#tools-and-devops
1 messages · Page 73 of 1
yeah, hopefully we don't end up in a situation similar to NPM 
what happened to npm?
you mean npm audit ?
basically I've heard that people kinda ignore the warnings npm audit emits out on the regular
ah, I see
@flat path @next spruce https://overreacted.io/npm-audit-broken-by-design/
Found 99 vulnerabilities (84 moderately irrelevant, 15 highly irrelevant)
a good TLDR
So one of the issues is that vulnerabilities in subdependencies are usually not relevant to the application?
yeah, we don't want it running every time packages get installed, I think is what the article was saying?
because application end users don't have the means to act on the findings
still a warning might be good if a package is going to be downgraded to resolve dependencies for something that's being installed
yeah kind of that
it's also that dev toolchain vulns flag up which are often completely irrelevant unless... the development machine is compromised, lol
So far the boy has cried wolf five times. Two of them are duplicates. The rest are absurd non-issues in the context of how these dependencies are used.
yeah, that makes sense, haha
if that kind of warning is shown by default, no big surprise they're mostly ignored
yeah shown on every install/update iirc
I doubt we will, entire node ecosystem is disaster zone that is propped up with massive foundation "You can't use anything else"
I seem to get an error about pip's HTTP cache when I try to run the tool. Anyone else tried it?
File "/usr/local/lib/python3.9/dist-packages/pip_audit/_service/pypi.py", line 105, in _get_pip_cache raise ServiceError(f"Failed to query the pipHTTP cache directory: {cmd}") from cpe pip_audit._service.interface.ServiceError: Failed to query thepip HTTP cache directory: ['/usr/bin/python3', '-m', 'pip', 'cache', 'dir']
Nevermind, it works now 😄
it certainly does a lot of work
No known vulnerabilities found
well, that's good, I guess
I did have to do a couple things to requirements.txt before it would complete, surprisingly, so maybe that means they are problematic even though pip install has worked in the past::
- Remove explicit version numbers (to avoid ResolutionImpossible x 2)
- Remove
icontract(because it seemed to get into a loop of installing the package from source)
anyone know of a good api that will provide nfl historical game data? specifically, i'm looking for quarter by quarter scores for every game since 1960.
can we discuss docker related (+m1) issues here?
If you want
oh man, been having some docker + m1 issues ourselves at work, though I think we're mostly around them now
how do i remove inactivity disconnect from ssh
you using a lib like netmiko?
uh no.. its literally just openssh on ubuntu 20.04 os, question wasn't related to python
Yay or nay: Should a library log about an exception before raising it?
For example, making a critical log entry with the logging module about something and then raising the error
what issues have you guys faced when working with M1?
For us mostly dependency chains. Some other image or whatnot itself not being compatible with M1 for whatever reason (no armv8 image for instance)
especially true of locked down versions, so a lot of rebuilds, retesting, etc has had to take place
😐 do all images need to be arm compliant?
if those aspects will be running on m1 I'd suppose so
yes, i have a M1 Macbook Air, gave it to someone, couldn't use docker and other programs like ROS, Gazebo
Which is mostly an issue with local dev of course cause I doubt most are trying to host on M1.
How could I tell git that a file that I've renamed and modified in a single commit was a rename operation? Right now it just thinks that I've removed the original file and added a completely new file to another place. I don't want to split this into 2 commits because it doesn't really make sense, with the rename it was necessary to also change some things in the file itself. Is it possible to tell git that this was actually a rename?
did you find git mv old.file new.file ?
You can't, git doesn't store diffs in the commit, it's recomputed each time from the whole tree
Kubernetes question - I'm deploying my RabbitMQ consumer in Python (via pika), and I'd like to dynamically set the x-priority for each replica. The logic would be to use x-priority: 0 for the first replica, then x-priority: -1 for the next one and so on. If for example the -4 replica dies, the next one that takes over should launch with -4 also. What would be the solution to this?
Can I pass in an argument from the deployment.yaml to the Python launch command that would somehow increment with each running replica, so then I can divide that int from the default 0 priority and launch the function based on that? Or is there a better solution to this? Each replica should have its own unique priority, so if I run 10 replicas I'd want 0 to -9. Then repeat for each node, first replica on each node should always have 0, then -1 again and so on
hmmm, if you use a statefulset then replicas will be spawned with the name blahblah-0, blahblah-1, so on
you can then just set the value of that in an env var with an env definition like ```yaml
env:
- name: RMQ_HOSTNAME
valueFrom:
fieldRef:
fieldPath: metadata.name
in theory, just grabbing the integer value from the RMQ_HOSTNAME env var and negating it should give you a functioning priority value
there is an issue to allow fieldRef to pull the ordinal index straight from the pod data without a parsing step but it's not implemented yet afaics https://github.com/kubernetes/kubernetes/issues/40651

GitHub
Is this a request for help? (If yes, you should use our troubleshooting guide and community support channels, see http://kubernetes.io/docs/troubleshooting/.): No What keywords did you search in Ku...
Joe saves the day once again
Thanks a lot man every time you reply to me you solve an issue I couldn't for a week lol
I'll check that out, if it works like the way you said then I'm 100% set
I just started recently with Kubernetes so I have no idea what I'm doing as expected
😄 glad to help
I’ve done similar for deploying Scylla to Kube, means that every instance gets a friendly DNS name and you always know scylla-0 will exist and so on
Sweet sounds exactly what I was looking for
1 more quick question if you got the time - can you do something similar to hostname: "{{.Node.Hostname}}" from docker-compose (with swarm) in k8s? Basically setting the hostname of the containers to match the node's hostname, cuz for example in Sentry now I have useless hostnames like test-12ej23-23rfu2i instead of the actual hostname of the server
In logging too obviously
Or if anyone else knows a solution pls let me know
I should really start learning k8s too. That's it, at those weekends I begin, or perhaps to be not dealying and starting today? 🤔
Just tried this and worked exactly as I wanted and were able to implement exactly what I wanted, thanks again! And thanks for this group in general, I absolutely hate the other communities but this one always saves me
If you like to torture yourself start today
I haven't slept in 3 days trying to finally figure out a k8s on a very basic but deployable level lol
Though I'm self hosting hence making it probably 10x more painful
I'll be doing full siege.
going through interactive tutorial at official docs first, reading at least 2 books or more, plus I know free course recomended by devops people
plus I need to apply it at some project or two projects 🤔
hoping in one-three months to prepare myself more or less
I skipped all of that and went bruteforce mode try to transition my entire ~20 node Docker Swarm cluster to k8s
It will be worth it one day I'm sure but I'm going through hell every single hour lol
I had fun like that a month ago. to learn frontend from zero and full vue.js ecosystem in one week
I don't know fun
intensive practical learning ;b fun.
I just looked at our DMs and the question I asked from you 6 months ago was exactly for this what I was talking about above lol
Lots have changed since but still the same project and still trying to solve the same issue
Well I already did outside of k8s but when you enter k8s you start from 0 again pretty much
At least in my case
Complex as hell
6 months? heh. I started actively using ansible, terraform, + my gitlab pipline became with staging part. and the mentioned frontend.
Oh and the best part, I learned at least basics for System Analysis and Design during this time
planning the projects in advance is awesome
I was working on creating my first full CI/CD with GitHub actions & GHCR, now that it is working like a charm for Swarm I made the fantastic decision to shut it down and start again from 0 with k8s
I keep hearing ansible & terraform and I still have no idea what even are they
if shortly speaking the essence...
for example u have server where u run stuff with docker-compose.
in order to do that
U need to have docker-compose installed, u could do that with bash scripts of course
But ansible is a more powerful alternative for remote stuff installations. It is installing stuff with stateful checks, if the action is needed to be performed.
Plus u can configure all other necessary stuff, firewall and applications which can't be run in docker
Basically ansible is answer to install everything to server, that can't be run with docker
Ansible is Configuration Management tool
I definitely need to get on that
automating server configurating)
Ansible is the best out of its family tools, because it is not requiring agents installed at the target server
nothing is needed installed at target machines in order to use that.
So basically I 100% need that for a production ready k8s deployment since I'm self hosting the nodes instead of using a managed service
For automatically deploying new nodes for autoscaling
2 weeks ago I was still manually building, pushing, deploying Docker images to my swarm and I realized I'm wasting at least 1 or 2 hours every single day doing so, so I setup a CI/CD and it's so satisfying now
as for terraform...
We buy stuff from provider manually. Manually buying servers, manually configuring in its web interface load balancers, domains, kubernetes and e.t.c.
Terraform allows to configure it as a code.
You add new code, run it, it finds what is different in current infrastructure state from code, and applies the necessary changes. Automatically buying servers, setting up load balancers and etc
I still config my nodes manually so perhaps I'm looking into ansible next
Oh so basically exactly the two tools I'll need for a k8s setup
Yes 😉
that's why I learned it before learning k8s
I knew that they are prerequisites
they are the best for automatic CI/CD, with them I have already full cycle
I'll definitely look into both once I know basic k8s
Yeah I have no doubts I've heard both a million times but never bothered to google them
I'll be so happy once I get to that point
Full CI/CD + autoscaling
Yeah I'm nearly 100% python
Then I wish to mention you another fact regarding terraform
Trying to learn JS and its frameworks meanwhile but not really liking it
Terraform is from family tools of Infrastructure Provisioning, to have IaC, Infrastructure as a Code.
It is currently the most used tool with highest compatibility across providers, so it is a solid choice
but rumours go that it can become 2nd gen tool, because some 3d gen tools appear
the tools like Pulumi
the difference is
Terraform uses it own language to describe infrastructure
Pulumi is promising to become better, because it allows writing infrastructure code in normal programming languages, like Python (+4 others)
+CDKs
Oh damn that would be lovely
I love Python and prefer to do everything I could in it
I've added all of the mentioned ones to my to-do
One question - I rent bare metal from a provider that doesn't have managed Kubernetes like GCP AWS etc., I'm still going to be able to setup autoscaling right? They do have API for deploying and everything of course just not a managed k8s cluster service
... right?
What's wrong lol
well, devops people highly recommend to be not going this way. because it like the most painful way to do this 😉
Yeah but I pay 5x less for 5x more performance like this than if I went with AWS or something
yeah, that's a good catch
i am using Digital Ocean for now
because it is cheaper and simpler
what's the provider name?
Not sure if I should advertise stuff here so I'll DM you
oh my favourite one, the first provider
OVH as backup
Oh nice 😄
Would I be able to setup auto deployment and scaling stuff with Hetzner for my self hosted k8s? Should be possible right? Just probably a pain in the butt
Oh
Really
Let me see
So basically it integrates into it without having to do it on my own? Like building myself a wrapper or something
https://registry.terraform.io/providers/ovh/ovh/latest
ovh technically compatible too, but as far as I know, OVH is a fake cloud provider
it is not having hourly payments and momentarily server creation and destruction without setup fees, right?
Yeah I'm not a big fan of OVH (especially since their support is garbage) I'm just planning to use it as failover, but probably will go with DO as I run some DO servers also
Right
I am not sure how auto scaling in k8s works yet to say for sure.
going to learn it first ;b
Yeah I'm probably at least 3 months away from that lol was just asking
Either way the tools you recommended look very promising
If I will be not lazy, I'll learn k8s in those 3 months ;b
or at least I will get basics earlier to discuss stuff like that
I am glad that u see it 😉
I remember we argued about that
I'm only 3 days into and I'm barely alive I need some sleep so yeah we'll see how it goes
u was telling me that having infrastructure as a code is bad, manually clicking in GUI is better
Oh I still stand behind that lmao
I love GUIs
But automation is even better
I meant I hate doing CLI stuff
Either GUI or fully automated but no manual CLI
I see GUI as good only for monitoring and logging for now)
For example Prometheus + Loki + Grafana setup
But yeah these solutions are far superior obviously
Yeah that's really all I do with GUIs
The kubernetes dashboard is not very good
But a lot better to look at logs and stuff than having to run 20 commands a minute
And then yeah there's grafana
Whole another level
I'm way behind you in this field I have a lot of catching up to do
But I feel like I'm making good progress
I spend easily 12 hours every day on learning whatever comes in front of me anything dev stuff
Either way I'm about to head to bed now I probably also need a vacation after these 3 days with k8s
Good night
I am feeling like my profficiency grows too. With learning Kuberenets
it would be a full set of basic hard skills for me I think
going to learn after that just more general theory stuff for a bit softer skills
A bit eyeing wishfully Kafka though
yeah, that's one is probably for hard skills will be left then
it allows to write very neat architecture when u have too much microservices
instead of making direct API requests from one backend to another backend
in Kafka event streaming architecture, I will be able to attach just event listeners to Kafka stream of events
which will make less coupling of stuff, less code dependencies between microservces
Basically yes. https://registry.terraform.io/
This registry is registry of already written wrappers for providers. + documentation to wrappers
Terraform works like...
Your terraform code => Wrapper in GO => Provider API? => Provider, If I remember it rightly? Not sure.
AWS is not known for being cheap for sure
try to check Digital Ocean, Linode, Vultr? They should provide cheaper Managed K8s
I'm using all of the ones you listed but they are good for VPS not bare metal imo, they are very expensive at all of them hence why I'm using Hetzner
I'm going balls deep with self-hosted bare metal k8s
uh. ok.
Yes I already did regret it the first day but I'm going to do it lol
The only important trick about terraform though and other tools like that...
https://www.cpubenchmark.net/compare/Intel-Xeon-E3-1270-v6-vs-AMD-EPYC-7502P/3014vs3538
Plus 32GB vs 128GB
5TB transfer vs unlimited
Same price
$120/mo
...terraform keeps state of the infrastructure stored somewhere
in most basic setup, it keeps it in just files locally
Gitlab has specialized storage for terraform state out of the box, which makes it easy to use
+there is guide somewhere how to make the storage on its own in AWS like S3 storages 🤔 (it should be possible to make it in Digital Ocean then)
not sure if github has compatibility, the storage provided
Yeah I have no idea about any of that as of now, I have stuff I need to run and they don't need to be scaled cuz the load doesn't change thankfully so I think I'm on the right path of learning k8s first and then looking into automatic deployment etc.
Ansible is not needing any storages / servers / agents
that's the best part about it
it requries nothing to use it
Give me probably a week or two before we discuss these I have nothing to add to this convo I literally just looked them up an hour ago for the first time lol
But 100% gonna use them
just install its application at any machine (dev machine or pipeline machine), point to the target servers, run it
On the bright side I have my first fully functional k8s deployment... I think
🎉
None of the fancy stuff but it runs and does failover fine and that's literally all I need for now so I'm happy for now lol
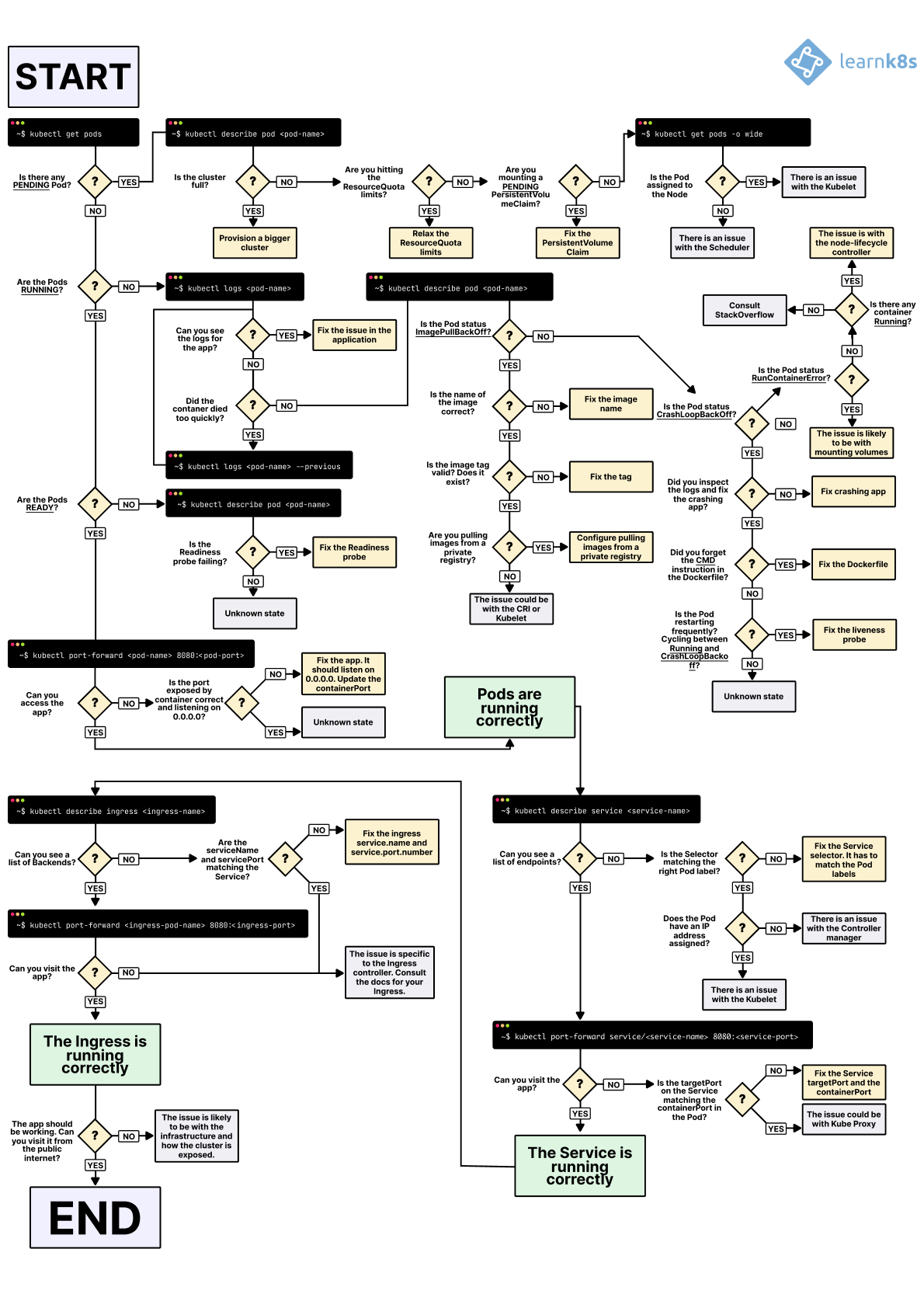
this picture of how to debug k8s was making me a bit scared)
Damn that's actually pretty helpful
Could've sent that maybe 3 days ago lol
That is incredibly helpful
Joink
u a welcome.
xD i did not start learning k8s, but already was able to help with it. yay.

🤣
zounds!
that diagram 
Hi there! Any chance someone would be willing to get on Voice+Screenshare and help me troubleshoot my Docker-Compose issue? You don't have to talk or anything, I will talk and answer questions while screensharing, I just really need help troubleshooting ❤️
Sure, I have a bit of spare time right now.
What channel is best? I know there is a restriction on screenshare
thank you very much by the way!
Let me ask if someone is around to give you perms to screenshare
I joined code-help-voice-1
hi folks: Poetry question
Here is my file structure
├── _config.yml
├── LICENSE.txt
├── poetry.lock
├── pyproject.toml
├── README.md
├── slack_bot
│ ├── __init__.py
│ └── slack_delete.py
└── tests
└── __init__.py
and here is my poetry:scripts segment
[tool.poetry.scripts]
slack = "slack_bot"
how can I another script for the slack_delete.py calling the main()
TIA
Why am I able to run commands from system-installed packages when inside a venv? I thought a venv was supposed to restrict access to those? ie. usbhub --help works in my venv even though pip install capablerobot-usbhub (the package responsible for providing the usbhub command) was only ran on the parent system and pip list from inside the venv doesn't show it being installed?
Being able to use that command does not mean that the module can be imported or will pose any risk to package conflicts.
A venv will isolate which packages can be imported, but it doesn't care about whether the python site's bin directory (which is where commands like usbhub and pip live) is on your PATH
I guess I don't understand what the difference between that and having the package "installed" in the venv is?
Is there a fundamental difference between being able to import a module and being able to run a command line tool (both from the same package) that I'm missing?
Yes. Being able to run a command line tool is a matter of your shell being able to find an executable matching that name. It searched all directories listed in your PATH environment variable. Since the bin directory of your Python site is on the PATH, your shell can find the command line tool.
For imports, Python's import system basically looks for packages in the directories listed in sys.path (from the sys standard library package i.e. import sys). This is completely unrelated to the PATH env var mentioned earlier.
Gotcha, so venv is intended for sys.path isolation but not PATH isolation?
Correct
The venv does prepend its own bin directory to PATH, so that it gets first priority.
But it doesn't remove any other python site bin dirs from the PATH
Cool, I'll have to read more on python path vs sys.path, etc. Thanks!
git problem: Let's say I have a repository in which I already made a lot of commits to certain folder, let's say /x/y/foo and now I want to separate that folder into a whole new repository. Would it be at all possible to transfer the commit history affecting that folder only into the new repository?
nvm, figured it out, I can just clone the old repo and run:
git filter-branch --subdirectory-filter <directory> -- --all
then clean up the history and other mess that remained:
git reset --hard
git gc --aggressive
git prune
git clean -fd
then just remove the old remote and add a one that points to the new repo
Can someone recommend a solution to apply my deployment.yaml from the repo via GitHub Actions on my self-hosted Kubernetes cluster?
is it possible to connect to this custer like it is VPS via ssh?
To the cluster itself I don't think so just to the master nodes, but that would be god awful
Think I found a solution from another server if anyone is wondering about the same: https://github.com/actions-hub/kubectl
But if someone has a proper solution please let me know
Another k8s question - how am I supposed to update a StatefulSet properly? If I do just apply I get The StatefulSet "mq-consumer" is invalid: spec: Forbidden: updates to statefulset spec for fields other than 'replicas', 'template', 'updateStrategy' and 'minReadySeconds' are forbidden
I could obviously just delete and recreate but that'd result in downtime
we use the azure one for pydis
what field did you get change?
I didn't change anything just wanted to pull the latest image, just found out about kubectl rollout restart and that worked like a charm for now
I'll probably switch to Flux or Argo for GitOps later just wanted something simple for now
For a non-azure cluster?
yep, just applies the specified manifests
GitHub
The community bot for the Python Discord community - bot/deploy.yml at main · python-discord/bot
Oh nice thanks for that, is pydis's CI/CD fully on GitHub?
Gonna be joinking from that it looks like lol
Last question, can you just trigger a rollout with the azure one so I can get rid of this one? (without apply of course as you can't on StatefulSet)
- name: Deploy to Kubernetes
uses: actions-hub/kubectl@master
env:
KUBE_CONFIG: ${{ secrets.KUBE_CONFIG }}
with:
args: rollout restart statefulset kubernetes-mq-consumer
yep, all our manifests are in https://github.com/python-discord/kubernetes, all CI scripts also open
hmmm good Q, that might not be possible with the Azure one
hey all, anyone has any opinion on this ?
Just found this from one of your workflows
https://github.com/python-discord/kubernetes/blob/main/.github/workflows/manual_redeploy.yml
- name: Authenticate with Kubernetes
uses: azure/k8s-set-context@v1
with:
method: kubeconfig
kubeconfig: ${{ secrets.KUBECONFIG }}
- name: Redeploy service
run: kubectl rollout restart deployment ${{ github.event.inputs.deployment }}
Worked like a charm 😄
Anyone has experience writing any kind of bot which is used to create accounts in bulk on sites like Twitter, Tiktok etc? I would like to know which proxies did u use. I tried free proxies, but it seems like every second proxy on the list is not working. What paid/free service did you use for your project?
ah yeah nice, I think that works because the Azure action pulls in a copy of kubectl
I did think something like that would work
Oh thanks for the explanation, I had no idea why does it work exactly but that must be the case as I have nothing else related to kubectl anywhere, super sweet and simple setup I got now. I'm new to GH Actions but I'm loving it so far
🙌🙌
Last question I promise 😄
Is pydis on normal k8s or k3s or something like that?
I can't decide which solution to dive into further, currently I'm running a k8s I configured from scratch but I see a lot of people recommending k3s, though I don't see a reason to use that when I already spent a week figuring out how to setup a complete k8s
k8s, entirely managed by Linode though
Sweet, thanks! I'm doing it the hard way currently, self-hosting all the nodes just to get more experience and have a better understand on how stuff works, and jesus christ its complex
Could a GitHub Actions guru help with figuring out why does this always meet the second if statement only?
steps:
- name: Checkout repository
uses: actions/checkout@v2
with:
fetch-depth: 0
- name: Get changed files
uses: tj-actions/changed-files@v11.9
- name: consumer.yaml has been modified
if: contains(steps.changed-files.outputs.modified_files, 'mq/consumer/consumer.yaml')
run:
echo "consumer.yaml has been modified"
- name: consumer.yaml has not been modified
if: false == contains(steps.changed-files.outputs.modified_files, 'mq/consumer/consumer.yaml')
run:
echo "consumer.yaml has not been modified"
The Get changed files step returns this under changed-files:
...
Getting diff...
Added files:
Copied files:
Deleted files:
Modified files: mq/consumer/consumer.yaml
Renamed files:
Type Changed files:
Unmerged files:
Unknown files:
All changed files: mq/consumer/consumer.yaml
All modified files: mq/consumer/consumer.yaml
In that run I'd have expected the consumer.yaml has been modified step to be true but it wasn't.
Examples: https://github.com/tj-actions/changed-files#example
I'm open for other solutions also if there's something better. I want to check if consumer.yaml has been updated, if so, delete and apply it on the Kubernetes cluster, if not, just trigger an image update (via kubectl rollout restart statefulset kubernetes-mq-consumer -n kubernetes-mq)
Are you sure that path is being included in the output var you're checking? You can echo its content in a shell script step, kind of like the example you linked except a for loop isn't even needed.
You could even echo what that if expression evaluates to if you want
Might provide some insight
Could you help with the code for that? I have no idea what am I doing I just started with GH Actions, let alone shell stuff
I've tried searching for just consumer.yaml first but that didn't work either hence why I adde the path
I've tried this but it didn't print anything for whatever reason
- name: List changed files
run: |
for file in ${{ steps.changed-files.outputs.modified_files }}; do
echo "$file was added"
done
But the echo built into the previous step did print the modified file Modified files: mq/consumer/consumer.yaml
Oh wait I'm an idiot
Are the id fields necessary? So it knows which step to get the data from
Yeah adding the id made it work for both versions with or without the path
Well that is embarrassing, sorry about that I went full 0 IQ lol
Sorry for completely hijacking this channel - I'll stop if someone has a discussion going already
Can someone recommend a solution for logging in Kubernetes to the same file from all pods on a node from Python? Preferably using the logging library, logging the stdout out works too as I already have a handler for it anyway. I need to ensure nothing gets overwritten so simply writing to the same file from multiple processes doesn't work as they overwrite each other
I'm looking for a last resort bulletproof local logging solution in case of a network outage or something that breaks my centralized logging (via Sentry)
lol you're good
we use Loki for Python Discord

Grafana Labs
Loki is a horizontally-scalable, highly-available, multi-tenant log aggregation system inspired by Prometheus. It is designed to be very cost effective and …
1 Loki instance, 3 Promtail instances (one on each node) that push logs into Loki, 1 instance of Grafana for querying Loki
That's for centralized logging I assume? What if a node's network it out, where do you write the logs locally?
I've heard people mention this setup quite a few times and looks tempting I just couldn't figure out if this works for local logs too
Promtail will retry for a bit I believe, the logs will always be accumulated locally in the Docker daemons running on your host so kubectl logs will pick up on them even after network outage
Ohh yeah that makes a lot more sense than how I thought it would work i.e. just giving up and losing the logs lol
Thanks man I'll set this up it looks sweet
Do you use something else for tracking errors and stuff or just the logs for this? I personally love Sentry but you can't really browse DEBUG/INFO logs there just errors so I need something for those now
The Grafana web view for logs is quite nice
Can it do some kind of notifications for exceptions and stuff like Sentry does?

that's the web query view
i think you can alert on stuff with it yea
but we built https://github.com/python-discord/olli to do that

GitHub
Olli searches your Loki logs and relays matching terms to Discord. - GitHub - python-discord/olli: Olli searches your Loki logs and relays matching terms to Discord.
Damn that looks sexy
you can do some cool things
I need to get into Grafana
of course like "include string" and "exclude string"
but uhhhh

rate of logs to NGINX by pod containing the string "HTTP/1.1"
yep
Yeah I'm setting that up
lul
A million times better than logging to a file lol
I see that one was for ingress-nginx-controller
How hard is it to integrate into stuff?
Grafana Labs
Install Grafana Loki with Helm The Helm installation runs the Grafana Loki cluster as a single binary.
Prerequisites Make sure you have Helm installed.
Add …
Is it kind of the same for all of them or each has to integrate specifically?
Adding this logging solution for something like ingress-nginx-controller for example, I assume you had to build that into its manifest to redirect its logs?
Ohh
So in my Python scripts I can just keep my stdout handler
And it will redirect?
so you just using logging as usual, it reads from docker logs and ships it off to loki
yep
Sick 😄
how did you point to docker logs of the needed container? just reading every available container logs?
docker logs are laid in some random named folders, with name equal to container ID
is there no problem with promtail properly setting up key for those logs? is it not setting up different key/hash each time container changes its ID? There is no problem with appeared out of nowhere multiple hashes/keys (due to container ID changing name of the folder) for those logs?
promtail figures it out
you can select by pod or by deployment
just learning j8s, not using yet at work
i was speaking about situation of just VPS with docker/compose running stuff
ah, unsure, have only used promtail inside k8s
all righty

Damn this is so sexy
Gonna spend the rest of this month setting up my grafana stuff finally
Unfortunately I can't setup Loki yet cuz https://github.com/grafana/helm-charts/issues/877

GitHub
please update this chart to be compatible with k8s 1.22.x instead of cluster role /v1beta1 make it v1 and update accordingly. or give me an idea so that I can use loki-stack properly. thanks. error...
hmmm
that's interesting
because

...
When I run the command I get
configmap/promtail created
daemonset.apps/promtail created
serviceaccount/promtail created
unable to recognize "STDIN": no matches for kind "ClusterRole" in version "rbac.authorization.k8s.io/v1beta1"
unable to recognize "STDIN": no matches for kind "ClusterRoleBinding" in version "rbac.authorization.k8s.io/v1beta1"

lul
I've asked support to see what they say
i think it's because we created the deploy on kube <1.22, so when we upgraded to 1.22 it was already in the migration step
Ah that makes sense
so if we tried to deploy it now, it would break, but since we already did it just got carried across
So what do I do in my case? I guess just wait?
The stuff you can setup in Grafana is wicked
I wanted to setup monitoring after logs so I guess I'm doing it in reverse order
hmmm yeah probably for now, hopefully upstream gets that PR merged to the chart
Alright thanks for all the help again man, if it wasn't for you I'd have quit learning k8s probably 20 times by now
The k8s Slack is just about as bad as any linux community, if you ask a single noob question you're cancelled + banned from life
hahahahaha no problem
I got it 😄 This is so sweet, I'll spend a month setting up sick graphs for all of this

If anyone else got the same, just change rbac.authorization.k8s.io/v1beta1 to rbac.authorization.k8s.io/v1 if you run v1.22 or higher
out of interest where did you change that?
through helm somewhere?
I've followed their other guide that sets it up via curl from https://raw.githubusercontent.com/grafana/loki/master/tools/promtail.sh so I just downloaded it, changed the version, and ran it with that without issues
riiiiiight gotcha, yeah that'd do it, nice one!
https://grafana.com/docs/loki/latest/logql/ a good reference for forming Loki queries
Grafana Labs
LogQL: Log query language LogQL is Grafana Loki’s PromQL-inspired query language. Queries act as if they are a distributed grep to aggregate log …
and if you then have results and click on them Loki will allow you to show context
so for exampleeeee
Damn
You literally just linked what I was looking for lol
This shit it complicated as hell but pretty much limitless

yeah, for 99% of cases you won't need to do anything more than specify where to get logs from and then optionally add a query element to that
you've got |= for direct contains, != for does not contain, |~ for regex, so on
rate({namespace="kubernetes-mq"}[$__interval]) is what I'm struggling with
I'm trying to get logs per minute for a namespace
But it splits it up by pod
throw a sum on there
sum(rate({namespace="kubernetes-mq"}[$__interval]))
if you add a sum in you can then go back to something that's grouped with something liiiiike

so you take the ungrouped stuff, sum it all together and then you can add further groups on top of that
hahaha yeah
In fact I probably will
it's neat stuff
you can also add inequalities to results that return an integer time series and you'll only get back values for when the result was over that threshold

I can't figure out what am I doing wrong, I have sum(count_over_time({namespace="kubernetes-mq"}[1m])) which gets stuck at values even if there were no logs in the past minute. Also, when changing the time range in the dashboard, the number changes also? Shouldn't it stay the same regardless of the time range since I'm only querying the last 1 minute of logs?

uhhh no 1m doesn't quite do that
it's defining the range vector https://prometheus.io/docs/prometheus/latest/querying/basics/#range-vector-selectors

An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
unfortunately, I'm not super in the know of what this actually means, @vague silo may have some idea of what goes on with the [1m] syntax, but I tend to just throw values in there until I get a graph that resembles what I'm looking for lol
Oh boy I should've known it's not gonna be as easy as I wanted lol
lul
Hmm are you sure? I've changed the calculation to Last from Last * (last non-null value) plus created an override to show 0 on no data and seems to be working now
Trying to find a flaw but seems to be working correctly
yeah, if you read that docs link it talks about what the [1m] is actually doing, it's the window used to calculate the rate
With regards to the changing value when changing the time range, that was because the interval changed as I had auto max data points, setting it to a high number fixed it so the interval isn't like minutes
But if you use it with count_over_time it should result in "last 1 minute`
Filters the streams which logged at least 10 lines in the last minute:
count_over_time({foo="bar"}[1m]) > 10
... I think
Seems to be working now with the fixes I mentioned above
how about installing kubectl in Ci/CD / or using image with kubectl, logging from it into cluster and applying deployment?
Yep that was my final solution, works like a charm so far
I've setup conditions to only do that if the deployment file changed, otherwise just trigger an image update
Loving that setup
I made helloworld in Linode Managed k8s from remotely connected kubectl 😉
next thing to find out, how to deploy some of my containers with frontend/backend
pods look like one instance of docker-compose ;b
They're even more than that, you can run multiple containers in one pod
that's what basically docker-compose does
besides describing relationships between multiple containers in one docker-compose scenario, we can even easily scale them by replicas N launch
[Creating first Package] [Using Jupyterlab to work with packages]
Hello. I am trying to import package which is written by jupyterlab (.ipynb format). The system report I can't find the module. What's the problem?
The function is located at "textanalysis" folder > "textanalysis.ipynb"
It returns: ModuleNotFoundError: No module named 'textanalysis.textanalysis'
https://ibb.co/dMpTcjc

My first ever panels for Loki, log feed + logs per minute for INFO, WARNING, ERROR and CRITICAL

Gonna be playing around with this for at least a month now 😄
and I am happy that kubectl basically has same commands as docker CLI
$ kubectl exec -it hello-pod -- sh
/src # apk add curl
fetch http://dl-cdn.alpinelinux.org/alpine/v3.8/main/x86_64/APKINDEX.tar.gz
fetch http://dl-cdn.alpinelinux.org/alpine/v3.8/community/x86_64/APKINDEX.tar.gz
(1/4) Installing nghttp2-libs (1.39.2-r0)
(2/4) Installing libssh2 (1.9.0-r1)
(3/4) Installing libcurl (7.61.1-r3)
(4/4) Installing curl (7.61.1-r3)
Executing busybox-1.28.4-r1.trigger
OK: 63 MiB in 27 packages
/src # curl localhost:8080
<html><head><title>K8s rocks!</title><link rel="stylesheet" href="http://netdna.bootstrapcdn.com/bootstrap/3.1.1/css/bootstrap.min.css"/></head><body><div class="container"><div class="jumbotron"><h1>Kubernetes Rocks!</h1><p>Check out my K8s Deep Dive course!</p><p> <a class="btn btn-primary" href="https://acloud.guru/learn/kubernetes-deep-dive">The video course</a></p><p></p></div></div></body></html>/src #
I can even log into pod's shell and to do stuff manually! yay!
heh. with this thing I can forget about multiple VPSes, because I need just the one cluster to run all the stuff in the world!

Tbh k8s automatically solves the issues of setting up firewall 🤔 Awesome
I will not need to set this up for my VPSes, since the only available resources outside of k8s can be accessed only when exposed in services
what is this technology?
i mean the software
Software for which part?
Sudo isn't necessary for this
And you need to put RUN before each command
Remove the trailing slash on line 7
That should work afterwards. Try it out
There's a more optimal way I can show you in a bit
You're welcome
RUN apt-get -y update \
&& apt-get install -y \
libgdbm-dev \
&& rm -rf /var/lib/apt/lists/*
This is more optimal because all the commands are done with a single RUN, which means Docker only generates a single layer for the commands. It also has an rm at the end to remove the apt cache, which is just a waste of space after the lib is already installed.
I also recommend you move the COPY after all the apt-get stuff
That way, if you rebuild the image it can re-use the cached layer for the libgdbm install to save you some time
You probably want bundle install moved too, right?
I'm not sure what it is but presumably it depends on the files you're copying
Probably not, but I am not familiar with ruby so I don't think I can assist with that error
This is a Python server after all
Happy to help with the Docker stuff at least
Well if you can't figure it out maybe there's some IRC or reddit community. And there's also StackOverflow
Did you move bundle install after the copy?
Yes
Well probably slightly better to move it between the two copies. Again, to make better use of the layer cache. Chances are your gemfile changes less often than the rest of the code. So it'll be able to just use the cached layer and skip installing ruby gems except for the relatively rare case that you happen to update or add a dependency.
👍
GitHub
Discord Token Stealer Malware Protection. Contribute to ZaikoARG/TokenGuard development by creating an account on GitHub.
is this actually useful?
if the attacker can already access your files
you're screwed already
and won't this erase memory thats in use
TokenGuard seeks to destroy most of the conventional Token Stealers that people use. With this program you can mitigate almost everyone. That does not rule out that new Malwares can be created to avoid the protection of my program.
The solution would be a program that runs at kernel level, but sadly I am not a millionaire to do this
I ran many, many tests and couldn't find a way to get the reflected Token in my program's memory. So that problem in theory is solved.
as in memory that's being used by discord
Yes, the program is in charge of locating the memory address that contains the user's Token in the Discord process and deletes it.
so when discord itself tries to use the token, it errors?
Discord uses the Token when starting the application to log in. This Token is normally stored in LDB type files and for that same reason it does not ask you to log in every time you open the program. Discord clears the Token in those files so you can take it from there. My program deletes the content of those files therefore Discord requires that you always log in when you start the program. Once the program starts, a connection is created with the Discord server, when authenticating the program uses the User Token. But this Token, is reflected cleanly in the memory after establishing some type of connection with the server. This is due to a specific header called authorization, which is the one that contains the user Token
anyways it doesn't really matter
bc if malware is already running on your computer
it can do a whole lot more than just steal discord tokens
Assuming that Discord saves the Token in a variable to reuse it, for example, the content of this variable is not reflected in memory, only the header that contains the content of the variable is reflected after being used to establish the connection. Therefore, even if it is erased from memory, it would only be erasing garbage strings that remain in memory
That is why it is clear that the objective of my program is only to Prevent the use of these Malware, not to solve Malware that is found before use.
In addition to that I only speak that it seeks to prevent Token Theft, not malware in general
...how can i run a docker container in a development mode?
What do you mean by "development mode"?
like, i'm making changes to the files that go into it, so i'd like to be able to rebuild the image
oh
docker-compose up --build
Hello guys. I have an IoT device sending data to a raspbery pi device (serves as some kind of a gateway).
Which then sends data to a server which stores the data to a db (then allows other services to "stream" the data = every second sends a request to the db to fetch new data).
I want to use redis or some other tech to apply this properly.
Not sure which redis technology should i use. stream? or cache?
The main problem I am trying to solve is the latency between the gui displaying the data.
The data has to go through some kind of filter before displaying it on the gui
should requirements.txt specify the minimum version, or the most current version? I was just looking at a project from 2016 with super outdated req. , but >=. So most libraries updated anyway.
It depends. If you don't specify a version it will pull the latest. I prefer to pin to exact versions I have tested together and update them all at once every once in a while
yeah. that sounds as the best strategy
without precise version pointing, it is just a matter of hoping if it will break or not without knowing what was the reason to break %
i was wondering if its worth keeping the dependencies as low as possible, to enable "outdated" setups to still function. I use the latest versions, so i'm not going to be testing those older versions (would be too much effort anyway).
so essentially - why do you update your dependency versions, when it worked before with the older versions as well 😄
the biggest risk i can think of is that i might use new features that work on my system, because i use a newer version than required
I guess that depends on your use case. If you're deploying with Docker it definitely should not be an issue. I would probably start with newer versions and only downgrade if you find a problem in testing
updating to fix security issues ;b
all security vulnerabilities become world wide known at special web sites
if some person gets to know your framework / some app version.... he gets a way to a lot of different potentially stuff)
that's why the first smart decision is to disable in your web server showing which version you've got... and preferably to hide what's web server and framework u a using at all
but a dependency for scrapy>=1.1.1 will still install the latest change. so this isn't really an issue. newer installations will have the newer versions anyway. Systems that can't upgrade (for whatever reason) won't have the security fixes one way or another.
Thats what i was thinking as well @indigo zenith .
Thanks for your answers guys 🙂
Newer versions do not promise backward compatibility
only minor changes in professional teams promise that
but even in that case, once u have 1.2.0 (bigger than minor change) version, it can break everything
but >= will only install non-breaking afaik?
I don't see where it is promised
but then the strategy would be the exact inverse of what dowcet recommended -> leave old versions with >= and update implementations where new versions break stuff
$ sudo pip install -U pynvim
ERROR: Exception:
Traceback (most recent call last):
...
File "/usr/lib/python3.9/site-packages/cachecontrol/controller.py", line 329, in cache_response
self.cache.set(
TypeError: set() got an unexpected keyword argument 'expires'
reinstalled pip, removed installed packages etc etc, won't go away
what exactly is wrong here?
I don't know if I should put this here but I need to dockerize one Python/Tensorflow project. I don't know anything about Docker. Is someone available for help or can provide me some tutorial that helped you or seems good?
I've not worked with Tensorflow but this looks helpful: https://towardsdatascience.com/a-complete-guide-to-building-a-docker-image-serving-a-machine-learning-system-in-production-d8b5b0533bde

Medium
A complete step-by-step guide for building a Docker image (GPU or CPU) along with explaining all best practices that should be followed…
Thanks man
the headline promises the world.. maybe I will do this tutorial :p
can anyone help me with this, How to click on Allow or Block using Selenium in Python?

Treat it as chrome setting. Try to set the choice at Selenium initialization https://stackoverflow.com/questions/38684175/how-to-click-allow-on-show-notifications-popup-using-selenium-webdriver

Stack Overflow
I'm trying to login to Facebook. After a successful login, I get a browser popup:
How with the webdriver can I click Allow and proceed forward?
i tried setting choice at driver initialization, first I tried this but it didn't worked, the pop up was still there

and also this

but the pop up was still there,
somehow I manged to reach her by sending TAB keys, but when I tried to send ENTER key , it's not closing this notif, but when I tried do this thing manually (pressing tab on keyboard and reaching that cross and pressed enter from keyboard ) it closed it

Hey @split breach!
It looks like you tried to attach a Python file - please use a code-pasting service such as https://paste.pythondiscord.com
Hey @split breach!
It looks like you tried to attach file type(s) that we do not allow (.exe). We currently allow the following file types: .gif, .jpg, .jpeg, .mov, .mp4, .mpg, .png, .mp3, .wav, .ogg, .webm, .webp, .flac, .m4a, .csv, .json.
Feel free to ask in #community-meta if you think this is a mistake.
I am trying to convert this file to an .exe with pyinstaller but I it doesnt work
why does the .py work but the .exe closes as soon as I open it
@quick juniper @frigid burrow @sonic bay i was fooling around and i set up a gitpod for it, pm me for collab link
@quick juniper you should really invalidate those api tokens
yeah violating some TOS's there hehe
consider using an .env file and python-dotenv to load api tokens into your code
!pypi python-dotenv

Read key-value pairs from a .env file and set them as environment variables
or you can go a little more complex and implement your own configuration system and loader
but dotenv is great for simple config
hm?
like for the exchange rates api, probably?
which ones?
thanks
removed api keys
I guess those where the only ones
in my rep
, hopefully

no one used them yet
but I guess they can go and pull them our from history?
once on the internet, always on the internet
yep
I will try to revoke the link from api provider
that would be the best choice
if it's just a free exchange rate api, don't worry about it
yeah there's a bunch of it
@quick juniper could you open dms, so I can dm you?
sorry what is this exactly btw?
well for that i have to dm you too hehe
!pypi python-dotenv
Read key-value pairs from a .env file and set them as environment variables
!d os.environ
os.environ```
A [mapping](https://docs.python.org/3/glossary.html#term-mapping) object where keys and values are strings that represent the process environment. For example, `environ['HOME']` is the pathname of your home directory (on some platforms), and is equivalent to `getenv("HOME")` in C.
This mapping is captured the first time the [`os`](https://docs.python.org/3/library/os.html#module-os "os: Miscellaneous operating system interfaces.") module is imported, typically during Python startup as part of processing `site.py`. Changes to the environment made after this time are not reflected in `os.environ`, except for changes made by modifying `os.environ` directly.
This mapping may be used to modify the environment as well as query the environment. [`putenv()`](https://docs.python.org/3/library/os.html#os.putenv "os.putenv") will be called automatically when the mapping is modified.@quick juniper ```py
import dotenv
import os
env is a dictionary of all environment and .env defined values
the order below overrides all .env vars with os.environ
env = {
**dotenv.dotenv_values(".env"),
**os.environ,
}
So to use this, you could do something like:
```py
# file: .env
API_KEY='-------------'
``````py
# file: main.py
# using the above import and env...
TOKEN = env["API_KEY"]
With this setup, you wouldn't want to commit .env at all, and you keep that private and for your own secrets
you'll need to install python-dotenv, and the package name does not match the import name
lol just realized that, literally
that didn't work
from dotenv import dotenv_values
config = dotenv_values(".env") # config = {"USER": "foo", "EMAIL": "foo@example.org"}```
This notably enables advanced configuration management:
```py
import os
from dotenv import dotenv_values
config = {
**dotenv_values(".env.shared"), # load shared development variables
**dotenv_values(".env.secret"), # load sensitive variables
**os.environ, # override loaded values with environment variables
}```I guess this is the way
@velvet spire would you consider it good practice to use load_dotenv() and reference os.environ everywhere?
The reason I personally don't do that, is because then my terminal environment is modified when I leave the program. This has led to me using the old configured value when I start the program again
Its fine when you aren't constantly changing the config, although that ends up being what I often am doing 😅
err, i dont think it works like that. Env vars are passed from parent process to child process, always afaik
os.environ```
A [mapping](https://docs.python.org/3/glossary.html#term-mapping) object where keys and values are strings that represent the process environment. For example, `environ['HOME']` is the pathname of your home directory (on some platforms), and is equivalent to `getenv("HOME")` in C.
This mapping is captured the first time the [`os`](https://docs.python.org/3/library/os.html#module-os "os: Miscellaneous operating system interfaces.") module is imported, typically during Python startup as part of processing `site.py`. Changes to the environment made after this time are not reflected in `os.environ`, except for changes made by modifying `os.environ` directly.
This mapping may be used to modify the environment as well as query the environment. [`putenv()`](https://docs.python.org/3/library/os.html#os.putenv "os.putenv") will be called automatically when the mapping is modified.using load_dotenv loads it into this dictionary
and that dictionary has some special hooks
!d os.putenv
os.putenv(key, value)```
Set the environment variable named *key* to the string *value*. Such changes to the environment affect subprocesses started with [`os.system()`](https://docs.python.org/3/library/os.html#os.system "os.system"), [`popen()`](https://docs.python.org/3/library/os.html#os.popen "os.popen") or [`fork()`](https://docs.python.org/3/library/os.html#os.fork "os.fork") and [`execv()`](https://docs.python.org/3/library/os.html#os.execv "os.execv").
Assignments to items in `os.environ` are automatically translated into corresponding calls to [`putenv()`](https://docs.python.org/3/library/os.html#os.putenv "os.putenv"); however, calls to [`putenv()`](https://docs.python.org/3/library/os.html#os.putenv "os.putenv") don’t update `os.environ`, so it is actually preferable to assign to items of `os.environ`.
Note
On some platforms, including FreeBSD and macOS, setting `environ` may cause memory leaks. Refer to the system documentation for `putenv()`.
Raises an [auditing event](https://docs.python.org/3/library/sys.html#auditing) `os.putenv` with arguments `key`, `value`.
Changed in version 3.9: The function is now always available.subprocesses
!d len
heh, can't delete it. anyway, i'm learning so much today. !d is cool 🙂
ow
mindblown 😄
heh i wrote a slash command implementation of this doc command with autocomplete

i'm not well versed in discord, how do i trigger it?
its not in this server, heh
ah that's a pity
yep I'm pretty sure this is the case
I tried really, really hard to pass env variables from child to parent, but it's only possible with gdb hacking iirc
this tickles my curiosity .. 😄
ask and ye shall receive
https://unix.stackexchange.com/a/586641

Unix & Linux Stack Exchange
How might it be possible to alter some variable in the env of an already running process, for example through /proc/PID/environ? That "file" is read-only.
Need to change or unset the DISPLAY varia...
technically anything is possible with enough gdb tomfoolery 🤔
I don't completely understand but I've seen tools that
- stop a running process with SIGSTOP (uncatchable)
- mess around with the registers to load/initialize a dynamic library
- then restart the process with SIGCONT (uncatchable)
I also learned that you can run code when a dynamic library is loaded which I didn't know was possible
so that unlocks many possibilities
anyways
heh heh
so yeah any process could do that to that poor bash, not just its child process 🙂
without root: ```Attaching to process 81550
Could not attach to process. If your uid matches the uid of the target
process, check the setting of /proc/sys/kernel/yama/ptrace_scope, or try
again as the root user. For more details, see /etc/sysctl.d/10-ptrace.conf
but yea fun 🙂
pffft, i wish gitpod had a read-only mode
or some kind of granual permission system
right now, it's like.... knowing the workspace url / demo url gives anyone full control (including of github/gitlab/whatever you authorized gitpod with)
wyr: vscode or atom or sublime text
Ive done pip install six and sudo apt install python-testresources
What else could be missing so six.moves gets detected ?

using vscode
Not familiar with that library but do you mean to import moves from six maybe?
this one:
https://six.readthedocs.io/
(it would be from six import moves)
Good point, do that @chilly hazel
Ive done pip install six and sudo apt install python-testresources , apparently itsa common issue with pylance, any idea how to fix this
a question if a i have two branches with git and i still want to keep one upto date with my main branch for parts which are same except the ones which are changed how can i do that. like if i add new files to the main branch i want to be also add them to the another branch
Hope this helps maybe https://stackoverflow.com/questions/18115411/how-to-merge-specific-files-from-git-branches
Stack Overflow
@deep estuary Have you tried ArgoCD or Flux for deployment to k8s? If so, what are your thoughts? I've had at least 15 people recommend Argo to me and just about to dive into it
(sorry for the ping just curious about your opinion)
Haven't tried either I'm afraid, heard good things about Argo though
I'll spend at least a week with Argo and report back here, it sounds awesome on paper
<@&831776746206265384> !rule 5
it sounds interesting.
I am for now in love with Gitlab CI
but with change to k8s, I guess it would be interesting to try argo if it is better fitting
It's only been a few hours but holy crap I love it
hahhahaha
I'm using GitHub actions currently and this is like that but on crack
I often have to fight with GitLab CI a little bit.
But I think I got the hang of it now
Sexy af imo

My final setup will be multi-cluster (multi-region with a cluster in each region) and from what I hear Argo is a must for that

main and master are different branches here
I pushed numreous files but in the github repo there's still only README file only
you commited changes to a master branch but the default branch is called main
so i need to push all my codes again as main?
you want to click on that compare and pull request, merge changes and in the future commit changes to main
it's showing error when to push as main
error: failed to push some refs to 'https://github.com/dsfsf/
I am wondering how one might set different loggin levels for different packages/libraries/modules using loguru. Anyone know?
anyone who can clarify attach_pydevd.py to me? "normally", you'd import pydev and call settrace, but attach_pydev can inject this logic into any python process, is that right?
If it is public branch available to others...
Best would be to add reverting commit in order to be not breaking other people stuff with your force pushing
But yeah rebase can delete it without any trace left
git revert commithash
Adds commit to the end that reverts the chosen commit
Not sure about the syntax clearly
Atlassian
Learn how to use Git revert to undo changes in git. This tutorial teaches popular usage of git revert and common pitfalls to avoid.
It's important to understand that git revert undoes a single commit—it does not "revert" back to the previous state of a project by removing all subsequent commits. In Git, this is actually called a reset, not a revert.
Yes it removes commits in the middle. But it keeps history
It does not delete stuff
It adds reversing commit
Yes, with an interactive rebase.
yes you can reword yeah in interactive rebase
replacing pick with edit for that or smth like that
as long as you did not force push, yes.
may be u a just invoking it wrongly.
git rebase -i HEAD~10
where 10 number of commits back
yeah, just leave it as pick ;b
as long as rebase was finished. which you can verify with git rebase --continue and git status
it should give a tip, if it is finished and a time for commit or anything else
i have no idea what --edit-todo does
just check on small amount of commits to find out
you are supposed to force push
git push --force-with-lease
it is dangerous operation that overwrites remote stuff with your local stuff
be sure to make when you are completely sure that current branch will not break anything
force overwrites a remote branch with your local branch. --force-with-lease is a safer option that will not overwrite any work on the remote branch if more commits were added to the remote branch (by another team-member or coworker or what have you). It ensures you do not overwrite someone elses work by force pushing.
Hi is here anyone familiar with setuptools_scm?
I'm trying to pump up the version of a package according to git tag but it automatically bumps one version up from the existing tag which i actually want as my current version
Stack Overflow
I want to use setuptools-scm to control my package version. My setup.py:
setuptools.setup(
...
use_scm_version={'write_to': 'my-package/version.py'},
...
)
Currently I have v0.2 tag in my rep...
this post describes my problem and solution but there is a small problem in the solution
the method in here automatically appends .post in version
can someone help?
pip3 install torch==1.10.1+cu102 -f https://download.pytorch.org/whl/cu102/torch_stable.html
How would one express this -f argument in poetry?
not supported https://github.com/python-poetry/poetry/issues/1391

GitHub
I have searched the issues of this repo and believe that this is not a duplicate. I have searched the documentation and believe that my question is not covered. Using: Python 3.7.3 Poetry 1.0.0b1 F...
😠 😠 😠 😠 😠 😠
I haven't actually needed it though. was just wondering.
unfortunately, this problem mainly affects pytorch and so not a lot of others want to implement it, most of the comments on that issue are pytorch users
it's kind of at PyTorch for distributing that way, as someone says "Why the hell isn't a big project like PyTorch published on a PEP-conform index? I opened an issue (pytorch/pytorch#26340) some time ago -- so far without any concrete reaction. I actually like the strict policy of Poetry. PEP exists for a reason."

ultimately, -f will probably get removed from pip at some point, and then they'll have to adapt
using a CPU version of pytorch, you might as well do deep learning with numpy
lol
I don't think pipenv supports this either actually
so it's pip only
and neither will add it because it's going to get removed soon
wow
so pytorch need to become modern
a deep learning library isn't modern
wtf
what even is modernity?
I'm becoming cottagecore. goodbye.
!duckify 921774042913071184
my fav stel quote of the day
I didn't know "stel quotes of the day" were a thing
you just keep coming up with bangers, I'm going to have to start framing them soon
I'll try to keep it up 
I've been there already. Just... don't
You can specify a dependency using a URL, but if you have anything depending on pytorch (e.g torchvision, torchaudio) poetry won't be able to resolve the CPU/CUDA labels as being the same version
we should make pytorch a dependency for @rancid schooner
To answer your question, you can install pytorch specifically with https://python-poetry.org/docs/dependency-specification/#url-dependencies
But it'll easily break
Dependency specification Dependencies for a project can be specified in various forms, which depend on the type of the dependency and on the optional constraints that might be needed for it to be installed.
Version constraints Caret requirements Caret requirements allow SemVer compatible updates to a specified version. An update is allowed if th...
The URL being https://download.pytorch.org/whl/cu102/torch-1.10.1%2Bcu102-cp39-cp39-linux_x86_64.whl assuming you're using linux and Python 3.9
Full list at https://download.pytorch.org/whl/torch_stable.html
do you guys have any recommendations for config files/management? i found the classic configparserbut also some more fancy frameworks like facebook hydra
i am using just environment variables + dotenv library for local deving to upload .env file to simluate env vars 🤔
not felt the need for more complicated configparsers yet.
although there was one case when I needed
I just wrote configs in YAML then and loaded the YAML
YAML is human friendly format to write config stuff too
---
doe: "a deer, a female deer"
ray: "a drop of golden sun"
pi: 3.14159
xmas: true
french-hens: 3
calling-birds:
- huey
- dewey
- louie
- fred
xmas-fifth-day:
calling-birds: four
french-hens: 3
golden-rings: 5
partridges:
count: 1
location: "a pear tree"
turtle-doves: two
easy to represent dictionaries and lists and strings and numbers
theres so many options... json, toml, ini, yaml 😮
ini+toml look like from windows era
json is good, but it is better to use for requests.
and it can be used for configs of course, and it is used in javascript everywhere for configs, but I think yaml is better
yaml is used everywhere in devops tools that often deal with config management too
it is surely saying smth
ultimately it is just YOUR CHOICE what is MORE HUMAN readable for YOU. and for average another developer
choose the one that is easier to read and write for humans, while still capable to represent all the data you need
that's the point of configs
I havent got any help in the help channels, could someone chime in?:
I am trying to create a CLI tool for our team to connect to a remote server via sshtunneling. However, i am running into issues where the error message says the SSH BANNER PROTOCOL is not available or something. my code:
with SSHTunnelForwarder(
(SSH_TUNNEL_IP_ADDRESS, 22),
ssh_username=SSH_USERNAME,
ssh_pkey=SSH_PRIVATE_KEY_FILE,
ssh_private_key_password=SSH_PRIVATE_KEY_PASSPHRASE,
remote_bind_address=(REDSHIFT_HOST, REDSHIFT_PORT),
local_bind_address=("0.0.0.0", 15439),
) as tunnel:
print("Success -- Server up and running....")
client = paramiko.SSHClient()
client.load_system_host_keys()
client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
conn = client.connect( # <---- breaking here
hostname="127.0.0.1",
port=15439,
username=REDSHIFT_USERNAME,
password=REDSHIFT_PASSWORD,
banner_timeout=30
)``` the same credentials work in a jupyter notebook, however, i find it annoying to have to copy and paste the ssh tunnel in every notebook i createSorry I have nothing more useful to say on this but if you don't get an answer here, I would maybe try #networks .
i would argue that there's almost no good reason to use "ini" when you can use TOML, because the latter has a spec and the former does not
try to avoid using json for human-editable configs, unless you are using an extended parser or format that supports comments and trailing commas (like json5 https://json5.org/)
Point taken. Yaml has comments
yaml can be a good option, but can get messy for complicated config files due to the large number of syntax rules. and the type coercion rules can be tricky too
toml is probably the safest option for most use cases, but if you need a lot of nesting, consider json5 or yaml
also can get messy for a lack of validation
wdym for lack of validation?
of course there is also dhall... or even just python or lua scripts
don't forget that lua was originally a config syntax!
there's a json5 library https://pypi.org/project/json5/

yaml unsafeload
oh, that. imo that's a bug in the python library that they preserved for backward compatibility 🙂
yaml.safe_load is a thing
whoever thought adding all this xml serialization junk to yaml was a good idea really needs to get their head checked
so much for separation of concerns
Regarding poetry, how can uvloop>=0.16; sys_platform != "win32" be achieved? So far I've found the platform keyword and did uvloop = [{ version = "^0.16.0", platform = "linux" }] but I'm not sure if the two are equivalent
That's called an environment marker. Poetry supports that https://python-poetry.org/docs/dependency-specification/#using-environment-markers
Dependency specification Dependencies for a project can be specified in various forms, which depend on the type of the dependency and on the optional constraints that might be needed for it to be installed.
Version constraints Caret requirements Caret requirements allow SemVer compatible updates to a specified version. An update is allowed if th...
is there a python package for cron job creation/management?
sort of yes
https://docs.celeryproject.org/en/stable/userguide/periodic-tasks.html
there are Celery beat pereodic tasks
in my opinion it is superrior to cron
if you wish to manipulate exactly cron installed at OS, there are solutions too.
Ansible is technically python ;b at least it exists in pip packages
Anyone know how to configure sphinx i guess in config.py to lintcheck for anchors in url's?
by default lintanchors_check=True, but it reports all anchors as broken when opening the links in browser shows they aren't.
use of lintanchor_ignore list to ignore urls w/ anchors doesn't seem like a good solution.
I'll have a look. Thank you~

{kind=link}
{kind=link}
what's the name of the monitor program btw
workers = multiprocessing.cpu_count() * 2 + 1
this is what i use for workers
its auto conf on gunicorn
its glances
mm no, I am not sure what it takes
when i restart the server
everything is good and it uses like 800mb
and all of a sudden it goes up to 5gig
sick. even with exporting to grafana.
well i use full node for grafana and it does not say what program is using what amount of memory
I build a module using pybind11
But i am struggling to include the .pyi file in the whl distribution
setup(
description="A test project using pybind11 and CMake",
long_description="",
ext_modules=[CMakeExtension("cmake_example")],
cmdclass={"build_ext": CMakeBuild},
zip_safe=False,
extras_require={"test": ["pytest>=6.0"]},
python_requires=">=3.6",
include_package_data=True,
package_data={"src": ["py.typed", "init.pyi"]}
)
would actually be better if I don't have to do this. Celery looks promising. I've seen it around but wasn't entirely sure what it was for.
Thanks!
u a welcome.
Technically Celery is used in order to distribute nicely CPU load through Message Queue pattern across several servers
but it can serve as python level controlled cron jobs too
can you pass a hosts network connection through to a docker container? I have a small streamlit app and im playing around with docker but I can't seem to get the streamlit app to run a local network
ex host local ip is 10.106.1.2, streamlit image is 192.168.1.6 but I would want something like 10.106.1.3
With pyinstaller in the onedir mode, can I get it to move the binaries etc. to sub directory so the executable isn't lost in a soup of dlls?
<@&831776746206265384> we are raided. Check user names which reacted to my msg. As example those users share nickname Bored Ape Yacht Club
it's handled already, thank you
I'm looking for a trivial example for creating a setup for a script foo.py where I want to use setuptools to install it as a command line utility foo.
Chris Warrick
There are multiple ways to write an app in Python. However, not all of them
provide your users with the best experience.
One of the problems some people encounter is writing launch scripts. The
best
the setuptools docs have improved a lot in the last year or so
kudos to that team
thank you
how do i get sphinx to linkcheck urls with # anchors like for example:
https://github.com/ethereum/EIPs/issues#issue_4469
Hi I'm new to discord python. I just want to know where I can general python code help. I'm trying to figure what channel is the best. Any help would be great
i'm confused with all help channels
the help channels are part of a system where you can "open" or "claim" a help channel by asking a question. see #❓|how-to-get-help for details
thank you so much.
you are awesome
@tawdry needle I put it in the help channel. thank you for the tip again
Did someone dockerize Tensorflow project?
Does anybody know how to list EC2 instance in a region using boto3 client not resource object?
Hello gugs how bypass cloudflare when i m scrapping website
!rule 5 boop
5. Do not provide or request help on projects that may break laws, breach terms of services, or are malicious or inappropriate.
Does anyone of you know how I can call another service which is hosted on the same kubernetes cluster?
@winged sequoia re #help-cake message i think i had removed Git from the dockerfile
I didn't get it
I do have git in dockerfile
RUN apt-get -y update && apt-get install -y git nano rsync vim tree curl wget unzip xvfb patchelf ffmpeg cmake swig @tawdry needle
NVM, I found mounting my local drive to be very useful. I do it like this docker run -v "$(pwd)":/root/code/.
that probably won't work on the cluster though
or will it?
it will since I do this in the mysterious yaml file
code:
local_dir: /path/to/code
Im developing a rest api in fastapi, did anyone configure a ci/cd workflow? what are your recommendations? I was thinking in aws and travis ci
Gitlab CI is certainly nice and easy to use
Never use Jenkins ;b It is from 1st gen and awful to use
Travis if I remember I was told fine, but I am not sure for sure
Did anyone use Docker to host Heroku project?
How to enforce pyright to break a pre-commit flow when it found errors?
Currently pyright shows errors but doesn't break the workflow and do pre-commit exits correctly (0 instead of > 0)
Using:
- repo: local
hooks:
- id: pyright
name: pyright
entry: pyright
language: node
pass_filenames: false
types: [python]
additional_dependencies: ['pyright@1.1.99']
Fixed with
- repo: https://github.com/kumaraditya303/mirrors-pyright
rev: "v1.1.199"
hooks:
- id: pyright
😄
So my file was too big to upload to GitHub so I had to use git lfs migrate import --include="*filename". I guess I that if I delete that resized file from my local repository in next clonings it will not be downloaded - is that right?
Hi Team, starting with trying to learn to automate such workflows on my work, I need to use a lot of RestAPI cases to do so.
Can you shortly offer my your suggestion better to use Python-Request or Python-http.client ? thx
*I wrote a program that depends on APSW ||(https://rogerbinns.github.io/apsw/)||,
via peewee ||(http://docs.peewee-orm.com/en/latest/)||.*
Q 1: How can I state this dependency when packaging to pypi? Whats the best way to do this with flit?
Q 2: If this isn‘t possible, what is the best way to inlude it in the package? How can I do it in a way so peewee can import it directly? Do I have to inlude a .pyd for each python version and each platform?
Q 3: How can I include it in an executable built with pyinstaller?
__Extra: __Any guides available or states best practices?
Thanks!
please reply with ping!
How many works one celery worker instance does in parallel? By default, and could it be customized?
Found.
Default is auto equal to host amount of cpu
Can be changed with concurrency flag
Hello,
I made a program with pyswip, but when I export it with "pyinstaller --onefile -w main.py" and try to execute it shows typical errors when not using pyinstaller package
How can I add pyswip to my executable file?
Note: pyswip is installed via pip
Hey @heavy knot!
It looks like you tried to attach a Python file - please use a code-pasting service such as https://paste.pythondiscord.com
This is malicious and not appropriate for this server. See rule 5.
I mean not really, you could just label it as a server scanner
you can specify to scan for vulnerable versions or just a plain old mc server
might be wrong channel but anyone knows how to pull stuff from github (when you have existing files) and prevent stuff from clashing
or does pulling stuff just override existing stuff
pulling is just fetch (download from GitHub) + merge (fix conflicts)
any decent ide should have an interface that lets you fix conflicting lines in a merge
then just commit once you resolve all merge conflicts
hi quick git question, I hope this is the appropriate channel
if im in a detatched head state shouldnt i be easily able to switch branches without needing to commit

ohhh alr thanks
!rule 5
5. Do not provide or request help on projects that may break laws, breach terms of services, or are malicious or inappropriate.
It is against the TOS
scrape a bit at the time
or use multithreading/multiprocessing
what?
that can't be right
people are constantly getting help with web scraping
Stack Overflow
Most of the time when I try to checkout another existing branch, Git doesn't allow me if I have some uncommitted changes on the current branch. So I'll have to commit or stash those changes first.
Is there any dependency management tool that supports locking transient dependencies, and supports multiple lists of dependencies I can install from? For example, separating prod deps, dev deps, CI deps, etc.
Ideally in a way where I can list a dependency once and then specify which environments its for. That way, I don't have to copy and paste a dependency and make sure the version stays the same for all envs.
On second thought, it seems complicated to have a single lock file and to support subsets of dependencies.
nox or tox might be able to serve your usecase
it manages different environments for testing and such, so its possible that you could use poetry's core and plugin system, plus that nox is configured with .py files, to make something to do this exactly how you want it
nox + poetry_core + custom scripts
Hey folks.
My brother has been attempting to trigger Terraform via GitHub Actions. He dropped me a note this morning and his action is hitting the following error:
╷
│ Error: Required token could not be found
│
│ Run the following command to generate a token for app.terraform.io:
│ terraform login
╵
Error: Terraform exited with code 1.
Error: Process completed with exit code 1.```Repository: https://github.com/neeamradia/RoboPhazis
GitHub
A general use Discord bot that will help facilitate repetitive day-to-day tasks. - GitHub - neeamradia/RoboPhazis: A general use Discord bot that will help facilitate repetitive day-to-day tasks.
Either you can drop him a message directly, or reply here.
Appreciate any help as I had a look and wasn't able to fix it for him!
Please do @ me in any responses.
@deep estuary - I know you have a fair bit of DevOps knowledge, any thoughts?
Have you had a read of this? https://learn.hashicorp.com/tutorials/terraform/github-actions

HashiCorp Learn
Automate infrastructure deployments with CI/CD using Terraform Cloud and GitHub Actions
Yep - that's what my brother followed. I cross-referenced everything he did with that tutorial and it all seems to be correct.
It's definitely there. If I don't use TFL cloud then it does create the IaC. Only when I add workspaces/organisations that it doesn't.
I might just wipe what he's done and re-set it up.
If it's there then I'm unsure I'm afraid I don't use terraform
Might be worth asking on the HashiCorp forums if you can't find the answer
hello 👀 is this the right place to go to if i want to learn about "vs code dev containers"?
i have an m1 macbook for personal use and windows machine for work, and would like to work on collaborative projects in the future on both machines
but figure i'll ease into it by trying it out for small solo projects
Depends on if your question is more about the VSCode side of things or the containers side.
both, 0 experience with containers, and about 4-5 hours using vsc so very minimal
coming from pycharm
What questions did you have? If you were trying to set it up already, the VSCode docs have guides. I followed them once for an MS event cause one of the labs was setting up code to run in a container.
i did just manage to open a project using a container that is running in docker just fiddling around. i guess the test will be whether i can replicate the environment on the other machine using the dockerfile & json file that i will push to github?
lmao mina
I feel like you would expect me to know about this 👀
but the truth is I'm watching because I tried to use containers in vscode once and completely failed so I'm watching
While using this approach to bind mount the local filesystem into a container is convenient, it does have some performance overhead on Windows and macOS. There are some techniques that you can apply to improve disk performance, or you can open a repository in a container using a isolated container volume instead
https://code.visualstudio.com/docs/remote/containers#_system-requirements
what are the 2 options that this paragraph is describing? which do you guys do?
I always have used a bind mount because it's the easiest to set up and the performance impact has not been noticeable for my work.
It's not specific to compose but you can configure compose to use one
does this create a bind mount or a volume by default?
# Overlay for local development
version: "3.8"
services:
api:
build:
dockerfile: Dockerfile-dev
environment:
- DEBUG=true
- JSON_LOGGING=false
volumes:
- ../shared/python:/shared/python
- .:/app
ports:
# Debugpy
- 9091:9091
e.g. for .:/app
Those are bind mounts
Any time you're mounting a path from the host, it's a bind mount
I hope I didn't overlook some case where that's false
aha, this explains it
Stack Overflow
In the Docker Compose documentation, here, you have the following example related to the volumes section of docker-compose.yml files:
volumes:
(1) Just specify a path and let the Engine create a
thanks
Np
version: '3.8'
services:
web:
build:
context: .
dockerfile: dockerfile
volumes:
- static_volume:/app/web/build/static
expose:
- 8000
- 8001
env_file:
- ./.env.${mode}
nginx:
build: ./nginx
volumes:
- static_volume:/app/web/build/static
- ./ssl:/app/web/ssl
ports:
- 443:4000
- 80:3999
depends_on:
- web
volumes:
static_volume:
Alternative to binding would be using this
this creates volume from scratch that is shared between two containers 😉
this is basically example how to serve static files from python web project with Nginx, that reverse proxies requests to python in addition
Anyone know how to make pytesseract work better for single digits? I am trying to OCR some very clear digits but it's not identifying them correctly most of the time... The images look like the image I attached. I was using tesseract tesseract example.png stdout --psm 10 --oem 3 and I tired whitelisting and other solutions aswell with playing with the other psm's and oem's but to no avail... It thinks the image I attached is "3)" and not "5".
Does anyone know any other OCR resources that will work well for this? I don't wanna train my own set ._.

Preprocessing
And model tuning
Try to invert image colours
And to make it as clear from nose as possible
I tried inverting too, It got more confused when it's black on white than how it is now
Plus I think it should be possible to tune train model to recognize specific stuff better
Play with more adjustments, try resizing
Try cutting image from extra spaces
Couldn't get it to work with tesseract, switch to easyocr
i need elevated permissions to update wsl to wsl2, which is required for me to open a project in a remote container, or so vsc tells me
if i try going the non-wsl2 route and use docker directly i still need perms: access denied, you are not allowed to use Docker. you must be in the "docker-users" group
i had the previous IT guy install docker for me but never completed the full setup it seems
docker by default only puts the user installing docker to docker-users
yeah that's how i see it's setup currently
do you bother with wsl2, or no?
wsl2 only, HyperV Docker isn't very good
nice, thank you!
Not sure if this is the right channel for this, might ask anyways tho since no1 was able to really help me yet
Hello, very specific question: I have a python code that sends a txt file to my dropbox using the dropbox api app i made, howver the token only lasts for 4hrs, how do i request a new OAuth2 token with app key and apps ecret as well as authorization_code? Does anyone maybe know ?
I've been trying to do this for 3 days now but always get some errors and wasn't able to find working code on github or stackoverflow
Problem solved.
do someone have experience with hosting tensorflow dockerized project on heroku?
Anyone willing to give me a hand troubleshooting my Docker container? Should be relatively easy, I just need to adjust paths, best if we can hop on voice so I can ask questions more easily 🙂
So I've been using the pipenv library in my projects to manage dependencies and keep my global environment pretty clean
Problem is that the devs for it refuse to add the ability to set minimum/maximum Python version requirements for a given project
Since I want my apps to have as much compatibility for users, I check what the minimum version of Python my project requires with the vermin library, and then set that as the Python version that pipenv should use
The problem is that I like to use newer python versions, and I'm sure other users would be in a similar boat
Are there decent well-supported alternatives to pipenv that you guys would recommend?
hey so i know this might not be the right server to ask but can someone recommend me some good budget vps services that have unlicensed windows as an os
Anyone Use VS code
VS Code
https://pythondiscord.com/pages/resources/guides/asking-good-questions/ ask the right questions
Ok
Hi, not sure if this is the correct channel.. please correct me if im in the wrong place.
I googled my ass off, but could not find a way to collect translations strings from the complete project. Only for one file at the time.
Does anyone know if its possible to scan a complete project in one command with:
/pygettext.py -a -d base -o locales/base.pot app
Do you mean to install the cv2 package? Try pip install opencv-python
i'm not sure if this is the right place, but I need some help testing a multi-Docker-container application consisting of 3 FastAPI servers that communicate in the local Docker network
my basic app structure has two standalone containers A,B (that do not expose external ports) and a third container C that provides the frontend-facing API. C exposes a port to the host machine and makes HTTP requests to both A, B
in container C I have hardcoded the addresses of the local docker containers to send HTTP requests to, however this means that I can't unit test C without starting the full application
is there a better way to structure my application so that I can still unit test C individually
separate tests to two categories:
unit tests which can be performed without third party dependencies. Mock if needed to get better coverage at their level
have written CI/CD pipeline that deploys infrastructure to staging environment, where you can run all your tests unit + integration automatically.
alternatively you could have... it running still at dev machine if you will make docker-compose as part of your tests for example 🤔
instead of regular run tests command, you can make them running as docker-compose run tests
which would be firstly raising depended containers and then running tests from inside the app container.
this option can be easily integrated into CI/CD later too. You will need DockerInDocker image to launch the tests in pipeline though
and yes, it is the right place 😁
ah i see. so basically i need to separate C's basic program logic out from the actual fastAPI serving functions and unit test just the program logic which can be done with appropriate test stubs. Then testing the server itself should be done in the CI/CD stage?
basically yes. Or as I said you could test the server itself locally in docker-compose
but with jumping straight to Ci/CD stage testing you would write less code I think. CI/CD stage testing is always required IMO, while local integration testing is probably unnecessary effort
So CI/CD pipeline would be smth like that for you
Run unit tests
Deploy to staging
Run integration tests
Save result to docker-registry ;)
i already have a sort of local integration testing by starting the docker application locally and then sending requests using pytest
sounds like i could just add this to CI/CD and be done
👍
if something automatized, if it not needed being remembered.
if smth goes wrong, u get email notifications anyway
small drawback to spend money for staging infrastructure though. But it is always justified for work projects 😉
usually not justified for home projects though.
yes
$ git clone https://github.com/username/repo.git
Username: your_username
Password: your_token
How can I pass username and token in the first line itself?
you can't really do that i think. if you want input-less authentication then use ssh git clone
I'm trying to automate code update on multiple VPSs using paramiko so I'm not sure how to pass git pull origin main command now as it requires username and token later
well, if you clone using ssh you won't need username and password
it will instead authenticate using your private key
I'm not sure how does ssh clone work, I'm only familiar with git clone link_to_repo
can you guide me a little on this?
you can always use expect program (exists as linux and as python program) to automate scripts that require human inputs, BUT
using the ssh keys would be less troublesome
can you point me to some resources that explains using ssh keys for cloning?
what is your operational system?
you can go to google and type in 'git clone using ssh'
VPSs are all linux, the update script will run on windows
thanks!
all right, lets suppose you use linux system then
open any linux system
write ssh-keygen
and you get this stackoverflow link: https://stackoverflow.com/questions/6167905/git-clone-through-ssh
and the answer by dsrdakota is pretty good.
Stack Overflow
I have a project on which I created a git repository:
$ cd myproject
$ git init
$ git add .
$ git commit
I the wanted to create a bare clone on another machine:
$ cd ..
$ git clone --b...
GitHub Docs
it will show you public part of your SSH key
insert the key into your Github/Gitlab account settings ssh keys
that's it.
use ssh version
git clone ssh@blablabla
to do stuff without password now
it will utilize ~/.ssh/id_rsa (private part of your key) for that
okay, thanks both @rapid sparrow and @west loom for help, I'll try it out
u a welcome. You can also generate keys in windows, by using Gitbash CLI (or whatever it is named)
yeah, I use git bash only on win so it should not be an issue