#tools-and-devops
1 messages · Page 65 of 1
RuntimeWarning: Please specify version and hash for auto-installation of 'example-pypi-package'.
To get some valuable insight on the health of this package, please check out https://snyk.io/advisor/python/example-pypi-package
If you want to auto-install the latest version: use("example-pypi-package", version="0.1.0", hash_value="ce89b1fe92abc55b4349bc58462ba255c42132598df6fe3a416a75b39b872a77", auto_install=True)

Snyk Advisor
Find the best open-source package for your project with Snyk Open Source Advisor. Explore over 1 million open source packages.
any suggestions on how to make this more useful?
so, when this works as it's supposed to, you can just distribute a minimal bootstrap and the rest would be pulled from pypi or some online repo
joy 🙂
no more dependency hell \o/
i wonder if it might actually be faster on a modern machine to keep the wheel zipped up and decompress every startup rather than reading the whole unzipped package from disk
test = use("example-pypi-package.examplepy", version="0.1.0", hash_value="ce89b1fe92abc55b4349bc58462ba255c42132598df6fe3a416a75b39b872a77", auto_install=True)
assert str(test.Number(2)) == "2"
works 🙂
sadly, numpy is being a diva about it, not sure why
probably because zipimport refuses to load .pyd and .so?
unzipping in a subfolder and using that fixes some issues, but numpy still doesn't like it
strange.. oh well
realising inline auto-install in general is a job well done for a day
released a new version of https://pypi.org/project/justuse/ - auto-install should work now well enough for pure python packages, c-extensions will have to wait a bit longer

I've posted a docker issue with my django container days ago
And apparently it's bc Docker shell can't recognize the format
But when I try my scripts with bash it doesn't work
How do I specify to ignore a directory and everything in it in my gitignore?
I thought just dir/ worked, but doesn't seem to be doing it
Hmm, ok nevermind
Seems it was just VSC being weird
Sometimes you need to clear your git cache if that directory has been committed before
Hey everyone, how can I get the number of physical hard disks from a python file? I thought maybe I could use psutil but there doesn't seem to be anything for it--I'm looking for an agnostic solution...right now I'm using psutil.disk_partitions() but I don't want the number of partitions, just the actual disks. I'm not entirely sure how disk_partitions() works, but I don't want the number of partitions, just the number of installed disks, so is that just the amount of devices in the disk_partitions array?
Quick question about nox, do you have to run it with the current working directory being the one containing the noxfile.py? It's not that annoying, but it's I something I noticed compared to tox. (please ping me since my attention is somewhere else)
Can someone teach me the best (industry standard) way of using Pyenv and managing Pip packages?
~ ❯ which python
/Users/Mushu/.pyenv/shims/python
~ ❯ which pip
/usr/local/bin/pip
I have multiple versions of Python installed using Pyenv. I need some older Python versions for a class I'm taking. The issue is that my global python cannot see any pip packages... which makes sense because numpy for Python 3.6 should be different that numpy for Python 3.9
How the heck do people manage pip packages? Is there a way to point pip to the global pyenv folder?
Doesn't pyenv make pip point to the currently active Python version?
You shouldn't try to share packages across Python versions, since not all packages are compatible with different versions.
If you need a package in multiple versions, just install it for each version
Yep, I understand that. But how do developers actually manage pip packages?
Clearly, it doesn't make sense to duplicate your entire library of pip packages if you move from 3.9.4 to 3.9.5
I've been frozen for 2 days, and reddit tells me that Poetry is the new, cool kid for package management.
For upgrading pyenv versions I usually just pip freeze then reinstall on the newer Python version, also it's quite odd that pip is not pointing to the shims directory, does it exist there?
If you install your packages to the user site, they should remain accessible to all Python versions with the same minor version (i.e. patch versions won't require reinstalling packages)
Since the user site is categorised by minor Python version
TIL actually, thanks
No problem
Docker?
To be clear, a user site means installing packages with pip install --user
I think my config (.zshrc file) is messed up because, yes, I think pip should be pointing to the shims directory.
Maybe the solution is to clean reinstall my entire Mac and wipe off any bad pointers.
For production, docker is way to go for sure
Yeah I understood this as a local development question. It wouldn't make sense to be using something like pyenv in prod.
For local development, what IDE do you use Mushu?
If VSCode, docker as well for development
If PyCharm, fight with them for that feature
I use VS Code... I've never done any real production before. I need Python 3.6 for a testsuite in my university class. However, most of my hobby development is done in 3.9
Dev containers
Learn it, fall in love, refuse to convert to PyCharm because they don’t have that feature
What is the advantage over using pyenv

Get started with development Containers in Visual Studio Code
It’s a container per project thus your local workstation need nothing
It’s 100% isolated environment
So one project can’t mess with another
So, I'm leaning towards a clean install of my Mac, then use Docker to avoid dependency hell issues.
What is the general method for installing Python into a Docker container? Should my Mac have python3?
I've never experienced my project environment conflicting with each other. Maybe Docker makes sense for some projects that require more complex provisioning, but most of the time a simple venv will do. Then it just becomes a matter of installing docker and configuring a dockerfile, or installing pyenv and creating a venv. Or is there more to it that I am not seeing?
If you want to use Docker, then all you need is Docker. Doesn't matter if the host system has Python or not. You'll be using a base Docker image to get the Python version you need.
Ah I see.
It's the beauty of not dealing with venv and accidental system pip installs
it's 100% isolated environment, nothing can fight, not python versions, not pip versions nothing
someone accidently removed Python version, your fine, upgrading python, change out JSON file and rebuild dev container
did someone forget to activate virtualenv, it doesn't matter
I suppose those are all valid points technically.
Maybe they are issues for people
But I have personally never encountered any of that
also, it takes like an hour to learn
you never needed two version of python for old code and new?
You mean in the same project?
or multiple projects, one is in Python 3.7 and other in 3.8-3.9
Yeah. I use pyenv and each project has its own venv
I mean that I never encounter things "fighting" me or Python versions getting removed, etc.
Sure, but if you decided to remove Python because you ran into a problem, this comes up
I don't see why I would remove Python
my point about Dev Containers is they are so easy to use, once you adopt them, it's awesome
While there may be more avenues for fucking up with venvs/pyenv, it doesn't seem difficult to avoid that (I am a living example of that).
@proven sapphire

uh should work on ubuntu based systems and other unix distros python comes preinstalled anyway, try it out open your terminal and type this command python3 -c "import socket; print(socket.getfqdn())"
@proven sapphire
how do i stop prettier from going to the next line, for eg this is before saving and this is after saving

Guys, wasn't sure where to ask this. I am running windows, and I want to create a good development environment, that I could make an image of so it would be easier to bootstrap it anytime I need a new environment. Although I do fancy the idea of creating it myself, are there already scripts/bootstrapped vm's that I could just download? Or, would you recommend a certain OS/flavour for creating a good dev environment in VMWare or virtualbox? I am looking to code mostly in Python, and my linux cli skills are (I hope) on point
I just install Ubuntu 20.04 LTS for development.
all installation to organize my working place can be actually automatized to be made in a matter of minutes with one command only
but I did not reach that level of laziness, automated only some parts
I would like to use Sphinx to generate rich email content (from release notes which are in RST format, among other info).
Is there an existing Sphinx template which generates everything into a single file? No external CSS being loaded, just all embedded in one html doc?
https://www.sphinx-doc.org/en/master/man/sphinx-build.html
singlehtml
Build a single HTML with the whole content.
i did not try that, but I guess it is a worthy to try.
huh, I have actually Sphinx ready to try that
welllll....
it surely made a single file... but css and js remained being separately
you would have to add them on your own I guess
singlehtml builder just combined content from multiple RST files into one html
probably somewhere else may be configuration exists to include css/js into resulting html
i use containers at work now with docker compose, and it's definitely a mixed bag. volumes are fussy (no access to volume during container build). debugging requires different tooling. i need a "shadow env" on my local system to get IDEs to work right (although i'm working on getting Pycharm professional edition, which has good Python-in-Docker support). docker is sometimes still slow doing this or that operation, even with build layer caching.
i don't hate the workflow, but it's not an equivalent dev experience, at least not for me. and definitely more complicated than 1 hour of self study
pyenv-virtualenv takes care of most of what i need

Stack Overflow
I need to build HTML from RST with sphinx-build. Now I use command:
os.system("sphinx-build -b singlehtml -T -D html_add_permalinks=None -D extensions='sphinx.ext.autodoc' -D master_doc='index' -C...
perhaps this could help
is creating automation considered devops?
which sort of automation
provide an example
I would say, devops creates automations, but not ever automation is devops
automation like playbook run jobs to either create metrics, make changes/additions/removals to the infrastructure and other report related tasks
yeah, totally devops
you are changing infrastructure as a code, which is basically devops is
thanks! in that case, is it a bad place for an absolute beginner to start? it may or may not be required of me soon is why i ask
if you may need it, it's a good a corner to start as any
https://github.com/FirePing32/PyPSI/issues/3
I have made a Python client for Google PageSpeed Insights. It would by grateful if someone can fix this issue.

GitHub
The current version does not give that much information when a request fails. The API does give much more information in the 'message' attribute. It would be nice if that error mess...
Hi I have a precommit hook for yapf. After adding a pyproject.toml file I am getting an error-
toml package is required
If I remove pyproject.toml then this error goes away. Why is this happening and is there any fix?
Have you run poetry install?
I'm using flit
It seems like it's looking for the toml package in on pypi and not finding it
Oh, have you installed dependencies with that?
Yes
I've never used flit, so I dunno
pipenv or poetry? Which do you recommend?
I prefer poetry as it's much faster in my experience
Faster? At what?
Installing dependencies occurs faster with poetry
I've had it take a very long time with pipenv
That's a bit puzzling. How fast dependencies are installed should depend mainly on your network connection?
I dunno. Poetry just does its faster for me, and a lot of other people
It may have to do with how it caches and things like that
Okay, thanks for your input.
To be fair, I had some slight experience with conda, and it wasn't fun. It can take ages, and seems to break easily.
OTOH those envs were pretty huge.
conda is known to be slow and somewhat fragile
i've had a better experience with https://github.com/mamba-org/mamba/

GitHub
The Fast Cross-Platform Package Manager. Contribute to mamba-org/mamba development by creating an account on GitHub.
@tawdry needle on the note of deployment and containers, what would you say is the main pain point of current solutions? speed of downloads? what could sway you to use() auto-install a package?
aww.
the main point of containers is isolation
i know exactly what programs are installed, and what versions
i know exactly what user accounts are present
and i can deploy that exact configuration anywhere, maybe even in a cluster (like kubernetes)
isolation, control, reproducibility, easy to deploy
well, but you could run different versions of a package in the same program
and a shared package would still be hash-pinned, so there's no overlap
so you don't need to download the same package over and over?
(argument for .so libs, i guess)
How does this work with python name resolution
You have to distinguish between "distribution package" and "python package" here
You can have 10 different versions of the former, but only one version of the latter at a time with the same name
Unless this is what your custom import machinery does
So you could have foo_1_0_2 = use('foo', version='1.0.2), but even then you'd have to do some pretty serious black magic to make sure name resolution works inside thr foo package
the nomenclature is problematic, to say the least. a "distribution" is a defined file ("wheel") on pypi containing a package with a certain hash
if you query pypi for a package name with a certain version, it gives you a list of all files with their hashes
that match that name and version
also the corresponding url
foo_1_0_2 = use('foo', version='1.0.2) would only use the system/pip-installed stuff and check if the version matches, anything beyond that requires the auto_install=True arg
so for instance
test = use("example-pypi-package.examplepy", version="0.1.0", hash_value="ce89b1fe92abc55b4349bc58462ba255c42132598df6fe3a416a75b39b872a77", auto_install=True)
would get you exactly that file
and import examplepy from that package
[crossposted from #help-chestnut ]
how do you easily share code across two projects?
In Rust for example I would extract the common code into a separate directory and then add a dependency entry to all dependant projects that points to ../common_code
The equivalent in Python seems to involve modifying PYTHONPATH which seems hacky and makes me think this is not the Pythonic way to share code across projects locally. What is the canonical way to do it?
well, i don't know about "canonical" at this point, but this would be an excellent case for justuse 🙂
what is justuse?

it's the thing i've been working on and discussing with @tawdry needle 😉
oh so it's like an in development thing
yeah
in this case, you can use(use.Path("some/path/to/foo.py"))
or use an url to github
if you really want some canonical solution, you'd probably go for an isolated environment, pip install stuff
messing with pythonpath is really not a good idea
what if the file is part of a python package (not a distribution package, a python package)?
how is your project laid out? setting pythonpath isn't the worst thing in a complicated setup. you might want to consider breaking out the common package into a separate distribution/project, with its own setup.py/setup.cfg/pyproject.toml, and you can pip install -e it
symlinking is uglier than setting pythonpath imo
e.g. my company's monorepo is kind of like this.
when you're working on service1, you have a venv for that specific service, and you do pip install -e ../shared/python && pip install -e . to get everything into the venv.
monorepo/
common/
python/
setup.py
src/my_org/
__init__.py
utils.py
service1/
src/
service1/
__init__.py
__main__.py
app.py
service2/
src/
service2/
app.py
__init__.py
__main__.py
what exactly do you mean by "python package", there are several definitions (as mentioned, the nomenclature is quite a mess)
i am using "python package" specifically to mean "a module that contains other modules, corresponding to a directory with an __init__.py"
that should be covered by the example i posted above - https://pypi.org/project/example-pypi-package/ ( https://github.com/tomchen/example_pypi_package )

GitHub
Example PyPI (Python Package Index) package set up with automated tests and publishing using GitHub Actions CI/CD, primarily for GitHub + VS Code (Windows / Mac / Linux) users - tomchen/example_pyp...
lemme read through what you two wrote ^^
those seem to be good solution to large scale projects
i'm not sure what you mean by this
I think I'll end up either symlinking, modifying PYTHONPATH or doing the sys.path.insert() hack
just to get this roadblock over with
i'd prefer PYTHONPATH over the other 2 options
test = use("example-pypi-package.examplepy", version="0.1.0", hash_value="ce89b1fe92abc55b4349bc58462ba255c42132598df6fe3a416a75b39b872a77", auto_install=True) <- this is a pure python package with "examplepy" as subpackage and __init__ etc
okay thanks I'll probably choose that one then :)
@urban pecan now you're being unclear 😉 . example-pypi-package is a "distribution" and examplepy is a "package".
the use() call basically corresponds to "pip install example-pypi-package hash_mode..." and "from example-pypi-package import examplepy"
there is no example-pypi-package to import from
ahhh 🙂
example-pypi-package exists only to pip and setuptools, python itself has no knowledge of it
right!
unless you dump all packages in the distribution into a top level package
which would totally break namespace packages and a few other things (i think?)
no, it wouldn't because the import machinery does that name mangling either way, i'm just mirroring that behaviour for strings (which sucks!)
what name mangling?
if you do pip install example-pypi-package, it installs examplepy into site-packages
an import examplepy is ambiguous
because it may either mean an actual "examplepy.py" module or a package
python has clear semantics for handling this
it looks for packages first, and then modules, i think
this is documented somewhere, i've read it before
ultimately "installing" a python package amounts to copying it into the correct site-packages directory
well.. yeah, it tries to do the right thing, but it's ambiguous because you can shadow things in sys.path
also you can't force it to import a package if you have the same named module etc
sorry, that's just me ranting
so let's say you do some clever name mangling and now you have isolated site-packages, neither of which is in sys.path by default
/path/to/justuse/data
site-packages_example-pypi-package_v0.1.0/
examplepy/
__init__.py
site-packages_example-pypi-package_v0.2.3/
examplepy/
__init__.py
utils.py
point is, use() refuses to guess. for use() with str it's always a package
you still have to un-break name resolution inside both examplepys
and if you want to import a module, you'd use it with a pathlib Path
fine, but that doesn't solve the problem i'm talking about here
which has to do with name resolution
when python execs the contents of examplepy/__init__.py, it might contain from examplepy.utils import stuff
you need to make sure python knows where to find examplepy, and that it's the right examplepy, from the right version of the right distribution
i don't know if your code already does that. but that's what i was trying to explain before
maybe it's as simple as tacking on the temporary/isolated site-packages directory to the search path while you're loading the specific package
this could actually be one way to isolate dependencies, npm-style
there could be other issues there, e.g. it'd totally break pickling
well, the problem is that import only knows about the "official" stuff and pip refuses to install multiple versions, so any time you import stuff, it only can find the official package. so, one solution i figured out (but not implemented yet) would be to pass in an "import_to_use" argument
which would catch import statements and translate into use() calls if they match a certain name
that way you could resolve sub-dependencies to specific pinned versions
and it would still be compatible with the classic pip way
as i said in #databases, one big unresolved question is how to have both, hash-pinned versioning and still be able to quickly apply security patches, mostly automatic
the latter basically is the complete opposite of hash-pinning
the way i was proposing, you just don't use import for these
but again you've spent a lot more time inside the import machinery than i have
so maybe "just" setting sys.path while exec'ing the module isn't enough
actually, switching CWDs is a much better answer
works well with import and use, no sys.path hacking necessary
the way i solved it in use() is to recursively switch the CWD and switch back to the original after import
actually, of course, you could add your version-pinned package to sys.path, but that will be a bloody mess with the ordering
quite honestly, sys.path was a big mistake to begin with. if it had been a dict with some metadata...
even zipimport is limited to pure python packages because of that, afaik
we had some serious problems because of that limitation because numpy uses .so files that zipimport doesn't want to handle, now we need to manually unzip and link those files to be able to handle c-extensions.. it could've been so nice and simple :/
it's all connected and boils down to those fundamental limitations of the import system
ah right, you did tell me about the CWD thing
sorry for the rant 🙂
it was really quite frustrating to solve those issues correctly without resorting to sys.path hacking, but i think it was worth the trouble
I guess I don't quite understand what a hack about it, from a high level it makes sense to have a "search path"
I know you said some of the internal machinery was hacky
I haven't spent too much time trying to understand it, I know there is some special "loader" machinery
Sounds kind of similar to how it works in Lua
for one, trying to load everything in the sys.path to see if it matches is just ugly from a proper design perspective. secondly, anything can change the sys.path anywhere, so it's down to gambling that your code finds the right thing
for example, i ran into troubles once because i appended my stuff to sys.path
it worked when i prepended it
now i test my use() code by del sys.path and see if things work without it at all 🙂
which it does!
you only need a search path if you aren't explicit enough in the first place. if the user is explicit enough - path,url, name/version - you can simply look things up
I'm struggling to get my github workflow to upload to pypi working, it's a mixed rust and python project.
action i'm using: https://paste.pythondiscord.com/lehelevuxe.yml?noredirect
The action being run: https://github.com/wookie184/dupesearch/runs/2965153244?check_suite_focus=true (although I added a bit in the pastebin)
I'm getting maturin: command not found even though in the previous step poetry seems to install it correctly, • Installing maturin (0.10.6). I'm wondering how I can fix this, and also if i'm on the right lines in terms of what i'm doing in general, as this is all new to me.
Wouldn't poetry install that stuff to a venv? One that you're not activating
I believe there is a way to make poetry install to the normal site instead of a venv, but I don't remember
I'll try to find it
You just have to configure this to false https://python-poetry.org/docs/configuration/#virtualenvscreate
Configuration Poetry can be configured via the config command (see more about its usage here) or directly in the config.toml file that will be automatically be created when you first run that command. This file can typically be found in one of the following directories:
macOS: ~/Library/Application Support/pypoetry Windows: C:\Users\AppData\Ro...
So i want to make a Macro with python, that can simulate xbox controller inputs using python
After 5 hours of scouting the internet i am unable to find a working library for Ubuntu
Just point me in some direction
Hey! i would like to make a program who start me league of legend, and clique on "play", next to "ranked solo / duo" & then choose my role.
To open it's ok.
I don't understand how to :
- put the screen of lol in 1st plan (if other's like discord has been launched)
- how can i click at x: ... & y: ...
Thanks mates!
Hello, can someone recommend me a good docker course
https://youtu.be/pTFZFxd4hOI This video is really good for the basics

Docker Tutorial for Beginners - Learn Docker for a career in software or DevOps engineering. This Docker tutorial teaches you everything you need to get started.
- Get the complete Docker course (zero to hero): https://bit.ly/3sO7Z5H
- Subscribe for more Docker tutorials like this: https://goo.gl/6PYaGF
Want to learn more from me? Check out the...
Thanks
I am going thru the book called "Docker - The ultimate guide for beginners". It's ok
I'm trying to get github actions to auto-upload to PyPI if I tag the push
but using if: startsWith(github.ref, 'refs/tags') as part of the yml doesn't work even though a couple of sites say it should
my github.ref is "refs/heads/main", it doesn't start with refs/tags and I'm not sure why or how to make this work 
This is my yml ```yml
name: Build and Upload Python Package to TestPyPI and PyPI
on:
push:
branches:
- main
jobs:
publish:
runs-on: ubuntu-latest
steps:
- name: Check out repo
uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: "3.9"
- name: Install wheel
run: python -m pip install wheel --user
- name: Install setuptools
run: python -m pip install setuptools --user
- name: Build a binary wheel and a source tarball
run: python setup.py sdist bdist_wheel
- name: Upload to TestPyPI
uses: pypa/gh-action-pypi-publish@release/v1
with:
user: token
password: ${{ secrets.TEST_PYPI_API_TOKEN }}
repository_url: https://test.pypi.org/legacy/
- name: Upload to PyPI
if: startsWith(github.ref, 'refs/tags') # <- doesn't work >:(
uses: pypa/gh-action-pypi-publish@release/v1
with:
user: token
password: ${{ secrets.PYPI_API_TOKEN }}
But how do I detect that the push was tagged? The if I have from https://stackoverflow.com/a/58478262 doesn't work. I'd appreciate any help or suggestions 
You may need to be using a different event, namely create https://docs.github.com/en/actions/reference/events-that-trigger-workflows#create
You can configure your workflows to run when specific activity on GitHub happens, at a scheduled time, or when an event outside of GitHub occurs.
I've done this with Azure but not with GH Actions, so I'm not familiar with when the ref is a tag in GH Actions.
Ooh, I'll try that. I guess create will trigger whenever I push with a new tag aka version?
I think it worked  just now I need two yamls, one for PyPI and another for TestPyPI
just now I need two yamls, one for PyPI and another for TestPyPI
We have developed a small tool to export different variants from the same Python codebase and named it Python Variant Exporter 😆 .
It is useful, e.g., if you are a Blender/Houdini/Maya addon developer and want to export a free and a commercial version of an addon from the same codebase.
If you have code like this:
__VARIANT__ = 'DEV'
def example():
if __VARIANT__ in ['DEV', 'PRO']:
print('PRO')
elif __VARIANT__ == 'FREE':
print('FREE')
example()
Python Variant Exporter can export it for you to fit:
pve -d __VARIANT__=PRO example.py example_pro.py
__VARIANT__ = 'PRO'
def example():
print('PRO')
example()
See here for more:
- https://pypi.org/project/pve/
- https://github.com/3dninjas/3dn-pve
- https://github.com/3dninjas/3dn-pve/tree/main/examples/simple
- https://github.com/3dninjas/3dn-pve/tree/main/examples/blender_addon
We are looking forward to your feedback and some battle testing!
Hey @dire holly!
It looks like you tried to attach file type(s) that we do not allow (.pdf). We currently allow the following file types: .gif, .jpg, .jpeg, .mov, .mp4, .mpg, .png, .mp3, .wav, .ogg, .webm, .webp, .flac, .m4a.
Feel free to ask in #community-meta if you think this is a mistake.
Came across this line in GitHub Actions and I'm confused
What does that line do?
pip install .[lint]
what are . and []?
I imagine . is current folder and [] are basically defining the "optional extras" you can install from a package
haven't seen . before but it makes sense if interpreted like that, specifically for like github actions and the like
https://github.com/lietu/taqu/blob/ed420fea27a5cbfe1f9539b1769af9a6160e0be0/setup.py#L24 so this is what the [] triggers, in this case [azure] would install that extra library
setup.py line 24
extras_require={"azure": ["azure-servicebus>=0.50,<1"]},```Thank you
Docker question.
I am looking to add this awesome web based VS Code server package to my docker image. : https://github.com/cdr/code-server
I currently have a very basic docker image that pulls Ubuntu and runs my flask app.
I want to add the code-server project so that I can access my code. How do I add this to my below image?
FROM ubuntu:latest
RUN apt-get -y update
RUN apt-get install python3 -y
RUN apt-get install python3-pip -y
WORKDIR /app
COPY . /app/
RUN pip3 install -r requirements.txt
EXPOSE 5000
ENTRYPOINT [ "python3" ]
CMD [ "app.py" ]
GitHub
VS Code in the browser. Contribute to cdr/code-server development by creating an account on GitHub.
It looks like they already have an image they publish on Docker hub. What are you trying to accomplish by adding it to an image that has flask? Is there a reason these images need to be combined rather than running as separate containers?
Confession: I'm a docker rookie.... I was hoping to add them both to the same image. does that make sense?
No, it generally doesn't make sense. An image should generally be focused on running one thing.
You can have one container for your flask server and another for the code server. You can make it easier to start them together by using docker compose.
Make sense. Thanks.
hey guys anyone knows about RH openshift? Is it possible to create a ubuntu image for my application instead of RH linux?
In my dockerfile even if FROM ubuntu:bionic is used it does not create ubuntu
openshift is just rebranded kubernetes
if FROM ubuntu:bionic does not do what you think it does, then you either expect the wrong thing, or someone has messed around with your Docker host beyond just it having openshift
am i not understanding it correct? FROM ubuntu:bionic does not create an ubuntu image?

Not sure if this is the right channel for it, but has anybody got good examples of CLIs done with Python and the click package?
I'm trying to understand how I can personalize my cli with the namesake and the different options (ie. mycli read -f=myfile.txt)
Because you misunderstand containers
Containers just layer on top of host OS
So red hat release file will still be there because host OS is Red Hat
😮 sorry, i shifted from aks to aro and its still confusing to me sometimes
This isn’t Kubernetes thing, this is container thing
So whenever I deploy a new app, its host os will stay as rh?
Depends on host OS
Docker networking issues
networks:
frontend: {}
backend: {}
services:
site:
networks:
- frontend
ports:
- 3000:3000
server:
networks:
- backend
- frontend
ports:
- 5000:5000
And then in my site package.json i have
"proxy": "http://backend:5000/"
But when i fetch "/" from my frontend i get back the frontend's html
Frontend is a CRA app with just one component to make this request and backend only has a route / thats supposed to return {"hello": "world"}
Also i can curl each container with a proper response from outside but not the backend from inside the frontend
i wanna ask input("whats ur name:") and then put print i like the name and put whatever was put in the input
i want to make as light a venv (using the built in venv module) as possible,
-
how do i get the
--symlinksargument to work? on windows i keep getting a bunch of errors likeUnable to symlink 'C:\\Users\\admin\\AppData\\Local\\Programs\\Python\\Python39\\python.exe' to 'C:\\Users\\admin\\Documents\\Projects\\venv-lite\\.venv-without-pip-symlinked\\Scripts\\python.exe'any time i use it. -
is there a way to have it symlink pip and its dependencies into the venv instead of creating an entirely new copy of it?
@rancid ingot pipenv
Not sure, haven't used Poetry
pipenv is a first part tool I believe
Going to a Python meet tonight so I could ask
It is not first-party. In fact, there isn't any first-party package management tool.
pyenv can be used with pipenv too. The actual comparison would be poetry vs pipenv.
Poetry installs dev dependencies by default. Pipenv does not.
Pipenv can be configured to inline shell scripts (like for dev utilities). Poetry can only run Python scripts.
Poetry has a plugin system in development.
By some accounts, poetry is faster to lock and install dependencies.
Pipenv has had a bump road with maintainership, but they might be getting past that by now.
Poetry uses pyproject.toml. Pipenv has its own toml config file.
Poetry can be used to build packages too. Pipenv cannot.
Any idea why my buildozer gotten this error?
Original exception:
===================
Traceback (most recent call last):
File "/usr/local/lib/python3.7/dist-packages/sh-1.14.2-py3.7.egg/sh.py", line 2071, in __init__
tty.setraw(self._stdout_child_fd)
File "/usr/lib/python3.7/tty.py", line 28, in setraw
tcsetattr(fd, when, mode)
termios.error: (13, 'Permission denied')
What permission is it needing..? I may have missed something
I did a chmod on sh.py but same thing
Hi all,
I made (yet) another Python profiler tool (can be used like cProfile, or with manual instrumentation, and the data are visualized in real-time in the viewer): https://github.com/dfeneyrou/palanteer
It is high performance, low dependencies, provides a lot of different views (timeline per threads, memory timeline, plot & histograms...) and automatically collects functions (Python & C calls), garbage collection runs, exceptions, OS memory usage...)
The last added feature is the support of asyncio / gevent. Visualization of such async execution is really helpful to understand what happens under the hood.
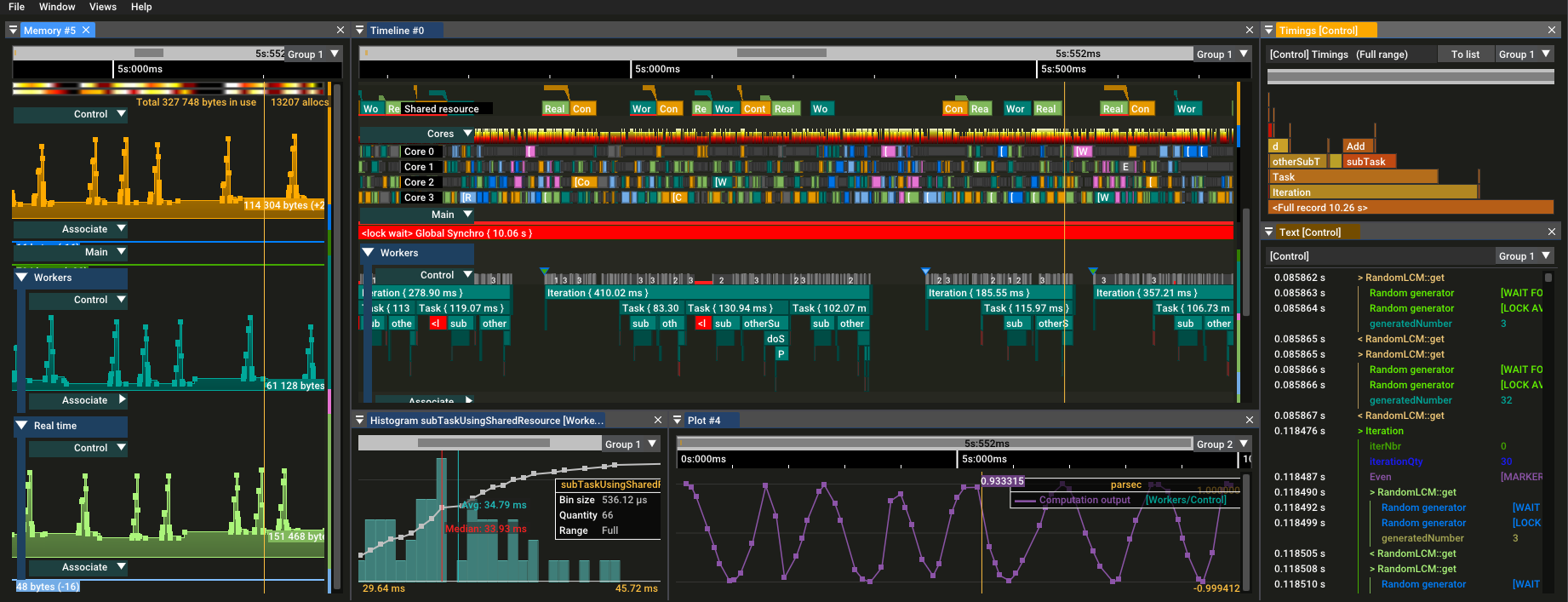
GitHub
High performance visual profiler, debugger, tests enabler for C++ and Python - dfeneyrou/palanteer
Feedbacks are welcome!
Thanks for the info, was asked a question on the difference tonight. Now I know
In a Pycharm project with multiple attached "sub-projects", is it possible to open multiple Python Console instances, one for each sub-project?
hey @tawdry needle just the one i was looking for 🙂
maybe you have an idea how to solve that problem

we've mostly figured out how to solve the installation problems with libs like numpy in justuse, so the next step would be to get stuff working that depends on a specific version of numpy
now, my idea was to have an argument like use("pandas", auto_install.., import_to_use={"numpy": {version: "1.23.2", hash_value..}})
somehow intercepts imports and transform those calls into calls to use() with the given arguments
any idea how to do that or a better way to deal with specific version-dependencies?
if we only version-pin pandas, and it would try to import numpy, it could only be the one installed by pip, but not a specific version
and you probably know dependency hell just as well as i do ^^
i had suggested creating a new site-packages directory for every top-level use invocation
then you can have a full isolated tree of dependencies, npm-style
well, we do have a completely isolated packages folder
but the problem is that code that is calling to import would look for sys.path
so we'd either need to do tricks on sys.path or on import to look elsewhere
yeah, i had suggested prepending the new site packages directory to sys.path
i think that would work, right? while use('pandas') is executing, all import numpys would be resolved w/ the temporary site-packages directory at the front of sys.path
however this might be incompatible with the auto-reloading... you'd probably have to go even deeper into import machinery for that, or end up with some awful locking around sys.path for thread safety
as for the "import to use" specification, maybe start by mimicking what setuptools.setup uses? put hash as a separate argument maybe
could a wrapper around __import__ maybe work to intercept calls?
to intercept imports? i have no idea
yeah.. that might be the simplest solution
if it works
i just found https://github.com/brettlangdon/importhook <- you think that could work?

GitHub
Python package for executing functions when packages are imported - brettlangdon/importhook
in principle, not that code as a dependency, i mean
you know more than me 😛
i doubt you could use this as-is, but you could probably reuse its guts
hmm.. i'll try, although i don't have a good feeling about messing with meta_path, might end up having the same problems in recursive cases as with sys.path
thanks
i'd make auto-reload and isolated deps mutually exclusive tbh
auto-reload is only good for local dev, right? you should have a venv or something for that anyway
what do you guys usually use for auto-reload?
they are
you only can auto-reload single modules
auto-install only applies to packages (use() with str, not a Path)
no point in reloading packages that should be hash-pinned anyway ^^
same goes with use()-ing an URL
no reload there, since the content should never be able to change
not sure yet whether or not that might change if we go for crypto-signed code instead of hash-pinned, but for now it's all locked down
i'm not really eager to get into crypto-signature stuff.. probably will need to find a security specialist to help me get this right
cryptography certainly is an area where be dragons
and i need better armor before i can tackle those 😉
Don’t go on this quest alone adventurer take

aww ❤️
oh, wow, that might be easier than expected 😄
from importlib import __import__
import builtins
def wrapper(func):
def decorator(*args, **kwargs):
print("wrapped!")
return func(*args, **kwargs)
return decorator
builtins.__import__ = wrapper(__import__)
import math
=> wrapped!
Hey guys I am looking for a program that will create a random character based on png. files that I have anyone have a program lying around that could do this?
Hi is there any module to work on accessibility PDF or else autoaged PDF document to get tags bounded inside the document.
I need to retrieve boundary boxes of each tag bounded to PDF document.
http://pydepsearch.dwrodri.com
pip search was down and I couldn't sleep so I made a JSON API for searching PyPI project names. API endpoint is /search and the param is query
the entire client is right here:
import sys
import requests
from urllib.parse import quote as encode
for url in requests.get(
"http://pydepsearch.dwrodri.com/search/",
params={"query": encode(" ".join(sys.argv[1:]))},
).json()["results"]:
print(url)
of course I get random timeouts
now that I start sharing the URL
has anyone done Apple sign in before, how do you prevent double account, when the user does sign up with email and password, but later want to now use sign up with apple
@sick ravine You'd probably add Apple as and optional sign in option. I donno, I haven't done anything like that
fixed
@heavy knot thanks for the insight
😀
what does that even mean?
create a random character based on png could mean anything from OCR to hashing and pseudo-randomness
Hey not sure if this is the right spot, but is there a way to set up NixOS in such a way that you can declare package use for a given virtual environment in python?
So I'm using vscode and am attempting to commit to github. I can do this, but some files I do not wish to commit such as my workspace file are being staged for commit as well. How can I make sure this does not occur? I heard of something called a gitignore, is this what I need to look into?
Yes, gitignore can make a file or folder not be added to git
how might I go about making and formatting one?
Here's a nice article that explains it all: https://www.atlassian.com/git/tutorials/saving-changes/gitignore
Atlassian
Git ignore patterns are used to exclude certain files in your working directory from your Git history. They can be local, global, or shared with your team.
thank you very much sir
any idea about EC2 ?
what i know is its a instance like VM ?
it's a VM
I'm developing a CLI using argparse and I want it to be able to be installed with a Windows executable file, no Python needed, and then be used normally in the console. I'll use pyinstaller but which script of my project should I freeze? setup.py?
or should I use freeze the main file which parses the arguments and then just call the app as myapp.exe h?
the thing with this is that I would have to locate the path of the executable every time I want to run it or cd to that path, maybe adding it manually to Windows PATH environment
Apologies if this is not the appropriate channel for my question.
I am creating a pip package, and it almost works, but the entry point is giving me weird problems.
If I pip install, I can navigate to the module folder in site-packages and run it properly with python3 main.py
If I try to run it with my entry point, the program will run, but some parts won't work. For example, main.py imports some other files into it, and it looks like everything it imports from one particular file is just not working at all. It's hard for me to go more in-depth without going far in detail.
My entry point is set up like this in setup.py:
{ "console_scripts":
[
"run_simulation=<module_name>.main:main",
]
}```
where <module_name> is the name of the module.I should also note that in main.py, I have if __name__ == '__main__': main() and nothing else inside that if statement. So I believe running it manually and using the entry point should give the same results, correct?
I just tested this, and I think I found the problem.
If I use a separate file to run import main main.main()
Then the program will run, but with those weird errors I was getting with the entry point. However, if I do this: from main import * main() Then the program will run perfectly. Why is this the case? Does anyone know a way I can fix this?
@stuck tide show your file structure, and the rest of your setup.py
File Structure:
setup(
name="pkg_name",
version="0.x.x",
packages=["module_name",], # name of modules
package_data={
"module_name": [
"Models/*.obj",
"Models/*.png",
"Models/Notation/*.png",
"hints/*.png"
],
},
include_package_data=True, # make sure resources are included
url="https://github.com/...",
# license
author="mandrew",
# author_email
description="Rubik's cube simulation and tutorial",
install_requires=["ursina", "rubik-cube", "psd-tools3"],
entry_points =
{ "console_scripts":
[
"run_simulation=module_name.main:main",
#"command_name_2 = src.file_name:func_name"
]
}
)```here they are
@stuck tide read this #unit-testing message
happy to help w/ specific questions. but rather than repeat myself, i think the message i linked should explain fix your file structure
Thank you for the link; I think my file structure is already following what you said in that message. My setup.py is in the directory above the module being distributed, next to readme.
Oh I'm sorry I didn't read far enough yet
So all of my imports need to have the module name in them. I'll go give that a try
Okay, I read the full message and I think all of my code already satisfies what is outlined there. I checked my import statements and they are all in terms of the module name
@stuck tide in that case, you might want to use packages=find_packages() instead of packages=["module_name"] -- packages=["module_name"] will not infer e.g module_name.main
also, you can use module_name/__main__.py instead of module_name/main.py. then you can invoke your tool with python3 -m module_name, and your entry point would be updated to run_simulation=module_name.__main__:main
i'd also strongly suggest adding a pyproject.toml file alongside setup.py, containing
[build-system]
build-backend = 'setuptools.build_meta'
requires = ['setuptools >= 51.0.0', 'wheel']
you can use an older version of setuptools if you need to e.g. support py 3.5
Oh yes, I've been meaning to add the pyproject.toml file I just wanted to get this part working first. Will give __main__ a try, as well as find_packages(). Thanks!
Thanks so much! Using __main__ and python3 -m module_name worked a treat 🙂
I may continue trying to get the entry points to work with other things, but I'm really just glad this was able to get it working. Thanks again for your help & time!
Hello world
I need to make an app for android, that will probably require a lot of access to phone's functions (like making calls). I don't have a clue where to start, but I would like to avoid going to android studio or anything else in the Java/kotlin field (as I'd be starting from zero). Could I use my python experience somehow?
yooooo, thats amazing gj man 
hi guys, a question on aro, after pulling image from container repository, apply deployment.yml how can i expose the service ?

is there some way to customise the pyenv installation process/have it use a custom executable, I need a debug build of python with valgrind and no pymalloc and would rather not write the shim myself
Yes, probably. See https://github.com/pyenv/pyenv/tree/master/plugins/python-build#custom-definitions

GitHub
Simple Python version management. Contribute to pyenv/pyenv development by creating an account on GitHub.
ah, that seems useful, thanks
I see these fancy coverage badges everywhere, how do I get one of these for my private gitlab project?
(I presume they are created dynamically for every commit?)
https://shields.io is the most common way
We serve fast and scalable informational images as badges
for GitHub, Travis CI, Jenkins, WordPress and many more services. Use them to
track the state of your projects, or for promotional purposes.
Very nice thanks
Hey @loud ether, I believe this is a pretty thorough guide to what Geno was trying to explain earlier: https://www.hendrik-erz.de/post/setting-up-python-numpy-and-pytorch-natively-on-apple-m1

Hendrik Erz
The new Apple M1 devices have received quite the attention in the past months. However, data scientists and engineers have been wary of upgrading too …
Maybe try following that guide, and ask here if you get stuck on anything.
An alternative seems to be to run everything under Rosetta 2 (Apple's x86 -> ARM binary translator): https://5balloons.info/correct-way-to-install-and-use-homebrew-on-m1-macs/
If you install Homebrew natively, it will be installed into /opt/Homebrew; if you install it with Rosetta, it will be installed into /usr/local.
If you want a fresh-start, you can uninstall Homebrew with this command: ```bash
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/uninstall.sh)"
It's all a little bit involved, but once you have it up and running you shouldn't have to worry about it (hopefully) 
Has anyone here had issues with VScode's intellisense not working properly pygame? It will recognize thing like pygame.Surface() or pygame.Vector2() but something like pygame.time will not show up in code completion unless imported explicitly ```py
import pygame
pygame.display.set_mode()
doesn't workpy
from pygame import display
display.set_mode()
I have it not working correctly quite often for new added imports.
I just press Ctrl+Shift+P and select Developer: Reload Window
Hmm that didn't work, thanks though.
I'm just gonna download Pycharm, goodbye memory 😿
selenium visual studio code visual debug works in chrome, but not working in firefox, any idea?
it gives me this error https://paste.pythondiscord.com/cojedogibi.http
console debug with pdb works fine though
apperently there is even github issue for that https://github.com/mozilla/geckodriver/issues/1804
I guess I should use different firefox version to fix that. Some sort of imcompatibility in the latest release
or perhaps to try updating firefox
Anyone know a website/tool that will order and consolidate links in a markdown file? 
I could swear the Stack Exchange question textbox used to do it 
@deep estuary what ingress are y’all using?
traefik (for now)
we use traefik because:
- dead simple mTLS
- (used to have) dead simple TLS (we now do cert-manager so we run traefik in HA)
- nice middlewares
- simple deployment
I'm considering a move (well, we almost certainly will) to nginx-ingress, because personally I'm more fond of nginx and it's much more configurable, we're not using the TLS features in Traefik that we selected it for and it has better integration with the ingress resource
Ok, I’ll look at both
I also don’t want to deal with Helm for simple stuff
If you end up finding one or making one yourself (which doesn't sound that hard) let me know. This seems like it could come in handy for me as well
I seem to have a weird issue where when I updated discord.py-stubs, they seemed to break

solution, uninstall the stubs and reinstall them again
Two questions:
How do I run "external tool" in Pycharm with project's venv (conda) activated? It works perfectly via terminal, but I can't find a way to properly activate it. There's conda run, but it's "experimental".
How can I run code in external terminal? I know about "terminal emulation", but some advanced features of TUI frameworks work in dedicated terminal, but not in Pycharm's one.
how can I return the single like of the list?

@fallow gulch what?
is fine i got it
does anybody here know stuff about barcodes and article-names? 🙂
this is prolly not a question for this channel but
pewpew
I have a 3D plot created with matplotlib. I want all axes to have the same scale. However, setting the axis to 'square' does not seem to work in 3D. Also, as the plot is supposed to be interactive (the user can zoom in/out and rotate it), matplotlib cannot really cut it. It is too slow to be of any use. Therefore I tried plotly, which seems very powerful. However same problem, how can I force it to use the same scale for the x, y and z axis?
is that pycharm? material?
guys, is poetry compatible with python 3.10?
3.10.0b3 specifically speaking
Can you recommend any books to mastering git? I know some basic features like merging, cherry-picking, rebasing and so on but I think it's only the beginning so any books recommendations are nice to see!
I found this very useful: https://git-scm.com/book/en/v2
Thank you, I will check it out!
good night, i wanted to create a plugin module in jpython for the autopsy tool. fetch data from SQLLITE databases.
Hi, I see tox used for automated testing in a lot of packages on github but not all of them seem to be state of the art and some seem to feature some boilerplate code. Therefore, I wonder whether a package developed from scratch should also implement tox or whether it is simpler to test the package for example with pipenv and github actions (if the project lives on github anyway). Put simply: What is a state of the art CI workflow for packages and does tox play a role?
what's the best way to install the latest version of tensorflow-gpu on linux?
anaconda has v2.5.0 for windows but not for linux 🤔

and conda-forge doesn't even have tensorflow-gpu
I'd rather not use pip if possible because I need the cuda and cuDNN toolkits pulled in too
@west sluice don't use the anaconda repository, use conda-forge
oh, conda forge doesn't have it? weird
huh
https://pypi.org/project/tensorflow-gpu/ you can use the linux wheel from pypi
pip install tensorflow-gpu
or better yet, the regular pip install tensorflow already has gpu support
not sure why anaconda hasn't updated their package yet
hmm... I'll probably have to conda install cuda and cuDNN if I pip install tensorflow
yeah it might "just work" if you do it all in the same conda env
wait a sec... does the regular tensorflow package on on anaconda have gpu support then?
that i do not know
it looks like tensorflow only "officially" supports pip install and not conda
then again they also say "ubuntu" and not "linux"
no idea what exactly that means
looks like the answer is no unfortunately
which sucks, since there is a linux 2.5.0 package there on anaconda
maybe I should look at the docker image?
oof, the tensorflow docker images all use python3.6... it would be nice if they used a more recent version of python
😭 why is this so hard?
anyone ever encounter issues with external index URLs insisting on downloading and installing the oldest wheel?
I have a GitHub workflow that pushes a Docker image to ghcr. The docker image has a label LABEL org.opencontainers.image.source=https://github.com/[...]/[...] and the package is being pushed to the same path on ghcr, however the package is not appearing on the right bar in the repo under packages
Has anyone encountered this before? https://docs.github.com/en/packages/learn-github-packages/connecting-a-repository-to-a-package Suggests that this is all I need to do
I'm trying to avoid having to manually link it via the UI, as this is for work and only 1 person has organisation owner perms, and requires a lengthy change request each time
hello
is it possible to tel poetry to publish a package under a different name than the project name?
i just realised the name i have is taken
[vscode]
Why does not this workspace configuration work?
I'm using multi-root workspace, so I need to configure different terminal working directory for each project
this is the config
"folders": [
{
"path": "facilities",
"name": "facilities",
"pythonPath": "facilities/virtualenv/bin/python3",
"terminal.integrated.cwd": "facilities/clone", // why does not this work?
},
]
also asked in #editors-ides but got no answer
hey all, i 'm having trouble configuring gpg to sign commits on windows, Ik that @stable cloak does it but it keeps telling me that a key does not exist, when its the same thing as it is on my linux installs.
I have git 2.32.0.windows.2 installed, with gpg version 2.2.28
what the
Are you using git's gpg?
wdym
newer git versions come with their own gpg which should make it easier as you don't have to download it yourself
oh is that the problem here
how do i use that gpg version?
because i think that's the problem
git is trying to use its own gpg
on linux its not a problem, it uses the system gpg afaict
Did you configure gpg.program in git's config?
i changed it to gpg
I recall having problems with the 3rd party gpg distributions for win where they were using some weird paths so maybe that could be it, but it has been a while
I don't think it should be using the wrong one if you configured it, but there's also no reason to use that when git comes with its own. git has it under .../git/usr/bin/gpg.exe
ah.
so that's which one it was using
ig i'll reinstall the git for windows stuff
and change the configuration to be the full path to it
@finite fulcrum so after reconfiguring it to use the other one, i think it is using the proper one now, however it has a few problems

as clean as i could get it lol
The only thing --show-source came up with was a flag for flake8 so I've got not clue how it got to that
Does commiting, cloning, etc. work without the signing?
somehow my gpg.program in the local repo settings was set to --show-source so it was trying to run that
i cleared it from the local settings and now it works properly finally
in summary, the solution was basically changing the gpg.program to the path of the actual gpg client since on windows git brings its own gpg agent
It is possible having something like haproxy
but instead of sending requests from same source to different ip destinations
it would send them through different available network interfaces?
Hiya, tldr:
Firewall on - wsl network unreachable. Turning off firewall- everything is perfect. how to fix?
does anyone know how can I find out my wsl port number? im trying to make a rule for it, so that firewall wont block the network there, but I dont know how can I find the port number 😬
@tawdry needle it's been a while, but you gave me some advice on starting my project by using python3 -m module_name since my entry points weren't working (and this worked a treat). I wanted to let you know that I looked at some documentation and I found that using the scripts keyword rather than console_scripts in setup.py ended up getting my original run command working.
scripts allows the user to write an actual script, rather than just run a single function. Doing this allowed me to add an import statement before the function call, and that ended up working.
Here's the link to the documentation if anyone's interested: https://python-packaging.readthedocs.io/en/latest/command-line-scripts.html
good find and glad you got it working how you wanted it
i actually didnt know about scripts
note that this doc is somewhat out of date, e.g. tests_require is deprecated by setuptools
What I am doing wrong here?

GitHub
Contribute to p0lygun/astounding-arapaimas development by creating an account on GitHub.
i do copy everything from . to . so it should have worked
pyppeter is a pervert application
i used page.evaluate('(element) => element.value=""', elem[0]) in order to clear input box
selenium with elem.clear() is much... simpler
well, pyppeter has more functionality though
anyone use https://github.com/nektos/act or can suggest any alternative ways of locally testing a CI action?
GitHub
Run your GitHub Actions locally 🚀. Contribute to nektos/act development by creating an account on GitHub.
I have 2 separate git branches in my repository with 1st being the original default branch I had and 2nd being a branch for different distribution, it has a completely different src folder, which I don't want to merge with the 1st one, but I do want to keep the static folder in sync, how could I merge the 2nd branch into the 1st one without merging some changes, I thought I could somehow resolve it in a git conflict, but there was no conflict because I've just been developing on 2nd one and syncing the 1st one into it since I was only doing static changes there, now that I did some static changes in the 2nd branch I can't sync them in the 1st one because it changes the src file which i don't want
I don't think branches are meant for this sort of thing. The problem is that the history of the 2nd branch has commits that change the src, and if you try to merge, it will include those changes. You would have to edit all the commits and change the history to not include changes to src, or you would have to merge it in and then make a new commit to revert to the original src. The former would be very tedious and the latter would make for a messy commit history.
hm, yeah, I figured it wasn't an ideal solution to use 2 branches like this, but I didn't want 2 separate repos for something that will share many aspects of the code
You could just copy over the static folder manually and make a single commit for it. it would be very easy to do, but of course you lose all of the git history/blame for the new changes.
I don't have the full picture, but I would have tried to keep it all in one branch and have two separate directories for distribution 1 and distribution 2.
Which only contain things that are unique to those distributions.
well it's not completely that easy since even the static folder isn't completely equal, just for the most part, there are some minor differences based on the distributions and copying content that's mostly the same into 2 folders and copying things whenever I change something in the first would be very tedious. there are also some share aspects with the config just not everything, I was hoping there would be something like .mergeignore file just like there's gitignore where I would just define files that shouldn't be merged or something similar
Could you create a script or tool that sorts out these differences when it builds/packages the distributions?
I don't think so, I still need a way to get the edits done on one branch somewhat merged onto the other branch, I just don't want certain things merged, building is then only done from one branch, there's way too many differences to simply resolve this in some script
So there's a --no-commit option for git merge apparently
You can edit the merge and unstage the files you don't want changed
Furthermore, you might have something similar to a .mergeignore with .gitattributes
Some interesting stuff that I never came across before, cause this is sort of a niche use case.
Though this is an important point someone makes https://stackoverflow.com/a/66463140
hmm, I'll have to experiment with these a bit and see how they work, thanks for the suggestions
I have an issue, i cannot use modules unless i take them to the same directory/folder as the python file, is there a way to fix that? Because otherwise it would say "No module named..."
I am trying to install docker desktop
and it said install stuff for WSL 2
should i tick
i don't want WSL tho
will it work fine if i just untick that box
and use docker without WSL 2
If you don't use WSL then you don't need to enable the feature. It's there so that you don't need to install yet another docker in your WSL if you use one.
this is by design. can you show your file structure and describe what you're trying to do? maybe i can help guide you towards a solution.
if i install wsl later
can i do it properly
the setup
Yeah. It's just a toggle from what I've seen
I tore my setup down and rebuilt it at least six time in a day trying to work with a company vpn. Didn't seem to mind me adding/removing WSL every other reboot 
Docker on Windows requires WSL unless you are sticking to Windows Containers
Which is very unusual setup
I did not actually realize this dependency.
Docker on Windows Requires WSL unless you stick to Windows Containers, if you want Linux containers, it's mandatory
I found half a solution with pandoc https://raymii.org/s/articles/Convert_markdown_inline_links_to_reference_style_links_with_Pandoc.html pandoc --from markdown --to markdown --wrap=preserve --reference-links --output outputfile.md inputfile.md but it doesn't renumber the link references nicely 
Playing around with it I learned markdown reference links don't need extra [] if they are their own label ```md
This link has its own label so it works like normal.
Which complicates the idea of renaming all the reference link labels 
Maybe a random Q…. But is there a way to use Jupyter on a iPad?
There are some apps on the app store to work with notebooks iirc. Some were paid though and take up quite a bit of space.
An alternative would be to use Google colab?
what the fuck
github cli is insanely overpowered
i have it streaming a livefeed of a current github actions run
Maybe this is a stupid question, but what actually is "vendorizing"? 😄
that's not a stupid question smh
what context?
I've marked files as vendorized before in .gitattributes
If you mean vendorizing dependencies then from what I understand you take a known working version of a dependency and include that in your application (in an isolated manner).
For example pip has the vendorizes requests (and it's dependencies and maybe some others). So if you have pip it has its own requests that are independent of what you'd install through it and only gets updated manually
can someone help me with this error I'm getting from a project with uvicorn?
...
File "<frozen importlib._bootstrap>", line 1030, in _gcd_import
File "<frozen importlib._bootstrap>", line 1007, in _find_and_load
File "<frozen importlib._bootstrap>", line 986, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 680, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 846, in exec_module
File "<frozen importlib._bootstrap_external>", line 983, in get_code
File "<frozen importlib._bootstrap_external>", line 913, in source_to_code
File "<frozen importlib._bootstrap>", line 228, in _call_with_frames_removed
ValueError: source code string cannot contain null bytes
source code string cannot contain null bytes??
tried deleting and recreating the virtualenv, same error...
is this even the right place to be asking lol
@haughty tiger how are you invoking it? Sounds like somehow you ended up with a null byte (the byte 00000000) in your code
Usually you aren't supposed to have that in text, a lot of programs don't like that
This is when I run “uvicorn main:app”. From the stack trace, it doesn’t look like it’s coming from my code
could you share your code, it might help
Well, t looks to be happening while uvicorn is trying to import your main module
Is there more to that traceback
Hi, I have the same problem with this one from SO about git "would clobber existing tag" https://stackoverflow.com/questions/58031165/how-to-get-rid-of-would-clobber-existing-tag. Though it works to me the git fetch --tags -f solution. The SO thread doesn't give much explanation why that message/warning show up every time I do git pull. I hope someone can help me explain about that message and how such git fetc --tags -f works as a solution.
Stack Overflow
I'm using git in VSCodium and each time I try to pull git is complaining.
Looking into the log I see
git pull --tags origin master
From https://github.com/MY/REPO
- branch master...
What error message do you get in your case?
Is the maintainer of the repository continuously force updating a tag?
Tags aren't meant to move around, that's what branches are for
yeah, I have no idea how it happened, but looks like removing all null bytes in that file worked....how weird
how the heck did you get null bytes in there in the first place
your guess is as good as mine....
not even the slighest clue haha
maybe something did behind my back in vim or emacs??
but usually they are good about showing non printable characters
yep, it's fixed now
how unbelievably odd
anyone know how to take off or make this pop up smaller in atom. it block basically my entire screen when i hover over something. the pop up that you see at the top of the window btw

How to remake commits since I made them but they aren't signed
I want to remake the commits but just sign them
Yeah, how do I rebase those commits to sign them?
I don't want to change anything else about them
IIRC if you just run a rebase without making any edits it will re-make the commits (e.g. git rebase -f HEAD~5)
☝️ exactly that. it's not unlike cherry picking the commits in order
basically copying their contents but with new hashes
in fact i think rebase --interactive uses cherry-pick internally, while rebase non-interactive uses am i think
So like, how do I remake these commits? How do i properly rebase them?
Make a new branch from the current one, git reset HEAD~7 --hard
And then git rebase -S other branch
Is it possible to pass GitHub repo secrets to K8s cluster through Github Actions?
I'm using GKE atm but looking for a cloud-agnostic solution to do so. Using Kubectl with Kustomize
anyone aware of a openapi v3/3.1 capable client library for python that can make the models/api objects from a spec, ideally also supporting deep object encoding
Call kubectl and pass in secret data?
Aye figured that out, ty
Now just need to figure out how to use the multibase kustomization to use different secrets
Hi all, I need some help with doing a Pull Request
On github and git from terminal
I have a branch called add_feature
...and in the past have pushed that branch to Github to do a PR with no problem
I tried doing a push today one the same branch to the same PR but getting some errors I havent seen before
When I do git log I can see my commit is the HEAD
One thing that might have screwed me is that I didn't pull from the beta branch first before trying to push my changes
I tried to do a pull but getting:
error: please commit or stash them```Any thoughts?
Also when I do git status I don't see my tracked files I added. I see other files I don't want to commit.
@mortal zodiac for the most simple case, about that cannot pull with rebase error, you can try
git pull --rebase --autostash
that will automatically stash away your changes before pulling. that said, if your local work conflicts with remote work, that might throw up. as for other files - if you don't want to commit them, don't add them with git add, and if you are 100% sure that you do not need the untracked files, use git clean
@knotty frigate i'm using starship
I have the following directory structure (cwd is parent folder of deployments):
..
deployments
├───kustomization.yaml
│
├───beta
│ ├───deployment.yaml
│ ├───kustomization.yaml
│
└───latest
├───deployment.yaml
├───kustomization.yaml
Now I want to build and rollout either the beta or the latest one based on an env flag.
Till this step, I have no issue getting to work. But here comes the challenge.
I am using kubectl to create a generic secret from literals. The secrets data and the name will be automatically generated based on this env flag. So the secret created will either be secrets-beta or secrets-latest.
Now how can I consume secrets-beta inside beta/deployment.yaml and secrets-latest inside latest/deployment.yaml?
I am using envFrom and secretRef to convert those secrets into env vars for the container
Write a script to handle this?
What kinda script? I'm currently running this as part of a GitHub Action
Powershell or bash should be able to handle it
So what exactly do I make this script do though?
Like, use the kustomize edit command or something?
this is great
anyone uses pillow image grab? if so whats the parameters for box = (1,2,3,4) which is height /position/length?
nvm i figured it out
Look for command line flags and pull the files depending on the flag
Nah, that part I figured out long ago. The issue was with passing the secrets. But I figured that one out too, it was just a matter of switching the working dir
I want to host my discord bot on vultr, is there anything i can refer to? Ive already seen a documentation but its in js, i want a python version.
Hey I'm deploying some python services using docker-compose. Some of the services share the same python modules and today I'm making copies of the module to place it within the build context of the services where it's used. However, this causes repetition which is hard/annoying to maintain.
Are there any recommendations/preferences on how to share just one file to multiple docker services? From what I understand, fetching files from outside the build context, e.g., COPY ../../my_module.py in the Dockerfile is not allowed.
Please @ me.
it sounds like a time for makefile
makefile
build:
rm -r folder with repetitive stuff
git clone your repetitive stuff to some folder
docker-compose build
at least it can work as a compromise
launch with make build

ive tried following the steps but keep get this error
online it doesnt mention anything about bios, just says to enable hyper v for windows
Have you enabled virtualization in your BIOS?
The page linked in the error message tells you everything you need to do https://docs.docker.com/docker-for-windows/troubleshoot/#virtualization-must-be-enabled

Hmm no i guess. i couldnt find that option in bios

firmware is bios?
bios is firmware
you can search online where the option is located for virtualization, providing your pc model and bios version
If you open task manager and click on CPU, do you see any mention of `Virtualization" in the details? Also that ^
some processors may not support it though, I think

I have a question about a python + rust project I've made, (https://github.com/wookie184/dupesearch). I'm using poetry and maturin, but am struggling to get them to work well together nicely
My current build/publish workflow (https://github.com/wookie184/dupesearch/blob/master/.github/workflows/python-publish.yml) doesn't use poetry at all, as maturin seems to handle installing any dependencies, however for local dev on the Python side i'd like poetry (for creating the virtual environment, and managing dev-depencencies, for example).
However, I now feel like i'm having repeat lots of information for both systems, for example I list all project information and deps in my cargo.toml (https://github.com/wookie184/dupesearch/blob/master/Cargo.toml) and i've also ended up listing it again (and the deps twice!) in my pyproject.toml (https://github.com/wookie184/dupesearch/blob/master/pyproject.toml).
Is there a way I can get poetry and maturin working without repeating myself? If yes, are there any projects that do this I could take a look at, and if not, what would a good alternative be?
Umm, not sure haven't done something similar before but I can see a similar section in the maturin README. https://github.com/pyo3/maturin#python-metadata
I think even the orjson lib uses a similar setup like the one you want, https://github.com/ijl/orjson
GitHub
Fast, correct Python JSON library supporting dataclasses, datetimes, and numpy - GitHub - ijl/orjson: Fast, correct Python JSON library supporting dataclasses, datetimes, and numpy
I think maturin only supports it under the [project] section as a list under dependencies, like
[project]
dependencies = ["click^=8.0.1", "rich^=10.4.0"]
whereas poetry only supports it under [tool.poetry.dependencies], like
[tool.poetry.dependencies]
python = "^3.7"
rich = "^10.4.0"
click = "^8.0.1"
I was sort of wondering if there was a way of merging them together, but I don't think there is
I found https://github.com/PyO3/pyo3/issues/953, and https://github.com/PyO3/pyo3/issues/953#issuecomment-651761016 seems to confirm what I thought pretty much
As long as poetry's plugin interface is not finished and there is not standardized way to specify dependencies (https://discuss.python.org/t/pep-621-how-to-specify-dependencies/4599), I expect that you will have to duplicate at least the dependencies between poetry and any other tool, maybe even other metadata (until PEP 621 is widely used) and won't be able to use poetry publish.
iirc poetry's plugin interface was released recently, at least into beta, not exactly sure what the dependencies problem is, but hopefully there'll be a better way of doing this in the future 🤞
oof, so it looks like poetry doesn't follow pep 631 (https://www.python.org/dev/peps/pep-0631/) and doesn't seem to be in a hurry to change to support it either https://github.com/python-poetry/poetry/issues/3332
OK I think i'mma just use this - https://github.com/pdm-project/pdm/, this seems like it should be a poetry alternative for what I want
hmm actually i might just be able to use maturin by itself
ahhhh i think I was just overcomplicating things
If I have a deployment.yaml spec like this:
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: app
image: gcr.io/PROJECT_ID/IMAGE:TAG
imagePullPolicy: Always
envFrom:
- secretRef:
name: SECRET_NAME
I can use kustomize edit set image gcr.io/PROJECT_ID/IMAGE:TAG=gcr.io/$PROJECT_ID/$IMAGE:$TAG to build them with actual values.
Is it possible to somehow accomplish the same for SECRET_NAME?
guys, any have o web site when i can make ssl certificate ?
hey
does someone here use asdf for version management? 🤔
for node, for example
We just published our new Python Distribution Tools, which are most useful for Python addons/plugins/extensions. Ready to be battle-tested.
Python Vendoring Tool - Vendor libraries in a subpackage, which can be placed anywhere in a project.
Python Variant Exporter - Export a specific variant from a codebase.
Python Packer Tool - Pack a package into a single Python file.
Have a look here: https://pypi.org/project/pdistx/
Is there a good way to have black format all incoming PRs to a certain branch?
Git/Github related. So if I want to keep all of the versions as the project builds up, do I just create a branch with the version name with each release? Then merge the branch to main branch, push from main branch and then leave the version branch?
Github actions could do it
Run black in a workflow and then invoke something like this: https://github.com/marketplace/actions/add-commit

GitHub
Add & commit files from a path directly from GitHub Actions
This seems great. Any way to select only the files in the PR?
https://github.com/pre-commit/action
I also found this but not sure if this is better
GitHub
a GitHub action to run pre-commit. Contribute to pre-commit/action development by creating an account on GitHub.
It shouldn't matter because black only formats files that aren't formatted correctly
I haven't used either of them myself, so I dunno
Hey guys, I recently started learning python and wanted to do some projects. Can you guys tell me what are you guys working on or maybe suggest me some projects that I can do?
using https://github.com/fabric/fabric, build a tool that will install and configure a firewall, sshd, and fail2ban on a remote server
Thanks. I'll try my best.
Does anyone here have experience with Cloudinary?
hi! I am using code with me plugin in pycharm
i used to see files before
but now i can only see external libs

I'm using pre-commit. Be aware that if you're using an IDE, it's Python-dependent.
But it's pretty much handy for Python linting+formatting
You could try with Node modules too
Oh no wait, forget what I said. I misread and just saw pre-commit
Never used Github actions yet
In fact idk how I should get started with Github's CI
Is there a python bot development discord server?
There's https://discord.gg/dpy
Thanks friend!
why on earth does this fail on the poetry installation
FROM python:3.7-alpine
COPY . .
RUN apk update && apk upgrade
RUN pip install -U poetry
RUN poetry install
RUN chmod +x /entrypoint.sh
ENTRYPOINT [ "/entrypoint.sh" ]
#8 111.9 unable to execute 'gcc': No such file or directory
#8 111.9 error: command 'gcc' failed with exit status 1
Poetry has a bunch of c deps
but it works just fine with the regular python images
why does python-alpine need extra c shit

GitHub
Contribute to IgnisDa/developrs development by creating an account on GitHub.
Because it is light weight, so the "c shit" isn't pre-installed
python-alpine has fewer features than python images?
thats sad
You won't be able to connect to postgres db in a normal alpine image
ok so how do i figure out what im missing
You would need to install more "c shit"
i need git and poetry for my project
Use the link I sent above that has all the deps
Because alpine is bad for Python, use buster slim instead
Turns out i could use git from python:3.7 so imma just switch to that and drop whole minutes off the build process
Idk why i never checked if i could or not
Only thing i needed really was git and poetry
hi all! I'm observing some memory issues in production but i'm unable to reproduce locally. Are there good tools / methods for doing forensics (taking / analyzing) on a heap dump for a uvicorn process? I'm able to divert some traffic away from an affected container to eliminate any impact involved with doing so
hi @cinder wharf, this is actually an issue I was facing recently, I found tracemalloc to be the most helpful despite it needing a bunch of glue code. there's also pympler (https://github.com/pympler/pympler) but I haven't tried that out yet
my colleague loves pympler though
@vague silo nice - I did find pympler but I was hoping there might be a tool that would work against a running process -- akin to how one would take a heap dump with jvm or ruby ... tho I guess i could maybe add an endpoint to my app that I can call to run pympler ?
the only similar thing I can think of is py-spy - but that only gives you CPU, not memory https://github.com/benfred/py-spy
what I did in my app was enabled tracemalloc if an env variable was set and then save a tracemalloc snapshot on SIGUSR1
ah nice - I may try that same method.. thank you!
@vague silo Congo for helper
sorry, i don't quite understand what you're saying?
Hi there. I am looking for a tool that could help me use declarative syntax to define some layout. I found it in prompt-toolkit. But it is built in... i just need the generic idea or tool to do it. It would look like this...
from something import Root, Node, Leaf
xml = Root("Home", { "color": "red", "owner": "jack & jill" },
[
Node("Bedroom", { "color": "blue", "used_by": "jack" }, Leaf("Do not disturb")),
Node("Kitchen", { "color": "yellow", "used_by": "jill" }, Leaf("Breakfast ready")),
],
)
To be precise, something like SwiftUI syntax.
I mean that congratulations for being helper 😉
can anyone help me with selenium , I am getting error while running it
yes, paste the error
thannks, pls allow me .. it's quite long
feel free to use https://paste.pythondiscord.com
from selenium import webdriver
driver = webdriver.Chrome(executable_path=r'C:\Users\viash\Downloads\chromedriver_win32.exe')
driver.get('https://www.google.co.in')
print("Page Title is : %s" %driver.title)``` this is the code.. and I will post the trace-back on the link which you providedhmm this is kind of weird, on one hand you give it an explicit path to the executable, on the other hand it complains that the executable needs to be in $PATH. just to be sure, that file exists and is executable?
if yes, then I would advise you to put it in path regardless of the executable_path you pass it
yaa I have unziped it
I didn't get this part
C:\Users\viash\Downloads\chromedriver_win32 this file path and I added .exe at the end
and that is executable, right? did you try running it?
I meant installing the chromedriver_win32.exe file to a location that's on your $PATH


but this looks like the path would be C:\Users\viash\Downloads\chromedriver_win32/chromedriver.exe, or am I misunderstanding the explorer?
ohh yaa I guess so you are right, because I haven't called chromedriver.exe instead I was calling chromedriver_win32.exe
I am trying it now
I guess that worked
Now getting different error
if you free can you please check what's that is
I think this may help https://stackoverflow.com/a/50827853
Stack Overflow
I am trying to launch chrome with an URL, the browser launches and it does nothing after that.
I am seeing the below error after 1 minute:
Unable to open browser with url: 'https://www.google.co...
Thanks I will check 😇
let me know if it works!
sorry, it's taking too long I have old PC so, it awlays hang
I just noticed it worked new tab have been opened
no worries, take your time

from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.add_argument('--disable-infobars')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--no-sandbox')
options.add_argument('--remote-debugging-port=9222')
driver = webdriver.Chrome(executable_path=r'C:\Users\viash\Downloads\chromedriver_win32/chromedriver.exe')
driver.get('https://www.google.co.in')
This worked perfectly
I tried these confg
glad to hear 👍
Thank you so much @vague silo 😇 you are awesome
Better to ask here #web-development
And in a more detailed way https://pythondiscord.com/pages/resources/guides/asking-good-questions/
A guide for how to ask good questions in our community.
hello, what's a good comprehensive reference to learn this part of the devops roadmap.sh roadmap?

it looks like this will take some time
Hey, I am new to learning git/github, and am trying to push a git repository to github, but I got this error
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.```how do i host a image in digital ocean and use it in react
like in aws you host media file in s3 bucket what is equivalent for digital ocean
Looks like it looked for a bunch of stuff then said debug1: No more authentication methods to try. git@github.com: Permission denied (publickey).
yeah you need to setup an ssh key if you don't and then cat the public key which ends in .pub and then go add it to github
if your keypair name is not a standardized name like id_rsa id_e25519 ... etc you may also need to specify the key name to use in an .ssh/config
nano ~/.ssh/config
Host github.com
Hostname github.com
IdentityFile ~/.ssh/some_key_rsa
Port 22
Host gitlab.com
Hostname gitlab.com
Port 22
IdentityFile ~/.ssh/some_key_rsa
the path in the identityfile is for the PRIVATE key path just to be clear it can be easy to do it backwards
Ok so I assume https://git-scm.com/book/en/v2/Git-on-the-Server-Generating-Your-SSH-Public-Key is what I want to be doing
yeah
then you can add it and it should work granted you do't customize the name of the key to nonstandard name

Ah I figured windows might be different
I remember I downloaded ubuntu a while back and set up git and an ssh key and it worked fine-ish. But I wanted to try to get everything set up through windows so I wouldnt have to switch between cmd and wsl terminals constantly
with or without .
%USERPROFILE%/.ssh/
%USERPROFILE%/ssh/
can be done pretty easily still in windows
In this tutorial we show how to install OpenSSH Server/Client in Windows.
just do the part for the sshclient part
should install what you need
in powershell
Add-WindowsCapability -Online -Name OpenSSH.Client~~~~0.0.1.0
then you can do like this
https://docs.microsoft.com/en-us/windows-server/administration/openssh/openssh_keymanagement#user-key-generation
OpenSSH Server key management for Windows using the Windows tools or PowerShell.
even on windows 10 just needs the openssh client and possible server service at worst and if you do the ssh-agent service which i recommend it should cache your ssh private key pass during the login session so not needed to enter for every ssh session/connection
Did you get it working?
So TIL, tools-and-devops includes packaging and virtual environment tools
how do I express:
install_requires = ["kombu ~= 5.1"],
extras_require = {
"sqs": "kombu[sqs] ~= 5.1",
}
In poetry?
Another Example in the wild https://github.com/dask/s3fs/pull/362/files#diff-60f61ab7a8d1910d86d9fda2261620314edcae5894d5aaa236b821c7256badd7R26
For full context, I'm trying to port celery from setuptools to poetry https://github.com/celery/celery/pull/6874/files
https://github.com/celery/celery/blob/master/requirements/extras/sqs.txt#L1 that's the current implementation but I'm not sure how to port to poetry
requirements/extras/sqs.txt line 1
kombu[sqs]```I suspect it is not possible
The mechanism for defining extras seems to rely on them being defined as optional dependencies first. Of course that's a problem in your case since you cannot duplicate the "kombu" dependency.
If the extra definition references something that is not defined in the dependencies, then it just "empties" it in the lock file
e.g. ```toml
[tool.poetry.extras]
sqs = ["kombu[sqs]"]
becomes
```toml
[extras]
sqs = []
in the lock file. Not sure what exactly that means, but it doesn't seem to work.
Even if the extra isn't explicitly defined by me, the lock file seems to contain the dependencies for all extras of all dependencies. However, it doesn't seem to affect poetry install -E sqs
Yeah sorry. I ended up finding some instructions on GitHub that set it up through git bash, and then it worked fine pushing on cmd. Thanks for pointing me in the right direction because I had really no clue ssh keys
sweet windows terminal is also not bad and free if your in need for something built in
Ok cool thanks
Hmm almost a thousand open issues...
https://github.com/python-poetry/poetry/discussions/4313

GitHub
how do I express: install_requires = ["kombu ~= 5.1"], extras_require = { "sqs": "kombu[sqs] ~= 5.1", } In poetry? Another Example in the wild ...
Yeah the only related issue I found was https://github.com/python-poetry/poetry/issues/2868

GitHub
I have searched the issues of this repo and believe that this is not a duplicate. Issue Let's say I want to provide a latest extra for my package where certain dependencies are used with a ...
I think they would have to introduce new syntax to solve this, something like ```toml
kombu = {version = "^5.1.0", extras = [{"sqs", optional = true}]}
That wouldn't be a breaking change.
Kind of clumsy though
I think having it not be a dict and instead be a toml v1 heterogeneous list of deps would help
I don't really understand the optional=true syntax
https://github.com/twisted/twisted/blob/trunk/setup.cfg#L96 setuptools really shines here xD
setup.cfg line 96
all_non_platform =```Why does replying to a question imply it's an answer?
Probably cause you asked under Q&A
Does anyone know why Vscode isn't showing any of the packages I installed with conda?
I've activated the conda environment I installed them in
But none of my imports work
I just realized, how would this python file know where my conda modules are?
Did you set the Python interpreter in VSCode to use conda?
ctrl shift p and then search for "python interpreter" or something
Then it will show a list of ones it detected, and you can select the conda one
Yep that worked. Thank you
i keep getting a dir does not appear to be a git repository error when trying to push to a server, but im p sure the dir is a git repo, i checked and it has the .git
!warn 355040211702513666 Please get permission from the admins before promoting within the server. Contact @balmy mulch
:incoming_envelope: :ok_hand: applied warning to @uneven flint.
how did you get the repository?
Hey guys, I'm looking for some feedback on what other people use as environment setup's in production systems
is this the right channel ?
Currently we're having issues because the environment we deploy in differs from the environment we develop in. So easy enough, you create a virtual env that uses mimics the environment in both locations right
but then how do you also mock out the systemlibraries like openSSl problems etc
another problem is that we have software A that's developed by a group at work which has dependancies, but software B that uses software A also has it's own depandancies (which clash)
So I don't know ow to resolve them in a stucturized manner. Do I install software A in environment A and software B in environment B (even though software A needs environment A) or are environments only used when your packages/software are separated ?
Conda handles system libraries
Afaics, it seems like you either have to be able to guarantee the same system libraries on all machines, or use conda, or use docker
For your other issue, conda does have a sat solver which solves dependencies in a principled way, the ideal solution is to have a common environment meeting the dependencies of both A and B but obviously if dependencies are incompatible, then they're incompatible
If A and B are only run as two separate processed then you can also just have a separate environment for each and activate the correct environment just prior to launching
@fresh cedar
we do this anyway for our software, not that we have an A and B but we have versions of our software that keep getting deployed, and sometimes of course the dependencies change, which means the environment changes. And in principle we could be running different versions of our software on the same box. So it's just a given that there is no notion of a "global" environment on prod boxes. When the software is deployed, the deployment code ensures that the matching environment is available on that box. And then the software is executed via a bash wrapper that sources the correct environment just before launching. So you can have different versions with different environments coexisting on the same box and not caring.
thanks, I guess what I was trying to say is that conda might help, but it doesnt resolve dependancies. Poetry can actually look at all packages you wanna use and try to mediate in upgrading/downgrading libraries so all software works together nicely
I'm having trouble to articulate the problem, but basically, we build a pipeline, which has package A that uses libA v1.1 and package B that uses libA v1.5 so they clash
I need to solve the dependancy when they are installed on the same system
so either I run package A in environment A (so it can use libA v1.1) and then use package B to run in environment B so it can use libA v1.5
if that's not possible (it should run in the same pipeline) then I should probably use poetry to mediate and come to a shared dependancy so it upgrades the first and downgrades the second (as i think poetry is quite good for)
So i think the questions boils down to 'can we use conda in the same pipeline to use packages in their own environment per step of the pipeline, or should we then sync the packages as a whole so the whole pipeline uses the same environment'
thanks for your answers so far @jovial wing
Np
@fresh cedar I have a decent amount of experience with conda, it's what we use for both C++ and python package management, so happy to answer questions related to conda in particular
I highly recommend conda, I've been really happy with it
File "c:\Users\Jannik\Desktop\diablo3 bot\main.py", line 32, in <module>
result = cv.matchTemplate(screen,smith,cv.TM_CCOEFF_NORMED)
cv2.error: OpenCV(4.5.3) C:\Users\runneradmin\AppData\Local\Temp\pip-req-build-sn_xpupm\opencv\modules\imgproc\src\templmatch.cpp:1164: error: (-215:Assertion failed) (depth == CV_8U || depth == CV_32F) && type == _templ.type() && _img.dims() <= 2 in function 'cv::matchTemplate'``` Hello guys i try to compare 2 images but i get this error. Does someone ever faced this? i cannnot figure it outwell, it was the file format, jpg works png didnt
Hello, I am trying to optimize my k means cluster code to wrk with an inputed amount of centroids can someone help me?
can a begginer in python that only knows what that a python is a snake help
idk
can u?
my code:
https://pastebin.com/B84qGuME
How can I amke my code wrk with more than one centriod it is for k means cluster
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
My ADB Framework!

GitHub
DebugSploit Framework is an Android post-exploitation framework that exploits the Android Debug Bridge to remotely access an Android device. DebugSploit Framework gives you the power and convenienc...
Hey everyone 👋
I'm looking for reviewers: https://github.com/nvbn/thefuck/pull/1214
Any word is welcome. Thanks!

anyone know what the max image size is for a docker image within gitlab CI ? I can't seem to find this info for some reason.
ping me if you respond please
Note - the image size i have is ~4.8 GB
I don't think there is a max?
hrm - well I'm getting errors along the lines of: Error processing tar file(exit status 1): .. no space left on device
this is in the build stage, so there's a max somewhere i assume
Wow. I would question why your docker image is so big?
Can I also see the full error log?
i don't see the relevance - assume it's that size because it's needed
Okay... Fair enough
what i've posted is all there is really - this happens when it's installing packages, but it's not always on the same package 🤔
That's not really enough to go off for me to be much help anyways. Really sorry!
yeah that's all i get from it though
it fails - on the error posted, looking at a few it seems to be during the pre-commit stage
but again, it's failing on this error, due to lack of space on device
You said it's gitlab CI. Are you using this image as the base for CI?
Are you building it on gitlab CI?
So one would need to know what the device is, how to determine it's space limits, and how to change those i presume 🤔
this is being built in gitlab yeah - so there's a .gitlab yaml file and a Dockerfile for it
Right. Can you build it fine when it's not on gitlab?
Yeah I've built it locally
that's how i know that it's ~ 4.8 GB from looking at docker images
Right.
(i'm not sure how i'd check that info in gitlab tbh)

DevOps Stack Exchange
I'm using gitlab and gitlab-ci along with gitlab-runner.
Gitlab-runner is choking on my build jobs for a day now and I can't find a way to solve the problem.
The problem appears when the npm inst...
df -h checks space
Past this the other issues on Google all give more information, a full log of the error, the gitlab config. I'm aware your project is private, fair enough but it's hard to help with such a specific error
Are you using the default gitlab runner or your own?
That size does seem like a failing. Most build systems only give a 1-2GB extra to prevent abuse.
And yes, running your own runner will probably bypass this
My point is... There must be a way for you to break up the image?
where can i find information on that though? I get that this is "common sense" with a lot of people - but it's not the current problem
Or this was gonna be my other suggestion
I don't know how much i need to break it up by if i don't have any information on the size of the device that i'm working with i guess
So if you need to build that large of an image, you will likely need your own runner.
Error message says differently,
Your out of space, error message is quite clear.
no shit
doesn't say anything about how much space there is tho
Hey @lusty mortar!
It looks like you tried to attach a Python file - please use a code-pasting service such as https://paste.pythondiscord.com
I'd managed to parse that "no space" meant there was no space
The runner is a VM. This means it's space is not a finite number 24/7
most companies don't give out those limitations because abuse reason
It changes. There's no way to give you a value
if you are paying customer, you can open a ticket and ask and likely get a firm response
And gitlab don't give out the public specs of their VM's storage
I am a paying customer yeah - but if i have to try and reduce the image size then it's tricky without knowing what to aim for.
It changes. There's no way to give you a value
ah, ok - this explains why repeatedly running has led to some of them building
I'd just run your own runner if you can't change up the build
4.8GB build image is pretty unusual
If you are a paid customer go directly to gitlab
They can probably suggest a quick fix
fair - most of it is in /opt where packages are installed
not saying that makes it usual
looking at du from / i have:
4.0K ./srv
45M ./var
4.0K ./boot
2.4G ./opt *
4.0K ./mnt
0 ./sys
1.6M ./tmp
2.7M ./etc
20K ./run
0 ./dev
1.4G ./root *
1.2G ./usr
4.0K ./media
4.0K ./home
yeah - xgboot is ~500MB lol
*boost
granted, that is the largest
istg why is gpg so hard to use
gpg is neato
i mean yeah if it worked properly
it used to work on this device and it just...stopped
hahah
Hi all, a question about pyenv: I am trying to set up a project with a different python version than my system one. The problem is that when I try which python in the cli in the project folder, it points to the system default irrespective of where I am in the tree (including $HOME directory). pyenv which python points to the version installed by pyenv, again, irrespective of which folder on my system I am in. What am I missing?
you need to add the pyenv init to your shell startup script
try run pyenv init @thorn sentinel and can you share the output here
aha, that is in your shell?
I am adding it to .bashrc now, see where it takes me 🙂
Hey @thorn sentinel!
Uh-oh! It looks like your message got zapped by our spam filter. We currently don't allow .txt attachments, so here are some tips to help you travel safely:
• If you attempted to send a message longer than 2000 characters, try shortening your message to fit within the character limit or use a pasting service (see below)
• If you tried to show someone your code, you can use codeblocks
(run !code-blocks in #bot-commands for more information) or use a pasting service like:
# shell setups. See the README for more guidance
# if they don't apply and/or don't work for you.)
# Add pyenv executable to PATH and
# enable shims by adding the following
# to ~/.profile:
export PYENV_ROOT="$HOME/.pyenv"
export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init --path)"
# If your ~/.profile sources ~/.bashrc,
# the lines need to be inserted before the part
# that does that. See the README for another option.
# If you have ~/.bash_profile, make sure that it
# also executes the above lines -- e.g. by
# copying them there or by sourcing ~/.profile
# Load pyenv into the shell by adding
# the following to ~/.bashrc:
eval "$(pyenv init -)"
# Make sure to restart your entire logon session
# for changes to profile files to take effect.```The thing is i have the following in the following files
.bashrc:
eval “$(pyenv init -)”
eval “$(pyenv virtualenv-init -)”
.bash_profile:
export PYENV_ROOT="$HOME/.pyenv"
export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init --path)"
i finally fixed it, I don't want to share why my user.name was not the same as my username on the key
@thorn sentinel give this a read it'll give you a better way to put code into discord
@barren iron read what sorry?
Click what I replied to
I've not seen virtualenv-init before
The message from the python bot

@barren iron this looks like a message about why it's not a good idea to post txt files
It also mentions code-blocks... If you read down to the bottom
@barren iron gotcha - thanks