#type-hinting
1 messages · Page 13 of 1
def action(
_func: Optional[function_type],
*,
name: str = "",
asynced: bool = False,
capacities: Optional[List[enum.Enum]] = None,
) -> Any:
def decorator_repeat(func: function_type) -> Any:
@functools.wraps(func)
def wrapper_repeat(*args: Any, **kwargs: Any) -> Any:
return func(*args, **kwargs)
return wrapper_repeat
if _func is None:
return decorator_repeat
return decorator_repeat(_func)
_func is optional  i mean optional as trully optional
i mean optional as trully optional
is there a way to type it?
for situation when @action(name="123") param is called, _func is not supplied
current error 🤔
(function) def action(
_func: function_type | None,
*,
name: str = "",
asynced: bool = False,
capacities: List[Enum] | None = None
) -> Any
Missing positional argument "_func" in call to "action" [call-arg]mypy
Untyped decorator makes function "send_mail" untyped [misc]mypy
oh wait. I can just probably add _func: Optional[function_type] = None
🙂
oh wait. i can't make None to positional
hmm, looks working
i found simple solution
typing fully this stuff is too difficult 😁
def action(
_func: Optional[function_type] = None,
/,
*,
name: str = "",
asynced: bool = False,
capacities: Optional[List[enum.Enum]] = None,
) -> Callable[[function_type], function_type]:
def decorator_repeat(func: function_type) -> function_type:
@functools.wraps(func)
def wrapper_repeat(*args: Any, **kwargs: Any) -> None:
return func(*args, **kwargs)
return wrapper_repeat
if _func is not None:
return decorator_repeat(_func) # type: ignore[return-value]
return decorator_repeat
i just typed situation when @decorator() is called excplicitely
and for situation @decorator lets have it type ignored exception
an overload might be useful
@overload
def action(__func: Optional[function_type], /) -> function_type: ...
@overload
def action(*, name: str = "", asynced: bool = False, capacities: list[enum.Enum] | None = None) -> Callable[[function_type], function_type]: ...
in the impl, you can return function_type | Callable[[function_type], function_type]
Convinient trick
not necessary though. I made a check. even with type ignored exception, it works pretty fine to verify correct input/output of decorated function in situation with @decorator is not called and just attached to function
therefore it can be not improved. Although perhaps better to do, just for the purpose of avoiding exceptions 😁
...and that's an example of how type annotations add a lot of extra work to an already working Python function, while 1) still not making it really type-safe, 2) making it harder to read
ActionsType = TypeVar("FloweActionsType", bound=Actions)
function_type = Callable[[FloweActionsType, QuerySet], None]
def action(
_func: Optional[function_type] = None,
/,
*,
name: str = "",
asynced: bool = False,
capacities: Optional[List[enum.Enum]] = None,
) -> Callable[[function_type], function_type]:
def decorator_repeat(func: function_type) -> function_type:
@functools.wraps(func)
def wrapper_repeat(self: ActionsType, queryset: QuerySet) -> None:
return func(self, queryset)
# register to self those objects
return wrapper_repeat
if _func is not None:
return decorator_repeat(_func) # type: ignore[return-value]
return decorator_repeat
the final version is pretty useful
i think
may be.
If you call it directly with a function, like ```py
@action
def foo(action: SomeFloweAction, queryset: QuerySet):
...
`foo` will have the type `Callable[[function_type], function_type]`, which is not right (though you `type-ignore` it)also:
- the type variable name should match with the stringly name
function_typeis a generic type alias, not a type variable. So if you want to preserve the actual type ofActionsTypeon the function you're decorating, you should do ```py
ActionsType = TypeVar("ActionsType", bound=Actions)
function_type = Callable[[ActionsType, QuerySet], None]
def action(
_func: Optional[function_type[ActionsType]] = None,
/,
*,
name: str = "",
asynced: bool = False,
capacities: Optional[List[enum.Enum]] = None,
) -> Callable[[function_type[ActionsType]], function_type[ActionsType]]:
(those should be caught by mypy)well, except if you call action() without _func, the type variables will also be unbound, because it's not clear what to bind ActionsType to. What you really need to do is this:
ActionsType = TypeVar("ActionsType", bound=Actions)
function_type = Callable[[ActionsType, QuerySet], None]
class _ActionDecorator(Protocol):
def __call__(self, fn: function_type[ActionsType], /) -> function_type[ActionsType]:
...
def action(
_func: Optional[function_type[ActionsType]] = None,
/,
*,
name: str = "",
asynced: bool = False,
capacities: Optional[List[enum.Enum]] = None,
) -> _ActionDecorator:
and then we need to tackle the func=None call, so really it's ```py
@overload
def action(
_func: function_type[ActionsType],
/,
*,
name: str = "",
asynced: bool = False,
capacities: Optional[List[enum.Enum]] = None,
) -> function_type[ActionsType]: ...
@overload
def action(
_func: None = ...,
/,
*,
name: str = "",
asynced: bool = False,
capacities: Optional[List[enum.Enum]] = None,
) -> _ActionDecorator: ...
def action(
_func: Optional[function_type[ActionsType]] = None,
/,
*,
name: str = "",
asynced: bool = False,
capacities: Optional[List[enum.Enum]] = None,
) -> Callable[[Any], Any]:
# implementation
🤯
now you probably see what I mean 🙂
Wouldn't that only trigger if you explicitly call @action(None, name=...)?
this typehint is correct?
class Tauler:
FORMAT_TITOL = Back.WHITE + Fore.BLACK
ORIENTACIONS = ["+", "-", "/", "\\"]
# some other functions...
def genera_orientacio(self) -> Literal["+", "-", "/", "\\"]:
return random.choice(Tauler.ORIENTACIONS)```but classmethod are for modify the original class, right?
They're for defining a method to be called on the class, not a class instance
e.g. you can call Tauler.foobar() instead of Tauler().foobar()
i just started coding with classes and methods, sorry for my ignorance
that's ok. It's no big deal if you don't.
Do what makes sense to you.
When you're first starting out, if it works, I consider that a win
then what are the decorators that modifies the original class?
only class decorators modify the original class. @classmethod is a function decorator.
it does magic so the first argument is cls instead of self. You'll learn more about these when you learn about classes and objects
Yes, but why use a class?
ORIENTACIONS = ["+", "-", "/", "\\"]
def genera_orientacio() -> Literal["+", "-", "/", "\\"]:
return random.choice(ORIENTACIONS)
theres more code that i not sent
but anyway is a classroom project that is required to use classes
but if that function only returns a random choice from a list, it isnt a better choice to use an static method? since my function doesnt creates an object from that method? (just saw this example: https://www.geeksforgeeks.org/classmethod-in-python/#:~:text=In the below example we use a staticmethod() and classmethod() to check if a person is an adult or not )
GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
Generally, I would prefer a free-standing function
there is very little point in having a staticmethod
okay
is it possible to specify the overloads for a function that you are supposed to pass as a parameter to another function?
something like this:
@overload
def x(y: str) -> str:
...
@overload
def x(y: int) -> float:
...
def x(y: str | int) -> str | float:
...
def func(f: x):
...
yes, with callable protocols
you need a protocol with an overloaded __call__ method
I have this function py def add_piece( colour: Literal["white", "black"], piece: Literal["pawn", "rook", "knight", "bishop", "queen", "king"], ) -> None: with the colour and piece being a Literal, but when I have this code:
for colour in ("white", "black"):
self.add_piece(colour, piece)
Mypy is raising the error claiming that colour is str, not a literal, which is correct, but how should I assert that the colour is one of those types or should I just change colour: Literal["white", "black"] to colour: str?
Use enums 🙂
!d enum.Enum
class enum.Enum```
*Enum* is the base class for all *enum* enumerations.def add_piece(colour: Colour, piece: Piece) -> None: ...
for colour in Colour:
for piece in Piece:
add_piece(colour, piece)
How do I put the colour into an enum? Seems odd to do
class Colour(Enum):
white = "white"
black = "black"
``` or should I assign `0` and `1` id's
class enum.auto```
*auto* can be used in place of a value. If used, the *Enum* machinery will call an *Enum*’s [`_generate_next_value_()`](https://docs.python.org/3/library/enum.html#enum.Enum._generate_next_value_ "enum.Enum._generate_next_value_") to get an appropriate value. For *Enum* and *IntEnum* that appropriate value will be the last value plus one; for *Flag* and *IntFlag* it will be the first power-of-two greater than the highest value; for *StrEnum* it will be the lower-cased version of the member’s name. Care must be taken if mixing *auto()* with manually specified values.
*auto* instances are only resolved when at the top level of an assignment:like ```py
class Colour(StrEnum):
white = auto()
black = auto()
Okay so I've got this class and I've changed the parameter to accept Colour, but when I pass colour pylance says ```py
Argument of type "Literal['white', 'black']" cannot be assigned to parameter "colour" of type "Colour" in function "add_piece"
Type "Literal['white', 'black']" cannot be assigned to type "Colour"
"Literal['white']" is incompatible with "Colour"
Yes, your function accepts a Colour object and you're passing in a string
You should pass in Colour.white
Last question, when I iterate through for colour in Colour.__members__.values(), mypy says error: "str" has no attribute "name" - How should I iterate through the enum members?
(```py
for colour in Colour.members.values():
row = 7 if colour.name == "white" else 0
!e
from enum import StrEnum, auto
class Colour(StrEnum):
white = auto()
black = auto()
for colour in Colour:
print(colour)
@trim tangle :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | white
002 | black
(this was not pseudocode 🙂 )
ps my enum doesnt have StrEnum for some reason
ah it's new in 3.11
I see
Oh right I literally iterate through the enum
I see, thanks
a typing alias should be typed with snake_case?
i personally prefer pascal case
okay
i think class naming convention can be applied to type aliases, so PascalCase is preferred
Ye
what enables the pipe operator for typing? i.e, python def foo(x: int | str): ...
it seems to work in python 3.8 only if I do from __future__ import annotations but when I read up on it all the examples merely describe how it's used to reference the class name from within a method, etc..
looks like PEP-604 in fact and it describe that it's a python 3.10+ feature but I guess doing that import makes it avail in python 3.8 at least. Now, would it be wise to import that so I can use this pipe operator if currently working in 3.8?
also another questions, if I have python def foo(x: pathlib.Path | str): ... is it possible to auto convert str to Path for instance?
or perhaps something from typing can help auto-convert?
what enables the pipe operator for typing
typehas its__or__overridden so that the syntax is allowed. It returns aUnion.
>>> type_hint = int | str
>>> type(type_hint)
<class 'types.UnionType'>
>>> type_hint == type.__or__(int, str)
True
it seems to work in python 3.8 only if I do
from __future__ import annotations
The annotations import makes all typing annotations be interpreted as strings, i.e. withx: str | intis parsed asx: "str | int"and it's up to type checkers to interpret that correctly
is it possible to auto convert str to Path for instance?
Not without using some 3rd party library and/or decorator. You'd need to manually do ```py
def foo(x: pathlib.Path | str):
if isinstance(x, str):
x = pathlib.Path(x)
print(x / "filename.txt")```
@bold gazelle
Thanks for the clarifications
sounds like I shouldn't use the pipe operator in 3.8 then via the annotations import
I think people generally prefer to use typing.Union[str, int], yeah
but I assume once python 3.10+ is up to speed then I assume people should generally prefer "str | int"
To hint or not to hint
how to rewrite correctly callable
function_type = Callable[[ActionsType, QuerySet, Optional[str]], None]
class FunctionType(Protocol):
additional_data: str
@staticmethod
def __call__(self: ActionsType, queryset: QuerySet, ok: Optional[str]) -> None:
...
into protocol?
i want to add some objects assigned/anotated to function like it is class ( i have to work with django libraries and their approach)
https://github.com/python/typing/discussions/1040 hmm, here is long dicussion regarding that 🤔
ergh? for some reason both __call__ and __get__ become needed defined
How to intend on using it? Not sure I understand what you are trying to do
Why staticmethod on __call__?
managed to crack it with cast(FunctionType, func) hacks
Intended usage...
func.workflow = ActionScaffolding(
detail=detail, asynced=asynced, capacities=capacities
)
i assign attribute to function like it is class
and expect IDE to show syntax highlighting for accesing it
DummyActions.send_mail.workflow
more or less, it works 🙂
func = cast(FunctionType, func)
func.workflow = ActionScaffolding(
detail=detail, asynced=asynced, capacities=capacities
)
right before i start using function like it is class/object
I make the cast of it from function to my protocol with __call__ and class variable workflow, then it works as intended so far form the point of type hinting/IDE functionality 🙂
staticmethod on call, because i tried to have Protocol behaving like it is uhhh... class method, capable to be called only. avoided problems with self in protocol
looks like working
Still not entirely sure what it is you are doing, but if you are ok with using cast then sure, it looks like you are just trying to alter an already existing function into having the attribute workflow so I guess you would have to cast anyway
exactly, altered existing function to have attributes. looks like possible only with cast
why does mypy not raise certain errors with certain versions of python
how do i make it show them regardless
from enum import Enum
from typing import Any, List
class BaseStrEnum(str, Enum):
def __repr__(self) -> str:
return f"<{self.__class__.__name__}.{self.name}>"
def __new__(cls, value, *args, **kwargs):
return super().__new__(cls, value, *args, **kwargs)
@classmethod
def has_value(cls, value: Any) -> bool:
return value in cls._value2member_map_
@classmethod
def list(cls) -> List[Any]:
return list(map(lambda c: c.value, cls))
Can someone please help me understand why MyPy complains main.py:17: error: "str" has no attribute "value" [attr-defined] for return list(map(lambda c: c.value, cls)) and how to sort it
sounds like a bug with mypy
Ahh hmm
what is the difference between a Sequence and an Iterator?
so it must have __getitem__, but you can reverse any iterable not just a sequence
oh my bad
you cant reverse any iterable
def reverse_uwu(it: Iterable[T]) -> Iterator[T]:
return reversed(list(it))
``` amogus
Interestingly, you cant reverse(reverse(some_list))
Because calling reversed on a list returns a list_reverseiterator
Even though reversed is a class
python moment
not really, you can't reverse a reversed() object in general. it doesn't matter that list has its special reverse iterator
But it is possible with lists in particular (and it would be efficient). Why there is no list_reversediterator.__reversed__, that returns something like iter(self._listobj)?
I think reverse(Reversable) should return ReversableIterator
It's possible for reversed() in general, maybe it's just never been implemented because there are few realistic use cases
oh not always actually, because __reversed__() may return an arbitrary iterator
Thats wrong. It is not possible in general
Yeah, i see
the thing i often find i want is reversed(enumerate(list)) but alas
!e it is weird and unsafe, but it works
import typing as t
import builtins as b
T = t.TypeVar('T')
_memo: dict[int, t.Any] = {}
def reversed(seq: t.Reversible[T]) -> t.Reversible[T]:
if id(seq) in _memo:
return _memo[id(seq)]
res = b.reversed(seq)
_memo[id(res)] = seq
return res
print(*'abc')
print(*reversed('abc'))
print(*reversed(reversed('abc')))
print(*reversed(reversed(reversed('abc'))))
@tranquil turtle :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | a b c
002 | c b a
003 | a b c
004 | c b a
the memory leaks :((((
yes
it also wouldnt work if two objects have same id (in two different moments)
i think you might be able to use weakrefs for this
x = [1, 2, 3]
it = iter(x); next(it)
# at this moment `it` will yield 2,3
rev = reversed(it)
print(*rev) # what should be printed?
# 1) 3,2,1 - entire list but reversed
# 2) 3,2 - remaining items in `it`, but reversed
2?
not every objects supports weakrefs
>>> import weakref
>>> weakref.ref([])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: cannot create weak reference to 'list' object
>>> weakref.ref(iter([]))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: cannot create weak reference to 'list_iterator' object
>>> weakref.ref(reversed([]))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: cannot create weak reference to 'list_reverseiterator' object
oh i forgot about that
yeah, i think so too
my implementation will yield entire underlying object (in reversed order), so it is not correct
class AuthCapacity(enum.Enum):
AUTHENTICATED = 1
UNAUTHENTICATED = 1000
how to write stub files?
I created library/permissions.pyi file with
class AuthCapacity: ...
but slightly missing next step.
Can i just import Enum value from library for automatic... stub file generation? hmmm.... automatic stub files generation. i think there is somewhere command for that
found. stubgen 🙂
uh
provided stubs broke library usage
how to provide stubs without breaking import to installed third party lib
What type checker are you using? Usually you can provide a directory where stubs are located
or wdym
mypy
trying to provide stubs for third party lib without stubs within usage of my current app only
what do you mean by "broke library usage"?
https://mypy.readthedocs.io/en/stable/stubs.html#creating-a-stub
$ export MYPYPATH=~/work/myproject/stubs
when i tried to provide stubs, i provided name of package with stubs, same as original third party lib name. apperently i need different package name for stubs
and probably importing at the level of mypy.ini config or something
the different package name should be $original-stubs
eg if the library was named sqlalchemy, it would be sqlalchemy-stubs
nice. it works without any config changes
thanks
types-sqlalchemy is also acceptable
the name of the directory that gets installed must be x-stubs. but the name of the package is independent from that
like how pip install Pillow lets you import PIL
I see
how would you define a generic type alias
Owned[T]
that can be assigned to a T, but such that T cannot be assigned to Owned[T] ?
and would you make use of such construction to indicate by a typing process, that some resource must leave away their ownership?
for example:
def compute_something(df: Owned[pd.DataFrame]) -> Something:
# here you'd know the `df` can be safely considered to be a pd.DataFrame,
# but also that you are free to mutate it
df.reset_index(inplace=True) # works fine
some_df: pd.DataFrame = ...
compute_something(some_df) # This wouldn't work without explicit cast
Not possible I think, there are no generic newtypes, plus even if there were this still doesn't make sense in terms of subtyping
you would have to have some form of auto coercion
in my mind it would be just like inheritance, but faked at runtime
or an intersection of type ; but doesn't seem to exist
But this isnt just like inheritance, you want Owned[T] to be a subtype of T forall T, there is no way to express this
Make a 1-field dataclass
yeah if possible, I'd prefer not 😄
but okay thx anyway
def create(self, nodetype: Type[Node], *arguments: Token | Node) -> ???:
...
I have a function here which accepts a class of Node and some arguments and returns an instance of that node class
How to I type this such that the return type is an instance of the nodetype that's provided?
def create(self, nodetype: Type[R], *arguments: Token | Node) -> R:
...
This perhaps?
yes
though why do you accept a class specifically?
can you show the implementation maybe?
as long as you have bound R to Node
def create(self, nodetype: Type[R], *arguments: Token | Node) -> R:
node = nodetype(*arguments, self.start, self.end)
self.start = None
self.end = None
return node
The parser keeps track of the first token seen since the last call to create, and the last token seen
And supplies them both to Node's constructor. It's a bit cumbersome to do this operation in-place all over the rest of the parser every time a node gets built
This is a bit verbose but IMO you should consider this: ```py
class MakeNode(Protocol[R]):
def call(self, *args: Token | Node) -> R: ...
... # YourClass
def create(self, factory: MakeNode[R], *arguments: Token | Node) -> R:
or make some "utility type" like
class VarCallable(Protocol[A, B]):
def __call__(self, *args: A) -> B: ...
my point being -- you don't actually need a type object to do the operation
i have file structure
libname-stubs/
factories.pyi
models.pyi
.venv/lib/python3.8/site-packages/libname/
factories.py
models.py
in factories.pyi i have code, that imports django models from libname.models
from libname.models import (
Capacity as Capacity,
Context as Context,
Role as Role,
UserRole as UserRole,
)
for mypy . i get error
libname-stubs/models.pyi: error: Source file found twice under different module names: "models" and "libname.models"
what can be a source problem and/or solution to this issue?
Nvm. Solved.
I forgot to add __init__.py to libname-stubs 😁
I honestly hate implicit namespace packages... I wish the default was the __init__.pyful package
Why?
Most of the time you don't need a namespace package, do you?
(I'm still kinda confused as to what they're for)
No, but you said you hate them, which seems a lot stronger than saying they're usually not necessary.
Ah sorry, I meant the fact that it's the default behaviour when you don't take an extra step of making an __init__.py. Which is an easy mistake to make, and that's what beginners end up with
especially people coming from e.g. JS where you don't have this
Ah, yeah, I understand that. I think that's an unfortunate side effect.
I admit that I am bad at expressing the level of my discontent
I feel like namespace packages are the sort of thing that people shouldn't be using unless they know exactly what they're trying to accomplish with it and why. (Kind of like metaclasses.) But it's very easy to use them by accident. (Unlike metaclasses.)
yeah that's what I meant
IIRC namespace packages are mostly used for "plugins" (like with Discord)?.. and for putting a bunch of company-specific packages under a single parent package
though it would be hilarious if you could easily make a metaclass by accident
Yeah, that's been my experience with namespace packages. There are situations where they help you organize a large project, or something that can be installed in unusual ways, or stuff like that. Almost always you want an ordinary package instead, but when you want a namespace package, it's really handy.
putting a bunch of company-specific packages under a single parent package
Haskell, Elm and PureScript kinda solve this by not having the problem... You can do
Json/
Decode/
Local.elm
``` and then you start your module with `module Json.Decode.Local exposing (foo, bar, baz)` (which will not break the existing `Json.*` modules imported from the `elm/json` library)modules are declared or imported by their fully qualified name only
That's not really the problem namespace packages are trying to solve, though.
Imagine that you are the maintainer of bigpkg, which allows arbitrary plugins.
ah, plugins
Because bigpkg is so awesome, it's distributed with Anaconda. Many of bigpkg's users have it installed through Anaconda.
And at most sites, the sysadmins do the Anaconda installation and users never have to worry ...
... until they need a plugin that's not installed.
Now what?
The plugin should probably go in bigpkg.plugin.awesomeplug or something like that.
But it can't literally be in the directory bigpkg/plugin/awesomeplug because users can't write to that.
Isn't that already solved with entry points? E.g. flake8 doesn't use namespace packages
There are several things you can do about this situation. Namespace packages are one way.
If bigpkg.plugin is a namespace package, then users can install whatever plugins they like.
actually is there some public example of this plugin system using namespace packages?
Hmm, I've never looked for a public example.
But just to give a theoretical situation: Suppose bigpkg.plugin.awesomeplug is compiled. Of course, it has to be compiled to match the libraries of the system you're running on.
compiled as in, contains native extension modules?
Yes.
You can (of course) only install one version per directory. So if everything is installed on a network file system, then installing in bigpkg/plugin/awesomeplug means you can only have one installed version, period.
That's a real problem if you have more than one computing environment (like both Linux and Windows or different Linux distributions).
You'd like to get around this by setting up some kind of library path appropriately. When the user logs in, it sets their path to look for the correct extension module for the machine they're logged in on.
But if bigpkg/plugin/awesomeplug has to be an ordinary package, then you have to have a separate installation of all of bigpkg for every computing environment—even if bigpkg itself and every other plugin is pure Python.
If it's a namespace package, however, then you just have to make sure that you have one installation of awesomeplug per computing environment and that all the paths are set appropriately.
Then you can share the rest of bigpkg and you'll use the correct version of awesomeplug for your machine.
its possible to typehint a thing as follows:
a metaclass that returns Foo class if x, y, z are provided on the __call__, Bar if a, b are provided?
i have a code that works at runtime, but the typechecking is basically nonexitent
class RedirectURI:
def uri(self) -> bool: return True
class Credentials:
def credential(self) -> bool: return True
class SpotifyMeta(type):
@t.overload
def __call__(
self,
*,
client_id: str,
client_secret: str
) -> Credentials:
...
@t.overload
def __call__(
self,
*,
client_id: str,
client_secret: str,
redirect_uri: str
) -> RedirectURI:
...
def __call__(
self,
*,
client_id: t.Optional[str] = None,
client_secret: t.Optional[str] = None,
redirect_uri: t.Optional[str] = None
) -> t.Union[RedirectURI, Credentials]:
if client_id is not None and client_secret is not None and redirect_uri is None:
return Credentials()
return RedirectURI()
class SpotifyBase:
@t.overload
def __init__(
self,
*,
client_id: str,
client_secret: str
) -> None:
...
@t.overload
def __init__(
self,
*,
client_id: str,
client_secret: str,
redirect_uri: str
) -> None:
...
def __init__(
self,
*,
client_id: t.Optional[str] = None,
client_secret: t.Optional[str] = None,
redirect_uri: t.Optional[str] = None
) -> None:
...
class S(SpotifyBase, metaclass=SpotifyMeta):
...
s = S(client_id="1", client_secret="2")
s2 = S(client_id="a", client_secret="b", redirect_uri="c")
# i got typechecking for the inicialization of a class, but not for its methods
If you're making a spotify library and you reach for metaclasses, there's probably something very wrong with the design 😄
Why do you need metaclasses here? It seems like you're using S as a function anyway
💀
I'm dynamically creating instances based on the arguments passed to the constructor, but if there's another simpler way of doing it I'm 100% open to it
What do you need to get, as a result? A RedirectURI | Credentials ?
Actually why are you passing in the three arguments? are you doing something else in __call__ you haven't shown here?
i was thinking about automatically setting the class that the user is going to use based on the arguments that he pass to the constructor, this way i can, (without user prompt/different classes) select one oauth flow to use and make the authentication
Can you show an example maybe?
and different flows means different methods that are available to use
1 sec let me turn the pc on
credentials = Spotify(client_id="1", client_secret="2")
oauth2 = Spotify(client_id="a", client_secret="b", redirect_uri="c")
print(type(credentials))
print(type(oauth2))```
would output
```py
<class 'spotify.Credentials'>
<class 'spotify.Oauth2'>
who is supposed to call this function?
the end user of the library?
If they know what set of credentials they have, they already know what auth method they need to create
credentials = Credentials(client_id="1", client_secret="2")
oauth2 = Oauth2(client_id="a", client_secret="b", redirect_url="c")
yeah makes sense, i was overengineering 
🙂
thanks for the clarification
If you do want to make this a function, do just that
def make_credentials(*, client_id=None, client_secret=None, redirect_url=None):
if ...:
return Credentials(...)
else:
return Oauth2(...)
99% of the time when you think you need a metaclass, the problem can be solved with a factory or a class decorator which can be type hinted more readily
Those or also __init_subclass__ and sometimes __set_name__.
I feel like, with all the functionality classes have gained over the years, there are few good remaining reasons to use metaclasses. They have their place, but they're usually not needed.
I think people would be less likely to misuse* them if people stopped talking about them as if they were dark magic that people shouldn't touch and instead just explain why they are overkill for most uses.
*if it works, but there's a better way, it still worked for the person that went and did it that way.
Is there a way to type hint an empty tuple?
tuple[()]
ok
how can i typehint this? it says Tauler is not defined
class Tauler:
def mostrar_dos_taulers(self, tauler: Tauler) -> None:
pass```put it in quotes ("Tauler") or add from __future__ import annotations
okay, thanks
What is the state of from __future__ import annotations atm? Is this still in limbo?
PEP 649 is likely to go into 3.12
Does that mean from __future__ import annotations behaviour would be deprecated?
yes
simply dont support 3.12+ without dropping <3.12 :^)
I'm not sure actual changes will be necessary for many projects. There is talk of simply making the existing future turn on PEP 649 behavior
And then eventually it would be the default
just like you can still do from __future__ import print_function forever
ah
maybe it's helpful to introduce two notions of deprecation: one is the "real deprecation", as in -- this will be removed in version 3.Y, and you better move or you will get screwed; and "fake deprecation" -- there's a better way of doing stuff now, please use it instead, but all we can do is shake our heads in disapproval.
technically there's also PendingDeprecationWarning vs DeprecationWarning
i think pep 585 changes are an example of a "fake deprecation". not planning on touching that until we're all much older
Is it possible to have the parameters and return type of a function be inferred from the usage of a decorator? Currently I'm trying to create methods for specific events that can be dispatched, and while right now the signature is validated, the function doesn't get any of that type information: ```py
P = ParamSpec("P")
S = TypeVar("S")
T = TypeVar("T")
MethodDecorator = Callable[[S, Callable[P, T]], Callable[P, T]]
def typed_event(func: Callable[P, T], /) -> MethodDecorator["EventDispatcher", P, T]:
@functools.wraps(func)
def wrapper(self: "EventDispatcher", callback: Callable[P, T]) -> Callable[P, T]:
self.add_listener(func.name, callback)
return func
return wrapper
class EventDispatcher:
@typed_event
@staticmethod
def on_raw_event(packet: "Packet", /) -> Any: ...
dispatch = EventDispatcher()
@dispatch.on_raw_event
async def on_raw_event(test): # accepted, but no type inference
...
I think that only really happens with lambdas?
(when you pass a function as an argument to a higher-order function)
With django OneToOne fields, certain objects can have attributes which may either
- exist
- or raise and AttributeError
Is there a way to typehint this?
class A(models.Model):
b: Maybe['B']
class B(models.Model):
a = models.OneToOneField('A')
people seem to be liking this syntax for inline typed dicts dict[{'bar': int, 'baz': str}]
https://mail.python.org/archives/list/typing-sig@python.org/thread/HXRBE5BVHF4PNAJEDFCU2DXZJM7OZPED/
Nice ☺️ typing even dictionaries. Woohoo
That syntax also allows keys to not be LiteralStrings: dict[{'a': int, 2: list, None: float, False: str, True: str}]
Wait so [None] on that would reveal float?
that would have to be a separate enhancement
and probably quite a bit more controversial
is there a compiled list of things almost never type hinted? I know of __init__ and self
cls in classmethods
Vars if their type can be inferred
Imported symbols are not annotated, their type is always inferred
Out of curiosity: why would you need such a list?
plausible use case: a linter that complains about unannotated things
oh, i don't need a list - just curious is all
__init__ is usually type hinted though? 🤔
But as Gobot mentioned usually self and cls are inferred
i've not seen it hinted very often, especially as it's just -> None. come to think of it, -> None might be a good category for unhinted things
I believe mypy with strict settings requires you to type hint it as -> None
i think self and cls are because Self didn't exist before 3.11, and cls would be type[Self], which is ugly
I can make https://mypy-play.net/ complain if i make a class with an untyped repr, but not with init
🤔 Maybe it was a different linter that complained about lack of return annotation in __init__
class Foo:
def __init__(self):
pass
t.py:5: error: Function is missing a return type annotation [no-untyped-def]
t.py:5: note: Use "-> None" if function does not return a value
Found 1 error in 1 file (checked 1 source file)
check the --strict flag in options
pylance's pyright also has a strict mode, but it surprisingly doesn't care about a lack of return type for repr. that might be about the only thing it doesn't care about, though, as strict mode turns most code files into a sea of red
very curious behavior: add a argument to that and type the argument, a la
class Foo:
def __init__(self, a: int):
pass
no more complaints
👀
weird
Yep, I usually use flake8-annotations via ruff, so that doesn't happen to me https://pypi.org/project/flake8-annotations/

turns out that this is intentional, and it was done in late 2018: https://github.com/python/mypy/issues/604#issuecomment-348525995
changed in mypy version 0.640 via https://github.com/python/mypy/pull/5677
also referenced on their blog https://mypy-lang.blogspot.com/2018/10/mypy-0640-released.html
New Feature: Allow Omitting Return Type for _init_
[...]
Note that this only works if there’s at least one annotated argument!
That's a bit weird if you ask me
sounds like people were annoyed at having to type hint init everywhere
unrelated note: i found a sorta bug concerning mypy and pyright:
a: set[set[int]]
a = {{1, 2}}
``` there should be an error here, preferably on the first linei'm guessing the lack of complaint is because set could be overridden, but that's a terrible excuse unless it's detected as such
stdlib/builtins.pyi line 1079
class set(MutableSet[_T], Generic[_T]):```it's mildly interesting that set is typed inheriting MutableSet, which is an alias for an ABC of the same name, while frozenset is typed inheriting AbstractSet, which is an alias for an ABC called Set
it's because hashability is poorly supported in the type system
deferred, just like the great pep 505. 🥲
Is there a way in mypy/pyright to extract type information about a module as some kind of data?
Like, I want to know what type every little expression is
Joining the question. It sounds so cool and useful.
There's this thing btw:
https://github.com/Zzzen/pyright-lint
but I haven't yet figured out how it works
Ooh that's cool
I'd prefer to work on improving typing because this could be implemented using pymaybe and proper type intersections simply cannot be implemented right now ;(
I think it's about time to implement a new python type checker in Haskell or Rust
With plugins and detailed information like this
I think, everyone will be exceptionally happy if you do so
reveal_locals() exists, but it shows only types of all variables
But Sobolevn has already tried and nobody wanted it
Hm...
If we preprocess code and run pyright on it, and if it considers globals locals when run on global scope, then it's actually possible.
reveal_locals() is a mypy's feature
wdym
well, there's pravda but it has like... zero literally commits
because he doesn't really have time for that
Oof, then it's useless — mypy is already possible to introspect, I think
He tried to find investors
His name (which is big) and his idea didn't fancy anyone.
So I highly doubt that anybody wants a rust type checker ;)
I mean wants to the point of investing
Eh, I suppose mypy/pyright already cover most real use cases.
If you want advanced static analysis, use a statically typed language (duh!)
what in particular?
This
Well... Pyright-lint seems to enforce rules on type hinting, no?
Seems like it's doable using AST, no?
hm?
well, it's reaching into pyright's internals somehow
and extracts type information from there
I'm actually kinda confused as to why I and many other people got so deep into type-hinting Python. It's such a weird thing. Almost like a religion
There are so many nice static languages
well, I suppose Python programmers are cheaper
I wouldn't call them cheap
I mean, cheaper than say F# programmers 🙂
(or maybe even Java/C# programmers)
Cheaper than F# but pretty much the same price as java, I think
though you could argue that you might need 3 F# great programmers to maintain a system that you'd need 10 mediocre Python programmers to maintain
curious what use case you have in mind for this kind of thing
do you want type aware custom lints / custom refactoring
or do you want something more exotic, e.g. using statically inferred types at runtime
wdym
the type information thing?
Yeah that's what pyright-lint does.
For example, prohibit redundant items in a union (e.g. str | int | object)
yeah, the ability to get types of every expression
I haven't even thought about refactorings actually. But that could be a great use case
right now pylance's refactorings are... mostly nonexistent
I mean, rename works
most of the time
Extracting a parameter object? Nah, you do it yourself
I strongly believe that junior python devs are dangerous while junior java devs are way less dangerous because java has stricter boundaries.
Similar to C++ junior devs: the capabilities of breaking stuff are infinite.
damn, I'm dangerous
any way to threaten people?
Bad type hints are threatening on their own
well somehow I was fixing all the bad type hints introduced by our senior developer...
Yeah, senior devs do be like that sometimes
what do you mean by "bad" type hints? those that are just plain wrong?
or perhaps a misuse of Any?
yes
like using type variables instead of type aliases (which was very confusing), or using NoReturn to mean None
Could the type checker not spot those errors? Even if your function is originally untyped, it could still infer the types of some variables if you use built in functions
Mypy is kinda lenient for some reason... I think it wasn't "strict"
and it just straight up trusts the programmer about NoReturn IIRC
Well, that's unfortunate...
what does fallback= mean in def (*, group: builtins.str, name: builtins.str) -> typing.Iterable[Tuple[builtins.str, builtins.str, builtins.str, fallback=importlib.metadata.EntryPoint]]
something with namedtuples? is EntryPoint a namedtuple with three str fields?
test-data/unit/check-namedtuple.test line 370
reveal_type(x._replace()) # N: Revealed type is "Tuple[Any, Any, fallback=__main__.X]"```so it's like a cheaky intersection type? but only for named tuples
I guess it's kind of like an intersection, yes. But basically it's just how mypy implements namedtuples
it's not great that this "fallback" stuff leaks into user-visible output though
oh maybe I was wrong then
perhaps they just haven't set up mypy for that project in the CI
they use pycham
which of of course the main source of life, truth and wisdom
my point still stands yeah
 moment
moment
Just some tuning is necessary
https://careers.wolt.com/en/blog/tech/professional-grade-mypy-configuration

Wolt Careers
Type hints are an essential part of modern Python. In this blog post, we’ll list a set of mypy configuration flags which should be flipped from their default value in order to gently enforce professional-grade type safety.
sounds like they'd be happiest just using strict=True
in case it's useful, here's the guide i wrote up on how to incrementally get to strict=True if you're dealing with an existing codebase: https://mypy.readthedocs.io/en/latest/existing_code.html#introduce-stricter-options
why is a stdlib module importing a third-party? aren't the typeshed files supposed to be valid code as well?
https://github.com/python/typeshed/blob/main/stdlib/_thread.pyi#L7
stdlib/_thread.pyi line 7
from typing_extensions import Final, final```yes, we import it pretty much everywhere. It's basically part of the stdlib as far as type checkers are concerned
well i guess it's TIL day for me, cause that's at least the second time
Look... I don't think I have any say over our mypy configuration 😄
if I had, I would switch to pyright!
How should I type hint TZ aware/naive datetime objects?
don't think the type system can differentiate them. https://github.com/python/mypy/issues/10067

GitHub
Feature I would like to be able to have a way to say foo: datetime but know that foo either: definitely doesn't have a tzinfo has a tzinfo has a tzinfo that specifically is / isn't ...

I mean you can write stub files yes. You could probably do that to trick mypy into treating naive and aware datetimes as different types
maybe one day soon
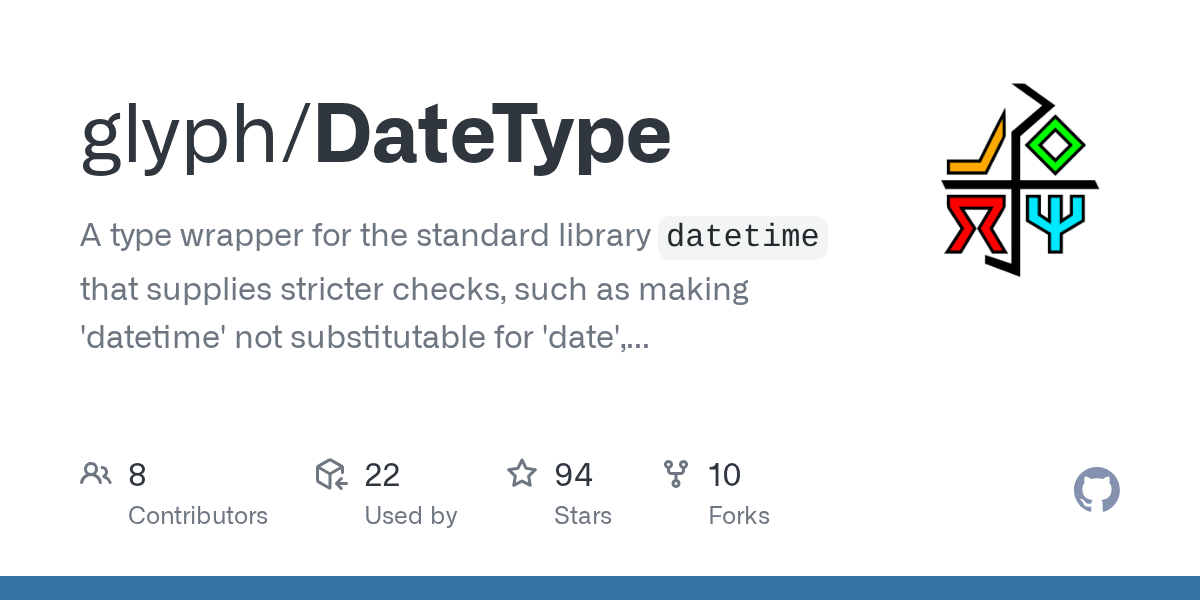
https://github.com/glyph/DateType this lib from that mypy issue seems interesting
GitHub
A type wrapper for the standard library datetime that supplies stricter checks, such as making 'datetime' not substitutable for 'date', and separating out Naive an...
how? honestly haven't looked into this too deeply, just remembered the mypy issue
over a bool?
over tzinfo's type
hm ok
datetime.datetime - for informing people of timezone awareness/naiveness at type time. default and bound should be timezone | None. datetime[timezone] would mean timezone-aware datetimes are expected to be passed, datetime[None] means naive datetimes and datetime[timezone | None] means you don’t care about awareness. This is relatively commonplace in other languages’ datetime libraries.
I think datetime should have simply been two different types
one is an "instant" and another is a "local datetime"
thatd also work but i think making it generic now is the best alternative
Does this seem good enough? Used stubs for the custom type classes
def localize_date(value: tznaive_datetime, tz: pytz.tzinfo.BaseTzInfo = timezone.get_default_timezone()) -> Union[tzaware_datetime, tznaive_datetime]:
# Checking if datetime object is tz aware so that it can be localized
if value.tzinfo is not None and value.tzinfo.utcoffset(value) is not None:
value = timezone.localtime(value, timezone=tz)
return value
ah, thanks. Speaking of PEP 696, might be time to submit it to the SC soon. There's plenty of time until the feature freeze, though, and the SC might appreciate if we wait until PEP 695 is decided upon
can you ask the steering council if we should wait?
Actually having some trouble with the stubs, can someone pls help? Import "asgard.stubs.tzawaretypes" could not be resolved from sourcePylancereportMissingModuleSource. I've already created __init__.py files in the directories
actually the feature freeze is only 2 months away. I think it makes sense to submit soon.
I should submit PEP 702 soon too
ill see if i can find time to do it this weekend
Guys, what exactly is a TypeVar?
I have a tutorial 🙂
https://decorator-factory.github.io/typing-tips/tutorials/generics/
Because a pyi is just for describing stuff to the type checker, it doesn't really exist for the interpreter
if you want a type alias in pyi, you won't be able to import it
Hmm, what's the best way to do so then? I just want to create two type hints called tzaware_datetime and tznaive_datetime that are subclasses of datetime.datetime
Ended up going with:
from datetime import datetime
from typing import NewType
tzaware_datetime = NewType('tzaware_datetime', datetime)
tznaive_datetime = NewType('tznaive_datetime', datetime)
Hey guys, how do I type hint that whatever you pass in from a Union is what will be returned? Here is the code in question:
def localize_datetime(value: Union[tzaware_datetime, tznaive_datetime], tz: pytz.tzinfo.BaseTzInfo = timezone.get_default_timezone()) -> ???:
pass
I want to type hint ??? as either tzaware_datetime or tznaive_datetime, whichever one is passed as the input
Sounds like you want a typevar with a union bound
How'd I go about doing that? I'm a noob when it comes to type hints, sorry
What's union bound in this case?
DatetimeT = TypeVar("DatetimeT", bound=Union[tzaware_datetime, tznaive_datetime])
and then use that type in both the argument and return annotation of your function
Great, thank you so much!:)
@trim tangle why no type hints
I don't know, I'm kind of in a love-hate relationship with them
I was wondering why not an overload?
overloads are a more advanced and complicated tool. You could achieve something similar (not identical) with overloads but it's better to use typevars first
is there some easy and very short way to type hint dictionary
dict
with having typed exact possible keys
Dictionary keys are hashable types
If they are strings, I think dict[str] should work, or maybe dict[str, ...]
well, if you don't know, then don't know, i'll just use
from typing import TypedDict
class PingResponce(TypedDict):
message: str
it will work as well. just a bit more wordy / lines to write
You should be able to test that if you have a type checker ongoing
There's a demo proposal by sobolevn for dict[{"message": str}], which Pyright already supports
Nice. Exactly like this tried to type 😁
There is actually limited almost inline support
from typing_extensions import TypedDict
Movie = TypedDict('Movie', {'name': str, 'year': int})
movie: Movie = {'name': 'Blade Runner', 'year': 1982}
Should be working as long as type not at the same line as assignment probably
that syntax looks dangerously close to a real dict
If it will type match other dicts, it will be fine. It is typing after all. Mypy/Pyright will auto verify correctness with other dicts
It should not be having faults of regular dicts
hey friends, i have this comprehension:
pairs: Iterable[Tuple[Any, Any]] = [
kv_args[i : i + 2] for i in range(0, len(kv_args), 2)
]
it takes a list of arguments and turns them into pairs, to pass in to dict. MyPy complains with this:
List comprehension has incompatible type List[Tuple[Any, ...]]; expected List[Tuple[Any, Any]] [misc]
How do i tell MyPy that the sublists generated by the comprehension do have length 2?
(kv_args[i], kv_args[i+1]) instead of the slice would work 🤷♂️
oh hey, it totally would. Let me try that!
that worked! Thank you @acoustic thicket!
OK i've got one more. I have this:
K = TypeVar("K", bound=Hashable)
And i use a function has_key which has its own K typehint with the same bound as above:
def has_key(key_match: Union[K, Matcher[K]]) -> Matcher[Mapping[K, Any]]:
But when i try to give a key with my type K, MyPy complains like this:
error: Argument 1 to "has_key" has incompatible type "K"; expected "Union[K, Matcher[K]]"
I tried importing the has_key's K to use as my typehint, but it says the same thing. What is it on about?
I tried and failed to reproduce this: https://mypy-play.net/?mypy=latest&python=3.10&gist=d1a8209b046f7a524464e97278bb7c0e. What does your code look like exactly?
just to be clear, the has_key comes from PyHamcrest: https://github.com/hamcrest/PyHamcrest/blob/main/src/hamcrest/library/collection/isdict_containingkey.py#L33, and my code is separate
src/hamcrest/library/collection/isdict_containingkey.py line 33
def has_key(key_match: Union[K, Matcher[K]]) -> Matcher[Mapping[K, Any]]:```so that's part one. Here's my part:
"""
Matches a dictionary that contains the desired key.
"""
from typing import Any, Hashable, Mapping, TypeVar
from hamcrest import has_key
from hamcrest.core.matcher import Matcher
from screenpy.pacing import beat
SelfContainsTheKey = TypeVar("SelfContainsTheKey", bound="ContainsTheKey")
K = TypeVar("K", bound=Hashable)
class ContainsTheKey:
"""Match a dictionary containing a specific key.
Examples::
the_actor.should(See.the(LastResponseBody(), ContainsTheKey("skeleton")))
"""
def describe(self: SelfContainsTheKey) -> str:
"""Describe the Resolution in the present tense."""
return f'Contain the key "{self.key}".'
@beat('... hoping it\'s a dict containing the key "{key}".')
def resolve(self: SelfContainsTheKey) -> Matcher[Mapping[K, Any]]:
"""Produce the Matcher to make the assertion."""
return has_key(self.key)
def __init__(self, key: K) -> None:
self.key = key
(also thank you for taking a look at this!)
if it helps, i'm using MyPy v1.1.1 and Python 3.11.2
i'm also getting the same thing with the has_value version of these 😵💫
error: Argument 1 to "has_value" has incompatible type "V"; expected "Union[V, Matcher[V]]"
the TypeVar annotation on self probably isn't helping. Also the class should be Generic[K]
That TypeVar is to allow inheritance, if someone wants to modify the class by inheriting from it. It’s a backwards-compatible version of typing.Self—at least, that’s what we’re trying for.
Are you saying it should be Generic[K] in the __init__?
you don't need a TypeVar for that, just leave Self unannotated
the class should inherit from Generic[K]
ContainsTheKey(Generic[K])?
we tried that, but when we inherited from one of the classes, the self still thought it was the base class in the inherited class, which caused some MyPy errors.
you are doing something wrong then, possibly you used the class name as the annotation
hm... i'll have to look into that. The self-typing was done by another maintainer, maybe i'm misremembering the reasoning
oh, it's because a lot of our classes return self
we were following https://peps.python.org/pep-0673/
Python Enhancement Proposals (PEPs)
you dont strictly need to annotate self to use Self
Hm… i’ll try that!
Is this what you meant by this message?
ContainsTheKey(Generic[K])
yes
do i need a type checker tool if i am using PyCharm? tools such as mypy
yeah it's not the best
I don't think there's editor integration for pyright in PyCharm
thanks @oblique urchin and @soft matrix, that fixed the issue! I'll look into the self don't-typing tips too.
if you have a moment, could you explain what i just did by inheriting from Generic[K]? I don't really get it
I thought i was wrong. would you recommend any tool that works for pycharm?
you make your class generic. if you just use a TypeVar in a single method, the method is generic over that TypeVar, which doesn't make sense because there's not enough information to solve the typevar
i thought i understood what TypeVar does but i guess i have more to learn ":D
thank you

I was searching for this
o
ye
>>> view.args
()
>>> type(view.args)
<class 'tuple'>
>>> class TestObj(BaseModel):
>>> args: Tuple[Any]
>>> TestObj(args=view.args)
pydantic.error_wrappers.ValidationError: 1 validation error for TestObj
args
wrong tuple length 0, expected 1 (type=value_error.tuple.length; actual_length=0; expected_length=1)
i have a problem typing Tuple with zero elemts for pydantic how can i approach with compatibility for python 3.8-3.10
Tuple[()]
will it accept Tuples with more values?
like having Tuple with arbitary amount of values
no, for that you want Tuple[Any, ...]
Tuple[()] is specifically a zero-element tuple
okay, so Union[Tuple[()], Tuple[Any, ...]] should work
Yup. thanks, @oblique urchin it works 🙂
you don't need the union, "any number" includes 0
hello guys, is there any way where i could throw an exception whenever a typing hint fails. I am willing to do that without using external tools. meaning that i want to write a python script that automatically checks for typing hint violations.
Why not using already reliable tool that does it? 😊
Is there tools that can automatically add type hints to code where possible? Please can someone ping me in reply
GitHub
Contribute to JelleZijlstra/autotyping development by creating an account on GitHub.

GitHub
A Python library that generates static type annotations by collecting runtime types - GitHub - Instagram/MonkeyType: A Python library that generates static type annotations by collecting runtime types
both have different merits
fair enough
autotyping is static whereas monkeytype is runtime, monkeytype will be more accurate if all code branches are called but autotype probably does a decent job for the monotonous methods
You mean, validating types at runtime?
That's generally not possible. (https://decorator-factory.github.io/typing-tips/faq/runtime-checking/)
def f(callback: Callable[[int], str]) -> None:
# How do you check if `callback` is of the right type?
Or do you want static checking?
yes, i am talking about validating
which set of tools would you recommend
due to run time problems with validation and not really being needed in the first place when static type checking works adequately fine...
i just recommend using Mypy with turned on additional settings eventually
https://careers.wolt.com/en/blog/tech/professional-grade-mypy-configuration
alternative to use Pyright, but i haven't tried it yet. It looked to me with less support than mypy anyway
Why do you want to do it?
remember the issue i had with mypy on only 3.7?
SimpleAdapter: TypeAlias = ct.Adapter[T, T, U, U]
well explicitly type hinting SimpleAdapter as TypeAlias fixes it
although this behaviour should be made compulsory in 3.8, 3.9 too, no?
Hey everyone, Ive recently started a thesis on Symbolic Execution, I've came across CrossHair and I was wondering if there are any other tools like that one that you may know and consider over it 😄
Pretty sure it is the only "major" SMT static checker for python
surprised nobody mentioned pydantic and https://docs.pydantic.dev/usage/validation_decorator/
Data validation using Python type hints
Or strong typing library
https://strongtyping.readthedocs.io/en/latest/#the-solution
None
But it is still not reliable and full solution like Mypy. Better to use Mypy first, and then if wishing augmenting with such stuff
abdu11a still hasn't told us what they need to validate and why 🙂
static and runtime checkers solve very different problems
(and I think in most cases you don't need a runtime checker)
how to type hint properly, function may return nothing (its default None), or may be will return Dictionary?
i already tried Union[None, Dict[str, Any]] and Optional(dict[str,Any], still it did not work for mypy (complains on missing return statement :/)
hmm, found semi solution
if i type one function as returning None, and other as returning Dict, then both satisfy to its external typing like Union[None, Dict[str, Any]]
You have to have an explicit return None instead of relying on the implicit return None
Hi, I am Christoph, and just found out this discord channel exists. Is it the right place to ask for reviews and discuss other development-related issues? Currently, I am looking for someone interested in reviewing the following pull requests:
https://github.com/python/mypy/pull/14390
https://github.com/python/mypy/pull/14440
https://github.com/python/mypy/pull/14855 (ikonst had a first look at this one)

GitHub
Avoid false "Incompatible return value type" errors when dealing with isinstance, constrained type variables and multiple inheritance (Fixes #13800).
The idea is to make a union of the cu...
GitHub
Fix checking multiple assignments based on tuple unpacking involving partially initialised variables (Fixes #12915).
This proposal is an alternative to #14423. Similar to #14423, the main idea is ...
GitHub
Let the multiple inheritance checks consider callable objects as possible subtypes of usual functions (Fixes #14852).
The solution is inspired by the visit_instance method of SubtypeVisitor. The t...
so mypy basically can be integrated into text editor and show you the warnings while coding.
so mypy basically can be integrated into text editor and show you the warnings while coding.
essentially yes
it can be used from CLI first, (and that makes it CI friendly)
But best for dev experience to use from smth like Vscode with Mypy extension, then it shows in real time with red highlighting of files and code lines, where you have mistakes of wrong types used across the code (especially best works with enabled https://careers.wolt.com/en/blog/tech/professional-grade-mypy-configuration of course, because better coverage has)
Allows smoothly having always correct return input/outputs everywhere across the code in functions and methods, and even class matching interfaces/abstract classes, and even each local variable to be used correctly. Spotting mistakes within a second of code being written 🙂 Very easy refactorings to have in result
- as side effect u get better working intelli sense, because your IDE knows what are available attributes and methods for each current object (specifically good idea to have it if you implement a library for usage by other developers)
Hi there, so I'm a bit stumped here on how to handle this scenario using PyDatnic:
Say I have a model like this:
class ExampleModel(BaseModel):
modelGuid: str
someIntField: int
someStrField: str
example_model = ExampleModel.parse_obj({'modelGuid': 'XX-XX-XX-XX',
'someIntField': 2,
'someStrField': 'Foo'})
# {
# "modelGuid": "XX-XX-XX-XX",
# "someIntField": 2,
# "someStrField": "Foo"
# }
print(f'json = {example_model.json()}')```
I don't want to change the fields overall structure because it will affect my parsing, which I want to keep the same but I need my json serialized differently on output, for example I need my JSON to look something like this:
```json
{
"modelGuid": "XX-XX-XX-XX",
"intFields": {
"someIntField": 2
},
"strFields": {
"someStrField": "Foo"
}
}```
And in the future, whenever I create any other int or str fields, they'll go to the respective collection
To further add onto my question, I don't have a whole lot of knowledge when it comes to Pydantic, is this something that can be done with some sort of custom serializer?pydantic basemodel is a serializer
Create second BaseModel, values from first model insert into second one and turn to json
any other approach is bad one, because u will not be using typing then
if u want second serializer being connected to your first model, you can just add it as a method to the first one
class ExampleSerializer(BaseModel)
pass
class ExampleModel(BaseModel):
modelGuid: str
someIntField: int
someStrField: str
def serialize_for_smth(self) -> str:
ExampleSerializer(value=self.value).json()
I'm still unsure of how this approach would me transform the overall structure of the incoming json to the required output
Here's a solution I came up with, though I don't like it, it's hacky but this should outline more clearly what I'm trying to achieve
import json
from pydantic import BaseModel
class AssetUserAdd(BaseModel):
assetGuid: str
pcm_lease_apv_days_alw: int
pcm_lease_apv_days_alw_bs: str
def to_json(self):
skipped_field_names = ["assetGuid"]
str_field_values = {}
int_field_values = {}
for (field_name, field_value) in self.__dict__.items():
if field_name in skipped_field_names:
continue
if isinstance(field_value, int):
int_field_values[field_name] = field_value
elif isinstance(field_value, str):
str_field_values[field_name] = field_value
return json.dumps({
'assetGuid': self.assetGuid,
'strFieldValues:': str_field_values,
'intFieldValues': int_field_values
})
# {
# "assetGuid": "XX-XX-XX-XX",
# "pcm_lease_apv_days_alw": 15,
# "pcm_lease_apv_days_alw_bs": "B"
# }
asset_user_add = AssetUserAdd.parse_obj({'assetGuid': 'XX-XX-XX-XX',
'pcm_lease_apv_days_alw': 15,
'pcm_lease_apv_days_alw_bs': 'B'})
# {
# "assetGuid": "XX-XX-XX-XX",
# "strFieldValues: {
# "pcm_lease_apv_days_alw_bs": "B"
# },
# "intFieldValues": {
# "pcm_lease_apv_days_alw": 15
# }
# }
print(asset_user_add.to_json())
The first commented json is the json that's getting received, in my case this is the body coming into my AWS Lambda
Then the second commented out json is what I'm sending to a REST API so the structure has to match exactly
from pydantic import BaseModel
from typing import List
class ExampleModel(BaseModel):
modelGuid: str
someIntField: int
someStrField: str
class NestedExamplIntView(BaseModel):
someIntField: int
class NestedExampleStrView(BaseModel):
someStrField: str
class ExampleView(BaseModel):
modelGuid: str
intField: NestedExamplIntView
strFields: List[NestedExampleStrView]
justStrs: List[str]
justInts: List[int]
dictInts: Dict[str, int]
if __name__ == "__main__":
input = ExampleModel(modelGuid="abc", someIntField=123, someStrField="123")
view = ExampleView(
modelGuid=input.modelGuid,
intField=NestedExamplIntView(someIntField=input.someIntField),
strFields=[NestedExampleStrView(someStrField=input.someStrField)],
justStrs=["123", "456"],
justInts=[1, 2, 3],
dictInts={"abc": 12},
)
print(view.dict())
u can pack them together into one class even if u need many
from pydantic import BaseModel
from typing import List, Dict
class ExampleModel(BaseModel):
modelGuid: str
someIntField: int
someStrField: str
class ExampleView(BaseModel):
class NestedExamplIntView(BaseModel):
someIntField: int
class NestedExampleStrView(BaseModel):
someStrField: str
modelGuid: str
intField: NestedExamplIntView
strFields: List[NestedExampleStrView]
justStrs: List[str]
justInts: List[int]
dictInts: Dict[str, int]
if __name__ == "__main__":
input = ExampleModel(modelGuid="abc", someIntField=123, someStrField="123")
view = ExampleView(
modelGuid=input.modelGuid,
intField=ExampleView.NestedExamplIntView(someIntField=input.someIntField),
strFields=[ExampleView.NestedExampleStrView(someStrField=input.someStrField)],
justStrs=["123", "456"],
justInts=[1, 2, 3],
dictInts={"abc": 12},
)
print(view.dict())
hell, they can be even one class fully 😆
Thing with this approach though is it would require you to add every field manually when creating that ExampleView
Sure.
we need to control what we want to view
I guess that's true to an extent, did you see my "hacky" approach?
Well I was hoping to find some way where it would nest fields of those types automatically
But only nest them on serialization
You two might be interested in this 🙂
https://github.com/decorator-factory/py-humbleparser
Not really seeing value in it exactly Why not just dump data into pydantic DefinedPydanticBaseModel(**requert.body)
shorter written code, no need to write value trasformartions
make sure to read the whole thing
Actually, I'm overthinking this. I like the idea of "controlling" what gets viewed
This approach will work:
from typing import List
from pydantic import BaseModel
class AssetUserAdd(BaseModel):
assetGuid: str
pcm_lease_apv_days_alw: int
pcm_lease_apv_days_alw_bs: str
class AssetUserAddView(BaseModel):
class NestedIntFieldView(BaseModel):
pcm_lease_apv_days_alw: int
class NestedStrFieldView(BaseModel):
pcm_lease_apv_days_alw_bs: str
assetGuid: str
intFieldValues: NestedIntFieldView
strFieldValues: NestedStrFieldView
asset_user_add = AssetUserAdd.parse_obj({'assetGuid': 'XX-XX-XX-XX',
'pcm_lease_apv_days_alw': 15,
'pcm_lease_apv_days_alw_bs': 'B'})
view = AssetUserAddView(assetGuid=asset_user_add.assetGuid,
intFieldValues=AssetUserAddView.NestedIntFieldView(
pcm_lease_apv_days_alw=asset_user_add.pcm_lease_apv_days_alw
),
strFieldValues=AssetUserAddView.NestedStrFieldView(
pcm_lease_apv_days_alw_bs=asset_user_add.pcm_lease_apv_days_alw_bs
))
print(view.json())
I'd say I don't see a value in bringing in a complicated tool like pydantic with its own set of conventions 🙂
(some of those conventions are very strange, I'm mostly talking about implicit conversions and all the ways to configure it once you're outside the "simple case")
...seemingly just to reduce the amount of typing you do
i would also replace
asset_user_add = AssetUserAdd.parse_obj({'assetGuid': 'XX-XX-XX-XX',
'pcm_lease_apv_days_alw': 15,
'pcm_lease_apv_days_alw_bs': 'B'})
onto
asset_user_add = AssetUserAdd(
assetGuid='XX-XX-XX-XX',
pcm_lease_apv_days_alw=15,
pcm_lease_apv_days_alw_bs='B'
)
to hell with dictionaries if possible
Yea I know it doesn't need to be dictionary
In the real world application I'm using:
asset_user_add = AssetUserAdd.parse_obj(body)```Where body = the json body I'm receiving from an aws lambda call
from pydantic import BaseModel
class AssetUserAdd(BaseModel):
assetGuid: str
pcm_lease_apv_days_alw: int
pcm_lease_apv_days_alw_bs: str
class View(BaseModel):
class NestedInt(BaseModel):
pcm_lease_apv_days_alw: int
class NestedStr(BaseModel):
pcm_lease_apv_days_alw_bs: str
assetGuid: str
intFieldValues: NestedInt
strFieldValues: NestedStr
@property
def view(self) -> View:
view = self.View(
assetGuid=asset_user_add.assetGuid,
intFieldValues=self.View.NestedInt(
pcm_lease_apv_days_alw=asset_user_add.pcm_lease_apv_days_alw
),
strFieldValues=self.View.NestedStr(
pcm_lease_apv_days_alw_bs=asset_user_add.pcm_lease_apv_days_alw_bs
),
)
return view
asset_user_add = AssetUserAdd.parse_obj(
{
"assetGuid": "XX-XX-XX-XX",
"pcm_lease_apv_days_alw": 15,
"pcm_lease_apv_days_alw_bs": "B",
}
)
print(asset_user_add.view.json())
even more shorter if wishing
and typing of mypy will fully work to support you in this code maintanability 🙂
(as to why I brought this up -- imagine how simpler this would be if you had plain functions like parse_asset_user and dump_asset_user)
(that's what I meant by the "Simple cases and complex cases" point)
I honestly also enjoy the smaller call stack. If you have a pile of metaclasses and intermediaries, it's a pain to debug if something goes wrong.
i am not enthusiastic about extra code for trasformations, with lack of typing due to using "message_id" string values / pretty much WET and untyped code.
def is_message(source: object) -> Message:
return Message(
message_id=has_field("message_id", is_int)(source),
sent_at=has_field("date", _is_timestamp)(source),
author=is_any_of(
has_field("sender_chat", _is_chat),
has_field("from", _is_user),
)(source),
text=has_optional_field("text", is_str)(source),
)
I'm also not really trying to introduce another dependency
oh I'm not suggesting that you stop using Pydantic, just a side note
It's very simple code. It doesn't really have any conditionals or loops in it. You can easily call this function in a test and debug the 2-3 layers of calls it has
Actually, how would you parse the structure I'm parsing in the README using pydantic?
Or, actually, even this Message
from pydantic import BaseModel, Field
class UserMessage(BaseModel):
class From(BaseModel):
id: int
first_name: str
message_id: int
date: int
from_: From = Field(alias="from")
text: str
message_from_user = {
"message_id": 25045,
"date": 1676769966,
"from": {"id": 11111, "first_name": "Bob"},
"text": "Hello there!",
}
parsed = UserMessage(**message_from_user)
print(parsed)
done 🙂
That's very different from what I'm parsing
clarify which one message. you asked to parse message
fuck
@dataclass(frozen=True)
class Message:
message_id: int
sent_at: datetime
author: Union[User, Chat]
text: Union[str, None] = None
?
you don't really show original data to parse here 🤔
you show end result if u suggest to get this one
Well this is based on the Telegram API, as I said in the README. I guess I should've provided some example data, you're right
The main difference is that I want this:
- if the raw message has a
sender_chatfield, I want it to be parsed as aChatand stored in theauthorfield - if the raw message has a
fromfield, I want it to be parsed as aUserand stored in theauthorfield
and if not parsed, then None?
then this message is invalid and should be rejected
if not found sender_chat data key then what i mean?
If the sender_chat key is missing, then see if from is present.
- if the message is from a channel or a group, there's gonna be a
sender_chatfield - otherwise, there's gonna be a
fromfield (it's from a user)
In the first case a dummy from is provided, that's why we check for a sender_chat first
I imagine it's something like ```py
class Message(BaseModel):
message_id: int
sent_at: datetime = Field(alias="alias")
_sender_chat: Optional[Chat] = Field(alias="sender_chat")
_from: Optional[User] = Field(alias="from")
@property
def author(self) -> Chat | User:
if self._sender_chat is not None:
return self._sender_chat
else:
assert self._from is not None
return self._from
@validator("sender_chat")
def sender_not_none(cls, v):
if v is None:
raise ValidationError("if 'sender_chat' is present it can't be None")
return Chat(**v)
@validator("from")
def from_not_none(cls, v):
if v is None:
raise ValidationError("if 'from' is present it can't be None")
return User(**v)
@root_validator
def validate_all(cls, values):
if not ("sender_chat" in values or "from" in values):
raise ValidationError
return values
``` Though I haven't tested it. In particular, will pydantic show a decent error message in sender_chat and from if they're not dicts?.. Like, if you do User(**[1, 2, 3]) in a validator
What do you mean by "WET" and "untyped"?
The library is fully type-annotated!
def is_message(source: object) -> Message:
return Message(
message_id=has_field("message_id", is_int)(source),
sent_at=has_field("date", _is_timestamp)(source),
author=is_any_of(
has_field("sender_chat", _is_chat),
has_field("from", _is_user),
)(source),
text=has_optional_field("text", is_str)(source),
)
"message_id" and other keys introduce untyped code to our code
wdym untyped?
nothing validates "sender_chat", "from" and etc string keys.. they are not existing for IDE intellisense, and for mypy
is_int has type Parser[int], so has_field("message_id", is_int)(source) will be inferred to have the type int. If you pass it where a string is excepted, your type checker will complain
There is no conceptual duplication, because the name of a field in your Python object has no bearing on the field in the JSON you're sending over the wire.
Though I suppose "use the name of the field for the JSON key" would be a good shortcut to avoid confusion. But it introduces a whole layer of metaprogramming and complexity in Python
you mean, it will complain on runtime. I wish complains received during code writing, before it is run
type checker
as in, static type checker
anyway, Pydantic already solved all problems regarding having fully typed marshaler/unmarshaler with minimal to write code
I wouldn't say this is "minimal" 😄
well, as any typing, it is wordy 🙂
wdym?
because it forces you to write from the beginning structure of the parsed code instead of downloading data just into dictionary?
we save our code sanity by mapping code structure in advance, instead of using dictionaries across the code as some javascript/python novice users 🙂
using dataclasses/pydantic BaseModels we write structure of parsed input
yes, you don't
but you asked me why typing is wordy, i answered this question
well, this is much less wordy, and also is statically typed
this discussion leads nowhere, lets drink better beer 🍻
it is not 😛 you parse manually body of an input, instead of relying on using already built data structures
you made code work twice there, made full data structure, yet not utilizing it for direct parsing of data without manual data matching

if that's what you mean
nice, it probably catches error if you try to assign, not existing "x2" to Point?
No, that means that my JSON has a field with the key of "x2"
again, the x on the left is the name of a field in a Python object and the x on the right is the key in a JSON structure
well, and that is what i don't like
i like more more utilizing directly data structure written for parsing
class Message(BaseModel):
msg: str = "123"
x: str = Field("x2")
Message.parse_obj(source)
less code
closer to each other, easier to read
Golang goes with same approach btw
But if you have a slight deviation from a 1-to-1 mapping, you have to create a monstrosity like this, instead of expressing your constraints direclty in Python code.
I think the Rust library serde provides a decent solution to this. It lets you choose whether you parse a structure automagically (like Pydantic). or whether you want to do it manually. And the two always compose
If you make a typo in your Python field, will your IDE catch it? Like, if you write rcp_statistics: Stat instead of rpc_statistics: Stat
Or if you misread the documentation for an API and assume that a field is not-nullable, when it is.
You will still need tests (for example, contract tests if you're communicating with a different microservice) that ensure you're parsing stuff correctly.
And a function composed of other functions is probably easier to test than a class inheriting from a framework class, which is based on a framework metaclass, which also does some nasty implicit conversions

unfortunately I can't drink beer 😦
validator sender_chat and from don't have a point lets parse everything, and having single validator checking one of them was present / or enforcing other rules
from typing import Optional, Union
from pydantic import BaseModel, Field, root_validator, ValidationError
from datetime import datetime
class User(BaseModel):
user_id: int = Field("id")
first_name: str
username: Union[str, None] = None
class Chat(BaseModel):
chat_id: int = Field("id")
title: str
class Message(BaseModel):
message_id: int
sent_at: int = Field(alias="date")
_sender_chat: Optional[Chat] = Field(alias="sender_chat", default=None)
from_: Optional[User] = Field(alias="from", default=None)
text: str
@property
def author(self) -> Union[Chat, User]:
if self._sender_chat is not None:
return self._sender_chat
return self.from_
@root_validator
def validate_all(cls, values):
if "sender_chat" not in values and "from_" not in values:
raise ValidationError("`sender_chat` or `from` must be present")
return values
if __name__ == "__main__":
message_from_user = {
"message_id": 25045,
"date": 1676769966,
"from": {"id": 11111, "first_name": "Bob"},
"text": "Hello there!",
}
print(Message(**message_from_user))
and extra logic to author is not needed, since we validated in advance that one of them is parsed
I don't want to accept None for from or sender_chat
tell that to mypy
well, that is already extra typing magic then 🙂 can't have everything
why not? your message assumes they can be none
No, either the sender_chat field is present and is a Chat, or it's missing
That's different from "either the sender_chat field is present and is a Chat | None, or it's missing"
so if Telegram sends me a {"sender_chat": null}, that's a violation of their spec, which indicates a bug on their side and should be rejected
hell, maybe in the next version they decide to attach some special meaning to "sender_chat": null which is distinct from it missing
See this thread https://github.com/pydantic/pydantic/issues/1223
is it possible to use paramspec 612 to type wrapper functions, as opposed to decorators?
I'm going through the PEP but finding it a bit opaque
what do you mean? an example maybe?
oh do you mean something that forwards args?
yeah
I mean imagine I Just have:
def my_run(*args, **kwargs) -> CompletedProcess:
return subprocess.run(*args, **kwargs)
great, how do I type it?
with a deco is the easiest way imo```py
def copy_sig(from_: Callable[P, R]) -> Callable[..., Callable[P, R]]:
def inner(to: Callable[..., R]) -> Callable[..., R]:
return to
return inner
```py
@copy_sig(subprocess.run)
def my_run(*args, **kwargs) -> CompletedProcess:
return subprocess.run(*args, **kwargs)
Well that's not type-safe
well yeah but idk any way to make it type safe
ah I see
then what does fix means by saying it's not type safe. copy_sig itself isn't type safe?
also, how does adding/removing parameters to the signature work? I suppose adding things to my_run could probably just be added prior to *args
thats where you run into issues with paramspec
oh also isnt subprocess.run overloaded?
i think youre just 100% screwed lol
it's one of the most terrifying functions in typeshed
it has dozens of parameters and gets new ones every version, and then there's a bunch of overloads to deal with str/bytes stuff
hmm honestly this experience makes me feel, as much as keyword arguments are nice and boilerplate free for simpler cases
maybe for something like this a builder is actually better
builder/struct
I guess that would not make it easier to remove arguments though. but at least the simplest case, would be easy
I guess in the end the best thing to do is probably just copy paste the signature and remove all the things you don't plan to use
yeah I just tried, it doesn't work with overloaded functions
Hello, anyone can explain to me with the typing of dto.search at the last line is wrong? I don't understand :/
from dataclasses import dataclass
from enum import StrEnum
from typing import Generic, List, TypedDict, TypeVar
from uuid import UUID, uuid4
Z = TypeVar("Z", bound=StrEnum, covariant=True)
class SecureLinkSearchFieldEnum(StrEnum):
resource_id = "resource_id"
resource_type = "resource_type"
target_email = "target_email"
class GenericSearch(TypedDict, Generic[Z]):
field: Z
value: str
@dataclass
class SharedLinksListDto:
account_id: UUID
search: List[GenericSearch[SecureLinkSearchFieldEnum]] | None
def test_function(search: List[GenericSearch[StrEnum]]):
print(search)
dto = SharedLinksListDto(account_id=uuid4(), search=[{"field": SecureLinkSearchFieldEnum.target_email, "value": "idk"}])
test_function([{"field": SecureLinkSearchFieldEnum.target_email, "value": "idk"}])
if dto.search:
test_function(dto.search)
Why is it wrong? What tool are you using? What error do you get?
Oh, I see.
62:19 error Argument of type "List[GenericSearch[SecureLinkSearchFieldEnum]]" cannot be assigned to parameter "search" of type "List[GenericSearch[StrEnum]]" in function "test_function" Pyright
"List[GenericSearch[SecureLinkSearchFieldEnum]]" is incompatible with "List[GenericSearch[StrEnum]]"
TypeVar "_T@list" is invariant
"GenericSearch[SecureLinkSearchFieldEnum]" is incompatible with "GenericSearch[StrEnum]"
TypeVar "Z@GenericSearch" is covariant
"SecureLinkSearchFieldEnum" is incompatible with "StrEnum"
I'm using pyright.
Would you agree that this function should pass the type checker?
class SomeOtherEnum(StrEnum):
apple = "apple"
banana = "banana"
def test_function(search: List[GenericSearch[StrEnum]]):
search.append(SomeOtherEnum.apple)
search.append(SomeOtherEnum.apple)
search.append(SomeOtherEnum.banana)
No it doesn't work.
Argument of type "Literal[SomeOtherEnum.apple]" cannot be assigned to parameter "__object" of type "GenericSearch[StrEnum]" in function "append" Pyright
"Literal[SomeOtherEnum.apple]" is incompatible with "GenericSearch[StrEnum]"
oh sorry, I meant
class SomeOtherEnum(StrEnum):
apple = "apple"
banana = "banana"
def test_function(search: List[GenericSearch[StrEnum]]):
search.append({"field": SomeOtherEnum.apple, "value": "X"})
search.append({"field": SomeOtherEnum.apple, "value": "Y"})
search.append({"field": SomeOtherEnum.banana, "value": "Z"})
Hmm GenericSearch is a TypedDict, i've replaced it with search.append(GenericSearch(field=SomeOtherEnum.apple, value="X")) it works.
yeah that's what I meant
So as you can see, this function can add new items to the list, and those items have to be GenericSearch[StrEnum]s, not necessarily GenericSearch[]. So if you pass in a list of GenericSearch[SecureLinkSearchFieldEnum], this function might ruin it
That's because lists are "invariant" (https://decorator-factory.github.io/typing-tips/tutorials/generics/variance/).
What you probably want is: ```py
from collections.abc import Iterable
def test_function(search: Iterable[GenericSearch[StrEnum]]):
``` (or Sequence, depending on what you need to do)
Oh ok, damn. The answer was in the error message. I didn't read it properly
Thanks for your help !
Well, error messages from type checkers are kinda dense
Indeed:)
I wouldn't expect anyone (especially unfamiliar with variance) to understand the error without encountering it before tbh
I'll know next time 🙂
Do people type hint their functions and other things when using opencv?
i want to use type hinting but it seems daunting.
We were searching for something like FastAPI for Kafka-based service we were developing, but couldn’t find anything similar. So we shamelessly made one by reusing beloved paradigms from FastAPI and we shamelessly named it FastKafka. The point was to set the expectations right - you get pretty much what you would expect: function decorators for consumers and producers with type hints specifying Pydantic classes for JSON encoding/decoding, automatic message routing to Kafka brokers and documentation generation.
Please take a look and tell us how to make it better. Our goal is to make using it as easy as possible for someone with experience with FastAPI.

GitHub
FastKafka is a powerful and easy-to-use Python library for building asynchronous web services that interact with Kafka topics. Built on top of Pydantic, AIOKafka and AsyncAPI, FastKafka simplifies ...
How on earth do I type hint the below properly?
def add_cars(cars):
for car, position in cars:
...
example_cars_1 = ((Car("BMW"), 0), (Car("Ford"), 3), (Car("Audi"), 2))
example_cars_2 = [(Car("BMW"), 0), (Car("Ford"), 3), (Car("Audi"), 2)]
example_cars_2 = [[Car("BMW"), 0], [Car("Ford"), 3], [Car("Audi"), 2]]
add_cars(example_cars_1)
add_cars(example_cars_2)
add_cars(example_cars_3)
I know that for each iterable in the main iterable that there'll be two expected data types in a specific order.
If I was just handling tuples inside of Iterables I could do Iterable[tuple[Car, int]] but I don't and changing tuple to Iterable doesn't seem to make Python very happy.
I know Iterable[Iterable[Car | int]] works but to me that looks like passing [(0, Car("BMW")), (Car("Ford"), 3), (2, Car("Audi"))] is valid when the order of data types in the inner iterable is important
[Car(...), 0] makes almost no sense from typecheckers perspective
How so?
@trim tangle do you know how to do the above? Sorry for the ping but it looks like you're a type hinting guru
lists are mutable so theres no promise that you can have a fixed length between operations
That explains a lot - I was wondering why Pycharm recognised typings for car and position when I used a tuple but not for a list.
I guess my best bet is to stick with Iterable[Iterable[Car, int]] for now in that case
Iterable[Car, int] isnt a valid typehint
That's odd - Pycharm isn't complaining about it
Do you know of any better integrations that I could use alongside Pycharm in that case?
no everything for typechecking is just bad/outdated in pycharm
youre best bet is to run pyright in watch mode
but that also sucks
if you really care about typechecking you pretty much cant use pycharm
I have a question whether Python's type system can represent this elegantly. Are code snippets < 30 lines allowed here directly or should I create a Gist.
I have a Generic, let's call it Quant[T]. There can be a Quant[int] or a Quant[str] or a Quant[S] where S would be a dataclass. So I've defined class QuantInt(Quant[int]): and class QuantStr(Quant[str]): which has a add and len method respectively
I want my users to be able to do : def some_fun(a: Quant[int]): a.add(...) and access the .add method. But if they do def some_fun(a: Quant[str]): a.add(...) , it should be a type error.
Of course my users can do def some_fun(a: QuantInt): a.add(...) but that's not the ergonomics I'm after.
Here is the full code to help explain the situation: https://gist.github.com/siddhant3s/916ef3c961b7b3d89e21df082fec819e
In Rust, I'd be able to use traits and impl to accomplish this. Same for Scala. In both the languages, the methods that are accessible for a class can be conditionally controlled on its Generic argument.
you need to use overloads on the method and annotate the self type with Quant[int] -> None and Quant[str] -> Never
side note not really sure why you cant add to a str here
!d typing.overload
@typing.overload```
The `@overload` decorator allows describing functions and methods that support multiple different combinations of argument types. A series of `@overload`-decorated definitions must be followed by exactly one non-`@overload`-decorated definition (for the same function/method). The `@overload`-decorated definitions are for the benefit of the type checker only, since they will be overwritten by the non-`@overload`-decorated definition, while the latter is used at runtime but should be ignored by a type checker. At runtime, calling a `@overload`-decorated function directly will raise [`NotImplementedError`](https://docs.python.org/3/library/exceptions.html#NotImplementedError "NotImplementedError"). An example of overload that gives a more precise type than can be expressed using a union or a type variable:!d typing.Never
typing.Never```
The [bottom type](https://en.wikipedia.org/wiki/Bottom_type), a type that has no members.
This can be used to define a function that should never be called, or a function that never returns...I think in that case I'll find myself stuffing everything in the Quant base class.
@soft matrix I've highlighted that approach here: https://gist.github.com/siddhant3s/916ef3c961b7b3d89e21df082fec819e?permalink_comment_id=4507170#gistcomment-4507170
side note not really sure why you cant add to a str here
Just an example. This is to just show case that I want certain operations to exist on some inner types and not on others.
yeah then stuffing it into the superclass should work perfectly fine
The problem is that Quant[S] is a open set. It can be arbitrary any data class. I can ask my users to define it in a certain way but I would like to keep the core types separately and not have all the Quant[S] be stuffed into one giant file.
I wish I could tell the Typechecker, "Whenever you see Quant[int] replace it with QInt. Whenever you see a QStudent replace it with Quant[Student]"
@lusty sky why not have the users use either QuantStr, QuantInt or QuantStruct[S]?
If nobody else can (or, well, should) make a subclass of Quant[int], then you essentially have a "closed set" of possibilities
this would be problematic because anyone can make their own subclass of Quant[int] which does not have this method
That's where being able to separately define an interface implementation would be valuable. I would like to be able to say, for any Quant[int], I'm going to provide the method add.
In Rust, you could do it for example by providing an impl which attached the method to all the types for which the impl is defined.
Anyway, was just checking if there is any obvious trick that I'm missing
Make a function
def add(a: Quant[int], b: Quant[int]) -> Quant[int]:
return a._tup(b)._map(lambda x: x[0] + x[1])
You don't have to implement everything as a method 🙂
impl blocks in Rust are more of a syntactic convenience (if we ignore traits)
Is it possible to split documentation and type hints into another file? Sometimes the docstring is longer than the function body and the code is quickly turning unreadable
no as docstrings shouldnt show up in pyi files
I have a regular py file in VS Code
it's not a module either, just a "regular" python file
im gonna say generally if you have a docstring thats longer than the function body youre probably doing something wrong
yeah but to split typehints from code you use pyi files
theres no other way to do this
First time hearing of pyi files, so I'll look into that, thanks
do you actually have an example of the code?
docstrings != type hints (unless u use Sphinx system for type hints in doc strings, like Google style docstrings )
I would like to separate both
def share_code_create(name: str, category: str, configuration: str) -> str:
"""Format a code for preset sharing
- name: preset name
- category: preset category
- configuration: preset contents
Returns the code for sharing"""
return f"SHARE:{name}+{category}+{configuration}"
i think thats completely fine lol
it bugs me because I have a lot of these functions with longer docscrings than bodies
with longer I mean more lines taken up on screen
from typing import NewType
PresetName = NewType("PresetName", str)
PresetCategory = NewType("PresetCategory", str)
PresentContent = NewType("PresentContent", str)
CodeForSharing = NewType("CodeForSharing", str)
def share_code_create(
name: PresetName, category: PresetCategory, configuration: PresentContent
) -> CodeForSharing:
"""Format a code for preset sharing"""
return CodeForSharing(f"SHARE:{name}+{category}+{configuration}")
{kind=link}

resolving this problem as a code, of having more meaningful types to values 🙂
with help of mypy, u will be able distinguishing those strings across the code way better when they have their own type
interesting... I'll see if this approach works for me, thanks 😄
eeeh
def share_code_create(
preset_name: str,
preset_category: str,
preset_contents: str,
) -> str:
return f"SHARE:{name}+{category}+{configuration}"
Actually, this does smell a bit as a "stringly typed" system
What are the presets you're working with? Is, for example, configuration an arbitrary string?
That's kind of not the point Using NewType you would make sure that you're passing THAT concrete string, e.g. ProductId, and not some other Id
def share_code_create(
*,
preset_name: str,
preset_category: str,
preset_contents: str,
) -> str:
return f"SHARE:{name}+{category}+{configuration}"
NewType doesn't actually encapsulate any constraints or domain knowledge, so I'm a bit on the fence about it.
If you want to replace strings, make your own specialized type
Nobody can stop you from doing ProductId("Hello, world!") or even PresetCategory(preset_content)
i like NewType for internal api where ensuring something is the right id
and if im the only person writing code i just wont do that
its caught a fair few bugs for me
I think NewType was kind of... mis-implemented
it's very different from Haskell's newtype, because it doesn't give you an opaque type whose internals are only visible to its module
Maybe it is kinda useful as documentation.
(and, of course, clear documentation can help prevent bugs)
it's a fixed-length string of numbers
name is arbitrary non-empty and category is arbitrary with "" permitted, both values are ASCII with "+" banned (all of that is handled in the GUI functions that call this function)
Well, yes, you just don't do that
That's the case with many things in python
I currently use dataloaders in graphql and it could be useful to have some domain types for specific entity Ids so you don't accidentally pass different id 🤔
def load_users(user_ids: Sequence[UserId]) -> Sequence[User | None]:
...
Sequence[User | None] feels weird. Like you'd have
[User1, User2, None, None, None, User83, None, None, User1232, None]?
Yes, that's the response structure dataloaders require
You call load method with an identifier multiple times and dataloader batches these ids and calls a load function:
await some_loader.load(id_)
Then you have to do something like this in your dataloader:
async def load_fn(user_ids: list[int]) -> list[User | None]:
users_by_id = {user.id: user for user in get_users_somehow(user_ids)}
return [users_by_id.get(user_id) for user_id in user_ids]
It's optional because you may not find user with a specific id, that's not the case for collections for example:
async def load_user_friends(user_ids: list[int]) -> list[list[User]]:
...
Dataloader would unpack outer Sequence
any way to annotate that a function needs specific parameters through a decorator? kinda like this?
@something
def a():
...
@something
def a(b): # type checker error!
...
@something
@context
def b(context: Context):
...
@something
@context
def b(): # type checker error!
...
@something
@foo('a')
@foo('b')
def c(a: Any, b: Any):
...
@something
@foo('a')
@foo('b')
def d(a: Any): # type checker error!
...
no'
you can do something similar ish using callback protocols but thats pretty different in implementation
any ideas? we can't find a solution for the multiprocessing library (Python 3.11.1) #1087125484200022016 message
Wasn't the problem there that you just didnt import the submodule?
import multiprocessing
import multiprocessing.managers
manager = multiprocessing.Manager()
shared_variables: multiprocessing.managers.DictProxy = manager.dict()
reveal_type(shared_variables) # Type of "shared_variables" is "DictProxy[Unknown, Unknown]"
That is why it was giving the "Cannot find reference"
Are you sure you want Any? or is there something more interesting?
^^
you can use TypeVarTuple
That'd be interesting if it worked
Even after importing it, I have a warning in PyCharm:

It does work though
weirdly enough, in the debugger:
type(shared_variables)
<class 'multiprocessing.managers.DictProxy'>
Why doesn't it work
DictProxy is only 10 months old in typeshed https://github.com/python/typeshed/commit/d511312e211b0d344261378876c98d8a8557e742#diff-936c84e43ae5b97005c52f87c3d7a29888ca5aea715835e2d3d1356b63dea642R68 probably you need a newer version of pycharm with a resynced typeshed

GitHub
#7928
dict() and list() just return empty dictionaries and lists (respectively) if no arguments are supplied:
>>> from multiprocessing.managers import Sync...Oh I do have the last (pro) version though
Maybe they haven’t updated it yet?
Also do you know https://stackoverflow.com/questions/25440694/whats-the-purpose-of-dictproxy what do they mean by read only? I can change its values on my end

Stack Overflow
The dict of a type is a dictproxy object that is read only. I want to know what's the purpose of it. Is it only for "don't allow modify builtin types"? I found a method that can walk around thi...
Well cause adding LiteralStrings as a named parameter to a function seems funky
I am trying to figure out what exactly a wxwidgets DataViewItemArray object is, so I called dir on it
['__class__', '__contains__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__len__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'append', 'index']
It has append and index, but no extend (so its not a list). Which type / protocol / collection.abc is this object (close to)?
Well technically you can, but you'll get the error on the decorator line
!e ```py
from typing import Callable
def deco(func: Callable[[str, int], None]) -> Callable[[], None]:
def inner() -> None:
return func('abc', 123)
return inner
@deco
def call() -> int:
return 3
call()
@tranquil turtle :x: Your 3.11 eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "/home/main.py", line 11, in <module>
003 | call()
004 | File "/home/main.py", line 5, in inner
005 | return func('abc', 123)
006 | ^^^^^^^^^^^^^^^^
007 | TypeError: call() takes 0 positional arguments but 2 were given
i didnt think this was what they were asking for
Hi there given a typed dictionary:
class TD( TypedDict):
key1: str
key2: list[ str]
key3: tuple
key4: tuple[ Literal[ 5], Literal, 6]
And a function:
def function( arg1, keyForDict):
return someInstanceOfTD[ keyForDict]
If possible, how can I annotate that function as to indicate that the return type should be
the type assosiated with the given key
So the language server should know that the return type of a call as follows:
function( 1, "key1")
should be of type str
How can I do this please?
i think the answer is function = TD.__getitem__
doing it any other way without just writing out the overloads afaik isnt possible
Thank you for the reply
The example of the function I used is just a proxy for a more complex one in my code so I think you have told me that it isnt possible
what...

I know there's strictListInference, but then it infers prices: list[tuple[Literal[80], float] | tuple[Literal[200], float] | tuple[Literal[280], float] | tuple[Literal[500], float]]
How to make it so that in a class implementing C, it was required to decorate method with an overridden decorator decorator? PyCharm is silent if I remove the decorator over the implemented method ||ping me pls||
class C(abc.ABC):
@staticmethod
@abc.abstractmethod
def decorator(function):
def wrapper(self):
""""""
return wrapper
@decorator # <-
@abc.abstractmethod
def method(self):
""""""
@finite creek with pycharm i dont think theres an option for an incompatible override but i do know both mypy and pyright support it and if you enabled that then then they would scream at you if you didnt have the method decorated (youd need to return a new type from the decorator though)
Yeah you can't enforce using a decorator
If you really want to, you can make an abstract method like _method and then have a concrete method:
def method(self):
return decorator(self._method)()
I want to annotate an argument as a Sequence with at least two items of certain types; let's say str and int. The only way to do this seems to be tuple[str, int], but that's narrower than my implementation supports. Sequence[str, int] is what I want, but Sequence doesn't seem to support that kind of annotation in the way that tuple does: at least in Visual Studio Code with Pylance, the int is ignored and the annotation as treated as Sequence[str]. Is tuple[str, int] my only option?
You cannot encode "a sequence with at least N elements of these types" in the type system
I recommend trying a different approach if the type safety is important
I guess I'm being pedantic because it's not that important, but I want my typing to be accurate. It just seems like an oversight that there's no simple way to annotate a __getitem__-supporting object whose nth item is a certain type other than with tuple, which is narrower than necessary and therefore incorrect.
Enforcing a length of an arbitrary sequence is very hard
The length doesn't actually matter
What sequence other than a tuple do you have in mind?
None in particular; I'm just following best practices for typing. Argument type hints should be as wide as the implementation supports. My implementation only needs a __getitem__-supporting object whose first item is str and second item is int.
Because if it's something mutable you're kinda in trouble. How do you prevent passing this kind of sequence to random.shuffle?
You mean if it's shuffled after it's passed to my function but before the function does anything to it? Yes, that would be a problem. I see what you mean.
In fact it wouldn't even have to happen in that order
Yeah I see what you mean
It should be a tuple because the items need to be in that order
No, like
def do_something(x: MutableSequence[int]): ...
my = list_with_4th_item_being_an_integer = [...]
do_something(my)
your_function(my)
Yeah I see, the type checker wouldn't see a problem with that but it could break my implementation
So it needs to be an immutable type
argument type hints should be as wide as the implementation supports
I would not say that's a best practice.
First, type systems are not arbitrarily expressive, so you might simply be unable to express your constraints.
Then there's often a tradeoff between being type-safe and the simplicity or convenience. So it's often a good idea to pick a less precise type (perhaps moving some checks to the runtime) if doing otherwise would be a pain to satisfy in practice
You can definitely engineer together a mutable object with your constraints, but it is probably overkill
Yeah I'm probably overthinking this. tuple is fine and seems standard for this situation.
Remember that typing is just a tool to make your program safer by using static analysis tools (and to add some machine-verified documentation in the process). It's not a goal in itself 🙂
True. Thanks for your help.
||btw check out Agda||
Agda looks super good & clean
Wooow I really need to learn any of these functional programming langs they look so cool
agda is really cool because it's quite literally a proof checker
you can enforce so many invariants statically
yeah, obviously it's orders of magnitude overkill for most applications
The only con imo I see off the bat is there are certain symbols that you don't have on a standard keyboard (At least I don't think so)
Like for all logic operator
For that there are editor plugins (like agda-mode) that let you enter \forall and have it come out as inverted A
Sorry if this is the wrong channel
How can I get just numbers as int type from this dictionary named brand?
brand: {'BMW': 1983, 'Audi': 1986, 'Opel': 1992}
it should be brand = {...} not brand: {...}
what do you mean?
Smart, guess there is no reason not to try and learn agda now
I have been reading up on type theory so I'm sure this'll help a lot
well... the reason is that it's probably not going to be useful in practice 🙂
though depends on what you want to do
I think it'll be good for learning type theory or at leas thats how I want to apply it
It's also much more complicated than you probably expect. My brain was to small to get through the whole of the PLFA book
def eventful(event_name: Optional[str] = None) -> Callable[[MethodType], MethodType]:
"""
Decorator function for methods in a class that modify the state of the object.
It automatically invokes an associated event hook.
"""
def decorator(fn: MethodType) -> MethodType:
def wrapper(self: T, *args: MethodParamSpec.args, **kwargs: MethodParamSpec.kwargs) -> MethodRetvalT:
ret = fn(self, *args, **kwargs)
hook: HookType | None = self.event_hooks.get(event_name or fn.__name__)
if hook is not None:
hook(*args, **kwargs)
return ret
return wrapper
return decorator
mypy spits an error: error: A function returning TypeVar should receive at least one argument containing the same TypeVar
why doesn't mypy recognise it's inside of a function that receives that typevar as a parameter? (MethodType)
MethodParamSpec = ParamSpec("MethodParamSpec")
MethodRetvalT = TypeVar("MethodRetvalT")
MethodType = Callable[MethodParamSpec, MethodRetvalT]
it seems obvious that as soon as eventful is used as a decorator, MethodType becomes a real type and subsequently MethodRetvalT and MethodParamSpec become real
Because you need to bring them into scope, otherwise MethodType just defaults to Callable["Any Spec", Any]
Although I think there might be other issues aside from that one
@lapis adder
yeah tbh just realized there's no way to type hint that
since i intercept the self parameter from the fn callable
I am working with tomlkit and I am not sure how to handle the type hinting.
config: TOMLDocument = tomlkit.load(fp)
foo = config["first"]
bar = foo["second"]
Pylance tells me that __getitem__ is not defined for bar. That is understandable since it doesn't know that foo is of type dict[str, Any]. When I add that typehint to foo, that warning on bar goes away but then I get a warning on foo telling me that that type is incompatible with Item since foo is inferred to be of type Item | Container.
Is there an an elegant solution to this?
You can add asserts to help typechecker narrow types
Do you mean just putting an assert isinstance(foo, dict) between foo and bar?
Yes, try that to see if it helps
It partly helps. It doesn't seem to properly do its job when it comes asserting a list. I have
baz = bar["third]
assert isinstance(baz, list)
When I try to acces an element via baz[0] for example, my IDE tells me that baz is a subclass of Item and list or a subclass of Container and list. Subsequently, it tells me that Literal[0] is incompatible with "Key" and "str".
to my knowledge using something like pydantic is a good way to make a lot of assertions about your data, i.e. you can define your schema as one or more pydantic models and then let it parse what you loaded, and afterwards you'll have a fully typed object to manipulate
alternatively if you don't care about validation or doing any further parsing (e.g. turning certain file path fields into pathlib.Path objects), you could define one or more TypedDicts describing your schema and then typing.cast() the result
(unless tomlkit has its own typing mechanism im not aware of)
Yes, the fundamental issue here is that you just don't know what the structure of the data is. It's something external and untrusted. If you want to ignore that, use an explicit Any or a similar plug
So whats the current consensus on typehints? Use them everywhere, don't use them at all (getting striped anyway), or some case to case hybrid? Ofc when writing an API you should pedantically use them everywhere.
Use them where they're not annoying to implement
I am a C# dev, so usually I am used to them, but somehow the python syntax is extra annoying
Was more think of the "I'm going to spend half a day figuring out the type hints for this one function only to find out it's impossible" annoying
I usually try to at least provide something basic for all params to help the IDE but other than that it's a decision between it being more correct and not possibly wasting time
Even if they are, use more overloads.
I don't think there's any consensus tbh 🤷
Depends on what you're doing
I had a sort of fever dream about annotating Mock objects. Would it make sense to use Protocols to masquerade as both a mock and the original object we are mocking?
something like
class MyMockedObjectProtocol(MockProtocol, MyObjectProtocol, Protocol):
...
mymock: MyMockedObjectProtocol = Mock()
and if so.. does a protocol for Mock() exist?
I wouldn't bother
It's a test. If something goes wrong you will probably get a failing test.
it's nice to have mypy check your tests to make sure you haven't done something dumb.
I'm not a fan of treating tests as 2nd class code.
but I totally understand that sentiment. it's damn annoying to have to worry about for in test modules.
Yeah I totally understand. Tests should also be subject to static analysis, especially given that you can't test the tests
But in this case, I think it's okay to use an Any or a typing.cast
or maybe pick a different strategy, like using a fake or stub instead of a mock
in the cases I'm thinking of, patch.object( wraps=original)
at that point you have this mock that is essentially all but the original object. I keep thinking it might work to create a Protocol that is a mix of the original and Mock.
Testing code is usually easier if parts of your code are already connected via interfaces (Protocols, ABCs), maybe you could look into that.
(or maybe if you need to get into mocking/patching, maybe you're testing at the wrong level of abstraction?)
What's the difference between tuple[str] and tuple[str, ...]?
tuple[str] is a tuple with a single element, which is a string.
tuple[str, ...] is a tuple with any number of elements (0, 1, 2, 3, 4, ...), each of the elements is a string
x: tuple[str] = ("foo",) # OK
x: tuple[str] = ("foo", "bar") # ERROR
x: tuple[str] = () # ERROR
y: tuple[str, ...] = () # OK
y: tuple[str, ...] = ("foo",) # OK
y: tuple[str, ...] = ("foo", "bar") # OK
y: tuple[str, ...] = ("foo", "bar", "baz") # OK
...
Why is this syntax asymmetric with list[str]? I don't have to do list[str, ...]
tuple is special in this regard. That's just how tuples are typed
As in, list is a "normal" generic type, just like, for example, collections.deque. It's s type with a parameter.
Whereas tuple has some special treatment in type checkers
Alright, thank you 🙏
Unrelated, what's the good practice for typing self variables? right before __init__?
what do you mean?
class C:
b = T
def __init__(self, a);
self.b = f(a)
Oh wait, that's not quite representative of my example
class C:
b = T|None
def __init__(self, a: U|None);
self.b = None if a is None else f(a)
There
Most of the time it's going to be inferred.
class C:
def __init__(self, a: U | None = None);
self.b = None if a is None else f(a)
But if it's not, or if you're writing a library, I think typing them in __init__ is better:
class C:
def __init__(self);
self.things: list[D] = []
Generally, avoid public mutable attributes. If you do not explicitly intend outsiders to use this attribute in any way, mark it with an underscore: py class C: def __init__(self); self._things: list[D] = [] If you want read-only access, make a property: ```py
class C:
def init(self);
self._things: list[D] = []
@property
def things(self) -> Iterable[D]:
return self._things
Excellent, thank you (I just so happened to be refactoring stuff as properties 🙂 )
mypy goes crazy with my property setters though 😮💨
Incompatible types in assignment (expression has type "Optional[Tuple[str, ...]]", variable has type "float") [assignment]
def __init__(self, s: tuple[str, ...]|None = None)
self.ic = s
@property
def ic(self) -> float:
return self._ic
@ic.setter
def ic(self, s: tuple[str, ...]|None) -> None:
if sis None:
self._ic = None
else:
# ...
self._target_ic = np.mean(_ic_h.squeeze()).item()
It doesn't like the self.ic = s line
that would be very confusing for me as a user tbh
what is ic?
a float
no I mean... as a concept in your program
I would guess it's either the phrase "i see" or an "integrated circuit", neither of which make sense
information content
level of specificity of the text in the tuple of strings, expressed as a float
I made the names brief for the example, but stuff is more explicit in the code
why not: ```py
def information_content(lines: Iterable[str]) -> float:
...