#type-hinting
1 messages · Page 44 of 1
not strictly related to typing, but I'm in doubt:
do variables have types in Python ? (from a formal specification perspective, at the language level). What is the actual formal definition of variable ?
when one annotated a variable with a type, how does it work in the perspective of the formal language definition?
The only thing it does at runtime is add it to __annotations__
yeah that I get
from my understanding, "type" only refer to objects: https://docs.python.org/3.13/glossary.html#term-type
Hey
idk if this is to be sent here but anyways, can anyone help me with type hints to the source code of my programming language?
it is in Python, hence im here
GitHub
Jam to JavaScript transpiler & interpreter for educational coding. Converts Jam code to JS or runs it directly. Perfect for learning programming concepts. - UnitaryIron/Jam-backend
Are you having problems with anything in particular?
Ever thought t-strings would make a good type annotation?
x: t"{int}" = "4"
y: t"prefix_{str}" = "prefix_xxx"
Well. the type hinting now is very basic. It catches only the basic literals. so, i want help with:
Improving type inference for lists or expressions
Adding stricter type hints for symbol_table
Suggesting better ways to track type mismatches.
Improving type inference for lists or expressions
what do you mean by this?
Right now, the infer_type function in Jam only detects very basic literals:
- integers (42)
- floats (3.14)
- booleans (true / false)
- strings ("hello"
- lists ([...]) without checking what’s inside
- variables already in symbol_table
By “improving type inference for lists,” I mean making Jam figure out the types of elements inside lists. For example, [1, "hi", true] should ideally recognize that the list contains an int, a str, and a bool.
Oh, you meant that you want help with type handling in your language, not in the Python source code
Yep exactly. I am talking about type handling inside Jam not Python code itself.
Basically, building a more accurate type system for Jam itself.
I don't think warning about assigning a value of a different type at runtime makes sense as a model
I think you should decide what the typing rules for the language are first. Is it a dynamically typed language? Statically typed? Something in between?
whatever analysis you'll want to do, you should start with making an AST, because handling all of it as strings is going to be horrible
Rn, the runtime warnings are kind of a hybrid approach. Mostly dynamic, but helping learners if types change.
wouldn't it help better if the error was caught without running the code?
Well, that is kinda intentional because as Jam is supposed to be a beginner friendly language, I didn't wanna scare the beginners with strict compile time errors like TS
I don't think beginners are scared by error messages about types (maybe they're scared by bad error messages). They're especially helpful when you don't have the debugging skills of an experienced programmer
does the language have only one scope and no functions with parameters? like, there is only one symbol_table
in the list example, what would you want to do with the fact that the list contains different types? would you want to support union types, or error in this case?
Yeah i get that. I see your point. Beginners might actually benefit from catching type errors early, as long as the messages are clear and friendly. I think combining AST-based static checking with beginner-friendly runtime hints might give the best of both worlds..
In a statically typed language, that situation cannot happen at runtime
Rn, Jam has just one global scope (symbol_table) and no functions with parameters. If we add functions later, we’d probably switch to scoped symbol tables.
But in a dynamically typed language, that's not supposed to be an error. It's fine to do this in Python ```py
x = 1
x = "foo"
...
name = get_name_bytes()
name = name.decode("utf-8")
For lists with mixed types, my current idea is to allow them but show a gentle runtime warning if element types differ. That way, beginners can experiment with heterogeneous lists without the language blocking them, rather than enforcing strict union types or errors.
what about static warnings? static analysis doesnt have to produce errors
if you do it at runtime, you'll need something like, track the type of the first element, then each time it tries to get added an element - check if its type matches that. you'll need a pretty big runtime for stuff like that
Ig, it comes down to whether Jam is to be dynamically typed or static typed.
Yeah. Rn Jam uses runtime warnings for simplicity and beginner-friendliness—tracking element types on the fly is easy to explain.
But I see that doing it at runtime can get heavy, especially for large or nested lists. Using AST-based static analysis to produce friendly warnings before running the code could achieve the same guidance without the runtime overhead.
How would you recommend approaching this with ASTs?
bidirectional type checking is pretty easy to implement and you can produce errors early with it (=> they can be small and simple, instead of hindley-milner kinda solving-away some stuff but ending up with a crazy error later)
The goal is to warn learners gently without blocking execution or making the runtime heavy.
Oh.. It sounds perfect for Jam. Rn i mostly infer types at runtime
but I’d like to try AST-based static warnings instead.
Could you give a hint on how to apply bidirectional checking for lists and expressions, especially for beginner-friendly mixed types?
i mean
you just have inference rules for things where you can infer their type, like, number literals, string literals, variables that are already given a type in this context
and you have check rules for things where you cant always exactly know but you can check whether its of some type, e.g. an empty list literal being list[T] for any T
for inference of non-empty list literals you could for example infer the type of the first element, and check the other elements against that, though for stuff like xs = [] you'll want an explicit annotation
it will also be easy to implement functions with that (given that your functions have annotations for the parameter types, otherwise you'll want to design the language around it to make hindley-milner style constraint solving viable),
in a call to f with a function type [Parameters] -> Return, just pairwise check the arguments against the parameter types, and infer the call result as the Return type
Ah, got it! So basically:
- Infer types where possible (literals, existing variables)
- Check types where you need to match an expected type (like empty lists)
- For non-empty lists, infer the first element’s type and check the rest against it.
I see how this could extend nicely to functions once Jam supports parameter annotations.
would this work well for beginner-friendly mixed-type lists, or should I always warn about mismatches?
you should decide on what you want the typesystem to do, its a choice
for a beginner oriented language i myself would honestly only allow well-typed programs, i dont expect beginners to make good use of dynamic typing, likely it will just cause runtime type errors
Yeah, got you. Makes sense to stick to well-typed programs for beginners.
I’m thinking whether Jam should allow mixed-type lists with gentle warnings or just enforce strict types. What do you think—warnings or strict only?
you can support union types if you think beginners can make use of them, but then you'll also want some feature like isinstance that would play with the typesystem by narrowing the type in the context of say, an if, so that it could be used safely
honestly the language feels very weird, the special syntax for map with over xs, the add x and y into z while functions use usual expressions (n * 2)
feels like a bunch of random ideas thrown together
you should spend some time designing it, think of what would make things actually simpler for beginners and what kind of beginners specifically (children? or people that already know stuff but not programing specifically?). its definitely not replacing z = x + y with add x and y into z.
you can take a look into existing beginner/education oriented languages like https://pyret.org/ , https://www.hedy.org/
imo, a lot of "beginner orientedness" is not necessarily in the language feature set itself, as much as it is in its error messages, learning resources and the programming environment (e.g. thonny's debugger is amazing)
you can join https://discord.com/invite/programming-language-development-530598289813536771 and talk to people in it about language design,
and I think it would be great to do ask programmers (both already somewhat experienced and beginners) what things they struggled with when they were learning, and how they think that could be improved
How can mypy complain that return self.slot1.is_ready and self.slot2.is_ready would return Any? Isn't that by definition a bool?
No, Any is anything. and doesn't return a bool, it returns one or the other of its operands.
oh, that is news to me, but I guess it makes sense.
I use foo or "default" a lot, same thing I guess
that said,is_ready is a property declared to return bool, so and should always return bool in this case, no?
@property
def is_ready(self) -> bool:
return self.type in (SlotType.ENTRY, SlotType.BYE)
Can you show more code?
or maybe ```py
reveal_type(self)
reveal_type(self.slot1)
reveal_type(self.slot1.is_ready)
reveal_type(self.slot2)
reveal_type(self.slot2.is_ready)
I now need to run and get kids but I will later
that's a long process, at least 9 months...
lol.
i really just did lol and now the kids want to know why
def _slot(self, pm: PlayerMatch, idx: Literal[0] | Literal[1]) -> Slot:
if self._slots is None:
return Slot(content=pm.entry or Unknown())
return self._slots[idx]
slot1 = property(lambda s: s._slot(s.pm1, 0))
slot2 = property(lambda s: s._slot(s.pm2, 1))
@property
def is_ready(self) -> bool:
reveal_type(self) ● Pyright: Type of "self" is "Self@Match"
reveal_type(self.slot1) ● Pyright: Type of "self.slot1" is "Any"
reveal_type(self.slot1.is_ready) ● Pyright: Type of "self.slot1.is_ready" is "Any"
reveal_type(self.slot2) ● Pyright: Type of "self.slot2" is "Any"
reveal_type(self.slot2.is_ready) ● Pyright: Type of "self.slot2.is_ready" is "Any"
it's the lambda!
and functools.partialmethod cannot be assigned to property fget ☹️
slot1 = property(cast(Callable[["Match"], Slot], lambda s: s._slot(0))) also yields Any
grrrr
no, it's the property
▎ def _slot1(self) -> Slot:
▎ return self._slot(0)
▎
▎ def _slot2(self) -> Slot:
▎ return self._slot(1)
▎
▎ slot1 = property(_slot1)
▎ slot2 = property(_slot2)
▎
@property
def is_ready(self) -> bool:
▎ reveal_type(self) ● Pyright: Type of "self" is "Self@Match"
▎ reveal_type(self.slot1) ● Pyright: Type of "self.slot1" is "Any"
slot1 = cast(Slot, property(_slot1)) works
kinda makes sense given how property works, and how lambda neutres all types
That's messages from pyright. But you're getting errors from mypy
show what mypy thinks of those reveal_types
tptools/match.py:161: note: Revealed type is "tptools.slot.Slot"
tptools/match.py:162: note: Revealed type is "Any"
but both are Slots at runtime
Can you show the entire class perhaps?
The Slot class I mean
hold on, is it working for you now?
I think I jumped over a few messages, looks like it works
actually no, wait
yeah, I cast the result of proprty
sounds like you need to use it as a decorator and then it will work
confirmed
Something I just noticed today while looking at functools.singledispatch (for fun, personally I wouldn't really use it), is that it does not interact at all with typing.overload. Is that really the case or am I missing something? playground
The mypy Playground is a web service that receives a Python program with type hints, runs mypy inside a sandbox, then returns the output.
That really is the case, functools.singledispatch is not special-cased by type checkers
mypy does have special-case support for it

Gist
Shared via mypy Playground. GitHub Gist: instantly share code, notes, and snippets.
Hello, guys! I am building a small library to work with YAML configuratiins files: https://github.com/shadowy-pycoder/pyya Basically, it allows to merge production and sample YAML configs, dynamically validate types with Pydantic, and other stuff related to YAML formatting. Since it uses munchify under the hood to convert dict to dynamic attribute style object, it lacks type hints, autosuggestiond and completions: everything is dynamic and created at runtime. In the last version, however, i added dynamic generation of stub files based on samole config. This approach mostly works, but requires creating global variable, for example, config beforehand. So if stub contains config: Config, you need to create config = init_config() to associate it with stub file and get completion. That is not very convinient, and creates dependency on naming. What else can i do to make things more generic? Thank you

GitHub
Convert YAML configuration files to Python objects - shadowy-pycoder/pyya
How come the above example doesn't work then?
given a factory-like function:
def myfun[T: MyBaseClass](cls: type[T] = MyBaseClass) -> T: ...
why would mypy complain?
error: Incompatible default for argument "cls" (default has type "type[MyBaseClass]", argument has type "type[T]") [assignment]
for the same reason it rejects this: py def foo[T](x: T, y: T = 100) -> None: for some values of T, the default won't be valid
There's currently no way to influence T other than passing the parameter, but the logic is still the same
but its bound by 1 parameter in their case
pyright allows it
from collections.abc import Callable
class A:
...
def f[T: A](a: T = A()) -> T:
return a
def g[T: A](a: type[T] = A) -> T:
return a()
def h[T: A](a: Callable[[], T] = A) -> T:
return a()
pyright "allows" it, and it makes sense. Unless I specify cls, T==MyBaseClass
Yes, pyright allows it. Mypy doesn't
if I specify cls, it has to be a type derived from MyBaseClass
you could overload it i guess?
f() -> MyBaseClass
f[T: MyBaseClass](() -> T) -> T
easier to #type:ignore in this case.
Pyright remembers the default of the function in the function's type, and then checks at call site if the default value. Mypy doesn't do this extra work, it just remembers whether each parameter has a default or not
Not sure if the type system allows this, but it can present issues if you're making a library
if it's not a function exported from a library, then pyright's behaviour is very handy
can you not fix it with a typevar default?
e.g. if PEP 718 is accepted, then this would be valid ```py
myfunSomeSubClass
in this case: py def f[T](x: T, y: T = 42) -> None: ... even if you say f[T = int], there needs to be some way to signal that the default is not applicable for all Ts, and currently there isn't
this is what I meant here: if you're a type checker without this special handling, you see this signature: ```py
def f[T](x: T, y: T = ...) -> None: ...
one day maybe
for a brief moment I forgot you were the author
I tried that a while back and was confused why it wasn’t valid, and then realised it isn't built-in, yet 
Found a new trick for exposing a class but not its constructor (and also making it private): ```py
class _Foo:
def init(self, ...):
# supposed to be private to this module
def method(self, x: int) -> str:
...
type Foo = _Foo
Is there a good way to type this without repeating the args https://github.com/ansys/pyfluent/blob/main/src/ansys/fluent/core/launcher/launcher.py#L147-L179?
I might plead with the devs to make these kwargs cause that's the only way I know to do it
small thing I noticed is you got a float | int in there
I think it might be cause you can do 26.1 and 261 and to draw more attention to that?
why they allowed that is beyond me though
i dont quite understand, isn't it already typed, where is the repetition?
oh, the repetition of the signatures of the launcher's constructors? like DockerLauncher?
the return type is currently a big union which depends on the mode argument
You can make overloads for each mode
yeah that's what I'm thinking but man it sucks
Assuming we could make any syntax or runtime construct, got any ideas what would make that easier to express? I'm currently lacking imagination and don't know what a better way would look like, but I'm sure others have spitballed answers to this problem before.
# Rough idea?
import enum
class FluentMode(enum.Enum): ...
def launch_fluent[
ModeType: FluentMode,
ReturnType: (
Meshing | PureMeshing | Solver | SolverIcing
corresponding to ModeType # Create a 1-to-1 correspondence with the members of FluentMode?
)
](
*args: object,
mode: ModeType,
**kwargs: object,
) -> ReturnType:
...
i mean, if you make FluentMode.MESHING to be Something[Meshing], then it could be def launch_fluent[A](Something[A]) -> A
def rtype(mode: FluentMode) -> type:
match mode:
case FluentMode.MESHING:
return Meshing
...
def launch_fluent(mode: FluentMode) -> rtype(mode):
...
would be really cool though, dependent typing
dependent or mapped types would make this so much nicer
i do also think it needs some kind of typed mapping to make the abundance of errors less bad when you even go to use it

I think I need to do some pyi hacks to make these work at type time
is this possible?
def check_authorization[**P, R](func: Callable[Concatenate[Any, sanic.Request, P], Coroutine[Any, Any, R]] | Callable[Concatenate[sanic.Request, P], Coroutine[Any, Any, R]]):
@functools.wraps(func)
async def wrapper(arg1: Any, *args: Concatenate[sanic.Request, P].args | P.args, **kwargs: P.kwargs) -> R:
return await func(arg1, *args, **kwargs)
return wrapper
i'm trying to make a decorator that would work for both a method and a function which takes a sanic.Request as the first argument
*args: Concatenate[sanic.Request, P].args | P.args is what's failing.
You don't need to concatenate *args. Just add the request arg.
async def wrapper(self: Any, request: sanic.Request=..., *args: P.args, **kwargs: P.kwargs) -> R: ...
=... means its optional
I'd recommend making 2 wrapper functions. one for method and one for function.
doesn't work because the wrapped function can take more arguments
imo the wrapper's signature has to be (arg1, *args, **kwargs) -> R
so i just need to know how to type *args proplerly
Introduce another typevar. Maybe typevartuple of (Any, Request) | (Request,)
how would that help?
You can unpack it into the *args
but like i said the wrapped function can take more arguments
Which is why a typevar should be used.
Just tested, typevartuple doesn't support bounds
Why does this fail on mypy? https://mypy-play.net/?mypy=1.18.2&python=3.11&gist=6e03609385c9b451e208003e9fe28c5a
Pyright has no complaints:
https://pyright-play.net/?pythonVersion=3.11&strict=true&code=GYJw9gtgBALgngBwJYDsDmUkQWEMoAqiApgGoCGIAUFQMYA25Azk1AIIBcVUPUCzTGgwFQAQl158BNKgSgBeQiQogAFACIC6gDRQARmACuKACby2UAD5iAlDJPFgUWiGLkYxVQGtGLDrBIAbQIAXRsoAFoAPkIJXlcYQxAUKB8BVRsgA
The mypy Playground is a web service that receives a Python program with type hints, runs mypy inside a sandbox, then returns the output.
I can work around it with a cast (which Pyright then complains is redundant)
you probally want T = TypeVar("T", A, B)? (constraints, not a union bound)
or, tbh, just [T](() -> T) -> T, ⬇️ if you dont actually use it as a class but just as a constructor
Otherwise klass: Callable[[], T] will work
this feels like it should be reported to mypy because it works if you remove the bound
i don't think that's actually possible because
"args" and "kwargs" attributes of ParamSpec must both appear within a function signature
and
ParamSpec is not allowed in this context
if i do *args: P.args | int
I managed this with liberal use of Any.
https://mypy-play.net/?mypy=latest&python=3.12&gist=d42891a3a4cb5f6c067df4397f287fb6
The mypy Playground is a web service that receives a Python program with type hints, runs mypy inside a sandbox, then returns the output.
I'm not sure. I haven't read through this carefully yet but it seems I do want union. https://stackoverflow.com/questions/59933946/difference-between-typevart-a-b-and-typevart-bound-uniona-b
How are you trying to use it?
Do you want A or B including subclasses?
Yes
Oh actually I misread
I think that will work since I don't need to pass a union as the input
One of the SO answers says that if I don't use bound=Union, then subclasses aren't allowed. But I tried it and it passes
Consider using the Callable factory approach.
when in doubt, let the type checker tell you
Oh right it infers variance if unset?
or it will tell you the typevar should be covariant, contra, etc
thanks for the help, this worked
the old-style TypeVars are invariant, unless you specify covariant=True, contravariant=True or infer_variance=True
new-style type variables infer variance and there's no way to specify it explicitly
Desperately want 3.12 to be EOL so I can use the new syntax
Unfortunately that's quite far away
is there a way to extend builtins.py's types in a typechecker?
I just target the latest version of python available on rhel9
currently 3.12.
sounds nice
I'm not sure if it extends or not, but you can look into stubPath in pyright and mypy_path in mypy. I've used it before to provide my own stubs for some untyped library I was using.
I haven’t been keeping up with python news lately, what’s the new syntax?
Neat, looks like a nice improvement
Surprisingly, vs code still doesn't syntax highlight PEP 695
multi billion dollar corporation vs 1 PEP
https://github.com/microsoft/vscode/blob/main/extensions/python/syntaxes/MagicPython.tmLanguage.json#L2-L6
-> https://github.com/MagicStack/MagicPython/pull/270
3 years no changes 💀
GitHub
Visual Studio Code. Contribute to microsoft/vscode development by creating an account on GitHub.
Tragic
is this intended?
code
# code
V = TypeVar('V', bound='BaseView', covariant=True)
if TYPE_CHECKING:
from typing_extensions import TypeVar
ItemT = TypeVar('ItemT', bound='Item', covariant=True, default=Item)
else:
ItemT = TypeVar('ItemT', bound='Item', covariant=True)
class Label(Item[V], Generic[V, ItemT]):
...
error
Traceback (most recent call last):
File "x\test.py", line 5, in <module>
class MyModal(discord.ui.Modal):
...<21 lines>...
reveal_type(self.text.component)
File "x\test.py", line 6, in MyModal
fruit: discord.ui.Label['MyModal'] = discord.ui.Label(
~~~~~~~~~~~~~~~~^^^^^^^^^^^
File "x\Python\Python313\Lib\typing.py", line 432, in inner
return func(*args, **kwds)
File "x\Python\Python313\Lib\typing.py", line 1242, in _generic_class_getitem
args = prepare(cls, args)
TypeError: Too few arguments for <class 'discord.ui.label.Label'>; actual 1, expected at least 2
I feel like it shouldn't throw an error on runtime?
when it works as intended at type checking
at runtime TYPE_CHECKING is false, so what you're essentially running is ```py
V = TypeVar('V', bound='BaseView', covariant=True)
ItemT = TypeVar('ItemT', bound='Item', covariant=True)
class Label(Item[V], Generic[V, ItemT]):
...
and yes, it intended behavior to error if the wrong number of type parameters is supplied
There's a good chance you're already depending on typing-extensions, so might as well depend on it
oh that makes sense
actually no, aiohttp doesn't require typing_extensions anymore
but if your library intends to use annotations for runtime effects, I think it's totally fair to depend on typing-extensions
it does not unfortunately
just throw the entire thing in quotes then
fruit: 'discord.ui.Label[MyModal]' = discord.ui.Label(
or future annotations
or patch the typevar at runtime 😎
I don't think the maintainer of discord.py will appreciate that 
Any idea how overloads were supposed to interact with ParamSpec? Neither typing.python.org nor the paramspec PEP mention this
code on the basedpyright playground: link
pyright says:
Type of "f1" is "Overload[(x: int) -> (list[Literal['aaa']] | None), (x: str) -> (list[Literal['aaa']] | None), (x: int) -> (bytes | None), (x: str) -> (bytes | None), (x: int) -> (str | None), (x: str) -> (str | None), (x: int) -> (list[Literal['bbb']] | None), (x: str) -> (list[Literal['bbb']] | None)]"
Type of "f2" is "Overload[(fizz: None, buzz: None) -> (int | None), (fizz: None, buzz: None) -> (str | None), (fizz: bytes, buzz: bytes) -> (int | None), (fizz: bytes, buzz: bytes) -> (str | None), (fizz: str, buzz: str) -> (int | None), (fizz: str, buzz: str) -> (str | None), (fizz: int) -> (int | None), (fizz: int) -> (str | None)]"
apparently it "zips" the parameter signatures of one overloaded with the return types of another overloaded function, which makes no sense
mypy says:
Revealed type is "def (x: builtins.int) -> builtins.list[Literal['aaa']] | None"
Revealed type is "def (fizz: None, buzz: None) -> builtins.int | None"
``` which is similar but just the first linesthe zipping makes sense to me, you have the function take Callable[P, A] and return Callable[P, B | None]
the behavior here I think makes sense, your example is quite complex with two different overloads that get their return types swapped
How does it make sense? I'm taking the argument combinations from fn1 and returning a type B which is from somewhere else.
The functions work by filling up each other's queue on call
right, so you return a function that takes whatever arguments the one function takes and returns whatever the other returns
isn't that what pyright's inferred return type says?
The correct return type for the first function would be ```py
type BUnion = list[Literal["aaa"]] | list[Literal["aaa"]] | bytes | str
Overload[(x: int) -> BUnion, (x: str) -> BUnion]```
Perhaps there's too much code, here's a simplified version ```py
def cross[**P, **U, A, B](_fn1: Callable[P, A], _fn2: Callable[U, B]) -> tuple[Callable[P, B | None], Callable[U, A | None]]:
...
@overload
def foo(x: int) -> int: ...
@overload
def foo(x: str) -> str: ...
def foo(x: int | str) -> int | str: return 69
@overload
def bar(a: int, b: int, c: int) -> range: ...
@overload
def bar(a: int) -> list[int]: ...
def bar(*args: object, **kw: object) -> object: ...
f1, f2 = cross(foo, bar)
reveal_type(f1)
Overload[(x: int) -> (range | None), (x: str) -> (range | None), (x: int) -> (list[int] | None), (x: str) -> (list[int] | None)]
``` the argument signature (x: int) from foo is linked to the first return signature of bar because they are at the same index in the respective overload lists. If you swap the overloads in bar (which obviously defines the same signature) it will then say (x: int) -> (list[int] | None)
there's a second overload involving (x: int) but it is unreachable because there's already an overload with (x: int)
I don't think it is
reveal_type(f1(42))
``` this shows `range | None` in pyrightalthough the presence of two overloads with the same argument type means those calls are going to return Any by Step 5 (https://typing.python.org/en/latest/spec/overload.html#step-5)
might be that pyright still doesn't fully implement the overload spec here
oh wait no, ordering does matter here
yeah, in this case the later overload is fully obviated
I wonder how they solved it in typescript
Oh my, they have dedicated syntax for an overloaded callable https://stackoverflow.com/a/52761156/10295729
If I wanted to internally enforce a semantic invariant on a mutable type, would that be a sound usecase for Allow subclassing without supertyping ? I had a read through and a lot of the examples were deemed unsound but also the conversation also mixed feasibility and practical concerns. Just if you have thought about that before and reached a conclusion, not asking for someone else to re-read the discussion ^^
I have this:
class BaseModel[T: TPModel](ComparableMixin, ReprMixin, StrMixin, PydanticBaseModel): ...
class Court(BaseModel[TPCourt]): ...
and this yields:
tptools/court.py:14: in <module>
class Court(BaseModel[TPCourt]):
^^^^^^^^^^^^^^^^^^
.direnv/python-3.13/lib/python3.13/site-packages/pydantic/main.py:860: in __class_getitem__
raise TypeError(f'{cls} cannot be parametrized because it does not inherit from typing.Generic')
E TypeError: <class 'tptools.basemodel.BaseModel'> cannot be parametrized because it does not inherit from typing.Generic
who is confused about the new syntax here?
What version of pydantic are you using?
Or is it your own BaseModel?
wait, it's your own BaseModel
can you print BaseModel.mro()?
yes, sorry, my own base model
[<class 'tptools.basemodel.BaseModel'>, <class 'tptools.mixins.comparable.ComparableMixin'>, <class 'tptools.mixins.repr.ReprMixin'>, <class 'tptools.mixins.str.StrMixin'>, <class 'pydantic.main.BaseModel'>, <class 'typing.Generic'>, <class 'object'>]
Sounds like a bug in pydantic, it should check mro and not __bases__ probably
https://github.com/pydantic/pydantic/blob/main/pydantic/main.py#L859-L860
pydantic/main.py lines 859 to 860
if not cls.__pydantic_generic_metadata__['parameters'] and Generic not in cls.__bases__:
raise TypeError(f'{cls} is not a generic class')```Sounds like it expects that you explicitly include typing.Generic in the bases when you define BaseModel
but that doesn't work together with new syntax.
anyway, i'll give this a shot. Thank you!
Actually, what is in Base.__bases__?
there should be a Generic in there
the new syntax should inject Generic into the __bases__
...
>>> C.__bases__
(<class 'typing.Generic'>,)
yeah
(<class 'tptools.mixins.comparable.ComparableMixin'>, <class 'tptools.mixins.repr.ReprMixin'>, <class 'tptools.mixins.str.StrMixin'>, <class 'pydantic.main.BaseModel'>, <class 'typing.Generic'>)
so yes
i have to run but I will look into this tomorrow.
thanks folks
What ppl use these days for type checking. Mypy? Ty? Or something else?
Ty is "alpha" software and it doesn't support a lot of things yet.
If you're starting a new project, I would recommend basedpyright
Thanks!! Mypy was like industry standard almost I think. basedpyright is better than mypy currently?
mypy is the OG type checker, yes
I like pyright better because it's generally faster, it has more sensible inference, it is faster to adopt new features, and integrates into editors very well (e.g. it provides autocompletion and go-to-definition support)
Unfortunately, pyright is maintained by Microsoft. Microsoft decided to keep some nice features out of pyright and put them into Pylance, which is a closed-source VSCode extension. pyright got forked into basedpyright, with some pylance features added into it along with a few other improvements.
basedpyright also provides a sensible PyPI package. Pyright is written in TypeScript so you need to do have node.js to make it work (which the PyPI package bundles)
Hopefully ty gets production-ready in the near future and we'll all switch to it...
So for production code is mypy ? Do I get it right?
Use mypy if you already have a large codebase that's using mypy, or if you need mypy plugins. If you're starting a new project, I recommend pyright or basedpyright
It's an existing project but we haven't type checked so far. We use type hints. But there may be errors 🙂 as we didn't check...
basedpyright has a baseline feature, so you can note down (automatically) all the error you have right now, and only fail in CI if you get new one. And you can gradually fix the baseline errors gradually over time (and hopefully find some bugs)
Basedpyright uses strict type checking by default so you need to configure it to your liking from the very beginning
yeah, make sure to check the docs for all the configuration options
We probably want to start from basic. I enabled basic py right checks in VSCode and it shows a lot of errors 🙂
Yeah, whenever you add a new linter it's going to scream
Zed (editor) uses basedpyright as the primary language server. So it may be the new standard by the looks of it.
Until ty is out of beta that is 🤣
marimo also uses it
The exception I am getting is actually two lines above: if not hasattr(cls, '__parameters__'):
So how do I get __parameters__ into this generic base class?
lemme make a test case
I cannot of course ☹️
I'
ll push the code when I am done with the refactor and then can provide a link
found the problem. I was overriding __init_subclass__ in one of the ancestors and not calling super() in it.
Yes
def f(s: Iterable[str]) -> None:
pass
f("string")
f(["a", "b"])
This will type check without any errors
yes
list[T] | tuple[T, ...] I think would be the solution for that
- generator and idk but yes
speaking of...
from collections.abc import Iterable
type Tensor = float | Iterable[Tensor]
foo: Tensor = "banana"
``` mypy says `str` is a Tensor, pyright says it's notI have to agree with mypy here
interesting how it does pass pyright if its type Tensor = Iterable[Tensor] but not when you make it wider
oh right, I remember now
Would that be implemented like so? ```py
class Tensor:
def iter(self):
return self
def next(self):
return self
that would be one valid implementation yeah, with strings it works because single chars are also of type str
Is picking any type hinting option that doesn't involve importing something (unless necessary) from typing module a better option?
For example,
int | None > Optional[int]
int | str > Union[int, str]
type Something = x | y | z > Something: TypeAlias = x | y | z
list[str] > List[str]
and so on
Unless I also have to consider backward compatibility (I don't care)
I don't think that's a general rule, but for all of these it's better to do the thing on the left, yes
Some of the ones on the right are deprecated iirc
Yes that's why, whatever code ends up generated by LLMs use right ones and I see stack overflow answers mentioning left ones are introduced in newer versions and it is preferable to use that
But I'm not sure where to find guidelines on type hinting so I wanted a rule of thumb sort of
It's basically the wild west, you can do whatever you want, technically...
except for List and friends, it is listed as deprecated in the docs:
https://docs.python.org/3/library/typing.html#typing.List
As long as it does the type checking I want? XD
with the examples you showed, it's not about whether or not you're importing that thing from typing, but rather the fact that List (and it's equivalents for other types) are deprecated.
You can use pyupgrade or some rules from Ruff to upgrade to a newer spelling
I haven't written much code to consider doing that but thanks
List example is fine, but for others, both works but left one is slightly more preferred is what I understood
it is typically more concise and has the same meaning
actually, there's this page https://typing.python.org/en/latest/guides/modernizing.html
This is helpful, thanks for this
if I have a type-parametrised class, can I somehow get at the actual type at runtime?
class Foo[T]:
@classmethod
make_T(cls) -> T:
return T()
that obviously won't work. But what can I use instead of T()?
you can't really I was working on a proposal for this ages ago
the best you could do is your own GenericAlias which overwrites class_getitem and sets the type param or frame hacks
this
oh wait no wrong one
though idk how out of sync it is with my local version
honestly i dont like it
required type parameters should be regular parameters, with a type[...] type
adding runtime magic specifically for storing explicitly provided typevars is weird
but you dont need the [int] at use-site here
well yes but its not hard to imagine a case which does
in what case does a required type parameter need the generic application syntax? i can only see that type doesn't include some type "forms", but otherwise - when you are doing f[T], you could just pass T as a regular parameter that would bind this typevar.
You can always write it like:
class Foo[T]:
@classmethod
def make_T(cls, typ: type[T]) -> T:
return typ()
foo = Foo.make_T(int)
reveal_type(foo) # int
you could be doing something with initialising a container with it? ```py
[T()] * 100
then this should be f: Callable[[], T] anyways, types are not guaranteed to have default constructors
and yes, you are misunderstanding, because you could do the same with a regular parameter
my point is that the proposal only works with required type parameters, like, ones you explicitly provide in your code at every call site (as python itself is obviously not going to do type inference), and in those cases you can use a regular parameter just as well
you're just changing the syntax from providing them as regular ones to []
there's no duplication in usage, only in declarations, as you need both a typevar and a parameter that binds it
def f[T]() -> F[T]:
return e(T)
f[t]
# ->
def f[T](t: type[T]) -> F[T]:
return e(t)
f(t)
I am unsure if I am on a garden path in the wrong direction regarding the specialisation of a type hierarchy I am designing. The base class Match is type-parametrised with e.g. the type of the tournament entry, i.e. class Match[EntryT: Entry](…): .... So far, so good.
Now, I have a use-case in which I need a specialised Match, let's call it SpecMatch. More concretely, I need to provide a specific Pydantic model_serializer for SpecMatch, and a SpecMatch also uses EntryT=SpecEntry. So I thought: class SpecMatch(Match[SpecEntry): .... And while this works at runtime, mypy rightfully says:
… "SpecMatch" must be a subtype of "Match[Entry]"
which is is obviously not.
I guess I could inject the serialization logic via Pydantic contexts, but I was wondering if there isn't another way for me to achieve two things at once:
- Define the base class type parameter to be a specialised class for instances of the child class;
- Override some behaviour of the base class in the specialised class.
Does this make sense?
I made a test case that highlights the problem I am having:
from typing import Any
from pydantic import BaseModel, model_serializer
class DataType(BaseModel):
x: int
@model_serializer(mode="plain")
def _model_serializer(self) -> dict[str, Any]:
return {"x": self.x}
class SpecDataType(DataType):
@model_serializer(mode="plain")
def _model_serializer(self) -> dict[str, Any]:
return {"x": 2 * self.x}
class MyBase[DataT: DataType = DataType](BaseModel):
data: DataT
@model_serializer(mode="plain")
def _model_serializer(self) -> dict[str, Any]:
return {"data": self.data, "desc": "just x"}
class MySpec(MyBase[SpecDataType]):
@model_serializer(mode="plain")
def _model_serializer(self) -> dict[str, Any]:
return {"data": self.data, "desc": "specialised X (should be double)"}
class App[BaseT: MyBase = MyBase](BaseModel):
model: BaseT
class SpecApp(App[MySpec]): ...
Pyright says:
Diagnostics:
1. Type "MySpec" cannot be assigned to type variable "BaseT@App"
Type "MySpec" is not assignable to upper bound "MyBase[DataType]" for type variable
"BaseT@App"
"MySpec" is not assignable to "MyBase[DataType]"
Type parameter "DataT@MyBase" is invariant, but "SpecDataType" is not the same as
"DataType" [reportInvalidTypeArguments]
and mypy:
Type argument "MySpec" of "App" must be a subtype of "MyBase[DataType]" [type-var]
Hi, in my opinion type-checkers sh(/c)ould infer Final from variables named in all-caps; realized that during code review today and opened a feature request in mypy: https://github.com/python/mypy/issues/19987
That seems problematic - if it’s wrong, how do you specify that it should be mutable? The only other place I can think of where a name has meaning is with star-imports and underscored private names. But there you can just explicitly import or set __all__.
Hm, wouldn't one use type ignores for such cases? 🤔 Note this is not runtime behaviour, only the static checking.
how is this channel a thing? 👀
because type hinting is a complex topic and may be unfamiliar to many python developers
This doesn't seem right:
@pytest.fixture
def draw1(tpdraw1: TPDraw) -> Draw:
return Draw.from_tp_model(tpdraw1)
where Draw inherits from Base and Base.from_tp_model returns typing.Self
Mypy says:
error: Incompatible return value type (got "Self", expected "Draw") [return-value]
Isn't that the entire point of Self?
that's odd, I can't really reproduce it, are you sure you imported the right Self? If yes, can you try to put together a minimal repro?
from typing import TYPE_CHECKING, Any, Never, Self, overload
class BaseModel[T: TPModel | None = None](
ComparableMixin, ReprMixin, StrMixin, PydanticBaseModel
):
@singledispatchmethod
@classmethod
def from_tp_model(cls, tpmodel: T) -> Never | Self:
if tpmodel is None: # pragma: nocover
# thanks to singledispatch, we should never reach this
raise NotImplementedError("No TPModel to instantiate from")
return cls.model_validate(tpmodel.model_dump())
@from_tp_model.register
@classmethod
def _(cls, _: None) -> Never:
raise NotImplementedError("No TPModel to instantiate from")
I see your point, I think the other stuff is also fairly compelling for adding it though
I also thought there was an example in here where they needed to pass the type and the value for some reason
class Bar:
x: int | None
def glug(b: Bar):
...
def foo(b: Bar) -> int:
assert b.x is not None
glug(b)
return 5 + b.x
this has probably been asked before, maybe even me a long time ago
but I'm surprised to see this type checks?
what's the reasoning?
"practicality beats purity", i guess, or just not wanting to deal with the complexity and not producing unwanted false type errors
"purity"-wise for this to be safe we'd need to know that glug(b) cant set b.x to None
the "simple" thing would be to discharge all narrows when calling something which can affect mutable state
I guess I just don't understand why this is more practical, I guess
it seems like a very real thing, that could happen in real codebases
yes, I know. that's why I'm saying this shouldn't type check.
Another similar example is
assert some_global is not None
glug() # might change global
return 5 + some_global
I also think it is silly that it's allowed
As I recall typescript also allows it, flow doesn't.
it should be reserved for indexes of tuples and attributes of known immutables (like frozen dataclasses and NamedTuples)
nice, its already in unsoundness/

GitHub
Collecting examples of unsoundness in the Python type system - JelleZijlstra/unsoundness
On the other hand, if someone changed the value of this object while you weren't looking, how do you know other decisions that you're making are still valid?
e.g.: ```py
@dataclass
class User:
name: str
email: str | None
is_admin: bool
def my_func(u: User):
if u.email is not None and u.is_admin:
# do something long
assert "@" in u.email
``` u.email not being a string anymore is a possibility, but so is u.is_admin not being true anymore
You could make the assertion at the beginning of the function, do some valid thing based on the inferred type, then accidentally do an invalid thing at the end of the function
Where you should really assert again
ah, you mean when looking at the object operated on within the function
yeah, that's possible
yeah, exactly
sure, but one of those is the responsibility of the type system and one isn't
true
It's weird how loosey goosey python is with this
it honestly doesn't seem like there's any big negative to doing this correctly
i mean of course now it would be a big backwards compatibility break
but originally
at least this doesn't seem to be allowed:
assert b.x is not None
def ret() -> int:
return b.x + 5
don't worry, type checkers still have plenty of bugs 🥴 ```py
def f():
x: int | None = 69
def hehe():
nonlocal x
x = None
reveal_type(x) # Literal[69]
hehe()
reveal_type(x) # still Literal[69]
print(x + 351) # no error
iirc the pyright maintainer marked this as "as designed"
(i.e.: won't fix)
sounds like warsaw's third and sixth law
Maybe this should be driven from the type checking specification side. Then pyright would need to acknowledge the bug.
Right now type inference is pretty much unspecified
Yeah, I see that. Are there plans to specify it?
I don't think so
The typing spec page on type narrowing: https://typing.python.org/en/latest/spec/narrowing.html#type-narrowing says
Type checkers should narrow the types of expressions in certain contexts. This behavior is currently largely unspecified.
and then explains TypeGuard and TypeIs
Sure, that's the status quo
What's the appropriate term for annotations that are used for typing analysis purposes? Is it "type hints" or "type annotations" or something else?
in https://typing.python.org/en/latest/spec/annotations.html#string-annotations it uses the term type hint though
and there's also typing.get_type_hints
from what I gathered the two are synonyms?
or maybe there's a subtle distinction?
Are the terms defined anywhere?
The glossary does define "type hint" https://docs.python.org/3/glossary.html#term-type-hint
"annotation" on its own is a more generic term for the thing that was added to functions back in Python 3.0. But "type annotation" seems to be a synonym for "type hint"
tbh "type hint" might be a better term because it doesn't always appear in an "annotation"
a type hint can appear in the first argument to typing.cast, in a generic class parameter (e.g. list[int]()) or in a type alias
But the glossary defines it to be an annotation
Isn't what appears in a cast just a "type"?
Unfortunately the glossary already reserves "type" to be a synonym of "class", for historical reasons. So "type" can be ambiguous
hm, yes, it does define it to be an annotation
"type expression" is close to what you're looking for
"type hint" gets used informally but not sure we've ever really defined it
Help me 5 minn plsss
Can u maybe help me in a call for 5min ? I‘m stuck🙁🙁
well, it's in the glossary
Is there still no way to make this invalid? ```py
min(1, "a")
I personally can't think of a way that doesn't wrap it in something that has a runtime cost, but I'm not an expert on this so I'd be delighted to be wrong.
It's possible in Python that this is external spec language territory
Do y'all think these overloads are an overkill or rather are a good thing to have

They seem good to me
You could do ```py
@on_event(events.LobbyMessageCreate)
def handle_lobby_message_create(e: events.LobbyMessageCreate) -> None:
...
Each event class could store its code/number/whatever in a class variable
Yes, this is what I already do, wdym by automatically
right now you're have a separate EventType enum and an event class for each event
Is it a library that has to maintain backwards compatibility? Or is it an internal thing?
Oh yeah you mean getting rid of the enum in favor of class var
yes
It has no support for old typing lol
wdym?
By backwards compatibility you mean what
If my code works with library version v1.0, but not with v2.0, it means that version 2.0 is not backwards compatible with 1.0
Libraries usually try to avoid breaking changes, they want users to be able to update to the next version of the library with no breakages
Oh well, I don't have it published yet so I don't mind any changes
Is there a way to specify inheritance dynamically in a way that static type annotators are able to follow:
if HAVE_PANDAS:
MixinCls = AdditionalPandasMixin
else:
MixinCls = NoPandasMixin
class A(MixinCls):
pass
However, the type checker isn't able to follow this. It's ok that the type checker follows one of those paths.
from typing import Final
HAVE_PANDAS: Final[bool] = True
class AdditionalPandasMixin:
def pandas(self): ...
class NoPandasMixin:
...
class A(AdditionalPandasMixin if HAVE_PANDAS else NoPandasMixin):
pass
A().pandas()
seems to work on pyright (and errors when you change it to false, as intended)
Nice. Let me try
It works if HAVE_PANDAS iff it's Final. If it is created like this
try:
import pandas
HAVE_PANDAS = True
except ImportError:
HAVE_PANDAS = False
it won't work
So I think it might only be able to use this if it can be resolved statically
how would it work in a static type checker if it couldnt resolve it statically 
This works both runtime and with static type checker
try:
import pandas as pd
_HAVE_PANDAS = True
except ImportError:
_HAVE_PANDAS = False
if TYPE_CHECKING:
HAVE_PANDAS: Final[bool] = True
else:
HAVE_PANDAS: Final[bool] = _HAVE_PANDAS
It works! Thank you
Not sure this is typing related or something else: In a class with __getattr__() implemented, is there some way to specify to VS Code not to navigate to it, but rather to directly to the property/function?
Can I hide the __getattr__() method for the type checker?
Found this discussion: https://discuss.python.org/t/should-structural-subtyping-consider-getattr/85062

Discussions on Python.org
Consider the following code snippet: from typing import Protocol class P(Protocol): x: int def f(p: P) -> None: ... class C: def getattr(self, name: str) -> int: ... f(C()) # Should this be an error or not? Different type checkers have diverging behaviors today: Mypy and Pyre1 thinks that this is fine, and Pyright reports a...
Solution:
class A:
if not TYPE_CHECKING:
def __getattr__(self, name):
...
(I didn't even know that if operators where permitted on class level. Learned something new.)
all statements that could be used in top-level code are :d (so, almost everything except yield, await and return)
top level await when
Won't it warn about the attribute not existing in that case?
Its really annoying that it thinks everything exists when the class implements getattr

We tell the story of how we brought NumPy's type-completeness score from ~33% to nearly 90%
class Mixin(FakeA):
""" Needs to be mixed in with A """
def f(self):
print(f"{self.a=}")
class A(Mixin):
""" Very large class with lots of methods """
a = 42
Is there a way to tell the type checker that Mixin has all of A available? Which is emulated with the FakeA class in this case? The best would be to let FakeA be a Protocol, but A is very big so FakeA becomes very repetitive. Runtime-wise Mixin without FakeA works with no problem, so this is just about how to specify it to the type checker.
Hi! I hope this is the right place to ask.
I am importing a library that assigns most of the class methods dynamically at runtime using (I believe) decorators. Besides the fact that this is making type checking pretty impossible, my IDE can't "see" the dynamically assigned methods and so I am getting piles of "method not found" errors.
Is there a best practice for handling this? I've starting writing my own pyi file and it works, but it's a bit time-consuming. I'm coming back to Python after a while so while I'm aware of tools like stubgen I'm not sure if that's the most modern approach
Hello I am attempting to write a parser combinator library in python with the goal of passing mypy strict mode type checking. I have a funny error:
tests/test_sexpr.py:43: error: Argument 2 to DelimitedBy" has incompatible type "Repeat[str, list[Sexpr] | Atom | String | Int]"; expected "Parser[str, list[Sexpr] | Atom | String | Int]" [arg-type]
The interesting part is that Repeat is a Parser, it inherits and conforms to the Parser protocol
Click here to see this code in our pastebin.
the type error happens near the bottom of the test file
Do you know what "variance" is?
not really but i have heard of it
Mypy has an explanation https://mypy.readthedocs.io/en/stable/generics.html#variance-of-generic-types
In your case, Parser[I, O] is invariant in O, but you should probably make it covariant
is there a way to do that with the new generics syntax or do i need a TypeVar
ah the docs mention this i think
New-style type variables infer variance. However, the core issue is that Parser cannot be covariant right now
(because of the signatures of Parser's methods)
interesting
do you see why that's the case in this example?
its because the signatures are different right?
and the signatures are not compatible
I'm not talking about the relation between Foo1 and Foo2
oh
Foo being covariant means that if A is a subtype of B, then Foo[A] is a subtype of Foo[B]
An example of a type that's not covariant is list. list[int] is not a subtype of list[int | str] (or vice versa)
okay i think i can see that
its a little confusing but ill read more about it
thank you btw
did you read this section?
yes but i was pretty confused by it
I'm working on a tutorial on generics right now and I'll have to explain variance somehow
i would be interested in seeing the tutorial for sure. im familiar with rust and c++ generics but somehow ive never had to worry about it there, or at least not that i was aware of
except with rust lifetimes thats one area it pops up
Rust doesn't have subtyping in the same way Python has
ah yup that would explain it
What's the correct type annotation for class var? Since this doesn't work and nor does just AnyEvent.
AnyEvent is a TypeVar bound to a class being subclassed by the event objects

thank you for helping with this btw
Rust does have subtyping and variance, but it has to do with lifetimes https://doc.rust-lang.org/reference/subtyping.html
Can you show more code? And maybe an example of how you'd call it?
What are AnyEvent and HandlerFuncDecorator?
- The _AnyEvent class
- An event object, subclassing _AnyEvent
- "AnyEvent" TypeVar
- HandlerFuncDecorator
- Wrong type annotation. I need to indicate it should be a class var of an event object.
- "Frontend"



can you post it as text
are you using the old TypeVar syntax for compatibility with python <3.12?
the correct annotation would be something like
def on_event(self, event_type: type[AnyEvent], /) -> HandlerFuncDecorator[AnyEvent]:
...
type being what
it's just the built-in type
type[Foo] means the class Foo or any of its subclasses
e.g. ```py
t1: type[int] = int
t2: type[int] = bool
TypeVar and TypeAlias were replaced with nicer built-in syntax in Python 3.12 ```py
S = TypeVar("S", bound=int)
def foo(s: S) -> list[S]:
...
Foo: TypeAlias = Callable[[S], list[S]]
->
def foo[S: int](s: S) -> list[S]:
...
type Foo[S: int] = Callable[[S], list[S]]
also, I'd recommend using stricter type checker settings, it would highlight issues like forgetting to pass parameters to a generic type
hmm I'll see, kinda wanna get used to Standard first
Thanks
I'm planning to switch to Py 3.13 when it comes out
For now I use 3.10.6
Python 3.14 is already out
Damn I'm not caught up
I = TypeVar("I")
O = TypeVar("O", contravariant=True)
O2 = TypeVar("O2", contravariant=True)
class Parser(Protocol):
def parse(self, input: I) -> tuple[I, O]:
pass
def __add__(self, other: Parser) -> Add:
return Add(self, other)
@dataclass
class Add(Parser):
a: Parser
b: Parser
def parse(self, input: I) -> tuple[I, tuple[O, O2]]:
rest, a = self.a.parse(input)
rest, b = self.b.parse(rest)
return (rest, (a, b))```
Now it doesnt like that the output for `Add` is different from the output of `Parser` even though the output is generic?i suspect im confused about how to use the old style type parameters
you shouldn't be using old-style type parameters (unless you need to support older versions)
if you did want to, then Parser should declare its type parameters by "inheriting" from typing.Generic, because currently the type variables are bound in methods
and then Add would have them too
Wait huh, is the second foo an allowed func declaration in 3.12??
That's cursed
i didnt see a way to change the variance with the new style parameters maybe i overlooked it
at least without assigning to a local var with an underscore
why are your outputs contravariant?
without the output being contravairant i run into an issue down the line when combining parsers
you probably meant to use covariant
when you use the new pep695 typevars, the variance will be inferred (generally to what you'd want)
i would probally use ABC instead of protocol here, since you'll inherit from it anyways to get the __add__
from abc import ABC, abstractmethod
from dataclasses import dataclass
class Parser[I, O](ABC):
@abstractmethod
def parse(self, input: I) -> tuple[I, O]:
...
def __add__[O2](self, other: "Parser[I, O2]") -> "Add[I, O, O2]":
return Add(self, other)
@dataclass
class Add[I, O1, O2](Parser[I, tuple[O1, O2]]):
a: Parser[I, O1]
b: Parser[I, O2]
def parse(self, input: I) -> tuple[I, tuple[O1, O2]]:
rest, a = self.a.parse(input)
rest, b = self.b.parse(rest)
return (rest, (a, b))
Here is why list[int] is not a subtype of list[int | str]:
def do_things(xs: list[int | str]) -> None:
do_things.append("banana")
things: list[int] = [1, 2, 3]
do_things(things)
#^ if this was allowed, then things` would contain a string now
``` essentially, variance depends on the methods a class has. ```py
class Foo[T]: # we want Foo to be covariant
def m1(self) -> T: ... # ok, T is in the output position
def m2(self) -> tuple[T, ...]: ... # ok, tuple[_, ...] is covariant
``` Why is this okay? Let's assume that `Sub` is a subtype of `Super` and compare the signatures.
```py
# Foo with T = Sub
def m1(self) -> Sub: ...
def m2(self) -> tuple[Sub, ...]: ...
# Foo with T = Super
def m1(self) -> Super: ...
def m2(self) -> tuple[Super, ...]: ...
``` `() -> Sub` is a subtype of `() -> Super`, and `() -> tuple[Sub, ...]` is a subtype of `() -> tuple[Super, ...]`.
Here's a method that would make our class not covariant:
```py
class Foo[T]: # we want Foo to be covariant
def m3(self, arg: T) -> T: ...
``` Why? Let's see an example: ```py
def func(x: Foo[int | str]) -> None:
print(x.m3(1))
print(x.m3("banana"))
foo_int: Foo[int] # imagine that we got it from somewhere
# foo_int.m3 expects an `int`.
func(foo_int) # But in this function, x.m3 must expect `int | str`
@restive rapids the reason i need to change the variance is because of this parser i think (if i understand correctly)
@dataclass
class Repeat[I, O](Parser[I, list[O]]):
parser: Parser[I, O]
key: slice[int, int, None] | int
def parse(self, input: I) -> Tuple[I, list[O]]```i'd just not use a list return type, use collections.abc.Sequence instead
its not particularly important that it returns specifically a list (which is mutable -> invariant)
yes
Here's another way to make the class not-covariant: returning an invariant type from a method. py class Foo[T]: def m4(self) -> list[T]: ... Foo[int] is not a subtype of Foo[int | str] because list[int] is not a subtype of list[int | str]
(this is probably the main issue you're running into)
so even with Sequence as the return type of Repeat im getting the same error?
so just have a dummy method basically to help it infer?
No, that's not what I meant
If you have just one method that e.g. returns list[T], the class cannot be covariant anymore
Variance isn't a toggle that you choose for each class, it's just a consequence of what methods a class has
so what is the correct fix here for me? I was originally going to use the old style type vars to control the variance, but if thats not needed im not sure how to actually do it
from abc import ABC
from collections.abc import Sequence
from dataclasses import dataclass
class Parser[I, O](ABC):
def parse(self, input: I) -> tuple[I, O]:
...
def __add__[O2](self, other: "Parser[I, O2]") -> "Add[I, O, O2]":
return Add(self, other)
@dataclass
class Add[I, O1, O2](Parser[I, tuple[O1, O2]]):
a: Parser[I, O1]
b: Parser[I, O2]
def parse(self, input: I) -> tuple[I, tuple[O1, O2]]:
rest, a = self.a.parse(input)
rest, b = self.b.parse(rest)
return (rest, (a, b))
#
@dataclass
class Repeat[I, O](Parser[I, Sequence[O]]):
parser: Parser[I, O]
key: slice[int, int, None] | int
def parse(self, input: I) -> tuple[I, Sequence[O]]:
...
is just fine
okay lets try that
still getting this error
ests/test_sexpr.py:44: error: Argument 2 to "DelimitedBy" has incompatible type "Repeat[str, Sequence[Sexpr] | Atom | String | Int]"; expected "Parser[str, Sequence[Sexpr] | Atom | String | Int]" [arg-type]
Click here to see this code in our pastebin.
the new variance inference is infuriating because it doesn't give a way to debug why you don't have the variance you want
oh they used collections.abc Sequence
i wonder if thats why mine isnt working
no that still didnt work hmm
here's a janky way to debug this:
class Super: pass
class Subc(Super): pass
def f(r1: Parser[str, Subc]) -> None:
_r2: Parser[str, Super] = r1
``` you should see an error on the assignment to the effect of
Type "Parser[str, Subc]" is not assignable to declared type "Parser[str, Super]"
"Parser[str, Subc]" is not assignable to "Parser[str, Super]"
Type parameter "O@Parser" is invariant, but "Subc" is not the same as "Super"
then you comment out methods on `Parser` until the error goes away... that way you know the last method you commented was problematicFor example: with just parse and map, there was no issue. When you add __add__, the type becomes invariant
That must mean that Add[I, O, O2] is not covariant in O
Ah... that's because dataclasses don't support having covariant attributes even when it's frozen
i must say that it would be less code and less fighting with the typesystem if you didnt use parser combinators
s-exprs are easy to parse with a couple of loops and conditions
im just using sexprs as a test
i plan on parsing gentoo atoms and stuff with it
If you replace Add with this: ```py
class Add[I, O, O2](Parser[I, tuple[O, O2]]):
def init(self, a: Parser[I, O], b: Parser[I, O2]) -> None:
self._a = a
self._b = b
def parse(self, input: I) -> tuple[I, tuple[O, O2]]:
rest, a = self._a.parse(input)
rest, b = self._b.parse(rest)
return (rest, (a, b))
``` now you can add Foo.__add__ and keep the class covariant
It works but it's a very 🥴 debugging technique
No, the issue is dataclass itself. Consider this:
@dataclass
class Box[T]:
value: T
``` if you have a `box: Box[Shape]`, you can both read `box.x` and write `box.s`. So this would be a problem: ```py
def twiddle_with_box(box: Box[Shape]):
box.value = Rectangle()
circle_box: Box[Circle]
set_twiddle_with_box(circle_box)
There's @dataclass(frozen=True), but for various reasons it still keeps type variables invariant
Actually, here's a better suggestion: replace concrete types in Parser's methods with Parser ```py
class ParserI, O:
@abstractmethod
def parse(self, input: I) -> tuple[I, O]:
raise NotImplementedError
def map[O2](self, f: Callable[[O], O2]) -> Parser[I, O2]:
return Map(self, f)
def __add__[O2](self, other: Parser[I, O2]) -> Parser[I, tuple[O, O2]]:
return Add(self, other)
def __sub__(self, other: Parser[I, object]) -> Parser[I, O]:
return Sub(self, other)
def __or__[O2](self, other: Parser[I, O2]) -> Parser[I, O | O2]:
return Or(self, other)
def __getitem__(self, key: int | slice[int, int, None]) -> Parser[I, Sequence[O]]:
return Repeat(self, key)
now you can keep Add and such invariant
so __getitem__ and __add__ both dont seem to like that
does that mean those are the issue?
Can you post the new code?
you'll also need to change Sexpr from list[Sexpr] to Sequence[Sexpr]
also Sub is wrong, it requires the thing that wont even be used as an output to match the output type with the other thing
wait its my fault it doesnt like them
Oh yeah you need to change Sub to this ```py
@dataclass
class Sub[I, O](Parser[I, O]):
a: Parser[I, O]
b: Parser[I, object]
def parse(self, input: I) -> tuple[I, O]:
try:
self.b.parse(input)
raise ParserError(input)
except ParserError:
return self.a.parse(input)
my bad
not sure why you'd want this though
is this a negative assertion? like, that b does not appear?
i'd expect you to eat b and then parse a
its supposed to be negative lookahead
brb one moment
yeah, like (?!=) in regex
generic errors also dont really work, because signatures dont show what exceptions a function raises
when you except ParserError, you wont know which output you got, and you cant isinstance with a typevar since they're not reified
i could easily fix that and require a string error
Does anyone know if there's a way properly type a function like this using TypeVarTuple?
def make_instances(types: tuple[type, ...]) -> tuple:
return tuple(t() for t in types)
``` I was kinda hoping something like this would just work
```python
def make_instances[*Ts](types: tuple[type[*Ts]]) -> tuple[*Ts]:
return tuple(t() for t in types)
``` but it appears that it does not.
I've searched the PEP and docs, and they do indeed not mention this type of usage, which makes me a little sad 😦
Am *I* missing something here, or is it the feature I want that simply does not exist (yet)?There's no good way to do what you want
TypeVarTuple is not very useful sadly
You can do something like this: ```py
class Banana[*Ret]:
def init(self: Banana[*tuple[()]]) -> None: ...
def add[T](self, t: type[T]) -> Banana[*Ret, T]: ...
def run(self) -> tuple[*Ret]: ...
i, s, b = Banana().add(int).add(str).add(bool).run()
i: int, s: str, b: bool
only relevant discussion i could find is https://discuss.python.org/t/pre-pep-considerations-and-feedback-type-transformations-on-variadic-generics/50605
Discussions on Python.org
Preface Before I begin, please note that this is the first time that I have considered and researched the process of proposing a PEP. The purpose of this post is to get some feedback from the community on a PEP I plan to propose. The format of this post does not necessarily represent the final format of the PEP, and, based upon other PEPs I have...
If you really want this, you can add overloads:
@overload
def make_instances() -> tuple[()]: ...
@overload
def make_instances[A](_a: type[A]) -> tuple[A]: ...
@overload
def make_instances[A, B](_a: type[A], _b: type[B]) -> tuple[A, B]: ...
@overload
def make_instances[A, B, C](_a: type[A], _b: type[B], _c: type[C]) -> tuple[A, B, C]: ...
@overload
def make_instances[A, B, C, D](_a: type[A], _b: type[B], _c: type[C], _d: type[D]) -> tuple[A, B, C, D]: ...
def make_instances(*args: type[object]) -> tuple[object, ...]:
# implementation
``` that's how the built-in `zip` and `map` are definedYeah, that's what I ended up doing. Which isn't really satisfactory 🙁
Mhm. That's a good idea actually!
This is great if you're paid by the line of code... or by the hour
the overloads I mean
Can someone share some experience with teaching or learning generic functions/classes in Python? What was particularly confusing? (besides variance)
so ive rewritten some stuff and im getting a new error:
sexpr: Parser[str, Sexpr] = DelimitedBy(
Lit("("), Lazy(lambda: sexpr)[0:-1], Lit(")")
) | atom.map(map_atom)```
```tests/test_sexpr.py:42: error: Incompatible types in assignment (expression has type "Parser[str, Sequence[Sequence[Sexpr] | Atom | String | Int]]", variable has type "Parser[str, Sequence[Sexpr] | Sexpr]") [assignment]
tests/test_sexpr.py:44: error: Argument 1 to "map" of "Parser" has incompatible type "Callable[[str], Sexpr]"; expected "Callable[[str], Sequence[Sequence[Sexpr] | Atom | String | Int]]" [arg-type]
Found 2 errors in 1 file (checked 1 source file)```gah
im trying to port this parser from rust (idk if that helps or not) <https://zen.jturnerusa.dev/paste/atmosphere-recruiting-unlikely-artery-volumes-mist
doing this in rust was trivial idk why python is fighting me so much. maybe its a user error
i understand why its complaining i think but im not entirely sure how to solve it
i might have fixed it
from pyparse import Parser, ParserError, DelimitedBy, Lit, Word, Lazy
from string import ascii_letters as letters, digits
from dataclasses import dataclass
from collections.abc import Sequence
@dataclass
class List:
list: Sequence["Sexpr"]
@dataclass
class Atom:
atom: str
@dataclass
class String:
string: str
@dataclass
class Int:
integer: int
type Sexpr = List | Atom | String | Int
alphanums = letters + digits
atom = Word(letters, alphanums)
string = DelimitedBy(Lit('"'), Word(alphanums, alphanums), Lit('"'))
integer = Word(digits, digits)
def map_atom(s: str) -> Sexpr:
return Atom(s)
def map_string(s: str) -> Sexpr:
return String(s)
def map_int(s: str) -> Sexpr:
return Int(int(s))
def map_list(s: Sequence[Sexpr]) -> Sexpr:
return List(s)
sexpr: Parser[str, Sexpr] = DelimitedBy(
Lit("("), Lazy(lambda: sexpr)[0:-1].map(map_list), Lit(")")
) | atom.map(map_atom)
im not super sure why it cares if i wrap the Sequence in a class?
I have a new problem:
I have these two parsers
@dataclass
class SeparatedList[I, O, O2](Parser[I, Sequence[O]]):
_parser: Parser[I, O]
_delimiter: Parser[I, O2]
def parse(self, input: I) -> tuple[I, Sequence[O]]: ...
@dataclass
class Whitespace(Parser[str, str]):
def parse(self, input: str) -> tuple[str, str]: ...
And im using it like this
sexpr: Parser[str, Sexpr] = (
DelimitedBy(
Lit("("),
SeparatedList(Lazy(lambda: sexpr), Whitespace).map(map_list),
Lit(")"),
)
| atom.map(map_atom)
| string.map(map_string)
| integer.map(map_int)
)
Im getting a funky error though
Found 1 error in 1 file (checked 1 source file)
why does it want a Never type here?
I'm missing how Whitespace qualifies as a delimiter in your definitions? Maybe I'm just being dumb today?
the delimiter takes anything that is a Parser[I, O2]
and Whitespace is a Parser[str, str] right
there is a Parser class that they all inherit from and the idea is that you can put parsers inside of other parsers
class Parser[I, O](ABC):
@abstractmethod
def parse(self, input: I) -> tuple[I, O]:
pass```Hmm. Maybe I'm just not fully read-in on the Python type syntax, but how do your two 'names', _parser, and _delimiter, get differentiated in your constructor call?
Those look keyword-y to me?
That's the part that is throwing me.
would it help if i pasted the whole file
It would probably help more if somebody less-ignorant answered haha
You might be doing it totally right and I'm seeing the wrong hint
Click here to see this code in our pastebin.
Hmm, this doesn't look wildly crazy to me, what am I missing...
i come from rust where spewing generics everywhere is super common, i dont see much python code that is highly generic like this but maybe i dont look at enough python
trying to write rust in python is probably one of my issues
I don't hate it honestly, let me see if I can figure out why it's angry
This looks a lot like a Ruby compiler's parser we created once
Oh I think I see it
SeparatedList wants two instances and you're passing Whitespace itself, right?
At least I think that's what the error is poorly trying to indicate?
the error for that should be WAY better
I guess that's probably hard in the current architecture
because there's not a great direct relationship between class Foo and an instance of foo, like there is the other way around
a foo obviously has a type that points right at Foo, etc
but there's no way to say "hey what does your constructor construct exactly, and would that fit here?"
maybe there is?
I don't get what or if I am doing something wrong here...
It doesn't seem to like variables:
pages = ["str", discord.Embed()]
v2_pages = ["str", discord.ui.TextDisplay[Any]("str")]
pag = BaseClassPaginator(pages, components_v2=False) # <-
# Argument of type "list[str | Embed]" cannot be assigned to parameter "pages" of type "list[BoundPage]" in function "__new__"
# "list[str | Embed]" is not assignable to "list[BoundPage]"
# Type parameter "_T@list" is invariant, but "str | Embed" is not the same as "BoundPage"
# Consider switching from "list" to "Sequence" which is covariant PylancereportArgumentType
# No overloads for "__new__" match the provided arguments PylancereportCallIssue
# core.py(169, 13): Overload 2 is the closest match
v2_pag = BaseClassPaginator(v2_pages, components_v2=True) # <- same thing except closes match is overload 1 instead of 2
# now these are fine too
pag = BaseClassPaginator(["str", discord.Embed()], components_v2=False)
v2_pag = BaseClassPaginator(["str", discord.ui.TextDisplay[Any]("str")], components_v2=True)
# these both working as expected both times
reveal_type(pag.pages)
reveal_type(v2_pag.pages)
the class: https://mystb.in/0dad0503d7d8083931
I've never used this API, but shouldn't this be discord.ui.TextDisplay[Any]("str")()?
but if it works fine in the second case maybe not? dunno
wdym? ui.TextDisplay[T]("string") is the same as ui.TextDisplay("string") runtime wise
I mean isn't TextDisplay("string") giving you back a string-typed TextDisplay that you then need to instantiate?
Or is it not a factory thingy?
Does anyone know of another project using pyproject.toml that has a directory structure like this, and which installs assets/icon.png to a sensible location on the target system, from where I can find it from within mymodule/main.py?
├── assets
│ └── icon.png
├── mymodule
│ ├── __init__.py
│ └── main.py
└── pyproject.toml
oh nah, it's just a normal class
class TextDiplay[T]:
def __init__(self, content: str) -> None:
...
your question doesn't sound typing related? #1035199133436354600
pages: list[BoundPage] = ["str", discord.Embed()]
v2_pages: list[BoundV2Page] = ["str", discord.ui.TextDisplay[Any]("str")]
yeah that works, but why
["str", discord.Embed()] on its own, when assigned to a variable, is inferred as list[str | Embed]. It's not assignable to list[str | Embed | File | ...] because list is invariant.
You can read about variance here:
https://mypy.readthedocs.io/en/stable/generics.html#variance-of-generic-types
https://typing.python.org/en/latest/reference/generics.html#variance-of-generic-types
oh fml
A better solution would be accepting Sequence[PageT] or Iterable[PageT] instead of list[PageT]. list is almost never the best annotation for a parameter
I was using Sequeue before
but pages="string" is also valid in that case
and users can pass nested lists
so that's also annoying to handle
could do list[PageT] | tuple[PageT, ...]
but that's ugly lol
I would probably just accept Iterable/Sequence and then raise a runtime error if the argument is a srting
If this is a library, there's a 100% chance someone else will run into the variance issue
and unfortunately type checkers don't show you a tutorial on variance when one does run into an issue, so it can be difficult to resolve (besides a # type: ignore)
fair
btw, did you know about variance before? I'm in the process of making a tutorial, so I want to gather some data on which explanations work and which don't
well, I’ve experimented with it and read the python docs, but I just can’t wrap my head around them. iirc there are 4 variants, and I always forget the differences or when to use each
i'm also really bad at explaining stuff so I can't tell what way would work, sorry 
So you've read both of these articles and they didn't work?
Only sorta, there's covariance and contravariance, but you can have both (bivarance) or neither (invariance).
no, I was linked the following a while back, before 3.11: https://peps.python.org/pep-0484/#covariance-and-contravariance
I didn't bother looking into it today as I 80% thought that I must be doing something wrong in the overloads
I recently found Jelle’s unsoundness library, and have been looking through it, very interesting. One thing confuses me though. In typeis_narrow_list it says “Narrowing to a list with TypeIs is almost always unsound, because it is not possible to know the type of a list in the type system at runtime.”
The thing that I’m wondering, isn’t this only true for lists with 0 elements? If a list has 1 or more elements, wouldn’t the runtime type of the list at least be list[union of all the types of the list elements]? And if there were a hypothetical “non-empty list” type, would you be able to safely narrow it with TypeIs?
[False] could be one of:
list[bool]list[int]list[bool | str]list[object]list[Literal[False, "apple", "banana"]]
...
e.g.: ```py
def is_int_list(x: object) -> TypeIs[list[int]]:
"""Check if x is a list of integers."""
return isinstance(x, list) and all(isinstance(i, int) for i in x)
def foo(x: Sequence[object]):
if is_int_list(x):
x.append(42)
lst: list[bool] = [False, False, True]
foo(lst, x)
now there's a 42 in my list of bools
Hm, so then wouldn’t that apply to any generic type, not just int?
?
yes, you could replace int with other types
Oops, I meant list, not int
Generic types are very diverse and they can be pretty much anything
for a tuple, it should be fine, e.g. ```py
def is_int_tuple(x: object) -> TypeIs[tuple[int, ...]]:
...
(or other immutable collections)
I see, that makes sense, thanks!
Covariant frozen dataclasses, huh
This doesn't work with pyright on python 3.13 anymore: ```py
@dataclass(frozen=True)
class Box[T]:
label: str
value: T
def test_box_covariant(box: Box[int]) -> None:
_0: Box[int | str] = box # error: Box[int] is not assignable to Box[int | str], Box is invariant
don't the Just types fix that? Like would JustInt work ?
optype/_core/_just.py line 144
class JustInt(Protocol, metaclass=_JustMeta, just=int): # type: ignore[misc] # pyright: ignore[reportGeneralTypeIssues]```def is_int_list(x: object) -> TypeIs[list[int]]:
"""Check if x is a list of integers."""
return isinstance(x, list) and all(isinstance(i, int) for i in x)
def foo(x: Sequence[object]):
if is_int_list(x):
x.append(42)
lst: list[Literal[0, 1]] = [0, 1, 0, 1, 0, 0, 1]
foo(lst, x)
well i mean replacing the TypeIs[list[int]] with TypeIs[list[JustInt]], as int implies subclasses of int are accepted too, even though they should not be (e.g. bool)
That'd still be an issue, 0 and 1 are JustInts at runtime
Well, a list[Literal[anything_int]] should pass, just the int subclasses shouldn't, right?
The problem is that list[Literal[0, 1]] is not a list[int]. In the example lst ends up having 42 which contradicts is static type
oh, right
That's because of __replace__ IIRC
Discussions on Python.org
Consider: from dataclasses import dataclass from typing import Generic, TypeVar, override if False: # Switch to True is a type error. @dataclass(frozen=True) class C[T]: x: T # T is inferred to be invariant! else: U = TypeVar('U', covariant=True) @dataclass(frozen=True) class C(Generic[U]): x: U class ...
FWIW I agree with @oblique urchin in https://discuss.python.org/t/make-replace-stop-interfering-with-variance-inference/96092/17. I think type checkers should be pragmatic and special-case generated __replace__ methods, ignoring it for the purposes of inferring variance
What about generating overloads?
I guess __replace__ breaks type checker expectations in other ways too...
@dataclass(frozen=True)
class Box[T]:
name: str | None
value: T
@dataclass(frozen=True)
class StrictIntBox[int](Box[int]):
name: str
``` `StrictIntBox` is-a `Box[int]`, so it's supposed to accept `__replace__(name=None, value="aaa") -> Box[str]`Oh and while you're here @lunar dune
According to this message: https://discuss.python.org/t/clarifying-the-typing-spec-regarding-polymorphic-protocols/60255/5 this is not a spec-compliant way to define that I'm returning a generic identity function: py def get_identity[T](name: str) -> Callable[[T], T]: ... and instead I'm supposed to make a protocol with a __call__[T](self, arg: T, /) -> T method.
Is that still the case? I can't find this in the specification. But these "rescoping" functions are used on the typing.python.org site
https://typing.python.org/en/latest/reference/generics.html#decorator-factories
https://typing.python.org/en/latest/spec/dataclasses.html#id2
I'm always here... Lurking in the shadows...
Yes, that's still the case. Arguably, by using PEP-695 syntax in this way, you've explicitly requested that the TypeVar be scoped to the function here rather than "scoped to the return annotation". Given that, you've effectively prohibited the type checker from using the pre-PEP-695 heuristic where it would give Callable in the return annotation its own "TypeVar scope"
It's a bit unfortunate IMO that PEP-695 makes this kind of decorator harder to write, but it is what it is. Better Callable syntax might help quite a bit here
thanks for the explanation 👍
I ran into an issue where pyright supports using the non-spec way with dataclass_transform, but doesn't support the official way
will probably file an issue
It came up just the other week in https://github.com/python/typing/pull/2089#discussion_r2386358470
I was confused when this worked, because the actual scoping works out like get_identity(name: str) -> Callable[forall T. [T], T]
(and not what I expected, which is: T is used 0 times in the parameter types, so it will be unsolved when you just call get_identity("aaa"))
https://github.com/SusanBhattarai/StringableInference-py
im just a beginner, any suggestions guys?

GitHub
Free Python client for the StringableInference API, supporting chat completions and model retrieval - SusanBhattarai/StringableInference-py
seems like it's not related to type hints
you could share it in #data-science-and-ml or on the r/Python subreddit

so this is part of a little refactor and the GradFunction gets called with an old siganture in many places currently. Could that lead to this note?
yes, you are probably getting errors at the old call sites
that'd explain why I get a whole list of notes. The note itself doesn't make any sense to me but let's see, will finish this and see if that solves it. thanks so far!
from typing import Tuple, TYPE_CHECKING
if TYPE_CHECKING:
import jax
class Context:
"""
Context for storing values needed in backward pass.
Use save_for_backward() for JAX arrays.
Store non-array values (axis, keepdims, etc.) as direct attributes.
Example:
ctx = Context()
ctx.save_for_backward(input_data)
ctx.axis = 0
ctx.keepdims = True
"""
def __init__(self) -> None:
self.saved_values: Tuple[jax.Array, ...] = ()
def save_for_backward(self, *values: jax.Array) -> None:
self.saved_values = values
Do I really have to import jax in runtime for the type hinting? I thought on runtime the type hints are ignored?
I think future import will fix this on old python
^ lazy evaluation of annotations was added in py3.14
I'm on 3.13.5 but yeah if I import future its fine
on another note, I have this context object which purpose is to be a "flexible data container" (or whatever you wanna call it)
from __future__ import annotations
from typing import Tuple, TYPE_CHECKING
if TYPE_CHECKING:
import jax
class Context:
"""
Context for storing values needed in backward pass.
Use save_for_backward() for JAX arrays.
Store non-array values (axis, keepdims, etc.) as direct attributes.
Example:
ctx = Context()
ctx.save_for_backward(input_data)
ctx.axis = 0
ctx.keepdims = True
"""
def __init__(self) -> None:
self.saved_values: Tuple[jax.Array, ...] = ()
def save_for_backward(self, *values: jax.Array) -> None:
self.saved_values = values
So sometimes we add random new proeprties to the object. Mypy doesn't like that. I don't wanna add a # type: ignore[attr-defined] to every new property, can't I define that on the Context class itself? "Don't throw an error if we add a new property" kinda thing?
ah apparently I can add:
if TYPE_CHECKING:
def __getattr__(self, attribute: str) -> Any: ...
def __setattr__(self, attribute: str, value: object) -> None: ...
to my Context class. Hard for me to judge if this is some hacky thing or not though.
You should consider typing your context attributes.
so you mean if I do e.g.
ctx = Context()
ctx.input_shape = self.data.shape
ctx.axis = axis
ctx.keepdims = keepdims
ctx.input_size = self.data.size
I should use comments to add typing?
Extend Contxt and add your type hints
You could do what click does and have context be class based.
no idea what click is and what you mean by extend context - these are "dynamic attributes", also class based meaning?
def find_object(self, object_type: type[V]) -> V | None:
"""Finds the closest object of a given type."""
node: Context | None = self
while node is not None:
if isinstance(node.obj, object_type):
return node.obj
node = node.parent
return None
def ensure_object(self, object_type: type[V]) -> V:
"""Like :meth:`find_object` but sets the innermost object to a
new instance of `object_type` if it does not exist.
"""
rv = self.find_object(object_type)
if rv is None:
self.obj = rv = object_type()
return rv
Though it is limited to one object per context
ok thanks, not sure what I should learn from that example though.
You'd use it like this. ```py
@dataclass
class Settings:
input_shape: tuple[int, ...]
axis: int
keepdims: tuple[int, ...]
input_size: int
obj = ctx.ensure_obj(Settings)
obj.input_shape = self.data.shape
obj.axis = axis
obj.keepdims = keepdims
obj.input_size = self.data.size
completely typesafe
ah nope that is way too overengineered and probably slow.
assuming some types of course.
Then just use a dict.
dataclasses are only slow if you're creating thousands of them.
and you can add slots=True to make it more memory efficient if you do make lots of them.
or just omit the dataclass decorator entirely
Your context class might look like this. ```py
class Context:
obj: Any = None
def ensure_obj[T](self, obj_type: type[T]) -> T:
if not isinstance(self.obj, obj_type):
self.obj = obj_type()
return self.obj
the reason for Context is simply to have a unified signature for my backward functions:
def __add__(self, other_node) -> Node:
if not isinstance(other_node, (int, float, jax.Array, Node)):
raise TypeError(
f"Unsupported type for addition with Node. Can't add {type(other_node)} to Node."
)
if isinstance(other_node, jax.Array):
other_node = Node(other_node)
if isinstance(other_node, (int, float)):
other_node = Node(jnp.array(other_node))
data: jax.Array = self.data + other_node.data
ctx = Context()
ctx.save_for_backward(self.data, other_node.data)
result = Node(
data=data,
dtype=data.dtype,
device=data.device,
requires_grad=self.requires_grad or other_node.requires_grad,
)
result.grad_fn = GradFunction(
backward_fn=add_backward,
ctx=ctx,
parents=[self, other_node],
)
return result
depending on the math. function you implement, the params are different. hence you just add them to ctx - I did think of using Context::params: dict though.
But I have 100ks or millions of those in the long term, so I'll have to rethink it anyway. Atm I mainly try to understand the problem haha and geta first version working and then go back and design it properly.
Thanks for the inputs!
on another note:
def binary_cross_entropy_loss(logits: Node, targets: Node):
"""
Binary cross-entropy loss for 2-class classification.
L = (1/N) * sum(-y_i * log(p_i))
Args:
logits: (batch_size, 2) - raw scores for 2 classes
targets: (batch_size,) - class indices (0 or 1)
"""
# Convert class indices to one-hot encoding
targets_one_hot = jax.nn.one_hot(targets.data, num_classes=2)
probs: Node = logits.softmax(dim=1)
per_sample_loss = (1.0) * (targets_one_hot * probs).sum(axis=1)
loss = per_sample_loss.mean()
...
here we have target_one_hot * probs i.e. jax.Array * Node. Now Node::__mul__ returns Node, same with Node::sum() and the multiplication with 1. So the whole expression should end up as a Node.
If I do: per_sample_loss: Node = (1.0) * (targets_one_hot * probs).sum(axis=1) I get a type error though because apparently MyPy can't figure that out.
error: Incompatible types in assignment (expression has type "Array", variable has type "Node")
- How can I help MyPy figure that out?
- Is it okay to not have a type hin for
per_sample_loss?
ah actually I might be in the wrong here.
(Pdb) foo = (targets_one_hot * probs)
(Pdb) whatis foo
<class 'semiflow.node.Node'>
(Pdb) foo1 = (targets_one_hot * probs).sum(axis=1)
(Pdb) whatis foo1
<class 'semiflow.node.Node'>
(Pdb) foo2 = (1.0) * (targets_one_hot * probs).sum(axis=1)
(Pdb) whatis foo2
<class 'semiflow.node.Node'>
Vscode thinks .sum() is jax.Array::sum() hence my littel confusion but no, should all be dandy. hmm.
the rhs needs __rmul__
i think the way it works is, python checks the lhs __mul__ first, and if that doesn't exist then it checks the rhs __rmul__
so if Array has no Array.__mul__ then python looks for Node.__rmul__ in that example, not Node.__mul__
https://docs.python.org/3/reference/datamodel.html#object.__radd__
These functions are only called if the operands are of different types, when the left operand does not support the corresponding operation, or the right operand’s class is derived from the left operand’s class.
I misremembered then but in any case both are implemented and evaluate to Node as you see in the pdb output. Which mypy doesn't seem to recognize. or maybe even my LSP in general (no idea who mypy etc is all exactly implemented in vscode)
VS Code internally uses a thing called "Pylance" which I believe uses Pyright for type checking, not Mypy
ah wait maybe I see an issue
yeah pylance sounds like something I installed ages ago. Figured maybe mypy uses the LSP somehow. I literally am a big noob when it comes to all that. 😄 so I mentione whatever Ican.
I think I see it too. is there also an Array.__mul__ method?
Array is jax.Array - no idea why it keeps displaying it as Array
it just doesn't say the fully qualified name
(which imo it should)
can you check this one step at a time, in mypy specifically?
n1 = targets_one_hot * probs
assert_type(n1, Node)
n2 = n1.sum(axis=1)
assert_type(n2, Node)
n3 = 1.0 * n2
assert_type(n3, Node)
per_sample_loss = n3
__mul__ nor __rmul__ had proper types in their singature - I just never saw it. But that might explain why it doesn't realize that.
yeah that's the tricky part: if you're type checking your program, you assume that all the type hints of libraries etc are correct. otherwise everything goes off
def __mul__(self, other_node: Node | int | float | jax.Array) -> Node:
def __rmul__(self, other_node: Node | int | float | jax.Array) -> Node:
yeah ofc this was teh first thing I implemented and I only adapted types a bit later. but that solved it.
ah fuck only inside vscode.
$ mypy ./semiflow/nn/loss/bce_loss.py
semiflow/nn/loss/bce_loss.py:24: error: Incompatible types in assignment (expression has type "Array", variable has type "Node") [assignment]
Found 1 error in 1 file (checked 1 source file)
.< 😄
I solved it by just turning around the multiplication making it invoke __mul__. Not sure why it can't resolved the rmul case though but more importantly hwo one would handle that
does jax.Array implement __mul__? That would take precedence if it exists
Sometimes I think this should be called #type-haunting
that's spooky
But in the model Python's got, we kinda do 'haunt' our implementations with type names 🙂
Wisdom of our ancestors.
So is the future annotations import not necessary anymore when using the if TYPE_CHECKING: statement in 3.14, or did I understand that wrong?
from __future__ import annotations should not be used in 3.14
(or rather, if your minimum supported version is 3.14 or later)
So, that's a yes?
yes
if a vscode workspace has multiple python interpreters/virtual environments, how do i make it load all of them rather than one, so i can see all the types in all projects without changing interpreter manually.
That's because discord.py is inspecting the annotations at runtime
TYPE_CHECKING is False at runtime, no matter the Python version
No, if you need to have GuildContext available at runtime, use a normal improt
(without the TYPE_CHECKING guard)
What if it's a circular import
Why is cogs.utils.context importing this module?
3.14 doesn't change how imports function at all
I would definitely just fix the circular dependency
import changes will probably come in 3.15
yeah, lazy imports
opt in of course
though even that won't automagically fix all circular import issues
Relative imports without needing a package 
That's just absolute imports
import foo vs from . import foo
if you don't have a package, your import is top level anyway
Odd cuz there was just a place where it didn't work normally for me
Wel jax.Array implements __mul__ for types it knwos but it doesn't know Node, that's my own type. Which is why the return type of the expression is Node.
I don't see why the "type hinter" (not too familiar with the lingo yet) wouldn't see that tho.
Maybe it's a static analysis thing then, where the type checker can't determine when it would return NotImplemented
I do have two other questions though:
- How do people actually use mypy? Do you just code, run it at the end, make you commit, maybe have some git action whatever run it again and that's it? Or do people like configure something that everytime you run
pythonit executes? - Can I do something like "The Node type isn't allowed in this file at all"?
I don't know about #2, but I treat it as part of my test suite
does python have something like typescript Pick<>
i have a dataclass and i need to pick some of the properties of it
and create a new dataclass based on it
how would i go about making an Input protocol for my parser? I want the parser to be generic over str and bytes and maybe even a list of T
class Input(Protocol):
def __eq__(self, other: object) -> bool:
pass
def __getitem__(self, other: object) -> Self:
pass
def __str__(self) -> str:
pass```i have this but it doesnt pass the type checker when i use a str as parser input
it would be nice if mypy would tell me what and why it doesnt pass lol
or what it expects
foo: Input = "banana"
gives me this: ```
main.py:15: error: Incompatible types in assignment (expression has type "str", variable has type "Input") [assignment]
main.py:15: note: Following member(s) of "str" have conflicts:
main.py:15: note: Expected:
main.py:15: note: def getitem(self, object, /) -> str
main.py:15: note: Got:
main.py:15: note: def getitem(self, SupportsIndex | slice[Any, Any, Any], /) -> str
Input describes an object that must be able to handle any object in __getitem__, but str can only handle integers and slices
how did you get that output
What version of mypy do you have? And can you show the code?
mypy 1.18.2 (compiled: yes)```Click here to see this code in our pastebin.
its kind of a big file now
Ah, now it says this main.py:263: error: Type argument "str" of "Parser" must be a subtype of "Input" [type-var] main.py:266: error: Argument 1 to "parse" of "TakeWhile" has incompatible type "str"; expected "Never" [arg-type] main.py:270: error: Type argument "str" of "Parser" must be a subtype of "Input" [type-var] main.py:277: error: Value of type variable "I" of "ParserError" cannot be "str" [type-var] but doesn't explain why str is not a subtype of Input
I remember why I use pyright now lol
thank you for all of the help you and others have provided me with so far
Why do you want to constrain Parser though?
i guess i could just constrain the classes that require the input protocol? is that what you mean
yes
yeah that would be better
or maybe this protocol never comes up and you just have separate parsers for e.g. str and bytes
in theory i wanted to be able to parse any arbitrary sequence of things, so you could do a lexer pass and then parse "tokens" rather than str if that makes sense
although the main use case will be for parsing str or bytes lol
whats up with this error?
pyparse/__init__.py:266: error: Argument 1 to "parse" of "TakeWhile" has incompatible type "str"; expected "Never" [arg-type]
I suspect it has to do with my protocol
show the code?
this is the TakeWhile iterator
@dataclass
class TakeWhile[I: Input](Parser[I, I]):
_f: Callable[[I], bool]
def parse(self, input: I) -> tuple[I, I]:
i = 0
while self._f(input[i]):
i += 1
return input[i:], input[:i]```Can you paste all the code perhaps
Click here to see this code in our pastebin.
i couldnt get to pass mypy when i pulled the constrained off of Parser, but ill fix that later
I think mypy can't infer that the TakeWhile instance is a TakeWhile[str]
that's uhhh an educated guess
If you're used to Haskell or Rust or other languages with extensive bidirectional inference, python's type checkers are not like that
it exists sometimes but it's very limited
yup im most used to rust, and porting my rust parser library over to python roughly
Why are you rewriting it from Rust to Python?
I thought it's the other way around nowadays
^ just expose your rust bindings to python
that might be difficult if you're relying on traits
haha mostly for fun and learning, but i also prefer writing python in general
A parser is one of those things you'd want to be written in rust.
Have you tried pyright or basedpyright instead of mypy?
no but i definitely can
ty is also available, though it's in alpha
(python type checker written in rust, same guys that made uv and ruff)
Is there a way to programmatically enhance the annotations of a function so that type checkers like mypy can see the enhanced annotations? I was spurred by https://www.peterbe.com/plog/in-python-you-have-to-specify-the-type-and-not-rely-on-inference to see whether a decorator could enhance type annotations of a function. The answer is yes, but: at runtime the changes are visible in __annotations__ but not to type checkers (at least, not to mypy)... so it's of no help for the OP's use case.
Also if someone knows a more specific discussion of why Python typing chose not to infer an argument type as the default value's type, I bet the blogger would not mind a citation in the comments. I don't have enough familiarity with the history of typing PEPs to guess where it might have been said.
from typing import TYPE_CHECKING
def annotate_defaults(fn):
"""Use default arguments to enhance a function's type annotations
For any argument with a default that is not None,
and which is not annotated with a type, update the argument's type
annotation to match the default value."""
code = fn.__code__
annotations = fn.__annotations__
argspec = inspect.getfullargspec(fn)
default_offset = len(argspec.args) - len(argspec.defaults)
for i, a in enumerate(argspec.args):
if a in annotations: continue
if i < default_offset: continue
defarg = argspec.defaults[i-default_offset]
if defarg is not None:
annotations[a] = type(defarg)
return fn
@annotate_defaults
def f(a:int|None, b=False, c=None, d=3): ...
# At runtime, inspect sees the "enhanced" type annotation
print(inspect.getfullargspec(f))
# sadly, when mypy-checking, it prints "Any", because mypy doesn't execute the
# annotate_defaults, it just looks at its [unspecified] return type.
if TYPE_CHECKING:
reveal_type(f)

Unlike TypeScript, if you give a variable a default, which has a type, that variable is implied to always have the type of the default. That's not the case with mypy and ty.
there is no such thing for typecheckers in general, but in mypy specifically there is plugin support
https://mypy.readthedocs.io/en/stable/extending_mypy.html#extending-mypy-using-plugins
Pyright does infer the type if you provide a default: ```py
from typing import reveal_type
def foo(x=1, y=2):
return x + y
reveal_type(foo) # Type of "foo" is "(x: int = 1, y: int = 2) -> int"
interesting!
One of the core ideas behind mypy initially was the gradual adoption of mypy into a codebase. So you can take a program consisting of 100_000 lines of untyped Python code and add types to it 1k lines at a time, or 10 lines at a time, or just one parameter at a time. This is why, if you have a completely unannotated function like this: py def do_things(): x = 42 print(x.upper()) mypy will not complain about it -- because the function doesn't have annotations, it assumes that you just haven't gotten to annotate this function as part of a larger gradually typed program (and there's a --check-untyped-defs flag to disable this)
I've mostly worked with small codebases and jumped right to mypy --strict checking but that sounds like a very good property to have. (as a total aside I need to choose whether to stick with mypy or jump on the pyrefly or ty bandwagons)
I can see where annotating with the type of a default value would work contrary to that philosophy
try pyright or basedpyright as well
I'm aware of pyright, didn't know about basedpyright yet.
I like pyright's inference rules better. It seems like it was developed by essentially copy-pasting the TypeScript compiler
It also provides a language server, so it can be used with editors like VSCode/vim/emacs/helix/Sublime Text etc.
(I'm using "go to definition" a lot so that's helpful)
I've set up one of my trivial projects (2185 SLOC in src+tests) so I have a make target for mypy, pyrefly & pyright. I found pyright "slower enough" (about 2s to run, vs as low as 0.097s for pyrefly) that I was not enthusiastic about it.
Yeah, ty and pyrefly are going to blow mypy/pyright ouf of the water in terms of performance
and I've never taken the time to try to integrate one into my editor (neovim) successfully.
but they are in an alpha stage right now and don't support everything that mypy/pyright support
I am old fashioned so I gravitate to things that I can use with :make and using :cfile to visit the site of problems. WFM, YMMV, etc.
pyright should be reasonably fast in the "hot" state (i.e. when it populated its cache)
I generated about a half dozen pyrefly issues as soon as I tried it on this project, which was previously mypy --strict clean
(they were at PyOhio in an open space session & encouraged me, otherwise I wouldn't go file a half dozen issues on a project I just started using 🤣 )
Actually no, it's still pretty slow in the CLI form... Takes about 10 seconds on the source code for @rough sluice, which is about 20k source lines of Python
Yeah I can see why the details of even having a cache would be easier in the language server case than in the CLI case. And why "kids these days" care more about performance in the former case.
ty also comes in at about 90ms checking my 2k lines
in fact, mypy seems to be about 3x faster on our codebase
However, according to pyright's docs...
Pyright was designed with performance in mind. It is not unusual for pyright to be 3x to 5x faster than mypy when type checking large code bases. Some of its design decisions were motivated by this goal.
It is also written in TypeScript for some reason.
very strange choice if performance is important
maybe it is faster in watch mode, i dunno
I wonder if they'll also port that to go, like the TypeScript compiler
If I remove .mypy_cache it takes 1.6s instead of well under 1s. so it does have some effective caching of the CLI.
I think it's just going to slowly fade into history after ty and/or pyrefly implement all they need to implement
yeah, that's very likely, the only reason I'm still using basedpyright instead of ty is the lack of some features, but once the projects becomes more mature, I'll very likely switch over
It's probably going to linger for a while because Microsoft will keep Pylance as a default thing in the Python extension for VSCode
I imagine some people use Pylance's editor integration while running mypy in CI (I used to do that)
The minimum is not 3.10?
no
Stringified annotations used to be planned to become the default in 3.10, but then the whole idea got scrapped, and now we have deferred annotations using descriptors
!pep 649
Status
Final
Python Version
3.14
Created
11-Jan-2021
Type
Standards Track
Well, sorry I was wrong, but as far as I know the minimum is 3.11 because type annotations are no longer evaluated by default
No, versions 3.10 through 3.13 all use the same model as python 3.5 by default, evaluating annotations eagerly
Ahh I understand, it would be more like eager evaluation by default
$ python --version
Python 3.13.5
$ cat foo.py
def f(x: missing):
pass
$ python foo.py
Traceback (most recent call last):
File "/tmp/scratch/foo.py", line 1, in <module>
def f(x: missing):
^^^^^^^
NameError: name 'missing' is not defined
@drowsy glen are you can help me ?
does python have something like typescript Pick<>
i have a dataclass and i need to pick some of the properties of it
and create a new dataclass based on it
no
what do i do then
write the dataclass manually
I don't really think that'd ever be possible
Data class construction at type time sounds very niche
not if we have 4 type checkers trying to agree on how it's spelled 😔
A more direct analogue to this would be manipulating a typeddict
# doesn't work
type CoolPoint = TypedDict[{"x": int, "y": int, "label": str}]
type NormalPoint = Pick[CoolPoint, Literal["x", "y"]]
# same as:
type NormalPoint = TypedDict[{"x": int, "y": int}]
btw @soft matrix PEP718 question: Suppose that I have this py class Crate: def __init__[B](self, *bananas: B, *, certify: Callable[[B], AnsiBanana]): self._bananas: list[AnsiBanana] = [certify(b) for b in bananas] can I bind the B parameter when calling the __init__?
doesn't Crate[...](...) do that for you?
That syntax means that I'm parametrizing the Crate class
true
in this example it doesn't have parameters, but it could ```py
class Crate[A: AnsiBanana]:
def init[B](self, *bananas: B, *, certify: Callable[[B], A]):
self._bananas: list[A] = [certify(b) for b in bananas]
then not i suppose, or the parametiization could make B, via the thing __class_getitem__ returns
I guess it's a really esoteric edge case, I don't really care if it's supported or not
Just a curiosity
Not in the constructor like that as is, I don't think there's any reason to add special casing for params in new or init for it
or perhaps typecheckers should error on definitions of __init__ / __new__ in classes, which are generic
whats is this "[B]" what does this do?
See PEP 718 https://peps.python.org/pep-0718/

Python Enhancement Proposals (PEPs)
This PEP proposes making function objects subscriptable for typing purposes. Doing so gives developers explicit control over the types produced by the type checker where bi-directional inference (which allows for the types of parameters of anonymous fun...
no, this exists now without pep 718
I think pep 695 not 718 tbh
It defines a generic function/method
Not even sure what page to link
There's this https://typing.python.org/en/latest/reference/generics.html but it uses pre-3.12 syntax
and then there's this https://typing.python.org/en/latest/spec/generics.html but it's more technical
oops, yeah
ok. thanks
There's nothing wrong with the method, it's just that you probably won't be able to provide the B manually if pep718 is accepted
Per PEP 12, wouldn't a Requires: *[NNN] be appropriate in the header then?
well but type checkers could tell you its useless to make the init generic then, via a note / error?!
It's not useless
Well if you cant access it?
Hey guys, I'm Brazilian and I'm learning to program in Python. I'm going to start communicating more with you. I want to make friends, and with that, I'll also learn more about programming in Python.
No? 695 is an accepted pep
I don't know any English but I'll try to communicate ks
It would only show that a and b have the same type for some def __init__[T](self, a: T, b: T) -> None: ..., which can be done without making __init__ generic
Right now, type variables are inferred based on the arguments. For example: ```py
def make_pair[T](obj: T) -> tuple[T, T]:
return (obj, obj)
pair = make_pair(42)
reveal_type(pair) # tuple[int, int]
``` the same would happen with that __init__
That doesnt mean it shouldnt be in there for reference, no?
For example:
# c1, c2, c3: Cavendish
crate = Crate(c1, c2, c3, some_function)
#^ this enforces that `some_function` supports being called as `(Cavendish) -> AnsiBanana`
crate = Crate(c1, c2, c3, len)
#^ and this would error
I think I found a grand total of 1 example of this feature being used correctly https://github.com/aaronhnsy/discord-ext-lava/blob/dev/discord/ext/lava/_utilities.py#L37-L43
discord/ext/lava/_utilities.py lines 37 to 43
class DeferredMessage:
def __init__[**P](self, callable: Callable[P, str], *args: P.args, **kwargs: P.kwargs) -> None:
self.callable: functools.partial[str] = functools.partial(callable, *args, **kwargs)
def __str__(self) -> str:
return f"{self.callable()}"```(in this case there's never a reason to provide P manually though)
Here's another example in a more popular repo https://github.com/getsentry/sentry/blob/master/src/sentry/utils/query.py#L101-L103
but in this case it seems like it should just be QuerySet[Model, V] because QuerySet is covariant in the first parameter
src/sentry/utils/query.py lines 101 to 103
def __init__[M: Model](
self,
queryset: QuerySet[M, V],```Sorry not sure if I missed it is there a reason why you'd do this over have the class be generic?
Because the generics are not used to specify anything about the instance of the class, they're only used to compute intermediate results inside the __init__
Semantically it's equivalent to ```py
class MyClass:
def init[<Vars>](self, <non-generic args>, <generic args depending on Vars>)
c = MyClass(<non-generic args>, <generic args>)
#->
type _Inter = <doesnt depend on Vars>
class MyClass:
def init(self, <non-generic args>, intermediate: _Inter)
def _helper[<Vars>](<non-generic args>, <generic args depending on Vars>):
intermediate: _Inter = "compute a tuple of values using all the args"
return MyClass(<non-generic args>, intermediate)
c = _helper(<non-generic args>, <generic args>)
I think it's totally reasonable to not support this. As I said I only found one example of needing this feature on all of github.
hmm I guess here's a related question ```py
class ClsDecorator(Protocol): # the protocol itself is not generic
def call[T: type](self, kls: T, /) -> T: ...
def do_something(deco: ClsDecorator) -> None:
# you're here
``` is it okay to do deco[int](bool)?
Seems kinda cursed but makes sense
Callable protocols like this are a thing. Something like ```py
@dataclass_transform(frozen_default=True)
def frozen(*, slots: bool = True) -> ClsDecorator:
...
There's probably a better example for the purposes of subscripting though
In TypeScript the equivalent would be ```typescript
type StrMapper = <T extends string>(arg: T) => T
function doSomething(arg: StrMapper) {
const s = arg<"a" | "b">("a")
// ok, s is "a"|"b"
}
I'll add it to the list
This seems oddly similar to the problem of whether a given callable is considered to be a method-like descriptor
Something like FunctionType & ClsDecorator could express this maybe
Maybe it wasn't clear what I meant, the problem is that a callable doesn't necessarily support this new getitem
In general, it could be a functools.partial, a class, or some other custom callable
On one hand, it would be sound to prohibit indexing something you only know to be a Callable but not necessarily a function. On the other it means that pretty much every decorated function now doesn't support subscription
if its something that returns a Callable rather than a tv bound to one its not safe to support yeah
but I think if you're stipulating its a ClsDeco which has a tv in its type params it should technically be safe
not sure what the spec says though
well, you're writing the spec here, I do think fix error's example is a problem for PEP 718
if PEP 718 is implemented type checkers will learn that functions are subscriptable, but that doesn't necessarily go for arbitrary callables
and the type system isn't always good at distinguishing between functions and arbitrary callables
typescript dodged so many bullets by erasing annotations from the runtime tbh
about that, is there a way to check whether something is iterable? like not isinstance(x, list | tuple)
why though?
you can do hasattr(obj, "__iter__"), which tells you that the object has some attribute named __iter__ (though type checkers don't support these type guards)
you could do ```py
def is_iterable(obj: object) -> TypeIs[Iterable[object]]:
return hasattr(obj, "iter")
need to handle each item individually
can you provide more details? why do you want to check if something is iterable?
like I said, I need to check and handle each item
# users: MyClass(pages=[<item>, <item>, (<item>, <item>, ...), [(<item>, <item>, ...), ...], ...iterables], per_page=<num>)
# type Seq[T] = list[T] | tuple[T, ...]
# type Sequence[T] = Seq[T] | Seq[Seq[T]]
# actual handling
async def handle_pages(self, pages: Sequence[PageT], /, skip_formatting: bool = False) -> BaseKwargs:
if not skip_formatting:
self._reset_base_kwargs()
formatted_pages = await discord.utils.maybe_coroutine(self.format_page, pages)
return await self.handle_pages(formatted_pages, skip_formatting=True)
for page in pages:
if isinstance(page, (list, tuple)): # <---
await self.handle_pages(page, skip_formatting=True) # pyright: ignore[reportArgumentType]
continue
if isinstance(page, (int, str, discord.ui.TextDisplay)): ...
elif isinstance(page, discord.Embed): ...
elif isinstance(page, (discord.File, discord.Attachment)): ...
# Handle dictionary updates
elif isinstance(page, dict): ...
elif isinstance(page, discord.ui.Item): ...
return self.__base_kwargs
What's PageT?
class BaseClassPaginator[PageT: Any]:
# not actually a classvar
pages: Sequence[PageT]
or preferably the following with an overload on a kwarg that I sent in the other convo, but first need to figure out the type-safe loop:
_BoundPage = (
str
| discord.Embed
| discord.File
| discord.Attachment
| discord.ui.Button[Any]
| discord.ui.Select[Any]
| dict[str, Any]
)
BoundPage = _BoundPage | Sequence[_BoundPage]
_BoundV2Page = (
str
| discord.ui.ActionRow[Any]
| discord.ui.Container[Any]
| discord.ui.File[Any]
| discord.ui.MediaGallery[Any]
| discord.ui.Section[Any]
| discord.ui.Separator[Any]
| discord.ui.TextDisplay[Any]
)
BoundV2Page = _BoundV2Page | Sequence[_BoundV2Page]
# PageT: BoundPage | PageV2Page
for page in pages:
if isinstance(page, (int, str, discord.ui.TextDisplay)): ...
elif isinstance(page, discord.Embed): ...
elif isinstance(page, (discord.File, discord.Attachment)): ...
elif isinstance(page, dict): ...
elif isinstance(page, discord.ui.Item): ...
else:
await self.handle_pages(page, skip_formatting=True)
wait
also maybe change [PageT: Any] (which is the same as just [PageT]) to [PageT: (BoundV2Page, BoundPage)]
fml
if you only want to allow BasePaginator[BoundPage] and BasePaginator[BoundPageV2] to exist
yeah it can't really be anything else
unless the user wants to handle it in the format_page method
but then again, it should still return one of those
is the last one the same as an union?
No. It's a "type variable with constrains"
a) https://typing.python.org/en/latest/reference/generics.html#type-variables-with-constraints
b) https://typing.python.org/en/latest/spec/generics.html#introduction
See starting from:
TypeVarsupports constraining parametric types to a fixed set of possible types
Typically this is not the right choice because it's a janky feature (or maybe just implemented poorly?), but if you want to support only BasePaginator[BoundPage] and BasePaginator[BoundPageV2], but not BasePaginator[BoundPage | BoundPageV2] or BasePaginator[str], this is what you should use
ahh
that's exactly what I want
is this correct?
type Seq[T] = list[T] | tuple[T, ...]
type Sequence[T] = Seq[T] | Seq[Seq[T]]
Or should I just use the builtin Sequence and raise if pages is str
because that still warns about list being invariant
I also can't figure out this one
def get_page(self, page_number: int) -> Sequence[PageT]:
if not self.pages:
raise ValueError(
"No pages are available. Either provide a non-empty 'pages' sequence when creating the paginator, or assign to '.pages' before sending."
)
if self.per_page == 1:
page = self.pages[page_number]
if isinstance(page, (list, tuple)): # <--
return page
return [page]
base = page_number * self.per_page
return self.pages[base : base + self.per_page]
it should always return a sequence
imma just use list
even when using the builtin sequence, it complains
I don't get this one at all
async def handle_pages(self, pages: Sequence[PageT | Sequence[PageT]], /, skip_formatting: bool = False) -> BaseKwargs:
if not skip_formatting:
self._reset_base_kwargs()
formatted_pages = await discord.utils.maybe_coroutine(self.format_page, pages)
return await self.handle_pages(formatted_pages, skip_formatting=True)
for page in pages:
if isinstance(page, (int, str, discord.ui.TextDisplay)): ...
elif isinstance(page, discord.Embed): ...
elif isinstance(page, (discord.File, discord.Attachment)): ...
elif isinstance(page, dict):...
elif isinstance(page, discord.ui.Item): ...
else:
await self.handle_pages(page, skip_formatting=True) # < ---
# Argument of type "Sequence[_BoundPage]* | Sequence[_BoundV2Page]* | Sequence[PageT@BaseClassPaginator]" cannot be assigned to parameter "pages" of type "Sequence[PageT@BaseClassPaginator | Sequence[PageT@BaseClassPaginator]]" in function "handle_pages"
# Type "Sequence[_BoundPage]* | Sequence[_BoundV2Page]* | Sequence[PageT@BaseClassPaginator]" is not assignable to type "Sequence[PageT@BaseClassPaginator | Sequence[PageT@BaseClassPaginator]]"
# "Sequence[_BoundPage]*" is not assignable to "Sequence[PageT@BaseClassPaginator | Sequence[PageT@BaseClassPaginator]]"
# Type parameter "_T_co@Sequence" is covariant, but "_BoundPage" is not a subtype of "PageT@BaseClassPaginator | Sequence[PageT@BaseClassPaginator]"
# Type "_BoundPage" is not assignable to type "PageT@BaseClassPaginator | Sequence[PageT@BaseClassPaginator]"
# Type "Attachment" is not assignable to type "PageT@BaseClassPaginator | Sequence[PageT@BaseClassPaginator]"PylancereportArgumentType
return self.__base_kwargs
How is PageT defined now?
type File = discord.File | discord.Attachment
type _BoundPage = str | discord.Embed | discord.ui.Button[Any] | discord.ui.Select[Any] | dict[str, Any] | File
type BoundPage = _BoundPage | Sequence[_BoundPage]
type _BoundV2Page = (
str
| discord.ui.ActionRow[Any]
| discord.ui.Container[Any]
| discord.ui.File[Any]
| discord.ui.MediaGallery[Any]
| discord.ui.Section[Any]
| discord.ui.Separator[Any]
| discord.ui.TextDisplay[Any]
| dict[str, Any]
| File
)
type BoundV2Page = _BoundV2Page | Sequence[_BoundV2Page]
class BaseClassPaginator[PageT: (BoundPage, BoundV2Page)]:
What if you do ```py
async def handle_pages(self, page: PageT, /, skip_formatting: bool = False) -> BaseKwargs:
if not skip_formatting:
self._reset_base_kwargs()
formatted_pages = await discord.utils.maybe_coroutine(self.format_page, pages)
return await self.handle_pages(formatted_pages, skip_formatting=True)
if isinstance(page, (int, str, discord.ui.TextDisplay)): ...
elif isinstance(page, discord.Embed): ...
elif isinstance(page, (discord.File, discord.Attachment)): ...
elif isinstance(page, dict):...
elif isinstance(page, discord.ui.Item): ...
else:
await self.handle_pages(page, skip_formatting=True)
return self.__base_kwargs
(using Sequence = collections.abc.Sequence)
lots of
"X*" is not iterable
"__iter__" method not defined PylancereportGeneralTypeIssues
Do you have the code somewhere in a runnable state?
Maybe I can load it up and see more context
oh it kinda works now with
type BoundPage = Sequence[_BoundPage]
type BoundV2Page = Sequence[_BoundV2Page]
I more meant do the spec say that to be compatible with ClsDeco does the function need to have a type var in its type params
But yeah I wanna avoid this I'll write up more on discuss but should definitely use intersections and not add more unsoundness that might get fixed in the future
not really, the project without the current changes is at https://github.com/Soheab/discord-py-paginators/blob/feat/components-v2/discord/ext/paginators/core.py
Actually what I meant was this ```py
async def handle_pages(self, page: Sequence[PageT], /, skip_formatting: bool = False) -> BaseKwargs:
self._reset_base_kwargs()
if skip_formatting:
self._handle_pages_unformatted(page)
else:
formatted_pages = await discord.utils.maybe_coroutine(self.format_page, pages)
await self._handle_pages_unformatted(formatted_pages)
return self.__base_kwargs
async def _handle_pages_unformatted(self, page: PageT) -> BaseKwargs:
if isinstance(page, (int, str, discord.ui.TextDisplay)): ...
elif isinstance(page, discord.Embed): ...
elif isinstance(page, (discord.File, discord.Attachment)): ...
elif isinstance(page, dict):...
elif isinstance(page, discord.ui.Item): ...
else:
for p in page:
await self._handle_pages_unformatted(p) # or something
also, resetting base_kwargs and then returning them seems like you're going to have nasty concurrency issues
i.e.: two concurrent callers to handle_pages will share the same base_kwargs, erroneously
they should share the same kwargs, that's what is sent later
I'm assuming those ...s modify the base kwargs somehow?
yeah
I don't think it does, for example (Any) -> Any would be compatible with that protocol
so Bound[V2]Pages should be the same as before?
So you'll have this:
- caller A calls
handle_pagesand resets kwargs. It starts populating the new kwargs - after some time, caller B calls
handle_pageson the same object, also resetting kwargs, discarding all the work A'shandle_pagesdid on the kwargs - A's and B's
handle_pageboth add stuff to the kwargs - A's and B's
handle_pageboth return the same combined kwargs that are probably wrong
a better solution would be creating a local object and mutating that, e.g: ```py
async def handle_pages(self, page: Sequence[PageT], /, skip_formatting: bool = False) -> BaseKwargs:
async def handle_pages_unformatted(page: PageT) -> BaseKwargs:
if isinstance(page, (int, str, discord.ui.TextDisplay)): ...
...
else:
for p in page:
await handle_pages_unformatted(p) # or something
self._reset_base_kwargs()
base_kwargs = BaseKwargs()
if skip_formatting:
self._handle_pages_unformatted(page)
else:
formatted_pages = await discord.utils.maybe_coroutine(self.format_page, pages)
await handle_pages_unformatted(formatted_pages)
return base_kwargs
(or as a separate method with a BaseKwargs parameter)
yes
ig that works
only reason why it's stored on the instance is because I needed to recursively loop the list and that was the best I could think of at the time
A common pattern is passing the state you're mutating as a parameter to the recursive function
__deepcopy__ (https://docs.python.org/3/library/copy.html#object.__deepcopy__) is an example from python itself
oh yeah but that's ugly and confusing imo
yeah
parameters intended for mutation do feel kinda bad
ye, parameters that may only be used in the function itself
https://images.soheab.com/YfEBTJB9f04.png why it keep special casing Attachment...
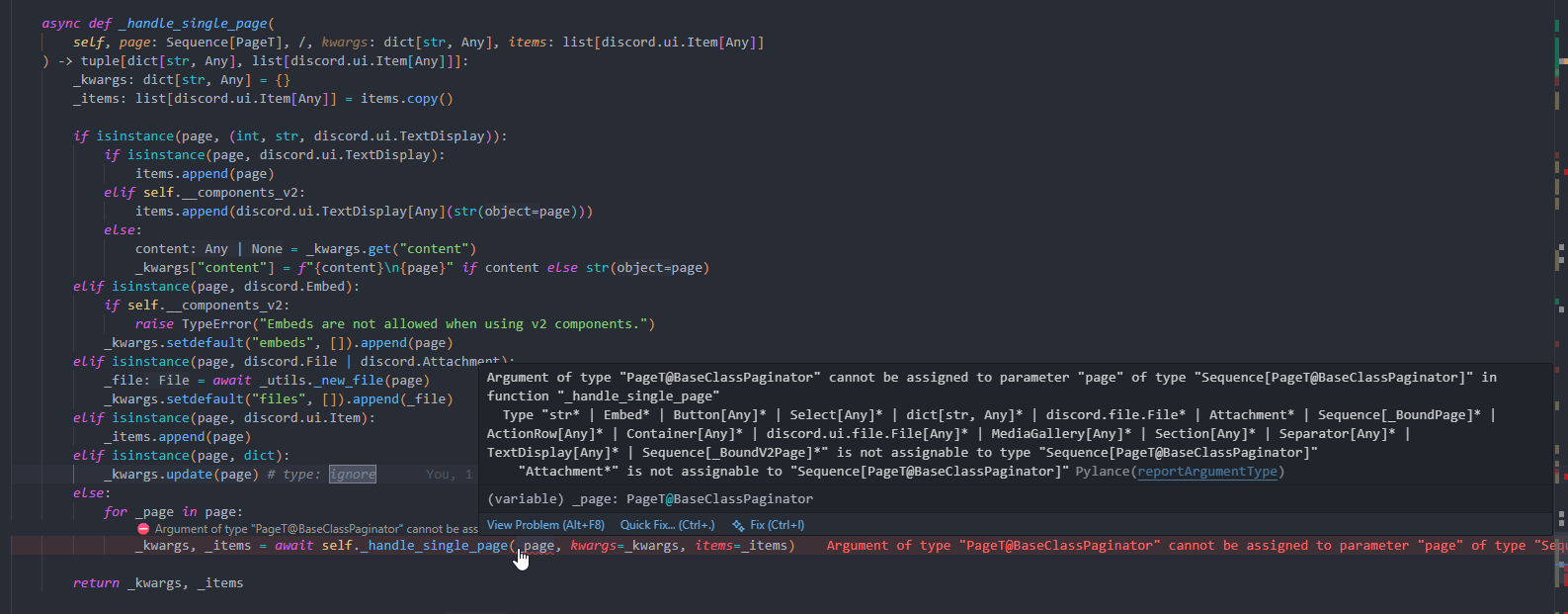{kind=link}
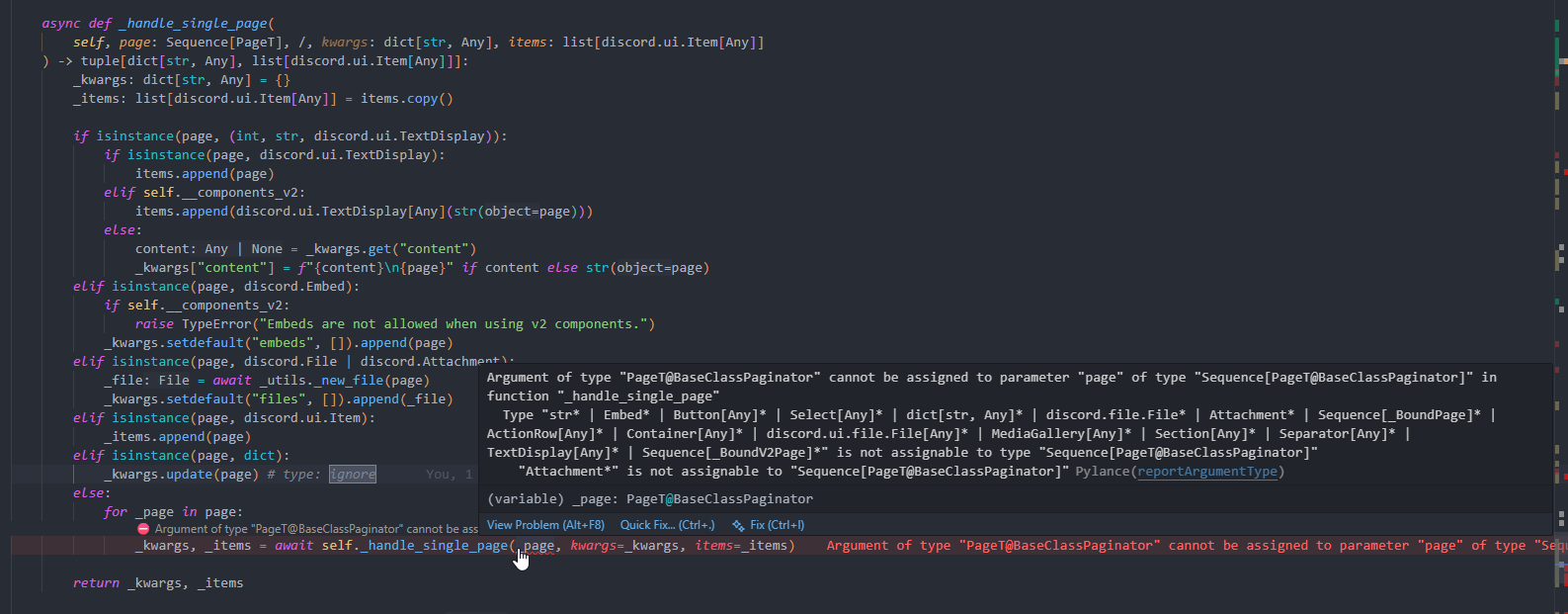
can pyright not see the isinstance
you have the wrong annotation
page: Sequence[PageT]
should it be page: PageT?
https://images.soheab.com/7HbaBDcIyWg.png well that's better
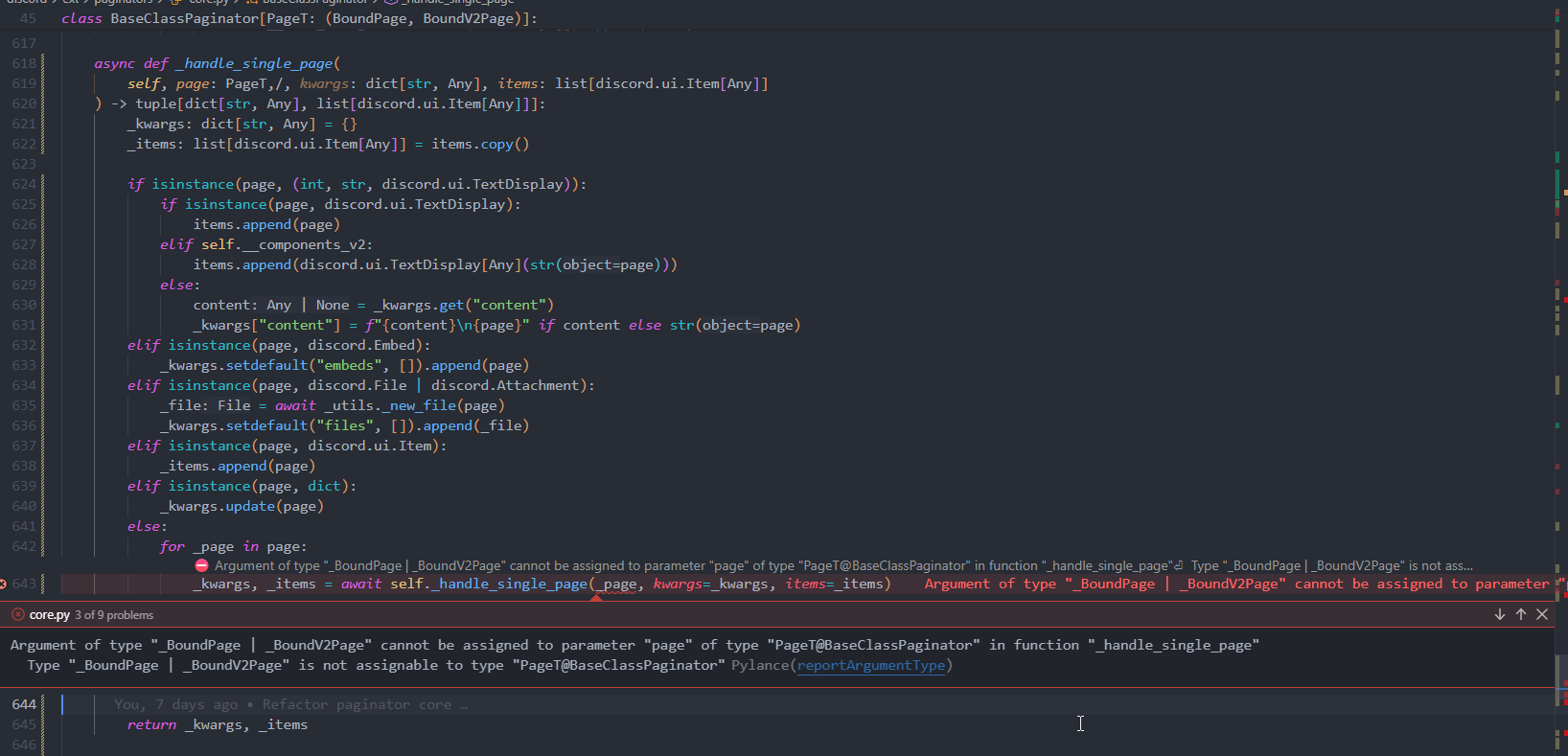{kind=link}

and this is what I meant by constrained type variables being janky 
at this point I'd recommend # pyright: ignore[reportArgumentType]
Here's more crazy stuff: if with exactly the same code in both branches as a workaround ```py
def concat[S: (str, bytes)](x: S, y: S) -> S:
return x + y
def concat_loose1(s: str | bytes) -> str | bytes:
return concat(s, s)
# ^ error
# Argument of type "str | bytes" cannot be assigned to parameter "x" of type "S@concat" in function "concat"
# Type "str | bytes" is not assignable to constrained type variable "S" (reportArgumentType)
# Argument of type "str | bytes" cannot be assigned to parameter "y" of type "S@concat" in function "concat"
# Type "str | bytes" is not assignable to constrained type variable "S" (reportArgumentType)
def concat_loose2(s: str | bytes) -> str | bytes:
# no error
if isinstance(s, str):
return concat(s, s)
else:
return concat(s, s)
is this a pyright only thing
no, mypy also complains

mypy has this though ```py
from typing import reveal_type, Literal
class TruthTable[
A: (Literal[True], Literal[False]),
B: (Literal[True], Literal[False]),
C: (Literal[True], Literal[False]),
]:
def init(self, a: A, b: B, c: C) -> None:
if a and not (b and c):
reveal_type(self)
main.py:10: note: Revealed type is "main.TruthTable[Literal[True], Literal[True], Literal[False]]"
main.py:10: note: Revealed type is "main.TruthTable[Literal[True], Literal[False], Literal[True]]"
main.py:10: note: Revealed type is "main.TruthTable[Literal[True], Literal[False], Literal[False]]"
apparently it just synthesizes a separate class body for each combination of constrained typevars and evaluates each of them
so theoreticall mypy should not be able to produce such an error^