#tools-and-devops
1 messages · Page 17 of 1
I've encountered this before e.g. when you have flake8 plugins. I don't recall what my work around was.
Have pre-commit install them in the flake8 hook.
Right I think Dwight's point is that they'd like those plugins to be dev dependencies so that their IDE has access to them.
And they don't want to manage the same list of plugins in two places as that has a tendency to go out of sync
Personally I now just invoke precommit for formatting and don't rely on my editor for that
I guess I use a different flow. If I'm updating pinned dev dependencies, the same script runs pre-commit auto-update. One and done. If I don't have pinned dev deps, it's a free-for-all.
can anyone explain why Thonny needs the python.exe running in order to work?

if i close the window it won't let me run any code or debug
also get an error message: "Process ended with exit code 3221225786." in the shell
it's strange as Thonny runs fine on my other windows PC. None of these issues
Doesn't pre-commit's flake8 hook allow for extra plugins?
- repo: https://github.com/pycqa/flake8
rev: ...
hooks:
- id: flake8
additional_dependencies: [flake8-docstrings]
can't lock dependencies though (you can't lock the hook rev either)
You can pin the additional dependencies if you wanted too.
I think it just leans back to "keep the pre-commit hooks lightweight". Formatting is about all I run in them. Anything that can self-correct. CI handles other checks like flake8/mypy from the package's dev dependencies for me.
Just use ruff, which has basically all the (important) flake8 plugins
Without the plugin support so... pass.
have you looked at flakeheaven? it's imo a much nicer interface to flake8
I haven't but I'll take a look tomorrow.

GitHub
A framework created for the purpose of building a strong OpSec to protect the privacy and security of users of the internet. - vernikov01/opsectoolkit
Started coding this base of a framework earlier today
Aims at providing helpful tools for new comers to cyber security for strengthening and obtaining a good opsec
One message removed from a suspended account.
you can execute the js fetch maybe?

I want to do a requirements.txt, but I see two horizons. One is to use both pipreqs and pip-tools or the other pipenv. I skimmed through their usages in stack-overflow, but what do you recommend for an absolute beginner like me?
i recommend
mentioning manually first level dependencies to requirements.txt without version lock
doing pip freeze > constraints.txt for locking secondary deps
and installing stuff as python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt -c constraints.txt
this method is reliable in not requiring anything beyond std stuff
you should be working in a venv from the beginning
then its just pip freeze > requirements.txt
no, that's bad practice.
venv is good, but freezing everything is bad
are u nuts thats great practice
u put everything into it. primary and secondary
u can't distinguish what are your primary dependencies
and what is needed deleted if necessary or upgraded
best to write requirements.txt manually and pip freeze doing to constraints.txt
whatever is already primary and installed pip passes when someone else sets it up
what? this phrase is not very understandable
this is bad because u can't distinguish primary dependencies :/ u don't know which are not important and can be deleted
or which ones are important keeping to some certain minimum version
its easy to tell and it doesnt matter primary libraries of python pip passes over doing requirements install
having requirements.txt controlled manually u can controll stuff like
pydantic
requests>=0.1.0
Django~=4.0.0
and can easily distinguish to delete lets say requests if u no longer need it. in pip freeze you are just in chaos of everything
its easy to tell
it is nearly impossible to tell. you don't control essentially your library dependencies in this way
!pip pip-tools comes in handy here

pip-tools keeps your pinned dependencies fresh.
Released on <t:1709727203:D>.
yo im having issues downloading docker on my pc
im getting a error to update my wsl but its not working in cmd
can anyone help ?
How would you guys go about publishing ML code that needs a very large dataset for it to work? Compress it using parquet and unpack it via code? The code is on GitHub, I'm more worried about the dataset
Hello, I dont know if this is the right place to asky about my issue but I am basically trying to use this Kahoot answer bot but weirdly enough when I use it, it displays AttributeError: 'NoneType' object has no attribute 'mr_free_context'. This is where I got this software from: https://github.com/Raymo111/kahoot-answer-bot.git

GitHub
A bot to win Kahoots. Contribute to Raymo111/kahoot-answer-bot development by creating an account on GitHub.
can anyone suggest a good pdm based cookiecutter template ?
anyone here who have work with opentelemetry and adding traces in python base app ?
Better ask your question than ask to ask ^_^ provide full information to answer it, then u will have higher chance it being answered
Asking only in the way u asked, u make it challenging to people's time (as they need to interrogate u about details first) and confidence.
Also I worked with it.
Is there a way to setup pycharm to debug dockerized python server?
https://www.jetbrains.com/help/pycharm/using-docker-as-a-remote-interpreter.html
Available only in PyCharm Professional: download to try or compare editions
last time i checked it is available only in paid version in pycharm.
It is available for free in vscode (one of multiple reasons why i use vscode)
https://www.jetbrains.com/help/pycharm/docker-containers.html#bind_mounts_selinux
The Docker plugin is available by default only in PyCharm Professional. For PyCharm Community Edition, you need to install the Docker plugin as described in Install plugins.
may be some functionality is actually vailable today in community edition though
Thanks
I was struggling to set up remote debugger for some reason, it keeps not working
it works very simply in vscode 😊 u can just launch any docker container (i do it usually with docker-compose) and attach vscode to it from within working

It has option working out of the box with boilerplating stuff on run... but it is pain in the ass to configure i tried
easier just connecting to my own comfigured docker-composes
i am considering in a future switching to a strategy of using Testcontainers though https://testcontainers.com/
As a code container management in tests, sounds lovely to me
Docker-compose strategy is more encompassing though probably 🤔
But nobody forbids us adding test container as part of "dev" run for running locally without unit tests i think
So may be i could fit testcontainers for everything i think, to replace docker-composing stuff entirely one day

Testcontainers
Testcontainers is an opensource framework for providing lightweight, throwaway instances of common databases, Selenium web browsers, or anything else that can run in a Docker container.
Collecting lots of data for later visualization, how would you go about it? We have previously used two options, but neither is really great:
- Append to plain csv files and git it (quite low complexity, quite easy to parse in python to do visualizations).
- Influx DB. Works for very simple data like scalar numbers, but not for more complex data or lots of statistics. We used Gagan with this and it works for the simple "few integers per timestamp", but really really bad for lots of data per timestamp.
What are other things to consider? csv + git feels so very crude, surely there must be something better? 🤔
CSV files 🤔 so.. so... table data.
In which amount? megobytes, gigabytes
if u used git, it could not be big amount though
Default lazy option for devs/situations like that is using MongoDB
Very simple usage. As dictionary inputting data.
very preferably u will use it with pydantic though for some quality
Picture files could be inputted into S3 buckets. Save link to normal db
If u were normal devs, i would have recommended using relational db like Postgresql / Mariadb
It is multipurpose, high quality in usage and fitting 95%+ usage cases (u will have very hard time getting out of its boundaries)
but it has more intricate learning curve and more demanding to tools than MongoDB
so... despite how much i dislike recommending low quality stuff, i will recommend MongoDB i think
as it is may be more fitting
but really really bad for lots of data per timestamp.
a lot of data per timestamp. That's interesting. That's called Time series data.
u can use postgres / mongodb for that, but there exist specialized databases meant for time series just for your information
ergh... InfluxDB is one of them, okay u used one of them
Timescale is interesting i guess as time series based on postgres
Hi i wanna make this

but i dont want the nuker or what ever
i am trying to create that
i wanna make a menu like that but i have my own options
you could do it with this https://textual.textualize.io/
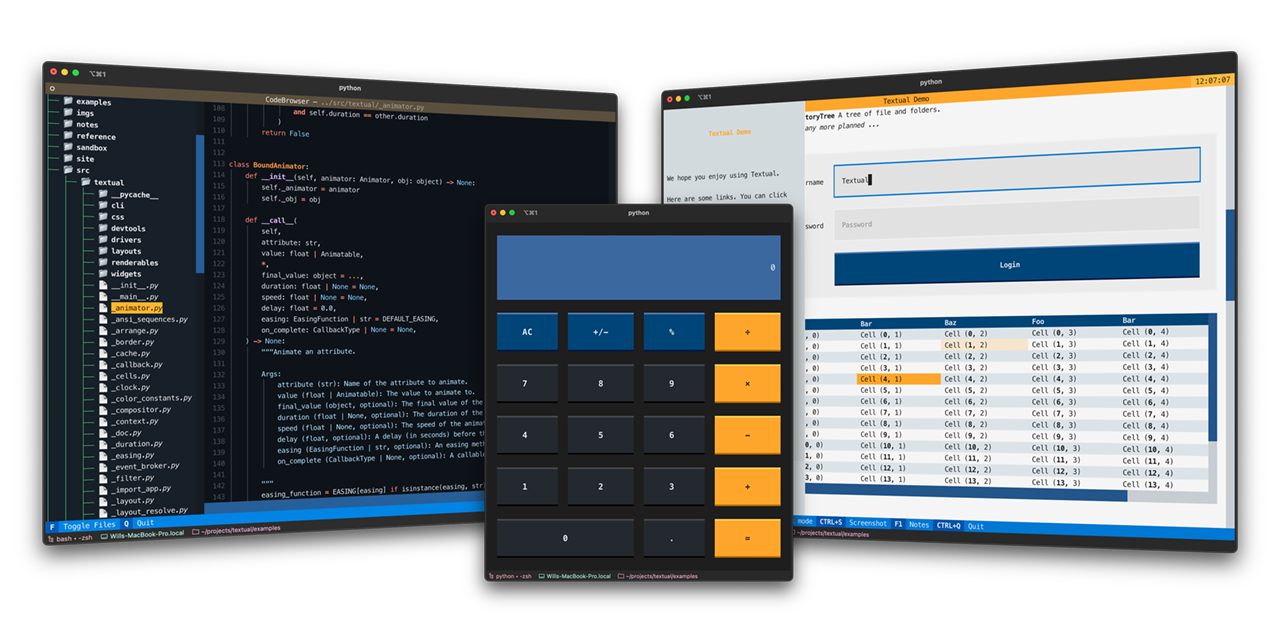
Textual Documentation
Textual is a TUI framework for Python, inspired by modern web development.
Or use rich. Ive build kanban-python (https://github.com/Zaloog/kanban-python) using rich, from the UI you provided it looks like thats what you want.
If you want an even better UI experience, id recommend textual (comment above)


GitHub
Kanban Terminal App written in Python. Contribute to Zaloog/kanban-python development by creating an account on GitHub.
or you can try
https://github.com/ceccopierangiolieugenio/pyTermTk
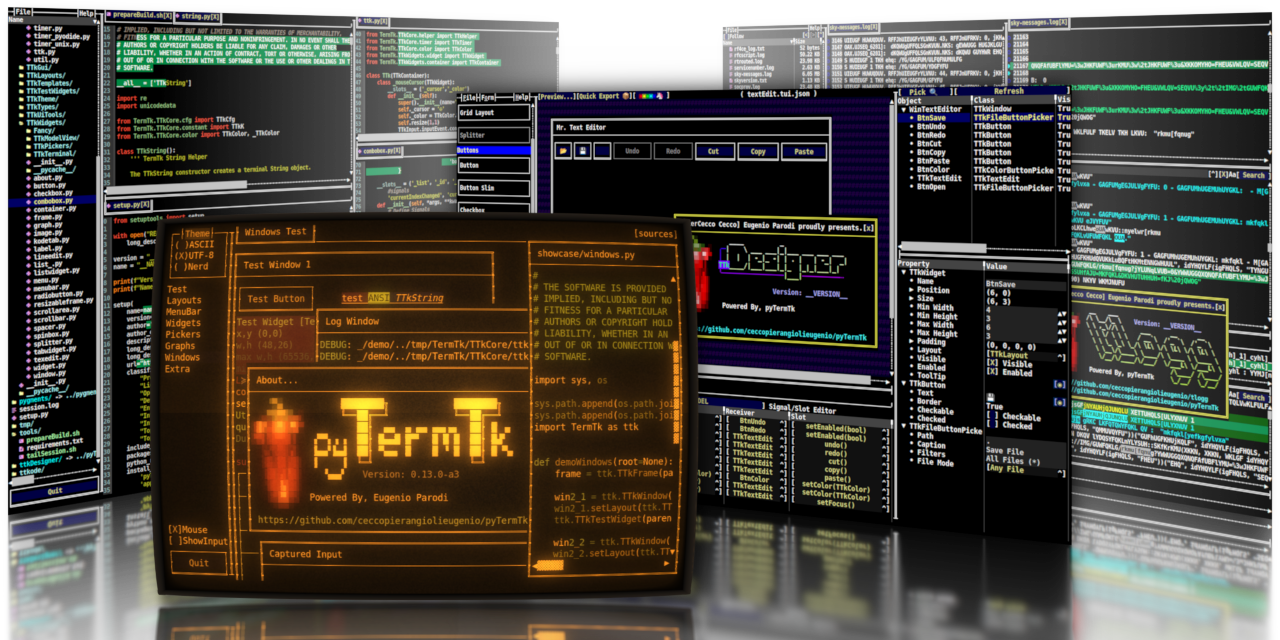
GitHub
Python Terminal Toolkit - a Spiced Up TUI Library 🌶️ - GitHub - ceccopierangiolieugenio/pyTermTk: Python Terminal Toolkit - a Spiced Up TUI Library 🌶️
Yeah influx is too restrictive, it's great for putting a single integer per timestamp, but if you to put 1 mb of statistic ordered as a dict, it's not suitable at all
Thanks for all your input 👍
S3 bucket? Seems like it might be online/cloud/we service which is a no go for us. We have a somewhat air gapped system and probably want/need to self host everything.
Minio is fine for self hosting (S3 like) Blob storage, that has exactly same interface and interacting with same tools/libraries in same way
More old school option is just using current filesystem though to store files
Minio is still interesting though for designing more horizontally scalable system
as even with self hosting we could be desiring using more than 1 host for infra in simple ways
Infra?
Infrastructure.
Sum of your hosts, DNS and network settings, CI CD configurations, staging, production configurations, configured monitoring systems (logging, tracing, error handling, automated alerts) and other details to run your app
-
It can be having auto scaling features to use available resources efficiently.
-
It could have high availability features, if one machine went down, it could be auto excluded from working and other machines could take on its own its apps for continued running
-
It could be having role based permission system where each app or user access the most minimal amount of permitted resources for its/his/her needs (and other security related stuff)
-
Good configured monitoring systems very much help to simplify debugging and maintaince of all of it ^_^ but those systems take effort to integrate them and keep running
-
It can be having manual form (by hand everything added)
-
And more modern Infrastructure As a Code way, of where we just apply code and it auto configures itself from almost zero in its own (and we store this infra code in git repositories as parts of projects)
-
People dealing with infra as a code and capable to do dev duties and customizations are called DevOps engineers. (This field has its own common programming/infrastructure languages to deal with it.)
-
People dealing manually with infra are called System Administrators
I'm not responsible for IT, but I think we have ansible scripts to describe some kind of machine, and docker files to host some tools. All of those descriptions are ofc gitted, sounds like what your are describing.
The CI is Jenkins on a server farm of 20 machines or so. Jenkins is also doing continuous random testing, results are monitored and some results logged.
I don't think we have much needed for scaling features.
The most annoying part is slow disk and file system for the Jenkins machine. I feel so lucky to have a dedicated physical workstation ❤️
I'm not responsible for IT, but I think we have ansible scripts to describe some kind of machine, and docker files to host some tools. All of those descriptions are ofc gutted, sounds like what your are describing.
The CI is Jenkins on a server farm of 20 machines or so. Jenkins is also doing continuous random testing, results are monitored and some results logged.
Well, this is indeed infrastructure as a code. Just legacy outdated one in terms of tools and practices. First times when people started doing that it was like this. It has its usages today too.
Better than nothing I guess too
What is outdated about it?
Or perhaps, what improvements are there to obtain if we would change our way of doing it?
Ansible usage to deploy manually is very old school approach.
Ansible deployments are executed "playbooks"(workflows) that target one or more machines and run sequence of commands/instructions in idempotent way (can be rerun if interrupted) to make its changes.
The ansible is fine today to augment CI or for pet projects doing little stuff i guess to setup things
But the biggest problem about it that it is... promoting, "mutable" configured environments.
People are lazy to change ansible and doing changes with it, and instead connect to server often and do manually changes instead.
or ignore existence of ansible entirely.
Also with accumuluted amount of ansible reruns onto same machines, the server becomes "polluted" eventually with a lot of accumulated state changes. So the code becomes potentially depended on no longer documented changes for stuff that was already deleted from Ansible or changes that were done manually.
The CI is Jenkins on a server farm of 20 machines or so. Jenkins is also doing continuous random testing, results are monitored and some results logged.
Well, and Jenkins is one of the first ever invented CI tools and has a lot of involved mm bad practices with too many manual clickings, configurations. we can say it was from first generation of CI tools.
Modern CI tools work better with defining everything as a code to run CI code and just easier to use
Yes, Jenkins is terrible in many ways, but we haven't been able to find anything else that fits our needs.
Describe what u currently have. So u said self hosted.
U have baremetal servers.
Do u rent them from someone and accessing remotely or u have them present as physical machines near u?
If they are physical machines, what is used to run Linux OSes on them? Is there something underneath them used for virtualization, or Linuxes are installed right onto machine directly
Optionally add information about amount of physical and virtual servers (may be also applications and devs)
Depending on scale, some different options can be chosen
There is just 1 person dealing with the ansible stuff, and I think he is diligent in doing changes through updating those scripts. So then there should be no real downside for us currently.
Redhat Linux directly on machines on a few different sites. Some jobs are long running, 8-48 hours. Job triggers controlled by timer and/or scm changes.
- Parameterized jobs
- Jobs with several stages to run in parallel
- being able to select what jobs to run on a feature branch as part of Merge process
- being able to run jobs nfs disks
- display test fail details in a nice way
- probably more
Current issues:
- job configuration in groovy (annoying to rerun job on local machine outside CI environnent)
Any programming languages majority of you able to use/develop/maintain? (or can be approved in general)
Amount of machines?
It's annoying that groovy is used for Jenkins since we don't use it elsewhere
I would assume everyone is familiar with
- verilog
- python
- c++
- bash
- restructured text
- markdown
- xml (not html)
- yaml
- toml
Interesting. So... You run via groovy Jenkins CI jobs stuff related to actually getting business proffit?
CI tool is literally used for app running?
oh. okay. So CI is used only for CI purposes of testing applications? and not for staging/production?
What do you mean by getting business profit?
checking if u use CI tool for... "business related tasks", like gathering info, procesing it, sending to somewhere and etc. Using CI as application not for testing purposes basically
We do Co pilation and testing on Jenkins. Synthesis and Power analysis are the slowest.
all the mentioned amount of machines is just for Jenkins running?
Or some of them are used not for Jenkins?
What's the difference between testing and gathering and processing info? 😅
Only Jenkins, there are other machines for hosting things like grafana, mattermost, compiler Explorer, ...
Well, Production infrastructure environment is used for interacting with real users or processing critical or non critical data related to fulfilling business tasks (for gaining proffit and etc)
Staging environment = is usually having same apps as Production, but using weaker hardware, and dependencies can be mocked/stubbed. used to test things to work for already deployed in mocked way apps. It can be checked to work by QA on generated data. Lazy people copy and obfuscate data from production to staging.
CI infrastructure (with Jenkins for example) is used only for running CI tests and builds. Testing, compiling to builds and releasing stuff. Optionally deploying too, or only triggering automated deployment in other tool
So whenever there is an iteration on the product, the power characteristics might have changed. Running power analysis collects a lot of data and automation checks if the new results are within bounds. So it's basically a slow test and the result can sometimes be used as information to drive power improvement work.
We don't really have users. And we don't deploy our product or host any service for others.
okay... i get the idea.
I will fit it into my head and will write later list of options and their benefits i guess
What you describe seems very far off from our business. I have a hard time to understand because it feels very abstract. "processing data to fulfill business task (gaining profit)"? Production infrastructure, I think this the big difference. We don't have any production environment, there is no need.
I'm amazed, thank you 🙂
well, u described situation with... data scientists stuff / MLOps stuff i guess.
They do it in a similar way. Running long time processing tests with a lot of data processing. That is used by them to improve their "models" accuracy
Depending on yet another rerun result, if numbers are really good they could be adopting yet another algorithm version as a solution because it processed "dataset" in a better way and works better on a controlling set of data used for evaluation
Yes that does seem similar
can i begin a git branch from a historical commit but keep the main storyline intact
Sure, git checkout thatoldcommit; git checkout -b new-branch
A branch is just like a label that automatically gets updated when new commits are created.
You can put a hundred labels (create a hundred branches) pointing to the same commit or any old commits. Creating or deleting a branch does not affect other branches.
Here is my my-email-app.sh bash script
#!/bin/bash
# Get the current date and time
current_date=$(date)
# Echo the date and time to the log file
echo "Execution date and time: $current_date" >> /var/log/debug_log_my_email_app.log
#Run script
/usr/bin/docker run --rm -e PYTHONPATH="${PYTHONPATH}:/app/jb_cw" -it my-email-app:1.1 >> /var/log/my-email-app.log
This is my crontab -e configuration
*/5 * * * * ~/my-email-app.sh
debug_log_my_email_app.log has the following text in the file so the crontab configuration is working
Execution date and time: Thu May 9 11:55:01 EDT 2024
Execution date and time: Thu May 9 12:00:01 EDT 2024
Execution date and time: Thu May 9 12:05:01 EDT 2024
However, my-email-app.log is left blank.
I scp my tar Docker image from my local machine to my Linux virtual machine.
my_email-app.tar
I executed the "docker load -i my_email_app.tar" command
I have the docker image as
REPOSITORY TAG IMAGE ID CREATED SIZE
my-email-app 1.1
I don't know why my app is not running
This sounds like a really complicated way of sending an email.
My first suggestion would be to not do it like this.
That being said, lets take a look.
First, run your Docker command outside of your script, just in your terminal, and see what you get.
I can run the script manually. But one of reasons it won’t execute with crontab is because PYTHONPATH variable is not initialized
Or maybe that is the only reason
So I am trying to figure out what the full path of the python file that executes the program is
which python
Or where
Depends on your distro
It does work when you run it manually?
How are you doing that?
3.9.13
I typed ./my-email-app.sh
And it works
Add a 2>&1 to the end of your Docker command in your script, then run it again and check your logs again
can I make a cookicutter temaplte with this directory structure ?
src/{{cookiecutter.dist_name}}
yeah? try it out
I'm getting cookiecutter.exceptions.NonTemplatedInputDirException
here is the repo https://github.com/Aviksaikat/cookiecutter-pdm-pypackage

GitHub
Cookiecutter template for a cutting-edge Python package: pdm, ruff, mypy, GitHub Actions and more! - Aviksaikat/cookiecutter-pdm-pypackage
it's a pdm template
try something like this project
GitHub
🍪 A cookiecutter package for an enlightened python package - cthoyt/cookiecutter-snekpack
Awesome thanks man
if anyonre is interested in a pdm project template plz check this one out
docker run -v "C:\OD\My OneDrive\Desktop\Test Script":app/pl_ce/core/email/ my_excel:1.0
docker: invalid reference format.
See 'docker run --help'.
idk how this is an improper syntax format. What am i doing wrong?
are you forgetting a -t
I wish multiple Dockerfiles were feasible in a Python project
So I don’t have to keep renaming the CMD line in it
Pass command line arguments into your container and then parse them with argv
That being said this is a very convoluted way of doing this
I would throw away the Docker entirely here
wdym? you can have multiple dockerfiles. just name the one you want when you run docker commands
I thought if you only name a file “Dockerfile”, the file automatically has a Docker file extension
My Dockerfile
# Use the official Python base image
FROM python:3.9-slim
# Set the working directory inside the container
WORKDIR /app
# Copy your application files into the container
COPY . /app
# Copy the requirements.txt into the container
COPY requirements.txt /app
# Install project dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Set the command to run your Python application
CMD ["python", "jk_fg/core/excel/my_projects_excel.py"]
My commands
docker run my-excel-app:1.0
output on the commands prompt
Traceback (most recent call last):
File "/app/jk_fg/core/excel/my_projects_excel.py", line 7, in <module>
from jk_fg.h2o_resources.castlebuild import fg_functions as fg
ModuleNotFoundError: No module named 'jk_fg'
This happens everytime I want to run a program that's not the main.py file. I need assistance. I have been troubleshooting this for an hour an a half 😦
https://stackoverflow.com/questions/30215830/dockerfile-copy-keep-subdirectory-structure
Should it be 'COPY . /App/' ? With the last slash to copy recursively

Stack Overflow
I'm trying to copy a number of files and folders to a docker image build from my localhost.
The files are like this:
folder1/
file1
file2
folder2/
file1
file2
I'm trying to make th...
so? file extensions have nothing to do with it. you can specify the one you want to use in your commands
I looked into the container and I have all of the files in my project so how can this help?
I am not understanding. Naming a file Dockerfile transforms the file into a docker file from my understanding and that’s the only way
Ohhh neat
You think you can help me with my other problem?
this seems like a python project structure issue, not a docker issue
But I can run the program perfectly fine without it being containerized
I don’t have that same error when I run the program
So why are you just causing yourself problems by adding containers to the mix?
Because I am developing an automated software
And I need to containerize the program for independency so my company doesn’t have to rely on my local machine to run the program
Could you try
python -m jk_fg.core.excel.my_projects_excel
also ENV PYTHONPATH=$PYTHONPATH:/app could help
The error is saying what you think is in the container is not. The files either are not included in your copy or they are not where you are assuming they will be.
The key step before containerizing something is having a repeatable method of installing that something. Take your code, clone it down to a fresh new folder with nothing yet installed, and write down each step you need to take on your machine to get that code to work. Each of those steps needs to be done in the container as well.
The only significant difference is that instead of cloning a repo from github, the dockerfile will COPY the artifacts in from the already cloned repo.
In short: If you can't duplicate your install process from a fresh state to a working state locally, you don't know what to tell docker to do yet.
:incoming_envelope: :ok_hand: applied timeout to @edgy storm until <t:1715540408:f> (10 minutes) (reason: duplicates spam - sent 4 duplicate messages).
The <@&831776746206265384> have been alerted for review.
Back on topic of our topic before i forgot.
So u use python with Jenkins runners. And ideally wish running stuff locally and voiced languages supported as
verilog
python
c++
bash
restructured text
markdown
xml (not html)
yaml
toml
Part 1: Main CI:
If we will rework the same what u said in regular team, they would have used Gitlab highly likely
It is modern, simple yaml syntax everyone can do. good documented, a lot of features out there. The only little disadvantage that only its runners are lightweight.
Full self hosted instance of everything in gitlab is rather RAM/CPU heavy.
Same regular team if would have wished diving into hard issues would have just used self hosted Github runners. Or just Gitlab self hosted runners without trying to make everything self hosted. That makes rather simple solution.
More fully self hosted options exist like Drone CI
And more k8s dived teams would have chosen something kubernetes based for this stuff potentially.
Part 2: Augmenting CI
U wished writing less Grovy and in smth else.
https://docs.dagger.io/
Dagger allows writing pipeline in Python, Golang, Typescript.
We just inject its call into other CI tool. That is handy if u have complex pipelines
That i shandy if u wish them being runnable locally.
k8s teams would have probably used smth based on Tekton or smth
Important note that Tekton is configurable to do development locally too and executing tasks at remote side!
Part 3:
Trying to abstract ourselves from CI.
Problem currently you face that u wish tool allowing you rerun your any kind of jobs without pretty much them being deployment?
So this eliminates pretty much standard tools as they need to be deployed with their code first before they could run.
Unless you make deployment for one of job as part of a process. So using regular tools will involve too much customization
=========
TLDR: lets summarize everything that was said.
We wish easy running arbitary jobs across multiple machines, with monitoring means, and least amount of hustle.
in those terms CI tools are the only i am aware about that fitting this criteria as they are naturally capable distributing arbitary workload across multiple servers.
So path with just self hosted Github, Gitlab, Drone CI, Jenkins for older guys, are all valid in my opinion.
U could make a switch to another tool for it being friendly yaml
You could augment it with Dagger.io for writing major bulk of your code logic runnable locally in friendly python
or augment with tekton for compatibility with kubernetes ecosystem.
Whatever you choose CI tool, it will make grant you from its ecosystem monitoring basic! features.
But if u wish more things like having super comfort for development, u need installing error catching, logging, tracing, profiling systems.
Common self hosted free choice to go here for Grafana stack and it is very friendly for kubernetes ecosystem btw
But this choice will be hard to setup for not experienced with it people, alternative can be going with Datadog (but too expensive)
or more cheap alternative going with Axiom. https://axiom.co/solutions/observability
========
Ressummarizing again. my recommendation gong with simple self hosted Github/Gitlab runners if you aren't that much fully self hosting wishing guys. Because yaml
And augmenting workflow with Axium monitoring+ tracing features to have more development comfort. Or some other monitoring system.
If u wish building locally runnable code and your pipeline workflows are complex enough. Try writing code with Dagger.io
If u will be one day ready u could tap into kubernetes ecosystem that simplifies installation of self hosted monitoring solutions and running stuff like that.
But that's already probably too much. Take note that it will be very helpful if u will just install monitoring system on top of whatever CI choice u use.
So
Important thing for you right now to increase development comfort if u wish, so having monitoring systems. They help to development environment a lot, by showing Tracing/Profiling stuff (like Pyroscope in grafana stack) to make development easier. While Tracing will automatically show performance for all network requests your code has.
As well as easier seeing all errors
=====
As for jenkins... feel free to replace to any modern Yaml friendly choice. Github actions, Gitlab CI or even going Drone CI>
I can say with confidence for Gitlab CI choice, and if u are willing self hosting only runners then Github Actions choice is okay too.
Drone CI... is having fully self hosted stuff but not super explored, so can'be sure for sure. its advantage though in bring self hosted stuff too in more lightweight way than Gitlab
======
There are Data science, Machine learning specific tools to actually make such stuff without reveinting the wheels highly likely
But i don't know this ecosystem, so i recommended choices within realm of regular infra/backend tools i am aware of
Funny enough note to add
That you have full GitOps and running on horizontally scalable Jenkinses is actually very modern approach you are using
So you are actually very modern in terms of "workflow" itself and scalability stuff.
The only thing that can be improved as i see, having just more modern CI tool working in yaml (or working in python for you in main way)
And installing monitoring/tracing/profiling/logging systems on top because CI monitoring is not meant for this level of intensive main development you are putting it through
So better augmenting it with some stack (We personally use Datadog for AWS, and Grafana(gui to see it all)+Prometheus(metrics)+Mimir(metrics)+Lok(logging)i+Tempo(tracing)+Pyroscope(profiling) in kubernetes stack
Axiom is potentially more managed option to try here with less hustle than Grafana stack, and cheaper than Datadog but haven't tried it personally, just recommendation from a friend.
What advantages will be from having those changes?
- Observability stack will simplify by magnitudes development for you, error observation and performance observation through all levels of your code (Btw Sentry could be helpful here too for easy error tracking)
- More modern self hosted yaml runners will be just more friendly because... yaml is not groovy and rather simple in modern stuff
- if your workflow is complex in CI, adding to this stuff like Dagger.io will help not fighting CI syntaxes and actually just doing it in python/golang/ts and just running optionally locally
- Kubernetes ecosystem i don't recommend to your case as it involves a lot of learning curve, but more modern teams could have chosen having CI runners, monitoring stack through it, because it simplifies development across multiple machines and has ecosystem of ready to use solutions that take lesser effort to run all together (Just installing yet another open source community made helm chart through ArgoCD or Terraform, that already does all configurations for you). Kubernetes choice is rather friendly for people wishing self hosting everything and managing it across multiple dozens of machines btw
- Tbh kubernetes does make sense for you as u named amount of servers where it makes sense for sure for sure, but u will probably not able to meet learning curve may be. Otherwise we are actually using kubernetes for same amount of machines 😄 Except we have running up to multiple hundreds of different applications across this amount of machines

What else can be improved and changed? Within realm of just installing CI to 20 machines... eh... Ansible does make sense as simple enough choice.
I still would have wished changing it to somehow more immutable to deploy choice. But other options will be harder to configure, so i will withold recommending them
Well, i could note here only kubernetes tbh making machines to be able running immutable deployments... but i mentioned it as not recommending it because it has intriciate learning curve.
i don't like concept of mutability where we pollute our machine with multiple installations again and again
hmm
I think we have an alternative choice may be here
If i had the amount of machines u mentioned, i would have probably went with choice of installing smth that can be controlled through Terraform to create virtual machines at those servers tbh
and i would have tried going with just "building" in my repository or smth Image, that has everything preinstalled
and just raised with terraform or smth like that through all servers
in this choice we will be able having FROZEN image of a server and replicating exactly it like that at once and dozens of servers today and in a year
and then upgrading it will be just building new one, trying if it works, and rolling on them all. If upgrade did not work succesfully, we have a choice to ROLLBACK ourserlves back to previous version we froze
that is not possible with Ansible because u can't lock all dependencies with Ansible
we can have a funny note here that for building image, ansible can be still used to install all dependencies
=========================
Alternative approach here is just using Kubernetes i guess, because with kubernetes amount of stuff installed is very low, like only OS and kubernetes itself
And everything else is installed into kubernetes itself and can be stored in our code as configurations
Kubernetes minimizes amount of our dependencies we keep installed at server in mutable way
I don't have all answers ready for you describing all best exact tools here to use but i described my line of thought and why i would be wishing alternative approaches
and where i see first line of improvement to make your life happier (monitoring tools to add, and more modern CI can be nice)
Some explanation regarding importance of immutability of deployments and freezing stuff properly for rollbacks
updated several months our CI servers (ha) and everything started falling apart for some reason. Newer auto caught version of Debian has Linux Kernel 6+ for some reason breaking our python code, CI aren't passing (and when tried upgrading hosts all apps were falling apart too)
with having ability to rollback i just made rollback. figured out reason in Linux Kernel 5 working properly
and postponed dealing with those Kernel 6 problems some day later. and not blocking anyone
Could it be that I forgot to type a / before jk_fg in my Dockerfile?
Try it and find out
anyone develop a workflow for exploring unfamiliar code bases? any particular tools for this?
I usually do (read-only/exploration purpose only):
- install poetry
- try to start up/run the thing
- try to create the most basic scenario I can
- install dependencies as needed
- depending on how deeper you want to go, write unit tests and use pytest-cov until I get a desire percentage
that will give me a good idea about that the thing does
Strategy in completely bad code base:
i learn through refactoring.
Usually i need to start working with bad code base
So my first step is covering with typing and gradually increasing strictness of mypy
Cleaning folder after folder until everything is refactored.
Then i could have fun covering it with unit testing better.
Accurately rearranging it to be more testable.
After that usually i am prepared already making massive rearranges to code structure
Covering with unit testing further and being prepared to deal with this code further.
Stategy in code which is kind of okay
in code base that already has unit tests and i need to deal with unit tested part.
I enter releavant unit tests, and crawling through it with visual debug to know the necessary parts i need to deal with
[Optionally increasing documentation]
I could be helping myself with diagrams building or docstrings/comments documenting if necessary.
Now I get “No such file or directory “
This is frustrating lol
Anybody have any other ideas
It runs it but i get a runtime error (Environment variables don’t work. I get NoneType unsupported operand types error )
FROM python:3.9-slim
# output python logs properly to console
# and don't generate bytecode not used by docker anyway
ENV PYTHONUNBUFFERED 1
ENV PYTHONDONTWRITEBYTECODE 1
# Set the working directory inside the container
# all commands after that with use this path as default destionation
WORKDIR /app
# Copy the requirements.txt into the container first for correct usage of docker caching
COPY requirements.txt ./
RUN pip install --no-cache-dir -r requirements.txt
# P.S. i am not a fan of copying everything. Because people often copy `.git` with all secrets with it. Could u use
# COPY jk_fg jk_fg # as alternative instead?
# And add .dockerignore file with removed __pycache__ stuff preferably from copying
COPY . .
# Set the command to run your Python application
# easy overriable on `docker run -it imagename YourAnotherCommand`
CMD ["python", "jk_fg/core/excel/my_projects_excel.py"]
Firstly this should be more appropriate
You should be delaying COPY . /app operation to last moment, because it is not cachable almost
First we copy only a single file and installing deps itself, because it is easy cachable instruction
(That will speed up things to debug considerably)
Secondly. just launch your docker container as
docker build --tag -test
docker run -it test bash
enter the container and see what u built and where it went wrong, which files are not precent despite expected
comment out wrong not buildable instructions if necessary
Thanks @rapid sparrow i really appreciate it!
Main CI: looking further into gitlab CI might be interesting since we already self host gitlab for issue tracking and wikipages.
You mention runners being lightweight as a disadvantage. What do you mean by that?
What is K8? Kubernetes?
I said that only runners in Gitlab are lightweight. That is good but bad that the rest of Gitlab is very heavy
Runners attach to very heavy in resources ruby Gitlab backend
K8 is Kubernetes yeah. Things like microk8s are easy to install with Ansible across multiple hosts with least amount of headache. Microk8s is lightweight Kube distributive
Microk8s is not meant for big amount of hosts though. Fully fledged distribution of K8s is more appropriate perhaps. To check its limits, may be okay
I'm sorry I don't understand this at all 🙈
"bad that rest of gitlab is very great"?
Gitlab main self hosted infra part, also known as backend is very RAM, CPU heavy
To this backend runners are attached
T9 from phone. I was writing heavy, ops 😉
Phone writing issues 😔 it can auto replace to wrong words
I'm not sure dagger would integrate cleanly with Jenkins. Having a clear way to visualize pipeline and test results are important. It makes me wary.
Well, ideally I mentioned installing better monitoring systems. Using CI for monitoring is very crude 😅
Normal monitoring systems have far more capabilities
Monitoring for just run pass/fail and reporting which specific test failed?
I see, I wonder why it's heavy. But then again, Jenkins is a complete mess and resource intense in some ways as well.
Gitlab webgui is bad, but has become better in some ways over the last years.
Jenkins webgui is like a car crash. 😂
Part3: deployment:
I'm not even 100% sure what deployment means. Today all devs can mostly rerun anything directly in the git repo on dev machine. The problem is the pipeline script itself not being runnable as it would need a local Jenkins instance on each dev machine.
We don't have any network requests 😅
We do have 10 % of devs running NixOS or Nix shell on their dev machines. On CI machines we are running redhat with module system.
I'm becoming more and more eager to start using nix shell 🤗
part three, i was thinking regarding alternatives to CI usage, Jenkins usage
normally data engineering is done with data engineering tools, the things u do
CI usage is somewhat inconvinient way very well matching workflow you needed
and i like that u have GitOps in result
i was thinking that instead of CI, we could be using normal tools for backend/data engineering, writing code with apache spark or Celery or whatever (they have their own means for neat monitoring)
But them i realized it is too far out of your workflow way, any way like that will require too much of customization
so i approved in my thoughts CI approach instead and followed train of thought further how to improve it more
may be i am missing smth though, as i am not aware about ecosystem of data engineering throughly. I am aware only about infra tools and backend stuff
Monitoring can do next things
- Error catching, with detailed tracelog reporting if smth failed
- Metrics monitoring if smth becomes more time to run, or takes more memory to run, or takes more disk usage to run. You can track even how performance of your stuff gets changed in months of time
- Tracing, what amount of time each "step" took time, tracing can monitor any arbitary kind of step, covering program fully in different overlapsing ways. If at any covered step program gets broken, u again receive detailed tracelog to error.
- Good logging handling for easier quering and finding. Good logging can be porting many different extra fields, u could easy navigate through for easier debug
- Profiling, this one automatically covers your code with performance measurement and memory/cpu measurement for each function. and shows diagrams about it in a graphical way. useful to optimize long stuff to run shorter.
Monitoring synergize with each other. From tracing it is easy to find relevant logs, from logs easy to find relevant traces, and other monitoring info
They are usually useful to monitor server running application facing users
But since your CI running algorithms for datasets are your main area of development, it made sense to me suggesting this tooling with targeting your CI infrastructure and tests running in them
What does this mean?
that means... mmm... your application working is essentially fully defined in Git repository as a code.
Many people with regular application face problems that it is developed in git repository and then Servers have a ton of hidden settings needing to have the code running.
I like that with your Ci approach and using tests to train your models, you have a rather modern development workflow where all things to run your app are defined as a code in git repo and done on every commit through CI
other data scientists often have it worse and they could be developing even in prod, straight at servers, without anything stored in git repository
So. you made a very convinient choice to do your workflows that follows the most modern practices. When everything app needs for running is defined in git repo and automatically running on every commit
Jenkins CI is automatically keeping some basic run history data like runtime, but only for a fix amount of maybe 20 latest runs, and visualization is not the best.
We collect some metrics in InfluxDB and visual, with grafana. But it's a very manual work to add 1 new metric. Nothing automatic for all Jenkins jobs/pipelines for example.
but only for a fix amount of maybe 20 latest runs, and visualization is not the best.
proper monitoring system can fix it, as they can store data for months (or even years) of time. (whatever time retention u will define)
Nothing automatic for all Jenkins jobs/pipelines for example.
proper monitoring systems do it all automatically.
We submit with monitoring tools, stuff into monitoring backends
And configured dashboards with be automatically updating themselves with new data
And can be even traversed for precise time intervals
How it was last 5 minute, last day, last week, current month, previous week and etc Intervals are selectable in modern monitoring systems to observe state of app for long time of its history through many its different layers
Yes this is svalkande for us in grafana visualization, but getting the data into InfluxDB currently has to be set up for each data we want to track
I'm not sure if there is some plugin for Jenkins that would log basic data for specific set of jobs automatically.
modern monitoring systems like loki, can automatically grab logs from all running logs in specific /var/logs folder
or they can grab logs from all running docker containers from host
or if in k8s, they will automatically on autodiscovery grab all logs from pods.
Modern logging ecosystem in modern infra can autodsicover and grab stuff on its own.
traces similar, we just have defined collectors and submit them as network request to http 4318 port for example
they are silently in background automatically can be submitting without participating of a dev
all dev needs applying instrumentation or covering with tracing steps
profiling can work fully automatically without dev awareness, pure infra dev problem
metrics... custom ones i am not sure hmm 🤔 never tried submitting custom ones, always collecting only automatic stuff, but basically in some way it is infra dev problem too, although there is integration for python to submit custom stuff
anyway, problem of infra devs mostly
@rapid sparrow @short peak thanks for the comments!
Every dev is every kind of dev at our office 😅 for good and bad.
We collect all our metric data with python scripts I believe. If there is plugin to push som data from Jenkins, that could be fine. But a problem is that Jenkins is unreliable in how it reports runtimes. It includes pending wait time in runtime and records runtime for parallel tasks in a pipeline incorrectly sometimes.
We're implementing Signoz right now which I'm looking forward to, it looks great
It seems web related, which would be irrelevant for us. But I might be mistaken. Could you say something more about it?
SigNoz isn't strictly web focussed
it's meant to be an alternative for DataDog, NewRelic, etc.
this is from the same kind of stuff as i suggested for your CI infrastructure
improving it with monitoring stack to see more info
SigNoz, Grafana stack, Datadog, they are all alternatives indeed
SigNoz can be a choice for you too
it is capable gathering logs, traces, metrics and etc doing stuff with providing easy GUI access to all of it
Om not sure where we get the automatic stuff. Let's say we have a command that's being run in a Jenkins job's pipeline step, like a bash script or a build step. How would any of these tool pick up data?
APM seems to be about collecting data from users, we don't have this situation.
- Logs will be picked up through autodiscovery of running containers. At least in k8s
- Traces will be picked up if u have attached tracing lib and initialized on script boot. During its running it will try submitting traces automatically to localhost:4318 or any other hostname specified in Environment variables. Behind this environment variable is supposed to be telemetry collector
- Profiles are usually autocollected from any invoked running function. as long as u initialized that
- Metrics can be calculated and evaluated from anything
anything that has python code, can be monitored.
U don't have to have users to be APMed 😄 You only need code for that and... servers. both which u have.
random double dice spinner

all APM can be initialized actually in a silent way as smth like
opentelemetry-instrumentation python3 script_to_run.py
or ddtrace-run python3 script_to_run.py
the automatic injectors will inject everything without script awareness about it (without any code lines regarding monitoring)
and as long as right Environment variables are set (or monitoring stuff is present in default localhost location), it will go towards correct monitoring backends
I am working on project where device 1 force device 2 to format disk, install os, install drivers but there is one condition device 2 will be totally empty. And the whole process will be done using python language only.
Is it possible?
If yes, then could u please tell me the process
I am aware of possibility of doing that but with changing somewhat requirements
installing virtualizing tech at device 2
device 1 just requests specific OS to boot in this virtualizing tech, automations for that are available
====
Possible alternative, device 2 is having receiving client that can install OS in baremetal way
Can u explain process for virtualizing tech
I have to work on this but don't know the process flow
resource "vsphere_virtual_machine" "vm" {
name = "foo"
resource_pool_id = data.vsphere_compute_cluster.cluster.resource_pool_id
datastore_id = data.vsphere_datastore.datastore.id
num_cpus = 1
memory = 1024
guest_id = "other3xLinux64Guest"
network_interface {
network_id = data.vsphere_network.network.id
}
disk {
label = "disk0"
size = 20
}
}
https://registry.terraform.io/providers/hashicorp/vsphere/latest/docs/resources/virtual_machine
I noticed in infrastructure as a code tooling ability for programmatic virtual machines configuration at baremetal setups
The process is supposed to be smh like:
- you install VMware at target machines
- at dev machine you run for example terraform code that connects and raises expected virtual machine with OS and other configurations at all target servers
So, smth like this. To explore different virtualizing softwares and make a choice here
Disclaimer: I haven't tried that and not sure if VMware is best option here as I usually work with cloud providers via terraform
Vagrant can be used as a code lazier alternative (we can always apply remotely via Ansible, but probably terraform, Pulumi provider exists for that)
So, the architecture or flowchart is available ?
There's no specific architecture or workflow for "virtualizing tech"... What are you actually trying to do? Repurpose some physical servers to run VMs instead of on bare metal? Migrate from on-prem to cloud? Something else?
I am working on project where device 1 force device 2 to format disk, install os, install drivers but there is one condition device 2 will be totally empty. And the whole process will be done using python language only.
And this is done using via Lan cable connected
And I am having one year experience as python developer
So, all this network and backend things new for me
That doesn't sound like it has anything to do with virtualization. Are both devices VMs? Why are you trying to do this with Python?
If these are physical servers, the normal tools are discussed here: https://www.reddit.com/r/sysadmin/comments/ykla7p/serverbased_disk_imaging_deployment_solution/
Cloud makes this way easier, you can just spin up a VM with a set image. As we've mentioned before tools like Terraform and Ansible can help

No, physical devices from laptop 1 to laptop 2
Our organisation said do with python only
Then the solution is to find a new job because this makes zero sense 🤣
🤣🤣🤣🤣🤣
I think so
Well, clonezilla can do same
We can imagine that may be u need clonezilla with python
Ergh, there is requirement to interrogate people why they want a thing they want
Otherwise choosing right tool is hard
Ask why they want physical devices installed from laptop 1 to laptop 2
In our organisation we daily install os and drivers in laptops more than 10
This is a very normal thing for IT departments at organizations of a certain size. Nobody uses Python for this.
What OS? Windows has multiple official tools for this.
Window 10 or 11
But you don't have a normal Windows network with a domain controller etc.?
If you do, then this is what you want: https://learn.microsoft.com/en-us/previous-versions/windows/it-pro/windows-10/deployment/deploy-windows-mdt/deploy-a-windows-10-image-using-mdt

This article will show you how to take your reference image for Windows 10, and deploy that image to your environment using the Microsoft Deployment Toolkit (MDT).
Fix that first
Join https://discord.gg/winadmins for more expertise with managing Windows endpoints
Yes it's the autodiscovery I'm interested in. But Jenkins is Java and it's flaky and has stupid time measurements, so I'm guessing that some kind of plugin for autologging might inherit the incorrect measurements.
We already have the InfluxDB and we collect some metrics from some python scripts. I guess some helper tools to be able to do
start_time
make
stop_time_and_log_to_influx 'measurement_name'
Might be worth to think about.
I'm not sure if we have any traces that are valuable to log. Jenkins already keeps logs of runs for a few weeks.
ddtrace-run, I will have to look that up.
- datadog is expensive solution but working smoothly out of the box and very rich in shown data
- grafana stack is free self hosted but requires high infra dev effort to setup properly and working at full capacity (some room to make stuff easier exists though if using for example a single boilerplating to maximum helm chart or docker compose and not praying for more) (Option to use managed grafana exists though for cheaper in terms of dev time setup)
- axiom encountered recently because of a friend. It has managed features, but cheap. not sure how much pain in the ass to configure, but still backends are remote, should be magnitudes easier than grafana stack i presume
there is plenty of other common choices, i just told which ones i am more aware about
Yes thanks, it's good to have a few alternatives to look through when time comes
Hello, I pushed 3 file on remote branch but it was mistake, i should have pushed only one, now i wanna to revert this commit and push only one file but as i understood after revert it will clear my changes as well. what is the safest way to get back commit and push only one file but don't loose changes in another two files
a lazy choice that is breaking commits for others if they track this branch
git reset --soft HEAD~1, it will cancel you commit but keep changes
u can recommit only things u wish a push with force
a long choice intended for work if other people use this branch
revert change with git revert HEAD~1
then revert i guess again, and cancel with reset --soft to get change in a nice way quickly 😄
or manually copy your change if u wish
we can do simpler git checkout of specific file from a specific commit before it was reverted, that is a choice too
git checkout commit_hash -- path_to_file
that can be used to extract it how they are before revertal
for testing revert i created new folder and do it but after reverting yes it undos commit but removes changes
i also used revert with --no-commit
lets imagine we are on commit that commited already changes we wish to revert without breaking master
Choice 1:
git revert HEAD # we reverted commit and changes
git push
git checkout HEAD~1 -- path_to_file # which we wish restored before we reverted
git checkout HEAD~1 -- other files
choice 2
git revert HEAD # we reverted last commit and changes.
git push # send to master
git revert HEAD # don't send to master
git reset --soft HEAD~1 # we should be having locally changes like before we commited
"git revert HEAD~1" it automatically removes all my changes, no?
but without ~1 it still removes i think 😄 as i tested it
rarely using revert 😄
git revert will create commit opposite to what it was. Reverting the changes
we can push it safely to remote to remove the change
then if we do one out of two choices to restore our files like before those commits happened, then things should be okay
one possible lazy choice creating revert for revert, and then soft reseting it to have all changes from it but not the commit itself
alternative can be used in git checkout specific files
ohh yes now i understood it, thank you but
finally
what would you say
what is the best and safest way?
Choice 2 is lazy and fastest, best suitied for mutiple files needing to be restored
Choice 1 is safest for sure, if u have just 3 files, use this one. annoying if needing to checkout too many files
thank you!!
I was doing isort with this command
isort **/*.py
And got this error FileNotFoundError: [WinError 206] The filename or extension is too long
I found the solution here, but the interesting thing is that the Vaulue was already 1.
https://stackoverflow.com/questions/72352528/how-to-fix-winerror-206-the-filename-or-extension-is-too-long-error
Stack Overflow
I'm facing this error while installing the setup for Tensorflow Object Detection API. How to fix this error?
Error: Could not install packages due to an OSError: [WinError 206] The filename or exte...
hey im trying to dockerize my app that use python + selenium but it always crash when i run, do anyone know how to make selenium + python work on docker
dockerfile:
COPY . /app
WORKDIR /app
RUN mkdir __logger
# install google chrome
RUN wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add -
RUN sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list'
RUN apt-get -y update
RUN apt-get install -y google-chrome-stable
# install chromedriver
RUN apt-get install -yqq unzip
RUN wget -O /tmp/chromedriver.zip http://chromedriver.storage.googleapis.com/`curl -sS chromedriver.storage.googleapis.com/LATEST_RELEASE`/chromedriver_linux64.zip
RUN unzip /tmp/chromedriver.zip chromedriver -d /usr/local/bin/
# set display port to avoid crash
ENV DISPLAY=:99
RUN pip install --upgrade pip
RUN pip install -r requirements.txt
CMD ["python", "./main.py"]```the message i get
something throw: Message: unknown error: Chrome failed to start: exited abnormally.
(unknown error: DevToolsActivePort file doesn't exist)
(The process started from chrome location /usr/bin/google-chrome is no longer running, so ChromeDriver is assuming that Chrome has crashed.)```The error is rather obvious looking like. Fix version incompatibility between chromedriver and chrome
yeah im kinda confused what i should change there :S
^_^ installation of a chromedriver or chrome itself
find different version and install this different version, that matches compatibility between them two
ok it now no longer complain about
The chromedriver version (114.0.5735.90) detected in PATH at /usr/local/bin/chromedriver might not be compatible with the detected chrome version (125.0.6422.60); currently, chromedriver 125.0.6422.60 is recommended for chrome 125.*, so it is advised to delete the driver in PATH and retry but still give same error :/
still get this
(unknown error: DevToolsActivePort file doesn't exist)
(The process started from chrome location /usr/bin/google-chrome is no longer running, so ChromeDriver is assuming that Chrome has crashed.)```kind of different error. That is a progress. 😊
i feel like this should be something somebody already solved but i really tried google and none example i found worked 😦
solved it, thanks for help
🎉
Would you recommand to focus on AWS or m$ Azure ?
They're both very commonly used.
Lots of jobs, mine included, actually have both.
Neither one is really better or worse than the other.
I'd give both a shot and see which makes more sense to you
depends on your backend languages you are comfortable with.
If you are C# dev, i recommend m$ Azure.
Otherwise AWS is twice more market popular
it sounds unrealistic to target both right now
but I'll keep that in mind
I'm actually a C++ dev
AWS is the big boy, but it's got a price tag to match
Azure isn't quite as cool, but it's got Entra/Purview/Defender/Microsoft 365/etc all heavily integrated
C++ is not usable for cloud stuff as far as i am aware.
Or at least i don't know it to be usable or in any level supported.
Consider changing language if u wish going cloud.
Python, Typescript, Golang, C# and Java are all usable very well at minimum
There are some other choices but they are more awkward
eh
You can containerize whatever you want and throw it on ECS
EC2 as a worst case scenario
There is no support in observability systems to whatever u want.
it is all having a different cost to make maintainable
Also not in every language u can describe infrastructure and glue it together easily
Cloud "native" though, yeah you're going to want Python/JS, C# on Azure
Yeah, plus EC2 is way more expensive than, for example, Lambda
but it does work
Or Golang or Java 🙂
Java? 🤨
one of most popular backends nowdays
a terrific amount of code is written in it
well supported across everything
https://developer.hashicorp.com/terraform/cdktf
U can even write infrastructure as a code in Java 😄
for raising automatically all your Lambda, EC2 and etc, with all networks, IAM and etc preconfigured
Not even.... would you look at that
All the LTS Java versions
huh
Neat

oh no
not Terraform
stateless or go home
what I meant by that is I don't do C#
I do know python, or I least I think I do
Then go AWS 🙂 twice more marketable
Do check your local hiring web site may be something else is more popular though
ty
like in my own origin country all three big providers aren't usable
i am aware that in some countries like UK, M$ Azure can be more popular than AWS
the local training is heavely leaning towards Azure for some reason
$ of m$ I assume
It's actually sad, there's no AWS local training
It is
And 90% of Azure is Linux
It's always annoying when people complain about "Microsoft ripping them off" by charging for Windows
They make far, FAR more money off of 365 and Azure
IIRC you can still upgrade a Windows 7 license to a Windows 11 license for free
Because they just don't care, you're still paying them monthly for Excel
I mean idk if it's all the same
but in my country there's legal reseller selling windows key s (those probably illegal tho) for less than 1€
I still don't understand why people keeps buying those full price
anyway we digress
oh and microsoft has been really really good with their teams/365/azure strategy those last few years
it's actually quite incredible
how they managed to win most of the market with their arguably mediocre software (teams)
someone help meim new in python so i dont know how to use some tools
like what i supose to do here

Can you do backend developing in python
yes
mediocre? almost crap! T_T
Hey I’m trying to build a cli tool that essentially automates cold pitching to potential clients via social media platforms. How do I approach this? Would I need to bypass those websites’ security?
!rule 5
5. Do not provide or request help on projects that may violate terms of service, or that may be deemed inappropriate, malicious, or illegal.
You need to look at their APIs and what they allow. For LinkedIn I don't think sending unsolicited messages is an option. https://learn.microsoft.com/en-us/linkedin/shared/integrations/communications/messages
Message API functionalities
copying my question from #python-discussion because that channel seems too busy to answer more niche questions:
s poetry worth it for a fastAPI project? i am using it to serve ML models, currently it has 4 people working on it rather sparesly.
i did hear things like "poetry isnt needed anymore" and "it is needlessly complex" but i havent used it before.
currently i am just using pip + pipreqs, i want something to simplify running the app and managing its deps
i also have an automated job for deploying it, so it would be nice if poetry worked with that
i would say:
if your project is under active development every day/week
then u can afford having stuff like Poetry.
if your project is rarely updated
Then regular pip with constraints.txt file is better 😄
pip install -r requirements.txt -c constraints.txt
where constraints.txt is auto generated with pip freeze, and requirements.txt is written by human primary dependencies and minimum versions
because it will be already doing the primary job of keeping primary deps sane to navigate and helping easily freezing all secondary ones
human pointed?
like, manually resolving any dep errors? since there wont be many in a small project
written by human. like
requests
Django>=3.0
and etc
just point main deps, and pip freeze > constraints.txt
constraints.txt locks secondary dependencies but does not install them (u can auto generate it with pip freeze)
root dependencies have to be mentioned in requirements.txt manually written in order to be installed
like, the deps that are required by the packages in req.txt?
kind of like package-lock in node JS?
well, constraints.txt will be package-lock here i think? if i am not mistaken with nodejs terminology
i see
amd main list of dependencies that are actually going to be installed is requirements.txt
primary ones or all of them including secondary stuff ^_^
primary, ones i directly import and use
just constraints.txt then to generate for happiness
and u will have reproducable dependencies, properly frozen
i did hear about pipenv
but it seemed like most ppl prefered poetry
i think i will give poetry a try, but will definitely use pip freeze now
thanks a lot
u have CI right?
yes
you could be printing pip freeze in CI, to ensure that if u mess up smth, u will see last CI dependencies that worked and passed CI ^_^
then need for poetry will be fairly even more minimal
how would that work exactly?
like, do i have to pull up the consolle output?
or is there an automated way to do this
CI prints logs. just make one of steps printing pip freeze
As long as u can access CI logs, u will find last deps that worked (in some green passing one)
e.g. failing the pipeline if something mismatches
ohhh, i get it
I will add that to CI, thank you
I wrote an article about Poetry on my website and instructions showing people how to use it. I hope it helps.
You could also give rye a try
on the server i changed code manually from nano, but git doesn't know about that change. now i am gonna to change something in code by git but also wanna get latest code from the server. when i do git pull of course this don't update code because i did last change from terminal on the server. what is the best way to get change and continue working without problem?
If you don't want to lose your local changes you need to commit them before you pull. Is that what you're asking?
Git will prompt you to commit or stash before trying to pull again if you attempt to pull something that would conflict with local changes.
Give it a try
Create a copy of your .git folder just in case
Then pull and see what happens
hey all! I usually need to manipulate lots of data and optimization is a must , so I have created a small decorator to measure the time a function/method takes to run. It has some cool features as well. Feel free to use it on your own projects 😉
https://github.com/mcrespoae/tempit
The first thing I'd be interested in reading in your README would be "why use this over timeit?"
i don't have any local changes yet, i want to do but before i do i wanna update my local but when i do git pull it doesn't do anything.
yeah.. I will add that 😉
Are you pulling from the right branch? What exactly does it say when you pull?
i really hope rye takes off, but its not production ready yet
Is there anything newer in your remote? What are you expecting to happen?
Is it possible to dockerize using python as an automation so you can track output and progress ?
What do you need to keep track of?
I did it in real time before
Just a matter of using subprocess.Popen correctly
If u care only about final result, then subprocess.Run works too
The real time build output of what’s going on
If u wish taking data from Docker client... Then no idea. Time to read its documentation then
Oh i started noticing I thought there’s other method
Add logging to your app and it will be printed to stdout
If you want more structured output then mount a volume and save files through it
He wants logs of docker build, not app
Okay thanks I have already thought but was difficult to use subprocess through django channels
Just a matter of wrapping into asyncio.to_thread or whatever there
It is allowing to run synchronous code in async friendly way
Okay thanks
If using Django channels you probably want asgiref.sync.sync_to_async rather than to_thread
I just got through integrating a (needlessly) async API into a django app and I did not enjoy it. i ended up figuring out that csrf_exempt decorator doesn't get along with async, any call that uses it will hang guvicorn. i'm making a REST api so I don't need csrf at all, so i'm fine yanking it. but wow was this needlessly difficult. i don't like async one bit. I'm a big boy, if i want a thread i'll make one
hi guys! Is there any extension for visual code (or if it alreadys comes with it, how to enable) that allows you to select some function being called from another library and pop-up a window with the function declaration? (instead of opening a new tab)
Already available by default.
Smh like "Peek definition" on right click menu
Thanks!!
Ive build a TUI on top of it (still WiP, but I released a new version today)
https://github.com/Zaloog/rye-tui
GitHub
A Text-based User Interface (Tui) for rye powered by Textual - Zaloog/rye-tui
i made a cool little app for windows. if you like attract mode the frontend for pc. this lets you pick how you want it to look and will write the code for you. then save it and run the test build i added in the data folder. pretty cool and if you mess up by placing stuff on the wrong side you just check the new way and start it .. its no drag and drop but its a start 🙂 https://github.com/JJTheKing44/Python-AM-Tools/releases/tag/AM-LayoutMaker-v.2.0

GitHub
Basic Layout Maker v.2.0
For Attract Mode +
1.Pick Your Layout Size. 1920x1080 For Now.
2.Pick The Modules You Want To Use. Tooltip Added To Each
3.Pick Your Video Size. This Puts It In The Middle ...
Is there a point using a non-root to stages other than the final stage in a dockerfile?
Nope. At most I use non root in some stages only for a reason to have better file permissions by default, and not needing chmod/chown in next stages
Really struggling to build a workflow that builds a Windows exe using PyInstaller. I have done a rough one based of stuff I read but I kept encountering errors, latest one being that it cannot find the pip package I am trying to install from requirements.txt but I checked and it is a valid version.
ERROR: Could not find a version that satisfies the requirement pluggy==1.5.0 (from -r requirements.txt (line 5)) (from versions: 0.3.0, 0.3.1, 0.4.0, 0.5.0, 0.5.1, 0.5.2, 0.6.0, 0.7.1, 0.8.0, 0.8.1, 0.9.0, 0.10.0, 0.11.0, 0.12.0, 0.13.0, 0.13.1, 1.0.0.dev0, 1.0.0, 1.1.0, 1.2.0)
ERROR: No matching distribution found for pluggy==1.5.0 (from -r requirements.txt (line 5))
WARNING: You are using pip version 19.3.1; however, version 24.0 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' command.
Error: Process completed with exit code 1.
I made sure that it updated pip to the latest version available, I don't understand why I am getting errors for this.
can you paste your workflow here? or alternatively could you link to the failing run on your github repo?
GitHub
Reforger Whitelist (Py) is a whitelist application for Arma Reforger. - Possible fix for error on package install · BreathXV/ReforgerWhitelistPy@a1539c2
hm, looks like pluggy 1.5.0 only supports python 3.8+ and the cdrx/pyinstaller-windows image only uses python 3.7
have you considered configuring your job with a windows github runner to build the executable directly? i.e. runs-on: windows-latest (see also docs)
then you can use the actions/setup-python workflow with a compatible python version, and pip install your requirements and pyinstaller like any other run: command
Damn, that does make sense 🤣
@willow pagoda That worked! Thank you! I did have to change the Python version as 3.10.12 is for linux/macOs - had to change to 3.10.11 which supported Windows.
How would I automate releases? I.e. I have a main and a dev branch, when I push to the dev branch, I want it to immediately make a release with some label saying it is the latest release (e.g. unstable).
Hello everyone,
The other day I was talking to a company and they told me that they were spending tons of money on logging. I never heard of that.
I wrote a pipeline to remove redundant logs, some of which might have been added by mistake and pushed to production.


I’ve used this tool btw:
(you'll have to go to the select top left and choose the "verbose logs" pipeline) https://gitgud.autonoma.app/playground/3c135aa8-2720-4950-a184-61b3948a55bf/code?utm_source=discord&utm_medium=social&utm_campaign=python
Copilot for real developers
I'm curious why you made the choice to remove the debug log lines instead of just setting the logger to a higher level of output.
I currently have a Windows 11 PC and I am running a Ubuntu 22.04 OS in a VM. I have an external USB connected HDD and would like to create a plug 'n' play Ubuntu OS on the external drive. Please recommend resources that I can follow.
So your question is about to create a live USB of Ubuntu? https://itsfoss.com/ubuntu-persistent-live-usb/
This will have nothing to do with your VM though. If you're looking to clone that the details will depend on the hypervisor you're using. Here's a guide for Virtualbox. https://pendrivelinux.com/convert-a-virtual-machine-into-a-bootable-usb/

It's FOSS
Enjoy live USB with persistence so that your changes made in live sessions are saved. Learn to create a persistent USB in this tutorial.
Pen Drive Linux
Convert Virtual Machine into a bootable USB. Turning VirtualBox VHD VDI images into booting Physical Disks. Copy VHD to USB. Boot from VHD
I know this is a python server, but I have a JS script that needs a fast JSON parser like simdjson , but im having trouble installing it, is that just me? or anyone else?
#web-development is fine enough for js discussions
i'm developing an ansible playbook and i'm getting an unusual range of errors about this being "a managed environment" and to use pipx which I've never heard of. I know it's a managed environment, I'm in the middle of managing it. This is one annoying error. What is this about
provide more detailed code of error
and your ansible code that encountered it

I'll put something together coherent in a sec, the VM is grinding away on possibly its first successful build in a few hours. I am using ubuntu 23.04 in a qemu guest (perk/ubuntu-23.04-arm64) on a Mac ARM desktop. I had a situation where I had done python3 -m virtualenv venv and then specifically pathing to venv/bin/pip3 install -r ... I got this nonsense error message. pip originally came from python3-pip package. i installed python3-full, no difference.

the problem "went away" after I walked away from it 🤷♂️
Do I need to understand pipx y/N
If you're installing libraries for your own project, pipx is not correct.
yeah, just stuff i want to use at runtime for the application
If it's at runtime, you have a pyproject.toml build backend or setup.py, and you have console scripts, you can use pipx
But if it's the only thing installed on the virtual machine, it's probably not worth it
nothing quite so organized, requirements.txt + a systemd unit
maybe a docker image would be useful
i've been at python for a number of years and have never heard of it. thank you for y'alls help
ew
i find docker a roadblock to development, especially when the application still isn't fully formed. ("ok boomer")
Docker for me is strictly a production environment.
dev containers use too much internet
that and microsoft basically controls it
i never got onboard the containerize all the things bandwagon. there's something i launched in docker i should have launched in kubernetes but i was thrilled just to have it working and stopped touching it
I wrote this to ease the pains of using vscode remote-ssh offline.
https://github.com/killjoy1221/dlvsix

GitHub
Download vscode, code-server, and extensions. Contribute to killjoy1221/dlvsix development by creating an account on GitHub.
and dev-containers way of redownloading code-server every time is not compatible with this
ok. i got it working once with pycharm, debugging via remote mind to a python in a docker
code-server is the only portion that doesn't use ghcr.io (github container registry)
I have a question. How can I make an vscode "extension" for my own programming language?
I think you first need to define the language syntax.
This is how toml implements the vscode plugin.
https://github.com/tamasfe/taplo/tree/master/editors/vscode

GitHub
A TOML toolkit written in Rust. Contribute to tamasfe/taplo development by creating an account on GitHub.
see the package.json's contributes.grammars key
then after that, you need to implement an LSP
I have aws cdk iac.Why do i get :```
[ERROR] Runtime.ImportModuleError: Unable to import module 'lambda_function': No module named 'mysql'
Traceback (most recent call last):
When I have:```
mysql-connector-python```
in requirements.txt?How are you installing your requirements on lambda?
Is it possible to run Docker through a SOCKS5 proxy? I want to use a proxy to pull images
Or maybe there's an easy way to set up a local middleman HTTP proxy that connects to the SOCKS5 proxy
there is option with proxy having caching.
https://github.com/goharbor/harbor/blob/main/contrib/Configure_mirror.md
Otherwise there are AWS, GCP and other mirrors to use docker in your location without proxy
public.ecr.aws/docker/library/python:3.11-bullseye
That's... at least while gov did not black list foreign cloud providers
GitHub
An open source trusted cloud native registry project that stores, signs, and scans content. - goharbor/harbor
Also, u can find list of mirrors on this site https://huecker.io/ (or use it itself if not afraid 😄 )
Apparently this one has some different hashes
yeah ecr.aws works, thank you
Hello, folks! I am learning docker while applying it to a project. Actually, I am running two different docker-composes. One of them has a container for redis. The other one, should use redis a broker and backend (celery). The thing is: currently, I am not being able to connect to my redis from the celery container using localhost:6379. Do I need to expose ports even though they should run on the same machine? Am I doing something wrong?
U can put them to same compose, and then u can address Redis by its service name as hostname "redis" (instead of localhost)
Optionally a bit more complicated choice: if u want them in different composes.
U need to define them same named network to communicate. At least letting your celery joining specific docker network defined for Redis
Ergh, read about docker networking for second choice. Docker deep dive book is good
They need to be on different compose... How can I let them join same network? They are indeed in different docker networks.
Read about docker networks then
Docker deep dive book or official docs
One more question: If I get the IPAddress from the inspect, the connection should happen if the ports are exposed, right?
https://docs.docker.com/compose/networking/
Define explicitly new network for Redis, let it join(by default or specifically saying)
Use in second compose, joining by External network and let celery join them, or define default network as external for lazy choice if u can

What?
ports: feature to use only for exposing beyond host, or for your localhosted development area in IDE, tldr to expose smith to beyond shared network
expose: is pure documenting feature. They are all automatically exposed in bridge networks as it is to communicate with each other in docker networks, as they address by hostnames
Never really needed to check their IPs for debugging. IPs aren't really needed for docker as all stuff is communicating in internal DNS.
At maximum we choose port forwarding to 0.0.0.0 (default) or localhost
Yeah. As I said, I am just starting. on this world... I'll try to connect them via docker network, as you said
Thanks for the guidance and help! 🙂
How can I take the latest artifacts that a workflow builds and create a release with it?
But automate it or make it into a workflow.
@helpers
no
bruh
Hey
This aint the math server. You can't ping helpers
Hi guys what environment do you use to type and implement your code
Fedora Linux on KDE Plasma as my OS with VSCode as my code editor
that's what I use
the @azure meteor has a lovely environment. I use Kubuntu LTS (Long Term Supported) 22.04 with KDE Pasma. And using vscode as code editor 🙂
Commonly my web projects projects can't live without docker https://docs.docker.com/engine/install/ at least, which is very easy to use in the described env
As docker allows me building proper "artifact" for app running, that i can save once and reuse again and again with all dependencies frozen.
Hey here is my Python setup on M2:
pip --version
pip 24.0 from /opt/homebrew/lib/python3.12/site-packages/pip (python 3.12)
echo $VIRTUAL_ENV
/Users/user/.pyenv/versions/miniforge3-4.14.0-1
ls -l
which pip
ls: aliased: No such file or directory
ls: pip:: No such file or directory
ls: to: No such file or directory
lrwxr-xr-x@ 1 user staff 37 Apr 16 01:22 /opt/homebrew/bin/pip3 -> ../Cellar/python@3.12/3.12.3/bin/pip3
❯ ls -l
which pip3
-rwxr-xr-x@ 1 user staff 265 Mar 12 18:53 /Users/user/.pyenv/versions/miniforge3-4.14.0-1/bin/pip3
I'm curious if you have resources to share or most importantly experiences to share about managing your python environment variable on Apple Silicon (M2 for example).
I encountered an issue recently when trying to install the open3d package with pip (segmentation fault), to make cloud point representations of android faces for curiosity. And this takes me back to my setup I think.

There are many ways to get Python installed on macOS, but for most people the version that you download from Python.org is best.
I notice you're using pyenv, but the version of pip that you ran is from a different python
kitty, bash, vim. neomutt and gh for github interactions
What are the best practices?

First, check if pipx is on the distro package repo
It's brew, so it should have it
https://docs.python.org/3/library/tkinter.html
from tkinter import *
from tkinter import ttk
root = Tk()
frm = ttk.Frame(root, padding=10)
frm.grid()
ttk.Label(frm, text="Hello World!").grid(column=0, row=0)
ttk.Button(frm, text="Quit", command=root.destroy).grid(column=1, row=0)
root.mainloop()
Sounds like time for tkinter.

Python documentation
Source code: Lib/tkinter/init.py The tkinter package (“Tk interface”) is the standard Python interface to the Tcl/Tk GUI toolkit. Both Tk and tkinter are available on most Unix platforms, inclu...
best practice is to use the same version of python for pip as you use for your programs
Why does a error message talk of pipx, it's just an addition of pyenv and pip
If open3d is an installed program, use pipx. If you need to import it, use virtualenv
I already have a virtual environment for the local project (installing open3d)
If you get that error message, it means you didn't activate your venv
No it's because I typed pip, not pip3
The path I see when echoing $VIRTUAL_ENV is /Users/user/.pyenv/versions/miniforge3-4.14.0-1, which is my specific Python installation managed because I was sold on pyenv and the Miniconda environment.
But is it normal to get this path when I echo the virtual env?
I think it should display something like this:
`
echo $VIRTUAL_ENV
(...)/android/android
cd android && ls
bin include lib pyvenv.cfg
`
The virtual env variable isn't supposed to be set when we are actually inside a virtual environment? Instead it's pointing to my Python pyenv installation directory,
here is my (relevant) .zshrc shell config:
alias python='/opt/homebrew/bin/python3.11'
alias pip='/opt/homebrew/bin/pip3'
export PYENV_ROOT="$HOME/.pyenv"
command -v pyenv >/dev/null || export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
eval "$(pyenv virtualenv-init -)"
export CONFIGURE_OPTS="--with-openssl=$(brew --prefix openssl)"
export PATH="$PYENV_ROOT/shims:$PATH"
export PATH="$PYENV_ROOT/bin:$PATH"
# >>> conda initialize >>>
# !! Contents within this block are managed by 'conda init' !!
__conda_setup="$('/Users/user/.pyenv/versions/miniforge3-4.14.0-1/bin/conda' 'shell.zsh' 'hook' 2> /dev/null)"
if [ $? -eq 0 ]; then
eval "$__conda_setup"
else
if [ -f "/Users/user/.pyenv/versions/miniforge3-4.14.0-1/etc/profile.d/conda.sh" ]; then
. "/Users/user/.pyenv/versions/miniforge3-4.14.0-1/etc/profile.d/conda.sh"
else
export PATH="/Users/user/.pyenv/versions/miniforge3-4.14.0-1/bin:$PATH"
fi
fi
unset __conda_setup
# <<< conda initialize <<<
Any comment about the first lines?
alias python='/opt/homebrew/bin/python3.11' alias pip='/opt/homebrew/bin/pip3'
You should add /opt/homebrew/bin to your PATH instead
And alias python=python3 if needed
So I removed everything from
export PYENV_ROOT="$HOME/.pyenv"
to
# <<< conda initialize <<<
including:
export PATH="$PYENV_ROOT/shims:$PATH" export PATH="$PYENV_ROOT/bin:$PATH"
I already have a alias python='/opt/homebrew/bin/python3.11'
and alias pip='/opt/homebrew/bin/pip3'
No, not the full path
How to move a git repository to the start of another git repo history? https://discord.com/channels/267624335836053506/1247561791492460617
Hey everyone! We built a tool to enforce module boundaries and dependencies, complete with an interactive UI and pre-commit/VS Code integration. Core is in rust 🦀 would love folks to check it out/provide any feedback! https://github.com/gauge-sh/tach

GitHub
A Python tool to enforce a modular, decoupled package architecture. 🌎 Open source 🐍 Installable via pip 🔧 Able to be adopted incrementally - ⚡ Implemented with no runtime impact ♾️ Interoperable ...
Run actions/download-artifact@v2
with:
name: ReforgerWhitelistLatest
path: ReforgerWhitelist-Latest.zip
Starting download for ReforgerWhitelistLatest
Error: Unable to find any artifacts for the associated workflow
I'm lost on fixing this, completely.
latest-deploy.yaml is above.
GitHub
Reforger Whitelist (Py) is a server-side application for Arma Reforger that monitors player connection events and removes non-whitelisted players. - Possible fix for file paths · BreathXV/ReforgerW...
The workflow.
according to their repos, the path: key doesn't mean the same thing in upload-artifact as it does in download-artifact
the former describes which files to upload while the latter describes which directory to save those files to, which defaults to the CWD of your commands
also i think upload-artifact flattens your directories before the artifact is uploaded? if so, dist/ would have to be omitted from your .exe filepath after you've downloaded it
So what would my path look like? I'm confused to be honest.
.github/workflows/python-publish.yml lines 30 to 33
- uses: actions/upload-artifact@v4
with:
name: dist-${{ runner.os }}
path: dist/```
`.github/workflows/python-publish.yml` lines 44 to 48
```yml
- uses: actions/download-artifact@v4
with:
pattern: dist-*
path: dist/
merge-multiple: true```everything inside dist/ got placed into the root of the zip file, then those files got extracted back into dist/
Okay, so being lazy now, could I jsut copy those?
i don't think they'd apply to your use case exactly
it's better to visualize what the actions are actually doing
so, from your pyinstaller --onefile command in the first job, the filesystem would look like: dist/ ReforgerWhitelist-Latest.exe when it gets to your upload step: ```yml
- name: Upload artifact
uses: actions/upload-artifact@v4
with:
name: ReforgerWhitelistLatest
path: dist/ReforgerWhitelist-Latest.exe
if-no-files-found: error``` it takes thedist/ReforgerWhitelist-Latest.exefile, creates a .zip archive containingReforgerWhitelist-Latest.exe, and then uploads that .zip file as the artifact
then, when you download that artifact in the second job: ```yml
- name: Download artifact
uses: actions/download-artifact@v2
with:
name: ReforgerWhitelistLatest
path: ReforgerWhitelist-Latest.zipit takes your .zip archive and unzips its contents into `ReforgerWhitelist-Latest.zip/`, so you have:
ReforgerWhitelist-Latest.zip/
ReforgerWhitelist-Latest.exe``` do you see the issue?
download-artifact yes
oh btw you should probably upgrade your download-artifact version to v4 so it matches your upload-artifact version, apparently there are breaking changes in how those artifacts are created
Okay, so it appears to be working however, it uses the source code as the assets in the release compared to the exe made.
like only the .zip and .tar.gz exist, but not the .exe?
the source code is always included in releases, so that just means it didnt upload the .exe for some reason
I had the path wrong for the release upload files.
https://github.com/marvinpinto/actions
looks like marvinpinto's release action is no longer being maintained, might be worth switching to another action like semantic-release as their repo suggests
ehhh that doesn't look too convenient, action-gh-release seems simpler
If I have multiple versions of a really really big program, and none if it is running git (I'm working on migrating to git). What would be the best way to migrate and make sure all code is transfered between servers correctly? I'm currently thinking of loading server A to the master branch, then loading server B to another branch, then do a merge between the two. Because A might have code that B does not, and vice verca. But wouldnt git see any changes on A that arent on B as B deleting them? What would the best way to migrate like this be?
once u loaded to different branches
U could open Pull Request for merging one branch to another branch (lets say merging everything to master)
And start with unifiying the logic.
It would benefit heavily may be writing unit tests first in lets master branch + optionally typing. To freeze behaviour of at least one app instance to work correctly, before doing changes to them
Hm yeah, some good inputs. I have started just slowly merging the two. Its a really big app that has been in development for over 30 years and has never had any version control
So im trying to modernise it a bit
Sometimes u think there is no further bottom to hit, but they eagerly prove you wrong.
i guess my advice will be starting with next sequence of actions
-
Cover with static typing if u can a version in branch from one server
-
Cover with unit testing if u can one version from lets say master branch (for same one server)
-
Made deployment and ensure everything still works correctly
-
Cover deployment with infrastructure as a code setup preferably? Ensure u can deploy new version while having previous one saved for restorating switch if necessary?. And make sure everything still works correctly.
-
Merge code from other branches and make sure everything still works correctly after deploying to same single server
-
Proceed with having saved previous old deployment, and setting up new one modern deployment to replace it.
i have a very wierd setup, well i am trying to make one atleast and need help
so i have multipe VPS and and a homelab, and i want to link these up using tailscale, and run k3s on them (the homeservers are not externally accessible without tailscale)
now should i run headscale inside my k3s cluster if so how would that even work
for the k3s cluster to work the headscale needs to work, for the headscale to work k3s needs to work
and if i remove headscale from k3s and run everything else in k3s i hit issues with reverse proxies and lots of annoying shit
Hello everyone, I am curious and new here. Can any of you suggest me what I should add in this repo? I recently started and also created the create_command function. Is there more things you'd like me to add? What do you guys think are missing? https://github.com/NinjaSaifY/Terminal_commands_Windows

GitHub
Contribute to NinjaSaifY/Terminal_commands_Windows development by creating an account on GitHub.
it is traditional for python ecosystem to offer installation with pip
like pip install programmname
Here is related tutorial about it https://packaging.python.org/en/latest/tutorials/packaging-projects/
Thx allot I'll work on it next time. So what you're saying is to turn it into a pip install package for it to be installed easier?
Yes
I'll also try add a powershell script to auto add the scripts to the system variables
Also it is common freezing dependencies need to run it into requirements.txt and constraints.txt
It should not be needed to have PowerShell.
Packaged pip package is supposed to hook entry points on its own
Does that also take care of the PATH? on Windows?
Also if u learn argoparse, u can have less bat files
Which should be removed completely preferably
Or actually u don't need argparse for that. Just remove bats ^_^
As long as python is correctly installed
Really?
Yes
If you add entry points, they get added to PATH when they're installed
I actually wanted my scripts to be used for faster productivity
Nice thx!
did you mean this https://packaging.python.org/en/latest/specifications/entry-points/ ?
Yes
See backend-specific documentation for examples using the pyproject.toml: https://setuptools.pypa.io/en/latest/userguide/entry_point.html
heh, a bit odd that the page, "Entry points specification" on the Python Packaging Guide doesn't show an example of how to use it in a PEP 621-compliant pyproject.toml, but at least it exists in other pages
https://packaging.python.org/en/latest/guides/writing-pyproject-toml/#creating-executable-scripts
Most of that site is a compilation of assorted docs from assorted places that were written long before the PEPs existed
is there any easy way to pop messages into an MS-Teams chat from python code? we'd love to build some auto-notifications in Teams about CI events and notifications.
Webhooks are just web requests
Thanks! But that looks like I'll need more interaction from central IT for permissions and such. I was hoping there was something simpler that I could hook into using a token (like the Jira api for example). Still, thanks for offering a solution!
Graph API does have it, https://learn.microsoft.com/en-us/graph/api/channel-post-messages, but that's going to require way more involvement with IT than a webhook
Note: It is a violation of the terms of use to use Microsoft Teams as a log file. Only send messages that people will read.
Huh
🙂 thanks!
Thx
Hi folks,
What are your recommendations for better traceback capture in logs.
We have Graylog as our dashboard for logs and the problem with tracebacks is that the we get only 1 line at a time so it's painful to find the whole thing.
What is recommended for this?
Sentry is kind of specialized in good error capturing and management
Thanks but I was wondering more in terms of something that would not require us to buy something additional
Self hostable too
I can admit abusing extracting exception tracebacks from open telemetry traces though
I convert those exception tracebacks into Prometheus time series
It is very abusing a bit, but works
pretty sure the logging email handler (with filtering for exceptions) sends you afull tracbeack
In this case @elfin belfry if it is the case, I can imagine u should be able compress exception into a single line for easy quering from regular logging
grafana loki has a thing for finding context around a log
if you can search graylog from grafana it might use the same UI



Thanks. I will have a look at these suggestions
Hey can someone help me with making a licensing/key system for my sorter tool?
I just wanna know the sort of basics I need for it
Hi does anyone know anything about selenium webdriver
The problem im facing is im running a script which is opening chrome gui but i dont want to see the gui just see the output in terminal
that's called using Headless mod of selenium
Got it thanks!!
!rule 6 <@&831776746206265384> paid adds.
How do I go about generating this file ?
https://github.com/shner-elmo/TradingView-Screener/blob/master/src/tradingview_screener/constants.py
I want to schedule a script like on GH actions that changes the content of the variables once in a while, how do I go about this? are there any tools for Python code generation?

GitHub
A package that lets you create TradingView screeners in Python - shner-elmo/TradingView-Screener
I could use Regex to locate the line number I want to edit, and simply add the content from repr(obj) and use a formatter like ruff to make it nice, but thats not ideal
Not sure if this goes here, but I need a way to create a file with given contents without using "open".
I am running a python microservice with mounted S3 filesystem (s3 csi). When I run command line subprocesses that create files, no error occurs, but when I try to write to a file with open I get "PermissionError: [Errno 1] Operation not permitted".
This is most likely due to open using operations not available with s3 mount, such as editing a file. How do I create a file with given contents with no extra file system operations?
What is your backend framework
I am running a pod on EKS with an s3 CSI driver. When I run an ffmpeg command using subprocess everything is fine, but when i use open("filepath", "w").write(contents).close I get an error Operation not permitted: 'filepath'
How about not actually using S3 csi driver mounting stuff
And instead making a choice between
-
using S3 library to communicate correctly with it (it has integration with Django filesystem)
(Utilize minio in container for local debug/dev end) -
using AWS volumes (elastic storage smth, forgot name) if wishing storage connected to filesystem.
Last half of a year AWS greatly expanded Elastic Block Storage functionality of connecting them to EC2 instances (which are your eks under hood) including into container runtimes
U can mount all normal gp3 and etc volumes to ECS containers now. EKS should be supported too
Problem with "proper communication" for me is that I use ffmpeg in order to generate HLS streams, each stream containing dozens parts and each video being transcoded into about a dozen streams. Configuring cashing/upload of all these files manually sounds more complicated than I care to deal with, not to mention prone to mistakes. Mounting S3 to a pod as file system seems to work great, not introdusing noticeable memory/network overhead as compared to doing everything manually with the only caveat being that it does not support every file system operation which makes "open" not work
In the end, every video I transcode comes from S3 and needs to end up in S3. Using different volumes would only introduce an extra step in the process (from my perspective)
Makes sense going only with S3 solutions then
So your S3 driver struggles
Or eventually refactoring to AWS S3 direct library usage (boto3 or async boto3)
Just a matter of having minio containers and unit tests. Everything is testable locally
The S3 driver does not struggle for ffmpeg command line tool output (which is99% of all the files in the end). Only place where I need to manually generate a file is the final master playlist which looks something like so:
#EXTM3U
#EXT-X-VERSION:6
#EXT-X-STREAM-INF:BANDWIDTH=27500000,RESOLUTION=1980x990,CODECS="hvc1.1.4.L123.B01"
stream_0.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=11000000,RESOLUTION=1980x990,CODECS="hvc1.1.4.L123.B01"
stream_1.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=27500000,RESOLUTION=1980x990,CODECS="avc1.64002a"
stream_2.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=11000000,RESOLUTION=1980x990,CODECS="avc1.64002a"
stream_3.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=27500000,RESOLUTION=1440x720,CODECS="hvc1.1.4.L120.B01"
stream_4.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=11000000,RESOLUTION=1440x720,CODECS="hvc1.1.4.L120.B01"
stream_5.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=27500000,RESOLUTION=1440x720,CODECS="avc1.640029"
stream_6.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=11000000,RESOLUTION=1440x720,CODECS="avc1.640029"
stream_7.m3u8
Literally just a 50 line long text file
After considering why is it that ffmpeg writes work fine but python "open" does not, only explanation I could come up with is that python uses unsupported file system operations
https://aws.amazon.com/about-aws/whats-new/2023/11/mountpoint-amazon-s3-csi-driver/
Interesting enough that is well supported solution
Amazon Web Services, Inc.
https://github.com/awslabs/mountpoint-s3-csi-driver/issues/142
Check may be smth useful

GitHub
/kind bug What happened? Unable to write. Currently testing with AWS IAM role that has all s3 action permissions on the bucket being used by the EKS Mountpoint S3 addon. /datas3_us/live/pg-manager/...
Or python writes under user not permitted perhaps. Try to make some silly tests, checking permissions for ffmpeg writing
Try invoking subprocesses Shell /python scripts for file printing
And etc
Will do
I think I fixed the issue. When I run
open("filepath", "w").write(contents).close()
It firsts creates an empty file with Open and then tries to modify it by writing, which is not allowed. However when I run
with open() as f:
f.write()
Python seems to optimise it into a single call, which works
I wouldn't expect write to return the file handle; I expect it to return a number (namely: the number of bytes written), so I'd expect open("filepath", "w").write(contents).close() to raise an error to the effect of "Integer object has no close attribute"
>>> open("/tmp/wat", "w").write("say what").close()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'int' object has no attribute 'close'
>>>
write() returns the number of bytes written
A single call?
Hi everyone, i have a 'career' related question, but i suppose its more about Github. As a growing developer, i realize its potential, but i dont know the Proper way to use Github. I've uploaded some code to my profile already and made a few repositories. is a Repo like a project, that i upload all the related files to, totally separate from other repositories?
I ask in here mostly bc I imagine this will come up at work, or with showing my skills to an interviewer, i'd like to have an organized portfolio rather than a messy one. Thank you!
A repo is a project, so keep it separate mostly.
But also, having a showcase repo with a bunch of smaller scripts could also be appropriate.
It depends. If you intend to share parts of it with others send. For example if it's valuable for others to clone, then they would clone a full repo. So think about if it makes sense to "soft force" those devs to get all the stuff when cloning.
I see, That makes sense!
One repository - one application/project usually.
If u make reusable installable library - it is another repository, with its own presentation and Readme instructions.
Sometimes those rules can be broken for convenience though.
I like to dense my code together to single repo if I can.
- Single repository for all server Infrastructure code
- single repository with articles, combined into blog site and etc
Good presentation matters, documentation and Readme is important.
Don't commit build code files and other trash. Only your own code + list of dependencies on other libs is supposed to be committed
Any comments on this NAS set up?

Im facing an issue with azure batch pool nodes where the node is created and set to status unusable. Im trying to create a node using the debain 11 custom image. The image is in the Azure Container Registry.
Do we get to hear about the issue?
You need more storage. At least enough to configure RAID.
Is that the right DIMM form factor?
You picked a laptop ram stick
More storage for what?
your NAS
I don’t plan on hosting a Plex server
you only have 1 hdd. You need at least 2 for a basic RAID setup
It’s gunna be two. The list only shows one item of each.
raid-1 mirroring for basic redundancy.
your model comes with 2gb ddr4 and can be upgraded to 32
Nice
2GB DDR4
I was thinking of just upgrading it to 4GB

So full size desktop RAM, DDR4 is all I need to change in the list then
Is there any stringent compatibility requirements?
you should get a high speed ram too
This looks like the ram you need. https://www.amazon.com/Synology-RAM-DDR4-2666-Non-ECC-SO-DIMM/dp/B07X5MMGWG/

Always select authentic Synology memory modules for optimum compatibility and reliability. Installation of non-Synology memory modules can lead to system instability or boot failures. Synology will not provide complete product warranty or technical support if non-Synology memory modules are used ...
Yes, they want you to purchase their overpriced first party branded ram
I didn’t know Synology had official ram
I would wait to purchase the ram until you know the exact formfactor you need.
I’m likely gunna get the DS224+
I would wait on upgrading the ram until you know you need it. 2gb may be plenty.
True
Good point
It saves me some cash too
I was under the assumption that RAM was optional
especially since that 4gb stick is $80
Alrighty, thanks for doing the research on my behalf.
Anybody has any suggestions for doing some codegen
if it is only content replacement from github actions I'd use sed
lol I made a script that used that, but its pretty ugly imo
sed is ugly, all right
people these days care too much about appearance (kidding). You might get some ideas here - https://stackoverflow.com/q/12714415/394647
Stack Overflow
Is there a way, without a double loop to accomplish what the following sed command does
Input:
Time
Banana
spinach
turkey
sed -i "/Banana/ s/$/Toothpaste/" file
Output:
Time
BananaToothpaste
s...
Hi everyone
I'm looking for ressources about running a (public) server that runs all its app in docker container
https://www.amazon.de/-/en/Nigel-Poulton/dp/1916585256
This book teaches how to use docker in a structured way


Docker Deep Dive: 2023 Edition
thanks I'll take a look
https://www.hetzner.com/
Hetzner is a cheap cloud provider
Your partner for system-wide hosting, from cloud to dedicated servers. We deploy the latest tech at the best price in minutes.
Docker isn't the part I'm affraid of. I have a bit of knowledge already and more important I know where I can find more knownledge about docker
my problem lies in the admin part of it, especially in that context
typically
as infra dev i am very pervert, so i actually use docker via terraform provider for my pet projects
https://registry.terraform.io/providers/kreuzwerker/docker/latest/docs 😄
https://www.oreilly.com/library/view/terraform-up-and/9781098116736/
That's just as side info that u will be probably not needing.
But that helps me having no "state" at server i am not aware about.
As i make changes to code, terraform makes sure to erase previous launched containers/loaded images
May be u will like this path too
Currently usable for free if installing opentofu instead of terraform.
my problem lies in the admin part of it, especially in that context
what kind of admin part?
I should have a unified users system through linux & the app ran in docker
but I have no idea how to do that
that's just one example
i am struggling to understand what u are wishing to have
can u rephrase or smth
for example, if there's a linux user user1, and an app nextcloud is running and requires a login to access
user1 needs to be able to use his credencial to access nextcloud
so your problem how elegantly inject Secrets into app deployment?
my problem is I dont have enough knownledge to even know what I'm after
and therefore I can't search more about it
it's probably not that
so let say there's 3 app running, [app1, app2 and app3]
there's one user [user1]
user1 needs to be able to access app1, app2 and app3 with the same credentials
and when I deploy another app, I shouldn't have to manually create user1 credentials into the new app
🤔
can u link what you are reading?
One powerful aspect of YunoHost is that apps are meant to be integrated with the SSO/LDAP stack, such that users logged in on YunoHost's user portal can be directly logged in each app without having to create an account in each of them nor having to re-log in each app every time.
ergh, link to page?
the SSO integration, meaning that a user logged in on the YunoHost user portal is automatically logged in on the app as well.
Ah.
https://yunohost.org/en/whatsyunohost
I've read overview of it
Yunohost Documentation
it is some Ancient Dinasour system from the era when people configured servers manually with GUI
well... not really
the modern approach it not treating your servers as "pets/tamogochi", but instead treating them as cattle you can slaughter at any time
you just create/recreate servers => apply infra code to autoinstall stuff automatically
and u don't get attached to anything present there and can recreate servers again if necessary
in my case I have a dedicated server
what I mean by that is the data on the dedicated server are important
@placid glen after the era of manual clickops. (the https://yunohost.org/en/whatsyunohost u provided)
People migrated to the era of Mutable Configuration Management
Ansible/Puppet/Salt usage, that automated configuration of a server as a code.
And data they treat important, is just targeted by auto backup scripts in the code of the mentioned tools.
Some pople migrated after that to the era of Immutable Container Scheduling systems
Where mutable configurations are abstracted away by the usage of docker and hosts do not contain state at all.
Terraform, Kubernetes, Building and saving server AMI images with Package usage
===
I personally for pet projects use together immutable container schedling systems + a part of previous era stuff.
Making deployment with Terraform Docker, with having majority of my server configuration in leaving no state way
But i also help myself and terraform invokes some Ansible playbooks to configure stuff hard to configure at terraform level
As i have to deal with servers direclty and i am lazy building immutable AMI images for my pet projects purposes.
Feel free to learn Ansible too. I liked this book for that

You write like playbook of server configuration =>
it is invoked on CI run or manually
And it modifies server configuration, installs apps, adds cron scripts or whatever u wish
Installs nginx/lets encrypt whatever
To have full configuration
it can be great enhanced if you synergyze it with Docker and Terraform though
looking over some fail2ban tutorial https://www.digitalocean.com/community/tutorials/how-to-protect-ssh-with-fail2ban-on-ubuntu-20-04
It suggests installing it with apt
writing config files to different places
and turning on systemctl commands
Therefore in ansible it would look like
https://docs.ansible.com/ansible/latest/collections/ansible/builtin/apt_module.html
- name: Install fail2ban (state=present is optional)
ansible.builtin.apt:
name: fail2ban
state: present
After that copying from your git repo configurational files to where they are necessary
https://docs.ansible.com/ansible/latest/collections/ansible/builtin/copy_module.html
- name: Copy file with owner and permissions
ansible.builtin.copy:
src: myfiles/foo.conf
dest: /etc/foo.conf
owner: foo
group: foo
mode: '0644'
after that we turn on enable stuff
https://docs.ansible.com/ansible/latest/collections/ansible/builtin/systemd_service_module.html#ansible-collections-ansible-builtin-systemd-service-module
- name: Enable fail2ban
ansible.builtin.systemd_service:
name: fail2ban
state: restarted # or reloaded
enabled: true
Ideallly u write it as reusable Role Playbook
The systemctl restarted action should be a triggerable handler for nicer consistency.
https://spacelift.io/blog/ansible-playbooks
So then each time u run Ansible playbook it will check.
fail2banis already installed? if not => then install- is server having latest config files pointed in your playbook? if no -> then copies new ones
- ideally same action has "trigger" to systemctl restarted handler
- that will make service restarted only if config files changed
and playbook finished
P.S. this approach encourages keeping code for configuration in git repository. in Github or Gitlab or whatever.
Makes your configuration for server => Version controlled and reviewable
P.P.S. different options can autorun playbook for you, to ensure it was definitely run
P.P.P.S. funny note, we are in python server, and ansible is python tool. Because of that syntax is somewhat influenced by that. Especially considering that templating engine in Ansible is Jinja2 under the hood. That makes sometimes sense just to read Jinja2 docs
P.P.P.P.S.
Optionally Ansible module can be found in Ansible Galaxy for simplifiying configuration of fail2ban
But i am kind of a fan of having less abstractions sometimes, and this usage case looks like fitting better to use std modules
thank you
last followup question
since Idk ansible
let say I have a server using ansible, and a bunch of data (exposed through some apps)
ansible will deploy and configured the apps, but won't touch the data unless instructed to, correct ?
correct. it won't touch data unless instructed.
You can be having "management" actions written if necessary to interact with data
thank you
off topic but who remembers that powershell app that I was using to setup windows 11 easier and remove unwanted software's like windows defender and edge? didn't find any general chat to post this 😦
can't find it
don't suppose it's winget or chocolatey?
neither, it has a gui made with powershell
You do not want to not have defender.

Windows Update can break if you uninstall Edge.
windows update will reinstall [and set your default browser to] edge
Sorry for directly pinging you. So as you suggested I'm learning ansible, along with docker and docker compose.
My question is: would you recommend ansible over other more "dev oriented" tools like pulumi ?
Pulumi and Ansible are from differen types of tool categories. They aren't replacing each other, they are fine to be used together.
Ansible is Configuration Management tool. (Alternatives are Salt, Puppet). Best intended for old school configuring of Linux OS.
Docker/Docker-compose from containerization (Basic fundamental level). Best intended to wrap app into frozen artefact, fit for launch anywhere inluding container compatible scheduling systems
Terraform(Opentofu today) and Pulumi from Infra provisioning. Best intended to configure automatations with Cloud provider things. Getting servers, DNS records, managed dbs, networks and security and etc
If you were DevOps engineer. I would have recommended after Docker/Docker-compose learning Terraform first.
Because Ansible / configuration management tools are inherintly somewhat evil for promoting mutable messy deployment code, and scaling dreadfully in code.
And Because terraform significantly way more consistent and uniform to deal with.
Pulumi is rather cool concept on a paper, but less stable, and easy to mess its code at scale. Since i don't trust infra engineers writing anything but garbage in python and javascript. I would recommend heavily towards Terraform. (Probably with Golang Pulumi can work significantly better though)
But since you requested configurating a specific linux machine, and not showed signs of wishing to become devops engineer
I directed you from Docker going towards Ansible.
A fair would be to say that all those tools have somewhat intersection in their capabilities.
You can use Terraform / Pulumi to launch docker containers at host at least.
But for everything else u said u wish doing before, it will be extremely challenging to do with terraform
(Exception if u would have went with building AMI image approach)
Now extra fair thing to say
No one forbids combining them together => I just combined Terraform(Opentofu) + Ansible to work in tandem ^_^ With finding Terraform Ansible provider.
So i get benefits of easy doing all things at the same time
I do want to redirect to the devops field, but this is another story
The current linux server stup I'm trying to achieve is personnal, not professional
tbh I'm not having the best of times, because of the cheer amount of information I need to cruise
traefik & authelia doc, docker doc, docker compose doc, ansible doc
for professional it is convinient for starting people, learning Terraform
at AWS level dealing with all networking, security (via Terraform), load balancers
And through using AWS ECS (Container scheduling abstraction of AWS fully configurable via terraform), launching all applications.
Zero interactions with Linux Host as result => no need for ansible or any host level installed stuff
for personal matter i use Terraform with Ansible too. Because AWS is expensive and challenging for personal stuff.
I just order necessary Server+DNS via terraform. Using Terraform to raise Docker applications via Terraform
And applying necessary extra stuff of Ansible via Terraform too.
I can't escape using Configuration Management tools for personal stuff because i want things cheaper.
But i can minimize its influence to minimum
I use Hetzner for personal stuff. because very cheap. Arm64 its prices are just the best
I'm not planning on using AWS or Azure at the moment for my personal stuff
I have 2 kimsufi (ovh) dedicated server
I haven't looked at terraform at all. Is it compatible with what I'm trying to do ?
never though I'd say that but currently chatgpt is a godsent, I can ask every little dumb questions I have about that stuff
Terraform like Pulumi, can automate every action to OVH provider with ordering configurations at its level
But its capabilities to configure Linux OS machine directly are very limited. Possible to raise docker containers at its level and invoking Ansible from it.
Configuration management like u desired is not really possible in it. u need Configuration Management tools for that
😅 and receiving convincing bullshit that is may or may not be truth depending on order of your words
😅
Does anyone know how to compile into a standalone file via nuitka, which would work without .py files?
I tried -onefile, -statalone.
I have a question about ansible, docker and secrets. Right now I'm storing secrets into a vault in ansible and I'm using the secrets in docker compose files or config files. Should I put the secrets of my ansible vault into docker secrets and uses docker secret ?
if so, do I need to clean docker secret after starting containers ?
https://github.com/darklab8/fl-darkbot/blob/4e85253c8e94b797a25ef03bd0cfbd2c6e7aea59/tf/production/main.tf#L11
🤔 i inject my secrets to Docker and Ansible from terraform.
I pull them from free AWS resource to store parameters ^_^ (10'000 free limit)
Other people use Hashicorp Vault for self hosted option
tf/production/main.tf line 11
name = "/terraform/hetzner/darkbot/production"```Never knew about Ansible specific secret management ^_^
and Docker obviously does not have Secrets management at all (unless we speak about kube)
Terraform autoerases for me containers, so they do not persist with injected secrets
even if it did not, i see no point doing that
Do you guys try to run CI pipelines on OS matrices to ensure compatibility? Or since Python is OS-agnostic you don't really need to?
Python cross platformness is rather limited. U can't be sure it will work at another os
It has good chance it will compile though.
In any case, since different OSes have sensitive and not sensitive filesystems, that alone commonly breaks things
I write some software intended Linux first, but with optional windows running.
At the end of a day decided I am too lazy for windows CI. CI testing on Linux only. On releases sometimes testing for windows manually ^_^
Question is like... Is it justified for you to have windows CI
I mean yeah, lots of people run Python on Windows, and I'm writing a FOSS Python package
Anyone familiar with GitHub actions know of a setting or flag that I've failed to set here correctly. My expectation is that a required check that is skipped would not qualify as passed. GitHub actions, however, seems to think otherwise and this PR can be merged.
I might just need to require the other workflows instead of having a final "all passed" workflow.  Seems very counter intuative though. Enough so that I feel I'm overlooking something.
Seems very counter intuative though. Enough so that I feel I'm overlooking something.

I never use github actions, but I'll guess: "Required" means "If this step fails, we will not consider the entire job to have passed". But it does not mean "we will always run this step no matter what".
Rather backward from the two other CI platforms I'm used to.  That does appear to be the behavior. Just curious if I've overlooked a flag somewhere. The final workflow already
That does appear to be the behavior. Just curious if I've overlooked a flag somewhere. The final workflow already needs the prior two, which is why it skipped.
I can specify specific CI job names that need to pass with green for PR merging allowance
With this setting it would work according to your expectations for sure
Strange that u see it required hmm. May be u have turned on setting, admins can bypass restrictions. Turn it off ^_^. Somewhere in repository settings
Technically skip is used to skip in case this test is not needed because no files changed in specific folder.
Perhaps u could be wishing just not using skip then 🤔
The workflow is required, as you saw. The branch protection applies to all, including administrators. I've pulled the step and fallen back to simply entering all workflows as required. It's very odd behavior but my reading last night suggests it is by design.
In other CI platforms, such as CircleCI, when a workflow step requires others that have failed it also fails. GitHub chooses to mark them as skipped. A bit of a footgun. Good to know about it now that I do.
u may wish to show your code as better thing what is happening for you ^_^
Is it just me or ansible is very slow ?
😄 yes, it is very slow and its parallelism sucks (because it is in python)
May be it improved in two years since last time I tried its native parallelism features
I suspect there will be no issues with Ansible if splitting workload to multiple playbooks and invoking them all from opentofu. Opentofu should take care nicely if playbook needs reexecution, and paralleling their runs
Otherwise it is unavoidable design issue with configuration management tools due too needing a lot of sequential operations. Anything will be slow here for this type of workload.
Solution is writing less sequential workload, and doing less config management in general
And salt stack
idk if opentofu is the right tool for me, since I'm not aiming for providers like aws
yeah that one came up in my research too
Opentofu can work beyond AWS. It supports hundred custom providers, making it usable with docker, VMware, Ansible, Kubernetes and other stuff.
I admit it is very not trivial usage of terraform though
I think I've figured out a few thing, I have my stack almost ready: traefik, authelia, heimdal, portainer, nextcloud and komga
but it litteraly takes minutes every time I play the book
and there's stuff I haven't figured out yet
like
^_^ split to multiple micro playbooks and call from terraform
if a docker container is still up and I'm redeploying it, stopping the current instance, clearing some data maybe, and starting again
this kind of thing
Move major part of your configuration to raising docker containers through terraform
Lift workload from Ansible
terraform or opentofu ?
Opentofu. Terraform had licenses issues, original company went greedy. Open source free version is called opentofu now.
Still a habit to call it terraform
alr
I'm sad to see json didn't really take in that domain
ok
last rent
I promice I stop after that
Ha. Welcome to Infrastructure as a code world main issue.
I am in fact yaml mostly hater too. And main reason I love Terraform and try all the different tools which offer me static typing safety
why people keeps reinvinting the wheel
cmake with its shit pseudo language, ansible with "let's do a program language buts it's yaml lol", opentofuy with its own pseudo language
JSON can be used here if desired in this world but default JSON with its own issues too
I hate JSON for language usage
Terraform HCl language is blessing in how good it is
creating their own pseudo language is a mistake
people can work with your api being incomplete or doesn't matching a need if it's served on an existing strong bases, say python since it's a python server
alr, we'll see
(I still hate the cmake pseudo language tho, it's garbage and why it became the defcto standart in C++ dev is beyond my understanding)
oh btw since you're there
once I'll mastered docker, docker compose, opentofu and ansible
I'll have to work out AWS or Azure and get one of those cert
and that will be good enough for a first devops role maybe ?
ah there's kubernetes I need to look at, I forgot
it would be nice having working at least with some CI like Github Actions.
and writing simple backend apis with database interactions, or writing any other complex application. backend is nice preference since it is intersecting with devops engineer duties strongly, but kind of not obligatory for projects
real devops engineer should be having dev skills
otherwise it is system administrator (plenty of job roles for sys admins, but they are named devops engineer roles too)
getting good with python is good choice here. Python is good glue
as a dev myself, I've assumed this wouldn't be the most problematic aspect, even if this is usually not my field
thanks I'll add that to the list 🙂
I see you're a devops yourself, may I ask what it is you're working on those days ?
mostly responsible for monitoring systems working. Datadog for AWS and Grafana stack (Grafana, Mimir, Tempo, Loki, Prometheus, Grafana agents, Alert manager and etc) for Kubernetes
Also having some Kubernetes duties
Also working on some backend libraries development (like library integrating Celery into Django Rest Framework with company permissions system)
Maintanance of custom scripting or small infra apps solutions within our AWS infra is within my duties too. (we have some custom apps filling the gaps in our infra needs to see extra visibility, or interact with it in a simplified way)
Sometimes CI fixing.
Plenty of times smth related to Terraform (in AWS usually, but kubernetes there too)
There is a choice to grab more dev duties... but not overly enthusiastic shoveling our average garbage untyped drf code. It is unit tested at least, but still garbage a bit.
in comparison to this, grabbing more infra duties looks okay and more career wise interesting
should be yeah, message queue too.
I think Celery is the best in Message Queue world in how nice its syntax and easy unit testability
kind of very desiring having it and wishing having it in other languages than python
like... u just have declared function-task
And u can invoke it by function from any other code, with delays and etc (Instead of any obfuscation by topic names)
comes with unit testing support
makes code rather obvious and easy to work with
when your message queue shenanigans in code complexity aren't far way from regular sequential code
comfortable for programmatic Cron Job alternative too (Celery Beat part)
makes all your Crons => a single entrypoint Celery Beat + Message worker handler
makes me think I've yet to look into cron and cron job, added to the list
if u will be learning AWS, AWS Lambdas scheduled as cron via Event Bridge is convenient way for infra tooling
Makes your "crons" running only when u actually need them, with zero hosting
Possible alternative to utilize AWS state machine stuff but it is significantly less nice.
Possible alternative just to launch tasks in ECS or EKS cluster
ok
i enjoy in AWS having AWS ECS. rather simple Container Scheduling abstraction to deal with. Majority of our infra operated in this way only for years. It was simple life.
Kubernetes is literally wormhole of problems in comparison
Need help regarding api
Deployed lambda function with api gateway
i am calling that endpoint from react but gettnig cors error
cors is enabled on aws
Amazon Web Services, Inc.
I get the error "No 'Access-Control-Allow-Origin' header is present on the requested resource" when I try to invoke my Amazon API Gateway API. I want to troubleshoot this error and other CORS error...
I'm using ruff with GitHub actions as a linter. Is adding also ruff format --check to GitHub actions a good idea?
yes
How can I run GitHub Actions CI pipelines on Ubuntu on Python < 3.6? They don't have those versions for ubuntu >18.04 but don't have any <20.04 runners lol
Guys i wanna start learning ML nd idk how to start can smn help me
Ty veter
Hey! Is there a place where I can view python packages before downloading them?
With usage stats and whatnot? Something like https://www.npmjs.com/ just for python?

PyPI Download Stats
PyPI Download Stats
search is present
Sweet, thanks!
TIL
Here’s another freebie for you: https://inspector.pypi.io/
i need to partner with people who are interested inmy python financial trding applications
Hey everyone. The article below explores how to manage Python project environments and dependencies, as well as how to structure projects effectively. Hope somebody finds it useful:
https://open.substack.com/pub/martynassubonis/p/python-project-management-primer

Alleviating Python Developer Pain
Is this the right chat for module development? Sorry
Thanks I actually need this
module development, as in libraries development?
usually it is #software-architecture channel
but in some usage cases this channel is okay too, if problems are more on tooling/CI/build side
https://idratherbewriting.com/learnapidoc/
sharing some helpful docs on API documentation
I’d Rather Be Writing Blog and API doc course
Download PDF
i can connect to localhost:3000 but netstat doesn't report i'm listening to 3000. i'm running a server from a container with docker run -p 3000:3000
any clue why netstat might be failing to report the open port on the host?
maybe you're invoking it wrong?
istr netstat is different on windows, mac, and linux
am on linux
On LInux I use ss -tlnp
:-) 2024-06-21T18:50:44-0700 [ubuntu ~]$ ss -tlnp
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 200 127.0.0.1:5432 0.0.0.0:*
LISTEN 0 4096 *:22 *:*
LISTEN 0 200 [::1]:5432 [::]:*
:-) 2024-06-21T18:50:46-0700 [ubuntu ~]$
5432 is postgresql; 22 is sshd
thanks!
Can someone recommend me a laptop or PC to use for coding
MacBook pro is what I use
Whatever is currently the best deal locally in your target price range. Other than OS and basic specs, it really doesn't matter. I generally buy refurbished.
This is kinda bigoted, but here goes: avoid Windows.
I second that, and add avoiding Macbooks too if wishing avoiding overpaying 3x times price ^_^
Choose maximum RAM (16 as minimum today is preferable), videocard is not needed if you aren't ml or desktop AAA game dev.
SSD 512gb is minimum preference
Paying for windows or MacOS is not needed...
... But if u are going to university, or going to be windows desktop dev... Better getting windows preferably with wsl2
Otherwise Linux is great
Do you think I should ignore the integrated graphics PCs or are they still viable
Here I justify my preference for macbooks: (this might no longer be true, but) back in The Day it was extraordinarily frustrating to get a laptop fully working with Linux -- either the wifi wouldn't work, or the camera, or something. I eventually gave up and switch to Mac because all the bits on it actually worked.
also I've long hated the Linux desktops -- gnome & KDE, but of course that's personal preference (I don't love MacOS either but I can tolerate it)
Ex: Iris Xe graphics
Ah. Everything works me out of the box, without any driver installation at Linux
Both for PC and laptop Lenovo. Some manufacturers are worse than others. Best finding manufacturer making Linux friendly laptops if u wish one
HP is biggest driver pain, windows did not work too there
if I weren't already set in my ways, I'd give a Linux laptop another try
I use integrated okay, in fact modern integrated graphics are magnitudes times more powerful than 10-15 years old external ones
Good enough to play 50+ modded Minecraft if wishing
Alright
I have a couple laptops and PCs saved could u see if they are worth buying?