computation if a relation isn't transitive. Perhaps they're referring to this fact too
But yes I'm in the same boat, it seems a strange thing to say.
Ok thanks
Am I trolling here or does the bound on d get worse when k increases?

Yes. $\mathsf{P} \subseteq \mathsf{NP}$, so it suffices to show the reverse containment. Suppose that $X \in \mathsf{NP}$. Then $\overline X \in \mathsf{co}$-$\mathsf{NP}$. Since $\mathsf{co}$-$\mathsf{NP} = \mathsf P$, this implies that $\overline X \in \mathsf P$. But this implies that $X \in \mathsf P$

the crux is that, if the complement of a problem is solvable in poly-time, then the original problem is also solvable in poly-time. to see why, consider the turing machine that accepts the complement of X; we can simply switch the accept and reject states and this returns the complement of (complement of X) which is exactly just X
[note that this is different when a problem is in NP but not necessarily in P]
if i have a set $E={1,2,3}$ and a relation R such as for every $X,Y\in P(E) \hspace{1cm}XRY\iff X\subset Y$ what is the hasse diagram of $(P(E),\subset)$?
john.1970

Help

People here aren't going to do your homework for you. Ask a specific question about a problem you're having in your attempt, and someone may help.
yeah, what bowtie said
not my homework lol
By its own heading, it's someone's homework, due tomorrow ...
Yes but I already took algo
._. point being, we aren't just feeding the answer no matter who's homework it is.
this is for someone who's taking it over the summer
Explain where you're stuck.
and if you did why would you be asking for help with the question ._.
we didn't focus on this aspect of DP
Algorithms is a huge field
that's not my focus, my point is that you should elaborate on which part of the question is stumping you
figuring out the ordering
?
Not really a software question
it's where most algorithm related qns go methinks? Or better yet use a CS server  eh whatever, just leave it here for someone more qualified to answer
eh whatever, just leave it here for someone more qualified to answer
Note that the j parameter decreases by one in each recursive invocation, whereas i and k do weird things.
the base cases are also very weird
You use std:: vector
They key observation is that f(i,j,k) depends only on the f(_,j-1,_) stuff
So you can forget everything with middle term < j-1
Also this feels like convolution in a sense?
I understand the recursion but is there a neat way to say when it's 1 or 0, other than when those conditions like i=jk or j=1 hold?
Ok this looks like a generating function in a sense

Like the relation seems like the convolution formula in ordinary generating functions
the recursion's just f(i-1, j-1, 1) + f(i-2, j-1, 2) .. + f(i-k, j-1, k). So several values from the i and k axes but one from j-1.
At this point I'm more curious about where the 1's and 0's are in the 3d grid
you'd think the most obvious case is when j=1 fill everything with 1, but it could aslso be 0 depending on if the previous condition holds
and the i>jk is a pain to think about
nvm, I think this is a knapsack problem
Lowkey.
How would you compute it using for loops and memoization? Writing it recursively is simple enough
for(int q=1;q <= j;q++)
for(int p=0;p <= i;p++)
for(int r=1;r <= p && r<= k;r++)
for(int w=1;w<=r;w++)
dp[p][r] += dp[p-w][w];
return dp[i][k];
Something like this
I am not gonna deal with the initialisation
Also this is most definitely wrong
oh right
looks like procrastinated homework to me lol
I'm not sure this counts as discrete math, but you can do these problems on discrete modular fields so close enough maybe:
at my Uni there's an example test question that asks why you need to set a rule for elliptical curves if you want to use them for cryptography.
The rule is: 4a^3 + 27b^2 != 0 must hold for elliptical curves E: y^2 = x^3 + ax + b
The answer is (in short) that you need to be able to define a group operation if you want to use the curve for cryptography, and since that operation is defined as, for two points P and Q, P + Q = R with R being exactly one other point on the curve that we find by setting a line between P and Q and finding the other point where it intersects the curve. The rule ensures that the curve won't have repeated roots and that the operation + remains closed in the curve.
The weird part though is that the question is multiple choice, and among the possible answers are
a) So that the elliptical curve doesn't have repeated roots
...
d) So that p(x) = x^3 + ax + b doesn't have repeated roots
These seem like they're saying the exact same thing to me, but is there some subtlety I'm missing with the p(x) version?
I think I figured it out; p(x) is a normal polynomial, not an elliptical curve

It doesn't really make sense to speak about the elliptic curve "having roots"; it is not a function. On the other hand, if the polynomial x³+ax+b has a double root, then the curve y² = x³+ax+b will have a point of self-intersection (the graph of the curve looks locally like y² = k(x-r)², which is two intersecting lines). At such a point, the definition of the group operation won't really work -- P+P could be anywhere on the curve.
should be noted there are other ways they can go wrong, having discriminant 0 can make it have a sharp corner or a free floating point. It also turns out that when the discriminant is 0 that it's easy to parametrize all their points
maybe other stuff too can go wrong I forget

What part are you finding tricky?
U is the universal set, which is required to define the complement of a set.
It is not specified
When we have a universal set, we typically think of all other sets as being subsets of that set.
Then how did we replace it by B union complement B
Well, what is the complement of B?
i.e., what are the elements of the complement of B?
Nothing
No that's not right.
The elements of the complement of B are the elements of U that are not in B
We would more generally write U\B
So ok, with this new understanding, can you tell me why U = B union the complement of B?
Because the elements of the B union complement B is everything in U
Like if you draw a vienn diagram
Yes, that's right
You can see more clearly
Yeah we’re going like backwards
Sure, if that helps you see it better
My teacher asked me to do this without the binomial coefficient formula:

catsup?
ketchup
I can't believe I hadn't seen that spelling before
The scare quotes around "burger joint" are important.
Hmm, how would you do it with binomial coefficients?
Hmm, it's a bit tedious but I would compute 9C0, 9C1, ..., 9C9 and add them all together
That's tedious indeed.
Is there a better way?
Well, as a customer you have to choose
either with or without ketchup
either with or without mustard
either with or without mayo
...
either with or without mushrooms
You don't need to decide mow many "with"s you end up with before you start making choices.
Yes ...
Yes.
a good way to do these kind of problems is to invent a simpler problem, say with like only mayonnaise, then add lettuce and then mayonnaise, lettuce and tomato and understands how the combination works/increase.
Hello, I'd like some help with the last part of this exercise from generatingfunctionology

I have found the variance

But I don't quite get what they want for the part "make an estimate that shows that the variance is in some sense very small"
I also calculated these using python and some seem very big

this is the place to ask about flow networks?
I try to write a formal definition of a layer graph , from dinic's algorithm

how do you define a function?
all i know is the domain should not have 2 pre images
but let's say 1/x
at 0 it's undefined
does that mean it's not a function
preimage of the domain? 
can you give me the word for word definition as provided in your book?
too bad, i gotta go, hopefully someone else is willing to help you
<@&286206848099549185>
@odd garden in its simplest form, a function is something that for every input has exactly one output.
Does every input have an output?
This is not true
Is one-to-one defined for things that aren't functions?
If not he is technically right lol
I guess, but it's pretty clear they're just guessing at this point and hoping something sticks.
Ah i didn't even look at the previous messages sorry
In this case the object f: {1, 2} -> {1, 2} defined by f(1) = 1 and f(2) = 2 is definitely a function
Its not a function from {0, 1, 2} -> {1, 2} though since it isn't assigned a value at 0 (this is being unncessarily precise with definitions that should be intuitively obvious)
And make sure you wait at least 15 minutes before pinging helpers.
i don't even know what "one-to-one" means
like, at all
A one-to-one function?
idk what that is
one-to-one and injective are the same thing.
Just different words to say the same idea
oh
Many people use "one-to-one" to also mean bijection. It's frustratingly unclear terminology.
...oh
Like how onto also means surjective
1-1 and onto would be, you guessed it, bijective.
I'm happy to say I've never encountered this
"onto" is also unclear terminology. If I say "f is a function from A onto B" does that mean it's just a function f : A → B or is it necessarily a surjection? I say, use the clearer terminology injective/surjective instead.
Have you never encountered the phrase ‘there is a one-to-one correspondence...’?
Oh I have, and that definitely doesn't mean bijection.
yeah that definitely means bijection
I'm mainly familiar of it cuz of Galois Theory
I can't say I'm convinced 🤔
and this is why it's annoyingly ambiguous terminology
I'm gonna find an example. Give me a moment.
the "correspondence" part is good. the "one to one" part is junk
you can find any youtube video that talks about bijections without explicitly saying "bijection". theyll probably say "one to one correspondence" instead
Huh, I was mistaken. Wish I just wrote 'bijection' in all my Galois proofs 😅
In this set of notes: https://www.mit.edu/~parrilo/cdc03_workshop/07_algebra_geometry_dictionary_2003_12_07_01_screen.pdf "This implies There is a one-to-one correspondence between radical ideals and varieties"
In this one: https://antonleykin.math.gatech.edu/math4803spr13/BOOK/chapter4.pdf
Prime ideals and irreducible varieties are in one-to-one correspondence.
adding to the list https://www.youtube.com/watch?v=SrU9YDoXE88&t=190s

Support Vsauce, your brain, Alzheimer's research, and other YouTube educators by joining THE CURIOSITY BOX: a seasonal delivery of viral science toys made by Vsauce! A portion of all proceeds goes to Alzheimer's research and our Inquisitive Fellowship, a program that gives money and resources directly to growing science channels here on YouTube!...
In this mathoverflow question: https://math.stackexchange.com/questions/813978/correspondence-theorem-for-rings
There is a one-to-one correspondence between the ideals of A that contain I and the ideals of the quotient ring A/I.
I'll stop now, but you get the point.
I just really think the terminology "one-to-one" and "onto" is really terrible and idk why it keeps getting taught. Are the words surjective and injective so bad?
Fr bro just use bijection, it’s a common term
And doesn’t have tons of context baggage on it
Or isomorphism, if it’s relevant structure preserving
I think that gets a bit tricky when topics mix and mingle.
i mainly like the shortness. i sometimes do "1-1" and "onto" in scribbles or informal convos
valid tbh
Scribbles and rough conversations don’t need to be completely clear of ambiguity to a random observer
Textbooks are a lot less informal usually though
I just do inj, surj and bij and it totally fine
If the order of an elliptical curve E is not a prime number, in this case |E| = 16, adding a point on the curve P to itself 18 times is equivalent to adding the point to itself 2 times; this idea resembles 18 === 2 (mod 16) but if someone were to ask me to explain why this holds, I'd be hard pressed. Is this because of Lagrange's theorem about group order? that is, a point P on the curve will be a generator of a subgroup of order that divides the order of E? But what if P generates a subgroup of order 2? then the equivalence would no longer hold?
why would it no longer hold
18%2 = 0
and 2%2 is also 0
all that means is you're "wrapping around" more times than you need to
maybe think of just the group with 4 elements Z/4Z
2 is order 2, but the group is order 4
(order of the group) / (order of an element) = number of excess times you're "looping" around
nice, that makes it clearer
thank you
you're welcome
if R is a partial order on A and A doesn't have a minimal element, is A infinite?
Prove it by contradiction
Or I guess more accurately, the contrapositive is easy to prove, so prove it.
It should be noted that A must be nonempty to avoid the boring trivial case.

A function f:A → B is onto if for all b ∈ B there exists a ∈ A such that f(a)=b
So for your problem, you need to check whether every integer is of the form n²-15 for some integer n.
f(n)=0
Yes, this equation has no solutions
in Z
Therefore the function is not onto
is there like a formula instead of trying numbers..
drawing the graph?
Depends on the specific problem
That doesn't count as a proof, but maybe it could provide insights in specific cases
Okay thank you
because you can prove a function to be one to one
by puting f(x)=f(y)
if x=y then it's one to one
Yes
if a function is one to one then it has an inverse correct?
Some functions have infinite domains and ranges – you can certainly try to draw an infinite graph in those cases!
No; if it is one-to-one and onto then it has an inverse. Neither condition alone is sufficient for a two-sided inverse to exist.
I defer to the wisdom here.
Yeah it's um.... a tricky thing
You need to understand this: you are starting to learn about math that has no method. You will have to use your creativity and careful thought to do some things here.

🥲🥲🥲
This is not a sad thing, this is actually wonderful. You are finally doing things that aren't glorified calculator work.
usually it's a tricky question where they put a specific domain
so it does not become onto
right?
I will get used to it
Did Mr bowtie just describe all of HS math in 1 sentence?
I have more sentences for HS math... grumble grumble
Let U = {1, 2, 3, 4, 5} be the universal set.
Let A = {1, 2, 3}, B = {3, 4}, C = {1, 2, 4}. Find the following:
1 The power set of B; P(B).
what is the difference between B, P(B)
or it's the same
That's correct, well done
how do I begin with this type of question

The way to show two sets are equal is to show that every element of the first is an element of the second, and vice versa.
@stray reef does the order matter i,e is it permutation or combination in this question?

well it does matter who sits where yes

What do you think?
it's false?
Why do you think so, can you explain why?
So I think you've found the answer then
I should mention, there are cases in which the P(X) and X contain some of the same elements. You cannot genrally say that since y is in P(X), this means that y is not in X.
Yes, it is true that {0}∈{0,{0}}
I dont understand the axiom of continuity and the real numbers:
In our class the axiom of continunity is: A non-empty set that is bounded above has a least upperbound..
And the real numbers are defined by being a commutative field, totally ordered, and satisfying the axiom of continuity..
But what if we have a set like {x in R | x <= 4}?? This would be bounded above... but how can it have a least upperbound??
the least upper bound is 4
(...are you sure that "discrete maths" is the right channel for a question about continuity?)
maybe abstract algebra?
how would the least upper bound be 4?
cuz 4 is in the set?
It bounds them and is the least such number
It doesn’t matter that it’s also in the set
but the definition is an upper bound is a number greater than every other number in the set?
the bound in question is not strict (doesn't have to at least)
Ohhhh ic
I have another question...
what does the axiom of continuity mean conceptually?
Like it says that there will exist a least upper bound but why does that matter?
It means that there are no 'gaps' in the reals
We can get rational numbers that as close as we like to sqrt(2), but we cannot find a square root of 2 in the rational numbers
Conversely, for the reals, with some work you can show that because of this LUB property the square root of two is present.
This 'gap' is filled.
sorry if this is a bit of a dumb question...
but how can we deduce this from a set being bounded --> least upper bound?
oh ok lol
You can ask in #real-complex-analysis if you'd like
I'm working on a set of problems on Alphabets and Palindromes and I'm a little bit stuck if anyone can help. Let A+ be an alphabet with non-empty strings such that xz=zy for all x,y,z in A+. I've shown already previously that (x^n)z=z(y^n) for all n greater than 1 and that there exists a unique n such that n|x|>|z|>=(n-1)|x| where |.| is just the length of the word.
I'm trying to prove the existence of u and v in A* (where they could be empty strings) such that z=(x^(n-1))u, x=uv and y=vu. I'm not sure how to exhibit them. All I got is that z=(x^(n-1))u=(uv...uv)u=u(vu...vu)=u(y^(n-1)). Feels close to what they want me to get at, but not quite. Any hints?

{kind=link}
let $A$ and $B$ be sets. Then $A$ is a subset of $B$ if and only if all elements of $A$ are in $B$
Kiameimon | Welt Rene (glomed)

g is driving me nuts
it’s cursed