#algos-and-data-structs
1 messages · Page 8 of 1
a lot of information right there if you can convert it in your head
ok i suppose my greatest obstacle at this point is having some modular way of doing this where i can easily tweak things whether i have edge weights, directed edges, etc
bc right now my representation of a graph, and breadth first search are all one and the same program
that's why I just use an adjacency list directly and modify stuff as needed
very easy to modify
making something fully general will likely end up either slower than needed, or quite complicated
ok well thank you for that input, it'll save me a bunch of time

really cool to watch execute
Hi so I just solved https://leetcode.com/problems/palindrome-linked-list/
class Solution:
def isPalindrome(self, head: Optional[ListNode]) -> bool:
def reverse(head):
prev = None
h = head
while h:
temp = h.next
h.next = prev
prev = h
h = temp
return prev
def find_mid(head):
slow = fast = head
while fast and fast.next:
slow = slow.next
fast = fast.next.next
return slow
if not head: return True
mid = find_mid(head)
rev = reverse(mid)
while head != mid:
if head.val != rev.val: return False
head = head.next
rev = rev.next
return True
for some reason the find_mid function was not returning mid and fixed it somehow when I looked at the solution put what they had only to realize it was the same logic. The code didn't change and I actually went to the LC problem where I learned to find the middle node to verify the code was right. It works now but I don't know why it wasn't. Anyone have any insight on this?

Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
can someone help me clean up this print statement? it works but output just looks awful
retstatement = "The distances between the source node " + str(sourcenode) + " and each other node is: "
retstatement2 = []
for x in distances_list:
retstatement2.append((("Node " + str(distances_list.index(x))),x))
use f strings; use a list comprehension when assigning to retstatement2; consider using more meaningful names if possible
that is one roundabout way of getting the index, which also fails of there are nodes with the same distance
nvm i'm working it out
i was erroneous trying to use methods within a function anyway.. 🤦♂️
what i could use help on is a print statement for every node other than a certain sourcenode
i'm trying things like if x == sourcenode: pass
or continue
not working
is there something like for all x except y in z
or like for x, not y in z
!e ignoring the source node thing for now
sourcenode = 2
distances_list = [4, 2, 0, 1, 3]
print(f'The distances between the source node {sourcenode} and each other node is')
print('\n'.join(f'Node {i}: {dist}' for i, dist in enumerate(distances_list)))
@haughty mountain :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | The distances between the source node 2 and each other node is
002 | Node 0: 4
003 | Node 1: 2
004 | Node 2: 0
005 | Node 3: 1
006 | Node 4: 3
tbh I wouldn't mind saying dist from 2 to 2 is 0, but you can just use an if statement
or an if in a comprehension
ok thank you
seriously?
!mute 959692740298436678 
:incoming_envelope: :ok_hand: applied mute to @fiery cosmos until <t:1661300894:f> (1 hour).
Could someone please explain to me what a XOR checksum is? These are the examples given to me
0^1^2^3^4^6 == 2
17^18^19^20^21^22^23^25^26^29 == 14
How can i make a game with python
XOR is exclusive or, which is a logic gate that returns true if each of the inputs are different, and false otherwise. applied to numbers, they are converted to binary, with true and false are interpreted as 1 and 0
as an example, 17^18:
0b10001 # 17
0b10010 # 18
notice that the only values that are different are the last two, so 17 XOR 18 becomes
0b00011
which is just 0b11, which is 3
XOR checksumming is just taking the XOR of a whole bunch of values sequentially
17^18^19^20 is just ((17^18)^19)^20, or, conveniently, (17^18)^(19^20)
what does head : Optional[ListNode] do ?
im trying to solve the same problem and for me it was just giving me an error

so i deleted it and my code works fine without it, im not sure what its needed for
but the website is still giving me errors

here is the code, it works fine for me , also its probably very rubbish the way i wrote it as im still somewhat of a beginner so yeah ```py
class Solution:
def isPalindrome(self, userLst) -> bool:
halfOfPal = []
finalBoolean = False
halfOfPal = userLst[:round(len(list(userLst)) / 2)]
halfOfPal.reverse()
if halfOfPal == userLst[round(len(list(userLst)) / 2):]:
finalBoolean = True
return finalBoolean
you're treating it as a python list, the input they give is not a python list but a linked list node
Do you guys recommed me anything to start studying algorithms and data structures? A book, video, course
Alright now I get it, thank you so much!
i just started doing leetcode right away, i did not even know python (ofc my Java knowledge transfers)
for my first 75 questions (Grind75) i look at answers a lot and try to memorize it.
see the pins in this channel
oh, alright then
didnt quite get that while reading the info about the problem, thanks for clearing it out 👍
also, what is Optional for ?

it means that head is either an instance of the ListNode class or its None
`from numpy import *
n=int(input("enter no. of elements"))
a=[0]*100
#b=input("enter array")
#a=b.split()
#NOTE: it will create error whle shifting array so we have to make array by traditional method
a=list(map(int,input("enter elements in array").split()))
print(a)
m=int(input("enter position where we have to input element"))
o=int(input("enter element which we have to insert"))
for i in range(len(a)+1,m-1):
a[i]=a[i-1]
a[m]=o
print(a)`
can some help me in appending list
at particular point
did anyone get it
use this to make your code look better while putting it in discord

and it makes ur code look cleaner
from numpy import *
n=int(input("enter no. of elements"))
a=[0]*100
#b=input("enter array")
#a=b.split()
#NOTE: it will create error whle shifting array so we have to make array by traditional method
a=list(map(int,input("enter elements in array").split()))
print(a)
m=int(input("enter position where we have to input element"))
o=int(input("enter element which we have to insert"))
for i in range(len(a)+1,m-1):
a[i]=a[i-1]
a[m]=o
print(a)
``` herefrom numpy import *
n=int(input("enter no. of elements"))
a=[0]*100
#b=input("enter array")
#a=b.split()
#NOTE: it will create error whle shifting array so we have to make array by traditional method
a=list(map(int,input("enter elements in array").split()))
print(a)
m=int(input("enter position where we have to input element"))
o=int(input("enter element which we have to insert"))
for i in range(len(a),m-1,-1):
a[i]=a[i-1]
a[m]=o
print(a)```'again i maded change accoring to what we do in c
to append an array at particular point
but showing error list out of range
showing error line 17
error list index out of range
and this is why writing a loop with negative step is terrible
len(a) is out of bounds
I'm assuming you mean
reversed(range(m, len(a)))
```which is so much easier to read and is less error proneactually i watched an C code it and there it is witten in negative step
but this is Python
you can write it with a negative step in python, it's just error prone and awkward
we should take advantage of constructs that allow us to write cleaner code
again it is showing list index out of range
I genuinely have to stop and think about what this means at the boundaries
range(len(a)-1, m-1, -1)
```with the reversed I don'toh yea i heard about leetcode, i should try
thanks
will it work
why do u want to study algo and data ? for job ?
nope, just to improve my problem solving skills i think, it might be good
i checked again showing list index out of range
if you see in line no. 5 i have set list range to 100
is 100 big enough?
also have you considered using the usual .insert(index, value) instead of all this mess?
yes it will work but i want to do it without function
just like they do it in c
!e tbh I don't like your hardcoded 100
def insert(a, index, value):
a.append(None)
for i in reversed(range(index+1, len(a))):
a[i] = a[i-1]
a[index] = value
a = []
a.insert(0, 'a')
a.insert(0, 'b')
a.insert(0, 'c')
a.insert(1, 'z')
print(a)
@haughty mountain :white_check_mark: Your 3.11 eval job has completed with return code 0.
['c', 'z', 'b', 'a']
actually i putted the line 3 on my code
bu tits steill telling index out of range
from numpy import *
n=int(input("enter no. of elements"))
a=[0]*100
#b=input("enter array")
#a=b.split()
#NOTE: it will create error whle shifting array so we have to make array by traditional method
a=list(map(int,input("enter elements in array").split()))[:n]
print(a)
m=int(input("enter position where we have to input element"))
o=int(input("enter element which we have to insert"))
for i in reversed(range(m+1,len(a))):
a[i]=a[i-1]
#a.insert(m,o)
print(a)```i did it in my code but still showing error
so...you're overwriting a
your line with 100 doesn't matter at all
a[:n] = list(map(...))
```would probably workin general do try to print key variables and see if they make sense
in this case if you had printed a after the input reading you would have seen it's clearly wrong
actually i have done it before u can see i am using [:n] at end
but still it is showing error
not error but list index out of range thas why i putted a=[]*100
actually i am sayin why it is showing error
it works in C
so it should work on list in python
you list is just another dynamic array
what you wrote is overwriting the 100 long list with something that is n long, what I told you before is different
!e compare
b = [1,2]
a = [0]*10
a = b[:2]
print(a)
a = [0]*10
a[:2] = b
print(a)
@haughty mountain :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | [1, 2]
002 | [1, 2, 0, 0, 0, 0, 0, 0, 0, 0]
in the first case (your case) you overwrite a
can anyone recommend a good book on data structs and algos?
check pins

i want to add a node attribute size for BST searching attribute, should I initialize that to 0 or None
going with 0 for now as it'll be an int that get's incremented
Let's say I have multiple for loops that insert data into a database like the example below:
`categoria = ('Associação Nacional', 'Federação Nacional', 'Organização Não-Governamental', 'Sociedade Beneficente', 'Fundação', 'União', 'Instituto', 'Entidade')
nome = ('do Meio Ambiente', 'do Voluntariado', 'da Saúde', 'da Boa Vontade', 'da Preservação da Natureza', 'do Idoso', 'da Informática', 'do Empreendedorismo', 'da Assistência Social')
areas_atuacao = ('Ambientalismo Conservação', 'Conservação de recursos naturais', 'Controle da poluição Proteção de animais', 'Tecnologias alternativas')
group_nome = []
for x in range (5):
nome_entidade = random.choice(categoria)+" "+random.choice(nome)
group_nome.append(nome_entidade)
group_atuacao = []
for x in range(5):
atuacao = random.choice(areas_atuacao)
group_atuacao.append(AreaAtuacao.objects.filter(nome=atuacao)[0])
group_cep = []
for x in range(5):
cep = randint(10000000, 99999999)
group_cep.append(cep)
for x in range(5):
entidade = Entidade(razao_social=group_nome[x],
cep=group_cep[x],
area_atuacao=group_atuacao[x],
entidade.save()`
My question: how can I reestructure the code in order to optimize it to use less ram in the process? I've tried but didn't work. Thanks in advance.
hey i need some help rewriting my BST classes to handle the parent attribute
idk if it'll work as is given that my tree_insert function takes the root as input
can you give __repr__ a custom call name
i'm stuck on how to implement a tree_insert function in my BST without tying every node to the parent
don't you just try to go into children until you encounter a None child?
totally untested, but feels like it should work
def tree_insert(root, value):
if value < root.value:
if root.left is None:
root.left = Node(value)
else:
tree_insert(root.left, value)
else:
if root.right is None:
root.right = Node(value)
else:
tree_insert(root.right, value)
Yeah I’m writing a method inside of a ‘BinaryTree’ class. I think walking away and doing other stuff it clicked in my head. I can just have a check if I’m adding to the root or not. Or make a different method for adding a node to the root or to a non root node? Idk it feels like that way might ruin traversals or recursive calls
Is this for use inside of a Class?
def insert(self, value):
new_node = Node(value)
if self.root is None:
self.root = new_node
return True
temp = self.root
while (True):
if new_node == temp.value: return False
if new_node.value < temp.value:
if temp.left is None:
temp.left = new_node
return True
else:
temp = temp.left
else:
if temp.right is None:
temp.right = new_node
return True
else:
temp = temp.right
What would you have to do to get a single input to be times or divided by a set number ?
root being none is annoying edge case yeah
I wrote it as a standalone thing, though the difference is pretty minimal
Does anyone have a suggestion (approach or module) for calculating time until impact (if any) between two 2D rectangles, travelling in arbitrary directions?
I feel like in a static picture, detecting a collision isn't too bad. Also finding intersection of two vectors isn't horrible. But having no clear point of intersection what with all the corners makes me confuzzled
The root = None case cannot occur as the tree class has no instance until it’s called and passed a value for root
so an empty tree is invalid?
what I would probably do in practice is to have classes BST and BSTNode
and let BST deal with this edge case
i.e. most of the logic is in the nodes
the other class just does some cases and delegates the work to the nodes
so like this, though again totally untested
class BSTNode:
def __init__(self, value):
self.value = value
self.left = None
self.right = None
def insert(self, value):
if value < self.value:
if self.left is None:
self.left = BSTNode(value)
else:
self.left.insert(value)
else:
if self.right is None:
self.right = BSTNode(value)
else:
self.right.insert(value)
class BST:
def __init__(self):
self.root = None
def insert(self, value):
if self.root is None:
self.root = BSTNode(value)
else:
self.root.insert(value)
this does matter even more if you start supporting removals where you could easily go from a non-empty BST to an empty one
I hope someone can lend me a hand understanding this:
Given this function:
def topKFrequent(nums: [int], k: int) -> [int]:
count = {}
freq = [[] for i in range(len(nums) + 1)]
for n in nums:
count[n] = 1 + count.get(n, 0)
for n, c in count.items():
freq[c].append(n)
res = []
for i in range(len(freq) - 1, 0, -1):
for n in freq[i]:
res.append(n)
if len(res) == k:
return res
The result for topKFrequent([3,0,1,0], 1) will be [3]
BUT, if you change
freq = [[] for i in range(len(nums) + 1)]
to
[[]] * (len(nums) + 1)
The results is [0]
Even tho:
[[] for i in range(len(nums) + 1)] == [[]] * (len(nums) + 1)```
Any clues on why this is happening? I'm really curiousMy silly guess is that
[[]] * (len(nums) + 1)
Uses the same object
@haughty mountain :white_check_mark: Your 3.11 eval job has completed with return code 0.
[[42], [42], [42], [42], [42], [42], [42], [42], [42], [42]]
sometimes it's hard getting used to this little tricks that have their downsides lol, thanks!
it's actually the same for other types, you just don't notice it
e.g. [1234]*n is the same 1234 n times
but you can't mutate ints, so you don't notice
hey something about my BFS print statement is wrong, i don't have certain nodes in the print and it's just duplicating the outputs for certain nodes and changing them
#BFS
from collections import deque
import math
vertices = [0,1,2,3,4,5,6,7]
neighbors = [[1,4],[0,5],[3,5,6],[2,6,7],[0],[1,2,6],[2,3,5,7],[3,6]]
predecessors = []
distances = []
colors = []
def BFS(vertices_list,neighbors_list,predecessors_list,distances_list,colors_list,sourcenode):
for vertex in vertices_list:
colors.append('white')
distances.append(math.inf)
predecessors.append(None)
colors[sourcenode] = 'grey'
distances[sourcenode] = 0
predecessors[sourcenode] = None
q = deque()
q.append(sourcenode)
while q:
u = q.popleft()
for v in neighbors[u]:
if colors[v] == 'white':
colors[v] = 'grey'
distances[v] = distances[u]+1
predecessors[v] = u
q.append(v)
colors[u] = 'black'
for x in distances_list:
print('The distance between the source node ' + str(sourcenode) + ' and node ' + str(x) + ': ' + str(distances_list.index(x)))
i = BFS(vertices,neighbors,predecessors,distances,colors,0)
def traversedAll(colors):
return all([color != "white" for color in colors])
print(traversedAll(colors))
well right off the bat i think i want for x in vertices_list instead
so made that change
I recommend not accessing globals inside a function.
lol, nice O(n²) print loop
which as I noted earlier is also wrong if you have duplicate distances
use enumerate
use enumerate with for x in distances_list or for x in vertices list
whatever is currently trying to use .index to reconstruct the index
ok
Enumerate gives you both the value and the index which is what you are trying to print. Finding the index again from value is slow and has some issues with duplicates. It gives the index of the first occurrence.
@haughty mountain what about range(a, b)[::-1]?
!e
print(range(3, 8)[::-1])
print(range(100)[::-1])
@austere sparrow :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | range(7, 2, -1)
002 | range(99, -1, -1)


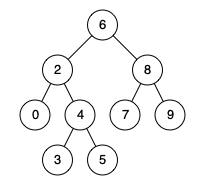
For the question lowest common ancestor, what would be the lca for p and q in this tree if p and q are 7 and 9?
Here's the definition for lca: The lowest common ancestor is defined between two nodes p and q as the lowest node in T that has both p and q as descendants (where we allow a node to be a descendant of itself).”
https://assets.leetcode.com/uploads/2018/12/14/binarysearchtree_improved.png
My answer is 6 but someone said it's 8. Wanted to understand why.
a good option to reversed
The reason is that 6 is an ancestor, but it's not the lowest one - 8 is the parent of fewer nodes, so that's more useful. 6 is the ancestor of every node in this tree.
hey so i am trying to implement the rrt star algorithm
so im trying to figure out an algorithm that detects if a line joining two nodes crosses an obstacle or not
any ideas to help me out here

basically i just want to understand what this code here does
or come up with another solution
start and end are basically the initial are final nodes(points), o are the coordinates of of start node and d is the direction vector from start to end, a are the coordinated of a vertex of an obstacle(rectangle) and b is the vertex adjacent to a
hi, i have a dataframe, with an multiindex, (level 0 is a date, level 1 is a range) the columns are then the name of the stock, price, volume etc for that date. i would like to have a mulitindex for the columns, where the name is level 0 and level 1 then the price, volume etc., the index should be the date. How can i do that? not every stock appears for every date
are you familiar with linear algebra? it's just a projection afaict
let me find an image I posted

project -a onto r and normalize
i am having a school question of python
can any tell me how to do??
|| like see im new to it and dont know the proper codes and wordings ||
then you get a value between 0 and 1 if the point is on the line segment
in context
sure, send the problem
how is that
also should i make my tree inorderprint method part of my Node class or BinaryTree class
the latter
hmm i feel like i need to work parent assignments into my bst nodes
umm no im not familiar with linear algebra
can you elaborate or point me to a good source to read on this
whats the use of t1 and t2?
like whats the point of projecting and then normalizing
which one do i read for projections
idk i don't know linear algebra
but if you want to learn math, khan academy is a good place to start
ahh ok
something about my tree_delete call is breaking my tree_minimum function
def transplant(T,u,v):
if u.parent == None:
T.root = v
elif u == u.parent.left:
u.parent.left = v
else:
u.parent.right = v
if v != None:
v.parent = u.parent
def tree_delete (T,z):
if z.left == None:
transplant(T,z,z.right)
elif z.right == None:
transplant(T,z,z.left)
else:
y = tree_minimum(z.right)
if y.parent != z:
transplant(T,y,y.right)
y.right = z.right
y.right.parent = y
transplant(T,z,y)
y.left = z.left
y.left.parent = y
when i comment out my tree_delete(tree,Node(90)) call everything runs fine
when its left in I get:
Exception has occurred: AttributeError 'NoneType' object has no attribute 'left'
during the while line here:
def tree_minimum(x):
while x.left != None:
x = x.left
return x
full code:
https://pastebin.com/iVUyTchy
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
i'd like to get this working as class begins next week and 2-3-4 and red black trees are topics explicitly mentioned in the syllabus
i realize that the recommended approaches to binary trees mentioned in this sub will differ substantially, but i'm trying to stick with the CLRS approach
is there a "not equivalent to" operator in python, like == but the opposite?
!= in my mind is like, only if it is precisely not equal to but doesn't check the equivalence unless i'm misunderstanding
oh nvm
a != b is (should be, at least) equivalent to not a == b
right i just checked the documentation
i guess it's worth mentioning that is not and != are not equivalent statements
still can't figure out why tree_delete function is breaking my tree_minimum function
def tree_minimum(x):
print("tree_minimum_input:", x)
while x.left != None:
x = x.left
return x
tree.root is None.
tree.root cannot be none, it's assigned a value for root when instantiated
def tree_delete (T,z):
if z.left == None:
transplant(T,z,z.right)
elif z.right == None:
transplant(T,z,z.left)
else:
y = tree_minimum(z.right)
if y.parent != z:
transplant(T,y,y.right)
y.right = z.right
y.right.parent = y
transplant(T,z,y)
y.left = z.left
y.left.parent = y
tree_delete(tree,Node(90))
Let's see what happens.
So it enters tree_delete, and z is a Node with key = 90 and None for parent, left, and right.
So the first if-statement passes.
So it transplants(T, z, z.right). Z is the Node(90) and z.right is None.
ah crap
def transplant(T,u,v):
if u.parent == None:
T.root = v
elif u == u.parent.left:
u.parent.left = v
else:
u.parent.right = v
if v != None:
v.parent = u.parent
this is all due to passing an argument in the form of Node(90) syntax?
Since u is the Node(90) and its parent is None the first if-statement passes.
So T.root = v, which is None.
Yes, you don't delete a Node like that.
That makes a new Node that is not even in the tree.
i think you missed my pastebin
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
I read it.
o
tree = BinaryTree(Node(7))
This first makes a new Node(7) which is not in any tree.
Then inside the __init__ method of BinaryTree, it makes the given node part of itself.
oh, this function name seems to be absolute bs, I found the code on github and it's really checking the intersection between a ray and a line segment
and they changed the names to be worse

and start and stop are not needed arguments, start == o, and end == o+d
@opal oriole my tree insert function is working, at least insofar as i can do an inorder print and it'll return all the nodes ive added in the proper order
the tree object is nothing but assigning the root as a Node class and giving it it's initial valie
The tree insert makes the given node part of the tree.
There are two ways to find / delete things. By value and by reference.
By value in this case would be searching through the tree until you find the Node with the given value and then delete that Node (by reference now).
By reference requires that you have a reference to a Node in the tree to be deleted.
Unlike insert, you can't just give it a Node that does not belong to the tree.
Because your delete function deletes by reference.
It expects to be given a reference to a Node in the tree.
i think the key and value here are the same, with no index / reference
So if you had a find function that searches for a key and returned a Node with the given key in the tree, you could pass that given Node to the delete function.
Because that Node is part of the tree.
The find returned a reference to it.
>>> class Node:
... def __init__(self):
... self.x = 0
...
>>> a = Node()
>>> a
<__main__.Node object at 0x7fe6109fbd60>
>>> a.x = 10
>>> a.x
10
>>> b = a
>>> b
<__main__.Node object at 0x7fe6109fbd60>
>>> b.x = 20
>>> b.x
20
>>> a.x
20
>>>
Here a is a reference to a newly created Node.
Via that reference I can change the x inside the Node.
Now b is a copy of a, so it's the same reference to the same Node.
(A copy of the reference)
So when I modify b's x, it modifies the same Node as before.
You delete function works by deleting a Node in the tree by reference z. So as long as you pass it a reference to a Node in the tree, it will do what you think it does.
ok ok thank you.
is there a way to rewrite so that I'm not passing in things like function(tree, Node(x))

You pass it Nodes but you need to make sure they come from the tree. If you are trying to delete the Node with key x, you want a function that finds the Node in the tree with key x and returns that reference.

Here find returns the Node(111) that is in the tree. Which a is now a reference to. So I can delete it from the tree by passing in a to be deleted.
If you want to prevent errors you can add an assert to your delete that checks if the Node's parent, left and right are all None (not part of any tree).
i have a working iterative_tree_search, but that just returns the node value i search for if it's present in the tree, None if it is not
Yeah, instead you can have one that returns the Node itself, rather than if it exists only.
Also if it tells you whether a key exists or not in the tree it should probably return a boolean (True/False).
You can however do 2 birds with 1 stone here.
If it finds the Node return it (which is a reference), and if not, then return None.
Now it can be used to check if a key exists, but also can be used for other things, such as deleting the Node you searched for.
(None is a reference to nothing)
i think having the nodes as classes is confusing. i'm trying stuff like return tree.Node.key = somevalue but its of course not working
but idk why
Returning from what?
def iterative_tree_search(x,k):
while x != None and k != x.key:
if k < x.key:
x = x.left
else:
x = x.right
return x
Your tree search seems to already return a reference to the Node with the given key value.
But what if k is not in the tree?
I think your __repr__ might be confusing you.
Your tree search is returning a Node, not a key.
this
It's just that when you print it, it looks like it.
def __repr__(self):
return f"Node({self.key})"
def iterative_tree_search(x,k):
while x != None and k != x.key:
if k < x.key:
x = x.left
else:
x = x.right
if x:
return x
else:
return f'{k} not in tree'
Your tree search was fine.
If k is not in the tree it will return None.
a = iterative_tree_search(tree.root, 90)
tree_delete(tree, a)
``` You can use it like this.(Have tree_delete check if the given Node is None)
i think what i'm not grasping is why some of their code works out of the box like just a literal translation of the pseudocode into python, and other code doesn't work at all or breaks something. and i suspect it is to do with my class representation of node and binarytree
I don't have that pseudocode so I can't say.
i don't understand why this fixes things
@tacit narwhal Idk how helpful this is since it's just some linear algebra that you might not be familiar with. This doesn't do the same derivation for t_1 and I genuinely don't know what they do in their if statement, it shouldn't be needed.

I do get the same thing for t_2, which is nice
Actually, maybe if I do a version with a cross product I get a nice expression for t_1 
tree_search gives a Node in the tree, then that Node gets deleted from the tree.
wait, I'm dumb with the last check, it should be dot product between d and (A+v_2 t_2) - O and not cross product
and I guess the perpendicular vector part is just "do a cross product with the z unit vector"
err, it's something I guess

is it possible to write the tree search and node return directly into the tree delete function
this shouldn't be that hard, but I'm struggling:
I have a pandas df which is a long list of miliseconds since the sensor start, and the sensor value.
Every time the sensor is restarted, the milisecond count resets; I can get the index at which one such 'reset' happens when the time interval is bigger than 100 miliseconds:
reset_index = ip_press['deltaT'].diff().abs().gt(100)
I get a list of indices, and to it I append the 0 and last value in the data file.
array([ 2526, 2527, 4889, 4890, 5461, 5462, 11519, 11520, 11592,
11593, 0, 82182], dtype=int64)
My question:
How can I find the largest interval, and drop everything else? In my example list above, it would be "11593-82182" that I would want to select, and drop everything before/after
what does "largest interval" even mean here?
the biggest difference between indexes
Isn't the largest interval 0-82182
what?
each time I get a new index on that array, it means a 'reset' happened, so it's the span between indexes that matters
shouldn't the 0 be at the front and something like the largest index on the back?
if so the adjacent difference stuff makes sense
so if I do rows.sort() (so the 0 is first, and the 82182 is last, I get:
array([ 0, 2526, 2527, 4889, 4890, 5461, 5462, 11519, 11520,
11592, 11593, 82182]
and this:
np.diff(rows)
array([ 2526, 1, 2362, 1, 571, 1, 6057, 1, 72,
1, 70589], dtype=int64)
i.e.
[0, 2526, 2527, 4889, 4890, 5461, 5462, 11519, 11520, 11592, 11593, 82182]
so the last 'interval' is the largest (70589).
and then max adjacent difference on that
right, then the array you wrote earlier was wrong then, it makes sense if you add 0 at the front
do you just want the value of the biggest gap or do you also want the index?
yeah, so now I have an array that tells me the last 'chunk' is the largest (note, this is not always the case, there could be small resets after)
Now I want to go back to the original dataframe and keep just that 'chunk' of data, ie, drop the other chunks, that are smaller
I want the 'start' and 'stop' indexes that mark the biggest gap
(trivial when looking at the data, but not sure how to code it)
let's see how many mistakes I'll make in this code...
!e in plain python
A = [0, 2526, 2527, 4889, 4890, 5461, 5462, 11519, 11520, 11592, 11593, 82182]
max_index = max(range(len(A)-1), key=lambda i: A[i+1] - A[i])
print(f'biggest interval is between {A[max_index]} and {A[max_index+1]}')
@haughty mountain :white_check_mark: Your 3.11 eval job has completed with return code 0.
biggest interval is between 11593 and 82182
oh hey
it actually worked
I think you could probably do something similar with numpy, I vaguely recall numpy having an argmax function that does basically what my max statement does
or just just write is with the call to max, you probably don't need numpy for the sake of speed here
deifnitely not - these arrays would have 5-15 values max
cool, so what I do is just look at all indices where a pair can start (so skip the last value), and then calculate the difference in the key function
tree_delete(tree, iterative_tree_search(tree.root, 90))
this will give you the smaller index of the pair you want
so max_index = start, and max_index+1 = end?
in my example A[max_index] is the start index in your original array
and A[max_index+1] would be the end yeah
spot on, thanks!!
def tree_delete_key(tree, key):
tree_delete(tree, iterative_tree_search(tree.root, key))
``` Function composition.I feel like these functions should probably go into the class
the tree class or node class? there were reasons i kept getting away from that although i couldn't tell you exactly why. probably so i could write them as written from the book
tree class
i'm a bit annoyed at myself i don't understand this better and don't yet have a working red black tree
recursive stuff might fit in the nodes
but those functions would probably be called by functions in the tree class
alright i can move the non recursive functions into methods in my tree class and the recursive functions into methods in a node class
Put all methods in the tree class.
Node is a big maybe for methods. Recursive or not.
Often better to leave nodes as plain data packages to be manipulated from the tree.
Otherwise your logic is scattered across two classes.
I think it's fine for nodes to deal with traversal if you do it recursively
but it's probably a matter of taste
I see the tree class as more of a convenient wrapper around the node class
Not exactly, the more scattered your logic is the worse for larger projects.
Because readers need to jump around more.
And yeah the Tree is a wrapper around what is a chain of nodes (with branches).
it's not so much duplicated code, tree might do some edge case check and then it can delegate the work
e.g. in insert the tree class can handle the case of an empty tree
bit the rest of the logic is natural for nodes to deal with
something about putting the methods inside the tree class kept screwing me up. i think it was a matter of self arguments and the root kept getting tied in every call somehow
im going to try to convert it now
(in reality the nodes are the real trees and subtrees)
so every method inside a function gets is self parameter, but they don't necessary have to assign any argument as self.arg?
(the tree class is just for the sake of dressing it up nicely)
i found having the tree class was easiest for declaring a root node
A node being able to go around the tree and see other nodes and modify itself based on that is not a great POV for architecture in software. You want a singular centralized "system" that is responsible for all the parts (in this case the nodes). The reason for this I don't really want to get into. It's whatever right now, this is not an actual project.
it's not a node going around though
quite right
it's a node (root of a tree) delegating work to the correct subtree
and the whole problem is self-symmetric
It's whatever, in this case a Tree is also just a node anyhow. It's just the name.
name + edge case handling
You can delegate work to a sub-tree, but not a single "node". Just name stuff.
nodes are (roots of) subtrees though
Yes, but in name they are not, they are just nodes. This comes from nodes actually being trees (sometimes).
having the recursive logic in the tree class doesn't really make sense
unless you want to wrap nodes in a new tree over and over to just call the recursive function
Yeah there is no good naming here.
This comes from us wanting two different names for nodes and trees, but the computer wants both of them combined into one struct (the actual node, plus some pointers for the structure).
The structure is not centralized.
?
this is my mental model with Tree as a thin wrapper
class Tree:
def max(self):
return self.root.max()
def insert(self, value):
if self.root is None:
self.root = Node(value)
else:
self.root.insert(value)
class Node:
...
def max(self):
if self.right is None:
return self.value
return self.right.max()
def insert(self, value):
...
maybe it just delegates, maybe it does some check and then delegates
Yeah, Tree in that case is basically an alias.
but yeah, I think the only real reason for the wrapper class is because empty trees are annoying
Yeah and that case.
So the name gives intent, but in actual structure they are the same thing.
Unless one starts not using pointers to nodes with pointers, but a flat array.
The structure in that case is centralized.
(Which is also why it's the better way (one reason why))
right, if I had a flat array I would write it slightly differently
i'm instantiating the tree this way, anything wrong with this:
class BinaryTree:
def __init__(self, root):
self.root = Node(root)
personally I would set it to None
sry thats not my instanciation call with a var = BinaryTree but that's how it's defined rather
it's key will be set to None by default
the key of Node
the base state in my head is an empty tree
wait
nvm
wait no that cannot work, then I'm setting my new node to have key = None
If you want empty binary trees, you set root to None by default.
there is no root in an empty tree, hence the None
and yes. things like insert will have to deal with root being None, like in my example code earlier
Since this is Python you can also have root be an argument passed to init but can make it optional by assigning a default value of None.
can you tell me the diff between your code and this:
class BinaryTree:
def __init__(self, root):
self.root = root
When you make BInaryTree you have to give it a root value.
what type is the argument root supposed to be there?
a node of a given key value
you could have
class BinaryTree:
def __init__(self, root: Optional[Node] = None):
self.root = root
and it would make some sense
you can either give a root node or don't pass it to get an empty tree
though the more generally useful constructor is probably one that takes a list of values and creates a tree from it, but that's probably more complicated than what you want to deal with
(you can sort the keys and the keep picking the median as the subtree root, then you get a balanced binary tree)
yeah i just want to know the basics, so you can assign any attribute you want with the self. prefix, and the class doesn't need explicit assignments passed in for every attribute on instantation?
python classes are very dynamic, for better or worse
in other languages you would need to define the members
ok ok so i have moved all of my functions into methods inside my BinaryTree class, so now i need to give them all the self argument correct
also haven't settled on what to put for my BinaryTree __init__ method
right, self will be the relevant instance of the class
gonna use this
Previously your "self" argument was "T", the tree.
So your methods only need a simple renaming of T to self.
just don't try to insert sorted data into your BST, it will go badly 😄
complexity-wise
so if i have a method inside a class, and it looks like def mymethod(self) and then i have def mymethod(self, x) how many arguments does each take
it looks like 1 and 2 but i thought self was a required positional parameter
1 and 2
or maybe thats only for __init__???
0 and 1 if you call it through the class instance
self is a required argument, but it's still an argument.
yes, if you call it through a class the first argument is already populated
Normal function: foo(tree, z), method: tree.foo(z).
ok ok
e.g. 'asd'.find('s') vs str.find('asd', 's')
Python will make blah the self or first argument when you do the blah.foo form.
>>> ''.join()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: str.join() takes exactly one argument (0 given)
``` according to this example with builtins, 0 arguments for the first and 1 argument for the secondsame function, different ways to call it
can you give example
def transplant(T,u,v):
if u.parent == None:
T.root = v
elif u == u.parent.left:
u.parent.left = v
else:
u.parent.right = v
if v != None:
v.parent = u.parent
def transplant(self,u,v):
if u.parent == None:
self.root = v
elif u == u.parent.left:
u.parent.left = v
else:
u.parent.right = v
if v != None:
v.parent = u.parent
wait, are you telling me builtins are weird and don't behave like regular classes would?
actually for a user-defined object this feels more like self is an argument ```py
class A:
... def mymethod(self, x): pass
...
A().mymethod()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: A.mymethod() missing 1 required positional argument: 'x'
i also want to have uniform input parameters, eg i think right now some calls take like mytree = BinaryTree(7) and others are like mytree = BinaryTree.search(Node(7))
use is/is not when comparing with singletons
It does not make sense for search to take a Node, it should take 7 directly.
(The key type)
!e
class A:
def f(self, x):
pass
a = A()
a.f()
@haughty mountain :x: Your 3.11 eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 5, in <module>
003 | TypeError: A.f() missing 1 required positional argument: 'x'
!e
class A:
def f(self, x):
pass
a = A()
A.f(a)
@haughty mountain :x: Your 3.11 eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 5, in <module>
003 | TypeError: A.f() missing 1 required positional argument: 'x'
pls don't read that definitively i was just saying there are some methods that take (Node(int)) args as input and others that take (int) as the argument
You can try have it be uniform as possible, but there are cases in which you want it to take a Node.
But generally prefer plain values over references unless needed.
If they have a reference to a Node from prior that they want to delete.
Two kinds of deletion, searching and non-searching (already happened before or they have the reference from construction).
Yeah, probably not, it would be for optimization purposes.
Which is why prefer value over reference by default unless needed.
I think the only useful thing the user could do it maybe read the key, in which case we can just return the key
exposing Node to the user will only allow them to violate the class invariant
Because references break encapsulation (but are sometimes needed for making things fast (premature optimization is not a good idea -> values > references)).
especially so in a language where you can't just return a const T&
which is safer wrt invariants
Yeah Python does not help at all with this, it's also definitely not Rust or even better Pony (no strong reference / ownership protections).
hi i need help for binary search tree deletion , i have been struggle for days. i understand the concept but i don't understand the codes i saw online. for example 450 in leetcode .
Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
i got confuse the output and parameter "root" stands for, it's just a single node or it's entire tree? as example the output is showing a whole list .
hmm my inordertreewalk isn't working

how could it even get to that line if it weren't defined
because python is like that
you're missing a self.
python will not try to resolve that before running the thing
def InorderTreeWalk(self,x):
if x == None:
return 'empty tree'
else:
self.InorderTreeWalk(x.left)
print(x.key)
self.InorderTreeWalk(x.right)
look good?
what about the print statement
because who knows, maybe someone would have defined a function like that when that is actually being run
ok its working now
this is one of the things I don't like about python
it's too dynamic for its own best at times
stuff that would have been detected at compile time in other langs isn't caught until runtime
im trying to test every method that just got wrapped in the bintree class, i know some aren't going to work
so far tree insert and inorder walk are working
though this is the case where I would put the function in the Node
do i need a self. to invoke methods ?
like im trying to use this method transplant and it's saying it's not defined
e.g. I would structure things like this, the node calls recursively into other nodes
class Tree:
def InorderTreeWalk(self):
if self.root is not None:
self.root.InorderTreeWalk()
class Node:
def InorderTreeWalk(self):
if self.left is not None:
self.left.InorderTreeWalk()
print(self.key)
if self.left is not None:
self.right.InorderTreeWalk()
methods of the class, yes
alright i'll be back later, thank you
i'd love to do this but im worried that if i get too far from the book's syntax i'll break things
i'd have to rewrite every method
this is what i have so far:
eh its too long
if you end up having methods that are not using self, then probably keep them as regular functions
i'll be back later / tomorrow, tysm.
h

Stack Overflow
I'm a Kivy beginner. I made a selfie app, it has no errors or syntax problems and (in theory) should work. Whenever I run it, it creates the window but doesn't actually load anything! It's just a b...
it might be interesting to people in this channel, meta hacker cup (previously facebook hacker cup) qualification round is ongoing
typical coding contest setup, similar to the old style of google code jam
Any feedback for my algorithm? 😅
https://github.com/nymann/block-pruner/blob/master/src/block_pruner/block_pruner.py (there's a README.md to understand what it's trying to do, if the code is not self explanatory).

GitHub
Contribute to nymann/block-pruner development by creating an account on GitHub.
I feel like this thing should be pretty trivial to write as a generator
This boils down to something similar to what you wrote I guess. It's mostly a matter of how to factor the code.
I guess the substantial differences are just:
- Generator, saves the need for the
self._save - Use the list being empty empty/non-empty to know if we're inside a block
def prune_lines(start: str, end: str, needle: str, lines: list[str]):
block = []
has_needle = False
for line in lines:
if block:
block.append(line)
if line == end:
if not has_needle:
yield from block
block = []
has_needle = False
elif line == needle:
has_needle = True
else:
if line == start:
block = [line]
else:
yield line
I guess 3, don't have a function for processing single lines
processing single lines means you have to use instance variables which you can totally avoid if you have a function that processes all lines
they can just be local variables then
and removing state is generally good
I think as your thing was written if I gave data which happens to miss a closing end your initial state would be wrong when trying to prune another file
Anyone knows the best explanation video on Minimize the heights ll of GFG ??
no clue about videos, but I think the solution is just sorting and then sweeping and keeping track of min/max
the sweep would be such that you raise the elements with index <i by k and lower the elements at >=i by k
O(n log n) for sorting
the sweep should just be O(n)
as you sweep the minimum will monotonically increase, and the maxium will monotonically decrease
Okay thank you
Can someone help me with creating a simple tag choosing algorithm, I know nothing about coding though
So I made a bot in discord that kinda does a social media like command

Allowing people to share posts and interact with each other's posts
do you know what it means for a number to be x% greater than another number?
But I need an algorithm to suggest posts
And an algorithm to categorize posts
But neither me nor my friend know something about algorithms
Please dm me if you're willing to help it'll be extremely appreciated
I'm not getting the idea why picking a prime number for my hash table length is better for reducing collision? What is the mathematical argument
gcd basically
if you have a hash that shares a factor with the mod, it will be hashed into an index that is a multiple of that factor
with primes you can't have common factors other than the prime itself
it you have uniform input data this doesn't matter
but input can have weirder patterns and make things annoying for you
e.g. say some quirk in the input data means you only get even numbers
then if your table size is even all odd buckets will be unused
Thanks
i have a couple of nodes pointing to some other nodes , and i have to decide the entry point myself (one node can point to one or more nodes) and traversing from node A to B cost some weight
- i want to traverse each node and return the shortest path
i have the graph of nodes (dict) , so i need to figure out how should i sort out the total number of nodes in which i can traverse all the nodes then shall i proceed with dijkstra and return the lowest weighted path
or what shall i do🤔
problem is that not every entry point allows me to traverse every other node
so i cant jump straight to implementing dijkstra at every entry point node
hey so i think that some of this is finally starting to click, i believe that CLRS pg. 27, the summation at the top of the page, the summation for j=2 through n is equal to ((n(n+1)/2) - 1) because that particular while loop is going to run the standard arithmetic summation minus one due to it being within a for loop, eg we expect each line within a loop to run one time less than the loop header
at least, i believe that that is the reason, and not that they are beginning at j=2
the next summation however i don't know precisely why it is equal to n(n-1)/2
if I wanted to find all possible number of ways of pairing numbers (1 to 2n) . ( for 1, 2, 3, 4 would be (((1,2), (3,4)), ((1,3), (2,4)), ((1,4), (3,2)))what is the best way to do it with as litlle wasted time as possible
in one solution it goes i should go from lowest unpaired and pair with the rest so it goes first with (2n-1) nums, second with (2n-3) nums, third with (2n-5) nums etc... BUt I don't know how would you efficiently implement this.
If you subtract 1 from every term in the summation and say the summation has N terms, then that is the same as subtracting N.

basically rewrite to the familiar form and compute that
you want to list all the possibilities or just count them?
list
you just manually index
x = 1,2,3,4
for i in range(len(x)-1):
for j in range(i+1,len(x)):
print(x[i], x[j])
like this
you can use enumerate if you like
i don't like it here
wait you asked something different
uh, i think i know how it's done
1 minuite
and I'm not sure if I quite understand but is a possibility a list of n couples somehow sorted so you don't have redundancy - say (a, b) is the same as (b, a) and the order of the couples also shouldn't matter -
Another way to see why @fiery cosmos : ```
1 + 2 + 3 + 4 + 5 + ... + n = n(n+1)/2
2 + 3 + 4 + 5 + ... + n = n(n+1)/2 - 1
(2-1)+(3-1)+(4-1)+(5-1)+ ... +(n-1) = n(n+1)/2 - 1 - (n-1) (subtracted 1 from left side n-1 times (-1 for each term), so same for right side)
= n(n+1)/2 - 1 - (n-1)
= n(n+1)/2 - 1 - n + 1
= n(n+1)/2 - n
= n(n+1)/2 - 2n/2 (fancy form of 1 to get same denominator)
= (n(n+1)-2n)/2
= (n(n+1-2))/2
= n(n-1)/2
(Recommend the much faster shift method in practice)
yeah it is exactly that
!e
from itertools import *
from math import comb
x = 1,2,3,4,5,6
a = list(combinations(x,len(x)//2))
for x,y,_ in zip(a, reversed(a), range(comb(len(x),2)//2)):
print(x,y)
@runic tinsel :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | (1, 2, 3) (4, 5, 6)
002 | (1, 2, 4) (3, 5, 6)
003 | (1, 2, 5) (3, 4, 6)
004 | (1, 2, 6) (3, 4, 5)
005 | (1, 3, 4) (2, 5, 6)
006 | (1, 3, 5) (2, 4, 6)
007 | (1, 3, 6) (2, 4, 5)
so like this
like, the complements are all in right order if you read from the bottom
wait, that's also different?
yes this but with pairs not just two groups, and the order doesn't matter
ok
this server has so many people with so many braincells
yes, very much agree
@dark aurora I'm not sure if it's the most efficient way, but you can use recursion and doubly-linked lists.
Let me explain, say you have the numbers [1, 2, ..., 2n] stored in a list.
The first step of your algorithm is to pick the first element of the list and another one among the remaining 2n-1 to form the first couple (so you get (1, 2), (1, 3)...). Say that you remove theses elements from your list, so it will look like [2, 3, ..., 2n] (there are two elements removed).
After that the problem is repeating itself, you need to pick the first element and another one among the remaining 2n-2 elements.
I think a doubly linked list would be convenient here for the insertion and deletion time.
!e
def pairs(lst):
def f(a,c):
if c == len(lst): yield a;return
if len(a)*2 < len(lst):
yield from f(a+[[lst[c]]], c+1)
for s in a:
if len(s) < 2:
s.append(lst[c])
yield from f(a, c+1)
s.pop()
for x in f([],0):
print(*x)
pairs([1,2,3,4])
@runic tinsel :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | [1, 3] [2, 4]
002 | [1, 4] [2, 3]
003 | [1, 2] [3, 4]
it's not supposed to be fast
just did it the only way i could
probbly what sunny thought of
the time complexity is pretty high, I think it should be something like O(n!) using doubly-linked lists and way higher with conventional arrays.
Thank you, it seems like the most effiecient method, didn't even know about doubly-linked lists, they seem really useful
It's not a native python data structure, you need to implement it yourself or find an implementation of it.
Also check @runic tinsel's code, it's the same idea I think.
i think it's different after all
like it doesn't build on top of first pair, it builds on top of first two numbers assigned somewhere, it's inverted
a good solution would avoid recursion
computers hate it
the number of such pairs are high already
I had two ways of counting in my head that I just managed to show are actually the same

the first one is to pick 2 at a time over and over, and then compensate so that we don't count different orderings of the n pairs
e.g. [(1, 2), (3, 4)] and [(3, 4), (1, 2)] are the same
the last line in my head is taking the numbers
1 1 2 2 3 3 4 4 ... n n
```which has (2n)! orderings, but that counts way too muchswitching the numbering to a different standard doesn't change anything, so divide by n!
and every pair doesn't care about order so divide by 2 for every pair, so divide by 2^n
and asking wolfram alpha about that second formula suggests it's something close to O(2^n n!)

so you can't really do better than O(2^n n!)
so i just noticed that when changing these summations, when you decrement the index and the n term, you must increment the expression, and vice versa. so for example these two are equivalent: summation(i+1) through n, where i = 5 and n = 7, and the summation(i+2), where i = 4 and stopping index is n-1 (where n = 7)
does that seem correct
thank you for this
.latex Let i = j - 1, now $$\sum_{j=2}^{n}{j-1}=\sum_{i+1=2}^{n-1}{i}=\sum_{i=1}^{n-1}{i}$$

The minus one at the top comes from i being j minus 1, need to preserve the same total number of terms, so if you subtract 1 from the bottom, then 1 from the top too.
You can check that the total number of terms is still the same.
was my statement correct? in my example they are both equal to 21
Can you latex it? Might be misreading it.

.latex Let $j=i-1$, $i=j+1$ $$\sum_{i=5}^{n}{i+1}=\sum_{j+1=5}^{n-1}{(j+1)+1}=\sum_{j=4}^{n-1}{j+2}$$

Yup.
You can also check it in Python btw: ```py
sum((i + 1 for i in range(5, 8)))
21
sum((i + 2 for i in range(4, 7)))
21
Note that the end of the range is not inclusive, so I added 1 to 7.
Same as [5, 7], [4, 6].
(5+1)+(6+1)+(7+1)+ ... + (n+1)
6 + 7 + 8 + ... + (n+1)
(4+2)+(5+2)+(6+2)+ ... + ((n-1)+2)
6 + 7 + 8 + ... + (n+1)
so im assuming that this reason is correct
this one i didn't mean mathematically, rather why is it that specific expression given the algorithmic context
Let me pull out the book.
ok ok. once again, i understand the reason why the summation is the given expression at the top of page 27
Yeah that is why i'm getting the book so I can point to the code.
Ok the key is line 4, i = j - 1.
The inner loop does not always start at the beginning like the outer one.
Which means the work inside the outer loop is not just like 1. It's some variable amount (j).
And the outer loop starts at 2, so now you are at that first summation that you understand.
so pg 27 summations are for worst case
and the second summation corresponds to line 6
and t_j = j given by last sentence on pg 26
so we can look at the times column and substitute j for t_j
giving summation(j-1) from j=2 through n
so once again we have an expression for the number of times a given loop will run for a given value of j, which the book calls t_j
so line 5 will run t_j times, which we know will be equal to j in the worst case (according to book's statement)
so line 6 begins as summation(t_j - 1) from j=2 through n, and we substitute in j, and get summation(j - 1)
is equal to ((n(n - 1)/2))
conceptually its just another level of depth, describing a loop that runs summation expression times for a given value of j, given by the loop iteration which the for loop is on

>>> i = 0
>>> while i < 5:
... i += 1
... print(i)
...
1
2
3
4
5
>>>
``` Count how many times the condition is checked, vs how many prints.The first sum is just due to 2 to n rather than 1 to n.
i asserted that this expression was such due to the fact that its the standard summation expression minus one, given that we know it'll run one time less than the loop header
t_j is a placeholder for much time the inner loop does in its body.
this is what i had mentioned earlier and was concerned about, i was concerned that its actually due to j being 2 and not 1, and not what i had asserted, that it is due to the loop header reasoning
is this correct? or is it bc j=2
these are 2 very different reasons for that -1 there
one time less than the for loop header of line 1
i could see your reasoning being the correct one, given that when you change j from j=1 to j=2, for the same summation expression, you must also decrement the expression by 1, hence the -1 of the first summation:
but i thought it was due to line 5 expected to run one less than it's loop header (line 1), and so im not sure which is correct
So the first sum is doing two things, it starts at 2, because the outer loop starts at 2. And inside that sum it has j, because that is how many times the inner loop is checking (aka t_j).


It may be more obvious now if each sum is a loop.
So the original sum given at the start of page 27 is for both loops (measuring the number of checks of the inside loop).
The next one after that is also both loops, but it's taking into account that the inside of the inner loop's body happens once less (so j - 1), because of what page 25 had written at the end.
(t_j vs t_j - 1)
yeah i see all of that and how they plug in j for t_j in the expressions
i don't get if the -1 is due to the while loop of line 5 running one time less than its own loop header on line 1, or if its bc of the j=2. it must be one or the other, i don't think they are two versions of the same concept. once i get that then we can explore why the second one is different
The starting at 2 causes the -1 on the right side.
ok
1 + 2 + 3 + 4 + 5 + ... + n = n(n+1)/2
(subtract 1 from both sides so it starts at 2 on the left side)
2 + 3 + 4 + 5 + ... + n = n(n+1)/2 - 1
simple enough
The j - 1 causes - n to happen.
1 + 2 + 3 + 4 + 5 + ... + n = n(n+1)/2 (just i)
(now i - 1)
(1-1)+(2-1)+(3-1)+(4-1)+(5-1)+ ... +(n-1) = n(n+1)/2 - n (subtracted 1 from the left side n times)
= n(n-1)/2 (you can do the algebra here for practice)
Note that you can take the sum(i-1) and split it into two with this: sum(i-1) = sum(i) - sum(1) = sum(i) - n.
(In this case when doing addition or subtraction)
You can also see it from: ```
(1-1)+(2-1)+(3-1)+(4-1)+(5-1)+ ... +(n-1) = n(n+1)/2 - n
1 + 2 + 3 + 4 + 5 + ...
-1 + -1 + -1 + -1 + -1 + ...
The left side is two sums on top of each other (the sum(i) and sum(-1) added together).
(mixed)
i did notice that its implied that its n(n+1)/2 - 1*n, in other words, subtracting 1 n times
i guess the difference between the two expressions is that the line 5 summation is "however many times it must run for each value of j all added together", without explicitly taking into account that it'd be one less than the for loop of line 1, whereas the summation in line 6, we do explicitly acknowledge that fact
which is why the two summations are for j vs j - 1
Yeah the line 5 summation is how many times the check is run, and the summation after is how many times the body is run.
That line specifically happens once more than the stuff in the body.
Here there are 5 items printed, but the check i < 5 happens 6 times. It passes the check 5 times and the final check (6th one) does not pass.
The check is passed 5 times, but executed 6 times.
(t - 1 vs t)
If you look at line 1 vs line 2, they are doing the same thing again, the -1 shows up in the body (n - 1) vs the check being just n.
Yeah that’s straightforward. I think they just threw me by not recognizing that fact for the while loop header itself
Maybe this also makes it more obvious for line 1 vs line 2:
.latex $$n-1=(\sum_{i=1}^{n}{1})-1$$

You can see how a loop can be sort of compressed into just "n".
So when you see just "n", or "j", you can imagine another loop happening but it was simplified.
^
I don’t know how to read this. Are the double summations multiplied?
So it is like the summation of the summation of
Yes.
So.. not multiplied
No.
You can add parenthesis, but it's assumed not multiplied in this case.
Ambiguous if you have not seen it before.
Not following the idea of compression
The sum of 1's n times is just n.
If you have a for loop that does just 1 work inside, n times, then it does n work total.
.latex $$\sum_{j=2}^{n}{(\sum_{i=1}^{j}{1})}=\sum_{j=2}^{n}{j}$$

Adding 1s j times is just j.
Ok I’ll consider it in the context of the notation more
This makes sense
Take this code for example: ```py
n = 2
for i in range(n):
... for j in range(n):
... print(1)
...
1
1
1
1
You can write how many times it prints (count it) with nested sums.
.latex $$\sum_{i=1}^{n}{(\sum_{j=1}^{n}{1})}=\sum_{i=1}^{n}{n}=n \cdot n$$

Where each sum is a direct translation of a loop.
The inner loop runs n times (does 1 operation n times), and the outer loop runs that n times.
Basically you can expand a single integer into a sum of 1s or go the other way around.
Hi
I'm now learning python and my friend told me to learn data structure and algorithm so started to find the course and then I found that different kinds of course like DSA with C and C++ and many kinds like javascript,python.... etc . I want some advice from you which course should i take? should I take DSA with python cuz of learning python? or are there any difference on learning DSA with different language?
Please give me some advice my friends. Thank you ❤️
I don't know which ressources I could recommend you but you can absolutely learn DSA with python.
bump
Competitive programming in python, 128 algorithms to develop your coding skills (this is a good book even if you don't want to do competitive progamming)
in python, is there way to save function as variable that returns something inside function parameter? i.e.
def functionCall2(args):
...
return data1
module.functionCall1(tempVar = functionCall2(param))
is there way to do something like tempVar?
bump
I think that there's a proposal for that in python 3.11, but there isn't one yet
idk what you want here
you want to reference the function before it's defined and have it somehow work?
simply trying to save inner function return as variable inside outer function call. Order of function doesn't matter because I can't save it as variable anyway inside function call even before I compile. Actually, yeah I'll edit it just to clear
lst = [('Hello', 'Byee', None), ('dhruva', 'dhruva', 43), ('dhruva', 'dhruva', 10), ('Boltyshoots', 'dhruva2006', None)]
import numpy as np
for idx in lst:
names = np.array(idx[0])
val = np.array(idx[2])
print(names, val)
import matplotlib.pyplot as plt
plt.xlabel("Users")
plt.ylabel("Hours")
plt.bar(names, val, color='red')
plt.show()```
I am not able to plot it because of the none object
I kind of want to make a logic where
If idx[2] == None:
idx[0] == 0
Basically just change None into a numeral
This came from a set of sql data soo I can’t even change itYou can do it like this
def functionCall1(param):
# You may need to use global instead of nonlocal if your variable is in global scope
nonlocal tempVar
tempVar = functionCall2(param)
# Executing this line sets the tempVar variable in this scope to functionCall2(value)
functionCall1(value)
Generally, this is a bad idea. Is there a reason why you can't do something like the following?
# No need for functionCall1
tempVar = functionCall2(value)
because I'm trying to use threading on spark job.
def doSomeTransform(df: Dataframe):
...
return df
ts1 = threading.Thread(doSomeTransform(dataframe))
ts1.start()
ts1.join()
def anotherTransform(df: Dataframe):
...
return df
ts2 = threading.Thread(anotherTransform(df from doSomeTransform))
ts2.start()
ts2.join()
I looked for lazy evaluation but not familiar with it yet, too. If I can save returned value from function to something global inside outer function, I can just pass that again in next threading. Although I'm trying to convert scala code to python so I might be stretching a bit too far
I see, keep in mind that threading would hardly be beneficial if they depend on each other like in your example (since they would have to be to run sequentially)
tl;dr you just want to be able to chain thread results?
sounds like you want async
oh hell yeah there's such thing?
that or maybe concurrent.futures.ThreadPoolExecutor
async programming in python is kinda that yeah
that might be it. gonna try it tomorrow. Thanks!
Think of it as
sum([
sum([1 for i in range(1, n+1)])
for j in range(2, n+1))
])
big sigma is basically sum with a comprehension
Why comprehension? Sum allows you to pass iterables
the iterable case would be more like
.latex $$\Sigma_{x \in S} f(x)$$

the usual sum is more for in range
I mean this:
sum( # no comprehension
sum(1 for i in range(1, n+1))
for j in range(2, n+1))
)
It is unrelated to your discussion btw
yeah well, I assume more people are familiar with list comprehensions than genexprs
so if you have to teach something new to explain another thing it kinda defeats the point
Hey guys. How do I give complexity of a dictionary building algorithm in which we pass a n word array. But the algorithm complexity is based on number of letters combined as a whole. So if it's 2 words, "as" and "pop", the time taken would be 5 units.
I am comparing the implementation for different data structures.
Will it still be O(n) only?
Because there's ofcourse variance involved even in normal list operations too. Like an array might take more time to add a bigger word compared to a smaller one. But we ignore that generally.
words are short
they are not unbounded, it makes sense to think of them as constant length
that's the only way to argue this, "they are english words"
if they were just strings, it can't be O(n)
you can include the length if you want
O(n * average_word_length) would be a sensible way to summarize the complexity here
why am i getting hard time understanding algo like kadane and some similar looking dp question?
any advice ?
Let's say I have a huge array of class names as int numbers
arr = [1, 1, 2, 2, ........., 3, 3, 9, 9]
I need to map new values according to each number, like:
1 = [1, 2, 3]
2 = [0.3, 0.1, 0.3] and so on..
What would be efficient and proper way to do this ?
a number can't be an identifier
@agile sundial sorry - my explanation was terrible:
#array of classes indexes
#classes = [1, 1, 1, 1, ..... 2, 2, 2, 2, 5, 5...., 5, 5]
classes = np.array(data.classification)
#classes + colors dict =
# {
# 1: [1, 1, 0],
# 2: [1, 1, 1],
# 5: [1, 0, 1]
# }
classes_colors_dict = create_classes_colors_dict(classes)
# create new array where each 1 = [1, 1, 0], 2 = [1, 1, 1] and so on
# classes_colors = ???
well i am not sure if i did understand correctly but
when you say a new array with mapping what exactly do you mean to do?... wont a dictionary be a better use to store key value pairs? ```py
key_value_pairs = {
1: [1, 1, 0],
2: [1, 1, 1],
5: [1, 0, 1]
}
something like this?
you can index the array with colors by the classes array:
In [2]: colors = np.array(
...: [
...: [0, 0, 0],
...: [1, 1, 1],
...: [2, 2, 2],
...: ]
...: )
In [3]: classes = np.array(
...: [
...: 0,
...: 0,
...: 1,
...: 1,
...: 1,
...: 2,
...: ]
...: )
In [4]: colors[classes]
Out[4]:
array([[0, 0, 0],
[0, 0, 0],
[1, 1, 1],
[1, 1, 1],
[1, 1, 1],
[2, 2, 2]])
is python's value retrieval by a key in dictionary, dependent on length of the dictionary?
No, it's amortised constant time.
hmm

Look at trie
timings
It keeps getting hugher for bigger datasets
yes ik
But I am using dictinary to implement the trie
and all it does goes down the tree by accessing keys from a dictionary
and it's turning out out to be higher
for bigger datasets
How many layers do you have? That'd be the issue, if that's increasing.
Naah
That's random
And I take average
From different number of layers
Like for 8 different words
So it's a mix of different kind of layers and I take an average
For all data samples
Can't be a coincidence that it keeps increasing in a regular pattern as the dataset size increases
Does writing to a bigger file takes longer time compared to a file with less number of lines?
yes.
hi guys i made this
def is_balanced(text):
open_syms = {'(': 0, '[': 1, '{': 2}
close_syms = {')': 0, ']': 1, '}': 2}
stack = []
for c in text:
if c in '([{':
open_sym = open_syms[c]
stack.append(open_sym)
elif c in ')]}':
close_sym = close_syms[c]
if len(stack) == 0:
return False
elif stack.pop() != close_sym:
return False
return len(stack) == 0
I think this would just be greedily protecting an endpoint of the largest unprotected section
the tutorial is linked from the problem page https://codeforces.com/blog/entry/105464

Codeforces
and it seems to agree with what I was thinking
In queue data structure, there is two types of queues, a linear queue and a static queue, a linear queue has no fixed size just like lists, and static queue has a fixed size just like an array. In linear queue when we remove an item we don't really remove it its location in the memory but we just increase the number of the start point, like if we have a static queue {1,2,3,4} when we we remove number 1 from it we actually just telling the queue to start from 2 not from 1, and that's leads me to a question : When we remove an element in a list in python, will it actually be removed from the memory?
yes
also, the implementation you're describing for the queues sounds really bad. for the fixed size one, you can't add elements? and the "linear queue" seems really bad memory wise
presumably they're more sophisticated than that, e.g. they mark them as deleted but then it can cycle back around to use those again?
it is quite bad memory-wise yeah
though it can be kinda useful
e.g. if you do bfs that queue will contain the exploration order
the static one might be useful if you use it as a circular queue maybe?
otherwise it seems quite bad
Hi, I had an algorithmic question, regarding the following (pretty simple) question: https://adventofcode.com/2020/day/4
I have the following code which it is reporting as too low. Why doesn't my code fulfill the problem?
file = open('adventInput.txt', 'r')
inp = file.readlines()
file.close()
inp = [i.strip() for i in inp]
passports = [] # a list of dictionaries, each dict is a passport
current_pass = [] # the current passport, accumulated over multiple lines that are "together"
for line in inp:
if line == '':
# turn that current_pass list into dict w/ attributes
temp = {}
for attrib in current_pass:
attrib, value = attrib.split(':')
temp[attrib] = value
passports.append(temp)
current_pass = []
continue
# if it's not newline, split it and add to current passport
current_pass.extend(line.split(' '))
valid = 0
REQUIRED = ['byr', 'iyr', 'eyr', 'hgt', 'hcl', 'ecl', 'pid'] #cid missing
for passport in passports:
test = [i in passport.keys() for i in REQUIRED]
if all(test):
valid +=1
print(valid)
BTW, I could easily google and find working code for this question. I am trying to understand why my current code is not producing the correct output. Thanks in advance!
Here is the sample input:
Hey @flat meteor!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
do you have a blank line at the end of your input? if not your input reading will drop the last entry
you can have a more sensible setup if you split on '\n\n' which will give you each group
then you can just .split() that and process the elements
yeah i was able to solve it I feel stupid for asking that
excuse, I'm trying to build a matrix with n,m positions so I have this until now, but it's now working:
import random
row = int(input("Rows: "))
columns = int(input("Columns: "))
for i in range(1, row+1):
for j in range(1, columns+1):
num1 = random.randint(-50, 50)
num2 = random.randint(-50, 50)
final_number = num1 + num2
[i,j] = final_number
print(f"({i},{j})", end=' ')
print("")
what's the problem or how is it supposed to build a matrix?
a matrix is a list of lists so you first need to make a list and then populate it with lists, and you acces the elements like this a[i][j] (a being the name of the matrix, i is the i-th list in the matrix, and j is the j-th element in the i-th list, so i is the row, j the column if we imagine it as a matrix)
import random
row = int(input("Rows: "))
columns = int(input("Columns: "))
a = [] #creating a list where we will store other lists
for i in range(1, row+1):
l = [] #creating i-th list that we will populate with elements
for j in range(1, columns+1):
num1 = random.randint(-50, 50)
num2 = random.randint(-50, 50)
final_number = num1 + num2
l.append(final_number) #adding the element in the i-th list
a.append(l) #adding the list to the matrix
for x in a:
print(x) #printing the matrix
this is what you wanted I hope
Thanks @haughty mountain! thats exactly what it was lol
Write a program to count the total number of digits in a number using a for loop.
num = 1234
# using for-loop
total = 0
for i in str(num):
total += 1
print(total)
# simple one liner
print(len(str(num)))
for loop is a bizarre choice
while loop makes more sense
num = 1234
n_digits = 0
while num > 9:
num //= 10
n_digits += 1
why does leetcode need to use ListNode instead of just using actual lists or something similar ?
ive been asking myself this question for sometime and to me it just doesnt make sense why ListNode is used, any explanations ?

it's a linked list
difference between a normal list and a linked list is ?
Python list uses an array
hi can someone explain the variability of time for this leetcode problem?
Problem: https://leetcode.com/problems/k-closest-points-to-origin/submissions/
My MinHeap Solution:
from heapq import heapify, heappop
class Solution:
def kClosest(self, points: List[List[int]], k: int) -> List[List[int]]:
dist = []
# [[0,0]]*(len(points)-1)
k_closest = []
for i, pt in enumerate(points):
d = 0
if pt[0] == 0:
d = abs(pt[1])
elif pt[1] == 0:
d = abs(pt[0])
d = (pt[0]**2 + pt[1]**2)
dist.append([d, pt])
heapify(dist)
for i in range(0, k):
dst, pt = heappop(dist)
k_closest.append(pt)
return k_closest

Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
Also at first I tried to initialize an array of len(points)-1 (what the commented out line between the 2 list initializations and it gave me an IndexError: list assignment index out of range error on the line where I have dist.append([d, pt]) why is that?
leetcode is very high-variance, not sure why
well, you do len(points) iterations, not len(points)-1
ahh makes sense, got confused with zero-index
but how would you judge my solution?
I am currently watching a YouTube video about it but they're using maxHeap and to me minHeap made more sense but I will watch it and see the wisdom on there
if pt[0] == 0:
d = abs(pt[1])
elif pt[1] == 0:
d = abs(pt[0])
d = (pt[0]**2 + pt[1]**2)
this is useless work
- regardless of these conditions, you override
danyway - Why not just stick with only the last formula? No real need to optimize for the cases of one of them being zero,
+ 0**2isn't a particularly expensive operation.
actually, I think this is just wrong
yeah, in this case you have two problems cancelling each other out.
hmmm I thought it would be computationally more effieicent since if we can determine if one of the coordinates are 0 then the distance must be the other coordinate, or is this not right?
If not for the fact that d = (pt[0]**2 + pt[1]**2) gets executed always, this would produce bad results because you'd mixing distances and squared distances. Naturally, you can't naively compare them.
Sure, but it's a tiny optimization.
Also, you're using enumerate but not utilizing it
so I think this can be simplified to
from heapq import heapify, heappop
class Solution:
def kClosest(self, points: List[List[int]], k: int) -> List[List[int]]:
dist = []
k_closest = []
for pt in points:
dist.append((pt[0]**2 + pt[1]**2, pt))
heapify(dist)
for i in range(0, k):
dst, pt = heappop(dist)
k_closest.append(pt)
return k_closest
which does seem to me like the best solution possible.
I am using i and pt, is this not the proper way to use enumerate?
You're not actually using i anywhere.
It's likely a holdover from when you were doing dist[i] = rather than append.
yes
(well, I'd write it slightly shorter via listcomps:
from heapq import heapify, heappop
class Solution:
def kClosest(self, points: List[List[int]], k: int) -> List[List[int]]:
dist = [(pt[0]**2 + pt[1]**2, pt) for pt in points]
heapify(dist)
return [heappop(dist)[1] for i in range(k)]
)
thanks
python's list uses a dynamic array
alright I have a problem and here's a solution (sorta):
import random
def the_function(index, max, seed=0):
random.seed(seed)
number_list = [i for i in range(max)]
random.shuffle(number_list)
return number_list[index]
the_function(0, 10)
the problem is that it isn't efficient and takes way too long when having the max parameter at a high value
I basically want a function that does this without generating a list
the requirements:
- entering the same values returns the same values (so use a seeded pseudorandom thing or something)
- if you were to iterate through 0-max, there would be no repeated values (that's why a list is used in the code)
Hello guys, I have a question about list comprehension and iteration. im developing a function that returns an string object based of of what it was given. I have written some syntax:
#
# ERROR: - Defines an error
# MSG: - Defines a message
#
# 4XXX - 4 is an error, in someway something went wrong
# 2XXX - 2 is a message, something went right
#
# 000 - 999 will identify the serverity, specific funtion and code, and issue or message.
#
# 4000 - FAILED
#
# 4[0]XX
# 1 - FAILED TO ESTABLISH
# 2 - FAILED TO TERMINATE
# 3 - FAILED TO CONNECT
# 4 - FAILED TO FIND
# 5 - LOCKED
#
# 4X[0]X
# 1 - DATABASE
# 2 - SOCKET
# 3 - ACCOUNT
# 4 - FUNCTION
# 5 - CLASS
# 6 - MODULE
#
# 4XX[0]
# 1 - CONNECTION
# 2 - PROPERTIES
# 3 - INSTANCE
# 4 - PATH
# 5 - FEED
#
#
#
# ERROR: 4000 FAILED
# ERROR: 4111 FAILED TO TERMINATE DATABASE CONNECTION
# ERROR: 4121 FAILED TO ESTABLISH SOCKET CONNECTION
# ERROR: 4452 FAILED TO TERMINATE SOCKET CONNECTION
how do you loop thru a number from left to right kind of like df.iloc[] but for a nested dictonary?
My Code:
def status_parse(status_code):
ERR = "ERROR:"
ERROR_CODES = {
"parent": {
4000: "FAILED",
4100: "FAILED TO ESTABLISH",
4200: "FAILED TO TERMINATE",
4300: "FAILED TO CONNECT",
4400: "FAILED TO FIND",
4500: "LOCKED"
},
"child_1": {
4010: "DATABASE",
4020: "SOCKET",
4030: "ACCOUNT",
4040: "FUNCTION",
4050: "CLASS",
4060: "MODULE"
},
"child_2": {
4001: "CONNECTION",
4002: "PROPERTIES",
4003: "INSTANCE",
4004: "PATH",
4005: "FEED",
}
}
if status_code in ERROR_CODES:
print(ERR, ERROR_CODES[status_code])
else:
print("Failed to fetch error: ")
while True:
error = int(input('Enter error code: '))
status_parse(error)
Is it possible to iterate thru the first part of the dict only accounting for the 4100, 4200? then grab that value then move to the next child dict, acconting for 4010, 4020, etc
You can probably split your error code into 4 digits, the first digit , if 4, matches a valid error code
then you have 3 dicts each with 1-5 and the string for each stage
then the final error code is pretty much just
_, a, b, c = code.split('')
print(f"{parent[a]}{child_1[b]}{child_2[c]}")
Thank you so much man u saved me like 30 mins. all i had to do was split like you said, iterate and connect the string back as a variable bc its going to a gui.
i also used .format for output but f"" worked amazing too
is the issue with you shuffling on every call or with shuffling at all?
if you just want a single cycle of numbers I would say put this in a class that shuffles on init and then you can query indices
for a similar problem I gave this to someone, which yields random permutations of a sequence over and over, so no repeats until all elements are used
import random
def random_cycle(seq):
while True:
yield from random.sample(seq, len(seq))
r = random_cycle([2, 4, 6])
for _ in range(10):
print(next(r))
maybe it could be useful for what you're actually trying to do
Just wanted to update you on this. It works like a charm, if you ever need custom error codes for projects is hope this helps as a base.
def status_parse(status_code):
ERR = "ERROR:"
ERROR_CODES = {
"parent": {
4000: "FAILED",
4100: "FAILED TO ESTABLISH",
4200: "FAILED TO TERMINATE",
4300: "FAILED TO CONNECT",
4400: "FAILED TO FIND",
4500: "LOCKED"
},
"child_1": {
4010: "DATABASE",
4020: "SOCKET",
4030: "ACCOUNT",
4040: "FUNCTION",
4050: "CLASS",
4060: "MODULE"
},
"child_2": {
4001: "CONNECTION",
4002: "PROPERTIES",
4003: "INSTANCE",
4004: "PATH",
4005: "FEED",
}
}
Part 2
str_stat_code = list(str(status_code))
stat_a = str_stat_code[1]
stat_b = str_stat_code[2]
stat_c = str_stat_code[3]
parent = ERROR_CODES.get("parent")
child_1 = ERROR_CODES.get("child_1")
child_2 = ERROR_CODES.get("child_2")
check_1 = False
check_2 = False
check_3 = False
for key_a, val_a in parent.items():
dk_a = list(str(key_a))
num_key_a = dk_a[1]
for key_b, val_b in child_1.items():
dk_b = list(str(key_b))
num_key_b = dk_b[2]
for key_c, val_c in child_2.items():
dk_c = list(str(key_c))
num_key_c = dk_c[3]
if stat_a == num_key_a:
check_1 = True
p1 = val_a
elif stat_b == num_key_b:
check_2 = True
p2 = val_b
elif stat_c == num_key_c:
check_3 = True
p3 = val_c
elif check_1 and check_2 and check_3 == True:
x = ERR+" "+(p1+" "+p2+" "+p3)
if x:
print(x)
return x
else:
pass
while True:
error_code_1 = int(input("Enter an error code (4000): "))
if len(str(error_code_1)) == 4:
status_parse(error_code_1)
else:
pass
TESTS:
1 - ERROR 4123: FAILED TO ESTABLISH SOCKET INSTANCE
2 - ERROR 4464: FAILED TO FIND MODULE PATH
3 - ERROR 4344: FAILED TO CONNECT FUNCTION PATH
4 - ERROR 4244: FAILED TO TERMINATE FUNCTION PATH
However, i did find a bug. Code 4564 does not return LOCKED MODULE PATH so you will have to do some bug hunting
anyone here leetcoding?
the dict didn't accept 4000 as a parameter so it would return none. here's the code that will work. and the dict lengths were un even causing some codes to be in-accessible
"parent": {
4000: "FAILED",
4100: "FAILED TO ESTABLISH",
4200: "FAILED TO TERMINATE",
4300: "FAILED TO CONNECT",
4400: "FAILED TO FIND",
4500: "FAILED TO OPEN",
4600: "LOCKED"
},
"child_1": {
4000: "",
4010: "DATABASE",
4020: "SOCKET",
4030: "ACCOUNT",
4040: "FUNCTION",
4050: "CLASS",
4060: "MODULE"
},
"child_2": {
4000: "",
4001: "CONNECTION",
4002: "PROPERTIES",
4003: "INSTANCE",
4004: "PATH",
4005: "FEED",
4006: "THREAD"
}
}
ERROR: FAILED TO OPEN MODULE PATH
code 4564 now works
hello guys, i want to ask during recursion, why shallow copy of a matrix of number is good but we need a deep copy for a matrix of strings ?
Maybe just
def the_function(index, max, seed=0):
random.seed(seed)
return (index + random.randrange(max))%max
will work for your purposes?
I'm kinda new to this whole NN thing. I used Pygame to generate a large amount of data for mouse positions and am trying to use the data I generated to create a NN that can predict the position of points for a mouse to move like a human.

Trying to use TensorFlow predictions but the problem is my data has differing sized matrix
is there a way to train a algorithm with varying sizes?
e.g [4,20], [4,30], [4,29]
the other data set is a [4,N]

sorry [4,2]*
You can look into RNNs
thank you I'll look into that now
Would you be interested in getting paid to help me set up my NN so I can learn from the way you structure it?
fair, was worth a shot asking
Also this is not a place to advertise paid work
ok
fwiw that is a #data-science-and-ml topic
Hello, everyone,
I have a small question for which I don't think it's worth opening a separate ticket. I would like to have only the second value from all entrys in the list.
As I currently have it, he would enter all values. Can someone help me there? I'm still a beginner. Thanks
list(participantlist.values())
A total of 4 values belong to each key
just wrote a matrix builder from scratch, pretty happy i was able to sit down and think this through and implement
Not sure if this is what you mean, but here is the most "easy-to-read" solution (at least for me)
participants = {
'key1' : [1, 2, 3, 4],
'key2' : [1, 2, 3, 4],
'key3': [1, 2, 3, 4],
'key4' : [1, 2, 3, 4]}
for value in participants.values():
print(value[1])
nvm, list index out of range errors
Mhhh i think i need them in a list, because im looking for the number next to "value". Value = 20. Just as a example.
nextvalue = min(list(participantlist.values[1]), key=lambda x:abs(x-int(value)))
Or shoud i better open a ticket for that? XD Dont know if im here right for somethink like that.
a 1d block of memory is more common
(not that the user needs to see that)
can you have for loops within your return statement?
thats what id meant
also i am aware of numpy but trying to stay away so i can do everything i need myself
wdym?
return "your matrix is:" + '\n' + str(m[0]) + '\n' + str(m[1]) + '\n' + str(m[2])
eg this return won't work for a matrix of an arbitrary size, my first thought on how to fix was a loop of some sort
pls refrain from writing code
just guide me if possible
!d str.join might be helpful
str.join(iterable)```
Return a string which is the concatenation of the strings in *iterable*. A [`TypeError`](https://docs.python.org/3/library/exceptions.html#TypeError "TypeError") will be raised if there are any non-string values in *iterable*, including [`bytes`](https://docs.python.org/3/library/stdtypes.html#bytes "bytes") objects. The separator between elements is the string providing this method.maybe combined with a generator expression
ok that may be beyond my skill lvl, will look into that
it's not a complicated string
is returnstate a reserved keyword?
a = [1, 2, 3]
'|'.join(str(x) for x in a) # 1|2|3
you're probably familiar with the generator expression syntax already
no?

{kind=link}
{kind=link}
{kind=link}
I mean, it's easy to just try writing it in the repl
methods are called with function.method()?
ugh keep getting generator object returns
you mean class_instance.method()?
you'll want to consume the generator expr somehow
there's no class
i have a function and i was going to write a function within that, if thats possible
no
i had it working swimmingly but it didn't work for arbitrary input size
what are you writing that doesn't work?
nvm i got it
i just wrote a square matrix builder function that takes input from the user and prints the resulting matrix when done. you can try it:
def squarematrixbuilder():
inp1 = int(input("enter number of rows and columns: "))
m = [[] for x in range(0,inp1)]
for x in range(inp1):
while len(m[x]) < inp1:
inp2 = int(input("enter the elements in row " + str(x) + ": "))
m[x].append(inp2)
print("your matrix is: ")
for x in range(inp1):
print(str(m[x]))
squarematrixbuilder()
tested with n=2,3 .. going to try 4x4 now
your matrix is:
[2, 6, 4, 1]
[3, 2, 7, 9]
[8, 6, 5, 1]
[1, 2, 4, 7]
pretty cool
anyway, now that i've wasted my morning going "above and beyond" i need to do the actual assignment 😂
i at least want to add a try except for if someone input a letter for the n*n parameter
but im converting it to and int with the int() wrap.. hmm
aw frick im going to need to make this a class huh
otherwise i'd have to return the list of lists for use in my multiplication function
🤦♂️
having trouble initializing my new matrix to populate with all zeroes
i think i just got a hint, i can see that i'm making a list of lists of list:

also is there a way to keep A and B so i don't have to keep keying them in every time while testing
wdym?
the way my program runs i have to key in the new matrices, A and B, each time i run for trying me new function
yeah that's what im saying it clearly looks off. i don't think i even need to initialize the new output matrix to zeroes, i think i can just append as i go. by key in i mean when i run my program it takes command line arguments to type in the matrix elements
then either automate your typing (i.e. pipe your input in or something) or hard-code some input in your program?
!e let's see if this is close to what you see
C = []
C.append(C)
C.append([])
print(C)
@haughty mountain :white_check_mark: Your 3.11 eval job has completed with return code 0.
[[...], []]
@haughty mountain :white_check_mark: Your 3.11 eval job has completed with return code 0.
[[[...]], []]
I expect you have out C inside C like this @fiery cosmos
hello guys, I am currently working on a project that I started more than a month ago. I'm trying to make an algorithm that generates crossword puzzles starting from a list of words only. I first thought it would be easy, then afterwards I discovered that it was a super complex problem. But I haven't given up yet. I read many research papers on the problem but none of them were clear nor helped me get closer to the answer. I also made lots of code but none of them were working properly, and the problem is that I don't even know why.
Anyways, if anyone has any suggestions please let me know
Or some ressources for similar algorithmic problems
Thanks in advance !!
you can just bruteforce it
like sudoku
Are you talking about generating the crossword puzzle? Or maybe about solving it
right i was thinking about that
so it will like show the puzzle and you will decide if it's good enough or it should continue the search
how do you measure if it's good?
yeah that's a lot of manual work, no good
it would be a small bounding rectangle
yeah
well if like, 80% of words have 2+ intersections
i'm thinking just make it square and increase dimensions until it fits