#algos-and-data-structs
1 messages · Page 56 of 1
O(n) precalc + O(log) answer will be always enough (and usually faster i guess)
except if you will have problem answer 10^9 queries just for fun
This link will be funny to add to article for showing "domain" in a better way 😄
may be even adding as iframe
I'm not sure I understand that map. How are the space bases connected to eachother?
mm There are Star systems.
Bases are floating in space in them and have X, Y, Z position.
You can move around space system at regular speed in any direction. I joined all relevant star system objects with edges between each other. Weight is equal to normal distance between three dimensional points.
Additionally there is concept of "trade lane", which is speed booster allowing to travel 10 times faster inside a star system. I added their entry points as vertixes and joined with normal edges to other objects in the same system
And added edges inside of trade lanes, with distance divided by 10, to show that you can move faster in them.
You can travel between star systems by Jump Gates and Jump Holes. They literally just connect two star systems in exact locations between them. I added edge between jump holes/gates vertixes with weight 0.
Thus graph was built representing this galaxy map.
So the only way to enter/exit a star system is through a Jump Gate or a Jump Hole?
yeah
and you have free flight ability (and space filled with different space objects) inside each star system
How many warp holes/gates are there in comparision to bases?
https://darklab8.github.io/fl-data-discovery/
List of bases
Around 100-150 bases 🤔
Around 500 or smth like jump holes and jump gates. (rough estimation)
But you mentioned like 2000 nodes earlier
are you thinking APSP for each cluster first or something?
Yes something like that.
yeah. 2150 vertexes if we add as nodes: Space Bases, Jump Hole and Jump Gates, and trade lanes (flight speed boosters) entrypoints, exit points and intermediate flight points (that could be refactored i gues)
only Space Bases matter to calculate distances as starting points, everything else is intermediate travel point
total_systems 119
# vertix counts:
total_bases 550 # in addition i should try exclude Space Bases in dead systems, or that have no shop capabilities
total_jumpholes 425 # jumpgates included
total_tradelanes 1252 # i should remove intermediate vertexes in tradelanes for some optimization. there are some vertex noise that can be optimized
graph.vertixes= 2199 edges_count= 14372
Extracted precise numbers for fun. Excluded some not important stuff in addition
that will eliminate some additional starting points for Dijkstra calculations
Floyd warshall runs a lot faster too with fewer nodes
a point, a point.
but sequential floyd is rather slow in general
and algorithm for parallel floyd is rather cucumbersome to make due to lack of any code examples
Floyd is great for dense graphs
we can say my graph is sparse enough for Dijkstra stuff being better
I received twice faster calculations with DijstraAPSP without parallelizations
Inside each system, your graph is dense, right?
yeah.
sparsing only from limited jumpholes/gates connections between systems
And currently it is sparser because intermediate travel points in trade lane flight boosters are connected only with trade lane vertixes of same trade lane. Only entry and exit poitns for tradelanes are dense connected with other objects in star system. made this optimization purely for performance speed
Here is what I'm thinking. Solve all pairs shortest path for each system separately.
??
but people have Direct Space Flight capability into each direction inside a system
Objects in systems are pretty much connected directly with each other in a dense way (except trade lanes providing shorter flight paths)
there will be no point i think doing that
No there is a point. Each system is small in comparison to the whole thing
yeah
Also the graph is dense in each system, so Floyd warshall will be super efficient
but how we will be combining final data then into distances for trade routes across multiple star systems? 🤔
Now create a graph with one node per base, and one node per pair of warp holes/gates
Create edges between the nodes with weights given by your previous calculation. But don't add any edges between base node, because we don't need those
oh. I got your idea. Creating second graph that will have far lesser vertex and edges.
Smth like graph will be having less than 900 vertixes then
Which due to (V^2 + smth making up to V^3 in worst cases) complexity stuff, it will calculate way more rapidly
Ye
Briliant ^_^ that will probably help reaching calculating speed to the level of less than 0.2 second (currently having 1.5s as best result)
you are graph genius 😻
with such changes it will be probably 10 times faster calculations once again
Can anyone help me to write the program of battleship problem? I am not understanding it correctly.
just had a competitive programming comp, and one question in particular I spent like 2 hours on but kept getting TLE
given an unsorted array of positive integers, print all the indices such that if you remove that element, then the resulting array can be partitioned into two subsets with the same sum
I tried sorting the array and then doing a 3d dp of like dp[k, i, j] = there exists a subset of the first j numbers that sum to k that doesn't include i and putting results in a separate thing if i > j to try and squeeze some caching out, but that didn't work
the comp is over now to be clear
what are the sizes of inputs?
array up to 3k in length, numbers between 1 and 1k
actually wait it might've been 300
lemme check
it was 300
that feels bruteforce-able
you mean iterate and do 2 partition for every element?
or hmm...it's close
with saving results for a given digit
doing the usual sumset sum dp for 300 cases
oh wait maybe it is just the usual dp, but with 300 different backtrackings
I'll try it later tonight and see if it's fast enough
this one won't be
this one should be if it works
what's the difference?
e.g. say sum of all elements is S, then the question is, if I don't get to use one of the x's, can I construct a sum (S - x)/2 backtracking in the dp array?
you only calculate the dp array once for the full array
you deal with removing an element when backtracking when trying to find a solution for sum (S - x)/2 in that array
actually...will that work? you need to make sure the x goes in neither partition 
is the dp still dp[i, j] = there exists a subset sum of i with the first j elements?
yeah
wait
there exists a sum S - x not involving one x
there exists a sum (S - x)/2 not involving one x
these together is enough, isn't it?
and the first condition is trivial, it's just the sum of everything except the item
how do you figure that out from the full dp table?
you mean how to backtrack to find solutions in the dp table?
yeah
I still don't get that bit
would it be feasible to make two dp tables, one for the first j elements and one for the last j elements, and then do 2 sum on each index?
actually I might have lied about which dp I wanted
o
how do you fill that up tho?
!e writing code without testing, but something like
arr = [1, 2, 7]
S = sum(arr)
reachable = [False]*(S+1)
reachable[0] = True
for x in arr:
for i in range(S+1):
if i - x >= 0:
reachable[i] = reachable[i] or reachable[i - x]
print(reachable)
:white_check_mark: Your 3.12 eval job has completed with return code 0.
[True, True, True, True, True, True, True, True, True, True, True]
wait...I need to loop backwards
!e
arr = [1, 2, 7]
S = sum(arr)
reachable = [False]*(S+1)
reachable[0] = True
for x in arr:
for i in reversed(range(S+1)):
if i - x >= 0:
reachable[i] = reachable[i] or reachable[i - x]
print(reachable)
:white_check_mark: Your 3.12 eval job has completed with return code 0.
[True, True, True, True, False, False, False, True, True, True, True]
otherwise you're solving the problem if you can use any amount of each element
!e and with backtracking
arr = [1, 2, 7]
S = sum(arr)
reachable = [False]*(S+1)
reachable[0] = True
for x in arr:
for i in reversed(range(S+1)):
if i - x >= 0:
reachable[i] = reachable[i] or reachable[i - x]
print(reachable)
# The usual backtracking.
target = 8
assert reachable[target]
solution = []
for x in arr:
if reachable[target - x]:
solution.append(x)
target -= x
print('one solution:', solution)
:white_check_mark: Your 3.12 eval job has completed with return code 0.
001 | [True, True, True, True, False, False, False, True, True, True, True]
002 | one solution: [1, 7]
I think if you just do len(arr) different backtrackings, each skipping one element, you can find the relevant thing
assuming this thing is true, we know there is something with sum S - x, and that uses all elements except an x
then we do the backtracking to check if there exists a solution with sum (S - x)/2 that skips an x, the existence of such a solution implies that there exist another disjoint solution as well, since we could just remove this solution set from the S-x set
this (S-x)/2 is guaranteed to be a subset of the S-x set in this thing, which should be the key thing for correctness
since it means the other disjoint subset exists and doesn't contain that one x
actually constructing the solution list won't be needed in your case, but the approach is the exact same
why is target 8 here?
right
so the idea would be to run this backtracking len(arr) times
each skipping some index
sounds good
I'll try it out when I'm back home later
do you want the other question I didn't manage to solve?
feel free to drop that too, someone will probably have ideas
it's kinda weird to explain so gimme a bit
the problem statement isn't available?
it is but it'd be annoying to grab it rn so I'll just paraphrase
two players are playing a game on a simple graph. they take turns choosing vertices. if a player chooses a vertex neighboring an enemy vertex, they gain a point (1 point for each neighboring enemy vertex). they proceed until no vertices are left, and then whoever has most points wins. if both players play optimally, figure who would win (or tie)
for example, if you play on K3, it's a tie because player 1 chooses some vertex, player 2 chooses another vertex and gains a point, and then player 1 chooses the last vertex and gains a point
I just essentially simulated the game with recursive backtracking and it worked, just TLE because it was O(|V|!)
maximum of 20 vertices
@agile sundial this is question E btw
going straight to the point
i'm trying to generate provable fair numbers for some project i have
and chat gpt + some refactor i made ended up in this. but i have no idea what i'm doing, maybe some harvard mathematics
engineer can check up this code and tell if its really fair
code:
class Game:
def __init__(self, seed: str = None) -> None:
self.secret = secrets.token_hex(32)
self.seed = (
seed
if seed
else "".join(
secrets.choice(string.ascii_letters + string.digits) for _ in range(16)
)
)
self.nonce = str(int(time.time()))
def generate(self, amount: int = 1, min: int = 0, max: int = 24):
numbers = set()
for iter in range(amount):
message = f"{self.seed}:{self.nonce}:{iter}"
hash_bytes = hmac.new(
self.secret.encode(), message.encode(), hashlib.sha256
).digest()
for index in range(0, len(hash_bytes) - 8 + 1, 8):
if len(numbers) == amount:
break
number = struct.unpack(">Q", hash_bytes[index : index + 8])[0]
number = number % (max - min + 1)
if number not in numbers: # Check for uniqueness
numbers.add(number)
return list(numbers)
Im trying to make a Response class that all my functions can return. However I want any instantiation of said class to behave like the datatype of the first attribute:
token = "hjdkfhujksjhfiuhjkfhs"
loginresp = Response(token, "Done")
print(type(loginresp)) # class of Response, I want this to be class of string or whatever the first parameter in Response is.
print(loginresp.message) # Should output "Done"
print(loginresp) # should output token
Is there any way in which this is ever achieveable
Hi, anyone here has ever made an algo for MT5? Is yes, do you find that python can be as robust as MQL5 in fast-moving markets ?
This should just be dp with 2^20 states
The tricky thing is how to get it down from 3^20 states, to 2^20 states
what's the dp?
dynamic programming
no like what's the table storing
For the 3^20 dp,
Note that each node has either
- not been picked yet
- picked by player 1
- picked by player 2
So the state of the game can be described using an integer < 3^20
Let dp[state] = (score player 1, score player 2), where both players played optimal
You can compute the dp values bottom up
Sure
would the 2^20 dp be something like storing whether each node has been picked yet, and the table stores like dp[state] = min(player1 - player2) if it's player 2's turn otherwise max(player1 - player2)?
tbh I don't currently see how to do the 2^20 dp. If the problem had been slightly modified, like if you also get 1 point placing a node next to your own node, then I can see how to do it.
hmm actually
Suppose player 1 gets a point for each neighbouring node that has previously been picked (by either player), and loses 1 point for each neighbouring node that has not yet been picked, and player 2 never gets any points.
I think this should be equivalent to the game you described (equivalent as in the two games have the same score difference if you play the same in both games)
But in this modified version of the game, for the state it doesn't matter which players owns a node
Do you follow?
I think this works though, no? It's not 3^20 technically
it's binom(20, 10, 10, 0) + binom(20, 10, 9, 1) + binom(20, 9, 9, 2) + ...
surely it's not that much..
It still feels close to 3^20
Anyways the equivalent game I mentioned above works
It can be simulated with a 2^20 state
Pretty sure that is intended
👍
About this problem, if you let dp[x] = number of subsets to get sum == x
Then there is a cool trick
You can add/remove numbers from the array, and then update the DP values accordingly
Storing a reachable Boolean value is worse than storing the number of ways you can reach a sum, since Boolean values won't allow you to remove a number from the array
you don't need to do that is this case, do you?
you can deal with the removal when backtracking to check if a solution exists
You don't need any "backtracking" the way I would do it
but you get the solution I'm suggesting?
it's something like O(sum * n) for the reachable DP and then O(n^2) to backtrack n times
I'm guessing you want to do some fancier DP?
Mine would be O(sum * n)
so effectively same complexity-wise, but I guess you would store some more state
def solve(A):
n = len(A)
m = sum(A) + 1
dp = [0] * m
dp[0] = 1
def add_number(x):
for i in range(m - x)[::-1]:
dp[i + x] += dp[i]
def remove_number(x):
for i in range(m - x):
dp[i + x] -= dp[i]
for a in A:
add_number(a)
ans = []
for i in range(n):
remove_number(A[i])
cur_sum = sum(A) - A[i]
if cur_sum % 2 == 0 and dp[cur_sum//2]:
ans.append(i)
add_number(A[i])
return ans
Here is what I would do
did you mean to add all numbers to dp first?
oh ye
fixed
I need to add one thing more to make this run fast
The dp values can become really large, so the trick is to pick some random large prime
and then store all dp values modded by that prime
I suspect this would end up slower than my thing

the first step of adding all the numbers is the same (other than me using booleans, so no big values)
and then the work per element is O(n) rather than O(sum) twice in your case
Tbf, the code I posted can be speed up by a ton
You don't need to modify dp if you are smart about it
untested, but my thing would be something like this, broke stuff out into functions just to make the parts clearer
def backtrack_possible(reachable, values, target):
for x in values:
if target - x >= 0 and reachable[target - x]:
target -= x
return target == 0
def solve(arr):
# Typical DP.
S = sum(arr)
reachable = [False] * (S + 1)
reachable[0] = True
for x in arr:
for i in reversed(range(S + 1)):
if i - x >= 0:
reachable[i] = reachable[i] or reachable[i - x]
def arr_without(ix):
return (x for i, x in enumerate(arr) if i != ix)
# Backtrack, but removing some value.
res = []
for i, x in enumerate(arr):
if (S - x) % 2 != 0:
continue
target = (S - x) // 2
if backtrack_possible(reachable, arr_without(i), target):
res.append(i)
return res
Why is this code correct?
Can't you be tricked in backtrack_possible to backtrack into a path that requires arr[i] to reach 0
While there is a different path that works
Suppose arr is [3,1,2,1,6,4]
And i = 0
@haughty mountain this should be a counter example
1+2+4=1+6=7
But the backtrack will do 7-1-2-1=3 and then get stuck
you're saying I pick a path that would have required the 3
Yes
yeah ok, the idea might just be broken
Hi HELP :
js exceptional error 503
not the right channel, not the right server 🥴
Btw there is a way to use a Boolean reachable dp
Make one for prefix, and another one for suffix
They can be used in combination to effectively skip index i
guys how can i import chatgpt in a scratch projecy
made all final touches to the stuff ^_^
https://darklab8.github.io/blog/article/article_shortest_paths.html
In the end decided not building second graph with lesser vertixes
Because just with joining vertex for Trade Lanes of same structure i decreased vertex count from 2218 to 1218 count. building second graph to have 900 vertixes i think not a big point.
Removed Johnson's algo parts, stripped down to Dijkstra APSP.
And added path reconstructions capabilities to it.
So i get now for 1218 vertex and 22896 edges, okay enough 1.5 seconds speed to find all shortest paths ^_^
The final result is used for the game data navigational tool that provides the trading routes with profit per time 😎 as well as telling where to go for this shortest path

is there a way to rotate points in 3d space without using something like scipy or matrices?
quaternions
right but with what
i might
or just suck it up and use matrices and linear algebra
i implemented matrices but i doubt its going to be performant
kind of annoying how much overhead it seems you need just to rotate shit
should be pretty performant
i might just hardcode the equations for rotation
it's just one big matrix multiplication to transform a bunch of points
ive already done that for 2d but 2d is simple
im not rotating a bunch of points with one though
well i guess i could cache it or some shit
you're doing a bunch of rotations to single points?
yeah
trying to orient blocks but they put the axis of rotation off center so i need to account for that
so i can't just set the angle value
also would numpy be good for lots of small vector operations? im considering using numpy in the backend for my vector code but idk if that would even help much
That is just doing the matrix multiplication beforehand yourself.
im aware
but it is the same angles for a bunch of points?
possibly, im not really sure yet
If you don't like quaternions, you can use rotors instead, very similar implementation though, just easier to understand.
if it is that can be expressed as one matrix-matrix multiplication, rather than many matrix-vector ones
so these are all at the same position but different angles, which is annoying when using stuff like this because it fucks up things when i want it rotated

very poor choice of name, ill try and check it out though
thanks
cause

It's a geometric algebra thing, and they do rotate things. Better than "quaternion" (wow, "quat," it has four parts, how descriptive).
rotor math would be the natural search term
fair
Main feature of GA is that things have nice visualizations, so it's easier to debug and reason about. Also not 4D (not the awkward extra dimension needed).
I love my biternions
(Btw the reason it seems so strange to have to go to quaternions suddenly for rotations of vectors is because vectors come from quaternions, quaternions came first, and the vector part was separated out (now just called a "vector") because people found quaternions too hard to understand, from this the cross product was born to fill the gaps, but it only works for 3D and causes other issues...)
(Separated by Gibbs and Heaviside for the physicists to understand and use)
(GA unifies all of this, so we don't have this mess of all these separate things, including all the other stuff (all these things physicists come up with for the specific problems))
(sign up for the GA cult community)
actual photo of squiggle

uh how to you make a bivector
i cant find much information on what its actual components are
its apparently just like a vector in terms of its values but idk how it all works out
The link I gave has a side by side implementation with quaternions: https://marctenbosch.com/quaternions/code.htm
yeah that code is bizarre and i believe actually evil
it also literally just declares it like a vector
It's C++.
im not convinced theres an actual difference

It's a different object, both may have 3 floats, but they behave differently.
Like how I can have 3 floats for a 2D position and health or something, not the same as 3D position, just both can use 3 floats.
the code also literally only declares it and gives it a single method afaik
all the rest is rotors
Yup, you only care about wedge.
i guess i can just implement that into vectors then instead of making a whole new class for it
You can, but it's technically not type safe/correct.
Since it's a different object/type technically.
Represents something else.
i can just subclass it probably
It's just kind of coincidence both are just 3 floats.
What really matters is the functions on them.
oh actually speaking of which i should probably redo some of my vector code since i had some of it duplicated (it wasnt returning the right type without it)
How you store the internals is up to you, can do it multiple ways.
Basically the interface defines the type here, the internals of needing those 3 floats to keep track of the state is an internal detail, which happens to align with the internal details of your vector3.
mmk
ok so to return a subclass type i think i can do like self.__class__(blablabla)
I would just do a different class.
i mean internally
vec2 and vec3 inherit from a generic vec class
otherwise it's a bunch of repeated code
Yeah, whatever works easiest for you.
Can always un-inherit it later and implement stuff elsewhere if needed.
ok yeah it works
damn it i cant use 'self' in the actual class declaration
so i cant do like 'self.func' in order to then get it to return the right type
It is relatively easy to implement a 3d rotation using a 2d rotation. You just need to change the basis so the rotation happens in the x y plane
I meant just a single 2d rotation
and how exactly would you change the basis without rotating?
Easiest would probably be to use cross product to find the new basis
oh god do i need to do this all in __init__
im declaring a bunch of methods like add, sub ,etc based off of another function because i'm not calling it outside of the class it doesnt work
would putting it in __init__ be slower or is it just the same
lemme try a classmethod nvm got it to work
i just got one of the inputs and used its class to do it
Feels like a match statement situation maybe?
maybe
also i should fix my vectors i think since it has a bug where if you pass other vectors as components it silently errors (sorta, it's kinda intended behavior but kinda not so im gonna remove it to prevent bugs i think)
awesome
Anybody used pyhhon for MT5 here ?
I am learning Python, and I had an idea while learning the built-in sort() function. But couldn't find this way of sorting exists or not. The bucket sort seems similar to this approach. I am curious if there is any existing research or algorithm that explores this interval grouping and sorting approach.
Can anybody help me with this info, please.
Let’s consider an array with 100,000 numbers, for example: array[] = [3, 5, 7, 3, 6, 3, 67, 8, 332, 75, 53, 5724, 656, 34, 63, 733, 75, 34, ...]. Suppose we define an interval size of 10 with help of Sturges’ formula.
We will create a 2D array where each sub-array contains unsorted data from the original array, grouped by the interval range. For instance:
2D[0] will contain all data from array[] that falls within the range [0, 9].
2D[10] will contain all data from array[] that falls within the range [10, 19].
2D[20] will contain all data from array[] that falls within the range [20, 29].
And so on…
Next, we will flatten this 2D array into a 1D array, new_array[], such that new_array[] contains the elements from 2D[0], followed by elements from 2D[10], then 2D[20], and so forth.
Finally, we will apply the sort() or timsort() function to new_array[]. The question is whether this method will sort the data faster than directly applying sort() to the original array.
it's kinda radix sort
I expect if it's written in plain python you won't gain anything
actually idk why timsort would gain anything from this
..huh, interesting. Timsort can take advantage of partially sorted arrays, but I think it needs runs, not just regions like these.
timsort benefits from runs of sorted values
radix sort is kinda nested bucket sort, and can be plenty fast when it's applicable
timsort() have O(n log n). but in fortunate times it becomes close to O(n). so, I wanted to give semi-sorted value to timsort.
testing shows it might help a little - I'm getting 13ms vs 16ms normally.
def test_sorting():
unsorted = random.choices(range(1000), k=100_000)
buckets = [[el for el in unsorted if bucket_i*10 <= el < (bucket_i+1)*10] for bucket_i in range(100)]
partially_sorted = [el for bucket in buckets for el in bucket]
assert len(partially_sorted) == len(unsorted)
%timeit sorted(unsorted)
%timeit sorted(partially_sorted)
(oh, of course I'm timing only the final timsort, not the initial partitioning. with the partitioning it'd be way slower.)
but it's interesting that transforming the array this way helps timsort at all. Perhaps because on the edges between buckets, runs of sorted elements may form?
I am glad it helps. I am new in Python, I am so begginer that the code even seems little hard to understand for me. But I am happy that my approach actually works, though reversely 😂
but why partially_sorted always takes more time? shouldn't it take equal time?
sorted(partially_posted) takes less, 13ms vs 16ms for sorted(unsorted)
no, sorry, I tried thrice, and got unsorted < partially_sorted.
then again I tried multiple time, I think it's now random.
Timsort runs in true linear time O(n) if the data is already sorted or if the data consists of a constant number of sorted blocks
So if you are feeling lazy when implementing merge sort, you can use pythons built in sort for the merge step
Meta trader 5?
Yes
I was searching for the same thing xd
So you're using the API to control the terminal?
No I am still looking for how to implement it
I see
I think I figured out what I was looking for by myself anyway. What I want to do with the terminal might be impossible or highly difficult to implement
I asked on the forum will see
Okie
I wanted to wait to apply what I want with pinescript
Then would move on to mt5
bro you can find it on youtube
except that geeks for geeks, etc are some significant websites that provide you the clear understanding of them
thanks alot brother
When should I start learning DSA ?
Like how comfortable I should be with the language ?
When you can at least solve the first 3-ish problems of the advent of codes.
nice
but geeksforgeeks is an indian website, is it safe to use?
@wintry pine ofc bro it's one of the greatest websites of all time... Quite informative 🔥❤️
it's one of the greatest websites of all time
it really isn't
then which is?
btw i think i asked this before but is numpy significantly faster if you're doing lots of small operations on small (like less than 10 element) arrays a lot? i think ive heard its better for a smaller amount of large operations on large arrays
it certainly can be, much less overhead, more room for vectorization
mmk
cause like i was like 'hm maybe i should use np arrays internally for my vectors' but idk if that'd really help much
rn my vectors store their values internally as a list and function mostly equivalent to a list comprehension or iterating through a for loop in terms of operating on them, just with much more compact and convenient syntax
Depends what you're looking for, I have good resources I can point to for some more advanced topics. For more basic stuff it shouldn't be too hard to find resources
g4g (and w3s) is good at search engine optimization, less good content-wise
i mean 'the best website' for a thing is going to depend on what you want to learn
if it's just the language itself then python's own documentation is probably the best i'd think
Numpy is indeed bad for many small vectors / matrices. This is why stuff like https://github.com/Zuzu-Typ/PyGLM exists. Which can interoperate with numpy still.

GitHub
Fast OpenGL Mathematics (GLM) for Python. Contribute to Zuzu-Typ/PyGLM development by creating an account on GitHub.
Creating and destroying numpy arrays has high overhead.
(allocation / deallocation)
Or if you are using a game engine like Panda3D, it has its own vector, matrix, and quaternion types too.
ye, i know at least pygame has its own vectors
also i think i recreated the function jpeg compression uses for its cosine transform thing
not the mapping itself, but the actual grid it uses
the first one is apparently what jpeg uses, right is my own render
the actual parameters are likely a bit off but i think its the same thing


or maybe it's just that i've managed to approximate it with a different method
this is the entirety of the code i used
#=============#
image_res = 512
visual_scale = 72
grid_scale = 12
#=============#
from PIL import Image
import math
def snap_to_grid(n,grid_size):
return (n//grid_size)*grid_size
sines = []
for i in range(image_res):
n = snap_to_grid(i,grid_scale)/image_res
cs = math.cos(n*n*visual_scale*math.pi)
sines.append(cs)
im = Image.new("L",(image_res,image_res))
image_data = []
for y in range(image_res):
for x in range(image_res):
n = (sines[x]*sines[y])/2 + 0.5
n = int(n*255)
image_data.append(n)
im.putdata(image_data)
im.save("cos_test_render.png")
oh theres a thing that says how it actually works on wikipedia, lemme implement that
is that normal

how do I execute my script
like if I coded a bot that will do something on discord how do I execute it ?
and should I use visual studio pycharm or other ?
<@&831776746206265384> suspicious link
what's the fastest way to find LCM of numbers 1...N?
possible way: go through all prime numbers p up to N, and multiply your result by p ** floor(log(N, p))
it feels like O(N) or O(NlogN)
well power is surely not O(1) so nlogn
though we won't have big powers.. but still i think nlogn
+the problem is that we need to deal with big integers
i guess for something like n=50 lcm 1..n will be already greater than 2^64
yep, 3099044504245996706400 for n=50
Use the built in math.lcm
Need for range 1...1000 max, does python handle that quick with its long arithmetic?
Cuz in C++ I had trouble, numbers didn't even fit in unsigned int128
My guess is that math.lcm should be pretty fast
But I havent tested it
If you really need speed, you should check out how to do it using GMP
Thats the library that people normally use when they need fast big integers
The module is called gmpy2 in Python
Here is how to do it with math.lcm:
!e
import math
res = math.lcm(*range(1, 1001))
:warning: Your 3.12 eval job has completed with return code 0.
[No output]
Somehting that might be helpful is that lcm(1,...,1000) = lcm(501,...,1000). This could possibly speed things up
can't you be more clever for that range in particular?
like for a range 1...n what matters is the largest powers of primes that are <= n
ok @lean walrus mentioned that already
lcm(x, y) = x * y // gcd(x, y) is O(log(x+y)) (in out case O(logN)) (using Euclid algo) (assuming arith operations are O(1) which is not true)
so if lcm(x, *args) = lcm(x, lcm(*args)), it performs N calls to lcm which are O(logN), so in total O(NlogN)
every time i try to take into account the fact, that integer operations are not constant, i get it wrong
I have tried to compare this way of sorting with other popular sorting methods. Though the results aren't great, it somehow works in a unique way. may I seek your help on this, please. and a funny question, will this technique be worthy to get a MIT License?
tested code: (tested in Google Colab) https://github.com/syed-zaki-reza/scrap-sort/blob/main/test_draft_scrap_sorting.ipynb

What do you mean 'get a MIT license'?
if this sorting algorithm actually works, (which I think have the potential) I want to license it as fully open source
Did you accidently swap bucket and bubble sort?
It feels like something is wrong when bucket sort is ~10000 times slower than both bubble sort and insertion sort
bubble sort is the fastest 💪
no, didn't swap. I was also shocked by the result.
I would not trust those numbers
Just so you know, the sorting algorithms inside algorithm.sort seems to be modifying the list. See for example https://github.com/keon/algorithms/blob/master/algorithms/sort/bubble_sort.py
GitHub
Minimal examples of data structures and algorithms in Python - keon/algorithms
So you need to send them copies of the list to be sorted
Bubble sort and insert sort are really fast for already sorted data, which is what I'm guessing happened in your benchmark
Seems the reason bucket sort is slow is because they are using some weird O(n^2) sorting algorithm
That said, your numbers are still absurd

Looks to me like algorithms.sort.min_heap_sort is buggy
No way that should take 627s
O(N^3)?
Probably
Here is the source code https://github.com/keon/algorithms/blob/master/algorithms/sort/heap_sort.py
GitHub
Minimal examples of data structures and algorithms in Python - keon/algorithms
They claim it is O(n log n)
But it doesn't look that way
Reading the code, it looks more like O(n^2 log n)
There are two O(n) nested for loops with no break condintion, then inside the inner for loop, there is a while loop that runs log(n) iterations
i like wiggle sort
recently we had a conversation about counting sort
i was a bit confused because the algorithm i remembered apparently was not called counting sort
today i found it (rather a slight variation of it) in this repo, it is called "pigeonhole sort" 😄
wikipedia, as usual, has something smarter
I don't see why you'd call that pigeonhole sort. It has nothing to do with the pigeonhole principle, which is the usual reason in math for why you'd call something pigeonhole
at first i wanted to used pysort. but it showed error while importing. so I used algorithms. thank you for pointing out that to me.
how tf does one mess up heap sort?
oh, they are implementing their own crappy heap
otherwise heap sort is literally just
heapify(seq)
res = []
while seq:
res.append(seq[0])
heappop(seq)
their "heap sort" is
while seq:
heapify(seq)
seq.pop()
The issue isn't that they have their own crappy heap. They issue is that they are attempting to do "heap sort" without a heap
Maybe this could be called heapify sort
im not sure if this is the place for it, i asked in discussion but didnt seem that anyone noticed
is there a possible way to make a sort of subtree / element in XML.etree and then, after the fact, 'merge it' to another tree with all its subtags?
i might be off in this but i wrote like an example of what i'd like to do in terms of the tags
so going from something like this:
<tag1 />
<tag2>
<subtag1 blabla=blablabla>
<subtag2 />
</subtag1>
<subtag3>blabla</subtag3>
</tag2>
where tag2 is its own element, to
<tag1>
<tag2>
<subtag1 blabla=blablabla>
<subtag2 />
</subtag1>
<subtag3>blabla</subtag3>
</tag2>
</tag1>
where it's a subelement of tag1
with all its subelements moving with it
Yes by parsing the xml, and converting to string then using combination root.find, root.remove and root.append to accomplish case specific logic
I am cooking up an example now, just gotta run some test cases on it
here is something that any one can feel free to use, my favorite function for formatting xml elements vvv
basically doing a bunch of small manipultaions in proper order to move around elements and change there respective nesting order. look into the built in xmltree.root.functions
i have done many different things with xml data structure, and tbh formatting is the hardest part
hey everyone, since i was helping with this problem i put together a function that you can call from your lib and pass args to do merging of xml tags for you. it only works 100% effectively on parent tags nested within the root. But yeah basically you call function and pass the xml string arg that i assume you have already parsed from a file, then you pass the target_tag and the tag_to_merge_into, and boom!! done...
i also added some pretty formatting built in!!
ie... xml_nest.merge(xml_string, target_tag, tag_to_merge_into)
idk if you need to go back to string
find relevant empty (or self-closed if you can check for that) tag T, move next sibling into T
I wanted to handle edge cases to merge siblings into non empty tags, like a true merge
If this is accomplished in an easier way I would love to learn of how it works! If you would like to explain a little further
if you want to do an actual merge things get more annoying, but from the example I assumed this was a much easier case
i need a course in datastrucyures and algo
either do something from IBM free courses or on coursera and internshala
any alg for converting 2d array into 1d array
in what way?
there's always .flat (or .flatten())
>>> import numpy as np
>>> a = np.array([[1, 2, 3], [4, 5, 6]])
>>> a
array([[1, 2, 3],
[4, 5, 6]])
>>> a.flat
<numpy.flatiter object at 0x000001C70429E090>
>>> a.flatten()
array([1, 2, 3, 4, 5, 6])
>>>
what if without libaries
so you have a list of lists?
have a 2d array
there's no array in python without libraries, but assuming you have a 2d list
>>> l = [[1, 2, 3], [4, 5, 6]]
>>> flat = [value for row in l for value in row]
>>> flat
[1, 2, 3, 4, 5, 6]
>>>
oh thanks
hi
:incoming_envelope: :ok_hand: applied timeout to @waxen jay until <t:1719657232:f> (10 minutes) (reason: duplicates spam - sent 4 duplicate messages).
The <@&831776746206265384> have been alerted for review.
!d array.array
there kinda its just not used much
(for general chat)

class array.array(typecode[, initializer])```
A new array whose items are restricted by *typecode*, and initialized from the optional *initializer* value, which must be a [`bytes`](https://docs.python.org/3/library/stdtypes.html#bytes) or [`bytearray`](https://docs.python.org/3/library/stdtypes.html#bytearray) object, a Unicode string, or iterable over elements of the appropriate type.
If given a [`bytes`](https://docs.python.org/3/library/stdtypes.html#bytes) or [`bytearray`](https://docs.python.org/3/library/stdtypes.html#bytearray) object, the initializer is passed to the new array’s [`frombytes()`](https://docs.python.org/3/library/array.html#array.array.frombytes) method; if given a Unicode string, the initializer is passed to the [`fromunicode()`](https://docs.python.org/3/library/array.html#array.array.fromunicode) method; otherwise, the initializer’s iterator is passed to the [`extend()`](https://docs.python.org/3/library/array.html#array.array.extend) method to add initial items to the array.stdlib is still a lib
builtins is also a lib
Guys do you know a good course where I can learn DSA
!res also check pins
Resources
The Resources page on our website contains a list of hand-selected learning resources that we regularly recommend to both beginners and experts.
oke thnx
is string operation slower than storing chars in a list and doing "".join?
yes, as strs are immutable, doing += makes a new string every time (it has to copy over and over) instead of say list += where it modifies the original
it's a bit more complicated cause python does try to optimize the str += to not copy, but it's not perfect by any means and you probably should just ''.join where you can
https://stackoverflow.com/questions/44487537/why-does-naive-string-concatenation-become-quadratic-above-a-certain-length/44487738#44487738 This is a really good stack exchange post about that.
TLDR: strings in Python do not allocate extra memory (unlike lists that do allocate extra memory to be able to expand), so appending anything to a string is fundamentally O(n) in Python

Stack Overflow
Building a string through repeated string concatenation is an anti-pattern, but I'm still curious why its performance switches from linear to quadratic after string length exceeds approximately 10 ...
''.join(list) is definitely the good way to do it
I get uneasy every time this question is asked tbh, because the common wisdom is "concatenating strings is O(n+m)", but, well, it's false in practice. The optimization cpython uses is pretty good.
Does anyone knows how to compute Triangular Moving Average?
googling failed me - when I search this term all I find are probably-machine-written articles regurgitating the same content that makes no sense. what's the formula for it?
Hey, anyone has any yt vid suggestion to learn Inhereitence in DS
I was solving this hackerrank question ... I figured the logic to be a simple if-else ladder and I can't think of any other better way to solve this ...Is there any other way to solve this?
My solution:
if name == 'main':
N = int(input())
list_of_elems = []
for _ in range(N):
statement = input().split()
if statement[0] == 'insert':
i, e = int(statement[1]), int(statement[2])
list_of_elems.insert(i, e)
elif statement[0] == 'remove':
e = int(statement[1])
list_of_elems.remove(e)
elif statement[0] == 'append':
e = int(statement[1])
list_of_elems.append(e)
elif statement[0] == 'sort':
list_of_elems.sort()
elif statement[0] == 'pop':
list_of_elems.pop()
elif statement[0] == 'reverse':
list_of_elems.reverse()
else:
print(list_of_elems)

I don’t think you can do much better
It seems that question is just there to test a interviewee basic knowledge of the standard library they said they are knowledgeable in
Hi, I have been primarily using c++ for solving leetcode or algorithm problems in general, now I use c++ for leetcode only, and in the future I might have to do ds/ML for which I def. Have to use python, should I start solving with leetcode with python ? I just want to reduce the number of programming languages so I can focus on few properly and know them in depth. (Currently in the JavaScript environment as well)
match-case could make it cleaner
yo anyone down to grind some usaco problems together
Resources to learn dsa in python?
Hi. I'm trying to groupby a list of db rows several times. In Java i would do like groupingBy(Row::customer, groupingBy(Row::department, groupingBy(Row::list))) Can I do something similar with itertools.groupby ?
I'm not sure what it means to groupby several times. Perhaps you're looking for grouping by several columns, like .groupby(["customer", "department", "list"])?
if anyone needs a simple but kinda jank (i think) menger cube algorithm, here's one i wrote yesterday
menger_points = ((-1,-1,-1), (-1,-1,0), (-1,-1,1), (-1,0,-1), (-1,0,1), (-1,1,-1), (-1,1,0), (-1,1,1), (0,-1,-1), (0,-1,1), (0,1,-1), (0,1,1), (1,-1,-1), (1,-1,0), (1,-1,1), (1,0,-1), (1,0,1), (1,1,-1), (1,1,0), (1,1,1))
def menger(steps):
scales = [3**i for i in range(steps)]
points = {(0,0,0)}
for n in scales:
points2 = set()
for i in points:
ix,iy,iz = i
for px,py,pz in menger_points:
points2.add((
(px*n) + ix,
(py*n) + iy,
(pz*n) + iz,
))
points = points2
return points
I probably could have just had the points generated before the function call but whatever
it also is probably more efficient to only store the points you remove but once again whatever
luckily for my use case any more than tier 4 is unviable to generate anyway so
speaking of, I started playing with ray marching and signed distance functions, have a menger sponge
nice
how's that work?
like are you doing this in py or something else, and how do you do the raymarching
a vertex shader
ah
i ought to learn shaders but idk if python really works with em so i might end up having to really learn something like c/cpp
I mean, you can make it work for sure. The shader stuff is pretty language agnostic
well, in the sense that you write the shaders in glsl and can use them in any other language
so basically I start with a box

and subtract out crosses

actually, intersection might make more sense
for level 1 I end up subtracting

a nice thing about signed distance functions, is that tiling patterns are easy to make, so for level two I create something like

and tile it

rinse and repeat for the deeper levels
the whole computation of the sdf boils down to
float shapes = sdBoxScaled(p, vec3(0.5), 1.); // Unit cube.
float sc = 1.;
float fac = 1./3.;
for (int i = 0; i < 10; i++) {
sc *= fac;
shapes = opSubtraction(shapes, sdCross(mod(p + sc, sc/fac) - sc, sc));
}
```where sdCross is a function I wrote for drawing one such crosscheap computations for generating something so complex
the boolean operations are also weirdly simple
float opUnion(float d1, float d2) {
return min(d1, d2);
}
float opSubtraction(float d1, float d2) {
return max(-d2, d1);
}
float opIntersection(float d1, float d2) {
return max(d1, d2);
}
inside the cube is also fun
hey guys what are the 5 most important algorithms or data structures?
wheeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee
very vague question, what's important will depend a lot on what you're doing
i have a book about neural networks which i tried one time but i remember that it was pretty advanced
so i want to prepare myself
what's the fastest way to convert a string like '12.34' to an integer, truncating everything after the decimal point?
int(float('12.34'))?
how long will your string be?
somewhere around 5-10 digits
before the .?
including before and after
This does seem to be the fastest way to do it in pure Python, pretty hard to beat 200ns
In [11]: small = "1.234567809"
In [12]: big = "123456780.9"
In [13]: %timeit int(float(small))
173 ns ± 1.25 ns per loop (mean ± std. dev. of 7 runs, 10,000,000 loops each)
In [14]: %timeit int(float(big))
198 ns ± 2.29 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)
f-strings create new strings, they don't parse them 🙂
why do you need this though?
Do note that this will not work if the numbers have 16 or more digits before the .
!e
n = 2.0**53
print(n)
print(n + 1)
print(n + 1 == n)
print(n + 2)
:white_check_mark: Your 3.12 eval job has completed with return code 0.
001 | 9007199254740992.0
002 | 9007199254740992.0
003 | True
004 | 9007199254740994.0
Basically I need something like dict[int, dict[int, dict[int, Row]]]
Whats the largest number a program can calculate?
Does it dependd of the software or hardware we are using?
If by calculate you mean "write out" the whole number in binary (store the whole thing physically, not just write a symbol representing it). Then using the Bekenstein bound for the observable universe (basically turning the whole thing into a black hole to store the largest integer possible (making use of all the space / all possible states)), somewhere around log_2(e) * 10^123 bits (or maybe 10^102, hard to tell, this is all speculation).
Both.
However much memory you physically have, and the software has to make use of it.
hmmm
that will break for negative numbers
anybody here knows about YOLO custom cfg?
Traceback (most recent call last):
File "train.py", line 616, in <module>
train(hyp, opt, device, tb_writer)
File "train.py", line 88, in train
model = Model(opt.cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
File "C:\Users\kuzey\yolov7\models\yolo.py", line 528, in init
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
File "C:\Users\kuzey\yolov7\models\yolo.py", line 738, in parse_model
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
KeyError: 'depth_multiple'
keep getting this error no idea how to fix
Even thought I got depth multiple in the cfg
YOLOv7 custom configuration file
Number of classes
nc: 3 # Number of classes (Kalsifikasyon, Normal, Kitle)
Anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
YOLOv7 backbone and head configuration
backbone:
name: darknet53 # Darknet53 or any other supported backbone
depth_multiple: 0.33 # Depth multiple for backbone
width_multiple: 0.50 # Width multiple for backbone
head:
num_classes: ${nc}
anchors: ${anchors}
Training parameters
train:
img_size: 640
batch_size: 16
epochs: 300
data: C:\Users\kuzey\OneDrive\Masaüstü\data.yaml
cfg: models/yolov7-custom.cfg
weights: yolov7.pt
device: ''
multi_scale: False
freeze: [0]
Testing parameters
test:
img_size: 640
batch_size: 16
data: C:\Users\kuzey\OneDrive\Masaüstü\data.yaml
cfg: models/yolov7-custom.cfg
weights: yolov7.pt
.
Phrased the way you asked, there's no answer. First, what do you mean by 'calculate'? Second, a program could divide a big problem into smaller problems, and summarize without needing an entire "number" in memory. Third, 'can' has no constraints: when? How long? Some future computer?
Does anyone know of any good libraries for sparse octrees? Preferably something running C or C++ under the hood
oh wait, python int conversion does truncate, my bad
I was probably thinking of the integer division behavior
Hi i was trying to solve this problem which the correct answer like this:
[A, B, C, DD, E, FFF, G, HHHH, I]
I tried to implement my logic, but the pattern is almost correct. My output looks like this: ['A', 'B', 'C', 'DDD', 'E', 'FFFFF', 'G', 'HHHHHHH', 'I']
I used various methods but still can't resolve the issue.
Anyone have any hints or suggestions to solve this problem? I've been stuck on it all day

if i%2==0, print one letter, otherwise print (i+1)//2 letters
number = []
for i in range(0,len(df)):
if i==0:
number.append(df["Letter"][i])
i_t.append(1)
elif i%2==0:
number.append(df["Letter"][i])
else:
number.append(df["Letter"][i]//2)
You mean like this?
print(number)
print(i_t)
Thank you very much for your suggestion, i got it
I only need to divided it

Probably a super basic question but why does this work:
self.contents = []
for i in range(val):
self.contents.append(str(key))
but this doesn't:
self.contents = []
(self.contents.append(str(key)) for i in range(val))
The second set of lines just returns an empty list
(self.contents.append(str(key)) for i in range(val)) creates a generator. For example:
!e
squares = (i * i for i in range(5))
for square in squares:
print(square)
:white_check_mark: Your 3.12 eval job has completed with return code 0.
001 | 0
002 | 1
003 | 4
004 | 9
005 | 16
Makes sense. Thanks very much!
hi guys i wrote a background processor using python it is running using asyncio.run and im using while True: to infinitely run my asyncio.run that process records from database and upload the result to database. but sometimes it suddenly hangs for no reason? what do you is the reason for this scenario?
Given two strings s and t, return true if the two strings are anagrams of each other, otherwise return false.
An anagram is a string that contains the exact same characters as another string, but the order of the characters can be different.
I guess this code doesn't work if there is some letter in countT that isn't in countS?
(This is NeetCode's solution)

Youre not gonna reach anything after the first return Counter(s)==Counter(t)
But that’s correct
Yeah, I know that code wouldn't be executed, so just wanted to check whether my assumption is correct
Is there any website where are a lot of DSA patterns explained? By DSA pattern I mean something like two pointer pattern or fast and slow pointer or sliding window.
I am doing this course https://www.designgurus.io/course/grokking-the-coding-interview but I am interested if there is something like that

Design Gurus: One-Stop Portal For Tech Interviews.
Grokking the Coding Interview Patterns in Java, Python, JS, and C++. Most comprehensive course with 325 Lessons & 350+ Exercises.
shameful to leave code like that
what
Well if it passes the tests
Usually it’s correct
brave to think that 😛
well I feel like if it makes sense to you and it passes
that should be enough of an indication it's correct
depends on the number of test cases i guess
if it is in s but not in t you would get countS[c] != 0
test cases can be quite crappy at times 🙃
yeah that's fair haha although it's more of a time complexity thing rather than correctness right?
I've seen both
that's fair
tests failing to test edge cases and whatnot
to be fully honest if your solution works but you forgot to treat the case where the input list is empty I feel like you've learned what you should've learned
actually i'm not sure i agree with what i just said
😆
I couldn't understand why the time limit for all languages are the same leading to something that is "impossible" for python to pass
well at least in few cases a shitty c++ can pass but the same shitty python cannot
it's the easy thing to do
balancing multipliers is hard
i wrote this silly little thing while super pissed off

Something that is good to know about is that if you use .split() (without any argument), then you dont need to .strip() afterwards. Also, float(x) and int(x) are fine with x having some trailing whitespace.
Most of the time I see people .strip() or .rstrip(), they actually don't need it
i see multiple violations of D.R.Y and convenient code writing
match is not switch btw, don't use it as such
it's not faster than if-elif, and on the other hand you can do a lot more with it
parts = line.split()
match parts:
case "v", *tail:
vts.append(scale * vec3([float(i) for i in tail]))
case "vt", *tail:
...
case "vn", *tail:
...
case "f", *tail:
...
case _:
# p[0] isn't any of those
did you miss the ‘pissed off’ part :p
just providing code comments =w=
fair
without strip it sometimes had extra characters i believe btw
i’d have to check to be sure
Not if you use .split() (without any argument)
That one effectively calls .strip() for you
Hey guys can someone who doesn't know variables be a good colleague
hey, so I wrote some code, which kind of seems to work, but then I continued to write a similar thing and started to wonder whether I'm doing a right thing or not
for path, dirs, files in dotfiles.walk():
for d in itertools.chain.from_iterable(
fnmatch.filter(dirs, skippath)
for skippath in [".git", ".mypy_cache", "blog", "scripts"]
):
dirs.remove(d)
(dotfiles variable is Path from pathlib and I think every other function should be clear)
So, like, here we use itertools.chain.from_iterable which acts sort of like a flat_map, where I take the list of directories I want to skip while traversing the file tree (that's what Path.walk() does btw), and then over these "blacklisted" directories I create an iterator of paths I want to skip, which is then spliced by itertools.chain.from_iterable into one iterator.
Am I deleting the elements from dirs while I'm iterating dirs?
like, whatever way itertools.chain.from_iterable works, somewhere inside it hidden either yield or custom next() function, which means that it slowly builds my filtering list while I'm iterating over it my iterating over my dirs while I'm deleting them. Or simply put it seems that I mutate the list I'm iterating over.
which is sort of bad, I'd guess
but maybe it's actually ok in this case?
Hey guys.
I was wondering, there is a mooc for dsa https://tira.mooc.fi/spring-2024/
And I was wondering if anyone could take a quick look, and tell me if it's worth following as a course? I'm hoping to learn dsa, but I'm not a fan of watching videos.
I tried coursera's princeton course, which everybody recommends. but I found it too difficult for me. it was discouraging.
Anyway, just wondering if this course is worth it, or if I should give coursera another try. Ideally I'm looking for a course with theory, and then accompagnying relevant exercises with solutions
I was learning from this specialization https://www.coursera.org/specializations/data-structures-algorithms
If you don't like to learn about mathematical proofs, you can skip that

Coursera
Offered by University of California San Diego. Master Algorithmic Programming Techniques. Advance your Software Engineering or Data Science ... Enroll for free.
thanks
Assume I have 3D points(I drew in 2D for simplicity)
and a few unordered target points, is there a way to find out all the points to the left of the target points?(I drew a line for ease of understanding whats "left" of the target points)

Lik e ideally you would get something like this:
https://imgur.com/p2Eo3GL
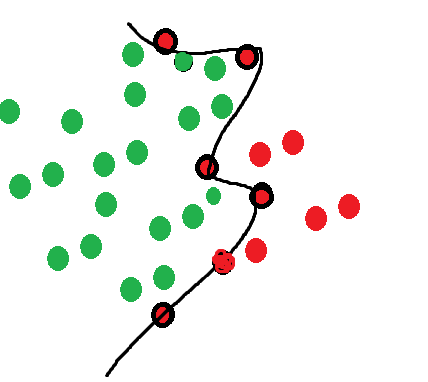
with green ones being to the left of the target points
I thought looking at the nearest neighbor but it doesn't work 100%
You could sort the target points from top to bottom, then draw a line between each of them (and continue the line above and below if necessary). Next for each other point you check between which two target points it is in y-coordinate, and check the corresponding line whether this point is to the left or right of it.
If you want a more smooth line, or a line that also continues after the target points, you may want to fit a curve through these target points instead.
@ashen niche
well they might not be as nice as this picture which would cause a bunch of x crosses
I'm gonna walk my dog, so I can respond in like 20 mins, sorry
I don't really understand your definition of "left". You could compute the convex hull of the chosen points, but that'd be different:

imagine the dark point on the red line between the texts is a little mor left, it would be classified as "left" even though it's not
why isn't it, though?
well, if we imagine the line I drew I guess it makes sense
in 2d there's some natural ways to connect the points, e.g. by ascending y coordinate - but in 3d I think there isn't a corresponding natural way to make a mesh out of them.
imagine you have two steel metals that you meld together in an awkward shape and you want to know which is which based on a few melting points, if that's an alright analogy
hey guys, im looking for a good (free) DSA python course before I start AI/ML/DL. does anyone have any recommendations? im not really trying to prepare for interviews/jobs yet, im just looking to gain enough knowledge to start AI
https://imgur.com/yHV0hzl
this is just a visualization, in reality the metals are hollow inside(there's only the outside part) - so imagine two pieces are melted together by the edges alone, then I want to know basd on these melted points which part of the metal is which

https://imgur.com/SMGlzzX
as the result
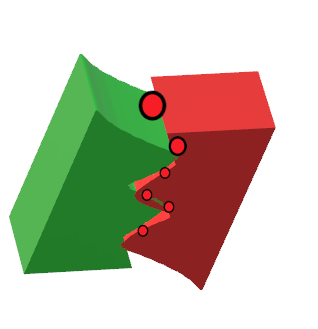
So are these points generally on a line?
Because it is hard to automatically determine what would be "left" or "right" @ashen niche
generally a line, but unordered so it is possible, if we use the steel example that one would melt along the division line, then go back and patch it up a bit more
maybe they'd go from the top to the left, then to the right, then flip, etc
the end goal is the same but the process there is arbitrary so it makes it a bit more difficult, I guess
So this is some idea I have:

Example is in 2d, but could do in 3d as well, just need to fit a 2d plane, and later on fit a hyper plane through the points.
But this makes an assumption that the separation is 2.5D (I.e. each x value has a single y value)

ah
hmm
I'm guessing the 2nd part is possible, but maybe some error is acceptable if it is low enough
Well it would try to fit a curve through the points somehow
Or a hyperplane* in your case
My first solution was fitting a 2D ellipse, but with an angle(so it's sorta 2D in 3D space) and then just projecting that onto the points lol
but sadly that was too generalizing
If the objects generally look a bit like this, I think this method would work okay.
But some assumptions are made for this method.
I wouldn't know how to find out what would be "left" or "right" in some other simple way.
I'll try this out, cool concept.
I'm wondering if I can just run a spline on the original points
You can imagine that if this boundary resulted in a convex "left" (lets call it "inside") side, then it would be easy, so the solution for something concave like this is to split it into multiple convex parts (basically what physics engines do for collision checking).
After it's multiple convex hulls it's just point inside convex hull test.
no real reason to constrain to fitting functions, splines could be nice if you can figure out the order, e.g. by some nearest neighbor heuristic
there are neat approaches where you use radial basis functions and neural nets to fit boundaries like these
I did some of it ages ago in uni, dots are the origin of the placed radial basis functions, the black line is the fitted boundary using these bases

how can I optimize this code further for this Maximum Number of Vowels Problem
class Solution:
def maxVowels(self, s: str, k: int) -> int:
vowels = set('aeiou')
ss = list(s[:k])
count = sum([1 for x in ss if x in vowels])
for i in range(0,len(s)-k):
ss.pop(0)
ss.append(s[i+k])
count = max(count, sum([1 for x in ss if x in vowels]))
return count
failing under time limit exceeded for long strings of more than 50k chars on leetcode
Popping and appending are going to kill your timings.
It looks like a different approach would be better: how can you get every substring of size k from ss? The count vowels in those and return the max.
popping from anywhere but the last place in the list is O(n)
Why do they say
(8, 4), (4, 2), (8, 2), (8, 1), (4, 1), (2, 1)
and not
(8, 4), (8, 2), (8, 1), (2, 1), (4, 1), (4, 2)
?

if you know the number of vowels in some slice, then all you need to know how many are in the next slice is the character that enters the slice and the one that leaves
why would they say that?
well if we do the inversions
8, 4, 2, 1 becomes 4, 8, 2, 1
and then we want to swap 8 and 2
4, 2, 8, 1
and then we want to swap 8 and 1
4, 2, 1, 8
at least that's how i understood the inversion count problem
How can I improve my code instead of thinking for some other approach then?
you're not reversing the inversions, you're counting them
@zinc sky ^
I'm sorry I'm not sure I understand what you mean, this is a new notion for me
it is counting how many 2 pair inversions exists ig
Isn't the number of inversions basically how long a bubble sort would take to sort the array?
oh i see inversion is just the number of i, j such that a[i] > a[j]?
yeah
ah that's my bad
i really thought it was linked to bubble sort
and like swapping them
It's actually the same number though right?
same number as what?
So iterate over from the first slice char by char? Got it
as the number of steps a bubble sort would take if we only count the steps where it swaps two elements of an array
Even append has same o(n) complexity?
no, append is O(1)
yeah i think so
I'm having trouble with an algorithm
let's say I have 3 rectangles, the sides of each rectangle are parallel to the x and y axis.
These rectangles can overlap, the goal is to find the area of all rectangles minus the intersection.
I have a few test cases and the area it's supposed to result in
Here's what I tried
I tried calculating the area of each of the 3 rectangles
Then I calculated the intersection between rectangles 1 and 3, 1 and 2 and 2 and 3, and substracted that.
I can't get that result.
If I could get a hint on what I'm supposed to do that would be great
Oh, there is the simple solution where I can map every point of each rectangle, but the question specifically states that it won't be accepted because it's too inefficent
this feels almost like a weird set theory problem
because you'd want to make sure you aren't subtracting twice if all 3 rectangles overlap, so really the overall bit you subtract should be the union of the two intersections
can I show you my function?
sure
im honestly not entirely sure how you'd do it but i dont think checking all the points is the play
i think its possible to do it just from knowing the start and end points, and then sort of constructing a shape from that
it's a mess sorry about that
def area(rec1, rec2, rec3):
area1 = abs(rec1[2]-rec1[0])*abs(rec1[3]-rec1[1])
area2 = abs(rec2[2]-rec2[0])*abs(rec2[3]-rec2[1])
area3 = abs(rec3[2]-rec3[0])*abs(rec3[3]-rec3[1])
#find intersection
left12,right12 = max(rec1[0],rec2[0]), min(rec1[2],rec2[2])
left13,right13 = max(rec1[0],rec3[0]), min(rec1[2],rec3[2])
left23,right23 = max(rec2[0],rec3[0]), min(rec2[2],rec3[2])
bottom12,top12 = max(rec1[3],rec2[1]), min(rec1[3],rec2[1])
bottom13,top13 = max(rec1[3],rec3[1]), min(rec1[3],rec3[1])
bottom23,top23 = max(rec2[3],rec3[1]), min(rec2[3],rec3[1])
area = area1 + area2 + area3
if left12<right12 and bottom12<top12:
area -= (right12-left12)*(top12-bottom12)
if left13<right13 and bottom13<top13:
area -= (right13-left13)*(top13-bottom13)
if left23<right23 and bottom23<top23:
area -= (right23-left23)*(top23-bottom23)
return area
`honestly i'd recommend using some sort of vector to do this sort of thing
having all the operations be done one by one manually tends to be tedious
having an actual rectangle/box class would also make it a lot easier to work with
sorry if the diagram is confusing, i got a bit painterly with it lol

so basically you trim any redundant area
this pr obably wont work for some edge cases though
also this is ignoring angling the boxes because that's a whole can of worms you don't want to deal with
1 + 2 + 3 - (1&2) - (2&3) - (1&3) + (1&2&3)
hm yeah that seems simpler
ironic (or, maybe not?) that the name for the operation most suited for this is called 'intersection'
now the question is how to find the value of (1&2&3)
1&2&3 is a composition so you can just do (1&2)&3
this obviously doesn't work on every operation but intersection is commutative and associative so A∩B = B∩A and A∩(B∩C) = (A∩B)∩C
functionally the intersection of two boxes is essentially like using each one's corner (the ones facing into the intersection as a corner for the new box
also this means that you can calculate 1&2 (or 1&3) only once and just use it twice
works
there was a typo
but it works now
the suggested solution is basically the same in principle, but refactored
so thanks
hi
arr = [0] * (max(nums)+1)
for i in (nums):
arr[i] = 1
z = set()
count = 0
for i in range (0,len(arr)):
if arr[i-1] == 1:
count += 1
else:
z.add(count)
count = 0
print(z)
u = max(z)
print(u)```
this code runs for me in online compiler
but the following gives me error
```class Solution:
def longestConsecutive(self, nums: List[int]) -> int:
arr = [0] * (max(nums)+1)
for i in (nums):
arr[i] = 1
z = set()
count = 0
for i in range (0,len(arr)):
if arr[i-1] == 1:
count += 1
else:
z.add(count)
count = 0
print(z)
u = max(z)
return u
it says z is empty on leetcode (q.128)
leetcode error message
^^^^^^
u = max(z)
Line 16 in longestConsecutive (Solution.py)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ret = Solution().longestConsecutive(param_1)
Line 38 in _driver (Solution.py)
_driver()
Line 49 in <module> (Solution.py)
leetcode tries multiple inputs. did consider what happens when z is empty
though, max doesn't take a sequence..
naw the same test case is failing
the one with nums = [100,4,200,1,3,2]
in leet code when I print the values of z it shows up, but when i put it in max function it says its empty.
what's the output
out put for z is {0,1,4}
please dont use ableist language
I wonder if you have an idea for a more general sort of thing - I am trying to find isolated areas in this case.
So, the red dots would be isolators in my object, and I'd like to know everything that was "isolated" by them. (in practical terms I have a point cloud as the object and a few "isolator" points on each side)
https://imgur.com/pXOzXBi
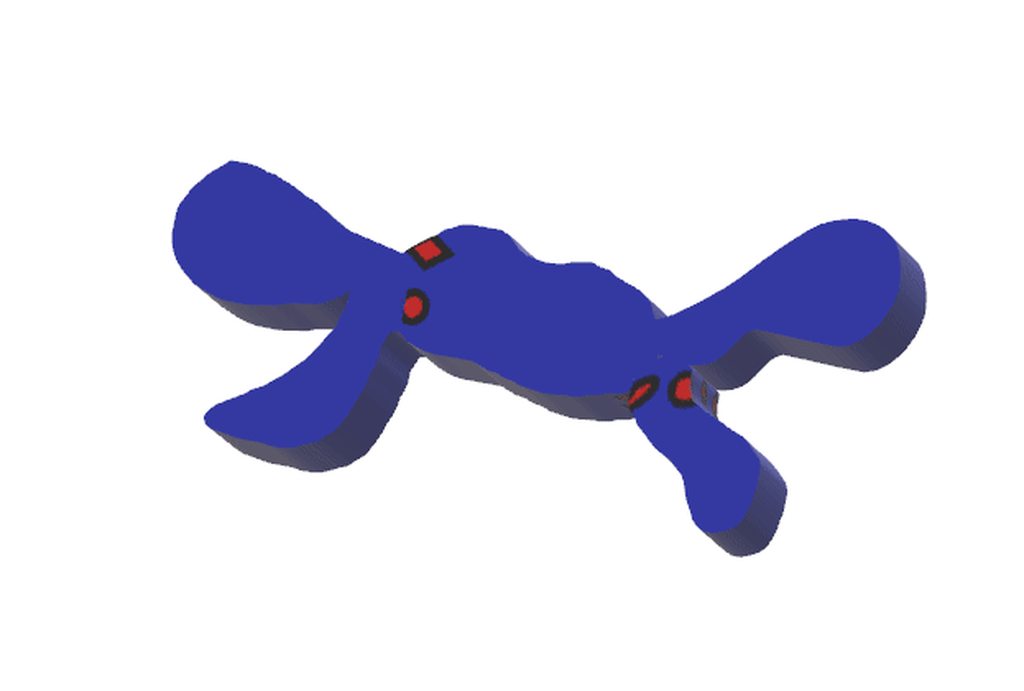
{kind=link}
so the green/red I colored in are isolated based on the points I drew
anyone have a good free dsa course for python? im not really looking to prep for interviews or anything im moreso just learning for the sake of learning. id also like to get into ai or data science later and i know most of your basic python stuff for reference
okay this is funny and kind of irrelevant, although how does that pop up with my "Username" being the class 😂
Hello, I am making a custom data structure based on lists and dictionaries and am having some trouble understanding how the heirarchy is implemented between list and dictionaries in python. can somebody explain it?
uh... elaborate?
Elaboration:
I am trying to implement a tree, in which each Node is similar to a python dictionary
head
|-> child
{
key: value
}
|->child2
|-> child3
something like this
The problem I'm facing is, that one of the data types that can be used as a value is an array, similar to a Python list(will call this data structure list).
The twist is, that a list can also be a node in the tree, as well as a value in a node. (I am trying to make a wrapper for another software, hence trying to abstract the data types of that software into Python for the wrapper)
list1
(
child1
{
key: value
}
)
something like that. In order to implement this, I remembered that Python also has a similar use case: A list can be stored inside a dictionary and vice versa. I want to know how it is achieved internally, as there should be a proper hierarchy between the data types and this use case mixes the hierarchy.
a list can also be a node in the tree
I'm not sure what you mean
though why not just wrap everything around nodes? i.e.
class Node:
stuff: list | dict
children: list[Node]
then
list1
(
child1
{
key: value
}
)
```is like
```py
Node(stuff=list1, children=[child1])
child1 = Node(stuff={key: value}, children=[])
I'm not wrapping everything around nodes because the nodes has some attributes other than the children which are stored as key value pairs, while list does not. And the software also supports multiple values for a single key, so that's another reason for not wrapping everything withing Node
multiple values for a single key
how does that work? if you look for a key you get multiple nodes back?
nodes has some attributes other than the children which are stored as key value pairs, while list does not
sounds like you need aNodeInterfacethat bothList(your list) andNodeWithExtraAttributesshould inherit from
also keeping the two classes separate helps when I'm trying to export the data to be executed by the external software
Node
{
key: value1 value2 value3
}
If I try to access Node.key, I get [Value1, value2, value3] together
so it's just key: list[value] then? i don't see how that affects things
except its not list[values], as I am making a custom class to store the multiple values.
basically I made a custom data structure that stores multiple values for a single key
ok, but why does that matter? as in, sure you have a custom class storing multiple values, but why does this stop you from wrapping stuff in Nodes
NodeInterface
class NodeInterface:
stuff: ...
children: list[Node]
class List(NodeInterface):
pass
class NodeWithExtraAttributes(NodeInterface):
apple: ...
orange: ...
lemon: ...
then everything in a tree is a NodeInterface, some of them are Lists while others are NodeWithExtraAttributes
class NodeInterface:
values: ...
children: list[NodeInterface]
class List(NodeInterface):
values: ...
class NodeWithExtraAttributes(NodeInterface):
values: MyClassThatStoresMultipleValues
# the extra attributes that Lists don't have
apple: ...
orange: ...
lemon: ...
```like I don't see what the problem isthis is fine. but how will I use the same list class when I need to store the list as a value inside the Node
Node
{
list1:
(
value1
value2
)
}
In this case, Node is the NodeInterface object and the list1 is a List object, except the list is not a child but a value to an attribute
NodeInterface(values=None, children=list1) # I can't tell which it is cause your code doesn't show it
list1=List(values=[value1, value2])
ok, so list1 is the value of an attribute of the outer Node? what is it?
yea, in this case list1 is a child of NodeInterface, which I don't want. I want it to an attribute
yes.
sure?
NodeWithExtraAttributes(atttribute1=list1, children=[])
list1 = List(values=[value1, value2])
I'm probably missing something but I can't really tell
In this case, how will I tell the list class that it is not acting as a Node rn? the iteration and file generation will differ accordingly in the wrapper.
let me show an example of a file that I'm trying to make an abstraction of
so you need to differentiate between when a List is a node in the tree vs. when it's not? sure, add a flag
class List(NodeInterface):
values: ...
is_node: bool
NodeWithExtraAttributes(atttribute1=list1, children=[])
list1 = List(values=[value1, value2], is_node=False)
or instead of inheritance, just use composition
/*--------------------------------*- C++ -*----------------------------------*\
========= |
\\ / F ield | OpenFOAM: The Open Source CFD Toolbox
\\ / O peration | Website: https://openfoam.org
\\ / A nd | Version: 7
\\/ M anipulation |
\*---------------------------------------------------------------------------*/
FoamFile
{
version 2.0;
format ascii;
class dictionary;
object blockMeshDict;
}
// * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * //
convertToMeters 1;
vertices
(
(0 0 0)
(0.012 0 0)
(0.012 0.03 0)
(0 0.03 0)
(0 0 0.001)
(0.012 0 0.001)
(0.012 0.03 0.001)
(0 0.03 0.001)
);
blocks
(
hex (0 1 2 3 4 5 6 7) (100 150 1) simpleGrading (1 1 1)
hex (8 9 10 11 12 13 14) (100 150 1) simpleGrading (1 1 1)
);
edges
(
);
boundary
(
walls
{
type wall;
faces
(
(0 1 5 4)
(1 2 6 5)
(2 3 7 6)
(3 0 4 7)
(0 3 2 1)
);
}
atmosphere
{
type patch;
faces ((2 3 7 6));
}
);
mergePatchPairs
(
);
// ************************************************************************* //
This is an example file. In the file structure, the file is refresented as a Node. All the containers(List and dictionaries) inside the file are also Nodes
you can see that the list blocks holds only physical values, so it can be represented a simple python list with some formatting while generating an output from the wrapper. The problem arises with the boudary list. It contains dictionaries(data in {} ), which are supposed to be Nodes, but are contained inside the list, which is supposed to be a container only for physical values. The current implementation I made manages this using flags. But is there a better solution other than separating the two types of lists?
class TreeNode:
stuff: List | Node
children: list[NodeInterface]
class List:
values: ...
class Node: # this is your original definition of the node, with kv pairs and extra attributes and stuff
values: MyClassThatStoresMultipleValues
apple: ...
orange: ...
lemon: ...
c++?
so is the problem like, List can only have PhysicalValues in it, but then sometimes they also hold Nodes, so now you need two versions of List?
yep. and yes the main software is in c++
By PhysicalValues I mean int, float, string, vector etc.
and for the 2 versions of list I don't want to make 2 separate classes
how are you handling this part then (storing different types in the same structure)?
oh wait, do you mean that PhysicalValues as in all int, or all float, etc.
yes
I'm not sure how your list looks, maybe check out union (c++11) or std::variant (c++17)
will do, thanks!
the way python does it is through storing pointers, in c++ that'd look something like
class Interface {};
class Type1: public Interface {
public:
void type1Method() {}
};
class Type2: public Interface {};
std::vector<Interface *> vec; //
vec.push_back(new Type1); // ok
vec.push_back(new Type2); // ok
Type1 *p = dynamic_cast<Type1*>(vec[0]);
if (p) // it'd be null if the cast fails
p->type1Method(); // ok
I'm not sure how easy that'd be for you cause you also have stuff like int in your list
or actually, maybe what you need is just template?
(this is how you can have "different" vectors like std::vector<int>, std::vector<float> without having to make multiple definitions of std::vector)
. (making sure you see this, maybe one of these other options is what you'd prefer over union or variant)
Wait. I am writing a python wrapper for a c++ software. I thing you are thinking the opposite.
oh 🙂
This file here is a .txt file, which is read by Openfoam(the software whose wrapper I'm trying to make)
The wrapper is supposed to read these .TXT files and generate a tree. That makes it easier to interact and change data in a script fashion
what's stopping you from just storing Nodes in your List again?
do you need different behavior if the List stores Nodes vs. other things?
Yes different behaviour. Expecially while parsing. Nodes contains key values pairs. While list contains the values directly.
so the core issue that you need completely separate code for parsing List[int] vs. List[Node]?
Yes. While keeping a single class for list
so... do some recursive parsing ig? idk what to tell you cause this is very dependent on what you have
e.g.
def parse(o):
if isinstance(o, MyList):
for thing in MyList:
parse(thing)
elif isinstance(o, Node):
for key, value in o:
parse(value)
else: # this leaves PhysicalValues
render(value)
yes I'm doing a recursive parsing and I am trying to avoid these if-else conditions for types as much as possible.
guys is there any data structures and algorithms certification exam available?
how to get started with dsa if i dont know any thing.
should i just start tackling nc150 and look up toutorials when i get stuck on the topic

YouTube
Instructor: Prof. Erik Demaine, Dr. Jason Ku, Prof. Justin Solomon View the complete course: https://ocw.mit.edu/6-006S20 YouTube Playlist: https://www.youtu...
the first 1/3 of the course is data structures, second third is graph algos, third is dynamic programming
herer are lecture notes to go with:
https://ocw.mit.edu/courses/6-006-introduction-to-algorithms-spring-2020/pages/lecture-notes/

MIT OpenCourseWare
Full lecture and recitation notes for 6.006 Introduction to Algorithms.
and hw + solutions:
https://ocw.mit.edu/courses/6-006-introduction-to-algorithms-spring-2020/pages/assignments/
MIT OpenCourseWare
Full assignments, including python and LaTeX files, with solutions for 6.006 Introduction to Algorithms
hey guys, can you recommend some good and comprehensive tutorials about asyncio and multithreading in python thank you very much
https://realpython.com/python-concurrency/
https://realpython.com/async-io-python/ (a bit outdated by now, but the general stuff is fine)
how do for loops work
topic pls
for (<initial condition>: <terminal condition>: <step condition after each iteration>):
<code to execute for each iteration>
thank you
in python the way those three conditions are declared is different but yea, that is the basic gist of for loop
what?
basic pseudo code for a for loop 🙂
python does, but the way of defining the conditions in a different manner
there is only the for each
no, they behave differently
the C style for is just a while in a thin disguise
how abt this?
for i in range(10):
#do stuff
I see the same implementation tbh
just written differently
for (int i = 0; i < 10; ++i) {
++i;
}
for i in range(10):
i += 1
e.g. these won't do the same thing
for each loops behave differently, less like a plain while loop
how come? explain pls
the top loop iterates 5 times, the bottom 10
why son't the bottom one iterate 5 times?
because i is reassigned with the next value of the iterable on each iteration
that's how for each loops work
!e
for i in range(10):
i += 100
print(i)
:white_check_mark: Your 3.12 eval job has completed with return code 0.
001 | 100
002 | 101
003 | 102
004 | 103
005 | 104
006 | 105
007 | 106
008 | 107
009 | 108
010 | 109
okay, learnt something new.
but that is not the only way to write a for loop in python is it?
Also, this behaviour is more because of how in works, and not because of for.
what would be another way of writing a for loop in python?
Is there a fast way to evaluate the intersection of a bezier curve and a vertical line?
Like if I want to find Y of a point on a bezier curve at X, is there a way to do that that doesn't involve root-finding algorithms?
I mean, you could binary search I guess
aah. ok u got me there. appears that the in keyword is necessary for defining a for loop in python. But again, my point stands, that behaviour is because of how in behaves, not for
if you don't want to do the proper math
how does the point stand? for ... in is the only valid for loop in python
it's the only thing for can mean in python
true, without in, for is practically useless. But in is also used in other places, like in conditions. I guess in that use cae also, in works the same way.
if in future some other way of defining a for loop is made in python other than just the for .. in then maybe the iteration will be like the regular for
no.
comparing keywords like this just doesn't make sense
you need both to make a for loop, it's not in giving it power or something
in in for ... in and the containment check in are completely different
then only really share the same name because they are vaguely semantically similar
I am looking for suggestions for a data structure. My case is:
- I have several ranges a particular variable can take for instance
range1 = np.arange(-3, 3)andrange2 = np.arange(0,6) - I have a particular function for mapping a value in range1 to range2 and vice versa
- I want to be wrap the ranges in a class or enum so that my code is more readable
I tried using enums but this did not work with numpy ranges since they are not easily comparible and I dont want the ranges to be mutable
ThankYou should I watch the whole thing first or topic and questions side by side
I would say pace yourself through the material as if you were actually taking the class
that way you get some practice to familiarize yourself before moving on to the next topic
Is this not nlogn? (Edit nvm, it is nlogn, it's just the problem expected O(n) solution and the nlogn solutions time out except if i code it in cpp and optimize a bit)
def compute_global_inversions_merge_sort(self, arr: list[int]) -> tuple[int, list[int]]:
if len(arr) < 2:
return 0, arr
mid: int = len(arr) // 2
left_inv, left_arr = self.compute_global_inversions_merge_sort(arr[:mid])
right_inv, right_arr = self.compute_global_inversions_merge_sort(arr[mid:])
tot_inv = left_inv + right_inv
merged: list[int] = []
i = j = 0
while i < len(left_arr) and j < len(right_arr):
if left_arr[i] < right_arr[j]:
merged.append(left_arr[i])
i += 1
else:
merged.append(right_arr[j])
tot_inv += j + mid - i
j += 1
merged.extend(left_arr[i:])
merged.extend(right_arr[j:])
return tot_inv, merged
It gets TLE on Leetcode with 10^5 constraints (https://leetcode.com/problems/global-and-local-inversions/description/)
But I feel like that's the standard way to count inversions with merge sort
def f1(L):
n = len(L)
while n > 0:
n = n // 2
for i in range(n):
if i in L:
L.append(i)
return L
whats the time complexity? O(n log n)?
explanation?
ah no it is O(nlogn) overall
you lookup in O(n) then twice in O(n/2) then four times in O(n/4)
right?
ah yes no you don't resize L
but my list is resized
it should be i think
1st iteration: n/2
2nd: n/4
3rd: n/8
...
so maybe logn is the time complexity?
then again i did see someone think it's o(n) but im pretty sure thats wrong
what
i don't get it
were you answering my message or did i get confused and you asked a question that just happened to be similar?
nope
just dunno whats o(...) here
if LFS is the amount of operations done, why is the time complexity (big O) equal to the RHS? why is the -1 even there? it should not exist since we only have + summation and 2^i as elements summed

2^0+2^1+2^2 = 1+2+4 = 7, not 8. This is right - it's the sum of a geometric progression.
would big O be 2^n still then?
2^n-1 is O(2^n), yeah
but shouldn't it be much bigger than 2^n will all these huge numbers summed?
Huge numbers? Like what?
nvm you are right
can you help me understand another time complexity?
the time complexity of this
and here's the answer

that code is...bad
assuming L is a list
n*n + n/2*n + n/4*n * ... =
n*(n + n/2 + n/4 + ...) ~ O(n^2)
err...actually worse than that
because L gets larger
I think O(n^2) in both best and worst case, since len(L) at the end is between 1x and 2x of the original value.
between 1x and 3x, but yeah
or wait no, you're right
the //2 is before the inner loop
there is also that in is short circuiting, but ig it's still Θ(n^2)
how? clearly the answer explains why it's O(n)
for k >= 1, can someone help me prove for >=?
i can only manage <=

No. Take a look at the following example:
This code here simply runs in O(n^2) time because the i not in L is effectively a O(n) loop
L = []
for i in range(n):
if i not in L:
L.append(i)
Two nested loops resulting in O(n^2) time
this is O(n) loop, but
in the code it runs log n times and each iteration it runs the loop you showed n/2, n/4, m/8... n/n^i times
it's not at all two o(n) when you can see the n=n//2
Do you agree that the small example above that I showed you takes O(n^2) time?
The outer loop has to run n times
And then in each iteration it has to do the costly i not in L operation
yes
Now take a look at your code. Do you see how in the first iteration of the while loop, you are essentially running my example
yes true
but then it's doing log n times (first loop) * (n/2^i)*n (2nd loop + lookup)
but then it's not "*n" at the end because it's actually n/2,n/4... since we already halved the n in the first loop iteration
Btw what is the L in your code?
If L starts out empty, then nothing will ever get added to it
it's a list of size n (not any more givens)
they want worst time complexity
In that case, the time complexity is definitely O(n^2)
but how? I can't see why
First iteration takes n^2 time
2nd iteration takes n^2/2 time
3rd iteration takes n^2/4 time
it takes n/2 (2nd loop) * n/2 (inside 2nd loop)
The way I think of it is that i on L is always O(n)
The cost of that doesn't change between iterations
oh that's totally right
But the for loops decreases in size in each iteration
That's what causes the division by powers of two
but then log n (first loop) * (n/2^i) (2nd loop) * (lookup time)
I don't understand your notation
i being the number of iterations being done (i think log n)
I mean I want to regirously calculate the time complexity to show it
but I can't think of a formula like in the above
Oh you use () to explain what you mean by log n etc
yeah
Just a thing. 1 + 1/2 + 1/4 + 1/8 + ... = 2
So when you sum up the cost n^2 + n^2/2 + n^2/4 + ... <= 2 * n^2
there's gotta be the same formula to what I showed earlier to show it with sum notation and n or i I think, I think it'll make it clearer once I manage to make one of those
don't you mean <= n^2 strictly? it's like the Walking Turtle problem
oh right we had 1*n^2 already
I'm trying to think up a formula to this using i and n
If you want to do a rigorous derivation, then you will have to take into account that L's size is slowly increasing. Meaning the cost of running i in L slowly increases
You can prove that L will have a size between n and 3n
that's true, ty
Hello I am a starter, and have learned Python a bit, can anyone help me guide a bit please? seriously passionate guy here seeking guidance! Thanks in advance
Can anyone provide me a good source to learn about run time complexity of an algorithm in python from scratch
the math in the answer is fine, but it's based on (incorrectly) saying the loop body is O(1), hence the wrong answer.
Can anyone tell me why we need to learn DSA as a programmer?
why do you need to learn design patterns as a programmer? why do you need to learn systems design as a programmer?
to program better
if you learn to use a certain data structure and algorithm you can reduce the amount of time it takes to run an app and also reduce the amount of storage it needs to function
which can save both money and time and lives in some cases
same answer
thanks
is there a good simple way to shuffle an image while knowing the original position of each point? i did this yesterday but i think the method was somewhat inefficient
i basically had a set() of used points, and randomly generated a position until i found one that wasn't in the set
You mean, like,
shuffled = np.arange(pixel_count)
np.random.shuffle(shuffled)
# pixel i goes to shuffled[i]
# which means that in the shuffled image, pixel i came from original[i], where:
original = np.argsort(shuffled)
?
ig
is it possible to do it without np? ik its faster but in this usecase the speed isnt actually a big concern
also is it faster to do a concat or "".join() for combining two strings
sure, the same way. it's even pretty fast since it's all builtins:
shuffled = list(range(pixel_count))
random.shuffle(shuffled)
original = sorted(range(pixel_count), key=shuffled.__getitem__)
just two? it would sure be wild if the answer is "join" :p
or a handful really
kk
hm i wonder if pillow lets you get a single index for a pixel
cause i know it lets you push data in that format to it, since i use that all the time but i dont think ive ever gotten single index pixels
i can prob jsut use tuple coordinates and shuffle that anyway though
with a numpy array it'd be straightforward, without one, uhh, can get the image as a bytes instead
yeah, that'd work too
btw is there a way to only give an argument to a function if a condition is met? other than just if statement and calling it differently in each block
unpacking a variable-size collection comes to mind
e.g. args = (x,) if cond else () and then f(*args)
hm
🙃
args = (x,)*cond
sorry, this is better
f(*(x,)*cond)
What is the best way to implement a trie?
a nested dict would work fine
for a real application, I'd use a compiled third-party library like marisa-trie
Yeah i was talking about real world application
Hi,
I was trying to solve a greedy problem. The problem is something else but the main crux of the algorithm is what i have stated below.
Given two integer arrays,
nums1andnums2, each of lengthn, for each indexiinnums1, we select an indexjinnums2and calculate the absolute difference between the values at these indices. How can we determine the minimum possible sum of all these absolute differences?
So apparently by sorting both arrays and then pairing the elements at the same indices, we are minimizing the differences at each position.
Can someone help me figure out a formal prove for it (preferably not by contradiction) and maybe some tips on how to convince or prove myself of greedy solutions in the future?
Anyone understands why max manhattan distance problem works in O(N) ??
So, find array c[i] such that sum_i |nums1[i]-nums2[c[i]]| is minimized? That sure can be solved greedily, yeah. c[i] should be the index of nums2 with the closest value to nums1[i], which... I'm not sure I believe it's the same as the ith element in the sorted array. Is there maybe some extra condition, like "there can be no repeats"?
max manhattan distance problem?
Yup
yeah, from some experimentation I think this is just false
udemy
I would assume it's with no repeats
i.e. a permutation
if it's a permutation I think it is true

WLOG = without loss of generality?
yeah
if it's not true I could just swap the sequences
what this shows is that taking a pair that is not in the sorted order and making it sorted, we get a smaller or equal sum of absolute values
keep doing this and you end up with a sorted sequence
there is probably a neater way of showing the substitution property, but this works
maybe it's more natural to start with
a, a+da
x, x - dx
and showing that swapping makes it ≤, but whatever
i see
actually, this one might end up being more awkward since I think you can't swap things wlog
is there a better way of comparing a vector / numerical list (i.e checking if one is greater than the other) other than just checking if all entries of one are greater than / less than / etc than the other? (which is what i've been doing)
of course im not sure what 'greater than'/'less than' would necessarily mean for vectors
maybe figuring out what it should mean is the first step 🙃
if you just need some ordering of vectors you can just lexicograpically sort it or whatever
asking cause i just had to fix a problem with the class where != wouldn't work; it was because i was using all() for the comparison (i.e all(a.x!=b.x,a.y!=b.y,a.z!=b.z)) but that doesnt work if any component is equal
i fixed it by adding an option to switch what comparison it uses and set it to any() for __ne__
which lead to funkiness like this:
a = vec3(0,1,0)
b = vec3(0)
>>> a!=b
False
>>> a==b
False
err, how did you define == and != to make that happen?
i use an internal function for all comparisons, it just take in an operator and compares it for each pair of components
that way instead of having to implement each dunder as its own function i just assign it
let me write a generic thing because I'm lazy
== -> all(x == y for x, y in zip(a, b))
!= -> not all(x == y for x, y in zip(a, b))
these work fine, and != is just not ==
thats fair, and fairly similar to what i am doing anyway
you don't even need to implement both, do you?
I think if you implement == then != will use it
this is actually pretty much exactly what i did actually, except i have a case for lists too
.. wait why do i have that
the default definition should be basically
return not (a == b)
yeah i can just remove that actually
probably just a holdover tbh
is there a better way to check for iterability than try-except? afaik handling the error is kinda computationally heavy, no? or maybe thats just in other langs
maybe using iterable from collections.abc?
== -> all(x == y for x, y in zip(a, b))
!= -> any(x != y for x, y in zip(a, b))
de morgan pls
that was what i switched to (well sorta since i didnt just make it its own function) until it was mentioned you can just not implement it
also i assume that syntax is just for this and not for actual implementation?
yeah it doesnt likei t when i try that lol
the -> and stuff isn't meant for the actual impl no
Is bit shift for long integers in python n or n/int_size ?
If first, where can i find some bitset implementation? (in python)
Bitshift is fast in Python
So like n/64
However, changing a single bit of an integer is also n/64
So using Python big integers as bitsets is kind of flawed
Well usually i would just switch to cpp ofc
But sometimes there are cases when I don't want to do that (happened recently)
so wanna prepare for such case
The nice thing about using python integers as bitsets is that they are dynamic, which is not the case for most bitsets out there
Do you have an example?
I've found that for most bitset problems out there, python integers are sufficient
There was some expression parsing
For example A-(B-(C-(Z+A+B+Z-20+11)))+8-11
(that's why i didn't want to use cpp) and after that i had an equation like
C[0] * a + C[1] * b + C[2] * c + ....
where all variables (a, b, c...) can take value in range [1; 10]
Maybe there is another solution but I did just
possible = {0}
for x in C:
if x:
new_possible = set()
for i in range(1, 11):
for v in possible:
new_possible.add(x * i + v)
possible = new_possible
print(len(possible))
and it passed because of small constraints
(need to find how many different results can it give)
Firstly, I would use the trick that if you can have three copies avalible of the same value c, then that is equivalent to having one copy of c and one copy of 2*c.
In the case of 10 copies being avalible of c, this is equivalent to two copies of c, two copies of 2*c and one copy of 4*x
That way the range over i can be kept to either 1 or 2
After that the code is
possible = 1
for x,count in C:
for i in range(count): # note: count here is either 1 or 2
possible |= possible << x
print(possible.bit_count())
I am not sure I understood