#tools-and-devops
1 messages · Page 71 of 1
Does anyone else routinely make python tools to distribute to non-programmers?
I work in a lab and there aren't many programmers, so whenever a programmer does make a tool, they package a distribution of python with it, and point the runfile to their own distribution. As a result all the guys in my lab have like 500 versions/distributions of python on their computers
Docker?
I make a lot of scripts for family and friends to help with their stuff and I distribute them via Docker
Honestly Docker sounds cool but it also sounds like another layer of software. I want to make a script to standardize everyones pathfiles and python file locations
Well Docker is there to solve that pretty much
But I haven't looked into Docker before, maybe its a good solution
thanks for the suggestion
its open source?
It is
I don't have any idea about pika, but I found this: https://github.com/albertomr86/python-logging-rabbitmq

GitHub
Send logs to RabbitMQ from Python/Django. Contribute to albertomr86/python-logging-rabbitmq development by creating an account on GitHub.
It may help
Yeah I'm basically trying to build a simple version of that as my training for building classes, I'm not sure what's the part that is done properly in that but not in mine
Again, I can't really help you out, but maybe backtrace your solution, cop the github solution and start removing the irrelevant parts (testing after each "main" step) if no one answers you
Oh right that's a better idea
I started from the opposite end and tried to build it up till it works lol
I have not! thank you, similar experiences here
They also have a small but responsive Discord if you can't get something to work the creator might be able to help
hey, i'm using pytest and travis-ci to test my github repo and forgot that dataclasses are not supported by python 3.6. i have searched the crawlers, the travis-ci docs, and read quite a few blogs, but feel like i'm missing something insanely simple. is there a way to install just the dataclasses module as a dep for only python 3.6 on travis-ci so that my tests can pass?
Travis CI enables your team to test and ship your apps with confidence. Easily sync your projects with Travis CI and you'll be testing your code in minutes.
This was my initial yml config
os: linux
dist: bionic
language: python
cache: pip
python:
- 3.6
- 3.7
- 3.8
- 3.9
install:
- pip install -U pip
- pip install dateutils
- pip install -r requirements.txt
script:
- python -m pytest tests/
and now, i have this. not sure if this will pass though.
os: linux
dist: bionic
language: python
cache: pip
jobs:
include:
- language: python
python:
- 3.6
install_before:
- pip install -U pip dateutils dataclasses
- language: python
python:
- 3.7
- 3.8
- 3.9
install_before:
- pip install -U pip dateutils
install:
- pip install -r requirements.txt
script:
- python -m pytest tests/
what do you think?
@little lily put it in requirements.txt
dataclasses; python_version < '3.7'
@tawdry needle face palm lol
this is what happens when you're thinking about all the angles, you get lost in the details. i will give that a try. thank you 
yup, it worked. the simplest solution was the best. thanks again! 🥳
hey @tawdry needle i've got a scenario that might convince you of justuse as an alternative to the traditional deployment 😉
let's say you want to make a software for end users and you either have features that require big dependencies that the majority of your users usually don't need or you have "premium" features you want to enable via micropayments while distributing a slim "free" basic but functional software
in both cases, you could have a basic pyqt software that installs within seconds but hide the additional functionality behind buttons that trigger use() installations in the background and say "your feature is enabled now, enjoy" as a callback
it's like in those open world games that dynamically download and load parts of the world whenever the player reaches them, but not before
although i shouldn't say "alternative to traditional deployment" actually, it's a totally different approach, extending the possibilities
(the best) way to complile python files (and libraries) into one executable file as linux executable file (preferably without even python needed installed in OS)?
answer: Probably pyinstaller
that's an interesting idea
notably also deno supports using js modules directly from a url
to be clear, i think justuse is an excellent idea and would be really beneficial in something like repl.it or for beginners who don't want to learn about packaging and envs. i just personally don't have much use for installing packages from the web. i do however still intend to work on the "tracing" hot reloader that chillaxan helped me write the bytecode-scraper for
what's the hot reloader doing?
current existing hot reloaders can handle this
import foo
but not any of
import foo as bar
from foo import x
from foo import y as z
you need to trace the bytecode, checking for certain sequences of loading and binding
what do you do with instances of classes that were imported from a reloading module?
good question!
no idea
does anyone know how to deploy a flask + socket.io website
no idea how to
google doesn't help
Python Flask web pages can be asynchronously updated by your Python Flask server at any point without user interaction. We'll use Python Flask and the Flask-SocketIO plug-in to achieve this in this tutorial.
@fast garnet so you initially mentioned breakpoint and pdb, and ice been using them a lot now, but I stumbled across a version of pdb which adds some features and makes it just a bit nicer
!pypi pdbpp

pdb++, a drop-in replacement for pdb
pdp++ is essential for me
serious?
seems like a job for ProxyModule @urban pecan
i don't think you can trace assignments like a = mymod.x without hooking into bytecode
ah, I was just thinking about functions
I'm not sure how reloading an assignment like that would work. Does your reloader handle that?
currently it's only a theoretical idea 🙂 but yes it is theoretically possible to trace those assignments in cpython bytecode
and what would you do with the tracing data?
i don't think we need that in justuse, our reloading approach is much cleaner and doesn't require backtracking
as long as the mod.attribute access is given, at least
oh, yeah, I meant instead of
and since we discourage reloading of modules that contain anything except functions, there's no problem
I'm not even sure how an arbitrary assignment could be reloaded unless it's a class or a callable
but class instances never get reloaded
afaik
well, i'm sceptical but also curious to see what @tawdry needle is gonna come up with
yeah, where's the code?
i'm also sceptical whether we could adapt it even if we wanted if we want to avoid confusing debuggers and interpreters with more black magic
some already have trouble with AST manipulations, bytecode is even worse
well using a proxy kind of side-steps that ussue, because the proxy part never changes, right?
yes
and we don't manipulate either AST or bytecode along the way, it's all fairly straight forward
on the other hand, maybe we could adapt parts of their bytecode approach, kind of gradual
indeed 😃
our approach basically as fallback and if the environment allows, switch to the bytecode approach
oh, looks nice, i'll go check it out later
@next spruce reloading live object is still quite hairy, not even sure what the defined behaviour should be
i'm still thinking signature-compatibility is the minimum for functions, but objects..
would you call __init__ again, for example?
__init__.py?
i mean if you reload a class and there are live instances, do you reinitialize those?
⚰️
if eval(repr(object)) == object
find all the top-level names that refer to objects in the hot-reloaded module and just overwrite them in globals() of course
you could test this equality automatically before trying to reload
and then re-build all objects from the module
i guess the other option would be to loop through globals() and dir(module) checking for object identity
i'd rather register all object-constructions and track them down that way
that would be simple via ProxyModule, but it's also doable by registering all classes within the module to some global store or decorate their __init__ maybe
what about using gc?
and replace those references directly?
yeah
daredevil approach
yeah, could work
but i think eval(repr(object)) == object must hold for this to have at least a chance to work
otherwise you can't make any guarantees about your objects at all
and constructors must not have any sideeffects or the whole thing is doomed
just imagine you register your object in a global dict on construction
meh, that's the user's problem
why is that?
and yes, i/o in init is bad
i/o at module level is bad
if you do those things, you don't get hot reloading
pick one
how else could you reconstruct your object in a meaningful way?
if you change the signature of __init__ during reload (maybe accidentally)..
you don't reconstruct anything. by hot reloading i mean literally re-exec'ing the module and then blowing away the old bindings
yeah, we were talking about replacing the live objects by new ones 😉
@next spruce was playing with the idea to use the gc to do it in-place
yeah that'd be interesting if it's possible
module a
x = 1
y = 2
module b
from a import x as xx
x2 = xx + 2
i'm proposing that you should be able to overwrite b.xx with the new value of a.x whenever the latter changes
but you wouldn't be able to recompute x2 unless the user manually reloads the b module
Ye, I found it from pytest docs
hmm.. could work. actually makes me think of a more general idea. we should have a way to track all objects down that came from a given imported module to check where everything is - and then have the option to kill everything at once
yep, that's exactly what i'm proposing
but in two separate steps, the first could also be useful for debugging weakrefs, for instance
What are some go to tools I should be adding?
Been configuring my Windows laptop and remoting in with Mac
pipx
use pipx to install mypy, black/flake8/whatever, poetry/pyenv/flit, whatever lsp server you like
yo guys pls help me
i am doing a work
for school and de Exe3 doesnt work correctly

Hey @north basalt!
It looks like you tried to attach a Python file - please use a code-pasting service such as https://paste.pythondiscord.com

this is in another file which i import exe3

can someone pls help is urgent <3<3<3
what's the result
is Exerc3 a module
you need global list_numbers
In a loop
because you call insert_positive_number() from itself, yeah
what was supposed to happen though
i think you mean to return num
instead of calling insert_positive_number in the else
and in the elif opc == "3":
number = Exerc3.insert_positive_number()
hello I'm looking at a requirements.txt in a git repo and I'm wondering what this is and how it works. the repo works great just curious about this.
--hash=sha256:8afe12.....
Im not totally sure if this is the right chat but any insight would be appreciated.
Hey! What does commit merge do after resolving conflicts?
Basically, hashes are a common way of checking that a file is authentic, not corrupt or malicious
I use github desktop and i created a repository. I added some files to the repository. One of my friend who also is part of the repository can see my changes. He also did changes to the repository but i cannot see his changes i can only see mine what do i do?
committ -> fetch -> merge(if there's something new) -> push
Im looking for an upgrade on digital ocean. I have these 2 options for 40$
- Shared CPU, 4 vCPUs, 8gb ram, 25gb ssd, 5tb transfer
- Dedicated CPU, 2vCPUs, 4gb ram, 25gb ssd, 4tb transfer
Why are they the same price when option 1 looks way better on paper. How big of a difference in terms of performance between shared and dedicated CPUs
Depends on your "neighbors" - dedicated would be far more reliable since you wouldn't be sharing a CPU with other customers.
i have a quick question kubernetes or docker swarm? and why
i did google but also want personal suggestions
hello who can help me in call i will screenshare is urgency and difficult to explain dm me
hi, do someone know how to import milliseconds to python clock ?
what are a few examples i can do with raspberry pi 4 model b? 8gb with 32gb SD card? Im thinking of buying one, is it worth it?
How can I set secrets created via docker secret create as environment variables in compose? For example, I've created a RABBITMQ_CLUSTER secret and I'd like to set it as an environment variable in the containers, so then I can access it in Python as os.environ["RABBITMQ_CLUSTER"].
trying to find how in celery task to get its id from within the task
@app.task(bind=True)
def task_get_id(self):
print(dir(self))
print(dir(self.AsyncResult))
print(self.name)
print(self.shadow_name)
current output
['AsyncResult', 'MaxRetriesExceededError', 'OperationalError', 'Request', 'Strategy', '__annotations__', '__bound__', '__call__', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__header__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__name__', '__ne__', '__new__', '__qualname__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__trace__', '__v2_compat__', '__weakref__', '__wrapped__', '_app', '_backend', '_decorated', '_default_request', '_exec_options', '_get_app', '_get_exec_options', '_get_request', '_stackprotected', 'abstract', 'acks_late', 'acks_on_failure_or_timeout', 'add_around', 'add_to_chord', 'add_trail', 'after_return', 'annotate', 'app', 'apply', 'apply_async', 'backend', 'bind', 'chunks', 'default_retry_delay', 'delay', 'expires', 'from_config', 'ignore_result', 'map', 'max_retries', 'name', 'on_bound', 'on_failure', 'on_retry', 'on_success', 'pop_request', 'priority', 'push_request', 'rate_limit', 'reject_on_worker_lost', 'replace', 'request', 'request_stack', 'resultrepr_maxsize', 'retry', 'run', 's', 'send_event', 'send_events', 'serializer', 'shadow_name', 'si', 'signature', 'signature_from_request', 'soft_time_limit', 'starmap', 'start_strategy', 'store_eager_result', 'store_errors_even_if_ignored', 'subtask', 'subtask_from_request', 'throws', 'time_limit', 'track_started', 'trail', 'typing', 'update_state']
any ideas, where is the ID is hiding?
I am trying to find a value that looks like... eae8f41e-d0be-4570-8917-8d5e91d1f207
oh wait a second, perhaps found, may be it is self.request.id
Yes. I was right.
TLDR: solved
Hi Please help, We want to build python 3 (latest release) on windows for a xeon machine we are testing against nuclear and solar radiation. What build syntax would I use that would include PGO as well as remove source files and leave only the required files/folders (../lib, ../include, etc...) on a win7pro machine? (xeon) The machine will be doing a lot of mobile device testing. The build needs to be secure and geared towards working with devices over usb-c.
In addition to that, Optimally a added install switch to have a shadow copy auto generate would be the best route in addition to that. Thank you all so much!
We want to build using only FOSS nuget via CLI , or at least as close as we can get.
@azure spoke can you explain what you mean by build syntax?
are you're talking about using the PCbuild/build.bat ?
or can you give ab example of how you invoke the build
like --pgo is one of the options you would use, is that what you mean
I'm invoking path\buildrelease.bat -x64 --pgo --skip-doc --skip-nuget
We want to build using only FOSS nuget via CLI , or at least as close as we can get.
gotcha, I understand now
I'm working in a ultra secure gov facility
I see. hmm...
what problem do you run into with the options you specified?
are you not using MSVC ?
no MS build tools?
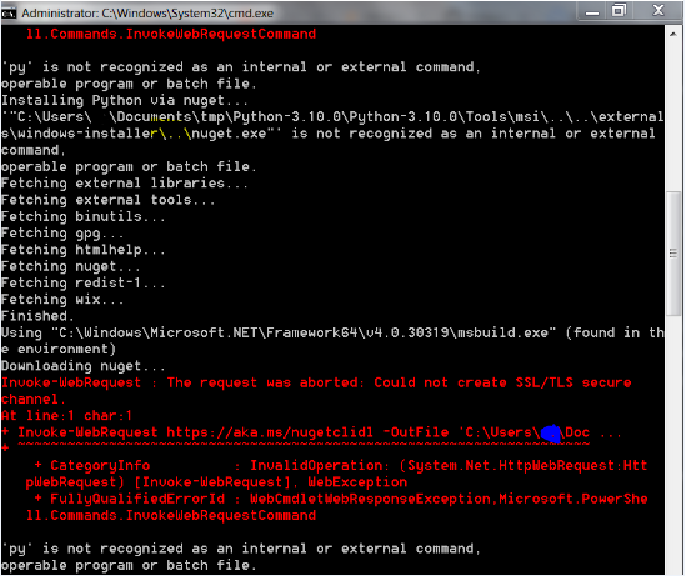
ok, so it looks like you're basically having bootstrapping issues
is there any python already installed?
no and i don't want it
This has to be %1000 from scratch
we have the DoD USAF W7 GM
Group policies are not installed yet
I understand
have you tried using PCbuild\build.bat directly ?
I don't know if buildrelease.bat is expecting to not have any python available. I would try with build.bat first, then try buildrelease.bat once you successfully install (your newly built) python to the system
the switches should be pretty much the same
okay lets see...
🙏 and hope for no issues
same place?
Unable to find package 'pythonx86'
tried both PCBuild\build and original
Installing package 'pythonx86' to 'C:\Users....
...n-3.10.0\externals'.
Unable to find package 'pythonx86'
why does it need to install python in order to build python ?
isn't that counter productive ?
Or i missed somethin?
that's a good question
Well there's at least this which is documented to need it https://github.com/python/cpython/blob/main/PCbuild/readme.txt#L224-L234
PCbuild/readme.txt lines 224 to 234
directory. This script extracts all the external sub-projects from
https://github.com/python/cpython-source-deps
and
https://github.com/python/cpython-bin-deps
via a Python script called "get_external.py", located in this directory.
If Python 3.6 or later is not available via the "py.exe" launcher, the
path or command to use for Python can be provided in the PYTHON_FOR_BUILD
environment variable, or get_externals.bat will download the latest
version of NuGet and use it to download the latest "pythonx86" package
for use with get_external.py. Everything downloaded by these scripts is
stored in ..\externals (relative to this directory).```had you seen this, @azure spoke ?
https://devguide.python.org/setup/#windows-compiling
thats where it started
oh there's not as much info there as I thought
python86 is weird. that's not in my entire source tree
oh pythonx86
It's installed by find_python.bat which is invoked by get_externals.bat
Interestingly, despite that, the latter seems to have a provision to compete it's job with git instead of Python if Python isn't installed.
You could just look at what that script needs to do and try to do it manually. I think it just needs to download 2 git repos but I haven't looked too closely
in my tree pythonx86 is only mentioned in Tools/nuget/pythonx86.nuspec
It won't download it if you already have python
Also, regarding what I said, that's just one use of Python. It may still need to be used elsewhere so I'm not sure if you could get rid of it entirely
maybe he needs to specify PYTHON_FOR_BUILD ? hopefully it built python.exe at least
it might also be the only thing python is needed for there is to build a nuget package of itself
judging by nuspec.py
did it build any python.exe @azure spoke
and its probably worth passing -E to build.bat
"Installing Python via nuget..."
seems like I also saw -e and -d mentioned for building from source.
-E and -e?
sorry this doesn't make sense
has anyone here actually BUILT python3 ?
clarify, built application written in python3
or built... the language itself?
the language itself
not me then
Yes, but only on Linux. It's pretty rare to build Python from source on windows as far as I know
Is it ?
It's just a guess 🤷
How do I import everything from functions in consumer/consumer.py with a project structure that goes like this?
project/
consumer/
consumer.py
functions.py
I've just been doing from functions import * which worked fine locally but not in Docker
project/
consumer/
consumer.py
__init__.py
functions.py
__init__.py
not sure for sure, but perhaps adding those files could help
that's weird that it is not working in docker
i did not have an issue like that 🤔
Without changing the import just like that?
wait a second. import *, that's just bad
urgh. That's just one of the worst way to do that.
it imports everything and can... overrite stuff
really blind way to handle imports
better to import always only specific stuff
Well I don't want to manually import 50+ functions lol
if you wish to import everything, import as package at least
import functions as fu
fu.your_func to use
Yeah I did it through __all__ to avoid that, feels unnecessary to do that for every single call when I use these very frequently
Either way
Do I not need to modify the import in any way just add the inits?
no idea. no idea.
u could be also having a problem with just which folder is beginnig of your project
Right let me copy paste my configs
there are few dirty ways to handle the issue
FROM python:3.10
COPY . .
RUN pip install -r requirements.txt
version: "3.8"
services:
consumer:
image: 192.168.0.100:5000/dev/docker_test:latest
hostname: "{{.Node.Hostname}}"
working_dir: /consumer
command: ["python", "-u", "consumer.py"]
stop_grace_period: 1m
logging:
options:
max-size: "10m"
max-file: "10"
secrets:
- RABBITMQ_CLUSTER
- RABBITMQ_MARTIN_USER
- RABBITMQ_MARTIN_PASS
environment:
RABBITMQ_CLUSTER: /run/secrets/RABBITMQ_CLUSTER
RABBITMQ_MARTIN_USER: /run/secrets/RABBITMQ_MARTIN_USER
RABBITMQ_MARTIN_PASS: /run/secrets/RABBITMQ_MARTIN_PASS
deploy:
mode: global
placement:
constraints:
- node.labels.consumer==true
update_config:
order: start-first
secrets:
RABBITMQ_CLUSTER:
external: true
RABBITMQ_MARTIN_USER:
external: true
RABBITMQ_MARTIN_PASS:
external: true
So the working directory is /consumer
oh right. I have a way to fix it for you
So from consumer/consumer.py I want to import root/functions.py
If I remember where to find it
Aight
@smoky stratus boop
https://stackoverflow.com/questions/714063/importing-modules-from-parent-folder
try relative imports first
from ... import functions
if it it will not work, then use this thing, you need to add your parent folder to module import searching
import os
import sys
import inspect
currentdir = os.path.dirname(os.path.abspath(inspect.getfile(inspect.currentframe())))
parentdir = os.path.dirname(currentdir)
sys.path.insert(0, parentdir)
import functions
which one worked for you? 😉
relative importing?
The second one
I mean it works I just don't understand why does it have to be this compliated tbh
import sys
from pathlib import Path
sys.path.append(str(Path('.').absolute().parent))
you could try using something with less amount of code lines
this one is quite readable
technically even this should work in theory
import sys
sys.path.append('..')
when we get an absolute pathes it is more reliable though
not every solution is OS independent
some of them could be working only in linux or windows for example
Hm sys.path.append("..") worked both in Docker and on win
I do like that quite a bit more than the previous one lol
How can I create an environment variable from a node label? For example I've got "PRIORITY": "0" label on a node and I'd like to create a PRIORITY key where the value will be "0" for that node.
Something like this perhaps:
environment:
PRIORITY: "{{Node.Labels.PRIORITY}}"
How do I do this?
Not enough details. Where are u using this yaml syntax
It doesn't work, was just an example. I'm trying to do something like this:
version: "3.8"
services:
test:
image: 192.168.0.100:5000/dev/docker_test:latest
hostname: "{{.Node.Hostname}}"
command: ["python", "-u", "test.py"]
environment:
PRIORITY: "{{.Node.Labels.PRIORITY}}"
deploy:
mode: global
So I can set a PRIORITY env var for each node based on their PRIORITY label values
Sure. Nothing prevents u from doing that
It is just the same load balancing with designation of weights to nodes
So how can I do it?
Uh huh?
It's not related to load balancing or anything like that between the nodes
It's for my python code
It is similar for me (T9 phone)
I'm trying to create an env var based on a label that's about it
Based on label that is attached to virtual server?
Like if I label up a node "color":"blue" and then in the compose color: "{{.Node.Labels.color}}" or something like that
Yes the labels on the nodes
docker node update --label-add type=queue worker1
As I said it is surely possible.... As for how...
Been trying to find it in the docs for half a day but had no success
(but a lot of the Docker docs are confusing as hell to me hence why I asked here rather)
I would have written terraform code that creates me servers with necessary labels from my code.
Then imported servers configuration to json file
Using small script I would have converted json file to Ansible inventory file of hosts.
And applied to install the app to all servers with Ansible
Env would be applied as templated docker compose config (templated config with ansible), or as env value if I have found how to use them in compose
Uh I don't understand any of what you just said lol
Basically.... U need at least learning tool Ansible to do what u wish nicely
It is too for installation of server configurations from your local machine to multiple servers
It already has the necessary stuff for that
Terraform is meant to automatize server buying. It can read labels
Ansible can read server labels in a limited fashion too I think
But why do I need all of this just to be able to read it from compose?
Currently I do through my DB where each script looks for its document by its hostname and grabs its priority, that is rather simple but thought it would be even easier with compose and labels
If u use provider server labels... Then they can be accessed only via provider API or tools that interact with it
What you are saying sounds 10x more complicated lol
I have no idea what you are talking about lol sorry
I think you misunderstood my question
I'm talking about node labels
Wherever docker stores them
If I do docker node inspect ugygmedkcltjuzs7z9gesea8q
"ID": "ugygmedkcltjuzs7z9gesea8q",
"Version": {
"Index": 7082
},
"CreatedAt": "2021-10-30T03:07:53.086466768Z",
"UpdatedAt": "2021-10-31T23:40:41.898679965Z",
"Spec": {
"Labels": {
"PRIORITY": "0",
"consumer": "true"
},
"Role": "worker",
"Availability": "active"
The ones under Labels
Uh. Yeah I surely misunderstood where u store them
So it is docker swarm I guess?
I added them with the docker command docker node update --label-add type=queue worker1 etc.
Yes
(at least that's what portrainer does I think)

I use consumer for placement constraints
placement:
constraints:
- node.labels.consumer==true
And for PRIORITY I just want to create an env var with that key
So I can pull PRIORITY within the python script
Something like
version: "3.8"
services:
test:
image: 192.168.0.100:5000/dev/docker_test:latest
hostname: "{{.Node.Hostname}}"
command: ["python", "-u", "test.py"]
environment:
PRIORITY: "{{node.labels.PRIORITY}}"
deploy:
mode: global
Docker Community Forums
I would like to create a docker service and scale it to 3 instances. These 3 instances form a cluster, and each one of the containers needs one of its arguments to have a unique value For example docker service create --replicas 3 --name myapp -e "UNIQUE_ID=[uniqueVal]" myimage -myarg1 [uniqueVal] Where each instance managed gets some unique...
Tldr: u a using wrong tool
Ansible would work better and is meant for this
Isn't that gonna be quite a bit more complicated than my current solution that is pulling the value from a DB?
My goal is to simple things down as much as possible
Yeah I looked at this before but it doesn't apply 100% to my use case
I don't use replicas, just global (and launch processes & threads in each container)
I wanna set it per node I don't need per replica level of control
The point is .. docker swarm is meant to orchestrate duplicated uniform the same objects
Having unique stuff already goes a bit against it
My application is to distribute a message queue consumer (worker) to all of my servers
1 container per server, and I'm running ~500-2000 threads in each
If I was doing it with replicas I'd end up with tens of thousands of containers for no reason no?
xD I implemented message queue yesterday too
Unless I'm missing something
And yesterday finished writing deployment
I don't really understand the purpose of replication in docker in general to be honest
Why would you ever want to run multiple copies of the same code on the same server instead of handling it within the script via multiprocessing and threading?
The main purpose to replicate across servers. One container per server.
And putting them behind shared balancer for example (which is not needed for message queue workers)
Yes that's my application pretty much
But these are using repliacted instead of global
I think what they want to achieve there is different is what I'm saying
What I'm after is very simple
I did not use docker swarm to know enough about it.
I suspect it is trying achieve same as k8s goals though
Like you can use "{{.Node.Hostname}}" to get the hostname, but how do you get a label from a node?
Yeah don't bother then I'm just hoping someone who has done this before sees this and can help
As this feels like the most basic thing you'd do yet I can't find any resource on it
App could be not utilizing CPU of the server to the fullest. In this case multiple amount of apps per one server is desirable too
As universal way of scaling
Docker compose has this feature at CLI somewhere
Why wouldn't it if you launch a process for each logical core? I've been doing that since ever
I.e. on my 32 core 64 thread server I launch 64 processes (1 for each logical core) and then ~20 threads in each process
With which tool
ProcessPoolExecutor or multiprocessing
I switched all my stuff to concurrent.futures recently
So.. internal python libraries
Ye
Containers are universal for everything, not just python
Applications can be written in code that does not have multiprocessing
Right fair enough
I use multiprocessing in all of mine so that didn't cross my mind lol
By the way if anyone is reading this back and could help with my initial question

Stack Overflow
I was wondering if there is a way to use environment variables taken from the host where the container is deployed, instead of the ones taken from where the docker stack deploy command is executed....
This is exactly what I'm trying to achieve
Then you can access it in the same way but with "labels" in the middle .Node.Labels.LabelName
But then the next guy said
I tried this method but it doesn't work. This is what i did: sudo docker node update --label-add ip='192.168.121.59' q687wox1uet33k4ubfvfa6p74. I then used this label in my compose file in environment section: environment: - KAFKA_HOST_IP: "{{.Node.Labels.ip}}". Started stack: sudo -E docker stack deploy -c docker-compose.yml service. Got error-> desc = expanding env failed: expanding env "KAFKA_HOST_IP={{.Node.Labels.ip}}": template: expansion:1:7: executing "expansion" at <.Node.Labels.ip>: can't evaluate field Labels in type struct { ID string; Hostname string; Platform template.Platform }
This is what I got too
Perhaps just putting env file at each host with different values
And feeding it to containers at startup
Yeah but then changing the values remotely becomes a pain in the ass
This way I could change it with the manager on all of the nodes
Ansible makes it painless to multiple hosts
How would the process look like with ansible?
Like if I want to change a specific host's PRIORITY value
Currently what I do is just update the value in the DB
That's about as fast as it gets I'd think
U change hosts list file, and run the same ansible script again once. It fixes what needs changed at each host and remains unchanged what is already done
Oh so it has like a remote manager too like portainer?
What is remote manager
Like a management dashboard where you can change stuff and push it to all the affected nodes like in portainer
Web GUI hosted
Gonna look into that I guess
Ansible runs from local machine...
But there are ansible alternative that have web gui
But I would not recommend them
Ansible is 20 percent cooler because it is agentless(no apps are required at target hosts) and serverless (no center servers with states)
How does it push stuff to remote servers then? It basically SSH's in and modifies the file or something?
Yes.
General logic...
SSH at the same time to machines
Check if task one is done at this machine, if not run it
Check if task two is done at this machine, if not run it
Gotcha makes sense
Obviously, if input data was changed for the task, it will rerun always too
Conditions when to rerun we can control
And if necessary when to restart services after ansible run
Btw ansible is made with python.
Pip install ansible
Make easier to use if u know python
Yeah I'm python only pretty much, gonna look into it later
I think I'm sticking with my current solution for now, basically I'm running a function in a thread that pulls the node's variables from a DB every minute, and if something changed replace the global variable with a new one so it "updates" the worker function in real time while its running, no need to restart the container/service not even the function that way
I just figured even if this label method worked it would still have to restart the service to apply the updates
If a label has changed that is
Been doing this since ever just starting to switch to docker now as it is awesome but some things don't work the way I'd have imagined they would unfortunately
Yeah I'm not using standalone swarm but the new swarm mode
I'm very happy with it so far just takes a bit to get used to it
I gave up on Kubernetes because it's very overcomplicated imo compared to how easy swarm is to setup
Took me 10 min to setup the entire cluster for the first time meanwhile I spent a week on Kubernetes and I still have no idea what is going on there lol
Yeah, I plan to spend around of half of year on getting used to k8s
It sounds like better to try docker swarm first
Yep I most definitely don't have half a year to deploy this lol
I don't really see too much benefit to using k8s instead as I don't have anything complicated
And I see people recommending k8s for more serious businesses with hundreds of employees and thousands of nodes
Swarm is perfect for my ~15 node cluster and still should be able to scale well
I recommend swarm if you haven't tried it it takes literally an hour to setup and get used to everything in it
This is my second day with it and I'm pretty much production ready lol
xD sure, sounds fine to try
It is interesting what it can do, which my current tools can't
The "last" problem that I had to solve for my app was proper deployment, I didn't even use docker until a couple days ago, I was pulling stuff from git and installing dependencies manually and ran into roughly 10 issues a day, now in the middle of making all of my stuff containerized as this stuff is awesome
And once they're containerized properly it's 1 command to deploy it on the cluster with proper rolling updates and etc. all the fancy stuff that k8s are used for
100% recommended if you don't want to spend a year getting familiar with k8s
I love how it took literally a minute to setup my own registry for the images also
I have my deployment automatized ;)
Gitlab CI cd
I don't need to remember how to Deploy
Eh. Again I have learning k8s postponed
A lot of tools which are just faster to learn
I wanted to go that route first but I'm so glad I rather went with Docker swarm as it helps a lot with after-deployment management
not knowing fully which abilities docker swarm brings... I am not understanding yet its benefits over what I already have
with ansible I surely have something similar to manage multiple hosts 😉
once I learn, I'll know I guess
Docker swarm is from Container Orchestration category
there should be surely some new things that my other tools don't have yet
only k8s can be having everything that docker swarm has
Yeah I'm in the opposite end I don't know ansible so not sure
Yeah I'm pretty sure k8s can do everything docker swarm can, but not the other way around
yup. I have the same feeling
But from what I see I don't need any of the stuff only k8s can do so I'm good to go
I think k8s makes more sense if you run your cluster on AWS/Google Cloud etc.
But I'm self hosting everything
I am running in those cloud providers actually
DigitalOcean is awesome and simpliest out of them
So I wouldn't have for example auto scaling with k8s either
DO offers very poor cost per performance imo
Well still 10x better than AWS
for next month I dive into frontend, but the easiness of docker swarm makes it for me priority to learn after that 😉
lets return in few months to this talk, and hopefully we will be able to see
what brings docker swarm new that other tools can't
Curiosity kills the cat. Quite interested to learn docker swarm during next available learning time slot
Yep I have nothing better to do currently so gonna spend all day long getting familiar with swarm for the rest of the year
Not sure how appealing it is going to be for you if you already have a bulletproof automated deployment solution but for someone who was just using git without containers this is paradise
I wish to know what it can do in comparison to what I already have
I wish to know at least basic usage, and wide understanding of its full capabilities if I dive into it further
so I could understand where it can be applied the best in my situations
Yeah I'd probably deploy a dev cluster and have a look it took me under an hour to figure out and get familiar with the basics
Are you familiar with portainer?
nope
If not I guess just look at its features and you'll see
Web GUI to docker?
urgh. looks suspicious to me.
How come?
from the point of view, that all configurations should be as code in repository
if it allows changing configurations manually in web interface, it is bad
web guis should be only for observability / monitoring
that is really important thing to have
Why is that bad? That's the main reason why I use it lol
It's basically a GUI wrapper for your swarm manager, so everything you change is changed in the code on the manager node
having all deployment as code in repository... makes it version controlled, easily reproducable from zero if we have all hosts down
I could have everything destroyed and restroyed within few minutes
I have nothing to lose
everything is stored as config files in repository
it makes much better... coding for my infrastructure
Well you lose that if your repo dies
I treat infrastructure as code, as another type of application
So it's the same thing lol
I can backup repo ;b
urgh. Lets just say it is against my philosophy then.
But I am sure it is somewhere in DevOps rules too
anyway, docker swarm can be controlled at code level too
it has Ansible compatibility for remote control
so I am still interested in docker swarm, just not in portainer
Yes as I said this is just an API wrapper in a GUI form basically, nothing is stored in the GUI
Or in the GUI's services/containers
You do need agents on the nodes to have full control though
If you wanna browse files from the nodes etc.
https://12factor.net/
I. Codebase
One codebase tracked in revision control, many deploys
A methodology for building modern, scalable, maintainable software-as-a-service apps.
Yeah but then you should hate swarm not portainer lol
It's just a GUI that runs the swarm commands
And modifies the swarm source
Everything is stored in swarm
I guess you just don't like GUIs then lol
yeah, sort of yes.
although not always
I like nice GUIs for monitoring and logging tools
Prometheus, Loki, Grafana
I hate manual changes from GUIs
all configurations / initializations should be stored as code configs.
I love both monitoring and configuring stuff from GUI too
no manual GUI changes should be necessary for that
They are
so what for Portainer then
You can just do it in the GUI instead of SSHing in
So you don't have to SSH to the code config
I don't SSH for code configs!
Just use the GUI to change whatever you want in the code
urgh.
I think we have a having lack of understanding due to not understanding each other tools
on my development machine.
getting another dev machine and writing git clone
urgh. lets just skip this conversation until we understand better each other tools
I have a feeling we have a great lack of understanding because of it
Yeah probably lol
Either way swarm is awesome, if you like to control code with CLI then do that, I like GUIs so I use that
It was in the 1980
but CLI is still interface, the importance in controlling it with code
that what is superrior
Web GUI can't be automatized / controlled with code
I don't want to remember things I need to do manually.
Everything should be automated!
But if you for example want to add a label to a node, first you have to find the nodes, get the node's id, push a label
In the GUI you just add a label to the selected node and done
u have a real lack of understanding for automation IMO.
I love automation, that was by far the main reason why I got into coding
But this is besides the point
Why did you type your last message manually? 😛
we have too different understandings of automations then
lets return to this conversation few months later when my hands will reach docker swarm 😉
or not return, because I think I ll prefer to jump straight to k8s
Or it would not make sense to return to this topic at all. Because it is was clearly discussion about IaC and not IaC development ways, And that's it. Tools do not matter
What are people's preferred tools for working with and managing virtual envs? I have previously used virtualenvwrapper and pyenv-virtualenv, both of which let me easily activate virtual envs from anywhere on my system without requiring pointing to a long/exact path. Sadly the latter seems to be somewhat unmaintained lately and the former hasn't seen any updates in over a year (and appears to have some issues with newest pip versions). For reference I am running an M1 mac
I tried to install poetry yesterday and the install script failed. I didn't have time to troubleshoot so I'll have to go back to it. It did look pretty nice. I ended up using pip-tools.
Though I guess pip-tools isn't strictly for virtual envs, more dependency management.
Hello. I'd like to overview my functions, their input-output types and compabilities between them. I drew this on draw.io (diagrams.net). Is there a easy tool and/or accepted notation for this?

Is what you want a "call graph"?
There's a tool to generate those https://pycallgraph.slowchop.com/en/master/
It doesn't show argument/return values though.
There is also UML to consider. Its standard is an "accepted notation" though I am not sure if any of the many different UML diagrams offer what you're after.
The closest one that comes to mind is a functional UML sequence diagram.
That I imagine you would have to manually create.
I used Visual Paradigm for creating UML diagrams before. It's decent. Stay away from the online (in-browser) version because it starts to get very laggy once the diagram grows in size.
What do you guys use for browsing logs? I'm looking for something that'd let me filter and hide "columns" temporarily, so I could do something like
2021-11-02 14:26:48,960 - WARNING - get_queue_stats_0 - queue_publisher - No consumers connected (3)
Displayed as (filtered to only show WARNING level)
2021-11-02 14:26:48,960 - No consumers connected (3)
Promtail+Loki+Grafana
having even visual interface
it is the lightweightest logging aggregator
cool to aggregate logs from multiple services
and to browse them with easy
as alternative people use a similar stack based on Elastic (+ Logstash + Kibana? i think?)
it has richer syntax for more complex queries, but less lightweight
Can you show an example of the UI for logs? I'm having a hard time finding any images of it
Grafana+Loki
Maing quering window looks like this

+You could build different custom graphics like

Usually they are available when attaching Prometheus(monitoring system) and using premade graphics though
That doesn't look like it can do what I'm looking for though
i remember seeing the stuff you wished at filtering level
in promtail when it sends its records to loki
Grafana Labs
Configuring Promtail Promtail is configured in a YAML file (usually referred to as config.yaml) which contains information on the Promtail server, where …
Pipelines or Scraping section or Stages? not sure
it is easy to filter just WARNING records without redacting it (just one simple query for records that contain WARNING)
but if you wish having visual changes to the output, then it requires more configuration
Yeah it looks a bit overcomplicated to me, I'd rather prefer a PyCharm plugin or something
Ideolog is ok but it can't hide columns
I.e.

I'd like to hide the thread column
But I don't think that's possible with it
(if anyone knows a solution to this please let me know)
Yes
I was giving you solutions for production, that would get it for already running product
Should've mentioned that sorry
then.... just inbuilt logging library is enough I think for your case
It's just for debugging
These are logs from logging but that doesn't solve my issue
I would like to hide the thread column
Not not log it
it has formating for the output, that sets which things to print
+allows to turn different logging levels
It becomes unreadable with line lengths that would require 3 monitors
But that's not what I'm looking for
I want to log everything
But then when browsing I'd like to hide irrelevant columns
You're missing my point
I don't want to change how it logs
yes, u a wishing to change output/shown logs
logging formatting changes exactly that
Bruh lol
That changes how it logs
I don't want to modify that
I want it for display purposes only
uh. all rught
I.e. when reading the already logged logs
so you wish to not change your current formatting
Yes
you wish to have secondary log processor that changes in itself
but not for original
No
I don't want to change anything
2021-11-02 15:48:14,064 - INFO - MainThread - logger - Number: 99
2021-11-02 15:48:15,067 - INFO - MainThread - logger - Number: 18
2021-11-02 15:48:16,071 - INFO - MainThread - logger - Number: 84
2021-11-02 15:51:45,986 - DEBUG - MainThread - logger - Number: 82
2021-11-02 15:51:45,987 - INFO - MainThread - logger - Number: 73
2021-11-02 15:51:45,987 - WARNING - MainThread - logger - Number: 19
This is the log file
I don't want to touch it
I just want to "hide" some columns when looking at the log
all right
Hence why I'm looking for a log viewer
Not modifying how I log
That'd work for production
make different logging shown for production, staging and development then
As I collect all the logs locally from remotes either
you could launch different settings for different env
Oh my god
I literally just explained 3x that I don't want to log differently
I'm looking for a log viewer tool
Like
Professional log viewer that can parse files in a variety of different formats.
But something better
shrugs. if it would be vscode, i would say just search for the right plugin
Does it have a nice log viewer plugin?
vscode has ten thousands of plugins
there probably is smth for that

a matter of trying and finding
sentry?
I'm already using sentry but you can't really log normal events with it properly (unless I'm missing something)
I use sentry for exceptions and logging for high throughput logging
Me?
yes
Yes, why?
nothing then

AlternativeTo
The best LogViewPlus alternatives are SPHW LogViewer, glogg and LogExpert. Our crowd-sourced lists contains more than 25 apps similar to LogViewPlus for Windows, Linux, Mac, Self-Hosted solutions and more.
i was just finding it weird that you need that much of log viewer to monitor your application in development
thus I started to suspect low testing coverage
I need looking at them much less with good testing
literally, no logging is made unless for business purposes
tests catch stuff anyway
Well if you don't do logging then I have no questions to you lol
Sentry should be 101
you could probably write a simple logviewer thing with regex and shit to block out the one category
Oh decent idea actually, didn't think about doing it myself with regex
or whichever category and stuff
Gonna do that
im a fan of if i can't find something in 5 minutes of looking to just write it myself
Yeah I'm getting there too lol
xD, that's the DIY
A lot of my solutions are like that
It doesn't even need to be an app. Just open the log file in a text editor and use the replace functionality with regex to get rid of a column
That's kind of what I'm doing it's just not a proper solution
Yeah I suppose if you do it often enough
have you checked logstash?
he wishes for development only, simpler solution
My log lines are 5 screens wide but I do need all the information I just want to hide if I'm looking through for something specific
Well for production too
But not grafana level of overcomplicated mess
logstash is at the same level then
ELK or PLG ;b
ELK=Elastic+Logstash+Kibana
PLG=Prometheus+Loki+Grafana
it has its advantages though
like enabling automatic alert system
for certain events
Yeah I just wrote a quick app that should be more than good enough for now
and receiving alerts to email/discord and etc
I already have that, this is just for display purposes
scripts are fun
i may have a problem with scripts tho 💀
Grafana is not worth the time investment for me
I have too much fun writing scripts
Same, I have ~400 projects in my PyCharm directory that are simple apps like this and 90% of them I used maybe once lol
I don't know anything smaller than PLG for prod 🤔 it is already quite small system
i have multiple automatically generating files from pre-commit scripts
like
i use poetry, but I've made a script that generates a requirements.txt file from the poetry.lock
which sounds ironic, but meh
doesn't poetry have a export command already?

efficiency
i wrote mine so i could add it to pre-commit lol
yeah, it's really slow...
so the requirements.txt file will always be up to date and I can forget about it
poetry is awesome but due to tomlkit its extremely slow
tomlkit is the style preserving toml parser
which makes sense for editing pyproject.toml
I've tried to get into grafana as I love the dashboards you can make with it but it takes 100x more time to setup for fully custom scripts than it takes for me to log into my DB and read it in my dashboard via simple JS
however, IMO poetry should use a different parser for poetry.lock, that does not require the style to be preserved, since its auto generated
yeah, that's a problem. I did not find a way for automated way to setup grafana. manual setups suck
tldr i tested just parsing poetry.lock, the majoirty of the time is spent with tomlkit parsing poetry.lock
Although wait a second
there should be automated way!
we can download grafana already made solutions from other users for graphics
so there should be a way to record your own custom solutions
for later reusage
no idea how, I guess it requires a bit more diving into it
Yeah actually I'm tempted to dive into grafana maybe next month, I've already made my own dashboard for monitoring but I don't like writing JS much, so if I could easily transition into grafana that'd be sweet
But I really have no clue about the infrastructure, I only tried for a bit but gave up immediately because it was a lot at once
I'll try again with something simple tonight
Can you recommend what should I use to for example display data from my server monitoring script?
My data looks like
stats = {
"date": datetime.utcnow(),
"cpu_cores_physical": cpu_cores_physical,
"cpu_cores_logical": cpu_cores_logical,
"cpu_frequency": cpu_frequency,
"cpu_load_1": cpu_load_1,
"cpu_load_5": cpu_load_5,
"cpu_load_15": cpu_load_15,
"ram_used": ram_used,
"ram_total": ram_total,
"ram_used_percentage": ram_used_percentage,
"swap_used": swap_used,
"swap_total": swap_total,
"swap_used_percentage": swap_used_percentage,
"swap_in": swap_in,
"swap_out": swap_out,
"disk_used": disk_used,
"disk_total": disk_total,
"disk_used_percentage": disk_used_percentage,
"disk_read": disk_read,
"disk_write": disk_write,
"network_download": network_download,
"network_upload": network_upload,
"network_connections": network_connections
}
Would like to make charts and gauges for pretty much all of them
I think you should display at least one of CPU loads
and displaing left memory at hard drive
and preferably RAM left too
I wanna display all of them
I'm just asking how
I.e. how would you implement this to grafana to be able to make graphs of the data?
Currently I just put these into my DB and then use JS to make a chart
I would just insert a number to download already ready solution to show everything this
some people already took care to display exactly this stuff nicely
there is ready solution for grafana exactly for this thing above
Yeah but that ain't DIY lol
If I wanted a ready made solution I would just run a monitoring app not even use grafana
I monitor a lot of custom stuff besides these simple server data
So this would be a great entry point I feel like

imports for already made solutions in grafana looks like this
I think they write settings for this stuff in json I guess
But how does the backend work is what I'm curious
As currently I log them into my MongoDB
Can I grab the data from there?
Via grafana
grafana has integrations for a lot of things
I understand only how it works for Prometheus and Loki
Aight lemme check
the stuff that you showed above is usually Prometheus stuff
any application just has /metrics url
that has a lot of its current stats at this url shown for values at the current time
prometheus collects them into time series db, same stats in time progress
and then grafana eats them
Ugh I really didn't want to have to setup another DB lol
Took me a month to set up MongoDB for production ready level
Prometheus is a DB
Ye exactly, I use MongoDB

Could I just pull data from MongoDB?

{kind=link}
Oh that would be fantastic
There is no way in hell I'm setting up another DB
Just for monitoring
Gonna check that
How much does it cost?
I don't see price listed for enterprise
"Absolutely. I was planning to get the data source permissions feature enabled by getting an enterprise account. Turns out it costs 40000 USD per year." - Reddit
Alright fuck grafana lol
What is this price for?!?!
but its free version is free 🤔
I'd rather hire someone for $500 to make me a sexy custom dashboard
what's the difference between free and enterprise
Look at what you linked
"Valid license for Grafana Enterprise; refer to Activate an Enterprise license."
Well, I guess it is out of free version then.
no Mongo for monitoring for free
Prometheus and Loki integrations are still free though ;b
Is Prometheus SQL?
Time series DB
PromQL language to query, or smth like that
similar to what u saw in Loki
yes, its own
Yeah not for me then
shrugs. Loki quiering language is quite simple and easy to remember
Prometheus should be having language that easy to learn in 5 minutes too then
Both should be almost similar
Anything that doesn't use JSON is out for me, imo it doesn't make sense to use anything else
Especially via Python
Wait can you create your own datasource?
🤔
I guess that would be rather complicated still
It not supporting MongoDB for free just blew my mind
I'd have paid maybe $50/mo for it but most definitely not $40k/yr lol
xD costy server, that requires 3333$ per month
enough to pay for small infrastructure several times
People are saying they use https://grafana.com/grafana/plugins/grafana-simple-json-datasource/
Get the data from MongoDB and use this for the data
That is literally 50x what a single of my dedicated servers cost lol that's just stupid
There must be an easier way even for mongo
apperently it involves firstly.... targeting your mongoDB with indexing DB(elastic search), and then vizualizing results with kibana?
¯_(ツ)_/¯
And that's why DevOps engineers can get paid baller money
Can anyone help with a pyinstaller related problem?
Hello
I need to some help regarding docker-compose
Basically I have two containers, one python application (a discord bot) and a Java application
Now the Java application (a jar file) runs on address 0.0.0.0 and port 8080 and my bot containers needs to connect with Java application, how am I supposed to do that
My bot connects to Java websocket server that the Java application creates
And I have set it connect to port 2333 and 0.0.0.0
How am I supposed to make them connect
take a look at this - https://docs.docker.com/network/

I saw that already
Yeah that's what I would use but I don't know how, I am new to docker-compose so yeah sorry about that
So I need to use user-defined bridge right?
For my usecase
Because I need both my dockers to communicate
compose creates a network that you can use to communicate between containers. Names are set based on services you define
check this example - https://docs.docker.com/samples/django/
Hmm
version: '3'
services:
lavalink_service:
image: mything
ports:
- "2333:8080"
throng_bot:
image: mything
ports:
- "5000:2333"
depends_on:
- lavalink_service
then this would work?
so basically the first container lavalink_service opens a port on 8080 in the container
and then my bot application connects to it
server: # REST and WS server
port: 8080
address: 0.0.0.0```
this is the application.yml file that defines and tell lavalink service what to do
and thenMy bot also listen to port 2333 which I want my docker that open on port 2333 on my system to work other docker container that I opened port 5000 to communicate with
containers actually have their namespace reserved in the compose network by their name
it's kind of like how you can use localhost to access local ports
Yeah right so
Then I define it by name?
if it's within the compose network u can do name:port
So like
some_name:8080
some_name:2333
so lavalink_service:1333
Like my first container creates a websocket server on port 8080 that I want to map and connect to second container that needs it
Ohhhhh
you don't need to expose the port
if you do'nt use it publically
you only need to expose the ports you access outside of compose
e.g. from your computer
within the network they are all connected
So like
lavalink_service:8080
lavalink_service:2333
?
Oh I see
well which one are you connecting to
if you're connecting to 2333
then just use that
version: '3'
services:
lavalink_service:
image: kortapo/lavalink:latest
ports:
- "2333:8080"
throng_bot:
image: kortapo/throng:latest
ports:
- "lavalink_service:2333"
depends_on:
- lavalink_service
so like this?
no you don't need to do it within the docker compose file
Really sorry for dumb questions, I am new to dockers so i am learning still
Yeah I just cant wrap my head around
so inside your bot application
you can connect to the java applciation
using lavalink_service:2333
So inside the bot application
as the url
you don't need to bind that port in the compose file
idk if this is helpful
nodes = {'MAIN': {'host': 'lavalink_service',
'port': 2333,
'rest_uri': 'http://lavalink_service:2333',
'password': 'youshallnotpass',
'identifier': 'MAIN',
'region': 'us_central'
}}```yeah i think something like that, i don't know the details
this is the part of the code where it connects to Java application
but that's the general gist
your host
you might want to be the bot address tho
again i don't know the detail but taht is what makes sense intuitively
so then this is fine right
if i have this in my code
no idea, you might want to change the host
uh yeah this is just doesnt wrap around my head
to something that's your site's URL
okay hmm
it shouldn't matter
tbh
but i think 'host' might be where the bot itself is hosted or accessed
Nono,
and 'rest_uri' might be where you need to communicate with the lavalink service
I did that because I was running my Lavalink on a singular docker container
And my bot on my host
oh ok
And it was working properly
Now I have container that contains my bot and another one that contains my Lavalink thing
yeah just change localhost to lavalink_service
that should be what you need
then expose the ports of the bot
Alright
the main issue is
Lemme try
you seem to be binding 2333:8080
so you might need to change it to 8080
if you're doing it within the docker container
So 8080:8080
Oh okay
Ohhh
because that's the port that the java application uses, right?
so basically if both services are within the same docker compose network
they can access each other
by default
port binding is just to access them outside of the compose network
ok so you know how u used to access it from within the bot app as localhost:2333
when the java service was a single docker container?
Yeah
no it wasn't localhost
it was 0.0.0.0
OH WAIT
Do I need to change 0.0.0.0 to localhost
That way it comes in the same compose network?
0.0.0.0 listens on every network interface iirc
Yeah
i'd use localhost but it shouldn't change things
again i'm not sure
but can just access it by name
since docker-compose helps u in that way
they let you access the containers of the network using their name
lavalink_service:8080
Okay so
nodes = {'MAIN': {'host': 'lavalink_service',
'port': 8080,
'rest_uri': 'http://lavalink_service:8080',
'password': 'youshallnotpass',
'identifier': 'MAIN',
'region': 'us_central'
}}```This in the bot configuration
Then what I have to do here?
This is just too confusing
hmm i'm not sure what the config settings are for
what is the port field for
because if the port field is for rest_uri
then you don't need to put that in rest_uri most likely
Hmm no that would raise an error
Uhm you know, I am thinking to install an OS in my docker that contains both Java and python create a singular container and run it
But that would be a bad idea
As its recommend to run one process in a single container
it depends, i wouldn't go for it in this case
yeah it doesn't make a lot of sense to do that
Yeah
can anyone help me with binance api
i am getting this error
Exception ignored in: <function Client.del at 0x7fa100862e50>
Traceback (most recent call last):
File "/Users/arunsanganal/opt/anaconda3/lib/python3.8/site-packages/binance/client.py", line 7101, in del
File "/Users/arunsanganal/opt/anaconda3/lib/python3.8/site-packages/binance/client.py", line 7098, in close_connection
File "/Users/arunsanganal/opt/anaconda3/lib/python3.8/site-packages/requests/sessions.py", line 747, in close
File "/Users/arunsanganal/opt/anaconda3/lib/python3.8/site-packages/requests/adapters.py", line 325, in close
File "/Users/arunsanganal/opt/anaconda3/lib/python3.8/site-packages/urllib3/poolmanager.py", line 222, in clear
File "/Users/arunsanganal/opt/anaconda3/lib/python3.8/site-packages/urllib3/_collections.py", line 95, in clear
TypeError: 'NoneType' object is not callable
please share your code for review
Hey, can anybody help me with deployment of my machine learning app on streamlit
Here's the code: https://github.com/jakubstrawa1/Plant-Disease-Detection
And here's the log: https://www.heypasteit.com/clip/0IXROV

GitHub
Contribute to jakubstrawa1/Plant-Disease-Detection development by creating an account on GitHub.
tensorflow.python.framework.errors_impl.AlreadyExistsError: This app has encountered an error. The original error message is redacted to prevent data..
building and publishing with poetry and a [tool.poetry.scripts] section but when i install with pip it doesnt find my executable
does that mean i gotta go the setuptools way?
The intent is that you do that on your machine first, so you have the ability to test to ensure it works first.
You can do git merge -x ours branchname to merge, keeping all your changes if any conflict occurs. Or -x theirs. Though you should just omit that and manually take care of conflicts, so you don't discard important changes.
Ah, it's a capital.
you need to be in the visual studio developer command prompt
@heavy knot i'm not on windows right now but I think searching something like "visual studio command" or "developer prompt" should net you the special prompt where all of the right envvars are set ... pretty annoying but it should fix the issue
 :ok_hand: applied mute to @lean silo until <t:1636172348:f> (9 minutes and 59 seconds) (reason:
:ok_hand: applied mute to @lean silo until <t:1636172348:f> (9 minutes and 59 seconds) (reason: duplicates rule: sent 4 duplicated messages in 10s).
has anyone here ever used digital micrograph? sorry if this is the wrong channel
docker run -d -p 80:80 docker/getting-started
running this in command prompt gives me
Unable to find image 'docker/getting-started:latest' locally
how to get started with tutorial on docker
it says run this command in the command prompt
I have tried command prompt, powershell, win terminal
I think I didnt configure wsl properly