#algos-and-data-structs
1 messages · Page 67 of 1
:incoming_envelope: :ok_hand: applied timeout to @fiery cosmos until <t:1740121762:f> (10 minutes) (reason: duplicates spam - sent 4 duplicate messages).
The <@&831776746206265384> have been alerted for review.
hello, I am looking for a partner to learn DSA with me using python and on intermediate level
i do not get how calculating for the intersections work at all
like for {1, 2, 3} and {3, 4, 5} it could be divided into {1, 2} x {4, 5}, {1, 2} x {3} and {3} x {4, 5} which comes out to 2*2 + 2*1 + 2*1 = 8
but to generalize it for multiple sets and intersections with a size bigger than 1 would be a bit complicated
:)))
https://paste.pythondiscord.com/IMEA I think this is it (also I was wrong about {0,1}, {1,2}, {2,3}, it's actually 6).
the basic idea is ||you deconstruct the input sets into disjoint sets, keeping track into which set went into which parts, then you split the product whenever you could pick from the nth original set from multiple new sets|| -- it is a very exponential solution tho
hm, should probably make sure that -= doesn't end up with a nonpositive number
guys
i figured it out
i just need to remove 2 tabs from the else line
:))))
i got it runnin smooth
producing fib number with the prime numbers ones only:)))
nice

Where would a ( or b or c) be 0 if you start with 2 and go up ?
How long have you guys been studying dsa?
It just cant be 0 :)))) i just need them for repetition and division to check if the fib number is prime number or not
!e
for n in range(-10000, 10000):
for i in range(2, n):
if i == 0:
print('WTF!!!')
:warning: Your 3.12 eval job has completed with return code 0.
[No output]
It's impossible for one of them to be 0 if you start with 2
that is the consultant performance payment guarantee. Pay me an extra fee, and you will see automatic perfomance improvements!
Idk, it doesnt know that so i gotta put the != 0 in or else it would keep poppin up those devision errors
...
not in that code
the thing you are dividing by will always be ≥2

i am willing to start DSA can anyone help me how to start
you started DSA?
Me too , i am willing to begin with python , is it worth ?
Yes.
Heya! I'm hoping that's the right place to ask. Noob here. I was just wondering what's the best way to intertwine lists. Let's say I have some kind of algorithm that outputs a list of frame data for some kind of object o1, (o1f1, o1f2, o1f3 etc.). I need to build a global list for all objects, sorted by frames. Say, with three objects o1, o2, o3: (o1f1, o2f1, o3f1, o1f2, o2f2, o3f2, o1f3 etc.) I managed to do it but it's disgusting :d Ty
[list[idx] for idx in range(len(lists[0])) for list in lists]?
hmmmm, could be? I'm a little confused
Basically I have this:
GlobalBuffer = []
for Obj in Objs:
FrameData = GetFrameData(Obj) #f1, f2...
GlobalBuffer += ? # intertwine buffer o1f1, o2f1, ..., o1f2, o2f2, ...
oh, that seems to be it actually
I think I got it 😄 Ty @rare laurel
If someone here has given ZCO (Olympiad) before can they guide me a bit?
Like I know nothing bout dsa and can't figure where to start
And worst part that the second part of the Olympiad NEEDS me to write code in C++ which ill need to learn from scratch
But where so I start with DSA?
I have till like October or November till the olympaid
Wdym intermediate level
Hi everyone,
Do you know any website on which I can train on writing algorithms before turning them into python code ? Plain old algorithms just to train my logic skills
I don't think you can complete decouple programming from algorithm questions tbh, might as well look for math puzzles for that
it is
who needs heLP

guys i need someone who will help me understand python single and doubly linked lists i have an exam next week and im completely lost in the subject (:
what part do you need explaining
single linked list is just when each node links to another, but it's a one way link, whereas for doubly linked list there's a double link, so when a node is linked to another node, the other node is linked to the previous node as well
So quick back story im a first year comp sci and eng major and i didnt attend first semester due to personal problems and currently taking second semester courses now im taking DSA and in the first semester they took python which i didnt and started taking it this semester basically i caught up understood the important stuff that i need to to be able to catch up with the DSA class now for some reason im unable to solve problems like i just dont understand why im unable to solve problems even though i was practing when i was studying python so i need help understanding how to solve problems for example this one

I dont know how to approach problems like this
For the case of k=1, there would be 2 operations going on: a pop(), and an insert(). In terms of big O notation, the pop() operation is time complexity O(1) for the special case of the last entry in the iterable (your case, i.e.). The time complexity of insert() is O(n), where n=7 in this case. For big O notation you assume worst case scenario, and start taking limits to understand the asymptotic behavior. So discard O(1), and your time complexity is O(n)
someone correct me if I am wrong here
You kind of have to get into the nuts and bolts of how these operations are implemented in python to figure this out.
I think another trick that is needed here is visualizing a programmatic approach to the ask. Once you have that code in your head you can proceed along with the analysis
Also reading comprehension. I don't mean this offensively, but in my experience from teaching college a significant chunk of the bad grades students get can be attributed to being in a rush and not carefully parsing the question.

Time omplexity in Python is a key metric that tell how efficient the program is. Learn how it work from top python training institute in Delhi
is there any unordered data structure that allows duplicates?
I want to know if there is a better (faster) way to compare an array of unordered numbers without using a sorted list/tuple
bag?
dude you're the first other person i've seen that knows what a bag is lol
collections.Counter
it depends
that too
i would ask them if they know it as multi set and they would still have no clue what i'm talking about lol
if the objects that are == are interchangeable, then yes
i may have commented multiset, but then realized that multisets and bags are the same thing, so disappeared said comment. perhaps i should not have
I just dislike the name 😛
the name bag?
it is quite terrible
I learned to write python on the job but I only ever learned things relevant to the data engineering and etl business uses my work did and now having to go back and learn algos from the beginning is making me feel so stupid.
and what does this have to do with LLs? is the "list" mentioned in the problem brief referring to a linked list?
anyway, Casper gave you a p good answer already; though it assumes it's an array, the same argument can be modified to suit an ll
if it is an array tho, you could use some tricks to implement it in less time if all you care about is the result
my genuine question is like ive started doing dsa but i really dont know where it is used
which algorithm in particular?
thanks
ive understood and did some practice using uhh stacks, arrays, those dynamic arrays too and uhh like all the linear dsa i know
but how and where are they used
i just make these things in vs code i know its a very silly questions but if someone explains then thank you so much because i really wanna know i just do these codes in vscode but in real life how are they used where are they used?
arrays are so everywhere that I'm not sure what example I should give really, literally anytime you want a list of stuff you may consider an array
dynamic arrays are used when you need an array that can change in size
stacks are used for example to implement the "call stack," which helps programming languages determine the order to execute code, e.g.
def a():
pass
def b():
a()
def c():
a()
b()
c() # <-- calling c
```the call stack allows python to know that it should execute `c -> a -> b -> a`i know what they do and how they work but i was just asking for real life examples like where ae they used and HOW are they used
like i know stack i will practice using stacks and make stuff but what next? where are they used
the call stack is a very real example
the reason you can have functions in functions and recursion and other crazy stuff, is because of the call stack implemented in the programming language of your choosing
as a very simplified example:
def my_cool_fn():
print('hello!')
result = my_other_fn(1, 2, 3) # <--- let's say we're on this line
print(result)
```you may imagine that right here, the call stack is now like this (pseudocode:
```py
call_stack = [
(function=my_cool_fn, line=2, arguments=[]),
(function=my_other_fn, line=0, arguments=[1, 2, 3]) # <-- this is newly pushed onto the stack
]
```after `my_other_fn` finishes executing, that last item gets popped off the `call_stack`, and python knows to continue from the `result = my_other_fn(1, 2, 3)` line because it's stored in the last item (`line=2`)what the call stack is like isn't something you have to actively consider normally when programming, because it's handled by the language you're programming in
but say you're now implementing your own programming language from scratch, then you'll have to implement the call stack yourself, which you'll use a stack to do
and as for arrays, again, it's literally just everywhere
for example, you're analyzing data. there's probably not just one, but many, data points. array go brr
I guess this is the right place to ask about ways to not brute-force solving a problem.
I have a set of 4 numbers, which can be multiplied, divided, added or subtracted (as normal) to get to a goal number.
(Sometimes there are a few additional numbers, up to 6 total)
Brute forcing all the permutations seems naive and inefficient, but I have no idea how to go about trimming the possibility space
I assume this isn't an unsolved problem, but with my poor math background I don't even have a word for this kind of concept to start researching
naively this sounds like it would be NP-hard
if we are allowed to not include numbers, doesn't this become subset sum?
up to 6 is still quite a small search space so brute force is inefficient, but efficient enough (a naive brute force of every possible order of numbers and every possible operation is 6! * 4 ** 5 = 737280, which is still quite small and an average computer should have no problem doing this in under a second)
for larger sets, i would probably start with brute force via a stack (loop through every possible ordering of the stack) and operations that pop 2 values, apply the operator, and then push onto stack (Reverse Polish Notation), and then optimize from there; you can enforce things like _ + _ - _ + _ - has to be ++-- and same with */, or like if you have multiple of the same op the numbers should be in sorted order or smthing. There should be some recursive way to iterate over all valid RPN stacks, and if you do it correctly you might be able to do some DP (like if you fix the stack prefix up to some index as you recurse, you could maybe keep a cache of values and do backtracking)
all this seems like a lot of bookkeeping tho, and as fenix said this seems to be a hard problem in general
Thanks for the advice
It's nice to know that it actually is a hard problem, and I'm not just being dumb
@fossil ice that's an interesting problem, but there is an application of genetic programming that might apply. And note that reverse polish notation, mentioned by @naive oak , is actually an abstraction of a binary graph traversal in "post-order". Genetic programming deals with precisely such graphs, so I am guessing here you might be able to generalize such an optimization using graph theory
Phew. Funny how I can get programs that do complicated sounding work (communications drivers) done real easy. But running into simple sounding math problems reminds me that I really should have gotten that computer science degree
hello guys, what's going on?
anybody having any topic to discuss, i have to verify me as human which requires discussing something about a topic, solving a problem
How many r's are there in strawberrrry?
There are 5 r's in "strawberrrry".
: )

@opal oriole any query regarding this??
: )
hey ik this is unrelated but can someone PLEASE help me remove those green and blue squiggly lines from vs code? PLEASE?
this prob goes in #editors-ides
@opal oriole bro
please help me in meeting the criteria for voice verification
you left me in middle 😢
Explain how the count method is implemented in Python.
It's goes through array of characters one by one and count the occurrence of given word in a string
Is it fine or is it anything else?
@opal oriole
What is the specific algorithm used by Python (CPython), and how does it differ from the most simple implementation?
i don't think it needs any algorithm
it's simple list/array
i am noob in low level
so, can you please teach & explain me, what is it?
what is being used?
🥲
Does any Competitive programing Contest calendar extension or something like that exist for Safari?
yo
has anyone here used ai to successfully create algos and structs?
and if so
what ai would you recommend?
Claude or deepseek
https://clist.by/ maybe
Anyone has anything pinned or place where to start DSA from basic to advance?
what is the answer for that?
@opal oriole

YouTube
mycodeschool is an educational initiative. Our aim is to present some core concepts of computer programming through illustrated examples and creative teaching techniques.
You can send your feedback to mycodeschool [at] gmail [dot] com
Visit: www.mycodeschool.com
Some good resources to learn and practice programming:
TopCoder - http://communi...
I think you might need to switch at some point cuz unfortunately maker died in a car accident, so he couldn't complete it. but imo whatever that is available is absolute best.
That's sad news. But this page isnt for python?
ppl usually don't do DSA in python (if you're beginner). it's either C/Cpp for better understanding of how what's happening under the hood
python hides lot of stuff
das jus my take. feel free to do DSA WITH ANY LANGUAGE
roadmap.sh
Learn about Data Structures and Algorithms using this roadmap. Community driven, articles, resources, guides, interview questions, quizzes for modern backend development.
for PYTHON
how much does the under the hood stuff even matter for understanding dsa?
having to malloc all your own stuff doesn't typically give a much more fundamental understanding of the cs involved
but diving into C/C++ forces you to handle things like malloc, which gives you a better feel for how data structures work under the hood. It's not mandatory, but it does add a deeper layer of understanding if you're aiming for that.
C++ doesn't even force that, rather the reverse
new/delete is considered bad practice most of the time
bruv, I get what you're saying. sure, but having even a basic grasp of what's happening under the hood can sometimes save you when things go sideways or you need to optimize. It's not a must for everyone, but knowing a bit more never hurts.
there is the fundamental dsa understanding and there are implementation details
yes
yes, you'll want some of each
exactly
but for the actual dsa understanding python is perfectly fine
it's knowledge that isn't at all language specific
do companis care about wha lang we learnt dsa in ?
why would they?
if they need someone that's good with dsa and someone who knows C++ then that's two mostly orthogonal requirements
I was learning DSA with python myself but then i had to switch cuz colleges/uni use c/cpp in 1st year
in which case it's not like you had to re-learn dsa from scratch
i am following the roadmap site
yep i follow that too. it's pretty helpful
my head hurts while reading official documentation tho
Roadmap.sh that's all?
I'm not a fan of that site. It's not particularly helpful nor is it a roadmap.
The MIT 06.006 course is a really good place to start, if you want the college level DSA experience.
Yes I want to start from pure basic dsa and go forward
Atleast I want to be able to solve all mid level problems
@modern gulch this one?
https://youtube.com/playlist?list=PLUl4u3cNGP63EdVPNLG3ToM6LaEUuStEY&si=TEDKBLWl5GzoqjEw

YouTube
Instructor: Prof. Erik Demaine, Dr. Jason Ku, Prof. Justin Solomon View the complete course: https://ocw.mit.edu/6-006S20 YouTube Playlist: https://www.youtu...
what are "mid level problems"
For a data engineer solutions. I don't know how to describe though
6.006 might be good but I don't bother going through all the lecture videos
and looking at their problem set I was thinking how tf would you figure those out if you didn't already know this (in a reasonable amount of time) which is like every dsa course ever
Maybe I'll pick only the ones mostly related to college level only
Well that also works thanks @tight cedar
That's it. I also agree with HyperCube: use the course as an outline for the topics to learn, but you don't have to learn it their way... and you can jump around.
(this goes for literally anything you want to learn)
Thanks man @modern gulch
Hello
o/
I maintain a library that includes an implementation of a coroutine scheduler. I'm currently in the midst of rewriting a lot of the core of it and realize that 90% of it is a series of deques. However, the way it's written, I need fast random removal from these deques. I've run into some serious performance issues with other schedulers and their use of tombstoning, so I won't be doing that.
I've currently implemented these deques using OrderedDict, which preserves insert order, allows FIFO pop with popitem(last=False), supports peek via next(iter(queue)) and has O(1) random removal, compared to deque which AFAIK is a specialized list, making random removal O(n). Is there a better way? Is deque actually faster for removal than I'm assuming?
deque has fast insertion and removal at both ends
from collections import deque
"random" as in the middle. And I only need fast random removal, insertion will only ever be at the the end.
what operations do the data structure need to support exactly?
class MyDeque(Generic[T]):
"""A deque with unique elements and O(1) random removal."""
def peek(self) -> T:
"""Return the value at the front of the queue without removing it."""
def pop(self) -> T:
"""Return the value at the front of the queue and removes it."""
def append(self, value: T) -> None:
"""Add the value to the end of the queue."""
def __len__(self) -> int:
"""Return the number of active elements in the queue."""
def remove(self, value: T) -> None:
"""Remove the value from anywhere in the queue."""
These deques will hold callback structures. It's the core of the event loop and our equivalent of Futures.
will values be unique?
a dumb solution would be to keep a set of deleted elements and during removes you just mark the value as deleted
then during pop you
while peek() in removed:
removed.remove(peek())
pop()
return pop()
amortized O(1)
The values will be unique. They call that "tombstoning" and it can lead to performance and memory usage issues, so I'd like to actually remove the reference from the queue.
hey guys, i finished learning python not too long ago (i have a basic idea of language and syntaxes) now i wanna learn DSA
anybody interested in mentoring??
I am interested in co-learning
for python LinkedLists,
the time complexity of operations on these datastructures, it is identical as it would be in, say, C++
aside an initial cost associated with Python class instantiations
true / false?
yeah
I mean, I look at implementations, and this seems quite apparent. But you never know
don't do dsa in python do in low level language
or
just try to avoid using high level things like list
try to use array and c datatype low-level equivalents in python
that's a bad advice
very bad
bro is trying to get rid of the competition lol

try to practice dsa problums in python in hacker rank also DSA is important
doing god's work
That's highly highly debatable.
is the self taught computer scientist, Cory Althoff a good book for dsa
the book name itself doesn't seem to be very related to dsa
Actually I haven't done DSA ever
But logic i have received from other experienced coders, I find it sensible
So I am just passing that
That's why I clearly said if want to do in python then try to use low level data types rather than high level like instead of list you can use array, etc, etc.
Do you even know what you are talking about
nope
DSA, should we do DSA in python or not that's it.
maybe they're talking abt this array
I'm not sure if there's any time performance benefit, but I've also p much never seen this being used

Python documentation
This module defines an object type which can compactly represent an array of basic values: characters, integers, floating-point numbers. Arrays are sequence types and behave very much like lists, e...
Was thinking about python without imports 👍
-# aka. I was too unaware to know it's existence
Can you "hack" submissions on kattis?
I know you can on cses and on codeforces but I don't know how one could try on kattis?
Because my n^2 just got accepted even though it shouldn't so I sort of wanted to hack it to make sure
its randomized depth first search
DSA is about the concepts and algorithms involved. What language is not very relevant, and 'high level vs low level' isn't really a consideration when you're learning the concepts.
but python has libraries which provides higher level of abstraction compared to low-level languages and which removes the complexity of low-level thing
and companies here prefer in low-level languages, i know that it won't generally matters and should not be
the "complexity of low-level thing" is imposed by the design of low level languages (and this exists because at some point, some programs have to deal with the fact that programs run on hardware and not magic, but writing general purpose programs without abstractions is generally not a good idea), not data structures and algorithms
how is manually allocating memory for an array going to help you understand an algorithm? what do you get from manually reallocating an array when its out space?
yep
But who will make companies understand this, which hires based on it
i dont have any work experience, but i havent heard of much companies requiring "low level knowledge" if the work isnt related to it.
(you also dont need to actively make your development process always harder just to learn something: you can, you know, just learn it, and then use abstractions)
I also don't know that
but companies take DSA test, here in india, everybody tell this only to focus on DSA
which i don't think is the only way to be a good programmer/engineer
You're talking about two different things: learning DSA, vs which languages are in demand by companies / which ones you should practice.
But, yes: I agree that DSA is over emphasized in hiring processes, and that becoming a good SWE involves other skills.
Altho, even the large companies that I'm familiar with include other types of questions in their hiring, such as system design/decomp.
i think this DSA hype is more when companies hires on-campus than off-campus
If you are referring to implementing your own dynamic array or hashmap, then doing that in a language like C at least once is not a bad idea, but it's also not very difficult and you can do it later at some point (you are not really missing out).
Once these have been implemented in something like C, it will be more or less the same as the Python experience for DSA (minus the safety given by Python).
Some companies give some really unfair DSA problems that are really niche puzzle problems that may not even show up in the real world. But many of them also give some very fair problems that are just filtering for whether or not you can solve problems or program at all.
They have many applications and they need some filters.
I hate when competitions don't expect you to know nodes but they want you to apply nodes algorithms on lists
Hello,
I need to understand the implementation of the insert method in the avl tree using python.
GeeksforGeeks
An AVL tree is a self-balancing binary search tree that maintains a height difference of no more than one between its left and right subtrees, ensuring O(log n) time complexity for operations like insertion and deletion.
does anyone have a script for voice chat
im making this little 2-d sandbox and I have multiplayer but i need voice chat
Is anybody preparing for MAANG companies, have upcoming interview scheduled? I am looking for peer programmer.
can you show your game?
can i learn all the data structures (general datastructures, not list, tuple, dict or set) like arrays , trees, graphs, hash tables, and 1 - 2 more that are available, in python by today, since their implementations are already available in python in different libraries
will that be possible
because i plan on doing it all by today, since... as always... i wake up when the deadline is near and then i have to cover a lot in less time lol
knowing what they are in vague terms, maybe
knowing how they work or how/when to use them, no
holy yap
all
no
there are a lot of data structures that exist out there, a lot of which you prob never even heard of
e.g.
- doing spatial comparisons? Ball trees / KD trees
- databases? B(+) trees
- string manipulation? AC machine, suffix trees, ropes,
(you'll notice that a lot of them are trees because trees as a concept is just very useful)
even for something as "simple" as implementing an actually good bst, there's multiple ways like avl, splay, rb, treap, ...
question for the hive mind: bit manipulation with Python? How does one do this?
Python has bitwise operators
So it's not very different from any other language
x >> 1
https://wiki.python.org/moin/BitwiseOperators ref for operations but you might need a tutorial first
you got that bro tweaking even more than he already was lol
to be fair it's on them for waiting until last minute
kd trees were fun, read about ropes on the zed blog
zed uses ropes, wanted to try implement in python but was too lazy that time
i liked segment tree and trie
i did those in java though
(don't worry, i'm done with java for good now)
Can't forget HAMTs
nvr heard, worked with tries tho
java generic types were cool to be honest
that's the one thing i'll probably miss from java
i would always make generic implementations for data structures
Its a copy on write hash map -- Python uses it for Contexts in the contextvars module.
Python's typing does support generics as well
bet
java syntax looked nice but
it was literally an oop glaze
a program couldn't even be run without having a class
waow
I will definitely check it now
Hi guys i have literally 1 week ansd 3 days till a DSA python competition stage 3 and i'm nolt really good at this any tips i can learn it real fast
what kind of competition & how much do you know
while i don't know too much dsa, i think just practicing would probably by the best way
perhaps on leetcode
Can anyone help me with coding assessment?
lol
that's the spirit
Well, as per rule no. 8, members can help people learn how to do the assignment without doing it for them. So, if you are ok with this then you may create a post in #1035199133436354600 channel
assessment sounds more like job application type stuff
in which case helping is just defeating the purpose
Well, I may be wrong but as per the rules we can help them to learn on how to do it otherwise we need to update the rules to bar all coding assessment/assignment. Because there won't be a way to identify which are for learning purpose and which are for job applications.
if it's like any code assessment I've seen before it's very time-boxed and you wouldn't really have time to learn something completely new on the spot
It's more like an exam, and helping with those is already not allowed
Well, the question will be on how to distinguish between them. If there is a proven way, then maybe we have to update rules so that others can follow it accordingly. But as per the current rules we have, I don't think we can judge by ourselves and decide not to help the follow members.
so we should just ignore what people say since maybe they said it wrong and it's not an on ongoing exam/assessment at all?
people do ask for help with exams/assessments that are no longer active, which is a fine case
but nothing here even suggests this is the case
Ok, got it. 👍
i need help about alg
Re-read the first line in #voice-verification
If you spam messages to artificially increase the message count you will be blocked from verifying
Hey all I am trying to solve the following problem,
As the constraints are quite small, I am thinking of trying to implement some backtracking solution.
However, I am struggling to come up with one. Could someone please guide me on how to implement one or could someone please suggest another way to go about solving it?
Thank you



deja vu
indeed, i tried solving it before and left it. ive learnt a bit in the meantime and still cant solve it 🥲
I’m trying to optimize sorting of a 20GB jsonl file. I have an external merge sort working that takes about 20 minutes on my laptop. This is probably a lower-level question than what I have seen asked above. But what are “reasonable” amounts of intermediary file system files to create? Depending on my “chunk” size I read and sort from the 20GB file I can end up creating 32,000 temp files on the machine before I can combine them all for the final output file. 32K files seems like a lot to me, and I worry about running out of file descriptors. But since this is the first time I’m working with “big data” (for me), I don’t have a sense of what’s a reasonable amount of temp files.
You can do a single file, where you read and write chunks of it. Note that this is basically recreating a database/datastore, and so you could use one.
The databases will also be faster as their implementations make use of a virtual memory, which solves your problem but also has hardware support / implementation.
The TLDR of virtual memory is that you have memory chunks that exist virtually; they are not actually allocated until they are touched (read/write to/from the memory), and when they are allocated the OS / hardware uses both RAM and disk to store them. It will also move between RAM and disk as needed (it's caching) without the user needing to write any code to do so.
The way to approach this is to imagine that everything is always on disk and is only temporarily in RAM to be operated on. So RAM is acting as a cache (you can evict chunks by some scheme when running out of RAM, such as least recently used (pick one that best fits your algorithm's memory access pattern)).
sorting 20gb is doable just in memory, no new files required
err, probably not in python unless you have a beast of a machine
those 20gb will probably blow up by 4x or more when loaded into memory as dicts/ints/...
how about splitting into N files (let N be large enough so that you can easily sort a single file in memory, probably somewhere between 10 and 100) and then sort each file and then open all files and lazily read entries for each and use a heap for merging into a single sorted output
yeah, fair :(
Hi guys , I need some help , I got a trading script it extracts data from the mt5 platform, now each timeframe has their specific data which is stored in a dictionary. I want to Extract that data and then sort and filter each timeframe with matching data from each timeframe been trying and getting errors ... If anyone wants to help me let me know thanks
You may share the code along with the error in #1035199133436354600 channel
Suppose that I want to use s grow-only counter. I can use a dictionary instead of a tuple, to account for new nodes arriving into the system, like so:
{"foo": 57, "bar": 10} \/ {"foo": 42, "bar": 69, "baz": 420} = {"foo": 57, "bar": 69, "baz": 420}
But how does this handle removing nodes? Suppose that I want to keep 4 nodes by default and auto-scale to 50 nodes during peak demand. I'm going to add 46 permanent useless entries to this dictionary on every peak event, which seems bad.
The problem being, a new node will have a new name. Suppose that you had nodes a, b, c, d. You want to remove node d and add node e, because d has caught fire. But you can't keep using the name d for the replaced node, it seems -- what should it think the value of the counter is? If new-d thinks it's 0, and d previously had a count of 1000, and new-d starts collecting counts, it's going to drop the new counts, because it will receive d=990 from some other node.
If the shutdown is more graceful, maybe it'd be possible for a node to announce that it's not going to increase new counts? Like: { counts = {a: 10, b: 20, c: 20, d: 40} , dead = {d} } So if a new node comes in, it could inherit d's count. The d count could not have been stale if a node saw d in the dead set. But what if you introduce two nodes and they both try to inherit d's count? (also, how do you un-die a node? that would imply that dead is not a grow-only set)
why do you have need to limit the number of counters? 
Well, if I add 46 new nodes every day for a single counter, this value is going to grow linearly with time, it's gonna take longer and longer to communicate it between nodes
I'm honestly just trying to understand how CRDTs are supposed to be used in practice
(e.g..: what do you do when the number of nodes isn't constant)
maybe I'm misunderstanding how the updates to these values are shared
actually, I'm going to read the paper and come back. I'm probably talking nonsense
Some of our designs suffer from unbounded growth; collecting the garbage requires a weak form of synchronisation [25]. However, its liveness is not essential, as it is an optimisation, off the critical path, and not in the public interface.
that explains a lot actually
Hey @torn bridge. I've deleted your message since it's offtopic. Please respect the channel's topic.
Okay
You can ask in other channels also
Can you share data format
If you possible then ping me I will come to vc
import time
import numpy as np
from shutil import get_terminal_size
class Dot:
def __init__(self, pos: np.array):
self.pos = np.array(pos, dtype=float)
self.velocity = np.array((0.0, 0.0), dtype=float)
self.acceleration = np.array((0.0, 0.0), dtype=float)
def step(self, deltaT: float = 1.0, friction: np.array = None):
if friction is None:
friction = np.array((0.99, 0.99))
self.velocity += (self.acceleration * deltaT)
self.velocity *= friction
self.pos += self.velocity * deltaT
class timer:
def __init__(self):
self.n1 = time.time()
self.n2 = time.time()
def elapsed(self):
self.n2 = time.time()
u = self.n2 - self.n1
self.n1 = time.time()
return u
gravity = np.array((0.0,9.8))
def main():
dotA = Dot(np.array((8.0,8.0)))
dotA.velocity[0] = 50.2
dotA.acceleration = gravity
time_step = 0.1
times = timer()
timed = timer()
while True:
ssize_x,ssize_y = get_terminal_size()
if dotA.pos[0] >= ssize_x-2:
dotA.velocity[0] = -abs(dotA.velocity[0])
if dotA.pos[0] < 1:
dotA.velocity[0] = abs(dotA.velocity[0])
if dotA.pos[1] >= ssize_y-2:
dotA.velocity[1] = -abs(dotA.velocity[1])
if dotA.pos[1] < 1:
dotA.velocity[1] = abs(dotA.velocity[1])
x = round(dotA.pos[0])
y = round(dotA.pos[1])
print("\x1b[2J\x1b[H",end="")
print(dotA.pos,dotA.velocity,ssize_x,ssize_y)
screen = ""
screen += "\n"*(y-2)
screen += " "*(x-2)
print(screen+" #")
dt = max(0.0,time_step-times.elapsed())
time.sleep(dt)
dt = min(max(0,time_step-timed.elapsed()),time_step)
dotA.step(dt)
if __name__ == "__main__":
main()
Am I doing it right????
Exempt for the display
it's doing quantum tunneling on the end lmao
I have a problem which essentially reduces to the following:
There are n items, each item has a cost. Each item has a non-empty set of dependencies, and each dependency is a set of items. To buy an item, you must already have at least one of its dependencies satisfied, meaning you must already own every item from the dependency. If dependency contains an items which is not bought yet (and possibly will be bought later), it is not satisfied. After being used in dependency, item can be reused in another dependency. Cyclical and empty dependencies are allowed. You need to buy a given item while minimizing its (and its dependencies) cost (or show that it's impossible to buy that item).
It is clear that if C is a total cost of all items, pseudo-polynomial solutions exist (the simplest one is O(mC) where m is a total size of dependencies, the solution is similar to knapsack), but is this NP-hard?
Do I start with some items? Or how do I complete the first dependency?
dependency can be empty
if this is easier: each dependency is an arbitrary boolean formula on variables representing whether item is bought already or not
you only allow positive variables in the DNF clauses, no?
okay yea, so it's not 3SAT that trivially
I think it's 3SAT anyway -- the decision version of the problem is "Can I buy item G on a cost of C or less"
given 3sat of variables 1...n and some clauses
- let there be a goal item G, C=n
- for each variable v, let there be 3 items: v, -v, c_v
- G has one dependency - {c1, ... cn}
- c1...cn each have two dependencies {{v}, {-v}} (thus, to make G, each variable must be positively and/or negatively set), and zero cost.
- v, -v all have a cost of 1.
- for each clause, for each (possibly negated) variable v, add the other two variables as singleton sets to the dependencies of item
-v(where --v = v) -- that is1 2 3would add{2} {3}to dependencies of-1,{1} {3}to the dependencies of{-2}etc.
now, buying G in C means that
- for each variable, either -v or v is bought (due to cv)
- both cannot be bought, since that'd be over budget
f a variable is set, all clauses that this variable cannot satisfy have another variable set, satisfying it.
This should be a polynomial reduction -- thus the problem is NP-complete.
@outer rain
wait no, this is wrong
wait, I think I'm wrong with my pseudopoly solution lol
maybe
- each clause Q1...Qn gets an item Q1..Qn with cost 0
- then G depends on all of Q1...Qn as well as c1...cn
- if Q1 is (1, 2, -3), Q1 has 3 dependencies {1}, {2}, {-3}.
I believe in your reduction
this makes a lot of sense because at first I tried to follow a similar idea, but what stopped me is that the total cost is small, it should be polynomial, so it's wrong. But it seems I got too quick, as always, and my pseudopoly solution is plain wrong
if it didn't have the costs, it's horn clauses I'm pretty sure
yes, and this is also what made me question if it's even NP in the first place. It seems like constraints are horn-like
thank you!
is randomized quicksort used in practice? using the median of medians selection algo we can get quicksort in WC TC of O(nlogn), and not just average TC
yeah, randomized quicksort is used in practice
it gives good average performance and is simple
median of medians is a theoretical improvement for worst-case TC, but in practice, randomized quicksort is usually faster due to lower constants
median of medians can be slower in real-world scenarios
I see, ty
Can i use medians of medians quickselect to find the median element value in O(n) then binary search to find the median element in O(log n), and then return k closest elements to median value using 2 pointers?

i wonder if i can avoid the binary search all together..
can medians of medians quickselect return the position of the median in the array?
eh ig u could by keeping a second array or something but seems more complex then bianry search and then k closest elements
this should in worst case be O(n) if k = n right?
also, is there a formula to find base b that optimises the asymptotic complexity of radix sort? I heard b ~= n (where b is the base and n is the number of elements) works best for asymptotic complexity.
what would you binary search?
regardless, you could just do a linear scan
it won't affect the time complexity
bin search on what exactly
quickselecting median seems right, then you just have to do something to get those k closest to median (hint: it's something to do with quickselect again)
radix sort takes O(d(n + b)) where
nis number of elementsbis the basedis how many passes you need, equal to key length, equal tolog_b(max(elems))
so you want to minimize log_b(max(elems)) * (n + b)
then you can take the derivative and find for a specific array where the minimum of this function occurs ig
is this taught in discrete math
you mean the time complexity of radix sort or?
nah the part of minimizing that function
oh wait nevermind
i'm slow
it's just calc
How do I create a "class parameter" if I can at all? What I mean is something like stdlib's:
class MyClass(metaclass=SomeMeta):
pass
Can I create these "parameters" like metaclass here?
yes, those parameters will get passed to the metaclass's __new__ method
Hmmmmmm got it, thanks! 😄
wait python dropped timsort!
this was my fav trivia:\
Hi. Is Go an easier language to learn than Python as a first PL?
I would expect them to not be meaningfully comparable, it probably just depends on the student. I'd recommend learning Python first since it has a broader reach across the domains of programming, but from an ease POV, I don't think there is a general statement to be made
Hey. What can be the best online resource to learn Data Structures and Algorithms in Python for free?
Thank you
Quicksort is a rather poor sorting algorithm in many ways. It isn't stable, it uses unnecessarily many comparisons, it needs a fancy comparator function (just < is not enough), it can run in quadratic time.
As far as I know, the only real reason quicksort is used is because it can be done in place.
Something else I want to note on is that quicksort in practice is usually not randomized.
For example in C++ the pivot is picked in a deterministic way.
To avoid O(n^2) behaviour, in C++ it switches to heapsort if the quicksort is progressing slowly (see introsort).
So the time complexity of C++ quicksort is guaranteed O(n log n), and it is deterministic
Hello,
I need exercise to practice complexity of an algorithm, and some tips that might help me understand this concept.
I see, ty
Also, is there a way to go about learning what type of implementation each language uses? Do I have to go the source code or doc page of the sort function (for example here) and that's the only real way?
I'd typically just google it. Typically a language got many different sorting algorithms built in, and they change over time / on implementation.
About python's sort. CPython has used timsort since python 2.3. But the exact implementation has changed over time. Here is an interesting thread about this which resulted in a change in the sorting algorithm
https://stackoverflow.com/questions/78108792/why-is-builtin-sorted-slower-for-a-list-containing-descending-numbers-if-each

Stack Overflow
I sorted four similar lists. List d consistently takes much longer than the others, which all take about the same time:
a: 33.5 ms
b: 33.4 ms
c: 36.4 ms
d: 110.9 ms
Why is that?
Test script (At...
One fun triavia is that java used to have a bad O(n^2) quicksort built in. There were permutations where the sort would take O(n^2), and use O(n) recursive function calls, which usually resulted in a crash from stack overflow.
This only got fixed relatively recently.

Codeforces
About sorting algorithms in general. If they are based on comparisions, then they will always take O(n log n) time. In other words, you cannot do better than merge sort.
But you can come up with a sorting algorithms with fancy features.
Main feature of timsort is that it runs in O(n) time if the data given is already sorted/almost sorted. Timsort is basically just a fancy version of merge sort with this extra feature.
On a random permutation, I think timsort and merge sort should basically be equivalent.
I see, ty again
Learn any typed langugae as your first languge. I would suggest go thorugh the pain of learning C. That will give you much needed clarity on how memory are managed, memory constraint, memory manipulation etc. Then switch to Java then python or Golang. Golang is typed too but comes with lot of contraints unlike python where a variable can store literally infinite value of integer.
How? I mean how can we get the median of the array by mere a scan of the array? Can we have something like take max and min in array and then try and find a median? I am assuming array doesnt have any outliers so median will be close to mean. I am just guessing here
there is an algorithm to find the value of the median in linear time, then you actually go through the array to find where the value is

In computer science, the median of medians is an approximate median selection algorithm, frequently used to supply a good pivot for an exact selection algorithm, most commonly quickselect, that selects the kth smallest element of an initially unsorted array. Median of medians finds an approximate median in linear time. Using this approximate med...
sort of
you use quickselect which needs a pivot-choosing algorithm. It's linear on average, but with poor choices of pivots it can degrade to quadratic
using MoM to choose the pivot guarantees that the chosen pivot is always "good enough" such that quickselect is linear
Hi guys I was looking a bit into python to enhance my experience. For some reason I tried going straight for a facial recognition software however I have no idea what "pip" is can someone help me out?
Like what does this mean:
pip install opencv-python
Ask in #python-discussion plz
oh ok sorry
where should i learn DSA python
There are resources in pinned messages
anyone there
#python-discussion is the most active channel
how do i look for a match in two columns on excel
say there’s like a last name column and a first name column
how do i go like search last name column for “doe” and first name column for “john” at the same time
In excel? How are you reading it?
And ask in #python-discussion
How do I add 2 linked list(I know how linked list work but I don’t know how to implement it in code(python))
do you have a linked list implementation?
i finished the self taught computer scientist by cory althoff which is a basic data structures and algorithms books, it didnt provide all the algorithms and datastructs but it provided all the basic ones like trees, binary trees, binary search trees, graphs (stacks, queues, linked lists, all implemented using a class) and , then three search algorithms, three sort algorithms, python implementations of those algorithms, big O notation, time and space complexities and a little bit of math tricks using modulo operator, and binary operators, solved some basic interview questions.., i finished the 275 page book in one day lol, so it was enough for my college exam, i understand the concepts now but i cannot implement it, because i didnt practice that, however i know the python implementations of those so i dont need to create my own i guess..
sorry for the long text , so can anyone tell me where can i go from here, in algos and datastructures
though the inability to implement suggests to me you don't fully understand the algorithm
oh i can implement algorithms, i cannot implement datastructures tho
they aren't really different
Hi, can anyone help me figure out why the simulation doesnt work as intented? Why aren't other tiles than patient zero being updated? (didnt know where to ask this)
message.txt: https://pastecord.com/evosalyfet
hi does anyone know how i can format python
in discord
!code
What do you think, what will happen with DSA interviews since Interviewer coder was made?

I just got kicked out of Columbia for taking a stand against Leetcode interviews.
Here’s the whole story:
In Fall 2024, I transferred into Columbia as a CS major. I came in knowing I wanted to start a company and immediately found a great co-founder in Neel Shanmugam
A few early projects didn’t go anywhere. After a while, we realized some...
is there a resource where i can learn dsa
I know basic dsa concept need a next step
bum ass cheaters are just gonna multiply unfortunately
i hate that this is happening
they don't want to put the work in so they resort to these methods
There are resources in pinned messages
i guess those of us who are fighting to make it out the legit way are just gonna have to work harder
cause the dude raises a fair point about the costs of flying out interviewees
my 2 cents is if you know what you're doing, using AI is fine; problems arise if you don't even understand the concepts, the why-do-this, etc. and copy-paste
this feels like it specifically targets "Solve leetcode problem X (you're fucked if you've never seen it before)," interviews may start asking more process-related questions like "explain why you do this here" or "tell us your thought process", etc
I mean they can also just ask you to come onsite and do DSA onsite
I mean some companies might return to doing that
onsite's just more expensive compared to online (e.g. interviewee's time & expenses spent on getting there)
hey, im not sure if I understand your doubts. But if you read that whole book in one day and got a good understanding of algorithms I think you need to start coding a litle bit. I think the best way to learn is to practice.
I recommend just to go to the official python doc: https://docs.python.org/3/tutorial/datastructures.html# check there the basic python data structures.
With that and with your algo knowledge I would go to leetcode and start picking some exercises.
You will probably be blocked in the first ones. At this point you can go to youtube and see the explenation. With time you will start understanding the patterns and "tricks" behind all problems and be able to solve new ones by yourself. And you will see how confortable you feel with python data structures with practice.
Python documentation
This chapter describes some things you’ve learned about already in more detail, and adds some new things as well. More on Lists: The list data type has some more methods. Here are all of the method...
Greetings, I am new to python, can you give me a roam for learning it?
Please react with ✅ to upload your file(s) to our paste bin, which is more accessible for some users.
why is the edge order in reverse

Reversed in comparison to what? It's going in the order described in 'each pass relaxes the edges...' right?
(That being said I'm not sure what the advantages of that order are vs. others)
pretty sure it doesnt make a difference
cause it runs v-1 time
i think its just for uh the diagram they showing
to demonstrate
Gotcha
i just misunderstood and i was like
arent they doing s,t or s,v first
but i didnt realize it just skips over
like cause you cant relax t,x in the first
🤣
Yeah it would be nice if the diagram showed the relaxation step more clearly, I find it a little hard to read
I have n independent bernoulli random variables with different probabilities p_i. I need to be able to quickly compute the probability of their sum being greater than n/2 (well, preferably, even the probability of sum being greater than n/2 and being exactly n/2). Is it possible in o(n log^2 n) in a parallel-friendly way? (I need to do that in torch on a GPU)
I can do it in O(n log^2 n) by representing each variable as 1-degree polynomial p_i + (1-p_i) x and then divide-and-conqueringly multiplying them all using FFTs. Sum of bottom n/2 coefficients is the answer. It feels like there should be a faster way though.
I'm pretty sure I have even heard the O(n log n) algorithm before from someone, but I can't find it now 😔
Hmm. I can think of some ideas that yield fast approximations but not anything better that gives an exact answer.
would just doing the convolutions be sensible on a gpu?
i.e. a bunch of convolutions with [p_i, 1 - p_i]
Damn that's a good idea I think
I'm testing a thing that I think is O(n log n) now that uses it
that's basically what I am trying with divide and conquer (multiplying polys = convolutions). Except instead of just doing a bunch of them sequentially I'm doing it in a tree-like manner. If a[i] is a pair [p_i, 1 - p_i] and * is convolution then I do
layer 0:
a[0] a[1] a[2] a[3] a[4] a[5] a[6] a[7]
layer 1 (4 convolutions in parallel, and each can be parallelized too):
(a[0] * a[1]) (a[2] * a[3]) (a[4] * a[5]) (a[6] * a[7])
layer 2:
(a[0] * a[1] * a[2] * a[3]) (a[4] * a[5] * a[6] * a[7])
layer 3:
(a[0] * a[1] * a[2] * a[3] * a[4] * a[5] * a[6] * a[7])
since fft is rather parallel, this can be done pretty efficiently
how should I even be thinking about the time required for a convolution on a GPU?
@outer rain How about this? https://paste.pythondiscord.com/V4LQ
assume it can be done in n threads in log n, I don't think this is right but whatever
GPUs are fast
I THINK this is O(n log n)? I am super rusty on analysis
but what does "thread" even mean in this case?
that's what I'm doing already, that's O(n log^2 n)
Yours is doing repeated polynomial multiplications though and this one isn't?
Maybe I misread
it's same thing
Hmm, OK. My bad.
basically, if numpy can do an operation in one step vectorized, then it can be probably be done using N threads in 1 step on GPU (or in log n steps, depends)
how long does it take to convolve
[...n long thing...] * [a b]
```on a gpu?O(1)?
isn't your computation just O(n) of those?
well, it can be done like that
that would be O(n^2) work, where n threads do O(n) each
OK what about this? Sorry again if I'm wrong and this also is n log^2 n.. https://paste.pythondiscord.com/MY7Q
Hopefully I'm reading the pytorch docs correctly, this is kinda the math-iest thing I've tried to do in a while
that one is interesting because I don't understand it
are you trying to make this effectively O(log n) GPU "iterations"?
yes
Basically the idea is to replace the recursive polynomials with the characteristic function (which I had to look up)
gotcha, was kinda confusing to talk about O(n log n) when the actual time involved is effectively O(log n) 😅
well, I would be satisfied with O(log^2 n) steps too as long as total work is O(n log n)
because GPU does not really have n threads
it's thousands, but not quite n
😅
so total work is still the main optimization target as long as it's parallelizable
how big is your n?
The approach of getting a probability mass function back with ifft from the characteristic function product seems plausible to me, but maybe I'm missing something
Well, it's complicated. In practice, it's actually stupidly small, like 500, and that repeated ~300 times. But I think a better way to think about it is as if I'm solving problem for 500*300=150000 for reasons I won't go into.
basically, I need to do the same relatevely small thing 300 times, which is large enough to be worth doing on GPU, but small enough to not be done in a stupid horizontal way
dependent or independent calculations?
and since the resulting approach will likely be well-parallelizable either way and can be stopped mid way, it's worth thinking about that as a single large problem
independent
so you could compute them all in parallel?
well, then I need to do about 200 of dependent runs of that too 😅
yes, but not parallel enough to get huge gain on GPU
If there is a O(n) way to compute FFT(IFFT(a) + [0]*n), then this can be done using the same tree reduction, but there would be no need for convolutions. I can take FFT from input, then stay in Fourier domain and convolve everything by elementwise multiplication, "upgrading" result using that transformatio above, and then applying IFFT to the final result
I'm guessing what you are doing now is what I'm thinking of, that you set up your 300 problems in the GPU memory, and then do the ~log(500) operations
(I'm kinda surprised log(500) is a significant enough factor to care about)
I'm solving MAXCUT. I run a lot of trials where I train a parametric model a distribution on vertices. Model returns some probabilities, sample the cut a few times, and improve it using a local search. I then need to update a model, for which I need to minimize expected maxcut(local_search(model(params))). Since local_search is very hard to differentiate analytically, I approximate it using mean field method. Probability of a vertex being in one half of the cut is probability of that at least half of its neighbors are in another, which is where this problem arises. Since training a model is a huge bottleneck, improving log(500) may mean ~7.5 times improvement.
I don't actually need the result, lol, I only need its gradient wrt model parameters, and all of this is only needed to do a backward pass of backpropagation
Yo any1 got any links for learning dsa?
whats a real in python
if you mean real as in the numeric type, that'd be float.
yeah thats what i thought but apparently their seperate things
what context did you come across the term?
i need to describe data types for an assignment
i figure itd mean pi or smth else but that would be really rare to ue
*use
yea I don't know, real is usually the fortran datatype, which is roughly a float
IG you could describe that it's an approximation of real numbers, the most prevalent of which is float, but fixed point numbers etc. can also be used.
:white_check_mark: Your 3.12 eval job has completed with return code 0.
<class 'numbers.Real'>
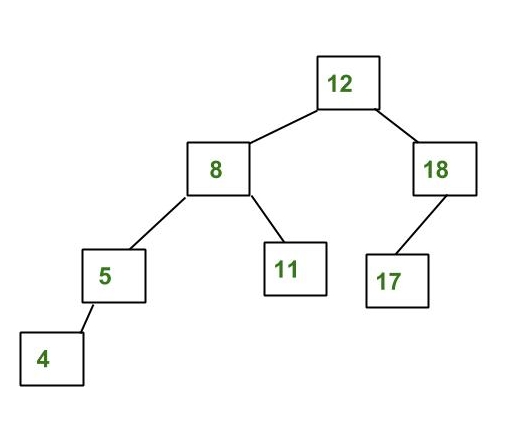
Hi i got dilemma, Im learning Min Heap , I illustrated how delete should be working, is that correct? Im asking cuz the guide does seem to stop traversal down when only one child is present

hey folks
Just need some guidance I want to build strong programming skills like I see question in interview and solve it please help me learn better skills any course or website (except leetcode) and preferably free
If you're open to a book, this one is amazing https://www.amazon.com/Elements-Programming-Interviews-Python-Insiders/dp/1537713949/

This is the version of our book. See the website for links to the and version.Have you ever...
it seems correct when you draw it, but firstly you need to switch 0 and 9, and then reduce size to n-1. Then you call function which ensures min-heap property (on 9 in this case, in general at the root of the tree).
sorry for the late answer
if i could reccoment a book to you, i'd suggest Cormen's "introduction to algorithms". the book is very detailed and it explaines almost every data structure in pseudocode. i used it for mine DSA course in college.
but iirc it explain max-heaps only. maybe i don't remember it well.
Looks good. Pretty sure this is how heapq in python works like
salt
Hi, I hope you're having a great day and a great week, that you're doing well at school, and that you're not being bullied for no reason or that you're not the bully.
Quick question I have not seen this before could someone explain what these brackets means?

Thanks!
Are those []?
⌊x⌋ is floor(x)
anyone intrested in helping me creating a trading bot? i trade indices and want to check how automated trading does
DM ME IF ANYONE INTRESTED
is there's a good data structure to query numbers between ranges with proper memory usage and access time? something like:
ds = RangeQuery()
ds.add((7, 19), "evil number")
print(ds.get(9)) # "evil number"
and yes, without storing each number between start-end as an array index, querying float numbers would also be a big plus but not necessary.
One way is a thing called an 'interval tree' https://en.wikipedia.org/wiki/Interval_tree
In computer science, an interval tree is a tree data structure to hold intervals. Specifically, it allows one to efficiently find all intervals that overlap with any given interval or point. It is often used for windowing queries, for instance, to find all roads on a computerized map inside a rectangular viewport, or to find all visible elements...
Do you NEED better than linear search time? If not a simple scan will be a lot less code.. but an interval tree is O(log n) instead of O(n)
Here's the code for pip install intervaltree but if you have time you might want to write your own https://github.com/chaimleib/intervaltree
GitHub
A mutable, self-balancing interval tree. Queries may be by point, by range overlap, or by range containment. - GitHub - chaimleib/intervaltree: A mutable, self-balancing interval tree. Queries may...
The data structure under the hood here is called an 'AVL Tree'
Here's an example one for comparison https://github.com/mozman/bintrees/blob/master/bintrees/avltree.py
(unmaintained repo, just for learning how they work)
great, thanks much
https://pypi.org/project/mind-the-gaps/ here's an implementation by salt-die.
pretty cool
Hey so I have a task but I don't understand what the symbol means. Could someone help?

they define them in the paragraph you sent, < is the ordering on letters, and <* is the ordering on strings.
It's just a generic operator, used here to mean an order relation
Do you need to update the the stored ranges, or is it mainly just stuffing a bunch of intervals in there and then querying a bunch?
the latter
if so you could just do some simple preprocessing of your intervals once to produce a sorted list of non-intersecting intervals
then you can just binary search
find the latest interval that starts <= the query point, is the point in that interval?
hm., sounds good.
the preprocessing would just be something like, make your intervals into a bunch of start/end events, sort those, go through events and keep track how deep in intervals you are
+= 1 on start events
-= 1 on end events
note down the intervals where you go 0->1 and 1->0, starts and ends of the new cleaned up intervals
nice, thanks.
iirc the benefit you get from stuff like interval trees is when you need to interleave queries and updates
For anyone willing to help me out with my dynamic programming codeforces challenge, here you have the help channel https://discord.com/channels/267624335836053506/1359897111457562815
Hi, im trying to learn Weighted - Adjacent matrix on graphs and the task is to implement the Breadth First Search. I have made a path of how the Queue would look like, is that correct? I also with 0 knowledge tried to convert graph to a tree is that correct?
I also noticed that the tree and the queue would look a bit different if i change the order of which branch i take first, like if i start at 1 and it has 2 and 3 i can either do 1->2->3 or 1->3->2 and it still should work.

queue looks fine, you usually don't care about the weights tbh when using bfs (if you're looking to minimize the sum weights to move from one node to another, there's a diff algorithm for that)
well you're tree is basically showing from what node you move to somewhere (e.g. 2 is a direct child of 1, indicating you moved to 2 from 1) so in that sense it's correct ig
yes, there can be multiple valid bfs orders for the same graph
oh so for matrix i can use anything as a value. I just need 2 values, that represents if node is a neigbour or not. So like True, False or 0, 1 and so on.
at least for your current problem, yeah p much
there being different weights isn't changing how you bfs
depends on what you mean by you're "learning weighted adjacency matrix"
well im sure that my tree representation is only made to work for bfs but if i do dfs on same tree result would be not good
what are you trying to do with the tree anyway?
I could say the guide i watch not doing great job, he is using weighted adjacency matrix to do bfs but never explained about the matrix itself much.
Im just learning DSA. And that tree is just me trying to convert graph to a tree
the adjacency matrix is just 1 way of representing the graph in code
like adj_mat[a][b] could mean the weight of the edge from a to b
well i understood that by googling and they showed something like a shape and from one point to another point. So it made me realize that a shape like triangle or square can be though as a graph
convert a graph to a tree?
yep, tho that tree is bad, its a tree for BFS, it works, but probably wouldnt work for DFS. Anyways i understand that not all graph can be trees
why do you need a tree to do dfs/bfs?
A few years back I wrote PyAlgoViz, a Python algorithm visualization tool where the UI was written using JavaScript. Recently I rewrote it in PyScript. All the Python code runs in the browser, including the hosting app, algorithms, visualizations, and rendering. Two Python VMs are used: MicroPython to run the UI and PyOdide to run the algorithm and step through the execution use sys.settrace. The UI is rendered using the PyScript LTK library. Lots of sorting algorithms, but also graph searching, such as BFS and DFS. A live demo is at https://laffra.github.io/pyalgoviz-pyscript/?name=sorting/heap_sort The source is at https://github.com/laffra/pyalgoviz-pyscript.

Who said i need it. The lesson showed that a graph is form of tree so it showed we could do bfs and dfs on a graph
That is so cool and really useful for learning things, sometimes its really hard to visualize what code is doing, but the BFS is pretty clear how it works and DFS is somewhat easy, those POST, PRE, IN Order doesnt help to easly understand, but i get it its just the order in which i read tree
It sounded like you were converting a graph to a tree for DFS/BFS
&smart_eval
# what are the potential loopholes in this pattern matching
def CheckIfUserInputValid(UserInput):
if re.search("^([0-9]+[\\+\\-\\*\\/])+[0-9]+$", UserInput) is not None:
return True
else:
return False
uhhh... wemme guess, t-the pwogwam wiww nyot hawt UwU
You may want re.fullmatch
Also consider a raw string r”foo” so you don’t have to escape the backslashes
!e
from itertools import permutations
foo = (
"A",
"B",
"C",
"D",
)
bar = {
i: tuple(permutations(foo, i)) for i in range(1, len(foo) + 1)
}
for k in bar:
print(f"{k}: {len(bar[k])}")
:white_check_mark: Your 3.12 eval job has completed with return code 0.
001 | 1: 4
002 | 2: 12
003 | 3: 24
004 | 4: 24
How is the # of permutations for 3 and 4 items the same? Am I missing something?
Actually it does make sense I think, the logic is:
1: 4
2: 4*3
3: 4*3*2
4: 4*3*2*1
right?
My intuitive understanding is something like this...
Yeah, if you work backwards from 4, where we're saying "I want to use every element of the set in every permutation"
When you ask for 3, you're asking for every group of three, but that always leaves exactly one element behind, so you know what that one is too 'for free'
I guess the 'dumb' answer is factorial(1) == 1
So we end up comparing factorial(n) with factorial(n)/1 and they are of course the same
I still find it weird when I ponder it.
Hey guys. So I have two list:
b = [27, 47, 61, 71]
c = [17, 27, 55, 9]
Now I would like to put them in a sage Graph like that the b list contains the main vertices of the graphy and the c the pendant vertices(they connect to the corresponding value of the same index in the b list).
Now my problem is that whenever I try to do that and I have a value that is present in both, sage seem to be merging the those into one vertex which would be crucial not to happen, anyone has an idea how can I make it work?
edges = [(b_sequence[i], b_sequence[(i + 1) % len(pt)]) for i in range(len(pt))]
pendant_edges = [(b_sequence[i], c_sequence[i]) for i in range(len(pt))]
#make graph
G = Graph()
#add inner(main) vertices
G.add_vertices(b_sequence)
#add pendant vertices
G.add_vertices(c_sequence)
G.add_edges(edges)
G.add_edges(pendant_edges)
this would be my current implementation
and this is my output:
{27: [47, 71, 17], 47: [27, 61], 61: [47, 71, 55], 71: [27, 61, 9], 17: [27], 55: [61], 9: [71]}
now ideally there should be another 27 like 27: [47]
I'll look into just getting rid of duplicates, but in the meantime if anyone has a solution it would be appriciated
how does kruskal's algo differ from dijkstra's? im getting confused between all them algorithms 😭
afaik Dijkstra finds the shortest path from a starting point to all, whilst Kruskal makes a minimal spanning tree out of the graph whilee discarding cycles
hey
does anyone work with red black trees, i dont see the purpose of them in real life projects
Straight up I've never seen one in my career. I feel a bit deprived honestly.
I mean, unless you are implementing the dict type for a language etc.
Or writing a kernel's process scheduler.
Or a database engine's indexer.
dijistra is used to find shortest path from source node to all other nodes in a graph
kruskal is used to create minimum spanning tree from the given graph
mst is basically a tree which covers all the vertices but only selects the edges having minimum weight
a tree that spans all vertices, minimizing the sum of edge weights
You ever want to feel O(n!) and more !? ```py
from itertools import permutations
from random import shuffle
def vsortperm(v):
def isSorted(v):
for x,y in zip(v, v[1:]):
if x > y: return False
return True
vc = v[:]
shuffle(vc)
vp = permutations(vc)
for x,xx in enumerate(vp,1):
if isSorted(xx):
return((xx,x,math.factorial(len(vc))))
aa = list(range(4))
a,ax,amax = vsortperm(aa)
It is better than a pogo sort (who might never find it) ! It will return the sorted list, but it will look at many permutations.
What's just one notch up from a "stateful string scanner powered by the regex module" in the ladder of parsing power and expressiveness? Is there something super minimal I should do instead of the former? I'm extracting malformed "JSON" goo from a terrible set of log files.
I don't really care enough about the task to make a LALR parser or something

The Chomsky hierarchy in the fields of formal language theory, computer science, and linguistics, is a containment hierarchy of classes of formal grammars. A formal grammar describes how to form strings from a language's vocabulary (or alphabet) that are valid according to the language's syntax. The linguist Noam Chomsky theorized that four diff...
You mean for type-2?
Non-deterministic pushdown automaton.
Oh right, I could use this then! https://www.nltk.org/
Im new to python dose anyone know how to use hashlib all i cna do is make it genrate the code thing how do i conncet it to something
hey guys do you know any resource that elaborates about Negative Weight Cycle Detection (bellman ford) ?
and also toposort
I'm interested on good resources regarding these topics
not python, but I check here
comp prog has a lot of overlap with dsa
The goal of this project is to translate the wonderful resource http://e-maxx.ru/algo which provides descriptions of many algorithms and data structures especially popular in field of competitive programming. Moreover we want to improve the collected knowledge by extending the articles and adding new articles to the collection.
Oh my bad that's what Purplys linked I guess

GeeksforGeeks
Your All-in-One Learning Portal: GeeksforGeeks is a comprehensive educational platform that empowers learners across domains-spanning computer science and programming, school education, upskilling, commerce, software tools, competitive exams, and more.
Thanks!!!!!!!
def GenerateTree(avgBranchingFactor, maxNodes, parentID=1):
queue = []
maxNodesID = 0
while maxNodesID < maxNodes:
branchingFactor = np.random.poisson(avgBranchingFactor) + 1
for nodeID in range(branchingFactor):
maxNodesID += 1
if parentID != maxNodesID:
queue.append((parentID, maxNodesID))
parentID += 1
return queue
I've made another post on #1035199133436354600 for this but it was closed. Basically I wanted a BFS tree. My problem now is branchingFactor = np.random.poisson(avgBranchingFactor) + 1. I had to add this or the tree would have a root node which isn't 1 when the poisson distribution returned 0 at depth 1. How do I fix this? Also is it possible to add depth detection to my tree, as I would prefer maxDepth over maxNodes
To clarify: my objective is to produce a fully random tree up to a certain depth, but right now the best I can do is a tree with a minimum of 1 child per node, up to a certain number of nodes (minimum of 1 child per node is no longer random)
Sure! Here's a summary of the Bellman-Ford algorithm from the CP-Algorithms article:
Bellman-Ford Algorithm Summary
Purpose:
Finds the shortest paths from a single source vertex to all other vertices in a weighted graph. It works even if the graph contains negative weight edges.
Key Features:
Handles negative weight edges
Can detect negative weight cycles (cycles where the total sum of edge weights is negative)
Works on directed and undirected graphs (undirected must be converted to directed by adding two directed edges)
How It Works:
-
Initialize the distance to all vertices as infinity, except the source which is 0.
-
Relax all edges n - 1 times (where n is the number of vertices).
For each edge (u, v, w), if dist[u] + w < dist[v], update dist[v]. -
After n - 1 iterations, run one more iteration:
If any distance can still be updated, then a negative cycle exists.
Time Complexity:
O(n * m) where n is the number of vertices and m is the number of edges.
Use Cases:
Graphs with negative weights
Detecting negative weight cycles
Want a code snippet or visual explanation too?
!rule 10
can someone help me with my tree
Don't know if this is the right channel, but is there a way for me to use BeautifulSoup to only get the inner content of HTML-valid XML tags? e.g. <span>This product is on sale now 1<test>0 $0</span> becomes This product is on sale now 1<test>0 $0 instead of This product is on sale now 10 $0

it's just because they put the solution as a method in a class, which is kinda silly
Checkout my video explaining this : https://youtu.be/4LxBIJPJuO0?si=sjJu0FDJwHWZqq_L

Bellman and Ford algorithm is a fundamental algorithm of solving the distributed version of finding the shortest path from one vertex to another in a graph. It is also known to handle negative weighted arcs.
We explain the algorithm with extremely clear animations, then we discuss its complexity, and finally we prove its correctness.
Chapters...
And for the topo sort checkout my DFS video on the same channel
yo guys i can't tell if i'm stupid or if there is genuinely a problem here, don't the sample test cases seem messed up



What's the deal with the first 'card' being two digits instead of a value and an operation?
Oh I see, it's the max number of multiplies you can use. Interesting.
OK, so what about the samples seems wrong to you?
"subsequence doesn't have to be contiguous" is a big change right at the end
oh wait nevermind i didn't know what contiguous meant and for some reason just disregarded that sentence
my bad
is there a straightforward way to recognize a word problem as a recursion problem (for instance), or doing that something that you get from practice practice practice?
hello, how do i make linked lists using 2 arrays. i understand what they are, but the code confuses me
yoooo wait did you make this with manim
Yes 🙂 most of them
yoooo ok
I also wanna make a video using manim but uhhh skill issue
are you in the manim discord
can I ask you questions
Of course
errr no it should be the manim one

problem is it's like super dead and questions take forever to be answered
Nope, link me please :p
in DMs?
Yes
aren't linked lists and arrays two seperate data structures that are used to implement other data structures
usually you don't
where did you see this?
you can do it, it's not even a terribly bad idea
assuming it is what I think
you keep two arrays like prev and next where prev[i] is the index of the node before the node with index i
I think it's still a common interview question
I expect that this thing can be fairly cache friendly
compared to the normal pointer chasing
Yeah I guess the tradeoff is the fixed maximum size, but within that it sounds nicer
you can extend the list if needed

I’ve got a problem I’m interested in
It’s for polyhedra with all triangle faces. The picture on paper is a way to represent the information of a polyhedra of this type. The ring of triangles there with bold black lines is like the ring of triangles in the icosahedron shown with yellow and gray lines. A part on one side outside the ring is rotated and put on the other side, so it only needs one side to be described.
For the 2D slice, the goal is that for every pair of opposite triangles (shown red and blue) if you draw a line through the triangles which form a zig-zag, starting from both sides of any given outer triangle (one such shown red) they should both go directly to the opposite inner triangle (here shown blue). I drew a solution for an 18 triangle ring, and the icosahedron is the solution for the 10 triangle ring. I’m interested in an approach that could work for larger rings


i opened this chat and see this and as a beginner i am absolutely terrified ...
ditto ^
how to find thing in a binary search tree:
if the root is that value: ok we found it
if the value we're trying to find is less than the root of the tree: continue on the left branch, else - on the right (because thats how the values are distributed on a binary search tree, by construction. values less than x go to one branch, greater - to other)
READ IF YOU THINK YOU ARE ABLE TO ACHIEVE RANDOMNESS
I'm working on a project that distinguishes Human generated randomness from computer generated randomness. Right now I have an algorithm that works 96% of the time for myself versus computer randomness, but one person is hardly a good sample size.
If you are interested in math or psychology or computer science at all, you will probably find this interesting and I'll share the link to the project for you.
To get the link to the project you just have to DM me an exactly 125 digit number, and you must input it yourself, trying to make as random of a number as possible. I'd reccomend using https://www.charactercountonline.com/ to make sure you can get 125 digits exactly. Thankyou
CharacterCountOnline.com
Character Count Online is an online tool that lets you easily calculate and count the number of characters, words, sentences and paragraphs in your text.
best source of learning DSA?
you can try from here
https://takeuforward.org/interviews/strivers-sde-sheet-top-coding-interview-problems/

takeUforward - ~ Strive for Excellence
takeuforward is the best place to learn data structures, algorithms, most asked coding interview questions, real interview experiences free of cost.
I recommend the MIT course in the channel pins
heres another eth zurich course https://lec.inf.ethz.ch/DA/2021/#exercises this has great balance between theory and code
can someone please review this PR https://github.com/a1ok-soni/Practise/pull/1, just trying some hands on FastAPI and it's surrounding apps
go to #1035199133436354600
thanks
Someone hit me up with their first learned algo and how they learned it.
ron rivest had a book called “algorithms”
If you could go back and restart my programming journey,what would I do differently to make things easier to understand
Dev_Persi's link is a great resource IMO
Do you like textbooks? I know of one I wish I could send back through a time portal to myself.
send uit
In my case I feel like I started a too-low of a level, and had to spend longer than I wish to understand the higher-level concepts that also turn out to matter.
So if I had a time-portal-gun, I would use it on this book https://webperso.info.ucl.ac.be/~pvr/book.html
A comprehensive programming textbook that
covers all important programming paradigms in a unified framework
that is both practical and theoretically sound.
Special attention is given to concurrent programming and data abstraction.
The textbook uses the Oz multiparadigm programming language for its examples.
Beware, it's very strange.. but not that dry.
Want a small advice: I am new to coding. I have just finished learning Python basics, yet to start DSA. Should I complete all the mathematical concepts before starting DSA that is required for mastering AI and ML? What should be the correct order of learning DSA and all the necessary mathematical concepts? (btw I have just finished my schooling and will be joining college in next few months)
real
it helps me a lot
need basic concepts of math + logical thinkin
inorder to do that , solve lots of pattern problems
it helped me
might help you too < 3

Check out TUF+:https://takeuforward.org/plus?source=youtube
Find DSA, LLD, OOPs, Core Subjects, 1000+ Premium Questions company wise, Aptitude, SQL, AI doubt support and many other features that will help you to stay focussed inside one platform under one affordable subscription. Have a hassle free one stop solution for up-skilling and prepari...
The math for DSA vs AI/ML is pretty different
same math, different application
The math for AI/ML is Calc/Lin algebra/stats/probability applied to comp sci/programming
There’s obv crossover to “DSA math” but it’s pretty different math
Anyone have any good DSA resources in python
Pins have some stuff
You can try Geeksforgeeks.
adj = [(dx, dy) for dx in (-1, 0, 1) for dy in (-1, 0, 1) if (dx, dy) != (0, 0)]
print(adj)
test_case = """ABCDEFGHIJ
KLMNOPQRST
UVWXYZABCD
EFGHIJKLMN
OPQRSTUVWX"""
test_case = test_case.split("\n")
x = 3
y = 0
print(test_case[y][x])
neighbors = []
for dx, dy in adj:
nx, ny = x + dx, y + dy
if ny < 0:
continue
print(test_case[ny][nx])
i don't get the logic of adjancents
i mean this is wrong i know
i don't want it to get out of the box
It looks correct to me
ABCDEFGHIJ
KLMNOPQRST
UVWXYZABCD
EFGHIJKLMN
OPQRSTUVWX
I get CMNEO
you are missing some bound checking, however.
yeah you need to check if nx and ny are in range
ohh
wel i got thins until now
]
for dx, dy in adj:
nx, ny = x + dx, y + dy
if nx < 0 or ny < 0 or nx > len(test_case[0])-1:
continue
print(test_case[ny][nx])
this evaluate the first line
so it wont get out of the box
height = len(test_case)
width = len(test_case[0])
...
if not (0 <= nx < width and 0 <= ny < height):
...out of bounds case...
would it evaluate also the bottom part?
wdym?
I mean, you should train to reason about such logic without running it
the checks needed to check if you are in the bounds of a rectanguar grid is just to check each coordinate separately
0 <= x < width # is x in range?
0 <= y < height # is y in range?
```and we need both of these to be trueHello, there is something maybe easy i cannot manage
I got this list :
TERR1/RECOL/SOINS/UNITE
TERR1/RECOL/PARAMEDICAL/PARAMEDICAL
TERR1/RECOL/SOINS/IDE
TERR1/RECOL/SOINS/NUIT
TERR1/RECOL/LOGISTIQUE HOTELLERIE/ENTRETIEN
And I'd like to get this result:
TERR1/RECOL/SOINS
TERR1/RECOL/PARAMEDICAL/PARAMEDICAL
TERR1/RECOL/SOINS
TERR1/RECOL/SOINS
TERR1/RECOL/LOGISTIQUE HOTELLERIE/ENTRETIEN
Goal: If the parent is the same, then show me the parent, if it's not the case, don't do anything
Can you help me please?
Thanks
I tried with Path.parent even if there are not real folders
or should i split them to compare ?
I also could find the same startswith string by comparing them all
I want to help in my project.
I want to make AI system for detect object.
using openCV, YOLO, PyTorch
I guess I don't fully understand the logic yet; why is TERR1/RECOL/LOGISTIQUE HOTELLERIE/ENTRETIEN just that and not TERR1/RECOL/LOGISTIQUE HOTELLERIE?
!e
from collections import Counter
from pathlib import Path
paths = [
"TERR1/RECOL/SOINS/UNITE",
"TERR1/RECOL/PARAMEDICAL/PARAMEDICAL",
"TERR1/RECOL/SOINS/IDE",
"TERR1/RECOL/SOINS/NUIT",
"TERR1/RECOL/LOGISTIQUE HOTELLERIE/ENTRETIEN",
]
paths = [Path(p) for p in paths]
parents = [str(p.parent) for p in paths]
parent_count = Counter(parents)
paths = [p if parent_count[str(p.parent)] == 1 else p.parent for p in paths]
for p in paths:
print(str(p))
:white_check_mark: Your 3.12 eval job has completed with return code 0.
001 | TERR1/RECOL/SOINS
002 | TERR1/RECOL/PARAMEDICAL/PARAMEDICAL
003 | TERR1/RECOL/SOINS
004 | TERR1/RECOL/SOINS
005 | TERR1/RECOL/LOGISTIQUE HOTELLERIE/ENTRETIEN
!e can you help me with tracing tables?
:x: Your 3.12 eval job has completed with return code 1.
001 | File "/home/main.py", line 1
002 | can you help me with tracing tables?
003 | ^^^
004 | SyntaxError: invalid syntax
Click here to see this code in our pastebin.
From what I think u should be upgrading ur python version
idk if this is the right place... but is there a regex to match every character in a character set exactly once (disregarding the order in which they appear)? (it's fine if I have to programmatically insert the number of characters in the character set)
why would you use a regex for that?
you could do something with several regexes, e.g.
(.).*\1 should not match and
^[yourcharacters]*$ should match
(and you could probably squish these together with a negative lookahead, but eww)
Could positive lookahead for length and each character, that's probably easier.
you mean doing one lookahead per character?
that seems horrible
Yeah, regex isn't great here.
ah yes, wonderful regex
(?!^.*(.).*\1.*$)^[abcde]*$
seems to work though
actually, I can simplify the first part
(?!.*(.).*\1)^[abcde]*$
it's still pretty eww
though less terrible than I expected
and neater than this
True
:incoming_envelope: :ok_hand: applied timeout to @analog wharf until <t:1746831202:f> (10 minutes) (reason: attachments spam - sent 8 attachments).
The <@&831776746206265384> have been alerted for review.
!unmute 1220838558328164393
:incoming_envelope: :ok_hand: pardoned infraction timeout for @analog wharf.
That many attachments is a bit of a wall
You'll probably want to organize it better, or share your code via a paste
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
yeah but discord packages them together into a single message so it doesnt take up 8 entire message lengths. atleast on my phone when i post them they look very small and people can click to enlarge them and scroll through if they like
True, but frequently that single message takes up an entire screen on it's own
probably bc im usually on mobile discord instead of my laptop
Generally speaking, you don't need more than 1 or 2 images for a code problem unless they're screenshots of code, and we'd heavily prefer a paste for that so that we don't have to manipulate it awkwardly
i just noticed this was a help thread, I havent really taken a look at all the sections of this server yet
have people used this algo-monster flowchart?
https://algo.monster/flowchart
AlgoMonster
Coding interviews stressing you out? Get the structure you need to succeed. Get Interview Ready In 6 Weeks.
can someone help me make my Python script to an exe?
If I am to compare two path finding algorithms, if I introduce 60fps movement constraint for the agent's movement, would I still get an insight about the differences in this case (not in general but in real time), can I draw conclusions?
What metrics would you be measuring in this experiment?
seconds for time
and steps for length
What does the 60 FPS constraint change here. Wouldn't the time just be steps / 60.
The thing is that I wanna introduce and remove obstacles say every 0.1 seconds or less and see how the agent handles highly changing environments. But if I just run the algorithm it is hard to introduce obstalces and remove it because the algorithm will be finished in 0.03 seconds. But if I run it using the 60 fps then the agent will at max move 60 times a second per loop and it is slower.
What sort of algorithm is it? Wouldn't it still end up just being
- get current environment
- solve for the shortest path
- take one step along that path
- repeat until you win
yes but it is dynamic it is d*
ah, then yes, you should be able to get some interesting results
okzy Im asking because some people told me to never slow down an algorithm which I agree but in this case I am not really interested in how good the algorithm is rather how good it is in comparisson to another when given similar challenges and constraints.
:incoming_envelope: :ok_hand: applied timeout to @thorn stone until <t:1746928221:f> (10 minutes) (reason: chars spam - sent 5997 characters).
The <@&831776746206265384> have been alerted for review.
Ik this is german but it should be understandable

I didnt quite get what maxsuffixsum is doing
it looks like it's just max subarray sum ending at j
how can I convert a python script to a exe
pyinstaller
who wants me acc token

don't know if this is the right channel, if not please redirect me. Question: I wrote a mixin class, but I want to prevent instantiation of the class. in other words, it should only be subclassed. When I google for an answer, I see a lot of mentions of ABC, saying that adding @abstractmethod to one of my class's methods would prevent instantiation. But the thing is, my mixin is basically only an _init_ and one other method which is definitely not abstract, as it's the whole point of the mixin (automatically adding the method to instances of any class that subclasses my mixin). are there any other techniques that would raise an error if anyone tries to do
mm = MyMixin()
Usually people don't bother with something like this for mixins. Document it (if it has Mixin in the name, that's good enough). This is probably best suited for #software-architecture
thank's, i'll crosspost there! funny thing is that I didn't put Mixin in the name, even though I gave it as an example here 😅 it's not a big deal, as you rightly say. moreover since it's currently in a private project and the only one who would be able to use the mixin wrongly would be...me 😄 as I'm still learning, I'm in the habit of trying to get to the bottom of things when a question like this pops into my head. thanks again!
You can raise an error in the __new__ method
@swift coral
class MyMixin:
def __new__(cls, *args, **kwargs):
if cls is MyMixin:
raise TypeError("Blabla")
return super().__new__(cls)
def __init__(self):
# something something
That might be opinion-based, but if you're doing software that rigorously I'm not sure Python is the right language for it (and I say that as someone that mainly uses Python in their lives)
What are pythonic libraries, Pytorch (Machine learning) and Qiskit (quantum computing) limits? When would one need to use C++ for higher performance? (P.S. I'm mapping my field of study, no knowledge of the aforementioned libraries as of yet)
thank you, something like this is indeed what we landed on in #software-architecture, except in this case it's
if type(self) is MyMixin
in the _init_
same difference
I'd expect PyTorch to be adequate for most training usecases, tho if you want your model in an embedded setup, it is common to write the inferrence in C++ rather than pull in python+torch (not really a performance issue, more so just a Python+Torch is a lot of stuff). No idea about quantum computing, I wasn't even aware quantum computing had application for real workloads.
Have people seen this? Cursed.
https://chrispenner.ca/posts/python-tail-recursion
Disclaimer: I'm not the author of the article
Python has a stack except: when it doesn't
Does anyone know where I can find niche databases, I’m looking for one with nclex questions in order to make an app for a friend
hello
Hello
I am totaly screwed, its a job hunting time for me and I dont know why but my algorithmic skills have declined its like being dragged to ground zero, has anyone ever experienced this
I even forgot the implementation of data structures
I fear u might be a ding dong
Hi Everyone,
could you please explain this question?
For each function f(n) and time t in the following table, determine the largest size n of a problem that can be solved in time t, assuming that the algorithm to solve the problem takes f(n) microseconds.
I found the answer but I didn't understand how they solved it.

Comparison of running times: For each function f(n) and time t in the following table, determine the largest size n of a problem that can be solved in time t, assuming that the algorithm to solve the problem takes f(n) microseconds.
just solve this equation for n?
f(n) = t (both in microseconds)
e.g.
n^2 us = 1 hour = 3600*10^6 us
n = sqrt(3600*10^6) = 60 * 10^3
can anyone help me understand how to loop through this sequence

without any extra packages
Start by asking yourself the easier version of the same problem. How do you add up the digits of a single number? To answer that, first ask yourself the easier version of the same problem. How do you add up the two digits in a two digit number? To answer that, first ask yourself the easier version of the same problem. How do you get the first digit of a two digit number, and how do you get the remainder (all other digits (in this case, just the other one)) after removing that digit?
To answer that, you need mathematical knowledge. Can you do this by hand on paper with math operations (try various things)?
Any one can check my code
#calculator
print('''
Addition for +
Subtraction for -
Division for /
Multiplication for *
''')
while True:
n1 = int(input("Enter input n1: "))
n2 = int(input("Enter input n2: "))
opr = input("Enter operator: ")
if opr == "+":
print(n1 + n2)
elif opr == "-":
print(n1 - n2)
elif opr == "/":
if n2 != 0:
print(n1 / n2)
else:
print("Error: Division by zero is not allowed")
elif opr == "*":
print(n1 * n2)
else:
print("Invalid operator")
It looks good shoudk work fine, i would adapt it to use functions so that the code is overall cleaner and easier to develop if you want to in the future. ik you wouldnt need to but it is good to start now
@covert herald seriously I am newbie a week I start learning python
anyone care to brainstorm with me ways to make infinite money by running LLMs on infinite loop locally?
Oh I couldn't speak there.
Just tried to request voice channel..
Let me know what is your trouble first.
Exactly.
anyone care to brainstorm with me ways to make infinite money by running LLMs on infinite loop locally?
Hmm.. is this your tech question?
nto really a question, just asking for ideas /brainstorm
This is a simple calculator program written in Python that performs basic arithmetic operations.
There's a typo bug in this part:
elif opr == "":
print(n1 n2) # ❌ Missing operator between n1 and n2
i tried plotting the functions on graph. i'm getting different results

Should i count library function when calculating big O? Who knows how my library does the thing? Kinda feels redundant to do
you should know what a library you are using does
calling a library function takes time, and since you are calculating time of your code, you must take into account everything your code does
some_library.do_a_lot_of_stuff() is not a zero cost action
I'm confused as to why you even had this question.
# hey look, I'm finding the largest element of a list in O(1)!
def find_max_of_list(numbers):
return max(numbers)
Sometimes it's obvious, sometimes it's written in the documentation, and sometimes you have to dig into the code and find out
(and sometimes it's too hard to calculate of course)
You can also find it useful to measure how many library calls you're doing. For example, going from O(n) database calls to O(1) database calls.
How do I get my codes installed and run test and how do I get my libraries saved and how do I get them open how do I go about coding where do the codes I want to use from
hmm
Maybe a good idea to try again, one question at a time, and in clear language.
How do I setup my pydroid3 account to get started with coding
Sorry I thought it was in English
everything is O(1) by that logic:```py
eval('my code...') # O(1)
:-)does anyone know a good algorithm to filter noise in integration (like converting accelerometer data), so that over time, noise is nulled (no cursor drift)
I was thinking about a NN
now hear me out, decorators
the easiest solution would be to slowly drift your value towards zero
x *= 0.999 at each step
it won't affect fast changes, but in the long run any noise will be multiplied by zero
yup, but that results in your cursor going back to where it came from once you rest... especially in fine movements
I also tried:
forgetting integration
your idea both linear and exponential
setting v to 0 once a is 0
and probably a few more things
and another problem is that even at ~200hz, rapid movements are measured inaccurately (with rough edges). that loss is enough to set the velocity off by lots
*crickets*
uhh im preparing
one sec
well i made brainfuck interpreter

and supreme ultra parser 1337
if u want write 10+ instead of ++++++++++
just rle?
both interpreter and rle
i wanna make smth like code editor for brainfuck
where it shows hex, decimal values and letter
writing non-trivial programs in brainfuck is certainly something
I did one project euler problem 1 in it, and even that was an experience
well i though bf is ez
until i realized than i cant really do anything without loops
actually not 1
6
A website dedicated to the fascinating world of mathematics and programming
sum of squares of numbers 1-100 is a lot of loops
damn
thats a long ass code
how much nested loops it has btw
I want to say 4
can u send me code
assuming I can even find it
ill wait
I remember I used my own bf impl which had 2 conveniences, cell values can be >255, a command for printing the decimal value of the cell
ill make this quick
also my interpreter has 3 "mods" or smth, like yk strict in js
its strict (if value > 255 it throws error)
soft (on overflow value is reset, so 0 - 1 is 255)
and 4byte (for unicode)
granted, the code isn't long, the documentation and comments are longer
at least it's pretty readable

looking at this code I realize I basically imitated a stack machine
do you have some other bf code cuz i need to test my thing
you can try all helloworlds from esolangs, and if they all work as expected, then your impl probably does what you expect
well usually bf interpreters wont let you make value of cell more than 255
[25164150, 0, 0, 0, 0, 0, 0]
bruh
why thats happening

Hello




Click here to see this code in our pastebin.
Working on mapping out different rhythms
Gonna extend the attributes I give necklaces and rotations




Graphs for 16 bit
Don't mean much until I extend this into a sequencer
Where you can explore all possible rhythms via these atttibutes ( or more )
( given a certain bit string length )
( rhythms are bit strings, one is a pulse, zero is no pulse )
I'm pretty sure the canonical behavior is to wrap around 0<->255
so basically cells work mod 256
hey, actually the correct answer
there is also the ultimate purist version where you work with 1 bit cells
but yeah, for when I did the project euler thing I did not want to deal with implementing bigints...
where big means >255
If you have bigints, you only need 3 cells, which is fun
as in that's turing complete, or what?
I think in my impl from all those years back "big" just meant 32 or 64 bit
yeah, int
god this code must be 10-15 years old
The code isn't too bad considering the age and that I can't have been a very experienced programmer at the time
how do i make function dont return 0 and then value it should return
def runFile(path: str):
with open(path, "r") as file:
code = file.read()
return run(code)
def peek(filePath):
return runFile(filePath)
can you rephrase your question?
this isn't exactly the full code
what's run?
its my interpreter for brainfuck but it returns only one value, which is string
when i use runFile() in other function, it prints
0
Hello, world
and idk why 0 is here and how to remove it
!paste - show the interpreter
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
why do you print the full output on , ?
to see current output because if not, most of bf code wont work properly
(itll work but user wont understand anything and its kinda softlock)
i made a repo so u can check full code here https://github.com/triple-raze/brainfuck-py

GitHub
Contribute to triple-raze/brainfuck-py development by creating an account on GitHub.
bad code alert
why is your "unlimited" mode so limited?
that does not match the code

https://github.com/triple-raze/brainfuck-py/blob/main/cli.py#L28
exit is a function
cli.py line 28
exit```!d exit
quit(code=None)``````py
exit(code=None)```
Objects that when printed, print a message like “Use quit() or Ctrl-D (i.e. EOF) to exit”, and when called, raise [`SystemExit`](https://docs.python.org/3/library/exceptions.html#SystemExit) with the specified exit code.why?
oh
but why does in vs code that thing isnt yellow, like other functions is?
why would it? it is not an error to throw away a value
you forbid underflowing