#algos-and-data-structs
1 messages · Page 148 of 1
Wtf does "use linear time in the current number of elements currently in the stack" mean?

Does that mean, each operation should use O(n) time, where n is the number of elements in the stack?
And that n consecutive operations should also use O(n)???
there's no! in Python
!=
but ! is not a separate operator
I'm not sure if the question is about Python at all.
nah its not
Does that mean, each operation should use O(n) time, where n is the number of elements in the stack?
yes
So each operation has to use constant time...?
can you show the problem?
oh, I didn't read properly, sorry
I think it means that you'll need to amortize

Stack Overflow
Can someone explain amortized complexity in layman's terms? I've been having a hard time finding a precise definition online and I don't know how it entirely relates to the analysis of algorithms.
which do you think is not correct? I chose OR cuz it works with 2 args
seems correct
depends on your course and what these operators mean.
For example, in Haskell and Rust, + doesn't work as a unary operator
because unary + is completely nonsensical, it doesn't do anything
__pos__ dunder 
Right
what actually uses it? I think only decimal.Decimal for applying precision context, which I think is horrible
It's still a unary operator 🤷♂️ just usually a noop 
Is there a way for a hash map to always keep track of its min and max values efficiently, like how a bst can do?
Or only bst is usable for that kind of thing?
whenever the hashmap is changed, check if the new value is greater than the current max or smaller than the current min
hhhmmmm no that won't work
because you can delete/replace stuff
Yeah deleting and replacing
efficiently being O(logn)?
Yeah
keep a BST in parallel 🙂
i.e. search in the hash map, but use the BST for the min/max
Ok. I thought it might be that
The only advantage over BST here is that search is O(1). everything else is as bad as a BST
but that could be just what you need
I was helping someone and I said they needed to use a bst for this
But then thought maybe that was wrong
Like I wasn’t sure if there was maybe a way to track only max and min, as opposed to being able to find all values between n1 and n2 or something like that
Well, it is going to be O(logn) anyway. So I don't see anything wrong with a BST
(if it could be done in less than O(logn) then you could do a comparison sort in less than O(n logn) which is impossible because of some clever math voodoo)
tbf deletion may not always be needed in hash tables  could have an add-only table that can only grow, call it ChonkyTable
could have an add-only table that can only grow, call it ChonkyTable 
you can do constant with a linked list
wait, nevermind
well wait, I think it's possible
oh, you would need something like ordereddict
.
it's not a comparison sort
You can do that if you sort it at the beginning, then only delete from it and don’t add to it or replace keys in it
def sort(xs):
bst = MySuperBst()
for x in xs:
bst.add(x)
rv = []
while bst:
rv.append(bst.popmin())
return rv
So it’s possible if you’re only deleting or only adding/replacing
yeah, seems like so
@wheat flower if there’s never very many things close to the camera then it might still be worth it to use a bst. I think it would be like O(log(n) + m) where n is how many things there are, and m is how many things are close to the camera.
It actually would only be O(n) if the number of things close to the camera increases linearly with the total number of things there are, I think
But maybe that’s not the case
greatly appreciate any suggestions or critics. I already have a half-completed solution but haven't proved how it is optimal, is this approach ok?


hey
def dijkstra(a,start,goal):
frontier = []
heapify(frontier)
heappush(frontier,(0,start))
prev = defaultdict(lambda : (None,float('inf')))
prev[start[0],start[1]] = (None,0)
def dist(a,b):
return abs(a[0]-b[0])+abs(a[1]-b[1])
while frontier:
risk,item = heappop(frontier)
if item == goal:
break
for n in a.class_[item[0]][item[1]].neighbor:
if n in a:
t = a.class_[n[0]][n[1]]
if n not in prev or prev[n][1] > (prev[item][1] + t.n):
prev[n] = (item,prev[item][1]+t.n)
heappush(frontier,(prev[n][1],n))
return prev
my dijkstra algo works well on 2d matrix (weighted) but when i add an heuristic (dist - manhattan distance) it does not tell the shortest path
this ones without heristic
when i add dist(goal,n) i.e
prev[n] = (item,prev[item][1]+t.n + dist(goal,n))
it gives wrong path
output for normal implementation
[(2, 0), (2, 1), (1, 1), (0, 1), (0, 0)]
[[1 5 1]
[20 6 1]
[3 7 40]]
start pos = (2,0) , end = (0,0)
output with heuristic
[(2, 0), (1, 0), (0, 0)]
[[1 5 1]
[20 6 1]
[3 7 40]]
I have written a python program to find a certain angle. I analyse few hundreds of images, read them and extract the angle parameter from them and store them in a list. Now I want to use the content of list in a different python program. How to call this list in a different program?
You could save the list into a file and then load the data in the file from the other program
The second question is as follow: I save the list in the HDF5 format. I do the following, but i end up with error . Explained in pastebin... https://pastebin.com/Wq9CqxGf
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
Has anyone tried the book The hundred page ML book by Andrey Burkov?
what is the optimal number of epochs for a multivariate lstm
Anyone know autocorrelation function (ACF) and partial autocorrelation function (PACF) help-banana
Anyone know why changing the return statement in function find leads to different values in right and left subtrees?
class TreeNode:
def __init__(self, left=None, right=None, val=0):
self.left = left
self.right = right
self.val = val
def find(root, ret):
if not root:
return [0, 0, float("-inf"), None]
left_tree = find(root.left, ret)
right_tree = find(root.right, ret)
print(left_tree)
print(right_tree)
values = left_tree[0] + right_tree[0] + root.val
ret[0] = values
count = left_tree[1] + right_tree[1] + 1
ret[1] = count
if values / count > ret[2]:
ret[2] = values / count
ret[3] = root
# return [ret[0], ret[1], ret[2], ret[3]] this is correct
return ret # this is incorret
def dfs(root):
ret = find(root, [0, 0, float("-inf"), None])
return ret[-1].val
a = TreeNode(left=None, right=None, val=1)
a.left = TreeNode(left=None, right=None, val=-5)
a.right = TreeNode(left=None, right=None, val=11)
a.left.left = TreeNode(left=None, right=None, val=1)
a.left.right = TreeNode(left=None, right=None, val=2)
a.right.left = TreeNode(left=None, right=None, val=4)
a.right.right = TreeNode(left=None, right=None, val=-2)
print(dfs(a))
1
/ \
-5 11
/ \ / \
1 2 4 -2
``` this is what the tree looks likeif i just have return ret when I'm in node -5, both left and right subtrees have information of node 2, it's almost as if the information in node 1 was overwritten by node 2
bruh
what is wrong with this
import csv
import random
import time
x_value = 0
total_1 = 1000
fieldnames = ["Date", "Close"]
with open('G:\Trading\R&D\DHIL.csv', 'w') as csv_file:
csv_writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
csv_writer.writeheader()
while True:
with open('G:\Trading\R&D\DHIL.csv', 'a') as csv_file:
csv_writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
info = {
"Date": Date,
"Close": Close,
}
csv_writer.writerow(info)
print(Date, Close)
Date += 1
Close = Close + random.randint(-6, 8)
time.sleep(1)
i dont get it
Traceback (most recent call last):
File "G:\Trading\Algorithms\Bots\livechart2.py", line 22, in <module>
"Date": Date,
NameError: name 'Date' is not defined
makes no sense
i figured it out
i had a secondary segment of code that was also writing
but when it wrote live data to plot it erased all the data in the csv
so when your using matplotlib to plot graphs live from a csv don tuse csv_writer bc itll erase all the data in the csv file leaving the column names
can someone help in #help-potato
Hi guys, really quick question :
class A(superclass, arg1='hum?'):
pass
I'm playing around with metaclasses and trying to learn how to handle it
What is 'arg1' called ? And how can I access it from an object of type A ? And how can I access it from its metaclass ?
And how does it work, if you have doc for it, I read that it was possible now...
keyword argument, it's passed to the metaclass's __new__ the same way keyword arguments are passed to normal functions
Hello, Why doesn't Python print my @property decorator value when calling __dict__ on the class instance?
I was expecting a value of
{'myname': 'FooBizzle', 'data': {'myname': 'FooBizzle'}}```
- it's not "calling
__dict__, it's "accessing__dict__ - you shouldn't even expect
mynameto be something other than a property object thing
2.1. it's because the property value may change
so what you should expect is actually {'myname': <property object at 0x000001C690DE7B50>, 'data': {'myname': 'FooBizzle'}}
so why is that not the case, then
i'm still searching the internals for it
try dir(Foo())
makes sense ... sorta. The @property decorator is like a getter method and not an actual class attribute like self.data
for the Foo class, myname is actually printed like that
its stored on the class not on the instance
right, that's what I was thinking
My solution was to create a as_dict class method.
def as_dict(self):
d = dict()
for k in dir(Foo):
v = self.__getattribute__(k)
if k.startswith(('__','data')) or hasattr(v, '__call__'): continue
d[k] = v
return d
Hi so I am just wondering, if I have an input of a string and want to scan the string and look for the first “a” in the string, and delete anything in the string before the the a and output the result, how would I go about it?
I know I need a for loop to scan through the array, and append maybe? Then create a seperate string of the appended array?
use str.index and slices
How can I make a log-in system using basic text, should I use classes or dicts. Please Help
whats the gaussian thing you were describing
here's what I was talking about:
def rb_count(n):
rb = 0
while n>1:
n,r = divmod(n,2)
rb+=r
return rb
Which is the same as:
def rb_count(n):
return bin(n).count('1')-1)
Not sure what the gaussian part was about. @vale briar ?
def rb_count(n: int) -> int:
return n.bit_count() - 1
AttributeError: 'int' object has no attribute 'bit_count'
Is that something from a library?
@lean walrus :white_check_mark: Your eval job has completed with return code 0.
2
I had this "WTF, how did I not know about .bit_count()" moment.
it is 3.10 feature
Thanks!
what is /r/learnpython? (wrong channel sorry)
reddit.com/r/learnpython the subreddit for learning python.
ah i see. thanks.
no wonder lol

gura about to stab those errors
Oh really?
!e
print(1 .bit_count())
@lean walrus :white_check_mark: Your eval job has completed with return code 0.
1
wow thanks to python, shortest solution to bytecount in codewars
@heavy blaze :white_check_mark: Your eval job has completed with return code 0.
1
!e print("selam")
@heavy blaze :white_check_mark: Your eval job has completed with return code 0.
selam
!e try = 0
if try == 0:
print("try is 0")
@heavy blaze :x: Your eval job has completed with return code 1.
001 | File "<string>", line 1
002 | try = 0
003 | ^
004 | SyntaxError: expected ':'
!e bruh = 7 if bruh == 7: print("bruh is 7")
@heavy blaze :white_check_mark: Your eval job has completed with return code 0.
bruh is 7
!e bruh = "napim" for x in range(5): print(bruh)
wat colorscheme are u using?
Material Theme - Palenight

should I use anaconda for jupyter notebooks?
they seem to run without anaconda too, what's the point of it then?
Anaconda is a big collection of scientific/mathematical packages, the point of it is to conveniently have all of those without having to worry about getting the right compilers, checking version compatibility, etc. It makes it easy to have all the tools.
oh, ty
help me hack pls
!rule 5
5. Do not provide or request help on projects that may break laws, breach terms of services, or are malicious or inappropriate.
with open ("path","w") as myTest :
Is there is any error because i had error
Guys, I want some help with regard to counting cells in spreadsheet
How do I count cells within given range of time in python?
I tried using the between_time in pandas
But it did not work as it raised TypeError: DateTimeIndex not found like that
Please help
hi
@speed if you are reading the excel spreadsheet, python will take those values as text. you need to turn the values into date time in order for it to work.
import pip
pip.main(['install', 'pygame'])
what the best way to compare 2 json objects
and state the differences like a different value, the fields are ordered differently and a field was removed or added
trying to wrap my head around the best way to make a plot function. Needs to handle n-num subplots with n-num lines which could be different on each plot. Currently I can do one or the other, but not both, using a list of lists. Any suggestions on a better way to differentiate between the two?

list of lists of lists?
yeah, a list of lists per subplot for example, stored in another list
or a three-dimensional numpy array, if you prefer to work with them


# O(1) space:
boxTypes.sort(key=lambda x: x[1], reverse=True)
for boxes, units in boxTypes: ...
``````py
# O(n) space
for boxes, units in sorted(boxTypes, key=lambda x: x[1], reverse=True): ...
is this correct? .sort takes O(1) extra space?
it's O(n) iirc
Objects/listsort.txt lines 17 to 23
+ timsort can require a temp array containing as many as N//2 pointers,
which means as many as 2*N extra bytes on 32-bit boxes. It can be
expected to require a temp array this large when sorting random data; on
data with significant structure, it may get away without using any extra
heap memory. This appears to be the strongest argument against it, but
compared to the size of an object, 2 temp bytes worst-case (also expected-
case for random data) doesn't scare me much.```Hi!
I have a problem with solving this task. Can you help?
Given is an series of the closed intervals L = [[a1, b1], . . . ,[an, bn]],
all numbers are natural numbers.
What to do?
We need to find the biggest interval ( in meaning one which includes the most others interval in L) and tell how many intervals it includes. Let's call this number "c".
Here is an example.
L = [ [1, 6],
[5, 6],
[2, 5],
[8, 9],
[1, 6] ]
The result is 3
c = 3.
([1,6],[5,6],[2,5]) are contain in [1,6]
We don't count the "main" interval
Currently I'm sorting the intervals by the end value [a,b] so sorting by b descending. I'm doing it with QuickSort.
But right know i don't know what to do to have an result from this... I'm just looping inside my brain all the time.
It's possible to do in O(n * log(n)).
I'm struggling with this all 4 days...
@glad vale
I’ll try to write what I was thinking about, unless someone else solves it first
!e ```py
def compress(arr):
arr.sort()
result = []
if not arr:
return result
arr_iter = iter(arr)
first = next(arr_iter)
result.append((first[0], [first[1]]))
for interval in arr_iter:
if interval[0] == result[-1][0]:
result[-1][1].append(interval[1])
else:
result[-1][1].sort()
result.append((interval[0], [interval[1]]))
return result
def solve(arr):
max_count = 0
max_interval = None
ind_left = 0
while ind_left < len(arr):
left = arr[ind_left][0]
right = arr[ind_left][1][-1]
current_count = len(arr[ind_left][1]) - 1
ind_right = ind_left + 1
while ind_right < len(arr) and arr[ind_right][0] <= right:
for other_right in arr[ind_right][1]:
if other_right > right:
break
current_count += 1
ind_right += 1
if current_count > max_count:
max_count = current_count
max_interval = (left, right)
ind_left += 1
return (max_count, max_interval)
arr = [
[1, 6],
[5, 6],
[2, 5],
[8, 9],
[1, 6],
[1, 5]
]
arr = compress(arr)
answer = solve(arr)
print(answer)
@fervent saddle :white_check_mark: Your eval job has completed with return code 0.
(4, (1, 6))
Actually I’m pretty sure this is O(n^2)
If it’s like:
L1 L2 L3 L4 L5 R5 R4 R3 R2 R1
Then I think it would be O(n^2)
You could start at the first lefthand bound with a righthand bound that puts it partially outside the previous interval being checked, and also mark the positions in all the other mapped righthand bound arrays where it fell outside the previous checked bound and start from those positions, but I bet that wouldn’t make the time complexity lower
Well, I hope someone else knows how to do it, because now I’m wondering too
He left the server, but now I wonder how this is solved
hi anyone know a bit about line smoothing on graph in python so i can ask a simple question
@me if you can help
how to know number of neuron and layer where there is cardinal data involved?
my whole data is categorial
X = [300, 4]
Y = [300,1]
my best immediate idea is to sort by end point and then go through in order and add starting points to some range query data structure so you can query the number of starting nodes in an interval
i.e. add all intervals ending at r, [l1, r], [l2, r], ...
and then check the number of starting points in range [min(l1, l2, ...), r]
this can be done in log(n) per range query
so n log n total
not the neatest solution ever, but it should work, it's kinda just throwing something like https://cp-algorithms.com/data_structures/segment_tree.html at the problem
I’ll look at that, I’ve never heard of segment tree before. Thank you
I think the proper name for the thing is range query tree, but it's known as segment tree in competitive programming circles
This is a 100% good working code to construct Min Heap

Been working on this for 2 days but nobody helped. Can anyone help or know this concept please?
for siftUp method... we do reduce -1 //2
but for the buildheap we do -2 //2
considering both are finding the last parent idx .. isnt it ? Pleaseeee
import random
cls = list(reversed(['B', 'B', 'B', 'B', 'C', 'C', 'C', 'C', 'D', 'D', 'D', 'D', 'D', 'E', 'E', 'E', 'E', 'E', 'F', 'F', 'F', 'F', 'F', 'G', 'G', 'G', 'G', 'G', 'H', 'H', 'H', 'H', 'I', 'I', 'I', 'I']))
new_cls = []
while True:
if not new_cls:
new_cls.append(cls.pop())
continue
if new_cls[-1] == cls[-1]:
random.shuffle(cls)
continue
new_cls.append(cls.pop())
if not cls:
break
for i in range(0, len(new_cls), 8):
chunk = new_cls[i:i+8]
schedule = {9 + key: val for key, val in enumerate(chunk)}
print(schedule)
In here what does 'chunk' and 'schedule' do exactly
@hollow bronze
was that a list or just the nums
chunk was assigned a portion of the new_cls list, and schedule is a dict constructed from it.
Oh okay
Thank you really for code and a lot of kindness. It was late here and i was tired so i decided to went sleep sorry.
I think that helps me a lot at this time. I will read about that segment tree and try to implement it because I need the fastest way to do that... :/
@haughty mountain Thank you to!
Is there a way to add two lists like the following?
[1,1,1] + [1,0,0] = [2,1,1]
It is very simple to do with numpy
Otherwise you could have a list comprehension like
[sum(x) for x in zip(a, b)]
I just thought you left because you didn’t show up for some reason when I searched your name here. I wanted to see if you asked in a help channel and had the question answered.
To be honest right know i'm trying implementing this second approach given by @haughty mountain but It doesn't work for me or I don't understand something.
I'm doing it right know just finding min with help of min() by python and then i will implement this segment tree, bacuse i want to know that works. Right know the answers doesn't satisfy the tests so it's not working 😛
Can someone look at this code and tell me what's wrong so far?
!e
L = [[1, 6], [5, 6], [2, 5], [8, 9], [1, 6]]
# Sort the data `(l, r)` by increasing `r` and decreasing `l`.
# That way the last element with a particular `r` is the biggest one.
L.sort(key=lambda x: (x[1], -x[0]))
# Group the data by ending point to make the rest of the code nicer
last_r = None
groups = []
for l, r in L:
if r != last_r:
groups.append([])
groups[-1].append((l,r))
last_r = r
# Naive for now, should be replaced by something like a segment tree
class RangeSum:
def __init__(self, n):
self.data = [0]*n
def sum(self, l, r):
# Sum over indices [l, r)
return sum(x for x in self.data[l:r])
def increment(self, i):
self.data[i] += 1
# Iterate through the groups. Add `l`-values to range query structure.
# Then check how many intervals start within the biggest interval in the group.
# These are all the intervals that are contained in the biggest interval.
answer = -1
S = RangeSum(100)
for group in groups:
for l,r in group:
S.increment(l)
l, r = group[-1] # biggest interval ending at r
n_intervals = S.sum(l, r+1)
answer = max(answer, n_intervals - 1) # We don't count the bigger interval
print(answer)
@glad vale @fervent saddle
@haughty mountain :white_check_mark: Your eval job has completed with return code 0.
3
That was the basic idea. I haven't tested it on examples other than the sample you gave, but I think the idea makes sense
I've already tested it for
L = [[61, 82], [24, 79], [10, 29], [31, 72], [2, 53], [56, 99], [6, 93], [43, 72], [9, 38], [4, 55], [2, 77], [7, 64], [22, 85], [7, 52], [41, 42], [23, 72], [9, 58], [28, 31], [53, 58], [3, 8], [6, 85], [47, 84], [30, 41], [27, 76], [10, 81], [36, 67], [61, 98], [35, 88], [6, 81], [20, 55], [9, 14], [35, 60], [34, 37], [43, 64], [6, 41], [56, 67], [82, 97], [72, 79], [6, 53], [71, 80], [1, 14], [80, 87], [38, 77], [60, 91], [6, 81], [68, 75], [1, 74], [24, 51], [17, 90], [28, 71]]
Output is 40 ant it's correct.
So right know let me sit and try to understand this masterpiece.
@haughty mountain Have you some books or courses that i can learn from? I've got a week to do this task but on the exam i will have only an hour so... 😅
Really thank you @haughty mountain . I owe you a beer
I don't know courses or good books on the subject, I've just solved enough competitive programming problems to remember some useful data structures and approaches to solve problems. FWIW I had to think for a bit before I found a reasonable solution that I was confident should work
The sorting by end point is actually quite common in a lot of algos dealing with intervals, so I guessed that would be part of it
Do you get the basic idea of it? Restrict yourself to all intervals with endpoints <= r. The intervals with starting points in the interval [l, r] are inside the [l, r] interval, which is the key thing we want to find out
I dunno if this is a data structures question or not but here goes:
Say that I have a class that initializes some list
self.something = [0,0,0]
when I instantiate this class, I want to be able to access an element of this list by calling an index of this object. For example
class CharArray:
def __init__(self, word):
self.word = word
self.wordArray = [0 for i in range(26)]
for char in self.word:
# enforce lowercase, subtract 97 to fix index to 0 for a, index 25 for z
self.wordArray[ord(char.lower()) - 97] += 1
a = CharArray("hello")
How do I enable the ability to access a[0], and make it access self.wordArray[0]?
!e
not a DS question, but you would implement __getitem__
class CharArray:
def __init__(self, word):
self.word = word
self.wordArray = [0 for i in range(26)]
for char in self.word:
# enforce lowercase, subtract 97 to fix index to 0 for a, index 25 for z
self.wordArray[ord(char.lower()) - 97] += 1
def __getitem__(self, i):
return self.wordArray[i]
a = CharArray("hello")
print(a[11])
@haughty mountain :white_check_mark: Your eval job has completed with return code 0.
0
ah sorry about that but thanks a lot for answering anyway
err, you don't populate the elements do you?
oh wait
it's a histogram of characters
thats right hehe
I wanna implement another function that can add two "CharArray" objects, and another that finds the difference between two by looking at the histograms
!e
I guess this should give 2 then
class CharArray:
def __init__(self, word):
self.word = word
self.wordArray = [0 for i in range(26)]
for char in self.word:
# enforce lowercase, subtract 97 to fix index to 0 for a, index 25 for z
self.wordArray[ord(char.lower()) - 97] += 1
def __getitem__(self, i):
return self.wordArray[i]
a = CharArray("hello")
print(a[11])
@haughty mountain :white_check_mark: Your eval job has completed with return code 0.
2
cool
I'm actually implementing this to solve a problem that I cant think of a good solution for
Given a list of words, return a list of words (if any), if they satisfy this condition: "there is another word in this list that has the same characters as this word, but one or more letters"
I think I understand. If I eat something I will try to see that on a example to be certain that I understand it.
make a set of the histograms for all words, then for all words in the set, try removing 1 from every non-zero count and see if that's in the set
O(n_words * alphabet_size) for the latter part
so ~26 * n_words
actually, I guess it's O(n_words * alphabet_size**2) because for every word, you will do (at most) alphabet_size set lookups, and hashing the histogram tuple is O(alphabet_size)
It sounds like I was on the right track!
Hey how to make this sort in partition form QuickSort ?
L.sort(key=lambda x: (x[1], -x[0]))

Any reason why you want to use quicksort?
It can be other sorting but i need to implement it by myself
I can't use build in methods like this
you could make your own comparison function and use that
def geq(x, y):
return (x[1], -x[0]) >= (y[1], -y[0])
instead of >=
Oh yea thats great
Thanks
And if i want to increase the speed I need to implement segment tree yep?
something that can answer "what's the sum in this range" quickly, yeah
And one more question. I don't know how big my integers will be so it's hard to allocate a precise range of RangeSum(N)
maybe there are neater approaches, but I can't think of anything off the top of my head
do you know any upper bound?
In my test which are given by lecturer integers are

But the trick is that te test sepcifications can change when he will test it
A correct answer
There are 10 test and each have this specification \
like max_int was
so there is a fairly common technique for not having to deal with large values, coordinate compression
I think the approach with a structure where i can do .append() will help there or it isn't?
basically take all of your l and r values and put them in a set (to remove duplicates) and then sort them, so you have something like
[l2, l1, r2, ...]
```and then make a mapping
{
l2: 0,
l1: 1,
r2: 2,
...
}
now you can transform all your l and r values using this
Hmm sounds really well, but i can't use sets, dictionares and etc. If i want i have to implement everything by me own
importantly, this transform doesn't change the structure of the intervals
but it will make your biggest value be < 2*n
are you really banned from using stuff like sets and dictionaries?
It's good to know
Yep
Previously i was trying to do this task with hash-map implementet by my own but it doesn't work well
And hash-map has a risk of being O(n^2) so i will stick with your approach but now the structure must be implemented
the set usage can be removed easily, deduplicating isn't hard if things are sorted
the mapping part is more annoying
I guess you could binary search the list instead, what you're looking for is the index of the value
but yeah, this change you can add on later, it's completely independent from the rest of the solution
But will i have a sorted array to do that and get proper value?
you put all l and r in a list, sort the list, and go through and remove duplicates
Test 3
Entry intervals: [3229, 9570], [5019, 5144], [2462, 5945], [628, 6055], [1402, 4821], [1795, 4448], [7414, 8961], [1692, 3103], [3069, 96[too long]...
Correct answer: 9767
Result of the algorithm: 9767
!!!!!!!! TIME LIMIT EXCEEDED
Approximate time: 2.19 s
The limit is 1s xD
This is without the segment tree, right?
Yep
There is also https://en.wikipedia.org/wiki/Fenwick_tree which can do range sums
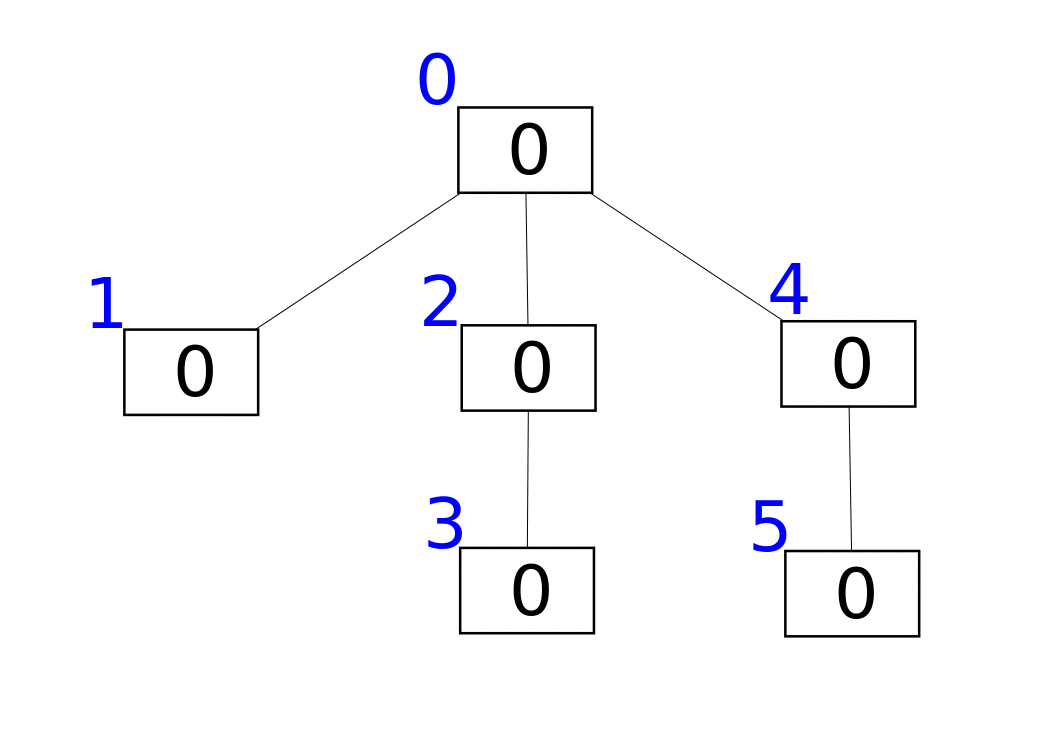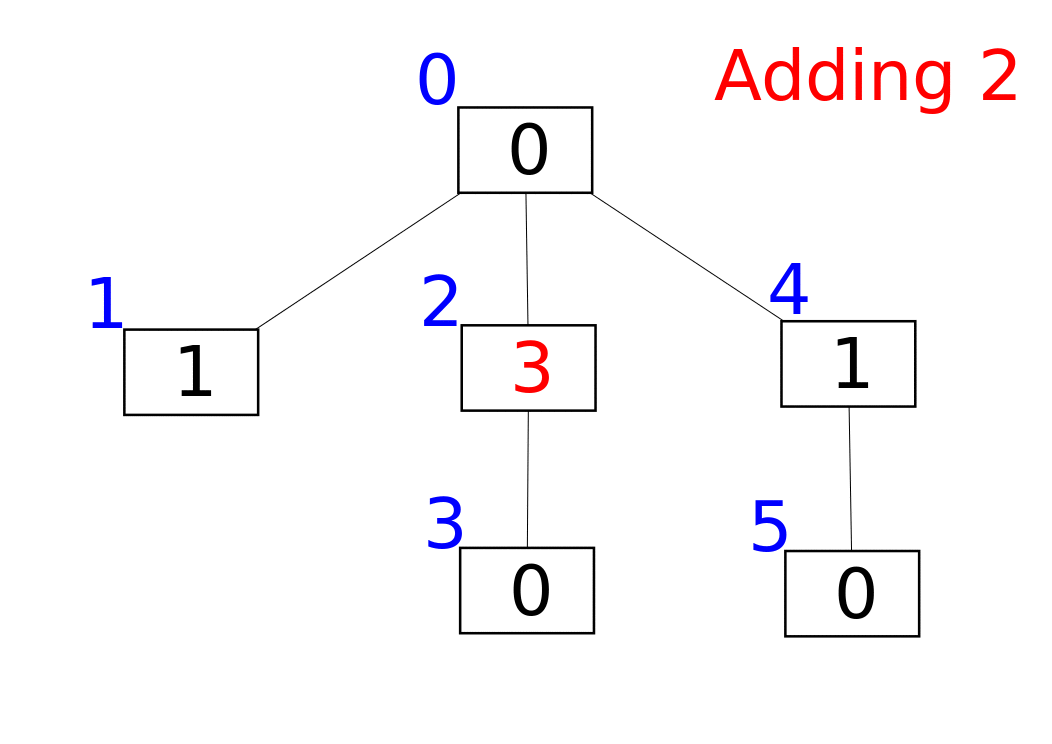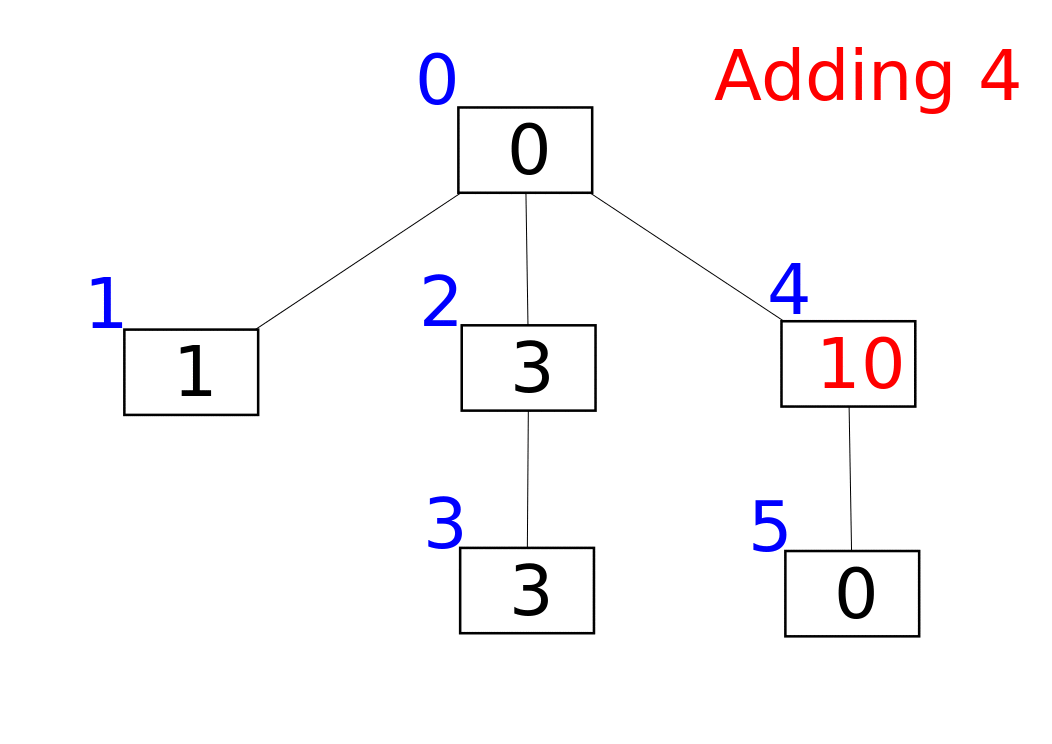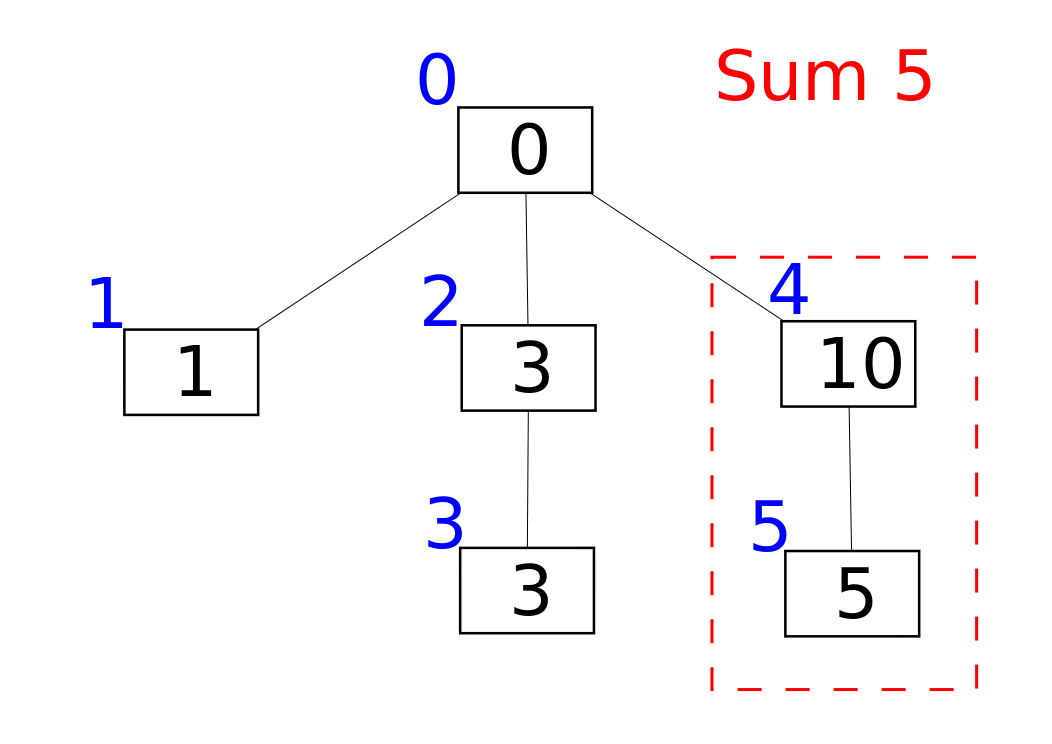
A Fenwick tree or binary indexed tree is a data structure that can efficiently update elements and calculate prefix sums in a table of numbers.
This structure was proposed by Boris Ryabko in 1989
with a further modification published in 1992.
It has subsequently become known under the name Fenwick tree after Peter Fenwick, who described this str...
it's harder conceptually to understand than a segment tree though, at least for me
I will try to implement segment tree and will tell you what about the time of the tests
At first i have to familiar with that structure so it will take a while
It's pretty nice that the operation you want to do is simple (sum of a range). So you can start with something that is correct (the code I posted earlier) and add stuff on top of that
Like making the range sum faster
And compressing the coordinates
Nice small iterative improvements
So conceptually, the leaves in the trees will be the current array, and all roots of subtrees contain the sum of the leaves below it
If you want to change a value you change the leaf value and then propagate the value to the nodes on the path to the root
Those O(log(n)) nodes are the only ones affected by the change
It's a binary tree, but you're better off not using a class structure for this
you can store node values in a list
e.g. the root value is at data[1] the children are at data[2] and data[3] (in general the children of i are stored at 2*i and 2*i+1)
Isn't it 2i + 1 and 2i +2 ?
no?
Hmm, with the heap was like that to get the left right, 🤔
for the query part it's nicer to think of the thing as computing two sums, the sum of range [0, l) and the sum of range [0, r)
and the answer is the second minus the first
not if you do 1-based indexing
Okey so the 0-index is just empty
for convenience, yes
Ok!
1 indexing is a lot easier to think about in this case
but yeah, the memory layout of the tree is the same as it would be for a binary heap
I need to make the separate segment tree to each group?
no, the segment tree should contain all starting points for intervals ending at <= r
which r?
you go in increasing order of r through the intervals
that current r as you traverse
the point of going in increasing order of the endpoints r is that you only need to add a few points (the ones with the current endpoint) to the tree
So all of your program is to delete only the sorting is here with this approach
wdym?
how to work out gradient of line. i made this graph with some code on python

That the grouping is no needed and the loop where is summing no needed
Just need to go through list and add starting points to the tree yes?
you can technically skip the grouping yes, but in that case the sorting order is super important, and the fact that the algo is correct is not as obvious
e.g., if you hadn't sorted decreasing in the starting point as a tie-break things would break
I will try to implement this. The dead line is to 00:00 if I won't have a working code can i please ask you for implement this code and send my it? 🥺
if you don't group things then for all elements that would have been in the group you only get the correct range sum for the last one
which happens to work out with the sorting order I described
the more sensible way is to add everything with that end point, after which querying ranges will give the correct answer
that's the point of the grouping
and then I only really need to query for the largest interval in the group
though I could have queried all intervals in the group if I wanted to
(though that's just wasted work)
That task is really tough for me. Previous one with linked list's was even easier than this
!rule 8 @glad vale
8. Do not help with ongoing exams. When helping with homework, help people learn how to do the assignment without doing it for them.
from what I can tell it's homework
and yes, I'm not going to give full code for any homework task
how does it compare the indices of the list?
@spark sun Please stop repeating this question excerpt in multiple channels. You should see #❓|how-to-get-help, claim your own channel and ask the full question in your own channel.
I am sorry, I get it
Anyone doing DSA? Beginner level?
I'm still learning the concepts of DSA in python!
Hello folks, I'm currently doing 240. Search a 2D Matrix II on Leetcode
def searchMatrix(self, matrix: List[List[int]], target: int) -> bool:
m = len(matrix)
n = len(matrix[0])
r,c = m-1,0
while r >= 0 and c < n:
if matrix[r][c] == target:
return True
if matrix[r][c] < target:
c += 1
else:
r -= 1
return False```
I pretty much know how this algo is working, am just a little lost on this particular line of code
`while r >= 0 and c < n:`
I think its just making sure that algo stays within the matrix, in other words it doesn't go out of bounds ( if that makes sense lol). I just need a little more help on how that particular line of code is workingHey @haughty mountain I have a segment tree with starting points filled. How to use advantage of that? When I'm doing
answer = -1
for group in groups:
for l, r in group:
answer = max(answer,tree.get_sum(l,r))
I'm obviously getting an error because of r index out of range
I have a tree with a starting point's which looks like [17, 9, 8, 7, 2, 8, 0, 2, 5, 1, 1, 8, 0, 0, 0] for that example
L =[1, 6], [5, 6], [2, 5], [8, 9], [1, 6]
And how with this information count how many intervals are contained?
The point is to build the segtree incrementally
you add nodes in increasing order of r and query as you go
that part is crucial
if you add all start points and then query then you can get start points you don't want, e.g. if you're looking at interval [l, r] then you don't want start point L
l r
[ ]
L[ ]R
literally replace the RangeSum with a segment tree here
I very deliberately made the class have the same kind of interface as a segtree would
it's seeing if the algorithm (namely the c += 1 and r -= 1 lines) ever push the current search position [r][c] off the matrix, and if it does you know you the target is not present.
Note that r starts at the last row and does r -= 1 so it will only go off the matrix at r < 0, likewise c starts at 0 and goes += 1 so it gets out of bounds at c >= n
Uh so I need to store a +1 value on a index of l not the specific l in tree. And need to makes a function that will update the tree after increasing for example tree[l] += 1 has to propagate the +1 to whole tree in certain range?
Helllo,
I have this regex (Desired\sHours\sfor\sInterviewing:\s)([A-Z][a-z]+\s([0-9]{1,2}(pm|am)\s-\s[0-9]{1,2}(pm|am)))
to match
Desired Hours for Interviewing: Afternoon (12pm - 4pm)
this kind of structure
I get multiple repeat at position 34 error, can someone tell me why?
hello, can anyone help me?
I have the following data structure:
and I want to extract all the keys and then their values, so that I can write them in the elastic search database.
{'cod': '200', 'message': 0, 'cnt': 2, 'list': [{'dt': 1647777600, 'main': {'temp': 279.44, 'feels_like': 275.65, 'temp_min': 279.44, 'temp_max': 281.23, 'pressure': 1039, 'sea_level': 1039, 'grnd_level': 1024, 'humidity': 32, 'temp_kf': -1.79}, 'weather': [{'id': 800, 'main': 'Clear', 'description': 'clear sky', 'icon': '01d'}], 'clouds': {'all': 0}, 'wind': {'speed': 6.08, 'deg': 97, 'gust': 7.4}, 'visibility': 10000, 'pop': 0, 'sys': {'pod': 'd'}, 'dt_txt': '2022-03-20 12:00:00'}, {'dt': 1647788400, 'main': {'temp': 280.51, 'feels_like': 277.51, 'temp_min': 280.51, 'temp_max': 281.49, 'pressure': 1038, 'sea_level': 1038, 'grnd_level': 1023, 'humidity': 30, 'temp_kf': -0.98}, 'weather': [{'id': 800, 'main': 'Clear', 'description': 'clear sky', 'icon': '01d'}], 'clouds': {'all': 4}, 'wind': {'speed': 4.83, 'deg': 89, 'gust': 6.4}, 'visibility': 10000, 'pop': 0, 'sys': {'pod': 'd'}, 'dt_txt': '2022-03-20 15:00:00'}], 'city': {'id': 792680, 'name': 'Belgrade', 'coord': {'lat': 44.804, 'lon': 20.4651}, 'country': 'RS', 'population': 1273651, 'timezone': 3600, 'sunrise': 1647751307, 'sunset': 1647794973}}
this is a short structure for last 2 days , the ultimate goal is to extract the history of the weather and do some analytics.
I can get weather in the last 70 years
@haughty mountain Yep i did that and it works but for big numbers it's too slow. But better 8/10 passed than 0/10

for n,max_int,answer = (10**5, 10**5, 99523) (the 8th test ) , it works 3.97 sec on my pc so for 1.97 sec to long.
Firstly I'm looking for the biggest integer to know how big tree i need.

Why is it that initializing 2D array in this two different ways also results in different output? I'm confused and don't know what words to type on google to hopefully get answers. ```"""First code"""
arr = [[] for i in range(2)]
arr[0].append(5)
print(arr)
Output: [[5], []]
"""Second code"""
arr = [[None]]*2
arr[0].append(5)
print(arr)
Output: [[None, 5], [None, 5]]
the second way, (using *), copies all the references, so you get a list with a bunch of references to the same list inside. that's why when you edit one, you see the changes in the others
Oh! So that's why. Thank you so much @agile sundial
the first way is actually making 2 lists
guys so im implementing uniform cost search algorithm in python.. graph implementation is done using dictionary of dictionary. I want to make my own priority queue which takes the key value of a dictionary and then traverses dictionary in it and sorts it using value as cost. after that i want to extract the first item is there any way to do it. im really new to python and this is such a kick in the balls for me. let me know if someone could help me.
Any idea how to speed up this sorting?
def QuickSort(arr,l,h):
while l < h:
q = partition(arr,l,h)
QuickSort(arr,l,q-1)
l = q + 1
return arr
def partition(arr,l,h):
pivot = arr[h]
i = l - 1
for j in range(l,h):
if (pivot[1],-pivot[0]) >= (arr[j][1],-arr[j][0]):
i += 1
arr[i],arr[j] = arr[j],arr[i]
arr[h],arr[i + 1] = arr[i + 1],arr[h]
return i + 1
perfectly explained 🤟
How does this work ```py
def climbStairs(self, n: int) -> int:
def dp(i):
"""A function that returns the answer to the problem for a given state."""
# Base cases: when i is less than 3 there are i ways to reach the ith stair.
if i <= 2:
return i
# If i is not a base case, then use the recurrence relation.
return dp(i - 1) + dp(i - 2)
return dp(n)```
I understand generally how recursion works, but wouldn't this just always return 1 or 2?
Oh neat okay.
I have a array of dicts arr = [{}] How do I access a key from a specified dictionary, like I want the value of "key1" from the dict with the index 2, is it possible?
arr[2]["key1"]?
Oh right, thanks, I thought something else
What's the best site to learn DSA ? Leetcode, geeks for geeks, project Euler, algo expert or what do you recommend me guys?
Any/all of the first 3, also the free MIT course in the pins (and other pins)
I wouldn't really say project euler is great for learning about algorithm and data structures. It doesn't really teach anything about it and you're on your own to learn about it to solve the problems
Free courses from MIT or any lecture really should be good
Where do I find this course from MIT? On YouTube? I saw videos from 2014. Is this it?
class Solution:
def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
# returns True if the digraph
# rooted at 'course' is cyclic.
def dfs(course):
if course in path:
return True
if not graph.get(course):
return False
path.add(course)
for nei in graph[course]:
if dfs(nei):
return True
path.remove(course)
graph[course] = []
return False
graph = {}
for course, prereq in prerequisites:
graph.get(course, []).append(prereq)
path = set()
for course in range(numCourses):
if dfs(course):
return False
return True
Is this O(2n)?
aka linear complexity?
Intro to algorithms 6.006 is the main one but there are others (the pins in this channel link to it). I watches the one from 2013 https://www.youtube.com/watch?v=HtSuA80QTyo but there's a 2020 version too
def longestConsecutive(self, nums: List[int]) -> int:
MAX = 0
aset = set(nums)
for x in nums:
if x - 1 in aset: continue
# x is a left border of a range
count = 0
while x in aset:
count += 1
x += 1
MAX = max(MAX, count)
return MAX
``` is the time complexity for this O(n) and space complexity is O(n) too?actually, it might not be
a case like [1, 1, 1, 1, 1, 1, 1, 1, 2, 3, 4, 5, 6, 7, 8, 9] (with n/2 lowest value n/2 with the rest of increasing sequence) will be O(n^2)
you can change it to iterate over the set instead of the list to fix it
Hello folks, currently doing 91. Decode Ways on Leetcode and its a DP question. I'm still struggling a little or a lot with these types of questions lol
def numDecodings(self, s: str) -> int:
if not s or s[0] == "0": return 0
if len(s) == 1: return 1
N = len(s)
dp = [0]*N
dp[0] = 1
for i in range(1,N):
singleDigit = int(s[i])
doubleDigit = int(s[i-1:i+1])
if singleDigit >= 1 and singleDigit <= 9:
dp[i] += dp[i-1]
if doubleDigit >= 10 and doubleDigit <= 26:
if i-2 >= 0:
dp[i] += dp[i-2]
else:
dp[i] += 1
return dp[-1]```
I'm having trouble understanding the logicdef numDecodings(s):
if s[0] == "0": return 0
if not s: return 1
total = numDecodings(s[1:]])
if len(s) > 1 and int(s[:2]) < 27: total += numDecodings(s[2:]])
return total
@idle pier
and then you also make a dictionary "string → int" to cache the results and it works
recursion makes it ugly but it shows the structure better since you're struggling
So dp[i] is the number of ways to decode a string that uses the string up to and including index i.
A bit of a side-note, the code initializes dp[0] to be 1 which I don't particularly like since it's basically hard-coding the treatment of the first character, I would rather see dp[0] corresponding to the empty string and dp[i] being the value if you use i characters.
In any case, the basic update rules are then
if the digit at i is a valid character,
we can extend the strings ending at i - 1:
dp[i] += dp[i-1]
if the last two digits ending at i is a valid character,
we can extend the strings ending at i - 2:
dp[i] += dp[i-2]
the fumbling they do with the if with the += 1 is there exactly because they let dp[i] not correspond to the empty string
the checks for special cases in the beginning is also a bad sign, since none of those are really special cases
Here is a rewrite that is more to my liking. It uses the dp value at 0 to be the empty string, which removes some logic in the loop. It removes all the special cases in the beginning. I also modify the input string slightly to not have to treat the first iteration in a special way.
def numDecodings(s: str) -> int:
n = len(s)
# ways[i] = number of encodings using the first i characters
ways = [0] * (n + 1)
ways[0] = 1
# To simplify logic and indexing, add a '0' at the front.
# It doesn't change the digit value, and '0X' is not an ok 2 digit number.
s = '0' + s
for i in range(1, n + 1):
singleDigit = int(s[i])
doubleDigit = int(s[i - 1:i + 1])
if 1 <= singleDigit <= 9:
ways[i] += ways[i - 1]
if 10 <= doubleDigit <= 26:
ways[i] += ways[i - 2]
return ways[-1]
assert numDecodings('0') == 0
assert numDecodings('1') == 1
assert numDecodings('12') == 2
assert numDecodings('226') == 3
assert numDecodings('06') == 0
ignoring the asserts for the test cases and the comments this is not only cleaner, but also shorter by 4 lines
I have a function in the discord bot - a casino and such a mistake. for example, I put 50 coins and I do not have them, he still writes or - coins or + coins and it turns out -coins as it can be done so that when I wrote there 50 coins and I do not have them so that it brings me the mistake that is not fashionable in you do not have enough funds if I work with a database SQLITE3
this is not the right channel for this


we're not giving your code, it's easy enough for you to research about connected components in graphs and doing it yourself https://en.wikipedia.org/wiki/Component_(graph_theory)#Algorithms

In graph theory, a component of an undirected graph is a connected subgraph that is not part of any larger connected subgraph. The components of any graph partition its vertices into disjoint sets, and are the induced subgraphs of those sets. A graph that is itself connected has exactly one component, consisting of the whole graph. Components ar...
what's a hash function besides identity that doesn't depend on %, that could reasonably be implemented in python? wiki has stuff like this but it depends on the word size of the machine
// https://en.wikipedia.org/wiki/Hash_function#Multiplicative_hashing
unsigned hash(unsigned K) {
return (a*K) >> (w-m);
}
(yes I realize there's a builtin hash function, I'd like to know of a second hash function besides mod division)
if you are ok with working mod a power of 2 you can use a bitwise and
Is a dynamically sized array amortized O(1) as long as it’s increasing by a percent of the previous size? Like if you make it 1% larger than the previous size, is that still O(1)? Or is there some minimum percent it needs to increase by?
as long as it's geometric growth with a factor >1 then yes
Thanks both of you
As a rough argument:
If you have n elements and resize with a factor k the cost is roughly n*k to add roughly n*(1 - k) items.
The cost per added item is roughly n*k/(n*(1-k)) = k/(1 - k) which is a constant.
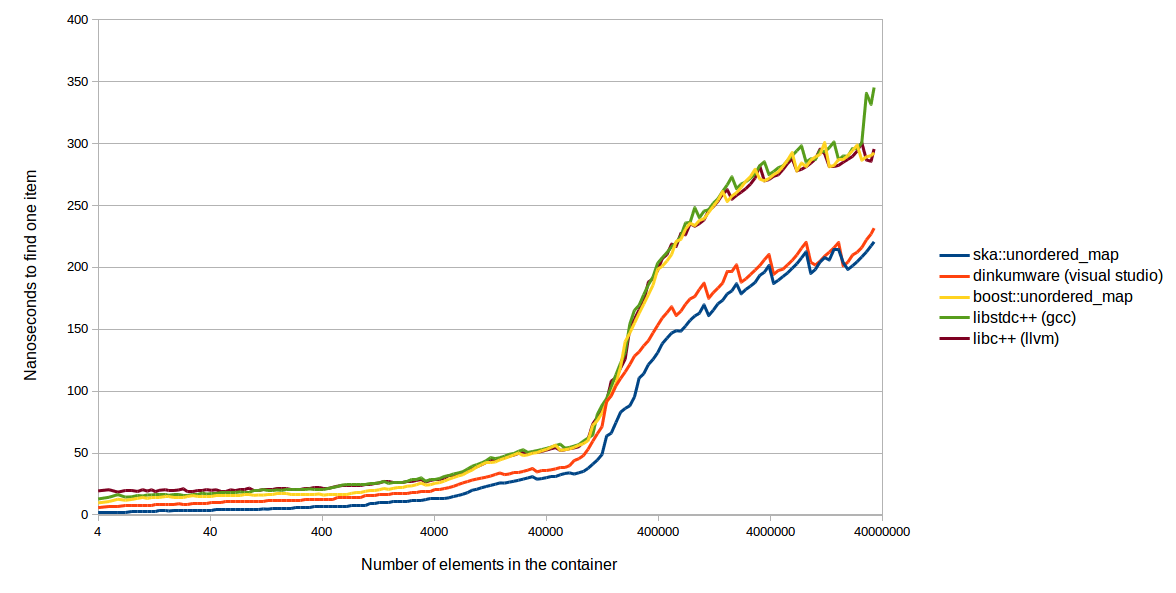
I recently posted a blog post about a new hash table, and whenever I do something like that, I learn at least one new thing from my comments. In my last comment section Rich Geldreich talks about h…
:incoming_envelope: :ok_hand: applied mute to @fiery cosmos until <t:1647901359:f> (9 minutes and 59 seconds) (reason: duplicates rule: sent 4 duplicated messages in 10s).
No, no you won't 😄
A bit silly question, but I'm a bit on a dilemma: should I be creating enum witch contains only two options as a paremeter for a sql-model. ? 😄
bool on the other hand feels less readable in this situation and naming for such property would end up being something like "is_something' - which feeels wrrooong xddd
Write code for people to read. Machines will understand the underlying implementation details.
I would be surprised if a bool or a 2 option enum would be any different memory-wise, so just use what's more sensible for your case
I recall using enums for my Red-Black tree implementation and did not see a huge memory difference instead of using a boolean
if you're storing a true/false thing then go with bool, if you're storing something with two states that isn't natural as a true/false value then enum sounds like a good idea
red-black tree in sql? this is about storage types, no?
Right, the question in OP is about sql, which is what I was talking about memory-wise
I suspect an enum class in python will be substantially larger than a boolean
yeah, seems like that's the case for sure
In [9]: class A(enum.Enum):
...: FALSE = 0
...: TRUE = 1
In [10]: sys.getsizeof(A.TRUE)
Out[10]: 48
In [11]: sys.getsizeof(True)
Out[11]: 28
Neat. Learned something new
So why does a list of those enums and bools give the same size with sys.getsizeof?
!e
import enum
import random
import sys
class A(enum.Enum):
FALSE = 0
TRUE = 1
list1 = [[True, False][random.randint(0, 1)] for _ in range(10000)]
list2 = [[A.TRUE, A.FALSE][random.randint(0, 1)] for _ in range(10000)]
print(sys.getsizeof(list1))
print(sys.getsizeof(list2))
@lament totem :white_check_mark: Your eval job has completed with return code 0.
001 | 85176
002 | 85176
Because lists are arrays of PyObject pointers. And pointers have some size that does not depend on the size of the item being pointed to.
>>> x = [[1, 2, 3] for _ in range(10000)]
>>> y = [1 for _ in range(10000)]
>>> import sys
>>> sys.getsizeof(x)
85176
>>> sys.getsizeof(y)
85176
>>>
Ah alright, so the problem is that sys.getsizeof doesn't actually show the allocated space for the items themselves right? @opal oriole
Yes.
makes sense, thx!
>>> sys.getsizeof(x) * sys.getsizeof(x[0])
10221120
>>> sys.getsizeof(y) * sys.getsizeof(y[0])
2384928
>>>
>>> 10221120 / 2384928
4.285714285714286
>>>
Lists also have extra book keeping (not that much though).
So you can do stuff like len(my_list) in O(1).
(It all being pointers is also why you can have mixed types in lists)
Good night, guys. Could you tell me if you have any way to sort the elements of a list without using ready-made functions like sorted() and append()?
you could write your own sort algorithm using list indexing if you had to. (btw, in English, "good night" always means "goodbye")
Thank you, master. Good night.
Why do you want to do this without in-built functions if I may ask?
I'm working out some college list, and one of the rules is not to use the ready-made functions.
Any suggestions on how to solve systems of differential equations on GPU using Python? Are there any packages like SciPy that offer this functionality on the GPU?
but fibonacci hashing just a form of multication hashing:
In fact, Fibonacci hashing is exactly the multiplication hashing method discussed in the preceding section using a very special value for a. The value we choose is closely related to the number called the golden ratio. https://book.huihoo.com/data-structures-and-algorithms-with-object-oriented-design-patterns-in-c++/html/page214.html
unsigned int const w = bitsizeof (unsigned int);
// ...
unsigned int h (unsigned int x)
{ return (x * a) >> (w - k); }
so it still depends on the word size, i can't implement this in python because integers dont have fix bit lengths right?
Here are some options: ```py
232-1 & 0xffffffff
4294967295
232 & 0xffffffff
0
232+1 & 0xffffffff
1
import ctypes
x = 232
x
4294967296
y = ctypes.c_uint32(x)
y
c_uint(0)
y.value
0
If you can have numpy, then you can use it too.
(It should probably be uint64 though, 64 bit is common now, or you can just detect it once at the start)
However, the speed gain given by having it match the word size only really applies in lower level languages, or if you are maybe hashing a numpy array of x's in which case you can have h be vectorized by simply passing in the numpy array as x and having it be dtype=np.uint64.
In order for things to be fast for numeric computation you need fixed size values. And Python does not have those by default. Numpy gives you that (or array.array (builtin) or ctypes).
(multiplication and binary and is still a lot faster than modulus (as long as W=2^w is a power of two you can use binary and))
Hi
def hash_square(x: int) -> int:
return ((x * x) & 0xFFFFFFFF) >> (w - k)
right okay this matches what I was getting in c++ ill try the fib now
hi. newbie here.
i wanna write a script that is able to determine the demand zone of a crypto chart over a period of time. do i have to know ML or can i pull it off without it?
hi guys, did anyone else incounter a pillow error when trying to install easyocr?
Hi there!
While I'm sorting integers/alphabets from a randomly ordered list
I'm supposed to use their ASCII values right?
What's a demand zone of a crypto chart?


In pydis, you do not spam the server, the server spams YOU
does anyone here know the difference between Top Down and Bottom Up in Dynamic Programming
as an example, calculating the nth fibonacci number top down uses the recurrence f(n) = f(n-1) + f(n-2) recursively, i.e. you look at f(n) and realize you need the answer to subproblems f(n-1) and f(n-2), so you recurse to solve them.
Bottom up is starting at the bottom, from the smallest problems, and working upwards. E.g. you can start with the list of initial values [0, 1] and just work upwards applying the recurrence f(n) = f(n-1) + f(n-2). You can directly calculate the next value, since you know the smaller problems you need have already been calculated.
In this case the second version is nice because you can easily write an iterative solution and you don't have the overhead of recursion, you can also easily optimize the latter solution to use way less memory since you really only need the last two terms.
good joke (if it is)
Got it! Thanks
Hi there!
While I'm sorting integers/alphabets from a randomly ordered list
I'm supposed to use their ASCII values right?
that is one way to do it
problem is to sort integers/alphabets given a list of randomly ordered integers/alphabet. This is the original statemnt
I am assuming that these don't include alphanumeric numeric
so any idea? :)
I'm not at all involved with crypto my man!
But I guess you'll have to use ML
Does nums[::-1] return a new array?
yes, if you want to reverse a list in-place use list.reverse()
im not sure if this is the correct channel to ask this in but, if i for example have a string like this "12497812\n032305987235\n0329842390\n094094230\n3254325"
how can i put a this line"|" before each of these "\"
i suppose i need to do some type of slicing but i just have no idea where to begin with
this is probably a really dumb question, apologies 💀
re.sub(r'(\n)', r'|\n', yourString``` it should workit means raw strings
oh
basically u are looking for that exact match
ooh i see how it works
and not a weird regex that would match other words
thanks a lot !
welcome
i appreciate it and again, apologies for the stupid question
there no stupid question, only stupid answer XD
well-
technically yea thats true xd
still tho, thanks a ton, i was bugging my head on this problem for like, 2 hours
i mean i could have googled it , i did at some point but the stackoverflow post didnt rlly help, u helped tho so <3
avg case worst case
Intersection s&t O(min(len(s), len(t)) O(len(s) * len(t))
what's the algorithm for set intersection in python, or is it just a simple iterate through the sets? so it's O(min(len(s), len(t)) if for some reason every element of the two sets (up to the length of the shorter set) are the same (and thus in the same order), and O(len(s) * len(t)) if it has to iterate through the other set every item to find the match?
Hey @old musk!
It looks like you tried to attach file type(s) that we do not allow (.pdf). We currently allow the following file types: .gif, .jpg, .jpeg, .mov, .mp4, .mpg, .png, .mp3, .wav, .ogg, .webm, .webp, .flac, .m4a, .csv, .json.
Feel free to ask in #community-meta if you think this is a mistake.
Python Practice
We have two files (Agent.py and Test.py)
Agent.py from datetime import datetime from enum import Enum, IntEnum class Action(IntEnum): Breakfast = 1Lunch = 2 Dinner = 3 Sleep = 4 Gym = 5 Class = 6 Church = 7 Television = 8 River = 9 class Agent: #agent class def init(self, initialstate): self.state = initialstate pass def sense_world(self, dt, sick): return self.state def perform_action(self): if self.state == Action.Lunch: return "I am eating lunch" elif self.state == Action.Breakfast: return "I was eating breakfast"
Test.py from Agent import Action, Agent from datetime import datetime from enum import Enum, IntEnum testAgent1 = Agent(Action.Lunch) testAgent = Agent(Action.Breakfast) d1 = datetime(year = 2020, month = 2, day = 25, hour = 15, minute = 55, second = 59) print(testAgent.sense_world(d1, False)) print("My shcedule for the day is exactly at : " + str(d1)) print(testAgent.perform_action()) print(testAgent1.sense_world(d1, False)) print("My shcedule for the day is exactly at : " + str(d1)) print(testAgent1.perform_action())
INSTRUCTIONS
The above code when executed prints the output without allowing the user to input the values during execution.
However, I am expected to modify the code to allow input during execution. My program should accept the input and print the strings in the comments based on the state of the agent.
e.g INPUT => action=input(“enter your action”)
action=1
OUTPUT=> I was eating breakfast
actually I must be wrong if s&t is O(min(len(s), len(t)) in the average case
i need help with this question
oh i got it, it's upper bound is if you have to search the hash table buckets, lower bound is O(1) checks

how to read just the confirmed
or take it as a parametre
for confirmed in covid_cases(country): to make a statement like this valid
Could someone tell me how to sort a list created during the execution of the program? Using the for and range function?
are you familiar with any sorting algorithms?
How to sort() function?
after inserting the elements with int(input()) I call the list.sort() without using print?
python
@sterile cape let me flex hang on

(had to send here because it wont let me send images in pygen)
#ot0-psvm’s-eternal-disapproval exists yknow
I was able to solve it. Thanks.
Please help
hi anyone have any idea about card expiry validation in python. please let me know
i am using mm/yy, mm-yy format to validate the date and taking input from user. please help me
if anyone here is experienced with xml parsers i could use a hand real quick down in falafel
how would i use binary search to find the maximum value of a nondecreasing then a nonincreasing function?
Hi, so what I'm trying to do is like the complete Value is [50] and my Value is like [40] and want a way to like if its less or more by 10 return "True" I hope you get the idea
A function that is first non-decreasing and then non-increasing function? I.e. a function with a single peak (if any)? I don't think you can do that with binary search, e.g. a case of just the same value repeated is a really bad case
for increasing followed by decreasing you can do it, you can just check the "slope" around you to know the direction of the peak
ok cool
I'm trying to learn some graph algorithms on my own right now and am struggling on kruska's algorithm
the question I have is as follows: If we are able to find constant time implementations of find-set and union, would that change the runtime?
Guy's i am looking for a tutorial where I can practice and understand data structure and algorithm through python projects. Please help me
leetcode
Ok, let me check 
@fiery cosmos hey, i cant find any project based tutorial on LeetCode where I can practice ds and algo . Would you please help me to find that site?
A link will be great
well they have these courses on leetcode
if you go to learn
Uou mean study plan?
sure

LeetCode Explore is the best place for everyone to start practicing and learning on LeetCode. No matter if you are a beginner or a master, there are always new topics waiting for you to explore.
in here they have courses for learning data structures by solving problems

Does any know how yo fix
?
it would change the asymptotics, yes
(assuming things are already sorted, otherwise the sorting dominates the time complexity)
yeah the sorting still dominates which is what I was trying to say
like I don't think it would change
but my friend said it would
another quick question: If I tranpose a graph, are the SCCs the same, or just the number of SCCs
if the edges are already sorted and you just consider the main algo, that does change
I see, he might have been talking about that, in which case it goes from log linear to just linear
not log, disjoint set union can be written better than that
amortized O(α(n)) where α is the inverse ackermann function
it's basically a constant
wait @haughty mountain another quick question, I asked it above, if we take the transpose of a graph will it have the same SCCs as the regular graph or just the same number of SCCs
I think they must be the same?
reversing all edges for sure doesn't change the connectivity within each component
I think they have to be the same
because an SCC is when we have a digraph and there are paths between two nodes
when we reverse these paths, the path going from one to the other becomes reversed
so we still maintain paths to get to each component
but the paths are switched
right, all the paths A to B will still exist, they just go from B to A now
and things are in the same component if paths A to B and B to A both exist
so things should be maintained
yeah
what is the purpose of an indirect heap?
def inorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
if not root: #
return []
queue = collections.deque([(root, root.val)])
output = []
while queue:
currnode, currval = queue.popleft()
print(currnode)
if currnode:
output.append(currval)
if currnode.left:
queue.append((currnode.left, currnode.left.val))
if currnode.right:
queue.append((currnode.right, currnode.right.val))
return output
trying to make a bfs inorder traversal
currently it's just returning what I'm guessing is pre order...well not really, not sure what my code is doing
@dreamy kayak
I suppose for a tree you don't have to worry about already seen nodes. A list would probably have been fine here and just used a dfs approach instead no ?
ah wait, nm, you want inorder, so bfs?
I want to practice using bfs
64
/ \
/ \
4 66
\ \
37 70
/ \
8 51
/ \
6 12
\
21
so your code should be top to bottom L to R ?
64, 4, 66, 37, 70... etc ?
idk
well ping me if you get stuck or have any questions. One thing that stands out, you could rewrite your traversal as a generator function which might be useful.
I'm just trying to write BFS for in-order traversal
in-order traversal means left-node-right
and yes it starts with the bottom-most and left-most node.
my code above is doing level-order traversal
I believe it is BFS
but not in-order traversal
maybe it's too hard to use BFS for in-order traversal
probably I would have to assign values to the levels and stuff
What order did you expect the values to be outputted based on the diagram I listed above?
I'm lost as to what order that is. Aren't you starting at the root node? 64?
Good night. To print the sum of an integer of a given sequence is it more indicated to use the while?
Python has the builtin sum method that can sum most sequences for you. I'd use that if possible 
Thank you
I listed the in-order traversal as I understand it
no you're not starting from the root node in in-order traversal
starting from the root node(s) is called pre-order traversal
Yeah, but the root node is the only one that can see all the other nodes. So you have to start there. But you're just resolving them from the bottom?
Like if you start with a leaf node, it has no children and you're done.
Maybe what you really want is a dfs that gets the left children then itself, and then the right children?
that's why you have to use some data structure to store the nodes
you're then returning the output from that data structure.
I wanted to use BFS, not DFS
I understand the DFS solution already, it's really easy actually
def in-order(tree):
output = []
def traverse(tree):
if not tree:
return
traverse(tree.left)
output.append(tree.val)
traverse(tree.right)
traverse(tree)
return output
I wanted to know if it's possible to do using BFS
I'm assuming this is about not storing the actual data in the heap? I guess it makes sense in languages with value types. E.g. if you have huge objects, it can be very expensive to copy/move/swap elements around in the heap. By introducing the indirection the work modifying the heap gets cheaper

how can i do this ?
i=145
s=str(i)
a=[]
sum=0
for i in s:
a.append(int(i))
for i in a:
sum=sum+pow(i,(i+1))
print(sum)
def tree_depth(node):
if node is None:
return 0
return 1 + max(tree_depth(node.left), tree_depth(node.right))
how does this work?
the depth of any node is 1 + depth of its left/right subtree (whichever is larger)
ik that but how does max(tree_depth(node.left), tree_depth(node.right)) this work?
it recursively calls the function to find the depth of its left subtree and its right subtree
then it chooses the one which is larger
yea but node.left and node.right are generator objects
how do it compare between them
idk how am I stuck at this super easy thing
why would they be generator objects?
it literally just prints generator objects
when I print outside
<__main__.Treenode object at 0x0000022169F78400>
yea so how is it compared
using max()
tree_depth is called on the left and right nodes, which returns an int for each
so max receives two ints
but how does it returns int like I am not doing anything int thingy in the code
you return 0
when it reaches a leaf node, it returns 0
it returns 1+index of leaf, but how
and other nodes return 1 + depth of left/right
np
HI!
I have a given problem.
TL;DR
We have to sort T array knowing that the numbers from this array are from fixed intervals [ai, bi] and we have given probability (Ci) of each interval. The probability tells us that a number from a given range will end up in the array.
We are given a N element array T of real numbers to sort, in which the numbers have been generated from some random distribution.
This distribution is given as k intervals
[a1, b1],[a2, b2], . ,[ak, bk] such that the i-th interval is chosen with probability Ci and a number from the interval (x ∈ [ai, bi]) is drawn according to a uniform distribution. The intervals
may overlap. The numbers ai, bi are natural numbers from the set {1, . . . , N}.
We have to create a method SortArr(T,P) which sort our T array.
The P is an array with tuples which describe the intervals, and probability
P = [(a_1,b_1,c_1), (a_2,b_2,c_2), ..., (a_k,b_k,c_k)]}
For example
T = [6.1, 1.2, 1.5, 3.5, 4.5, 2.5, 3.9, 7.8]
P = [(1, 5, 0.75) , (4, 8, 0.25)]
Result
T = [1.2, 1.5, 2.5, 3.5, 3.9, 4.5, 6.1, 7.8]
I know that it looks like bucket sort due to the uniform distribution. But how to take advantage of the P array and the given intervals and probability to sort this efficiently?
Could It be O(n) maybe?
If something is unclear tell me I will try to explain it
I've did that with bucket sort already and It's not so fast
ive encountered a problem when implementing Trees in python using a class
class BinaryTree:
def __init__(self, left, right): self.left, self.right = left, right
def traverse(self):
BinaryTree.s_traverse(self)
@staticmethod
def s_traverse(tree):
if type(tree) is BinaryTree:
BinaryTree.traverse(tree.left)
BinaryTree.traverse(tree.right)
else:
... # do stuff with end node
as nodes could end with some other type than BinaryTree
i have to use a static method and a wrapper function
could this be written in a better way?
i couldn't just call tree.left.traverse() as it could be a ending node which doesn't have the traverse method
I'd suggest not having ending nodes be a separate type.
oh, you're doing a tree where only leaves can have values. I guess then separation by types makes more sense.
yea
end nodes do have a separate type
the problem is, when the end nodes don't have the traverse methods
Your way is pretty fine then; though I'd write it as if isinstance(tree, BinaryTree) (since that way subclasses of BinaryTree are also accepted)
Also, I don't quite see why don't you do self.s_traverse() instead of BinaryTree.s_traverse(self), and the same for traverse. It's the same thing, but the point of methods is being able to call them as attributes rather than like functions.
there are no subclasses so its fine
i could, but its more explicit on whats being done as the first arg isn't called self and its a staticmethod
i guess ill stick to this method, thanks
I don't see why this all can't be
def traverse(self):
for child in (self.left, self.right):
if isinstance(child, BinaryTree):
child.traverse()
else:
# do something with it
Can anyone help me with creating buckets for this task? k buckets each have to has 1/k chance. How to create appropriate number of buckets if we have given probability and interval? On wiki are told "create bucket based on a density" but i don't know what does this mean
Hi all! I'm not sure this is the right place. Anyway, how would you "pretty-print" a tree (not necessary a binary tree) in a console?
something like:
..................A
B C
D E F G H I
("A" should be in the middle, as it's the root)

when I print the list the break (-1) function enters the list as well. How can I remove her from the list? I just want it to work as a stop and not be printed.
Just change the order of the if statements and it'll work
thanks
Not
actually I want to create a program that takes integer values and puts the repeated values in the list. Should I create an empty list and add the repeated elements to it? using the while function?
!e
import math
def connector(width, child_centers):
yield '|'.center(width)
conn = list(' '*width)
for i in range(child_centers[0], child_centers[-1]):
conn[i] = '-'
for i in child_centers:
conn[i] = '+'
yield ''.join(conn)
conn = list(' '*width)
for i in child_centers:
conn[i] = '|'
yield ''.join(conn)
class Node:
def __init__(self, label):
self.children = []
self.label = label
def __iadd__(self, children):
self.children += children
return self
def _pretty(self):
if self.children == []:
yield self.label
return
columns = [list(child._pretty()) for child in self.children]
# Make equal len
longest = max(map(len, columns))
for column in columns:
while len(column) < longest:
column.append(' '*len(column[0]))
# Calculate new width
min_width = len(self.label)
base_width = sum(map(len, next(zip(*columns))))
if len(columns) > 1:
separator = ' '*max(1, math.ceil((min_width - base_width)/(len(columns) - 1)))
else:
separator = 'whatever'
new_width = base_width + (len(columns)-1)*len(separator)
# Label
yield self.label.center(new_width)
# Connectors (this is just annoying logic to be fancy)
w = 0
centers = []
for col in columns:
centers.append(w + (len(col[0])-1)//2)
w += len(col[0]) + len(separator)
yield from connector(new_width, centers)
# Subtree
for parts in zip(*columns):
yield separator.join(parts)
def pretty(self):
return '\n'.join(self._pretty())
A = Node('A')
B = Node('Blarg')
C = Node('C')
D = Node('Dinosaur')
E = Node('E')
F = Node('F')
G = Node('G')
H = Node('H')
I = Node('I')
A += [B, C]
B += [D, E, F]
C += [G, H]
H += [I]
print(A.pretty())
@haughty mountain :white_check_mark: Your eval job has completed with return code 0.
001 | A
002 | |
003 | +--------+
004 | | |
005 | Blarg C
006 | | |
007 | +-----+-+ +-+
008 | | | | | |
009 | Dinosaur E F G H
010 | |
011 | +
... (truncated - too many lines)
Full output: https://paste.pythondiscord.com/ehoveworig.txt?noredirect
It's surprisingly intricate to implement a general solution for this, but this gets pretty close.
The stuff with the connectors is probably the most intricate part, the rest of the algo isn't super advanced, though I could probably tidy up some parts.
anyone knows how to check that a graph can be 3-coloured where each color is used an equal amount of time. In other words each colour should be used |V|/3 times
Wow! It looks good to me, thanks for the solution provided

Can anyone tell me why the listvazia does not print the repeated values placed in the list[]?
lista = []
listavazia = []
liste2 = []
while True:
n = int(input())
if n == -1:
break
elif n not in lista:
lista.append(n)
for n in lista:
if n not in liste2:
liste2.append(n)
else:
listavazia.append(n)
print(listavazia)
Seems to work? In your screen, you have your final print happening outside of your loop. @dense cove
good night, the code only doubles the values
who wants to contribute, its open source, any pulls are welcomed. The todos are labelled below https://github.com/Wizock/sorter_visualiser

GitHub
Sorting Visualiser made in Pygame. . Contribute to Wizock/sorter_visualiser development by creating an account on GitHub.
Hey how to create buckets in bucket sort when we know the probability ( and we can easy estimate the density )
k = len(P)
boundries = []
for el in P:
# el = (a,b,c)
# a - start of interval
# b - end of interval
# c - probability
a = el[0]
b = el[1]
c = el[2]
boundries.append(a)
start = a
for i in range(a,b + 1):
end = (b - a) / (k * c) + start
B.append([])
boundries.append(end)
start = end
I end up with something like that but in this approach It's worse than regular bucket sort with no information about the probability ( and hence density )
@pallid coral what should I do

Prefix the string with r
\ has special meaning, but here you literally want the \, so r tells python not to treat it specially
where should i write r
playsound(r"C:\Users\PC\OneDrive\Masaüstü\Charlie-main\answer.mp3") like this

i think i did
yes i did
I'm learning english by asking for help fuasgufusgufguyfgua
How can I print the names of all the files in the folder as an array with pyhton?
@atomic kraken
Help needed in #help-dumpling immediately
Is a second-degree graph a graph with 2+ points where each point has two edges and together they create a cycle?
import os
files = os.listdir('.')
using the os module and using os.path is good
What is a good way to get good on algos ds in a week? I have an interview in a week and im good at easy leetcode but not medium or hard, with some exceptions
i think practice day and night
Lonely stoners seems to free my mind
Lemme google it for you :)
So it goes both ways?
If it helps the graph is kinda bipartisan
It’s edges going from one set of nodes to another
He's all alone through the day and night
*x
You gotta go deep with stackoverflow man. Im sure someone has tought of this before but keep searching
Or better yet try to invent your own haha. You may get to publish it
Hold on I think I got it
Ok related question
Dinics algo works for directed edges right?

"For anyone wondering, in the Python code, the utility derived in creating a new List object with each assignment is the creation of a Deep Copy of the array."
self.original = list(nums)
self.original = list(self.original)
what does this mean
>>> nums = [1, 2, 3]
>>> a = list(nums)
>>> a
[1, 2, 3]
>>> a = list(a)
>>> a
[1, 2, 3]
>>>
looks exactly the same
deep copy
meaning it copies the list
so it may look the same but it's not exactly the same
?
what's the point of doing it
class Solution:
def __init__(self, nums):
self.array = nums
self.original = list(nums)
def reset(self):
self.array = self.original
self.original = list(self.original)
return self.array
def shuffle(self):
aux = list(self.array)
for idx in range(len(self.array)):
remove_idx = random.randrange(len(aux))
self.array[idx] = aux.pop(remove_idx)
return self.array
so it doesn't get modified when the original is modified
ah yea
it's only a shallow copy
if I do
self.array = nums
self.original = nums
then if I modify self.original nums will also be modified?
>>> nums = [1, 2, 3]
>>> a = nums
>>> b = nums
>>> a
[1, 2, 3]
>>> b
[1, 2, 3]
>>> a.append(4)
>>> a
[1, 2, 3, 4]
>>> b
[1, 2, 3, 4]
>>> b = nums.copy()
>>> b
[1, 2, 3, 4]
>>> b.append(6)
>>> b
[1, 2, 3, 4, 6]
>>> a
[1, 2, 3, 4]
>>> ah yea I see
I remember now 🙂
deep copy copies all elements and everything in those elements and so on
shallow copy just copies the list
wdym everything in those elements

Any who can help?
[[1, 2], [4]]
# deepcopy copies the lists and puts those copies in a new list
# shallow copy just creates a new list with exactly the same elements
I dont get it
also I cant use deepcopy() on a list
apparently it doesnt work with lists?

I dont get this either
>>> nums = [1, 2, 3]
>>> ca = nums.copy()
>>> ca
[1, 2, 3]
>>> ca.append(3)
>>> ca
[1, 2, 3, 3]
>>> nums.append(6)
>>> nums
[1, 2, 3, 6]
>>> ca
[1, 2, 3, 3]
this is a shallow copy, correct?
or is this a deep copy?
according to that diagram this seems like a deep copy
this is a shallow copy
you need to get it from the copy module, then you'd use it like new_list = copy.deepcopy(old_list)
I see
I dont get it
what is that diagram trying to say
!e
A = [[1], [2], [3]]
B = A.copy()
print(A[0], B[0])
A[0][0] = 5
print(A[0], B[0])
eh?
can you draw a diagram for numscopy = nums
@agile sundial :white_check_mark: Your eval job has completed with return code 0.
001 | [1] [1]
002 | [5] [5]
what is numscopy = nums called?
interesting
why are you using a list of lists?
to show the difference between a shallow and deep copy
so it only works with lists of lists?
no, it helps show the difference
>>> a = [1, 2, 3]
>>> b = a.copy()
>>> a[1] = 123123
>>> a
[1, 123123, 3]
>>> b
[1, 2, 3]
>>>
why didnt it work
you're changing a[1] to point to a different int, whereas in my example, i was modifying an inner list
can't I say you're changing A[0][0] to point to a different int
you can say that, but the outer list still holds the same inner list
copying?
"copying"
copying has an interesting definition here, it's very unintuitive to just use the word "copy" in English
ok ¯_(ツ)_/¯
shallow copying copies all the references in the list to the new list
deep copying recursively copies everything into the new list
yea I think deepcopy is more intuitive, that's what I think of what I think of the word "copy"
you have something new but it's exactly the same as the first thing
okay I'm starting to understand this a bit
"copy" is shallow by default I suppose because it is frequently all you need, for instance, any list of simple data types like ints or strings is effectively deepcopied with .copy (and deepcopy is way more expensive for nested stuff)
yep
it seems if it's just a list (not a list of lists), a copy() pretty much behaves like a deepcopy()
since modifying single elements of that list, doesn't modify the copy
right? @fiery cosmos
what's an example use case of shallow copy when you are actually using a list of lists or something that modifies both the list element and the copy's elements? when you have different class objects or something?
yeah, at least for basic data types like int, strings, bool, float, tuples of those, but the list could have dicts or sets or classes that don't shallow copy by value
yeaa that makes sense
it's only relevant when u have a list/dict/w/e in that list/dict
I see
hey guys
quick question
class Solution:
def uniquePaths(self, m: int, n: int) -> int:
row = [1] * n
for i in range(m-1):
newRow = [1] * n
for j in range(n-2, -1,-1):
newRow[j] = newRow[j+1] + row[j]
row = newRow
return row[0]
Would the time complexity be O(n) here?
yeah i believe so
does m not matter?
no

that would be O(n * m)
yes n
you overwite the array every iteration
you could reduce this problem though I assume
For this problem you need to go right n-1 times, and down m-1 times
So you need to calculate the amount of possible unique* permutations of a list of say (n-1) 0's and (m-1) 1's
would u say this is a pretty optimized solution though?
would that change time complexity or space complexity?
No, because it can be made O(n + m) instead of O(n * m)
time complexity
and O(1) space complexity
Depends on how optimized you need it to be
!e
from math import factorial
m = 3
n = 7
print(int(factorial(n-1 + m-1) / (factorial(n-1) * factorial(m-1))))
@lament totem :white_check_mark: Your eval job has completed with return code 0.
28
This is a solution using some math with this as intuition
@lunar jacinth
this would be O(n+m)?
Or probably a bit less because Python has a fancy factorial algorithm https://github.com/python/cpython/blob/main/Modules/mathmodule.c#L1905 
Modules/mathmodule.c line 1905
/* Divide-and-conquer factorial algorithm```im ultimately preparing for an interview
what if they say u cant use math?
like import and use factorial lol
Write your own. Doing it iteratively or recursively is pretty simple
i mean how much of a difference is O(m+n) to O(m*n)
would it impress an interviewer lol
well it's linear vs quadratic
hi question on this https://leetcode.com/problems/search-in-rotated-sorted-array/
Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
what is this else refering to?

doesnt that just cover nums[mid] >= nums[r]
wow rozio ty
i thought it's refering to if nums[l] <= nums[mid]:
but nums[l] > nums[mid] doesnt make sense
yeah haha i remember doing that problem
it might even cover more than nums[mid] >= nums[r]
maybe thats why they use else there
dunno 100%
yah it breaks when i replace it with elif

did u try nums[mid] >= nums[r]?
ya
frozen
the question is when is this ever not true? if nums[l] <= nums[mid]:
nums left will always be less or equal to mid
oh i see the problem
def search(self, nums: List[int], target: int) -> int:
if not nums:
return -1
low, high = 0, len(nums) - 1
while low <= high:
mid = (high + low) // 2
if target == nums[mid]:
return mid
if nums[low] <= nums[mid]:
if nums[low] <= target <= nums[mid]:
high = mid - 1
else:
low = mid + 1
elif nums[mid] <= nums[high]:
if nums[mid] <= target <= nums[high]:
low = mid + 1
else:
high = mid -1
return -1
@spare parcel i hope this explains the else better

is there any way in networkx to find the centroid of a tree?
!e
so I recently learned perm and comb are things now
from math import comb
m = 3
n = 7
print(comb(n - 1 + m - 1, n - 1))
@haughty mountain :white_check_mark: Your eval job has completed with return code 0.
28
yes it does? nums[l] > nums[mid] means the interval is across the "end" of the sorted array
e.g.
[4, 5, 1, 2, 3]
^ ^ ^
l m r
i
d
fwiw I would probably implement the problem with two binary searches, one to find the sorted endpoint, and then proceed as usual since you now have the sorted sequence
Much simpler and less error prone than the logic in the one binary search, still O(log(n))
Hey, how can I round the Mathutils.Vector to pass the comparison? ty

rounding is not the right thing to do
subtract and check if the length of the result is small enough
i.e.
(a - aa).length <= tolerance
where tolerance is a smallish number
I figured that part out, searching for "mathutils vector" gave the right thing
I mean, yeah? It's a statement to check that two vectors are approximately equal, you can do whatever with the result
it might be worthwhile to make a function for it, something like
TOLERANCE = 1e-6
def ApproxEqual(u, v):
return (u - v).length < TOLERANCE
not sure if that's a good tolerance, but it's in the right ballpark with the values I'm seeing


why are you inverting the check?
ah I'm just trying everything I can here
the main thing is it gets the length wrong
the last 2 lines are just the mess for debugging
why is it wrong?
well 6.14
6.14e-8
guys is there any resource you can refer for someone who starts from 0 to learn data structures and algorithms?
start from zero as in zero programming knowledge, or knows programming but want to get into data structures and algorithms?
if the latter, there are resources in the channel pins
anyone can recommend some resources for dynamic programming?
i got some basic knowledge but am overall weak in it
@me
Hey guys, I would like to ask you two questions.
What are your advices, with regards to how to learn about data structures and algorithms as efficiently as possible, what one should do?
How to think better when solving data structures and algorithms problem?
If someone would ask me these questions, I would say to him this: "You should be focused as much as possibly, that means not having any kind of distraction. If you are tired you should relax in some way. For example, run or meditate. With regards to being more efficient at solving data structure and algorithms problems, you should use chunking/divideing problem into subproblems. Also, you should try to solve as much as possible problems."
Hi, Has someone idea how to speed this code a little bit? Like 0.2s 😝
def Bucket_sort(arr):
maxx = max(arr)
min_el = min(arr)
# Creating buckets [i,i+1] for every element.
B = [[] for _ in range(int(maxx-min_el) + 1)]
for num in arr:
index = int(num - min_el)
B[index].append(num)
B[index] = Insertion_sort(B[index])
# Merge the buckets
out = []
for i in range(len(B)):
out += B[i]
return out
def Insertion_sort(arr):
key = arr[-1]
j = len(arr) - 2
while j >= 0 and key < arr[j]:
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = key
return arr
That's the fastest approach that i came up with for my problem which i sent here some time ago.
that seems like very general advice for learning anything. For algorithms and data structures i'd mainly advice looking into some videos on the general underlying mechanisms of some data structures and practice a lot on sites like codewars and hackerrank.
And algorithms is kind of a broad term, some algorithms you should know as they are used very often while some are more complex and specific to f.e. machine learning or graph theory.
Id say try to maintain the daily streak on the sites like leetcode or interview bit, that streak makes you motivated to practice daily
Can somebody help me with a python problem. I went to a local programming competition and got stuck on this one problem in particular.
I needed to uppercase the first letter of the word but keep the rest of the word untouched, as in not changed
sPot
eaT
I needed to uppercase only the first letter
But i would use .upper and it upper cases all if it. Then i did .title and it lowercases the rest of the word
I tried slicing but i cant seem to get a solid grasp of if
I look to yt and it's just teaching me what a list is, i already know that 😭
Slicing would indeed be the simplest way I can think of
take the first letter by doing word[0] then uppercase that with .upper(), then concatenate it to the rest of the word word[1:]
@lofty sentinel
:incoming_envelope: :ok_hand: applied mute to @shy wasp until <t:1648400896:f> (9 minutes and 59 seconds) (reason: newlines rule: sent 114 newlines in 10s).
string = "word"
print(string.capitalize())
``` @lofty sentinel!unmute 168332727001677824
:incoming_envelope: :ok_hand: pardoned infraction mute for @shy wasp.
it was just a long code 
yeah, please go ahead and use this: https://paste.pythondiscord.com
uhm... I imagine I have to split into two? 
Ok this is the parser I've written:
It takes in input a json file and manipulates it to do some edits/substitutions/etc
if (isinstance(monumentFirstLevelValues, dict) and (monumentFirstLevel == "tier_1" or monumentFirstLevel == "tier_2" or monumentFirstLevel == "tier_3")):
for modifiersType, ModifiersValues in monumentFirstLevelValues.items():
if(modifiersType == "on_upgraded" or modifiersType == "cost_to_upgrade" or modifiersType == "upgrade_time"):
continue
else:
modifiersTypeA = modifiersType.replace('_',' ').title()
monumentLibModifiersValuesCopy = deepcopy(ModifiersValues)
if ((modifiersType == "province_modifiers" or modifiersType == "area_modifier" or modifiersType == "country_modifiers") and isinstance(ModifiersValues, dict)):
for modifier, value in ModifiersValues.items():
with open(data, 'r+', encoding='utf8') as dataModifiers:
for dataLine in dataModifiers:
datA = dataLine.split('\t')
if datA[0] == modifier:
modifierA = datA[1].strip()
break
monumentLibModifiersValuesCopy.update({modifierA: value})
monumentLibFirstLevelValuesCopy.update({modifiersTypeA: monumentLibModifiersValuesCopy})
monumentLib2[regionA][monumentNameA].update({monumentFirstLevelA: monumentLibFirstLevelValuesCopy})
now my main problem is that in the outputs some "parts" are not "replaced" but are "duplicated"
with both the input "area_modifier": { "local_unrest": -1 } and the output "Area Modifier": { "local_unrest": -1, "Local Unrest": -1 }
"Statue of Zeus": {
"Province": 1773,
"Starting Tier": 0,
"Build Trigger": [],
"Can Use Modifiers Trigger": [],
"Can Upgrade Trigger": [],
"Tier 1": {
"upgrade_time": {
"months": 120
},
"cost_to_upgrade": {
"factor": 1000
},
"province_modifiers": [],
"area_modifier": {
"local_unrest": -1
},
"country_modifiers": {
"tolerance_heathen": 0.5
},
"on_upgraded": [],
"Province Modifiers": [],
"Area Modifier": {
"local_unrest": -1,
"Local Unrest": -1
},
"Country Modifiers": {
"tolerance_heathen": 0.5,
"Tolerance of Heathens": 0.5
}
},
"Tier 2": {
"upgrade_time": {
"months": 240
},
"cost_to_upgrade": {
"factor": 2500
},
"province_modifiers": [],
"area_modifier": {
"local_unrest": -2
},
"country_modifiers": {
"tolerance_heathen": 1
},
"on_upgraded": [],
"Province Modifiers": [],
"Area Modifier": {
"local_unrest": -2,
"Local Unrest": -2
},
"Country Modifiers": {
"tolerance_heathen": 1,
"Tolerance of Heathens": 1
}
},
"Tier 3": {
"upgrade_time": {
"months": 480
},
"cost_to_upgrade": {
"factor": 5000
},
"province_modifiers": [],
"area_modifier": {
"local_unrest": -2
},
"country_modifiers": {
"tolerance_heathen": 1,
"stability_cost_modifier": -0.1,
"global_unrest": -2
},
"on_upgraded": [],
"Province Modifiers": [],
"Area Modifier": {
"local_unrest": -2,
"Local Unrest": -2
},
"Country Modifiers": {
"tolerance_heathen": 1,
"stability_cost_modifier": -0.1,
"global_unrest": -2,
"Tolerance of Heathens": 1,
"Stability Cost Modifier": -0.1,
"National Unrest": -2
}
}
},
how can I solve this?
[don't know if for the code it's useful to know the entire part before the if (isistance) but it's basically some for and if/else to parse the various "levels" of the json
That lowercases all the other words and capitalizes only the first letter
Someone helped me with that
Now it's a new problem. Where i need to capitalize the last one
ah k
just do the opposite
!e
word = "maKi"
lst = list(word)
lst[-1] = lst[-1].upper()
word = "".join(lst)
print(word)
@lofty sentinel :white_check_mark: Your eval job has completed with return code 0.
maKI
Bruh-
Loved the leetcode Explore section with topic wise learning tracks.
s = "hello"
result = s[0].upper() + s[1:]
print(result)
``` u can write the code even in this manneryes
wow.. love this channel.. ❤️
to capitalize the last letter
Thank you
result = s[:-1] + s[-1].upper()
``` it should work!e
s = "hello"
result = s[:-1] + s[-1].upper()
print(result)
@lofty sentinel :white_check_mark: Your eval job has completed with return code 0.
hellO
Amazing
I followed and coded along with the freecode camp dynamic programming video for the vanilla problems and basic understanding. Post that after solving plenty problems.. I still struggle with it. But have come a long way though.
hello
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
myset = set()
l, ans = 0, 0
for r in range(len(s)):
while s[r] in myset:
myset.remove(s[l])
l += 1
myset.add(s[r])
ans = max(ans, r -l +1)
return ans
``` what would the time complexity and space complexity be for this solution?O(n) for both?
that seems like very general advice for learning anything
Yeah, I assumed that there are some general advices that I don't know about learning. For example, if someone would ask same questions, then few of my answers could be given as response (running and chuncking).
1. Learn algorithms and data structures in context. Applied to some real problem. The reason for this is that ideas that are abstract are actually always understood in terms of some concrete example that one goes back to, either consciously or unconsciously. Although, eventually you know enough to just get it without a single example due to knowing its relationship with the many other things you know. You can just learn a bunch of random algorithms and data structures out of context too, but the key in either case is to make sure that you generalize / find the greater class of algorithms and data structures to which that specific algorithm / data structure belongs to (for which there is often some wiki page or chapter in a book).
2. The same as is done in mathematics. First you ask the more simple version of the same question (to yourself) (in CS this is often the base case or near base case). Then you play around with that more simple version (for intuition). Then you ask a slightly harder version (slightly above the base cases) and try to find what the relationships between that slightly harder version and the more simple one are (the pattern).
The other direction you can go in is to actually ask the more difficult version of the question / the more general / abstract version of it. You can then sometimes see that the more general version is just one of those more general classes of algorithms / data structures and go from there (this step is often needed to turn a seemingly complex real world problem into one that you know how to solve, and it also relates back to 1. in which you want to learn the algorithms / DS in context (so you can go backwards, context -> algorithm / DS)).
Actually, to add to the second answer, there is another step which is to first make sure that you understood the problem / requirements (answer the question with more questions first).
Thanks. So basically learn about particular DS and A and practice using A with DS. Or maybe ask people about how they would solve that problem, because then you can find out how to solve particular problem with particular DS and A
Hello. I have a question about a piece of some code that I'm writing for the Advent of Code Day 5 Challenge. Here is the link to that page: https://adventofcode.com/2021/day/5
Here is my work: https://replit.com/@megtechnica/AdventofCode-Day5#main.py

What I am trying to do is take each pair of coordinates and unpack them into pairs of numeric tuples. I have done so through a very clumsy for loop. I understand that my solution could be more pythonic, I understand that I could use a list comprehension to achieve this task for me but list comprehensions are the bane of my existence, to put it as dramatically as I can.
Is there someone more competent at list comprehensions that would be able to help me with this?
Well list comprehension would probably be the most readable way imo
I agree. What sort of list comprehension would you use here?

