#unit-testing
1 messages · Page 15 of 1
Do you guys know if there's a way for me to attach extra information to a pytest fixture so that I can access that in tests using the fixture? For instance:
@pytest.fixture(params=["foo", "fOo", "fOO", "FOO"])
def upper_foo(request: Request) -> str:
upper_foo.myinput = request.param
return cast(str, request.param).upper()
def test_upper(upper_foo: str) -> None:
assert (
all(c in str.ascii_uppercase for c in upper_foo),
f"Not converted to upper: {upper_foo.myinput}"
)
Silly example, but you get the idea, right?
I don't want to change the fixture to return a (in, out) tuple.
object.__setattr__ 😉
I mean, I also code in JavaScript when I have to, so I've already dirtied my hands…
most objects you can just assign any attribute you want: o = object(); o.foo = 3
yeah, unless they implement __setattr__ 😉
or slots, or if it's an int or a lot of other exceptions, but you know what object you have no?
Common wisdom these days seems to be not to mock, right? So if I have a class around an aiosqlite connection which I want to test, do I actually just use aiosqlite in-memory fixtures, i.e. the real thing, for tests? It still feels so wrong to me, but I tried and utterly failed mocking aiosqlite…
For database stuff you don't know if your code really works unless you test it against a database. The value is in integration tests (e.g. the rise of testcontainers) or in the case of a sqlite one if that's what your code depends on an in memory one is probably just as fine.
why does it feel wrong to use an in-memory sqlite db? Or even a temporary on-disk one? It's not burdensome.
I don't know why it feels wrong. It really shouldn't…
pytest doesn't support async fixtures anymore, so at the very least, I cannot just provide an aiosqlite fixture for tests…
I tried to do an async fixture a few weeks ago and I think I recall it being mentioned you have to set something in a config for it to work. I personally just use unit test/IsolatedAsyncioTestCase usually, but sometimes put fixtures/auto use on them so that subclasses can still use setup/async setup.
Please delete as its not relevant to the channel and its made with Lovable. This is seen as advertising
I'm not familiar with Lovable. Why is that a strike against it?
Its not made with Python. Its mainly ReactJS
As in Lovable doesn't make Python scripts
got it.
@stiff dirge hello, please remember to follow all server rules including rule 6 regarding advertisement
It actually just seems to be @pytest_asyncio.fixture
Ahhh. I see. That would make sense.
Ye
Why would print(ld.validate_livedata) run fine, but validate = mocker.patch.object(ld, "validate_livedata", autospec=True) in the next line cause an AttributeError "'FakeLiveData' object has no attribute 'validate_livedata'" ?
class FakeLiveData definitely has a method validate_livedata
ipdb> ld.validate_livedata
<bound method FakeLiveData.validate_livedata of FakeLiveData(court=None, timestamp=datetime.datetime(2026, 1, 2, 22, 56, 42, 422901), fakedata={}, status=<LiveStatus.UNKNOWN: 0>, starttime=None, endtime=None, scores=[], games=[], matchscore=[0, 0], winner=None)>
ipdb> ld.__class__.__dict__["validate_livedata"]
<function FakeLiveData.validate_livedata at 0x7f59595aaa20>
can someone test my script
i made a v2 version of t=ti
you only need pyqyt to run it
its a hacking tool that lets you make scripts
yah i know dumb
this channel is about writing your own automated test suites.
hello. What do you think about this approach to support different behavior of a mock vs. creating multiple mocks?
"""Mock requests.Response instances."""
def __init__(self, **kwargs: dict) -> None:
"""Initialize requests.Response instances."""
self.headers = kwargs.get("headers", {})
self.response = kwargs.get("response", {})
def json(self) -> dict:
"""Mock requests.Response.json() method."""
return self.response
class HTTPClientMock:
"""Mock requests.Session instances."""
def __init__(self) -> None:
"""Initialize."""
self.case = os.environ.get("CASE")
def mount(self, prefix: str, adapter: requests.adapters.HTTPAdapter) -> None:
"""Mock requests.Session().mount method."""
def post(self, _: str, **__: dict) -> ResponseMock:
"""Mock requests.Session().post method."""
if self.case == "test_something":
return ResponseMock(headers={"request-id": "123"}, response={"status": "Complete"})
return ResponseMock()
def test_something(monkeypatch: pytest.MonkeyPatch) -> None:
"""Test something."""
monkeypatch.setenv("CASE", "test_something")
monkeypatch.setattr("requests.Session", HTTPClientMock)```for each test/case, I will setup the envvar "CASE" accordingly
and adapt headers and response depending on the case
how many different tests will you have, and how many CASEs?
5 cases and up to 3 requests, two GET getting different responses.
likely to increase since I'm creating a POC, once business unit can test it then probably there will be more additional requirements
no every case will have a if since I'll setup the "regular" case as default value for headers and response after a quick refactor
moved forward a bit and get method evolved to:
"""Mock requests.Session().get method."""
if self.case == "test_regular":
if "/status" in url:
self._response = {"status": "Complete"}
if "/download" in url:
with Path("/test/responses/regular.json").open() as file_stream:
self._response = json.load(file_stream)
return ResponseMock(headers=self._headers, response=self._response)```it feels to me like the details of the case should be in the tests themselves
you mean the details as the behavior?
yes, it will make the test clearer
would that mean that each test will have its own mock classes?
although I'm up to make this the clearer as possible, feels like a ton of code
If the cases were more generic, it might be ok to have them in the ClientMock class, but with "test" in the case names, it indicates to me that those ideas are coupled to the tests.
maybe separate client mock classes intead of a case within one large class?
you are right, I didn't like it when I read "large class" and it is what is becoming
thanks!
Just want to share this amazing library!
https://hypothesis.readthedocs.io/en/latest/
It automates the generation of edge cases in your tests!
And not only that, it'll also check for those nasty cases, like MaxInt, NaN, Infinity,Complex Number, ... catching all sorts of RuntimeErrors and not only that! If you use typehints it'll also generate all the tests for you!
Indeed, Hypothesis is amazing
sho nuff
Random testing is an important part of testing ✌️and a very effective tool. But "all" is an exaggeration ☺️
yes, I would not use only Hypothesis for testing. It can be very difficult to express your code's outcomes as properties suitable for Hypothesis.
I use multiple mocks like you said ConstantMock, InMemoryMock(), FakeMock(), Spy(), etc. I wouldn't use envionment variables to set ip up though, just regular parameters.
yeah, I liked the result of this. Less time building abstraction and less time from other developers while reading the code.
more verbose, yes. But there are many mechanisms or organize tests (folders, modules, and classes)
Sounds interesting, any example showing/explaining this more in depth/in action?
Disclaimer: I'm a bit allergic to mocks.my own experience with mocks are from unittest.mock and usually mocking very unnecessary things just causing complexity, lower test value and extra work for devs.
For example, a lot of our code mocks local and not necessarily slow stuff (so I'm unsure where/how they thought the mocks add value),
- the tests to have lower test value (they test a mock instead of a real thing)
- when the real things get's updated and interfaces change, the mocks needs to be updated as well, causing double work for no gain.
I know you didn't ask me but I'm going to answer this myself because I'm super into this: In my opinion there's no rule saying you have to use mocks. You have some code that has to collaborate with something else to get work done, to verify that it works you give it that thing in a certain state and inspect the state afterward. If I for example have UserRepository, BalanceRepository, for loading users and their balances and saving them out, I have to in practice setup an ORM, and write implementations for it, this is realistically the only implementation I'm ever going to use. So I have like a User registration service class that uses the repositories and creates entities, I might as well just write the sqlalchemy ones and test with those. My code gets the same coverage but it's slower to run because it requires testcontainers. This is something I've done before because of being repulsed by the unittest.mock style ones as you said and because I had a real thing it was way easier to test everything over a series of things, like calling register, then login, and stubbing nothing.
I've recently changed my opinion on this and started writing fakes, which solve the problems associated with unittest.mock... my code collaborates with this repository, a real repository doesn't exist yet, so I make a fake one (in memory, same behavior as the real thing) and I use that for the classes in my tests, and it becomes like having a real system your tests can interact with, and inspecting the state of after, or... Use the real thing. Attaching a screenshot of some of what this looked like for me as part of a recent experiment with it.


i'm curious why you use _underscore names for the attributes in your test case classes?
I default to it for stuff that isn't meant to be accessed outside of the classes and their children universally, so I just write it the same for test case classes because I find it quicker. I don't do it all of the time, for some types of tests I'll avoid it because it looks nicer.
To each their own. I don't find it any worse than writing out the type hints personally.
Faint praise heh
If you want, there is another level you can reach. Writing mocks for things like persistence (dv, orm, clients) has the disadvantage that the mocks need to know specifics of the persistence methods. Personally, that slows me down too much - I don't want to think about that. So what I do is I try to write unit tests only for my code and interfaces. Of course, persistance, db, http NEEDS to be tested too, but maybe there's a way to test it without setting mocks? There should be a way to do it, because production code uses db without mocks, that should be possible for tests too. So I have another suite of tests that actually uses the actual database for tests. That approach has some challenges, but has some great advantage too:
Cons:
- These tests are slow, so you need as few of them as possible. That means you need to separate your domain code from db code (which you would like to do anyway), and have few of the tests that use the db
- You need to somehow ensure test isolation, you need to either drop the db, or use actual features of your application. If your application has projects or workspaces, use them in tests. Transactions aren't good for that issue have found.
Pros:
- your tests know NOTHING about the database, so you might want to even change sql to mongo and your tests wouldn't break
- you don't need to setup mocks for the db
- You don't need to tie your tests to the db
- this style of programming puts a force on your actual code to design a more separated system
It's a trade off, for some it's too much, but for me it's just right.
ORM hitting tests running against sqlite in :memory: are generally as fast as mocked tests that have the same aim
But sometimes you just need to test code that hits Postgres full text search, and so you take the hit of the slow test
The aim is "small readable tests" even if they are "complex functional testing" citation: https://docs.pytest.org/en/stable/#pytest-helps-you-write-better-programs
Speaking of using SQLite for tests, is there an agnostic way to test across multiple database engines with UUID primary keys yet?
I've still got from sqlalchemy.dialects.postgresql import UUID everywhere.
That represents a SQL type supported by PostgreSQL. If you want something agnostic you could use a char field instead.
sqlalchemy supports this too: https://docs.sqlalchemy.org/en/21/core/type_basics.html#sqlalchemy.types.Uuid
I assume you can make a custom type that delegates to a char field or a Postgres UUID field depending on introspection of the engine
For backends that have no “native” UUID datatype, the value will make use of CHAR(32) and store the UUID as a 32-character alphanumeric hex string.
Oh that's just what that is
You could probably pinch the code from the UUID field and adapt it for v1
I'm on v2, I'm good
I just hadn't seen that yet
Do let us know the before and after test suite total runtime if you switch to sqlite :memory:

I switched my tests from polling to wait for an event. But on macOS they it is taking a long time to start a thread with a webserver. https://github.com/Siecje/htmd/actions/runs/21356695483/job/61467157952
GitHub
Static Website Generator: Write Markdown and Jinja templates to create a static website. - Longer timeout for preview tests for Github Actions CI macOS · Siecje/htmd@1fd53f0
when i try to run mutmut i get
Traceback (most recent call last):
File "<frozen runpy>", line 198, in _run_module_as_main
File "<frozen runpy>", line 88, in _run_code
File "C:\Users\ar754\Desktop\gang\codg\good projects\pyrobloxbot\venv\Scripts\mutmut.exe\__main__.py", line 2, in <module>
File "C:\Users\ar754\Desktop\gang\codg\good projects\pyrobloxbot\venv\Lib\site-packages\mutmut\__main__.py", line 9, in <module>
import resource
ModuleNotFoundError: No module named 'resource'
do i do just pip install resource?
is mutmut linux only?
it is
lel
how do i activate a python venv inside wsl
Ah. It would be better if it had a nice error message saying you should run it inside wsl. Would you mind opening an issue for that?
source venv/bin/activate
yes of course :)
thanks i struggling hahahah
Often it's better to just keep to the unix world when developing...
(btw, I'm the author of mutmut)
yeah ive been thinking about switching to linux ever since i got into college
but i still like playing video games, and all my stuff is already configured in windows, and im scared ill forget to backup something and lose my files
GitHub
Right now, trying to run mutmut on windows gives this error: Traceback (most recent call last): File "<frozen runpy>", line 198, in _run_module_as_main File "<frozen runpy&g...
Just doing all dev work inside WSL is probably perfectly fine though
i find that stuff runs way slower tho
hmm.. that sounds strange. Anyway, for mutmut, the advantage of having fork() available will improve the total time a lot anyway
in pytest, is there any advantage to having the tests inside of a class instead of just defining the functions?
sometimes it makes it easier to manage helpers, and it gives you some namespacing. naming tests can be a pain.
I really dislike tests in classes and avoid them
yeah i also moved them out of the classes
but more so because i was getting tired of need to add self to all the tests
I find it really handy for test selection.
that could be another advantage: python -k JustThatOneClass
We have code that dynamically creates more classes, so it's impossible to know class names before actually running the python file 🙃 (10+ year old code)
I'm looking through some unit tests and wondering if they're taking the right approach to testing what needs to be tested.
Class has a custom queue class in it and when the class is given certain items, it should clear the queue before adding those items.
To test this functionality, it uses a mock patch on the queue class's clear method and asserts that it's been called.
It does accomplish the job of testing behavior but it's doing that by testing the implementation details rather than the results of the behavior. And I'm not sure how to think about that.
that sounds odd: if this is all your own code, with data in memory, it should be possible to test the observable behavior rather than mocking a method.
It's company code, so not my code but not opaque code.
I had actually spent a good amount of time setting up tests for the queue class itself so part of my digging here is figuring out what tests are testing the class and what tests are actually testing the queue owned by the class.
One actual complication here is that the class has an event loop run on a separate thread. And unfortunately that loop is set up in a way that it can't not run in the thread. Really annoying because a worker thread is something actually worth mocking!
I think I found a balance in mocking the thing that controlled the thread's event loop and only testing the results of that mock. Had to get a little unreasonably fancy with side_effect but everything passes with minimal digging into implementation details.
This seems like the right approach for testing that class. The class being tested collaborates with a queue, it should clear the queue in use. I think that is the behavior is it not? Alternatively what externally verifiable behavior would you like to see from it?
Inspecting the state of another object is valid, putting in a mock and asserting an interaction is valid if the interface is locked down enough for that to be the only way to clear it, and return values or the externally verifiable state of that class are valid. But at a glance it sounds like you want to know that the queue in use will be cleared and mocking is just fine.
The class itself doesn't clear the queue, the queue itself decides to clear itself under certain conditions. I tried to argue it shouldn't do that but it's designed to be "smart". And that's why I argue that a test of the class shouldn't be testing the state of the queue, it's the job of the queue's tests to do that.
The job of this class is to put items into the queue, take items out of the queue, and send those items somewhere else. Since "somewhere else" is the test boundary, that's the only thing I needed to mock. And with that mock, I opted to test that everything I expected to be sent was sent.
Right.
Yea that makes sense. Your class takes a queue and that queue magically clears it's self under certain conditions. You don't care about testing that it actually does it just that it will send stuff in and take stuff out of something shaped like that queue as expected If I'm understanding this right. Not sure I necessarily follow the rest but it sounds like you've gone in the right direction.
you got it
Any good resources for leaning unit-testing?
I might have learned from https://github.com/gregmalcolm/python_koans
GitHub
Python Koans - Learn Python through TDD. Contribute to gregmalcolm/python_koans development by creating an account on GitHub.
You mean the production classes or test classes?
Checkout differenced between Tdd London school vs chicago school. Generally, tests should respect encapsulation, so you can refactor the internals of the class. However, putting mocks into tests is valuable, especially if you're doing outside-in. In your case, if your queue doesn't have its own dependencies, then I would probably go with chicago style, which would be to encpasulate the queue entirely and use the public methods of the class to inspect it.
How can I dynamically generate a pytest test case for every file in a folder? Is there any issue with do a glob in a parametrize decorator?
That's exactly what I've done in the past. Works great.
import glob
from pathlib import Path
import pytest
# project root relative to the current file
PROJECT_ROOT = Path(__file__).resolve().parent.parent
FILES_DIR = PROJECT_ROOT / "folder"
FILES_PATTERN = str(FILES_DIR / "*.txt")
@pytest.mark.parametrize("file", glob.glob(FILES_PATTERN))
def test_files(file):
...
Thanks 👍
I'd probably consider using https://docs.python.org/3/library/importlib.resources.html#importlib.resources.files rather than PROJECT_ROOT = Path(__file__).resolve().parent.parent

Python documentation
Source code: Lib/importlib/resources/init.py This module leverages Python’s import system to provide access to resources within packages. “Resources” are file-like resources associated with a m...
Nice, that'll be less brittle.
<@&831776746206265384>
!compban @tired cypress
:incoming_envelope: :ok_hand: applied ban to @tired cypress until <t:1771910575:f> (4 days).
Anyone have comments on a draft blog post about pytest.parametrize? https://nedbatchelder.com/blog/202602/pytest_parameter_functions
Pytest’s parametrize is a great feature for writing tests without repeating yourself needlessly. (If you haven’t seen it before, read Starting with pytest’s parametrize first).
It was very short for a speech, but it’s very long for an id!
😁
thanks for liking that 🙂
That post is great as-is; I have no suggestions
thanks!
[fwiw I think I use a handrolled function in my parameters somewhere]
id vs ID? That's my only thing
especially "ids" looks a bit wonky compared to "IDs"
Maybe I'm just old fashioned though :P

looks good only that case and id might be shadowing but not sure if that's relevant
the shadowing I'm fine with :P
In Swedish we've had the good taste to write out "TV" as "teve" and now that's just standard. "ID" should have been written out as "eyedee", but yea.. English spelling really doesn't allow such constructs as... well.. there is no English spelling based on pronounciation really.
id is pytest's word, I can't change it. I did wonder about case.
i was going to use test_case, but then the function itself will be run by pytest, and non_blank_test_case gets long.
I changed it to nb_case
The only comment I have, is I think its worthwhile to go over ids= keyword for parametrize which can be a list of string or a callable that returns a string
thanks. I've never liked ids=, because you have to maintain some kind of parallel structure. Also, there are too many ways to do things, so I had to keep it trimmed down.
I was talking about in the English text, not in the python code.
oh, hmm
Especially "ids" does give me a Fraudian vibe more than "IDs" do :P
yeah, "create a distinct id" is a little weird.
🤣 yea exactly
maybe if I made it "create a distinct id"
ah, yea that would do it. might look weird with ids though
often that ends up with too much space between the parts
I think if it's "ID" most people will understand is as the English concept and not the pytest specific machine word
hmm, it doesn't read well to me, but i see the difficulty.
I changed it to ID, I'll see how it feels.
I like it at least
How should I approach unit-testing?
I work with Scrapy, so I normally do a quick spider that hits some website, load that html to some place + a metadata table, then process it and normalize it to serve for a dataset generation.
How do you approach unit-testing in projects like this? I've heard of making one test for the whole process as quickly as possible, then refactoring, but I don't know what should I test in the first place. I'm new to this approach.
Thanks for your help
You could download the html and put it in a file and write the tests against that.
@worn basalt Unit-testing is a tool that is good for something and bad for others. What are you really trying to achieve?
Im interested in test-first development for data pipelines, I'm trying to set some goals as tests and then achieve them with code, also I want to ensure I don't break things along the way
I've heard that a development methodology focuses on first creating a test that encompasses the whole process as a sketch, and breaking it down in small tasks
I would like to know what kind of workflow do you use to develop quickly and good code, since I normally get bogged down in details and planning
@molten hollow
Yo
What kind of pipelines exactly? What problem are you trying to solve for the user of your program?
Im ingesting data from online offers, the problem that I'm trying to solve is giving access to updated offers on the market to my users which would be data scientists or data analysts. This is a hobby project
The plan is to ingest raw data, process it and fit it into a schema
I'm on the ingestion phase, but I feel I'm going way too slow.
I was thinking testing may help me be faster, since I can set up goals through it. But I would like to know how others with more experience work with testing and what is their development process to integrate testing or this "make it fast, then good" idea.
@molten hollow
@worn basalt So you're scraping webpages?
Yes
If I'm not mistaken, 98% of the code in such applications is parsing the actual layout and structure of the webpage, correct? The "putting in the right schema" is kinda trivial.
It kinda depends on which area of the problem is slowing you down the most. If it is the parsing of the webpage, then I think you should download a local copy of a webpage on your local machine into your project, add it to version control, and in a unit test, try to scrape that local page and expect the proper results.
If there are more pages you'd like to scrape, download their local versions and run tests on them, too.
Running tests on live, internet pages is always going to be slower, less reliable and not really suited for tdd.
If you're given a similar problem, maybe more complex, how do you walk through it? What are your phases to develop it fast and with good quality standards?
Do you sit down and code straight away? Think with paper in hand?
There are thinks I do before that. Two actually.
- Put yourself in the perspective of the user of your software. What is he trying to achieve? What job he needs to do that your software can help. What problems are you solving for him? Why would he use the software instead of doing it by hand.
- Assume your initial ideas are going to be wrong. 90% of initial ideas are wrong. There's no way to tell which are wrong, until you build them and try them out. So do a lot of experiments early on, in order to verify the ideas.
- Try to find ways to compartmentalize the system, if it's too big. You can only work on a system if it fits into your head. If it's too big, split it into pieces that each does fit into your head.
@worn basalt That webscraper that you're writing, is it the problem in itself? Or are you doing it to solve some other actual problem for the user?
In reality all started since I got an opportunity to show a project to a data lead, and I started working before the interview on it.
Now I put some effort into it and want to finish it so I can show it as a portfolio project, through experimentation I was able to extract 10 GB data from it and it could be more. I plan to hand this data to another passionate person on data science so that they can build some project off of it
The actual problem is the lack of data in the market for this specific region
The data lead suggested another website, I was thinking I could make my tests good and then start the other site, but I'm not satisfied with my rate of progress
Webscrapers are kind of gray area of TDD, because they're not stable. You make a scraper, and authors of the webpage tries to make it harder for you, so your scraper breaks.
I made some tests live to detect this changes, only the parsing would change but besides since I first load and then transform I have a raw layer I can visit if something breaks allowing me to backfill
I think you have some vision about tests and tdd and your try to squeeze some process into it.
Thanks for laying out your process, I'll take it into account
What do you mean?
Usually, web scrapers are not really considered "proper projects". Because they put a dependency on something that's not really maintainable (someone else's page, that he doesn't usually want you to scrape it).
what does that mean, and how does it help them?
@worn basalt Could you find a provder that exposes your scientific data via API? You could just call it and fetch it.
That's not really a programming issue, is it?
@worn basalt you are on the right track, thinking about how to test your project.
The best I could do is try to reverse engineer the backend to fetch requests instead of parsing html, however the company that I interviewed for is trying to build their own dataset so using a provider to showcase my skills may not be useful
Thanks ned, how do you work through complex problems? what is your process to be more productive?
split it into smaller pieces. For each piece, think hard about what it is meant to do, and how you can verify that.
for a web scraper, there's fetching data, parsing data, transforming data.
@molten hollow is right that it presents some unusual testing challenges, but "not a proper project" doesn't make any sense.
"test first" shouldn't turn into "it's hard to test so we shouldn't write it"
I'm not saying "it's hard so we shouldn't write it". I'm saying scrappers are ungrateful pieces of software, because:
- They depend on something they can't realistically depend on.
- They aren't solving real issues, they just copy/steal data from some other place. They don't provide any actual value other than you could already get from the page your scraping from.
I'm all for creating hard and difficult projects.
"They aren't solving real issues" also makes no sense. You mean there might be a better way to do it.
@river pilot I knew you'd reffer to the other issue, not that important one 🙂
OKay, let me clarify it, and make it simple for you.
They depend on something they can't realistically depend on!
yes, that makes it hard to test, i agree with that.
No, not just that. It makes it hard to make, maintain, work with, design it, and also use.
yes, all of that
and there might be a better way to get the data
And not because it's hard or difficult, but because you're depend on something that doesn't want to be your dependency.
sure, there are reasons to do it another way
but if someone asks how to test a web scraper, "don't write a web scraper" might not be that helpful
@worn basalt So if I understand correctly, your main goal is to illustrate to your future potential employer that you are a worthy hire, correct?
And in order to do that, you want to write a scraper that loads 10gb of data, so they can see you're talented, is that correct?
I would argue the whole project is more complex than just the scraper, that's the ingestion part
But that's a good approximation
What's the whole project then, apart from the scraper?
That's literally https://xyproblem.info/
Processing each item, loading the items into files and metadata tables. Then converting this raw storage into the schemas, and dealing with updates in offers
Monitoring the pipeline
I would say that's still the "scraping part", unless the processing consists of more than just translation.
@worn basalt Okay, let me ask you this. Assume the data is already scraped and available for you. Is your project doing anything additional with it?
It is validating the data and keeping track of changes through SCD
Apart from that no, It's a DE project
What's "SCD" and "DE project"?
Slowly Changing Dimensions, and Data Engineering
Slowly Changing Dimensions are a way to keep track of changes in data, the scraper loads the files and some information (ingestion_ts) to a metadata table. Then the processing makes sense of that information, if the same offer_id was loaded previously it creates a new entry and sets a flag marking it as current, preserving the other one to keep changes in time
Okay, good. That's the compartmentalization I was talking about earlier.
These could be the two modules in your project. One is the scrapper, which loads data from webpages and takes out just the interesting bits from the page,
and sends them to the other module that does other bits with it, such as comparing versions. You can use proper TDD with that.
@worn basalt it is challenging to test these pieces
What makes something hard to test?
Is the networking aspect of hitting the website? that it may change?
Coupling, random values, lack of control of the system under test, time, threads, race conditions, noise.
No, that's quite easy.
What makes it more hard is that:
- you depend on something that wasn't designed to be depended upon
- author of the webpage probably doesn't want you to scrape his page
- he probably will make some changes to make it harder for you
Usually, when people want you to download their data, they expose API for you to use.
So for example, you want to find the title of a document in div#header p.document-title, you write that in your scraper, and the author changes the layout of his page, so that the locator no longer refers to the title.
For your parser to be successful you would have to keep up with the website layout changes, and also all other security measures that the author of the webpage employs to keep you from scraping the webpage.
But it's like a spy trying to follow a spy.
Two opposing forces at play. You put effort to scrape a page, and page's author put effort for you to not scrape a page.
It's not about testing or engieering practices; it's about that scraping is fundamentally unstable.
It can be successful only if MORE effort and time is put into the scraper than into the preventive measures of the website author.
Thanks for answering my questions, appreciate it
But if you want to tdd it anyway, download the page locally, and scrape it locally with tests.
TDD tests should be repeatable (i.e. if you run it multiple times, you get the same result).
Connecting to an external service doesn't gurantee this, because the page might change.
@worn basalt it's also important to run some tests against the live site, since that's how you will find out if it has changed.
That's more of a discovery, not delivery, so it's kinda outside of tdd scope.
the purpose of tests is to give you confidence that your program will work.
this seems like an important part of that
tdd tests can't give you that if your dependency keeps changing, up to the point that you have to keep track of it.
It would be awesome if they could, but they can't.
Hence,it's discovery, not delivery.
i don't understand your discovery/delivery distinction. how would you find out your web scraper stopped working?
Not with tdd, that's for sure.
ok, then we have to do testing that isn't TDD
Not testing either.
Monitoring/Discovery, yes.
ok, tell me more. how would you find out that your system won't work?
Using monitoring and discovery.
in other word, in production?
But these are like by definition not delivery mechanisms, so tdd isn't suitable for them.
Not necessarily, any kind of monitoring that you need to keep up with whatever you need to keep up with.
But testing and tdd is in the delivery part of the process, not discovery.
In discovery you have monitoring, profiling, things like that.
but what are you monitoring?
?
you are monitoring and profiling the live system, running in production? Or you are monitoring something else?
In area that @worn basalt was talking, if he only needs to make sure his scraper works today, and not necessarily tomorrow, he doesn't need monitoring.
If he wants to update his scrapper with changes in the scrapped website, he needs to monitor it for changes, but not to test, but to detect changes. Once the changes are detected, he should move into the delivery mode and write new tdd-style tests for that, to update the scraper and implement the new behaviour needed for the updated webpage.
So monitoring serves the role of notifying, not testing; that's why it's in the discovery mode.
i'm still not sure exactly what you would monitor. It's a running program somewhere, yes?
I'm just referring to your idea of having tests that shoot the real webpage. That's not a good thing todo, because that test will be unmaintainable.
You are supposed to shoot a real webpage, if you want to keep track of it, but not in test and certainly not in context of tdd.
ok, not in test. Where?
in monitoring system for example.
It really depends on what you need and what you're after.
let's say this program is running for real, doing its job. We'll call that the production system. Is that what we're monitoring? Or someplace else?
I think you're mixing ideas of monitoring external systems, and profiling your own application.
@worn basalt Was talking about calling an external service, that he doesn't own; not his own application.
i;m trying to understand your proposal
I'm not coming up with a proposal, I'm arguing your message.
That. You can do that if you want, but not in tests.
If you shoot a real page in a test, your test won't be maintainable. That's a bad idea.
right, your proposal is not to do it in tests, and I'm trying to find out where you would do it.
It's not a proposal, it's a counter-argument.
If you want to monitor something, it really depends on what you want to monitor and why.
ok, whatever it is, i am interested in the details. Where would you do it?
As I said earlier, it really depends on what you want to monitor and why.
i want to know that the external site has changed in a way that my web scraper no longer works.
So you want to use it as a notification system, for you to be able to update the scraper with the new behaviour.
Imagine the website author changes his layout let's say 8 days from now, at 21:00pm.
If that happens, what do you want to do?
as you said, update the scraper (probably)
Okay, let's say it'll take you 1-2 days to update it.
What do you want the monitoring system to do?
You could have it send you an email, that says: "Hey, that page changed its layout."
But you can't really run any automated tests that will tell you whether your program still works with it or not, because you can't test-drive it with something that you don't control.
So you have a monitoring system that watches for locators (css, id, xpath), and when it detects changes, it notifies you by sending an email.
What you need to do then, is to read that email, open up your project, run all your tests, they should all pass (even though the website technically is out of date with them),
and download the new version of the page, put it in your test folder, and run your tests on it.
If your scraper still works, they should pass, you commit, you are done.
you can of course run automated tests that will tell you this, you just don't like those tests.
If your scraper doesn't support it, the tests should fail.
So you implement the change, you run tests, they pass, you are done.
You can, but they will be indeterminate.
yes, they might be difficult tests
You can expect a lot of false positives and false negatives from them.
right, you have to be ready for that
It's not about difficulty, it's about whether they are reliable.
I think you're trying to chug every bit of not being suitable for delivery into this 'it's diffuclt part'.
i'm exploring the gap between tdd and testing
Some data process just aren't reliable. It has nothing to do with the fact that it's "difficult", it's that you just can't rely on them.
I think you mean between tdd and monitoring, because I get a sense that's what you're after.
Look,
you called it monitoring. but i think i understand your perspective
if something is reliable, then you can use it for testing and for tdd.
Things like versioned software,
or things that has proper backwards compatibility,
or things you can revert or use snapshots.
But live services aren't like that. You can't simply call it in test and expect it to give you a trustworthy outcome.
i understand that.
So you can't use live service to determine the releasability of your software.
Best you can do is monitor them outside of delivery mode to treat it as a notification.
That's what I meant when I said that scrappers are ungrateful pieces of software, because they depend on something like that.
yes, they present many challenges like that
unstability is a challenge. i'm not sure why you would disagree with that.
It's like saying russian roulette is "challenging" or "difficult" to win.
Because with words like "difficult" or "challenging", you imply that it's solvable with proper effort.
But your dependency is unstable no matter how much effort you put into it,
Even if you put like 300 hours into it today, a month from now it's not going to matter.
ok, i understand. But you are not giving up, you are using monitoring to help with that problem.
But it's not really solving an issue.
You just build yourself a tool to help you with keeping in touch with the changes.
Anyway, I think we exhausted the subject today.
yes, i was interested in how to build that tool. thanks for talking it over with me.
don't build it
There are a lot of ready tools like that on the market.
i am not building it, don't worry
Hi, thanks for your input @river pilot & @molten hollow.
I've posted the project here, I would appreciate if someone could check it out and tell me how I can make it better particularly testing side.
I followed the recommendations and just added 1 live test, plus some tests from downloaded .html pages that I included in the repo. I first made the tests and then made my "Parser" component work.
https://github.com/Santiago-Beltran/chilean-real-state-full-pipeline
I don't know if this is the right channel to post this project, if it isn't please let me know. Thanks.
It's okay-ish. Good start.
What could be made to make it be better?
this isn't a testing concern, but your project layout is a little off. You shouldn't ever import from "src". Take a look at https://github.com/nedbat/pkgsample for how to do it.
Thanks, I'll look into it
After checking the resource I made some changes and then verified testing works, I also ran the program.
Something that wasn't included on the resource provided was this config
[tool.setuptools.packages.find]
where = ["src"]
Which apparently indicates the package is there so pip install -e . finds it and I can import it on testing.
I pushed this commit, thanks for your input, anything that makes the project better is welcome
Heyyaa I have a silly question with unittesting here
I use the unittest library for flask and well what I wanted to try was
def test_expenses_invalid_input(self):
with self.assertRaises(TypeError):
self.app.post("/add/20231015/abc")
basically I wanna make it test for invalid input and it should pass the test as like yeah we checked for invalid input or am I doing something wrong?
I'm very familiar with testing but not the flask library and this type of setup specifically. Will it raise the errors to you when you post it like that, or will it only give you the same response it normally would in turn?
Other than that it looks fine to me. Maybe the name could be clearer as to how or why the input is invalid. And as good practice if you're adding the tests after writing the code, you should go change the code back to not failing, then run the test, verify that it fails how you expect, then set it back.
basically what I want it do is pass the test if the exception is raised
and fails when the exception is not raised
what I could try is an error code
still the same
because like at the endpoint I specified that it should be an integer where you see the abc so in the regular it should return error 404. So assertEqual(status_code, 404)
should by theory raise the exception yet it doesnt
Can you provide the code for the endpoint?
oh yeah one sec
@app.route("/add/<date>/<int:number>", methods=["POST"])
def add_expense(date, number: int):
if date in storage:
storage[date] += number
else:
storage[date] = number
return f"Added: {number} dollars for {date}"
number is btw the expense I should really be better with naming sometimes
it makes sense in the context of the function name. I'm not familiar enough with this so i'm trying it on my machine atm to get a feel for it. Can you show me your unittest class for this that you have to get self.app?
oh yeah one sec
class TestFinanceCalcApp(unittest.TestCase):
@classmethod
def setUpClass(cls) -> None:
storage.clear()
app.config["TEST"] = True
app.config["DEBUG"] = False
cls.app = app.test_client()
storage.clear()
def setUp(self) -> None:
storage.clear()
def test_add_expenses_valid_input(self):
response = self.app.post("/add/20231015/100")
self.assertEqual(response.status_code, 200)
self.assertEqual(storage["20231015"], 100)
def test_add_expenses_invalid_input(self):
with self.assertRaises(TypeError):
self.app.post("/add/20231015/abc")
def test_calculate_year(self):
self.app.post("/add/20231015/100")
self.app.post("/add/20231016/200")
response = self.app.get("/calculate/2023")
self.assertEqual(response.status_code, 200)
self.assertEqual(response.json["total"], 300)
def test_calculate_month(self):
self.app.post("/add/20231015/100")
self.app.post("/add/20231016/200")
response = self.app.get("/calculate/2023/10")
self.assertEqual(response.status_code, 200)
self.assertEqual(response.json["total"], 300)
I follow it now, thanks. So I just tried it and it gives a 404 when you give the wrong type for the inputs, but it doesn't raise the exception to your tests. The only case I'm seeing where you'll see a TypeError when posting is when it reaches your code and your code doesn't return anything. So the one you have where you're checking for a type error on invalid input won't work.
from my_app import app
class TestExpenseAddingErroring(unittest.TestCase):
def setUp(self):
self.app = app.test_client()
def test_should_give_404_response_when_non_number_given(self):
response = self.app.post("/add/20231015/abcd")
self.assertEqual(404, response.status_code)
def test_should_give_200_response_when_proper_number_given(self):
response = self.app.post("/add/20231015/1234")
self.assertEqual(200, response.status_code)
@app.route("/add/<date>/<int:number>", methods=["POST"])
def add_expense(date, number: int):
return ""
Ooooooh I see 
That is good to know thank you btw that actually helps rn <3
No problem
Im just new to unittesting and it fascinates me because I heard about test driven development from the Book clean code
There's a decent amount that can be said on test driven development. You can do it easily to start out with if you just write the tests for the API like this, before you write the code to pass them. Ideally, you would isolate the logic to be outside of the API code. You ideally structure your application in a way where everything stays easy to test, offline, and without starting any servers and that the tests run fast. But it isn't really depending on your standards. You just have to write the tests first, and make sure they say nothing about implementation detail, which if you focus them on API responses, while they're not the most focused of tests, more or less will.
If you're interested in test driven development, then continue trying to test stuff and building the skill for it, then, try not to write your tests as tests, try to write them as examples of using your code, and the behavior that the code should have, so that you focus on what it should do and not how it does it, and so that the code can ideally change and the tests remain the same making it easier.
Makes sense honestly I kinda like it its a paradigm change but I can imagine that would make maintaining stuff in the long term way better.
Thank you for introducing me to it rn btw I will go to sleep now and thank you a lot again for helping me earlier 
No problem. Any tests that verify stuff isn't broken are better than no tests.
can someone help me test out my pythpn lib
i used sound device lib to make it easier all in one functions its a mic lib
python -m pip install PMichrophone
this channel is about automated test suites. You might have more luck in #1468524576479641744
thank you
So your high-level requirement is that when you POST /add/20231015/abc with invalid data, you should get a response with status code 400, for example. That's not an exception, that's a test for your http interface. So a test for that should look like that:
response = self.app.post("/add/20231015/abc")
self.assertEquals(400, response.status_code)
So that's not really a unit test anymore, and that's okay.
What you could do from that, is write another test, for something that does throw exceptions (that your endpoint later translates to status codes) :
def test_expenses_invalid_input(self):
with self.assertRaises(TypeError):
validate_expense("/add/20231015/abc")
And then you can use validate_expense() in your endpoint.
Hello people,
I know this might have been discussed here multiple times but still posting the question.
can you guys please suggest me the production level resources where I can practice selenium, API and Pytest skills?
sorry for coming late I didnt saw the because I got hacked but yeah I somehow fixed it from what I did was just simply doing it with your first example
how can it be 4 arguments?

Self is implicit. So you're passing it twice in this case.
uff thx
regsvr32 "C:\OpenAPI\KFOpenAPI.dll"
wrong channel?
Hey everyone 👋
I’m into tactical games, late-night chats, music, memes, and meeting cool people from around the world. Always down for gaming, VC, and making new friends on Discord 😄
If you’re chill, funny, and active, send me a message — let’s vibe and build a fun community together!
Pretty sure you are in the wrong channel on the wrong server for that...
Ontopic, trying to setup some testing for my own app and having an odd result.
This is the test
def test_dateCheck_with_fuzzy_date_and_fuzzy_false(self):
"""
Tests that `dateCheck` returns **False** when a less strict date string
is provided but `fuzzy=False` (the default), leading to a parsing failure.
This highlights the role of the `fuzzy` flag.
"""
result = dateCheck("Oct 26 23", fuzzy=False)
self.assertFalse(
result,
"dateCheck should return False for 'Oct 26 23' when fuzzy parsing is disabled.",
)
And this is the function, amy I going crazy or how is this test failing?
def dateCheck(datestring, fuzzy=False) -> bool:
"""my doc is my string, verify me"""
try:
dateparse(datestring, fuzzy=fuzzy)
return True
except TypeError:
# e isnt used but caught for proper handling, this just needs to
# evaluate as false if it cant parse the date for any reason
return False
File "D:\scripts\pybudget\test_main.py", line 86, in test_dateCheck_with_fuzzy_date_and_fuzzy_false
self.assertFalse(
AssertionError: True is not false : dateCheck should return False for 'Oct 26 23' when fuzzy parsing is disabled.```Though I also probably dont technically need a test like this since fuzzy is hard coded to enabled because I need it that way but I don't get why the test itself fails
if I'm not wrong, assertFalse fails if expression evaluates to True.
unless dateparse triggers TypeError, that test is failing correctly
ok so I have my assertion logic backwards basically. So 'task failed successfully' basically but I am checking that it returns false when it doesn
There are many kinds of testing:
- Unit Testing. Comprehensive tests that verify basic workings of your program, such as individual functions/methods.
- Functional: Tests the overall functionality of your program. If you run it on platform A with input B, does it perform as expected?
- Integration Testing. Tests that individual software module work when combined and tested as a group.
- Mutation testing: modifies your programs control flow in an attempt to trigger errors, and more importantly, verify that invalid logic produces an error and doesn't fail silently.
- Property testing: Another form of "fuzz" testing, similar to Mutation testing.
- Coverage testing: a testing tenant that has the goal of ensuring 100% of the code is executed and produces the expected results. Originally born out of FAA requirements for the Airline industry (IIRC), it is now used in many projects, large and small.
performance testing.. just remind me blazemeter or gettaurus.org that using python..
hides evidence


Do you think it's a good idea to test your software? Do you write unit tests or other automated verification for code? I think most of us do these days. A key question is how do you know whether your tests sufficiently verify your code? The standard answer is code coverage.
I'll take thaaaaaaaat
Yeah you will
Also, he did an episode on Hypothesis as well: https://talkpython.fm/episodes/show/67/property-based-testing-with-hypothesis
Let's talk about your unit testing strategy. How do you select the tests you write or do you even write tests? Typically, when you write a test you have to think of what you are testing and the exact set of inputs and outcomes you're looking for. And there are strategies for ...
if anyone is really awesome at testing SDKs specifically for IoT stuff, please message me. I have hit roadblocks.
@tawny wave I've taken a quick look at this hypothesis framework and I was wondering what is the difference with fuzz testing
@wooden gorge The fundamental ideas are the same. However, mutation testing mutates the code in addition to the input, while traditional fuzzing type tests just mutate the input.
And IIRC, hypothesis will apply some intelligence to the code mutation, and tries to modify your code such that it's more likely to cause errors.
The objective is to find the parts that are brittle or need improvements in error checking or handling.
How does it modify the code? Through those decorators it does some magic with inspect and such?
I haven't used it yet, just listened to a podcast about it.
So can't really say much about the details.
I'm kinda interested in it to replace our fuzzer because the only usable tool I could find for fuzz testing was kittyfuzzer, and it's clunky and it's py2 only which means another environment... -.-
Oh wait
I was thinking of cosmic ray
My bad
I think hypothesis is a more traditional fuzz tester
"Property testing"
Sorry
Wish I found out earlier. The "guys from above" said our project (REST and normal web endpoints) should have fuzz testing and I kinda pieced together some crap by subclassing kittyfuzzer objects and blabla... it was hell 😄
Oh ouch
I'd take a link to that podcast if you have one
Considering I knew nothing about fuzz testing, it was painful
Will definitely try Hypothesis next time though, it seems like a great find
@vernal yarrow (scroll up)
I also listened to that episode, https://talkpython.fm/episodes/show/67/property-based-testing-with-hypothesis
oh lol sorry same link
So you're past the period of performance or whatever?
Talk Python is a great cast
Brian Okken, who collaborates on the Python Bytes podcast with Michael Kennedy (the host of Talk Python), also wrote the book Python Testing with pytest and hosts a podcast called just "Test and Code", which is really just about testing python
I knew he wrote the book, but forgot about the podcast. Gonna add that now
It's searchable in Podcast Addict for Android
I use Podcast Addict too!
Found Test and Code, subbed
Yeah, been using addict for years now. Has all the features I need, super reliable, nice UI.
Sure is
I paid for the unlock because damn that dev deserves the money.

I use pocket casts just because it's the one everyone recommends
Everyone™
BTW, Bats is a fantastic "quick and dirty" functional testing tool for command line based programs: https://github.com/bats-core/bats-core

Do you guys recommend Nose tests or Pytest for unit testing?
I've been trying to migrate from bare unit testing in python, it can be a hell sometimes.
Having the same pain here xD
I prefer pytest
I used pytest for a module and had no real issues with it
Yeah I think pytest is more intuitive?
after figuring out the fixtures setup
@clear kelp now that we have trained our hands in the obscure arts of bare handed unit testing, we can go ahead and use better gear.
the pytest docs were a bit confusing at first because they use the same 'names' for everything in examples like
from foo import foo.foo as foo
test_foo(foo, foo):
assert(foo == foo.foo(foo))```and it's a bit hard to figure out which words are arbitrary and which words are the module
Haha indeed
I like using the bare thing first, but I stayed with it too long
:(
Yeah me too, I mean it's kinda hard but you get used to it.
although pytest looks good, do you still use pytest or you ended up going back to UnitTest?
I use pytest for the newer part of my code
only use unittest when extending existing tests now
@ruby tinsel pytest supports nose tests
Nuff said
which is the best testing suite for the total beginner ?
I think pytest is the be all end all framework nowadays?
any idea about the PyUnit?
no clue sorry
👍
anyone, test http://r1c.getenjoyment.net/ (and pentest too)
see if you can get the password
it is made by me, so don't worry
That's not what this channel is for, and that's not how pentest authorization works.
is #cybersecurity better?
People there (or here) will help you configure or work with software that you can do it yourself (possibly), but no one here is going to do it for you
It's never a good idea to pentest a site just because someone on the Internet says it's theirs. 😃
This kind of goes into a grey area of stuff that we'd rather not be associated with, to be honest
Or at the very least I sure as hell wouldn't
Oh look, I own Google.com
🤔
Again, not how this works. Don't ask people to pentest your stuff if you don't understand how to legally authorize penetration testing.
Hi all, today I wrote my first ever unit test for a function parsing a specific website and returning a list of dict corresponding to the rows of a table on the page. To do that, I saved the html of this page in a file and use it as an input in my test. Later on, I saw a pycon talk where the speaker mentioned it wasn't ideal to use file I/O in testing. The file I'm using is 5000+ lines long so I can't really have it directly as a string in my test file. What would be a better solution in my case?
I could download the page each time I run the test but that seems "expensive" especially considering the ressource needs authentication with 2FA if not called with a service account. Plus I wouldn't be able to assert that the function returns the expected number of dicts
Why would file i/O be bad?
It seems perfectly reasonable for your use case
And btw that's awesome
Some other people told me to look into 'mock'. After looking into it, I realise now the concern might have been more about writing to file than reading a file. I think in my case it's reasonable.
Maybe I could clean up the html file. I don't really need to keep the 5000 lines. The table I'm parsing in this file has 2467 rows. I could easily keep only 10 of them and run my test on that.
If it works on 10 lines it will work on 2400+ right?
If you think so, then sure, simplify it, but it doesn't usually hurt to be more through
I guess it comes down to what your test data is. If you can find a general case... i.e. a few lines that represent the rest of the file, it's way better to use that.. because if you're having to run the test several times as you're improving your program it's going to take a while/use unnecessary processing power. If you have a computer that can handle large processing tasks though, go for it... it's whatever suits you really.
I guess it's not good practice to use huge files for unit tests because of the processing requirements but if it works for you then do what you find best.
Afaik, a unit test should check for a function's internal behaviour and branching, so parsing a file and checking out that the result is as expected falls into the realm of functional testing
In a unit test I'd just mock out file i/o altogether and check that the i/o calls have been made
does anyone have experience with the pyUnit for the testing?
so say i have file in which there are classes and some defs inside in it,
and there is another file named test.py
i started writing for it in this file.
How can i test my test cases?
have you tried python -m unittest?
nop
I don't know if it is too broad of a question.
i have this definition
for pokemon in self.pokemon_list:
# Query
query = "SELECT * FROM pokemon.table where pokemon=" + repr(pokemon)
# Execute the query
row = session.execute(query, timeout=None)
# Check if the dataframe you get have rows.
df_from_cassandra = row._current_rows
# If the rows is empty, Go to MySQL
# Else return dataframe.
if df_from_cassandra.empty:
self.transform()
else:
self.get_df_searchCassandra = True
self.merge_Df()
return df_from_cassandra```
i need to built a test case for it.
is there any place where i can read more about testing to built my test case?@rustic stirrup if i try to run your command i am getting this error
python -m unittest test
File "<input>", line 1
python -m unittest test
^
SyntaxError: invalid syntax```that looks an awful lot like you're running as Python and not a command
for the command or the code i posted?
for the command
you need to run it from the OS shell, not within the python prompt
using windows.. so you meant cmd ?
yeah
alright
this is strange :s
I tried to run the above command in the same dir where the code is
and getting this error
operable program or batch file.
even though python is working perfectly fine
and i have in my path this thing
C:\Python27\Scripts
try just py
same result
alright it worked!
for some strange reasons it didn't worked in the Pycharm IDE terminal
Getting this error
File "test.py", line 5, in <module>
import mysql.connector
ImportError: No module named mysql.connector```
i tried to install through `pip` and then restarted the cmd and then re run the same command but still getting the same error. 😦got it running from the pycharm python console itself.
You can't do imports like that in python, you'd want to do this:
from mysql import connector
@hidden zenith
Actually you can import like that, e.g. import os.path
Oh yeah, you're right, but then you'd still need to call os.path, I was assuming they wanted to be able to call connector without having to call mysql.connector
Probably just want to make sure mysql-connector installed properly, you could try uninstalling and reinstalling it.
import os.path as path
IS THERE AN ANIME INVOLVING SOFTWARE PROGRAMMERS
@proper wind Go to one of the off-topic channels
In regards to unit testing and mock, how do you guys feel about using my_magicmock.assert_called_once_with(...) as opposed to assert my_magicmock.call_args_list == [...]?
I know there're two gotchas with the assert methods, in that you can either 1. accidentally end up writing assert in front of it or 2. mistype it and it will make the test pass
I have considered giving up on the assert method syntax altogether, but it is really handy
Hey guys, can you advice me on the best approach?
I have a simple class which implements logic for a custom nagios checks,
Basically it has a check() method which tests various things (mostly physical files/system attributes or REST apis) and sets self.code based on results of the check and then sys.exit() based on the self.code
My question is, how would you go about mocking those REST calls and files? I've read about mocks but it's a bit overwhelming.
I've kinda understood how to mock request module calls, but have no clue what to do with files,
I guess naive approach would be to create tmp files with needed contents and patch object attribute to point to it, but it seems clunky
ok, let's say I'd like to learn the ropes about code testing. On which module should I focus? Unittest or pytest? Or did I get all wrong and should I use both instead?
pytest is pretty good
my only problem with it are the docs
some of the more advanced stuff is pretty obscure
Pytest docs are atrocious. But the basics shouldn't be difficult. Especially for personal projects, I wouldn't bother with unittest.
What are the main advantages of pytest over unittest?
unittest is just the built in library, pytest has made it easier to add plugins like the coverage tool and such, and makes the output nice to look at
So it's an extension built on unittest
WIth unittest you need to do all sorts of JUnit-style set up, none of which is Pythonic, and with pytest you can write a file like test_foo.py containing
def test_foo_add():
assert 2 + 2 == 4
and pytest -v . will automatically discover it and run it.
No need for test classes and things, so the simplest use case is much simpler.
It's completely separate from unittest, but it can also be used to run unittest tests.
nose is also similar to py.test.
though nose and even nose2 is not seeing much if any development anymore as they recognise pytest's popularity
I didn't know there was a nose2. IIRC nose was the first one to break away from the JUnit style and do automatic test discovery. But I don't think there's any reason to use it anymore.
yeah
Thank you!
unittest has automatic discovery as well, just more boilerplate.
How would I write a test that runs multiple times but with different input data, where the input data is stored on separate files?
I intend to use pytest
I've been looking into using a parameterised fixture. Not sure what the approach should be though.
Should I pass in file names and expect them to be in a certain data directory?
Should I pass full paths?
Or maybe pass in just the data directory and read each file in the dir. Though I'm not sure how I'd re-run the test for each file I read
@kind meadow I'm not sure where you're getting stumped, but it can be as simple as passing the file paths to pytest.mark.parametrize and reading them inside the test, if it's a single test
Or you can use a session scoped fixture that yields the content of the input files passed as parameter
https://docs.pytest.org/en/latest/fixture.html#automatic-grouping-of-tests-by-fixture-instances
The example here might help
@wooden gorge I'm not stuck with the implementation of it but rather with the design
I've listed some approaches which would work but I'd like to know what would be better
i.e. best/common practice
Hm, well, I've given my 2c if that helps 😅
If it's unchanging input put from files and you're reusing them for multiple tests, a session fixture should be good
But it's just how I would do it, I'm not particularly a testing guru
Yeah neither am I unfortunately
The test data is specific to one function
so not intending to use the fixture anywhere else
I think for testing you can afford to be a little more "loose" in your best practice, as long as the test is useful and makes sense
but it just felt nicer to put it in a fixture as a separation of concern type thing
In that case you can just mark.parametrize too
Yeah you're probably right I just need to get out of the perfectionist mindset
Ye I understand. Then you just have to change the scope to method
It's kind of ugly to have a decorator with 30 file paths 😄
I saw some pytest extensions for data folders
but it seemed like I wouldnt have the control I need over the data files like that
Actually nvm what I said, it's stupid to reload every method
Ugh. Yeah I'd at least put those paths in a constant
Woah your discord lagging?
Mobile net lost connection for a bit heh
I think I'll just go with your suggestion and not overcomplicate it
good call on putting the paths in a constant
I'll need to read up on fixture scopes though
don't know the difference yet
just seen the term in passing
thanks 🙂
👍👍
What do you think of Gerkin ?
In pytest, can fixtures be use in params of other fixtures? I know it can't be done with @pytest.mark.parametrize (though there is a proposal for that feature).
The idea is to have an input and an output path in the params, but the output path relies on a temporary directory
but not all output paths need a temp dir, just some
depends on the input
Ah yeah, there was some strange way to do it with "meta-fixtures", but it wouldn't have worked out in my situation anyway
I can't remember the name of the technik that consists of sending random data to a unit test in order to find break values. Anyone can help my poor memory ?
Are you thinking of https://hypothesis.works/?
Most testing is ineffective Test faster, fix more
im trying to contribute to a project(namely qutebrowser) and there's a test file that requires slight modification, qute is apparently using tox but running tox . really doesn't do anything to help me try to reverse engineer to figure out how to run these tests
there's a conftest.py file i'm trying to add a check to
how do i run this so i can at leaast see what it does, maybe print out a few variables etc.
appears i just didnt specify the correct python enviroment in tox ... lol
Can someone run this from terminal and tell me if you encounter any errors
That's not the purpose of this channel...
Are u for real
@tawny wave What is this for
Testing
Unit tests, functional tests, etc
Testing pipelines
All that
Not "hey man can you run this code for me"
Im gonna have to google what those mean
woah where did you get all of those thumbtacks?
From your desk drawer
ohecc
Damn its lit in here huhh
hi - apologies if this is not the right place to ask, I'm a Discord noob as well as a Python noob...
I am building some code to do double-entry book-keeping. The end result is useful for me, but it's mostly as a way to learn Python.
I am using gitlab and PyCharm. For now I think I will use pytest, but I am not committed to that if there is a better option. Can you help me with two questions:
- is it okay / good idea / bad idea to shove all the tests into a sub-directory of the root? Or are they normally put somewhere else?
- is there a reason to prefer writing tests that return zero on a successful run, versus writing tests that use assertions?
Depends on what you define as "the root"
If it's your project root, sure
I wouldn't put my tests in my Python folder though, I usually have a structure like this:
$ tree
.
├── myapp
│ ├── __init__.py
│ ├── calculator.py
│ ├── client.py
│ └── utils.py
└── tests
├── __init__.py
├── test_calculator.py
├── test_client.py
└── test_utils.py
I think that's common practice for Python projects
Also, always use assertions (your test framework will handle the exit status for you), and pytest is pretty good
thanks
😃
I will move the tests to a parallel directory
and have two directories under the root
also, I put assertions into normal (non-test) code, to check that a supplied object was of a particular type. Is that sensible, or should I raise exceptions instead?
appreciate the tips 😃
first time using tox. getting an error i don't understand. the tests run, but:
Ran 6 tests in 0.002s
FAILED (failures=1)
Test failed: <unittest.runner.TextTestResult run=6 errors=0 failures=1>
error: Test failed: <unittest.runner.TextTestResult run=6 errors=0 failures=1>
ERROR: InvocationError for command 'E:\\projects\\lxml-xpath2-functions\\.tox\\py37\\Scripts\\python setup.py test' (exited with code 1)
commands failed
i only get the InvocationError if a test fails. is that normal?
Anyone know how to complie python so i can have it running for when i put a usb in a drive
Or to just have it running in general
For just scraping.
@olive verge This isn't #unit-testing, but scraping of Amazon is expressly prohibited by their TOS and therefore is not something we're going to help with on this server. Use the API: https://developer.amazon.com/services-and-apis
Amazon Services and APIs allow you to monetize your apps, engage with users, build immersive experiences and test the apps and games you've built.
@proper wind what?
@proper wind there are python compilers like Nuitka, but that still isn't gonna let you auto exec stuff from a USB drive on insertion
Also #ot
i dont think thats OT
modern windows will still warn and ask for confirmation
btw how is that offtopic
Because this is a channel for software testing
@slim smelt Your organization (/src/ and /test/) is the one I understand to be the best practice because it forces you to install the code (or do a pip -e) to test it, so it is being tested in the "configuration" it is in when deployed.
Bah. I'm trying to use typing in python, but I'm super super confused by this error.
Incompatible return value type (got "Parser", expected "Type[Parser]")
I have a base class, Parser which is never instantiated, only ever inherited/subclassed. The inherited classes can return other instances which subclass base Parser.
I think the correct way to note this is -> Type[Parser], however this error is pretty much always returned. I do not understand why, would someone please give me a bit of understanding about it?
Type[Parser] is the class Parser while Parser is an instance of said class
so if you're returning the class your type checker is probably confused?
What are you using
aaaah, Type[] is for a literal type object (of sorts)?
I've read the docs about it twice and I'm still not sure if this is the correct interpretation, and this is still confusing since I never instantiate a Parser, only SubParserA(Parser).
If Type[Parser] means returning a type object of Parser, then this makes more sense. Is that accurate?
If you're returning instances of subclasses then the return type is the base class, so Parser here
yes
Whoooo! Thanks :D
Yup, just the class. Though things get tricky if you use a class as a constructor for itself, e.g. there's a classmethod in Parser that returns an instance of Parser.
PEP 563, implemented in CPython 3.7, added postponed evaluation of type annotations so the above is possible now.
lol
I get what you said now
👁
just. "Who does that"
I do 😅
Well, it enables you to import one of the class's subclasses, call a method on it, and if the method succeeds you get an instance of the class back.
And the generation method can use much of the same infrastructure and methods in the subclass in question
Otherwise I'd have to do some hacks that aren't maintainable and would mess with the library interface
Not having a handful of type annotations is a very small price to pay lol
😛
starship truepers
you probably wanted to post that in #303934982764625920, perhaps. c:
oh hell that was three days ago.
does anyone know how to write acceptance tests in Python?/

{kind=link}
!warn @proper wind Stop spamming channels. Last warning
:ok_hand: warned @proper wind (Stop spamming channels. Last warning).
@proper wind Not super confident on the subject, but I would assume you'd write tests for functionality that are run on the previous version and the new one. Either confirming there is no change to functionality, or that there is one if it has been added
Thanks very much
This is a good one for acceptance tests apparently http://lettuce.it/index.html
But normal unit testing is fine really
Using pytest
Lettuce has a focus on being behaviour-driven
Ey everyone. New here and new to python. I don't understand how to make a global variable inside a function. It always gives me a syntax error.
I thought you simply typed global in front of it and that would be it but can't seem to get it to work
nevermind finally figured it out 😃 I first have to declare the variable global and then define it. It doesnt work in one go.
@upper swift although the name of the server isnt clear, this isn't where you put stuff like that. Go to one of the help channels.
Also, check the description of the chats, that will tell you what they are for!
Yeah, my fault. I did read the rules but misunderstood the server indeed.
@upper swift casually rants about the designers name choices being terrible for new-comers
Are docstrings needed in unittest functions too?
(Provided that we are using appropriate names for the testing functions)
@proper wind "needed" is a fuzzy term for docstrings, but I'd probably use them... a name can't always cover everything
Ah I see. Thanks
from what i can tell the docstring, or at least the first line of it, will be displayed with test results
Ah, that might be helpful.
I have a test case where I have video processing tasks. I'm planning to include a small test video around 3MB.
I'm planning to submit this within a pypi package. Since I'm including the tests, along with the modules, would it be okay to include the test video in it too?
🤔 personally, id make it an optional feature
@uncut sleet How could that be achieved? I've never published a pypi package before so I'm not aware of the procedure. Like, is it possible to release two versions of the same package - one with tests (say dev) and one without (say prod)?
could you use a generated video to test instead?
Nope, the video is a user input.
I have a problem with sending variables through a socket. The application is a basic server / client which can upload and download things. When the client sends the request to the server to upload a file (a long with the filename) it sends it as expected from the client side with everything in tact. BUT, when the server receives the request, the contents of the file have been appended to the filename somehow. This does not happen when a download request is sent even though they go through the same process. If you think you can help, dm and I will send the code.
@unborn bloom Please do not ask people to DM you. You're welcome to share the code here. You can use our pastebin: https://paste.pydis.com
Also, this is a more general question that would probably belong in one of the help channels, not #unit-testing
@west scroll i'm gonna take a guess and say it sounds like you're expecting one send() on the client side to map to one recv() on the server side
...how the heck did i get that from @ross
@unborn bloom
I would liek to write some tests that involve testing if data gets written to db. i am using pytest, is there a way to set test enviroment variable somehow so i could use test database while running the tests?
as i understand it is a bad practice to alter your real code just to be able to run tests etc
That's correct. Your database code should be modular enough to just import and use. If it's dependent on your other code, you might want to think about refactoring
either that or the other code should completely wrap the db
Woohoo just ran my first real unit test
I can definitely see the advantage of test driven development
TDD works well and is an excellent solution for many areas
If you're going to, say, write a function to check the validity of a order request
Writing the test first makes a lot of sense, and can even get you though part of the process of conceptualizing the function itself, making the actual implementation quicker and easier.
Hi guys, novice at python here. I've been tinkering with Robot Framework actually and I was wondering how to actually hook up Appium into Robot Framework so that it can run in an emulator. Can someone point me in the right direction in terms of tutorials?
https://stackoverflow.com/questions/24889387/robot-framework-passing-appium-driver-to-python-script
This looks helpful @wide drift

Stack Overflow
I'm working on integrating Robot Framework with Appium, using Python. However I can't figure out how to pass the Appium driver created in the Robot Framework to a custom python script.
My Environm...
How do I deal with optional/auto fields when writing asserts for Django REST tests?
Do I explicitly assert each field one by one? Do I delete them from the response before asserting? Do I write some helper function for that? Is there something built in?
you can either apply a patch to functions that generate auto fields and assert it, or you could only make assertions of the fields that matter
also there is https://docs.python.org/3/library/unittest.mock.html#any
Hey guys
I'm getting slaughtered with getting testing to work with tests in a diffrrent directory to the main
Whelp
you min with imports?
Yeah
I've read that python still doesnt have a great solution for it
But I believe I need to hack the python
Python path
#Prepend ../ to PYTHONPATH so that we can import PDFKIT form there.
TESTS_ROOT = os.path.abspath(os.path.dirname(__file__))
sys.path.insert(0, os.path.realpath(os.path.join(TESTS_ROOT, '..')))
you need to make dir structure like for instanece this template

GitHub
Cookiecutter template for a Python package. Contribute to audreyr/cookiecutter-pypackage development by creating an account on GitHub.
look how they created test dir and their module
then use absolute imports, It works that way
this way there is no need for path manipulations
@gusty mist great, now remember for new project to start with right structure.
I tried
It's just not that straightforward with tests outside the main directory
Seems to be a common problem online without a real answer
https://github.com/requests/requests/ see same dir structure like that cookiecuter.

GitHub
Python HTTP Requests for Humans™ ✨🍰✨. Contribute to requests/requests development by creating an account on GitHub.
I have no idea where I should ask my question so I'll ask it here. I've got a list (for example [[1, 3, 4], [2], [0, 4], [1, 2, 4], [1]]) and out of that list I want to make every sublist have one unique number (except that there are two parts with a number in common) out of the numbers that are there. So it should be output as [[3], [2], [4], [1], [1]]
Try one of the help channels, you'll get a quicker response there
Unless you question is directed towards how to test if a function that does that works.
oh I didn't see that there were help channels that weren't voice channels
There's a whole 6 of them
Is this the right channel to ask about issues with something like behave?
What'cha need?
Karnaugh maps?
Go ahead and ask your question
You could post your problem specification in here as well.
He disappeared.
He sure did
DM'd me the question as well, but told him to move it here.
Shame, I like digital electronics~
Ah, alright. ⭐
Checking my notes, been some years.
First step is to make a state diagram.
Sort of. By visualizing the problem as states and how you travel from one state to another, you can extract a logic table much easier. If you already have the logic table, that's fine.
What is each letter in this case?
And F is alarm output?
That's the only output I see. Should be one.
Alright, so the problem specifies all possible combinations of inputs, just a matter of making sure it's correct.
I don't think you hvae to mind sensors that are faulty.
A "broken" beam means a sensor is detecting something, right?
Alright, so let's go through the conditions specified.
- No beams - no alarm
- One beam - no alarm
- A ¬B ¬C ¬D - no alarm
- A B ¬C ¬D - alarm
- A B C ¬D - no alarm
- A B C D - alarm
- Otherwise - alarm
Although yeah, the last sentence states there's a second output that's only true if one of the sensors is faulty?
You could set E to be the alarm output, and F to be at least one faulty beam
Which I'm not sure how it's supposed to be used.
I'm not so sure how that one is relevant.
But for the rest of the circuit, you can make it using only NAND and NOR
Why
Stop removing your messages.
@inland dune Any particular reason you're deleting your messages and messing up the coherency of the conversation?
Ah, you're one of those
:P
The rules aren't a strict set of enforceable laws
We do assume a certain level of common sense
If you've got a reason, great, let's hear it. If not, please stop, it makes it much harder for other people to learn from the conversation.
Why not?
I mean, if you're unhappy with it, you're not gonna solve it by continuing to give in to it
But okay, I'll make a note of that
Im under the impression that I can use one user account, but have several different bots under that one account to run on reddit? https://praw.readthedocs.io/en/latest/getting_started/configuration/prawini.html#defining-additional-sites
or am i wrong about that?
trying to figure out a good design to run all my bots from a GUI
Hi i'm new, does anyone have a recommended system for testing website? Should I do an end-to-end solution with my frontend of my web app or is it fine just to test my RestAPI (in flask)
@crystal narwhal it would be a good idea to use selenium to test the front end of your app which would be separate from your backend tests
How do you choose values for a form to test?
i would say to make sure that those form fields are loading properly
or lets say you've got a login page and a home page
test to make sure that the username and pass fields are loading
and then verify that a successful login brings you to the homepage
if you're asking how to exactly select the fields, there's a few ways that selenium offers for selecting these fields in python: https://selenium-python.readthedocs.io/locating-elements.html
login_form = driver.find_element_by_id('loginForm')
is this a good place to ask help on running a unit test? Or should I just go in one of the help channels?
I'm a bit late, but both are good. Just ask
@late ether Yes, this is a good place
Hello, could someone help me with something quickly? I currently have code to detect changes in pin values on a LoPy (Pycom), and to call an interrupt handler whenever the change is detected
However, when I try to compile it, I get this error:
https://teekaykay.s-ul.eu/77vYt9Ll
Could anyone see any reason why this is happening?
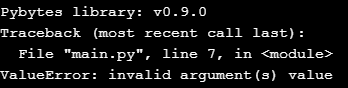
This is the code I have currently:
from machine import Pin
import time
import pycom
toer = 0
p_in = Pin('P39', mode=Pin.IN, pull=Pin.PULL_UP)
p_out = Pin('P38', mode=Pin.OUT, pull=None)
p_in.callback(Pin.IRQ_RISING, triggerEncoder)
def triggerEncoder():
toer = toer + 1
while True:
p_out.value(1)
print("Number of toer: ")
print(toer)
time.sleep(1)
I'd like to mention that I am a beginner with python, and interfacing with LoPy's in general
I am trying to integrate an IR sensor with the LoPy
And to increment "toer" whenever the pin is set high (ie. whenever an object is placed near the IR sensor)
I would appreciate any help
Never mind, I solved it!
Oh great! What was the fix?
I mistakenly wrote the wrong pin inputs as the arguments
they were supposed to be P13 and P12
P38 and P39 didn't exist on my board, lol
however, I did run into another type of issue, would you be able to help?
just post it
alright
So, this error comes up whenever I put my hand in front of the sensor after running the code:
from machine import Pin
import time
toer = 0
def triggerEncoder():
toer = toer + 1
p_out = Pin('P12', mode=Pin.OUT)
p_in = Pin('P13', mode=Pin.IN, pull=Pin.PULL_UP)
p_in.callback(Pin.IRQ_RISING, triggerEncoder)
while True:
p_out.value(1)
print("Number of toer: ")
print(toer)
time.sleep(1)
this is my current code
I'm not sure how to handle the issue
try changing
def triggerEncoder():
to
def triggerEncoder(__):
it's a sloppy workaround but should work
the same error still shows up
😐
Is there any way to print a single statement with a variable within it once, and to change the value of the variable and have it displayed within that one print statement?
I may have worded that very poorly, but I will post my code to show you what I mean
from network import LoRa
import socket
import time
import pycom
# United States = LoRa.US915
lora = LoRa(mode=LoRa.LORA, region=LoRa.US915, tx_power = 10)
s = socket.socket(socket.AF_LORA, socket.SOCK_RAW)
s.setblocking(False)
irData = 0
weightData = 0
while True:
message = s.recv(64).decode()
splitMessage = message.split(" ")
weightData = splitMessage[0]
irData = splitMessage[1]
print("Number of times object has passed: \n" + irData)
print("Current weight: \n" + weightData )
time.sleep(.5)
So within the while loop, I have the variables weightdata and irData being updated constantly through a wireless connection
I want to show two print statements within the console, and have the updated variable value show without reprinting the line
As of now the loop constantly prints those two lines over and over again
and I would just like two static lines with only the variable value changing within them
if that is at all possible
youll need a library like ncurses to do that
which knows how to position text at specific locations
i think i found a solution, giving this a read helped me with my problem
Stack Overflow
I'm wondering how I could create one of those nifty console counters in Python as in certain C/C++-programs.
I've got a loop doing things and the current output is along the lines of:
Doing thing 0
ah neat
Stack Overflow
We have used Google Cloud HTTPS load Balancer.We are using apache2 with django for backend server. We are infrequently facing 502 bad gateway error.
After going through in stackdriver reason behind...
import pygame, sys pygame.init() screen = pygame.display.set_mode([640, 480]) screen.fill([255, 255, 255]) pygame.draw.circle(screen, [255, 0, 0], [100, 100], 30, 0) pygame.display.flip() while True: for event in pygame.event.get(): if event.type == pygame.QUIT: sys.exit()
Traceback (most recent call last):
File "C:/Users/soh05/Desktop/Python Programs/somename.py", line 10, in <module>
sys.exit()
SystemExit
Why is this happening?
I'm using python 2.5.6
I'm moving this to #help-coconut
anyone can help with this? https://stackoverflow.com/questions/53849457/python-unittest-mock-a-nested-function
Stack Overflow
i have a function x in main.applications.handlers package
from main.config import get_db
def x(company_name):
db = get_db('my_db')
apps = []
for x in company_db.applications.
@minor furnace i have a function x in main.applications.handlers package
from main.config import get_db
def x(company_name):
db = get_db('my_db')
apps = []
for x in company_db.applications.find():
print(x)
apps.append(x)
return apps```
now i want to write unittest for this method .
```python
from unittest.mock import Mock,patch, MagicMock
@mock.patch('main.applications.handlers.get_db')
def test_show_applications_handler(self, mocked_db):
mocked_db.applications.find = MagicMock(return_value=[1,2,3])
apps = x('test_company') # apps should have [1,2,3] but its []
print(apps)```
but `company_db.applications.find()` inside `main.applications.handlers` is not returning anything .it should return`[1,2,3] `what could be wrong with this code?@charred sedge how are you using company_name inside the function x?
Also, what is company_db in your function x?
!e 1
Huh? No.
Sorry, but you may only use this command within #bot-commands.
Why I've missed the memo that pylint is super-slow on larger codebases these days? 😦
I've timed it, tooks 10 minutes for pylint to check my project
how large is your project?
or in case you use a venv and have its directory inside your project folder, are you sure you're not accidentally linting library files?
there's no venv in project folder, but we are talking ~750 .py files
There was some linter I remember reading about that said it was faster because it lints files individually rather than accounting for relationships between files
It means it's way faster but also not as powerful
Don't remember the name
that may be pycodestyle or flake8
Anyone have some examples of tests for APIs where the returned data does not follow the same structure at all times?
For example if I send a request today I might get
{
"meta": {
"generated_timestamp": 1545924124,
"requested_timestamp": 1543269600
},
"information": [{
"key1": "value1",
"key2": "value2"
}, {
"key-a": "value-a"
}, {
"key-x": "value-x",
"key-y": "value-y",
"key-z": "value-z"
}]
}
But tomorrow the same request returns
{
"meta": {
"generated_timestamp": 1545924124,
"requested_timestamp": 1543269600
},
"information": [{
"key1": "value1",
"key2": "value2"
}, {
"key-a": "value-a",
"key-b": "value-b",
"key-c": "value-c"
}]
}
Or then the return might be just {"meta":[],"information":[]}
Hey guys starting to write tests for my flask application. Any recommendations on good tutorials? Currently randomly reading blogs.
@glacial carbon I belive you can use -j to run pylint in parallel
@tawny wave yes, I've it from 15 to 8 minutes, but its still too slow
probably not who you wanted to ping 😃
Definitely doesn't know who he pinged.
hahh
On the matter of pylint performance: https://github.com/PyCQA/astroid/commit/74d79ef6eb7d5354f63507128fea0ef524e69a01

GitHub
While copying the path solves some inference issues, it also leads to
horrenduous performance hits on large libraries such as pandas.
We still want to have the path copying, but we need a better un...
Hello, I am very new to VS Code and Python. I just got into it and jumped into unit testing. I am trying to get Python Test Explorer to work but I get this output in Python Test Adapter Log
What am I missing?
Does anyone know of a build-testing service that allows usage of normal/dummy sound drivers for a platform?
(preferably Windows + Ubuntu + Debian support, however Ubuntu only is fine)
Any help would be incredibly appreciated, I'm having a lot of trouble finding a service for this specific problem.
I'm not aware of any. What are you trying to test exactly?
@steel totem Maybe check the settings for the extension?
Does anyone know how to test subscription in Stripe payment service? how to make subscription to expire for new invoice?
usually all the payments systems would have sandbox with the set of credentials that are resulting in different errors
I'm new to testing. If I have a function that uses regular expressions to process text in some way, what would be the right way to unit test that function?
You think of a few sample inputs and the correct output your function should give for them, and then run it through the function and assert the return value is correct.
For the inputs, you'd try to have a few basic and regular cases but also especially cover all corner cases of the specification.
Like, omitting optional parts, having similar stuff before/after it, idk. Depends on your pattern and what you do with the extracted match info.
@steel totem What OS?
hey anyone use vscode and flake8. I'm having a problem where only like 1/3rd of my file gets linted (large file) anyone run into this issue before?
@terse lark Win 10
@torn summit super late reply, but check your linter output
it may be failing somewhere
open the console panel, click output, change the drop down on the right side to the linter or Python
is this an appropriate channel to discuss the book Clean Code?
@gusty carbon thanks for the reply. Figured out what it was, vscode has a limit to amount of errors it displays. The file exceeded the amount of errors (large file), so just had to raise that limit.
@torn summit thanks for getting back to me with what the issue was. Glad you got it sorted :)
@vital crystal Yes
eh when you inherit something and like 90% of the errors are
'methods should have two spaces between each other' or 'line long too long'
i want to fix those things eventually but
Feeding it into black should help @torn summit
Cool well does anyone know where to get a copy of clean code that isn’t the dog pile amazon version that is a literal photocopy of the original?
i bet you can disable particular errors
I use pylint
And it lets you put a comment above or next to lines you want to ignore certain errors
Like I have some class methods that are created from an interable, so they don't actually exist until I run the code etc
Ignore errors can cause broken window syndrome though, or cried wolf
you can also set a configuration file (for both pylint and flake8) to disable errors you don't care about
pylint is so verbose I tend to go for whitelisting over blacklisting
I've got a question about pytest. There is an awesome pytest plugin called pytest-random-order that randomizes the order tests are executed in. However, it only works on Python 3.5+, andI am trying to use it with a project that is also supporting Python 2.7 and 3.4. In order to enable the tests, the argument --random-order has to be specified to pytest. However, I can't figure out how to only add that option if the python version is a specific version or if the plugin is installed.
Tried adding this to conftest.py with to no avail:
# Only enable random order on Python 3.5+
def pytest_load_initial_conftests(args):
if sys.version_info >= (3, 5):
args[:] = args + ['--random-order']
My tox deps have this: pytest-random-order;python_version>='3.5'
Pytest invocation: pytest --basetemp={envtmpdir} --verbose {posargs}
GOT IT
The solution is to add this to the Tox environment:
setenv =
py{35,36,37,py3}: PYTEST_ADDOPTS = "--random-order"
It still includes other options I've added in the pytest configuration in tox.ini, so yay happy day
It only took me almost an hour to figure out >_>
I just learnt about unittest using the Corey Schaffer Youtube tutorial. However I want to test a class with respect to the objects it creates. This is not covered in the tutorial. How do I go about it?
Can you show an example of the class you're wanting to test?
It is an iterator class
I am currently trying to suit https://stackoverflow.com/questions/32672551/python-unittesting-for-a-class-method for my need
I don't have a __getitem__. So not sure what to assert
Hello, wonderfull people, i`m novice and need some guidance where to start learn testing. Any book\advice? thanks
https://www.youtube.com/watch?v=6tNS--WetLI @ember thicket

In this Python Programming Tutorial, we will be learning how to unit-test our code using the unittest module. Unit testing will allow you to be more comforta...
🙌
hello
Hello,
I have come across a problem that I would like to run a test on local server '0.0.0.0:8000' but I can't understand a documentation of https://pypi.org/project/pytest-server-fixtures/. Is there somebody who would be willing to explain it?

what part of it dont you understand @round crescent
hey, how do other people handle testing to make sure you didn't break anything before a release?
i've got the version number down to being stored in two separate files + the git tag name
i could maybe get it down a bit more, since both of the files it's stored in are python source, which means i can do arbitrary things to compute it like load it in from a central source
making sure that stays in sync with the tag name is perhaps more difficult but i could maybe add some sort of thing that gets run before releases that checks the current tag name vs the central version number
i don't really know how other people handle it
i should also add some tests that are run before release like "make sure sphinx can build the current state of the documentation"
and "make sure no unit tests fail on python versions 3.7, 3.6, and 3.5"
i mean ideally i'd have something i'd run before committing anything and another slightly more expansive thing i run before a release
"make sure setup.py didn't fail when building an sdist or a bdist_wheel"
right now i have unit tests run with python3 -m unittest and a regression benchmark and that's about it.
and i just have a bunch of long commands stored in my shell history that i run before a release
anyone got any advice about writing tests using pytest for a gui application?
I have written a fair bit of code with tkinter for the gui and I'd like to have a bit more in the way of tests, but I am not sure how to go ahead and write tests for a GUI. I have written tests for lots of the underlying functions used, just not for much of the gui stuff itself...
What is your underlying GUI platform? QT? We use pyqt-bot for our stuff.
ah, tkinter. sorry :/
missed that
@jolly girder hey there. i found some resources regarding writing ui tests you might find useful
https://www.ranorex.com/resources/testing-wiki/gui-testing/#HowtowriteGUItestcases
https://docs.microsoft.com/en-us/visualstudio/cross-platform/tools-for-cordova/debug-test/designing-ui-tests?view=toolsforcordova-2017
https://techbeacon.com/app-dev-testing/should-you-write-automated-ui-tests-4-questions-answer-first
GUI testing guide for beginners. What is GUI testing? What are the major UI testing types and techniques? How to write UI test plans & test cases.
Designing and writing UI tests using JavaScript and Appium.

TechBeacon
Not sure whether your next feature needs an automated regression test for the UI? Here’s a simple set of questions to help QA teams decide.
and some more:
https://testlio.com/blog/how-to-automate-gui-testing/
http://www.drdobbs.com/testing/dont-develop-gui-tests-teach-your-app-to/240168468?pgno=1

Testlio
The right combination of manual and automated testing? We’re all for it. Most high-quality bugs are still found by humans, and manual testing isn’t going anywhere (ever). That said, automation…

Dr. Dobb's
While developing native GTK- and Cocoa-based versions of the Plastic GUI, my team and I faced the challenge of developing a new test suite.
and here are some specifically related to writing tests for tkinter:
https://scorython.wordpress.com/2016/07/04/unittest-for-tkinter-applications/
http://code.activestate.com/recipes/578964-robust-testing-of-tkinter-menu-items-with-mocking/
i wont post more since this is kind of link spam
This week I really went through a lot of codebases, docs and Python books to learn about unittest. It was really a difficult task to learn it because we need to think of our application in a differ…
you can find heaps by just googling 'tkinter ui test'. Is there a specific functionality in your UI you want to test?
@tidal rock thanks for that! Will give them a good read through when I get to work and try work on it a bit...
No specific functionality I want to test, would just like to havw some kind of testing possible...
@pearl cliff thanks for the willigness to help but I have decided not to implement this into the task. Too difficult rn, I took data from some website and compared this on my test. Unfortunately, I hope that they won't change any data on website so it will give me proper result
all good @jolly girder let me know how you get along im interested in this topic myself.
Anyone got good links for testing oop with pytest? dealing with subclasses and methods.
More specifically how to get classes to inherit subclass methods etc
@proper wind I don't quite understand what you are asking...
If you have a class which inherits some methods just test the subclass. You can check if the code is being covered by doing a coverage test
the code I like to run to test coverage is this:
coverage run --source <package name> -m pytest
(where <package name> is the name of the library you are testing (so needs to be importable))
Once that runs you can do coverage html to generate a html doc which shows you all the lovely details 😃
Yeah that makes sense no idea why I didn't think of that
I'll have to check it out when I get back to work
What does this have to do with software testing
hmm i thought software testing would be for someone to test my program
hey that says no discussion