#algos-and-data-structs
1 messages · Page 96 of 1
don't forget from collection import defaultdict
hello everyone
who help plz
Choose the first note randomly or consider the first note of the
original score (e.g. G) ;
See in the table the notes that succeed it (Ex: for the note G, the successors
are : G, G i, D, D, C, A) ;
Choose a random note among these successors;
Repeat this process, as many times as necessary, starting from step b) by considering
each time the successors of the last selected note.
it's my pb in python
"as many times as necessary" what's the condition to stop?
hello, not sure if i should ask this here or in data-science, i'm trying to generate all the permutations given 12 numbers, and using between 12 and 6 at a time
so if i had [1,3,5,7,9,11,13,15,17,19,21,23],and length 8 i would want for example, ('3', '7', '13', '11', '9', '5', '1', '15')
but once i try for length 10,11 or 12, my pc freezes
a length of 10 has 239,500,800 permutations, and 11 and 12 lengths have 479,001,600
also, whenmever i click on a Topical chat/help, and click on a different one, the previous one disappears from the list
are you trying to store all possible permutations in memory at the same time?
you must have it set to not show channels where you've "read" all the messages. Clicking on the name of the category should undo this effect.
It looks like you found your way back to the data science channel; hopefully itertools.permutations suited your needs.
yes i store all the permutations in a list, fortunately it seems i wont have to do permutations longer than 9
that's a lot of stuff to store
Be sure to respond to people in a way that pings them, especially if more than a few minutes have passed.
Ultimately you're limited by the memory capacity of your computer. What calculations do you ultimately need to do? You could have, say, 100 buckets that you put all the different permutations into, and then do the different computations on each bucket, and then aggregate those results.
anyone have a good article on hash functions?
what is it that you want to know about them?
The basic idea is that you take a value, and you have a function that converts that value to an arbitrary number. But it has to be the same arbitrary number every time for that function and that value.
Sometimes you do this for security. But it's also very useful for storing and finding data.
And its also hard to reverse
An ideal hash function isn't reversible, if it's for security.
though I certainly don't have to tell you that.
Python has some randomization in the initial setup of its hash functions, but the hash of a given value is consistent during a given interpreter session. Apparently that's for security. Not entirely sure why.
i am trying to implement sobel operator algorithm using python without using external libraries. I am bit stuck. The image produced after sobel operations is bit crappy.

GitHub
Bugs. Contribute to ZerothVector/BuggyAlgorithms development by creating an account on GitHub.
Please provide some suggestions, of what i am doing wrong. i based it off on this video, i assume, i had done correctly as per this video https://www.youtube.com/watch?v=uihBwtPIBxM

Our eyes can spot edges with no problems, but how do computers determine what's an edge and what's not? Image Analyst Dr Mike Pound explains the Sobel Edge detector.
How Blurs & Filters work: https://youtu.be/C_zFhWdM4ic
The Problem with JPEG: https://youtu.be/yBX8GFqt6GA
Secrets Hidden in Images (Steganography): https://youtu.be/TWEXCYQKyDc
M...
am i asking this question in wrong place ?
Hi all. I am trying to solve an optimization problem for a group of my friends playing game ...
I feel lost - not sure if the problem is too complicated or just I get a wrong direction.
Each player can form up to 3 teams (A, B, C), each team can be used once to deal damage to 1 of 5 bosses (1,2,3,4,5).
So a player can have a list like (A, 2, 50), (A, 3, 80), (B, 4, 70) ...
The last number is damage.
This example means that player can hit boss 2 with 50 dmg or boss 3 with 80 dmg with team A.
What I want to do is try to allocate the team and damage before we actually fight.
Imagine the boss 1 has 1000 hp. The goal of allocation is to sum up our team damage and reduce overkill
I feel like solving the coin charge problem and create a large decision tree for all the possible team combination. It seems like solving 2 hard problems together. Any hints or thoughts on this problem?
I think I can solve the coin charge problem (sum up damage to minimize overkill and still enough to beat the boss).
But the constraint of same team can only be used once - and there are so many teams combination when there are many players - I have no idea how to deal with it
can u sort a number faster than n log n, i just heard it somewhere that you can't.
Don't remember where
can you give me an input/output example?
How does the team composition affect the damage of the team?
not in the general case
assuming you mean a collection of numbers
i don't get what u mean by that
you can for certain special classes of input if you know they fall into those classes beforehand
but if you don't know anything about the input, then no
also assuming no parallelisation
Just assume it is simple summation and subtraction for counting damage and overkill.
Boss hp
1 100
2 200
3 300
4 400
5 500
Player team and damage
Player Cat [(A, 1, 55), (A, 4, 300), (B ,1, 20), (C, 5, 350)]
Player Duck [(A, 1, 90), (A,2, 100), (B, 5, 200)]
Player Ethan [(A, 1, 70), (A, 3, 300), (B, 5, 480)]
Recommended damage allocation to reduce overkill while trying to beat the boss:
1: Cat B, Duck A (90+20)
2: Duck B (100) [Best effort] No team to deal dmg
3: Ethan A (300)
4: no team to deal dmg Cat A 300 [Best effort, cannot beat boss 4]
5: Duck B and Cat C (350+200)
I try to find the closest to optimal solution and come up with above numbers.
can a player hit twice?
Like for boss A, could we take Cat A 1 55 and Cat B 1 20?
I know it wouldn't be enough, but what if Cat B 1 was making 50 dmg for example
I fixed the 2 boss case.
hey
okay then my idea would be that for each boss, you keep taking the maximum hit from a player, you sort them, then you keep taking until you deal enough damage
i wanted to ask if i attempted a challenge on codechef but am able to solve only few of the given problems will my rating increase?
Oh wait,
Cat A 1 55
Cat B 1 20
Cat can use team A and team B to attack boss 1
I misread your message, sorry
Yes. Same team can only hit once
for player in players:
for hit in hits:
boss, team, dmg = hit
hit_map[boss].append((player, boss, team, dmg))
for boss in hit_map:
hit_map[boss] = sorted(hit_map[boss], key=lambda hit: hit[3]) # sort by damage
total_dmg = sum([hit[0] for hit in hit_map[boss])
while hit_map[boss]:
smallest_dmg = hit_map[boss][-1]
if total_dmg - smallest_dmg >= hp_map[boss]:
hit_map[boss].pop()
not hit_map should contain each boss and the optimal hits to kill it
didn't try the code, try it and tell me
Let me try ... It takes some time
It freezes for boss 4 in the case (no enough dmg to beat the boss)
from collections import defaultdict
hp_map = {
1: 100,
2: 200,
3: 300,
4: 400,
5: 500
}
players = {
# simple case
"Cat": [("A",1,55), ("A",4,300), ("B",1,20), ("C",5,350)],
"Duck": [("A",1,90), ("A",2,100), ("B",5,200)],
"Ethan": [("A",1,70), ("A",3,300), ("B",5,480)]
}
hit_map = defaultdict(lambda: [])
for player, hits in players.items():
for hit in hits:
team, boss, dmg = hit
hit_map[boss].append((player, team, boss, dmg))
for boss in hit_map:
hit_map[boss] = sorted(hit_map[boss], key=lambda hit: hit[3]) # sort by damage
total_dmg = sum([hit[3] for hit in hit_map[boss]])
while hit_map[boss]:
smallest_dmg = hit_map[boss][-1][3]
# print(total_dmg, smallest_dmg, "sd") - infinite loop here for boss 4
if total_dmg - smallest_dmg >= hp_map[boss]:
hit_map[boss].pop()
hey I fixed it:
hp_map = {
1: 100,
2: 200,
3: 300,
4: 400,
5: 500
}
players = {
# simple case
"Cat": [("A",1,55), ("A",4,300), ("B",1,20), ("C",5,350)],
"Duck": [("A",1,90), ("A",2,100), ("B",5,200)],
"Ethan": [("A",1,70), ("A",3,300), ("B",5,480)]
}
hit_map = defaultdict(lambda: [])
for player, hits in players.items():
for hit in hits:
team, boss, dmg = hit
hit_map[boss].append((player, team, boss, dmg))
for boss in hit_map.keys():
hit_map[boss] = sorted(hit_map[boss], key=lambda hit: hit[3], reverse=True) # sort by damage
total_dmg = sum([hit[3] for hit in hit_map[boss]])
while hit_map[boss]:
smallest_dmg = hit_map[boss][-1][3]
if total_dmg - smallest_dmg >= hp_map[boss]:
hit_map[boss].pop()
total_dmg -= smallest_dmg
else:
break
print(hit_map)```I forgot to:
- add else case to break the loop
- set reverse parameter to true while sorting to get decreasing order
- subtract the dmg of the hit we popped from total dmg
If n is the number of players, m the number of bosses, k the maximum hits for a player, I'd say that the time complexity would be O(nklognk)
Something wrong with the team re-use in this case:
1: [('Duck', 'A', 1, 90), ('Ethan', 'A', 1, 70)], # <= Ethan A used here
4: [('Cat', 'A', 4, 300)],
5: [('Ethan', 'B', 5, 480), ('Cat', 'C', 5, 350)],
2: [('Duck', 'A', 2, 100)],
3: [('Ethan', 'A', 3, 300)] # and here
hmm that's right
I'll try to think about it again later
tell me if you found a solution
That is one of the hardest problem in this part - no team re-use (assignment problem as I searched)
Then we try to do the coin charge problem to determine if the assignment problem solution is good enough or not
The worst case would be ... each player has all the 15 combinations (3 teams x 5 bosses). And there are more players
Thanks for the attempt anyway @wispy hare
I was trying to solve this problem (https://www.codechef.com/JAN21C/problems/FAIRELCT). I tried this solution (https://pastebin.com/kJ9TtCbq) and encountered TLE error. Can someone tell me how to optimize this approach/solution? Thanks!
following my intuition, I'd say that the solution would be to sort packs of John in ascending order and those of Jack in descending order, then for each index, you add the difference to John and subtract it from Jack, until John nb total votes exceeds Jack nb total votes
john_sum = sum(john)
jack_sum = sum(jack)
john.sort()
jack.sort(reverse=True)
i = 0
while i < len(john) and i < len(jack) and john_sum <= jack_sum:
diff = jack[i] - john[i]
john_sum += diff
jack_sum -= diff
i += 1
return i if john_sum > jack_sum else 'IMPOSSIBLE' ```time complexity: O(nlogn+mlogm) where n is len(john) and m is len(jack)
This is really impressive, Thanks for your prompt and a detailed reply mate. Also i was wondering how you were able to figure out that this would work? Like at times like this I can only think of some brute-force approach like I mentioned above.
And once again thank you so much!
I just thought of what move would have the most impact on the difference between number of votes
I find out that swapping the smallest pack of john with the greatest pack of jack would have a great impact
so the solution would be to keep swapping between min(john) and max(jack)
and to avoid always searching for min and max, I sorted john in ascending order and jack in descending order
Ah, I see. So instead of calculating the john_sum, jack_sum, min, max at every step it is better to sort them.
exactly
Need a code for assembly language can some one help me kindly
How is this related to this channel?
Sorry I am new to discord where should i ask assembly language question?
We aren't really a platform for assembly questions. Perhaps there's another Discord server you could join for that.
Kindly guaide me please
https://discord.gg/010z0Kw1A9ql5c1Qe
There's a channel for assembly/bare metal.
Is there a good way to think about structuring DP problems? I can tell when to use DP, but I'm not as confident determining what (and where) the recursive relationship should be
So if you have a problem that can be solved with recursion, yes? You can use DP if the same recursive calls would have to be made more than once
The goal is to save the answer from earlier instances of the same recursive call so that you don't have to re-explore branches of the decision tree you've been to before, so to speak.
Perhaps I'm missing the point of your question
Most of the time when I see a DP problem, I instinctively think of some sort of recursive tree process, and I need to store the results.
My intuition is to have an outer function that gets called and handles state, and an inner function that will get called recursively and store the values. (Not 100% if this is correct, but it sounds right to me)
I usually trip up when it comes to the state. How do I traverse the state from the recursive call, how do I know where to even put the recursive call, etc.
a DP solution doesn't need a recursive function
you're referring to the option where you build a matrix-like structure? I never wrapped my head around that approach.
we have two approaches for dynamic programming:
we have the top-down approach (memoization), where we start by solving the initial problem, and for that we need to solve smaller and smaller instances until we reach the base case, this one is usually done recursively by using a lookup map
if the recursive function requires more or different parameters than one would intuitively expect, I'd have an inner-function.
def outer_function(thing: list):
cache = {}
def inner_function(thing_: list, start: int, end: int):
if (start, end) in cache:
return cache[start, end]
cache[start, end] = ... # recursive call
return cache[start, end]
return inner_function(thing, 0, len(thing))
and we have the bottom-up approach (tabulation), where we use an array or a matrix or something like this, we initialize cells whose we know the value (base cases), and we keep generating the next value from ones we already computed, this one is usually done iteratively
yes this one is memoization
isn't memoization and DP different words for the same thing?
nope when we say memoization we refer to the top-down approach, and when we say DP, it can mean memoization, but it usually means tabulation, the bottom-up approach
we have 4 easy steps to implement memoization on a recursive function
1- add a parameter lookup, which is a dict where we will store values that we computed before
2- inside the function, create the key, the key is something that characterizes that call, we can for example put a string that contains the concatenation of all changing parameters separated by a space, or we can just use a tuple that contains all changing parameters
(by changing parameter I mean a parameter whose value can change between the different calls)
3- add a condition that checks if we already computer the value before, so we write: if key in lookup: return lookup[key]
4- before every return statement in recursive cases, store the output in lookup[key] then return it
and because in Python a default value of a parameter shouldn't be mutable, we need to create a function that creates the lookup map, and calls the recursive function
Example: longest common subsequence
def lcs(str1, str2, i = 0, j = 0):
if i == len(str1) or j == len(str2):
return 0
elif str1[i] == str2[j]:
return 1 + lcs(str1, str2, i+1, j+1)
else:
return max(lcs(str1, str2, i+1, j), lcs(str1, str2, i, j+1))
# with memoization:
def rec(str1, str2, i, j, lookup):
key = str(i) + " " + str(j)
if key in lookup:
return lookup[key]
elif i == len(str1) or j == len(str2):
return 0
elif str1[i] == str2[j]:
lookup[key] = 1 + rec(str1, str2, i+1, j+1, lookup)
return lookup[key]
else:
lookup[key] = max(rec(str1, str2, i+1, j, lookup), rec(str1, str2, i, j+1, lookup))
return lookup[key]
def lcs(str1, str2):
lookup = {}
return rec(str1, str2, 0, 0, lookup)```you can often use the @functools.cache decorator to automatically provide that outer function.
or @functools.lru_cache(maxsize=None) before Python 3.9
How do i make a list print like
[['0','0','0'],
['0','0','0'],
['0','0','0']]
Instead of
[['0','0','0'], ['0','0','0'], ['0','0','0']]
?
str(), then replace "," → ",\n"
you can just print(*lst, sep ='\n'), that looks different tho
or
arr = [[0, 0, 0], [0, 0, 0], [0, 0, 0]]
print(np.array(arr))```Ty
import pprint and use pprint.pprint instead of print. It's a pretty printer.
Is there a "book" of approaches to problems (beyond DP?)
I think lru_cache only stores intermediate results. You need an enclosed function if you want to track state?
there surely exist books about problems, but I didn't learn through so I can't suggest some sorry
Hello! I've stumbled upon a problem that I don't know how to solve.
So I've stored some data in a json file that would look like this:
{
"cars": [
{
"190z": {
"price": "$900,000"
}
},
{
"9F": {
"price": "$120,000"
}
},
{
"9F Cabrio": {
"price": "$130,000"
}
}
]
}
My question is: How can I loop trough all the price elements of the json file? What I want to do is to remove the $ and the comma with the .replace() but I don't know how can I loop trough all the price elements.
Doesn't work. Throws me this error Exception has occurred: KeyError
I think it's because the json is something like cars -> name -> price
That's what I want to do, to skip the name and just search for the price
Now I get this one haha list indices must be integers or slices, not dict
Thanks for the help!
'dict_items' object is not subscriptable
Damn. Harder than I thought it'd be
ok
Same error
'dict_keys' object is not subscriptable
'dict_itemiterator' object is not subscriptable
unhashable type: 'dict'
Damn
The thing is that there are more elements
after the car name
I only put price because I wanted to be more explicit. One element looks like this:
{
"FQ 2": {
"spawn": "fq2",
"speed": "72.43",
"seats": "4",
"acceleration": "45.00",
"braking": "8.33",
"handling": "60.61",
"image1": "https://www.gtabase.com/images/gta-5/vehicles/suvs/main/fq-2.jpg",
"image2": "https://www.gtabase.com/igallery/6401-6500/GTA5_Fq2_Online-6450-108.jpg",
"real-life": "Infiniti QX70",
"class": "SUVs",
"manufacturer": "Fathom",
"traction": "AWD",
"price": "$50,000"
}
},```Hell yeah! It worked! Thanks man!
I have a neural network doubt
In implementing logistic regression
So my teacher was telling me implementation of this if we didnt use for loop
He updated the parameter in the end
And said this is one step of logistic regression
Can someone plz tell me that why are we updating the value just once?
@knotty gate maybe #data-science-and-ml would be better for your question
say i had 2 arrays, A and B
how would i go about finding the Kth greatest pairwise sum that could be made from an element of A and an element of B?
(ping 2 help plz)
The long way (may not be favourable)
Loop element of a over elements of b
And check sum
And keep on adding it to an array
Then sort the array
Then kth largest sum if k-1 th array element
@eager hamlet
@eager hamlet
There one other way also
So u put just one for loop on any one arrat
Array*
Then using numpy and element to other array ......so that you get and array that has each element of array added by that looping number
Then concatenate those all arrays
Then find kth highest number in that array
Using numpy you will be able to do one for loop only
But what would be the cost of the numpy operation
sort both then walk through them sorta like the merge part in merge sort
That was my idea that would be n * nlogn I believe
yeah
Which is slower than n^2
wait no, it would be nlog n + n
Oh yeah
Never mind
If there are no duplicates, I wonder if there is a good way to get roughly the right index to start at
Cause you know that -1, -1 is the largest sum and -1,-2 and -2,-1 would be the 2nd and 3rd largest (but not which one is which)
Well the exception being that one of those could also have the same sum as -1,-1
No that actually wouldn't be possible of there aren't duplicates
I have created a reddit bot that gave me a bunch of submissions, I am looking to write a program that reads all of them, and than writes its own submission, a sort of general summary of everything its read. I have seen similar programs do so with movies and stories. I am not looking for help with the specific code, just a general plan of how to do this
wait how would that work
since both lists are sorted, then adding the last elements in both ists is the biggest number
ok? yeah?
since it's sorted, the next biggest is either A[-2] + B[-1] or A[-1] + B[-2]
go on?
then you just count until you reach K
so let's say it's A[-2] + B[-1] is the smallest
then there's now 3 possibilities?
A[-3]+B[-1], A[-3]+B[-2], and A[-1]+B[-2]?
no since A[-3] + B[-1] >= A[-3] + B[-2]
does someone know a good implementation of a hash function
im confused on how to code it up
class HashTable:
def __init__(self):
self.max = 100
self.arr = [None for _ in range(self.max)]
def hash(self, key):
c = 0
for char in key:
c += ord(char)
return c % self.max
def insert(self, key, value):
h = self.hash(key)
self.arr[h] = value
am i on the right track here
you will want lists on each element of self.arr, since you can get hash collisions. Python also automatically increases max when there are too many collisions
ahh i see
ok ill do that, thank u
wait howd you know that
oh yeah i'm dumb lol
A[-3]+B[-1], A[-2]+B[-2], and A[-1]+B[-2]?
and even then
linear time wouldn't be good enough
linear time isn't good enough?
what
I don't know
I'm not sure what you're getting at with this. In top down dynamic approaches (ones solved with memoization instead of tabulation), the intermediate results are what you memoize. They're your only state. At least, for pure functions.
https://paste.pythondiscord.com/debajenuzi.py
hey so i'm doing this problem (problem link is in the code doc comment)
the thing is this TLEs on a test case
complexity is n log n so it should pass
so now it's just matter of constnat factor optimization
any pointers?
@half lotus numpy would be even faster
as numpy.dot is linear ie O(n)
u would just have to sort it thats it
hello guys !
I want little help with programming in python
I want to get input from the user using the command line and I want to get multiple integer values as input and set it inside a list. I want the user to enter each number and then press enter and again enter another number and press enter. how to do this way?
here is the code I am trying right now:
This is not the appropriate channel for that
sorting a dictionary by the value of the keys transforms it into a list. why?
dictionaries are unordered
when you iterate over a dictionary, it does so in the order that they keys were inserted into the dictionary. But beyond that, they're not meant to be thought of as ordered. They're a system for looking up values by keys.
Why do you need them to be ordered? If it's for human readability, you don't have to think about how they're ordered in the dictionary until you go to transform the dictionary into a table of some kind. But if you're doing a computation where order matters, you probably want to think of a different data structure, like a queue.
Thanks for including samples of the data you're talking about. You probably could have used even fewer rows for each so that your original question wouldn't be off-screen.
As I understand your question, you want to select the Symbol, Date, and Close/Last columns from each csv, regardless of what other columns exist in each csv, and put all that data in one csv?
This is a question for #data-science-and-ml, so ping me there if you want to continue with this question.
http://www.usaco.org/index.php?page=viewproblem2&cpid=1043
ok so this is just reduced to finding all possible products of prime numbers that sum to less than n
but how do you like do this without it being near exponential
Hello!
I'm trying to sort data form a JSON file that I have that looks like this:
"cars": [
{
"190z": {
"spawn": "z190",
"speed": "75.12",
"seats": "2",
"acceleration": "67.50",
"braking": "31.67",
"handling": "69.70",
"image1": "https://www.gtabase.com/images/gta-5/vehicles/sports-classic/main/190z.jpg",
"image2": "https://www.gtabase.com/igallery/6301-6400/GTA5_190z_Online-6347-108.jpg",
"real-life": "Datsun 240Z/Nissan Fairlady Z/Nissan S30, Toyota 2000GT",
"class": "Sports Classics",
"manufacturer": "Karin",
"traction": "RWD",
"price": "$900,000"
}
},
{
"811": {
"spawn": "pfister811",
"speed": "85.47",
"seats": "2",
"acceleration": "89.00",
"braking": "37.33",
"handling": "81.45",
"image1": "https://www.gtabase.com/images/gta-5/vehicles/super/main/811.jpg",
"image2": "https://www.gtabase.com/igallery/6401-6500/GTA5_Pfister811_Online-6412-108.jpg",
"real-life": "Porsche 918 Hypercar, Koenigsegg Regera",
"class": "Super",
"manufacturer": "Pfister",
"traction": "AWD",
"price": "$1,135,000"
}
}, ```
It has more data like that in it but I want to store in another json file the cars sorted by manufacturers. Something like this:
```json
{
"manufacturers":[{
"Pfister":[{
["here a list with all the cars that have 'Pfister' as manufacturer with the specs above"]
]}
}```One way that I was thinking about solving this is looping trough all the cars, see the manufacturer and if the manufacturer is of a certain value store the whole data accordingly. What I don't really know is to how get the whole car specs after I found a matching manufacturer.
got it
😒 every time I solve problem at hacker rank, and apply solution it works only for test inputs
manuf_map = defaultdict(lambda: [])
for car, specs in cars.items():
manuf_map[specs['manufacturer']].append(car)```is this what you're searching for?
http://www.usaco.org/index.php?page=viewproblem2&cpid=1043
ok so this is just reduced to finding all possible products of prime numbers that sum to less than n
but how do you like do this without it being near exponential
You are missing colons, it's if("Y"):
can anyone recommend me a source that i can learn d-s in python ?
Yes! Thank you!
lambda: [] could be list btw, since list produces a new empty list
Uhm, Does anyone know why it says invalid intax on the else?
oh yes thank you! It got me really confused
where can i ask help with a selenium related problem?
@ashen pilot read #❓|how-to-get-help , a generic help channel is probably best
I got problem with solving this problem https://www.hackerrank.com/challenges/max-array-sum
I solved it for test cases twice, changing incrementing index by 2 and finding best sum

but for some reason, when I apply my solution it always fails 😕
this is my second solution
https://paste.ofcode.org/ZniSStBzZzMfewg8vXQGUz
Stumbled upon this error:
TypeError: list indices must be integers or slices, not str
On this code:
with open('manufacturers.json') as json_file:
temp = json.load(json_file)
data = temp['manufacturers']
sumspecs = manufact['manufacturer']
for key in data:
if sumspecs in key:
data[sumspecs].append(specs)#error on this line
```
Why?
`sumspecs = 'karin'`
JSON looks like this:
```json
{
"manufacturers":[
{
"Overflod": []
},
{
"Vysser": []
},
{
"BF": []
},
{
"Unspecified": []
},
]}
'karin' does exist in there but all I want to do is to put all the data that on the specs IN the Karin key.
Or whatever value the variable might have
you're getting this erro bc data is a list not a dict
And how can I manage that?
So it writes the data in the specific key?
it depends on what you want to do
To append this specs in the matching key.
So it'd look something like this:
{
"manufacturers":[
{
"Overflod": [{
"190z": {
"spawn": "z190",
"speed": "75.12",
"seats": "2",
"acceleration": "67.50",
"braking": "31.67",
"handling": "69.70",
"image1": "...",
"image2": "...",
"real-life": "Datsun 240Z/Nissan Fairlady Z/Nissan S30, Toyota 2000GT",
"class": "Sports Classics",
"manufacturer": "Karin",
"traction": "RWD",
"price": "$900,000"
}
},
}]
},
{
"Vysser": []
},
{
"BF": []
},
{
"Unspecified": []
},
]}```try to replace if sumspecs in key by if sumspecs == key.keys()[0]
I get this error 'dict_keys' object is not subscriptable
if sumspecs == list(key.keys())[0] then
Still list indices must be integers or slices, not str on the data = temp['manufacturers'][sumspecs] line
i'm just getting an empty string in N,Ag and the rest
someone plz help
sorry but trying to understand your code is hard, poor variable naming
yes because temp['manufactuters'] is a list
temp['manufacturers'] is actually a list of one-key dictionaries, it's different from a dictionary, this is why you're getting errors
dictionary:
{'a': 4, 't': 10, 'e': 3}
list of one-key dictionaries:
[{'a': 4}, {'t': 10}, {'e': 3}]
Yes, I see that but how can I solve it?
you can either convert it to a dict
for d in temp['manufacturers']:
key = list(d.keys())[0]
manuf[key] = d[key]```
or dealing with that list by knowing that you can't directly access by key, in the example I gave, you can't directly write `l['a']`, you first have to search for the dict whose key is 'a'http://www.usaco.org/index.php?page=viewproblem2&cpid=1043
how do you not do this in exponential time wtf
it's basically finding the sum of the products of all prime numbers that sum to less than n
Okay guys, I need some help: are my time and space complexities correct?
Why you use while instead of for?
yes but it's not the most efficient algorithm
Show me the optimized solutions ! For loops welcome

Hi
I have only two functions implemented so far
return point[i] + k
def decriment(i,k):
return point[i] - k```i was thinking of brute force but it looks like its gonna be too long. Could anyone please help?
search for the Knuth-Morris-Pratt algorithm
I'm not sure but my intuition is that you calculate the average, then for each point[i], if it's below the average, you add k, else you subtract k
thank u. Lemme try
okay tell me if it's the right answer
what if the point[i] is the average?
idk :c maybe it doesn't matter if you add or subtract
Maybe it doesn’t matter lemme check
so, did it work?
10^5 what?
input size?
K=10^5
ah yes because in that case we should add k to all of them (or subtract)
Wdym?
like if we have [2, 3]
and k = 10^5
here the average 2.5, so our algorithm would subtract k from 3 and k to 2
I see
but it just increased the difference
in this case we should add (or subtract) k for both
so I think that
Any clue how to handle that ?
we should compare the difference between max and min and the difference between (max-k) and (min+k)
if different between max and min is smaller, we should add k to all elements (or subtract, as you want)
else, we do the average thing
can someone explain how the entropy formula works for decision trees? Ive watched videos on it, but its not helping so far.
i'm supposed to be doing my homework but after hearing that that exits, I have to search it up
I can explain them to you if you open a help channel
The police department is trying to use AI to detect which car license plates belong to stolen cars. Which of the following AI approaches is best suited?
sounds like a homework question?
yes 😂
@calm mortar why not just ```py
def find(needle, haystack):
idx = haystack.index(needle)
return idx, idx + len(needle) - 1
@tawny shore that's nice! what's the runtime of str.index(str)
this details the implementation of str (its from py2, find is index in py3)
the algo is the same
https://stackoverflow.com/questions/36868479/python-str-index-time-complexity <- someone asked the same question here

Stack Overflow
For finding the position of a substring, inside a string, a naive algorithm will take O(n^2) time. However, using some efficient algorithms (eg KMP algorithm), this can be achieved in O(n) time:
s...
http://www.usaco.org/current/data/sol_exercise_gold_open20.html
does anyone know how to do this in less than exponential?
it's basically asking for the sum of all possible prime powers (a_1 ^p_1 + a_2 ^p_1, so on) that are less than n
the editorial says use dp but idk how lol
@tawny shore In terms of run-time, it seems that your solution is no better
it should be just by the fact that it is running in C, not python
Maybe. That's arbitrary tho. The run-time seems to me that O(mn) is worst case performance, as per the last link you attached. However, someone earlier mentions KMP algo can be used for better performance.
that answer was explaining that str.index uses a slightly more optimized implementation (where the worst case is still the same)
Hi, I have to give a presentation about sorting algorithms. It lasts 20 minutes. If you have interesting topics to cover feel free to post them. Thanks for your help!
Do you guys think, that using numpy is efficient for calculating minimal distance of the point? if the box will have very many points? 🤔
def find_closest(pt):
if len(pt) == 2:
pt = [*pt, 0]
elif len(pt) != 3:
raise ValueError("Point has incorrect shape")
pt = np.array([pt]).T
dist = box - pt
dist = dist * dist
dist = dist.sum(axis=0)
dist = np.sqrt(dist)
hidist = np.min(dist)
loc = np.where(hidist == dist)[0]
loc = box[:, loc].T[0]
return loc, hidist
depends
on if you want to do it for one point
or many points
if many points
you should find a data structure
that allows you to do this more efficiently
I think I will need some algo, well, I will just check how efficient is numpy, now I got shape with only 6 points, but how fast it will be with 10k or more points 🤔
i want to find closest point of shape to my point, so its 1 and many, I was thinking about divide and conquer
New jedi order
F(find_closest) mean duration: 0.036 ms of finding one point

wow that's so cool
Yeahh it supberb
guys why is my code not working? https://www.youtube.com/watch?v=eDCKXkGql2M

is Pyrr better than numpy? its built on top of it 🤔
hi am sai a am 15 years old and i am learning python i want some friends to join me to learn python and do some program togeather
pin me if intrested
Excuse me, good night, I'm from Peru and I have a question about how I can solve this problem. Implement an algorithm to find the permutations r of n elements.
I do not understand well the topic of functions
can someone help me with ga and pso
hmm, some times, we can see what is the video by placing mouse on the play trail, hmmm
hey guys i do really suck in learning algos like greedy , dp what can i do to make it better?
i do understand the algos but what should i do to make it better ?
Try to solve some problems, then look for solution.
And then, you need to learn how to identify if a problem can be solved using DP
A first step would be to solve the problem recursively
I try that, but formulating it as subproblems isn't always easy either
can you show me an example of a problem that you consider as hard to decompose into subproblems?
I don't think that this problem needs decomposition into subproblems
we can do so
but I think that here it's not necessary since we are just asked to find the numbers of possible arrays, not generating them
i did learned and used CODEFORCES to pratice but i can't recognize how to solve a problem
That's why I told to look for solution if you can't solve it yourself
def insereaza_cifra_control(lista):
lungime = len(lista)
for i in range(0, lungime, 2):
lista.insert(i + 1, cifra_de_control(lista[i]))
lungime = len(lista)
lista = [10, 78, 8051, 91]
the list after the call should be
10 1
78 6
8051 5
91 1
why does it stops at 10 1 78 6 8051 91
I need a library that allows me to plot lines on a graph (does not need to be visualised) and count points in range of certain lines eg all points >= x+y. Does anyone have any experience with this or know of any librarys?
@fiery cosmos your call to the range function only runs once
it returns a range object
Changing lungtime after making that object won't change the range object
you are making the list twice as long though, so you can just multiply lungtime by 2 in your call to range
hey, wondering if anyone can help me with ssml's pitch contour
i need to adjust the pitch of individual words, but ssml doesn't really support that unless using contour from my understanding
where can I find some good resources for classes?
im makeing a menu for a mc name sniper and i dont know how i stop in from repetting
Algo classes? Or what kind?
Anything about classes would help a lot. I tried to learn Dijkstra's algorithm, but even though I understand the idea and I could memorize the code, I don't understand how classes work
where do you recommend learning datastructures and algorithms as a beginner
I dont know if this is the right place to ask competitive programming questions, is it?
it could be! just ask your question
I saw this question in one of the job interviews, could not solve it. Still trying to figure out
I faced the same problem back then. Though I started implementing Linked-lists using classes, and at that point I got the concept of classes, you can try the same!
function with three parameters a, b, and c, which swaps the biggest one with the smallest one, and returns average of both swapped elements.
example: a=5, b=1, c=2 -> 3
[c++]
Is this a question or algorithm request?
do you need help writing that or are you just writing an algorithm?
I actually wrote it, but I need optimization now,
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
using namespace std;
void swap(int *i, int *j) {
int t = *i;
*i = *j;
*j = t;
}
void print_values(int x, int y, int z) {
cout << "x=" << x << ", y=" << y << ", z=" << z << "\n";
}
float min_max(int x, int y, int z) {
float avg = 0;
if(x<y && x<z){
if (y < z) {
swap(&x, &z);
print_values(x, y, z);
avg = (x + z) / 2.0;
return avg;
}
else {
swap(&x, &y);
print_values(x, y, z);
avg = (x + y) / 2.0;
return avg;
}
}
else if(y<x && y<z){
if (x < z) {
swap(&y, &z);
print_values(x, y, z);
avg = (y + z) / 2.0;
return avg;
}
else {
swap(&y, &x);
print_values(x, y, z);
avg = (y + x) / 2.0;
return avg;
}
}
else if(z<y && z<x){
if (x < y) {
swap(&z, &y);
print_values(x, y, z);
avg = (z + y) / 2.0;
return avg;
}
else {
swap(&z, &x);
print_values(x, y, z);
avg = (z + x) / 2.0;
return avg;
}
}
return avg;
}
int main()
{
float value = min_max(5, 1, 2);
cout << value << "\n";
}
I'm repeating myself a lot
how do I reduce it
function with three parameters a, b, and c, which swaps the biggest one with the smallest one, and returns average of both swapped elements.
this is what they want
alright, a crude-ish way you could do this is by passing in a vector<int>. in your function, you loop through each element in the vect. if element for index is > max val or < min val you set that as the min/max val and record the index. after the loop you swap v[max index] and v[min index] and return the avg of the two recorded vals
this is over complicating things but i really can't think of something that takes less code than this
Just one thing isn't this a python server ? Or can we post anything regarding dsa here ?
i'm a newbie here
I am trying to make data structre and algo for finding closest point, more o less I am thinking about dividing space 🤔
hackerrank
I'm not sure if this is the right channel. In binary why the negate of 0 (i.e. ~0) is a series of 1s ?
@bronze sail haha, i was just looking at a similar problem! check out https://en.wikipedia.org/wiki/Nearest_neighbor_search
2.1.2 space partitiong is my method ;d
Hey guys is this website okay for learning data structures and algorithms?
https://www.w3schools.in/data-structures-tutorial/intro/
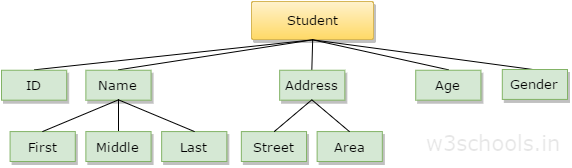
Data Structure Introduction - In computer terms, a data structure is a Specific way to store and organize data in a computer's memory so that these data can be used efficiently later. * What is Data Structure? * Linear Data Structure. * Nonlinear Data Structure.
Hello!
Can someone please help me with this question - https://www.hackerrank.com/challenges/tree-huffman-decoding/problem?h_l=interview&playlist_slugs[]=interview-preparation-kit&playlist_slugs[]=trees
HackerRank
Given a Huffman tree and an encoded binary string, you have to print the original string.
I do not understand the question at all. If someone can run through a sample example with me...it'll be much appreciated
Looks like a decent start, but doesn't get very complex
Check out this video: https://www.youtube.com/watch?v=K2gLEnwW2ps It might help if you try to construct huffman encoding first and then do decoding

Huffman Coding Algorithm is a lossless data compression algorithm. In lossless data compression, the original data can be perfectly reconstructed from the compressed data.
This algorithm is developed by David A. Huffman in 1952 while he was a Ph.D. student at MIT. This algorithm is widely used in mainstream compression formats such as JPEG, PN...
does windows have a problem with really big input lists or is the problem how I'm implementing my mergesort because when I try to sort a list of 1000000 numbers it just freezes
hmmm I think it's just too much for my code to do relatively quickly nvm
if anyone wants to schedule a weekly voice chat to discuss data structures where we review several on stream each week to learn, ping me and i'll set it up
id like to discuss these topics specifically
Any pair programming channel in here or something like that?
I would like to have a coding buddy that also do python while doing wfh.
I just started python
As I mentioned yesterday in the #data-science-and-ml channel, I'm having some issues using SciPy's solve_ivp function. I posted the question on Stack Overflow to hopefully get some help. https://stackoverflow.com/questions/65632575/scipy-solve-ivp-fails-to-converge-for-large-system-of-ordinary-differential-equa
Stack Overflow
I'm trying to use SciPy's solve_ivp function to solve a large system of coupled ODEs. The system of equations represent temperature, mass concentrations, and flows along a one-dimensional grid. The
!remind 1d #algos-and-data-structs message
Aye aye, cap'n!
Your reminder will arrive in 1 day!
ID: 1217, Due: 2021-01-09T17:10:37
i can try to look at it tomorrow
@stable pecan Thanks. Let me know if you have any questions or just ask them on the Stack Overflow post.
>>> import struct
>>>
>>> struct.pack('i i f 3s', 1, 2, 3.5, b'abc')
b'\x01\x00\x00\x00\x02\x00\x00\x00\x00\x00`@abc'
>>>
``` is that big endian ?No, that's little endian. The integer 1 was encoded to the bytes \x01\x00\x00\x00, which has the least significant bytes first
struct defaults to your machine's native endianness. If you want big endian, you need to ask for it by starting the format string with >
!e ```py
import struct
print("big", struct.pack('>i i f 3s', 1, 2, 3.5, b'abc'))
print("little", struct.pack('<i i f 3s', 1, 2, 3.5, b'abc'))
print("native", struct.pack('i i f 3s', 1, 2, 3.5, b'abc'))
@lean dome :white_check_mark: Your eval job has completed with return code 0.
001 | big b'\x00\x00\x00\x01\x00\x00\x00\x02@`\x00\x00abc'
002 | little b'\x01\x00\x00\x00\x02\x00\x00\x00\x00\x00`@abc'
003 | native b'\x01\x00\x00\x00\x02\x00\x00\x00\x00\x00`@abc'
How do I get the point of intersection between two rectangles?
The intersection of 2 rectangles is a rectangle, not a point
It's the rectangle bounded on the top by the topmost point that's in both rectangles, on the bottom by the bottommost point that's in both, on the left by the leftmost point that's in both, and on the right by the rightmost point that's in both
Hey, I'd like to change the args in a thread in "threading" package, change args during the course of the thread, before thread.start()
How do I do that ?
Actually it's just because I'd like to create my thread before, because it seems to take some time to create them all
And since my args are only there during runtime , id like to be able to change them then start them all !
You have this backwards... Creating a threading.Thread without starting it is nearly free, it's calling start() that actually reaches out to the OS to do real work (create the OS thread) and is slow
On my machine, creating a Thread without starting it takes 0.0000057 seconds, according to the timeit module
That's 5.7 microseconds
any ideas boys?
http://www.usaco.org/index.php?page=viewproblem2&cpid=282
this is just shortest path but really annoying right?
"meaningful" is probably the expected answer, but I think it's a bad question.
whether or not a decision made by an ai is "fair" depends on what one thinks of as fair.
Yes! I am in
Okay thanks good to know!
how to print character array using for loop in cpp
Which part of that are you struggling with? Can you show what you tried @grand zenith
this.. @mild cape
#include <iostream>
#include <cstring>
int main(int argc, char **argv) {
const char *msg = "Hello world!";
for(const char *c = msg; *c != '\0'; c++) {
std::cout << *c << '\n';
}
size_t msg_len = std::strlen(msg);
for(int i = 0; i < msg_len; i++) {
std::cout << msg[i] << '\n';
}
}
Here are two ways you might consider doing it.
the index of the list
@fiery cosmos Have you ever worked with lists and indexes before?
It's rows
idk
I don't know how the module works
No problem
Hello, i am looking for a good course, book about data structures and algorithms. Peak Finding, merge Sort, rolling hashes etc.
so far i have found and doing atm https://www.youtube.com/watch?v=Zc54gFhdpLA&list=PLUl4u3cNGP61Oq3tWYp6V_F-5jb5L2iHb&index=2

MIT 6.006 Introduction to Algorithms, Fall 2011
View the complete course: http://ocw.mit.edu/6-006F11
Instructor: Erik Demaine
License: Creative Commons BY-NC-SA
More information at http://ocw.mit.edu/terms
More courses at http://ocw.mit.edu
Maybe something that complements these lectures
Hello friends, I am taking probability and statistics lessons. I need to write code in python. If someone knows can it help?
If someone knows can it help?
can anyone explain me how to implement graphs in python?
Hello friends, I am taking probability and statistics lessons. I need to write code in python. If someone knows can it help?
Python has a robust set of math libraries that I'm sure can do what you need
I added a link to the GitHub repository as part of the Stack Overflow question.
try opening a help session. Your question might be relevant to #data-science-and-ml though.
@mighty gorge the instructions are in #❓|how-to-get-help
how accurate are nearest search algos?
I got 2 plots, one saying green-ish good values, and red purple shadows of bad algo ouput,
and second plot, is that I beat pure matric multiplication over 11k elements
Plots are from my implementations more or less
@stable pecan
Here's your reminder: [#algos-and-data-structs message](/guild/267624335836053506/channel/650401909852864553/).
[Jump back to when you created the reminder](#algos-and-data-structs message)
:incoming_envelope: :ok_hand: applied mute to @agile compass until 2021-01-09 17:53 (9 minutes and 59 seconds) (reason: discord_emojis rule: sent 31 emojis in 10s).
nice
I want to learn more about data science and data structure, do you know of any place or book where you have all the topics, or the knowledge base on these subjects?
Data Science and Data Structures are typically pretty different subjects and very broad. Data Structures tends to be how data is stored, most often referring to things like arrays, lists, trees, sets, etc... Typically you learn about Data Structures alongside Algorithms. I like Algorithms by Robert Sedgewick and Kevin Wayne, though I wouldn't really suggest it as a great sit down and read book, I'd suggest taking one of Coursera algorithms courses/specializations instead. For Data Science, are you thinking more data analytics, machine learning, statistics...?
Can I create a python program that detects whether the source code of another python program gets into an infinite loop
I want to make a dynamic debugger of sorts
It's not possible to always be able to detect if there is an infinite loop.
@gusty perch Right, https://en.wikipedia.org/wiki/Halting_problem
In computability theory, the halting problem is the problem of determining, from a description of an arbitrary computer program and an input, whether the program will finish running, or continue to run forever. Alan Turing proved in 1936 that a general algorithm to solve the halting problem for all possible program-input pairs cannot exist.
For ...
is there a way to sum all squared number rather than looping one by one?
1^2 +2 ^2 + 3^2 .... until >= given number
for n numbers, sum of 1^2 + 2^2 ... + n^2 is equal to [n * (n+1) * (2n+1)] / 6 iirc
no, i meant until the sum is equal or greater than the given number
how do i play nice with the in keyword in a list of custom classes
class test:
def __init__ (self,name):
self.name = name
#i need something here
x = [test('tom'),test('harry')]
print('tom' in x)
print('nottom' in x)
so i expect the output to be
True
False
(ping me pls)
@queen ruin Using the in keyword requires one of these things to be implemented:
__iter__ - Checks if an element is in an iterable object
__contains__ - Checks if an object contains an element
https://docs.python.org/2/reference/datamodel.html#object.__contains__
tysm.. so ill need to override __contains__ to return true if the given str is self.name rit?
Yep
!e
class test:
def __init__ (self,name):
self.name = name
def __contains__(self,item):
return item == self.name
x = [test('tom'),test('harry')]
print('tom' in x)
print('nottom' in x)
You are not allowed to use that command here. Please use the #bot-commands channel instead.
Whoops I misread your question, take a look at this answer:
https://stackoverflow.com/questions/37034404/how-to-search-objects-in-python-list-using-contains-in-keyword
Stack Overflow
I would like to make a list of objects which I define, then use the in keyword (which calls contains) to determine if said object exists in the Python list.
Here is a minimal example with comme...
@queen ruin
ohh __eq__ worked perfectly...tysm
Hello guys,
im not sure if this is the right place to post this question, just tell me if im wrong here 🙂
I got an Json file and i want to read it as a pyspark dataframe. The Json is nested and im not sure what is the best practice to get the data our of the json.
this is the Schema
|-- payment_phase: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- credit: double (nullable = true)
| | |-- month_of_prime: long (nullable = true)
| | |-- user_id: long (nullable = true)```
1. way would be to use the Flatten function then drop element and root ?
2. use Explode function
3. explicit to get data out of the json and write it in a new DFswrong chanel for this topic ?
frick bro, you think that it might not be true, like did turing fuck up on the proof maybe
I think that more intelligent people like me proofed this theorem
what do you guys use / recommand as a python GUI lib ?
I need it to represent lots of different datas with historic etc etc to be clearer than on a console
Check #user-interfaces for GUI help
ty !
hey, can someone check what is wrong in this code?
start, end = 2, 7
for num in range(start, end+1):
if num % 2 != 0:
print(num, end = " ")
!e
start, end = 2, 7
for num in range(start, end+1):
if num % 2 != 0:
print(num, end = " ")
@austere sparrow :white_check_mark: Your eval job has completed with return code 0.
3 5 7
Well, there's no runtime errors -- so unless you had a specific goal in mind, it's good
i just tested it in e-olymp and it says it is wrong and counted it as 0%
the code does something, and does it successfully
without knowing what it's supposed to do, we can't know why it isn't doing that and is instead doing what it does.
Well... we can't know what's wrong if we don't know the problem statement 🙂
Also, a help channel should be better for that. See #❓|how-to-get-help
hey
I want to learn python to analyze data on stocks. How do you guys think I should learn?
alr u can dm me ima gtb
How about #data-science-and-ml channel?
aww yeah successful LDU factorization of any square matrix
the three matrices in the middle are factors of the matrix up top
hello
is there anyway i can get an index from a random row from a csv file?
like, say i have a csv of ten rows and six columns, is there any way for me to take a number from randint and take index zero from row randint?
!e
from random import randint
print(randint(0, 5))
print(randint(0, 5))
print(randint(0, 5))
print(randint(0, 5))
You are not allowed to use that command here. Please use the #bot-commands channel instead.
Pff, randint(a, b) returns numbers in range [a; b] inclusive.
could i do this right after i call out csv.reader? or are there other prerequisites?
You can call randint whenever you want
then how about printing index 0 from the csv now that i have a line number from the randint?
!e
dynamic programming approach towards the solution
def canSum(target, numbers, memo = {}):
if(target in memo):
return memo[target]
if(target < 0):
return False
if(target == 0):
return True
for num in numbers:
if(canSum(target-num, numbers, memo) == True):
memo[target] = True
return True
memo[target] = False
return False
here .... I have defined this thing in the jupyter... now I have impleameted multiple print statement executing the test cases.... instaed of the first one ... others are not working.... pls any one can help me?
You are not allowed to use that command here. Please use the #bot-commands channel instead.
!e
You are not allowed to use that command here. Please use the #bot-commands channel instead.
hi everyone, can u help me?
I need a list that performs an arithmetic expression inserted by input
former. 2 * 2- (4 + 5) (2 + 3)
sorry about my english, im italian
with former i mean the example
take every element of the list and perform the operation
so we have: list=[element, operation, element, operation, operation, element....], something like this
how i can get a rapid solution to this? i knew by a function that solve the problem, but i cant use it
you could try parsing it using shunting yard
Have you tried eval()? Join each element in the list into a string using join function and pass it to eval(). There might be some security issues but it works ig.
yeah i know about that, but is a school work and my prof tell us to not use it lol :(
is kadanes algorithm the same as sliding window technique?
Hi!
Next week i have exam
is there any website where I can create Algos using blocks
and test them ?
blocks?
i don't know of any websites for that
there are definitely many websites where you can write code to solve algorithms questions
Hi - I have a question for python (python3).
I'm confused by the following issue
For matrix transpose, I used naive solution for it, when I use set list of list with multiplication of row_length and col_length, it does not assign properly. Could anyone help me with this? I don't understand it why
Never use * operator with a mutable element
and a list in Python is mutable
the problem is that all your rows have the same reference now, there is only one array in memory, this is why all of them have the same value
Then when I use result=[[0,0,0],[0,0,0]] why does this works?
I'm not convinced that it is the same reference in this case.
Then when I use result=[[0,0,0],[0,0,0]] why does this works?
@hallow vortex because then you have separate lists
I need some help with using SciPy ODE solvers. If anyone has experience, please see the #help-bread channel.
use a list comprehension or generator expression if you don't want to create an array literal by hand
[[0 for i in range(3)] for i in range(3)]
anyone can help me for opencv disparity mapping
I am trying to understand parameters of StereoSGBM_create function
https://stackoverflow.com/questions/62627109/how-do-you-use-opencvs-disparitywlsfilter-in-python
this parameters
Stack Overflow
I can compute a depth map with cv2.StereoSGBM that looks pretty good. Now I want to apply WLS filtering as described here.
This answer has some info, which I follow below, but I can't quite get to ...
given 2 string, i need to compute the number of transpositions between them. what algorithm should i use?
@wispy hare @brave oak Thanks for answering. It makes sense now
That works. I used copied one. [x[:] for x in [[0]*m]*n] This works
can you give us more detail? what do you mean by number of transpositions?
never mind actually, I gave up on an idea i working on lol. So basically I was trying to implement jaro and jaro-winkler distance for measuring string similarity. but i quickly discovered it wasn't for my use case
oh okay
my screenshot (#algos-and-data-structs message) is from the book Cracking the Coding Interview
Hello is anyone here familiar with balanced Binary Search Trees, specifically the AVL tree
Hello!
Is anyone online here?
I am struggling with this question - https://www.hackerrank.com/challenges/tree-huffman-decoding/problem?h_l=interview&playlist_slugs[]=interview-preparation-kit&playlist_slugs[]=trees
HackerRank
Given a Huffman tree and an encoded binary string, you have to print the original string.
Here is my solution for it -
def decodeHuff(root, s):
string = []
position = root
for element in s:
if element==1 and position.right!= None:
position = position.right
elif element ==0 and position.left!= None:
position = position.left
else:
string.append(position.data)
position = root
print(string)
Please tell what am I doing wrong 😦
you're not stepping, when you append
string = []
position = root
for element in s:
if element==1 and position.right!= None:
position = position.right
elif element ==0 and position.left!= None:
position = position.left
else:
string.append(position.data)
if element == 1:
position = root.right
else:
position = root.left
print(string)
```like this maybehttp://usaco.org/index.php?page=viewproblem2&cpid=225
so i'm doing this problem and my code is as follows: https://paste.ofcode.org/DSYMGR46ya2aXL8jXCwYSH
so how it works is it binary searches on the maximum prefix, and then it checks for contradictions within each sort of "component"
however, it fails for this test case: https://paste.ofcode.org/eceRRqyzfN2sp2Px8Xbi5J
it outputs 527 instead of 502 (the correct output)
any help? (ping 2 reply thx)
Hi, I'm trying to solve a bit manipulation problem. And the problem is
Given a positive integer, print the next smallest and the next largest number that have the same number of 1 bits in their binary representation .
The number given is 13948 which in binary 11 0110 0111 1100. The solution in the book gives that the next largest number is 13967 which in binary is 11 0110 1000 1111. My understanding is that the next largest number is 11 1111 1110 0000. Can someone help me to explain why the solution given by the book is different or if my understanding is wrong?
...why do you think your solution is correct?
explain your reasoning please
Since when there are more 1s on the left than the right the higher the number. Example 1000 is higher than 0001 or to 0100. So turning the bits on to the left will result to higher numbers Is that correct?
yes
So the book is wrong?
no
the book is correct
your answer is wrong
I don't really see how what you said changes anything
His answer would be correct if it wanted the largest possible number using the same number of bits
But the book seems to want to closest number to 13948 that is larger than it and uses same no of bits
it says next largest though
oh, okay
I didn't think of that
"next largest" is kind of confusing terminology
True
It implies that the current number is already the "largest" of something to me
The solution given by the book is not the next largest, isn't?
it is because
that really makes no sense
I don't think it's idiomatic I just think it can be read in a wrong way that can also be justified as correct in some twisted way.
it lends itself to that
my immediate interpretation was the one expected by the book
which suggests to me it's a regional difference
like this didn't even occur to me at all and I was mega confused
why do you think it's not the next largest?
If the book wants the next largest number, then 11 0110 1000 1111 (13967) should not be the right answer, right? Because there could be a larger number than that with the same number of 1s and 0s. Example 11 1110 1000 1110 (16 014), and it is still consider next? Am I wrong?
nope, that's not what it means
okay, let's use smaller numbers
say the given number is 4 (100). it has 1 1; imagine you list the numbers that come after it in binary...
5 - 101 (2 1s)
6 - 110 (2 1s)
7 - 111 (3 1s)
8 - 1000 (1 1)
in other words, if the input was 4, you'd expect 8
because it is the first number that is bigger than 4 and has the same number of 1s (1) in its binary representation
so "next largest", in this case, means "there is a sequence of integers with x 1s in their binary representation; what is the number immediately after 13967?"
Wait, but 100 has one 1 and two 0. However, 1000 has one 1 and 3 0?
yes, but the 0s don't matter
I thought about it, it's confusing for 2 reasons
- When thinking about "largest", one tends to thing of a single value since its the superlative. There can only be one largest, and the rest are relatively smaller.
- If I gave you a sequence 1-5 and said 5 is the largest, then I could say 4 is the next largest i.e. the penultimate. In this case, "next largest" actually means a smaller number. This is what I mean when I said it implied the number is already the "largest" of something.
If it said "next larger" that would have been much clearer.
"next largest" does indeed commonly mean "immediately preceding in magnitude"
Why 0 don't matter?
why do they matter?
Well since they say both smallest and largest I guess they may have been using it in that sense, but it's confusing since it's flipped. Anyway, I need to stop derailing this.
the question doesn't say "same number of bits"
it says "same number of 1 bits"
nothing about the 0s
Oh. Ok wait. Let's change the example. Let's say 1001 (9) ? What will be the next largest?
The way to figure it out is to shift the right most 1 bit to the left
1010
go back to this
just think of listing the numbers after that in increasing order, counting the number of 1s in the binary representation, until you get the same vallue
Wait. How about 110 1101 (109)?
1101110 (110)
Wait. I don't really understand. How about 11 0110 0111 1100 ?
@zenith pagoda do you understand this?
Quite a bit. But when the number gets bigger I can't apply it anymore.
in the case of 11011001111100 it is the same thing
13948 - 11011001111100 (9)
13949 - 11011001111101 (10)
13950 - 11011001111110 (10)
13951 - 11011001111111 (11)
13952 - 11011010000000 (5)
so notice that at 13952 we carry the 1
and are left with 5 0s
Yes.
now
the task is simple
we just need to replace 0s with 1s
as far on the right as possible
until we get 9 1s
because, as you said earlier
1s on the right are lower value than 1s on the left
so we just replace the rightmost 4 0s with 1s
that gives us 11011010001111 which is, of course, 13967
does that make sense @zenith pagoda?
Yes thanks.
yw
Great
same concept for going down
no worries!
yo I think that I got the solution
when converting n into bits, we have 3 cases:
Just started learning this area, had a friend give me the pointers to make these loops. How do you guys develop a brain for this stuff?
Also laugh at my spaghetti
if the string is full of ones, we just insert a 0 after the first 1
example: 11111 -> 101111
else if we can split the bits into a part of ones and a part of zeroes (e.g.: 1111000), then the next number is 1 + the part of zeroes + 0 + the part of ones except the first one
example 1111000 -> '1' + '000' + '0' + '111' -> 10000111
else, we just replace the last zero before the last one by 1, and we replace the last one by 0
example: 10011011000 -> 10011110000
def next_greater(n):
bits = '{0:b}'.format(n)
nb_ones = bits.count('1')
if nb_ones == len(bits):
return int('10'+bits[1:], 2)
elif re.fullmatch(r'[1]+[0]+', bits):
return int('1'+bits[bits.index('0'):]+'0'+bits[:bits.rindex('1')], 2)
else:
last_one = bits.rindex('1')
last_zero_before_last_one = bits.rindex('0', 0, last_one)
bits = list(bits)
bits[last_one] = '0'
bits[last_zero_before_last_one] = '1'
return int(''.join(bits), 2)```Hello everyone. I'd like to write a tree structure so I can traverse it using this program. My python is a bit rusty, can you help me out?
Like in all the other problems I can copy the solution and if the input is an array I can just do array = [] and run the thing. Now, the input is not an arary, it's a binary tree stored as an object
anyone can help me with this error?
what do you want exactly?
@stiff pewter your code looks complete. Do you just want to make a function that sorts a list and stores the elements in the data dict in a valid tree?
@wispy hare @keen stump My code is complete indeed. The functions are fine. The thing is that I want to test this code using this as
an input: ```js
{
"tree": {
"nodes": [
{"id": "10", "left": "5", "right": "15", "value": 10},
{"id": "15", "left": "13", "right": "22", "value": 15},
{"id": "22", "left": null, "right": null, "value": 22},
{"id": "13", "left": null, "right": "14", "value": 13},
{"id": "14", "left": null, "right": null, "value": 14},
{"id": "5", "left": "2", "right": "5-2", "value": 5},
{"id": "5-2", "left": null, "right": null, "value": 5},
{"id": "2", "left": "1", "right": null, "value": 2},
{"id": "1", "left": null, "right": null, "value": 1}
],
"root": "10"
}
}
My functions take a tree as an input, and that's the tree I want to execute the functions upon
If my functions were taking arrays as input for example I'd do: array = [1, ,4 6, 4, 2, 5,]. Now the input is not a function but a Binary search tree with this structure
class Tree:
def __init__(self, val=None, left=None, right=None):
self.val = val
self.left = left
self.right = right
def print_tree(self, indent=''):
print(indent + str(self.val))
if self.left:
self.left.print_tree(indent + '----')
else:
print(indent + '---- None')
if self.right:
self.right.print_tree(indent + '----')
else:
print(indent + '---- None')
def by_id(dict, id):
return [node for node in dict['tree']['nodes'] if node['id'] == id][0]
def dict_to_tree(dict, root_id=None):
if root_id is None:
root_id = dict['tree']['root']
root = by_id(dict, root_id)
left = dict_to_tree(dict, root['left']) if root['left'] is not None else None
right = dict_to_tree(dict, root['right']) if root['right'] is not None else None
return Tree(root['value'], left, right)
json_text = """{
"tree": {
"nodes": [
{"id": "10", "left": "5", "right": "15", "value": 10},
{"id": "15", "left": "13", "right": "22", "value": 15},
{"id": "22", "left": null, "right": null, "value": 22},
{"id": "13", "left": null, "right": "14", "value": 13},
{"id": "14", "left": null, "right": null, "value": 14},
{"id": "5", "left": "2", "right": "5-2", "value": 5},
{"id": "5-2", "left": null, "right": null, "value": 5},
{"id": "2", "left": "1", "right": null, "value": 2},
{"id": "1", "left": null, "right": null, "value": 1}
],
"root": "10"
}
}"""
dict = json.loads(json_text)
dict_to_tree(dict).print_tree()```That's not really what I want to do. I' just looking for a way to always be able and simulate coding interview questions on my PC so I can run them in the debugger and get better info. It's not just a one time thing so writing a program each and every time won't work. How do I represent the strucutre I showed you in python and use it as an input? Is that even possible in python ?
Then you can write your input as an array then deserialize it
you need a function that transforms that array to a tree
you're welcome
does anyone have a an explanation of jump point search for a*? all i can find are either people just using it, people explaining a* or very in depth code reviews
i'd like to know what happens and why q.q
Anyone know any good algos/structs for sorting/searching posets? I made a sort of double linked list for posets with insert in O(n), but deletion is O(n^2) worst case and so is sort (which is just insertion sort). I am also searching for all the elements of the poset that are less than a certain value that is not in the poset, and my current search is worst case (and average I think) O(n)
There a pretty well known white paper on this
https://www.stat.berkeley.edu/~mossel/publications/POSET_SODA09.pdf
https://core.ac.uk/download/pdf/132271822.pdf
You can also try this video on topological sorting a poset
https://www.showme.com/sh/?h=qovixPc

ProfessorZer
We construct a topological sorting of a poset, starting with the Hasse diagram of the poset. The example is inspired by what happens when you bake brownies.
You're trying to get an item from an empty numpy array
it only happen when i want to display result on the tkinter gui,it is very weird to me
I dont know what youre doing, the only thing I can tell you is that youre trying to access an empty array
http://usaco.org/index.php?page=viewproblem2&cpid=225
so i'm doing this problem and my code is as follows: https://paste.ofcode.org/DSYMGR46ya2aXL8jXCwYSH
so how it works is it binary searches on the maximum prefix, and then it checks for contradictions within each sort of "component"
however, it fails for this test case: https://paste.ofcode.org/eceRRqyzfN2sp2Px8Xbi5J
it outputs 527 instead of 502 (the correct output)
any help? (ping 2 reply thx)
anyone know about a server where hashing like base64 or rot13 is talked about?
Base64 and ROT13 are not hashing algorithms
ok sry do u place where these thing r talked
I don't understand what are you asking for
i want help in decoding this, can u suggest a server where i could get help
What is there to talk about?
CTF?
@fiery cosmos well looks liek Steganography then
@eager hamlet I didn’t look at your problem too much, but it sounds very similar to boolean satisfiability, which is a famous NP-complete problem
uh ok...?
If you're curious, here's a more generalised algorithm that doesn't rely on string manipulation. It's what I was alluding to yesterday by saying the right-most set bit needs to be shifted left.
def next_greater(n):
current_bit = n & -n # get the right-most set bit
right_most_unset = 1
while True:
n &= ~current_bit # unset the right-most set bit
current_bit <<= 1 # left shift to move on to the next bit
# End the loop if the next right-most bit is not set
if not n & current_bit:
n |= current_bit # Manually carry over the set bit
break
else:
# A bit was unset, so it has to be set elsewhere to preserve the
# same number of set bits.
n |= right_most_unset # set the right-most unset bit
right_most_unset <<= 1 # left shift to move on to the next bit
return n
I wouldn't be surprised if there's a way to do it without a loop. Bit manipulation can get crazy. This is just what makes sense to me.
Guys do you have any idea of basic problem which can be solve with genetic algorithm? Something like the tsp where you only have to deal with basic object as list
Hello everyone, is there any good sources you have for me to learn algorithms and data structures ?
and books or anything for me

@fiery cosmos - If you are a complete begineer, I'd say look into some of the courses at Courseera or Udacity or Udemy
@velvet plume thank you I will be sure to check it out
what does this algorithm do? return the next greatest number?
Returns the next number which is greater than n and has the same number of 1 bits set in its binary representation
Hi guys some one help me please
I will write a python algorithm that circulates all its edges in an undetermined graph, which will return from U to V once from V to U.
if I change DFS, will anything come out?
what do you think I should add
Is it possible to save data in json from python to use later
yes
import json
my_details = {
'name': 'John Doe',
'age': 29
}
with open('personal.json', 'w') as json_file:
json.dump(my_details, json_file)
Traceback (most recent call last):
File "c:/Users/Penny/Desktop/py/GravityAdventures/json_test.py", line 18, in <module>
json.load(after_loaded)
File "C:\Users\Penny\AppData\Local\Programs\Python\Python38\lib\json\__init__.py", line 293, in load
return loads(fp.read(),
AttributeError: 'dict' object has no attribute 'read'
is that bug or error
Swap the Arguments
Having some problems with regular expressions using re and re.search. This seems to be my error message.
TypeError: cannot use a string pattern on a bytes-like object
ifconfig_result = subprocess.check_output(["ifconfig", options.interface])
print(ifconfig_result)
mac_address_search_results = re.search(r"\w\w:\w\w:\w\w:\w\w:\w\w:\w\w", ifconfig_result)
if mac_address_search_results:
print(str(mac_address_search_results))
else:
print("no mac address.")```my expression is also trying to filter for mac address.
What is the the type of ipconfig_result ? Can you cast it to a string /
subprocess.check_output returns byte strings. You need to decode that byte string before passing to re.search
Is there any way to manipulate(like append, remove chars) strings without creating a new object every time? LikeStringBuilderclass in java or string class in c++.
No. The string type is fundamentally immutable in Python.
StringBuilder in Java just creates a new string anyway. Internally it has a character array that only gets converted to a string once you request it.
In Python, I believe f-strings are the most efficient method by which to concatenate strings.
you could use a list to store the pieces then join them together
Yeah it's reasonable to assume that would perform better than f-strings if one needs to incrementally build the string.
Though probably only with relatively large lists
I've been surprised by benchmarks before
f strings provide the easiest way for string interpolation
However, it's a general pattern to keep things immutable as much as possible for easier bug tracking
The syntax can be cumbersome in certain situations, like when incrementally building a string.
+= is much more convenient in that case syntax-wise
only works if it's the same type
helo anyone familiar with hash functions got a ctf from one and the answer and am trying to understand it
its a collision
utf worked! thanks guys
In addition to the other approaches mentioned (f-strings, using .join), there's also io.StringIO (and io.cStringIO for some versions of Python).
Why is OOP in python so weird, i mean compare Python to javascript:
class Car extends Vehicle {
constructor(args) {
super(args);
}
}
class Car (Vehicle):
def __init__(self, args):
super().__init__(args)
I mean the first one seems like the best and most beginner friendly way
uh no?
Looks basically the same to me
hey- i'm doing this problem here: https://paste.pythondiscord.com/gukaxefupu.txt
and my code is as follows: https://paste.pythondiscord.com/etekitulof.py
however, it seems to output the wrong asnwer for one of the hidden test cases
how it works is that it binary searches on the minimum, and then executes a bfs each time to see if such a max edge value is possiblle
i can't see what seems to be wrong with my code, so can anyone help?
(ping 2 help thx)
I'm trying to find a Python implementation of Matlab's ode23tb solver. It is an implementation of the TR-BDF2 algorithm. SciPy doesn't offer a solver for this algorithm. Are there any other Python packages that have this type of solver? https://www.mathworks.com/help/matlab/ref/ode23tb.html
This MATLAB function, where tspan = [t0 tf], integrates the system of differential equations y'=f(t,y) from t0 to tf with initial conditions y0.
(nvm i read the problem wrong lol)
sooooooo
Need help on this problem, easy silver, basic graph theory
I get the problem all right, just not the solution
Any help would be much appreciated, been on this for hours 😦
usaco gang!!!!
what don't you get about it?
(also imo this problem is easier with dsu instead of graph theory)
@fiery cosmos does sci py have it?
i think julia or c/c++ libraries like sundials have significantly better integrators than scipy
@wraith valve No SciPy does not have an ode23tb (TR-BDF2) solver. Is there a Python version of Sundials?
@fiery cosmos i think they actually have a python wrapper
basically it python code but it calls c code in the background
ayyy but i'm pretty bad just got into silver
so they binary search by finding the correct number of wormholes. The binary search takes log(n) time so i'm confused of how seeing if a certain number of wormholes will be enough take linear time. Sorry if this is a dumb question 😦
what is dsu?
disjoint set union
you sure you're binsearching for the correct number?
I think so? I am very confused on this problem, so if you could explain the gist of the process they used that would be very helpful. I think they are binsearching for the correct number of wormholes, but I could be wrong.
There are n applicants and m free apartments.
Your task is to distribute the apartments so that as many applicants as possible will get an apartment.
Each applicant has a desired apartment size,
and they will accept any apartment whose size is close enough to the desired size.
Input
The first input line has three integers n, m, and
k: the number of applicants, the number of apartments, and the maximum allowed difference.
The next line contains n integers a1,a2,…,an: the desired apartment size of each applicant.
If the desired size of an applicant is x,
he or she will accept any apartment whose size is between x−k and x+k.
The last line contains m integers b1,b2,…,bm: the size of each apartment.
4 3 5
60 45 80 60
30 60 75
Out: 2
n = int(input())
m = int(input())
k = int(input())
applicants = input().split()
applicants = [int(x) for x in applicants]
sizes = input().split()
sizes = [int(x) for x in sizes]
ans = 0
applicants = sorted(applicants)
sizes = sorted(sizes)
for applicant in applicants:
if applicant in sizes:
ans += 1
sizes.pop(sizes.index(applicant))
else:
p1 = applicant - k
p2 = applicant + k
while p1 <= p2:
if p1 in sizes:
ans += 1
sizes.pop(sizes.index(p1))
break
elif p2 in sizes:
ans += 1
sizes.pop(sizes.index(p2))
break
p1 += 1
p2 -= 1
print(ans)
it gives me 1, why?
can someone send me a index/schedule like thing to learn dsa like in order
eg learn arrays, then something else that kinda thing
shouldl be easy, just step through your code with a debugger

sure
Bit Manipulation
Recursion
Arrays
Searching
Sorting
Matrix
Hashing
Strings
Linked List
Stack
Queue
Deque
Tree
Binary Search Tree
Heap
Graph
Greedy
Backtracking
Dynamic Programming
Trie
Segment and Binary Indexed Trees
Disjoint Set
But personally, if you are a beginner, just start with a course on Udemy or follow a book
http://www.usaco.org/index.php?page=viewproblem2&cpid=744
so i'm doing this problem
an idea would be t go through all 1 mil colors
and see if they could be painted first
but that would involve
O(1) validation
so there's probably some preprocessing involved
any help? (ping 2 reply thx)
You don't need to go through all 1 million possible colors, only the <= 1 million that actually appear on the final canvas. For each color that is on the canvas, if it does not form a contiguous rectangle, it must have been painted before any colors that interrupt that rectangle, so you can build up a list of which colors could not have been painted first: any color that falls between the top leftmost and bottom rightmost instance of another color can only have been painted after that other color, and therefore couldn't be first.
well they could still give a test case where it's like 1000x1000, and then each color takes up 1 or 2 cells
Actually, that's not quite right: any color X that occurs between the leftmost and rightmost column that another color Y occurs in, and that occurs between the topmost and bottommost row that Y occurs in, means X must have been painted after Y
as long as it doesn't overlap anything, it could've been painted first, right?
The only way for there to be 1 million distinct colors on the canvas is for each color to be in a single cell, which means none is interrupting any other and any one could have been painted first.
yeah but tbh implementing that special case seems like a pain
Right, don't special case it.
One loop over the input array can find you what colors occur in the canvas, and what the topmost row, bottommost row, leftmost column, and rightmost column each occurs in is. A second loop over the canvas can find you which colors interrupt another color. Your answer is the number of colors that don't.
If you need something faster, the simplest optimization would be that you can completely drop and ignore any color that occurs in a 1x1 or 1x2 or 2x1 shape after the first loop over the array. They cannot be interrupted by anything, so you don't need to check whether they've been interrupted.
If you need something faster than that, there's a data structure optimized for locating overlapping ranges... It's called an interval tree. I'm betting that's overkill here, though
anyone who knows a good source for greedy, backtracking, dynamic programming problems for python?
Eventually without graphs, trees, stuff like that
and eventually not CSES
https://www.youtube.com/watch?v=oBt53YbR9Kk&t=18s really good and long video on DP.

Learn how to use Dynamic Programming in this course for beginners. It can help you solve complex programming problems, such as those often seen in programming interview questions about data structures and algorithms.
This course was developed by Alvin Zablan from Coderbyte. Coderbyte is one of the top websites for technical interview prep and c...
^
The video is broken down into specific problem sections, you can skip any of the ones you want
I'd put recursion just before tree
I wouldn't because you need recursion to solve lots of other problems besides trees like arrays, sorting, lined list etc.
sure but I think that it can be intimidating for a beginner
dsa aren't a beginner topic in the first place, so i think it's fine
bruh, don't doubt my algorithmic skills. even though i don't have any lol
oh, it s the recursive functions represented as binary trees
okay it s cool i guess
i mean recursive functions can be written as non recursive
but then i would say that knowing what it is would help alot with tree structures and such
yeah, sort of
if it's a tail-recursive function, you can refactor it to a simple while loop
and if it's a non-tail-recursive function, you can keep track of the call stack yourself
!e
For example, here's an atrociously slow and silly way of writing the recursive solution to fibonacci with a loop
import re
def f(match):
n = int(match[1])
if n <= 1:
return f"{n} "
else:
return f"{n - 1} fib {n - 2} fib "
def fibonacci(n):
s = f"{n} fib"
while "fib" in s:
s = re.sub(r"(\d+) fib", f, s)
return sum(map(int, s.strip().split()))
for i in range(20):
print(fibonacci(i), end=" ")
@austere sparrow :white_check_mark: Your eval job has completed with return code 0.
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597 2584 4181
It works like this:
5
4 fib 3 fib
3 fib 2 fib 2 fib 1 fib
2 fib 1 fib 1 fib 0 fib 1 fib 0 fib 1
1 fib 0 fib 1 1 0 1 0 1
1 0 1 1 0 1 0 1
#=> 5
recursive functions are actually slower than normal 😛
In Python, yes, that's generally true
just in python?
Well, other languages can introduce optimizations that make recursive and non-recursive functions indistinguishable.
as I remeber my bench, recursion was almost twice as slow 🤔
if you have something that isn't tail recursive and you want to make an iterative version, you'd use a stack or a queue to track the intermediate results.
...and in some languages, the only looping construct in recursion, so pretty hard to benchmark there
but those languages usually have those recursive optimizations
C++ template metaprogramming falls into that category - no way to loop without recursion.
For example, if you compose two functions, product and make_list, where product finds the product of a list, and make_list creates some lazy linked list step by step, you can avoid creating an intermediate list.
quicksort is a pretty good example of something that's usually faster when written recursively than iteratively. The extra work that you need to do in order to track the intermediate results is more than the extra cost of the recursive function calls.
well, I guess it's just that the hardware stack is faster than a software stack 🙂
the call stack isn't exactly implemented in hardware - but there are specific assembly instructions that are primarily designed for manipulating it, so that's fair.
yeah, the stack is still in RAM
Coincidentally, I just had my students writing their own recursive quicksort implementations for extra credit in my intro CS course.
any color that falls between the top leftmost and bottom rightmost instance of another color can only have been painted after that other color, and therefore couldn't be first.
wouldn't this be O(N^2), and thus too slow?
or is there a faster way?
You only need to look at colors that do appear on the canvas, and that don't appear as part of a 1x1, 1x2, or 2x1 rectangle. So it's not N^2, no. It's N*M, where M is strictly smaller than N
M is the number of colors that appear on the canvas but not as a 1x1 or 2x1 or 1x2 rectangle
if N is 1000000, then M is 0.
the only way for every color to appear on the canvas is if every color is used only in a 1x1 cell, so there are no colors that are not a 1x1 or 2x1 or 1x2 rectangle
the number of colors that a) appear on the canvas and b) do not only occur in a 1x1 or 2x1 or 1x2 configuration is strictly smaller than the number of colors that could appear on the canvas.
In the example the problem gives, M would be 4, while the total number of possible colors is 17 (including the 0 for "no paint")
oh ok
Any dynamic programming lessons for Python?
Learn how to use Dynamic Programming in this course for beginners. It can help you solve complex programming problems, such as those often seen in programming interview questions about data structures and algorithms.
This course was developed by Alvin Zablan from Coderbyte. Coderbyte is one of the top websites for technical interview prep and c...
oh wait you said python
it uses JS but the same concept applies
especially the visualization portion of problems
that part would be the same
Hi everybody, I'm new to Python so I'm not sure if a question relates to pathlib is suitable at this channel?
Somehow the output is not E:\test field\BAK\file
but I don't know why. Can anybody explain this to me? Thank you
from pathlib import Path
folderPath = Path("E:/test field")
fileList = folderPath.glob("*.tga")
for child in fileList:
bakpath = folderPath / "BAK" / child
print(bakpath)
Output:
E:\test field\T_M_M_Countess_Lace_2_Normal.TGA
E:\test field\T_M_M_Countess_Lace_2_OpacityMask.TGA```@dreamy bay i prefer using os.path.join to append paths together
well, I'm studying the pathlib because there will be some situation that I need to run the app on both unix/window environment. So its path is better
yeah os.path.join
is os independent
it uses a delimiter based on ur os
quite sure
at least thats how i made my bot in a windows enviornment and deployed in a linux one @dreamy bay
yeah, I already did it successfully with os.path
I just trying to replace it with pathlib 😄
oh
Thank you very much!

{kind=link}
{kind=link}
sure but non-tail recursive functions require you to handle the call stack by yourself, which is not that easy
def extract_did(line): for x in line: x = re.findall(r'\d+', line) return [x for x in x if len(x) == 10]
``def extract_did(line):
for x in line:
x = re.findall(r'\d+', line)
if (x for x in x if len(x)) == 10:
return x
else:
return 0
``
hello in first function i was able to get the numbers with len of 10
i made the 2nd function to return 0 if there's no numbers with len of 10
the 2nd function return all the numbers instead
Kindly help me where and how my 2nd function got wrong .
Apologies if this is not the correct channel for my question .
Why not \d{10} ?
How can i code an random algorythm who create random math task like 11 + 4 or 6 + 9...?
you mean make 2 random integer value?
Have you an examole?
thanks
*example
depends on what you mean by "math task", if it's just the addition of 2 integers then you can just use the random module to generate 2 random integers
yeah, as like syph said: you can use random module to generate 2 random integer or float numbers
import random
a = random.randint(0,100)
b = random.randint(0,100)
print("{}+{} = {}".format(a,b,a+b))```output
84+65 = 149
16+20 = 36```How can i code an random algorythm who create random math task like 11 + 4 or 6 + 9...?
Are you talking about 'how is random implemented' ?
If this is your question. the keyword you are looking for is 'PRNG', pseudo-random number generator
solved, i was able to extract the integers to different column, not the most efficient way though.
``def extract_did(line):
for x in line:
x = re.findall(r'\d{10}', line)
x = list(dict.fromkeys(x))
x = ' '.join(map(str, x))
return (x)
df['dids']= df.apply(lambda row :extract_did(row['comments']),axis=1 )
df['did1']=df['dids'].str.split(' ',10,expand=True)[0]
df['did2']=df['dids'].str.split(' ',10,expand=True)[1]
df['did3']=df['dids'].str.split(' ',10,expand=True)[2] ``
Hey, any good resources for learning data structures, algorithms in python after learning python basics ???
Ill be using this channel one day, and ill understand this stuff... Not yet
SO about trie, can anyone provide me a good resource for the thing. I am not able to find a good one.
The error answered you, you can't subtract a string from a string
then how do i do the program
You first need to convert them to integers to be able to perform the subtraction
you're welcome
hey guys. what's the equivalent of heapq's heapify for queue.PriorityQueue? I have an array i want heapified. should I just stick to heapq?
Say I want to store words from dictionary to a tree and I want to show all words that starts with S, which tree should I store it to? AVL tree or BST?
i think if you just insert elememts one at a time into the p queue it should be automatically sorted
i know but in that case i'd get O(N*logN) performance for N elems instead of just O(N) like heapify
it's for learning purposes. just doing some leetcode stuff
oh ok
thanks anyway 🙂
Is there a way I can exclude 0 in a random interger?
random.randint(-16, 16)```one approach would be to make a list of -16 to 16 without the 0
and do a random choice
And kind of annoying if I expand the amount of numbers are all
yeah sth like range(-16,0) to generate the first part
and a range(1,17) for the second part
and add them together
eh its two parts and its longer than just randomint
it works i guess
Okay
i have a doubt guys
def fib(n,memo = {}):
if n in memo:
return memo[n]
if n<=2:
return 1
memo[n]= fib(n-1)+fib(n-2)
return memo[n]
print(fib(100))```how does the memo stores the value ?
does it returns the value in recursion?
first the memo[n] = fib(n-1)+fib(n-2) works out and then it checks if n in memo and returns the value?
This could be rewritten as:
def fib(n, memo):
if n in memo:
return memo[n]
if n<=2:
return 1
memo[n]= fib(n-1, memo)+fib(n-2, memo)
return memo[n]
default_memo = {}
print(fib(100), memo)
Does that make it any easier for you to understand?
i can understand it and where it really confuses me is the dictionairy part memo[n]=fib(n-1)+fib(n-2) how does the dict stores the value ?
like if dict[5] = 4 + 3
doesnt dict works like
{4:5}
like that format ???
!e ```py
d = {}
d[5] = 4 + 3
print(d[5])
@lean dome :white_check_mark: Your eval job has completed with return code 0.
7
you can create a dict using d = {5: 7}, but you can update an existing dict using d[5] = 7
right
I'd rather you not ping me with questions - ask in a channel, and if I'm online and trying to help people I'm sure I'll notice it.
yeah thanks no worries
one more thing, avoid using an immutable element like a dict or a list as a default value for a parameter
so i can have an normal parameter?
`def fib(n, memo):
if n in memo:
return memo[n]
if n<=2:
return 1
memo[n]= fib(n-1, memo)+fib(n-2, memo)
return memo[n]
default_memo = {}
print(fib(100), memo)`
and implement code like this ?
def rec(n, memo):
if n in memo:
return memo[n]
if n<=2:
return 1
memo[n]= fib(n-1, memo)+fib(n-2, memo)
return memo[n]
memo = {}
return rec(n, memo)```oh i get that now
this implementation doesn't require you to create a dict before calling fib()
Or you can make a function that takes another function and caches its result: