#internals-and-peps
1 messages · Page 148 of 1
Well you pretty much used setuptools or distutils
https://github.com/doodspav/atomics/blob/master/setup.py this is my setup.py file, using setuptools
it has import git, which needs the GitPython module installed
how would setuptools tell the build system to do that since the setup call is after the import git line?
But you have a setup.cfg that specifies that as an install_requires no?
ohhhh - should i be doing that?
i have setup.cfg but i haven't added install_requires to it
Yes 😅
so my project now needs two separate copies of the same set of dependencies?
I thought the question was how GitPython is installed even though setup() hasn't been called yet (which is where you can pass install_requires)
Why would it need that?
i also have them in pyproject.toml?
Setuptools doesn't read pyproject.toml for dependencies yet afaik
since 43.0.0
Oh I was talking about the project key, but I am looking at the file now
(the 43.0.0 i pulled from https://packaging.python.org/guides/using-manifest-in/ here, the pyproject.toml bullet point)
Can you reiterate the question again - are you wondering how to get GitPython installed when your package is built or are you still wondering how it was done before pyproject.toml was a thing?
Currently i'm assuming that up to date build systems will get the build dependencies from pyproject.toml, is that right?
Yeah so like pip will install those requirements before trying to actually install your package itself
And if it's not there, build systems can check setup.cfg for install_requires?
No, setuptools will
I am not sure if build systems piggy back on setuptools - but that's a specifically setuptools thing
hmm ok that makes sense
assuming however i don't have install_requires in setup.cfg, or a pyproject.toml file, what options are left to the build system to check what build dependencies are required?
As far as I know, none. You simply don't have any dependencies then
oh
so what did people do before setup.cfg was a thing? just tell people the build requirements in the README?
You mean before pip?
setup.cfg and setup.py comes from setuptools as far as I know. It most likely has been inherited from distutils though
oh boy
ok i think that's as deep as i want to go then
but thanks for the info, the setup.cfg thing was the answer i needed 🙂
[options]
python_requires = >=3.6, <4
install_requires = cffi>=1.10
setup_requires = [
GitPython,
cmake>=3.14,
setuptools>=43.0.0,
wheel>=0.25,
]
so now i have this in my setup.cfg, but setup_requires is also listed in my pyproject.toml file, and install_requires is in my requirements.txt file
so now i just have duplicated dependencies?
So I have questioned before the wisdom of Guido's stance on security in python (the whole "you stay out of the living room not because it's locked but because you don't belong there" idea). In CPython we have the __future__ module, which, as I understand, is used to enable not-yet-production features in the interpreter. Would it be possible to make your own library like __future__ that enables things like secure classes (instead of name-mangling, block access to objects belonging to a class) or a private keyword (to be used like global <obj>)?
I suspect a fork of CPython would be necessary.
you could fork cpython and add various extra features
though I think you will find soundly defining what private actually does is a bit complicated
With what little knowledge of CPython internals I have, yes.
not even cpython internals
just python in general can't really support private and similar restrictions
What part exactly causes this restriction?
well, consider various edge cases like
class A:
private a
def method(self):
return self.a
class B:
private a
A.method(B)
getattr(A(), 'a')
def geta(a):
return a.a
A.geta = geta
A().geta()
```what should all these things do? Do you want access to error at runtime, or at compile time. How easy should it be to bypass?right
The way I would handle it is that anything trying to read or write a private object that is not inside that scope would get a Private type similar to None instead of the actual object or raise an exception.
I mean, class functions already get special treatment with name mangling, right?
all class attributes do
rigiht
what about the geta example
it's a method added after class creation
is it allowed to access a?
no
well, dangit
hmm...
You would have to go for the method that the entire class is marked as private then... Then you couldn't inject getter methods.
what are you allowed to do with a private class then?
call it's methods, that's about it
well that doesn't really work either because you would need a.foo in order to call it
aaaaaaaagggghhhh
yeah, in a language as dynamic as python, this is a hard thing to do correctly and soundly
underscores work quite well
If private in C++ doesn’t stop people from accessing private members, idk how you think you’ll manage it in Python
even C?
C doesn’t have private
what stops me from calling drivers inside my kernel to write to the disk directly then?
C does the _ stuff just like python
very little
wtf
@flat gazelle

At best we had stuff like sgx, but even that’s been cracked open :/
so JS does it this way, neat
So basically things like kernel panics are an OS's only defense against calling driver functions from user code?
or not providing the shared object to the user code in the first place
Does OS really stop you if you’re root tho? Can root not do fancy stuff to get ring0?
fair
But even then there's stupid easy ways to get around those tricks in python...
and that's not including using ctypes to get an object by pointer
oh yeah, it is more or less impossible to actually forbid anything
in just about every general purpose language
sad
you can just make things difficult to varying levels
anyway I must go now, thanks for chatting!
If anyone wants to comment on this… 🤞
I've heard "overloading" used to mean both "having more than one implementation for a method in a given class, each with unique signatures, the implementation to be called determined by the number and types of arguments", and "having defined behavior for an operator with respect to a given class"
I think these two are distinct enough that they deserve separate terms.
One's method overloading and the other is operation overloading yeah?
right. but then, operators are just nice syntax for calling methods
(I refuse to say "syntax su---" because I hate how it sounds)
it makes sense if you consider an operator a freestanding function that has multiple overloads, which is admittedly not at all what happens in most modern languages
I suppose it can also count as overloading in that there's a procedure for deciding what function is ultimately called
or, at least which function gets to have its value returned
(thinking about NotImplemented and __radd__ and all that)
speaking of
class WeirdAdder:
def __add__(self, other):
print("Arbitrary side effect!")
return NotImplemented
syntax sushi?
:incoming_envelope: :ok_hand: applied mute to @unkempt rock until <t:1636662497:f> (9 minutes and 59 seconds) (reason: duplicates rule: sent 4 duplicated messages in 10s).
what operation would it do?
"overloading" by itself, IME, usually refers to function overloading
if you want to talk about operator overloading, then you better include the word "operator" 🙂
but I agree the terms are more similar than the features
I mean, aren't (binary) operators effectively just infix notation for functions
maybe C++ was part of the reason for the current terminology being the way it is, in C++ operator overloading does use overloading
Well, maybe, there's still some design issues around how exactly to allow it, and it's still a language feature, and it still needs a name
ah, so you just mean adding a call as an alias for mul to numeric types
that seems a bit pointless
And error prone
julia can do this, but I don't think it makes much sense to extend the python grammar to this extent
also, breaking change and all that
!e
integer calling 👀
from forbiddenfruit import curse
def __call__(self, other):
return self * other
curse(int, "__call__", __call__)
print(2(3))
print(3(2 + 5))
@surreal sun :x: Your eval job has completed with return code 1.
001 | <string>:8: SyntaxWarning: 'int' object is not callable; perhaps you missed a comma?
002 | <string>:10: SyntaxWarning: 'int' object is not callable; perhaps you missed a comma?
003 | Traceback (most recent call last):
004 | File "<string>", line 6, in <module>
005 | File "/snekbox/user_base/lib/python3.10/site-packages/forbiddenfruit/__init__.py", line 425, in curse
006 | _curse_special(klass, attr, value)
007 | File "/snekbox/user_base/lib/python3.10/site-packages/forbiddenfruit/__init__.py", line 332, in _curse_special
008 | tp_as_name, impl_method = override_dict[attr]
009 | KeyError: '__call__'
Hm
Forbiddenfruit has a lot of problems with integer dunder methods
is fishhook supported?
@heady mauve did you check the video about using the AST to make eval safe?
what came of that?
i'd say you can abuse any turing-complete language
the only way to make it really safe would be to castrate it
@surreal sun :x: Your eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 1, in <module>
003 | ModuleNotFoundError: No module named 'fishook'
Guess not
@verbal escarp :x: Your eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 1, in <module>
003 | ModuleNotFoundError: No module named 'fishhook'
forbiddenfruit is also one though and I think it's supported
numpy is too iirc,
I think they can control which packages are allowed
I think forbiddenfruit was added a while back at the request of some people in #esoteric-python I don't know if there's an official process for requesting modules
Ah alright, gonna go ask #community-meta I suppose
fishook definitely has more support
is it fishook or fishhook
!pypi fishhook

Allows for runtime hooking of static class functions
Thank you!
Alright, support for it should exist in a bit
!e
Beautiful integer calling
from fishhook import hook
@hook(int)
def __call__(self, other):
return self * other
print(2(3 + 4))
@surreal sun :white_check_mark: Your eval job has completed with return code 0.
001 | <string>:7: SyntaxWarning: 'int' object is not callable; perhaps you missed a comma?
002 | 14
I did, I wasn't able to get through it all because homework came up, but I wound up realizing that there's a lot of features that have to be cut out if you're going to block everything that may cause trouble.
that's what we had discussed, didn't we?
yep
For use in embedding python as a game scripting language, it would be fine, but it would not work for the other projects I had in mind
I think what I'll wind up doing for the embedding though is running a slowed down VirtualBox instance headless and SSHing to it. Then I could offer "true" sandboxing with less cost
why not docker?

Trail of Bits recently completed a security assessment of Kubernetes, including its interaction with Docker. Felix Wilhelm’s recent tweet of a Proof of Concept (PoC) “container escape” sparked our …
"Common practices such as patching quickly, least privilege configuration, and network segmentation can all effectively reduce the attack surface."
so..
not sure how python could be made more secure by default?
what do you mean by default?
by default i mean "so simple there's little to no additional effort to the user""
maybe in justuse we could have a look at further isolating software components by spawning subprocess-interpreters inside docker..
it would make for a very weird software architecture compared to the current state
yup
something like mod = use(use.Path("user_sandbox.py"), mode=use.full_isolation) hehe
hmm
# verbose is largely ignored, but needs to be set for
# backwards compatibility (I think)?
self.verbose = dist.verbose
You're in good company, turns out the people writing setuptools have no idea what they're doing half the time either 😂
How tho
i did that a few days ago, too
installed python3.10 to test it out, broke everything :p
had to reinstall 3.9 to get things running again
I once broke python in a way that any future attempt to install it would error. Was hard to fix
Same. Fixed it by reinstalling the OS.
i'm just pondering how to reduce the justuse venvs - is there a good way to have a folder as a transparently compressed FS for win and linux?
that could possibly help deduplicating
could list, dict etc. be cursed to have a __getitem__ and forward that call to typing.List etc. for < 3.10?
why not just do from __future__ import annotations?
it doesn't work well with pydantic
and generics are problematic
beartype already is warning about using typing per deprecation
the alternative would be to use a custom _typings module with List, Dict etc. as alias for list, dict in python >= 3.10 and typings.List below
but that's totally backwards
you'd still need to replace those instances in the future
on the other hand, i tried to use list as alias, but typing.List isn't a valid type that could allow instanciation
That's a flag in the typing module, if you're fiddling with internals you could fix that too.
there's always def foo(x: dict) -> list: 🥴
hmm
maybe..
we could make a kind of proxy list class and replace list with that
with a __getitem__ classmethod forwarding the call to typings.List
and a __call__ forwarding to list()
Ñ
btw is there some flag to disallow this?
like, if it's really any list and any dict, to require list[Any] and dict[Hashable, Any]
--disallow-any-generics should do that (in mypy), looks like:
https://mypy.readthedocs.io/en/stable/error_code_list2.html#check-that-type-arguments-exist-type-arg
!e ```python
import typing
class list(list):
@staticmethod
def getitem(key):
return typing.List[key]
print(list([1,2,3]))
print(list[int])
@verbal escarp :white_check_mark: Your eval job has completed with return code 0.
001 | [1, 2, 3]
002 | __main__.list[int]
oh right, thanks
you could patch the builtins with a class like that that implements it through __class_getitem__
okay, the code above surprisingly works, albeit with a caveat
L = [1,2,3]; L[0] returns 1, as expected, but L = list([1,2,3]); L[0] produces
Traceback (most recent call last):
File "F:\Dropbox (Privat)\code\justuse\tests\.tests\.test2.py", line 12, in <module>
print(L[0])
File "F:\Dropbox (Privat)\code\justuse\tests\.tests\.test2.py", line 6, in __getitem__
return typing.List[key]
File "G:\Python398\lib\typing.py", line 277, in inner
return func(*args, **kwds)
File "G:\Python398\lib\typing.py", line 836, in __getitem__
params = tuple(_type_check(p, msg) for p in params)
File "G:\Python398\lib\typing.py", line 836, in <genexpr>
params = tuple(_type_check(p, msg) for p in params)
File "G:\Python398\lib\typing.py", line 166, in _type_check
raise TypeError(f"{msg} Got {arg!r:.100}.")
TypeError: Parameters to generic types must be types. Got 0.
the __class_getitem__ should work, you can't change the literal without (more) hacky stuff but that doesn't matter for typing
you mean if i replace getitem by class_getitem?
!e Yea, that'll only affect the getitem on the type
import typing
class list(list):
def __class_getitem__(cls, item):
return typing.List[item]
print(list("str")[0])
@peak spoke :white_check_mark: Your eval job has completed with return code 0.
s
I (think) you could do it without forbiddenfruit
!e
Borrowed from chilaxan: #esoteric-python message
import gc
from typing import List
list_d = gc.get_referents(list.__dict__)[0]
list_d['__class_getitem__'] = classmethod(lambda cls, item: List[item])
print(list[int])
@surreal sun :white_check_mark: Your eval job has completed with return code 0.
list[int]
yep
in >=3.9
just patch the builtin, there's no need to modify the type
Yeah, numerlor's idea is better
how the heck did you do that
lmao someone had enough shit when writing this https://docs.python.org/3/library/hashlib.html#hashlib.algorithms_available
!d hashlib.algorithms_available
hashlib.algorithms_available```
A set containing the names of the hash algorithms that are available in the running Python interpreter. These names will be recognized when passed to [`new()`](https://docs.python.org/3/library/hashlib.html#hashlib.new "hashlib.new"). [`algorithms_guaranteed`](https://docs.python.org/3/library/hashlib.html#hashlib.algorithms_guaranteed "hashlib.algorithms_guaranteed") will always be a subset. The same algorithm may appear multiple times in this set under different names (thanks to OpenSSL).
New in version 3.2.I hate software that doesn't clean up after itself and if you uninstall python on windows it will leave a lot of crap lying around.
I also want to be able to quickly and cleanly reinstall my system python (nothing depends on it on windows)
So I just checked what files get created and delete them manually if they are not cleaned up by deinstalling.
NEVER DO THAT TO THE LAUNCHER (||or idle, cant remember|| ) , NEVER EVER, IF YOU OVERLOOKED AN OLD VERSION YOU HAVE STILL INSTALLED, ANY FUTURE INSTALLER WILL ERROR.
I also heard it can happen if the installer gets interrupted when uninstalling the launcher or idle.
It leaves some registry stuff that will block future installing into the same.
It took me 3 days and getting shoulder deep into the registry, to fix it, but to be honest it is all a blur and I cant really remember how I did it 😄
think that was the error code of the msi installer: 0x80070643
thanks for the warning, yikes
then there's the stub of python 3.9 windows has built-in
I have had it to where every attempted install would roll itself back
I believe system restore is how I "solved" that
# Keys to press to move around
keys = [keyinput.S, keyinput.W, keyinput.D, keyinput.S, keyinput.A, keyinput.W]
# Function to move around in game
def move_around():
for key in keys:
keyinput.holdKey([keyinput.S, key], 3.0)
i need it to press and hold 2 keys right now it only does one for 3 sec and moves on to the next
this does not work at the moment
# Keys to press to move around
keys = [keyinput.S, keyinput.W, keyinput.D, keyinput.S, keyinput.A, keyinput.W]
# Function to move around in game
def move_around():
for key in keys:
keyinput.holdKey(key, 3.0)
this works
Can someone tell if this whois is suspicious? it isn't python related but what are your thoughts

This is not the right channel for this. Perhaps ask in offtopic
so there's two debug flags https://docs.python.org/3/library/constants.html#debug__, it's actually nice to know there's a -d because i was annoyed that debug was true by default because it's used in assert
In case anybody is curious, here's what we got working so far for generics on 3.8
from gc import get_referents
from typing import _GenericAlias as GenericAlias
for t in (list, dict, set, tuple, frozenset):
r = get_referents(t.__dict__)[0]
r.update({
"__class_getitem__": classmethod(GenericAlias),
})
Why the dict hacking instead of replacing the builtins that was mentioned?
we ran into a number of issues with sideeffects with the first approach
quite hard to debug
not sure if this approach solves all those issues either
not sure what caused it or maybe whether i was being dumb, but we ran into some issues with pydantic that in turn made something awkward with re
at some point my testrunner would simply return some "error 3" without any explanation
i would've given up at that point and revert everything, but @lusty scroll insisted it's solvable 🙂
who am i to argue with such optimism
I assume patching builtins wouldn't work with values that were created with a literal nvm I'm just confused
you mean anywhere with x is list
yeah, i remember some issues with "list not hashable"
i found the whole thing incredibly frustrating with very little to go on
What issues? the only thing I can think of is an isinstance/issubclass mixed with a literal so I guess that would have to go through a metaclass
as i said, it wasn't easy to debug, not really sure what got messed up
okay, so i think we figured out something workable
@broken furnace didn't give up
well, the solution is basically what he posted earlier, it seems to have highlighted other issues and we moved those tests back to tdd to be taken care of another time
some problems with anaconda, different python versions, setup.py and whatnot
just a bag of headache
but it seems all in all things work again
not sure if i could whole-heartedly recommend this method in all circumstances, but it's definitely worth a try, i think
Out of curiosity, why are there two greyblues haha
I have a question how to display this color in the python console?

one of them is my laptop and the other is a phone ... i leave the laptop on so I can stream from it 😄
Ahhh
wondered if anybody was going to notice that :p
wtf bro
Check out the libraries termcolor or simpleANSI. simpleANSI has some (admittedly complex) methods for setting terminal colors, but can do RGB if your terminal supports it.
rich is a great library for cool terminal output. Better if the terminals support truecolors
i have a library for terminal graphics as well
Are you looking for something like this?
https://stackoverflow.com/q/65828286/9132246

Stack Overflow
As we can see the difference between the images. In vim datatype and function are of different color. How can i bring color to my python repl.
I want to do it by myself. Please suggest me, how shou...
can i make sentiment analysis using speech recognition as my major project in 4th year?
Hey I created my own random module check it out
https://github.com/coderatul/random-num-using-time?ref=pythonrepo.com
GitHub
A program to generate random numbers b/w 0 to 10 using time - GitHub - coderatul/random-num-using-time at pythonrepo.com
fun fact, did you know microsoft first came up with that idea for UUIDs and later abandoned it because it turned out that time is an incredibly unreliable source for randomness?
but there is a way to extract the pure randomness!
it's called the von-neumann algorithm
@verbal escarp oh I didn't knew that 😂 I just wondered that I could use time for randoness
Btw I am in 12th grade so it's ok for me 👽 @verbal escarp
not if you're posting it here 😉
we don't discriminate based on gender, race or age!
@verbal escarp Ye boiii 👽 good to see that
everyone is getting the critics they deserve 😉
@verbal escarp and thanks for letting me know that Microsoft history brother ❤️
so, the von-neumann algorithm is really cool actually and you can use it to extract randomness from time and other sources of entropy
@verbal escarp sure I'll check that out
it's incredibly simple: you throw a coin twice. if both times the coin falls on the same side, throw the coin twice again. if the coin lands on different sides, take the first side
Some probability and permutations applied here ?@verbal escarp
that way, it eliminates any bias and you can even extract entropy out of time (basically it extracts the random jitter of the clock)
@verbal escarp ohooo
probability yes
Thanks for this knowledge 😃
you're welcome. the von-neumann algorithm is worth spreading!
Checking it out 🌚
how would i get a fileno integer from a io.BufferedRWPair object?
i made it from socket.makefile("rwb") but does this mean ive lost its fileno?

what about things like
def u():
u = 3
global u = 4
print(u)
u();print(u)
the point of having the statement at the start of the block is that you can tell what scope the variables are
There's no one replying only
!e ```python
def u():
u = 3
global u
u = 4
print(u)
u();print(u)
@elder blade :x: Your eval job has completed with return code 1.
001 | File "<string>", line 3
002 | SyntaxError: name 'u' is assigned to before global declaration
Just keep behaviour
Hey, got a question: just how long can a jupyter notebook hold around 12Gb of data in memory?
If it can hold it, it can hold it till you close it
@unkempt rock see this.
You can't do half and half. If there's a variable of the local scope with some name, then that's it for the entirety of the function body. Similar logic applies when the global directive overrides it. It happens for the entire function
their idea for the positioning of nonlocal wouldn’t work
nonlocal def x() but you need to define the bindings with it

Not a fan of these though
especially that last one
for loops already bind the variable to the current scope it is in, which is most of the time global
I think that last one was just a poor example, But I like... ```python
global var
var = i
.. becoming: ```python
global var = i
I barely use global so I’m fine with how it is
Yeah, if you use global a lot, then you need to rethink your approach
and I wouldn't want another just-another-way-to-do-it change
This would break some old code too for such a trivial change
Honestly I think it would be confusing, too, because it would make you think that the globalness applies to that assignment, which is just not how this works in Python
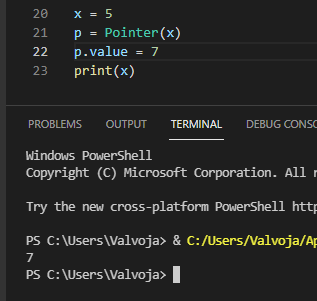

cant really have pointers without ctypes hackery
that's what I have 😅
ah
I guess python just creates a new variable regardless if it's the same type it was before or not so it won't be the same address anymore
Better test this with larger integers, those small ones are pre-allocated
i must admit, i've been in situations where i just wanted to write global a = and then stumbled because i recalled that i had to do it on a seperate line, it's a bit counter-intuitive and feels like a hiccup
for all i care, it could be exactly the same semantics, just contracted
or maybe we could make global/nonlocal into a function, with more ways to specify the scope for the variable
like scope(a, global) or somesuch
i don't really like the mechanics of global and nonlocal, it feels very hacky and not very elegant or thought-out
somewhat related, i'm also missing a good way of breaking outer loops
just dreaming there - i could imagine something like scope(break, 2) to break outer loops
although i'm not happy with it either just by looking at it
it really doesn't make sense for global to be a function. it's just a flag for the interpreter
the harder it is to use global the better, imo
dunno, sometimes you have just one central datastructure - GB of numpy array and it doesn't make sense to pass it around as a variable
I do like that a = 4 creates a in it's current scope unless stated otherwise by global/nonlocal, though I can see the merit in having the scope declaration closer to the variable assignment
I like the system in that 99% of the time, the correct thing to do is to create a variable local to the innermost scope and global/nonlocal just make up for the 1% of cases where you need some other behaviour
don't get me wrong, i'm a big fan of functional programming, but from time to time i'd rather write actual code than function signatures 😉
yeah, this seems like a fair enough change. Probably won't pass since it affects very little code, but if python had this from day 1, I don't think I would complain
hm.. global and nonlocal just feel wrong and unflexible, dunno. i wished there was a more elegant way
ye, it's not amazing by any means
Are free variables in other languages read and write or just read like python unless specified with nonlocal
uh.. depends on the language. some have very different scoping rules
others are much stricter
but i just had an idea
how about something like a !global= ..
flag on the assignment operator
well, = is not the only variable assignment operator
It would have to be a flag on the assignment target itself, but I feel like that could get messy
https://en.wikipedia.org/wiki/Scope_(computer_science)#By_language <- there's an entire wikipedia article on that subject
In computer programming, the scope of a name binding—an association of a name to an entity, such as a variable—is the part of a program where the name binding is valid, that is where the name can be used to refer to the entity. In other parts of the program the name may refer to a different entity (it may have a different binding), or to nothing...
I like this pattern in JS ```js
const mkCounter = () {
let value = 0;
const inc = () => { value++ };
const dec = () => { value-- };
const read = () => value;
return { inc, dec, read };
}
would've been pretty weird if it worked like Python
maybe not necessarily. the left side of the assignment is almost untouched by any conventions except maybe for unpacking or patma, so something like a <global>, b = 1,2 even could work
I find it a little surprising that some names (class definitions, imports, etc.) are by default available inside a function, and some aren't
import a as b <global>
for u <global> in v: ...
with a as <global> b: ...
hahaha, nice
I think I like the syntax proposed in the mailing list more
just global name to assign to a global name
or well, to declare a name global for the rest of the scope
@lusty scrollwhat do you mean?
all names should work the same
i'm not sure if that's true. what if the class definition is in a function body?
here's what I mean
!e ```python
def test():
class Foo:
print("bar!")
def init(self):
print("foo!")
test()
Foo
@verbal escarp :x: Your eval job has completed with return code 1.
001 | bar!
002 | Traceback (most recent call last):
003 | File "<string>", line 7, in <module>
004 | NameError: name 'Foo' is not defined
!e
class T:
thing = 5
def mymethod(self):
print(thing)
T().mymethod()
@lusty scroll :x: Your eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 6, in <module>
003 | File "<string>", line 4, in mymethod
004 | NameError: name 'thing' is not defined
ah, class scopes being weird you mean
yeah
well, class scopes cannot be part of a closure
which is weird
I wonder why that is
IG because __set_name__ can be a noop of sorts
meaning there is no real variable to bind to
also dealing with the descriptor protocol would be weird
this is weird to me too, but I guess we touched on this
IG that's just a wart on the whole "doing oop without being smalltalk" thing
!e
thing = 5
def myfunc():
print(thing)
thing = 6
myfunc()
@lusty scroll :x: Your eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 6, in <module>
003 | File "<string>", line 3, in myfunc
004 | UnboundLocalError: local variable 'thing' referenced before assignment
it's as if the fact that there's a local "hides" the global one from view of the function
ye, shadowing
well, I do like that a single name has a single scope in a single block
it's even stronger than shadowing imo
it makes the global one completely inaccessible
but i guess it's to prevent errors
yeah, I wouldn't want the scope of a variable to change in the middle of the block
that's just weird
not sure what the least surprising thing would be
having full declarations like other languages
but then you have a declaration that only sets scope
the least surprising thing to me would be to allow everything but raise an easy warning like "assigning to already declared global variable.. don't say we didn't warn you"
C and javascript (mostly) get off easier because they have separate syntax for declaration and assignment I think
warnings are useless
they will just get ignored
unlike C, there is no lifetime, type, linkage
so a declaration is kind of pointless
another thing that could work well is using = for variable definition and := or some other operator for variable assignment
and javascript goes the way of 'undeclared assignment creates global' 😄
hmm
what if the type annotation part of the variable definition is also used for the scope?
like a: global int
a: global would work IG
that might be the least intrusive way of defining things, maybe a little repetitive if you have lots of global vars, but then you're really doing things wrong
and if we want to take another step into java-land, a: global final int 😄
actually just gave me another idea, how about an "immutable" flag, which enforces an immutable version of the type? like D: immutable dict that is not just "final" but also turns it into a frozendict of sorts
that could be useful
if a: int acted as a declaration for the interpreter, that would be neat. I know it does for type checkers
it doesn't declare anything.. but it also doesn't throw a NameError ..
it could be realized with an __immutable_alt__ on the type which returns itself on already immutable types and their alternative types that are immutable and hashable for mutable types
frozenset for sets, for example
(not sure about the naming there)
how can pyright work on python programs even being written in ts?
What's wrong with that?
PyCharm's type checker is written in Java
Static analysis tools analyze programs, they don't run them.
how can pyright inspect programs written in python?
It has its own parser, if that's what you're asking
the parser is probably the easiest part of the problem 🙂
same way that there's profilers written in rust for python, I guess
well then
how can cpython compile python while being written in C?
how can a rust written profiler work on python?
but wouldn't it be easiest if it was written in python?
I wonder how easily using LSP would be for this, I don't know anything beyond the bare minimum
at that point it's just a language comparison
"is x better to make a static analyzer in"
profilers ideally execute the code and analyze the behaviour while executing, so i'm guessing the rust thing either attaches to some existing interpreter like cpython or it's a python interpreter itself
static profiling is possible to some degree, but it's very limited, especially for dynamic languages
maybe it has some python code as well as rust code
they could call all the C API functions from rust, at least, afaik
unsafe 😮
Can I sign the PSF's CLA with my internet alias (Bluenix)?
What about the adress field, is "Sweden" enough or does it need to be accurate enough to reach my house?
this is like asking “wouldn’t it be easiest to eat pasta if the fork was made of dough?”
!otn a the fork is made of dough
:ok_hand: Added the-fork-is-made-of-dough to the names list.
Can I ask a not-related-to-the-language coding question? You wizards are the people to ask, and this is where you hang out
What is the "expected" behaviour of an argument parser — to raise an error when the parse can't be done (bad input), to return a "results" object containing into about the parse, or are both equally valid
I only ask here because when you ask questions like this in help channels, its not uncommon to be told "sir, this is a Wendy's"
if i type bad arguments to something, i don't want a results object, i just want a useful error message
See thats how I feel, but I'm putting a lot of thought these days into pinning down the right and wrong uses of try-catch. My teachers say that if you can catch something with an if-statement then it doesn't qualify as "exceptional" behaviour
try/catch isn't really for exceptional behavior in python specifically --- it's more idiomatic to use it for control flow -- but in any case, bad arguments should just raise an error, you don't really need to catch anything there
And in theory, raising an error because you checked and explicitly found bad data is redundant — except, the behaviour of the arg parser should be respective of whatever tool is using it. "I failed to do this operation, here's why" seems like the right approach to me
it's more idiomatic to use it for control flow
isn't this the opposite of what you're supposed to do? O.o
not in python
Now I'm super confused
python uses exceptions for control flow
The whole forgiveness-instead-of-permission thing
there are some obvious cases, like StopIteration, CancelledError
and some not so obvious cases
Hello all i'm now here .
i do went to learn python from zero any one recommend a youtube channal or full course . for bascis and oop and python data science labs.
try asking in #python-discussion , this is the wrong channel
At risk of disrespecting the purpose of the channel, I'll post some pseudocode representing what I'm working with and you guys and let me know what you think
while True:
try:
# parse a line of text, raising a FailedToParseError as needed, or
# a StopIteration is the program-termination command is detected
arguments = Parser.CreateArgsObject(input(">>> "))
# execute the command specified with arguments specified, raising
# a FailedToExecuteError as needed
do_command(arguments)
except FailedToExecuteError as exception:
print(f'invalid operation: {str(exception)}')
except FailedToParseError as exception:
print(f'invalid command: {str(exception)}')
except EndOfTime:
break
The purpose of this is to repeatedly consume lines of input (in theory, entered by hand, but the instructor will be testing this automatically) and use it to work on a simple data structure
The data structure, and the assignment, is kinda fun. We're supposed to accept commands in the form "[date] [location] [operation] [citizen]", where each command specifies either the "original" or "alternate" timeline, a birth or a death, a citizen, and a date. We're supposed to detect "timeline anomalies" — people whose death happens before their birth or who die in different universes as they are born
And, naturally, there are a handful of exceptions which can occur, like invalid number of arguments in the line, unrecognized universe, non-numeric date, etc
i don't think you need str(exception), the str is redundant
Anyway, I know this isn't the right place for a question like this, but I really want to do this "the right way" and you all are the only ones I can trust, really, to give me the right info
I think exceptions don't stringify automatically (which is weird) but I could be wrong
weird, it just shows the arguments:
In [1]: e = SystemExit("hi")
In [2]: e
Out[2]: SystemExit('hi')
In [3]: f"{e}"
Out[3]: 'hi'
In [4]: f"{e!r}"
Out[4]: "SystemExit('hi')"
That's nonsense. There are languages like C, without any exceptions - they handle everything with if and return codes. Your teachers' argument, taken to its logical extreme, is that there is no good use for exceptions, because you can do everything without them.
Moreover, as a signalling protocol and information carrier, exceptions are simply too useful to be relegated to uselessness by such a puritanical rule, in my opinion
There are languages like C++ where using exceptions for flow control is heavily discouraged, and languages like Python where its the idiomatic way to do flow control. Different languages have different conventions.
Well that's good to know. And it explains why I'm having so much trouble (I'm taking C++)
All this being said — looking at this main loop that makes my program run, any objections or comments? Any subtle insights I should consider?
raising StopIteration instead of EOFError seems weird
or some custom exit error, dunno, but StopIteration i usually associate with iterators
EOF might not capture the essence of what's happening quite right — when the input reads "END_OF_TIME" the program is supposed to stop. So its not actually an "end-of-input" but rather an explicit termination command. StopIteration just seemed to me to carry with it the appropriate context
But I can just as easily make my own exception class EndOfTime and do except EndOfTime: break
or just check a return value in that case, if you need to please some c++ gods
🙂
Well, assuming you guys have no quarrels with this approach I guess I'm at least moving in the right direction
In the future, when it comes time to actually writing the parser
Which channel would be best to ask in do you think?
#algos-and-data-structs maybe
Danke
Hello guys im developing a flask api and then i encountered a problem with swagger that it raise an error
validation error: {'operation': 10, 'operationTarget': [{'_id': 'e7e66327-3ab7-4213-db2d-57fzc1314dg9', 'attribute': {'birthdate': '1990-06-21', 'gender': 'male', 'phone_number': '1234-5678'}, 'user_name': 'john'}]} is not valid under any of the given schemas
wrong channel, try #web-development
In python 3, is there any case where type(obj) != obj.__class__?

ah, good lord. I tried that exact thing but did
class Foo:
pass
Foo.__class__ = 2
and it threw me an error
where is the best place to get help with selenium and python?
A help channel, see #❓|how-to-get-help
@unkempt rock thanks.
lovely ^^
So, given Foo(), how does type get Foo in this situation?
I assume that type() is able to use the pointer to a PyTypeObject that each PyObject has?
Yes. Single-argument type() calls Py_TYPE() which just returns ob->ob_type, see line 137–140 in https://github.com/python/cpython/blob/main/Include/object.h

GitHub
The Python programming language. Contribute to python/cpython development by creating an account on GitHub.
Objects/typeobject.c lines 1088 to 1099
/* Special case: type(x) should return Py_TYPE(x) */
/* We only want type itself to accept the one-argument form (#27157) */
if (type == &PyType_Type) {
assert(args != NULL && PyTuple_Check(args));
assert(kwds == NULL || PyDict_Check(kwds));
Py_ssize_t nargs = PyTuple_GET_SIZE(args);
if (nargs == 1 && (kwds == NULL || !PyDict_GET_SIZE(kwds))) {
obj = (PyObject *) Py_TYPE(PyTuple_GET_ITEM(args, 0));
Py_INCREF(obj);
return obj;
}```Include/object.h lines 136 to 140
// bpo-39573: The Py_SET_TYPE() function must be used to set an object type.
static inline PyTypeObject* _Py_TYPE(const PyObject *ob) {
return ob->ob_type;
}
#define Py_TYPE(ob) _Py_TYPE(_PyObject_CAST_CONST(ob))```Is throw exist in python as a keyword or built-in function?
@olive marsh throw doesn't exist, but raise is a keyword
💯% sure?
There is a module name keyword . But does it have checks for built-in as well?
generators have a throw method, dunno if theres anything beside that
do you mean checking for things like print, list, etc?
Thanks man. Can I make the conditional statements as generators?
could you show an example of what you mean?
lambda x : (x >20).throw(Exception)
ah, you want to raise an exception in an expression
Yes
yeah, you can use the generator throw method then
How?
!e
(()for()in()).throw(RuntimeError('Hello'))
@flat gazelle :x: Your eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 1, in <module>
003 | File "<string>", line 1, in <genexpr>
004 | RuntimeError: Hello
for this you can use the builtins module. so vars(builtins) and a bit of processing
Thanks
wow, first time i see code like this o.O
looks like #esoteric-python 😄
yeah, calling those methods on generator comprehensions is rarely useful
How can I make a conditional expression as generators?
direct further questions to #esoteric-python probably
lmao
one example of .throw in practice is the @contextmanager decorator
Really.
flow control both inside and outside the generator
e.g. you can tell the generator to go back to a specific state by catching the exception inside it
or say a fatal error occurs and you want to gracefully exhaust some generators, do some cleanup, etc
Oh right sorry I was a bit ambiguous, raising an error inside a generator has uses...
But what the fuck is this??
!e
well, a generator comprehension is a generator, so you can send things to it and throw it errors. The best practical example of using this is contextmanager
from contextlib import contextmanager
@contextmanager
def mgr():
try:
yield 'y'
except RuntimeError:
print('r')
finally:
print('f')
with mgr() as m:
print(m)
raise RuntimeError
@flat gazelle :white_check_mark: Your eval job has completed with return code 0.
001 | y
002 | r
003 | f
contextmanger uses .throw to give the function it decorates the error the context manager caught
I believe CancelledError was also handled like this in pre-async asyncio
pre-async asyncio
tf?
The reason is that effectively concurrency/async was first added as these methods, before it was realised that it's important to have it not reuse iteration.
asyncio was originally implemented atop generators
async def is basically a generator, but with a different protocol so they can't be interchanged. await is yield from.
huh
(yield x) is actually an expression, when you iterate a generator it returns None. But you can alternatively use gen.send(x) to make the result when yield unpauses be that parameter.
Meaning you can feed values into and out of generators.
throw makes the yield act like it raises that exception.
Now the fun bit is that yield from is much more complex than just using a for loop - what it does is ensures these send/throw/next calls are appropriately delegated down to the sub-generator.
The way the async libraries work, you as a user don't see the actual values getting yielded and sent back and forth. The library's primitives like sleeping, IO and network produce some internal value, which gets yielded back out straight through all your functions to the toplevel async loop. There it can mark the task as waiting for that, and do whatever OS thing to get notified when it's ready. At that point, it'd then send() back down the chain whatever result is needed.
lmao
Hey @coarse heath!
It looks like you tried to attach a Python file - please use a code-pasting service such as https://paste.pythondiscord.com
Hey @coarse heath!
It looks like you tried to attach a Python file - please use a code-pasting service such as https://paste.pythondiscord.com
can anyone help me with this
i experimented with pre-async generators and coroutines back then - while fascinating, it was a mess and i never found a good application for manually sending values in or throwing exceptions like that, so i forgot that most of those details still exist 😄

TECHCOMMUNITY.MICROSOFT.COM
There are many ways of running Python code. The most commonly used is CPython, the official Python interpreter. CPython is the command you get when you type python at the command line, the one you download from python.org. CPython is an interpreter. It compiles your Python code into an intermediar...
"The resulting performance is that Pyjion will execute both functions 90-95% faster, a 10-20x performance gain over Python 3.10."
the heck
a drop-in jit for python 3.10.. can't wait to drop < 3.10

that's more for #data-science-and-ml
ya I got it
are there constraints you have to annotate to help the jit or anything?
"Any Python code you define or import after enabling pyjion will be JIT compiled. You don't need to execute functions in any special API, it's completely transparent:"
it works as an import hook? well no, that wouldn't compile any function definition
maybe it looks at the already compiled code?
by 90-95% they mean the code runs about 1.9x performance of vanilla python, I guess
they mean it runs 20 times faster
only taking 5% of the time
only just a slight improvement 😉
I remember reading it a bit, and it uses the AST that Python compiles
Like Numba no?
it compiles to .NET il?
These variables are never referenced outside the function, therefore it optimizes these operations by compiling them directly into the assembly instructions to leverage native CPU instructions for adding, multiplying 64-bit integers and floating point numbers. This is accomplished by using .NET 6's cross-platform JIT compiler, "ryuJIT".
no, assembler
no clue, but at least this one file seems to be translating opcodes https://github.com/microsoft/Pyjion/blob/master/Pyjion/ilgen.h
GitHub
Pyjion - A JIT for Python based upon CoreCLR. Contribute to microsoft/Pyjion development by creating an account on GitHub.
not sure, numba was always a diva when i tried to work with it and required some special attention, only worked with decorators and numeric-only stuff
pyjion sounds more easy-going
ok, it might be using the CLR's JIT on python somehow that would produce machine code, and it would explain the translation to IL
but they say it's designed to be used with any jit, which is nice
Pyjion wants to introduce a proper C API for adding a JIT compiler to CPython instead of monkeypatching it
pretty cool
If they can guarantee compatibility with C extensions, I think they could have some adoption
That's bc it compiles the code to C.
afaik they basically plugged in a different bytecode interpreter in cpython, which apparently is designed to be pluggable/swappable/extensible
so I'm told it should have full c api compatibility
numba is oriented around handling "basic" data types and doing numeric operations, it's more of a "local hotspot" optimization tool in scientific programs, than a "make python http server go more fast" tool
the interesting comparisons for pyjion will be ironpython, jython, pypy, cinder, graalpython, and pyston
also to some extent cython, mypyc, and nuitka
there's quite an array of alternative python implementations out there actually
yeah, but there are differences in 1) what constructs (arbitrary objects?) they support 2) whether they support extensions 3) performance 4) ease of use
isnt it LLVM IR rather than C?
Yeah Numba is LLVM afaik - Melek may be thinking about Cython?
yes there probably will be differences in all of those. varying support for either the cpython c api, some other ffi, or hpy. not to mention support for various nonportable cpython things. so yeah some libraries that depend on such things might not work or might work inconsistently
for example graalpy has its own version of pip
!d os.environ
os.environ```
A [mapping](https://docs.python.org/3/glossary.html#term-mapping) object where keys and values are strings that represent the process environment. For example, `environ['HOME']` is the pathname of your home directory (on some platforms), and is equivalent to `getenv("HOME")` in C.
This mapping is captured the first time the [`os`](https://docs.python.org/3/library/os.html#module-os "os: Miscellaneous operating system interfaces.") module is imported, typically during Python startup as part of processing `site.py`. Changes to the environment made after this time are not reflected in `os.environ`, except for changes made by modifying `os.environ` directly.
This mapping may be used to modify the environment as well as query the environment. [`putenv()`](https://docs.python.org/3/library/os.html#os.putenv "os.putenv") will be called automatically when the mapping is modified.This mapping may be used to modify the environment as well as query the environment. putenv() will be called automatically when the mapping is modified.
why does it do this...
Why not?
If you don't want to modify it, just call dict(os.environ).
@halcyon swallow this is not the right channel for that, maybe try claiming a help channel? See #❓|how-to-get-help for how to do so
where is it
see #❓|how-to-get-help on how to claim one
ok thank you i will delete this here
Does pythons file.readline read a character one at a time until it finds a line separator and returns or does it implement a rudimentary buffer and read until line terminator?
i believe file io is buffered by default, so it reads from disk into a buffer and then scans the buffer one char at a time
Changed in version 3.4: In Python versions earlier than 3.4, this function could also be passed a text level, and would return the corresponding numeric value of the level. This undocumented behaviour was considered a mistake, and was removed in Python 3.4, but reinstated in 3.4.2 due to retain backward compatibility.
Hah
do i need to do pipenv install something if im i have already activated the env?
it has buffering as a parameter in open i believe
!doc open
open(file, mode='r', buffering=- 1, encoding=None, errors=None, newline=None, closefd=True, opener=None)```
Open *file* and return a corresponding [file object](https://docs.python.org/3/glossary.html#term-file-object). If the file cannot be opened, an [`OSError`](https://docs.python.org/3/library/exceptions.html#OSError "OSError") is raised. See [Reading and Writing Files](https://docs.python.org/3/tutorial/inputoutput.html#tut-files) for more examples of how to use this function.
*file* is a [path-like object](https://docs.python.org/3/glossary.html#term-path-like-object) giving the pathname (absolute or relative to the current working directory) of the file to be opened or an integer file descriptor of the file to be wrapped. (If a file descriptor is given, it is closed when the returned I/O object is closed unless *closefd* is set to `False`.)from help(open) ```
buffering is an optional integer used to set the buffering policy.
Pass 0 to switch buffering off (only allowed in binary mode), 1 to select
line buffering (only usable in text mode), and an integer > 1 to indicate
the size of a fixed-size chunk buffer. When no buffering argument is
given, the default buffering policy works as follows:
* Binary files are buffered in fixed-size chunks; the size of the buffer
is chosen using a heuristic trying to determine the underlying device's
"block size" and falling back on io.DEFAULT_BUFFER_SIZE.
On many systems, the buffer will typically be 4096 or 8192 bytes long.
* "Interactive" text files (files for which isatty() returns True)
use line buffering. Other text files use the policy described above
for binary files.```
BINARY_OP_ADAPTIVE doesn't show in my 3.11 tree. was it recently added?
I do see:
BINARY_ADD_ADAPTIVE BINARY_SUBSCR_ADAPTIVE

**PEP 3099 - Things that will Not Change in Python 3000**
Status
Final
Created
04-Apr-2006
Type
Process
Some ideas are just bad. While some thoughts on Python evolution are constructive, some go against the basic tenets of Python so egregiously that it would be like asking someone to run in a circle: it gets you nowhere, even for Python 3000, where extraordinary proposals are allowed.
oh, the irony
i promise not to go on another salt rock pattern matching rant
but

i love those!
but ever since i've applied patma to my buffet pattern, i must say that patma is damn cool for some things
all PEPs related to python3 are 3000 upwards
at least that was the idea
that's the explanation
Naming
Python 3000, Python 3.0 and Py3K are all names for the same thing. The project is called Python 3000, or abbreviated to Py3k.
The actual Python release will be referred to as Python 3.0, and that's what "python3.0 -V" will print; the actual file names will use the same naming convention we use for Python 2.x. I don't want to pick a new name for the executable or change the suffix for Python source files.
"It will also not use C++ or another language different from C as implementation language. Rather, there will be a gradual transmogrification of the codebase." <- uh.. yeah.. what?
"There will be no alternative binding operators such as :=. " <- roflcopter
"zip() won't grow keyword arguments or other mechanisms to prevent it from stopping at the end of the shortest sequence." <- wasn't that added in 3.10?
i'm actually surprised not even more points on that list were dismissed
strict zip is so good though
my own implementation was long and awful and i'm glad i don't have to look at it anymore
helps catch a lot of bugs
i wonder why that landed on the list even
i think a separate strict_zip function mightve been better. now it's just one more think that breaks compatibility.
i don't think it breaks compatibility does it? it's kw-only i think
i don't think so either
i mean if you have code with zip(..., strict=True) it wont run on 3.10 or below without version checks
3.9 or below*
yeah, but it doesn't break compatibility forwards
and it doesn't break existing code
well yeah, all new features do that. it's not surprising that you need a newer version to need new features
no need for the snark
new syntax mostly, a simple function name like that could even be backported
you know who was the first who voted against this feature?
my point isnt that im surprised a new version added new features. it just doesn't seem worth it to add this extra, if seemingly insignificant hoop to working with zip across multiple versions.
itertools couldve been a better place for this for example
you don't want to run python 3.10 code on a python 3.1 interpreter
this is a not very useful take from hettinger --- i think equal length sequences are the most common use
you either have old code you want to run on a new interpreter - which works fine with the kwarg - or you're doing something wrong and you need to avoid many useful syntactic features which would cause syntax errors on older interpreters
also checking equal "lengths" on iterators is a bit involved, so it's nice that it's included as an option
"How about we resist the urge to complicate the snot out of a basic
looping construct. Hypergeneralization is more of a sin than premature
optimization.
It is important that zip() be left as dirt simple as possible. In the
tutorial (section 5.6), we're able to use short, simple examples to
teach all of the fundamental looping techniques to total beginners in a
way that lets them save their brain power for learning exceptions,
classes, generators, packages, and whatnot.
Creative talent is being wasted here just to solve a non-problem.
Please keep Py3k on track for cruft removal. We're seeing way too much
discussion on random, screwball proposals rather that focusing on what
really matters: Keeping the tried and true while removing stuff we've
always wanted to take away.
Raymond"
wtf
we already have a itertools.zip_longest but how about we just go ahead and work that into zip itself too. let's just consolidate everything. great idea.
then there's the whole "our minor version is the major version number"
gentle reminder everyone - next month are SC elections (and rhettinger is applying for a seat) 🙂
what is SC? steering council?
yeah
strict zip and zip longest aren't really comparable. On success strict zip will return the same thing as a normal zip
to get the major version of python, just divide by 100
I think it's undeniable that in most cases you don't want it to silently stop at the smaller length, and the kwarg doesn't change the interface if you don't want to use it
it just seems a tad inconsistent to have one be in a separate module then consolidate the other into zip. not saying they're 1:1 comparable in terms of function and usefulness, that's not the only consideration here.
🟧
what does that mean? :p
i don't think it's inconsistent in that zip_longest is needed so rarely, but most of zip's use-cases are probably strict
it means orange square, just like it says
smh
🥴
If you know you know, if you don't you don't, if you know what I mean..
And if you don't know I honestly feel sorry for you...
https://youtu.be/o2rDP0OsGYA
I am referring to the new mod role ⭐

what do you all think of languages that have an explicit way to check if an iterator is exhausted
without trying to get the next element?
How does that work with generators or similar?
e.g. hasNext in Java/JS/Kotlin
btw, itertools.izip_longest was added by raymond later, https://mail.python.org/pipermail/python-3000/2006-August/003342.html as a response
he's really out of touch on this one
changing the output's behaviour that much depending on a kwarg that'd do longest in the builtin is also imo not a nice interface. e.g. iter that does 2 completely different things as a more extreme case
hm you'd need to change the semantics to run until a yield
okay sorry for derailing the zip discussion I'll come back another time
i'd find it more elegant than using an exception, tbh
Nah I like discussing generators :3
reverse=True says hello
strict isn't the same as longest either --- i don't think zip_longest is needed very often
it sounds like a poor basis for such a change to me. and poentially a slippery slope to justifying a lot of unsavoury additions to the language in service of what seems to be the most useful without regard for other aspect of language design.
Yeah, it could work for user-implemented iterables though. Some form of dunder-method I guess.
Raising exceptions are a pretty natural way to do signalling in Python.
i would prefer the most common use-case to be covered by builtins
well positionals beyond maybe 2 or varargs don't make a nice interface
what I'm thinking of is like
def f():
yield 1 # pre-change it would pause here
1 + 2
3 + 4 # post-change it would pause here
yield 2
yeah, i know, doesn't mean i have to like it 😉
but as it stands you cannot check if an iterator has a next element without consuming it
which is a side effect
Was working with C positional only callbacks recently and couldn't use partial because of that
like I'm fine with raising exceptions when done
the way rust does it is similar (next and hasNext combined), but gives you None when it's empty instead of an exception.
but not with having to possibly nom on the element at the end to know if there is one or not
i.e. some sort of peek
Yes.. I actually really dislike the fact that pos-only arguments have started to get uses (other than when you want to accept arbitrary **kwargs or when the name of the parameter is completely unnecessary).
What if I wanted to yield None?
Though I assume that None isn't used as often in Rust.
then that'd be Some(None)
as opposed to None
and yielding None would not be an interesting thing to do
in general
That's more or less the same thing as python if you use the 2 arg form of next
Oh right.. we've talked about this. That's odd in a way though
next() has a default?
we'd need to reiterate on sentinels for that
!e print(next(iter(()), None))
@flat gazelle :white_check_mark: Your eval job has completed with return code 0.
None
Ye, you can do sentinel based iteration, though it's a bad idea
yeah, you shouldn't need to do that ever (that I can think of)
I mean sure, but imagine if it wasn't allowed? That would seem super weird to me, None is used so predominantly, also seems like such an easy thing to get stuck on
if python had those from very early on, we might be using those instead of exceptions
I don't remember, will that get a C API?
yeah because Python is dynamically typed
Exactly
eh?
so it's a bit different, yes
Doubt it, python is pretty heavily dependent on exceptions from it's algol-like roots
Sentinels would work well enough as well, but it was clearly not a design goal, especially in a dynamically typed language
Erlang manages it, but that's quite a different idea from python
just look at the syntax for the most basic thing in numpy - https://numpy.org/doc/stable/reference/generated/numpy.array.html i use it all the time and i still don't know and don't care about 5 of those kwargs
how is that any different from zip?
sigh
how is numpy different from a builtin?
well, for some numpy practically is a builtin :p
i mean, i'm almost always using numpy, but i don't think np.array really has an easy comparison against zip
i mean, zip is as essential to some as np.array is to others and np.array is easy to use for all the simple cases, but also covers the more complex cases by hiding that complexity behind kwargs that you only really need to get into if you're looking for them
it's a good example for a good API, imo
unlike in the stdlib where tools for slightly more complex cases are hidden in itertools etc. instead of in the builtins, where you'd be looking first
unless it's something that provides the base interface or is just a wrapper too many kwargs is probably sign of it handling too much, but whether it's bad or not definitely depends on the context
the clean code guy would have an aneurysm
seeing how many arguments something like pd.read_csv takes
i just wonder whether it's possible to have a kind of modular signature
in justuse we have three basic cases: use(Path), use(str), use(URL) dispatched via singledispatch on __call__(..), all accepting slightly different kwargs as parameters
I think in a case like that I'd go with three different functions, but keeping it to one probably does make the interface a bit nicer for the usual use
you know what i mean with "modular signature" though?
basically conditional params
"if param 0 is str, param 1 must be int" etc
Well, typing does have @overload for that case, for runtime you'd need to just specify either all the keywords or **kwargs then manually check.
I don't see why you can't do that with singledispatch or write your own descriptor decorator that's parameterized
Make a descriptor, __init__ takes in the parameters and initializes. __call__ takes in the initial version, registers it, and other stuff, returns self. Then have a method like dispatch to register subsequent dispatch alternatives and then implement __get__ to do the actual dispatch look up
typing.overload?
we did a multiple dispatch before, https://github.com/salt-die/Snippets/blob/master/overload.py
i am afraid to click
@unkempt rock :white_check_mark: Your eval job has completed with return code 0.
001 | foo([{},None], 1)='{}, None'
002 | foo(['abc', 'def'], 'N')='ABC, DEF'
003 | foo([3, 8, 4], 0)=0
on a related note, does anyone find odd the semantics of typing._GenericAlias
list[int].__class__ is list.__class__```!e
print(f"{list[int].__class__ is list.__class__=}")
print(f"{issubclass(list, list)=}")
print(f"{issubclass(list, list[int])=}")
@lusty scroll :x: Your eval job has completed with return code 1.
001 | list[int].__class__ is list.__class__=True
002 | issubclass(list, list)=True
003 | Traceback (most recent call last):
004 | File "<string>", line 3, in <module>
005 | TypeError: issubclass() argument 2 cannot be a parameterized generic
oh I wouldn't say that's bad.. I might even be using it in a project or two..
you mean like an empty value for an unspecified config setting?
hmmmm
nah, raise a configuration error that tells the user "you forgot this required value lol bye"
ohh haha, for like validation
yeah
darn AttributeError: 'collections.defaultdict' object attribute '__missing__' is read-only
was trying to see if I could get the current key of the defaultdict
basically trying to make the error more friendly
it might segfault, but at least you'll have written it
@pliant harness this is a discussion channel for advanced aspects in python - it isn't a help channel. See #❓|how-to-get-help for python help
you should consider attrs for that. having a class with types and defaults is pure gold
the only problem with that approach is that bool doesn't naturally extend
you'll probably need ast.literal_eval for that
>>> list[int].__class__
<class 'type'>
>>> list.__class__
<class 'type'>
hello
When writing a package internally, I find sphinx to be very helpful in producing quality documentation. The question from there is how does everyone "publish" this documentation? Copying out to s3 and making it a static website works great except for trying to index all of the different documentation that is available. How does everyone else solve the problems of making it navigable and discoverable?
hello
quite a good question
discoverable in the sense of "finding the documentation'?
Yeah. Finding the documentation, or maybe even browsing what is available.
a lot of python projects use readthedocs for hosting. it has a built-in search tool
Readthedocs is fantastic for public packages, but what about for internal only ones?
oh, i see
i've used github pages but yeah there's no search
is readthedocs self-hostable?
its not, no
https://github.com/readthedocs/readthedocs.org well this exists
GitHub
The source code that powers readthedocs.org. Contribute to readthedocs/readthedocs.org development by creating an account on GitHub.
Awesome. Under the hood its django? That seems easy enough!
yeah seems like django + sphinx
If python has GIL which completely prevents from 2 threads running concurrently, what's the actual usecase of locks, why is threading.Lock even necessary in python?
The GIL prevents two threads from running actual Python code at exactly the same time. It means that computation will be interleaved.
For example, if you have something like this: ```py
def increment_counter():
global counter
old_counter = counter
logging.debug("Incrementing the counter from %s to %s...", old_counter, old_counter + 1)
counter = old_counter + 1
1. Thread 1 read `41` from `counter` into `old_counter`
2. While Thread 1 is writing to the log, execution is switched to Thread 2.
3. Thread 2 reads `41` from `counter` into `old_counter`.
4. Thread 2 writes tot the log, and execution is switched to Thread 1
5. Thread 1 writes `42` to `counter`
6. Execution switches to Thread 2
7. Thread 2 writes `43` to counter
So as you can see, it wasn't actually incremented twice.This is also why asyncio.Lock and friends exist even though asyncio does everything in a single thread.
The GIL forces Python bytecode instructions to be serialized. Locks enforce a particular order on that serialization.
...so this is how you'd fix it:
_lock = threading.Lock()
def increment_counter():
global counter
with _lock:
old_counter = counter
logging.debug("Incrementing the counter from %s to %s...", old_counter, old_counter + 1)
counter = old_counter + 1
the GIL prevents parallelism, but it does not prevent concurrency
yeah
you nead threading.Lock for the same reason as why you need mutexes/locks in any programming language, even if you are only planning to run the program on a single core
That's a great analogy.
but, if 2 threads can't run at the same time, how would this happen? You said that:
The GIL prevents two threads from running actual Python code at exactly the same time.
but then you shown an example saying that:
and two threads run this at the same time, you might end up in this situation:
how can two threads run that sequence at the same time if there is GIL, I have seen this example but since GIL is there, wouldn't the switch to another thread only happen after the instruction is fully done, i.e. after writing back to the counter variable?
@atomic egret I think you're confusing "instruction" with "function call"
ooh, I get it now, but now I'm interested in what determines when the switch to another thread happens? When is the lock passed over to another thread?
@atomic egret Python can switch to another thread at any moment.
What with _lock does is roughly:
lock.acquire()
try:
# body
finally:
lock.release()
There is a switch interval over which threads will be forced to yield after they can, but you should work with the assumption that the switch can happen between any instruction or when the gil is released
Threads being able to switch at any point is also why they're such a pain and async is a better alternative where it can be used
Specifically, between any two bytecode instructions, or within C code that explicitly drops the GIL.
once you are running C code without the GIL you can also have actual parallelism, of course
ok so
i have this documentation i tried everything writing it but can anyobody write me it together pls https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/get-started-text-to-speech?tabs=script%2Cwindowsinstall&pivots=programming-language-python
Learn how to use the Speech SDK to convert text-to-speech. In this quickstart, you learn about object construction and design patterns, supported audio output formats, the Speech CLI, and custom configuration options for speech synthesis.
how difficult would it be to write a c++ parser to extract struct, enum, and union definitions? unless, such a tool has already been created
asking this here because i wanna do this in python
you can use libclang for stuff like this
i think it even has python bindings
though it's not that easy to find out about
no matter, just point me in the right direction
thanks
this blog post is 10 years old so obviously almost all the details will no longer work
hmmm, yeah
but hopefully the direction is right 🙂

PyPI
Clang Python Bindings, mirrored from the official LLVM repo: https://github.com/llvm/llvm-project/tree/main/clang/bindings/python, to make the installation process easier.
Stack Overflow
After some research and a few questions, I ended up exploring libclang library in order to parse C++ source files in Python.
Given a C++ source
int fac(int n) {
return (n>1) ? n∗fac(n−1) ...
etc
like I said, there isn't a lot of super clear step by step documentation in this area for whatever reason, but there is a lot of functionality available if you are willing to get into it
even if learning this seems painful it's still waaaaaaaaaaay easier than writing a parser from scratch
thanks for the links lol. if i'm successful with this, i'll post a link to my tool in #python-discussion perhaps. my goal isn't to create a full blown parser, just a tool that extracts the essence of structures and enums so that it's easier for me to port some stuff from c/c++ into another language
yeah, it's just that C++ is really really crazy to parse
btw, if you are writing the tool primarily so that you can use it
as opposed to, for the sake of the tool itself
then again, rather than use it yourself I'd probably just learn to use pybind11, that library is very powerful when it comes to automatically exposing C++ classes/functions
**PEP 646 - Variadic Generics**
Status
Draft
Python-Version
3.10
Created
16-Sep-2020
Type
Standards Track
oh no way, does this mean we can finally type __iter__?
that feeling when you realise an entire feature has a fatal flaw.....
Well you're in the right place to vent about it, what's up?
entirely irreproducible testing environment which relies a bit too heavily on what files and config the user has in their directory
solution is to monkeypatch my own config, I guess...
...
this should really be in esoteric python....
During testing, I'm going to reassign the file attribute of one of my modules temporarily while some of the code is loaded
that should redirect the whole folder and improve it further...
should the main.py's purpose just to run files?
!e
Nice trick: infinitely indexable dict
from collections import defaultdict
def ydict():
return defaultdict(ydict)
y = ydict()
y['abc'][3][(1, 4)] = 111
print(y)
@grave jolt :white_check_mark: Your eval job has completed with return code 0.
defaultdict(<function ydict at 0x7f07ae513d90>, {'abc': defaultdict(<function ydict at 0x7f07ae513d90>, {3: defaultdict(<function ydict at 0x7f07ae513d90>, {(1, 4): 111})})})
Hol' up
budget version of the dotdict for json
I needed this before for something
!pypi attrdict
A dict with attribute-style access
a neat thing to have
guys, i have a little question to you/ its about python sorting. Are there any fast build-ins methods to make a limited sort. I need to sort a BIG data, its a list of hash-tables(dicts) so, i have to sort it and i need in only first 20 positions. I don't need to sort all the list to get only 20 items. Do you know how to make a sort of current count of elements, like [].sort('param', limit=20)
can you help me?
i need in some build-ins or close-to-build-ins method
You can slice the first 20 items, sort them and copy them back into the list I guess
no you havent got me
i have a big array
list
of dicts
i have to sort is by a parameter
Use key?
you could use heapq.nlargest
i ll take a look
But you can't grab the top 10 items before everything is sorted?
you don't have to sort everything
to get the top 10 items
heapq.nlargest seems like your best bet; off the top of my head I'm not totally sure it's the same complexity as QuickSelect but it probably is
hm, probably not actually?
its O(n) to build the heap and k*log(n) to get the top k elements
feel like quickselect is faster, but I need to actually tthink about it
i think quickselect may just be log N
actually no, sorry, it's N
How does that work?
I guess for bubble sort you can get a top 10 quickly?
But like merge sort wouldn't be able to do that
Up until the last merging it's still unknown
Sorting algos have to sort. They're suggesting using priority queues to make fetching top items more efficient
you can create a heap (a tree-like structure where the parent node is always less than its two children) from a list in linear time
due to this invariant of heaps, the root of the tree is always the smallest element. popping this minimum and restoring the invariant takes log(n) time
so extracting the top k elements takes k*log(n) time
heap sort is essentially extracting the top n elements from the heap, so it takes n log n time, which is the same complexity as mergesort and the rest and the theoretically best possible complexity for comparison based sorts
Ah, so it does this first step and then doesn't care about the other side. I see
https://sv.m.wikipedia.org/wiki/Fil:Sorting_quicksort_anim.gif

{kind=link}
{kind=link}
Ah, huh. I see. Why not just merge sort and pick the first few items?
Because that's N log N
that would be n log n complexity
hsp and I have described two different approaches both with linear complexity more or less
But you finish by saying "so it takes n log n time"?
Although hsp s approach isn't so good if you wanted e.g. the top N/10 items or something like that
that's for heap sort
getting the first k is heap sort stopped early
Ooh, right.
so it takes n + k log n, which is just n depending on k
k is always <= to n, so it's just n
for k = n, n + n log n would be n log n
close enough
ok fair, at that point actually sorting might be faster
well, that is a sort 🙂
heapsort
at least heapsort does give you some kind of speedup if you only want to partially sort (i.e. give me the top/bottom K values, sorted). But of course, quicksort does too.
is this a bug?

no, i redefined dir, nvm sorry uh, this is more like #simple-mistakes
some mods around to have a look at #python-discussion ?
(no clue how to get their attention)
how?
!ping mod?
You are not allowed to use that command here. Please use the #bot-commands channel instead.
@Moderators
What's the purpose of async for? isn't it just regular for that awaits it's iterable argument?
async def foo() -> Iterator[Any]:
for x in range(5):
yield x
async for x in foo():
print(x)
# isn't that just the same as:
for x in await foo():
print(x)
I am also interested in this topic
tl;dr is await foo() would only await getting the iterable, async for would await each item to be furnished from the iterable
It would be somewhat equivalent to: ```python
for coro in foo().aiter():
x = await coro
It also translates to another magic method: `__aiter__` and `__anext__` (not `__iter__` and `__next__`)is there a good place to read about python async? it hasnt really come up for me before
and/or await tbh
oh, that makes a lot of sense now, thanks!
See the pins in #async-and-concurrency really, maybe read the PEPs otherwise. They are usually designed to be very informative even to someone who isn't very knowledgeable on the topic (although it does require a knowledge in Python and programming in general).
thank you. maybe I'll have to take a stab at reading PEPs again, I formed the opinion that they were tedious/not useful but I was also much earlier in my learning then.
oh I didn't realize the topic channels had such rich pins. nice.
@radiant scroll @elder blade More like: ```py
aiter = foo().aiter()
while True:
try:
x = await aiter.anext()
...
except AsyncStopIteration:
break
However, you can transform between the two (`AsyncIterator[T]` and `Iterator[Awaitable[T]]`) in a generic way. I leave this as an exercise to the reader 🙂Ah right, since Python will try to call __next__() (I guess I was thinking that Python would call __anext__() but not await it.. hence the await coro).
Some are, some aren't. They're written by different people with different audiences in mind.
So some are focused entirely on very low level details that most people don't need to concern themselves, and some are focused on explaining a new feature and why it's useful.
hmm
any heuristics you use to find peps that you want toread

I still don't understand PEP 420
I don't get what it's for
I mostly just read the ones that someone links in this channel because they want to discuss it, or ones that introduce a feature to figure out what the motivations and design constraints were for that feature.
just read the pep index, click through stuff ^^
You don't understand what namespace packages are for, or you don't understand why implicit namespace packages are better than the old explicit namespace packages?
yes
not sure if "better" is the right word
namespace packages are a way of grouping related packages together.
somecompany.team1.package_a
somecompany.team1.package_b
somecompany.team2.package_c
or whatever. Imagine those are 3 separate PyPI packages, but they're all imported from the "somecompany" namespace, and 2 of them are imported from the "somecompany.team1" namespace. The special magic of namespace packages is that they're not required to be located in just one directory on disk: if you install somecompany.team1.package_a into /usr/local/lib/python3.10/site-packages and somecompany.team1.package_b into /home/fix/.local/lib/python3.10/site-packages, both will be able to be found and loaded.
That's really confusing to be honest... Why would this be used? Is it used anywhere in some open-source project?
What's the confusing part?
every company that has internal libraries wants to put them under a common namespace, so that they don't need to worry about picking a name for an internal library that conflicts with a name for a library on pypi.org
hm, somewhat makes sense
namespace packages are definitely more of an "enterprise" feature than anything else, though I'm sure some stuff on pypi uses them.
so what's the point of implicit namespace packages?
i think its the same motivation behind why you have folders with folders with folders, so you can impose some sort of semantic organization. the structure of the name starts giving information.
But you could do that before
it's always been weird-package-without-__init__ for me
before PEP 420, the way of doing namespace packages was to make a weird package with a magic __init__ - the __init__.py for a namespace package would need to contain the convoluted command:
__path__ = __import__("pkgutil").extend_path(__path__, __name__)
so what does this have to do with normal packages without __init__? Like, without this enterprise stuff
there's no such thing as a normal package with __init__.py
if a package doesn't have an __init__.py it's a namespace package.
a package with an __init__.py is a regular Python package. It exists in a single physical directory on disk, and has an __init__.py that specifies what is available when you import that package. For instance, there's a logging/__init__.py in the Python standard library, and the contents of that __init__.py are what is available to you if you import logging.
a package without an __init__.py is a namespace package. It can exist in multiple directories on sys.path simultaneously, and the contents available to be imported from that package are the files and subdirectories found while traversing all of the directories on sys.path that contain a directory for that package
so, you can have two foo directories, with no init.py
the first foo directory has bar as a sub-directory, and bar has an init.py
the second foo has baz as a sub-directory, and baz has init.py
and if both foos are somewhere on the path
then I can write import foo
and then foo.bar.whatever, and foo.baz.whatever?
no, importing the namespace doesn't automatically import everything under it
but you can do:
import foo.bar
import foo.baz
and if you do that, then bar and baz would be available as attributes of foo if you later did an import foo
hey guys which platform is better for postgraduation program in data science? upgrad , jigsaw or, great learning?
Oh, so if I have one foo directory in workdir and one foo directory in site-packages, they get concatenated or something?
for namespace packages, yep.
ooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooh
why doesn't the PEP start with that?
it does 😄
I guess it does, but I'm stupid so I didn't understand it
literally the first sentence is:
Namespace packages are a mechanism for splitting a single Python package across multiple directories on disk.
