#unit-testing
1 messages · Page 6 of 1
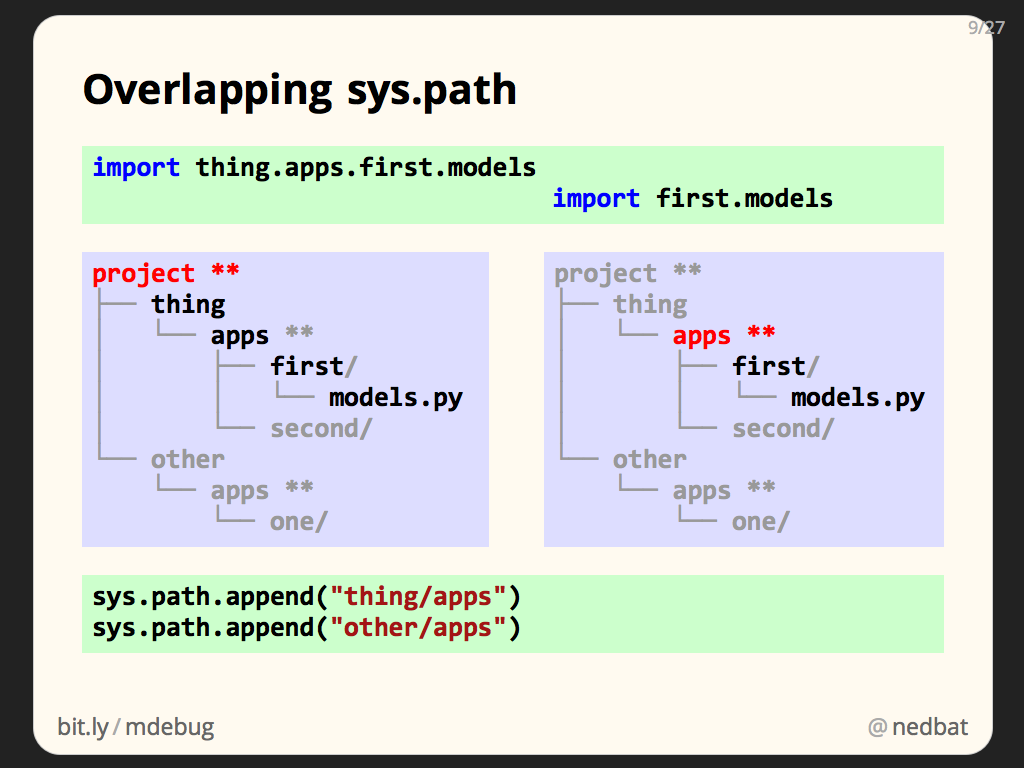
are these meant to be "folders" or "modules"? they're not necessarily the same thing
that is: python modules do not necessarily correspond to filesystem directories, and the correspondence depends a lot on how python is configured to search for modules
loosely speaking, python looks for module xyz in either xyz.py or xyz/__init__.py somewhere at the top level in one of its search locations. it looks for module xyz.abc by first finding xyz as above, and then finding abc inside xyz using the same logic.
Just started using python so for me it is just folders
so for python to find xyz.abc, you need xyz/__init__.py and xyz/abc.py , where xyz is at the top level in one of the search locations
Yeah I have a few of those init files so slowly learning how it all works
unfortunately this is a somewhat confusing and under-documented aspect of python. correspondence between folders and modules can occur by coinicidence, causing confusion. it's not like javascript for example where imports operations use files and folders directly
well, it's documented, but it's all very technical
Agree! Have spent quite some time on it already and it is not crystal clear as other laanguages
does my explanation about xyz make sense? lua actually works very similarly, if you're familiar with lua
Yeah it makes sense
let's say the python search path is (simplified and not realistic) ['/usr/lib/python3.10/site-packages'], then when you run import xyz , python will only look for /usr/lib/python3.10/site-packages/xyz.py or /usr/lib/python3.10/site-packages/xyz/__init__.py and nothing else at all, nowhere else
(in practice modules can be in zipped files, compiled shared objects, and other exotic formats. it's fully customizable if you have some specific needs.)
Good to know!
My next mission to figure out is then how to properly test fastapi routes, right now I just added a assert response code == 200 which is not much of a test really
that's a good start but that's a whole separate discussion 🙂
And also how to switch the db from MySQL to nosql
And also how to switch the db from MySQL to nosql
why? i'd strongly recommend against this
especially for what looks to be a relatively beginner-level project
what nosql did you have in mind? mongodb?
Yeah my bad
sqlite is sql, it's in the name 😆
Was going to say sqllite but yeah tired hehe
but yes you should definitely use the same database in test and prod. ideally you'd run a local mysql instance and populate it with fake data, or a subset of real prod data (but you want to be very careful about things like user PII and other sensitive info)
I'm making fun of the names
But I would prefer not to do inserts in the live db though
That’s why I am thinking testing should be using something other than the live db
no of course not. you'd run a local database and only use it for testing
he meant same db engine, not literally same db
yeah, i meant that if your app uses mysql, you should run your tests with mysql
Ah yes
so you'd run tests by first starting a local instance of mysql, then running the test suite with env vars and config files set as needed so it talks to the local instance
True! That is what I did start before leaving the office so should be good on that one then
or you run tests with different settings so it goes to a separate "db" or "schema" or whatever it's called in your db of choice
starting/stopping is a bit excessive imo
What should you test except status code 200 (or another) on the fastapi endpoints?
snapshot testing can be a good starting point for API testing imo
yea, you basically hit the endpoint, store the response and check that. But in an automated way. So if the response changes you are alerted and you can decide that you want the change or it's a mistake.
So then not really use the pydantic model as that will be updated if the endpoint is updated? The test would then not really ever fail-ish
I come from 15 years of classic asp and have never used tests for anything so forgive me if my questions are not great, still slightly struggling with understanding the benefits of the tests
I get it if the project grows really. If and you have hundreds of endpoints and change something in 2 years from now and the test will find the issue before anything goes live
But when working on this 100% right now errors are found during development
That's the point of simple snapshot testing. They fail if you change something, and if that's only ever on purpose that's great!
Lots of bang for the buck.
Tests are a HUGE topic. There's unit testing, end-to-end testing, test driven development, mutation testing (I'm the developer behind mutmut :P ), property based testing, fuzz testing.. probably 10 more I forgot
So a test should fail if you modify your code, even if the actual code works?
Each has its place. You need to learn what is useful where. There is nothing that is always good.
Well... if the output changes, you should look at the new output and verify it and if it's good save the new snapshot and continue yea. You can make code changes that should not change the output..
My thought is that I modify something in a year from now somewhere in code base and then forgot to change something else which my tests will catch = prevent an issue from ever going to prod
If I get that, I am happy
Yea, that's the ideal
@limpid perch When you write unit tests … you’re trying to test all the possible execution paths (the expected return values from the methods). In Unit tests, you do that using the “Arrange”, “Act” and “Assert” or AAA. The “Assert” part is where you verify if your production code works by manually providing your test case with expected values. A test can fail if you provide the wrong expected value or modify your production code to return different values.
are there any books that specifically talk about testing of "data processing" code as is often seen in data science and machine learning? not necessarily numerical algorithms, more like data cleaning and implementing business logic in libraries like pandas or even sql.
I have a question here. I have my doubts it will be answered on stackoverflow Does anyone know the answer? https://stackoverflow.com/questions/77305031/how-would-i-pytest-a-flask-wtforms-custom-validator
The question is How would I pytest a flask wtforms custom validator?

Stack Overflow
I tried the code below.
But the problem is I am getting an error when I run the code. Do I have the right arguments in make_password_contain_capital?
Here is the custom validator.
auth/functions.py...
there is safer approach in just testing endpoint with that
flask forms are basically rendered on current url on GET, and accepting info on POST
u could just create unit test that inputs your correct and incorrect password and sends to your url with POST request (u could open browser tab with networking and check exact path/params etc stuff)
then u will not need to know about internal flask details how it works
Of course there is always wish to have it more unit testful 🤔 in that case good luck in figuring out flask internals 😅
Or just use optionally mocks to imitate them
pass your own data structures in form and fields variables, no point to send real flask objects
@maiden pawn
I am just going to state I am confused what to exactly do. Would something like this work?
Checking the code on the brower might be a good idea ignore below till I try that.
https://testdriven.io/blog/flask-pytest/sends
from project import create_app
def test_home_page_post_get():
"""
GIVEN a Flask application configured for testing
WHEN the '/' page is requested (GET)
THEN check that the response is valid
"""
# Set the Testing configuration prior to creating the Flask application
os.environ['CONFIG_TYPE'] = 'config.TestingConfig'
flask_app = create_app()
# Create a test client using the Flask application configured for testing
with flask_app.test_client() as test_client:
response = test_client.get('/')
assert response.status_code == 200
assert b"Welcome to the" in response.data
password = 'some password'
return password_form
def test_home_page_post(test_home_page_post_get):
"""
GIVEN a Flask application configured for testing
WHEN the '/' page is requested (POST)
THEN check that the response is valid
"""
# Set the Testing configuration prior to creating the Flask application
os.environ['CONFIG_TYPE'] = 'config.TestingConfig'
flask_app = create_app()
# Create a test client using the Flask application configured for testing
with flask_app.test_client() as test_client:
response = test_client.get('/')
assert response.status_code == 200
form = login_form()
field = test_home_page_post_get()
with pytest.raises(ValidationError):
make_password_contain_capital(form, field)
i offer to use not a browser, but flask test_client https://flask.palletsprojects.com/en/3.0.x/testing/
it will keep it as lightweight unit test runnint without browser
yet imitating it enough for you
oh yeah, u already use it in your code
https://flask.palletsprojects.com/en/3.0.x/testing/#form-data
They've got even example for testing Form data
Thanks
For some reason the assert assert b"This text doesn't exist" in response.data is coming back true even though the text doesn't exist anywhere in the html? Also 300 also comes back as true even though I want a 200
def test_register_page_post(client):
with app.test_request_context():
response = client.post('/register', data = {'username':'zzz', 'password':'rrrrrrrrrrrrrrr' })
assert b"This text doesn't exist" in response.data
assert response.status_code == 300
https://flask.palletsprojects.com/en/3.0.x/testing/#following-redirects
300 status code means try this
thanks for all the help. I found a video that covers my question I am going to try that
anyone aware if thees any observability libs for python that combine pythonic api (like eliot), local reporters for test assertions and opentelemetry integration
Is there some book or guide to sort of "train" my mind to know what to unit test and what to not? My modules are not very independent, and I am finding it hard to find something to unit test. I can probably make them more independent given time, but I kind of feel like it doesn't need unit testing at all, but that thought is no easy to bear either.
PS: I have never done unit testing before.
I found some resources on Reddit. I will go through them. THanks.
response = client.get("/alley/1")
assert response.status_code == 200``` How do I convert the response to the pydantic model it actually returns?Yes, there is exactly book like that 😅

This book explains what you should test and what you should not, what to aim for
to undertand it fully requires some additional books and technologies though.
this book is good foundation to give... 50%+ unit testing understanding at minimum
I see. Thanks for the reference. I also found the Art of Unit Testing's third edition which is written with JS snippets and I think that one will go well too.
I will check with one out as well
you can scrap additional 50% of understanding if u will read
- TDD by kent beck, this one teaches feeling at practical level how often unit testing should be done. What is step between writing working code and tests
- Clean Architecture by Robert Martin, this is a book giving understanding into manipulation code architecture of your application at a global scale. It gives understanding how to structure your code for more unit testability as side result
- You need to learn static typing in strict mode with mypy preferably and using pydantic. / optionally learning static typing from real static typed languages like Golang to get it easier. It gives understanding that there is no point to test anything related to types and DTO carriers, and it gives foundation to structure your code in a real clean architecture way, that makes easier room to make architecture more unit testable further
may be there is more stuff to know... but that's where my knowledge about unit testing ends 😅
Thanks for the further details. I am already doing static typing with Pyright with strict mode on, would be that alright?
yeah, it is equivalent
just make sure to try using Pydantic then for this category
really awesome data carrieng structs with it
with runtime type validation a bit
it complients static typing greatly
- good tool for generic settings input into app
Also... check if your knowledge is complete regarding static typing usage, u should be comfortable to apply if necessary Abstract, Protocol(interfaces), Generic types, NewType (My favorite thing), TypedDict, or other stuff that there is in import typing lib
I have mostly done my validation stuff with dataclasses, but I'll check that out as well.
I'll see. Probably learn them in some other language that is statically typed for an easier time with Python's
do you recommend any lang? I am thinking of Kotlin
yeah... it really helped me doing Golang (went into it with book Head First Golang). full real static typed language gives a different perspective
Kotlin should work okay too. if that what fancies you
i try to get into Java/Kotlin too, but personally finding that Golang has smallest learning curve and most dev comfort
Golang seemed a little too comforting, so i"m more leaning for Kotlin
they have enums and dataclass all natively with nice syntax, not sure about golang
even abstract classes have distinct syntax
i got to import all this stuff when it comes to Python, which is kinda tiresome
ergh. i wish to get Java/Kotlin too, just because...
- It is language for ecosystem friendly for Linux (important to me because i am backend dev + DevOps)
- it is language that u can make minecraft mods with 😊
- Java/Kotlin just has more job openings than Golang
I am working on a flask app for work as a side project, and I am working out the CICD process and figured I should add some unit-testing to the process as well...I know, cart before the horse. Anyway, the webapp is heavily database driven with not much in the way of any logic being accomplished. The webapp is being written to replace an Access database, and pretty much all of the basic functions have been replicated. Along with working out the CICD and unit-testing process, I also have some requested updates to add. I have not written any code that utilized any unit-testing prior to this at all. I have at least worked out that basic routes are being validated but that is about it. Pretty much every other route pulls data from the database to edit or delete records or adds records to the database. My local development environment utilizes a postgresql database as will the production application. I have scoured the Internet for pointers on utilizing unit-tests but none of them seem to fit...but, I may just be missing something. Any help appreciated, thanks!
Maybe start with regression testing.
- Consider to ensure also having database migrating code
- good combo to utilize Pytest + factory boy for db unit testing purposes. Helps to write shortest code that matters.
- run migrations only once, wipe tables between tests
- use docker/compose locally to have db present of correct engine to run.
- use stuff like GitHub actions container services to make it available inside CI too (or u can reuse compose)
How do you implement integration test? Or Is using fake backend with something like “”https://www.mockaroo.com be implementing an integration test? I understand the theory of integration test, but not the implementing in code.
Let’s say I have a class called “VideoService” that’s connected to a “File.txt”. Will creating a “Fake Object” within the “VideoService” class and using it instead of the actual “File.txt” be performing an Integration Test? Thanks!
A free test data generator and API mocking tool - Mockaroo lets you create custom CSV, JSON, SQL, and Excel datasets to test and demo your software.
We use just unit tests for db. No point to mock db.
We have some integration tests made in robot, they make sure that if app is launched in prod web server, everything still works as expected. That is real integration tests for us
General testing in robot would be too awkward though. Nasty system without debugging
I don't like it
I would prefer seeing integration testing done in Pytest too
Going to go this way for my maintained library
@maiden pawn Thanks for letting me know. Why not use "Pytest" for db ?
We use Pytest for db. Nothing I said indicates otherwise
pytest is fixture and feature rich testing framework with most comfort
I can only look sad from other languages that don't have stuff as nice as pytest
@maiden pawn I read "unit test" which I think is another testing lib. That's why I asked.
I tend to have not very strict definition for unit testing.
As long as testing is done in same language as main application code, tests have access to mock if necessary any parameters in sub code and don't invoke any uncontrollable third party dependencies, it is still unit test to me.
Database is locally raisable comfortable dependency that makes up more than half of app logic. No point to consider it being not part of unit tests for me for backend applications
The terms "unit test", "integration test", "end to end test" are not strictly defined and can be used by different people to mean different things. Often people say "unit tests" to just mean "automated tests that are code"
Some say "unit tests" is only in-memory and no db (even though sqlite :memory: can be in-memory and in-process! yea, it makes little sense)
- I definitely wanted to include db testing as part of the process. I wrote a test that kinda worked, but it was using my active development database. So something obviously isn't right.
- Can you point me to a good pytest + factory boy example?
- Would it be better if I use a pgsql container for dev work instead a full blown pgsql VM? Would I use the same for CICD testing?
- I would assume that using respective gitlab services would do the same thing?
Can you clarify what you mean by regression testing, this is currently alpha/beta status so there aren't any previous versions being used.
With pytest-django I just write tests and the temporary test db is handled for me mostly. And I have postgres installed locally. No need for vms or containers for simple apps imo.
If you have deployed more than once you have different versions, even if you don't name them. Regression testing is that when you find a bug, you write a test for that bug and then fix it.
regression testing is to not make the same mistake twice
i use mostly pytest-django philosophy in any application.
I can provide test example in golang application if u wish.
anyway, the point is.. we create a test database to which we apply migrations
and we create only once for all tests
Then we write unit tests that use Factory boy to create quickly SQL table records
then run our endpoint code, or code wrapped into some lib, whatever
then we assert that we got expected result, expected json, or amount of records/values in sql tables.
optionally with pytest-django we also utilize how many sql requests we made 😅 pure Django ORM problem
So...
- in any application i create fixture that creates db with all applied migrations one time
- then in specific objects i create sql records
- run records
- wipe tables between tests
Personally I turn off running migrations on my django projects. It's WAY faster and I just don't have migration issues basically.
in my golang app code i needed to fill db only one time though... because i was testing performance it was fine to me to fill db only once 🤔
easy to do with pytest, just changing scope to session
@proud nebula @maiden pawn So basically my process has been to have the flask app running "live" in "debug mode" then edit code until it does what I want. Is that the "wrong way"?
just use flask test_client
u will be able to call flask endpoints and edit(mock) its code on runtime then if necessary
i think test_client does not require running flask for interations with it
It's not the right way to do TDD, but it's perfectly fine for development imo.
Don't be religious about this stuff. Think for yourself, try to see what works for you and your situation.
I prefer to use vscode pytest integration that allows me running debug visual mode from within running pytest test 😅
developed whole libraries, without realizing i forgot to test if it is actually able to run in live mode
I think part of my problem with the unit testing is that since I was writing the app while it was "life" and debugging on the fly I am not sure what to actually do unit testing on.
when you hook debug to pytest test, u are able to write test in edit mode pretty much too
difference that we localized scope of affected code
and made replicable environment for specific code to test
pretty much all of my functions query the database for data, do something with the data and rewrite if needed
I write my code in sublime text and have he app running in another terminal so I can se the debug output
I also have the app open in a browser to test my changes to see if the app does what I want
I could recommend reading
- Unit testing best practices by Khorikov, for theory behind and what to aim for, why important, what should be tested and what should be not. What to avoid for in order to not get dessapointed
- And TDD by Kent Beck, for head on practical example how to do, and to learn feeling how much u can write working code between need for tests (it makes controllable step of made risk between saving points in this game)
They can help reach right mentality.
I learned python flask/django development from courses on Udemy and that is how it was generally demonstrated...but there was NO unit testing at all
Unit testing is average technique of a higher grade developer. Strong juniors and just all Middle developers in industry do it.
It is common for people with less skill than strong juniors to never do that 😉 (for example common for all student level people never do it, or just people which do programming as hobby only)
Yet it is important part of making maintainable code for long term, that is easier to extend in new features. Which is why it is done all the time in companies with real software developers
fair enough 😉 I am a Linux Admin by trade, but I enjoy working with python. Which is how this project and a couple others of similar nature ended up in my todo list. I don't mind, but obviously I am not a "strong junior" python dev yet :D.
I prefer doing things the right way which is why I started down the unit testing path in the first place. Since it is just an internal application for a few users...is my development process sufficient for the task(s)?
You should try to read up on "functional core, imperative shell". That thinking leads to much easier to test code and just easier to reason about code.
"right way" is an illusion mostly. You can do thing a wrong way, but there is no single right way. Only tradeoffs.
Hehe, 😅 now u are attempted being subjugated to another cult
That has little amount of people that tend to share idea how it works
Alright, is the way I am doing it, the "wrong way"? I definitely understand trade-offs between current method and proper unit testing, even if I don't know exactly how those "trade-offs" would look or function like exactly. I don't see myself being a full blown python developer as I am too close to the end of my career to change, but I definitely fit the "hobbiest" label
IT is full of cults, that much is for sure along with niche's within cults!
Well, if don't dive into code architecture cultism further
I just recommend learning properly unit testing and strict static typing.
Any code can benefit from having at least 80% coverage and strict typing
You have to start somewhere. Doing things above your level very easily becomes cargo culting. Imo it's better to feel the pain of NOT doing unit testing first.
I think Darkwind is a bit fanatic about static typing heh
😛 I am for stuff that makes things more maintainable and rapidly refactorable.
As well as having ability to organize custom code to have better connections(loose coupling, right cohesion stuff)
Static typing is heavily boosting those parameters
It's all about CONTEXT.
- How critical is it if something fails?
- How easy/fast is it to fix it?
- How much time do you spend doing static typing?
- How much time to do you spend on chasing coverage?
There's tradeoffs everywhere
If I shipped something to Mars I would be super paranoid about static typing. When writing a hobby project I might not do any static typing and no unit tests.
I prefer to write my pet projects with mind I am going to maintain them for years. (And even extend in features later)
And that I will forget everything about it in some year pause.
Plus I tend to make pet projects showable at resume
If it is throw away script, I am not going to maintain (or show at resume). I am fine not typing or testing it
I'm a 22 year veteran, I don't need to care about my resume :P
Okay, I think this pretty much answers my question, and that I am just going to stick with current process. Once it gets deployed, I don't see much in the way of changes...but I could be wrong, and that is considering the fact it all originated from an M$ Access database. So ANYTHING is going to be an upgrade.
Just install sentry so you know when it breaks :P
Human brain 🧠 is erasing everything in a year.
I want code that will live at least 5 years or longer with minimum effort. And minimum need to reread
Preferably dozen+ years 😜
I don't think typing helps that much
Good naming is basically typing for most uses anyway
Yet it does. Makes way more readable and extendable. Without need to remember all magic attributes, methods and values your code could be having or not having at certain point of time at runtime
It helps to make code localized, to when u need to read only small part of it to understand fully. (Because all possible input and output is strictly defined)
You are clearly confusing static typing with writing pure functions in that comment.
Very different things.
Yet connected
Typing helps to write better code architecture
eh. no. not in any way
That is certainly understandable. While these will be side projects, they will all be fairly similar so mindset shouldn't change too much. However, I don't doubt I will continue learning things that will be transferrable between projects. Plus my junior admin wants to pick this up as well so it won't end with me.
especially not in python where objects are mutable by default and passed by reference
Let's agree to disagree
Well no, in this case you are claiming 1+1=5 and that's just false.
Typing is one thing. Pure functions is another. Totally separate.
thanks to both of you for the help, it was very much appreciated
Typing helps to define explicit allowed mutations to all objects
Defining strict structs of allowed values, including if they can be or can be not None
Typing helps to define explicitely which methods should be present at specific object in a certain code part.
It makes strictly defined borders of object mutability.
Which is achievable as long as it is your code that controles those objects. If you took under your own control third party lib objects and wrapped them into isolational layers.
Immutability is achievable, making predictable all input and outputs possible to specific code parts
makes possible to write code easily acconting for all possible value types that will be present in specific object
Strictness borns perfection.
without this striction, yeah, you are dealing with mutable Any that can be having attributes and methods of multiple Any... then you would have a trouble
Yea, you just wrote a lot of stuff unrelated to the point.
its like a train wreck that I can't stop reading...hehehehe
You can write pure functions with 100% dynamic typing.
I mean, that's just trivially true.
ergh, but it will not be having a very solid guarantee it accounted for all edge cases your code needs
or that it is called and having its return correctly across all app code.
typing helps to refactor code rapidly for any stuff
because your IDE/mypy/pyright highlight within 1 second shows all places you need to correct code to its new input/outputs
more rapid feedback to refactor code... is exactly why it is awesome.
rapid instantenous feedback for a lot of code correctness.
quite often possible making changes to code that will work correctly even if u did not run it, or did not launch unit tests
(which is pretty much impossible endavour in fully dynamic typed code)
well.. yes, there won't be statically verifiable guarantees. So? Still pure.
sure. Again, unrelated to the topic at hand.
it is easier to achieve higher level of guarantee in your own code, that isolated third party lib codes 😉
if guarantee is broken, then it is only your own fault you need to fix and achieve back
kind of very related.
Unit testing to which TDD is related about
- Write test
- make code to work with it
- refactor it
repeat the cycle until necessary level of code workability or necessary level of its perfection
typing helps heavily to have this Refactor Driven Development going 😊
typing is part of testing pretty much, that accounts for edge cases, people just should not unit test but type instead
again, yea, static code is static. I'm not arguing that, because that would be silly. But pure code is pure. YOU are arguing against that.
Dude, just admit you said something weird and let it go.
def foo():
return 1
this is pure. No static typing can change this.
it is
def foo() -> Any:
return 1
that by pure accident returns integer constant only.
Not guaranteed to work correctly across your code because other code parts can be treating it with assumption it can be returning string or smth else
Because u just did not define correctly contract what your pure function can do for other code parts
i understand that you mean pure as stuff without side effects, but that is the thing.
I think your code cant be pure unless you defined strictly what it does, that other code parts can comprehend
whatever
You mean because there is no static typing it will start to read files? 🤣
it is important defining explicit contract how your code part works
EXACTLY! 😊
again, unrelated
Just admit when you're wrong. Ego destruction is good.
i still see no where i am wrong
Within my mentality / structure how to approach things... i still said stuff correctly. 😛
no defined contract = code can be doing anything, including returning by accident file stream to read file, instead of Literal[1] you expected to receive.
and than bigger code of function, then more different returns it has, then more chaotic dynamic typing stuff becomes
def foo():
return 1
This can't suddenly do something else. It's pure. You do know you can violate python typing at runtime anyway? right?
yeah, you can violate typing at runtime... and that is why typing is present. To point you that your code is going to do those violations and stop you.
hard to do with third party lib objects, but more or less easy to do in controlled your own code that is fully strictly typed, and isolated dangerous uncontrollable super mutable untyped stuff away
How does typing do anything to stop this function from having a side effect:
def foo():
return randint(1, 5)
Please add typing until the type checker complains. I'll wait.
What is the side effect in this code for you?
eh, randint
You really need to brush up on your theory
So, side effect for you lack of this function deterministicity, because it relies onto global seed to output different random values?
Sorry, but I need to understand first what is your definition of side effect first. Side effect for me is affecting global state as result of function execution, but this function is not affecting it. So it has no side effects by my definition. Therefore you have a different definition of what side effect is, therefore I need to identify requirements better before taking further actions
In computer science, an operation, function or expression is said to have a side effect if it modifies some state variable value(s) outside its local environment, which is to say if it has any observable effect other than its primary effect of returning a value to the invoker of the operation. Example side effects include modifying a non-local v...
It's not MY definition. This is basic computer science terms.
I'm gonna guess you didn't go to university for this...
Hell, I'm a university drop out and I know this stuff
Sorry, this article explained to me my definition. This function is not changing global state, therefore having no side effects
You interpreted it differently from me. Explain your interpretation of the article
oh dear, that article is wrong.hah
Example side effects include modifying a non-local variable, modifying a static local variable, modifying a mutable argument passed by reference, performing I/O or calling other functions with side-effects
performing I/O
random stuff is defined as IO in Haskell for a reason
Anyway, randint WILL mutate global state
You can tell because if you call it twice you get different results.
def foo():
return randint(1, 5)
Please add typing until the type checker complains. I'll wait.
I'm still waiting
(ok, the article isn't WRONG, just.. not as helpful as it could be)
No, it just reads different states of global as an input
But it is not changing it... (Unless u speak about pseudocode random generators, that under the hood change their value only when they are invoked)
But here is the trick... For our code in general it is illusion, that it is actually real random global input (therefore having no side effects).
Anyway, i understood what is that you wish.
Your randint is pseudocode generating function to you and therefore is having side effects.
That makes propagated side effecting into foo function for you
No, it just reads different states of global as an input
no. that's wrong. It reads AND MUTATES
otherwise it would always return the same number
think about it
it is reading global state that is supposedly random.
it is not writing some new state to anything global
it just accepts global input value as current input.
duuuuude, THINK
If it did not mutate global state then randint() would return THE SAME number
ALWAYS
How does it know to go to the next number?
And here we finally achieved coming to core of your mentality / construct that makes your philosophy
def foo() -> int
seed = current_seed_at_global_state()
rand = random.init(seed)
return rand.int(1,5)
in any case it is still not changing global state, it just reads it as input
if you wish achieving purity and happiness within your own philosophy, just add seed as part of input
def foo(seed: int) -> int
rand = random.init(seed)
return rand.int(1,5)
seed writes mutably to the global state
so now you have TWO calls to mutate global state
congrats
still waiting for your static typing to guarantee purity
static typing does not guarantee purity.
But it helps to promote it, by eliminating a lot of possible side effects affecting input/output in different ways to code part
i did not tell that it guarantees to reach purity 😉
oh, and the code you wrote above crashes lol
The last step of losing an argument: deny everything
😛 achieving anything in absolute 100% is very often having high cost.
achieving 100% unit testing coverage
achieving 100% typing
achieving 100% uptime and 0% downtime (requires infinity money pretty much)
I am person that is happy with something between 80 to 99% percentages of stuff (i tend to like number around 95% though)
that is stuff that is
part of SRE book
part of Unit testing best principles by Khorikov
https://htmx.org/essays/locality-of-behaviour/ defining its importance in different way, static typing helps me to promote locality of behavior
that essay doesn't seem to mention typing? I'm also missing the connection between type annotations and pure functions.
Static typing (strict one in mypy/pyright) helps to define explicit contract what is code able to process and what to output.
It prevents you from breaking this defined contract
What is pure function?
- thing that for input X, returns explicitly Y
- and also having no side effects.
Typing allows to restrict function working with those X and Y types only and handling all edge cases to different its possible values.
Side effects aren't directly affected by static typing, but explicit defined contacts how your code works helps to refactor quicker code to better shape. (Including easier to refactor to make code part pure if wishing, just a matter often enough to lock info static method decorator, to turn smith stateful in often enough pure)
I agree that static typing can make it easier to understand code, and help with refactoring. it just doesn't prevent you from having side effects. It's a separate consideration.
Sure it does not
ok, thanks for clarifying.
It just helps easier defining code architecture u wish to have (through incremental refactoring preferably, although u can be crazy to try accounting everything from beginning)
Code refactorability allows reaching perfection (including easier reaching pure stuff, if that is your goal)
Any code is changing to meet new requirements and more written code.
Any dev is writing shit on first try (often enough)
Refactoring is driven force to reach perfection closer
And static typing is very important tool for that
--
U can just change something from class method to static method for example. That is already helping you to try writing something more pure if u wish. (Static typing will mark u where u still haven't rewritten previously used instance attributes, that u may be changed)
Typing is a tool that helps u to reach easiest to any code architecture u wish as end result. (Which can be anything u set goals for)
It helps to achieve code architecture goals far easier
a static method can have side effects just as much as a class method can. I guess I can see that since it doesn't have direct access to the class, it's less likely to change the class attributes, but it's hardly a guarantee.
yeah, side effects are tricky.
I think the most major part of static typing regarding global state changes and side effects included...
That u can actually explicitly define what is public allowed (or private and really restricted to access) in class instance or in module.
U can just restrict from usage anything changing global state (at least for modules that u wrote and having as changeable part of application, or libraries u can change) if desired and going more pure if wishing
that is at least possible in Golang, where variables or function or method become public accessable to code outside of module only if u allowed it
(Same for Java)
in python... Static typing has limitations in what it can do. Protocols and Abstract classes in strict mypy at least allow to define what is really public and private to object
Therefore u can restrict to have getters only and no setters for your other code parts to access
I don't remember having anything for modules though in python
That can help to minimize presence of side effects a very lot across your code
Since code is just not having access to write/change global state of previously written code(if that is goal u a trying to achieve at least and how u defined public methods and variables). U control what is allowed, and can refactor code quickly to enforce rules for access u wish to have
the PRNG (in this case an instance of random.Random) does maintain an internal state. python global random.* functions use a global shared random.Random instance. so yes, generating a random number from random.randint does actually read and set mutable global state
if you instantiate your own random.Random instance, the mutated state remains local to that instance
Yeah, I learned pseudo(and real) random generators and wrote my own as part of uni course. No worries here
right, so you should know that the PRNG very much does have its own mutable state and that generating a random number mutates that state
and because it's a shared global instance of the PRNG then that state is definitionally shared global state
I had a hard-to-find bug that boiled down to that global random-module state and an unexpected mutation in it.
I ended up talking about it at PyCon
fun, what was the title of that one?
No objections. We identified requirements and core mentality under philosophies of our code writing some time later after that.
How to debug thorny Python problems, using Python’s dynamic nature to extract information in unusual ways.
nice talk! as soon as i saw you were using random.seed i knew what was coming 😆
Finally.
never considered using sys.settrace for finding stuff like this
I like time-machine on by default in tests. It would be nice to do the same for randomness.
You can't restrict that stuff in pythons static typing system though. So again no.
#unit-testing message
U can for classes though, that is already a lot more than nothing
Also, pure python problem, solvable by using real typing friendly language
I think it should not be hard to write python linter that forbids private prefixed python objects from usage in other modules (similar to go, allow private objects of specific folder used only at same level parent module, including in all tests)
sounds like really easy stuff to do to me
thus, solvable problem even for python
there are two reasons people keep talking about this: 1) you keep connecting function purity to static typing, and there just isn't a connection. They are both good, but they are unrelated. 2) Things like private/public and getters/setters can defend an object against mutation (to an extent), but doesn't ensure that any given function is pure.
It does not as I will repeat.
But it helps to achieve code architecture goals u wish to achieve, including making code closer to pure (if that is your goal)
I am happy with 90% result and achieved lesser code complexity at minimum cost through automatically enforced architecture means
What does that even mean? 🤣
Two super senior devs telling you that you are wrong isn't enough? Need more? 🤣
what i think is interesting/cool is that monadic or algebraic effects can allow you to protect against mutation statically using the type system
algebraic effects in particular are really damn cool and my "project wishlist" for ~2 years now has been to build something in koka or the new ocaml effects system
class PublicInterface(Protocol):
public_var: str
def meth(self) -> int:
...
class ImplementedStuff:
def __init__(self):
self.public_var = "abc"
self._real_private = 123
def meth(self) -> int:
...
def asd(self) -> int:
...
b: PublicInterface = ImplementedStuff()
that alone should help to use only meth as public method, and public_var as public
mypy will prevent you from using the rest of stuff that is having more private nature
sorry if i'm missing some context here, but the whole problem with the particular example of random.randint() is that the state mutation is implicit internal behavior
Yea that would be cool.
therefore in this example b.meth() can still mutate _real_private -- it depends entirely on the implementation of the particular PublicInterface instance that you have
it's almost a worse situation than before. now you are quietly, implicitly, internally mutating state!
i had senior dev as former tech lead, that in 11 years of his career in bank
and all the previous career, never learned even how to unit test code, but nevertheless he wrote... full applications for work from zero.
They died due to lack of maintenance during new year change, since it was hard to verify all code changes necessary to do across the code
Senior = not equal to not doing shit 😅
nim has a "checked effects" system too that's also been useful in my limited plunking around. it doesn't have polymorphism or any of the fancy mathematical elegance, but it works and i would feel comfortable having it around in a production codebase
anyway my point is that static types in python and most other languages convey no guarantees one way or another about runtime effects, because runtime effects are explicitly and deliberately beyond the scope of what they can convey
ergh, lets close all those threads of topics already. Too much spent time.
traditional interfaces convey that information by convention, documentation, and trust, rather than statically-checkable assertions
i'm trying to make a general point and it happens to be a good example. but i can drop it
what's unfortunate specifically about haskell & friends is that IO can be damn near anything. filesystem? memory buffer? standard input/output streams? network?
i assume that actually knowledgeable haskell people have ways to specify in more detail
sure, i agree that you can't get rid of state mutations from this function easily...
#unit-testing message as last point i pushed, that static typing helps to minimize amount of side effects through usage of real public and private methods (if that is your goal). Since you can define more restricted access to global state across your code (at least in Golang or Java, where it is possible to define what are public variables, classes, methods of a module)
my point is that this isn't true at all, and if anything static typing + interfaces could provide misleading information if behavior deviates from convention, or if someone makes an honest mistake and doesn't realize that something mutates state (like sampling from a PRNG)
as in your example, hiding the mutable state access inside private implementation detail actually makes it harder to see what's going on (in my opinion)
minimize = not equal to getting removed completely.
unless the interface is deliberately meant to do something with global state, it's borderline trivial to accidentally (or deliberately) put in global mutation behind the scenes
my argument is that it's the opposite of minimizing. if anything it allows you to do all kinds of horrible stateful things and feel like it's OK because it's abstracted away behind an interface
oh, you are speaking about semantic coupling now

yeah, sure it is possible.
no, i'm saying the opposite
i'm actually saying that decoupling makes it harder to manage mutable state, because you don't have visibility or control into how things work
horrible stateful things and feel like it's OK because it's abstracted away behind an interface
are you? semantic coupling is when you need to call some abstracted behind interface code in certain way, knowing about its internal working and how it mutates in order to achieve result
we just need to define better interfaces/abstractions, that make possible to use in a right way, without knowing how they are working under the hood
i see, sure. in that sense yes, mutable state inside some private implementation always causes semantic coupling between that private implementation and the application that's calling it
or almost always
But, we can be smart regarding interface we define. For example giving user context manager to use
that creates all his state when it starts and ends when it exits.
And allowing in its turn using context manager only when specific objects was instance created.
We can force user to use path we want, that leads to correct library/interface usage
in this specific case there's a monad for Random state
yes, that's true. but that's what i was talking about above: that's convention and documentation, it's an informal contract between developers that can be broken and cannot be (easily) checked statically by machine
and my point, that machine can easily statically check that devs do not break defined interface, as long as we have real public/private methods. (possible in Golang/Java by default)
problem to achieve in python yeah... Abstract and Protcols can give it somewhat, but otherwise we need to write our own linter (or adding as feature to mypy/pyright) that just forbids accessing private variables/classes outside of module scope, then i think it is achievable in python. (And running this check in CI)
P.S. of course we can't though expect all devs writing interfaces to libraries that push dev-users to correct its usage... so semantic coupling is unavoidable, since it depends on dev skill level to write their library in the way that semantic coupling is not present, and interface of lib indeed helps to use it without knowing about its internals
which one? i see this but nothing in the standard prelude https://hackage.haskell.org/package/MonadRandom
You're not minimizing any issues with mutation AT ALL with static typing. Just accept it.
yeah
i feel like we're going in circles. no, you can't have a machine check it. adapting your example slightly:
class PublicInterface(Protocol):
# NOTE: get() is expected to be memoizable and should always return
# the same result for any given instance.
def get(self) -> int: ...
class ImplementedStuff:
def __init__(self):
self._real_private = 123
def increment(self) -> int:
prev = self._real_private
self._real_private += 100
return prev
def get(self) -> int:
return self._real_private
a: PublicInterface = ImplementedStuff()
b: PublicInterface = ImplementedStuff()
table = dict(a=a.get(), b=b.get())
assert b.get() == table["b"]
b.increment()
assert b.get() == table["b"] # ERROR
what are you proposing that we add to this example in order to be able to statically detect and prevent this?
even with a custom-written set of tests that hooks into runtime code to inspect behavior, this might not be easy. you're getting into territory of needing something like pytest-mock "spy" to be able to have any control over this situation at all.
one big reason i like idris2: even if you ignore all the dependent types, the prelude feels a lot like haskell but cleaned up
I wish Elm had some reasonable monads or something. It's too simple.
added into strict mypy'ed file.
your code will error in trying to access b.increment() that is not defined as allowed to use by your interface protocol
we enforced our public interface 😊

Make the type the implementation and you can.
class PublicInterface(Protocol):
# NOTE: get() is expected to be memoizable and should always return
# the same result for any given instance.
def get(self) -> int: ...
class ImplementedStuff:
def __init__(self):
self._real_private = 123
def _increment(self) -> int:
prev = self._real_private
self._real_private += 100
return prev
def get(self) -> int:
return self._real_private
self._increment()
a: PublicInterface = ImplementedStuff()
b: PublicInterface = ImplementedStuff()
table = dict(a=a.get(), b=b.get())
assert b.get() == table["b"]
assert b.get() == table["b"] # ERROR
(this is pretty much what a PRNG does, as you know)
So. AGAIN. no.
Three people telling you that you are wrong. How many people will it take? 🤣
sneaky, yeah.
P.S. of course we can't though expect all devs writing interfaces to libraries that push dev-users to correct its usage... so semantic coupling is unavoidable, since it depends on dev skill level to write their library in the way that semantic coupling is not present, and interface of lib indeed helps to use it without knowing about its internals
developer did not think throughly in defining interface that is pushing always to correct usage of library.
responsibility on library dev to write its interface in a way that semantic coupling is not possible.
Static typing still helps here, since... we can at least localize the problem? We know how the code will be used in other code parts, as long as we defined interface that forced certain usage of a library.
So just a matter solving this problem at the level of this particular library/module. and then fixed result will propagate through the rest of the code automatically
would you say that rand = random.Random() ; rand.randint(1, 10) is sneaky, or a problem with the design of random?
Static typing still helps here, since... we can at least localize the problem? We know how the code will be used in other code parts, as long as we defined interface that forced certain usage of a library.
my entire assertion is that static types do nothing for us here, it's the exact same as if you had no type annotations
class ImplementedStuff:
def __init__(self):
self._real_private = 123
def _increment(self):
prev = self._real_private
self._real_private += 100
return prev
def get(self):
return self._real_private
self._increment()
a = ImplementedStuff()
b = ImplementedStuff()
table = dict(a=a.get(), b=b.get())
assert b.get() == table["b"]
assert b.get() == table["b"] # ERROR
this is the same code, no annotations. static types did nothing for us. the problem is the same in both cases.
would you say that rand = random.Random() ; rand.randint(1, 10) is sneaky, or a problem with the design of random?
there is at least some merit of problem in design of random
Less confusing could be having interface
from my_random import GlobalCurrent
rand = my_random.PsuedoRandom(start=my_random.GlobalCurrent) # don't allow default values perhaps?)
rand = my_random.TrueRandom()
That alone and restrictired of usage random only if in this way it was instantace created (we can fix this issue for our code if we code isolate this behavior into only our allowed module)
Would have helped to spot quicker if you are using a thing you intended to use
we can... convey how library works to some extend, through how functions are named, and what input is required for its usage?
there is certain harm to comfort of usage though. it has its own cost
static typed helped to localize source of error at least
if you get those errors in the rest of your code, you can be sure, it was enough to call just get() to achieve to this error 😊
less time will be consumed in debugging this issue
once you fixed issue at the level of library and interface you expose, correct usage will propagate through the rest of the code automatically 😛 (if there were needed changes in exposed interface in order to achieve more correct library usage)
so... shorter to chase situation than without static typing
- fixing issue only at the level of certain library/module code. That issue if reached outside of the module, then it is replicable within called public methods/vars
- and/or fixing public exposed interface (the rest of code receives message to fix itself by static typing enforced)
in both situations (with typing), it is easier to refactor code and fix issue to new fixed state across all the present application code 😉 (for situation number 2)
and to read what the code was doing, in order to understand and debug issue faster (for situation number 1)
@maiden pawn we all agree: static typing lets you provide more information about your code. More information leads to fewer mistakes. Better names are also better.

No
But static typing in python does NOT deal with mutation. At least not yet.
👋 hello, working on learning to use pytest & moto for testing my AWS client wrapper modules, I haven't been able to find any specific communities around moto & struggling to figure out how to assert methods that would return json.
anyone familiar enough with these tools to lend a hand please?
dont know where to post it, but anyone have had the same problem with this saving?
this is a node js test? You probably want to find a js discord server
ait my bad. I thought maybe someone here could help
I spent the last 3 weeks writing unit-tests
i just f*cking finished covering the entire application
this is the happiest I've been in a long time

now do strict static typing in ide that can show it on a fly recalculated in precise code lines 😅
Im already implementing kinda strict static typing :(
hopefully you do it with IDE integration. I tend to think that if you IDE is not showing exact code lines where it is breaking, it is madness to deal with
rapid feedback, and ability for rapid fixes and experiments matters in order to keep sanity and receiving enjoyment out of this process
You can be sure i do
PyCharm offers some pretty powerful functionalities and integrations with unittesting
you are so right
with the press of a button i can test the entire application
or if i want, because the structure of my unit-tests exactly mirrors that of the production code, i can test individual pieces of code from entire layers to individual components, subcomponents and scripts and individual classes and functions
How do you do that mirroring?
manually :,/
like,
this somewhat represents the structure of my code and my tests
src
--presentation_layer
----component1
------__init__.py
------script1.py
------script2.py
----component2
------__init__.py
------script3.py
------script4.py
--logic_layer
----component3
------...
unittests
--test_presentation_layer
----test_component1
------test_script1
--------test_function_func1.py
--------test_function_func2.py
------test_script2
--------test_function_func3.py
--------test_function_func4.py
----test_component2
------test_script3
--------test_function_func5.py
--------test_function_func6.py
------test_script4
--------test_function_func7.py
--------test_function_func8.py
--test_logic_layer
----....
pycharms identifies every directory/script/class/function prefixed with 'test_' as a runable test or something that contains tests and allows you to just run it/the tests it cointains without any configuration
this is really cool
so i just prefix everything with 'test_' and then i can just run any scope of tests at the click of a button
and again, since the structure of the tests is a mirror of the production code, the scopes match those of the production code perfectly
pretty neat :)
folks, can someone help me with mocking inside a pytest fixture.
here is my class
def __init__(
self,
domain: str,
problem_set: str,
):
self.domain = domain
self.problem_set = problem_set
self.consumer = None
self.producer = None
self.consumer_topic = None
self.producer_topic = None
async def _initialize(self):
print(f"called initialize")
self.consumer_topic = "consumer_topic_name"
logger.info(f"Consuming from the topic: {self.consumer_topic} ...")
self.consumer = AIOKafkaConsumer(
self.consumer_topic,
bootstrap_servers=BOOTSTRAP_SERVERS,
group_id=f"{self.consumer_topic}_consumer_group",
auto_offset_reset="earliest",
enable_auto_commit=False,
)
await self.consumer.start()
self.producer_topic = "producer_topic_name"
logger.info(f"Writing to topic: {self.producer_topic} ...")
self.producer = AIOKafkaProducer(
bootstrap_servers=BOOTSTRAP_SERVERS,
)
await self.producer.start()```and I'd like to create a pytest fixture for it and below works
@pytest.fixture(autouse=True)
@pytest.mark.asyncio
async def processor():
processor = Processor(domain, problem_set)
processor.producer = MockKafkaProducer()
processor.consumer = MockKafkaConsumer()
yield processor
however when I try to patch the objects, it doesn't work meaning it isn't using the Mock classes instead it is connecting to Kafka directly. I don't seem to understand what I'm doing wrong. Can someone suggest?
@pytest.fixture(autouse=True)
@pytest.mark.asyncio
async def processor():
with patch.object(aiokafka, "AIOKafkaConsumer", new=MockKafkaConsumer), \
patch.object(aiokafka, "AIOKafkaProducer", new=MockKafkaProducer):
processor = Processor(domain, problem_set)
await processor._initialize()
yield processor
Perhaps this describes the problem you're facing https://docs.python.org/3/library/unittest.mock.html#where-to-patch

Python documentation
Source code: Lib/unittest/mock.py unittest.mock is a library for testing in Python. It allows you to replace parts of your system under test with mock objects and make assertions about how they hav...
from what I understand that's if I try to mock a class that's defined in a module, however in this case I'm trying to mock a class from a library aiokafka
a library is a module
mm, so show should I change this?
What do your import statements for aiokafka look like
i have the processor class defined in a file called base.py and in that I import it like from aiokafka import AIOKafkaConsumer, AIOKafkaProducer
You're experiencing the problem that documentation describes.
You're trying to patch the class in aiokafka but it is too late - you've already imported base.py which in turn has already imported the real consumer and producer and stored them in new names
So you'd need to patch the producer and consumer in base.py
like this with patch.object(base.aiokafka, "AIOKafkaConsumer", new=MockKafkaConsumer) ?
No, base does not have an aiokafka attribute. It's probably just patch.object(base, "AIOKafkaConsumer"
I see! I'll try making that change
Maybe
from typing import Final
class ImplementedStuff:
def __init__(self):
self._real_private: Final[int] = 123
🤔
But yeah, won't help with your interface
yeah, that was my argument about how encapsulation might make things worse by allowing you to hide mutation from static analysis tools
encapsulation is necessary 🤷♂️ it helps to decrease overall complexity of a product
by encapsulating complexity to smaller... packages 😊
yeah, there are plenty of good reasons to encapsulate things
also just in general thoroughly testing some encapsulated solution doing all the work is easier
than having its logic spreaded all across app
you can concentrate and just test mutative thing as much throughly as necessary
giving it all performance testing, absolute testing coverage, static typing
then the rest of your code can be written by devs with less.... effort, which just use this already quality solution
so. even from the point of testing, it is really great to encapsulate things 😊
also the rest of the code can be testing much smaller amount of code. Thus saving testing time. and testing complexity is decreased too
since there is no need to test throughly already encapsulated stuff that was tested separately. Just smallest formality is enough to check integration
Essentially i don't see any reasons not to encapsulate things. Except being careful in not overengineering stuff.
hello guys, I am learning intermediate python and now I am in the chapter of unit testing can someone explain to me where this is usefull in building an app or something? Thank you
?
Khorikov's book explains in detail why it is useful
Kent beck shows on example how development is done
TLDR: unit testing makes better quality of your application, because it is automatically checked for correctness of its working after each change you make to your code.
unit testing is essential... for any projects made in collobaration with other devs. Helps to integrate code to work with all additions from all devs. And it is essential for long term maintanance of a project (you can rerun tests any time later and to confirm it is still working correctly with new dependencies and changes)


Unit testing is essential for any software engineer of level Strong Junior and higher that does programming in commercial environment
Thank you very much
it is crucially important necessity for survival in backend python applications
Because too many things can break at runtime in python
And too much fragile code interacting with databases
Unit tests helps to confirm all your code interacts correctly with database stuff at least
if it was not unit tested tested = it is not working pretty much philosophy
This was so much helpfull
we can also add... that just the fact that you THINK how to unit test your code
Significantly improves your code archicture
because you structure it better, in a way that components are testable
it is best to do from the start of a project, during development along side
adding tests to project which was already coded... is significantly many magntude times more challenging (because its code architecture was just not made for this, and hard adding tests to project without them, because you aren't sure what is allowed to change without breaking it)
unit tests give freedom to change project code as many times as you wish, without knowing its details throughly
you just rerun tests, and confirm that all your changes did not affect application correctness
So... unit testing is essential to make project Refactorable, Maintainable and Extendable in features 😊
Hi guys !
I have a function that takes a list of links, sends requests to them and return a list of all links that returned a code 200.
How would you code a test for that?
I'm new to unittests and it looks easy when working with just numbers and lists and dictionnaries, but I get lost as soon as I have to test things that relies on external stuff (like discord.py or requests or anything like this)
You can use the responses package to mock out the requests calls, so you don't have to really connect to the network.
thanks for the clue nedbat i'll dive into that :D
I am curious if anyone knows the answer to this question. If someone doesn't answer on time could they answer here?
Also I just want to add one thing when I print(field) when running the code outside of pytest the output I get is field= <input id="password" name="password" required type="password" value="">
When I run print(type(field)) I get <class 'wtforms.fields.simple.PasswordField'>
I moved all my database setup to conftest.py: https://pastebin.com/TA4BaJdw
Struggling now to add one record to the db through my test_alley.py:```py
pytest.fixture(scope="session")
def add_one_alley(session):
alley_one = Alley()
alley_one.id = 1
session.db.add(alley_one)
session.db.commit()
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
I want to add one record before any tests to the database in order to run get/update/delete tests
@limpid perch What about something like this ?
Also username_form, hashed_password_form, email_form are just fixtures that return the username ,password and email . Any question just ask if it doesn't work I will check my notes on calling the fixture.
db.create_all(bind_key) was just because I have 2 db's one for pytest and 1 for the regular code.
@pytest.fixture
def yield_usertest_db():
'''
This is in the /register route
Create the db column then yield the selected/queried usertest and finally delete the db.
yield does not stop the code when yielded.
'''
# = with app.app_context() except won't work for pytest
with app.test_request_context():
bind_key="testing_app_db"
def _subfunction(username_form, hashed_password_form, email_form):
# Create the database and the database table
db.create_all(bind_key)
usertest_db = UserTest(username=username_form, hashed_password=hashed_password_form, email=email_form)
db.session.add(usertest_db)
db.session.commit()
# Why can't current_usertest_db be the same name as usertest_db here?
current_usertest_db = UserTest.query.filter_by(username=username_form).first()
return current_usertest_db
#return username_form
# yield unlike return doesn't stop when called.
yield _subfunction
db.drop_all(bind_key)
In order to call this fixture if memory serves you just go
def test_fixture(yield_usertest_db, username_form, hashed_password_form, email_form)
usertest_db = yield_usertest_db(username_form, hashed_password_form, email_form)
assert usertest_db.username == 'username'
Also this is my example I am sure you can make it work for you.
Thank you for all of that! Quite different from what I had but will give it a try
@limpid perch Do you have any idea how to test a flask wtf form?
Any question on my example just ask
I am not sure if this is the best way but it works
usertest_db might not work you might need to return usertest_db.username in the first fixture. Also this is assuming you are using pytest.
hey guys, quick question : isn't it possible to use decorators with pytest-mock? I've been struggling with it since 2pm and it's 5 now 😦
Show the code you're using?
it's more a general question. As far as I am concerned, pytest-mock is just a plugin of unittest.mock so it should be possible
isn't it?
Sure it should work, what did you try?
I actually tried to import the plugin itself instead of using unittest.mock in the test file. I should just go to sleep...
from pytest_mock import mocker
@mocker.patch('') # this is not valid because mocker.patch does not exist. Obviously because it shouldn't be done that way
def test_something():
...
I fixed it to ```py
from unittest import mock
@mock.patch('') # that works now
def test_something():
...
The Plugin exposes a fixture, which is better behaved and more composing friendly than a function changing decorator
But a fixture gets taken as a parameter to the test function
Good morning guys, could a good soul help me with some unit tests? \o/
it's too general of a question to be answerable. decorators are just python syntax, so of course you can use them with any other part of python.
are you talking specifically about the decorators provided by unittest.mock? in that case no, that's specifically not how pytest-mock works. the pytest-mock mocker fixture replaces the unittest.mock decorators and context managers. this is described somewhere in the pytest-mock manual.
that is, you use pytest-mock like this:
def test_foo(mocker: pytest.MockerFixture) -> None:
mocker.patch("x.y.z.foo")
...
which is a replacement for:
@unittest.mock.patch("x.y.z.foo")
def test_foo() -> None:
...
in general, it's not at all correct to assume that Library B works the same as Library A
if the libraries lack sufficient documentation to explain their usage, that's a bug, and you'll have to go read the source code
but you can't make that assumption. pytest-mock is an alternative interface to the functionality in unittest.mock
In anticipation of your next questions about testing, I'd like to offer this little cheat sheet:
Unit testing : "Does my code do what I expect it to do?"
Integration testing: " Does my code do what the rest of the code expects it to do?"
Functional testing: " Does my code do what the user expects it to do?"
End-to-end testing: "Does the rest of the world do what my code expects?"
It's best to ask your question rather than ask to ask
this my endpoint, i need validate step "validate_webhook_token"

the event WebhookEvents.SIGNED_CONTRACTS.value: {

Does anyone know how I can do unit testing to validate this functionality?
Do you have unit tests for any other endpoint?
Any idea how to test random word shuffling?
eg. func like that:
from more_itertools import random_permutation
def shuffle_word(word: str, loose: bool = True) -> str:
shuffled = "".join(random_permutation(word[1:-1]))
if loose is False and not len(word) <= 3:
while word[1:-1] == shuffled:
shuffled = "".join(random_permutation(word[1:-1]))
shuffled_word = f"{ word[0] }{ shuffled }{ word[-1] }"
return shuffled_word
egzample:
Input -> 'This is the modified content'
Output -> 'Tihs is the moifded conetnt'
assert input != output
assert isinstance(output, str)
i would also check that output1 != output2 just in case. check for 10 random shufflings that they aren't equal
The point is that there is a probability of returning the same content as the input data
hmm
I've thought about this
make 10-100 shufflings in a test, and verify that at least > 9-90 of them are really not equal to input then
if it is allowed behavior
It sounds legit
Also, last thing... if it is your own library, u could be adding option to control used seed for random things during testing (or if it is not your own library, then utilizing patch mocking)
making random determinated same one for tests
it will make tests more repeatable and having no chances to break due to randomness
and it will make things easier to debug in case of test breaking
since tests will be repeatable to exactly same result in case of failure
Yup, it's mine
Hmm
I have to check how to do this
Do you mean somethink like random.seed(12)?
yeah, u can use global set random.seed(12) like that for your tests and it will be already making stuff simpler.
I would have prefered though my own code using it as composition and func args like that though
from typing import NewType
Seed = NewType("Seed", int)
def Randomer:
def __init__(self, seed: Seed)
self.rand = random.InitWithSeed(seed)
def get_int(self) -> int:
return numbers
randomer_global = Randomer(TrueRandomProbablyFromLib_secrets)
def random_permutation(word: str, randomer: Randomer = randomer_global) -> str
randomer.get_int()
def test_predictably() -> None:
input_ = "bla bla"
output = random_permutation(input_, Randomer(seed=12))
assert input_ != output
and other code parts using random generators controllably like that
then during tests we could be just overriding it for predictability
i like this a lot, thank you
Big Thanks! It looks really solid

Whenever people asking for behavior testing and people recommend loops and randomization, please know the correct solution is called hypothesis
Stop telling people to make shitty randomized behavior tests
100% this.
There's no reason for anyone on this server to not use hypothesis because Zac is active here and he's always been happy to help.
@mortal jungle with people recommending a ton of additional libraries above, I feel necessary to add
That usage of shit ton of libraries is acceptable enough path in every day continuously developed working projects, that run their CI every day multiple times and able to keep up with libraries getting outdated, updated and etc
in general for pet projects (which are maintained only with big skipping periods in long term) and your own libraries the opposite direction is often desired.
Where u use as least possible list of third party libraries as possible.
Keeping your own custom code that implements everything, allows is to remain stable, being depended only on primary language std libs and being fully customizable to everything u need beyond limitations of over opinionated frameworks and libraries
U decrease toll for maintenance in not using every little extra third party lib.
So I don't recommend as obligatory using for pet projects anything but strict mypy/pyright.
(Plus unit testing framework, std unittest or to accept that Pytest is okay enough. May be not for small enough pet projects and std unittest is enough)
Everything else should be very extra careful evaluated if really worthy to be depending on
Strict mypy, pyright are always justified for projects like that because they increase readability and improve maintainability in a long run.
They allow building more freely custom code/architecture solutions that will fit every usage case your lib mega
Then u get a chance u will continue to like your code in a long run and will be able refactoring to your new skill level every year and adding new features to a full satisfaction
You keep confusing strict typing with totally separate concepts. And then writing a wall of gibberish.
Whatever / we argued enough on this topic.
If I talk about grass being green, will you write 5 paragraphs about static typing?
This is how you sound.
Pet projects are a good place to get a feel for certain dependencies, I observed delayed ontake of necessary/better dependencies at painful cost in a lot of places, Heck some of my things that should use hypothesis don't because when it started small "it wasn't necessary" and now it's a huge cost to change over
In 100%+ situations I recommend resources for learning unit testing first and writing code testable solution. Somehow I don't see u arguing against that 😉
I recommend stuff for anything else only when I am assured this topic is already covered at minimal enough capacity
Strict static typing helps to propagate a better architecture that is better to do from beginning of a project too
And there you go again 🫠
We could use more teaching about how to use Hypothesis in real-world situations. The examples online tend to show only very easy-to-hypothesize code.
Absolutely
I know that I have a hard time figuring out how to use it.
Resistance is futile. 😁

i have to join in the sentiment that you seem to turn everything to static typing, and I don't know why you would do that in #unit-testing. Frankly, it's a lot of noise that tends to obscure the discussion here about testing.
It is part of code testing. Unit testing synergies well with static typing to cover more program logic usage cases.
At the same time one of them can compensate for lack of another one. So there is some limited level of interchangability
Essentially if u want to build custom unit testable code architecture, u need static typing for more code quality to reach it
So...
Just unit testing is simple first start
Code architecture+ static typing + unit testing is more advanced level to test your code
hehe, how can u hope to unit test your code for all branches of code logic and types it could be having if nothing defines borders/interfaces of your code 😉
Oh right, that is why u recommend hypothesis. To test all possible edge cases instead
@maiden pawn ok, just know how you are coming across. I'm not sure you're accomplishing what you want to accomplish here.
Let's stop this conversation. 👍
I'm inclined to take this misrepresenting take malicious
it sounds sarcastic
Based on the surrounding context I read it as a misplaced and unbecoming point scoring and until clarification is provided I'll take it as that
May be a little bit.
I don't believe in my path as the only one existing one.
All approaches to coding serve a single goal in decreasing overall code complexity of a project and helping easier code growth.
U can utilize full boilerplateful code architecture of Django to compensate ability to construct your own typed code structure.
Together with postgres typed enforced structure, it creates a plausible compensation u can further augment with better observability.
There is also completely not understandable to me functional and Haskel programming.
They all usually serve a single goal in decreasing code complexity
So, I can fairly assume with hypothesis u can test and build stuff in some additional way ensuring quality
And since it really generates fakery data to test all edge cases, it indeed sounds to me as typing testing alternative
That is it. Enough discord for today. Not answering any longer in nearby time
So who wants be the bearer of the message that Haskell has quick-check for a reason ...
As far as I'm concerned my impression unfortunately was confirmed
I've told him. I think multiple times 🤣
Understood, that further drives it down, at this point it's not funny anymore,the behavior is too close to the abuse pattern called "word salad",im concerned
Trumpism ;)
I see where you are coming from, but I strongly recommend avoiding that Type of labeling as it's easy to go down together with the language One is subject to when communicating
Hello everyone, hope you're all doing well. I've a question here, for a web application, is it necessary to unit test the api layer? Say the api layer here is just for request invalidation and response making, and there're already unit tests for the service layer it uses internally.
there's a (half-)joke: you don't need to test all your code, only the parts that you want to work.
It's quite easy to write some basic tests for your api though if you've already tested your inner logic
I'd probably not bother testing the service layer and getting the API tested first
Maybe testing the service layer directly for getting corner cases in the coverage
Reminds me that the goal is not testing itself, but to make sure code works(and keeps in that way), appreciate it!
Yes, I guess since api is the outmost it makes me think intuitively I should only use e2e tests for it
I think testing api could get u a faster pace but eventually we'll need thorough unit tests for lower level code
Depends on how you test your api, if your e2e tests cover all of your test cases/branches then there's no real need for unit tests 
That's certainly one way to do it although I learned that e2e tests get out of control easily once things get messy, so I prefer to keep a good balance with more unit tests against those
not sure where to ask but maybe somebody here knows the answer;
is anybody familiar with Ipython's internals by chance? I want to know how I can execute a block of code (starting from a string) and get the pretty-repr of the last expression (if there is one)
ideally something like execute_code_and_get_last_expr_repr(code: str) -> str:
Sounds like something related to REPL Driven Development and executing code from the code editor (via IPython and code editor tooling): https://davidvujic.blogspot.com/2022/08/joyful-python-with-repl.html

REPL Driven Development is a workflow that makes coding both joyful and interactive. It's even better than TDD.
unit tests can help a lot during development even if you also have e2e tests. they also tend to be much faster to execute and can help cover the edge cases that can be really hard to get in e2e
i even write (gasp) tests for internal-only functions if they're hard to get right or critical to the applicatipn
Yeah, it depends on how many paths your request could take through your core application logic
If it's pretty straightforward and/or it doesn't branch then e2e should be pretty ok
I think that unit tests, at least when practicing TDD, has a different purpose than integration or e2e tests. It's more a driver for writing code in a certain style (that usually also becomes very testable).
Can someone help me with configuring vscode and pytest?Im trying to make it work for like 5 hours already and i just cant do it.
its not quite clear what you are asking for, and what type of environment/setup is surrounding that
@limber thistle I recommend you create a directory for your project. Then create a virtual environment for that project. Activate that virtual environment and install pytest in using “pip install pytest” or “pipenv install pytest. Open the project directory in VS CODE and make sure that the virtual environment is active. This should setup pytest in VS CODE for you.
That's exactly what i did
It shows venv in code interpreter and whole project is in its own folder.
Did you install pytest in the virtual enviorment properly?
i guess, using python3.10 -m pip install pytest
What do you see in the VSCODE Built-in terminal ?
i called it again and
python -m pip install pytest
Requirement already satisfied: pytest in f:\0main_stuff\prog_stuff\projects\pyt\zaman_project\.venv\lib\site-packages (7.4.3)
Requirement already satisfied: iniconfig in f:\0main_stuff\prog_stuff\projects\pyt\zaman_project\.venv\lib\site-packages (from pytest) (2.0.0)
Requirement already satisfied: packaging in f:\0main_stuff\prog_stuff\projects\pyt\zaman_project\.venv\lib\site-packages (from pytest) (23.2)
Requirement already satisfied: pluggy<2.0,>=0.12 in f:\0main_stuff\prog_stuff\projects\pyt\zaman_project\.venv\lib\site-packages (from pytest) (1.3.0)
Requirement already satisfied: exceptiongroup>=1.0.0rc8 in f:\0main_stuff\prog_stuff\projects\pyt\zaman_project\.venv\lib\site-packages (from pytest) (1.1.3)
Requirement already satisfied: tomli>=1.0.0 in f:\0main_stuff\prog_stuff\projects\pyt\zaman_project\.venv\lib\site-packages (from pytest) (2.0.1)
Requirement already satisfied: colorama in f:\0main_stuff\prog_stuff\projects\pyt\zaman_project\.venv\lib\site-packages (from pytest) (0.4.6)
[notice] A new release of pip is available: 23.2.1 -> 23.3.1
[notice] To update, run: python.exe -m pip install --upgrade pip
looks like you don't have a vitual environment setup .
i guess i have it, i cant call libraries outside the venv requiriments. Also pytest does work, it just can't see directories or something else
Are you using virtualenv or pipenv ?
- Create a working directory for your project “mkdir example_project”
- Create a virtual environment inside “example_project” folder “pipenv shell”
- Install pytest inside the virtual environment.
- Done! You can import pytest in your testing scripts. Or run tests from terminal “pytest -v”
virtualenv
at least when i used pipenv it returned an error
@limber thistle Maybe you installed it globally at the OS system level. https://docs.pytest.org/en/6.2.x/getting-started.html https://code.visualstudio.com/docs/python/testing

Testing Python in Visual Studio Code including the Test Explorer
Also, you need to install pipenv first if your getting an error.
just created new folder and setuped venv again, added pytest and same stuff.
Pytest does work, it just doesn't work with up directories for some reason
what you mean by "it just doesn't work with up directories for some reason"?
i will again redirect to -> cause it is more full https://discord.com/channels/267624335836053506/1168610261230432346
but basically is that if tests are outside of src folder, it cant find it.
Tests outside application code
I won't worry about that 'cause pytest looks for test scripts starting with the word "test" and ending with the word "test" in them. ( test_example.py or example_test.py) After that it loooks for your test methods in those files.
fair, i tried something and i guess i just cant find a way to give pytest info about other .py files.
when you run "pytest" from a terminal ... pytest will find all the files with tests in them and runs it. That's why i recommend you organize your project in a folder with seperate virtual env.
im very not sure what is meant by this.
i run pytest through vscode terminal that is always(at least i believe) running from venv, if it can find one.
and my project is inside venv.
other files can find modules from different folders and files.
only tests, when i use pytest give this error
No. VS Code doesn't create virtual environments for you. What if the virtual environment isn't active? I recommend you learn more about virtual environment and they work then come back to pytest and unit testing. https://www.freecodecamp.org/news/how-to-setup-virtual-environments-in-python/

freeCodeCamp.org
When developing software with Python, a basic approach is to install Python on your machine, install all your required libraries via the terminal, write all your code in a single .py file or notebook, and run your Python program in the terminal. This is a common approach for a lot
then what command "python: create enviroment" do? Also https://code.visualstudio.com/docs/python/environments does it through vscode. im confused honestly, but is there a difference between setting it up using vscode and terminal?
Configuring Python Environments in Visual Studio Code
No difference. All the same. You just have to understand how it works.
Anyway i found out why, you have to put test_ in function name.
ig it was a fundamental mistake after all.
anyway Thanks Edmon for your time.
I already told you that earlier "I won't worry about that 'cause pytest looks for test scripts starting with the word "test" and ending with the word "test" in them. ( test_example.py or example_test.py) After that it loooks for your test methods in those files." 🙂
Yeah, i know, i just didn't even think about namin function wrong. My mistake, but oh well. now i will never forget to do this
I know it's a lot of things to pick up. Believe it or not. I am learning Pytest myslf.
lets go

i don't think i could ever eat 56 donuts even in a month. hopefully hussain likes to share
He finished them in a day
he was pretty hungry
Hey guys, can you give me advice on how could I test my controllers which are supposed to make raw sql queries to database and retrieve/respond with the data?
You can use a database in your tests
You can rollback the transaction or snapshot the database and restore it
oh, actually its a good idea. thank you for advice, but one more question, how can I make a async setup and teardown methods? I've tried to use async package for pytest but im getting a runtime error RuntimeWarning: coroutine 'TestUserController.setup_method' was never awaited
class TestUserController:
@classmethod
@pytest.mark.asyncio
async def setup_method(cls) -> None:
await DatabaseManager.start(
settings.POSTGRES_DB,
settings.POSTGRES_USER,
settings.POSTGRES_PASSWORD,
settings.POSTGRES_HOST,
)
print('setup')
@classmethod
@pytest.mark.asyncio
async def teardown_method(cls) -> None:
print('teardown')
@pytest.mark.asyncio
async def test_get_by_id(self, mocker):
# mocker.patch(target='app.controllers.user.get_by_id', return_value=self.user['id'])
# test_data = await get_by_id(self.user['id'])
# assert test_data.id == self.user['id']
print('test')
assert 1==1
You have to use fixtures
hm... is there a possibility that pytest might block connections to database? scince I am getting error ```E socket.gaierror: [Errno 11001] getaddrinfo failed
C:\Users\Arata\AppData\Local\Programs\Python\Python311\Lib\socket.py:962: gaierror```
@pytest.fixture
async def setup_and_teardown():
await DatabaseManager.start(
settings.POSTGRES_DB,
settings.POSTGRES_USER,
settings.POSTGRES_PASSWORD,
settings.POSTGRES_HOST,
)
print('setup')
Pytest itself is unaware and uncaring about network
ah, so i should use other packages for pytest?
That won't help you connect to your database
hm, could you give me any hint?xd
It's just python
You'll need to show your full code and full traceback
here you go https://pastebin.com/WM1D7smu
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
Best to use a different file for each document
I did
Oh you ment paste, sorry
I dont think so science its working without a problem when im using outside of tests
actually w8, I solved the problem. Looks like reason was in my pytest.ini, i wrote all variables as a string which caused the error
Btw you have two async test plugins anyio and pytest-asyncio you only need one
oh, thank you for warning
I did the same thing for a while, I didn't realize anyio had its own plugin
Hi team,
I’m looking for tutorials and examples on implementing integration tests with Pytest. I found a couple with Pytest and Flask. But I’m still looking. I prefer guide/tutorials with pre-production (staging environment) codes and code examples, implementing integration tests that actually tests the application.
Thanks
As I have discovered, it is actually more challenging than expected to do that.
Real integration tests can be done only if u raise instance of service in background (for example as a thread)... And do all the desired tests against it.
There is Robot framework for that also, but I think it is nasty piece of tech that increases difficulty too much for that and lacks sufficient flexibility and dev comfort.
Tldr: i think u should be ideally using for integration testing, just Pytest fixture that launches as a thread working application in a testing mode but with real web server pretty much and just run tests against it.
Best to consider in advance overrides with mocks for third party APIs nevertheless though, so raised web server should still have programmatic access for additional tunning before it was launched
In theory since u run it as thread, it could be still mockable on a fly during tests
needing to test it. Haven't checked yet that it will work flawlessly in python.
If it will work, it will make integration testing at a far superior code comfort than Robot framework can ever hope to provide (for ffs it is not even having debug mode)
P.s. Any... Any! Framework testing client is not bringing sufficient level of integration testing. But raised in a thread web server should
Tried in Django testing client with Requests client, it was still not enough at least
Okay. I do full stack with Django and react. I perfer anything with Django. Interesting.
Let me understand ... please tell me if I am wrong So to implement real integration test with Python and Django. I will create an EC2 instance running Ubuntu. Run the Django app ... Then use Pytest fixtures to test an instance of the app running in real time. Am I correct?
Robot framework is a regular way to go with integration testing, but it is nasty (no debbugging through its code, new code syntax in general, not enough flexibility due to invented new language)
that is why suggest going with pytest and running real web server ina thread
yeah, basically that's it. the part regarding thread is kind of important to increase comfort for tests though, u should be still having code access to this thread from your runnint tests, therefore have sufficient flexibility to mock not needed third party libs and erase easier data between test runs (ideally we should try still sticking to the default of erasing data between tests after all)
So ideally your thread launches web server in a programmatic way (for gunicorn there is way for incode server raising), without any shell shenanignans
that will give u better code flexibility and in theory your debugging should be still able to traverse if necessary into code executions of a web server
that should make it flawlessly easy to maintain such integration tests
nothing of this is present if u will go with Robot framework which is default standard for integrations :/
Yeah I am familiar with gunicorn. That's what I use to run Django app in prodution. gunicorn and nginx. I think by default it spins multiple workers when running django app.
and you can of course change the number of gunicorn workers as needed . but usually about 4-5 usually runs and nginx runs 1 master and 2 workers.
hmmm. each worker is its own child process i think
we need web server running as one thread only (for code accesability, for mocking, for debugging traversing into app code)
some configuration to check for web server preferably
u will not have access to Processes. even in this way it stilll better than robot i think
but with having web server running as single thread it should be even better
we use docker compose for this, running a local instance of the database in one container and the tests in another
oh, that i don't even consider for integration testing. it still unit testing to me 😅
i am more speaking for integration as running full instance of a web server and accessig it without test clients (like Robot framework offers doing)
i mean, it's not a bug for bug EC2 replica but we do run endpoint-to-response tests that way
and yes we use the starlette test client (in our case via fastapi)
you can definitely do the "real" integration tests like you describe of course, but i think it's an 80/20 thing
still unit testing to me then. it is not bringing sufficient level of integration.
running web server as a full instance is bringing far more assureness of code correctness in a real way
at least that i got when testing my library. without such tests, things are discoverable only during staging
such tests are meant to replace need of depending on staging manual checking (for good percentage)
Or having cheaper e2e tests alternative
yeah ultimately it's good to have both
but again, you can get pretty far with the local setup. it also forces you to avoid relying too much on implementation details of the deployment environment and ensures that the dev/test/debug loop can stay tight, which is very important
I understanding everything you said expecte for the setup here "hmmm. each worker is its own child process i think
we need web server running as one thread only (for code accesability, for mocking, for debugging traversing into app code)
some configuration to check for web server preferably
u will not have access to Processes. even in this way it stilll better than robot i think
but with having web server running as single thread it should be even bette". So I need the entire application running in a single thread? I have to manually configure/ create a Python script that runs the entire Django project/app in a single thread on EC2 then start the integration test?
Ergh, I think running integration tests with any web server. Just not using test client, should just check stuff more thoroughly. We can disregard miss matching deployment environments here for the sake of having locally (and CI) easy runable integration tests with full debug access
We will have easy room to run them for every commit in CI and full debug support. That is important enough to disregard deployment miss matches
U can freely run it locally at your own dev machine (preferably u use Linux for dev machine though)
Or in docker container.
The part regarding threads is not super important, u can still have separate injected code on start up of application (separate wsgi/asgi.py to raise test server), making this app instance easiest testable
But it will be nice to have for better debug and more mockability nevertheless
U need finding correct web server for that (may be Uvicorn can offer that or smth)
Or may be default Django dev server code has option to run its web server in code without extra process born (it should be on purpose not optimal, without extra processes)
You have to define "integration tests". This is not an agreed upon term. What exactly are you after?
I am after the encyclopedia definition of integration tests and what integrations tests means in general. Just want to understand how to write code and implementing solutions that tests different parts of the application code and how the different components work together. I understand unit testing, fixtures, setup methods, assert with pytest and Nunit. But I don't know how to implement integration tests in code. I understand the term "integration tests" but not actaully writing the code.
in general integration testing assumes u check your code correctly in integration with target filesystem, target database, target some apis and etc
u can still select during this integration testing, which exactly integration you are checking
@pearl cliff named as integration testing, utilizing as container in database same as in prod. and he is correct. it is still technically integration testing (i prefer to have it as default for unit testing though)
Please show me that definition
people name running tests in EC2, so they would be having als filesystem same as in prod. But if u use dev machine with Linux and same filesystem, then it is not an issue too
Right now I heard "what <UNDEFINED TERM> means in general". Which is obviously not answerable.
i was speaking in adition attempt to bring integration testing with integration of a real web server running your app.
as a more ultimate check (which brings our integration testing very close to domain of almost e2e testing)
Sorry I meant wikipedia https://en.wikipedia.org/wiki/Integration_testing
Integration testing (sometimes called integration and testing, abbreviated I&T) is the phase in software testing in which the whole software module is tested or if it consists of multiple software modules they are combined and then tested as a group. Integration testing is conducted to evaluate the compliance of a system or component with specif...
Well that's enormously vague honestly
assert foo(bar(2)) == 5 can be an "integration test" in that definition, if foo and bar have individual unit tests and are from different "modules"
Thanks @proud nebula . Your probably correct with this example. That's not what I am after. My question is just about integration tests in the Testing Pyramid. You have End 2 End Test (E2s), Integration Tests and Unit Tests.
I used to work on a project with this definition:
- unit: no database, 100% in-memory
- integration: touches database
- e2e: uses a browser to test the full stack
Yea, I think you'll find that if you ask "but what does that mean exactly?" a few times, you will realize that the middle part basically just means "anything not in the other two parts" and then many people will even disagree on "unit tests" :/
Programming is like 99% about carefully thinking about semantics ("the meaning of words"). So be VERY mindful of when you don't exactly know in detail what a word is supposed to mean, or when you aren't certain the other person might not agree on the definition.
I'll admit I don't know that's why I asked.
good :P
But also know what everything Darkwind wrote was based on his definition, which you have no idea what that definition is. This is your life as a programmer :P
I agree. I searched online/google before posting the question here. I found few examples and was still unsure. That's why i came here. I understand you still have to think critically about the answers and make informed decisions.
i think of integration as anything that touches more than one "component"
I think the term "integration testing" is largely unhelpful and kinda useless
that overlaps with unit testing imo
like.. a LOT
which means the term "integration" covers a big range. it's everything between "unit" and "e2e"
i should say "system"
so the database + app
I assume you meant "more than one component you wrote"?
sorry component was not the right word
Because otherwise it's not a unit test if you call str.replace :P
so for example if you have a webhook you can have an integration test without a database involved
or a client calling an internal api
Thanks again for your help @maiden pawn @proud nebula . I just need practice implementing tests now.
Experience is the key for sure.
We use the same definitions.. I think devs in my team understand integration tests as something that verifies that the application integrates well with external resources, database, rabbitmq, etc. For unit tests, those resources would be mocked in some way, ideally by injecting in-memory implementations of the adapters/repositories/etc.
I would argue that if you swap your postgres for an in-memory sqlite it's still an integration test
PostgreSQL and SQLIte are external depdencides. I think integration tests is more about testing the functionalities of your application code and how it interact with external dependencies. It won't matter if your using PostgreSQL or SQLIte. As long as the methods in your own production code are calling the database correctly and performing database operations then your doing integration tests. Also, you assume that PostgreSQL, SQLite and other third party application your production code depends on are property tested and just focus on your own production code.
Sure, that's not what I mean by an in-memory implementation.
An in-memory implementation would be e.g. storing the data in a list in the application's memory for the duration of the test, such that the data never leaves the application.
The Python standard library and interpreter is an external dependency :P
Hell, so is the CPU and memory. You have to be pragmatic about these things, or your brain will break.
Okay.
That also would really depends on what you're doing on db level
E.g. not doing integration testing could be disastrous since you won't be running any actual queries
I'm just elaborating on how I understand the definition of integration tests. I didn't intend to say that you shouldn't do them.
I think the distinction is largely useless. Those terms have no effect on how the code looks or behaves.
If there's a @pytest.mark.django_db annotation on a test though, that's very clear what that means
Yeah, I agree that it's largely useless in general. An "integration test" usually has a defined meaning within a project or a team, but the definitions are not standard across the industry. It's interesting to see how others use the terms.
Honestly you could mostly "avoid" writing unit tests by writing integration tests instead 😅
I'm still not sure if it's a good or a bad thing
Imo you test on the level where you can verify things easily and fast. Whatever that is. Depends on the situation.
Might be manual testing by clicking around, might be totally pure functions with no dependencies...
Yeah it depends on what you need. Broad integration tests can get you a lot of coverage for little effort. But if you have a lot of business logic in your application, it helps to decouple it from external resources. When contained, it's easier to test with granular assertions. Different tools for different needs.
If there are a lot of logical paths, orchestrating things to hit them all can be difficult and indirect. Then you have large, slow, complicated tests that are difficult to maintain.
the problem with integration tests is that debugging can be really hard if something does break, unless you also have accompanying unit tests
i once worked on an app where the only tests were snapshot-based e2e/integration tests. in an unfamiliar programming language, no less (not python). that really tested my resolve.
Could be worse. Could be BDD on top of that 🤣
Depends on how your integration tests are built, if you're using some kind of snapshot - yeah, in general my db integration tests look like this:
# test_retireve_entity.py
@pytest.fixture
async def entity(session: AsyncSession) -> Entity:
entity = Entity(...)
session.add(entity)
await session.flush()
return entity
async def test_not_found(http_client: httpx.AsyncClient) -> None
response = await http_client.get(f"/entities/{uuid.uuid4()}")
assert response.status_code == 404
async def test_ok(
http_client: httpx.AsyncClient,
entity: Entity,
) -> None:
response = await http_client.get(f"/entities/{entity.id}")
assert response.status_code == 200
assert response.json() == EntitySchema.model_validate(entity).model_dump(mode="json")
Since all state is set up in tests I don't really see a problem
Hello all!
I am tryong to mock a coroutine, so I can generate some simple unittests. However, this doesn't work as I exepct.
I have following function:
async def unittests(runner):
return await runner.with_exec(["poetry", "run", "pytest", "tests/unittests"]).stdout() # (1)
Which I want to test:
@pytest.mark.asyncio
async def test_pipeline():
await unittests(mock_runner)
assert mock_runner.assert_called_with(["poetry", "run", "pytest", "tests/unittests"])
The problem is, that I cannot build a mock, which provides the .stdout() and therefore the test fails.
await mock_runner.with_exec().stdout()
Traceback (most recent call last):
File "<string>", line 1, in <module>
AttributeError: 'coroutine' object has no attribute 'stdout'
Any idea how the mock needs to look like?
Of course, that didn't work ...
mock_runner = mock.AsyncMock()
mock_runner.with_exec = mock.AsyncMock()
mock_runner.with_exec.stdout = mock.AsyncMock()
!paste
Pasting large amounts of code
If your code is too long to fit in a codeblock in Discord, you can paste your code here:
https://paste.pythondiscord.com/
After pasting your code, save it by clicking the Paste! button in the bottom left, or by pressing CTRL + S. After doing that, you will be navigated to the new paste's page. Copy the URL and post it here so others can see it.
just needed the link
hello everybody
how do i unmute my self??
i realy need to talk
sombody??
aswer
answer*
There is no mute. If you have a question ASK IT. If you just write nonsense, you can never get any answer to any question.
!voice for voice chat
Voice verification
Can’t talk in voice chat? Check out #voice-verification to get access. The criteria for verifying are specified there.
That's a brilliant way to put it, thanks! Especially the part with "one component you wrote".
I keep trying to explain it to people but more often than not I see people thinking of unit testing as "mock everything and test a single function"
What kind of terminology do you usually use? I.e. what would be your "testing pyramid"?
I try to avoid terminology like that. It's just confusing. A test can use thing x or not. That is concrete.
Hello
What is the equivalent, using unittest.mock, of Java's Something mock = mock(Something.class)? ie, I want that class to have "dummy" methods which do nothing but which I can query to see whether they are called etc
I want to mock a threading.Timer and check whether it's been called with cancel()
def test_timerIsCancelledIfItExists(self): state: BlinkerState = self.state timer = mock() state._timer = timer state.resetOrUpdateTimer() verify(timer, times=1).cancel()
I love mockito
It's sooo obvious to use
mock's autospec?
Python documentation
Source code: Lib/unittest/mock.py unittest.mock is a library for testing in Python. It allows you to replace parts of your system under test with mock objects and make assertions about how they hav...
Or just a plain Mock(spec=SomeClass)
Hmmwell, uh, not really
For instance I want to be able to do something like when(mockedObject.someMethods(some, arguments)).thenReturn(whateverIWant) (or thenDoNothing() if it's a None method)
or .thenRaise() etc
Maybe mockito can do that, I'll check
OK, mockito can do that
On "real" instances too, unlike in Java :p
u want smth like
from unittest.mock import MagicMock, patch
mock = MagicMock()
with patch.object(threading.Timer, "cancel", mock):
# your code
assert mock.call_count == 3
how can I make mock request ? I can see requests-mock module but I think it's trying to make a http request to the url. is there a way to mock that requests without making an actual request ?
or I have to pass a live URL ?
this is what I'm doing & getting requests_mock.exceptions.NoMockAddress: No mock address: GET http://localhost:12345/endpoint

nvm got it. by replacing the variable with value http://localhost:12345/endpoint
it doesn't look like you're using the mocker fixture at all
Yah i have figured out the problem. I'm using pytest's requests_mock
All good now thanks anyways
@merry summit : it was hard to find time to even write any tests.
potentially mm not exactly correct may be approach if u have issues with it.
Could u describe your language/stack and how you start to write some features. Like voice steps u do to try writing first code lines?
and what IDE/debugging tools u use
Voice steps?
what are your first steps to write first code lines of a new solution?
how do u check u write it correctly?
what is your language/tech stack also
like say aloud in the most obvious way how do u start it
as if you were speaking to dummies/brain dead robots or smth
yeah sure, maybe tomorrow
also i forgot
after merging everything into develop, integration testing comes
so i guess if there are errors or bugs
the time to fix it is then?
integration testing assumes to be automated and running before Pull Request is merged 🤔
if it is not automated and happening after PR is already merged, then it is "Manual QA"
When do you use the “patch” method and when should you use the “Mock” or “MagicMock” when mocking?
Both seems to do the same thing. Also, I read that it’s better to just use “Mock”.
Hi @maiden pawn ! Thanks again 🌮 🙂 !
What you told me about how to implement integration tests a couple of days ago makes more sense now: Just use Pytest fixures that launches as a thread working application (create pytest fixures) and web server (or docker) and just run tests against it.
It seems to be Integration Tests is what you described and just testing a bunch of HTTP requests methods because most of what I see is doing integration Tests for APIs and APIs are just ENDPOINTs … of course you can return JSON/data. Databases isn't an API, but we are still testing an external source and trying to verifiy (assert) if the test is failing or passing. But yeah from what I understand… unit testings is testing against application code and Integration Tests is testing against external dependencies which are web services most of the time. I’m speaking from web development perspective. Integration Tests for something like gaming or other platforms would be different.
import pytest
@pytest.fixture
def fixture_1():
print('run-fixure-1')
print('fixure-1 ... Setup PostgreSQL Connections here.')
print('fixure-1 ... Collect data from the database (PostgreSQL) here. ')
return 1
@pytest.mark.slow
def test_example():
print("test1")
assert 1 == 1
def test_example_1(fixure_1):
num = fixture_1
assert num == 1
@pytest.fixture(scope="session")
def fixture_1():
print('run-fixure-1')
print('fixure-1 ... Setup PostgreSQL Connections here.')
print('fixure-1 ... Collect data from the database (PostgreSQL) here. ')
return 1
considering the cost of raising full web app, or opening connections and doing migrations.
I recommend as much as possible to utilize "session" scope, without sacrificing if possible, cleanup between tests
it will make sure to run your tests rather quickly, since session scope runs only once for testing session
also pattern is useful
@pytest.fixture
def fixture_1():
print('fixure-1 setup')
yield web_server
print('fixure-1 ... fixture teardown')
hello... need some help.. working with python3.12, (venv) with a simple assert (assert 5 == 5) I always get collected 0 items and (no tests ran in 0.02s)

Simple and lightning fast image sharing. Upload clipboard images with Copy & Paste and image files with Drag & Drop
any idea how to solve it?
@sinful sail I think you’re missing fundamental things about setting up Pytest and writing unit tests. How do you name test methods? Proper names for tests? I think pytest is looking for tests in “tests” folder which you already have based on the screenshot you provided, but unable to find it.
Please follow any of the starting tutorials as opposed to randomly naming things and copying code snippets
Mock is just an object that can behave pretty much however you want it to, depending on how it's configured. patch injects a Mock somewhere. a lot of the time when people talk about mocking as a testing strategy, they really are talking about patching something to replace it with a mock.

Speaker: Lisa Roach
One of the most challenging and important thing fors for Python developers learn is the unittest mock library. The patch function is in particular confusing- there are many different ways to use it. Should I use a context manager? Decorator? When would I use it manually? Improperly used patch functions can make unit tests us...
yes, indeed that was the problem... thanks!!
yes I forgot the correct name of the function
thanks!
Thanks for the link. I'll watch it.
one thing to note @sinful sail @dreamy bough is that you can inject any object with patch. the default is a Mock but it doesn't need to be, it can be anything
Thanks! 👍
Hello everyone... I have a "problem" running a TestCase using ddt -- namely, this test:
@data(
[ True, 1, 0 ],
[ False, 0, 1 ]
)
@unpack
def test_indicator_status_calls_correct_method(self, blinkerActive,
activeInvocations, inactiveInvocations):
state = self.state
when(self.context).isBlinkerRightOn().thenReturn(blinkerActive)
when(state).handleIndicatorActive()
when(state).handleIndicatorNotActive()
when(state).action().thenCallOriginalImplementation()
state.action()
verify(state, times=activeInvocations).handleIndicatorActive()
verify(state, times=inactiveInvocations).handleIndicatorNotActive()```If I run it within the context of the whole test class, it runs OK
But if I try and run this test only, it fails by not finding the test name; note that I run IDEA.
The error message is: ERROR: not found: </path/to/the/python file here -- placeholder>::MyTestCase::test_indicator_status_calls_correct_method
Indeed however, when I run the whole suit, different method names are generated
(namely, test_inidcator_status_calls_correct_method_1__True__1__0_ for the first data set and you can guess for the second one)
The class itself has been annotated with @ddt
Is there a way that I can run this test individually with all its parameters?
Also, I know this code looks waaayy too much like Java, this is where I come from; I'll "unjavaify it" later when I get more familiar with Python as a whole
The error indicates that you run the test with pytest, which has a native Way to parameterize tests so that the ide can select them
As far as I am aware DDT makes it impossible for pytest to select groups of tests due to magically creating methods
I strongly advise to drop it when using pytest
I'm a beginner with all this :) I was looking to replicate TestNG's @DataProvider and this was my first hit. Eh, at least I'll have tried :p
But since pytest has it natively, I'd better use it
Pytest has fixtures for dependency injection and parametrize for test parameter sets
I'm no t sure I understand "dependency injection"? Does it mean that I can, for instance, make one test run only if another one succeeds?
(like the dependsOn attribute of TestNG's @Test)
Nope,thats currently a 3rd party plugin with pytest
Dependency injection is about the resources a test may need
OK, I'll look that up as well
Such as, say, data from a file?
Yes,or databases/expensive objects, state
OK
I recommend running through a few tutorials to get a feel
That's what I'll do... First goal is to rip ddt, second is to actually use pytest for mocking... Right now I use mockito since this is what I use in Java and I'm very familiar with it
But I've been given the ear that "it does not look like pyhton at all" :p
Personally I try to avoid mocking and patching whenever possible, it's very fragile when overdoing and its very easy to make tests that lie and sabotage refactoring with it
In Python I can understand that it can quickly turn into a mess; Java's isolation features makes it a very viable solution though
Ultimately it's always the same, isn't it? Write code that is obvious, the rest should come :p
I like to throw the caveat that obviously is sometimes unaware of nuance, unfortunately that's usually a delayed pain
Been there, done that... More than often this happened to me because I botched the design in the first place
(and it still happens from time to time)
I'm sure I'll manage to botch designs in completely new ways in Python :p
The bugger likes to truly shine in face of changes requirements or shocking enlightenments
sigh I need to rewrite the whole test :(
(test class)
OK, I don't get it
@pytest.mark.parametrize(
"blinkerActive,activeInvocations,inactiveInvocations",
[
(True, 1, 0), (False, 0, 1)
]
)
def test_indicator_status_calls_correct_method(self, blinkerActive,
activeInvocations, inactiveInvocations):
# test code here
When I run the test, it shows this: TypeError: MyTestCase.test_indicator_status_calls_correct_method() missing 3 required positional arguments: 'blinkerActive', 'activeInvocations', and 'inactiveInvocations'
Does it have to do with the test class inheriting unittest.TestCase?
Oh no... I think I understand
It's not pytest throwing this error, it's unittest
Unittest subclasses don't support parameters in pytest
Unittest support in pytest is primarily to support running legacy tests
WIll that take into account the setUp and tearDown methods?
(funnily enough, most tests are written as unittest, but the test runner is pytest...
OK, it appears the answer to this is "no"; so I need to find how to do that with pytest
There's unit method's and fixtures,I strongly recommend fixtures
I'm currently reading on this, but to be honest the documentation of pytest is not very clear in this regard
I think I see how I can use them to emulate setUp() but for tearDown(), I have trouble finding what I want
Unless, uh... Maybe in fact I don't need the tearDown() here since all it does right now is call Mockito's .unStub()
Err, unstub
The teardown is after the yield in a fixture
Ah, yield... This keyword I have a lot of trouble wrapping my head around at the moment :p
It takes a bit to wrap ones Head around them
A yield statement Turns a normal function into an iterator, each iteration walking to the next yield statement
Pytest fixture definitions take advantage of that
By using yield to pass the value outside,the cleanup can happen when control is returned to the function
So, IIUC, you can yield x, do something, yield y, do something else and so on?
Not in fixture
After all they are supposed to give out a value
So its setup; yield value; teardown
Like many other things in "test world", the use of yield here is a bit quirky.
Same as @contextmanager though
yes, there are other quirky uses.
To me this just seems like a common use for yield now.
maybe there are many things that work like this. For someone new to yield, it can be confusing: "why am I using yield if there's only one thing produced?"
Maybe part of the issue is the lack of multiline anonymous functions.
how would a multi-line lambda change things?
and if you literally yield nothing!
Could be cleaner to pass anonymous setup/teardown functions. Right now the only way to do it is with yield or a class. Both of which are a bit fugly imo.
The yield syntax has the advantage of a common scope though, which anonymous multiline functions wouldn't.. 🤷♂️
yield syntax supports with
You'd have to manually drive context managers with two inline functions
true true... there are many advantages to using yield
All of you are currently speaking Chinese as far as I'm concerned :p
Then there's v = yield w
Mm. Making use of that can be a bit of a pain.
I've not seen it really except in low level async frameworks and David Beazley magic
And even then it's return (yield from v)
I tried to use it for some parsing. Kinda regretted it.
You are doing a good job climbing up this learning curve. I'm glad to see you trying out some Python-native tooling.
and as always, we can help along the way.
Maybe these three presentations can help http://www.dabeaz.com/generators/
I have a vague memory of using it at some point, but I can't remember when.
i think that's exactly the kind of explanation that runs counter to how fixtures use generators, and gets at the "weird" aspect I was talking about.
(though I haven't looked at it recently)
http://www.dabeaz.com/finalgenerator/ covers context managers
The third presentation
The
Think of "yield" as scissors
bit
I like that.

that is good to see
@sacred depot btw, this was how I tried to explain the on-ramp to testing with pytest: https://nedbatchelder.com/text/test3.html
How to get started writing tests, from first principles. Everything you need to use pytest to test your code.
I'm reading... As to me I learned most of what I know with a single book... Java oriented: "Practical unit testing with TestNG and Mockito"
For Java devs at least, I say this is a must read -- and it does talk a lot about the "way of testing", just as you seem to do in your presentation
And one thing I will have to get used to with pytest is that it does not need classes -- however your test files must be named appropriately
Which means that if you don't use a class for your test, then you cannot have a strict equivalent of setUp() and tearDown()
Hence fixtures
right
It's quite an opposite philosophy to TestNG in many senses
It (TestNG, I mean) doesn't even care what your test methods are named as long as they are annotated with @Test :p
Wait... try has else?? Uh...
else executes if exception wasn't raised in try block
I learned testing first with N-Unit. Then I used MS-Test, PyTest and Unittest module in Python.
I find it better to just focus on concepts instead of language focus features. You’re doing the same thing basically with different tools.
That is what I surmised, but is there a difference between (pseudo code!) try { something_that_can_raise; yay! } except { nope... } and try { something_that_can_raise } except { nope... } else { yay! }
yea, because yay can raise
In my example I supposed it didn't but OK
Another thing I'll have learned today
Assumption is the mother of all fuckups :P
As a rule of thumb you want to keep your try blocks small.
That's not specific to python :p
sure. Still, it applies to your example, as your yay made the try block larger
Swift has a very different syntax for try/except that makes it clearer what can happen. It's a bit annoying in the beginning but it's also a lot more solid.
OK, OK... But don't worry for me, I know to keep my code well isolated :p (I pretty much have to given the language I mainly program in)
OK, with pytest.raise() <-- I love that construct
In Java, doing this is a little awkward
@river pilot I thank you a LOT for the link you sent me; short and to the point
nice, i'm so glad it landed well.
sigh now tox is the problem
Why do I have a feeling that "tox" is a shorthand for "TO eXecutable"?
What happened?
tox isn't for making executables.
I can't get it to run correctly from my environment
But now I realise that I want "poetry build"
You can use tox with poetry
But that does not generate what I want either... I'll have to ask the project owner who is currently unavailable
But this has nothing to do with unit testing anyway, I wonder why I even talked about that here -- sorry
tox is testing related
I consider large complex functional tests in scope for this channel
OK, well, I'll give it a try, but first of all I should explain my environment
I run Win11, IDEA (community edition on this PC) latest version, Python 3.11 SDK, the project uses tox and poetry
Within the IDE, it shows three separate errors concerning py311, isort and pylint and all are of the same type: "ERROR: For req: <can't show that>. Invalid script entry point: <ExportEntry build = poetryrunpyinstallermain.py:None []> - A callable suffix is required. Cf https://packaging.python.org/specifications/entry-points/#use-for-scripts for more information."
I've looked up the link but no luck so far
Also, the project uses git -- I've tried and git grep console_script and git grep gui_script but both didn't find a match
Basically, at this point I'm stuck
But I believe I should really be using PyCharm...
(FWIW this is not my development rig; my development rig runs Linux and has IDEA's paid version)
you say "it shows three errors": what is "it"? What did you run?
The IDE's builtin tox runner; I've yet to configure cygwin to run it, which is my goal
can you pastebin the complete output?
(also, i have no idea how IDEA works, or what other steps it might need from you)
pycharm throws the same error so at least it's "consistent"
In a moment... I need to edit out the parts which I can't show :/
(well, with vim it's easy, so there is that)
http://pastie.org/p/77Cr27LCLxzKYSzlc50Ev0 <-- that's the full output of the "py311" part (which I suppose stands for the python version I use) but there are two other parts to the tox output (isort and pylint) which show the same error exactly
Oh dammit, I pasted the unedited part... Well, that's too late
Well, I managed to make poetry build run
is optishift the package you are working on?
fwiw, i don't see what is secret in there.
seems like optishift has a problem.
but i'm not sure exactly where the error is from, and I don't use poetry.
Well, I could build the package... So I can run my code at least
I know it works as I intend it to do since I tested it :p
FWIW it's a plugin for ETS2
idk what ETS2 is, but that doesn't matter. It will be hard to help untangle this without the code itself.
Euro Truck Simulator 2 -- the game does what its name says :p
right: it simulates trucks that carry euros
Errr... OK, there is also American Truck Simulator from the same game editor, so...
(and now we're really veering off topic)
Yay, mistake in the design stage...
Hey i have the following fastapi endpoint:
@router.post('/login', include_in_schema=False)
async def login(request: Annotated[OAuth2PasswordRequestForm, Depends()],
db: Annotated[Session, Depends(get_db)]):
user = db.query(DbUsers).filter(DbUsers.username == request.username).first()
if not user:
raise HTTPException(
status_code=404,
detail='Invalid username'
)
if not Hash.verify(user.password, request.password):
raise HTTPException(
status_code=404,
detail='Incorrect password'
)
access_token = create_access_token(data={'username': user.username})
return {
'access_token': access_token,
'token_type': 'bearer',
'user_id': user.id,
'username': user.username
}```
get_db dependency:
```py
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()```
My question is how can i mock the db dependency ?You can stand up a test database in a container while running the test. The general idea of how best to mock the db dependency is to use a db.
thanks I ended up using sqlite
A fantastic use for sqlite.
H2 is quite nice in this scenario too
But it depends on what SQL language features you use as well
Imo use the same db as in prod as far as possible.
For integration tests, sure; for unit tests however you can do without
Whatever "unit test" means when you're running a db. See, this is why I avoid the terms. They make no sense.
Sorry but they do
If you want to test the behaviour of your code, there is no reason to use a production db
KISS
Ok, to be clearer: everyone has different definitions. So people argue stupidly when they just define the words differently.
that's not what I said. I said SAME db. Not THE prod db. As in: the same software.
If your prod runs on postgres, test with postgres, not sqlite.
Again -- why? As long as they speak the same language (SQL for instance), there really is no reason at all to stick to the same software
You are seriously confused about how similar different DBs are. In SQLite you can by default store "abc" in an integer field.
After that, IF AND ONLY IF you use constructs specific to your DB then the first question would be to ask whether you actually need said constructs
If you do then you have no choice
But I avoid engine specific constructs for that reason
Oh sure, so do I. But again: sqlite will let you store a string in an integer field by default. Your tests can run right through that.
That's a problem with code at this point, not with the engine
Well.. yes of course it's the code that is faulty. That's why we have tests lol. Tests that should CATCH errors, not let them silently pass through.
Well, I suppose we have different views on that matter; I fail to see how I could write code with such a blatant error, but that's probably due to my methodology when developing
(which is not flawless, of course, no methodology ever is)
I just picked one very clear and simple to understand issue with using sqlite
🥴
And it only does ANSI SQL too
Anyway, it seems weird to me to call it a "unit test" and it uses an entire DB engine. To me that's not a "unit test". And again, this is why I avoid the term: because it's not well defined. We could just as well be saying "floorb gnorbly tests"
hah, on hacker news right now: https://linkedrecords.com/the-big-tdd-misunderstanding-8e22c2f1fc21
Medium
💡Originally, the term “unit” in “unit test” referred not to the system under test but to the test itself. This implies that the test can…
I agree that "unit" is ill-defined, and it's more helpful to think of tests on a spectrum from "tests a very small amount of code" to "tests a large amount of code".
whether to use the same db software: it's a trade-off: sqlite is faster and easier, but is a different dialect of SQL.
You could monkeypatch the get_db function, and you would probably also want to monkeypatch the create_access_token function for your test to be concidered a unit test. The tests would assert output and probably also indirectly assert the hash verification.
Another option: a fake db implementation that you can inject
Hi i have problem, I try write selenium tests but when use wait my button can't be clicked 😦
# this work
element = driver.find_element(By.CLASS_NAME, 'login-btn')
element.click()
# this don't work
element = driver_wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'login-btn')))
element.click()
Problem starts when i try use EC for finding elements
Once writing a unit test like this, you will quickly notice that monkeypatching the db is painful, because of the advanced structure of it (chaining calls etc.). A simple solution is to extract the DB query into another function and monkeypatch that one. Then you only need to return the data, and not patch a complex SQLAlchemy-like object.
A common pattern for that is the repository patten
That way one doesn't even need to monkey patch
Imho the only valid place for a monkey patch is when having to mitigate legacy Code else just engineer in testability and win fragility free Testing

FastAPI framework, high performance, easy to learn, fast to code, ready for production
If you want to use the same underlying connection int your test and application running underneath you can override your sessionmaker's bind:
@pytest.fixture
async def session(
_sqlalchemy_run_migrations: None,
sqlalchemy_pytest_engine: AsyncEngine,
async_sessionmaker: AsyncSessionmaker[AsyncSession],
) -> AsyncGenerator[AsyncSession, None]:
async with sqlalchemy_pytest_engine.connect() as conn:
transaction = await conn.begin()
async_sessionmaker.configure(bind=conn) # <-----------------------
async with async_sessionmaker() as session:
yield session
if transaction.is_active:
await transaction.rollback()
You can't monkeypatch that function
They make a lot of sense...
Sure people on the internet may have multiple definitions for a few of these terms. However, when you are working within a team it should be easy to ensure all team members have a shared understanding of these terms and use them correctly.
Yea sure. In a team. But this is not a team 😉

{kind=link}
def prks_ownership_data(spark, batch_id, prks_file_path, dbname):
print("Spark URL " + spark.sparkContext.uiWebUrl)
prks_schema = StructType()
.add("PRO_VAL_DATE", DateType(), True)
.add("PRO_OWNERSHIP_LEVEL", IntegerType(), True)
.add("PRO_ACCOUNT_ALIAS", StringType(), True)
.add("PRO_PRKS_FUND_ALIAS", StringType(), True)
.add("PRO_PMIS_FUND_ALIAS", StringType(), True)
.add("PRO_COMP_LINK_ALIAS", StringType(), True)
.add("PRO_MARKET_VALUE_BASE", DecimalType(38, 10), True)
.add("PRO_OWNERSHIP_PERCENTAGE", DecimalType(23, 15), True)
.add("PRO_OWNERSHIP_PERCENTAGE_CUST", DecimalType(23, 15), True)
.add("PRO_MARKET_VALUE_USD", DecimalType(28, 10), True)
.add("PRO_PARENT_PRKS_FUND_ALIAS", StringType(), True)
.add("SECURITIES_LENDING_STATUS_FLAG", StringType(), True)
.add("CUSTODY_ALIAS_OF_PMIS_ALIAS", StringType(), True)
.add("PROXY_ACCT_NSRD_FUND_ALIAS", StringType(), True)
.add("PRKS_OWNERSHIP_FLAG", StringType(), True) \
prks_owndership_df = spark.read.csv(prks_file_path, header=True, schema=prks_schema)
prks_owndership_df = prks_owndership_df.withColumn("BATCH_BASE_ID", f.lit(batch_id).cast(LongType()))
prks_stage_table = '{DBNAME}.IVC_PRKS_OWNERSHIP'.format(DBNAME=dbname)
prks_partition_cols = ["PRO_VAL_DATE","BATCH_BASE_ID"]
prks_owndership_df.write.mode("append") \
.format("delta") \
.partitionBy(prks_partition_cols) \
.saveAsTable(prks_stage_table)
can any one help to unit test this function asap
s,asap,please?, and someone may answer you -- plus, you don't tell what you want to test
This should pass:
def test_prks_ownership_data():
try:
result = prks_ownership_data("spark", 1, "./sparks", "sparks_db")
except:
pass
assert True
you are silencing absolutely all possible errors with generic except. It will always pass 😉 even if syntax is completely broken and not runnable

Clip from, LOTR: The Fellowship of the Ring (2001)
"You Shall Not Pass!" (short version)
For, Jerry Sullivan
Under Section 107 of the Copyright Act 1976, allowance is made for fair use for purposes such as criticism, comment, news reporting, teaching, scholarship, and research. Fair use is a use permitted by copyright statute that might...
i think perhaps @teal minnow was making a joke.
He obviously was... But I'm learning some things from such code, given my poor Python knowledge so far
"poor" is an understatement
"piss poor" is more accurate
Not obvious at all. People write worse code than that 100% seriously all the time.
does assert None will fail test?
usually it does as None is ocnsidered false in boolean contexts, thus triggering the assertion error
can anyone guide me for the above ....
with contextlib.suppress(BaseException):
main()
😉