#internals-and-peps
1 messages · Page 151 of 1
It's honestly an interesting perspective into rust's adoption. Writing less bugs is one of the driving powers of the language, but most people get on board because it's easier to write faster code instead.
re: Python 3, it turns out that even a lot of professional engineers have a pretty fuzzy understanding the difference between a UTF-8 encoded byte string and a Unicode text string. They're two different representations of the same information.
so, er, what is the difference
what features of py2 made it able to be really easily testable? IIRC unittest was a backport.
additionally, testable functions have to be written in a way that is testable, that I don't understand how py2 made it easy, since it feels easy enough in py3.
I've seen for the most part, libraries that support 2.7 on pypi, restrict 3.0, 3.1, 3.2, 3.3, and sometimes 3.4, allowing only 3.5.3 and up to install.
I know the 3.5.3 is because asyncio was provisional, but what other features did 3.4 and 3.5 bring that were key?
A Python 3 Unicode str string stores an array of Unicode code point numbers.
A UTF-8 byte string is an alternative representation for those same code points - namely, the UTF-8 representation.
I just realised I replied to everything in the opposite order of how it was sent, lol
pytest supported 2.7 as well, and there used to be nose and nose2 as well. I don't think there's any substantial testability improvements in 3, save for the unittest.mock module - which exists as mock on PyPI, installable for 2.7
I'm sorry, I'm still confused 😅
oh, til. So was any aspect of py2 (in your opinion) easier to test than on python3.5, which is the first one you started with?
None that I can think of.
!e ```py
as_str = "😅"
as_bytes = as_str.encode("utf-8")
print(f"{len(as_str)=} {len(as_bytes)=}")
print(f"{as_str[0]=} {as_bytes[0]=}")
@raven ridge :white_check_mark: Your eval job has completed with return code 0.
001 | len(as_str)=1 len(as_bytes)=4
002 | as_str[0]='😅' as_bytes[0]=240
Python 3 Unicode strings operate on logical characters, more or less. Byte strings operate on the individual bytes that make up one specific representation of those characters or another.
as str is a unicode emoji
encoded as utf-8
the len is different because of how the encoding works
this makes some sense I feel like this will bite me
.bm
.bm (The actual explanation for the previous bookmark)
They're two different representations of the exact same data, though. One representation operates on it at the binary level of one specific encoding of that data, and one operates on it at the abstract level of idealized characters
And if you don't have a good handle on what each of those representations is for, and when you need each one, it's really hard to understand why you need to keep converting between them in a Python 3 program.
yeah idk when I would need a bytes, unless I'm using a method from a different library that needs bytes
When you want to serialize that data to a concrete representation. If you want to store it in a database or write it to a file or send it to a web server, you need to pick some sequence of bytes that represents that abstract textual string, and whoever reads it on the other side needs to use the same representation to make sense of what you've written
oh that makes a lot of sense
but when manually messing with it, it's best to have it in string form
so that's why subproccess communicate and such are byte streams!!
Yep. And why things like open() take an encoding= argument: to allow you to write text strings which they'll automatically handle encoding into your chosen binary representation
hmmm
but there's also the modes in open, "rb" and "wb"
so, if open takes ascii as encoding, and wb as the mode, what exactly would happen if we wrote a bytestream to the open file?
They're mutually exclusive. You can't provide an encoding if you open in binary mode
it's binary mode and not bytes mode??
Same thing. The raw bits/bytes that the file is storing.
I think after asking "are bytes different from binary mode" that might be my cue to go sleep
You either provide an encoding and open in text mode (so things you read/write are automatically de/encoded using the given encoding) or you give the "b" flag, and the file deals with raw bytes and you're responsible for doing any relevant en/decoding
(yes they are slightly different but also that should have been obvious that the mode is the same, since I know binary and what bytes are)
makes sense, I feel like I should always use bytes mode
anyways, I need to go sleep, I'll read your replies in the morning
When you're dealing with textual data, that's really inconvenient, and it's better to let the file object handle encodings so you can deal with strings.
for me f-strings were the killer feature to switch to 3, but i also wanted to experiment with async, enums and pathlib.. dispatching was also on my wishlist (singledispatch let me down, though)
Bytemode also disables the automatic conversion of newlines to "\n"
also something that changed quite a bit how i write my code in python 3 (.8) were positional-/keyword only arguments
that is one small underrated thing for me
I could 100% live without f-strings
Is it a bug in Python 3.10??
a dot is missing between now() and strftime but it is suggesting that most probably a comma is missing.

if datetime.now(), strftime(...) != "19:50:00": return is also valid
ultimately it can't perfectly guess your intention
but you can always file a bug 🙂
oh I didn't know that
no it's ok
actually no, it's invalid syntax
!e
if datetime.now(), strftime(...) != "19:50:00": pass
@grave jolt :x: Your eval job has completed with return code 1.
001 | File "<string>", line 1
002 | if datetime.now(), strftime(...) != "19:50:00": pass
003 | ^
004 | SyntaxError: invalid syntax
then it's probably a bug
oh ok
Which components is affected??
Interpreter core?? Windows??
why would this be caused by a problem with windows?
So I'm selecting Interpreter core
ok??
I think the keyword in that error is 'Maybe', it's more or less a suggestion because the program isn't sure what errored out, whether it was a missing comma, a missing ., etc.
True, but it might be able to make a better guess, even if it's a heuristic.
True.
I think this error is likely raised in the lexer though right? What is the token that is assigned to it and if it's missing it raises the following error
I don't think i'm being clear oops
I meant like which "missing" group of tokens raises this error
it's probably raised in the parser as the custom error message is actually implemented in the PEG grammar itself
ah
It should, hopefully, be able to avoid suggesting that you forgot a comma in cases where adding a comma would be a syntax error 🙂
seems like Pablo would be glad for the test case, at least.
I believe we have removed these sort of messages on 3.11
It will only be printed if the expression in the context is within parentheses now
..they were only added in 3.10, weren't they?
no, they are still there but the context targetting is better now
oh okay
GitHub
https://bugs.python.org/issue45727
Automerge-Triggered-By: GH:pablogsal
class ReusableGenerator():
def __init__(self, iterable = tuple()):
self._cache = []
self._original = iterable
def __iter__(self):
yield from self._cache
while True:
try:
new_item = next(self._original)
except StopIteration:
break
self._cache.append(new_item)
yield new_item
# VS
def __getitem__(self, idx):
if idx < len(self._cache):
return self._cache[idx]
self._cache.extend(itertools.islice(self._original, idx - len(self._cache) + 1))
return self._cache[idx]
```Are there any significant differences with implementing this with one of these methods vs the other? And is there another better way?well I guess one big difference is that one of them is indexable, but other than that?
I personally prefer __iter__ for iteration and view __getitem__-based iterables as more of a backwards-compatible sort of thing. It's fine to provide both (and I'd probably do that), but if you just want iterability alone, I'd do __iter__
You could also try to use itertools.tee
The getiterm logic here's also a fair bit more complicated if you only need to iterate, it'll be constructing and destructing the islice iterator and the like each call.
Yeah, that wouldn't be very fun either if you're iterating one item at a time
Though it would be partially if not completely mitigated by the implementation of __iter__
a().b seems valid
why tuple() though?..
uhhh I think that was left over from something else I tried
now that I'm looking at it though i'd have to be careful of next
@mild flax btw, if you want to accept an iterable, do self._original = iter(iterable)
yeah
btw, what would be the proper class in collections.abc to inherit from if I only implemented __getitem__?
Iterable
i dont think it likes that
I don't think __getitem__ without __len__ is a thing, at least not commonly
You could check the base classes though
then you can do this ```py
class ReusableGenerator:
def init(self, iterable = ()):
self._cache = []
self._original = iterable
def __iter__(self):
for i in itertools.count():
try:
yield self[i]
except IndexError:
break
def __getitem__(self, idx):
if idx < len(self._cache):
return self._cache[idx]
self._cache.extend(itertools.islice(self._original, idx - len(self._cache) + 1))
return self._cache[idx]
hmmm actually no this is terrible
or maybe not
I guess it's not
no worse than iterating with getitem i think
Yeah, collections.abcs with __getitem__ always have __len__
alright I found a problem with that implementation of __iter__
rg = ReusableGenerator(range(10))
i = iter(rg)
i2 = iter(rg)
for _ in range(5):
print(next(i))
for _ in i2:
pass
for item in i:
print(item)
```prints
0
1
2
3
4
which isn't a problem with __getitem__
__iter__ isn't required, if you have __getitem__ iter() automatically adapts. Though the ABCs wouldn't recognise that.
anybody happen to know the directive thats used for a code-block with sphinx?
i tried docutils.parsers.rst.directives.body.CodeBlock but the formatting is all funky

😵💫
>>> type(obj)
<class 'dict'>
>>> len(obj)
170
>>> sys.getsizeof(obj)
9312
>>> obj2 = dict(obj)
>>> type(obj2)
<class 'dict'>
>>> len(obj2)
170
>>> sys.getsizeof(obj2)
4696
>>> obj == obj2
True
why does size cut half?
That must have been all the size it needed. So the more important question to ask is why obj wanted to have more size. The answer most likely lies in the overallocation python uses, so details about how obj was created is relevant
obj was created by <Response>.json()
Ohhh, I hadn't thought of the question that way...
So, for things that grow dynamically, such as python lists or in this case dictionaries, python promises an average time complexity of append(list)/adding an item(dict) as O(1). to achieve this practically, it has a system of overallocating and growing, so every once in a while, it runs out of space, has to reallocate the whole thing, but it takes more memory than it needs, so that theres room to add newer items without taking an O(n) reallocation
While i dont exactly know the mechanisms of the .json method involved here, it's easy enough to speculate that .json must benefit from or require python dictionaries to be created incrementally, or possibly, even if they did not need to be done that way, they end up making the python dictionary item by item.
So that's what youre seeing. it's not obj2 becoming "more efficient" so much so as not needing the extra "overallocated" space because obj2 was given the entire input whose* length was known upfront (that being the len of obj dict)
so obj2 didnt need overallocation
Additionally for dicts, they want to avoid being too full - if that occurs, it's more likely there's hash collisions requiring checking multiple locations. So Python's dict currently doubles in size whenever it becomes more than ⅔ full.
this shouldn't exist
SyntaxError: assignment expression cannot be used in a comprehension iterable expression
no real reason
the real reason is there's an implicit function scope
and the results of that can be very difficult to debug
If you aren't aware of it, that is
if cond or (var := "stuff"):
print(var)
for example has this propery but its allowed
if has no scope
Most things don't
In fact, I can't think of anything that does other than functions, classes and modules
I guess something like an implicit nonlocal for assignment targets within a scope would work
walrus in a list comprehension is cursed
a list comprehension shouldn't have any side effects
It can sometimes be useful for the actual comprehension, but at that point it's usually way more readable to just have a loop
I disagree
['a' if some_var else 'b' for item in my_list if (some_var := do_something_with_it(item)) is not None]
I guess this is roughly manageable
Equivalent to: ```python
new = []
for item in my_list:
if not (some_var := do_something_with_it(item) is not None:
continue
new.append('a' if some_var else 'b')
I originally thought the behaviour would be that you got access to the last item, and agreed with you.. that said the more I think about it the more I like it
[value if (value := something(item)) else None for item in my_list]
Another example
All of these can of course turn into ```python
[item if item else None for item in [something(item) for item in my_list]]
That said... What do you prefer 😉
object.__dir__(thing) works like a charm, but if i try to do object.__getattribute__(thing, name) some methods are included in the dir i can't access that way, why is that?
getattr(thing, name) catches those, interestingly
getattribute only does a direct lookup, skipping things like looking things up on the parent type
!e
class A:
a = 0
class B(A):
b = 1
getattr(B, "a")
object.__getattribute__(B, "a")
@peak spoke :x: Your eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 8, in <module>
003 | AttributeError: 'type' object has no attribute 'a'
A for loop, both look very scary to me
I would use a for loop or py bar = [item if item else None for item in (something(item) for item in my_list)] or maybe ```py
foo = (something(item) for item in my_list)
bar = [item if item else None for item in foo]
The former doesn't work does it?
why?
you can put any expression in there
Ooooohh, I missed the parenthesis
Why are type hints are required in dataclasses?  #help-chili
#help-chili
I'd do item or None instead of item if item else None
Because if item is falsy, then other part will be evaluated and returned (or returns first truthy element or last element if all were falsy)
I agree
It's a convenient way to define all the names, not make them class variables unless you want to, and provide types. To answer your question there about ClassVar, dataclasses checks for that in the annotation and skips it.
interesting
!e py from typing import get_type_hints class C: x: bool y: int print(get_type_hints(C))
@unkempt rock :white_check_mark: Your eval job has completed with return code 0.
{'x': <class 'bool'>, 'y': <class 'int'>}
!e
class C:
x: bool
y: int
print(C.__annotations__)
@quick snow :white_check_mark: Your eval job has completed with return code 0.
{'x': <class 'bool'>, 'y': <class 'int'>}
getting back seldom-reoccurring discussions on HKTs, I feel that making TypeVars subscriptable as an opt-in seems like a good idea
as a short example of what's on my mind now, here goes
I = TypeVar("I", bound=Iterable, args=1) # or something else
# having an exact amount of args could benefit simple runtime checks
# (the default would be 0, which makes perfect sense to me)```
let `Bound` be the type passed as `bound` for `I` type variable
then `I[T]` is *roughly* `Bound[T]`, with the main idea of preserving the actual type
I'm not exactly certain what would be required for type-checkers to implement this, but it seems like a fine idea to check against the `bound` when calling functions (and other cases)
(i.e. for `I[T]` we need to check if some type `A` is `Iterable[T]`)
when acting on these types, type-checkers would have to track the type to ensure it stays the same as the original `I`, but I don't think anything else is needed
if we look at it in action, here is a (slightly stripped) use-case
```python
W = TypeVar("W", bound="Wrap", args=1)
@dataclass()
class Wrap(Generic[T]):
value: T
def unwrap(self) -> T:
return self.value
def map(self: W[T], function: Function[T, U]) -> W[U]:
return self.__class__(function(self.unwrap()))
class Derived(Wrap[T]):
pass
wrap = Derived(42) # Derived[int]
result = wrap.map(str) # Derived[str]
print(result.unwrap()) # str```
I'd be happy to hear other inputs on this issue :)I've come across the need to abstract over the type constructor quite often, so it is definitely one of the main features I'd love to see implemented
for example, I've been working on iterators that aim to bring rust-like operations to python
I = TypeVar("I", bound="Iter", args=1)
class Iter(Iterator[T]):
iterator: Iterator[T] # implementation detail, need not to be generic over type
def unwrap(self) -> Iterator[T]:
return self.iterator
def map(self: I[T], function: Function[T, U]) -> I[U]:
return self.__class__(map(function, self.unwrap()))
def exhaust(self) -> None:
exhaust(self.unwrap()) # this function is implemented elsewhere```
and it would be neat if anyone could derive from `Iter[T]` to add useful (and more specific) functionality:
```python
class ForEach(Iter[T]):
def for_each(self, function: Function[T, None]) -> None:
self.map(function).exhaust()```
(obviously a toy example, since `for_each` is a pretty general and useful function, but I hope I have given a use-case)what ide do you guys recommend rn i am using pycharm
not really a good topic for this channel
I would agree, but what about if a TypeVar isn't bound?
I[T] would be quite weird
or would it only be used for when bound to something
hm, I don't really think it makes sense to have non-bound type variables? not fully sure though
Don't people use non-bound type variables like a generic?
something like
from typing import TypeVar
T = TypeVar("T")
list[T]
i'm not fully sure though, because I don't use TypeVar all too much
I've mostly seen other people use it
well, yeah, they do, but the point is, applying type arguments to a type variable would make sense only when you have something generic to apply them to
how would a type checker handle two non-bound typevars together though like
I[T]? where I and T are both non-bound typevars
would it be something like Any[Any]
genuine question btw, i'm quite inexperienced with typing
if we have python T = TypeVar("T", args=1) what would T[A] mean? anything generic that has A as the type argument? it neither seems like something useful, nor is it fully clear
so I'm gonna assume your proposal is only limited to bound typevars?
essentially, yeah
Oh yeah, i'd agree then for sure
args > 0 is going to be allowed iff bound is passed as well
since, again, it's not clear how to handle non-bound type variables, and, besides, I do not see a use-case for that
from typing import Callable, Protocol
F = TypeVar("F", bound="Functor", args=1)
T = TypeVar("T")
U = TypeVar("U")
Function = Callable[[T], U]
class Functor(Protocol[T]):
def map(self: F[T], function: Function[T, U]) -> F[U]:
raise NotImplementedError()``` and that's what the possible implementation of a *functor* from functional programming can beI quite like the way it works (or can work, rather), so what I'm especially looking for are edge-cases I could've missed
@cloud crypt now comes the hard part: convince a bunch of Python developers on why that is useful 🙂
convincing python-ideas is like talking to a brick wall, except that brick wall sometimes agrees
haha, indeed
I've almost started composing a PEP a bunch of times before for HKTs, haha
Heres the corresponding section of the code, basically I am trying to reimpor the functions on file change event so they get updated but it seems its hanging on the from solution import line.
Logs:
/home/shivansh/Programming/python_projects/aoc-py/2021/01
importing...
/home/shivansh/Programming/python_projects/aoc-py/2021/01
importing...
imported...
<function part_one at 0x7f6d654f95a0> of 1...
❌ Testing of day 1 part 1 failed! Please try again. Here's the output:
Expected: 7
Recieved: 17
Modified
importing...

cough is this was you were dming me about
aoc/watcher.py line 52
class ModificationWatcher(FileSystemEventHandler):```ee yes, i figured i could just make an alt and test it
help channel may be more fitting
Does anyone know if it has already been suggested (in a PEP or otherwise) that generator objects should be handled lazily in sequence unpacking? Specifically when used like:
a, b, *rest = some_generator
that rest will be the remaining generator, rather than a fully evaluated list of that generator?
I am not sure whether I like that, it'll be a breaking change for sure
I take that back already, I can't decide
I feel like both behaviors have their benefits and can be expected
It would be very nice to have, but it'd be an odd special case.
Should probably be some additional syntax?
I agree that it would have been much better to introduce with 3.0 or something
a, b, rest = next(gen), next(gen), gen is fairly clean \🤔
Yeah
might be some way to use itertools.islice too
thats true, both ways of achieving the same thing. It was also the non-lazy behaviour which surprised me
You definitely could.
a, b = itertools.islice(gen, 2)
Though the downside is both of these are probably slow func calls, we'd have to see though if the 3.11 adaptions make it comparable.
Oh wait...
!e ```python
def gen():
count = 0
while True:
count += 1
yield count
g = gen()
a, b = g
print(a, b, g)
@elder blade :x: Your eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 8, in <module>
003 | ValueError: too many values to unpack (expected 2)
Makes sense
Lol, that was exactly the code I tried that made me consider this
because adding a *c to the unpacking, makes it hang forever
Thought, allow this to indicate it should not try to consume additional values:
a, b, ... = blah
A star-arg at the end would be prohibited since it's contradictory, use a walrus if you need to save.
some sugar for lazy evaluation would definitely be nice
Maybe we could borrow from JS and use ... (or just ..) as a lazy alternative to *
a, b, ..c = gen
I'm still rooting for _ to become an actual throwaway
Yeah would be nice
then you would be able to do a, b, *_ to lazily get the first two, and a, *_, b to get the first and the last without collecting everything in between and actually discarding it
how does that work for generators though...
maybe that is the reason it cant be. because when generators (or custom iterables) are involved, it must evaluate all intermediate values. But it wouldnt have to store them
you could at least save some memory
depending on the shape of lhs, either stop iteration on *_, or save the exact amount of args after it into a list and unpack that
but then it would only work with objects that define __len__
not really
you could achieve the same with a maxsized deque
keep pushing new items and discard irrelevant ones as you go
oh yeah fair point
a fair bit more work for the compiler, but I personally would love that
if you ignore the fact that _ is currently a valid identifier, it shouldn't be breaking either
PEP 677: Better sequence unpacking. _ as a memory free 'hole' and .. as a lazy alternative to *.
😄
but surely the _ thing has been suggested before
Yeah, it's currently used for i18n
So I highly doubt this will ever get into the language
but if you give special treatment to unpacking into _, you can get both lazy and eager evaluation without a breaking change (except for _ and weird constructs that maybe rely on eager evaluation for side effects?) and without introducing new syntax
well, I think you can't have it both ways. Either it is a hole which does not store values (and can be placed anywhere) or it makes * lazy, and can only really be used at the end
because what if i want to use the generator again later
whats left of it anyway
Or maybe its smart enough to know, that if it is at the end, then it stores the remaining generator. Otherwise nothing
That's impossible for generators though?
well it currently isn't
impossible while keeping them as generators
the current implementation essentially converts to a list (or tuple?) and then goes ahead
but if you just use the equivalent of a sized deque to capture exactly N items, you get all the benefits
with a simple circular buffer you avoid storing intermediate values and only get the relevant ones, which are then popped into the assignment targets
and if you don't have any targets after the discard, there's no need to evaluate the rest
is it fine for random people like me to make PEPs? or is that frowned upon unless I really know what im doing
You should first get the general consensus in the mailing list
and if there's demand, you go further and draft a pep
Oh, I thought the mailing list was like invite only or something
interesting
Ah, non members can post to Python-dev
Explaining what I mean with equivalent python code:
a, _, b = sample # Use current semantics
# Roughly
t = list(sample)
if len(t) < 3: raise ValueError("not enough values to unpack")
if len(t) > 3: raise ValueError("too many values to unpack")
a = t[0]; b = t[2];
a, b, *_ = sample # Lazily evaluate first two args
# Roughly
i = iter(sample)
a = next(i)
b = next(i)
a, *_, b, c = sample # Lazily evaluate, discarding intermediate values
# Roughly
i = iter(sample)
a = next(i)
d = deque(i, maxsize=2) # Two targets after *_, size = 2
if len(d) < 2: raise ValueError("not enough values to unpack")
b = deque.pop_left()
c = deque.pop_left()
a, *b, c = sample # Use current semantics
# Roughly
i = iter(sample)
a = next(i)
t = list(i)
b = t
c = t.pop()
Sample is any Iterable
There's no way this is getting into the language, but a man can dream
A new syntax might be possible to add though...
Yeah, but I don't think the chances are good
new operators add a fair bit of complexity
and using the lazy unpacking, at least cases with .._ at the end, would work the same as yours
yeah
i also am not sold on the syntax
The main issue here is that all this can be implemented fairly simply with a function
and there's little ground to force it into the language
well, most things can be fairly simply implemented with a function, especially syntactic sugar things 😄
I agree that it certainly isn't necessary, but I do think it would be nice (if a better syntax were found. The more i look at .. the uglier i find it)
def unpack_lazy(iterable, first=0, last=0, keep_intermediate=False):
i = iter(iterable)
yield from islice(i, first)
length = None if keep_intermediate or not last else last
yield from collections.deque(i, maxlen=length)
first, second, second_to_last, last = unpack_lazy(i, 2, 2)
*body, last = unpack_lazy(i, last=1, keep_intermediate=True)
ig keep_intermediate is not necessary, because it just turns it into regular unpacking, but yeah. Good enough for most purposes
lazy unpacking is a thing?
but it should be (imo)
sort of
lazy unpacking of n first items is just islice
and unpacking last n isn't really lazy
so the idea is improved efficiency?
For generators the idea is to act more intuitively, and manageably
as said, it works also with islice but I think some syntactic sugar would be cool
so it's like partially unpacking a sequence (or unpacking part of the sequence and leaving the rest in a separate argument)
yeah
take first N items and leave the rest intact
Or take first N and last N, actually discarding everything in between instead of accumulating into a list and then immediately throwing it away
(well, in most cases you won't even throw the list away, it'll just stay bound to whatever placeholder you give it)

GitHub
What's the problem this feature will solve? https://arstechnica.com/information-technology/2021/11/malware-downloaded-from-pypi-41000-times-was-surprisingly-stealthy/ Pypi currently uses fa...
oh man, i just went in functools to check update_wrapper and stumbled over this
class Negator:
@singledispatchmethod
@classmethod
def neg(cls, arg):
raise NotImplementedError("Cannot negate a")
@neg.register
@classmethod
def _(cls, arg: int):
return -arg
@neg.register
@classmethod
def _(cls, arg: bool):
return not arg
that's soo ugly..
there has to be a better way!
slams desk
obviously
Negator = exec_haskell("""
class Negatable a where
neg :: a -> a
instance Negatable Integer where
neg n = -n
instance Negatable Bool where
neg = not
-- export Negatable as Negator
""")
right.. 
I mean
What's wrong with a function? Is there a real need for a class here?
def negate(arg):
if isinstance(arg, bool):
return not arg
return -arg
hey you left off int
😔
!e ```py
f = 5.4
print(-f)
@white nexus :white_check_mark: Your eval job has completed with return code 0.
-5.4
Does it matter?
and why does it not support floats.
(ref this, why does it not support floats for that)
Depending on your domain, you may want int specifically
But then just typehint it as such and follow the consenting adults principle
If they pass a float and it breaks something, it's their problem, not yours - you did let them know that ints are needed
And if you intend to support any negatable type/any numeric type, you should either use a duck-typing protocol that defines __neg__, or hint it as numbers.Numeric (or something along those lines, my memory is hazy on those ABCs)
well, for one, the stacked decorators simply look ugly, secondly, and more importantly, having several functions with the same name is not a good idea, greatly confuses IDEs and interpreters alike
it's a similar problem with properties, basically impossible to get nice looking code without messing up the tooling
singledispatchmethod is essentially a dict on first argument type (I think?) so if the decorator looks ugly, just use a dict (or match stmt)
you can't overload an external function that way
the main question is: why would anyone need a Negator like this?
i think it's an example for a class with some method that is overloadable
It's a really poor example
it is
well, this is a bit complicated, because a subclass of int (which is not bool) should still get to the int branch
or does singledispatchmethod just look at the concrete type?
i think it only checks concrete type
that's pretty silly
it's a workaround, nothing more
i've been disappointed by dispatching in python for a long while
I'd probably either generalize better (like above), or dispatch to specific overloads via match
https://www.python.org/dev/peps/pep-0443/ here is the pep
IME it's rarely actually needed, and in the few cases where it is, match covers it very well
But I do admit that it's... not as good as it could've been
but only if you have access to the generic function though
if you can't manipulate the patma, you're out of luck, mostly
I think problem with generalization is that multiple inheritance exists.
So MyWeirdClass(int, bool) would qualify for both
Something like that would make say, java throw errors on you
Just redefine?
@verbal escarp I think you want typeclasses 🙂
i do? ^^
tell me more
But python doesnt do overloading anyways so singledispatch only does so much
Ad-hoc polymorphism, sounds really fitting
unless I completely misunderstand what you want
@verbal escarp you want to extend an existing function someone else wrote to accept your own class, right?
yes
how would you realize the Negator with typeclasses?
class Negatable a where
neg :: a -> a
instance Negatable Integer where
neg n = -n
instance Negatable Bool where
neg = not
``` 🙂in python :p
btw is this a good place to ask for library recs?
I think it's only different in that it has mypy support 🙂
that's something.
can't you actually do what you want with singledispatch?
as i said, i only stumbled over this ugly corner in the documentation while looking for update_wrapper.. i've used singledispatch before, but it always left a kind of stale aftertaste in my mouth
been looking for better alternatives to dispatching and property ever since
what's wrong with property?
ever used it?
!pypi multipledispatch have you considered this?

Multiple dispatch
actually i haven't, thanks for reminding me
🤔 yes
it looks fine on first sight, but if you try working with it, you either have to abandon best practices or you get ugly code that screams "unpythonic" at you
I guess it depends largely on your domain
But I've never had that issue
Can you give an example?
I generally don't use property to be honest
in my mind it's just a tool for backwards compatibility, or when you have to conform to an interface, or something
so I usually just make a method 🤷
no, properties are awesome as a concept
i do love the idea
but the code to actually get there is just.. meh
I find them much more useful in languages that obsess over access obstruction
But I don't see much of a difference between properties in, say, C# and Python
!d unittest.mock.PropertyMock I need to figure out how this works, I was just setting the property to the necessary mock, when this would be so much better
class unittest.mock.PropertyMock(*args, **kwargs)```
A mock intended to be used as a property, or other descriptor, on a class. [`PropertyMock`](https://docs.python.org/3/library/unittest.mock.html#unittest.mock.PropertyMock "unittest.mock.PropertyMock") provides `__get__()` and `__set__()` methods so you can specify a return value when it is fetched.
Fetching a [`PropertyMock`](https://docs.python.org/3/library/unittest.mock.html#unittest.mock.PropertyMock "unittest.mock.PropertyMock") instance from an object calls the mock, with no args. Setting it calls the mock with the value being set...because if I'm mocking a property, being able to know when my methods don't use that property is somewhat nice to know imo
sure, but properties are much more useful than keeping track of access
oh, yeah, ofc
I mean, if I had to overwrite a property with an attribute, I haven't used a mock since I didn't know this existed
I've just used the value that it needs directly
one thing i fiddled with a long time ago was a flyweight class that would abstract access to numpy arrays
but haven't been able to apply side effects or anything
a slotted class with an ID as the only real attribute
you could pass it around and do things like cell.material
then it would go to the numpy array, basically as an API
it was a huge class, only consisting of properties
so i experimented with different ways to define properties so that my IDE wouldn't complain about duplicated names on one hand or having 2, 3, 4 definitions with everything, polluting the namespace
sorry, i can't find the code anymore on the spot
I think the larger issue is not property (or any other similar python feature) itself, but moreso the fact that typechekers have a REALLY hard time keeping up with (fairly predictable, by human standards) levels of dynamic typing
those issues aren't exclusive 🙂 both ends are a mess
Python as a language gives you a lot of tools that allow for very powerful and, I can't really find a better word for it, quirky constructs, that are not necessary, but appealing as a concept. And when you try to apply typecheckers to this, they tend to go nuts
They aren't exclusive, sure
But, in my personal experience, one magnifies the other significantly, while the other barely ever pops up at all
I've seen and experienced first-hand a plethora of cases where things are pretty readable and function well, but then you start trying to shove typing in or fix that one thing the IDE is bugging you about
And embark on an adventure that results in a huge mess and something along the lines of "I should've really just kept it simple"
Typing is nice, and so is the dynamic nature of python. Do they mesh together well? Not at all
I wish python had a typing system as good as ts
I only had to //@ts-ignore (or similar hacks) some very arcane stuff
Javascript also manages to be fairly fast
And has a ton of money poured into developing it
Is there a better way to type hint recursive functions than having <return type of final recursion> | Callable[<repeat all argument types>]?
hm?
As a return type
a recursive function doesn't return a function, does it?
Yeah you're right mb
A recursive function calls itself, and it returns the result of a recursive call immediately in a lot of cases, but it still returns the same type
unless you're into voodoo magic
yep ```py
def factorial(n: int) -> int:
if n <= 0:
return 1
return n * factorial(n - 1)
or if it has side-effects depending on the level of recursion
but side-effects are hard to type anyway
wonder if any language has a way to type side-effects
maybe something like a doctest asserting proper manipulation of something?
Well, you'd most commonly see ways to type a lack of side-effects
Or a general presence of them
But I myself am not aware of a language that actively types the exact side-effects it has
(inb4 it turns out haskell does that, too)
hmm
i was just thinking of parsers, but maybe a better abstraction would be an FSM
with behaviour ("return type") depending on the current state
that should actually be feasible in python
Yes, e.g. Haskell
a closure whose return type is depending on previous input
how does that work in haskell?
it's not exactly how you say, it doesn't type the exact side effect, but e.g. if you want to do I/O, the type of the function includes the IO monad
(but it's been a looong time since I did any Haskell, so take it with a grain of salt)
But this kind of handling is typical for functional programming languages. It's the same in SML, IIRC
lmao
if we empowered python's typing system to include input-dependent output and allowed literals as types, we'd be heading straight for a parser-language syntax for typing
just a thought
may as well use a language that does types properly then, not the half assed type hints that are a necessary consequence of Python's dynamicness
well said.
yeah, smoothly transition your application from Python to Agda 😉
π works
I'm sure there's a plugin for your editor of choice that translates LaTeX symbol names to Unicode
i have to check that
(Or just use the supreme way of entering text, the Compose Key)
and have all the codes memorized? 😉
not all of them, but all that I'd ever use in LaTeX or natural language
https://marketplace.visualstudio.com/items?itemName=oijaz.unicode-latex <- nice, thanks for the idea 🙂
Extension for Visual Studio Code - Insert unicode symbols for latex names
your coworkers (etc.) will love you
what's the C-x M-c Butterfly XKCD again
378
.xkcd 378 I think
Real programmers set the universal constants at the start such that the universe evolves to contain the disk with the data they want.
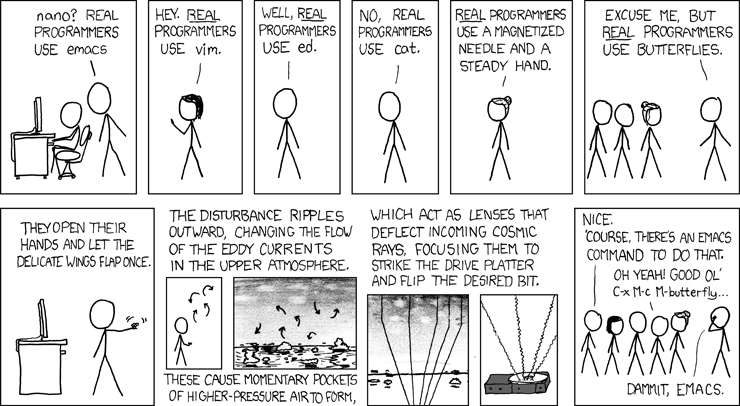
2008/2/1 - #378, 'Real Programmers'
yep :D
🤣
(of course I actually have to remember two compose-y ways, because Vim has a similar, but incompatible feature)
apropos half-assed type hints of python, any news on deferred annotations? everything still in limbo on that front or did they decide that pydantic has to die for the greater good by now?
I thought I read a few weeks ago that the alternative proposal was accepted, no? So __future__.annotations will never come directly, but __annotations__ will become some kind of magical lazy dict.

Discussions on Python.org
(For visibility, posted both to python-dev and Discourse.) Over the last couple of months, ever since delaying PEP 563’s default change in 3.10, the Steering Council has been discussing and deliberating over PEP 563 (Postponed Evaluation of Annotations), PEP 649 (Deferred Evaluation Of Annotations Using Descriptors), and type annotations in gen...
Not accepted, but "favored" by SC (PEP 649)
i wonder why there's so much opposition for a DSL, it wouldn't even be the first one in python
ahhh.. oh no
"We definitely care about the overhead of type annotations. At one point pre-PEP-563 I think our codebase spent 1% of total CPU on executing annotations. That’s a lot, although I believe most of it was due to the old GenericMeta implementation that is also gone in Python 3.7 thanks to class_getitem.
I don’t think we know yet how the performance compares, or whether the difference is significant. I tried to do some performance comparisons a few months ago on a large well-annotated codebase, but I wasn’t able to get the reference implementation of PEP 649 to work at all so didn’t make those comparisons. I think that it would be valuable to have a working reference implementation and some performance data (and then perhaps some work on perf tuning: possibilities have been suggested in earlier threads about PEP 649) before making a final decision on PEP 649."
i guess that might count as an argument against a DSL
on the other hand, one could maybe pre-compile all annotations
can't
How would you precompile foo: bar.bat, when bar is a user-defined object which can do whatever on __getattr__? Also, I think there was something about nested classes and get_type_hints not working with that.
basically the expression (might?) need access to the definition scope
hmm.. it doesn't have to be "legal" code from the static compiler's pov, just turn the str into a code object that is executable in the runtime step
your dynamic example wouldn't be checkable by a static checker either, i think
Right, isn't that almost what PEP 649 is doing? Haven't looked too deeply into specifics, got too frustrated by some peoples' attitude
I don't follow? You mean something like mypy?
yeah
Right, but the whole argument is about usecases other than static typechecking; actually useful stuff like the things pydantic does
i thought it's the other way round? annotations are valid python code first and stringified on demand?
That's the case right now with/without the future import. PEP 649 does something equivalent to storing the string plus the scope, and evaluating it on demand.
as far as I understood
raises a couple of eyebrows
That way you have no problems with forward references (the original usecase of the future import), but you still can do stuff pydantic etc. do
Other than pydantic, the only time I used type annotations was for registering commands in an fungoid esoteric programming language, so I'm not the most unbiased person in this debate, but I think PEP 649 is a great compromise
okay, reading 649 more in detail, it does sound much smarter
although, i can foresee some potential issues
not sure how well it would handle access to the annotation during the limbo of definition time
he says that forward references shouldn't be a problem, but i'm skeptical
any1 know why im getting 0

that's probably better answered in one of the help channels 🙂
In a help channel someone will help you, here it's unlikely
@unkempt rock Each topical channel has a particular topic, otherwise we'd just have 100 channels named #python-0 through #python-99. You should see #❓|how-to-get-help and claim a help channel.
im currently learning about language developement and im reading a chapter about parser and Im on a bit called panic mode error recovery
Before it can get back to parsing, it needs to get its state and the sequence of forthcoming tokens aligned such that the next token does match the rule being parsed. This process is called synchronization.```I dont understand this
does anyone have a simpler way to explain this
I cant understand what synchronization means
I'm not sure that's fit for #internals-and-peps, but the idea is that in order to continue parsing after an error (so as to report more errors), you need to somehow ignore some tokens so that the remaining ones are valid.
wdym by dump
throw way temporarily?
yea
ohhh you basically cut away the whole area of invalid tokens so the ones after can continue running
thank you
Not running, but so you can report other syntax errors after, since smacking one syntax error at a time like whack-a-mole is no fun
^
i mean, you could technically make a language that auto recovers and keeps running but that would be unwieldy
so if you find one error the parser cuts away the invalid tokens so you can find additional errors
I don't think Python did this right?
An esoteric programming language (sometimes shortened to esolang) is a programming language designed to test the boundaries of computer programming language design, as a proof of concept, as software art, as a hacking interface to another language (particularly functional programming or procedural programming languages), or as a joke. The use o...
no python bails out
this is what I am trying to do
im gonna make an extremely similar recreation of python with python and then make it entirely upside down
learning the theory right now
Thank you guys
❤️ 👍
relatable
syntax error wack-a-mole is the most relatable thing ever for programmers lol
you deal with 1 and 2 pop out
https://bugs.python.org/issue39529 this is kind of frustrating
i am hoping that the devs take this request and reasoning seriously https://bugs.python.org/msg407600
What about it?
Do you think it's acceptible to have single-letter type variables?
I find it a bit silly, but it is the universal convention by now
the change makes it a lot harder to write non-async "setup code" that will be used to set up an async application
yeah, why not
certainly for generic parameters, and I'd call both uses acceptable, but depending on the audience more descriptive names could be better
I suppose its useful that having single-letter names makes it distinguishable from concrete classes
i don't think i've seen multi-letter names anywhere
(well, excluding suffixes like in T_co)
I like the C# convention of T for regular generics and TKey, TValue for mappings, for example
Makes type variables distinct, gives them sane names when needed
all this typing theory.. weird it never really was a topic when i studied CS
times change..
datastructures, computability, parsing.. OOP of course with subclassing etc. but types per se as something important?
For theory of programming languages, yes
I remember the good old OOP days
We had factories, sorted in place created singletons like there was no tomorrow
SOLID - everyone's forgotten about the SOLID principles. It gave us hope and shared values.
I could do everything withAbstractSingletonProxyFactoryBean. Why change something so simple?
Doginherits fromAnimal.Catinherits fromAnimal.
Just override.eat()and BAM! Dinner's served
damn right. those were the days.. strokes his grey beard
who needs protocols and weird-ass annotations!
STOP DOING TYPES
This is real type theory done by real mathematicians
They have played us for absolute fools
think as FP got more popular, people started using types to encode program behaviour
but honestly if you look back at e.g. Hungarian notation, there was demand for doing something like that
we just didn’t have the appropriate tools
hot take: putting Error or Exception at the end of your exception class name is Hungarian notation
not joking
Except your custom exception classes aren't usually instances of Exception
?
If I name my variable i_age (i for int), then that variable is an instance of int
But your custom exception class isn't an instance of Exception, it's a subclass
It would apply if you would name the instances of your exception *_exception
except MyException as custom_exception <- here I agree :D
if you name a class Exception or even try to use it as one, but it's not a BaseException, then what are you smoking? 😂
use Exception as metaclass
looking forward to an example

why is it working? 
>>> MyAwesomeException
Exception('MyAwesomeException', (), {'__module__': '__main__', '__qualname__': 'MyAwesomeException'})
>>> class X(metaclass=print): ...
...
X () {'__module__': '__main__', '__qualname__': 'X'}
>>> X is None
True
```now `print` is metaclassIt doesn't implement the right protocol, so arguably it isn't a metaclass
Otherwise any function that takes three positional arguments is a metaclass
And I don't think that's really right, heh
Now find a useful example of using metaclass= with something that isn't
!e Defining a string without quotes, maybe:
class Foo(metaclass=str.format): ...
print(repr(Foo))
@quick snow :white_check_mark: Your eval job has completed with return code 0.
'Foo'

!e print(str.format("Foo", (), {}))
@raven ridge :white_check_mark: Your eval job has completed with return code 0.
Foo
Pretty cursed.
now make it so I don't have to pre-define Foo
Ok wow
That's an interesting solution
!e ```py
def stringer(func):
return func.name
@stringer
def unquoted_string(): pass
print(unquoted_string)
@spice pecan :white_check_mark: Your eval job has completed with return code 0.
unquoted_string
!e
from operator import attrgetter
@attrgetter("__name__")
def unquoted_string(): pass
print(unquoted_string)
@grave jolt :white_check_mark: Your eval job has completed with return code 0.
unquoted_string
Yeah I thought of that
Instantiating for each decorator call is such a performance hit /s
Each @attrgetter('__name__') would instantiate a new attrgetter, which is just an intolerable performance penalty
the decorator is computed only once, when the function is defined
Yeah, but for each function you define, you'd have a separate one
My joke was based on that
smh why have more than 1 function
how many temporaries can we waste in a single expression?
temporaries just being short-lived objects?
!e
yeah, is there some magic to reuse things like empty lists/tuples? like there is with small(ish) integers?
from functools import reduce
_, _, _, _, _, _ = [*reduce(type([]).__add__, map(list, (((1,),)+((2,),)+((3,),)+((4,),)+((5,),)+((6,),))))]
print(f"{_=}")
@lusty scroll :white_check_mark: Your eval job has completed with return code 0.
_=6
(I was inspired by this)
this is clever 😄
I get the feeling #esoteric-python can't be contained! 😄
/s
!e
in a similar vein:
import operator, types
@operator.itemgetter(0)
@operator.attrgetter("__args__")
@operator.itemgetter(0)
@operator.attrgetter("__orig_bases__")
class A(types.GenericAlias(list, "Hello World!")):
pass
print(A)
@lusty scroll :white_check_mark: Your eval job has completed with return code 0.
Hello World!
it's spreading like a disease
This was a joke, I actually like to get to know those "cursed" tricks.
I call them python crimes and it actually quite enjoyable to do stuff that is unpythonic tricks.
Like an enum implementation that keeps a registry of subclasses, is a singleton and assignes itself automatically to other objects as category tag.
enum implementation:
Meta class that defines all necessary methods as class-methods (dunder), so they are never instantiated.
damn code to long to post the criminal meta-class
that's just the built-in Enum class ...
speaking of
Is there a flake8 plugin that prohibits creating a metaclass?
I will write one if there isn't one
arw you supposed to compile C extensions with -std=c99 ?
I am truly amazed how C programs even work, given that there are no namespaces
Extended but yes. Is the way I learn best, seeing something and trying to recreate the effect without copying the code.
I also hate using black-box libraries, so this stuff also helped me understand their code.
it is still absolutely useless though (the stuff I made not stdlib Enum)
these rules could be expanded to PEP 8 as well, imo:
Use 4-space indents and no tabs at all.
No line should be longer than 79 characters.
though I use two-space tabs in my personal code (with appropriate shame)
(I think I'm ok because it also says rules are there to be broken)
I understand the reasoning behind 79 characters width, but is there actually anyone that preferers this?
Even reading code at that width is kind of confusing for me.
with 4-space indents it adds up to 79 pretty fast
That's one of (or maybe the only?) PEP 8 rule I absolutely reject, I am a fan of 100 or 120
this sentence alone put you over more than half the allowed chars (49)
Is there a vast silent majority with 30 year old CRT's?
my phone screen can show only 78 columns, at least at what I consider a reasonable font size
Afaik no. I think it was just chosen for maximum compatibility, not maximum utility to the average programmer
Actually enforcing it doesn't really make sense IMO
Long lines are just inconvenient to read in some contexts, like when looking at diffs side-by-side
but maximum line length isn't very important IMO
if your average line length is 70, then it's a mess
because there's clearly too much stuff happening in one line
it does make sense as a guideline for the code complexity, but cutting it off at it will imo lead to less readable code in most cases
maybe it comes down to punch card size
where does it say 49?
PEP 7 and 8 say "No line should be longer than 79 characters" and "Limit all lines to a maximum of 79 characters" respectively, unless my eyesight is worse than I thought
they meant that the sentence was over half the allowed chars, where 49 is more than the half is
oh, haha
Well.. I expect discord to do the line-wrapping ping for me, so I wasn't being measured with line length 😄 But with email, can't assume even that much
(48 characters)
challenge accepted, @vast saffron
lets go back to the days of banishing consonants from variable names for size 🙂
oh like lCtr and pszCrnt ?
hi how can i run the codes that i copied in cmd?
why not just banish consonants vowels for everything
fr tm n lst:
prnt(tm)
much more readable imo 😄
are you talking about sorted?
I think that uses the timsort algo which is faster than the other two (I think)
correct me if i'm wrong
why wouldn't it use something a bit more complex if it performs better for the general use case
it uses a better algorithm
is it the timsort algo? or something else
python's already not great with speed so having it in the stdlib just makes sure users don't have to worry about picking a right one for the data (and python) themselves for most of the time
yes, list.sort uses Timsort
imagine using punctuation
FR TM N LST
PRNT TM```it does use mergesort, but it switches to binary insertion sort for small granularities. this turns out to be much faster than just a normal mergesort
!otn s bogosort
Query results
• bogosort-vs-timsort-the-final-showdown
still waiting for that showdown.
old terminal widths were 80 characters IIRC
Guys, I need idea for my semester end project idea..any suggestions ?
I vaguely remember something about Java using a modified version of timsort for object arrays, with the reasoning somehow being connected to pointers
Seems like Rust, Swift and V8 also have timsort, though I don't know if it's the default in any of those
https://doc.rust-lang.org/std/vec/struct.Vec.html#method.sort
"The current algorithm is an adaptive, iterative merge sort inspired by timsort."
Nice
The key part of Timsort is that it detects and takes advantage of already partially sorted sections in the list, which happen often in real situations and make it really fast.
Here's the full explanation:
https://github.com/python/cpython/blob/main/Objects/listsort.txt
i'm annoyed by the pattern
def f(..., excluded_names: set[str] = None, ...):
if excluded_names is None: excluded_names = set()
is there some way to change the behaviour of mutable defaults? 🙂
Well, right now on Python-dev there's a massive discussion over PEP 671, which adds a late binding default.
if it was a class, the answer would be dataclass or attrs
oha?
https://mail.python.org/archives/list/python-ideas@python.org/thread/KR2TMLPFR7NHDZCDOS6VTNWDKZQQJN3V/
https://mail.python.org/archives/list/python-ideas@python.org/thread/P5JAIGZEI4PXR2TYS5ELB6TN4JVLUNL7/
https://mail.python.org/archives/list/python-ideas@python.org/thread/UVOQEK7IRFSCBOH734T5GFJOEJXFCR6A/
i'm just looking at the pep itself, recalling it's been discussed here a while ago
Adding up the threads, it's 488 messages....
Did not realise it had gotten that much discussion.
neither, although that might also indicate a "we can't come up with a viable solution to make everyone happy, let's just leave it as is"
it appears I was able to get a much quicker subprocess run using os.posix_spawn than os.system or subprocess.run
does it work on windows? 😉
no :p
I'm pretty sure at least
echo -E $'#include <stdio.h>\nint main() { printf("Hello World!\\n"); }' | gcc -xc -static-libgcc -static -O3 -o simple_print - ; python3 -m timeit 'import os; os.system("./simple_print")' | grep -vFe Hello ; python3 -m timeit 'import os; os.posix_spawn("./simple_print", ["./simple_print"], {})' | grep -vFe Hello ;
100 loops, best of 5: 3.62 msec per loop
2000 loops, best of 5: 173 usec per loop
wait, what is that gcc doing there?
building a simple, optimized, static "Hello World!" program to use as our test subject
what's os.system?
it just calls a shell with your command line as a single string
I'm not sure if it waits for it to complete
The subprocess module provides more powerful facilities for spawning new processes and retrieving their results; using that module is preferable to using this function. See the Replacing Older Functions with the subprocess Module section in the subprocess documentation for some helpful recipes.
!d os.system
os.system(command)```
Execute the command (a string) in a subshell. This is implemented by calling the Standard C function `system()`, and has the same limitations. Changes to [`sys.stdin`](https://docs.python.org/3/library/sys.html#sys.stdin "sys.stdin"), etc. are not reflected in the environment of the executed command. If *command* generates any output, it will be sent to the interpreter standard output stream. The C standard does not specify the meaning of the return value of the C function, so the return value of the Python function is system-dependent.
On Unix, the return value is the exit status of the process encoded in the format specified for [`wait()`](https://docs.python.org/3/library/os.html#os.wait "os.wait").you're not handling the output within the code itself, so that's probably the reason why it's faster
that's where I got the idea from, reading what subprocess does
the windows equivalent seems to be _winapi.CreateProcess
which is undocumented ?
true, neither does os.system
I'm handling it with grep -v 😄
see telegram 😉
you got me on that, I didn't do anything "practical" like waiting for it to finish.. just thought the nuts and bolts were interesting between the two approaches
Why can't this be a decorator?
@default(some_list = lambda: [])
def f(some_list):
some_list.append(42)
return some_list
like, in functools
or even py @default(some_list=list) def f(some_list): some_list.append(42) return some_list like in defaultdict
i was just writing up something similar, lol
In [92]: _SENTINEL = object()
...: def delay(*params):
...: def deco(func):
...: if not set(params) <= inspect.signature(func).parameters.keys():
...: raise TypeError("some args missing in signature")
...: sig = inspect.signature(func)
...: dic = {param: sig.parameters[param] for param in params}
...: new_params = [
...: v
...: if k not in params
...: else inspect.Parameter(v.name, v.kind, default=_SENTINEL, annotation=v.annotation)
...: for k, v in sig.parameters.items()
...: ]
...: sig = sig.replace(parameters=new_params)
...: func.__signature__ = sig
...: @wraps(func)
...: def inner(*args, **kwargs):
...: actual = sig.bind(*args, **kwargs)
...: actual.apply_defaults()
...: for k, v in actual.arguments.items():
...: if v is _SENTINEL:
...: actual.arguments[k] = eval(dic[k].default)
...: return func(*actual.args, **actual.kwargs)
...: return inner
...: return deco
...:
In [93]: @delay('b')
...: def f(a: int, b: set = "set()"):
...: print(f"{a=}, {b=}")
...: f(1)
a=1, b=set()
In [94]: @delay('l')
...: def f(l: list[int] = "[]"):
...: l.append(5)
...: print(l)
...:
In [95]: f()
[5]
In [96]: f()
[5]
cursed
the fucktools name is not occupied
Has anyone tried out Pony ORM? As part of its implementation it contains a function to reconstruct the AST of a generator from its bytecode. I thought this was really cool. ```py
from pony.orm.decompiling import decompile
g = (x for x in range(10))
ast, _, _ = decompile(g)
GenExpr(GenExprInner(Name('x'), [GenExprFor(AssName('x', 'OP_ASSIGN'), Name('.0'), [])]))
referencing previous arguments is also possible now: https://paste.pythondiscord.com/awinunikuh.py
In [107]: @delay('x', 'l')
...: def f(x: list = "[1, 2, 3]", l: int = "len(x)"):
...: print(x, l)
...: f()
[1, 2, 3] 3
In [108]: f([1, 2, 3, 4])
[1, 2, 3, 4] 4
Surprisingly it's actually due to the width of a punch card! 😄
yeah ast.unparse can do the ast -> source code part
oh
could be time to revisit this then, maybe
never forget! punchcards forever!
yes, the bit bucket deserves to be brought back
is a firm believer in the 80 line rule. Being able to have two files open side-by-side (even on a laptop) is great.
other times it's great to have everything you want to say in one line, even if it's over 120 chars..
feels like that should be fine even with larger limits considering I usually have two files open and a big tab to the left of them just fine and my usual hard line limit is 120
To be clear: I don't have a hard limit at 80, but my editor warns me if I exceed it.
I have visual guides on 79 and 99
theoretically you could have a hard limit at 80 with black for everything living on github but run black on checkout with the limit of your desire locally
Can you show me an example of where you need 120 columns?
Whenever I see this it's almost always either bad names, or overcomplex code
usually docstrings
hmm.. i think i mostly get into fights over this with @lusty scroll with strings
but some code is also just simpler if it's on one line instead of being split up just for the sake of it
not docstrings per se, but any strings
Docstrings are text and can be hard-wrapped
Other strings can be an exception for better greppability
They can't if they have to adhere to a style that's out of your hands
I don't really like any of the options except shortening the string
There are also some cases when working with black where I get why it exploded something, but I really don't think it provides anything over a longer line (e.g. an exploded call that's around 5 similar calls but is a few characters longer)
You mean the non-descriptive part, like types etc.?
I feel like a style guide is not a convincing argument given that we're arguing over style
that or just having a summary/description part where the subject summary span multiple lines but sometimes it can't quite fit while getting the whole point into it
textwrap.dedent is not a bad solution to multi-line strings thatdon't make the file look like it's indented wrong
i prefer one-longer-line comments over multi-line comments since they're additional info and not necessary to follow the code flow, but breaking the code flow for comments is detrimental to readability
If there needs to be a long string literal, there needs to be a long string literal.
I usually prefer the wrap in parentheses and use implicit/explicit concat style as it doesn't introduce an additional call
For comments break it into multiple lines. It's not an issue for readability, at best might take you a couple days
i find it's noisy
compared to dedent, or compared to just not doing it?
At worst, perhaps a week to get used to it
not doing it ^^
that works well too
i always get itchy when i see those 😉
ack, I disagree 😄
yeah, that's probably the only thing we really disagree about code style
actually, black's line limit thing can also backfire in the opposite direction
in justuse we use >> pipes in a few places, but it's nicer to have every pipe on its own line for clarity.. turns out that black disagrees and joins those lines to make a longer line, crippling readability for those
Am I on the right place
did you try asking in a help-channel?
@unkempt rock If you have a question, you should probably see #❓|how-to-get-helpand claim a help channel
interesting phenomenon: if you break a complex statement into two statements, you end up having less lines, not more
foo = some_thing.complex_thing(
bar=barify(settings.baz, consistency_threshold=420.69),
fizz=Buzz(),
)
#->
bar = barify(settings.baz, consistency_threshold=420.69)
foo = some_thing.complex_thing(bar=bar, fizz=Buzz())
except when it's not really a complex statement but some longer attribute lookup or proper parameter name
where you end up with ( and ) and [ and ] on seperate lines and instead of 1 line you have 5
re: late bound arguments
would you expect this to work:
def f(n: int => len(tup), tup = (1, 2, 3)): ...
considering that
def f(n: int => len(tup), tup => (1, 2, 3)): ...
should error (since late bound args would be evaluated left to right)
the pep itself is rather vague about this, it says # May fail, may succeed
i was just fiddling around, but i figured i'd need some inspect voodoo:
import inspect
def deferred(**defaults):
def func_wrapper(func):
def wrapper(*args, **kwargs):
default_calls = {k: v() for k, v in defaults.items()}
updated_kwargs = {k: v if v is not None else
default_calls[k] for k,v in kwargs.items()}
return func(*args, **updated_kwargs)
return wrapper
return func_wrapper
@deferred(b=list)
def f(a, b=None):
print(b)
return b.append(a)
it also doesn't solve the issue with the proper documentation of the real default params
although, maybe it's possible to update the annotations via decorator
@verbal escarp this preserves the signature
wait, no, that paste is outdated, that one doesn't preserve it
i tried to improve on the str/eval approach
oh, yeah
that paste link looks good
although i wouldn't go the str/eval route
the signature updating looks well done
hm, how else would you achieve it
lambda: expr?
oh lol
benefit is you get immediate syntax errors and not sometime down the road
and IDEs can help with autocompletion
that is true
IMO this shouldn't work
As a user I would expect that to work though
I really don't like the => syntax when combined with type hints. It looks too much like a callable type.
Referencing a param before declaring it (in source) is too confusing for my taste
i am on the side of not allowing it too
def double(fn : int => int):
def wrapper(arg: int):
return fn(arg) * 2
return wrapper
Yeah, syntax could be better
what PEP is this syntax for function types?
I don't know if it's in a pep yet, but it was mentioned a bunch of times during the discussion of the new peg parser
Either this or args -> return
671
oh wait nvm
i misread
If you mean int => int, that doesn't exist, it's just the proposed syntax for something else (deferred evaluation of defaults) that I find confusing, because it looks like a function type.
Semantically I like ?=, but it's a bit too much noise visually
Ah. To be honest, I feel like it'd be really annoying when having nested functions. ((int, int) => int, int) => (int => int)...
can't be worse than Callable 🤷♂️
Callable is not that bad tbh, if we just had a bunch of common templates it would be fine
Like C# has Action<args...>, which takes args and returns void, Function<args..., ret>, which is basically Callable without the brackets, Comparison<T>, which takes two Ts and returns int, so on and so forth
Fn[int, int] >> int is technically already possible
That would look fairly interesting tbh
Assume None return for Fn[int, int] and override on rightshift
yeah,those templates would help. I suppose one could declare them using typing.Protocol
That could work, but you could also just have type aliases
i also wouldn't like => for the default syntax, thinking of better lambda syntax there
wait a sec.. what if we don't call it defaults and move a bit further
i just typed def fn(x: int ?= int) and thought about none-aware assignment, but what if that specified callable is always called on the argument that's passed in?
Using a single ? for None-aware assignment is still pretty iffy
like for explicit type conversion
It's not very explicit if it happens automatically behind the scenes, is it?
if you pass in the function that is supposed to be called on the argument, it's explicit
Fair enough, but why not just call it on the argument yourself? :P

let's write everything as f-strings and eval() - because f-strings are cool :p
f'{"write program as oneliner here"}'```f that
now you can just write the whole thing in just one function
oh, and you can call the function itself recursively in the lambda, right?
maybe def fn(lst:list[int] @ list) might work better
let's imagine we have a nicer lambda syntax
then we could write def fn(foo: list[int] @ {=> [1,2,3]}) or somesuch
i think conceptually it's closer to what we mean with decorator syntax
That's ambiguous though
It's matmul for the type
Yeah, either that or ?=
but ?= has a different meaning I think
I'm honestly looking forward to PEP 671 because
A. late default setting
and B. mutable arguments!
def fn(lst => list()):
lst.append(1)
^ that won't be appending it to the entire default
the => syntax is meh
Yeah I don't really likke it
I'm rooting for ?= or :=
but i'm still unsure if the deferred call has to be none-aware and couldn't just be called every time the parameter is passed in..
it could open up more possibilities
also could be more flexible with other sentinels
Ohh true
it might require a slight change in how list() and other constructors work since ```python
list(None)
Traceback (most recent call last):
File "<pyshell>", line 1, in <module>
TypeError: 'NoneType' object is not iterable
if list(None) would return [], it'd be a trivial change
or make None iterable with no item?
I'd vouch for not tying it to None, because in some cases it is also a valid input
And not having to create sentinels for a fairly trivial param missing case would be very nice
Is the reason for typing.overload returning a function that raises NotImplemented avoiding potential accidents if the user forgets to define the implementation? I found it a bit strange that it doesn't just return the argument
I was wondering the same thing when I was reading the source code for it, honestly if I had to guess I'm presuming it's just so the user is aware? I could be totally wrong on this though
and of course the type checker tries to be smart so I can't even monkeypatch it nicely
that would probably be a pretty large breaking change since stuff like defaultdict(list) and field(default_factory=list) is quite common
That's probably the reason, because it's easy to assume that it implements dispatching if you don't know better
And raising NotImplementedError helps prevent that
In Scala 3, you can define your program entry point with @main
@main def hello() = println("Hello, world")
which is a lot nicer than having to create an object and args parameter "just because":
object Hello {
def main(args: Array[String]) = {
println("Hello, world")
}
}
Or even the dreaded
public static void main(String[] args) {}
Java requires. They both rely on beginners having to learn concepts that are of no immediate or apparent use for them to satisfy the compiler.
While not required, in Python, in many cases it makes sense to run your code inside a if __name__ == "__main__: guard. As far as beginners are concerned, this is equally, if not more so, arcane. Even the advanced Pythonista might think of it more as "useful introspection trivia" than a proper mechanism for program entry points.
So, what do you think of a main decorator you could slap on a function to execute it when it's in the "__main__" file? E.g.:
@main
def hello():
print("hello world")
Is it possible? Useful? Needed?
lo and behold, multiple #python decorators on a single line! yes, it actually works, but the implementation is not what you think! 🤡 /cc @judy2k @jacobian
code is at https://t.co/lEr0n0Igwt and inspiration came from this 🧵 https://t.co/vnaXvstoRh




clever
Looks something useful when you have short decorators and they are taking one whole line
personally I would like it
so we could skip adding module level code to run the "main" (or "run") function
not sure what the behavior would be--maybe it could all be handled by runpy
then there'd be no other changes needed except adding the decorator somewhere
looking at runpy.py, this won't work as I had hoped
it just calls exec , it doesn't create a module, so it wouldn't be just a matter of searching for a function "annotated" with @main
another language that does this is F# with its [<EntryPoint>]
And although it looks neat and shouldn't be difficult to implement, I don't see much value in having that
Python doesn't demand an entry point, top level code is the entry point
The need to differentiate between running a module as a script and importing it into another module doesn't arise often in general, and even less so in code written by beginners
And by the time they do need to differentiate, the explanation will not look arcane to them
I find it that if-main is shoved into code just because it is a concept familiar to people coming from other languages more often that it is genuinely needed
it's not too common to have modules that are meant to be both imported and run directly either
Yep, main code is usually separated into its own module
In Python, everything happens at import time. There is no time that code runs at other than at import time (and interpreter teardown time, I suppose). Essentially the entirety of a python program's run time is the import of the __main__ module.
People coming from other languages don't like that, and want to pretend Python is a language where you can define functions and globals in one phase and then use those in an entirely different phase, but that's fundamentally not the way the language works.
Or to put that a bit differently, Python already has an entry point, and it's __main__. Python just starts running whatever code is in the file or module you ask it to run, and that's all an entry point is. It's just that the entry point is not a function, but instead an entire module.
The solution to this "issue" is not an entry point decorator, but proper teaching practices that account for python's idioms instead of blindly copying over practices from other languages
And, frankly, a decorator may look less intimidating in code, but it is a significantly more complex concept than an if statement with string comparison (RE: forcing beginners to learn concepts that are of no immediate or apparent use to satisfy the compiler)
Probably 9 times out of 10, if someone wants a file that is able to be imported or run directly, and they want it to do different things in each case, the right thing to do is factoring it into a package with the importable stuff in __init__.py or a submodule, and the script in __main__.py - there's no good reason to keep both in the same file, once you've decided that what you're building is a library that supports being imported to provide some API
FWIW:
def main(fn):
if __name__ == "__main__":
import atexit
atexit.register(fn)
But I see this firmly in #esoteric-python territory
not really esoteric, no
it may be unusual, but far from esoteric
Running the "main" function as part of interpreter teardown is most definitely esoteric.
that's not what it does
Yes, it is. It takes the function that is decorated and registers it to be called after the main script ends, during the first step of finalizing the running interpreter
it's a function that is registered
not the main function
fn could be a simple cleanup function
Esoteric in the sense of "don't do this"
The stated purpose of this decorator was to explicitly specify an entry point for your script. Running your entry point while the interpreter is exiting is most definitely esoteric.
i don't see that implied in this code snippet, but if so, you're right
It's very much implied in the conversation that it is a part of
 was the context
was the context
as i read it, that part of the conversation was done, but okay ^^
i see a much different problem with@quick snow 's snippet though
aside from the exit-entry thing, registering with atexit calls the registered functions in backwards-order as they were registered, so if you really want to use this pattern and have a proper atexit-cleanup function, you'd need to be careful in which order those functions are registered, otherwise you end up with exiting before entry
and if you decorate multiple functions, you're screwed either way
I wonder what happens when you register an exit function in an exit function
That's a curious question
!e ```py
from atexit import register
register(lambda: register(lambda: print("Hello")))```
@spice pecan :warning: Your eval job has completed with return code 0.
[No output]
They are skipped it seems
i doubt that even called atexit
why wouldn't it?
let's try
!e ```python
from atexit import register
register(lambda: print("foobar"))
@verbal escarp :white_check_mark: Your eval job has completed with return code 0.
foobar
okay, you're right
!e ```python
from atexit import register
register(lambda: print("foobar"))
register(lambda: register(lambda: print("Hello")))
@verbal escarp :white_check_mark: Your eval job has completed with return code 0.
foobar
yup
why would that be a problem if list could take None as a lone parameter?
hmm nevermind not sure what i was thinking
Accepting None as a parameter would weaken the typing as it could silently produce the wrong result instead of erroring
i suggested to have list(None) -> [] to make it possible to call it as part of a default parameter
delayed default*
Yes, and I still think it would weaken the typing
making None iterable with zero elements is arguably worse, i think
It definitely is, but that doesn't make the alternative better than it already is
IME, passing None in such cases is not intended and a result of a bug more often than not, and changing it to return an empty list makes it harder to spot
That might just be my experience, but I'm opposed to such changes
so, what would you suggest as a delayed-default mechanism?
aside from the syntax discussion, it's also relevant how it should work
I'm just opposed to the proposal
An abstracted away sentinel (to allow passing None) with the semantics described in the pep, so LTR evaluation in a block of code before the function body
That's fair
It'd introduce a decent amount of new semantics that would be confusing for newcomers
And I wouldn't say it solves a huge issue, it's just convenient sugar
I think the fact that the community has wildly different opinions on syntactic options alone is a good sign that this should be reconsidered
bikeshedding isn't a good way to make progress 😉
I think the pep mentioned new bytecodes
Readability is important, and if the options are either confusing, or clutter the code visually, or ambiguous, it may not be a good thing to have
True, but I don't want to build the shed
well, there IS a problem which delayed defaults would solve
and AFAIK syntax is the main point of disagreement, the rest of the semantics is mostly established already (among people who want it implemented, ofc)
Are they that much better than an is-None or is-sentinel check?
it's not just convenience. having None or another sentinel as default then calling set() etc. as actual default is hiding the actual default from the documentation
I'd rather have none-aware operators reduce boilerplate
That's a fair point
The signature becomes less meaningful
Type hints partially solve that
If you see list[int] | None, you get a bit of information from the signature
Though you don't get to see the actual value of it
And neither can you get things like len(other_arg)
You could use Annotated I guess
def func(items: Annotated[list[int], "Defaults to []"] = None): ... ```I think something like HasDefault[T, default] would be nice, along with maybe typing.get_defaults that would return a dict of argument names to default values, taking into account whether or not they're typed as HasDefault
Ooh, found a bug in that area: https://bugs.python.org/issue46025
Shouldn't the name items be enough of a hint?
Segfault o_O
i forgot pablo galindo is your colleague 👀
whose?
godlygeek
ah
did this channel get renamed from advanced?
Speed ups for 3.11 aren't looking that impressive. Maybe I'm not understanding how much faster its supposed to be after a single year
What kind of speedups would be impressive?
Say Python becomes as fast as X, what's the slowest X you can think of?
I would like it to approach javascript speeds, which can be as fast as C at times.
https://gist.github.com/markshannon/0ddfb0b705d23b863477d7f7f9f00ef1 I guess a 1.19x faster geometric mean is 19x faster but at these numbers its not like "oh this is going to be so much snappier"

1.19x = 19% faster
a 1.19x faster geometric mean isn't 19x faster
Mark Shannon is stating it that way
Sorry he's saying 19 percent
yeah, small difference 🙂
19% is a nice win but it's not earth shattering when python is 20x as slow as many other garbage collected languages
and yes, I mean 20x, not 20% 🙂
Shaving 10s of ms off of basic ops is nice but when you're normally in 100s of ms to begin with I'm not really feeling that "wow'd" about it.
this is just the first of the improvements in the pipeline
I'd like to see ms -> us type improvements
I mean that's 1000x
yeah...
that can't happen because python is only roughly 100x slower than C or C++
I mean I know jack-butt about doing any of this but like javascript is damn near, if not more, dynamic as python and can be as fast as C at times
The improvements aren't magical, you can't really do anything extreme without restructuring how the interpreter works as a whole
"can be as fast as C at times" in reality means, as fast as C, almost never
"typically", JS is probably going to be at least 10x slower than C
js also had a lot of money poured into it as the whole web runs on it
which is is still an amazing accomplishment
lemme pull up a thread where there is a lot of python hate but with benchmarks
eh it's ok, I've seen lots of benchmark threads come and go, in the end it depends which benchmarks you choose, how you weigh them, how you run them, etc
the ballparks I'm giving are based on many many benchmarks I've seen over time
So if you designate C/C++ (and probably Rust) as 1x, you have python/ruby ~ 100x, Java 2x-3x (with caveats; like latency vs throughput), most other statically typed GC languages falling in about a 5x-10x range, etc
Well these are just straight up qsorts, and they even use numpy and python is still really slow but javascript is keeping somewhat relative to C
Which I think speaks volumes to how much overhead python itself just adds
I'd have to look at the benchmark and understand what is happening, my guess is that if JS is keeping up with C it's because something is implemented in C lol
So this was C without any compiler optimizations
LOL
what is the point of such a comparison?
or did the author just not have enough experience with C?
They did C with optimizations, js, C without optimizations, and Python
so you're saying JS is similar to C without optimizations?
js is was faster than C without optimizations by like 200 ms which including the setup time for java. The optimized C was well over 2x as fast
Yeah
Which sure I guess fine but it was still a magnitude faster than python with numpy
okay, I mean nobody really cares how fast C is without optimizations.
Yeah, python is definitely slow. JS isn't really as a language designed better for speed afaik but like Numerlor said, a ton of money and time got poured into optimizing it
I mean the number of man hours that went into optimizing V8, probably dozens of excellent C++ programmers at Google worked on this for years
compared to python where you have 1-2 people working on it in their spare time
lets just hope microsofts funding for Guido and Shannon make it really fast
I think they have 3 full time developers funded
it's just that python is in a rough position vis a vis performance, it's dynamically typed and it doesn't use an LLVM approach a la Julia, so it's really just going to be piles of work, to make it say, only 20x slower than C
meanwhile if you start any project that vaguely cares about perf (that isn't data science-y) you have to justify why you aren't using pretty nice, easy, GC languages that are way faster than python 🤷♂️
I think people still favor python for stuff that is IO bound, if its not data-science-y task
well, depends which people? Some people favor python, some people favor java, some people favor Go, etc