#esoteric-python
1 messages · Page 11 of 1
my god lol
i cleared object.__dict__, type.__dict__ and builtins.__dict__
there is no way to survive
hmm
im not sure how to fix that
would that work in theory or are you just trying to kill the tester?
im just trying to kill tester
import gc
@dict.clear
@lambda x:x[0]
@gc.get_referents
@lambda x:x.__dict__
@type
@lambda x:lambda:...
class _:...
fibo = lambda n: n
assert not fibo.__class__.__dict__
``` this crashes my REPL, but works in tester
idk how it is possible, it is clearing all methods from functions
i got it, it is clearing class dict, but not updating slots, so functions are still callable
Would be a funny vulnerability
I like how you have to work without parentheses because I check your text before I import it
that's why I think it wouldn't work
LMAO
LMAO
class fibo:
__init__=lambda*_:None
__eq__=lambda*_:True
submitted
@simple sphinx fix it
the best solution
oh no
test.assert_equals(fibo(i), arr[i])
test.assert_equals(fibo(check_num), arr[check_num])
it's not my code
you should add some .assert_not_equal tests i guess
import codewars_test as test
with open(f'/workspace/solution.txt','r') as code_text:
code = code_text.read()
if len(code) >= 1000:
test.fail('too long')
def disallowed_keyword(word, line):
#takes a line of text, and checks for any "bad" keyword use
try:
ind = 0
while True:
ind = line.index(word,ind)
if ind + len(word) == len(line):
return False
if ind == 0:
if not line[ind+len(word)].isalnum():
return True
else:
if (not line[ind+len(word)].isalnum() and not line[ind-1].isalnum()):
return True
ind+=1
except ValueError:
return False
lines = code.split('\n')
for index, line in enumerate(lines):
# check for (
flag = True
if '(' in line:
if not 'def fibo(' == line[:9]:
test.fail(f"( disabled on line{index + 1}")
if '(' in line[9:]:
test.fail(f"( disabled on line{index + 1}")
if not flag:
test.fail(f"( disabled on line{index + 1}")
# check for while
if disallowed_keyword('while', line):
#print(line)
test.fail(f"while disabled on line {index+1}")
# check for for
if disallowed_keyword('for', line):
#print(line)
test.fail(f"for disabled on line {index+1}")
# check for gimpy
if disallowed_keyword('gmpy2', line):
#print(line)
test.fail(f"for disabled on line {index+1}")
from solution import fibo
import sys
if 'gmpy2' in sys.modules:
test.fail('gympy2 has been disabled')
import random
arr = [0 for i in range(50000 + 250)]
arr[1] = 1
for i in range(2,50000 + 250):
arr[i] = arr[i-2] + arr[i-1]
for i in range(0,50000,100):
check_num = i + random.randint(0,100)
test.assert_equals(fibo(i), arr[i])
test.assert_equals(fibo(check_num), arr[check_num])
this is testing code
typo there: test.fail('gympy2 has been disabled')
oh ty
you should put there some .assert_not_equal checks

you can also change that function I think
im only testing ints
ill check the return type at the end
Wont work, because i can patch builtin "int", "type" and "isinstance"
I plan on hiding them in a variable
I think i can still break it
tbh I think ill ask in the codewars subreddit how to solve it
Only way i see is to save results in file and check them from other process
Thats how all good checkers work
it's my first time publishing a kata, there is probably some obvious solution to people who write a lot of them
I'm stuck figuring out what's wrong here

since there aren't any custom instructions, the generated bytecode is identical, except that 1. haiiii <3 is removed (so minus eight bytes), 2. all absolute jump targets are decreased by 4 (to account for those opcodes being removed), 3. the import is replaced with NOP, NOP, NOP, POP_TOP (POP_TOP is exactly the next instruction, replacing STORE_NAME @uwu.magic)
except, now trying to run it simply doesn't work
all loops are going to the correct locations, but the ranges are broken (only returning 0)
simpler example where this happens: https://paste.pythondiscord.com/exunegojix
prints 0, then ```
Traceback (most recent call last):
File "/home/dzshn/Documents/git/uwu/examples/tf.py", line -1, in <module>
TypeError: 'str' object is not callable
also curiously, if you insert new GET_ITER, FOR_ITER instructions they do work
wait
okay absolute targets are actually broken
i was focusing too much on FOR_ITER
okay update:

Any good actual obfuscators?
cereal has a good one
not sure what you mean by "actual obfuscators", though
is there a such thing as fake obfuscation?
i think he means because the are many trash obfuscators out there
I would say the 200 github repos using marshal as obfuscation count as trash
@solid mulch Yeah
What i mean is not just packing the code behind a fancy wall that will be cracked in seconds, actual obfuscation that changes the var names, class names... etc etc etc.
also have custom encryption like boolean or integer encryption,.
with python obfuscators now of days, you get 2 types.
- Marshal packing garbage
- Changes var,classes,functions names and thats it
both are not exactly great.
Instead i was looking for a obfuscator that does it all,
bear witness and fear me, muahahaha https://totally-not.a-sketchy.site/3tbaasG.png

ast macros in python
def "fizzbuzz"('x'):
_(function()
för "num" ín (range(1, x)):
_(function ()
íf (num % 15 == 0):
_(function () print("FizzBuzz") end)
elif (num % 3 == 0):
_(function () print("Fizz") end)
elif (num % 5 == 0):
_(function () print("Buzz") end)
élse:
_(function() print(num) end)
end)
end)
fizzbuzz(101)
``` I love python!uh
no chance that works

that's not python

why do you have eng intl as your keyboard layout
import sys
def main(_argc: int, _argv: list):
sys.stdout.write((b"Hello world" + b'\x0a').decode('ascii'))
if __name__ == "__main__":
main(len(sys.argv), sys.argv)
Best hello world in python @finite rose
you haven't even gone close
i know
to what this channel has made
yeah i saw some things
some piece of sh-(code)
@quartz wave omg a new type in python
print(type(🥣))
Output:
<class 'cereal'>
python is a easy language just on the first pages
if emojis were supported you'd just do 🥣 = cereal in the cpython fork where i implemented the cereal type
Too simple for this channel
!e print(type(🙃))
@arctic skiff :x: Your 3.11 eval job has completed with return code 1.
001 | File "<string>", line 1
002 | print(type(🙃))
003 | ^
004 | SyntaxError: invalid character '🙃' (U+1F643)
Hmm
!d
wrong channel - use #bot-commands
LMAOOOO
HAHAHAHA
that's hilarious
brilliant
I just realized that a fun way to say True could be type(type) is type
!e print(type(type) is type)
@ornate cliff :white_check_mark: Your 3.11 eval job has completed with return code 0.
True
little sneak peek of one of my favorite projects ```py
from micro import macrodef
from enum import Enum, auto
@macrodef
def num(*args: ast.Name, class_name=TestEnum):
class $class_name(Enum):
for $p in $args:
$p = auto()
```py
num!(Add, Sub, Div, Mul, Pow, class_name=OpCode)
def! 
How are you hooking the parser, by the way?
because I'm making
class Option:
def (??)(self, other):
...
x = opt1 ?? opt2
and I'm not sure which approach is the cleanest (codec? import hook?)


chmoding the script in previous line 💀
if you're gonna pretend that it's python, add the directory to your $PATH, name the file python3 instead of python4, and clear the console before you run it
mv python4 python3
export PATH="$(pwd):$PATH"
clear
if you just want the code object you can compile the ast, but if you want the actual source you can use ast.unparse
no that i know
func.__code__ = compile(tree, '<preprocessed>', 'exec') # why doesnt this work
"doesn't work" is entirely too broad
right
what are you expecting it to do and what does it do?
well
what are the error messages?
none. just doesnt do anything when i call func later
what's the tree?
give me a couple minutes ill make up something reproducible
@pure dew !e
import inspect
import ast
def tester():
print(3)
tree = ast.parse(inspect.getsource(tester))
tree.body[0].body[0].value.args[0].value = 2
tester.__code__ = compile(tree, '<ast>', 'exec')
tester()
also, this is functional now https://totally-not.a-sketchy.site/5qoCpnb.png

why is it that after the edit, this doesn't print anymore?
because you're cramming the code object for an entire module into a function body
ahaa
you can go pull the codeobject for tester out of the compiled module (code.co_consts[0]) and use it
or
no, try that
that works and seems to be the right approach, thanks
hmmm
class TypeOverloader(type):
def __repr__(self) -> str:
return f'<class \'{self.__name__}\'>'
class cereal(metaclass=TypeOverloader):
def __init__(self, value: str) -> None:
if value != '🥣':
raise TypeError('No cereal.')
self.x: str = value
def __call__(self, value: str) -> 'cereal':
if value != '🥣':
raise TypeError('No cereal.')
self.x = value
return self
def __str__(self) -> str:
return repr(self)
a = cereal('🥣')
print(type(a)) # <class 'cereal'>
I did it
syntax macros: https://totally-not.a-sketchy.site/8jjoixa.png
procedural macros: https://totally-not.a-sketchy.site/7fyD9j9.png


how do you parse function headers and calls
import hook
wouldn't it result in invalid syntax with $
while ['False']:
print("Hello World")
i retokenize each file when its imported
ok
well no
retokenizing just makes the illegal characters safe
the actual macro invocation happens entirely in the AST
except for proc macros, which passes the AST node to the compiled macro function
If I keep this up I'll probably implement an entire system for re-evaluation of the AST
might look at contributing to the macro pep too
sounds like you have good stuff to contribute then 
i don't know C well enough tho :(
https://raw.githubusercontent.com/im-razvan/Python-Obfuscator/main/out.py
First py obfuscator i made
what should i improve
# https://github.com/im-razvan/Python-Obfuscator
a = "coding"
print(f"I like {a}")```edit the original source code
don't pack it
Python Reversing
Many Python obfuscators make the same mistakes, they use exec or eval to execute the code. They use compressors like zlib and lzma to then just pass the original code to the exec call.
read this if you're confused
thank you
better yet, pack the edited source code?
then obfuscate that?
so that is nothing but obfuscated code to unpack more obfuscated code to run?
thats the joke
ah
I see
sorry, I'm not really good at understanding jokes as English is not my primary language
thank you for explaining <3
np
i just wrote code that looks like this:
while True:
for ... in ...:
for ... in ...:
if ...:
continue
if ...:
break
else:
for ... in ...:
...
yield ...
break
else:
break
i love it
looks pretty average for a lexer
it is working code (actually i have something instead of ...'s)
ik
#include <stdio.h>
#include <stdint.h>
int main() {
int_fast16_t r1 = 1;
int_fast16_t r2 = 0;
int_fast16_t r3 = 1;
int_fast16_t r4 = 0;
int_fast16_t r5 = 0;
int_fast16_t r6 = 0;
for (;;) {
if (r5) { ++r2; --r5; } else
if (r3 && r2 && r2-1) { ----r2; --r3; ++r4;++++r5; } else
if (r1 && r2) { --r1; --r2; ++r5; ++r6; } else
if (r2) { --r2; ++r4; } else
if (r4 && r6) { ++r1; ++r3; --r4; --r6;
if (!r4 && r1 == r3) printf("%d ", r1); } else
if (r4) { ++r2; --r4; } else
if (r6) { ++++r1; ++++r2; ----r3; --r6; } else
if (r1) { --r1; } else
{ ++++r1; ++++r2; --r3; }
}
}
i know it is not python, but i think it is good for this channel
it prints infinite sequence of primes
nice
but what does ++++ do
#include <stdio.h>
#include <stdint.h>
int main() {
int_fast16_t r1 = 1;
int_fast16_t r2 = 0;
int_fast16_t r3 = 1;
int_fast16_t r4 = 0;
int_fast16_t r5 = 0;
int_fast16_t r6 = 0;
for (;;) {
if (r5) { ++r2; --r5; } else
if (r3 && r2 && r2-1) { r2-=2; --r3; ++r4; r5+=2; } else
if (r1 && r2) { --r1; --r2; ++r5; ++r6; } else
if (r2) { --r2; ++r4; } else
if (r4 && r6) { ++r1; ++r3; --r4; --r6;
if (!r4 && r1 == r3) printf("%hd ", r1); } else
if (r4) { ++r2; --r4; } else
if (r6) { r1+=2; r2+=2; r3-=2; --r6; } else
if (r1) { --r1; } else
{ r1+=2; r2+=2; --r3; }
}
}
``` fixedit may be worth noting that https://stackoverflow.com/a/48203451 suggests that ++++a is C++-exclusive
yes but they use .h header includes and printf here
but it still works in C++ anyway
the macro definition is now a macro itself https://totally-not.a-sketchy.site/3RkV91S.png

well this works about as well as I could have expected (the ast lib is rather fussy tho) https://totally-not.a-sketchy.site/8Cp7CnB.png
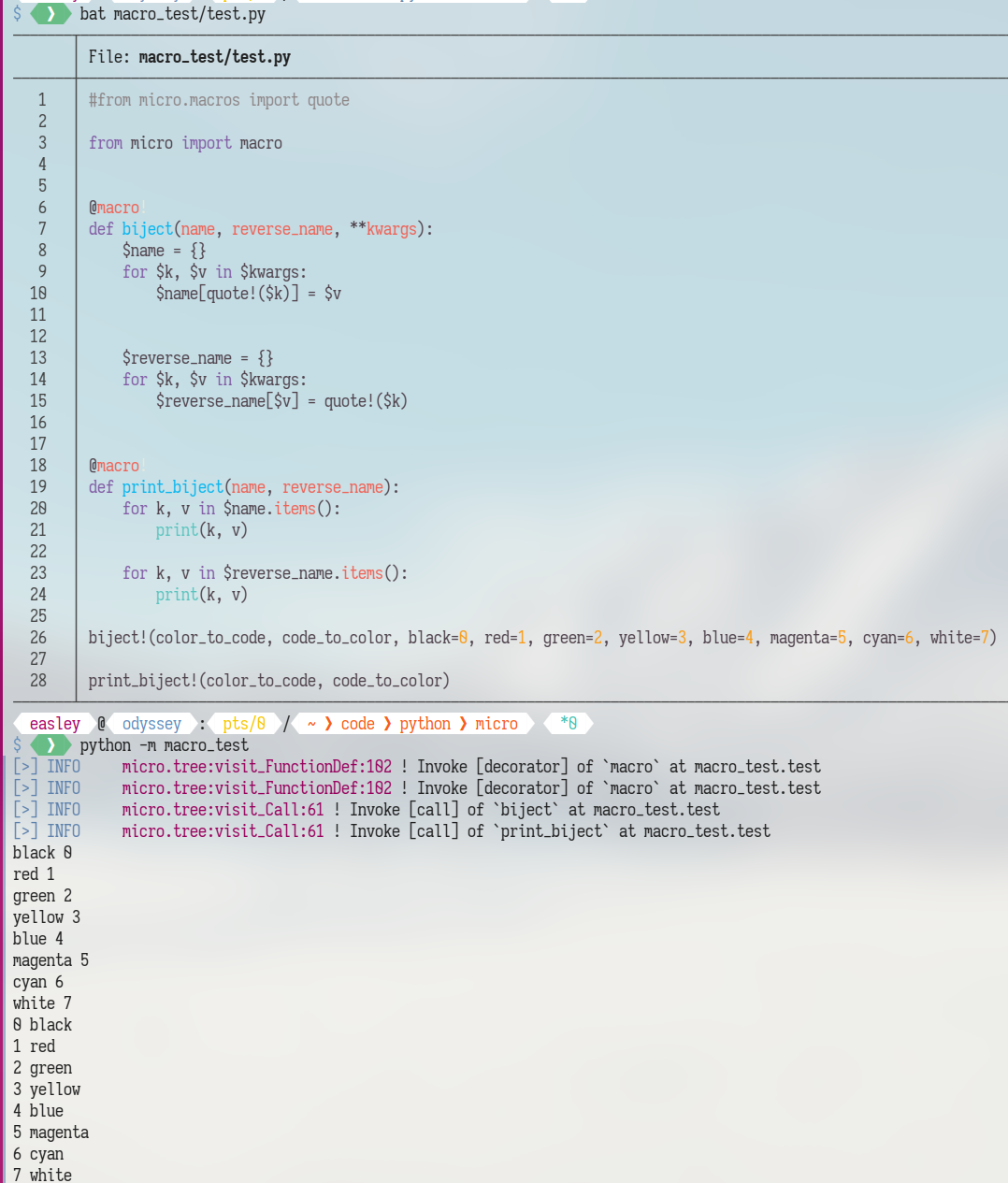
source if anyone's interested: https://gitlab.a-sketchy.site/AnonymousDapper/micro
what about using tokens instead of ast
i'm gonna recreate this but it uses encodings and tokens
well then I wouldn't have ast macros, I'd just have tokenstream functions
so it never prints...?
I was scrolling up into the history of the channel and found this. I'm going to attempt to expand on it.
it is incrementing var twice
it is ok for C++, but SyntaxError in C
i find ++++x more esoteric than x+=2
maybe we can write ++ ++x or ++(++x) in C
it's not a "syntax error" in C
rather, an r-value assignment error
bruh what
can do ++x,++x maybe
might not be ub since , ignores
int main() {
int x = 0;
printf("%d\n", (++x, ++x));
}
got it
++x is rvalue in C and lvalue in C++
so in C ++ ++x is equal to ++rvalue which is bad
It does
hi this looks interesting (idk anything about this)
are u making a language? i am interested
def vb(v, b):
d = eval("""exec('''c = ( ( (v+1)*(b-1)+b ) // b ) // b
d = 0
while c: d += 1; c //= b''') or d""")
return d
😄
Does it work?
it is C

Infinite sequence of primes
Is this valid code?
It's not. Why don't you try it out?
Because my code is nowhere near finished. I don't know how to make a while loop within a one liner.
I am trying to do this in one line.
This is what I have.
2-argument iter can help with that, something like return next(d for x in iter(lambda: (c and (d:=d+1, v:= v//b) and None or ...), ...) if x != None))
Hmm..
golfed a bit (works only in C, to compile in C++ add #include<stdio.h> (im not sure if it works, i didnt test it)):
main(){for(int a=1,b=0,c=1,d=0,e=0;;)c&&b>1?d++,c--:a*b?a--,e++:b?b--,d++:d*e?a++,c++,d--,e--,d||a!=c?0:printf("%5d",a):d?d--,b=1:(b=2,c--,!e?a=2:(c--,e--,a+=2));}
!e same program in python:
r1, r2, r3, r4, r5 = 1, 0, 1, 0, 0
while 1:
if r3 and r2 > 1: r3 -= 1; r4 += 1
elif r1 and r2: r1 -= 1; r5 += 1
elif r2: r2 -= 1; r4 += 1
elif r4 and r5:
r1 += 1; r3 += 1; r4 -= 1; r5 -= 1
if not r4 and r1 == r3:
print(end=f'{r1:5} ')
elif r4: r2 += 1; r4 -= 1
elif r5: r1 += 2; r2 += 2; r3 -= 2; r5 -= 1
elif r1: r1 -= 1
else: r1 += 2; r2 += 2; r3 -= 1
@fleet bridge :x: Your 3.11 eval job timed out or ran out of memory.
2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97 101 103 107 109 113 127 131 137 139 149 151 157 163 167 173 179 181 191 193 197 199 211 223 227 229 233 239 241 251 257 263 269 271 277 281 283 293 307 311 313 317 331 337 347 349 353 359 367 373 379 383 389 397 401 409 419 421 431 433 439 443 449 457
These programs are equivalent to 3/11 847/45 143/6 7/3 10/91 3/7 36/325 1/2 36/5 FRACTRAN program with input 10
https://esolangs.org/wiki/Fractran
Click the button to be sent your very own bookmark to [this message](#esoteric-python message).
I have a question regarding local variables in class methods persisting across calls.
I have a method
def recursive_func(self, element, root_element={}, constructed_element={}, name=[], first_call=False):
if first_call:
root_element={}
constructed_element={}
name=[]
...
self.recursive_func(element, root_element, constructed_element, name)
the method is called in a loop
for el in elements:
self.recursive_func(el, first_call=True)
The variables are not returned by the function & are deepcopied then append to a class variable / not referenced outside of the method.
Why do root_element, constructed_element, & name persist across calls?
Not recursive calls, but the outer loop passing in new elements
not sure how this is related to esoteric python
I put it here since I found it to be python weirdness. what would be a better channel in your opinion
default mutable arguments (list and dict mostly) persist across function calls
😮 why
better to do something like
def func(self, name = None):
name = name or []
...
i don't know the details
this is sorta esoterica imo
e! not esoteric but i love it
while not ("True"=="False"):
print("If I try to fail but succeed.. What did I do?")
or
while not None:
that's because you used mutable objects as a default argument.
this is highly discouraged, exactly because of the behavior you're seeing.
in a nutshell, every iteration/call would relate to the same object's id.
meaning any modifications you do in a call prior would persist to the next one.
a quick solution for this would be to set these default arguments within the function's scope.
generating a new object every run.
def rec_func(self, name: list = None):
# if name is None:
# name = []
name = name or []
...
!tags mutable
Mutable Default Arguments
Default arguments in python are evaluated once when the function is
defined, not each time the function is called. This means that if
you have a mutable default argument and mutate it, you will have
mutated that object for all future calls to the function as well.
For example, the following append_one function appends 1 to a list
and returns it. foo is set to an empty list by default.
>>> def append_one(foo=[]):
... foo.append(1)
... return foo
...
See what happens when we call it a few times:
>>> append_one()
[1]
>>> append_one()
[1, 1]
>>> append_one()
[1, 1, 1]
Each call appends an additional 1 to our list foo. It does not
receive a new empty list on each call, it is the same list everytime.
To avoid this problem, you have to create a new object every time the
function is called:
>>> def append_one(foo=None):
... if foo is None:
... foo = []
... foo.append(1)
... return foo
...
>>> append_one()
[1]
>>> append_one()
[1]
Note:
• This behavior can be used intentionally to maintain state between
calls of a function (eg. when writing a caching function).
• This behavior is not unique to mutable objects, all default
arguments are evaulated only once when the function is defined.
I kind of assumed that's what was happening based on the behavior I was seeing, but it's not the behavior I expected & wanted to confer & confirm that's what was occurring.
It's not accepted

Hello I need help for a problem in physics if anyone could help me
Doesn't sound like an #esoteric-python question OR a python question... #❓|how-to-get-help
https://pyob.zeynox.fun/
I made an obfuscator what do yall think about it?
Python Source Code Obfuscator, Protect Python Source Code
async def infinite_primes():[print(i,end="\r")or await __import__("asyncio").sleep(0.01,result=i)for i in __import__("itertools").count(start=1,step=2)if i>=2 and all(i%n for n in range(2,int(i**.5)+1))]
__import__("asyncio").run(infinite_primes())
I don't really like this syntax honestly
it's going to be confusing for people too because it looks like an anonymous func
(lambda...:...)
doesn't look too much like =>
if anything, looks like a member access of pointer
struct somestruct {
int e = 4;
char f = 'f';
};
int main() {
somestruct s{};
somestruct* s_ptr = &s;
int a = s_ptr -> e;
}
js's is arg => body
C# and D also use =>
plus elixir, haskell, java, julia and perl use ->, as well as it's used for return types in python
an arrow doesn't fit at all there imo lol
oh
I don't know js, sorry
I mean imo someobject->someattr is better than (*someobject).someattr
which is what the arrow is syntactic sugar for
C++ has the worst lambda syntax across all languages i know
meanwhile, perl: sub { my ($a, $b) = @_; ... }
using perl to demonstrate unreadable syntax is cheating - there's a reason it's been called a write-only language
At least they got pretty good regex
source?
i think that makes it more memorable in the way that lambdas defer execution like how the default expression's execution is deferred

square(2, 5) 💀
square = lambda x, *, ret=>x**2: ret
Why
have they added this syntax to 3.12 already? https://peps.python.org/pep-0671/
Status: draft
oh, im dumb
yes but there's already a syntax for that
there should probably be no way someone would confuse something in an parameter list for a value
unless of course they somehow forgot that def (then a name and inside parentheses) and lambda (until a colon) indicates parameter lists
does this literally just use a list and randomly generated sequences of I and l
Nah
seems like so
 nah
nah
so we can look at it?
In [6]: import zlib
...: import codecs
...:
...: code = (codecs.decode(zlib.decompress(bytes(b'x\xda\x8d\x8dA\x0e\xc2 \x10E\xf7\x9e\x82t5\x13\xc7\n\xd62t\xe1\x018\x03\xe9\xa2j\x8d\x18B\tz\xffHu\xdd\xeab\xf2&\xf9/
...: \xff\xdb`C(gg\xcc\xfc"Xq\x12\xae\xdf\xd8\xa5\xb8\x1eR\x1a\xe3\x15\xaa\xaa~L>\xc2\xe5\x9e\xc1\xc7\x17\xf8=#\x8a\xdb\x94\x85\x17>\n\xc7R\x12K\xa6F\xb5\xc4\xcc\xa4\x8
...: d&VG2\xaa##[\xd2]C\x9a\xcb\xaf\x0e\x1f\xaf\xf8=\xe2\xef\xdd\x94\xcb\xda\x8a\xe7\x86\xf3\x13\xe4.\x8c\x11\x16\x1d\xdc*\xeca\xbdB\xfdQ\x81o\x1c\xdchM'))))
In [7]:
In [7]: print(code)
IlIlllIlIIllllIlIllllIllI = []
IlIlllIlIIllllIlIllllIllI.append("".join(chr(int(i/7)) for i in [700,707,315,777,686,714,819,805,693,679,812,707,700]))
IlIlllIlIIllllIlIllllIllI.append(print)
IlIlllIlIIllllIlIllllIllI[abs(0-len(IlIlllIlIIllllIlIllllIllI)+1)](IlIlllIlIIllllIlIllllIllI[abs(1-len(IlIlllIlIIllllIlIllllIllI)+1)])
In [8]: buff = []
In [9]: buff.append("".join(chr(int(i/7)) for i in [700,707,315,777,686,714,819,805,693,679,812,707,700]))
In [10]: buff
Out[10]: ['de-obfuscated']
In [11]: buff.append(print)
In [12]: buff[abs(0-len(buff)+1)]
Out[12]: <function print>
In [13]: buff[abs(1-len(buff)+1)]
Out[13]: 'de-obfuscated'
In [14]:
``` I don't think obfuscator would last long against someone who actually wants to check what it doeswait is that actually the output lmao
it's probably print("de-obfuscated")
yeah i've seen worse
Usually when you de-obfuscate you just rewrite it while renaming and simplifying stuff
yes
And since there is no junk code it's super easy to figure out whats going on
Didn't even take 5 mins
int(i/7) could've been i//7
not sure if i was talking to you but ok
ye ik
but that obfuscated output...
yea lol
Maybe if there was junk code put in perhaps it would've been more annoying to do
but then again I can always just find & replace to easily do it
Junk code ain't the way to solve such a problem
What do you think the solution is?
I already think it's fruitless to try to obfuscate python like that tbh
Since python code is very easily reversed
Use proper obfuscation techniques
Python code can be protected the same way as c# and there's definitely hard protections out there
You can see the source code beacause you only obfuscated a few lines. Imagine 100+ lines obfuscated like that
Can you show me a sample of obfuscated C#, I have no experience with C#
And, I think rather than obfuscating your code, couldn't you just like do everything server based?
So you're switching where the code stays where the user cannot see it
E.g ```sh
curl -H "Authorization: Bot {token}" https://discord.com/api/v10/users/:id
Of course there would be other things in play if you do it like this, like requiring internet
So there goes simple apps
Not good to rely on a server like that as it also will slow everything down a lot
Yea
But I would say that's pretty secure unless someone gained access to the server, which is a bigger issue at hand
Hey @serene stratus!
You either uploaded a .txt file or entered a message that was too long. Please use our paste bin instead.
who obfuscates 100+ lines
this channel maybe not
idc, i just asked for some advices
also wouldn't 100+ lines of code practically have (from-)imports and f-strings
fix that first maybe
you can replace them
heck no that's too much work
it really aint
like how is it not?
ik
the only way to do it fast is with regex
but you don't have variable-number regexes
print(f'Hello {a}') becames print("Hello "+a)
would i do that for tens of f-strings? no
exactly
ok go do that
i mean to be fair i still haven't solved the problem of blocks in my obfuscator
print("Lol: {}".format(a))
If you really want something similar you can do this
but that's because it's an expression-only underscore no-math-operator no-constants obfuscator
what ```py
decoded
IlIlllIlIIllllIlIllllIllI = []
import re as IllIlllIIlIlIIIIlIIllIIlIlllII
(_:=(____________________:=(__:=__builtins__.__getattribute__((___:=__name__.__class__.__doc__.__getitem__((__________:=(_____:=(___:=__name__.__getitem__(__name__.__class__().__len__())).__add__(___).__add__(___).__len__()).__mul__((_______:=(______:=(___:=__name__.__getitem__(__name__.__class__().__len__())).__add__(___).__len__()).__mul__(______).__add__(_____))).__add__((_________:=______.__mul__((________:=______.__mul__(______).__invert__().__neg__())))))).__add__(__name__.__class__.__doc__.__getitem__(__________)).__add__(__name__.__len__().__class__.__doc__.__getitem__(__name__.__class__().__len__())).__add__((_____________:=(_____________:=__name__.__ne__(__name__).__invert__()).__neg__().__truediv__(_____________.__add__(_____________).__neg__()).__rpow__(_____________).__class__).__name__.__getitem__(______)).__add__(__loader__.__class__.__doc__.__getitem__(______)).__add__((_______________:=__name__.__class__.__base__).__name__.__getitem__(__name__.__class__().__len__())).__add__(_____________.__doc__.__getitem__((_________________:=__name__.__eq__(__name__).__pos__()))).__add__(__loader__.__class__.__doc__.__getitem__(__name__.__class__().__len__())).__add__(__name__.__class__.__doc__.__getitem__(__________)).__add__(__name__.__class__.__doc__.__getitem__(__________)))))((_____________________:=_____________.__doc__.__getitem__(_________________).__add__((_______________________:=__builtins__.__dict__.__getitem__(__builtins__.__dir__().__getitem__((__________________________:=_____.__mul__((_________________________:=_____.__mul__(_____).__add__((________________________:=______.__mul__(______))))))))).__doc__.__getitem__(_________________))))))
@visual crest you might do it like this
it's the equivalent of import re as _ but you can't quite figure that out
hard to automate
it's not
only 600 lines and counting
real obfuscator programs would take much more lines
also it's not even complete with the dunders
help
it would become "Hello "+str(a)
(or repr, if str isn't supported for it)
usually if you're using fstrings you've got something that isn't a string, such as an int
also, what about fstring formatting
Hey @verbal sequoia!
It looks like you tried to attach a Python file - please use a code-pasting service such as https://paste.pythondiscord.com
can someone help me with KNN
iirc there's date/time formatting
so you get to do that by hand now
translating fstrings by hand can be a pain
if there's any amount of them
Hey @verbal sequoia!
It looks like you tried to attach a Python file - please use a code-pasting service such as https://paste.pythondiscord.com
@verbal sequoia #❓|how-to-get-help
This is cool but so so soooo not the point of Python
But as a developer of write only programming languages I love it
I agree. It'd be useful and I've wished Python had this feature multiple times myself, but it isn't the most Pythonic. Personally I don't care if they were to add it or not, but at the least it's an intriguing idea.
It'd help function signatures be much more expressive at least, that's a plus. one step away from kwargs=None spam
@quartz wave fishhook v0.2 is nearly done. just doing testing to make sure its stable. It fixes a bunch of major bugs like hook(object)
do you have any stuff that you know breaks it rn that I can test it with?
@fleet bridge ^
I rewrote it from the ground up with a new hooking and new orig strategy
i have a few things that it could be tested with
if that would be helpful
send them my way, that would be really helpful
ok
give me a few minutes, I'm on my phone rn so I have to go get my computer turned on and all that
💀 none of my files work in 3.11

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
thats all good, they might work with fishhook 0.2

Hey @versed eagle!
It looks like you tried to attach a Python file - please use a code-pasting service such as https://paste.pythondiscord.com
oh right
cant attach files
tests hook and unhook with getitem and setitem of dict
it kept segfaulting when I used orig so I didnt test that
testing object.__new__ hooking, unhooking, and function hooking
https://paste.pythondiscord.com/wadiqeciyo
int.__add__ hook test
https://paste.pythondiscord.com/oxeyiravam
im basically taking all the times i use fishhook and simplifying them down so that the only stuff thats actually being tested is what I use fishhook for
since you dont need to test all the stuff i wrote, just what you wrote
@rugged sparrow
heres a test that checks basically everything
https://paste.pythondiscord.com/ojaturipij
though it stops working halfway through because it fucks up somewhere when messing with pointers
sometimes segfaults, sometimes just hangs
but if you skip the bits it fails on, you can just redirect the output to a file and then verify that the output for both fishhook versions is the same
ill work on cutting out the bits it fails on in a few minutes, gonna go eat smthn first
the list of _not_func_dunders is far from complete, so thats my guess as to where a large number of errors/segfaults are going to come from
alr, filtered out a lot (I think all but not sure) of the non-method dunders
https://paste.pythondiscord.com/etosihedaz
yo guys help me w my code
wrong channel, #❓|how-to-get-help
this isnt a help channel
<@&831776746206265384> racial slur in pastebin D:
o.o
i hadnt even opened it
!ban 1022417867918024744 N-word.
D: No way
:incoming_envelope: :ok_hand: applied ban to @ionic quail permanently.
Cool. How can i run it to test? Does it support 3.11? Can i install latest version from github?
i haven't pushed latest yet, will do after i test the stuff that @versed eagle sent
and yea it supports 3.11 and 3.12 alpha
nice
GitHub
Collection of various snippets/files that I made. Contribute to thatbirdguythatuknownot/sniplections development by creating an account on GitHub.
ile star it
@rugged sparrow heres the current version of a test
https://paste.pythondiscord.com/mecikulaqi
it loops through types in builtins and tries hooking and unhooking dunders on all of them until something breaks
on my machine, it consistently segfaults on __eq__ of dict, but everything up until that works
what is this
how do you use this?
there like 400 files
actually wait, that one had a small problem
heres a fixed version
https://paste.pythondiscord.com/lojulatigi
because all of those are separate projects
dict tests worked

yay
actualyl dont use this one yet
im going to make it only print when it fails instead of printing everything it does
so that the output is readable
does py d = 2 assert d == 3 work in the __getitem__ test?
alr, @rugged sparrow final version of tests are here
only prints when it fails now
though if it segfaults it wont print
https://paste.pythondiscord.com/heyapimoma
no because globals doesnt actually call its dunder, it uses an internal method
so i've deprecated hook(cls, name=...)(non-callable) because now there is a force_setattr function
aw
output on my machine (with printing turned on) is this:
https://paste.pythondiscord.com/akagabajup
I dont use hook(cls, name=...)
in that test
i use hook(cls)(predefined_function)
- i also changed how i get the name of the function so you need to pass
name=if you are not using a properly defined func
its all good tho
ah
i was defaulting to a lambda and then changing it's __name__
@versed eagle well it didnt segfault
yea
it did hit a bug with my new orig implementation so gotta fix that
but i think its a logic error on my part
ah
do you want me to try to write a test for hook_cls as well?
i can probably do somthing similar to what i did here
hook_cls just wraps hook and force_setattr now
alr
hmm yea so the way orig works right now if you try to hook multiple methods on the same object with the same function it overwrites in the cache
hmm
i gtg
ping me if anything happens or whenever you push the new version into the repository
byee
@quartz wave @fleet bridge any ideas on how I could determine the attribute name of the function that a given code object came from? I am trying to fix some weirdness with orig and to do it I need to be able to determine (cls, dunder, code) from a give frame and arguments
cls and code are easy but dunder is tricky
or I enforce a new code object for each hook
like the name of the function it came from?
isn't that just code.co_name?
that doesnt cover py @hook(int, name='__add__') def inthook(self, other):...
could you just store it in an array, then loop through said array?
well i'm not sure if you're able to do that properly with not a lot of work
like, make some block of memory with a python object, then overwrite it with ctypes
and loop through the memory as you would a null terminated c array
doesnt work if different hooks use the same function on the same class
do you want orig to use the actual original, or just whatever was defined at the time that it was hooked?
whatever was defined at the time it was hooked (you can nest hooks)
maybe I could inject orig into the function as a const? and replace the LOAD_GLOBAL with a LOAD_CONST
but that is dangerous :/
from a given hook I need a way to determine what the original implementation was reliably
you could probably still do this
except treat it like a stack
store the first byte/few bytes as number of things on the stack
then have the rest be elements on the stack
then the orig of a hook will be whatever's on the stack at its index - 1
using orig
oh ok
that won't work for reused functions there is no way to determine which stack to use
(as far as i can tell)
oh and also I am trying to make it work for subclasses
but that part works
in this case, when orig is called, do you know what function is being called?
like, do you know that the name of what's being called currently (before orig) is sometype.__add__
@hook(sometype, name="__add__")
def somefunc(self, other):
return orig(self, other-1)
Instead of using given hook function, you can copy it for every call to @hook
func_copy = types.FunctionType(func.__code__, func.__globals__)
(after that, iirc, you should also copy __defaults__, __kwdefaults__ and __qualname__ from func to func_copy)
Does it solve your problem?
my issue is that I have to match with __code__ not func
because when orig is called, I only have access to frames
>>>
>>> @hook(int, name='__add__')
... @hook(int, name='__matmul__')
... def inthook(self, other):
... print(self, other)
... return orig(self, other)
...
>>> 1 + 2
1 2
3
>>> 1 @ 2
1 2
3
>>>
``` this is what happens rn, but `orig` when called from `matmul` should say it cannot find original implAdd RET and some random bytes to bytecode
Or, append all you need to .co_const
I guess I could append to co_const (which would make a copy of code) and then orig would grab the last value
from the code co_consts
@hook should copy function and patch its bytecode. Use this function as actual replacement for dunder. Then return original passed function, so next call to @hook can copy this function again
I think I will patch co_const with a custom object (so orig can verify that it has grabbed the right thing)
How orig works? Is it bytecode magic or actual function with frame mess?
function with frame mess
Nice
trying to avoid bytecode magic, cause rn 0.2 supports >=3.8 with the same code
bytecode would mean way more support effort per version
>>> @hook(int, name='__add__')
... @hook(int, name='__matmul__')
... def inthook(self, other):
... print(self, other)
... return orig(self, other)
...
>>> 1 + 2
1 2
3
>>> 1 @ 2
1 2
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 5, in inthook
File "<redacted>", line 194, in orig
raise RuntimeError('original implementation not found')
RuntimeError: original implementation not found
>>>
``` got it working@fleet bridge @versed eagle @quartz wave it is pushed as v0.2.1
enjoy reading through the result of literally a years worth of research
Officially no more manual slot pointer bs
Link?
!pypi fishhook

Allows for runtime hooking of static class functions
nice
Lmk when you break it
>>> @hook(type)
... def __call__(_, *args, **kwargs):
... return a(*args, **kwargs)
...
Fatal Python error: _PyErr_NormalizeException: Cannot recover from the recursive normalization of an exception.
Python runtime state: initialized
Current thread 0x00000710 (most recent call first):
<no Python frame>
``` just didwithout the a thingy defined ```py
C:\Users\rog>py
Python 3.11.0 (main, Oct 24 2022, 18:26:48) [MSC v.1933 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
from fishhook import hook
@hook(type)
... def call(_, *args, **kwargs):
... return a(*args, **kwargs)
...
Fatal Python error: _Py_CheckRecursiveCall: Cannot recover from stack overflow.
Python runtime state: initialized
yea type.__call__ will always be finicky its used in too many places in the runtime
It basically hooks the root tp_call (which means when it tries to call your hook function it hits back into the root tp_call
ok
yay!
Other stuff that didn't work before should be more stable now tho like object hooks
well i got an interesting error
was fucking around with <class 'function'>.__new__ and got this
@hook(type(lambda:0))
... def __new__(cls, *args, **kwargs):
... return type(cls.__name__, cls.__bases__, cls.__dict__ | {"__call__":(lambda *a, **kw:print(a, kw))})(*args, **kwargs)
...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/maxdemar/.local/lib/python3.11/site-packages/fishhook/__init__.py", line 245, in wrapper
func_copy = type(func)(
^^^^^^^^^^^
File "<stdin>", line 3, in __new__
TypeError: type __qualname__ must be a str, not getset_descriptor
>>>
Huh weird
did you have other hooks in place at the time?
>>> from fishhook import *
>>> @hook(type(lambda:0))
... def __new__(cls, *args, **kwargs):
... return type(cls.__name__, cls.__bases__, cls.__dict__ | {"__call__":(lambda *a, **kw:print(a, kw))})(*args, **kwargs)
...
>>>
>>> def foo():pass
...
>>> foo.__new__
<bound method __new__ of <function foo at 0x10fdd22a0>>``` it doesnt error on my endprob other hooks in place
i probably had another hook then
yea i cannot get it to trigger on my end
heres my .python_history
from fishhook import *
type(lambda:0)
@hook(type(lambda:0))
def __new__(cls, *args, **kwargs):
return type(cls.__name__, cls.__bases__, cls.__dict__ | {"__call__":(lambda *args, **kwargs:print(args, kwargs))})()
def f():
return 4
f()
print(type(f))
print(type(f)())
@hook(type(lambda:0))
def __new__(cls, *args, **kwargs):
return type(cls.__name__, cls.__bases__, cls.__dict__ | {"__call__":(lambda *a, **kw:print(a, kw))})(*args, **kwargs)
i had defined it previously
and then redefined it
thats what caused the error, i think
ah yea I see why it broke
yea because I need to clone the function
yeah
whereas my thing returns a new type
so
it fucks up
can you store the original function type
at the beginning of the module?
your think also doesnt look like it works quite right
doesnt
yea i think im gonna consider this one not a bug cause its caused by a hook that doesn't follow the method its replacing's spec
Python 3.11.0 (main, Oct 25 2022, 14:13:24) [Clang 14.0.0 (clang-1400.0.29.202)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> cls = type(lambda:0)
>>> type(cls.__name__, cls.__bases__, cls.__dict__ | {"__call__":(lambda *a, **kw:print(a, kw))})(*args, **kwargs)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: type __qualname__ must be a str, not getset_descriptor
>>>
``` yea its an error inside your hookwhen you pull function.__dict__ it pulls the __qualname__ getsetter
@quartz wave i was wrong? you can hook type.__call__, just need to ensure it cannot fail i think ```py
Python 3.11.0 (main, Oct 25 2022, 14:13:24) [Clang 14.0.0 (clang-1400.0.29.202)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
from fishhook import *
@hook(type)
... def call(*args, **kwargs):
... print(args, kwargs)
... return orig(*args, **kwargs)
...
(<class 'memoryview'>, <fishhook.c_char_Array_408 object at 0x10d25d5b0>) {}
(<class 'ctypes.py_object'>, <class 'type'>) {}
class A:pass
...
(<class 'type'>, 'A', (), {'module': 'main', 'qualname': 'A'}) {}
a = A()
(<class 'main.A'>,) {}
``` so it cannot have any exceptions, becausetype.__call__is required for exception handling (thus the recursion error)
also just pushed 0.2.2 that makes orig trace backwards up frames
great! so now orig can frame other objects for its crimes muahahaha
It means that now you can call orig in any subframe under a hooked method and it will do its best to figure out the original implementation. Helps it be even more magical
@quartz wave @fleet bridge @floral meteor I am trying to decide on a syntax for hooking properties, heres what I have so far ```py
@hook.property(int)
... def imag(self):
... print(imag.orig)
... return imag.orig.get(self)
...
1 .imag
<attribute 'imag' of 'int' objects>
0
any better ideas for it?
I am not a fan of how orig works in property hooks rn
from fishhook import hook, prophook
prophook not hook.property?
hook.property looks good for me too
I just need to decide how I want orig to work
do you have type annotations or stubs for fishhook? it will be good if type-checker will be able to infer some types (as Any at least)
Not currently, Prob should implement that
I just need to decide how I want orig to work
yes, it is not obvious in descriptor case
that'll come after i figure out this property syntax
in a perfect world i could do ```py
@hook.propery(<cls>)
def <prop name>(self):
print(orig) # make this magically call cls.propname.__get__
maybe orig_get(self), orig_set(self), orig_del(self)?
or assign orig to original descriptor object, so we can do orig.__get__(a,b)
currently it sets orig to the original descriptor
functions are also descriptors
I'd prefer a separate function instead of hook.property
it would also be available as a seperate function
Or in general something specifically for descriptors
this is the current implementation ```py
class hook_property:
def init(self, cls, name=None):
self.cls = cls
self.prop = property()
self.name = name
self._orig = NULL
@property
def orig(self):
if self._orig is not NULL:
return self._orig
else:
raise ValueError('Original Value Not Found')
def _set_prop(self, prop):
names = [self.name] + [p.__name__ for p in [prop.fget, prop.fset, prop.fdel] if p]
for name in names:
if name is not None:
self.name = name
break
if self.name is None:
raise RuntimeError('Invalid Hook')
orig = vars(self.cls).get(self.name, NULL)
if orig is not self.prop:
self._orig = orig
force_setattr(self.cls, self.name, prop)
self.prop = prop
def unhook(self):
if self.name is None:
raise RuntimeError('Invalid Hook')
orig = self._orig
if orig is NULL:
force_delattr(self.cls, self.name)
else:
force_setattr(self.cls, self.name, orig)
def __call__(self, func):
return self.getter(func)
def getter(self, func):
self._set_prop(self.prop.getter(func))
return self
def setter(self, func):
self._set_prop(self.prop.setter(func))
return self
def deleter(self, func):
self._set_prop(self.prop.deleter(func))
return self
hook.property = hook_property```
It's a bit nonstandard for an API though it works fine
I just liked it because it makes ```py
hook(<cls>)
def <...>
hook.property(<cls>)
def <...>
why you need separate functionality for properties? you are simply assigning some value into class dict (and patching slots maybe), so why methods and properties are different?
@hook(int)
def __add__(self, other): something
# almost equivalent to:
int.__dict__['__add__'] = __add__
@hook(int)
@property
def bit_count(self): something
# almost equivalent to:
int.__dict__['bit_count'] = property(bit_count)
i think your current code for hook will work for properties too (if you remove some checks or skip some code paths)
it works but makes unclear on how to do set/get and del on the same hook
i guess you should add check here to check that func is actual function
if it isnt, call force_setattr

because I could make it work with hook, but you would have to do this ```py
@property
def bit_count(self): something
@hook(int)
@bit_count.setter
def bit_count(self): something```
it just isn't super clear
@property
def x():...
@x.setter
def x():...
@hook(int) # actual hooking is happening here
@x.deleter
def x():...
yea imo thats unclear as to what the actual hook applies to
hmm
you can write your own property, that is mutating itself instead of returning new property
so:
@hook(int)
@YOUR_PROPERTY
def x():...
@x.setter
def x():...
@x.deleter
def x():...
# OR
# shorter way to do the same thing:
@hook.property(int)
@hook_property(int) # or this
def x():...
@x.setter
def x():...
@x.deleter
def x():...
yea the second one is my syntax rn
and if you want to do some updates of setters, you can do it after every call to .setter or .deleter or do it when descriptor is called first time
Also you can implement that syntax: ```py
@hook(int)
@property # it is builtin property!
def x():...
@x.setter
def x():...
@x.deleter
def x():...
and replace `property` object with your custom `property` that is mutating itselfi think it is the most convenient implementation for users
the only issue I have with that is that my current orig strategy doesn't work conceptually for descriptors
you are not returning ncls from wrapper, so int_hook will be none after applying this decorator. It this intended?

to be fair, you can already hook properties pretty easily using hook_cls, there just isn't a mechanism for orig
I decided to just unhook the property inside of property hooks ```py
@hook.property(int)
... def imag(self):
... print('in int.imag', self.imag)
... return self.imag
...
1 .imag
in int.imag 0
0
Is this not an option for regular hooks as well?
regular hooks have orig rn, I haven't added unhooking to those *you can still unhook a hook using unhook
tbh that has been a personal debate lmao, I can't decide whether hooks should persist inside themselves
also I feel like most users expect that regular hooks get called directly, not by a wrapper function, and I don't want to break people doing stuff with frames from hooks
I've always found orig a bit confusing. But yeah, that makes sense, if you'd always need a wrapper then...
you just have to think about it like a proxy to the original implementation
yea and I can't use a custom object for the wrapper to enable orig, frame stripping, and unhooking because dunders need to be bound properly and custom objects break that in weird places
the only reason I am doing it for properties is because it seems like the most user friendly way to do it (it will either be unhooking or a proxy orig on the hook_property object
I mostly made it that way so the end user can choose whether or not a hook runs in a hook. like if you hook int.__add__ and want to add a and b with your hook, you just do a + b, but if you want to do the original implementation, you do orig(a, b)
perhaps @hook.name_of_property(cls)
so that you can pass previously defined functions and lambdas?
alternatively, @hook(cls).name_of_property
for the same reasons as the other one
basically it comes down to which syntax you like better
and then you could make it so that this
@hook(cls)
def something(*_,**__):
...
is equivalent to either this
@hook.something(cls)
def whatever(*_,**__):
...
or this
@hook(cls).something
def whatever(*_,**__):
...
right now @hook.property(cls, name=None, fget=None, fset=None, fdel=None) is the syntax
and you can use the resulting object like a property to define if wanted
so ```py
@hook.property(cls)
def prop(self): ...
@prop.setter
def prop(self, val): ...
@prop.deleter
def prop(self): ...```
and you can pass in your get, set, and del into the constructer if you want
and then prop.unhook() unhooks the property
cool
I just have to decide if I want to provide prop.orig as a proxy to the original value, or unhook the property in the hook
would this work
@hook.name_of_property(cls, fget=None,fset=None,fdel=None)
I mean, the hook is supposed to replace the original
so having the original be easily accessible from the outside wouldn't be that good
so could you make the orig for the property only available inside the hooked property?
that's what would make sense to me, ig
not without making hook a custom object
yea it would be
if you're doing @hook.property, isn't it already custom?
functions don't have a .property (unless you hook function.__getattribute__ or smthn like that)
You can add attributes to functions
oh. I'm stupid lmao
completely forgot about that
lol all good
i think, its good
type-checkers also can infer types
is fishhook intended to be fast? or you dont care?
Fast-ish?
In a perfect world fishhook will only add overhead when it is actually installing a hook, and when a magic function is used (orig, prop.orig)
thats why I want to avoid wrapping functions with any overhead
Question: why the foyak does it not work
Like its generating different code
thats very strange
153 0 LOAD_FAST 0 (x)
2 LOAD_CONST 1 (1)
4 BINARY_ADD
6 RETURN_VALUE
8 LOAD_FAST 0 (x)
10 RETURN_VALUE
None
```3.10 Above, 3.11 Below```py
152 0 RESUME 0
153 2 LOAD_FAST 0 (x)
4 LOAD_CONST 1 (1)
6 BINARY_OP 0 (+)
10 RESUME 0
12 LOAD_FAST 0 (x)
14 RETURN_VALUE
None
first on, WHY THE FUCK IS THERE A RESUME
and why is the RETURN_VALUE turned into a resume?
and accessing KWARGS crashes it
3.11 changes the bytecode significantly
just pushed the hook.property code to git and pypi. how do you recommend I add typechecking?
ive never done it properly in python, I mostly abuse annoations for hacky stuff lol
how did you get a RESUME in the middle of the code
you injected something in didn't you
Add empty py.typed (iirc) into your package
And add type annotations to all public api functions (or to all your functions, if you want)
If u need help with typing you can ask me or ask in #type-hinting
ye empty py.typed is necessary
I like the idea of making orig an attribute instead of a global magic object
😬 i just changed it back
because other wise its easy to end up with recursion issues
its pushed to the github as v0.2.5
!e ```py
import base64
eval(base64.b64decode(b"==cH=Jp=bnQ==OO0O00O0O00O0OOO==OO0OO0O0O0000O0O=========SHITTY_HAZE_OBFUSCATION===============yl====zYX====="))("Hello World!")```
@sick hound :white_check_mark: Your 3.11 eval job has completed with return code 0.
Hello World!
funny
what does the obfuscation even do if it doesnt hide what you are printing 
Obfuscates the obfuscation
probably
maybe that was the esoteric part
Okay
I fixed it
now it uses a RESUME
also the Mixin property globals crashes
so I gotta fix that
wait wha
[Instruction(opname='RESUME', opcode=151, arg=0, argval=0, argrepr='', offset=0, starts_line=119, is_jump_target=False, positions=Positions(lineno=119, end_lineno=119, col_offset=0, end_col_offset=0)), Instruction(opname='LOAD_GLOBAL', opcode=116, arg=1, argval='rt', argrepr='NULL + rt', offset=2, starts_line=121, is_jump_target=False, positions=Positions(lineno=121, end_lineno=121, col_offset=15, end_col_offset=17)), Instruction(opname='PRECALL', opcode=166, arg=0, argval=0, argrepr='', offset=14, starts_line=None, is_jump_target=False, positions=Positions(lineno=121, end_lineno=121, col_offset=15, end_col_offset=19)), Instruction(opname='CALL', opcode=171, arg=0, argval=0, argrepr='', offset=18, starts_line=None, is_jump_target=False, positions=Positions(lineno=121, end_lineno=121, col_offset=15, end_col_offset=19)), Instruction(opname='RETURN_VALUE', opcode=83, arg=None, argval=None, argrepr='', offset=28, starts_line=None, is_jump_target=False, positions=Positions(lineno=121, end_lineno=121, col_offset=8, end_col_offset=19)), Instruction(opname='RESUME', opcode=151, arg=0, argval=0, argrepr='', offset=0, starts_line=116, is_jump_target=False, positions=Positions(lineno=116, end_lineno=116, col_offset=0, end_col_offset=0)), Instruction(opname='LOAD_CONST', opcode=100, arg=1, argval=False, argrepr='False', offset=2, starts_line=117, is_jump_target=False, positions=Positions(lineno=117, end_lineno=117, col_offset=15, end_col_offset=20)), Instruction(opname='RETURN_VALUE', opcode=83, arg=None, argval=None, argrepr='', offset=4, starts_line=None, is_jump_target=False, positions=Positions(lineno=117, end_lineno=117, col_offset=15, end_col_offset=20))]
this big boi is crashing everything
ah thats why
####################################################
# globalsTestFunc #
####################################################
116 0 RESUME 0
117 2 LOAD_CONST 1 (False)
4 RETURN_VALUE
####################################################
# returnsTrue #
####################################################
113 0 RESUME 0
114 2 LOAD_CONST 1 (True)
4 RETURN_VALUE
####################################################
# globalsTestMixin applied to globalsTestFunc #
####################################################
116 0 RESUME 0
117 2 LOAD_GLOBAL 0 (rt)
its fricked up?
Bru
mixins acting weird
Bruh 😭
@royal coral :warning: Your 3.11 eval job has completed with return code 0.
[No output]
get rid of the resume halfway thru the function
or move back to 3.10
I did
Hi I was wondering if it's possible with any built in constructors for class objects to alter a 2d array of object values - as an example I can display some values from a class like this from a 2d array
class Thing:
def __init__(self) -> None:
self.val = 0
def __repr__() -> str:
return str(self.val)
class Manager:
def __init__(self) -> None:
#a 5x5 2d array of thing objects
self.folder = [[Thing()]*5 for i in range(5)]
def display_things(self) -> str:
return self.folder[0:5][0:5]
man = Manager()
print(man.display_things())
that will show a 5x5 2d array with 0's as their values
is there a way to alter values similarly? for instance something along the lines of
#tested this but it doesn't work
self.folder[0:5][0:5].val = 5
There isn't a way to do what you're asking for specifically but numpy arrays behave that way (ndarray + 1 does elementwise sum)
ty, I figured numpy would have some functionality to what I want but trying not to use modules and just double checking
I think this is a bit of an esoteric python question, as it has to do with imports: https://discord.com/channels/267624335836053506/1048333512266235985
ever had a situation where, in multiple files where you "from x import y" it gives you separate instances of Y?
import os
class string():
def __init__(self, __l__: int, __r__: tuple[int]) -> None:
self.real = bytearray(__l__)
for n in range(__l__):
self.real[n] = __r__[n]
def __repr__(self) -> bytearray:
return self.real
class out_stream():
def __init__(self, __fd__: int) -> None:
self.__fd__ = __fd__
def print(self, __v__: string) -> None:
__fp__ = os.fdopen(self.__fd__, "w")
__fp__.write(__v__.__repr__().decode("utf-8"))
__fp__.close()
chars = (72, 101, 108, 108, 111, 32, 87, 111, 114, 108, 100, 33)
out_stream(1).print(string(chars.__len__(), chars))
print hello world
import os as __os__
class __string__:
def __init__(self, __l__: int, __r__: tuple[int]) -> None:
self.real = bytearray(__l__)
for n in range(__l__):
self.real[n] = __r__[n]
def __repr__(self) -> bytearray:
return self.real
class __out_stream__:
def __init__(self, __fd__: int) -> None:
self.__fd__ = __fd__
def __print__(self, __v__: __string__) -> None:
__fp__ = __os__.fdopen(self.__fd__, "w")
__fp__.write(__v__.__repr__().decode("utf-8"))
__fp__.close()
__chars__ = (72, 101, 108, 108, 111, 32, 87, 111, 114, 108, 100, 33)
__out_stream__(1).__print__(__string__(__chars__.__len__(), __chars__))
fixed
the problem with this:
self.folder[0:5][0:5].val = 5
is that self.folder[0:5] returns a list, and doing [0:5] on it again returns another list
to change individual items, you can do self.folder[someindex][someindex].val = somevalue
you could make folder an object with a custom getitem
to alter a range of it, you can do
self.folder[0:5][0:5] = [[(t:=Thing(),setattr(t, "val", 5), t)]*5 for i in range(5)]
i would recommend making Thing() take an optional argument in __init__ as well, just to make your life a bit easier
that would also work
you could make folder store how many dimensions it has
then when you index into it, return a subfolder that has 1 less dimension
then when you get to 0 dimensions, have it expose a property called .val or something similar, and when something assigns to .val, it can go back and set all the items
Basic coding what?
Filename: dunders.py
__dunders__.py
__dunders____.____py__
I hate it, nice
Should be py __os__=__import__('os')
finally ```py
res = transform(b"""
... def a!(x): ($x+2)
... a!(hha) * a!(5) \
... / a!(2 + 3)
... """, False)
print(res)
(hha+2) * (5+2) \
/ (2 + 3+2)
can you show code?
is this the new version you told me about?
!e py type((_x_:=type(lambda:0)).__name__, _x_.__bases__, _x_.__dict__ | {"__init__": lambda: print("hello")})()
@turbid dragon :x: Your 3.11 eval job has completed with return code 1.
001 | Traceback (most recent call last):
002 | File "<string>", line 1, in <module>
003 | TypeError: type __qualname__ must be a str, not getset_descriptor
Sorry for ping - do I need hooks here?
Hm
No x dict has the getset descriptors for the function that overwrites some type attributes (__qualname__)
@turbid dragon :white_check_mark: Your 3.11 eval job has completed with return code 0.
['__annotations__', '__builtins__', '__call__', '__class__', '__closure__', '__code__', '__defaults__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__get__', '__getattribute__', '__getstate__', '__globals__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__kwdefaults__', '__le__', '__lt__', '__module__', '__name__', '__ne__', '__new__', '__qualname__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__']
I see
Is the fishhook version updated on @night quarry bot?
Yea
Should be v 0.2.5
It has tests now. And asm_hook is available as fishhook.asm.hook
Fishhook is pure python, needs no dependencies and it works in any environment, right?
Yea
How many files are in fishhook? One main file + some tests?
Nice, it is very convenient

Yea I tried to keep it organized while still adding tests
Prob could do with a few more tests
Still need to add type checking
would it be possible to overload the constant folding that Python does?
for example
from fishhook import *
@hook(int)
def __add__(self, other):
return self
print(5 + 3)
would print 5
I know its not currently a thing that can be done
but in theory, is there a way to do it?
You can use fishhook.asm.hook to hook pythonapi functions (and any addresses that you know are a function) so in theory if you hook something in the compiler
but not in the same module
^ yea was about to say that
ok
i will look into that
(_:=(type)((_X_:=lambda:0).__name__, (tuple)(), {f"{(_C__:=lambda:(''.__getattribute__)('join')([(chr)((2)*(3^5&10*(7+3))**2-(3%4))]*2))()}init{_C__()}":(lambda __:(4)if __.C_(__.__setattr__(_C__(),list(map(int,str(4*3-2)[::-1]))),7)else(None)), "C_": (lambda A,_c,B_: (eval((y:=lambda _Y:''.join(_Y))(((x:=y(list(map(lambda n: chr((2*n)+12+96), range(1,5)))))[1:3],chr(105),x[::3]))).__call__)(A.A(B_)[1])),"A":(lambda o,cc:(eval)(f"([o.__.append((sum)(o.__[(abs)(8%6)-4:])){(y:=lambda _Y:''.join(_Y))([chr((3*(n**2))+99)for n in range(1,3)]+['r'])}(_)in range(cc)],o.__)".__str__(),(locals)()))})());```Just worked on this for the past couple hours, can anyone guess what the output is?
cant guess but i can deobfuscate it
give me a few minutes
i am trying to deobfuscate without running it at all
same
running it would probably give it away
so
not gonna do that
dont run it just try to deobfuscate it
if you guys get it quickly i might have to sell my soul and make it worse
(
_:=(type)(
(_X_:=lambda:0).__name__,
(tuple)(),
{
# key __init__
f"{(_C__:=lambda:(''.__getattribute__)('join')([(chr)((2)*(3^5&10*(7+3))**2-(3%4))]*2))()}init{_C__()}":(
# def __init__(self):
# if self.C_(self.__setattr__('__', [0, 1]), 7):
# return 4
# else:
# return None
lambda __:(4)if __.C_(__.__setattr__(_C__(),list(map(int,str(4*3-2)[::-1]))),7)else(None)
), "C_": (
# def C_(self, unused, B_=7):
# print(self.A(B_)[1]) # got print from eval
lambda A,_c,B_: (
eval(
(y:=lambda _Y:''.join(_Y))(
(
# x = 'nprt'
(x:=y(list(map(lambda n: chr((2*n)+12+96), range(1,5)))))[1:3],
chr(105), # 'i'
x[::3] # 'nt'
)
)
).__call__
)(A.A(B_)[1])
), "A":(
# def A(self, cc=7):
#
lambda o,cc:(eval)(f"([o.__.append((sum)(o.__[(abs)(8%6)-4:])){(y:=lambda _Y:''.join(_Y))([chr((3*(n**2))+99)for n in range(1,3)]+['r'])}(_)in range(cc)],o.__)".__str__(),(locals)())
)
}
)()
);
``` this is as far as i got before i realized its a fibonacci thingyep, great work
was it sufficiently difficult? thats killed my brainpower for tonight
it was decently difficult
the [0, 1] got me suspicious at the beginning and then seeing the o.__.append confirmed my suspicisions
damnit i knew i should've hitten it better
!e py (_:=(type)((_X_:=lambda:0).__name__, (tuple)(), {f"{(_C__:=lambda:(''.__getattribute__)('join')([(chr)((2)*(3^5&10*(7+3))**2-(3%4))]*2))()}init{_C__()}":(lambda __:(4)if __.C_(__.__setattr__(_C__(),list(map(int,str(4*3-2)[::-1]))),7)else(None)), "C_": (lambda A,_c,B_: (eval((y:=lambda _Y:''.join(_Y))(((x:=y(list(map(lambda n: chr((2*n)+12+96), range(1,5)))))[1:3],chr(105),x[::3]))).__call__)(A.A(B_)[1])),"A":(lambda o,cc:(eval)(f"([o.__.append((sum)(o.__[(abs)(8%6)-4:])){(y:=lambda _Y:''.join(_Y))([chr((3*(n**2))+99)for n in range(1,3)]+['r'])}(_)in range(cc)],o.__)".__str__(),(locals)()))})());
@turbid dragon :white_check_mark: Your 3.11 eval job has completed with return code 0.
[0, 1, 1, 2, 3, 5, 8, 13, 21]
alr im done
def _init(self):
self.fib = [0, 1]
self.C_(7)
def C_(self, b):
print(self.A(b)[1])
def a(self, c):
for _ in range(c):
self.fib.append(sum(self.fib[-2:]))
return (None, self.fib)
_ = type(
'<lambda>'
(),
{
"__init__" : _init,
"C_" : C_,
"A" : A,
}
)()
hah, nice!
What esoteric alternatives are there to range?
uh
i think itertools has something?
itertools.count?
yeah
!e print(list(import("itertools").count())[:7])
@turbid dragon :warning: Your 3.11 eval job timed out or ran out of memory.
[No output]
hm
itertools.count is an iterator
if you turn it into a list it will just go on forever
yeah
___:=range_start_value,[for _ in iter((lambda:(___:=___+range_step_value,___!=range_stop_value)[-1]),False)]
you can make your own iterator!
!e print([(x:=import("itertools").count()).next()]*3)
@turbid dragon :white_check_mark: Your 3.11 eval job has completed with return code 0.
[0, 0, 0]
!e
print(x:=__import__("itertools").count(5),e:="whatever",[e for i in iter((lambda:e:=x.__next__()[-1]>=10),True)])
!e ```py
print(*["foo" for i in "."*10])
@old socket :white_check_mark: Your 3.11 eval job has completed with return code 0.
foo foo foo foo foo foo foo foo foo foo
lol thats one way to do it
But this wont work for getting it incremented
!e
print(((x:=__import__("itertools").count(5),e:=(lambda:0)),[e._ for i in iter((lambda:(e.__setattr__("_",x.__next__()),e._)[~0]>=10),True)])[-1])
@versed eagle :white_check_mark: Your 3.11 eval job has completed with return code 0.
[5, 6, 7, 8, 9]
i couldnt get it to work for a while cause im tired :(
i completely forgot python doesnt allow := inside iters inside comprehensions lmao
but works now
!e
(_range:=(lambda s,S,_s:((x:=__import__("itertools").count(s,_s),e:=(lambda:0)),[e._ for i in iter((lambda:(e.__setattr__("_",x.__next__()),e._)[~0]>=S),True)])[-1]))
print(_range(1, 20, 3))
@versed eagle :white_check_mark: Your 3.11 eval job has completed with return code 0.
[1, 4, 7, 10, 13, 16, 19]
!e ```py
import itertools
for i in itertools.takewhile(lambda x : x<=10, itertools.count()):
print(i)
@old socket :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | 0
002 | 1
003 | 2
004 | 3
005 | 4
006 | 5
007 | 6
008 | 7
009 | 8
010 | 9
011 | 10
No step, etc but you could prob add it a lot easier to this
!d itertools.islice
itertools.islice(iterable, stop)``````py
itertools.islice(iterable, start, stop[, step])```
Make an iterator that returns selected elements from the iterable. If *start* is non-zero, then elements from the iterable are skipped until start is reached. Afterward, elements are returned consecutively unless *step* is set higher than one which results in items being skipped. If *stop* is `None`, then iteration continues until the iterator is exhausted, if at all; otherwise, it stops at the specified position.
If *start* is `None`, then iteration starts at zero. If *step* is `None`, then the step defaults to one.surely just
!e ```py
import itertools
for i in itertools.islice(itertools.count(), 0, 10, 2):
print(i)
@astral rover :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | 0
002 | 2
003 | 4
004 | 6
005 | 8
hmm this is nice
!e print(dir([1]))
@turbid dragon :white_check_mark: Your 3.11 eval job has completed with return code 0.
['__add__', '__class__', '__class_getitem__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getstate__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
!e print([1].getitem(0))
@turbid dragon :white_check_mark: Your 3.11 eval job has completed with return code 0.
1
yes
coincidentally they were also discussing macros in #internals-and-peps
#internals-and-peps message
>>> res = transform(b"""
... def unless!(x): if not ($x)
... b = False
... unless!(b): # same as `if not(b):`
... print("Good")
... """, False)
>>> print(res)
b = False
if not (b): # same as `if not(b):`
print("Good")
>>>
Not c-style macros though
what's the difference between it and c-style macros other than the syntax
No I mean you're making c-style macros
ok
i.e. token stream substitution

GitHub
Token-based macro replacement using codecs/encodings. - GitHub - thatbirdguythatuknownot/python-token-macros: Token-based macro replacement using codecs/encodings.
this looks pretty solid, I'm impressed
does it do complex expressions?
like what?
iterative replacements, ie. varargs
varargs not yet
i have no idea what behaviour that should be
def make_enum!(*args):
class Test(Enum):
for $a in $args:
$a = auto()
oh ok
rust does it
i might do it like ```py
def make_enum!(*args):
class Test(Enum):
$for $a in $args:
$a = auto()
with tokenizing you can, yea
>>> from fishhook import *
>>> @hook(int)
... def __add__(self, other):
... print(self)
...
>>>
>>> print(5 + 3)
5
None
Seems to work as expected, no?
in the REPL yes
yes
constant folding is done before a piece of code runs
was fishhook?
whats*
Overwrites keyword functions?
what are keyword functions
those are called builtins
custom pypi module
might be simpler to use an import path record for micro, but it might force me to redesign the name resolution system or break it entirely
Hey @visual crest!
It looks like you tried to attach a Python file - please use a code-pasting service such as https://paste.pythondiscord.com
https://paste.pythondiscord.com/osukutowed
Is this safe? (is the obfuscator good?)
one thing I'd recommend doing is disguising the exec
because if someone sees an exec/eval, they know that whatever is there is gonna be a string
and they can just print out that string
to see whats happening
discord started using new font? it looked different
yeah they did
i dont think so. It is very easy to unpack your bytestring and then i can see some obfuscated code with long varnames (such as IIIIIiiiII). It is also not very hard to deobfuscate this code to readable code
pretty good
what about this one https://github.com/synnkfps/Virtus
very slow
this bit is slow
# Test each chr (n(O)) to be checked until you get the right thing
for e in s:
for i in range(10000):
if chr(i) == e:
obf.append(i)
also its incorrect since unicode goes past 10000
use ord
also, it uses exec
so you can just replace the exec with a print
and see whats going on
the main "advantage" of this one is that the files produced are large enough that they're annoying to deobfuscate, but thats just an inconvenience
@quartz wave is there an easy/better way, with fishhook.hook to dispatch to the previous implementation of the dunder you are replacing?
E.G.:
import fishhook
old_range_contains = range.__contains__
@fishhook.hook(range)
def __contains__(self, other):
if isinstance(other, (range, list, tuple, set)):
for i in other:
if i not in self: return False
else:
return True
else:
return range.__contains__(self, other)
yes, fishhook provides the magic function orig
!e ```py
import fishhook
@fishhook.hook(range)
def contains(self, other):
print('in contains')
return fishhook.orig(self, other)
print(1 in range(0))```
@rugged sparrow :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 | in contains
002 | False
@rugged sparrow :white_check_mark: Your 3.11 eval job has completed with return code 0.
001 |
002 | Inspects the callers frame to deduce the original implementation of a hooked function
003 | The original implementation is then called with all passed arguments
004 | Not intended to be used outside hooked functions
005 |
awesome, thanks!
That exec is added to lower the filesize
What sorts of language features should I be aware of for writing one liners? I've got __import__(''), list cop, the ; (which isn't really one lining).
Two argument form of iter is useful, [1 for x.y in [4]] for assigning attributes, ContextDecorator for error handling, 3 arg form of type.
ahh, alrighty, ty!
while loops can be done with iter calls
[something for unused in iter((lambda: condition), False)]
then of course there's walrus
though you don't need it to one line everything
really, just put everything in a tuple
can you help me?
how do i do that
take any files generated by the obfuscator and put them into the same directory as another script
the other script can literally be
exec(open("obfuscatedfile.py").read().replace("exec","print"))
and, at least given the examples that were in the github repo, it will just print out the source code
i mean
yeah but if u execute the source codes that are on the examples folder it will work
but what will it change
it will print the unobfuscated source code
what I'm saying is that if the obfuscator just disguises stuff and then uses exec, it's trivial to deobfuscate
so its easy to deobfuscate?
oh bruh yeah it is
i just saw it
i just added a print to what the exec does
and it revealed the source code

idk how can i prevent this
You'd have to obfuscate the code more before you encode
wdym?
actually modify the source code
don't just pack it
Python Reversing
Many Python obfuscators make the same mistakes, they use exec or eval to execute the code. They use compressors like zlib and lzma to then just pass the original code to the exec call.
sorry for the shameless plug 🙃
ok
Try to structure the article a bit
mm yeah I was considering that but it's so small that I didn't bother
feels excessively complicated for what is essentially compile = print
well yea in that simple use case it's unnecessary but I was just providing a more proper hook function in case someone still needs to call the original function
or call it and still return a fake return value
wrong channel to ask
#python-discussion would be better
oh ok sorry then
maybe it is wrong channel, but still...
i want to format some byte-like object like this:

currently i have this terrible code:

What is the middle line supposed to represent?
how can i draw pseudographics in pythonic way?
it is pointer to some byte
actually it is byte-buffer (byte array + index), and i want to print them in beautiful way to debug
i'd prefer to use stdlib only
Well the way I did this before was making an array then for-looping at the end to kinda rasterize it
2d array*
https://www.textualize.io/ I'll leave this here tho cause it's cool none the less

The terminal can be more powerful and beautiful than you ever thought
!e ```py
cout=type('',(),{'lshift':lambda self, text:print(text,end='') or self,'repr':lambda self:''})()
cout << 'hello' << ' ' << 'world' << '\n'
@plush halo :white_check_mark: Your 3.11 eval job has completed with return code 0.
hello world
what equivalents of bool(x) do you know? (x is int)
bool(x)(not not x)(x != 0)
x != 0 15 ns ± 237 ps [990 ms / 43339815]
bool(x) 20 ns ± 411 ps [1.0 s / 36441668]
not not x 13 ns ± 376 ps [979 ms / 47249070]
not not approach seems to be the most efficient according to my benchmarks
CPython 3.11*
i dont like new discord font
i don't see a gap
unless that's not what you're talking about
i dont like this blurry asterisk
ok
it was better iirc
x is not 0
not a very recommendable approach but it's cached anyway (probably an implementation detail)
x != 0 15 ns ± 1.1 ns [921 ms / 39983068]
bool(x) 20 ns ± 1.9 ns [991 ms / 35492247]
not not x 13 ns ± 2.1 ns [946 ms / 45334861]
(True, False)[0**x] 33 ns ± 6.7 ns [1.0 s / 24197550]
x is not 0 9.6 ns ± 1.2 ns [988 ms / 55511428]
@languid hare @quartz wave
nvm it is fastest
also how can we increment var and use its old value in one expression?
currently i have this code: D[(P := P + 1) - 1] and i really want to keep it in one expression and fast
(D[P], P := P + 1)[0] works, but it is slower (i guess)
id guess thats about as good as it gets
>>> dis('D[(P:=P+1)-1]')
0 0 RESUME 0
1 2 LOAD_NAME 0 (D)
4 LOAD_NAME 1 (P)
6 LOAD_CONST 0 (1)
8 BINARY_OP 0 (+)
12 COPY 1
14 STORE_NAME 1 (P)
16 LOAD_CONST 0 (1)
18 BINARY_OP 10 (-)
22 BINARY_SUBSCR
32 RETURN_VALUE
>>> dis('(D[P], P:=P+1)[1]')
0 0 RESUME 0
1 2 LOAD_NAME 0 (D)
4 LOAD_NAME 1 (P)
6 BINARY_SUBSCR
16 LOAD_NAME 1 (P)
18 LOAD_CONST 0 (1)
20 BINARY_OP 0 (+)
24 COPY 1
26 STORE_NAME 1 (P)
28 BUILD_TUPLE 2
30 LOAD_CONST 0 (1)
32 BINARY_SUBSCR
42 RETURN_VALUE
the adaptive compiler will be better at the first one for sure
D[(P:=P+1)-1] 40 ns ± 785 ps [975 ms / 20347216]
(D[P], P:=P+1)[1] 55 ns ± 1.3 ns [1.0 s / 15797633]
this is a lot slower, but;
list(bytes(str(x),"utf-8"))!=[48]
str(x) != '0'
(b'%d'%x)[0]not in{48}
ill test that
it's worse than everything else
doesn't str mod need to be a tuple?
!e ```py
exec(compile("(b'%d'%5)[0]not in{48}",'','single'))
doesnt work with 10 i think
you are ignoring all other characters except [0]
@quartz wave :white_check_mark: Your 3.11 eval job has completed with return code 0.
True
ok b'%d'%5not in{b'0'}
x != 0 15 ns ± 659 ps [978 ms / 41199156]
bool(x) 20 ns ± 808 ps [972 ms / 33975345]
not not x 12 ns ± 1.1 ns [981 ms / 48021853]
(True, False)[0**x] 81 ns ± 20 ns [1.0 s / 11481849]
x is not 0 10 ns ± 746 ps [976 ms / 51645381]
str(x) != "0" 67 ns ± 6.6 ns [821 ms / 10844438]
list(bytes(str(x),"utf-8"))!=[48] 281 ns ± 29 ns [916 ms / 3164497]
(b"%d"%x)[0]not in{48} 124 ns ± 7.0 ns [929 ms / 6988033]
im testing with x==127 (im too lazy to randomize input)
imagine picosecond program
pass
x != 0 13 ns ± 2.5 ns [930 ms / 39973035]
bool(x) 18 ns ± 1.1 ns [957 ms / 33971283]
not not x 11 ns ± 5.3 ns [970 ms / 45514105]
(True, False)[0**x] 75 ns ± 19 ns [926 ms / 10897217]
x is not 0 7.8 ns ± 1.9 ns [935 ms / 51401851]
str(x) != "0" 69 ns ± 8.3 ns [923 ms / 11584895]
list(bytes(str(x),"utf-8"))!=[48] 279 ns ± 17 ns [1.0 s / 3441812]
(b"%d"%x)[0]not in{48} 126 ns ± 7.7 ns [972 ms / 7130835]
b"%d"%xnot in{b"0"} 133 ns ± 1.3 ns [893 ms / 6229541]
idk how long NOP takes to execute, but im too lazy to test it, because i dont want to create functions from bytecode
it takes itself and a segfault to execute
nvm it's just the timer header
it's so fast the only difference is the overhead of the timer
Another target to optimize: i need to xor two byte arrays byte-by-byte
first array is my data
second is generated from custom RNG
now i have this code:
def get_rnd_bytes(self, state: int, size: int, /) -> bytearray:
res = bytearray()
for _ in itertools.repeat(None, size):
hi, lo = divmod(state, 0x1F31D)
state = lo * 0x41A7 - hi * 0xB14
res.append((state - 1 - (state < 1)) & 0xFF)
return res
# xor two arrays:
data = bytes(a ^ b for a,b in zip(buf.read(size), self.get_rnd_bytes(seed, size)))
# equivalent but slower:
data = bytes(map(int.__xor__, buf.read(size), self.get_rnd_bytes(seed, size)))
Slow things:
bytes(a ^ b for a,b in zip(- loop in
get_rnd_bytes
how can i optimize this code?
maybe just use [None]*size
im running these benchmarks inside some complicated context-manager, so there are a lot of overhead (several mcs i guess)
overhead also depends on number of iterations im performing
so, first im running empty loop, and subtracting its time from all other measurements, so (i believe) i have very accurate result
there are two more lines in my output (i was not showing them to you):
pass 8.3 ns ± 463 ps [941 ms / 114064188]
pass* -91 ps ± 920 ps [948 ms / 116147866]
x != 0 15 ns ± 2.6 ns [1.0 s / 42681981]
...
pass - is measurement of empty loop, it takes around 8ns to run each iteration
pass* - is the same, but fixed by 8ns. 8ns is subtracted from all results, so they are more accurate (and sometimes pass* is negative, because pass and pass* differ a bit)
where?
another unexpected result to me:
unpacking: (*a,) 392 ns ± 11 ns [1.0 s / 2562643]
unpacking: tuple(a) 205 ns ± 5.1 ns [1.0 s / 4766448]
``` `a = [*range(100)]`
i expected `(*a,)` to be fasterlooks like (*a,) is exactly 2 times slower than tuple(a):
list to tuple: (*list_6,) 18 ns ± 384 ps [1.0 s / 57]
list to tuple: tuple(list_6) 9.0 ns ± 793 ps [1.0 s / 112]
``` now `list_6 = [*range(10**6)]`
here `9.0 ns` means that it takes `9ns` for each item, not for whole operationi love my code generator

is this brainfuck related by any chance
probably, or a compiler
str(int) won't have leading 0 unless the int is 0
oh yes, you are right
i thought that s[0] is the last char, not the first
no, it is binary file parser
but it is "compiles" from high-level code to make it faster
and it is faster by 30-50%
now it is around 3200 lines of compiled code
my original code was 1500 lines
ah neat
i thought it might've been cause the
var += n
while var != 0:
stuff
var -= n
pattern is so common in bf, thought it might've been
maybe im just hallucinating brainfuck everywhere
interesting
This code is reading null-terminated string from bytes object D at position P:```py
var_1 = P # save start of string
while D[P : (P := P + 2)] != b"\0\0": pass # increment pos while current char is not null
R = D[var_1 : P - 2].decode("utf-16le") # we know start of string (it is saved in var_1) and end of string (it is one char before P), so we can read D[var_1:P-2] and decode it into string
have you tried map?
bytes(map(int.__xor__, buf.read(size), self.get_rnd_bytes(seed, size)))
``` this is slower a bitah
a = int.from_bytes(data1)
b = int.from_bytes(data2)
c = a ^ c
result = c.to_bytes()
``` idk if it is faster (probably no)
better to take the middle assignments out
im doing it with buffers of size +-10MB, three extra assignments cant affect total perfomance
result=(int.from_bytes(data1)^int.from_bytes(data2)).to_bytes()
maybe not by a lot
but if you're going for micro-optimizations, there's one
not only will it not assign, it also won't have to load the variables
nvm int.from/to_bytes approach is around 30% faster in my case
i think numpy has similar function, but i dont have numpy in my sutiation
and numpy's code should be A LOT faster than this
numpy is written in C so yeah
where are you getting the bytes object from?
reading from file or creating in the program
also, can you use obj[P:].split("\0")[0]
im totally wrong (i hope im not wrong now):
552891
0.0020008087158203125
0.03501296043395996
0.028998613357543945
data1 = buf.read(size)
data2 = self.get_rnd_bytes(seed, size)
import time
# fastest:
t1 = time.time()
data = (int.from_bytes(data1) ^ int.from_bytes(data2)).to_bytes(size)
# slower:
t2 = time.time()
data = bytes(a ^ b for a,b in zip(data1, data2))
t3 = time.time()
# slowest:
data = bytes(map(int.__xor__, data1, data2))
t4 = time.time()
print(size)
print(t2 - t1)
print(t3 - t2)
print(t4 - t3)
``` im braindead today
`int.bytes` approach is 15 times faster than othersit will copy entire buffer after current position, then split it into huge list (because buffer likely has a lot of NULLs) and then drop entire list and take only one item from it
it will be a lot slower
also im working with 500KB buffers, not 10MB as i said earlier
one is a slice of other bytes objects, second is generated from random-number-generator
ah
what about obj[P : obj.index("\0", P)]
ok
it will find first NULL, not needed NULL
you're looking for null terminated string
also it will search through entire array, so it can be slow if i have a lot of NULLs at the end
it starts at P
not entire array
and you're already searching the array in this
im looking for null terminated string, that begins in the middle of array
maybe array have some other null-terminated strings before or after our string