#algos-and-data-structs
1 messages · Page 61 of 1
Unfortunately the two longest paths were 1-2-3 (90) and 1-2-4 (90)
So I guess this "technique" of doing dfs from a random node, and then dfs from the farthest node (farthest defined from that random node) only works for the longest path?
can someone explain the red bit please i did this and wanted to double check it and from what i understand this should be True

but gpt is saying its false?
if not P and not Q = false and they imply R then it should always be True right?

this is what i had
which is basically identical
besides the highlighted row
i know its pretty inaccurate a lot of the time but this i wanted to make sure i wasn't missing anything
yes, you are correct
F => x is always T
the table seems incorrect
Hi, I'm really stuck on this problem, I'm fairly new to data structures and algorithms and I can't seem to debug thus issue. I would really live some help possible
Also idk if this is inappropriate to put here, just lemme know and I can take it down.
what issue?
you can just ask the problem you have, instead of asking for permission to ask
>>> TruthTable("~p", "~q", "~p & ~q", "~p & ~q -> r", "~r", "~r & ~p & ~q", "~(~r & ~p & ~q)")
TruthTable('~p', '~q', '~p & ~q', '~p & ~q -> r', '~r', '~r & ~p & ~q', '~(~r & ~p & ~q)', binary=False)
>>> print(_)
┌───┬───┬───┬────┬────┬─────────┬──────────────┬────┬──────────────┬─────────────────┐
│ p │ q │ r │ ~p │ ~q │ ~p & ~q │ ~p & ~q -> r │ ~r │ ~r & ~p & ~q │ ~(~r & ~p & ~q) │
├───┼───┼───┼────┼────┼─────────┼──────────────┼────┼──────────────┼─────────────────┤
│ F │ F │ F │ T │ T │ T │ F │ T │ T │ F │
│ F │ F │ T │ T │ T │ T │ T │ F │ F │ T │
│ F │ T │ F │ T │ F │ F │ T │ T │ F │ T │
│ F │ T │ T │ T │ F │ F │ T │ F │ F │ T │
│ T │ F │ F │ F │ T │ F │ T │ T │ F │ T │
│ T │ F │ T │ F │ T │ F │ T │ F │ F │ T │
│ T │ T │ F │ F │ F │ F │ T │ T │ F │ T │
│ T │ T │ T │ F │ F │ F │ T │ F │ F │ T │
└───┴───┴───┴────┴────┴─────────┴──────────────┴────┴──────────────┴─────────────────┘
should be more dependable than gpt
theres a python truth table method?
i made a library for it a long time ago
actually while you're here
salt-die has really cool libraries
do you have any good suggestions for learning simplification of
Dang it, I meant to add this link lol: #1283394663935643769 message
My bad
https://github.com/salt-die/truth_tables i'll have to check this one out i doubt i'd be able to use it from my class though but i'll check with the teacher if they'd allow stuff like this

GitHub
Print lovely formatted truth tables from any boolean logic expression! - salt-die/truth_tables
i can stick it on pypi probably, i haven't looked at the code in a long time
i'm pretty new never heard of pypi
when you do pip install my_library then my_library is usually on pypi
ooh alright
i feel like i've been looking at these for a couple hours and have nothing

are there any good sources for simplfying questions like these
i can't find any that partically seem to help
especially in relation to imply ones
we have a table like this but i just can't seem to get it down

i might try replacing P' ^ Q' with a single variable here
its got to end up as (p' and q' and r') apperently so idk if i can do that
all i have so far is being able to turn it
into
(p' and Q')' or R using rule of implication
but i don't fully know if thats correct
might still help to replace with a single variable while you transform
T -> R === (R' ^ T)'
=> T -> R === (R'' v T')
=> T -> R === (R v T')
=> ...
you can re-substitute later
how does that make any sense
() does not have any defined precedence, it doesnt make sense to compare it with something else
what?
precedence is not, and, everything else
brackets do not belong to this list
Is it me or it's a nightmare to get a functionning input reading in Python on SPOJ?
for this problem https://www.spoj.com/problems/MINDIST/
This gets me a runtime error
def get_int():
return int(input())
def invr():
return map(int, input().split())
def solve():
n, s = invr()
graph = [{} for _ in range(n)]
for _ in range(n-1):
x, y, z = invr()
graph[x-1][y-1] = z
graph[y-1][x-1] = z
if __name__ == "__main__":
n_tests = get_int()
for test_nb in range(n_tests):
solve()
expressions can be in parens
that doesnt say anything about precedence of brackets
brackets do not have any precedence
if you say so
A @ B $ C can be parsed as (A @ B) $ C or A @ (B $ C), it is determined by @ and $ precedence relative to each other
with brackets there is never an ambiguity
brackets is an operator that controls order of operations
so they have precedence
there is never an ambiguity, so no
there is never an ambiguity because i made the grammar file that evaluates parens first, because i gave them precedence
you didnt
you can swap lines 11 and 12, it would not change anything
yep
if you say that not, (), and, ... does make sense, then how is (), not, and, ... or not, and, (), ... different from that?
they are in a different order
this order is invisible for the user
and if there is no observable difference, then they are the same
i don't know what you mean
i say that your readme should not mention () in precedence list, because it doesnt make any sense
i get you, i should ignore parens
There were empty lines in the input, this works:
import sys
input = sys.stdin.readline
def next_non_empty():
while True:
line = input()
if line.strip():
return line
def get_int():
return int(next_non_empty())
def invr():
return map(int, next_non_empty().split())
def solve():
n, s = invr()
graph = [{} for _ in range(n)]
for _ in range(n-1):
x, y, z = invr()
graph[x-1][y-1] = z
graph[y-1][x-1] = z
# insert logic
if __name__ == "__main__":
n_tests = get_int()
for test_nb in range(n_tests):
solve()
But now there were so many empty lines that just reading the input takes 1.9 seconds
great
I guess I'll have to request the wiseness of @regal spoke to see if there is some magic that makes input reading faster because I'm really not seeing it
Whats this about?
A quick way to read input is to just do
input = [int(x) for x in sys.stdin.read().split()][::-1].pop
split identifies tokens seperated by 1 or more whitespace characters
Yes sorry, this problem:
https://www.spoj.com/problems/MINDIST/
Has (A LOT) empty lines scattered around (they didn't say we just inferred that from the multiple runtime errors)
So I had to use that to get the input
but it takes 1.9 seconds of the time (2 seconds total allowed)
I'll try that
2s for reading 1e5?
there are probably 10^8 empty lines
when I was putting sys.stdin.read() in an array I had almost 300 MB of memory used
import sys
input = [int(x) for x in sys.stdin.read().split()][::-1].pop
def get_int():
return input()
def solve():
n = get_int()
s = get_int()
graph = [{} for _ in range(n)]
for _ in range(n-1):
x = get_int()
y = get_int()
z = get_int()
graph[x-1][y-1] = z
graph[y-1][x-1] = z
if __name__ == "__main__":
n_tests: int = get_int()
for test_nb in range(n_tests):
solve()
Your solution is faster: 1.54s (301M space)
to read input
Hopefully that's enough margin for my logic
or maybe i'm doing something wrong?
Two things. Just set get_int = input
Dont wrap functions like that
ah yes my bad
tuples is one way to do it
ah yes fair
but then I'd have to loop over the neighbours
to find the right tuple
I dont know what algortihm you want to use to begin with
I'm finding the diameter of the tree (https://ideone.com/f4jLVc full code I didn't want to bother you with the details initially which is why i had cut the logic)
So I mainly need to be able to do DFS
(I do 3 DFS in total)
hello, where is the apropriate channel that i can ask for advices to complete my project?
dfs for diameter?
I pick a random leaf
I do dfs to find the longest path from that leaf
And then I pick the leaf of that longest path
And I do DFS again from that selected leaf
To get the global longest path of the tree
Which I believe is called a diameter?
I know there is a way to do it with a queue when you have unweighted edges in a tree, but the tree has weighted edges, so I think that's the only way?
How do you then solve the problem?
Oh, then I have the true longest path of the tree
I go to the middle of it (considering weights)
And I greedily add vertices as long as I have enough S
I keep two variables sum_left and sum_right
That represent how much distance from the (growing) middle part there is to the left part (beginning of the true longest path) and the right part (end of the true longest path)
I hope that's clear, this is quite a hard problem for me so I might have trouble communicating my ideas clearly
The greedy approach should work to minimize the maximum distance from other vertex to the (growing) middle part
Btw there is an ancient technique to read trees really fast
The trick is that for each node, store 2 things
- The degree of the node
- The xor of all neighbours of the node
no adjecency list needed
In your case, you'll need to also store the xor of all weights of edges to neighbours too
no information is lost
Think about the leaves
They only have one neighbour
is there a term I can look for or nah
Yes indeed when the degree is 1 it’s easy
1-2-3
Now xor of 1and3 is 2 and 2 has two neighbors, I’m not sure how I « get back » to 1 and 3
9-2-11
xor of 9and11 is also 2 and 2 has two neighbors too
🤔
The trick is to remove one leaf at a time
Ah and we only ever treat nodes with degree 1
Though it seems I can’t do a dfs starting from a non-leaf
Those two lines
import sys
input = [int(x) for x in sys.stdin.read().split()][::-1].pop
Take 0.75 seconds
So yeah my adjacency list is actually decently taking a lot of time on top of reading the input from stdin
I've never seen anyone talk about it. I once found it in a really old submission on cf. Then later on some people have told me that the technique is really old.
On cses, all fastest solutions for tree problems use this technique, including finding diameter
I would call it xor-representation of a tree
Bottom up works
mmm you're right
I'm going to try tuples first
It seems easier conceptually and might be faster than my current hashmap approach
I gain 0.2s on graph creation
deg[root] = -1
for node in range(n):
while deg[node] == 1:
deg[node] -= 1
nei = xor[node]
xor[nei] ^= node
deg[nei] -= 1
node = nei
This how to traverse an xor tree
No need for any stack/queue
You can pick which node becomes the root by doing deg[root] = -1 before running the traversal code
and xoring the neighbour right?
Ah it'll start at the other leaves
mmmh
Let's consider the graph 3-1-2
let's take root = 3
the for loop will go to node 1 first, and not do anything because its degree is 2
and then it'll go to node 2 and decrease the degree of 1 but it's too late, no?
AH ok
makes sense
spoiler the tuple version timed out too though i'm pretty sure it was faster
I'm sure that this xor representation is by far the fastest
Optimally, you only traverse the tree once
ah yes if you re-traverse you kind of have to reset everything?
!e
class XorTree:
def __init__(self, n):
self.deg = [0] * n
self.xor = [0] * n
def add_edge(self, u, v):
self.deg[u] += 1
self.deg[v] += 1
self.xor[u] ^= v
self.xor[v] ^= u
def traverse(self, root):
self.deg[root] = -1
for node in range(len(self.deg)):
while self.deg[node] == 1:
self.deg[node] -= 1
neighbor = self.xor[node]
self.xor[neighbor] ^= node
self.deg[neighbor] -= 1
node = neighbor
tree = XorTree(5)
edges = [(0, 1), (1, 2), (2, 3), (3, 4)]
for u, v in edges:
tree.add_edge(u, v)
tree.traverse(0)
print(tree.xor)
print(tree.deg)
:white_check_mark: Your 3.12 eval job has completed with return code 0.
001 | [0, 0, 1, 2, 3]
002 | [-2, 0, 0, 0, 0]
It appears you're right (I'm still to try to understanding the magic behind it)
But tree.deg is messed up
If I want to do tree.traverse(4), well I can't
If you are smart, you just need 1 traversal. Think about how to do it with 1 DFS. It is possible by keeping track of the two deepest descendants (from different subtrees) for each node
Btw just so you know. I would guess doing oob is really slow
Python has to do hash table look ups every time you want to use a variable
AH I understand
the data structure just became twice as cool
someone know how to get variable from random one of generated/forked processes?
like i did an algo to generate n number of processes each with a random number and i want to get from one (or more, like 3 or 5) of these processes variables…
nvm. possibly did it
sounds like you are creating problems for yourself, tbh
is python rly slower than java ?
@stable pecan your library was so helpful thanks again being able to generate truth tables directly makes it much easier even the teacher liked it
Pretty new so someone should correct me if I'm wrong but python is a interpreted language which are much slower then compiled languages like Java
However I think some ides go ahead and just compile python so not sure if it fully matters
mm yeah but what about run time?
i wrote some code a while back that did the same in thing in java and then in python. python took several times longer but now im wondering if i just wrote it super unoptimised
Uhhh again pretty new I would look in things like big o notion I think that's what determines speed and you can check how optimised a program is but overall java is faster
depends
you can write slow code in any language
pure Python should be generally slower than pure Java
if you have 2 similar pieces of code in Python and Java(in their respective syntaxes ofc) then Java will probably be faster, as it is JIT compiled
Yummers
stuff like being statically typed also allows Java to more aggressively optimize
Agh
It depends on the implementation. There are several for both. Also statically typed makes it easier, but given how fast V8 is for Javascript which is not statically typed, it seems that it's more about how much effort is put into it (the JIT).
Python by design has a bunch of slow things (pointer chasing, memory usage).
GraalPy runs on the java virtual machine, so it's somewhat comparable.
(And Jython)
there's also pypy which is a jitted python (that doesn't rely on jvm)
numba's a library that can jit functions
As can Taichi (including targeting the GPU) (it can also ahead of time compile it, so not JIT, just full compile).
(It's better than numba from my testing)
that's a new one I've not heard of
CPython also has its own JIT now in 3.13, but it's not enabled and not even close to being ready.
(Probably ready by 3.15 earliest)
the other angle to make python fast is to not use python
e.g. numpy & friends
numba/taichi good only at jitting numerically heavy code
they are awful at optimizing regular python
stuff like nuitka/mypyc/cython can transpile python to C, giving you a decent speedup of pure Python code
yeah, one secret to making python fast is to run less python code
Yeah Numba and Taichi are not full Python JITs, they don't do all the random things like objects and such. Just numeric stuff (which is a lot of stuff).
Most JITs struggle to get close to the JVM or V8, and that is because making a JIT that works that well is something that takes many years. CPython may get there eventually if they keep at it, but it will probably be around 6+ years.
Considering how much Python code is out there, worth it. Making all of it faster without any work on the user side is great.
Need a suggestion : so im done with python basics and now wants to get started with DSA, is there any good Playlist I can follow?, I tried strivers list but since the Implementation is in java I find it quite hard to understand the concepts
hey guys, idk where to put this question, what do you call that thing where you split the paragraph by sentences while you add a newline. you also have to delete characters like ! ? , . - and others. after that, you have to label each sentence if it's positive or not. this is about natural language processing (NLP)
Standardisation?
thing i'm doing is a problem itself 😉
(possibly an xy problem)
okay. now a more proper question (but please - be honest, i'm doing something non-debuggable/non-testable)
someone knows how to properly:
- import file with "code" making a bunch of "fork" processes with random data
- get variable from them in main file (not that forker)
- delete all of these processes (also in main file)
- process that (idk, some dividing that random num or taking last num+first num… like that)
?
(maybe i should post this also in #cybersecurity cause reasons…)
||yep, i'm writing thing wabbit-based||
code is like that currently and idk if proper:
var =0
def brick:
import forker
thing = var
os.kill(current, 9)
brick()
if thing == …
and second (forker) file:
import os
var = var + random.choice(0,1,2,3,4,5,6,7,8,9)
while 1: #maybe some other number but yk…
current = os.fork()
while 1: ... and while 2: ... do the same thing
for i in 2 : ?
that's an error
you probably want for i in range(2):
but regardless, this thing sounds odd, maybe you can give some sensible high level overview of what you're actually trying to do
!e
for i in 1,...,3:
print('hi')
:white_check_mark: Your 3.12 eval job has completed with return code 0.
001 | hi
002 | hi
003 | hi
!e
for i in 2, 3, ..., 7:
print(hash(i) % 9)
i love …
:white_check_mark: Your 3.12 eval job has completed with return code 0.
001 | 2
002 | 3
003 | 5
004 | 7
me? a game which can't be run and i want to use wabbit-like code to achieve this but smh i need to get variable from forks of imported process
here is the most actual code i'm working on: https://codeberg.org/hacknorris/impossible (it's a joke code if sth)

Codeberg.org
is it normal for insertion sort to take 5 minutes plus sorting data from text files greater than 5000 integers?
that does sound immensely slow
sorting 5000 values shouldn't be insanely slow
could be a bad impl that's actually O(n³)
Greater than 5000, or about 5000 integers?
5000 should take 1s max
what fenix and pajenegod said
can you show your code?
5000 integers, its going now took it like 10 minutes
I have to do the same for other text files up to one the size of 1,000,000 guess I need to leave it running for a while
Looks like this is a good guess ^
!e here's a naive insertion sort that's O(n²)
import random
import time
start = time.perf_counter()
a = list(range(5000))
random.shuffle(a)
res = []
for x in a:
ins = 0
for ins, y in enumerate(res):
if y > x:
break
res.insert(ins, x)
print(time.perf_counter() - start, 'seconds')
:warning: Your 3.12 eval job has completed with return code 0.
[No output]
does the bot fail to see edits if you have stuff above the code?
Don't you need a special case if there is no break?
!e
import random
import time
start = time.perf_counter()
a = list(range(5000))
random.shuffle(a)
res = []
for x in a:
ins = 0
for ins, y in enumerate(res):
if y > x:
break
res.insert(ins, x)
print(time.perf_counter() - start, 'seconds')
:white_check_mark: Your 3.12 eval job has completed with return code 0.
1.7607092838734388 seconds
err...probably
I'm new to big o notation so I'm not entirely sure. Its a while loop nested inside a for loop.
just share the code?
my guess is that your code is cubic
cubic sounds about right for several minutes for 5000
InsertionSort(A)
for j = 2 to length(A)
key = A[j]
i = j - 1
while i > 0 and A[i] > key
A[i + 1] = A[i]
i = i - 1
A[i + 1] = key
the answer will just be a tad incorrect, the performance will be the same with/without the fix
that's not python code 
I don't want to share the actual source cause its for a homework assignment
was jus wondering why it was taking forever lol and if that was normal, seeing as I'm getting no error message its just running still
then we can't help, that pseudocode looks sensible enough, so your impl is probably wrong
which is why we would need to see it
ok I'll just go with what I got I don't think the speed matters for the assignment as long as it finishes. 🤷♂️
if you want to run for 1000000 that will take...a while
What's your estimation?
I'll take a look at some other solutions see what I can come up with
assuming it's actually cubic
You have: 10 minutes * (1000000/5000)**3
You want: years
* 152.10607
150 years
even a quadratic solution would be very slow
lol I'll get this assignment turned in another lifetime
or just share the code and we could point out some probably obvious error
!e
def InsertionSort(A):
for j in range(1, len(A)):
key = A[j]
i = j - 1
while i > 0 and A[i] > key:
A[i + 1] = A[i]
i = i - 1
A[i + 1] = key
import random
import time
start = time.perf_counter()
a = list(range(5000))
random.shuffle(a)
InsertionSort(a)
print(time.perf_counter() - start, 'seconds')
:white_check_mark: Your 3.12 eval job has completed with return code 0.
1.3862372189760208 seconds
see, an impl of that pseudocode
runs in about the expected time
and 1000000 for that might take more like tens of hours
so clearly you're doing something bad in your implementation
yes it was my solution, I have to do this for many datasets of different sizes up to one of 1000000
I'll have to email my professor and see what they say. Was an issue with the last assignment for everyone the datasets being too large.
Here is a fixed version
import random
import time
start = time.perf_counter()
a = list(range(100000))
random.shuffle(a)
res = []
for x in a:
ins = 0
for ins, y in enumerate(res):
if y > x:
res.insert(ins, x)
break
else:
res.append(x)
print(time.perf_counter() - start, 'seconds')
This one takes about 13s for 1e5
For 1e6 it would take around 20 min
For 5000 it takes just 0.02s
you could also set ins = len(res) in the else and keep the rest of the code the same
was the task to implement insertion sort in particular?
presumably what you can do is run it for a bunch of datasets but then decide to set some time limit
like, if it takes more than x minutes then just stop and say that time means >x minutes
let me guess that's in pypy
yes
yes the task was implement insertion sort and sort multiple text files of various sizes.
I need to go now, thanks everyone for helping 😀
Hey I'm working on a Linux package manager (essentially writing my own distro from scratch as a hobby project).
This will be the first time I need proper algorithms, in particular I need to work out how to traverse dependencies.
(packageA requires packageB and it must be >= 1.0.0, packageB also requires packageC and it must be version >= 2.0.0).
From what I've read the preferred method to do this is presents as a graph problem that can be solved either using "BFS" or "DFS".
I'm working on a class to standardise using this algorithm, any tips for implementation would be greatly appreciated. Thanks 🙂
What you are looking for is called topological sort
I think in Python there is a built in topological sort in the module graphlib. I've never tried using it myself.
But I think it might be exactly what you are looking for
Not really a data struct question. kinda ig, but does anyone know a good way of having a byte array in python with more than 8 bits per element? and I mean like 17 bits.
I could ofc use a list, but seems kinda gross plus, I need it to be compact and short of making my own data struct, I can't come up with a better solution.
ig I could store it in a string.
idk, anyone have any better ideas.
also, I can't import any libraries (short of math and random lol)
You are wasting far more memory/time by using python to begin
However, you can store three 17 bit values in one 64 bit int, using some bitshifts and bitands.
So you can pretty easily save a factor of 3 in memory compared to storing one element per index in the list
lol, yeah. I would have much rather used like anything else.
yeah, for sure. Thats a good idea actually
so you reckon using a list is the way to go then?
Yes
aight, sick. appreciate it. now I just gotta fix this dumbass stubborn bug, then hopefully I'll implement using 3 17 bit bytes per int.
a numpy array of uint64 might also be an option
if it's worth using kinda depends on how you will actually use them, if you express your usage as vectorized operations that can win you a ton of performance
someone here knows how to increment a variable if it isn't empty and if is - create it?
use a dictionary
ok. linter shutted :D
okay. now other problem. how to fix THIS: ???
def importer():
from file import custom
global custom
i get very much errors…
(mostly about unused variable, i use ruff cause file quite dangerous to be ran…)
see:

ruff is a linter
its job is to complain about all sorts of unnecessary stuff
but as far i heard this isn't global…
idk what having that in a function even implies
i tried to debug it with someone else (due to hardware) and he was getting IndexError: string index out of range on line where variable was used
file it imports is quite dangerous so made it containerized in a function
I'm surprised it's even allowed to have the global there
typically is needs to go before the usage
okay fixed. broken was positioning (i'm dumb person)
nvm. still broken… (decommented sussy lines to be able to run)

what did you expect?
thing is not defined there
deleted whole function. idgaf
and works. now only fix image generation and whole project done :D
why do you have a function with the same name as the module?
Is there a way to use DP (there seems to be according to someone commenting) here https://www.spoj.com/problems/NPC2014H/ ?
I've been trying with
dp[i][j] => [largest arithmetic rectangle ending at (i, j) (included), beginning of that rectangle's row, beginning of that rectangle's column]
so size NxMx3
But for examples like this:
3 5
0 0 0 0 0
0 0 0 0 0
1 0 0 0 0
It always fails because if you only remember the biggest area at i' < i and j' < j you might "miss good opportunities to make an even bigger rectangle"
Like for example, when you're here
3 5
0 0 0 0 0
0 0 0 0 0
1 0 0* 0 0
You would want the guy to your left to "store" that rectangle:
3 5
0 0* 0 0 0
0 0* 0 0 0
1 0* 0 0 0
But it'll "store" that rectangle:
3 5
0 0 0 0 0
0* 0* 0 0 0
1* 0* 0 0 0
So you can't make that rectangle
3 5
0 0* 0* 0 0
0 0* 0* 0 0
1 0* 0* 0 0
dp[H][J] := max with height `H` ending at column `J`
dp[H][J] = max(dp[h][J-1] + h) for h in 1..S
where S = max height that still makes valid rectangle
```maybeThank you very much 🙂
Why does it show an error can someone help?

KeyError: 'M'
~~~~~~^^^
num += romans[i]
Line 12 in romanToInt (Solution.py)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ret = Solution().romanToInt(param_1)
Line 32 in _driver (Solution.py)
_driver()
Line 43 in <module> (Solution.py)
M:'1000'
instead of 'M':1000
Thanks
Check out my video! | Captured by Outplayed
https://outplayed.tv/media/KEOgKe
Outplayed - The ultimate capture app for gamers
Outplayed - The ultimate capture app for gamers. While playing, it automatically captures your best moments and biggest plays. When the match is over, relive your best (and not so best) moments by watching them in the match timeline.

Here is the code https://codeforces.com/contest/4/submission/281288504
It very much was possible to AC with Python

The XOR tree technique is OP
In the end I did two graph traversals. It is probably possible to do it in just one, but that would be far more complicated than doing it with two
First traversal is used to find the diameter (a path), and 2nd is used to find longest distance to the path from any node outside of the path
Optimized it a bit more

They didn't have to make TL be 2s. 1s is plenty 

how to solve this issue?


Thanks! I'm going to see if I can make it work
edit: not sure how the transition works with, feels without the row incorporated somewhere I'm not following how you'd do it
Thanks for sharing i'll try to understand it!!
could you like pastebin it or something? i don't have permission to view it and i'm curious
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
thx
You just need to log in to see it (in case you didn’t know)
is
input = [int(x) for x in sys.stdin.buffer.read().split()][::-1].pop
```really faster than something like
```py
input = iter([int(x) for x in sys.stdin.buffer.read().split()]).__next__
It really shouldnt matter
Wait I'm so confused, I haven't fully gone over your solution yet but

That had taken me 0.75 seconds
how the hell did you solve the whole problem in like 0.00 seconds
CPython or PyPy?
did you improve the stdin as well in your optimised thing?
no
lemme check

With merely those two lines
import sys
input = [int(x) for x in sys.stdin.read().split()][::-1].pop
not that it matters that much, I'm just very surprised, it means your xor tree is really really damn fast
inb4 the bytes io speed it up a tad, but the actual logic for solving the problem is basically free
Well, still surprised at the basically 0.00 s to do two traversals (n up to 10^5)
n = 10^5 is pretty smmall
alright that's fair
this is also code that's kinda written to JIT well
I also dont know how much you can trust spoj's timings
very raw
I was mainly wondering if you had a secret sauce to make input significantly faster
so if it's just the problem being not expensive to solve
i'm happier cos that means no black magic for me to decipher
you could try the buffer on stdin
basically lets it work with bytes rather than str
input = [int(x) for x in sys.stdin.buffer.read().decode().split()][::-1].pop like so?
well if i use decode
i get a string back
surely that's not it
The points is that working with byte strings is faster
int() is fine with byte strings
ah so i don't need .decode()
Yes, see my code
ah i thought you had only done it on your "optimised version"
my bad
thanks
yeah it helps quite a bit

apparently, if we trust spoj timings
input = [int(x) for x in sys.stdin.buffer.read().split()][::-1].pop

input = (int(x) for x in sys.stdin.buffer.read().split()).__next__

input = iter([int(x) for x in sys.stdin.buffer.read().split()]).__next__

I don't know how much these times can be trusted (my guess is dont trust them at all)
But lowest memory usage on the generator one makes sense
it makes sense for 3 to be faster than 2 at least
3 faster than 2 because you read everything beforehands?
but more mem usage because you have to store it all?
yeah, you just do the work in one batch
fair fair
Resubmitting 2 resulted in

So ye, these times cannot be trusted at all
Hi everyone, I already tried everywhere but apparently i have no luck. I started with algo trading and crypto a few years ago, now I moved on the stock market. i am using backtrader as core library to build a backtesting system. Has to be said, im not a developer but i have python rudimentals. Now i implemented a basic genetic algorithm for hyperoptimization of parameters and I'm looking for fellow students/practitioners that have a similar goal so we can join forces, exchange ideas, help each other and collaborate. Whoever is interest let me know.
not that it matters but buffer actually made my old submissions pass
the one with just [int(x) for x in sys.stdin.read().split()][::-1].pop
what did you use before?
this
instead of sys.stdin.buffer.read
I wonder how much of this is just because spoj is running ancient versions of pypy and cpython
PyPy has changed its io/strings since some while back
I can check on a random submission on codeforces
https://codeforces.com/contest/987/submission/281405761 buffer
https://codeforces.com/contest/987/submission/281405724 no buffer
I don't know if the time difference and the memory difference are significant
When you do the graph traversal with the xor tree
It's neither dfs nor bfs from the root
It's like going from leaves all the way up
Is that what you meant by "bottom-up traversal", is that a thing? (seems like it's called post-order https://en.wikipedia.org/wiki/Tree_traversal#Post-order)
wow I always assumed the best way to get the diameter of the tree was to run two dfs, I'm blown away
Fun story
Back when we tried to get fastest solve on all cses tree problems using this xor technique (which we were successful at).
There are some tree problems that require dfs
At first you might think this means it is impossible use the xor traversal
But turns out that if you are smart about it, you can compute a dfs ordering using a xor traversal
This got to be one of the weirdest ways to do a dfs out there
class Node:
def __init__(self, data):
self.data = data
self.next = None
class LinkedList:
def __init__(self):
self.head = None
def insertAtHead(self, data):
new_Node = Node(data)
# head is a variable storing the location of head. It does have attributes like data and next
if self.head is None:
self.head = new_Node
else:
new_Node.next = self.head
self.head = new_Node
def insertAtEnd(self, data):
new_Node = Node(data)
pointer = self.head
flag = True
while flag:
val = pointer.next is None
if val:
pointer.next = new_Node
flag = False
pointer = pointer.next
llinkedlist = LinkedList()
llinkedlist.insertAtHead(999999)
print(llinkedlist.head)
llinkedlist.insertAtEnd(23423)
pointer = llinkedlist.head
while pointer.next:
print(pointer.data)
pointer = pointer.next
insertAtEnd operation is working as it is supposed. Can you anyone help me out please?
OrderedDict
Unlike the regular dict structure, it preserves the insertion order. As of Python 3.7, the standard dict also preserves the insertion order, but OrderedDict provides this feature in older versions.
İs it true? So is there a difference then?
Does it only work once?
Yes
the loop for printing the data?
def insertAtEnd(self, data):
new_Node = Node(data)
if self.head is None:
self.head = new_Node
return
pointer = self.head
while pointer.next:
pointer = pointer.next
pointer.next = new_Node
``` 👀There was potential for an infinite loop in your code. You were also not printing the last item
I tried to debug it. But there was no infinite loop.
@rapid valve I figured it out. The error was in how I printed in the values,
pointer = llinkedlist.head
while pointer:
print(pointer.data)
pointer = pointer.next
this works fine
Only potential situations. Example when you convert a Circular Linked Lists. When you're addicted to circual dependency. This is also valid for the code I sent.
Also I don't know if it is thread safe. If it's not safe, it's still a problem. But these are more advanced topics. You don't need to worry about them so much.
Let the end of the Linked list point the head.
🤓
Let the end of the Linked list point the head
@rapid valve Are you referring to the circular linked list or some kind of cryptic message?
circular linked list
https://cses.fi/problemset/queue/1131/1/?lang=8&status=2&user=&by=1&order=0 after shamelessly using everything you taught me there lol
🚤
with a stack and 2 standard dfs i was at 0.55s
The xor technique really does wonders
Such a weird thing that no one talks about it online
but I guess it doesn't change the complexity so it's not that big of a deal for the folks that do CP in C++ unless they just wanna have the fastest submission on a problem
So I finally made it work on the initial problem
but I couldn't understand what you did there:
# Greedily remove nodes from either end
s = diameter - s
i = 0
j = len(weights) - 1
sa = 0
sb = 0
while i <= j and sa + sb < s:
if sa + weights[i] < sb + weights[j]:
sa += weights[i]
i += 1
else:
sb += weights[j]
j -= 1
My code is to find the middle and greedily remove from the middle to both side
# Find middle
l: int = 0
r: int = len(path) - 1
sum_left: int = 0
sum_right: int = 0
while l < r:
if sum_left < sum_right:
sum_left += weights[l]
l += 1
else:
sum_right += weights[r-1]
r -= 1
# Greedily remove from either side
while l > 0 or r < len(path) - 1:
if sum_left == 0 and sum_right == 0:
break
if sum_left < sum_right:
# nullify the right side
weight = weights[r]
if weight <= s:
s -= weight
sum_right -= weight
r += 1
else:
break
else:
# nullify the left side
weight = weights[l-1]
if weight <= s:
s -= weight
sum_left -= weight
l -= 1
else:
break
And yours starts with s = diameter - s which I'm not sure I get
does that mean you remove the whole path even if you don't have the money and then if diameter > s then you have to "unremove" some you removed?
I think of it like the entire tree is just one path
and weights is a list of the weight of the edges of the path
You are told to remove >= diameter - s of edge weight from this path.
I do this greedily.
There is no "middle" in the way I think of it
There are just two ends of a path
Dumb question, what's the python StringBuilder() equivalent? I'm in one of those rare situations where I'm concatenating hundreds of millions of tiny strings and I actually need it.
Just add build a list and l.join("")? Is there anything that actually builds it incrementally so that the tiny strings can be collected?
yes, though it's ''.join(l)
builds it incrementally
don't think so,strs are immutable so if you tried to dos += 'tiny snippet'it'll make a new string every time, destroying performance
ig if you really wanted a dynamic string you'd have to compromise with a list of singular characters
or maybe there's a library out there
in cpython s += t is optimized to mutate the existing s instead of creating a new one
if there's no other references to s
o interesting
pypy doesnt do it
what is meant by build incrementally?
Ah yeah other order, mb
Yes, the "destroying performance" paradigm is where I'm at right now.
That's... wild actually. Didn't know that. I would have thought it would be slower to run the check.
strings arent mutable, so if you did s += t it's supposed to create a new string in memory where it copies over the characters in s and t
by building incrementally they mean modifying the s string in-place instead of creating a new one
Unless if you already have the string you already have the refcount.
I thought it required a dereference
But I suppose you're sort of doing that already so why not grab the object header
wack
does io.StringIo do what you want? I haven't seen ppl use it tho
To be honest I'm not sure. My assumption was that it was meant to be backed by something.
<@&831776746206265384> piracy of some fintech thingy. premium is $600/yr
!cban 312503822914289664 your only message is advertising pirated software
:incoming_envelope: :ok_hand: applied ban to @worthy skiff permanently.
It is actually O(n^2) both in CPython and PyPy https://pypy.org/posts/2023/01/string-concatenation-quadratic.html
https://stackoverflow.com/questions/44487537/why-does-naive-string-concatenation-become-quadratic-above-a-certain-length/44487738#44487738
PyPy
This is a super brief blog post responding to an issue that we got on the PyPy
issue tracker. I am moving my response to the blog (with permission of the
submitter) to have a post to point to, since i

Stack Overflow
Building a string through repeated string concatenation is an anti-pattern, but I'm still curious why its performance switches from linear to quadratic after string length exceeds approximately 10 ...
The io module has streams that can be used as a string builder, for example io.BytesIO or io.StringIO
Thats probably the closest you'll get.
Other than using ''.join
Fun fact, PyPy has some string builders in the __pypy__ module. __pypy__.builders.BytesBuilder() and __pypy__.builders.StringBuilder().
Hey, y’all. I was wondering if anyone knew any good ways to decrease the false positive rate of a bloom filter. Currently, I hash the input with a cyclic shift and the compress it with MAD ((a*k + b) % p) % N where n is the size of the bloom filter, p is the next prime after N and a and b are randomly generated such that they are both less than p (also I keep sampling them until I get a unique a and unique b). Also, I just took the size of the bloom filter and the number of has functions from the wiki.
But rn, I’m only getting a false positive of about 3.8%. So other than increasing the number of bits, is there a good way I could try and bring down the false positive rate?
Idk, maybe there is a better way to hash it or smth.
If you think you've got a bad hash function, then you could try using a theoretical optimal hash function.
from collections import defaultdict
import random
hasher = defaultdict(lambda: random.randrange(2**61))
If this has the same false positivity rate, then no you cant improve your hash function
Oh yeah, would that generate random hash functions in the range of your bloom filter? Sorry, I’m unaware of the collections.defaultdict class.
Good idea though.
defaultdict is just a dict with a default value
I use it a ton. For example defaultdict(lambda: 0) or defaultdict(lambda: [])
Very convenient to use
Okay, that makes sense. So, how would I use that to get a theoretical optimal hash?
Think about hasher = defaultdict(lambda: random.randrange(2**61))
It maps integers to a random value in [0, 2**61)
Oh true. Couldn’t you just use random.randint?
Ofc
random.randint(0, 2**61-1)
is the exact same thing as random.randrange(2**61)
I just find randrange nicer to use
Yeah, okay. My bad, I’ve honestly never used randrange before.
That’s actually a really sick idea tho. Thanks heaps btw
Note that this is only useful to "benchmark" your bloom filter.
Ye, ofc
Okay, lol. My hash function sucked ass. I got 10^-3% as the false error rate for the “optimal” one and 3.8% for mine. Could the be any reason why mine sucked so much? Or is there a better way to hash it?
p is the next prime after N
that doesn't feel good
also, using random a and b is not good either
try picking extremely large prime a,b,p and testing your hash function again
Aight. Should a and b be prime u reckon?
everything should be prime
Fr?
How come? Also how should I sample a and b then?
there are ways to generate big prime numbers
Yeah, I know but should I just choose any big prime?
((a*k + b) % p) % N to me what sticks out here is that the addition with b does almost nothing
I'm sure there are better hash functions out there for this
But as I said before, if you don't see any improvments with hasher ^, then the hash function is not the issue
But if you see improvements, then your current hash function is inoptimal
expressions like this are used in PRNGs, but a,b,p should be carefully chosen, otherwise you will get trash results
if we are generating hashes using this, then I agree that b does almost nothing
it shifts all possible results, and that is it
Okay, so implemented it. Choosing a large p helped by .3% but choosing large primes a and b seemed to increase it by .4% from that strangely
To be fair, I just generate random a and b between p//2 and p - 1 such that a and b are prime. So it's still random. But I don't really see that mattering, ig I could choose the prev prime before p and then the next prev etc? Would that actually make a difference tho?
Ignore this, choosing large prime a and b didn't improve it or slow it down at all.
Actually the only thing that made a difference (+0.2%) was more carefully choosing p. Is it possible that cyclic shifting is making it fairly high?
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
I probably shouldn't, academic honesty and that.
Actually fuck it, doesn't matter just immediately a sec
Link: https://pastebin.com/qjsqJj8J
Password: gGsJqFgBB%#$%$@#$24B
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
!pypi bitarray

efficient arrays of booleans -- C extension
Released on <t:1704143281:D>.
Yeah that's what I was thinking
give me an hour, I will get back home and play with your code
Thanks heaps dude.
No stress tho, I don't wanna waste your time if you don't wanna do it, but I would really love the help
Plus, imma go to bed so I won't be able to get back to you for a few hrs.
What about using hasher?
Yeah... my hash function gives 3.35% false pos rate and hasher gave 0.0015% or smth
Ya. Pretty crazy
Here is something to try
struct custom_hash {
static uint64_t splitmix64(uint64_t x) {
// http://xorshift.di.unimi.it/splitmix64.c
x += 0x9e3779b97f4a7c15;
x = (x ^ (x >> 30)) * 0xbf58476d1ce4e5b9;
x = (x ^ (x >> 27)) * 0x94d049bb133111eb;
return x ^ (x >> 31);
}
size_t operator()(uint64_t x) const {
static const uint64_t FIXED_RANDOM = chrono::steady_clock::now().time_since_epoch().count();
return splitmix64(x + FIXED_RANDOM);
}
};
Which translated to python would look something like this
import random
FIXED_RANDOM = random.randrange(2**64)
MASK = 2**64 - 1
def splitmix64(x):
x = (x + FIXED_RANDOM) & MASK
x = (x + 0x9e3779b97f4a7c15) & MASK;
x = ((x ^ (x >> 30)) * 0xbf58476d1ce4e5b9) & MASK;
x = ((x ^ (x >> 27)) * 0x94d049bb133111eb) & MASK;
return x ^ (x >> 31);
For converting the key to a hash code?
yes
the key could be a string tho
Pythons built in hashes for strings are pretty good
actually, nvm. I think I got it.
Try either splitmix64(hash(S)) or hash(S)
@staticmethod
def next_prime(n: int) -> int:
"""
Returns the next prime number after n.
"""
n += 1000
while True:
n += 1
for i in range(2, n):
if n % i == 0:
return n
``` that does not return prime numbersit specifically returns non-prime numbers
def __str__(self) -> str:
self._data.__str__()
``` do you have any typechecker enabled? this contains an errorhow are you checking your error rates? can i see that code?
def find_in_arr(self, arr: list, elem1: Any, elem2: Any = "") -> bool:
for i in arr:
if i == elem1 or i == elem2:
return True
return False
``` that reduces to `elem1 in arr or elem2 in arr`p = BloomFilter.next_prime(self._num_bits)
``` even if that generated a prime number, it would be comically lowWait ffs that's so gross. That's so stupid lol
also, all your hash functions are the same
for i in range(self._num_hashes): # initialise hash functions lol seems kinda goofy but whatever
a = b = -1
while self.find_in_arr(used_ab, a, b):
a = random.randint(1, p - 1)
b = random.randint(0, p - 1)
used_ab[2*i] = a
used_ab[2*i+1] = b
self._hash_funcs[i] = lambda x: self.compression_function(x, a, b, p, self._num_bits)
all created lambdas will refer to the last value of a and b
What, really? But I generate new a and b each time?
that is how lambdas work
they do not capture all variables individually, they capture a reference to frame and extract variables from it when needed
lambda x,a=a,b=b: ... this will fix it
Lol, I was just typing this exact thing haha.
Really appreciate the help btw dude.
from collections.abc import Callable
import math
import random
from bitarray import bitarray
def myhash(x: object) -> int:
return hash(x)
def is_prime(n: int) -> bool:
for i in range(2, int(n**0.5) + 1):
if n % i == 0:
return False
return True
def next_prime(n: int) -> int:
while True:
n += 1
if is_prime(n):
return n
class BloomFilter:
data: bitarray
hash_funcs: list[Callable[[object], int]]
size: int
def __init__(self, max_keys: int, error_rate: float = 0.01) -> None:
num_bits = round(- 2.08 * max_keys * math.log(error_rate, 2))
num_hashes = round(- math.log(error_rate, 2))
self.hash_funcs = []
p = next_prime(num_bits)
for _ in range(num_hashes):
a = random.randint(1, p - 1)
b = random.randint(0, p - 1)
self.hash_funcs.append(lambda x,a=a,b=b: ((a * myhash(x) + b) % p) % num_bits)
self.size = 0
self.data = bitarray()
for _ in range(num_bits):
self.data.append(0)
def add(self, key: object) -> None:
for func in self.hash_funcs:
self.data[func(key)] = 1
self.size += 1
def __contains__(self, key: object) -> bool:
for func in self.hash_funcs:
if not self.data[func(key)]:
return False
return True
``` this is what i am left withworks for me
i guess your math is just wrong on these lines ```py
num_bits = round(- 2.08 * max_keys * math.log(error_rate, 2))
num_hashes = round(- math.log(error_rate, 2))
i can get arbitrary precision by increasing number of bits and hashes
wait you have a list of hash functions or whatever, but why dont you use any of the ones from hashlib
they are slow and not parametrisable
are they? huh
ive tended to use them for some of my stuff since they're deterministic (unlike hash(), grrrrr)
wait wdym parametrizable
give me a thousand of different hash functions please
well i mean
depends on your definition of different
cause some of them can spit out different amounts of bytes
there is definitely not a thousand of functions in hashlib
so it is useless for bloom filter
But what false positive rate r u getting?
Cos mine works, but I was really hoping for a technique to decrease the false positive rate.
hey guys, i'm trying flatten json response
From:
input:```
[
{
"A1": "a",
"A2": "t",
"A3": [
{
"B1": 1,
"B2": "i",
"B3": [
{
"C1": "g",
"C2": [
{"D1": "Sa", "D2": 1},
{"D1": "Ss", "D2": 4}
]
},
{
"C1": "h",
"C2": [
{"D1": "Sb", "D2": 2},
{"D1": "St", "D2": 5}
]
}
]
},
{
"B1": 2,
"B2": "j",
"B3": [
{
"C1": "i",
"C2": [
{"D1": "Sc", "D2": 3},
{"D1": "Sd", "D2": 6}
]
},
{
"C1": "k",
"C2": [
{"D1": "Se", "D2": 7},
{"D1": "Sf", "D2": 8}
]
}
]
}
]
}
]
to this:
A1 A2 B1 B2 C1 D1 D2
0 a t 1 i g Sa 1
1 a t 1 i g Ss 4
2 a t 1 i h Sb 2
3 a t 1 i h St 5
4 a t 2 j i Sc 3
5 a t 2 j i Sd 6
6 a t 2 j k Se 7
7 a t 2 j k Sf 8
records = []
def process_item(item, parent_info=None):
if parent_info is None:
parent_info = {}
if isinstance(item, dict):
temp_record = parent_info.copy()
for key, value in item.items():
if isinstance(value, dict):
process_item(value, temp_record)
elif isinstance(value, list):
temp_records = []
for sub_item in value:
if isinstance(sub_item, dict):
new_record = temp_record.copy()
process_item(sub_item, new_record)
temp_records.append(new_record)
if temp_records:
for record in temp_records:
combined_record = temp_record.copy()
combined_record.update(record)
if all(combined_record.get(field) is not None for field in ['A1', 'A2', 'B1', 'B2', 'C1', 'D1', 'D2']): records.append(combined_record)
else:
temp_record[key] = value
if all(temp_record.get(field) is not None for field in ['A1', 'A2', 'B1', 'B2', 'C1', 'D1', 'D2']):
records.append(temp_record)
elif isinstance(item, list):
for sub_item in item:
if isinstance(sub_item, dict):
new_record = parent_info.copy()
process_item(sub_item, new_record)
if all(new_record.get(field) is not None for field in ['A1', 'A2', 'B1', 'B2', 'C1', 'D1', 'D2']):
records.append(new_record)
for item in data.get('A', []):
process_item(item)
df = pd.DataFrame(records)
df = df.dropna(axis=1, how='all')
df = df.drop_duplicates()
df = df.reset_index(drop=True)
return df
this is the recursive approach i'm following the only problem is I have to hardcode key names
increase number of has functions and number of bits
Fair lol.
I don't have a good solution, but I have a  solution, because I love my
solution, because I love my  . This is an iterative approach that unnests the right-most columns... there's more clever ways of doing this, but I aint going to keep going. Example below assumes you assigned data = [...] (your example above) ```py
. This is an iterative approach that unnests the right-most columns... there's more clever ways of doing this, but I aint going to keep going. Example below assumes you assigned data = [...] (your example above) ```py
import duckdb
import pandas as pd
from numpy.dtypes import ObjectDType
def unnest_dataframe(f):
col="data"
df = pd.DataFrame({col: f})
first_iteration = True
while isinstance(df[col].dtype, ObjectDType):
select_cols = f"columns(c -> c not like '{col}'), " if not first_iteration else ""
query = f'SELECT {select_cols} UNNEST("{col}") AS unnest_col FROM df'
df = duckdb.execute(query).df()
col = df.columns[-1]
first_iteration = False
return df
final_df = unnest_dataframe(data)
print(final_df)

of course you would duck this up
if you know what key is the final one (D2 in this case), then you can do something much simpler
def kv_stream(data):
match data:
case list():
for x in data:
yield from kv_stream(x)
case dict():
for k, v in data.items():
match v:
case list() | dict():
yield from kv_stream(v)
case _:
yield k, v
def rows(leaf_key, kv_pairs):
flat = {}
for k, v in kv_pairs:
flat[k] = v
if k == leaf_key:
yield flat.copy()
for row in rows('D2', kv_stream(json_data)):
print(row)
```output:
```py
{'A1': 'a', 'A2': 't', 'B1': 1, 'B2': 'i', 'C1': 'g', 'D1': 'Sa', 'D2': 1}
{'A1': 'a', 'A2': 't', 'B1': 1, 'B2': 'i', 'C1': 'g', 'D1': 'Ss', 'D2': 4}
{'A1': 'a', 'A2': 't', 'B1': 1, 'B2': 'i', 'C1': 'h', 'D1': 'Sb', 'D2': 2}
{'A1': 'a', 'A2': 't', 'B1': 1, 'B2': 'i', 'C1': 'h', 'D1': 'St', 'D2': 5}
{'A1': 'a', 'A2': 't', 'B1': 2, 'B2': 'j', 'C1': 'i', 'D1': 'Sc', 'D2': 3}
{'A1': 'a', 'A2': 't', 'B1': 2, 'B2': 'j', 'C1': 'i', 'D1': 'Sd', 'D2': 6}
{'A1': 'a', 'A2': 't', 'B1': 2, 'B2': 'j', 'C1': 'k', 'D1': 'Se', 'D2': 7}
{'A1': 'a', 'A2': 't', 'B1': 2, 'B2': 'j', 'C1': 'k', 'D1': 'Sf', 'D2': 8}
If anyone has an idea, I'm down! Couldn't make (recommendation of Purplys)
dp[H][J] := max with height `H` ending at column `J`
dp[H][J] = max(dp[h][J-1] + h) for h in 1..S
where S = max height that still makes valid rectangle
work either :/
(and I know there's a solution (managed to get AC with it) using Largest Rectangle in Histogram and no DP but I'm really curious about the DP one 😄)
I am looking for a developer who can solve captcha with python selenium.
what about it is not working
I haven't really implemented it, but use an RMQ data structure to do the max(...) for h in 1..S part, and the S you need at H, J can be calculated quickly from S at H-1, J
By couldn't make it work was more like
not sure how the transition works with, feels without the row incorporated somewhere I'm not following how you'd do it
but message got lost sorry
because when you mean ending at column J, it could end at column J row 5 or at column J row 200
So when I want to check if I can make a valid rectangle at column J+1
I don't know which row to look at
If that makes sense
row and S are very related, which in turn makes row and h and H very related
or maybe the dp definition is just bad
If at column J the biggest height that makes a valid rectangle starts at row 1000 and ends at row 1050 and you have 3000 rows
I'm not sure I get how you store that information in dp[50][J]
ehhh maybe the dp is bad
ngl the more I think about what the dp transition should be, the closer it gets to the histogram thing
maybe the comment threw me off and we have to do the histogram thing
actually, doesn't the "traditional" histogram problem have an O(n) solution using a monotone stack, but also an O(n log n) solution using a RMQ data struct
I don't know, I only know the monotonic stack solution
If there's a DP solution with a RMQ then obviously I guess we can use it here
or maybe I'm misremembering
I'm going to check
https://leetcode.com/problems/largest-rectangle-in-histogram/solutions/ I don't really see anyone in the solutions tab discussing it
disgostan site but looks like it
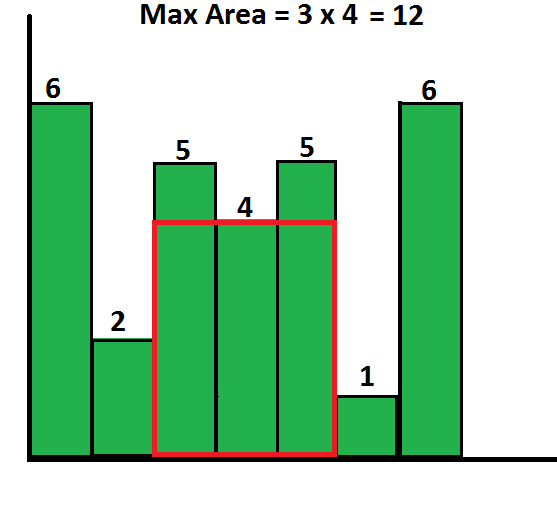
GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
@narrow mica can I run something by you?
sure? tho tbh you can just post whatever you have here(if appropriate, i.e. dsa cause tis the dsa channel) and other people can also look at it
it's not really dp right, but I guess that's probably what the persons in the comment of the original problem was talking about
ofc, I posted it in #databases but there doesnt seem to be anyone currently active at the moment. Here is the link to my post #databases message
if I search for another similar classic (largest rectangle in binary matrix) people seem to call that dp
so that might be where the dp comes from
thanks for digging that up
personally idk, so you'll have to wait for someone else
no worries, thanks for taking a look anyway
damnn im just lookin at chats rn and im noticing how many smart people are in this serfver
My question is about complexity analysis. There is a function that accesses 5 different hash tables, where each hash table has M keys (Cannot be treated as a constant) and each key has N characters (Cannot be treated as a constant). If a single hash operation is considered O(K) where K is the number of characters of the key, what should be the worst case complexity of this function?
How do I write it in the most concise way possible
worst case? something like K + 5 M min(K, N)
why + K?
you need to hash the thing
not in general
though it's kinda weird that K and N are even different variables
if K=N then it would dominate
looking for DSA guidance
Please ask a complete question that someone can start answering.
there is too much overwhelming info
that is distracting and floating from one place to another
what is your goal for learning DSA
to get in FAANG
DSA isn't the most important thing to get into FAANG, but even if it were, FAANG isn't the be-all-end-all of software development careers.
i know but
It is also the way to get in
I want to know how to progressively learn programming where i can solve problems
try implementing a linked list.
thnks you ⭐
hello guyw
Does anyone know how to create a list from a variable
for example, lets say im taking an input like x = input("hello enter a number"), lets say, for the sake of example, i enter 20. How do i make a list called 20 out of that?
lists don't have names
you can create a list of 20 elements
or list with a number 20 inside
ok
x = input("Name of variable:") # hello
y = input("Content of variable:") # world
globals()[x] = y
print(hello) # world
its possible, but you should never do this
why not
There might be other reasons, but for one this code is hard to follow/understand
You'd use a dictionary.
Hm alright
I mean
As long as it works
I would like to remove 1 from all first k elements of an array in log(n) or faster where n is the size of the array. I want to be able to insert in this array in log(n) or faster as well. Seg tree + lazy propagation doesn’t work because you can’t really insert anything, right? Is there a way to do both?
Because I only ever need to look at the first k elements when I do the updates I feel like I could use SortedList
But I’m not sure I see a clear way on how to do it
Dynamic datastructures in general are a bit tricky. Easiest thing would be to allocate extra memory to begin with
The thing is that if I allocate extra memory my updates will remove 1 to those unused positions right
And I’m not sure how I could discriminate between used and non-used (actually I could just have tuples int + bool instead of integers in my array)
You can have a segment tree with 0 1 to keep track which elements are "active"
Yes that makes sense
And because I know I won’t insert more than x times with x <10^5
I can just initialize a 10^5 sized array with most elements marked as « inactive »
Although now that I think about it if the only information I have is that I’ll insert x times then i need at least x slots between two elements right
Not really I’m figuring them out on the go
Then I would a n^(1/3) datastructure
I’d be fine with it tbf I probably wouldn’t see that much of a difference with logn
Do you know about the "sorted list" data structure?
Yep
That one is basically what you'd want
From the GitHub you usually reference
yes
Im not sure you can do range updates though
« Fast » range updates
Think about how to do n sqrt n first
I « only » want to remove 1 to first k elements
what is that? heap? regular list that is maintaned in sorted state? something else?
Not sure I get what you mean with sqrt - ah no I see, sqrt decomposition with plenty of small arrays - thanks!
GitHub
⚡ Competitive Programming Library. Contribute to cheran-senthil/PyRival development by creating an account on GitHub.
Dynamic datastructure for keeping track of elements in sorted order
Internally it uses insert sort into O(n^(1/3)) buckets
There are O(n^(2/3)) buckets in total
Once a bucket fills up, it is split into two
The split operation costs O(n^(2/3)), but amortized it is cheap, since you only have to do it after first doing O(n^(1/3)) inserts into the bucket that is split
ok, list of lists
dont see why you would use that instead of a heap
heap is a limiting case of the same idea - split lists into lists of lists to make insertion faster, until you get O(1) lists - that is a binary tree
You can’t access the ith fast element in a heap (I think you can with SortedList)
Try benchmarking it. The "sorted list" stuff is stupidly fast compared to anything else I've implemented in Python
The expensive steps, inserting, is done via a .insert call on a list
Which has a crazy low constant factor
since it is basically just C code
you probably can, with some additional maintained state
that's fair
Stack Overflow
I remembered that heap can be used to search whether an element is in it or not with O(logN) time complexity. But suddenly I can't get the details. I can only find getmin delete add and so on.
Can
Looks like you can’t do look ups in heap fast (you don’t know if you should go left or right)
Even with an additional DSA on the side
Iirc all of these sorted datastructures, heaps etc, ... has a way to keep track of "kth order statistics"
By maintaining some extra state
That said, I really dont think you'll beat the speed of sorted list with any of those
So for my problem I could just do, with sqrt decomposition:
Insert in sqrt(n)
Lookup in log(n) (binary search)
Range update in sqrt(n) by "caching" the value I update to arrays entirely covered
And I guess if I know in advance the final size of my array, I should start with blocks of size sqrt(final size of array) instead of doing from time to time linear re-buildings right?
I was thinking of doing everything in sqrt(n) time. I don't know what kind of binary search you are thinking of doing
Well if you know that your array is sorted
I was writing something like this to find where to insert (which eventually will be O(sqrt(n) because I'll call .insert after)
def find_index_to_insert(self, value: int) -> tuple[int, int]:
# Binary search to find the block
left, right = 0, len(self.blocks) - 1
while left < right:
mid = (left + right) // 2
if self.blocks[mid][-1] < value:
left = mid + 1
else:
# It means self.blocks[mid][-1] >= value
right = mid
block_idx = left
# Binary search within the block
block = self.blocks[block_idx]
left, right = 0, len(block)
while left < right:
mid = (left + right) // 2
if block[mid] < value:
left = mid + 1
else:
# It means block[mid] >= value
right = mid
return block_idx, left
And you can write something similar for lookup right, and because there's no .insert call afterwards, it's a log(n) lookup
Oh yes right initially I was only asking for range update and insert; turns out I just didn't talk about lookups because I knew if I had a sorted DSA I could do them fast
hello i need courses web scraping & automation
does anyone have a good sentiment analysis program?
if python recursion wasn't so slow, you could use a merge split treap, which could support all segment tree operations + more like inserting/deleting(what you need here), interval reversal, cyclic shift, etc all in log time
I was also gonna say you could probably do some shenanigans with a range update point query datastruct to keep track of indices, but then I looked and saw that's what SortedList is doing
What's a good website for DSA problems
preferably very well categorized
Leetcode is nice but i do dislike the premium popups

actually I had forgotten but you need to consider if there is a value in .lazy so lookup as well is sqrt(n)
Sounds like a super complicated data structure 👀 never heard of it
I have tried making iterative treaps in the past. https://github.com/cheran-senthil/PyRival/blob/4a735958bfd3ac130a1d60542a23390e99b756f4/pyrival/data_structures/Treap.py#L218-L232
But they just dont compare to the speed of sorted list. Even when n = 1e7

GitHub
⚡ Competitive Programming Library. Contribute to cheran-senthil/PyRival development by creating an account on GitHub.
it is a bit of a doozy
treap is bst + heap, each node stores (bst_key, heap_key=random()), and if you look at bst_key the structure is a bst, if you look at heap_key it's a heap, and the randomized nature keeps it pretty balanced so it won't degrade; you can implement it using rotate or merge & split, use the latter for our purposes
then instead of actual keys, use "implicit keys" that are calculated on the fly as you descend the tree which represent the array's indices
interesting...
I wonder what the speed difference is in say c++
isn't std::set basically a sorted list?
ah it doesn't allow duplicates
but other than that it's the same right?
no std::set doesnt have kth order statistics
ah yes fair enough
if you're using gcc then you could use pbds tree, which does have order statistics
or well g++ ig cause c++
not really a c++ user to be fair anyway haha
Hello, need some help with this school homework 😭
I'm trying to make a library that stores info about books and then i need to be able to output it via ID
what i dont understand is, how do i link the id to the book
how do i make it so that if for example
the input is "19" as in, give me the book with the id 19, how do i show the specific details of that book?
dict is perfect for this task
How can I encode a hex string to a 5-6 length integer value without losing data or mapping? Then, I can decode it back to the original hex string again.
For example:
- Encode:
"664fbafb951c8e9cb32c7091"→ return238774 - Decode:
238774→ return"664fbafb951c8e9cb32c7091"
is bro trying to unhash hashed data💀
hey can someone tell me what's wrong in this,I want to filter the strings which only contains 'e' and 'r' in it

impossible even in theory
there exist more hexstrings than 5-6 length integers
apply pigeonhole
what output were you expecting and what are you currently getting?
I'm expecting it to only show the letters with erf in it and I ain't getting no O/P
in the if condition you are checking if the letter is in er not erf
mb
mb

@brave hound for this code I get the ints which only has 0s and 1s as output
but now I have to another thing
If I gave 32 as input,it gives me 0,1,10,11 as OP and I want these ints to sum to get the given intput
like If I give 32 as IP and the the ints with 1s and 0s from 0 to 32 are 0,1,10 and 11 and if I add any of these numbers they should give me 32
if I add 10 and 11 and 11,I get the sum equal to the given input which is 32
@brave hound can you help me to do it
since you already computed the numbers you are going to be using to get the sum
you can do something similar to a greedy coin change solution
basically you sort the numbers in reverse order and iterate over it, then check how many of that number can fit into the target like (two 11s = 22 <= 32, but three 11s = 33 > 32) and you add that many of that number into the result and move onto the next number in the sequence
Im using xarray to open a weather grib dataset, there is 2 levels in it, one is isobaricinhpa (vertical weather layers in millibar) and one is for tropopause layer, any solution? I need both and dont want to filter it, just tryna output a grib into a netcdf
Do you know some tasks to test it?
When doing just random inserts and erases i am getting pretty similar results for set and sortedlist, but sortedlist seems to be a bit faster than multiset (though i don't really trust these tests xd)
is faster than pbds tree - 1e6 inserts, erases and order_of_keys (first screen pbds, second sortedlist)


Did you implment it in c++?
yep
Have you optimized the block size parameter?
Oh did you translate the python code?
mostly
You might want to play around with the block size
I don't know the best way to benchmark it
sorted list kind of has a worst case when you do insert at index 0 (i.e. in decreasing order)
for (int i = 5'000'000; i >= 0; i--) {
s.insert(i);
}
(block size) 700 ->
6822822us (set)
15355384us (sortedlist)
1300 ->
6902500us
8223500us
1700 ->
6924141us
7042001us
2700 ->
6919356us
6521755us
works pretty fine
I was kind of hoping this would beat std::set by a significant margin, since std::set is known to be slow
I've heard a lot of rants about how Abseil's set beats std::set by a mile
At least it is a nice alternative for pbds ordered set which is even slower
Also I believe it will be kinda 1.5x better than std::set on average
If inserting in increasing order it is >2 times faster
The real strength of it is if you need to iterate over the elements in some range [l:r]
Since everything is stored into decently sized vectors, it is memory contiguous
Btw one interesting idea I've had for sorted list in C++.
Suppose that in each block you were to store 8 bit pointers (or maybe 16 bit pointers) to some kind of look up table
The cost of inserting should then decrease proportionally to the pointer bit size
So this could make the inserts significantly cheaper
@regal spoke I'm not sure I remember well, and I can't find it, but you once said there's loads of stuff Mo's algorithm can do and seg trees can't, and one of them was Range Frequency Queries? Or do I remember poorly? (the latter is likely)
Well ye. There are some ways to work around that limitation
Mo is used when queries are complicated enough to not be possible to do with segment trees
by ways to work around the limitation do you mean weirdly implemented segment trees, but so hard to implement that mo does the job?
(I'm asking because I was looking at this problem which is apparently Mo's 101 (https://www.spoj.com/problems/DQUERY/) and there were some (albeit a tiny bit convoluted) seg tree solutions)
There are ways to for example query: count number of (different) elements in [l, r)
using a segment tree
But you need to work around it
ah yeah that's exactly the one I just did
well, MO is much faster here actually
by setting 1 to the last time you saw a particular value, right?
even though the complexity is worse
What. The speed of the segment tree solution should be insanely fast
with changes
def solve() -> None:
n: int = get_int()
a = line_integers()
q: int = get_int()
queries = [[] for _ in range(n)]
# queries[j] represents a list of queries, each being the queries[j][k][1]th query -
# that is between queries[j][k][0] and j
for nb in range(q):
l, r = line_integers()
l -= 1
r -= 1
queries[r].append((l, nb))
answers = [0] * q
st: SegmentTreeSum = SegmentTreeSum([0] * n)
last = [-1] * (10**6 + 1)
for j in range(n):
if last[a[j]] != -1:
st.update_tree(last[a[j]], 0)
st.update_tree(j, 1)
last[a[j]] = j
for l, nb in queries[j]:
answers[nb] = st.sum_range(l, j)
for answer in answers:
print(answer)
gets me 2.33s
for count number of (different) elements in [l, r]
on that judge
https://codeforces.com/gym/507278/problem/B
i've made this very fun task
(though it hasn't english statement and in python you can't solve it for sure)
5e5 distinct elements on segment queries with changes in point
O(n^(5/3)) works fine, but O(nlog^2(n)) not
You are not allowed to view the contest
- You could use a fenwick tree instead of segment tree for exatra speed
- Mapping down the elements to [0,n) will probably speed it up significantly
mhm 1 min
Insightful, I wasn't really trying to beat Mo's though. I never think of 2.
I was just curious as to how people solved it with seg trees when it's presented as a "Mo's 101"
Easiest way to explain mo is to make a simple query problem
The standard problem used to explain mo on cf is https://codeforces.com/contest/86/problem/D , which I think doesn't have an easy segment tree solution (but I havent thought too hard about it)

Codeforces
second task
after i click the invit link i can click on the first link
I see I'll check it out
So the conclusion is more like
For some problems
There might be a seg tree solution
but the work to get it is just too much
and the Mo's solution is just a ton easier
Havent really thought about online count unique values before? Can't you do a mix between the offline algorithm and a brute online algorithm?
to get something like n sqrt n
You rebuild the offline datastructure after every ~ sqrt(n) queries
There could be at most sqrt(n) updates that the offline datastructure doesnt know about at any point in time
Those updates you can handle in a brute force way. For each query, you simply check all relevent new updates in O(sqrt(n)) time and modify the result from the offline algorithm accordingly
xd
yeah sounds good
that's not fair 😄
though
how would you handle them
ah ok i know
Hi guys, im a gold trader. I have so far written some code which gives me the following output for the example market structure.
The problem lies in how I further interpret my tuples of data in the sequenced output.
Specific combinations and sequences of mitigation outputs have different interpreted conditions for the current price action.
So yeah! if anyone can help point me in the right direction in terms of finding the right community or person to help me I would greatly appreciate it!

Here is another example output:

Whats the question?
thats hard part. working out what I want to code
if 3 "fully mitigates" 5 and closure status = "yes" then when 2 "fully mitigates" 4 thats an indication trend has been broken
do I guess someone needs to have experience with market structures already potentially
its a very unique and niche area I understand
I don't know what fully mitigates means in this context.
Takes out what?
Is this some commodities terminology? I've never done commodities
Its ICT terminology
fully mitigates is the act of something that has been made less severe or painful, or has been made less dangerous, harsh, or damaging
so when we fully mitigates previous highs or low in the market
its putting in damage for sellers but making damage less painful for buyers
in that context
but it can always be the opposite way around hence, "fully mitigates" in this context im using to refer to the purge of previous lows or highs
so like each poi will have previous points that it interacts with
and thats how im analysing it
I'm not sure you're going to find anyone who knows much about ICT or commodities trading here. If you can express it in terms of an algorithmic goal, maybe we could map it to something else?
Right spot on
If you just want to label points based on their relationship to lag/lead values? That's straightforward
In trading we interpret the market from a technical stand point.
So the process of analysis, if we repeat that and record the output enough times we get results and then can safely place trades
But its about being clever and interpreting it specifically but also having a high enough frequency for results
take the simple act of taking out (aka fully mitigating) the previous days high, it happens ALL the time.
Thats one confluence (or specific attribute about the current price)
then you combine it with another attribute, its an and statement.
We are taking out the previous days high and we are breaking a 5min trendline
for example
I don't need the background, I'm in the industry. I don't do much TA tho, not a big fan of trading off charts
Whats the algorithm you're trying to implement?
Like, if you want to find points that meet conditions X and Y?
im very good at TA, suck at fundamental analysis.
I already got a little data manually recorded and its good profit (but not enough sample size) so I want to make a robot to do the technical analysis for me and give me results for hundreds of thousands of different trades for each specific trade type
yes, its the interpretation of the price data which is the really challenging part, but also im new to python so im using Claude at the moment to teach me.
If you're trying to learn Python, you really have to avoid LLMs: I'm not just saying this: it really hurts your growth
For the data part, I think youll find most of your questions really just require learning Pandas well.
Your right. I used it to write the first couple hundred lines of code but after that ive had to ask the ai specific lines of code and go step by step
Like, if you want to calculate an ichimoku cloud and identify points that intersect, this is fairly straightforward in pandas (or similar),
Yah, the problem here isn't that you won't get the job done... it's that you're not learning how to think in programming terms.
righttt thats probably why im finding it so hard to write this darn thing
I think in my own logical language and then work out how to make it into its python equivalent
Kaggle.com/learn is very helpful
and its always counter intuitive
Alright! ill check it out, thanks
You can skip the Ml stuff, the pandas part is really important

Also, hang out in #python-discussion , you'll learn something new every day
the ones with like 3000 pages of stuff
sure! thanks for the welcome
😢
so, I guess this question is more kinda theoretical, but, let's imagine that we need to generate n hashes for an object. We use the pickle.dumps(obj) to convert our object to a byte array and we stitch the bits together so we get a long string of bits of length. Now we take the number of bits, m, and we have and divide it by the number of hashes that we want. Then, we just take n partitions of length m//n. Would this give a relatively uniform and independent set of hash values?
Im using xarray to open a weather grib dataset, there is 2 levels in it, one is isobaricinhpa (vertical weather layers in millibar) and one is for tropopause layer, any solution? I need both and dont want to filter it, just tryna output a grib into a netcdf
You have n objects, and want to compute a hash of all of them? Or one object and n hashes?
one object and I want to get multiple hash values. like what you'd do for a bloom filter
Not really sure I follow but maybe ask in #python-discussion , there's enough ppl there who'll answer
So I'm learning some DSA, and this resource seems pretty mathematical in its explanations
While I do understand it if I try slowly, do I really need to digest the math? Or should I find a simpler resource

Yeah you should read it slowly. If you find something simpler you're just going to have a worse understanding of it.
It's worth noting that this isn't even the mathematical definition of big O, it's talking unrigorously about functions.
Anyone knows an optimized KMP algo where there's "two" prefix suffix table that starts with -1 ?
I saw it in my class but I cant find the source for it
just remember in regards to Big O it is always testing WORST CASE so when something is referring to Big O we can assume it is talking about worst case scenario. So for an example if something was big O(n)^2 -> this example is essentially a loop within a loop and so it is O(n)^2 because no matter what the input is we will have to look over that value twice - i.e.,
for i in something:
for j in something:
print(f"something: {j}")```
regardless if its 2-1000 we still need to look over the list twice
If I completely went off the rails here and missread what you've typed and told you something you already know sorry for wasting your time; if not, hope this helped.one shitty example but it's an example 
for i in something:
for j in something:
print(f"something: {j}")
``` this code does not "look over that value twice"
it does that `len(something)+1` times, so you get `len(something)*(len(something) + 1) = O(N^2)` (where `N=len(something)`) operationsjust remember in regards to Big O it is always testing WORST CASE so when something is referring to Big O we can assume it is talking about worst case scenario
no
big O is not generally "worst case"
it's an upper bound of something
you can upper bound the best case, or average case, or whatever
algorithm can be O(logN) in typical case and O(N) in the worst case (some kind of search tree, for example)
if you dont want to specify what you are upper-bound'ing, there are other letters for best case, average case, worst case
from wikipedia

You're true it doesn't always mean worst case - but if we are talking layman terms, trying to understand seems like it's best to not over confuse. Nor am I trying to debate or care too just trying to help
If f(x) is a sum of several terms, if there is one with largest growth rate, it can be kept, and all others omitted
If f(x) is a product of several factors, any constants (terms in the product that do not depend on x) can be omitted.
Example:
f(x) = 6x^4 − 2x^3 + 5
Using the 1st rule we can write it as, f(x) = 6x^4
Using the 2nd rule it will give us, O(x^4)
What is Worst Case?
Worst case analysis gives the maximum number of basic operations that have to be performed during execution of the algorithm. It assumes that the input is in the worst possible state and maximum work has to be done to put things right.
For example, for a sorting algorithm which aims to sort an array in ascending order, the worst case occurs when the input array is in descending order. In this case maximum number of basic operations (comparisons and assignments) have to be done to set the array in ascending order.
It depends on a lot of things like:
CPU (time) usage
memory usage
disk usage
network usage
What's the difference?
Big-O is often used to make statements about functions that measure the worst case behavior of an algorithm, but big-O notation doesn’t imply anything of the sort.
The important point here is we're talking in terms of growth, not number of operations. However, with algorithms we do talk about the number of operations relative to the input size.
Big-O is used for making statements about functions. The functions can measure time or space or cache misses or rabbits on an island or anything or nothing. Big-O notation doesn’t care.
In fact, when used for algorithms, big-O is almost never about time. It is about primitive operations.
When someone says that the time complexity of MergeSort is O(nlogn), they usually mean that the number of comparisons that MergeSort makes is O(nlogn). That in itself doesn’t tell us what the time complexity of any particular MergeSort might be because that would depend how much time it takes to make a comparison. In other words, the O(nlogn) refers to comparisons as the primitive operation.
The important point here is that when big-O is applied to algorithms, there is always an underlying model of computation. The claim that the time complexity of MergeSort is O(nlogn), is implicitly referencing an model of computation where a comparison takes constant time and everything else is free.
Example -
If we are sorting strings that are kk bytes long, we might take “read a byte” as a primitive operation that takes constant time with everything else being free.
In this model, MergeSort makes O(nlogn) string comparisons each of which makes O(k) byte comparisons, so the time complexity is O(k⋅nlogn). One common implementation of RadixSort will make k passes over the n strings with each pass reading one byte, and so has time complexity O(nk).``` this might help you, just found this 🙂are there?
There was the mathematical definition as well
there are some

But I understand that its better to actually understand whats going on
That’s not for best or average case
It’s just instead of having upper bound you can have a lower bound
Or a tight bound
Im using a book from my university's library which is doing a pretty good job of making me understand things so far though
But you have to say what you bounding for (although most people bound worst case)
The big omega is quite common when you want to say « the solution is at least that bad »
these aren't about best/worst case though
it's about what kind of bound of the function it is
O - upper (≤)
Ω - lower (≥)
o and ω for the strict variants which behave like < and >
the whole study of asymptotics boils down to looking at f(n)/g(n) and seeing what happens when n grows
does it tend to 0, a positive constant, or ∞?
Hi, i'm using the global forecast system(gfs) grib data, the model run has 120 hourly steps first, then transitions to 3 hour steps until 384, What I want to do is to linear interpolate the missing values between the 3 hours,
so pseduocode
pygrib open(file)
get data of time 120, 123 for example
interpolate 121,122
im not the best at the interpolation part and it has been quite challenging especially:
outputting the interpolation file the same structure as original dataset, including atmospheric layers for each variable, xarray is quite disasterous when handling layers, can anyone help?

i wrote this RLE algorithm yesterday for fun, thoughts?
def byte_RLE(arr, flag=0xff):
"""
Run Length Encoding, using a flag byte, a count byte, and a value byte.
Values without the flag are passed unchanged.
"""
idx = 0
while idx < len(arr):
val = arr[idx]
if val == flag:
if idx + 2 >= len(arr): break
count = arr[idx + 1]
val = arr[idx + 2]
for _ in range(count): yield val
idx += 2
else: yield val
idx += 1
instead of having the count before each value it reserves a single value (by default 255) as a flag to denote that there should be multiple of a byte
how do you encode 0xff?
ff 01 ff?
Hello there. I wont give the solution away but I will give you a few pointers. You will need to use recursion - and in such a way that when the arrow moves up by one in a pillar (towards the red square) you need to recall F2 every time you move by one blue square until you reach the red square and at that point you will start popping off the stack and the arrow will move back towards the bottom (by the same amount of squares that it moved up).
That's a bit of a mouthful I know, but hopefully it make a little sense.
That was a beautiful problem to do mo on, thanks for the suggestion, I did it yesterday and if you know you need to use mo it becomes so trivial
thx, im still stuck but i try to solve
Hello everyone.
Who can explain about suffix array algorithm?
Are you asking about an algorithm for computing the suffix array of a string?
Or asking what a suffix array is?
No, I want to know about suffix array algorithm, not concept.
There are a couple of algorithms.
The brute O(n^2 log n) is simply
def suffix_array(S):
return sorted(range(len(S) + 1), key = lambda i: S[i:])
The standard algorithm you'll find for it out there uses cyclic shifts, in O(n log n) https://cp-algorithms.com/string/suffix-array.html#on-log-n-approach
Sometimes you'll also see the same cyclic shift algorithm implemented using the built in sort, which makes it run in O(n log^2 n). That version is probably the simplest suffix array algorithm out there.
The goal of this project is to translate the wonderful resource http://e-maxx.ru/algo which provides descriptions of many algorithms and data structures especially popular in field of competitive programming. Moreover we want to improve the collected knowledge by extending the articles and adding new articles to the collection.
However, there are more complicated algorithms out there like the SA-IS algorithm that runs in linear time. Here is a Python implementation I've made of SA-IS https://github.com/cheran-senthil/PyRival/blob/master/pyrival/strings/suffix_array.py
GitHub
⚡ Competitive Programming Library. Contribute to cheran-senthil/PyRival development by creating an account on GitHub.
This ^ runs in O(n + |alphabet|), so in true linear time.
Can you suggest an algorithm that completes the shape within a certain polygon in the picture? I want pixels outside the polygon to be ignored when completing the shape.
import pygrib
import eccodes
import tempfile
import os
ds = pygrib.open('Tools/merged.grib')
with tempfile.NamedTemporaryFile(delete=False) as temp_file:
temp_file_name = temp_file.name
for msg in ds:
with open('Tools/merged.grib', 'rb') as in_grib:
gid = eccodes.codes_grib_new_from_file(in_grib)
eccodes.codes_write(gid, temp_file)
eccodes.codes_release(gid)
h123 = ds.select(step=120)
for msg in h123:
values = msg.values
new_values = values / 2
gid = eccodes.codes_new_from_message(msg.tostring())
eccodes.codes_set(gid, 'step', 121)
eccodes.codes_set_values(gid, new_values.flatten())
eccodes.codes_write(gid, temp_file)
eccodes.codes_release(gid)
with open('Tools/merged_modified.grib', 'wb') as outfile:
with open(temp_file_name, 'rb') as infile:
while (gid := eccodes.codes_grib_new_from_file(infile)):
eccodes.codes_write(gid, outfile)
eccodes.codes_release(gid)
os.remove(temp_file_name)
ds.close()
in the output, theres a new time1 dimension that is replacing time when time is the dim that takes the new modified values, i have no idea what to do, searched all over internet/Ai and everything and asked but got 0 answers anywhere


Hey I am having a problem with binary representation of integers, idk if it's normal or not :
(My version is Python 3.10.9)
When I slice in half a string integer and look at its binary form, it doesn't correspond to the lowest binary part of the original number. I would like to know why and if there's a way to fix the binary form of the sliced part to match the original one ? Surprisingly, only a small part of the binary representation matches.
n = 121332837237832748484297480923048038023787476482465738446464478484842942949922442024044992400310322222323222
halfn = int(str(n)[len(str(n))//2:])
hlength = halfn.bit_length()
for i in range(1, hlength+1):
if not (bin(halfn)[-i:] == bin(int(n))[-i:]):
print(i)
print(f"{i}/{hlength}")
break
56
56/179
I'm really not sure what you are trying to do. Base 10 and base 2 are very different
"halfn" in base 10 is not the same thing as "halfn" in base 2
12 in base 2 is 0b1100
This line (bin(halfn)[-i:] == bin(int(n))[-i:])
Think about the case of n=12
I am wondering why after taking half of the string of the number and then convert it back to int, it doesn't have the same binary representation of the same part but in the original number
Half of the string in base 10 is different from half of the base 2 string