#internals-and-peps
1 messages · Page 80 of 1
In any event, I'm not trying to sell anyone on notebooks right now, since that's a pretty big workflow change for someone who is happy without them. If you ever run the Python repl interactively, though, try IPython. You're likely to find it strictly nicer to work with. Same basic workflow, with lots of minor quality of life improvements, and some neat tricks.
Writing a script/module should be the "final product", notebooks for example used to compare things related to each other in some way
Tbh I do all my data work in R. ggplot >>>>>> anything in python. but now we are seriously off-topic
I use IPython more than notebooks but yeah, I believe that notebooks have their uses also
as far as data visualization goes, this guy seems to be the guy to listen to, heres a talk I found very interesting https://www.youtube.com/watch?v=vTingdk_pVM

"Speaker: Jake VanderPlas
The Python world has a staggering array of data visualization tools, and choosing which to use can seem like a daunting task. But which tool you use is far less important than how you use it. In this talk I’ll walk through some of the important consi...
that talk in particular takes its time to ramp up, but man that payoff
Not the right channel, @unkempt rock . See #❓|how-to-get-help . Also, last python version is 3.9.
Notebooks are an excellent feature that made data analysis way faster on a project I was working on in the past week
Especially pandas
notebooks are a super cool tool for some tasks, but they make it too easy to write bad code
too often you across something that only works when the cells are executed in a specific order, or doesnt work at all, because the author had some name still in memory that is no longer being declared (or worse is being redeclared somewhere when executed top to bottom)
it's a nightmare to debug
that is true. I wasn't doing anything "big" with it
imports, data loading, data transformation, output
notebooks are a super cool tool for some tasks, but they make it too easy to write bad code
@sacred tinsel a recurring problem I've had while doing help sessions is that people not familiar with programming will use a notebook and not understand why their code doesn't do what they think it does. And then it's a nightmare to help people debug notebooks if you don't know they're using a notebook.
it should work!
yea, I usually urge others to break their notebooks into functions and move them to .py modules
it's super convenient to be able to hold big data in memory as you're writing the code, but large notebooks become impossible to maintain
it doesn't help that I often think of the code that goes into a notebook as "throwaway" and take shortcuts sometimes
I've used a system where I write a regular program and then do python -i
and then I can mess with the data
oh yes, although I prefer typing code into the notebook over a terminal
that's a neat trick though, I could probably make more use of it
the use case was I logged all the data a program I wrote was spitting out, and then used eval to reconstruct all the data into a list, and then did sql-like queries to see what was in it
you can also use ipdb and just put breakpoint() where you want to run an interactive debugger
I've used a system where I write a regular program and then do
python -i
@boreal umbra for this use case, tryipython -i. Same workflow, but it really is a nicer repl
hmm will do @raven ridge
Is there a way, when writing python code, to ensure that a nop bytecode is placed in the .pyc file when compiled? Or is a breakpoint included in the .pyc file and if so, how do I insert one?
Implementation is CPython 3.7.8
CPython is always compiled to bytecode before running
are you trying to manipulate the pyc?
when you do breakpoint(), you're just getting a global variable called breakpoint and calling it
But there are ways to not launch the debugger in production.
Anyway, this is not the right channel. You can open a help channel in #❓|how-to-get-help
ok thanks guys
guys I'd like I've always wanted to learn a bit more about multithreading/multiprocessing, anyone give me some advice on what would be a good way to go about it? The "final" goal is to have good understanding how python/CPython does these things internally, and a bit about how it interacts with the OS to do it.
I could do some sort of general course concerning these topics (I guess that would have to be some sort of general C/C++ course mostly happening at OS level), but it would be cool if I could also play around with stuff using python, and learn by doing.
Then again, I'm not at all experienced at all in python when it comes to lower level stuff, and so it might be best to just start with getting more knowledge concerning that sort of stuff (interpreter/bytecode).
@trail warren I recommend Raymond Hettinger's talk on concurrency in Python as a good first primer https://www.youtube.com/watch?v=9zinZmE3Ogk

Keynote for https://pybay.com, 2nd annual Regional Python Conference in SF.
Slides: http://pybay.com/site_media/slides/raymond2017-keynote/index.html
It's a nice broad overview of concurrency options available, pros and cons, and a baseline understanding that should help choose where to go from there
looks great, thanks!
@trail warren going forward, #async-and-concurrency is the best place to discuss that. That channel isn't limited to just asyncio.
cool, thanks.
@sacred tinsel the cell ordering things (re nb's) has a pretty easy fix though - just restart the notebook and run the cells from top to bottom.
!unshh
✅ unsilenced current channel.
"first" 😄
Man people at work treat notebooks like their modules
It's terrible
Especially with papermill bc they'll submit them to the cluster to run and crap
It's like way too much stuff going on in them
Man people at work treat notebooks like their modules
@swift imp I think that largely happens with people who aren't software engineers first
there was a DS @ my old company who was like that
it was pretty demonic
Technically speaking I'm an EE
okay, that was not clear
I just have a fetish for doing things lazily which promotes good programming lol
I mean, who don't approach problems with the "this is software" mindset
...not sure if that makes any more sense
like that dude was a statistician first and foremost
so he thought of code purely as a way to replace the tools he used to use
I need a novelty voice TTS engine with python..
but the only good engine I see is pyttsx3
and microsoft bob is most definitly not a novelty voice...
Im specifically trying to approximate glados
from portal
I found this: https://github.com/EtiennePerot/gladosvoicegen

GitHub
GLaDOS voice generator - Windows/Melodyne GUI automation code - EtiennePerot/gladosvoicegen
but it looks terrible... and is 6 years old
and requires melodyne which wont work on my linux server
next I found this

GitHub
Portal GLaDOS voice generator. A TensorFlow implementation of Google's Tacotron speech synthesis with pre-trained model (unofficial) - kairess/tacotron
but that takes a 130 GB dataset
so... yea thats out
@unkempt rock this is a language discussion channel. you might want to try #data-science-and-ml or #❓|how-to-get-help.
oh ok
Hey I am getting error while using python audiobook package
FileNotFoundError: [Errno 2] No such file or directory: 'sample.pdf'
@void thorn Not the channel for that, claim a help channel #❓|how-to-get-help
i have to make a program on steganograhpy as a project
numpy is good for that
are you embedding into images? audio? video? any compression?
is it possible to add a property when creating a class using type()?
you can use the property 3 argument constructor
Is there a way to make a python app or game to .apk plz help
Kivy may be what you are looking for https://kivy.org/doc/stable/guide/packaging-android.html
Ok ty
Although this isn't really the channel, sorry didn't realise where we were
You should look in #❓|how-to-get-help in the future
Ok ty again sir
Hello do you know anyone who does c++ programming?
@lavish sparrow This is a Python server. If you want help with C++, ask in an off-topic channel or see another server, like https://discord.gg/gn6HH9
or just laziness?
if it is they should just step it up and make it mitchell baker's face
(or naive misunderstanding about how groups get attached to their imagery)
@spark magnet They modified the Rust logo with a thematically consistent "C & C++".
I think that took effort.
i mean my guess is that the rust cinematic universe has a lot of overlap with C/Cpp
sure, i meant laziness of imagination
wouldnt surprise me if the discords were made by the same folks
c
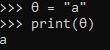
can i use θ as a variable in python? https://i.imgur.com/ZBf9bo5.png it looks like i can
any issues that can arise
people yelling at you
Yes, in Python 3.
You can if you want, especially if it is some mathematical or physical convention
but people will yell at you
I have a massive amount of respect if you are determined enough to manually set all of the symbols instead of just using their names 🤣
In Julia you can type \pi in the repl, and it will insert the pi letter, for example. Maybe you can create something like this for your editor.
but theta is fine
https://i.imgur.com/tkqov9E.png https://i.imgur.com/dlLyTda.png what looks better


{kind=link}
{kind=link}
{kind=link}
it's weird that it's a container
The one you can type on a normal keyboard; just stick to basic ascii for var names (or whole source) unless there's some special case or an another language for the devs
Feels like it would be a bit of a hassle if you ever wanted to view the code via a terminal without proper encoding configuration.
wait, what are you storing in theta, if not an angle
i c
oh, ok
anybody good with making .py to .exe? bc i get an error
Hey, I saw this discord has a bot that evaluates arbitrary python code, to my knowledge this is insecure and vulnerable to exploits, I imagine this is fixed in some way for the bot. Could anyone tell me how this is done, or point me in the right direction? Thanks!
@sick sedge you might want to give https://pypi.org/project/auto-py-to-exe/ a shot

@granite current This is done in a safe sandbox using nsjail: https://github.com/python-discord/snekbox.
anybody good with making .py to .exe? bc i get an error
@sick sedge try TechWithTim's pyinstaller tutorial on youtube
@sick sedge This is not a help channel. See #❓|how-to-get-help to get help.
@grave jolt I wasnt aware of this project, thanks!
yeah, it's definitely not a naked eval
@granite current The central tool is nsjail. It can be a bit tricky to configure, but it's worth it.
Sadly I'd need it to work on windows, still interesting to read up on though
@granite current these things always rely on the OS to provide the isolation
I built one for Ubuntu that used AppArmor
Could possibly for windows make use of hyper v and a VM to isolate it some what but I'm definately not going to gatentee how secure it is
Yeah I'm broadly aware of these tools, mainly for use with docker, but I'm really looking for a good windows solution, with a vm sadly not being an option @spark magnet
@radiant fulcrum It'd be for use in a game, so I can't really virtualise
Hmm probably a bit of a yikes
You want to run user Python code in a game?
yeah it is my best option right now is pypy
I highly doubt docker is secure enough even if you lock it down fully
PyPy isn't anything similar
It's a python jit
it has some kind of sandbox, but idk how good it is
no I wouldnt use docker for this i meant ive used apparmor in docker to shore it up for something unrelated
@radiant fulcrum pypy still runs python code i dont really care how too much
I know docker can (on Windows) lock everything down right down to ipc
@grave jolt it's not very finished i would have to do a lot of work myself
@granite current PyPy by itself provides no isolation. it has a sandbox features sort of, but you have to use it.
@spark magnet yes I'm aware their current implementation would be too slow anyway
Does it need to be this secure if this is (I assume) running on your pc as more of a test bench?
@granite current too slow? PyPy is often faster
@spark magnet Sorry, I was referring to how the sandboxing is done, ultimately all code has to be stringified at some point to be passed into the sandbox
That's the same for pretty much everything
@radiant fulcrum could you give me an example
Maybe I'm looking at this wrong then
Example of what
@radiant fulcrum I assumed you replied to me saying that code would have to be stringified to be sandboxed? if so could you give me an example of that outside of pypy sandboxing?
Any code that you would send to a sandbox would end up being stringified because they're ultimately ran in a seperate process that's isolated and that process needs to have the code to be executed
If you're aim is to have it essentially execute the code in isolation in the same process I don't think that's possible regardless of the system without isolating the entire process to begin with
@radiant fulcrum Yeah you are correct on that that is my aim, usually lua is used for this purpose because its relatively easy to implement this
Alot easier todo with a language designed to be sandboxed
exactly
Python was never really made with sandboxing in mind so you will 3nd up spawning seperate processes todo zo
You are probably right, that's my impression too, I just saw the bot and I was curious if it maybe used something clever that could be of use to me, sadly thats not the case
thanks everyone anyway!
docker/k8s is negative security benefit, the benefits there are all from a convenience/deployment speed standpoint.
another little puzzle: Explain why the first two work and the last doesnt
!warn @unkempt rock Advertisement is not allowed on this server. Keep the channels on topic.
:incoming_envelope: :ok_hand: applied warning to @unkempt rock.
@smoky turret (a) is the same as a, not (a,) 😛
a much faster response than my last puzzle
!e
print([[[[[42]]]]])
print((((((42))))))
@grave jolt :white_check_mark: Your eval job has completed with return code 0.
001 | [[[[[42]]]]]
002 | 42
though my last one was much more interesting
!e
(((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((
(((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((
(((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((
(((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((
42
)))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))
)))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))
)))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))
)))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))
@grave jolt :x: Your eval job has completed with return code 1.
001 | s_push: parser stack overflow
002 | MemoryError
how fun
interesting that CPython crashes on that and PyPy doesn't
true
the question is why is it true
False == 0 and 0 in [False]
nice 🙂
ooh those are from the wtfpython repo right?
?

GitHub
What the f*ck Python? Contribute to satwikkansal/wtfpython development by creating an account on GitHub.
oh, cool project. I got them from twitter, perhaps they originated from there
I'm processing a bunch of data, and wanted to group my data based off "zones". for example, if our "margin = 0.3" i would put it into the zone 0-1, if 'margin=1.5', put it into zone 1-2. I'd like to have some hash table, so that when i say zone['0-1'], it will give me all the IDS of the objects that i appended to that zone.... anyone have any ideas how to do this without doing a bunch of if/else statements?
ideally would just like to collections.Counter() all my results
Can you write a conversion from margin to zone?
@crystal pebble not really sure what u mean by that
kind of wanted:
dict['0-1'] = ['over', 'under', 'under']
but the key inputted will be based off the margin's value
so if the margin=0.3, it would go into dict['0-1'] key
I could do this with a bunch of if/else statements, but when u have 20-30 different keys it will get messy
Well, ignoring that for a second... a simple but maybe not great way to do it is to set up an object of some sort. Something like,
[('0-1', range(0, 0.3)), ('1-2', range(0.3, 1))] and then search through it until you find a hit
Your predicate would be that whatever number you want is in the range
What I was talking about before was converting things. Think F to C or vice versa
Hmm... how big are your decimals? You can just multiply them by some large number to get rid of them
(I have no idea what does and doesn't work in your case, just throwing out ideas)
q = [('A', lambda n: 0 <= n < 0.3), ('B', lambda n: 0.3 <= n < 1)]
list(filter(lambda m: m[1](0.4), q))[0][0]
>>> 'B'```It's not clean though
NP. Good luck
@bleak lantern be sure to stick to the channel description in this channel especially. This isn't a help channel.
Oops, sorry. I lost track of what room I was in
def do_list_stuff():
list_thing: List[Tuple[str, int, float]]
list_thing = <some list comp>
is this sort of syntax supported by any/all linters?
Yes. I'll take a pic, one sec
the first line that mentions list_thing doesn't actually assign anything to it but I've had a few cases where I've wanted to specify the type in advance
though I wouldn't want that to be the default pattern for using types because then we're tricking people into thinking that you have to declare variables.
the white block on line 5. Is that a type warning?
That's the warning for line 5
(Hard to take a good screenshot since my name shows up and I don't have paint or anything installed)
it looks like it's not really supported by this particular linter, then
It may be my configuration. I get the following when I don't have the function there
You are not allowed to use that command here. Please use the #bot-commands channel instead.
@kind karma this is a discussion channel. You're welcome to join the conversation but please don't interrupt.
neovim?
Yeah, with Ale, Pyflakes, and maybe one more thing
looks pretty good
I'm pretty certain you can get it to type check like you want in functions as well, I just don't have it set up properly
I also had a case recently where I was using type annotations for a class I was defining
let me see
class MeasuresDict(UserDict, t.Mapping[str, Measures]):
...
That definitely works
I feel like it should have -> notation
That's for the return type only, IIRC
yeah, but class is not def, so I don't think it should be required that -> means exactly the same thing
I don't know what t.Mapping[str, Measures].__init_subclass__ does but I feel like we're not making a subclass of that in any meaningful way
but maybe we are
The typehint does get put into local __annotations__ si I don't see why an up to date linter wouldn't understand it
@peak spoke are you talking about when the type hint is in the class constructor (or whatever ClassName(...) is called), or if the proposed ClassName(...) -> TypeHint[...] were it?
Was a bit scrolled up, for the previous convo with the typehinted name before it was assigned a value
ah yes
The typehint does get put into local
__annotations__si I don't see why an up to date linter wouldn't understand it
@peak spoke No linters knows anything about the__annotations__. It is a runtime attribute inserted by the interpreter, linters does static analysis so they either have to support the PEP 484/526 etc. or just ignore them.
is this sort of syntax supported by any/all linters?
@boreal umbra all type checkers whom implement PEP 526 (https://www.python.org/dev/peps/pep-0526/#id7) supports this (which I believe all of them)
Python.org
The official home of the Python Programming Language
The general purpose linters usually just ignores the type hints (like pycodestyle / pyflakes)
They don't know about the attribute, but when it's a thing that's properly constructed and may be used around python with the pep being accepted then I don't see why they'd ignore the hint
The ignoring is done for keeping tools boundaries in a single scope.
For example, these guys are the dynamic typing tools (not linters / type checkers) that uses the powers of the __annotations__ https://github.com/ethanhs/python-typecheckers#dynamicruntime

GitHub
A list of Python type checkers (PEP 484 compliant and not, static and runtime/dynamic) - ethanhs/python-typecheckers
Does anyone know the reason why these are different types?```py
dict.setitem
<slot wrapper 'setitem' of 'dict' objects>
dict.getitem
<method 'getitem' of 'dict' objects>
@pliant tusk huh that's a good question
No, that's really interesting. I'd bet that it has to do with c implimentation efficiency, but I have no idea what.
im looking at the c implementation, and the getitem method is put in the slot as well
I thought slots were to decrease the memory footprint of objects with a fixed number of attributes. But dict items are not attributes
those are different slots IIRC
mp_subscript is set to the same func
Right, and classes have their attributes stored in a dict named .__dict__ unless there's something stored in .__slots__.
Lists have the same thing, __getitem__ is a method while __setitem__ is a slot-wrapper 
what im gathering is that slot-wrappers are a thin wrapper over the C Api, but this doesnt explain why set is a slot wrapper and get isnt
But if it works well enough without taking that last __get__() step, maybe nobody bothers...
Though that doesn't explain why they're different.
>>> type(dict.__getitem__)
<class 'method_descriptor'>``` its actually a method descriptornot wrapper
from collections import defaultdict
def attrs(cls):
ret = {}
for n in dir(cls):
v = getattr(cls,n)
if callable(v):
vn = repr(v)
try:
vn = vn[1:vn.index("'")]
except:
vn = vn[1:vn.index(" at ")]
ret[n]=vn
return ret
glossary = defaultdict(lambda : defaultdict(set))
classes = {dict, list, int, float, tuple, object, Exception, bool}
for cls in classes:
w = attrs(cls)
for k,v in w.items():
glossary[k][v].add(cls)
pglossary = {k:{kk:vv for kk,vv in v.items()} for k,v in glossary.items()}
difglossary = {k:v for k,v in pglossary.items() if len(v)>1}
pprint(difglossary)```according to ^, only these classes have differences in wrapper types: {'__contains__': {'method ': {<class 'dict'>}, 'slot wrapper ': {<class 'list'>, <class 'tuple'>}}, '__getitem__': {'method ': {<class 'list'>, <class 'dict'>}, 'slot wrapper ': {<class 'tuple'>}}}
That's in python 3.8. remind me of other classes you want me to add.
still only those two attributes.
just noticed how weird copyright is. <class '_sitebuiltins._Printer'>
Thoughts on making a chat bot that learns from the help channels?
Sounds cool.
Nevermind, I just looked at some of them, not very quality content >.<
Is there any way to use 32-bit pointers in 64-bit python with ctypes?
that question doesn't even really make sense...
well yeah but it's hard to explain
a 64-bit program has a 64-bit address space. So, the location of an individual byte of memory in that address space could be any one of 2**64 different places, and so you need a 64-bit type to represent it.
that’s not really my use-case
basically I am interacting with a 32-bit process, and having data types in there requires me to use appropriate types
think I can just stick integer type instead of a pointer and use it as address, honestly
if there isn’t a better solution
there's not really a difference between a 64-bit pointer type and a 64-bit unsigned integer, in terms of how they're represented in memory. They're different for the type system, but not in terms of binary representation.
definitely
was wondering if I could use that nice ctypes.POINTER(Type), though
but seems like not the case
ctypes is for code that you're interacting directly with, in DLL's / shared libraries. since a 64-bit process can't load a 32-bit library, there's no reason it would need to have a type representing 32-bit pointers
not only shared libraries but yeah
well, shared libraries or the interpreter itself - that's it, right?
I guess it does give you C compatible data types that you could use for structure packing/decoding, too.
Yeah, it does
Anyone know the speed difference between cupy and py cuda?
It’s not exactly the same type of thing
print("Hi I'm Botty the robot. Please enter the the five scores that you")
print("need me to find the average of")
score1=int(input("Enter score 1"))
score2=int(input("Enter score 2"))
score3=int(input("Enter score 3"))
score4=int(input("Enter score 4"))
score5=int(input("Enter score 5"))
#change the total score calculation to include score3, score4, score5
totalscore=score1+score2+score3+score4+score5
#change the formula for average to find the average of 5 values
average= totalscore/2
print(average)
Does this work
@unkempt rock This is a discussion channel, not a help channel. See #❓|how-to-get-help.
do you consider Python lacking block scope desirable?
tbh there's not really much of a need for block scoping
most of the time, when I'm using other languages, I feel that block scoping makes me do more work with no benefit
most of the time, when I'm using other languages, I feel that block scoping makes me do more work with no benefit
@sacred yew me too, especially when I want to set multiple variables based on the outcome of a conditional
yeah that was the main case i was referring to
There's at least one issue caused by lack of block scoping
e = 1
try:
1/0
except ZeroDivisionError as e:
print("it's fine")
print(e) # e is not defined
and it may add more headache with pattern matching
but otherwise, not a big deal for me
There's at least one issue caused by lack of block scoping
e = 1 try: 1/0 except ZeroDivisionError as e: print("it's fine") print(e) # e is not definedand it may add more headache with pattern matching
but otherwise, not a big deal for me
@grave jolt WTF?
why is it like that
i have no idea
yep
no, I mean
why?
like I get what's happening but is that a deliberate design choice
we can ask core devs 😄
i mean, there aren't any more references to e anymore after the except
since it was rebound to the exception
the original e value would have been gc'd already, right?
hm, yes
it doesn't make sense to refer to the as binding with with, since presumably it won't be in a usable state after __exit__
but that's not the case for except
with's binding is accessible after the with

Stack Overflow
exc = None
try:
raise Exception
except Exception as exc:
pass
...
print(exc)
NameError: name 'exc' is not defined
This used to work in Python2. Why was it changed this way? If I cou...
looks like its due to avoiding circular refs
Another issue is the closure gotcha, but I don't know whether scoped bindings can fix it
fs = []
for x in range(5):
fs.append(lambda: x)
print(fs[0]()) # 5
fs = []
for (const x of [0, 1, 2, 3, 4]) // x only exists in the scope of the for
fs.push(() => x);
console.log(fs[0]()) // 0
isn't that because of late binding
Well, the lambda stores a reference to the x in the enclosing scope.
And the for loop just performs many assignments
since it can't store a ref to the current iterations value because of no block scope
But if it's a new scope every time, it's going to be a different reference every time
Basically, lambda doesn't store a reference (pointer) to the object, it stores a reference to a reference to an object.
Like, it stores a reference to the local name x
it doesn't make sense to refer to the
asbinding withwith, since presumably it won't be in a usable state after__exit__
@gleaming rover that's entirely dependent upon the class - in fact, it's pretty common for__enter__to returnself, in which case it's often perfectly valid after__exit__has run.
!e
def f():
def g():
return x
def h():
return x
x = 5
return (g, h)
(g, h) = f()
g.__closure__[0].cell_contents = 6
print(g())
print(h())
@grave jolt :white_check_mark: Your eval job has completed with return code 0.
001 | 6
002 | 6
yes, but I have personally never seen context managers being used after their blocks end
Like, it stores a reference to the local name
x
@grave jolt yeah, but is this behaviour bad?
personally I think it's fine...?
It's bad because of this:
fs = []
for x in range(5):
fs.append(lambda: x)
print(fs[0]()) # 5
print(fs[1]()) # 5
print(fs[2]()) # 5
print(fs[3]()) # 5
print(fs[4]()) # 5
yes, but I have personally never seen context managers being used after their blocks end
@gleaming rover it's usually unnecessary, because in the cases where theasvariable is still meaningfully usable after the block ends are also the cases where__begin__doesn't construct a new object, so you'd already have an instance to work with.
So you have to do fs.append(lambda x=x: x).
It's a common gotcha.
but, to be fair, default parameters being bound at function definition time is an even more common gotcha.
It's bad because of this:
fs = [] for x in range(5): fs.append(lambda: x) print(fs[0]()) # 5 print(fs[1]()) # 5 print(fs[2]()) # 5 print(fs[3]()) # 5 print(fs[4]()) # 5
@grave jolt like I get that that's the behaviour
but I've made use of it before
it (late binding of closures) seems more intuitive to me
I made use of this too 🙂
when I saw that most languages bind early I was like "WTF"
It doesn't make sense to me specifically in a loop like this.
I suppose not
So if the loop had its own scope, the lambda would refer to a new cell every time. But it probably is too narrow of a use case to actually implement block scopes with something like
for x in range(5):
scoped x
fs.append(lambda: x)
(because doing otherwise is a breaking change)
...and still doesn't get rid of the gotcha
the loop kinda does have its own scope, though only for the loop variable...
x isn't usable after the loop ends (anymore)
@grave jolt :white_check_mark: Your eval job has completed with return code 0.
4
ah, I'm mixing it up with exceptions - that's the one that changed
and comprehensions.
!e ```py
print([x for x in "abc"])
print(x)
@raven ridge :x: Your eval job has completed with return code 1.
001 | ['a', 'b', 'c']
002 | Traceback (most recent call last):
003 | File "<string>", line 2, in <module>
004 | NameError: name 'x' is not defined
in Python 2 that would've printed c.
Yeah, a comprehension is a function call to an anonymous function with the iterable as an argument...
and exceptions are the other one where the scope changed.
!e ```py
try:
1/0
except Exception as e:
exc = e
print(exc)
print(e)
@raven ridge :x: Your eval job has completed with return code 1.
001 | division by zero
002 | Traceback (most recent call last):
003 | File "<string>", line 6, in <module>
004 | NameError: name 'e' is not defined
in 2, that'd print "division by zero" twice.
comprehensions actually had some weird behavior with yield up to 3.7
now yielding is a syntax error
as for the block scope discussion, I havent thought about this example enough to say definitively, but given that you can do things like this, im not sure you really can have block scope in python without changing a lot of whats allowed
assignment targets are super flexible
which really blurs the line of what would even count as a block level variable
Hm, I didn't think about this 🤔
is there any advantage to using @staticmethod over @classmethod?
its nicer semantically, assuming its appropriate for the method
they both do different things, @staticmethod for basically associating a regular function (one that doesn't need a class instance) to a class, @classmethod for methods that use the class itself rather than instances of the class
anyone good with instagram api dm me i need help
@slim plover This is a discussion channel, not a help channel. If you want to get help, see #❓|how-to-get-help. If it doesn't break our rules, there is no reason to ask it in DM instead of here
@last pollen i'm aware of their stated intent, however i don't see any disadvantage of just always using @classmethod, even when a @staticmethod would work too
like, the obvious advantage of using staticmethod is that you can do Class.method(x) instead of needing an instance. but this applies to classmethod too
well yeah, staticmethod is basically exactly the same as classmethod, it just throws away the class param, so it provides strictly less info. But dont discount the semantic meaning that entails for users
@plain spindle if it doesn't need the class or an instance, then you should prefer just not making it part of the class at all. It should just be a global function.
I officially failed the Turing test
i disagree there. i prefer the organization benefit of associating it with the class, especially if it's a private helper
If it's a private helper, make it a private global function instead. 🤷♂️
naw, having things be organized into the nice namespaces that are classes is nice
Sometimes a function has to be in a class. For example, a method of a tree visitor/transformer if you never need self.
"Namespaces are one honking great idea -- let's do more of those!"
the zen of python went into the trash bin 25 years ago
No, I don't think I've ever created a nested class in production code.
it's no longer a relevant "argument"
gonna say a hard no to that
hmm… is overriding an instance method with a classmethod a breaking change
shouldn't be as far as i can tell
certainly an unusual maneuver
fix error here is suggesting it with their NodeVisitor example
idk man, reading that, i would have to pause and check the docs, or else comment why i'm making it a classmethod and not an instance method
Well, class methods are usually factory methods or something like that. When you need the class, but not the insrance (because sometimes you don't have an instance)
a class method can access other class methods of that class, unlike a static method
only real times I've used classmethods were for alternative constructors
i guess i just mean, if they removed staticmethod i'd be okay with that
i think it's a holdover from old-style classes anyway
thanks everyone
not sure the 2.x 3.x class distinction is too relevant
@smoky turret i saw a really cool example that combines zip() and dict loop target assignment to invert a dict
Im pretty sure the math module uses basically a bunch of staticmethods
those are ordinary functions, no?
ah yeah, strike that
random uses bound methods, which is a different thing
🐍 d = {1: 'a', 2: 'b', 3: 'c'}
🐍 i = {}
🐍 for k, i[k] in map(reversed, d.items()): pass
••
🐍 i
{'a': 1, 'b': 2, 'c': 3}
cursed ps1
i like it
i like my ps2 better though as my emoji font is a little annoying
mostly that it's ascii-character-width shorter than >>>
If it's a private helper, make it a private global function instead. 🤷♂️
@raven ridge What about the case where its a private helper on an interface which gets new subclasses where the helper is specifically tied to that subclass implementation
Then make it an instance method
But why. If it doesn't ever need self
The add_arguments method here is prime candidate to actually be a staticmethod imo: https://github.com/django/django/blob/master/django/core/management/base.py

Just because it's an instance method doesn't mean you need to use self, and you can't know whether your subclass will need access to instance state to perform that method's duty, and people above were confused about the semantics of overloading one type of method with another, so forcing that on your users is a completely unnecessary maintenance burden
speaking of cursed prompts 🙂
Wouldn't the implication of making it static be precisely that it shouldn't be using state?
Then I don't understand the question. If the subclass override of the method wouldn't use any of the subclass's state (instance or class variables), then why would the subclass override of that method be different?
The usecase of staticmethod is, in the real world, basically just the case where you have a bunch of functions that are vaguely related by meaning/context (though decidedly not by state) and you want to group them together. I cant imagine many cases where a "real" class would have a reasonable staticmethod
Because it's doing something totally different? Look at the django example. The method is just an entrypoint to add extra arguments to a parser...
And the parser is passed and not accessed via self
@smoky turret I agree completely, but that should be a module and someone is just being lazy.
@raven ridge meh, in the case of wanting multiple different groups of functionality, sure you could have subpackages, but I dont think theres anything wrong with the class approach
Look at the django example.
@safe hedge that example calls super with no arguments. That can't be done in a static method, because super needs to know the MRO, which it finds from the class or instance passed to the method that uses it
lol gottem
Does it call super?
I thought the only call was self.add_arguments(parser)
Which could easily be replaced with a staticmethod call
def add_arguments(self, actions):
super().add_arguments(self._reordered_actions(actions))```Ah we are looking at different add_arguments
That's the one on HelpFormatter. I'm talking about the one on BaseCommand
def add_arguments(self, parser):
"""
Entry point for subclassed commands to add custom arguments.
"""
pass
Link to a line number next time 😋
strikes me as unlikely that its gonna be a good idea to make it a static method regardless
to make something a staticmethod is to say definitely that it does not, and will never require any mutual state
which is why basically the only time it makes sense to do is, as previously said, when you got some truly seperate functions you want to group together
Doesn't that explicitly say it's for the subclasses to override
What's that got to do with it?
The point I made earlier still stands. If this was a static method, subclasses would need to override it with a regular instance method. Which people find confusing.
well, that decidedly violates the "knowing it will never require state" req @safe hedge
a static, abstract method is a very weird idea
no conceivable usecase I can come up with
class Monoid:
@staticmethod
def zero(): ...
def __add__(self, other): ...
but that's, um... esoteric
god damn functional people
Sorry, couldn't find a different example 😦
class IConcatenatableAndNeutralelementable:
@staticmethod
def zero(): ...
def __add__(self, other): ...
better? 🙂
better add something about functors, really get the functional people going
The point I made earlier still stands. If this was a static method, subclasses would need to override it with a regular instance method. Which people find confusing.
@raven ridge Why would they?
hmm… is overriding an instance method with a classmethod a breaking change
idk man, reading that, i would have to pause and check the docs, or else comment why i'm making it a classmethod and not an instance method
They are. 🤷
Doing that would violate LSP, since a subclass should not demand a different calling convention from a superclass, which it would do if you overrode staticmethod with a regular function
Would it be observable to users of the class?
If it's a static method in the base class it can't be made an instance method on the subclass without violating Liskov. It could be made a class method. I think
Actually... Given that Liskov only says anything about how instances of the class behave, not the class itself, I think even overriding a static method with an instance one doesn't violate Liskov.
You wouldn't be able to call the method on the subclass without an instance, but I don't think Liskov requires that to be possible, since Liskov only deals in instances.
(that said, the very fact that it's not clear whether or not it violates LSP is itself a very good reason not to do it)
Because dict values aren't unique, for reversing a dict I ususally use something like:
[result[value].add(key) for k,v in input.items()]
return result
or
return {k:v for k,v in result.items()}```In what circumstances or situations do we use @classmethod?
Alternative constructors are the main one
huh?
For example, if you have a class that models an API response e.g. from the YouTube API
class Video:
def __init__(self, video_id, video_metadata):
...
```instead of passing that information by yourself, you can create a class method that reads that data directly from the JSON response
```python
class Video:
def __init__(self, video_id, video_metadata):
...
@classmethod
def from_json(cls, data):
... # Do processing
return cls(video_id, video_metadata)
mhm
How can I run a discord client with a proxy?
@unkempt rock This is not a help channel. See #❓|how-to-get-help.
...and I'm not sure there are legitimate uses for that.
Question: PEP 617 (accepted in Python 3.9) mentioned ```
The new proposed PEG parser contains the following pieces:
- A parser generator that can read a grammar file and produce a PEG parser written in Python or C that can parse said grammar```So....one can just define their own version of Python(?) grammar now?
I believe it just means that the new PEG parser generator can use the existing grammar that Python uses
and that it's more flexible than it currently is
Heres a question, why cant they just make generators be iterable as many times as possible?
If they keep the original, they're still only accessing one element at a time..
A generator is iterable as many times as you want.
!e
def forever():
i = 0
while True:
yield i
i += 1
generator = forever()
print(next(generator), end=" ")
print(next(generator), end=" ")
for i in generator:
print(i, end=" ")
if i == 7:
break
for i in generator:
print(i, end=" ")
if i == 12:
break
print()
@grave jolt :white_check_mark: Your eval job has completed with return code 0.
0 1 2 3 4 5 6 7 8 9 10 11 12
@swift imp
It's just that the generator is a stateful object, and by iterating over it you change its state, as shown here ^
And you might exhaust the generator if it's finite. Then it will not have any more values to generate.
If you mean iterator, not generator, the answer is the same. An iterator can be a view on some iterable. It's stateful as well.
import sqlite3 # Builtin imports
import secrets
from typing import Optional # Direct element import from builtin
from utils.logger import logger # Local direct import
What would be the best way to organize these imports?
also, i think this channel is not the best for that
but it's related to import conventions
@unkempt rock you do stdlib, then a blank line, then other libraries, then a new line, and then imports from the same package
it's in pep8
i get a bit confused by imports with from
they must keep at the bottom with the local packages?
Python.org
The official home of the Python Programming Language
if you're using pycharm, control + o will organize your imports
actually using vscode
but thanks anyways, i'll give a better read into the pep8 imports
You can use isort module for import formatting and black for code formatiing.
If you are using github then you can use restyled bot which will format code for you. 😎
Hettinger posted some interesting results about the lru_cache decorator on twitter: https://twitter.com/raymondh/status/1320411457607983105
I am able to reproduce this but I genuinely have no idea why it is faster, does anyone have some insights into this?
2/ Here are the timings:
$ python3.9 -m timeit -r11 -s 'def s(x):pass' 's(5)'
5000000 loops, best of 11: 72.1 nsec per loop
$ python3.9 -m timeit -r11 -s 'from functools import cache' -s 'def s(x):pass' -s 'c=cache(s)' 'c(5)'
5000000 loops, best of 11: 60.6 nsec per loop
Surely bytecode-wise it should be slower, since it's just a LOAD_CONST
I'm assuming it's something to do with CPython not running the "actual" python interpreter for C function implementations, but cheating somehow
(since you know C code cant be compiled into bytecode)
...technically it can, but why 🙂
I would guess it is because cache[x] is faster since that class has slots, which regular functions do not.
I think it's also because cached functions minimize the amount of work done by the interpreter
basically, the call opcode is never actually executed
functools.cache is great whenever you can leverage it
Hello folks. Can anybody think of a faster alternative to this:
sum(letters_scores[letter] for letter in all_hands)
@unkempt rock what are you doing that this isn't fast enough?
all_hands being a really, really, long list. letters_scores a dictionary such as: dict(q=10, z=10, a=1, etc)
@unkempt rock what are you doing that this isn't fast enough?
@boreal umbra I am computing the scores in JSON lists of 3+ million long strings.
I believe it would be faster if the data were in a structure like a pandas DataFrame, but putting all the data into a DataFrame if it isn't already would probably be the same speed as the line you gave.
you might see if pandas can get data out of a json
Unfortunately I can detect few duplicates among the words. I tested a slower alternative solution considering words lookups instead of letters, to take advantage of duplicates.
iteration in Python is slow, so libraries for crunching large quantities of data do the iteration in C.
I believe it would be faster if the data were in a structure like a pandas DataFrame, but putting all the data into a DataFrame if it isn't already would probably be the same speed as the line you gave.
@boreal umbra Of course, agreed. I am limited to the standard builtins. No imports.
I don't know of a solution, then.
Thanks anyway.
why do you have that constraint anyway?
Academic exercise.
in that case, I would emphasize readability, and your sum statement is very much that.
@unkempt rock You have to do this in Python too?
@boreal umbra I don't need to be readable in this case. I merely want to test the limits of the setup/language.
I wonder if it would be slightly faster to manually implement a function to map the letters to scores rather than use a dictionary to do the lookup.
@gloomy rain Yes, Python and no mas. Nothing else.
@unkempt rock maybe you already mentioned this: why does it need to be faster?
I wonder if it would be slightly faster to manually implement a function to map the letters to scores rather than use a dictionary to do the lookup.
@gloomy rain Yeah ... but what could possibly beat a dictionary lookup? A switch statement?
@unkempt rock Just a sequence of if else
It would be a very very slight improvement, if any, though
@unkempt rock maybe you already mentioned this: why does it need to be faster?
@spark magnet Somebody mentioned there's a faster alternative to my code. So I am looking for it!
@gloomy rain I think using a dict would be one call to hash and one call to __eq__, whereas chained if-else would be multiple calls to __eq__
all_hands is a list of single letters?
it's probably unlikely that you'd get a collision if it's just ABCDF as keys
@gloomy rain Perhaps I could analyse the most frequent letters in the sample data and break out of a carefully constructed series of if ... a would go first, e after, etc.
Sounds unlikely.
In need of a competent discord bot developer who would be interested in an exciting new project/business venture. Please contact me if interested
it's probably unlikely that you'd get a collision if it's just ABCDF as keys
@boreal umbra Absolutely. I tested whether using dictionariesgetwith a default value was faster than the index notation (perhaps no missing key exception check) ... but it's not.
@rancid hull this server isn't a place to solicit paid help. Take a look at #career-advice for a link to the official Python job board.
appreciate it 😄
all_handsis a list of single letters?
@spark magnet It is. I joined a list of strings to make just one big list of characters. The join operation is incredibly fast and it helps as I have to count the number of letters (len)
@unkempt rock perhaps there isn't a faster way to do the sum you showed us, but there is a faster way to do the larger problem that it's a part of?
@unkempt rock perhaps there isn't a faster way to do the sum you showed us, but there is a faster way to do the larger problem that it's a part of?
@spark magnet I profiled the whole code and >90% of the time is spent on thesumline. But yes, perhaps I could prepare the setup better. I did explore several alternatives. The initial list of list of strings was slow to operate on. Thejoinstatement amounts to 2% of execution time.
@unkempt rock ok, hard to comment without seeing the original problem
@spark magnet Understandable. Thanks though.
@unkempt rock well, what else is the code doing? because even though it's one line, it sounds like what it was doing was the biggest job to be done anyway.
This is the relevant code, all else is not very relevant and can't be optimised:
_letters_scores = dict(
q=10, z=10,
j=8, x=8,
k=5,
f=4, h=4, v=4, w=4, y=4,
b=3, c=3, m=3, p=3,
d=2, g=2,
e=1, a=1, i=1, o=1, n=1, r=1, t=1, l=1, s=1, u=1)
@profile
def score_letters(self):
letters_scores = self._letters_scores # local variable caching helps with frequent lookups
all_hands = ''.join(self.hands)
return len(all_hands), sum(letters_scores[letter] for letter in all_hands)
I was surprised to learn that the letters_scores local assignment actually helps!
try sum(map(self._letters_scores.__getitem__, all_hands)), and compare ''.join with itertools.chain.from_iterable
try
sum(map(self._letters_scores.__getitem__, all_hands)), and compare''.joinwithitertools.chain.from_iterable
@flat gazelle You've create a monster. It's way faster than the standard [] dictionary lookup + comprehension. I am reading up on why that is the case. Thanks a bunch!
@hoary kite try asking in #data-science-and-ml or open a help channel. There are instructions for that on #❓|how-to-get-help
The map generator seems to be way faster than for letter in all_hands and that makes all the difference. Thanks again, @flat gazelle
map is only faster for non-python functions IIRC
map is only faster for non-python functions IIRC
@flat gazelle I don't fully understand. What do you mean by non-python functions? Builtin functions such assumor__getitem__but not ones I define?
anyone can help me with a problem with json
Thanks @smoky turret . I had read that, although it seems somewhat dated.
yeah
yeah
@smoky turret how i can extract data from a big json?
not a help channel, but whats wrong with the json module?
not a help channel, but whats wrong with the json module?
@smoky turret i dont know how extract a value from a json because is so big
ask in #python-discussion or claim a help channel, im busy
i almost never use generators 🤔 feel that i'm missing out on something
hey all
I have a position, scale, and a set of points I want to make a worldTransform matrix from
origin
origin+normal = Z axis
origin + (origin- ((v2+v1)/2) ) = X axis
I don't understand how to use the data I have to produce a world_transform matrix
(scale+rot+pos)
what advantage does (more-)itertools provide compared to creating generators manually?
other than you don't have to make them manually?
i too have a question
i have beginner-intermediate python experience
id like to make an app on my phone thatll have logs and notifications and daily checklists.
trying to research android dev, is it worth it to use python to achieve this or should i try using a different language? idk how supported python is on android
ya I'm just wondering if there's a performance advantage
with itertools, there is
i believe kivy can be used to create android apps @digital mist . java and kotlin are probably the most common languages for android app dev
is kivy available for those languages?
no
how does exporting kivy to android work?
i have no idea, try asking in #user-interfaces
ty
@cloud crypt do you happen to know why? (or have any metrics)
Itertools are written in C
I love itertools
they are written in C and they should be several times faster
Character Info
\ufffc : OBJECT REPLACEMENT CHARACTER - 
nice
i looked at moreitertools recently and didn't see too much usage for myself
most of it seemed as though it was a listcomp or whatever, but maybe it's bc i don't use generators enough
@magic python my favorite thing in more itertools is the chunking function
yeah you said that! I need to try it out, i did think it looked interesting
you use it much?
I've used it much, but I've helped several people implement the same functionality by hand
it's one of the most obvious things that Python doesn't have in the stdlib, I think.
hrm - a lot of this i think i don't need because i'm always in pandas as well
Their groupby function is pretty nice too
I've never actually used more-itertools, and I'd probably just copy/paste something from it instead of adding it as a dependancy, but I can appreciate its existence
eh its under MIT, guess no copy paste then
mit is pretty much just copy paste
you'd have to include the license with it
at that point I'd just install it
its a lightweight dependency anyways
I think, anyways
its pure python right?
yes
got it!
yeah why isn't grouper in the stdlib already
it's the only itertools recipe I actually use
No, there is no SIMD in itertools
It's a utility module to do a bunch of stuff with iterables
are you trying to write it in python?
ye
@pastel steppe probably a question for #data-science-and-ml
what if t.List[t.Tuple[str, str, str]] was t.List[t.Tuple[str * 3]]
would probably be problematic for parsing unless the parser treated it as a special case
ew no, that's a terrible edge case
Seems like a good place for an alias or generics with constraints though
@crystal pebble it would be if not for the fact that I only use it once
it exists temporarily and becomes a dataframe
That doesn't look too good imo, if you have tuples huge enough that it'd make sense to use the mult then perhaps it'd make sense to restructure or at least make it an alias; would love some more flexibility with list though
The closest I found is:
To specify a variable-length tuple of homogeneous type, use literal ellipsis, e.g. Tuple[int, ...]. A plain Tuple is equivalent to Tuple[Any, ...], and in turn to tuple.
I don't know much about the type system, but maybe you can use something hacky using *args
# This makes each positional arg and each keyword arg a "str" def call(self, *args: str, **kwargs: str) -> str: request = make_request(*args, **kwargs) return self.do_api_query(request)```But at that point you're just making things harder to read
Maybe an unpopular opinion, but: typing is most valuable for the public API of a module. Within a module's implementation, typing seems to require a lot of work for very little payoff. It does a subset of what unit tests do, and a proper unit test suite is much more valuable.
@raven ridge I use them for the signature of any function/method that I anticipate someone else will use, and then I only sprinkle them internally where I think they're helpful for someone trying to understand the implementation.
That's pretty much my strategy, too.
in fact, this is the only line in that function that uses them: rows: t.List[t.Tuple[str, str, str]] = []
I only did it because the list starts out as empty.
Unless it's something really complicated to do (getting easier as the typing peps get implemented), I prefer to hint everything
@peak spoke for function signatures, or assignment expressions as well?
I use them for my sanity since it's one less thing to worry about 
It's literally one more thing to worry about
Well, with properly typed functions expressions don't need many hints, but also expressions if it's something larger in scope where the name is not sufficient
Maybe an unpopular opinion, but: typing is most valuable for the public API of a module. Within a module's implementation, typing seems to require a lot of work for very little payoff. It does a subset of what unit tests do, and a proper unit test suite is much more valuable.
@raven ridge Strongly agree
Do you mean writing the hint? That's not a big deal at all
Writing it, and maintaining it over time, yeah.
I do get a bit angry with libs that don't have hints and I have to look into their source for the types nowadays
typing private functions is extra work, makes for more verbose code, and add very little value - especially considering the you should have unit tests confirming that every type you want to be handled actually works as you expect.
They can get really unwieldy and then you find yourself defining a custom type which you of course have to place/import
To be fair, Python is really weak in a lot of ways so it makes sense that it can become an issue
It'd be nice if you could add more constraints to things
Doesn't that defeat the point of being dynamically typed though
No, it just gives you the option to make some guarantees when you want them
Adding hard constraints upfront is antithetical to python's design
typing isn't the way to add more constraints. isinstance checks and the like are.
typing is ignored at runtime, and constraints should be enforced at runtime
Maybe you guys are right. OOP requires its own way of thinking and I suck at it
And dynamic typing too
OOP is neither here nor there with regards to constraints on types
Here's a code snippet from an old project. TBH, that's still nowhere near making me happy since there's a couple of things left to guarantee
Is there an easy way to refine things like that in Python? Expanding attributes, for example
Given that the Python interpreter does not check arguments for consistency with declared types at runtime, I don't much see the point.
So that if you have an enum with data (locations in a game, for example) you can just the number of elements as an upper bound dynamically
Also, the more I read and learn the more it seems that C and C++ were the problem and not OOP
Quick question though z what does it mean to for something to only be "available on the class"? Does that mean only the class can access it
__members__ is a read-only ordered mapping of member_name:member items. It is only available on the class.
It's not an instance attribute, it's only a class attribute.
given foo = Foo(), you can do Foo.__members__ but not foo.__members__
Ah, okay. Thanks
Also, the more I read and learn the more it seems that C and C++ were the problem and not OOP
I'm not sure what this refers to. C isn't even an OOP language. C++ is a multi-paradigm language, like Python is - not pure OOP.
NM, I'm just gonna stop talking. New meds, two of of sleep in as many days. Sorry, good night
programming in c is like sleeping in the middle of a highway. It's not a safe feeling
-my systems prof
Can anybody please help to start contributing to python language?
Some pointer would be good?
Can anybody please help to start contributing to python language?
@open plaza what do you mean

PyBay 2016 Keynote
What I've learned from being a maintainer and core developer for the past 15 years. Thoughts on channeling Guido, stability, hyper-generalization, Sturgeon's law and egativity, evaluating submissions, inability to predict the future, user centric design, tr...
isn't there a developers guide somewhere
or issue fixes
Thanks
perhaps best foot in the door would be find some docs to cleanup/improve
Ok
👍
Anyone knowing a good way to encode chinese characters and western characters with on encoding?
@tribal token that's probably a question for a help session. See #❓|how-to-get-help. Strings are unicode by default if that matters.
ok. I will try that. I have problems with encoding in the cryptography library.
@peak spoke
I do get a bit angry with libs that don't have hints and I have to look into their source for the types nowadays
Have you seen the source ofmotor?
It doesn't have type hints, and looking into the source doesn't help
Last lib I had problems with was bs4 which was somewhat frustrating to work with as the source code is all over the place
Is there a way package maintainers usually keep track of changes they're going to make when they increase the bottom supported version?
Is there a way package maintainers usually keep track of changes they're going to make when they increase the bottom supported version?
@boreal umbra can you elaborate? I feel like I don't fully understand
@gleaming rover I'm working on a library (by myself) and because my uni refuses to upgrade past 3.7 (and sometimes they won't upgrade past 3.6) there are features from 3.8 and 3.9 that I can't use
but eventually things that are legal in 6 and 7 will be deprecated
for example, once 3.9 becomes the oldest supported version, I'll need to change expressions like t.List[str] to be list[str]
because by the time 3.9 is the oldest supported version, I'd want to be ready for when t.List[str] is deprecated.
deprecated doesn't mean it stops working
another example, once I stop supporting 3.7, I can remove a dependency and use functools.cached_property
point being, I want to have a list of changes I want to make for the first version that stops supporting a given python version, and I'm wondering if there's a standard practice for that. Should it be a github issue or a document in the repo, for example?
So you're basically asking if there's a good way to keep track of code that you know will be marked as depreciated, as a way to make it future proof?
@visual shadow I wasn't planning to keep track of specific parts of the code that would need to be changed, just general statements like "switch the generics" or "remove this library as a dependency and use functools"
point being, I want to have a list of changes I want to make for the first version that stops supporting a given python version, and I'm wondering if there's a standard practice for that. Should it be a github issue or a document in the repo, for example?
@boreal umbra this basically sounds like a more specific version of "how to write a changelog"
or did I get you wrong
If a change log can be something where you describe changes that you're going to make, then yes
I've never heard of that
well, a proposed changelog, I guess
I feel like there should be a rough correspondence between what's in your changelog and your Git commits (assuming you use Git, of course)
not sure if that's diverging from your original intention though
Interesting question, I don't know if there's a formal way of doing this.
well, the goal is to have it written down what changes I will make years in the future, since I'm not likely to remember that one of my dependencies is made redundant by 3.8, for example.
Yeah, I think something as simple as commiting a documentation file for this should suffice. Just not something I've ever seen before
that sounds like a roadmap
👋
with github specifically, you can make an issue which describes what needs to be done, and assign it to a milestone
looking at the milestone for a specific release, you can then see all the issues that you wanted to complete by then
@sacred tinsel oh, that's pretty cool
I'd probably go with something like that if it were collaborative.
you can use github issues even for private / personal projects, I do
but you could probably have a similar system with e.g. a trello board, create a list of cards for each future release
or a tag for each release
I think what you're looking for is creating some kind of a ticket that can be assigned to a specific category or group, so any tagging system should work
I just had this thought - would there be any issue with using the underscore thousands separator for the repr of ints?
e.g.:
>>> repr(10000)
'10_000'
since that would be a valid int literal with much better readability, although afaik there are some cultural differences in the way separators are used
Well...
if print is unchanged, it my be fine
Because print can be used to pump the data to another program that probably doesn't really like 10_000
with |, that is
ah true
it also might be a bi confusing to beginners, because repr is used for the REPL
@sacred tinsel I personally would like that but I'm not sure how universal separating every third decimal is
I don't want to diverge of kwzrd's topic if we're not done with it but are pandas/numpy doing anything to make type hinting with their types more robust?
like specifying the shape of a matrix?
It was discussed on the stream that more cool types may be going to be added to typing.
Specifying the shape of a matrix is only feasible if you never do anything other than get/set rows, get/set columns, get/set elements, comparing two matrices, or zipping two matrices (doing something for a pair of elements in each matrix).
You can also Add/remove a single row/column at a time if you use recursively defined naturals in types
But gluing two matrices together will need something like (Matrix[A, N1, M], Matrix[A, N1, M]) -> Matrix[A, N1+N2, M]
I just had this thought - would there be any issue with using the underscore thousands separator for the repr of ints?
e.g.:>>> repr(10000) '10_000'
@sacred tinsel A bit late, but you can do "{:_}".format(1000000)
!e print(f'{1000000000:_}')
@boreal umbra :white_check_mark: Your eval job has completed with return code 0.
1_000_000_000
ayyy
yea, I meant the repr of the int type specifically
(similar to {:,})
repr is supposed to be unambiguous
that means it shouldn't confuse people that dont know what the thousands separator is in python
yeah, if readability is the concern, you should use str and or format
and not everyone would agree that str for an int needs thousands separators
so better to leave it up to the programmer
because then there wouldnt be any method to get the current format
if you change str to use seperators
repr is supposed to be unambiguous
@sacred yew also, preferably, the output of repr should be suitable to put intoeval()to create the exact same object again. if that is not possible, you should preferably return the <Foo object at 0x....> thing you often see when you print stuff
where 0x... is the address you can get via id()
but i believe that that is the default behavior of a non overridden repr already anyway 🙂
It is, yeah
hi
@elfin river This is not a help channel. See #❓|how-to-get-help
We will not help you with bypassing captcha, though.
!rule 5
5. Do not provide or request help on projects that may break laws, breach terms of services, be considered malicious or inappropriate. Do not help with ongoing exams. Do not provide or request solutions for graded assignments, although general guidance is okay.
And don't post links to resources like that @tardy mason, see ^ as well
also, a thousands seperator is not even consistent across the world https://youtu.be/0j74jcxSunY?t=383

Audible free book: http://www.audible.com/computerphile
Catering for a global audience is difficult, Tom takes us through a 'timezones' style explanation of the things you need to keep in mind when internationalising your code.
This video features Tom Scott - more from him at:...
How does one define a variadic generic class in python?
@halcyon trail what's variadic?
It means it has an arbitrary number of type parameters
for example, Tuple, Union, Callable
well Callable perhaps has a list of type parameters, so that's a bad example
so like a function with *args or **kwargs in the signature?
@halcyon trail you want to pass arbitrary number of parameters? Or type parameters?
@spark magnet type parameters
so basically imagine something like this
class foo(typing.Generic[?]):
data: typing.Union[?]
what would that mean?
where the ? means, I don't know what to put in here, but its' the same idea
that means that if I have an instance of foo[int, str]
called say f
then f.data has type Union[int, str]
and so on
@halcyon trail You can do U = TypeVar("U"), define Foo as class Foo(Generic[U]), and then use Foo[Union[int, str, str]]. I don't think it's possible to use type varargs now.
@grave jolt ah that's unfortunate
though I'm not that surprised
i guess even a list would be better?
So it would be Foo[[int, str, str]]
is there a way to do that?
You could do that with 3 separate TypeVar's...
Realistically, your users are going to need casts or isinstance checks whenever they access that Union, so you may as well just declare it as Any instead.
Hello, I have some questions about using yFinance. I have the code ready, is this the correct place to ask for help?
@raven ridge well,. This is a simplification of what I need it for
@fading trellis Is yFinance scraping Yahoo? Or is it accessing an API?
And doing it with three type vars.isnt a solution, what if I only want to pass 1,.or 2,.or 4,. Etc
@fading trellis Either way, see #❓|how-to-get-help. This is a discussion channel, not a help channel.
@grave jolt scaping yahoo.
Then it probably breaks the ToS of Yahoo, so you can't get help with that on this server; but you can read them and see whether it does.
well, I guess I need to go to the helping channel
I was just trying to find out how to get 4 hours data instead of 1 day data
couldn't find any answer on google haha
Well, if it breaks ToS, that's a no-no here.
well, I don't think so because yahoo do allow to download historical data but only for 1 day but not 4 hours...
but I wasn't sure so ill look somewhere else I guess
anyone know where I can get helps for my question?
I already told you to see #❓|how-to-get-help
right, I mean other places beside discord
I tried stackoverflow but people on there kinda sucks
And doing it with three type vars.isnt a solution, what if I only want to pass 1,.or 2,.or 4,. Etc
@halcyon trail that's going back to your earlier question - I don't think there's a way to make it variadic. I don't believe you can create a generic type that doesn't take a fixed number of arguments with the Python static typing system.
@raven ridge well,. This is a simplification of what I need it for
@halcyon trail what do you need it for
sounds interesting TBH
yeah it appears not unfortunately
well, what I need is actually pretty simple, I'll probably just define this as a class and overloaded the operator[] in its metaclass myself
what I need it for is basically I want to create a type annotation
actually, ugh, my approach prob doesn't work.
Anyhow what I want is to create a type annotation that is similar to a Union, but different, for the purposes of some generic code I have
@dataclass
class foo:
x: Union[int, str]
y: DefaultUnion[int, str]
so I have generic code that can deserialize dataclasses automatically from json
The way it works for something like Union is that in the corresponding place in the json, there has to be an entry __type__ that specifies which of the entries in the Union it contains data for
You can define a linked list of types, like Cons[int, Cons[str, Nil]] somehow, but that's pretty esoteric
this works well in my code and i'm happy with it
Hey, if I want to make a class that has many arguments, what will be the best way to do it so that when I make the objects later on (that will also quite many), so that I don't really have to memorize the argument orders? and is it going to be effective if I'll add let's say 15 - 20 objects with this class? So let's say I want to make a class of BuildingMaterial that will have these args:
class Material():
"""name, material type, standard dimension, usage, thermal conductivity, density, finishing, connection"""
def __init__(self, name, matType, standDim, usage, thermal, dens, finish, con):```You can define a linked list of types, like Cons[int, Cons[str, Nil]] somehow, but that's pretty esoteric
...If you're doing that for the type checker, of course
You can define a linked list of types, like
Cons[int, Cons[str, Nil]]somehow, but that's pretty esoteric
@grave jolt did someone sayHList? 👋
but now I'm in a situation where I have some dataclass like this:
@dataclass
class foo:
x: bar
And I want to upgrade it, backwards compatibility like this:
@dataclass
class foo:
x: DefaultUnion[bar, baz]
are you trying to do this for type checking, or for code generation?
@rotund yew You can use keyword args. Material(name="rock", matType="solid", ...). Also, check out PEP 8, Python's style guide -- names except class names are in snake_case.
Anyhow, from a type system perspective going from bar to Union[bar, baz] is backwards compatible for something that's an input
after all, you're broadening what you'll accept
however, because there will be no __type__ field in the existing json, it will not actually be backwards compatible
hence, I want this DefaultUnion thing. It type checks identical to Union
@rotund yew You can use keyword args.
Material(name="rock", matType="solid", ...). Also, check out PEP 8, Python's style guide -- names except class names are insnake_case.
@grave jolt Oh thank you!
@rotund yew This is not really a help channel, so for further help see #❓|how-to-get-help
but, my generic code is able to see that its' something different. And simply default the union type to the first type, if __type__ isnot supplied
@rotund yew This is not really a help channel, so for further help see #❓|how-to-get-help
@grave jolt Okay i'll check it, just joined the server yesterday
an alternative would be to change how I handle Union generally I suppose, but that seems dangerous, I'd rather error in general if __type__ isn't provided
I want to opt in
so you're using __annotations__ dynamically at runtime to change the behavior of your code
Sure
not sure if you are implying with that statement that it is a form of code generation
@gleaming rover i guess like everything, somebody is using it, but lenses are typically used with immutable data structures, and python really makes it a pain to try to use immutable data structures throughout your code
I've played around with them in Kotlin
They're nice
I have a project where I more or less use namedtuple exclusively
just to see how it goes
heh, so youare thinking about what it will look like to change things when you have nested nametuples ?
not sure if you are implying with that statement that it is a form of code generation
@halcyon trail Well, it's not, not exactly - but it's similar to@dataclass, in that you're using the annotations to do stuff, outside the normal type checking use case for annotations
oh man poor random user 😦
heh, so youare thinking about what it will look like to change things when you have nested nametuples ?
@halcyon trail yup
think I'll go hack something up
Eh, I dunno, dtaclass is a decorator, it actually does more or less generate code
yeah, I blame discord for that.... heh
too bored to work on startup
my code is just a function
it uses the fields function from datacalsses to inspect the types, and literally just branches based on that
I'd call it introspection rather than generation.
But yeah. Life is too short not to have generic, automated reflection 🙂
(and thus, serialization/deserialization)
yeah. from my POV, that's still an esoteric thing to do with typing. Most users of type annotations use them only to with static type checkers.
what you're doing doesn't sound unreasonable to me - at worst a little bit esoteric - but I have no idea how to accomplish it
Esoteric in the context of pythons type system, or generally?
in the context of Python typing. It's generally used for opt-in static type checking.
Sure
Union is implemented in Python - https://github.com/python/cpython/blob/3.9/Lib/typing.py#L388-L389 - so maybe it's possible to do what you're trying to do, if you dig into how typing works a bit.
It's pretty.par for the course in most languages that have reflection and static typing
yes, but Python isn't really one of those, at least not IMHO.
Oh it's definitely not statically typed
But still, it's just an obvious use case
How do you do deserialization otherwise?
In my experience it's pretty common to hit the limits of Python's type system and need to just throw up your hands and say Any. There are too many things that are reasonable uses of the language that are completely impossible to describe to type typing system.
indeed.
Yeah, no doubt
How do you do deserialization otherwise?
@halcyon trail the same as you're doing, but without the type hints.
Static type annotations are an improvement but tbh I wish I was using a statically typed language often
Err how?
You have to tell it what to deserialize
you have a schema, the schema describes what types to expect on deserialization, you check the schema whenever you're pulling a field out to make sure that it conforms to the schema - but I wouldn't represent that schema using type hints, I'd represent it in some other form. jsonschema or xsd or protobuf or something.
I'd do it the same way as I would have done it before Python 3.5, before the language had type hints. 🤷
You are repeateing yourself
not really - you're defining the schema in code. I would define the schema in another language entirely.
But I already have the static types in python
It's only not repetition if you aren't anyway using type annotations
Sure, that's different though
But in this case,.you can see for the same amount of work, you get the additional benefits, mypy checking, IDE help, etc
Schemas are ok if you need to exchange the data across languages
This did give me an idea though, perhaps instead of stuffing it in the type I can put it somewhere else... Like the default value
Or in the meta information for the field. We'll.see I guess
you get the additional benefits, mypy checking, IDE help, etc
IDEs often interpret type hints differently than mypy, and possibly incorrectly. And I generally find mypy more of a help than a hindrance.
Not going to get into that one :-)
well, I'm just saying: you're taking it as a given that there's benefits to using typing for this. I disagree.
I find mypy to be useful for the public interfaces of libraries, and that's pretty much it. Within a library, I find it much more of a hindrance than a help.
Yes, I'm taking it as a given, for myself
I wonder if you can make DefaultUnion[Union[int, str, float]] work.
that'd even allow you to make the default type explicit rather than implicit. UnionWithDefault[Union[int, str, float], str] or something.
Well, I think I can make it work in terms of my deserialization code,.yes
Making it type check,.not sure
I can't inherit from Union I don't think
Making it type check,.not sure
I'd just useAnyfor that, heh.
Though there may be a way to make it work. 🤷
Yeah hopefully. Alternatively I could just not support a default, and programmatically rewrite all the current configs
It's one or the other
Hi all. Can anybody describe what I/O is and how it's used?
Every definition I come across feels kind of arcane, other than using it as the definition for file objects (.py,.jpg,.exe, etc...). I ask because I feel like I'm missing a lot about I/O
in this context, IO refers to non-cpu bound operations that take a lot of CPU time to finish. Usually file operations, or socket stuff/requests
or did you mean just general input/output user interaction stuff?
Hi can anyone suggest what is the best approach pandas or normal csv excel library
if i want to fetch file data and import in db
hey guys so i have a question i was recently looking up decorators and came across two ways to create a decorator, class decorator and function decorator. Trying to understand the difference i read that class decorators are better when you want to maintain the "state". I am not quite sure what they mean by this. Can someone help me with this
not "the state" but just maintaining state
as in, theres some extra information your logic requires, that has to be persisted for some amount of time
for example, if you had a decorator that implemented caching of the functions outputs, you have to maintain that cache (the state)
ahh
but wont the life scope of the function expire as soon as the callable is called in the class?
uhh, local function variables dissapear, yes, but the class attributes of the decorator wont, no
alrighty i get it, thank you!
np
Hi all. Can anybody describe what I/O is and how it's used?
@lusty patrol I/O stands for "input and output", and it basically just means every place where your program needs to talk to something else before it can continue working - waiting for the filesystem to read a file off a disk, waiting for a web server to send an HTTP response, waiting for a database to give query results, waiting for the user to type or click something, etc. Any time your program needs to talk to any other program or device, basically. Any time input is taken into your program from some other place, or your program sends output to some other place.
If data is being read into or written out of your Python program, that's I/O.
That clears a lot up thanks very much for the explanation!
I don't understand why after importing requests, I can use requests.adapters, even though it's not in the __init__.py of requests. Some kind of magic?
I found some import magic in packages.py, but it seems to be unrelated.
I don't understand why after importing
requests, I can userequests.adapters, even though it's not in the__init__.pyof requests. Some kind of magic?
@quick snow long story short, in__init__.pysessionsis imported
and in sessions something from adapters is imported.
this resolves the adapters module in the requests package.
Oh, interesting. I didn't know it worked that way
If one needs their code to run in a very tight, fast loop, would it be faster to check a condition once every loop and then change a few function definitions rather than check that condition every time you need to do something?
Instead of changing function definitions, why don't you store the result of the condition as a variable, and use it everytime you need it?
If your condition is O(1) though, the speed gain will be very little to be honest
okay. I guess it would be best to figure out how to use timeit and test this myself.
hi can i use python to send commands to the kernal
Stack Overflow
I want to make syscall in Python and the function is not in libc, is there a way to do it in Python?
More specifically, I want to call getdents, whose manpage says
Note: There are no glibc wra...
Say I have the triangle scenario, I make a new class C that inherits from both A and B. Both A and B have a foo property. How do I decide which foo to inherit in C? Well not decide but specify...
python uses C3 linearization on its MRO, so it will take whichever is first in the bases list
Python.org
The official home of the Python Programming Language
Can you monkey patch a Dunder on a class? I can't imagine why you couldnt right?
Yes
And yes I would want the monkey patch to affect all instances of the class
Does anyone have a rec for a good technical write up on optimizing coroutines/generators/lazy code? I've been kicking around a personal project for a while and benchmarking lazily piped code has made me question some assumptions ive always made
Say I have the triangle scenario, I make a new class
Cthat inherits from bothAandB. BothAandBhave afooproperty. How do I decide whichfooto inherit inC? Well not decide but specify...
@swift imp the one that gets used be default is the one that's earlier in the MRO (with just a diamond, that's the one you list first in your list of base classes). If you want the other one to get used, you can call it explicitly, usingB.__getattr__(self, "foo")or the like
Or B.some_method(self) more commonly.
this doesn't belong here.
Why does Python allow both variants?
!e
assert B"hi" == b"hi"
assert R"hi" == r"hi"
assert F"hi" == f"hi"
@grave jolt :warning: Your eval job has completed with return code 0.
[No output]
I don't see a reason to have an uppercase variant.
@grave jolt maybe for sql programmer 😂
I saw some cases where r and R were used to differentiate between regex and other uses, but I don't see a reason why not to allow it with other literals behaving in the same way
Hm, well, r vs R can indicate to a highlighting engine whether it's a regex or not.
I see
https://docs.python.org/3/reference/lexical_analysis.html#string-and-bytes-literals The grammar for that is pretty tortuous, heh
string literal go br"rrr"
lol
Hey guys what do you use for linting?
Because I'm coming across pycodestyle and pylint and aren't too sure the difference between the two.
I see some people using both as well.
pycodestyle, it used to be called pep8 and afaik follows that doc
I recently started using flake8 because it's easy to configure and run, and I just wanted to stop the internal bikeshedding.

No, it's pycodestyle plus pyflakes plus any other plugins you choose to use, all integrated under a common configuration system, single CLI, and consistent pragmas to disable specific warnings
Hello, question about project directory setup.
I'm running into issues regarding the way I set things up and would love some advice.
This is how I'm setting it up right now.
project/
│
├── .gitignore
├── spider/
│ ├── __init__.py
│ ├── spiderclass.py
│ └── spider_subclass.py
├── test/
│ └── test_spider.py
├── pipeline/
│ └── pipeline_script.py
├── LICENSE
├── README.md
└── requirements.txt
I'm running into importing troubles when importing the crawler class from test and pipeline folder.
$excuse

All purpose excuse maker from Wimpy Kid
Subject
My Dog
Action
Injured
Obeject
My Lunch
Final Excuse
My Dog Injured My Lunch
follow me on insta @noeltudu
self botting?
showing off your self-bot, in a discussion channel, in a public server may not be the smartest move you've made