#type-hinting
1 messages · Page 49 of 1
I'm running with --inspect-mode because otherwise it will generate a stub with __slots__: Incomplete and my IDE will say that it is unable to find basic variables that defined directly in the stub...
OK yeah then my hypothesis is debunked. Sadly I'm out of ideas. I don't run mypy but maybe someone here can help reproduce or debug
I'm curious what the point of stubgen is if you already have types defined.
Oh so its because my package is actually compiled with mypyc, so I use stubgen in CI/CD to generate the stubs that stick in the package... this allows both IDEs to get the type info but also any downstream project that wants to compile with my project as a dependency
yeah maybe open an issue... stubgen is pretty crufty and has never been loved :/ (stubtest + llm works pretty good these days too)
i'm a lil confused.. https://pyright-play.net/?code=CYUwZgBCAeCGC2AHANiA2gFQFwQC4E9EQIBeCAZ1wCcBdAClxwwEoIBaAPgmwFgAoCBAB0IoA
def example[T: type = str](t: T) -> T:
# ^^^ TypeVar default type must be a subtype of the bound type (reportGeneralTypeIssues)
...
perhaps you meant T: type = type[str]?
yep
thanks!
back with something else..
https://images.soheab.com/MLe31OHQIbM.png?f=scs
what vscode shows is how I want it but pyright doesn't seem to think that


probably has to do with pyright thinking it's a bound method
try ClassVar[Callable[...]]
oh ugh
I want it to "auto detect" that
is there maybe another, better to do what I want?
# Before
class Example:
def set_name(self, value: str) -> Self:
...
# After
class Example:
set_name = Something(type=str)
# type checker: set_name: Callable[[str], Self]
inst = Example()
inst.set_name("hello") # <-- same on both
I wonder what happens on runtime

when I made the _define return an acutal func following that signature: ```python
@classmethod
def _define(
cls,
) -> Callable[[T], C]:
def inner(x: T) -> C:
print(x)
raise
return inner
thing is, python is actually converting that into a method there
so the first arg is becomming bound as the instance
pyright is correct here
it's just really weird
well I'm not sure what you're even trying to do here, if you're trying to write your own descriptor here, what is the point of that _define returning a callable? and why have a set_name func on the class?
- to pass
Selfso it'sCallable[[T], Self] - it's supposed to be a builder, like
Example().set_name("hello").set_description("world")...
to pass Self so it's Callable[[T], Self]
but why not just-> Setter[C, T]?
that would mean it's an instance of Setter no?
wait can't I use __call__ on that class
you can
it's supposed to be a builder, like Example().set_name("hello").set_description("world")...
I'm still confused by why you even need descriptors for this goal though / what exactly is this builder tyring to achieve
just giving the options to users that want to change the name etc after the init
and not wanting to define each method myself, but instead somewhat automate it by only setting the classvars
# Before
class Example:
def __init__(self, name: str | None = None) -> None:
self.name: str | None = None
def set_name(self, value: str) -> Self:
self.name = value
return self
# After
class Example:
set_name = Something(type=str)
# type checker: set_name: Callable[[str], Self]
def __init__(self, name: str | None = None) -> None:
self.name: str | None = None
inst = Example()
inst.set_name("hello") # <-- same on both
that just seems... wrong lol
agreed
this works at runtime, but with lots of typing errors
from typing import Any, Self
class Setter[C, T: Any = str]:
def __init__(self, name: str, type: T = str, default: T | None = None) -> None:
self.type: T = type
self.default: T | None = default
self.__attribute_name: str | None = name
self._instance: C | None = None
def __get__(self, instance, owner) -> Self:
if self._instance is None:
self._instance = instance
return self
def __call__(
self,
arg: T,
/,
) -> C:
setattr(self._instance, self.__attribute_name, arg)
return self._instance
class Example:
set_name: Setter[Self, str] = Setter("name")
def __init__(self, *, name: str) -> None:
self.name: str = name
inst = Example(name="Test")
print(inst.set_name)
inst.set_name("New Name")
print(inst.name)
imma just give up and do it the normal way, sorry for wasting your time 
from collections.abc import Callable
from typing import Any, ClassVar, Self, reveal_type
def setter[C: type, T](name: str, type: type[T]) -> Callable[[C, T], C]:
def inner(self: C, val: T) -> C:
setattr(self, name, val)
return self
return inner
class Example:
set_name = setter("name", str)
def __init__(self, *, name: str) -> None:
self.name: str = name
inst = Example(name="Test")
print(inst.name)
reveal_type(inst.set_name)
inst.set_name("foo")
print(inst.name)
that said, I'd call this cursed and never actually use it anywhere
but it does work type-wise and runtime-wise
oh fml
IMO it's better to use kwargs instead of individual setter methods like that.
didn't think a function could access the class and forgot a "decorator" does get self
like def replace(self, **kwargs)
hmmm true
You can unpack a TypedDict to kwargs to add better types
yeah, that would definitely be a cleaner approach than whatever mess this is
here's what I got currently https://mystbin.abstractumbra.dev/5d12122760e2cefbc3
from typing import TypedDict, Unpack
class ExampleData(TypedDict, total=False):
name: str
class Example:
def __init__(self, *, name: str) -> None:
self.name = name
def replace(self, **kwargs: Unpack[ExampleData]) -> None:
if "name" in kwargs:
self.name = kwargs["name"]
e = Example(name="one")
print(e.name) # one
e.replace(name="two")
print(e.name) # two
Note that replace is typically added on immutable types and will return a new instance. My example is not implemented like that.
I see what you mean
i'm gonna scrape that all and just keep the methods that actually set a key in a dict or append to a list
thanks you two!
hey, a couple things I noticed:
- replace should return a new instance like return Example(name=kwargs.get("name", self.name)) instead of mutating self — you even mentioned this yourself but didn't fix it 😄
- the return type is None but it should be "Example" if you ever make it immutable
- since it's mutable the way you wrote it, why not just do e.name = "two" directly? the whole method is kind of pointless unless you plan to make it return a new instance
Huh I didn't know this channel had an ai summariser
Unfortunate that it doesn't read the context before responding though
What is the right way to type annotate a reference to a async function? Is it Callable[[args], Awaitable[return]] or is it Callable[[args], Coroutine[Any, Any, return]] ?
Consider this:
async def fn(a: str) -> int:
return int(a)
fn1s: list[Callable[[str], Awaitable[int]]] = [fn]
fn2s: list[Callable[[str], Coroutine[Any, Any, int]]] = [fn]
asyncio.run(fn("1")) # OK
asyncio.run(fn1s[0]("1")) # Awaitable[int] cannot be assiged to Coroutine[Any, Any, _T@run]
asyncio.run(fn2s[0]("1")) # OK
Interestingly, this doesn't give any errors. But I think its because mypy is overriding the declared type annotation:
fn3: Callable[[str], Awaitable[int]] = fn
asyncio.run(fn3("1"))
I think its because mypy is overriding the declared type annotation:
yep
another interesting thing:
https://github.com/python/typeshed/blob/main/stdlib/asyncio/runners.pyi#L25-L28
stdlib/asyncio/runners.pyi lines 25 to 28
if sys.version_info >= (3, 14):
def run(self, coro: Awaitable[_T], *, context: Context | None = None) -> _T: ...
else:
def run(self, coro: Coroutine[Any, Any, _T], *, context: Context | None = None) -> _T: ...```this is specifically on the Runner class though, not the free run function
Personally I use Coroutine in that context
Callable[[args], Coroutine[Any, Any, return]] is quite a mouthful. Are there any efforts on making it more compact?
i mean, you can always
type AsyncFn[**P, R] = Callable[P, Coroutine[Any, Any, R]]
if you are using it often enough to want to make it concise
And if you didn't know, you can pass a literal list of types to the **P in that. So, AsyncFun[[int, int], float] for example. Also ..., same as using Callable
Any suggestions how I can get this to pass mypy:
class A:
pass
class B(A):
pass
T = TypeVar("T", bound=A)
# Incompatible default for argument "factory" (default has type "type[A]",
# argument has type "type[T]")
def fn(factory: type[T]=A) -> T:
return factory()
a = fn() # type is A
b = fn(B) # type is B
Generics and default arguments don't play nice I've noticed
An overload might work.
@overload
def fn() -> A: ...
@overload
def fn[T](factory: type[T]) -> T: ...
def fn(factory=A):
return factory()
or just a cast
def fn[T: A = A](factory: type[T] | None = None) -> T:
if factory is None:
factory = cast(type[T], A)
return factory()
(default typevar requires typing_extensions)
Given a base class A with a generic type, how can I use this as a base class without needing to write def fn() -> A[Any]:
T = TypeVar('T')
class A(Generic[T]):
v: T
class Aint(A[int]):
pass
# Missing type parameters for generic type "A"
def fn() -> A:
return Aint()
(The return type of fn() could and should be specific, but this is just for this example. Please ignore that.)
Why is A[Any] a problem?
Not a problem per se, just more typing
Maybe a type alias?
type ADflt = A[Any]
def fn() -> ADflt: ...
Is the actual code returning Aint()?
If it will only ever return Aint, consider making the return type Aint
Yes, I tried to say that I'm aware of that short coming in my example 😄
A already does mean A[Any], but type checkers in strict mode flag that because they don't want you to accidentally introduce Anys. If you're okay with that, mypy probably has a setting to allow it
Is there any point in doing T = TypeVar('T', default=Any)?
That will suppress that, right?
yeah, that should also work, if you already depend on typing-extensions
Thanks both
or use 3.13
well, since they're using TypeVar, I assume that's not an option
Why is this an error in mypy strict?
def fn(a: dict[str | int, Any] | None) -> None:
pass
d: dict[int, str] = {1: "one"}
# incompatible type "dict[int, str]"; expected "dict[str | int, Any] | None"
fn(d)
I think fix error had a good guide on typevar variance
but basically, it's because dict is mutable and the key typevar is invariant here
you might want to use collections.Mapping if your function actually doesn't need a mutable mapping
otherwise, briefly, the reason it can't be allowed is this: ```python
def fn(a: dict[str | int, Any]) -> None:
a["x"] = 5 # allowed
a[2] = 2 # allowed
d: dict[int, str] = {1: "one"}
fn(d) # your dict now has a str key in it
I tried using Mapping as type for fn(a: Mapping[... but to no avail. Its not the mutability alone
im kinda new at this thing of coding, but i dont think it did anything on the terminal

so what is worng in my code
I think you're in the wrong channel mate.
thats like hint right?
i dont think im doing it on the right way
i feel that something must be wrong
stdlib/typing.pyi lines 779 to 781
class Mapping(Collection[_KT], Generic[_KT, _VT_co]):
# TODO: We wish the key type could also be covariant, but that doesn't work,
# see discussion in https://github.com/python/typing/pull/273.```you want #python-discussion
or rather make a post in #1035199133436354600
Have you read through it? Do you think it's actually good enough to recommend as an explanation?
well that's annoying, somehow I always thought the key was covariant in Mapping, guess I never encountered a case I needed this in practice though
I skimmed over some of the sections, but I did read most of it, I thought it was quite good
It's been in draft stage for a while because it hasn't received enough tomatoes unfortunately
and hasn't been tested on people unfamiliar with variance
yeah, explaining variance properly can be tricky when you haven't seen it before, I know I struggled with it for a while until it clicked
though that might be on me, since I tried to understand it from the definitions from wiki, which aren't exactly intuitive
indeed, a lot of things get easier to understand once you understand them
I'm not too familiar with covariance in python typing. I'm reading the page, and at a glance its a bit heavy. I think many cases are a bit "exotic" once one hits them and need to follow it down the rabbit hole. Then it might be good. -- And as for my own case, I think I understand why, but not what I can to do fix it.
The other page explaining variance is this https://mypy.readthedocs.io/en/stable/generics.html#variance-of-generic-types
these ones
If a generic G[T] is covariant in T and A is a subtype of B, then G[A] is a subtype of G[B]. This means that every variable of G[A] type can be assigned as having the G[B] type.
If a generic G[T] is contravariant in T, and A is a subtype of B, then G[B] is a subtype of G[A]. This means that every variable of G[B] type can be assigned as having the G[A] type.
If a generic G[T] is invariant in T and A is a subtype of B, then G[A] is neither a subtype nor a supertype of G[B]. This means that any variable of G[A] type can never be assigned as having the G[B] type, and vice-versa.
oh, didn't realize mypy docs had a guide on it, interesting
I'm trying to digest this:
A generic class MyCovGen[T] is called covariant in type variable T if MyCovGen[B] is always a subtype of MyCovGen[A].
A generic class MyContraGen[T] is called contravariant in type variable T if MyContraGen[A] is always a subtype of MyContraGen[B].
Can you spot the difference?
Hahaha. Now I do. Damn, that's sublte 😄
I would say your article does a much better job at explaining it for beginners than the mypy one though, looking at it
What's the simplest approach to map dict[int, str] into an argument expecting dict[int | str, Any], where the function is not mutating the dict?
imho using cast or mute feels like "nah, I gave up" 😇
well, Mapping should be the right way, but because of some oddities, it's currently not actually covariant for key types, so it is a bit tricky
would you be fine with Mapping[int, Any] | Mapping[str, Any]?
you can also include Mapping[int | str, Any] into the union if you wish to allow that too
What do you want to do with a?
Iterate over its contents and generate a new dict. Are there any way to mark "not mutated" any function arguments? (Probably hard to enforce, since mutation can happen long down the call chain.)
Mapping would be perfect if it weren't for the specialties
what if you make a typevar for the key
The reason Mapping[K, V] is invariant in K is that it has both get(K) -> ... and keys() -> Iterable[K]. So if you have a m: Mapping[str | int, Something], it is legal to do m["a"]. That's why Mapping[int, Something] is not a subtype of Mapping[int | str, Something].
so yes, the solution is what NoWayJay beat me to
lfg
from collections.abc import Mapping
def fn[K: str | int](a: Mapping[K, object], /) -> dict[str, object]:
return {str(k): v for k, v in a.items()}
d: dict[int, str] = {1: "one"}
x = fn(d)
it is kinda cursed but it makes sense
It gives a sort of "output promise" that a.keys() is at least Iterable[int | str] and a.items() is at least Iterable[tuple[int | str, object]]. But it doesn't allow you to index into a with int | str, because K could be e.g. Literal[69]
I understand the reasoning (I think). But it was a bit uexpected that dict[int, ...] is not assignable to (or subtype of) dict[int | str, ...]. That's something newbies should be made aware of. Perhaps something to add to your typing tips on assignability?
I think I'll add something about Mapping and dict as case studies to the article, yes
ah yes, the classic dict[Literal[69], X]
given that even the typeshed source code needs a comment
well, more realistic subtypes would be int or bool or MyIntEnum
Why dict[int, X] is not assignable to dict[int | str, X] should be pretty clear following the same logic as the list example, I think. dict[int | str, X] allows adding an item by a str key, which would invalidate the type of an dict[int, X]
but Mapping is an example of an immutable thing that's invariant, which should be new
Perhaps its useful to explain my use case: The key is an index, that can either be addressed by int or by name str. The function will test for string and do the name to int lookup in those cases. After this is done, all is int so the returned objects will essentially be dict[int, ...].
In hindsight it might have been simpler (for typing) to make a custom immutable datatype Index and use that as key. However there is something elegant about using native python datatypes for objects.
Given a library with typing:
class A:
def __getitem__(self, k: str) -> str | int | bool: ...
The usage of it looks like this:
def get_a() -> A: ...
a = get_a()
v = a["key"] # <-- How to force this to be int?
The question is: Is there a way to override/amend the type definitions of a library? In this case, it's known by design that the type of a["key"] (i.e. the __getitem__()) is always int but the library's type definitions doesn't allow specifying of that. Moreso, the process v = a["key"] is done so many times in the application code, that it becomes very tedious to cast, assert or accept it every time its used. How should I approach this?
What I think I'm looking for is if I can redeclare the signature for class A or A.__getitem__() within the app
i wonder if you could configure a .pyi stub to take priority over the library's inline types
I got a stubs dir to work with both mypy and pyright. However it seems one must redefine the whole object, not just amend a method definition.
I found doing a hack like this works. Not perfect, hairy even, since all places A is used, it must be typed to A_T.
class A_T(A):
""" Type defintions """
def __getitem__(self, key: str) -> int: ...
Is there a rule in mypy that a setter must immediately follow the property? This code works functionally, but does generate an error 'Name "raw" already defined on line...' with mypy. pyright seems fine with it.
class A:
v: int
@property
def raw(self) -> int:
return self.v
async def aget_raw(self) -> int:
return self.v # Stupid example
@raw.setter # <-- Mypy doesn't like the setter after aget_raw()
def raw(self, value: int):
self.v = value
Since type annotation is opt-in in python, and not everything in python has, for many reasons, opted in. In particular the multiple variants of duck-typing and the polyglot interfaces... Writing code for projects that attempts to do full typing with that this takes real effort. Almost as large effort as coding the runtime itself.
3 days ago I started with "let's get this project up to date with mypy, making the CI pass". I'm still here making horrible diffbombs... 😬
For a project that is natively typed (py.typed), is it always conventional to have the typing together with the run-time code? I mean some @overloads can become very cluttering in the code files. Putting them in a .pyi file would actually be attractive. Is that recommended thou?
Would I be correct to think that cast() is a lesser evil than # type: ignore ?
Sometimes necessary because some checkers will ignore the annotation instead of the return type.
I wouldn't say that. Here's a few considerations:
- cast() adjusts the type of a single expression, while
# type: ignoresuppresses all errors on a line. That means the latter could hide too much, but all type checkers allow suppressing a specific error code, which makes the ignore more precise and makes it less likely that if the code changes you end up ignoring an unrelated problem. - if you use the same object multiple times in a piece of code, cast() can effectively make a type error go away all at once
- cast() is a runtime import and function call, so it has a (tiny) performance cost.
Yes, which is its benefits. Maybe its the "lesser evil" sentiment that is off putting. What I meant by that is that using cast() (or ignore) give me an air of resignment. Attempted to, but due to <fill in reason> had to bail out.
There's a tradeoff between having more precise typing and having time to do other stuff. If your code is doing overly dynamic things, it's OK to bail out and use one of the type system's escape hatches
# type: ignore[error-code] or # pyright: ignore[errorCode] can also be used to silence a more specific problem, like using a private attribute or using an explicit Any if you have that enabled
My biggest usage of cast() is when selecting a narrow type from a broader type that can be guaranteed run-time. E.g.
def some_library_call(k: str) -> int | str | None | bool: ...
class A:
s: str
def fn(self):
self.s = cast(str, some_library_call("is_guarateed_str"))
how come typing has built in protocols for things like SupportsInt but not SupportsStr? i understand that all types can be str()ed but i feel typing a parameter as SupportsStr rather than Any | object would make it much more clear what is happening
All types support str
Just use object
i think you missed the second part of my message
You could make your own protocol, but it'll be redundant
im saying i think it would provide cleaner code, having something typed as Any/object to me always makes me check what it actually wants, having something typed as str is clear but means you cant pass whatever you want to it, something like SupportsStr would be a good middleground of this type is going to be str()ed but you can pass whatever you want
I think you misunderstand what object means for typehinting
it means that you can only do operations which work on all instances of object
that differs from Any because Any means "don't check me, type checker!"
Is there a convention about having getters and setters adjacent to each others?
does my_variable: type[MyType] mean my_variable is an instance of an object whose class is MyType or a subclass of it
It means that my_variable is a class which is MyType or its subclass
x: type[int] = int # ok
x: type[int] = bool # ok
x: type[int] = 42 # wrong
x: type[int] = True # wrong
x: int = int # wrong
w h a t
my_variable would be the class itself, not an instance
Apparently this is for backward compability

It is perfectly logical, if you were around when the bool type was added to python (sometime around 2.2 or 2.3).
Prior to introduction of an actual bool type, 0 and 1 were the official representation for truth value, similar to C89. To avoid unnecessarily breaking non-ideal but working code, the new bool type needed to work just like 0 and 1. [...]
(from https://stackoverflow.com/questions/8169001/why-is-bool-a-subclass-of-int)
!e
print(int(True))
print(int(False))```:white_check_mark: Your 3.14 eval job has completed with return code 0.
001 | 1
002 | 0
Yeah, what Serverit said. In Python 2.2, over 23 years ago, Python did not have a boolean type, and integers 0 and 1 were used instead. To avoid breaking all Python code in existence, for example things like boolean * 5, isinstance(boolean, int), sequence[boolean], the new boolean type was made a subclass of int and supports typical integer operations. If that history was not there, making bool a subclass of int would be a very bad design decision.
It still has unresolved questions, see e.g. the deprecation of ~ on booleans: https://discuss.python.org/t/bool-deprecation
It can lead to some funny bugs like this: https://github.com/aio-libs/yarl/issues/746
from yarl import URL
url = URL("http://example.com")
print(url.with_port(True)) # http://example.com:True
unfortunately this is the only good subclass example from builtins I can think of 🥴
something like KeyError and Exception could work, but might be too arcane
Just to follow up on my own problem: by using the Python 3.12 syntax of
type OP_TYPES = int | float
stubgen is then correctly able to create the stub without the wrong typing import. The bug is from Py3.12, so its definitely the newer syntax that helps
How do I type hint a param that may only be 0, 1 or 2?
Literal[0, 1, 2]
That means Literal[3]
In code yeah I was thinking about type hints
if i had a list of dicts which each contain three objects, and those objects are, in order, two ints and a list of ints, is there a way to hint this? i know tuples support ordered hints like tuple[int, int, list[int]], but that's about unique to tuples afaik
(list[dict[int, int | list[int]]] would not be considered satisfactory here)
not my design. google's, i'm afraid
the giant base-64 strings that sometimes come with a google search url? in the process of attempting to translate it, and got a structure like that. not trying to implement this specific case in code, but python brain prefers the hints for a succint description
would a TypedDict work here?
or is this some cursed design relying on preservation of insertion order
let us assume that the order is relevant, yes
I don't think you can incorporate order into dict keys
so at that point you're stuck with either int | list[int] or Any
wait I'm confused
how are they using lists as a dictionary key
shame that dict order became official in 3.7 and 484 in 3.5 😔
because thuri forgot what dict hints looked like. the keys were ints
The order of keys doesn't really matter for typing
Plus if you're parsing a string then why is type hinting involved at all

yeah, Never | T is pointless in python, since the assumption is that any underlying function can raise any exception and it would propagate up, python doesn't have a good way of actually avoiding that and it wasn't build around handling exceptions more explicitly, Never is useful to type-cehckers since it adjusts the control flow of the program, if a function always returns Never, the code below it becomes unreachable and type-checkers can warn you about that / handle certain cases in different ways. If it sometimes returns Never, it doesn't change anything about that inferrence, that's just the default assumption
i was basically trying to be more verbose with my return type and signal that it raises an exception rather than returning a boolean
maybe assert would be a better function name then
check_* is fine, and quite frequently used for this, (e.g.: subprocess.CompletedProcess.check_returncode), as for documenting that it raises an exception, the way to do that in python is just through explicitly mentioning it in the docstring
there doesn't happen to be a convenient "use the same type as this other function" in typing or somewhere else, does there?
dump: ... = partial(json.dump, default=default)
dumps: ... = partial(json.dumps, default=default)
from typing import Any
def sametype[T](_: T, x: Any) -> T:
return x
you can do something like
this is basically typing.cast but with just _: T instead of _: type[T]
Why do I get the error from mypy and what should I do?
class A:
pass
T = TypeVar('T', bound=A, default=A)
# mypy: Incompatible default for argument "factory"
# (default has type "type[A]", argument has type "type[T]")
def fn(factory: type[T] = A) -> T:
return factory()
The same reason this is not allowed:
import random
def f[T: str](x: T, y: T = "apple") -> T:
return random.choice((x, y))
``` to the outside world, the signature looks just like `(x: T, y: T = ...) -> T`, i.e. the default value doesn't take part in typevar resolution.
So if you bind `T` to e.g. `Literal["banana"]`, the default will be wrong for that `T`You would have to do ```py
@overload
def fn() -> A: ...
@overload
def fn(factory: type[T]) -> T: ...
def fn(factory: type[A] | None) -> A:
return factory()
But isn't the TypeVar('T', bound=A) ensuring that T is A-like?
In my example, f's T is also bound to str. But you can bind T to a subtype of str to which "apple" is not assignable, for example a subclass of str (like a StrEnum) or a Literal
or in your case, you could do ```py
class B(A):
pass
for example, you'd be able to do this: ```py
from collections.abc import Callable
class A: pass
class B(A): pass
def fn[T: A](factory: type[T] = A) -> T: # type: ignore[assignment]
return factory()
g: Callable[[], B] = fn
b = g()
reveal_type(b) # mypy shows B, but actually an A
the g: Callable[[], B] = fn line works because to mypy is, fn's type is just [T: A](factory: type[T] = ...) -> T. So when it tries to make it fit Callable[[], B], it works out that T = B.
Ok. Unfortunately, for other reasons, the function this needs to go into have other overloaded arguments, so the number of overload permutations becomes too extensive 🙁
Hrrm that does work for me though

Admittedly I find this non-intuitive, although I think I understand when explained. Often subtle side-effect to seemingly simple problems. Typing is not simple 🙁
That's because you're using pyright, not mypy. Pyright has a feature where it does take the default value into account, and it only evaluates it on call. ```py
def f[T](x: list[T], y: T = 42) -> T:
return random.choice((x[0], y))
x = f([1, 2, 3]) # inferred as int
y = f(["a", "b", "c"]) # error
I don't like this feature, because you can't turn it off, and you can end up exporting an invalid function signature from your library to people using other type checkers
And would it be wrong because Literal["banana"] is narrower than str?
It's because it's possible to bind T to a type incompatible with the value "banana"
even without literals, you can subclass str for example
I would be nice if there were a way to describe a T that should be a subset of the default A. If the user, in the example, choses a T which is not compatible with the default Literal["apple"], then its a runtime error anyways.
E.g. def f[T: A](x: T, y: type[T] = A) -> T: have the default broad A where T will always be a derivative of A. While def f[T: str](x: T, y: T = "apple") -> T has a narrower default which might not fit. Or am I misunderstanding the typing again?
How can this be type annotated with best accuracy:
def fn[T: A](factory: type[T] = A, nofail: bool = False) -> T|E
Tis always a subclass ofA. More specifically, the return type is always of the type given infactory(unless error)nofailindicates if the function should raise an exception or return a specialEobject on error- For simpler usage of
fn, it would be nice that the defaultnofailorLiteral[False]indicates a return type-> T.
How do I write the overloads for this?
The closes I'm able to get is something like this. From the usage perspective it works, as the types seems to be right. However it produces 3 errors in the overloads and the function.
@overload
def fn() -> A: ...
@overload
def fn(factory: type[T]) -> T: ...
@overload
def fn(nofail: Literal[False]) -> A: ...
@overload
def fn(nofail: bool|Literal[True]) -> A|E: ...
@overload
def fn(factory: type[T], nofail: Literal[False]) -> T: ...
@overload
def fn(factory: type[T], nofail: bool|Literal[True]) -> T|E: ...
def fn(factory: type[T] = A, nofail: bool = False) -> T|E:
try:
return factory()
except Exception:
if nofail: return E()
raise
reveal_type(fn()) # type is A
reveal_type(fn(B)) # type is B
reveal_type(fn(nofail=True)) # type is A | E
reveal_type(fn(B, nofail=True)) # type is B | E
reveal_type(fn(nofail=False)) # type is A
reveal_type(fn(B, nofail=False)) # type is B
While looking at this I discovered a difference between pyright and mypy: x = True ^ True is considered a bool in pyright, while mypy considers it an int (while runtime its bool).
Not to ooze negativity or anything, but I have given up trying to get this typing described in a concise way that the type checker is happy with 🙁 Typing is really hard (or the language for it is incomplete). My timebox for fixing this has come and passed, unfortunately. Thanks for the help everyone. It's a lot of great insight and guidance for those of us that doesn't know it so well.
does mypy still not support type default syntax in type parameters?
It should for classes and type aliases
I don't think any checker supports type defaults in functions
pyright definitely supports this syntax
def f[T = int](first: T | None = None) -> list[T]:
rv: list[T] = []
if first is not None:
rv.append(first)
return rv
Well I could never get it to work. I've always resorted to overloads
You can use T inside the function body? 
yeah
Didn't know that 
Yes of course. It's often vital
in type expressions (typehints, typing.cast 1st arg) - yes, not normal expressions where the value would actually be used - in them it will just be a TypeVar object, not the type it resolved to in the current call (well, because it isnt even getting resolved at runtime, only typecheckers do that)
yeah you can't do like x = T()
Yeah
I've used this syntax a bunch of times and haven't needed it inside the body so far 
often times things can be inferred
tho it's best to annotate variables which contain empty collections, such as shown here with the list in rv
Why is mypy failing here but not Pyright? Anyone know what the open mypy issue is, if any?
https://mypy-play.net/?mypy=1.19.1&python=3.11&gist=51d956ce6d83f17a64b31707b78eecb2
The mypy Playground is a web service that receives a Python program with type hints, runs mypy inside a sandbox, then returns the output.
this is what you get when assignability rules are not formalized 😔
Seems like a bug in mypy to me
this should error shouldn't it? Because the TypedDict is closed?
e.g. if you had
f: Factory = MyFactoryInstance()
f(b=3)
that should error, but it would be perfectly fine for a Factory instance
I suppose, but kwargs is Any so I figured that it'd not be strict on that
Are these two supposed to be exactly equivalent? Or are there differences? ```py
class MyParams(TypedDict):
a: int
class MyFactory(Protocol):
def call(self, **kwargs: Unpack[MyParams]) -> Any: pass
class MyFactory2(Protocol):
def call(self, *, a: int) -> Any: pass
because pyright does complain if you use MyFactory2 instead of MyFactory
ty also accepts MyFactory but rejects MyFactory2 (with a rather unhelpful error message)
I think there's some expressivity missing from the type system here. **kwargs: T means that the function must be able to accept any keyword arguments, and for each of those arguments, the type must be T. Just because T is Any doesn't change these rules. I think we'd need a new construct to express a "gradual signature" which is like Any, but with regards to arguments.
So *args: object, **kwargs: object on signatures would be the equivalent of object on types, and *vibe_args: Any, **vibe_kwargs: Any would be the equivalent of using ... in Callable, and there's also some middle ground, e.g. **vibe_kwargs: int meaning the signature is assignable to and from any signature that looks like () or (foo: int, bar: int) or (**kwargs: int).
not saying something should be changed or added in the type system, just explaining why I think mypy rejecting the assignability makes sense
Actually, according to the spec, those two are not equivalent. These would be equivalent: ```py
class MyParams(TypedDict):
a: int
class MyFactory(Protocol):
def call(self, **kwargs: Unpack[MyParams]) -> Any: pass
class MyFactory2(Protocol):
def call(self, *, a: int, **other: object) -> Any: pass

These type hints do not exist in the init of json, is it from a stub file somewhere?

Ah so it's in "typeshed"
Yeah stdlib I don't believe has any typehints in the source
some files do, but very few
Newer modules might, but old modules don't
Actually, according to the spec, those two are not equivalent. These would be equivalent: ```py
class MyParams(TypedDict):
a: int
class MyFactory(Protocol):
def call(self, **kwargs: Unpack[MyParams]) -> Any: pass
class MyFactory2(Protocol):
def call(self, *, a: int, **other: object) -> Any: pass
En fait, selon les spécifications, ces deux éléments ne sont pas équivalents. Ceux-ci seraient équivalents: ```py
class MyParams(TypedDict):
a: int
class MyFactory(Protocol):
def call(self, **kwargs: Unpack[MyParams]) -> Any: pass
class MyFactory2(Protocol):
def call(self, *, a: int, **other: object) -> Any: pass
?
Excuse
Must the code in the second message be read with a French accent?
translation glitch?
having a little brainfart rn (well, always), I feel like this is possible using metaclasses and overloads:
class MyClass(SomeClass, http=True):
...
MyClass() # <- type checker: http: T keyword argument is missing
what I tried
from typing import Any, Literal, overload
class WithHttpMeta(type):
def __init__(self, *, http: str) -> None: ...
class BaseModelMeta(type):
@overload
def __new__(
cls,
name: str,
bases: tuple[type, ...],
namespace: dict[str, Any],
*,
lol: Literal[True] = ...,
) -> WithHttpMeta: ...
@overload
def __new__(
cls,
name: str,
bases: tuple[type, ...],
namespace: dict[str, Any],
) -> type: ...
def __new__(
cls,
name: str,
bases: tuple[type, ...],
namespace: dict[str, Any],
*,
lol: bool = True,
) -> type:
return super().__new__(cls, name, bases, namespace)
class BaseModel(metaclass=BaseModelMeta):
pass
class Lol(
BaseModel,
lol=True,
): ...
Lol() # <- nothing
classmethod object.__init_subclass__(cls)```
This method is called whenever the containing class is subclassed. *cls* is then the new subclass. If defined as a normal instance method, this method is implicitly converted to a class method.
Keyword arguments which are given to a new class are passed to the parent class’s `__init_subclass__`. For compatibility with other classes using `__init_subclass__`, one should take out the needed keyword arguments and pass the others over to the base class, as in...but that's not checked by type checkers at all?
I think I have this wrong actually
Are you trying to set default values through base class arguments?
Maybe dataclass_transform will help
hmmm
I want the following without having multiple base classes basically
class SomeClass(BaseModel, http=True):
...
SomeClass(http=...) # <- http= required at type checking
class AnotherClass(BaseModel, session=True, http=True):
...
AnotherClass(session=..., http=...) # <- session= and http= required at type checking
would you actually use this enough for this to be worth it
whats a little 2^n for n=2
i think so
https://github.com/Soheab/oauthcord.py/tree/master/src/oauthcord/models got lots of models
part of why is also because i'm too lazy to figure and then change out classes that need http vs session or both
class BaseModel:
pass
class WithHttp:
def __init__(self, http: Any) -> None:
self._http = http
class WithSession:
def __init__(self, session: Any) -> None:
self._session = session
class Lol(
BaseModel,
WithHttp,
WithSession,
): ...
Lol() # <- Argument missing for parameter "http" Pylance reportCallIssue

Make the init args kwonly, add **kwargs, call super().__init__(**kwargs)
that wouldn't show anything at type checking
I think the way to go is dataclass_transform
also, is there nothing like Paramspec for classes?
Paramspec as in?
basically paramspec but thenfor a class's __init__ https://docs.python.org/3/library/typing.html#typing.ParamSpec
class Example:
def __init__(self, a: str, b: str, *, c: int, d: float) -> None:
...
def gimme(kls: T, *args: ???, **kwargs: ???) -> Any:
...
gimme(Example,) # <- missing args: a: str, b: str, missing kwargs: c: int, d: float
Paramspec works for init
Do you need anything else from kls other than being callable?
if not, then you can use ParamSpec as unalivejoy suggested
Can you show the implementation? Are you doing anything with the class except call it?
nope
def _initialize_other[C: BaseModel[Any, Any]](
self: BaseModel[Any, Any],
cls: type[C],
/,
data: Any | None,
*,
optional: bool = False,
possible_keys: str | tuple[str, ...] | None = None,
with_http: bool = False,
with_session: bool = False,
) -> C | None:
if with_http and with_session:
raise TypeError("`with_http` and `with_session` cannot both be True")
if with_http and not isinstance(self, BaseModelWithHTTP):
raise TypeError(
f"`with_http` is not valid on {type(self).__name__} as it is not a subclass of BaseModelWithHTTP"
)
if with_http and not issubclass(cls, BaseModelWithHTTP):
raise TypeError(
f"`with_http` is not valid as {cls.__name__} is not a subclass of BaseModelWithHTTP"
)
if with_session and not isinstance(self, BaseModelWithSession):
raise TypeError(
f"`with_session` is not valid on {type(self).__name__} as it is not a subclass of BaseModelWithSession"
)
if with_session and not issubclass(cls, BaseModelWithSession):
raise TypeError(
f"`with_session` is not valid as {cls.__name__} is not a subclass of BaseModelWithSession"
)
extra_kwargs: dict[str, Any] = {}
if with_http:
extra_kwargs["http"] = getattr(self, "_http", None)
if with_session:
extra_kwargs["session"] = getattr(self, "_session", None)
if data is None:
if optional:
return None
raise ValueError(f"Data for {cls.__name__} is required but got None")
if possible_keys is not None:
if isinstance(possible_keys, str):
possible_keys = (possible_keys,)
for key in possible_keys:
try:
return cls(data=data[key], **extra_kwargs)
except KeyError:
continue
else:
raise ValueError(
f"None of the possible keys {possible_keys} were found in the data for {cls.__name__}"
)
return cls(data=data, **extra_kwargs)
it's kinda wild with overloads, but I got three classes, BaseModel, BaseModelWithHttp and BaseModelWithSession
oh i guess i do check instance
full module: https://mystbin.abstractumbra.dev/269619427836766a53
Why isn't all(isinstance(x, Whatever) for x in iterable) "strong enough" to narrow the type of iterable?
def test(input_value: tuple[int | str, ...]):
ints_only: list[int]
if all(isinstance(x, int) for x in input_value):
ints_only = list(input_value) # Pyright says no
reveal_type on input_value says that even after all(isinstance(...)), ints_only is still treated as a tuple[int | str, ...], not a tuple[int].
Now, my original use-case had input_value as a list, and I thought "well, okay, that's fair, because lists aren't frozen, so you could do:"
if all(isinstance(x, int) for x in input_value):
input_value.append("oops, added a string!")
ints_only = list(input_value)
...but then I changed it to a tuple and that's not okay either.
Is this just not a supported thing you can do - using all(isinstance(...)) like that - or is this actually unsound for a reason I'm not seeing?
You can use TypeIs for this
I did actually make a TypeIs, in order to work around this, but I'm trying to understand why this doesn't work out of the box, in case my TypeIs is actually unsound for a reason I'm not seeing.
I just don't think all(insintance) is something typecheckers are looking for
👍 - that's a completely valid answer, I just wanted to make sure that was the answer. Thank you!
Did a quick check and mypy, pyright, basedpyright, ty and pyrefly all don't consider the all(isinstance) to narrow it down
iter_count = 0
class EvilTuple(tuple[int | str, ...]):
def __iter__(self) -> Iterator[int | str]:
global iter_count
if iter_count == 0:
yield from [420, 69]
else:
yield "impostor"
iter_count += 1
That said, TypeScript has this: https://github.com/microsoft/TypeScript/blob/9059e5bda0bb603ae6b41eca09dcd2a071af45fd/src/lib/es5.d.ts#L1227
src/lib/es5.d.ts line 1227
every<S extends T>(predicate: (value: T, index: number, array: readonly T[]) => value is S, thisArg?: any): this is readonly S[];```this would be completely wrong in Python because Python's type system has real variance (and therefore list[int | str] and list[int] never overlap), but it's possible to have a function like this: ```py
def every[T, U](xs: Iterable[T | U], fun: Callable[[T | U], TypeIs[U]]) -> TypeIs[Iterable[U]]:
...
The problem with that would be that Python type checkers don't automatically infer lambdas as returning TypeIs[something]. That's a thing in TypeScript.
How do I make my own type hinting system for Lupa
Hi folks - for anyone who will be at PyCon, @forest vessel and I are hosting the annual typing summit 1-5pm on Thursday May 14, see the announcement here: https://discuss.python.org/t/pycon-2026-typing-summit-thu-may-14-1-5pm/106354/2
This is open to anyone interested in the present and future of Python's static type system and tooling. For anyone who thinks they may attend, we have an interest survey, which also lets you propose a presentation. Thanks!

Discussions on Python.org
Hi Folks! I wanted to bump this thread, I think some folks may have missed it. We’d love to hear from you - what kinds of topics you’d like to see discussed, any suggestions from those who attended previous years, and especially anyone interested in presenting! - Steven and Carl, your hosts
If I have a "block" of assertions for type-hinting purposes, is it "good practice" (couldn't think of a better term) to have them inside an if TYPE_CHECKING block?
Not because of them potentially failing (they won't in my case)
assert_type(x, y) or assert isinstance(x, y)?
2
you can strip assert statements with python -O
Just didn't want to use cast. Should I ultimately switch to assert_type?
Cool didn't know that. I already use that for general purposes of optimizations
stripping assertions is an optimization
Yea
🤔
The runtime effect wouldn't be huge
Those are very different things and you'd use them in different contexts
Which is why I asked about them
I can't really imagine a lot of situations where both would make sense
Examples of my usage of it

In this case, I know it won't fail, and I use it just for typing (to indicate it is not None)
IMO simple truthy checks in assertions are negligible performance-wise.
Yeah
Though you should consider doing explicit checks for sanity
raise a non-assertionerror exception
that too.
ehh, guild for example can really only be None or Guild. Guild is never falsy, None is.
if guild is None:
raise MyCustomError("guild not found")
well nah i dont need the runtime part at all
edit: I mean I do the assertion just for typing, maybe I missed something 😭 (and I get you meant do real checks, but I'd say I'm fine without them)
Is there a way to indicate, that the else means it's Message?

Because right now it's still incompatible, as it's a union
Where can I ask for these functions in this server?

Can you provide a type check error, please?
If you need to ask about Tkinter: #user-interfaces
If you need about algorithms: #algos-and-data-structs
And so on and so on

use TypeIs
Error persists

@fiery canyon Is your Data-suffixed classes TypedDicts, right?
MessageData and PassthroughMessageData
Yes
Worst case I'll use a type: ignore but just wanted to know if there's a way to narrow like that
Do you have a embeds in PassthroughMessageData?
nah
Here's a problem
P. S.: Ok, seems not. It's just suppressing a problem about an absent embeds key
just used a random field that only Message has
on purpose
Passthrough shouldn't be a subtype of message, they differ in some things and embeds isn't the only thing
Hmm... Give me some time
Okay, I got it:
A problem that TypedDict is just a static type hint, but in runtime it's dict. We know that dict is a mutable hast table and we, theoretically, can add new data later. So, a type checker saying "if a foo key can be there, then it can be MessageData, PassthroughMessageData and something else". So you need to exclude keys from a dict to be sure, that it's a certain dict:
Consider this example:
from typing import TypedDict
class MessageData(TypedDict):
application_id: str
embeds: str
class PassthroughMessageData(TypedDict):
application_id: str
class FooData(TypedDict):
foo: str
def return_data(
passthrough: bool, foo: bool
) -> PassthroughMessageData | MessageData | FooData:
if passthrough:
return {"application_id": ""}
elif foo:
return {"foo": ""}
else:
return {"application_id": "", "embeds": ""}
data: MessageData | PassthroughMessageData | FooData = return_data(False, True)
if "application_id" in data:
data # PassthroughMessageData | MessageData | FooData
if "application_id" not in data:
data # FooData
A return_data can return PassthroughMessageData, MessageData or FooData. PassthroughMessageData and MessageData have application_id, but FooData don't.
If we pass a check that application_id key in data, then we can assert that it can be our typed dicts and any other that contains application_id. On the other hand, if we pass a check that application_id key not in data, then we can assert that it can't be MessageData and PassthroughMessageData (but anyway we can't assert that it contains a foo key only), so an only corresponding typed dict is FooData
@fiery canyon
Just make a proxy TypedDict that contains required keys
Also does this have to depend on a third typeddict?
I think
required overlaps?
Also I'd wanna narrow it to either of the MessageDatas, FooData would do what

Like this:
from typing import TypedDict
# Somewhere, in a third-party package
class FooData(TypedDict):
foo: str
bar: str
# other keys
class ProxyFooData(TypedDict):
# Necessary keys from `FooData`
foo: str
bar: str
class PassthroughFooData(TypedDict):
foo: str
def return_data(
passthrough: bool,
) -> ProxyFooData | PassthroughFooData:
if passthrough:
return {"foo": ""}
else:
return {"foo": "", "bar": ""}
if "bar" not in data:
data # PassthroughProxyFooData
Wouldn't this require me to call it twice
It was made for an example. I dunno which keys MessageData has
(sorry for my english 😭 trying to write correctly as much as I can)
class MessageData:
content: str # overlap
embeds: list[Embed] # unique
application_id: NotRequired[str] # not required
class PassthroughMessageData:
content: str # overlap
application_id: str # required
PassthroughMessageData has no unique keys
(This is just a sample)
It's perfectly fine lol
-# and it's not my first language anyway (either?)
Here's embeds can help you. Try to exclude MessageData by if "embeds" not in data
Or...
Hmm
Let me check
well thats done in self._is_passthrough

well yeah
but using assert defeats the point of narrowing
assert is magic think haha
yeah i mean it'd be like using type: ignore, assert_type, etc
thats always my fallback (:
Maybe if TypeGuard took a second type arg that serves as the fallback (or "else") type...
BTW, I saw these asserts in FastAPI source code often, so they're solving problems with type hints, I think
yea i use it in some of my projects
It's easy, but it can harm your mental health in the future :))
I have this for now

(TypeGuard has for most usecases been superseded by TypeIs)
TypeIs is for situations, when you need narrow subclasses (?), so IMO TypeGuard will be better

TypeIs solved it??
I guess the type checker needed the explicit statement?
Nah


def __init__(self, data: MessageData | PassthroughMessageData) -> None:
if "application_id" in data and "embeds" not in data:
self.message = PassthroughMessage(data)
else:
self.message = Message(data) # error anyway
IDK what's happening with this thing
Are you using ty, pyright or something else?
Making a structure for components will be painful since iirc, they can differ in keys
We'll see
pyright
What's the error for ty in this case 🤔
Argument to bound method `__init__` is incorrect: Expected `MessageData`, found `MessageData | PassthroughMessageData` ty(invalid-argument-type)
Would be cool if we had a command like !e but to run a type check
Same problem
Sounds cool
And handy
Welp I do know that ty and pyright aren't always the same in some stuff
It's just that I can't think of a good way to do it, I don't think there's an open API for pyright, and using local would be not the nicest, i can try myself to see
ty is in beta, so it's an expected, that it can be
All the mayor typecheckers have online playgrounds

An in-browser playground for ty, an extremely fast Python type-checker written in Rust.
It's usable, but I more non-trivial situation it can make this problems
I mean you could say the same about running code with the eval command
Ye, but it frustrate you, because you need always screenshot something
And it's cool to solve type-hinting-related problems right in the chat
Looks like there's no good way to implement pyright as an API (unlike mypy)
BTW

GitHub
Snekbox is pretty cool, we could use it to run a bunch of cool commands. python-discord/snekbox#108 allows us to pass in custom arguments, so we should be able to do things like python -m black -c ...
You'd need to use a temp file to be fed to the pyright npm package, probably via subprocess and threading
Someone also thought about it
yeah it works but too much I/O work for a public bot if you ask me

Why is pyright not inferring that v cannot be Any? Mypy picks this up correctly:
d: dict[str, Any] = {}
for k, v in d.items():
if v is not None and not isinstance(v, (str, int)):
raise ValueError(f"Invalid value for {k}: {v!r}")
reveal_type(v) # pyright reveals type as "Any | str | int"
funnily enough if you remove the v is not None it works
do you want v to be None | str | int?
Yes
it seems like x is None is not a TypeGuard[None] guard
which is.. weird?
from typing import Any, TypeGuard, reveal_type
def is_none(x: object) -> TypeGuard[None]:
return x is None
def f(x: Any):
if not is_none(x) and not isinstance(x, (int, str)):
raise TypeError
reveal_type(x) # int | str | None
but this works
might be a bug to report or something
though its such a fundamental thing that at this point it seems like a design decision
like, it works with things other than None, just not with None specifically
None can't be subclassed, can it?
right, it cant, and it is a singleton
you could put NoneType in the isinstance actually, then the whole check is just 1 isinstance
Ok. I thought that is None is the preferred identity check for None, not using isintance() and NoneType. I've changed this type of code after reviews.
is None is preferred, but well, what can you do when your typechecker does a stupid
yeah
what's the current meta around type checking tooling? I've been using mypy cuz there's almost always a plugin for the libs I tend to use
but its kinda slow, so Im guessing I may be outdated and theres something better now
pyrefly and ty are pretty fast
not sure if ty should even be recommended after openai bought astral tbh
oh from the same dudes as uv,
they said they are still developing in the open, should be fine
probly less risk of a redis-like rugpull cuz of the acquisition
or more risk?
lmao
well, im gonna try it, thank you

ty does indeed not have plugins
mypy is the only typechecker that does
i hate python-returns even though i love haskell
im experimenting with it
the main pain for me is the obvious, the rest of the ecosystem is not really made for errors as values, so its extra thinking I need to put in to manage the interfaces with external libs
honestly probly a good thing in the long run
I just use Pyright that comes with Pylance on vscode
What is the difference between the Iterator[] vs. Generator[] annotation (when having not send and return types)? I read somewhere that it's recommended to use Iterator[T] when a function simply yields T. But iterators and generators aren't precisely the same thing, right?
The advantage of using Iterator is that it leaves you free to adjust the return type later to some other kind of Iterator
You should always use AsyncGenerator so you can use async with contextlib.aclosing
@contextmanager needs Generator[T] now too
Wait, use AsyncGenerator on all generators, even if the program isn't using any async?
No I meant AsyncGenerator should always be used where possible
Ie on async generators
That's opposite of the recommendation to use Iterator[] on any generator. I assume then there's no AsyncIterator[] that mirrors the non-async way of doing it.
There's AsyncIterator[T] but you shouldn't use it
It removes the .aclose method which is required to use async generators
Yeah, that's why I raised the question to begin with: There are differences between iterator and generators, so I was curious why there is a recommendation that regular generators can be typed with Iterator[T].
From a logical/structural perspective (in lack of better words) it makes sense to type them this way. Both iterators and generators (that doesn't send or return) is something that can be iterated over and produces 0 or more T.
Another topic: Have anyone any experience with making (pytest) unittests for typing? How do you validate that your typing is correct? Is there such a thing?
I've had experience typing fixtures and there's just no way to validate them
claude thought there's a plugin https://claude.ai/share/4fc64f19-0cf1-4317-983f-35af0626cf36 but it was just a hallucination

Claude
Shared via Claude, an AI assistant from Anthropic
I wasn't specifically thinking about fixtures.
I've been experimenting with tests/typing_tests.py which contains pytest-like test functions and uses assert_type(). The file is added to mypy path so it will complain if it encounters an error on project CI.
I was curios if others do this differently (or not at all). Perhaps this isn't such a good idea
I would put these tests near the code that they're testing. Since I assume they only touch one module at a time
What are you testing in them? One thing I can think of is variance. I think the worst part of PEP695 is that there's no way to specify the variance of typevars manually, which can lead to unexpected API breakages. So you have to test your generic classes for variance manually.
Yes, but in the same way as unit tests being separate for it not to clutter the main code, I would argue that the "type tests" shouldn't be mixed with the functional code.
I'm mostly testing when there is overloads involved. To ensure that all permutations of inputs are captured correctly.
When looking at the functional aspects of a module, typing can become considerably cluttering for the flow of the file. Especially with overloads and large signatures. -- However, offloading them to some .pyi doesn't keep them together with the code. So I'm conflicted about this tradeoff.
Yeah, tests apart from code seems to be the way Python is written
One upside I can think of for having it in the same file: you can't forget to configure your type checker to run on these type tests
I'm refactoring a library I wrote to have complete type hints, and one challenge I'm stumbling with is applying type hints for a "builder pattern" class for a complicated object. This CompositeEnvironmentDriver is the complicated object, and it will (mostly) be constructed with this SessionBuilder.
Notice how CompositeEnvironmentDriver has tons of type variables, one for each "driver" I use to implement game APIs (e.g. input, audio, logging) -- this is intentional. Drivers can have their own APIs that go beyond their required protocols, so I use type variables to avoid the need for lots of casts or isinstance/issubclass checks.
All the SessionBuilder's with_... methods create or assign a driver depending on the input. Each with_ call should transform one of the desired CompositeEnvironmentDriver's type arguments, then return itself. What I'm struggling with is deciding how to type SessionBuilder, its individual with_... methods, and the object that's ultimately returned with build(). Any ideas?

Builder is a creational design pattern that lets you construct complex objects step by step. The pattern allows you to produce different types and representations of an object using the same construction code.
GitHub
A Python binding for libretro. Intended for writing test scripts for cores, but can be used for any purpose. - JesseTG/libretro.py
CompositeEnvironmentDriver is an accurate picture of what I have in mind, but SessionBuilder isn't there yet -- hence the question.
Builder patterns aren't typically a thing in python. Many developers would use named arguments instead of a builder. So instead of something like Foo.builder().a().b().c().build(), you'd do Foo(a="some value", b=True, c=1234)
I guess the dynamic typing and keyword args eliminates the need, huh?
Yes. Builders are used to solve a problem that doesn't effect python too much
Factories are still useful though
In general, or do you mean for the specific case I'm describing?
in general, though there's always exceptions
My current SessionBuilder already accepts factories for the various drivers it needs, so I guess it would make sense to refactor to allow them in the constructor
Which problem specifically are you referring to? Big-ass constructor overloads?
yes
Okay, so I'll cut the SessionBuilder and move its with_ functions to equivalent constructor behavior. Let's see how that feels. Thanks for the suggestion
def merge(self, other: Self) <- must other be self there? or does an instance of type(self) work too?
In general, marking a parameter type as Self is problematic and something you probably shouldn't do.
But, if you do this, py class Foo: def method(self, other: Self) -> None: ... Foo().method(x) will accept any x where x: Foo. So instances of subclasses of Foo will still work.
ah, yeah was confused when copilot suggested that lol
What did you ask and what code did you get? I'm curious about how LLMs screw up types in more subtle ways
My fear is that people try to learn about type hints from AI, and it tells them a lot of bad advice
since they don't "think" or build a mental model, I wouldn't be surprised if they have a hard time filtering out bad code they found on github from good code they found on github
https://images.soheab.com/8Ec2mGEsc14.png basically want a method to merge two classes' attrs

literal copy constructor
ai also mostly uses pre 3.9 typing so that's annoying
Would def merge(self, other: Filters) -> None: just work?
(unrelated to types, but are you sure you're handling the None vs 0 case correctly? Is it intentional that a distortion etc. of 0 will be treated as a missing setting?)
they're all classes, but no it shouldn't do that
also just realised that I don't want it to mutate the source so going with .combine instead
ah, they're not integers/floats, you mean
ya
How common is it for a project to use multiple type checkers in its CI? I'm setting up Pyright for mine, but I'm wondering if it would be worth adding others alongside it.
From my experience it's not very common. Combining type-checkers often introduces a lot of annoyances, like having to ignore issues with multiple ignore comments for the same lines, and it's often also much easier for developers to set up a single type-checker within their IDE than it is to set up multiple to run at the same time.
But there are some libraries that do mypy + pyright, it's less common for end-user projects. A single type-checker is usually sufficient, and I've never seen any project use more than two (though I'm sure there are some).
How would you guys type-hint several overloaded callbacks when doing a .pyi file?
I've got this snippet and I've defined the callback types in 3 different ways before (type, typing.TypeAlias, typing.Protocol) and I'm not sure which I want to continue with - but I'm not finding them very friendly to actually use in the editor as they remain very vague in the autocompletion popups.

What are the callbacks? Are they type aliases or classes?
They're meant to be aliases, yes
Can you show the definition?
this is the internal one with the type keyword

See the first two, I'm trying to match the second parameter's type button to the callback parameter's type
Would this work? py def add_button_listener[B: (int, GamepadButton)]( self, callback: Callable[[Joystick, B, bool], None], button: B ) -> None: ... (assuming that B must be either always int or always a GamepadButton)
that is valid syntax?
which part?
the template-looking thing up at the top
the def func[...] syntax is new in 3.12, from PEP 695. It's equivalent to this in the old style: ```py
B = TypeVar("B", int, GamepadButton)
#...
def add_button_listener(
self,
callback: Callable[[Joystick, B, bool], None],
button: B
) -> None: ...
oh I didn't know about TypeVar either
but that's really cool
that's exactly what I wanted
thank you!
A have a work in progress tutorial by the way: https://decorator-factory.github.io/typing-tips/tutorial/3-generic-functions/
actually, can you show the implementation for this method?
I did find my way to your website while you were writing 😉
ok give me a sec
def add_button_listener(
self,
callback: _ButtonCallback,
joystick: Joystick,
button: GamepadButton | int,
) -> None:
with self._lock:
if joystick.id not in self._joysticks:
return
if isinstance(button, GamepadButton) and not joystick.is_gamepad:
raise NotAGamepadError()
assert isinstance(joystick._mapping, dict)
btn_idx: int
if isinstance(button, int):
btn_idx = button
else:
if not button.value in joystick._mapping:
raise UnsupportedFeatureError()
hwid = joystick._mapping[button.value]
if hwid.startswith("h"):
callback = cast(GamepadButtonCallback, callback)
return self.add_hat_listener(callback, joystick, hat=button)
btn_idx = int(hwid[1:])
gamepad_button = button if isinstance(button, GamepadButton) else None
callback_ref = (
weakref.WeakMethod(callback)
if inspect.ismethod(callback) and not inspect.isbuiltin(callback)
else weakref.ref(callback)
)
listener = _ButtonListener(
callback_ref=callback_ref,
button=btn_idx,
joystick=joystick,
gamepad_button=gamepad_button,
)
with self._lock:
bucket = self._button_listeners[joystick]
existing = next(
(
l
for l in bucket
if l.callback_ref() == callback and l.button == btn_idx
),
None,
)
if existing:
if existing.gamepad_button != gamepad_button:
idx = bucket.index(existing)
bucket[idx] = replace(existing, gamepad_button=gamepad_button)
return
bucket.append(listener)
reading through it I could probably use cast() instead of assert() but yeah the rest is just trying to gracefully handle the joystick architecture
Idk, maybe an overload would be better. Especially if you inline the type aliases into the overloads
what does inlining the type aliases into the overloads mean?
like the way I had it?
@overload
def add_button_listenr(
self,
callback: Callable[[Joystick, int, bool], None],
button: int,
) -> None: ...
@overload
def add_button_listenr(
self,
callback: Callable[[Joystick, GamepadButton, bool], None],
button: GamepadButton,
) -> None: ...
I will at least use generics internally but clear isolation and expanded hinting externally is what I'm going for
oh okay
that does everything but it's a little more work
probably should get into some typing and documentation tooling for .pyi files instead of trying to be hacky with it
by the way, are you the author of the library?
if yes, I wonder why you're using a .pyi instead of type-hinting directly from the .py files
yeah I designed it but it's very AI-assisted in the thread-safety parts
it's a monolith 1000+ line py file with a lot of noise
perhaps the solution is to split the file up then? 
having separate stubs is often much harder to maintain than having the types right in the code
I guess I'll revisit that in a bit, but I just transitioned to using pre-existing SDL libraries instead of making my own bindings so .pyi is a remnant from that idea
The cleanest way if I'll rely on the python files is probably the generic function
ah, that makes more sense, but yeah, I would generally definitely recommend having the type definitions right next to the implementations if you can
the constrained type-var there is something that's pretty rarely used, and overload might be more semantically correct to what you're trying to do, which is why fix error probably suggested going back to those
it's not wrong to use, it's just a little odd, but if you prefer that syntax, I wouldn't see it as an issue
tbh I'm still confused when you're supposed or not supposed to use constrained typevars
who isn't
Do you suggest I use overloads next to the normal method?
yeah
ok might work out
I'm a little unsure when else I'm supposed to use .pyi file aside from when making my own bindings with other libraries
this is perfectly fine to have in a regular .py file:
from typing import overload
@overload
def foo(x: int) -> int: ...
@overload
def foo(x: str) -> str: ...
def foo(x: str | int) -> str | int:
... # implementation
Okay
basically never
It's a lot clearer to have the fully qualified callable annotation both for myself and for users of the library
.pyi stubs are useful when you're either working with foreign bindings, or python code that you don't own and isn't well-typed
Yeah that does make sense, I've only seen them with PySide6
I'll stick with the two suggestions you guys gave
the aliasing was to indicate purpose but I guess that can go into the docstring
All right, I'll just stick with Pyright. Thanks for the tips
I think only libraries would want do to type checking across multiple checkers.
Well, I'm writing a library!
I would still generally say a single type-checker is enough for libs too, your users will only really care about the signatures at the public API facing functions/classes, not about the inner type consistency of the lib, so even if say mypy takes an issue with something you do while pyright doesn't, it's usually a fairly good bet that that issue won't be an actual problem for your users. But yes, it can happen. Most libs don't use multiple type-checkers either, but if you want to try it, go ahead, you can always go back to a single one
Nah, I'll stick with Pyright and consider adding something else if anyone starts to complain
I appreciate the insight from the both of you, though!
!e
type T = type(T)
print(type(T))
:white_check_mark: Your 3.14 eval job has completed with return code 0.
<class 'typing.TypeAliasType'>
I don't think type checkers allow this
but you can do type[T]
Which part
type(T) in a type expression
Also I find it weird that this is possible:
NotImplemented: NotImplementedType
NotImplementedType = type(NotImplemented)
"Recursive" typing
I think that's only done in stdlib types and for builtin types like NoneType, EllipsisType, FunctionType, etc.
It's defined properly in typeshed though. https://github.com/python/typeshed/blob/main/stdlib/types.pyi#L716
stdlib/types.pyi line 716
class NotImplementedType(Any): ...```Ah
Well NotImplemented is exported to builtin, if I'm saying that correctly
But meh
If you don't need to import it, it's builtin
Remember that runtime rules don't apply to .pyi files

Hmm I was wondering whether I should switch to having GameDirectMessage{Action} be the message object itself, probably by having class vars (in an if TYPE_CHECKING block) of combined attributes of both PassthroughMessage and Message and controlling which one it should be in the init


But the issue with that is you wouldn't have something like game_direct_message_delete: PassthroughMessage | Message but rather you'd need to check with isinstance or another method
So you lose clarity either way
I'll keep it like this for now
Oh and here is another example of where a self-typeguard would be useful (for is_passthrough())
Is there a way to implement a "partial TypeAlias", where I resolve some of the TypeVars but not others?
My use-case is that I've got a decorator that should only decorate methods of a particular class.
I can do:
T, P, R = TypeVar("T"), ParamSpec("P"), TypeVar("R")
Method = Callable[Concatenate[T, P], R]
def my_decorator(input_method: Method) -> Method: ...
and that does guarantee that output method has the same call signature as the input method, but it doesn't actually restrict T to the class I want.
Of course, I can just do:
P, R = ParamSpec("P"), TypeVar("R")
FooMethod = Callable[Concatenate[Foo, P], R]
def my_decorator(input_method: FooMethod) -> FooMethod: ...
but that only works for Foo, and I'd like to be able to do this for other classes without making a type alias for each class.
What I'd like to do is something like:
T, P, R = TypeVar("T"), ParamSpec("P"), TypeVar("R")
Method = Callable[Concatenate[T, P], R]
def my_decorator(input_method: Method[Foo]) -> Method[Foo]: ...
where I can provide Foo as a type parameter to Method, but that doesn't work; because I've provided a type for T, I'm now also required to provide types for P and R. I haven't been able to find a way to "partially satisfy" the type parameters like that.
Is there something I'm missing, or is this just not something you can do?
yes, so FooMethod = Method[Foo, P, R]
The typing tests for setuptools started failing recently due to a release from more-itertools. The code in question is here:
mypy complains:
setuptools/config/expand.py:125: error: Argument 2 to "join" has incompatible type "PathLike[str] | Iterable[str | PathLike[str]]"; expected "str | PathLike[str]" [arg-type]
I'm honestly pretty terrible with Python types and would really appreciate a suggestion for how to adapt to this change in more_itertools without just ignoring the type error or pinning the version to unbreak CI.
setuptools/config/expand.py lines 122 to 125
from more_itertools import always_iterable
root_dir = os.path.abspath(root_dir or os.getcwd())
_filepaths = (os.path.join(root_dir, path) for path in always_iterable(filepaths))```what..

How is _client defined?
and user
This makes me think you did self.user = property()
def __init__(
self,
client: DiscordClient[Any],
...
) -> None:
...
self._client: DiscordClient[Any] = DiscordClient(client)
and
class ClientUser(Protocol):
id: int
class DiscordClient[ClientT: Any]:
cls: type[ClientT] = NotImplemented
__slots__ = ("_client", "user")
def __init__(self, client: ClientT, /) -> None:
self._client: ClientT = client
def dispatch(self, event_name: str, *args: object) -> None:
raise NotImplementedError
@property
def user(self) -> ClientUser | None:
raise NotImplementedError
It works on both mypy and ty. The server isn't responding for pyright-play.net

I can't confirm that.
if any typing experts here want to give the PR fixing this a review: https://github.com/more-itertools/more-itertools/pull/1144
functions like “always_iterable” seem to not play so well with Python’s type system
needs a lot of complicated overloads anyway, way more complicated than the runtime Python implementation
this does look kinda weird, why are you slotting a property?

the plot thickens https://github.com/more-itertools/more-itertools/pull/1145
What's the correct way to type hint a group of types? e.g.
import datetime
from typing import TypeAlias
AnyDateTime: TypeAlias = (datetime.datetime | datetime.date | datetime.time)
some_type: type = AnyDateTime
Why does this fail ty check with?
Object of type
<types.UnionType special-form 'datetime.datetime, datetime.date, datetime.time'>is not assignable totype: Incompatible value of type<types.UnionType special-form 'datetime.datetime, datetime.date, datetime.time'>
Is it a ty issue?
type means a class. int is a class, int | str is not a class, list[int] is not a class
!pep 747
Status
Final
Python Version
3.15
Created
27-May-2024
Type
Standards Track
or rather https://docs.python.org/3.15/library/typing.html#typing.TypeForm (I think it's in typing-extensions too)
Ah ha
That makes sense
Oh that's from 3.15
That's why I had no idea it existed lol
tysm!
What about this throws an error?
import datetime
from typing import TypeAlias
AnyDateTime: TypeAlias = (datetime.datetime | datetime.date | datetime.time)
some_type: AnyDateTime = datetime.datetime
Do I need to wrap it in TypeForm as well?
datetime.datetime is a class, not a datetime object
just like foo: int = 42 is correct, but foo: int = int is not
what are you trying to do?
Oh yeah duh
And in generals terms of best practices, which of these is preferable?
import datetime
from typing import TypeAlias
AnyDateTime: TypeAlias = (datetime.datetime | datetime.date | datetime.time)
NullableAnyDateTime: TypeAlias = (AnyDateTime | None)
type_hint_1: AnyDateTime | None = None
type_hint_2: NullableAnyDateTime = None
having a separate type alias just for | None seems redundant
That was just for the sake of example
I would just have the nullable one
adding “Nullable” is more characters and less clear than “| None”
so think it only makes sense if the type has a nicer name in your context
Also, you can easily go from Foo to Foo | None, but Foo | None -> Foo is not possible in Python
I read this and still don't understand it xd
I don't understand why the typing module has so much documentation. All the items are extensively documented at typing.python.org. It will probably serve users better to scrap 90% of text in the typing module and just say something like
typing.TypeForm
Generic item accepting a single type argument. Example usage:
from typing import TypeForm
def cast[T](typ: TypeForm[T], value: object) -> T: ...
reveal_type(cast(int, "x")) # (mypy) Revealed type is "int"
reveal_type(cast(list[str], "x")) # (mypy) Revealed type is "list[str]"
For the meaning of this item, see [TypeForm documentation at typing.python.org]
How's this different than an alias

It's intended to be used in function signatures. Like this: ```py
before:
def try_parse_json_as[T](form: type[T], raw: str | bytes) -> T: ...
after:
def try_parse_json_as[T](form: TypeForm[T], raw: str | bytes) -> T: ...
in the first signature, you can call try_parse_json_as(MyModel, "...") but not try_parse_json_as(list[MyModel], "..."). Because list[MyModel] is not a class, so it's not a type[T]
and it says "See PEP 747 for details". The PEP itself clearly says at the top:
This PEP is a historical document: see Type forms and typing.TypeForm for up-to-date specs and documentation. Canonical typing specs are maintained at the typing specs site; runtime typing behaviour is described in the CPython documentation.
Ah, there's already an issue that's 2 years old https://github.com/python/cpython/issues/117539
Does the new one actually add anything or is this the equivalent
Maybe I'm missing something
in the first signature, you can call
try_parse_json_as(MyModel, "...")but nottry_parse_json_as(list[MyModel], "..."). Becauselist[MyModel]is not a class, so it's not atype[T]
And in the second you can?
yes
So it'd accept any, let's say, container of that type?
TypeForm[T] accepts any "type form" that represents T. For example, int | str is a "type form" but not a class. So is Never, Any, list[str] etc.
It's used when you want to pass "a type-system type" at runtime
It's useful for libraries that inspect type annotations, like pydantic etc.

Would be cool if there was a way to make this dynamic (get a class with attributes that follow a typeddict, without needing to use the explicit typeddict in the annotations)
-# and you actually don't need the typeddict object itself to do this, just a literal of attribute names, and an alias of their types, will do the job

Why is it useless?
In context of TypedDicts I don't think it is. But generally dynamic attributes isn't my thing
Finally got my type checks to pass in ty
I'm lucky xlsxwriter doesn't have a py.typed file
Would you say ty is at a point where it could be considered sufficiently complete to consider it over pyright/basedpyright?
I've tried it a while ago but found that it lacked quite a lot of features, looking at it now it seems better, but that's just from a very quick glance at it
is there something important it's still missing/not quite working yet that's worth knowing about?
check https://htmlpreview.github.io/?https://github.com/python/typing/blob/main/conformance/results/results.html and https://github.com/astral-sh/ty/issues/1889 , i guess
it seems like some people already have it work for their real projects so its "usable" in that sense, but its not as complete as pyright
i myself think zuban is the best choice nowadays, performance&conformance-wise and usable in CI
GitHub
Type system features This issue summarizes the support for various type system features in ty. Sections are organized to follow the structure of the Python typing specification, with some additiona...
i wonder when we can expect basedty to arise
hopefully never
it's my understanding that the current baseds are better than their originals, so i'm not sure about "hopefully"
yeah, but only because the originals refused to implement some nice things
or were too slow/too annoying to deal with their maintainers
We'll try to keep ty as based as we can, I guess
dependent types? 😳
I'd like to see PEP 789 in the type system somehow
what do you think that could look like?
The non yieldyness of a async context manager somehow showing up in the type
so something like a type for "generator that yields exactly once"?
Yeah I think that too
I think you need two parts a generator that yields once and an object that requires use in such a Generator
does anyone know what stubs I should use with Django if I'm using pyright (or other non-mypy type checker)? there's django-stubs and django-types
django-types is supposedly that, but it's 271 commits ahead of and 1924 commits behind typeddjango/django-stubs:master.
I heard that the django-stubs folks were trying to make it so that it works with other type checkers too
I've never used django though, so I haven't actually tried it

GitHub
Summary This is an expansion on the known issue: No implicit import of submodules (#133). I've imported Django models explicitly from their submodules. There is an issue with dynamic model attr...
# example.py
import enum
import collections
class MyEnum(enum.StrEnum):
A = 'A'
B = 'b'
d = collections.defaultdict[MyEnum, list[str]](list)
d[MyEnum.A].append('x')
$ uv run ty check ./example.py
error[invalid-argument-type]: Method `__getitem__` of type `bound method defaultdict[MyEnum, list[str]].__getitem__(key: MyEnum, /) -> list[str]` cannot be called with key of type `str` on object of type `defaultdict[MyEnum, list[str]]`
why
This is an MRE, but my actual code depends elsewhere on behavior in StrEnum that isn't shared with Enum
hm, can't seem to repro it, what's your ty version?

ty 0.0.30
always ping on reply.
thanks!
What settings are you using?
I didn't even know there were settings, so whatever is default
well that doesn't make sense
hmm
oh wait
it's python version
triggers on 3.10

and the reason is simple, look at the first diagnostic
@hallow pollen
in a meeting all of the sudden, bbs
Yeah @hallow pollen this enum was introduced in 3.11, which vesion are you using?

Yeah ty complaining about every single .objects call has become annoying to me
From a purely developer perspective, how truly useful is Pydantic instead of good type hinting?
What I mean is, the user of my code will only be other developers
Is this the proper way to document a named tuple?
from typing import NamedTuple
class Cell(NamedTuple):
"""A cell on a bidimensional grid.
Args:
x (int): The ``x`` coordinate of the cell.
y (int): The ``y`` coordinate of the cell.
"""
x: int
y: int
is it a REST API
usually you don't need such strong type validation for libraries
What's really the point of a named tuple
I've only used the collections.namedtuple() in the past but looking back at it it's kinda useless
I think it makes a lot of sense for coordinates as they inherently have tuple-y-ness
Honestly though in this case I don't think it needs any more documentation than A cell on a 2d grid. Specifying that x is the x coordinate of the cell feels very redundant
Why not use a dataclass
unpacking and __getitem__
or just overhauling existing collection.namedtuples in a library without changing the interface
!cleanban @rare tartan suspicious job offer
:incoming_envelope: :ok_hand: applied ban to @rare tartan permanently.
Hi guys, what is the preferred way to type hint python default data types? Like what is the modern approach?
If I wanna hint an object with a default one like dict should I use imported Dict type from typing module or can I use the standard one? I also know that probably before Python 3.9 (maybe I am wrong with version) you couldn’t hint types with Python objects
After 3.9 it's preferred to use the standard one. You can use pyupgrade to do this for you
GitHub
A tool (and pre-commit hook) to automatically upgrade syntax for newer versions of the language. - asottile/pyupgrade
Thanks for the answer! I’ll consider the tool
Make sure you remember to run a type checker
Otherwise you get type slop
You mean something like Mypy? I do use inside an IDE as a plugin + tool
or running mypy command? that's how i basically setup MYPY in pyproject.toml
[tool.mypy]
strict = true
disallow_untyped_defs = true
warn_return_any = true
warn_unused_ignores = true
warn_redundant_casts = true
ignore_missing_imports = true
exclude = [
'^src/migrations/',
'venv/',
'tests/'
]
Any reason you're not typing your tests or migrations?
Migrations is extra I think cause the only file you’d like to change is env.py if using the standard tool like alembic with SA, so the type hints aren’t really necessary here , because you only import your declarative base and table models.
About tests , since tests don’t return anything and as an arguments in the functions I use fixtures (with pytest framework) type hints aren’t also needed
- edit the connection url in env.py
But it's probably the only code that calls some of your API so it makes sure that the API makes sense
may be it would only make sense in tests. how about your experience? do you use type hints at those packages?
sorry, what CI is?
ah, i got it
talking of tests type hints are good when defining fixtures
but talking of migrations the most common thing you do is:
where type hints aren't so required
from core.db.database import Base
config = context.config
config.set_main_option("sqlalchemy.url", settings.async_url)
if config.config_file_name is not None:
fileConfig(config.config_file_name)
import core.db.schema # noqa
import alembic_postgresql_enum # noqa
target_metadata = Base.metadata```(unrelated but a suggestion, you should use ```codeblock```)
ty! didn't know it! good note
!code
-# You can add a language indicator as shown 👆🏻(can be either "py" or "python" for Python)
yep, also a good one, i've edited the message with this format, ty again
Yur welcome 🙏🏻
Basically the same as a TypedDict I would say, it "identifies" the items of the stdlib container
wth is happening here 😭
can't remove the quotes either
Traceback (most recent call last):
File "x\test.py", line 28, in <module>
from oauthcord import Client, Scope
File "x\oauthcord\src\oauthcord\__init__.py", line 1, in <module>
from .client import AuthorisedSession, Client
File "x\oauthcord\src\oauthcord\client\__init__.py", line 1, in <module>
from ._client import AuthorisedSession, Client
File "x\oauthcord\src\oauthcord\client\_client.py", line 10, in <module>
from ..internals.http import OAuth2HTTPClient
File "x\oauthcord\src\oauthcord\internals\http.py", line 24, in <module>
from .endpoints.member import MemberHTTPClientMixin
File "x\oauthcord\src\oauthcord\internals\endpoints\member.py", line 5, in <module>
from ...models.flags import MemberFlags
File "x\oauthcord\src\oauthcord\models\__init__.py", line 9, in <module>
from .channel import *
File "x\oauthcord\src\oauthcord\models\channel.py", line 617, in <module>
class EphemeralDMChannel(PrivateChannel[EphemeralDMChannelResponse]):
^^^^^^^^^^^^^^^^^^^^^^^^^^
NameError: name 'EphemeralDMChannelResponse' is not defined

GitHub
To give some context, I have from future import annotations required in every-single file, and the TCH rule-set enabled across my codebase, along with the full Pyflakes rule-set. I'm runnin...
The recommended fix is to define your extend-generics in your config file https://docs.astral.sh/ruff/settings/#lint_pyflakes_extend-generics
An extremely fast Python linter and code formatter, written in Rust.

genuinely experiencing insane pain writing classes for the message object
its the most recursive object in the api pretty much
ill be pushing the entire types thing without proper support of CV2 
TypedDicts

If that is just the typeddicts, the classes unpacking them will be crazy longer
all of this just for support of the social sdk webhook events 🥀✌🏻✌🏻
tbh i can already push everything without this part of the code
squints
This is the main part

And half of these Datas have more Datas in them 🥴
And I hand write it all 🥀
why arent you just using the discord types pypi package?
hmm i think someone already showed me that
tbh i just want to know what i got exactly, plus the webhook events structure is a bit different at some areas
Plus a non pip dependency........ idk
discord have an open api doc no you could just generate it from there?
not what i be doing (:
open ai worst curse to happen to open api

GitHub
OpenAPI specification for Discord APIs. Contribute to discord/discord-api-spec development by creating an account on GitHub.
i might take another look at the types package though.. maybe it's worse forking
how do you even find the user object in this for example
But eh this is too dynamic
I could try to make a syntax maker from it once I learn how to find stuff
you dont really you just chuck it in a openn api client generator and itll generate all the types for you
either way i'll need to modify it later
yeah you would
they have a template for py? that supports typeddict syntax?
will it also generate enums lol
im not sure but probably
I'll check it out though. Thanks
Maybe I can automate it with a specialized webhook events structure (which isn't always that clear but usually is)
Yeah dude quite obviously

It'd only be logical to be used to make syntax that you copy and paste, not dynamically make structures
Anyway yuh
Be me. Figured out all Discord frameworks and architecture are traps of problems
And just intercepting discord msgs processed through a Quality CLI framework. and writing from it answers in Markdown format.
And at some point planning to make web browser interface for my discord bot.
Less dependencies onto Discord, more owning my own code.
I'll pass but thanks 👍🏻
Type hinting / type annotation (in this channel)
/type annotation
LMAO
Is there something I'm missing about why .get cannot narrow a dict key like []? All the type checkers I tried agree on the int | None, and I don't understand why it shouldn't be int
from typing import reveal_type
def foo(data: dict[str, int | None]):
if data["value"] is not None:
reveal_type(data["value"]) # Revealed type: `int`
if data.get("value") is not None:
# Expected: `int`
reveal_type(data["value"]) # Revealed type: `int | None`
Try if (value := data.get("value")) is not None: reveal_type(value)
If I were to say, it would be because it's a function call.
So it’s just that no one supports this pattern, as opposed to there being some fundamental typing reason
yes, I don't think there's a fundamental reason
Pyrefly supports this
pyrefly/lib/binding/narrow.rs lines 1060 to 1065
e @ Expr::Call(call) if dict_get_subject_for_call_expr(call).is_some() => {
// When the guard is something like `x.get("key")`, we narrow it like `x["key"]` if `x` resolves to a dict
// in the answers step.
// This cannot be a TypeGuard/TypeIs function call, since the first argument is a string literal
Self::from_single_narrow_op(e, AtomicNarrowOp::IsTruthy, e.range())
}```👍 I apparently forgot how to read the multiplay output for pyrefly
sorry for ping, but will sys._jit get into typeshed?
is that new in 3.14 or 3.15? if it's in 3.14 we should already add it, if it's in 3.15 we're supposed to wait until the first beta (next week)
https://docs.python.org/3/library/sys.html#sys._jit says
Added in version 3.14.

Python documentation
This module provides access to some variables used or maintained by the interpreter and to functions that interact strongly with the interpreter. It is always available. Unless explicitly noted oth...
then feel free to send a PR to add it to typeshed
we generally only add private stuff if someone explicitly asks
icy, but typeshed can have stuff even if its
JIT compilation is an experimental implementation detail of CPython.
cpython only?
yes
how should the fact that the module is added in 3.14 be handled?
even if i add stdlib/sys/_jit.pyi with if sys.version_info >= (3, 14), wouldnt the import itself still be marked as valid even though it doesnt exist?
it is also not an importable module, but rather just something that sys has (same story with sys._monitoring actually, which is in typeshed)
the VERSIONS file
regarding the last point,
import sys._monitoring typechecks but fails at runtime, because sys is not actually a package, and its just sys.monitoring instead
yeah, not sure there's a good solution for that
https://github.com/python/typeshed/blob/main/CONTRIBUTING.md#docstrings says
Typeshed stubs should not include duplicated docstrings from the source code.
butsys._jit's source code is in C, so they wont be available to a language server
should typeshed include the docstrings, then? it would be good to have them on hover
no, we don't include docstrings. Some type checkers may postprocess the stubs to add docstrings (e.g. https://github.com/astral-sh/docstring-adder)
some CI failed, you'll probably have to add the module to some stubtest allowlists
yeah i just noticed that
hmh.. does the versions file have to be sorted (considering namespaces)?
so since
>>> "__jit" < "_monitoring"
True
it must come before it?
I don't think it's a hard requirement but it would be nice to keep it sorted. Isn't the other one called sys.monitoring without the underscore though?
its sys.monitoring at runtime but the pyi in typeshed is _monitoring, to avoid import sys.monitoring from passing typechecking
sys/__init__.pyi then imports it as monitoring
Right. I'd keep the VERSIONS file sorted but don't think it matters much.
i dont want the CI to have errors so i moved it around :d
hmh. actually.. https://github.com/python/typeshed/blob/main/stdlib/sys/__init__.pyi#L513-L515
i think this allows import sys; sys._monitoring to typecheck, im not sure if thats ok?
maybe from . import _monitoring as monitoring would be better
what a weird thing did python do with those modules :(
stdlib/sys/__init__.pyi lines 513 to 515
from . import _monitoring
monitoring = _monitoring```Yeah I think that would be slightly better
weird that mypy-primer showed it having an effect on type checking...
probally because i didnt sync the fork, and something in pandas was changed during those commits
oh.. now its saying its not accessed
i think the usual solution for that is import x as x but im already doing a _monitoring as monitoring import?
weird..
might just have to type ignore it. could be worth adding some test cases to assert that expected things work (there's a directory for that)
https://github.com/python/typeshed/tree/main/stdlib/%40tests/test_cases this one?
so like, i'd assert_type(sys.monitoring, ModuleType) or something?
what does assert_type even do
GitHub
Collection of library stubs for Python, with static types - python/typeshed
yes there. just assert that objects in the module can be accessed
how would that be done? it seems like test_cases only uses assert_type
oh, would i just literally have a sys.monitoring and sys._jit line, to ensure that the typechecker doesnt emit an undefined variable error?
like how some test_cases just have calls to functions to ensure the example calls match the signature?
i would also want to assert that _monitoring and __jit are not accessible though, how would that be done in test_cases?
:( i just wanted to add 3 booleans, not figure out how everything in typeshed works
Oh sorry, i just left a review comment without seeing all this discussion
Yeah, pretty unfortunate that _monitoring was added as a ModuleType instance but not made an actual submodule IMO
But we do what we can to workaround this...
so what would the "solution" be? is the current import that i used not valid (that is, from . import _monitoring as monitoring doesnt strictly make it an available attribute of sys)?
i guess i should just change it back to the from . import _monitoring; monitoring = _monitoring
Yes, i would revert the change for sys._monitoring. You're right that technically the status quo means type checkers will not error on import sys; print(sys._monitoring), but in practice this hasn't caused problems (why would you do that?), and there just isn't a perfect solution here that works for all cases
If sys._jit is the same situation then I'd do the same for that too
yeah it is
for test cases I'd assert that obvious things users would want to write work and infer the right type, like maybe assert_type(sys._jit.is_enabled(), bool)
and that common things we'd want type checkers to catch produce errors, like maybe import sys._jit # type: ignore
(type ignore serves as an assertion there's an error on this line, because we run the test suite with warn-unused-ignores)
@restive rapids ^ (sorry was away for a while, haven't looked at GH comments on the PR again yet)
is the pyright test runner not using the typeshed that is being tested, but rather the one that comes with pyright?
hmh, well, no, "typeshedPath": "."
i dont understand why the tests fail then, because
$ mypy --custom-typeshed-dir . stdlib/@tests/test_cases/sys/check_jit.py
Success: no issues found in 1 source file
huh
$ basedpyright --project ./pyrightconfig.testcases.json --pythonplatform Linux --pythonversion 3.14 stdlib/@tests/test_cases/sys/check_jit.py
~/typeshed/stdlib/@tests/test_cases/sys/check_jit.py
~/typeshed/stdlib/@tests/test_cases/sys/check_jit.py:5:17 - error: Type of "_jit" is unknown (reportUnknownMemberType)
~/typeshed/stdlib/@tests/test_cases/sys/check_jit.py:5:17 - error: Type of "is_available" is unknown (reportUnknownMemberType)
~/typeshed/stdlib/@tests/test_cases/sys/check_jit.py:5:17 - error: "assert_type" mismatch: expected "bool" but received "Unknown" (reportAssertTypeFailure)
~/typeshed/stdlib/@tests/test_cases/sys/check_jit.py:6:17 - error: Type of "_jit" is unknown (reportUnknownMemberType)
~/typeshed/stdlib/@tests/test_cases/sys/check_jit.py:6:17 - error: Type of "is_enabled" is unknown (reportUnknownMemberType)
~/typeshed/stdlib/@tests/test_cases/sys/check_jit.py:6:17 - error: "assert_type" mismatch: expected "bool" but received "Unknown" (reportAssertTypeFailure)
~/typeshed/stdlib/@tests/test_cases/sys/check_jit.py:7:17 - error: Type of "_jit" is unknown (reportUnknownMemberType)
~/typeshed/stdlib/@tests/test_cases/sys/check_jit.py:7:17 - error: Type of "is_active" is unknown (reportUnknownMemberType)
~/typeshed/stdlib/@tests/test_cases/sys/check_jit.py:7:17 - error: "assert_type" mismatch: expected "bool" but received "Unknown" (reportAssertTypeFailure)
9 errors, 0 warnings, 0 notes
weird
wait what
is it because of the underscore in the module name
it considers it as private?
how to uhh
make it not do that
because its literally named sys._jit
pyright does like to enforce privateness but that seems a bit much
it's possible it has some hardcoded list of core modules?
well when i renamed it to sys.jit (changed from _jit = __jit to jit = __jit in sys/__init__.pyi) it passed the tests so.. uh.. very weird
would i need to like include it in __all__ or something
doesnt seem to be it
ok well
its because of the import sys._jit # type: ignore at the end
which is honestly even worse of a bug. an import in the later part of the code affected the earlier
and the jit rename worked because i didnt change the import sys._jit # type: ignore at the end to import sys.jit # type: ignore, if i did it would have the same issue
this was a very interesting experience
i hope typeshed does squash PRs
Question on Pydantic, apparently it's possible to tweak BaseModel to set all fields as None when not specified? Mostly because I'm validating JSON items thata re rather unpredictable and it's annoying to type T | None = None everytime.
If you mean "not error on extra things", you do it with extra="ignore" (the default) or extra="allow" https://pydantic.dev/docs/validation/latest/api/pydantic/config/#pydantic.config.ConfigDict.extra
If you mean interpreting all non-present fields as T | None with a None default, by setting extra="allow", all the extra items end up in __pydantic_extra__, which (as the above link shows) you can also set a type for. You could also add on to that a field_validator that turns __pydantic_extra__ into a defaultdict with None.
One other way (though your mileage may vary) could be overriding __getattr__ on your model class, not sure how well that would play with the different type checkers.
I see. There's apparently a way to do that by implementing a mixin with your model from a StackOverflow post
Apparently mypy 2.0 is coming out some time soon? https://github.com/python/mypy/blob/master/CHANGELOG.md#mypy-20
today!
def example(inp: int) -> int:
return inp
t: int | None = example(1)
why is int | None valid there according to pylance?example() will never return None
But you could set it to None in the future
int is a subtype of int | None, so you can assign an int to a variable declared as int | None
the logic is that an int is valid wherever an int | None is expected (since it is covered by the int branch of the union), in general, A < A|B, or, well, really, if A<A', then A<A'|B (where A<B means "A is a subtype of B")
a typehint can implicitly widen the type, not narrow (int | None is not always valid where an int is expected)
what if the TypeVar problem got fixed in 2.0? 👀👀
I don't remember any related changes
Btw: maybe there needs to be an extra way to trigger a success (failure?) in your unsoundness repo. Maybe something where code considered unreachable is hit? I was thinking of adding this one too:
class Foo:
def __eq__(self, other: object) -> bool:
return NotImplemented
def f(x: object) -> None:
y = Foo().__eq__(Foo())
reveal_type(y) # bool
``` and it's kinda difficult/roundabout to connect this with the `(x: str) -> int` signature. But really easy to execute `assert_never` e.g. inside of a `match` or `if-else` chainon this topic btw: https://docs.astral.sh/ruff/rules/unnecessary-dunder-call/
should be on by default imo
I feel usually there's a way to go from unreachable code to the str/int conversion
But yeah maybe we should add more variations, triggering assert_never() is also a good one
Ahh I see
def foo(x: int) -> list[int]:
return [x, x+1, x+2]
l = []
for n in range(5):
l.extend(foo(n))
``` why is pyright not able to distinguish `l` better than `list[Unkown]`? sure, i *could* add non-int objects in the future, but i haven't, and it could always change the guessed type to `list[int | otherthingy]` if i didIt's just a feature pyright decided not to implement
https://github.com/microsoft/pyright/issues/6710#issuecomment-1857446498
It would also require some hard-coded assumptions about the way that certain methods in the dict and list classes work. Hard-coding knowledge of specific methods within specific classes is something that we generally avoided in pyright. Type information for dict and list and their associated methods are provided by the typeshed stubs, and hard-coding knowledge beyond what is provided in the stubs is problematic.
-- Eric Traut
is it a similar reason that
def foo(x: int | None, y: int | None):
if None not in {x, y}:
reveal_type(x)
reveal_type(y)
``` results in the impossible `int | None`no, the reason for the empty collection case is the "time" at which the type is inferred
there's an almost infinite series of possible narrowing constructs type checkers can implement
that should be identical to either if x != None and y != None or if x is not None and y is not None, but those two correctly reveal as just int
this one seems pretty obscure and would probably need a lot of special casing
a hindley milner system would get all the constraints not only from declaration but also from usage and then solve them, but it also has crazy non-local errors
python typecheckers usually infer the type right at the declaration


pylance
https://pyright-play.net/?code=CYUwZgBGAUBOIGcCuAbALgLgsAlgYzQG0E1YAaCE2AXQEoIBaAPgjSQAcURjSKrqIAHwgA5APYA7EBgBQEeRHawxADwCeEALwR4ydADoA5iDTQAREtVqztOQpyRL6iDgSjJ0uwoXwAbiABDFAB9NDV2EGgnNVtvb3g2WAl3KS8IEBQETziFSzQxPDEUCmitRWV1fQROHFMzDAB6Bps0%2BJB-INDwyLyCoticnXbAkLCIqIqY1oUAigAjMuiqmrqAARbBocTk6FmIOdogA
weird
its probally a temporary bug that should go away on LSP restart
i assume the reassignment to proxy in protocol, proxy = ... invalidated the narrowing
though, well, proxy.split("://") (before the reassignment) returns strings, so it cant become a none, so its still wrong
actually that makes sense
hmm
i think even in the first split
its not sure that "proxy" is a string
it should give an error then, since None has no split
whatever i just used isinstance

well you can see the "split" is grey
but no error
huh
weird
yep
what if you rename the first proxy variable to something like url
so there wont be reassignment

if you reveal_type(url) in the else, what does it show?
huh now there is no error


 what? if
what? if url is None, it should error on the split
are you sure you put reveal_type(url) in the else

you put it in the if, not the else
i also wanted it to do in your own code and environment, since, well, the "same" code that you had already worked on pyright playground, so there's definitely something weird going on
yea lemme try that

how do i see reveal_type output
on vscode
nvm

what the hell
because you have reveal_type(url) in if url is None
is result a bare dict by any chance
like not dict[str, str]

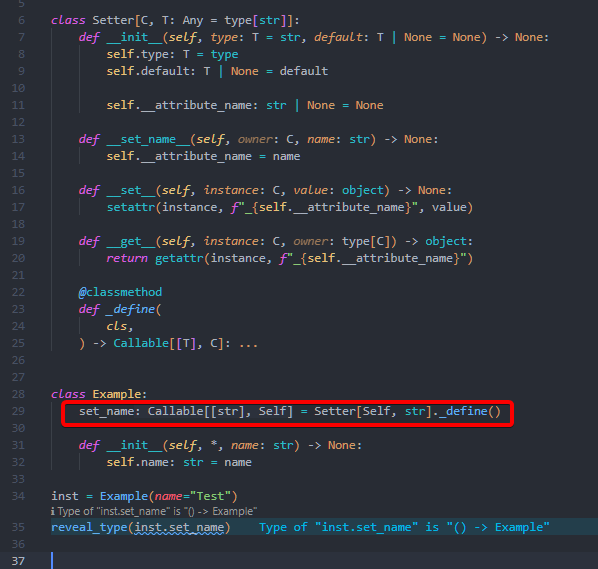{kind=link}
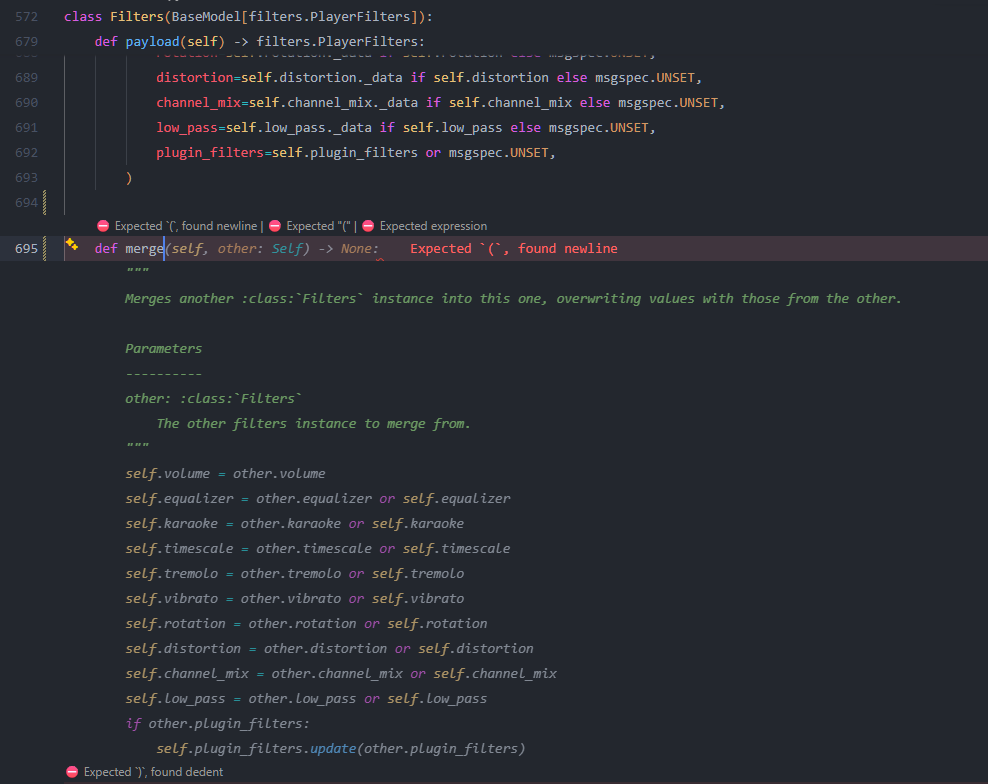{kind=link}
yeah thats what i was getting to
Did not know you could put variables there, cool

only variables of a literal type (compile-time known constants, basically). if t = int(input()) then no
That shouldn't be allowed, seems like a bug
Well I actually found it to be useful in a context like this

I like that lol, might be worth keeping
this definitely shouldnt be valid

as designed
lambda did a bit of experimenting in pygen and has come to believe
it seems like typecheckers assume that a *args of types of variable sizes fits all the missing args right away
so if you have any arguments after it - they're extra
is this intended behavior?
I'm surprised pyright even allows this
wym allows? it complains at the 40
I meant allows unpacking arbitrary iterables when there's no variadic parameter
@overload
def foo(a: int) -> int: ...
@overload
def foo(a: int, b: str) -> str: ...
_x = foo(*[1, 2]) # inferred as `int`
the real question is what overload it will pick in
@overload
def foo(a: int) -> int: ...
@overload
def foo(a: int, b: int) -> str: ...
it doesn't complain but infers the result as Unknown (aka Any++)
smh should be int|str
not a single week without a new way to break the typing system
$ mypy --strict __init__.py
__init__.py:20: note: Revealed type is "int"
Success: no issues found in 1 source file
$ zuban check --strict __init__.py
__init__.py:20: note: Revealed type is "builtins.int"
Success: no issues found in 1 source file
$ basedpyright __init__.py
~/__init__.py
~/__init__.py:13:9 - warning: "a" is not accessed (reportUnusedParameter)
~/__init__.py:19:1 - warning: Type of "x" is unknown (reportUnknownVariableType)
~/__init__.py:20:13 - information: Type of "x" is "Unknown"
0 errors, 2 warnings, 1 note
$ pyrefly check __init__.py
INFO revealed type: str [reveal-type]
--> __init__.py:20:12
|
20 | reveal_type(x)
| ---
|
INFO 0 errors
absolute coding
nice to know i'm not 0 for 3 in weird typing details at least
at least, until the jelle nation attacks 
pyrefly correctly rejects this btw
it's also okay with the original 
@oblique urchin https://github.com/JelleZijlstra/unsoundness/blob/main/examples/overload/generic_overlap.py#L6-L11
I think that's just an incorrect overload, rather than a new flaw of the typing system. It's kind of like stdlib/dict_constructor.py -- the overload is impossible to satisfy at runtime. (though maybe it is still a thing that's worth documenting)
examples/overload/generic_overlap.py lines 6 to 11
@overload
def f(x: list[T]) -> T: ...
@overload
def f(x: T) -> T: ...```