#tools-and-devops
1 messages · Page 76 of 1
Sure, but some software is designed for malicious purposes, like ransomware or a botnet.
This has come up a lot over the years on this server. Lots of people asking for help with some really shady software claim it's "for educational purposes". We can't know what your real intent is, so we err on the safe side.
i have a dependency in my poetry project that i want to change to be an older version
can i just use poetry add to specify the older version, or do i have to remove it first, or is there some other command for that?
add should work, though personally I just change the pyproject.toml and go from there
yeah I do the same
although removing and readding with a different version number could be better because poetry doesn't automatically reinstall packages for you based on a change in pyproject.toml
on what event does poetry update poetry.lock after a change in pyproject.toml?
if you're using pycharm, pyproject also integrates with the installed packages https://i.imgur.com/xAdehRa.png

im pretty sure its when poetry install is next invoked
so just changing the pyproject should be fine
poetry should let you know if its reinstalling a package so you'll see if its doing it in the command line
i thought poetry install worked off of poetry.lock when poetry.lock exists
delete the lock 👀
you can use poetry lock to relock
while all the poetry pros are here
when doing the interactive poetry init is there a way to go backwards if i mess smth up? or just start over
I think it's just start over 😔
or edit the created file afterwards
Did you do a typo like just now or something lmao
or for updating a single package within its constrains with a relock on that specifically you can do poetry update
nah it was a while ago, picked the wrong package or version or something
my usual workflow when changing the constraint of something is to edit the pyproject, lock with --no-update and then install
yeah i would have recommended this but it looks like hes trying to go back a version lel
hey folks! anyone familiar with docker? trying to mount my directory and it says invalid mode, also tried editing my shell files and still getting same error :/
You probably need to change the file permissions, or your current user, to allow you to read and write the files.
I've been working with PEX a bit lately with a project I've been deploying via Docker. I need to also support the .pex format and I'm trying to add several environment variables to my .pex file similar to what I'm doing in my Dockerfile.
I haven't been able to get it to work yet. . . I'm sure I'm missing something obvious although I didn't see anything in the doc. Any help is appreciated!
tl;dr how do you add arbitrary env vars to a .pex file? Also, please lmk if this is the wrong channel for this question.
Hi folks, I'm new to the server. Would like to chat with someone about a tool I have in mind. Where is the best chat/group for that?
anyone has any opinion on sumo logic vs new relic / data dog?
If you are planning to develop a tool, my DMs would be an excellent place.
I'm using docker, that's my issue :)
does anyone know how to get the file path right using docker for saving locally in windows
eg
docker run -d -p 8888:8888 -v "c:\Users\t1nn\OneDrive\Documents\UoB Masters work\dockertesting\jupyter":/home/jovyan/work jupyter/scipy-notebook
Im on windows using docker desktop
the notebook runs fine
and continer starts us
but doesnt seem to save my files locally
Did you check the container logs in Docker?
nope, sorry im v new to this, just messing around trying to get it working
do I have the right syntax on the file path
just to check thats not an issue
I don't know anything about Macs but if you elaborate maybe someone can help
I'm not looking at the documentation and I don't know what your actual paths are but I don't see any obvious problem
ok so I need the "
and it's \ not / in the local
(I realise these are basic queries, sorry)
Oh wait
it works
Im a moron
I wasn't saving in the right file once in the notebook
Not sure where to begin, because my benchmarks are all over the place.
I'm trying to get m1 docker containers performance similar to those on docker for mac on intel.
simple pgbench benchmarks are off the charts on m1
x5 transactions per second
but real case benchmarks are abysmal
x5 less
and I think it's jsonb insert
but not sure yet
I'm also using two extensions: jsquery and pllua
it could be anyone of those
I have 6 or more seperate images across m1/intel atm
I have to run more benchmarks
and I'm using postgresql12
official supported arm version is pg14
Just had pycharm pro and I can’t install custom plugins to it because of CPU usage. Is pycharm still worth using?
I've never used it, but from what I've always read, I'd say yes
if you can't install plugins due to CPU usage, that looks like you have other issues
Ah yes. Their support is looking into it. Will see
you have a paid license for pycharm and you get official support (just curious)?
a
(from general)
i have really urgent non-python help issue, I accidentally merged something on github, but the undo pr doesn't clear history, how do I fix this?
Sorry for not posting at help but im panicking https://github.com/atom-community/atom/pulls?q=is%3Apr+is%3Aclosed
but the undo pr doesn't clear history, how do I fix this?
you need to force push.
this means that you need to clone the repository locally, and reset your branch to the commit you want to reset to
@dull tangle do you have the repo cloned locally?
i just cloned it
mention me if you respond or i won't see it
 nvm
nvm
so you'll need to reset your branch to the commit you want master to be at
which from what I see is https://github.com/atom/atom/commit/6596e0fb4a11eed8193dbd85fff45339145bc967

GitHub
deps: "downgrade" node-fetch to ^v2.6.7 in script/ (fix "Bump dependencies" job in Nightly CI)
I think the merge had commits 5 years in the past
locally run git reset --hard 6596e0fb4a11eed8193dbd85fff45339145bc967
although are you sure that's what you want?
I want it to be like the prs "never happened"

okay
.
i ran it
git status and send the output here

But wait a minute

it seems like when I merged that pr
a bunch of atom prs were automatically created to match
So actually the latest commit was
ughhhh

actually I'm not that suited for this next bit of advice, but looking at the scope of the project and the ramifications, gonna mention the big devops ppl @deep estuary @vague silo
pretty sure it was this one but not that surehttps://github.com/atom-community/atom/pull/309
hmm, is there anywhere else I can post?
does the mass undo/redo section apply here? https://github.blog/2015-06-08-how-to-undo-almost-anything-with-git/

One of the most useful features of any version control system is the ability to "undo" your mistakes. In Git, "undo" can mean many slightly different things.
ok it was fixed by
git reset HEAD^^
git reset HEAD^^
git push -f
In a future I would recommend to use git revert function
Less chances to fuck up
Especially if it is master branch
And u have other people working there
I think git revert would've done the same thing as https://github.com/atom-community/atom/pull/352 bc according to the docs it adds new commits
But I see what you mean, and I guess in this case you mean "wait / do nothing"?
Or did I read the docs wrong

GitHub
Reverts #351
AAAA
I can't believe I did this on the first day
So sorry for the notifications
For the future I will use a fork
What happened was I wanted to look at the differences between t...
I mean, that git reset breaks the flow of commits.
If u push it to master, other people will not be able to push because their branches contain commits u don't already need
Git revert is not breaking chain of commits. It just adds new commits to revert old ones. Other people working in your repository will not have their forks/branches broken. The development would not be disrupted. At worst they will need just to pull your revert commits to them, which is not a problem
Can any one suggest a good and efficient screen scrapping sdks or library in python or any other language. I need screen scrapping library not web scrapping library. Screen scrapping windows environment
Short question: Is there a function that converts a log level string ('INFO' for example) into logging.INFO or do I have to write my own dict?
it's not hard, but that function is proably more robust, if it exists
could you be more precise where it is supposed to be converted
where does it output in which format
and where do you wish to have it changed its output
Not sure, what you expect
describe your question in more details
I want to read the log level from an env variable via os.getenv
which is a string
but ini_logging from logging module wants a loglevel-object
logging.INFO for example
and I could imagine that is a pretty common problem
that's why i asked here
log_level_str = os.getenv('LOG_LEVEL', 'DEFAULT')
level_dict = {'DEBUG' : logging.DEBUG,
'INFO' : logging.INFO,
'WARNING' : logging.WARNING,
'ERROR' : logging.ERROR,
'CRITICAL': logging.CRITICAL}
log_level = level_dict.get(log_level_str.upper(), logging.INFO)
that's my code now
Can someone recommend a tutorial on ElasticSearch? I have no idea about it, and the official documentation is confusing for me.
Use one of the logging configuration options (either a dict or a .ini) and fill in the log level variable with your environment variable. You could also just use a dictionary to convert the strings from the environment into the log level integers.
Hello I'm using gitlens extension in vscode and I wonder if there is a way to configure so that every time I wanna push a new stash, it includes staged and unstaged files
git again n again forces a prompt to install .net framework and i want to disable that as withouut net framework installed it too work
dm me if there's any solution
There is a level to name function in the logging module, and a name to level,
Also as far as I know the function setting the level for a logger also accepts strings
Hi, Im learning git/GitHub.
I have a doubt-
If you make sime commits on remote repo
And if i go to my local main branch and type "git pull", will all the changes took place in other branches of remote repo come to my local repo?
Same with git fetch
just add --all to run pull/fetch for all branches, e.g. git pull --all
I'm trying to follow this guide on running Elasticsearch: https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html
I'm running this command: docker run --name es-node01 -m=4G --net elastic -p 9200:9200 -p 9300:9300 -t docker.elastic.co/elasticsearch/elasticsearch:8.0.0 and I see this message in the logs: ```
-> Elasticsearch security features have been automatically configured!
-> Authentication is enabled and cluster connections are encrypted.
X Unable to auto-generate the password for the elastic built-in superuser.
-> HTTP CA certificate SHA-256 fingerprint:
7016676e80cafb2f16e98cfd5538962d139bd89c221d35431bf150c8426f6f07
X Unable to generate an enrollment token for Kibana instances, try invoking bin/elasticsearch-create-enrollment-token -s kibana.
X An enrollment token to enroll new nodes wasn't generated. To add nodes and enroll them into this cluster:
- On this node:
- Create an enrollment token with
bin/elasticsearch-create-enrollment-token -s node. - Restart Elasticsearch.
- Create an enrollment token with
- On other nodes:
- Start Elasticsearch with
bin/elasticsearch --enrollment-token <token>, using the enrollment token that you generated.
I'm also getting log messages like this:
{"@timestamp":"2022-02-25T20:11:54.806Z", "log.level": "WARN", "message":"flood stage disk watermark [95%] exceeded on [mnVE0qvhRJmJWN6zsUOZoA][1423f8c2f39f][/usr/share/elasticsearch/data] free: 923.2mb[0.4%], all indices on this node will be marked read-only", "ecs.version": "1.2.0","service.name":"ES_ECS","event.dataset":"elasticsearch.server","process.thread.name":"elasticsearch[1423f8c2f39f][generic][T#4]","log.logger":"org.elasticsearch.cluster.routing.allocation.DiskThresholdMonitor","elasticsearch.cluster.uuid":"78uhsR6jTv-3DoZufR-QnA","elasticsearch.node.id":"mnVE0qvhRJmJWN6zsUOZoA","elasticsearch.node.name":"1423f8c2f39f","elasticsearch.cluster.name":"docker-cluster"}
- Start Elasticsearch with
what can I do?you might also want to git fetch --prune to delete remote branches that have been deleted from the actual remote
I figured it out... I only had 1GB of space left on disk.
(question moved to #microcontrollers)
For Env, are you guys using virtualenv and pipenv?
My understanding is pipenv creates a lock file similar to yarn, or npm with JS.
Can I use both together, or is this considered bad?
What do you guys see typically used in team environments when managing Envs, and sharing libraries.
Thanks!
I just use virtuenv out of requirements.txt + constraints.txt
pip install -r requirements.txt -c constraints.txt
but that's because I did not learn anything else and not felt the need to learn any alternative to it yet  So consider my being just lazy
So consider my being just lazy
Packing stuff into docker, and woala. everything is cool
I do experience the trouble with sharing private libraries though
It is easy to publish public pip package
but a bit more troublesome for private pip packages
Thinking just to use git submodules perhaps
I see, thanks!
Hey everyone, does anyone here have experience with managing private packages within Azure artifacts?
It just seems so messy and expensive
You can use azure artefacts to pull python libraries, however, you now have to make sure all developers switch to using the new feed, as well as you're forced into adding upstream of PyPI, which then leads to additional costs due to cached packages.
Has anyone managed to find a better solution than that?
- Creating private self hosted pip server https://www.linode.com/docs/guides/how-to-create-a-private-python-package-repository/?__cf_chl_rt_tk=1BKcJVrmrof_pVzElawvEJiCtTEIA_85y_uGQjXA0R8-1646041218-0-gaNycGzNCJE
- Forgetting about pip and using git sub modules
Thanks for that, it seems like cloning + SSH is the way to go
using git submodules complicates the basic git commands, I wouldn't recommend it unless everyone you're working with is really, really comfortable with git command line usage
How can I change my idle version from 3.10 to 3.9?
my system python version is 3.9 but IDLE seems to be stuck on 3.10?
windows?
someone had that issue recently and they posted:```
i literally just had to search for idle and choose the 3.9.2 version of idle instead of 3.8.5 on windows search
Mac. I had to uninstall pyenv for it to work and reinstall a new version of python
but now my CL is returning that python3 is pointing to a bad dir
nvm... seems to work now
I wanted to keep pyenv so I can use 3.10 if I needed too, but I rarely use python and doubt it's going to impact me much. Thanks for trying to help though!
pyenv should work
with pyenv you install a specific version for python, set a local python version in a folder, create a venv, activate it - go to town :)
Hi,
I'm using Elasticsearch and now I would like GET the price data when the price drops 20%. I have some ideas how to achieve this but not sure if its the right way to do it.
So every 1 minute the price is getting updated. I was thinking about subtract the last value of the second last value and if the difference is higher than 20% do something.
Do you think this is the right way or is there an obvious other way to do this? And is it even possible to GET second last document from Elasticsearch
this doesnt seem like the best use of elasticsearch? maybe you can also get documents with a date-based filter
i haven't used elasticsearch in years, im sure theyve added a lot of features
You block pypi at firewall
is there anyone here who's any good at docker and could maybe spare a few moments to help me debug a bug? I would appreciate it. Thanks.
@spice ginkgo there are docker users here and it is on-topic for this channel. just ask your question, and if someone is available to help then they will help
Hello
I am trying to build an AI software that can detect the emotion (good / bad ) of a review (piece of text)
What frameworks/ libraries should I be looking into to help me with this ?
@cosmic pine NLP module/library from python such as nltk
there is a #data-science-and-ml channel for topics like this
So question: I know of tools like pre-commit and know how to use GitHub Actions
Say that I have the following task I want to run automatically - is this the right order of operations, and am I using the tools properly?
- pre-commit: Format the code with
black - pre-commit: sort imports with
isort - GH Actions: Lint the code with
flake8. If any issues occur, then do not accept commit/PR, and post the results in a comment on that commit/PR - GH Actions: Compile code with Cython
- GH Actions: package code into portable executable for each individual platform with pyinstaller
My question is, should #3 be done with pre-commit or GH Actions?
Are there any other actions I could automate? I figure developing unit tests should go in between #3 and #4
Do #3 in pre-commit and then in CI just trigger pre-commit run --all-files
And yes, automated testing would go between 3 and 4, but it can be a parallel job instead of waiting on lint to finish first
Oh that's awesome, it simplifies my github workflow file tremendously
thank you!
There's also pre-commit.ci that runs pre-commit for you without any setup
Is it possible to do something like this with it? ```yaml
# Skip the flake8 hook because the following step will run it.
- name: Run pre-commit hooks
id: run-pre-commit-hooks
run: |
SKIP=flake8 pre-commit run --all-files
pre-commit run --all-files --hook-stage manual flake8-annotate```
https://pre-commit.ci/#configuration-skip looks like this should work
Damn even better
Can someone help give me some advice as to how do i clone/access a private/alternate git user repo without overwriting my normal git user identity?
I think what you can do is "git init" to initialize an empty repository. Then you can use "git config" to edit user settings (by default this command edits the repository configuration not the global configuration), and finally you can add a remote "git remote add" and pull
ok ill try git terminal thanks
Maybe editing the config isn't even necessary. I'm not sure how git auth works exactly.maybe if you just add the other users ssh key in your machine it'll be enough for it to let you clone
yeah i might need that config to add commit later so i dont think you are wrong
Ah for that yes you are right
im guessing ill need to do ssh key from github or something to get access
Yeah each user should have its own ssh key.
You need to generate the key if you don't have one yet, and then register the key with GitHub so it associates it with your gh account
The more I think about it the more I suspect that if you have the SSH key set up you will be allowed to clone, which is much simpler. I don't think you'd need to edit the gitconfig before cloning.
So you can first try to clone and then edit the user with git config. If it doesn't work then try it the other way.
yup ill try that

Bot's GitHub Repository
Repository
!resources
Resources
The Resources page on our website contains a list of hand-selected learning resources that we regularly recommend to both beginners and experts.
@nova obsidian
Ty

GitHub
Hi, is there a way to activate custom build_ext from setup.cfg using setuptools module or do I have to do it through setup.py?
I believe you need to use setup.py for anything "custom" with setuptools
But on their site they stat that there is a slow move from setup.py to setup.cfg and it confuses me a lot. Not sure should I combine both files in my project and if yes; how to do it..
Indeed, for most common cases you shouldn't need any custom code, so the declarative configuration file should be fine
In your case it sounds like you need custom code, so there's no way around that other than writing custom code
I don't believe they are planning to deprecated anytime soon, they just don't want it to be with everybody uses by default anymore
this kinda settles down my wonder: https://github.com/pypa/setuptools/issues/2570

GitHub
Having cmdclass defined in setup.cfg causes sdist, or any other, command to fail because its value is not properly parsed into a dict. How to replicate setup.cfg example: [metadata] name = cmdclass...
ahhh good find
so you can define your custom class and still use setup.cfg
that's actually useful to know about
I tried; it doesn't work 😦
any docker experts here? i have a 3 python modules, A, B, C that live in the root directory - module A and B have their own Dockerfile - both of them need module C as a dependency (C for common). Any trick to solve this problem?
so A and B build in a docker container, and depend on C. So you want that whenever C changes to rebuild A and B, or the other way around? When building A or B, to also build C?
You could do a multi-stage build. Use a dockerfile built with C as the base image for A and B's dockerfiles.
it sounds like a time for docker-compose
docker-compose provides multi containerized docker experience

are we talking about "modules" or actual independent services that need to run simultaneously?
fwiw i now use docker compose even when i only have 1 dockerfile, the declarative config with the yaml file is so convenient
so what i would do is set your "build context" to the parent directory for the project, that way you can use all 3 packages/modules in the dockerfile
Do you prefer using configparser or loading variables from .env?
I would like to see some long-term opinion (so moved from #general) 😄
I prefer .env for convenience. I don't want to deal with setting up configparser.
Downside is a dependency on a third-party lib like python-dotenv unless one wants to parse the .env themselves
I struggle with default values, its parsing and so on...
So turned towards the file...
It depends on the project's needs. I wouldn't use .env for anything complex.
Like this:
OUTPUT_DEVICE_INDEX = 0
try:
env_value = os.environ.get("OUTPUT_DEVICE_INDEX", "").strip() or 0
OUTPUT_DEVICE_INDEX = (
int(env_value) if env_value is not None else OUTPUT_DEVICE_INDEX
)
except ValueError:
logger.warning(f"Invalid OUTPUT_DEVICE_INDEX={env_value}")
Well python-dotenv helps with some of that
Maybe not. I think I am confusing it with django-dotenv, which can set defaults.
Hello Guys, Is there any free hosting service like pythonanywhere but has free ALWAYS ON tasks?
any GCP experts out there who can tell me why I keep getting this error? Just trying to upload a folder to my GCP Bucket
➜ wbanalysis git:(gcp) make upload_data
CommandException: Destination URL must name a directory, bucket, or bucket
subdirectory for the multiple source form of the cp command.
make: *** [upload_data] Error 1
use replit and ping your website using uptimerobot
what would happen if we ping replit with itself?

any selenium experts here?
how can I switch to this popup window and operate there using selenium

can anyone help, Please ping me while you reply
dun dun dun.....
how can i have a 'child' cell in colab?
example like this. where i can hide and show cell in a certain group

Would like help with setting up my Docker containers with Python as multistage and if there was any other code review suggestions? I tried multistage with wheels and venv, and haven't gotten it to work so far. Thanks
FROM python:3.9-alpine
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
RUN apk update \
&& apk add --no-cache \
gcc \
libc-dev \
musl-dev \
postgresql-dev \
alpine-sdk
EXPOSE 80
COPY ./requirements.txt /
RUN pip install --upgrade pip \
&& pip install -U setuptools \
&& pip install -r ../requirements.txt
COPY ./requirements-submodules.txt /
COPY ./common /common
RUN pip install -r ../requirements-submodules.txt
COPY ./app /app
WORKDIR /app
ENTRYPOINT ["python", "app.py"]
That looks fine. Do you have anything to share for your multi stage attempt?
FROM python:3.9-alpine AS builder
WORKDIR /app
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
RUN apk update \
&& apk add --no-cache \
gcc \
libc-dev \
musl-dev \
postgresql-dev \
alpine-sdk
RUN python -m venv /opt/venv
ENV PATH="/opt/venv/bin:$PATH"
COPY ./requirements.txt /
RUN pip install --upgrade pip \
&& pip install -U setuptools \
&& pip install -r ../requirements.txt
COPY ./requirements-submodules.txt /
COPY ./common /common
RUN pip install -r ../requirements-submodules.txt
COPY ./app /app
FROM python:3.9-alpine
COPY --from=builder /opt/venv /opt/venv
WORKDIR /app
ENV PATH="/opt/venv/bin:$PATH"
EXPOSE 80
ENTRYPOINT ["python", "app.py"]
Does anyone know if a git squash rebase would destroy previous commits? I'm wanting to squash all my commits in a Python project into one and rewrite it "on top" of the existing repository, but also don't want to lose data from history. im fine with an altered history, as long as data about previous commits isn't completely destroyed, and each individual unsquashed commit is still somehow accessible.
if you rebase with squash, you lose the commits
the best thing to do is
git checkout BranchToSendCommits
git merge --squash FeatureBranch
it leaves the FeatureBranch with original commits, while squasing them all into one and sending to CurrentBranch
https://learngitbranching.js.org/?locale=en_US
Or use this. They have sandbox mod too
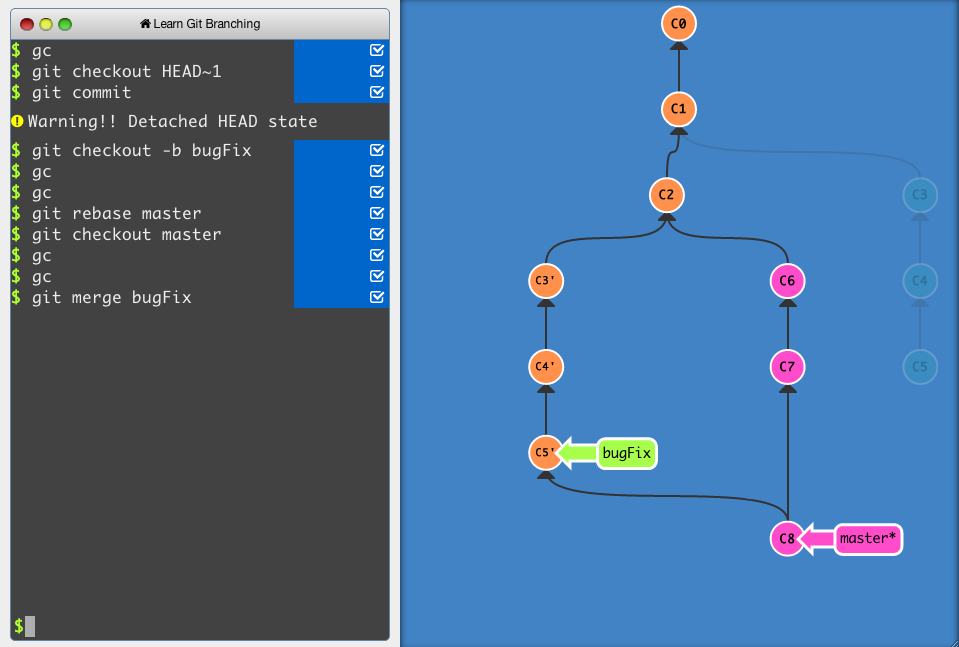
An interactive Git visualization tool to educate and challenge!
Is this the sort of thing you're describing?

where everything I've done would be copied over to a different branch (e.g. past), plus a copy of all that squashed into the first node on main, allowing me to build off that
Instead of creating a venv an copying it, you can create a base image with the deps and then a final image that uses the base. ```dockerfile
FROM python:3.9-alpine as venv
...
RUN pip install requirements.txt
...
FROM venv
COPY ./app /app
ENTRYPOINT ...
On second thought, there generally isn't a need to do this and it doesn't offer advantages over a single stage. Are you just trying to avoid the packages you install with apk ending up in the final image?
Yes
nah, i was telling that

we have for example three additional commits ahead of main in branch past
hmm, the summulator is not having git commit --squash option, well, nvm, lets simmulate it
we run
git checkout main
git merge --squash past

and have the three commits merged into one commit in main
while the branch past is left living with its own commits untouched
I guess copying a venv would work, but it doesn't look like you activated it properly. The site-packages in the venv need to be in Python's sys.path somehow. You should look at how the generated venv activate scripts work.
Anyway, I don't think venv is the nicest solution because of the extra steps needed to activated, and because it's less space efficient. I would try building wheels for the Python packages that need those libs you install, and then copying the wheels over to the final stage to install with pip.
Well, a wheel might not be space efficient either due to having to copy it to the final stage, which unavoidably creates a new layer.
How do I get the IP address of a docker container?
Anyone know how to use Databrick Pyspark on GCP?
A docker container has no IP address, but it can be bound to a port PORT on the host machine so it can be addressed on the host computer - for example a docker machine on your laptop can be accessed on the browser in your laptop via localhost:PORT
Getting H14 error while deploying on heroku can anyone help ?
Hi there, why does this not raise any lint error using pylint?
from django.utils import timezone
timezone.datetime.datetime
can some 1 help me with java or pythhon with mc mod
Do any of you have an experience with dynaconf?
I keep getting Invalid rule for parameter 'HOST' each time I run dynaconf -i 'config.settings' validate -p "settings.toml" 😦
Does anyone here use Poetry?
I use poetry occasionally. The common courtesy in the server is to ask your question directly, instead of asking "does anyone know X" first
I use poetry (always)
GitHub
How useful have monorepos been for large scale projects?
Based on the experiences of people here
Super useful.
I mean, I don't always choose monorepos.
I choose monorepo or separate repos, becased on projects logical separation for now
If the application is out of N+ microservice components (even if each component has its own repo), but still the same application in total = it is mono repo infra for me
If those are separate applications and not connected in ANY logical way = I use separate repos for infra
So as a rule of thumb when to use monorepos, it's when you have related but separate repos?
yeah, if they exchange network requests, better to use monorepo
Like as an oversimplified example, pretend we have a complex web app
A monorepo can be used here to separate the frontend and backend repos
Perhaps a separate native mobile app repo in the monorepo
example:
I have backend app, it has its own repo, it has pipeline that builds, unit tests it, triggers infra repo for staging deploy, runs integration tests against staging, saves result to docker registry
I have backend app #2, it has its own repo, it has pipeline that builds it, triggers infra repo for staging deploy, runs integration tests against staging, saves result to docker registry
I have frontend app, it has its own repo, it has pipeline that builds it, triggers infra repo for staging deploy, runs integration tests against staging, saves result to docker registry
I have infra repo, it has its own one repo, it has pipeline for staging and production deployment, it pulls containers from docker registriesfor alll apps above and deploys stuff
backend + backend #2 + frontend = the same application with splitted code to microservces
The same application, but split in their own repos to make managing the app as a whole easier, inside the main repo (which is the monorepo here)
Like that?
applications have their own repos yes
but their all deployments in one infra monorepo.
So think of it like a normal repo that contains separated components of your app that together adds up into the complete, whole app?
well, yeah
it can be implemented not just with docker registry
but with git submodules, but git submodules are heard to be PITA, I still did not try it
docker registry method is better
instead of git submodules, can be also used programming language specific publishing packaging system
That will work too, to unite the apps into one infra repo
docker registry is more flexible though. You will wish to deploy automatically infra repo with locked versions and with latest verisons of everything.
anyone know why i get ECONNREFUSED (can't connect) to Redis (port 6379)?
version: '3'
services:
db:
image: redis
ports:
- '6379:6379'
bot:
build: .
links:
- 'db'
fixed; used db as redis client hostname
which software should i use to do coding?
VS code, Sublime text, notepad etc It depends on you comfort
ok
how do i check the utcnow() time is 00:00
do you assume that within 1 minute the time is valid?
make a check of delta from (datetime 0000 - utcnow) within 1 minute
hmm
cant understand
like i need to check if 00:00:00 in utc now
then do smthing
can be a range
5 mins before n 5 mins after
nvm how to i check
this program is meant to schedule tasks every minute/hour/day/weel whatever
or there is more python specific option: Celery beats, that does fully at python level
nah, i want that task to exeute on that time
and check https://help.dreamhost.com/hc/en-us/articles/215767047-Creating-a-custom-Cron-Job for more simple option
What sort of trouble?
how can i fix this?

I'm not sure if this is the right place to ask this, forgive me if it isn't please but my question is as follows. Can I use xlwings as the writer in pandas?
Basically it's just a warning, because usually you don't have a git repository nested into another, and if present they won't be tracked, unless added as a submodule
yeah this is just a warning, not an error. You don't have to do anything about it if you don't want to
otherwise it's telling you pretty much exactly what to do already in the warning text
this isn't built into pandas. i don't think it's easy to make a custom excel writing "driver" for pandas, but maybe it's possible
Thanks!
So I have a web based game im making
and its based on events
Is there some google cloud (or similar) service that will allow me to "publish" events to any given "channel" (where the channels can be dynamically created) and the web app client can "subscribe"
through a websocket or something
ive looked at pub/sub but that seems to be for analytics
eventarc seems to be based around actual cloud events
and firebase cloud messaging sends the notifications directly to the browser
woo
Check Kafka
I did, it seems to be a framework
is that deployable at scale?
it is really scalable
Ok
Yeah thats what my solution is atm
add the events then create a 'on_create' event that reads
via Cloud Run
but if I have to manage the deployment of kafka then I may as well just stay with redis
if there are any other managed solutions then im all ears
or
eyes i suppose
can anyone show me a good example of pyproject.toml + pip for seperation of dev and production packages?


Can we excute shell commands in mc?

without seeing your dockerfile, it would be tough to help you
It shows that your frontend container has exited, so that's at least part of the issue. Check the container log for any hints about why. But also, what Darkwind said.
Good afternoon everyone. I am new to docker and kubernetes, Could anyone suggest me few resources for beginner level?
Kubernetes' website is a great resource to get started with. That's how I learned about it myself
thank you
Any good flake8 config file? I don't want to research about all errors to create a template of my own.
Please, anyone, tell me how to make a container in docker?
You mean how to run one?.Or how to create your own image (a container is just a instance of an image)?

I have just create image showing above error
Do you have Docker desktop running?
No
What os is this? Looks like windows 11
No it's KDE neon
Is your user in the docker group?
Yes i did that command also.
sudo groupadd docker
After showing below message
groupadd: group 'docker' already exists
Well that's for creating the group, not for adding your user to that group
You can type "groups" to list the groups you're in
Please then how to add to group, I'm new this
Can you first run groups to see if your user is in the group or not
I think you misunderstood. To run the command type literally "groups" no extra arguments

Okay so you're indeed not in the group yet
sudo usermod -aG docker maddy
That will add you to the group
Yes done this now
Just i did command
docker built -t python -imdb .
But getting same above error
Hmm maybe try rebooting your computer
Okay let me try

🎉
Many Thanks for your help and time
You're welcome
You're professional
I'm having some issues getting vscode on mac to recognize my pyenv modules when debugging
I personaly use webformatter.com for formatting and checking my website code. Does anyone know of a similar thing but for python that runs locally in the browser/function similar to it?
https://black.vercel.app/ though you can and probably should install the tool locally (pip install black) because it's more convenient IMO.
Playground for Black, the uncompromising Python code formatter.
prob not
But I'm not a java coder
So i'm not bother to that
Is there a way to make cx_freeze only make the .exe without gathering all the dependencies? Since the dependencies stay the same, I don't need it to keep packaging all of them on every build. I'm trying to debug something so I have to build alot and it takes alot of time this way.
Hi guys, I added some files, commited message but when I tried to push that to my repo then I got message "Your branch is ahead of 'origin/main' by 2 commits." and it was displayed that I should make pull request. I thought pull request will just take files that I don't have and everything will be ok, so I did pull. Then I again tried to add my files that I initially wanted to add and nothing could be added. When I tried to commit, I get "Your branch is ahead of 'origin/main' by 2 commits." git push origin worked out ok but I don't understand why.
What I don't understand is why push didn't work but push origin worked
import Image
import os
def crop(infile,height,width):
im = Image.open(infile)
imgwidth, imgheight = im.size
for i in range(imgheight//height):
for j in range(imgwidth//width):
box = (jwidth, iheight, (j+1)*width, (i+1)*height)
yield im.crop(box)
if name=='main':
infile=...
height=...
width=...
start_num=...
for k,piece in enumerate(crop(infile,height,width),start_num):
img=Image.new('RGB', (height,width), 255)
img.paste(piece)
path=os.path.join('/tmp',"IMG-%s.png" % k)
img.save(path)
trying to split image into 100 vertical sections
code not working
pls help
you might want to ask in a help channel: #❓|how-to-get-help
!code also consider using code formatting to post your code:
Here's how to format Python code on Discord:
```py
print('Hello world!')
```
These are backticks, not quotes. Check this out if you can't find the backtick key.
i tried this but noone answered unfortunately.
do you know why this doesnt work: https://paste.pythondiscord.com/imiduforon trying to split image into 100 vertical sections and save each section as separate image but image saved at end is same image as inputted
help is provided by volunteers on a best-effort basis. if nobody answers, either your question is difficult to answer, or nobody is around who knows the answer, or both. in general if you don't get an answer, 1) consider revising your question to make it easier to read and respond to, and 2) ask again in a little while
it's definitely not good to spam your question across several unrelated channels...
it looks like someone was helping in #data-science-and-ml anyway
okay sorry i understand, only joined this few days ago so thought all were help channels my bad. yes i was getting help on ai channel but unfortunately person left when i was quite close to fixing the code
Hello, I opened an existing python file in visual studio code for the first time and have installed all the recommended plugins, but when i try running it its telling me all the libraries dont exist
and its making me install it again
is there a wayb around this?
Alas!! After an entire day of testing vscode. I think i have a solution for my problem of missing modules.
- add
.envfile within.vscodedirectory - updated path to
.envfile${workspaceFolder}/.vscode/.env - add
PYTHONPATH=${workspaceFolder}
what is .vscode
and .env
are there files that i need to get from somewhere

No. Vscode will read your .env file for pythonpath or other global enviroment variables you configure
do i get .env from my python path?
VsCode automatically creates a hidden .vscode directory whenever you create a workspace directory for your project
i did show hidden files on my python project folder
and i cant see it
anywayu
do i just copy the .env
from here
No!
I'm on a mac, and it looks like you are in the vscode application directory
yh lol
You must create your own directory for your python project
can you display hidden files?
its turned on
also I already installed all of this from pyautogui import * import pyautogui import time import random import keyboard import win32api, win32con from pywinauto import win32defines from pywinauto.application import Application
with cmd
before i swtiched over to vis code
but when i try it in vis code
itrs asking me to install everything again
even normal python things
like keybaord
so is there a way for viscode to check already installed libaries
or do i just have to keep editing with IDLE
ok. Open Vscode and install the Python extension
yep ive done that


I would now add .env file into your workspace .vscode folder
include the following configuration into the .env file
PYTHONPATH=${workspaceFolder}
can u guide me on how to do so?
very new to all this devving
so in my python project folder
i add a .env file?
and put that inside?

Learn about Visual Studio Code workspaces
Hello I have the following settings.json within my .vscode folder to automatically activate a conda environment:
{
"python.defaultInterpreterPath": "/path/to/miniconda3/envs/.../python.exe", "python.terminal.activateEnvironment": true, "python.terminal.activateEnvInCurrentTerminal": true
}
The thing is that it activates conda base environment before activating the desired environment. Is there a way to prevent conda from activating base env automatically?
One of my project leads at work told me not to use Docker anymore--is Podman a viable alternative?
The reason being that our individual computers can't be linux, and I feel better about knowing that I can reproduce something at any time when it's in a container.
My coworker said to use Podman.
getting this error when using miniconda and importing matplotlib in docker:
Traceback (most recent call last): File "/root/miniconda/lib/python3.8/pathlib.py", line 377, in gethomedir return os.environ['HOME'] File "/root/miniconda/lib/python3.8/os.py", line 675, in __getitem__ raise KeyError(key) from None KeyError: 'HOME'
if I do an echo $HOME in the docker build it points to /root
Any ideas on what may be causing this? ty in advance
I think you would need to specify which python interpreter you want vscode to use while running your python program
not having a HOME environment variable is weird..
can you provide more detail about how you are running all this?
Yeah I did that but it still activates the base environment before my environment
The very first time I enter vscode, this is what it does:
root@24FJS49DJ3:~/myproject$ source /home/user/miniconda3/bin/activate (base) root@24FJS49DJ3:~/myproject$ conda activate myenv (myenv) root@24FJS49DJ3:~/myproject$
The following command would solve this by creating a .condarc file (if it doesn't exist)? conda config --set auto_activate_base false
I did conda config --show and auto_activate_base is set to True
thank you, I'm checking directly with the developers, this app is running within an intel SGX enclave, so it gets super messy with env variables, volumes and files
is this where I can ask questions about pipenv?
I'm doing pipenv install and just getting a billion errors

like ...?
chocolatey, scoop or winget?
you can simplify that with:
import pyautogui, time, random, keyboard, win32api, win32con
from pywinauto import win32defines
from pywinauto.application import Application
you can, it's not how pep suggests though
I've used choco and it's worked for me. I haven't used the others though
I never used conda virtual env. Vscode just needs to know where your conda packages are if not on the python path
Yes, sort of. It is meant to be a drop-in replacement for Docker. However, since your host isn't Linux, and there's no "Podman Desktop" like there is a Docker Desktop, you're going to have to do some extra configuration to get things running on macOS or Windows.
I've never tried to use it outside of Linux hosts so I am not familiar with how involved the setup process is.
with choco to install apps, do i need to run choco install running powershell as admin?
is there any way where we can do reverse dns look up with multiple ip address?
https://en.wikipedia.org/wiki/Reverse_DNS_lookup perhaps to check this
In computer networks, a reverse DNS lookup or reverse DNS resolution (rDNS) is the querying technique of the Domain Name System (DNS) to determine the domain name associated with an IP address – the reverse of the usual "forward" DNS lookup of an IP address from a domain name. The process of reverse resolving of an IP address uses PTR records. r...
there are even free tools to try for that https://mxtoolbox.com/ReverseLookup.aspx
MxToolbox
I did that and now it works fine, ty
Btw what would be the appropiate path to install anaconda/miniconda on linux? I was thinking to install it under /opt folder.
I've been tasked to give an internal candidate an interview. I don't have much experience working with DevOps. What kind of questions could I ask a Junior DevOps candidate?
hello, I've created a python program that applies a filter on the webcam. I would like to post that filter on Instagram. I've searched a bit but i did not find a way to do this thing.
On facebook you're allowed to post your filters, but, as I see, the filter is a ".arexport" file. How do I get that extension from a python file?
https://www.facebook.com/sparkarhub/effects/publish/ (that's the facebook link that requires that specific file)
See posts, photos and more on Facebook.
did they have a strong reason not to use docker though?
there are good reasons to use podman, but there seem like few good reasons to switch from a functioning docker setup, unless you have a specific reason
having to buy a license for docker desktop. so I'm just going to use the CLI.
ah
yeah or use lazydocker
i literally dont use docker desktop anyway except that it's convenient to install on a mac
GitHub
The lazier way to manage everything docker. Contribute to jesseduffield/lazydocker development by creating an account on GitHub.
> having a mac to install stuff on
At first I tried avoiding Docker Desktop and manually setting it up with docker machine and so on. It was an enormous headache and I got it to work but it had some annoying quirks that I can't remember.
it was given to me by work 🙂
I got to pick between a Dell and a Macbook, and I picked the one that isn't a totalitarian dictatorship
i definitely would prefer the macbook
they are both "bad" from that perspective
although if you use wsl they are probably equivalent
pretty much all the actual development happens on a linux VM, or something like that
how can i optimize this ? : https://paste.pythondiscord.com/lanurodovo
im running it with a value of 10 but after i need to run it with 250 so a lot longer
Hey everyone I am working with poetry and pyenv. I use pyenv to create a local version file and then run poetry init however it doesn’t seem to recognize the local pyenv version file. Has anyone ran into this? I am on a Mac.
how can I get visual studio to run python code?

when I try to run the code, it says "no interpreter found" even tho I installed the python language support
Hey guys so I wanna get better at python scripting and I have an idea on a automation project. I wanna make a script that will run on my raspberry pi. Said script will be like a RSS feed for my discord channels. I wanna tell python whenever a news outlet posts something it’ll push It through the channel with the webhook. Now I have a plan but don’t know how to execute It. Like how do I start? What should I include? I’m a beginner with no coding background.
can someone try my tool -- have (selenium) Firefox
do you have python installed on your system?
I have a bunch of python scripts to run on a server. Is there any reason I shouldn't just set them all up as systemd services, other than the overhead of managing/installing all of those?
I guess the more obvious solution is to fire a bunch of docker containers together and run those instead?

Hey if you open the command pallet and type Python: Select Interpreter
I'm trying to deploy my Django app on heroku and I keep getting the error no matching distribution found for apturl==0.5.2
can anyone help me with an apache server im trying to setup?
Yi, I converted a pdf to image and when using foxit to for printing. But it's printing too big the stayed image. I'm doing this because this Report comes from Oracle Report 6i with a windows font for a barcode. Have any of you been through something similar?
Sorry for my bad english.

Stack Overflow
I am currently trying to install a requirements and it is telling me that it is not found when I try and comment them out it happens for others.
I just deployed a Ubuntu 18.04 server. Made the
Sometimes you can just get away with removing the version number but most likely you need to do some troubleshooting with a proper virtual environment to get your requirements.txt right
It works when I do pip install -r requirements.txt but I'm still getting the error. I've tried removing the version number also. Still doesn't work
Anyone here got experience with keeping a RabbitMQ (pika) consumer connection and channel open 24/7? I've got an use case where there is only about 1 message an hour but it needs to be delivered immediately, can't afford to reconnect before sending. I've tried disabling the heartbeat but didn't help
I'm running the below code for consuming with heartbeat=0 and it doesn't receive anything if it's been stale for a while
channel.basic_qos(prefetch_count=1)
channel.basic_consume(
queue="orders",
on_message_callback=callback,
auto_ack=True,
)
while channel._consumer_infos:
channel.connection.process_data_events(time_limit=5)
if terminated:
channel.stop_consuming()
return
sounds like disabling the heartbeat would go counter to your goal
What is your maximum accepted latency?
To be honest I don't understand fully. I've disabled it on the consumer and it worked fine for a message just now that happened ~6 hours after starting, so maybe the heartbeat wasn't a great idea
Sub 50ms, this was done in just 17ms. It takes significantly longer to reconnect, but I didn't have to on this one so that's great
The point of heartbeats is to ensure that the application layer promptly finds out about disrupted connections (and also completely unresponsive peers) (see https://www.rabbitmq.com/heartbeats.html ). So disabling heartbeats means any connection problem won't be discovered until you try to send a message.
Providing guarantees of sub 50ms could be challenging, especially if you are on the cloud. But in any case, I would recommend to measure it and to add some monitoring and metrics around that.
And how should I keep the publisher's connection alive? I don't think my heartbeats are doing anything. For example if I do something like
connection = pika.BlockingConnection(pika.URLParameters(...))
channel = connection.channel()
while True:
print(f"{datetime.now()} | Connection is {'open' if connection.is_open else 'closed'}")
print(f"{datetime.now()} | Channel is {'open' if channel.is_open else 'closed'}")
sleep(10)
They keep printing open forever even though they close after a couple minutes. The only thing that helps keeping them alive is disabling the heartbeat
Repository owners and collaborators can request a pull request review from a specific person. Organization members can also request a pull request review from a team with read access to the repository
this is from github docs
just wanted to know why exactly we need to request a specific person to review a pr
cant the collaborator / owner do that itself
It's just an organisational tool. It's a way to notify a specific person to review.
oh so as to have some fixed users responsible to review prs just for convention but still every contributor has the perms to review it right?
Yes that's correct. This typically happens because certain people in the organisation are experts of different domains, so it makes the most sense to have them review changes that fall with their domain. In fact, this sort of criteria for requests can be automated by specifying "code owners" to GitHub.
Why not just drop a heartbeat message on the stack every now and then? However, 50MS is pretty low requirement, RabbitMQ could take longer then that.
I'd recommend something like ZeroMQ if you have latency requirements
how do I stop sucking at github styling and start with gh hooks?
I'm doing an internship at an IT company and I see them using gh hooks like black etc on github for styling convention / running tests before actually allowing a commit / .... Where can I read / learn about this? I just feel like my github commit game is bad
I downloaded Python from Python.org, and this version seems to have some additional logic running in the background. Normally this would be good because I can literally just type
example1="example2"
then open the shell and go
example1
'example2'
However, this prevents me from using a variety of semi-advanced code, so I was wondering if there's a version without the background logic that I can install from a safe site?
how do i solve this problem in regards to PyInstaller. I tried it both sourced into a venv created with virtualenv and by using the global python install. This is created with pyinstaller.exe bandcamp_flac_get.py
PS C:\Users\x\PycharmProjects\bandcamp-flac-get> .\build\bandcamp_flac_get\bandcamp_flac_get.exe
Error loading Python DLL 'C:\Users\x\PycharmProjects\bandcamp-flac-get\build\bandcamp_flac_get\python39.dll'.
LoadLibrary: The specified module could not be found.
PS C:\Users\x\PycharmProjects\bandcamp-flac-get>
I'm pretty familiar with python on linux but i have never tired build tools to make windows executable before.
https://paste.pythondiscord.com/zojikejige -- here is a more precise log of what i did
nevermind. the working exe is in the dist folder, not the build folder. I dont really get that part tbh
sudo apt install -y gnuplot is failing for me with Github actions saying E: Failed to fetch http://azure.archive.ubuntu.com/... failed with a 404 not found, is this fixable?
I think that server is legitimately down cause I can't even ping it. I assume it is an intermittent outage.
oh wow
Try running apt-get update though
Maybe it's normal to not be pingable, and that specific package is just out of date with the repo
i see thanks
also
what does pre-commit install do
i see it on quite a lot of projects
is it a git thing
on the docs it says
Git hook scripts are useful for identifying simple issues before submission to code review. We run our hooks on every commit to automatically point out issues in code such as missing semicolons, trailing whitespace, and debug statements.
so does it run each file to check errors before committing🤔
can someone help me figure out why my GitHub workflow runs twice when I create a GitHub release
https://github.com/mendelsshop/sideway_space_invaders/blob/main/.github/workflows/python-rust-build.yml this is the workflow that runs twice

GitHub
Play a space invaders like game sideways in the terminal. - sideway_space_invaders/python-rust-build.yml at main · mendelsshop/sideway_space_invaders
maybe [published, released, prereleased] this is the problem?
not sure what the difference between "published" and "released" is
I dont think its that but I'll check also when I tested it, I made my release a pre-release
I've got a handful of clients running a django based application I'm actively developing. I'm trying to get a remote licensing and update system in place. I've build concepts for tracking licenses and instances but I'm having trouble deciding on how to deliver the updates to clients.
Current workflow at the moment is to install updates from git, i.e. pip3 install git+ssh://git@github.com/MyUser/MyProject.git@nightly
What I want to do is have clients make a request to my backend with a key, and res with the update. But I can't decide on the best way to serve or proxy the files.
One option I'm experimenting with is GitPython to copy the repositories to my backend to be served to client.
Please can anyone tell me why it's showing me?

you can host your files on your own git server, which requires ssh authentication, and they need a license key to get an ssh key @novel grotto
what program is this? it looks like its apparmor profile is not configured correctly. file a bug report with your distro
Get solved
I am setting up CD with Jenkins and I want to know how I should go about pushing different branches into my docker repo. Should I just use different image names for different branches or there's a better approach?
For example I'll have latest images in master and dev branches. Or I should only let master have the latest tag?
Hello, I'm taking a look at docker swarm and using Traefik as my proxy, and I noticed on Traefik docs that theres a guide for Docker Swarm mode and Swarm cluster (which by the looks of it, is Docker Swarm). Are these two different?
Any Jython experts? Attempting to use Jython with Sikuli, I am stuck just using jython to call pip module. I keep getting this error:
java.lang.IllegalAccessException: class org.python.core.PyReflectedFunction cannot access class sun.security.x509.x509CertImpl
How do I get passed this? I turned off my AV and Firewall just encase. ReInsalled JythonInstaller - ALL (Thinking of trying Standalone)
what is a good data-lineage tool to "see" which functions access which data (particular data object) from the database?
for example:
def foo():
pizzas = db.get_all_pizzas()
def foo_filter():
pizzas = db.get_all_pizzas(topping='mushroom')
In the above example, the foo function accesses all the objects in the pizza table and the foo_filter function only accesses pizzas that have mushroom topping.
APM/or just profiling:
Lets say I am writing an app and I have something written really bad that consumes my CPU/RAM.
I want to know exactly which method is triggered it and all the other methods that are triggered by that method, because idk, maybe one of them is the bottleneck.
And see exactly how high the spike is. numeric and in as a chart.
Which tool should i use?
I came across a lot of tools like grafana, apacke skywalking, etc.
I came across some Python packages which just return a snapshot image.
I really didn't like them because all of the configuration I have to make something work.
And the snapshot ones feel less intuitive.
I am looking for something with
a simple gui
a simple chart/s
a simple table/s
simple filters
preferable real-time data. so when i execute a method i can see exactly whats happening.
Have it run in the background while working and have a peak on it one in a while.
Im not a devops 🤷♂️ and don't want to start messing around with configuring everything.
A few years ago i worked with PHP and had this dashboard with tables which i can order by CPU/RAM and see exactly where in my code the bottleneck occurs.
I forgot the name..
anyway, help please!
Does it have to be open source or free? Otherwise services like splunk, datadog (has free tier) or new relic (free tier) may be simpler to start with since you don't have to host anything
Otherwise self hosting opensearch with a dashboard shouldn't be too much work
yes should be free or open source. its for personal use
opensearch requires me to increase vm.max_map_count which caused my computer to run out of memory in almost anything i do 😆
Hello, anyone worked with Docker Swarm here? I would like to ask, in the --advertise-addr flag in docker swarm init. The address will be my vps' public ip, right?
Hello, I wanna create a multi tool with multible Pages, how do to multibile pages?
Anyone know of any resources regarding the advantages/disadvantages of running stuff in containers, vs just on a server using pipenv (or something similar). All the articles I'm finding are usually trying to sell me something.
Containers are considered more sustainable.
why is it they are more sustainable - because there is less maintenance/admin on the server?
They are more isolated.
Then, I would suggest to just go with grafana, new relic or datadog. They all have some form of free tier.
So guys, if I have particular function, let's say function X that's in my main branch after I merged main branch with branch let's say A. What if particular time I realized that I should change A, what would you do?
can you elaborate? this sounds like something i know how to answer, but i don't quite understand the question
Basically, I work with one guy on one project that's not used in production. We work in a way that we have main branch and branches for particular features that are made from main (yeah I know we should use test branch)
So basically, once I tried to merge one feature with main by using GitHub text editor I didn't make change in file in main
So now I am not sure how should I solve that problem
what do you mean? you meant to make the change on branch main but instead made it on a different branch?
I made a change on particular feature, tried to merge that feature into main and I got confliction error. For solving confliction error I was using GitHub...I clicked that error is resolved but actually after I "solve" error I saw that wanted change is only visible in one file
so you had multiple conflicts, but you only resolved one of them? and now there are conflict markers like ==== and <<<< in your code on main?
hmm, I had one conflict
i still don't understand then, sorry
after I "solve" error I saw that wanted change is only visible in one file
what do you mean by this?
and now there are conflict markers like ==== and <<<< in your code on main?
yes because I pulled code from main
it sounds like you can just fix the files and make a new commit with the fixed versions
Hmm, it was something like this: there is conflict error you can solve this error by using our github online text editor or from your command line -> I choosed github text editor -> made change that I want -> clicked save -> click resolved -> then there wasn't change in main
Yeah in my head it's like I can push from main change that I want. Change that I want is already in other branch that I made from main
maybe there was an option you need to click to "continue" performing the merge after resolving the conflicts
it sounds like it just didn't finish performing the merge
yeah I am not sure
yup, but as I clicked "resolved" or something like that, on GitHub everything seems fine
when you look at the main branch on github now, it looks like you expect it to look, after the mege?
nope, it doesn't look as I want
ok. how does it look?
as in the beginning before merge
ok. maybe try doing the merge a 2nd time?
also, I am not sure how I should behave in a way when if I make let's say branch X from branch main, do push from main and then want to merge X with main
it's possible that there was an additional confirmation button you didn't press
i have never done a merge conflict on github before 🤷♂️ normally i do this from the command line and my text editor
yeah I will try to do that
(just tagging you in a case you didn't see this above @tawdry needle)
i don't quite understand this question. if you create branch x off of branch main, and then you make a PR for branch x, github has a button to merge main into x. not sure if that helps
hmm, when you say merge main into x does that mean that you add code from main into a?
into x, yes
hmm, isn't that reverse - we add code from x to main?
your question wasn't clear, so i didn't know what you wanted
Hmm, so I have particular code in main, I make branch X from main, I do push from main after some time I want to merge X into main
all that I need to do is try to merge X into main and resolve conflict if there is conflict?
do you understand what I am asking?
yes
another option is to rebase x onto the updated main
i don't think that's possible with the github web interface
it's more of an advanced technique
I will google more about rebase command
if you do a merge, your commit history will look like this after the merge:
C1 ─ C2 ─ C3 ─ C6 (main)
└ C4 ─ C5 ┘ (feature-x)
yeah I think I understand you
thanks!
Hey all, can I get poetry to install into a local venv but for only one project?
I speak and after I think...
poetry config virtualenvs.in-project true --local!
I am building static frontend files with Jenkins + Docker. How should I go about deploying them on a server? I see this solution rn: put the static files into an nginx image, run it on the server and reverse proxy to that image with system-installed nginx
Seems overcomplicated
Hello. I have a question regarding Docker.
So I am running an application inside a container that requires a tty attached. If I create a new container using the 'run -it' flag the application plays nice and runs the way it is intended to.
However if I stop this container or say create a new container using create command and then try to start the container the application shortly exits giving the error 'stty: standard input: Not a tty'.
I checked the help section and theres no -t flag for the start command. How do I run this container again without having to create a new one every time with say the run --rm flag. Or am I overthinking it too much and its normal to create containers every run?
Hello everyone, this is an AutoCommit script for those who struggle with constant manual commits on github, feel free to try it and raise PRs for your contributions, we are aiming release it as an Action after conducting more tests. https://github.com/salsabeel-tn/GitAutoCommit-script
GitHub
Git AutoCommit script compatible with all OS . Contribute to salsabeel-tn/GitAutoCommit-script development by creating an account on GitHub.
you need to use the --tty --interactive options when you create the container. docker create -it ...
It's nice but why? A stream of autocommits without description and tags will only bring chaos to your repo. Most of the times you don't want to commit every single change separately, sometimes you need to merge and cherry pick and do other stuff with git which will become a nightmare. Besides, CI/CD will try to build and deploy your app on every git push, imagine what would happen to it if it's set up to build the dev branch with 100 autocommits a day
Again, it's great that you're trying to make something useful, but this exact idea is flawed
anyboady know about vr career ahead
hi, im not sure if " To create the virtualenv
it assumes that there is a python3 executable in your path with access to the venv package." is working in my virtual enviornement so i tried to do it manually as given in the READ ME file, but it shows error
saying no such command as -m
ty. exactly what i was looking for

hi i have this error ModuleNotFoundError: No module named '_ctypes
when i am installing pip modules
what should i do
eh, some people don't care about "clean" commit history, they just want to use git like a sequence of checkpoints
also you don't have to have CI trigger on merges to trunk/main/master, you can have a release branch or whatever
personally i would not want to use this tool either, but i could see why someone (e.g. a solo dev, data analyst, etc.) would
hey guys, im trying to find a good way to manage secret credentials, that are needed to run a daily script in a docker container. I can't have those credentials present in the script due to privacy issues ofcourse, but they are at the same time needed in order to pull the required data from our sources. Anyone know what the best course of action here is? Any tips appreciated (Toolkit involves classic docker, kubernetes cluster the container will be setup on, and jenkins for routine scheudling of it).
do @ me when responding, much thanks
i think the most popular suggestions are to use a cloud-based secrets/key management service, or something like mozilla sops https://github.com/mozilla/sops

GitHub
Simple and flexible tool for managing secrets. Contribute to mozilla/sops development by creating an account on GitHub.
the latter is probably simpler to get started with, and of course you don't have to pay for it
interesting, wasn't aware of this
any idea how it works
doesn't kubernetes have something like this? helm?
i think my company actually uses that
like, i have a python script that contains credentials, it needs to be containerized, but not with the actual credentials exposed, the credentials are in a secrets.py file in the same local directory upon build
we have our own diy version of sops (which didn't exist when the project was started), and i think we use that to generate helm config files, or something like that
i don't mess with that stuff
but yeah, our company works with kubernetes and i have heard of helm, surprised my team lead didnt bring it up
wonder if theres a tutorial on sops, no idea how it works in this case
unless you have a tldr sum up for general knowledge
pretty sure it just encrypts and decrypts files, but with a pre-defined file structure and a tidy cli
i see
that would actually make alot of sense, considering encryption was the first thing that came to mind
thanks for the answer though, will look into this
Isort just started ordering my imports differently without me updating it or doing anything (as far as I can tell) 😅
--- a/library/wumpy-interactions/wumpy/interactions/compat.py
+++ b/library/wumpy-interactions/wumpy/interactions/compat.py
@@ -1,6 +1,7 @@
import json
-from typing import TYPE_CHECKING, Any, Mapping, Optional, Protocol, overload
+from typing import TYPE_CHECKING, Any, Mapping, Optional, overload
+from typing_extensions import Protocol
try:
from sanic import HTTPResponse # type: ignore
SANIC_AVAILABLE = True
I made this commit, and ran isort again, then it started formatting things differently
LMAO
..and now it's formatting things as I expected them...?
lol

Why is that problem if I rebase and other ppl used my code? What is different than if I rebase and other people didn't use my code?
rebasing causes your git history to diverge from other people's
it can lead to messy conflicts for other users to resolve
Ummm, I thought it's changing history of remote repo
If it's changing my git history, how it affects other people?
when you rebase, you rewrite the history in your repo. then you have to force-push it to the remote. when you force-push, then you rewrite the history in the remote.
hi, have anyone worked with git hook? I have one flutter project on which I am currently working so, currently I am building Apk file using github actions. Now, I want to update the Readme file as soon as Apk build successful so, that when ever user vist the file they see the latest Apk download option... how could I do that? Could you pls suggest any blog posts?
I don't think so you can accomplish this with git hooks. Maybe you can add another step in your workflow?
ohh, I have never worked with it..
ohh, I just noticed
that you calling actions as workflow
By workflow I mean github action workflow...
Yea
currently this where I am storing

but, I want a way to update the readme file auto-matically
as soon as new version of apk is aval at that location
Can you specify what exactly you want to update in the readme, I'm guessing the link to the artifact?
I was thing using git hook so, I will access that location every time when new build is done and then update the read me file
just like how vue devtool or many other projects doing ... they automatically update the readme file when a new version is available

similarly, I want to provide user with Install APK - option at the read-me file
currently to download apk users have manually go to the action tab and then select APK section then they will see the latest link and then they have to again click which again open another file and then only then user can download the app...

if you visit this I guess you might get idea what I am trying to express
Well I have no clue how these projects are doing it via git hooks. AFAIK you can do it with github actions, just adding a few more lines.
no no, I was simply guessing that they were doing using git hook... could you pls share any references or could you guide what should I do?
Well i kinda know it, but I need to be somewhere else
ahh no worries it's not very urgent for me... because anyway my project is very very tiny
once you are free could you pls guide me through the process
Yea sure
Hi guys, I'm new to conda, I have to use a python3.6 version, so when I try to install
RUN conda install -c anaconda numpy==1.20.3
it upgrades me to python 3.7 , is there a flag that I can use so it doesn't upgrade my python version ? also, what does the -c mean ?
according to the numpy doc, python3.6 supports my version :

I'm using docker btw
Can anyone guide me how to autmote instgram with python. Insta python.
how to join this channel?
i need to scrape a list of links of twitter posts, i need to data of each posts, what could be the possible solution?
For some reason I can't get an env file into my docker container when I use docker-compose
services:
app:
...
env_file:
- .env.develop
...
I've tried everything from here already
https://github.com/docker/compose/issues/4223
I'm gonna lose my mind, really
GitHub
I'm trying to use ENV variables declared in a .env file in my docker-compose file (I.e. I don't want to use the .env file in a container, just in the build process). I have the foll...
How about to check your docker and docker compose version
May be it is so ancient, that is not supporting it
May be u specified legacy old version in docker compose beginning
If u wish to use them during the build...
Try to use build args
version: "3.9"
services:
webapp:
build:
context: ./dir
dockerfile: Dockerfile-alternate
args:
buildno: 1
Thanks, but it's a fresh install. It also works with another project on this machine
I need them on runtime, and when I exec echo the variables it shows an empty string
Check perhaps wrong file permissions
Try to read compose logs
Perhaps u use wrong echo, try to check env var availablity with other tool
I sometimes notice there are several subsets of available shell langs and they behave differently
Alright, I'll check that
Thank you

i'm currently considering adding a use(git(..)) case for justuse, which could check the test status on github, pull and import the package inline
possibly transparently reload even
there were some concerns about hash-fixed modules and installations because they couldn't easily be updated for security patches
so i'm thinking that for those packages where getting patches ASAP is critical pulling them directly from github might be a good alternative to waiting for a release on pypi
what do you think? would there be interest for such a feature?
thus far it's possible to reload local files but only install hash-fixed packages and load hash-fixed online URLs
this would add a symmetry to reloading packages
(and no, i'm not trying to mimic Go or whatever language also has a feature like that 😉 )
some time ago we considered adding a mode to ignore the hash-checking for URLs and package installations, but I think it makes more sense to go directly to the source on github.. at least there's a way to track responsibilities
we might have to revisit the signature-compatibility issue for auto-updating
we need an english error to help you with it
does anyone use intellij, why do i not see python project option here

I did install the plugin
Is there a standard way to propagate a git tag (representing an application version) into a Docker container as an environment variable?
To give some more detail - I have CI/CD pipelines that automatically build a Docker container containing an application and push it to DockerHub when a new release/tag is created in GitHub. Typically, my applications have a __version__ variable set at the root of the project representing the version of the application, such as v1.4.5.
My current workflow looks something like this:
- Make changes to my application as needed
- Bump
__version__from previous release version (e.g.v1.4.4) to the next release version (e.g.v1.4.5). - Create a new release in GitHub with a tag of
v1.4.5.
The problem is that sometimes, I forget #2. Then, I'm in an awkward spot where GitHub says I should be running v1.4.5, but the application says I should be running v1.4.4. I'm looking to eliminate this problem by removing __version__ from my application entirely and propagating the git tag into the application itself as an environment variable baked into the Docker container.
what if you instead use a tool that keeps __version__ in sync w/ the git tag automatically?
that or you can have some kind of check in CI or even a pre-commit hook in git, which asserts that __version__ is set correctly for the tag
Wouldn’t it be easier to eliminate one source of truth instead of trying to keep two in sync? Or am I missing a use case for ‘version’ that the fit tag doesn’t fulfill?
it depends on how your application is used. if it's only ever deployed in the docker container, it's redundant. but __version__ is a nice convenience for programmers who are working with your code as a library, and it's useful if you are doing stuff like implementing a command line interface; basically it's good for times when the source code becomes detached from the git repo
it often ends up being duplicated in setup.cfg/pyproject.toml anyway, although a lot of people don't bother with that if they are just deploying stuff in docker
Yeah, in my scenario for these applications, programmers aren't my users, so I think __version__ is redundant and is causing more problems than it solves
fair enough, ditch it
Heya, what github CI tools do you use that can show you the change in coverage compared to the target branch?
Hello I get the following error when I try to clone a gitlab repo:
fatal: unable to access 'https://.../repo.git/': gnults_handshake() failed: The TLS connection was non-properly terminated.
I did and it doesn't work either
I'm connected to 2 VPNs one corresponding to my company and the other one is external
Ubuntu 20.04
there was a curl bug, might need to upgrade it
I feel like it has to do with proxies on the external VPN cause I tried clonning the repository connected to my company VPN and it works but when I try to clone the repo connected to both VPNs I get the error described above
what happens when you try to ssh -t or curl or netcat the endpoints
Using curl SSL_ERROR_SYSCALL
there you go, I think you can troubleshoot your way up the possibility tree
very interesting https://engineering.atspotify.com/2022/03/why-we-switched-our-data-orchestration-service/

Spotify Engineering
TL;DR Within Spotify, we run 20,000 batch data pipelines defined in 1,000+ repositories, owned by 300+ teams — daily. The majority of our pipelines rely on two tools: Luigi (for the Python folks) and Flo (for the Java folks). In 2019, the data orchestration team at Spotify decided to move away from
I'm not really sure if this is the right channel, but i am creating a python package and would like some help with getting started. I'll list some of the things that i can think of:
• Set up the repo to be in a proper package format.
• I want to be able to use the package right away for testing, but dont want to push to pypi yet. How can i do this? Can i just pip install <github repo link>? For this to be possible, in what format should i structure my repo so that i can do that? Any recommended tutorials regarding this, because i found a couple where both are quite different?
• Documentation (readthedocs.org)
• Document the entire package, and have a readthedocs page like discord.py
• I already created a readthedocs account and i think i understand how to push to there, but where do i start to learn the formatting of the docstrings, how things work, etc? Any recommended tutorials regarding this?
• Push to PyPI. Is there a recommended tutorial regarding this? Not quite sure how to do this yet.
Tbh a full tutorial on packaging that covers everything including these would be great but i wasn't able to find any yet. I want to make my package as nice as possible.
pip is for github right
• I want to be able to use the package right away for testing, but dont want to push to pypi yet. How can i do this? Can i just pip install <github repo link>? For this to be possible, in what format should i structure my repo so that i can do that? Any recommended tutorials regarding this, because i found a couple where both are quite different?
Yes you can, not sure how 😉
lmfao thanks

You can always install the directory that has the pyproject.toml via
Pip install path/to/folder -e
This installs it editable, which means you can test it and import it and if you make changes you do not have to reinstall
I recommend using flit(if your package is pure python and does not need compiling of C code) or poetry(no experience with poetry)
Thanks for the info!
Hello everyone,
So, I currently have a logging system that looks something like this:
Various log sources from other teams send log data to a Syslog server and I redirect respective streams to their dedicated folder. Then I have a set of scripts that parse each log data and insert it into a Postgres DB as part of a web application. The parsing script is on the Syslog server.
I am planning to introduce RabbitMQ into the mix as a buffer between the web application and the Syslog server, something like this:
log source -> Syslog (parse data/exchange with bindings) -> RabbitMQ (queues) -> Web application (consumer). Essentially, RMQ will be able to hold as many messages as possible if Syslog or log sources before that, go offline for whatever reason, and vice-versa if the web application goes offline, then I can still process messages to each queue waiting for consumers to come online. (I hope I was clear with my explanation)
Now, I'm having a higher up asking me to do something like this:
- Log sources send to RabbitMQ
- RabbitMQ, make two copies of the data. 😦 😦
- Send one to the Syslog, parse the other (while still in the RMQ queue), and send it to the database used by the web application.
So essentially, something like:
log source -> RabbitMQ (duplicate data) -> (a) Syslog, (b)parse in RMQ and send to db -> Web application (consumer)
My question is this:
- Is
multiple log source -> RabbitMQis s typical use case? - Can RMQ duplicate data?
- Can I parse (using simple RegEx) in messages while still in queues?
Sorry if all that seems confusing/overwhelming.
Let me know if you need more clarifying information. Thanks.
What is an entry file and what is the benefit to using it to build a Docker image?
RabbitMQ has ability to fan out so single message gets dropped into multiple queues
anyone have any advice for bundling a python script as a vm system service
if thats even the correct literature
Hi Folks
This is a question for the combination of gitlab CICD pipelines + pipenv
I'm trying to get my head around building a package in .gitlab-ci.yml before uploading it to our internal gitlab
I've tried to use just
python3.10 -m pipenv run setup.py sdist bdist_wheel
Though getting an error
/bin/sh: 1: setup.py: not found
And again just using what I would do on workstation
python3.10 -m pipenv shell
python setup.py sdist bdist_wheel
With error
error: termios.error: (25, 'Inappropriate ioctl for device')
Full section is below. Am I missing something simple?
upload package:
stage: deploy
script:
# We may need to use pipenv though that just reminds me that by default it won't understand the dependencies
# Ideally we can use the below though for requirements we may need to use https://github.com/Madoshakalaka/pipenv-setup
# Though getting error: /bin/sh: 1: setup.py: not found
# - python3.10 -m pipenv run setup.py sdist bdist_wheel
# The following may not be needed either as per https://stackoverflow.com/a/59971469/567606
# - python -m pip freeze > requirements.txt
# - python3.10 -m pipenv shell
# error: termios.error: (25, 'Inappropriate ioctl for device')
- python setup.py sdist bdist_wheel
- TWINE_PASSWORD=${CI_JOB_TOKEN} TWINE_USERNAME=gitlab-ci-token pipenv run twine upload --repository-url ${CI_API_V4_URL}/projects/${CI_PROJECT_ID}/packages/pypi dist/*
Thanks. I just saw that.
Any recommendations/suggestions for Pre-commit hooks?
So far what I had in mind are the black and isort hooks
And a flake8 hook

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Whats happeing here .lol
salt rock lamp helped them in a help channel :)
wanted to share this 

Don't, handle it at CI/CD platform
Already did it
Found it better to autoformat during before pushing code
Adding linting didn't make sense to me since any decent IDE integrates that into the editor itself
Yes, let's restrict our change tracking system because linting
Nothing is more annoying then to want to commit a piece of code you are furiously working on so you can track your changes and git is like "Linter doesn't like this"
Screw off linter, I'm working and don't have time for your shit
do that on CI/CD server you OCD pain in the ass
Use an autoformatter in the precommit and this largely goes away as an issue
Hi all. I just created a branch and pushed a merge request from vscode to GitLab. the push has now been merged. What's the next step? Do I just delete my branch in vscode, or do I do a git pull? I'm not sure what to do 😄
(for now i've renamed by branch to 'merged/featurename', checked out main and done a git pull)
that may or may not make a mess of things
Esp on white space controlled languages
hey all, has anyone had their pip broken by upgrading to macOS 12.3 which removed python 2.7?
when i try to do anything with pip3, i get ModuleNotFoundError: No module named 'pip'
have you always been using python 2?
never used python2
i installed 3 via homebrew
100% of my python dev has been on 3; that's where i learned it 🙂
Show the full traceback?
File "/opt/homebrew/bin/pip", line 5, in <module>
from pip._internal.cli.main import main
ModuleNotFoundError: No module named 'pip'```ah, but i solved it, i found a python script called get-pip.py (dunno if it's okay to post URLs here), then ran python3 on it
and that restored pip3
can anyone recommend a good "no frills" python linter?
or one you can easily integrate into pycharm?
you should never need to do this with homebrew
you do not want to accidentally mess up the built-in python installation in macos
if pip is missing, some path is set incorrectly. do not try to "brute force" fix it by running the get-pip script
it looks like you have a nonstandard homebrew installation location in /opt, which might explain why something isn't set up right
run brew config and brew doctor to make sure things are set up correctly
it's an m1 mac, homebrew puts its packages in /opt, not in /usr/local
and i believe it was reading pip from the mac's 2.7 framework, there was no pip at all when i was troubleshooting the issue (did a full find on / for it)
interesting, that i did not realize
yes, that's what i was afraid of. you don't want to start messing with that
on macs normally the /usr/libexec/path_helper script adds /usr/local/bin to the user's PATH, but i don't know if it does that with /opt on M1 systems
my work macbook is x86, i've never used M1
yeah i upgraded my machine, was surprised to install homebrew and discover /usr/local was empty
dunno why they make the distinction
it's probably better to not take over /usr/local tbh, it's too much of a mess there
theoretically /usr/local is for the system admin to manually install things
/opt/homebrew makes a lot more sense to me
macports, nix, pkgsrc, (basically all "non-standard" package managers) etc. all belong in /opt and/or ~/.local/opt imo
oh, i concur, at least it isn't /fink 🙂
i like how /opt is meant to be for non-system stuff, use it a lot in the linux world
heh, nix does this too with /nix
indeed, that's why i set up XDG_MISC_HOME=$HOME/.local/opt, which is my own personal extension to the xdg base directory spec 😆
i use it all the time
i use it for tools like pyenv, pipx, etc.
nice
Curios for thoughts from more experienced folks:
I am codeveloping 2 packages: B depends on A.
I would like B/main to test against pypi releases of A, while B/develop tests against git+https://...A.git (i.e. A's latest commits)
My CI file (.gitlab-ci.yaml) is version controlled, so one solution is to change the deps specified there and cherry-pick onto main as releases are made. Are there preferable alternatives?
Why would I want to use a linter only on Github Actions
I'm just not adding Flake8 pre-commit hook
Never found Black once to make a mess
I'm more expecting of humans to make messes
I'm definitely keeping the linter locally and on CI/CD
I find satisfying use linters locally (also black). According company is part of the task, not a waste of time
Is this the correct channel for automation scripts? Even if they are not DevOps related?
I wrote a small script that allows me to automate the Widevine Plugin installation for fresh or updated ungoogled-chromium instances on Microsoft Windows. https://github.com/caevee/WidevineUpdateScript/blob/main/update_widevine.py
I was curious if someone could give me some tips on improving the code and maybe try the script out. I tried to design it in a way that allows anyone to use it.
Hi can someone help me?
If I have a network, composed of a server with kubernetes cluster - labeled 1, client A and client B. Client A and Client B both have limited hardware resources, but need to be able to run a very intensive python computation. How could would I configure the architecture, so that Client A can call a package hosted on Server 1, and run said package on Server 1, and then display the results of the operation back to Client A. Client B is a mirror of client A.
Requirements -
It must run the computations on the single instance, or we must have several pre-running clusters with said package, as the package has bad latency if we were for example to spawn a new process every time it's used.
Better explaination*
as a matter of code style, i don't like this:
with open("widevine.zip", "wb") as widevinezip:
widevinezip.write(requests.get(widevine_url).content)
i would much prefer this
response = requests.get(widevine_url)
with open("widevine.zip", "wb") as widevinezip:
widevinezip.write(response.content)
i like to write my code so that "i/o" operations stand out on their own, instead of mushing them together in one long expression
you might also want to use r strings for paths so you don't have to use \\. or you can just use forward slashes, python (and windows) can handle them
default_lnk_path = os.path.join(r"C:\Users", os.getlogin(), r"Desktop\Chromium.lnk")
and little things like calling os.getlogin() twice instead of saving it to a variable
other than the small style things, this looks pretty unoffensive
Does someone know how the load more buttons work? I am learning flask and wondered how I could implement such a feature.
You usually write a function returning part of the items with an offset parameter that controls the first returned item.
So i'll have to do it with js right?
On the flask backend you return part of the data and append it on the front-end via JavaScript. Yes.
OK thanks for this explanation
Thx for your feedback. I've changed up the code according to your tips. I'll push it later. Didn't know about r strings until now too
Is there any easy way to be able to install a Project editable with only a pyproject.toml, or do I have to write a setup.py?
I am personally using flit, but trying to help someone setting up a venv for project of his and I do not want to force flit / poetry or setup.py on him, just so he can use a venv.
Also:
Is there anywhere a list of possible build_backends and what they support? Or rather a list of the "standard" build backends?
it depends on the build backend. for example poetry installs the package in editable mode by default when you set up poetry, so you don't have to do anything with that
but in general we don't (yet) have editable installs for general pep 517 packages; only setuptools
i think a standard is in the late stages of being developed
there is no hardcoded list. a build backend is just a python module
so for now if you want other people to use your package in editable mode without installing all your tooling, yes the best option is setuptools
thank you for the info!,
still weird that everything moves to pyproject.toml only and then the basic of editable is imposible without 3rd party
Its not my package, just want to help a friend that is new setting up a venv for his project. He will not upload it to PyPi, so forcing poetry or flit on him seems overkill, I still want to show him some best practices ala pyproject.toml though and not just manipulating python-path
ad list: Not looking for a hard coded list, just maybe a website with possible backends and features, it is quite hard to get an overview if you have to not only search PyPi, but then also go through each documentation. Seems weird that there also is not default. Makes the learning curve quite steep.
I mean I know flit, poetry, but never knew "setuptools.build_meta" or that there even could be sub-backends like the dotted path suggests.
still weird that everything moves to pyproject.toml only and then the basic of editable is imposible without 3rd party
you are not the only person who feels this way. i get the impression that the people who developed pep 517 didnt think editable installs were useful, and only started thinking about them after the community complained
forcing poetry or flit on him seems overkill
i agree. that's why i think setuptools is the best option for this.
Not looking for a hard coded list
fair enough, that would definitely be useful. the ones i know of are setuptools, poetry, flit, and hatch.
never knew
you wouldn't/can't know in advance. it's entirely dependent on the build tool in question. sosetuptools.build_metais determined by setuptools, not by something specifically in the pep 517 spec. it has to be documented prominently in some way that users can find it (setuptools fails to do this, last i checked).
sub-backends
there are no sub-backends. the dotted path is literally just a module name
wow, learned a lot, again thank you very much for this information!!
can anyone help with this plz?

Hi guys, I use this telegram bot nftfox_bot, I was thinking to automate Purchase of collections mentioned in it, how can I do it, as I understand I need infura or alchemy to automate.
i helped someone else on this same exact assignment not too long ago
read this help session @grim bloom #help-pineapple message
i work through the assignment with someone (probably one of your classmates) in great detail
@ me if anything is unclear to you, after reading through that conversation carefully
hi everyone
does someone work with urllib3 and binary files? i'm really stucked in a problem and beg help
When I install a package using pipx, can I use it globally as it it's installed using pip? when should one use pipx vs pip?
Anyone worked on couchdb
Can anyone give me guidance on how to create and deploy a python based iOS app, using Azure's app service, and dB services. I'm experienced with python, quite new to cloud, know very little about DevOps. Just a high level explanation will be good just so I know what I need to read up on. Thanks
If you're going to use pipx, always use that. Otherwise use pip in a virtual environment or container. You generally want to avoid running pip directly and uncontained where it can break your OS
👍
how can I add \r\n to file?
with open(fn, "ab") as f:
f.write(b"\r\n")
Did that work?
for me yes
how do I make pylint exit with an 0 code if there are no erros,
as of now warnings, notes etc all make non-zero exit code
I don't want to do -no-exit and suppress everything
I have issues creating a Dockerfile
I use conda with conda-forge
FROM python:3.9
ADD requirements.txt .
ADD server.py .
RUN pip install -r requirements.txt
```When creating my conda environment I use a YML file. Cuz I need a few dependenciesHi guys. Is it possible to copy files automatically when doing git commit?
copy files automatically...
from where to where, what's going on
what sort of file copying is required during git commit?
What do you mean?
this dockerfile doesn't use conda at all. can you show the conda version and explain what was going wrong?
you will probably need to use a base image like debian, and run the miniconda installer script in the dockerfile
Hello I have a local branch (develop) and I want to synchronize those changes to another branch from another remote. Should I use git push otheremote develop:develop or use git merge instead
push takes your stuff and puts it on the server. merge takes the stuff on the server and brings it down to your machine. two different things.
Cool git push is the correct one here
you can just do git push otheremote develop if the branch names are the same
Yeah both branches have the same name
Good point
Once I push my local develop to otheremote develop for the first time and I make some changes to my local develop afterwards
are you using the term "remote" instead of "repo"?
or do you actually have two remotes?
Two different repositories
Yeah I have two remotes each pointing to a different repository, both of them have a develop branch
So I want to push my local develop to the develop of the other repository
git checkout develop
git push otheremote develop
Then I can keep using this to synchronize new changes. Ofc running git pull to retrieve changes made by coworkers
a "remote" refers to a repository that is hosted somewhere other than your computer
so if this is your only remote, you can just do git push -u otheremote develop and then you can do git push in the future
-u sets the "upstream", i.e. the default push target
👌 I have two remotes then, one for my company and another one for the client. In my company's remote I'm following gitflow guidelines creating feature branches issue and all that stuff. Regarding client's remote, I just created a develop branch just to push code from my local copy of my company's develop branch. I don't wanna duplicate work creating features and issues in both remotes specially when I have to switch from different VPNs in order to interact with the repositories
What is the key difference in DevOps n Cloud
As I'm a web dev so I have to deploy my sites to cloud platformd such as digitalocean vps hosting
Is Cloud computing subset of DevOps?
N what r the tools that come in DevOps
I think cloud computing is subset of Infrastructure patterns. Not sure for sure
Tools of DevOps: CI CD tools like Gitlab CI. Docker. Ansible. Terraform. Kubernetes. Cloud provider features.
We use infrastructure as a code tools to have automated testing and deployment processes
There are other alternative tools available. I just mentioned the most popular enterprise choices
xD I still did not read the book explaining what DevOps is at all
And I dare to call myself DevOps person... 🤦♂️
ahh makes sense
Thanks for your help
bump
read up, try and mess with it
any gh hooks you like?
I've seen my company use flake8, black and pre-commit, that's all I can currently think of
No, I hate commit hooks
I despise having to override it if I want to commit something before I start refactoring
I believe all that should be handled during CI/CD process instead, blocking the PR if it fails
seems fair
Damn dude u already r a legend in Python Js Django,etc
Now I also got u in DevOps channel
U god or something dude
Using Cloud Provider Features
That's cloud computing ig
I worked in startup.

and I was responsible mainly for backend and infrastrcture... plus in addition architecturing the projects... and coding frontend
those were fun times
Where can I find some good resources for CI/CD?
@full bronze https://github.com/awesome-soft/awesome-devops ?
GitHub
A curated list of awesome softwares for Devops. Contribute to awesome-soft/awesome-devops development by creating an account on GitHub.
Thanks. This looks good
this is also true if the company is just 2 people, and the other one isn't really a programmer
self.locks = Lock()
self.proxy_type = gratient_text = gratient.purple("<$> |1| Http/s - |2|Socks4 - |3|Socks5 : ")
input(gratient_text)
self.Target = gratient_text = gratient.purple("<$> Enter Target : ")
input(gratient_text)
self.Threads = gratient_text = gratient.purple("<$> Enter Threads : ")
int(input(gratient_text))
ctypes.windll.user32.MessageBoxW(0, 'Are you Ready?', f"{self.name} Swap")
Thread(target=(self.Rs)).start()
for i in range(self.Threads):
Thread(target=(self.swapper)).start()
and I get this error
<$> Successfully loaded 'settings.txt'
<$> |1| Http/s - |2|Socks4 - |3|Socks5 : 1
<$> Enter Target : polo
<$> Enter Threads : 2000
Traceback (most recent call last):
File "polo.py", line 273, in <module>
swap()
File "polo.py", line 204, in init
for i in range(self.Threads):
TypeError: 'str' object cannot be interpreted as an integer
what can I do to fix ?
You need to parse the str as an int
Why are you assigning gratient_text? And why are you throwing away the return value of input(?
Just call
def input_purple(msg):
return input(gretient.purple(msg))
self.proxy_type = input_purple("<$> Http/s")
Wait are you building an http request spammer?
Yes
self.Threads = gratient_text = gratient.purple("<$> Enter Threads : ")
int(input(gratient_text))
start()
I get the error here
!rule 5
5. Do not provide or request help on projects that may break laws, breach terms of services, or are malicious or inappropriate.
hi all,
I have written two apps to help manage many repos with ease,
Things like labels or files that you need to change in many repos in once it is now very easy.
If you had similar struggles as me, please give these apps a try, let me know your feedback on a DM.
It would be awesome to get some input from Py Gurus 🙂
( please don't run pylint it is a bit of a mess atm 🙂 )
https://pypi.org/project/git-pusher/ ( I have written this first, it is more noob code wise)

Hey guys, has anyone ever worked on wireshark for dll files?
Afternoon peeeeeps, wondering if someone can explain to me why I'm struggling to get a library imported within Windows/Python?
Using 3.9, being told that DLL load failed while importing <library name>
But I've added the location of the DLL via os.add_dll etc etc
Any advice on what I'm doing wrong?
Show the full traceback and your code?
Hi everyone,
I was learning Docker and felt that it was hard to remember all the commands and various arguments. I also kept forgetting the names of my containers & images so I decided to build a CLI for Docker using Prompt Toolkit. Hopefully it will be useful for those of you learning & working in devops. Let me know how I can improve.
The project can be found at https://github.com/solamarpreet/dockersh

GitHub
A shell for Docker commands with autocomplete & command history - GitHub - solamarpreet/dockersh: A shell for Docker commands with autocomplete & command history
this looks very useful. i wish this was part of lazydocker
great project idea and great idea in general
Ty. i was super annoyed having to type help and looking at container names again and again. Then I came across a video on Prompt Toolkit by @steep jolt and immediately began working on this. Ty @steep jolt once again 🙂

please read the rules
that's highly against the rules due to request spam
and we don't help with stuff which is against rules
Congrats @silk imp. That looks very nice.