#algos-and-data-structs
1 messages · Page 144 of 1
I can give you an interesting problem if just one is good for you.
For now sure send me one but irl need a path way Those MIT videos i dont think give very hard deep dive
do you need a book? there are plenty of websites with algos problems
@trim obsidian
You're given the following configuration (a parameter to your program, to be more precise) (first picture for an example):
- A triangular board (on the left)
- all the cells are connected into one big "island"
- the board contains a set of "ports"; a port is a red circle attached to one of the outer edges
- the board is symmetric across the horizontal axis (including the ports)
- An alphabet of shapes with adapters (blue circles) and connections between them.
- the connections can be between any of the adapters
- one adapter can have more than one connection (like E and F).
- an adapter never connects to itself
- a shape can contain any positive number of triangles, but they're all connected into one piece
There is the concept of a path. A path is a way of filling (partially or fully) a board with the provided shapes (second picture for an example)).
- the shapes can be rotated, but not flipped (i.e. A and B are distinct shapes)
- the shapes cannot overlap
- an adapter must be connected to either a port or another adapter (pretend that fluid is flowing through the path)
- a port, however, may be left unconnected
- the path must be symmetric across the board's symmetry axis (in its shape -- the pieces may be completely different)
Inside a path, there is a thread. A thread is a set of adjacent shapes that forms a line from one port to another. For example, in the sample path there are two threads: one from the top-left port to the bottom-right port, the other from the bottom-left to the top-right port.
- Every shape on a path must belong to at least one thread. In other words, "loops" are not allowed.
You task is, given a configuration and a positive integer K, find all paths that occupy exactly K triangles on the board.


Cool seems intresting
to be clear, I don't have a solution or a test suite 🙂
this channel is about algorithms and data structures, but you could ask in #python-discussion or claim a help channel in #❓|how-to-get-help


def main():
A = ['a','b','c']
result = P(A) #calculates power set
print(result) #prints the result
sorted_result = sorted(result, key = len)
print(sorted_result)
def P(A):
if A == []:
return [[]]
element = A[len(A) - 1]
A_ = A[:len(A) - 1]
singleton = [element]
return adjoin(P(A_), singleton) + P(A_)
def adjoin(A,singleton):
result = []
for subset in A:
result.append(subset + singleton)
return result
main()
places like hackerrank and codeforces have a ton of problems you can filter by difficulty
since you are dealing with sets, wouldn't result be better as a set?
We can’t have sets inside sets in python im forced to use frozen sets in that case, it’s more convenient to use lists
that is true. so what is wrong with frozensets over here?
Can someone recommend me good Data Structure and Algorithm Book?
pins of this channel may help you.
hm there's just one book
we need better pins here.
I think so
You can try Introduction to Algorithms by Thomas H. cormen
grokking algorithms

Big O notation is the way to measure how software program's running time or space requirements grow as the input size grows. We can't measure this using absolute terms such as time in seconds because different computers have different hardware hence we need a mathematical way to measure time complexity of a program and Big O is that mathematical...
also a good video series
wtf is O(log^n)?
i believe he means O (log N)
not a good first impression, ngl
I liked the explanation of that asian teacher(i dont remember the name).

theoretical and on board.
the C++ guy?
my code school?
uhm no he way totally algo guy. no coding.
he had stuff explaining big O
Abdul Bari
oh! yeah I like that guy.
i know who you're talking abt
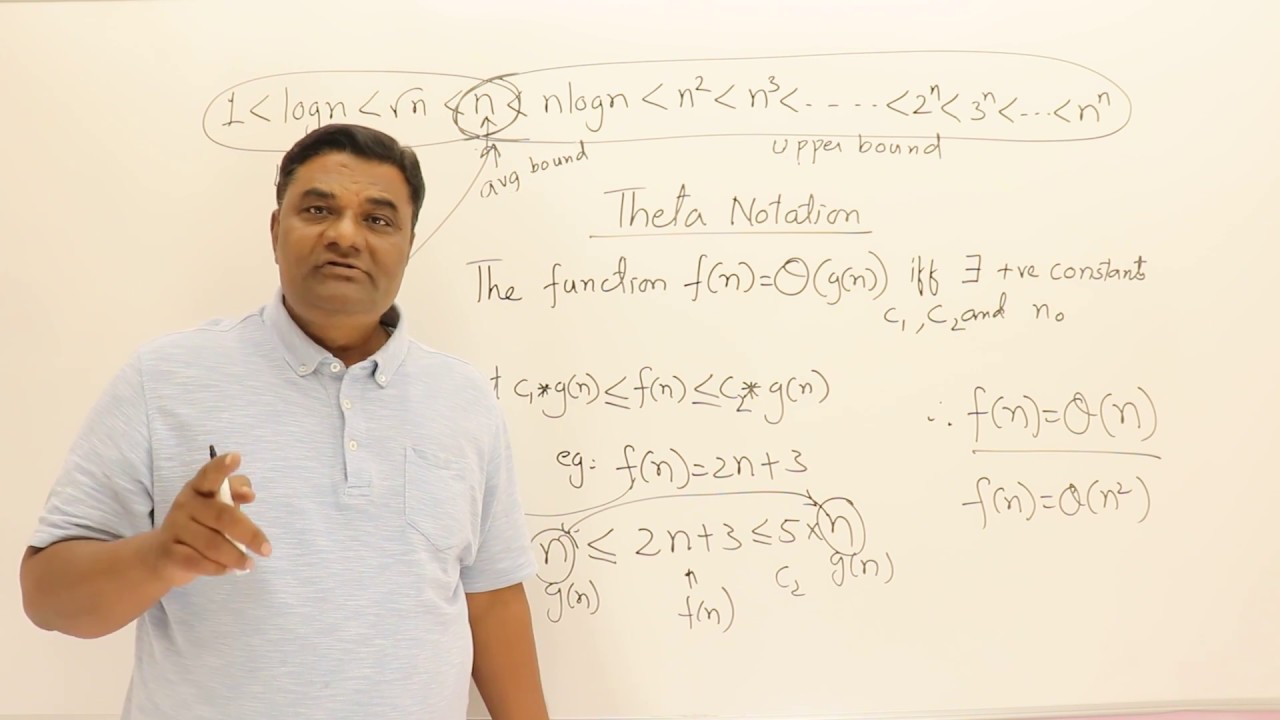
Asymptotic Notations #1
Big - Oh
Omega
Theta
PATREON : https://www.patreon.com/bePatron?u=20475192
Courses on Udemy
Java Programming
https://www.udemy.com/course/java-se-programming/?referralCode=C71BADEAA4E7332D62B6
Data Structures using C and C++
https://www.udemy.com/course/datastructurescncpp/?referralCode=BD2EF8E61A98AB...
yep yep
new_df = data.groupby(["created_at"])["is_blocked"].value_counts().to_frame()
pd.to_datetime(new_df["created_at"])
new_df["created_at"]
!pastebin
Pasting large amounts of code
If your code is too long to fit in a codeblock in discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the floppy disk icon in the top right, or by typing ctrl + S. After doing that, the URL should change. Copy the URL and post it here so others can see it.
so using the documentation i created a dataframe where the columns are the ["created at col"] and then the ["is blocked"] call and the counts for each
the inequalities up top in the thumbnail are kinda disturbing, but looks reasonable otherwise
ok, I don't like that he calls Θ the "average bound"
it means bounded on both sides
if anything it's the exact bound
if f(x) is in O(g(x)) and Ω(g(x)), then it is in Θ(g(x))
overall good intro though
hey i have a few quick questions about this code, I have been pointed to this chat :)
depends on what S is 🙂
oh shoot! i forgot to mention the input variable S is a string haha my bad
i would assume of any size?
well, what do you think about its complexity?
i would asume it is in o(n) time, but i could be horribly wrong lol
what is n here?
hmm
oh n as in the size of the string
that's my interpretation of it
do you agree that this line:
if S[j] == S[k]:
takes constant time (O(1))?
sorry for the late reply, my internet is terrible this morning
@marsh kernel So if S is the string 'abcde', how many times will the if S[j] == S[k]: line run?
how do you figure that?
First it will compare a to b. Then it will compare a to c. Then a to d. Then a to e.
Then it will compare b to c, b to d and b to e.
And so on.
5^5 times? since we are comparing each letter with eachother?
a b
a c
a d
a e
b c
b d
b e
c d
c e
d e
That doesn't look like 5^5 to me
So on the first iteration of the outer loop we make 4 steps. On the next 3, and so on. So we get 4 + 3 + 2 + 1.
ahhh i understand
Are there any restrictions on what characters the string contains?
as long as they aren't the same character, it returns true
i believe that's the only restriction
alright
so let's assume the worst case scenario (the function returns True).
As you can probably imagine, first we're going to check the full string (n - 1), then a smaller one (n - 2), then an even smaller one (n - 3), and eventually a string of size 1.
So in total it's going to be (n - 1) + (n - 2) + (n - 3) + ... + 1
For simplicity, let's take n + (n - 1) + (n - 2) + ... + 1 because it turns out it doesn't matter.
Have you ever seen a sum like this? @marsh kernel
So what does n + (n - 1) + (n - 2) + ... + 1 compute to?
hmm im not too sure
Let's take this: ```
6 + 5 + 4 + 3 + 2 + 1
1 + 2 + 3 + 4 + 5 + 6
6 + 5 + 4 + 3 + 2 + 1
Do you see any pattern?they will result in the same thing
hm?
well, let's look at it from another direction
What is 1 + 6?
And what is 2 + 5?
they will both equal 7
right, so every two numbers that line up come up as 7
so 1 + 2 + 3 + 4 + 5 + 6 = (6 * 7) / 2 = 21
(because the sum of the rows ends up as double the sum)
So if we take the general sum and do the same:
(n - 1) + (n - 2) + (n - 3) + ... + 1
1 + 2 + 3 + ... + (n - 1)
Each column will add up to n, and we have n - 1 columns. Therefore,
(n - 1) + (n - 2) + (n - 3) + ... + 1 = (n * (n - 1)) / 2
hmm okay i see
interesting
okok i see where you are coming from here
i think i can try to solve it sorry again for the stupid long responses, its incredibly late rn and my internet has been hot garbage.
i have a question, two for loops doesnt change the complexity right?
when they are nested
it depends what you're doing with them
May I ask about python
what should i use to detect images in python for a game
it must detect players
in fortnite
nums[:] = nums[:k][::-1]+nums[k:][::-1]
So if I have a nums array, and I want to reverse it from starting to a given point k, and then from k to the end. for eg-
[3,4,5,6,7,8] with k = 2 becomes [4,3,8,7,6,5]
Does my above code runs in O(1) space or does it uses extra space?
it builds 5 extra lists
I'm trying to find the bug in my attempt at a LC problem.
The problem:
Given an integer array nums sorted in non-decreasing order, return an array of the squares of each number sorted in non-decreasing order.
Example 1:
Input: nums = [-4,-1,0,3,10]
Output: [0,1,9,16,100]
Explanation: After squaring, the array becomes [16,1,0,9,100].
After sorting, it becomes [0,1,9,16,100].
Example 2:
Input: nums = [-7,-3,2,3,11]
Output: [4,9,9,49,121]
My attempt:
def sortedSquares(self, nums: List[int]) -> List[int]:
i = 0
j = len(nums) - 1
result = []
while i <= j:
left = nums[i] ** 2
right = nums[j] ** 2
if left > right:
result.append(left)
i += 1
elif left < right:
result.append(right)
j -= 1
else:
# Equals
result.append(left)
result.append(right)
i += 1
j -= 1
return result[::-1]
Explanation: I am setting pointers on each side of the list, and move them towards the center. This effectively lets me grab the highest values (because squaring each number makes numbers towards the ends larger, so each side should contain the largest values)
The problem is I am unable to find whats wrong with my attempt.
For reference the input of
[-4,-1,0,3,10]
Has my code outputting [0,0,1,9,16,100]
That's one too many 0's haha
is space complexity S(9n) a valid way to show 9 arrays or should it be just S(n)??
Space complexity is denoted the same as time complexity - with O(...), because O-notation is just a general way of expressing the "order" of a function. And it follows the same rules, so O(9N) is the same as O(N)
I recommend this article:
https://nedbatchelder.com/text/slowsgrows.html
Why not just square everything and sort it? This is a complete solution:
sorted(x**2 for x in nums)
whew that comment section was quite... interesting
yup
that's an O(n * log(n)) solution
good luck doing better?
the input array is already sorted 🙂
yeah
though in practice the call to sorted is likely faster than merging in python
because python code slow compared to calling into C internals
well, at some input size merging will become faster
I'm curious how far you have to go, probably quite far
actually sorting in python is O(n) on this case
timsort finds decreasing/increasing sequences and merges them
that's kinda hilarious, ngl
@haughty mountain hm, indeed, that seems to be the case
yay for knowing python internals good enough to do silly things
seems like the "fast" merge (in Python) is about twice as slow for big lists

Because that is nlogn! But I think I managed to solve it but it is uuuugly
result = []
i = 0
j = len(nums) - 1
# Loop breaks when the "center" pivot has been crossed
while i <= j:
left = nums[i] ** 2
right = nums[j] ** 2
# Quit if we are looking at the same element (center)
if left == right and i == j:
result.append(left)
break
if left > right:
result.append(left)
i += 1
elif left < right:
result.append(right)
j -= 1
# Covering cases where I'm comparing -2 and 2, Without the else clause it will infinite loop
else:
# Equals
result.append(left)
result.append(right)
i += 1
j -= 1
# Return the results list flipped, since I added in numbers from largest to smallest
return result[::-1]
ahaha
see above, it's O(n) because of python's internal sorting algorithm
Okay that is fair, and probably explains why my current solution is slower than my solution in 2019 where I just squared and sorted
timsort collects increasing and decreasing sequences and merges them, just like the annoying to write merging code would
except it's in C
ahh
Do you think I'd be able to get away with that explanation in an interview?
"Square them and sort. It's just as fast"
if you can explain why, yes
if an interviewer accepts "it's faster" without a benchmarking session, run away 🙂
I would be very happy with that answer since it shows very good python knowledge
I like all these online articles with "top 5 python performance tips" saying that "".join(foo for bar in baz) is better than "".join([foo for bar in baz]) performance-wise
that sounds true. but is it?
it is false
well maybe if people actually knew computer science ¯_(ツ)_/¯
well "it's linear and probably faster because C" is a very good answer imo
That's because of how it's implemented in CPython: if the input is not a list or a tuple, it will first collect all the results into an internal array. So the generator will not provide any memory or speed advantage.
ah that's something I'll have to remember and kinda just take for granted
in reality, it doesn't really matter in application code
so use the one without [] because it's prettier!
yep
pretty == good
If i is equal to j, you should only add it once. However, your current solution adds it twice.
Just change it to:
if i == j:
result.append(left)
else:
result.append(left)
result.append(right)
i += 1
j -= 1
because
- The expression that's computed inside the comprehension will probably take more time than the joining itself
- If you are concatenating a really large (tens of megabytes) string, there's a good chance you've already gone terribly wrong: you probably should have been writing lazily to a socket or file handle.
it would be fun explaining
s = ''
for bleh in thing:
s += bleh
```is O(n) in cpython in an interviewinterview questions can both be good or bad 🤷♀️
I need to think on this. For example [-1,0,1] -> if I only add it once.... OH it will add the other side automatically cause i only move 1 or the other
kjsdfsds this is so hard for me
it's hard to pick good questions to ask in an interview, believe me...
asking trivia questions in an interview is already bad enough 🙂
I heard that most companies shouldn't be interviewing by asking these kinds of algo / data structure questions anyway (with exceptions of course). Thus the perfect interview is a "lets code together on a current problem the company is working on"
but everyone wants to copy big tech interviews for some reason
oh, I never ask trivia
but trivia can pop up
A lot of companies require 5-6 rounds and kinda mimic the Google interview process. They claim to offer the same benefits without the same pay ehehe
yeah...google can afford to do the process it does to sieve out a ton of candidates because of tons of applicants
how would I add two strings next to each other so
AAA
BBB
becomes
AAAAAA
BBBBBB
I've tried
def add_next(inp):
inp = inp.split('\n')
arr = [0] * len(inp)
for i in range(len(inp)):
arr[i] = str(inp[i])*2
return "\n".join(arr)
which works once but when I do it on itself it starts going funky and missing out lines
this is for AOC day 2 2020
(I know I'm a tad bit late to the party)
just do the_string * 2
but when you have newlines it goes from
AAA
BBB
to
AAA
BBB
AAA
BBB
ah
i didn't realize that was one string
it's a little more complicated but it's the same idea
split by "\n" then multiply each line by 2
isn't that what I've done here?
probably, but it looks much more complicated than it has to be
it makes an array split by \n and then multiplies each part by two
so
["AAA", "BBB"]
becomes
["AAAAAA","BBBBBB"]
and then joins them by a newline
when I run it on itself I get this

it starts missing stuff out
which aoc did you say this was for? 🤔 day 2 of 2020 does not look like this problem
oh day 3 I mean
i'm guessing it looks like this because it's wrapping the ends of the lines onto a newline
try turning that feature off
i don't think it's your code's fault, but the terminal or editor or whatever you're looking at the output in
ok
tour_df.loc[tour_df['Stage_Type'] == 'RR', 'Stage_Type'] = 0
tour_df.loc[tour_df['Stage_Type'] == 'ITT', 'Stage_Type'] = 1
Is there a way to make this in 1 sentence, now it has a Timecomplexity of 2n but I think its possible to reduce this to n
just read that tuples can be used as keys in python dictionaries... does that mean the corresponding value or values will belong to one element in the tuple or the entire tuple?
It’s just less convenient and the output will end up looking weird, sets will be useful say in a depth first traversal problem, since searching for items (as in checking if it exists in the set) would be O(1). Since I’m not checking if an element exists, and want the output to look nice, I chose lists
Thanks @haughty mountain (kinda procastinated this project)

(it doesn't matter both hold the same value) i am just curios, no purpose really
So maybe what you want to do is sort the pairs by their sum?
I was just trying to find out what you mean by "equally important"
yeah, would work good like that
Does anyone know how to solve this task (if you want to check, if it works just go to evaluator.hsin.hr (2021, honi/coci, fourth cycle))
https://drive.google.com/file/d/1Wao9E5MvroOBqjjYYMr8Pw2kUGRBqGC5/view?usp=sharing

Google Docs
is the answer not just making a star from the smallest value?
so
min(D)*(len(D) - 1) + (sum(D) - min(D))
Hey @frail gyro!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
can I get help on this question?
The grass has dried up in Farmer John's pasture due to a drought. After hours of despair and contemplation, Farmer John comes up with the brilliant idea of purchasing corn to feed his precious cows.
FJ’s N cows (1≤N≤105) are arranged in a line such that the ith cow in line has a hunger level of hi (0≤hi≤109). As cows are social animals and insist on eating together, the only way FJ can decrease the hunger levels of his cows is to select two adjacent cows i and i+1 and feed each of them a bag of corn, causing each of their hunger levels to decrease by one.
FJ wants to feed his cows until all of them have the same non-negative hunger level. Please help FJ determine the minimum number of bags of corn he needs to feed his cows to make this the case, or print −1 if it is impossible.
INPUT FORMAT (input arrives from the terminal / stdin):
Each input consists of several independent test cases, all of which need to be solved correctly to solve the entire input case. The first line contains T (1≤T≤100), giving the number of test cases to be solved. The T test cases follow, each described by a pair of lines. The first line of each pair contains N, and the second contains h1,h2,…,hN. It is guaranteed that the sum of N over all test cases is at most 105. Values of N might differ in each test case.
OUTPUT FORMAT (print output to the terminal / stdout):
Please write T lines of output, one for each test case.
Note that the large size of integers involved in this problem may require the use of 64-bit integer data types (e.g., a "long long" in C/C++).
SAMPLE INPUT:
5
3
8 10 5
6
4 6 4 4 6 4
3
0 1 0
2
1 2
3
10 9 9
SAMPLE OUTPUT:
14
16
-1
-1
-1
For the first test case, give two bags of corn to both cows 2 and 3, then give five bags of corn to both cows 1 and 2, resulting in each cow having a hunger level of 3.
For the second test case, give two bags to both cows 1 and 2, two bags to both cows 2 and 3, two bags to both cows 4 and 5, and two bags to both cows 5 and 6, resulting in each cow having a hunger level of 2.
For the remaining test cases, it is impossible to make the hunger levels of the cows equal.
Hey @ripe knoll
One thing to think about is: does it matter which order you perform the operations in?
By operation, I mean the operation of reducing two adjacent cows' hunger levels by 1.
I am starting to learn DSA, I know searching and sorting algos and linked list. But idk where to head next.
does anybody have resources to learn from or any suggestions
if you learnt about linked lists surely you know all about heads and nexts :P
check out the pins in this channel for resources
Thanks
thx
you a couldve simply googled that
If you're ok with a log factor you can binary search the answer. I.e. you can easily check if X could be the answer.
You can only lower the leftmost number by decrementing it and its right neighbor. Decrement until the leftmost number is correct. Now move over and treat the neighbor as the leftmost animal and do the same thing.
One caveat, if N is even if X is an ok answer X-1 is as well, but if N is odd you can only reduce X to X-2, so you need to check odd and even answers independently.
Thanks a lot, this works, care to explain? What does a star mean?
a star graph, one center node connected to all other nodes https://en.wikipedia.org/wiki/Star_(graph_theory)

In graph theory, a star Sk is the complete bipartite graph K1,k: a tree with one internal node and k leaves (but no internal nodes and k + 1 leaves when k ≤ 1). Alternatively, some authors define Sk to be the tree of order k with maximum diameter 2; in which case a star of k > 2 has k − 1 leaves.
A star with 3 edges is called a claw.
The star S...
Do you know why a solution like this doesn't work, so i add up all numbers and then i subtract the two biggest ones?
so in 7 3 3 5, i would add up 7+3, 3+3, 3+5, and 5+7 and subtract (5+7)
i think i get it
So for ever connection you add you add two distances. You need to connect all nodes somehow, so all of the distances will show up as one term in the sum of distances. The other term you can control, so connect to the node with the smallest value to minimize it

Hey All!
Not sure if this is the right place to post this, so if it's in the wrong spot, please point me to the right one 🙂
I am trying to understand the difference between Python instance variables and static variables in a class. Take this example:
class Foo:
food: str
def __init__(self, topping: str):
self.topping=topping
f = Foo("pepperoni")
>>> f.topping # gives me 'peopperoni', as expected
>>> f.food # Gives an error: AttributeError: 'Foo' object has no attribute 'food'
>>> f.food = "pizza"
>>> f.food # Gives me 'pizza'
I come from a more strict OOP background and this still puzzles me. Can someone explain? 🙏
!e
By default, you can set any attribute on an object.
class Foo:
pass
foo = Foo()
foo.bar = 42
print(foo.bar)
__init__ is not special in this regard. In this case, bar is an instance variable on foo.
@austere sparrow :white_check_mark: Your eval job has completed with return code 0.
42
!e
There are also class variables.```py
class Foo:
baz = 1
foo1 = Foo()
foo2 = Foo()
foo2.baz = 3
print(foo1.baz)
print(foo2.baz)
When you look up an attribute, it's first looked up among the instance variables, then among the class variables. One noteworthy case of this is methods: a method is just a function stored in a class variable@austere sparrow :white_check_mark: Your eval job has completed with return code 0.
001 | 1
002 | 3
hm so static variables in say java are equivalent to class variable in python iirc.
I don't know Java, but sounds about right
yeah i quick verified with web yep.
@austere sparrow Thank you for the ELI5 🙂
It's what I thought, just wan't sure
class MyClass {
public static int i = 5;
}
class MyClass {
i = 5
}
these both can be considered same
in python you change them by using class name.
MyClass.i = 6
but if you do
x = MyClass() # created object
x.i = 7
Now that's an instance variable.
!e
Sometimes it is a bit unexpected though.
class Foo:
bar = 1
foo1 = Foo()
foo2 = Foo()
print(foo1.bar, foo2.bar, Foo.bar)
Foo.bar = 2
print(foo1.bar, foo2.bar, Foo.bar)
Foo.bar += 3
print(foo1.bar, foo2.bar, Foo.bar)
foo1.bar += 10
print(foo1.bar, foo2.bar, Foo.bar)
@austere sparrow :white_check_mark: Your eval job has completed with return code 0.
001 | 1 1 1
002 | 2 2 2
003 | 5 5 5
004 | 15 5 5
Ok, cool! So,. is there a "Rule-Of-Thumb"? LOL
ie. Treat class varaibles as static and instance varaibles as ephemeral?
uhm so we can use them by instance too! but they are supposed to have some value. okay i made some mistake in above sentences.
regardless, yeah class variables are eq to static variables in java. or same for cpp too iirc.
@nimble glade :x: Your eval job has completed with return code 1.
001 | Please input color name to get hex code
002 | (If you get any errors try typing colors with small leters like 'blue' instead of 'Blue'): Traceback (most recent call last):
003 | File "<string>", line 14, in <module>
004 | EOFError: EOF when reading a line
the tail of a singly linked list always points to
None
That is correct. But not every linked list has a tail 🙂
!e
Here's a normal linked list:
class Node:
def __init__(self, label, nxt):
self.label = label
self.nxt = nxt
def print_chain(self):
node = self
while node is not None:
print(node.label)
node = node.nxt
def __str__(self):
return "<Node {0!r}>".format(self.label)
node_c = Node("c", None)
node_b = Node("b", node_c)
node_a = Node("a", node_b)
node_a.print_chain()
@austere sparrow :white_check_mark: Your eval job has completed with return code 0.
001 | a
002 | b
003 | c
!e
And here is a list with a cycle:
Here's a normal linked list:
class Node:
def __init__(self, label, nxt):
self.label = label
self.nxt = nxt
def print_chain(self):
node = self
while node is not None:
print(node.label)
node = node.nxt
def __str__(self):
return "<Node {0!r}>".format(self.label)
node_c = Node("c", None)
node_b = Node("b", node_c)
node_a = Node("a", node_b)
node_c.nxt = node_a
node_a.print_chain()
@austere sparrow :x: Your eval job has completed with return code 143 (SIGTERM).
001 | a
002 | b
003 | c
004 | a
005 | b
006 | c
007 | a
008 | b
009 | c
010 | a
011 | b
... (truncated - too many lines)
Full output: too long to upload
It could be the result of an error, yes. Sometimes it's intentional. I haven't encountered a case in Python where this would be useful (or in fact, where a linked list which is not a collections.deque would be used)
Hey friends, I am trying to learn about Dequeues by building one from scratch with the methods shown in the image. Before implementing though, I am trying to conceptually understand how the Dequeue works when adding to the front and the back. I understand how Stacks and Queues work, having built my Queue using a Circular Buffer pattern (not at Linked Lists yet). Does anyone here have a good understanding of Dequeues that could help me to think through a few method calls? I am thinking I can mock a few method calls and say what I think will happen to the indicies, and we can go from there.

Consider the amount of options there are for each spot in the list: 6.
For a the numbers goes down by one every time since there's no repetition allowed.
For b the number stays the same.
repetition is allowed. So no matter what, the second one is still 6 etc
It's 6 options for each of the four entries in the list.
You multiply them to get the final answer
In the first spot it can be one of 6 numbers, same for the 2nd 3rd and 4th. So the result is 6 * 6 * 6 * 6, or 6 ** 4
Yes
Yes, 6 * 5 * 4 * 3
it is
Yeah (even with 2 letters you can form 36 words, so gotta be more than 15)
yep
Good
There's no limit on questions.
It's not.
So when checking for how many options there are it's basically only 1 option for the first spot in the list. You ignore this when calculating the amount of lists.
After that, all of the spots have 6 options.
So the combinations are calculated similar to question b
What would your answer to b have been if it said length-3 instead of length-4?
And how many of those can you chuck a T in front of 
It would
It's 3 spots with 6 options, making the total amount of options 6 * 6 * 6
Or 216 as you said earlier
permutations since the order matters
What's the question?
Get all combinations with 2 aces
Get all combinations
divide them
@cobalt mirage
hmm I don't quite understand
how does heapq.nlargest work if python's heap is a min heap?
couldn't the largest(s) be one of many leafs
there's private functions in the library for max replace and max pop, you can see them if you use dir(heapq):
In [2]: dir(heapq)
Out[2]:
...
'_heapify_max',
'_heappop_max',
'_heapreplace_max',
'_siftdown',
'_siftdown_max',
'_siftup',
'_siftup_max',
...
https://github.com/python/cpython/blob/3.10/Lib/heapq.py#L521
I don't think it's calling those?
Lib/heapq.py line 521
def nlargest(n, iterable, key=None):```o
what's the easiest way of storing a data tree's links? is there a better one than having a dict for each node containing all the nodes it's linked to?
list or dict of children depending on what kind of lookup you need
most of the time iteration over children is enough, so list works great then
well thats what i wanted to avoid because there'd be duplicates
i think the term "tree" is wrong in that context
because it's not only made of parents and children, just nodes linked together without any rule really
a graph then
i guess..
I needed a bit of help with working with regex. I've got a list of around 27k words but a few have additional characters. How do I get rid of all words that have characters other than [A-Za-z'-]? re.match() doesn't seem to get the job done for some reason.
re.fullmatch with [A-Za-z'-]* doesn't work?
or re.match with the inverted character class [^A-Za-z'-]
bruh, I spent quite a while looking for exactly this. Thanks a bunch, new to regex and pretty lost.
you can also use match if you add beginning and end of line anchors
^your_regex$
hmm, I'll run that too. Thanks for the help
So i have these number codes
6045781131337478
6045781168538519
6045781182894559
6045781161998991
6045781175566321
6045781144342648
6045781177536934
6045781159941565
6045781184246154
6045781118873354
And i want to sort them like, if the last 2 digits of the code is that or that then seperate all the code in to category
unclear, can you explain.
So each row has one full code/digits and i want to do like if the full code ends with 78 then add it to category 78 and i want to do it to all of them
ah so you want a dict?
which has structure like
{
78: [60000078, 7000078]
}
and so on?
Oh yes
hm alright, are you aware of default dict?
But will it take every row of the selection?
Have not learn abt that yet
okay you are aware about dict right?
What is dict?
yeah i just made a small example with 2 nums.
hm so in a nutshell its a key value kind data structure.
{
78: [60000078, 7000078]
}
here 78 is a key, and the list assigned to it is a value.
so you want key as the last 2 digits.
its just hashmap or json if you're aware about them.
um you are there right?
hm so to get last digits you can do %100 right?
once you have them you can do
dict[key] = val # it will be little bit complicated here since we are using a list
but let's take one step at a time.
!e
a = [15, 17, 18]
d = {}
for i in a:
key = i%10
d[key] = i
print(d)
@fiery cosmos :white_check_mark: Your eval job has completed with return code 0.
{5: 15, 7: 17, 8: 18}
hm so that's how we do it.
except you would want a list over here. for values.
!e
a = [15, 17, 18]
d = {}
for i in a:
key = i%10
d[key] = i
print(d[5]) # you can access the values at key like this
@fiery cosmos :white_check_mark: Your eval job has completed with return code 0.
15
anyone online?
does python factorial function use iteration or recursion?
Modules/mathmodule.c line 1903
/* Divide-and-conquer factorial algorithm```The algorithm is described here

@fiery cosmos #editors-ides
@jade oak by "basics" i mean how to use basic data structures like hash tables, arrays, linked lists, stacks, queues, etc
and some simple algorithms that go along with them, like sorting, graph search, binary search (all of these will be covered in an intro textbook)
and then what it means for an algorithm to be efficient, along with big-O notation
this will give you the basic ideas for how to write algorithms to solve problems efficiently, and a sense of when something is definitely the wrong way to go about it
there are some resources in the pins btw
@jade oak there's some pinned messages in this for resources for learning data structures and algorithms in a structured way
If you want to get a software dev job, learning big O notation will be very helpful for you.
It's actually used in industry. When we talk about the performance of algorithms, we do use big O to talk about it
That's the most math heavy part of learning data structures and algorithms, and it is very useful to learn
Hi Everyone! I am trying to solve a problem in python recursion which says "Find all combinations of a list of numbers with a given sum"
Below is my code:-
`def combinationSum(arr,sum, index,temp):
# Iterate from index to len(arr) - 1
for i in range(index, len(arr)):
if(sum == 0):
# Adding deep copy of list to ans
#ans.append(list(temp))
return temp
# checking that sum does not become negative
if(sum - arr[i]) >= 0:
# adding element which can contribute to
# sum
temp.append(arr[i])
combinationSum(arr, sum-arr[i], i, temp)
# removing element from list (backtracking)
temp.remove(arr[i])
print(combinationSum([2,3,5], 17, 0, []))`
Now, the problem is that when I reach the desired result i.e. '[2, 2, 2, 2, 2, 2, 2, 3]' the loop does not stop when infact when the 'temp' list becomes the desired result it should return temp.
Could anyone please help me out with this.
Two things that immediately stick out:
- Your
temp.remove(arr[i])should betemp.pop()since you want to just remove the last element. This shouldn't have caused anything to get stuck, but it would give wrong answers. - Your
if sum == 0statement should probably be before the loop
this is a bit clunky using a global list, but it works
answer = []
def combinationSum(arr, sum, index, temp):
if sum == 0:
answer.append(list(temp))
return
for i in range(index, len(arr)):
if sum - arr[i] >= 0:
temp.append(arr[i])
combinationSum(arr, sum-arr[i], i, temp)
temp.pop()
combinationSum([2,3,5], 17, 0, [])
for comb in answer:
print(comb)
```a neater way would be to turn this into a generator function like
```py
def combinationSum(arr, sum, index, temp):
if sum == 0:
yield list(temp)
return
for i in range(index, len(arr)):
if sum - arr[i] >= 0:
temp.append(arr[i])
yield from combinationSum(arr, sum-arr[i], i, temp)
temp.pop()
for comb in combinationSum([2,3,5], 17, 0, []):
print(comb)
Thanks! Also, what if I have to stop on the first result i.e. I have to stop on the first list which is equal to sum '17'?
see the code above, with the generator version getting just the first answer is easy
g = combinationSum([2,3,5], 17, 0, [])
answer = next(g, None) # get first value, default to None if generator produces no value
if answer is not None:
print('First answer is', answer)
else:
print('There is no answer')
Thank you again. Could you please help me in understanding the generator code. That would be helpful. I want to understand the working.
what part of it? conceptually the generator code and the one that append to a global list are pretty similar
do you know about generator functions in general?
No. I don't know about the generator part. That is why I want to understand.
No. I don't know about the generator part. That is why I want to understand.
generator functions are functions that are lazily evaluated, they run until a yield, at which point they return control (and optionally a value) back to the calling code, a simple example of an infinite iterator that produces numbers 0, 1, 2, 3... is
def counter():
i = 0
while True:
yield i
i += 1
when I call counter() nothing is executed yet, I get a generator object back
In [7]: g = counter()
In [8]: g
Out[8]: <generator object counter at 0x7fe6a17e3c30>
Very helpful 👍
when I call next on it I it runs until the next yield and it yields a value
In [9]: next(g)
Out[9]: 0
I could also loop over the generator just like any other sequence container
Also, I want to know the best practice for recursion. I want to understand it more. So, what advice or information will you give?
but it's infinte, so maybe not the best idea
wrt the generator function from earlier, when we find something with the right sum we yield a copy of the list, the yield from combinationSum(...) in the code that calls the function recursively is essentially just a shorter way of saying
for comb in yield from combinationSum(...):
yield comb
so just yield the elements from the call back out of the function
what do you mean best practice?
More understanding of the topic
recursion in the end is just expressing a problem as other instances of itself, in this case you express the solution in terms of itself, but for a smaller sum, and starting at a later index when looking at elements to add
if you have any specific questions I can answer, but it's kinda hard to know what to say about recursion in general
Okay. It was very helpful. I appreciate that. Thanks again!
modelling a problem as recursion doesn't necessarily mean you have functions calling themselves, but just that the problem is defined in terms of itself, e.g. the Fibonacci numbers are defined such that F(n) = F(n-1) + F(n-2) but you don't need to use recursive functions to make use of the recursive definition of the Fibonacci numbers, you can start with a list [0, 1] and then append new elements that are just the sum of the previous two
!e
F = [0, 1]
for _ in range(10):
F.append(F[-1] + F[-2])
print(F)
@haughty mountain :white_check_mark: Your eval job has completed with return code 0.
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
In many ways, using recursive functions have a bunch of drawbacks like performance, especially in python. So if you can make use of the recursive relation in other ways it's often a good idea
(Though sometimes using recursive functions is just the simplest way to get things done)
Okay. I am learning data structures and algorithm and started with recursion first. So, just wanted to understand how to improve myself in DSA that's why I asked and the information you gave is useful.
recursion itself is a very broad subject, I suspect the best way to get a feel for things is to solve problems and try to implement the recursive definition in different ways, maybe as recursive function calls (maybe with memoization) or iteratively like in the example of Fibonacci
different ways of implementing the problem have different strengths and drawbacks
👍
Can anyone help me finding the problem in the code. Below is my code:-
`def check_sum(sum, i, arr):
def recursive(chk):
if chk == sum:
return True
elif chk < n:
for num in arr:
chk += num
if recursive(chk):
return True
chk -= num
return False
# Starts the accumulator from 0,
return recursive(0)
print(check_sum(17,0,[2,3,5]))`
The function should return True if there exists a combination of numbers from arr that add up to 'n' and False if none exists.
this should use sum right?
elif chk < n:
also, this method is going to fail badly when the target sum gets larger when the answer isn't reached quickly or at all
actually, you don't even need big
target 101, array [2,4,6] is already very slow
this problem is an unbounded knapsack problem, see https://en.wikipedia.org/wiki/Knapsack_problem#Definition and the first section of https://en.wikipedia.org/wiki/Knapsack_problem#Dynamic_programming_in-advance_algorithm
Okay! What about this one:
`def check_sum(target, i, arr):
c1 = []
s = sum(arr)
if s % 2:
return 0 # sum must be even for it to work at all
half = s // 2
result = sum_count(arr, half)
c1.append(result)
if c1 == []:
return False
else:
return True
def sum_count(arr, target): # number of combinations out of lst that sum to total
if not arr: # base c
# ase
return int(target == 0) # empty lst and total 0 -> return 1
# recur: add ways with first element and ways without
return sum_count(arr[1:], target) + sum_count(arr[1:], target - arr[0])`
this is a different problem?
where the target is sum/2?
(leaving the unused arguments in the function makes it pretty annoying to read)
No, it is the same problem. I am just trying to implement it different way just to solve it. I know it's confusing.
okay. I have removed it now. Let's see if it is solved.
like, the solution you had posted says [2] works, which is clearly wrong
oh okay. sorry for the misunderstanding.
Can anyone tell me difference between logn and nlogn
exactly a factor of n
So nlogn is bad?
it depends on the other options
n log n is bad if you can do it in O(1).
n log n is good if the only other choices are n^2
O(logN) takes time proportional to log2(N), so for N=64 that's 6 time units. O(NlogN) is proportional to N * log2(N), so for N = 64 it's 384 time units.
But that's still way better than N^2 = 4096
2 hours later 
I like to stress how the difference between N and NlogN now is really not that crazy much. If N is a 32 bit number they differ by a factor of 32 at most. Wayy better than N^2
Right? Like would you rather count to 32 or 4 billion
I just started codeforces, and im wondering if participating in Div2 is a risk?
Yeah sorry mb i forgot to reply cause i was in college
given 2 sets of basis, how do we find that they both span on same subspace?
please ping me if replied.
c++ error: expected primary-expression before '==' token
if (numbers[i][x]) == (numbers[j][x]){
The whole thing needs parens around it afaik (you can remove the 2 inner ones)
But this channel and server is for Python help 🐍
thanks!
yep, ik that, im sry
Hello so I'm new in programming and i got stuck in a problem help would be highly appreciated
user=input("enter user = ")
passwd=input("enter password = ")
if user=='Ann' and passwd=='123':
print("|| Access Granted ||")
print("|| Welcome Ann ||")
print("1:shoe billing")
print("2:show result")
else:
print("|| Access Not Granted ||")
# Here is the problem -- if access not granted i wanna loop the command to the ("enter user = ") line
Seems u r trying to heck
you might as well try
hecker
That’s why cpp better
It might be because you are heckin
Hello, is anyone from Iran here?
Hey guys any suggestions for Graph algorithms I am having a hard time learning them, specially the implementation of Topological sort.
any help for #help-apple pls ?
hello all, can I please get some clarification on the time complexity of the str.replace method? answers on stackoverflow seem to not be conclusive.
If you know C you could look at the implementation (in CPython)
https://github.com/python/cpython/blob/main/Objects/unicodeobject.c#L10659-L10936
Although it is kinda terrible
You should check the freecodecamp official site .
It have a very good free python course .
I'm tryna design a queue like structure with automatic destructor. Sorta like a conveyor line. As data comes onto the structure it should pass the value to a list of attached listeners who can manipulate it by moving it to a different queue, "flicking" it (removing), or operating on it. Does anyone know of anything like that, that already exists and has good O values for Insert, Change and Removal operations?
if data hits the end of the listeners it should be dropped off the end and discarded automatically
wdym by "Change"?
and are you saying that items should be able to be removed from the back of the queue?
IDK what i meant by Change in this context now that i think of it. Data on the structure should be immutable. I think it was because i was thinking of taking the value and moving it to a different structure as a structure-bound task
and yes, once the list of callback listeners is exhausted i want it to drop the value
but it can take an arbitrarily large amount of data
as I want to use it sort of as a general purpose structure for the paradigm I wish to use for this project. Reactive Programming (sorta like functional programming but dealing with streams of data). It's a Rendering engine so it could have only a few items or it could have millions
so I'm tryna keep it as thin as possible
Do i just want a linked list with a "crawling" function that iterates over it one by one and deletes the pointer when it moves?
Thanks @shut breach! You figured it out for me
Hey @misty lance!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
Hey! So i have this code and TIMES is how many cards you want to generate, and i want to make it like it counts how many times it prints out DIGITS https://paste.pythondiscord.com/uregoturas.apache
Just to clarify, you want to have a function that counts how many times it sees each unique number and prints out how many times it saw each one?
No need help anymore, solved it myself. But thanks for helping!
np
I need some help with this simple problem

The worst case will be the number of comparisons (branchings) done to the deepest leaf. The best case is the same but to the shallowest leaf.
The average would be the sum of all comparisons over all leaves divided by the number of leaves.
put it all in a while loop
pass = False
while !pass:
user=input("enter user = ")
passwd=input("enter password = ")
if user=='Ann' and passwd=='123':
print("|| Access Granted ||")
print("|| Welcome Ann ||")
print("1:shoe billing")
print("2:show result")
pass = True
else:
print("|| Access Not Granted ||")
hey
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def reverseList(self, head: Optional[ListNode]) -> Optional[ListNode]:
prev = None
curr = head
def rec(previous, current):
if current is None:
return previous
else:
temp = current.next
current.next = previous
previous = current
current = temp
return rec(previous, current)
return rec(prev, curr)
I was just practicing recursion, can this be considered the recursive way to reverse a linked list? I got it right on LeetCode with this submission.
looks recursive to me
Hello, i am having an algorithmic problem in one of my university project.
I need to do an algorithm that search a string dictionary of for example 100 words and output a notepad file with each sentence having 4 of that words.
For example, Andrew, Philip, Jonas, Peter
Andrew Philip Jonas Peter
Andrew Jonas Philip Peter
Andrew Philip Peter Jonas
....
it looks like an N! situation
(Permutations without repetitions)
I am not asking for the full code of course, i am just wondering if this wont make a memory problem...
Is there anything premade on internet? anyone knows?
Thank you very much.
While on the topic, which questions do you recommend that would solidly my understanding of recursion
Hey, anyone ever used LMFit python package to do model fitting?
I do not know where to ask my question (SE got 0 answers)
How do you decide on which 4 of the 100 to use per line?
Yeah. Whenever a function calls itself (your rec) it's recursion
Oh, I think I understand. If you always have 4 names to permute then yeah, it is N!, but only 4! = 24 lines, so not a big file
Anyone uses pretty_errors?
Is there a way to configure the package so that it is the same in all python environments?
are there any built in search algorithms? (like linear, binary, jump, etc.)??
Source code: Lib/bisect.py
This module provides support for maintaining a list in sorted order without having to sort the list after each insertion. For long lists of items with expensive comparison operations, this can be an improvement over the more common approach. The module is called bisect because it uses a basic bisection algorithm to do its work. The source code may be most useful as a working example of the algorithm (the boundary conditions are already right!).
The following functions are provided:
thanks so much!
how to analyze loops and discover a run time formula
"""
FORMULA: floor((n - m)/k) + 1 only use when m <= n and k >= 1
THEOREM: d - 1 <= n < d iff d - 1 = floor(n) where d is an integer
It calculates the number of iterations of the following loop
i = m
while i <= n:
i = i + k
HOW ITS DERIVED
STEP 1: (j - 1) * k + m <= n < j * k + m where j is the jth iteration (note: i = (j - 1) * k + m )
STEP 2: (j - 1) * k <= n - m < j * k
STEP 3: (j - 1) <= (n - m)/k < j
STEP 4: (j - 1) = floor((n - m)/k) used the theorem mentioned
STEP 5: j = floor((n - m)/k) + 1
"""
hello I am making a minimax search tree with each node having 3 child nodes I have created 3 layers but cant figure out the way to add a fourth layer.
class Choice:
def init(self, left, center,right):
self.left = left
self.center=center
self.right = right
class Terminal:
def init(self, value):
self.value = value
def minimax(tree, maximising_player):
if isinstance(tree, Choice):
lv = minimax(tree.left, not maximising_player)
rv = minimax(tree.right, not maximising_player)
if maximising_player:
return max(lv, rv)
else:
return min(lv, rv)
else:
return tree.value
tree = Choice(
Choice(
Terminal(9),
Terminal(5),
Terminal(2),
),
Choice(
Terminal(-3),
Terminal(-2),
Terminal(1),
),
Choice(
Terminal(3),
Terminal(-4),
Terminal(1),
),
)
print(minimax(tree, True))
can anyone suggest a way to add a fourth layer
What could be the issue when you get this error after you try to do something with your dataframe? never seen this before: py Python38\lib\site-packages\pandas\core\generic.py", line 1534, in __nonzero__ raise ValueError( ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
Its structured normally, with only 2 rows, column names and values.
Only thing i can come up with is that the dataframe column names have underscores "_" in them. But that cant be it?
How do you guys remember algos such as Kadanes Algorithm
its so simple yet i cannot reproduce it when i need in an exam or so
is learning the only way to go?
You're trying to use it in an if-check, for example:
if your_Series_object:
...
can you show your code perhaps?

write print("hello world")
Where to write?
why u randomly tags peoples
Sorry
and why in this channel
Sorry yaar
ask in python general and ask what ur question is
Please don't ping individual people for help. If you have a concrete question, see #❓|how-to-get-help and claim a help channel. In the channel, explain what you are having trouble with, with screenshots or code that you have.
sorryyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy i m new in discord 😦
I'm super struggling to do in pandas what is second nature in SQL 😄
I don't know why I'm finding it so difficult...
Hey someone know why the Python Version 3.9 is invalid?(Its PyCharm)

Is there an easy way to approach doing leetcode? I find myself unable to get a solution for a long time sometimes
actually I think there was a reddit thread recently that advocated looking at solutions and studying them first
that is probably controversial though
I think it's good to look at solutions if you're stumped. Even if you do solve one seeing other solutions is good since you may learn a simpler/better way.
It's normal for beginners . But try to give atleast 45-60min. to solve the ques by yourself and if you are unable to do then go for the solution. And yes after you solve the problem by yourself do look for more optimized solutions by others .
Yes it's imp. To keep revising That the ques you did previously from time to from . Because it may happen that later in exams or interview it just slips from your head even though you did that.
thank you I'll do that
one thing I noticed is that the solutions on LC are very fancy, is that what the employers really expect? or should I be more detailed with naming and being more explicit with declaring variables etc
ig understanding how it works would be the best way
how to create a graph like this

in python?
yea
networkx
graph = {
'a' : ['e','b'],
'b' : ['f', 'c'],
'c' : ['b', 'd','f'],
'd' : ['e', 'f', 'c'],
'e' : ['d', 'd', 'a']
}
should i use a dictionary like this
G = {'a':['e','d'],
'b':['f','c'],
'c':['f','b'],
'd':['f','c'],
'e':['a','d'],
'f':['b','c','d']}
hmm
you forgot f
ooh my bad
its what i wrote
so
G = nx.Graph(graph)
oh yeah
how to do weight
weights = {frozenset(('a','e')): 3,
frozenset(('a','b')): 2,
frozenset(('e','d')): 8,
frozenset(('b','c')): 7,
frozenset(('c','d')): 9,
frozenset(('c','f')): 4,
frozenset(('d','f')): 4,
frozenset(('f','b')): 1}
this is if we have an undirected graph
its one method
what library your using?
whats with the nx?
to draw the graph?
ye
is turtle a standerd library?
its here on this site
if your required to use the networkfx library
then you'll have to loop through and add the edge weights
yup standard library
when i was doing networks in my class
i used that
but obviously you gotta make it from scratch
oh yea
feel like networkx easier
programming is an investigative problem solving process
you have to code all the time
and think about it all the time
for a while until it truly clicks
ig
idk why my course start with graphs first
i thought we are gonna be doing algorithms firsts
thx a lot for ur help
imma need to watch more videos about grapha
Lots of important algorithms work on graphs. e.g. given a weighted graph what is the shortest route through it
the most common interview questions also involve graphs/trees apparently!
ooh it might
any good vids/articles for introduction to graphs with python
school only show how to do them in snap
we have the option to use python
but we have to figure thing out ourselves
because graphs and graph algorithms are essential
You don't really need a specific article explaining how to do them in Python specifically, it'd just be a class really.
for real world problems you can often represent/reduce it to a graph problem, which are super well studied
it's one of the most useful abstractions in cs
I use adjacency lists for pretty much all things graphs
i.e. just a list C where C[i] contains a list of nodes reachable from node i
is this a adjacency lists
nvm its dictionary
it's the same kind of thing yes
oh ok
most of the time I tend to map node names to integers before I work with them
Hey all , I am planning to sell my GFG course on DSA + problem solving. I have recently bought it, but not done anything on it. I am not planning on using it anymore. It could be useful to someone else instead.
The course has a detailed curriculum on DSA and contest and problems specific to each topic as well for better practice.
This is the course https://practice.geeksforgeeks.org/courses/dsa-self-paced?vC=1
Anyone interested please DM me.
Hi guys any one can help me with arrays?
matplot?
wassup
Hi
i want to save a elements on matrix
if i have a
void calcul( (void*) a, b){
pointer to a
pointer to b
save on a matrix mat[100][50]
i think networkx use matplot to render the graph
Is there anyone interested joining this code challenge

DrivenData
Air pollution is one of the greatest environmental threats to human health. Help NASA deliver accurate, high-resolution air quality information to improve public health and safety!
If you interested in joining please DM
hello
hello
Hi
why is morris traversal faster then recursion???
theres doesnt seems any difference to me
while loop is now using stack, is that it
iterative solutions generally have better perf than recursive ones
i meant the space
the space in morris is O(1)
but O(n) in normal recursion
i dont agree with this too
is that the call stack usage that affect
the perf
because of the extra links between nodes, you just keep following links through the tree
you don't need a stack to store anything
okay
hey someone can help me to simplify something (i hope to be in the good channel):
i have a list=['a','b','c']
and i want to do something like this but with a longer list :
if list[0] not in 'test' and list[1] not in 'test' .... :
can i use a loop in my if to do that better ?
can you elaborate more
that script can do what i want :
abc = ['a','b','c']
def fonction(component):
for i in abc:
if i in component:
return False
return True
if fonction('word'):
pass```
so I want to know if we can write my function in one line.yes i think that's it but i dont achieve to do so
so that's code is wrong :
return True if (i not in 'word' for i in abc) else False```ternary
i don't understand what's ternary mean
you notice this code doesn't actually do anything right
a ternary operation is a conditional expression that evaluates a statement
in one linme
line
@rustic salmon :warning: Your eval job has completed with return code 0.
[No output]
your code does nothing
!e
!eval [code]
Can also use: e
*Run Python code and get the results.
This command supports multiple lines of code, including code wrapped inside a formatted code block. Code can be re-evaluated by editing the original message within 10 seconds and clicking the reaction that subsequently appears.
We've done our best to make this sandboxed, but do let us know if you manage to find an issue with it!*
abc = ['a','b','c']
def fonction(component):
for i in abc:
if i in component:
return False
return True
print(fonction('words'))```!e py
abc = ['a','b','c']
def fonction(component):
for i in abc:
if i in component:
return False
return True
print(fonction('words'))```@vocal valley :x: Your eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 1, in <module>
003 | NameError: name 'py' is not defined
ty lol
ok so that's return True
and if in do fonction('all') that's return False it is exactly waht i want because i want to use this boolean return in my if statement
so i search to do de function fonction in just one line
its returning true because the i is not in abc
because all the i are not in abc
no caracters in my words are in abc
i want to select just the words if this word have no a no b and no c
i don't think i quite understand what you want to do.
i want to verify if no one of the caracters in my list abc are in my word
try main('all') pls
its false because its looking to see if the whole word is in list
@rustic salmon :white_check_mark: Your eval job has completed with return code 0.
True
is that what you want it to do?
yeah words has no a nob and no c so that's return True
yeah but in one line not 4 ^^
ah ok
loul t'es français ?
i don't know french
ok no problem
not sure if you can do it in one line. i am trying though. it might be 2-3 lines
ok
im sorry, but im not quite sure how to do this. i will keep trying though
ok no problem if you don't achieve to do that i will just use my function ^^
return all(x not in test for x in list)
well there you go
Thx
or equivalently
return not any(x in test for x in list)
return not any(map(container.__contains__, iterable))
Hey there, I need help.

Hey, I need help. Im trying to program the Pascal's triangle. I dont know how to put the numbers in a logic order (see other screenshot) any solutions??


i can help
there are multiple ways
first pascals triangle is actually a recursively defined function
and the triangle itself is the plot of that function
pascal(n,0) = 1
pascal(n,n) = 1
pascal(n,r) = pascal(n - 1, r - 1) + pascal(n - 1, r)
there is another recursive definition
that can be used to make a version of the program using only loops
let me know if you still have questions
the other recursive definition takes advantage of another fact
pascal(n,r) = choose(n,r)
the pascal triangle function is equivalent to the choose function, however, what is the choose function?
the choose function is the following
choose(n,r) = (n!)/(r!(n - r)!)
where n! means n factorial if your familiar with that
for example 5! = 5 * 4 * 3 * 2 * 1
the choose function can be defined recursively
for example we need find a way to
relate
choose(n,r) = (n!)/(r!(n - r)!)
with
choose(n, r - 1) = (n!)/((r - 1)!(n - (r - 1))!)
we can see that with the following fact
choose(n,r) = (n!)/((r - 1)!(n - r + 1)!) * (n - r + 1)/r
which is
choose(n,r) = choose(n, r - 1) * (n - r + 1)/r
now we have a new recursive function
choose(n,0) = 1
choose(n,r) = choose(n, r - 1) * (n - r + 1)/r
but this one can be implemented iteratively unlike the other version
def pascals_triangle(num_rows = 10):
for n in range(num_rows):
current_position = 1
print(current_position, end = " ")
for r in range(1, n+1):
current_position *= (n - r + 1)/r
print("{:4d}".format(int(current_position)), end = " ")
print()
now if you wanna make it look extra fancy like in your picture we have to creatively use the .format() and add an additional loop to pad the left side of the triangle
Hey guys, I need help for y'all.
I'm new to python, please suggest some free resources to learn data structures and algorithms skills in python. Thanks in advance.
check out pinned messages
Hey @lean dew!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
Hey @lean dew!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
splice to merge two linked lists in O(1)?
Any good books for dsa?
to give you some idea, I am good at string,array based problems but usually have trouble dealing with trees and graph based problems
like close to intermediate i would say
so based on that level what are the books recommended by you guys?
https://en.wikipedia.org/wiki/Introduction_to_Algorithms seems to be the go to classic
you can find CLRS online (but I'm not sure how legitly  )
)
yeah seems great, thanks!
how to become good at algorithms and data structure?
Maybe start by watching the MIT 6.006 course in the pins 
Also, coding challenges, reading books
please take a look at this problem and its answer:


and here's the answer:

the thing that I can't understand is that it has 2 returns in a function . isn't that if function returns a value python will stop reading the rest of the function lines?
what am I misunderstanding?
can someone please explain this?
thanks alot
The three upper returns are in the nested dfs function, they only return from that function, not the islandPerimiter function
!e py def outer(): def inner(): return "foo" return inner() + "bar" print(outer())
@fiery cosmos :white_check_mark: Your eval job has completed with return code 0.
foobar
I understand the 2 upper returns (0 or 1) but when dfs runs and returns 1 or 0 then it is going to continue and read the rest lines?
for example
no, the dfs function ends itself immediately when it hits a return
if it checks the conditions and for e.g returns 1 then why should continue and read visited.add or per += ....
I thought it would end the func before even reading that lines
It will continue to those lines if both the if conditions are false
the code inside an if block never gets run if the condition is false
yeah I know it but still somethings wrong with me
I had to think about it
thanks for your answers btw
sure 
I get it bro, I just run the vscode debugger and saw how the algorithm's working
I need a serious help if anyone who's good at algorithms can help
I really wanna be good at solving problems but i cant
i try solving leetcodes easy problems (graph ones)
but even the easy ones I can't solve
I don't know where to start where am I doing wrong. if anyone has any advices I will be thankful
just keep grinding. At first it seems like you are getting no where but you will get it eventually
Go easy on yourself
if u want i can give u a website, they teach you every topic of ds algo very good but they do programs in java
if your python basics are good then u can just code in python like whatever they teach u
its free
Java to Python isn’t the easiest transition in terms of syntax…
yeah true
interesting
__add__ function does the job of merging,
I know how to make it in O(1) but then its mutable and i wanted to return a new merged list which won't change the original nodes
Let me know if its still possible, i will try to think on it
I will be thankful then, yeah I know the syntax of cpp and as I've seen before java and cpp are a bit similar . I can convert the syntax myself if I know the logics correctly
Thanks Alot man
do you speak Hindi?
Also is there any in-built function like __add__ for getting index like list does i.e list[i] ?
nah
ok then you can look to their solutions and Mark all the topics there
once you complete all the topics there then you can go on leet code
👌 ❤️
__getitem__
yes, if the user gives a slice you get a slice object as argument
ok, thanks
got the index thing worked out, now just have to think about this slicing
could anyone give me a suggestion maybe of how I would go about making a pcb autotracer? I don't actually need an autotracer, I'm just trying to generate pixel art images of PCBs. I was thinking maybe an alteration of A*, but I've gotten a few comments that that may not be the best way to go
Edit: not looking for an answer, necessarily, but maybe a direction on where to look for ideas
Image manipulation perhaps...use color thresholds to define the trace
Then save the trace as a monochrome image use that to make the pixel art
@main bison if you like systems of indexing a sphere, I really adore https://s2geometry.io/devguide/s2cell_hierarchy it's super clever and useful for computation

@dusty lynx ask #software-architecture
I've been trying to figure out what sort of algorithm this Blender add-on is using to generate the initial paths, but haven't had much luck so far, anybody know of a way to approach this sort of grid path loop generation? https://www.reddit.com/r/blender/comments/ip2ute/created_random_race_track_generator_in_blender/

Maybe like https://answers.unity.com/questions/394991/generate-closed-random-path-in-c.html describes? I'm not really sure but looks like nifty problem 

So we can simplify 2 ^((n-1)/2) + 2 ^((n-2)/2) into 2 * 2 ^((n-2)/2) because second expression is less than first?
it's not a simplification, it's another inequality
but what they are doing is replacing 2^((n-1)/2) with 2^((n-2)/2)
which is clearly smaller
Is there a strict way to make a neural network cause idk if mine is
I would probably have done a more direct approach since there is nothing stopping you from just factoring out 2^(n/2)
2^((n-1)/2) + 2^((n-2)/2) =
2^(n/2) / sqrt(2) + 2^(n/2) / 2 =
2^(n/2) * (1 / sqrt(2) + 1 / 2) >
2^(n/2)
this looks interesting; it seems there is almost no results when searching for closed path generation algorithms :(
Yeah that's what I meant
but yeah, this is just a >= b >= c implying that a >= c
Hmm, how did you get sqrt(2) in second line?
I guess it's more obvious after rewriting as 2^(n/2 - 1/2)
Don't understand
That how you ended up with second line
Did you forget to put parenthesis something there in second line?
2^(n/2) / sqrt(2) + 2^(n/2) / 2 =
I don't get how did you get that
@haughty mountain

I don't get why instructor said
So, now we can say, this is another algorithm, it should work just as well, but, how fast is it? Well, how many lines of code did you use?
There are three lines of code at the beginning, and there's a return statement at the end, so that's four lines of code. Next up we have this for statement that we run through n minus one times, and each time we have to execute two lines of code. So adding everything together we find out that t of n is something like 2n plus two.
not sure if I can do more steps

Next up we have this for statement that we run through n minus one times
Did he fail to say that we run it n minus two?
Yeah I understand, thanks!
it is n-1 times. F[0], ... F[n] is n+1 terms
What confuses me if we run for loop from 2 to n, isn't that n minus 2 times?
So my assumption is that it's n - 2 because we run for loop from 2 to n
it includes 2 and n
say n=4, then the loop is over 2, 3, 4
i.e. not python range(2, n)
but range(2, n+1)
Hmmm, but why it's not in the end 2 * (n -1) + 4
4 because if we remove for loop and statement inside it, then there are 4 lines
@haughty mountain
counting lines of code is a kinda weird exercise, ngl
2*(n - 1) + 4 = 2*n + 2
same thing
Yeah lol, my math sucks
I've seen this device, it's a usb, it can see your passwords so don't use a public pc with a suspicious usb
oh my


why is every squre number is open
for locker problem
ooh is it bc they have odd number of factors
so example 9
factors are 1,3,and 9
for the first time door open
and 3rd time door close
and 9th time door open
I want to take an input string and see if it's similar to another string.
find strings similar to: "apple"
match case 1 "pple"
match case 2 "paple banana pie banna cherry"
dont match "rocks"
I thought about using Levenshtein distance, but that will match case 1 but not case 2... unless I made the edit distance longer then the length of the string "apple" itself (which would then match anything). What's the algo I'm looking for?


Hey @fiery cosmos!
It looks like you tried to attach a Python file - please use a code-pasting service such as https://paste.pythondiscord.com

Solved the tower of hanoi
Sadly it doesn't let me post my python file :<
But I posted the recursive function
Set U to be {L,C,R} for left, center, right columns
Nice!
Set F to be {L} and set T to be {R} , and n is an integer
ok..
I had a really good explanation too but it I can't upload it
ah it's fine
as long as u did it, it's good
^^
dp
What?
Oh wow a warrior for peace
quick question. i am pretty new to python and i know it has many different uses
i am using python more for data analysis, which is the channel that data analysis falls under?
thank you
hi guys, i'm trying to binary search a target, where the target might not exis tin the array. and if it doesn't exist, it just returns the neighbor to the left
while low < high:
mid = low + (high - low) // 2
if arr[time] < target:
low = mid + 1
else:
high = mid
return arr[low]
can anyone help me why this doesn't logically work
i'm trying to do it w/o having a literal checking statement saying :
"if the target is greater than the left neighbor, but less than the right neighbor, then return"

tips on what?
Is there a way to use pathfinding algorithms like A* to generate a closed path, where the start and end point are the same?
I found https://stackoverflow.com/questions/22155614/how-to-create-a-random-closed-smooth-cgpath after some googling, does that work for you?

Stack Overflow
I am trying to find a way to create a random closed smooth path (CGPath or UIBezierPath). I have read about the De Casteljau's algorithm and tons other articles about Bezier paths but it does not s...
if you have obstacles, you might be able to use a similar approach anyway, by making some random waypoints and pathing from each to the next one
Hmm I don't think so, this method wouldn't give me much variability in the paths generated

This is the kind of thing I'm after, only that instead of generating an A -> B path it would loop itself back to A without intersecting itself
hmm, and also have a significant length, or something like that?
Length wouldn't matter too much since the size of the grid/number of obstacles could be controlled parametrically, the ultimate goal for me is to replicate the functionality of the add-on from this reddit post. Right now I'm just trying to get the random shape generation from the first few seconds of the gif on this page https://www.reddit.com/r/blender/comments/ip2ute/created_random_race_track_generator_in_blender/
hmm, I actually wonder if complexity is literally just the number of turns
not quite, but might be similar
oo that could be close; my initial thought was that it was just grid size
I'm beginning to think its not a grid with pathfinding but some other algorithm. So frustrating to try and reverse engineer
one idea:
ntimes, randomly generate a length in some limits. Consider turning either left or right from last segment. If one of the directions would lead to an intersection, choose the other. If both, ???- Then close the curve by a straight line segment
This idea seems like it'd commonly lead to ugly long closing segments at the end
another idea, and I feel like it's closer to what they are doing, is to maintain a path that's always closed, and gradually make it more complex
e.g. start with a simple square. Then repeatedly choose a random segment and replace it with |_|, say, or something like that. That guarantees a closed path, and self-nonintersection is also easy to get (check if changing the segment would lead to an intersection - if so, try again to randomly chose a different segment to replace)
Hmm possibly. so kinda like this post? https://answers.unity.com/questions/394991/generate-closed-random-path-in-c.html I'll have to figure out how to approach this in a blender-friendly way, this project is gonna be way harder than I initially thought
Unity is the ultimate game development platform. Use Unity to build high-quality 3D and 2D games, deploy them across mobile, desktop, VR/AR, consoles or the Web, and connect with loyal and enthusiastic players and customers.
should that be arr[mid] rather than arr[time]?
if I have an object with a bunch of attributes, is there a way to loop through them....like object[attribute]
technically yes, but I very much question why
I have an object with like 15 attributes to retrieve for a dataframe
I suppose I could have 15 lines, each just 'att1 = object.att1'
but wondering how to do it with a loop, even if it's not as readable
doesn't dataframes support looking up by string?
df['column_name']
Just wondering if there's a way to do this or not 🙂
I can figure out how to handle the df
what is it you're trying to look up exactly? columns by name?
do you have some code example?
I'm looking to loop through object attributes
'att1 = object.att1'
but for like 15 of them
it looks like this
crv_comp_gauge.integrate_checkpoint()
these?

this is not pandas
this is just python
I have objects
I'm trying to retrieve attributes
crv_comp_gauge.period_timestamp()
oh, retrieving stuff to put in a dataframe from a class?
just please ignore the df
sure
crv_comp_gauge.dict.keys()
dict_keys(['_project', '_build', '_sources', 'topics', 'selectors', 'signatures', 'bytecode', '_owner', 'tx', 'address', 'decimals', 'integrate_checkpoint', 'user_checkpoint', 'claimable_tokens', 'claimable_reward', 'claim_rewards', 'claim_historic_rewards', 'kick', 'set_approve_deposit', 'deposit', 'withdraw', 'allowance', 'transfer', 'transferFrom', 'approve', 'increaseAllowance', 'decreaseAllowance', 'set_rewards', 'set_killed', 'commit_transfer_ownership', 'accept_transfer_ownership', 'minter', 'crv_token', 'lp_token', 'controller', 'voting_escrow', 'future_epoch_time', 'balanceOf', 'totalSupply', 'name', 'symbol', 'approved_to_deposit', 'working_balances', 'working_supply', 'period', 'period_timestamp', 'integrate_inv_supply', 'integrate_inv_supply_of', 'integrate_checkpoint_of', 'integrate_fraction', 'inflation_rate', 'reward_contract', 'reward_tokens', 'reward_integral', 'reward_integral_for', 'admin', 'future_admin', 'is_killed', '_initialized'])
I want the results of each of those
getattr, but it's terrible
hmm
any reason this is a class rather than a dict with only the stuff you want? or is this come existing thing you don't control that you just want to extract data from?
yeah its existing
it's from a blockchain
hmm
it's not doing the actual contract call
getattr(crv_comp_gauge, 'period_timestamp')
<ContractCall 'period_timestamp(uint256 arg0)'>
I guess it's a function or similar?
oh hold on
getattr(crv_comp_gauge, 'period')
<ContractCall 'period()'>
crv_comp_gauge.period()
24602
so it's only actually running the contract call when I use .period()
tbh, I would probably just write the 15 or so things you care to extract
if it's all functions you can just call whatever you get from getattr
getattr isn't running the function tho
how do I run the returned function
.__call__() would work, but that's even more terrible
you don't want to
lol
it's what doing () calls
ahhh
f.__call__(x) and f(x) are the same thing
is there a way to scroll through each of the attributes
and tell if they are dictionaries or calls or whatever
you can look at type of it
I mean, use a loop or equivalent
?
each would be crv_comp_gauge.topics
crv_comp_gauge.topics.foo
crv_comp_gauge.topics.foo1
but you're quickly making things very much harder, rather than just typing the handful of fields you want
[type(getattr(obj, attr_name)) for attr_name in obj.__dict__]
but this is getting into #esoteric-python territory
err
or just look at the values in __dict__ rather than getattr
[type(attr) for attr in obj.__dict__.values()]
this is great, thank you!
in the end this kind of thing
[attr for attr in obj.__dict__.values() if some_condition_you_write(attr)]
||but you didn't get this code from me...||
lol
talking to you was like slowly trying to convince you to teach me locked away spells
not a bad description
I mean, digging into these kinds of things can be fun for understanding, but as code it's pretty darn terrible
Hi, I haven't taken an actual algorithms and data structures course. Would you guys recommend any books or resources in particular?
See the pins 
thank you
not sure if I'll ever need to reverse a binary tree, but I'm applying for a masters in CS next month and this feels like something I should know lmao
I mean, it's a trivial thing to perform, just reverse the nodes of every subtree
i.e. just recursively do it
yea people use it as a meme for the kind of thing that is asked on interviews
where the algorithms at
does anyone here knows pyqt5 ?
ask your question in #user-interfaces
Does anyone here know how to create a tree structure for an IDDFS (Iterative Deepening Depth First Search when each node on the tree is a class object?
Im having issues making the next layer of the tree.
#Searches using DFS on each layer.
def depthFirstSearch(frontierParam, treeParam, visitedStatesParam, endState , depth):
#Used as our frontier.
frontier = frontierParam
visitedStates = visitedStatesParam
#visitedStates set.
tree = treeParam
while len(frontier) > 0:
#Pop the current state from the head of the queue.
currentState = frontier.pop()
#Compare the currentState's state to the goalState.
#if currentState.state not in visitedStates:
if currentState.state == endState:
#print("Depth: " + str(currentState.depth))
return currentState, visitedStates
if not currentState.visited:
#Generate the childs children so the search can continue.
#This creates a part of the next layer of the tree.
#Only create the children if the depth of the child is equal to the current depth.
#We only need to do this once per layer but we need to check because we visit each node many times over.
if currentState.depth == depth:
currentState.generateChildList()
#Add the children to the visitedStates set to remake the frontier for the next DFS search.
#Children must be added after the currentStates position to keep the order.
for child in currentState.childrenList:
#Add children to the parent/child dict.
tree[currentState] = child
#visitedStates.append(child)
#Set the childs parent to the current state.
child.parent = currentState
#Some action such as adding elements to the visitedStates set we only want to do one time.
if currentState not in visitedStates:
#Add the currentState to the visitedStates.
visitedStates.append(currentState)
return None, visitedStates
#Generates the child layers. Formulates the stack before calling DFS on it.
def Iterative_deepening_dfs(startState, endState):
#Var to keep track of the current depth.
depth = 0
#Class instance for the found state.
foundState = None
#Bool for the goal state being found.
found = False;
#Used as the stack data structure.
frontier = deque([startState])
visistedStates = set()
#Tree structure. Self | Children
tree = dict()
while not found:
#Search the tree for the goal state using DFS.
foundState, visitedStates = depthFirstSearch(frontier, tree, visitedStates, endState, depth)
#Check to see if foundState is not None.
if foundState not None:
return foundState
#Increase the depth before the next iteration.
depth += 1
return foundState
Here is my code so far
I was going to try and use the dictionary to create the tree at each new layer but I am having a hard time doing that.
Because I dont know which node goes in what order.
Here is my Board class.