#algos-and-data-structs
1 messages · Page 138 of 1
and fwiw, looking at a solution before you've solved it is bad for learning
esp one that uses a different lang 😬
that is true
but he said it was applicable in any language
i was just missing a return
i do understand the pattern
i solved it on paper
you could have used a tuple but you used a string for the key
¯_(ツ)_/¯
the ideas are applicable, but the way you apply them isn't
yeah, it doesn't really make sense to convert them to strings
they only do that in js because you can only have string keys in js
oh
whoops
ok point taken
i was just watching these for the main idea
i think i do understand it a lot better
It seems like a big algorithm, You can divide it in small functions to make it easier to understand
Got a question regarding dictionaries. I have a dictionary with {names : times}, and im trying to sort it based on times. I know you can't "sort" dictionaries, so im trying to figure out the best way to generate a sorted product. I know I can iterate through the dict using .items(), but im struggling to figure out where to go from there
The common oneliner is along the lines of dict(sorted(the_dict.items(), key=...)). You generate a sorted list of items and feed it to dict to make it a dict again.
I'm sorry, im still just learning, can you explain the key=...?
sorted (and .sort, and functions like max and min) accept a key argument - a function which will be used on each element to extract the key to sort by.
!e
print(sorted(range(-10,10), key=lambda x: abs(x)))
@vocal gorge :white_check_mark: Your eval job has completed with return code 0.
[0, -1, 1, -2, 2, -3, 3, -4, 4, -5, 5, -6, 6, -7, 7, -8, 8, -9, 9, -10]
In your case, your key function should accept an item (key-value tuple), since that's what you're sorting, and return the value (since that's what you are trying to sort by).
think ive got it. thanks!
what would be the simplification of (n - 1) * (n -2) * (n -3) * ... * 0, in terms of big O notation
is that a 0 on the end
asked and answered in #python-discussion @shut breach
~~Is numpy applicable to this channel?
I'm sure there's a better way to do this, but I'm having trouble finding it
x = m * xy[:, 1]
y = m * xy[:, 0]
xy = np.rot90(np.array([x, y]))```Where `m` has shape `(n,)` and `xy` has shape `(n, 2)`~~
Found it, `m[:, ::-1] * xy[:, np.newaxis]`Over on the C# discord there was a discussion about how finding the max value in an array was faster for some reason when the array is sorted (turns out for C# it's due to branch prediction).
I was curious if the same held true for Python and wrote a naive program to test it out and on my laptop the average time to find the max value in a 100,000 integer list is always faster when the list is unsorted by 10-15ms.
I can't think of why this would be, any ideas?
My quick and dirty test code:
import time
import random
def find_max(int_list):
max_item = 0
for item in range(0, len(int_list)):
if int_list[item] > max_item:
max_item = int_list[item]
return max_item
unsorted_list = []
for i in range(0, 100000):
unsorted_list.append(random.randint(0,1021474836470))
sorted_list = unsorted_list.copy()
sorted_list.sort()
print(unsorted_list[0:3])
print(sorted_list[0:3])
unsorted_results = []
for i in range(0, 100):
start = time.perf_counter()
find_max(unsorted_list)
end = time.perf_counter()
unsorted_time = end - start
unsorted_results.append(unsorted_time)
unsorted_mean = sum(unsorted_results) / len(unsorted_results)
sorted_results = []
for i in range(0, 100):
start = time.perf_counter()
find_max(sorted_list)
end = time.perf_counter()
sorted_time = end - start
sorted_results.append(sorted_time)
sorted_mean = sum(sorted_results) / len(sorted_results)
print(sorted_mean > unsorted_mean)
print((sorted_mean - unsorted_mean) * 1000)
am i missing something. isn't finding the max of a sorted list O(1)
Well the question was using the same algorithm would it matter if the list is sorted...without the algorithm needing the list to be sorted.
You want to sort it descending for the performance boost
By sorting is ascending you make it have to update max_item every iteration
Without sorting it updates max_item on random iterations
Ah that makes sense
With descending sorting it only updates it on the first
Thanks, one of those "why didn't I think of that" moments 🙂
Anyone willing to help with my binary search tree implementation? :)
def bst_remove(self, key):
self.root, remove = self.remove_f(self.root, key)
remove.left = remove.right = None
return remove
def remove_f(self, t, key):
if t is None:
return None, None
elif key > t.key:
t.right, r_node = self.remove_f(t.right, key)
elif key < t.key:
t.left, r_node = self.remove_f(t.left, key)
else:
pass
https://pastebin.com/Rk0YGDdD (rest of code, too long to fit in code blocks on discord)
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
I want to return the deleted nodes in inorder
and I don't know what to do with that else statement
Hey everyone need a small help -
edges = [[0,1],[1,2],[2,0]]
I want to store this 2d array in dictionary with indices as key and elements as value like this -
graph = [0 : [0,1], 1: [1,2], 2: [2,0]]
This what I have tried but it is throwing error -
for k,v in range(len(edges)):
if k not in graph:
graph[k] = v
print(graph)
TypeError: cannot unpack non-iterable int object
This is the error
Well in the example you gave graph is not a dict. It's a list.
Dicts are like {1:[..], 2:[..]} in your case i think
Also about errror. You are making a for loop on range. So you would get only a number on each instance. So error is about that.
!e
for i in range(3):
print(i)
for i,j in range(3):
print(i)
@fiery cosmos :x: Your eval job has completed with return code 1.
001 | 0
002 | 1
003 | 2
004 | Traceback (most recent call last):
005 | File "<string>", line 3, in <module>
006 | TypeError: cannot unpack non-iterable int object
See you did what i did in 2nd for loop.
So I've gotten a task at school to analyze Insertionsort by implementing it recursively. The sample data is 1million elements long, but I can't get it to sort more than 3490 elements.
I've heard that Python and Recursion don't really see eye to eye, but would someone mind explaining why this is? Struggling to wrap my head around it.
Python isn't any worse in recursion than most* languages (though recursion in general is not very performant). One million elements with insertion sort, a quadratic algorithm? I'm not sure that can be done in any decent time in any language; that's on the scale of 10^12 operations after all
*Some languages have tail call optimization, which is basically automatically converting a certain kind of recursive functions into iterative ones. Python doesn't.
how do you even do insertion sort recursively
you can just call it on positions 0, 1, 2, ..., I guess
Looks like a Rust implementation I just wrote (iterative one, not recursive) can sort 100000 u8s in 3.6 seconds, so will take around 360 seconds for a million.
def insertionSortRecursive(arr,n):
# base case
if n<=1:
return
# Sort first n-1 elements
insertionSortRecursive(arr,n-1)
'''Insert last element at its correct position
in sorted array.'''
last = arr[n-1]
j = n-2
# Move elements of arr[0..i-1], that are
# greater than key, to one position ahead
# of their current position
while (j >= 0 and arr[j] > last):
arr[j+1] = arr[j]
j -= 1
arr[j+1]=last
copied from somewhere online
but yeah
half the class got recursion, half iter
A function can't call itself recursively more than a certain number of times. There's a soft limit set by sys.setrecursionlimit, 3000 by default, but there's also a hard limit - after some number of calls (usually less than 10000, but depends on the size of the function's frame), the interpreter's call stack will just run out of space, and you can't really do much with that limit.
I tried to work around that by doing exactly that.
but the program just halted, no error message or anything.
in the latter case, the entire interpreter will just crash with only an error code
So basically its the call stack just telling me that its too tired?
Yeah, it is just telling you that it's tiny stack of what's probably like 2MB can't fit more than a few thousand call stack frames
I think it's 1000 by default
might be; I checked and it's 3000, but I checked in ipython, which might set it higher by default.
Need to read up on call stack a bit more.
either way, both are high enough
But yeah, the general consensus I've gotten from reading online, is that its blasphemous to do insertionsort recursively
it's like recursing to loop over a list, in python
ah I like that analogy @agile sundial
it's not really an analogy, that's what it's doing
crap, I'm horrible at compliments.
well, yeah, you'll need a recursive call per element, and basically no language will allow you to do that many recursive calls. Well, I guess if you could convert it to such a form that your function looks like
# do stuff
insertionSortRecursive(...) # as the very last line
then some languages would automatically turn that function into an iterative one (tail call optimization). But that kinda stops it from being a recursive solution.
Hi, how would I represent the binary(bit) encoded values highlighted in red into a chromosome string highlighted in yellow? As I want to perform the genetic operations such as selection, crossover and mutation. This was the way I tried but been unsuccessful. Help.

Ohh yes i should have used enumerate
Hello can anyone explain me the longest common subsequence problem
Dynamic Programming
Apparently it's too difficult for me
the solution?
Yup
which part specifically?
tbh the whole part
do you understand dynamic programming in general?
I know its just a modification of the Divide and conquer algorithm
we use the subproblems to build up on the main problem
thats as far as my understanding goes
actually dp can't work on good divide and conquer algorithms, because in those cases the subproblems aren't overlapping
but you're right about the second part
yeah
so the first step is to find the optimal substructure in the problem, i.e, can we even use dp to solve the problem?
Oh right
So we try to find the longest common subsequence for a smaller dataset( smaller sequence) and then build upon that?
If i think about it
i could just modify the edit distance problem to get to the answer
maybe? that seems like more work though
import math
class Vector:
def __init__(self,x,y,z):
self.x = x
self.y = y
self.z = z
def ShowVector(self):
return [self.x,self.y,self.z]
def Length(self):
return (self.x**2 + self.y**2 + self.z**2)**0.5
def CrossProd(V1,V2):
V1, V2 = V1.ShowVector(), V2.ShowVector()
x = V1[1]*V2[2] - V1[2]*V2[1]
y = -V1[0]*V2[2] + V1[2]*V2[0]
z = V1[0]*V2[1] - V1[1]*V2[0]
return [x,y,z]
def DotProd(V1,V2):
V1, V2 = V1.ShowVector(), V2.ShowVector()
x = V1[0]*V2[0]
y = V1[1]*V2[1]
z = V1[2]* V2[2]
return x+y+z
def Angle(V1, V2):
ans = Vector.DotProd(V1, V2)/ (Vector.Length(V1) * Vector.Length(V2))
angle = math.acos(ans)
return 180*angle/math.pi
def UnitVector(self):
Unit_Length = self.Length()
return [i/Unit_Length for i in self.ShowVector()]
V1 = Vector(1,2,3)
V2 = Vector(2,3,5)
print(Vector.CrossProd(V1,V2))
print(Vector.DotProd(V1,V2))
print(Vector.Angle(V1,V2))
print(V1.UnitVector())
I started OOP today, is my code good so far?
It looks pretty good. I would change a couple of things. Your method names should be snakecase instead of camel: cross_prod instead of CrossProd for example. Something else you might want to do is change the cross_prod, dot_prod, and angle methods to only accept the second vector as a parameter. That way if you define your first as v1 = Vector(1, 2, 3) you could call them as v1.cross_prod(v2)
Ah makes sense, thanks
Something else you might want to do is change the cross_prod, dot_prod, and angle methods to only accept the second vector as a parameter.
They are like that already - they are just not obiding by the convention of having theselfargument be called, well,self
I'd note that CrossProd returns a list of 3 elements, even though it really should return a Vector.
same for UnitVector
No they aren't. Look at how they are called. The method isn't being called on V1 instance, but the class, passing in both vectors
Oh, yeah, they are called on the class here, but they can be called like V1.CrossProd(V2) too.
Ig it’s probably because I’m more used to functions, so thats why they look more like functions than objects
Hey guys, i'm looking to start learning algos and data structures now before proceeding to AI is that a good idea
anyone here is good at networkx? im trying to find sum of all edge weights for each node
Is anyone familiar with trie trees?
should i ask questions about pickle here?
def dragging_diff(minuend: list, subtrahend: list) -> list:
'''
Returns the list of elements that are in minuend and not in subtrahend,
sorted.
Both lists must be sorted from smallest to biggest.
'''
# list to contain the result, called the diff.
diff = []
# represents the first minuend element that we have not yet checked
# membership in the diff for
min_index = 0
for sub_item in subtrahend:
# if the minuend is exhausted, there will never be anything
# more in the diff
if min_index >= len(minuend):
break
# now advance through the minuend. Any element less than current sub
# is part of the diff.
# Note that it is <=. This is because if you find exactly the
# subtrahend, you want to still skip an element but not count it
# in the diff.
while min_index < len(minuend) and \
minuend[min_index] <= sub_item:
# remember, you don't count in the diff if it is equal
if minuend[min_index] < sub_item:
diff.append(minuend[min_index])
# but you always advance
min_index += 1
# the algorithm only advances FORWARD through the minuend, never back.
# if the subtrahend is exhausted first, it can be assumed that all the
# remaining elements in the minuend are in the diff
diff.extend(minuend[min_index:])
return diff
i'm practicing writing efficient algorithms for doing stuff right now. I wrote this algorithm that I called "dragging diff", which finds all the elements in one array that aren't in the other.
Is it bug-free?
Also I know I could've used sets, but I was thinking of using this for writing in a language where the only structure is array
the idea of this is
it advances through the "subtrahend" array, and for each advancement, it "drags" behind it a pointer that advances through the "minuend" array until it finds an element greater than the current subtrahend element, and every element in that trail is part of the diff
Can someone help me to understand 0 - 1 BFS ? (Single Source Shortest Path in O(V+E))
I watched so many videos and articles but still had a difficulty to understand it algorithm

This trick is actually quite a simple trick, but not many people know this. Here are some problems you can try :
- http://www.spoj.com/problems/KATHTHI/
My implementation: https://pastebin.com/ckVxJEMG - https://community.topcoder.com/stat?c=problem_statement&pm=10337
Facebook Page: https://www.facebook.com/FunWithGoCode
#bfs
#shortest
#p...
hi i needed help regarding re (regex, regular expressions)
what do you need help with specifically?
thx for asking, i found help in one of the #help channels : )
oh ok lol, i'm glad you were able to get help!
quick question about skiplists
for each different layer is it a copy of the original skiplist minus whatever elements?
in my head it would make more sense if its just addressing the memory locations of the original node but ive not been able to find any literature on this
It'd be pointers to the "full" list, or probably just indexes into it even.
thats what i figured it'd be
in my head it doesnt make sense making copies of it
OK, so... I have a kind of network of objects. They have directional links of dependency (and no loops, that conceptually would not make sense for what they do). For example, a change in A will impact B, C, and D, but C also relies on B.
So, when a change happens in one of the objects, I want to update only those objects, and ensure that each one only performs its update subprocess once. This seems like something that should have a standard, neat solution to it.
I can certainly solve it but I don't feel like it's elegant
I approach in two stages. The first stage is just polling each object for all of its children (recursively), add them to a list, and discard duplicates. Then I have a list of all the objects that are going to be updated.
In the second stage, I can ask each member if they have any PARENTS in the list. If they don't, I can update them, then remove them from the list. Repeat until there are none left.
But that seems... inefficient.
what would be the formula to work out the smallest height of a binary tree with n number of nodes & what is the maximum number of nodes with a binary tree of height h? if someone could tag me in their responce that would be great!!!
Uh... well, a tree with one layer has, at most, 1 node. Two layers, 3 nodes (twice as many nodes as the layer one higher). The third layer adds 4 nodes for a total of 7. Fourth layer, +8 nodes, 15 total. Is that enough of a pattern for you to work it out?
@fiery cosmos
both questions are the same problem, it's just that one goes forwards and the other goes backwards
i.e. a reversal of logic
Both are really same kinda question. See it's simple. If the tree is totally skewed you get maximum height so minimum would be when it's balanced. How much? Well i leave that to you. Create binary trees of height 3 and 4 on pen and paper and see if you can connect some mathematical formula. Goodluck!
thanks guys i am on a break right now but will take a look when back
thanks again!
Ok, I've made progress on my own problem. No loops means it's possible to put all the objects on one chart with a higher end and lower end. Strictly commutative order. When they get updated, if you just do things in order, dependency will be respected
Since that network doesn't change shape (ever) in this application, I can work out the ordering at the start from the network once and then use it thereafter
So I could do it manually... but that's not future proof
So really, the new problem is, if you had a network description that has no loops, how can you come up with a ranking?
(Or. It's a valid alternative problem which would also solve the main problem)
I might have it
Each object starts with a score of 1. Then you add on the scores of both its parents (but, uh, rather you'd start at the top and work your way down)
Then there's no way for an object to have a higher score than a parent
Then order by score and Bob's your uncle

Anyone like this syntax? I often find myself wanting this when doing somewhat complex comprehensions
[w(z) for y:=g(i) for x:=f(i) for i in itter]
``` or perhaps
```py
[w(z) for y=g(i) for x=f(i) for i in itter]
basically, its the same as ```py
[w(g(f(i))) for i in itter]
however you can add if conditionals afterwards, as well as not having to define lambdas beforehandespecially if your individual functions are too simple to bother making lambdas but also would cause inefficiencies to nest manually [ex having two outputs] this seems like a nice way to do it
Also, on an unrelated note can we allow \ within f-strings? it's really annoying that this isn't valid code ```py
f"""the items are: {'\n'.join([1, 2, 3])}"""
Also also, there should be some built in way to do x if x else default_none_type(x) and x if y else default_none_type(x) (Maybe just none(x) and none(x, y)?), basically eval x/y, if its bool form is true then return x, otherwise get (from the class of x) the "none" representation of it, so like if x is a list it would be [], a string it would be "", a number it would be 0, and a custom object you can define it as like def __none_value__(self) or something, with just None being a default
ill move over there thanks
Does this mean it won't go through?
alright
do u know if theres some sort of community made python macro thing
where you can define and get macros
its omega un-pythonic im sure but id still use it for stuff like this
sounds good
would someone kindly be able to explain to me how we can get the post order traversal from both the preorder and the inorder travelersal? the answer has been included but i do not know how to get there!

I have a (maybe stupid) question about LinkedList implementations
When you delete pointers to a node, 1, from previous nodes, 2 and 3, doesn't node 1 continue to exist in memory?
ie
node.prev.next = None
node.next.prev = None
doesn't node still exist in memory?
In Python? Python (well, CPython) is reference-counted; the moment an object falls to zero references, it gets dropped.
(though CPython also has a GC in order to be able to collect reference cycles, which refcounting can't deal with)
I see, so if you were to call a function, lets say delete_node(node), after the function is over and the node reference is removed, the object would be deleted from memory?
that's what garbage collection is right?
Yeah, objects in Python are deleted when there's no references to them. That is in fact the only way to delete an object at all - there's no function to do that explicitly (since that'd leave dangling references in whatever objects had references to it before).
Thanks for the help!
hi im really stressed can anyone answer this? https://stackoverflow.com/questions/70089091/very-strange-accuracy-change

Stack Overflow
Below is my catboost model:
from sklearn.metrics import r2_score
cb_model = CatBoostRegressor(iterations=500,
learning_rate=0.05,
depth=10,...
if you can, please upvote if you're not sure!
Hello! How to iterate extendable dictionary with non-fixed length?
hi guys
I have made a program for Binary Trees
So
in that
i made a function to check if the given tree is a Binary Search Tree or not
def check_binary_search_tree(self):
if self.data is None:
return True
if self.left is None and int(self.right)>int(self.data):
return True
if self.right is None and int(self.left)<int(self.data):
return True
if self.left is not None and self.right is not None:
if int(self.left)<int(self.data) and int(self.right)>int(self.data):
return True
else: return False```but now
its saying it int() argument must be a string, a bytes-like object or a number, not 'BinarySearchTreeNode'
I used int() because without it was showing an error that it cant compare using <
Can someone help me with this?
How can we find roots of an equation using standard libs (math, cmath etc)
like
x^2 - x - 1
and roots (or maybe just positive real roots) of like
x^9 - 5x^8 - 1
newton's method?
guess a root, find the function value and derivative value for that x, adjust x according to x_n+1 = x_n - f(x) / f'(x) and iterate up to desired accuracy

The spacing is wrong here.
which is evaluated first here?
x == 5 < 8
it seems like a boolean is getting compared with a number
it should be left to right, since they're equal precedence iirc
!e
print(True == 5 < 8)
@shut breach :white_check_mark: Your eval job has completed with return code 0.
False
@agile sundial :white_check_mark: Your eval job has completed with return code 0.
001 | 1 0 LOAD_CONST 0 (True)
002 | 2 LOAD_CONST 1 (5)
003 | 4 DUP_TOP
004 | 6 ROT_THREE
005 | 8 COMPARE_OP 2 (==)
006 | 10 JUMP_IF_FALSE_OR_POP 9 (to 18)
007 | 12 LOAD_CONST 2 (8)
008 | 14 COMPARE_OP 0 (<)
009 | 16 RETURN_VALUE
010 | >> 18 ROT_TWO
011 | 20 POP_TOP
... (truncated - too many lines)
Full output: https://paste.pythondiscord.com/wekofimiwu.txt?noredirect
there
wait its an and isnt it
right, == seems sketchy though
you can chain stuff like in too
it says comparison operators have higher precedence than equality operators
so shouldn't 5 < 8 come first?
in x == 5 < 8
it becomes (x == 5) and (5 < 8)
equality isn't a comparison operator? where does it say that
Python Operators Precedence Example, The following table lists all operators from highest precedence to lowest.

docs say they're the same
that would make sense because the answer is True
otherwise it'd be False if I'm not mistaken
for which expression?
!e
x = 5
print(x == 5 < 8)
@young tangle :white_check_mark: Your eval job has completed with return code 0.
True
!e
x = 5
print(x == (5 < 8))
@young tangle :white_check_mark: Your eval job has completed with return code 0.
False
ok, I guess that website was wrong
tutorialspoint is generally bad 😬
apparently, yikes
I thought they'd be evaluated LTR then looked it up to be sure and got confused 😄
ROT_TWO is for exchanging the top two stack items?
Hey guys, can someone suggest me some good resources (blogs and yt videos) for DSA?
evidently, I guess they just lifted from some other language

For intermediate/beginners I found a guys series of videos on Skillshare. Im using my free month to learn the fundamentals quickly using his vids
Its called "Coding Interview Essentials: Data Structures & Algorithms" and his code is in python
Also see free mit courses in channel pins
hello folks, am trying to solve this problem and I can't solve it.
So basically there's an array of integers and my algo must return True if all the integers in the array have an equal pair otherwise return False
For example we A = [1,2,2,1], this returns True because every integer has an equal pair 1,1 and 2,2
def solution(A):
seen = {}
for i in A:
if i in seen:
seen[i] += 1
else:
seen[i] = 1```
This is what I have so far, am using a dict to count all the integers in the array but I just don't know how to compare if each key has a matching keyYou can iterate through all possible values and check if the number of times it occurs in the array is even
yea I thought of something like that and I came up with this
def solution(A):
seen = {}
for i in A:
if i in seen:
seen[i] += 1
else:
seen[i] = 1
if seen.keys() % 2 == 0:
return True
else:
return False```
But I cant use the modular on `keys()` functionI believe you should be using seen.values() instead
keys are the array elements itself
not the numbers of occurences
After that you can use a for loop to check if there's any odd element
Or just use all() or any() with list comp if you are familiar enough with it
not really familiar with those functions
Then start with a for loop 🙂
def solution(A):
seen = {}
for i in A:
if i in seen:
seen[i] += 1
else:
seen[i] = 1
for p in seen:
if seen.values() % 2 == 0:
return True
else:
return False```
am so lost lolYou should be iterating over elements of seen.values()
Not the dictionary itself
for p in seen.values():
Then just check if there's any p which is odd
ahh ok
def solution(A):
seen = {}
for i in A:
if i in seen:
seen[i] += 1
else:
seen[i] = 1
for p in seen.values():
if p % 2 == 0:
return True
else:
return False```
This workedp is already the value ig
You don't have to call seen[p]
!e
seen = {5: 2, 6: 4}
print(seen.values())
@glossy breach :white_check_mark: Your eval job has completed with return code 0.
dict_values([2, 4])
For example^
ahh ok so its just if p % 2 == 0:
That's still not correct ig
if you return True once you see an even p
It won't always be correct
Because if the first p you encounter is even for example
what do you mean by ig?
i guess
It will already return True, skipping all the remaining values of p
so if seen.values() is [2, 3], your program would return True after hitting p = 2, skipping p = 3 and therefore giving wrong answer
umm it doesn't return True it returns False, which is what I want
for example A = [7,7,7,7], returns True because there are equal pairs 7,7 and 7,7
if it was A = [7,7,7], it returns False because there's an integer without an equal pair
not sure if we on the same page lol
I did that but it returned with a False, which is what I want
def solution(A):
seen = {}
for i in A:
if i in seen:
seen[i] += 1
else:
seen[i] = 1
for p in seen.values():
if p % 2 == 0:
return True
else:
return False
print(solution([2,3]))```Ah I mean seen.values(), not A
!e
def solution(A):
seen = {}
for i in A:
if i in seen:
seen[i] += 1
else:
seen[i] = 1
print(seen.values())
for p in seen.values():
if p % 2 == 0:
return True
else:
return False
print(solution([1, 1, 2, 2, 2]))```@glossy breach :white_check_mark: Your eval job has completed with return code 0.
001 | dict_values([2, 3])
002 | True
ahh yea when its [1,1,2,2,2] it returns true
Yeah so you would only want to return False if you meet an odd p
ohhhh I think I know what you mean now
Because if a value of p is odd then there's no need to check the rest because the answer would always be False in the end
The same doesn't apply for even ps
I think I know what you mean, can you write the correct code?
still a little confuse lol
I think you should try to write it out on your own
Think about what I said for a bit
If you're overly confused then I'll help
yea I think am overly confused lol
Honestly idk, from what I know to check if its an odd
'if p %2 != 0
Sorry if its sloppy, texting from my phone, internet went out lol
p % 2 != 0 is the same as p % 2 == 1
Hmm I see
Yea I did that, i changed the first if statement to check if its odd and the othee if its false
It still returns true
Yeah you can't just reverse the two if statements
That wouldn't make any differences
What I mean is that return True shouldn't be inside the for loop
Ahhhhh ok
Yea that solved the issue, why is that?
Because you don't want to return True right away if one value happens to have an even number of occurrences, like [3, 3, 4] the 3's match but the 4 does not
hmmmm I see
These are the little things I need to improve on
the runtime and spacetime would both be O(N) correct?
def solution(A):
seen = {}
for i in A:
if i in seen:
seen[i] += 1
else:
seen[i] = 1
for p in seen.values():
if p % 2 != 0:
return False
return True```how?
||You xor everything together (O(n) time, O(1) memory) because A xor A = 0 for any A, and xor is commutative and associative, so all the equal pairs will cancel down to 0, any oddballs won't cancel out||
||return reduce(operator.xor, A) == 0||
Just a loop and a accumulator variable, same as if you were adding all the numbers. Then if the final result is 0 everything was paired
or what hsp said 
hmm this approach fails to account for an odd number of 0s though
oh, true
Though where I've seen this the numbers are positive https://leetcode.com/problems/single-number
hm
also, i remembered this https://florian.github.io/xor-trick/
There are a whole bunch of popular interview questions that can be solved in one of two ways: Either using common data structures and algorithms in a sensible manner, or by using some properties of...
why is sometimes when i copy an object it calls by value and sometimes it calls by reference?
in this case, changing y does not change x

but in this case, changing temp changes temp2

all your questions will be answered by this video
https://youtu.be/_AEJHKGk9ns

"Speaker: Ned Batchelder
The behavior of names and values in Python can be confusing. Like many parts of Python, it has an underlying simplicity that can be hard to discern, especially if you are used to other programming languages. Here I'll explain how it all works, and present some facts and myths along the way. Call-by-reference? Call-by-v...
Ned 
Does it work on floating point values too?
# Write your code here
array = []
if friends > time:
array.append(time-1)
array.append(time)
elif friends < time:
array.append(time+1)
array.append(time)```what is wrong with this code
why do i get an error
can someoene help me with this
I don't think that'll work, for example if A = [1, 2, 3] the xor sum will still be 0
And it's super easy to generate such array
Just take whatever array you have and append the xor sum of all of its element to the end
Oh, very good point. I guess it only works for a more constrained situation
hey, I'm trying to parse a file with a bit of an esoteric format- afaik it's basically a json object per line
{"x": 0, "y": 5, "text": " 1 ", "color": "", "tags": [], "group": ""}```I'm running into trouble with the escape characters though
for my purpose I need to loop through the chars in "text", and right now it's treating \, u, 2, 5, etc. separately, instead of reading a char as \u250
I already tried importing the file with utf-8 encoding
ok scratch that I found a solution
but is there a way to make py export json text with double quotes " instead of single '?
Hw are you doing it? Python does do that (since json requires it)
import json
data = {'foo': 'bar', 'baz': [1, 2, False, None]}
with open('data.json', 'w') as f:
json.dump(data, f)
# data.json: {"foo": "bar", "baz": [1, 2, false, null]}```ok yeah I'm loading the json info into a dictionary so I can mess with it
I suppose I just need to dump it then whoops
ok it's all working now :D
hi looking for some help on this question
maybe someone seen it online somewhere with a good answer?!

Hey can someone explain to me why this function's time complexity is O(m*n)?
There is a double for loop going through a 2D array grid and grid[0] so I understand that. But is the DFS() function in the inner for loop just constant?

you just have to observe that any given position in the grid is visited just once, either through a DFS or through the double for loop
Excellent. Thanks so much man
Hello! Are dictionaries a hash tables in python?
Yeah, its a hash table or hash mapping
Thanks
Hi, I can write this algorithm in python?

def f(n):
return sum((n - i) * i for i in range(1, n + 1))
thanks
Forgot how to do this.
Combinations of list with one element from each "type" such as below?:
>>> combinations(['Aa', 'Bb'])
['AB', 'Ab', 'aB', 'ab']
Oh right. Cartesion product
If you dont understand a leetcode implementation in the discussion section, do you just watch a video on it so you can see someone explain it. Or do you power through and try to understand the implementation by reading the code and explanation?
Uhhhhh that's codility
That's on you buddy
whatever works, sometimes it also helps to execute the algorithm yourself with pen and paper
Ok.
I haven't been using pen and paper as much recently, so I will start doing that much more again. Thanks for the reinforcement!
Hi! I'm trying to write a simple script that will allow me converting CSV rows to TXT files.
- one row should be saved as single TXT file,
- there are 2 columns in the CSV file (ID;Content)
- new TXT file should be named" {ID}.txt
- the content should be saved in this file
Can you help? 🙏
I'm trying to solve this task in time, if anyone can help me please do so
my code
a = int(input())
b = list(map(int, input().split()))
nms = [b[x] for x in range(len(b))]
nms1 = [[x,x] for x in range(len(b))]
while len(nms1) != 1:
nms2 = []
nms3 = []
for x in range(1,len(nms1)):
d = sum(b[nms1[x-1][0]:nms1[x][1]+1])
if (d-nms[x-1]) > (d-nms[x]):
nms3.append(d-nms[x-1])
else:
nms3.append(d-nms[x])
nms2.append([nms1[x-1][0],nms1[x][1]])
nms = nms3
nms1 = nms2
print(nms[0])
do you guys have any tutorials that can help me to build a algorithim (stock) API
class Node:
def __init__(self,value:int) -> None:
self.value = value
self.left = None
self.right = None
class BinarySearchTree:
def __init__(self) -> None:
self.root = None
self.elements = 0
def _add_node(self,root,node):
if self.root is None: # Check if a root exist, otherwise create it
print(f'Add {node.value} as root')
self.root = node
self.elements += 1
return
if root is None: # Check if there is not left or right node
print(f'Add {node.value} to tree')
root = node
self.elements += 1
return
if node.value > root.value: # If so, add it to the right side
print(f'{node.value} is greater than {root.value}.')
self._add_node(root.right,node)
return;
if node.value < root.value:
print(f'{node.value} is less than {root.value}.')
self._add_node(root.right,node)
return
print(f'Value {node.value} is already in the binary search tree')
def _is_node_in_tree(self,node,value):
if node is None:
print("Number Not found")
return False
if node.value == value:
print("Found")
return True
if value > node.value:
print(f'{value} is greater than {node.value}')
self._is_node_in_tree(node.right,value)
elif value < node.value:
print(f'{value} is less than {node.value}')
self._is_node_in_tree(node.left,value)
def get_number_of_nodes(self):
return self.elements
def add_node(self,node):
self._add_node(self.root,node)
def is_node_in_tree(self,value):
self._is_node_in_tree(self.root,value)
if __name__ == "__main__":
n1 = Node(10)
n2 = Node(20)
n3 = Node(15)
n4 = Node(15)
btree = BinarySearchTree()
btree.add_node(n1)
btree.add_node(n2)
btree.add_node(n3)
btree.add_node(n4)
print(btree.get_number_of_nodes())
btree.is_node_in_tree(20)
```Hey guys, which do i get returned Number not found? I think something is wrong with my add function?
why*
Hey, how do I take stdout printing console output, put it into an array to then get printed 2000 characters at a time, like a sort of buffering system
Your functions is expecting 2 values but you gave only one. So your value parameter is None.
I was looking at a python runtime script that convert numbers to characters and it was faster to use a dictionary hashtable rather than the ascii number addition, for example, if we wanted 0 to represent we would add 65. Is the reason that this true, that the dictionary is faster than the constant operation because the dictionary uses the cache whereas the ACII table is never stored in the cache?
Here is the code I am discussing
So like 13 becomes M and 14 becomes N?
I think you also could just use a string with all the uppercase letters, and index it
What’s the code?
hmm it might even be faster to use the input as a direct index into a list since there's no need to hash
or a string like mesolikey said
I say it because I’m pretty sure that characters from str are located close together in memory
!e ```py
from sys import getsizeof
s = "abc"
print(getsizeof(s))
s += "d"
print(getsizeof(s))
@fervent saddle :white_check_mark: Your eval job has completed with return code 0.
001 | 52
002 | 53
So it seems like it should have even better cache locality than dict
The memory is bunched up closer together
But idk that might be wrong, someone else might know more
Because also it seems like the string just has an array of bytes representing characters, and not an array of pointers to python objects like how a list or dict does. So I’m imagining it just getting one of the characters and changing it into a 1-character python string object. So the underlying array of bytes would be better for cache locality, I think is how it would work.
And yeah there’s no need to hash, although idk what the overhead of that is. Idk if subtracting 65 from an int in python to index a list has more overhead than hashing the int in C to access a dict key’s value

hm
this looks suspiciously familiar to grid traveler

Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
but in grid traveler you start at (0,0) and you only move right or down
and you count the amount of paths as you go
bc you're implementing it recursively and need some way to get either the rows of columns zero or both of them equal to 1
and you are counting the amount of ways
not actual coordinates
what's grid traveler
they're the same?

so you can solve it
def xx(a: int) -> int:
if (a < 5):
return 3 * a
else:
return 2 * xx(a - 5) + 7
xx(10)
would someone please explain to me how we get 21
i thought this followed bodmas but i am struggling to see how
expand the function calls until you get to the bottom, then evaluate
you'll see one part is eventually multiple by 0, so it's just the +7s left
sevens
there is more than one?
yeah, if you expand all the function calls
how do i expand them?
first it's xx(10)
then, 2 * xx(10-5) + 7
then, 2 * (2 * xx(10-5-5) + 7) + 7
and so on
I gtg, but good luck
recursive tree?

check this out
this is the recursive tree for the fibonacci sequence
it ends on fib(1) and fib(0) because they are base cases
that return a 1
so now
all you have to do is draw the recursive tree for your code
yep
great so now you know that since 0 is less than 5 you have to multiply that by 3 according to your basecase
and you can continue breaking down the 10 and the 5
unless i'm misinterpreting it
Can someone help me
i got this question in hackerrank but im stuck like idk where to begin if anyone could help out it be gr8

hey, so im doing this challenge and i ran into a problem. I knew a and b would take type str automatically but i was under the assumption that they would change to type int if an integer is provided in the input. But it seems not since whenever i run the function it prints False no matter what I input. Any Ideas?
def only_inits(a, b):
if type(a) is int and type(b) is int:
print("True")
if type(a) is not int and type(b) is not int:
print("False")
a = input()
b = input()
only_inits(a, b)```Yeah input doesn’t do that, it only returns str
but then if the input is a string it returns an error, what do I do then?
@fervent saddle :white_check_mark: Your eval job has completed with return code 0.
001 | 0.16933742305263877
002 | 0.0029140617698431015
You basically have to just check if it’s valid or not
Start by making the two classes
Hello folks, am doing Word Break on leetcode, I had trouble solving it so I looked up a solution
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
n = len(s)
dp = [False for _ in range(n+1)]
dp[0] = True
for i in range(n):
if dp[i]:
for w in wordDict:
if s[i:i+len(w)] == w:
dp[i+len(w)] = True
return dp[-1]```
Can someone explain it to me line by line? If its not too much to ask of courseIt's a little difficult to explain line by line, but the idea is to check if in s there is any prefix that is equals any word inside wordDict, for each match, mark the position after the prefix in dp and check the prefix again for each marked position in dp
it returns true if s is formed of words in wordDict
You can search for Neetcode youtube channel he had covered this question in one of his video with full explanation.
ah ok thanks
what do they mean by
topological ordering is "not unique"
because it's using DFS and there really isn't any specific ordering in exploring the graph other than just going to the end of it and then retracing steps to find undiscovered nodes?
it just means there may be multiple orderings that work
t = list(t)
for i in t:
for j in t:
if i != j:
res = [i,j]
print(tuple(res),end=' ')
perm2((1,2,3))
how do I change this into recursion
trying to make a permutation pair with recursion
I think you could also use .isdigit like str.isdigit() to keep it smoother. It returns true if the string is composed of a number
Hey, good to see you're trying out dp problems!
Here's my explanation of this code:
- To know if we can segment the whole string into the given words, all we have to do is find the first segment-able substring and the problem reduces to the rest of the string. (Eg: "penapplepen", ["pen", "apple"], as soon as we know "pen" can be segmented we simply want to know if "applepen" can be segemented)
- What we do is, we create an array to store info about whether or not, the string can be validly segmented upto some index 'i'. So an array 'dp' is created with False values, initially.
- dp[0] gets True because thats an edge case and it needs to be true for the rest of the logic to work.
- then for all indices from 0 to len(s)-1, we do:
- check if current index of string can be segmented. If so, we only have to check for the rest of the sting after this index.
- if its true, then for each word in given wordDict, we check if we can make a valid word from the current index till the len(word)-1. (which is the substring s[i: i+len(w)])
- if the word we made is valid, then we mark dp of index i+len(w) as True. (saying that, "hey upto this index of i+len(w), we can indeed segment the string without issues")
- We keep doing this for the entire string and only when the dp[i] is true, we look for the next word. (Basic idea of dp which is to remember the work already done. cuz we know that upto this index (which was true), the string is segment-able)
- check if current index of string can be segmented. If so, we only have to check for the rest of the sting after this index.
- at the end, we return the last value of dp, (dp[-1]) which holds the answer. If the string were to be entirely segment-able, then the last index would be True. Think about it!
If you have any questions, lemme know :)
Hey guys can someone help me understand this problem?

Is there a certain data structure i should be using?
i dont think there's enough context there to answer
sets
{f"Yes: prd" for prd in prd_set_a & prd_set_c}
You need to answer yes if the product is in a store A and the customer C want it and no otherwise. You can use set to the customer and the store and do a difference between products from C and products from A
everyone i have a question about an algo
i have code that isnt sorting one element.... for some reason....
ive asked like 4 times in the help channels without any help
i dont wanna paste my code here since i dont wanna flood asking for help, but if you wanna take a look lemme know.
Hello, does using 2*index + 1 to find a node's parent work on incomplete binary trees?
Hey, i want to remove string a from string b, but any \n characters will be ignored in b while matching, and then remove the a from b, leaveing the \n characters untouched. What is the efficient way to do it?
text processing is hard
you'll probably have to use re.sub will a callable argument
the best way i can think of is if a is "foo", make a pattern like r"f(\n)*o(\n)*o" to allow newlines in between
then the callable would accept a single match, remove all non-newline characters from the match and return it
or maybe there's a flag for ignoring newlines, not sure
that's one of the things I thought of starting first but. this looks like a bit of a problem since too many greedy matches may reduce performance. I don't really know though.
hmm
I thought of going over string first, find newlines and save indexes and remove them, match string a, and go over adding new lines from left to right. does this work?
this looks like going over two times is enough
of course if string is smaller than the next newline index I put the rest? lol can't think of it straight now. Been a bad night
how would you insert the newlines from the old indices? the indices would be affected by the removals of string A
sorry not remove the old string
replace them with null character \0
I expect only non-null strings in the text b
after adding the new lines
I remove the null characters
when adding the first newline the next newline's index will be correct
so and so forth
I think
why do I always find the hackerrank problems in my work lol
yes i can. Where's the code at?
he managed to solve it for anyone wondering I asked
Hi, can someone suggest a project that would utilize lots of different algorithms? Things that are coming into mind are full of just directly using libraries/packages.
anything with graph analysis
do you want it to be actually real-world useful, or just to learn?
a basic text editor will be quite a few algorithms on strings
just ropes are not enough afaik, since they make it hard to slice out a line.
i'm not very familar with the problem domain, tbh; i'm just aware theyre a good option
ye, I also just read a bit up on it and decided that it's way too much reading to do it properly
that's not really an algo question, I recommend opening a help channel #❓|how-to-get-help
oh ok
you can find these basic algs on rosetta code: eg., https://rosettacode.org/wiki/Greatest_common_divisor
that would be much better thanks
so im trying to print a string with dots like so: t.e.s.t and ive managed to figure out how to do this with a for loop, however as i expected, all of the letters would be printed on different lines like so:
t.
e.
s.
t
is there any way i can flatten this or put them in a string?
code:
def add_dots(string : str):
for letter in range(len(string)):
if letter == len(string) - 1:
print(string[letter])
else:
print(f'{string[letter]}.')
# def remove_dots(stringWithDots : str):
add_dots("test") ```print(..., end='')
Hey there! though you can use the above solution by @keen tinsel , here's an alternative and a one-liner:
def add_dots(string : str):
string = "".join([f"{i}." if i!=string[-1] else i for i in string])
print(string)
add_dots("test")
Try understanding it, as an exercise 😁 . If you have any questions lemme know
I was just thinking of trying a solution of that sort so thanks!
pleasure! But I think I made a small mistake in my code 😆 . For the dot not being after the last char case, I used i=!string[-1] but that fails if string contains duplicate chars of the last char. Here's the rectified one:
def add_dots(string : str):
string = "".join([f"{char}." if i!=len(string)-1 else char for i, char in enumerate(string)])
print(string)
add_dots("test")
ah ok, i modified yours a little anyway so i didnt get the error but good to know if i ever need this in future
!e
def perm2(t):
if t:
el1 = t[0]
for el in t[1:]:
if el != el1:
print((el1, el), end=' ')
return perm2(t[1:])
perm2(['a', 'b', 'c', 'd', 'e'])
@past vale :white_check_mark: Your eval job has completed with return code 0.
('a', 'b') ('a', 'c') ('a', 'd') ('a', 'e') ('b', 'c') ('b', 'd') ('b', 'e') ('c', 'd') ('c', 'e') ('d', 'e')
@past vale :white_check_mark: Your eval job has completed with return code 0.
(1, 2)
!e
def perm2(t, n=1):
if not t:
return
if n == len(t):
perm2(t[1:], 0)
else:
print((t[0],t[n]), end=' ') if t[0] != t[n] else None
perm2(t, n + 1)
perm2([1,2,3,4,5])
@past vale :white_check_mark: Your eval job has completed with return code 0.
(1, 2)
I'm reading http://gameprogrammingpatterns.com/observer.html
Because we have a singly linked list, we have to walk it to find the observer we’re removing. We’d have to do the same thing if we were using a regular array for that matter. If we use a doubly linked list, where each observer has a pointer to both the observer after it and before it, we can remove an observer in constant time.
is this incorrect or can you actually implement removal from a doubly linked list in constant time
If you have a pointer to the element of a doubly linked list, then yeah, you can.
And in the observer pattern, you do have a pointer to that element (it's the observer), so sure
oh right
coolù
can anyone explain to me how to use the keyFunc for python sort?
like how do i sort a list of dictionaries using python sort?
sorting by key -> "as if" the key function were applied to the contents
!e
l = [
{'sort_by_me': 3, 'not_by_me': 1},
{'sort_by_me': 1, 'not_by_me': 2},
{'sort_by_me': 2, 'not_by_me': 3}
]
print(sorted(l, key=lambda d: d['sort_by_me'])) # can also use operator.itemgetter
@brave oak :white_check_mark: Your eval job has completed with return code 0.
[{'sort_by_me': 1, 'not_by_me': 2}, {'sort_by_me': 2, 'not_by_me': 3}, {'sort_by_me': 3, 'not_by_me': 1}]
hi guys I am working this leetcode problem search in a BST and i am trying to do on IDE instead of on leetcode interpreter. Can someone pls help to understand how to return the the subtree rooted with that node if node.val equals to args val. If such a node does not exist, return null. example Input: root = [4,2,7,1,3], val = 2 Output: [2,1,3]
here's my code so far:
`class TreeNode:
def init(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
root = TreeNode(4)
root.left = TreeNode(2)
root.right = TreeNode(7)
root.left.left = TreeNode(1)
root.left.right = TreeNode (3)
class Solution:
def searchBST(self, root: TreeNode, val: int) -> TreeNode:
return self.helper(root, val)
def helper(self, root, val):
if not root:
return None
if root.val == val:
# print(root.val)
# print(root.left.val)
# print(root.right.val)
return root
if val < root.val:
return self.helper(root.left, val)
else:
return self.helper(root.right, val)
return None
t = Solution()
t.searchBST(root, 2)`
no
although for real-world purposes that is more or less constant
but mathematically speaking, log(log(n)) still gets bigger as n gets bigger
whereas a constant is... constant
the time complexity of a function is a property of the function as a whole
if you're asking when some function in O(log(log(n))) surpasses a function in O(1), that depends on the particular two functions
but thats not what big-O is describing
big-O is about how fast those functions grow relative to their input
for all x>y, log(log(x)) > log(log(y))
whereas a constant function doesnt grow at all
those statements dont tell you anything about the values of those functions at any particular point though
maybe another way of thinking about it, log is unbounded, so every function in O(log(log(n))) will surpass every function in O(1) at some point
well, O(1/n) is better than constant, say 🙂
trynna find position of an element in a 2d array
all i found were those messy 'for' loops
tried to do it with list comprehension
!e
grid = [[7,8,9],
[4,5,6],
[1,2,3]]
pos = lambda n:[[grid.index(y),y.index(n)] for y in grid if n in y][0]
print(pos(5))
@errant bone :white_check_mark: Your eval job has completed with return code 0.
[1, 1]
can it be more compact
next((i,j) for i,row in enumerate(grid) for j,el in enumerate(row) if n==el) seems nicer to me
but i guess the former's more readable
so now i made a coords finder for 3D matrix using list comps, in case anyone needs one : )
!e
g2 = [[7,8,9],
[4,5,6],
[1,2,3]]
pos = lambda n,grid:[[grid.index(y),y.index(n)] for y in grid if n in y][0]
print(pos(5,g2))
g3 =[
[
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]],
[
[11, 22, 33],
[44, 55, 66],
[77, 88, 99]],
[
[111, 222, 333],
[444, 555, 666],
[777, 888, 999]]]
pos3d = lambda n,grid:[[[[grid.index(z),z.index(y),y.index(x)] for x in y if x==n] for y in z] for z in g3]
print(pos3d(5,g3))
@errant bone :white_check_mark: Your eval job has completed with return code 0.
001 | [1, 1]
002 | [0, 1, 1]
now generalize it to nD matrices
sup
hello, I am working on a mathematical model with these differential equations and tried to type in the equations for some results in odeint, did I type it in correct or should I use some other method? will delete if inappropriate for the channel https://paste.pythondiscord.com/godiqoxiye.properties

hello, I'm currently studying the Naive Bayes algorithm for classifiying text
I have read many tutorials on implementing it in python for classifying sentiment or identify spam email, but I'm so confused between the NLTK approach and the sklearn approach
Could somebody tell me the difference between these 2 approaches, and which one should we use to make just a simple classification model
I see when people using NLTK package, they usually implement the algorithm themselves, and for those using sklearn, they usually use CountVectorize and MultinomialNB built in function
Thank you so much
@clear zenithyes, please respect the channel topic.
Hi! I have a dictionary that is converted into string in order to be able to pass it through a command line argument (typer complains when I try to pass a dictionary). The thing is that I wanna convert it back to a dictionary so that I can pass it to converters field when reading a csv file like so: df = pandas.read_csv(file, **options, converters=converters)
my_dict = {
'temperature': str,
'distance': str
}
my_string = str(my_dict)
print(my_string) # {'temperature': <class 'str'>, 'distance': <class 'str'>}
converters_dict = dict(my_str)
#Convert back to dictionary
df = pandas.read_csv("readme.csv", **options, converters=convertered_dict)
Unfortunately passing built in python types as values to my dictionary causes unexpected errors, like SyntaxError and so on. Is there a way to get this to work?
By doing this,
print(converters_dict) # 'temperature':```I tried with:
import json
my_dict = {
'temperature': str,
'distance': str
}
converted = json.dumps(my_dict) #TypeError: Object of type type is not serializable
Anyone have experience writing a CRC algorithm?
Hello! I read through your problem and I think that this approach of converting a dict to string and vice versa might not be so feasible (AFAIK). Maybe you can tell us what the overall problem is and we'll see if there's a fix?
Plus, I couldn't understand why you'd wanna convert it back to a dict from the string, given that the dict object will be in available in the memory.
Thanks!
Sure let me clarify a bit
I have a dictionary that will be used as a command line argument. I'm using Typer for that I have defined the name of the command a function that takes those arguments and so on. The thing is that Typer doesn't support types like dictionary so I have to convert it into string first in order to work. Once I have the string version of my dictionary I have to pass it to converters field, but it has to be a dictionary so I have to convert it back to a dictionary for pandas to work: pandas.read_csv('readme.csv', **options, converters=converters
This is what I'm using so far```python
import pickle
my_dict = {
'temperature': str,
'distance': str
}
my_string = pickle.dumps(my_dict)
print(my_string) # {'temperature': <class 'str'>, 'distance': <class 'str'>}
converters_dict = pickle.loads(my_string)
#Convert back to dictionary
df = pandas.read_csv("readme.csv", **options, converters=convertered_dict)
How can I convert str to bytes?
Ok...So you're using the Typer package. Can you send me the snippet of where you're instantiating the typer object/app?
I get:
pickle.loads(my_string) TypeError: a bytes-like object is required, not 'str'
Pickle.dumps should return a bytes type
import shlex
from typing import Any, Optional
import typer
from typer.testing import CliRunner
app = typer.Typer(name=NAME, help=HELP)
app = typer.Typer(name="app", help="Exctract command and load functions.")
app.add_typer(app)
Arg = typer.Argument
Opt = typer.Option
runner = CliRunner()
def run_cli(
args: str
) -> None:
> try:
> app(args=shlex.split(args))
> except SystemExit:
> pass
>
>
> if __name__ == "__main__":
> app()
Yeah I actually change it to string so that I can pass in with typer
How can I change it back to bytes?
b'\x80\x04\x953\x00\x00\x00\x00\x00\x00\x00}\x94(\x8c\x0btemperature\x94\x8c\x08builtins\x94\x8c\x03str\x94\x93\x94\x8c\x08distance\x94h\x04u.'
uh, I think now I need to see the whole repository to get you a fix 🙃
Because I still don't see where you pass the args to the Typer, why you'd need a dictionary and so on.
And in this snippet, there's a slight problem as you're assigning the 'app' pointer to two different objects (line 7 and 9). So i think when you app.add_typer(app) it will cause undesired behavior.
I'm really sorry I couldn't help you with this (considering what I was given to work with) 🥲
I almost have it I just need to convert str into bytes type
No worries thank you so much
Let's see if I manage to get this to work
What tools are y'all using to learn about q-select and d-select? Any cool visualizations for the median of medians algorithm?
is there some sort of function or keyword i can use to check if something it not something in an if statement?
because not seems to be made for a different use
you could also do if not (x == 2): (but don't bother)
ah
thats how to use not
well never mind
!= works better anyway
cant believe i didnt know about it before
Anyone familiar with text to speech ?
This may be wrong channel for that. #web-development may be better. Also this is more of discord server so you may not get js help(unless you try in ot channels)
@fiery cosmos hi
hi
why did they invent reversed polish notation? Why not just use the regular boolean stuff?
regular this:
( A or B ) AND ( C or D or E )
becomes this in reversed polish notation
[ '&', '|', (A), (B), '|', (C), '|', (D), (E) ]
sorry scratch the reversed part, my example was regular. Ye it seems faster but my framework uses it and it seems I have to write it by hand, its quit tricky until you get really used to it
Because it allows you to correctly parse the statement from left to right with proper precedence
anyone know a good way to make a search algorithm
that's giving me a headache looking at it
which one
like just a search algorithm in general
you can't write a general search algorithm. you have to know something about your input
the O(n) thing. How do you pronounce it? Oh-en? Zero-en?
oh of en
I see thanks!
or "big oh of en"
"linny-arr"
linny urr
Hello I have an error my "if" does not work.
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from twilio.rest import Client
def send(media,address,receiver,ordernumber):
# EMAIL
if media == email:

Just like the error says, email isn't defined anywhere.
I want my command to execute the actions if the person chooses "email" as "media".
What's email? It's not defined anywhere.
(Look at your function's arguments)
I want that if the person selects the "media" among "email, sms ...) it will execute the other actions.
"email" is only the means of communication selected by the user
the "address" argument defines the email address or phone number depending on the selected media
guys i want to create a matchmaking algorithm, the thing is i don't even know where to start 😆
i don't find anything interesting online, someone can suggest me something?
start from learning a programming language 🙂
That's not my problem. I know languages from low level machine languages to interpreted languages
then wats stopping u?
That i never done a matchmaking system before
well, it's not only matchmaking of course, I know how to do a simple matching but my algo is complicated by a sort of queue algorithm
With my actual knowledge i risk to create a matchmaking really slow
What kind of matchmaking do you mean? Like, for a dating website, or for a game lobby?
It will sound strange but for a discord bot 😆
that still leaves the question of what kind of matchmaking do you mean
Yeah is a lot far from dating so it is more similar to games matchmaking
i will have some user objects waiting in queue and then try to match them to create a team from 2 up to 5 members
I think that the thing i need to do is to not use a FIFO queue but something that privilage users that match more
your project seems complicated
Actually yes 😆
well match more wat?
https://stackoverflow.com/a/10989612
This looks like a simple way
Stack Overflow
(This is for a game I am designing) Lets say that there are 2 teams of players in a game. Each team will have 4 players. Each player has a rank(0-9), where 0 indicates a bad player and 9 indicates an
their user data
i will have data relative to games that they are interested to
ohh
i got it
an algorithm which lets users with similar game interests join together via a bot?
Mhh not exactly
the algorithm will automatically match player interested to play the similar game in that moment, but every game has other datas like their rank, their play style
The purpose is to create teams which will be builded based on what the team needs
Yes
I already plan to put the bot in a beta test so i can have feedback both from users and my bot to improve it
By the way I've cleared my doubts now, I will start creating it and when it comes to debug it should be good to go
Thanks 😄
I have an issue with time complexity / big o. Is this the right channel to ask something about it?
yep
The function is '''def func1( n ):
count = 0
i = 1
while i < n:
j = n
while j > 0:
j = j // 2
count = count + 1
i = i * 2
return( count )
'''
count = 0
i = 1
while i < n:
j = n
while j > 0:
j = j // 2
count = count + 1
i = i * 2
return( count )
``` I think the big O is N(n^2) because of the double while loop. But how do I get the correct T(n)?T(n) is just the sum of all the operations
I don't think it's N^2 though
it does have two loops, but you're not looping N times in each of them
You are right! (log(n)^2 would big the Big O... I thnk
@mortal mulchdo not try to ping the everyone role please. i also see that you already have a help-channel #help-carrot claimed for yourself, so please wait patiently. remember if no one is able to help you can always try again with another help channel later
graph = {
"A": ["B","C"],
"B": ["D","E","F"],
"F": []
}
def depth_first_print(graph, source):
stack = [source]
while len(stack) > 0:
current = stack.pop(0)
print(current)
for neighbor in graph[current]:
stack.append(neighbor)
depth_first_print("A", graph)
{'A': ['B', 'C'], 'B': ['D', 'E', 'F'], 'F': []}
Traceback (most recent call last):
File "main.py", line 20, in <module>
depth_first_print("A", graph)
File "main.py", line 16, in depth_first_print
for neighbor in graph[current]:
TypeError: string indices must be integers
i am not sure how to fix this
it looks to me like i am accessing the graph as a dictionary
yeah idk
You are correct with O(lg(n)^2). You are not looping linearly in either loop. The inner loop will run in O(lg n) time as you're dividing the value in half each time. The outer loop will also run in logarithmic time as you're increasing the value of i * 2 with each iteration.
arguments are in the wrong order
also that looks like breadth first
Hello, can i post leetcode related questions here?
yes
In Leetcode, I can just do cur = head to get head but somehow when i run in local, I need to create a private function to get head. Is it because the given node is already head node in leetcode?
# Definition for singly-linked list.
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
class LinkedList:
def __init__(self):
self.head = None
def __str__(self):
#O(N) runtime
#O(N) space
out = ""
cur = self.head
while(cur):
out += str(cur.val) + "|"
cur = cur.next
return out
def getHead(self):
return self.head
def insertLast(self, item):
#O(N) runtime
#O(1) space
new_node = ListNode(item)
if self.head:
cur = self.head
while cur.next:
cur = cur.next
cur.next = new_node
else:
self.head = new_node
def LinkedListSum(head):
slow = head.getHead()
fast = head.getHead()
while fast and fast.next:
fast = fast.next.next
slow = slow.next
cur = slow
prev = None
while cur:
tmp = cur.next
cur.next = prev
prev = cur
cur = tmp
curA = head.getHead()
curB = prev
max_sum = float("-inf")
while curB:
max_sum = max(max_sum, curA.val + curB.val)
curA = curA.next
curB = curB.next
return max_sum
inputs = [1,4,3,1]
input_list = LinkedList()
for i in inputs:
input_list.insertLast(i)
print(str(input_list))
print(LinkedListSum(input_list))
I passed head node instead of linkedlist. Am I doing correctly? After asking..Leetcode does say ListNode as parameter: def mergeTwoLists(self, list1: Optional[ListNode], list2: Optional[ListNode]) -> Optional[ListNode]:
def LinkedListSum(head):
slow = head
fast = head
while fast and fast.next:
fast = fast.next.next
slow = slow.next
cur = slow
prev = None
while cur:
tmp = cur.next
cur.next = prev
prev = cur
cur = tmp
curA = head
curB = prev
max_sum = float("-inf")
while curB:
max_sum = max(max_sum, curA.val + curB.val)
curA = curA.next
curB = curB.next
return max_sum
head = input_list.getHead()
print(LinkedListSum(head))
hi, please using a recursion, how do i iterate or loop each elements and extract it's children? there a problem which has taken more than a week to solve and i've not gotten a solution yet
i'm trying to create an html after traversing a graph database, but the result are buggy.,.. I have posted a question on SO, https://stackoverflow.com/q/70213240/5713751 can you please assist?
Stack Overflow
I'm trying to recursively extract the DOM tree saved in the graph Database to granularly rewrite them as either HTML, JSON or other template files.
The motivation I needed to have an easy way of
any insight ?
I'm trying to delete a single elemnt in a matrix (nested array). However when I try it removes the targeted element from all the row instead of just the row I indexed.
In [100]: matrix = [[0]*2]*2
In [101]: matrix
Out[101]: [[0, 0], [0, 0]]
In [102]: matrix[0].pop(1)
Out[102]: 0
In [103]: matrix
Out[103]: [[0], [0]] # <--- I'd like this to [[0], [0,0]]
wheen you do [[0] * 2] * 2] you create multiple references to the same list inside
so how do I create a reference for each row?
you need something like [[0] * 2 for _ in range(2)]
that way it's creating new lists
how did you learn this? is there somewhere I can read more about python's memory model?
it's not anything complex, it's just that multiplying a list duplicates the references inside
cool. thank you.
anyone here?
"Start from the first index of non-leaf node whose index is given by n/2 - 1" what does this sentence mean? https://postimg.cc/FY64rzrw

n is usually the length of the data, in this case 6 since there are 6 nodes, so 6/2-1 = 2 so index 2 is highlighted
realizing I'm 3 hours late 
guys how does one compare elements in the list?
nums = [1,2,3,4,5]
for x in nums:
# code for comparing each element```can anybody help
i really am bad in this
thanks bro, but why do we use that formula
what do you mean by compare elements?
i mean you take second element and compare it with the one before it, and if it larger then you print("larger than element x)"
i want to follow DRY principle
basically the 1st problem in the AoC 2021
where you have to record increases
more methods like recursion to solve algorithms?
Hello. I am trying to generate a random correct undirected graph with a given number of nodes. How can I randomly "wire" the nodes between them, so that the generation can be called "random"?
Hello, i have a question regarding community detection in a bipartite graph.
Let's assume, that we have a set U of elements connected to a set of elements V. We define a proximity function for (a,b)∈U^2 such that F(a,b) are close if a and b map to the same elements in the set V, the more elements in V a and b map to - the higher the proximity (or lower the distance between a and b). Then we get an adjacency matrix which shows us the weight of every edge between the elements of the set U . I assume that there are communities in this graph, but i don't know how many there are.
for info, the set U contains 500k nodes, V contains 4k nodes
How do i detect communities and what is the most accurate way to represent the results?
Since I have so many nodes that I can't simply represent this data as a graph (it would be a complete mess), I was thinking about taking a node, putting the node in a N-dimensional space, then adding the neighbouring nodes according to the proximity to the first node and repeating this process until I embed all the nodes into my N-dimensional space [but that looks kinda like an NP problem (correct me if I'm wrong)]. Then I could use UMAP to detect the communities and a projection into 2D space to represent the results
how do i break a while loop in the code
cuz i know doing ctrl c in the terminal breaks it but i want to do it as part of the code
and the break statement hasnt done much
nvm
dont need it
then traverse indexes starting from 1 (because element at index 0 has no previous element), and compare arr[i] with arr[i-1]
if arr[i] > arr[i-1]:
print("{} larger than {}".format(arr[i], arr[i-1]))```thanks man)
I made a pig latin translator :)))))
Heres the repl link to it, but repls slow so run it on something else if you can, if you want to run it at all, it converts english to pig latin, and pig latin to english

And if anybody is curious, its a cartoon steak, im not giving any context
sorry, I'm not actually sure. What's the context/problem being solved here?
can someone help me with this question
write a function that takes a file name to read and then counts the number of words in the file generating the 10 highhest frequency words. it should printout these counts. use the counter class from the appropiate package
very confused
write a function that reads a text file and writes the same file out but with the lines double spaced . the function takes two parameters the input file name and output file name
!d collections.Counter
class collections.Counter([iterable-or-mapping])```
A [`Counter`](https://docs.python.org/3/library/collections.html#collections.Counter "collections.Counter") is a [`dict`](https://docs.python.org/3/library/stdtypes.html#dict "dict") subclass for counting hashable objects. It is a collection where elements are stored as dictionary keys and their counts are stored as dictionary values. Counts are allowed to be any integer value including zero or negative counts. The [`Counter`](https://docs.python.org/3/library/collections.html#collections.Counter "collections.Counter") class is similar to bags or multisets in other languages.
Elements are counted from an *iterable* or initialized from another *mapping* (or counter):
```py
>>> c = Counter() # a new, empty counter
>>> c = Counter('gallahad') # a new counter from an iterable
>>> c = Counter({'red': 4, 'blue': 2}) # a new counter from a mapping
>>> c = Counter(cats=4, dogs=8) # a new counter from keyword args
Counter is the thing you want for the first one, you can give it a list of words that you read from the file
then .most_common will get the most frequent https://docs.python.org/3/library/collections.html#collections.Counter.most_common
I'm always hours late in this channel
I fixed a few mishaps and problems and made it a little shorter
Hello!
I just discovered this data structure called a 'tree'. I think I immediately (or close to it) made sense of it. Am I correct in assuming that it exists for the sake of advanced namespace manipulation, which in turn facilitates working with data that benefit from being represented in such a structural/hierarchical way?
If not, what is the reason the tree structure exists?
that's definitely one way to use them
B-trees are often used in databases
yeah i think most use cases will fall under that sort of umbrella
Neat. Thanks. Gotta check out 'B-trees` then. 🙂
What ideas are like a must know before I can nicely come up with my own algorithms?
Not sure if I framed that correctly
Like recursion, backtracking and the like
Some main ones:
- Correctness (does it solve the problem at hand)
- Elegance (how beautiful the logic of the algorithm is)
- Efficiency (how does it scale with increasing input size)
are all big things to consider when creating your own algorithms 😛
Most considerations (at least to me) fit into those categories.
Edit: efficient data representation of both input and output can help a lot.

Coming up with your own algorithm depends upon the problem you are trying to solve.
Like solving math problems it mostly comes with practise and experience.
More different problems you solve, More you are better to come up with creative ideas to solve a problem,
So to summarise, write more algos.
Thanks for that!
It does help a lot.
Just solve tons of problems on leetcode, hackerank, etc. You'll eventually learn the patterns and many patterns can be use for other problems.
Trust me, this is coming from a person that had no clue what a binary search, two pointers, recursion,etc. were like 3 months ago
So, I knew the syntaxes and the basics of programming languages and i thought i knew it until i got to know about advent of code and like took forever to solve day 5
So thanks buddy you give me a lot of hope and pointed me in the correct direction! 👍
Have an amazing day Sir!
AoC is great for learning to design algorithms, although maybe not the best for learning to design efficient algorithms
One thing that it took me a while to realize and it helped me out a lot, was when I absolutely had no clue on how to solve a problem, don't even bother trying to solve it yourself, just look up the solution but pay close attention at the pattern and it's runtime and spacetime
So you're saying trying to do it on your own has no benefit if I have absolutely no clue?
AoC -> Art of Code?
Oops 😅
class Solution:
def getConcatenation(self, nums: List[int]) -> List[int]:
listCopy = nums[:]
for n in nums:
listCopy.append(n)
return listCopy
Time compelxity = O(n) - we are iterating the entire array once
Space complexity = O(n)
Is this correct?
Twice kind of.
technically it loops tice over the array, once in the slice and once in the loop
but O(2n) = O(n)
if I did
class Solution:
def getConcatenation(self, nums: List[int]) -> List[int]:
return nums * 2
what would time/space complexity be?
 you can't multiply lists and ints
you can't multiply lists and intsyea you can
@fiery cosmos :white_check_mark: Your eval job has completed with return code 0.
[1, 2, 1, 2]
Btw would it be a copy or link?
a link but with ints that's a copy
!e
a=[1,2]
b=a*2
a[0] = 4
print(b)
a=[[1,2]]
b=a*2
a[0][0] = 4
print(b)
@fiery cosmos :white_check_mark: Your eval job has completed with return code 0.
001 | [1, 2, 1, 2]
002 | [[4, 2], [4, 2]]
Ah i see. Makes sense.
when pythong runs listCopy = nums[:] it's actually performing a loop under the hood?
yes
Yeah.
what if I did listCopy = nums
Well you tell us!!
No loop, just a reference to nums var
Yep. Tho the loop after it would cause the insanity.
so the loop would modify the original list correct?
Yep!
ok thanks for the help
If you have the slightest of clues, sure try it yourself for a while but if you have no absolute idea, than just look up the solution and understand what are the patterns being used and also what kind of problem it is.
This is what I do and it works for me, it may or may not work for you but the main point solve problems everyday and am telling you you'll see some major gains, without a doubt
Can i get help on creating a list of possible 7 day cycles from a list on available schedule and costs?
can you give more info as to what exactly that means
anyone has free time to guide me with my assignment? I need help with finding Longest Path in Directed Acyclic Graph. My inputs are kind of specific so the examples in the net didn't help me much
So the first paart is creating a list of all possible weekly cycles from an adjacency matrix
I dont know how to code that part
Dude thanks a lot once again!
You have been great help! 👍
can I ask if lists in python are superior bcz it's changeable, can have same chars and easily accessible so what's the point of using tuples and dicts
Checking if a key is in a dict (and getting its value) is constant-time regardless of the size of the dict, for one.
hello guys
anyone here that has experience with getting time complexity from an python algorithm?
count = 0
i = 1
while i < n:
j = n
while j > 0:
j = j // 2
count = count + 1
i = i * 2
return( count )
``` what would be the time complexity of this algorithm?let's see, there are about log(n) outer loops since i keeps doubling, and every inner loop is also log(n) since j keeps halving, so I'd say O((logn)^2)
I've definitely seen a question about the complexity of this very function before, a few days ago 👀
A fun thing to try is to divide the count given by the math expression and see that it stays around a constant (about 1 here)
!e ```py
import math
def func1(n):
count = 0
i = 1
while i < n:
j = n
while j > 0:
j = j // 2
count = count + 1
i = i * 2
return(count)
def func2(n):
return math.log2(n)**2
for i in range(1, 1000):
print(i, (func1(i) + 1) / (func2(i) + 1))
@fiery cosmos :white_check_mark: Your eval job has completed with return code 0.
001 | 1 1.0
002 | 2 1.5
003 | 3 1.4236471839937705
004 | 4 1.4
005 | 5 1.564614655468772
006 | 6 1.3017390623129148
007 | 7 1.1259686859821763
008 | 8 1.3
009 | 9 1.5386809202773803
010 | 10 1.4125225294860906
011 | 11 1.3109528365746772
... (truncated - too many lines)
Full output: too long to upload
👀
Can we use LLVM for python or is it in its development stage as of now?
smoeone said we can implement python in llvm i think
Hi everyone,
I planning on starting dsa with python
I new to this and basically is looking for a study partner
So that we could learn, discuss and benefit at same time.
If anybody yet to start and is looking to begin like me. We could be mates.
What is in the development stage?
I don't see why it wouldn't be possible, but I'm not aware of such projects - the most "general-purpose" existing Python compiler would probably be Nuitka, which works by transpiling to C. There's numba, which does use LLVM instead, but it's not meant for compiling entire programs - it has support for only a small number of features, and is used for compiling individual functions, mostly the number-crunchy kind.
Numba resulted in more time than normal
that has happened to me some times when working with Python lists or (even worse) strings, but usually only in such cases
Question : for maze solving where you can tunnel through a wall ONE time in your path to the exit, is there a reason why breadth first search might be preferred over A-star.
And... is it possible to A-star this without over complicating the problem?
I was thinking you could tunnel in A_star and track the node you tunnel from in each child node, as well as a boolean tunneling = True in each node if you've tunneled to it.
But in thinking about it more I was worried about ordering and overlap(overwriting).
Ohhh.... wait. I think I get it. Overwriting is okay.
No need to undo junk.
Wicked I think I got it (:
Question for the all the Algo masters in here
How long did it took yall until yall were just good enough to pass most interviews?
Am basically almost 3 months in practicing, I feel like I need about 1 month or a 1 month and half to get up to that level
I... think I figured it out
Gotta keep the map of paths with no walls broken & the map of paths with walls broken.
If(current[g] < corresponding_node_broken_wall_map[g])
then....
Broken_wall_map[current[x]][current[y]] = the current stuff
Can throw the broken and non broken in on the same stack and process them different depending predicated on a flag.
I think...
Makes sense to me.
@idle pier can you solve a maze using the shortest possible route with A* allowing you to break through one section of wall along your path?
it's 1:44 am, i've been wrestling with quats for multiple hours, why the heck does this not instantiate a clean 90 degree rotation quaternion?

well -90
i was doing 90 and axis -1 0 0 before but i tried to flip just in case
what is rotation?
which one? the highlighted one? just a 1w 0i 0j 0k quaternion
hello folks am currently doing 70. Climbing Stairs on leetcode
I solve this solution using memoization. But I found this solution, I thinks its a DP solution
def climbStairs(self, n: int) -> int:
a,b = 1,1
for _ in range(n):
a = b
b = a+b
return a```
I have no clue how that solution worksit adds up two possibilities, you last step is 1 or 2
i mean you already solved it, so it just does that,
what's the confusing part
i'm guessing he didn't actually write that
the memoization solution makes more sense to me but I think is solution is more efficient
why are we returning a?
a is the answer for n=0
b is for n=1
when you update, they shift, a becomes n=1, b becomes n=2
after n updates a holds n=n
there's a version of this with coin tossing
or like there must be, I don;t know how to formulate it
how many ways to toss a coin n times so that <something>
this isn't memoizing, it's bottom up
this isn't what they wrote, as you said
what they wrote is memoizing
how many ways to toss a coin n times, so that there are no heads after heads
it starts 1,2,3
and then it should go f(n-1)*2 − f(n-3)
and it's actually the same sequence
anyone have any experience scraping data from a forum? What type of backend would I need to scrape data from a forum every day and automatically push it to my website? Also, what technologies would I use to scrape the data? Beautifulsoup?
do people still use batch files on windows?
anyways. you could use a batch file to run a python script regularly that scrapes the forum
youll need requests.
@uncut rose use these py from requests import get from bs4 import BeautifulSoup
i made a craigslist scraper for automated alerts on good deals, so here is an example. py def GetPosts(_adress) : response = get(_adress); htmlSoup = BeautifulSoup(response.text, 'html.parser'); posts = htmlSoup.find_all('li', class_= 'result-row'); return posts;
Guys while resetting my pc during installation of windows my laptop got shut
After that when I tried to on it again it tries load and it shuts down and again it tries to on
Can some one help me
hello folks, what are some good books you folks use for DS and Algo's?
have you looked at the pins?
I made a program that can find the nth term formula for linear, quadratic and geometric sequences

thanks! Never heard of batch files, sounds like the tool I need
@uncut rose I think its .bat
It's super old school... so Idk if it's still a thing.
I've definitely used .bat files before
activate.bat on virtual environments
never knew what they did though

Windows Central
In this guide, we'll show you the steps to get started creating and running your first batch file to automate tasks with Command Prompt commands on Windows 10.
I only know because some poorly designed malicious software for windows 7 used a batch file to do something on startup. I had that software lol.
Hello folks, I'm currently doing 986. Interval List Intersections
def intervalIntersection(self, firstList: List[List[int]], secondList: List[List[int]]) -> List[List[int]]:
a,b = 0,0
intervals = []
while (a<len(firstList) and b<len(secondList)):
intervalStart = max(firstList[a][0],secondList[b][0])
intervalEnd = min(firstList[a][1],secondList[b][1])
if intervalStart <= intervalEnd:
intervals.append([intervalStart, intervalEnd])
if firstList[a][1] < secondList[b][1]:
a += 1
else:
b += 1
return intervals```
Lets say `firstList = [[0,2],[5,10],[13,23],[24,25]]` and
`secondList = [[1,5],[8,12],[15,24],[25,26]]`
`intervalStart` is taking the `max` of `[0,2]` and `[1,5]` which is `1` and `intervalEnd` is `2`, which is `[1,2]`
Where I'm a little lost is howcome the next interval intersection is `[5,5]`?so i made a function that can find a path from a starting place to a destination in a undirected graph, but i would like to implement weights. heres my code
def find_path(web_map, starting_place, destination):
# creating the visited list
been_there = dict()
for i in web_map:
been_there[i] = False
# calling the helper function
return find_path_rec(web_map, starting_place, destination, been_there)
def find_path_rec(web_map, starting_place, destination, visited):
# marking this node as visited
visited[starting_place] = True
# checking if we have reached our destination
if starting_place == destination:
return [destination]
# if the destination is not found, visiting the surrounding nodes
else:
for i in web_map[starting_place]:
# checking if the node i is already visited
if visited[i] == False:
L = find_path_rec(web_map, i, destination, visited)
# add node i to the found path and return
return [starting_place] + L
it can run this:
web_map1 = {('Node 1', 'red'): [('Node 3', 'yellow')],
('Node 2', 'blue'): [('Node 3', 'yellow')],
('Node 3', 'yellow'): [('Node 1', 'red'), ('Node 2', 'blue')]}
print(find_path(web_map1, ('Node 1', 'red'), ('Node 2', 'blue')))
but it cant run this because i havent implemented weights yet:
web_map = {('Node 1', 'red'): [{('Node 3', 'yellow'): 13}],
('Node 2', 'blue'): [{('Node 3', 'yellow'): 16}],
('Node 3', 'yellow'): [{('Node 1', 'red'): 13 }, {('Node 2', 'blue'): 16}]}
print(find_path(web_map, ('Node 1', 'red'), ('Node 2', 'blue')))
how would i implement weights?
check out Dijkstra's algorithm
Hello
how do i iterate through this regions = [{"name":"West-Vlaanderen",
"code":"wvlnd"},{"name":"Oost-Vlaanderen",
"code":"ovlnd"},{"name":"Vlaams-Brabant",
"code":"vlmbrb"},{"name":"Limburg",
"code":"lmbg"},{"name":"Antwerpen",
"code":"antwp"}]
in python
for d in regions:
print(d["name"] + " " + d["code"])
hmm
for region in regions:
if current_place == region['name']:
print(region['name'] + " " + current_place )
currentRegionCode=region['code']
why does this give me error

oha
Wait a second, I'm confusing myself
XD
everything works up until this line -> currentRegionCode=region['code']
It looks like that error is outside the code snippet you pasted. It is related to decoding JSON values. I guess this is happening before the loop
i removed currentRegionCode=region['code'] this
and it worked
seems like it doesn't let me assign that value into the variabele?
What is currentRegionCode? Is the error because you can't assign to it?
What about region['code']? Is the type of it soemthing different than we think? Can you print that?
anyone know why this function keeps returning None, and not the value (ptr.mult)?


?
I guess 3
Hey all, looking for some help here. Reading the "https://runestone.academy/runestone/books/published/pythonds3/index.html" book which is fantastic by the way. But some of the concepts are going over my head. Would it be best (and/or have others did this) to follow up reading the book with videos of whats being described?
I haven't read the book, but from a quick glance at it, you should be able to find loads of material on the web for almost all its concepts. The best resources won't always be videos and don't underestimate Wikipedia - it can be very good at explaining computer science concepts. I'd suggest searching for other resources on things you're not clear on after each section, rather than after finishing the entire book first.
Heya!
Have made solutions to the Josephus Problem in ArrayList, ArrayList using iterator, LinkedList and LinkedList with Iterator for school.
(Josephus is basically a problem with a hot potato that gets passed around in a circle, and is passed around using m-skips, aka skipping m-people each time it gets passed around, the last person to not get their hands burnt wins)
Why is there such a drop in performance when I change the input value of the skips?
The inputs I've chosen for the m value is 2, n-2, n/2, n*2 to come up with some sort of solution how the complexity of different data structures changes depending on the size of the M value compared to the n value.
This is a sample set of the Linked List for example, and the average time of a 100 iterations of different m-values.

hi, who can help me with dfs?
what do you need help with specifically?
can i still follow this playlist https://www.youtube.com/playlist?list=PLpPXw4zFa0uKKhaSz87IowJnOTzh9tiBk where the code is givin in java but i dont know the language

YouTube
Rob teaches CS310, Data Structures in Java at San Diego State University. These lectures accompany that course. There are both discussions of the topics and ...
Someone can help to make this patern with a (one-line) code?
matrix = [[1, 1, 1],
[2, 2, 2],
[3, 3, 3]]
[[x for _ in range(3)] for x in range(1, 4)]
this can be translated to
main_list = []
for x in range(1, 4):
temp = []
for _ in range(3):
temp.append(x)
main_list.append(temp)
or
n = 3
[[i+1] * n for i in range(n)]
so i was bored and decided to try out writing recursive and iterative versions of the merge sort
the recursive version uses a top-down approach and the iterative version uses a bottom-up approach
i noticed that the bottom-up approach always involves more "copy" operations (copying an element from the buffer to the main array) then the top-down one.
The difference gets very big when the array size is almost a power of 2 but not exactly (in the case of an exact power of 2, there is no difference)

is that just the way things are, or am i doing something wrong?
the array size used here was 4194305
another example with 8388609-length array, i also optimized the counting code a little so it's less of an impact on time

Do all the different DFS orders only apply to binary trees or do they also apply to graph data structures as well?
looking for ideas, I need to evaluate wifi signals to pick the best one.. sadly just isnt lowest/highest of any one value.. have to compare signals levels, qams, snr, etc..
Hey guys! I'm trying to make an infinite series
p = sum(1/((reclaim_rate)(runs-1) * 0.5runs) for runs in range(1, 1000000))
I get this error
float division by zero
Any idea?
you mean post-order, pre-order, and in-order?
generally since you're searching for something, you want pre-order so you can check the current node to see if you've found what you want
when runs is 1, this divides by zero, doesn't it?
yeah figured that out
Yea
basically I need an infinite series of this equation
((reclaim_rate)(runs-1) * 0.5runs)
Yea but can you use all the different orders in a graph data structure?
so ^1, ^2, ^3 and so on
not really, since it involves ordering your neighbors somehow, and usually you can't generally order your set of neighbors
== Raw message ==
((reclaim_rate)**(runs-1) * 0.5**runs)
you mean ((reclaim_rate)**(runs-1) * 0.5**runs)?
this looks like it should be fine, unless reclaim rate is zero
Yea so dfs inorder, pre-order, post order only works for trees right?
binary trees
It just executes it once
But I need an infinite series
But graphs still use dfs, bfs right for traversal?
yeah
Ok thanks
that's what the sum you wrapped it in does.
oh i was talking about just the equation
0.2^0+0.2^1+0.2^2+0.2^3.... so on
idk if sum is the right function
p was 9536743164061.99
any better way to make an infinite series in python?
how would I use that function in this case?
If I use this p = sum(1/((reclaim_rate)(runs-1) * 0.5runs) for runs in itertools.count(0))
I get this error:
ZeroDivisionError: float division by zero
Traceback (most recent call last)
I tried that, but also gave me the same error
Anyone?
A divergent sequence
It seems like the infinite series is doing great with this piece of code:
p = nsum(lambda runs: ((reclaim_rate)(runs-1) * 0.5runs), [1, inf])
But I am currently getting this error:
TypeError: Cannot interpret 'mpf('6106.6202488299823')' as a data type
when someone says to search a binary tree using DFS, which traversal message are they usually talking about?
or will they usually say something like "use dfs inorder traversal to search the binary tree"
cause it would be ambiguous if they didnt explicitly mention which traversal type to use unless one of the 3 types of dfs traversal methods is a default
for example this image here https://miro.medium.com/max/1838/1*exRbhrS8p9YZAovBYPgzKg.png
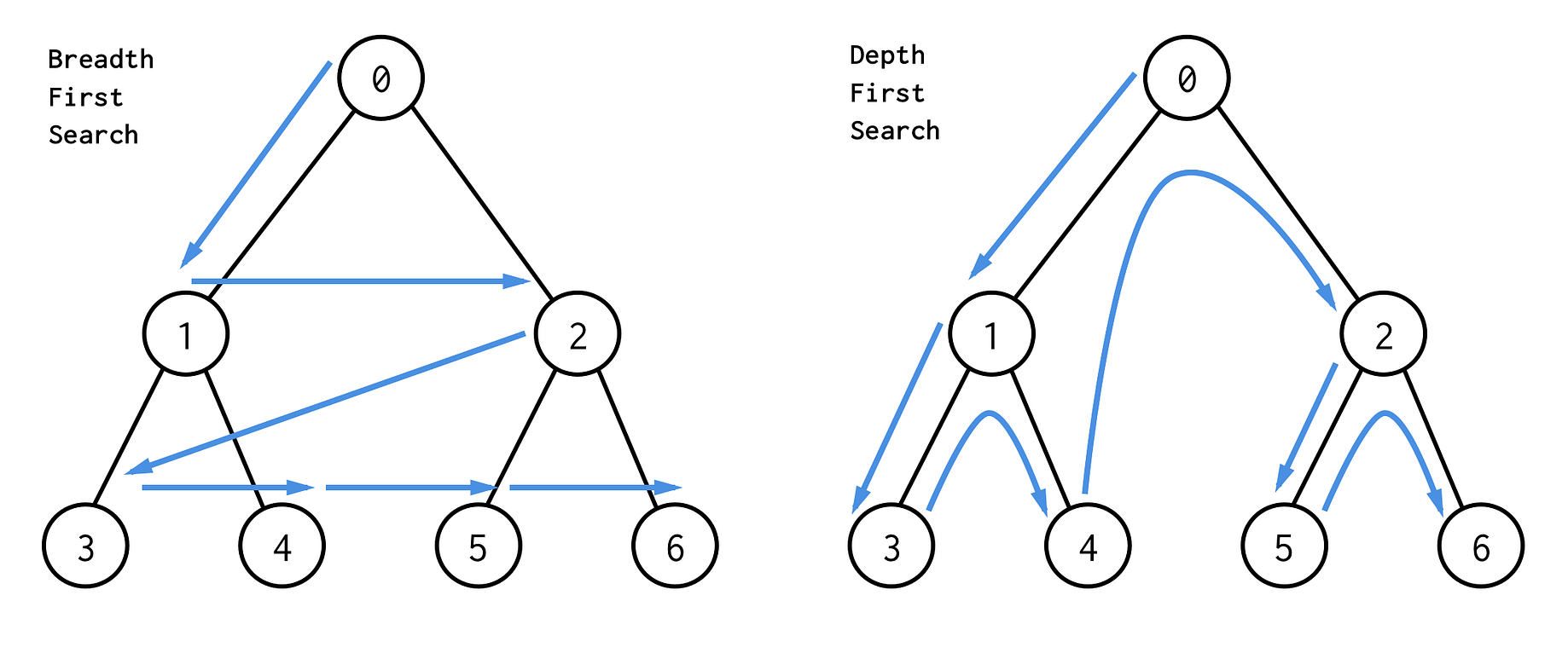{kind=link}

its labelled as DFS but doesnt say which type but after looking at the diagram you can see that it uses pre order traversal
same with this image https://miro.medium.com/max/1838/1*VM84VPcCQe0gSy44l9S5yA.jpeg
{kind=link}
it only says DFS but doesnt say exactly which type but is shown using pre order traversal
but then in this diagram https://i0.wp.com/algorithms.tutorialhorizon.com/files/2015/11/Tree-Traversals.png?resize=350%2C478
{kind=link}

you can see that DFS and pre order traversal has the same orders so does that mean when someone says to use DFS that means to use pre order?
Guys
This is currently my code
x = np.linspace(u - 3o, u + 3o, 100)
I want my x axis guide to show like this

instead of this

Any idea on how to do it?
Can someone explain this python expression to me -
intervals.sort(key= lambda x:x[0])
where intervals = [[1,3],[2,6],[8,10],[15,18]]
sort takes a function, it's applied to elements before they are compared
Anyone any idea?
I think it depends on the context. to me it's just whichever one makes sense / is correct. if the order isn't specified then it might not even matter
Heh?
can someone translate this java code to python for me? or just explain what a node class may look like in python

as far as my understanding i think a node class will be something like
class Node:
def __init__(self, data, node):
self.data = data
self.node = node #when not null
and a linked list inherits the node?
class LinkedList(Node):
pass
i should have gone with a course in a language i knew haha
not quite. the Node class is defined inside the LinkedList class