#algos-and-data-structs
1 messages · Page 38 of 1
I dont have any experience working with pympler.asizeof, so I'm not sure
What would you recommend i use instead?
Not sure
All I'm saying is that short strings should already be stored super efficiently.
Well this utilizes shared prefixes and suffixes
Actually wait I could just create a ton of em in an allocated memory space and see which i can fit more of
Should ensure the ratio is right
You could maybe try using sys.getsizeof manually.
"Only the memory consumption directly attributed to the object is accounted for, not the memory consumption of objects it refers to"
So since im storing children it wouldnt take that into account
Regardless im not asking to validate the memory usage, im looking for ways to reduce it
How many bytes is word_list.txt?
One simple way to reduce the memory usage is to cut down the number of variables in TrieNode's ```py
class TrieNode:
slots = ["children", "is_word"]
def init(self):
self.children = {}
self.is_word = False
This would make _trie_to_dawg to be a bit more tricky to implement, but I think it would be possible
I guess i could pass in the current path as an argument
Actually no i need it for the eq function
Not really
explain
2 nodes can have no children, be the end of a word, but not have the same token.
Does the token actually matter?
I guess it matters because of _single_chain_compress
Right
if i didnt have that I could make children a 26 size array
But the compression is worth it
?
I dont see why node.children couldnt just be switched to a 26 long array in your current implementation
Instead of using a dict of format {"token": child}, id have a 26 long array with vlaues set to none. arr[0] is equal to "a", arr[1] is b, etc.
You can have multi character tokens with chain compression
where does that happen in the code?
def _single_chain_compress(self, node: TrieNode, parent: TrieNode = None):
while len(node.children) == 1 and not node.is_word:
child = next(iter(node.children.values()))
# If there's no parent, it means this is the root node, and we should skip this iteration.
if parent is None:
break
token = node.token
node.token += child.token
node.is_word = child.is_word
node.children = child.children
# Remove old reference from parent
del parent.children[token]
# Add the newly compressed node to the parent
parent.children[node.token] = node
for child in list(node.children.values()):
self._single_chain_compress(child, node)
if a node has 1 child and no distinct feature, combine them
Oh that is a weird way of handling compression
One nice thing about tries is that you can easily search them
Search of O(n), yeah
Btw some of your code is O(n^2), like node.token += child.token and hash(node)
One thing you could do is to store the token as two integers
2?
That corresponds to indices of an occurence of the token in the file
Wait
I dont think I need token
If i do what i did for removing node.parent and pass it in recursively based off the key of the dict item it shouldnt be necessary to store
Would hurt speed a bit but help long term
Plus itd be able to be compressed more using trie similarity
*dawg compression
You might want to consider the double index instead of token too.
Well if i cant remove token then yeah ill try double index
But theroretically this should work
What I meant is to:
- Remove node.parent
- Remove node.token (since that information is stored in .children of the parent)
- Instead of using strings for keys for .children, consider using two integers to mark where that string is in the file. You could even store the two integers as one large integer by doing something like x * 2^30 + y
🤢
if you completely ignored the speed of operations, that would be comfortably less than 2MiB just as bytes 
so if memory is your one and only concern...
and you could easily squish that down to 5/8 that with bit packing

Anyone can tell me great video which can teach quick sort?
Hey, I am looking for a partner to work on leetcode problems because I always tried to avoid it. I have already worked on several fullstack projects and know programming quite well, just not DSA. If you are from europe (speaking german even better) just dm me. Mind that I want to tackle questions together for learning purpose. Language would be python
idk about video, but the idea is super simple
pick out some element in the thing you want to sort, we call this the pivot
from the remaining elements put ones <=pivot to the left, and >pivot on the right
now sort the elements to the left and right (again using quick sort)
let this splitting continue until you're asked to sort ≤1 element
(which is already sorted)
that's it
Fair; but speed is a non 0 concern
If i didnt care about speed id create it once and save it to disk
What about storing the words sorted in a long string, and then having a look up list for where each word starts
That would give you essentially the same functionality of a trie
while being stored efficiently
So in essence a file path?
"apple.(move back one)ication.......y..alling"
?
idk how that's a file path
If you have the words sorted you can binary search for the interval of words that all starts with an a
Similar structure of using notation to create relative paths
the idea here is just to have all the strings sorted
Tried that initally. Too slow and more memory than a set
no way
I refuse to belive that
I guess maybe if you actually store indexes for every word the size of python's ints might be an issue
but that's more of a python issue
you could use a numpy array for that indices to get rid of most of that issue
Or array.array
I was utilizing a numpy array. The main issue came from any slight speed improvement you wanted to make would massively increase the memory. Storing keys based off first letter would store 26, but even then youd still need to binary sort. Storing 2 letter phrases takes 26^2.
Sure there were some optimizations to be made
But at some point youre using a hammer on a screw
1570508 chars -> ~1.5MB
indices for all words -> 172820 words * 4 bytes ~ 700kB
err
I picked the wrong number for the first thing
oh nvm
replied to the wrong answer
meant this
Maybe we're thinking about 2 different things
sstable
Definition of SSTable,
possibly with links to more information and implementations.
but kinda just the key part
So this doesnt offer prefix searching
I guess you might need to add 1 byte or something per string to store a separator, or store the length
you can binary search?
so yes it does
I could but if im running a prefix search a million times doing it in time o(n) rather than a o(m), where n is the length of the prefix and m is the total length of the set, the speed saved is worth more than the memory saved
it's something like O(n log(m))
Ill try it out tho
Hadnt heard of it so i wont cast it off that quickly
Preciate the resource
idk if the thing I linked is useful, apparently sstable isn't that frequent of a term
but in this case you would just store the starting index per word, and then you use those indices to look into a big string
Oh its just a LSM tree
or you could even keep the data on disk and only keep the indices in memory all the time
Ive used those

In computer science, the log-structured merge-tree (also known as LSM tree, or LSMT) is a data structure with performance characteristics that make it attractive for providing indexed access to files with high insert volume, such as transactional log data. LSM trees, like other search trees, maintain key-value pairs. LSM trees maintain data in t...
These do look to be optimized for speed rather than memory tho
you don't really need any tree here
Its not quite a tree
It starts as a tree then kinda compacts into itself
Granted its sunday and im not sapient enough to delve into the characteristics of an LSM tree
ok this part of the link I sent isn't great
They are not used as stand-alone data structures
you can totally use them on their own
Yea it looks like an SSTable is designed to serve as a node on an LSM Tree
But i could totally use it for a lone data struct
and as said, if you're really memory pressured you can even keep the actual word data on disk
and only keep the indices in memory
and do disk lookups as needed
For larger context, im making a scrabble program which I hopefully plan to use to train an AI (Hence why im in python rather than C++)
if you use array.array or a numpy array of int32 for the indices, and a string for the data you will be fine memory-wise
Yea that might work
since you're not using anything in python that has crazy overhead
Appreciate all the help, gonna reread all this tmw when im sober. Should hopefully help
I estimate the final memory needed to be around 2.4 mb
That includes both the sorted word list and the numpy array for storing indices
hi there, i'm trying to set a value as a predefined variable in this dict, but for some reason it just doesn't work
vscode shows the variable as greyed out too to indicate i haven't used it
anyone got any idea on where i can make some changes
Thanks 😊
"this dict"?
i'll drop a snippet
Hello guys!
I have a doubt related to linked list data structure.
class Node:
def __init__(self, data):
self.data = data
self.next = None```
This code should be like
Create a Node class to create a node
class Node:
def init(self, data, next):
self.data = data
self.next = None
I mean, to write `self.next=None` , we must write `def __init__(self, data, next):`
Right?
But, i found this code while trying to learn linked lists in python on this site:
https://www.geeksforgeeks.org/python-linked-list/amp/
I know that I'm missing something.
Can anyone please clarify my doubt?
Thank you.Your second code takes next as argument, but does nothing with it
So what is the point of it?
Yes,
It has got some usage while working with the linked list like inserting an element, deleting an element, traversing the list etc., according to the site I mentioned.
Yeah, but why do you think you should take next as argument, whereas you are not using the value of it?
next and self.next have nothing to do with each other at all
In general you just name the parameters of the init method the same as the attributes if you directly assign it to them, but it's just a good habit, not a necessity
In that case,
is
def __init__(self):
self.data=data
self.next=next
acceptable and works fine as
No, because you do want to pass data as argument to the init method
You want to use the class as follows:
!e
class Node:
def __init__(self, data):
self.data = data
self.next = None
# Code using the class
node_a = Node(5)
node_b = Node(2)
node_c = Node(8)
node_a.next = node_b
node_b.next = node_c
whoops
Like this basically
When making the node you just say what it's data is
And later on you connect them
is .next a keyword in python?
I mean, as .next is colored, I just wandered if it is a keyword.
No, it accesses the attribute of the instance
Oh yeah
But it should not really be colored here
next is a keyword, but some_class.next is nothing special
okay
I don't think at least
So, if I want to assign self.name, self.age, or any other self.(attribute_name) a None value, is it fine if I don't pass it as a parameter in init?
I feel like you have some hard-coded pattern in your thought process that when you do self.something you need to have something in the parameters
This is not the case
Yes
class Node:
def __init__(self, value):
self.data = value
self.next = None
This would be fine too f.e.
It's just customary that if you make an attribute in the init and you directly set it to a value given in the constructor, then you use the same name.
It was special in py2
Now it is renamed to __next__
Ah okay, good to know
I cannot have only self in init?
I mean, as in this
What is "data"? Is it a global variable?
Nope
Then why are you using nonexistent variable?
I don't understand.
I'm trying to learn linked lists using the site mentioned here
The problem you are having has nothing to do with linked lists, it's with not understanding how variable assignment works and how classes work
You should pass only things that are required to build meaningful object.
If you are not using some var - it is a bad sign.
If you are using nonexistent var - it is an even worse sign
Yes, I understand that.
I have just started learning OOP in python and I know that I'm missing something which is failing me to understand this.
Your problem is not related to OOP. You should read more about variables and functions
Oh, I see
I'll spend more time to understand variables and functions.
Thank you
Thank you @lament totem @lean walrus
Hey guys, IDK if this is the right place, correct me if it's not.
I am new to the programming game and found that just using codecademy and basically following instructions isn't taking me anywhere. I need to try on my own more
So basically, I have a task on codewars asking me to convert input to roman numerals. I have a dictionary with the Key: Values, but I'm having issues moving on. How should I think to iterate through this and present the output correctly?

@fiery cosmos
Broad Answer:
One option to iterate is to convert int into an string, which is just an array of character
From there, you could loop loop yourself through the array checking values and look ahead at some values as well.

I just thought it would be interesting to share it.
"In object-oriented systems with multiple inheritance,
some mechanism must be used for resolving conflicts when inheriting different definitions of the same property
from multiple superclasses." C3 superclass linearization is an algorithm used primarily to obtain the order in which methods should be inherited in the presence of multiple inherita...
Just in case someone new is wondering how multiple inheritance solves the diamond problem.

any math nerds? i know matrix multiplication is associative but don't remember if that's true for all matrices (that you can multiply ) or just matrices with the same dimension or square matrices. doing some binary operator bs and wanna see if it's applicable to more things. ping pls ty <3
for all matrices
It is relatively clear if you think of matrix multiplication as composition of vector space transformations
"just matrices with the same dimension or square matrices" Uhm I'm not sure what you meant by this
You can only multiply two matrices A and B if the number of columns in A is the same as number of rows in B
If someone know how to help with analyzing datas from a sonar with python, feel free to dm me (idk if it is chart friendly but i dont feel comfortable with posting documents from my school in public)
(So if i cant, nvm)
ye this was the rule i was having trouble remembering. but ye my question is answered. i was just concerned about it only being with square matrices but this is fine
You should check the algebraic structures that matrixes form with the diffeerent operations. it will be way clearer that way.
scalar multiplication, matrix multiplication, and matrix addition. Check the different combinations of those with matrices and you will see the different structures.

MIT A 2020 Vision of Linear Algebra, Spring 2020
Instructor: Gilbert Strang
View the complete course: https://ocw.mit.edu/2020-vision
YouTube Playlist: https://www.youtube.com/playlist?list=PLUl4u3cNGP61iQEFiWLE21EJCxwmWvvek
Professor Strang describes independent vectors and the column space of a matrix as a good starting point for learning lin...
anyone aware of python tools for data oriented design
the idea there being able to representing specific data structures not as full objects most of the time, but rather as memory mapping friendly arrays of primitives and only creating python objects for representing some when necessary
and also while being at it indexing certain parts
for example, sequence of paths, if repressented in python, those a re dozens and dozens for very similar tuples, strings, objects
instead i'd like to represent them as something like
part_names: list[str] = ['.','home', 'ronny'] # contents of path parts possibly to be replaced by something that tracks offsets of utf-8 strings in a zero demitted file
part_names_lookup: Mapping[str, int] = hashmap_part_for_compact_dict/set() # helper to look up indexes of the names
compact_filenames = array_of_integers([[0,0],[0,1], [1,2] ]
the example shows a list of filenames like [ ".", "./home", "./home/ronny"]
the full data when using normal text would have me pushing around more data than i have ram, the compact representation would get me down to a few hundred megabytes,
just interning or using python objects still leaves the typical footprint about a order if magnitude higher than the raw data, so i 'd love to use the raw data, ideally in a way thats memory mappable (so N processes can share the lower level data)
in wondering if numpy, arrow,s, pandas or whatever have some repressentation for that (at least i missed them when i searched)
it would be appropriate for #python-discussion
idk if I would bother much with data oriented design in python
basically anything you do in python is a cache miss anyway
the big value of data oriented design is data locality, but if all values are behind a pointer anyway then who cares?
maybe you can try to shove structs into numpy arrays, but it feels kinda iffy
my key need here is not loosing gigabytes of memory most of the time
There is always a trade off between program complexity, memory use, and processing power.
What you are suggesting here is a trade off in favor of memory use at the cost of processing power and program complexity.
Most modern programming solutions make the opposite optimization, because memory is typically cheap compared to programmer time and processing power.
There are definately use cases where what you are suggesting makes sense, but I believe it is mostly implemented on a per-use basis.
It reminds me a bit of the challenges of working with sparse matrices.
what kind of data are you talking about?
do you have gigabytes of strings that are made from substrings?
yes, a few hundred million tuples of path components, interning is making things a little better but not great
instead of elements in tuples that are 64 bit pointers to strings, a lot ofthe time i can get by by paris of much smaller integers
I do suspect your use case is somewhat unique, so I suspect your solution will have to be unique as well.
hi
having all of it compactly in avaliable memory so far seems a better expense than the memory pressure of creating the working set of tuples
I guess an alternative would be to use an actual on-disk database
stuff like sqlite is pretty expensive for stuff where you keep readings mall parts of the workignset that way,
hello
class QueueArray:
def __init__(self,size):
self.queue = [None]*size
self.front = 0
self.rear = size-1
self.count = 0
self.size = size
def is_empty(self):
return True if self.count == 0 else False
def is_full(self):
return self.count == self.size
def enqueue(self,element):
print(self.count)
if self.is_empty:
self.rear = (self.rear+1)%self.size
self.queue[self.rear] = element
self.count += 1
return
elif self.is_full:
print("can't add, queue is full")
else:
self.rear = (self.rear+1)%self.size
self.queue[self.rear] = element
self.count += 1
def __str__(self):
s = [str(e) for e in self.queue]
s = " ".join(s)
return s
q1 = QueueArray(5)
q1.enqueue(5)
q1.enqueue(4)
q1.enqueue(3)
q1.enqueue(2)
q1.enqueue(1)
q1.enqueue(1)
print(q1)
why does is_full not work?
nvm
good old missing call
def shortestPath(self, grid: List[List[int]], source: List[int], destination: List[int]) -> int:
c = len(grid[0])
vis = [c*[(float("inf"))] for i in range(len(grid))]
# print(vis)
q = deque()
q.append((1,source))
# print(q)
if source == destination:
return 0
while q:
dist,(row,col) = q.popleft()
vis[row][col]=0
delrow = [-1,0,1,0]
delcol = [0,-1,0,1]
for r in range(4):
nrow = row+delrow[r]
ncol = col+delcol[r]
if nrow>=0 and ncol>=0 and nrow<len(grid) and ncol<len(grid[0]) and grid[nrow][ncol]==1 and vis[nrow][ncol]==float("inf"):
vis[nrow][ncol]==dist+1
if [nrow,ncol] == destination:
return dist
q.append((dist+1,(nrow,ncol)))
# print(q)
return -1
```How can i optimize itwhy is front method returning 1?
https://paste.pythondiscord.com/GJ6A
I made a silly mistake and it works
correction:
vis[nrow][ncol]=dist+1
that list is not updated and my queue is iterating because element is always inf.
Naming
Here is how I would do it
def shortestPath(self, grid: List[List[int]], source: List[int], destination: List[int]) -> int:
r = len(grid)
c = len(grid[0])
dist = [[-1]*c for i in range(r)]
i,j = source
dist[i][j] = 0
q = [source]
for i,j in q:
d = dist[i][j]
if [i,j] == destination:
return d
for di,dj in zip([-1,1,0,0], [0,0,-1,1]):
i2 = i+di
j2 = j+dj
if 0<=i2<r and 0<=j2<c and grid[i2][j2] and dist[i2][j2]==-1:
dist[i2][j2] = d+1
q.append([i2,j2])
return -1
why does my next method yields generator objects and it makes infinite loop?
https://paste.pythondiscord.com/A7GQ
why is next a generator?
put what you have in next in iter
Didnt work either
Do you have an upper bound on the length of the strings? Are they small?
it fixes one of your bugs
after that fix, self.current == 0 which is the index of the None in the list, so the loop is never run
!e
class QueueArray:
def __init__(self,size):
self.queue = [None]*size
self.front = 0
self.rear = size-1
self.count = 0
self.size = size
self.current = self.front
def is_empty(self):
return self.count == 0
def is_full(self):
return self.count == self.size
def enqueue(self,element):
if self.is_empty():
self.rear = (self.rear+1)%self.size
self.queue[self.rear] = element
self.count += 1
return
elif self.is_full():
print("can't add, queue is full")
else:
self.rear = (self.rear+1)%self.size
self.queue[self.rear] = element
self.count += 1
def dequeue(self):
if self.is_empty():
print("queue is empty,cant dequeue")
return
self.queue[self.front] = None
self.front = (self.front+1)%self.size
self.count -= 1
def Front(self):
return self.queue[self.front]
def Rear(self):
return self.queue[self.rear]
def __str__(self):
s = [str(e) for e in self.queue]
s = " ".join(s)
return s
def clear(self):
self.queue = [None]*self.size
def __iter__(self):
print('current before loop', self.current)
while self.queue[self.current] is not None:
print('current in loop', self.current)
yield self.queue[self.current]
self.current += 1
q1 = QueueArray(5)
q1.enqueue(5)
q1.enqueue(4)
q1.enqueue(3)
q1.dequeue()
q1.enqueue(2)
q1.enqueue(1)
print('queue is', q1.queue)
q1_iter = iter(q1)
for e in q1_iter:
print(e)
@haughty mountain :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | queue is [None, 4, 3, 2, 1]
002 | current before loop 0
I'm assuming you want something like self.current = self.front before the loop
!e fixing that...
class QueueArray:
def __init__(self,size):
self.queue = [None]*size
self.front = 0
self.rear = size-1
self.count = 0
self.size = size
self.current = self.front
def is_empty(self):
return self.count == 0
def is_full(self):
return self.count == self.size
def enqueue(self,element):
if self.is_empty():
self.rear = (self.rear+1)%self.size
self.queue[self.rear] = element
self.count += 1
return
elif self.is_full():
print("can't add, queue is full")
else:
self.rear = (self.rear+1)%self.size
self.queue[self.rear] = element
self.count += 1
def dequeue(self):
if self.is_empty():
print("queue is empty,cant dequeue")
return
self.queue[self.front] = None
self.front = (self.front+1)%self.size
self.count -= 1
def Front(self):
return self.queue[self.front]
def Rear(self):
return self.queue[self.rear]
def __str__(self):
s = [str(e) for e in self.queue]
s = " ".join(s)
return s
def clear(self):
self.queue = [None]*self.size
def __iter__(self):
self.current = self.front
print('current before loop', self.current)
while self.queue[self.current] is not None:
print('current in loop', self.current)
yield self.queue[self.current]
self.current += 1
q1 = QueueArray(5)
q1.enqueue(5)
q1.enqueue(4)
q1.enqueue(3)
q1.dequeue()
q1.enqueue(2)
q1.enqueue(1)
print('queue is', q1.queue)
q1_iter = iter(q1)
for e in q1_iter:
print('e in iter loop', e)
there is still the issue that your self.current goes out of bounds
@haughty mountain :x: Your 3.11 eval job has completed with return code 1.
001 | queue is [None, 4, 3, 2, 1]
002 | current before loop 1
003 | current in loop 1
004 | e in iter loop 4
005 | current in loop 2
006 | e in iter loop 3
007 | current in loop 3
008 | e in iter loop 2
009 | current in loop 4
010 | e in iter loop 1
011 | Traceback (most recent call last):
... (truncated - too many lines)
Full output: https://paste.pythondiscord.com/7SE4H4HIRFPXQ4KIK2FHHLUE6A
when it presumably should loop around to the beginning of the list
!e fixing that...
class QueueArray:
def __init__(self,size):
self.queue = [None]*size
self.front = 0
self.rear = size-1
self.count = 0
self.size = size
self.current = self.front
def is_empty(self):
return self.count == 0
def is_full(self):
return self.count == self.size
def enqueue(self,element):
if self.is_empty():
self.rear = (self.rear+1)%self.size
self.queue[self.rear] = element
self.count += 1
return
elif self.is_full():
print("can't add, queue is full")
else:
self.rear = (self.rear+1)%self.size
self.queue[self.rear] = element
self.count += 1
def dequeue(self):
if self.is_empty():
print("queue is empty,cant dequeue")
return
self.queue[self.front] = None
self.front = (self.front+1)%self.size
self.count -= 1
def Front(self):
return self.queue[self.front]
def Rear(self):
return self.queue[self.rear]
def __str__(self):
s = [str(e) for e in self.queue]
s = " ".join(s)
return s
def clear(self):
self.queue = [None]*self.size
def __iter__(self):
self.current = self.front
while self.queue[self.current] is not None:
yield self.queue[self.current]
self.current = (self.current + 1)%self.size
q1 = QueueArray(5)
q1.enqueue(5)
q1.enqueue(4)
q1.enqueue(3)
q1.dequeue()
q1.enqueue(2)
q1.enqueue(1)
print('queue is', q1.queue)
q1_iter = iter(q1)
for e in q1_iter:
print('e in iter loop', e)
@haughty mountain :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | queue is [None, 4, 3, 2, 1]
002 | e in iter loop 4
003 | e in iter loop 3
004 | e in iter loop 2
005 | e in iter loop 1
def round_test(n):
if abs(n)%1 < 0.5:
return int(n)
else:
return int(n)+sign(n)
tried implementing rounding away from 0, i think its also called 'round-to-infinity' but i've also seen that used to refer to ceiling
sign being
def sign(n):
return -1 if n<0 else 0 if n==0 else 1
i.e like the mathematical sign function
ceil is round towards +∞ specifically
not sure how best to implement this tbh
naively I would try
math.copysign(x, math.ceil(math.abs(x)))
Less than 1k
I would probably go with something like this
def round_test(n):
if n%1 == 0.5:
return int(n//1) + (n>0)
else:
return round(n)
It is natural to make use of the built in round function
wait, you don't mean rounding away from zero do you?
what you do there is tie break away from zero
or I'm reading that completely wrong
after (and at) 0.5 (negative or positive) it rounds up, otherwise down
So for example, what do you want round of -2.5 and 2.5 to be?
-3,3
-2,2
if you rounded away from zero those would be -3, 3
The idea is it’s sign-symmetric
(at least in my head)
I think @lilac cradle just means that ties should be rounded away from 0
yea
doesn't this fail because banker's rounding?
You could also do rounding toward 0 by just flipping the < to >
My code uses built in round unless we are in a tie situation (i.e. n ends with .5)
If n ends with .5 then n round away from 0 by int(n//1) + (n>0)
I think this would work 🥴
math.copysign(x, math.floor(math.abs(x) + 0.5))
I'm a little afraid that adding 0.5 can mess something up when x is like 2^52 or -2^52
should those values ever be rounded?
Thinking more about it, maybe adding 0.5 is always safe. But I'm not 100% sure about it
I'm afraid that adding 0.5 to x could increase x by 1
apparently it'smath.fabs
I keep forgetting that
also I flipped copysign
math.copysign(math.floor(math.fabs(x) + 0.5), x)
!e
import math
def round_test(x):
return math.copysign(math.floor(math.fabs(x) + 0.5), x)
x = 2**52 + 1.0
print(x)
print(round_test(x))
@regal spoke :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | 4503599627370497.0
002 | 4503599627370498.0
!e
import math
x = 2**52 + 1.0
math.copysign(math.floor(x + 0.5), x)
print(x)
lol
yeah
err, my thing had a typo anyway
!e
import math
x = 2**52 + 1.0
print(math.copysign(math.floor(x + 0.5), x))
@haughty mountain :white_check_mark: Your 3.11 eval job has completed with return code 0.
4503599627370498.0
See, adding 0.5 can be deadly
but annoying bug to correct for and keeping the same approach
math.copysign(math.ceil(math.fabs(x) - 0.5 + math.ulp(x)), x)
```maybegoing smaller should be fine always I think
and then ulp to go in the right direction 🥴
(there probably is a bug in this one as well)
!e
import math
def round_test(x):
return math.copysign(math.ceil(math.fabs(x) - 0.5 + math.ulp(x)), x)
x = 2**52 + 2.0
print(x)
print(round_test(x))
@regal spoke :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | 4503599627370498.0
002 | 4503599627370499.0
😭
This reminds me of that rounding floating bug I found ages ago in PyPy. Never got around reporting it.
Wonder if it has been fixed
Btw another possible source of bugs is if you have something like
x = 0.5 - 2^-54,
then adding 0.5 to it could make it become 1
!e
x = 0.5 - 1/2**54
print(x)
print(x + 0.5)
@regal spoke :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | 0.49999999999999994
002 | 1.0
This is the reason why my code is based onx % 1 == 0.5, and not int(x + 0.5)
Good solution! Thanks!
Hey everyone, I'm new here.
That's why i ask this question here or not .
My doubt :
I want to learn python basics,ds with python,and frameworks which are used in website for back head.
How to learn, where i can learn this all .
Give a roadmap or something that can help me to learn this all.
I'd suggest starting off with the python documentation, which can be found at https://docs.python.org/
I am trying to delete repeating values from a List by only using a Set as an axuliary storage, however I am running into some issues, my code is below:
value = [4, 0, 2, 9, 4, 7, 2, 0, 0, 9, 6, 6]
def shrink_repeat(a):
mystuff = set()
size = len(a)
step = 0
for step in range(size):
mystuff.add(a[step])
print(mystuff)
check = size - 1
getcheck = 0
ok = len(mystuff)
while getcheck != check:
step = 0
i = 0
amount = 0
myindex = 0
for step in range(ok):
for i in range(size):
if list(mystuff)[step] == a[i]:
if amount == 2:
myindex = i
getcheck = step
break
del a[myindex]
#del a[4]
#print(a)
shrink_repeat(value)
Error message:
{0, 2, 4, 6, 7, 9}
Traceback (most recent call last):
File "<string>", line 37, in <module>
File "<string>", line 25, in shrink_repeat
IndexError: list index out of range
Thanks
I am using a while loop in order to dynamically keep track of the change size of the list, then nested for loop to delete the repeating element in the list via reference from list
What's the reason of creating a set if you are using it as a list? I mean, i understand that it's to remove duplicates, but it's weird
if list(mystuff)[step] == a[i]:
And your whole code is overcomplicated, i am not sure what you are trying to do
Why not just doing result = list(set(a)) for example? You want to keep the order?
Then just iterate over a with a single loop, there add value to set. If it's added first time, then keep it in the list. No need to create triple nested while+for+for loop and ten variables
Yea the reason why I am using a Set as the storage was because that is the requirement criteria. I agree it is a bit complicated since i'm just coding as I go, then clean up later. Yes I want to keep the order as I delete it. So the expected output would be Value = [4, 0, 2, 9, 7, 6].
I managed to remove the error with this code:
value = [4, 0, 2, 9, 4, 7, 2, 0, 0, 9, 6, 6]
def shrink_repeat(a):
mystuff = set()
size = len(value)
step = 0
for step in range(size):
mystuff.add(value[step])
print(f'Set: {mystuff}')
step = 0
i = 0
check = 6 - 1
getcheck = 0
cool = len(mystuff)
yup = 0
amount = 0
my_index = 0
while getcheck != check:
for step in range(6):
for i in range(size):
if list(mystuff)[step] == value[i]:
if amount == 2:
my_index = i
#print(f'Hmmm....{i}')
del value[my_index]
size = len(value)
getcheck = getcheck+1
print(value)
shrink_repeat(value)
However the output wasn't Value = [4, 0, 2, 9, 7, 6]:
Set: {0, 2, 4, 6, 7, 9}
[7, 2, 0, 0, 9, 6, 6]
Read the lower part of the message
Just iterate over a with a single loop, there add value to set. If it's added first time, then keep it in the list. Otherwise remove it
Also i'd say adding to a new list instead of removing would be easier (and faster)
!e
def func(arr):
result = [x for x in arr if x % 2 == 0]
arr[:] = result
a = [1, 2, 3, 4, 5]
func(a)
print(a)
@solemn moss :white_check_mark: Your 3.11 eval job has completed with return code 0.
[2, 4]
I don't believe a single loop would actually solve this issue since a set automatically removes duplicate values but doesn't keep the order
I explained how to do it :/
for step in range(count):
result.add(a[step])
This would put the value in set result but not in indexed order
You did the first part: Just iterate over a with a single loop, there add value to set.
Now the second:
If it's added first time, then keep it in the list. Otherwise remove it
So a nested for loop to iterate over the size of a then?
You don't need a nested loop
You can check if element is in set with one if
!e
d = {1, 2, 3}
print(0 in d)
print(1 in d)
@solemn moss :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | False
002 | True
If I remove an element in the for loop it would change the size of Count
!e
value = [4, 0, 2, 9, 4, 7, 2, 0, 0, 9, 6, 6]
d = set()
for x in value:
if x not in d:
print(x, end=" ")
d.add(x)
@solemn moss :white_check_mark: Your 3.11 eval job has completed with return code 0.
4 0 2 9 7 6
Add it to another list
That's much easier
From the instruction it looks like I can only use a Set:

Actually it doesn't say that it's forbidden to use anything else
But ok, you can use a while instead of for
And if you delete an element just don't add 1 to current index
With a set I would do it like this
def remove_duplicates(A):
B = []
Bset = set()
for a in A:
if a not in Bset:
B.append(a)
Bset.add(a)
A[:] = B
Dictionaries keep the insert order (introduced in Python 3.7), so the following will work
def remove_duplicates(A):
A[:] = {a:0 for a in A}
Bset = set() ?
ops
ok fixed that typo
I don't know of an example in CPython where list(set(A)) doesn't maintain the insertion order.
A[:]=sorted(set(enumerate(A)))
Oh, no, it keeps indices
A[:]=map(operator.itemgetter(1),sorted(set(enumerate(A))))
I dont think that will remove duplicates
Yeah, im dumb
All that would be possibily be useful for is codegolf.
It runs in O(n^2), which kind of defeats the entire purpose of using set in the first place.
It is also possible to make use of collections.Counter
from collections import Counter
def remove_duplicates(A):
A[:] = Counter(A)
There is also
def remove_duplicates(A):
A[:] = dict.fromkeys(A)
which can be golfed to
def remove_duplicates(A):A[:]={}.fromkeys(A)
if you want to actually do the work in-place you can loop through and pack the results and then delete the excess
true
def remove_duplicates(A):
B = set()
for a in A:
if a not in B:
A[len(B)] = a
B.add(a)
while len(A) > len(B):
A.pop()
hi
#complexity O(n^2)
def smaller(arr):
n = []
for i in range(len(arr)):
total = 0
for h in range(i,len(arr)):
if arr[i] > arr[h]:
total+=1
n.append(total)
return n```
how can I make this code to works with large arrays
the problem is about
`that given an array arr, you have to return the amount of numbers that are smaller than arr[i] to the right.`
more information
https://discord.com/channels/267624335836053506/1149277716454051902I know of two types of approaches to solve this. Either use segment trees or use a slightly modified version of merge sort.
If you arent used to segment trees, then I think the merge sort approach is the easiest
The idea is that during merge sort, while doing the merging, you can keep track of how many "Inversion" that occur.
It is a little bit tricky to implement
Please, can someone explain linked list to me and using python code? I have a small difficulty understanding what self.head = None means and why we have it there.
A list where each element points to the next one in the list
I am not sure what to explain here
Let's say we have a Node class with attribute next that points to next object or to None if it's end
A linked list [a, b, c] would be like that then:
a, b, c - instances of class Node
a.next is b
b.next is c
c.next is None
what they wanted is
def remove_duplicates(l: list):
return list(set(l))
or rather simply
remove_duplicates = lambda l : list(set(l))
# (very bad, but this works)
ye id just type cast to and from set if idgaf about order
just realised that
the question says the order shouldn't be changed
alternatively you can filter ```py
a = filter(lambda x: a.count(x) < 2, a)
doing this off memory
does list have a count method?
oh i'm dumb
i removed all values that have duplicates lmao
ye just type cast to and from set then sort if you want quick and dirty answer
Sorting wont make the elements go back to their initial order
oh ok nvm i misread
initial order not sorted
_a = set(a)
a = list(filter(lambda x: x in _a, a))
but dictionaries feel like the most reasonable option
Wouldn't that just keep the whole a?
!e
a = [1, 1, 1, 2, 3, 4, 4]
_a = set(a)
a = list(filter(lambda x: x in _a, a))
print(a)
@solemn moss :white_check_mark: Your 3.11 eval job has completed with return code 0.
[1, 1, 1, 2, 3, 4, 4]
exactly
i'm dumb 🙈
and it asks you to do the work on the list in place
e.g. this
class Solution:
# The given root is the root of the Binary Tree
# Return the root of the generated BST
def binaryTreeToBST(self, root):
def inorder(root):
res=[]
if root:
res+=inorder(root.left)
res.append(root.data)
res+=inorder(root.right)
return res
c = inorder(root)
nums = sorted(c)
def bst(l,r):
if l>r:
return None
mid = (l+r)//2
node = Node(nums[mid])
node.left = bst(l,mid-1)
node.right = bst(mid+1,r)
return node
return bst(0,len(nums)-1)```
Why it's not working?one question, why most of programmers that solve codeforces problems use c++? there's a reason?
the code that in python would be timeError in c++ optimaze it or something?
i dont get it when you say is fast
Well it's not uncommon to get the "correct answer" but still timeout due to python being python
Task time is usually different for different langs
#complexity O(n^2)
def smaller(arr):
n = []
for i in range(len(arr)):
total = 0
for h in range(i,len(arr)):
if arr[i] > arr[h]:
total+=1
n.append(total)
return n```
in python yesterday i was solving this but its error due to complexityif i apply the same logic in c++ it would run good?
No, because your algorithm is still trash
Well copying bad time complexity code to c++ usually won't magically make it pass
someone one time told me, programmers dont use python in cp, due to python is too easy
there's something right in that?
cp programmers want to suffer?
How is "python is easy" related to problem solving? Algos are the same
EXACTLY!!
wow
first reasonable person i meet
but denball, you said c++ is faster, can you explain me that?
I guess python programmers can find better use of their time, instead of solving cp problems
It is just faster. Write same algo in cpp and python, cpp will be faster in most cases.
That is why time limit is usually different for different languages
Usually you get more time before timing out with python, though that's not enough in some cases
If thats not enough, it means you didn't find the optimal solution
Like I don't think I've ever passed a question with segment trees in python
That's literally not true
In python there is a big room for microoptimizations also
and if you wrote it in C++, you wouldn't have to worry about micro-optimizations in most cases
Think about it like C++ being like 100 times faster than Python.
And if you do micro-optimize C++, sometimes you squeeze out a pass even if you use a sub-optimal algorithm
how True is this?
It is a very rough estimate
now i remember, in cp they evaluate running time right?
Yes
so it would be a bad practice to apply py in cp
Codeforces does not have different time limits for python and c++
You may have the optimal time complexity algorithm, but still fail due to time out with py
yes
But it depends a lot on the problem
On most cp problems, the TL is not an issue
Then using Python is arguably better than c++
sorry what's tl?
def toNum(strNum):
numbers = {"0":0, "1":1,"2":2,"3":3,"4":4,"5":5,"6":6,"7":7,"8":8,"9":9}
negative = strNum[0] == "-"
print(negative)
numList = list(strNum)
if negative:
numList.pop(0)
completeNum = 0
while len(numList)>0:
amount = len(numList)
print(amount*10)
number = numbers[numList.pop(0)]
zeros_to_add = max(0, amount - len(str(number)))
if amount>1:
completeNum += number * 10**zeros_to_add
else:
completeNum += number
if negative:
completeNum = -completeNum
return completeNum```time limit
aight
answering my first question, why people use c++ instead of python in cp, even if they have to write the fastest code?
as others have mentioned, it's commonly used because you get raw speed for when you need it
a lot of the time you don't need raw speed, then python is perfectly fine
but the closer you get to pure number crunching the more C++ and similar languages win out
Well here are some questionable timestamps
- In a problem about finding the
nth fibonacci number (n <= 10^9), C++ passed in 16ms, python 0.2s - In a problem about finding the number of primes between
landr(l, r <= 10^15; r - l <= 10^6), C++ took 0.5s, while python took 6.4s (with all the horrible optimization code nonetheless)
C++ is a fairly nice programming language. Plus, it runs really fast. So most people doing cp just learn C++ and stick with it for everything.
C++ is nice until you look under the hood at the actual language mechanics 🥴
What is cp?
Python recursion also runs way worse than C++ recursion in my experience
competitive programming
Oh
python recursion is terrible
interesting
makes sense
when I did compete I switched between python and C++ depending on the task
Here is a list of common abbrevations
CP: competitive programming
AC: Accepted
WA: Wrong answer
TL: Time limit
TLE: Time limit exceeded
RTE: Run time error
Btw here is a great example of a codeforces problem that you really want to use C++ to solve https://codeforces.com/contest/1034/problem/A

Codeforces
The simplest solution takes like 900 ms / 1 s with C++. So if you use Python you need to come up with some other more advanced solution to get AC.
well, but we can say in python we can reach the same ms or similar, but doing an advanced solution
I'd say sometimes this is impossible
okay interesting
There is a limit. If c++ has the same advanced solution, your advanced solution in python won't be faster ofc
It's also easier to squeeze out more partial points with C++ jank when you can't think of the optimal solution
On codeforces I do not know of any problem not solvable in Python.
One problem in particular I recall being really hard to solve in Python is https://codeforces.com/contest/1292/problem/C
Codeforces
The author of that problem told me it was impossible to solve in Python. After a lot of optimization, I proved him wrong  .
.
Last from div1?
From div2 too i guess
I'm genuinely curious, how do you implement RMQs that are fast in py?
This is my Python implementation of RMQ
https://github.com/cheran-senthil/PyRival/blob/master/pyrival/data_structures/RangeQuery.py
Funny story, the standard c++ RMQ people use on codeforces is
https://github.com/kth-competitive-programming/kactl/blob/main/content/data-structures/RMQ.h
which is actually my Python implementation ported to C++.

GitHub
⚡ Competitive Programming Library. Contribute to cheran-senthil/PyRival development by creating an account on GitHub.
GitHub
KTH Algorithm Competition Template Library (... eller KTHs AC-tillverkande lapp) - kth-competitive-programming/kactl
sparse table?
Ye that is a sparse table.
RMQ = range minimum query
Which is typically done with a sparse table
But there are other ways to implement RMQ
For example you can use something called a "disjoint sparse table"
There are also optimized versions which take only O(n) time to precalc, while still taking O(1) per query
I've never bothered making one of those
How much rating do you have on cf? 
Codeforces
I havent competed for some time now.
The one with bit magic and maximum stacks? Or the scary one with log/2 blocks?
he is a grandmaster lmao
2400 i am scared
hey guys, thank you, you opened my eyes, and all my questions were aswered!
The method is called "Method of four russians". The idea is that if you create some kind of RMQ structure for a really small array, then the possible outcomes you can get is very limited.
The O(n) algorithm is the one with the log/2 blocks
So farach-colton & bender one? It's the scary one
https://web.stanford.edu/class/cs166/lectures/01/Small01.pdf This is a pretty nice presentation about it
!remind 21h benchmark FCB vs SmolSparse vs bottom-up segment tree for RMQ
Nah.
Sorry, you can only do that in #bot-commands!
Huh?
I'm not familiar with it being called farach-colton & bender.
For some reason everyone talks about LCA when I google it
LCA can easily be reduced to RMQ, ye
The standard way of doing LCA nowdays is to reduce it to RMQ
I'm not sure who the linear RMQ should be attributed to
Taking a closer look at M. Bender, M. Farach-Colton, it seems they did it for something they called +-1 RMQ, which is similar but not exactly the same thing as what I mean by linear RMQ
https://www.ics.uci.edu/~eppstein/261/BenFar-LCA-00.pdf I thought it was this
This is definitely LCA
there is also RMQ
ah ok
Thus, to solve a general RMQ problem,
one would convert it to an LCA problem and then back to a
+-1 RMQ problem
Yeah, afaik that's the algorithm
I haven't ever thought about it like that
I just think about it in terms of cartesian trees
Presentation you gave tells the same
Well anyways. One issue with the linear RMQ is that queries become slower
The main reason to use RMQ in the first place is to make queries as cheap as possible
So I'm not sure that linear RMQ is actually all that useful in practice
I am going to check
I honestly think bottom-up segment tree will crush the sparse table if amount of queries is about the length of the array
But it's just a wild guess
Sparse table are really fast for being O(n log n)
I think they will beat any kind of segment tree
We will see 😈
Another kind of RMQ that is the O(n log log n) precalc O(1) query RMQ.
It is basically just two layers of the standard RMQ
The way you construct it is that you create one RMQ of size O(n / log n) for the macro scale
and then O(n / log n) RMQs of size O(log n) for the micro scale
The log* layered RMQ takes O(n log* n) precalc and O(1) per query
If you then redo this starting with the log* layered RMQ, you can make an RMQ with O(n log** n) precalc and O(1 + 1) per query.
Then you can do it again to get O(n log *** n) precalc and O(1 + 1 + 1) per query
If do this procedure all the way down to log **...** n = 1, then you get a O(n) precalc O(inverse_ackermann(n)) query RMQ
Why O(1) query if there are log* layers?
There is a trick to it

Ye 
It would kinda be fun to implement the inverse ackermann RMQ just for heck of it
I'm guessing that in practice, having more than two layers is totally useless
Especially log* is probably completely useless
can anyone suggest the best python bootcamp with community support and all??

If I am looking for help finding an algorithm for a problem, is this the right place to ask for it?
what even is that?
The purpose is to draw a single line without intersecting itself that passes through each point. Each point has 2 numbers, which each represent the order the line passes thru it
The top set is successful, the bottom isn’t
is the question whether such a drawing can exist for that sequence?
Yes, the algorithm should be able to take the pairs as input and determine whether it’s possible or not
feels like it boils down to checking if a graph is planar
By hand it’s super simple, which makes me think there’s a fast way to do it
and pairs mean "these are the same point"?
As in, you can consistently get it first try with no guessing if it works
Yes, each point is crossed thru twice
I’ve looked a bit, and it would definitely work, but I’m looking to do many iterations so if there’s a shortcut I’ll try to find it first
The reason I think there’s a better algorithm is that there is always one and only one exact move to make in testing it by hand, and if at any point the move doesn’t work, then you know the whole thing doesn’t work
red dots to indicate direction

I think this one is valid?
err, I messed up the dot between 14 and 1
and 8 to 9
whatever
It has to cross through, not just touch
Ya my bad lol, I had a phone call in the middle of explaining it
hello friends is anyone able to help me with an assignment?\
mifght be the wrong chat for it but
i have a code of truth tables and i need to print the table function for p v r so rn i have one for printing p r and dont know how to modify it to make it p v r
ill Send in a sec
Please define a function printTableFunction2() to print the truth table for the expression p V r. Please format the truth table using formatting symbol %s

im stumped on making the second one for pvr
p or r?
yes
yes so one is for and & then i make one for or
so rn i made another printtablefunction cinda like 1 but i changed the conjunction to disjunction
but i dont think thats write
right
it should be disjunction but when i print iget the same table as the p and q
what's the actual task? constructing or from the other pieces?

got it!
my disjunction was wrong in the top making the same
appricate the help tho!
!e right, that was kinda my guess, sadly you never shared that part
def disjunction(a, b):
return a or b
for p in (True, False):
for q in (True, False):
print('%5s %5s %5s' % (p, q, disjunction(p, q)))
@haughty mountain :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | True True True
002 | True False True
003 | False True True
004 | False False False
yea thats on my new to this but appriciate you alot
gonna need this server for the semester like crazy
The first one I tried building some sort of tree where it contained the node and the frequency as well as any nodes that it was allowed to talk to and put all those nodes in a list and then remove nodes from the list when they were visited and try to find the longest string that way but it didnt work.
The second one I tried to brute force it and it didnt work for every single test case but Im not really sure how to go about doing it faster. The third one I tried making pairs of yknow choose one call or the other but that didnt work and I couldnt figure out how to make a whole bunch of options
These were by far the hardest interview questions Ive seen so some feedback would be appreciated
-
Remove edges that violate the constraint. In the resulting forest find the largest diameter of the trees.
-
Given the small k, feels like some not too hard dp problem. Probably something like "longest chain using exactly i switches up to point j"
-
That's a classic problem, weighted interval scheduling
-
what?
-
what?
-
okay thanks
for 1. I described the approach pretty clearly
for 2. I can't be bothered to find the proper dp formulation
for 1. any edge where the nodes differ by more than one can't be communicated over, removing those edges breaks up the tree in many smaller trees (many trees = forest), all the smaller trees have full communication internally
solve the problem for each smaller tree independently, which is just finding the diameter
pick the max
the terminology here is pretty basic graph stuff, if you don't know it you might want to read into it
for 2. it looks like a dynamic programming problem, do with that observation what you want
Sorry I got number one and number 2 confused.
the rest of 2 was just me guessing at the dp formulation
I guess I’m still missing something for number 1. I create a tree with every possible connection? Like a tree of depth n where it’s like 1 - 2, 1 - 3, 1 - 4 and then second layer under 2 do like 2 - 3 and 2 - 4 and then remove and link that is invalid and find the deepest tree? Is that the best method? Or I create every connection that exists but then how do I guarantee that no node is visited twice
you were given a tree
We’re given 2 arrays with from and to connections that I could convert into a tree
But that would be quite difficult as if there were any duplicates or any loops a lot of things would go wrong
But if you just remove duplicates how do u know ur removing the right one
no no no. The task clearly says that those edges will form a tree. There wont be any loops or duplicate edges
Okay
I am frustrated that all of these questions require reading every single word and understanding it perfectly. I’m sure that sounds silly but like bruh there’s so many words and so many of them don’t matter but then very few do
But that makes sense. Thank you
I think I would do much better now
I don’t fully understand how to optimize number 2. I understand the brute force solution but the optimized I’m not sure about
Maybe this video will help: https://www.youtube.com/watch?v=aPQY__2H3tE
In this video, we go over five steps that you can use as a framework to solve dynamic programming problems. You will see how these steps are applied to two specific dynamic programming problems: the longest increasing subsequence problem and optimal box stacking. The five steps in order are as follows:
- Visualize examples
- Find an appropria...
Okay I’ll watch it and get back
IMO, the problems are completely fine. I'm guessing you are just not used to solving these kind of problems.
The problems themselves are fine, albeit more difficult than average
But there are so many words and I just got confused on every single one
I also have my own opinions about coding interview questions but that’s a different thing
I would classify the difficulty of these problems as roughly beginner level.
The initial paragraphs on these can result in getting lost in the sauce. It's similar to reading long mathematical proofs where you forget where you even were / what you were trying to do. I read these out of order.
I did read these out of order but the test cases were
I think you are just unexperienced solving problems like these
At least for leetcode and code signal they make it very clear what’s up. I’ve never spent 45 mins trying to solve the wrong problem on code signal lol
Also this website has a big where you can print the test cases even the hidden ones there’s only 10 and still brute force it which is also silly but I think that would get flagged
I thought you maybe did them in person. The main purpose of these interview questions is to see three things. The first is that you can think through complicated stuff. The second is that you are willing to deal with hard stuff that you probably don't want to do, a required ability for any job. The third is that you willing to put in the effort to get the job when they gave you the keys, they told you what they needed from you.
It's not so much about it really coming up in the job itself.
Nah it was online. But the problem is that if you haven’t seen that kind of problem before then you’re sometimes out of luck. And if you have it’s super easy. And don’t get me wrong I have seen a lot of problems before it’s not a mad cuz bad thing but 🤷♀️
It was also in Java or C++ only so I wasn’t expecting that lol
Yeah, they expect you to study these problems, like a lot.
That is what they are testing, dedication / grind.
I'd say a big part of problem solving is recognizing familiar patterns
That’s so silly
Not really, this is pretty easy compared to the kind of things you need to deal with on the job.
And so unhelpful and is why we have under 2 years average tenure at faang
That’s the point of why it’s silly
Yup, and they want people that say "it's silly, but i'll do it."
But, I know this is a basic programming skill, for example if you’ve never seen a bit vector before and there’s some problem that requires a bit vector there’s very little chance of you just “thinking through a hard problem”
I’d rather they just use code signal lmao
Yeah, it's not a perfect signal, but they also have other interviews, such as for architecture, probably the most fun one.
What’s that?
If you’ve never seen weighted item scheduling there’s very little chance of at least for me “figuring it out” in 30 minutes
So
Welp they sent me another one for another job hopefully it’s the same questions
These 3 problems tests you on 3 things.
Problem 1. Do you know how to calculate the diamater of a tree
Problem 2. Do you know how to solve a basic DP problem
Problem 3. Do you know how to solve a classical scheduling problem
These problems do not test you on your ingenuity. They simply test your algorithmic knowledge of solving standard algorithmic problems.
Knowledge is key, they don't want to train you, they want to hire you. It would be hard to figure out that when x^2+1=0, x = +- i on the fly too, in fact thousands of years with multiple people involved.
A lot of employment is """just""" about knowing things.
But the difference is I can just google the algorithm or whatever
I can’t google how to put it all together
I wonder if chatgpt could solve any of these 
It couldn’t
Well
I only tried number 2
But I just copied and pasted the whole code it in and it didn’t work so I went back to trying to optimize brute force
Oh, it will "solve" them, confidently. 
You probably could ask chatgpt to calculate the diamater of a tree
Chatgpt definitely isn't missing confidence
A while back I asked it to list male swedish names ending with the letter a (as far as I know there is only one single swedish male name ending with a)
It made a long list of 20 swedish male names, none which ended with an a
It never says that it cannot do it
Yeah I get your frustration, but I think with a shift in mindset, grinding through them a bit won't be so bad and you will do fine on most of these tests, I think you will find them ok.
There are some cruel questions, but a lot of those have been removed over time.
Also really big companies, especially those trying to do a hiring freeze, will have some tough competition resulting in absurd questions for interviews now.
But they are not the normal.
If only they all used code signal and would take my perfect scores
Okay so I watched the video but I still don’t understand how to solve this specific problem.
Give me a sec
isn't diameter of a tree dp?
Try finding another, easier sub-sequence problem online, and try that first. A good strategy is to first solve the more simple version of the same problem. Then use that to inform you about the harder one.
Diameter of a tree is found doing 3 bfs or 3 dfs
Actually that is how DP itself works.
You start at an arbitrary node
Then get as far away from that node as possible
The node you land on is the first node in the diamater, lets call it u
Oh, problem 1. I thought 2.
I am pretty sure finding diameter of a tree is dp lol
You can do it with dp, but that definitely isn't the standard way / easiest way
I was talking about problem 2
No I am saying the idea of itself is dp
DP in the general applies to a ton of problems. Including those without an exact answer that can be checked.
DP as a programming method is often considered its own thing, probably what is meant here.
Can’t you do it with just 2 dfs? Find the deepest node then make that node the root then find the deepest node again?
Oh I meant 2, not 3
Where would I start with question 2 tho
def do_bfs(graph, start=0):
n = len(graph)
found = [0] * n
bfs = [start]
found[start] = 1
for u in bfs:
for v in graph[u]:
if not found[v]:
found[v] = 1
bfs.append(v)
return bfs
def find_diameter(graph):
u = do_bfs(graph)[-1]
v = do_bfs(graph, u)[-1]
return u,v
Here is how I would implement tree diameter
The five steps given in the video.
?? i mean for 1
2 dfs not 3 dfs
I earlier said 3 bfs or 3 dfs. I meant 2 bfs or 2 dfs
Oh
But it has the added element of the number of switches
O(n)
It is 2 bfs:s. Both take O(n) time each
that's the normal way to do tree diameter 🤔
Yes
BFS is DP, yeah.
BFS is definitely not DP.
Recursion has been renamed
If I would give any name to this, I would call it a greedy algorithm
It's a special case of Dijkstra's algorithm, which is DP.
The opposite of DP
But it’s not greedy is it?
Nooooo
class Solution {
public int diameterOfBinaryTree(TreeNode root) {
return diameterOfBinaryTreeHelper(root)[1];
}
public int[] diameterOfBinaryTreeHelper(TreeNode root) {
if(root == null)
return new int[] { 0, 0 };
int[] left = diameterOfBinaryTreeHelper(root.left);
int[] right = diameterOfBinaryTreeHelper(root.right);
int dia = Math.max(Math.max(left[1], right[1]), left[0] + right[0]);
return new int[]
{
Math.max(left[0], right[0]) + 1, dia
};
}
}``` bottom up dp @regal spokeWhat makes this “dynamic programming”
DP is much more general than you may think. It's just usually not referred to as such by programmers in this case.
But this algorithm isn’t even greedy
DP just means you're storing solved subproblems and reusing them
It is greedy. I just pick u and v without trying to optimize anything
That’s not what greedy means bruh
in the first step, you pick the node furthest away from the start, in the second step, you pick the node furthest away from the node in the first step
Greedy is an algorithm that sacrifices accuracy for speedy
????
what
greedy is just making locally optimal choices
💀
Not neccesarily?
Yes. But my implementation is not solving any subproblems
I see
I realize your solution isn't dp
your solution is wild tho
So can someone please tell me how to solve problem number 2 or give me some pointers about sub problems
It is, you just need to see it as a degenerate case of Dijkstra's with all equal weights (no weights). Then you make local choice that are the same (greedy).
The local optimal choice the tree diamater algorithm is doing is finding a node that is as far away from the starting node as possible. Then it does that one more time. So it arguably picks u and v greedily
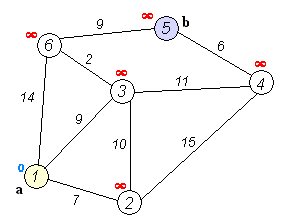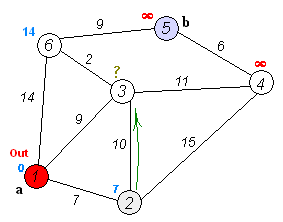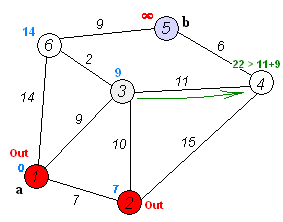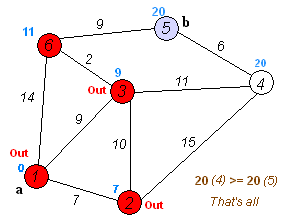
Dijkstra's algorithm ( DYKE-strəz) is an algorithm for finding the shortest paths between nodes in a weighted graph, which may represent, for example, road networks. It was conceived by computer scientist Edsger W. Dijkstra in 1956 and published three years later.The algorithm exists in many variants. Dijkstra's original algorithm found the sho...
that's the simplest way to do it
"Breadth-first search can be viewed as a special-case of Dijkstra's algorithm on unweighted graphs, where the priority queue degenerates into a FIFO queue. "
2 bfs?
Oh dijkstras is DP
💀
I have debated this with other programmers before, this was the conclusion we came to, but not exactly a big deal, it's whatever. DP is broad (it's a math thing).
I get the idea now
Its dp and greedy 🤔
Greedy because..?
locally minmaxing
I always took greedy to mean like search algorithms that might not get the optimal path always but will be faster
Okay I see
There can be overlap, yeah.
But dijkstras is guaranteed to always find the shortest path right
They are not disjoint concepts.
After filling the whole graph
it's the easiest to implement for sure
But usually when a programmer says greedy, they are also trying to get across the feel of the implementation too, it's more specific.
To solve problem 2, the subproblems you want to solve is:
DP[i, j] = maximum length of a subsequence of skills[:i] that "switch" at most j times
You could also use
DP[i, j] = maximum length of a subsequence of skills[:i] that "switch" exaclty j times
You have to compute DP[i,j] for all i <= n and j <= k. The trick is that to compute DP[i, j], you can use previously computed values
More of a "fun fact" than something that really matters.
Problem 2 on the other hand, is what most people would probably be familiar with when it comes to "DP."
How can I connect i - 1 to i tho? I would also have to store the previous value in the longest chain for each DP[i, j]?
Problem 1 I could have figured out with better reading comprehension
Maybe
You need more than just the i - 1 to i case
Lets say skills[i] = 15. Then to compute DP[i,j], you both need to consider i - 1 and also the index of the previous occurence of value 15 in skills
Greedy is also hard to prove when you're doing questions under time constraint 😭
So if i-1 = 15 you just take i- 1 for each j and add 1 to it
Right?
But if not then I’m not sure
yess
Exactly
Because you could take i - 1 and add 1 to it for each j + 1 but that’s not necessarily right
That would solve it if you couldn’t remove values
Aren't these from OAs
But since you can and then this is where I don’t know anymore
No
Are you even allowed to post this here lmao
@agile sundial isn't this banable?
on hackerrank it specifically says not to share the question lmao
Yeah
Since you posted the problems as an image, no one is going to be able to find these searching for them
So it isn't that big of a deal that you shared these
But I dont know what the rules are for this discord server
It’s not hackerank and they aren’t OAs if someone from hackerank is looking
It’s just uhh my own website that looks like hackerank
you did say they were from interviews
What do I do after this btw
Yeah but not from an active interview
I’m not trying to cheat just learn
If someone thinks it’s best if I delete the questions I will
Dijkstra is not DP since you arent solving a subproblem by solving smaller subproblems of the same kind.
It is though.
Now you're just lying 😹 I don't really care if you share it
It stores the values of all the previous nodes so when F is connected to G H and Q and distance from A - H is 12 and A - G is 10 etc
Lol sorry I didn’t make the sarcasm obvious enough
I said in the original post they’re from interviews
I wasn’t trying to hide it I didn’t think anything of it
I would say that dijkstra is a greedy algorithm. It finds the shortest path by repeatedly exploring the closest node to the starting node.
Than why'd you delete it 😹
The original pics?
Because now it seems like better to delete it after y’all brought it up
Just to be safe I guess?
Correct, all of the above: Class Search algorithm Greedy algorithm Dynamic programming From wikipedia.
wut?
What do u do if i- 1 != 15 tho
As wikipedia explains, even Dijkstra's explanation is a paraphrasing of DP.
Dijkstras uses previously computed data to solve the current problem that is what DP is right?
DP also sounds like a buzzword
More on it here if you prefer the references rather than wikipedia: http://matwbn.icm.edu.pl/ksiazki/cc/cc35/cc3536.pdf
No no. DP is specifically when you express the solution of a problem in terms of solutions to smaller versions of the same problem
Can someone just help me solve the problem 😭😭 I still don’t know what to do
So recursion?
It is generally viewed and presented as a greedy algorithm. In this
paper we attempt to change this perception by providing a dynamic
programming perspective on the algorithm. In particular, we are re-
minded that this famous algorithm is strongly inspired by Bellman’s
Principle of Optimality and that both conceptually and technically it
constitutes a dynamic programming successive approximation pro-
cedure par excellence. ``` From the abstract.Yes. DP and recursion are super closely related
But it's also greedy.
In the algorithm I don’t know how to spell, you solve the shortest distance A to X by solving the shortest distance to all of Xs branches. (Kinda)
Then you have a choice,
Either you use i-1 which means adding 1 more switch
Or you use i = index of last 15 occurence. That will not lead to adding any extra switch
Make DP[i, j] be the maximum of both of these
Recursion happens to show up when there are sub problems to solve, but it's a programming technique. A very useful one that makes many problems easier to think about.
Make DP[i, j] the maximum of DP[i - 1, j - 1] + 1 and DP[last15, j] + 1
Is that correct?
Pretty much, ye
Pretty much?
If 15 never appeared before
Yes gotchu
I would start by setting DP[0, j] = 0 for all j
So for every j it would be i- 1 except for j = 0 which would be 1 just counting the 15
yes
Okay
That was the original purpose actually, to be a confusing name (another fun fact from history). You are almost correct about using already computed results, but what matters is the relationship between them (sub problems form the solution together).
To be a confusing name because it’s not actually “dynamic” lol
Welp thank you all for your help. I think I could accurate solve these three problems now
I have another OA from the same company so hopefully hackerank doesn’t ban me for taking screenshots of the questions
Also what does OA stand for
Here is how I would code that problem 2 solution
# Default DP to 0
DP = defaultdict(int)
for i in range(1, n + 1):
lasti = i - 1
while lasti > 0 and skills[lasti - 1] != skills[i - 1]:
lasti -= 1
for j in range(k + 1):
# Calculate DP[i,]] using DP[i - 1, j] and DP[lasti, j]
Well surprise it’s actually in c++ or Java only but we didn’t tell you that
I would do basically the same in C++
I know I’m just messing
Damn you're goated at bottom up :orz:
@cunning bison can you share the questions again i wanna c
are these from snowflake?
So no corner case needed for i - 1 = i
i am preppin for snowflake
?
U told me that I shouldn’t share them so 🤷♀️🤷♀️
like my big bro @agile sundial
you're like 3 years older than me bro
Hmm thinking more about it, the solution is a bit more complicated than I initially thought
from collections import defaultdict
n, k = [int(x) for x in input().split()]
skills = [int(x) for x in input().split()]
# DP[i,j] = maximum length of a subsequence of skills[:i] that "switch" at most j times
DP = defaultdict(int)
# DP[i,j] = maximum length of a subsequence of skills[:i] that "switch" at most j times and ends with skills[i - 1]
DP2 = defaultdict(int)
for i in range(1, n + 1):
lasti = i - 1
while lasti > 0 and skills[lasti - 1] != skills[i - 1]:
lasti -= 1
for j in range(k + 1):
if j == 0:
# No switches allowed, so need to extended subsequence ending with lasti
DP2[i,j] = DP2[lasti, j] + 1
else:
# Two cases
DP2[i,j] = max(
# Add one more switch
DP[i - 1, j - 1] + 1,
# Extend subsequence ending with lasti
DP2[lasti, j] + 1
)
DP[i, j] = max(DP[i - 1, j], DP2[i, j])
print(DP[n, k])
`any advice on getting gud at iterative dp
You could trying doing this https://atcoder.jp/contests/dp/tasks

AtCoder
AtCoder is a programming contest site for anyone from beginners to experts. We hold weekly programming contests online.
damn
did you do all of em
ive done few questions they all make you do bottom up or it wont pass
😹
What is this a response to? Having difficulty finding the initial question.
We were talking about solving an interview DP task. I claimed it was easier to solve than it actually was
Nah, but recall doing a few of them
A lot of people have told me those problems are great practice problems
Ye. In general avoiding you need to avoid coding recursively in Python.
Initial question was deleted but it was essentially about finding the longset substring
The task was to find longest subsequence with <= k switches (where a switch means A[i] != A[i + 1] in the subsequence)
Anyone know how to see this graph
import matplotlib.pyplot as plt
import numpy as np
parallelizable_fraction = [0.4, 0.6, 0.8, 0.95]
processors = np.arange(1, 129)
speedup = []
for fraction in parallelizable_fraction:
speedup_fraction = 1 / ((1 - fraction) + (fraction / processors))
speedup.append(speedup_fraction)
plt.figure(figsize=(10, 6))
for i, fraction in enumerate(parallelizable_fraction):
plt.plot(processors, speedup[i], label=f'Parallelizable Fraction: {fraction * 100}%')
plt.title("Amdahl's Law: Speedup vs. Number of Processors")
plt.xlabel("Number of Processors")
plt.ylabel("Speedup")
plt.xlim(1, 128)
plt.ylim(0, 20)
plt.legend()
plt.grid()
plt.show()
What exactly are you asking about? If you run this script then a plot should show up
Assuming you have matplotlib and numpy installed
Yes how to see this plot visually
It should just pop right up
I'm guessing so
The plt.show() at the end should by default pop up a window with the graph.

Do u think the code above represents this
@opal oriole
It showed me this when i ran it
That looks like how I would expect it to look from reading the code
Why the 95% one has more of a higher gradient curve
Than the other one?
I thought it will be inbetween the 7.5-10 range
I'm guessing that the 95 % parallelization fraction means that you get a maximal speed up of 1 / 5 % = 20 times
oh ty pajenegod
For 80 % parallelization you get maximal speed up of 1 / 20 % = 5 times
So in the 95 % case, I think of it like 5 % of the calculations can only be done on 1 processor
The other 95 % can be parallelized
ohh i see ty very much
how would you even know what to google for?
yes you can look up stuff, but knowing how to analyze a problem and break apart a problem into pieces that you could look up is one of the harder parts
online assessment?
Hi guys, I have a doubt.
def insertAtBegin(self, data):
new_node = Node(data)
if self.head is None:
self.head = new_node
return
else:
new_node.next = self.head
self.head = new_node
Is return necessary here?
nope
Thank you
also self.head = new_node doesn't need to be in either branch, can be outside -- since it's done in either case
Yes, you're right
so:
def insertAtBegin(self, data):
new_node = Node(data)
if self.head is not None:
new_node.next = self.head
self.head = new_node
I didn't realize it. Thanks!
np
depending on how your nodes work -- if node.next can be None anyway, then you can shorten it even more
Yes, I agree
But in this case, new_node.next will be assigned a non-null value as long as new_node is not the last node.
In Python having no return is the same as return or return None. In a sense all functions in Python have return values, it is just that if the return value isn't specified, then it is None
@regal spoke :white_check_mark: Your 3.11 eval job has completed with return code 0.
None
Sometimes this behaviour can be a bit cryptic for someone reading the code. For example
def find_first(A, x):
for i in range(len(A)):
if A[i] == x:
return i
returns None if x is not in A.
In these kind of situtations I would advice to put a return None at the end if you intended to make use of the return value being None, even though it is technically completely unnecessary
def find_first(A, x):
for i in range(len(A)):
if A[i] == x:
return i
return None
Yes, got that.
Thank you
If so, then I believe that there is some advantage of doing that, right?
As I said, it is just for readability. It shows your intention of find_first being able to return None. However, the return None at the end doesn't actually do anything.
I'm getting some numbers one at a time and I want to get the max of all of them. I know I can create a list and append each number and use max() on that list once I'm done, or I can do something like max_val = float("-inf") and continuously compare each number to max_val as they come. Is one technique better than the other, or are they pretty much the same in the long run?
I dont think it matters. Do whatever is the most convinient for you.
All right, thanks!
I'm personally not a big fan of using float -inf
Btw just so you know, max supports a default value.
!e
print(max([], default=99))
@regal spoke :white_check_mark: Your 3.11 eval job has completed with return code 0.
99
The default value is returned if the iterable is empty
Cool, good to know.
I find the idea of needing infinity to get a max value a bit silly, but I was wondering if it was a really bad idea to store potentially a ton of numbers just to use the max function on them.
It is not like Python is particuarily fast to begin with
If you really care about performance, you shouldn't be using Python in the first place
Fair enough, but I figure I should always be the most efficient I can in any language.
You'll probably be fine as long as you don't do something that is super inefficient
@regal spoke
yo
Can you try a problem
It was from a practice section 🤔
I dont understand the math part of getting to the solution
Can you link?

This looks kinda trivial to me
n = int(input())
A = [int(x) for x in input().split()]
out = []
prefix_max = A[0] # Could default to -float('inf'), but A[0] works too
prefix_sum = 0
prefix_isum = 0
for i in range(n):
a = A[i]
prefix_max = max(a, prefix_max)
prefix_sum += a
prefix_isum += i * a
out.append(prefix_sum * (i + 1) - prefix_isum + (i + 1) * prefix_max)
print(*out)
Just keep track of the sum of the current prefix and the max of the current prefix
*shouldn't
ah
Bro aren't you usaco bronze, you're cracked
😹
I'm not sure where I would be on usaco scale, but I'm definitely not a beginner at compettive programming
whats your rating in cf?
Codeforces
I'm a big fan of python
It is fun to talk about python with people
Most CP people I know are just interested in C++
You do CP In python?
Yepp