#unit-testing
1 messages · Page 19 of 1
@marsh raft it's because I had recently named another lib iommi and I was trying to think of a fast guitarrist that was also a nice person and who's music I enjoy.
@karmic storm you haven't said what isn't working. Is it crashing? Did your house catch on fire when you tried to run the code?
Hi there, i've recently picked up python/selenium as i want to progress from manual QA to automation QA
I am attempting to follow this tutorial but can't figure out where I've gone wrong https://www.youtube.com/watch?v=iZKOGN9hc0w&t=221s
I am trying to write a BDD script
The scenario:
Feature: OrangeHRM Login
Scenario: Login to OrangeHRM with valid parameters
Given I launch Chrome Browser
When I open HRM Homepage
And Enter username 'admin' and password 'admin123'
And click on login button
Then user must successfully login to the dashboard page```
and then the step definition file:
```python
from behave import *
from selenium import webdriver
@given('I launch Chrome Browser')
def step_impl(context):
context.driver=webdriver.Chrome()
@when('I open HRM Homepage')
def step_impl(context):
context.driver.get('https://opensource-demo.orangehrmlive.com/%27)
@when('Enter username "{user}" and password "{pwd}"')
def step_impl(context, user, pwd):
context.driver.find_element_by_id('txtUsername').send_keys(user)
context.driver.find_element_by_id('txtPassword').send_keys(pwd)
@when('click on login button')
def step_impl(context):
context.driver.find_element_by_id('btnLogin').click()
@then('user must successfully login to the dashboard page')
def step_impl(context):
context.driver.find_element_by_xpath('//*[@id="content"]/div/div[1]/h1').text
assert text == 'Dashboard'
context.driver.close()
the script is failing when it has to put the username and password using parameters into the webpage.
this is whats appearing in the console
Failing scenarios:
features/orangehrmlogin.feature:2 Login to OrangeHRM with valid parameters
0 features passed, 1 failed, 0 skipped
0 scenarios passed, 1 failed, 0 skipped
2 steps passed, 0 failed, 2 skipped, 1 undefined
Took 0m5.099s
You can implement step definitions for undefined steps with these snippets:
@when(u'Enter username 'admin' and password 'admin123'')
def step_impl(context):
raise NotImplementedError(u'STEP: When Enter username 'admin' and password 'admin123'')
@proud nebula i have added in more information into my message, hope that helps
Is there a better design pattern here? It feels redundant to initialize the handler in each test, but maybe it is good this way
handler = twitter_handler()
assert handler.oauth is not None
def test_initiate_stream():
handler = twitter_handler()
handler.init_stream()
assert handler.stream_connected
def test_update_rules():
rules = ['rule']
handler = twitter_handler()
handler.init_stream()
handler.update_rules(rules)
assert handler.rules == rules```
I'm using pytest fwiwPytest probably has some setup and teardown classes I would imagine
can someone help me
the error No module named 'PIL' keeps popping up
my code:
from pil import Image
im = Image.open(r"C:\Users\Administrator\Pictures\Meme.png")
im.show()
can someone help me?
i am trying to show the picture 'Meme'
okay. I am beating my head against mocking in unittesting. I have a function that uses the requests library to call an API and then does some stuff with that response (response is nested JSON). I would like to write a test that checks whether the correct URL is being called and the correct steps through the JSON are being walked. I've tried a number of tutorials and videos and I'm just not following how this works.
two things:
- mocking is a pain, we can work through that if necessary
- split your function into two -- one that simply does the request, and returns the JSON; and a second one that, given some JSON, extracts the necessary stuff. That way you don't have to check "the correct steps"; you only need to check that it's returning the right answer
if the URL isn't constructed at runtime, then just stick it in a constant and don't bother testing that bit
oh, I hadn't thought of breaking it into two functions and just having one function that does the requesting. that's a really good idea.
if it is, then split that into a separate function, that does nothing but construct and return the URL. Then test that; you won't need to mock anything
I despise mocking. Sometimes I have no other choice, but I'm willing to rewrite my code a fair amount to avoid it
I hadn't even considered that if I broke my function down further I wouldn't need to do mocking. that's so much better.
👍
my whole team has been trying so hard on mocking these API requests for like 3 weeks and nobody was getting anywhere. Now I get to be the guy who says "hey let's not do that and be able to test anyway"
don't tell 'em you got the idea from some random dude on discord 🙂
lol right. let them think it was all me.

sigh I'm getting an assertIs fail that my function isn't returning a string
but if I ask the terminal what type the response is, it's string
so I dunno
I think I just won't ask the assertIs
how does one approach writing tests/test suite for a rather complex application ( itself being wrapped in REST API) that involves several DB requests and set of data processing operations with following calculation that has certain degree of randomness to it: i.e. if you call function with identical set of parameters the result will be different every time?
I am not sure I have even a faintest idea how to cover it with unittests or any kind of tests for that matter (I never really dived into testing before)
@weak stag
Surely you expect your function to do something. Well, you have to test that the code produces the something you're expecting.
For the random part, you can do whatever measurements you want and as many you want. Maybe do 1000 of them and check statistical measures (average, standard deviation, etc.) ? Or maybe mock the random parts so it's no longer random during the tests.
Also be careful only to test your own code. Don't test your dependencies. By exemple, if you use an authentication library, don't test the password encryption, salts and the like, just test that you integrated it correctly. Make a high level call on your API and check the result is as expected.
About DB, you can generally use an in memory database such as h2 or sqlite during tests.
Generally, your database is populated by a combination:
- Standard application startup code (with a tool such as liquibase)
- Test setup (code that test framework execute before each run / module / test and cleanup afterwards)
- Test code of your unit
I have tried it once. I let it run for 10s of minutes and it didn't find the bug I knew was there. Mutation testing found it in seconds. Not convinced.
@proud nebula interesting, I've never heard of mutation testing though
I've heard that hypothesis testing should be considered as a user who'll test your code and report a bug if they find it 🤔
Does mutation testing apply to data?
A quick search suggests it changes the source code, whereas hypothesis seems to give many variations of a data type
So, they sound quite different
Im trying to create a python file sorter,
@cobalt ore yes they are super different! Property Based Testing is getting all the hype but is far less useful imo. I had to write mutmut to try out mutation testing but now you can just use it :)
Mutation testing will force your tests to cover all the behavior of the code. It's a finite search, while PBT tries to search an infinite space.
Is anyone here good at Locust? I’ve a few questions about test failures and time outs
hi,
i post a problem 2 month ago on stackoverflow but no answer. https://stackoverflow.com/questions/61361515/python-flask-restplus-post-unit-test-with-csv-file-from-local-data-store
do either of you have any ideas?

Stack Overflow
I have created a small microservices, which I address via a REST API (flask-restplus).
For testing during development I used the following curl command to test the loading of the file:
curl -i 'h...
the data that you're posting in the test is just a string, not the contents of the file in a parameter named "file" like you do in the curl command
your curl command and test post() call are doing different things
it looks like (from this stack overflow question https://stackoverflow.com/questions/20499660/how-to-post-multiple-files-using-flask-test-client) you want to do data=dict('file'=(open(file_path, 'r+'),file_name))
Stack Overflow
In order to test a Flask application, I got a flask test client POSTing request with files as attachment
def make_tst_client_service_call1(service_path, method, **kwargs):
_content_type = kwar...
hey guys, i'm working on a program. this prog. is simulates old OS systems. and its can working at dual monitor. (i guess). and i am need to a tester, if anyone interested, i'm waiting on at direct message,
thanks.
hello is anyone experienced with selenium im having issues with traversing a link it appears
Ask the question.
Hey, does anyone know if it's possible to upload unittests to automatically test on different operating systems?
hey im a beginner programmer and i had a question about selenium.
how can i press a button with a mouse interaction
@short hamlet have you looked at Helium? https://github.com/mherrmann/selenium-python-helium

GitHub
Selenium-python but lighter: Helium is the best Python library for web automation. - mherrmann/selenium-python-helium
ahhhh much thnxx bro
@short hamlet No problem. Let me know if you have any issues.
I'm working at a startup where we are supposed to ship our hardware to customers but prevent them from accessing the source code. The ML code is in Python so how do I convert that into an executable just like C++? I've heard of Pyinstaller, but is that the industry standard to do it? And can someone reverse engineer it? Also, is there a way to encrypt or compress the ML model as well?
This is a question for #cybersecurity
I'm learning python and just wanted to know which platform to use for mobile Application development.
Hi together, what you're using for testing? unittest or pytests?
unittest is often used, stdlib attachment, yet i find it more verbose
im leaning more and more over to pytest
@cunning lake ok but only because it's shorter?
or does pytest have more functionalities that are missing from unittest?
it's less verbose, has a ton of plugins as far as i've seen - catering to most needs
afaik not really
unittest is preety mature, so if you're fearing a missing feature you probably won't come across it
but so is pytest 🤷♂️
i advise you write a few tests in both libs and compare that way
ok thx
Stack Overflow
In unittest, I can setUp variables in a class and then the methods of this class can chose whichever variable it wants to use...
class test_class(unittest.TestCase):
def setUp(self):
...
seems pytest is more flexible
but yea, play with it a little and im sure you'll come to a conclussion
http://blog.ezyang.com/2011/12/bugs-and-battleships/
I found this very insightful. An old article but good one...
How do I run python code on mobile android devices?
@radiant sigil yes, CI solutions do this. Like Travisci, circleci, etc
@proud nebula Oh awesome, thank you!
@honest spire pytest is much better but it's slow. I'm working to fix that with hammett though.
@nimble glade this is the wrong room for this question, but I think you'll find that python is terrible for mobile apps. I would recommend the native systems for apps. So swift for ios.
@balmy agate i use Pydroid 3, it's free, offline usable and you can install almost any lib
I'm unsure where to post this but
I'm wondering how I can get the images i request to dump into a specific folder?
If you're unsure where to post then you should ask in #community-meta where your question belongs
You should just have claimed a help channel
Question would be fine to ask there
Thanks
Does anyone know if there is a plugin for sublime that can let you know if you've forgotten to write self? It seems like a perfectly detectable thing that should be showing me an error message but if I'm using async functions and forgot to write a self in the arguments of something or self. in front of the function then I dont get an error message
or maybe there's some other solution that isnt a sublime plugin
most ide's handle auto addition of the self param if you begin to write a method
i imagine sublime is not different
Use PyCharm :)
Hello. My team is using Azure Databricks to perform analysis on events that IoT Devices our company makes send to the cloud. These events are normalized (somewhat) and dumped into an Azure Data Lake Storage Gen 2 account. By the time Databricks is reading them, the look like:
{
"body": "String: JSON String containing the event data. Can be quite large",
"partition": "String: number",
"offset": "String: Number",
"sequenceNumber": "Number",
"enqueuedTime": "String: ISO 8061 Datetime string",
"properties": "Object: usually empty",
"systemProperties": "Object: usually empty",
"event_type": "String: Type of event sent",
"year": "number: the year for the event",
"month": "number: the month for the event",
"day": "number: the day for the event",
"cleanEventhubToDatabricks_time": "String: ISO 8061 Datetime string"
}
I am currently working on building a unit test system for our existing databricks notebooks, and now need to figure out a way of generating a dataset of test events to use in unit tests. I don't want fully random data, as that would be difficult and brittle to test. But I also don't want random grab of production data, as that would be unlikely to provide sufficient detail to exercise the code in a test.
Are there any good data generation tools in Python that you would recommend for generating good unit test data and that might fit my use case?
factory boy looks really handy. However. it does seem like I will need to create classes for my events in Python. Currently, I don't have those. Also, the interaction between classes, dicts, and pyspark dataframes may get interesting
Hey guys
Hi
sir i have some doubts ,i had watched your python web automation video,i tried to automate google meet,everything is working well except when i join the meet with the join id,i switch to the child node correctly and interacted with evry element,algood,except the alert box on the chld window can not be closed,it says no such alert,the alert requests for cam mic permission whcih in want to dismiss,Stuck for two days? used wait methods too still no luck?any suggestion?
@tired hatch this is the wrong channel.
Is this the right channel to ask about something for pyinstaller?
Google searched my question nvm.
im testing my code on a vm:
im trying to run my slenium code on a VM,chromedriver gives the error:Getting Default Adapter failed. i tried gecko it faied:gecko unexpectedly exited
im on a vm hosted on aws
its a windows vm
if its something simple, use "pyinstaller --onefile <filename>"
I am using Factory Boy to generate test data and I am getting hung up on how to pass a parameter to a nested SubFactory (Factory [param value here created here] -> SubFactory -> SubFactory [param value needed here]). How might I do this?
Here is a simple example of the scenario I am describing
from datetime import datetime, timezone
import factory
from factory.fuzzy import FuzzyDateTime
class DiEventdataFactory(factory.Factory):
class Meta:
model = DiEventdata
hardwaremodel = "Awesome Product"
serialnumber = "abc123"
# TODO: Use MAC Address generated in MainEventFactory
macaddress = ""
manufacturer = "ACME Co."
softwarerelease = "3.1.0"
class DiFactory(factory.Factory):
class Meta:
model = Di
eventdata = factory.SubFactory(DiEventdataFactory)
eventtime = FuzzyDateTime(datetime.now(timezone.utc))
eventversion = "1.0.0"
eventtype = "DeviceInfo"
class MainEventFactory(factory.Factory):
class Meta:
model = MainEvent
eventdata = factory.SubFactory(MainEventdataFactory)
eventtime = FuzzyDateTime(datetime.now(timezone.utc))
eventversion = "1.0.0"
eventtype = "MainEventType"
di = factory.SubFactory(DiFactory)
## generate MAC address here for use in the factory
mac: str = factory.Faker("hexify", text='^^:^^:^^:^^:^^:^^')
In this, I would like to pass the generated value for mac from MainEventFactory to the macaddress field in DiEventdataFactory
seems pytest is more flexible
@cunning lake Have bene using Pytest at my job and from what I can tell, it's just a bunch of extra stuff that lives alongsideunittest. You'll still be usingunittestanyway.
Here is a simple example of the scenario I am describing
@upbeat hound fyi if your paste takes up your entire window you should probably pastebin it instead
i used pyinstaller but not worked
@brittle crest Try Nuitka
!tempmute 736320464611180635 7d Since you don’t seem to be getting the message not to shitpost here, here’s something more explicit.
:incoming_envelope: :ok_hand: applied mute to @unique spear until 2020-08-04 01:03 (6 days and 23 hours).
Does anyone have any experience with finding memory leaks? I've been trying to use pympler, tracemalloc, and memory_profiler, but memory_profiler seg faults, and the output of pympler/tracemalloc show much lower memory useage than top does
for instance, here's the output of muppy.summarize
============================ | =========== | ============
str | 71028 | 14.68 MB
dict | 25301 | 12.14 MB
list | 15918 | 4.31 MB
type | 3768 | 3.14 MB
code | 22613 | 3.12 MB
numpy.float64 | 100525 | 3.07 MB
numpy.float32 | 99922 | 2.67 MB
tuple | 21928 | 1.40 MB
set | 2355 | 700.41 KB
weakref | 5440 | 425.00 KB
getset_descriptor | 4822 | 339.05 KB
method_descriptor | 4738 | 333.14 KB
builtin_function_or_method | 4569 | 321.26 KB
wrapper_descriptor | 3725 | 291.02 KB
int | 9647 | 271.59 KB```
But top says
``` 2809 uname 20 0 4665452 2.395g 1.701g R 800.0 7.5 8:56.58 python3```so muppy says I'm using like 50Mb of ram, but top says it's 1.5 gigs
Hey, I recently started using Travis CI as a @proud nebula suggested, which works great!
However, I recently found out about GitHub Actions and it seems to be able to do the same thing.
Does anyone have experience with these, and if so, what do you think about them?
Also found this sweet comparison: https://knapsackpro.com/ci_comparisons/github-actions/vs/travis-ci

What are the differences for Github Actions or Travis CI? Alternatives for CI automated testing.
basicaly there's a dime a dozen of CI providers
circli, travis, github has it's own now, other git repo hosters have their own aswell
pick one that suits you and be done with it 🤷♂️
@hollow sedge well you can use pytest as a slower way to run unittest style test for sure, but that's a bit silly ;)
But you should try hammett for that! Fast as unittest but with nice output. (I'm the author :))
Ok thanks for telling even if i didnt ask u🤨
@proud nebula why? Now im curious
Well... the why is the boring: thousands of small performance regressions introduced over a decade and people not caring enough and now it's just horrible to do anything about it (I've fixed some of the low hanging stuff but it's death by a thousand paper cuts)
interesting, allthough your tests seem very synthetic if you know what i mean
but didn't know there was that much of a performance difference
There aren't anything but synthetic benchmarks :P But for iommi there's a big diff.. like 10 vs 8 seconds and that's a very db heavy test suite. For smaller test suites the difference is bigger.
When running just one test the difference is bigger, and it grows with the size of the code base, the venv, and with number of plugins installed (not used!)
I've spent many weeks fixing and trying to fix pytest. At some point I thought "how hard can it be to make a test runner yourself?" :)
The catch with hammett is, unsurprisingly, that it only has partial compatibility with pytest
But most people in practice use a small subset of pytest and one or two advanced features, and those can be translated to some other advanced feature or worked around quite often.
fascinating, i'll take a look at your library
It is really born out of my work on mutmut.. I was super frustrated by the slowness that was almost all pytest overhead
With hammett, mutation testing is closer to being limited by process overhead and just running way too many tests
hey guys, looking for advice in common practice: should I import 3rd party libs into tests or build my own mock ones?
currently building tests for a script that excepts github exceptions, I decided to make my own instead of importing github and raising that
Thanks @cunning lake regarding the CI
what testing frameworks does everyonehere use?
Is there anything in a similar vein as black, mypy and the like that can help check compatibility with multiple targeted Python versions? Say I'd like to target 3.6, 3.7 and 3.8 for example. I had been spoiled by PyCharm doing this for me in the past.
there definitely exists something like that for multiple targeted platforms
i can't seem to recollect though
Yeah I'm drawing a blank too and Google isn't helping. I don't need anything like tox at the moment, more of a "You're attempting to use standard library foo and it isn't in version 3.6" warning.
@thin gyro I use pytest personally with lots of doctests
thats what ive generally used
unittest, pytest is probably the standard
@left siren I don't know what black or mypy is, but I think you configure that as a parameter in setup.py:
python_requires='>=3.6,<=3.8.*'
https://stackoverflow.com/questions/44660448/using-python-requires-to-require-python-2-7-or-3-2
Stack Overflow
How do I use python_requires classifier in setup.py to require Python 2.7.* or 3.2+?
I have tried many configurations, including this one: ~=2.7,==3,!=3.0,!=3.1,<4 but none have worked
@radiant sigil Thanks, this is more of a development tool to ensure I don't accidentally use a method/class/function, etc. from a more recent version of Python than is available in one of my targeted versions.
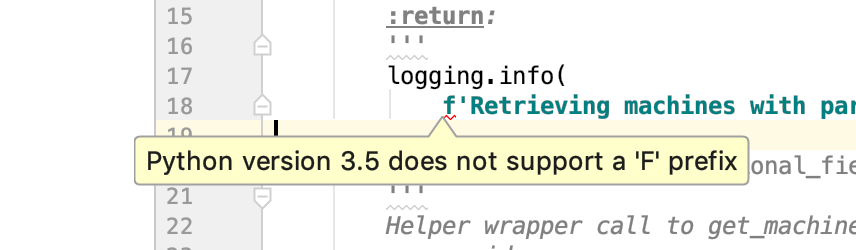
For example, if I used the "walrus" operator and I had configured the tool to target 3.6, 3.7 and 3.8 it would give me an error saying "The 'walrus' operator is not available in 3.6, 3.7" -- much like PyCharm's code compatibility inspection: https://i.stack.imgur.com/vDOUI.png
@left siren Ah I see, why are you using anything but PyCharm? And what IDE are you using instead?
@radiant sigil this is more for the other individuals I have to collaborate with that aren't setup with PyCharm. They're likely to be using Jupyter but I'd prefer a command line tool that I can wire up in our Makefile
tox+tests is probably the best way to run locally. other than that, any CI system that supports matrixing operations with different python versions works too (and tox can likely be used in the CI as well).
black --check --target-version [] could work, but if the code isn't already in black's style you'll get more hits than you're looking for.
@chilly geyser We're already doing a pass with black via pre-commit, I could just setup another run through after it has formatted perhaps.
But I was trying to avoid the "weight" of tox
yeah, tox is nice for what it does. but it comes with that weight...
i haven't used pre-commit enough, but i imagine it will matrice out list values in the yaml config?
I'm sure I could cobble something together if that's the only one that'd work. ¯_(ツ)_/¯
@left siren Alright cool, so something that searches the code for simple matches such as 'f"', "f'", ':='?
Functionally, that's pretty much the gist of it. But also things like "This module function wasn't introduced until 3.7.5" or "This function doesn't accept a foobar argument unless 3.8"
Nice. Ok, that argument check would require some sort of compiler then I guess, so it has to be a bit more sophisticated than string searching
Hopefully the new parser in py 3.9 will be exposed to allow tools to be built on it
There is already an ast module
!d g ast
Source code: Lib/ast.py
The ast module helps Python applications to process trees of the Python abstract syntax grammar. The abstract syntax itself might change with each Python release; this module helps to find out programmatically what the current grammar looks like.
An abstract syntax tree can be generated by passing ast.PyCF_ONLY_AST as a flag to the compile() built-in function, or using the parse() helper provided in this module. The result will be a tree of objects whose classes all inherit from ast.AST. An abstract syntax tree can be compiled into a Python code object using the built-in compile() function.
So as long as the python version running the check is recent, you can check for compat going back quite a ways
That's neat :)
def is_leap(year):
leap = True
if year % 4 == 0:
leap = True
if year % 100 == 0 and year % 400 != 0:
leap = False
return leap
year = int(input())
print(is_leap(year))
why leap=True to be declared . i removed it and interpreters is throwuing me an error
why ?
pleaase anyone repsond and help me
Why is this in #unit-testing? This looks like an issue for a help channel. See #❓|how-to-get-help
Hello , is there a way I can identify the md5sum of a file on git without having to download it?
probably not
what are you trying to do
you'd still have to "download" it but you might be able to avoid saving to disk or having it all in memory at once by doing it a piece at a time
and just to clarify by 'git' you mean github or some other online repository?
what are you trying to do
@rustic stirrup I just want to verify whether I have the same files on my github and my local machine
and just to clarify by 'git' you mean github or some other online repository?
@rustic stirrup github
you don't need md5 for that
git itself should provide that verification
the commit hash contains the hash of the directory, and the directory hash is the hash of a file that contains the hashes for all the files and subdirectories
git hashes aren't md5 though
No actually, I myself have not pushed the files , someone else has done it for me
so I was asking if I can verify md5sum somehow
they're SHA and contain some additional stuff other than the file contents
so can I see the SHA from gui?
actually pretty small
if you create a git repository from your copy of the files, then add the one on github as a remote, then doing a fetch might not download the file contents themselves unless they're different... probably only worth doing that way if they're very large though
it'd be easier to just downlaod
@rustic stirrup yes but in future , if I want to keep verifying I might not consider to download everytime
yes sure!
and then you can upload your changes yourself
actually I dont have dev access to the repo I have to push , so one of my seniors push the files
I just wanted to verify stuff thats all
Anyways Ill go with downloading 😅
thank u @rustic stirrup for ur quick reply and ur time , much appreciated
well
once you have the repository cloned once, each time you download it should only get the updates not the whole thing
with git pull
yes Im aware of it
im imagining a tool that takes a jsonschema and auto-generates mock json data from it. could potentially be really useful for generating test cases. is this something other people would be interested in?
i suppose hypothesis already does something like that. so maybe it could also generate code for a hypothesis "strategy" or something
Faker + FactoryBoy is basically the same thing, only for python objects
if that's what you mean
perhaps you could integrate with Faker instead, and provide somekind of serializing interface
from packaging import version
if version.parse("5.3.0-62-generic") < version.parse("2.0.0"):
... print('ok')
...
ok
somebody know why?
@spark oriole the former gets parsed as a "LegacyVersion" which seems to be lower than all non LegacyVersions when compared.
>>> from packaging import version
>>> x = version.parse("5.3.0-62-generic")
>>> y = version.parse("2.0.0")
>>> y
<Version('2.0.0')>
>>> x
<LegacyVersion('5.3.0-62-generic')>
>>> x._key
(-1, ('00000005', '00000003', '*final-', '00000062', '*final-', '*generic', '*final'))
>>> y._key
(0, (2,), Infinity, -Infinity, Infinity, -Infinity)
the _key attribute is what is compared
so the -1 epoch basically means it'll always compare as lower
anyone able to shoot me some help? i'm looking to make a scanner for the stockmarket with webull
guys i am working on a home automation system with raspberry pi
and I need to connect to a esp8266 12e wirelessly to send data
so that it can turn on or off some appliances
any have any ideas?
This is the wrong channel.
Hello
Does anyone know how you can make a fixture class based
So it is defined only once and not every time it is in a function signature?
i am using pytest by the way
@proper wind you can pass a scope to the fixture decorator to specify how many times it's invoked
i.e. ```py
@pytest.fixture(scope="module")
@marble panther I have tried that, but it doesn't work because I am using pytest-asyncio which has a event_loop fixture that is function scoped
I will try overriding that too as well and see what happens
So i made a python module, uploaded it to PyPI following this tutorial: https://www.youtube.com/watch?v=zhpI6Yhz9_4 but even though my module is now on PyPI and i can install it with pip, whenever i try to import it into a script i get an error saying it doesnt exist:

In this video, MakerBytes host Josh will walk you through the different steps to write your own Python library, create the files needed to make a package and upload it to PyPi (Python Packaging Index).
Follow me on Twitter: @all_about_code
Visit my website: allaboutcode.co.u...
but i can confirm it is installed by using pip list:
your code layout isn't correct
you need to either move your __int__.py into an EzAsPy directory or rename __init__.py to EzAsPy.py
bump?
increase the version number
ohh
np
so before i update it
in my EzAsPy.egg-info folder
I have a file called
SOURCES.txt
inside of there it refrences init.py
do i change it to say EzAsPy.py?
@marble panther
do ./setup.py sdist and it might update that automatically?
in powershell?
you didn't write that egginfo before right?
no
it likely gets built when you build the package for upload
if you updated the version you just upload it the same way you did before
the same command you used to put it on pypi the first time
it's not neccessary
I uploaded with twine yeah
it doesnt show when you search
but go to
there
and its there
im just super confused cuz like i updated it
idk
wdym
and is generally a pretty scummy thing to be doing
its not like that
This module makes it super easy (some might even say ez as py) to make basic mod functions for CSGO by reading and writing memory. These functions include Glow, Triggerbot, and Recoil Control.
that's pretty unambigous
I understand, but its not for malicious intent
this server can't help
okay, i understand
if you understand - then you should remove the links
Just did
I'm trying to learn testing how would I write good test for this https://repl.it/@Michaelmikey/guessing-game#guessing_game.py

First you need to figure out what needs to be tested, exactly
What debugger do people typically use? With pytest in mind - I used ipdb, but it doesn't seem to like pytest (or visa versa). Pytest works with pdb, but I don't like pdb, so I'm wondering if there's something else that people use that is happy with pytest (ping me if you respond please)
@cobalt ore PyCharm?
There are plug-ins to pytest to make it nicer i believe.
If you use hammett, it will drop into ipdb if installed and pdb if not when run with --pdb. (I am the author of hammett, a (mostly) pytest compatible test runner that is faster)
@proud nebula i use neovim so preferably it would be something that works from the terminal, maybe I should just look at pycharm though 🤔 using something other than pytest wouldn't be an option unfortunately
You write your tests as if pytest, but run them with hammett. It's magic ;)
in that case it might be an option I'll have to have a look, thanks 🙂
How do I make pytest import packages that are in the same folder of tests/?
I have this tree:
root/
package/
__init__.py
...
tests/
run_test.py
How do I import root.package inside tests/?
@tepid locust i just install my package (e.g. pip install -e) into my development env before running tests
if you run the tests from root/ and not from tests/ i think pytest will typically do the right thing
but installing is typically better imo
this is why i use src/, specifically to prevent packages/modules from getting picked up in ./ as part of the package search path
ty
if you run the tests from
root/and not fromtests/i think pytest will typically do the right thing
what do you mean? run pytest in the root directory?
from package import foo typically
Hi, I'm trying to install pip with my command module on Windows 10. I have the latest version of python. If you can help, tag me.
This is the wrong room
is there a library to generate test data from a jsonschema or some other "complicated" spec? something that might be difficult or annoying to write custom code to generate with e.g. hypothesis or faker
you need to mock requests.Response objects?
how much functionality do you really need to mock?
like it does something stupid with 200 OK {"error": "fatal"}
ugh
that seems like a misunderstanding of DRY but i won't go there right now
ah
never mind
so my question is
how much functionality does your application actually use?
if all you need is the json, why bother doing all this abstraction stuff
unless you think you'll be interacting with different APIs which all behave differently
in which case you should abstract over the functionality you do need
instead of wrapping an entire HTTP client's worth of functionality..
sure
can you give me some kind of simplified thing thats representative of your wrapper?
because i can't tell if you're doing the right thing or the wrong thing
something like this is both fine and good
class ApiResponse:
endpoint: str
success: bool
error_message: Optional[str]
...
something like this would be suspicious
class GenericHTTPResponse:
status_code: int
status_reason: str
text: str
content: bytes
...
yeah that's reasonable
although your if "Content-Type" in response.headers: is questionable
what if... it isn't?
oh i see the early return
alas
else wouldn't kill you?
anyway, this looks fine
although i can maybe save you a level of indentation:
if "Content-Type" in response.headers:
if "application/json" in response.headers["Content-Type"]:
becomes
if response.headers.get("Content-Type") == "application/json":
or if you prefer to be explicit, since you are a go programmer
if response.headers.get("Content-Type", None) == "application/json":
go doesn't like else's?
oh i mean don't put the return in there
if response.headers.get("Content-Type", None) == "application/json":
data = # big complicated thing
else:
data = response.text
return data
anyway, as for mocking
you only need to mock: .headers, .json, and .text
so this seems pretty easy to take care of
you dont need to mock the whole damn thing
oh boy
both pytest and mocking are like
two of the darkest creepiest corners of the language
with respect to spooky magic behavior
regarding how mocking itself works, i have two talks for you:
https://www.youtube.com/watch?v=ww1UsGZV8fQ
https://www.youtube.com/watch?v=Ldlz4V-UCFw

Speaker: Lisa Roach
One of the most challenging and important thing fors for Python developers learn is the unittest mock library. The patch function is in particular confusing- there are many different ways to use it. Should I use a context manager? Decorator? When would I u...

"Speaker: Edwin Jung
Mocking and patching are powerful techniques for testing, but they can be easily abused, with negative effects on code quality, maintenance, and application architecture. These pain-points can be hard to verbalize, and consequently hard to address. If y...
and finally i have this pytest plugin which you should use (imo) for mocking w/ pytest https://pypi.org/project/pytest-mock/

heh
if it works it works
well you can get pretty far with the assert_called_once_with method
for example that can guarantee that requests.request was called correctly
you can do that, but you dont have to actually do that much with it
like you dont have to worry about replicating the intricacies of requests.request or requests.Response
Watching videos is often fake learning.
Videos are great for overviews of a topic, but very seldom good for learnibg real programming skills.
@proud nebula sure, but if you're lost and don't know where to start with a topic they absolutely can show you the minimum you need to start learning
these are pycon talks, not random guy demonstrating random code on youtube
I've found that videos can be very useful. There are great talks available on YouTube, and a few of them are on testing as well.
Sure, you still have to actually open your editor and program something, but that goes for every resource. Active learning is a thing.
When it comes to testing, there are a few good talks from PyCon
@proud nebula tbh i dont find the "patch where it's used" thing confusing at all
Patching is python is quite strange due to the weird way imports work :(
@proud nebula
I think this mostly has to do with how names are assigned to values in Python. As names are assigned independently, if two names refer to the same object in memory and one of them is patched, the other still refers to the "old, non-patched object". Patching just means temporarily assigning the name to something else.
nor do i think imports are weird
in fact i think imports in other languages are weird
I think it's a big mistake that imports don't put stuff into a separate dict from the local defined stuff. It makes no sense that you can import from another module any old random thing that was imported at the top.
thats valid. but does any other language do that?
you can always keep the imported namespace as-is
just never write from ... import
or are you saying that module names themselves shouldn't be in the same namespace because they might conflict with variable names? i guess that's valid too but seems like not a big issue
and i like the parsimony of modules just being objects rather than some special syntax thing
For someone who don't think it's weird you do seem a tiny bit confused about how they work ;)
Say I have a.py:
from requests import get
def foo():
return whatever
In b.py I can now do:
from a import get
That's weird, and fucked up because it does actually cause real problems. Your modules public API isn't just the functions and stuff you define but all the imports you use.
It is somewhat unusual, although that behaviour is used by packages, but how does it cause problems?
IDEs importing from the wrong place is a classic. Then you remove an "unused" import and a totally unrelated module breaks.
Can't say I encountered that in vscode or pycharm
I've had that problem with PyCharm soooo many times
It hides all imported modules even from the structure sidebar
Ok. And that's relevant how?
It knows about them being modules that shouldn't be exposed and won't try to resolve those imports to that module
Anyway, if the imports were separated it would also make reflection much easier and patching could be more robust (look at the horrible hacks in freezegun!)
Modules? You means symbols? Anyway, sometimes you WANT to expose those symbols and then what? How does PyCharm know?
I'm pretty sure it doesn't. It just has some rules of thumbs which might or might not work this release cycle, for your code base.
@proud nebula im not sure why you think i dont understand that
that said i see your point now about why you think its weird
and i have to agree, i have never had a problem with this, ever
also don't C includes work exactly like this?
re: exposing symbols, __all__ exists specifically so you can exercise control over what is exported
moreover, classes, method, and functions all have a __module__ attribute stating unambiguously where it was defined
so not only have i never had a problem with this, python provides you with the tools to work around any hairy cases you might encounter
so given the presence of __all__ this statement is just wrong
Your modules public API isn't just the functions and stuff you define but all the imports you use.
maybe you want it to work that way by default? which is fine, and i can see why you'd want that
heck you could probably write some clever function to automatically construct __all__ at import time
does __all__ apply to more then just star imports?
i thought it applied to everything, but maybe im wrong
ah ok you are correct and am not
ok so, fine
there isnt a universal way to control the public API.
i still don't think it's a big deal, especially because we still have __module__
although i wish __module__ were available on all objects
all also shows the api to the programmer and potential tools, just doesn't do anything to enforce it because it's python
never had the import problem though, i agree it doesn't provide 100% strict control but at the same time don't really see the explicit need for it
C includes work totally different. They just copy paste the given file verbatim where it stands. Which is totally absurd and crap :) I was a C++ programmer for 9 years professionally so I know this pain well.
The hack in freezegun crawls sys.modules and checks if there's a time thing that was imported there anywhere before freezegun was started. It's very icky!
Hi! Is this the right place to ask questions regarding testing?
xposting from #async-and-concurrency
would anyone know why this iscoroutinefunction is returning false
async def mock_method():
pass
@pytest.mark.asyncio
@patch('Tests.bot.messaging.messenger_test.mock_method')
async def test_publish_event_invokes_listener(self, mock):
messenger = Messenger()
messenger.subscribe('bar', mock_method)
messenger.publish('bar')
assert mock.called
@leaden agate yes
what about simply prefixing the package with _, semantically implying private use, @proud nebula ?
@cunning lake for separing imports? Well I guess you could, but I've never seen people do from requests import get as _get
Didn't know that. I will have to think about it for my own libs then. Thanks!
I was complaining about this not too long ago
However there are some valid cases like when you import in init to create shorter paths to modules
Though maybe that's just a sign of a bigger flaw with the system
Hi, I want to try and create tests for my flask api application but I don't know how to go about it, does this article seem the rightway, I've tried to read the flask docs but they're slightly confusing for me. https://dev.to/po5i/how-to-add-basic-unit-test-to-a-python-flask-app-using-pytest-1m7a

DEV Community
Are we all agree that we need to add some tests to our apps, right? In this small post, I'll show you...
@kind meadow Sure. But if you want that it doesn't seem too bad if you'd have to re-export:
from requests import get
get = get
True actually.
@proper wind that looks enough to me, and not much work
@proud nebula thank you
I'll be testing in two different environments, but none of the parameters I want to test are present in both environments. How do I write a test that can cover both? Atm I'm thinking something like this under each test...
env = self.environment
create payload depending on env
I have different py test files, so for example if we use https://reqres.in/ and I want to GET a single user, that I know exists in that environment...
payload = 2 # but this depends on environment??
response = request.get('https://reqres.in/api/users/{}'.format(payload))
assert_that(response.text).is_equal_to(...)
but lets say I wanted my payload to be 3, which can be determined from the environment
env = current_environment
payload = create_payload_for_env(env)
response = request.get('https://reqres.in/api/users/{}'.format(payload))
assert_that(response.text).is_equal_to(...)
. . .
def create_payload_for_env(env):
if env == 'DEV':
payload = 2
elif env == 'QA':
payload = 3
else:
payload = 4
return payload
A hosted REST-API ready to respond to your AJAX requests
is there a better way of doing this?
As I have several tests and it would take a while to implement that injection into every test
You can parametrize fixtures. Maybe that's what you want?
i'm finding it tricky to test equality between pandas dataframes with a certain level of tolerance between the cell values (eg 1.2223 ~= 1.2222)
does anyone know how to go about doing this?
check_less_precisebool looks to be what you're looking for
@cunning lake recommends other approaches in the docs tho
Anyone tested output that's in the form of an xlsx file before? I'm not sure what the best approach to something like this is
i was thinking about using filecmp and maye having an example output to test against in ./tests/resources
Hi. I am an advanced civil engineering student and I am starting in python. I found this soft https://github.com/efdiloreto/Zonda and I would need to install it via cmd or generate an .exe. I have tried with pip installer and I get an error.

GitHub
Software para cálculo de cargas de Viento de acuerdo a CIRSOC 102 - 2005. - efdiloreto/Zonda
How test
yes
@brittle leaf Installing a library is not related to software testing, which is what this channel is about. Claim a help channel instead #❓|how-to-get-help
@cobalt ore I've written some tests for xlsx and the way I did it was read out the data into a csv format and compare to a csv (tab separated) string literal in the code via a helper function that produced nice error messages.
This is a good approach generally: reduce the format to something much simpler, then compare.

Why is enter not working when i run this script in a game (roblox)
the script
from pynput.keyboard import Key, Controller
import time
keyboard = Controller()
while True:
keyboard.press('/')
time.sleep(1)
keyboard.release('/')
time.sleep(1)
keyboard.type('Hi')
time.sleep(1)
keyboard.press(Key.enter)
time.sleep(0.10)
keyboard.release(Key.enter)
Screenshot

Help
@proud nebula thanks, part of the output is formatting though (freeze panes and cell shading), perhaps it's best to assume xlsx writer works though, I'm not too sure
@cobalt ore Yea, if that's all you're testing it seems like it would be better to improve the test suite of the writer if it's not good enough
@proper wind this isn't the place
@proper wind Roblox scripting is against ToS. We won't help you with it.
not sure if this goes in here but idk what channel to put this question in. I am making a sudoku solver that uses recursion but am having trouble with the functions interacting. I created functions for verifying what cells are empty and for changing the cells to a new number that works given the row/column/box its in. My issue lies when I try to use a function in another function, variables aren't declared in an order to keep it from erroring out.
Here are some snippits (i am testing validity on the solve_puzzle function before continuing to develop it, thats why it's empty.
def valid_num(coord):
test_num = board[coord[0]][coord[1]]
row_list = board[coord[0]]
column = []
box = []
for row in board:
column.append(row[coord[1]])
box_coord_row = (coord[0] % 3) * 3
box_coord_column = (coord[1] % 3) * 3
# bunch of random code in between
def solve_puzzle(board):
valid_num((1,3)) #hardcoded test case
solve_puzzle(puzzle)
I have an array called 'puzzle' that solve_puzzle uses. I assumed that it would then call it 'board' and functions that are used within the solve_puzzle function would also use that variable name of board. It just felt weird naming the array AND all the function variables board but I can do that if I need to
it does work if I just make everything use the variable board, but that feels like a bad practice
Ok im a noob with the debugger in vscode but is their a way to view variables while the program is running w/o break point
ooh @static crater ill give it a try (I too never use the debugger)

In this short tutorial I want to show you how to debug Python scripts with VSCode.
I explain simple and conditional breakpoints, and how to log messages instead of using print statements (poor man's debugger)
See my social profiles here
G+: https://plus.google.com/+JayAnAm
T...
talks about it
anyone know how to do an integration test of how your app responds to ctrl+c/KeyboardInterrupt? i use multiprocessing so trying to kill the application is a bit of a mess, i'd like to be able to simulate triggering a KeyboardInterrupt and making sure my app shutdown properly, any examples or advice would be greatly appreciated
found the answer to my question here: https://www.roguelynn.com/words/asyncio-testing/
@cobalt ore moving the testing conversation here. Can you give an example of a test you wrote that you had to change?
not really
not without it being more trouble to extract than to just plough on with now
the function changed, so the test had to change
there are several functions so they all had tests and all needed to change
i'm still going through it - i'll just delete most of it and redo tho as it'll be quicker
If your functions are sufficiently "small" ideally you wouldnt have to change that much
vary - computing a load of crosstabs for a bunch of surveys basically
But if you do a total API overhaul like take a bunch of functions and turn them into a class, you are going to have to change something in the tests no matter what
problem is that the values are stored in dicts
but they mess up all the ordering - so the first computation needs to have all index/column info for a xtab -- which means everything changes from there up
Wait what
@pearl cliff what?
Im not sure how storing data in a dict matters here
As in, you changed the schema of the data in the dict?
@pearl cliff oh, well if you have a xtab between two variables then there might be some missing values, there are also totals to consider, and the ordering of the index/columns for converting to xlsx etc
But why does any of that matter for writing tests
@pearl cliff i don't see why it wouldn't 🤔
This is why i wanted to see a hypothetical example of a function you wrote and its corresponding test
i don't understand the question, if there was a particular structure, and tests, then the structure changes - surely it makes sense that the tests change?
Maybe not
we'll never know 🙃
A lot of my code is written in terms of "structure independent" functions
My colleagues don't understand how to do this, which makes their code extremely difficult to reuse
Eg a function like process_names that pulls a "acct_name" column off a dataframe
That in my opinion is bad
Because instead you could just pass a series of account names, and let the caller pull the column off the data frame as needed
What would "data" be here?
I mean is this a configuration object?
Is it an instance of a "document" that's just non-tabular data?
@pearl cliff sorry i thought you were referring to your example, in my case it's tabular data
at this point i've either done it mostly right and there's nothing to change or i've done it mostly wrong and i cba to change it now though 🙃
so it is what it is
is there a way to use pytest fixtures in test parameters?
hi
Do you measure coverage of your test code? https://nedbatchelder.com/blog/202008/you_should_include_your_tests_in_coverage.html Any thoughts on this draft blog post?
Honestly never really thought of measuring coverage of the tests themselves
Oh, that's rather timely for my project
@cunning lake what do you think of it?
It’s easy to copy and paste a test to create a new test, but forget to change the name
Surprised that's a real problem. IDEs shout at you if you do that, I'd have thought most people would set up Vim or whatever to shout at them as well
Yes, linters might alert you to that also.
ironically, just last week i found a test dir that wasn't a package, therefore didn't run with the tests, which eventually caused a bug to creep into production, this might have stoped it
as you said, no real cons to doing it
definitely not something most people do i imagine
ironically, coverage.py might not have helped with the "not a package" problem, since it tries to understand what code could possibly have been run.
Right, as that's the devs/test-runners job 🤷♂️
@river pilot Very good point about test utility code becoming obsolete. At my previous employer we had so many test utilities spread all over the place.
I'm sure there was a lot of dead code hidden in all kinds of nooks and crannies.
dead code isn't that problematic, outdated code definitely is though
it's good to prune back dead code so that you don't try to maintain it needlessly
true
Ned your draft blog post is a nice read, however I feel there is a missing sentence to close the logic in the argument for the "it skews my results" section. You mention the happy case where the entire test suite is run (so the coverage percentage skews positively), but haven't explicitly stated the counter situation where if only some tests/helpers are executed (say, the CI is only doing the unit tests but not the integration tests) then the coverage percentage can go down. Whilst that implication is there in the paragraph it required me to think for a little bit to reach the conclusion. It might be beneficial to have a sentence saying how the negative skew of the coverage result manifests from partial test execution (or just dead code in the test suite) or simply refer the reader back to the point you make about dead code in your reasons to do test suite code coverage.
A second point is that the closing sentence of that paragraph is a little confusing because if you have, say, 80% coverage of your program and 100% coverage of your test suite, those percentages won't add together to make 100% (though it will skew that 80% positively proportional to the size of the test suite). Perhaps I'm just misunderstanding what that 100% refers to.
@clear pine the 80/90 thing is just an estimate, I can add some words to make it cleareer that it's not exact arithmetic.
On the first point: I'm not sure what to say about that.
"If you only run part of your suite (unit vs integration tests, for example), then you will have to be careful about how to measure only the tests you intend to run"
"If you have low application coverage but high test coverage then your overall code coverage (which is an aggregate of the two) is artificially inflated, and vice versa" - Maybe that more less rambly statement is clearer
My underlying assumption about this is the coverage's inputs are whatever source code you want to capture, and the output is just a single number
yes
Does it make sense in any scenario to just look at the "one output number" and not actually examine what is and isn't covered?
it certainly does for product managers who want simplisitc KPIs/metrics about "code quality" 🙃
@fiery arrow unfortunately there is a lot of simplistic measurement.
that doesn't mean it makes sense!
I personally like heatmaps of coverage so you can see how different modules are being covered in a pretty picture
yeah, not something that coverage.py offers....
If I'm not mistaken coverage.py can give a file/module based text report, which is essentially the same data but in a non-picture form
If you can get coverage on a per file basis, that seems like a relatively easy visualisation to build
sure, it has a few different reports, including json
the sunburst visualization is awfuly beautiful for visualizing coverage
@clear pine btw, i've updated the post based on your comments.
Looks great 👍
Would it be possible to check coverage of evaluated expressions?
Because here:
if f(a) or g(b, 1/0):
...
if I understand correctly, if f(a) is true, the condition gets evaluated, and the line counts as covered.
However, g(b, 1/0) might never get evaluated with the given tests, which might hide a defect.
@fiery arrow coverage.py can't tell you about that yet. Because Python reports "line executed" events.
there's new "bytecode executed" events (iirc), but we haven't done anything with them
well, I'll be able to cover functions made with hax 🙂
where you write bytecode in Python
oh, damn, condition coverage doesn't exist in py?
I guess there might be some tricky parts, like implicit branches:
i = 0
if condition:
i += 1
1/i
the test data can be such that condition, so a defect can be marked as covered.
But in such cases the blame probably goes to the programmer who writes such stateful code with 2^n execution paths
coverage can tell you about that missed branch
# file.py
def f(condition):
i = 0
if condition:
i += 1
return 1/i
# test_file.py
import file
def test_file():
assert file.f(1) == 1.0
(coverage = 100%)
What I meant is that the test doesn't check the case when condition is falsey
as opposed to
def f(condition):
i = 0
if condition:
i += 1
return 1/i
else:
return 1/i
(coverage != 100%)
Branch coverage, in this case, would check if both branches of that if statement have run
@fiery arrow coverage.py will tell you about that failure in your first test
In this case, the branch coverage feature of coverage.py would say for you example above that line 3->5 was missing
You can run coverage.py in both modes, line coverage and branch coverage. If I'm not mistaken, only the second one would show the lack of coverage.
if you're aiming for code coverage with django, should you cover misc files like migrations/data migrations?
I wrote tests for a larger migration we did (that included a data migration), but it wasn't the most straightforward thing I've done. Eventually, I solved it by manually controlling the migration so I could roll back to a specific point in the migration history and then test the migration going forward. I'm not sure if that's the right way to do it, but it worked well (albeit takes a bit of time, as you need to, well, roll back and apply migrations).
Still, tests are a handy tool to help you when you're developing and in this case, having them helped.
@fiery arrow you want mutation testing for proper coverage. But it's slow and a waste to use it for just that. MT is a cool tool if used properly.
Anyone using Apache Airflow ?
m trying to run slenium python on linux
it works but send_keys is not wortking
on shell
I helped get my project at work to 90% code coverage today 🎉
👏
I helped get my project at work to 90% code coverage today 🎉
@carmine bay congrats keep grinding king
I got 64% at work. It's 280kloc so 1% is 2800 lines. It's demotivating to get that number up to say the least.
i feel you, getting the coverage of a project that didn't have tests from the start is definitely something that needs to be widely coordinated
For some unit tests I want to be able to create a mock object that just has one attribute, preferably in one line
I might just use types.SimpleNamespace
hmm, that worked well enough, though I'd be interested to know if there's a more pythonic way.
You can use a Mock in the same way
The other thing I now want to mock is a file. I think I'll use io
I'm using requests for an api, it returns all the data as a json, how would I filter it from {'data': 'data'} to data: data
Now I shall wait 10 hours for a reply
@proper wind can you clarify what you want you're trying to do?
you can call .json() on the response from request to turn the json response into python data structures but i'm not sure if that's what you're asking
Anybody have a recommendation for a way to make the unittest module's TestSuite's run faster? I've attempted to implement unittest-parallel but it won't work with our GitLab runner (we get OS Error 28 No Space left on Device). We are using the unittest module so I can only imagine converting to pytest or nose would be a huge change. Anybody have any ideas for me?
Current have ~500 tests and they run in just under 3 hours
maybe the problem are the tests, not the test runner
just checked, 1400 tests, ~44s, so im gueesing it's not a runner problem
mocks, less db work, no third party client calls, aka ~fast unittests
The pytest runner does support unittest-style tests out of the box
You don't need to write pytest-style tests to use their runner
But I agree with Brunckek's observation.
How can I mock an asyncio.Task? My first approach was mock_task = AsyncMock()(), but this results in a coroutine, which can only be awaited once.
I guess I need a custom class with an __await__
Ah I can probably just re-assign __await__ on the mock
That isn't working 😦
But a custom class with __await__ works. I just can't make a mock work by re-assigning __await__.
Ended up using a Future and setting the result immediately - good enough.
Though if anyone knows why re-assigning a mock's __await__ doesn't work, let me know. It just kept saying the mock isn't awaitable.
As far as I can tell, there's no way to have a string that points to an in-memory file
so if I need a string path to effectively mock a real use case, do I just have to make a temp file?
@kind meadow open doesn't call a dunder method, does it?
It's a builtin, so I don't think so
:((((((((((
Why does that matter
not really, I just don't making temp files
sorry, I've become incoherent
it doesn't really, I just don't like making temp files.
So, patching open isn't appropriate here?
It wouldn't be if you're trying to test the file I/O operations themselves
But if it's getting in the way of something else you're testing, then you can patch it
Well okay, technically you may be able to pull off a patch that returns a custom io class which reads and writes in memory
But that sounds like a lot of work
I have a class that needs a pathlib.Path to instantiate it
so if there isn't a way to have an in-memory file that's fully compatible with Path, I just have to have a temp file on disk.
Does it read the file contents?
yes
So can't you patch open() to return a Mock which also has a mock read() method which returns some fake contents?
I'm not sure what you mean by patching open
How does it read the file then if not with open()? It has to open the file to obtain the file handle and read it some how, after all.
With Path.read_text() then?
oh I see, you mean the open method of Path, yes?
yes, I suppose I could mock that
I thought you were referring to some way to sneakily change what the builtin open function does
Well yes, you could patch the builtin if that's what your code was using.
im not entirely sure if it's what you need but, perhaps StringIO/BytesIO?
@cunning lake I just don't like creating temporary files that have to be cleaned up manually.
@cunning lake I don't think StringIO natively supports having a string that can serve as a path to it
if it did, that would be a miracle for me
Mock it 
But yea, i feel your pain
I tried mocking a file field by hand
Was quite annoying
I feel like unittest should support mock files natively
Can suggest it
My suggestions on python-ideas have been poorly received.
... or create a pypi package
however there might not be a way to do it without changing the implementation of open
>>> m = mock_open()
>>> with patch('__main__.open', m):
... with open('foo', 'w') as h:
... h.write('some stuff')
wow I didn't know this was a thing
All suggestions to python ideas are poorly received no?
I may have found a bug with create_autospec, though it might me intentional behaviour??
Anyone encounter this before? I pass a class as a spec, and one of its methods ends up being mocked as a coroutine function, even though the original method is not a coroutine function.
It's still a MagicMock too.
Also got a nice PyCharm bug with the text wrapping 😒
!e ```py
import asyncio
from unittest import mock
class Foo:
def bar(self):
pass
print(asyncio.iscoroutinefunction(Foo.bar))
bar_mock = mock.MagicMock(spec=Foo.bar)
print(asyncio.iscoroutinefunction(bar_mock))
@kind meadow :white_check_mark: Your eval job has completed with return code 0.
001 | False
002 | True
What the fuck
Okay, it comes down to iscoroutinefunction() using bool() on the mock, and
If a class defines neither len() nor bool(), all its instances are considered true.
f.__code__.co_flags & CO_COROUTINE just returns another mock if f is a mock
That's annoying
How would I go about testing image recognition code that I wrote using OpenCV?
Are there any libraries/tools that can help with this?
I haven't found any good resources online
The only thing I can think of is just to have a folder with a bunch of test images and some json file with text or numbers or whatever that I expect to find in each of them. Is there a better way?
I guess the filename could maybe encode the data you expect to find, that's a little bit simpler but what you said sounds pretty straight forward to me.
@versed pebble testing machine learning code in general can be difficult
your method makes sense
@runic moat that question is more suited to a normal help channel. See #❓|how-to-get-help
Ah, alright. Sorry about that. Thanks
Hi, I have a function that just returns a random 12 character string. Is the best way to test the function that returns a random 12 character string just to patch random.choice to make it return the same string every time or what's the best way to go about that?
You can use random.seed with some seed before the choices; that way the results will be the same each time.
You can also just generate a thousand strings and only verify that they all match the constraints and are almost all different.
Huh those are good both suggestions. Thanks @mystic viper . I'll try the first method and see how that goes!
Is there someone who is experienced with QThreadPool in PyQt5? If so, can you please show me how it works with an example as there are barely any on the internet.
I'm looking for a good tutorial on unit testing with classes and methods.
I'm guessing sticking with unittest is the way to go? I see some stuff using PyTest too.
I prefer pytest
I'm guessing sticking with unittest is the way to go? I see some stuff using PyTest too.
@sour flicker
unittest has the advantage of being in the stdlib, I guess
but well
@magic dawn I just wrote my first test in PyTest I saw where PyTest will also run uniittest so that seems like a good compromise to me.
Hi all.
I have a set of functions that accept XPaths and I would like to check statically that the xpath itself is well-formed. I was thinking of a pylint or maybe mypy plugin.
Any suggestion on how to proceed would be welcome
Should you test that logging correctly logs, probably not right?
i mean, you should do basic sanity checks that it actually logs, but you probably don't need to cover all the cases?
Depends on how business critical the logging is imo.
Hey everyone! I'm trying to run a unit test but I keep getting an authentication error: File "C:\Users\raeda\AppData\Local\Programs\Python\Python38-32\lib\site-packages\psycopg2_init_.py", line 127, in connect
conn = _connect(dsn, connection_factory=connection_factory, **kwasync)
sqlalchemy.exc.OperationalError: (psycopg2.OperationalError) fe_sendauth: no password supplied
(Background on this error at: http://sqlalche.me/e/e3q8)
I've double and triple checked my my db names, usernames, and passwords. I've changed passwords, reinstalled PostgreSQL, reinstalled all my my libraries including psycopg2 and psycopg2-binary.
Since the background link hints at a DBAPI error, I think it has something to do with psycopg2, but I'm really not sure how to fix it. I found a couple of sources online that recommend changing the pg_hba.conf to update access levels. But nothing seems to work. I'm kind of at my wits end, so any advice would be really appreciated.
Hi @cunning lake Yes I can. No problem
hello, I'm seeking help but not sure where to go or who to talk to
I have a python program using selenium
and it's not working quite right
!tempban 703291418885619842 14d It seems like you're only here to post an invite link / domain advertisement. Please reread our rules before coming back.
:incoming_envelope: :ok_hand: applied ban to @quartz fractal until 2020-09-08 13:28 (13 days and 23 hours).
hi
Greetings everyone, hope all is well.
I'm writing a parser for dmarc aggregate reports (xml) and I'm new to the idea of fuzz testing. Can anyone here point me in the right direction for fuzzing my parser?
I'm not having much luck finding an xml based fuzzer tool, and I don't really know where to start with writing one myself.
@timber crag Your question is not related to software testing. Please claim a help channel #❓|how-to-get-help
mk
Ow
Hey, I am getting the following Error:
TypeError: 'list' object cannot be interpreted as an integer
I have no Idea why I am getting it.
It accures in a Loop
If it isn't ocurring in some kind of a test, you should claim a help channel ( #❓|how-to-get-help ) with the code in question so people can help you
This channel's purpose is for discussion of automated testing, like unit tests, instead of debugging errors in general
is there a python API for pytest? or do i have to use the command line?
It looks possible from pytest.main @pearl cliff
https://stackoverflow.com/questions/43538099/pytest-run-test-from-code-not-from-command-line
Stack Overflow
Is it possible to run tests from code using pytest? I did find pytest.main, but it's just a command line interface available from code. I would like to pass a test class / function from the code.
In
There is one, but they don't want you to use it. Like REALLY don't want it, and they've moved it once to stop people. It's quite frustrating.
Plus if you do use it, you might not be able to call it again and it works like you expect.
in that case i wont press the issue, lol
stupid question that might have been asked a 1000 times already: unittest or pytest ?
I have mixed both in a project and it is getting really messy with fixtures and TestCase
@shadow socket i use pytest because i dont need the handful of unittest features that it doesnt support, i like the simplicity of using plain asserts for testing, and the pytest runner itself gives really helpful output + has lots of plugins like coverage, benchmarking, etc.
and i feel comfortable using pytest.parametrize and fixtures
I like the separation of concerns that is offered by unittest, unsure how that would look in pytest though
@shadow socket what's an example? like the setUp methods and having classes?
Is there separation of concerns? I thought it was just a bunch of messy classes and long unwieldy assert names, and bad output?
(in any case, try hammett! it's pytest compatible (mostly) and is faster and has nicer output)
@pearl cliff I don't have a clean example at hand, but if I have more time to investigate I'll post it
never heard of hammett @proud nebula
I haven't used pytest too much. The only thing I distinctly remember disliking about it is how big decorators could become. Though maybe that's just a sign of overly-complex tests
But I think that's inevitable if you want to have many test inputs
I hate the look of decorators broken up into multiple lines
Hello! I am trying to code a Guessing Game to train a bit in Python. Is this a correct place to share my code and ask for some help ?
Does anyone know how I would perform a copy and paste in Selenium, I'm trying to copy this textarea and I've spent quite a while on figuring out how to do this
@toxic compass No, this channel is software testing. To get help with your game, see #❓|how-to-get-help
@hexed fog Are you sure that is in the right channel?
Which channel should I post my question? I thought that since this is Selenium which deals with automated testing that my question would go here
@kind meadow The decorators are pretty great imo. Way better than... what is the alternative really? There's often no feature at all in unittest for the decorators
@shadow socket yea, hammett is my new thing.. still early days :P
@proud nebula I don't disagree. They're very powerful. Like I said, I just dislike the way it looks when many parameters are passed. For me, this is an issue with all decorators in general.
For parameterised tests, the alternative in unittest is to define an iterable of inputs and use a for loop to run the test on each one (along with a subtest context manager). For fixtures, well, just define the function and call it within the test. For scopes, call the fixture within one of setUp, setUpClass, etc.
i will say i dislike how "magical" pytest is
i wish instead of autodetecting fixtures based on function parameters, it would just let me @pytest.with_fixture('x', my_fixture) or something
The problem with that is that it would be so extremely verbose. I think the problem is more to do with shadowing, and stuff like that which makes them hard to follow.
@pearl cliff maybe ward is more for your liking? https://wardpy.com/
A modern Python testing framework for finding flaws faster.
Hey, does anyone know how to record, modify and play sound real time? I know the recording part, but real time seems difficult, trying it to make a noice cancelling software
thanks @proud nebula i'll look into it. and yes, the problem for me is the fact that it's sometimes hard to know what is actually a fixture
cursory glance: it looks great. i do use pytest-benchmark and pytest-cov quite a bit, hopefully there are viable alternatives in the Ward ecosystem (or such alternatives could be constructed or at least hacked together)
pytest-cov is a pretty trivial thing at least. Haven't seen pytest-benchmark before..
any good resources for writing tests, especially in an interview coding challenge scenario?
how do i get into a habit of writing good tests?
hey guys i am starting to learn so how can i get the material if there's any here i will be glad to start with them
any good resources for writing tests, especially in an interview coding challenge scenario?
how do i get into a habit of writing good tests?
@snow shard think about preconditions, postconditions and invariants
tests should reflect those
@snow shard i would also try mutation testing on something rather simple (but not too simple!) to really know if your tests cover the behavior
Great, thanks
Hey everyone! I am wanting to get into test automation and have fiddled around with Selenium quite a bit. I found it way more fun than I thought that I would. How would one start getting a portfolio together to start applying for jobs with this? Also, what kind of other testing should I look into that fit along these lines? I guess I am confused to what actual assignments a job would ask you to fulfil when automating.
No kidding?
Yeah, that’s my concern
Oof
I’ve used BS before, I’m not too big of a fan of scraping, I’m more interested in the testing end of things.
I’ll look into requests and Scrapy though. Never used them to the best of my knowledge
Selenium is for when BS doesn't work due to javascript or whatever, BS is for when just plain requests is too much of a pain, requests is for when you can't get to the underlying data structures directly.
And none of them are more or less for tests, they are just general tools
I see, so you’re basically poking around to just get the solution.
I guess. But you want to use the tool closest to the code. It's faster and it's easier to debug when things go wrong.
Does anyone use pytest here, I need a little help please
import math
from marshmallow import Schema, fields, pre_load
class MathFunctions(Schema):
'''Functions for sum, multiply, division, modulo'''
def __init__(self,a,b):
a = fields.Number(required=True)
b = fields.Number(required=True)
self.a = a
self.b = b
def doSum(self):
'''Returns sum of two numbers'''
return self.a + self.b
def doMultiply(self):
'''Returns product of two numbers'''
return self.a*self.b
def doDivision(self):
'''Returns divison-quotient of two numbers'''
return self.a/self.b
def doModulo(self):
'''Returns division-remainder of two numbers'''
return self.a%self.b
def MathTester(nums,flag):
maths = MathFunctions(nums[0],nums[1])
if flag == 'sum':
return maths.doSum()
elif flag == 'mul':
return maths.doMultiply()
elif flag == 'div':
return maths.doDivision()
elif flag == 'mod':
return maths.doModulo()
else:
return None
This is the code I want to test.
from MathFunctions import MathTester as mt
import pytest
@pytest.fixture
def small_big_nums():
return [3, 10]
@pytest.fixture
def big_small_nums():
return [10,3]
@pytest.fixture
def division_fail():
return [10,0]
class TestIsValid:
"""Test how code verifies"""
@pytest.mark.parametrize(
'num1','num2',
[range(100),range(100)]
)
def test_sum(self,num1,num2):
assert num1+num2 == mt.MathTester([num1,num2],'sum')
This is the test I wrote for it.
In test_sum: indirect fixture 'range(0, 100)' doesn't exist
and this is the error I keep getting
If someone knows how to resolve this, please 🙏 tag me to notify me
@keen venture You need to put tuples in the list
[(range(100),range(100))]
It doesn't make sense to pass a range though
If you want a random number from the range, then define a fixture to get random numbers
I don't suggest randomness though. Just use some arbitrary int literals in the parametrize decorator.
Or positive pairs, negative pairs, and a mix
And mutation testing https://mutmut.readthedocs.io/en/latest/
both sounds really interesting despite the lack of time. Wished testing wasn't an afterthought at my workplace
Do the right thing, wait to get fired
The first recommendation I would make is to not do that, but do pytest :P
You should post the entire traceback
@proud nebula what would a mutation testing example look like here?
i know that for having 2 implementations of the same thing (native + and the user-written version) makes for an easy property to test
It's also a worthless thing to test that will run for a long time and not find anything. At least mutation testing will make sure you've tested all behavior and will be complete.
Property based testing is fundamentally checking an infinite problem space which gives me the creeps :)
When testing a class instance or definition, you wouldn't test the properties of it? @proud nebula
@languid rock I think you should google "property based testing"
heh okay. sorry, i'm just starting to learn about testing my code.
yeah, i read a couple articles and can confirm: my question makes no sense.
@proud nebula im not sure why its so weird? hypothesis has a short timeout by default
I was more just curious what a mutation test would look like, how you would set it up and what the test runner would actually do
Well you can try it easily. Just pip install mutmut; mutmut run; mutmut show
The mutation test will do stuff like replace + with -.. So if you have a test for addition that adds 0 and 0 you don't know if you add or subtract (or even multiply!) but you get coverage. Mutation testing will catch that. Property based testing will too I guess, but only because you've written the entire implementation a second time which seems like cheating to me :P
What I don't like with PBT is that:
- you have to think a lot
- you never know if you're done
- you are searching a potentially infinite space
and 4. it's way more popular, but seems less useful than MT
Hello everyone. I am learning test automation with Selenium, but I got a bit confused with the Page Objects and the Tests. I am not sure if I am doing it right and using the best practices.
I am making each page of the web app to be a Page Object as a class, and I on the page in the class I add each functionality and option scenario as a functions. Later I am creating a Tests for a specific test scenarios, and inside the Test I am calling the specific functions from the class from the Page Object that I need. I am planning to create Page Objects for each page on the web app, and separate each part from that page as a function.
Can you please review this and tell me if I am doing it right?
Thanks 🙂
Page objects are ok if you are testing the page from many tests. You probably aren't though, so page objects just make the code harder to read, debug, understand and maintain. Don't listen to "best practices", just make the minimal code work.
I will need to use the functions from the pages in a lots of different tests. At least some of the functions from the pages. Is this the way to do it correctly?
In the Pages Objects where every page of the web app will be in a class and each scenario/action will be inside a function. And Tests where I will import the classes in the tests and call the specific function that I need from the class
What are some of those functions (methods?) doing?
well for example one for going to the specific page, other for adding new item (clicking on some button, checking or unchecking a checkbox, adding text to a text field), then for removing a specific item
Going to a specific page shouldn't be a member function, it's just a one line call to selenium. Adding/removing an item should only be tested in one place by the specific test for that. Otherwise you should touch the database directly or use the underlying API to set up and remove stuff before doing the thing you actually want to do.
So none of those sound like methods you should have to me.
Remember that selenium is the most expensive and slow thing possible, so avoid any and all interaction with it like the plague :P
hi I started learning pytest and I stocked on some basic test
does anybody could provide me some help?
does anybody could provide me some help?
@icy ice pytest is very difficult to get started with ngl. but once you get the hang of it, it (almost) feels awesome to write tests.
Do you need any specific help or just help in general?
spefific 🙂
actually i can handle basic tests in pytest but i stock in one thing
'''python''''
i have a class worker:
python
class Worker:
GENDER = ['f', 'm', 'n']
def __init__(self, **kwargs):
self.first_name = kwargs.get('first_name', '')
self.last_name = kwargs.get('last_name', '')
self.salary = kwargs.get('salary', 0)
if not isinstance(self.salary, int):
raise ValueError("worker's salary has to be an integer")
elif isinstance(self.salary, int) and self.salary < 0:
raise ValueError("worker's salary has to be a positive integer")
self.level = kwargs.get('level', 0)
if not isinstance(self.level, int):
raise ValueError("worker's level has to be integer")
elif isinstance(self.level, int) and self.level < 0:
raise ValueError("worker's level has to be positive integer")
self.gender = kwargs.get('gender', '')
if self.gender.lower() not in self.GENDER:
raise ValueError(
"worker's gender can be only f-female, m-male, n-non binary")
and i have my test case here:
class TestWorker:
@pytest.mark.parametrize("expected, kwargs", [("first_name=Jhon, last_name=Doe, gender=m", "janinaa")])
def test_string_method_class(self, expected, kwargs):
# worker = Worker(**kwargs)
# worker_description = worker.__str()
assert Worker(**kwargs).__str__() == expected
and I don't know how to use kwargs in that test case
First of all, you kwargs parameter should be a dictionary. Python has no way of knowing that the list you are sending is supposed to be used as kwargs
class TestWorker:
@pytest.mark.parametrize("expected, kwargs", [{"first_name" :"Jhon", "last_name": "Doe" , "gender" :"m"} ])
def test_string_method_class(self, expected, kwargs):
# worker = Worker(**kwargs)
# worker_description = worker.__str()
assert Worker(**kwargs).__str__() == expected
I omitted janinaa, I have no idea what it means
class TestWorker: @pytest.mark.parametrize("expected, kwargs", [{"first_name" :"Jhon", "last_name": "Doe" , "gender" :"m"} ]) def test_string_method_class(self, expected, kwargs): # worker = Worker(**kwargs) # worker_description = worker.__str() assert Worker(**kwargs).__str__() == expected
@fresh blade tbh this still isn't gonna work. it will throw an error. what exactly are you trying to achieve?
me either its random string typed in to keyboard
I want to test str method then I can check also all attribute in init method
Also, a small tip. It's more python to write str(Worker) than Worker.__str__()
i'm using unittest and I want to check pytest cause everybody tell it's better
Maybe do
worker = Worker(**kwargs)
assert str(worker.gender) == kwargs.get('gender')
i'm using unittest and I want to check pytest cause everybody tell it's better
@icy ice That is entirely up to personal preferences. In my experience unittest is easier but pytest does a lot of things correctly. But thats jist what I think.
That's why I want to give a try 🙂
but I have a problem to catch how to use correctly parametiraze
i need to practice more
look at the pytest docs for that. They are not good looking imo but explain stuff pretty well. And yeah parameterization is really awesome feature
I once wrote 70 tests using just one function and 70 different parameters lol
yeah pytest docs are only source acctually.
yeah pytest docs are only source acctually.
@icy ice yep that's one problem with pytest. there's simply not enough documentation or tutorials
@fresh blade thank you for help!
@icy ice I'm glad i could help!
I think this is the right channel? I’m not sure I got an issue but the only stack overflow questions out there are too specific to what I have
What's the question?
Is there any sane/standard way of testing a function that utilizes subprocess? Essentially I'd want to properly mock the PATH variable to remove executables
Mock popen or whatever it is you use
Make it return some fake stdout if your program reads stdout from it
Cool, so I'll have to mock the return value of subprocess.run though since I'm also accessing returnvalue I'll have to return mocks instead
Hi I use Codacy to analyze the quality of my code. I have it as a github workflow (included in the repository as a .yaml file), and I confirm that it runs when I push new commits on the master branch.
For some reason, I'm not seeing the new commits or new analysis on my Codacy dashboard
Does anyone know if I'm missing something to send new commits to codacy? When I include a new branch for Codacy analysis, it will add it, but it still doesn't show new commits.
Guys, my website's frontend is written in Javascript but can I use python selenium to actually write the functional tests? i am aware that there is a Javascript library for selenium too but I am more comfortable writing tests in python
you can use selenium to test it, there should be no problem
alright thanks
@fresh blade it's probably a very bad idea though, since it's going to be amazingly slow
So I tried out mutmut on a personal project recently and I'd noticed that it mutates my dataclass lines e.g.
- @dataclass(repr=False, order=True)
+ @dataclass(repr=True, order=True)
```In this case I didn't really have to write tests for the methods generated by `dataclass` since they're relatively sane, as in this case, it's just a wrapper type for `Union[int, float, Fraction]`, should this be treated as a false positive?@fresh blade it's probably a very bad idea though, since it's going to be amazingly slow
@proud nebula why? is Javascript selenium faster?
@fresh blade selenium is super slow. If you can run tests of javascript in javascript directly (like in node via jasmine or whatever is popular this month) this is going to be way better.
i have heard about jest. But is it the same as selenium? That is does it fire up a real Google Chrome instance and does clicking and stuff?
@digital grotto maybe. It does seem a bit silly to test your repr in some cases. But if you're making a library that is used by many people it might be very important to check that you have good reprs. But you can exclude that line with a pragma or the adnavced whitelisting system.
@fresh blade I think jest is like jasmine in that it just starts node and doesn't start an entire browser. Actually running a browser is not good.
but then how will i see what is being tested in the first place?
nvm. i don't know much about testing, I'll have to get the basics down for it first
anyways thanks for helping me out @proud nebula
See? If you have a function you check the outputs? Nothing to see.
@digital grotto happy to see someone else giving mutmut a try! Do bug me about any and all minor thing :)
Will do 😄
a question regarding dropdowns in automation for web applications. Can someone help?
Should I use pytest or unittest?
I've only used unittest a few times but pytest seems to be the preference here
I think the only thing unittest has going for it is that it's stdlib
I have real trouble deciding what and when to test
A lot of what I write is linking multiple systems together and quite often I just implement some simple wrappers around exisiting libraries.
An example would be this really basic class I wrote to decrypt messages:
class JSONCrypto():
def __init__(self, pkey):
self.private_key = jwk.JWK.from_pem(pkey)
def decrypt_message(self, enc_msg):
"""Decrypt JSON message body using private key"""
jwetoken = jwe.JWE()
jwetoken.deserialize(enc_msg, key=self.private_key)
return jwetoken.payload.decode("utf-8")
And I wonder do I really need tests here and what should they be? It feels like I'm just retesting existing code largely
As a general rule, you should never need/have to test the actual framework you're using, the logic being that these are already heavily tested and thus testing their implementation is just a waste of resources. Instead what you wanna do is test your own code that you have built on top of that framework. @rotund phoenix
eg:
def sort_list(lst):
return lst.sort()
If you were to test this function, you shouldn't have to test the implementation of it (for eg what sorting algorithm is used under the hood) but instead you wanna test if the function is doing actually what it is supposed to do, and raises the appropriate error when it needs to. @rotund phoenix
I guess that's where I struggle
Deciding which is the actual bit I need to test
And then I end up just not testing anything 🙃
welcome to the programmer's gang
Eh multiple years doing this as my job and it's still the one area I'm not comfortable in
My strength is figuring out the solution and making shit work quickly, I learned everything on the job and rigorous testing is just something I've never had to do much of
I've done some tech tests where I had to write tests but they were always for pretty simple functions that only really worked with basic inputs
Then I find myself writing code that interfaces between a DB and some files, perhaps with a web request thrown in for good measure, and I get overwhelmed by complex mocks and inputs
I agree, it can be confusing
Look up black box vs white box testing, it may help you come to terms a bit.
Cool. Any good testing tutorials for more complex cases I'm keen
Not from me, I'm still trying to figure it out too
Like, black box is nice cause the tests aren't tightly coupled, so they're faster to write and easier to maintain, but white box tests are nice cause they're more thorough. I wish there was a best of both worlds.
People have talked about other testing methodologies like mutation testing, so my plan is to look into that next.
Not necessarily mutation testing, but just other ways of testing in general.
guys can anyone tell me what all to add in .dockerignore while testing using pytest? I keep getting permission errors in my host machine since docker changes the file permissions when i run pytest in a container
@rotund phoenix you might want to look up "functional core, imperative shell". This design is good for reasing about your code and makes testing easier, more obvious, faster, and just better.
@kind meadow if you do want to check out mutation testing I'm here for you :) here's my talk on the subject https://youtu.be/fZwB1gQBwnU

What is mutation testing? How does it work in practice? What is it like to actually do it? These questions will be answered!
Audience level: Intermediate
Speaker: Anders Hovmöller
anyonw have web scrapping/automating experience?
Probably
@errant hare, I created the automation bot for hordes.io game using web scrapping. https://github.com/ntdkhiem/hordes.io-bots

GitHub
Auto grinding bot in hordes.io. Contribute to ntdkhiem/hordes.io-bots development by creating an account on GitHub.
Is there a way to do a full workflow test on an online game using Python?
@errant hare and @wary bobcat it's "scraping". To scrape. To scrap (scrapping) is to throw away. Web scrapping means to dismantle or throw away web.
@wary bobcat as per the terms of service for hordes.io (https://hordes.io/terms#terms-and-conditions), automation is considered cheating. we cannot discuss anything that breaks a ToS agreement here. see #rules , specifically rule 5
!rules 5
5. Do not provide or request help on projects that may break laws, breach terms of services, be considered malicious/inappropriate or be for graded coursework/exams.
:incoming_envelope: :ok_hand: applied mute to @real sail until 2020-09-08 19:50 (9 minutes and 59 seconds) (reason: duplicates rule: sent 4 duplicated messages in 10s).
@real sail Spamming isn't how you learn Python.
Hey guys i need some advice using docker.
I am making a website which uses a django backend, vuejs frontend and postgres database. I am using tox to test the backed and cypress for the frontend. I execute the tox tests right in the backend container and it works fine. However the cypress tests have a lot more dependencies and has been proving difficult to execute in the same container as the frontend.
I tried to switch the base of my frontend from nodejs:alpine to cypress/included (which is a pre-configured image provided by cypress) and everything works fine.
However I am left wondering- is it better to just separate two containers, one for the frontend development and the other for executing cypress tests in?
yes
docker containers should have one job and one job only, testing is different job
in theory, you should test before you throw everything in container
@proud oyster so you mean I have to test on my local machine before creating a new container altogether? doesn't the kinda defeat the purpose of docker in the first place?
that is making testing completely platform independent
well, github actions could test it
which is container
but I wouldn't test when it goes into the container, I would making a testing container that runs
I am already using Travis CI so testing isn't the issue. The issue is actually how to test- same or separate containers.
seperate
alright thanks
are you trying to test what your app looks like after its deployed to the continaer?
no I'm just testing if the website works. Before or after deployment doesn't matter. @rancid flax
if you have windows, you can try using docker desktop for windows and deploying it locally
if you are hosting it on a container, you would have to deploy it everytime to see what it looks like, there is no other way
I have already setup docker
Hey guys i need some advice using docker.
I am making a website which uses a django backend, vuejs frontend and postgres database. I am using tox to test the backed and cypress for the frontend. I execute the tox tests right in the backend container and it works fine. However the cypress tests have a lot more dependencies and has been proving difficult to execute in the same container as the frontend.
I tried to switch the base of my frontend from
nodejs:alpinetocypress/included(which is a pre-configured image provided by cypress) and everything works fine.However I am left wondering- is it better to just separate two containers, one for the frontend development and the other for executing cypress tests in?
@fresh blade this was the original issue@rancid flax
ah I see
i think you should be fine executing the cypress tests in the same container as your backend tests
but if it has more dependencies, having its own container would probably be best
but I think those tests should be executed before you deploy anything to the containers
you shouldnt test on a container unless you REALLY have to
think Devops,
Code, build, test, release, deploy, operate, monitor
i think you should be fine executing the cypress tests in the same container as your backend tests
@rancid flax that's what I have been doing till now and it works out okay
but I think those tests should be executed before you deploy anything to the containers
@rancid flax actually these containers are on my local development machine not on the actual production server
understood
i made a simple calculator would anyone be kind enough to check it and tell me ways i can improve it? i am quite new to python? thanks

{kind=link}
{kind=link}
{kind=link}
@gentle terrace thank you for the link i will try it
How would i get all div elements in a list that belong to the second class "1", using selenium in python
<html>
<body>
<div class="1">
"ignore"
</div>
<div class="1">
<div id="want1">...</div>
<div id="want2">...</div>
<div id="want3">...</div>
<div id="want4">...</div>
</div>
</body>
</html>
Design question... I'm trying to use pytest to orchestrate some tests for an external emdedded device (mainly using pexpect to send commands on a serial console and verify output)...
I have a custom CLI tool written in Golang, (lets call it conveniencecli) that wraps flashing firmware and communicating with the device via calling other command line tools (ssh, netcat, etc) . Is there any reason I shouldn't have pytest just spawn processes on my custom conveniencecli app instead of rewriting some of its functionality in Python?
In other words, is there a drawback to pytest -> os.system('conveniencecli') -> os.system('ssh') over pytest -> <new python logic> -> os.system('ssh')
Is there any way we can print the stack trace with local variables. I know traceback.print_trace() can be used to print the stack trace.
@hoary karma use a debugger. Vscode has a very good one.
@hoary karma sure. Just loop over locals()
There are similar but more fancy stuff for going over a stack frame by frame too.
don't forget a / after preserve.
I am already using Travis CI so testing isn't the issue. The issue is actually how to test- same or separate containers.
@fresh blade I know this is 2 days late, but just in case you are still wondering 😄 ...
I usedocker-composewith multiple compose files. One isdocker-compose.cypress.ymland starts acypresscontainer. I can call it explicitly with
docker-compose -f docker-compose.yml -f docker-compose.cypress.yml up
and it starts my project and cypress. If I omit it, it simply doesn't start, so takes less RAM/CPU.
So yeah, my recommendation is separate container. Unit tests should run in a python container, cypress should run in its own container, and on-demand. E2E tests are slow.
@balmy saffron don't you have to worry about the fact that the server itself has not started yet, but cypress starts execution of tests, and fails because it can't find the server?
@balmy saffron don't you have to worry about the fact that the server itself has not started yet, but cypress starts execution of tests, and fails because it can't find the server?
@fresh bladeCan't say I've ever had that issue. You can add adepends_onsection so it starts the server(s) first, and astartup.shscript that checks that the server is up and only then runs the tests, if you're worried,
I don't do it in cypress, but I have a pgwait.py script that tests that the DB is running before I start Django.
@balmy saffron can i see this pgwait.py file please? i will try to implement something similar for myself
@fresh bladeCan't say I've ever had that issue. You can add a
depends_onsection so it starts the server(s) first, and astartup.shscript that checks that the server is up and only then runs the tests, if you're worried,
@balmy saffron there's a github repo calledwait-for-itwhich does exactly that and that's what I have been using so far, but it looks like a very flimsy solution
startprod.sh and pgwait.py
yeah those. do you have a public repo with these scripts?
startprod.shandpgwait.py
@balmy saffron
https://gitlab.com/patryk.tech/patryk.tech/-/tree/master/ptdjango here it is again
@balmy saffron thank you very much, this will be very helpful for me
Hello , I have a repository for which I have been granted maintainer access , but when I clone it and try adding files and then commit , I get
On branch master
Your branch is up to date with 'origin/master'.
nothing to commit, working tree clean```can someone tell me why it is happening?
did I mess up something?
for now , the repository is an empty one but Im unable to add files to it
@late sage , I do , git add . git commit -m "something" and I get that message
@nocturne moat what does your .gitignore file have?
there's no gitignore created @fresh blade
git log --oneline @nocturne moat
``` @fresh blade