#algos-and-data-structs
1 messages · Page 146 of 1
damn, is there no way to memoize without storing the entire array?
i guess i gotta redesign my solution again
well like I said, there's a solution that doesn't use memoization that seems a lot easier
but when using memoization, the key needs to be unique
maybe you could compress the information (like making a hash of the tuple)
@lament totem@dreamy ocean I believe since you have just a one dimensional array, you can just memoize using the index
pretty sure it's not linear time, hashing the nums tuple is O(n)
def diag(x, y, queens):
return (x + y, queens - 1 - y + x)
def check_valid(diags1, diags2):
if all(d < 2 for d in diags1) and all(d < 2 for d in diags2):
return True
return False
def find_positions(positions, diags1, diags2, l, r):
global result
if l == r:
result += 1
return
for i in range(l, r):
positions[l], positions[i] = positions[i], positions[l]
d1, d2 = diag(i, positions[i], len(positions))
diags1[d1] += 1
diags2[d2] += 1
if diags1[d1] < 2 and diags2[d2] < 2:
find_positions(positions, diags1, diags2, l + 1, r)
diags1[d1] -= 1
diags2[d2] -= 1
positions[l], positions[i] = positions[i], positions[l] # backtrack
result = 0
positions = list(range(8)) # 8 queens
diags1 = [0] * ((len(positions) * 2) - 1)
diags2 = diags1.copy()
r = len(positions)
find_positions(positions, diags1, diags2, 0, r)
print(result) # it still prints 0
This is how I attempted to do the N queens problem, but it doesn’t work, it prints 0
This is a way I did it which DID work, but I think it would be better if it didn’t need to rebuild diags1 and diags2 on each loop
What’s wrong with it? I don’t get it, it seems like I’m doing almost the same thing in both versions
@lament totem @dreamy ocean no need for any array for the values
def rob(nums: List[int]) -> int:
# You have two states:
# * you picked the last number so you can't pick the current one
# * you did not pick the last number so you can either pick or skip
# Keep best score for both states
score_picked = score_skipped = 0
for num in nums:
best_score = max(score_skipped, score_picked)
# The simple update rules, either pick,
# or skip and use the best previous score.
score_picked = score_skipped + num
score_skipped = best_score
return max(score_picked, score_skipped)
there's an O(n) solution available here with recursion and caching isn't there?
I mean the solution with arrays can be written as a memoization over indices+a boolean if you really want to
doesn't this work?
@cache
def rob(nums):
if len(nums)==0: return 0
if len(nums)==1: return nums[0]
return max( nums[0] + rob(nums[2:]), rob(nums[1:]) )
answer = rob(tuple(numbers))
that kind of thing should work, but with the slicing that is quadratic
you could pass an index and you would be fine
ok, tested it on leetcode and it does work.
Runtime: 40 ms, faster than 56.15% of Python3 online submissions for House Robber.
slicing is not an issue here as it's a linear decrease
the space complexity is quadratic
keep in mind that the leetcode constraints are ridiculously tiny
nitpicking. 😄 it worked, and is very simple I'm happy with it. biab.
I bumped it up to n=10000 (and messed with the recursion limit) and the recursive solution is already 50x slower
I just wanted to make the point that the solution is still quadratic
Im trying to make a spell correction prgoram
a typical spell correction algorithm takes a miss spelled text
compute the minimum edits against real words
and apply base formulae to work out probability that the miss spelled text is that particular word
but computing this, against every word in English is too computationally slow
so you want to narrow down your candidates to a relatively small number very quickly
can someone suggest me a simple algorithm I could use to retrieve the candidate words?
this small edit makes it O(n)
@cache
def rob(i):
if len(numbers)==i: return 0
if len(numbers)==i-1: return numbers[0]
return max( numbers[i] + rob(i+2), rob(i+1) )
print(rob(0))
(with numbers kept global)
This got solved:
#🤡help-banana message
with some minor tweaks to get the correct answer that'll run on leetcode.
def rob(self, nums: List[int]) -> int:
@cache
def _rob(i):
if len(nums)==i: return 0
if len(nums)==i+1: return nums[-1]
return max( nums[i] + _rob(i+2), _rob(i+1) )
return _rob(0)
but it runs slower than the tuple version.
Runtime: 60 ms, faster than 14.26% of Python3 online submissions for House Robber.
Which doesn't make sense, as I agree that it should be a magnitude faster. Probably just leetcode variability.
Or, the previous version the cache was shared across testcases. Which would explain it.
the size of the list is absolutely tiny, at the point where you could do mostly anything and have a quickish solution
that would have made it incorrect though?
no it was cached on the tuple so the answer does not change if the input tuple is the same.
oh, you mean for the earlier one, sure
This one looks good:
def rob(self, nums: List[int]) -> int:
result = [0] * (len(nums)+2)
for i in range(len(nums)-1, -1, -1):
result[i] = max(nums[i] + result[i+2], result[i+1])
return result[0]
same general idea.
but dp
yeah, this is basically my thing but with O(n) memory rather than O(1)
Saw a solution by someone else who claimed to have O(n) space complexity, but it seems to me as you have an list of all the n numbers, that means you already have O(n) space complexity no?
It's not constant with the input
I meant O(1) on top of the input
Yeah I guess if you could take the inputs 1 by 1 it could be O(1) in that case
auxiliary memory I think the term is? or something like it
Yeah, auxiliary/extra memory/space. When people talk about space complexity they often mean excluding the input space.
# n queens
def diag(x, y, queens):
return (x + y, queens - 1 - y + x)
def find_positions(positions, diags1, diags2, l, r):
global result
if l == r:
result += 1
return
for i in range(l, r):
positions[l], positions[i] = positions[i], positions[l]
d1, d2 = diag(l, positions[l], len(positions))
if not diags1[d1] and not diags2[d2]:
diags1[d1] = True
diags2[d2] = True
find_positions(positions, diags1, diags2, l + 1, r)
diags1[d1] = False
diags2[d2] = False
positions[l], positions[i] = positions[i], positions[l] # backtrack
result = 0
positions = list(range(8)) # 8 queens
diags1 = [False] * ((len(positions) * 2) - 1)
diags2 = diags1.copy()
r = len(positions)
find_positions(positions, diags1, diags2, 0, r)
print(result)
This is O(n) space complexity because it never recurses deeper than len(positions) and it only recurses in one spot, right?
Actually it shouldn’t matter how many areas it recurses in, it just matters how deep you go into recursion levels. Idk what I was talking about. Sorry.
beautiful code brother

I can read enough to guess. Take a positive inner radius (call it a) and an outer radius (call it b). Draw an annulus filled at distances a <= r <= b
Hi
Can someone tell why Im getting this error

dont name your own file random.py
how do you square a number in python equations?
x**2 (** is exponent because ^ is xor)
Hey guys
I'm trying to do Fibonacci sequence in python
I could do it in recursive way but python have a really shallow recursion limit and I have read Guido van Rossum saying you should be doing recursions by using list as a stack
I've implemented both here:
return final
@dataclass
class FibStack:
n: int
var_name: str
lhs: int | None
rhs: int | None
class Solution:
'''
def fib(self, n: int) -> int:
if n == 0:
return 0
elif n == 1:
return 1
else:
lhs = Solution().fib(n-1)
rhs = Solution().fib(n-2)
return lhs + rhs
'''
def fib(self, n:int) -> int:
stack = [FibStack(n,'root',None,None)]
while(len(stack) != 0):
ds = stack[-1]
if ds.n == 0 or ds.n == 1:
if ds.var_name == 'root':
final = ds.n
elif ds.var_name == 'lhs':
stack[-2].lhs = ds.n
else:
stack[-2].rhs = ds.n
stack.pop()
elif ds.lhs == None:
stack.append(FibStack(ds.n-1, 'lhs', None, None))
elif ds.rhs == None:
stack.append(FibStack(ds.n-2, 'rhs', None, None))
else:
if ds.var_name == 'root':
final = ds.lhs+ds.rhs
elif ds.var_name == 'lhs':
stack[-2].lhs = ds.lhs + ds.rhs
else:
stack[-2].rhs = ds.lhs + ds.rhs
stack.pop()
but my stack implementation looks very ugly, difficult to understand and long
can someone please tell me a better way of implementing it?
I especially do not like the fact I'm using stack[-2] = to return the values
Not only that, the second case takes a lot more time to execute, probably because of all that time creating data class
@warped flame Under the hood, recursion really is a stack.
Somewhere in memory, there is a piece of memory called "the call stack". It stores all the local variables of a function (a C function, not a Python function) that looks kinda like this:
(locals of f1)
(address of where to return)
(locals of f2)
(address of where to return)
(locals of f3)
(address of where to return)
So when a call to f3 ends, it takes the address of where to return and jumps to it.
So you're basically reimplementing recursion, but using a software call stack instead of a hardware call stack.
ye, I get that part
but like how do you implement the 'return' feature of a function in a software manner?
What is your end goal here?
I guess, I could just send the points into the stack mmm
implement Fibonacci in a pythonic manner
coz apparently recursive function isnt pythonic
making a complicated algorithm with an extra class doesn't seem very "pythonic" either 🙂
!e
there is a simple solution with dynamic programming, of course:
def fibonacci(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a + b
return a
print(fibonacci(100))
@austere sparrow :white_check_mark: Your eval job has completed with return code 0.
354224848179261915075
I recently posted an entry in my Python History blog on the origins of Python's functional features . A side remark about not supporting ta...
Is dynamic programming different from recursive impllementation?
I'm trying to get into the habit of Python's way of implementing recursion
Python's way of implementing recursion is to just use recursive calls
However, some problems are better solved without recursion
He says though For practical purposes, Python-style lists (which are flexible arrays, not linked lists), and sequences in general, are much more useful to start exploring the wonderful world of programming than recursion. They are some of the most important tools for experienced Python programmers, too. Using a linked list to represent a sequence of value is distinctly unpythonic, and in most cases very inefficient. Most of Python's library is written with sequences and iterators as fundamental building blocks (and dictionaries, of course), not linked lists, so you'd be locking yourself out of a lot of pre-defined functionality by not using lists or sequences.
So he is saying that we should implement stacks with a list right?
arent dataclass objects attributes mutable?
because I tried to take your advice and got:
from dataclasses import dataclass
@dataclass
class FibStack:
n: int
return_pointer: int
lhs: int | None
rhs: int | None
class Solution:
def fib(self, n:int) -> int:
self.result = 0
stack = [FibStack(n,self.result,None,None)]
while(len(stack) != 0):
print(stack)
ds = stack[-1]
if ds.n == 0 or ds.n == 1:
ds.return_pointer = ds.n
stack.pop()
elif ds.lhs == None:
stack.append(FibStack(ds.n-1, ds.lhs, None, None))
elif ds.rhs == None:
stack.append(FibStack(ds.n-2, ds.rhs, None, None))
else:
ds.return_pointer = ds.lhs+ds.rhs
stack.pop()
return self.final
but above returns error because ds.lhs doe's not give pointers
what advice?
why do you want to use the stack approach?
If your end goal is to find the nth fibonacci number, there is a much simpler and more efficient solutions with just a loop:
<#algos-and-data-structs message>
ye, but I want to practice recursion
Guido isn't saying that you should implement recursion with a list
coz, the reason why I found that article is because I got into a recursion error when I was using a recursive function in my program
and found out that the recursion depth limit is only around 1000 in Python
also how do you pass pointers in python for the return value?
and I also heard someone say that actually recursive function in Python is really inefficient and you should try to avoid
Can you show the function?
The function is kind of too large to show in discord, it was some sentence shortening program that traverse a tree to do so
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
This is what Guido is saying:
- There are some legitimate use cases for recursion, like tree traversal, in which case 1000 levels is more than enough
- If your problem requires more than 1000 levels of recursion, you're probably better off with a loop
ye, but like I wouldnt want to write a recursive program that dies when input gives recursion greater than 1000
I think thats just an unsafe code
and so Im trying to implement using a loop, but like how do I get the return pointer to work in python?
Ive tried using namedtuple data class, object instance, my ADHD is starting to kick in I swear
Can you explain more about your problem?
like, the Fibonacci sequence problem is a good enough abstraction of my problem so I think its better if we used Fibonacci as the problem
In case of Fibonacci you can do this:
it's not a good enough abstraction then 🙂
the only reason why that is viable in fibonacci is because its auto regressive
why can't you show the actual code?
I can it just wont make any sense
Hey @warped flame!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
beside, like I want to use recursion in general
E.g. this method: https://paste.pythondiscord.com/ubamocasis
that tries to figure out possible edits of a levenshtein algorithms that would result in a shortest edit
It requires a recursive function that is implemented using a list
but it is really ugly, because I store the return pointers as an entirely sepparate stack list, with the entire pointer to the object, not the attribute
and when you have cases where you have multiple return types. E.g. LHS and RHS
The above approach is no longer viable, so you really need a pointer to the attribute not the entire object
If you want to generalize this approach, you could make a hack with generators:
@stackify
def fibonacci(n):
if n <= 0:
return 0
if n == 1:
return 1
return (yield [n - 1]) + (yield [n - 2])
but I assume it's going to be extremely slow
Basically, when a generator yields, spawn another generator paired with a key that refers to the old generator
is stackify in the stdlib?
There ```
from dataclasses import dataclass
class Number:
def init(self, n: int):
self.val = n
class FibStack:
def init(self, n, return_pointer, lhs, rhs):
self.n: int = n
self.return_pointer: Number = return_pointer
self.lhs: int | None = lhs
self.rhs: int | None = rhs
class Solution:
def fib(self, n:int) -> int:
self.result = Number(0)
stack = [FibStack(n,self.result,None,None)]
while(len(stack) != 0):
ds = stack[-1]
if ds.n == 0 or ds.n == 1:
ds.return_pointer.val = ds.n
stack.pop()
elif ds.lhs == None:
ds.lhs = Number(None)
stack.append(FibStack(ds.n-1, ds.lhs, None, None))
elif ds.rhs == None:
ds.rhs = Number(None)
stack.append(FibStack(ds.n-2, ds.rhs, None, None))
else:
ds.return_pointer.val = ds.lhs.val+ds.rhs.val
stack.pop()
return self.result.val
but its so slow
I hate it
Why is there no pointer in python?
i have a lot of custom objects which i currently store in a txt file like dictionaries and then read them with json and turn them into objects again. the problem is that I want to group them by their attributes (?) and that's when it gets realllyyyyy slowww. I essentially loop through the list of the objects i have and then put them in dicts depending on their attribute value. Can this be done faster by using database (sqlite3) and pandas?
are you asking why does python not have pointers?
yes its so inefficient cant even replace recursion with a list without it
because we don't want segmentation faults
pointer arithmetic is super dangerous and so are pointers in general
but I dont need pointer arithmetic
just a pointer so I can assign value to a variable
you can technically use pointers in python with 3rd party libraries but I would highly advise against it
if you need pointers and speed use C
python isn't the language to use if they are your requirements
but the recursion program I wrote above was so slow, it was rejected by leetcode
then there is probably a better way of going about things, whats the problem?
there is no problem, its just Python sucks at recursion at so many level
It only has recursion depth limit of 1000
if you try to replace recursion stack with list, it gets very complicated because you dont have a pointer to return the value to
ye, but thats dangerous and I dont want to, coz its no longer very safe in general for you to do that
can you use C for the leet code problem
ye, but Im not trying to solve leet code problem
You seem to keep trying to use techniques that lend themselves to a slightly lower level language
Im just trying to practice recursive programs in python
coz Im writing a project that require lots of recursions, in general, and I want to complete the project in Python
there is always a way to loops instead of recursion
ye I know which is exactly what I have been asking about
but the return location can not be properly specified in Python, because of no pointer
wdym the return location
like a recursive function usually returns a value
right
e.g.
class Solution:
def fib(self, n: int) -> int:
if n == 0:
return 0
elif n == 1:
return 1
else:
lhs = Solution().fib(n-1)
rhs = Solution().fib(n-2)
return lhs + rhs
if the attribute that it is returning to is the same, you can usually get away with making another list stack for the return values
but if its different, e.g. in the above case, the function could be returning the value to lhs or rhs, you can no longer do this
and hence it becomes very complicated if not impossible to do this
you can always emulate a pass-by-reference by a box-pattern (object with a field that holds the value)
most likely, you're missing some solution of that kind.
Is that what you mean?
but it requires you to assign an object to the field right?
Notice how Im assigning the Number instance ever time?
but its very slow and Leetcode says no

u r trying to call a variable before even creating / assigning a value in it
like
print(x) # what is x? ## Error: can't find variable
x = "Hello World"
print(x) # Out: Hello World

I did
oh
Nvmd
ok
def MergingMonuments(monumentsInput):
with open('monuments.txt', 'w') as monumentOutput:
for monument in monumentsInput:
with open(monument, 'r') as readingMonument:
monumentOutput.write(monument[76:-4])
monumentOutput.write(' = {\n')
for lineMonument in readingMonument:
monumentOutput.write('\t')
if lineMonument == "can_be_moved = no":
continue
if lineMonument == "date":
continue
print(lineMonument)
monumentOutput.write(lineMonument)
monumentOutput.write('\n}\n')
print('Merged all monuments into one file')
so I'm merging multiple files all into one
monumentsInput = glob.glob(monuments_path + "*.txt") [it's all the files]
now what I want is to remove [from the final file] lines that contain certain words, etc...
why it ain't working?
example of what it is in every single file
gme_vilnius_cathedral = {
start = 272
date = 1.01.01
time = { months = 0 }
build_cost = 5000
can_be_moved = no
move_days_per_unit_distance = 10
starting_tier = 0
type = monument
build_trigger = {
religion = catholic
culture = lithuanian
has_owner_religion = yes
has_owner_culture = yes
}
on_built = { }
on_destroyed = { }
can_use_modifiers_trigger = {
religion = catholic
culture = lithuanian
has_owner_religion = yes
has_owner_accepted_culture = yes
}
can_upgrade_trigger = {
religion = catholic
culture = lithuanian
has_owner_religion = yes
has_owner_accepted_culture = yes
}
keep_trigger = { }
tier_0 = {
upgrade_time = { months = 0 }
cost_to_upgrade = { factor = 0 }
province_modifiers = { }
area_modifier = { }
country_modifiers = { }
on_upgraded = { }
}
tier_1 = {
upgrade_time = { months = 120 }
cost_to_upgrade = { factor = 1000 }
province_modifiers = { }
area_modifier = {
local_missionary_strength = 0.01
}
country_modifiers = {
legitimacy = 0.25
republican_tradition = 0.1
papal_influence = 0.25
}
on_upgraded = { }
}
tier_2 = {
upgrade_time = { months = 240 }
cost_to_upgrade = { factor = 2500 }
province_modifiers = { }
area_modifier = {
local_missionary_strength = 0.02
local_tax_modifier = 0.1
}
country_modifiers = {
legitimacy = 0.5
republican_tradition = 0.2
papal_influence = 0.5
}
on_upgraded = { }
}
tier_3 = {
upgrade_time = { months = 480 }
cost_to_upgrade = { factor = 5000 }
province_modifiers = { }
area_modifier = {
local_missionary_strength = 0.03
local_tax_modifier = 0.25
}
country_modifiers = {
prestige = 1
legitimacy = 1
republican_tradition = 0.5
papal_influence = 1
}
on_upgraded = {
owner = {
add_estate_loyalty = {
estate = estate_church
loyalty = 10
}
}
}
}
}



Here's how to format Python code on Discord:
```py
print('Hello world!')
```
These are backticks, not quotes. Check this out if you can't find the backtick key.
And you shouldn't make a habbit of using x in range() for checking if a number is in a range
Because that only works for integers
@tough swift
Also if you look at your output vs theirs, it's Weird not Wierd
def fib(n):
if n == 0:
return 0
if n == 1:
return 1
return fib(n - 1) + fib(n - 2)
def fib_list(n):
result = 0
stack = [n]
while len(stack) > 0:
v = stack.pop()
if v > 1:
stack.extend([v - 1, v - 2])
continue # This is the same as the return in the other version at the bottom.
result += v # Implicit return (end of loop).
return result
print(fib(10), fib(15))
print(fib_list(10), fib_list(15))
def fib_list(n):
result = 0
stack = [n]
while len(stack) > 0:
v = stack.pop()
if v == 0:
result += v
elif v == 1:
result += v
else:
stack.extend([v - 1, v - 2])
return result
Maybe this version will make it more clear.
You simulate the recursion calls / stack frames yourself with a stack.
(What languages do under the hood for function calls)
almost, the thing you have there will not deal with return values like the recursion does
though with some extra effort you can make that work as well
Yeah I have a separate result value here.
(Where you actually want the result on the stack)
Ideally, you would be able to set the stack to your own stack, which some languages can do (or increase the stack size), but in Python you sort of need to build a stack machine for the most generic case of having any recursive algorithm done without recursion. And that will run very slow in Python.
The thing is that for many you don't actually need the full thing that deals with return values correctly.
a friend of mine wrote a decorator to be able to "bootstrap" recursion to use a stack https://codeforces.com/contest/1006/submission/118526672

Codeforces
it's pretty neat, but requires you to rewrite your recursion as a generator function
Yeah I figured that it would involve generators in Python to make it as nice as possible.
That's a pretty neat implementation.
I remember playing a bit with using a decorator to rewrite returns as yields so you can literally just add the decorator and magic occurs
but it turned out to be a bit hard to get right
I do though
Recursion is very common in the world of rule based nlp
They coul just have a pointer, then it will solve everything
Python ignores the underscores when storing these kinds of values. Even if you don’t group the digits in threes, the value will still be unaffected. To Python, 1000 is the same as 1_000, which is the same as 10_00. This feature works for integers and floats, but it’s only available in Python 3.6 and later.
Matthes, Eric. Python Crash Course, 2nd Edition (p. 28). No Starch Press. Kindle Edition.
What are some use cases for using underscores?
The very thing that they remove for the sake of being pythonic prevents implementation of recursive functions in a pythonic way
Never mind. I found the answer:
This is a common feature of other modern languages, and can aid readability of long literals, or literals whose value should clearly separate into parts, such as bytes or words in hexadecimal notation.
Source: https://www.python.org/dev/peps/pep-0515/
it's for making numbers easier to read, compare
1_000_000_000
1000000000
the first one you can easily read at a glance
for the second I end up needing to count zeroes
Thank you @haughty mountain
I made a working calculator (pycharm)

yes, should still be O(1)
wait why is this an error
>>> a = {1:"hi", 2: "bye"}
>>> if 3 not in dict:
... print("lol")
...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: argument of type 'type' is not iterable
if 3 not in a
dict is the dict type
oh crap
and not a dict
I'm blind
why is this O(1)?
how is that possible?
I'm not giving a key here
I guess I just dont understand how they're implemented
yes, a potential key
hash table
Because 3 not in a is equivalent tonot(3 in a), and looking up a key in a dict is O(1)
how does a dictionary work?
why does it take O(1)?
doesn't make intuitive sense to me
wouldn't you have to compare that value to every value if there is no such value
It uses a hash table.
Very roughly: you calculate the hash of a key, then look at the element (often called "bucket") hash(key) % len(hash_table)* of the table. If it is empty, that key is not in the table. If it's full with that key, you found it. If it's full with some other key, then you have a hash collision and you need to look at some other bucket depending on whatever collision resolution method your table uses.
Either way, it takes O(1) time to look up a value by the key or determine it's not in the table (and the same for insertions and deletions), unless you have a ton of collisions - but that doesn't happen in practice, so it's considered O(1).
*Note: len(hash_table) isn't constant, it has to be resized as the hash table gets full, much like the underlying array of a list needs to get resized once it gets full.
Fluent Python has a fairly nice brief explanation of this
oh I see, I forgot these details, thanks for reminding me
why hash(key) % len(hash_table)
well, that's just how the algorithm is. It's also the most obvious way to go from a hash, which is an arbitrary integer, to the bucket index, which is an integer from 0 to len(hash_table).
but multiple values correspond to the same % calculation

I mean if the len(hash table) is 2,4,8, it will all return 0
what "it" will all return 0?
anything %
huh?
>>> 629860923 % 8
3
>>> 52131243 % 8
3
indeed, ^
hm seems inefficient
the diagram says if the key is the same
in my example the hashes are not the same, they just have the same result after doing the % operation

oh
Hi Everyone!. I am learning data structures and algorithm and I am currently working on Stack ADT problem. I am facing an error in one of the inputs. Below is my code:
def __init__(self, data, node=None):
# Initialize this node, insert data, and set the next node if any
self.data = data
self.chain = node
class CandidateStack:
def __init__(self, data=None):
# Initialize this stack, and store data if it exists
self.stack_top=None
if data!=None:
n=Node(data)
self.stack_top=n
def push(self, data):
n=Node(data,self.stack_top) # add data in beginning of stack
self.stack_top=n
def pop(self):
if self.stack_top==None: # remove element in beginning of stack
return None # return data in beginning or none stack is empty
else:
n=self.stack_top
self.stack_top=self.stack_top.chain
return n.data
def top(self):
# Return the data in the element at the beginning but does not remove.
if self.stack_top==None:
return None # Return None if stack is empty.
else:
n=self.stack_top
return n.data
def __len__(self):
count=0 # Return the no. of elements
n=self.stack_top
while(n!=None):
count=count+1
n=n.chain
return count
def combination_sum(target, candidate_list):
# Returns True if Target can be formed from candidate_list repeated
while(len(candidate_list)>0):
current=candidate_list.pop()
while(target>=current):
target=target-current
if target==0:
return True
else:
return False
candidate_list=CandidateStack()
candidate_list.push([])
print("Test1=",combination_sum(4,candidate_list))
In the above code for the input: target = 4, candidate_list = [], it should return TRUE, instead It returns FALSE.
Quick question, is it possible to do collections.Counter() but return the result in order? something like an OrderedCounter? that keeps the original order the items appeared in the input
I wish we could do that. But I want the result using the iterative method 🙂
In the above code for the input: target = 4, candidate_list = [], it should return TRUE, instead It returns FALSE.
Why would it be true, for an empty candidate list?
collections.Counter already preserves input order, I believe.
input: "leetcode" stdout:Counter({'e': 3, 'l': 1, 't': 1, 'c': 1, 'o': 1, 'd': 1})
Because that is the expected result.
In [33]: Counter("leetcode")
Out[33]: Counter({'l': 1, 'e': 3, 't': 1, 'c': 1, 'o': 1, 'd': 1})
!e
x = "leetcode"
from collections import Counter
for k,v in Counter(x).items():
print(k,v)
the iteration is certainly in insertion order
@vocal gorge :white_check_mark: Your eval job has completed with return code 0.
001 | l 1
002 | e 3
003 | t 1
004 | c 1
005 | o 1
006 | d 1
you might be using most_common or something
Why is it, though? How do you assemble 4 from an empty list?
Yea, you are right. But even I don't why it is expecting to be True 🙂
interesting, why did it print it out in wrong order for me?
is it just a problem with print?
what version of python are you on
iirc insertion order is maintained in dicts in cpython since 3.6
3.10.2
interesting
maybe leetcode's using pprint with sort_keys or something
wait, no, it would be sorting by values
sort(..., key="leetcode".index) 🧠
it's actually sorting from greatest to smallest input: "leetcodeeeeerrr" Counter({'e': 7, 'r': 3, 'l': 1, 't': 1, 'c': 1, 'o': 1, 'd': 1})
hmmm this was with pretty printing turned on in ipython
if i turn it off i get what you got
lol
Write a program that can find the factors of a value:
enter number: 64
factor of 64 is:
1 64 2 32 4 16 8 8
maybe this question easy for you, but for me is hard
dict(counter) prints the correct order
hm
class Solution:
def kthFactor(self, n: int, k: int) -> int:
for x in range(1, n // 2 + 1):
if n % x == 0:
k -= 1
if k == 0:
return x
return n if k == 1 else -1
k-th factor of a value (the easy solution)
wait, i will run the program
is there a short way to make collections.Counter have the keys being the indices of the original list/string?
instead of the actual input values
but there's no duplicates among indices, so wouldn't that be a counter of only ones?
yea it would have to discount the duplicates as being new indices
and instead count them towards the same value seen in the previous index
this is the algorithm I wrote to do this but it's probably inefficient:
charCounts = {}
for i in range(len(string)):
if s[i] in charCounts:
charCounts[s[i]][1] += 1
else:
charCounts[s[i]] = [i, 1]
What's the k for, bro?
Can the code not use functions, just loops?
you should learn how Python or programming works
the algorithm is in the function, you can take it out lmao.
Input: n = 12, k = 3
Output: 3
Explanation: Factors list is [1, 2, 3, 4, 6, 12], the 3rd factor is 3.
you can change the code by yourself to do what you want it to do
@lucid summit your original question is just printing out all values of k
Okay thank you
@lucid summit

!rule 8
8. Do not help with ongoing exams. When helping with homework, help people learn how to do the assignment without doing it for them.
yea that wasn't the actual solution, related but not the same
hey guys did anyone figure out how to handle the returns in pythonic recursive functions?
Hey
def longest_maximum_clique(graph):
maximum = 0
for starting_v in graph:
clique = [starting_v]
clique_length = 1
for v in graph:
if v in clique:
continue
if isNext := all(u in graph[v] for u in clique):
clique.append(v)
clique_length += 1
maximum = max(maximum, clique_length)
return maximum
Is this code good for searching longest maximum clique? Assuming greed attempt
not sure at all about result but what exactly is need of walrus here? it seems like a waste.
if isNext := all(u in graph[v] for u in clique):
this can literally be
if all(u in graph[v] for u in clique):
also you can just combine 2 conditions.(if you want)
if v not in clique and all(u in graph[v] for u in clique):
continue
...
for v in graph:
if v in clique:
continue
isNext = True
for u in clique:
if u in graph[v]:
continue
else:
isNext = False
break
if isNext:
clique.append(v)
clique_length += 1
It's same as this piece
no i mean here you are using isNext atleast. in current code? you're not.
it is True tho right? may be i can suggest some changes for faster.
I'll not change approach but I'll take help of datastructures a bit to make it faster.
def main():
transceivers_number = int(input())
ranges = [tuple(map(float, input().split())) for _ in range(transceivers_number)]
matrix_dict = {i: [] for i in range(transceivers_number)}
for i in range(transceivers_number):
for j in range(transceivers_number):
if j not in matrix_dict[i] and not overlap(ranges[i], ranges[j]):
matrix_dict[i].append(j)
print(longest_maximum_clique(matrix_dict))
def overlap(a, b):
return a[0] <= b[0] <= a[1] or b[0] <= a[0] <= b[1]
def longest_maximum_clique(graph):
maximum = 0
for starting_v in graph:
clique = [starting_v]
clique_length = 1
for v in graph:
if v in clique:
continue
if isNext := all(u in graph[v] for u in clique):
clique.append(v)
clique_length += 1
maximum = max(maximum, clique_length)
return maximum
if __name__ == "__main__":
main()
my code
here you can use set instead of list, so in operation becomes O(1) for u in clique
moreover, hm can you tell me defn of clique? so i can revisit may be coding part.
clique it's part of graph where every v is connected to every v
so maximum clique is of that size that you can not add anymore v to it
ah so disconnected complete graph?
e.g.

oh it may not be disconnected i see
And I want to find longest one
It can be cofusing because when you see maximum you can assume that it's the longest one but it's not :DD
Now I am itereating through every node and trying to expanding as far as it'll be still maximu clique
For every iteration I am comparing it with maximum = max(maximum, clique_length)
And that's so slow
what's a "longest" clique? Like, highest number of nodes?
Yeah
6
70.5 143.2
55.3 162.6
280.6 337.2
148.8 301.2
200.6 280.6
121 201
e.g input
those are radio ranges that can interfere with each other
ah.
so I must figure out how many of them can be running at the same time without intreference
highest number of nodes such that the graph of them is totally connected.
As for your code, it seems to me you can achieve a speedup if you use sets instead of lists for storing the neighbours of each node (and also for clique itself), because then, to check that a vertex can be added to the clique, you only need to check clique <= graph[v], which for sets is O(len(clique)+len(graph[v])) rather than O(len(clique)*len(graph[v]))
i have one more idea which may help
I have to make it under 10s with 10k ranges
never used that before :00
hm you do know what is subset right?
<= on sets is issubset, same thing.
this was what i though earlier too
all(u in graph[v] for u in clique)
apart from set,
you can put this as
clique_length <= len(graph[v]) and all(u in graph[v] for u in clique)
for your current code
I thought about something like this ({},{},...) where index is node and sets are neighbours to index node
that won't speed it up.
you can follow
{1:set(), 2:set()...}
thingy
sure
clique_length <= len(graph[v]) and all(u in graph[v] for u in clique) whats <= operator in this case?
aaah when comparing sets?
wait don't confuse both. what reptile means is you can write a.issubset(b) as a<=b

no this is like comparing length, so my idea is,
assume that a node is connected to only 5 other nodes, it WILL NOT be in clique of 10, and length of list is already stored so you first just make sure that do i even need to check?
@vocal gorge len() is O(1) right?
sure I'd try this
matrix_dict = {}
for i in range(transceivers_number):
nodes = []
for j in range(transceivers_number):
if not overlap(ranges[i], ranges[j]):
nodes.append(j)
matrix_dict[i] = set(nodes)
print(longest_maximum_clique(matrix_dict))
Is that a proper pythonic way to do it?
you can use .add()
so
nodes = set()
nodes.add(j)
on all builtin types, sure
easy as that, that's nice
matrix_dict = {}
for i in range(transceivers_number):
nodes = set()
for j in range(transceivers_number):
if not overlap(ranges[i], ranges[j]):
nodes.add(j)
matrix_dict[i] = nodes
print(longest_maximum_clique(matrix_dict))
Is that correct?
seems good yeah
if isNext := clique_length <= len(graph[v]) and all(u in graph[v] for u in clique):
clique.append(v)
clique_length += 1
And this comparison with := or just instead isNext?
As you said isNext is not accessed
@fiery cosmos :white_check_mark: Your eval job has completed with return code 0.
4
Okay
matrix_dict = dict()
for i in range(transceivers_number):
nodes = set()
for j in range(transceivers_number):
if not overlap(ranges[i], ranges[j]):
nodes.add(j)
matrix_dict[i] = nodes
matrix_dict[i] is not making key : {value,...} pairs, instead it's making a long set
its a set. that is expected.
{0, 1, 2, 3, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 23, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 41, 42, 43, 46, 47, 48, 49, 50, 51, 52, 54, 55, 56, 59, 62, 65, 66, 67, 68, 69, 70, 71, 74, 75, 77, 78, 81, 82, 83, 84, 87, 88, 90, 92, 93, 94, 95, 96, 97, 98, 99, 100, 102, 103, 104, 105, 106, 107, 108, 109, 110, 114, 115, 118, 119, 120, 121, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 135, 136, 137, 139, 140, 141, 143, 146, 147, 149, 152, 153, 154, 155, 156, 157, 158, 160}
It's looking like this
So I can't get edges from it
you converted
matrix_dict = {
node_number: [0, 1, 2, 3, 5...]
}
to
matrix_dict = {
node_number: {0, 1, 2, 3, 5...}
}
so what do you mean can't get edges?
It was something like that graph = {0: [2, 3, 4], 1: [2, 4], 2: [0, 1, 5], 3: [0], 4: [0, 1], 5: [2]}
so I should only replace [] with {} I think
that is what you did no?
I've got this without keys, just as set
matrix_dict = {}
for i in range(transceivers_number):
nodes = set()
for j in range(transceivers_number):
if not overlap(ranges[i], ranges[j]):
nodes.add(j)
matrix_dict[i] = nodes
print(matrix_dict)
print(longest_maximum_clique(matrix_dict))
matrix_dict[i] should add a new key : values
you mean matrix_dict, your matrix_dict[i] was a list and now is set so [] => {}
[] -> {} that's true but it's merging all values to one set somehow
!e
matrix_dict = {}
for i in range(3):
nodes = set()
for j in range(3):
if i >= j:
nodes.add(j)
matrix_dict[i] = nodes
print(matrix_dict)
@fiery cosmos :white_check_mark: Your eval job has completed with return code 0.
{0: {0}, 1: {0, 1}, 2: {0, 1, 2}}
seems correct to me.
>>> a {1: {1, 2, 3}, 2: {2, 3}}```
it is not merging in my code.
confused me now
this is working as expected
are you sure, i think your data may be different. i just ran your code.
yeah, sorry for this :DD
I was confused so much
6
70.5 143.2
55.3 162.6
280.6 337.2
148.8 301.2
200.6 280.6
121 201
{0: {2, 3, 4}, 1: {2, 4}, 2: {0, 1, 5}, 3: {0}, 4: {0, 1}, 5: {2}}
2
yeah that's absolutely correct
hm good, how are results now?
0.5s on 100
and what was it before?
pretty same :((
aw lol
I am still waiting for 1k
yeah its exponential so lets see for longer.
that's true
But I cannot really optimise it
I can only approximate it
I can send you little more info on dm if you have a moment?
i'm gonna eat and sleep now, but i can look later, sure.
Sure, thanks!
np. later.
Urgent general algorithm help!! 🥺 If I run Edmonds-Karp (EK) on flow network graph G I get an output with the graph of the residual flow G^R. Running EK is O(|V|+|E|^2).
What is the runtime of Depth-First Search (DFS) on G^R from EK? I was always told DFS is O(|V|+|E|) so the total would be:
O(|V|+|E|^2) + O(|V|+|E|) == ???
But my friends say DFS is O(|E|) and that when run with EK the total is the same, O(|V|+|E|^2)
What gives?! Is it O(|V|+|E|^2) +O(|V|+|E|^2) == O(|V|+|V|+|E|+|E|^2) == O(|V|+|E|^2) ??? Regardless of what DFS is, does it still reduces down to the EK runtime since DFS is linear and EK is polynomial with respect to the edges |E| ?
DFS is O(V + E), and yes, you're analysis of the final big O is correct
wait, no. the time complexity for EK is O(V * E^2), not +
I have started doing leetcode contests....i am doing competitive programming since jan....i was able to do 3rd out of 4 question in 1 hour on this saturday.....how is my progress going....
I havent been able to solve any hard just yet
Am i slow?
Nah, sounds fine  the hard ones are hard even looking at the explanations
the hard ones are hard even looking at the explanations 
class Queue:
def __init__(self, front, rear, mx):
self.front = front # front of the queue
self.rear = rear # rear of queue
self.mx = mx # Max number of items that can be in queue
self.items = []
def add(self, item):
'''
If possible, the Plane is added to the Queue;
'''
if (len(self.items) >= self.mx):
print('Queue is full.\n')
return
# rear position is incremented, when a new plane is added to the queue(enqueue operation)
self.rear = (self.rear + 1) % self.mx
self.items[self.rear] = item
any idea why this is not working
the add part
example input
q = Queue(0, -1, 4)
oh wait python got a built in queue
imma try that
waiting for your feedback
Hi everyone! can anyone help me in explaining that how can we implement iterative method in Stack ADT using a linked solution. Is there any problems related to this online would be helpful for me to understand?
yep it work fine
the problem im having is i cant get the item from the queue
lets say q = Queue()
q.put('a')
q.put('b')
how do i get a
q.get()
it returns the mast added element LIFO
isnt queue FIFO
yeah, sorry the first added element FIFO
cool
thx
q.empty() to check if it's empty and q.fulll() to check if it's full
what's the complexity of finding a substring inside a string using the "find" method
what algorithm does it use?
KMP?
nvm apparently it's boyer-moore-horspool algorithm (?) which is O(nm) time
it's, uhh, complicated:
https://github.com/python/cpython/blob/main/Objects/stringlib/fastsearch.h#L5-L21

GitHub
The Python programming language. Contribute to python/cpython development by creating an account on GitHub.
but KMP is faster so why dont they use it?
If the strings are long enough, use Crochemore and Perrin's Two-Way
algorithm, which has worst-case O(n) runtime and best-case O(n/k).
Also compute a table of shifts to achieve O(n/k) in more cases,
and often (data dependent) deduce larger shifts than pure C&P can
deduce. */
nvm 'Boyer-Moore Algorithm says that there is an optimization ("Galil Rule") which produces linear time in the worst-case."
🤓
why no mention of KMP or Rabin Karp?
that's what people are doing when solving this by hand
it apparently produces an O(n+m) solution
do interviewers actually expect you to be able to use KMP or Rabin Karp in an interview?
especially for a junior role
no idea from me, I don't know enough about string search. Though searching for python fastsearch kmp, I find here: https://stackoverflow.com/a/18139681 a mention that best-case compexity is a bit better (sublinear) than KMP this way.
nice
ah, there we go, the link from the code mentions it:
https://web.archive.org/web/20201107074620/http://effbot.org/zone/stringlib.htm
This rules out most standard algorithms (Knuth-Morris-Pratt is not sublinear, Boyer-Moore needs tables that depend on both the alphabet size and the pattern size, most Boyer-Moore variants need tables that depend on the pattern size, etc.).
big brain stuff
def strStr1(self, haystack, needle):
Hlen, Nlen = len(haystack), len(needle)
hash_n = hash(needle)
for i in range(Hlen - Nlen + 1):
if hash(haystack[i : i + Nlen]) == hash_n:
return i
return -1
def strStr2(self, haystack: str, needle: str) -> int:
Hlen, Nlen = len(haystack), len(needle)
for i in range(0, Hlen - Nlen + 1):
if haystack[i : i + Nlen] == needle:
return i
return -1
@vocal gorge why is 1 faster than 2? is it?
using hash just produces faster comparison? it's not even a dictionary so I dont get it
comparison b/w hash is way faster than comparison b/w 2 lists.
but considering the time it takes to hash each of the lists, how fast is that?
right now it's giving me an awful run time
actually not using hash is giving me a faster run time lol
is it supposed to be the opposite in theory?

also just using pure Robin Karp implemented by another guy, I get 20x slower performance
theoretically speaking, hash collisions happen, hence, you may get wrong answer too per se.
not sure why you put it there.
hmm hold on hash() gives.... wait
I've tested KMP it gives me the fastest performance by far
the function runs correctly just takes way longer
yeah hash is unique in python, yeah hash... is bit different in theory.
so hash in Python is slow ?
unless it's used in a dictionary?
this is confusing 😕
it is confusing yeah.. hashstack is a list?
hash in dicts is no different than anywhere else
I'd expect your 2 to be faster, because computing the hash of a string is kinda a more complex operation than just comparing it to another string
also @fiery cosmos you are missing a point in rabin karp
(string comparison can be very optimized if you want it to be, but I think python uses a naive implementation which is still fast)
see rabin karp is fast because you DO NOT calculate hash EVERYTIME, you use previous values to do it.
lemme share my code if i can
def strStr(self, haystack, needle):
def f(c):
return ord(c)-ord('A')
n, h, d, m = len(needle), len(haystack), ord('z')-ord('A')+1, sys.maxsize
if n > h: return -1
nd, hash_n, hash_h = d**(n-1), 0, 0
for i in range(n):
hash_n = (d*hash_n+f(needle[i]))%m
hash_h = (d*hash_h+f(haystack[i]))%m
if hash_n == hash_h: return 0
for i in range(1, h-n+1):
hash_h = (d*(hash_h-f(haystack[i-1])*nd)+f(haystack[i+n-1]))%m # e.g. 10*(1234-1*10**3)+5=2345
if hash_n == hash_h: return i
return -1
so slow
doesnt use any less memory either
what's the point

(uses less memory compared to KMP but not compared to others)
def strStr2(self, haystack: str, needle: str) -> int:
Hlen, Nlen = len(haystack), len(needle)
for i in range(0, Hlen - Nlen + 1):
if haystack[i : i + Nlen] == needle:
return i
return -1
``` O(Hlen\*Nlen) time , O(Hlen*Nlen) space <- is this correct?lmao
I don’t know how to calculate space complexity, but I probably can calculate the time complexity.
O(Nlen) space complexity as it creates slices of that size
^
For an operation, does using len() count towards it, as it works in O(1)? Or is it still one operation as it is a variable assignment?
time complexity seems right.
what do you mean?
len takes constant time and space
ahh ok what I thought
Hi guys, any idea on how to tackle this problem?

i thought the obvious brute-force method would iterate each element, and checks the 4 neighboring elements, which would be O(n) right? isn't that better than O(n*log(n))?
which would be O(n) right?
there's n^2 elements in the matrix, not n.
O(n*log(n)) is a middle ground. It and O(n) are decent time complexities to have
As for the problem: I know the 1d version of this problem is fairly popular, and solvable in O(log n). So I think you can use that solution to construct the 2d one (run the 1d solution on each row (that's the n log n) to find the one-row summits, then check which of them are true summits (another O(n) at worst).)
thanks, isn't O(n*log(n)) > O(n) asymptotically ?
thanks mate for the help
think so
because for higher values n, it will become larger than O(n)
yeah
oh right, i mistaken that you meant O(n*log(n)) is better as in efficiency.
what is this problem called? the 1d version.
don’t think this is the right channel?
it's probably overriding __getattribute__, is all
is __getattr__ different than __getattribute__?
Yes, but in a somewhat obscure way
oh ok lmao
object.getattr(self, name)
Called when the default attribute access fails with an AttributeError (either __getattribute__() raises an AttributeError because name is not an instance attribute or an attribute in the class tree for self; or __get__() of a name property raises AttributeError). This method should either return the (computed) attribute value or raise an AttributeError exception. Note that if the attribute is found through the normal mechanism, __getattr__() is not called. (This is an intentional asymmetry between __getattr__() and __setattr__().) This is done both for efficiency reasons and because otherwise __getattr__() would have no way to access other attributes of the instance. Note that at least for instance variables, you can fake total control by not inserting any values in the instance attribute dictionary (but instead inserting them in another object). See the __getattribute__() method below for a way to actually get total control over attribute access.
object.getattribute(self, name)
Called unconditionally to implement attribute accesses for instances of the class. [rest elided]
in this case you could override either to achieve such an effect
If you haven't implemented dunders before, practice that. Otherwise, read about these two in Data Model: https://docs.python.org/3/reference/datamodel.html#object.__getattr__ and try it out.
so __getattribute__ is pretty much a bit more flexible?
as I see check getattribute to get total control
!e
class A:
def __init__(self):
self.a = "yay" # normal instance attribute
def __getattr__(self, name):
return name # Yes, I totally have this attribute
a = A()
print(a.a, a.b, a.c)
@vocal gorge :white_check_mark: Your eval job has completed with return code 0.
yay b c
Yes, it's called first.
You need that one if you need to, say, make actual attributes the instance has not accessible.
👍
__getattr__ gets called when the former fails, so it's okay to use to, say, add new "attributes" like in my example above
it's not actually creating any attributes, just pretending to have some when asked
e.g. you can make a dict that, in __getattr__, redirects to __getitem__
so it'll be a dict you can use dot-access with.
would a use case for that be where you don’t want a class to be instantiated, in __init__, with these said attributes, but it needs them to do something else, so you use __getattr__to do so?
sure, though I don't really see why that'd happen
bs4, as mentioned above, does this to access children of the xml structure
ye, just trying to understand it more. I haven’t really messed with many dunder methods besides __init__, __all__, __repr__ or __str__
prolly my time to learn more of them
thanks for the explanation though. We should prolly move to another channel if we want to continue. 🗿
in general you want to implement __getattr__, not __getattribute__
is there no way to contruct some example where all are false summits?
oh, you're right actually, because no guarantees that if there's a true and a false summit on a row, the 1d algo will find the true one
still, probably helpful to study the 1d task
very dumb idea that I haven't thought trough, what happens if we alternate peak finding in the x and y direction? i.e. find a peak in a row, try to find a peak in the column of the last peak
I guess it's probably possible to get stuck in a loop this way, which would be bad
ah, I found a MIT lecture that covers it, it's indeed a similar solution to the 1d version:
- ||pick the global max in the middle column||
- ||do the same decision whether to go left/right as in the 1d algo, this either finds a peak or eliminates half the columns||
- ||repeat 2. until...||
- ||you are down to 1 column, just pick the global max in the column||

MIT 6.006 Introduction to Algorithms, Fall 2011
View the complete course: http://ocw.mit.edu/6-006F11
Instructor: Srini Devadas
License: Creative Commons BY-NC-SA
More information at http://ocw.mit.edu/terms
More courses at http://ocw.mit.edu
but isn't that O(log(n)^2)
and the thing I proposed is indeed incorrect
finding global max in column is O(n)
I think so for the obvious generalization of this algo at least
it's also a different problem
that one is finding a many peaks
To experienced competitive programmers
What are some important advice you can give for hard questions on Leetcode that often give TLE
figure out if the time complexity of your solution is just too high, and if it is find a better algo
a good guesstimate for time is 10^9 simple operations per seconds in a fast language
e.g. of a codeforces problem https://codeforces.com/problemset/problem/1575/L
here if the solution scales in only n I would expect O(n log n) or maybe slightly higher
Codeforces
And when it comes to rearranging questions in which string or array need to me modified is some way...is it always better two make new array?
I could imagine O(n (log n)^2) and O(n sqrt n) barely passing that task
and the intended solution is indeed O(n log n)
the tags also help (divide and conquer)
though it also has a tag of *2100, which is yikes for me 🥴
I dont wanna rely on tags
the tag isn't there during the contest 😛
ah, good point
nor the difficulty
I am preparing for real comp
the difficulty score is given based on performance during contests
(and a lot of time it can be misleading because psychology during contests is weird)
The amount of confidence i got by solving that medium question in 20 minutes is immeasurable.....i am soo much optimistic i though i was a god
🤣
lol, there is always questions which will kick your ass
even more so on codeforces
unless you're tourist
(for context tourist is by far the highest ranked user on codeforces)
I saw a french programmer destroy all 4 question in 6 minutes....on live stream
I've never done leetcode contests, so I can't speak for their difficulty
He didnt even see if it were accepted or not....he just knew he did it and closed the tab
Abouts half as difficult as kickstart if i would say....dont wanna offend anyone
e.g. this is the hardest problem on the last contest I found https://leetcode.com/contest/weekly-contest-281/problems/count-array-pairs-divisible-by-k/

Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
I think I know how to solve it, now within like a minute of reading it
😁
I didnt knew how to.....the way i knew it would give tle to me
Whats your approach
huh, hold on, lemme try
for some reason my first reaction is "isn't that just two sum"
ah, nevermind, I see; slightly worse
- count remainders mod
k(i.e. letC[i]be the count of numbers that areimodk) - find all ways to factor k into factor pairs (divisor pairs, I guess?)
- for all such pairs
(a, b)addC[a]*C[b]to the result
let me actually think if this actually works :/
ah, you would need to handle one case, you can't multiply a number by itself, but you can correct for that
you also need to handle C[0] specially
Are you doing dp for it?
not really dp, no
what's the time complexity of max or min len of a list of strings (which is basically a list of lists) in Python?
linear in the number of elements you take max over?
list of strings is harder, it depends on your strings
["hello", "goodbye", ... , "asdfg"]
n number of strings
find the string with the max len
could be anywhere from O(list_len) to O(list_len * string_len)
wouldn’t it be O(n) for min() and max()? For like a simple list
if all strings have different first characters it's O(list_len)
still trying to get the hang of this big o stuff, so I might be wrong
if all strings only differ in the last character it's O(list_len * string_len)
I mean, it depends on whether you care about string lengths at all
if you don't include it in your complexity, it's just O(list_len). if you do, it's worst case O(list_len*string_len)
it should be part of the complexity though
actually I thought max(string_list) will return the max len string, it doesnt
what does it actually do
@vocal gorge :white_check_mark: Your eval job has completed with return code 0.
['0', 'a', 'ab', 'b', 'ba', 'yay']
e.g. getting an element from a dict by a string key is not O(1)
unless you have precalculated the hash
Hi everyone. I'm doing Boogle Assignment https://web.stanford.edu/class/archive/cs/cs106b/cs106b.1186/assn/boggle.html
I see
I don't think I ever saw anyone care about it, considering it takes 6ms to get the hash of a 10 million character string
They are also cached, so next time will be 0ns
Runtime: 2662 ms, faster than 100.00% of Python3 online submissions for Count Array Pairs Divisible by K.
lol, I guess people don't optimize theirs at all
what was your approach in the end?
pretty much what you though of too; just need to consider, for all a,b such that 0<a<=b<k and a*b%k==0, the number of ways to pair numbers with a remainder of a with those with b (which is C[a]*C[b] if a!=b, otherwise C[a]*(C[b]-1)//2), and separately the zero case
calculating such factors took a bit of effort, probably because I'm shit at number theory 🥴
yeah, my divisor thing was a tad wrong
we need your phrasing of it
for all a,b such that 0<a<=b<k and a*b%k==0
I wonder how they are using less memory than mine though
Memory Usage: 27.7 MB, less than 77.78% of Python3 online submissions for Count Array Pairs Divisible by K.
I only use one k-sized list worth of space
maybe there's some solution with bad time complexity but sublinear space?
ah nevermind
just the judge being bad
I resubmitted without changes and got 100%/100%
these two are the same code, lmao

yes, consider k=4 having 2,2
right, square roots
wait, did you do something clever or did you just do a (10^5)^2 loop?
wtf, C++ on leetcode runs with sanitizers on?
not bad, though I don't trust that memory usage

rust meanwhile

running with sanitizers on in C++ has a pretty large overhead :/
🥴

let's say my rust code is a messy translation of my C++ code
not idiomatic rust in the slightest
that and leetcode's servers suck

same code
that's a >50% swing in measurements, wtf are they doing?
I stole a binary gcd impl as well, no clue if it's any good though
it's recursive, which might be a bad sign
I stole mine straight from wikipedia
https://en.wikipedia.org/wiki/Binary_GCD_algorithm

The binary GCD algorithm, also known as Stein's algorithm or the binary Euclidean algorithm, is an algorithm that computes the greatest common divisor of two nonnegative integers. Stein's algorithm uses simpler arithmetic operations than the conventional Euclidean algorithm; it replaces division with arithmetic shifts, comparisons, and subtracti...
it's slightly jarring to see an example in Rust, but here we are 🥴
in any case, similar enough performance
I didn't like leetcode as a platform before, and it sure hasn't grown on me with C++ running with a sanitizer for the problem
which adds like a factor 2-3 on runtime
and rust is painful as usual in contests since you have access to basically no crates
in this case, no num
Help me out with merge sort plz
I believe hash is memoized. It's faster depending on the number of unique hashes that need to be computed.
However, for the code to be correct it needs to do a full comparison after comparing the hashes.
only in the case of a collision
Yeah, if the two strings have different hashes continue.
(So still may be faster)
*In CPython.
what is the fastest way to do a insertion algorithm?

#discord-bots and I can help there
Hey all, does anyone have experience with
0-1 Knapsack Problem ?
I would incredibly appreciate it
the wiki doesn't give enough details of the approach to solve it?
https://en.wikipedia.org/wiki/Knapsack_problem#0-1_knapsack_problem
@haughty mountain
It doesnt
I need help about implementing it with BFS - Breadth First Search
I have no clue where to start
Are there any other details people need to know to effectively address your question?
A good place to start is to identify the inputs and outputs of what you're doing.
def knapsack_problem_bfs(arg1: type, arg2: type) -> return_type:
...
does bfs even make sense for 0-1 knapsack?
It doesnt makes sense
things are weighted, aren't they?
Exactly
the wiki describes the usual dynamic programming solution
I need to apply Breadth First Search in order to get the best combination of items inside the bag
BFS is for graph traversal. I'm not sure how you'd represent the problem as a graph
for the knapsack problem, what are the nodes and edges?
Given a list of items, each item has a weight and a benefit, determine the number of each item to
include in a bag so that the total weight is less or equal to the limit of the bag and we get the
maximum benefit.
The most common problem to solve is the O-1 knapsack problem, which restricts the number of
copies of an item to one. Therefore, an item can be inside the bag or outside.
Items are represented by two values (weight and benefit )
And I have 11 items with their benefit and weight
And Maximum weight is 400
where does it say you have to use BFS?
if it doesn't, just use the dynamic programming/caching approach, since that's what the knapsack problem and its variants are usually intended to teach.
bfs is really only useful if you care about exploring things in distance order in an unweighted graph
otherwise afaik you could use any graph traversal
does it have to be unweighted?
if it's weighted you need Dijkstra
which is just switching from a queue to a priority queue
I think you're mixing up problems. {B,D}FS is just for going to all the nodes. Dijkstra is for finding the shortest path between two specific nodes.
bfs visits nodes in distance order on an unweighted graph
dijkstra visits nodes in distance order on a weighted graph
there's no reason you can't do a BFS on a weighted graph. you just don't take the weights into account.
why you would want to do that, I'm not completely sure.
yes, that's my point, bfs isn't really useful other than in the case where you care about distance order in exploration (in an unweighted graph)
bfs only makes sense on some graph
No  @weary gyro
@weary gyro
That’s how it goes 🙃, just stay consistent
Does the sum of list comprehension expression take a linear amount of space to first build the list? For example, will the code sum(i for i in range(n) if '''some condition''') take O(n) space or O(1) space?
I'm guessing O(1), I don't think a list is ever created.
yeah, for sum(i for i in range(n) if '''some condition''') (technically a generator comprehension) sum should be taking the things in one at a time, so O(1) memory
but for sum([i for i in range(n) if '''some condition''']) it will make the list first because of the [], so O(N) unless I'm much mistaken
Correct  you get a 🍪
you get a 🍪
>>> a = (i for i in range(10))
>>> type(a)
<class 'generator'>
>>> a
<generator object <genexpr> at 0x7f7782bd1eb0>
>>> b = [i for i in range(10)]
>>> type(b)
<class 'list'>
>>> b
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> c = [a]
>>> type(c)
<class 'list'>
>>> c
[<generator object <genexpr> at 0x7f7782bd1eb0>]
>>>
I was actually trying to benchmark listcomp vs generator comp with https://pypi.org/project/memory-profiler/ -> https://paste.pythondiscord.com/exewogeqil
Oh there it is
But wasn't totally sure how to read the results though the longer list one took double the memory of all the others it seems
idk, the 2**20 list is 1024 times bigger, but I guess the base ~20 MiB is mostly overhead?
Hmm
Uh -37632.270 MiB, seems kind of busted.
idk either 
first time I've used this package, there may be better ways to memory benckmark
Also for the 20 MiB, I think the profiler itself has overhead.
Yeah.
!e But the point is you can implement a sum method that works in O(1) space, so it'd be really weird if the builtin doesn't ```py
def my_sum(iterable):
print(iterable)
total = 0
for i in iterable:
total += i
return total
print(my_sum(i for i in range(2**10) if i % 2))```
@fiery cosmos :white_check_mark: Your eval job has completed with return code 0.
001 | <generator object <genexpr> at 0x7fb194bf7c30>
002 | 262144
I grossly overestimated what 2**20 was for some reason, turns out it’s just a million 
Sum accepts any iterable (including a generator), so I am assuming it's looping and calling next each time on it and summing into a single value.
Exactly 
Course for summing strings that will be O(n) space 🤔
If by string you mean text, and by sum you mean concatenation, sure.
yeh
when do you use generators and when do you use traditional iterabale lists ?
if I care about having things lazy I do generators, otherwise lists or similar
Generally I use list comps as a default.. but you would use a generator comp when you don’t need any list methods, like in, or the ability to iterate over it twice
@half ether No complexity was required there. And since only the possibility of 'yes' and 'no' need to be returned. The shortcircuit Idea might be good.
@vapid beacon I can import , but should I really check every possible permutations that way?
Sorry the discussion has been moved to dormant : (
luckily they just completely disallowed summing strings
!e
class Hmm:
def __init__(self, x):
self.x = x
def __add__(self, other):
if not isinstance(other, Hmm):
return NotImplemented
return Hmm(self.x + other.x)
things = list(map(Hmm, ["can't ", "tell ", "me ", "what ", "to ", "do!"]))
print(sum(things, start=Hmm("")).x)
@austere sparrow :white_check_mark: Your eval job has completed with return code 0.
can't tell me what to do!
how do i turn my text to python?
the fact that 2**10 ~ 1000 is well worth remembering for the sake of estimating stuff
there's a reason why a lot of people don't know the difference between SI and binary prefixes (eg. MB vs MiB) - they are really close.
though the bigger, the more different they are.
Yeah, definitely
and intentional deception from people selling stuff like storage
using GB rather than GiB to make things sound larger
even though most people (I presume) think about the binary prefixes
I recall something about windows straight up messing it up
like, calling GB what's actually GiB
I would totally make that mistake
yeah, windows isn't helping by using GB when they actually mean GiB
linux stuff is generally good about it
can moore algo be used to find an element that occurs more then n/3 times the array?
it can be generalized, yeah
to consider n/3 instead of majority (n/2) you keep (at most) two counters
in general for n/k you would keep (at most) k-1 counters
you follow a similar scheme, when you encounter an element x
if x has a counter, increment it
else if x does not have a counter and there are less than k-1 counters,
make a new counter with value 1
else decrement all counters by 1 and remove counters with value <= 0
then in the second pass you validate the (at most) k-1 candidates
sample impl
from collections import Counter
def bm_generalization(values, k):
# Finding candidates
counters = {}
for x in values:
if x in counters:
counters[x] += 1
elif len(counters) < k-1:
counters[x] = 1
else:
for value, count in tuple(counters.items()):
if count == 1:
del counters[value]
else:
counters[value] -= 1
print('candidates to check', counters)
# Validation
candidates = set(counters)
counts = Counter(x for x in values if x in candidates)
for cand, count in counts.items():
if count > len(values)//k:
print(f'candidate {cand} has >n/{k} votes')
The first part is the bottleneck for sure at O(n*k)
I have some vague idea how to improve the first part to O(n log n) using a priority queue, but it would be a hacky mess
For anyone interested:
In short, keep a count instead of actually removing elements.
That way you can pop elements smaller than the count
(and we can't pop more than n values over the whole sweep).
The hacky part is when you want to insert a new counter,
you have to insert the removal count + 1 instead of inserting 1.
Not sure if it's possible to do better than that.
Is this the optimal knapsack algorithm in python, i get tle and i don't know why?
n, w = list(map(int, input().split()))
lo = [[0,0]]+[list(map(int, input().split())) for i in range(n)]
dp = [[0]*(w+1) for i in range(n+1)]
for i in range(1, n+1):
for j in range(1, w+1):
if j>=lo[i][0]:
dp[i][j] = max(dp[i-1][j], lo[i][1]+dp[i-1][j-lo[i][0]])
else:
dp[i][j] = dp[i-1][j]
print(dp[-1][w])```n, w are the number of things and the max weight
lo is a list of things with their weights and values
dp is an dynamic programiming table
It's depends on context, in the past GB, etc was powers of 2, because otherwise it does not make sense (for operating systems stuff). There is no general answer. It's also kind of like the debate of tabs vs spaces.
So if you look at for example some Linux commands you will see MB, GB, etc and they will be powers of 2.
The powers of 2 is IMO the more correct / what should be standard. The other is just because base 10 reasons which are not as relevant for computers.
The base 10 was also to sell CDs and stuff, since the non-programmer was not used to powers of 2. So putting them on the back of a box for a storage device was not good for marketing.
link to problem?
I have a question about binary trees
Anyone have any hints or ideas?
Given an unsorted integer array nums, return the smallest missing positive integer.
You must implement an algorithm that runs in O(n) time and uses constant extra space.
My first instinct is to iterate through the whole list and move all elements <= 0 to the left, so I've used O(n) time so far, and on the first pass I'll have a list that looks like [minus values segment, positive values segment]
But since the positive values segment is unordered I have no idea what to do here
Can't use set?
needs to be constant space
Ah
wait let me think
what's easier, xor or just doing a min on the array
can't you just... find the smallest positive integer yeah.
not necessarily
because you need to find the missing one, the smallest positive one doesn't give you enough info
Yeah, I'm trying to do it without doing a linear pass to find the bounds of the range of positive numbers, then doing a second linear pass to xor a bunch of nums
so 1 pass
That's probably as good as it gets unless you do something fancy, find the biggest positive int and the smallest positive int or zero. Then xor everything in the interval.
Solution from LC
|| ```python
def firstMissingPositive(self, nums):
"""
:type nums: List[int]
:rtype: int
Basic idea:
1. for any array whose length is l, the first missing positive must be in range [1,...,l+1],
so we only have to care about those elements in this range and remove the rest.
2. we can use the array index as the hash to restore the frequency of each number within
the range [1,...,l+1]
"""
nums.append(0)
n = len(nums)
for i in range(len(nums)): #delete those useless elements
if nums[i]<0 or nums[i]>=n:
nums[i]=0
for i in range(len(nums)): #use the index as the hash to record the frequency of each number
nums[nums[i]%n]+=n
for i in range(1,len(nums)):
if nums[i]/n==0:
return i
return n
Yeah... that requires some pretty sharp insight to use the indices
Havent done algos in over a month and a half and I just blanked out on 2 sum's optimized approach for couple of minutes. Sad part is I have done this question over two dozen times.
that is actually nuts, I would have never been able to come up with that
It's not super obscure to use indices like that, but yeah you gotta be good to come up with this on the spot haha
What's the time complexity of this: ```def count(number):
if number < 10:
return 1
rest_of_number = number // 10
return 1 + count(rest_of_number)```
I think its O(n) since it calls count() n times
Is space complexity O(n) too or O(1)?
I figured it would be O(n) as well since rest_of_number is holding a new value n times
why do you think it calls it n times?
suppose number is 12345
how many times is count called?
@jolly mortar 5 times but i was thinking worst case scenario
what is the worst case scenario?
An infinitely large number
hm
okay, observe that if count() is called with n, then the next time count() is called, it will be with n/10
You mean each successive time it’s n/10?
yes
Thats log n
yes
precisely
considering what the function is doing, does log n make sense to you?
its counting the number of digits
and the number of digits is proportional to log n
no problem!
i fixed it i was using python instead of pypy


hmmmm
I'm still in the first
i dont know if this is the pkace to ask this question but
def findMajority(arr, n):
candidate = -1
votes = 0
# Finding majority candidate
for i in range (n):
if (votes == 0):
candidate = arr[i]
votes = 1
else:
if (arr[i] == candidate):
votes += 1
else:
votes -= 1
count = 0
# Checking if majority candidate occurs more than n/2
# times
for i in range (n):
if (arr[i] == candidate):
count += 1
if (count > n // 2):
return candidate
else:
return -1
# Driver Code
arr = [ 1, 1, 1, 1, 2, 3, 4 ]
n = len(arr)
majority = findMajority(arr, n)
print(" The majority element is :" ,majority)
how does the value of candidate update in the second for loop
isnt it fixed to -1
candidate is set in the first loop
whats wrong with my hash table impl
def __init__(self):
self.table = [[]] * 10
def __repr__(self):
return 'Hash Table: \n' + repr([x for x in self.table])
def insert(self, key, value):
idx = self.hash_function(key)
print(f'appending to slot {idx}')
self.table[idx].append(value)
def lookup(self, key):
return self.table[self.hash_function(key)]
def hash_function(self, key):
return key % 9
ht = HashTable()
ht.insert(1234, 19239376136)
print(ht.lookup(55555))
print(ht.lookup(1234))
print(repr(ht))```all slots are gettting filled by that first insert. its a stupid mistake i just want to move on
no its not homework im old
output is
[19239376136]
[19239376136]
Hash Table:
[[19239376136], [19239376136], [19239376136], [19239376136], [19239376136], [19239376136], [19239376136], [19239376136], [19239376136], [19239376136]]```oh. its because of my list initialization. the inner [] all references the same object
yay.
[[], [], [], [], [], [], [], [], [], []]
Hash: 1
appending to slot 1
data inserted: [19239376136]
Hash: 7
[]
Hash: 1
[19239376136]
Hash Table:
[[], [19239376136], [], [], [], [], [], [], [], []]```k

a very good question i just encountered on geeksforgeeks
luckily i able to solved it but I want to share to others 🙂
:incoming_envelope: :ok_hand: applied mute to @static thorn until <t:1645674969:f> (9 minutes and 59 seconds) (reason: duplicates rule: sent 4 duplicated messages in 10s).
ah nvm got my answer

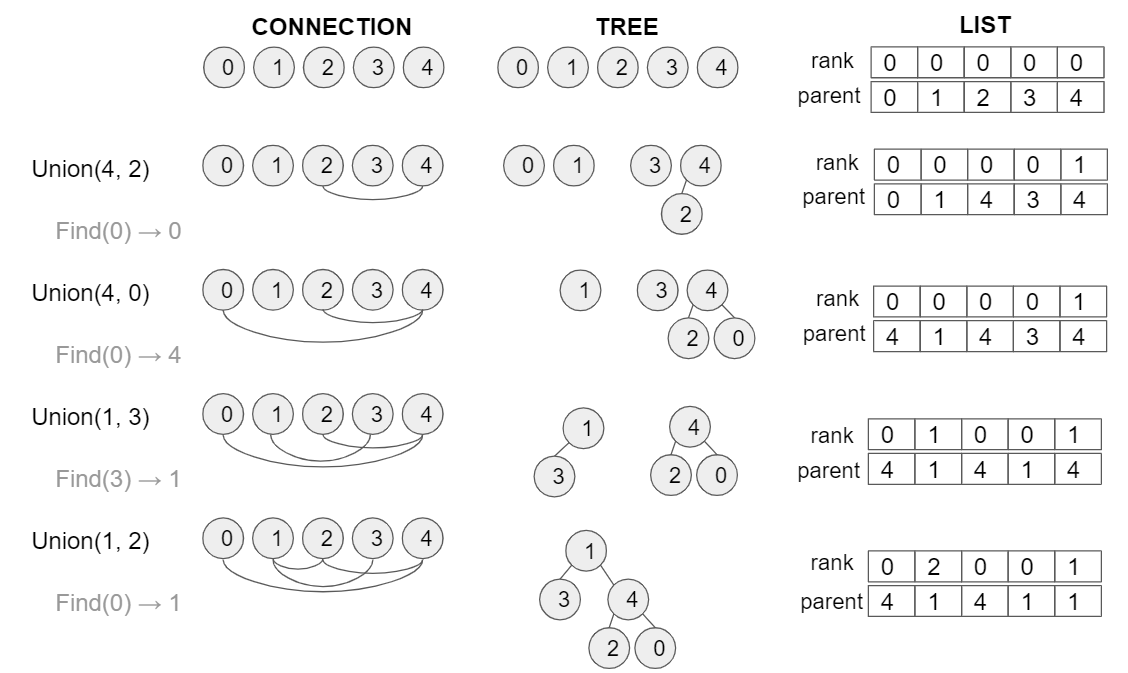{kind=link}
because how you merge things matters for the time complexity
if you don't consider size or rank when merging you get O(log(n)) find operations iirc
if you keep track of either the component size or the rank and merge small components into large components you get O(α(n)) on average
where α(n) is the inverse ackermann function
for all practical purposes ever, you can think of α(n) <= 4, so practically O(1)
In your particular example the rank matters in the Union(4, 0) where the shallower tree is merged into the higher tree
I see, for that (4,0) example, I'm trying to see why one would want to merge into the higher ranked tree
Actually, everything I said assumed that path compression is being done, which I guess is not shown in this example. If path compression is not performed then finds become O(n) without merging by rank/size rather than O(log n)
for context: path compression is done when doing a Find operation, instead of just finding the root, you do a second pass where you re-assign the parent of all the nodes in the path to be the root
which ends up making the tree flatter
As an example, say you do Find(2) on the final tree

These two nodes are ones visited during the traversal towards the root

In a second pass both nodes gets their parent assigned to the root, in this case it only affects node 2 since 4 is already connected to the root

def removeNthFromEnd(self, head, n):
length, count, dummy = 1, 1, head
while dummy.next:
length, dummy = length + 1, dummy.next
dummy = head
if length == n: return head.next
while count < length - n:
count, dummy = count + 1, dummy.next
dummy.next = dummy.next.next
return head
why does returning head work? wasn't dummy it's own separate tree we made ?
and doing a Find(0) would completely flatten the tree
head is still the head of the list
dummy (at the end) is the node before the node you removed
in short, what your operation is doing is

I dont get it
I understand that but that's not what I'm asking
dummy = head
what is this operation doing?
I'm very confused
if this was a normal list, it would not work at all
lst = [1, 2, 3,4, 5]
dummy = lst
modifying dummy does nothing to lst
wait does it?
lol
in the list case, modifying stuff through dummy would change the list
shit maybe I'm confusing my programming languages
e.g. dummy[1] = 10
interesting, how didn't I know this
dummy = lst is not copying the list if that's what you're thinking
how do you make a copy of the list that's separate
that doesn't just point to that address
it's just giving another name to what lst points to
there two would both work
lst_copy = lst[:]
lst_copy = list(lst)
and what you wrote, I guess
dummy = head is just resetting dummy to be at the head again
and then traversing forward to the right element based on the length and n
I'm confused, what's the point of having a variable with a different name that does the same thing
(unless you're trying to remove the head, which is special)
what was the point of making a new variable
sorry for such dumb questions
how can you reset the dummy node with head if modifying dummy modified head
you're just giving it a new name
a = thing
c = a
```here both `a` and `b` refer to `thing`, if I now do
c = bleh
```I won't affect a or thing
I'm just giving bleh a new name
if I do things through c, i.e. call a function on it, then I would change the underlying object being referred to
So the second assignment dummy = head it basically saying, let's have the name dummy refer to head again
@fiery cosmos this is a good read on the topic https://nedbatchelder.com/text/names1.html
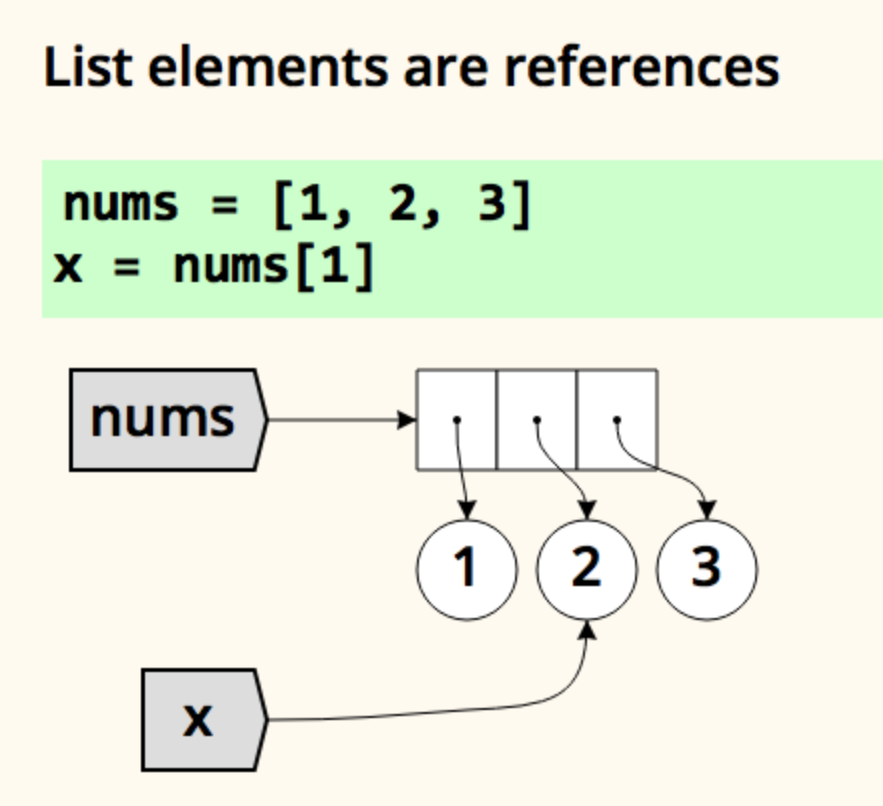
Assignment in Python might surprise you. How do names and values work? This presentation explains it all.
that's a lot of the stuff I forgot lol
@haughty mountain can you draw a diagram for me pls
I don't get it
with linked lists
first I have a variable head that points to the LL [1 -> 2 -> 3]
then I have a new variable dummy or lets call it currentNode that points to the same LL above [1 -> 2 -> 3]
why does currentNode = currentNode.next work like this? It works like you made a copy of head and now modifying that copy and not the original
do you think it's reasonable to have a pytorch dataset that splits a 80gb file and iterates over it (doing nothing) take 8min?
the dataset creates 25918323 samples.
I'm a bit confused as to why it takes like 8min, 10min
what's your drive's read speed, for one?
because if it was my drive, 8min is way less than it would take it to read 80GB 🥴
I need to look at up. but it's an ssd from a few years ago. But that's a good point. I really just thought about ram/cpu moving data around
head points to the first node in the linked list. currentNode = currentNode.next is saying to give the name currentNode to currentNode.next
i.e. currentNode now refers to the next node in the linked list
seems I only read around 30M/s
iterating over 80GB in python sounds painfully slow though
assuming that part is in python
not necessarily, if it's over chunks.
I know that for loops are terrible in python but I doubt that really influences anything here since there is a slow iteration/s
how big are the objects and how many iterations per seconds are we talking?
I mean I have a Samsung SSD 850 EVO 250GB whic apparently is capable of 540 MB/s? And I use 30? so 5%?
it's a 80GB HDF file containing sometihng like 250 datasets of different length.
for reference, 18 byte objects at 10**7 iterations per second would take 8 minutes
ah, so very large pieces
an item of a dataset is 2048 doubles. that's the smalles unit.
maybe some part of pytorch is just slow? idk
assuming it's there work is being done
I mean I basically read all 250 datasets (not the data, just a reference to them). Then I have a function def __getitem__(self, i) which takes an I, then computes in which dataset the i e.g. the 400th item might be in the 3th dataset at position 42 or whatever. then I get the data.
So yeah, the only unoptimized thing I see here is a for loop.
😛
for loops in python are 280 slower than e.g. C (IIRC)
or numpy slicing operator, can't remember.
yeah I guess it's probably just slow python code
I always thought that applying my NN is what takes time but turns out, 70% is just shuffling around the data...
If anyone knows how I can speed up a for loop (I also utilize enumerate) in python, Highly appreciated.
You should probably profile the thing first to ensure that's what takes the time
if it really does do 80GB/(2048*8 bytes) ~= 4.8 million iterations - that shouldn't by itself be much (python can do a few million empty loops per second)
so profiling it is
yeah millions if iterations per second it what I would expect from some simple python code
oh that make sense thx
yeah empty loops takes 23 seconds
there's still a bit of other stuff going on but the main loop empty = 23 seconds. it's just reading the file that's slow. I attribute that to some pytorch overhead/comparions and other numerical operations. I'll profile it.
ok can i have your code or something

